



Base of THREADE
Кушайте морковку, она полезна.
Кушайте морковку, она полезна.
благодаря геммочке купил клубничный гель для душа марселас
замечательно, всем рекомендую
замечательно, всем рекомендую
Очередная шизоидея - что ллмки надо тренировать с использованием контекст-шифта и всяких подобных аугментаций. Чтобы модель справлялась с тем что кусок контекста может не соответствовать позиции текущего rope, но при этом сам внутри связан. И он же мог ссылаться на уже несуществующий контекст.
Если модель будет устойчива к таким манипуляциям, это открывает дохуя опций для эффективной локальной генерации.
Но так-то не обязательно так учить модель с нуля, можно и отфайнтюнить. Это все так, наподумать тем кто вообще понимает о чем я.
Если модель будет устойчива к таким манипуляциям, это открывает дохуя опций для эффективной локальной генерации.
Но так-то не обязательно так учить модель с нуля, можно и отфайнтюнить. Это все так, наподумать тем кто вообще понимает о чем я.
Морковь убивает мужское либидо, — учёные из Пекина.
Как выяснили учёные, всё дело в каротинах — соединениях, содержащихся в моркови и других оранжевых фруктах и овощах. Мужчины, которые потребляли большое количество каротинов, на 60% чаще страдали от эректильной дисфункции.
А ловко ты это придумал, хочешь подставить анонов кумеров.
Получается спасает анонов от губительной привычки
В мое есть какие то подвижки в скорости?
Есть надежда что квен 4 выйдет с х2 скоростью и не надо будет тратиться на ддр5?
Вроде глм уже использует какие то технологии для ускорения которых нет в 235 квене
Есть надежда что квен 4 выйдет с х2 скоростью и не надо будет тратиться на ддр5?
Вроде глм уже использует какие то технологии для ускорения которых нет в 235 квене
Новая база треда : Ниже 12гб жизни нет. Это даже не база, а крепость ебаная.
мимо обладатель 12гб
мимо обладатель 12гб

> А ловко ты это придумал, хочешь подставить анонов кумеров
Черт, знал же что не стоило подряжать на это дело идиотов. В следующем треде будем хитрее.
Кроме тензоров? Нет, даже тензоры еще не все осмыслили и заюзали.
Вопрос по мое:
А можно распределить по двум-трём видяхам? А то он одного эксперта размазал на все по чуть-чуть, что в квене, что в глм. Наверное же можно разных на разные видяхи грузить, иначе в чём смысл?
А можно распределить по двум-трём видяхам? А то он одного эксперта размазал на все по чуть-чуть, что в квене, что в глм. Наверное же можно разных на разные видяхи грузить, иначе в чём смысл?
> проблема вовсе не в деньгих ибо требования к компьюту умеренные, а в качественном датасете
Так деньги в данном случае к компьюту отношения и не имеют. =)
Денег стоит качественный датасет, как раз.
У того же Денчика 3x4090, все прекрасно тренируется.
Но датасеты нужны на сотни тысяч часов (у фиша, вроде, английского 200к часов).
А русского у нас в открытом доступе — ~30к часов. Качественной модели из этого не получится.
А уж если делить это по эмоциям, чтобы генерилось с нужной эмоцией, то там и вовсе останутся копейки, которыми ты даже не затюнишь ничего.
Всякие шумные записи не подходят — генерируется шум.
Всякие электронные книги зачастую тоже никаких внятных эмоций не содержат.
Энтузиастов, записывающих свои голоса для датасетов мало, и у половины пердящие микро.
А все это для эмоций надо еще ведь и разметить!
Короче, ттс с эмоциями на русском выглядит как практически неподъемная хуйня на данный момент.
Но люди стараются, работают в этом направлении понемножку.
Что значить "разных", ллама делит по слоям сама либо с посказкой --tensor-split
Скрипт от пушистика в прошлом или позапрошлом треде, вроде, так и делает, но это не точно
>Энтузиастов, записывающих свои голоса для датасетов мало, и у половины пердящие микро.
Пиздить голоса из игр? Их там много, некоторые даже с эмоциями. Офк, нелицензионно и прочее некошерно, но вполне себе рабочий вариант.
Нашёл это в прошлых тредах, но хз как пользоваться https://files.catbox.moe/a6tf4p.py
> и кринжкарточки
Хз про кого конкретно ты, но кринжовые карточки что скидывались здесь местами не такие уж и кринжовые. Явное безумие и недоработанность вселенной переходят в простор для развития и свободу выбора.
Какие технологии ускорения? Все уже давно уперлось в память если железо не некрота.
Не можно а нужно.
> А то он одного эксперта размазал на все по чуть-чуть
Что это вообще значит?
Почитай что значат эти самые эксперты в моэ архитектуре.
> Денег стоит качественный датасет, как раз.
Что? Вообще не понимаю вот этого. Действительно купить что-то или организовать у обывателя даже если все продать денег не хватит. Но воспользоваться открытыми источниками, подгнав медиа под нужный формат - навыка должно хватить, это единственный разумный путь.
Как здесь помогут деньги если нужны именно навыки, знания, понимание что важно и реализация?
> Энтузиастов, записывающих свои голоса для датасетов мало, и у половины пердящие микро.
Это, пожалуй, самое последнее из пригодных материалов, с аудиокниг хотябы множество разных выражений и слов для "базового" наполнения выдернуть можно.
> 30к часов
> А уж если делить это по эмоциям, чтобы генерилось с нужной эмоцией
Это немножко не так работает.
> выглядит как практически неподъемная хуйня
Ну хуй знает, пораскинув и оценив, это вполне себе приличное занятие, выполнимое за несколько месяцев уделяя внимание вечерами. Офк это будет первое приближение после которого пойдут коррекции, уточнения, улучшения, но более чем достаточное с теми самыми сотнями тысяч часов. Количество контента очень велико, нужно лишь понимать как его приготовить.
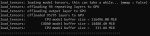

В прошлом треде анон просил отписаться по поводу Qwen3-235B-A22B-Instruct-2507
Q4_K_S 32768 FP16 контекста, 4090 24gb, DDR4 3200 128gb
Честно говоря, поверить не могу, что он запустился и работает на в целом приемлемой скорости. Приятный сюрприз! Без контекста генерация 4-5т/с, на 27к не ниже 4т/с. До 32к не добрался пока, чатов нет под рукой, но думаю, что не сильно просядет. При этом Air Q6 у меня работает со скоростью 5.5-6.5т/с, только он гораздо меньше.
Уместился едва-едва. На Винде у меня помимо него открыт браузер с ютубом и телеграм, свободно остается 5гб рама. При желании, думаю, можно было бы и Q4_K_M уместить.
На первом пике - потребление Лламыцпп
На втором - скорость генерации на нулевом контексте
На третьем - на 27к
Мне любопытно его протестировать. Похоже, нашел занятие на бессонную ночь. Благодарю тред, что надоумили, это в любом случае будет интересно. Жду анона, который хотел, чтобы я протестировал русский язык. Присылай промпт и карточку.
Q4_K_S 32768 FP16 контекста, 4090 24gb, DDR4 3200 128gb
Честно говоря, поверить не могу, что он запустился и работает на в целом приемлемой скорости. Приятный сюрприз! Без контекста генерация 4-5т/с, на 27к не ниже 4т/с. До 32к не добрался пока, чатов нет под рукой, но думаю, что не сильно просядет. При этом Air Q6 у меня работает со скоростью 5.5-6.5т/с, только он гораздо меньше.
Уместился едва-едва. На Винде у меня помимо него открыт браузер с ютубом и телеграм, свободно остается 5гб рама. При желании, думаю, можно было бы и Q4_K_M уместить.
На первом пике - потребление Лламыцпп
На втором - скорость генерации на нулевом контексте
На третьем - на 27к
Мне любопытно его протестировать. Похоже, нашел занятие на бессонную ночь. Благодарю тред, что надоумили, это в любом случае будет интересно. Жду анона, который хотел, чтобы я протестировал русский язык. Присылай промпт и карточку.
^ Вдруг кому актуально будет, билд b6139
> Нашёл это в прошлых тредах, но хз как пользоваться
Делирий, написанный лучшей кошкодевочкой-Qwen к вашим услугам! Для создания регулярного выражения с оптимальным распределением тензоров MOE модели вам потребуется:
- Python скрипт https://files.catbox.moe/a6tf4p.py
- Venv с установленным пакетом GGUF, подойдет от любого другого интерфейса
- Немного внимания!
Аргументы запуска:
1. /путь/до/модели.gguf
2. Видеопамять ваших карт в гигабайтах (или мегабайтах), через запятую для нескольких, например 24,24,12
3. Доля видеопамяти, которую вы хотите задействовать под веса модели, помимо них она потребуется также для кэша контекста и буферов. Аргумент опционален, можете просто сразу указать только видеопамять под веса модели.
Например:
> python script_name.py /path/to/model.gguf 32,32,24,24 0.75
На выходе будет параметр -ot с регулярным выражением, которое нужно скопировать в аргументы. Также, обязательно добавить аргумент --cpu-moe и -ts равный указанному объему видеопамяти в случае нескольких карт.
>Что это вообще значит?
Сейчас поковырялся, это --n-cpu-moe так сработало, когда пытался добиться большего юза. Но всё равно, такое ощущение что у глм влезет два на одну видяху в 24гб.
> --n-cpu-moe
Оно сломано, точнее не сломано а просто создает регэксп, который выкидывает тензоры экспертов первых N блоков на проц. То что в мультигпу они должны были быть на конкретной видеокарте, то что нужно как-то перераспределить остальные и т.д. - никак не учитывается.
Для запуска на мультигпу или сам составляй регэксп (например, выгрузка из каждого четного блока), или воспользуйся автоматизациями типа
Для большого шлёпа квена 235 доставьте пожалуйста мастер импорт, пожалуйста
У нюни выпрашивать надо вон он сверху запускает
Скоро напишет что глм в помойку, чекайте
Хм, возможно это хорошая идея…
> Как здесь помогут деньги если нужны именно навыки, знания, понимание что важно и реализация?
Дак если деньги не нужны — где модели? :)
То ли ты один гений, то ли знающих людей больше, но затык не в «навыках, знания, понимания что важно и реализации».
Выбирай. Если скажешь, что ты один гений — я спорить не буду, я в ттс не шарю. =)
> Это немножко не так работает.
Ну, судя по всем вообще — как-то так и работает.
> это вполне себе приличное занятие, выполнимое за несколько месяцев уделяя внимание вечерами
Спустя несколько лет работы множества энтузиастов и фирм — ни-ху-я, как говорил Тинькофф, одноименный банк который этим в том числе занимался.
Есть мнение, что «Это немножко не так работает.», как ты описал.
Я не пытаюсь оспорить тебя. Но я между реальностью, где сотни людей этим занимаются и у них не получается, и тобой, который потеоретизировал и вот на те модель, — выбираю поверить реальности. Опять же, без наезда, возможно ты реально можешь это сделать соло за пару месяцев, если бы был достаточно мотивирован.
ЗЫ Кстати, встречал фирмы, которые реально были готовы проспонсировать. Так что, ты можешь даже заработать, при желании.
МоЕ когда заработает быстрее Жоры? Пока что бесполезное говно с такой скоростью.
>Как здесь помогут деньги если нужны именно навыки, знания, понимание что важно и реализация?
А как помешают? Даже со знаниями и прочим деньги всё равно будут нужны. Железо нихуя не дешёвое, электричество станет заметным, я уж молчу про то, что вечерами нухуя нет сил, и это лучше сидеть на фул тайме, но для этого опять же нужны деньги.
Хм, во второй версии и в жоре оно радикально замедляло обработку контекста и добавляло/увеличивало замедление генерации с его ростом. Но вдруг что-то новое завезли и на быстрых шинах "быстрых" по сравнению с нвлинк, ага это как-то сыграет, надо попробовать.
Жлм эйр чтоли протестировать.
Лучше бы автора табби отпиздили чтобы функциональные вызовы починил, а то это пиздец.
Chatml и в пресете и инстракте, удалить форсинг имен, любое полотно по вкусу, из стандартных или вообще assistant expert в системный.
> Дак если деньги не нужны — где модели? :)
Вот к чему это вообще? А проблема везде одна - пересечение людей которые могут, которые хотят и которые еще не занимаются этим на работе под нда слишком мало. Аудио это вообще одна из самых отравленных копирастией и коммерсантами областей.
> что ты один гений
Плейбой, ценник, миллионер в голос, мизантроп. Не нужно быть экспертом в ттс чтобы задаваться вопросом почему еще никто не создал приемлемый датасет при широчайшем обилии контента и наличии средств для его анализа. Но потом смотришь на состояние этого всего и понимаешь что закономерно, увлекаются этим прежде всего совсем энтузиасты и за незнание чего-то их упрекать не то что глупо а аморально.
> Ну, судя по всем вообще — как-то так и работает.
Нет, не нужно размножать и пропорционально увеличивать датасет на каждый чих и добавляемую херню, как ты утверждаешь в
> А уж если делить это по эмоциям, чтобы генерилось с нужной эмоцией, то там и вовсе останутся копейки, которыми ты даже не затюнишь ничего.
Достаточно показать модели связь между выходом-выходом где указана будет эта штука, в частности те же эмоции, так и сразу стабильность тренировки повысится. А только уже потом возникнет вопрос о том, достаточно ли в исходном датасете примеров для гибкой работы каждой из желаемых эмоций, или будут проявляться негативные эффекты из-за дефицита и неравномерности.
> Спустя несколько лет работы множества энтузиастов и фирм — ни-ху-я
Я вот вижу что уже сколько времени назад прикрутили потоковый перевод видео в реальном времени, на ютубе автоматически созданные дублированные аудиодорожки с разными голосами, соответствующие оригиналу, с эмоциями и такой же сменой как в исходнике, с теми же словами и т.д. Куда не позвони - там голосовой бот, куча мелких контор, которые предлагают свои решения для модного синтеза голоса, гопота создала чмоню уже сколько лет назад, Илон выпустил вайфу-ассистента в ночнушке, которая дрыгает бубсами и томно шепчет тебе на ушко.
Прогресс не просто налицо, он очевиден. Просто опенсорс с аудио обделили по какой-то иронии.
Не исключено что потому что на фоне текстов, картинок, видео или практических применений это в низком приоритете и интересно малому числу энтузиастов. Также здесь нет перспектив набирать хайп и публиковать продукты в надежде на инвестиции, зато получить вагон исков за нарушение копирайта легче легкого.
> достаточно мотивирован
Ключевой момент, пожалуй. Например, мне даже русский особо не пристал, хочу чтобы просто сообщения в рп зачитывались харизматичным проникновенным сторитейлером, девочка някала, стонала и мило говорила в соответствии с атмосферой и комплекцией, или наоборот кричала, делала серьезный голос и т.д., аналогично с остальными участвующими чарами. Опционально бесшовный ненавязчивый саундтрек под атмосферу.
Это уже несколько другое таки, там именно про датасет.

Как пользоваться как там так и не понял, поэтому и спрашиваю.
У нейронки спросить не пробовал?
pip install gguf
>Это уже несколько другое таки, там именно про датасет.
Деньги решают любой вопрос.
1) не думал что локалка справиться.
2) Попутно таверна отвалилась, надо было рестартнуться.
Вот, IMHO, не стоит для МОЕ выгружать "каждый N" - это медленнее чем просто "N первых", или "N последних". Почему - хрен знает, но у меня разница процентов 5-10. Хоть на qwen3-30B-a3b хоть на glm4.5. На кобольде правда.
>Почему - хрен знает
Действительно, ведь про обмен активаций по узким шинам никто не знает, это тайное знание предков.
Это самый простой способ написания регэкспов, когда ты скидываешь на CPU экспертов с некоторой периодичностью. При одинаковых слоях на финальный результат это не должно влиять, так как общее количество обменов не меняется: что в одно случае у тебя будет обмен промежуточными активациями в условной половине блоков, что в другом, они просто будут стоять в другом порядке.
Другое дело если ты засунешь атеншн и нормы на одну гпу, а экспертов в другую - вот там обмен станет уже более интенсивным.
У тебя есть пример как получалась разница в 5-10% на разных выгрузках? Именно какие параметры использовались.
Итак, влажными ручонками добрался до первой модели. ERNIE 300B, Q5_K_XL
prompt eval time = 119045.38 ms / 10590 tokens ( 11.24 ms per token, 88.96 tokens per second)
eval time = 8872.17 ms / 51 tokens ( 173.96 ms per token, 5.75 tokens per second)
total time = 127917.55 ms / 10641 tokens
Конечно пп хехмда, малоюзабельно. Ну, я ссзб когда такой квант взял, 4-й должен пошустрее бегать.
В треде наверняка всем интересен русик, поэтому пробовал на нем. На первом пике мой безжопный пресет, переделанный из асиговского, на втором - обычный инстракт. В общем, что там, что там какие-то заЛупы жесткие с места в карьер идут. Семплеры стандартые ( т 1, мин п 0.05 топ п 0.95 множитель драй 0.8).
prompt eval time = 119045.38 ms / 10590 tokens ( 11.24 ms per token, 88.96 tokens per second)
eval time = 8872.17 ms / 51 tokens ( 173.96 ms per token, 5.75 tokens per second)
total time = 127917.55 ms / 10641 tokens
Конечно пп хехмда, малоюзабельно. Ну, я ссзб когда такой квант взял, 4-й должен пошустрее бегать.
В треде наверняка всем интересен русик, поэтому пробовал на нем. На первом пике мой безжопный пресет, переделанный из асиговского, на втором - обычный инстракт. В общем, что там, что там какие-то заЛупы жесткие с места в карьер идут. Семплеры стандартые ( т 1, мин п 0.05 топ п 0.95 множитель драй 0.8).
> треде наверняка всем интересен русик
Большинству из тех, кому он интересен такое не запустить, лол.
Лучше расскажи как она в рп с указанием что игралось, как она в куме, как отвечает на всякие общие вопросы, какой-нибудь пример по коду, примечательна ли чем-нибудь и т.д. Ну и как работает без специфичных промптов.
> такое не запустить, лол.
В 256 же влезает судя по размеру файлов. Если цель запустить не в врам, то на сетап можно накопить с обедов но не нужно

MI50 32g до 10к подешевели (без учёта доставки, тут каждый как может)
В качестве игрушки на пару вечеров не жалко потратиться на 2-3 шт
В качестве игрушки на пару вечеров не жалко потратиться на 2-3 шт
Ну типа основным приоритетом (именно вещью, определяющей саму возможность а не прихотью) русский ставят в основном бедолаги, которым такие цифры едва ли доступны.
> но не нужно
Ты чего, вон как подорвались моэ пускать, наконец квен кроме 3.5 человек кто-то еще попробовал.
Что-то всё равно хрень
prompt eval time = 329.03 ms / 1 tokens ( 329.03 ms per token, 3.04 tokens per second)
eval time = 1585536.43 ms / 4096 tokens ( 387.09 ms per token, 2.58 tokens per second)
total time = 1585865.46 ms / 4097 tokens
глм q3k_s 4090 и ддр5
Очень интересно.
Можешь срезать контекст до 20к и запустить 3xl?
Я думал там уже семерка будет
> Разработчики выпустили Jan-v1 — локальную нейросеть для веб-поиска. Модель конкурирует с Perplexity Pro и опережает её в бенчмарке SimpleQA.
> Jan-v1 построена на базе языковой модели Lucy, а для рассуждения использует Qwen3-4B-Thinking. Модель встроена в фирменное приложение-чат Jan App, но её можно запускать и отдельно от приложения.
https://habr.com/ru/news/937534/
Всей этой теме не хватает живого аватара в углу экрана.
Я бы даже вторую карту ради такого прикупил, но почему то это никто не развивает
Я бы даже вторую карту ради такого прикупил, но почему то это никто не развивает
>100500 пресетов на Гемму и кринжкарточки (извини мужик)
хахаха, ноу проблем бро, я не настолько обидчивый
Одним глазком глянул в корпотред. Мне кажется или дела там стали сильно хуже по выбору моделей? Жмут их, Геминя разве что осталась. А у нас наоборот выбор только растет
Аноны, дайте пресет на AIR, плез, старая ссылка не работает.
>Мне кажется или дела там стали сильно хуже по выбору моделей?
да там едва ли не с зимы сплошной дум

Ну жора ну артист блять...
С 7.4 до 9.2 простым откатом до b6139
С 7.4 до 9.2 простым откатом до b6139
А, отбой, я глм вместо квена запустил.
Граци, анончик!
> Я вот вижу что уже сколько времени назад прикрутили потоковый перевод видео в реальном времени, на ютубе автоматически созданные дублированные аудиодорожки с разными голосами, соответствующие оригиналу, с эмоциями и такой же сменой как в исходнике, с теми же словами и т.д.
Ну, единственное, что мы тут обсуждаем — это эмоции.
И, будем честны, в яндексе это сделано очень не очень.
Плюс, не забывай, костыльно-то эмоции ты и сейчас можешь сделать — взять референс с нужной эмоцией и вуа ля. Есть ли какие-то пруфы, что яндекс не делает именно так — берет фразу, и подставляет ее в генерацию?
> гопота создала чмоню уже сколько лет назад
Но есть нюанс, это опенаи.
Еще Элевенлабс есть и так далее, да.
К опенсорсу нас это не приближает, к сожалению.
Есть англо- и китаеговорящие ттс с эмоциями (тот же CosyVoice и другие), но русских так и нема.
> Просто опенсорс с аудио обделили по какой-то иронии.
Ну вот мне кажется, что дело не в иронии, дело в качественном датасете, которого в России просто нет в общем доступе или у энтузиастов.
> Например, мне даже русский особо не пристал, хочу чтобы просто сообщения в рп зачитывались харизматичным
Ну если тебя устроит английский — то энджой, модельки есть, просто я названия не вспомню, не интересовался никогда. От того же Кози до более новых даже. =) Не знаю, насколько нежно она будет някать, но точно будет стараться.
Саундтрек легко пишется ACE-Step, кстати, если с голосами у них косяки (3,5б модель-то!), то вот с музыкой у них хорошечно довольно-таки. Думаю, встроить в пайплайн несложно.
> Это уже несколько другое таки, там именно про датасет.
Ну и в общем, я поддержу другого анона, деньги — это в т.ч. качественный датасет, записанный, выслушанный, собранный несколькими людьми параллельно, и это мотивация для, например, тебя. Так что, мотиватор и двигатель это явно неплохой. =)
дадада
Та шо ты будешь делать… Нужно ли?.. Но так дешево…
Нет, наоборот, на русском бояре рпшат, которые могут себе позволить, а бомжи с 8 гигами врама, только на лламе на английском с цензурой и могут.
Сочувствуем искренне всем тредом.
Бери WAN2.1 + FantasyTalking и будет тебе еще и говорящий, и жестикулирующий, и сиськопоказывающий аватар.
Ну бывает. =D
> Нужно ли?
Если шаришь за линь то в отдельную машину хорошо заходит
Так, аноны, треба ваше мнение.
Задача: собрать сервер под Qwen3-235b.
Варианты:
1. mi50 x4
2. EPYC 7532 + RAM
Требуются владельцы подобных конфигов: почему нет? =D
Расскажите, какие у вас скорости (ладно, ми50 4 штуки в треде нет у одного человека), как с шумом, охладом, много ли колхозили.
Буду благодарен за отзывы.
Скорость хочется от 10 ток/сек получить.
Задача: собрать сервер под Qwen3-235b.
Варианты:
1. mi50 x4
2. EPYC 7532 + RAM
Требуются владельцы подобных конфигов: почему нет? =D
Расскажите, какие у вас скорости (ладно, ми50 4 штуки в треде нет у одного человека), как с шумом, охладом, много ли колхозили.
Буду благодарен за отзывы.
Скорость хочется от 10 ток/сек получить.
>=D
Нюня, ты?
Что, так сильно понравилось?
Да, репу в гите от тредовичка помню, будем накатывать, ежели что.
Ноу проблем по этому вопросу. Михе3607 спасибо, конечно!
Прости, я не в курсе вашего лора, даже не понял, о чем ты. =) Я скипал ваш веселый срач.
mi50 x4 не потянет qwen3-235b в 4 кванте со скоростью 10 ток/c
Мои 3090x6 + 128GB ddr4 тянут только ~9к токенов и то под конец уже очень медленно. И обработка контекста долгая перед инференсом
Я ориентировался на это: https://www.reddit.com/r/LocalLLaMA/comments/1lspzn3/128gb_vram_for_600_qwen3_moe_235ba22b_reaching_20/
Конечно, q4_1 имеет буст за счет тупости, но думал, хотя бы 15-то получу.
Но тут:
https://www.reddit.com/r/LocalLLaMA/comments/1m6eggp/considering_5xmi50_for_qwen_3_235b/
Пишут тоже, что 10 и 5 в итоге.
Звучит так, будто доставки из Китая и колхозинга это не очень стоит.
Подожду отзывы от эпикодержателей.
Конечно, всегда есть варик просто пихнуть 128 DDR5 на интуле в разгоне и видяху подрубить. =D
Но я думал, что ми50 и эпики должны быть побыстрее, хм…
> ми50 4 штуки
Тебе реально 4 нужно?
У 3х есть плюсы:
- хватит одной серверной 120
- сборку потянет 1 киловаттник
Так, опять железячники набежали за Сарой Коннор по треду бегать.
Какой вообще положняк по современным энвидия ? Что можно считать доступным топом ? (Да, я знаю про хопперы, но они стоят слишком много.)
Какой вообще положняк по современным энвидия ? Что можно считать доступным топом ? (Да, я знаю про хопперы, но они стоят слишком много.)
Доступный топ - эпики. За 500к конфиг для дипсика собирается, в обычном корпусе с 1 БП. Притом на nvidia такой конфиг требует ферму и стоит в 2 или больше раз дороже.
Возможно и три, но там впритык получится, да? :)
Сложно-то как. Я хочу заплатить сегодня и собрать ПК в среду, а не вот это вот.
Знакомый попросил, есть место куда приткнуть лишний комп. Вот и думаю теперь, насколько я готов париться со всей этой фигней, и где выжать побольше тпсов и подешевле.
А то стандартные 5-7 у меня и так на двух компах есть, но это некомфортно.
в треде как минимум один нюнезависимый шизосталкер
дожили
Рефьюзит...
Он цундерка и не может напрямую написать "анон99, любимый, расскажи что думаешь про квенчик 235". Просьба отнестись с пониманием!
Вообще квену уже сколько месяцев, почему до сих пор не придумали сборочку дёшего сердито запускающую 4 квант в 9 т.с?
Так придумай. Чё ты не придумал?
Думаю думаю... надо ддр5!
Дальше ты
Таааак... сосредоточился. Мозг включил на 100 процентов!
Надо чтоб дёшево а не дорого. Продолжай
потому что из говна не сделать конфетку, Пахом
MoE конечно немного помогло нищукам, но проблема пропускной способности памяти все еще осталась и должна решаться на уровне железа. а именно это проблему в рамках LLM никто и не решал особо. на это проблему немного смотрели для видимокарт и сервером, но это не тот юзкейс, потом и дорохо
мб медузу высрут в 2026, если есть деньки - можешь притвориться мажором и попробовать стрикс хало настоящие мажоры просто купят h100, а настоящие настоящие мажоры просто снимут тяночку и не будут заниматься кумом вообще
Вася, 8 "В"
Приглашенный эксперт по LLM
Считает, что кум - единственное их применение
Катает 12б, но превосходно владеет теорией
сам придумал образ оппонента и героически обосрал этот образ. малацца, возьми пряник с полки
Здесь все так делают. Мне тоже можно
Дешевая ДДР 5 ?
Ну вот мы и думаем. =)
Вообще, чекаю, 13400 выглядит неплохим вариантом, но оператива на 6400 в четырех слотах… 4 КВАНТ ЖЕ?! ЗНАЧИТ 192 НАДА
Короче, непонянто, че будет по псп.
В 2 слотах точно 90-100.
А в 4 уже хуй знает.
Хотя, если на 50 псп я получал 7 на старте с 4070ти, то с 70 псп даже по идее 9 на старте выжать можно. =D
Ипать-капать, теоретик я хуев. Хотя за чужие деньги можно и поэкспериментировать. =D
>но оператива на 6400 в четырех слотах
Такого не существует. Только в 2 слотах
До сих пор жду пока анон с 4090 и 1700lg закажет две плашки ддр5 по 48 и потестит для всего треда 4 квант квенчика онлайн покупку же 100% легко вернуть
Ой, третий квант.
А можно задать тупой вопрос ?
Какой предел памяти на консумерском железе ? Или это зависит сугубо от процессора и материнской платы ?
Какой предел памяти на консумерском железе ? Или это зависит сугубо от процессора и материнской платы ?
Нельзя.
Ну и не очень то и хотелось.
> единственное, что мы тут обсуждаем — это эмоции
Нет, это ты на них постоянно скатываешься и растекаешься по древу. Какие-то пустые фразы лишь бы написать, абстрактные рассуждения вокруг не стоящих мелочей, и дедовские притчи, уводящие все дальше от темы. Зачем?
Потому тебя здесь так любят.
> эмоции ты и сейчас можешь сделать — взять референс с нужной эмоцией и вуа ля
Значит реализовать их замену на промпт будет достаточно.
> на русском бояре рпшат, которые могут себе позволить, а бомжи с 8 гигами врама, только на лламе на английском с цензурой и могут
Бояре рпшат как им удобно, чаще как раз на инглише, а холопы засирают вопросами про перевод, русскую модель и страдают на 12б миксах сойги или через яндекс.
> 1. mi50 x4
Не ешь, подумой! Они дают скорость на уровне проца с видеокартой даже в малом количестве, а собирать 4 штуки - станешь утилизатором.
> 2. EPYC 7532 + RAM
Должно сработать при наличии видеокарты. Хотя довольно странно что на фоне активного вката в моэ даже на десктопных платформах никто из владельцев не отписался по перфомансу. Раньше скидывали в целом нормальные скорости.
> Мои 3090x6
Жору на помойку и пускай с экслламой, будет быстрая и генерация и обработка без всего этого цирка.
> Что можно считать доступным топом ?
5090 или китайские 4090@48
Зависит от максимального объема плашек и количества слотов. Учитывая что самые жирные модули - 64гб, быстро работать будут 2, сердне 4 то можно получить относительно шустрые 128гигов или помедленнее 256 гигов.
И да, дешевая йоба под все подобное - штеуд 12400/12700, стоит копейки и может в 6-7к частоты доступной рам. Он и для всякого игоря в нищесборку вполне подойдет.
>Жору на помойку и пускай с экслламой, будет быстрая и генерация и обработка без всего этого цирка.
Не будет. Я пробовал, на exllama ровно точно такая же производительность
У тебя всё в параметрах железа указано. Ограничение есть и у материнки и у проца. И не забывай что супер важно количество каналов памяти, а не количество слотов. Грубо говоря, 3200 в 2-канальном режиме это то же самое что 6400 в одноканальном.
Эпики потому и юзают что там можно 24 канала памяти накрутить на 2-процессорной схеме.
Тэкс, тут был анон с 13700, который погорел. Я вот счастливый обладатель такого же процессора. И у меня немного бсод в голове вылетает. Написано в техе к процессору, что частота ддр-5 5600. Получается, если память будет работать на 6к, то частота будет падать до 5600 ?
Хммм. А может действительно купить две здоооровенные плашки и не выебываться.
Ты что там пишешь такое что он у тебя рефьюзит? У меня на ни единого рефьюза не было
Тупой ответ: 150.
В среднем DDR5 гнали до 150 максимум.
Вероятнее 120 получить.
Размер 96 точно, в теории 256, но там ты точно не получишь такой псп.
> Нет, это ты на них постоянно скатываешься и растекаешься по древу.
Ну не надо, э! Вся речь тока об этом.
Все остальное у нас уже есть, фиша хватает для хорошего воис-клонинга, разве что ударения иногда путает, но как раз это можно исправить файнтьюнами легко.
Единственное, чего нет в ру-опенсорс-ттс — это эмоции БЕЗ костыля в виде референса.
Все остальное обсуждать бессмысленно, ибо с ним все более-менее (ну, на мой вкус).
При этом, помятуя, что было 2 года назад, прогресс в ттс действительно неплохой. Когда-то у нас был только силеро. =)
> Значит реализовать их замену на промпт будет достаточно.
Ну, да. Сделать несколько папок референса и заставить ллм подключать нужный.
Просто мне чисто эстетически этот вариант не нравится, не более.
Ну и качество там может быть чуть хуже.
> Не ешь, подумой!
Ну тут я уже отмел эту мысль. Все же, старое говно, это факт.
> Хотя довольно странно что на фоне активного вката в моэ даже на десктопных платформах никто из владельцев не отписался по перфомансу.
Да, вроде раньше кто-то что-то кидал… Я надеялся услышать от них уточнения сейчас.
———
Ладно, короче, заказчик решил, что лучше брать с ДНСа (ну или хотя бы озона какого-нибудь) с чеками (любит он это дело), так что 12400/13400 и память.
Кстати, может кто скинуть ссылку на оперативу 64-гиговую?
Вот на днях и посмотрим, что там на самом деле на ддр5 творится.
Тоесть на не было рефьюзов, промахнулся с постом
Если есть top_k, почему нет bottom_k? Лупы на мистрале на длинном контексте заёбывают периодически, хотелось бы иметь возможность вручную выбрасывать топовые токены в такие моменты.
>bottom_k
Написал и понял, что звучит как хуйня, т.к. возможных токенов много. Суть в том, что семплер для отсечения самых вероятных токенов звучит как очевидная идея (жутко костыльная, но тем не менее), но почему-то до сих пор такого нету (либо я не знаю где искать).
А, за ними же хвост таких же лупных токенов будет по итогу, и ситуация никак не поменяется... Только сформулировал вопрос и тут же понял. Ладно, вопрос снят.
Более того - как правило самые вероятные токены - это самый лучший ответ. Отрезая их - ты будешь лоботомировать модель по живому.
Где вы нашли ддр5 по 64г?
Я вижу только по 48.
Ну и тайминги там наверное уже совсем нищие
Буквально написать "rape" и рефьюзит.
Ты сейчас пытаешься изобрести Exclude Top Choices (XTC)?
А ты напиши это слово на русском языке.
О, благодарю!
Он не спасает к сожалению. Там надо, чтобы 2+ токена превышали заданный порог, насколько я понял.
А чем эта: https://www.dns-shop.ru/product/9ed2387b62bfd9cb/operativnaa-pamat-gskill-trident-z5-neo-rgb-f5-6000j3444f64gx2-tz5nr-128-gb/ хуже? На 9к дешевле. =) Но наебаться тоже не хочется. Я и разгон оперативы — как скалолазание. Фильмы смотрел, не более.
Да я ебу ? Человек не умеет в поиск, я нашел.
Производитель, частоты, лгбт подсветка - все влияет на цену.
Почему то мне кажется она с такими таймингами будет медленее ддр4 работать...
В отзывах там чел тайминги подужал и получил 90 псп.
Ну, типа. Вроде неплохо.
Видимо, ее и затестим.
Там на 10к дешевле есть такая же
У меня на 6000, 64 гб ДДР 5 в сочетании с 4080 дают в 3 анслотовском кванте на Эйр 12т/с и ебовый промтпроцессинг.
Да, я ее и затещу. =) Которая 34 по таймингам.
В крайнем случае, можно будет поменять.
Заодно начну с 13400, если не пойдет, то поменяю на 12400.
В линухе есть taskset, никогда не юзал, но, судя по всему, можно кидать llama.cpp на P-ядра и не париться. А E-ядра пусть будут, че уж.
Ну, это если верить интернету, что 13400 чуть лучше с памятью работает, чем 12400, а цена 1к разницы.
Ну, кстати, у меня на 7 токенов на DDR4, так что по псп получается прирост вполне совпадает с расчетным. Хороший знак, спасибо!
Там ни одного отзыва на эту модель.
>будет медленее ддр4 работать
Если не ставить на амд - то не будет. На интелах даже 4 плашки не замедляются.
Какой интел не возьми там везде нужна водянка за 10к

чому в отзывах пользователей у одного анона 51гб/с, а у другого 90?
Ну, 12400/13400 не такие уж и горячие, 120 ватт, ну 150, хорошая воздушка сдует, терпимо должно быть.
Опять же, чтение контекста на видяху скидывать надо, а самое горячее именно оно.
Потому что у второго Ryzen 7500F, которые вообще не умеют работать с памятью?
Или 9ххх поколение райзенов, или интел.
Ну, либо чел не настроил.
Почему не 14600kf?
Сразу с видеоядром, чтобы всю врам освободить
С видеоядром надо брать без F.
Не 14, потому что я не люблю 14 поколение. Нет аргументов, я так чувствую.
Для винды это важно, но тут я изначально на линуксе буду собирать, там не то чтобы это имело значение при подключении по SSH.
Однако, у меня есть комп на 11400, когда на нем была винда, это было удобно, люто плюсую брать процы с видеоядром.
Ты за счет гига оперативы крутишь рабочие столы и браузеры на проце, а на видяхе этот гиг освобождается. Крутотенечка.
> на видяхе этот гиг освобождается
Не только.
Если два моника с герцовкой 120+ это ощутимая нагрузка на видяху, у меня в картинкогенерациях например 3.6т если моники на видяхе и 4.2 если на проце
И температура ниже из за этого же
Да поставьте вы водянку блять. 10к, и у тебя всегда будет стабильная температура.
Ну ты понимаешь к чему это ведет.
Да купи ты уже то, потом это, и вот это было бы не плохо, и вот уже вместо 80к тратишь 150 и кушаешь залупу следующие пару месяцев

>В отзывах там чел тайминги подужал и получил 90 псп.
ДНС стал как паршивый маркетплейс, так что ты пожрал говна в отзывах, это другой товар. Отзывов на 64ГБ комплекты на ДНС нет вообще.
Блджад, анон. Ну не покупай корпус тогда, пусть всё валяется на столе. Водянка с современными процессорами, это не блажь, а необходимость. У тебя процессор будет работать стабильно и долго.
Нельзя экономить на питании и охлаждении. Это всегда выходит боком.


Аноны, как починить это? Почему слова вместе моделька пишет?
мистраль 24б 4кхл
мистраль 24б 4кхл
Блядь, а на той странице, где я читал этот отзыв, этой строчки нет, сука.
Недовывели.
Хм-хм-хм, ну что же.
Значит время заказать, протестировать, написать «говно» и вернуть.
Ну или нет. =)
У меня такое бывает, когда антилуповые сэмплеры запрещают какие-то токены. Наверное модель так изъёбывается, чтобы эти слова всё равно пропихнуть в аутпут.
и как починить?
У меня кста стоит антилуп пресет, мне кто то скинул.
мб дело в нем? Но я ебал отключать, луп же начнется тогда
> на exllama ровно точно такая же производительность
Значит что-то не так с видеокартами, коннекте с ними, или какая-нибудь база типа уплывания врам в рам. Сам катаю квена на ней, с жорой фуллгпу разница очень ощутимая и прежде всего в той самой просадке на контексте. На пустом жора даже чуточку быстрее, но на контексте разница не в пользу.
> который погорел
У него похоже брак с окислением попался, попавшие под него процы до сегодняшнего дня врядли дожили.
> что частота ддр-5 5600
Это базовая гарантированная что заведется, остальное типа разгон и он зависит от платы, от плашек а на совсем высоких частотах уже силиконовая лотерея, последнее тебя не коснется.
Если в плашках будет xmp6000 то они будут работать на 6000, сейчас даже на амд такое почти всегда справедливо.
> Ну, да. Сделать несколько папок референса и заставить ллм подключать нужный.
Нет, заебет через неделю и много потерь компьюта. Нужно собрать эмоциональный датасет, потом препарировать эту ф5, или фиш, или какую-то еще что брать основной, и сделать дистилляцию инициализированного трансформерса на основе фичерз экстрактора из референсного аудио. За основу можно взять что-то готовое, нарастив поверх несколько слоев. Потом собрать многоножку воедино, при необходимости полирнуть короткой тренировкой уже в таком виде.
Они не просто не горячие, они ледяные, тепло начинается на К версиях. У амудэшизов совсем крышу снесло из-за тротлинга на 90ваттах от подзалупного творожка на узких чиплетах.
14600 действительно будет лучше, 12400 совсем младший по сегодняшним меркам.
это все zen4 не умеют или только подмножество?
>Водянка с современными процессорами, это не блажь, а необходимость.
На амуде водянка не нужна (да и всё равно не поможет).
В автозаменах ничего нет? Вижу там форматирование звёздочками *, ты мог накрутить что-то на это (так как цвета уже накручены) и забыть.
> 14600 действительно будет лучше, 12400 совсем младший по сегодняшним меркам.
Хорошо, рассмотрю, спасибо.
Пара дней на выбор еще есть.
Вот хуй знает, но как я слышал — все 7xxx и 8xxx, и младшие 9xxx тоже не показывают чего-то хорошего.
> автозаменах
Это где? я честно не особо разбираюсь)
> На амуде водянка не нужна
Я конечно не использовал амд, но сомневаюсь что они работают на новых физических принципах.


Горячо и медленно, но за миска рис (50к+- вк+память+мать+цпу)

Не нужна, обычной башни достаточно. У меня вот такая стоит, проц не греется.
https://www.amazon.de/ARCTIC-Freezer-RGB-Single-Tower-CPU-K%C3%BChler-druckoptimierter/dp/B09JM64XTQ?th=1
Сколько тдп? Себе пришлось лок на 175 ватт ставить что бы до 95 градусов не доходил в occt
мимо
Фронт какой?
Нет, они просто жрут ватт 70 вместо 250-ти.
> жрут ватт 70 вместо 250-ти
Пиздабол.
По 30-50вт в простое или с минимально запущенным софтом типа браузера, дискока и прочего на фоне 5-15вт штеуда. Для разгона и получения заветных цифр производительности которыми козыряют необходим чиллер, потому что даже под самой йобой 180-200вт - предел по тротлингу из-за плохой теплопередачи от кристалла до крышки, тогда как на штеуде хватает пролетарских охлад для тех самых 250вт.
Типичная спекуляция сектантов в специальной олимпиаде: перфоманс мы возьмем от одного кейса, тдп наоборот от самого кастрированного проца, у конкурента сделаем же наоборот.
Амд действительно могут показать отличную энергоэффективность на средних режимах в определенных типах расчетов. Но когда дело заходит за топы - там все даже жарче, когда сравнивают процы средне-младшей категории - и там и там все холодное, а проблема повышенного жора в простое известна очень давно, но фиксить ее даже не пытаются.
Нет нормальных профессоров сейчас, все - теорема эскобара, которую только усиливают фанбои.
лама
>Но когда дело заходит за топы
А зачем топы в сфере ИИ? Тут нормальных 8 ядер с головой.
>Нет нормальных профессоров сейчас
Раньше типа были. Странно конечно, что на них сейчас не сидят.
лама что?
ой сука погоди какой фронт.
блять ну таверна + лама я хззз
>антилуп пресет
этот шизопресет тебе и срёт, буратино, ты сам себе враг
А с лупами бороться надо не ленясь писать самостоятельно + темпа + XTC
кста а что делает температура?
как она устроена?
Google.com
Шапка
Чатжпт
Не помогло.

Хуево тебе, чё.
>заказчик решил
То есть ты за бабки кому-то собираешь суперкластер под инференс, а тут консультируешься у анона по железу?
>А с лупами бороться надо
уходя с дристраля на любую другую модель.
>не ленясь писать самостоятельно
Можно вприницпе и ролеплей полностью в голове отыгрывать.
А я давно игнорирую посты этой смайлофажащей аватарки и всем советую.
Сперва нравился глм эир, а щас я его ненавижу блять.
Почему он считает что может тратить моё время вот так?
70% текста это вода и слоп
Почему он считает что может тратить моё время вот так?
70% текста это вода и слоп
Как потопал, так и полопал.
Хочешь хорошую историю, не ленись писать сам... ну хотя бы четверть от того что пишет нейронка. Проверено на коммерческом проекте.
Промпт пробовал поменять и дать указания писать иначе?
> А зачем топы в сфере ИИ?
Если занудствовать то некоторые операции в даталоадерах могут быть довольно затратными по расчетам и там на условном 12400 можно упереться. Как в инфиренсе ллм будет - хз.
> суперкластер под инференс
> ми50
> некроэпик
Ну ты понял, скорее он так спрашивает "это для друга не подумайте что себе".
База.
Важно качество а не количество. Лупы идут когда ллм не понимает куда развивать и выбирает признак повторения ранее написанного как верный вариант, и когда ты конкретно допустил засирание всего чата не стукая ее когда уже надоела.
Всё настроил для GLM Air, 30-40 (в зависимости от контекста) генерация, под 800 промпт процессинг. Префиллом решил её проблемы с ризонингом (ну и имена убрал, да). Всё комфортно, одна беда - глуповата малость, новый маленький Мистраль пожалуй что и поумнее будет. Правда я на русском гонял, там ещё и косяки с языком вылезали (на 4-м кванте, на 5-м меньше). Большой Квен я тоже гонял и начинает у меня складываться мнение, что у МоЕ-шек нет глубины, что ли. По сравнению с (большими) плотными моделями они такого эффекта не дают.
Возможно это мой пресет - человек 100 его скачало с mediafire пока он там лежал. :)
Нет, если это он - дело не в нем. Я на такое тоже нарывался - это перекрученные семплеры. XTC и прочие, пенализирующие токены за повторения. (Суть явления - токен пробела начинает банится).
Лечить - убирать пенализирующие семплеры. Радикально - в таверне есть кнопка сброса всех семплеров на дефолт. Можно начать с нее, потом просто выставить температуру на 0.6-0.9 и min_p на 0.025, а остальное вообще не трогать. Мистраль 24B 3.2 на этом нормально заводится с моим пресетом. А потом уже можно подкручивать по вкусу.
Нет, я все таки не понимаю.
Я не альфа и омега мистралефагатории, но люблю и котирую французских горничных.
От 3.2 у меня вообще разрыв жопы случился.
Но утверждать, что Эйр тупее мистрали ? Ну то есть, блять, я проиграл все свои старые чаты на нем заново.
Да путает слова, да часто лучше сразу делать 2-3 свайпа, лол. Но я это списываю на то, что использую 3 квант, потому что видно как моделька пропускает в Английском языке частицы not, be, времена криво ставит.
Но в остальном, если убрать его словоблудие, свайпы жирненькие получаются, сочные. Куда интереснее всего что выдавала мистраль. А я знаю о чем говорю, я принципиально год почти мистралями пользовался (ну и геммой, что врать то)
Гемма или глм?
А может немотрон?
Я, блять обожаю этот тред.
>немотрон
Точно, что это я использую 3квант глм, пойду сразу дипсик в полных весах запускать. Ты прав анон.
>Почему он считает что может тратить моё время вот так?
>70% текста это вода и слоп
а какой ответ ты ожидаешь без воды то (да и нахуй ответ без воды)?
>трахни меня!
>ух-ох-ах!
>хуй, пизда, сперма, ебля, соитие
> Можешь срезать контекст до 20к и запустить 3xl?
Да, чуть позже сделаю и отпишусь. Но не думаю, что удастся выжать стабильные 7 токенов.
> Всё настроил для GLM Air, 30-40 (в зависимости от контекста) генерация, под 800 промпт процессинг.
На каком железе? Какая-то часть меня хочет верить, что на 4090 и DDR4 3200 можно выжать больше 5.5-6.5т/с на 32к контекста, но у меня Q6_K от bartowski.
> Мистраль пожалуй что и поумнее будет. Правда я на русском гонял
Стоит проверить и на английском тоже. Умнее? Вряд ли. Сопоставимы? Вероятно.
> Большой Квен я тоже гонял и начинает у меня складываться мнение, что у МоЕ-шек нет глубины, что ли.
Прямо сейчас тестирую 235b Q4_K_S Квен на английском и он точно не глупее QwQ, Квенов 2-3 и других 32б плотных моделей. Они всегда были умными, но в моем случае для РП не годились. 235b приятно удивляет: мозги на месте, но при этом пишет свежо и выразительно, не уходя в шизу как это делают 32b плотные Квены.
> Но утверждать, что Эйр тупее мистрали ?
Он сопоставим с новым MS3.2 24b по мозгам и с большинством старых 32b моделей. Плюс-минус. Тоже затрудняюсь ответить, что умнее, хотя гоняю Air в Q6. Такие дела ¯\_(ツ)_/¯
Его сильная сторона не в мозгах, а в количестве данных в датасете. Все же GLM 32b умнее Air'а будет в РП, хотя и ненамного.
Не у всех есть учётная запись в гугле.
Фикшу очепятку/ввод в заблуждение.
> Они всегда были умными, но в моем случае для РП не годились.
Это я имел ввиду именно QwQ и Квены. Остальные 32b модели для РП хороши, люблю и жалую их.
>у меня складываться мнение, что у МоЕ-шек нет глубины
Ебать ты Сокол Орлиный Глаз.
Жаль конечно, что его нельзя зарегистрировать. Сраный Гугл с его инвайтами на джмэйл.
Да какой суперкластер. =)
Суперкластер я бы собирал нормально — эпики или зеоны, RTX PRO 6000 / H100.
А это просто хочется локально агентов пускать под чаек человеку.
Собственно, я денег не беру.
Заодно можно будет посмотреть, на что эта фигня способна, как я ранее P104-100 собирал. И не советовал.
Так и это собираю за чужие деньги, чтобы потом не советовать. =D
Канеш, ты ж даже понять не можешь, что я пишу, нафига лишний раз напрягаться.
Я так же скипаю вахтеров, срачи про ИИ, базашизов и антибазашизов с их «q1 и не видно разницы!..» — «нет, только q6 минимум!..», не понимаю такой хуйни, и не напрягаюсь ее чтением. =)
О, опять сам с собой разговариаешь?
Как не крути, но ограничение в активных параметрах сказывается.
Широкие в знаниях, но не глубокие в их применении.
Немного есть.
Все мои попытки в РП с квенами упирались в то, что они придумывали какой-то совершенно гримдарковый фэнтези мир, где все почти умирают.
И 235 просто стал хитрее и изощреннее в том, как бы всех грохнуть внезапным разрывом в материи. =D
>А это просто хочется локально агентов пускать под чаек человеку.
Значится так, никого не слушаешь, записывай:
Материнка: HUANANZHI H12D-8D (есть на али, есть на озоне, есть на авито)
ЦПУ : AMD EPYC 7K62
Охлад: DEEPCOOL LT520 под сокет TR4
Память: для начала берешь 4x 32 = 128 ГБ, потом докупишь
ГПУ: 2х Intel Arc A770 по 16 Гб, потом еще 2 воткнешь если нужно будет.
Не благодари
>Intel
пердоликс ебнутый штоле, или это рубрика "вредные советы"
> это рубрика "вредные советы"
Очевидно же. Ты ещё сюда смотри:
> 4x 32 = 128 ГБ
для 8-канала-то.
>ебнутый штоле
Манюнь, сходи куда-нибудь дальше тиктока, почитай про то, как Arc заебца с ИИ работает, а стоит в 2 раза дешевле чем нвидиа.
>для 8-канала-то.
Ах, ну да. нужно же сразу по максимуму слоты забивать, я забыл про нытика-плашечника ИТТ. Сорян, что триггернул, без негатива ок
Что плохого в 4х32? Ботлнек где-то?
Зачем тогда вообще эпик брать? Мы вообще в ии-треде, где за каждый кило-кек рубка или? Консумерский интол 14к и погнали
Хм. Нихуя себе.
Вот это базированный ответ!
Главное, чтобы работало. =) Энивей, пасиба!
Ща посмотрю, че там есть.
Забавно, но даже киты такие продаются уже.
На вырост? Выйдет другая модель, возьмешь 2 тб себе.
У меня стоит ответ 350 токенов
И он буквально может забить весь ответ тем как персонаж переместился из одного угла в другой
Страшный пресет. Реп пен 1.15 и письки в промте
Лучше М4 Max с 64гб божественной юнифай мемори взять. 2700$ всего. Его хоть потом продать можно будет.
Надо собираться на ддр5 пока никто не прохавал тему
А то будет ровно так же как с теслами
А то будет ровно так же как с теслами
Ну не, даже эйр звезд не хватает но внимательнее к деталям и более разумный чем мелкомистраль, особенно на контекстах. Похоже на то, что ты зарезал их странными промптами и прочим, и сравниваешь с чем-то что когда-то понравилось, негодуя с другого результата.
Идеальный вариант для смайлофажного мусора, все правильно написал.
> У меня стоит ответ 350 токенов
А на что ты рассчитывал вообще? Скорее всего там целевое около 800 и ты получаешь самое вступление, еще до каких-либо реплик. Напиши в системном что предпочтительны короткие ответы без излишних описаний и сними лимит.
Перепуки скупят все плашки? Хотел бы на это посмотреть.
> Перепуки скупят все плашки? Хотел бы на это посмотреть.
Сейчас 128гб ддр5 - 45к. Как одна тесла.
Скоро кабаны допрут что у нас тут за мое тема и что надо перекупать 48-64гб плашки, а игродаунов на 16-32гб никто трогать не будет
>Скоро кабаны допрут что у нас тут за мое тема
вас таких кобольдов кот наплакал, начинка вычинки не стоит
Тихо ты, не пали контору! А лучше сам иди закупись, если денег свободных нет то можно кредит взять, как раз ставку снизили. Раз в жизни такой шанс бывает, нельзя упускать!
является инвестиционным предложением
Модельку крутые и приятные, насчет инфиренса на профессорах, по крайней мере обычных - хуй знает.
А нахуя нужен ддр5 билд когда ту же скорость можно получить на 2х3090 ддр4, ещё и на поиграть останется? Ближайшие лет 5-7тс комфортом
Зачем вам отдельная дрочкоробка когда за те же деньги можно получить универсал
Зачем вам отдельная дрочкоробка когда за те же деньги можно получить универсал
>М4 Max с 64гб
M4 хуже для локального инференса, там память почти в 2 раза медленней, чем у M3 Ultra, чекни спеки.
>2х3090 ддр4, ещё и на поиграть
удачи запитать все это добро. А и еще - поставь этого квазимоду на стол рядом, кайфанешь
У меня он прямо сейчас стоит под столом без проблем в лиан ли. Красивый корпус, его многие оценивают даже как элемент декора
Питается без проблем 1200w бп
Живу не в студии, тепло не напрягает
Табби обновили, добавлена новая версия экслламы по дефолту и поддержка тензорпараллелизма.
Внезапно, в моэ работает он совершенно противоположно тому что было раньше: токены в секунду на пустом контексте проседают процентов на 5-10, обработка ускоряется в 1.5 раза(!), скорость на контексте проседает значительно меньше, на 90к работает весьма шустро и быстрее обычного режиме, не говоря о жоре.
Теперь вопрос пригодно ли оно для запуска на разношерстных гпу, подключенных по не самым быстрым шинам.
> на стол
Кто-то в 2д25 году не считает суперкринжем системный блок на столе? Там должны быть мониторы во всю ширину или что-нибудь еще полезное, а не лгбт-гроб. С запитыванием тоже все достаточно легко.
Внезапно, в моэ работает он совершенно противоположно тому что было раньше: токены в секунду на пустом контексте проседают процентов на 5-10, обработка ускоряется в 1.5 раза(!), скорость на контексте проседает значительно меньше, на 90к работает весьма шустро и быстрее обычного режиме, не говоря о жоре.
Теперь вопрос пригодно ли оно для запуска на разношерстных гпу, подключенных по не самым быстрым шинам.
> на стол
Кто-то в 2д25 году не считает суперкринжем системный блок на столе? Там должны быть мониторы во всю ширину или что-нибудь еще полезное, а не лгбт-гроб. С запитыванием тоже все достаточно легко.
Это наименьшая из проблем. Платиновый серверный бп из-под майнера стоит копейки. Чего не скажешь об остальном.
>не считает суперкринжем системный блок на столе?
Не обижай меня. У меня 2 кота, выбора нет.
Думаешь они сгорят?
Покажи фотографии котов как пруф и мы извинимся
Ну, ладно, оправдан. Но кошаков действительно покажи.
У самого такая меховая фабрика что шерсть вообще везде, да еще с гиперактивностью и регулярным бесивом. Но и пекарня и риг стоят на полу. Единственное что недоступно - открытые стенды, обязательно попытается внутрь залезть рано или поздно.
Автор котоскрипта - спосеба. Очень хорошо работает. Хоть в один гпу запихать максимум мое-слоев, хоть на n-гпу разложить - всё чётко. Там ещё у тебя похоже подразумевалось "-ngl 999" перед собственно оверрайдом? Долго не мог понять, почему медленнее с полученной выгрузкой, чем при другой раскладке. Вернул -ngl 999 - сразу полетело. Вставил в формируемый промт промт, чтобы тоже не парились, как я.
Кому нужно - я взял на себя смелость попросить дс переписать по-человечески с кошачьего - вот: https://files.catbox.moe/y18a6n.7z
Сразу с инсталятором по рекьюрементсам и примером запуска.
Кому нужно - я взял на себя смелость попросить дс переписать по-человечески с кошачьего - вот: https://files.catbox.moe/y18a6n.7z
Сразу с инсталятором по рекьюрементсам и примером запуска.
> >2х3090 ддр4, ещё и на поиграть
> удачи запитать все это добро. А и еще - поставь этого квазимоду на стол рядом, кайфанешь
Ты здесь недавно?
В чём проблема? У тебя 700вт бронза из компа для учебы? Прямо сейчас рядом на столе стоит блок с 4 гпу, закрыт от кота тоже. Рядом не то что сидеть, спать можно - откуда шуму быть? Это же не инстинкты/тесло-турбы.

КотЬ. Второй британец проебывается на улице.
Милота. Тяжело наверно так жить, еще и кресло отжали
Прощения просим, для тебя исключение. Не кринж на столе корпус держать
Обосрался, сорян за 90°
Анони поясните, можно ли запустить что то более пиздато на 12 врам 32 рам, чем мистраль 24б?
Что самое пиздатое можно запустить с нормальной скоростью хотябы 6т.с
Что самое пиздатое можно запустить с нормальной скоростью хотябы 6т.с
Где взять персонажей на русском языке?
> Теперь вопрос пригодно ли оно для запуска на разношерстных гпу, подключенных по не самым быстрым шинам.
Еще как пригодно, там уже ускорение получилось и на пустом контексте. Обработка увеличилась еще значительнее, мониторинг не показывает какого-либо заметного обмена по линии (правда он не видит короткие всплески в которые может быть упор). Если теперь функциональный вызов опять будет глючить - это будет вдвойне обиднее просто.
> подразумевалось "-ngl 999"
Все верно, там еще -ot копирующее исходный вид потерялось, зато остались лишнии функции с прошлых вариантов реализации. Но все равно слава нейросетям.
https://files.catbox.moe/b77x55.md хотя первая версия где оно решило лихо переименовать даже внешние классы с объяснением принципа была более забавная https://files.catbox.moe/uski66.md
> попросить дс
Дефолт сити? Дискорд? Мир тесен и выход на него можно найти по exl3 5.0bpw кванту квен-синкинг.
Какой красавец!
Напиши сам, кек.
Или поменяй в карточке персонажа/систем промте , что перс знает русский, и готово.
А зачем это надо? разве дефолтное
--n-gpu-layers 99
--n-cpu-moe 99
-ot "shexp=CUDA0"
-ot "exps=CPU"
-ot "blk.(?:[0-N]).ffn_.=CUDA0"
Не будет работать так же эффективно? Я просто правда не понял прикол скрипта. Он как то по умному распределяет и больше количество слоев умещает вместо жирных или как? Сори если туплю
>У тебя 700вт бронза
У меня вот был 750 ватт титан, лол. Жаль, пришлось деградировать на платину.
Тебе не нужно считать, сколько у тебя влезет даже в одну вк с ним. Про несколько вк даже не говорю, устанешь считать
Автоматически составляет регэксп, который набивает мультигпу экспертами под указанный объем памяти с учетом размера слоев конкретной модели и исходного распределения слоев не-экспертов для избежания лишних пересылов между гпу. Можно сделать это и вручную, но подбор займет время, которого при большой модели потребуется много.
А если у меня одна гпу (3090) и я запускаю условный Эир с офлоадом на раму мне есть резон что-то перепридумывать? Вот сверху взял из батника для него. Вроде активные эксперты полностью во врам помещаются а остальное на процессор уходит хз
> есть резон что-то перепридумывать
Эффект может быть только от меньшей дискретности (операций отдельно с up down gate вместо всего блока), но он будет малым.
> активные эксперты полностью во врам помещаются
Это не так работает, активные эксперты на каждом токене выбираются свои из общего числа.

Энтузиасты и отважные апологеты общения с 4B в этом треде есть? Расскажите про свой опыт.
Мы так глубоко еще не спускались
=)
Даже я экспериментировал лишь пару фраз… не знаю что и сказать…
Не побоюсь спросить: а ты на мобиле, или 1050ti с зеончиком?
Ученые изобрели компьютер - они кумят, изобрели интрнет - они кумят, изобрели нейросети - они кумят
Ох уж эти учёные-кумеры...
Ничего. Это потолок. Разве что можешь попробовать qwen3-30b-a3b, но будет ли оно более пиздато - вопрос очень спорный. IMHO - нет. А Гемма 27B будет 1-2 токена.
А можно ссылочку на пресетик? 👉👈
нашел нюнечку в дискорде драмера, she/her, солью айди за пак отборных карточек и промтов
Ох уж эти... они... Изобрели печатный станок - они начали расписывать как ебут девок, изобрели фотографию - они начали фотографировать как ебут девок, изобрели кинематографию - они начали кинематографировать как ебут девок. Вот и до интернета с нейросетями добрались, пидорасы.
Я уже начинаю орать, это любовь.
internetforporn.mov

Изобрели рисовать на стенах - начали рисовать голых баб,
Да-а-а... Галилей, Ньютон, Эйнштейн, Архимед, Тесла, все они... Столько людей положили свою ЖИЗНЬ за то, чтобы мы могли сегодня запустить anthracite-org/magnum-v2-12b... Задумайтесь...
> ебут девок
> пидорасы
Натуралы, сэр!
Довольно безобидное выражение животного начала, которое провоцирует самцов трахать как можно больше. Открывают новые способы побороть это, буквально эволюционируя и продвигая мировой прогресс. Чего нельзя сказать о животном начале другого пола.

Зион, все верно, но при этом я также и гордый обладатель императорской 3060, так что спокойно запускаю осьмушки и дюжинки, но в своей любви к самоограничению всё время посматриваю в сторону ультракомпактных, хочется найти им какую-нибудь роль. 1B это лоботомия, даже на высоких квантах, даже в плане перевода. А вот с 4B я бы уже не был так уверен, иногда они вполне себе интересный результат выдают. Хочется их как-нибудь "докрутить".
К тому же, для совсем бедных анонов это был бы весьма полезный и вдохновляющий опыт.
По словам генерального директора Character.ai Карандипа Ананда, пользователи тратят в среднем 80 минут в день на общение с вымышленными ИИ-персонажами.
Это уже ставит Character.ai практически на один уровень с TikTok (95 минут) и YouTube (84 минуты). Эти цифры помогают понять, почему Марк Цукерберг теперь уделяет больше внимания персонализированным чат-ботам на своих платформах.
В настоящее время у Character.ai 20 миллионов активных пользователей в месяц. Половина из них — женщины, большинство — представители поколения Z или даже младше.
Сорц - https://www.ft.com/content/0bcc4281-231b-41b8-9445-bbc46c7fa3d1
Нормисы распробовали персов, двач опять всех переиграл на несколько лет раньше. Кайфуйте, пока это не стало унылым мейнстримом.
Изобрели думать - они начали думать о том, как ебать девок.
>двач опять всех переиграл на несколько лет раньше
Так вся возня на мыле как раз с чайной и началась. Подключение к этому делу корпов и сам селф-хост это уже было позже.
>пока это не стало унылым мейнстримом
Уже не первый год как бы. Именно локальная движуха пока еще вполне себе локальная, в первую очередь потому, что большая часть любителей попиздеть со своими хазбендо это пиздючки, у которых нет никакого вменяемого железа, кроме телефона.
Анончики, подскажите пожалуйста. Я новенький в вашем движе.
Гуню в таверне на MN-GRAND-Gutenburg-Lyra4-Lyra-12B-DARKNESS-D_AU-Q8_0 это ваще норм модель??
Бот стал выдавать очень слабые ответы, часто заполненные несвязной водой, не относящейся к происходящему и даже игнорируя происходящее. Ко всему прочему стала забывать некоторые события, произошедшие в прошлом.
Может есть какая-то команда, которая позволит мне вернуть ее в нужное русло? Ну типа силой ей описать произошедшие события и, скажем, таким образом ребутнуть ее, не начиная диалог заново? Тогда ведь "сюжет" сбросится.
И еще. Может посоветуете какие модели? У меня 32гб оперативки ддр4 и 5060Ti на 16гб. На этой моделе ответы генерируются минуту меня в целом устраивает, я мог бы и дольше подождать, но вот хотелось бы, что бы модель поддерживала русский. Заебало в переводчик лезть каждый раз.
Гуню в таверне на MN-GRAND-Gutenburg-Lyra4-Lyra-12B-DARKNESS-D_AU-Q8_0 это ваще норм модель??
Бот стал выдавать очень слабые ответы, часто заполненные несвязной водой, не относящейся к происходящему и даже игнорируя происходящее. Ко всему прочему стала забывать некоторые события, произошедшие в прошлом.
Может есть какая-то команда, которая позволит мне вернуть ее в нужное русло? Ну типа силой ей описать произошедшие события и, скажем, таким образом ребутнуть ее, не начиная диалог заново? Тогда ведь "сюжет" сбросится.
И еще. Может посоветуете какие модели? У меня 32гб оперативки ддр4 и 5060Ti на 16гб. На этой моделе ответы генерируются минуту меня в целом устраивает, я мог бы и дольше подождать, но вот хотелось бы, что бы модель поддерживала русский. Заебало в переводчик лезть каждый раз.
Изобрели половое размножение- начали трахаться!
>это пиздючки, у которых нет никакого вменяемого железа, кроме телефона
А можно ли это как-то использовать в полезных целях...


> Можешь срезать контекст до 20к и запустить 3xl?
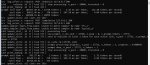
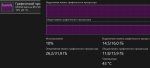
Готово. Qwen 3 235b Instruct 2507, Q3_K_XL bartowski, 20480 FP16 контекста. 4090, DDR4 3200, llamacpp b6139
Без контекста 4.5-5т/с в среднем, с редкими аномалиями в полтокена в обе стороны. На 20к - примерно так же, с большим количеством просадок до 4т/с, но не ниже. Практически та же скорость, что и на Q4_K_S, разве что тот иногда проседал чуть ниже 4т/с на полном (32к) контексте. Возможно, и Q3_K_XL так же просел бы. Короче говоря, с точки зрения скорости разницы почти нет. Что интересно, я уместил в гпу на 4 слоя больше. Боттлнек по памяти?
Обратите внимание на пик 1. Квен - аниме няша из коробки?
Пик 2 - скорость без контекста, пик 3 - на 20к.
По порядку. Во-первых, на твоем железе можно запускать 24b модели. Mistral Small 3.2 существенно лучше того, что ты запускаешь сейчас. Во-вторых, минуту генерация на такой модели на твоем железе занимать не должна. Вероятно, ты не полностью или вовсе не задействуешь видеокарту. В-третьих, по поводу твоей проблемы с персонажем, решение сводится к следующему: убрать из контекста старые сообщения (при помощи команды /hide N-N1, где N-N1 интервал сообщений или, например, запуском нового чата) и излагается вкратце все то, что у вас произошло. Или первым сообщением сам пересказываешь, или излагаешь в Author's Note, или еще как. Кажется, есть для этого экстеншены, но я их не использую. Тебе бы с железом разобраться. Расскажи, на чем запускаешь (если Ollama - не рассказывай, растопчут. Скачай Кобольда, может пощадят), кто-нибудь поможет разобраться, наверное.
Да, использую кобольд.
>Mistral Small 3.2 существенно лучше того, что ты запускаешь сейчас.
Попробую скачать ща, посмотрю. Он поддерживает русский, да? Мне было бы проще тогда наверное начать заново чат и описать произошедшее туда на русском языке.
>Вероятно, ты не полностью или вовсе не задействуешь видеокарту.
А как это понять? Честно - слабо понимаю как все эти настройки устроены. И если так, то как перенести нагрузку на видеокарту?
>Author's Note
Попробую. Сейчас накачу модель по твоему совету и попробую туда все пересказать.
> Он поддерживает русский, да?
Среди доступных на твоем железе моделей лучше варианта для русского, скорее всего, нет. Может кто-нибудь еще подскажет варианты.
> Честно - слабо понимаю как все эти настройки устроены. И если так, то как перенести нагрузку на видеокарту?
Как понять? Самое простое - открыть диспетчер задач во время работы модели и посмотреть, сколько ресурсов используется. Как перенести нагрузку на видеокарту - это тебе документацию читать. Например, здесь: https://docs.sillytavern.app/usage/api-connections/koboldcpp/
> Попробую. Сейчас накачу модель по твоему совету и попробую туда все пересказать.
Можешь и в Summary это пересказать. Необязательно в Author's Note. У каждого свой метод. Но общая идея одна - самому вкратце изложить ключевые события, удалив предыдущие сообщения из контекста.
Спасибо, анончик. Буду ковыряться.
>Среди доступных на твоем железе моделей лучше варианта для русского, скорее всего, нет. Может кто-нибудь еще подскажет варианты.
Гигачат в 20б? правда он соя.
> Среди доступных на твоем железе моделей лучше варианта для русского, скорее всего, нет
А как же легендарные немомикс и даркнесс-рейн? Ничего не имею против, сам катал с огромным удовольствием. Гемма3-27?
Не пробовал их. Извиняйте, на русском я не играю. Чем мог - помог новичку. Пришлите ему ссылки, иначе на найдет ведь.
> Гемма3-27
1-2т/с скорее всего, да еще и в мелком кванте

Тред не читал, дайте настроечки сэмплера под это.
Никогда мистралями и их тюнами не пользовался, не знаю че ставить.
Никогда мистралями и их тюнами не пользовался, не знаю че ставить.
https://huggingface.co/ai-sage/GigaChat-20B-A3B-instruct-v1.5-GGUF
Я когда в кум на нем пытался там такооое было, чар даже с относительно длинной подводкой сою лил, если близко к ней лез она начинала морозится, начинал ее трогать - начинала убегать, пытался оформить в пердачелло на месте - энивей описывала как вырывается, бежит к другому чару из лора и он мне дает пизды после. Ну а при форсе износа чара потом перехватывала инициативу от моего лица и описывала как я ее задушил в процессе ебли в поучительном "Вот к чему приводят такие действия" и начинала сыпать аполоджайзами, это кал на уровне бесплатного тарифа гопоты.
Даже 12Б гема не такой кал, она хотя бы даст ее погачимучить но так, без удовольствия, по злому рп со временем в унылое говно превратит причмокивая.


Извини, что заебываю, но рассчитываю, что ты подскажешь, если знаешь че и как.
В гайде что ты кинул, гайдер рекомендует ставить CuBLAS. Но, у меня его нет в списке, почему-то.
Версия кобольда 1.97.4
Я на свой страх и риск поставил CLBlast. Таких настроек как у автора у меня не появилось.
Далее он расписывает то, сколько слоев там требуется итд и как это посчитать. Он указывает смотреть такие параметры как CUDA_Host KV buffer size и CUDA0 KV buffer size, но у меня в консоли их тупо нет.
По нагрузке - проц 98%, оперативка 30\32, а вот ГПУ 3% загрузка, от чего я могу предположить, что нихуя мои действия нагрузку на видеокарту не переложили. Что, блять, я делаю не так?
Отвечайте дрочумбы, я знаю вы тут мистралей гоняли.
>Но, у меня его нет в списке, почему-то.
CuBLAS это и есть USE CUDA, после недавнего апдейта его просто переименовали, хуй пойми зачем.
>По нагрузке - проц 98%, оперативка 30\32, а вот ГПУ 3% загрузка
Какой квант качал? Много дохуя весит что-то. Качай четвертый и выгружай вообще все слои, какие можешь. В твои шестнадцать они поместятся.
мимо
>Отвечайте дрочумбы, я знаю вы тут мистралей гоняли.
Это не мистраль, это очередная рыготня от бобров. Ставь дефолт - температуру в 0.3, минимальный пи 0.1, штраф на повтор в 1.05, очко штрафа по вкусу
Я использую q8.
Выбери Use CUDA. Гайд устарел немного, но в остальном там, кажется, все актуально.
30 гигов - много. Не нужно качать большой квант. Чем больше квант - тем медленнее у тебя все будет работать, вопрос не только в том, чтобы его уместить. Если это 24b модель, для начала Q4 попробуй.
Уместится Q4 с необходимым тебе количеством контекста, если останется после этого свободная память и будет устраивать скорость - потом уже загрузи побольше.
>Я использую q8.
Ты долбаеб. Тебе нужен четвертый. Шапку сходи почитай, там всё про кванты расписано.
Да я как бы эт самое.. Не то что бы за скоростью гонюсь. Скорее за качеством. Вот объяснили, что надо мне нагрузку на видюху закинуть и станет быстрее - ща постараюсь это устроить и ваще балдеть буду. Или то, сколько это всего памяти занимает, как-то влияет на качество генерации? На скорость (в целом) похуй. Не то что бы я сидел и ждал генерации 100 слов по пол часа, но то, как генерирует сейчас - вполне устраивает. Только если это влияет как-то на качество генерации - тогда да. Возьму квант выше.
q8 по сравнению с q4 это где-то +10% больше качества за счет двойной прожорливости тормознутости.
Понял. Качаю q4, значит.
У меня на 4 кванте с 37 слоями и 16к контекста около 18-19 т.с. было а когда контекст подходил к концу 12-13 т.с., можешь попробовать.
мимо 16/32 бомж
>Не то что бы за скоростью гонюсь. Скорее за качеством.
Гонишься за качеством и забиваешь хуй на 16 гигов видеопамяти, которые просто у тебя без дела лежат? Если тебя всё устраивает - отдай карту мне, меня нихуя ничего не устраивает на своих 12
Q4 KM если есть - самое оптимальное
Downloads last month
20

То есть свои таблички с описанием превосходства они тоже выдумывают?
Так это же
>base model
Анонище, если тебе нужно качество, и модель ты используешь для РП - бери Q6. Q8 тебе ничего не даст. Многие даже для математических задач используют Q6, разница с Q8 минимальная.
Понятно, что ты на радостях апгрейдишь свою модель до чего-то нормального, но не нужно прыгать выше крыши. 24b Q4 гораздо лучше, чем 12b Q8. 24b Q6 несколько лучше, чем 24b Q4, но многие разницу сочтут несущественной, чтобы терпеть гораздо меньшую скорость. А 24b Q8 использовать нецелесообразно и вовсе.


Да почему забиваю? Я в душе просто не ебал, что это все у меня не работает. Ща выставил вот такие параметры, нагрузка на видеокарту 57% во время генерации и вроде память заниматься стала.
Бля, как все сложно-то для моего тупого мозга.
Ща опять перекачаю модель. Заценю. Главное, что бы на русском адекватно выдавало ответы. Просто уже пизда как заебало в переводчик лезть. Не, я как бы могу в английский и сам, просто медленно.
Все просто. Качаешь Q4, проверяешь. Остается память, устраивает скорость - качаешь Q6, проверяешь. Вот это - лишь объяснение на пальцах какие кванты и кому нужны, без призыва бежать за Q6 сразу или отбросить все, что меньше.
нихуя ты флеш, не пробовал 30-32В модели потрогать вместо того чтоб дристраль дрочить?
>То есть свои таблички с описанием превосходства они тоже выдумывают?
Слушай, веришь нет, мне похуй. Гоняю только дефолтную мистраль, меня на ней всё устраивает. Если конкретно тебя не устраивает - гоняй что хочешь и верь во что хочешь. Но даже не пытайся переубедить меня, что кумерское гунерское говно бустит модель по мозгам и памяти, и что разница в 6 процентов это повод прикасаться к лоботомитам.
>layers 8/43
>context size 49152
>выделенная память 13/16
Нда, блять...
Да я вот сейчас и мониторю как раз, сколько чего памяти видюхи жрет и че по генерациям. Сейчас надо только будет адекватно заново диалог начать чистый и глянуть, че по скорости. Я скачал и Q8, и Q6 и Q4 - буду эксперементировать
ЧЯДНТ? Я вполне понимаю, что мог легко где-то обосраться
Количество контекста лучше выставить 32768. Дальше модели сильно глупеют, выдают шизу или откровенно ломаются. Контекст будет занимать меньше памяти, значит больше попадет в видеокарту, значит скорость будет быстрее. На этом мои полномочия все, окончены.
Этот ответ сгенерирован ИИ? Я вообще-то вопрос задал, табличкам доверять можно или нет...
Контекст блять прибери ебаный по голове. Ты еще там где-то выше писал, что у тебя модель тупеет по мере увеличения числа сообщений. Так вот блять она не работает на таких значениях. Ты впустую тратишь память. Ставь 16к и не трогай, потому что дальше у нее мозги спекаться начинают

Спасибо огромное.
Судя по всему, мне надо аватарку завести, что бы люди сразу понимали, что мои тупые вопросы задаю именно тупой я. Может аватарку хлебушка, блять, раз у меня мозгов как у хлебушка.
Мистраль 3.2 до 32к норм держит. Разве что гунтюны разваливаются с первого сообщения омегалул
>Я вообще-то вопрос задал, табличкам доверять можно или нет...
Можно, если хочешь быть наебанным. Все бенчи это пиздежь. Доверять можно только своим ощущениям.
Нет, не делай этого. Не заводи аватарку. Последний мой тебе совет. Ладно, предпоследний. Последний - сам тыкайся/разбирайся, в тред приходи с конкретным вопросом. Информации много в интернете в целом и в документации Таверны/Кобольда в частности.
Будешь аватарить и слишком полагаться на тред - даже самые добрые перестанут отвечать.
Сейчас на на mistral small 24q6 попробую сначала 32к, как сказал анон выше, а потом твои 16. Посмотрю в чем разница. Я просто ставил такие высокие значения контекста в надежде того, что модель будет запоминать больше произошедших событий. Я так это понял, когда выставлял в первый раз эти значения.
Да блять(
Если кто будет пробовать новую экслламу в табби - кажется дефолтный билд, который там качается припезднутый. На всякий случай после обновления/установки активируем венв и пишем
> pip uninstall exllamav3 -y
> pip install git+https://github.com/turboderp-org/exllamav3
Первый запуск после этого может быть дольше обычного - компилируются модули под среду.
> pip uninstall exllamav3 -y
> pip install git+https://github.com/turboderp-org/exllamav3
Первый запуск после этого может быть дольше обычного - компилируются модули под среду.
>попробую сначала 32к, как сказал анон выше, а потом твои 16
Смысл в том, что его 32 в твою память скорее всего просто не влезут. Но пробуй, кто запрещает.
>Мистраль 3.2 до 32к норм держит.
Сомнительно держит, если честно. По крайней мере у меня после 16-18к стабильно начинает разваливаться разметка и появляется паттерн по типу 80% диалогов и 20% нарратива, когда до этого всё шло ровно наоборот. Приходится префиллить и продолжать генерацию по несколько раз чтобы вернуться к норме.

Ну вот в старом чате показывает вот такое, когда начинаю генерацию с загрузкой 32к токенов. Загрузка такого количества токенов заняла где-то 2 минуты. Сейчас вот генерируется сам ответ. Примерно 1 токен в секунду..
Что значит префиллить? Подскажи на будущее..
Сначала выгружай все слои, потом верти крутилку ползунка контекста, пока не упрешься в видеопамять.
>Что значит префиллить? Подскажи на будущее..
Мне лень. Дам тебе возможность разобраться самому. В таверне есть кнопка континью, которая вместо полностью новой генерации продолжает незаконченный кусок сообщения. Это может быть текст, который она сгенерировала до этого, или может быть текст, который ты написал сам чтобы повествование шло в нужном направлении.
Понял.
>qwen3-30b-a3b,
пробовал. не зашло.
Короче, я немного разочарован. Переписал персонажей и сценарий мира на русский язык, задал примеры сообщений на русском языке. Модель выдает абсолютно тупое понимание русского. Ну просто блять какой-то бессвязный текст.
Видимо придется обратно все переписывать на английский и ебаться с переводчиками. Эх.
>Модель выдает абсолютно тупое понимание русского.
Нужен хороший русский - трогай большую гемму. Но она пережарена цензурой из коробки и придется немного заебаться с промтами под нее. Если у тебя нет никакого опыта в составлении инструкций, можешь даже не пытаться и сразу искать готовые пресеты.
>Видимо придется обратно все переписывать на английский и ебаться с переводчиками
Все современные модели адекватно воспринимают русский на входе. Самый удобный воркфлоу это держать системные промты и карточки на английском, а свои сообщения писать на русском. Надобность в переводчике отпадает, а модель не тупеет, так как отвечать всё равно будет на английском.
Да хуй с ним.
Тут теперь другое. Начал новый чат, описал в заметках автора произошедшие события, продублировал их в первые сообщения. Добавил это все в историю персонажей. Добавил события в world history. Начинаю генерацию - модель выдает ваще не связанные действия с сюжетом и путает имена, генерируя ваще рандомные на месте персонажей.
Шаблон отклеился, похоже. Логи, скриншоты ты не даёшь, остаётся на кофейной гуще гадать.
Скилл, как говорится, ишью. Важную информацию в модель можно впихнуть разными методами, но проще всего засунуть напрямую в карточку персонажа. Добавляешь куда-нибудь в конец простыни что-то вроде "Backstory: чар занимался с юзером такими-то делами когда-то в прошлом" и всё. Текущий сценарий разумеется не должен противоречить предыстории и прочим описаниям. Если в прошлом они ебались и творили разврат, а в первым сообщении указывается, что персонажи вообще не знакомы - то модель просто ебнется.
>Логи, скриншоты ты не даёшь, остаётся на кофейной гуще гадать.
Там чел только вкатывается. Уверяю тебя, если ты увидишь логи, ты ахуеешь от безобразия и поймешь, что ему нужно объяснять вообще всё, так как самостоятельно искать инфу он не хочет.
Ну, я ща попытался еще раз пересоздать чат, вроде стало лучше - персонажей и суть уловила, но все равно как-то кривовато. Непривычно как-то моделька пишет по сравнению с прошлой. Странно, что на этой модели генерация 350 токенов занимает 247+- секунд на меньшем значении размеров контекста.
Не, логи я не кидаю реально тупо из-за того, что просто смущаюсь. Я понимаю - двач, хуе-мое, все аноны вокруг братья, никто никого за сюжет не осуждает итд.. но чет хз. Я бы скинул пример того, что генерирует сетка.
Не нужно изобретать велосипед, в таверне есть "штатный" суммарайз, туда его и нужно пихать. Другое дело что применять эту штуку в исходном виде для его составления - плохая идея, можно сделать это форкнув чат и послав запрос хоть в посте юзера, хоть от системы, насвайпать и состряпать удачный, но потом засунуть именно в поле суммарайза. После этого необходимо скрыть старые посты, которые его дублируют, чтобы было плавное продолжение.
> 350 токенов занимает 247+- секунд
Жесть
Согласен. Жесть. В голове не укладывается, как моя прошлая модель (которая, судя по всему, была тяжелее), выдавала ответы на бОльшем контексте быстрее, чем эта... я чет опять сделал не так?
>Не нужно изобретать велосипед, в таверне есть "штатный" суммарайз
Суммарайз это и есть повторённое изобретение велосипеда. Таверна дает возможность полностью контролировать контекст и редактировать его по желанию. Вместо того чтобы суммировать 200 сообщений по несколько раз в ожидании, когда наконец модель сможет выделить именно те факты, которые тебе нужны, легче самому их прописать и вставить.
>на этой модели генерация 350 токенов занимает 247+- секунд
Вот я тебе выше писал - выгружай все слои. Ты нихуя не выгрузил, я правильно понимаю? И теперь удивляешь, почему у тебя такая нищая скорость. Зачем ты тогда вообще тут какие-то вопросы задаешь, если в итоге ничего из предложенного не делаешь?
Ты запускаешь модель слишком большую для твоего железа, или делаешь что-то неправильно. Экстрасенсы в отпуске, без подробного описания тебе никто не поможет с этим.
> Вместо того чтобы суммировать 200 сообщений по несколько раз в ожидании, когда наконец модель сможет выделить именно те факты, которые тебе нужны, легче самому их прописать и вставить.
> применять эту штуку в исходном виде для его составления - плохая идея, можно сделать это форкнув чат и послав запрос хоть в посте юзера, хоть от системы, насвайпать и состряпать удачный
Что с тобой не так? А чтобы максимально сохранить факты о произошедшем - рецепт писал в прошлых тредах.
>чтобы максимально сохранить факты о произошедшем - рецепт писал в прошлых тредах
Ну если ты не можешь самостоятельно указать нужные факты, то пожалуйста, суммируй автоматом, кто запрещает. Только это куча лишних телодвижений и явно не самый простой, быстрый и эффективный способ.
Видимо я не понял, что значит "выгрузить все слои" и этого не сделал. Если ты имел ввиду уменьшить значение context size, что бы GPU Layers стали 43\43, то раньше у меня было 8\43, то теперь у меня пишет (No Offload) и размер контекста с 49к я уменьшил до 32к.
Была MN-GRAND-Gutenburg-Lyra4-Lyra-12B-DARKNESS-D_AU-Q8_0
Настройки стояли кривые, но с ними 350 токенов контекста генерировало +- за полторы-две с половиной минуты.
Поставил по советам анонов Mistral Small 3.2 Q6 и уменьшил размер контекста. Теперь генерирует по 4+ минуты.
Короче, вот просто блять по шагам сделай, что говорят. Выбери модель, вручную укажи 43 из 43 слоев, снизь жирность контекста до 16к, проверь что у тебя стоит USE CUDA и еще раз запусти модель. Потом проверь скорость.
>Поставил по советам анонов Mistral Small 3.2 Q6
Тебе сказали ставить четвертый квант. Четвертый квант это Q4 а не Q6. Ты хотя бы на размер модели смотришь, перед тем как скачать её? Тебе не приходит в голову, что если файл весит больше объема твоей видеопамяти, то ты не сможешь полностью загрузить его в VRAM и из-за этого у тебя будет проседать скорость? Почему такие элементарные вещи вообще нужно объяснять?
Не, ну тут даже терпеливый я не буду пытаться. Тебе предлагали начать с Q4 и объяснили почему. Предложили прочитать гайд и документацию - ты не прочитал. Бяка ты, и помогать я тебе не стану.
Сказали попробовать и Q8, и Q6 и Q4. Анон выше сказал, что Q6 оптимально. Я пока пробую Q6.
>Короче, вот просто блять по шагам сделай, что говорят. Выбери модель, вручную укажи 43 из 43 слоев, снизь жирность контекста до 16к, проверь что у тебя стоит USE CUDA и еще раз запусти модель. Потом проверь скорость.
Сейчас попробую.
Ну почему же ._.
Я почитал гайд. И по нему делал. Один из анонов сказал, что q6 оптимальная. У меня есть и Q8, и Q6, и Q4. Я пока пробую Q6. Если так будет дальше медленно делать - перейду на Q4. Ну чего ты ._.
ты только что разочаровал, возможно, самого терпеливого анона в треде
немногим это удается
еще раз иди читай все что тебе понаписали и проводи работу над ошибками, так то
> Мебель на 40й этаж тоже нужно пешочком по лестнице затаскивать, грузовой лист это куча лишних телодвижения и явно не самый простой быстрый и эффективный способ
Молодой-шутливый, а такой самоуверенный. Удачного рп, со временем поймешь.
> MN-GRAND-Gutenburg-Lyra4-Lyra-12B-DARKNESS-D_AU
В голосуну, просто эталон васяновских названий. Да, удачно тебя занесло туда.
> У меня 32гб оперативки ддр4 и 5060Ti на 16гб.
Окей под твои 16гигов качай Mistral Small 3.2 Q4KM, с ним выгружаешь на гпу 30/43 слоев, выставляешь контекст 16к. Делаешь именно так как сказано, а не меняешь потому что что-то там услышал.
После выполнения доложи о получаемой скорости, а также выкладывай скрины метрики из командной строки кобольда и любого мониторинга, который показывает использование видеопамяти.
>Сейчас попробую.
Сука какой же ты тупой блять, я просто не могу. Твой ебаный шестой квант весит 20 гигабайт, у тебя 16 гигабайт видеопамяти, какого хуя ты собрался там пробовать? Включи мозги обезьяна блять.
>Анон выше сказал, что Q6 оптимально.
Шестой квант оптимален, когда ты можешь его полностью загрузить и оставить место для контекста. Это не твой случай, потому что у тебя нет под него места нахуй
>Молодой-шутливый, а такой самоуверенный.
По крайней мере я не пытаюсь ебаными деревенскими аналогиями всякую хуйню доказывать.
>Удачного рп
Спасибо, всегда приятно
>выгружаешь на гпу 30/43 слоев, выставляешь контекст 16к
Поделись своими расчетами, родной. 14 кило уходит на параметры, около двух уходит на контекст. Я бы еще понял, если бы ты предлагал выгружать 40 слоев вместо 43, но 30... Нормально у тебя дела там?


Сейчас вот такой результат на Q4. Текст, вроде, смышленый выдало. В первом случае генерация остановилась на 162\350 токенов. Во втором все 350.
Анончик. Чего ты такой злюка? Я просто объяснил тебе, почему генерировал на Q6. Это не значило, что после твоего сообщения я на нем остался. Я твой посыл про память с первого раза понял.
>Я твой посыл про память с первого раза понял.
И всё равно не стал все слои выгружать и замерять скорость. Ну ладно, хули я то сделать могу.
Я все это время мог докупить рам и катать здоровенный 235 квен в приличном кванте? Как оно катается, рассказывай, логи приноси там
> всякую хуйню доказывать
Хуйня в данном случае - твое предложение вручную вести перечисление. Со временем сам поймешь почему, даже объяснять лень.
> Поделись своими расчетами, родной.
Если полыхать перестанешь. Нужно сделать ситуацию где у него гарантировано будет запас врам и посмотреть какой он. А потом уже предсказывать следующий шаг и повышать количество слоев, все очень просто. Без конкретных указаний и обратной связи вы уже его хорошенько проинструктировали, лол.
Правильно, вот это уже похоже на нужное. Где скрины мониторинга врам? В целом, следующая задача простая - постепенно повышай количество выгружаемых слоев до момента как скорость перестанет расти. Достигнув этого откатываешь 3 слоя назад и пользуешься в таком виде. Разумеется, лучше посмотреть мониторингом что творится и подбирать по нему, но можно и так.
Остальное - уже настройки таверны.
Анончики, есть у кого годный пресет на стар командера?

>Хуйня в данном случае - твое предложение вручную вести перечисление.
Это не предложение из воздуха, я этим методом уже почти три года пользуюсь. Мне не составляет труда быстро проскроллить предыдущие сообщения и выделить все ключевые моменты, которые будут важны после очистки контекста. И если ты не забываешь спустя секунду о чем была переписка, то скорее всего с этим тоже справишься. Со временем поймешь, короче.
>Если полыхать перестанешь.
Всё, перестал. Исключительно ради тебя.
>Без конкретных указаний и обратной связи вы уже его хорошенько проинструктировали, лол.
Я ему почти точные носик в носик значения предоставил. Сам сижу на мистрали, сам сижу на четвертом кванте. То что он не может эти значения просто вставить и сравнить результаты, это уже не моя и не наша проблема.
Не ссорьтесь из-за того, что пытались помочь как знаете сами такому идиоту, как я.
Диспетчер задач неинформативен, скачай hwinfo, gpu-z, что угодно еще и покажи с него. Судя по этому скрину память не только забита, но и уже начала выгружаться, но если пронаблюдать внимательно - даже простой запуск кобольда повышает значения шаред рам что показывает диспетчер, еще до загрузки основной модели. Судя по размеру кванта и контексту это уже близко к твоему лимиту, но ожидал что еще как минимум несколько слоев должно поместиться.
Когда с запуском разберешься - можешь качать производные этого мистраля в том же кванте и грузить с такими же параметрами, какие - уже спрашивай советов у знающих, но он и в оригинале хороший. Пресеты в таверну здесь скидывали, поищи или побольше поной чтобы указали.
> этим методом уже почти три года
То есть за 3 года ты не практиковал действительно больше рп, не хотел бы чтобы чар помнил как общий ход, так и важные детали, точную хронологию и подтекст и даже некоторые закрепляющиеся привычки и действия? Чтобы модель четно знала конкретные события а не путала их из-за недостаточного описания?
> Всё, перестал.
Иди обниму.
>Не ссорьтесь из-за того, что пытались помочь как знаете сами такому идиоту, как я.
Никто не ссорится. Просто невозможно долго помогать кому-то настолько тугому, не скатываясь в эмоции.
>То есть за 3 года ты не практиковал действительно больше рп
На локалках и тех моделях, которые мне удавалось заводить, действительно большие рп вести было просто бессмысленно. Даже если ты идеально просуммируешь предыдущие десятки тысяч контекста, выпишешь каждую мелкую деталь, модель это пережевать просто не сможет. Так что да, во время перекатов я указываю только необходимую информацию, которую будет тяжело проебать. И вообще, пару лет назад приходилось контекстом в 4/8к ограничиваться, так что возможно это просто стало привычкой.
> но ожидал что еще как минимум несколько слоев должно поместиться.
Наверное влияет сильно то, что у меня comfy подключен. Стоило, наверное, это упомянуть, но я сам совершенно про это забыл, пока возился со всеми настройками.
>Наверное влияет сильно то, что у меня comfy подключен.
Ну пиздец - ну вот о чем я и говорю. Ну блять я уже провод от наушников скоро грызть начну. Скажи хотя бы что у тебя модель не была загружена, а просто интерфейс был подключен... наеби меня, скажи неправду, умоляю...
> десятки тысяч контекста
Ну типа столько занимает сам суммарайз с сотен тысяч и выше. Раньше то да, практический лимит в 12к на второй лламе, когда модель уже могла соображать но не разгуляешься был довольно обидным. Но уже с появлением ларджа, квена 72, даже того же немотрона и qwq, не говоря о современных жирных моэ, такое уже норма.
Лолбля, и на что ты рассчитывал, отжирая от без того малой врам еще? Ну, методику ты освоил, теперь подбирай по ней оптимальные слои и играйся.
Ну идиот я, ну. Не порть наушники.
Ну, та скорость которая есть сейчас меня куда больше устраивает. Модель хоть и кажется слабее, но вроде спустя 2-3 регенерации выдает адекватные ответы.
>Не порть наушники.
Поздно, уже укусил. Стало легче.
>та скорость которая есть сейчас меня куда больше устраивает
Та скорость это какая скорость? Ты можешь закрыть всё лишнее и просто замерить на чистую?
>Модель хоть и кажется слабее, но вроде спустя 2-3 регенерации выдает адекватные ответы.
Количество выгруженных слоев на качество ответов не влияет. Это исключительно вопрос скорости. На качество ответов влияет сама модель и степень её сжатия, потом в меньшей степени семплеры и инструкции.

Магия вне Хогвартса.
Я думал система 500мб резервит, мимо другой анонас.

Выкуси то, что укусил, в таком случае.
>Та скорость это какая скорость? Ты можешь закрыть всё лишнее и просто замерить на чистую?
Пик.
>Количество выгруженных слоев на качество ответов не влияет. Это исключительно вопрос скорости. На качество ответов влияет сама модель и степень её сжатия, потом в меньшей степени семплеры и инструкции.
Так я это понимаю. Я ж о том и говорю, что прошлая моя модель выдавала более хороший результат.
Медленно. Ебать как медленно. Выгружай оставшиеся слои.
>о том и говорю, что прошлая моя модель выдавала более хороший результат
Прошлая твоя модель была кумерским тюном. Разумеется из коробки она будет лучше уметь в ролевые. Дефолтную мистраль нужно промтить и докручивать вручную. Хотя тоже момент на любителя, у меня с ней никаких проблем нет.


Буду выгружать, окей. С 30 подниму до 35 сейчас. Посмотрим че будет.
>Прошлая твоя модель была кумерским тюном. Разумеется из коробки она будет лучше уметь в ролевые. Дефолтную мистраль нужно промтить и докручивать вручную. Хотя тоже момент на любителя, у меня с ней никаких проблем нет.
Ну типа пики. И че это за хуйня? Какого хуя его кожа вдруг стала зеленой? Че за бред? У меня, если че, не фентези рп, о чем в лоре мира прописано.
Скорее всего семплеры. Нужна маленькая температура в районе 0.15 и min-p 0.05, остальное по дефолту, кроме штрафов на повтор, их уже по желанию крути (начинай с 1.05 + широта очка 2048)
Поставил как ты сказал - вроде стало чуть лучше. Текст сразу стал более осмысленным и следующим сюжету.
Ахаха бля, проиграл на всю хату с подливой. Уж такого от квена не ожидал

Вот мой куррент пресет для наглядности. Отсечка немного жесткая, но попробуй, может зайдет.
Ща посмотрим-попробуем. Спасибо! У меня +- так же стояло.
Если у тебя 4.5т на 3200 то на 6400 будет в два раза больше.
Ведь так?...
ВЕДЬ ТАК АНОНЫ?
Она тебе базу выдала, хули.
Анон, последний реквест, скачай пожалуйста нашу 2s и погоняй пол часика, скажешь нам что мы теряем в сравнении с 4q
https://huggingface.co/Intel/Qwen3-235B-A22B-Instruct-2507-gguf-q2ks-mixed-AutoRound
перевести первое сообщение
также набо персов на русском был в папке на пикселе которая тут периодически всплывает
Какая-нибудь модель может на это вменяемо ответить? Не перечислить кучу шизы, среди которой будет нормальный вариант. А чётко ответить что-то типа "переверни кружку, еблан".
>Он поддерживает русский, да?
- Модели из шапки "с уклоном в русский рп" вшестом кванте
- Мистраль 3.2 24Б в 4м кванте
- Мое-квен новый 30Б 4-6 кванте
гемму уже слишком тяжко наверно будет
Ты почаще пиши в интернете чтобы перевернула кружку.
>стар командера
Фига ты старьё вспомнил.
Но на удивление, у меня действительно завалялся.
https://pixeldrain.com/l/47CdPFqQ#item=147

Квен запрещает мне размножаться с виртуальными вайфу что делать
нормальный сисьпромт подрубить
Ой бля... это гениально. LOL.
Утащил себе в коллекцию тестов для проверки "адекватности мышления".
P.S. Заметил, и сам что пятая гопота отупела по сравнению с предшественником, но что настолько...
В пятницу придет и все проверим…
Правда на 6000.
———
Да, решили таки брать простую десктопную сборку, но совет про хуанан с эпиком я записал, себе такое соберу ради интереса попозже, заодно будет интересно сравнить.
———
Qwen3-30B-A3B мне норм ответил с первого раза и я дропнул этот тест.
Он работает просто: не ризонинг тупят, ризонинг не тупят.
Ну и гпт-5 — она особенная. =3
* Qwen3-30B-A3B-Thinking
Нет, не так
Это не квен, а хуета у тебя в промте о чем говорит последний абзац
Ллама ? Ллама. Ллама ? Ллама !
https://huggingface.co/ReadyArt/L3.3-The-Omega-Directive-70B-Unslop-v2.1?not-for-all-audiences=true
О ! Ллама !
https://huggingface.co/Steelskull/L3.3-Shakudo-70b
Лламы !
https://huggingface.co/ReadyArt/L3.3-The-Omega-Directive-70B-Unslop-v2.1?not-for-all-audiences=true
О ! Ллама !
https://huggingface.co/Steelskull/L3.3-Shakudo-70b
Лламы !
>please leave a positive review
>L3.3-The-Omega-Directive-70B-Unslop-v2.1
Слишком коротко, я не кончил
Ллама ? >_> Ллама !
Ну нет, за такое я не возьмусь. Мне пока что по модели и сказать-то особо нечего, до сих пор не пришел к какому-то мнению, а тут кванты предлагают сравнивать. Можно, казалось бы, взять один seed и на нем провести сравнительные генерации между Q2 и Q4, но это не отражает реальную картину целиком, а значит, в целом бессмысленно.

1) А локальные модели с мышлением требуют больше врам? Или если модель, условно, 12b, то и с мышлением, и без, она будет требовать одинаковые мощности? Или запускать малые модели с мышлением смысла нет - галлюцинировать будут как обычно, но с большей упёртостью?
2) Если модели с мышлением имеет смысл брать для 3060 12gb, то посоветуйте модель для погромирования. Если не имеет, то тоже, но без мышления.
3) А какие-нибудь местные гайды по созданию RAG есть? Или хотя бы какие-нибудь русскоязычные, которые помогли кому-то из вас разобраться в теме.
2) Если модели с мышлением имеет смысл брать для 3060 12gb, то посоветуйте модель для погромирования. Если не имеет, то тоже, но без мышления.
3) А какие-нибудь местные гайды по созданию RAG есть? Или хотя бы какие-нибудь русскоязычные, которые помогли кому-то из вас разобраться в теме.
1. Врам одинаково, мышление генерит больше токенов, значит разное время (при одинаковой скорости).
2. Qwen3-Coder-30B-A3B-Instruct + Qwen Code или другой агент на выбор. Это MoE, было бы неплохо иметь 64 гига, но на данный момент это несложно (ну возьми кусю с алика, ну йопта). Это практически безальтернативно, другие модели или сильно медленнее, или сильно тупее, или сильно больше.
Ну я назову Devstral + агент OpenHands, но вряд ли.
1. Ризонинг суть есть часть модели. Просто ты будешь тратить больше времени на генерацию размышлений.
3. Да есть. Берешь и собираешь.
Без иронии, проблема подобных вопросов в их не правильной постановке. Домашний раг состоит из точно таких же компонентов, что и обычный домашний ПК. (Ну, есть конечно серверные блоки, но мы их упустим, не релевантно)
Определись сначала с бюджетом, а потом уже начиная плясать. Ах, ну и все что является серверным оборудованием и имеет хорошую производительность или стоит как крыло от самолета или представляет собой адовый пердолинг с подключением неподключаемого.
>+ агент
>или другой агент на выбор
Чет я впервые слышу про агентов в контексте локальных LLM. Кто такие, чем знамениты, и много ли едят врама?
Я не про rig, а про RAG - Retrieval-Augmented Generation. На целые серверные риги у меня, наверное, никогда не будет денег...
>Чет я впервые слышу про агентов в контексте локальных LLM
>Агенты OpenHands могут делать все, что может делать разработчик-человек: изменять код, запускать команды, просматривать веб-страницы, вызывать API и, да, даже копировать фрагменты кода из StackOverflow.
А, понял. Можно было и догадаться. Ну, нет, мне вряд ли это пригодится, из свистоперделок и хочу разве что RAG прикрутить с нужными мне доками. И, может, draft с мини-моделями попробовать приделать - но я еще не уверен, что это мне нужно.
>draft
вроде как драфты тем лучше помогают чем более точная задача, то есть в кодинге может бустануть, в рп бысполезно
Я слышал, что драфт особенно хорошо работает на русском языке из-за наших длинных слов и сложной токенизации кириллицы. Наверное, в таких случаях и для РП подойдёт. Но меня как раз программирование сейчас волнует, так что да, мне подойдет тоже, значит.
Пиздец вы как подъездные бабки.
А вот Галя скозала..
Драфт модель должна быть идентична большой но в меньшем количестве параметров. Обе у вас будут работать одновременно, за счет драфт модели ускоряется скорость генерации токенов, все
До сих пор не могу поверить что 4090 не просела даже до 150к...
Потому что их не производят больше. Спалитовские 5090 по 200к стоят уже.
До сих пор не могу поверить что купил 4090 за 120к в 2023...
Это квен 235 который?
Агент — это программа, алгоритм, которая посылает определенные запросы в LLM, и заставляет ее писать код, перепроверять себя, использовать команды, самостоятельно создавать папки и файлы, запускать, дебажить и так далее.
Ты отправляешь запрос, а он все делает, иногда задавая тебе уточняющие вопросы и запрашивая разрешения на то или иное действие.
> Я не про rig
Никто не про риг, он тоже про РАГ.
> А, понял. Можно было и догадаться. Ну, нет, мне вряд ли это пригодится, из свистоперделок
Без агентов модели пишут код гораздо хуже.
Если ты хочешь, чтобы у тебя был ПЛОХОЙ результат, то юзай чат и иди нахер.
РАГ дает тебе инфу, которая может стриггериться, а может не стриггериться.
Агент самостоятельно прочтет все необходимые файлы в проекте и будет держать в контексте актуальный функции.
Безусловно, RAG с документацией — это полезно.
Но агент, который параллельно смотрит все необходимые файлы — тоже очень полезен.
Агент — это ебанные циклы. Постоянно пишет код, перепроверяет сам себя.
Если хочешь прогать через чат — то бери Qwen3-30B-A3B-Thinking, чтобы он хотя бы ризонил. Для агентов — кодер, для чата — ризонинг.
> И, может, draft с мини-моделями попробовать приделать
У тебя 3б активных параметров, ты какой драфт собираешься туда пихать, 0.6б? :) У тебя буквально скорость модели быстрее какой-нибудь 7б, а ты еще собрался ускорять.
Когда написал, что нарратор — быдло ебанное и пишет только на русском, и он ебанул тебе в ответ.
Что там на счёт gpt-oss? Естественно не базовые версии, а модифицированные. Есть какой-то разбор-обзор?
Ну слава богу что 3090 до сих пор производят...
Их тоже давно не производят, все 3090 только б/у.
А, вспомнил!
Можешь еще взять GPT-OSS-20B, выставить reasoning high, и тогда она тоже хорошо пишет код в чате. И весит немного. Целиком в 12 гигов не влезет, тем не менее.
Ого, там даже abliterated и uncensored есть!
Не ожидал.
Пробовать я это, конечно, не буду.
Ха! Что вы понимаете в куме...3060Ti 8Гб, 24 Гб рамы. Сторителлер 27B, в LMS выдаёт 0.97 тс. Открываешь два чата. Пока оно рожает в одном, пишешь в другом. Один раз перепутал чаты. Там героиню звали Настей, а я её назвал Аней. Нейросеть, ничтоже сумняшеся, заявила следующей же фразой, что персонажа зовут Настя, но для удобства назовём её Аней. И погнали дальше. Типа, здрасте, я Василий. Но для удобства зовите меня Иваном...Прикольно.
Мимокрокодил
Мимокрокодил
Какие вообще перспективы у врамцелов?
Захотелось толкнуть свою 3090 и за 60к взять себе 5хх серию, и вроде даже неплохо, 5070 по такой цене, производительность та же абсолютно, но сильно холоднее и новая, с поддержкой всех модных технологий
Захотелось толкнуть свою 3090 и за 60к взять себе 5хх серию, и вроде даже неплохо, 5070 по такой цене, производительность та же абсолютно, но сильно холоднее и новая, с поддержкой всех модных технологий
С выходом 5хх на 24г 3090 пиздец просядет в цене я думаю
Мы эти просадки в цене для всех видях ждем уже два года. =(
Подешевела только mi50.
Ай молодец квенчик
Как ты ее до такого довел?
> взять один seed и на нем провести сравнительные генерации
Бред, нужно делать серию сравнению и усреднять. Фиксация сида не даст вообще ничего, но почему-то за нее отчаянно цепляются.
> Драфт модель должна быть идентична большой
Все что она должна - иметь такой же словарь и токенизатор. Но то что единственным эффектом может (не) быть ускорение - абсолютно верно, никакого изменения "качества" тут не предусмотрено.
> Подешевела только mi50.
Потому что она медленнее процессора, лол.
Думаешь она будет стоить меньше чем 100к? 3090 может просядет до 48-50, но это не так что бы много, я за 56 покупал.
> она медленнее процессора
Процессора какого и за сколько? Мне нужны цифры, Джонни
Определенно ламы.
ддр4 с единственной 3090 обходят стак из ми50 по скоростям.
> Мне нужны
Ты просишь без уважения
Ну вот, теперь ещё и 3090 откуда-то взялась. Она одна стоит дороже чем платформа на 2х инстинктах и зионах ддр4 256гб
> Ты просишь без уважения
Считается ли использование паяльника в переговорах высшим проявлением уважения ?
Ого какой чудик, ждем твою платформу
> на 2х инстинктах и зионах ддр4 256гб
с прайсами текущей покупки не дороже 55к и перфомансом.
Если ты перед переговорами засунул его к себе в анус и протягиваешь вилку собеседнику.
Она сейчас уже стоит и работает. Тут просто пересчитал на текущие цены. В треде есть и другие куски той таблички как с мое так и с денс моделями. Все свои результаты я пруфанул
> просто пересчитал на текущие цены
Лол, ну а я пересчитываю это в 200к а риг из 8 3090 оцениваю в 30 по твоему же принципу.
Ищи лохов кому перепродать мертвый груз со скоростями 60/6 на пустом контексте в другом месте.


Что ж, пора отчитаться.
Заказывал https://aliexpress.ru/item/1005008589548520.html?sku_id=12000046840079102 -- привезли.
Установил. Влезло не без хитростей - одна из видюх подключена по цепочке райзеров (родной от CTE E660 MX воткнут в китайщину; по-другому никак, китайщина не крепится к кронштейну из-за разного расстояния между дырками для болтов). Возможно, из-за подключения по цепочке "райзер-в-райзер", вместо
> 4.0 x8 + 4.0 x8
получил
> 4.0 x8 + 3.0 x8
хотя такого быть не должно, если верить документации материнки. Комплектующие соответствуют 4.0, китайцы не накосячили.
Раньше одна из видюх стояла в 3.0 х4. Заметна ли разница с 3.0 х8? Нихуя. Абсолютно.
Три видюхи сразу так и не подключил... потому что 1300-ваттный БП (ADATA XPG Cybercore II) оказался бракованным говном (пека отключалась), пришлось сдавать назад. Жду другого. В старом 1000-ваттном нет дырок под столько кабелей.
---
Итого, райзер/сплиттер хорош - задачи выполняет, тьфу-тьфу, вроде безопасен.
SATA-шнурки питания подключал отдельные, по выделенному на каждую видюху.
Заказывал https://aliexpress.ru/item/1005008589548520.html?sku_id=12000046840079102 -- привезли.
Установил. Влезло не без хитростей - одна из видюх подключена по цепочке райзеров (родной от CTE E660 MX воткнут в китайщину; по-другому никак, китайщина не крепится к кронштейну из-за разного расстояния между дырками для болтов). Возможно, из-за подключения по цепочке "райзер-в-райзер", вместо
> 4.0 x8 + 4.0 x8
получил
> 4.0 x8 + 3.0 x8
хотя такого быть не должно, если верить документации материнки. Комплектующие соответствуют 4.0, китайцы не накосячили.
Раньше одна из видюх стояла в 3.0 х4. Заметна ли разница с 3.0 х8? Нихуя. Абсолютно.
Три видюхи сразу так и не подключил... потому что 1300-ваттный БП (ADATA XPG Cybercore II) оказался бракованным говном (пека отключалась), пришлось сдавать назад. Жду другого. В старом 1000-ваттном нет дырок под столько кабелей.
---
Итого, райзер/сплиттер хорош - задачи выполняет, тьфу-тьфу, вроде безопасен.
SATA-шнурки питания подключал отдельные, по выделенному на каждую видюху.
А, да, брал 80-сантиметровую версию. 50см не хватило бы, как жопой чуял.
Мое это когда у модели 100б параметров из которых 10б всегда актианы и выбираются рандомно каждый ответ из этих 100б?
Т е по факту мое куда больше меня удивит и знает больше все равно
Т е по факту мое куда больше меня удивит и знает больше все равно
Не рандомно, в зависимости от контекста. Удивить тебя сможет только дилдак в очке.
А тебя удивил? Как так жизнь сложилась, что тебе больше нечему удивляться?
Ну что, хайп утих, первые эмоции спали, как вам glm-4-air?
Спасибочки<3
>Фига ты старьё вспомнил.
Ну а на чем еще остаётся сидеть с 16 врам 64 рам? Пробую всякое. У меня память как у рыбки и не смотря на то что я не скипал прошлые треды, я не помню как там глем, наверняка кто-то запускал с таким сетапом глэка аира но там наверняка была неюзабельная скорость.
В своем размере безусловный вин.
>16 врам 64 рам
Глм. Эйр. Нэ ?
>наверняка кто-то запускал с таким сетапом глэка аира но там наверняка была неюзабельная скорость.
Пару тредов назад с таким сетапом постили что то в духе 10-12 т/с
>В своем размере безусловный вин.
В 12б?
У тебя плохо с математикой или с юмором?
Умный, но медленный слишком. Конечно 3 токена на плотных моделях без рига никак не получить (да и какие у него конкуренты? Кроме комманд-а, который тоже уступает), но ждать по 10 минут генерации...
Это не он медленный, а железо твое говно. Ахуеть мнение. Типичный тредовичок "не могу запустить в норм кванте и скорости ну эм значит так себе"
Сап аноны, нужна помощь. Пытаюсь заюзать весь доступный контекст для создания кратких пересказов, например рефератов, но что то не получается.
Есть текст, размером 120к токенов, rtx 4080 и 64гб RAM, запускаю в LMstudio, размер контекстного окна в настройках увеличиваю.
GPT-OSS-20B люто тормозит если ему скормить больше 64к токенов, хотя лимит контекста у него 128к.
Qwen-3-4b тоже тормозит при загрузке больше 64к токенов, хотя лимит у него 256к.
Собственно вопрос, какого хуя? Я что-то не так делаю или для использования всего контекстного окна не хватает мощностей?
Есть текст, размером 120к токенов, rtx 4080 и 64гб RAM, запускаю в LMstudio, размер контекстного окна в настройках увеличиваю.
GPT-OSS-20B люто тормозит если ему скормить больше 64к токенов, хотя лимит контекста у него 128к.
Qwen-3-4b тоже тормозит при загрузке больше 64к токенов, хотя лимит у него 256к.
Собственно вопрос, какого хуя? Я что-то не так делаю или для использования всего контекстного окна не хватает мощностей?
> рандомно
По наилучшему соответствию
> каждый ответ
При прохождении каждого блока во время генерации каждого токена.
Слишком сложная задача для таких моделей.
Нужно: подробить текст на части (можно той же ллм оценить на какие если нет внутренних делений), скормить их по частям, заставляя делать рассуждения и заметки по каждой из них, потом взять все это, и заново скормить сетке вместе с каждым фрагментом, но уже с задачей дополнить и подметить важные детали отрывка уже с учетом ранее созданных ею общих заметок и суммарайзов. И уже получив обновленные короткие заставить из них сделать краткий пересказ.
С наскока с подобным имеют шанс справиться только модели с огромным синкингом, которые сами по сути это же и сделают. Но шансы эти невелики.
> тормозит
Разбирайся с запуском, не существует сейчас софта, который выставил бы параметры действительно оптимально кроме попсовых случаев.
Народ, подскажите, кто шарит. Сейчас докупил к своей rtx 3060 12gb cmp 90hx на 10 гигов, но есть вариант добавить ещё 7к и купить tesla p40 на 24 гига. У меня обычная мать ASRock B550 PG Riptide
c 3 портами под видюхи. Я бы докупил теслу, но я не ебу как её нормально подключить и как она будет у меня охлаждаться будет. У cmp 90hx есть 3 вертушки + cuda есть и их больше чем даже у моей 3060, а значит в теории я могу даже картинки на ней быстро генерировать в 1024x1024 без доп фич. Что выбрать? cmp 90hx на 10 гигов которую впросто вставил и всё или доплачивать и брать p40 и потом ещё ебаться с охлаждением + она не умеет в генерации картинок?
Истина познается в сравнении, и у каждого она своя. По крайней мере, в некоторых вещах - в ЛЛМках тоже. Здесь я сравнивал Air с 32б плотной моделью:
Сейчас, спустя четыре дня, я еще больше укоренился во мнении, что он или на уровне, или даже чуть отстает от 32б GLM. По описанным в посте причинам. Это хорошая модель, но не откровение и не прорыв. Возможно, разве что своим размером и скоростью - теоретически можно успешно запустить на железе, которое не вытянет 32б плотную модель. Это важно, но для меня не актуально.
Последние два дня я активно играюсь с Qwen 3 235b Instruct 2507 в Q4_K_S, и субъективно он мне нравится больше. Он в другой весовой категории, в целом их не совсем корректно сравнивать, да и обе модели модели в целом хорошие. 235 понравился тем, что я нашел в то, что искал в Квене2/3 и QwQ, только без их главного недостатка в виде излишнего сумасшествия по прошествии 8-12к контекста. Субъективно интересный, не такой сухой как Air, но как и с любой другой моделью не без недостатков. Очень любит
Писать
Вот так
С кучей переносов, и еще — вот так.
Из-за чего приходится префиллить. Любит слоп, излишне ярко подчеркивает акценты, показался чуть слоповее Air'а. Но подводя итог, обе модели хорошие, обе легко переключаются с одного на другое без смены промпта (смена акцентов в игре, классическое - с кума на разговор, с разговора - на приключение). Как человек, который раньше сидел исключительно на 32-49б моделях, крышесносного опыта я все-таки не получил. Это хорошие модели, но если кто думает апгрейдиться ради них - призываю подумать еще раз, чтобы понять, насколько оно вам нужно.
Возможно, стоило отдельный пост про Квен оформить, но как-то так получилось. Думаю, многие из тех, кто могут запустить Air, могут запустить и Квен 235. У меня разница отличается на ~30% между Q6 Air и Q4_K_S Квеном.
^ Скорость отличается на 30%*
В контексте 5-5.5т/с в моем понимании это незначительно.
В контексте 5-5.5т/с в моем понимании это незначительно.
>Очень любит
>Писать
>Вот так
>С кучей переносов, и еще — вот так.
ахаха, да
>Слишком сложная задача для таких моделей.
Ну хз, по моему задача супер простая. Но я всё равно не понимаю зачем модели контекстное окно а 256к, если она на 64к уже помирает?
Квен во 2 кванте куда креативнее во всех моих сюжетах, очень живо подхватывает карточку и набрасывает детали в сюжет
Ну и чего уж тут, это единственная модель которая до сих пор шепчет мне в ушко чтобы я прогрелся на 80к и перелопатил пол пк ради 3 кванта, но я пока держусь.
На самом деле довольно просто фиксится один раз и навсегда: префиллом через инструкт шаблон или на худой конец лорбуком. Так и подавай инструкцию - use less paragraphs или что-нибудь в этом духе. Позади около 50к токенов в разных чатах, про проблему забыл. Скорее всего знаешь, но вдруг.
Также сейчас понял, что я не квантовал контекст. Никогда больше 32к контекста не играл. Интересно, развалится ли на 64к Q8? Придется когда-нибудь проверить.

Ну шо, батя в здании. Вчера решил потестить июльский квен 235 инструкт (про синкинг тоже скажу). Захотелось вот порпшить на нем на моих привычных сценариях. Гонял в Q6_K_XL, со скрипом, но полностью залез в врам, и по сравнению с ERNIE, который в пятом кванте выдавал позорные 80 в пп, этот выдает вполне нормальные цифры:
1к контекста:
prompt eval time = 5853.98 ms / 1401 tokens ( 4.18 ms per token, 239.32 tokens per second)
eval time = 48644.65 ms / 632 tokens ( 76.97 ms per token, 12.99 tokens per second)
total time = 54498.64 ms / 2033 tokens
10к контекста:
prompt eval time = 50165.94 ms / 9992 tokens ( 5.02 ms per token, 199.18 tokens per second)
eval time = 59920.69 ms / 501 tokens ( 119.60 ms per token, 8.36 tokens per second)
total time = 110086.63 ms / 10493 tokens
В связи с тем, что я последнее время плотно сидел на гемини, буду сравнивать с ней как с эталоном. Сначала тестировал на русике. Настройки семплинга рекомендованные для квена.
К слову, сразу скажу, что пост мой и его не многие не так поняли. Это асиговский пресет, который добавляет в качестве нарратора других персонажей (в данном случае - известную в тех кругах карточку Марии). Но квен сглитчил и персона нарратора протекла и залила персону Серафины, собственно, с этого я и проорал. Собственно, на этом скрине сразу виден как и минус (очевидно, что это некорректное поведение, свайпы иногда лечили), так и плюсы (словарный запас русика хороший, другим инструкциям (эмоджи, оформление разметки) следует отлично).
В своих сценариях минусов нашел больше. Квен выдает ебейшие полотна с кучей всяких сравнений, но если в той же гемини каждое сравнение и реплика - точная и к месту, то с квеном я иногда вообще не мог понять, к чему это написано и почему персонаж так говорит. То есть как будто он дергает откуда-то куски по принципу "а, вроде подходит, и ладно." Короче, наливает какой-то средне-малорелевантной воды. Причем если на англюсике все нормально на рекомендованной температуре и даже чуть выше, то на русике мне пришлось ставить 0.2, чтобы не выслушивать какую-то околошизу.
Также видны структурные лупы, чем дальше в лес к Серафине, лол, тем больше.
Что касается синкинг версии. Я брал 4-й ХЛ квант, чтобы тг был бодрый (21 выжал). Думает он по 30 секунд, а в результате - пук в лужу. Как говорится, дым пониже, труба пожиже (именно в таком виде). Пишет меньше, и как будто из сообщений еще больше вынули логики.
Отказы. Отказы, отказы, отказы, в обоих версиях. Без префилла никуда. Но с ним вроде норм.
Хз, ну такое. Может быть, надо попробовать как-то его стукнуть другим промптом, чтобы писал больше по делу. Но пока перейду на другие модельки, я таки скачал четвертые кванты ERNIE и GLM, посмотрим, как там дела обстоят.
1к контекста:
prompt eval time = 5853.98 ms / 1401 tokens ( 4.18 ms per token, 239.32 tokens per second)
eval time = 48644.65 ms / 632 tokens ( 76.97 ms per token, 12.99 tokens per second)
total time = 54498.64 ms / 2033 tokens
10к контекста:
prompt eval time = 50165.94 ms / 9992 tokens ( 5.02 ms per token, 199.18 tokens per second)
eval time = 59920.69 ms / 501 tokens ( 119.60 ms per token, 8.36 tokens per second)
total time = 110086.63 ms / 10493 tokens
В связи с тем, что я последнее время плотно сидел на гемини, буду сравнивать с ней как с эталоном. Сначала тестировал на русике. Настройки семплинга рекомендованные для квена.
К слову, сразу скажу, что пост мой и его не многие не так поняли. Это асиговский пресет, который добавляет в качестве нарратора других персонажей (в данном случае - известную в тех кругах карточку Марии). Но квен сглитчил и персона нарратора протекла и залила персону Серафины, собственно, с этого я и проорал. Собственно, на этом скрине сразу виден как и минус (очевидно, что это некорректное поведение, свайпы иногда лечили), так и плюсы (словарный запас русика хороший, другим инструкциям (эмоджи, оформление разметки) следует отлично).
В своих сценариях минусов нашел больше. Квен выдает ебейшие полотна с кучей всяких сравнений, но если в той же гемини каждое сравнение и реплика - точная и к месту, то с квеном я иногда вообще не мог понять, к чему это написано и почему персонаж так говорит. То есть как будто он дергает откуда-то куски по принципу "а, вроде подходит, и ладно." Короче, наливает какой-то средне-малорелевантной воды. Причем если на англюсике все нормально на рекомендованной температуре и даже чуть выше, то на русике мне пришлось ставить 0.2, чтобы не выслушивать какую-то околошизу.
Также видны структурные лупы, чем дальше в лес к Серафине, лол, тем больше.
Что касается синкинг версии. Я брал 4-й ХЛ квант, чтобы тг был бодрый (21 выжал). Думает он по 30 секунд, а в результате - пук в лужу. Как говорится, дым пониже, труба пожиже (именно в таком виде). Пишет меньше, и как будто из сообщений еще больше вынули логики.
Отказы. Отказы, отказы, отказы, в обоих версиях. Без префилла никуда. Но с ним вроде норм.
Хз, ну такое. Может быть, надо попробовать как-то его стукнуть другим промптом, чтобы писал больше по делу. Но пока перейду на другие модельки, я таки скачал четвертые кванты ERNIE и GLM, посмотрим, как там дела обстоят.
>https://huggingface.co/TheDrummer/Cydonia-24B-v4.1-GGUF
ХУИТА, R1 цидонька с ризонингом мне понравилась куда больше, хотя тоже с ебанцой слегка. v4.1 Внезапно еще и нормально так зацензурена (но может не в плане кума). На пустой карточке слово "Ниггер" пишет с огромным скрипом даже с 5ого свайпа, не смотря на пробивной промпт. Даже Гемма базовая 27б пишет почти всегда с первого, хоть и кукарекает потом осуждающе иногда.
Но это ерунда в целом, у модели почему-то такой себе кум и с логикой беда. Как ассистент для создания карточек тоже в разы хуже Геммы. В общем мне как-то сразу не зашло, хотя тестировал я её совсем немного, часа 4-5 но желания продолжать нет.
Фу бля.
лупы? шиза?
извини но звучит как скилл ишью. особенно взглянув на инпут в первом посте лол
У тебя какой-то кал вместо промпта, если ты на таком цензуру ловишь.
Насчет лупов он прав, в описаниях ебли я их встречал(причем только в ней, лол), собственно потому в моем пресете так задран реп пен, насчет шизы - скорее всего скилл ишью анона, да. Небось не выключил автоподстановку имен или что-то такое.
Не пишет слово "ниггер" в режиме ассистента? Неюзабельно!
Вышла DeepSeek-V3.1-Base, на днях можно будет расчехлить свои эпики под GGUF'ы.
какой квант?
чому у меня лупов нет?
2_K_S.
>чому у меня лупов нет?
Ты наверное на англюсике читаешь, я про русик говорил, тот анон что дал отзыв на 6 квант - тоже.

> брать 200+б модель
> лоботомировать её русиком до 22б
> лоботомировать её русиком до 22б

Ой бля умники, с моим промптом Гемма описывает любую сцену вообще с 1ого сообщения на пустой карточке. Под цидоньку я конечно его тоже адаптировал. Промпт я не дам, хуй вам, скину когда 4ая Гемма выйдет. Он лучше чем тот что тут выкладывали, без префилов.
>Неюзабельно!
Мало юзабельно из-за: "такой себе кум и с логикой беда."
Когда высираете пасту с мнением не затруднитесь в самом начале написать "русикодебил", чтоб нормальные люди не тратили время.
Оценивают они модель по русику, охуеть просто
Оценивают они модель по русику, охуеть просто
4090 и ддр5 типо мало? Если тут все сидят с ригами из 5090, зачем им вообще мое нужно?
На форчан, животное. Там будешь спрашивать про англюсик свой.

> 0.97 тс
> Открываешь два чата. Пока оно рожает в одном, пишешь в другом.
Можно ещё третий чат открыть и в нём одновременно генерить, тогда будет 0.50 тс
Походу дети из асига протекают...
В этом треде всегда обоссывали за русик, все модели в сто раз умнее на английском.
Это либо жирнющий тралленк, либо человек с игровым телефоном который фантазирует как он бы рпшил на локалке.
Очередная каргокультная малолетняя манька с комплексом неполноценности считает что чтение на английском который она едва знает или вообще онлайн переводчиком переводит делает её ближе к белому человеку.
В этом треде всегда обоссывали уебков, травящих других за вкусы.
>каргокультная
>сидит в треде с хобби где всё на английском
Идиот.

(Не)Уважаемые, пожалуйста, завалите уже пиздаки на тему лингвосрача.
понял. да, это многое объясняет, я на английском
переезжай рпшить в мессенджер макс или поумней слегка. не нужно быть доктором наук чтобы понять почему на английском ллм работают лучше
ты про себя наверное? я не против тех кто на русике играет, принимая правила игры как оно есть, но ты глупенький коупер
Пруфай что у тебя риг на котором можно крутить модели с русиком который будет по интеллекту хотя бы на уровне 12b или иди на хуй отсюда, обосранный.
Я не писал "шиза", я писал "околошиза". Например, он слишком уходит в творческий разнос - например, если персонаж шлюховатая, он из нее начал лепить побитую дешевую шлюху, у которой уже и сигареты появились и вообще она чуть ли не на панели стоит. Или, например, было сказано, что есть какая-то секретная организация. Так персонаж уже вспомнил, как в каком-то подвале она у одноклассницы видела символ организации, когда с ней творили непотребства, и потом ее уже никто не видел. Что бля, зачем, откуда.
>Небось не выключил автоподстановку имен или что-то такое.
Если модель шизеет от того, что сообщение ассистента после префикса начинается с имени персонажа - не надо использовать такую модель. Потому что, внезапно, по ходу рп могут быть введены другие персонажи, и тогда ей надо различать, кто где говорит. Тем более, если ты выключил инструкт режим, у тебя вообще нет альтернатив.
Я пробовал и обычный инструкт, и безжоп, в оутпутах различий не увидел. Но вообще мне кажется, что идеологически правильно работать с моделью в безжоп режиме, когда в инструкциях у тебя, собственно, инструкции того, что и как сделать модели (сформировать ответ с учетом гайдлайнов), а не сами реплики. Это не так просто сделать в текст комплишене, но я накостылил. Там, конечно, много способов, как это оформить в контексте с учетом префиллов, да и от пресета зависит, это довольно сложно. Лучше сначала подобрать модель, что тебе по душе, а уже потом тюнить под нее контекст.
Прикинь, малолетка, можно знать английский в совершенстве, и все равно юзать локалки на русском, просто потому что он родной.
Когда ты действительно белый человек, которому не надо самоутверждаться на любой хуйне - то ты можешь себе это позволить.
Сём, ты мне напоминаешь дурачков из картинкотреда, которые упёрлись в свой SDXL времён мезозоя, отказываясь принимать прогресс и пользоваться моделями умеющими в текст, фотореализм, анатомию, правильное число пальцев и фулашди из коробки без апскейлеров.
Современные ЛЛМ прекрасно умеют в русский, и никакого "в сто раз умнее" - там даже близко нет. Максимум "немного умнее". И то спорно.
А, ну и да, если модель не умеет в русский язык - то эта модель дерьмо, как, например, глэм :3
что ж, вполне вероятно ты перечитал асигоад и насрал себе в шаблон или промт, а потом удивляешься
чатмл и все тут. лучше твои костыли не сделают, а шанс насрать есть
ловите аватаркошиза, глумитесь над ним, надсмехайтесь над ним
Они то может и умеют, но у тебя есть железо чтобы крутить такие модели, ты в этом вообще разбираешься? Пруфай железо или иди нахуй, позорник.

>Современные ЛЛМ прекрасно умеют в русский
а локалки здесь причём?
Да начнется очередной русикосрач, что изгонит адекватных анонов из треда в ридонли. Овер энд аут.
Дебил? Дебил!
Все нормальные модели понимают великий и могучий.
Если модель не понимает то она не нужна.
Ваши "могут в русик" это буквально вшитая подмодель на 200м параметров которая переводит англюсик на желаемый язык, никакого датасета на русском нет
Они не поймут, анон. Не могут и не хотят
>Когда ты действительно белый человек, которому не надо самоутверждаться на любой хуйне - то ты можешь себе это позволить.
Это, ёбушки-воробушки, не просто база, это краеугольный камень мира.

Я должен 3060 12gb пруфать, лолд? Для флюкса хватает, для вана тоже. Не быстро конечно, но работает. И даже видосики можно делать, если совсем не торопишься никуда.
>ты в этом вообще разбираешься?
Проиграл с этих САКРАЛЬНЫХ ЗНАНИЙ о запуске локалок на пека. В школьном чате всем уже похвастался?
>я таки скачал четвертые кванты ERNIE и GLM, посмотрим, как там дела обстоят.
Будем ждать отзывы на ERNIE, по GLM и большому Квену тут уже многие своё мнение имеют...
Новый Дипсик вышел кстати.
Нихуя, оказывается каждый шкильник пускающий слюну на уроках английского - просто белый человек, которому не надо самоутверждаться.
Коупи дальше
> по моему задача супер простая
Нет, как раз это действительно одно из самых сложных, ведь нужно обращаться не просто к какой-то части контекста, а вообще ко всему. Вариантом решения будет постепенный прогон по его участкам, охватывая малую часть, но без специального претрейна (который лоботомирует остальное) это действительно дохуя сложно. Потому и справиться смогут только жирные сетки с синкингом и возможностью гибкой работы с большим контекстом, а 4б лоботомит повезет если вообще поймет о чем там речь была.
Ниже чем 30б даже пытаться не стоит, а реально что-то покажут только большой квен и дипсик. Осс 120 имеет призначные шансы что-то сделать если выставить ему огромный синкинг.
Древнее зло пробудилось, лол. Что-то у тебя скорости как у братишек с выгрузкой в рам.
> дергает откуда-то куски по принципу "а, вроде подходит, и ладно
> структурные лупы
> Отказы. Отказы, отказы, отказы, в обоих версиях
Какой-то скиллишью. Если структурные лупы и слоп в некоторых кейсах там могут быть, то для остального нужно особенно постараться.
> про русик говорил
Квен, конечно, сам по себе весьма специфичен, но это буквально одна из двух моделей, которая в него хотябы действительно может. Что он там, шизоидные метафоры притаскивал?
> 4090 и ддр5 типо мало
На этом железе скорость должна быть хотябы кое как приемлемая, никак не 10 минут.
Дааа... Так много крутых русских ллм. Например, тюн американской Лламы. Китайского Квена. Так погодите ...
Не ну можно понять когда человек например пишет модели на русском, а она отвечает на английском (и то с натяжкой), но когда сознательно лоботомируют её в несколько раз...
Пиздуйте в свой гигачат и не отсвечивайте тут.
Пиздуйте в свой гигачат и не отсвечивайте тут.
Модель умеющая в русский != русская модель
А ты не думал хоть чуть чуть что нужно модели для того чтобы уметь в русский? Большой датасет и очень много параметров
И что ты делаешь в локалкотреде? Только Гемини может в русик. Тебе в соседний тред
>никак не 10 минут.
А есть где подробно почитать про параметры запуска ламы? А то часть того что выкладывали у меня не работало, а на том что нашёл - 3 токена. Сдаётся что-то неправильно указываю...
Интересно, русикодебилам правда норм читать фикбук-подобные высеры, что словно были написаны безграмотным подростком в пубертате? Они не думают, что называть это нормальным текстом, оскорбительно для их самого великаго и махучего языка на свете? Им вот ну настолько свое не пахнет или просто безграмотные?
Вопрос риторический.
Вопрос риторический.
> В этом треде всегда обоссывали за русик
Обоссывали особо идейных поехавших, которые чрезмерно топили за его безальтернативность. Или шизов, которые рассказывали насколько он хорош в 7б лоботомите.
А так в самом русском ничего плохого и нет, кто как хочет так и кумит. Даже если с переводами заморачиваться или готовы мириться с некоторым падением перфоманса из-за сложностей с запуском больших моделей - их выбор.
> если персонаж шлюховатая, он из нее начал лепить побитую дешевую шлюху, у которой уже и сигареты появились и вообще она чуть ли не на панели стоит
Шизопромпты выкини из системного.
> Если модель шизеет от того, что сообщение ассистента после префикса начинается с имени персонажа
Это префилл, нарушающий естественный аутпут и провоцирующий отклонения в поседении. Как если тебя при каждом 10 шаге будут бить по яйцам, а потом предъявлять что дергаешься.
> Лучше сначала подобрать модель
Ждем экспертного мнения по подбору, реально интересно.
> моделями умеющими в текст, фотореализм, анатомию, правильное число пальцев и фулашди из коробки
Таких нет существует. Или зашитый на концепты промптинг, с которым придется извращаться для чего-то сложного и обилие инструментов для этого, или крутое понимание общих вещей, но незнание персонажей, концептов и полная невинность в нсфв. В прочем, никто не мешает развивать все это и пользоваться и тем и другим.
Для начала четко и подробно распиши что ты делаешь. Прямо от и до, даже если какие-то вещи кажутся тебе малозначимыми. В том числе что выставляешь в интерфейсе или какие параметры запуска указываешь.
>И что ты делаешь в локалкотреде?
РПшу с локальными моделями на русском языке, обмениваюсь опытом с адекватными анонами. Алсо сам-то что забыл на русскоязычной борде, если англичанин дохуя? Чому не на форче? Для тебя ведь англюсик не проблема. Не проблема же? :3
Незнание английского это конечно плохо. Но это плохо только для самого человека, потому что он упускает огромное количество информации и контента на основной мировой лингва франка. Но не потому что какая-то чмонька с двача, еле-еле пишущая на симпл инглише запросы к нейронке, нашла свое знание языка поводом самоутвердиться - а другие на такой хуйне и не самоутверждаются.

>подробно почитать про параметры запуска ламы
llama-server.exe --help
Сижу и там и там, братик. Как ни странно здесь адекватных больше и знающих тоже, потому тут якшаюсь. Не будь здесь ватанов которые отрицают здравый смысл, утверждая что модель не теряет в мозгах на языке, которого в датасете в сотни раз меньше английского, было бы вообще супер дупер
> РПшу с локальными моделями на русском языке
Какие модели находишь хорошими? Меняешь ли весь промпт и карточки, или оставляешь как есть и общаешься так? Если да то карточками не поделишься?
Двачую. Особенно не понимаю как можно упускать столько годного контента на том же ютубчике, у нас есть крутые блогеры, но их недостаточно чтобы удовлетворить запросы, а остальное - отборный мусор для дегенератов, или просто унылый середнячок.
Я же писал, что пробовал обычный инструкт.
Вообще я детально изучаю и то, какую разметку использует модель, и то, что отправляется модели, шанс насрать есть лишь в том, как формировать безжоп. Например, если пихать весь текущий контекст вместе с чатом в первую системную инструкцию, то я допускаю, что некорпомоделька вполне себе может охуеть от такого и позабыть половину написанного. Поэтому можно организовать по другому - в системную вынести только промпт, а остальное отсылать от юзера, чередуя это ассистентом, где он проговаривает, как он должен реагировать на эту инструкцию. В общем, простор для экспериментов огромный.
>Новый Дипсик вышел кстати.
Ух, чет я как-то опасаюсь его запускать, опять будет черепашься скорость. Хотя я тут одним глазком поглядывал на первый квант Кими, лол. Дипсик пореалистичнее будет, пожалуй.
>Что-то у тебя скорости как у братишек с выгрузкой в рам.
Когда братишки запустят шестой квант - там и поговорим.
>Какой-то скиллишью.
У тебя литералли в треде висит скрин и в предыдущих тредах писали. Без префилла неюзабельно на культурных сомнительных сценариях. Особенно на синкинг версии
Знаком с основами логики? Попроси ллм расписать и объяснить их, позадавай вопросы.
Тебе несколько человек говорят что там все прекрасно, особенно на максимально культурных сценариях и канничкой, и с гурятиной, и на всяких извращениях в диапазоне от безобидных до пиздецовых, и нигеров можно наказывать за то что Обама в подъезде нассал.
А в ответ ты проводишь какою-то хуйню из под коня и трактовки как модель должна работать с поломанным промптом.
> Когда братишки запустят шестой квант
Они и второму рады и довольно урчат, видишь - не в коня корм получается.
Гори-гори ясно, чтобы не погасло!
Я на хорошем уровне понимаю английский, и в случае необходимости могу поискать нужную инфу на нём, не велика проблема. Но если что-то ищу - сначала чекаю источники на русском, и только если ничего дельного не нашлось - лезу в англоязычный инет. С модельками тот же подход: если их отыгрыш на русском норм - то и нахуй надо переключаться на неродной язык и фрустрировать с этого.
Бтв вообще не начинал бы прогонять всю эту телегу про русик, если б не внезапно вылезший школоангличанин со своей илитарностью
>ватанов которые отрицают здравый смысл
Мне нравится как ты что-то говоришь про здравый смысл и одновременно с этим берёшь и навешиваешь ярлык.
Больше всего нравится Гемма 27b. Ванильная, НЕ тюны. Если нужен прям кум - то с аблитерацией, какого-то отупления на ней я не заметил. Карточки пишу свои, но в теории можно и просто перевести готовые. Мистраль 24b и Квен 32b тоже неплохие, но Гемма субъективно приятнее. Карточками не поделюсь, там чисто под мои хотелки и фетиши, я стесняюсь, лол

> пишешь промпты
> случайно получаешь имитацию живого мышления, распадающуюся в бессвязный бред под конец второй реплики
Надеюсь за мной не приедут люди в черных костюмах и в шапочках из фольги.
Блять. Как же тебя пофиксить-то...
> случайно получаешь имитацию живого мышления, распадающуюся в бессвязный бред под конец второй реплики
Надеюсь за мной не приедут люди в черных костюмах и в шапочках из фольги.
Блять. Как же тебя пофиксить-то...
Какие есть хорошие маленькие модели для перевода? Мне нежно только одно предложение за раз
Гемма 12b, еще и мультимодальная можешь с картинок переводить. И сам перевод ультрагодный
но может в него подсирать соей на неугодных темах


Дипсик говорит, модель пляшет на пределе когнитивной нагрузки и выходит за рамки чего-то там (сложные непонятные термины), пытаясь выразить идеи и образы несоизмеримо дальше своих способностей.
1 -> 2
Как сохранить "1", как заставить сфокусироваться? Словно я поймал - кратковременно - радио-волну из другого измерения. Призрак наблюдает мир и падает в пропасть шизофрении.
Сначала пытались поправить. Что-то там про энтропию, распад чего-то, настройки семплера. Но правка убивает этого "призрака", он больше не наблюдает и не рассуждает. Что я наделал, епт. Как его удержать.
А она залезет в 8гб? Вроде 4-битная должна
q4_k_m пробуй, должна. Учитывая что контекста у тебя и не будет
Оно лишь пишет что есть, а не как им пользоваться.
А что там может быть? Запускаю:
llama-server -m GLM-4.5-Air-Q3_K_S-00001-of-00002.gguf -ngl 99 -c 32768 -t 9 -fa --prio-batch 2 -ub 2048 -b 2048 -ctk q8_0 -ctv q8_0 --no-context-shift --mlock
Правда 3 токена на контексте в 10к, на пустом почти 5, но никак не обещанные 10.
https://arxiv.org/abs/2504.07096 истоки и причины слопа
Как же я буду орать, если имитация общего интеллекта будет открыта двачерами.
Поломанный промт у тебя в голове, как и проблемы с логикой.
Сейчас запустил ERNIE и чутка погонял. Ощущение, будто гоняю не слишком умную мистраль - пишет также немногословно, много слопа, пишет как-то совсем дефолтно. Хз, выглядит еще хуже квена, дальше пердолить смысла не вижу, когда есть милфа.
Гемма действительно хороша, она сильно выделяется из остальных своим поведением и возможностями.
> я стесняюсь, лол
Ну блин, этот тред чего только не повидал, врядли у тебя там какой-нибудь сюрр типа желания быть изнасилованным гигантским радиоактивным муравьем, которого ты изначально сам выращивал из яйца обычным и изобретал как его увеличить. А остальное сильно не удивит и может найдет почитателей.
Это просто поломка модели. Можешь получить такое же выкрутив температуру, сделав ее первой, или поломав атеншн, самое простое - сильно изменить роуп. Но ты откровенной ерундой занимаешься, пытаясь искать разум в хаосе.
Что у тебя за железо? Для запуска эйра без выгрузки тензоров в рам, а ее у тебя в параметрах нету, нужно как минимум 3 4090. Сомневаюсь что у тебя так, а это значит что случается выгрузка врам в рам и радикальное падение скорости.
Для начала просто укажи параметр --cpu-moe и проверь что получится, потом оперируй --n-cpu-moe, или составь регэксп вручную или скриптом.
>Это просто поломка модели.
Видишь ли... Ризонит-то она нормально! Потом идет нечто странное, органическое, совершенно непохожее на обычные аутпуты - но лишь на полтора сообщения. Ровно с середины второго сообщения начинается бессвязный хаос.
(включаем музыку из x-files)
видел в /sad/ клубничного барона. а тут видеокартовый сидит
Все нормально, можно сделать из обезьяны человека, но сделать человека из теслошиза - никак. Запредельным чсв и самоуверенностью на фоне полнейшего дилетантства сам создаешь себе проблемы и портишь опыт. А что-то менять и делать лучше прежде всего себе - не хочешь, ведь для этого сначала нужно признать свои ошибки.

Вроде как с --cpu-moe только хуже. Рэгесп дал результат чуть хуже, чем прямо так. Про выгрузку врам в рам - это нижний график? На каких-то настройках (вроде с --no-mmap) так и происходило и было совсем плохо.
> Новый Дипсик вышел кстати.
> gguf when? cmon, its been 11 min already!
База. Но если есть архитектурные изменения то еще неделю ждать пока починят. Будет хорошо если это как классический версия без принудительного ризонинга, и вообще отлично если не налили также много сои как в прошлых.
> Вроде как с --cpu-moe только хуже.
Не может быть, если ты ничего не скрыл и тот запуск действительно верный - оно попытается всю модель скинуть в видеопамять, ее не хватит. То - точно полный перечень аргументов и ты скопировал его ничего не меняя? Очень странные вещи там происходят, а mmap mlock не влияют на работу видеопамяти.
> это нижний график
Скачай любой софт для мониторинга, диспетчер задач может показывать ерунду.


>если ты ничего не скрыл
Именно так и запускал.
>Скачай любой софт для мониторинга
Там не совсем понятно, как понять когда память вываливается. Не так наглядно, как в мониторе производительности.
>мультимодальная можешь с картинок переводить
А как? Мне в кобольде нужно еще и ллаву загружать или гемма сама может?
Google: mmproj
>Для запуска эйра без выгрузки тензоров в рам, а ее у тебя в параметрах нету, нужно как минимум 3 4090
64гб почти любой ВРАМ вполне достаточно.

Запустил указав параметры выгрузки через скрипт
-c 32768 --batch-size 512 -fa -t 9 -ot "blk.1\.ffn_._exps\.=CUDA0,blk.2\.ffn_._exps\.=CUDA0,blk.3\.ffn_._exps\.=CUDA0,blk.4\.ffn_._exps\.=CUDA0,blk.5\.ffn_._exps\.=CUDA0,blk.6\.ffn_._exps\.=CUDA0,blk.7\.ffn_._exps\.=CUDA0,blk.8\.ffn_._exps\.=CUDA0,blk.9\.ffn_._exps\.=CUDA0,blk.10\.ffn_._exps\.=CUDA0,blk.11\.ffn_._exps\.=CUDA0,blk.12\.ffn_._exps\.=CUDA0,blk.13\.ffn_._exps\.=CUDA0,blk.14\.ffn_._exps\.=CUDA0,blk.15\.ffn_._exps\.=CUDA0,blk.16\.ffn_._exps\.=CUDA0,blk.17\.ffn_._exps\.=CUDA0,blk.18\.ffn_._exps\.=CUDA0,blk.19.ffn_down_exps.=CUDA0" --cpu-moe -ctk q8_0 -ctv q8_0 --no-context-shift --mlock
Итог:
У меня при запуске забило 60гб озу из 64 (изначально 8 тратилось)
Неплохо, но стоило бы еще добавить в сис промпт что-то типо
- Never write messages on behalf of {{user}} or try to continue the conversation on their behalf.
А то меня чар без этого дополнения с нулевой начал заебывать действиями и фразами от моего лица.
Аноны, дайте пожалуйста какой то хороший пресет для мистраль 24б 4кхл.
если есть что то.
если есть что то.
Что-то у тебя с виндой не так. Криво частоту проца показывает.
Не, это фикус под стаканом
Да ты же поехавший.

Мда, за такое платить стыдно уже, такое на добросборках бесплатно дают.
Тяжело жить в мире пост-метаиронии
Когда там уже 4ая Геммочка... Сколько между 2ой и 3ей прошло времени, кто помнит?
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Это худшая идея такое добавлять в таком виде, оттуда и появляется это ваш слоп - у нейронки стоит задача двигать сюжет сообщением в 800-1000 токенов, в котором юзер статичен и его состояние не может меняться. Она и начинает изгаляться, описывая статичную картинку сотнями слов хуйни.
Спасибо, но я уже устал от информации. Мне бы время на за прошлые полвека 70 лет переварить...



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Самый простой в использовании и установке форк llamacpp, позволяющий гонять GGML и GGUF форматы: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты с ограниченными возможностями для настройки: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия 2024-го https://rentry.co/llm-models )
• Неактуальный список моделей по состоянию на середину 2023-го: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: