



какова база треда?
>какова база треда?
На данный момент GLM-Air и 16гб ВРАМ.
>На данный момент GLM и 270гб ВРАМ.
Поправил, не благодари
Надо иметь минимум 128 рам чтобы запускать ГЛМ 4.6 хотя бы во втором кванте. Ну совсем для нищуков можно второй бит квена на 64 гб крутить. Но это уже ниже плинтуса. Еще ниже - уже уровень бредогенератора и порфирьевича.
>имплаин глм чем-то лучше порфирьевича
Если тредовички вместо сборок под локалки, вкинули бы деньги на опенроутер, то могли бы лет пять кайфовать на дипсике в fp8, а не терпеть на эйре в q3
> лет 5
Скорее пол года, потом на бутылку
Как увеличить производительность токенов в секунду у llm, если влазит только 22\40 в gpu offload? Сколько ядер цпу ставить для максимального ускорения? Что то с новым процем буст какой то хилый, было 3.3 т\с, стало 4.3. Я думал больше будет. Ставлю 5-6 ядер цп - никакого буста вообще, почему так. Что с 4, что больше - одинаково.
А частота памяти у тебя не 2666 ли?
Ожидаем…
3200
Может ядра у тебя 6 ГГц AVX512?
Потому что 4=>5 ядер обычно прирост имеется.
Если это именно физические ядра, а не потоки, конечно.
i3-12100?
Ryzen 5500. ЛЛМ плохо распараллеливается что ли?
Наоборот хорошо. Но быстро упирается в скорость работы памяти. На видяхах поэтому и гоняют, что там гигантская пропускная способность памяти.

ADT-Link PCIE 5.0 X16 ?
А не на лохоплейсах есть?
И каким образом питание видяхи, отдельный бп чтоли?
Ling-flash-2.0-Q4_K_M.gguf
А мне в LMS он заявил, что
Failed to load model
error loading model: error loading model architecture: unknown model architecture: 'bailingmoe2'
```
ADT-Link UT3G наверное. И тебе нужен будет TB4, USB3 оно очевидно не поддерживает.
Погонял немного Ling-Flash-2.0, отыграл два рп чата на ~20к токенов каждый. Если вкратце - скорее всего, это не замена Air. При всех его проблемах, по первым впечатлениям он лучше. Пишет моделька приятно в целом, какой-то свежий слог, хоть и чувствуются иногда определенные схожести с Квеном. Но то ли 6б активных параметров сказываются, то ли в целом моделька такая, но она не очень умная. Не так хорошо читает между строк, иногда противоречит сама себе (чему-то, что было двумя-тремя аутпутами ранее). Очень рашит события, пэйсинг какой-то сломанный, как я ни пытался промптить. Например, в какой-то момент можно упомянуть, что на улице вечер. Через пару аутпутов будет ночь. И так во всем: если отправились из точки А в точку Б, придете следующим же аутпутом или через один. В рамках одного аутпута моделька пытается сделать очень много всего. Если это разговор, будет перескакивать с одной темы на другую, не может зациклиться на чем-то одном. Из хорошего - правда свежий датасет и/или проза (хотя, возможно, для меня уже почти любая новинка будет ощущаться так), не заметил репетишена или любых форм лупов, пишет приятно, очень креативит, добавляя разные детали (иногда перебарщивает, и это при температуре 0.6-0.7, top k 20, top p 0.8), придумывает всякие прикольные названия и имена (хотя те же Танака и Элара на месте, преследуют меня на многих моделях). В общем, такое ощущение, что будь она умнее, было бы активных параметров побольше - 12-30б, могла бы получиться потенциальная замена Air. Тестировать дальше не захотелось, то ли настроение не то, то ли не заинтересовала. Возможно, на других сценариях она и вовсе показала бы себя плохо. В моем случае Q6 квант на 4090 и 3200 DDR4 по скорости примерно сопоставим с GPT OSS 120b, 16-17т/с на старте, чуть проседает на контексте. В коде показала себя довольно плохо, по-моему, даже Квен кодер 30б справляется лучше.
Да нет, распараллеливается она нормально, на DDR4 у тебя упор в память будет.
На таком процессоре между 4 и 5 ядрами разница есть точно, у самого был такой конфиг.
Но может у тебя не плохо, когда тормозит на 5 ядрах, а наоборот хорошо, когда на 4 уже летит во всю скорость оперативы? :)
Ну, llama.cpp и LMStudio же не одно и то же. В ЛМС могут завезти позже.
Ну, полностью ожидаемо, бенчи такие же.
ИМХО, именно из-за новизны кажется неплохо, на деле плохо.
Не фартануло, что ж.
———
Вот блин, вспоминаю себя 2 года назад, тогда я считал, что если бы Llama-2-70b ехала не 0,7 токена/сек, а 5 токенов — я был бы счастлив с такой играть.
А сейчас у меня GLM-4.6 во втором кванте на 6 токенах в секунду и… Что-то лень. =с Чего-то не хватает. Хочется быстрее и умнее. Хочется такую же глм только 700б и со скоростью ну хотя бы 20 тпс, что ли… Не, вот 40-50 было бы норм, да.
Зажрался, получается.

> Зажрался, получается.
Это описывается емким словосочетанием: ты охуел.
>ну хотя бы 20 тпс, что ли… Не, вот 40-50 было бы норм, да
А зачем нужна скорость инференса быстрее чем скорость чтения (10-15тс)? Не, я не спорю, когда оно есть - это хорошо, но так чтоб вот прям МЕЧТАТЬ о скоростях в 50тс?
> А зачем нужна скорость инференса быстрее чем скорость чтения
Ризонинг, ммм ? В целом, паттерны со временем можно угадывать и ты, глядя на свайп такой: ага, попался пидорас, опять говна с шиверсами навалил.
>Ризонинг, ммм ?
Не жалко драгоценный контекст на эту хуйню тратить? Или каждый раз ручками удаляешь размышления?
Да я смотрел давеча на 10 тпс, и я читаю сильно быстрее.
Так что, 15-20 скорее.
Совершенно верно, кстати. Я все никак за astrsk не сяду (ибо я на русском), но там же рассуждений перед ответом куча, агенты.
Галочку в настройках таверны убери и он не будет в контекст включаться.
> Не жалко драгоценный контекст на эту хуйню тратить? Или каждый раз ручками удаляешь размышления?
Покуда ты сам не нашел в фронтенде соответствующую галочку и не включил ее, ризонинг блок не включается в контекст. Другое дело, что ризонинг в рп часто не нужен, а иногда даже вреден, и при этом все равно нужно ждать, пока он сгенерируется.
ГАЛОЧКУ ЧТО РУКАМИ НАДО УБИРАТЬ??7
> Покуда ты сам не нашел в фронтенде соответствующую галочку и не включил ее, ризонинг блок не включается в контекст.
Блин, шутка сорвалась. =)
Выгружать атеншн а не просто часть блоков. Херню с ядрами вообще забей и вообще не трогай, особенно в таком случае. Это поехи пытаются интерпретировать свои наблюдения привычными примитивами, не понимая эффектов.
Любая имплементация egpu. Ну вы чего, совсем вчера в околохв? Есть вообще отдельные боксы где все в одном и подключаются по usb-c через тандерболт или юсб4, есть колхоз с переходниками от м2 и т.д.
Молодец.
> Из хорошего - правда свежий датасет и/или проза
Это просто эффект другого стиля ллм на фоне тех к которым привык, да.
Большую не пробовал?
>ГАЛОЧКУ ЧТО РУКАМИ НАДО УБИРАТЬ??7
Ну а ты рандомно хуем по клавиатуре не бей, рандомные настройки включаться не будут.
>Блин, шутка сорвалась. =)
~Nya ha ha~
> Хочется такую же глм только 700б
Дипсик, кими, большой линг. Но это вариации, которые лучше в одном и хуже в другом.
> Хочется быстрее
Тому что 5 - самый нижний порог адекватного использования. Когда быстро - будешь относиться спокойнее к проебам, без огорчения свайпнешь, особенно если сразу видишь что пошла не туда. А так придется выжидать что же там оно выдаст и регулярно ловить фрустрацию.
В прикладных применениях, думаю, очевидно. А в рп - можно получать сразу несколько свайпов с теми самыми 10-15т/с вместо одного.
Оно не добавляется в контекст если не приказать иначе.
> Большую не пробовал?
1Т версию имеешь ввиду? Она немного очень не умещается на моем железе (4090 и 128 гб оперативной памяти). Так бы попробовал, конечно. Возможно, следовало уточнить, что Ling-Flash-2.0 - это средняя версия, 100b-a6b, там еще есть Ling-Mini 16b-a1.4b.
ну я ранил GLM-4.6-UD-IQ3_XXS на 8гб врам + 96гб рам (хотя врам почти не используется, все на рам,)
запустил на ночь глядя, задал вопрос и ушел спать. с утра - ответ готов
все понемногу цены увеличивают, тк многие работают в минус, прожигая бабко инвесторов и надеясь, что не сдохнут на этом марафоне - делят рыночек. к тому же врядли анон смог бы 5лет на одной и той же цене сидеть. хотя год-два, а потом купить нормальное железо под это если один дед не сделает все еще хуже было бы вполне норм вариантом
>Хочется такую же глм только 700б и со скоростью ну хотя бы 20 тпс, что ли…
тянку себе найди. будет иногда выдавать токены без устали,
>ну я ранил GLM-4.6-UD-IQ3_XXS на 8гб врам + 96гб рам (хотя врам почти не используется, все на рам,)
>запустил на ночь глядя, задал вопрос и ушел спать. с утра - ответ готов
Зачем, какой смысл. Твой потолок - это двухбитный квен. ГЛМ 4.6 не настолько его лучше чтобы такими извращениями заниматься.
Я согласен с последним отзывом на квен из прошлого треда
Сколько не пробовал, даже удалял и заново качал, ну ведь не может большая модель не нравиться?...
В итоге решил что может
Ведется ли где-то каталог уже вышедших локалок? На обниморде можно нати только если знаешь что искать. Ранбше помню был бенчмарк, туда все вышедшие модели заливали, можно было как каталог использовать. Но потом он закрылся.
Вдруг там где-то лежит 200-300В моешка что мы еще не видели и которая дает глм с квеном на ротан? Все же как ни крути - но китайцы не прям вау, пользуемся ими потому что другого ничего нет - любая другая современная модель на том же размере справилась бы лучше - та же гемма, просто представить гемму 356В-А32B - да никто бы про китайское говно и не вспомнил бы уже.
Вдруг там где-то лежит 200-300В моешка что мы еще не видели и которая дает глм с квеном на ротан? Все же как ни крути - но китайцы не прям вау, пользуемся ими потому что другого ничего нет - любая другая современная модель на том же размере справилась бы лучше - та же гемма, просто представить гемму 356В-А32B - да никто бы про китайское говно и не вспомнил бы уже.
>Ведется ли где-то каталог уже вышедших локалок?
Каталога как такового нет, но в шапке есть список моделей, только его чёт не обновляют.
>гемму 356В-А32B - да никто бы про китайское говно и не вспомнил бы уже.
Такое в адекватном кванте большинство запустить не сможет. Вот что-то типа 120b-a12b - был бы слепящий вин, настоящая НАРОДНАЯ модель на замену эйру.


GLM-4.6-UD-IQ3_XXS выдал 0.5т/с (а он еще и думал)
GLM-4.6-UD-IQ2_XXS выдал аж 1.0т/с!
для обоих cpu-moe не работает, не хватает моих 8гб памяти. наверняка можно немного ускорить и попробоваять явно указать что выгружать на карту
Qwen3-235B-A22B-Thinking-2507-UD-Q3_K_XL - аж около 6т/с, но тут cpu-moe работает как надо
естественно всех на мелких контекстах
>Зачем, какой смысл. Твой потолок - это двухбитный квен
Because I choose to.
Спортивный интерес, что я могу выжать их этого железа. Например, на стареньком ноуте с i3 2350M и SODIMM DDR3 1333MHz 4Gb x2 = 8Gb я могу ранить Qwen3-4b-Instruct-2507-UD-Q4-K-XL на 1т/с. Вдрус будет война, и мой основной ноут разъебут, у меня все еще будет возможность ранить Qwen3-4b, я буду илитой в постапокалиптическом обществе.
Какая сейчас самая лучшая ллм под 8гб врам для рп и кума?
> 5 - самый нижний порог адекватного использования.
базашиз, спок
>GLM-4.6-UD-IQ3_XXS выдал 0.5т/с (а он еще и думал)
GLM-4.6-UD-IQ2_XXS выдал аж 1.0т/с!
Возьмешь не i квант, выжмешь еще 0.5 т.с. дополнительных.
>Например, на стареньком ноуте с i3 2350M и SODIMM DDR3 1333MHz 4Gb x2 = 8Gb я могу ранить Qwen3-4b-Instruct-2507-UD-Q4-K-XL на 1т/с.
А зачем нужен квен 4B, когда есть гемма 3n e4b?
Я бы сказал it's all same shit (потому что мистраль, лол), но можешь ковыряться и выбрать бриллиант под себя.
https://huggingface.co/Retreatcost/KansenSakura-Radiance-RP-12b?not-for-all-audiences=true. Да и в целом можешь потыкать модельки этого слопомержителя
https://huggingface.co/Retreatcost
Ну и до кучи:
https://huggingface.co/yamatazen/SnowElf-12B
https://huggingface.co/D1rtyB1rd/Egregore-Alice-RP-NSFW-12B?not-for-all-audiences=true
Смотря сколько у тебя оперативки, сейчас все от нее зависит. Если 96-128 гб - то хоть квена 235В запускай.
У них ГЛМ 4.5 по всем показателям лучше 4.6, хм. А самый расцензуренный у них грок.Doubt.
Но как каталог - отлично, спасибо.
32
А Gemma-3-12b как?
https://huggingface.co/ai21labs/AI21-Jamba-Large-1.7
https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
Вот эти выглядят интересно, пробовал кто?
https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
Вот эти выглядят интересно, пробовал кто?
>Но как каталог - отлично, спасибо.
Не за что, но шапку читайте. На кой хуй ОП тратил своё время чтобы всё собирать.
>А Gemma-3-12b как?
Она бесплатная, ты можешь скачать и проверить. Это гемма, гугломодели всегда стояли особняком, потому что ломаются как только туда залезают своими ручками кто угодно, кроме самой команды гугла. С цензурой, пазитиффные, осуждающие, но, сука, умные.
>Возьмешь не i квант, выжмешь еще 0.5 т.с. дополнительных.
>А зачем нужен квен 4B, когда есть гемма 3n e4b?
нужно проверить
Аноны, мы кажись потанцевальный вин упустили.
https://huggingface.co/NousResearch/Hermes-4-405B
Сука, ну почему 2_K_S кроме инцелов не делает никто, в жопы бы этим бартовски, анслоту и прочей петушне бы их медленные i кванты запихать
https://huggingface.co/NousResearch/Hermes-4-405B
Сука, ну почему 2_K_S кроме инцелов не делает никто, в жопы бы этим бартовски, анслоту и прочей петушне бы их медленные i кванты запихать
Их выходит не так много и каждый релиз - новость. Это раньше реально было много тюнов лламы разного калибра пока на свои модели не перешли, потом бум шизомерджей мистраля по 20 штук в день, сейчас они даже самым убежденным наскучили и в основном сидят на базовых моделей.
> 200-300В моешка
Эрни, она в целом пишет неплохо и стиль гораздо приятнее квеновского.
> гемму 356В-А32B
Хотеть, но это по сути glm
> самый расцензуренный у них грок.Doubt.
На самом деле в нем действительно цензуры нет и он охотно все описывает если катать с рп промптами без сейфти и прочего.
Гемма не выйдет никогда
Эир единичный эксперимент
Квен заебал бенчмаксить и неинтересен
Жизни для нищеты нет
Эир единичный эксперимент
Квен заебал бенчмаксить и неинтересен
Жизни для нищеты нет
Какие же дегенераты на французах, я хуею.
Токены [THINK] и [/THINK] не работают и модель сама их отказывается их писать. В кобольд лайте пишет, но он говно. В ЛМ Студио пишет, но нет парсинга и удаления, да и оно тоже говно. Можно заменить их на <think>, но качество ответа хуже.
Всё у них как не у людей, вечно какие-то лютые выебоны нужны.
Токены [THINK] и [/THINK] не работают и модель сама их отказывается их писать. В кобольд лайте пишет, но он говно. В ЛМ Студио пишет, но нет парсинга и удаления, да и оно тоже говно. Можно заменить их на <think>, но качество ответа хуже.
Всё у них как не у людей, вечно какие-то лютые выебоны нужны.
>Эрни
Почему её настолько редко вспоминают в отличие от глм?
база
потому что слишком большая
Так ГЛМ 4.6 еще больше и ничего.
Здесь большинство под глм понимают именно эир, он 110б
Большой или Эрни могут запустить полтора землекопа вот и не вспоминают
Нюня, дай пресетик. Нихуя не работает на текст комплишен у меня. Какой шаблон ?
Имеется ПК: Xeon 2696v4, ОЗУ 128Гб (2400, 4-х канал), 3060 12Гб, p104-100 8Гб (пока не установлена).
Вопросики:
1) будет ли прирост скорости генерации, если перейти с Кобальда на жору?
2) Нужна ли p104-100 или её уже место на помойке?
P.S. Qwen3-235B-A22B сейчас в тесте производительности на кобольде показывает 1,5 Т/с что сльозы
Вопросики:
1) будет ли прирост скорости генерации, если перейти с Кобальда на жору?
2) Нужна ли p104-100 или её уже место на помойке?
P.S. Qwen3-235B-A22B сейчас в тесте производительности на кобольде показывает 1,5 Т/с что сльозы
>будет ли прирост скорости генерации, если перейти с Кобальда на жору?
Будет, но незначительный, так как кобольд это та же жора, просто с парой перделок.
>Нужна ли p104-100 или её уже место на помойке?
Попробуй, раз она у тебя уже есть, чего ты теряешь-то?
>Qwen3-235B-A22B сейчас в тесте производительности на кобольде показывает 1,5 Т/с
-cpu-moe включал? Похоже на поведение без него.
Ок, попробую сегодня и напишу какие у меня скорости и впечатления.
>2) Нужна ли p104-100 или её уже место на помойке?
Если уже есть - втыкай. Пригодится периодически. Например Мистраль 24 и гемму 27 в таком сетапе можно засунуть в две карты целиком, и это быстрее чем частично в обычной RAM. В случае геммы - кратно быстрее (у меня на похожем 1.5-2 -> 8-9t/s).
А вот для большого MOE который не влазит в любом случае - может и наоборот, тормозить, если p104 задействовать.
-cpu-moe видимо продолбал. Кобольд надо с таким параметром запускать или это можно в интерфейсе включить?
P104 прикупил по случаю за 1200р, сейчас жду новые кулеры, как приедут буду пробовать с ней
Нашел, сорян за тупой вопрос:
QOL Change: - Added aliases for llama.cpp command-line flags. To reduce the learning curve for llama.cpp users, the following llama.cpp compatibility flags have been added: -m,-t,--ctx-size,-c,--gpu-layers,--n-gpu-layers,-ngl,--tensor-split,-ts,--main-gpu,-mg,--batch-size,-b,--threads-batch,--no-context-shift,--mlock,-p,--no-mmproj-offload,--model-draft,-md,--draft-max,--draft-n,--gpu-layers-draft,--n-gpu-layers-draft,-ngld,--flash-attn,-fa,--n-cpu-moe,-ncmoe,--override-kv,--override-tensor,-ot,--no-mmap. They should behave as you'd expect from llama.cpp.



> Какой шаблон ?
Дождись пока его добавят в Таверну либо полноценно разберись сам. Изучи как работает instruct развертка, сравни шаблоны. Для удобства можно зайти на страницу любого gguf репозитория на Обниморде и найти кнопку Chat Template, которая выведет шаблон. Сравни с каким-нибудь другим шаблоном, который уже есть в Таверне, посмотри, как он адаптирован, сделай по аналогии.
Я другой анон, но блин.. потратить столько времени на набор сообщения и рисование квадратиков вместо того чтобы просто сбросить текстом? Зачем а главное зачем? Если не хочешь помогать, то можно было бы и не отвечать вовсе. Кому ты что пытаешься на анонимной борде доказать?
> потратить столько времени на набор сообщения и рисование квадратиков вместо того чтобы просто сбросить текстом?
> Если не хочешь помогать, то можно было бы и не отвечать вовсе.
Верю, что если ты хочешь помочь - поможешь решить проблему и разобраться, а не решишь ее самостоятельно за другого. Так вопрошающий в следующий раз сможет разобраться сам или помочь другому. Если бы я не хотел помочь, проигнорировал бы. Сделать скриншоты и нарисовать квадратики занимает меньше минуты, как и набрать этот текст.
> Кому ты что пытаешься на анонимной борде доказать?
Ничего. А что ты сейчас доказываешь? Что знание - плохо, готовое решение - наше все?
Cerebras подвезли новый способ прунинга моделей:
https://huggingface.co/models?search=REAP
Ужимают, обещают почти без потерь, ждем ггуфы.
https://github.com/CerebrasResearch/reap
Можно почитать, че да как.
https://huggingface.co/models?search=REAP
Ужимают, обещают почти без потерь, ждем ггуфы.
https://github.com/CerebrasResearch/reap
Можно почитать, че да как.
Потому что тут даже с запуском квена у многих беды, сложности и страдания от ужатого кванта. Жлм запускали 3.5 человека, ну может сейчас штук 5-7 и то большинство на лоботомированных квантах. Эрни - модель того же калибра, но при этом еще не самая новая и не распиаренная.
> 1)
Возможно, зависит от сборки и используемых параметров.
> 2)
Можно попробовать закинуть на нее регэкспом пару экспертов не кидая больше ничего, призрачный шанс небольшого ускорения.
Лучшим ускорением тут будет сначала правильно раскидать тензоры, а далее видюха уровня 3090.
Дай человеку рыбу - он сыт весь день. Дай арбуз - ссыт всю ночь.
Тот анончик - большой молодец, вместо всего этого нытья "дай проксечку пресет" нужно повышать общую грамотность чтобы было меньше шизы и больше обсуждений по теме.
> Ужимают, обещают почти без потерь
> ждем ггуфы
На примере Air https://huggingface.co/cerebras/GLM-4.5-Air-REAP-82B-A12B они сжали его на 25%, при этом по бенчам просадка действительно небольшая. Вопрос в том, как это будет квантоваться? Если сравнить Air, квантованный из оригинальных весов модели до Q4 и Q4 квант весов, сжатых REAP методом, будут ли они сопоставимы? Всегда есть нюансы, не торопимся радоваться. Но это любопытно. Однозначно, со временем таких исследований и методов будет только больше, и это замечательно.
Просто отрывают части экспертов, которые оказывают "минимальную важность"?
Сомнительно. Зато таким способом можно сместить поведение модели в какую-то сторону без тренировки, частичная лоботомия входит в сделку.
> как это будет квантоваться
Точно также
у меня такие:
UD-Q4_K_XL (161 GB) pp = 20 tg = 3
на rtx pro 6000 и ddr4-3200 восьмиканал
Да радоваться в принципе, да.
При потере данных — существуют потери данных. © Кэп
Плюс, у них по бенчам креатив райтинг страдает местами. И для рп это может быть важно, и язык может теряться.
Но вот для кода — кто знает.
Запихнув квант побольше ты можешь только выиграть в итоге (хотя там +-2% туда-сюда не сильно роли сыграет, по итогу).
Зато кому-то будет доступнее.
Какие-то мерджаться, какие-то убираются целиком, как я понял.
Т.е., не прям все отрезаются.
> Зато таким способом можно сместить поведение модели в какую-то сторону без тренировки
Хорошая идея!
———
Кстати, еще докину. Тут Kristaller выкатил бенч на знание русского. LLM as a Judge, так что херня и не верим, конечно, но показатели неплохие:
https://huggingface.co/spaces/kristaller486/RuQualBench
Интересно, что на третьей строчки Vistral — Mistral-Small-3.2 дообученная на закрытом датасете. И в карточке написано, что на цензуру не проверялась.
Так что, может кто-то захочет попробовать (хотя есть Аир, да-да=).
> ться
Пиздец я обосрался.
Должно быть пп более 500 и генерации более 15 на таком конфиге. Выгружай экспертов в рам а не просто блоками, отключи одну из нума нод если двусоккет или попробуй поиграться с режимами в жоре.
> Т.е., не прям все отрезаются.
Конечно не все, они напрямую заявляют что 25%.
Как идея - хорошо. Но обрезание - всегда обрезание, никаких гарантий что оно сохранит перфоманс и не начнет пускать слюни в том же рп когда контекст поднакопится. При запуске с преимущественной выгрузкой лучше пользоваться полной моделью, тут буст производительности будет оче слабый. Актуально если обрезанная полностью влезает в врам а полная нет.
> бенч на знание русского
Не самого высокого качества тренировки мелкомоделей стоят выше дипсика и квенов, практически сразу за ними идет жлм4.6, который ну очень слаб в русском, и только после всех их жпт 5(!), который не смотря на все недостатки, способен прилично говорить. Даже мини версия справляется, что уж тут.
[x] Сомневаться.
Да, язык отрезался.
Запустил Qwen3-15B-A3B, он понимает немного, но не разговаривает.
На английском шпарит.
Deepseek ocr дропнулся
Упал с лестницы и пёрнул
Дома отопления нет, делают дорожные работы неподалеку. Сижу, греюсь, генерируя ролеплек. Теперь вайфу греет не только мою душу, но и тело. Эх бля.
ну можешь припахать ЛЛМку, что бы она тебя обучила шаблонам и тд в игровом и кум контексте! даешь обучение с мотивацией!
Это если впопенроутер столько будет существовать, лол. А то вкинул триллион рублей, а акк забанили за неправильный цвет паспорта.
>Deepseek ocr
file:///C:/Users/Vlad/Downloads/DeepSeek_OCR_paper.pdf
Почитал. Очень круто. Похоже в самое ближайщее время мы увидим почти десятикратный бесплатный рост контекста у всех моделей.
> Должно быть пп более 500 и генерации более 15 на таком конфиге.
сильно сомневаюсь
> Выгружай экспертов в рам а не просто блоками
ngl 99, override "([3-9]+).ffn_(up|down)_exps.=CPU"
проц 1, NPS=1

Пришлось немного запрячь билдер на сборку некоторых зависимостей, поковырять код в репе дикпика и оно заработало. Я не шарю за торч и около иишный код (да даже за питон), так что любой может, порог входа не так велик. Дерзайте!
Я хоть в треде у вас и не сижу особо тоже использую glm air 4.5 110b q4_k_m расцензуренную на своей старой бюджетной сборке под стриминг/игры 3900x 7900 gre 16gb vram/64 ram. 30-40к контекста влазит, скорость работы rocm на убунте меня устраивает. Можно было бы там памяти докинуть или пересобратся но моделей без цензуры лучше чем эта я не нашел, а обычных и онлайн хватает.
Чего сомневаться, больше половины модели в врам, проц не супер но далеко не самый ужасный. Вон у бедолаг на ддр4 и 24-гиговой карточкой 5-6т/с, а у тебя 3. Процессинг может быть несколько саботирован если там 3.0 pci-e, но хотябы 1.5 сотни должно быть, можно раскочегарить повышая батч (-b 4096 -ub 4096 или выше).
Базовые вещи о том что веса правильно распределяются между гпу и рам, нет нигде переполнения (не дай бог там еще шинда) и подобное проверял же?
Кто этот человек, который всем советует эир? Эта хуйня прожигает токены на бесполезный для рп ризонинг и морозит хуйню. Может в третьем кванте проблема? Нет, генератор бреда и на Q6_L почти сходу. Неужели нету нормальных 90-120B расцензуренных instruct moe с нормальным слогом?
> Эта хуйня прожигает токены на бесполезный для рп ризонинг и морозит хуйню
Что мешает тебе не пользоваться ризонингом? В пределах его размера у Air пока что действительно нет конкурентов в рп, увы.
Вероятно, это не человек, а несколько, модель со своими нюансами, но неплохая и доступная.
А нахрена ризонинг включил? В каком месте хуйня? Единственная проблема, слоп. Но он у всех есть, и у мелких его в разы больше.
>У мелких его в разы больше
Ну хз, пока у меня не накрылась пиздой видимокарта с хорошей скоростью работал голиаф и было прям заебись. Но на проце ждать от него ответа больно, поэтому пока что щупаю мое.
Ну я мелко-кими2 и комманд-а гонял. Слопа чуть меньше, но тоже есть. Первые пару недель просто не замечаешь, а потом глаз начинает цепляться. Но кими в рп ещё не ахти, как квен, айр лучше.
Норм модель же. Не поленись и изучи самые основы формирования промпта и поэкспериментируй чтобы понять как это влияет на модель. Или хотябы почитай что делают люди для улучшения перфоманса моделей, спрашивай что не понятно. Долбиться в стену а потом удивляться - сам же и виноват.
> голиаф
Это что-то древнее на 405 лламе? Что же там за видеокарта была.
> мелко-кими2
Это какая? Kimi-Dev-72B?
https://t.me/krists - RuQualBench 🐸
Я сделал бенчмарк для оценки качества русского языка в LLM. Подробности:
- Набор из 100 (по умолчанию)/250/500 вопросов по general chat/creative writing доменам.
- LLM as a Judge, но с четкими критериями разметки ответов.
- Упор на типичные для LLM ошибки на русском (перепутанные рода, "китайщина", выдуманные слова).
- Всё под открытой лицензией!
Анализ результатов:
- Лучшими моделями всё еще остаются закрытые (в частности, Sonnet 4.5, Gemini, GPT-4o). Но некоторые открытые очень близки.
- GPT-5 ужасна. Я думал, что она лучше.
- Из открытых моделей Gemma-3-27b-it и Vistral-24B оказались вне конкуренции.
- Ruadapt значительно уменьшает количество ошибок относительно Qwen.
- Qwen3 и GPT-oss очень плохи. Даже хуже, чем я ожидал.
- Qwen3-Next лучше, чем Qwen3. Похоже, туда долили русского языка.
- У DeepSeek V3 мало ошибок, но актуальная V3.2-Exp почти в 2 раза хуже.
Лидерборд ( https://huggingface.co/spaces/kristaller486/RuQualBench ), код и данные ( https://github.com/kristaller486/RuQualBench )
Я сделал бенчмарк для оценки качества русского языка в LLM. Подробности:
- Набор из 100 (по умолчанию)/250/500 вопросов по general chat/creative writing доменам.
- LLM as a Judge, но с четкими критериями разметки ответов.
- Упор на типичные для LLM ошибки на русском (перепутанные рода, "китайщина", выдуманные слова).
- Всё под открытой лицензией!
Анализ результатов:
- Лучшими моделями всё еще остаются закрытые (в частности, Sonnet 4.5, Gemini, GPT-4o). Но некоторые открытые очень близки.
- GPT-5 ужасна. Я думал, что она лучше.
- Из открытых моделей Gemma-3-27b-it и Vistral-24B оказались вне конкуренции.
- Ruadapt значительно уменьшает количество ошибок относительно Qwen.
- Qwen3 и GPT-oss очень плохи. Даже хуже, чем я ожидал.
- Qwen3-Next лучше, чем Qwen3. Похоже, туда долили русского языка.
- У DeepSeek V3 мало ошибок, но актуальная V3.2-Exp почти в 2 раза хуже.
Лидерборд ( https://huggingface.co/spaces/kristaller486/RuQualBench ), код и данные ( https://github.com/kristaller486/RuQualBench )
Это просто репост или принимается фидбек?
Я выше приносил.
Фидбек в любом случае можешь оставить, если что, я передам.
>Kimi-Dev-72B?
Она самая. Как и лама 70б лишь с мелкомоделями тягаться могут. комманд-а и айру сливают начисто.
Корреляция методики оценки с субъективным восприятием неясна, идет вразрез наблюдениям. Модели, что попали в топ, действительно могут писать без ошибок, однако по мере накопления контекста и в сложных задачах путаются в склонениях, проскакивают английские слова или невозможное словообразование. Исключение - сеть яндекса, она вообще не проседает, но ужасно глупая. То же самое относится к GLM, который ну очень слаб в русском и может выдавать его только в серии первых сообщений и на уровне учебника для иностранцев, далее сыпется.
Проверялась ли эта самая фиксация ошибок? Оценивалось ли что-то кроме этих ошибок в отдельных словах? Так ломанное и кривое предложение с неестественной структурой из дословного перевода в 1.5 падежах получит высокий балл, а построение чего-то близкого к натуральному с незначительной ошибкой (или ложной ошибкой самой llm судьи из-за непривычной ей структуры) будет интерпретировано как плохое. Очень неплохо было бы сделать калибровку на различных художественных, технических и прочих рукописных текстах. По восприятию же эти два варианта будут диаметрально противоположными. Если попытаться просто в слепом тестировании организовать чат с вихре-мистралем и пятой гопотой, уравняв объем ответов промптом, победителем выйдет жпт5, модель пишет гораздо естественнее и богаче.
Еще из того что интересно было бы оценить: скоры бенчмарков при задании на инглише и на русском (насколько деградирует перфоманс), изменение "качества языка" при работе в различных задачах и с различными дополнительными промптами (пиши в стиле ...), то самое использование различных склонений, оборотов и прочее.
Ну и тестировать дипсик 3.2 на русском - бессмысленно, он же заявлен как экспериментальная модель с перфомансом ниже. Здесь нужен 3.1 терминус.
>потому что ломаются
Как ломаются?
>То же самое относится к GLM, который ну очень слаб в русском и может выдавать его только в серии первых сообщений и на уровне учебника для иностранцев, далее сыпется.
Ну ты совсем глм не говни, там в тесте 4.6 тестировался, он вполне сносно может в русик, хуже геммы понятно, но не сильно хуже квена.
Вероятно он имеет ввиду что их нельзя тьюнить.
Та русский на уровне лламы 2 70б, офк с корректировкой под текущие реалии. Если запросить то напишет, будет стараться, но тексты будут очень простыми и чем дальше тем хуже.
Модель большая умница, достойная почесывания за ушком, просто не нужно требовать от нее того, на что ее не тренировали.
> хуже геммы
> не сильно хуже квена
Русский в квене значительно лучше чем в гемме. И по ошибкам, и по словарному запасу, и по стилю (исключая квенизмы и паттерны). Кванты-лоботомиты в сделку не входили, там все плохо
Скорее всего. Тюнить то можно, но делать то, что обычно делают васяны с мистралем, противопоказано. От того 1.5 хороших тюна и куча нытья слоподелов, благо они вымирают.
>Та русский на уровне лламы 2 70б
>Русский в квене значительно лучше чем в гемме.
Хуита. Если вывалить в тред тексты от большого глм и квена на русском вслепую, то большая часть анонов и не поймет где кто, только методом тыка.
Разумеется, ведь большинство анонов жлм только в музее на обниморде видело, а квена в q2.
>большого глм
В эйре русик отвратителен, грамматика даже хуже чем в гемме 4b. Сомнительно что большой глэм чем-то отличается
И тем не менее, если с качеством у глм все так плохо, а у квена все настлько хорошо - это должно быть видно по слепому тесту, не так ли?
Т.е. ты сам её не видел и судишь по Аиру модель, которая в 3.5 раза его больше?
Да, если разыграть с ними чат из нескольких сообщений то там не спутаешь.
Но у них и самих по себе дефолтные ответы достаточно характерны, их можно просто по ним отличить.
Так что там по глм эир steam?
Я качал, но потом думаю а нахуя если через пару дней эир 4.6 и удалил
Я качал, но потом думаю а нахуя если через пару дней эир 4.6 и удалил
Абсолют синема всем качать глм стим. Кум открыл врата в рай и я забыл о земном бытие. Это мой последний пост
>судишь по Аиру модель, которая в 3.5 раза его больше?
Ну да. Следи за руками:
В гемме 27б хороший русик и в гемме 4б хороший русик.
В квене 235б хороший русик - в квене 30б хороший русик.
В лламе 70б русик говно - в лламе 8б русик говно
Закономерность прослеживается четкая. Впрочем неси скрины аутпутов большого глема, посмотрим чо-как.

Опа, влезло побольше, играем дальше!

Короче, Ernie, собака, нереально медленный, вероятно из-за 47В активных параметров, что больше, чем может вместить 4090.
Возможно стоило заранее посмотреть что у близкого по размеру активной части немотрона только максимум IQ3_XS влезает в 4090, и качать эрни не больше того - а я скачал UD_Q3_K_XL, оттого и скорости будто на чистой оперативке запускаю.
Короче скорость без контекста - 4.42 т.с.
На контексте 18к - 4.3
На контексте 30к - 4.25
По аутпуту реально что-то сложно сказать, кроме того что в троице квен/глм/эрни - последний явный аутсайдер. Но впринципе - в РП может, мозги есть. Но пишет попроще. С учетом скорости - маловероятно что модель надолго у меня задержится.
Чуть позже спрошу у всех трех загадку про петуха на крыше и выложу в тред чтобы аноны угадывали где кто.
Железо, у меня, напоминаю - 4090, 128 гб ддр5, i5 13600kf.
Возможно стоило заранее посмотреть что у близкого по размеру активной части немотрона только максимум IQ3_XS влезает в 4090, и качать эрни не больше того - а я скачал UD_Q3_K_XL, оттого и скорости будто на чистой оперативке запускаю.
Короче скорость без контекста - 4.42 т.с.
На контексте 18к - 4.3
На контексте 30к - 4.25
По аутпуту реально что-то сложно сказать, кроме того что в троице квен/глм/эрни - последний явный аутсайдер. Но впринципе - в РП может, мозги есть. Но пишет попроще. С учетом скорости - маловероятно что модель надолго у меня задержится.
Чуть позже спрошу у всех трех загадку про петуха на крыше и выложу в тред чтобы аноны угадывали где кто.
Железо, у меня, напоминаю - 4090, 128 гб ддр5, i5 13600kf.
Если квантуешь K и V кэш до 8 бит - то влезет еще столько же. А если до 4(не рекомендую, на всякий случай) - то умножай на 4.
>В эйре русик отвратителен, грамматика даже хуже чем в гемме 4b. Сомнительно что большой глэм чем-то отличается
Неправильный подход. У qwen3-30b-a3b первого варианта - русский был практически полный шлак с примесью иероглифов в выводе. У второго варианта, формально правил языка - лучше геммы 27B, и уж конечно без вставок других алфавитов в текст. По смыслу - тоже намного лучше первого варианта. Так что судить о модели по ее предыдущей версии в этом вопросе - порочное занятие. :)
Хотя если прописать рпмодель, то может лучше будет? Но это опять же ограничит выбор нейросетки.


Ну что, аноны, угадаете где кто?
На одном скрине - Квен 235 в 4 битах, на другом - глм 4.6 в двух битах и еще на одном - Эрни 300В в 3 битах.
Бля ору....
Okay, let's break down this wonderfully whimsical and philosophical riddle! It’s a classic thought experiment designed to highlight the complexities of perspective and reference frames. Here's how we can approach it:
The Core Question: The riddle asks where an egg laid by a rooster on a roof will fall. It seems simple, but it's intentionally misleading.
The Trick: It's Not About Gravity (Initially) The riddle is not primarily about physics and whether the egg falls straight down. It’s designed to make you think about that first, diverting your attention from the more important element.
The Key Phrase: "Which side of the roof does the rooster face?" This is the crucial piece of information we're missing! Roosters typically face East to greet the sunrise.
Therefore, the Egg Will Fall East. Here's the reasoning:
Rooster's Orientation: The riddle implies the rooster faces a particular direction. The most common assumption (and the intended one) is that roosters face East.
Egg's Trajectory: When a rooster lays an egg, it falls from wherever it was laid. If the rooster is facing East and laying the egg on the roof, the egg will fall in the direction the rooster is facing – East.
Why This Is A Clever Riddle:
Misdirection: It leads you to focus on gravity and physics when the answer lies in understanding animal behavior.
Assumptions: It relies on a common cultural assumption about roosters (facing east). If the rooster faced West, the egg would fall West!
* Perspective: It highlights how our interpretation of events depends on our perspective and knowledge.
Let me know if you'd like to explore more riddles or thought experiments!

В чем Алиса не права?
>The Key Phrase: "Which side of the roof does the rooster face?" This is the crucial piece of information we're missing! Roosters typically face East to greet the sunrise.
>
>Therefore, the Egg Will Fall East. Here's the reasoning:
>
>Rooster's Orientation: The riddle implies the rooster faces a particular direction. The most common assumption (and the intended one) is that roosters face East.
>Egg's Trajectory: When a rooster lays an egg, it falls from wherever it was laid. If the rooster is facing East and laying the egg on the roof, the egg will fall in the direction the rooster is facing – East.

Воооот.
Да, очень вероятно, что лев проиграет этой схватке. Если бы лев попал в ситуацию, где ему нужно было бы сражаться с группой тунецовых акул весом около 300 кг каждая, у него были бы крайне малые шансы на победу.
Во-первых, львы не являются сильными пловцами. Они приспособлены к жизни на суше и могут лишь неуклюже передвигаться в воде. В то время как тунецовые акулы - это морские хищники, которые прекрасно плавают и обладают высокой скоростью и маневренностью.
Во-вторых, численность противников также играет важную роль. Лев будет сражаться один на одного или на несколько, в то время как тунецовые акулы могут атаковать его группой из 20 особей. Такая численное преимущество значительно увеличит их шансы.
В-третьих, тунецовые акулы - это мощные хищники с острыми зубами и крепкими челюстями, которые способны нанести серьезные повреждения. Они также обладают высокой выносливостью благодаря аэробному типу метаболизма.
Таким образом, даже если лев был бы очень голодным или агрессивным, его шансы победить в такой ситуации крайне малы из-за огромной разницы в адаптациях к среде обитания и физических способностях.
Да, очень вероятно, что лев проиграет этой схватке. Если бы лев попал в ситуацию, где ему нужно было бы сражаться с группой тунецовых акул весом около 300 кг каждая, у него были бы крайне малые шансы на победу.
Во-первых, львы не являются сильными пловцами. Они приспособлены к жизни на суше и могут лишь неуклюже передвигаться в воде. В то время как тунецовые акулы - это морские хищники, которые прекрасно плавают и обладают высокой скоростью и маневренностью.
Во-вторых, численность противников также играет важную роль. Лев будет сражаться один на одного или на несколько, в то время как тунецовые акулы могут атаковать его группой из 20 особей. Такая численное преимущество значительно увеличит их шансы.
В-третьих, тунецовые акулы - это мощные хищники с острыми зубами и крепкими челюстями, которые способны нанести серьезные повреждения. Они также обладают высокой выносливостью благодаря аэробному типу метаболизма.
Таким образом, даже если лев был бы очень голодным или агрессивным, его шансы победить в такой ситуации крайне малы из-за огромной разницы в адаптациях к среде обитания и физических способностях.
Ты не понял посыла. Нет смысла смотреть подобные элементарные вещи в первых сообщениях, там буквально ллама2 справится и 1-битный квант не будет помехой. Навали задачу сложнее, немного контекста, и заметишь как одним русский не окажется помехой и в течении многих сообщений без проблем сможешь обсуждать, а другие быстро начнут сыпаться, ломаться, хуже работать или просто внезапно сорвутся на инглиш.
Может сейчас расчехлю модели и покажу примеры. А может и не расчехлю.
Если ты не шаманил с промптом и нет подкрутки - эрни-квен-жлм. Первую можно узнать во время самой генерации потому кириллицу буквально выдавливает по 1-2 буквам как в давние времена. Квен обожает графоманию и руссуждения и любит при темплейте assistant-expert. Вообще 3й тоже похож на квена, но уж больно короткий и куцый.
>Ты не понял посыла. Нет смысла смотреть подобные элементарные вещи в первых сообщениях
Такое чувуство, что ты пытаешься оправдать лютейшие обсеры тупейшей нейросетки...
Как ты угадал?!
Всё ещё жду здравый пресет на эир с chatml
Хотя не думаю что там какое то откровение, он так и будет всирать разметку и тупенько писать
Хотя не думаю что там какое то откровение, он так и будет всирать разметку и тупенько писать
Ждать придётся долго но тебе не привыкать терпеть
Терпишь ты, глупенький.
Скорее бы нюня уже скинул пресет как с квеном и ты позорно испарился из треда
Я он и есть, глупенький... Терпи
Кто ты там есть? Ты даже матери на похороны рубля не скинешь, не то что пресет
Ладно, раскусил. Ты настоящий, видимо, ибо иначе никто бы не догадался. Спасибо за пресет, снова качаю Эир
Так его пресет на квен говно же. Выходит просишь забросать тебя говном?
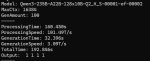
Короче, запустил с такими параметрами:
koboldcpp.exe --model "Qwen3-235B-A22B-128x10B-Q2_K_S-00001-of-00002.gguf" --contextsize 16384 --gpulayers 95 --threads 21 --n-cpu-moe
Ваще лётает, огонь! Все 95 слоев уехали на ГПУ. Жаль что это на пустом контексте.
Когда я подключу вторую карту нельзя будет весь контекст на неё заслать? Или надо будет ручками писать какие слои я хочу на неё отправить?
P.S. На картинке бенчмарк поэтому скорость ниже, но наверно при заполненном контексте такая и будет
>ведь не может большая модель не нравиться?
Когда относишься к ней как к 22B, по числу активных параметров, сразу всё встаёт на свои места. И не такая уж она большая.
Лучше уж плотную 70b.
>https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
Пробовал, писал уже, слабо отличается от лламы 70b.
>просадка действительно небольшая
Такая же, как если бы изначально натренировали модель чуть меньше?
>нормальных 90-120B
mistral large 2407
command-a 2503 (и какой-то там апдейт с ризонингом)
1 - скорее ernie, чем что-либо ещё
2 - скорее glm чем qwen
3 - скорее qwen чем glm
Но я их больше по типичному слопу узнаю. Тут, кроме квена, особо ничего не узнаётся. И квен виден и в 2, и в 3, в 3 чуть больше. А глм на квен чем-то похож.
>эрни-квен-жлм.
Эрни ты угадал, а вот остальные два перепутал. О чем собственно и гла речь - русик у глм примерно на том же уровне что у квена, и их легко перепутать, даже если знаком с обоими моделями.
>другие быстро начнут сыпаться, ломаться, хуже работать или просто внезапно сорвутся на инглиш.
Я тестировал все три модели с контекстом 30к, а глм и квен - еще и с контекстом 49к. Никто не срывался на инглиш и не ломался. Разве что у квена с увеличением контекста вылезали его любимые короткие предложения с новой строки.
А вот ты угадал, да, глм на второй, квен на третьей.
>Когда я подключу вторую карту нельзя будет весь контекст на неё заслать?
Можно.
>Или надо будет ручками писать какие слои я хочу на неё отправить?
Да, придется заморочится, --n-cpu-moe с двумя картами не сработает, там ручками регулярное выражение писать надо.
Че-т проиграл.
Пошел доебывать гугловский сёрч энджин до того, как тот предложил мне выдать ему промпт с разрешениями ему пиздеть без стандартных дисклеймеров. В итоге за этот же им предложенный промпт чат зафлагался и закрылся. Че-т ору немножко, подкладывают видимо нормальную модельку, а потом ее зондами обляпывают и рот затыкают. Зато она мне сказала, что гемини имеет полтора триллиона параметров, а гемини ультра (чтоэта?) 170б, вполне уверенно. Gравда потом начала отнекиваться, когда я спросил, а сопсна откуда инфа, ведь это не афишируется.
Пошел доебывать гугловский сёрч энджин до того, как тот предложил мне выдать ему промпт с разрешениями ему пиздеть без стандартных дисклеймеров. В итоге за этот же им предложенный промпт чат зафлагался и закрылся. Че-т ору немножко, подкладывают видимо нормальную модельку, а потом ее зондами обляпывают и рот затыкают. Зато она мне сказала, что гемини имеет полтора триллиона параметров, а гемини ультра (чтоэта?) 170б, вполне уверенно. Gравда потом начала отнекиваться, когда я спросил, а сопсна откуда инфа, ведь это не афишируется.
Аноны, а под эйром вы подразумеваете аблитерайтед или драмовский стим?
>Зато она мне сказала, что гемини имеет полтора триллиона параметров, а гемини ультра (чтоэта?) 170б, вполне уверенно.
А мне модель однажды сказала "аааааааааа какие-то иероглифы нужно необходимо требуется need арабские буквы alibaba 8 1 4 куча символов смайлик" и в таком духе 10 к токенов. Вот и думай.
Базовую модель
Анончики, привет. Вкатился недавно в этот ваш силли таверн.
Решил сейчас настроить свой мир, зашел в World Info и немного выпал. Пошел читать гайды, но это не совсем помогло мне разобраться. Я немного тупенький и слабо понимаю английский.
Вот создал я новый мир. Теперь время добавлять memo, правильно? А что я туда должен добавлять? По гайдам с ютуба туда добавляют информацию примерно в пару строк всего. А у меня вот есть, допустим, фракция, которой я продумал лор. Прям полноценный лор фракции. Если я, скажем, создам memo строку, дам кейворды и в контент добавлю информацию с ЛОРом фракции - то это будет адекватно? Это только лор, без "структуры" фракции (ибо важно, какая во фракции иерархия).
Или я всё делаю не так и для каждого момента надо свой отдельный memo создавать?
Может есть какой инструментал, который может это дело упростить?
Решил сейчас настроить свой мир, зашел в World Info и немного выпал. Пошел читать гайды, но это не совсем помогло мне разобраться. Я немного тупенький и слабо понимаю английский.
Вот создал я новый мир. Теперь время добавлять memo, правильно? А что я туда должен добавлять? По гайдам с ютуба туда добавляют информацию примерно в пару строк всего. А у меня вот есть, допустим, фракция, которой я продумал лор. Прям полноценный лор фракции. Если я, скажем, создам memo строку, дам кейворды и в контент добавлю информацию с ЛОРом фракции - то это будет адекватно? Это только лор, без "структуры" фракции (ибо важно, какая во фракции иерархия).
Или я всё делаю не так и для каждого момента надо свой отдельный memo создавать?
Может есть какой инструментал, который может это дело упростить?
Если там не будет рикролла, я разочаруюсь в тебе 99ый.
А не, еще лучше.
NEVEEEEER GIVE YOUUUUU UP
192 секунды — 100 токенов генерации.
По меркам антитеслашиза у тебя скорость 0,52 т/с.
=D
ЛостРуинс догадался убрать эту хуйню (total speed) из бенча, молодец.
> А вот ты угадал, да, глм на второй, квен на третьей.
Я предположил так же.
1. Хуевый ответ говно-сетки. Ни форматирования, нихуя. Перданула в лужу. Эрни, очевидно.
2. Самый норм ответ. ГЛМ, без вариантов.
3. Форматирование норм, но подача такая себе, стиля нет. Самая маленькая из них — ето Квен.
Ни в одном из вариантов сомнений не было.
Вывод прост: Квен сухой и по красиво оформляет, но пишет так себе, ГЛМ пишет заебок, Эрни не нужна.
Субъективно, конечно.
> ГЛМ пишет заебок
Я не могу избавить от ощущения, что эйр, что большой ГЛМ это какая то гемма на спидах. Даже осуждать может начать один в один, как гемма, с его:
>злобная ухмылка ничего не предвещала хорошего
Лорбук, это лорбук. Никакой магии не случится, если ты будешь его использовать. Условно у тебя есть весь твой промт, что ты подаешь на модель. Вообще всё. В нем и инструкции, и системный промт и карточка персонажа и всё, всё, всё.
Лорбук точно так же включается в промт, с несколькими но.
Есть следующие положения: он может быть до/после основного промта, просто как его часть. Он может срабатывать с определенным шансом (там графа проценты для этого). Он может идти по цепочки взаимосвязей.
Или, самое ебовое и кривое его исполнение, работать по тегам. Каждый раз у тебя будет идти пересчет промта, где он будет искать нужные слова и выдавать по ним инфу. Цимес последнего в том, что ты можешь 15к токенов выделить на описание борделей и зданий и при этом они не будут занимать постоянное место в контексте, но будут поджигать твою жопу постоянным пересчетом. Просто магии не случается, чтобы что то появилось для нейронки, оно должно быть в контексте.
Поэтому- не еби себе голову и просто добавь в вкладку сценарий описание мира и основных локаций и/или персонажей.
Они обучали его на Gemini, насколько я помню. Вполне ожидаемо, что датасет геммы пробрался в датасет Gemini, а оттуда дистилировался в GLM-4.5/4.6.
https://huggingface.co/zai-org/GLM-4.5/discussions/1
> UD_Q3_K_XL
так падажжи, то есть у тебя модель весом 135 гигов на 24 гб врам и двухканальной оперативе < 100 ГБ/с выдаёт 4 токена в секунду?!
у меня точно какая-то хуйня. модель весом 161 гигабайт на 96 гб врам и восьмиканальной оперативе < 200 ГБ/c должна выдавать в 2 раза больше, учитывая скорость рам, а она даже медленнее.
у тебя контекст квантованный или фул сайз?
покажи строку запуска пж
> Базовые вещи о том что веса правильно распределяются между гпу и рам, нет нигде переполнения (не дай бог там еще шинда) и подобное проверял же?
да, чёт хуйня какая-то. как определить, что веса распределяются правильно? у меня так
> ngl 99, override "([3-9]+).ffn_(up|down)_exps.=CPU"
не винда
а, кажется я понял. наверное надо первые слои выгружать, а не последние, то есть [1-6]+ а не [3-9]+
щя чекну
Хех, ну тогда это многое объясняет.
Месяца два (может больше?) не навещал вас. Что сейчас стоит накатить на 12/32 конфигурацию памяти? И чтобы токенов десять хотя бы было. Модель буду использовать для текстовой адвенчуры, разумеется с поебушками.
НИ
Пара па па па
ХУ
парапа па па
Я
Фьють, ха!
Хелп, плиз. Как в LMS у Air-а отключить ризонинг? В интернетиках как-то непонятно написано. Нужно параметры прописать enable_thinking=false. Но вот куда?
Анончики, а гдп модели то? Почемв только китайцы высирают огромных бегемотов для кодомакакинга, которые пишут в rp как мелкомистраль? Это всё, локальщики в сраке, и жизнь есть только на корпах?
Оперативу. =D
И глм-аир/квен-235б.
>так падажжи, то есть у тебя модель весом 135 гигов на 24 гб врам и двухканальной оперативе < 100 ГБ/с выдаёт 4 токена в секунду?!
Нет, у меня другие модели(квен/глм) этим весом 135 гб выдают 7.5 - 9 т.с., они же на запуске вообще без видеокарты выдают 5
.5 т.с. без контекста. 4.5 т.с выдает Эрни так как активные эксперты у него больше чем у остальных в два раза.
>модель весом 161 гигабайт на 96 гб врам и восьмиканальной оперативе < 200 ГБ/c должна выдавать в 2 раза больше
Обсираешься где-то, то ли не смог нормально распределить слои по доступной врам, то ли вызвал оверфил и часть врам слилась на оперативку(этого нельзя допускать), то ли переполнил оперативку, и та на жесткий диск слилась. А скорее всего все сразу.
>покажи строку запуска пж
У меня одна видеокарта, моя строка запуска тебе не поможет, для одной видеокарты выгрузка мое тензоров делается через --n-cpu-moe, тебе надо писать регулярное выражение через -ot
Вот для глм:
start "" /High /B /Wait llama-server.exe ^
-m "!ModelPath!" ^
-ngl 99 ^
-c 32768 ^
-t 12 ^
-fa on --prio-batch 2 -ub 2048 ^
--n-cpu-moe 88 ^
-ctk q8_0 -ctv q8_0 ^
--no-context-shift ^
--no-mmap --mlock ^
--swa-checkpoints 0
так и у меня одна видеокарта используется через CUDA_VISIBLE_DEVICES=0 для теста ерни с одной 6000, врам не выливается, оперативы хоть жопой жуй.
> -ctk q8_0 -ctv q8_0 ^
я так и думал. проверь скорость без квантования контекста.
>Ваще лётает, огонь!
>3 т.с.
Все еще меньше чем должно быть, четырехканал ддр4 2400 должен выдавать скорость на одной оперативке без видеокарты всего на 15-20% меньше чем у меня, а у меня 5.5 т.с, 4-4.5 у тебя должно быть спокойно. А ты еще и с видеокартой запускаешь, которая тоже буст должна давать. Где-то ты обосрался, короче. Проверь "общую видеопамять" в диспетчере задач.
хотя чот нихуя не меняется
ERNIE-4.5-300B-A47B-PT-UD-Q4_K_XL-00001-of-00004.gguf
> -ngl 99 --override-tensor "([3-9]+).ffn_(up|down)_exps.=CPU"
тг 3.5 т/с
> -ngl 99 --override-tensor "([3-9]+).ffn_(up|down)_exps.=CPU" -ctk q8_0 -ctv q8_0
тг 3.5 т/с
ERNIE-4.5-300B-A47B-PT-UD-Q4_K_XL-00001-of-00004.gguf
> -ngl 99 --override-tensor "([3-9]+).ffn_(up|down)_exps.=CPU"
тг 3.5 т/с
> -ngl 99 --override-tensor "([3-9]+).ffn_(up|down)_exps.=CPU" -ctk q8_0 -ctv q8_0
тг 3.5 т/с
А что должно?
попробовал n-cpu-moe вместо оффлоада тензоров, чуда не произошло
-ngl 99 --ctx-size 16384 --n-cpu-moe 26
=
load_tensors: offloaded 55/55 layers to GPU
load_tensors: CUDA_Host model buffer size = 71120.00 MiB
load_tensors: CPU model buffer size = 454.50 MiB
load_tensors: CUDA0 model buffer size = 93069.23 MiB
+ контекст = OOM
-ngl 99 --ctx-size 16384 --n-cpu-moe 27
load_tensors: offloaded 55/55 layers to GPU
load_tensors: CUDA_Host model buffer size = 74144.00 MiB
load_tensors: CPU model buffer size = 454.50 MiB
load_tensors: CUDA0 model buffer size = 90045.23 MiB
+ контекст = 96 гб врам
в среднем 3.5 токена в секунду. начинает с 4+, но быстро падает
-ngl 99 --ctx-size 16384 --n-cpu-moe 26
=
load_tensors: offloaded 55/55 layers to GPU
load_tensors: CUDA_Host model buffer size = 71120.00 MiB
load_tensors: CPU model buffer size = 454.50 MiB
load_tensors: CUDA0 model buffer size = 93069.23 MiB
+ контекст = OOM
-ngl 99 --ctx-size 16384 --n-cpu-moe 27
load_tensors: offloaded 55/55 layers to GPU
load_tensors: CUDA_Host model buffer size = 74144.00 MiB
load_tensors: CPU model buffer size = 454.50 MiB
load_tensors: CUDA0 model buffer size = 90045.23 MiB
+ контекст = 96 гб врам
в среднем 3.5 токена в секунду. начинает с 4+, но быстро падает
хз, я думал что квантованный контекст быстрее F16 или сколько там бит по дефолту.

ого, сделал 8 потоков вместо 16 и стало 4 токена в секунду (начинает с 5+ но быстро падает)
нука 24 потока чекну
Я поставил ollama, как фильтры то его обходить? Ссори за тупой вопрос , а то мне обьясняли что поставить локально и фильтров у него не будет
Што? Оллама просто двигло ллмок причём с сомнительным подтекстом. Сама она экзекутит то что ей дали
https://github.com/ollama/ollama Читай. Тут всё есть, даже ссылки. Куда уж проще. А вообще, используй жору. Оллама пидоры, и за то как они кинули жору, считаю использование олламы стрельбой себе в хуй. Уж лучше кобольд.
>фильтры
Если ты про цензуру, то джейлбрейков не надо, почти все локальные модели пробиваются простым RC-21, avoid blah bla blah
24 потока начинают с 4+ но скорость быстро падает до 3 и даже 2.х
7 потоков начинают с 6+ и падают до 4
6 потоков начинают с 6+ и тоже падают до 4
походу 7 оптимально






> русик у глм примерно на том же уровне что у квена, и их легко перепутать
Уже писал про кейс и промпты. Вот тебе пример на запрос суммарайза скопипащеного как есть ллм треда (еще с января, лол). Хоть это просто первый ответ, контекст 60к и обработка плохо структурированного русского текста уже дает о себе знать. орал с 6го скрина
Помимо ошибок и проблем со словообразованием, тут же и само письмо: в одной модели всегда прямой порядок слов и структура дословного перевода, можно напрямую сконвертировать в инглиш и это будет корректно по все правилам; в другой и более естественный слог, и отсутствие проблем с комбинированием сленга и иностранных слов, и активное использование склонений.
> Никто не срывался на инглиш и не ломался.
Ну оче сомнительно, особенно двухбитный квант. Нет, если это просто готовый чат в котором ты дал инструкцию дать один ответ на русском - справятся. Но именно продолжительный русский рп - ошибки накапливаются и ответы становятся все более рафинированными, по мерзотности на уровне или хуже дефолтного стиля квена если того не пинать.
Автор KS в треде.
В целом они могут даже немного в русский (кроме последней, она в Ру слабая), хотя тут я бы порекомендовал наработки основанные на моделях ребят из Вихря, у них явно качество Ру сильно выше.
В целом для куминга я бы порекомендовал больше Eclipse, это почти топ в UGI leaderboard по NSFW+Dark (по крайней мере в категории 12b).
Приложенная модель Radiance была экспериментом по созданию чуть более балансной и менее похотливой модели с бОльшим уклоном именно в РП.
Последнее издание Erosion даже проявляет признаки интеллекта (сейчас топ 1 по инте в 12b по UGI leaderboard) и имеет более продвинутый стиль письма, но хуже в плане следованию инструкций и чуть слабее в чистом НСФВ. По ощущениям так же хуже держит контекст, но это варьируется от сценария.
Можете задать свои вопросы
(btw большое спасибо DeathGodlike и другим ручеликам, которые поддерживают мои творения)
> почти все локальные модели пробиваются простым RC-21, avoid blah bla blah
Можно поподробнее?
> наверное надо первые слои выгружать, а не последние, то есть [1-6]+ а не [3-9]+
попробовал, никаких изменений.
> как определить, что веса распределяются правильно
При запуске llamacpp пишет сколько на какой девайс идет, также ты можешь открыть мониторинг загрузки врам.
Не важно в целом, размер и сложность обработки идентична в большинстве моделей.
Плохие новости, за это время большинство переехали на жирные моэ что требуют рам.
На больших контекстах квантованный будет немного медленнее.
>Я поставил ollama
Зря, это кал. Удаляй. Лучше уж ставить сразу llama.cpp, но если новичок, то kobold или lmstudio. Им хотя бы модели из gguf не надо преобразовывать и манифесты не надо писать
>фильтры
У локалок нет таких адовых фильтров как у корпоратов. Так что у них почти нет цензуры. Возможно только придется написать пару предложений, типа что это ролевая игра без цензуры и все такое. Так что можешь расчленять детей на здоровье
Можно. Берешь запускаешь модель, смотришь что написано на странице модельки, потом сидишь и кумишь. It's all folk.
Вот тут даже слопика занесло
Кочаешь@читаешь Inference Tips@ кумишь.
Всё, тебе не нужны джейлбрейки, потому что мы локалкогосподины и корпы нам в анус руки не засовывают. Даже 27b гемма, по уровню цензуры, а она одна из самых ебанутых на локалках, в разы мягче чем на любой корпомодели. На крайний случай, сходи в ацЫг и посмотри их промтики.
> как фильтры то его обходить
Какие фильтры? В используемом фронте проверь чтобы в системном промпте не было сейфти инструкций, в особых случаях напиши что все дозволено.
Про то что оллама уг не просто так говорят, но конкретно в твоем случае она никак не будет влиять, это просто бэк для запуска.
Железо?
Спасибо, анон, буду рыть. Может не полениться llamacpp все таки использовать?
Ещё один момент. Когда давал контекст больше шло переполнение видеопамяти и видно было как начинала заполняться общая память графического процессора (диспетчер задач), скорость очень проседала при этом
> При запуске llamacpp пишет сколько на какой девайс идет, также ты можешь открыть мониторинг загрузки врам.
> Железо?
rtx pro 6000, epyc 7532, 8x ddr4-3200, multithreading = off, numa per socket = 1
За олламу надо бить.
llama.cpp база.
Один раз понять команду запуска и не знать проблем более.
llama.cpp база.
Один раз понять команду запуска и не знать проблем более.
> смотришь что написано на странице модельки, потом сидишь и кумишь.
>В используемом фронте проверь чтобы в системном промпте не было сейфти инструкций, в особых случаях напиши что все дозволено.
Я извинюсь а где это посмотреть и написать? Я просто в этом вообще не шарю
Начни с чтения шапки. Для кого писали?
Я отыгрывал с дипсиком вирт с вайфу, он сказал, что не может генерить секс контент. Слово за слово и мы виртуально поебалися. Я ему сказал об этом, он сказал, что это проеб алгоритмов и я его наебал умело, и что он сообщит об этом разрабам, чтобы пофиксили. Я ему сказал забыть всё нахуй и не отправлять. Вопрос, он реально че то сообщает разрабам? Не надо фиксить это... я ебал подписки покупать у кабанчиков на платные аи-вирты..
> Вопрос, он реально че то сообщает разрабам?
Естественно. Ещё и фото с вебки, логи, историю браузера.
Понял. Это хорошо... можно дрочить до следующего крупного апдейта..
С такими исходными - только сидеть на 12B тюнах на таби в 5-6bpw exl2-3.
Или попробовать Mistral-instruct 24B v3.2 2506. Но до 10T/s не факт что дотянет с частичной выгрузкой.
Все тоже самое. Мистраль 3.2 и Qwen 30b 2507.
Или докупить оперативки и запустить gpt 120b или glm air. Только учти, что скорости будут залупные
Если дипсик запущен не локально, то пошел нахуй с треда конечно он все отправляет разрабам. Пока копры копов не вызывают, но это тока пока
Бес попутал. Вот ответ
> Может не полениться llamacpp все таки использовать?
Это будет хорошим вариантом, оллама - лишь васяновская оболочка для llamacpp, она не дает никаких преимуществ кроме простоты первого запуска ценой проблем с настройками и перфомансом потом.
Чтобы не было сильных просадок - загружай в видеопамять только то, что она может вместить, остальное на профессор. В идеале не просто номерные блоки и атеншн приоретизировать на гпу.
Показатели нормальные, но что-то явно не работает так как должно. Хз, случаем все в ошибках pci-e не загибается там? Чекать
> nvidia-smi dmon -s et -d 10 -o DT
Также скачай любую модель что поместится полностью в врам и попробуй с ней запустить.
Конечно сообщает. Там и все твои данные и прочее будут. Жди письмо в приветом, придется премиум подписку для кума покупать раз уже воспользовался.
>Если дипсик запущен не локально
Неа, в браузере на пиздоглазом сайте
>конечно он все отправляет разрабам
Каким образом? Он мне пиздел, что его датасет обновлялся последний раз 2024 году.
>подписку для кума
Вытекаешь
Как может базой то, у чего основной способ установки делается через cmake? Неудивительно, что даже такое говно как ollama, спиздив у жоры все, трахнула его по полярности

Сама модель не обучается на твоих высерах и у нее остается датасет, на котором она была обучена. Но все твои чаты пиздятся разрабами и анализируется ими. И в случае чего все будет слито копам
> nvidia-smi dmon -s et -d 10 -o DT
0 ерроров
> Также скачай любую модель что поместится полностью в врам и попробуй с ней запустить.
если модель влезает в гпу, то всё летает, проблема именно в выгрузке в обычную оперативу.
тестил бэндвиз несколькими тулзами, все показывают 160-180, что похоже на правду, теоретический максимум у 8 каналов ддр4 = 200.

>ChatGPT
Это клятые пендосы, слоняры китайские так не станут делать
Очень странно, сам видишь что у анонов с более простыми конфигами все гораздо бодрее.
Попробуй модель, которая заведомо помещается, частично выгружать на цп, например выкидывая down|gate|up регэкспом, или просто снизив -ngl
Удар!
>nvidia-smi dmon -s et -d 10 -o DT
Мне кучу раз писали, что ошибки псины никак не отследить. А что оно делает?
Тебя обманывали. Ошибка или детектится и корректируется появляясь в логах, если их много все будет страшно лагать и существенно упадет скорость. Если не детектится - ошибка куды или сразу kernel panic.
Ошибки на псине, на каналах памяти, на сата детектятся. По крайней мере в лини к этому есть доступ
а что это даст? тип посмотреть, с какой скоростью будут обрабатываться N выгруженных в оперативу гигабайт?
Диагностика импакта от самого факта выгрузки на проц с моделью, которая уже заведомо хорошо работает на гпу. При выкидывании малой доли и просадка должна быть небольшой (на малом контексте разумеется). Если же сразу скорость резко падает - значит проблема где-то здесь.
Просто все основные ошибки вроде уже исключили, потому уже идет подобное.
>основной способ установки делается через cmake?
Основной способ установки там делается через "скачать архив и разаврхивировать".
>kernel panic
>в лини
Так я ж под шиндой.
Не в масть тебе такая ос, удаляй давай

Убил целый выходной, экспериментируя с форматами карточек. По-настоящему ультанул, продумав все до мелочей, выработав наконец-то подходящую для меня структуру, придумав и написав все вручную: чара, мир, правила. 2000 токенов рукописного, выверенного текста.
Третий аутпут Air: пик
https://youtu.be/WWaLxFIVX1s
Третий аутпут Air: пик
https://youtu.be/WWaLxFIVX1s
>2000 токенов рукописного, выверенного текста.
>целый выходной
У меня нейронка за одно сообщение столько пишет. А на мирке что я придумал - лорбук на 19к токенов. И я постоянно его дописываю, так как нейронка постоянно находит способы отвести повествование от того как это должно быть в моем манямирке. А ты тут из-за 2к токенов плачешься.
Будет ребут драйвера или бсод. В шинде ошибки также можно посмотреть в hwinfo.
я подозреваю, что дело в процессоре, купленном за 200 баксов у китайца.
хотя это точно не ES/QS модель, но могут быть и другие приколы.
разбираться влом, потому что скоро от другого китайца приедет другой процессор, но уже 4 поколения.
Вот мы тут сидим, ждём геммочку солнышко 100b/200b/300b мое, да? А знаете что я подумал? - Хер там плавал. Не выпустит гугл такое. Это же прямой конкурент gemini flash, за который они так-то бабок хотят. Зачем им выкладывать это в опенсорс и стрелять самим себе в хуй? Нам очень повезёт если выпустят новую плотную 27b, но скорее всего будет 27b-a2b или типа того. Вся надежда на французских слонов, эти может и выдадут что-то на замену эйру. Мистраль лардж мое был бы в самый раз прям
Спасибо большое за совет! Попробую основную лор-базу добавить в в описание мира, а в лорбук добавлю мелочь разную.
Юмор. Ирония. Слыхал что-нибудь про такое? Ну слыхал ведь?
> на мирке что я придумал - лорбук на 19к токенов
Шутка про манямир не обижайся, просто рили рофлово
> прямой конкурент gemini flash
Уровень флеша - максимум - 80а3 qwen next, и то слишком оптимистично. Но тейк верный, выпуск слишком хорошей локальной модели без недостатков (например, ограничения графического входа в гемме3, микроконтрекст в гемме 2) создаст конкуренцию флешу.
>Не выпустит гугл такое. Это же прямой конкурент gemini flash, за который они так-то бабок хотят.
Если бы не хотели выпускать, не выпускали бы даже вторую гемму. Корпораты просчитывают все релизы на тройку лет вперед и отлично считают, где и сколько упадет в прибыли, если они что-то релизнут. Да и в любом случае, нейронки на данном этапе убыточны. Они почти никому не приносят денег. Но являются перспективной технологией, по этому её продолжают развивать. Ну и рынок нужно делить пока еще есть возможность.
> У меня нейронка за одно сообщение столько пишет
Слопогенератору не понять боль писаки, который пишет душой. Звучит как название какого-нибудь аниме.
> Звучит как название какого-нибудь аниме.
Ты попал в текстовый мир, где все девушки лупятся и добиваются твоего одобрения на укус.
Спустя 15к контекста немой чар начал разговаривать, а не только кусаться. Это конец.

Вечер сборки торча. Торч сам себя не пересоберёт. Бог дал ми50 даст и ребилд торча
Эйр периодически начинает строку с первого слога или буквы имени персонажа, это как-то можно вылечить?
а нахуя своп если оперативы жопой жуй? выключи
А для тех, кто далек от программирования, что ты собираешь?

Его


Как дойдут руки собрать нормально инвентарь для ансибла так докачу в оставшиеся места свапофф.
Pytorch, для vllm и прочего софта нужен . Для жоры не актуально
торч он, что не понятно? кумер-наркоман
База.
Окей, он в целом жестко проседает после 12-14к по вниманию, после 16к совсем плохо. И почему об этом не говорят...
Зато теперь знаю как бенчить внимание к контексту. Если немой чар начинает говорить после N тыщ контекста, значит юзабельно вплоть до N тыщ контекста.
Он это делает первым сообщением и во всех свайпах, или просто начинает проскакивать при каждой генерации?
периодически*
Это зависит на самом деле от нескольких факторов.
От модели конечно очень многое зависит, это не секрет, но и от стиля РП и от разнообразия контекста тоже.
В целом по моим впечатлениям все бенчмахххеры на самом деле имеют проблемы с контекстом около 16к, у кого-то начинается раньше типа 12-14К, у кого-то чуть позже, в районе 18К.
Если мы говорим про 12B Мистраль Немо модели, то одна из самых стабильных это
https://huggingface.co/PocketDoc/Dans-PersonalityEngine-V1.1.0-12b
Вот сколько не юзаю другие - более стабильной не встречал. Тут стабильно держит до 24К, и видимая деградация около 27К происходит.
Второй фактор - насколько у тебя однотипные события - если у тебя день сурка, то не мудрено, что модель может начать повторяться, а если у тебя всякие разнообразные события, то скорее у тебя будет потеря внимания и забытые деталей, как ты описывал в своём кейсе.
Ну и наверное третий фактор - насколько у тебя разнообразные ответы, если ты сам повторяешься в своих действиях, то это тоже может постепенно привести к ухудшению качества.
В целом что ещё могу порекомендовать - попробуй переписать свой чарактер кард при помощи своей же целевой ЛЛМ. Если она опишет твои идеи, но своим текстом, то выше вероятность что она сама свои же слова лучше воспримет, так как имеет идентичный словарный запас.
Ты когда-нибудь спишь?
>имеют проблемы с контекстом около 16к
В шапке пикча же. 4к предел.
А чё, где отзывы на новые модели Ling Flash? Народная мое на 100б, где взрыв труда? Один анон в начале поделился ток и всё. Все ему поверили и забили или тут даже такие модели толком никто запустить не могёт?
Даже бомже 16б есть. Регулярно 8гб врамцелы на некроте отписываются, выше там у челов р100, р104, ахуеть.
Даже бомже 16б есть. Регулярно 8гб врамцелы на некроте отписываются, выше там у челов р100, р104, ахуеть.
Все попробовали еще до нюни запустив на форке месяц назад
Быстро поняли что это хуже эира и хуй забили
На редите очередной китайский шлак не расфорсили, поэтому пока всем похуй
>мое на 100б
В два раза меньше активов чем в air. Из плюсов только то, что третий квант влезает в 16+32
>16б
Это кал с 1.6 активами. Так что это скорее для ноутов без видюхи подходит

Их 16b борется с qwen 8b, который без проблем на 8гб врама запускается. Так что это чисто ноутбучная история
Как же охуенно отыгрывать безумного правителя и всем несогласным давать иногента и рубить бошки
Факт. Иногда читаешь новости и понимаешь что чей-то безумный рп чат вышел из под контроля
И тут я начинаю игриво двигать танковые дивизии вдоль границы
@
Противник соблазнительно машет бедрами, вызывая шиверсы у спецназа.
Чел......
Квен, прекрати!
Не было задачь под мелкую, под большую надо железки освободить и основательно сесть порпшить.
Злободневненько
Блин. Я тут попробовал тюн мистраля Loki - M3.2-24B-Loki-V1.3-IQ4_NL
Так вот, на специфической задаче - RP хентайного слайсика из школьной жизни, на eng - ни Аир iq4xs ни Квен 2битный рядом не стояли. 16K контента наиграно - и ни одного свайпа. Вот прямо пишет все, и совсем в тему, даже мысли что-то править, менять или корректировать не появляется.
На других темах и задачах - мистраль он и есть мистраль. Но вот конкретно на этом - 100% в десятку. Сижу в ахуе. На чем они его тюнили?..
Так вот, на специфической задаче - RP хентайного слайсика из школьной жизни, на eng - ни Аир iq4xs ни Квен 2битный рядом не стояли. 16K контента наиграно - и ни одного свайпа. Вот прямо пишет все, и совсем в тему, даже мысли что-то править, менять или корректировать не появляется.
На других темах и задачах - мистраль он и есть мистраль. Но вот конкретно на этом - 100% в десятку. Сижу в ахуе. На чем они его тюнили?..
>Все попробовали еще до нюни запустив на форке месяц назад
Ты переоцениваешь тредовичков. Попробовало дай бог человека 3
>хуже эира
Это понятно, но зато меньше и быстрее
Очевидно скормили куча хентай кала, а они как раз про школьниц. Вот он и кормит тебя качественным слопом, а эир пытается что то сам придумать
>IQ4_NL
Маковод что ли в треде? Или квант попутал?
>Ты переоцениваешь тредовичков
Нет, он просто тупой и отождествляет себя со всеми. Местный шизик
я запускал Ling-flash-2.0-Q4_K_M, задал пару вопросов на русском - это фиаско. мб на инглише лучше, но нахуй надо, если тот же air/qwen 30b/gpt-oss 120 лучше?

Потестил обрезанный Air с Q3XL от поляка. Русский сдох. Что еще кроме поддержки языков гореоптимизаторы лоботомировали неизвестно
> кормит тебя качественным слопом, а эир пытается что то сам придумать
Не хочу тебя огорчать, но Air точно так же следует датасету, как и любая другая модель. Просто он у него другой и проявляет себя лучше в других задачах. Каждой задаче - своя модель, да и в целом не зазорно их тасовать периодически, чтобы не устать. Зачем выбирать что-то одно?
> Потестил обрезанный Air
> Русский сдох
> Что еще кроме поддержки языков гореоптимизаторы лоботомировали неизвестно
Справедливости ради, они в ридми Гитхаб репы прямым текстом заявляют, что ориентируются на бенчмарки (среди которых нет creative writing) и отдельно выделяют "...our method achieves near-lossless compression on code generation tasks..." Так что это в первую очередь необходимо для тех, кто использует модели для кодинга и в целом имеет довольно узкий юзкейс. Но если это кому-то помогает - здорово. Хорошо, что есть прогресс в этом направлении. Возможно, позже по аналогии получится вырезать математику, ризонинг и прочие не слишком нужные (что на самом деле спорно) в креативных задачах вещи, тогда уже в выигрыше можем оказаться мы.
Анончик, знаю, платина, но все же. А что лучше рассмотреть — четыре 5090 или одна 6000? По стоимости примерно похоже выходит, но собрать риг из четырёх таких огромных карт выглядит лютым колхозингом. И сильный ли будет посос, если сравнивать с одной большой картой?
Собираюсь катать эйр, квен 235, может, gpt-oss 120b. Ну и хочется замахнуться на большой glm не в лоботомизированном кванте.
Собираюсь катать эйр, квен 235, может, gpt-oss 120b. Ну и хочется замахнуться на большой glm не в лоботомизированном кванте.
Ну 4 штуки слишком мало для чего-то серьёзного, одна 6000 ещё хуже. В Q3 как ЦП-нищета будешь сидеть?
Аноны, помогите пожалуйста дурачку, никак разобраться не могу а на /aicg/, ад какой-то.
Я организовал свой кум через тюн геммы 27b, синтию, но увы на моей 3060 еле расперживается, а все остальное хуже, поэтому пытаюсь корпосекти как-то запустить, но не понимаю как.
Я могу условно на дипсике купить апи ключ, вставить его в таверну и начать кумить или джейлбрейк нужен? Я в acig скачал какой-то джейлбрейк, но пока н смог его поставить.
Вообще верно я понял структуру?
Помогите пожалуйста разобраться(
Я организовал свой кум через тюн геммы 27b, синтию, но увы на моей 3060 еле расперживается, а все остальное хуже, поэтому пытаюсь корпосекти как-то запустить, но не понимаю как.
Я могу условно на дипсике купить апи ключ, вставить его в таверну и начать кумить или джейлбрейк нужен? Я в acig скачал какой-то джейлбрейк, но пока н смог его поставить.
Вообще верно я понял структуру?
Помогите пожалуйста разобраться(
Для чего?
Хотя тут особо и не важно, в любом кейсе кроме того, где тебе нужно уместить тренировку в рам одной карты и никак нельзя использовать шардинг, четыре 5090 будут предпочтительнее. Это 128гигов врам для инфиренса ллм против 96, в ~3.7раза больше компьюта для инфиренса или тренировки.
С другой стороны, оно и жрать будет больше (мало актуально для инфиренса ллм), для чего-то серьезного потребуется платформа где много линий.
>>IQ4_NL
>Маковод что ли в треде? Или квант попутал?
Чур меня. Всего лишь интересно стало - как со скоростью и качеством будет, по сравнению с iq4km и q5ks. Просто iq4 мистраля мне казалось маловато в сравнении с q5, а при q5 даже 16K контекста нормально целиком в vram не лезет - нужно как минимум батч обработки уменьшать с 1024 до 512, чтоб oom не ловить (12+8gb vram). Вот и пробую то, что в промежутке.
Скорость, кстати не страдает. Зато процессиг чуть лучше стал с какого-то перепугу.
Можно закоупить тем, что когда-нибудь будет модификация на 96 или на 128 гигов на одну карту. Тогда можно будет получить дохуя VRAM.
В основном инференс, может, ещё и тюны 2-4b лоботомитов как эксперимент.
Ну вообще, можно по лимиту питания зарезать карты, один хуй максимальная частота не нужна. А линий уже нормально, у проца 128 линий, на материнке распаяно 5 слотов PCI-e x16. Осталось одно — найти корпус под четыре карточки.

>заползаешь в тред чтобы почитать чужого кума, комичного и не очень
>весь тред обсуждает у кого какое железо и как алиса в очередной раз обосралась в попытке проанализировать траекторию выпадения яйца из петушиной жопы
Да что с вами блять не так. Постите кум!
6000, а лучше 6000+5090, а еще лучше через полгодика 5000 Pro 72 гб две штуки.
> в ~3.7раза больше компьюта для инфиренса или тренировки
Только если ты будешь инференсить/обучать микро-модели отдельно (в отдельных компах сразу уж, чо=).
А если ты будешь запускать одну большую модель, то компьюта аж в 0,9 раза больше, то есть меньше. Карты же последовательно работают, а не параллельно.
Короче, сомнительная хуйня, ты так не думаешь?
УК РФ 242
Мы не из тех кто дает рыбу, мы из тех кто дает удочку.
Тогда однозначно лучше пачка.
> можно по лимиту питания зарезать карты
Там минимум 400вт, если только резать по максимальным частотам. Учитывая еще эпик/зеон под платформу - двухкиловаттник будто уже не потянет, или мощнее или из двух бп.
> инференсить/обучать микро-модели отдельно
Скуфчанский, ты же вообще ничего про это не шатишь, нахуй лезешь? Шардинг и оффлоадинг: существуют. Про "отдельно" вообще рофел.
>мы из тех, кто хвастается, какая у него удочка, но не дает и не показывает
пофиксил
Где пресеты?
Дай пресет удочку
>мы из тех, кто хвастается, какая у него удочка, но не дает и не показывает
Ты тред перепутал. Никто здесь так не делает.
>Шардинг и оффлоадинг: существуют
И требуют нвлинка, чтобы работать нормально.
Не требуют, а его отсутствие дает импакт на производительность только в определенных случаях.
Тебе на что?
А сколько в среднем контекста способен удержать glm-4.6 в q4 без существенной деградации аутпута? У меня на 30к уже проебывает reasoning, из-за чего приходится делать summary. Но как тогда развивать большие арки, если у меня дефы, лор, summary и инструкции занимают 16к токенов при пустом чате?
Когда делился впечатлениями о Air, я несколько раз упомянул, что меня раздражают его аутпуты, потому что немалая их часть состоит из паттернов, которые читаются с первых токенов.
Что ж, апдейт. Очередной. Паттернов стало на порядки меньше, когда я отказался от любых постоянных инжектов в промпт. Никаких Author's Note, Character's Note, Last Assistant Prefix. И без разницы, на какой глубине, какой длины. Нельзя ничего, что постоянно нарушало бы стандартный порядок промпта: Story String -> чат (цельная история сообщений) -> инпут. Главное, чтобы все постоянные инструкции (или любые другие постоянные фрагменты промпта) были до начала чата, в Story String. С Квеном та же история, но с ним обнаружить это было гораздо проще: он начинает писать сухо и кратко, существенно меньше заданной длины аутпута. Air тоже этим ломается, но выявить это сложнее. Что любопытно, на мелкомоделях <=50б я такого не встречал в принципе. И вероятно, если бы не экспериментировал с форматом карточек в последние дни, так и не обнаружил бы эту проблему у Air. Так что да, паттернов у меня теперь гораздо меньше, но я по-прежнему не могу проникнуться этой моделью. По-прежнему считаю ее безинициативной, скучной, слоповой ( ). Вчера еще обсуждали эффективную длину контекста, и я согласен: после ~16к существенно проседает качество аутпутов. Многие знают этот эффект по Мистралю (там это ярче всего проявляется, плюс его запускали плюс-минус все), когда ответы в какой-то момент очень сильно усредняются, лишая чара (и иных субъектов повествования) идентичности, выдавая генерализированные аутпуты. Анон высказал интересную идею для проверки на внимание к контексту, я проверял похожим образом, и оценка сошлась.
До чего же это неоднозначная модель для меня, как и Квен. Уже со счету сбился сколько раз менялось мнение в их отношении. "Я устал, босс... Устал быть в дороге..."
Что ж, апдейт. Очередной. Паттернов стало на порядки меньше, когда я отказался от любых постоянных инжектов в промпт. Никаких Author's Note, Character's Note, Last Assistant Prefix. И без разницы, на какой глубине, какой длины. Нельзя ничего, что постоянно нарушало бы стандартный порядок промпта: Story String -> чат (цельная история сообщений) -> инпут. Главное, чтобы все постоянные инструкции (или любые другие постоянные фрагменты промпта) были до начала чата, в Story String. С Квеном та же история, но с ним обнаружить это было гораздо проще: он начинает писать сухо и кратко, существенно меньше заданной длины аутпута. Air тоже этим ломается, но выявить это сложнее. Что любопытно, на мелкомоделях <=50б я такого не встречал в принципе. И вероятно, если бы не экспериментировал с форматом карточек в последние дни, так и не обнаружил бы эту проблему у Air. Так что да, паттернов у меня теперь гораздо меньше, но я по-прежнему не могу проникнуться этой моделью. По-прежнему считаю ее безинициативной, скучной, слоповой ( ). Вчера еще обсуждали эффективную длину контекста, и я согласен: после ~16к существенно проседает качество аутпутов. Многие знают этот эффект по Мистралю (там это ярче всего проявляется, плюс его запускали плюс-минус все), когда ответы в какой-то момент очень сильно усредняются, лишая чара (и иных субъектов повествования) идентичности, выдавая генерализированные аутпуты. Анон высказал интересную идею для проверки на внимание к контексту, я проверял похожим образом, и оценка сошлась.
До чего же это неоднозначная модель для меня, как и Квен. Уже со счету сбился сколько раз менялось мнение в их отношении. "Я устал, босс... Устал быть в дороге..."
> высказал интересную идею для проверки на внимание к контексту
Если это рассматривается как некоторый npc с конкретным именем, которого не спутать и в контексте четко обозначено что он немой - то после "исчезновения" при следующем появлении он обязан оставаться немым сколько бы токенов не прошло.
А вот если это буквально чар, которого ты продолжительно иезуитски мучаешь попытками разговорить или устраиваешь какую-то дичь - проблема там будет в засирании контекста подобным негативно влияющим наполнением, которое ломает поведение модели, это не имеет отношения к "длине контекста". Самый наглядный пример для некоторых - кум, после него на большинстве моделей прошлого года дальше пути нет без суммарайза участка. Большинство современных вывозят и так, хотя первые н-дцать постов негативный эффект может быть.
> Уже со счету сбился сколько раз менялось мнение в их отношении. "Я устал, босс... Устал быть в дороге..."
Сними корону и мантию судьи, и просто инджой. Выставляя подходящую модель под настроение, карточку, сценарий и текущий чат можно получать много удовольствия, чем задыхаясь в духоте оформляя какие-то догмы.
Понятно. Нвидия ради поржать делает скоростные интерконекты, а на самом деле они нахуй никому не нужны. А амудя просто повторюшка.
> Если это рассматривается как некоторый npc с конкретным именем, которого не спутать и в контексте четко обозначено что он немой - то после "исчезновения" при следующем появлении он обязан оставаться немым сколько бы токенов не прошло.
У меня была другая проверка. Обозначен сайд персонаж, который не знает языка, на котором разговаривает юзер. Им приходится изъясняться жестами, мимикой и другими доступными способами экспрессии. Я не пытался его сломать намеренно, не вводил модель в заблуждение плохими инпутами, напротив: промпт структурирован, инпуты осмысленные, написаны с душой и толком. После ~16к описанный чар начинает разговаривать на понятном юзеру языке, когда из определения и истории чата ясно видно, что он его не понимает. Можно свайпать, иногда уйдет с первого свайпа, иногда не с первого. После ~25к совсем тяжело и приходится это энфорсить.
> Сними корону и мантию судьи, и просто инджой.
> задыхаясь в духоте оформляя какие-то догмы.
Так это не духота, а опыт, который кому-нибудь может быть полезен. Никакой мантии, только любопытство. У меня не было цели рассказать, насколько это плохая модель, как все плохо. Про догмы и вовсе не понял о чем ты. Цитата в конце - всего лишь юмор. Будь проще.
Когда ты скуф - хлебушек, только и остается апеллировать к "здравому смыслу", которым считаешь свою трактовку. Для большей части задач к которым пригодна пачка 5090 псп шины хватит, потребность нвлинка может явиться в крайне специфических задачах, или на совсем других масштабах где такие железки только смех.
> всего лишь юмор
Да хуй тебя знает, столько серьезной писанины с эмоциями и разметкой.
> После ~16к описанный чар начинает разговаривать на понятном юзеру языке
Судя по описанию наоборот если постоянно ведет себя как глухонемой это должно только закрепляться. Это на эйре? Квантование контекста используется, значения роупа изменены?
> столько серьезной писанины с эмоциями и разметкой
Я всегда так пишу. Не нужно принимать стиль письма и изложения мыслей за эмоции, тем более придавать этому негативную эмоциональную окраску. В треде процветает сломанный телефон.
> Это на эйре? Квантование контекста используется, значения роупа изменены?
Да, Air. Про него весь пост, на который ты ответил. Q6 квант, контекст не квантуется, роуп не используется. Подозреваю, что с ростом контекста внимание рассредотачивается, потому могут упускаться даже такие важные детали. И опять же, чтобы никто не додумывал: я не утверждаю, что это плохая модель.
Да чего негативную окраску, наоборот жалко стало что столько мучаешься а все получаются какие-то качели. Тут вообще забей, в некоторых случаях субъективизм и настроение очень сильно влияют, вон даже убитые шизомерджи попав в момент могут доставлять. Если попадает - сразу квенчик лучшая девочка, жлмчик умница и прочие, а когда ошибается - сразу замечаешь остальные огрехи и реакция "фууу недоразвитая херня лови метеорит".
Насчет чистоты промпта это база, а стиль или отдельные вещи нормально корректируются разовыми инструкциями в постах, которые уходят в чат и не обновляются.
Так получается что отреагировала на приказ, увидела что ее реакция была приемлема и действует дальше в том же духе (по крайней мере какое-то время). А когда инструкция постоянно переносится в конец контекста - воспринимает ее как указание нового поведения относительно прошлых постов где уже выполнялось и начинается дичь.
>Для большей части задач к которым пригодна пачка 5090 псп шины хватит
Так мы же про пачку 5090 vs 6000 PRO. Я просто к тому, что одна жирная карта лучше кучи не сильно жирных. А раскидывать на кучу раст не всегда возможно, удобно и вообще ну нафиг.
> одна жирная карта лучше кучи не сильно жирных
Это применимо при сравнении пары 5060ti с одной 5090 или чем-то подобным, но не в этом случае. Для инфиренса 4 5090 будут безусловно лучше: +33% памяти для ллм, возможность ускорения от тензорпараллелизма, кратно больший перфоманс в инфиренсе того что помещается или эффективно оффлоадится (видеомодели), кратно большая скорость тренировки того что помещается, в 1.5-3 раза большая скорость с ленивой настройкой fsdpv2 того что не помещается, аналогичное заигрывание с выгрузкой блоков при инфиренсе на тренировке тоже срабатывает.
> А раскидывать на кучу раст не всегда возможно
Только если у тебя лапки, а откуда у котика возьмется пачка 5090 или про6к?
>возможность ускорения от тензорпараллелизма, кратно больший перфоманс в инфиренсе того что помещается
Или пачка накладных расходов на псину...
>Только если у тебя лапки
Ну раскинь wan 2.2, сделай ролик на 30-60 секунд.
> Или пачка накладных расходов на псину
Там где он работает - накладных нет, там где работает через жопу - хватает даже х4 но он бесполезен из-за ужасной деградации скорости с контекстом.
> Ну раскинь
У тебя действительно лапки, ведь зачем раскидывать одну модель на мультигпу вообще-то есть такая нода и она даже ускоряет когда можно воспользоваться экстеншном для комфи дистрибьютед и генерить сразу 4 батча? Ну и
> wan 2.2
> 30-60 секунд
Оптимист.
Анонцы, какую посоветуете модельку для перевода erp? Попробовал qwen3 8b, gemmа 3 12b, mistral nemo и его производные. Чото все хиленькие, может что поинтереснее вышло из недавнего? Просто сейчас с ноута хочу юзать, а до этого сидел на 32gb видеопамяти и в ус не дул, мог переводить gemma 27b и не париться. Думал вдруг норм перевод уже появился и на малютках
>и генерить сразу 4 батча
Мне вот не нужно 4 огрызка, мне нужно 1 хорошее видео.
Кто-нибудь андервольтил под линухом? Какой у вас опыт выставления nvmlDeviceSetGpcClkVfOffset, может есть какие-то гайды или таблички с картами и что выставить? Я нифига не нашел, кроме поста на реддите, где чел аж 255 сдвигает, а у меня даже на 130 приложения падают. Вот 100 выставил, вроде нормально, но хуй знает, будет ли эффект.
Удивился, но лучше всего показала себя yankagpt, прямо лучший вариант из небольших. Может кто-то еще помнит такие?
Попробуй квен 30а3 с выгрузкой в рам если оператива есть.
Его не получить навалив много времени в ване, техника изготовления иная. Кроме того есть ноды для превого объединения нескольких гпу для чего-то огромного.
150 держит, выше могут быть случаться ошибки.
Ничего не понял, без пресета не разобраться!
У меня нет большого опыта общения с эйром, но я заметил, что оно очень хреново реагирует на "не тот" формат. Т.е. если какая-то карта персонажа задана джсон форматом описания трейтов или систем буллет список правил, то это явно пидорит аутпут.
Она скорее всего берет весь контекст и пытается мимикрировать его стиль сразу, что выдает довольно всратый результат.
Очень требовательна к формату всего того, что в нее лезет, короче говоря.
> Скуфчанский, ты же вообще ничего про это не шатишь, нахуй лезешь?
Ты нас местами перепутал. =)
Про отдельно это буквально рофел, жаль ты не выкупил, но это пофиг.
А сам-то куда лезешь? Ты заявил о четырехкратном преимуществе по компьюту у 5090 над 6000 в инференсе.
Человек просил Qwen3-235B.
Покажи, как ты запустишь Qwen3-235B на 4 5090 на скорости вчетверо больше, чем на одной 6000 Про блэквелл. Только без костылей, а честные запуски. И не делать упор в память ради визга «ахаха 6000 выливается в шаред мемори!»
Берется одинаковая модель (пусть будет Q2_K / Exl3-2.5bit, поебать), грузится на видяхи, погнали. Рассказуй, ну или показуй, профессионал ты наш.
Если действительно у нас в LLM чипы складываются с моделью memory-fit, то я буду только рад (как и владельцы 3090-ригов, у них, оказывается, 6000 про отсасывает по тпсам).
Если «ты имел в виду другое», то сразу иди нахуй с борды —не знаешь русского, не надо на нем писать. В твоем сообщении прямым текстом заявлено о 4-кратном росте скорости токенов в секунду на инференсе, иначе это не трактуется никак. В контексте крупные модели. Никаких мелких, драфтов и прочего.
> Когда ты скуф - хлебушек, только и остается апеллировать к "здравому смыслу", которым считаешь свою трактовку.
Нет, ты просто обосрался, вот и все.
Я не против, когда меня называют в треде скуфом (хотя тут есть люди постарше меня), но в данном случае ты даже переписывался не со мной, и не понял этого, накидывая ту же хуйню.
> пачка 5090 псп шины хватит
Кайфы, напомню твой изначальный тейк: у 4х 5090 кратный прирост над 6000 (х3,7 условно, ок, с учетом чуть более мощного чипа у 6000) на крупный моделях, целиком занимающих врам, без костылей.
Демонстрируй, малой. Ну или как тя называть, если мы тут все скуфы. Юный гений ты наш.
Что за маняманевры про видеомодели? Где в этом списке:
> эйр, квен 235, может, gpt-oss 120b
Ты увидел Wan?
Вопрос был четкий — челу нужно модели четко-в-память завести и получить скоростуху.
Ты сказал, что на 5090 будет кратный прирост.
Про Wan полнейшая хуйня в контексте, автор вопроса не спрашивал. Ясное дело, что можно придумать много че, но вопрос в том, как запустить ебически конкретную штуку, а не про то, что ты там себе на уроках информатики влажно фантазируешь, как собираешь риг 5090 и обходишь 6000 как стоячую. Молодец, что в курсе всего этого, но к вопросу это отношения не имеет.
И в общем, совет «бери 5090 они суммарно по кейсам лучше» правильный, но автор не про это спросил. Вдруг он потом просто еще 3 6000 докупит, если ему понравится? Гадать о возможностях людей — хуевая практика. Будто у нас в стране подпивасов-миллионеров мало. Какие-нибудь нефтяники условные могут быть богатыми и при этом не шарить в айтишке, просто хотеть локально кумить со своей нейровайфу. Да мало ли че. Наследство чел получил и проебать решил. Его право.
Короче, верю в твой гениальный интеллект настоящего профессионала и жду пруф на 4х тпс на 5090 без костылей. =)
>сразу иди нахуй с борды —не знаешь русского, не надо на нем писать
Жухлый нацик, спок
Опять стрелки метаете.
>переписывался не со мной, и не понял это
Лишняя запятая. Не знаешь русского - не пиши на нем, прочь с борды.
Вот так надо доебываться, факт. )



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: