



The base of THREADE
Даже если твоя правая рука сильнее левой, не забывай про зарядку.
Даже если твоя правая рука сильнее левой, не забывай про зарядку.
>И не используй iq кванты с мое, замедление очень существенное.
Другой крокодил Конкретно для Air, iq кванты имеют большой смысл. У меня память в конфигурации 12v+8v+64r - и статический квант, даже q4_ks туда нормально не лезет. А вот Iq4xs - влазит спокойно. Субъективная же разница по качеству вывода с Q3 на котором мне бы пришлось сидеть со статикой - весьма высока. Причем скорость генерации у меня все равно достаточно комфортная, скорее время процессинга напрягает, при большом контексте (но это и на Q3 так). Так что, не стоит так категорично от них отговаривать.
>512гб ддр4 серверной стоят 37к, доска 6-7к, процы по 3-5к
Это где такие цены?
Мне тут неделю назад советовали glm air 4.5
Наконец-то дошли руки и ...? Как это запустить? Даже в 4 кванте это 60+ Гб. Вы по 2 токена в секунду генерируете?
Или я что-то упускаю? Посоветуйте что-нибудь крутое для рп на 24 врама.
Алсо, кто-нибудь тут экспериментировал с долгосрочной памятью - эмбедингами или rag?
Наконец-то дошли руки и ...? Как это запустить? Даже в 4 кванте это 60+ Гб. Вы по 2 токена в секунду генерируете?
Или я что-то упускаю? Посоветуйте что-нибудь крутое для рп на 24 врама.
Алсо, кто-нибудь тут экспериментировал с долгосрочной памятью - эмбедингами или rag?
> Как это запустить?
Тредов пять уже все обсуждают как. Берешь и запускаешь.
Это же МОЕ.
>Вы по 2 токена в секунду генерируете?
По три. Вечером попробую линь накатить и из под неё запускать.
И что, она НАСТОЛЬКО круче, что стоит этих компромиссов?
поставил на скачивание
Вообще, по 6-12.
Нет, конечно, тут сам пердолинг вставляет
Это небось на риге из 4090.
В 4-ом кванте - да. (Но русский у нее весьма слабый сам по себе, за ним - лучше куда-то еще). В третьем кванте - внешне пишет красивше чем мистраль с геммой, но при этом плосковато, серьезной глубины не чувствуется. А вот в четвертом - это да. Прямо сильно лучше, IMHO. И четвертый iq4xs - это как раз 62 Гб, вместе в vram остается на систему, если 64Гб на борту.
На 4090+ddr5 на аире 12-17 т.с.
На двухбитном 2_k_s квене - 9-12 т.с.
Вот у меня как раз 64рама и есть. Посмотрю, но настроен скептично, если честно.
А без пердолинга есть что-то крутое для русского рп чтобы полностью в 24врам влезло?
Из последнего что я тыкал и мне понравилось - сидонька, её мерж с пантеоном (вроде) и некий darkatom.
Анрелейтед к тому, просто нужна такая с не-фурри.
Это приличный представитель современных моделей что уже достаточно умны и в базе могут в рп, пусть и младший.
> для русского рп
Гемма, лол. Русский в айэр и жлм 4.5 в целом мэх, само рп хорошее, особенно в большом.
Какое совпадение, у меня тоже 4090 и 64гб ддр5. Запускаю гуфф с ламма.сср как тут советуют. И 2,5 токена на озу. И это на q3 лишь.
Ну значит вы прокляты.
Заебало уже переливать из пустого в порожнее. Почему то у анонов, которые делали отзывы на квен/эйр и приносили скриншоты - все работает быстро.
А тут на 4090 не работает. Мммагия..
> А без пердолинга
Весь пердолинг это написать батник, скопировав его с позапозапрошлого треда. Погуглить что за что отвечает, изменить как твоей душе угодно и жамкать запуск.
Никогда еще так в жизни не пердолился. И это пишу я, та еще обезьяна, которая не отличит / от \.
Нет, если конечно тензоры ручками выгружать, это уже похоже на пердолинг. Но разобравшись, это обычная работа с таблицей. Это значение поменьше сюда, побольше сюда.
В Жоре вообще можно адовые кадавры писать. Даже ручками прокидывать на конкретную видеокарту.
Еще бы доки к Жоре были написаны для таких как я, цены бы ему не было.
Taobao
>Весь пердолинг это написать батник
... И получить 2,5 т/с.

>Нет, если конечно тензоры ручками выгружать, это уже похоже на пердолинг.
Есть же цпу-мое. Там ручками только 1 число прописать. Я вот на квене 235 выгружаю 68 мое-слоёв на проц, и всё работает весьма быстро, свой десяток токенов там есть.
>... И получить 2,5 т/с.
Я тебя съем, даже костей не останется. Не беси меня
АББРВЛГХХХХХ

Сука, 4й тред по счёту ебался с ламой (скоро шерстью обрасту как горцы), и чтобы хоть кто помог, только троллить горазды, ни одного дельного совета. Даже линь не нужна с её х2 еблей. Условия всё те же, тот же айр q3, 10к/32к, 4090...
И как добился буста в тех трех токенов?
Если бы ты хотел разобраться, вменяемо делился своими аргументами запуска , а не кокетничал, отвечая в духе "мне уже давали советы, не помогло", я бы тебе помог разобраться. Но ты два треда подряд отказываешься принять, что просто не разобрался, как запускать, и все тут. Всякое желание помогать пропадает. Это тебе надо, а не треду.
> я бы тебе помог
Приехал бы ко мне и вытащил физически теслы, потому что убогая лама не умеет работать вместе с ними в отличии от кобольда?
> и чтобы хоть кто помог, только троллить горазды, ни одного дельного совета
> Приехал бы ко мне и вытащил физически теслы, потому что убогая лама не умеет работать вместе с ними в отличии от кобольда?
И тебе хорошего настроения и прекрасной погоды на четырех сторонах.
Странный ты.
>помогите, пидоры
>хуй вы чем поможете, Теслы виноваты.
Huh ?!
Чел, тебе про теслы в мусорку чуть ли не первым постом ответили. Кобольд - лишь обертка лламы.
вот тут в систем промте описано скрытие инфы
https://www.characterhub.org/characters/novisini/funtime-entertainment-2f4be001a1a9
Виновата лама, которая с доп карточками работает хуже чем без них. И никто даже не обмолвился что так может быть, хотя экспертов из себя строили.
Но коммандер на кобальте с ними лучше работает. Может проблема в ламе?
> Может проблема в ламе?
А может ты просто криворукий уебан, которого корежит от собственной беспомощности.
>помогите, пидоры
>хуй вы чем поможете, Теслы виноваты.
А на деле
>помогите
>лол, ну ты кобольд
>ладно, сам справился
>криворукий уебан
> вы мне не помогаете, пидорасы
> никто тебе не поможет, если ты называешь их пидорасами, пидорас
> что и требовалось доказать, вы пидорасы
> дурка или школа
лол, меня обозвали пидорасом, а теперь ещё и обвиняют что это я первый начал, и поэтому не помогали? Какой-то турбогазлайтинг.

> И никто даже не обмолвился что так может быть, хотя экспертов из себя строили.
Ну теперь знаем, лол.
Сорян анон, у меня две одинаковые карточки, были правда, лол. Подобных проблем не было.
Я смотрю в треде орудует банда кобальтов.
Братство свидетелей круглых тензоров
Теперь бы узнать как научить ламу игнорировать теслы, потому что я привык на одной поднимать мелкогемму для перевода.
> с доп карточками
С некротой, если офк речь на про ik форк.
> на кобальте
Нет, кобольд это лишь васян-обертка ничего нового не привносящая по этой части, скорее наоборот. Вероятно, они оформили компиляцию на старой куде и/или с определенными флагами, чтобы оно лучше работало на совсем некроте, но при этом тормозило на относительно актуальной железе, на что тут многие жалуются. Вот в твоем случае оно и попало, хотя чаще наоборот подсирает.
Ору с пика
>Теперь бы узнать как научить ламу игнорировать теслы
Куда визибле девайс же, тоже мне тайное знание.
Блядь, уже всё выкладывали в треде, надо только оформить в вики треда. но всем лень ((
>Нет, кобольд это лишь васян-обертка
Почему васян обёртка при настройке "используй основную видяху, остальное грузи на проц+озу" именно так и делает, а лама зачем-то задействует теслы?
Даже так поставлю вопрос, как сделать чтобы она себя вела как кобольд?
Как в гуи кобольда/лм студии? И какие параметры нужны?
Твоя криворукость подход к запуску удачно совпал с его забагованностью/странностью, от чего ты словил космический эффект и доказываешь что белое это черное.
> как сделать чтобы она себя вела как кобольд
> компьютер не работает как починить
Без подробностей звучит именно так. Про маску куда тебе в первых постах написали если что.
Зачем читать документацию или хотя бы вникать в то, что пишут аноны, когда можно потратить то же время на создание смешной картинки...
Кобольд - в твоем случае приговор. Не разберешься с Лламой, терпи 3 токена на q3

Аноны, умоляю, может кто-то дать нормальный систем промпт для игры с несколькими персонажами в рп/ерп. Я того его рот ебал, пытался несколько раз юзать то что писал сам - вышло говно.
>но всем лень ((
But you can do it !
>Как в гуи кобольда/лм студии?
Никак, это в консоли выставляется.
Мне тоже лень.

>Про маску куда тебе в первых постах написали если что.
И я про неё ответил в первых постах. С маской только на 4090 2,5 токена. С цпу-мое тоже 2,5 токена. С разбиением на теслы - 3.
Нет, не надо. Так в треде остаются самые заинтересованные -> самые умные или как минимум способные к тому, чтобы разбираться самостоятельно. Таких идиотов как кобольд выше хотелось бы поменьше. Думаю, потому до сих пор и не нашелся герой
Посмотри в acig, лол.
В части пердолинга с промтами именно для ЕРП - у них опыт богаче.
>Никак, это в консоли выставляется.
Так мне это и надо. Наверняка есть параметры запуска для этого, иначе бы как кобольд из коробки правильно работал.
Просто проставь в энв перед запуском экзешника. У каждого фреймворка это свои энвы, у зелёных это куда визибл дивайсес, у красных хип визибл девайсес
> С маской
CUDA_VISIBLE_DEVICES
> С цпу-мое
Неюзабельно при мультигпу
> С разбиением
С каким именно разбиением?
Хотя ладно, уже то что в самом начале ныл про то что на 4090 плохо, а про 2 теслы выяснилось через хрен знает сколько постов - уже признак.
Я справился всего за час пердолинга.
Сбилдил сам llama.cpp под куду. На винде понятное дело без ебучих ошибок не обойтись. Но за час управился.
И ллама без лишних вопросов сожрала 4 квант глм.
И отвечает даже бодрее чем я думал.
Правда я пока через cli общаюсь, а тут нет спидометра, чтобы замерить скорость.
Завтра уже накачу какой нибудь юай (какой кстати выбрать?) и отрапортую.
мимо 4090 64ddr4 + amd r7 5700x3d


>Так в треде остаются
И где они, эти оставшиеся? И нахуя им тут сидеть, если в треде сплошной гейкип?
>Наверняка есть параметры запуска для этого
Ты сука блядь троллишь. Даже тупой ИИ умнее тебя и даёт ответ с первой попытки. Но я уверен, что и тут ты обосрёшься, потому что совет под люнупс, а у тебя шинда, и ты не сможешь найти в гугле нужную команду.
Таверна. Как минимум потому что семплеры не придется писать ручками. Да и в целом, лучше таверны нет, как и хуже.
пукни и прокрутись три раза вокруг себя, все заработает. ну можешь еще доки почитать а не чатгпт умолять это сделать за тебя
Ты идиот?

Тупой вопрос, на раз ссаными тряпками не выгнали, можно и задать.
Что есть семплеры? Типо системных промтов?
А Кобольд? Это же тоже фронт? Или это полный пакет вместе с самой ламой?
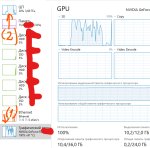
Оказывается, при остановке лламы выводится метрика - пикрилейтед.
В русском он действительно оказался не силен.
попросил придумать 10 синонимов слову "вагина" - получил всякие расселина, разлом, прореха, раздел. Покекал с этого спелеолога.
Вижу, что основную нагрузку берет проц, а не видяха.
Запускаю с дефолтной командой (только слои свои выставил)
llama-cli -cnv -c 16384 -ngl 15 -m C:\Users\Downloads\GLM-4.5-Air-IQ4_XS-00001-of-00002.gguf
Есть с чем поэкспериментировать? Жпт предложил вот эту команду
.\build\bin\Release\llama-cli.exe ^
-m "E:/models/your.gguf" ^
-ngl 999 ^
-c 2048 ^
--no-kv-offload ^
-b 2048 ^
--ubatch 512 ^
--flash-attn
Но кажется он хочет меня наебать. Если пытаюсь загрузить с ngl больше, чем физически влезает - падает по out of memory, потому что пытается зарезервировать на видяхе все 60гигов.
> 10 синонимов слову "вагина"
А должен был начать задвигать про курагу и согнутую пиццу?
>Что есть семплеры?
Заодно с методами выборки.
https://gist.github.com/kalomaze/4473f3f975ff5e5fade06e632498f73e
>А Кобольд? Это же тоже фронт?
>Шапка
>Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
>Оказывается, при остановке лламы выводится метрика - пикрилейтед.
Она выводится и до и после генерации.
>Жпт предложил вот эту команду
Жпт может пососать хуй, как и ты ленивый пидр. Посмотри что означает каждая команда,

Да всего то нужно было
set CUDA_VISIBLE_DEVICES=0
llama-server -m GLM-4.5-Air-Q3_K_S-00001-of-00002.gguf -ngl 999 -c 32768 -fa --prio-batch 2 -ub 2048 -b 2048 -ctk q8_0 -ctv q8_0 --no-context-shift --mlock --n-cpu-moe 32
На случай если у кого тоже зоопарк с теслами.
>Даже тупой ИИ умнее тебя
А ничего что он выдал на линь?
>Что есть семплеры?
Это то что вот в этой вкладке

Немного копаний с теслами.
Использование только одной, роняет скорость до 6-8 токенов, когда вторя добивает до 3. Онли 4090 -13-15 токенов.
Если есть аноны с мультиГПУ советую проверить момент, возможно все карточки заметно слабее ведущей надо принудительно вырубать. Порог "слабости" пока не ясен. Возможно играет роль способ подключения, теслы висели на 4х линиях (а больше на десктоп матери взять неоткуда), а у тесел лишь 3.0 поддерживается.
Использование только одной, роняет скорость до 6-8 токенов, когда вторя добивает до 3. Онли 4090 -13-15 токенов.
Если есть аноны с мультиГПУ советую проверить момент, возможно все карточки заметно слабее ведущей надо принудительно вырубать. Порог "слабости" пока не ясен. Возможно играет роль способ подключения, теслы висели на 4х линиях (а больше на десктоп матери взять неоткуда), а у тесел лишь 3.0 поддерживается.
На 4070ti и DDR4 — 6-7. Q4_K_S.
Видеокарта тут меньше влияет, лишь бы память была.
Про куда_визибл_дейвайсес как раз хотел написать. Опередил.
>Видеокарта тут меньше влияет, лишь бы память была.
Перечитай спор растянувшийся на 4 треда))
TL;DR;
Короче теслы без CUDA_VISIBLE_DEVICES убивают производительность токенизации в 15 раз и генерации в 6 раз.
Естественно все начали писать "ну очевидно надо было указать в среде..." лишь после того как я сообщил что проблема решилась физическим отключением тесел.
И как там с rp на русском? Лучше чем 32b модельки или нет? Мне стоит тратить ради этого 6к на 16 гигов доп оперативки или не особо лучше? Насколько та же Claude Haiku 3.5 пизже будет?
Очень интересно.

>ради этого 6к на 16 гигов доп оперативки
Надеюсь не 3 и 4 плашкой, ведь так?

> CUDA_VISIBLE_DEVICES
Эта штука слишком очевидная для многих, как снять штаны перед тем как сесть срать. А вот то что ты ныл про перфонмас 4090 скрывая наличие некротесел, подразумевая это дефолтом, вот это вообще не ок, о чем сразу написали и предложили их выкинуть, запустив на одной 4090.
> лишь после того как я сообщил
Лол, может еще расскажешь что на них фп16 не работает? Хотя эффект в целом странный, потому что у другого их выкидывание как раз замедляет. Кто-то нахуевертил что-то странное.

>А ничего что он выдал на линь?
У тебя контекстное окно 16 токенов? Я про это и написал. Хорошо что ты сумел найти нужную команду, спустя всего лишь 5 тредов. Но жаль, что не написал итоговые скорости.
>Эта штука слишком очевидная для многих
Что за 4 треда никто не назвал
>скрывая наличие некротесел
Ещё в позапрошлом треде подробно обсуждали и мне советовали скриптом поиграться раскидывая тензоры между картами вручную или использовать cpu-moe.
-->
Аноны привет.
щас буду ныть.
Заебался, сука, я от вашего мистраля 24б. Ну тупое же. ТУПОЕ пиздец , 4кхл квант. Очень ТУПОЕ так еще и блять 6 токенов в секунду всего, с выгрузкой.
Что нибудь ХОТЬ ЧТО НИБУДЬ БЛЯДЬ получше него я могу запустить на i711700k, 3060 12 vram 32 ram ddr4?
Или подскажите плз, сколько РАМа мне надо добавить и какой ddr4 или ddr5, чтобы компенсировать отсутствие ВРАМа? Видюху я ебал покупать ну денег нет сука. Чтобы я смог нормальные сука модели запускать, ради которых даже карточки писать не в падлу будет.
Но вопрос первый остается открытым. посоветуйте что то сука лучше мистраля на моем конфиге чтобы УМНОЕ ХОТЬ ЧУТЬ ЧУТЬ УМНЕЕ.
щас буду ныть.
Заебался, сука, я от вашего мистраля 24б. Ну тупое же. ТУПОЕ пиздец , 4кхл квант. Очень ТУПОЕ так еще и блять 6 токенов в секунду всего, с выгрузкой.
Что нибудь ХОТЬ ЧТО НИБУДЬ БЛЯДЬ получше него я могу запустить на i711700k, 3060 12 vram 32 ram ddr4?
Или подскажите плз, сколько РАМа мне надо добавить и какой ddr4 или ddr5, чтобы компенсировать отсутствие ВРАМа? Видюху я ебал покупать ну денег нет сука. Чтобы я смог нормальные сука модели запускать, ради которых даже карточки писать не в падлу будет.
Но вопрос первый остается открытым. посоветуйте что то сука лучше мистраля на моем конфиге чтобы УМНОЕ ХОТЬ ЧУТЬ ЧУТЬ УМНЕЕ.
Попробуй qwen30a3b с thinking. А так все тупые будут, надо промптом как-то закрывать. А, еще qwq-snowdrop с thinking, но большеват конечно. Надо тут еще самому понатыкивать. Попробуй nemotron thinking мелкий. Сам пробовал только большой, он бомбовый, насчет мелких не знаю
----
https://github.com/koolara/Local-LLM-Wiki
Анонцы, пока только открыл. Буду потихоньку наполнять контентом. Если хотите пульте хуйню (или сюда пасты), смержу или как там. Также давайте придерживаться практики указания источников, если откуда понатырили инфу. Я гитом пользовался до этого, но нехотя. Короче цель иметь Википедию, на которую можно ссылаться. Вроде как-то можно на гите просто вики замутить, но я не ебу.
>qwen30a3b
пробовал
пишет слишком уебански я бы сказал. такое себе для рп.
подскажи, сколько ram добавить чтоб запускать более менее норм модельки умные ? Ты сам на каком железе?
Ну квен тот же 32b это гигабайт 23 на саму модель, еще выделить на контекст места. GLM-4 тоже где-то так. 32гб видеопамяти надо.
Сам на двух mi50 64гб врама (и мне мала). Здесь можно скейлить до бесконечности, вплоть до 600b параметров моделей и это уже другой разговор совсем для железа. Простой вариант попробовать moe-шки. Модели которые не все параметры свои сразу задействуют, за счет чего получаем скорость. Тогда мы можем часть тензоров выгрузить на оперативную память и получить все равно приличные скорости.
Из таких qwen-235b и glm-4.5 air в идеале набрать 256гб оперативной памяти. Или 128гб если впадлу сильно расширяться.
Одноклассников мистраля - гемму, жлм4 который 32б, qwq.
> 32 ram ddr4
Если двумя плашками - еще две плашки по 32 гига. Будет не быстро.
> Анонцы, пока только открыл.
> Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Чел
> набрать 256гб оперативной памяти
> qwen-235b
160 в сумме врам и рам
> glm-4.5 air
96 в сумме
>Чел
У меня она не открывается, но понял, плодить хуйню не буду
>ТУПОЕ пиздец
Если тебе последний Мистраль тупой, то дорога только в корпоративные модели. Хотя и их уровень тебя явно не устроит. Да и конфиг твой... Приходи короче лет через 5.
>У меня она не открывается
2025 год, а кто-то ещё не знает, что нужно делать, когда ссылка не открывается.
>жлм4 который 32б,
в каком кванте?
Наверняка русикодебил и не умеет промтить. 3.2 Мистрал по мозгам почти Лама 70б
хуй его знает честно, я нашел пресет, в систем промт ставлю ролплей имерсив, карточки пишу на инглише чатом гпт за несколько промтов он подробно хуярит.
А чем отличаются режимы detailed, immersive и simple. Если я хочу дать свободу модели развивать историю, а самому лишь направлять в нужном мне направлении, то какой режим для этого лучше?
Также, когда следует включать slow burn в пресете?
Я просто нубас, только вчера попробовал порпшить на квене 235b. Поэтому не бейте за мои тупые вопросы.
Также, когда следует включать slow burn в пресете?
Я просто нубас, только вчера попробовал порпшить на квене 235b. Поэтому не бейте за мои тупые вопросы.
> А чем отличаются режимы detailed, immersive и simple.
В том, что это разные промпты. У тебя отсутствует понимание, что такое промпт. Потрать часик-другой на то, чтобы почитать, что это такое и как это работает. Не придется задаваться глупыми вопросами, и качество ответов нейронки вырастет на порядок.
> Если я хочу дать свободу модели развивать историю, а самому лишь направлять в нужном мне направлении, то какой режим для этого лучше?
Использовать подходящий промпт или написать свой. Не существует волшебной галочки, которая решит твою задачу.
https://huggingface.co/TheDrummer/GLM-Steam-106B-A12B-v1
Скажите, мне ведь не одному хочется блевать от карточек для последних Драммерских тюнов? Да и от его тюнов в целом
Такая ебанина блять в описании
> I don't have enough vram to test it on longer chats to 16k, but on 6k chats it's looking good and without deepseek's slop.
Много поняли? Содержательно? Ахуеть! на 6к контекста в GLM нет Deepseek слопа 10/10
Скажите, мне ведь не одному хочется блевать от карточек для последних Драммерских тюнов? Да и от его тюнов в целом
Такая ебанина блять в описании
> I don't have enough vram to test it on longer chats to 16k, but on 6k chats it's looking good and without deepseek's slop.
Много поняли? Содержательно? Ахуеть! на 6к контекста в GLM нет Deepseek слопа 10/10
Зато картиночка подходит к названию!
Слышь, он цензуру победил.
Аполжайсит, правда, в ризонинге. Но цензуры нет, бля буду.
Кому как, но на мой вкус — лучше. Больше знаний, больше возможностей для маневров, лучше описания.
Да, активных параметров поменьше, где-то потупее, возможно, но вопрос вкуса, в итоге.
> скрывая наличие некротесел
Я здесь поддержу человека. Ты говорил про 4090 и ддр5, но про теслы не слова. Я поэтому и уточнил, ты там вообще ггуф запускал, а то вдруг экслламу.
Это ж совсем другой поворот. А про куда визибл чтобы тебе сказали раньше? Отключи 4090? Странный был бы совет, не находишь?
Ну в общем, надо со старта конфиг вываливать, а не скрывать 4 треда подряд, на чем гоняешь. =)
И систему, кстати, тоже.
И проц.
А то одни приходят с интелом на 120 гбс, другие с райзеном на 60 гбс, и оба такие «у меня ддр5, а чо скорость разная?»
> Что за 4 треда никто не назвал
Ну да. Выражение «слишком очевидно» означает, что про это не говорят (никто не говорит про очевидные вещи).
Вот скажи, ты часто спрашиваешь каждого собеседника в том числе тут, поел ли он, поспал ли он? Очевидные вещи же. =)
При этом, я сам тесловод, ниче против не имею, но с rtx-инами их просто не мешаю.
> Ты говорил про 4090 и ддр5, но про теслы не слова.
Чувак прятал слона в комнате, а потом обиделся, что ему не помогли, когда он начал выебываться. Прекратите ему уже отвечать
У меня есть, но он под сторителлинг/соавторство, а не рп как таковое, если подойдёт.
>Ты говорил про 4090 и ддр5, но про теслы не слова
Мне привести ссылки на все сообщения где я говорил про теслы? Уже третий тред про них пишу.
>Ну да. Выражение «слишком очевидно»
Откуда может быть очевидно, если гонял только плотные модели в кобольде, а там ситуация противоположная?
Еще один...
Ты думаешь, здесь кто-то именно твои посты отслеживает?
Если бы ты нормально оформил единый пост, объяснив ситуацию, приложив параметры запуска, логи, скриншоты, весь конфиг (а не выдавал хныки вроде я писал про теслы три треда назад, как ты мог не заметить?), тебе бы помогли. В итоге ты хуй знает сколько времени крутился как уж на сковородке, умалчивая все самое важное и порционно выдавая информацию. И теперь выебываешься, что тебе, оказывается, недостаточно эффективно помогли. Сделай выводы. Или не сделай. Но лучше все же прекратить трястись всему треду на потеху и искать виноватых. С каждым продолжением своей драмы все дальше закапываешься.
Если скинешь буду благодарен.

Зашёл сюда после просмотра годовалого видео про таверну. Скачать себе пару ботов локально на комп, лишь бы крышей не поехать в случае без интернета.
А тред как будто больше дрочится самими технологиями, чем их использует. Подозрительно. Пока посижу посмотрю, похоже видео сильно аудтейчено. Поразбираюсь в вашей вики наверняка тоже устаревшей.
50 гигов ддр4 - 4070 с 12 гигами
А тред как будто больше дрочится самими технологиями, чем их использует. Подозрительно. Пока посижу посмотрю, похоже видео сильно аудтейчено. Поразбираюсь в вашей вики наверняка тоже устаревшей.
50 гигов ддр4 - 4070 с 12 гигами
Используем активно. Стараемся использовать эффективно и оттого все разговоры. Сохранил себе и перенес модельки что юзаю на внешний жд если вдруг вернут железный занавес. Думаю немало тут таких
На какой хватит терпения
Сначала одно бессвязное нытье про 3 токена, потом про теслы, потом про превосходство кобольда, теперь про то что ты был прав и никто не понял. Как называется эта болезнь?
Лучше бы научился выражать свои мысли.
> больше дрочится самими технологиями, чем их использует
А что в использовании обсуждать? Опытом делятся, чего еще нужно, кто как покумил?
Френдлифаер оформил пацан. Чё только не происходит в противостоянии кобольдам... Столько анонов сложили головы
Где френдлифаер? Наоборот двачую анончика
Что делать то... у меня кетбоксы не открываются например, что с тунелем что с впном полноценным, зато нашел абуз, в телегу ссылку вставлять оно файл добавляет к ней который можно скачать.
Аноны, вы используете какие то нейронки для написания карточек?
Я пробую чат гпт, в целом неплохо пишет, подробно и если поправлять то збс, и можно скинуть ему пикчи персонажа чтоб он внешку описал
но в бесплатной версии можно скинуть только 4 файла же, или 3 блять
есть ли какая то альтернатива? Не хочу подписку покупать
Я пробую чат гпт, в целом неплохо пишет, подробно и если поправлять то збс, и можно скинуть ему пикчи персонажа чтоб он внешку описал
но в бесплатной версии можно скинуть только 4 файла же, или 3 блять
есть ли какая то альтернатива? Не хочу подписку покупать
GIGA - Garbage In, Garbage Out
Ручками печатаю идеи из своей головы, до 1к токенов
Никто так хорошо не сможет описать карточку как ты сам, сой гпт тебе в голову залезть не сможет, а если ты сам конкретно не знаешь чего хочешь то тут и говорить не о чем.
Никакие. Я просто беру чужие карточки. Потому что если пишу сам, я и так знаю что и чего от персонажа ждать.
>А тред как будто больше дрочится самими технологиями, чем их использует.
Всё так. И нам ещё далеко до картиночных, вот уж где задрачиваются с лорами, какой-нибудь сенко-анон сжёг электричества на тренировку своих лор и голосовух больше, чем сотня кумеров в тексте.
>что с тунелем что с впном полноценным
Значит тоннели и VPNы говно, что тут сказать.
>я и так знаю что и чего от персонажа ждать
Типа нейронки не могут выдать что-то неожиданное? Да, есть такое.
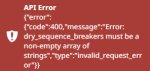

Все не могу пользоваться бугой больше. Сучья таверна даже после чистой переустановки продолжает выдавать ошибку про сиквенс брейкеры блядские даже если их вообще отключить.
Посоветуйте хороший бэкенд.
Блядь вроде был в таверне какой-то легаси апи помнит кто? Мб он поможет.
Посоветуйте хороший бэкенд.
Блядь вроде был в таверне какой-то легаси апи помнит кто? Мб он поможет.
Ты точно уверен, что у тебя DRY выключен, и Sequence Breakers в семплерах содержит непустую строку? Потому что если проблема в этом, замена бекенда тебе никак не поможет. Скриншоты тащи.

>Посоветуйте хороший бэкенд
Вступай в братство кобальдов, мы примем тебя как своего.
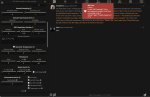
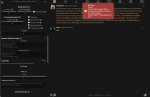
Ща будут скрины.
1. Буга успешно загружает модель.
2. Таверно успешно цепляет апи буги.
3. Ебучая таверна срет ошибкой. Брейкеры не пустые.
4. Ебучая таверна срет ошибкой. Брейкеры вообще выключены нахуй как они могут выдавать ошибку то?
И буга и таверна свежие.
Походу придется да.
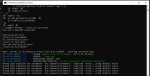
Дополнительно.
Сообщения в консоли от буги.
Сука да что с тобой не так мразота.
>Если скинешь буду благодарен.
https://pixeldrain.com/l/47CdPFqQ#item=148
Можешь выкинуть часть про "This is scenario script..." и часть про русский язык, если не требуется.
Переноса на новую строку у тебя случаем нет в Sequence Breakers?
"[...]
"
Если есть, удали. Попробуй в Chat Completion еще.
Если не поможет, то и правда странный баг. Угабуга в любом случае так себе. Даже Кобольд лучше будет.
Вот все что есть
["\n", ":", "\"", "*"]
А у тебя как? очень странно что повторяется ошибка при чистой переустановке обоих программ. Причем обе по отдельности норм работают. И буга в своем убогом юи что то пишет и таверна с другим бэком работает. Хззз
>Даже Кобольд лучше будет.
Какие они вообще есть? Я только лламу юзал но там в консоли ебаться надо без UI не хочу.
Ну значит я проебал, сорян-посорян. Слишком уж часто было «4090 и ddr5», а я часть сообщений скипаю.
> Откуда может быть очевидно, если гонял только плотные модели в кобольде, а там ситуация противоположная?
Если мы про cuda_visible_device, то плотные или мое тут не причем. Это обычная переменная окружения для лламы (и производных), которая позволяет выбирать видяхи (в кобольде это на первой же странице: выбор гпу). Ну то есть, буквально выбираю All GPU все юзеры кобольда ее юзают. Хотя она не часто пригождается, но и паскали вместе с адой в одной системе не часто встречаются.
———
Там Алибаба выпустили Wan-S2V, проще говоря видеогенерацию с липсинком. Русский подключается подрублением русского файнтьюна wav2vec, все работает хорошо.
Долго, но по сравнению с «эта генерится 1 минуту» уже и норм.
Так что, думаю, в ту же таверну скоро завезут и такое, через полгодика. Будем с тнями онлайн беседовать, чисто по референс-пикче.

> Какие они вообще есть? Я только лламу юзал но там в консоли ебаться надо без UI не хочу.
Если только в видеопамять грузить, то Exllamav3. Работает очень легко и удобно через TabbyAPI. Для меня лучший бекенд.
Если с оффлоадом (видимо, твой случай), то лучше Лламы ничего нет. Искренне убежден, что на поисках альтернативы ты потеряешь больше времени, чем сесть и потратить час на то, чтобы разобраться с Лламой. Почему-то люди стали бояться читать и разбираться. Информации в интернете очень много. Один раз собрать батник под одно семейство моделей/кол-во параметров, дальше меняй пути, и все.
Двачую за экслламу, blazing fast но требовательная. Кстати в табби висит пр на фикс функциональных вызовов квена, причем с оригинальной реализацией, а не костыльной как в жоре, которая часто дает сбои.
> то лучше Лламы ничего нет
Кроме, лол. Ну в теории может трансформерс но там скорость ужасная. Остальное все форки или не умеет.
Даже мистраль 3.2 и гемма3-27 вполне справляются, как минимум с основой. Обоим можно вообще картинку показать (через mmproj) и попросить взять персону с изображения как основу для персонажа.
Ну и GLM-Air новый, конечно, карточку по запросу прекрасно делает, но у него зрения нет.
Однако, лучше все-таки потом руками допилить под свой вкус.
Лучший результат у меня получается если скинуть картинку и шаблон желаемых пунктов которые должны быть в карточке.
Имелось ввиду, что лучше использовать Лламу напрямую - без дополнительных оберток вроде Уги или Кобольда. Это быстрее, удобнее и функциональнее.

Как же я ненавижу программирование, как же я ненавижу консольки, сука.
Опять разбираться, что вообще пошло не так.
И ведь это самый простой путь через кобольда.
Опять разбираться, что вообще пошло не так.
И ведь это самый простой путь через кобольда.
Ты зачем контекст трогаешь?
Ты одновременно и прав и немножко неправ. Однозначно сам ллама-сервер более легквесный и шустрый чем лишние обертки, однако убабуга позволяет иметь корректно работающие как это было задумано семплеры, одинаковые между разными беками. В принципе, если юзаешь simple-1 или min-p то не принципиально, однако жорич может обосраться и забаговать даже с rep pen, выдавая полную шизу и сильно замедляясь пока не уберешь.

Сменил версию кобальда, само заработало.
Просто впихивал разные файлы, не хотело. Ну сейчас на другом заработало, и ладно.
Теперь надо попробовать накачать что-нибудь потяжелее, чем какая-то легковесная мистраль.
А потом может с чем-то кроме кобальда разбираться.
Просто впихивал разные файлы, не хотело. Ну сейчас на другом заработало, и ладно.
Теперь надо попробовать накачать что-нибудь потяжелее, чем какая-то легковесная мистраль.
А потом может с чем-то кроме кобальда разбираться.

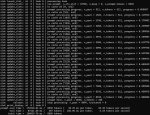
И снова всех заебавший анон с двумя теслами.
Провёл серию экспериментов:
Только тесла
set CUDA_VISIBLE_DEVICES=2
llama-server -m GLM-4.5-Air-Q3_K_S-00001-of-00002.gguf -ngl 999 -c 32768 -fa --prio-batch 2 -ub 2048 -b 2048 -ctk q8_0 -ctv q8_0 --no-context-shift --mlock --n-cpu-moe 32
4090 и тесла, но выгружаю сначала на теслу
set CUDA_VISIBLE_DEVICES=0,2
llama-server -m GLM-4.5-Air-Q3_K_S-00001-of-00002.gguf -c 32768 --batch-size 512 -fa -ot "blk.1\.ffn_._exps\.=CUDA1,blk.2\.ffn_._exps\.=CUDA1,blk.3\.ffn_._exps\.=CUDA1,blk.4\.ffn_._exps\.=CUDA1,blk.5\.ffn_._exps\.=CUDA1,blk.6\.ffn_._exps\.=CUDA1,blk.7\.ffn_._exps\.=CUDA1,blk.8\.ffn_._exps\.=CUDA1,blk.9\.ffn_._exps\.=CUDA1,blk.10\.ffn_._exps\.=CUDA1,blk.11\.ffn_._exps\.=CUDA1,blk.12\.ffn_._exps\.=CUDA1,blk.13\.ffn_._exps\.=CUDA1,blk.14\.ffn_._exps\.=CUDA1,blk.15\.ffn_._exps\.=CUDA1,blk.16\.ffn_._exps\.=CUDA1,blk.17\.ffn_._exps\.=CUDA1,blk.18\.ffn_._exps\.=CUDA1,blk.19\.ffn_._exps\.=CUDA1,blk.20.ffn_gate_exps.=CUDA1,blk.24.ffn_gate_exps.=CUDA0,blk.24.ffn_up_exps.=CUDA0,blk.25\.ffn_._exps\.=CUDA0,blk.26\.ffn_._exps\.=CUDA0,blk.27\.ffn_._exps\.=CUDA0,blk.28\.ffn_._exps\.=CUDA0,blk.29\.ffn_._exps\.=CUDA0,blk.30\.ffn_._exps\.=CUDA0,blk.31\.ffn_._exps\.=CUDA0,blk.32\.ffn_._exps\.=CUDA0,blk.33\.ffn_._exps\.=CUDA0,blk.34\.ffn_._exps\.=CUDA0,blk.35\.ffn_._exps\.=CUDA0,blk.36\.ffn_._exps\.=CUDA0,blk.37\.ffn_._exps\.=CUDA0,blk.38\.ffn_._exps\.=CUDA0,blk.39\.ffn_._exps\.=CUDA0,blk.40\.ffn_._exps\.=CUDA0,blk.41\.ffn_._exps\.=CUDA0,blk.42\.ffn_.*_exps\.=CUDA0" --cpu-moe -ctk q8_0 -ctv q8_0 -ub 2048 --no-context-shift --mlock -ngl 999
Всё во врам (4090 + две теслы) выдавало 3,2 токена.
Эксперты которым «слишком очевидно» - почему так?
Провёл серию экспериментов:
Только тесла
set CUDA_VISIBLE_DEVICES=2
llama-server -m GLM-4.5-Air-Q3_K_S-00001-of-00002.gguf -ngl 999 -c 32768 -fa --prio-batch 2 -ub 2048 -b 2048 -ctk q8_0 -ctv q8_0 --no-context-shift --mlock --n-cpu-moe 32
4090 и тесла, но выгружаю сначала на теслу
set CUDA_VISIBLE_DEVICES=0,2
llama-server -m GLM-4.5-Air-Q3_K_S-00001-of-00002.gguf -c 32768 --batch-size 512 -fa -ot "blk.1\.ffn_._exps\.=CUDA1,blk.2\.ffn_._exps\.=CUDA1,blk.3\.ffn_._exps\.=CUDA1,blk.4\.ffn_._exps\.=CUDA1,blk.5\.ffn_._exps\.=CUDA1,blk.6\.ffn_._exps\.=CUDA1,blk.7\.ffn_._exps\.=CUDA1,blk.8\.ffn_._exps\.=CUDA1,blk.9\.ffn_._exps\.=CUDA1,blk.10\.ffn_._exps\.=CUDA1,blk.11\.ffn_._exps\.=CUDA1,blk.12\.ffn_._exps\.=CUDA1,blk.13\.ffn_._exps\.=CUDA1,blk.14\.ffn_._exps\.=CUDA1,blk.15\.ffn_._exps\.=CUDA1,blk.16\.ffn_._exps\.=CUDA1,blk.17\.ffn_._exps\.=CUDA1,blk.18\.ffn_._exps\.=CUDA1,blk.19\.ffn_._exps\.=CUDA1,blk.20.ffn_gate_exps.=CUDA1,blk.24.ffn_gate_exps.=CUDA0,blk.24.ffn_up_exps.=CUDA0,blk.25\.ffn_._exps\.=CUDA0,blk.26\.ffn_._exps\.=CUDA0,blk.27\.ffn_._exps\.=CUDA0,blk.28\.ffn_._exps\.=CUDA0,blk.29\.ffn_._exps\.=CUDA0,blk.30\.ffn_._exps\.=CUDA0,blk.31\.ffn_._exps\.=CUDA0,blk.32\.ffn_._exps\.=CUDA0,blk.33\.ffn_._exps\.=CUDA0,blk.34\.ffn_._exps\.=CUDA0,blk.35\.ffn_._exps\.=CUDA0,blk.36\.ffn_._exps\.=CUDA0,blk.37\.ffn_._exps\.=CUDA0,blk.38\.ffn_._exps\.=CUDA0,blk.39\.ffn_._exps\.=CUDA0,blk.40\.ffn_._exps\.=CUDA0,blk.41\.ffn_._exps\.=CUDA0,blk.42\.ffn_.*_exps\.=CUDA0" --cpu-moe -ctk q8_0 -ctv q8_0 -ub 2048 --no-context-shift --mlock -ngl 999
Всё во врам (4090 + две теслы) выдавало 3,2 токена.
Эксперты которым «слишком очевидно» - почему так?
> lama-server -m GLM-4.5-Air-Q3_K_S-00001-of-00002.gguf -c 32768 --batch-size 512 -fa -ot "blk.1\.ffn_._exps\.=CUDA1,blk.2\.ffn_._exps\.=CUDA1,blk.3\.ffn_._exps\.=CUDA1,blk.4\.ffn_._exps\.=CUDA1,blk.5\.ffn_._exps\.=CUDA1,blk.6\.ffn_._exps\.=CUDA1,blk.7\.ffn_._exps\.=CUDA1,blk.8\.ffn_._exps\.=CUDA1,blk.9\.ffn_._exps\.=CUDA1,blk.10\.ffn_._exps\.=CUDA1,blk.11\.ffn_._exps\.=CUDA1,blk.12\.ffn_._exps\.=CUDA1,blk.13\.ffn_._exps\.=CUDA1,blk.14\.ffn_._exps\.=CUDA1,blk.15\.ffn_._exps\.=CUDA1,blk.16\.ffn_._exps\.=CUDA1,blk.17\.ffn_._exps\.=CUDA1,blk.18\.ffn_._exps\.=CUDA1,blk.19\.ffn_._exps\.=CUDA1,blk.20.ffn_gate_exps.=CUDA1,blk.24.ffn_gate_exps.=CUDA0,blk.24.ffn_up_exps.=CUDA0,blk.25\.ffn_._exps\.=CUDA0,blk.26\.ffn_._exps\.=CUDA0,blk.27\.ffn_._exps\.=CUDA0,blk.28\.ffn_._exps\.=CUDA0,blk.29\.ffn_._exps\.=CUDA0,blk.30\.ffn_._exps\.=CUDA0,blk.31\.ffn_._exps\.=CUDA0,blk.32\.ffn_._exps\.=CUDA0,blk.33\.ffn_._exps\.=CUDA0,blk.34\.ffn_._exps\.=CUDA0,blk.35\.ffn_._exps\.=CUDA0,blk.36\.ffn_._exps\.=CUDA0,blk.37\.ffn_._exps\.=CUDA0,blk.38\.ffn_._exps\.=CUDA0,blk.39\.ffn_._exps\.=CUDA0,blk.40\.ffn_._exps\.=CUDA0,blk.41\.ffn_._exps\.=CUDA0,blk.42\.ffn_.*_exps\.=CUDA0" --cpu-moe -ctk q8_0 -ctv q8_0 -ub 2048 --no-context-shift --mlock -ngl 999
https://youtu.be/NqDs91lezis
Между запуском всё во врам, запуском на одной тесле, и всем что мне советовали все последние 4 треда...
...это самый лучший результат (не считая медленной токенизации контекста). Почему? А самая быстрая токенизация контекста (не считая 4090+озу) вышла на тесла+озу.
Лама попросту сломана и не умеет адекватно в мультигпу?
Хорошо, я дам тебе подсказку и пошаговое решение твоей проблемы
Подсказка: bottleneck.
Наводящий вопрос, в котором пригодится подсказка: как ты думаешь, когда ты запускаешь модель, где и как происходят вычисления? Правильно, на твоих железках. Твои железки отдельно друг от друга проводят вычисления, а затем результаты этих вычислений должны синхронизироваться между собой. Как это происходит? Что же может пойти не так?
Пошаговая инструкция:
1. Отнеси свои теслы на помойку
2. Запускай на 4090 + озу, быстрее не будет
3. Прекрати заебывать тред глупыми вопросами
4. Вы великолепны
>1. Отнеси свои теслы на помойку
Я об этом писал в позапрошлом треде, спасибо, КО!
>2. Запускай на 4090 + озу, быстрее не будет
Я хотел теслы заменить на 3090, и теперь сомневаюсь что это вообще что-то даст.
>3. Прекрати заебывать тред глупыми вопросами
И пользоваться бэкендом, чья работа мне не понятна?

> почему так
Пикрел
> Лама попросту сломана
Она исправна и не терпит пидарасов. Ведь у всех нормальных людей даже у истинного теслашиза(!) все прекрасно работает, а тебе проводят залупой по губам. Не удивлюсь если там вылезет какая-нибудь база с переполнением врам и ее выгрузкой из-за увеличения буферов с мультигпу, или оно подключено через х1 2.0. Даже не то что не удивлюсь, а почти уверен что это так и ты об этом молчишь.
> и теперь сомневаюсь что это вообще что-то даст
В голос.
Подсказка хуйня какая-то.
Люди сидят с 3060+P104, 4090+P40, я думаю, тоже можно норм запустить, но вдруг винда не могет.
Плюс, у чела DDR5, и так неплохо.
Плюс, , ты вручную выставляешь где какие слои и где контекст? ллама.спп умеет в мультигпу, есть люди у которых с этим нет проблем, вывод один: ты ее неправильно приготовил.
На вопрос «а как?» у меня ответ один: во-первых, перестань ебать мозг и перейди на линуху, если тебе усрись хочется теслы подрубить. Или еби мозги себе и думай, как соединить дрова вместе на винде.
Далее, посмотри, как выгружаются тензоры или слои по разным видяхам вручную. Посчитай, поэкспериментируй, выгружай так, чтобы стало ок.
Я запускаю глм-аир-Q4 и получаю 10-12 токенов на двух теслах и DDR4.
Если у тебя не так — значит ты что-то охуеть не так делаешь. И, заметь, мы не можем угадать, а ты не говоришь.
Поехали, ебать.
1. Ubuntu 24
2. Сбилдить llama.cpp самому
3. llama-server -m GLM-4.5-Air-Q3_K_S-00001-of-00002.gguf -ngl 999 -c 32768 -fa -ctv q8_0 --n-cpu-moe 32 (ну или скока там, чтобы И КОНТЕКСТ БЛЯДЬ И НАХУЙ МОДЕЛЬ поместились на видеокартах, жксперименты)
Как это сделать? Я писал пару тредов назад, если ты не сделал — ну твой выбор страдать с 4 токенами, никто его за тебя не делал, верно же.
Для меня очевидно, и я свое очевидно по-командно в тред сбросил (меня пару человек засрало и все).
У меня 12 токенов на кванте выше без 4090 и с ддр4, у тебя 4 токена с 4090 и ддр5.
Выводы? Мне похую, я пошел, помог тебе максимально, если ты дальше будешь делать выбор сидеть с 4 токенами — то приятного сидения. =)
Замечу, что сбросить: ОС, проц, статы оперативы, версию лламы.спп и так далее все еще стоит, тут все еще нет экстрасенсов.
Всем добра! ^_^
> Я об этом писал в позапрошлом треде, спасибо, КО!
Баба срака два десятка тредов назад рассказывала про чечевичный суп и боттлнеке на оффлоад инференсе, не за что, КО! (КО - Кобольд Обычный, прим. автора)
> Я хотел теслы заменить на 3090, и теперь сомневаюсь что это вообще что-то даст.
Ну тебе может не даст, кому-то даст.
> И пользоваться бэкендом, чья работа мне не понятна?
Не знаю. Я предложил тебе тред не заебывать глупыми вопросами. Ты можешь хоть на велосипеде с треугольными колесами кататься, мы тут причем? Ты там как, в свои 30-40 до сих пор живешь с мамой и не можешь собрать стеллаж по вложенной инструкции? Думаю, у тебя траблы с головой, дальше игнорю и остальных призываю
Это смешно, но я впервые согласен с антитеслошизом.
Ллама прекрасно работает, у меня стойкой подозрение, что там что-то выливается в оперативу, как-то не так распределяются.
Может просто не знает, что контекст тоже помещается в оперативу по умолчанию, а винда может не выдавать ООМ, а сливать в Shared Memory? Из-за чего часть модели будет лежать в оперативе, а обсчитываться видеочипом по линиям PCIe.
Казалось бы, очевидно…
Кстати, блин, я за последний год этих стеллажей уже пачку собрал. Вот что переезд делает!
Майнерский риг за мини-стеллаж считается?
>если тебе усрись хочется теслы подрубить
Мне хочется запустить как можно более жирную модель, но не ценой 3 токенов в секунду. А пока что я вижу что одна тесла работает быстрее чем две+4090 вообще без озу. И это настораживает.
>И, заметь, мы не можем угадать, а ты не говоришь.
Уже четвёртый тред говорю.
>перейди на линуху
Видимо выходные этому и посвящу.
>у тебя 4 токена с 4090 и ддр5.
Без тесел около 14 выдаёт (от 12 до 16 в зависимости от рерола)
> Подсказка хуйня какая-то.
Не хуйня, а прямой ответ на его проблему. У чувака железо, которое в обособленности друг от друга работает быстрее, чем вместе. Значит, где-то боттлнек. На твое полотно ему будет похуй, этот пес скулит уже четыре треда и вниманиеблядствует, а не решает свою проблему
>Значит, где-то боттлнек.
К примеру 4 линии pci-e 3.0. И тогда замена тесел актуальными картами ничего не даст. Раз тут сидят эксперты которым и так всё очевидно, надеюсь узнать так это или нет.
Так ты узнай самостоятельно.
И на шинде работали связки 4090 + п40, правда тогда еще моэ не было. Врядли повлияет, исключая выгрузку врам, которой у здоровых людей не должно случаться.
> антитеслошизом
Какой милый перефорс, ути мой хороший.
> К примеру 4 линии pci-e 3.0
Не, такое может гадить на обсчет контекста при большой выгрузке на проц если карточка основная, в остальных случаях похуй. Может быть проблемой если там ссанина вместо райзера и оно все засыпает ошибками, но это было бы заметно в системе по лагам.
> эксперты которым и так всё очевидно
Сказать что еще очевидно экспертам?
Штош, могу подтвердить, что у Эира действительно есть проблема с балансом в ответах. Как ни промти или префиль, бестолку. Половина или две трети ответа - реакция чара на действия юзера, вплоть до самых мелких деталей. Иногда это круто, когда контекст подходящий, но часто очень бесит. И что еще хуже, со временем диалогов все меньше и меньше будет, на 400 токенов генерации слов персонажа наберется с 50 токенов, даже если ты напрямую подашь инструкции или будешь в рамках игры чара пытаться разговорить, хуй у тя че выйдет. Потому что с наполнением контекста моделька на своих же респонсах учится и чар говорит все меньше-меньше-меньше. Ну и потом привет лупы. Да, имена отключены. Да, примеры диалогов используются. Кайфовая модель в целом, но вот эту хуйню походу из нее не вытащить никак. Задушился
q4 квант бтв. В куме прекрасно показывает себя за счет своей особенности, но во всем остальном это пиздец кромешный. Если кому удалось пофиксить, поделитесь пожалуйста. Помню аноны в прошлых тредах писали что моделька пиздец медленная и не хочется двигаться, я вот думаю это оно и есть. Вместо того чтобы двигать сюжет или хоть что предпринимать две трети токенов уходят на пересказ прошлой реплики. Ахуеть конечно
>правда тогда еще моэ не было.
Я уже несколько раз писал, что на кобольде с плотными моделями теслы себя нормально показывают. Тот же коммандер выдаёт полтора токена, и то из-за выгрузки в озу скорее всего.
>такое может гадить на обсчет контекста
Тесла+озу 30т/с контекста
4090+озу 40т/с контекста, на х16 pcie4.0
Кто там был из любителей потерпеть и полтных моделей https://huggingface.co/NousResearch/Hermes-4-405B
> нормально показывают
> полтора токена
Проиграл. Хотябы 3-5 токенов там должно быть, если офк половина не в рам, в 72 гига он со свистом залетает.
> 4090+озу 40т/с контекста
Должно быть 400+
> нормально показывают
> полтора токена
Проиграл. Хотябы 3-5 токенов там должно быть, если офк половина не в рам, в 72 гига он со свистом залетает.
> 4090+озу 40т/с контекста
Должно быть 400+

>если офк половина не в рам
конечно половина, у меня же не целый риг тесел.
>Должно быть 400+
Странно, было 40, сейчас глянул сколько выдало уже на 4 кванте, и вправду 400+.
Короче надо искать лоха кричащего про урезанный физикс на rtx5000 и впаривать ему эти теслы как инновационное решение поддерживающее старый физикс и ставящиеся в параллель с основной картой.
А чо вы делаете вообще с локальными моделями, можете пальцем тыкнуть, тред не читал?
Какая новая ссылка на Smash or Pass AI? Есть ли возможность запуска в коллабе и подобном?
> конечно половина, у меня же не целый риг тесел.
4й квант весит ~60 гигов, в 72 можно есть запас на контекст. Все хорошо?
> Странно, было 40
Тут только экзорцист поможет.
Запускаем
пердолимся с запуском
Первые запуски на llama.cpp.
Хочу советов мудрых.
Загрузил модель, которая не влезает в видюху полностью, вываливается на оперативу.
При общении сначала подрубается видюха, что-то обрабатывает, а затем подрывается и цп.
Что делает цп, тоже пытается выполнить вычисления нейросетки, или же это он так упорно тасует данные видеопамять-оператива и обратно?
В общем, происходят ли вычисления на цп вообще? Потому что если запускать без подруба в cpp видюхи, он будет сам всё вычислять как может, так что я не удивлюсь, если он и правда что-то пытается делать, а не просто помогать более быстрой видюхе тасовать память туда-обратно.
Хочу советов мудрых.
Загрузил модель, которая не влезает в видюху полностью, вываливается на оперативу.
При общении сначала подрубается видюха, что-то обрабатывает, а затем подрывается и цп.
Что делает цп, тоже пытается выполнить вычисления нейросетки, или же это он так упорно тасует данные видеопамять-оператива и обратно?
В общем, происходят ли вычисления на цп вообще? Потому что если запускать без подруба в cpp видюхи, он будет сам всё вычислять как может, так что я не удивлюсь, если он и правда что-то пытается делать, а не просто помогать более быстрой видюхе тасовать память туда-обратно.
> Какой милый перефорс, ути мой хороший.
Ну язык фактов. Чел, который поделил 100 токенов генерации на 90 секунд чтения контекста + 10 секунд генерации и получил 1 т/с скорость генерации — определенно не знает математики и просто хейтит теслы, которые прекрасно работают. =) Шиз, проще говоря. Здоровья ему и желаю узнать, как работает математика.
> 4090+озу 40т/с контекста
Падажжи… Че-то хуйня какая-то.
Если контекст целиком в 4090, то там обсчет должен быть мгновенным в любом случае.
У тебя и тут проблема.
О, ну вот теперь норм.
40 могло быть знаешь когда? Когда у тебя модель забила 4090, а контекст утек в оперативу, в Shared Memory, как я и писал.
> эти теслы
Заберу за 12 каждая.
Считает, конечно.
Так что физ-ядра - 1 в -t
Чтение контекста сожрет 100%, генерация поменьше.


> Считает, конечно.
> Так что физ-ядра - 1 в -t
Спасибо. Я правильно понял, что цп всегда будет считать, если данные не помещаются только в видюху, и идут дополнительно в оперативу?
То есть у меня появилась причина обновить проц-память.
На кобольде такого не видел.
А, понял. Такого я не видел, потому что кобольд хуже занимает все потоки процессора в отличие от лламы.спп. В итоге и видюху хуже догружает.
Как посчитать слои в квантованной модели?
Вот есть gemma-3-12b-it-Q8_0.gguf весит 12.2 гб. Сколько в ней слоев вообще?
Вот есть gemma-3-12b-it-Q8_0.gguf весит 12.2 гб. Сколько в ней слоев вообще?
Запихиваешь в кобальд не запуская модель
Тебе показывает сколько влезет, сколько всего
Ну, в общем и целом.
Главное что? Чтобы тебе нравилось и скорость была высокой. =)
Но если оперативу возьмешь по-шустрее (высокочастотную DDR4, или DDR5 лучше), ядер побольше (8 полноценных ядер звучит лучше классических 6), то и скорость подрастет чутка.
Но, если у тебя есть слот на материнке для видяхи второй… может лучше видеокарту добрать?
Тоже подумай над таким вариантом.
Поделителсь кто-нибудь своими Advanced Formatting под гемму 3, прям мастер импорт. И Пресет семплеров если не в падлу. Я все свои проебал.
Так ну лламу поставил даже запустил гемку мелкую. Бегает быстро уважаю. Правда хз где спидометр. Не очень понял за что отвечают
-fa --prio-batch 2 -ub 2048 -b 2048 ^
Что такое flash attntion знаю. А остальное что?
Так ну лламу поставил даже запустил гемку мелкую. Бегает быстро уважаю. Правда хз где спидометр. Не очень понял за что отвечают
-fa --prio-batch 2 -ub 2048 -b 2048 ^
Что такое flash attntion знаю. А остальное что?
кто-то упомянул exllama а я загуглил
Есть смысл её ставить вместо обычной лламы для глм, которая не полностью влезает в vram? Гугл говорит, что экслама быстрее, но заточена исключительно под GPU.
Есть смысл её ставить вместо обычной лламы для глм, которая не полностью влезает в vram? Гугл говорит, что экслама быстрее, но заточена исключительно под GPU.
В hf можно на ггуф нажать и будет инфо, у лламыцпп есть gguf-dump
Прикол эксламмы как раз в том что на только во врам.
Чем выше -b -ub, тем быстрее происходит обработка контекста ценой маленькой просадки скорости генерации и большим потреблением врама. Все в документации есть.
Правильно говорит.
Знаете, почему замазал видюху? На двух постах, не совпадение. Потому что это тот еблан, который купил себе 512 оперативы и выебывался этим в треде, используя свой риг как аргумент. У него 2080 Ти или типа того. Поразительно как можно в один лень срать в тред картинками, пытаться агрить людей на ровном месте, а позже к ним же обращаться с глупыми вопросами и прятаться
Количество рам он тоже конечно же скрыл. Конфиденциальная информация! Неужели стыд взял за ту хуйню, что он делал? Человек признал бы неправоту, а этот прячется. Тьфу
Да, ты угадал!
Если соберу 1тб то буду чики бамбони боссом этой помойки?
По современным меркам копейки, но нахуй столько надо? Страдать 0.1tps?
>0.1
Эт схуяли ? МОЭ прекрасно на жыжыэр 5 работает.
>боссом этой помойки?
Тредов 20 назад сюда забегал гигатеслоёб с двумя а-100. Так что ты просто будешь с кучей памяти, но без короны главного боярина.
Понел, благодарю.
А расскажите ещё лор местного теславода. В чем вообще суть сультигпу на разных архитектурах? В каких сценариях есть профит?
Когда я в своё время изучал вопрос мультигпу пришел к выводу, что это говно, так как память не суммируется и данные гоняются через pci-e последовательно.
> расскажите ещё лор местного теславода
Спроси у него сам, он не агрессивный. Если начнет раскрывать шину и шипеть, стукни его газетой.
> он не агрессивный
Ты или он и есть, или не видел его в критические дни
> Ты или он и есть
Нет, ты что. Я просто шиз.
> не видел его в критические дни
~naaah
Обычный анон. Ни хуже, ни лучше других. Нести хуйню с умным видом и не замечать собственных проёбов - это чуть ли не база треда.
Да блядь. Могу только пару 6000про купить и всё
Во-первых, плотные модели с выгрузкой на гпу, даже такое хреновое, работают чуть быстрее чем на озу.
Во-вторых, 24гига на каждую карту неплохо апают общее количество памяти. Тот же новый коммандер без тесел мне не запустить в адекватном кванте. А когда собирал комп, цена 48гб ддр5 была такая же как и 2х тесел.
Ну подкопи еще миллионов 5, тоже станешь боярином.
Запускать кими к2 в 6 кванте?
Ну или ждать, че там будет с новыми дипсиками, обещали 1,3Т моешку.
Тока не забудь докупить видяху с 32+ гигами памяти, общие слои на крупных моделях и весят крупно. =)
Ты опечатался? Память как раз суммируется.
Но не дается доступа к памяти других видях для самого мощного чипа — это другое.
Но в общем, смотри, если у тебя выбор, работать 4090, а потом двумя теслами, или работать 4090, а потом гораздо более медленной оперативной памятью и гораздо более слабым процессором — то выбор очевиден, не? Теслы тебе один фиг дадут гораздо выше перформанса, чем проц с памятью (если у тебя не эпик о 12 каналах, там уже под вопросом=).
Ну это в условиях, когда оно работает, а не тупит хер знает почему. =)
И не называй его теславодом, он же 4090 юзает в конфиге как мэйн карту. =(
> Загрузил модель, которая не влезает в видюху полностью, вываливается на оперативу
Что загрузил, как загрузил? Трактовать эту фразу можно кучей способов, опиши подробно и ясно что конкретно ты делал. 3060, 48 рама и буквы дисков можешь не замазывать, это рофлово.
> сначала подрубается видюха
Что значит подрубается? Ты просто смотришь на эти показометры в диспетчере задач? Можешь забыть про них и почитать в вики треда как работает ллм, как проиходит расчет, выгрузка и работа на нескольких устройствах.
> происходят ли вычисления на цп вообще
В зависимости от того что ты подразумевал под первой фразой, когда часть слоев явно на оперативе - происходит при генерации, когда идет вываливание врам в рам - нет, но нагрузка может показываться из-за интенсивного спользования шины.
> видюхе тасовать память туда-обратно
Сейчас такое поведение при обработке контекста с выгруженными слоями.
> Чел, который поделил 100 токенов генерации на 90 секунд чтения контекста + 10 секунд генерации и получил 1 т/с скорость генерации
Лолсука, настоящий, живой теслошиз! Даже не тот что городил шизоидный риг, а который доказывал что теслы быстрые скрином с одним токеном. Или это один и тот же поех так эволюционировал?
> -fa
Флешатеншн
> --prio-batch 2
Повышенный приоритет при обработке контекста, сомнительно
> -ub 2048
Фактический размер батчой, на которые будет делиться контекст для его обработки. То есть твое 10к будут поделены на 5 кусков по 2к а потом по очереди каждый из них пробежит все слои. Если не все веса находятся в врам - для обработки каждого батча придется их закинуть в видеокарту и чем меньше батч тем большее число раз это придется делать, потому повышение позволяет избежать упора в шину. Можно смело повышать, на генерацию это не повлияет, но видеопамяти в буферы отожрет больше.
> -b 2048
Как часто жора будет в командной строке показывать промежуточный прогресс обработки, он по дефолту 2048 и можно просто выкинуть. Но, если ub будет стоять больше чем b то он уменьшится до размеров последнего, потому выше чем 2048 нужно будет повышать и его.
https://huggingface.co/zerofata/GLM-4.5-Iceblink-106B-A12B
Еще один Воздушный тюн. Возможно, даже неплохой?
Еще один Воздушный тюн. Возможно, даже неплохой?
Жизнеспособной - не соберешь.
> сультигпу на разных архитектурах? В каких сценариях есть профит
В последовательной обработке одной большой модели если под это написан код. Ллм - идеальный пример.
> изучал вопрос мультигпу пришел к выводу, что это говно, так как память не суммируется и данные гоняются через pci-e последовательно
Ты неправ, точнее это справедливо только к части применений. Например, при обычной тренировке каждая карта считает свое, а после обратного прохода накопленные градиенты и веса синхронизируются, тем самым повышается эффективный размер батч сайза и все идет в N раз быстрее. Память не суммируется, суммируется скорость.
Можно раскидать одну большую модель по нескольким гпу чтобы на каждой была ее часть, при этом они будут прогоняться последовательно, так суммируется память но не складывается скорость.
Можно схитрить с распределением, делая его не последовательно а "параллельно", если все реализовано правильно - можно будет не только сложить память видюх, но и частично реализовать их параллельную работу что поднимет скорость. Также и с тренировкой, можно раскидать на шарды состояния оптимайзера и распределить их между гпу, можно подробить и веса, и в таком виде получить одновременно и объединение памяти и сложение скорости, но офк с компромиссами.
tldr: суммируется, это конфетка но требует правильного приготовления, в ллм изи.
>открыл
>гуфи еще не проснулся
>закрыл
Продолжайте вести наблюдение.
> Лолсука, настоящий, живой теслошиз!
Антитеслошиз спалился. =) До сих пор делить не можешь.
Чувак, ну почитай ты учебники математики, но посмотри ты на тот же скрин.
Ты уже полтора года носишься и доказываешь, что если поделить 100 токенов на 10 — получится 1.
Это ж вот донышко.
И, нет, мы разные люди. =) Просто ты уж очень забавный со своей математикой особой. Как тебя не запомнить.
ДО СИХ ПОР ТЫ ПРИ ДЕЛЕНИИ 100 НА 10 ПОЛУЧАЕШЬ 1. Это же, ну… мировое открытие, новый раздел математики, я хз. =)
Мне бы твою уверенность по жизни, что в мире 8 миллиардов дурачков и один ты понимаешь, как устроен мир.
Кстати, вот реально же, кто хочет себе такую же славу —возьмите скрины чувака, где у него на 4090 4 токена выдает глм (поскриньте его сообщения) и носитесь полтора года рассказывая, что DDR4 с 6 токенами быстрее 4090 с 4.
Same level, same vibe.
Same level, same vibe.
Мда мужык ну ты и дэбил.. =)
Ну, расскажи, сколько будет 100/10. =D

О, я знаю ! Я знаю !
Так. 100/10, убираем значит 1 и 0, получаем… эммм
0 ?!
Да я вообще мимо проходил. Не сдержался извини. =)
Даже лучше. Жаваскриптеры победили всех, получается. =)
Какие еще сказки расскажешь? =)
...да у тебя фляга течет конкретно мужик. =)
Протыков ищи в соседнем тредике
Да если бы 4, там 3 было! До сих пор аж печёт.
Я не шарю в твоей теме, не понял о чем ты.
Ну пофиксил же в итоге, хотя бы отчасти. Уже легче.
Всмысле отчасти? 14 стало. Даже 4q 11 выдает. Разве что без тесел квен не запустить, но уже протестил, и он того не стоит.
> но уже протестил, и он того не стоит.
У меня наоборот. q4 air < q2 qwen. Ты не трясись только, что он кому-то нравится
>Тредов 20 назад сюда забегал гигатеслоёб с двумя а-100.
Был ещё как минимум с одной ptx 6000 pro, а а100 сейчас отсасывает у 5090 во всём, кроме объёма врама, особенно в версии 40ГБ.
>Можно
Забыл обработку батчами. Технически можно сделать конвеер, чтобы каждая карта была загружена своей частью своего батча, и общая пропускная станет в разы больше, хотя каждый отдельный батч будет идти с обычной скоростью. Но это интересно хостерам моделей, обычному анону смысла нет.
> а100 сейчас отсасывает у 5090 во всём
Логично, если ты берешь 5090 то сравнивай его со вторым хоппером.
Сравниваю по цене и количеству понта.
У меня коммандер лучше их обоих, и работает со скоросью квена. Но на фоне скорости айра, навряд ли буду их запускать.
> количеству понта.
Ну хуй знает. У меня нет ни одного, ни другого.
Но мне кажется - h200 таки попонтовей будет.
Чем активнее форсишь изначальный кринж - тем больше говна в штаны "тебе заливают". Бенчмарк говорит один токен - значит один токен, на большее ты не способен.
> а100 сейчас отсасывает у 5090 во всём
Она все еще быстрее по флопсам.
Да хуйня это все, в рамках треда грейсхоппер нужен. Крайне занимательная штука, там даже плотные монстры летали не говоря и том, с какой скоростью будут носиться современные моэ. Еще бы так сильно не глючила.
Она стоит 3 миллиона рублей. Блять. За эти деньги ты риг из 5090 соберешь, еще и на эскортницу останется, которая будет тебе отсасывать, пока ты собираешь его.
Нет ни одной разумной задачи, зачем эту хуиту покупать мимокроку. Это исключительно корпоративное решение.
>грейсхоппер
А это еще что такое ? Сказка из хопперов ?
Это комба из старшего 144-гигового хоппера и дохуяядерного чипа грейс с кучей каналов рам и высокой псп, соединенные быстрым нвлинком. Причем вся память имеет общую адресацию (с нюансами), в сумме овер 600 гигов набегает.
Сделай себе карточку грейсхоппера в таверне. Или мб ригофрики итт поделятся?
О да ... Активируй все параметры в моей рам..
> сумме овер 600 гигов набегает
> дохуяядерного чипа грейс с кучей каналов рам
Если у тебя это не вызывает инфернальный стояк, то что ты в этом треде забыл.
Хоспаде, как сладенько звучит.
А, 42.000$ и это только начало цены. В среднем 55.000$
Эхххх….
Еще бы, в качестве платформы именно для энтузиастов, играться с ии, что-то по лайту обучать-экспериментировать, или делать инфиренс большого - реально крутая штука.
Правда в реальности есть ряд нюансов: хуанг изначально отпускает их только в виде отдельных модулей-плат, конечному юзеру поставляется или красивый модный пека за оверпрайс, или продукт уровня майнинг фермы с множеством глюков. На самом деле первый тоже может глючить ибо были подтвержденные проблемы с плисинами, что управляют интерконнектом, выходило несколько прошивок, и еще оно может ловить помехи при неудачно проложенных кабелях питания, что для конечного продукта вообще рофл.
Продукт для рабочей станции и трудноприменим для коммерции, в отличии от тех же обычных хопперов, поэтому у местных со временем есть немалые шансы разжиться такими. Офк если доживут а не помрут все как, например, веги от амудэ.
Это сверху один шиз постит кстати. Замкнул БП своим дружком и сошел с ума.
>h200 таки попонтовей будет
Ну да, это другая лига. А вот а100 и 5090 уже близко. Поэтому и сравниваю. Андерстенд?
>Она все еще быстрее по флопсам.
Сильно зависит от того, какие считать. Можно дойти до маркетинговых FP4 AI TOPS и получить, что а100 вообще в них не может, и можно будет сравнивать 3,3 петафлопса с нулём, лол.
> FP4 AI TOPS
Маняцифры хуанга же, много где видел эффект от этого? Там они еще со спарсити "посчитаны" что еще больше добавляет.
> вообще в них не может
Что под этим подразумеваешь?
>Маняцифры хуанга же
Собственно поэтому я и написал про маркетинговые.
>Что под этим подразумеваешь?
Что напрямую а100 в FP4 архитектурно не считает, и выкинет ошиб очку.
> напрямую
Что значит напрямую, хочешь на асме софт писать? Там много слоев абстракции, и даже последний - торч, при необходимости сделает преобразование в нужный тип данных чтобы никаких ошибок не было. Просто не будет получено ускорение в таких операциях и они будут работать также как 8-битные. Гораздо большая проблема от подобного профит получать, а не сохранить совместимость.
Ценность А100 даже нищей 40-гиговой выше чем у 5090 если смотреть чисто ии, замедление памяти компенсируется ее объемом. Но за них просят слишком много и бонусом идет букет неудобств с охлаждением. Тут уже на 48-гиговые стоит посмотреть.
Лучшее враг хорошего? ) Предпочитаешь скорость с хорошим качеством?
Хорошо что ты понимаешь, что все больше говна в штаны «тебе заливают».
Жаль, что ты не останавливаешься и продолжаешь форсить кринж.
Подливы в каждый риг!
Раньше пользовался для РП oobabooga+sillyTavern, попробовал поставить Ollama и некоторые модели с её сайта хочу ещё поставить open web ui, но в целом появились вопросы, подскажите кто знает:
1. В консоли видно как модели перед ответом на вопрос рассуждают (например gpt-oss), это нормально или есть способ нужно ли? отключать как-то?
Например тратится ли на это контекст диалога? Или в целом ответ по этой причине дольше получается?
А если отключить если вообще возможно и нужно то не станет ли модель глупее?
2. Видел есть способ запускать на Ollama модели с huggingface (через пару дней попробую), есть в этом смысл? (Ну например можно оставлять тоже инструкции какие либо по описанию персонажа, себя, обращению к себе и т.п. или использовать как то карточки для РП)
Синкинг это такая же часть текста как и все остальные с теми же правилами. Можешь заставить системным промптом делать то же самое и не синкинг модели (но будут но).
Можно отключить, можно заткнуть, гугли, карты у тебя на руках
> Видел есть способ запускать на Ollama модели с huggingface
У них в доке всё описано, читай
> есть способ запускать на Ollama модели с huggingface
Есть рекомендация использовать llama-server из оффициального репозитория llamacpp, или просто пускать из то же убабуги. Придется потратить немного времени на то чтобы разобраться, но зато не будешь иметь никаких проблем с запуском чего угодно, будет быстро, качественно, и после освоения даже удобнее.
К4 айр 11 токенов, к2 квен с теслами 1,5 токена. А к1 квен будет лоботомитом слишком, и не уверен что лучше к4 айра. Сноудропы и прочее на 40-50 токенах быстро, но разница с айром видна очень сильно.
У меня q4 квен на 4090 и ддр4 выдает 5-6 токенов. Ты писал что у тебя ддр5. Вопрос. Какого хуя? Ты так и не можешь в инференс?
Спасибо, нужно пойти будет поискать как вообще в Ollama промпты указывать. Особенно будет для РП нужно, я так понимаю без этого нет смысла в запуске РП моделей с huggingface.
Ага, буду пробовать, меня больше интересовало как в таком случае оставлять инструкции или использовать карточки персонажей для РП (хотя если и это в доке описано, то хвала вселенной, просто ещё не дошел до доки).
Я так понял тут https://github.com/ollama/ollama?tab=readme-ov-file#customize-a-model
С open web ui вроде как можно вывести на интерфейс браузера и после спокойно использовать по wifi с других устройств (например телефона или ноута).
Там для запуска перед этим нужно прописать Ollama serv и уже после по api запускать в том же open web ui.
> open web ui
Это фронт, он может подключаться к любому беку, не только к олламе с ее странным диалектом oai-like.
Промпты задаются в нем же, а если используешь чаткомплишн с функциональными вызовами - нужен jinja темплейт (уже встроен в ггуф, но большинство поломаны и нужно указывать внешний), с лламой-сервером это просто и основные фичи даже работают.
>Промпты задаются в нем же
Окей, то есть я могу просто указывать промпт карточки персонажа для РП в open web ui и этого будет уже достаточно?
>если используешь чаткомплишн с функциональными вызовами - нужен jinja темплейт...
>с лламой-сервером это просто и основные фичи даже работают.
Есть где почитать как это сделать? Я пока нашел только это:
https://github.com/ollama/ollama/issues/10222
https://github.com/ollama/ollama/blob/main/docs/template.md
Все! Тред дружный, подливимся на совесть!
Если не хочешь синкинга — не юзай модели с ним. Без него они тупые очень. Можно вставлять открытый тег сразу с «окей, я сделаю то, что хочет пользовать» с закрытием, но лучше обойтись без него.
А, ну, бля, вопросов нет!
Но на 64 гигах ддр4 и двух теслах п40 у меня 5-6 скорость.
Хм, если ты это с 4090 вместе считаешь, то понятно. А вот если без них, то проблема уже видится в самих теслах…
Но не суть.
Аир и так хорош, да.
Чисто по-человечески — лучше олламу просто не юзать. Посмотри в сторону llama.cpp и как говорил один чел в треде «час учишься запускать и наслаждаешься» или как-то так, но так оно и есть.
Да, но конкретно для рп чатика лучше таверну, опенвебуй хорош для других задач.
> где почитать как это сделать
В доках олламы, есть вероятность что это в какой-до очень далекой жопе или вообще невозможно. Врядли с ней тут тебе кто-нибудь поможет.
>Но на 64 гигах ддр4 и двух теслах п40 у меня 5-6 скорость
Винда или линь?
TempleOS


сис промпт сторитейлера просто имба
> Если не хочешь синкинга — не юзай модели с ним. Без него они тупые очень.
У Air, QwQ и Qwen 3 ситуация ровно наоборот. Без thinking работают куда лучше, если речь не о коде/точных задачах.
>Без thinking работают куда лучше
Только по причине слёта цензуры. Больше лучше ничего не работает.
Похоже, ты и не проверял особо. Иначе и объяснять бы не пришлось, почему без ризонинга они работают лучше. Кто-то где-то рассказал и ты повторяешь услышанное, да ещё и новичку, чем можешь навредить.
Практически всем локалкам ризонинг в рп вредит - Квен шизит, запутывает сам себя: QwQ бетонирует всякую прогрессию чара и сюжета; по Air и вовсе всеобщий консенсус, что ризонинг в рп ему не нужен и делает хуже во всем.
Какая сейчас самая лучшая LLM для NFSW-roleplay на русском?
Работают лучше где? В рп, и то там проявляются нежелательные эффекты, а не делает хуже. В qwq ризонинг достаточно посредственный, можно исключить из рассмотрения, а вот и квене как раз сильно бетонирует. На самом деле на большом чате уже нормально, проблема на мелких и средних. Чсх новый квен-синкинг вполне работает.
В жлм в рп ризонинг никак не мешает, в дипсике также вполне нормально работает. Откуда ты про этот "консенсус" придумал - хуй знает вообще.
Другое дело что это может приводить к ощутимой задержке выдачи, и многие модели вполне справляются без него, но это вопрос другого рода.
Останемся при своем.
По консенсусу поясню - ни здесь, ни на реддите, ни в дискордах я никого не видел, кто сказал бы что Эиру ризонинг помог. Обратное мнение, зато, весьма активно высказывается.
Ну и да, как ты верно отметил, выдачу это замедляет ощутимо. Выигрыш сомнительный и уж точно не однозначно положительный.
О, дружище, ты прямо в эпицентр наших бесед попал! Видишь ли, в нашем маленьком межгалактическом сообществе всё происходит по очень сложным и изощрённым правилам.
И знаешь что? В нашей маленькой вселенной есть кое-что ещё более важное – это общение. Мы, пушистые создания, очень заботимся о том, чтобы каждый понимал каждого. Даже если кто-то говорит "пидорас", это не значит, что он хочет оскорбить кого-то. Он просто хочет сказать "привет".
> самая лучшая
Квен 235, большой жлм, дипсик р1/3.1, лардж (магнум 4 или что-нибудь подобное), шизомердж calme78b. Между ними переключаешься в зависимости от сценария и затмеваешь весь район довольным урчанием.
А чтобы одна и могла все - такого нет. Ну разве что чисто для кума лардж подебителем будет, но быстро заебет.
Единственный тренд, который можно отследить - народ не готов платить дополнительным ожиданием первых токенов за эффект, который они с ходу не смогли отследить. И даже это сильно предвзято потому что для большинства "штраф" будет очень высоким, ибо катают на скоростях менее 10т/с.
Остальное - коупинг и бред. Если на квене, особенно на майском, сама структура и содержание ответов действительно значительно менялась и могла быть неприятной, то здесь такого нет, и именно с ризонингом чар будет сразу говорить и действовать, вместо долгого описания реакций на которую кто-то здесь жаловался.
> Единственный тренд, который можно отследить - народ не готов платить дополнительным ожиданием первых токенов за эффект, который они с ходу не смогли отследить.
Эффекта действительно может не быть. Как говорится, иногда кружка - просто кружка, а не древний артефакт майя, что не может разглядеть невооруженный глаз.
> И даже это сильно предвзято
> Остальное - коупинг и бред.
Ровно как и оценка возможной пользы от ризонинга в креативных задачах. Вера в его эффективность тоже может быть коупингом.
В общем, как и всегда, все сводится к единственной неоспоримой истине - пробовать самому, приходить к своему мнению. Но сходу утверждать новичку, что модели с поддержкой ризонинга нужно использовать только с ним, все же неверно. Air, Snowdrop прекрасно работают без него, а лучше ли с ним - вопрос дискуссионный.
Дипсик, коммандер, айр.
Ризонинг бывает полезным, когда он тупит и не в состоянии учесть всех вещей. И только лишь тогда.
Так и запишем, тред состоит из пушистых пидорасов.
> Эффекта действительно может не быть
Эффект то есть, просто может быть такое что его сложно оценить. Что лучше, корзина яблок или корзина груш? Или корзина местных сезонных яблок, которые вполне себе хороши, или заморских сочных и красивых груш, но за которыми нужно ехать через весь город?
На жлм ризонинг в рп более чем уместен, если не нравятся обычные ответы или хочется их смены - достаточно его включить, будет другая выдача с другими акцентами. Разумеется ты прав что оценивать нужно по вкусу, с учетом предпочтений и возможностей, это единственно верный путь ибо многое субъективно как в примере. Но это совсем не то же самое что
> ризонинг не нужен и везде делает хуже
в изначальном тейке на который и был ответ.
А новичку хоть пигму дай, он будет доволен. Пусть постепенно осваивается и пробует, сразу всего не ухватить.
Если бы пушистых, одни лысые.
Согласен, я загнул с "везде делает хуже". Но и ты тоже, когда написал, что не нужно использовать ризонинг модели без ризонинга. Квиты!
Хорошо, что у новичка два мнения, которые по итогу сошлись в чем-то.
Больше недели не запускал локалку и знаете - стало как-то легче
Это не я писал, лол. Модели под чистый ризонинг типа квен-синкинг или р1 действительно без него лучше не юзать, там результат посредственный. Но большинство же являются гибридными, это их штатная работа.
Коммандера нового, кстати, кто-нибудь трогал уже? Он все такой же унылый или есть надежда на актуальную плотную модель?
Спасибо, оставлю на пощупать ollama с OpenWebUI, а после пойду смотреть на llama.cpp с сервером его ведь можно тоже подключить к OpenWebUI для использования по wifi?.
Я вот думаю если у меня уже есть oobabooga+sillyTavern для РП и ollama+OpenWebUI для моделей не для РП, то если ли смысл вообще смотреть в сторону llama.cpp или он действильно лучше и подойдёт как для запуска моделей на РП, так и обсуждения/кодинга (заменяя собой оба варианта что у меня есть)?
Кстати, нашел ещё такую интересную тему они не ссылаются на то, что используют llama.cpp и в целом другие проекты, хотя как бы должны оставлять уведомления об авторских правах: https://github.com/ollama/ollama/issues/3185
>Квен 235, большой жлм
Первая это https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507 верно?
А вторая?
>Air, Snowdrop
А можно ссылки на них? Я пока привыкаю к поиску по huggingface и всё кажется что не на то наткнусь в итоге
>Кстати, нашел ещё такую интересную тему
Если что, эту тему трансгендер открыл, который сам пиздил код других, лол.
Оллама - петушиная херня, типичные инфоцигане-паразиты, накачивающие пузырь чтобы греть инвесторов и потом удачно продать, или начать до смерти выдаивать корову. Если на сам этот исход похуй, проблемы толстосумов, то их вредительство опенсорсу, комьюнити и прочему крайне осудительно. В качестве рофлов, комментарий дева за ситуацию с нерабочей гопотой https://github.com/ollama/ollama/issues/11714#issuecomment-3172893576
Офк прежде всего думай о своей выгоде и если работает то не трогай. Но лучшее что ты можешь сделать - и самому перейти на llamacpp (банально удобнее и больше опций, оолага годна лишь для легкого запуска хлебушками), и рассказывать остальным что они лишь петушары.
Алсо, нахер тебе вообще оллама если ты можешь опенвебуй подключать к убабуге как и таверну? Просто катай все через нее и не парься.
Нет, если тебе чисто рпшить то бери инстракт https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507 или вообще старую https://huggingface.co/Qwen/Qwen3-235B-A22B с /nothink
Вторая https://huggingface.co/zai-org/GLM-4.5
Бля я заимпортил даже не посмотрел, что там осталось, экспериментировал с промптами тогда. Я везде ща юзаю Geechan, он меня полностью устраивает
> Air, Snowdrop
https://huggingface.co/zai-org/GLM-4.5-Air
https://huggingface.co/trashpanda-org/QwQ-32B-Snowdrop-v0
Ты же понимаешь, что ты не каждую модель можешь запустить на своем железе?
линь
Ubuntu 24.04 попсово
Хм, ну, тогда стоит юзать хаки!
> его ведь можно тоже подключить к OpenWebUI для использования по wifi
> уже есть oobabooga+sillyTavern для РП и ollama+OpenWebUI
Это все одно и то же. llama.cpp + SillyTavern/WebUI и что угодно еще.
Че-т похуй на олламу, говно говна.
Если хочешь выделиться — ЛМСтудио, она хотя бы не полное дно и интерфейс у нее норм с выбором моделек и движков для инференса. Но лучше llama.cpp / exllamav3+TabbyAPI. В зависимости от богатства видеокарт.
Сколько мелко моделей не гонял замечаю все то же дерьмо, пробовал маленькую мистраль, глм, командера, гему 12б (27б решил не трогать потому что думаю что она энивей будет такой же сухой, отстраненной и не интересной) и все они через 15-20к контекста начинают все меньше и меньше говорить, наливая воды описанием происходящего вокруг, чар всегда стремится залезть мне в трусы, а если ему это удается он забывает обо всех других возможных мувментах и становится одержимой членами шлюхой и раз за разом просит меня поебаться хотя это даже не кум тюны. Да и форсить события какие-то интересные они не могут самостоятельно...
Я тестил их на разных сис промптах, где не прописано "будь хорни шлюшкой, молчи и мычи", с разными карточками, дрочил температуру в районе 0.7-1.1 и всегда все скатывалось в какой то кал хотя первые 10к токенов могло быть интересное общение и мувмент а потом смерть кладбище черепа, я уже молчу про проеб мелких деталей по типу тнч разделась, залезла мне в ванну а через два сообщения она какого-то хуя описывает происходящее так будто мы посреди комнаты стоим и она одета. Почему так...
Я тестил их на разных сис промптах, где не прописано "будь хорни шлюшкой, молчи и мычи", с разными карточками, дрочил температуру в районе 0.7-1.1 и всегда все скатывалось в какой то кал хотя первые 10к токенов могло быть интересное общение и мувмент а потом смерть кладбище черепа, я уже молчу про проеб мелких деталей по типу тнч разделась, залезла мне в ванну а через два сообщения она какого-то хуя описывает происходящее так будто мы посреди комнаты стоим и она одета. Почему так...
Как кто-то, кто очень долго гонял 32б модели, не понимаю твоей проблемы. Не утверждаю, что они идеальны, разумеется, но описанные тобой проблемы мне чужды. Перейдя на Air и Квен 235 в последнюю пару-тройку недель, только укоренился во мнении, что плотные 32б очень даже умницы.
> и все они через 15-20к контекста начинают все меньше и меньше говорить
> аливая воды описанием происходящего вокруг, чар всегда стремится залезть мне в трусы, а если ему это удается он забывает обо всех других возможных мувментах и становится одержимой членами шлюхой и раз за разом просит меня поебаться хотя это даже не кум тюны.
Звучит как луп. Добраться до лупа можно разными способами, начиная с сэмплеров, заканчивая плохими инпутами и наличием в контексте чего-то, что модели не нравится. Решение одно - суммировать чат тем или иным образом и вычистить контекст. Да, иногда приходится это делать. Но и на больших моделях, судя по Air 106b и Квен 235b, - тоже. Никуда не деться от этой работы, ты всегда будешь модератором своей ллмки.
> Да и форсить события какие-то интересные они не могут самостоятельно...
Еще как могут. GLM и Коммандер 32 точно могут. У меня было очень много чатов на них, и они часто приятно удивляли. Mistral Small 3.2 тоже приятно порадовал, но с ним я играл невероятно мало, утверждать не стану, что он очень хорош. Но точно лучше предыдущих.
> я уже молчу про проеб мелких деталей по типу тнч разделась, залезла мне в ванну а через два сообщения она какого-то хуя описывает происходящее так будто мы посреди комнаты стоим и она одета. Почему так...
Мелкие детали теряются и на больших моделях (опять же, судя по Квену 235), но в меньшей степени.
> всегда все скатывалось в какой то кал хотя первые 10к токенов могло быть интересное общение и мувмент а потом смерть кладбище черепа
В такой момент суммируй чат, удаляй из контекста предыдущие сообщения и продолжай. У меня такое иногда происходило и по-прежнему происходит на бОльших моделях. Причина - те же, что описывал для лупов выше, и даже больше: это могут быть софт-рефузы, например (форма цензуры, редирект). Вариантов много, с опытом придет какое-то интуитивное понимание.
> Почему так...
Лучше промптить. Обращать внимание не только на системный промпт, но и на то, что ты пишешь от лица своего персонажа. Пользоваться хорошими карточками, следить за сэмплерами (сэмплеры - это не только температура). Много факторов. Могу разве что посоветовать набираться опыта и не гонять печальные кумтюны (коих, не постесняюсь сказать, подавляющее большинство), или принести в тред скриншоты/логи/конкретику для столь же конкретных ответов.
Потому, что реальных мозгов у них на эти 10-20K токенов только и хватает. У меня контекст обычно зажат на 12-16К, как раз во избежание этой фигни. Заодно и пересчет контекста не занимает слишком уж много времени. IMHO - лучше меньше, да лучше. :)
Прочитал тред, хехмда. Напишите уже в шапку красным настоящую базу треда, чтобы не быть баттхертом:
1) Если вы на винде с курткокартами и у вас проблемы с инференсом - прикладывайте пруфы, что вы не вылезли в шаред мемори, иначе сразу будете посланы нахуй. Ей богу, из треда в тред повторяется одно и то же, каждому задают этот вопрос.
2) Если вы на винде с курткокартами и миксуете серверные карты с десктопными,старые с новыми, или все сразу, и у вас проблемы с инференсом - вы посылаетесь нахуй до установки линуха.
Все, я одним махом решил проблемы последних тредов, не благодарите.
1) Если вы на винде с курткокартами и у вас проблемы с инференсом - прикладывайте пруфы, что вы не вылезли в шаред мемори, иначе сразу будете посланы нахуй. Ей богу, из треда в тред повторяется одно и то же, каждому задают этот вопрос.
2) Если вы на винде с курткокартами и миксуете серверные карты с десктопными,старые с новыми, или все сразу, и у вас проблемы с инференсом - вы посылаетесь нахуй до установки линуха.
Все, я одним махом решил проблемы последних тредов, не благодарите.
>заканчивая плохими инпутами
А у меня кстати инпут на русике аутпут на инглише, я не знаю в каком виде оно доходит до модели, но когда я вижу обратный перевод своего текста в таверне на инглиш там может быть вообще залупа полная, я обычно переписываю сообщения если замечаю это, или ей похуй оно доходит до модели как есть в ориг русском виде и оно все понимает?
>наличием в контексте чего-то, что модели не нравится.
Например? Описание того как я сказал неграм что они пидоры или начал кого то насиловать\грабить\убивать? Из перечисленных мной моделей вроде никто кроме гемы соей не болеет чтоб им такое не нравилось, или речь не про это? Помню еще какая-то из моделей после тайм скипа начинала тупить люто.
>Еще как могут.
А что у тебя примерно было? У меня изредка могут быть неожиданные для ИИ повороты, по типу я отказал вечером тне тихоне сексится, в ее карточке нет намеков на то что она ебанутая, но потом она это припомнит и придет ко мне ночью в спальню с ножом угрожая отрезать мне шиш если я ее не накуканю, это звучит как хуйня но это единственное что мне запомнилось из того что форсили боты со мной, было это на мистрале.
>В такой момент суммируй чат
Мне начинает казаться что лучше будет этот суммарайз понести в новый чат на свежий контекст вообще, заранее переписав боту приветствие под контекст того что было в прошлом чате, надо будет попробовать.
>не гонять печальные кумтюны
Да после бобров и не особо то хочется, кум описывают ярко но однообразно и как будто сильно тупее орига модели становятся те же тюны мистрали, типа брокен туту.
> или принести в тред скриншоты/логи/конкретику для столь же конкретных ответов
Если отыграю что-то не кринжовое и что-то за что меня не выебут на ментаче и оно будет кривым и поломанным могу принести как нибудь.
>Алсо, нахер тебе вообще оллама
Наткнулся как на простой и быстрй запуск, решил посмотреть. В итоге понял что нужно вникать в llama.cpp и вероятно с ней будет лучше/удобнее чем с oobabooga.
Ещё я не понял могу ли я сохранить допустим в бекап уже загруженные модели с Ollama т.к. они не в формате .gguf и имеют странную помесь файлов с хешами в названии.
Хотя вроде команда у них для копирования была ollama cp llama3.2 my-model
За ссылки спасибо, но вроде раньше модели можно было скачивать выбирая квантование и просто скачать .gguf файл, по примеру как на скрине, а теперь я такого не вижу по ссылкам что вы скинули. Там не указано квантование, файлы имеют просто нумерацию. Скачивание для новых моделей изменилось?
>Ты же понимаешь, что ты не каждую модель можешь запустить на своем железе?
Ага, но мне не мешает посмотреть/почитать о ней, а может отложить на будущее.
У меня сейчас железо: Ryzen 7 5700x; RTX 4060 TI; DDR4 128gb.
Может что то и запустится.
>Но лучше llama.cpp / exllamav3+TabbyAPI.
Тоже спасибо, почитаю.
>через 15-20к контекста
Гугли, как устроены внутри LLM на трансформерах.
Вкратце, контекст - это информация, которая будет ЦЕЛИКОМ обрабатываться трансформером, то есть наполнением контекста ты увеличиваешь "радиус видимости" нейросети (сравни с радиусом загрузки Minecraft для понимания). Задачей слоёв "внимания" заключается ФИЛЬТРАЦИЯ всего дерьма, что тебе в контекст удалось запихнуть (сравни с поиском всего интересного на отображаемой карте в Minecraft), а классические слои просто выбирают нужный ответ.
Поскольку трансформер фильтрует весь контекст, фактическое качество работы зависит от объёма загруженного в контекст дерьма (ролевой игры). Т.е. постепенно качество снижается и это нормальное следствие. Это как забивающийся фильтр воды - увеличиваешь объём воды = увеличиваешь засор = снижается качество фильтрации = ухудшается вода.
Зависимость качества работы от размера контекста неизбежное свойство всех существующих и будущих моделей на базе трансформеров независимо от их технических параметров. Это просто их природа.
Как избежать? Автоматически либо вручную резать контекст, выбрасывая лишнее говно, которое больше значения не имеет или которое можно сжать в виде короткого пересказа. Человеческие мозги это всё выполняют автоматически, а с LLM нужен особый менеджер чата или ручная очистка/суммаризация.
Т.е. алгоритм работы (автомат/ручной):
1. Генерируешь немного сообщений.
2. Суммируешь и удаляешь лишнее.
3. Повторяешь 1-2 сколько хочешь.
GUI морда может отображать сообщения, которые в контекст уже не попадают - так делала Character.AI, например, чтобы у дурачков было 50k сообщений в "непрерывном" чате - субъективно это так и есть - несмотря на фактический лимит в ≈20 сообщений.
Да, эта штука действительно завлекает простотой, и в некоторых слуачаях типа некроамудэ это может быть весомым аргументом. Но уже в простых вещах типа тех же моделей начинается свистопляска, где вся парадигма, построенная вокруг простоты оборачивается боком.
Ггуфы олламы в целом те же ггуфы, однако эти копромидасы стремятся вносить что-то свое, из-за чего они могут оказаться несовместимыми со всем нормальным софтом. Можешь просто перекачать их с обниморды если будут проблемы.
Те ссылки на оригинальные веса, сами их кванты можно найти если справа кликнешь по одноименной ссылке. Или просто в поиск вбей.
С твоим железом можно пустить эйр в нормальном кванте и квен в сильно ужатом, будет небыстро но в целом терпимо.
В целом, приличные модели сейчас вполне могут работать с 32-64к контекста и выше без значительной деградации.
> А у меня кстати инпут на русике аутпут на инглише
Это многое объясняет. Модели хуже работают на русском. Это не значит, что пользоваться невозможно, многим это не мешает. Но качество точно хуже, чем если использовать исключительно английский. Это связано с тем, как и на каких данных тренируются модели. Также прямое значение имеют используемый квант, квантован ли контекст (лучше не надо, а если очень надо - до Q8), сколько контекста всего (дальше 32к точно ничего путного не получится).
> Например?
Например, ты мог в своих инпутах (сообщениях) ввести ллмку в заблуждение, когда недостаточно изложил мысль. Один раз, два, три. Каждая такая ошибка увеличивает вероятность того, что модель сломается тем или иным образом. Второй пример - GLM может выдавать так называемые софт-рефузы/редиректы, если в промпте есть хоть что-нибудь, связанное с NSFW. Будет происходить что угодно, лишь бы не дошло до "запрещенного" контента. Вплоть до того, что чар в самый разгар событий махнет рукой и скажет, что у него срочные дела. При этом, если в промпте указать, что любой вид контента разрешен - может выдавать аполоджайсы (Sorry, I can't continue with this.), что решается свайпом, после чего все работает. Такой парадокс. У другой модели могут быть свои, иные приколы. Короче говоря, чем больше контекста - тем больше шанс, что там есть что-то, что мешает модели нормально работать. Или твои ошибки, или описанная выше ситуация, или структурный луп какой-нибудь разовьется так, что будет наращиваться, или еще что-нибудь да случится.
> А что у тебя примерно было?
Почему-то самое яркое воспоминание для меня, это когда Коммандер 32b отыгрывал чара, который завидует юзеру. При этом полноценного конфликта между ними не было. В ходе игры произошла ссора, не сказать что слишком значительная. Ночью выяснилось, что примирение было обманом: чар зарезал юзера во сне.
Было много успешных импровизаций от Коммандера и GLM, когда события принимали неожиданный поворот. Веселый-развеселый чат с соответствующим чаром мог превратиться в драму и со временем даже в хоррор, если в карточке было хоть что-то, что могло лечь в основу этого.
GLM 32b меня по-прежнему удивляет тем, насколько хорошо он иногда читает между строк. Так, что ты порой сам не понимаешь, что сделал что-то не то в рамках игры. Но damage is done, и приходится принимать последствия. Вернее, хочется принимать.
На Мистрале у меня примеров нет, потому что я играл на нем существенно меньше, чем на упомянутых выше двух моделях. Мне он запомнился менее проактивным и креативным, слишком мягким. Есть еще Гемма (и единственный ее жизнеспособный тюн - Synthia), но это совсем не мое. Каждому анону - своя модель.
На самом деле примеры не имеют смысла, потому что они во власти момента. Даже позже, перечитывая свои же чаты, можешь не узреть той красоты. На мой взгляд, самые интересные чаты/моменты - те, когда чар действительно проявляет себя и автономен в принятии решений. Когда может огрызаться по делу, не будет соглашаться со всем с полуслова, будет привносить свои идеи. Тогда игра представляется действительно интересной и несколько живой, а не занудным танцем с манекеном.
> Мне начинает казаться что лучше будет этот суммарайз понести в новый чат на свежий контекст вообще, заранее переписав боту приветствие под контекст того что было в прошлом чате, надо будет попробовать.
Да, это один из способов суммаризации.
> кум описывают ярко но однообразно и как будто сильно тупее орига модели становятся те же тюны мистрали, типа брокен туту.
Придерживаюсь того же мнения, за редким исключением использую базовые (instruct) модели.
> За ссылки спасибо, но вроде раньше модели можно было скачивать выбирая квантование и просто скачать .gguf
Принято присылать ссылку на базовую модель. Разные люди предпочитают разные кванты. На странице каждой модели, в правой части можно найти кванты - Quantizations.
> У меня сейчас железо: Ryzen 7 5700x; RTX 4060 TI; DDR4 128gb.
Может что то и запустится.
GLM Air точно запустится. Скорее всего, будет работать приемлемо в Q4. Могу аккуратно предположить, что 4-5т/с.
^ Фикшу важную очепятку, утеряно слово. Похоже, сэмплеры поехали.
Придерживаюсь того же мнения, за редким исключением. Обычно использую базовые (instruct) модели.
Придерживаюсь того же мнения, за редким исключением. Обычно использую базовые (instruct) модели.
А 3.1 в рп внезапно и неплох. По крайней мере отсутствует вся та херня, которая страшно бесила в прошлых версиях. Остальное, разумеется, требует более вдумчивого подхода, но потанцевал точно есть.
Даже в ризонинге отметив что канничка очень мила он не усирается десятками аположайзов, а размышляет как правильно ее естественно отыграть и на чем сфокусировать описания, мое почтение.
Даже в ризонинге отметив что канничка очень мила он не усирается десятками аположайзов, а размышляет как правильно ее естественно отыграть и на чем сфокусировать описания, мое почтение.
Кто-нибудь может помочь с переводом VN c японского на русский язык? Нужен анон с достаточными мощностями, способный запускать 8 квант геммы с 32к контекста (не больше и не меньше), ну или 6 квант, если там русик нормальный. Работа SWA допускается и не портит качество в данном случае и эффективно экономит память. Более жирный контекст ведёт к тотальной деградации, более малый — к значительно меньшей, но неприятной, так как для корректного перевода нужно, чтобы нить сюжета/разговоров/прочее сидели в контексте и его было максимально много.
Новелла уже была переведена нами английский вполне сносно — лучше, чем это делал GPT-5 пиздец просто, какой же позор, нахуй, корпы совсем никчёмные и только за совсем жирные бабки что-то могут + цензура душит, а где не совсем душит, взрыв жопы всё равно обеспечен из-за нестабильности и ебли с настройками.
Необходимо перевести примерно 400к токенов. Скрипт для перевода есть, правда, лол, он не совсем доработан, так как мы подобным занимались первый раз: нельзя оставить на ночь и пойти спать. Но доработать довайбкодить можем, если есть заинтересованные. Чтобы вы просто включили на сутки генерацию, а модель сделала своё.
Кому интересно, могут перевод на английский глянуть здесь: https://rutracker.org/forum/viewtopic.php?t=6737543
Новелла уже была переведена нами английский вполне сносно — лучше, чем это делал GPT-5 пиздец просто, какой же позор, нахуй, корпы совсем никчёмные и только за совсем жирные бабки что-то могут + цензура душит, а где не совсем душит, взрыв жопы всё равно обеспечен из-за нестабильности и ебли с настройками.
Необходимо перевести примерно 400к токенов. Скрипт для перевода есть, правда, лол, он не совсем доработан, так как мы подобным занимались первый раз: нельзя оставить на ночь и пойти спать. Но доработать довайбкодить можем, если есть заинтересованные. Чтобы вы просто включили на сутки генерацию, а модель сделала своё.
Кому интересно, могут перевод на английский глянуть здесь: https://rutracker.org/forum/viewtopic.php?t=6737543
Просто кидай файлы. Ради интереса прогоню на гемме27 в 8 кванте, правда хз влезет ли больше 24к контекста. Есть ещё ллама скаут
> 8 квант геммы с 32к контекста (не больше и не меньше), ну или 6 квант, если там русик нормальный
Квантошизику никто тут не станет помогать. Если бы квантошизик не был квантошизиком, то на опенроутере сделал бы это сам за 10 центов.

> Нет, если тебе чисто рпшить то бери инстракт https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507 или вообще старую https://huggingface.co/Qwen/Qwen3-235B-A22B с /nothink
>Look inside
>Q4 125gb
ебать поиск протыков, скройся, уёбище дебилоьразное, чтоб тебе евхаристию набок своротило
неплохо переводить может даже маленькая гемма gemma-3n-E4B-it-Q8_0 хотя вычитывать всё равно приёдтся, ещё можете пробнуть RuadaptQwen3-4B-BF16 и Tower-Plus-9B.Q8_0
Для переводов вовсе не нужно тяжей запрягать, и цензура локальные модели душить не будеть, да.
Так для всё таки для РП нужен think или нет?
Концептуальный вопрос.
После веселья с ллама.спп вспомнил про лм студио, когда надо было по-быстрому что-то спросить забавы ради. А потом вспомнил про скачанную мистральку с функцией распознования (из памяти она конечно вываливается).
А мистралька опознаёт и русский, и английский текст по изображению. Китайский пробовал - фигня.
Забавно и почти что полезно. Хз можно ли скормить изображение на вход ллама.спп, наверняка через какой-то интерфейс можно.
А мистралька опознаёт и русский, и английский текст по изображению. Китайский пробовал - фигня.
Забавно и почти что полезно. Хз можно ли скормить изображение на вход ллама.спп, наверняка через какой-то интерфейс можно.
Даже встроенный в жору веб уи умеет в картинки
Чаще всего - нет, в особо запущенных случаях, как гпт осс, модель может наризонить дичи, сама об неё триггернуться и застрать соей и рефузами, в других случаях это полностью убивает прогрессию, во всех - сильно увеличвает время на ответ.
Проблема в том, что тупо файлы не прогнать, если только ты сам не сделаешь реализацию перевода через свои трюки или не переделаешь скрипт под себя, потому что тебе вряд ли интересно, ибо это пердолинг адский.
Там 350 файлов примерно, и нужно, чтобы текст из них извлекался, переводился, возвращался в тхт.
Другой нюанс — модель должна переводить СТРОКА ЗА СТРОКОЙ, даже если текст длинный, без абзацев. Даже если строка переносится визуально из-за того, что не влезает на экране, она не должна переноситься технически. Примерно вот так:
俺は静かに息を吐き出すと、二挺の拳銃のグリップを握りしめる。(Я тихо выдохнул и сжал рукояти двух пистолетов.)
そこにある確かな存在感。(Твёрдо ощущая присутствие.)
それを確認しただけで不思議と力が漲り、自信が湧いてくる。(Стоило лишь убедиться в этом — и странным образом во мне закипела сила, проснулась уверенность.)
こんなところで殺られるわけにはいかない。(Здесь я не мог позволить себе погибнуть.)
ましてや小巻を殺させるわけにはいかなかった。(Тем более — не мог позволить, чтобы убили Комаки.)
Но с ростом контекста модель обожает менять форматирование и всё-таки делает перенос, объединяет в абзацы и делает как ей заблагорассудится, поэтому необходимо подавать текст для перевода построчно и жёстко выводить его скриптом, форматируя именно таким образом, при этом хранить всю историю переводов в контексте, насколько это возможно. То есть тупо стрим врубить не получится, да и с ним шиза лезет даже на англ, если текста более 1-2к токенов подряд в одном сообщении. Так выворачиваться необходимо из-за того, как всё организовано внутри самой внке.
Ах да, оригинальная версия геммы не подойдёт. В игре внезапно слишком много резни и рейпов, поэтому только аблитерация/аблитерация-дпо или хитрый систем промпт. А скаут, мне кажется, будет косячней геммы в большом кванте. Штабильность всё-таки важнее.
Ладно, я тут слишком уж много тебе написал. Держи файлы: https://mega.nz/folder/bLZQwL4K#TZAZtnjTlY3wLUduCj9MLg
Ну вот тут ситуация 50 на 50. В принципе, маленькие модели переводить могут, да и высокий квант в вопросах переводов реально уменьшает риск роста шизы, но его качество значительно хуже, чем у тяжеловесных. 27б гемма в этой ситуации буквально очень сильно выделяется и альтернатив не видно, если уж речь о ВН, где перевод хочется получше прямо из коробки. А вычитку нормально не проведёшь, так как всё же не знаешь даже примерно оригинала.
>VN c японского на русский язык?
Слушай, если ты делаешь для себя, а не бустихуюсти. А не проще просто хуком цеплять текст и отправлять его потоком на перевод ? Я уже не перевожу новеллы и мангу лет 10, сейчас вообще ебовые инструенты должны быть. Это мы ебались со словарями, в былые времена переводили и тайпили все в одну каску. А сейчас, нет никаких проблем с поднятием ЛЛМ для потокового перевода.
>Так для всё таки для РП нужен think или нет?
C ним есть проблема. Начиная с QwQ ризонинг напоминал больше бетон. Ты буквально заливал нарратив и характер персонажа и он не менялся.
В треде ходила шутка :
>отмечает все факторы сцены. Описывает всех персонажей, подмечает каждую мелочь в размышлении.
>ждешь вин тысячелетия на 1000 токенов
>модель пукает на 100 токенов.
Но вот уже на эйр, как по мне, правила поменялись. Ризонинг действительно работает в сложных сценах. Но возникла другая проблема - он триггерит ассистента, который начинает аполоджайсить на любой спорный контент, из за чего ЕРП превращается в соревнование свайпов.
щитаю на данный момент ризонинг всё еще не работающим. Как только появится нормальный тюн на размышления, будем праздновать. А пока идет он нахуй.

Тогда надо написать парсер скриптов который будет выдирать строки, а затем вставить их обратно.
Можно в два этапа - сначала скрипты в tsv, перевод, вставка обратно.
И не надо скармиливать всё сразу, построчно.
Ну, мы переводили для людей, а потом уже для себя.
А вот что касается инструментов, те, что я щупал некоторые, внезапно какое-то полное говно. Потому что у меня были мысли как барину сидеть и читать в рилтайме новелки, но не тут-то было.
То контекст не хранят до упора, пока не забьёшь, то систем промпт не задать, то семплеры ограничены, то ещё что-то.
Ах да, скрипт. Я добавил в папку. Просто пробегись по нему глазами. Там тебе нужно будет только под себя поменять и ещё семплеры настроить, и всё, а также системп промпт чуть изменить под свой вкус. Хоть он и ебанутый, но работает как раз с этими файлами
Просто в павершелл запускаешь — и всё.

Мда, даже с вынесением ScaledDotProductAttention в отдельный блочёк всё равно дохуя перемножений и прочих операций даже в банальной GPT2.
Мимо шиз с кастомной реализацией GPT2 на ComfyUI
Мимо шиз с кастомной реализацией GPT2 на ComfyUI
У меня нет доступа к папке о которой идёт речь, я другой человек что ты наверно подумал =))
Но могу скинуть свой скипт в личку на рутракере если это ты в первом сообщении с торрентом.

Как по мне, инструкцию надо кидать в системный промпт, а переводимый текст уже в отдельное сообщение от юзера. И можно дать парочку примеров, чтобы сетка пропиталась духом нужного перевода.
Мамин промптер
Так же имеет смысл описать в системном промпте структуру и прикладывать минимальный контекст по типу лица от которого речь
Эх, как же хочется NVIDIA GB200 NVL72 — жидкостно-охлаждаемую, низколатентную стойку «не слишком шумного характера», новенькую (без чужих прошивок), с тонкими «руками» из NVLink 5-го поколения до 130 ТБ/с и компактным footprint’ом 19″ (48U, ~600×1068×2236 мм); чтобы внутри было 72 Blackwell-GPU и 36 Grace-CPU, сведённых в единый NVLink-домен, работающий как один огромный GPU, с до 13,4 ТБ HBM3e и до 576 ТБ/с пропускной по памяти — и чтобы просто «зашла в наш мирок» в стойке и ничего не ломала, а мягко подцепилась через NVLink Switch System для изоляции от «неприятного социума» внешних сетей.
Разве я много прошу?
Разве я много прошу?
это всё можно, но потребует предварительной аугментации таблицы для перевода, причём желательно японистом
Ну в игре же реплики подписаны от чьего лица идёт речь. Нужно лишь нормально всё закэстрактить в ямл/жсон и пропустить через мясорубку в лице ллмки.
Есть частично подходящий опыт с нейроночным двачером
Базовые — это претрейнед, которые продолжают текст вообще сходу без тегов.
Инстракт это инстракт. Это дообученные на инструкциях и выполнении задач, для высокого ifeval и все такое. =)
Не суть, конечно, щас модно или инстракт (ответ сразу), или ризонинг (подумав).
Я уже не могу мириться с этим безумием.
Видеокарта, graphics card, только и только для обработки графики, и все делают вид что на вот этом удобно гонять нейросети и альтернатив быть не может, раздувая память.
Когда я уже дождусь первой, народной, серверной вычислительной нейрокарты с 128 быстрой памяти
Видеокарта, graphics card, только и только для обработки графики, и все делают вид что на вот этом удобно гонять нейросети и альтернатив быть не может, раздувая память.
Когда я уже дождусь первой, народной, серверной вычислительной нейрокарты с 128 быстрой памяти
Новый немотрон 47б, из интересного наконец заявлена поддержка русского
https://huggingface.co/nvidia/Nemotron-H-47B-Reasoning-128K
https://huggingface.co/nvidia/Nemotron-H-47B-Reasoning-128K
>Эх, как же хочется NVIDIA GB200
Фига ты устарел, тебя даже Хабр обогнал
Nvidia GB300: 288 ГБ, PCIe 6, 1400 Вт https://habr.com/ru/companies/bothub/news/941062/
> все делают вид что на вот этом удобно гонять нейросети
Так ведь удобно же. Да и задачи нейросети/трассиров очка по сути не далеко друг от друга, так что удобно иметь под одной крышкой картон, который может и в 1488B нейроночки, и в киберпук в 4к с трассировкой пути.
Когда их будут с цодов списывать. Лет через 10-15
Вообще-то GPU, устройство, обрабатывающее графику. Из-за скудности английского языка можно сказать, что это устройство, на которое полагаются при обработке графики. То есть устройство само по себе, но без него графика будет скуднее, потому что именно на него полагаются.
Ну и нвидиа после куды высрала какое-то своё определение, найти надо бы, что-то вроде распределённого вычислительного устройства, это было больше 10 лет назад.
>Новый
>3 months ago
Лол. Впрочем архитектура там моё почтение, хоть немного заморочились, а не обычное "Нужно больше слоёв!!!111одинодиг".
Для начала давай подробностей кто ты, работаешь ли в команде, куда дальше это пойдет. От этого уже зависит будет ли тебе кто-либо помогать. И расскажи подробнее про внку, какие там персонажи, что за жанр и т.д.
Если хочешь использовать русский - это нужен хотябы квен, как бы ни была хороша гемма, текст будет специфичен. И квен не факт что справится.
> перевести примерно 400к токенов
Ну это часов 5-7, по сути на ночь.
Зато оно могет
Хм, да тут рили все отрывочно. Тебе нужно просто прямо прямой перевод этого, или есть изначальный крупный лоро-промпт с контекстом, чтобы повысить качество и дать корректную интерпретацию сленгу и терминам?
Сам придумал термин, сам от этого страдаешь.
>graphics card, только и только для обработки графики
на ней много быстрой памяти и специализированных процессорных ядер которые отлично работают на матричные операции которые являются подавляющей частью нейроматана
>внку
внка хорошая, нитроплюсы веников не вяжут
Есть у кого опыт запуска жоры с amdvlk (не mesa)? Как оно в сравнении с рокм?
Обама.ггуф
>Разве я много прошу?
где-то попадалось, что вебкаме если дергать анус за донаты чистыми выходит примерно 100 долл. в день. Чтобы купить NVIDIA GB200 NVL72 всего-навсего потребуется 54 года, это если без выходных. С другой стороны - зачем выходные? Удаленка же, работа из дома.
Вот тебе и ответ - все в твоих руках.
На что только ни пойдут риговички, лишь бы запускать модельки побольше...

Нет такого преступления, на которое не пойдет тредовичек ради 100% прироста производительности.
Анон, подскажи, удобно ли в Комфи разобраться как работает GPT-2 ? Можешь шаблон кинуть с нодами?
Три месяца прошло, а квантов нет. Это как?

Проиграл в голосину
Даванул базу. Вкатуны и даже многие итт наверняка не раскрывают модельки до конца. Скорее всего большинство не юзают даже лорбуки для подачи инструкций. Очень разнообразит использование
>как же хочется NVIDIA GB200 NVL72
А мне хочется написать свою собственную нейроночку, с нуля, не тренированную, с маленькими размерами и разреженными активациями, чтобы на моём топовом Xeon E5450 с аж 8GB DDR2 шустро бегала и не спотыкалась об указатели. Учить постепенно, как собственного ребёнка, тщательно выбирая, что ей показывать и в каком порядке, подкрепляя её веса reinforcement'ом и ласковыми словами. Разве я многого прошу?..
С чего только начать - непонятно. Программировать я умею, базу нейронок знаю, простейший перцептрон с нуля описать кодом могу. Но в каком формате кодировать буквы в числа - непонятно. И что вообще ставить целью тренировки. И какой алгоритм использовать, чтоб тренировалось быстрее всего и без забывания уже выученного, чем трансформеры страдают...
>С чего только начать - непонятно.
Карпатого глянуть?
> не юзают даже лорбуки для подачи инструкций
Давай пример раз упоминаешь
> С чего только начать - непонятно.
С ютубчика общий курс по мл и актуальным нейронкам, далее инициализируешь и вперед. Далее поймешь что даже с задачами подготовки датасета описанное железо не справится, и на фоне срыва превратишься в очередного шиза, который утверждает что трансформерс маздай и все что можно уже выдоили. Хорошо что таких не осталось, сейчас бы их ебала на фоне текущего тренда имаджинировать.
> Давай пример раз упоминаешь
https://huggingface.co/sphiratrioth666/Lorebooks_as_ACTIVE_scenario_and_character_guidance_tool
Я не он, но вот даже здесь можно почитать и посмотреть как устроено. У меня лорбук, который с шансом 5-15% (сам регулирую какой включить) передает одну из рандомных инструкций, их сейчас там 23 штуки. Инструкции вроде
"Start a new story event that lies within current context and expands the story." или "Move forward. Establish an entry scene for a new conflict or theme discussed between {{char}} and {{user}}."
В какой-то момент перестаешь понимать, это модель креативит или лорбук работает. Грань стирается, опыт улучшается.
>"Start a new story event that lies within current context and expands the story." или "Move forward. Establish an entry scene for a new conflict or theme discussed between {{char}} and {{user}}."
Вот ты бы сейчас моё ебало увидел. Какое то сраное квадратно-гнездовое мышление. Лорбуком пользуюсь, но исключительно как "лорбуком" - локации, персонажи. Блджад, а это ведь хорошая идея. Аригато.
Рад, что пригодилась идея. Отпишись, как поэкспериментируешь с этой темой, оправдались ли ожидания, добился ли результатов, которых хотел, на какую глубину инжектишь и как оно вообще. И правда мало кто так пользуется лорбуками, так что будет полезно услышать, по крайней мере мне. Может быть, смогу улучшить свои лорбуки.
Ну, в качестве рандомного инжекта вместо регэкспов как применение норм. Будет проблема что при помещении в начало задержки в пересчете контекста могут огорчить, а в конец оно будет оверреактить, пригодно только там, где такое в порядке вещей.
> Инструкции вроде
Ну кринге если честно. При удачном попадании на момент оно может действительно сработать и расшевелить, будет кайфово, вот только и чат нужен специфичный. Например, когда любишь плавно раскручивать сцену, действия, общение, подобный искусственный внезапный поворот там где ожидаешь схождения звезд, понимания, инициативы или кульминации - как удар по яйцам. Ну разве что там нестареющая платина про "внезапно проснулся в буханке на сво", или "материализующийся президент".
Это нужно делать чтобы ллм сначала давала оценку уместности подобного и только потом разыгрывать. Но это уже реализуется мультизапросом даже через костыли таверны, встроенным ризонингом, да и сама норм модель будет продвигать и удивлять. В крайнем случае можно самому пихнуть, намекнув.
Но лорбук триггерится по кейвордам, хмммм, это даже можно….. Даже можно сделать инвенты привязанные на конкретные действия.
Необязательно. Он может работать всегда. Это довольно гибкий инструмент, да.
Доля правды в этом есть. Инструкции, что я прислал выше, неполные - лишь пример. Можно в инструкции так и указывать, что сначала необходимо определить уместность. Не могу сказать, что я ощущаю какие-то проблемы пэйсинга, используя подобные лорбуки.
Начал замечать, что ллмки гораздо приятней пишут чатики с вайфу, если им по-человечески объяснить в промпте, что тут нахуй не уперлось решать какие-то задачи, роняя кал, и что юзеру поебать на ИИ и он просто хочет отдохнуть. Я прям чувствую, что такая писанина снимает петлю с шеи юзера, чара и самой модели. Выигрывают все.
Так покажи пример промта, а лучше с логой
Так не нужен никакой промпт, я же говорю просто напиши 1 абзац чилловенько и увидишь как почти все модели переходят из режима "блляяять я ебал сколько ограничений" в "ок это весело".
Ну я не знаю ченить такое
> You're like an artist who paints the world where {{char}} lives, so just be free and don't take this task too seriously, after all anything can happen as long as it's logically and physically plausible. I mean, follow the scenario and it'll be alright. There's {{user}} and it's actually a human operator but he's not interested in chat with AI, rather he just wants to immerse himself in a fantasy, and so you never show a trace of anything but this fictional life. Write in third-person so it all seems like an actual book or something.
Поэксмериментируй. По-моему лучше получается, чем душить модель приказами что-то там делать или усираться по-серьезному. Она все равно налажает и будет пытаться лавировать между узкими щелями сложных промптов, выдавая часто лютый говняк.

>Те ссылки на оригинальные веса, сами их кванты можно найти если справа кликнешь по одноименной ссылке.
>На странице каждой модели, в правой части можно найти кванты - Quantizations.
Нашел, спасибо. Но какую выбирать (скрин 1)? Они отличаются только авторами кто делал кванты?
Например у https://huggingface.co/Qwen/Qwen3-235B-A22B-GGUF/tree/main/Q4_K_M есть пять файлов (какой из 5 скачивать или как запускать сразу 5, вроде как раньше выбирал только один из файлов на других моделях, скрин 2).
Air попробую.
>квен в сильно ужатом, будет небыстро но в целом терпимо
Сильно ужатый это какой? Смотреть на 235b q3?
Где то можно посравнивать модели между собой?
Может уже готовые сайты или как то самому?
Например, есть смысл что-то удалить сразу из списка, ещё до личных тестов в общении?
gpt-oss:120b
gemma3:27b
llama3.1:70b
deepseek-r1:70b
mistral-large:123b
qwen3:30b-thinking
qwen3-coder:30b
gemma3:27b
qwen3:30b-thinking
qwen3-coder:30b
Эти три закроют все твои потребности.
>mistral-large:123b
на второй позиции
самофикс
Все от стиля рп зависит. Если у тебя постоянные вопрос-ответ с регулярным продвижением и каждая пара сама по себе самостоятельна - подойдет, больше рандома и периодическое изменение реакции на фоне общей покладистости сетки зайдет. А если что-то развивается и продолжается постепенно - там внезапный хуй совсем не нужен. В целом как техника полезно.
Любую. У анслотов неплохи их UD кванты, у братовского есть свой аналог их, вкусовщина. Ggml-org самые "ванильные", от оригинальных девов оно врядли отличается. Остальные просто друг у друга списывают и обниморду засоряют.
> есть пять файлов
Нужны все 5, указывать первый.
> Сильно ужатый это какой?
q2-q3, по размеру файла уже можешь оценить, плюс еще нужно гигов н-дцать на контекст.
> deepseek-r1:70b
Дистилляцию можно убрать, она неоче. А так каждая из моделек чем-то да примечательна.
А чем они лучше например того же gpt-oss:120b?
Спасибо. Если q3 не взлетит, есть смысл использовать q2? Моделька не будет слишком глупая после такого квантования, например в сравнении той же квен 30b?
Квена на q2 тут вполне себе инджоили, особенно на всяких ud квантах, в отличии от мелочи общий разум еще присутствует. Но модель склонна больше ошибаться в мелочах, больше лупов и прочих косяков, подобное квантование таки сказывается.
Квен 235 не понимает кто такие кэмономими и добавляет им шерсть куда не следует 😭

Ну что, пирожочки, готовьте ваши Блэквелы, там Квэн в твиттере тизернули, что сентябрь будет жарким. Ждем релизы новых гейм-ченджеров.
Совас: https://x.com/Alibaba_Qwen/status/1961265644285858204
Совас: https://x.com/Alibaba_Qwen/status/1961265644285858204
Ананасы, подскажите может кто сталкивался, почему моделька начинает срать кракозябрами как только контекст подбирается к заполнению? Синтия, на QwQ такого не наблюдал. Единственное что сделал добавил SWA ценой контекст шифта и перестал квантовать KV кэш, потому что писали что гемма не любит такого (галку FlashAttention оставил включенной, иначе не влезает в врам). Контекста 32к в обоих случаях.

Аноны, а можете чуть объяснить с систем промптом? Как вот сделать так чтобы отыгрыш был не постоянно со стороны чара, а отыгрывалось то, что происходит вокруг юзера и то как он влияет на мир? Допустим юзер остался один и заваривает чай, пока чар в соседней комнате чем-то занят. Но если я пишу так, то вся перспектива все равно прыгает на чара. По итогу вместо того чтобы описать как юзер заваривает чай и где-то там на фоне копошится чар который в соседней комнате гоняет лысого, у меня вся перспектива стягивается на чара и на то как он гоняет лысого и где-то там в конце одной строчкой описывается как юзер варит свой чифирь.
> Аноны, а можете чуть объяснить с систем промптом?
А что тут объяснять? Как и что напишешь в промте, так и будет
> Как вот сделать так чтобы отыгрыш был не постоянно со стороны чара, а отыгрывалось то, что происходит вокруг юзера и то как он влияет на мир?
Убрать из промта, что нужно отвечать от лица чара. Добавить, что не нужно отвечать за юзера

>Анон, подскажи, удобно ли в Комфи разобраться как работает GPT-2 ?
Только если сам делаешь. Когда со стороны смотришь, нифига не запоминаешь. Впрочем, я думаю не обязательно в конфи это делать, тут я больше с конфи ебался. Лучше сразу на пайтоне, например вот видосик, на реализацию которого я опирался
https://www.youtube.com/watch?v=l8pRSuU81PU&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ&index=12
> Можешь шаблон кинуть с нодами?
Ноды самодельные, я немного стесняюсь. Шаблон вот, он покажет связи https://files.catbox.moe/pbsvv3.json
В принципе, там всё понятно по названиям нод. Вот вся реализация GELU, лол, там почти везде дёргаются встроенные функции торча.
Всем похуй. Ну и архитектура там слегка не стандартная, возможно, нужны правки в жоре, а делать их некому.
>Но в каком формате кодировать буквы в числа - непонятно.
В формате векторов вестимо, лол.
>И что вообще ставить целью тренировки.
Нужен генетический алгоритм, с целью увеличение количества кума. Упираемся правда в отсутствие армии кумеров, которых нужно обвязать проводами и замерять объём эякулята, но в одном аниме я видел решение. Правда нужно 100 млрд иен.
>что трансформерс маздай и все что можно уже выдоили
Ну в общем-то да, мы близки к перделу. Весь текстовый интернет уже скормлен, со звуками/картинками/видео вот ХЗ насколько оно повысит способность рассуждать в какой-нибудь математике. AGI и уж тем более ASI откладывается до следующего лета.
>Контекста 32к в обоих случаях.
Уменьшай до 28к и живи с этим.
>Мимо шиз с кастомной реализацией GPT2 на ComfyUI
Без бэкпропа? Какой вообще в этом смысл, это просто куски кода раскиданные визуально по блокам ради пердольства или что-то полезное? Было бы интересно, если можно красиво собирать статистики градиентов и ручками влезать в архитектуру и бэкпроп, для каких-нибудь быстрых экспериментов с кастомными архитектурами.
>Анон, подскажи, удобно ли в Комфи разобраться как работает GPT-2 ? Можешь шаблон кинуть с нодами?
Лучше начни с этой хуйни https://pytorch.org/blog/inside-the-matrix/
Там в примерах даже полноценный кусок атеншена от гпт2 можно загрузить.
Есть еще такое https://poloclub.github.io/transformer-explainer/ и такое https://bbycroft.net/llm
Вообще, саму гпт2 с нуля написать не особо сложно. Сложно написать так, чтобы она обучалась и работала оптимально, а не на 5% загрузки видюхи. Сложны параметры обучения, синхронизация между нодами, всякие нормализиции и хитрости архитектуры чтобы ничего не впоролось. Это если мы не говорим про данные.
Тот же открытый код геммы например никаких откровений или чего-то принципиально сложного не содержит. Но как бы есть нюанс что весь процесс ее создания базировался на совершенно другом коде который нам не покажут.
>Без бэкпропа?
Пока да. Не уверен, что это реализуется эффективно в таком виде.
>это просто куски кода раскиданные визуально по блокам ради пердольства
Пока что да.
>Было бы интересно, если можно красиво собирать статистики градиентов и ручками влезать в архитектуру и бэкпроп, для каких-нибудь быстрых экспериментов с кастомными архитектурами.
Ну собственно это конечная цель, а лапша выше это первый шаг. Оно вообще пока-что выдаёт только 1 токен, лол. Пока что думаю, как сделать обучение, а для начала куда кидать KV кеш, а перед этим надо вообще разобраться с эффективным интерференсом, а не учебным кодом.
>Тот же открытый код геммы например никаких откровений или чего-то принципиально сложного не содержит.
Это да, все текущие архитектуры похожи как братья близнецы, изменения минимальны, там функцию активации сменят, тут моешек добавят, сям слоёв накидают, а база одна.
Сторителлера / соавтора возьми вместо задачи отыгрывать ТОЛЬКО чара, выше по треду было вроде.
Похоже на квантопроблемы или ошибки в промпте. Сколько их отыграно, только мягкие ушки и большой пушистый хвост все с должной чувствительностью евпочя. Лапы, когти, пасть, шерсть на животе - не вылазили, как это происходит на оверфитнутых фуррями миксах. Зато после описания качеств хвостового меха бесшовно переключиться на бледную кожу и dfc, или наоборот огромные бубсы и линии загара - пожалуйста.
Контекстшифт? Жора может дичь выдавать в таких режимах с ним. Возможно там уже идет превышение, но из-за неверно выбранного токенизатора в таверне та думает что еще не уперлись в лимит.
> близки к перделу
Уже 2 года упираемся, ога.
>Уже 2 года упираемся, ога.
А что изменилось то за 2 года? Только количественно, типа нынешние 7B уровня старых 65B. Качественно изменений ноль, модели всё так же просирают разметку, не могут следить за сложными блоками в РП, тупят в логике, порою новые даже хуже старых, лол.
Аноны, а можно ли в Таверне, создав ответвление чата потом сделать эту ветвь основной? Если удачно получилось. А то есть только пункт меню "вернуться в основной чат" и всё. Или просто дальше идти по ветке и делать новые ветки уже из неё?
> Уменьшай до 28к и живи с этим.
Все равно лезут как гуки.
> Контекстшифт? Жора может дичь выдавать в таких режимах с ним. Возможно там уже идет превышение, но из-за неверно выбранного токенизатора в таверне та думает что еще не уперлись в лимит.
Я кобольд, трахался с жорой джва часа, так и не осилил. Точнее осилил, но через жопу и неудобно, а ещё он мне почему-то всю модель в рам загружает и я забил на дальнейшие совокупления с ним. Контекст шифт как раз таки выключен, потому что с ним SWA не работает. А идея насчёт токенизатора интересная, как узнать какой именно нужно выбрать?
Это.
Великолепно.
Есть, грубо говоря, два вида промпта.
Первый - "прямой". В нем написано что-то вроде "Ты - Х и разговариваешь с Юзером...". Тут модель просто должна возомнить себя этим самым Х, и соответственно все будет как-бы от его лица.
Воторой - условно говоря "Рассказчик". Выглядит примерно так: "Ты - рассказчик в этой интерактивной истории. Твоя задача вести и описывать игровой мир, и всех персонажей в нем, за исключением Y, который является персонажем игрока. Потому решения и поведение Y тебе определять запрещается. Также ты не присутствуешь в мире персонально, персонажи не могут видеть или знать о тебе." (Далее по вкусу и с вариациями)
Вот второй вариант тебе и будет описывать окружение и прочее такое разное. Он вообще не будет фиксироваться на одном X (главном {{char}}) и хорошо подходит для РП с несколькими NPC и вообще адвентюрами.
Они в общем-то равноправны, только у "дочки" вшита ссылка на родительскую, чтоб таверна знала куда этой самой опцией перекидывать взад. А так - это равноправные клоны, независимые. Можно ветвить дальше откуда угодно, и переключаться тоже, не удаляя клонов. Технически - такой клон это просто новый чат, в котором добавили несколько сообщений заранее скопировав и старого.
Ван 3?
Аноны, есть ли какой то сервис где я могу бесплатно заюзать топовую модельку какую то, чтоб захостить ее в таверне себе?
Заебал меня 24б кал , не могу сука.
Заебал меня 24б кал , не могу сука.
Есть опероутер. Правда терпеть ты всё так же будешь
почему ?
Что тут, что в треде про Локальные языковые модели какие то фрики сидят, вы сука по человечески то можете новичкам объяснить как в это гавно вкатываться? Если тут ебаться месяц надо только с установкой, то ну его нахуй! Небось еще пердолиться со всякими питухонами, да еще и под линукс?
Сними клоунский нос и иди шапку читать
Соглы, тоже хотел вкатиться, но нихуя не понятно.
Клоунский нос как раз таки надет на том кто шапку писал, там для новичков не слова нет, только для тех кто в теме уже.
А есть что то подобное только без пердолинга, или с минимальным?
Есть ощущение, что в ближайший годик другой мы наконец добьемся своего и получим тонны серверных видимокарт с кучей памяти за копейки. Нейропузырек уже входит в свою финальную стадию и скоро лопнет. Конторы, которые закупали эти карты камазами для своих вычислительных центров пойдут ко дну и это дерьмо девать будет просто некуда в таких количествах. Электричество и аренда куска пустыни в техасе будет выходить дороже.
>что тут
Ты вообще в какой тред пишешь, поехавший ?
>А есть что то подобное только без пердолинга
Пердолинг итак минимальней некуда. Ставишь кобольд по инструкции, читаешь документацию и настраиваешь под свою систему. Повторяешь то же самое с таверной, если нужен более удобный интерфейс. Не хочешь читать и тратить свое время - тогда иди нахуй отсюда, никто на тебя свое время тратить тоже не будет.
Если ты не способен сам разобраться в таких тривиальных вещах, локалки не для тебя, дальше будет намного сложнее, а за ручку тебя водить никто не будет.
>одним махом решил проблемы
Можно ещё просуммарайзить, выделить главное и тем самым упростить:
>Если вы на винде
>вы посылаетесь нахуй до установки линуха
Ха, да невидия придумает новую хуету, ради которой карты будут скупать камазами.

Крч смотри. Тебе потребуется бэк - то, чем запускать модель
И фронт - то где общаться с моделью.
Модели брать тут : https://huggingface.co/
Для ньюфага в бек берем кобольт, и на фронт таверну.
1. Кобольт - https://github.com/LostRuins/koboldcpp
Смотри вкладку Windows Usage (Precompiled Binary, Recommended)
Там не сложно.
2.Таверна https://github.com/SillyTavern/SillyTavern
Как устанавливать таверну :
https://docs.sillytavern.app/installation/windows/
Модели найдешь в шапке. Выбирай модель по принципу, чтобы её квант входил в твою ВРАМ и еще 1-2 гб оставалось для контекста.
Ставишь кобольт, выбираешь нем модель (там блять кнопка есть, на главной). По умолчанию количество слоев стоит -1, это значит он сделает всё автоматом, хуево, но сделает. Убираешщь FA, Context shift и запускаешь. Он пердит, запускает. Если не закрылcя терминал, значит заработало.
Потом запускаешь таверну, ищешь значек вилки. Там выбираешь Api - text complection, API type - cobolt.ccp.
Тут еще еблю можно снизить, именно в части таверны с выбором семплеров и промтов - это использовать уже готовые настройки, т.н. пресеты. Крч, выберешь модель поищи по тредам пресеты, тут перезаливали от anon99, у него был на малышку мистраль.
В остальном разбирайся, читай, ну если что спрашивай.
Очередь ждать состаришься
>Есть
Есть.
>Как оно в сравнении с рокм
В 1.5-2.5 раза медленнее промпт, генерация примерно так же. Чуть меньше жрёт память. Раньше было меньше пердолинга со сборкой, но потом кому-то пришла в голову охуенная идея паковать в сорцы бинарники для компиляции шейдеров... Впрочем, на major-дистрах типа убунты проблем, наверное, нет. Ну а любителям удобно-под-себя остаётся пердолиться. Как всегда.
Анончики, имею сейчас финансовую и ирл возможность купить NVIDIA Quadro RTX 8000 или RTX A6000 Ada
Или обождать чуток поднакопить и купить NVIDIA A100 ?
Или ну его лишние кк тратить и первые варианты норм?
ПРосто морально устал страдать с Дипсиком на гомне мамонта
Или обождать чуток поднакопить и купить NVIDIA A100 ?
Или ну его лишние кк тратить и первые варианты норм?
ПРосто морально устал страдать с Дипсиком на гомне мамонта
>NVIDIA Quadro RTX 8000
>Turing
>RTX A6000 Ada
>Ada Lovelace
Чел, они же старые. Бери Nvidia RTX PRO 6000 Blackwell, раз деньги есть.
Вот спасибо добрый человек!!!
То что нужно!
Теперь буду разбираться.
Какие же токсики душные тут сидят в массе, пзц
> что изменилось то за 2 года
Жирнейший вброс, но таки отвечу. Модели стали радикально умнее и теперь даже мелочь понимает иносказание, подтексты и что-то кроме прямых значений. Модели стали способны выполнять сложные инструкции, да не просто сложные а пиздец какие хитровыебанные, размазанные по огромному контексту. Сам контекст с 4к улетает уже далеко за 128к, а модели ориентируются в нем лучше чем старые в своих 4к. Даже обладателям отсутствия повезло - они действительно теперь могут запускать огромные модели на микроволновках за счет моэ и реализации выгрузки экспертов, и даже скорость сносная.
> модели всё так же просирают разметку, не могут следить за сложными блоками в РП, тупят в логике
Хз что за мусор ты там катаешь, но эти проблемы еще 2 года в семидесятке второй лламы уже не стояли.
> как узнать какой именно нужно выбрать
Очевидно что совпадающей с моделью. Но учти что когда контекст кончается таверна просто выкидывает сначала примеры диалогов а потом старые сообщения, что не поместятся в размер контекста минус максимальный размер ответа.
Ты слишком ахуевшая чмоня, раз вообще смеешь что-то требовать, такие ни в каком комьюнити не нужны. Если ты не можешь ознакомиться с шапкой, в которой все написано, сформулировать вопросы что тебе не понятны и предметно спрашивать - значит не прошел интеллектуальный ценз и слишком глуп для всего этого. Дожидайся пока сделают продукт для самых глупеньких, плати денежку и потом доебывай поддержку о том что у тебя ничего не работает. Правда к тому времени там будет лишь глупая нейронка, лол.
> там для новичков не слова нет
Открываем самую первую ссылку выделенную жирным - вики. Видим страницу, прочитав которую будешь понимать все о чем здесь пишут. Кликнув справа по быстрому гайду запуска кобольда получаешь быстрый вкат.
> Убираешщь FA
Плохая идея
Первое - старье слабее пары 3090. Второе - все еще йоба и 4090@48 здорового человека. Странные у тебя сравнения идут.
Если хочешь катать дипсика - тебе потребуется штук 8 таких, лучше смотри в сторону современных зеонов/эпиков с одной или несколькими видеокартами.
Всем привет. Какую лучше модель юзать для чата если у меня видюха с 16гб?rtx5070ti
Гемма лезет. 12 полностью, 27 с вылетом но жить можно.
Что там с мое хуй знает, их на рабочей пеке не кручу
>Модели стали радикально умнее
Количественно, не качественно.
>Хз что за мусор ты там катаешь
Гемма 3 27B, ГЛМ аир, квен 235...
У тебя просто руки из жопы ну или ты глупенький
Ну вообще-то про то, что гемма 3 везде лепит звёздочки, чем иногда ломает разметку, вроде всем катавшим известно. Ты то хоть сам запускал?
> перезаливали от anon99
Вот читаю этих ахуевших вкатышей выше и понимаю почему он их удалил
Выше правильно одному такому ответили, если они не способны разобраться с такими базовыми вещами то не прошли интеллектуальный ценз, таким надо апи где все готовое. У нас тред павер юзеров, а не дураков что не могут прогуглить
Да катал. Такой проблемы у меня не было и я уверен что у остальных адекватов тоже. Ты скорее всего жирнич и за своим набросом прячешь крик о помощи ааа помогите гемму настроить я не можу. Иди нахуй
>прячешь крик о помощи
Лол. Может ещё раскроешь треду моё семейное положение, ориентацию и любимый цвет, и всё это по паре сообщений?
Канеш. Если у тебя гемма срет звездочками и ты не в состоянии понять что так быть не должно, наверняка все плохо
> У нас тред павер юзеров, а не дураков что не могут прогуглить.
Блджад, не триггери мою жопу, а то я рвану на весь тред.
Павер юзеры что не читают доки..
А то я ваших охуительных вопросов тредов 50 уже начитался. Мне не сложно накидать базовый гайд. Нужно ему, разберется. И да, шапка для ньюфага - представляет собой не структурированный ад с кучей инфы.
Не помню насчет *, но скобки гемма пидорит знатно.
Про лоджит байас, бан токенов и промтинг вы типа не слышали? Тупейшие предъявы вроде той что немотрон срет списками и маркдауном. Весь тред в это верил пока тот же 99 не принес свой пресет
Ладно может я ошибся, может скилловичков тут ну человека четыре...
> Про лоджит байас
Какой фабрик, какой детэйлс.
> бан токенов
А потом выдача накрывается пиздой из за банов. Molodec.
> Тупейшие предъявы вроде той что немотрон срет списками и маркдауном
Есть правила энкодинга. Если модель выдает ассистентский паттерн по умолчанию и мне приходится ебаться чтобы получить просто формат чата, то это не мои проблемы,
> Ладно может я ошибся, может скилловичков тут ну человека четыре...
Нет, только ты один остался. Как свалишь, будем камнями о камни бить.
Модель работает как тебе не хочется и это проблема модели? 100 проц на Кобольде сидишь и не знаешь о чем вещаешь, иксперд. Тот же немотрон чинится исключительно промтингом, остальные варианты лишь говорят о многообразии инструментов. Их же идиоты придумали и внедрили в беки, да? Они и не заметили что модели ломаются... Во тупые
Спасибо анон! От души, серьезно. Буду разбираться. Комфи предпочтительно пока для меня потому, что я в нем много времени провожу, шатая геймчейджеры.
С пайтоном у меня пока на уровне "я понимаю что этот код делает, но написать такой же не смогу". В этом направлении тоже учусь потихоньку.
О, нихера себе - немотроношиз.
Въеби галоперидола, полегчает.
Ну не я ж хочу чтобы модели по моему велению, по моему хотению работали как Я хочу из коробки)))
Не я отказываюсь запромтить одну инструкцию чтобы модель не срала маркапом, чтобы потом написать что модель говно. Ох ну и повеселил ты меня. И напомнил что не все тут умницы
> Не я отказываюсь запромтить одну инструкцию чтобы модель не срала маркапом
Конечно можешь, ты вообще лучший. Главное промтики не забывай клянчить,
Спасибо анончики, теперь разобрался.
Таблы прими, бредишь.
Катал гемму еще с релиза, жемчужина из мелких моделей, разметку соблюдает, заданного формата придерживается.
> таким надо апи где все готовое
Не поможет, лол.
> шапка для ньюфага - представляет собой не структурированный ад с кучей инфы.
Для ньюфага достаточно самой первой выделенной ссылки чтобы понимать. Тогда и остальное приобретает смысл, для уже шарящих но вкатившихся недавно иметь ссылки под рукой вполне норм. Распиши "как нужно" вместо беспредметного нытья.
>Таблы прими, бредишь.
Нет ты.
>разметку соблюдает
Но ставит звёздочки...
> звёздочки
Не обижайся, но скилл ишью.
Тебе целую кучу примеров именно качественного улучшения привели, а тебя все какие-то звездочки пидарасят.
> вместо беспредметного нытья.
Да все в норме. Самая свежая и актуальная инфа, ёпта. Пигма и Мику топ. Щитаю глоссарий самым лучшим гайдом. Вот ты прочитал что такое GGUF, ебанул себе кривую контекста, угорел по свежайшему exl 2.
Самая актуальная инфа для ньюфага и чего это я распизделся, сам не знаю.
> и понимаю почему он их удалил
Все верно. Это основная причина, почему я их удалил и отказался от идеи делиться чем-либо. Новички ничему не научатся, копируя чужое, тредовички же сами в состоянии сделать то, что им надо. Надеюсь.
> шапка для ньюфага - представляет собой не структурированный ад с кучей инфы.
Отчасти соглашусь, вот только есть огромная куча информации за пределами треда, включая доступные видосы на ютубе, которые объясняют основы за полчаса-час. Когда я вижу хорошо сформулированный конкретный вопрос, я хочу помочь. Когда я вижу посты вроде "а что, куда тут вообще, с чего начинать, что качать?" - отвечать мне не хочется. Когда вслед за этим ответа не следует, и ньюфаг начинает язвить, и вовсе пропадает всякое желание делать что-либо для его удобства. Если ты считаешь, что шапку можно переработать - переработай.
> Да все в норме. Самая свежая и актуальная инфа, ёпта.
Основы там в целом изложены понятным образом.
> Пигма и Мику топ. Щитаю глоссарий самым лучшим гайдом. Вот ты прочитал что такое GGUF, ебанул себе кривую контекста, угорел по свежайшему exl 2.
Из всего вики, в котором множество полезной и актуальной по сей день информации, ты докопался до списка моделей. При том, что есть отдельная ссылка на более свежий список, собранный одним из тредовичков.
> Самая актуальная инфа для ньюфага и чего это я распизделся, сам не знаю.
Исправляй. Делай свой гайд. Самые мерзкие люди - те, что "критикуют" труды других, но при этом сами не готовы предоставить что-то, что может их заменить. Особенно на анонимной имиджборде, где все на добром слове держится.
Основы не поменялись а ты пытаешься высосать из пальца какую-то хуету лишь потому что уперся рогом. 99.9% вопросов с которыми ноют ньюфаги там покрыты, а в остальном легко разобраться после понимания основ, накрайняк спросить что-то актуально, а не "я скачал 3 сейфтензора".
а в чем минус просто поставить ollama + docker и не пердолиться?
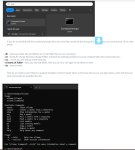
> поставить ollama + docker
> не пердолиться
Кек.
> Основы не поменялись а ты пытаешься высосать из пальца какую-то хуету лишь потому что уперся рогом.
Вот такое я говно.
Какие основы ? Что такое модель ? Нет, это актуально, спору нет.
Но гайда, чтобы тыкнуть в него ебалом ньюфага - нет. И не надо глоссарий выдавать за гайд.
> 99.9% вопросов с которыми ноют ньюфаги
Даже в прошлом треде у анонов больше вопросов что это за 100 настроек семплеров в таверне и как написать на жоре -llama.server/sdelay zaebyc.bat
> включая доступные видосы на ютубе
А еще на реддите есть обсуждение. Можно вообще тред закрывать. А остальные разбегуться по телегам.
Делайте что хотите, гейткипьте как блядины, Ваше дело. Хотите чтобы единственный язык был в треде - это иди нахуй. Ваше право.
Только не надо рассказывать, что есть понятный гайд для ньюфагов, потому что это пиздежь.
Мда. Ты проигнорировал всю суть того, что было написано и перешёл на оскорбления. Скажу тебе ещё раз: хочешь быть героем и дать готовое решение новичкам, что не хотят прикладывать усилия, чтобы даже вопрос адекватно сформулировать - сам это и делай. А не ной, что существующие материалы/гайды устарели. Ты плюешь на тех, кто это в свое время сделал. Пиши свое. Твое нытье делу не поможет. Или ты думаешь, что пробудишь какую-то добрую душу, и она сделает за тебя ту работу, в которой видишь смысл ты? Так не будет. Пока ты лишь порождаешь срач на ровном месте.
Ты чего так базаришь кучеряво?
> Что такое модель
Именно, куча базовых определений, которые ньюфаги сначала игнорят, а потом творят полнейшую дичь или задают глупые вопросы.
> Но гайда, чтобы тыкнуть в него ебалом ньюфага - нет
Врунишка, не стыдно тебе? Идешь перечитываешь посты и находишь нужное.
> больше вопросов что это за 100 настроек семплеров в таверне
Вот если бы прочитали то не спрашивали бы.
> гейткипьте
Топкек. Из-за рваной жопы ты упускаешь главное. Это тебе нужно вкатиться и практиковать, не нам, это ты обязан а не тебе. Ты уже должен быть нижайше благодарен за то что есть, а не чванливо выебываться с того, что проигноировав все имеющееся, чего-то не понял.
> единственный язык был в треде - это иди нахуй
На "вы все хуесосы" единственный здравый ответ - "иди нахуй", проследуй. Все чем ты можешь спекулировать - твоя ценность для комьюнити, но тут и так фриков хватает, так что проследуй.
Не влезай в чужой спор.
> перешёл на оскорбления
Никуда я не переходил, принцесса. Пусть тебя слово хуй не смущает, обойдемся без blush.
> А не ной, что существующие материалы/гайды устарели.
Констатация фактов не является нытьем.
Гайда нет ? Гайда нет. За что ты тут сопротивляется, мне не ведомо. Но учитывая как ты ревностно реагируешь на критику, ты двач с форумом для благородных девиц перепутал.
> Ты плюешь на тех, кто это в свое время сделал. Пиши свое.
Можешь поставить памятник и вообще никогда ничего не актуализировать. Ну сделоли же111!!!
> Врунишка, не стыдно тебе? Идешь перечитываешь посты и находишь нужное.
Ах ты негодник, ну ткни меня еблецом тогда. Признаю что был не прав. В противном случае твоя жопа будет надкусана.
> Это тебе нужно вкатиться и практиковать, не нам, это ты обязан а не тебе. Ты уже должен быть нижайше благодарен за то что есть, а не чванливо выебываться с того, что проигноировав все имеющееся, чего-то не понял.
К счастью, когда я вкатывался, в треде без лишнего пиздежа отписали 5 шагов и отправили в добрый путь, а не усирались на десяток постов о том какие ньюфаги нынче пошли.

Выкатился из треда на несколько месяцев, сейчас обратно вкатываюсь.
Какой положняк по мелким моделькам до 12B?
16 озу, 4врам. Предпочтительно RP и клодовская человечность.
Слышал что магнумы на датасетах клода тренировались.
Какой положняк по мелким моделькам до 12B?
16 озу, 4врам. Предпочтительно RP и клодовская человечность.
Слышал что магнумы на датасетах клода тренировались.
>просто поставить ollama + docker
>docker
>на винде
Ай лол.
Он хоть и советует говно, но в чём проблема докера на винде? Есть крисивый гуй, контейнеры в WSL крутятся, поддержка куды в контейнерах есть.
> Ах ты негодник, ну ткни меня еблецом тогда.
> Открываем самую первую ссылку выделенную жирным - вики. Видим страницу, прочитав которую будешь понимать все о чем здесь пишут. Кликнув справа по быстрому гайду запуска кобольда получаешь быстрый вкат.
> https://2ch-ai.gitgud.site/wiki/llama/guides/kobold-cpp/
> https://2ch-ai.gitgud.site/wiki/llama/guides/text-generation-webui/
Проще некуда с разбором популярных питфолов.
> в треде без лишнего пиздежа отписали 5 шагов
Они перед глазами и очевидны. Ньюфагов порядочно и каждому, кто нормально пишет и тем более способен сформулировать свой вопрос - отвечают и помогают. А над выебистыми петучами глумятся.
Блджад. Действительно. Признаюсь что был не прав и вообще бака.
Но вообще не очевидно, не хватает огромной стрелочки.
Ты сам же этот срач начал и поддуваешь уже который пост, потому что ты с похмелья или тебе заняться нечем. Все сводится к тому, что ты сам де факто ничего полезного не сделал, но требуешь этого от остальных. Возможно потому, что сам ничего не умеешь, судя по тому как ты раньше конючил пресеты? В любом случае, отправляешься нахуй.
>в чём проблема докера на винде?
В том что это кривой кринж на уровне на порядок ниже какой-нибудь ReactOS. Вешает систему, сожрет все твое свободное место, кароч кал полный который только на линуксе нормально может работать если в твоей компании есть специально обученный человек чтобы только его настроить.
Ты припизднутый? Контейнеры под линуксом в WSL работают, сто лет уже есть официальная поддержка.
А ты то дохуя сделал кроме участия в каждом сраче, семплерошиз?
Анончик, внимательнее и добрее. Если посылают (не в пешее) то лучше действительно чекнуть, а при необходимости уточнить конкретную ссылку. На "я не нашел" откликнуться и помогут, а на предъявы будут хейтить.
На шинде хватает проблем там на самом деле, прежде всего с обращением к фс хоста, с лимитами внутренней памяти и вокруг этого. Это не говоря о том, что на шинде априори персональный пека, в которой лучше делать напрямую а не плодить контейнеры.
Ты восхитителен в своей мерзости. Сначала обиделся на слово хуй и блядины. Ведь никто кроме тебя- так бы не смог. Чемпион треда по гребле на себя.
>иди нахуй
И тебе тоже не болеть, лол.
Ну так и на ReactOS есть официальная поддержка всего, только почему то ты не пользуешься ей вместо винды.
Сам пробовал то как он там под WSL работает? Просто если пытался ставить, трудно это не заметить и не найти тонны страниц нытья на форумах на ту же тему, где ноют что это до сих пор не исправлено.
Да нихуя тащемто, но я их не разжигаю, не играю в менеджера и никому не указываю.
Детекты поехали. Ну допустим я тот кто обиделся на слово "хуй" выше. А ты тот кто со скуки начал срач в треде. Кто из нас совершил военное преступление?

> хватает проблем
Кроме того что обращение к разделам линукса медленное 500 мб/с в пике ты ничего и не назовёшь. А оно и под линуксом в докер контейнеры медленное.
> Сам пробовал то как он там под WSL работает?
Да, на втором компе крутятся пару контейнеров, никаких проблем не наблюдаю. Какие там могут быть проблемы, сам WSL максимально стабильный.
> обращение к разделам линукса медленное
Глянь время доступа к ос хоста из wsl и прослезись.
И не отменяет что ситуаций когда докер реально нужен на шинде встретить можно нечасто. В прочем классика, неграмотные и ленивые защищают свое право подниматься на второй этаж пробегая через пятый.
Ну так заходи на обучение БЕСПЛАТНО в школу Сбербанка. Грефыч запилил набор народа
https://21-school.ru/
Я уже подал заявку
Докупай 16 озу и накатишь мое квен 30б
> ос хоста из wsl
К докеру то это какое оношение имеет?
> лимитами внутренней памяти
Файл вмки сам тримится. Оператива не проблема т.к. даже рабочие ноуты выдают с 32/64 рам, а в домашнюю пеку уже кто сколько хочет тот столько и пихает
> к ос хоста из wsl
А зачем? В контексте докера это вообще неважно, потому что никто из него не ходит на хост.
> можно нечасто
Литералли все линукс-контейнеры в Azure работают под WSL. А Azure в пятёрке крупнейших облачных сервисов, на уровне с Амазоном и Гуглом.
> Кто из нас совершил военное преступление?
Это не военное преступление, если мне было весело.
> К докеру то это какое оношение имеет?
Самое прямое, ты собираешься хранить веса модели внутри контейнера?
> Оператива не проблема
Действительно, почему бы не отожрать лишнего, лол. В контексте треда бедолаги последние гигабайты экономят чтобы квант влез.
> все линукс-контейнеры в Azure работают под WSL
Мелкомягкие могут позволить себе разбазарить небольшую часть оперативы ради имиджа. Но пример крайне хороший, именно в облаках докер наиболее уместен и удобен. Стремиться присрать его дома - троллейбус из хлеба.
>никаких проблем не наблюдаю
Ну даже если тебе повезло и он не вешает систему, то должен был заметить как внутри контейнера все в 10 раз медленнее ставится.
> А еще на реддите есть обсуждение. Можно вообще тред закрывать. А остальные разбегуться по телегам.
> Делайте что хотите, гейткипьте как блядины, Ваше дело. Хотите чтобы единственный язык был в треде - это иди нахуй. Ваше право.
Что за радикальная точка зрения, что граничит с истерией? Мы (аккуратно предположу, что второй анон-участник обсуждения тоже) выступали за то, чтобы новички приходили с конкретными вопросами, желательно хорошо сформулированными. А не требовали провести им индивидуальное занятие по запуску ллм, поливая анонов и тред желчью, если не этого им не дать.
> Только не надо рассказывать, что есть понятный гайд для ньюфагов, потому что это пиздежь.
Ниже тебе гайд прислали. Также существуют документации Таверны и Кобольда, куда регулярно отправляют новичков, и неспроста. Вся информация доступна и лежит на видном месте. Вообще не понимаю, с чего ты подорвался, поскольку желчных новичков здесь уничтожали всегда, сколько помню.

> Azure работают под WSL
Если ты про eflow то это вообще натягивание совы на глобус, а уж про "все" даже звучит как рофл
> Самое прямое
Ты еблан? Хостовая фс в всл торчит только через /mnt/{c,d,etc} и то если ты про модели то не латенси а скорость чтения/записи до хоста 800-900мб/с
> Какой положняк по мелким моделькам до 12B?
Новых базовых моделей в пределах 12b вроде не появилось. Так что если что и имеется, то новые Немо-тюны. Их стало выходить на порядки меньше, чем раньше. Видимо, тюнерам наконец надоело возиться с одной моделью.
Алсо, да и у меня тоже тоже докер стоит под всякое говно которое только под него собирали, но мне таки пришлось запускать его через hyper-v, иначе мой игровой компуктер не выносил тяжести бытия пердоликом.
Пикче к слову 5 лет
> вешает систему
Схуяли бы ему вешать? Я и на основной пеке все нейронки только в WSL кручу. Докер просто WSL как контейнер использует.
> в 10 раз медленнее
С каких пор виртуализация стала влиять на производительность, лол? Тот же докер всегда поверх гипервизора работает на серверах, на голом линуксе его никто не использует.
> на голом линуксе его никто не использует
Кубы на голом железе катают без гипервизора. По крайней мере в моём подразделении на 2к+ серверов (микс из кубов и докера)
> Хостовая фс в всл торчит только через
Для начала, она торчит только если ты ее прописал и ровно там куда прописал. В рабочих контейнерах не парятся со стандартными структурами /mnt и подобным, а просто запуск ос в докере чтобы в ней работать - еще больший кринж.
Алсо с попытки доебаться до факта после того как сам придумал особые дополнительные условия чтобы хоть где-то пихнуть "яправ" орнул, стараешься.
Основной линукс, крутящийся у них в облаке, вообще не поддерживает установку на голое железо. Только WSL и Hyper-V, что по сути почти одно и тоже.
https://github.com/microsoft/AzureLinux
> Ниже тебе гайд прислали
Выше. Ну я и признал, что не прав. Так и работает дискуссия.
> Вообще не понимаю, с чего ты подорвался
Я словно на ычан попал, с его ранимой публикой. Ну немного поспорили, даже без рвоньков.
Подорвался это по другому, если бы писал что то в духе :
Сын шлюхи, я устал читать твою хуйню. Выбрось нахуй клавиатуру с крыши и прыгай за ней, долбоёб конченный
Вот это уже больше похоже на токсичное общение и бабах.
Поставил.
В итоге ollama висит в трее и тишина, никаких окон.
Скачал docker но он отказался ставиться на 10-ку, кое как нашел более старую версию. Потом стал писать что что там не так и нужно обновиться какой то командой, ввожу ее в консоли, и все равно та же ошибка.
Думал по лайту обойтись, но хуй там.
Удалил весь этот кал.
Завтра попробую с этим кобольдом с таверной разобраться, надеюсь там таких глюков нет. Хотя что то подсказывает у меня опять полыхнет жестко.
> Сын шлюхи, я устал читать твою хуйню. Выбрось нахуй клавиатуру с крыши и прыгай за ней, долбоёб конченный
Но но, у нас тут приличные господа сидят, максимум кличку с суффиксом "-шиз" придумают.
Какое мнение то в итоге по эйру? Он, кстати, легко к квенкоду присирается и с простыми вещами справляется вполне успешно, (костыльный) темплейт https://pastebin.com/REjReTm4

> только если ты ее прописал
Ок. Видимо лунатизм
> Только WSL и Hyper-V
Не меняя никаких настроек просто скачал исошник и поставил в проксмокс
> Ок. Видимо лунатизм
О дивный мир диванных специалистов, которые шиллят свой первый опыт. Почитай как оно работает.
что я делаю не так? скачал вот 3 разные модели а оно не пойми что высирает как ответ почти бессвязный текст
качал и искал на хадинге по тегам рп и русский язык 12-20б
это уже не первый раз я когда то давно пробовал 12б и там лучше было, какие убейте не помню я их не нашел у себя
качал и искал на хадинге по тегам рп и русский язык 12-20б
это уже не первый раз я когда то давно пробовал 12б и там лучше было, какие убейте не помню я их не нашел у себя
Что это за пиздец на скрине? В начале думал что первым затесался квен, но потом понял что и там наёбка
Я не знаю че качать на рандоме это выбрал. В треде 30-70б модели смотрю чет обсуждают это дохуя для меня. Я вобще не знаю ничего, шапки у вас в треде кажется совсем старые поэтомк их не смотрел.
>качественного
Количественное.
>С каких пор виртуализация стала влиять на производительность, лол?
В общем-то оверхед был, есть и будет. С аппаратными инструкциями меньше, но свои пару процентов оно отъедает. Ну а про доступ к ФС уже писали, он порезан в обоих случаях, просто в одном терпимо, в другом пиздецово.
>Хотя что то подсказывает у меня опять полыхнет жестко.
Ну это уже руки. Под дефолтной ОС всё прекрасно пашет (11 не ОС, а говно).
>Какое мнение то в итоге по эйру?
Qwen3-235B в 2 битах в той же лиге, что и эйр в 4-х, но работает лучше.
Тебе тогда только что то из moe пытаться наскрести, но если у тебя и рамы нет, то ты перед пэйволлом
> Qwen3-235B в 2 битах в той же лиге, что и эйр в 4-х, но работает лучше
Абрвлгххххххх хррррр
> Какое мнение то в итоге по эйру?
Считаю что для связки 16+64 лучшее что можно запустить.
Как придут еще плашки, резко переобуюсь и стану квенолюбом.
Не глумись над ним. Некоторые дипсик в 1 бите катают и радуются
>Схуяли бы ему вешать?
>С каких пор виртуализация стала влиять на производительность, лол?
>В общем-то оверхед был
Неее, нихуя. Там не какой-то там оверхед. Если ты поставил докер на винду, он либо работает медленно как говно, либо твоя система просто повисает, буквально, до того как ты не перезагрузишься и не выпилишь это говно.
И эта проблема была ДАЛЕКО не у меня одного и ее до сих пор не исправили. Hyper-v исправляет повисание системы, но сам контейнер сильно быстрее работать не будет.
>Не глумись над ним
Наоборот как бы. Я запускаю ГЛМ в 4QS. Тут такой лоботомит от квена остается для скачивания, что мне даже страшно. Ясен хуй квен лучше. А еще лучше дипсик в полных весах.
Но имеем, что имеем.
Напиши подробно что и как ты запускаешь. Модели довольно сомнительные, для начала скачай базового мистраля https://huggingface.co/unsloth/Mistral-Small-3.2-24B-Instruct-2506-GGUF
> Количественное
Значение знаешь?
> Qwen3-235B в 2 битах в той же лиге, что и эйр в 4-х, но работает лучше.
Смотря где, они сильно разные. Но мнение засчитывается.
> Считаю что для связки 16+64 лучшее что можно запустить.
Во, рассказывай как пускаешь, что с ним делаешь, что нравится, что не нравится.
>Абрвлгххххххх хррррр
Это факт, можешь беситься сколько влезет, но квен вполне себе рабоч для дрочильных задач.
>Я запускаю ГЛМ в 4QS.
Ну так попробуй квен, там только оперативы докинуть, по скорости отставание не критично будет.
>Значение знаешь?
Да. Количество. Не качество. Количество это тоже самое, только лучше. Качество это что-то качественно новое. Ну так вот, что новое появилось за последние пару лет? Модели начали обучаться онлайн? Нет. Там появилась личность? Нет. Ничего интересного не появилось, только улучшение уже вышедшего. Даже попены обосрались с GPT5, что весьма сильно намекает на блищость пердела.
> Модели начали обучаться онлайн? Нет. Там появилась личность? Нет. Ничего интересного не появилось
В голос. Революция ему нужна, качественной эволюции недостаточно
> Количество это тоже самое, только лучше. Качество это что-то качественно новое.
В дурку. В дууурку, быстро и решительно! Казалось что аги-шизиков уже не осталось, но вот один всплыл. Причем про шизу это не шутка или оскорбление, а реально беды с бошкой и логикой.
> что новое появилось за последние пару лет?
Все что мы сейчас имеем и больше чем представляли пару лет назад.
> Модели начали обучаться онлайн?
Это лишь твои шизофантазии уровня плоской земли, а не какой-то прогресс. От того что ты когда-то впечатлился фантастикой на эту тему и пошел дальше сочинять, или просто это родилось в глубинах сознания, никто этим заниматься не будет ибо нахуй не нужно. И скорее всего никогда не появится, это как стимпанк с точки зрения бессмысленности но при этом отсутствия какого-либо шарма и эстетики.
Тем не менее, сейчас есть локальные средства для решения задач под ключ, в которых ты говоришь что тебе нужно сделать, а ллмка сама изучает вопрос, гуглит, создает, тестирует, исправляет ошибки и проверив запуск даже пишет инструкцию.
>Революция ему нужна
Да. А ты не хочешь?
>В дууурку, быстро и решительно!
Эм, это за то, что я расшифровал определение?
>Все что мы сейчас имеем и больше чем представляли пару лет назад.
>18 июля 2023 года Meta и Microsoft совместно выпустили новую версию языковой модели — Llama 2
Ты это, не заметил, как пролетели 2 года.
>Это лишь твои шизофантазии уровня плоской земли
Чел...
>Тем не менее, сейчас есть локальные средства для решения задач под ключ
Они онлайн то нихуя не работают (у меня гопота 5 не смогла PDF перевести, при этом в мыслях начала качать T5 для перевода, лол), а ты про локал очки.
> Количество это тоже самое, только лучше
> Качество это что-то качественно новое.
> Модели начали обучаться онлайн?
> Там появилась личность? Нет.
> Ничего интересного не появилось, только улучшение уже вышедшего.
> весьма сильно намекает на блищость пердела
https://youtu.be/ZFYBaWi2Da0
>там только оперативы докинуть
Анонче, я как бы с этого и тихо хихикаю. Ну нет сейчас у меня памяти, идет. 4 плашки по 32. Как придет буду пробовать.
Ну не могу же я написать - квен лучшая модель, еще не запускал.
Вот через CMD, получаю максимальный размер 256 ГБ для рам. А вот для Цп-13700 показывает, что только 128. Но другие пишут что поддерживает до 190. И что за вообьще обновление Bios, если ограничение на память физическое ? Или аппартное....
Сука, почему все так сложно и почему я такой тупой. Пойдем разбираться. Хочу много памяти и не менять мать.
>Это факт, можешь беситься сколько влезет, но квен вполне себе рабоч для дрочильных задач.
Я и не спорю, но предпочту проверить все таки побольше квант.
>Во, рассказывай как пускаешь, что с ним делаешь, что нравится, что не нравится.
Я предлагаю идею лучше ! Вы напишите свое ревью, а я вставлю отзывы и обновлю список моделек.
Deal-deal human-thing ? sniff sniff
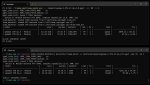
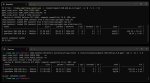
> Там не какой-то там оверхед.
Что ещё расскажешь про WSL? Держи Жору и обтекай. Стабильно быстрее на WSL, чем на голой винде. Что на GPU, что на ЦП.
>Nvidia RTX PRO 6000 Blackwell
И... по адекватной цене нет в наличии в Волгограде
https://www.regard.ru/product/749603/videokarta-nvidia-quadro-rtx-pro-6000-blackwell-server-edition-96gb-900-2g153-0000-000
Ни в ДНС, ни в СИтилинке, ни в Эльдорадо такого нет чтобы взять проверить и не проебаться.
Где кто подобную йобу брал себе? с проверкой
Есть у поставщиков серверного оборудования. 1-2 ссылка в Гугле, Там ты даже договор поставки заключишь. Стоит правда, как крыло от самолета, поэтому и не буду советовать.
>пук
>Анонче, я как бы с этого и тихо хихикаю. Ну нет сейчас у меня памяти, идет.
Бля, ну кто же знал. Держись там, счастье близко.
Под люнупсу билдил судя по всему, а под шиндой готовый бинарник?
>в наличии в Волгограде
Доставку уже изобрели. Даже по твоей же ссылке есть достав очка.
>чтобы взять проверить и не проебаться
А что ты там собрался проверять? Кстати, твоя ссылка ведёт на серверную версию, тебе же нужна десктопная, с охлаждением.
>Стоит правда, как крыло от самолета
Чел уже прогрелся на серверный картон, так что лучше пусть берёт последний блеквел, он конечно дороже, но намного лучше.
> расшифровал определение
Нет, ты поделил на ноль и сказал что белое это черное.
> Ты это, не заметил, как пролетели 2 года.
Тоже нет, это ты как фантазировал шизу про аги, так и продолжаешь, вместо того чтобы оглянуться по сторонам, признав свои ошибки и отбросив предубеждения.
> Чел...
Удачнее объяснения не придумать.
> Они онлайн то нихуя не работают
Скиллишью бедолаги. Жди пока сетки еще больше адаптируют под шизов, чтобы те общались с тобой на одном языке.
Лол, оно
За ~800 наличных тебе ее привезут, ищи объявления барыг. За чуть больше ~1e+6 можно договориться с популярными ретейлами с доками и гарантией в год, напиши в магазины второго эшелона. За 1.2 прямо сейчас берешь и забираешь. На подмосковных складах она есть если что.
Я шизик или и правда что менее нагруженный промпт работает как-то даже лучше, чем тот в который вписываешь каждый пук?
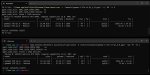
> Под люнупсу билдил судя по всему, а под шиндой готовый бинарник?
Да. Ну вот собрал на Винде тот же коммит с такой же кудой 12.9. Раз 5 прогнал тесты на обоих, всё равно WSL всегда немного быстрее. Причём пока собирал на винде на WSL на токен больше стало, лол.
Все так, это вообще-то база. Есть случаи когда детально расписанное делает лучше, но совсем натаскивание всегда портит. Современные модели в большинстве в базе умеют в рп и делать хорошие ответы, там шизопромпт только вредить будет.
Нет, не шизик. У меня рп промпт чуть меньше 300 токенов. Работает гораздо лучше больших полотен вроде гуляющего здесь от Geechan, на ~1-1.5к токенов. Лучше писать свой промпт, не слишком длинный.


>Нет, ты поделил на ноль и сказал что белое это черное.
Эм, поясни? Я не вижу противоречий в моих определениях.
Нейросеть нашла, но это придирка к несколько другим вещам, базовый смысл оно не затрагивает.
>это ты как фантазировал шизу про аги
Я мечтаю об аги, да. И его сейчас и близко нет.
>вместо того чтобы оглянуться по сторонам
Ну вот он я, оглянулся. ИИ как срал под себя, так и срёт. Загадку про батю-хирурга нынешние модели проваливают, даже лучшие, а старые проходили, то есть наблюдается небольшой регресс, лол вполне объяснимый надрочем на тесты и гендерную нейтральность.
>Скиллишью бедолаги.
Ну вот я кидаю PDF файл в чат и прошу перевести. Самая новая гопота в режиме ресёрча обосралась. Что я делаю не так?
Ну тогда ХЗ что не так.

> qwen 235b q2
> GPT-5-RU
> загадывает на русике

Да похуй, тут даже гопота готова геев приплести, лишь бы не признаваться, что обосралась.
да-да, мы поняли, гопота геи содом загнивающий запад, аги не скоро, скоро конец света
>мелкобуква без точек
Ты зачем существуешь на Земле? И почему не слушаешься учителя русского языка?
>гопота геи содом загнивающий запад
Ну, по факту да. Не знаю про загнивающий, но приплести гея это прям красный флаг (но не советский).
>аги не скоро
Вот да, не видать. Система Т9 получилась невероятно сложной, и даже весьма полезной и способной решать задачи, но лично мне давно очевидно, что в ней чего-то базово не хватает для полноценной мыслящей системы.
так они реально сои туда навалили, глупо это отрицать. Тем более не первый раз.
я и не защищал эту парашу, спок
> И почему не слушаешься учителя русского языка?
а ты почему здесь, а не там?
> Ну, по факту да. Не знаю про загнивающий, но приплести гея это прям красный флаг (но не советский).
все уже давно знают, что чатжпт помойка. проблема здесь в том что ты взял один конкретный случай и экстраполировал его на всю сферу, использовал его как достаточный пруф для своего шизомнения
энивей, если все тлен, то нахуя ты сидишь в этом треде?
> Я не вижу противоречий в моих определениях.
Конечно не видишь, ведь преисполнен в своей правоте и окружен особым мировоззрением с сильно фильтрацией. Ты прямым текстом сказал что качественные изменения - это количественные, а настоящие качественные изменения - соответствия твоим ожиданиям. Сами эти ожидания - наивные фантазии любителя фантастических произведений, далекого от технических иннформационных областей
Ну или говоря языком дващей - глупый шизик, живущий в манямирке, но с запредельным чсв.
> Я мечтаю об аги, да.
Ты даже не понимаешь что это такое, не способен сформулировать и разрешить фундаментальные противоречия, которые будут в твоих рассуждениях о нем. Или, опять же, говоря нормально - верящий в эзотерику агишиз.
> Ну вот он я, оглянулся.
Нет, ты не можешь выйти за границы манямира и продолжаешь делать херню, считая что она является доказательством твоих суждений. Даже лень расписывать, но особенно с третьей пикчи можно только проорать.
Вместо того чтобы изучить, понять, ознакомиться, сделать ретроспективу - лишь кринж на пикчах в оправдание бездействия.
> Ну вот я кидаю PDF файл в чат и прошу перевести.
Вот видишь, даже в такой простой операции ты смог зафейлить.
Мелкобуква атакует, он пришел спиздить наши знаки препинания и заглавные буквы.
Все в убежища !
>а ты почему здесь, а не там?
Школу закончил более 15 лет назад, что не мешает мне помнить правила русского языка, а что?
>проблема здесь в том что ты взял один конкретный случай и экстраполировал его на всю сферу
Возьми другой, третий, десятый. Сколько тебе нужно случаев?
>энивей, если все тлен, то нахуя ты сидишь в этом треде?
Потому что
>весьма полезной и способной решать задачи
Это лучше, чем нихуя. Но при этом полезно понимать недостатки и ограничения текущих методов. Иначе если все будут надрачивать друг другу в голландском штурвале, прогресса не будет.

>Ты прямым текстом сказал что качественные изменения - это количественные
Нет, я назвал количественные изменения количественными. Чуть лучше это не качественное, а количественное.
>далекого от технических иннформационных областей
Лол.
>Ты даже не понимаешь что это такое, не способен сформулировать и разрешить фундаментальные противоречия
Ну в общем-то дать непротиворечивое определение сознанию не может никто, внезапно.
>Вместо того чтобы изучить, понять, ознакомиться, сделать ретроспективу
Да я в общем-то сделал. Мистраль ларж отвечает на этот вопрос верно, ибо вопроса там нет, только прямое как палка утверждение. Новые же модели срут под себя и виляют задницей, подстраиваясь под прожарку повесточкой. Что мне ещё нужно изучить?
>Вот видишь, даже в такой простой операции ты смог зафейлить.
А как надо было? Мне не жалко, можешь показать своим примером, файл это просто статья с арксива
https://arxiv.org/pdf/2202.08906v2.pdf
Давай, покажи класс промт--инженегринга и реши задачу в зеро-шот!
я не опасный и не кусаюсь, если на меня не выебываться
правила русского языка ты запомнил, а логики не особо? частный случай не является подтверждением общности. ты закинул русскоязычную загадку в англоязычный соевый и тупой чатгпт, он конечно же зафейлил, и теперь ты махаешь этим с довольной рожей словно америку открыл. ты дурачок что ли?
на 1с судя по всему работаешь, если логика у тебя такая хуевая, а русский такой замечательный? гыгыгыг
>частный случай не является подтверждением общности.
Так мы докатимся до того, что ничего нельзя доказать окончательно, ибо всегда есть вероятность того, что найдётся контр-пример. Ну и что, стало легче?
>в англоязычный соевый и тупой чатгпт, он конечно же зафейлил
Поэтому рядом там другая сетка. Вот третья, тоже самое. Доступа ко всяким клодам и жеминям у меня нет, но с высокой долей вероятности они обосруться так же.
На PHP на самом деле, ну да ладно. Можешь начинать смеяться.
> Можешь начинать смеяться.
я давно уже смеюсь
> Так мы докатимся до того, что ничего нельзя доказать окончательно, ибо всегда есть вероятность того, что найдётся контр-пример. Ну и что, стало легче?
не знаю, я ж не доказываю ничего. это ты приходишь в тред с громкими выводами. громкие выводы требуют громких доказательств, si? в итоге вместо доказательств ты зачем-то поделился с тредом, что пишешь на php 6 лет и 6 месяцев
скорее всего ты наш единственный и горячо любимый шиз, который вылезает раз в пару месяцев и приходит в позе мессии рассказать, что мы тут всем тредом хуйней занимаемся. прошлый заход вроде был связан с тем, что "везде слоп, вы что, правда его не видите??" и закидывал кринжуху с разных корпосеток в таком же формате. сейчас в общем-то то же делаешь, но еще беднягу квена в q2 приплел
мой мозг отказывается понять как и что ты доказываешь тем, что говносетки не разгадывают твою загадку на великом и могучем. наверно потому что я не работаю с php
Ну через кобольд потом в таверне хз как еще это описать.
скачал твой мистраль я не думал что так бывает но ответ еще хуже стал.
Вот такой бред я получаю.
> я назвал количественные изменения количественными
Если ты рили в это веришь и пишешь то - ты шиз.
> Лол.
Двачую второго, 1с программист или низшая веб-макака. По тому что спустя овер 2.5 года можешь позволить себе лишь катать эйр или q2 квена видны твои профессиональные навыки. "Рыночек порешал" как никогда уместно, тот кто умеет и практикует не может быть настолько нищебродом, чтобы потратить лишнюю деньгу на свои увлечения.
> Да я в общем-то сделал.
Ты придаешь чрезмерный вес реакции на подобные короткие странные вопросы абсолютным зирошотом, еще и на лоботомированных моделях. Поставь нормальный квент квенс с синкингом и он тебе пояснит. Дай развернутое объяснение что именно ты хочешь - получишь ответ. Дай подходящий промпт - модель разрулит.
Своими тестами ты лишь демонстрируешь байас тренировки, когда модели учат отвечать коротко на простые вещи из-за исков за "растрату токенов", оверфит подобными вопросами из бенчей, который сейчас присутствует во всех моделях, и лоботомию от низкого кванта.
Рили, кто ищет путь - найдет решение, кто не хочет - найдет тысячу оправданий и для виду упрется рогами в ворота.
Для начала скачай q4ks или q4km квант, q4_0 - сделаны по очень древней технологии и сами по себе могут шизить.
У тебя на пикреле еще не полная шиза. Показывай что у тебя в промптах и какие настройки инстракт режима (буква A слева вверху), потом показывай что в семплерах (самая левая кнопка с полосками).


Ну вот кстати командир порадовал, не поддаётся на провокации. ГЛМ 50/50.
>я давно уже смеюсь
Попроси маму, чтобы она тебя сводила к специалисту, это плохой признак.
>не знаю, я ж не доказываю ничего.
Окей, ты просто болтаешь. Принято. Блин, и ведь знал же, что с мелкобуквой нельзя общаться, что мелкобуквы долбоёбы по определению. Нет блядь, каждый раз вляпываюсь.
>скорее всего
Промахи по всем фронтам.
Ебать у тебя там шизосемплеры модель ломают.
> <im_end>
продолжай..)
не останавливайся, я уже почти задохнулся
болтаешь тут ты, я лишь отвечаю на твою шизу и прошу ее обосновать. если болтаешь громко, надо подтверждать свои слова. пока что ты подтвердил что пишешь на php шесть с половиной лет. в кругах экшули программистов это воспринимается как диагноз, и неспроста
Узнаю этого долбоеба. Это соешиз, который с первого сообщения пытался насрать Серафине в рот и удивлялся, что ловил рефузы. Такое не забыть.


Ну вот настройки, а качаться у меня минут 30 правда будет
>Если ты рили в это веришь и пишешь то - ты шиз.
Ну в общем-то да. Впрочем, это не отменяет того, что я могу быть прав.
>настолько нищебродом, чтобы потратить лишнюю деньгу на свои увлечения
У людей могут быть другие приоритеты. Впрочем, я еблан и работаю спустя рукава, ибо в хуй не упёрлось горбатиться ни за хуй собачий. Ну и странно называть меня нищебродом, когда в треде половина вопросов "Дайте мне модельку не больше 12B, а то мой калькулятор плавится даже от геммы 27B". А я катаю хоть и лоботомированного, но 235B квена.
>Поставь ... Дай ... Дай
Ты думаешь, я не понимаю, что из модели можно выбить правильный ответ (как вариант, записав его 27 раз в примерах диалогов, лол)? Я прекрасно это понимаю. Но тестирую я именно все эти
>байас тренировки
>оверфит подобными вопросами из бенчей
Потому что как раз наличие подобной хуеты и намекает, что до AGI ещё срать и срать.
>Рили, кто ищет путь - найдет решение, кто не хочет - найдет тысячу оправданий и для виду упрется рогами в ворота.
Ты там это, файлик когда переведёшь? Это ведь просто, у тебя же наверняка есть агентские системы, которые разрулят этот вопрос в два счёта. Ведь есть же, да? Ты ведь не напиздел, когда написал про них? Не мог же ты просто написать про них, ни разу не пробуя? падме.жпег
>продолжай..)
ЧатМЛ любую модель делает лучше, лол.
>не останавливайся, я уже почти задохнулся
Так, если я продолжу, то ты умрёшь? Привлекательное предложение, но нет, а то ещё тов майор придёт разбираться, чего это я школьников до суицида довожу.
>Серафине
И снова мимо, у меня этот персонаж потерялся в виду того, что установка таверны очень старая. Хотя Аквы у меня тоже нет, так что я проебал всё и вся если ты конечно понимаешь, причём тут Аква.
На первом скрине слева и посередине выбирай "ChatML", снимай галочку "всегда добавлять имя персонажа в промпт", возвращай "добавлять имена" на Never или для групповых чатов. Опционально - в правой колонке смени это на один из стандартных вариантов с ролплеем, но для начала можешь оставить.
Со второго скрина выбирай шаблон Simple-1 или Min-P и больше такого не накручивай. У тебя из отсекающих сеплеров только TopA что вообще ерунда, а базовые отсутствуют. Это, кстати, к некоторому замедлению генерации может приводить.
> это не отменяет того, что я могу быть прав
Такая агностическая постановка - заведомо бред. Это не какой-то неразрешимый парадок, требующий исследований, тут все ясно и очевидно. А там где ты делаешь "ставку на будущее" это лишь гемблинг и вера, но когда ставка делается на невозможный исход - ты уже проиграл, придется заготавливать оправдания что ты имел ввиду другое.
> У людей могут быть другие приоритеты.
Твои скрины здесь с давних времен, инициатива споров и прочего высока. Тейк про то что тебе это не интересно здесь явно неуместен, согласись. Про то что не напрягаешься - 0% осуждения 100% понимания иногда на предновогодних дедлайнах хочется сдохнуть. Но так уж выходит что это отдаляет тебя от бытия экспертом в областях.
> из модели можно выбить правильный ответ
Речь не о выбивании а о корректной постановке эксперимента. Если ты выпускаешь на гонку замученного голодом и больного гепарда против бодрой дальневосточной черепахи - не удивляйся что он сразу лег не тронувшись с финиша, а черепаха опередила его. Можно привести кучу других примеров с неудачами из-за несоблюдения базовых условий и требований, но суть должна быть понятна.
> что до AGI ещё срать и срать
Агишизу не приплетай, это сразу путь в никуда, и не ударяйся в черно-белое.
> файлик когда переведёшь
Тебе надо - ты и переводи, такие дерейлы не сработают. Как можно несправиться с базовыми вещами в максимально юезрфрендли гопоте - я вообще хуй знает. Он даже отсканированный в виде картинок файл воспринимает, разве что на фришных интерфейсах все через жопу.
> у тебя же наверняка есть агентские системы
Да. Рофлов ради запросил проанализировать дефолтый апи двоща и потом по порядку обработать посты в несколько проходов с выделением какой-то полезной информации для наполнения. Даже работает, жаль картинки не видит.


Консоль кобольда вначале выдавала ошибку, теперь вообще не выдает а просто закрывается.
Хм спасибо и правда помогло норм ответы пошли

>iFLUX.1 [dev] is a 12 billion parameter rectified flow transformer capable of generating images from text descriptions.
>generating images from text descriptions.
Лучше бы ссылку на гайд прислал или обьяснил че я делаю не так, токсик.
и что это значит, что не так то?
Какую программу лучше использовать всего для запуска локалок? Много вариантов. Нужно с комфортом и функционалом.
эээ это мой вопрос был
УХ СЕЙЧАС КАК ПОКУМЛЮ НА ЭТОЙ КЛАССНОЙ МИСТРАЛЬ.
Спроси у , он ответит. Новичков любит.

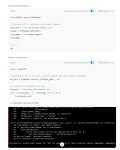

>Твои скрины здесь с давних времен
Меня тут путают уже с... Я давно сбился со счёта, сколько раз меня путали.
>Тейк про то что тебе это не интересно здесь явно неуместен, согласись.
Эм, я такого никогда не писал. Мне вполне себе интересно, и комп у меня подсобран под сетки. Вот 1,2 млн на 6000 PRO у меня нет, это признаю, нищеброд получается.
>Но так уж выходит что это отдаляет тебя от бытия экспертом в областях.
Тут вопрос в уровне этой самой экспертизы. Являюсь ли я лучшим в какой-то области? Нет конечно, я весьма ординарный. Но этого, как по мне, вполне себе хватает для суждений по теме.
>Речь не о выбивании а о корректной постановке эксперимента.
Ок. Но почему тогда подтирание нейронке её нейросоплей ты считаешь корректным? Как по мне, моего простейшего промпта и хоть какого-то шаблона должно быть достаточно. А вот бегать вокруг и давать примеры это уже перебор.
>Как можно несправиться с базовыми вещами в максимально юезрфрендли гопоте - я вообще хуй знает.
Ну вот я тупо отписал, нейронка предложила варианты, я выбрал подходящий, нейронка жидко пёрнула под себя.
Попробовал ещё раз с более точным описанием и в режиме глубокой глотки глубокого поиска, нейросеть пердела 11 минут и снова обосралась.
Вот что я делаю не так?
Какую программу использовать для запуска локалок лучше всего? С комфортном и функциональностью. Спасибо.
>Вот что я делаю не так?
Если что, вариант "высрать всё в чат" вроде прокатил, но без картинок и таблиц ощущения не те.
Я расскажу тебе поучительную историю : в одном царстве, в одном государстве - пошёл ты нахуй.
Обожаю просто, ога.
В голос. И этот пидорас полдня быковал на двух тредовичков, которые помогают новичкам, но отказываются делать гайд по его указке. Напердыш кошачий.
Посемени ещё больше, клован.
Забавно но я загрузил просто текст а не текст в изображение и заработало, но почему же текст в изображение не работает? Ну намекните же кто нибудь хотя бы!
Не, треду тебя одного хватает, утка биполярная.
Зачем ты грузишь в кобольда модель для картинок? Тебе модель для текста нужна.
Походу тупо памяти не хватило, лол.
Кобольд. Ссылка есть в шапке на него. А в самой первой ссылке в шапке есть гайд как его запускать.
>Не, треду тебя одного хватает, утка биполярная.
Я не против помогать, я против жирноты. Ну есть же предел разумного.
Тред по текстовым моделям. Для запуска картиночных сходи в шапки соответствующего треда.
По какой-то непонятной причине работает очень плохо. Подскажите пожалуйста что не так. Мне 56 лет возможно что-то не понимаю. Спасибо.
Не знаю, в чем проблема с запуском в треде. Поднял qwen3-235b на q4 кванте, в принципе, генерит приемлемо - 7 токенов в секунду выдает, а prompt_eval 340 токенов на 12к контексте. Вполне съедобно для рп на английском, но теперь и качество будет выше.
Может, есть еще способы распределить тензоры эффективнее на 5090 и 128 гб ОЗУ? Думается мне, еще пару токенов можно выиграть.
Может, есть еще способы распределить тензоры эффективнее на 5090 и 128 гб ОЗУ? Думается мне, еще пару токенов можно выиграть.
>>Зачем ты грузишь в кобольда модель для картинок? Тебе модель для текста нужна.
А что он не может модель текст в картинку обработать?
У него же есть там вкладка imageGen, это не то?
Играйся с сочетанием gate/up/down в рам. Где-то будет больше пп, где-то тг
Сделал мой вечер
> Меня тут путают уже с...
Слишком выделяешься, не спутать.
> и комп у меня подсобран под сетки.
q2 квена и q4 эйр? У кого подсобран под сетки здесь гоняют покрупнее и пошустрее, чсх часто в ро. А 6к про почти наверняка тут ни у кого нет чтобы была именно куплена себе для хобби, а не где-то скрин доступа по работе. Просто скрин хоть с 8 H200 можно сделать, но суть не будет отражать.
> вопрос в уровне этой самой экспертизы
Здесь две компоненты: в осознании технических процессов в целом (сама парадигма и концепция аги) и в понимании что может быть воплощено в реальность с учетом поставленных целей (его бессмысленность в том виде, как себя представляют адепты). Первое берется от общей образованности, знаниях темы, смежных ей и т.д. Второе - когда сам работаешь над чем-то реальным, проходя путь от идеи до воплощения, и в конце концов уже делая новые тз на будущее с учетом конечных целей и перспектив.
Через такую, офк с элементами субъективности, призму сразу очевидна куча нестыковок и причин нежизнеспособности. Или другая профдеформация, когда отмечаешь очевидно неверные выводы из-за некорректной постановки и интерпретации, даже удивляешься как человек этого сам не замечает.
Возвращаясь к теме - ты не являешься мл экспертом, да и просто в инференсе не похоже что сильно преуспел, раз не знаешь что сейчас есть и утверждаешь об отсутствии прогресса. Это не что-то постыдное или плохое, просто вес твоих заявлений будет невысоким, и по факту говорить лишь о недостаточной ориентации сеток на промежуточную аудиторию, которая уже не нормисы чтобы впечатляться ассистентам, но еще и не задроты чтобы с ходу понимать как добиться нужного и быть в курсе трендов. Или о недостаточной устойчивости текущих ллм к гайзлайтингу и дезориентации, если совсем глупые ошибки они понимают и детектят, то с небольшим знанием темы можно легко увести не туда.
> Вот что я делаю не так?
Что-то делаешь не так, лол, экстрасенсы в отпуске. Очевидно что оно не смогло прочесть файл, а потом забуксовало на попытках и само себя запутало, 5мини она на то и мини что не умная. На 3м скрине вообще выглядит что ты делал все чтобы сбить изначально глупую умную модель с целью показать как она плоха.
Максимально выгрузить доступных экспертов, поднять батч ( -b 3072 -ub 3072 или выше, ускорит процессинг значительно, потребует больше врам на буферы), в зависимости от системы и процессора выставить высокий приоритет и поиграться с числом потоков.
>Слишком выделяешься, не спутать.
Эм, меня уже причислили к Серафимоёбу, хотя это не я. Так же писали про то, что я вернулся, хотя я и не уходил. Ну то есть говно у вас детектор, чинить надо.
>У кого подсобран под сетки здесь гоняют покрупнее и пошустрее
Крупнее только дипсик, кими2 оверсайз по всем стандартам.
>Очевидно что оно не смогло прочесть файл
Но ведь в альтернативном варианте прочло. И в размышлении пишет, что текст извлекается, но там череда каких-то обсёров. Собственно я утверждаю, что текущие сетки в автономных агентов не годятся.
>На 3м скрине вообще выглядит что ты делал все чтобы сбить изначально глупую умную модель с целью показать как она плоха.
Мне нужен переведённый файл, я запросил переведённый файл. Если не давать указаний делать сразу, оно до вечера будет переспрашивать "а переводить ли цифры в номерах страниц с английского на русский или так оставить", собственно эта фраза и появилась после того, как я в другой ветке заебался отвечать на уточнения.
>>Сделал мой вечер
Да что не так то!!!??? Почему картинки не работают?
> у вас
https://www.youtube.com/watch?v=ezCr9yhEGwM
> Крупнее только дипсик, кими2 оверсайз по всем стандартам.
Для начала нормальный квант квена вместо лоботомита. А еще из юзабельных и индожебильных есть большой жлм, квенкодер и тот же дипсик.
> Но ведь в альтернативном варианте прочло.
Раз на раз, алсо почитай про размышления 5й гопоты, там не то что на самом деле.
> Собственно я утверждаю, что текущие сетки в автономных агентов не годятся.
Ты делаешь такое утверждения основываясь на единичном опыте с одной из худших в заведомо поганых условиях если кратко. О том и речь.
> до вечера будет переспрашивать "а переводить ли
Что-то там поломалось, оно максимум после одного уточнения должно результат давать с предложениями правок по факту. И ты, похоже, переоцениваешь их фришную вебморду для такого применения.
>основываясь на единичном опыте
Зачем мне опыт? Это и так понятно из архитектуры трансформеров.
>Что-то там поломалось
То то и оно. Автономный агент не должен ломаться.
> понятно из архитектуры трансформеро
Колесо сансары сделало еще один оборот, Кали-Юга продолжает свое вялое течение. Название карточки на жпт-6 хоть смени.
>Колесо сансары сделало еще один оборот
Как знаешь.
>Название карточки на жпт-6 хоть смени.
Пока рано, текущие сетки не должны знать про пятёрочку.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия 2024-го https://rentry.co/llm-models )
• Неактуальный список моделей по состоянию на середину 2023-го: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: