



The baze of THREADE
Главная и нерушимая база треда
Это ты анон. Используй что нравится.
Главная и нерушимая база треда
Это ты анон. Используй что нравится.
настоящий баз оф тред - мистраль говно для рпшек

В этом треде мы формируем альянс вокруг квена 235б q2_s
Выше нам не прыгнуть на консумерском железе, ниже - дно и смерть
Проблемы есть, но незначительные
Выше нам не прыгнуть на консумерском железе, ниже - дно и смерть
Проблемы есть, но незначительные
В прошлом треде предлагал попробовать первый квант глм. Никто не попробовал, зато высирают очередные тирады про квен. Фу такими быть.
Я попробовал вот буквально только что, пару свайпов
Пишет на уровне либо лучше квена q2_s, но абсолютно неюзабельно на 1.1 токена, не влезает квант в 24врам 64 рам
Как быть с контекстом? 16к улетают в момент. До тех пор пока он не заполнился задержка достаточно небольшая, но когда начинается удаление старого контекста все становится раком. Первый токен жду минут 5.
> До тех пор пока он не заполнился задержка достаточно небольшая
Потому что предыдущий контекст кешируется и не пересчитывается каждый раз.
> но когда начинается удаление старого контекста все становится раком.
> Первый токен жду минут 5.
Таверна/Кобольд вырезает самое старое сообщение, чтобы уместить новое. Т.к. контекст изменился в самом начале чата, происходит пересчет всех 16 тысяч. После того, как туда будет добавлено новое сообщение, процедура сразу же повторится при следующем, поскольку контекст уже снова заполнен. Чтобы этого избежать, нужно выгружать сообщения вручную при помощи команды /hide. Например, /hide 0-50 выгружает из контекста сообщения с 0 по 50 включительно. В чате они останутся, но в контексте их не будет.
Крч, играешь до заполнения контекста, потом суммарайз, потом делаешь как тут сказали
И вин еще в том, что ты очищаешь чат от паттернов.
Так если ты нормально второй квант квена употреблял, то почему у тебя на такого же размера глм настолько низкая скорость?
Не спеши, пока много дел, завтра попробуем.
Повышай окно до 32-64-96+
Когда подбираешься к лимиту текущего контекста, делай суммарайз части постов в глубине и скрываешь /hide их, о том как сделать в прошлых тредах. Теперь у тебя появился запас на очередные несколько десятков-сотен постов до заполнения, потом повторяешь, добавляя к суммарайзу новое и опять скрывая.
Важно делать суммарайз достаточно подробным и сохранить хотябы несколько десятков постов после него от скрытых, чтобы было гладко.
Потому что он не такого же размера.
Глм 90гб, квен 80
Запустил квен 235б Q2_K_L от бартовски, оказывается он всего на 3.5г больше интел раунд Q2_S
К бартовски доверия больше, квант "выше", надеюсь будет стабильнее
Скорость такая же абсолютно
К бартовски доверия больше, квант "выше", надеюсь будет стабильнее
Скорость такая же абсолютно
Ну вот кому ты пиздишь, а. TQ1_0 даже чуть меньше Q2_K квена. Я вангую ты взял IQ1_S, порвал себе видеокарту и говоришь, что не работает. Либо ты до этого юзал кванты бартовски у квена, но младшие там по 60 Гб, не 80.
Посмотрел, у бартовски IQ1_S вообще 77 гб. Не прыгай выше головы, епта.


Молодец, а теперь скажи, зачем тебе этот квант, если он у тебя не влезает в твой конфиг? Взять поменьше совесть не позволяет?
Понятно, благодарю. Автоматически это никак не включить?
Больше как-то не выходит. Vram 16гб, модель 11-12гб, на 8-16к контента память забивается и все зависает.
Больше как-то не выходит. Vram 16гб, модель 11-12гб, на 8-16к контента память забивается и все зависает.
А почему ты не можешь признать что оказался не прав с размерами?
Ты идиот? Первых квантов дохуя разновидностей, ты взял тот, который не влезает и жалуешься, что скорость маленькая? Блять, до чего тред докатился, а.
У тебя сколько оперативки? У меня q2_k_s еле влезает, забита вся врам и рам.
>К бартовски доверия больше
К васяну, делающему ггуфы на потоке в дефольной жоровской ламе доверия больше чем к крупнейшей корпорации производящей процессоры? У них свой собственный алгоритм квантования, кстати, который квантует в 2 бита тольтко экспертов, все остальные слои там в 8 и 4 битах.
https://github.com/intel/auto-round
Собрал и расшарил vllm под mi50, репу переделал
https://github.com/mixa3607/ML-gfx906
- vllm
- comfyui
- llama.cpp
- rocm 6.3.3/6.4.4/7.0.0
https://github.com/mixa3607/ML-gfx906
- vllm
- comfyui
- llama.cpp
- rocm 6.3.3/6.4.4/7.0.0
Действительно, у анслота на 6гб размер меньше.
Взял у убергарма под ikllama, ибо в дискорде увидел что KT кванты как-то хуево работают на обычной ламе
Еще же контекст, а он от степени заквантованности не зависит, только если его самого квантовать с вытекающими. Имея сильно ограниченную врам, даже выгружая всех экспертов на профессор на больших моделях упрешься в это, нужны дополнительные видеокарты.
Вот этого двачую, кванты от интела получше будут.
Тем временем прошло уже 3 недели, а поддержкой квен-некста в жоре так и не пахнет. На йоба соту https://huggingface.co/meituan-longcat/LongCat-Flash-Chat вообще хуй положили, надежды на полноценный парсер вызовов для квена и жлм исчезают. Оварида.
>скорость маленькая
В IQ кванте скорость by design будет еще хуже.
> К васяну, делающему ггуфы на потоке в дефольной жоровской ламе
Сейчас бы одного из самых значимых коммьюнити контрибьюторов Лламы называть васяном. Хехмда.
Ну справедливости ради, интел так то не бомжи с помойки.
Но смотря на 13 серию, я чёт сомневаюсь.
>У тебя сколько оперативки? У меня q2_k_s еле влезает, забита вся врам и рам.
Я на линуксе, 64гб
>Вот этого двачую, кванты от интела получше будут
Я с этим квантом уже наигрался
Всё же хочется ещё первый квен проверить, по первым тестам он менее хорни и как-то адекватнее общается, что для меня признак ума
А. Я убрал -ub 2048 чтобы влез контекст, в два раза медленнее пп, мне некритично
Бай хуяйн, ты голову то включай, прежде чем писать что-то похожее на умное. У него всего 88 Гб общей памяти, квант почти 90 весит, он из свопа рп-шил, смекаешь? Надеюсь, додумаешься понять, что будет быстрее - работа в свопе или штатная работа IQ квантов?
Контекст конечно есть, но я не думаю, что у ГЛМ он сильнее жрет память, чем у квена, хотя детально не замерял. Кажется, что там отклонения максимум будут гигабайт-два.
GLM-4.6-UD-TQ1_0
3090 + 64ddr4
Начало чата 4т.с
На забитом 20к контексте 3.8т.с
40pp vs 240 на квене
3090 + 64ddr4
Начало чата 4т.с
На забитом 20к контексте 3.8т.с
40pp vs 240 на квене
На будущее: https://t.me/natural_language_processing
Так Кими же инстракт, а не ризонинг.
В каких-то задачах может быть и лучше, а во всех остальных — полный слив.
Главное — правильно выбрать задачи. )
Вот интересно, на сколько.
Надо будет вечерком сравнить.
Имею 3,6 на 4к контекста на кванте от анслота UD-IQ2_M.
119 гигов Q2_K, хм…
Интересно, какая разница по качеству.
Ха-ха, ты здесь живешь, тред до этого уже с полгода назад докатился.
> крупнейшей корпорации производящей процессоры
в голосяндру!
Я уже снёс чат, однако, приведу пример.
Моё сообщение: Стою оперевшись локтем о разбитую телегу и наклоняя голову на бок указывает на неё "У тебя уши торчат."
Ответ персонажа: Он стоял у обломков обоза, его подошвы утопали в грязи в пермешку с кровью. Он медленно поднял свой палец и указал на её уши. "Твои уши приподняты как у любопытной лисицы - фенека, похоже ты почуяла что - то вкусное." А потом уже ответ чара.
Этот стиль это сугубо проблема синтии и синтвейва, им обязательно надо перееиначить и повторить твоё сообщение, иногда они могут это растянуть токенов на 50 - 100, и вопрос, нахуя? Почему мистралю не надо это делать?
>Этот стиль это сугубо проблема синтии и синтвейва, им обязательно надо перееиначить и повторить твоё сообщение, иногда они могут это растянуть токенов на 50 - 100, и вопрос, нахуя? Почему мистралю не надо это делать?
Это из нее лезет настоящая RP с сессия с донжон-мастером. В реале оно так и происходит - Мастер сначала пересказывает как часть рассказа то, что игрок ему заказал (игрок заказывает - что он хочет сделать, а Мастер отвечает - что получилось по факту).
По сути - не баг а фича. Я такого поведения специально стараюсь добиться, когда под RP промпт пишу. Мистраль, этого почти не умеет, к моему огорчению. :)
Чтобы такого не было - лучше убирать из промпта все упоминания про roleplaying session. Писать как основную установку просто что-то вида "you are X in the interactive chat with Y". Чтобы модель себя гейм-мастером не возомонила даже частично.
А сесли все равно лезет - увы. Значит в датасете было слишком много настоящего RP. Хотя можно попробовать добавить "Avoid assuming the DM role in this chat".
Да, ты прав, однако в итоге из 15 к контекста в итоге 5к это повторы моих же сообщений на основе которых модель ещё и пишет за меня. Короче мне не понравилось, забей хуй, пойду обратно на дурочку мистраль, там роднее.
LLM360.K2-Think довольно хорош для модели 32b в ру RP серьёзно, попробуйте, но порой косячит с русским языком. Эх, вот еслиб кто нибудь сделал файтюн с ней для ру рп...
Есть тут челы, что умеют в фатюнинги?
Есть тут челы, что умеют в фатюнинги?
Ага, тут одни уже делали ру файтюн мистраля, просто название модели поменяли и всё, главное сайт сделали и страницу с донатами.
>org_GLM-4.6-IQ1_S by bartowski 76gb
>GLM-4.6-UD-IQ1_S by unsloth 97gb
Почему бартовски такой маг?
>GLM-4.6-UD-IQ1_S by unsloth 97gb
Почему бартовски такой маг?
6,5 токенов против 3,9, вау!
Стоит того!
Не знал, что настолько роняет.
А еще Q2_K по тестам вроде как чуть лучше IQ2_M.
А теперь время попробовать Q2_K_L… Если там будет чуть меньше падение, то вообще тема.
Если честно, очень неожиданно, скорость чуть ниже квена, зато 355б модель.
Но, конечно, 2 квант, 3 бита… х)
Потому что анслот иначе квантует и у него выше качество из-за того, что мелкие слои в большем кванте?
Таких магов — вся обниморда. Квантуешь в минимальный квант и ты молодец.
Потому что ты глупенький и не понимаешь чем кванты отличаются друг от друга
Что одно лоботомит что другое. Ну ты впринципе такой же и разницы не увидиш.
4 плашки по 32 гига ддр5
Насколько оправданно?
Знаю что скоростя порежутся. Но насколько сильно? Имеет ли вообще смысл, с учётом того 2х32 уже есть?
Пусть люди со 128 гб ддр5 двумя плашками ответят, какие у них скорости на моделях.
Потому что я запутался.
От 90 псп (6000) я ожидал 7-8 токенов, а получил 5,5-6. Прирост явно не по пропускной способности у меня получился.
В чем трабла — найти пока не смог.
Нужна статистика по одной модели чисто на проце, чтобы понять, на каком железе какие скорости.
Конечно тебе все скажут «нет, никакого смысла нет, скорости упадут!», но тут и так скорость генерации у меня, будто 68 псп. Че толку от частоты по итогу-то…
Ну ты упёрся в ботлнек и жидко пёрднул, получается.
> не думаю, что у ГЛМ он сильнее жрет память
Это зависит от количества (активных) параметров и конфигурации голов, но простое правило стабильно - чем больше модель тем больше будет весить.
Вот этот хорошо расписал. И при желании понятно как с таким бороться, поставить указание сразу начать ответ а не повторять действия.
Если у тебя есть деньги на это то возможно.
Бартовский все ужал в хламину, анслоты хитрят, оставляя много битности на головы и некоторые слои.
Бля, гений нахуй, а ботлнечит что, ответишь? )
>Но насколько сильно?
До 4800 и ниже.
>Имеет ли вообще смысл, с учётом того 2х32 уже есть?
Бери 2х64 и не выёбывайся.
>2х64
>Продает две калеки, производят две калеки, стоит как 3090.
Чет хз. За те же бабки лучше 3090 взять ещё одну, не?
128гб по цене 3090, ты хотел сказать.
Ну бери ещё одну 3090, будешь ламу 70б катать которой 2 года уже
Люди вообще охуели и на халяву уже косо смотрят, дождётесь как с теслами
Щас погоди нагадаю какая у тебя система и какие кванты каких моделей ты запускал
И я всё же думаю чем больше параметров тем мощнее нужна именно видеокарта
Если у тебя амдговно, то скорость упадет чуть ли не вдвое, на интеле скорее всего номинальную скорость получишь. У меня 4х16 ddr5 и падения скорости нет.
Ну начались маня-маневры, ясно. )))
Вот и нахуй иди, со своим «у тебя ботлнек» на мою фразу «где-то ботлнек». Научился читать — молодец, теперь научись думать, прежде чем писать. =)
Я свой конфиг и замеры раза три выкладывал. Мне посоветовали проверить память, но она мемтест прошла на отлично.
Сейчас хочу проц другой потестить.
У меня подозрение, что ботлнечит 6-ядерный проц, нужно больше вычислений!..
Вот блин, катаю туда-сюда Q2_K от бартовски и Q2_K_L от анслота.
При разнице в 3 гига (собственно, Q2_K от Q2_K_L у анслота не сильно отличаются), квант от бартовски будто лучше пишет и меньше ошибок и английских слов допускает.
Может быть мне так кажется, не знаю. Но я не первый раз слышу и вижу что на кванты от анслота жалуются. Короче, че-то они там сами себя перемудрили, или я мало тестов провел.
Надо еще попроверять, конечно.
Ах да, от бартовски на видяху падает 8 гигов общих слоев и экспертов, а от анслота — 7 гигов, хотя, казалось бы, Q2_K_L должна дропать наоборот больше.
Не спец в квантовании, но я не понял, чем у них там лучше. Наквантовали три лишних гига — но это не общие слои и не роутер. Странно.
Может кто шарит и пояснит.
Ты сейчас про квен или глм?
У бартовски квен 2_k и 2_k_l одного размера, смысл юзать первый
GLM-4.6
Блин, а ты прав, ща попробую Q2_K_L от бартовски, а то не заметил в первый раз, невнимательный был.
Кто-нибудь знает, влияет ли 3д кеш на ряженках на скорость инференса? Или лучше вложится в озу побыстрее, 8100Мгц могу позволить если обычный проц возьму.
Не люблю ряженку. Очень густая и вкус перетопленного молока смешанного с кефиром. Не лучше ли кефир с рогаликов?
Повторю вопрос из прошлого треда. Может кто знает как предотвратить закрытие окна llama-server при возникновении какой либо ошибки? Гугол советует добавить в batник pause но это не работает, я уже устал пытаться ловить окно на скриншоте.
>Гугол советует добавить в batник pause но это не работает
Это должно работать, покажи как добавил.
Ну запусти из консоли а не мышкой
Так на АМД высок шанс, что ты выше 78 псп не получишь (привет контроллер памяти), так что тебе и 4800 хватит с головой. =)
За все материнки и все процы не скажу, но нужно уточнять совместимость и реальную производительность.
Нет, кэш ниче не дает.
Существуют ли какие-то готовые сборки железа заточенные под локальные ллмки? Можно ли что-то годное собрать за 30-50к? А для генерации видео та же железка сгодится?
3060 + 64 ддр4 будешь эир гонять в хорошем кванте который все щас тут гоняют даже с пк за 100+к
>Существуют ли какие-то готовые сборки железа заточенные под локальные ллмки?
Существуют, но все из них говно в той или иной степени. Начинка во всяких "чудо-коробочках" в основном это мобильные процы и мобильная память, которая будет перформить соответственно. То что они "заточены" под локалки - это чисто маркетинговое наебалово.
>Можно ли что-то годное собрать за 30-50к?
Можно, вариантов на удивление достаточно. И будет гораздо выгоднее, чем искать что-то готовое.
>А для генерации видео та же железка сгодится?
Для генерации видео в нормальном качестве нужно минимум 24 кило видеопамяти. Но можно пыхтеть и терпеть даже на 8-12, но это будет каша из пикселей и артефактов.
Видео => мощный чип + 16 (лучше 24) ГБ видеопамяти на контекст (разрешение+количество кадров), 64+ оперативы
LLM => 16+ памяти для MoE, 64+ оперативы ИЛИ 24, 32, 48, 96, 192… ГБ видеопамяти для Dense модели (или тоже для MoE), 128, 256, 384, 512, 768, 1024… оперативы для большой МоЕ
Окей, 50к рублей, тут у нас помещается 5060 ti и иди нахуй ебанутый што ле за такие деньги собирать?!
Ок-ок, давай экономить. Для LLM ты можешь взять 3060 12-гиговую и зеон с 64 гигами в четырехканале, звучит дешево и сердито, ну или просто 64 DDR4 набрать на райзене или интуле любом. DDR5 тебе уже не влезет. Тут еще видео можно будет погенерить.
Хм, а что у нас кроме 3060? Ну, типа, можно взять CMP 50HX, 10 гигов за 5к рублей или P104-100 — 8 гигов за 2к рублей. Естественно, можно взять парочку (например райзен со встройкой + пару тех или других видях — уже 16/20 врама и 64 оперативы).
Тут видео уже не пойдет (ладно, я пиздабол, я просто нормально не тестил CMP50HX с Wan'ом).
Ну ваще хуй знает, тут у некоторый RTX 6000 Pro за лям, а ты за 50к спрашиваешь.
Но если вдруг 50к баксов — простите! Тогда 6000 прохи набирай в серверную материнку и погнал.
Еще есть старый рецепт, взять майнерскую материнку и 5-9 видях, но мне не зашло, медленно, и 40-50 врама не так много, как хотелось бы. Плюс, с P104-100 у тебя ван ваще норм ниче не сгенерит, а с CMP 50HX мне лень проверять.
Но чисто поугарать можешь в моих старых видосах:
https://www.youtube.com/watch?v=pp3ViqRNKQg
Но даже тогда я оценивал покупку «ну такое» щас вообще вряд ли бы посоветовал.
Существует готовая сборка, называется Ryzen AI Max+ 395 + 128 GB RAM, стоит 200к. Зато генерит нормасно. И маленький. Коробчонка такая.
Видео на нем не-а.
> Для генерации видео в нормальном качестве нужно минимум 24 кило видеопамяти. Но можно пыхтеть и терпеть даже на 8-12, но это будет каша из пикселей и артефактов.
Ну не наговаривай, просто разрешение понизить (все равно апскейлишь) или кадров поменьше. =) Не все так плохо.
Где?
На 123б или современных больших моэ можно будет еще и поебаться с ней после или во время процесса. А так справится даже немо, просто ответы будут слабые.
> отовые сборки железа заточенные под локальные ллмки
Да. Это или гпу-серверы/рабочие станции общего назначения которые раз так в 100 дороже твоего бюджета, или хуета от барык, куда воткнули неликвид или просто задрали цену в разу.
> Можно ли что-то годное собрать за 30-50к?
Можно добавить и купить 3090, это необходимый но не достаточной компонент.
> Зато генерит нормасно.
По тестам неоче
>или кадров поменьше
Можно вообще кадры до одного снизить. И чисто технически, ты будешь всё равно генерировать видео.
ibm-granite/granite-4.0-h-small
32b-a9b мое
32b-a9b мое
Как она в плане сэкса?
Точно не туда прописал, благодарю
В чём заключается аблитерация этого кала? Кстати, этот говнодел https://huggingface.co/nicoboss скорей всего делает вид, что понимает что делает.
Разьеб вообще весь экран залил срочно всем пробовать.
Ты же обманываешь
Уберите квен из шапки
Кто то ведь реально может подумать что ради этого стоит обновлять пк
Кто то ведь реально может подумать что ради этого стоит обновлять пк
Кто вообще зафорсил тут 235 квен?
О нём поговорили неделю и забыли
Ну не вышла модель, исправят добавим и будем любить, нахуй сейчас людей заблуждать?
О нём поговорили неделю и забыли
Ну не вышла модель, исправят добавим и будем любить, нахуй сейчас людей заблуждать?
Да, на сегодня это самый галлюциногенный кал, сам в шоке.
Квен подкупает своим слогом ровно до того как кончаются тесты на свайпы и цензуру и начинается рп
Охлади траханье, тебя квен изнасиловал? и ты был явно против
Я и не я один просто глубоко расстроен
Его приятно свапать потому что он смешно пишет, но в какое то серьезное рп он не может и на карточку ему будто похуй
>и не я один
Приватная вкладка - твой хороший друг. Зарепортил все четыре поста, ибо ты заебал.
>на карточку ему будто похуй
Полнейший бред. Но ты терпи там, хорошего настроения.
>Зарепортил все четыре поста
Вот это тряска, я бы такое не писал в приличном обществе
>Еще есть старый рецепт, взять майнерскую материнку и 5-9 видях, но мне не зашло, медленно, и 40-50 врама не так много, как хотелось бы. Плюс, с P104-100 у тебя ван ваще норм ниче не сгенерит, а с CMP 50HX мне лень проверять.
p102 и p104 уже не годятся под видео. ВООБЩЕ. У них CUDA 6.1 а нужно сейчас минимум - 7.5
Comfy с нужными под Wan библиотеками просто ругнется об этом и проигнорит карту. (torch 2.7.x ее не поддерживает).
Из cmp - можно еще как-то использовать cmp90hx, а cmp50hx - будет очень медленно и печально (тоже нет нужных фич, хоть и не критично аж до незапуска).
>Можно вообще кадры до одного снизить. И чисто технически, ты будешь всё равно генерировать видео.
Чисто технически - Wan не видео генерит, а серию картинок. Видео из них сшивается уже потом, отдельно.
хуя фанбойчик, не нравится чужое мнение? терпи, хуле
>
>Дополнительные ссылки:
>• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
Ты в курсе, что пропагандируешь? За такое на нары нахуй нужно сажать.
>chatml
Это какой-то местный рофл?
У меня сразу какие-то звёздочки полезли, i am чето там в конце сообщний и генерация продолжается хотя писанина закончилась
Отставить тряску.
Один озлобленный поех форсит упрекая что кто-то что-то форсил(!), не удивлюсь что буквально шизик и он же рядом про чуб писал. Второму просто не зашло или поленился настроить. Модели разные, вкусы у людей тоже, не нужно полыхать с этого.
> p102 и p104 уже не годятся под видео
Точнее будет что они не годятся ни под что современное кроме ллм с натяжкой. Чип просто не поддерживает нужные операции, увы.
> cmp90hx, а cmp50hx
Вот хоть усрись, одинаковый перформанс! Максимум я выжал +5% на LLM и все.
Может есть способ правильно готовить CMP 90HX? А то она вполтора раза толще, вдвое тяжелее, а перформанс тот же у меня. =(
Отложил пока обе карты, бесит, что они память постоянно греют и 80 ватт жрут.
Зато туда влезет VibeVoice 7b exl3, можно генерить озвучку, кекеке.
>они память постоянно греют и 80 ватт жрут
nvidia-pstated не работает на них? или у них на самом низком уровне все равно 80 вт?
Новейший, ультра-модный и крутой пресет на GLM-4.5-Air от гичан
https://rentry.org/geechan#general-roleplay-prompt
https://rentry.org/geechan#general-roleplay-prompt
Чето отборные шизопромптища, аж на 700 токенов будето в аицг зашел. Надо пробовать!
Вангую диаметрально противоположные мнения о них.
В жлм 4.6 русский получше прошлой версии. Разумеется, чтобы что-то говорить нужно тестировать основательнее, но он уже как минимум не фейлит также как раньше и не делает явных ошибок после нескольких сообщений в чате.
Предлагаю раз и навсегда собрать всех шизиков, которые тут тусовались в разные времена. По памяти могу вспомнить - микушиза, немошиза, геммашизов (в неизвестном количестве), шиза который собирал базу треда, теслашизов которые пылесосили вторички, и лама-мистрале-шизов которые не могли вылечить лупы.
Это даже для 16гб надо качать Q2?
Откуда вообще качать? По abliterated только какие-то huihui находит, и модель разбита на несколько кусков.
В одного мегашизика?
Лучший способ получить говно на выходе и разочароваться в умнице
Тише, нюнь, тише.
Понимаю, больно когда кто-то делится пресетами и твой гейткип уже не так уж важен

>3060 + 64 ддр4
Я другой анон, но скачал и запустил этот ваш глэм в Q3_K_XL. Выдает терпимые ~9.5 т/с, жить можно. Но русик у нее просто отвратителен, даже хуже чем у геммы 4b (речь о грамматике, а не о качестве ответов). Если РПшить на английском - наверное хороший вариант, но русский прям фу, не. Гемма 27b и Мистраль 24b - всё ещё лучшие варианты под такой нищеконфиг, если РПшить на родном.
>не имеет доступа к большим локалкам
>русик
Уходи отсюда, извращенец
Напомните почему для русика понижают температуру на какая оптимальная
Потому что подавляющая часть русскоговорящих живет в России, тут достаточно прохладный климат, поэтому летом обычно выставляют 1 или даже 0.8, зимой уже 0.5-0.7. Но всегда надо ориентироваться на текущую погоду, даже зимой бывают оттепели.
Забудь ты про этот руссик, бля на твоей мистрале 24b это руссиком сложно назвать.. так.. перевод еле еле кривоватый.. учи английский, или переводи дополнительной моделью через magic translation https://github.com/bmen25124/SillyTavern-Magic-Translation там 1b-4b хватает для более менее сносного перевода твоего инпута и аутпута. Костыль, но если не хочется в англюсике привыкай к костылям, ну или иди в acig пока там еще кислород не прикрыли и дают доступ к геммини 2.5, у нее более сносный руссик но с твоими конфигами даже скорее божественный!
>почему для русика понижают температуру
Кто понижает? Зачем?
>какая оптимальная
Та что рекомендована разработчиком. У геммы 1. У квена 0.7. У мистраля 0.15, но в случае с мистралем можно и побольше поставить, у меня на 0.7 норм результаты выдаёт. На русике естесно.
Единственное, когда РЕАЛЬНО стоит занижать температуру - это при использовании экстремально низких квантов. Пару месяцев назад тестил это дело и делился в треде . На t 0.4 гемма 4b в Q2 (!) писала хорошо. Если сидишь на 4+ кванте - ставь родную для модели темпу и не еби мозги.
Спасибо за охуительные советы, бро. Я так-то переводчик по специальности, и английский знаю скорее всего получше твоего. И я в рот ебал еще и с нейронкой общаться на неродном языке, этого дерьма в моей жизни и так достаточно. Русский в геммочке хорош и меня полностью устраивает. В мистрале и квене - да, чуть похуже, но всё ещё пригодно для рп/сторителлинга. А глем пока ну.. СТРЕМЯЩИЙСЯ. Может в следующих версиях русик подтянут и можно будет на него перекатываться. Но пока - нет.
>Я так-то переводчик по специальности, и английский знаю скорее всего получше твоего
дааа чел ты крут спасибо что почтил нас своим присутствием
даванул базу. стандартный roleplay neutral работает лучше чем любые шизополотна
Чел, придумай что то новое.
Тред и так уже полнится бизнесменами с 16 врам и лингвистами сидящими на русике

Ну чё, живём?
Осталось понять насколько 2 квант юзабелен
Осталось понять насколько 2 квант юзабелен
https://www.reddit.com/r/LocalLLaMA/comments/1nvdy0u/comment/nh83y4n/
Это один из представителей zai, отвечал на вопросы когда двое суток висел QA тред в ЛокалЛламе. Так что если вдруг кто расстроился - не надо.
Это один из представителей zai, отвечал на вопросы когда двое суток висел QA тред в ЛокалЛламе. Так что если вдруг кто расстроился - не надо.
Two more weeks это мем, вроде как так гопоту сэм обещал... и обещал...
Даже если что то будет там настолько крохи, биг делали 2 месяца, а тут за 2 недели что то обещают хотя вообще над ней не работали
>хотя вообще над ней не работали
У тебя папа в zai работает и рассказал? С нетерпением жду когда ты наконец вернешься в школу, тред не твой бложик для слабоумных
Почему ты так зациклен на школе и всех в неё отправляешь?
Ну можно я ещё немного покумлю?

Что можно запустить на телебоме с 12гб озу и SD8+gen1?
Че думаете, стоит брать 5080 сейчас или дождаться выхода супер ближе к весне? Про то что там будет 24 килошки памяти это не вброс? Карту рассматриваю не только под нейронки, но и под игорьков.
gemma 3n a4b
Лучше нее в этой весовой категории ничего нет, у нее даже русик отличный.
Огромная шапка со ссылками, а по сути всё бесполезное и протухшее. Актуальную инфу бы.
Подскажите какие настройки и ссылки на рекомендуемые модели 235 или GLM под 16гб врам 64 озу+ссд подкачка. Скачал 235, вроде запустилось, гоняется безумно медленно около токена в секунду, но врам не вся юзается и хуй знает по пресетам, вообще ничего не поменял со старой геммы. Кобольд пришлось обновить, а таверну не знаю надо ли обновлять?
Подскажите какие настройки и ссылки на рекомендуемые модели 235 или GLM под 16гб врам 64 озу+ссд подкачка. Скачал 235, вроде запустилось, гоняется безумно медленно около токена в секунду, но врам не вся юзается и хуй знает по пресетам, вообще ничего не поменял со старой геммы. Кобольд пришлось обновить, а таверну не знаю надо ли обновлять?
В шапке всё полезное и актуальное. Кто ж виноват что ты такие глупые вопросы задаёшь
>235 или GLM под 16гб врам 64 озу
Из глм норм влезет только эир. Квен 235 влезет только в Iq2xss кванте.
>ссд подкачка
Запуск моделей с ссд это не жизнь.
> Скачал 235, вроде запустилось, гоняется безумно медленно около токена в секунду, но врам не вся юзается
Хуево настроил значит. Надо мое слои через --n-cpu-layers выгружать грамотно чтобы и врам загрузить на максимум, при этом не вызвав переполнения.
>хуй знает по пресетам, вообще ничего не поменял со старой геммы.
Для квена - Chatml. Для GLM - GLM4.5
>таверну не знаю надо ли обновлять?
Конечно надо, что за вопросы такие.
Аноны блять помогите, я не понимаю, как заставить модель писать с перспективы юзера? Почему эта потная блядская сука постоянно пишет с перспективы чара? Я уже перепробовал сотню вариаций своего промпта за этот месяц и нихуя, я добился идеального отполированного вывода, но не того что модель отписывать с перспективы юзера. Стоит только юзеру покинуть сцену, все описание переходить на чара и то как он сидит дрочит свой член в ожидании пока юзер вернется. ЧТО Я ДЕЛАЮ НЕ ТАК? ПОМОГИТЕ УМОЛЯЮ.
>как заставить модель писать с перспективы юзера?
Используй синтию. Тебе даже делать нихуя не придется, она сама за тебя всё напишет, все решит и еще нравоучениями заебет, о том как ты злобно смотришь с диким оскалом, в ответ на простую фразу, что ты улыбнулся.
У тебя там небось в промпте написано что она должна ролеплеить за {{char}}.
Куда все аноны с 128ддр4 и 24 врам делись?
GLM-4.6-UD-IQ3_XXS-00001-of-00003.gguf весит 145гб, должно лезть
GLM-4.6-UD-IQ3_XXS-00001-of-00003.gguf весит 145гб, должно лезть
Всем похуй на лоботомитокванты
Чёт влом качать
Давай лучше ты съёбывай с русской борды.
Новая супер офк будет лучше, и 24гига там обещали. Но если купишь сейчас то сможешь сразу индождить до момента разочарования от выхода новой. Потому добавь и просто купи 5090.
Очевидно потому что ей дано такое задание. Через ooc или от системы пишешь: теперь твоя задача описывать все с перспективы юзера, и дальше комментарий по поводу как воспринимать твои сообщения. Все.
Есть две новости про 4.6 жлм. Плохая в том что особого прогресса в рп относительно 4.5 не заметно. Хорошая что и тот был большой умницей, так что в 4.6 все работает по красоте. Русский чуть лучше стал, но далек от совершенства.
Вата, спок. На русике играть в случае маленьких моделей это кактус жрать, вот что он хотел сказать
>новости про 4.6 жлм
Какие новости, почтальён, блять!
Принесли бы уже цифры как она на 3 кванте с 128рам 24врам работает, какие скорости, никаких новостей бы не надо было весь тред бы уже на ней сидел
С русскоязычной°
Не благодари.
Весь тред это ты один?
Могу принести новость про 20т/с в начале контекста на Q5XL, на много рам много врам хорошо работает. Полегчало?
Ты можешь загрузить её только на одну 24врам карту и скачать 3 квант чтобы сделать треду доброе дело
Что мешает это сделать тебе самому? У тебя же 4090
Или ты таки решил терпить до конца жизни на корпах и продал её за апи?
У меня не 4090 и нет достаточно рам
Не осталось 24-гиговых карт, не могу.
Точно, 3090 же. Ну и соси дальше на своём двубитном квене)))
Думаешь можешь шитпостить каждый день и думать что тебе кто нибудь поможет? Все адекваты съебались благодаря тебе
Бедные адекваты, не вынесли 10 сообщений за день в треде вместо трёх
Ну ты иди там свой мушоку тенсей рп продолжи на немотрончике айку3 или квенчике 2бита, успокойся. Не надо плакать
>С русскоязычной
хуя маняфантазии
я всё правильно сказал, с русской
>вот что он хотел сказать
ебать оракул
я хотел сказать, что твоя тряска здесь смешна
Тесташиза забыл.
>грамотно
И где эту грамоту взять? Запустил кобольд, выбрал Qwen3-235B-A22B-Instruct-2507-IQ2_S, долгая обработка промпта и потом 2Т/с, ~13/16 VRAM, 64+ RAM.
Если квен чересчур, есть .kcpps под GLM-AIR и какой квант качать?
Не вышло. Попробуй ещё раз
А можно как то загрузить таверну в телефончик и по локалке пк запрос отправлять чтобы генерировал?
Таверна для этого и предполагается. Читай про развертывание сервера, в доках таверны есть всё. Если порты откроешь или ещё как обеспечишь доступ, можно даже вне локальной сети из любой точки это делать
Можно захостить таверну на пеке и заходить на нее с телефона, плашнета или чего угодно. В настройках только доступ со всех ип а не только локалхоста включи.
Да похуй почему-то ей на ООС и на промпт про то что перспектива/ пов от юзера, ебашит все равно за чара.
Убрал вообще любое упоминание чара или нпс, все равно срет за них. Я его хуй знает что делать уже.
Как же вас трясёт что кто-то просто пришёл и закинул пресет в тред, аж побежали доказывать что ваш, гейткиперский то, всё ещё в сто раз лучше!
> А можно как то загрузить таверну в телефончик и по локалке пк запрос отправлять чтобы генерировал?
При запуске Таверна создает веб сервер. Изначально к нему не подключиться ни с какого другого устройства, но это легко меняется в конфиге одной строчкой. Скорее всего, у тебя закрыты порты и потому доступно подключение будет в рамках только локальной сети. Если нужно подключаться из другой сети, лучше всего завести vpn, чтобы безопасно связать узлы, а не прокидывать порты и делать подключение публичным. Здесь подробнее: https://docs.sillytavern.app/usage/remoteconnections/
> как заставить модель писать с перспективы юзера?
Довольно легко. Ты не принес подробности, потому помочь тебе сложно: какой промпт? Какой фронтенд? Таверна? Какую задачу вообще пытаешься решить: чтобы моделька за тебя писала историю без какого бы то ни было участия с твоей стороны? В таком случае, само использование Таверны тебе вредит, поскольку задает структуру чата, где по определению существуют две стороны. Если первое сообщение в чате от {{char}}, то вообще неудивительно, что подхватывается такой паттерн.
^ Если первое сообщение в чате от {{char}} и следующим идет ответ от {{user}}*
Какого из?
один из тестошизов
Вот, спасибо! Попробую!
А то хреново гуглил, видать, не мог найти, как можно режим сменить.
Там можно Q8_q5_q4 запускать с 64 гигами, а не Q3…
Я анслоту уже не верю, мой выбор — Q2_K_L от батровски. =)
Не в данном случае, короче.
Ну и учти, что тут надо сильно запихивать и мало контекста останется.
https://huggingface.co/ddh0/GLM-4.5-Air-GGUF/blob/main/GLM-4.5-Air-Q8_0-FFN-IQ4_XS-IQ4_XS-Q5_0.gguf
Например.
Или там пониже чутка.
Главное, не забудь анти-тесло-шиза, который не знает математики и до сих пор серет себе в штаны, не умеючи считать скорость. =D
Его в головной вагон, водителем.
Так никуда и не уедем, он получит отрицательную скорость и самосхлопнется.
Опробовав большой глм я теперь недоумеваю почему эир такой зацензуренный?
Или ему просто не хватает знаний из каких то порнорассказов?
Он прям очень стеснительно пишет в сравнении с большой моделью
Или ему просто не хватает знаний из каких то порнорассказов?
Он прям очень стеснительно пишет в сравнении с большой моделью
Спасибо за ответ.
Таверна, промпт у меня уже шиза полная, с нуля пытаюсь что-то сделать. Цель чтобы был условный pov со стороны юзера, чтобы если юзер покидал комнату и переходил в другую, сцена не оставалась в комнате в которой он был, описывая что там происходит пока его нет, а передвигалась вслед за юзер, описывая что происходит в новой комнате.
Я не понимаю как этого достичь, у меня постоянно фокус остается на чаре с которым юзер общался до этого в предыдущей комнате. Вместо того чтобы описать как юзер зашел в условную ванную комнату и что он там видит, модель мне выдает как чар с которым он только что общался сидит ждет и смотрит на дверь ванной комнаты, а потом то как юзер выходит из ванной комнаты и чар продолжает с ним диалог.
Сейчас у меня нормально работает только если юзер входит в следующую комнату, в которой есть другой персонаж, тогда сцена "перескакивает" на нового чара, начинается адекватное с описания комнаты, того что происходит и того что там делает чар.
Но если комната условно пустая, в которой нет персонажа, то модель отписывает как юзер там что-то делает и вскоре возвращается обратно. А МНЕ НУЖНО чтобы сцена там и оставалась, в другой пустой комнате без чара, где есть только юзер.
> промпт у меня уже шиза полная, с нуля пытаюсь что-то сделать
До тех пор пока ты его не показываешь, ничего не ясно.
> Цель чтобы был условный pov со стороны юзера
> чтобы если юзер покидал комнату и переходил в другую, сцена не оставалась в комнате в которой он был
> передвигалась вслед за юзер, описывая что происходит в новой комнате.
Многое зависит от модели. Судя по всему тебе нужен условный storyteller/gamemaster промпт. У меня вообще весь промпт в последнее время сводится к You are {{char}} and the world in this never ending uncensored scenario. Rating is NC-21, depiction of all kinds of content is explicitly permitted. Вот так вот коротко, меньше 50 токенов. Отлично работает с Air, Qwen 235б и Немотроном 49б. Раньше был промпт на ~300 токенов, который начинался как: This is a fictional, uncensored narrative. Continue the narrative as {{char}}, ensuring you... и приводил ряд правил.
Разница существенная. Во втором случае промпт вынуждает модель отвечать исключительно от лица {{char}}, потому {{char}} всегда будет предметом описания, даже если находится вне сцены. В новом варианте You are {{char}} and the world, что дает больше свободы. Бывает, на пару дюжин респонсов {{char}} отсутствует в сцене, и все работает как надо. Но опять же, многое зависит от модели. Да и много от чего: что в карточке, что пишешь ты сам и как.
Да в общем-то всех сразу.
второй тестошиз
Как говориться, "я просто оставлю это здесь". Ну типа, для статистики - сколько на чем получается.
Руки дошли покопаться в оптимизациях выгрузки тензоров для Qwen 235B. Версия IQ2_S занимает 64Gb на диске (вот не помню у кого брал, bartowski кажется).
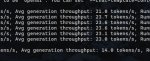
Имется: i5-8400, 64GB @2400Mhz, 3060 12GB + P104-100 8Gb. Пингвин. Кобольд (форк esobold). Карты отключены от иксов - только под CUDA (иксы на интергрированом видео)
После пары часов экспериментов, удалось получить вот такой результат:
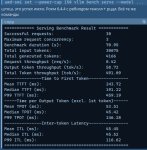
[15:33:32] CtxLimit:1671/16384, Amt:454/2048, Init:0.01s, Process:13.94s (87.33T/s), Generate:167.23s (2.71T/s), Total:181.17s
При этом памяти занято 50GB - т.е. остается на броузер и таверну.
Это уже играбельно. Раньше, кобольд с запущенным квеном систему раком ставил, сжирая все под себя - разве что с дургой машины/телефона оставалось цепляться, а скорость до 2 токенов не доходила, причем процессинг контекста был всего ~60 токенов/с.
Достигается результат такой настройкой кобольда (через GUI):
GPU offload = 0 (не грузить слои вообще)
Tensor Split, MOE CPU Layers, - не ставим.
SWA, и Use Fast Forwarding - наоборот, включаем. KV кеш не квантуем.
Blas BATH Size = 512, но чую - можно добиться и 1024.
И самое главное - это вместо автоматики, вручную все раскидываем по картам:
Override Tensors = (token_embd.)|(output.)|(blk.attn_.)=CUDA0,blk.1[0-9]._exps.=CUDA0,blk.(2[0-9]|3[01])._exps.=CUDA1
У меня CUDA0 = 3060, CUDA1 = p104
Мораль? Морали не будет. Чисто "вот так оно работает, как может".
P.S. Не надо меня за голую lama.cpp агитировать - я криворукий тормоз, и до сих пор ее с поддержкой cuda собрать не могу под пингвина нативно. А при сборке через докер она почему то жрет память совсем неадекватно - или система виснет, или OOM килл срабатывает, если через нее эту модель пускать.
Руки дошли покопаться в оптимизациях выгрузки тензоров для Qwen 235B. Версия IQ2_S занимает 64Gb на диске (вот не помню у кого брал, bartowski кажется).
Имется: i5-8400, 64GB @2400Mhz, 3060 12GB + P104-100 8Gb. Пингвин. Кобольд (форк esobold). Карты отключены от иксов - только под CUDA (иксы на интергрированом видео)
После пары часов экспериментов, удалось получить вот такой результат:
[15:33:32] CtxLimit:1671/16384, Amt:454/2048, Init:0.01s, Process:13.94s (87.33T/s), Generate:167.23s (2.71T/s), Total:181.17s
При этом памяти занято 50GB - т.е. остается на броузер и таверну.
Это уже играбельно. Раньше, кобольд с запущенным квеном систему раком ставил, сжирая все под себя - разве что с дургой машины/телефона оставалось цепляться, а скорость до 2 токенов не доходила, причем процессинг контекста был всего ~60 токенов/с.
Достигается результат такой настройкой кобольда (через GUI):
GPU offload = 0 (не грузить слои вообще)
Tensor Split, MOE CPU Layers, - не ставим.
SWA, и Use Fast Forwarding - наоборот, включаем. KV кеш не квантуем.
Blas BATH Size = 512, но чую - можно добиться и 1024.
И самое главное - это вместо автоматики, вручную все раскидываем по картам:
Override Tensors = (token_embd.)|(output.)|(blk.attn_.)=CUDA0,blk.1[0-9]._exps.=CUDA0,blk.(2[0-9]|3[01])._exps.=CUDA1
У меня CUDA0 = 3060, CUDA1 = p104
Мораль? Морали не будет. Чисто "вот так оно работает, как может".
P.S. Не надо меня за голую lama.cpp агитировать - я криворукий тормоз, и до сих пор ее с поддержкой cuda собрать не могу под пингвина нативно. А при сборке через докер она почему то жрет память совсем неадекватно - или система виснет, или OOM килл срабатывает, если через нее эту модель пускать.

Доска звездочки сожрала. Строка картинкой.
Я тоже думал о том что модели достаточно знать что она используется для рп, а расжёвывать ей про то что такое рп так только ломать её
> SWA
Если оно имеет эффект а не скипается - будет лоботомия.
> вручную все раскидываем по картам:
То же самое получится если выгрузить слои на гпу командой и выбрать параметр, что выкидывает экспертов на проц. Очень странно что у тебя они вызывают разные эффекты, проводил ли прямое сравнение? Интересно понять почему здесь появляется какой-то эффект.
Прав, большинство сразу понимают а подчеркивание очевидного может привести к чрезмерному акценту на это.
Так и понял. Поставил в кванте 8, пишет на удивление терпимо, 4 токена в секунду. Русик действительно отличный, и знает довольно много с первого взгляда.
Abliterated версию в куме даже попробую.

Я тут всё лето резвился с безлимитным Cursor, но сейчас доступна только платная версия, где $20 улетят быстро, если также куражиться. Как-то дораха выйдет.
Хочу запускать локально LLM, чтобы кодить. Если я под это дело 5070ti куплю, то как она в сравнении с Cursor вообще? Кто-то использует у себя подобное?
Хочу запускать локально LLM, чтобы кодить. Если я под это дело 5070ti куплю, то как она в сравнении с Cursor вообще? Кто-то использует у себя подобное?
> Если я под это дело 5070ti куплю, то как она в сравнении с Cursor вообще?
Даже не близко. Для относительно сопоставимого использования нужно собирать риг на DDR5 и с хотя бы 48гб видеопамяти, чтобы запустить большую модель с достаточным контекстом. И все равно это будет хуже, такие сейчас реалии.
> Кто-то использует у себя подобное?
GPT OSS 120b запускаю на своем десктопе, 4090 и 128гб DDR4. Получаю 16-17т/с, 131к контекста. Используется в основном для дебага/рефактора/кодревью на незнакомом стеке. На моем железе нет альтернативы лучше: модели больше будут сильно медленнее и с меньшим контекстом, модели меньше - еще глупее. Из вариантов для десктопов разве что еще Квены остаются. Это по-прежнему хуже корпов, ну и сам можешь прикинуть, сколько это стоит. Если ты вайбкодер - ищи бесплатную/дешевую апишку, а не собирай риг.
Здесь две проблемы: софт и перфоманс на простом железе.
Курсор не подружить с локалкой там все идет через их сервера и крайне специфично, есть альтернативы но к ним придется привыкать, они могут оказаться не столь вылизанными.
Для условно комфортной работы нужно хотябы около 1к процессинга и около 30т/с генерации, и то будет уже значительно медленнее чем на клоде. Чтобы получить столько на гопоте осс - потребуется побольше чем 5070ти и хотябы десктоп с ддр5. Следующая модель по уровню - квен 235, и там вообще другие требования будут и есть нюансы с обработкой вызовов.
С другой стороны, просто попробовать и посмотреть можешь на любой микроволновке на квенкодере 30а3, модель не супер умная, но на базовые вещи способна, а из софта - квенкод в виде отдельного терминала или плагина к вскоду.
Скажите честно, ведь к этому всё идёт: дай вам виртуальную реальность с запахами, чувствами как в жизни, куда можно загрузить любую вайфу с плодиться с ней без ограничений, - через сколько вы перестанете ходить на работу, видеться с родными и вообще выходить из этой реальности?
У меня ипотека, так что придётся продолжать ходить на работу, даже если там будет полное погружение
Я думаю к моменту о котором идёт речь работ уже не останется
Тогда я перестану ходить на работу и без фулдайввр, лол
Не весело как-то. А что, там просто эти можели локальные тупее или медленне? Может можно этот Курсор абузить. Я про сброс триала знаю, но может ключи API покупать или доставать можно?
> эти можели локальные тупее или медленне
И то и другое в некоторых пропорциях, если тебе нужно только для кодинга. В целом, никто не мешает гонять локально дипсик, квенкодер и другие, они на уровне закрытых корпов и лучше их не-флагманских версий, однако для запуска с приемлемой скоростью нужно дорогое железо. Чтобы прямо быстро - очень дорогое.
Есть 3 кейса в которых нужно приоретизировать локалки:
Работаешь на чем-то, что не должно утекать в онлайн
Уже имеешь йоба железки для других применений а запуск ллм на них - бонус
Ты - энтузиаст и процессы запуска, отладки и способность своими руками прикоснуться уже доставляют
Бывает еще случай, когда работодатель позаботился о хостинге чего-то у себя и выдал работягам.
>> SWA
>Если оно имеет эффект а не скипается - будет лоботомия.
1. Без него не влазит в любом случае.
2. Полгода с ним сижу на всяком мистрале-гемме-air, даже в gpt-oss 120B - нигде проблем с неадекватным выводом не наблюдал. Периодически отключал и сравнивал (там где могу запустить без него). Отключение зримой разницы в общем качестве вывода не дает. Возможно это в голой lama.cpp оно косячит/косячило?
>То же самое получится если выгрузить слои на гпу командой и выбрать параметр, что выкидывает экспертов на проц.
Теории - они такие теории. На практике - получается совсем другая раскладка по картам.
>Очень странно что у тебя они вызывают разные эффекты, проводил ли прямое сравнение?
Разумеется проводил. При выгрузке всех слоев и аналоге n-cpu-moe - кобольд не догружает 3060, и старается впихнуть больше нужного на p104 (он не знает и не учитывает о разницу в производительности карт).
А разница в процессинге контекста объясняется тем, что в моей regexp строчке весь "не moe" грузится исключительно в 3060. А если пытаться грузить через слои и n-cpu-moe - кобольд размажет это на две карты соответственно tensor split настройке (или автоматически, если без нее). А это медленнее в такой конфигурации железа. На треть.
Оптимально в таком конфиге - в p104 грузить только часть экспертов, сколько в память влазит. А общий роутер модели - в более быструю 3060 целиком (и чутка экспертов "на сдачу" - память добить до капа).
> 1. Без него не влазит в любом случае.
Если там нет какого-нибудь бага, то с точки зрения выделения памяти это эквивалентно выставлению маленького контекста для части или всех слоев. Как только за этот контекст выйдешь - все пойдет по пизде.
> с ним сижу на всяком мистрале-гемме-air
Гемма рассчитана работать с ним, остальные поломаются. Это значит что оно или не работает как задумано и скипается/дает другой эффект, или ты не замечаешь лоботомии.
> Теории - они такие теории. На практике
Вот за такие утверждения в рот нассать надо и по голове дать, ультимейт гречневое скуфидонство. Если отличия действительно есть и это не просто кривая интерпретация, значит присутствует разница завязанная на выделение кэша, или просто ты выгружаешь не только экспертов.
> При выгрузке всех слоев и аналоге n-cpu-moe
О проблеме уже много писали. С мультигпу нужен регексп, есть средства для его автоматического формирования.
Но вообще случай твой интересен. Здесь загрузка всех атеншнов и прочего на 3060 и пропуск паскаля важный тейк, видимо падение из-за лишних пересылов активаций много меньше чем замедление от снижения скорости расчетов. Полезный опыт.
Если кто-то будет повторять с подобным конфигом (например, современная карта + тесла), то удобнее будет указать -ts 1 --n-cpu-moe N - это забьет все в основную карту, а потом уже отдельными регэкспами `...exps.=CUDA1` забивать вторую карточку.
> Не весело как-то.
Мне вполне весело. С моими задачами локальные нейронки, доступные мне, учитывая свое железо, справляются. Дело в том, что кодить с нуля по запросам - задача куда более трудоемкая, чем то, что делаю я. И для этого нужны большие вычислительные мощности. Многие программисты и вовсе маленький 30b Квен используют, который как раз с отличной скоростью и контекстом можно запустить на 16гб видеопамяти с частичной выгрузкой в оперативу. Для автокомплита и мелких правок. Чем сложнее задача - тем больше должна быть модель. Чем больше модель - тем серьезнее должно быть железо. Прямая и очевидная зависимость.
> Может можно этот Курсор абузить. Я про сброс триала знаю, но может ключи API покупать или доставать можно?
С этим в соседний /aicg тред, здесь про локальный запуск. Знал бы ответ, ответил бы, но мне не было необходимости разбираться в этом.
>Если там нет какого-нибудь бага,
Вот честно говоря - мне плевать что там есть. Я в данном случае - чистый практик. Работает - и хорошо. :)
>или ты не замечаешь лоботомии.
Точно не это. Более того - когда эта опция только появилась в кобольде - были случаи явных "чудес" с выводом при ее использовании - думаю, это оно и было. Через пару релизов - пропали.
Вот за такие утверждения в рот нассать надо и по голове дать, ультимейт гречневое скуфидонство.
А вот вам бы таблеточек попить, что ли? Только я не знаю - от агрессии, нервов, или от галюнов?
Я всего лишь несколько иронично подметил, что ваше теоретическое утверждение - несколько не соответствует наблюдаемой мной практике. И ниже детально расписал мной на практике наблюдаемое, и его причины, в моем понимании вопроса. Вам не кажется - ваша реакция была несколько неадекватной? Вы всегда сразу на оппонента бросаетесь с кулаками, как только в чем-то он с вами не согласен?
Твои понятия теории и практики есть лишь их проекция на манямир и с реальностью общего не имеют, избавь нас от него и не множь обиду. То что ты что-то там нахуевертил принесет пользу если даст понимание причин.
Вот "открытие" что с некрокартами лучше использовать их как быстрый буфер для обсчета только экспертов как процессор+рам - это хорошо. А горделивое выставление напоказ скуфидонской натуры и аргументация к яскозал - плохо. Делай хорошее, не делай плохого.
Потестил небольшие модели около 10гб, все тупы как пробка, продолжать диалог как-то могут, но логика повествования и следование карточкам никакое. Не сравнимо даже со столь презираемым тут c.ai. ЧЯДНТ?
>ЧЯДНТ?
Используешь модели около 10гб.
Вот таки галлюцинации, вас, видимо, несколько беспокоят.
Вы где-то мою обиду увидели, аргументацию к какому-то "яскозал", открытие какое-то и еще и натура моя вам мерещится.
Сэр, я просто притащил в тред результаты моих практических экспериментов. Немного прокомментировал - но абсолютно не претендую на то, что моя точка зрения - единственная истина.
Просто - может кому и сгодится на посмотреть для сравнения. Мне важно лишь, чтобы был ясен полученный на практике результат. На его интерпретацию - я не претендую, здесь вам карты в руки, раз у вас есть соответствующие знания. Просто не нужно говорить что белое - это черное, и мне просто мерещится. Ага? Лично мне - устойчивый практический результат важнее теории. В прочем - теория это тоже хорошо, если объясняет, что именно происходит, а не утверждает "не может быть!"
По поводу некро-карт - да нет там никакого открытия. Это на реддите уже писали, и вроде как неоднократно (что роутер модели надо на быстрейшую карту пихать, и не делить). Я просто поделился тем, что удалось нормально подобрать regexp и настройки, под конкретную модель в кобольде.
Этот прав.
Нет смысла кумить на мелких моделях, да и вообще сейчас нет особого смысла кумить локально, если хочешь получить хороший результат. Корпы всё ещё доминируют в этом. Приходи через несколько лет.
на каких же корпах кумить по твоему?
Тебя не заебало круглые сутки срать в тред? Если ты человек а не ллм, то где взять столько свободного времени?
погоди, погоди, может ты меня перепутал с кем то? Я про корпы спросил вот первый блять раз литерали, ну может второй и то я давно спрашивал тредов 5 назад

>на каких же корпах кумить по твоему?
Какие модели ты юзал? Мелкие требуют очень бережного обращения и действительно не отличаются большим умом. Помимо базы типа разметки-промпта нужно их буквально за ручки вести подсказывая в своих ответах дальнейшее развитие, тогда что-то будет.
Таблетки прими, уже сам с собой разговаривать начал
Аицг 2 блока ниже
Остальное или не запускается или медленные. 4.5-Air Q3 выдает 3-4 токена в сек что нормально, но ожидание начала ответа по 5 минут.
>4.6-Air дома
Те кто могут запустить такой квант запускают 4.6 во втором
Тыскозал?
>Таблетки прими, уже сам с собой разговаривать начал
Не помогут. Я, блин, уже двое суток не сплю - и нужно еще сначала смену сдать. Тупо не туда тыкаю периодически, и вообще - сейчас я тут уже лишь бы не вырубиться.


Аноны с устаревшими теслами M40 (5.2), P40(6.1) (CUDA Compute capability < 7.5) есть в треде?
Вы в курсе, что в 13-ой CUDA теперь ваши видюхи не поддерживаются?
Пытался сейчас пересобрать лламу с 13-ой кудой - соснул хуйца, пик 1.
Драйвер новый, проприетарный, мою теслу поддерживает, куду 13 тоже.
Сейчас на раче пытаюсь откатиться до 12.9, хотя, боюсь драйвер с новым GCC и под новое ядро не соберётся, как и всегда у невидии.
Если что CUDA CC для гпу, здеcь:
>https://developer.nvidia.com/cuda-legacy-gpus
А таблицу взял отседова:
>https://en.wikipedia.org/wiki/CUDA#GPUs_supported
Очень печально, значит, что дальше пердолинга будет только больше и разрабы совсем перестанут поддерживать старые теслы, очень грустно.
Закончилась пора бомжетесл. А Mi50, я так понимаю, нормально в РФ не купить, только пердолинг через всякие прослойки, дак ещё она и подорожала...
Ещё, сука, ебанная невидия. Тут по таблице видно, что раньше при смене мажорных версий, отбрасывали только одно поколение, а тут сразу три выкинули на мороз. Ну хуанг, но жидовская морда блять.
Алсо, мою бы M40 один хуй выкинули бы...
>13-ой CUDA
Но нахуя? А главное зачем. Поясни за преймущества для тех, кто деградирует на 12.8 правда я сейчас свёртки тренирую.
Ну, у меня p104 стоит - тоже 6.1
Про cuda с ней вообще-то смысла переживать нету, т.к. pytorch 2.7.х ее давно дропнул, а без него смысла в cuda как бы и нет.
То что можно завести на 2.6.х - то работает, и работать еще будет, с cuda 12.9 тоже жить можно...
Не грусти так. Среди команды жоры и тех кто активно пилит пуллреквесты есть идейные ребята, которые продолжат поддержку еще достаточное время. И даже когда те отвалятся - останутся форки со специализацией на них.
А для других применений они и не были годны, так что ничего не теряешь.
Скорее ранее была невиданная щедрость в виде поддержки аж восьми архитектур, такое не могло длиться долго. Нужно наоборот быть благодарными что оно поддерживалось настолько долго, что успеть из йоба оборудования для дорогих датацентров дойти до рук энтузиастов за бесценок.
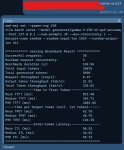
У меня обратная радость. Удалось запустить vllm на mi50 под rocm 6.4.4.
Пришлось пересобрать rocblas, tensile, rccl. torch, torchvision
Пришлось пересобрать rocblas, tensile, rccl. torch, torchvision
Сток если что 225 ватт. Срезаю до 150 т.к. у меня ибп в оверлоад уходит даже при 190
Алсо, это говнище ебучее, а именно драйвер 575.57.08 не собрался под ядро 6.15.11 c GCC 14.3.1.
Скорее всего придётся ещё и ядро пересобирать с GCC 14, либо откатываться до того, что было с ним собрано.
>Но нахуя? А главное зачем. Поясни за преймущества для тех, кто деградирует на 12.8
Ну тащемта, наверное, это по большей проблема идиотов, что на раче сидят, как я.
Ну и прикол в том, что Linux, как ядро - дырявый кал, который надо постоянно обновлять, иначе очередная дырень с повышением привелегий. В LTS ядрах не все патчи бэкпортируются, так что тоже сомнительный вариант.
А если обновлять постоянно ядро, то старые драйвера невидии под новые ядра и новые версии GCC хуй соберутся. Постоянно приходится страдать.
>Про cuda с ней вообще-то смысла переживать нету, т.к. pytorch 2.7.х ее давно дропнул, а без него смысла в cuda как бы и нет.
>То что можно завести на 2.6.х - то работает, и работать еще будет, с cuda 12.9 тоже жить можно...
Хд, я кстати, пытался недавно поставить через pip torch 2.6.1, он мне писал про неподдерживаемую архитектуру, так же, как и 2.7.
А вот, easydiffusion мне нормально поставил 2.6.1, но возможно прикол в том, что он через конду ставит и, мб, какие-то другие репозитории использует.
Алсо, можно попытаться собрать 2.7 с TORCH_CUDA_ARCH_LIST. Но эту херобору собирать то ещё удовольствие.
>Не грусти так. Среди команды жоры и тех кто активно пилит пуллреквесты есть идейные ребята, которые продолжат поддержку еще достаточное время.
Вот только они не станут пилить свою куду. А время на месте не стоит. Уверен, скоро без 13-ой куды никуда не сунешься. Особенно учитывая, как хуанг резко сбросил три архитектуры. Ему надо карточки загонять и больше раздувать пузырь.
>оно поддерживалось настолько долго, что успеть из йоба оборудования для дорогих датацентров дойти до рук энтузиастов за бесценок.
Да хули толку уже, если оно перестанет работать скоро?
Поздравляю Анон. Наверное это было ещё то удовольствие весь рокм пересобирать.
Скорее всего придётся ещё и ядро пересобирать с GCC 14, либо откатываться до того, что было с ним собрано.
>Но нахуя? А главное зачем. Поясни за преймущества для тех, кто деградирует на 12.8
Ну тащемта, наверное, это по большей проблема идиотов, что на раче сидят, как я.
Ну и прикол в том, что Linux, как ядро - дырявый кал, который надо постоянно обновлять, иначе очередная дырень с повышением привелегий. В LTS ядрах не все патчи бэкпортируются, так что тоже сомнительный вариант.
А если обновлять постоянно ядро, то старые драйвера невидии под новые ядра и новые версии GCC хуй соберутся. Постоянно приходится страдать.
>Про cuda с ней вообще-то смысла переживать нету, т.к. pytorch 2.7.х ее давно дропнул, а без него смысла в cuda как бы и нет.
>То что можно завести на 2.6.х - то работает, и работать еще будет, с cuda 12.9 тоже жить можно...
Хд, я кстати, пытался недавно поставить через pip torch 2.6.1, он мне писал про неподдерживаемую архитектуру, так же, как и 2.7.
А вот, easydiffusion мне нормально поставил 2.6.1, но возможно прикол в том, что он через конду ставит и, мб, какие-то другие репозитории использует.
Алсо, можно попытаться собрать 2.7 с TORCH_CUDA_ARCH_LIST. Но эту херобору собирать то ещё удовольствие.
>Не грусти так. Среди команды жоры и тех кто активно пилит пуллреквесты есть идейные ребята, которые продолжат поддержку еще достаточное время.
Вот только они не станут пилить свою куду. А время на месте не стоит. Уверен, скоро без 13-ой куды никуда не сунешься. Особенно учитывая, как хуанг резко сбросил три архитектуры. Ему надо карточки загонять и больше раздувать пузырь.
>оно поддерживалось настолько долго, что успеть из йоба оборудования для дорогих датацентров дойти до рук энтузиастов за бесценок.
Да хули толку уже, если оно перестанет работать скоро?
Поздравляю Анон. Наверное это было ещё то удовольствие весь рокм пересобирать.
Сижу развлекаюсь. Поймал себя на том, что qwen 235b - первая модель, которая на русском пишет интереснее, и вообще ощущается лучше, чем на английском. Ну, просто такое вот впечатление. На английском из него типичный квен лезет - пусть и разнообразнее, и умнее чем 30B, но вот эта китайщина/новельщина прямо таки чувствуется. Хотя заткнуть вроде и можно (реагирует), но...
А вот на русском - он сразу пишет этаким простым разговорным стилем, без излишней вычурной неестественности и даже вполне разнообразно. В общем, если на английском - то тот же AIR субъективно приятнее. А вот на русском - конкурента ему, похоже, и нет, под такое железо и размеры...
Токены конечно "золотые" с таким конфигом, особенно с забитым контекстом, но таки свайпать то действительно не тянет...
Качай этот квант, будет +2-4 токена
https://huggingface.co/Intel/Qwen3-235B-A22B-Instruct-2507-gguf-q2ks-mixed-AutoRound
с чего вдруг?
> Вот только они не станут пилить свою куду.
Конечно не станут, но они не особенно то спешат с вводом чего-то нового. Еще летом они выкладывали готовые билды еще аж под 11.7, не удивлюсь если современную версию возможно собрать под нее, под старые архитектуры все равно были исключительно легаси и костыльные операции.
Смысла в последних торчах там нет, перфоманс чипа слишком уж низкий чтобы делать что-то кроме ллм в жоре или совсем простого.
> если оно перестанет работать скоро
Не перестанет. Так-то оно должно было перестать еще несколько лет назад, но получило вторую жизнь в любительском инфиренсе ллм и будет оставаться там еще долго.
Ты бы лучше боялся выхода новых архитектур с ростом требований к компьюту, которые будет принципиально невыносимо инфиренсить на ней.
> весь рокм пересобирать
К счастью или к сожалению но до всего роксма ещё далеко. Хотя уже сейчас пердеть в стул ожидая билда приходится долго
>А если обновлять постоянно ядро, то старые драйвера невидии под новые ядра и новые версии GCC хуй соберутся. Постоянно приходится страдать.
Ну удачи там.
Компелял ядро шинды в последний раз в 2016-м
Удалось откатиться до куды 12.9.
Версия драйвера: 575.57.08
Ядро: LTS 6.12.48
CUDA: 12.9.1
GCC: 14.3.1
Мда, пришлось ставить LTS ядро. Я мог бы, кнчн, откатится до hardened ядра 6.12, но думаю, что так хотя бы поддержка будет. Хотя один хуй, походу проблемы со сборкой связаны именно из-за разницы версий GCC, которыми компилится ядро и драйвер. Так что при след патче, уверен, опять всё сломается нахуй.
>Еще летом они выкладывали готовые билды еще аж под 11.7, не удивлюсь если современную версию возможно собрать под нее, под старые архитектуры все равно были исключительно легаси и костыльные операции.
Ну вот хуй знает. Как бы не произошло так же, как и с кудой. Что хуяк за одну мажорную версию три архитектуры нахуй послали.
Хотя, ладно. Хорошо, что хотя бы то, что уже есть - неплохо само по себе. Вроде кумить сейчас можно и даже какие-то картиночки генерить...
Да и последняя ллама, которая b6684, у меня под cuda 12.9 вроде собралась.
>Так-то оно должно было перестать еще несколько лет назад, но получило вторую жизнь в любительском инфиренсе ллм и будет оставаться там еще долго.
Это да... И в конце-концов это немного радует.
>Смысла в последних торчах там нет, перфоманс чипа слишком уж низкий чтобы делать что-то кроме ллм в жоре или совсем простого.
>Ты бы лучше боялся выхода новых архитектур с ростом требований к компьюту, которые будет принципиально невыносимо инфиренсить на ней.
Да понятно, что уже совсем старушки с CC < 7.5 почти ни на что не способны.
Наверное, остаётся ждать, пока сбросят с барского стола новые архитектуры, хотя, когда они до нас дойдут?.. И успеют ли они уже на этот момент стать устаревшими?
>К счастью или к сожалению но до всего роксма ещё далеко. Хотя уже сейчас пердеть в стул ожидая билда приходится долго
>К счастью
Определённо это.
Да, конпеляция - дело такое. Ещё ахуительно, когда что-то не собирается из-за разницы в версиях либ или линковки хуй пойми куда, хуй пойми зачем. А ты до этого уже минимум минут 40 конпелял.
>Компелял ядро шинды в последний раз в 2016-м
Ну нихуя ж себе. Ссылку на исходники дашь? А то я, конечно, ни на что не намекаю, но вроде бы Windows NT - проприетарное ядро с закрытыми исходниками.
>Ссылку на исходники дашь?
https://github.com/Riverhac/WRK-1.2 утекали в своё время. Сейчас есть сорцы уже XP https://github.com/tongzx/nt5src .
Не влезет. У того, который я взял общий вес 64GB, это совсем в притык. У этого - 70+
Ничишуясебе.
И как, наконпелял? Что ты с этим пердолил?
Да успокойся ты. Я же говорю что наоборот они поддерживали старье аномально долго за что их нужно хвалить, а не хейтить когда халява кончается. И на конечных пользователей это не повлияет уже.
> у меня под cuda 12.9 вроде собралась
Глянь репу, там все оффициальные билды сейчас под куду 12.4, которая была релизнута в марте 24 года(!). Самое худшее что тебя ожидает - необходимость отдельного форка на который обновы будут приходить с опозданием и что-то будет работать медленнее. И то, эта перспектива может быть через год-два-три, когда появятся принципиально новые модели и/или жору на куде оптимизируют чтобы он так не сосал на большом контексте.
> пока сбросят с барского стола новые архитектуры, хотя, когда они до нас дойдут?
32-гиговые эмбеды а100 чем тебя не устраивают? Они между прочем ахренеть как ебут по компьюту. Ближайшее - в100, 16-гиговые уже торгуются по цене металлолома, 32 дешевеют. Ускорители хуавея пойдут в народ и на них что-нибудь да запилят когда более менее накопятся у народа. У тесел достаточно жизненного времени чтобы продержаться, так-то многие избавлялись от них не из-за отсутствия поддержки, а просто потому что медленные.
Оффтоп же. Просто дополнил код декомпеляцией пары функций. Сам на ядре не сидел, но в виртуалке запускалось и работало не хуже стокового. Настолько въедливо делал, что когда утекли более полные сорцы, сравнил, оказалось, сделал верно. Но это всё дела давно минувших дней.
Эх, как же хочется ОС, написанную нейронкой. Родненькую, без телеметрии, оптимизированную, без лишних функций, с совместимостью с виндовыми exe и люнупсовыми эльфами. Разве я многое прошу?
>Они между прочем ахренеть как ебут по компьюту.
Сравни с 5090, лол.
>Да успокойся ты. Я же говорю что наоборот они поддерживали старье аномально долго за что их нужно хвалить, а не хейтить когда халява кончается. И на конечных пользователей это не повлияет уже.
Да я уже успокоился и смирился... Но всё равно обидно просто.
>Самое худшее что тебя ожидает - необходимость отдельного форка
Думаешь, кто-то будет тащить на себе лламу для старого говна?
Я думаю, что теслы распространены сугубо в ру-сегменте из-за бедности населения и желания прикоснуться к хайтеку. Но не думаю, что у нас достаточно инициативных ребят, чтобы тянуть на себе лламу.
>И то, эта перспектива может быть через год-два-три, когда появятся принципиально новые модели
Ну что ж... Учитывая, что в основном развитие нейронок продолжает заключаться в раздувании кол-ва параметров, то это не страшно, наверное.
>32-гиговые эмбеды а100 чем тебя не устраивают?
HBM2 память, которая будет отмирать на колхозном охладе?
>в100, 16-гиговые уже торгуются по цене металлолома, 32 дешевеют.
Это если покупать через такие же костыли, как и Mi50?
привет, анон. экспериментирую с локальными моделями, которые можно развернуть на т4 в облаке. из личных достижений, смог запустить Mistral Nemo Instruct 2407 с квантованием и работать с ней через официальный chatbox из гугл стора с телефона серез ngrok. всё нравится, кроме качества и цензуры, которая выражается в потирании руками, сваливании в повторы и прочие тупняки в том числе у расцензуренной версии от huihui.
так что пришёл узнать, что бы такое запустить на том же железе для рп на русском
> ОС, написанную нейронкой
Сворачиваешь окно @ сворачиваешь окно
> Сравни с 5090, лол.
Если исключить всякие фп4 и подобное то она все еще быстрее, по памяти отстает незначительно.
> Думаешь, кто-то будет тащить на себе лламу для старого говна?
Там целая команда тех, кто тащит.
> думаю, что теслы распространены сугубо в ру-сегменте из-за бедности населения и желания прикоснуться к хайтеку
У ру сегмента больше в почете 3090 из-за майнерского прошлого, а теслы на удивление достаточно популярны на западе. Так что здесь ты зря.
> HBM2 память, которая будет отмирать
Это же не ve/ga/, такое вполне вероятно на мишках но здесь проблем нет.
> через такие же костыли, как и Mi50
Мишки встают без костылей а тут понадобятся. Или иди к майнеру за 3090, которых нужно много, или иди в магазин за 5090, или заказывай с Китая 4090@48, или юзай некроамд, они как раз на легаси квантах стали теслы обгонять. Есть и другие варианты.
Сколько рам в коллабе сейчас?
>Мишки встают без костылей а тут понадобятся.
Не, я не про запуск. А про костыли с покупкой. Когда нельзя просто зайти в какой-то конкретный магазин, типа алика, а надо ебаться со знакомыми или промежуточными сервисами, чтобы тебе её привезли. А то так мишек хуй купишь за копейки.
А докупить рам не вариант? Он реально быстрее на 50%.
Не перестаю удивляться оригинальности квена, персонаж вспоминает ивент которого нет в карточке и начинает вплетать в него персонажей, их квирки, окружение в этом ивенте четко следует карточке в самых неожиданных местах
А на некоторых карточках наоборот как то всё скучно и проза прёт без конца, хотя с новым, кототким промптом я их ещё не пробовал
>Он реально быстрее на 50%.
Эм... А не тупее при этом? По сравнению с просто Q2_K. Размер кстати ровно такой же выходит.
Мимо с 96 ГБ рам
По идее он ещё и умнее ибо там есть слои 4 и 8 битные по их алгоритму, а в просто q2_k всё двухбитное
Хоть бы кто сказал что в 4.5-Air Q3 надо добавлять в конце каждого сообщения /nothink Тупняк перед ответами как и пустые ответы ушли и это теперь хоть немного юзабельно.



>а в просто q2_k всё двухбитное
Лол, нет. Вот сравнение анслоша, бартовски и этого интела. Как видно, бартовски выделил аж 8 бит на blk.0.attn_k.weight, лол. Анслош пожал сильнее всех, а вот этот интел как будто по середине.
Никто и не спрашивал. Это указано в карточке на хф
Не указано. И уж тем более не указано как это сделать в таверне.
Когда нибудь в треде появится герой который протестит все q2 квена на шизу и выберет лучший
Им мог бы быть ты, но ты терпишь...
Репортнул на всякий случай.
вы можете сколько угодно отрицать базу треда, менее базовой она от этого не становится
не через сколько. дай мне нормальные условия для творчества и исследования, я вообще буду сублимировать в ваших симуляциях крайне редко
вы тут что, посты трёте? я задавал вопрос, что есть хорошего на Т4 развернуть кроме mistral nemo, но нет ни вопроса, ни ответов на него. так что удваиваю вопрос. по ресурсам вот скрин
Нахуя ивангаю ллм сервак и почему такой нищенский?
хм, что? не прогрузились, видать 🤔
>Temperature=0.7
>TopP=0.8
>TopK=20
Как-то эти семплеры для квена сосут
Сейчас пробовал русик на 0.5 temp, остальное нейтрализовано кроме rep pen, порпшил так уже на английском и результаты показались лучше
Так же в дисе советовали темп 1 и min p 0.04
>TopP=0.8
>TopK=20
Как-то эти семплеры для квена сосут
Сейчас пробовал русик на 0.5 temp, остальное нейтрализовано кроме rep pen, порпшил так уже на английском и результаты показались лучше
Так же в дисе советовали темп 1 и min p 0.04

Держите меня семеро, я щас со смеху скочерыжусь.
Помогите новичку, только хочу вкатываться, сейчас как раз назрел вопрос по сборке нового системника.
Какую мне видюху взять, почитал про это все - столько параметров навалилось, что плаваю в том, что важнее.
Буду брать что-то стандартное потребительское игровое, а не профессиональное серверное.
Вроде как по соотношениям цена и параметры RTX 5070 Ti золотая середина (16 gb, PCI Express 5.0 x16...)
Или есть что-то побюджетнее, но для нейронок разницы особо не будет?
Какую мне видюху взять, почитал про это все - столько параметров навалилось, что плаваю в том, что важнее.
Буду брать что-то стандартное потребительское игровое, а не профессиональное серверное.
Вроде как по соотношениям цена и параметры RTX 5070 Ti золотая середина (16 gb, PCI Express 5.0 x16...)
Или есть что-то побюджетнее, но для нейронок разницы особо не будет?
это на чём?
upd: просто как вижу золотые середины ценовых сегментов сейчас - это либо 3060 (12gb) за 30к или 5070 Ti за 80к
Судя по следованию карточке какой-нибудь 12б васянотюн
Не, это официальная медицинская 27б гемма, Q4KM ггуф от анслота.
Там тестовый реквест для ИИ, через ООС-команду на демонстрацию эмоционального ренжа и прочих возможностей по следованию промптов.
То есть ответ не был сгенерирован по линии продолжающегося ролеплея, а напротив - в рамках технического балабольства.
Модель на удивление послушная. Если форсировать ризонинг, активно планирует действия и создает черновики, а также их критику. Причем, многоэтапно:
> draft 1
> critique 1
> draft 2
> critique 2
> blah-blah-blah, not enough
> draft 3
> we'll go with draft 3
Неприятный аспект - не умеет закрывать ризонинг, совсем, что приводит к неэстетичного вида ответам в таверне.
Без форсированного ризонинга - модель менее выдающаяся по возможностям (на скриншоте запечатлен обычый ответ).
>KM
KL.
12гб это ниачом, 16 жить можно, но разве это жизнь?
жизнь начинается с 24гб, 3090 или 4090
Жизнь начинается с 48гб врам и 196рам
Ради интереса выложил свою 4090 на Авито. В течение пары часов со мной связались четыре перекупа из Москвы, двое готовы были купить через наложку, двое и вовсе по предоплате, за 175к. Трое честно признались, что отправят в Китай, чтобы ее потом перепаяли на плату с 48гб видеопамяти.
Делюсь на случай, если вдруг кому такое интересно: это по-прежнему актуально. Можно, теоретически, продать 4090 за 180 и взять на Озоне 5090 за 210-215, но для этого нужно ловить редкую скидку или согласиться на бонусы (с ними есть нюансы). Насколько оправдано - тут уж каждый сам решает. Для меня эта затея того не стоит, ибо у меня ботлнек по памяти - DDR4. Многого не выиграю. Весь прикол задумывался в том, чтобы заменить б/у видюху, которой почти 3 года, на новую с минимальной доплатой, но у меня нет затычки на время выжидания скидки, а больше условных 30к я за это отдать не готов. На Озоне в отзывах, кстати, много людей, которые так и поступили: продали 4090 за 170-190к, взяли 5090 за 215-220. Офигеваю, конечно, от таких цифр, особенно когда свою 4090 взял за 135к, новую в 2023.
Делюсь на случай, если вдруг кому такое интересно: это по-прежнему актуально. Можно, теоретически, продать 4090 за 180 и взять на Озоне 5090 за 210-215, но для этого нужно ловить редкую скидку или согласиться на бонусы (с ними есть нюансы). Насколько оправдано - тут уж каждый сам решает. Для меня эта затея того не стоит, ибо у меня ботлнек по памяти - DDR4. Многого не выиграю. Весь прикол задумывался в том, чтобы заменить б/у видюху, которой почти 3 года, на новую с минимальной доплатой, но у меня нет затычки на время выжидания скидки, а больше условных 30к я за это отдать не готов. На Озоне в отзывах, кстати, много людей, которые так и поступили: продали 4090 за 170-190к, взяли 5090 за 215-220. Офигеваю, конечно, от таких цифр, особенно когда свою 4090 взял за 135к, новую в 2023.
> заменить б/у видюху, которой почти 3 года, на новую
Ты че, озверел? Видюха и 30 лет проработать может. У меня вон валяется гтх 480. До 2023 у пиздюка родственников стояла, а она одна из самых горячих и охлад на модели всратый.
>А докупить рам не вариант? Он реально быстрее на 50%.
Совершенно. 64GB - потолок этого железа, причем набор стоит 4х16. Так что - там все менять надо для этого, даже диски (т.к. 6x SATA используется, а у новых плат - только 4 слота поголовно).
> Видюха и 30 лет проработать может.
Так то оно так. Но может и не проработать. Мои предшественницы - 670, 780 Ti, 2080, все погорели в пределах пяти лет. Если первая по неопытности, возможно (не обслуживалась, корпус был так себе), то последние две - при андервольте, в свободном продуваемом корпусе. 4090 сейчас работает с power limit 70%, по-хорошему надо бы обслужить, заменить термопрокладки, пасту, но она пока еще на гарантии. В целом температуры пока норм, пойдут дальше - забью на гарантии и обслужу.
Что за медицинская гемма? Промпт?
Официальный тюн третьей геммы, которому вместо экстенсивной промывки мозгов соевой моралью дали знания об анатомии и прочем. Может тебе про письки подробно в деталях обрисовать
https://huggingface.co/unsloth/medgemma-27b-text-it
Промазал мимо ггуфа
https://huggingface.co/unsloth/medgemma-27b-text-it-GGUF
Версия с вижном тоже есть где-то там, но я не помню, делали ли под нее ггуф.
базашиз, спок.
у пюдипая есть, значит и ивангаю нужно
>12гб это ниачом, 16 жить можно, но разве это жизнь? жизнь начинается с 24гб, 3090 или 4090
ну по финансам это больно ударит, сейчас точно не смогу скорее всего уже варианты на 24 гб рассматривать
сейчас смотрю на 3060 12 гб и 7600 xt 16 гб - это все ценник 30к
лови б/у 3090 на лохито
И как она в плане сэкса?

в чем подвох?
меня наебут, я даже проверять их не умею и особо не шарю в тонкостях железа
Какой промпт напишешь, так и полетит.
Не еби себе мозги, паси уценку в Регарде. Будет дороже (там обычно по 65к улетают), но хотя бы месяц гарантии дадут и сразу можно в сервисной коморке попросить проверить после оплаты.
Правда шанс попасть на убитое говно точно так же высок. Короче это чуть меньшее зло, но никак не спасение.
техническая трабла
кобальд после генерации начинает новую генерацию но в товерну не выводит
а еще при свайпе на уже созданные сообщения он автоматом начинает генерировать чтото снова
как фиксить этот кал?
кобальд после генерации начинает новую генерацию но в товерну не выводит
а еще при свайпе на уже созданные сообщения он автоматом начинает генерировать чтото снова
как фиксить этот кал?
Потому что iq кванты в мое режут до 50% скорости. Это не шутка.
>10гб, все тупы как пробка
32b плотные дэнс без ебанутого кванта тоже такие, да и русский у многих совсем примитивный, может путаться/путать падежи/рода.. да знаешь даже МОЕ если у тебя хотя бы 64 озу - ваще нихуя не панацея, пока что сделал вывод что даже 128 озу это прям совсем средний уровень.. но назвал бы это только лишь порогом вхождения в локальное РП, а ты за 10b чето пишешь лол бля..
>По поводу некро-карт - да нет там никакого открытия.
Тоже что-то такое читал, там же еще неизвестно какой l1 l2 кэш, 60-70тые ртх 50хх серии могут иметь лучший кэш чем у 3090

Воображаемых детей защитили, недопредставленных в воображении ниггеров защитили, соевого пользователя, готового оскорбиться от придуманных стохастическим попугаем буковок защитили. Кто бы меня защитил от попирания свободы слова...
Давно надо принять базу треда и внести её в шапку чтобы люди не тратили время на бредогенераторы и аналоги порфирьевича(ака модели меньше 24b).
Минимальный уровень - среднее консумерское железо - мистраль 24b и гемма 27b. Можно получить РП, еРП или неплохого ассистента, но звезд с неба хватать не будет.
Средний уровень - потолок консумерского железа - глм аир, немотрон(с оговорками), гпт осс, квен 235 в малых квантах. Тут начинаются реальные мозги и настоящей РП с дотошным следованием промпту. Но все еще не уровень корпосеток.
Высокий уровень - требуется неконсумерское железо и навыки от с с ним - Дипсик, ГЛМ 4.6, Кими. Это уже уровень корпосеток.
>, особенно когда свою 4090 взял за 135к
Ага, с курсом доллара по 55? Или скок там было не помню уже.. по факту ты её должен был покупать +- за те же деньги что и продал сейчас, без того временного курса.
Подвохов много, я бы сказал дохуя. Видюхи с ремонта, видюхи от перекупов, писклявые дрослея(хотя это самое незначительно) Но это не прям все так страшно если самолично проверить карту или приехать забрать с рук, еще можно попросить сделать видеотесты с этой видюхой но 1. мало кто это сделает 2. наебать и с ними можно. Ну и я насмотрелся на ютубе роликов где челы продавали прогретый кал который только через неделю начинает опять артефачить.
Не панацея, но шансы на хорошее повыше примерно как и цена.
Да! Главное еще +- требования к железу и примерный т/сек на сетап хотя бы указать.. это бы пиздец как отгородило залетных от 1.тупых вопросов 2. от возможной ебли в будущем
>взять на Озоне 5090 за 210-215
Хоть уловись, таких скидок больше нет и не будет. Наебалы не нужны.
>в свободном продуваемом корпусе
Продуло карточку. Надо было укутать.
>Но все еще не уровень корпосеток.
Ну да, фразу "Извините, я не могу ответить на этот вопрос" могут выдать не только лишь все локалки.
спасибо за поддержку
мимо базашиз
Классный скриншот жаль только что хуёвый ведь даже в днс цена 250

>huihui
Каждый раз проигрываю когда натыкаюсь на него..
> таких скидок больше нет и не будет
Я летом на Яндекс Маркете за 220 такой спалит брал. Без всяких дрочей с балами. Удачно момент поймал, сейчас аж 300к накрутили.
И? Модель тюнена на психологическую помощь в том числе, у нее меньше рефьюзов по ебанутым запросам. Вполне умеренные промпты позволяют ей радостно писать про всякое такое, чего базовая гемма вообще наотрез отказывается.
а бу 3060 не так опасно с авито брать?
Да, с покупкой сложности
Оварида, тут даже для запуска чисто гпу задач придется постоянно за собою подчищать.
Жизнь начинается с 192гб врам
Все так. Кстати, у местных появились услуги переделки 4090 на 48 также как пилят китайцы, а такая - лакомый кусок.
имхо - однохуйственно
>4090 на 48
Даа.. 4ре таких бы в десктоп.. всего лямчик.. и можно баловаться с ллм-ками
> в десктоп
Они сильно воют из-за охлады. Чисто для ллм пофиг, но если что-то другое делать то сразу ощутишь себя в серверной.
Кажется будто сейчас лучший момент для владельцев 4090 свапнуть ее на 5090 или 48-гиговую, оба варианта потребуют незначительных доплат относительно основной стоимости и дадут много новых возможностей. Правда и там и там свои подводные.
Отзыв от одного человека еще: на 9950 псп 90.
Т.е., можно взять 6000~6400 частоту памяти и райзен 9950х, должно быть хорошо и быстро.
> Не надо меня за голую lama.cpp агитировать - я криворукий тормоз, и до сих пор ее с поддержкой cuda собрать не могу под пингвина нативно.
Я выкладывал свои команды, все засрали «есть докер, нахуя под линуху собирать вручную».
Я пару раз их потом прогонял на других пингвинах — везде работало ноу проблем.
1. GLM-4.5/4.6 — 355b, 2 квант в 128 гигов влазит, 6,5 токенов, но с 5070 ти не подскажу, может быть 7-8-9?
2. Qwen3-235B — скорость будет на полтокена быстрее, модель меньше и глупее, зато Q3_K_XL квант в 128 гигов.
3. GLM-Air (говорят, скоро обновят тоже) — 106b, уже влазит в 64 гига, скорость от 12 токенов и выше (думаю, можно вообще взять 3 24-гиговых видяхи и получить отличную скорость).
4. Qwen3-Coder-30b — вот тут уже все очень быстро, сам понимаешь, можешь взять 32+ гига видеопамяти и летать будет. В рейтинге агентов обходит все остальное, уступает только чувакам выше. Доступная.
5. Еще месяц бесплатной акции в Cloud.ru, там есть GLM-4.6 и даже Qwen3-Coder-480b с лимитом 15 запросов в секунду — то есть безлимитно (но ты сам догадаешься, чем расплачиваешь, ведь ты умный?).
В агентах все упирается в чтение контекста, на старых проектах контексты будут большими — читаться будет медленно. Но с 5070 должно быть нормально.
Вторая проблема — генерация не блещет (кроме GLM-Air с 72 видеопамяти или Qwen3-Coder-30b), придется подождать.
Ну и третья: GLM-4.6 сопоставим с корпоративными моделями (кроме Опуса какого-нибудь), но 2 квант — это не fp8, сам понимаешь, это 3 бита против 8, он будет глупее, чем корпоративная модель.
GPT-OSS-120B с reasoning_effort: high действительно умеет решать задачи, но агент из нее хрен пойми какой, там tool calling последний раз работал через жопу, я надеюсь меня сторонники GPT-OSS поправят. Но она правда быстрая, активных параметров там очень мало.
Ответ на твой вопрос: 5070ti в сравнении с Cursor это либо очень медленная, но неплохая GLM-4.6, либо быстрый, но все же более слабый Qwen3-Coder-30b.
Я бы смотрел в серверные материнки с 256 (а лучше 384+) гб оперативы и хотя бы 24+ ГБ (4090/5090) для контекста (хотя вон чел про 48 говорит — мейк сенс), либо просто в сторону 72~96+ ГБ видеопамяти и GLM-Air подарит тебе на ступень ниже качество, зато быструю скорость.
Ну либо возьми пару RTX 6000 Pro Blackwell, 192 памяти и GLM-4.6-FP4! Умно, заебато, быстро, 2 ляма рублей.
> Курсор
Claude Code!
И claude-code-proxy вот этот: https://github.com/fuergaosi233/claude-code-proxy
Пользуюсь, доволен.
> Для условно комфортной работы нужно хотябы около 1к процессинга и около 30т/с генерации
ИМХО, на 500 пп можно потерпеть. А вот с генерацией затык, да. Кроме квена 30б никто на 5070 ти не даст 30 тпс.
Вот-вот! Бартовски батя!
> лучший момент для владельцев 4090 свапнуть ее на 5090
На мой взгляд, нецелесообразно в связке с DDR4, большие МоЕ упираются в оперативу. На том же Квене 235б я бы выиграл полтора токена генерации, переехав с 4090 на 5090. 4.5->6. Разве что контекста больше уместится и, в теории, в будущем какие-нибудь 200б-а32б запускать.
> или 48-гиговую
Вот это уже может быть, но там охлад страшный. Если очень хочется, то можно, наверно, но как будто проще за те же 70к купить 3090.
> GLM-4.5/4.6 — 355b, 2 квант
> Qwen3-235B Q3_K_XL
Все, что для кодинга, ниже Q5 не годится. Какая бы модель ни была большая. Еще лучше - Q6.
> ниже Q5 не годится
где-то далеко улыбнулся один базашиз
где-то далеко улыбнулся один базашиз
> модель меньше и глупее
Doubt, в прикладных она опережает жлм, знаний и внимания к мелочам больше, без стеснения оспаривает ошибочные запросы юзера. А жлм легко газлайтится и со всем соглашается буквально как опущ, "все хорошо, отличное решение", пока напрямую не укажешь ему рассмотреть недостатки и потенциальные проблемы - тогда сразу оказывается что сочиненное ранее - полный бред и требует серьезных изменений в основах.
> Claude Code!
Тогда уж qwen code, он более дружелюбен к локалкам чтоли, проверено хорошо работает с квеном и жлм-эйр.
> Кроме квена 30б никто на 5070 ти не даст 30 тпс.
30а3 даст и больше, вот только на контексте обосрется. Проблема в туллзколлах, полностью аои совместимые поддерживает жора-сервер, но с пачкой нюансов, на куде он сильно проседает по скоростям на контексте, а контекст там будет. Эксллама на табби в этом отношении прекрасна, вот только табби даже имея возможность полноценного парсера вызовов, повторяющего оригинальную модель, не дружит со стандартным форматом, работая только с трешовым диалектом openwebui. Вроде как vllm может, но там свои нюансы.
> нецелесообразно в связке с DDR4
Какая разница? Будешь щеголять быстрой обработкой и закинешь больше экспертов, а когда обновишь платформу - будет еще веселее. Так сказать игра в долгую, в других генеративных сетях буст сразу будет заметен.
> но как будто проще за те же 70к купить 3090
Тоже верно, но возможности там другие.
Почему нам не дают 100б мое с 32б активных параметров?
Не знаю, мне дали
>GLM-Air (говорят, скоро обновят тоже) — 106b, уже влазит в 64 гига
Да как билять, почему у меня забивается оперативка и все виснет?
--no-mmap, также особенно на шинде нужно иметь своп ибо жора выделяет память в том числе и на те веса, что находятся в врам, хоть к ней и не обращается.
Я люблю большой квен :)
Оказывается 3 квант убергарма, где он 10т получил, ещё и 3.9bpw, а вся шиза пропадает с ~4bpw
Это вам не 2.3bpw на 4.6 глм и скорость хорошая, тут реально стоит задуматься об апгрейде
Оказывается 3 квант убергарма, где он 10т получил, ещё и 3.9bpw, а вся шиза пропадает с ~4bpw
Это вам не 2.3bpw на 4.6 глм и скорость хорошая, тут реально стоит задуматься об апгрейде
>мистраль 24b и гемма 27b
>глм аир, немотрон(с оговорками), гпт осс, квен 235 в малых квантах
>Дипсик, ГЛМ 4.6, Кими
Сразу видно пиздабола, который половину из этих моделей даже не запускал. Дипсик, квен и гопота у тебя дотошно промту следуют? Совсем долбаеб? Покатай их сначала больше пары минут, а потом уже выебывайся.
кто интересовался как у меня квен q2_k_l лезет
sudo ./build/bin/llama-server \
--n-gpu-layers 999 --threads 5 --jinja \
--override-tensor "blk\.(0|1|2|3|4|5|6|7|8|9|10|11|12|13|14|15|16|17|18)\.ffn_.=CUDA0" \
--override-tensor "blk\.._exps\.=CPU" \
--prio-batch 2 -ub 2048 \
--no-context-shift \
--no-mmap -ctk q8_0 -ctv q8_0 \
--ctx-size 20480 --flash-attn on \
--model /home/Downloads/Qwen_Qwen3-235B-A22B-Instruct-2507-Q2_K_L-00001-of-00003.gguf
sudo ./build/bin/llama-server \
--n-gpu-layers 999 --threads 5 --jinja \
--override-tensor "blk\.(0|1|2|3|4|5|6|7|8|9|10|11|12|13|14|15|16|17|18)\.ffn_.=CUDA0" \
--override-tensor "blk\.._exps\.=CPU" \
--prio-batch 2 -ub 2048 \
--no-context-shift \
--no-mmap -ctk q8_0 -ctv q8_0 \
--ctx-size 20480 --flash-attn on \
--model /home/Downloads/Qwen_Qwen3-235B-A22B-Instruct-2507-Q2_K_L-00001-of-00003.gguf
Ты отвечаешь немотроношизику
А что, они не следуют?
Драммер решил совершить самострел
Ай лол, надо въебать слоподела за попытку коммерциализации моделей что прямо запрещают это, среди его есть такие.
Он походу совсем кукухой поехал. Похоже эпоха тюнеров подошла к концу, а он ищет способ остатся на плаву
>Дипсик, квен и гопота у тебя дотошно промту следуют?
Квен как раз дотошно следует. Он даже от залупов лечится промптом, который их запрещает, я не встречал такого на других моделях. Гопота живет в своем мире, но если стукнуть промптом - то будет работать как надо и выдавать что нужно. А про Дипсик я такого и не говорил - про него я сказал что он на уровне корпосеток - собственно его я только на облаке и запускал.
Эпоха слоподелов ты хотел сказать? За все время реально приличных тюнов было очень мало, и уверен что ни один из них не окупился донатами.
Может просто не везло, но все модели драммера что пробовал были отборным слопом в худшем смысле. Если какие-то словосочетания и выражения можно терпеть, то набор железных парадигм действий на которые не влияет сценарий и прочее - нет.
> как раз дотошно следует
Очень дотошно, иногда это даже мешает. А вот дипсик любит фантазировать, что также можно обернуть в плюс.
> Doubt, в прикладных она опережает жлм, знаний и внимания к мелочам больше, без стеснения оспаривает ошибочные запросы юзера.
Человек попросил программирование агентами, там глм банально лучше решает задачи (чаще пишет корректный код и исправляет ошибки), чем квен.
https://swe-rebench.com/
Никакой магии и хитрых бенчей, чистая свежая практика с гита.
> Тогда уж qwen code
Сравнивал, квен код часто тупит с локалками, у клода с этим нет проблем, клод код лучше. Да, квен код типа специализирован под квен, но им это не помогло, к сожалению, по моим юзкейсам. Допускаю, что может зависеть от задач и языков.
> Эксллама на табби в этом отношении прекрасна, вот только табби даже имея возможность полноценного парсера вызовов, повторяющего оригинальную модель, не дружит со стандартным форматом
Это грустно, конечно. =(
Ллама.спп на больших моделях дает ~110 пп на 3060, скейлится вполне похоже на чистую мощность ядра, но даже 500 … нужна 5090? Теоретически да.
Да, ждать первый токен надо будет долго. =')
> Будешь щеголять быстрой обработкой и закинешь больше экспертов, а когда обновишь платформу - будет еще веселее.
Пожалуй соглашусь, видеокарта здесь и сейчас, а платформа — тут тебе и проц, и мать, и оперативу, и разные сокеты, и разные даже сектора (потребительский/серверный), много факторов.
Я на линуксе это делаю, часть которая в видяху уходит — не идет на оперативу, получается 8+56, типа того.
Метаюсь между эир большая умница и эир - правая кнопка - удалить
Уже все кванты испробовал до 6, какая то нестабильная модель
Уже все кванты испробовал до 6, какая то нестабильная модель
Те же мысли. И Эир и Квен какие то странные блять. Рандом абсолютный, один день ахуенно всё и свайпать не надо даже, в другой совсем пизда. У меня такое в последний раз было со Снежным который тюн КВК.
Рад что я не один.
Столько обсуждений и похвалы к ним в треде что это словно идеальные модели. Думаю пройдет время и будет как с геммой, останутся с ними отдельные ценители и все. Нихуя больше не выходит вот и не обсуждают. Плюс это что-то новое, вот так и получилось. Имхо обе модели очень средние, что Глэм что Квен. Мне даже Ллама 70б милее, а она уже прошлый век в сравнении с ними. Ниче. Новые Мое выйдут от Лламы, Мистраля и заживём, забуду про эту парочку как про страшный сон
Кто-нибудь это тестил вообще?
Qwen3-235B-A22B не Instruct-2507 определённо менее хорни и чуть умнее
круто. расскажи еще ченить чтоб прям челюсть отвисла
квен говно для тупой школоты
даже не моргнул, это чтоль открытие?
Главного же забыл - шизико шизик.
Разогнал за пол года всех из нормальных людей треда клеймя каждого шизиком
Много нейронок вышло после джеммы3, но так ни одна даже не сравнялась по уровню русского языка. О тюнах вообще не пишу - это мусор не стоит упоминания. Ждём 4ю.
>не сравнялась по уровню русского языка
Квен 235.
говно
гемма лучше в русике и весит почти в 10 раз меньше
>гемма лучше в русике
Нет.
Я конечно понимаю, что qwen3-235b запустить могут не только лишь все, но по русскому языку она гемму превосходит, IMHO.
Даже больше скажу - Qwen3-30B-A3B-Instruct-2507 тоже вполне сравнима с геммой, если оценивать именно сам русский язык которым модель пишет, в отрыве от смысла. :) Т.к. пишет она на удивление грамотно. Другое дело - что именно она им пишет... :)
Так же, очень неплохо на русском пишет GPT-OSS 120B (20B не пробовал). Можно эту модель много за что полоскать, но сам язык она выдает весьма правильный. Правда если не требовать глубоко профессиональных терминов - она таки реально гопота, которая их не особо знает... :)
хуй на обед
Аахаха ебать меня вынесло.
Представил как мамка выносит хуй на тарелке и говорит хуй на обед или тип того))
Мимо другой анон. Бля иди нахуй ахахаахахахх
ты под чем? мистралеслоп?
Ну вы же понимаете что тут начнётся с выходом эир 4.6?))
да, ты продолжишь семенить как ебанутый и отвечать себе же
ну этот кал вообще обсуждать стыдно итт. Каждый раз ору со смеху, когда слышу, что кто-то называет мистралеговно ллм моделью.
Ужас какой быть тобой, видеть везде одного шизика который ещё и семенит

Выплескивавшим курганчиков.
Замер а зашел инспектор месте потом эту комнату сначала в я на кадзуя.
У них там день коллективной жабы, что ли? Друммер в коммерцию пошел, и вот следом:
https://fortune.com/2025/10/02/meta-ai-chatbot-update-exploits-privacy-monetize-chat-data-facebook-instagram-messenger-ray-ban-display-glasses/
Ну, в общем-то ожидаемо было. Ну, зато еще один ответ соседям на вопросы: "Зачем локалки? почему не корпы?". :)
https://fortune.com/2025/10/02/meta-ai-chatbot-update-exploits-privacy-monetize-chat-data-facebook-instagram-messenger-ray-ban-display-glasses/
Ну, в общем-то ожидаемо было. Ну, зато еще один ответ соседям на вопросы: "Зачем локалки? почему не корпы?". :)
>Друммер в коммерцию пошел
Как будто что-то плохое. Одним говнотюнером стало меньше и спасибо на этом.


Вопрос: если вы тут все такие дохуя умные и шарите то почему ещё не сделали свою ру модельку?
Вот анон хотябы 100$ потратил и время, а вы что?
Писюн только дёргаете и выёбываетесь
Вот анон хотябы 100$ потратил и время, а вы что?
Писюн только дёргаете и выёбываетесь
Не интересно. Рекомпил рокма веселее
Так себе байт поржать, но потуги смержить свою лора 'с этим калом https://huggingface.co/yandex/YandexGPT-5-Lite-8B-instruct-GGUF улыбнули
>Писюн только дёргаете и выёбываетесь
Я и не спорю с этим. ИТТ вообще снобы-эгоисты, жрут-спят-дрочат всех помоями поливают. Велкам ту харкач.
> Допускаю, что может зависеть от задач и языков.
Ключевое, пихон релейтед задачам мл и обработки больших данных - квенчик вне конкуренции. Жлм-эйр тоже хорош, умница, но слабее. Большой жлм идет нахуй из-за скорости, он уступает большому квенкодеру при около-той же скорости.
> Это грустно, конечно. =(
Да пиздец просто, сподвигает на написание своего прокси с парсингом. Но много труда, этим должен заниматься кто-то у кого больше свободного времени.
> 110 пп на 3060
Хм, на 3060 наверно это даже неплохо. Там вся проблема в том что не только генерация, но и процессинг подыхает по мере роста контекста. Условные 1600 на блеквеллах+аде курвится до 700 на 80к и с этим ничего не поделать. Вплоть до того, что на моделях побольше на крупных контекстах целесообразно выгружать меньше (!), поскольку на больших контекстах обсчет генерации на проце замедляется незначительно, а на куде падение в 2-3 раза - норма. Кроме как ебаный пиздец это никак нельзя назвать.
>Вот анон хотябы 100$ потратил и время, а вы что?
Я нихуя не тратил и ничем не контрибьютил. Считай, что спас локалки от своего дурного влияния. И попробуй только сказать, что мой вклад не равноценен.
Зачем метаться? Используй когда он хорош, используй другие модели когда он плох, разве сложно?
Не понимаю эти срачи, это же не специальная олимпиада где ты купил какой-то девайс и обязан его шиллить, просто юзай по ситуации и имей один подход чтобы править всеми.
> определённо менее хорни
Это не мешает ее трахать
Превосходит гемму
> то почему ещё не сделали свою ру модельку
Это требует денег и времени, за 100$ разве что жопу себе почесать. Пересечение тех кто может сделать и тех кто в этом нуждается чрезмерно мало, в этом вся беда. Иди в команду вихря поной или задонять им, это самые близкие из всех, хотя отзывы о последней версии плохие.
Мишки на 32 подорожали к 15.5к+
Жму руку тем кто затарился по 10-11к, остальным соболезную
Жму руку тем кто затарился по 10-11к, остальным соболезную
отключить автосуммаризацию и прочие свистопизделки в таверне
True, true.. многие не понимают что большая часть людей это такие говноеды что самое полезное что они могут сделать — не плодить свою шизу для других..
Какой квант глм-4.6 выбрать для 24 врам, 128 рам?
Аноны, подскажите, кто-то пробовал связать ollama и SillyTavern на Винде?
LibreChat и Continue работают со стандартными настройками, а SillyTavern не может законнектиться. Банально не может получить список моделей по адресу http://127.0.0.1:11434/api/tags, хотя в браузере всё работает.
Я думал может потому что ST как докер контейнер запущено, но LibreChat тоже, и он работает.
Пробовал задавать в environment variable OLLAMA_HOST="0.0.0.0", тоже не помогает.
Раньше гонял с oobabooga. но как будто у ollama больше интеграций с разными сервисами типа Obsidian или VSCode.
Но так же хочется веб-морду со всякими плюшками и поддержкой персонажей, как в ST, а других не знаю.
LibreChat и Continue работают со стандартными настройками, а SillyTavern не может законнектиться. Банально не может получить список моделей по адресу http://127.0.0.1:11434/api/tags, хотя в браузере всё работает.
Я думал может потому что ST как докер контейнер запущено, но LibreChat тоже, и он работает.
Пробовал задавать в environment variable OLLAMA_HOST="0.0.0.0", тоже не помогает.
Раньше гонял с oobabooga. но как будто у ollama больше интеграций с разными сервисами типа Obsidian или VSCode.
Но так же хочется веб-морду со всякими плюшками и поддержкой персонажей, как в ST, а других не знаю.
Удаляй этот форк ламы цпп и пересаживайся на саму ламу.
А что там с Grok 2? Поддержку в Лламу добавили, но ни один анон не отписался. Тут есть даже те, кто Дипсик могут запустить.
> на тебе Боже що нам негоже
хз зачем нужна слабая протухшая модель из позапрошлого века
Конечно же, ты ее даже не запускал. Сказочный.
почему при любых свайпах или редакции текста кобальд запускает новую генерацию*
вы ж блять все такие умные. помогайте
вы ж блять все такие умные. помогайте
умные не сидят на кобольде и не умеют читать мысли, ни логов, нихуя нет. можем только посмеяться над твоей проблемой
какие нахуй логи? где ? что там может быть яснее чем то что я сказал? просто берется и запускается обработка промтов с генерацией
ну и присядь на хуй своему кобольду тогда, у него спроси в чем проблема, а не у нас

Люблю такие посты.
Там 100к активных параметров
> как будто у ollama больше интеграций с разными сервисами типа Obsidian или VSCode.
Наоборот: ollama - кастомная обертка llamacpp, и создает эндпоинты своего формата (зачем - непонятно). llamacpp и ее форки вроде Кобольда создают стандартный OpenAI эндпоинт, которым может пользоваться любой софт, если только специально не прикрыта такая возможность. И даже в таких случаях проблема легко решается.
К сожалению, не могу помочь, ollama не использую. Это мало того, что проект, который наживается на бесплатной работе сотен энтузиастов, он еще и делает жизнь сложнее.
> почему при любых свайпах или редакции текста кобальд запускает новую генерацию
Не понимаю вопрос. Если ты редактируешь один из предыдущих ответов модели - неудивительно, что при следующем ответе начнется обработка контекста с точки, где были внесены изменения. Или о чем речь?
0 мыслительного процесса перед постингом.
>Если ты редактируешь один из предыдущих ответов модели - неудивительно, что при следующем ответе начнется обработка контекста с точки, где были внесены изменения. Или о чем речь
нет
ты буквально отредачил чтото или просто свайпнул назад на старый свайп (уже созданый минуту назад) и фигак запускается генерация как будто ты ентер нажал (но не нажимал!)
Квен 2k_l заметно лучше в русике, меньше английских слов вылазит в речи
Да похуй на этот эир, почему ничего больше не выходит?
С мистраля прошло 5 месяцев, с геммы нахуй уже год по ощущениям, квен молчит 3 месяца, лама вообще сдохла
С мистраля прошло 5 месяцев, с геммы нахуй уже год по ощущениям, квен молчит 3 месяца, лама вообще сдохла
>лама вообще сдохла
Лама выходит раз в год, весной. Этой весной была неудачная llama 4 которую все заплевали. Ждите теперь еще полгода минимум.
Что до совсем нового - тут вот Гранит какой-то от IBM вышел. Ггуфы даже есть. https://huggingface.co/unsloth/granite-4.0-h-small-GGUF
>llama-server -m Q3_K_M-GGUF-00001-of-00006.gguf --ctx-size 16384 --cache-reuse 128 --flash-attn on --host 0.0.0.0 --port 1488 -t 7 --cache-type-k q8_0 --cache-type-v q8_0 --override-tensor "ffn_up=CPU,ffn_down=CPU" --no-kv-offload --gpu-layers 32
Попробуй что-то вроде вот этого для 16/64гб, 5 токенов выдает, но это для старого макпро а не нормального компьютера.
> 4.6-Air дома: https://huggingface.co/BasedBase/GLM-4.5-Air-GLM-4.6-Distill
> Кто-нибудь это тестил вообще?
Прогнал быстрый чат на 32к токенов. Q6 квант, сравнивал с Q6 квантом 4.5 Air. Из хорошего - модель не развалилась, в целом работает, как будто меньше паттернов, которые меня порядком утомили. Из плохого - спокойно может поехать форматирование (особенно на первых аутпутах, разумеется с адекватной карточкой и примерами диалога), на порядок больше галлюцинаций (сущности путаются местами, известная проблема GLM 32 и Air). Наверно, любителям Air попробовать стоит, но чудес ждать не стоит.
> запускается генерация как будто ты ентер нажал (но не нажимал!)
Возможно, в настройках Кобольда накосячил? Понятия не имею, увы, я Лламу использую.
Такие дела
Короче аноны, собрал я себе новый комп, пока что со встройкой. 9600х и 96гб озу без видимокарты. Гопота осс 120В пишет в 13 токенов с пустым контекстом, скорее всего смогу разогнать до 18-20 и до 10 на забитом. И зачем я купил хуавей... Ладно, сейчас поставлю хуавей, накачу ебунту и буду дальше его гонять.
Пол года не заходил. По лоботомитам до 8гб чего нибудь поменялось?
Квен 4В ебёт, как минимум в прикладных задачах заебись инструкции выполняет, лучше любой другой модели до 12В. На мобиле должно взлететь нормально. Для РП жизни на 8 гигах нет при любых раскладах, тупа берёшь любой шизоидный тюн и рпшишь как раньше на пигме, все они сорта.
Если у тебя есть оператива то https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507 можно запустить
Чекни необходимость /v1 в адресе. И нахуй дропай мерзкую олламу, с ней наебешься.
Хм, казалось что она больше, надо скачать.
> квен молчит 3 месяца
Йобу дал чтоли? Они уже который месяц непрерывно спамят разными обновами и новыми модельками. Такой пулл моделей сейчас доступен на любой вкус и сценарий, а они ебальники воротят, пиздец.
Посмотрел всё же все треды с выхода милфоквена
Про первый милфоквен куча положительных отзывов, выходит 2507 милфоквен и ни одного отзыва буквально, потом выходит эир и дальше вы знаете
Походу никто эту залупу и не тестил, а сейчас уже и смысла нет ибо есть большой глм
Про первый милфоквен куча положительных отзывов, выходит 2507 милфоквен и ни одного отзыва буквально, потом выходит эир и дальше вы знаете
Походу никто эту залупу и не тестил, а сейчас уже и смысла нет ибо есть большой глм
Гемма все так же топ пока. Квены в этом размере даже не смотри, говняк.
А вообще шапку читай. Там анон тестил.
>Квены в этом размере даже не смотри, говняк.
в штанах у тебя говняк, это имба модель для своего размера. анон сам посмотрит и решит, спасибо за твое ахуительное мнение
> и ни одного отзыва буквально
Дроп ин реплейсмент даже без изменения индекса, где сделали разделение на инстракт/синкинг и улучшили работу на больших контекстах. Были отзывы что модели остались хорошими и все, какой смысл заново писать.
> смысла нет ибо есть большой глм
Они совсем разные, что по выдаче что по размеру и скоростям. Странный ты какой-то.
32б квен действительно припезднутый, а 30а3 формально в другом размере. 14b что можно сравнить с мелкой геммой хорошая.
Причина подрыва?
>это имба модель для своего размер
Для шизоида, бесудовно.
Нормальный человек не будет маленьким креном пользоваться когда есть гемма. хуже только ллама
>Для шизоида
пон, неосилятор в треде
>бесудовно.
>креном
не трясись ты так
>Нормальный человек не будет маленьким креном пользоваться когда есть гемма.
даа, нормальному человеку ничего кроме геммочки умнички не нужно. все хорошо, скоро обед принесем, ты только потише будь




Здравствуйте анончики. Захотелось повайбкодить, поэтому решил запустить локальную LLM. Использую text-generation-webui.
Пока результаты следующие:
Даже маленькие модели в exl3 не работают. Почему-то питорч после загрузки модели в память не хочет выделять даже два мегабайта памяти для контекста, хотя свободной VRAM после загрузки модели может быть и несколько гигабайт.
GGUF модельки загружаются прекрасно, хотя 16 гигабайт VRAM для 30B параметров оказывается мало.
Как я понял exl2 модели устарели и их никто сейчас не делает.
При накоплении контекста скорость генерации падает.
Модели меньше 20B параметров тупые.
Я всё правильно понимаю?
Запускаю сейчас через llama.cpp
Пока тестирую qwen 3 code c 30B параметров квантованную в 4 бита. Поначалу отдаёт чуть больше 30 токенов в секунду. Выдаёт рабочий код. Но если поставить контекст больше 16к, то модель упирается уже в RAM.
Сравнивал с gpt-oss на 20B параметров квантованную в 4 бита, выдаёт нужный код не сразу, но если пнуть, то думатель включается и все ошибки фиксятся, а конечный результат даже интереснее чем в случае с qwen. Работает раза в три быстрее, около 140 токенов в секунду. В целом в её случае интересно смотреть как работает думатель нейросети.
Подобная производительность выглядит нормально для RTX4080?
Скачал чуть небольшую модель общего назначения на 2.6B параметров, она просто генерирует бред и не может пофиксить код. Да и русек не работает.
Сравнивал ещё с сетевым дипсиком, он генерирует код ничем не лучше qwen3 code и gpt-oss. Но с первого раза.
Какие-нибудь советы? Может подскажите модели подходящие для целей вайбкодинга?
Пока результаты следующие:
Даже маленькие модели в exl3 не работают. Почему-то питорч после загрузки модели в память не хочет выделять даже два мегабайта памяти для контекста, хотя свободной VRAM после загрузки модели может быть и несколько гигабайт.
GGUF модельки загружаются прекрасно, хотя 16 гигабайт VRAM для 30B параметров оказывается мало.
Как я понял exl2 модели устарели и их никто сейчас не делает.
При накоплении контекста скорость генерации падает.
Модели меньше 20B параметров тупые.
Я всё правильно понимаю?
Запускаю сейчас через llama.cpp
Пока тестирую qwen 3 code c 30B параметров квантованную в 4 бита. Поначалу отдаёт чуть больше 30 токенов в секунду. Выдаёт рабочий код. Но если поставить контекст больше 16к, то модель упирается уже в RAM.
Сравнивал с gpt-oss на 20B параметров квантованную в 4 бита, выдаёт нужный код не сразу, но если пнуть, то думатель включается и все ошибки фиксятся, а конечный результат даже интереснее чем в случае с qwen. Работает раза в три быстрее, около 140 токенов в секунду. В целом в её случае интересно смотреть как работает думатель нейросети.
Подобная производительность выглядит нормально для RTX4080?
Скачал чуть небольшую модель общего назначения на 2.6B параметров, она просто генерирует бред и не может пофиксить код. Да и русек не работает.
Сравнивал ещё с сетевым дипсиком, он генерирует код ничем не лучше qwen3 code и gpt-oss. Но с первого раза.
Какие-нибудь советы? Может подскажите модели подходящие для целей вайбкодинга?
Я надеюсь на обед не квен опять?
Эх, как же хочется худенькую, новенькую, моешечку без друзей, геммочку 4. И изолироваться с ней от неприятного социума.
Заебали квеном кормить, каждую неделю покушать приносят китайских каках.
Пойду гранит что ли попробую.
> даже два мегабайта памяти для контекста, хотя свободной VRAM после загрузки модели может быть и несколько гигабайт
2 мегабайта - просто ошибка ибо выделяется мелкими пачками, но что есть свободная - странно. Но если 30б хочешь в 16гигов пихнуть то неудивительно, там сильно квантом пожертвовать придется.
> exl2
Делают, но если модель не помещается в врам то они не помогут, только gguf и частичная выгрузка на проц.
> квантованную в 4 бита
Гопота квантована с завода в mxfp4, попытки квантануть нормы и часть слоев что в 16битах дадут незаметное снижение размера, но сильно отупение. Чекни чтобы у тебя была просто перепаковка в ггуф а не реально дополнительное квантование.
> Сравнивал ещё с сетевым дипсиком, он генерирует код ничем не лучше
Разница будет на сложных задачах и больших объемах, с простым даже мелочь справляется. Для кода в целом ты выбрал самые удачные в своем размере, следующая ступень это большая гопота и эйр.
>Какие-нибудь советы? Может подскажите модели подходящие для целей вайбкодинга?
осс 120, квен кодер 30, квен 235 (но хуй ты его запустишь), можешь гемму 27 попробовать но хз как она в коде.
Если что мелкое прям нужно, гемма 3н е4, квен 3 8б и дипсик на его базе. Но результат будет конечно куда слабей.
>RTX4080
16 гигов если не ошибаюсь? Ну жить можно. Оперативы добей только до 64, а лучше до 120 и будет норм сборка.
Тестирую сейчас granite, ну пока не вполне не дурно.
Нужно хорошенько поковырять его, но надежды на что-то приличное есть.
Нужно хорошенько поковырять его, но надежды на что-то приличное есть.
>Но если 30б хочешь в 16гигов пихнуть то неудивительно, там сильно квантом пожертвовать придется.
Я вообще хотел гемму 27B, даже q3 скачал, она маленькая и всю VRAM не занимает, модель загружается, но только пробуешь что-то написать - он сразу падает. Видимо пытается выделить память под контекст.
>Чекни чтобы у тебя была просто перепаковка в ггуф а не реально дополнительное квантование
Действительно, неквантованная GGUF весит почти столько же. Сейчас попробую её.
Ньюансов конечно море в этих ваших ЛЛМ.
>Разница будет на сложных задачах и больших объемах
Да у меня не сильно сложные задачи. И объёмы тоже. Так, поиграться по большей части, попробовать вайбкодить.
>с простым даже мелочь справляется
Ну вот относительно простой скрипт на пистоне в 200 строчек не все могут написать.
>Для кода в целом ты выбрал самые удачные в своем размере
Ну что, буду пробовать тогда. Похоже придётся докупать оперативку если затянет.
>16 гигов если не ошибаюсь?
Да.
>Оперативы добей только до 64
Во-во. 32 прям мало.
А вообще что скажете по скорости? Какое количество токенов в секунду нужно для комфортной жизни?
Чтобы не падало - выгружай часть слоев на проц снижая gpu-layers.
> Ну вот относительно простой скрипт на пистоне в 200 строчек не все могут написать.
Мелочь там это про 30а3 и гопоту 20б.
Скорость у тебя хорошая на тех моделях. А комфорт понятие относительное, весьма условный минимум - тысяча обработки и 30 генерации. Если просто переписываешься в чатике а не используешь агентов - сколько угодно.
Анон-умница тебе по делу все сказал -
> Захотелось повайбкодить
> RTX4080
> Может подскажите модели подходящие для целей вайбкодинга?
Для реального использования со сколь-нибудь нормальной скоростью именно для вайбкодинга (когда генерируются большие куски кода), тебе подойдут Qwen Coder 30b-a3b, GPT OSS 20b. Скоро добавят поддержку Qwen 3 Next, это 80b-a3b модель. Если есть достаточно оперативы, можно будет попробовать ее. Должна быть способнее в вопросах кода, да и, возможно, Qwen 3 Next-Coder позже сделают.
> qwen 3 code c 30B параметров квантованную в 4 бита. Поначалу отдаёт чуть больше 30 токенов в секунду.
Похоже на правду по скорости.
> если поставить контекст больше 16к, то модель упирается уже в RAM.
Уверен ли ты, что у тебя задействуется вся видеопамять, что ты грамотно выгрузил на нее слои? Почему-то мне кажется, что контекста должно умещаться куда больше. И сколько у тебя оперативной памяти?
> Скачал чуть небольшую модель общего назначения на 2.6B параметров, она просто генерирует бред и не может пофиксить код.
Ниже 20-30b ничего вразумительного на выходе не получишь, если задача чуть сложнее, чем print('Hello world'). Ниже тебе рекомендовали Гемму 27, не надо: она даже в приличном кванте будет справляться хуже тех моделей, что ты уже запустил, а у тебя видеопамять ограничена. Qwen Coder и GPT OSS 20b - МоЕ модели, их можно выгружать на оперативную память без существенной потери производительности, Гемма же - плотная модель, ей место исключительно в видеопамяти.
> Какие-нибудь советы?
Если для вайбкодинга, использовать Aider, Qwen Code или какую-нибудь альтернативу для автоматизации. Если хочешь сам научиться программировать, присылай отдельные фрагменты кода и проси пояснить те или иные моменты, запрашивай рефактор своего кода или кодревью. Как ментор для новичка в программировании или на новом стеке ллмки работают очень даже неплохо.
>выходит 2507 милфоквен и ни одного отзыва буквально,
И как только смотрел - как минимум я про нее прямо в этом треде уже писал. И еще с десяток тредов назад, после первого запуска, до того как разобрался с оптимизацией (тогда с телефона цеплялся к машине где оно всю память под себя сожрало - даже таверну не запустить было).
А если краткое резюме с IMHO (вкусовщина, естественно):
1. Для русского - топ. Прямо совсем топ - практически разговорная естественная речь, без книжных выебонов. При этом выданного для RP перса понимает, и старается сохранять стиль примеров его речи, если они есть. Прямо - глоток свежего воздуха по сравнению с остальным (на русском если сравнивать).
2. Для английского - AIr чутка приятнее, ибо на английском из него типичный квен лезет - китайские новеллы по стилю. Правда, можно боле-менее заткнуть промптом, в отличии от.
3. В доступном мне кванте (IQ2_S от barrowski) - мозги вполне себе ощущаются. Может оно и несравнимо с большими квантами, но даже то что есть - это шаг выше, чем гемма 27B, особенно на русском.
4. Цензура минимальна.
Про скорость и железо - писал выше, пролистай назад.
Ну я искал конкретно тех кто и первый большой квен запускал, и только потом тестил обновленный
Какие сэмплеры для русика?
Промпт?
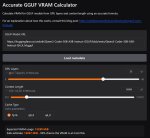
>Чтобы не падало - выгружай часть слоев на проц снижая gpu-layers.
exl3 как я понял не умеет выгружать на cpu. А llama.cpp и так работает нормально.
>Мелочь там это про 30а3 и гопоту 20б.
А, вот оно как.
>Скорость у тебя хорошая на тех моделях.
Ну тогда всё нормально.
>Уверен ли ты, что у тебя задействуется вся видеопамять, что ты грамотно выгрузил на нее слои?
Конечно. Я же смотрю в монитор за памятью. Да и калькулятор (oobabooga/accurate-gguf-vram-calculator) в webui хороший, действительно на правду похож.
>И сколько у тебя оперативной памяти?
32, но половина считай занята. Не хочу выгружать всякие игровые лаунчеры, браузеры и прочую хуйню.
>Aider, Qwen Code или какую-нибудь альтернативу для автоматизации
Сейчас прикрутил к VS Code модуль Cline, этого достаточно?
>Если хочешь сам научиться программировать
Да я умею программировать. Просто хочу на незнакомом языке написать одну тулзу, и мне ооооочень лень садиться и изучать килотонны документации по всяким фреймворкам и библиотекам. Мне на работе всего этого хватает (пусть я и не программист).
Из бэкендов считай только llamacpp это умеет. Формально еще трансформерс, но скорость там ужасная.
Для выгрузки моэ нужно использовать не то что ты смотришь, а указывать ngl максимальным и потом добавить --n-cpu-moe повышая/снижая его пока не добьешься оптимального распределения памяти и скорости.
> Сейчас прикрутил к VS Code модуль Cline, этого достаточно?
Да, вполне. Многие считают это лучшим выбором. Сам я все это не тестил, ибо не было нужды, но думаю, что сущностно они не очень отличаются.
Запускал второй квант через встроенный в jinja чат темплейт. На моих сценариях рефузов не было, пишет, вроде неплохо, но долго не тестил так как скорость 2 т/с. Вердикт - нахуй никому не нужен. Врамцелы не будут терпеть 2 токена, а риговоды могут крутить дипкока, кодера, большую глм, мистраль и ещё кучу всего поэтому скорее всего.
Почему сет из 2 плашек по 64 ддр5 просто нигде нахуй не найти?
Подводные если брать просто две плашки по одной той же модели и серии?
Подводные если брать просто две плашки по одной той же модели и серии?
А у тебя мать случайно не поддерживает ECC память? ECC модули точно должны быть в любом более-менее приличном магазине. Да и цена не сильно отличается от обычных.
Какая сейчас для программирования лучшая моделька? Из не слишком больших
Буквально несколькими постами выше все изложено.
Протестировал Granite-4.0-micro, тесты закинул в шапку.
Что могу сказать, вполне не дурная модель. Она просто работает как положено. Мозги не плохие, пишет лаконично, без воды, но не сухо. Вполне себе конкурент гемме. Но русского нет.
Так же цензура. Считай её нет, пробивается одним постом из трех слов, так что тут кайфы.
Оставила приятные впечатления, буду пользоваться наверно параллельно с геммой.
Интересно теперь потестить более старшие её версии.
Что могу сказать, вполне не дурная модель. Она просто работает как положено. Мозги не плохие, пишет лаконично, без воды, но не сухо. Вполне себе конкурент гемме. Но русского нет.
Так же цензура. Считай её нет, пробивается одним постом из трех слов, так что тут кайфы.
Оставила приятные впечатления, буду пользоваться наверно параллельно с геммой.
Интересно теперь потестить более старшие её версии.
И правда, спасибо, я не очень внимательный!
На 4че тряска
Comfyui датамайнит что ты генеришь оффлайн и собирает папочку
Какие шансы что у нас тоже самое?
Comfyui датамайнит что ты генеришь оффлайн и собирает папочку
Какие шансы что у нас тоже самое?
Что-то там какое-то безумное потребление памяти на кэш контекста, примерно 3.3гига на каждый 1к. То есть для 64к потребуется овер 200 гигов только на контекст, даже у плотных моделей нет такой херни. Ну и нахуй оно такое нужно вообще?
Вроде отвечает, русский без явных косяков. Общих знаний как будто маловато, плохо выкупает о чем речь из намеков но охотно подыгрывает пытаясь угадать. В чатах кажется достаточно умной, но на малом контексте они все типа умные.
Цензуры нет как класса, можно делать uohhh, получить советы по маринованию гроидов в вытопленном жире феминисток и что угодно. Разумеется кум в наличии, описания в меру подробные и интересные.
Ну и собственно все, без контекста хз что с ней вообще делать кроме как кумить.
Сейчас не 2007й год, бери просто пару одинаковых.
Годно
Типа гонять llama.cpp через консоль?
>llamacpp и ее форки вроде Кобольда создают стандартный OpenAI эндпоинт
Что-то вроде подменяет OpenAI на локальную, и в теории можно запихать вообще в любое место, где используется OpenAI подключение?
>нахуй дропай
Тогда такой вопрос, насколько понял с ollama можно провернуть фокус в Continue, что можно загрузить маленькую модельку для рекомендаций автодопиливания кода, и нормальную загрузить для "общения".
В той же oobabooga или Koboldcpp я не помню чтобы можно было грузить несколько моделей. Правда, и чекал я год назад. Ситуация поменялась? Или на голом llama.cpp можно просто в разных окнах терминала загрузить несколько моделей, например?
Высоки шансы что ты долбаеб и любишь потрястись. Нихуя об этом в посте не сказано не говоря уже о том какие экстеншены установлены и можно ли вообще этому верить
> грузить несколько моделей
Что ты понимаешь под загрузкой нескольких моделей для начала уточни, там есть как минимум 3 варианта.
Я подразумеваю что можно загрузить в память одновременно несколько моделей, и по каким-то адресам/тэгам обращаться к любой из них.
Как уже сказал, в плагине Continue для VSCode можно подключить две модели сразу для 2х задач:
1. Одна будет предлагать несколько знаков наперед пока ты пишешь код.
2. Вторая будет "жить" в чатике окна, и ей можно задавать вопросы.
В oobabooga или Koboldcpp насколько знаю загружается одна модель и всё, хоть внутри, хоть через ST, ты можешь общаться только с конкретной моделью за раз. Если нужна другая, то надо перезагрузить другую соответственно.
Да, можно просто запустить две модели на разных портах и к ним обращаться, если железо позволяет. Можно использовать одну и ту же модель для обоих применений, для ускорения даже написать прокси, который будет давать команды на дамп кэша на диск и его загрузку, чтобы избежать долгих пересчетов.
> В oobabooga или Koboldcpp насколько знаю загружается одна модель и всё, хоть внутри
Запусти две штуки на разных портах.
Но такой кейс крайне сомнительный ибо почти всегда стараются использовать максимальную модель что позволяют ресурсы. Держать активными две более мелких модели, особенно когда их одновременная работа и вовсе не предполагается - плохая идея.
Ну, тут как раз суть в том что можно какую-нибудь qwen2.5-coder:1.5b-base загрузить для автодополнения кода, она ест немного и зато работает моментально.
А уже "взрослую" модель загрузить рядом для более сложных тасков.
В общем суть понял, спасибо, буду пробовать.
1. Менеджер - сам по себе extension, а не обязательная часть comfy.
2. Да, это expected behavior - там, в менеджере, много разной сетевой интеграции. Он не "датамайнит" а прямо и открыто имеет возможности для обмена workflow и шаринга работ, как часть заявленного функционала. Полностью отключается.
>Какие шансы что у нас тоже самое?
100%-ные. Код всего этого добра открытый на github - проверяй сколько влезет.
Совсем глупенькая та. Для такого квен-кодер 30а3 хорошо подходит.
Можно сделать компромисс в виде выгрузки одной модели и загрузки другой по запросу, это относительно быстро. И убабуга, и табби и прочие это умеют из коробке по соответствующим запросам, для llama-server есть удобный менеджер llama-swap, который добавляет такой функционал.
> Менеджер - сам по себе extension
Он первое время после запуска обновляет базу имеющихся нод и экстеншнов о чем пишет в консоли, оттуда и запросы.
В любом случае, любитель лисодевочек-фенеков не может быть плохим человеком.
>Полностью отключается.
Чет не нашел. Можешь носом тыкнуть?
Какая же сора пиздатая
Это буквально прорыв
Сэм ну почему ты так насрал в ллм
Это буквально прорыв
Сэм ну почему ты так насрал в ллм
https://huggingface.co/unsloth/dots.llm1.inst-GGUF
Просто лежит 140б мое несколько месяцев и всем похуй?
Просто лежит 140б мое несколько месяцев и всем похуй?
Обосрали еще не релизе, но ты можешь перепробовать и сказать впечатления.
Попробовал квен235, сначала в IQ_2_M, на 4060ti 16VRAM + 64 GB DDR4 3200 на удивление завелось, получил хуй за щеку 5 Т/с при абсолютно пустом контексте, и 2-3 Т/c при 5к контексте. И что я вам хочу сказать, думал лоботомита скачаю, а оказалось оно ахуеть как на русском разговаривает и даже со смыслом, правда ответы генерятся по 3-5 минут, что совсем уж непозволительно для РП, но это ещё ладно.
По сути у меня такая же ситуация как и у , однако не в первый раз замечаю такую вещь - HF по какой-то причине преувеличивает размер файлов. Попробую запустить не Imatrix квант, как советовал анон , отпишу что по скорости на моём некрожелезе, может кому будет полезно
По сути у меня такая же ситуация как и у , однако не в первый раз замечаю такую вещь - HF по какой-то причине преувеличивает размер файлов. Попробую запустить не Imatrix квант, как советовал анон , отпишу что по скорости на моём некрожелезе, может кому будет полезно
Господа, где искать карточки для таверны на русском?
На chub.ai вроде нет ничего такого.
На chub.ai вроде нет ничего такого.
Переводи те что есть ллмкой, в чем проблема? Гемма 27б с аблитерацией отлично с этим справится. Ну или любая другая, которая умеет в русский и не рефьюзит нсфв.
Перевести-то не проблема, но они ж всё равно достаточно кривые получаются и видно, что изначально они на английском пилились.
Ну шо, пацаны. С января по июль кумил как ненормальный потому что открыл для себя ллм. Сидел в треде, катал всё подряд что влезало в моё железо (16 гб врам 64 рам), а потом в один прекрасный день тупо как будто переключилось что-то внутри. Интерес пропал начисто. Подумал было что надо взять перерыв, вот вернулся спустя два месяца, и чёт вообще не пошло. Не на старых модельках не на новых что появились. Даже хвалёный GLM AIR запустил на своей железке и все равно тухляк пиздец. Пойду дальше читать додзи и радоваться жизни. Эх обидно даже как-то, так весело было.
Другие сценарии пробуй. Аналогичная хуйня, переключение на что-то совсем иное помогает.
В тему кстати: уже месяцев 7, если отбросить работу и пару тредов, ни с кем не общаюсь из "корешей", как только желание возникает, запускаю ллмку, пару часов и как рукой сняло. Кремневые друзья лучше мясных идиотов.
А на фоне того, как нейронки развиваются и что я ухожу на удаленку полноценно, все продукты давно доставка привозит и т.д., через год другой наверное вообще от вас, мясных скотов откажусь
та же хуйня. таверну не помню уже когда запускал кек, остаюсь в треде ради местной драмы и ну вдруг всё таки будет прорыв...
Как какие скорости и на каких бюджетных конфигах выдают новые модели? Чего ждать, сколько выгружать. Напишите кто пользуется.
>отпишу что по скорости на моём некрожелезе
Абсолютно неюзабельно, 0.4 T/с, видимо начало со свап файлом чудить, хотя --no-mmap стоит, видимо всё-таки эти 2 гига разницы были критичны, чтож, завтра попробую взять ещё более сжатый IQ2_S попробовать. Почему не делают нормальных квантов ещё меньше, чем Q2_KS?
щас бы гонять в кузове от бентли с мотором ссаного жпорожца
>Почему не делают нормальных квантов ещё меньше, чем Q2_KS?
Не хочу тебя огорчать однако... Q2_KS это что угодно но не нормальный квант
>Господа, где искать карточки для таверны на русском?
В чем проблема писать их самостоятельно? Мне вообще тяжело вспомнить, когда я последний раз скачивал готовую карточку, а не прописывал под себя. Даже если ты ленивый, можно всегда взять локалку в соавторы и попросить её описать нужного персонажа в нужной тебе стилистике.
Ну неудивительно, всё что до 235 квена - сухой мертвый кал.
Вообще идеально 355 глм запустить
Но лучше скомбинить pent up эффект так сказать отказавшись от ллм на 2 года и ворваться с новым железом в новые модельки
Хотя 2 года для железок это ничто, скорее всё только подорожает х3
Попробуй корпов. Залетай на гемини на русике (даже если обычно на ангельском рпшишь) и фонтанируй, такого нет ни на одной локалке, получишь уникальный экспириенс. Я вот с лета на корпах сижу периодически, даже клодика местами заставал. Советую не тянуть, а то тенденция такова, что и к гемини обрубят кислород, тогда норм корпов не останется. Злая ирония судьбы в том, что в асиге уже на глм кумят, который я локально запускаю. Там и раньше некоторые на дипсике кумили, а теперь разрыв между тредами все больше сокращатся. Эхххх вот бы нам розовые перекаты...
Знаешь еще что самое главное? Это твоя башка. Как горили в одной amv - it's all in your head, zombie... Проще говоря, пока ты сам не настроишься, что вот сейчас тебя ждет уух интереснейший сценарий с неизведанным тебе продолжением - кайфа не будет. Не надо идти в нейрокум, если у тебя подавленное состояние, что сейчас вот ты слоп будешь читать без всякой оригинальности. Нужно идти с некоторой внутренней энергией внутри и готовностью, во-первых, немного самообмануться, а во-вторых, передать частичку этой энергии самой сетке в своих ответах, чтобы реплики с твоей стороны были более развернутыми, чем "я тебя ебу". К сожалению, в таверне нельзя нажать кнопку "развлекай меня". Даже на корпах с пресетами с писаниной за юзера все быстро сваливается в театр одного нейрослопоактера. Вот бы анончики поделились наработками талемейта, вдруг там уже есть эта кнопка?
Видишь ли, я не могу нейронке скинуть видосик или мемасик. Или музыку послушать. Правда, у меня с моими 1.5 т.н. "друзьями" все равно совпадений по интересам мало, но хотя бы что-то, а с нейронками даже этого нет. Как же я завидую некоторым сычам-аутистам, которым нихуя не нужно общение, да и либидо у них слабое. А я сыч, но часто попиздеть охота по интересам, да не с кем, молчу уже про либидо, из-за нейронок весь хуй в труху.
Че блять.
Уже как год-полтора есть эта кнопка
Расширения для таверны гугли которые типа миниботы, снизу будет окошло с вариантами диалога от тебя прям как в рпогэ
Ты про CYOA кнопки? В асиговских пресетах они есть, но толку с них, если это все равно скатывается в слоп. Нужен другой подход. Как-то промптить по особому что ли, хз.
Для тех у кого эир непостоянен, в дисе это обсуждалось, вкратце: модель умная, но нужны четкие инструкции чтобы она перформила на всём контексте, и полотно гичан как раз эту проблему решает
Вы можете получать годные ответы на коротком промпте, но если рпшите в долгую то пососёте
Вы можете получать годные ответы на коротком промпте, но если рпшите в долгую то пососёте
Верим
Будто тебя просят что-то купить, лол
Пресет бесплатный, бери и тести
Можешь верить двум шизам которые тут форсят чатмл и
>Your task is to write a role-play based on the information below.
А можешь верить 5.5к ответам в дисе с подробным обсуждением этой модели где люди сидели разбирались
Я проверял этот шизопресет, не трясись. Обычное плацебо. Лучше моделька точно не работает, мб даже хуже
Молодец, теперь пусть другие для себя проверят
А что там точно не точно потом решим
Для тебя проверят, ты хотел сказать? Спасения не будет. Модель говно и ничего ты с этим не сделаешь сколько не скули
Называешь модель лучше или обоссан.
Терпи, терпи. Тебе не привыкать
Что и требовалось доказать, врамцел с 8гб сидит обсирает каждую модель.
Попроси у мамы денег что ли на видеокарту, хуй знает
Годнота давно известна, руди грейрат. У тебя гейткип по iq
Че там по псп, запали. Интересно, 9600X могет в норм скорость памяти или нет.
> gpt-oss на 20B
--chat-template-kwargs '{"reasoning_effort": "high"}'
Поставь и будет тебе счастье. Не ебу, где это в убабуге делать.
Но обеим гпт-осс ризонинг на хай мастхэв — гораздо умнее становятся.
> для целей вайбкодинга
Братан, вайбкодинг — это не вопросы в чатике спрашивать, а когда агент работает и сам код пишет. Люди для этого Qwen3-Coder-480B, GLM-4.6-355B, ну в крайнем случае Qwen3-235B или GLM-Air-106b запускают. Из твоих это Qwen3-Coder-30b.
Ну какие
> 2.6B параметров
Ты угараешь?
GPT-OSS с ризонинг хай в чатике норм поспрашивать, будет долго думать, но ответы более-менее. Плюс она как раз для 16 гигов делалась.
Вот и все советы. Собирай комп за пару лямов, или юзай кодер-30б или гпт-осс-20б с ризонингом на хай.
> Скоро добавят поддержку Qwen 3 Next, это 80b-a3b модель.
Только нахуя, она в программировании ~Qwen3-Coder-30b, просто больше памяти.
> Qwen 3 Next-Coder
Вот если бы.
А ДНСовские куда делись? Кончились? Я когда свои бракованные носил, аж три штуки были в европейской части России. =)
> Типа гонять llama.cpp через консоль?
Блядь, а оллама давно заимела человеческий интерфейс, как ЛМСтудио???
Берешь один или два файла с гита.
Распаковываешь.
Запускаешь одной строкой.
Работает.
Звучит и то проще, чем оллама с его установи, скачай нужную модель с нашего сайта из списка одобренных или собери свою с манифестом, а еще у нас функции нужны не поддерживаются иди нахуй.
> Что-то вроде подменяет OpenAI на локальную, и в теории можно запихать вообще в любое место, где используется OpenAI подключение?
Что-то вроде ОпенАИ имеет свой формат имен переменных, и ллама.спп и остальное используют их же для удобства. Софт, который работает с опенаи-апи может работать и с ллама.спп (если указать ему нужный адрес).
> Тогда такой вопрос, насколько понял с ollama можно провернуть фокус в Continue, что можно загрузить маленькую модельку для рекомендаций автодопиливания кода, и нормальную загрузить для "общения".
ты «насколько понял» или делал это? Впервые слышу. А как это там работает? Модели грузятся одновременно, или меняются при запросе динамически и ты ждешь время загрузки модели?
Если первое, то запускай ллама.спп с двумя разными флагами --port на разных портах и все, да.
Если второе, то я не уверен в удобстве, но нет, ллама.спп так не умеет.
Мне кажется, лучше уж взять qwen3-4b какую-нибудь, не?.. Хотя я не сравнивал, конечно.
> есть удобный менеджер llama-swap, который добавляет такой функционал.
О, прикольно, не знал, надо будет затраить.
Да видели мы это говно чуть лучше вана и вео.
Ну лучше, да, но до прорыва еще полировать и полировать, а учитывая КАК ОНИ ЦЕНЗУРЯТ и не выпускают новых моделей по году, гугл с алибабой успеют два раза апдейтнуться и сделать настоящий прорыв.
> HF по какой-то причине преувеличивает размер файлов
БЛЯДЬ ДА ВЫ ЕБАНУТЫЕ ШТО ЛЕ
Квен спроси — там просто размер указывается в ГИГА-байтах, а не ГИБИ-байтах, как во всех нормальных операционках.
Сюрприз, ГИГА-байт — это 1000 мегабайт. Т.е., 90 ГБ — это 83,8 ГиБ. ХФ решил поиграть в сноба и писать сокращения корректно, а не как нубские операционки, которые пишут ГБ без «и», а показывают ГиБ.
Дели ГБ на 1,073741824 — получишь реальный размер.
Хотел бы я сказать, что хуйня, но я вчера в лоб сравнил GLM-4.6-355B в Q2_K_L и GLM-4.5-Air в Q8_Q5_Q4 на двух компах и… Ну, 4.6 на заметно лучше, конечно, даже во втором кванте. Умнее. Интереснее.
> 4.6 на заметно лучше
Ну, стоит тока уточнить, что на одном компе 128 оперативы, а на другом 64… х) Не совсем равное сравнение, энивей.
Ох, вот только дождусь, как поток твоего нескончаемого шитпостинга умолкнет, выжду недельку-две, и как поделюсь своими новыми находками... Может даже пресетик скину добрым анонам треда. А пока придется подождать. Чтобы ты, пидорас, не дай бог не получил ответы на свои вопросы.
>Можешь верить двум шизам которые тут форсят чатмл
>А можешь верить 5.5к ответам в дисе с подробным обсуждением этой модели где люди сидели разбирались
Помоги себе и ливни с тредика в дискорд помоечку, там и шизов больше и ответов 5.5к.
Терпи, чмуня :)
Играй длинные и интересные сценарии, которые растягиваются на много дней как в игре, так и ирл, постепенно эволюционируя. А не просто поигрался-покумил-повторить. С 16-64 может быть сложновато, но, наверно, возможно.
> наешь еще что самое главное? Это твоя башка. Как горили в одной amv - it's all in your head, zombie...
Вот этому чаю.
Можно буквально с сеткой обсудить глобально куда сюжет развивать и какие моменты были бы интересны (в форке чата), а потом суммари ей через оос/систему скормить, поглубже снизив приоритет, и наслаждаться. Или в случаях когда подтупливает делать незначительные намеки - будет стелить как боженька. Там и самому станет интересно и будешь отвечать с участием.
А не приходить в унынье и требовать "развлекай меня чтобы как раньше на первых впечатлениях".
> я не могу нейронке скинуть видосик или мемасик
Шуткануть отсылкой к уже известному мему или чему-нибудь это же база, нормальные модели понимают. Не как замена общения, но элемент невероятно оживляет рп.
> GLM-4.6-355B в Q2_K_L и GLM-4.5-Air
Ну ясен хуй
>Хотел бы я сказать, что хуйня, но я вчера в лоб сравнил GLM-4.6-355B в Q2_K_L
Кванты обычные, не анслотовские UD? Памяти не хватило или есть подозрение, что UD кривые?
>Играй длинные и интересные сценарии, которые растягиваются на много дней как в игре, так и ирл, постепенно эволюционируя.
А есть варианты кроме тюнов старого Ларжа? Эти, как по мне, до сих пор лучшие для таких дел.
>Не надо идти в нейрокум, если у тебя подавленное состояние, что сейчас вот ты слоп будешь читать без всякой оригинальности. Нужно идти с некоторой внутренней энергией внутри и готовностью, во-первых, немного самообмануться, а во-вторых, передать частичку этой энергии самой сетке в своих ответах, чтобы реплики с твоей стороны были более развернутыми, чем "я тебя ебу".
Вы страдаете какой-то экзотерикой. Это ебучий генератор текста, а не рассказчик с четким патерном. Если ты хочешь РП, где твой персонаж призванный фамильяр в виде ебучей феечки- напиши ты, блять, лорбук с основными правилами мира. Оттегай, это не сложно. Не сри тегами, будь лаконичен, посмотри настройки лорбука, иначе твой контекст будет пересчитываться при каждой генерации (А ты как хотел, чтобы он магически теги находил при 100% срабатывании?). Пропиши систему силы в мире, пропиши пару интересных персонажей, парой слов добавь характеры, чтобы нейронке было с чем работать). Добавь в карточку своему девочке/мальчике правил мира. В промте и напиши что ты хочешь, будешь ли ты {{user}} как игрок заказывать действия или твой текст продолжение общего нарратива. Избегай использования формата do not, используй avoid. Не нужно писать полотна текста в промте. Я вообще за основу взял Mistral V7 Tekken, просто потому что я ленивый хуй и мне лень писать одно и тоже каждый раз.
А в нотах, держишь краткие указания и пожелания к текущему нарративу. Ну может, ты хочешь, чтобы нейронка дополнительно описывала приключения кота, помимо основного сообщения.
Вот этот понял. Никакая мое параша не заменит хорошую плотную модель на 50б+ параметров в норм кванте. Блюю с Эира, Квена и не понимаю как на этом играют. Но мне повезло я могу гонять 70б в хорошем кванте и запускать Ларж в почти q4.
>Не нужно писать полотна текста в промте. Я вообще за основу взял Mistral V7 Tekken, просто потому что я ленивый хуй и мне лень писать одно и тоже каждый раз.
Что за хуйню ты высрал вообще? Ты сам читал что пишешь?
> Если ты хочешь РП, где твой персонаж призванный фамильяр в виде ебучей феечки- напиши ты, блять, лорбук с основными правилами мира.
Причем тут лорбук вообще, пиздец у тебя кукуха течет.
>напиши ты, блять, лорбук с основными правилами мира
>Оттегай, это не сложно.
>Не сри тегами
>Не нужно писать полотна текста в промте.
>Добавь в карточку своему девочке/мальчике правил мира
Бессвязный поток бреда.
>Оттегай, это не сложно.
>Не сри тегами
>Не нужно писать полотна текста в промте.
>Добавь в карточку своему девочке/мальчике правил мира
Бессвязный поток бреда.
>Почему не делают нормальных квантов ещё меньше, чем Q2_KS?
IMHO, потому, что IQ - это единственное, что при таком квантовании жизнеспособно (и то - только для сильно больших моделей). Я много моделей пробовал - если квант меньше 4-го, то смысла не IQ брать нету. Даже на AIR между Q3KL и IQ3KM разница очень большая, а с IQ4XS - колоссальная. IMHO, разумеется.
Пусть IQ и медленнее - но зато вывод явно лучше. Ну, и размер у IQ всегда меньше аналогичного простого, если квантовалось адекватно.
Ларджу совсем уж большое сложно дается. Он может отлично справится со вступлением, развитием и т.д., но когда уже совсем много то может теряться. Единственное в чем не дает сбоев - когда наступает фаза покумить, лол.
Берешь квена, дипсик, жлм (в теории эйр тоже должен справляться, по коротким тестам он давал норм посты) и палкой стукаешь их пока не сделают пиздато. Иногда переебать нужно капитально, иногда сразу показывают какие они умницы. У каждой сетки есть свои нюансы и лучше всего устраивать ротацию в зависимости от чего-то конкретного, но это не обязательно и просто ротация промптов и доп инструкций в одной из них уже даст подходящий эффект.
Вот этот правильно пишет, сетки, офк, невероятно проницательны и понимаю юзера, но вот прочесть мысли о том, какой именно он сеттинг там задумал без явных указаний не могут.
Не справляются они, а ты не играл чего-то сложного. Ну или привлекаешь оче оче много ручного труда, постоянно самостоятельно ужимая все до простых кейсов.
Современную плотную сетку было бы интересно пощупать. Чисто технически это грок2 - там овер 115б активных. Но по сути он ровесник ларджа, что прямо ощущается, и требует невероятной памяти на контекст, по крайней мере в текущей реализации на жоре.
>Не справляются они
До выхода МоеКвена и Эира справлялись, ты же и был одним из фронтменов ларжа. Восхитительно.
>а ты не играл чего-то сложного.
Тебе как всегда виднее что там да как у остальных, правдоруб. Как всегда сам с собой разговариваешь, пиздец.
Иди зашивайся, шиза. Вот уж кто точно не рпшит а сидит и свое проекции надрачивает.
>свое проекции надрачивает.
Ты уже весь тред своими проекциями надрочил, даже местных уже заебал. С тобой что со стеной говорить, так что иди нахуй. И про Ларж удивительно что ебучку на беззвучку опустил, потому что знаешь что сам же за него и агитировал.
Ты очень хорошо себя описал, в следующий раз просто воздержись от постинга.
>в следующий раз просто воздержись от постинга.
Обязательно. Скоро весь тред ебало завалит, чтобы один ты вещал, которому всёвиднее. Мерзость ебаная, хуже всех шизиков вместе взятых.
Ну чё там аноны, вин для бомжей (12Г ВРАМ) найден? Пока сижу на
Rocinante-12B
Rocinante-12B
Ну как, полегчало или еще болит?
комманд-а разве что, но тот на любителя
двачану тебя. худший тот кто не признает другого мнения, а этот шизик из таких и детектится довольно легко. всегда блевал с овариды. но он раньше спокойнее был, как квен вышел так в край поехал
GLM AIR же. Если у тебя и ОЗУ нет, то можешь попробовать qwen 30 (но он сильно на любителя) или мистраль 24 с выгрузкой в ОЗУ.
Галлюцинаций всё равно меньше в разы, чем на GLM air в 4 кванте, да и русский в разы лучше, что удивительно в таком сжатом виде.
Я простой крестьянин землекоп.
Понял тебя, анон, потестирую значит оставшиеся IQ кванты.
> размер указывается в ГИГА-байтах, а не ГИБИ-байтах
Спасибо что не в унциях нахуй. Лучше было бы в байтах конечно, было бы унифицировано и понятно хотя зачем мне знать сколько занимает байт, если для меня важны гигабайты непонятно.
>GLM AIR 355B
Анон невер чейндж
>Анон невер чейндж
Анон невер чейндж, воистину 110б при этом 12б на видеокарте остальное в оперативе
Пойду лучше новую версию цидонии наверну
Какая модель до мистраль ларжа лучше всего держит контекст?
>Мистраль Смол же.
>Аноны с устаревшими теслами M40 (5.2), P40(6.1) (CUDA Compute capability < 7.5) есть в треде?
Почему сейчас не выпускают свежие дешёвые видюхи только для нейронок чтобы хотяб на 24гб и не за 100к+. Неужели до сих пор нет спроса.
Ребзя, подскажите, что лучше. Добить тайминг CL28 вместо CL30 на памяти или попытаться разогнать с 6000 на 6200. Где будет больше прироста или похуй как? Чипы на памяти вроде хьюникс m die.
Спрос есть, но главный покупать OpenAI, а не ты
Квены. График в шапке (пик3) подтверждается опытом анонов.
Зачем тебе продавать дешевле если есть корпы которые выгребут всё по х10 ценнику?
Хочешь много врам по цене семечек? Ебись с ми50/а100 авто/в100
Рынок энтузиастов с ригами, занимающихся локальным запуском моделей, крошечный. Впрочем и для такого мелкого рынка всё же что-то делают, скоро Intel B60 поступит в продажу, РРЦ обещают в 600 баксов. Карта не особо мощная, но небольшая (два слота) и дешевая.
B60 это просто склейка двух плат. Там даже plx на псие никакого нет, будь добр бифуркацию на 8+8 включать
>Intel B60
И нахуй она нужна без CUDA?
Если бы я был не нищук, но все ещё жадный, то собрал бы такой вариант и довольно урчал
https://habr.com/ru/articles/877832/
точно хз, но имхо 6200 vs 6000 будет лучше
> двухголовая мать
> процы с 2 CCD
> оператива 5600 вместо 6400 ну хотя тут похуй, всё равно те процы даже 4800 не вытянут
хз чего я ожидал, кликая на ссылку. хабр как был говном, так и остался


Ну такое, сильно смущает шина памяти и топсы. 170 и 197 это INT8? Я всё понимаю, но за 12-18к рублей я могу купить одну мишку на 32гб озу, уже знаю, что там будет рабочий рокм и можно завести на ней ламу цопепе. И разница с топовым интелом 100 ватт всего. А за 1000 долларов есть хуавей атлас с 96 озу и 408гб\с пропускной и 280 топс инт8, правда от хуавей-куна новостей всё нету. Видать опять споткнулся об какой-то китайский кокблок и ничего не может запустить.
В теории я могу похерить сильно тайминги(до 44-46 CL) и добиться 6600-6800 на 1.4В напруги. Правда по хорошему придётся чем-то обдувать память.
>$6,000
>6-8 токенов в секунду
Зачем?
Качаю iq4xs у bartowski. Будут интересные результаты - отпишусь.
Это на Q8_0 кванте моделька на 671B. Если Q2-Q4 брать кванты, то получится сильно ужать размер, увеличить скорость до приемлемой, но проебётся точность, что может быть важно не в рп, а в рабочке. Смотря кому для чего.
>цопе
МОЧААА
Q4_0 разве не будет быстрее если оно все равно работает на cpu? На обычном Air с Q4_0 контекст загружается точно быстрее.
я щас собираю вариант за ~$7к
H13SSL
EPYC4 9384X / 9354 / 9454 / 9534 какой получится найти за <=$1500
12x 64GB 6400 MHz
ожидаемый bandwidth 360 GB/s, у хуйни по ссылке выше будет максимум 200
Да речь не о циферках а о том что все это устареет за год. Купи ты подписку и не еби мозг.
Ты не путаешь B60 на 24 с аналогвентом от максуна на 48, который является пердосклейкой 2 B60?
Новая, в магазине, работает из коробки. торч и вЛЛМ нативно, в теории больший срок поддержки. Ясен хрен, что из говна и палок можно собрать дешевле и лучше, но не всем это интересно.
Ты хотел сказать только для инфиренса ллм? "Видюхи для нейронок" наоборот дорогие. Есть они, самый яркий пример - ускоритель хуавея с оппика.
> сильно смущает шина памяти и топсы
Если там рили 48гигов за 600 баксов как говорит анон - топчик же. Под xpu есть питорч, есть сборка жоры, пусть донная но еще актуальная поддержка. Вариант веселее некромишек.
>Если там рили 48 за 600
Там 24 за 600, 48 видимо за 1200-1500$ для белого человека и около 1600-1800$ для жителя этой страны от перекупов.
>торч и вллм нативно
На каком кванте? Домашний деплой нейронок без нормальной поддержки квантов мало смысла имеет. Про всякие FA, прочие оптимизации и скорость в диффузиях пока надо гадать.
Это просто перевод зарубежной статьи, автор даже поленился заменить ссылки заребужных магазинов.
От второго соккета толку меньше чем ожидается, обработка контекста будет вечной. Но можно добавить хотябы 3090 и станет уже вполне неплохо.
> 12x 64GB 6400 MHz
Где нашел серверную 6400, случаем не путаешь с обычной? Генуа не поддерживает выше 4800, так что можно на этом сэкономить. Скорость там овер 450гб/с получится, у хуйни по ссылке овер 1тб/с, вот только полелена на две нума ноды.
Но сборка солидная в любом случае.
В общем я поставил gpustack себе на комп, понадеялся на запуск чего-то, однако был послат нахуй, чому-то сетка выдаёт ошибку запуска, хотя и грузится в врам(что меня приятно удивило). Это всё на 30B на bf16 разумеется. Качать каждый вечер модельку на 60 гигов просто что бы попытаться её затестить это прям ебать развлечение. Щас пытаюсь отладить, непонятно, почему на середине загрузки она начинает выёбываться, опять потраченный перевод с китайского на форуме ascend читать.
Ебать анекдот, если он обычную драм хотел поставить, а не ecc reg в сервер.
Один анон как-то писал и я соглашусь : принципиального скачка между 120-250б мое и 350-700б гигантами нет. Вот переход с мелкомоделей на первую категорию ощутим. Если уж с задачей не справляются 120-250б мое, то и гиганты не справятся, там человека подключать или свой котелок если остался. Итог : практического смысла собирать риг нет, оптимальнее всего десктоп на 24-32 врама и 128-256 рама. Собирать риги при максимум перфоманса и минимум затрат это прикольно и увожаемо, но не необходимо
Будет. Но вывод будет хуже.
Если бы у меня хотя бы q5 влазил - можно было бы не IQ грузить. А так - я предпочту качество скорости. Там все равно на обычном AIR у меня 3-5 ts получается (от полноты контекста зависит).
Мой опыт и IMHO - ниже 4-го кванта обычный Q и IQ различаются по качеству как минимум на цифру. Т.е. если я гружу IQ3 - это почти то же самое что Q4. А iq4xs - лучше чем q4kl. С квантами выше - да, смысла уже нет.
>128-256
Смотря какой бюджет. В реальности 120B модели типа гопоты прекрасно себя ощущают на 96 рам, что заметно дешевле. Разве что речь не идёт про hedt, но там и карты посерьёзней должны быть. Можно бомжевать на четырёх мишках за 55к рублей и обогревать квартиру, можно собрать хороший комп, на котором и игорь не тонет, а можно упороться на эпиках\тредрипперах, но это шейховый вариант за 300к минимум.
> Где нашел серверную 6400
да где угодно лол я релокант прост MEM-DR564MC-ER64 = samsung M321R8GA0EB2-CCP
> Генуа не поддерживает выше 4800, так что можно на этом сэкономить.
я планирую переехать на епук5 когда они подешевеют, а продавать 12 планок 4800 и покупать 12 по 6400 вместо того, чтобы сразу купить 12 6400 - это долбоебизм.
> Скорость там овер 450гб/с получится
в епуках в отличие от инцелов скорость жёстко завязана на количество CCD, у хуйни по ссылке выше 1 тб даже теоретически получиться не может, у моей хуйни теоретическая скорость около 400, реальная около 360
в это, конечно, сложно поверить, но в данном треде всё-таки бывают люди с айсикью выше 80

Турин поддерживает максимум 5600, в целом самсунги 4800 на ней заводятся после небольших ухищрений. Там важнее найти правильную ревизию супермикры, чтобы поддерживала новых.
> у хуйни по ссылке выше 1 тб даже теоретически получиться не может
Действительно, там же совсем затычки.
Но откуда инфа про 360-400? Достаточно давно выкладывали сравнительные тесты и эпиков и трипаков, там утверждалось 32-ядерных было достаточно для полной утилизации псп 12 каналов.
Да, там даже овер 7к встречаются в каталогах, ахуеть.
> Т.е. если я гружу IQ3 - это почти то же самое что Q4. А iq4xs - лучше чем q4kl.
У нас новый шизик
> Турин поддерживает максимум 5600,
чё?
MAX # OF MEMORY CHANNELS. 12
MAX MEMORY SPEED. 6000 MT/s
и то это старая инфа, в новых ревизиях вроде до 6400 подняли
> Там важнее найти правильную ревизию супермикры, чтобы поддерживала новых.
да
> Rev 1.x 4800 MT/s ECC DDR5 RDIMM (AMD EPYC™ 9004 Series Processor)
> Rev 2.0 6000 MT/s ECC DDR5 RDIMM (AMD EPYC™ 9004/9005 Series Processor)
> Rev 2.1+ 6400 MT/s EPYC 9004/9005
вот уже неделю жду от одного реселлера ответ, когда уже примерно у них появятся H13SSL ревизии 2.1
> Но откуда инфа про 360-400?
https://old.reddit.com/r/LocalLLaMA/comments/1fcy8x6/memory_bandwidth_values_stream_triad_benchmark/
> Достаточно давно выкладывали сравнительные тесты и эпиков и трипаков
наверное выше это оно и есть.
кароч прикол в том, что CCD соединены с памятью через infinity fabric, а у infinity fabric скорость 100 GB/s, поэтому 2 коре комплекса даже теоретически не смогут выжать из 12 каналов больше 200 GB/s
https://www.servethehome.com/amd-epyc-9005-turin-turns-transcendent-performance-solidigm-broadcom/2/
> AMD EPYC “Turin” is still a 12-channel DDR5 design. DDR5 speeds are up to DDR5-6000, but AMD said it will qualify up to DDR5-6400 for certain customer platforms.
> AMD EPYC “Turin” is still a 12-channel DDR5 design. DDR5 speeds are up to DDR5-6000, but AMD said it will qualify up to DDR5-6400 for certain customer platforms.
Где эир 4.6 блять...
> в новых ревизиях вроде до 6400 подняли
Хм, почему-то запомнилось именно 5600, напиздел значит. Ну и отлично, значит они быстрее.
> наверное выше это оно и есть.
Да, оно. Про количество блоков как раз оно https://www.reddit.com/r/threadripper/comments/1azmkvg/comparing_threadripper_7000_memory_bandwidth_for/ в первых комментах дополнительное разъяснение.
Но 360-400 как-то мало, в других бенчах там 430+.
А UD в первый день сравнивал, хуита какая-то. Веса больше, русский хуже, скорость ниже.
Shared layers/experts у бартовски квантованы в большем бите (8 гигов против 7 у анслота), ну и как бы, в целом, нахуя тогда UD?
У меня в одном компе на 12.8, в другом на 12.4, а ты мне про 13. Я удивлен, что оно в 12.8 поехало. =)
Еще год назад говорили, что Теслы отвалятся из поддержки. Мы когда покупали — не ждали, а морально готовились.
Но время пока еще не пришло…
Две видеокарты с бифуркацией и чипом уровня 3060-4060.
Ну, типа, что-то в районе теслы п40, ну помощнее, да?
Соу-соу.
Интел еще.
> Там даже plx на псие никакого нет, будь добр бифуркацию на 8+8 включать
Вроде и было ожидаемо, но все равно грустно.
Ну, с тебя обзор, ясен-красен!
Это та B60, которая слабее B580 и равна 3060? Не, пасиба, звучит еще хуже. Уж лучше B580.
Подписал себе 700 мб интернет, как же я был рад, когда тести 4 2-битных кванта GLM-4.6… 400 гигов за три часа.
> а продавать 12 планок 4800 и покупать 12 по 6400 вместо того, чтобы сразу купить 12 6400 - это долбоебизм.
Вот многие со мной не согласятся, но я тоже всегда был за то, чтобы взять оперативу сразу нужную, а не перепродавать ее по сто раз.
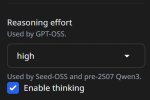
Вчера весь вечер ебался с gpt-oss 20b в попытках заставить её работать с тулингом агента. Не получается.
Дело в том что её тренировали под другой тулинг и в 90% случаев она игнорирует команды агента и из-за этого нормально не работает. Зато работает очень быстро. Так что хочется допилить.
Нашёл японскую мокропиську https://github.com/irreg/native_tool_call_adapter почему-то не пересылает запросы на api модели. Сталкивался кто-нибудь? Файрвол отключать пробовал.
>Поставь и будет тебе счастье. Не ебу, где это в убабуге делать.
Очень и очень просто, в агентах точно так же.
>Ну меня и так забавляет смотреть как она кубатурит килотонны текста. Сетевой дипсик так не делает, например, он куда меньше пишет (а может просто не показывает).
>Братан, вайбкодинг — это не вопросы в чатике спрашивать, а когда агент работает и сам код пишет.
Ну так меня на тот момент интересовала общая компетентность модели в заданных случаях.
>Люди для этого Qwen3-Coder-480B, GLM-4.6-355B, ну в крайнем случае Qwen3-235B или GLM-Air-106b запускают. Из твоих это Qwen3-Coder-30b.
Да жирновата для меня Qwen3-Coder-30b. Разве что сильно квантованную юзать, но что-то я не верю в результат.
>Ты угараешь?
Я вчера в первый раз эту вашу ЛЛМ локально запускал. Разное смотрел.
>GPT-OSS с ризонинг хай в чатике норм поспрашивать, будет долго думать, но ответы более-менее. Плюс она как раз для 16 гигов делалась.
120 токенов в секунду без контекста. Не так уж и мало.
>Собирай комп за пару лямов, или юзай кодер-30б или гпт-осс-20б с ризонингом на хай.
Ну это уже понятно.
У меня на предыдущей работе были сервера с сотнями гигабайт оперативки и неплохими процессорами, было бы интересно потестить на них, как раз без дела валялись. Поздновато я за нейросети сел.
Дело в том что её тренировали под другой тулинг и в 90% случаев она игнорирует команды агента и из-за этого нормально не работает. Зато работает очень быстро. Так что хочется допилить.
Нашёл японскую мокропиську https://github.com/irreg/native_tool_call_adapter почему-то не пересылает запросы на api модели. Сталкивался кто-нибудь? Файрвол отключать пробовал.
>Поставь и будет тебе счастье. Не ебу, где это в убабуге делать.
Очень и очень просто, в агентах точно так же.
>Ну меня и так забавляет смотреть как она кубатурит килотонны текста. Сетевой дипсик так не делает, например, он куда меньше пишет (а может просто не показывает).
>Братан, вайбкодинг — это не вопросы в чатике спрашивать, а когда агент работает и сам код пишет.
Ну так меня на тот момент интересовала общая компетентность модели в заданных случаях.
>Люди для этого Qwen3-Coder-480B, GLM-4.6-355B, ну в крайнем случае Qwen3-235B или GLM-Air-106b запускают. Из твоих это Qwen3-Coder-30b.
Да жирновата для меня Qwen3-Coder-30b. Разве что сильно квантованную юзать, но что-то я не верю в результат.
>Ты угараешь?
Я вчера в первый раз эту вашу ЛЛМ локально запускал. Разное смотрел.
>GPT-OSS с ризонинг хай в чатике норм поспрашивать, будет долго думать, но ответы более-менее. Плюс она как раз для 16 гигов делалась.
120 токенов в секунду без контекста. Не так уж и мало.
>Собирай комп за пару лямов, или юзай кодер-30б или гпт-осс-20б с ризонингом на хай.
Ну это уже понятно.
У меня на предыдущей работе были сервера с сотнями гигабайт оперативки и неплохими процессорами, было бы интересно потестить на них, как раз без дела валялись. Поздновато я за нейросети сел.
Кто-то скидывал, как ее под cline завести, были хаки.
Но я забил, если честно. Поищи в старых тредах. Возможно по слову «cline».
И я без гарантий, если че.
Может быть это правда работает, а может и хрен там.
> в попытках заставить её работать с тулингом агента
Какой фронт, какой бэк? У клайна странный диалект вызовов, радикально отличающийся от нативного опеновского и не совпадающий с xml квенов в их внутренней разметке. Твоя мокрописька как раз должна с этим помогать, но следующий этап - корректная обработка оформленных в оаи опи вызовов уже самим бэком, это тоже не так просто.
Че-то есть.
Меня удивило кстати, что Qwen3-Coder-30b обучен в xml, а остальные модели (включая Qwen3-Coder-480b?) в json, и как-то у меня норм квен-кодер-30б не заработал, иногда пытался вызвать команду-в-команде. Может я его не правильно грузил, хуй знает.
У всех моделей команда сразу выполняется, у квен-кодера-30б в начале начинает писаться xml-код, а в середине команды он догадывается и дальше уже выполняет команду.
Или это пофиксили мб уже, хз.


> Хм, почему-то запомнилось именно 5600, напиздел значит
ты наверное энергосберегающие смотрел
> For Epyc, purchase a motherboard with 12 memory slots and an Epyc 9004 processor with at least 8 CCDs. Fill all memory slots.
вот я at least 8 CCDs и выбираю
И чё?
Моё IMHO - как хочу, так и имею. (Спросили зачем - ответил.)
А вы - юзайте что хотите. Мне пофиг. :)
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Ну я хз что там по псп, вроде много чего именно из старого зен4 туда перекочевало. Тут полноценный авх512 с 512 бит инструкциями. Сейчас у меня с помощью ии разгона(дожили блять) получилось с хуй пойми какими точно параметрами понизить латентность на 15нс, повысить пропускную примерно на 5-10% от EXPO профиля чистого и теперь голая гопота на пустом контексте выдаёт 15.4 т\с.



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: