


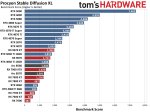


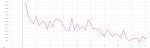
14 часов достаточно агрессивной тренировки на продижах с идеально выдроченным микродатасетом, и ошибка все еще снижается.
Вопрос: какая комбуха из лосс функции и оптимайзера по вашему мнению имеет наиболее быстрое, эффективное и мощное схождение?
Вопрос: какая комбуха из лосс функции и оптимайзера по вашему мнению имеет наиболее быстрое, эффективное и мощное схождение?



Loss это не метрика. Он куда угодно идти может. Пикрил на 1 пике датасет на 3к пикч с парой десятков концептов, лосс как будто бы даже вверх идёт, потому что некуда сходиться, все пики разные, вот и лосс как рандомный шум. На втором пике датасет из 10 пикч на стиль, с абсолютно такими же параметрами. Оба оттренились как положено.
> лосс функции
Пик3 - как выглядит loss настоящих мужчин.
>Loss это не метрика. Он куда угодно идти может.
Позвольте, снижение ошибки предсказания это главная метрика стабильного вывода.
>Пикрил на 1 пике датасет на 3к пикч с парой десятков концептов, лосс как будто бы даже вверх идёт, потому что некуда сходиться, все пики разные, вот и лосс как рандомный шум.
Это говорит о том, что модель не может сообразить как правильно предсказывать, поэтому наоборот старается вычленить более общее сначала и лосс растет. В далеком будущем она обобщит лучше и лосс будет снижаться. Плюс надо иметь в виду что вероятно это лора, а она парметрическую емкость низкую имеет.
На втором пике у меня лосс вниз пошёл потому что было 500 эпох, а в первом случае 3. На качество финального результата это никак не влияет, это ты просто видишь как сетка запоминает конкретные пикчи. Попробуй потренить большой датасет в одну эпоху с тем же стилем как и у модели, тоже не увидишь снижения лосса.
Для тренировки на noobai нужно ставить debiased_estimation_loss если с edm2 тренируешь? edm2 же автоматически выставляет приоритет таймстепов, а как я понял debiased_estimation_loss тоже выставляет приоритет, только статически и увеличивает важность последних шагов
это нормально, что Forge больше чем в 2 раза быстрее, чем automatic1111? там в районе 250% ускорение - было примерно 2 it/s, стало примерно 5
я что-то не верю в такие оптимизации и мне кажется, что где-то что-то отвалилось или скипается посередине генерации.
модель и лоры запускаю такие же, семплеры и их конфиги тоже такие же, настройки в Settings тоже вроде похожи, а картинки генерятся быстрее, что за фигня? или там реально прям так сильно оптимизировано (или автоматик1111 - тормознутая хуйня?)
я что-то не верю в такие оптимизации и мне кажется, что где-то что-то отвалилось или скипается посередине генерации.
модель и лоры запускаю такие же, семплеры и их конфиги тоже такие же, настройки в Settings тоже вроде похожи, а картинки генерятся быстрее, что за фигня? или там реально прям так сильно оптимизировано (или автоматик1111 - тормознутая хуйня?)
>(или автоматик1111 - тормознутая хуйня?)
Да, если бы ты сидел на нём с начала, ты был бы в курсе кто его и руками из какого места торчащими делал.
Что то одно юзай
> или автоматик1111 - тормознутая хуйня?
Да, на заре эпохи xl было буквально в два раза медленнее, чем сейчас можно выжать
а в каком тренере едм2 вкостылен нормально?
скорее всего такая большая разница из-за версий сопутствующего софта. автоматик1111 я запускал с питоном 3.11 и какими-то старыми трансформерами и торчем, а форж с питоном 3.13 и свежими трансформерами и торчем.
так шо не всегда обновления делают только хуже, иногда и улучшают.
Клайбиус накодил наканецта свой магнум опус оказывается
https://github.com/Clybius/Personalized-Optimizers/blob/main/TALON.py
Что ето: Temporal Adaptation via Level and Orientation Normalization, адаптивный оптимизатор, направлен на стабильность, адаптацию к направлению и масштабу градиента, и устойчивость к шуму (судя по мои тестам полностью насрать в хорошем смысле на неоднородность даты и количество концептов). Наследует идеи из Compass, AdaNorm, Adam, Adan, DoRA и адаптивных спектральных нормализаторов, но соединяет их в единую систему, при этом не требуя тонкой настройки гиперпараметров (там буквально нечего менять, вставил и поехал).
Общие майлстоуны:
1. Отдельно отслеживает знак и величину градиента через два EMA, рассчитан на работу с высоким lr.
2. Применяет атан2-нормализацию вместо обычного деления (то есть никаких клипперов использовать дополнительно не нужно, если ты используешь, но атан2 замедляет обучение вместо деления, имейте в виду).
3. Может использовать спектральное клиппирование (вкл по дефолту), инвариантное преобразование (тестовая опция, выкл) и ортогональные градиенты (опция, выкл).
Погонял на нескольких типах даты и он хорош, просто целенаправленно двигается к обобщению и практически не вываливается в шизофрению по пути.
Из личных минусов разве что медлительность с Huber с адаптивным snr (что очевидно, т.к. талон сам супер осторожный, а тут еще слабые сигналы от snr фильтра хубера, кароче мультипликативный эффект), там прямо чуть ли не 1e-1 скорость можно выставлять, шестичасовой тест на 1e-3 с двумя десятками эпох дал прекрасный тонкий результат без говна в выдаче, но точно скорость можно выше выставить, возможно требует дельту подкорректировать. С l2 работает бодрее и lr наоборот пониже. l1 не тестировал.
Debiased est loss переваривает отлично (многие оптимайзеры не переваривают задранные таймстепы), так что в целом любое вмешательство в них допускается, кому не лень может едм подрочить.
https://github.com/Clybius/Personalized-Optimizers/blob/main/TALON.py
Что ето: Temporal Adaptation via Level and Orientation Normalization, адаптивный оптимизатор, направлен на стабильность, адаптацию к направлению и масштабу градиента, и устойчивость к шуму (судя по мои тестам полностью насрать в хорошем смысле на неоднородность даты и количество концептов). Наследует идеи из Compass, AdaNorm, Adam, Adan, DoRA и адаптивных спектральных нормализаторов, но соединяет их в единую систему, при этом не требуя тонкой настройки гиперпараметров (там буквально нечего менять, вставил и поехал).
Общие майлстоуны:
1. Отдельно отслеживает знак и величину градиента через два EMA, рассчитан на работу с высоким lr.
2. Применяет атан2-нормализацию вместо обычного деления (то есть никаких клипперов использовать дополнительно не нужно, если ты используешь, но атан2 замедляет обучение вместо деления, имейте в виду).
3. Может использовать спектральное клиппирование (вкл по дефолту), инвариантное преобразование (тестовая опция, выкл) и ортогональные градиенты (опция, выкл).
Погонял на нескольких типах даты и он хорош, просто целенаправленно двигается к обобщению и практически не вываливается в шизофрению по пути.
Из личных минусов разве что медлительность с Huber с адаптивным snr (что очевидно, т.к. талон сам супер осторожный, а тут еще слабые сигналы от snr фильтра хубера, кароче мультипликативный эффект), там прямо чуть ли не 1e-1 скорость можно выставлять, шестичасовой тест на 1e-3 с двумя десятками эпох дал прекрасный тонкий результат без говна в выдаче, но точно скорость можно выше выставить, возможно требует дельту подкорректировать. С l2 работает бодрее и lr наоборот пониже. l1 не тестировал.
Debiased est loss переваривает отлично (многие оптимайзеры не переваривают задранные таймстепы), так что в целом любое вмешательство в них допускается, кому не лень может едм подрочить.
> градиент-клиппинг погоняет градиент-клиппингом
Бесполезное говно, как и десяток подобных до него, ещё и медленное. Смысл чистить всратый mse/huber-лосс душением градиентов, если уже давно придумали делать wavelet-декомпозицию лосса, сужай сколько хочешь влияние мусора.
Цифры бы увидеть, метрики или хоть какой-то живой результат, а то хуй поймешь шиза это или нет.
Вот мюон например уже показали что на 30% лучше работает, но только если с нуля обучать, но если не с нуля то хотя бы память экономит. Но может вызывать дополнительную нестабильность на долгой тренировке.
А на лорах это вообще другой мир где по нюансам оптимизации 0 работ.
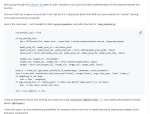
>делать wavelet-декомпозицию
Ты про эту хуйню с пика из дифужн4к чтоли? Не работает с bf16, только с флоат32 -> на хуй идет.
>Бесполезное говно
Мне понравилось, рукопожатие крепкое, не выебонит на сверхмалых или сверхвсратых датасетах и всегда знаешь что не пизданется и не начнет ходить по кругу.
>как и десяток подобных до него
Перечисляй.
>ещё и медленное
Медленное это FMARSCropV2, а тут чуть медленнее продижей.
> Не работает с bf16
С чего бы ей не работать? Всё работает.
пруфы
Пруфы чего? Я сейчас только так и треню, обычного лосса нет у меня, выше скрин кидал с кодом расчёта лосса с автоматическими весами от timestep.
ну дай код реализации и как впендюрить в скрипты, че из тебя щипцами вытягивать?
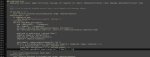


кароче вроде впердолил эту поебистику
нигде нихуя не написано как куда сувать, как будтов се погромисты дохуя
1. в трейн нетворке
строка 465 loss = train_util.conditional_loss(noise_pred.float(), target.float(), args.loss_type, "none", huber_c, timesteps)
строка 470 loss = loss
(вероятно будут ошибки если с классическими лоссами включать обратно, не проверял)
2. в трейн утиле
а) пик1, ввести новый тип лосса
б) после импортов запихать пик2
в) добавить в импорты
import torch.nn.functional as F
from pytorch_wavelets import DWTForward
вроде работает гавно, уже сдохло нахуй
>уже сдохло нахуй
ха, прикол, не сдохло с такими конскими значениями оказывается, прям четенько результат уже на первой эпохе

Там кстати погромист который дрочится с вейвлетом полевельно веса сделал, можно типа отключать каждый лвл отдельно и влиять только на чтото конкретное, в коде отсюда не реализовано
кароче можно пул реквест для кои открывать, пусть добавляет, ток проверю как с другими лоссами работает теперь
ну это прям шикардос результы у меня с этим, я еще таких крутых тренингов не делал ни с л2, ни с хубером, почему это еще не зарелизено везде по дефолту-то, дифужн 4к вышел в марте такто
А в пулах лежит оказывается внедрение вейвлетов https://github.com/kohya-ss/sd-scripts/pull/2037 ток там какая-то суперпедольная реализация с миллиардом выведенных отдельно настраиваемых параметров.
Потому что веса для уровней не очень универсальные, надо под задачу подбирать. А тренировка без весов заметно хуже чем правильные веса. А с автовесами ещё больше подстроек надо, я довольно долго пердолился чтоб ширину пика подобрать.
Можно для XL проще делать - трансформации Фурье. Результат тоже лучше mse/huber.
Все волны кроме haar говно, я уже всё это говно перетестил давно. У него ещё в списке недискретные, они не работают с дискретным DWT. Тот кто делал pr явно отбалды все возможное параметры впердолил не тестируя.
>Потому что веса для уровней не очень универсальные, надо под задачу подбирать. А тренировка без весов заметно хуже чем правильные веса. А с автовесами ещё больше подстроек надо, я довольно долго пердолился чтоб ширину пика подобрать.
>Можно для XL проще делать - трансформации Фурье. Результат тоже лучше mse/huber.
Эта часть поста ответ на ?
>А тренировка без весов заметно хуже чем правильные веса.
А почему ты взял именно 6 уровней?
>А с автовесами ещё больше подстроек надо, я довольно долго пердолился чтоб ширину пика подобрать.
А что если их адаптивными сделать от timesteps или num_levels?
>Можно для XL проще делать - трансформации Фурье. Результат тоже лучше mse/huber.
Есть код?
>Все волны кроме haar говно
В чем их проблема?
>А что если их
Его, в смысле пик
Кстати твоя реализация отлично работает с дебиаседом. Несколько более когерентные результаты получаются и чуть быстрее тренирует.
Вкратце можно как работает эта частотка с латентами? Латент в сд же говно, не инвариантен к масштабу/поворотам/сдвигам, и канал для формы сильно отличается от цветности и яркости по структуре.
>как работает
прицельно настроенные веса уровней
> Есть код?
Брал отсюда либу - https://github.com/tunakasif/torch-frft
Просто пропускаешь латенты через трансформацию. Там на выходе будет тензор с комплексными числами - амплитуда и фаза. Фазу можно просто выкинуть скастовав к float, без неё немного другой результат. Обычный лосс с комплексными числами не работает, mse будет вот так: torch.mean((pred - target).real ⚹⚹ 2 + (pred - target).imag ⚹⚹ 2)
Если упороться, то можно ещё маску накинуть, центр спектра с шифтом по центру.
> В чем их проблема?
Они усредняют пиксели латента. Всякие номерные типа db4 берут большими блоками пиксели, 4 тут - это в 4 раза больше блок. Ещё и смазывают если волна плавная. У haar просто резкие 2х2 блоки, для мелких деталей лучше всего должно быть.
Латент это не картинка. Особенно в канале "формы".
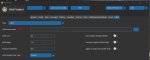
Нужен ли warmup при продолжении тренировки?
После использования каких счедулеров лучше не продолжать тренировку?
После использования каких счедулеров лучше не продолжать тренировку?
вармап в принципе излишный страховочный элемент, можно им вообще не пользоваться
Аноны в предыдущих тредах говорили что на начальных этапах шума слишком много чтобы извлечь полезную информацию и это сбивает модель. Ну и после увеличения вармап, у меня вроде как семплы стали более вариативные, но это не точно.
Позволяет оптимайзеру с накоплением (считай все) выйти в режим и не взорваться в начале при прохождении выбивающихся данных. При продолжении достаточно будет короткого, но его наличие крайне желательно.
>Аноны в предыдущих тредах говорили что на начальных этапах шума слишком много чтобы извлечь полезную информацию и это сбивает модель.
Ну я контраргументирую следующим:
1. Адаптивным лосс функциям насрать на взрывы градиентов при инициализации. Huber + SNR неубиваем практически. Вейвлеты рассмотренные выше по треду тоже стабильные на этот случай. L1 просто похуй на взрывы. Единственное что может обосраться от них это L2, не пользуйся л2 да и все.
2. На каком лр гоняешь? Если это не выше 1e-4 то выгода от вармапа сомнительна, т.к. все что ниже 1e-4 считается низкой скоростью и сила обновлений недостаточная чтобы поломать все.
3. Если ты обучаешь на датасете, который доменом уже имеется в модели - вармап тоже не нужен. Условно у тебя модель с бабами, ты берешь фотки бабы - резкой смены домена данных не будет.
4. Ты тренируешь лору а не фуллфт, у тебя нет огромного батча и биг даты чтобы переживать о взрыве знаний при инициализации.
5. Если ты используешь шедулерфри оптимы, то тем более тебе не нужен вармап, т.к. они по сути адаптивны и сами себе сделают вармап где нужно.
6. Если ты используешь CosineAnnealingWarmRestarts или какойнибудь вансайкл тоже вармап нинужон.
>Нужен ли warmup при продолжении тренировки?
Если не сохранил состояния оптимизатора, то нужен.
Прогрев нужен для того чтобы адаптивные оптимизаторы и моментумы накопили статистику. Иначе у тебя первая картинка может получить вес в 10 раз больше чем другие, как пример проблемы.
Этот бред не слушай, не имеет отношения к проблеме.
Разве что 6 имеет смысл, может быть 5.
Спасибо, раз он не наносит вред тогда лучше перестраховаться.
Я по итогу дропнул wavelet лосс, говно какое-то. Надо дрочить веса, но как бы их не дрочил всё не то. Всегда что-то лучше становится, что-то хуже, а чтоб прям заебись было невозможно подобрать. Перешёл на Фурье, с ним стабильность просто ахуевшая и ничего не надо пердолить, что дало возможность сделать то что раньше ломало картинку - сделал фиксированный шум для каждого пика, а не как в ваниле рандом. С mse от такого пережаривало и почти неюзабельно было, а с FFT тренится заебись и при этом вариативность генераций огромная и стабильно всё. Ещё и на оптимизатор focus перешёл.
> Перешёл на Фурье, с ним стабильность просто ахуевшая и ничего не надо пердолить, что дало возможность сделать то что раньше ломало картинку - сделал фиксированный шум для каждого пика, а не как в ваниле рандом.
Дай код реализации то

Одна строчка. Либа вверху.
пиздос опять пердолить трейнутиль
Так, а насчет
>сделал фиксированный шум для каждого пика, а не как в ваниле рандом
а def mse_complex код какой?


Я при кешировании латентов шум генерю и потом только его использую, без генерации нового, у каждого латента свой фиксированный шум.
Выше писал же.
>Я при кешировании латентов шум генерю и потом только его использую, без генерации нового, у каждого латента свой фиксированный шум.
а ну то есть если у меня не кешируется ниче, то мне нинужно
Вопрос по B-LoRA
Как корректно в toml указать таргеты на conv слои?
Если в таргет модулях указывать conv2d, то оно начинает вообще все тренировать практически, независимо от регекса в таргет юнет
В фуловой лоре естественно conv_in и conv_out для таргет юнет нет, и при enable_conv = true и с/без конвин/конваут никакие конволюшены не тренируются.
Если брать базовые блоки в таргет модулях ResnetBlock2DDownsample2D Upsample2D то оно сразу перетренировывает моментально, супер анстейбл кароч
Как корректно в toml указать таргеты на conv слои?
Если в таргет модулях указывать conv2d, то оно начинает вообще все тренировать практически, независимо от регекса в таргет юнет
В фуловой лоре естественно conv_in и conv_out для таргет юнет нет, и при enable_conv = true и с/без конвин/конваут никакие конволюшены не тренируются.
Если брать базовые блоки в таргет модулях ResnetBlock2DDownsample2D Upsample2D то оно сразу перетренировывает моментально, супер анстейбл кароч
>Выше писал же.
запустил кароч, а че он такой реактивный, в три раза быстрее считается чем другие
ну прикольный результат, учитывая еще скорость бешеную
В ваниле каждую эпоху у тебя разные сиды для одинаковых пиков, но логичнее чтобы одинаковые пики были с одним и тем же шумом. Но проблема в том что оно с mse оверфитится адово, до того как успеваешь что-то натренить лора уже запорота, а FFT фиксит это. Оно станет ещё быстрее трениться и повысится вариативность генераций. Тут где-то был любитель обобщения, ему это в первую очередь надо делать. При претрейне так не делают по очевидной причине - мало эпох и они большие.
Там авторы перебором нашли наиболее важные для тренировки слои. Тренятся только attentions.0 и attentions.1 в up-блоках. Один из них концепт, другой стиль. Вообще не рекомендую, у тебя будет всегда недотрен. Есть смысл только если тебе надо прям жестко отделить стиль и сам стиль довольно простой. Из плюсов оверфита нет, можно и надо тренить до усрачки, смысл б-лоры - это хуяк-хуяк как попало и оно даже норм натренилось. Если ты врубил другие слои, то это уже не б-лора.
>Там авторы перебором нашли наиболее важные для тренировки слои. Тренятся только attentions.0 и attentions.1 в up-блоках. Один из них концепт, другой стиль.
Да я в курсе что там атеншены, мне нужно просто конвы указать правильно чтоб оно локальные данные изучило для точности т.к. с одними атеншенами прямо видно недостаточность ортоганальных изменений, я уже проверил такой вариант когда конвы врубаются - он рабочий, но конкретно указать конволюшены связанные с аутпут блоками 0.1 и 1.1 я не могу нормально.
>Вообще не рекомендую, у тебя будет всегда недотрен.
Я бы не скозал, зависит от настроек, плюс я офт надрачиваю, оно сохраняет данные основные слоев и юзаю в основном с плюснутым dmd, результат конфетный.
>Если ты врубил другие слои, то это уже не б-лора.
Ну называй как хочешь, разряженная тренировка, мне нужны конвы хоть тресни.
>но логичнее чтобы одинаковые пики были с одним и тем же шумом
обоснуй на чем основана логика, мне всегда казалось что рандом нойз это метод регуляризации типа дропаутов, ты типа не подвязываешь сетку жестко к данным, таким образом давая ей свободу выражения
пока писал спросил у гпт, оно также сказало, что жестко обучать на фикс нойзе нахуй надо
У тебя генерации из шума. Если тренишь один пик на разных сидах, то модель и учится генерить один и тот же пик на разных сидах. Если так долго тренить, то модель начинает тупо с любых сидов генерить пики из датасета. И делает она не потому что оверфит или ещё что, а именно из-за того что ты научил её из любого шума их генерить. Собственно я это и на практике вижу, фиксированный сид даёт больше разнообразия генераций.
> гпт
Нашёл у кого спрашивать что-то, лол.
> Если тренишь один пик на разных сидах, то модель и учится генерить один и тот же пик на разных сидах.
но модель не учит картинки, она учит признаки на основе текстового описания
>фиксированный сид даёт больше разнообразия генераций.
как оцениваешь разнообразие?
>Нашёл у кого спрашивать что-то, лол.
че за трансформерный шовинизм? он мне код правит и он работает, да и нет смысла не доверять нейросетке в вопросах нейросеток
Кмк, смысл есть и там и там. Сделать шанс или заготовленного шума или случайного и получать профиты без подводных.
> нет смысла не доверять нейросетке в вопросах нейросеток
Они могут просто не понять твой вопрос и притащить случайную ассициацию, или просто взять предложенный тобою же вариант если в вопросе уже заложен ответ. Попросить ллм проанализировать вопрос с разных сторон и дать какую-то инфу о практике и как это может сыграть - хорошая идея, но желательно посвайпать оценивая выдачу. Требовать сделать вывод и дать ответ - плохая.

>Они могут просто не понять твой вопрос и притащить случайную ассициацию, или просто взять предложенный тобою же вариант если в вопросе уже заложен ответ. Попросить ллм проанализировать вопрос с разных сторон и дать какую-то инфу о практике и как это может сыграть - хорошая идея, но желательно посвайпать оценивая выдачу. Требовать сделать вывод и дать ответ - плохая.
> че за трансформерный шовинизм?
Скорее гопотный. Жпт очень тупая, если это не о-модели.
> нет смысла не доверять нейросетке в вопросах нейросеток
Нейросетки обычно гонят банальщину, выдают самый попсовый вариант ответа.
Bump

Спустя полгода дрочки я понял структуру сдхл наканецта, что основные концепты датасета (форма, цвет, объекты, особенные особенности) пиздятся напрямую в ffnet и proj слои, причем в основном в конечные инпут блоки и мидл блок. При этом ффнет просто запоминает все подчистую (и по факту обладает наибольшей выразительностью), а не обобщает, являясь очень мощным фильтром, который способен любой вывод атеншенов перекроить, т.к. независим. А прожекшен слои это входы выходы для атеншенов, которые имеют более высокий приоритет над данными самих атеншенов, как бы рамки для атеншена, а атеншен это само наполнение рамок. Гдето в атеншенах еще нормы сидят, но я их не обучал для теста практически, не могу сказать фактическое влияние.
То есть логика сдхл такая: атеншен строит суть картиночки, прожекшен конструирует финальную структуру, которая пропускается через MLP ffnet, который независимо обмазывает уникальными независимыми параметрами, полученными из датасета внимание ПОЛНОСТЬЮ ВНЕ КОНТЕКСТА. То есть вся проблема переобучения строится на том что в ффнет подается слишком сильная дата, которая его ломает - отключи вест ффнет и модель/лору невозможно убить никаким конским лр. Алсо все лоры убыстрялки и модели дистилляты из которых их экстрагировали содержат переобученный, но нормализованный для конкретного семплера ффнет за счет которого и идёт выигрыш в скорости.
При этом все атеншены очень стабильные и осторожные, напичканные селфчекингом, поэтому невероятно трудно переобучить/дообучить конкретно их (как в блоре, где одни атеншены).
То есть фактически для корректного обучения требуется обучать самый большой блок инпута т.к. он финализирующий и содержит основную дату для картиночки в середине процесса денойза, какуюто часть мидл блока или полностью потому что это параметрический финализатор и сборщик скрытых признаков в одно целое и обучать первые два блока аутпута (поздний этап денойза), которые собирают картинку из общей формы и среднечастотных деталей. При этом имеет смысл обучать ффнет и прожекшены на более низкой скорости в виду их огромной силы. Все остальное буквально излишество.
Надеюсь кому-то поможет данная инфа, основанная на рисерче из овер 300 моделек.
То есть логика сдхл такая: атеншен строит суть картиночки, прожекшен конструирует финальную структуру, которая пропускается через MLP ffnet, который независимо обмазывает уникальными независимыми параметрами, полученными из датасета внимание ПОЛНОСТЬЮ ВНЕ КОНТЕКСТА. То есть вся проблема переобучения строится на том что в ффнет подается слишком сильная дата, которая его ломает - отключи вест ффнет и модель/лору невозможно убить никаким конским лр. Алсо все лоры убыстрялки и модели дистилляты из которых их экстрагировали содержат переобученный, но нормализованный для конкретного семплера ффнет за счет которого и идёт выигрыш в скорости.
При этом все атеншены очень стабильные и осторожные, напичканные селфчекингом, поэтому невероятно трудно переобучить/дообучить конкретно их (как в блоре, где одни атеншены).
То есть фактически для корректного обучения требуется обучать самый большой блок инпута т.к. он финализирующий и содержит основную дату для картиночки в середине процесса денойза, какуюто часть мидл блока или полностью потому что это параметрический финализатор и сборщик скрытых признаков в одно целое и обучать первые два блока аутпута (поздний этап денойза), которые собирают картинку из общей формы и среднечастотных деталей. При этом имеет смысл обучать ффнет и прожекшены на более низкой скорости в виду их огромной силы. Все остальное буквально излишество.
Надеюсь кому-то поможет данная инфа, основанная на рисерче из овер 300 моделек.
Какая-то каша у тебя в башке. Фид-форварды нужны для нелинейности трансформера, т.к. трансформер только трансформирует данные, в трансформере даже активаций нет.
> в ффнет подается слишком сильная дата, которая его ломает
Во всех тренерах, в том числе у кохи, по умолчанию фф не тренится. Только если ты специально выбираешь тренить вообще все линейные, по умолчанию тренятся линейные в трансформерах (to_q, to_v, to_k, proj). А поломка почти всегда происходит в первых слоях, именно первые слои очень чувствительны к тренировке и легко превращают всё в кашу. Естественно у тебя средние слои менее чувствительны к кривой тренировке, ведь там уже нет пиксельных данных латента.
> для корректного обучения требуется обучать самый большой блок инпута
Для корректного обучения надо просто правильно обучать, ничего там не ломается при обучении фф/конволюшенов, если сделал всё правильно. Все попытки задушить тренировку отрубанием слоёв/обрезкой градиентов/душением лосса по snr и прочим весам - это лечение симптомов и проблема где-то в другом месте.
> Какая-то каша у тебя в башке.
Я бы поотвечал на каждый пункт, но ты невоспитанный и категоричный, чувства такта нет, да и пост написан в ультимативной форме (я понимаю что тебе очень нужно чувствовать себя экспертом на анонимном форуме, но впредь держи себя в руках, мне лично твои "ря ты криворучка, просто дыши пук пук хрюк" неинтересны), я по таким правилам не буду играть. Добра, щастья, здоровья.
Двачую а ты слишком болезненно реагируешь на замечание по сути.
> невоспитанный и категоричный, чувства такта нет, да и пост написан в ультимативной форме (я понимаю что тебе очень нужно чувствовать себя экспертом на анонимном форуме
Вот этот пост много постулатов, никакой конкретики и примеров.
> невоспитанный и категоричный, чувства такта нет, да и пост написан в ультимативной форме (я понимаю что тебе очень нужно чувствовать себя экспертом на анонимном форуме
Вот этот пост много постулатов, никакой конкретики и примеров.
>Фид-форварды нужны для нелинейности трансформера, т.к. трансформер только трансформирует данные, в трансформере даже активаций нет.
Нелинейность и в софтмаксе атеншена есть. Ну и чет с "Фид-форварды нужны для нелинейности" орнул. Типа, по твоему они нужны ТОЛЬКО для нелинейности?
>Во всех тренерах, в том числе у кохи, по умолчанию фф не тренится.
Пиздабол. ff_net адаптеры присутствуют для всех млпшек, в дефолтной лоре.
>Для корректного обучения надо просто правильно обучать, ничего там не ломается при обучении фф/конволюшенов, если сделал всё правильно.
И по классике ты нам конечно не расскажешь как правильно. Просто пук в воздух.
Так что реакция вполне оправдана.
Впрочем, какие-то осмысленные выводы из изначального поста я не могу сделать. Настройку лр по слоям обычно просто так не делают, те же проекции атеншена частично впитывают в себя инфу вместе с ff, которая выбьется только другим устойчивым сигналом и переполнением емкости. Нахуя просто понижать лр для ff? То есть хочешь сказать, что нам надо усиленно тренить атеншн? Опять же, даже если мы треним только атеншн, проекции спокойно навпитают инфу как и ff. У меня одна из самых популярных лор одноранговая, на стиль, вполне хватает. Работает нормально.
Про переобучение спорно, какого-то конкретного пайплайна и сравнений нет. Кароч, очень интересно но нихуя не понятно.
>Настройку лр по слоям обычно просто так не делают,
layer-wise LR decay делают в больших тренировках большие вумные дяди обычно, лораёбы не заморачиваются конечно такой хуйней
>те же проекции атеншена частично впитывают в себя инфу вместе с ff, которая выбьется только другим устойчивым сигналом и переполнением емкости. Нахуя просто понижать лр для ff?
Ffnet это независимый фильтр и часть MLP, если ты полностью тренишь, то впитают, если не полностью то впитает только прожекшен.
Мой тезис был в том, что так как ффнет независимая часть сети и равномерно распределен во всех блоках, которые имеют разную емкость, то в каких-то его частях неизбежно так скажем бутылочное горлышко для фф из-за малого батча, малой даты, накопления градиентов от однотипных паттернов и гиперов оптимайзера (например стандартная бета для ффнет скорее деструктивна на микробатче и малой дате, т.к. ффнет запоминает паттерны даты без обобщения, а бета накапливает моментум - то есть на деле моментум приводит к накоплению старых градиентов, которые могут сохранять переобученные шаблоны ffnet, особенно при малом батче и нестабильной дате, что замедляет адаптацию к новым градиентам и форсирует запоминает мусорных паттернов в ффнет, которому поебать что запоминать;
это подтверждается тем, что если тренировать полные самые большие блоки без декомпозиции с бетой 0.999, то результат будет хуже, чем бета 0.25 скажем - так происходит потому что у фф сила явно больше чем у атеншена, и если их тренировать сепарированно, то получается тот же результат. Вероятно ффнет сделан изначально так чтобы с большим моментумом (а равно большей параметрической емкостью) запоминать активнее, что имеет смысол когда у тебя сотни миллионов картинок и тысячные батчи, но это больше умозрительное заключение.
Таким образом получается палка где на одном конце непопадание в оптимальный лернинг рейт, но фф не страдает, а сеть при этом обучается долго и неэффективно, либо использование нормального лернинга как у больших дядек с корпусами датасетов, но тогда фф уничтожается.
Из этой ситуации можно выйти двумя путями - тренировать фф (и прожекшен) отдельно с другим лр, чем все остальное, или тренировать все сразу на нормальной скорости но с низким моментумом или вообще без моментума, целясь только в эффективные блоки.
Помимо этого надо учитывать, что ранние и поздние блоки сдхл не настолько важны для инъекции новой даты, они больше функциональные для полноценной модели, где первые инпут блоки занимаются понижением "разрешения" вычленяя признаки, а с середины аутпут блоков происходит незначительная относительно всего пайплайна инференса доводка картинки перед декодингом, соответственно внедрение узкой малой даты на протяжении всех блоков это скорее негативный эффект и призыв переобучения, т.к. ранние блоки это низкоуровневые признаки edge-level/shape (а мы работаем на основе модели, которая уже прекрасно умеет строить представления такого плана на основе массивной даты на которой ее обучали), а поздние для доработки структуры и цветовой координации (что также базовая модель и так умеет). Не вижу никакого фактического смысла перекраивать ранние и поздние блоки с помощью минимальных датасетов (менее 10к картиночек), поэтому внедрение узкой даты в эти блоки вредное действие и нужно действовать от принципа не навреди: да, блоки важны при генах, но не дают существенного прироста качества при их дообучении на малой дате из-за переобучения и затопления признаков. Проверяется элементарно - изолируй и тренируй только ранние или поздние блоки - выйдет какая-то хуита без задач (можешь не пробовать, я пробовал).
Сдхл по факту модульная бандура, сюда напрашивается аналогия про "если в машине сломался дворник, то не нужно делать рестайлинг", ни в одной комплексной системе не имеет смысла полностью переписывать все подчистую или внедрять всякое в каждый модуль чтобы внедрить новую фичу или починить неработающее.
>То есть хочешь сказать, что нам надо усиленно тренить атеншн?
Нет, не хочу сказать.
>Опять же, даже если мы треним только атеншн, проекции спокойно навпитают инфу как и ff.
Только проекция и впитает, если только атеншен. Но носитель именно новых данных из датасета это ффнет, а не атеншен.
> У меня одна из самых популярных лор одноранговая, на стиль, вполне хватает. Работает нормально.
Тут вопрос не в том что хватает и с чем можно смириться и какой у тебя юзкейс (может ты просто форсируешь генерацию по референсу), а в самой логике тонкой эффективной донастройки модели на малой дате и малом батче при использовании консумерских карт.
Плюс не обучая все разом, а поблоково или по частям сети ты получаешь гораздо больше свободы, т.к. в ликорисе есть отдельный алгоритм full, который не декомпозит в лоуранк матрицы, что является полноценной тренировкой.
То есть направляя тренировку в нужные эффективные элементы (предположим стандартные output_blocks 0 1, output_blocks 1 1, и input_blocks 8 1) ты можешь на наиболее популярной карте типа 3060 12 гигов все эти три блока разом полноценно засунуть в 12 гигов в 1024 разрешении на 1 батче и на выходе получить максимально нативную тренировку высокого качества, там модель получается в районе 2 гигов и просчет одной итерации в 5 секунд при этом на нормальном современном оптимайзере с FFT лоссом который выше обсуждали, это ниже чем даже дефолтная лора с ее 8 секундами, т.к. нет дополнительных преобразований. А на 16 гигах уже и мидл блок вприкуску влезет и чтонибудь еще (допустим можно в шахматном порядке по всем блокам выбрать эффективные слои оставшиеся), а это считай одномоментный полноценный файнтюн практически целой модели (2 гига от трех инпут/аутпут и 800 метров от мидла), но не нужно пердеть на зануленом fp8 или ухищряться с баквардпассами на адафакторе или восьмибитном кале. Если тренировать любой тип лор с конкретными блоками, то там еще плюсом меньший размер будет, помимо увеличенной скорости просчета, но минус в том что влияние лоры на модель не полноценное и все равно надо будет туда-сюда крутить силу как обычно, но лора это в любом случае компромисс. Сплошные плюсы в общем.
Уточню, что я не выступаю против полноблоковой тренировки, если она делает то что требуется, но меня всегда дико бесила все эти танцы с бубном чтобы выдрочить гиперы, выдрочить датасет, выдрочить соотношения чтобы не бох лора не сделала рухнум. Я кароч за принцип "если позволяет - упрощай".
Случайно придумал самый шизовый вариант инициализации лоры. Вкидываю чисто чтобы не забыть и уйти спать, может кому не лень будет протестить.
Кароч надо взять какую-нибудь другую модель и слить с нее экстракт.
Далее примерно логика как в
Добавляем экстракт к исходной (той, которую хотим обучить) модели. Из наэкстракченой модели вычитаем исходную. Из исходной вычитаем наэкстракченую и это новая "исходная" модель.
В лору подсасываем чистый слитый экстракт. Объединение этих двух вещей должно давать исходную модель, но только в качестве инициализации лоры у нас экстракт другой, вот такой прикол.
Только надо не забыть сделать исправление из гайда, иначе все сломается. Для надо после получения экстракта закинуть его обучаться как лору на 1 шаг на минимальном лр и сохранить.
Ну и наверное есть смысл за инициализацию брать не полный экстракт, а разностный, может как-нибудь еще намешать их.
Если я нигде не обосрался с математикой, может получиться интересный эффект в виде мягкого пересаживания biasов с одной модели на другую в процессе просто обучения лоры на вообще другой задаче. По моей логике это может дать толчок лоре пойти по тому же пути по какому шла другая модель.
Важно, повторюсь, здесь именно обучается полноценная исходная модель которая как бы никак не модифицирована, но она разрезана на лору не по SVD как в том методе, а как бы плоскостью другой модели.
Кароч надо взять какую-нибудь другую модель и слить с нее экстракт.
Далее примерно логика как в
Добавляем экстракт к исходной (той, которую хотим обучить) модели. Из наэкстракченой модели вычитаем исходную. Из исходной вычитаем наэкстракченую и это новая "исходная" модель.
В лору подсасываем чистый слитый экстракт. Объединение этих двух вещей должно давать исходную модель, но только в качестве инициализации лоры у нас экстракт другой, вот такой прикол.
Только надо не забыть сделать исправление из гайда, иначе все сломается. Для надо после получения экстракта закинуть его обучаться как лору на 1 шаг на минимальном лр и сохранить.
Ну и наверное есть смысл за инициализацию брать не полный экстракт, а разностный, может как-нибудь еще намешать их.
Если я нигде не обосрался с математикой, может получиться интересный эффект в виде мягкого пересаживания biasов с одной модели на другую в процессе просто обучения лоры на вообще другой задаче. По моей логике это может дать толчок лоре пойти по тому же пути по какому шла другая модель.
Важно, повторюсь, здесь именно обучается полноценная исходная модель которая как бы никак не модифицирована, но она разрезана на лору не по SVD как в том методе, а как бы плоскостью другой модели.
Аноны, как персонажа вырезать на прозрачность? Перепробовал все доступные через интерфейс A1111 расширения для уберания бэкграунда - говно какое-то. У персонажа либо остаются арефакты во всех местах, либо края силуэта прозрачные.
Специально делаю генерацию на белом однородном фоне, размер под 2к. Даже с этим не справляются "вырезалки" эти.
Посоветуйте как быть. Нужно обработать огромное количество изображений.
Специально делаю генерацию на белом однородном фоне, размер под 2к. Даже с этим не справляются "вырезалки" эти.
Посоветуйте как быть. Нужно обработать огромное количество изображений.
> A1111
Чел...
Что чел? Под него штук 7 плагинов только для этой задачи написано. И они что на авто работают, что на форджах.
Лапша же ничего принципиально нового тут не предложит, больше чем уверен.
Если нужно идеально - только руками вырезать.
Ни одна модель не даст 100% точности в 100% случаев, косяки будут даже с белым фоном. Косяки будут всегда.
Можешь найти что-то более-менее точное, если повезет. Цивит покопать попробуй.
Ничего не нашел толкового чел. Потому и спрашиваю. А ещё, потому что есть СЕРВИСЫ, которые вырезают идеально, но они конечно платные, там на поток процесс не поставить. Просто существование этих сервисов как бы говорит что где-то существует хороший варианты. Я больше чем уверен что все эти "сервисы" это просто аферисты, которые с гитхаба репы понабрали и продают воздух, ни каких своих закрытых разработок у них нет. Вот потому и спрашиваю в треде. Где-то есть хорошая вырезалка, просто её надо найти.




> Лапша же ничего принципиально нового тут не предложит, больше чем уверен.
Тем не менее в лапше я могу вырезать фон нормально. На реалистике ещё проще.


Аниме пики с обводкой никогда не были проблемой.
Плохо получается именно реалистичных персонажей вырезать.
У тебя на третьем пике 3д генерация, выглядит неплохо. Но при ближайшем рассмотрении есть много мест с белой короной и в спорных местах, например где волосы, появляется такой кисель из прозрачности. В этом плане А1111 даже лучше делает. Но это всё равно не подходит, таким вырезаниям нужна пост обработка всё равно. Сервисы же, например китайский 佐糖 таких косяков не делают.


Ну хуй знает. Ебись тогда сам.
Не плохо, но я как набивший шишки сразу чую подвох. Такой результат надо на "шахматном фоне" смотреть, по моему горькому опыту многие модели просто делают края вырезаемого объекта немного прозрачными, это может выглядеть как идеальное вырезание, но по факту ты такой вырезанный объект на другой фон не поставишь, у него вся окантовка будет как у привидения.
Чем ты это вырезал, дай посмотрю, напиши плз адрес репы или модели или другую инфу чтобы я нашел.
>нормально
Нет.
Как я и говорил, куча косяков на всех картинках.
https://huggingface.co/spaces/jixin0101/ObjectClear
https://huggingface.co/spaces/briaai/BRIA-RMBG-2.0
А вообще знаешь что такое проблема XY? Самое главное забыл - сказать нахуя тебе это вообще надо и какую проблему ты собрался решать генерацией огромного количества изображений которые тебе надо вырезать? Ну и вопрос качества которое тебя устроит.


Чёт второе как-то слишком говно, а первое не завелось. Его как комфи ноду можно юзать?
А вот у тебя выглядит любопытно, чем чистил?
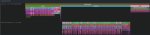

Wan тут кто-нибудь тюнит? Как с говном пикрил бороться? На первом пике XL, приемлемо выглядит. А на втором Wan, обратный проход в 6 раз дольше форварда. Хуйня с copy - это переключение на вторую карту, но хули в форварде обе карты одинаково отрабатывают, а на обратном одну с одинарными блоками растягивает как шлюху? Что за забор блядский? Заебался уже, не хочу тренить по 3 часа 1000 шагов.

BiRefNet хотя бы возьми, а то у тебя совсем плохо.
В репо козистра https://github.com/kozistr/pytorch_optimizer/tree/main загружено семейство Emo оптимайзеров. Фишка в том что компутит доп скаляр исходя из лооса, т.е. получает усреднённое значение лосса (ema) (затем превращает это в скаляр), по которому вычисляется коэффициент влияния. Кароче бля параметры плавно тянутся к прошлым значениям, если loss подсказывает, что надо откатиться.
Для лор еще терпимо, а если фул матрицы тренить то там EmoNavi оригинальный с селективными блоками x2 врама жрет, EmaFact (емо + адафактор) +50%. Так что имейте в виду.
Для лор еще терпимо, а если фул матрицы тренить то там EmoNavi оригинальный с селективными блоками x2 врама жрет, EmaFact (емо + адафактор) +50%. Так что имейте в виду.

Опять душат удава.
> если loss подсказывает, что надо откатиться
Это вообще неблагодарное дело ориентироваться на лосс в генерации картиночек в разрезе соседних значений. Какой-то референс лучше, какой-то хуже - лосс скачет как ебанутый и это норма. Пикрил литералли всегда на Хроме, просто рандомный шум, при этом тренится заебись.
> x2 врама жрет
Лучше бы делали чтоб меньше жрало без диких просеров как у 8-битных bnb. И так DiT приходится частично в q8 квантовать чтоб не сосать даже с 48 гигами врам.

Аноны, обнаружил тут ВНЕЗАПНО, что у репозитория A1111 уже как год не было обновлений. Он что ВСЁ? Заброшен? Сдох?
Дело в том, что в А1111 меня всё устраивает, всё работает, плюс привычка, не один год в нем ковыряюсь, плагины настройки всё под себя идеально подстроил и привык.
Поверхностный гуглинг показал что сейчас модно КомфиУИ использовать, на втором месте Фордж, который говорят как раз для тех кто к А1111 привык.
В сявзи с этим вопросики.
1) Расширения для А1111 не встанут на этот ваш Фордж? Пологаю что разумеется не встанут, просто хочу уточнить.
2) В Форже другой синтаксис промптов, отличный от А1111? Т.е. все эти BREAK и [(shit:1.3)::0.7] там не работают?
Дело в том, что в А1111 меня всё устраивает, всё работает, плюс привычка, не один год в нем ковыряюсь, плагины настройки всё под себя идеально подстроил и привык.
Поверхностный гуглинг показал что сейчас модно КомфиУИ использовать, на втором месте Фордж, который говорят как раз для тех кто к А1111 привык.
В сявзи с этим вопросики.
1) Расширения для А1111 не встанут на этот ваш Фордж? Пологаю что разумеется не встанут, просто хочу уточнить.
2) В Форже другой синтаксис промптов, отличный от А1111? Т.е. все эти BREAK и [(shit:1.3)::0.7] там не работают?

Второе, как написано, основано как раз на BiRefNet. Оригинальный BiRefNet - это пожалуй самый лучший вариант из всех что я перепробовал. Наверное лучше ничего не придумали.
Кстати этот BRIA-RMBG-2.0 делает вот такую шляпу, про которую я писал ранее. Он Может в некоторых случаях половину обьекта прозрачным сделать. Оригинальный BiRefNet в этом плане даже лучше.
>Он что ВСЁ? Заброшен? Сдох?
Ну автоматик перестал кодить в принципе. Или работка или выгорел, это ж все на энтузиазме для портфолио сделано.
>Дело в том, что в А1111 меня всё устраивает, всё работает, плюс привычка, не один год в нем ковыряюсь, плагины настройки всё под себя идеально подстроил и привык.
Ну плохая привычка на самом деле, время выходить из зоны комфорта.
>Поверхностный гуглинг показал что сейчас модно КомфиУИ использовать, на втором месте Фордж, который говорят как раз для тех кто к А1111 привык.
Не модно, а уже года джва является самой мощной и обновляемой средой для любых видов нейрокалов + парк расширялок монструзный. Буквально если что-то новое выходит (ну вон ван 2.2 например), то через пару часов оно уже поддерживается.
Фордж это говнина от ильясвила, который факас, контролнеты и прочее пилил, фордж тоже заброшен. Не заброшены форки форджа, типа рефорджа https://github.com/Panchovix/stable-diffusion-webui-reForge
>1) Расширения для А1111 не встанут на этот ваш Фордж? Пологаю что разумеется не встанут, просто хочу уточнить.
Рандом. У форджа в принципе свои нерешаемые баги были насколько я помню, ну и они в форки перекатились. Какие-то расширения встанут, какие-то нет.
>2) В Форже другой синтаксис промптов, отличный от А1111? Т.е. все эти BREAK и [(shit:1.3)::0.7] там не работают?
Фордж это форк каломатика, так что скорее всего работает это говно плацебное.
Спасибо за пояснение, анон.
>плацебное
Чому плацебное ? Можно в реальном времени менять весь промпта (shit:1.2) и прямо наблюдать как результат меняется на такую же фракцию процента. По-моему очень удобно, не может быть чтобы в современной КомфиУИ чего-то подобного не было.
>время выходить из зоны комфорта.
Для меня очень важно чтобы старые промпты можно было как-то повторить, я часто возвращаюсь к тому что делал год назад, например. Если синтаксис другой то понятное дело что повторить результат будет сложно. Может есть какой-нибудь плагин для КомфиУИ который позволяет использовать синтаксис промптов из Авто1111?



Как делать разбор полетов после тренировки? Про то что андерфит это когда результат слабо виден, а оверфит это когда лора воспроизводит датасет и не слушается промпта, я знаю. Но есть и другие ситуации когда лора берет знания из модели вместо датасета, когда низкий лр делает оверфит и пр. Хочу про это прочитать, чтобы хоть немного сориентироваться че за хуйня у меня происходит. Как извлекать информацию из результатов?
Месяцами тренирую разные стили в сд1.5, у меня шизу генерирует на при любом ЛР/количестве шагов. 2 и 3 пик разные попытки, но результат тот же.
>Можно в реальном времени менять весь промпта (shit:1.2)
обычный вейтинг токенов в комфе есть, я про брейки которые типа разъединяют кондишены и вот это [(shit:1.3)::0.7] которе я даже не помню че делает, а еще есть типа морфинг когда на лету в таймстеп инъекция другого токена происходит. Это кароче все полумеры и иллюзия управления. Вот допустим тебе два кондишена по 75 токенов надо - берешь две ноды для разных кондишенов в комфе в нужной конфигурации их смешивания и делаешь как задумано в сдхл изначально, а не костылем который придумали из-за UI вида "все в одном окне".
Но если тебе прям нужно дрочить синтаксис каломатика, то есть ноды для текста, которые поддерживают этот синтаксис.
>Для меня очень важно чтобы старые промпты можно было как-то повторить, я часто возвращаюсь к тому что делал год назад, например.
>Если синтаксис другой то понятное дело что повторить результат будет сложно.
Так у тя еще проблема в том откуда инишл нойз берется для генерации. То есть чтобы повторить ЗАЧЕМ, это же нейрослоп, всегда можно сделать лучше то что ты делал на каломатике тебе надо соблюсти неочевидные команды в поле промта (скачать ноды которые поддерживают такое) + ноды умеющие управлять инишл нойзом чтобы брался нойз с гпу, потому что в каломатике берется с гпу, а не с цпу, а это нестандартное решение, по классике должно быть с цпу т.к. это более унифицированнее (даже в том контексте что не у всех нвидия, некоторые дрочатся на линухе с амдкалом, а так свой инишл с гпу идет).
> Может есть какой-нибудь плагин для КомфиУИ который позволяет использовать синтаксис промптов из Авто1111?
Конечно, есть ноды под такое. Но лучше не пытайся создавать костыли заново.
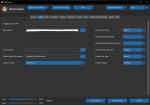
Еще вопрос, могут ли эти косяки быть из-за того что я в этой менюшке я выбрал fp16 но в остальных всех fp32 хотя моя видеокарта не поддерживает half-preccision (gtx1660)?
Бле, я думал за шум отвечает только сэмплер, что это такой типовой алгоритм, который имея идентичную модель и все прочие настройки сможет воспроизвести тот же результат по промпту.
Но это как-то странно. На сивиай же например в инфе по генерации не пишут на каком она софте сделана, а повторить всегда получается, не 1 к 1, но очень близко обычно.
32bit нихуя не изменилось.
Нормально ли подобное (видео рил) ухудшение в начале разогрева?
Lion Cosine
U-net LR 0.0001
Text encoder LR 0.00005
Warmup steps 731.0
Repetition per epoc 1
Batch 1
Epoc 50
Датасет 70 пикч
Lora rank 64
Lora Alpha 1
Все остальное дефолтное.
Нормально ли подобное (видео рил) ухудшение в начале разогрева?
Lion Cosine
U-net LR 0.0001
Text encoder LR 0.00005
Warmup steps 731.0
Repetition per epoc 1
Batch 1
Epoc 50
Датасет 70 пикч
Lora rank 64
Lora Alpha 1
Все остальное дефолтное.
> Как делать разбор полетов после тренировки?
Э ну чтобы мучительно не надеяться на удачу и заниматьс разборами выходного продукта надо разобраться как работает модель (сам процесс генеративный) и гиперпараметров тренировки.
>Про то что андерфит это когда результат слабо виден, а оверфит это когда лора воспроизводит датасет и не слушается промпта, я знаю. Но есть и другие ситуации когда лора берет знания из модели вместо датасета, когда низкий лр делает оверфит и пр.
Ну вот ты видишь симптоматику, а что вызывает ее ты не знаешь. Не знаю насколько тебе поможет, но если кратко рассматривать проблему то не в лр дело а в том что ты тренируешь.
Предполагаю что ты тренируешь просто целую лору, которая охватывает все слои и все блоки. Так вот материнская модель состоит из трех частей - инпут блоки распиздячивающие картиночку, ботлнек мидл блок с общей инфой для приведения к единому знаменателю, и аутпут блок для сбора картиночки обратно, это происходит строго последовательно, блок за блоком и слой за слоем.
В каждом блоке содержатся компоненты:
1. Конволюшн блоки, которые содержат инфу о локальных данных. Они очень чувствительные к шуму и начальным данным и собственно изза них рекомендуется делать вармап в качестве страховки. При этом конволюшны не однородны в своих возможностях: конвы в мидл блоки устойчивые к любым данным, конвы в поздних аутпут слоях тоже, т.к. содержат стабильные конечные сборочные детали. Но конволюшны в позднем инпут блоке (кондесация в низкое разрешение), в первых четырех группах слоев инпута (низкоуровневые контуры) и первые два блока аутпута (крупные пространственные признаки, глобал текстуры и цвет) очень нежные и если в них подается кривой сигнал говна, то пизда твоей модельке прямо с первого шага, конволюшн будет накапливать неверные признаки.
2. Линейные слои - практически полностю то из чего состоит модель, представляет из себя атеншн слои и частично MLP. Все линейные слои стабильные и практически не переобучаемые.
3. Feed forward слои, идут после атеншенов и являются носителями новых данных, которые не обобщены. Представь, что это фильтр для собираемой картинки, который обмазывает выходной сигнал во что-то независимо от контекста. Если конволюшны носители локальных данных, то фф носитель уникальных признаков.
Помимо этого есть слои текстового енкодера, которые занимается связкой текстового описания и признаков из слоев. Текстэенкодер в принципе независим, и достаточно простой в тюнинге и требует небольшой лр относительно основных весов сети, но не всегда. Тренировка текстэенкодера буквально бустит понимание твоего датасета и гибкость модели. В текстовом енкодере опять же последовательно обрабатывающиеся слои от общих признаков до локальных узкий концептов (условно от woman до small green dog in forest smiling like a whore). Трен текст енкодера напрямую управляет управляемостью модели конечной, так что тут ситуация как с конволюшнами - если ты лезешь обучать поздние блоки с жестким нефильтруемым потоком данных, то пизда твоему текстэенкодеру.
Поэтому что? Поэтому тебе нужно изучить регекспы для toml конфигов тренировки чтобы делать изолированную тренировку эффективных слоев, если ты хочешь стабильный результат, а не сейфовую выдрочку полномодульной лоры на низком лр, которая может десятки тыщ шагов тренироваться до приемлемого результата. В любом другом случае когда ты просто выбрал "а тренируй мне вот этот алгоритм на этом датасете спасибо пока" в лучшем случае сделает тебе генератор картиночек по типу тех что в датасете, никакой глубокой донастройки сети получить скорее всего не выйдет. Плюс учитывай что у тебя консумерский тренинг на нищем батче 1 и с маленьким датасетом (все что ниже 10к картинок считается как маленький датасет), то есть к вышелписанным ограничениям сети и нежности ее некоторых частей прибавляется бутылочное горло в виде не разряженного батча и малой даты в датасете, что бустит оверфит само по себе, если ты тренируешь полноблоковую модель.
Второй важный подводный камень это оптимайзер, они разделены по семействам и имеют разные так скажем возможности и скорость до нахождения решения. Основной параметр оптимайзера это моментум, он управляет памятью о предыдущих градиентах (бета1) и реакцией на новые градиенты (бета2). Есть разные оптимы, где есть один моментум, пять моментов, вообще без моментов, но в основном оптим имеет два моментума. Соответственно если у тебя хуевый сигнал говна, то чем больше память моментумов тем хуевее твоей сети будет что конкретно отражается на управляемости финальной моделью. Чтобы понять принцип работы моментума можешь взять сгд с нестеров моментумом или amos с одной бетой и покрутить туда сюда. Алсо чем ниже моментум, тем быстрее сходимость до цели но при этом побольше нестабильность т.к. моментумы в целом предназначены для сглаживания неоднородной даты на больших батчах.
Вообще оптимов самых разных великое множество, протестировать все у тебя жизни не хватит, поэтому можно выбирать с помощью синтетических тестов например отсюда https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md , растригин функция особо не нужна, она показывает залипание на гипотетических локал минимумах, для задач тренировки визуальных паттернов лучше смотреть на росенброк функцию, т.к. она напрямую показывает насколько оптимизатор силен в достижении особо уникальных паттернов в кривом косом прострастве признаков и насколько он делает это быстро и стабильно. Еще сюда можно совет впихнуть что если ты новичок и не хочешь ебаться с подбором лр под оптим, то бери адаптивные оптимайзеры, или шедулер фри. Но адаптивки обычно имеют более долгое достижение результата, т.к. ради сейфовоц адаптивности жертвуют скоростью.
Третий важный момент это регуляризация самой тренировки. Все эти команды типа макс град норм, скейл вейтс, дропауты, дебиасед естимейшены, шаффлы, аугментации - все они придуманы чтобы снижать влияние деструктивной полноблоковой тренировки на малом датасете с малым батчем. Условно дебиасед снижает влияние расшумленных таймстепов, и повышает влияние более важного и четкого сигнала поздних таймстепов - следовательно насрать в конволюшены с дебиаседом будет чуть сложнее. Или дропауты в лорах - отключают рандомные нейроны по ratio чтобы сеть не выдрачивала саму себя на твой маленький датасет, штука против оверфита.
Четвертвый момент это сама функция лосса. По дефолту у тебя доступны l1, l2 и huber. L1 очень медленный но стабильный, отсекает все критические ошибки. L2 быстрый но неустойчивый к ошибкам вообше, особенно на высоких скоростях и низких моментумах. Huber гибрид из двух предыдущих с удобной фильтрацией по SNR (что важно при малом батче и малом датасете), на практике является наиболее френдли лоссом к малым датасетам и быстрым скоростям из доступных изкаропки. Лоссов тоже очень много разных, все они впердоливаютя вручную, вон в этом треде вейвлет лосс и ффт лосс дрочили, я на ффт сижу теперь, батя грит малаца.
>Хочу про это прочитать, чтобы хоть немного сориентироваться че за хуйня у меня происходит.
Комплексного гайда нет, просто ходишь по интернету и гптшкам и читаешь.
>Как извлекать информацию из результатов?
Имеешь в виду как понять что модель не говно? Ну есть небольшой лайфхак это использовать вместе с лорой дистиллят лору dmd2 под LCM 1CFG, она очень хорошо правит все огрехи тренировки, даже если лора полностью убита к хуям будет пытаться дать нормальный когерентный результат и показывает визуально куда упор при тренировке был сделан и надо ли пониже лр, есть ли оверфит на локальные признаки, насколько следует промту и тд и тп.
Сюда же хайпер лора, лайтнинг, турбо, пцм, тцд, но мощнее всех дмд конечно, эталонная дистилляция.
Я вообще в целом редко когда генерирую без дмд2 в контексте сдхл, к хорошему и быстрому привыкаешь быстро, но если тебе важен именно нативный ген без улучшалок убыстрялок дмд поможет определить туда ты тренируешь вообще или нет. Еще помогает определить эпоху перетренированности, это примерно когда при использовании дмд с лорой у тебя буквально срется картинками из датасета. Удобно кароч.
Но минус есть конечно - при 1 цфг у тебя не работают негативы и обобщение при генерации максимальное, поэтому сильно промт не имеет смысл расписывать вообще, буквально gay sex best quality пишешь и готовый результат оцениваешь.
> 32bit нихуя не изменилось.
И не должно. На 32 бита стоит уходить только если NaN лезут, но bf16 для этого предпочтительнее.
> Нормально ли подобное (видео рил) ухудшение в начале разогрева?
Не очень. Первые 200-300 шагов можно простить, но дальше должно нормально идти.
> Lora Alpha 1
Хуй знает как у тебя там альфа работает, попробуй сделать её как rank. При инференсе альфа берётся из лоры или если в лоре её нет - ставится как rank. Может у тебя она некорректно отрабатывает. Она у всех по разному работает - у кохи одно поведение, у ликориса другое, в peft третье. И на пики валидации сильно не ориентируйся, для начала протести финальную лору, может в валидации насрано.
> Еще вопрос, могут ли эти косяки быть из-за того что я в этой менюшке я выбрал fp16 но в остальных всех fp32 хотя моя видеокарта не поддерживает half-preccision (gtx1660)?
Нет, точность это про другое. Можно эффективно тренировать ирю на фп8 и на q4, да даже на q1. Фп32 нинужно, это для карт и больших дядь с бизнес грейд датацентрами для тренировки, там есть фп32 и соответственно точность выше нужна тем кому нужна. Если у тебя 1660 то у тебя выбора особо нет, только фп16. А так в идеале если 3000 серия и выше то бф16 надо, оно стабильнее и в целом лучше фп16.
> Нормально ли подобное (видео рил) ухудшение в начале разогрева?
Ту мач агрессив. У тебя верхнепороговая скорость 1е-4 стоит, оптим хз какой, лосс хз какой, от нуля до 1е-4 при 1 к 64 соотношение добавляемой даты исходя из альфы и дименшена (0,015625 per step) на стадии вармапа это очень жесткие изменения. Снижай лр и показывай полный конфиг тренировки.
Еще стоит козин в качестве шедулера, а у него кстати прикол есть что дефолтный без аргументов практически не снижается во времени (тензор борд открой посмотри на график), типа за 1к эпох он от условных 1е-4 упадет до 3.9е-5, что фактически не снижает ебку скоростью. Так что если тебе надо нормальный козин под конкретное количество шагов эпох то бери из библиотеки торча с аргументами настраиваемыми козины ихние.
> условных 1е-4 упадет до 3.9е-5
"3." лишнее
>оптим хз
А все увидел лион. Промежуток между 1е-5 - 5е-5 на нем вроде достаточно сейфово и без тупняка, но от лосса ещё зависит
>1) Расширения для А1111 не встанут на этот ваш Фордж?
В большинстве - встанут.
>2) В Форже другой синтаксис промптов, отличный от А1111?
Тот же самый.
>вот такую шляпу
Пишешь экшн для фотошопа, который дублирует базовый слой и сливает их между собой, и так несколько раз, потом сохраняет и закрывает файл.
Прогоняешь им всю папку с картинками.
Но, очевидно, что косяки на краях после такого вылезут во всей красе.
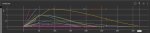
Проблема проверок всех этих параметров это сколько ждать нужно. 3600 шагов занимает 6 часов.
Хорошо сейчас понял что простой промпт (1girl, solo) за ~20 мин (3 эпока) разоблачает косяки.
Анон, мне нужна хоть какая-то победа. Сколько я бьюсь об стену и вижу этот шизофренический результат с искривленными руками. Либо странный андерфит где лора дает минус к анатомии. Мне нужно хоть какая-то надежда, хоть какой-то позитивный результат.
Мне кажется тут много того что ты написал что понадобится уже на более тонких вещах. Если у меня неправильно выставлена температура мне кажется трогать бета1 или 2 будет только сильнее запутывать. Т.е. если если вместо сломанных правых рук станут сломанные левые, то я вряд-ли это замечу. Если я не смогу хотя бы немного исправить текущий пиздец с экспериментируя 1-3 параметрами, то блять, вообще хуй с тренеровкой лор. Столько уже времени вложил, что еще столько же я уже не выдержу. Я готов сильно пожертвовать качеством если смогу убрать шизофринию.
Все эти аналогия на счет машинного обучения про то как обучения это слепой идет и изучает
>В каждом блоке содержатся компоненты:...
Мне кажется тут нужен набор знаний которого у меня нет.
У меня SD1.5 если что.
>Хуй знает как у тебя там альфа работает
Альфа 1.0 полное обучение без помех, 0.5 половина силы.
Понятно.
>верхнепороговая скорость
>соотношение добавляемой даты исходя из альфы и дименшена
>пики валидации
>peft третье
Моя твоя не понемай.
>Еще стоит козин в качестве шедулера, а у него кстати прикол есть что дефолтный без аргументов практически не снижается во времени (тензор борд открой посмотри на график), типа за 1к эпох он от условных 1е-4 упадет до 3.9е-5, что фактически не снижает ебку скоростью.
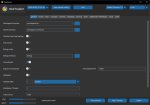
Пик1
>Снижай лр
У адаптивных оптимайзеров, если в начале изменения слишком маленькие у них крышу срывает, по этому нельзя вармап. А обычные нормально относятся если в начале слишком низкий ЛР.
>Проблема проверок всех этих параметров это сколько ждать нужно. 3600 шагов занимает 6 часов.
Так чтобы понять принцип работы того или иного параметра тебе буквально нужна 1 картинка, 1 тхт файл описания и 5 репитов на этот датасет из 1 картинки и условно 10 эпох тренировки длиной в 5-10 минут. Не надо выдрачивать по 6 часов, это так не работает вообще: если сеть изначально сломалась, то она из жопы магическим образом не вылезет дальше есть пара вариантов когда может, но это особая магия с косинанилингвармрестарт шедулером и не всегда работает. Забей хуй на тренировку, пробуй следующий вариант, если у тебя в первые 5-10 эпох нет когерентного результата.
>Хорошо сейчас понял что простой промпт (1girl, solo) за ~20 мин (3 эпока) разоблачает косяки.
Ну да. Но есть чуть более точный тест: сначала генишь примерно то на что тренил, затем генишь диаметрально противоположный концепт - скажем кот сидит на скамейке в городе, если оба теста проходит и ничего не поломалось, то модель сумела в обобщение. Естественно надо учитывать что от сида тоже зависит и если на одном сиде не работает, то на другом может работать, это норма для луковичных юнетов.
>Анон, мне нужна хоть какая-то победа. Сколько я бьюсь об стену и вижу этот шизофренический результат с искривленными руками. Либо странный андерфит где лора дает минус к анатомии. Мне нужно хоть какая-то надежда, хоть какой-то позитивный результат.
Если тебе нужен стопроцентный простой удобный результат, то берешь технику тренировки b-lora, это как раз про изоляцию и таргетированную тренировку. Там по дефолту отключены фф и прожекшен слои и конволюшены в конфиге, так что будут тренироваться только линейные слои в конкретных блоках, вследствие чего у тебя будет вопервых долго тренироваться до результата, а во вторых вообще насрать на гиперпараметры - оно сожрет практически любые.
Сам концепт описан тут https://b-lora.github.io/B-LoRA/
Конфиги тут https://github.com/ThereforeGames/blora_for_kohya/tree/main/lycoris_presets
Если захочешь включить все кроме конволюшенов в тренировку обратно, то в регулярных выражениях для юнета пропиши заместо старого
"output_blocks\\.0\\..$",
"output_blocks\\.1\\..$",
"input_blocks\\.8\\..$"
Текстовый енкодер там два слоя тренируется
"text_model.encoder.layers.0",
"^text_model\\.encoder\\.layers\\.1(?!\\d)(\\..)?$"
>Мне кажется тут много того что ты написал что понадобится уже на более тонких вещах.
Мой псто скорее про то что сначала изучи как работает мотор прежде чем заниматься его починкой изолентами.
>Столько уже времени вложил, что еще столько же я уже не выдержу.
Ооо ты бы знал сколько я времени убил впустю вообще наверно в окно выпрыгнул.
>Мне кажется тут нужен набор знаний которого у меня нет.
Ну я вроде описал принцип работы, теперь есть.
>У меня SD1.5 если что.
А, ты еще и на полторахе. Ну в принципе с изоляцией слоев в небольшом дименшене без текст енкодера и в фп8 юнете и фп8 оптимайзере сдхл должна влезть в 6 кеков даже на 1024 разрешении, а уж 768 и подавно. Могу проверить если хочешь и потом конфиг дать, сдхл во всем будет лучше полторахи даже в фп8 тренинге за счет того что там модели попизже будут базовые.
>Моя твоя не понемай.
У тебя стоит 0.0001, это в сайнтфиик нотейшен 1e-4, достаточно агрессивная скорость для лиона и лор в целом.
Дименшен и альфа работают так: ты указываешь дименшен ранк 64 и альфу 1, следовательно коэффициент влияния модуля лоры каждый шаг будет 1 поделенный на 64, то есть 0.015625силы влияния, что осторожно и не должно так въебывать уже на вармапе. Альфа это регуляризационная залупка кстати тоже.
>Пик1
А у тебя в вантрейнере выставлен num_cycles зависящий от тоталстепс, по дефолту его нет, я предположил что ты может выставляешь вечную тренировку на козине.
>У адаптивных оптимайзеров, если в начале изменения слишком маленькие у них крышу срывает, по этому нельзя вармап. А обычные нормально относятся если в начале слишком низкий ЛР.
Ну адаптивным и не ставят вармапы. А у тебя лион, он не адаптивный, у тебя 700 шагов на вармап при датасете в 70 картинок, это в целом дохуя и смысола не имеет, 5% от всего рана или эквивалент 1-2 эпохам достаточно, ато он 10 эпох дрочился у тебя до мощной скорости зачем-то (я только только видос посмотрел твой), только время проебал.

>Мне кажется тут нужен набор знаний которого у меня нет.
>Ну я вроде описал принцип работы, теперь есть.
Конволюшн блоков в этих u-net пикчах я не вижу.
Я попробую несколько раз перечитать твои посты но башка от сложности взрывается. Просто в большинстве туториалов говорят "хуяк-хуяк, поэкспериментируйте температурой и эпохами и все!". А тут непросто знать что каждая хуйня делает, нужно еще знать на какие еще 10 вещей она влияет, от каких 5 вещей зависит и какие 3 вещи делают её ненужной, а как все эти вещи работают вместе.
>сдхл во всем будет лучше полторахи даже в фп8 тренинге за счет того что там модели попизже будут базовые.
У меня gtx1660, full precision only. Генерация SDXL даже 768p 20 шагов занимает 2 минуты. Там вообще никак не поэкспериментируешь, я уже не говорю про тренировки.
>У тебя стоит 0.0001, это в сайнтфиик нотейшен 1e-4, достаточно агрессивная скорость для лиона и лор в целом.
>Дименшен и альфа работают так: ты указываешь дименшен ранк 64 и альфу 1, следовательно коэффициент влияния модуля лоры каждый шаг будет 1 поделенный на 64, то есть 0.015625силы влияния, что осторожно и не должно так въебывать уже на вармапе. Альфа это регуляризационная залупка кстати тоже.
Т.е. другими словами непонятна причина пиздеца?
Бонус: мнение. Аналогия с слепцом который ходит по горам, учится рельефу, и пытается найти дно, не отображает реальность машинного обучения. И это не просто грубое упрощение а активно мешающая пониманию процессов. Т.к. если вам задут хоть немного технический вопрос эту аналогию невозможно будет применить, потому что она изначально не имеет смысла. Лучшая аналогия необходима и поможет всем. Имхо.
Ты пиздец его изнасиловал сейчас инфой скорее всего, он хоть усрётся не получит нихуя от полторахи как не трень, ни анатомии, ни рук, ни стиля, может скорость только получит приемлемую
Что ты хоть тренить то собрался? Тебе легче будет в тредах попросить тебе потренить с твоей 1660, но про 1.5 можешь вообще забыть, сколько её не еби, оно мёртвое даже по сравнению с XLями. Но вообще с XL фп8 оптимайзер, фп8 веса, градиент чекпоинтинг, 1 батч, без энкодеров, может сниженное разрешение даже влезет в 6, в 8 точно влезает без энкодеров второй батч в 1024
> 3 эпока
Я очень надеюсь что ты не по методикам вин10твикера это всё пытаешься делать
Я насколько я знаю для фп8 нужны RTX 30ХХ+ серии (bitsandbytes), если конечно есть то чего я не знаю о 16xx серии И да те 2 минуты за 768px 20 шагов это на квантованных чекпойнтах. Обычные не влезают в ВРАМ.
> 3 эпока
>Я очень надеюсь что ты не по методикам вин10твикера это всё пытаешься делать
3 эпока это я преувеличил но так я ссылался на этот видеорил

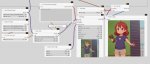
>Конволюшн блоков в этих u-net пикчах я не вижу.
Конволюшн слои внутри блоков, отдельных блоков с конволюшнами в сетях нет.
У тебя пикча схематичная, там справа снизу легенда расписана где стрелочки отдельные это и есть конволюшны частично.
Кароче, чтобы понять из чего состоит модель тебе надо взять любою лору натренированную даже на одном шаге, но с таргетами по всем блокам со включенными конв слоями, а дальше эту лору засунуть в верификатор лор, без разницы вручную через питон скрипт или через уи типа https://github.com/bmaltais/kohya_ss , на выходе ты получишь список всех слоев в твоей лоре, пикрелейтед, он для сдхл но тоже самое делается и для 1.5.
У тебя в пикчах твоих кстати выше стоит пресет attn+mlp, то есть ты изначально не тренируешь конволюшны, то есть они отпадают как причина агрессии или кривости лорки. Остается просто высокая скорость и недостаточная регуляризация.
Если надо тренить с конвами то переключись пресет на full и потрень 1 шаг с сохранением чтобы потом посмотреть состав лоры. Вообще вантрейнер я бы не использовал на твоем месте, он достаточно неудобен.
Рассказать как пользоваться говном для тренинга лучше?
>Я попробую несколько раз перечитать твои посты но башка от сложности взрывается.
Задавай вопросы что непонятно.
>Просто в большинстве туториалов говорят "хуяк-хуяк, поэкспериментируйте температурой и эпохами и все!". А тут непросто знать что каждая хуйня делает, нужно еще знать на какие еще 10 вещей она влияет, от каких 5 вещей зависит и какие 3 вещи делают её ненужной, а как все эти вещи работают вместе.
У тебя два стула буквально в контексте лоры - тренить вечность на низкой сейфовой скорости на уровне до 1e-5, но не думать о том, как оптимизировать процесс чтобы не обосраться, либо тренить эффективно но избегать страданий от переобучения через таргетинг (вот у тебя аттн+млп пресет, это по факту таргетная тренировка, ток ты изначально не так с ней работаешь) и тонну гиперпараметров.
>У меня gtx1660, full precision only. Генерация SDXL даже 768p 20 шагов занимает 2 минуты. Там вообще никак не поэкспериментируешь, я уже не говорю про тренировки.
Я имею в виду чтобы ты подготовленные сконверченный чекпоинт можешь использовать для генерации, через пик2 например, это мой скрин годичной давности почти, там потребление врама в пике 5.5 гигов, теоретически оно влезет тебе в 6 гигов твоей 1660, потому что были репорты что в 1050ти с 4 гигами влезало и терпимо было.
А тренинг тренируется через специальный параметр --fp8_base_unet, переводящий fp16 чекпоинт в fp8 точность, плюс использование оптимайзера с 8бит точностостью. То что у тебя карта не держит фп8 нативно это не проблема вообще, оно не влияет особо.
Я уже скозал ранее что могу проверить сколько будет врама съедать, тренинг в суперэконом режиме с изоляцией слоев с отключенным TE, попозже напишу.
>Т.е. другими словами непонятна причина пиздеца?
Ну как такового пиздеца нет, из того какие данные от тебя я вижу ты зачемто тренил вармап 10 эпох до конского пика скорости и спрашиваешь а че почему в жопе все. Надо по другому тренить, помягче и поэкономичнее.
>Бонус: мнение. Аналогия с слепцом который ходит по горам, учится рельефу, и пытается найти дно, не отображает реальность машинного обучения. И это не просто грубое упрощение а активно мешающая пониманию процессов. Т.к. если вам задут хоть немного технический вопрос эту аналогию невозможно будет применить, потому что она изначально не имеет смысла. Лучшая аналогия необходима и поможет всем. Имхо.
Лучшая аналогия обучения нейросети это раб, которого бьют плеткой (лосс функцией и регуляризацией) за каждый неверный мув (ошибку) чтобы он больше таких мувов не делал и был хорошим рабом. Если бить раба слишком сильно, то он помрет не сделав ничего полезного, если недостаточно, то он будет филонить. Осуждаю, но выглядит это именно так. Обучение с тичером и подкреплением вообще концлагерь аналогией будет.
>
> Ты пиздец его изнасиловал сейчас инфой скорее всего,
Бля ну я не хотел, мне кажется лучше сразу показать что тренинг это не тяп ляп и результат как будто гпт 5 натренировал а ты сем альтман, в реальности ебешься будь здоров как и в любой деятельности которая с виду преподносится как жмаканье кнопки сделать пиздато.
>он хоть усрётся не получит нихуя от полторахи как не трень, ни анатомии, ни рук, ни стиля, может скорость только получит приемлемую
Ну кстати да, полторашка сама в целом сосет. Лучше пусть продает свой 1660 мусор и покупает срук 3060 12 кеков или из 4000/5000 серии ченить с 16 гигами если интересен процесс тренировок, не такие уж большие траты, 8 раз в пятерочку сходить.
>Вообще оптимов самых разных великое множество, протестировать все у тебя жизни не хватит, поэтому можно выбирать с помощью синтетических тестов например отсюда https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md
Нельзя.
Осмысленных выводов по этим картинкам сделать невозможно.
>Еще сюда можно совет впихнуть что если ты новичок
Найс кормишь новичков дерьмом.
>бери адаптивные оптимайзеры, или шедулер фри.
Это хотя бы верно.
>dmd2
)))
В остальном вода без конкретики с привкусом шизы. Ну шедулер фри, ффт лосс, эти хуйни с планировщиком таймстепов имеет смысл юзать, но у него в огрызке гуя оно есть?
>Lion
Выкинь, он не умеет обороты сбавлять и фулл лр хуячит, емнип.
1е-4 тем более с ним будет дохуя.
>Альфа 1.0 полное обучение без помех, 0.5 половина силы.
Не так. Ставь альфу как корень из ранга. В твоем случае 8. Альфа прост косвенный множитель инициализации весов. Он еще на ранг делится, так что полное это 64.
>У адаптивных оптимайзеров, если в начале изменения слишком маленькие у них крышу срывает, по этому нельзя вармап. А обычные нормально относятся если в начале слишком низкий ЛР.
Наоборот. Моментумы без прогрева могут дать очень большое обновление. Или просто временно "отключаются", и будет идти обучение как по обычному сгд.
И можно не плавно поднимать лр, а проехать сколько-нибудь на нулевом лр, а потом поднять. Это изначальная логика как задумывалось. Просто с маленьким лр можно не тратить шаги впустую а чутка успеть обучиться и никуда не улететь пока момент плавно стабилизируется.
Поставь аккумуляцию побольше, даст то же самое что и батч. Отключи ТЭ. Потести лоссфункции, включи дору.
Пресет слоев у тебя какой, где написано только атеншены? В этом гуе я хз, но если только атеншены тренирует то это не то.
Добавь wd, дропауты.
Ну и выкинь лион, ставь адамW обычный.
Можешь инициализировать лору через SVD для стабильности. Выше есть ссылка, требует только пердолинга через гуи. В твоем наверное должно работать, но надо будет поставить кохьевский гуй и комфи.
>Ну адаптивным и не ставят вармапы.
Пиздеж.
>Я попробую несколько раз перечитать твои посты но башка от сложности взрывается.
Ой бля лучше его не слушай, там надо шарить чтобы понять что мусор а что нет.
Лучше возьми да залей датасет и сюда вкинь, тут получше твоей некторы карточки будут. Да и я могу натренить если мне не лень будет. Только дай модель и тестовые промты. Прост интересно ради чего ты так ебешься.
И вообще нахуя 1.5? Она же кал. Если xl хотя бы запускать можешь, зареквесть других натренить. Сборка датасета это все равно самое ебаное из всего процесса, а на трене уже работает видимокарта а не ты, лол.
>Лучшая аналогия обучения нейросети это раб, которого бьют плеткой (лосс функцией и регуляризацией) за каждый неверный мув (ошибку) чтобы он больше таких мувов не делал и был хорошим рабом. Если бить раба слишком сильно, то он помрет не сделав ничего полезного, если недостаточно, то он будет филонить. Осуждаю, но выглядит это именно так. Обучение с тичером и подкреплением вообще концлагерь аналогией будет.
Хуйня аналогия. Вот лучшая:
Параметры нейросети это многомерные координаты, для многомерного ландшафта по которому она идет. Градиент дает направление и условно-относительную силу шага для каждого параметра-координаты. С каждым шагом ландшафт немного меняется, потому что параметры воздействуют друг на друга. Поэтому сильно шагать по вычисленному направлению мы не можем, только по чуть-чуть. Разные параметры влияют на ландшафт по-разному. И для того чтобы вычислять такие параметры придуман второй момент в адаме, который старается не дрочить сильно параметр если градиент по нему часто меняет направление.
И никаких аналогий не надо.
>Лучше пусть продает свой 1660 мусор и покупает срук 3060 12 кеков
3060/12 можно за 15к достать с мобильным чипом. Якобы новую из китая. Б/у за 12.
Мобильные 3080/16 в районе 20. v100/16 еще есть за 20 с небольшим, но там пердольная плата с охладом.

Блять. Как минимум половина проблем была в Aspect Ratio Bucketing.
Новый тест с другим чекпойтом:
Пик1 Слева оригинальный датасет с разным соотношение сторон, справа датасет с квадратами Aspect Ratio Backeting ВЫКЛ (чужой датасет и абсолютная шиза в нем, у всех пикч один промпт, а теги со всякими мастерписями, 32к и пр)
Сорян, сегодня не отпишусь тем кто ответил.
Какой же комфипидор всё же пидор. У него некоторый код инференса в режиме обучения. Видимо когда впердоливали ноды обучения никто даже не чекнул остальной код и не сделал torch.no_grad() как положено. Из-за этой хуйни "протекает" память, хотя на самом деле это так торч устроен - веса модели нельзя удалить из памяти пока на них ссылается тензор с requires_grad. Чекается легко, есть ли в воркфлоу говняк - генерим и жмём "выгрузить все модели", если память не очистилась под ноль, а после нажатия "инвалидация кэша" всё же освободилась, то говорим спасибо комфипидору. Пока тензоры в кэше нод не будут удалёны, не очистится и память моделей, зависящая от них. Хорошо хоть глобальное отключение автограда помогает и не надо разбираться в этом говнокоде. А ведь я помню как это чмо ещё пиздело на автора Форджа что он не знает что делает, по итогу это комфипидор не знает как менеджмент памяти в торче работает.
>обучать в комфе
двач_помогач_как_есть_с_ножа.тхт
Так я и не треню, это инференс сломан там этим говно для обучения.

Экспериментировал с CAWR шедулером, и случайно получилась такая кривая скорости из-за достижения лимита в min_lr.
Примерно с того момента как график отзеркалился (70 шаг) внезапно пошел ебический буст четкости и сходимости. Это я так понимаю обратная пилообразная синусоида, но я их ни разу в кастомных шедулерах не встречал потому что согласно всем обоснованиями базовая логика обучения подразумевает что из общих форм со временем высекается более точные формы на низких скоростях (нисходящий шедулинг). То есть получился эффект не варм рестарта, а ээээ вармап рестарта.
Сталкивался кто с подобным шедулингом?
Если что код тут https://pastebin.com/EHaTb1WY под классом
CosineAnnealingWarmupRestartsPD
Примерно с того момента как график отзеркалился (70 шаг) внезапно пошел ебический буст четкости и сходимости. Это я так понимаю обратная пилообразная синусоида, но я их ни разу в кастомных шедулерах не встречал потому что согласно всем обоснованиями базовая логика обучения подразумевает что из общих форм со временем высекается более точные формы на низких скоростях (нисходящий шедулинг). То есть получился эффект не варм рестарта, а ээээ вармап рестарта.
Сталкивался кто с подобным шедулингом?
Если что код тут https://pastebin.com/EHaTb1WY под классом
CosineAnnealingWarmupRestartsPD
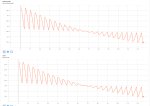
а да настройки цикла
--unet_lr=1e-3 ^
--text_encoder_lr=5e-4 ^
--lr_scheduler_args "max_lr=1e-3" "min_lr=5e-4" "gamma=0.95" "first_cycle_steps=кол-во картинок в датасете" ^
Разворот произошел и на te и на unet планировщике потому что в коде шедулера пропорционально сделано исходя из стартовых значений скорости.
Че узнал щас почему те пиздошится: оказывается скорость текстового энкодера любая которую назначаешь при тренинге является фейковой, т.к. лосс считается на выходе юнета, но градиенты для TE проходят через юнет в любом случае. Таким образом допустим большой шаг у юнета = большие изменения в распределении активаций на входе в TE при обратном проходе => TE начинает получать непредсказуемые градиенты => эффективно увеличивается лр TE по созависимости, хотя на бумаге он каким был таким и остался.
Тут каждый тред про это пишут, а дурачки всё продолжают его тренить с lr почти как у unet.
>Тут каждый тред про это пишут
Не видел
АнонИИ, вижу тут разбирающиеся люди есть, тама Chroma v50 (это какой то гибрид 1dev и schnell) вышла, подскажите как на неё лоры тренировать кто в курсе? Я залетный и много не прошу мне бы только на лицо натренировать. Можно как то сделать это через one trainer или flux gym или аналоги не сложные?
Скорость не фейковая, тут вопрос в том хули в текст энкодер большой градиент приходит?
Норму градиента можно мониторить, и можно делать константной, при желании.
Лучше замерять это инструментально, прежде чем делать какие-то выводы.
> это какой то гибрид 1dev и schnell
Нет, это просто крайние слои от Флюкса отрезали и заново натренили с cfg.
> как на неё лоры тренировать кто в курсе?
В официальной репе есть код тренировки лор со скриптами запуска, должен работать. Я его адаптировал под свой тренер, всё чётко было. Но ты учти что надо либо две карты, либо квантовать, желательно через HQQ. В int8 чтоб в 24 гига залезло надо разрешение ниже 1024 опускать, что-то типа 768, хотя я думаю это не проблема, некоторые Ван в 256х256 тренят, лол. Для комфортной тренировки желательно конечно 5090. По скорости 2000 шагов в час на 5090.
Решил посмотреть, какая математика лежит в корне VAE. Охуел пиздец. И это мне нейронка с упрощения расписала. А ведь когда то я играюче разобрался бы в это, техвышка это вам не шутка. А щас пук среньк, не могу даже интеграл взять
Посоветуйте книжку по городу генеративным сетям. Чтобы все основные компоненты, и вае, и клип, и u net разбирались. Я знаю, как они работают, но не настолько глубоко, как бы хотелось.
Посоветуйте книжку по городу генеративным сетям. Чтобы все основные компоненты, и вае, и клип, и u net разбирались. Я знаю, как они работают, но не настолько глубоко, как бы хотелось.


> Посоветуйте книжку по городу генеративным сетям. Чтобы все основные компоненты, и вае, и клип, и u net разбирались.
Ну посоветую, это скорее историческая энциклопедия охватывающая всю историю нейросетей, чем что-то специальное узконаправленное
Книги бесплатны на сайте автора
Тут пишут что это шинель
>что надо либо две карты, либо квантовать
Flux же не квантованный нормально тренируется на 24гб 3090 в 1024, а тут я так понял урезанный flux чего бы он не влез?
Если ты про эту репу https://huggingface.co/lodestones/Chroma/tree/main?not-for-all-audiences=true , то чтото я тут не нашел скриптов ничего такого чтобы можно было запустить не сложно.
Буду пробовать ее под флюкс жим подкладывать, под видом обычного flux 1dev.
Sd scripts ветка sd3, хрому добавили ещё две недели назад
> Тут пишут что это шинель
Да это шинель
> Тут пишут что это шинель
Потому что у него лицензия нормальная, от шнеля там ничего не осталось, кроме архитектуры DiT.
> Flux же не квантованный нормально тренируется на 24гб 3090 в 1024, а тут я так понял урезанный flux чего бы он не влез?
Только если свапать блоки, но это дно по скорости. Как раз коха такими извращениями занимался.
> Если ты про эту репу
https://github.com/lodestone-rock/flow
Эх вот бы лайтовую версию хрен-имейдж на примерно 5 миллиардов параметров, изи килл сдхл...
> не квантованный
В fp8, что ещё хуже квантов. На Флюксе от этого лоры шакалили генерации, выдавая блочные артефакты. Если хочешь что-то вменяемое натренить, то модель должна быть либо в bf16, либо в нормальных квантах. Сама лора естественно должна быть bf16 всегда.
>https://github.com/lodestone-rock/flow
Ага спасибо, качнул от туда flow, буду разбираться, но похоже консоль дрочить придется и руками писать а не параметры в окошечках выбирать.
Спасибо за подсказку, но вроде на FLUX неплохая лора получалась, модель была flux1-dev.sft на 23 гига
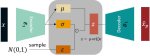

>Решил посмотреть, какая математика лежит в корне VAE. Охуел пиздец. И это мне нейронка с упрощения расписала.
Нейронки плохо умеют правильно упрощать.
Вообще вае это несложно, там просто математики насрали как обычно своей хуйней, которой не существует.
На самом деле есть просто обычный автоэнкодер, понять как он работает - тривиально. Если ты его просемплируешь на большом наборе данных, увидишь что латенты распределены всрато и неравномерно, они кучкуются в определенных областях пространства, в остальных есть дыры. Попытка взять случайный латент выдает сломанный результат, ибо ты почти всегда попадаешь в дыру или недопустимую комбинацию значений.
Задача вае сделать распределение равномерным. Достигается это двумя путями. Первый это просто дополнительный лосс на сами латенты, чем дальше значение от "центра", тем больше ошибка.
Это сила которая стягивает латенты к центру.
Второе - вводится дополнительный канал, который будет предсказывать насколько важно каждое значение латента. Если значение важное, значит оно сильно влияет на выход в данный момент и его нельзя сильно отклонять.
В момент прямого прохода будет взято случайное число из диапазона, который предсказан этим каналом, и прибавлено к латентам, затем отправлено в декодер.
Кароч суть в том что из-за этого канала в латенты постоянно подсирается шум, но если градиент ошибки большой, то канал учится ослаблять шум.
В итоге это становится силой, которая расталкивает латенты и все это вместе делает распределение гладким, а само обучение - осмысленным и структурированным.
На дополнительный канал тоже накладывается лосс, только наоборот, тянущий его от нуля. Иначе бы энкодер сразу схлопнулся и предсказывал бы одни нули на этих каналах, потому что они только мешают работать декодеру. Каждый канал начинает учиться выдавать большое значение только когда сильный разброс допустим и низкое когда нет. За счет разброса как раз закрываются дыры, декодер учится работать с полным диапазоном значений.
Можно представить латенты в процессе обучения, как в симуляторе частиц, на которые действуют разные силы. Если это визуализировать в динамике, оно примерно так и будет выглядеть.
На этапе инференса эти дополнительные каналы не нужны, их значения игнорируются. Работает как обычный автоэнкодер.
https://xnought.github.io/vae-explainer/
https://education.yandex.ru/handbook/ml/article/variational-autoencoder-(vae)
Дополнение:
На второй картинке как раз видно, что итоговый латент получается таким, что если сделать небольшое отклонение, то попадешь по крайней мере во что-то похожее. Соответственно, получишь меньший лосс, и так автоэнкодер естественно учится делать хорошую и нужную нам структуру.
На второй картинке как раз видно, что итоговый латент получается таким, что если сделать небольшое отклонение, то попадешь по крайней мере во что-то похожее. Соответственно, получишь меньший лосс, и так автоэнкодер естественно учится делать хорошую и нужную нам структуру.
В общем мы с flow не подружились то одно ему надо то другое то вересия питона слишьком высокая то слишьком низкая то вообще на линуксе делать надо.
В флюксжим пропихнуть тоже не удалось не под видом дев не под видом шенель...
Поставил Ai toolkit красивый приятный удобный, все нормально влезло в 24 гига. Пришлось правда VS2022 переустановить ибо по дефолту он уставнолен был в програм файлс с пробелом и питоне не мог им пользоваться нормально. И тренить можно много чего, даже ван видео.
> даже ван видео
Там поддержка только старого 2.1. Ван 2.2, к сожалению, можно тренить только в говне кохи, которое ещё более говняное чем его говно для тренировки sd. Столько лет чел кодит и всё как в первый день, когда он писал код для тренировки лор полторахи.
Вроде и понятно, но если начнут задавать уточняющие вопросы - развалюсь.

2.2 есть только для 5B модели, ну можно сказать что и нет...

Сделал шедулер обратного косинуса с рестартом с независимыми скоростями для весов и те, работает заметно лучше чем классика. Основная проблема нисходящего шедулинга в том, что стартовые значения переоценены и потом эти переоцененные значения подкручиваются еще сильнее на стадии дикея, особенно если шумные входные данные, поэтому на одном и том же датасете получились совершенно разные эффекты (картинки заебусь прикладывать поэтому текстом) - в первом случае где старт с 1е-2 до 1е-3 (при эффективной скорости обучения примерно от 5е3 до 1е2) сильно жжет веса и конволюшены впитывают слишком мощный шумный сигнал (конкретно фьючерсы стилистики со всеми характерными засветами и квалити демеджом в датасете), во втором случае при бесконечном восхождении от 1е3 до 1е2 жарево полностью исчезает и теперь сеть не агрессивно подстраивается под датасет, а датасетные данные подстраиваются под сеть за счет бесконечного эффекта вармапа.
Эффект получился схожий с трапезоидальным шедулером, где весь график это вармап-плато на высокой скорости-косинусный дикей до нуля обратно, только там он длиной во всю тренировку, что усложняет контроль лучшей эпохи и может не докручивать себя чтобы найти более лучшее решение. Попробую сделать и попробовать циклический трапезоидал, где вармап длиной в датасет-плато длиной в датасет-дикей длиной в датасет и затем повторы, вероятно это наиболее удобный и сейфовый вариант тренировки будет вообще, но даже обратного косинуса как будто бы достаточно, особенно с большим батчем на уровне 10-50 картиночек за раз.
Кстати кохака чето высрал
>Кстати кохака чето высрал
Наверное, то самое, что он для рекламы своей вае тренировал.
>Ещё и на оптимизатор focus перешёл.
А с какими параметрами?
>Я при кешировании латентов шум генерю и потом только его использую, без генерации нового, у каждого латента свой фиксированный шум.
как эту хуйню въебать в сдскрипты пиздец че за квест
кароче нужна ревизия
вариант 1 - определять принадлежность фиксед нойза по хеш сумме (добавить аргумент --fixed_noise)
def get_noise_noisy_latents_and_timesteps(
args, noise_scheduler, latents: torch.FloatTensor
):
"""
Генерация фиксированного шума на основе содержимого latents.
"""
if args.fixed_noise:
# Переводим в float32 перед numpy()
latents_bytes = latents.detach().to(torch.float32).cpu().numpy().tobytes()
hash_int = int(hashlib.sha256(latents_bytes).hexdigest(), 16) % (232)
g = torch.Generator(device=latents.device).manual_seed(hash_int)
noise = torch.randn(latents.shape, generator=g, device=latents.device)
else:
noise = torch.randn_like(latents)
вариант 2 - через имейдж индекс но я ебал код кои в рот чтобы найти точно какой индекс откуда берется, но в любом случае этот вариант тоже работает я тренировочку прогнал, вероятно может бесоебить если каким-то образом нарушится последовательность латентов и вообще я не ебу может там один нойз лол
def get_noise_noisy_latents_and_timesteps(
args, noise_scheduler, latents: torch.FloatTensor, image_index: int = 0
):
"""
"""
if args.fixed_noise:
g = torch.Generator(device=latents.device).manual_seed(image_index)
noise = torch.randn_like(latents, generator=g, device=latents.device)
else:
noise = torch.randn_like(latents, device=latents.device)
юзал вместе с ффт лоссом, не сказал бы что качество прям скакнуло но управление промтами стало определенно лутше и четкость наверно получше собирается
нужен твой комент за всю хуйню
алсо второй вариант почему-то более пиздатые результаты дал
Хотя если быть точнее то первый вариант определенно на одном шуме обучался и у него бешеная сходимость
второй вариант лучше показывает себя в качестве фьючерс грабера, вероятно это из-за того что шум таки один на все латенты изза int = 0, и прямой инференс отличается от тренинга без фиксед нойза в чуть лучшую сторону но фактически выходные результаты одни и те же что тренировка без или с фиксед нойзом
такто технически должен был быть один или похожий результат если шумы фисятся и там и там, а на далее ну соврешенно противоположное говно
>а на далее ну соврешенно противоположное говно
Так вроде логично же? У тебя разные сиды для шума, в пером считаются из хеша латента, во втором из его индекса.
Так там прикол в том, что если результат с хешей, то он в разы более консистентный, а в случае индекса (который я предлагаю кривой, т к ну по факту там надо еще пару блоков кода для передачи индексов корректно) он почти такой же как результат с тренировкой на рандом нойзе.


Я в датасете на моменте кеширования латентов просто вот так делаю. А потом достаю вместо генерации шума.
Внгую индексы там бесполезны из-за перемешивания семплов, т.е. в разных эпохах один и тот же индекс будет указывать на разные семплы.
можешь глянуть как правильно в трейн утиль твой код внедрить?
Народ, подскажите, кто шарит. Сейчас докупил к своей rtx 3060 12gb cmp 90hx на 10 гигов, но есть вариант добавить ещё 7к и купить tesla p40 на 24 гига. У меня обычная мать ASRock B550 PG Riptide
c 3 портами под видюхи. Я бы докупил теслу, но я не ебу как её нормально подключить и как она будет у меня охлаждаться будет. У cmp 90hx есть 3 вертушки + cuda есть и их больше чем даже у моей 3060, а значит в теории я могу даже картинки на ней быстро генерировать в 1024x1024 без доп фич. Что выбрать? cmp 90hx на 10 гигов которую впросто вставил и всё или доплачивать и брать p40 и потом ещё ебаться с охлаждением + она не умеет в генерации картинок?
c 3 портами под видюхи. Я бы докупил теслу, но я не ебу как её нормально подключить и как она будет у меня охлаждаться будет. У cmp 90hx есть 3 вертушки + cuda есть и их больше чем даже у моей 3060, а значит в теории я могу даже картинки на ней быстро генерировать в 1024x1024 без доп фич. Что выбрать? cmp 90hx на 10 гигов которую впросто вставил и всё или доплачивать и брать p40 и потом ещё ебаться с охлаждением + она не умеет в генерации картинок?
p40 это старое поколение паскаль вопервых, вовторых там нет тензорных ядер, втретьих на фп16 чекпоинтах будет критическое падение производительности, это будет в разы хуже чем твоя 3060
плюс есть неприятный эффект апкастинга изза того что карта фп32 онли по факту - ты не сможешь юзать нормально фп16 чекпоинты выше чем половина врама, т.к. на карте фп16 будет апкаститься до фп32 что означает x2 врама
единственное что на тесле норм это ллмки
Так, я понял, P40 говно для генерации картинок. Но это я и до этого знал. А что по nvidia cmp 90hx?
>А что по nvidia cmp 90hx?
>10 гигов
Даже если она быстрее (хз вообще, так ли это) - будешь постоянно в низкий потолок VRAM упираться. Что совсем не круто. Более-менее нормальная жизнь начинается с 12 гигов, и твоя 3060 - до сих пор топ за свои деньги. Но лучше, конечно, 16 или вообще 24.
вопервых на майнинговом говне ебля с дровами
вовторых насколько мне известно там тоже порезаны операции с плавающей точкой, только целочисленные операции, то есть держи в уме что это LHR наоборот - все убито нахуй кроме операций вычисления хеш сумм для фарминга крипты, то есть хоть и карта базируется на 3080 но ты получишь производительность не сильно лучше опять же свой 3060
втретьих 10 гигов камон, прошлый век, даже 12 гигов уже подбираются к званию мусора для нейронок если ты конечно не жоский фанбой сдхл как я
просто для примера тебе из той же серии
NVIDIA CMP 40HX (чип TU106 как у 2060-2070, прямой аналог 2060 супер вроде по остальным хар-кам) 3.48 итераций дает
при этом обычная GeForce RTX 2060 5.18 итераций на тех же настройках
делай выводы
Окей, я могу немного пойти ваканк, докинуть ещё 25к и купить 5060 ti 16gb. Насколько она лучше в генерации картинок чем 3060 12gb?
Какие ранги для XL для стидей норма. Читал, что 16-хватит-всем.
Можно до 64 подниматься, чтоб быстрее тренить.
тонко
>Насколько она лучше в генерации картинок чем 3060 12gb?
3060
3600 куда ядер
112 тензорных ядер
192 бита шина
5060ти
4608 куда ядер
144 тензорных
128бит шина
Это примерно 1.5-2 раза быстрее 5060ти будет кароче, в зависимости от архитектуры нейросети.
Если что лучший топ нищевариант это 3090 с лохито на 24 гига.
Ранг это просто размер и толщина добавочной матрицы с новой инфой. Чем больше размерность матрицы, тем больше параметров может хранить, чем больше параметров тем больше уникальных паттернов и их взаимодействия может изучить сеть. Хочешь более пиздатую модель - тренируй с большим рангом.
А такто и lokr с фактором декомпозиции -1 с выключенной декомпозицией второго блока (ранг >10240, альфы не работают) с тренировкой input_blocks.8, output_blocks.0, output_blocks.1 хватит на простую задачу за глаза, а это размер выходной лоры в 4 мегабайта между прочим.
>Если что лучший топ нищевариант это 3090 с лохито на 24 гига.
В "дополнительные 25к" он тут вряд ли уложится.
Даже БУшные 3090 довольно дорогие.
Но 5060 и так нормально смотрится. Можно выжимать все из XL-моделей, и щуть-щуть потрогать всякие флюксы, ваны, квены и видео-генерацию.
> ваны, квены и видео-генерацию.
трогаю на 3060
>на 3060
Ну это уже экстрим какой-то.
Медленно же.
убыстрялочки наше всё
>4 мегабайта
кому интересно это технически 2 миллиона параметрических значений в bf16, или 0.06% параметров всей сдхл

Я отказываюсь принимать и терпеть то, что стадия стабилизации на сдхл это фундаментальное ограничение обучения. Должен быть какой-то лайфхак уровня тичер-ученик, который убыстряет стадию стабилизации. Мнение?
Циферки эпох умножайте на 5 чтобы количество шагов получить.
Циферки эпох умножайте на 5 чтобы количество шагов получить.
Скорее у тебя оптимизатор говно. За 1000 шагов любой датасет из 5 пиков уже натренится.
>Скорее у тебя оптимизатор говно.
Нет, я тебе больше скажу - результат есть на первых 50 шагах, особенно если плюсить к убыстряющим лорам. Но снижение ошибки раз за разом рисуется именно в таком паттерне - хаос, стабилизация, снижение ошибки, и это вообще независимо ни от сверхнизких или сверхвысоких бет, скорости обучения или всяких дополнительных ёб типа едм - сдхл раз за разом требует на отрисовку паттерна поведения ошибки около 2к шагов для лоры. Это как будто заложено в самой сдхл.
Лосс не метрика, нет смысла смотреть что там на графике, особенно на лорах.
>Лосс не метрика
Повторяемость паттерна говорит о том, что это таки метрика. А если смотреть что делают челики используя конфигурацию из учитель-ученика, то там паттерн лосса сжимается во времени.
>нет смысла смотреть что там на графике, особенно на лорах.
То же самое поведение если тренировать полные матрицы, но в виде модуля дополнительного.
Это я понимаю, вопрос скорее был про какое-то минимальное/начальное значение для нюкеков.
Алсо аналогичный вопрос по локону - какие ранги конвов ставить? Есть ли какие-то соотношения конвов к линейкам или можно фигачить какой-нибудь 16/4 в оба?
>вопрос скорее был про какое-то минимальное/начальное значение для нюкеков
Ящитаю, что какое в карту залезет. Если хочешь тренировать быстрее, то подбери размер под увеличенный батч (помимо добавленных gradient_accumulation_steps фейкобатчей), если у тебя например 3060 то в 12 кеков вполне влезет батчсайз 2 на сниженной размерности.
>Алсо аналогичный вопрос по локону - какие ранги конвов ставить? Есть ли какие-то соотношения конвов к линейкам или можно фигачить какой-нибудь 16/4 в оба?
Зависит от того как и что тренируешь - полностью все блоки или селективно.
У каждого блока и почти у каждого слоя в сдхл есть пачка слоев которые считаются конволюционными при тренировке:
emb_layers - управляют вставками эмбедингов с фьючерсами от текстового енкодера, по факту не конволюшены даже, а просто своеобразные линейные слои, но в премейд пресете кои который тренирует конв онли они берутся и не фильтруются, очевидно чтобы при тренировке только конв с текстовым енкодером был смысл тренировать текстовый енкодер вообще
in_layers - конвы на входное преобразование
out_layers - конвы выходного преобразования
skip_connection - конвы соединяющие разные блоки, в основном находятся в аутпут блоке сдхл и соединены с инпут блоками
конвы это локальные данные, поэтому они очень нежные в большинстве ранних слоев и если ты подаешь в них сразу агрессивный шум, то они могут его и запомнить и больше не забыть, исключение составляют емб и скипы - им похер, плюс конвы в мидл и конечных аутпут слоях достаточн стабильны так как финализирующие
соответственно чисто логически чтобы не вызывать переобучение на шумные данные при обучении полных блоков обычно их размерность снижают относительно линейных слоев, процент подбирается индивидуально от 10 до 75%, прямой зависимости "количество блоков относительно линейных - размерности" нет, там в основном зависимость от скорости - если у тебя сейфовая низкая скорость на миллион шагов то можно такую же размерность брать что и у линейных, если агрессивная высокая с мощными шагами обновлений - ставь ниже
плюс зависит от алгоритма, у локона емкость сети в целом низкая поэтому вызвать переобучение на говняк в конвах проще, а например если тренировать diag-oft или boft то там матрица не коверкает основные данные сети и встраивается максимально нативно в модель, поэтому можно одинаковое значение брать
>Зависит от того как и что тренируешь - полностью все блоки или селективно.
Я так понимаю ты про locon preset? Пока не ковырялся с ним и сижу на дефолте (full).
У меня на 4080 в принципе лезло 20/18 с батчем 2 или 3, но результаты были ужаренные и я пока на 16/16 тестирую.
Собственно сейчас пытаюсь получить не ужаренную лору на 16/4 (ранг/альфа) на линейки/конвы, локон+дора, без дропов. Оптим AdamWScheduleFree, LR=2e-4, wd=0.1, шедулер константный без прогрева. Эта хрень медленная, но вроде пока не так сильно жарит глаза/руки на арте.
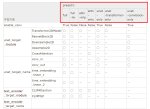
>Я так понимаю ты про locon preset? Пока не ковырялся с ним и сижу на дефолте (full).
Премейд пресеты кои пикрел. Ты можешь свой томл конфиг создать под нужное, ток регексы надо изучить и состав сети чтобы понять что исключать.
Если надо будет подсказать как оформлять регексы обращайся.
>не ужаренную лору на 16/4 (ранг/альфа) на линейки/конвы
Альфа это регуляризационная штука, не крути ее если не знаешь как точно будет лучше - либо единичку ставь, чтобы обновления разных прогонов лор с разными настройками были так сказать сравниваемы между собой по влиянию на сеть, либо одинаковый размер с рангом чтобы масштабируемости вообще не было и крути вес лоры во время инференса просто.
>wd=0.1
От вд никакого практического толка для маленьких датасетов, можешь смело не использовать никаких вейтдикеев вообще, это для миллионных датасетов регуляризация.
>шедулер константный без прогрева
У тебя шедулерфри, ему шедулер не нужен вообще, он сорт оф адаптивный.
>Эта хрень медленная, но вроде пока не так сильно жарит глаза/руки на арте.
Пережарка это проблема переобучения на агрессивной скорости на агрессивные шумные данные ранних слоев блоков сети которые отвечают за мелкие и тонкие фичи. От этого частично помогает вармап. Я предполагаю что у тебя проблема зажара от конв и идет, потому что линейные зажарить это надо еще суметь.
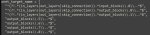
>>Зависит от того как и что тренируешь - полностью все блоки или селективно.
>Я так понимаю ты про locon preset?
Уточню, что под селективным методом я имел в виду пикрел например, потому что пресеты кои сконструированы так что либо тренятся только конвы, либо фул, либо только линейные, это как бы тоже селективное, но ты тренишь с конвами и у тебя выбор ток из фулла и конвонли без линеек.
> Ты можешь свой томл конфиг создать под нужное, ток регексы надо изучить и состав сети чтобы понять что исключать.
Знать бы еще что туда включать...
>Альфа это регуляризационная штука, не крути ее если не знаешь как точно будет лучше
Ну я в треде увидел совет ставить как корень из ранга, так и поставил. Вроде как тоже должно выдавать сопоставимые результаты при масштабировании ранга.
Алсо можешь что-то посоветовать по подбору LR? 2e-4 как-то слишком медленный получается, но я подозреваю что выше начнет жарить сильнее.
Пережарка абсолютно никак не зависит от ранга. Для начала попробуй обычную лору натренить, может опять обсер с альфой при инференсе у ликориса.
> слишком медленный получается
Это из-за AdamWScheduleFree, он и должен быть медленный.
>Знать бы еще что туда включать...
Стабильные блоки и слои. У сдхл вообще интересно архитектура работает, она явно разделяет контент, стиль и план сборки картиночки по блокам (и слоям), на этом принципе основан селективный тренинг b-lora https://b-lora.github.io/B-LoRA/ (причем обязательно тренировать сразу все вместе, а потом разделять по блокам если надо, т.к. отдельная тренировка указанных блоков не является стабильной и консистентной).
>Ну я в треде увидел совет ставить как корень из ранга, так и поставил. Вроде как тоже должно выдавать сопоставимые результаты при масштабировании ранга.
У меня гдето ссылка была где челик мощно тестил аргументы и прочие регуляризационные штуки, в том числе альфу, так вот там никакого профита использовать что-то кроме 1 или числа равного рангу найдено не было в контексте альфы.
>Алсо можешь что-то посоветовать по подбору LR?
Как такового метода подбора лр нет. У оптимов в инит прописаны скорости обычно, но они тебя не касаются т.к. или взяты от балды если это прям кастом кастом от васяна, или указаны из расчета тренировки на гигантских корпусах данных как у лицокниги с ее шедулерфри штуками. Хочешь не ебаться с подбором лр и шедулера к нему - бери полностью адаптивные оптимайзеры, например https://github.com/LoganBooker/prodigy-plus-schedule-free
>Для начала попробуй обычную лору натренить, может опять обсер с альфой при инференсе у ликориса.
Попробовал, и походу жарит сильнее локона с дорой.
Настройки остались те же что и для доры.
короче докинул 30к и заказал себе 3080ti на 12 гигов с озона
А можешь поподробнее про эти пресеты рассказать, Как свой добавить, на основе чего делать и т.п.
Я так понимаю на втором пике примерно то, что тут
и описано? Т.е. выкинуты входные/выхожные конвы и фокус на глубоких слоях энкодера и больше на декодере. Но зачем тогда скипы тоже выкинуты, если они стабильны?

>Как свой добавить, на основе чего делать и т.п.
Добавить просто: создаешь файл с расширением toml, в нем прописываешь рыбу
enable_conv = true если нужны конвы
dora_wd = true если нужна дора
unet_target_module = [
"модуль1",
"модуль2"
] если нужно модули, по дефолту просто пустые квадратные скобки
unet_target_name = [
"фильтрслоя1",
"фильтрслоя2"
] тут основные таргеты слоев
text_encoder_target_module = [
] здесь можно указать модули енкодера, по дефолту пустое, т.к. в целом целый енкодер тренировать не нужно тоже на малом датасете, достаточно общие концепции простые с первых слоев подрочить; либо можно указать CLIPAttention например
text_encoder_target_name = [
"фильтрслоя1",
"фильтрслоя2"
] таргеты слоев енкодера
еще есть алгомаппинг, позволяющий разграничить какие алгоритмы с какими размерностями и настройками будут тренировать части сети, это нужно чтобы достичь максимальной скорости тренинга в оснвоном, т.к. допустим обычная лора быстро тренит conv, а lokr тренит быстро линейные, указываем это в алгомапе и получаем лучший вариант по скорости с отдельными настройками под каждый алгоритм, но это тебе не нужно наверно
Делать на основе любой лоры, вот у тебя есть лора натрененная с пресетом full, кидаешь ее в валидатор слоев чтобы прочекать состав, получишь выходной список всего говна внутри типа пикрел на много строк. В основном тебе нужны просто названия слоев, но если прям глубоко фильтровать то рядом с каждым слоем есть в скобочках форма, т.е. например (1280-20) это значит что лора 1280 канальный вектор ужимает до представления в 20, а обратный порядок наоборот восстанавливает. Там где 4 цифры - последние две это размер ядра, по сути размер окна фильтра через который лора смотрит на локальный участок фьючермапс. То есть
1x1 не смотрит на соседние пиксели, а только смешивает каналы
3x3 учитывает соседние пиксели (локальный контекст) и дает пространственное преобразование. Можно глубоко фильтровать короче, например выкинуть канальные миксеры вообще, т.к. это неполные данные (а тренировать неполные данные на шумно датасете это может быть вредно), или обучать только максимально вариативные вектора, где из низкого ранга условно вылезает 10240 каналов.
Валидатором я пользуюсь из https://github.com/bmaltais/kohya_ss , там он называется верифай лора, но можно отдельно скриптом с командной строки смотреть.
>Я так понимаю на втором пике примерно то, что тут и описано? Т.е. выкинуты входные/выхожные конвы и фокус на глубоких слоях энкодера и больше на декодере.
Да.
>Но зачем тогда скипы тоже выкинуты, если они стабильны?
Просто открыл первый попавшийся конфиг, ничего не значит. Это когда тестил влияние отдельных слоев делал.
>Как свой добавить
А забыл написать как кастомным томлом пользоваться.
Просто указываешь абсолютный путь к томлу в аргументе пресета "preset=K:/папка с томлом/master.toml"
>12 гигов
Нафига?
У тебя уже есть карточка на 12 гигов.
Нафига тратить столько бабла, чтобы выиграть только во времени генерации, но не в объеме доступных задач?
для генерации он распараллелить может, допустим квенимаге в q4 веса на 1 карту, все остальное на вторую, еще места останется под кал всякий
а тренинг тоже можно распараллелить, считай у него одна карта 24 гига со скоростью чето среднее между этими двумя картами
>2e-4 как-то слишком медленный получается, но я подозреваю что выше начнет жарить сильнее.
лр это не скорость изменений а объем изменений
хочешь чтобы быстрее реагировало на датасет - снижай беты
я настолько преисполнился что почти всегда гоняю тренинги на 0.1765 по бете? почему именно так - это первое нижнее значение первой константа Фейгенбаума от значения 1 когда ничего не происходит, идея такая что нейросеть хаотическая система переходящая в стабильную, значит к ней применимы те же константы, моментум можно представить как геометрическую последовательность и тд и тп
Звучит как пердолинг ради пердолинга, если честно.
ну а как ты думоешь ллм гоняют на 70 гигов? так и гоняют
С такими размерами как раз понятно. Когда в одну карту оно физически не лезет.
Но брать две на 12 - очень странно.
> а тренинг тоже можно распараллелить, считай у него одна карта 24 гига со скоростью чето среднее между этими двумя картами
Не совсем, есть определённый невыгружаемый буфер, ну допустим 7гб хл модели, которые будут висеть мёртвым грузом в памяти второй карты, тогда как если бы это были нативные 24, 7 лишних гигов не отъедались бы, ну если мы говорим конечно про распараллеливание акселерейтом

Кароче апдейт, нашел как убыстрить, регуляризационные имеджы помогли.
Для чистоты обучал на класс.
Красное до, синее после, результаты у синего в стопицот раз быстрее достигаются и лутше.
В регулярки кинул 1/10 голых генов с основной модели без какого-либо промптинга.
>1/10
датасета
Олсо периодическое жарево, "дымка" и неконсистентность генераций (когда нога коня в ноге человека например) тоже ушли. Прекрасно.
Тупо рандомный ген без промта в папке регулярок?
Да, пустой промт в негативе и позитиве, размер одинаковый, в папке 1_класс, у основного датасета тоже 1_класс.
Настройки тренинга одинаковые, gradient_accumulation_steps обоих проектов 20.
>Если упороться, то можно ещё маску накинуть, центр спектра с шифтом по центру.
Попробовал накостылять это, и что-то простая круглая маска с сигмой=0.5 адски бустит стабильность и перенос стиля.
Как-то слишком хорошо выглядит, надо еще на паре датасетов погонят.
>Попробовал накостылять это
код скинь
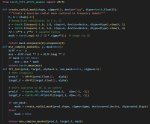
Пока такое.
Нейронка тебе такое сваяла? Инпут тоже должен шифтится и диапазон маски у тебя какой-то странный. Для недискретного преобразования есть уже с правильным шифтом функция в либе - frft_shifted, но она требует размер инпута чётный. Или от угла без шифта можно маску делать, но она несимметричная будет.

Что-то типа этого?
А регуляризационные латенты не пробовал? Оно там вроде включается, хз как именно работает, должно быть можно заранее их нагенерировать.

>А регуляризационные латенты не пробовал? Оно там вроде включается
Нет, не вижу где в сдскриптах такое есть.
Зато я в качестве эксперимента запихал в регулярки плазма и пинк нойзы, скормил зашумленный большой датасет и получил лору, которая выучила фичи датасета и стала давать эффект сорт оф денойзера. А плазма вообще оказывается работает как жесткий фильтр объектов, то есть частичные эпохи выдают генерации где класс датасета как будто вырезан из датасета, а маскированная область представляет собой плазма нойз. Интересный эффект, возможно стоит попробовать накинуть 50% плазму или 50% пинк на весь датасет и кинуть как регулярку.
> возможно стоит попробовать накинуть 50% плазму или 50% пинк на весь датасет и кинуть как регулярку.
Попробовал на плазме. Взял датасет, наложил на каждую картинку одинаковый плазма шум с опасити 50%, выставил константную агрессивную скорость в 1e-2 (на порядок больше чем нужно, обычно на 1e-2 по пизде все идет инстантно), прогнал с дефолтным --prior_loss_weight=1 - практически сразу сеть начала обучаться на плазму из рег датасета, но изображения консистентные в целом, ток шумные. Из фич замеченных - как только начало переобучаться, то начинала превалировать плазма в генерациях.
Снизил --prior_loss_weight до 0.1, прогнал с низкой бетой и высокой - очень стабильные выводы получились в обоих вариантах, ток лорку чуть-чуть снижать надо по силе влияния, т.к. геометрия немного плывет.
При таком приор лоссе для рег датасета плазма тоже начинает проявляться на полном весе, но больше в рандомных эпохах, пока не понял от чего зависит, потому что плазма может вылезти на ранней эпохе, а потом пропасть вообще.
Олсо обучал все блоки, что не мог себе позволить на 1e-2 вообще практически никогда. Так что метод в целом рабочий, если кому интересно то плазма (и прочие виды шумов) генерятся вот этим https://github.com/Jordach/comfy-plasma
Отается проверить чисто плазма нойз в качестве регуляризации без подмешивания его к датасету.

>prior_loss_weight=1 - практически сразу сеть начала обучаться на плазму из рег датасета, но изображения консистентные в целом
Интересный график лосса на этом варианте кстати (красный), где поднятие произошло там лора начала убиваться и убилась начав генерить просто шум похожий на плазму, до поднятия консистентные генерации и все. Вот тако вот сорт оф наглядный майлстоун переобучения получется.


Ровно на 108 эпохе плазма стала базой модели, до этого генерилось отлично. Снизу вверх 107, 108, 109 эпохи. Есть эпоха вплоть до 195, ни на одном шаге не стабилизировалось обратно.
Короче пока остановился на этом. На тестовых латентах спектр выглядит отцентрованным. Без двойного dfrft он был сжат либо по вертикали либо по горизонтали.
Сделал пару тестовых прогонов и выглядит неплохо, пропало жорево мелких деталей, но по ощущениям стало что медленнее сходиться.
В общем если полностью чистый плазма нойз (который является фракталом, то есть структурированной в понимании модели штукой, собсно как и пинк или браун нойз, а не обычным рандом нойзом, с которым сдхл обучена бороться и игнорить) кидать в качестве регуляризации то выходные данные таки получаются сглаженными и отденойзенными на ранних эпохах, в отличие от варианта, где в рег дате датасет с накинутым шумом. К результату в обоих случаях оба тренинга приходят одинаково (да и результаты схожи максимально), но с разной скоростью - на чистом нойзе результат получается позже на пару эпох. Так что смысол есть в варианте, где подкидывается не чистый шум, а именно шум + дата хотя бы минимальная.
Еще момент по обучению: рег датасет берется в равной степени к датасету обучения, то есть если допустим в датасете 5 картинок, а в рег дате 1, выставлен батч 10, то возьмутся 5 картинок датасета и 1x5 рег деты, никакой деградации замечено не было от такого варианта, так что можно сэкономить на кешировании и брать небольшой рег датасет.
Остается прочекать влияние процента шума на рег дате, потому что сейчас 50% зашумленность и результаты хорошие, может с другим процентом будет лучше. Еще нужно прочекать приор лосс, но по виду 0.1 достаточно, надо прогнать с 0.5 хотя бы.
В целом плюсы плазмы в том, что она доджит переобучение на фон и сохраняет его управляемость хорошо так отделяя объекты.
Сейчас тестирую параллельно пинк нойз, и он как будто больше направлен на выхватывание особых уникальных паттернов, но в целом эффект что плазмы, что пинка плюс минус тот же, возможно пинк более предсказуемый с датой поэтому на нем проще регуляризацию сдхлке считать. Возможно есть смысл соединить плазму, пинк и дату в равной пропорции чтобы получить бонусы от каждого варианта.
https://huggingface.co/Anzhc/MS-LC-EQ-D-VR_VAE
Вышла новая версия EQ VAE 5 дней назад, которая нормально работает со скриптами в отличие от кохаковской залупы которую я не ебу как заставить работать.
Вышла новая версия EQ VAE 5 дней назад, которая нормально работает со скриптами в отличие от кохаковской залупы которую я не ебу как заставить работать.

Кто будет тренировать на этом имейте в виду что это новое латентное пространство для сдхл и нужно дополнительное время для создания всех связей в сети чтобы корректно натренировалось, плюс вполне вероятно нужно подкрутить старые настройки, которые хорошо работали с оригинальным вае в сторону большей агрессивности.
Синее - оригинальный вае, остальное EQ.
Смысл вообще от этого, если оно перетренировки всей (?) инфраструктуры требует?
Вот бы чего-нибудь такого, чтоб воткнул на стандартные модели, и оно лучше стало, без всех этих расплывающихся мелких деталей которые я на своих картинках уже заебался фиксить.
Такого не будет, все со стандартным sdxl-vae уже перепробовали, что бы не требовало перетренировки всей модели.
>Смысл вообще от этого, если оно перетренировки всей (?) инфраструктуры требует?
Ну вообще не требует, я уже успел тройку тестовых лор прогнать, представление латентов для обучения в разы лучше, сеть моментально схватывает всё на пикчах, сразу видно что сигнал латента чище. Единственная проблемы это то что или стабилизация дольше (первые эпохи уже дают результ качественный в смысле содержания, но качество изображения далеко дольше подтянется), поломать конволюшны проще забив их сатурированным сигналом, и судя по всему вывод оче сенсетивный к шедулеру при инференсе, а так гораздо удобнее дефолтного вае.
> Синее - оригинальный вае, остальное EQ.
Так на твоём графике понижение лосса - это адаптация к поломанным латентам. Оно никакого отношения не имеет к повышения качества тренировки.
Ну и нахуй это говно нужно. На XL никогда не было проблем с тренировкой концептов, а вот детализация всегда сосала из-за всратого 4-канального вае. Теперь ещё хуже будет. Да и вообще все эти дрочи трупа XL не вызывают оптимизма, уже пора дропать XL, она только в аниме жива, для реалистика XL уже слишком устаревшая. Лучше бы что-то с Квеном придумали, как размылить его, чтоб с Хромы на него начинать перетренивать лоры.
Видел какие-то эксперименты, но чем закончилось - не в курсе.
>уже пора дропать XL
Пока качественной (и, самое важное, доступной на базовом железе) замены не появится - XL будет жива.
И что-то пока на горизонте такой замены не вижу.
Так что продолжать улучшать XL - вполне себе вариант.
>Так на твоём графике понижение лосса - это адаптация к поломанным латентам.
Чище сигнал => сеть меньше ошибается => меньше потерь, такая логика.
>Оно никакого отношения не имеет к повышения качества тренировки.
А я про качество писал только в контексте что для его достижения нужно вложить время. И вообще смотря что ты подразумеваешь под качеством. Я охочусь за адаптацией, точным грабингом фич с датасета и следованием промту - это для меня качество, сэтим это вае определенно лучше справляется чем дефолт. Если тебя просто качество самой картинки интересует чтобы генерить по референсу, то это второстепенное на самом деле.
>Ну и нахуй это говно нужно.
Прост чище сигнал дает.
>На XL никогда не было проблем с тренировкой концептов
Но есть проблема с точностью.
>Да и вообще все эти дрочи трупа XL не вызывают оптимизма, уже пора дропать XL, она только в аниме жива, для реалистика XL уже слишком устаревшая.
Слишком категорично, ни одна модель не работает также быстро как сдхл и ни одна модель не имеет настолько большой пак мокрописек для обвязки. Плюс единственная модель которую можно в лайв моде использовать без болей в жопе.
>Лучше бы что-то с Квеном придумали, как размылить его
Лучше бы квену запилили модель на 5 раз меньше параметров.
>чтоб с Хромы на него начинать перетренивать лоры.
Ну хрома это кал, имхо.
>Если тебя просто качество самой картинки интересует чтобы генерить по референсу, то это второстепенное на самом деле.
референс ген вообще ипадаптером и флюх калтекстом решается, смысл дрочки тут на качество тренировок как таковых вообще не вижу, лоры и фуллфт для другого тренируются
> качественной
Как на Хрому/Ван пересядешь, так уже к XL не захочется притрагиваться. С промптингом на DiT всё отлично, как и с переносом концептов за пределы датасета.
> ни одна модель не работает также быстро как сдхл
С учётом того что 4/8-шаговые XL очень шакальные, ещё и в два прохода надо генерить чтоб нормальное разрешение иметь, то 8-шаговые DiT не так уж медленнее. И с тренировкой всё отлично, внезапно 14В/20В DiT тренится всего раза в два медленнее XL. На Квене вообще как на XL можно за 15 минут лоры на 1000 шагов хуяк-хуяк делать.
> пак мокрописек
Wan/Qwen уже обогнали по функционалу XL, где кроме пары контролнетов и всратого ип-адаптера ничего нет.
>Как на Хрому/Ван пересядешь, так уже к XL не захочется притрагиваться.
а я какраз попробовал хромог и ван, а потом вернулся на хл, аналоговнет

>С учётом того что 4/8-шаговые XL очень шакальные, ещё и в два прохода надо генерить чтоб нормальное разрешение иметь, то 8-шаговые DiT не так уж медленнее.
Што? Я конечно не далбаеб чтобы гигантизм генерить на сдхл постоянно не больше мегаписеля делаю, но вот 1768x1280, 15 шагов, 14 секунд, 1 проход на 3060, с какой-то рандомной говнолорой на стиль, и это я еще ничего не постобрабатывал или не включал в пайп шринки хуинки и адаптеры.
>Как на Хрому/Ван пересядешь
Художников знают? Персонажей, может быть, конкретные стили? А сисик-писик сгенерить могут?
Пока модель с незацензуренным датасетом не появится - разговаривать не о чем, тюны XL вне конкуренции.
На "Извините, я не могу выполнить этот запрос" я и в облаке посмотреть могу, на гораздо более умных и продвинутых нет моделях.
> А сисик-писик сгенерить могут?
Хрома в ваниле может.
Если тренировать вместе с нормами через train_norm=True, то шумы моментально уходят и ваешка дает почти то же качество что оригинал, не в смысле содержания - по точности ебет как ебало, а в смысле что шумов от другого латент спейса практически перестает быть. Но проверил только на пресете full. До этого тренил на кастом модулях без трейннорм, и там конечно хорошо по содержанию, но два латента в одной генерации прям конфликтуют между собой, надо попробовать селективно с нормами прогнать.
Алсо в репе есть фикс паддинг артефакта:
for module in self.model.modules():
if isinstance(module, nn.Conv2d):
pad_h, pad_w = module.padding if isinstance(module.padding, tuple) else (module.padding, module.padding)
if pad_h > 0 or pad_w > 0:
module.padding_mode = "reflect"
Но я его чет не могу в пайплайн скриптов всунуть. Если кто знает как напишите.
А так с тренировкой норм бага этого нет почему-то.
>надо попробовать селективно с нормами прогнать
Да, все работает. Если тренирова на EQ отдельные блоки и включить тренировку norm, то получается модель, которая работает с оригинальным вае с качеством основной модели, но все фишки полученные от EQ. Пользуйтесь, нормы имба с EQ.
Текстуры сосут у этого VAE, ненужно.
скилишуе
Покажешь примеры где текстуры не сосут? Я пока не видел.
Какой-то беспредметный разговор уровня "пук хрюк мыло кококо" из сд треда.
1. Сначала определи что значит "текстуры сосут"
2. Далее покажи лоры или модели натренированные с этим вае где текстуры по твоему заявлению сосут
3. Покажи лору или модель которые были натренированы без данного вае и с данным вае для прямого сравнения эффекта
4. Определи как текстуры в латентном представилении могут сосать (с ссылкой на папер, подтверждающий это с метриками)
К вопросу о ваехах.
Рекойлми высрал ваешку https://huggingface.co/AiArtLab/sdxl_vae без нового латентного пространства но по бенчам чище EQ кохака. Прогнал тест с нохалф, вроде прикольно, однозначно будет лучше чем всратый дефолт.
Рекойлми высрал ваешку https://huggingface.co/AiArtLab/sdxl_vae без нового латентного пространства но по бенчам чище EQ кохака. Прогнал тест с нохалф, вроде прикольно, однозначно будет лучше чем всратый дефолт.
> Пока качественной (и, самое важное, доступной на базовом железе) замены не появится - XL будет жива.
Насчет доступных замен https://huggingface.co/AiArtLab/sdxs
Чел, тот VAE в принципе мыльнее оригинального. Они боролись с шумами и сделали ровно то что хотели - мыло. Ещё и тренили только на аниме с бур, заруинив окончательно всю детализацию. Собственно если ты датасеты чистишь всегда, а не просто жипеги гонишь в модель, то у тебя никогда и не будет проблем с какими-то шумами.
> покажи
Литералли примеры авторов посмотри, у них шумодав адский.
Мылошиз, ты?

>без всех этих расплывающихся мелких деталей которые я на своих картинках уже заебался фиксить.
Можешь взглянуть на хрому радианс, которая безвайная - так вот, этих расплывающихся деталей пруд пруди. Так что я б не стал надеяться именно на фикс деталей.
Ты ещё забыл добавить что все натрененные до этого лоры надо выкинуть. 4-шаговые лоры и контролнеты - тоже выкинуть. Литералли всё перетренивать, а иначе падение качества. А ещё оно потом чувствительно к весу лоры, ведь у нас в лоре адаптация к новому латенту и изменение веса ломает её. Бесполезное говно, откатывающее на 2 года назад. С таким подходом проще сразу на DiT тренить.
Эта вот без замен
>Limited concept coverage due to the small dataset.
>The Image2Image functionality requires further training.
И на картинке по ссылке лютая хтоническая жуть.
Нет, спасибо.
Все эти поделки хороши только для буратин с десятком-другим H100 чтобы потом их дотюнить до чего-то юзаебльного, либо для потешных картиночек с большими носами для твитора.
Пока не будет чего-то, уровня нуба или хотя бы люстры (и их аналогов для 3д) - оно нахуй не нужно.
Пока не будет чего-то, уровня нуба или хотя бы люстры (и их аналогов для 3д) - оно нахуй не нужно.
Что-то непонятно, как этим пользоваться.
Скачал вместе с конфигом, переименовал, закинул в папку с VAE, так рефордж ругается при попытке генерации с этой штукой.
>RuntimeError: Error(s) in loading state_dict for AutoencoderKL:
>Missing key(s) in state_dict:
Где там чего менять надо чтоб завелось, объясните хлебушку.
> AutoencoderKL
Оно в формате автоматика, а не диффузерс. Мне тоже пришлось поебаться чтоб конвертнуть в диффузерс, чтоб тренить с ним. И с ним пайплайн диффузерса не работает нормально, хуй знает почему, при том что ручной энкодинг/декодинг работает нормально. Это к тому что если Фордж использует ванильный пайплайн как-то, то не будет работать.
Вот этим скриптом можешь конвертнуть, пути только пропиши в load/save - https://textbin.net/ptpvcqkpph
Поднял венв с папки вебуя, загнал в него скрипт с прописанными путями до оригинального вае, и куда перезаписывать (заместо "in" в скрипте в двух местах).
Вроде конвертнулся, файл обновился, но все равно не заводится.
Ошибка с виду та же, вот целиком.
Loading VAE weights specified in settings: D:\StableDiffusion\stable-diffusion-webui\models\VAE\AiArtLabs_Conv_VAE.safetensors
Traceback (most recent call last):
File "D:\StableDiffusion\stable-diffusion-webui-reForge\modules_forge\main_thread.py", line 37, in loop
task.work()
File "D:\StableDiffusion\stable-diffusion-webui-reForge\modules_forge\main_thread.py", line 26, in work
self.result = self.func(self.args, *self.kwargs)
File "D:\StableDiffusion\stable-diffusion-webui-reForge\modules\sd_vae.py", line 267, in reload_vae_weights
load_vae(sd_model, vae_file, vae_source)
File "D:\StableDiffusion\stable-diffusion-webui-reForge\modules\sd_vae.py", line 212, in load_vae
_load_vae_dict(model, vae_dict_1)
File "D:\StableDiffusion\stable-diffusion-webui-reForge\modules\sd_vae.py", line 239, in _load_vae_dict
model.first_stage_model.load_state_dict(vae_dict_1)
File "D:\StableDiffusion\stable-diffusion-webui-reForge\venv\lib\site-packages\torch\nn\modules\module.py", line 2584, in load_state_dict
raise RuntimeError(
RuntimeError: Error(s) in loading state_dict for AutoencoderKL:
Missing key(s) in state_dict:
ГПТ-5 мне еще конверсию на safetensors.numpy посоветовал сделать.
https://textbin.net/wik0emkkok
Точно такая же ошибка.
Хуй знает о чем ты, латент это просто компактные признаки изображения формы, текстуры, цвета в закодированном виде, говорить о мыле каком-то мифическом это некорректно, отличия у ваех в точности циферок, что собсно видно на примере из EQ. Нету такого что вае каким-то чудесным образом не видит текстурки, у него задача вообще любое говно кодировать в скрытоспейс, кто-то точно делает, ктото нет, вот и вся разница. То что ты видишь как тестовые крашеные латент в примерах это не реальное представление латента к тому, оно ток границы форм в основном показывает, представить полноценно латент в ргб пространстве невозможно.
>то у тебя никогда и не будет проблем с какими-то шумами
Так епта вопрос не про шумы вообще, а про точность картинка-признак-картинка, чем неточнее представление тем хуже конвергенция.
Я с екюшкой лорку натренил щас - спиздило все текстурки подчистую.
>что все натрененные до этого лоры надо выкинуть
Ну да, нахуй они нужны, куски кала
> 4-шаговые лоры и контролнеты - тоже выкинуть.
Ну тут нет, архитектура осталась на месте, EQ работает с убыстрялками и калтролнетами.
Там тренинг все еще идет, в вандб можешь чекать эпохи и примеры, там ток к 1 миллиону шагов подбирается. А вообще че ты хотел? Это пруф оф концепт по сути, берешь и тренишь целую модель на своем датасете с 16 канальным вае с мульти те и кайфуешь с результата.
> Хуй знает о чем ты
Вае всегда как деноизер работает, он не умеет в латентном пространстве нормальный шум сохранять. И мылит он легко, если так натренили.
> EQ работает с убыстрялками и калтролнетами
Ты ведь не пробовал даже. С DMD и 4-шаговой лорой под Нуб он плохо работает, на выходе артефачит. Контролнеты вообще очевидно сломаются, т.к. они кодируют пиксели в определённый формат латента и если у тебя там другой, то получаешь распидорас.
>Что-то непонятно, как этим пользоваться.
>Скачал вместе с конфигом, переименовал, закинул в папку с VAE, так рефордж ругается при попытке генерации с этой штукой.
в комфе работает искаропки при генерации
>Оно в формате автоматика, а не диффузерс. Мне тоже пришлось поебаться чтоб конвертнуть в диффузерс, чтоб тренить с ним. И с ним пайплайн диффузерса не работает нормально, хуй знает почему, при том что ручной энкодинг/декодинг работает нормально.
на сдскриптах вообще без ебли запускается (и eq тоже), просто папку указываешь с конфигом и вае через --vae
>Ты ведь не пробовал даже. С DMD и 4-шаговой лорой
Как раз это и пробовал, у меня постоянно в тестовом вф стоит включенным. Все с EQ нормально работает.
>под Нуб он плохо работает, на выходе артефачит
Так нубай в принципе с дефолтным дмд обсирается делая 24/7 вектор-лайк графин, можно через спо нуб поправить и будет получше но все равно ебашит слишком агрессивно, в этих репо https://huggingface.co/YOB-AI/DMD2MOD https://huggingface.co/YOB-AI/HUSTLE есть попердоленные дмд которые в целом хорошо работают с нубаем, в сд треде пользуются.
>Контролнеты вообще очевидно сломаются, т.к. они кодируют пиксели в определённый формат латента и если у тебя там другой, то получаешь распидорас.
Я все не тестил, но депфы и кани которые у меня есть вроде ок.
>в комфе работает
Ну кто бы сомневался.
А потом оказывается что нет, не работает, и лапша из-за ошибок при чтении этой фигни без вае генерила.
Ну что за фантазии...
bump



Предыдущий тред:
➤ Софт для обучения
https://github.com/kohya-ss/sd-scripts
Набор скриптов для тренировки, используется под капотом в большей части готовых GUI и прочих скриптах.
Для удобства запуска можно использовать дополнительные скрипты в целях передачи параметров, например: https://rentry.org/simple_kohya_ss
https://github.com/bghira/SimpleTuner Линукс онли, бэк отличается от сд-скриптс
https://github.com/Nerogar/OneTrainer Фич меньше, чем в сд-скриптс, бэк тоже свой
➤ GUI-обёртки для sd-scripts
https://github.com/bmaltais/kohya_ss
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
➤ Обучение SDXL
https://2ch-ai.gitgud.site/wiki/tech/sdxl/
➤ Flux
https://2ch-ai.gitgud.site/wiki/nai/models/flux/
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам:
https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA
https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге:
https://github.com/KohakuBlueleaf/LyCORIS
Подробнее про алгоритмы в вики https://2ch-ai.gitgud.site/wiki/tech/lycoris/
✱ Dreambooth – для SD 1.5 обучение доступно начиная с 16 GB VRAM. Ни одна из потребительских карт не осилит тренировку будки для SDXL. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://rentry.co/lycoris-and-lora-from-dreambooth (англ.)
https://github.com/nitrosocke/dreambooth-training-guide (англ.) https://rentry.org/lora-is-not-a-finetune (англ.)
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet:
https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer:
YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
Подробнее в вики: https://2ch-ai.gitgud.site/wiki/tech/yolo/
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb
➤ Полезное
Расширение для фикса CLIP модели, изменения её точности в один клик и более продвинутых вещей, по типу замены клипа на кастомный: https://github.com/arenasys/stable-diffusion-webui-model-toolkit
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайд по ControlNet: https://stable-diffusion-art.com/controlnet (англ.)
Подборка мокрописек для датасетов от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
NLP тэггер для кэпшенов T5: https://github.com/2dameneko/ide-cap-chan (gui), https://huggingface.co/Minthy/ToriiGate-v0.3 (модель), https://huggingface.co/2dameneko/ToriiGate-v0.3-nf4/tree/main (квант для врамлетов)
Оптимайзеры: https://2ch-ai.gitgud.site/wiki/tech/optimizers/
Визуализация работы разных оптимайзеров: https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
https://rentry.org/2ch_nai_guide#апскейл
https://rentry.org/UpscaleByControl
Старая коллекция лор от анонов: https://rentry.org/2chAI_LoRA
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdgoldmine
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/badhands/makesomefuckingporn
https://rentry.org/ponyxl_loras_n_stuff - пони лоры
https://rentry.org/illustrious_loras_n_stuff - люстролоры
➤ Legacy ссылки на устаревшие технологии и гайды с дополнительной информацией
https://2ch-ai.gitgud.site/wiki/tech/legacy/
➤ Прошлые треды
https://2ch-ai.gitgud.site/wiki/tech/old_threads/
Шапка: https://2ch-ai.gitgud.site/wiki/tech/tech-shapka/