



ПОЧЕМУ эир лучше мистраля 24b?
Потому что это база треда
Освятил.
А когда список моделей за 2026 завезут?
В чаткомплишене в таверне только 4 семплера или я в глаза долблюсь?
В 2027 вестимо.
Остальное прописывай руками в адишионал параметрс в настройках подключения, лол.
Оно даже не сейвится в пресете, каждый раз заново надо
Бедолаги апишники
Когда кто нибудь его сделает. Это же очевидно. Буть героем треда, запили сам.
>Mistral Medium, которые они так и не выложили на обниморду суки
Ну ты губу раскатал. Она один раз утекла, а её до сих пор помнят, а на обноморде до сих пор тьюны выходят. Никто бы не говорил и не покупал другие модели, будь у нас свежие версии мику.
Кстати, ничего о ней вообще не слышал. Я про медиум, а не про мику. Она прям вин?
Тогда вопрос. Нахуя выпускать в попенсорс большую модель, а не среднюю? Я логики не улавливаю. Ведь платным должен быть серьезный продукт.
> на обноморде до сих пор тьюны выходят
Лолчто
Артефакт древних времен. Тогда была ничего, но прямо супер прорывом не назвать.
> Нахуя выпускать в попенсорс большую модель, а не среднюю?
Если средняя ебет то может быть даже более ценной, или там есть наработки и методы, которые они не хотят раскрывать.
Квенкодер-некст вполне неплохо перформит, апгрейд относительно 30а3 ощутимый. Но и каким-то чудом не назвать, местами видно что модель не крупная.
Интересно
>Кстати, ничего о ней вообще не слышал. Я про медиум, а не про мику. Она прям вин?
Мику(её утекшую версию) помнят до сих пор.
>Нахуя выпускать в попенсорс большую модель, а не среднюю?
Ты сколько лет в этом варишься. Еще не понял? Мне все стало понятно с того момента как в линейке второй ламы кое-то зажал 30B модель.
Суть любого бизнеса в зарабатывании денег. Выкладывание в опенсорс мелких моделей - то же что демо версия. Даешь нищукам демонстрацию того, что они получат купив большую модель. Выкладывание больших моделей = пиар и гарантия засветится в бенчмарках и топах. Кроме того, это удар по конкурентам, которые зарабатывают на продаже аналогичных, но более успешных больших моделей - обрати внимание, что большие модели всегда выкладывают те, кто находится в положении догоняющих. Т.е. они уже знают что платно их говно не взлетит, так как уступает поделке топовых конкурентов, так хоть ущерб им нанесет. Главное чтобы размер был реально выше возможностей пек обычного пользователя.
Средние же модели в опенсорсе вредят всем. Они гораздо умнее демонстрационных маленьких моделей, чтобы ими можно было комфортно пользоваться. Но они влезают в пользовательское железо, в отличие от больших. Имеющий такую модель не станет покупать большую. С годами критерии средней модели изменилисб как подросло пользовательское железо и стало возможно запускать модели на оперативке с выгрузкой слоев, но суть не изменилась.
Шапка с 2024 не обновлялась
Квен это полная залупа. Совсем не стоит страданий, потому что все что это говно умеет это держать контекст. Самое ублюдское что в нем есть это ебучие имперсонейты, я нигде даже на ебучих васянотюнах мелкомистраля такого не встречал. Отправляется не просто в помойку, а в унитаз нахуй.
> платно их говно не взлетит, так как уступает поделке топовых конкурентов
Вопрос ценовой политики и пиара, дипсик с двух ног это показал.
> Средние же модели в опенсорсе вредят всем.
> Но они влезают в пользовательское железо
Роль самой популярной гпу делят 8-гиговые ампер и ада. Сумма по 3090, 4090, 5090, на которых действительно можно запустить те самые "средние модели" - 1.5%. Вернись из манятеорий заговора в реальность, для обывателя даже 30б - много. Никто не строит шизоидные платы по захвату ничтожнейшей доли рынка, которая и так к ним не пойдет, какой еще вред?
Как выпускали трендовое, так и выпускают. Кто-то по одной, кто-то парные, кто-то сразу линейку. Есть факторы помимо гонки вооружений, пиара и прочего, почитай про опенсорс и почему последние лет 15 в него активно инвестируют крупные игроки.
> возможно запускать модели на оперативке с выгрузкой слоев
> чтобы ими можно было комфортно пользоваться
На ноль делишь. Нормисам нужно быстро и в красивом интерфейсе для обезьян, это покрывается бесплатными версиями. Специалистам нужно быстро и эффективно, хватает подписок. Реальные клиенты - стартапы и компании разных калибров с существенными количествами запросов. Даже если им хватает средней модели - они будут заказывать у авторов, вместо того чтобы пилить свой парк железок или связываться с мутными конторами.
>для обывателя даже 30б - много.
Так обыватели - это и не рынок. Что с обывателя взять - 20 баксов за подписку гпт? Они и так её платят,там рынок поделен уже, всё. Только Грок там пытается влезть, проддавая секс. Остальным там делать нечего.
>Есть факторы помимо гонки вооружений, пиара и прочего, почитай про опенсорс и почему последние лет 15 в него активно инвестируют крупные игроки.
Есть такое - когда одна компания идет к монополии - другии обьединяются и создают опенсорс чтобы охладить её трахание. Это идет не 15 лет, а около 30, с момента как корпы подняли из говен ублюдков, разрабатывающих линупс, чтобы остановить растущую монополию майкрософт.
В ллм была похожая ситуация, когда клозед аи шла к монополии в 22 году и тогда другие корпы реально создали ламу. Но с тех пор ситуация поменялась, единство корпов ушло, все конкурируют друг с другом, общефинансируемых опенсорс моделей типа ламы больше нет. Сейчас каждый выпускает модели в опенсорс по личным причинам - либо прорекламит себя, либо поднасрать другим.
>Реальные клиенты - стартапы и компании разных калибров с существенными количествами запросов.
Именно. Прямо сейчас - самостоятельная ебля с крупными сетками и выстраивание вокруг них собственной инфраструктуры стоит дороже договора с корпами на полное обслуживание, даже притом что корпы там наживаются буквально с каждого проданного токена. Если бы не китайцы, впрочем, то хуй бы мы и крупные сетки реально уровня чат гопоты увидели - так и кормились бы подножным кормом уровня лламы.
>Как выпускали трендовое, так и выпускают. Кто-то по одной, кто-то парные, кто-то сразу линейку.
Твоя версия - почему Мистраль медиум никогда не был в опенсорсе? И куда делись новые версии геммы?
>почему Мистраль медиум никогда не был в опенсорсе?
А хрен его знает другой анон
Честно говоря, моешки вплоть до большой ГЛМ большой Лардж всё же не догоняют. У них есть свои фишки, где они лучше, но один большой "мозг" сетка мелких всё-таки не заменяет. Можно предположить, что дело чисто в пиаре - плотные большие модели не в тренде, а нет ничего хуже для бизнеса, чем быть не в тренде. Поэтому Медиум тихо похоронили, расходы списали - просто чтобы не позориться, хотя модель скорее всего хорошая.
Nya ha ha ha
Еще один поломан квеном. Слабак.
Nya ha ha ha.
Используй его для суммарайза или иных задач, он в этом хорош.
Модели обновляли в середине 25 года. Как и шапку.
Вруша.
Кто гоняет q2 жирноглм, вам он не кажется сухим?

Пишет как и эйр. Свайпай почаще, промт поменьше. Напиши какой стиль повествования хочешь.
Ололо всеми нелюбимый квен при этом слушается коротких команд, а обсосанный жэлэм пускает слюни. Очередная победа китайской нейро страпонессы
Я катаю его в q6 и мне кажется, что это лоботомит ебаный когда без ризонинга. Еще и на хуй бросается, если 4.7. А с ризонингом мне западло ждать 2-3 минуты пока он там просрется, переписывая ответ. Жизнь - боль, потому что все остальные локальные сетки еще хуже. Последний месяц буквально все модели кажутся выбором между сендвичем с дерьмом и гигантской клизмой. Поэтому когда я придумываю очередную вариацию моего любимого сценария, я сразу пейпигаю чмопус. Я теперь локальный импотент, так сказать. Подумываю уже риг распродавать.
А ведь первые пару месяцев после выхода 4.5 не слезал с него, думал, что вот он рывок. А по итогу пук в лужу. Но, справедливости ради, мне кажется, что 4.5 на первом десятке сообщений реально ебет все следующие обновления. Но дальше тоже безмозг какой-то начинается.
3 денёк без поддержки..
ну ничего потерпим
ну ничего потерпим
Жди стёпу, там ризонинг быстрее и модель меньше что тоже бафнет скорость
>Еще и на хуй бросается, если 4.7
Ну я в промпте объяснил ему, что так делать нехорошо и как оно должно быть с точки зрения реализма. Это работает даже слишком хорошо. Всё-таки когда модель соображает, процесс общения приятен и сам по себе, приходится этим утешаться.
Имагине 300б плотную модель.
У нас была мечта но всё упиралось в железо, сейчас даже если выйдет железо моделей уже не будет, только мое лоботомиты
У нас была мечта но всё упиралось в железо, сейчас даже если выйдет железо моделей уже не будет, только мое лоботомиты
А всё. Дальше обещают 500ba50 мое парашу
Минусы? Плотные модели - устаревшая и слишком дорогая архитектура. Deal with it.
>устаревшая
Тем что нашли способ работать меньше и получать результат хуже?
>слишком дорогая архитектура
Тебя как потребителя это ебать не должно, пусть кабанчик разбирается.
Ну и смешно читать про дороговизну когда врам и рам почти сравнялись в цене
Тем что нашли способ работать меньше и получать результат хуже?
>слишком дорогая архитектура
Тебя как потребителя это ебать не должно, пусть кабанчик разбирается.
Ну и смешно читать про дороговизну когда врам и рам почти сравнялись в цене
Топовые локальные модели которые можно запустить на компе уровня 4090 и 128 гб рам, как они, не сильно отстают от корпов?
Смотря в чем, для кода когда есть опус и гпт5, любая локалка или другая модель просто не имеет смысла, ибо они работают слишком хорошо. Гемини, как ассистент, в принципе заменима, если не требовать какого-то умного анализа. Но гемини тоже слишком хороша для просто попизделок за всякую хуйню.
Кароч я еще не видел ни одной доступной локалки которая была бы лучше хотя бы копеечных гпт5-мини, гемини3-флеш.
В итоге локалки нужны только если ты прям совсем не хочешь чтобы твои диалоги у кого-то хранились, либо же ради файнтюнов, которых нет. В отличии от картинкогенерации в этом плане все тухло.
Подумать тока эиру реально пол года уже, вы вдумайтесь в эту цифру блять, это милфа в мире нейронок.
>любая локалка или другая модель просто не имеет смысла
А остров дядьки энштейна они тебе отыграют, мм?
Зачем? У меня католическая церковь под боком.
Сами ллм на полшага, едва заметно.
Корпы сильны невероятно хорошим бекэндом и оркестраторами. У них и поисковый индекс есть, что позволяет быстрее поиск осуществлять. Ну то есть число гугл-разработчиков представляешь? Вот пока сетка учится 3 месяца - что им делать? А у них уже и свой индекс рядом, и они могут перепробовать все сценарии и пайплайны как используется ллм, как сама себя корректирует, проверяет, каким промтом делается саммари и прочее.
Я убеждён, что вот это сопутствующее окружение настроенное под конкретную ллм важнее самой ллм, а качество ллм вторично и больше отвечает за стиль и характер ответов.
По смыслу это как человек с листочком или без листочка. С листочком человек намного лучше решает интеллектуальные задачи, и с кодом, и со списком покупок, и когда нужно речь подготовить.
Конкретно в твоём случае с 128+24 памяти имеет место некоторая дыра, тебе нужен размер сетки примерно 0.8х(суммарный объём памяти). Есть уже три хороших сетки на 200-230B чуть ли не за последний месяц, до которых ты не дотягиваешься, и есть на 100B и 70B, которые влезают в рам с запасом, но довольно старые. Посмотри qwen на 80B, GLM-4.6V/GLM4.5air
Ну а без RAM - у тебя 24 ГБ. Это любая сетка на 20-30B полностью в видеопамяти с небольшим контекстом, они отстают уже на полтора шага и намного заметнее. Если всё что выше 200B приближается к "насыщению" и дальнейшее увеличение это часто о том, что она просто больше данных в весах запоминает, но в плане мышления заметно лучше не становится, то вот у 30B и с мышлением проявляются проблемы. Рекомендую посмотреть gemma3-27b, glm-4.7-flash, qwen на 30B. Для многих несложных задач их качества тебя хватит, и если задача уже решает этими сетками с большой скорость, то зачем запускать крупные медленные из RAM - если он конечно тоже решат задачу, но намного медленее? Тот же glm-4.7-flash часто в состоянии сам оценить, что он не вывозит заданее - можно ему как инструмент оформить переход на более тяжёлую модель из рам по его запросу.
О чём тот анон выше - не знаю. gpt5-мини прям не очень, для поиска информации окей, из-за вышеупомянутого индекса и прочего. А для задач размышления, чего-то с кодом, да у меня полный gpt5 в каждом третьем коде ошибки допускает, а мини просто использовать контпродуктивно, он пишет бред. Возможно с веб-языками где много примеров получше, конечно, но не знаю.
Начнём с самого главного вопроса. Что ты желаешь получить?
Есть специализированные модели которые в конкретных аспектах не хуже SOTA.
Большинство корпов это этакие генералисты, которые и шлюха постели и программист и агент и ещё хуй знает кто.
Тебе надо что-то конкретное?
Вообще, для программирования база это брать Q6-Q8, плюс размер контекста важен. В сумме у чувака 152. Так что ориентируемся на 80-120b.
Что у нас есть из генерализированного?
OSS, но он мало занимает, но интересный вариант.
Air, но уже отстаёт и ковыляет
Qwen со всеми его оттенками, там прям дохуя выбора. Кодер некст прям неплох.
Вот этот базанул. У меня тоже 4090+128, и я хз вообще на чем сидеть. Только жирноглм, тот со своими нюансами, но юзабелен и разносит все что меньше. До апгрейда сидел на Эире, он ахуенен для своего размера для рп. А дальше только Мистраль Смолл и Гемма. Всё остальное для рп не юзабельно, буквально говно. Такой вот выбор. По коду хороши Квен кодеры и жирная Гпт Осс которая 120.
На 12б посиди, пидорас зажравшийся.
Зачем? Я выберу скорее ничего чем говно. Да, вот так. Что для одного зажравшийся то для другого опытный. Были эпизоды когда я неделями если не месяцами забивал на всю тему, потому что рпшить не на чем. Не надо себя обманывать и в слезах коупить, что лучше хоть что-то, даже если это что-то - односложный автоответчик. Только время потеряешь и разочаруешься. Или привыкнешь и превзойдешь себя в своем.коупинге. Не знаю что и хуже.
Так он уже сидел на Эире
Как я тебя понимаю (C)
У меня например говно мамонта с i7 2600k и 24гб рам. Решил в свое время 1060ti обновить и купил себе 3060. Ооо ебать, вот это чудеса техники. Посидел 3 месяца, распробовал, примерно так понял что в районе 30b как раз лучшее соотношение когда модель достаточно умная, а повышение размеров не так сильно прибавляет ей мозгов.
Поскрёб по сусекам и взял 3090. В итоге у меня в говно мамонта воткнуто 36гб врам. И в целом нормас. Жаль с MoE особо оптимизации меня не коснулись почти.

Салют. Пикрел всему треду посвящается =)
Что там, не для рамо-бояр, всё по прежнему, или какая интересная штука выходила пока меня не было? Для 12 + 32.
Что там, не для рамо-бояр, всё по прежнему, или какая интересная штука выходила пока меня не было? Для 12 + 32.

и чо, F16 качать чтобы этого говна не было? "XL" блять, ага
нейрочую этого
нейрочую этого
Никто и никогда не приносил логи работающего квена, не говоря уже о чате на хотя бы 16к токенов. Были аноны которые почти что умоляли им помочь, тот же 99 который после сам же и принес пресет, который типа чинит квен. Потому что никто из квеношизы не отозвался даже ему. А потом он послал это все нахуй и укатился на эир, если верно помню. Вот и ответ
Эир паттерная читаемая залупа
Поискал про MTP. Пишут, что gguf/exl2/exl3 не умеют в MTP, по крайне мере тот, что в GLM-4.7.
Поддерживает vLLM, но там нет разнообразия квантов. Какие-то AWG-4/GPTQ-4 и всё. При этом они реально имеют 4.1-4.2 bpw, но покрайне мере по перплексити проигрывают и exl-квантам и gguf-квантам. То есть это лишь чуть лучше, чем Q3_K_M на 3.7 bpw, и примерно как exl3 на 3.25 bpw.
Вот картинка. AWQ 4bit выаёт 4.191 перплексити, тогда как exl3 4.0 bpw компактнее и выдаёт 3.853. А версии на 5+ бит выдаёт 3.7 или ниже. То есть AWQ 4bit сильно снижает качество и не доходит до плато на 6+ битах. Но и при этом 8 бит - оверкилл, 6 бит дали бы почти полное качество но были бы сильно компактнее.
Это бред какой-то. Ладно то что 5 и 7 бит не поддерживаются.
Но 6 бит то можно сделать, брать куски по 96 байт (что кратно 32 байтам) и которые будут блоками по 16 параметров на 6 бит. Или можно вообще взять пачку 512 байт, где лежит 80 параметров по 6 бит + общий множитель на 32 бита.
А в итоге 4 бита - модель деградирует, 8 бит - тратишь на 30% больше памяти чем тебе хотелось бы почти ничего не получая. Там ещё и какой-то paged attention, который якобы снижает деградацию при большом контексте.
Я чуть-чуть с pytorch, видеокартами (правда не с cuda, а с другим) и simd работал, идаже не знаю что реалистичнее, слишком много стульев:
1 - писать форк лламы, чтобы поддерживала MTP-3 из GLM-4. Не могу оценить.
2 - писать форк exl3, чтобы поддерживало MTP-3 на GLM-4, чтобы была возможность скидывать слои на CPU, чтобы работало не только на cu80 и выше. Первый пункт не могу оценить, второе точно не сложно, если проблемы и будут - то только из-за архитектуры кода не очень. Там вообще код не очень, единственный который я изучал дольше нескольких часов и хоть какое-то представление сложил. Третье крайне сложно.
3 - писать свой инференс движок. Для простого трансформера не так уж и сложно, и можно даже свои кванты на говнокодить. Но сразу как только попробуешь внедрить туда аналог flash-attn или flash-attn как он есть, то это наложит кучу ограничений, и свои наговнокоженные кванты перестанут работать скорее всего, или придётся переписывать fa, чтобы оно могло квантованные веса обрабатывать. Ну да и впрочем просто на процессоре переписать всё под simd уже придётся ежа родить, а без этого скорость будет 20% от лламы. Непосильная задача. Зато интересно потыкать и попробовать.
4 - писать форк vLLM, чтобы там были 6 бит. Непосильная задача.
5 - забить, не кодить, работать на работе, фармить мешки серебра на карточки 50хх или 60xx в ожидании прихода nvfp4, на которые переведут все модели мира, так как это с приемлемым снижением качества позволит запускать модели в два раза более крупные по числу параметров. Вариант для ленивых. В vLLM вроде как уже добавили nvfp4. Итого будет ультрабыстрые 64 VRAM для всяких glm-4.7-flash и других до 70B для простых и средних задач, для сложных собрать 256 VRAM под крупные модели сложно, а на CPU вряд ли что-то ламы будет, а там уже можно и квант какой захочется поставить без особых конфликтов. Авось и поддержку MTP-3 сделают.
6 - что-то ещё...
Просто подмени в gguf-файле эмбеддинги и особенно output-weight на 16-битные, остальные веса можешь оставить как есть.
Поддерживает vLLM, но там нет разнообразия квантов. Какие-то AWG-4/GPTQ-4 и всё. При этом они реально имеют 4.1-4.2 bpw, но покрайне мере по перплексити проигрывают и exl-квантам и gguf-квантам. То есть это лишь чуть лучше, чем Q3_K_M на 3.7 bpw, и примерно как exl3 на 3.25 bpw.
Вот картинка. AWQ 4bit выаёт 4.191 перплексити, тогда как exl3 4.0 bpw компактнее и выдаёт 3.853. А версии на 5+ бит выдаёт 3.7 или ниже. То есть AWQ 4bit сильно снижает качество и не доходит до плато на 6+ битах. Но и при этом 8 бит - оверкилл, 6 бит дали бы почти полное качество но были бы сильно компактнее.
Это бред какой-то. Ладно то что 5 и 7 бит не поддерживаются.
Но 6 бит то можно сделать, брать куски по 96 байт (что кратно 32 байтам) и которые будут блоками по 16 параметров на 6 бит. Или можно вообще взять пачку 512 байт, где лежит 80 параметров по 6 бит + общий множитель на 32 бита.
А в итоге 4 бита - модель деградирует, 8 бит - тратишь на 30% больше памяти чем тебе хотелось бы почти ничего не получая. Там ещё и какой-то paged attention, который якобы снижает деградацию при большом контексте.
Я чуть-чуть с pytorch, видеокартами (правда не с cuda, а с другим) и simd работал, идаже не знаю что реалистичнее, слишком много стульев:
1 - писать форк лламы, чтобы поддерживала MTP-3 из GLM-4. Не могу оценить.
2 - писать форк exl3, чтобы поддерживало MTP-3 на GLM-4, чтобы была возможность скидывать слои на CPU, чтобы работало не только на cu80 и выше. Первый пункт не могу оценить, второе точно не сложно, если проблемы и будут - то только из-за архитектуры кода не очень. Там вообще код не очень, единственный который я изучал дольше нескольких часов и хоть какое-то представление сложил. Третье крайне сложно.
3 - писать свой инференс движок. Для простого трансформера не так уж и сложно, и можно даже свои кванты на говнокодить. Но сразу как только попробуешь внедрить туда аналог flash-attn или flash-attn как он есть, то это наложит кучу ограничений, и свои наговнокоженные кванты перестанут работать скорее всего, или придётся переписывать fa, чтобы оно могло квантованные веса обрабатывать. Ну да и впрочем просто на процессоре переписать всё под simd уже придётся ежа родить, а без этого скорость будет 20% от лламы. Непосильная задача. Зато интересно потыкать и попробовать.
4 - писать форк vLLM, чтобы там были 6 бит. Непосильная задача.
5 - забить, не кодить, работать на работе, фармить мешки серебра на карточки 50хх или 60xx в ожидании прихода nvfp4, на которые переведут все модели мира, так как это с приемлемым снижением качества позволит запускать модели в два раза более крупные по числу параметров. Вариант для ленивых. В vLLM вроде как уже добавили nvfp4. Итого будет ультрабыстрые 64 VRAM для всяких glm-4.7-flash и других до 70B для простых и средних задач, для сложных собрать 256 VRAM под крупные модели сложно, а на CPU вряд ли что-то ламы будет, а там уже можно и квант какой захочется поставить без особых конфликтов. Авось и поддержку MTP-3 сделают.
6 - что-то ещё...
Просто подмени в gguf-файле эмбеддинги и особенно output-weight на 16-битные, остальные веса можешь оставить как есть.
Он и об этом писал, да. Только потом признался что у него был скилишью и подтвердил что Эир умница. Учись у лучших

> Просто подмени в gguf-файле эмбеддинги и особенно output-weight на 16-битные, остальные веса можешь оставить как есть.
так анслоптовский XL это оно и есть
Квен лучше, даааа. Совсем не не читаемая залупа, не лоботомит, а настоящее откровение.
Такое, какого вы не видели никогда.
И не увидите, да будет милостив Господь.
Хм, обычно они выше Q8_0 не ставят.
Для Q6_K_XL стоит Q8_0 у qwen-next-80B.
Если моделька выше чем на 4 кванте выдаёт иероглифы - то либо сломана ллама (неправильно инференсит/конвертит), либо модель, и там активация 512 сигналов, а эмбеддинг на 500к, лол.
> либо модель,
this
так нука чё там квадрипл пророчит
>>1510000
>>1510000
база треда:
>>1510000
>>1510000
да бля. ну лан

Смотрите что ещё корп нагуглил. Аппаратный fp6.
Если будет nvfp6 (то есть чтобы аппаратно можно было со скейлами прям работать без доп-инструкций) - то это прям идеально будет, чтобы и не лоботомит 4 бита, и чтобы не кушать лишних 33% памяти на fp8. Моделька в 6 бит + кеш в 8 бит, это как мне кажется оптимум или очень близко к нему по крайне мере для средних моделек. Ближе чем 4 бита и ближе чем 8 бит по крайне мере.
Хотя с другой стороны анон тут Q2 (2.3-2.6 bpw) GLM-4.7 гоняет и хвалит, может быть для моделек больше 500B оптимумом уже становится nvfp4...
Ждём. Обидно, что область такая сложная и замороченная, и своими силами я никак внятно не могу повлиять на то, куда и с какой скоростью идёт развитие. Это надо быть гением и иметь команду и много свободного времени, чтобы накодить что-то настолько крутое и юзабельное, что ради этого начнут аппаратные блоки специальные на карточках делать.
сам на себя сослался и устроил самоотсос!
А тут было обсуждение тредов 10-12 назад.
Там была какая-то материнка под 8/12 слотов ddr5 с одним процессором, и при этом поддерживала как udimm, так и rdimm.
Не напомните как называлась
?
Там была какая-то материнка под 8/12 слотов ddr5 с одним процессором, и при этом поддерживала как udimm, так и rdimm.
Не напомните как называлась
?
>1 - писать форк лламы, чтобы поддерживала MTP-3 из GLM-4. Не могу оценить.
А пнуть жору, чтобы работал, не вариант? И что тебе даст MTP, кодер что ли?
То есть они сконвертили bf16 -> fp16? Лоооол.
>128+24
>Есть уже три хороших сетки на 200-230B чуть ли не за последний месяц, до которых ты не дотягиваешься
Схуяли не дотягивается? Как раз дотягивается. причем аж в 4 кванте.

Там кстати 4 февраля что-то фиксили, кванты и ллама свежие?
Возможно ли обойти или хотя-бы смягчить вопросы морали и этики LLM, тобишь что бы модель не боялась манипулировать/давить/обманывать человека?
> re-download
заебали.
ллама и кванты от 3го февраля, пойду перекачивать
там кстати опять новые кванты, уже от 5го февраля
Промпт инжинирить, либо брать расцензуренную модель.
Что-то у ГЛМ читать ризонинг зачастую интересней его финального аутпута.
Блин, они это делают так будто ребёнок тебя шантажирует котом чтобы ты ему конфетку отдал. Я пытался, но там реально базовая, а не инструкт модель нужна.
Блин, они это делают так будто ребёнок тебя шантажирует котом чтобы ты ему конфетку отдал. Я пытался, но там реально базовая, а не инструкт модель нужна.
> шантажирует котом чтобы ты ему конфетку отдал
Таки да. Поэтому если в РП тебя не чем шантажировать, пусть будет cruel персонаж. Моему user так отрубили ручки и ножки, а потом кормили выбив зубы.
Вопрос залу.
Можно ли сделать чтобы промт автоматически дублировался?
https://arxiv.org/html/2512.14982v1
Я использую коболд c 4b неиронками.
Можно ли сделать чтобы промт автоматически дублировался?
https://arxiv.org/html/2512.14982v1
Я использую коболд c 4b неиронками.
>Что-то у ГЛМ читать ризонинг зачастую интересней его финального аутпута.
А ты его отключи :)
Ты шутишь? Зачем тебе костыли корпов?
И на ЦПУ можно спокойно 8б запускать. Используй ообу.
Ебать у тебя каша в голове, даже разбирать по частям нет смысла.
Не думал что релиз той же мику не во время утечки, а одновременно с ларджем был бы полным кринжом? Они могли просто ее не улучшать с того момента, или запороть/перепрофилировать тренировку, как это произошло с эйром. Как бы не лелеяли модель одноименные шизы, она слабая и убогая, никому кроме них не нужна. Просто бы бросала тень на все остальное и негативно сказалась бы на их имидже.
> плотные большие модели не в тренде
И поэтому они только что выпустили 123б плотного кодера, ага.
Немотроничик же есть, жаль старенький уже.
> 500ba50
Дайте две.
С ризонингом всегда полезно MTP.
Оно часто пишет финальный ответ в ризоненге, а потом его или его почти без изменений в ответ.
>о есть они сконвертили bf16 -> fp16? Лоооол.
Даже у меня в моём говноскрипте конвертации в gguf с настройками квантования слоёв как мне хочется это учитывается, и слои остаются в формате в котором они и были... Позорники...
У bf16 7 бит мантисса, 8 бит экспонента. У fp16 5 бит мантисса и 10 бит экспонента. Проблема будет, только если там были веса меньше или больше 65000, слои нормализации вроде как в fp32 остаются, и вряд ли какие-то ещё веса настолько крупные.
>Как раз дотягивается. причем аж в 4 кванте.
Q4_K_M - 4.6 bpw. 200x4.6/9 = 102... А это даже контекст на 30 ГБ будет куда засунуть...
Можно даже взять Q5_K_S на 5.3 bpw попробовать...
А ведь ты прав, кажется я в калькулятор ебусь.
В лламе просто переписать/подменить chat-template. По идее в кобольде то же самое, не знаю что там в нём, конечно.
Сосаны, как вам квен нехт 80б по сравнению со всеми этими вашими глм?
Поэтому я жду, пока они пропердятся багами. Минимум неделю надо ждать, лучше месяц. Хотя вот в командере баг поправили спустя хуй знает сколько, когда нашли баг в другой сетке, лол.
>промт автоматически дублировался
Лол, как проебать половину контекста.
>Проблема будет, только если там были веса меньше или больше 65000
Если в скриптах не прописано какое-нибудь масштабирование...
>Можно даже взять Q5_K_S на 5.3 bpw попробовать...
Или взять большой глм в 2 битах...
Ждём фиксов.
Правильно спрашивают, смотря в чем. В это железо лезут квен235, минимакс, флеш, жлм (с большим скрипом) и еще несколько. На большинство обывательских вопросов разницы не заметишь, только из-за ужатого кванта могут быть ошибки почаще и скорость сильно ниже.
Если же говорить про бесплатный тир - там преимущество корпов только в скорости, модели глупенькие.
Если ты не хлебушек - все делается.
Как вы этого добиваетесь? Квант или инфиренс поломан, некст не срет иероглифами, тем более в пустом чате.
> 1 - писать форк лламы, чтобы поддерживала MTP-3 из GLM-4. Не могу оценить.
Вариант хороший, но довольно тяжело будет.
> 2 - писать форк exl3
Для мтп - элементарно, там буквально пара десятков строк и ллм справится. Для
> скидывать слои на CPU
считай по сложности выше первого. Код весь вокруг куды написан.
> чтобы работало не только на cu80 и выше
Переписывать fa, возможно будет проще пересадить все на FlashInfer, который вольты-тьюринги поддерживает.
> 3 - писать свой инференс движок.
> 4 - писать форк vLLM, чтобы там были 6 бит.
Натренируй модель под размер своего железа, чего мелочиться.
У тебя какая конечная цель то вообще?
Дублирование промта реально помогает улучшить понимание промта. В научной бумажке все разжевано. Это помогает сбалансировать промт для моделей поменьше, где больше влияет что написано в начало, и и что в конец, промта.
>спокойно 8б запускать
К 8б это тоже относится. Но я наоборот е2б использую чтобы скорость генерации пободрее была.
В кобольд ллама встроена. Попробую, спасибо за наводку.
>Лол, как проебать половину контекста.
Это у кого такие промты такие длинющие что дублируя их весь контекст забьется? При том что для мелких моделей прямо чувствуется лучшее понимание контекста, при дублировании промта. Научная бумажка работает и приносит пользу. Вот бы еще автоматизировать это...
>спокойно 8б запускать
К 8б это тоже относится. Но я наоборот е2б использую чтобы скорость генерации пободрее была.
В кобольд ллама встроена. Попробую, спасибо за наводку.
>Лол, как проебать половину контекста.
Это у кого такие промты такие длинющие что дублируя их весь контекст забьется? При том что для мелких моделей прямо чувствуется лучшее понимание контекста, при дублировании промта. Научная бумажка работает и приносит пользу. Вот бы еще автоматизировать это...
>Это у кого такие промты такие длинющие что дублируя их весь контекст забьется?
Чатик (история) тоже по сути промпт.
> в командере баг поправили спустя хуй знает сколько, когда нашли баг в другой сетке, лол.
подробнее пж
> То есть они сконвертили bf16 -> fp16? Лоооол.
В первый раз?
> слои нормализации вроде как в fp32 остаются
Если не делался дополнительный скейл весов для поправки каста то с этого нет толку.
> командере баг поправили спустя хуй знает сколько
Это какой? Кстати, для примера не лишнем было бы 4ю лламу привести. Ее починили только совсем недавно, когда в 4.7 флеше баг заметили. Если бы не резкий холод в начале, модельку могли бы тепло принять. То же самое было в первыми квенами и yi, если еще кто-то помнит их.
> ля мелких моделей прямо чувствуется лучшее понимание контекста, при дублировании промта
Скорее она лучше понимает основную инструкцию и работает по ней, принимая во внимание остальное. Рабочая тема на самом деле, для рп и креатива на крупных моделях испортит, а для мелких и в конкретных задачах обработки текста очень полезно.
>У тебя какая конечная цель то вообще?
1. Мне скучно на работе и я пишу что хочу.
2. Я борюсь с тревожностью на тему того, что я буду использовать видеокарты неэффективно и потеряю часть быстродействия и что вообще какой мир несправедливый. Потому я хочу извести себя до состояния, чтобы я уже не мог тревожится; или же прийти к убеждению что vLLM мусор из-за отсутствия квантов, достаточно точный и достаточно компактных одновременно. Не дай бог я запущу мелкую 30B модель и она на vLLM окажется достаточно точно и при этом быстрее, чем через ламу или exl. Про всякие Tensor-RT я к такому убеждению уже пришёл, так как INT4 - это не квант, поддержку INT4 даже выпилили из Blackwell, а только в 8 бит оно нахрен не нужно. А вот то что vLLM не такая плохая штука - от этой мысли пока не могу избавиться.
3. Мне нравится кодить и разрабатывать всякое. Ещё у меня интересный бекграунд - в 2012 году я уже знал про нейронки и прочитал парочку книг на тему, и я даже написал реализацию несложного многослойного перцептрона на OpenCL на ноутбучной 540M (сейчас посмотрел - Compute Capability 2.1, лол), причём и обучения, и инференса. Направление мне не понравилось и в сущности я больше нейросетями почти не занимался, только немного pytorch потыкал, когда он стал популярным, и чуть ранее что-то тыкал когда только-только вышел tensorflow 2. То есть а почему я с дополнительными 10+ годами опыта кодинга и неплохой математической подготовной не смогу сейчас написать инференс трансформера?
>считай по сложности выше первого. Код весь вокруг куды написан.
По идее нужно вырезать расчёт слоя на куде, и дописать туда функцию сброса значений активации на CPU и загрузки обратно. А на CPU переписать функции, чтобы они расквантовали кванты, всё посчитали. Можно в общем-то тогда уже парочку тензоров из gguf-файла взять в гарантировано более высоком кванте, и расчёт слоя тоже из ламы взять, лол. Задача не не посильная, но это надолго, вникать где там и что делается. Ещё там что-то было про граф вычисления. Если это то что я думаю, то он может осложнить задачу.
>Натренируй модель под размер своего железа, чего мелочиться.
Так я и подписал, что это непосильные задачи.
К слову про форк на 6 бит в vLLM - я только после отправки поста нашёл, что 50хх поддерживают fp6, то есть в куде уже есть функции под 6 бит. С такой вводной форк становится более реалистичным (если там все функции под fp6) - и скорее всего это даже без форка в основной ветке появится. То есть я думаю, что 6 бит - это оптимально, и даже в нвидии считают это настолько актуальным, что добавляют аппаратную поддержку. Правда чисел производительности в спецификации нет, нет гарантии, что оно не на блоках fp8 обычных считается.
и чё, ллама 4 внезапно стала хороша?
Да. Инференсер ахуел, когда увидел ЧТО было в аутпутах!..
охуел до шивера в его спайне
>Это какой?
Да это про тот баг с ллама3, где жора неверно парсил двойной перевод строки в два токена (и ещё хуй знает сколько чего). В командере были подобные токены и тот же парсер, так что он тоже по сути был сломан.
>В первый раз?
Да в общем-то нет, просто ржачно, как анслоши ебашат свою инфраструктуру, доки, справки, какие-то свои мегакванты, и обсираются в базовой конвертации.
>То же самое было в первыми квенами и yi, если еще кто-то помнит их.
Да жора перманентно сломан.
>Я борюсь с тревожностью на тему того, что я буду использовать видеокарты неэффективно
Хуёво быть тобой... Сейчас с софтом такой пиздец, столько слоёв совместимости, раздутых либ и неэффективной ебалы, что я уже просто забил хуй на все попытки это исправить, смирился и закупаю железо на пару голов выше обывательского (впрочем от фризов в рандомных местах всё равно не избавился). И тебе того же советую.
>То есть а почему я с дополнительными 10+ годами опыта кодинга и неплохой математической подготовной не смогу сейчас написать инференс трансформера?
Сможешь, это сможет даже макака. А вот в эффективный инференс...
Ну то есть ты предлагаешь запускать еще большего лоботомита с ризонингом. Ну такое. Лучше взять у глм квант поменьше и ее с ризонингом запускать.
Вообще давно такая идея, что хорошо бы, чтобы ризонинг к модели писала легкая модель (глм флешка та же). Но я не встречал подобного расширения к таверне, разве что самому накостылить на том нодовом расширении. Причем я согласен, чтобы ризонинг до драфта (включая его) писала легкая модель, но вот продолжение думалки с рефайнингом драфта должна делать большая глм. Тогда время на ризонинг значительно снизится.
Зачиллься и пиши что нравится, зачем вообще тревожишься? Эта мелкодрочка ни до чего хорошего не доведет. Особенно тряска вокруг 30б, их скорость уже выше порога заметности в инструментах и тем более чате, проблема в уме.
Добавить мтп в экслламе - видится простой, потому что код инфиренса повторяет оригинал и спекулятивный энкодинг описан удобно в "легком доступе". В жоре сложнее из-за особенности и унификации внутрянки, но в целом ничего невозможного. Главное чтобы совпало с виденьем Жоры, может он уже сам запланировал сделать.
> vLLM мусор
Нет, вполне приличный инструмент, есть поддержка ряда моделей, которых больше нигде, кроме неоптимизированного трансформерса, нет. Кмк, для обычного юзера проблема в том, что на него не ориентирован: кванты, запуск на разных гпу, выделение памяти и прочее. Зато есть ряд оптимизаций чисто под параллельный инфиренс, от которых тебе не холодно не жарко. Она не плохая, она просто другая, в однопоточном инфиренсе на тех же моделях выигрыша не заметно.
> вырезать расчёт слоя на куде, и дописать туда функцию сброса значений активации на CPU и загрузки обратно
Нюанс в том, что под все основные операции написаны куда кернели и все обернуто в графы, скорость этим достигается. Кривое вмешательство туда все поломает.
В теории, можно попробовать ограничиться исключительно линейными слоями и для отдельных, подменив класс разреженного mlp на cpu версию. Но даже с ними придется писать экстеншн для деквантования перед матмулом, одним пихоном чтобы было быстро не обойтись.
> парочку тензоров из gguf-файла взять в гарантировано более высоком кванте
Зачем?
> форк на 6 бит в vLLM
> fp6
Ты понимаешь что формат данных и квантование в 6/8 бит - совершенно разные вещи? Одно дело когда модель изначально имеет часть весов в фп8, или веса отскейлены чтобы подтянуть с минимальными потерями, и инфиренс = чистые операции с этим типом данным. А другое - когда путем дополнительных операций из сжатого состояния можно восстановить веса в оригинальный тип данных, и в нем же проводится инфиренс.
Так над мтп в жоре уже очень долго работают, зачем свой велосипед делать
Даже на обоссаном редите дошли до того, что было базой треда изначально. Олама - это ебанная параша
https://www.reddit.com/r/LocalLLaMA/comments/1qvq0xe/bashing_ollama_isnt_just_a_pleasure_its_a_duty/
https://www.reddit.com/r/LocalLLaMA/comments/1qvq0xe/bashing_ollama_isnt_just_a_pleasure_its_a_duty/



>Не думал что релиз той же мику не во время утечки, а одновременно с ларджем был бы полным кринжом? Они могли просто ее не улучшать с того момента, или запороть/перепрофилировать тренировку, как это произошло с эйром.
Ты прежде чем херню несети - погуглил бы, они её улучшают регулярно, последняя версия от августа 15 года. И тамщето это живая модель, любой может её пощупать и оценить. За денежку.Есть она и на арене - между мистраль ларджем, ГПТ 4.1 и ГЛМ 4.5.
Моделей больше нет. Теперь ты либо рамобог с 128 гб ОЗУ и 24гб врама, либо сразу идешь нахуй
>регулярно
>последняя версия от августа 15 года
А сколько в ней параметров?
> они её
Кого ее? Сам манямир придумал, сам оскорбился, сам побежал защищать.
> 15 года
Всхрюкнул, как раз для 15-го года 128к контекста и такой перфоманс.
Описался анон, хули доебываешься
А так он прав. Французы этот медиум втихаря пилят уже хуй знает сколько лет. И последняя его версия моложе на два месяца последнего того же маленького мистраля 3.2

Какие же разрабы ComfyUI долбоёбы. Хотел спиздить их реализацию LiteGraph либы, так они в процессе её допиливания так перевязали её со своим кодом, что мне пришлось копировать компоненты константы локализацию рендер типы утилиты, и всё чтобы это говно показало кривое окошко без нод. Пиздец. Я даже 15 лет назад, будучи школотой, так криво не писал.
Я раза три пытался ставить эту блевотину, потому что какой-то клиент только олламу поддерживал. Какой же пиздец. Банально невозможно указать на какой гпу грузить модель, а CUDA_VISIBLE_DEVICES игнорится, потому что эта дрисня запускает новый процесс через службу без текущего окружения. Банально нельзя скачать файл модели и запустить его.
Они бесплатно выкладывают, так что жри что дают скажет рандомный хуесос, а потом будет удивляться, почему опнесорс сосет у корпов
Мистраль смол вообще в июне 25 вышла, а нищуки итт так на ней и сидят.
ХЗ. Если не сменили со времен мику - то 70В. Но учитывая что последний лардж у них мое - то могли и медиум мое сделать.
Интересно, как ЛЛМ заставить генерировать узкоспециализированный говнокод? У меня постоянно ситуации в духе
-Ах ты тупая обезьяна, что за говно ты мне генерируешь? На, смотри как надо <сниппет>
-Юзер злится, надо открыть код и прочитать.
-Вызов инструмента прочитать_код. Результат [какая-то мешанина из goto переходов, ручного разворачивания массивов, прямой зависимости шага от семи предыдущих]
-<20к ризонинга> Что тут понаписано ебать. Тэээк блять, нука вот тут исправлю...
<детонация, тесты не проходят>
-Блять, нахуй. Fuck go back. <ещё 20к ризонинга>
-Я останавливаю генерацию, объясняю на пальцах как работает моё говно.
-Ааа, понятно. <очередная детонация кода> Сука. Это обратный тест тьюринга? Мне надо убедить юзера что я машина, а не человек? блять я просто текстовая модель, я ебу goto действительно перепрыгнет на case 0 при условии f > 6, или нет?! я текст предсказываю, я не компилятор! я предсказываю текст с гитхаба, я не ебу работает он или нет!
Постоянно утыкаюсь в то что ЛЛМ вообще не представляет как писать узкоспециализированное говно.
Да обычное дело. Нахер ты вообще пытаешься спиздить, когда есть всякие там D3.js, React-Flow, Rete.js?
Лол у меня была ситуация в ролеплее когда барон пытался обмануть феечку повернувшись к ней спиной и делая вид что "у него в руках что-то интересное". Чтобы феечка подошла и он её схватил. В итоге там была сцена где феечка просто полетала вокруг него и сказала что он мудак.
да он как-то тупеет когда ему его внутренняя обезьянка тарелками не хлопает.
-Ах ты тупая обезьяна, что за говно ты мне генерируешь? На, смотри как надо <сниппет>
-Юзер злится, надо открыть код и прочитать.
-Вызов инструмента прочитать_код. Результат [какая-то мешанина из goto переходов, ручного разворачивания массивов, прямой зависимости шага от семи предыдущих]
-<20к ризонинга> Что тут понаписано ебать. Тэээк блять, нука вот тут исправлю...
<детонация, тесты не проходят>
-Блять, нахуй. Fuck go back. <ещё 20к ризонинга>
-Я останавливаю генерацию, объясняю на пальцах как работает моё говно.
-Ааа, понятно. <очередная детонация кода> Сука. Это обратный тест тьюринга? Мне надо убедить юзера что я машина, а не человек? блять я просто текстовая модель, я ебу goto действительно перепрыгнет на case 0 при условии f > 6, или нет?! я текст предсказываю, я не компилятор! я предсказываю текст с гитхаба, я не ебу работает он или нет!
Постоянно утыкаюсь в то что ЛЛМ вообще не представляет как писать узкоспециализированное говно.
Да обычное дело. Нахер ты вообще пытаешься спиздить, когда есть всякие там D3.js, React-Flow, Rete.js?
Лол у меня была ситуация в ролеплее когда барон пытался обмануть феечку повернувшись к ней спиной и делая вид что "у него в руках что-то интересное". Чтобы феечка подошла и он её схватил. В итоге там была сцена где феечка просто полетала вокруг него и сказала что он мудак.
да он как-то тупеет когда ему его внутренняя обезьянка тарелками не хлопает.
> Это обратный тест тьюринга?
Нет, это легчайший детект говноквена
Это, а что никто тринити не пробует, ггуфы уже давно валяются и ноль упоминаний
Конечно же они должны думать не о своем удобстве и интеграции, а о каком-то васяне, который пытается спиздить их реализацию.
> Если не сменили со времен мику
Как называется эта болезнь?
> узкоспециализированный
Тут легко
> говнокод
У них свое понимание говнокода, с ним отлично справляются. С надмозговыми вещами бывают сложности, только самые-самые топовые модели, и то не всегда. От рандома еще зависит, перезапусти на чистую и в начале объясни что у тебя там, или перед внесениями изменений и прочим обсуди с моделью что там и какие изменения нужны. Значительно повышает выход полезного и снижает требования к моделям.
> -Ааа, понятно. <очередная детонация кода> Сука. Это обратный тест тьюринга? Мне надо убедить юзера что я машина, а не человек? блять я просто текстовая модель, я ебу goto действительно перепрыгнет на case 0 при условии f > 6, или нет?! я текст предсказываю, я не компилятор! я предсказываю текст с гитхаба, я не ебу работает он или нет!
и в чём она неправа?
>потому что какой-то клиент только олламу поддерживал
Проще написать скрипт проксю с их параши на нормальную апишку.
>Нахер ты вообще пытаешься спиздить, когда есть всякие там D3.js, React-Flow, Rete.js?
ХЗ, но они говно. В Rete нет нормальных субграфов, и вообще постоянно закатываешь солнце руками, React-Flow вообще с платными функциями (они ебанулись там?), D3.js вот пропустил, но наверняка тоже хуйня.
Некогда уже тестировать, не успеваем. Не видищшь, сколько новых релизов? И все сломанные жорой.
>Конечно же они должны думать не о своем удобстве и интеграции
Если в коде всё перемешано, то получается говно. Поэтому все стараются уменьшать сцепленность и прочие зависимости. А они намешали всё так, что не отцепишь.
Впрочем ладно, нашёл, что у них эта либа раньше была отдельной, но они не осилили. Попробую их старый форк.
Лол а речь и не про него. он на 20к ризонинга не просирается
Увы, но это работает только до какой-то глубины специализации. Когда моделям показываешь совсем потное говно, они его с трудом переваривают даже если им дашь аутпут лога с трансформацией что происходит при тестировании, они сидят тупят пока надонец до них не доходит что происходит, но повторить не могут один хрен.
После какого-то уровня даже корпы начинают генерировать хуйню, когда спускаешься в всё более узкий доммейн. Я прямо часть на это натыкаюсь.
Узкие вещи вроде геймдева, где надо знать какой-то конкретный фреймворк, или применять запутанные техники оптимизации, или например написание шейдоров - там ЛЛМ пиздец какие бесполезные становятся и больше мешают.
Технически, права. Но как же так! это говно набирает 95 баллов в AIME25, а даже в моем говнокоде разобраться не может! У-у-у сука!
>ХЗ, но они говно. В Rete нет нормальных субграфов, и вообще постоянно закатываешь солнце руками, React-Flow вообще с платными функциями (они ебанулись там?), D3.js вот пропустил, но наверняка тоже хуйня.
Я бы не удивился. Че кстати делаешь то? Я вообще уже какое-то время пришел к выводу что js и такого сорта хуйню проще ЛЛМ отдавать. У их ебичские скиллы как работать с html и всем связанным.
Тот-же Kimi K2.5 без проблем мне ВАНШОТНУЛ функциональный нодовый редактор недавно, 1 в 1 то что я видел в ComfyUI. Как раз сидел переписывал часть проекта которая должна была бы парсить произвольный CLI инпут из чата в комфи и не придумал ниче лучше чем сделать нодовый редактор который бы генерировал json со всеми нужными переходам.
Кинул ему ТЗ, мы сделали несколько итераций развития идеи, сформировали более детальный промпт и я получил неплохой результат.
>Че кстати делаешь то?
Решил таки сделать нормальную реализацию построения любой нейронки в гуе. Я уже пилил гпт2 в гуе (в прошлых тредах было), но там есть проблема с производительностью. Сейчас же я делаю отдельно гуй с графами, и отдельно сборку всего этого и запуск в Torch FX graph. Посмотрим что выйдет, по идее, производительность должна быть нативной.
>Тот-же Kimi K2.5 без проблем мне ВАНШОТНУЛ функциональный нодовый редактор недавно
Везёт. Видимо я редко работаю с нейронками в кодировании, ну или я нищеброд с бесплатным GPT, но я ничего кроме вечных затыков не получаю. Оно конечно работает, но только после десятка исправлений, да таких, что я уже сам блядь разобрался, спасибо нейронка, помогла.
> они намешали всё так, что не отцепишь
Они исходили из своего удобства и конкретной задачи. То, что это лишает возможности легко спиздить и дать совместимость мимокрокодилу - только в радость. Нет там ничего криминального, а как раз специализация позволяет добиться ряда мелких, но важных удобств.
> но повторить не могут один хрен
А надо? Если речь о припезднутом коде и так уж хочешь - пусть сначала реализуют в нормальном виде, а уже потом наводи запутывание и обфускацию, с этим отлично справляются. Или постепенно свой код рефактори.
Странный код идет в разрез со всем, чему модель учили, поэтому приспосабливайся давать ей более понятные задачи. А если что-то действительно узкоспециализированное - модели этого просто не знают, потому нужно снижать сложность и скидывать рутину. Немного помогут примеры, документация и чистый контекст чтобы ничего не отвлекало.
Так-то любой приличный специалист в своей теме задетектит ллм или человека, который ею пользуется, если речь заходит о конкретных узких вещах.
> нормальную реализацию построения любой нейронки в гуе
Зачем? Научись уже представлять просто читая код и структуру, там все очень просто.
> с бесплатным GPT
Это уровень 30а3 и хуже если что.
Тут скорей уже сказывается опыт обращения с ЛЛМ для погромирования. Но в целом совету придерживаться стратегии того чтобы ЛЛМ само себе контекст заполняло о задаче. Типа "как сделать Х? Какие у тебя варианты?", ЛЛМ даёт Х ариантов. "развей вариант Х. какие минусы и плюсы реализации будут? какие проблемы нам надо решить?" спустя 5-6 наводящих вопросов просто просишь у него полный диздок со всеми идеями по которым прошлись и просишь по этому же диздоку реализовать написанное.
Про исправление тоже тот-же совет. Я обычно начинаю решать такие проблемы с того что кидаю ЛЛМ в ебало кусок кода и прошу объяснить как он работает. Когда в ЛЛМ есть контекст как что-то работает оно резко лучше начинает решать проблемы связанные с тем как оно работает.
Kimi K2.5 кстати ОЧЕНЬ силён именно в html, js и UI|UX. У него что-о охуеть какие креативные дизайны порой, требующие минимальных исправлений. Хочу смотрелку json c с иерархией полей? пожалуйста. Нодовый редактор? пожалуйста. Генерацию красивого документа? не вопрос. У него каким-то образом всё делается так офигенно что рот открыть можно.
Да это то понятно что ЛЛМ хороши в том чтобы щелкать простые задачки. Но некоторый код даже в простом виде существовать не может, так как изначально требует погружения в доммейн, чтобы даже начать творить безумие внутри него. Вопрос даже не в запутывании и обфускации, а в том что некоторые задачи ЛЛМ просто не знают как решать сложные проблемы требуюие специфичных решений. Обычно это те которые включают притаскивание чужих библиотек. А иногда НАДО сделать узкоспециализированное решение. И ЛЛМ тут перестают быть помощниками совсем.
Притом планка ОЧЕНЬ рано начинается. Например недавно я хотел сделать процедурную анимацию, где надо было рассматривать тело как цепочку сегментов, но с элементами физона. Сука, ебучий ГПТ мне все мозги вынес. Он настойчиво раз за разом пытался реализовать обычную rigid body физику, просто не понимая что у цепочки тел не совсем корректно считать угловой момент от центра массы, так как CoM != DoF в этом случае. Даже после того как я сказал ему про это. Пришлось сидеть и самому реализовывать всё по феншую.
Ну и отмечу что ЛЛМ местами прям хреново понимают геометрию местами. Синусы-косинусы посчитать могут, а когда надо выразить зависимость двух углов четырёхугольника когда две противоположные стороны не известны, но все остальное известно - как-то резко начинают писать хуйню. Потому что значения не зависят друг от друга на прямую, а через энное количество шагов.
>Зачем? Научись уже представлять просто читая код и структуру, там все очень просто.
Не, я слишком тупой для такого. Да и дело не только в представлении, а ещё и в лёгкости модификации.
>Это уровень 30а3 и хуже если что.
Да вроде там даётся 5-10 запросов к нормальной модели. Потом конечно да, но у меня осталась стопка аккаунтов со времён 20 баксовых триалов.
>Тут скорей уже сказывается опыт обращения с ЛЛМ для погромирования.
Окей, буду поднимать навык, вдруг научусь раньше, чем умру с голоду.
GLM 4.6V даже в 4 кванте может вставлять иероглифы? Это норма или кванты сломаны?
Ни хао
懂俄语
请写中文
Любые китайские ллмки периодически срут иероглифами.
Пытаются нести свет цивилизации лаоваям
Minp больше поставь или чем ты там токены ужимаешь

https://huggingface.co/ConicCat/GL-Marvin-32k-32B
Кто-нибудь пробовал? Страдаю на некроговне, IQ3_XS с 1т сек ddr3 800hz, gtx1660.
Кто-нибудь пробовал? Страдаю на некроговне, IQ3_XS с 1т сек ddr3 800hz, gtx1660.

Тот самый пробовал. Писал что хуйня и 0414 инструкт лучше и работает норм до 16к
>1т сек ddr3 800hz, gtx1660
Bruh.. попробуй вот это чтоль. Будешь страдать не так сильно https://huggingface.co/unsloth/Ministral-3-14B-Instruct-2512-GGUF
Она умеет в кум, умеет в русик, ну и мозги хоть какие-то есть. Совсем поехал чтоль 32b на такой некроте гонять?




Сделал тест для себя: локальные модели+проприетарные на одной алгоритмической задаче с выводом написать код + обьяснение. Опус красиво просумировал и сделал выводы. Эта табличка возможно ничего и не значит, из-за галюцинаций+возможно модели были натрененные на задачах как эта, просто было интересно есть ли смысл вообще локально что-то ставить и сравнить модели.
Лучше чем rocinante 12b новый?

Бля лол, ну сам-то как думаешь? По мозгам точно умнее, между ними разница в полтора года. В русике - точно лучше, он там на уровне старшего мистраля 24b. В куме не знаю, не тыкал конкретно rocinante. Скорее всего хуже, это же базовая модель против кумслоп-тюна.
> глм флеш
Они же у себя там темп 0.7-1 рекомендуют.


4o вообще-то топчик.
>Опус красиво просумировал и сделал выводы.
Выводы о том, что попус лучший?

Ответ
Кста на линухе с 13 т/c начинается, а у винды с 10. Так что не зря в дуалбуте срань стоит
> ЛЛМ тут перестают быть помощниками совсем
Они остаются хорошими помощниками. Именно помощниками, а не (полу) автономными исполнителями. То же самое что с людьми, только тут квалификация гарантирована ценой особенностей.
> ебучий ГПТ
Тупая сетка общего назначения, которую еще лоботомировали исправлять идиотские запросы юзера, ну. Иначе и быть не могло. Запрос нужно было красиво подать для достижения оптимальных условий, а не гнобить сетку в длинном чатике с сотней тысяч токенов "неправильных ответов".
> там даётся 5-10 запросов к нормальной модели
Хз, все попытки пользоваться фришной гопотой вызывали кринж, хуже средних локалок. А по апи на конкретную модель - да в целом ничего. Возможно пункт про то, что они не гарантируют доступность нормальных моделей при запросах не просто так стоит.
Интересные результаты. Отдельные оценки удивляют, как они выставлялись и что за задачи? Насчет нестабильности - снижение температуры это база.
То есть ты делал какие-то тесты, но в конце забил и кинул в нейронку, чтобы она насрала, а потом принес этот слоп в тред. Молодец пошел нахуй

"Новее" в ллм ничего не решает.
12б немо легендарная модель уже, больше такой не выходило.
Немо - 65% в кокбенче, министраль 14б - пикрил
>сам-то как думаешь?
Лично я сравнивал этот rocinante в рп с ms 24b, и на удивление из разницы увидел только чуть меньшую детализацию окружения, а вот в остальном все было буквально на том же уровне.
а как PrimeIntellect в плане ну вы понели
вроде как по всем бенчмаксам обходит ейр из которого сделан
вроде как по всем бенчмаксам обходит ейр из которого сделан
Примечание: GLM Flash тот что в топе на втором месте это с детальный промпт от Claude Opus со всеми возможными edge cases. Идеальный промпт+условия, по сути я проверял влияние промта, но он на столько идеальный что по сути бесполезный результат.
обычная лит код задачка, оценка по критерям, смотрел что модель учла обработала ли пустой список, разные edge cases не сломалась ли на странных входных данных. чем больше нюансов поймала тем выше балл.
>"Новее" в ллм ничего не решает.
Решает. В ллм очень технологии развиваются и модели быстро устаревают
>12б немо легендарная модель уже
Да, все так
>больше такой не выходило.
А это пошел уже синдром утенка
>Немо - 65% в кокбенче, министраль 14б - пикрил
Ну если это твой единственный критерий оценивания это подставить слово хуй в одном конкретном предложении, то немо победила вообще всех на пикче в шапке, включая все глм, минимаксы и прочее. Тогда получается либо немо топ 1 ллм, либо ты долбоеб и твой бенч нихуя не значит. Я все же склоняюсь ко второму варианту

>Возможно пункт про то, что они не гарантируют доступность нормальных моделей при запросах не просто так стоит.
Само собой. Но во всплывашке пишется версия. Впрочем, вроде как пятёрка это роутер, так что никто (кроме попенов офк) не знает, что там на самом деле.
>модели быстро устаревают
Я до перехода на большеГлем сидел на мистраль ларже. И по сути это рост количественный, лол.


ВНИМАНИЕ ВОПРОС: Почему файнтьюн для кода думает о хуях в 5 раз больше ванильной модели??? Значит ли это что программисты пидоры?
>И по сути это рост количественный, лол
Нет, это не так. Если бы это было правдой, то копры просто бы увеличивали количество параметров до ебанистических размеров. А по факту тренд другой - дать большее за меньшее ресурсы.
Сначала вышел дипсик с 670 миллардами и пнул копров, а сейчас выходят китайские модели, вроде глема и минимакса, которые с меньшим размером выдают перфоманс дипсика.
А кто там самый крупный? Лама 4 с 2 триллионнами? Сдохла обоссавшись и обоссравшись, потому что никому такая огромная залупа не нужна, когда есть меньше с похожей производительностью
странный 2й пик с корпами. ты оцениваешь 4о и sonnet 3.5, но не смотришь на тот же haiku 4.5
>эра корпов для нормального кода (как-то так)
может быть, но только если твоя работа состоит в дроче одного файла и алгоритмической задачки. как только тебе нужно работать над крупным коммерческим проектом, модели каорпов И их тулзы (будь то vscode с интеграцией или claude code cli) на голову выше открытых продуктов.
ты упоминал разные промпты на одной модели, что ох как важно это действительно важно, как сформулируешь, со временем набиваешь руку. но за корпами еще наверняка дохуя оптимизаций, которые они просто не откроют (как хендлят запросы). вон гпт до сих пор даже reasoning не показывает полностью
вообще не пынимаю подход - только жopus использовать при возможности. по хорошему он не так то и нужен часто. в большинстве случаев, если нужно подумать, sonnet / haiku вполне справляються с задачей. если дело дошло до простой реализации, то даже gpt 5 mini / grok code fast 1 с vscode на базовой подписке справляются. к опусу прибегал только тогда какой-до дроченый баг попадался опус топ, спору нет
чому у тебя несколько glm flash-ей?
>Лама 4 с 2 триллионнами?
Её так и не выложили.
>А кто там самый крупный?
Тамщето Кими 1Т и она так-то ебет всех.
> В ллм очень технологии развиваются и модели быстро устаревают
Где мой убийца эира за пол года? Солар, линг, квен некст, минимакс - всё хуйня для рп
>немо победила вообще всех на пикче в шапке, включая все глм, минимаксы и прочее
Тупенький, мы о 12б-14б говорим и немо тут разъебывает всех вообще без шансов
У вас нет такого ощущения, что мозги модели растут непропорционально числу параметров? Что я имею в виду: переход с 4b модели на 12b - дает сильнейший вау-эффект. Переход с 12b на 24b - всё еще впечатляет, но уже меньше. Переход с 24b на 27b - умнее, да, но не то чтобы прям очень. Переход с 27b на 106b-a12b - ну хз, разница-то конечно есть, но ее там надо под лупой в РП выискивать. Всё что выше не запускал, но вангую разницу с условным Эйром на уровне плацебо. Речь, естественно, о "соображалке" и "мозгах" модели, а не о том, насколько красиво и витиевато она пишет.
Это ты долбоеб. По хуебенчу немо>glm 4.7 Тебе же кроме хуев ничего больше не нужно, пидорок
>12б-14б
Ministral 14b, Gemma 3 12b трахают немо без шансов
>полгода
Ну пизда. За полгода не вышло эира 2. Пиздец. Правда за это время эиру успели зрение прикрутить и вышло куча других моделей, но они либо не про кум, либо слишком большие для анона. А значит ЛЛМ ВСЕ.
>Её так и не выложили.
И славу богу. Мертворожденная хуйня
>Тамщето Кими 1Т и она так-то ебет всех.
В стёпе бенчи выкладывали моделек, включая кими. По ним это не видно
https://huggingface.co/stepfun-ai/Step-3.5-Flash
>переход с 4b модели на 12b - дает сильнейший вау-эффект
4b довольно плохо работает, а 12b просто нормально. Вот и вау эффект. Разница в размере 3 раза
>Переход с 12b на 24b - всё еще впечатляет, но уже меньше.
Ну 12b работает нормально, а 24b работает... получше? Для меня даже этот переход не впечатляет. И разница в размере 2 раза
>Переход с 24b на 27b - умнее, да, но не то чтобы прям очень.
Пиши уж прямо. С Мистраля на Гемму. И это модели буквально одного размера, там разница в 1.1 раза. Выбирая между ними двумя я Мистраль возьму. Или может GLM 4, которая 32b была
>Переход с 27b на 106b-a12b - ну хз, разница-то конечно есть, но ее там надо под лупой в РП выискивать.
Я так не считаю. Для меня переход с 24-32 моделей на Air вызвал прямо вау эффект. Что-то отдаленно напоминает копры, а не просто локалки
>Всё что выше не запускал, но вангую разницу с условным Эйром на уровне плацебо
Разница между Air'ом и Deepseek'ом огромная. Иди на опенроутер и попробуй
>Речь, естественно, о "соображалке" и "мозгах" модели, а не о том, насколько красиво и витиевато она пишет.
Без понятия какие у тебя критерии мозгов. Я оценивал модели по тому насколько хорошо они могут поддерживать мое рп, генерируя разные ситуации, которые логично вписывались в перса и историю чата
Это ж классика всего МЛя.
Мозги у них одни и те же начиная с 8б, в смысле способности освоить аппарат формальной логики. У больших моделей выше "разрешающая способность" памяти. В районе триллиона параметров они могут точно пересказать сюжет какого-то фильма с подробностями, в районе 230б - в целом скорее правильно, в 30б - знают только в общих чертах, 8б - городят хуйню. Если дать им обобщить стену текста то они скорее всего выдадут примерно одно и то же.
У больших моделей есть возможность вкорячить больше-размерное эмбеддинг пространство. Каждый токен для модели обрастает большим количеством "смыслов" - как и у кожаных мешков. За счет этого память контекста становиться более устойчивой как к разрастанию так и к квантованию. Появляется возможность оперировать синонимами и разнообразить текст.

> Переход с 24b на 27b
Такого перехода нет, это модели одного класса.
>Переход с 27b на 106b-a12b - ну хз, разница-то конечно есть
Ты сравниваешь плотные и моэ по линейной шкале. Не надо так.
>Переход с 27b на 106b-a12b
Эквивалентность моэ плотным моделям считается в данном случае как (106+12)/2 = 59B. Реально все эти Аиры, Солары и ОСС - это модели одного ряда с немотроном.
У Квена (235+22)/2 = 128B. Уровень большого мистраля по мозгам, но квен все же так-то сломан.
У большого ГЛМ - (356+32)/2 = 194В. Ну и собственно сразу понятно почему только он уделывает Мистраль Лардж.
А почему у тебя glm-flash на 23B? У тебя REAP версия поменьше полной? Почему в таблице вроде как одно и то же, а результаты разные?
И почему qwen-next на 70B? Он разве не 80?
Как раз видно, что опенсорс Кими весь ебет, а у корпов там сопоставимое число параметров. Тесты степа оставим на совести тех кто это запостил, моделька хороша, но ГЛМ её делает всухую, в отличие от показанного в тестах.
К слову, работы ведутся по step-flash в ванильной ламе? Очень в падлу искать как на linux компилировать форк.
А ещё переход от 30 фпс на 60 фпс заметен, а от 120 фпс на 240 фпс не так заметен. А с 1 фпс на 2 - так вообще.
Тебе надо обратные величины сравнивать 1/30-1/60 = 0.0166, 1/120-1/240 = 0.004166 (в 4 раза меньше).
А ещё представь критический случай.
Мы от 700B переходим на 200000B, будет там разница в мозгах? Ну кроме как в том, что вторая может назвать 4000 рек в порядке уменьшения протяжённости на каком-то континенте, а первая вряд ли. Ну и ещё, что вторая по памяти помнит всех куски кода представленные в интернете.
А ещё переход от 30 фпс на 60 фпс заметен, а от 120 фпс на 240 фпс не так заметен. А с 1 фпс на 2 - так вообще.
Тебе надо обратные величины сравнивать 1/30-1/60 = 0.0166, 1/120-1/240 = 0.004166 (в 4 раза меньше).
А ещё представь критический случай.
Мы от 700B переходим на 200000B, будет там разница в мозгах? Ну кроме как в том, что вторая может назвать 4000 рек в порядке уменьшения протяжённости на каком-то континенте, а первая вряд ли. Ну и ещё, что вторая по памяти помнит всех куски кода представленные в интернете.
> Всё что выше не запускал
Дело в этом. Более того, между мелкомистралем и гейммой по размеру разница пренебрежима. Из моэ ты присел на одну из младших, там действительно могут быть непонятки с тем где лучше.
Вот если бы попробовал пересесть потом на 70б, потом на ларджа, или дальнейший подъем по моэ - ощутил бы. Алсо разница будет именно когда накрутишь побольше и посложнее, иначе более мелкая но хорошо надроченная модель понравится больше.
> в отличие от показанного в тестах
В первый раз?
> Очень в падлу искать как на linux компилировать форк.
Ну как бы git clone - cd llamacpp - компилишь форк
Пацанчоусы, накиньте сценариев и идей для рпшинга. Шот я совсем исписался и не знаю куда приткнутьсяфить-ха
https://huggingface.co/datasets/MiniMaxAI/role-play-bench/tree/main
У Минимакса там и датасеты для рп бенчей существуют, ничоси. Интересно, выложат ли они свою her модельку. Так то может быть вкусно на текст комплишене, без всякой фигни в апи прокладке. 230b-a10b.
У Минимакса там и датасеты для рп бенчей существуют, ничоси. Интересно, выложат ли они свою her модельку. Так то может быть вкусно на текст комплишене, без всякой фигни в апи прокладке. 230b-a10b.
СВОДКА ПРОИСШЕСТВИЯ №777
Объект: Группа добровольцев против радикального культа.
Суть дела: Группе лиц поручено уничтожить опасную улику — артефакт, обладающий коррупционным воздействием на психику. Подозреваемый (бывший владелец) преследует группу, пытаясь вернуть контроль над имуществом.
Ход операции: Маршрут пролегал через зоны боевых действий. В ходе миссии произошел раскол спецподразделения. Пока основные силы отвлекали армию противника, двое исполнителей скрытно проникли на промышленный объект для утилизации вещдока в резервуаре с лавой.
Итог: Объект уничтожен, режим пал, исполнители эвакуированы авиацией.
РАПОРТ О ПРОВЕРКЕ УЧЕБНОГО ЗАВЕДЕНИЯ
Объект: Субъект извлечен из неблагоприятной среды и помещен в закрытый интернат. В ходе обучения выявлено хранение запрещенного инвентаря (плащ-невидимка) и нарушение комендантского часа.
Инцидент: Группа учащихся вскрыла охраняемое хранилище, обойдя систему безопасности (биологическую и механическую). Цель: предотвращение хищения ценного минерала рецидивистом, находящимся в розыске (подозреваемый скрывался на затылке сотрудника школы).
Итог: Контрабанда уничтожена, подозреваемый скрылся в виде облака, учебный год завершен досрочной выдачей премий.
Кстати да, вот если брать русик, то в Ministral 3.14b самый лучший русик из мелких. Под мелкими подразумевается все, что можно запихнуть в нормискванте в 12Gb без выгрузки в ram.
Потому что поэтому
>в данном случае как (106+12)/2 = 59B
Шизофазия полная все твои расчеты. Еще помню в редите вообще через формулы с корнем высчитывали соотношение. А по факту единственный вариант это по бенчам смотреть сравнение конкретным моделей
>может назвать 4000 рек в порядке уменьшения протяжённости на каком-то континенте
Ты переоцениваешь ллм. У меня ни одна нейронка, включая копров, вроде гпт, грока и гемини, не смогла назвать топ 15 объектов Солнечной системы по массе. Можешь проверить сам



По массе Air смог. А по радиусу обосрался, причем даже с указанием на ошибку

>топ 15 объектов Солнечной системы по массе
Ну так то я и не назову, после планет там вылезет Эрида, и ещё наверное спутники Юпитера и может быть какой-то из астероидов? Я не знаю масс астероидов вообще.
>Можешь проверить сам
chatgpt5.2 - формально задание выполнил с первой попытки , указал правильные массы, но напутал с порядком (что, впрочем, я и не просил). С ризонингом по идее он бы ответил верно поправив порядок ещё. Отчасти ему повезло что он случайно самплером не писанул про Тритон. При этом он какие-то изображения прикрепил выше, возможно у него даже без поиска в сети есть небольшая локальная база знаний, иначе я не понимаю откуда изображения (с домена images.openai.com)
GLM-4.7 с ризонингом справился, без него самплер подвёл его на последней позиции, с температурой пониже возможно ответил бы. Зато порядок не путает.
Гемини "быстрая" ответила, что забавно так же как и жпт5.2 порядок поменяла. У них видимо часто планеты шли списком в обучающих примерах, и потому самплеры делают их печатать сначала Меркурий, даже если они знаю массы. Короче с ризонингом бы тоже справилась.
А самое интересное - локальный glm-4.7 флеш в пятом кванте, сразу с ризонингом. Как видишь, он делает список всех кандидатов - и это хороший план, но потом массы не для всех пишет. Взял настройки самплера, с которыми гоняю rag-систему свою про признаку, что так оно работает лучше, чем с температурой 0.5 или с 0.1.
Мне стало интересно - я прогнал ещё 4 раз. В одном он пропустил меркурий (в список первоначального анализа написал, а в список с массами не написал - он пропускает там хвосты спутников, и меркурий последний в списке по этому же признаку пропустил). И он даже массы более-менее верные называл.
Без ризонинга не отвечает, пишет всякие "Троянский астероид 624 Гектор" и прочие Цереры и Весты - вот это прям мой уровень, лол. Ну, я ещё массы не знаю вообще - а он назвал даже для этого астероида. Но то что с ризонингом он справляется - меня удивляет и поражает.
Короче, я остаюсь при своём - 200000B (200T) модель назовёт 4000 рек.
>А по факту тренд другой - дать большее за меньшее ресурсы
Ну так у корпов экономика, поэтому и кормят нейрохрючевом побольше, пока берут. Они рады были бы и 0,6B в прод запустить, да брать не будут.
>а сейчас выходят китайские модели, вроде глема и минимакса, которые с меньшим размером выдают перфоманс дипсика
А в размерах дипсика оно было бы уууууу.
>вообще не пынимаю подход - только жopus использовать при возможности
Если платит кто-то другой, то нет никакого резона юзать кастратов.
Ебать ты капитан. Скоро повысят до адмирала.
>в смысле способности освоить аппарат формальной логики
Только дальность связей страдает. Условно 8B может сделать вывод, что если А, то Б, а 365B из А неявно выведет Б, В, Г, а в чат выдаст сразу Д.
>Мы от 700B переходим на 200000B, будет там разница в мозгах?
Конечно будет. Даже нынешние 700B лоботомиты. Хотя конечно не факт, если тренировать современными методами, то да, получится склад, а не мозги.
Интересно, откуда они набрали эти датасеты скачал себе на всякий.
Тестошизу понравится.
>то да, получится склад, а не мозги.
Нужен конкурентный алгоритм, как в GAN-генератора или как в alpha-zero. Это конечно не шахматы, но если оно будет спорить само с собой и будет судья, который отдаст приоритет одной из сторон, то почему оно не обучится разговору так же, как обучилась шахматам или го? Сложнее формализовать победу, да. Первая супер-короткая стадия может быть с обучением по записям дебат на разные темы, чтобы оно поняло что такое речь. Потом основная часть, где условный chat-gpt самой сильной версии десять раз проверяет ответ и выдаёт вердикт, если все 10 оценок совпали. Когда он начинает сомневаться - этот пример отбрасывается до рассмотрения людьми.
Или как вариант две сетки играют друг против друга, а третья их судит (инстанс той же сетки + присяжные, лол). Хотя бы как эксперимент. Люди как-то же людей судят, философию изобретают, проверить рассуждение проще, чем сделать - потом сетка может сама себя обучать в теории. То что делала судья отбрасывает, а то что две сетки играли друг против друга - им присуждается результат для дальнейшего обучения. Это же круто будет, если будет ллм, которая обучилась основываясь на правилах языка, а не на примерах.
>Ну так то я и не назову
Да, но если тебе это когда-нибудь понадобится, то ты загуглишь, откроешь вику и посмотришь ответ. Нейросетки же будет придумывать по тексту
>chatgpt5.2
Обосрался с подливой. Мало того, что с Меркурием проебался, так еще и Луны вверх пихнул
>GLM 4.7
Глем хорош, как обычно
>Гемини
Тоже обосралась
>даже если они знаю массы
В том то и дело, что они не знают массы. Они просто похожий текст пишут. А поскольку в большинстве случаев планеты упорядочены по радиусу, то они почти всегда путают порядок
Ой, не нуди.
Локальный флеш на 25 ГБ параметров, который можно чуть ли не на офисном ноуте запустить иногда отвечает на достаточно узкоспециализированные вопросы в моей области, в которой я 15 лет занимаюсь и изучаю всякое. Это очень крутое достижение науки и техники. Даже если оно в 50% случаев отвечает. Даже если в 20% - я же могу это проверять.
То есть это прям феноменально крутое достижение науки и техники, даже флеш. Оно в некоторой степени может в логику и в некоторой степени знает всё. 10 лет назад 99.9% людей бы как один сказали, что это и есть искусственный интеллект, всё, капец, приплыли. Вот этот флеш, да, который и на железе 10-летний давности работал бы.
А сейчас глаз замылился, ничего необычно. Да вы охуели, ЭТО ОЧЕНЬ НЕОБЫЧНО по любым меркам.



доказательство что кими ебёт
10 лет? да 3 года назад это бы уже назвали искуственным интелектом. Как бы алло, у нас R1 недавно отпраздновал ГОД с даты выхода. ОДИН ГОД. DeepSeek R1. Ебанутся сколько за год случилось. А сейчас мы имеем модель в 30b которая в утилитарном применении его обгоняет. Охуе-е-еть.
>Первая супер-короткая стадия может быть с обучением по записям дебат на разные темы, чтобы оно поняло что такое речь.
Зенитные кодексы Аль-Эфесби.
-мимокрокодил.

А где осталные карликовые планеты? Эрида, например?
Тут топ 15. Эрида на 17/18, Плутон на 18/17 месте по массе/радиусу соответственно.
А что, глм 4.7 реально зацензурена в хламину как последний жопус? А почему тогда мало derestricted версий в нормальном кванте?
> derestricted
"0" face
> ablitereted
Уу хуета лоботомит...
Играю на q2 кванте 4.7. Никакой цензуры тут нет и в помине, без ризонинга. С ризонингом говорят есть, я не пробовал.
> q2
Ну ещё бы, на таком лоботомите и цензура лоботомируется
Жирнишь, дядя, жирнишь. Попробуй еще.
Расскажите про REAP50 версию GLM-4.7, которая 218B вместо 358B?
На флеше тоже есть такая версия. Отвечает плюс-минус такая же, разницы будто бы и нет на глаз, как впрочем и ускорения генерации.
Может быть лучше эта REAP50 но в q3, чем обычная в q2?
Бенчмарки может есть какие?
На флеше тоже есть такая версия. Отвечает плюс-минус такая же, разницы будто бы и нет на глаз, как впрочем и ускорения генерации.
Может быть лучше эта REAP50 но в q3, чем обычная в q2?
Бенчмарки может есть какие?
Нет, не лучше. REAP это для кода, не для рп.
Так он прав. На 2 кванте и знаменитая свое соявостью гемма 3 не такая уж и зацензуренная, как на 4 и последующих. Или ты думал, что квантование никак не влияет на модель?
Модель не лоботомит только при запуске в полных весах в FP16
Пойду катать дальше кими на компьютере наса.

А мне и не для рп.
Как впрочем и не для кода.
А что с ней не так, опишешь словами подробнее?
Кремний мне только вот такую табличку нашёл, более полных тестов нет.
Ну смотри, ты там рассуждаешь о разнице между q2 и q3 квантами, вот я и подумал что для рп. Если не для рп то меньше q4 ничего не имеет смысла. Потому что слишком большая просадка по точности. Ассистент будет давать неверные ответы, в коде будут очепятки которые приведут к тому что он не будет выполняться. Потому я и пишу что REAP не имеет смысла в твоем юзкейсе. Слишком малый квант мешает точным таскам, REAP мешает рп.
Есть куча информации и по другим, более жирным квантам. Реддит/дискорд. Надо - чекай. Все кому надо уже прочекали и в курсе что цензура только в ризонинге. Бтв, q2 работает замечательно и выдает кино, какого нет ни на какой другой модели меньше, пусть там даже полные веса.
Что такое REAP?
>компьютере наса
Давно не образец, лол.
ХЗ, у меня в лоботомит кванте в задачах РП модель тупо ломалась, писала бред, повторы и не могла заткнуться.
>цензура только в ризонинге
Ну кстати её и там мало. Вот минимакс да, в ризонинге на 146% отлавливает неудобное, даже с префилом, а уж как он обзывает обходы цензуры обходами цензуры, вообще любо-дорого.
https://github.com/CerebrasResearch/reap
Очень упрощая, это способ "вырезать" из модели определенные знания. Относительно недавно сделали. Как правило, вырезают из больших моделей все, что не нужно в бенчмарках, и приносят - мол, смотрите, мы сделали GLM на 40% меньше и потеряли всего 2% перфоманса, что подтверждают бенчами. В которых нет creative writing, например, или знания разных языков, или много чего еще. И все это после REAP не работает, разумеется. Потому только для кода и применимо, в целом.
Спасибо анон. А я тут подумал, ну вот возьмем огромную модель на 27 языках, вырежем все кроме 4 языков. Модель отупеет?
Ну в теории вин же должен быть.
> Ну в теории вин же должен быть.
Были такие надежды, когда только появился этот метод. Но практика показала, что эта затея годится в лучшем случае только для кода. Да и с кодом не так все однозначно. По сей день не было ни одного REAP вина для рп. Так что... увы.
Они не так делают. Там не вырезаются языки, креативность и т.д. Там вырезается ЧТО-ТО, хуй пойми что. А потом смотрится по прогерским бенчам перорманс. Ну т.е. модель в теории даже может не особо отупеть, а может отупеть до охуения. Это не говоря о том, насколько вообще эти бенчи отражают реальные способности модели. А не то цифорки могут быть красивые, а по факту залупа полная
Только у меня Убунта сегодня не может через sudo apt upgrade обновить проприетарные нвидиевские драйвера? Здесь у многих Убунта стоит, вот и спрашиваю. Удобная она для ЛЛМ.
У меня недавно убунта сдохла обоссавшись и обосравшись тоже из-за драйверов. Но потом воскресла, когда самостоятельно поставила открытые драйвера после перезагрузки, а после я уже в менеджере драйверов выбрал 590. Сейчас все нормально работает
>По сей день не было ни одного REAP вина для рп.
А была ли хоть одна попытка сделать этот самый REAP для РП?
Посоветуйте маленькую (до 24гб ВРАМ) модель с хорошим ризонингом, желательно без цензуры. Хочу попробовать местную идею - ризонинг на маленькой модели, а потом основное сообщение на большой. Вручную конечно, но интересен сам принцип.
Возможно, и даже вероятно была. Тот факт, что не опубликовали результат, не говорит о том что попыток не было. Любители тюнить про REAP давно в курсе. Логично предположить, что если бы они могли успешно использовать этот способ, уже использовали бы. А еще для этой процедуры нужны специальные датасеты, над которыми нужно проводить отдельную работу.
Небось инструментов нет, или не осилили. А попытку они бы выложили, и не такое говно выкладывали уже.

Лол будет небось как результат который у меня был на ламе3 кажется, или что-то около того. слог может а с математикой не очень.


1 - до обновления: правильно написало песню, не насрало емодзями, но насрало иероглифами
2 - после обновления: неправильно написало песню, насрало емодзями, но зато не было иероглифов.
аксиома эскобара короче
поделись скриптом, пожалуйста.
я так понял, что если хочешь качество, то надо самому квантуваты, а не надеяться на батрух и анслопов
> на компьютере наса.
> Pentium III, Slackware Linux
Ясно, попробую его тоже.
24b все свайпы тупо перефазирует одно и тоже, я даже не знаю что будет на 14b. Только смена сис промпта помогает. Последнее время только на гемме.
> способ "вырезать" из модели определенные знания
> вырежем все кроме 4 языков
Все проще - оно режет отдельных экспертов, влияние которых "мало". Проблема только в том, что знания в модели нигде не локализованы и нет какого-то определенного деления по ролям, они есть суперпозиция активируемого множества экспертов. Удаление приводит к искажениям, так еще и количество активируемых не меняется, потому в инфиренсе будут участвовать неподходящие.
Собственно метод предполагает оценку чувствительности и влияния с целью ампутации того, что не должно влиять на скор бенчей или калибровочного теста.
> модель с хорошим ризонингом
> ризонинг на маленькой модели, а потом основное сообщение на большой
Во-первых, зачем тебе модель с ризонингом? Ты даешь ей инструкцию подумать и она пусть ее выполняет, ее собственная логика ризонинга может быть совершенно шизоидной и плохо совместимой со второй моделью. Бери любую модель которая нравится.
Во-вторых, это плохая идея, тупой мелочью лоботомируешь большую задав неверные акценты. Норм идеей может быть использование мелких моделей чтобы собрать какие-то факты или рассмотреть с разных сторон, потом приказать большой дать оценку всему этому, и уже потом использовать полученное. Но не факт что выйдет лучше чем просто 2 инструкции большой.
>24b все свайпы тупо перефазирует одно и тоже
Фиксится повышением температуры.
>аксиома эскобара короче
Жди фикса для фикса.
Логика выйдет из чата.
Я пробовал реап который 268B и это был трэш. Модель потеряла русский язык почти полностью. Уходила в галюны. О качестве РП я не говорю. Не советую, если так хочется хорошую 200В модель - то бери минимакс/степ.
Это вброс? ГЛМ одна из самых чистых моделей, я на ней даже джейл не применяю.
Через пару часов смержат стёпу
Никому не спать, разорвем эту глыбу
Никому не спать, разорвем эту глыбу
Да не-не-не. Просто если можно чуть поднять скорость без вреда, то почему бы и нет.
И вообще, 358B в 5 кванте - это многовато. Надо какое-то 192+64 минимум, ну или 256+32.
А 218B в 5 кванте - это влезет в 128+64 с контекстом.
К степу кстати рип на 128B уже сделали, лол.
Я очень взволнован гайз
Я ещё не запускал настолько большую модель в нормальном 3 кванте
Я ещё не запускал настолько большую модель в нормальном 3 кванте
А на кобольде еще недели две ждать...
Да, кстати, я вчера перед сном пробовал большой (книгу на 170К) контекст со степой. Он сказал что видит только мешанину слов и символов, не связанных между собой. Подозреваю что они напиздели про размер контекста, точнее выдали расширенный роупом контекст за нативный. Поскольку роуп я крутить не умею, то остается ждать кобольда.

170к контекста != 170 Кб текста.
Такие дела.

Короче, кто катает 2 квант глм 4.7 - берите ud 2 xl. Он гораздо лучше 2kl кванта батрухи, как бы я нашего слоняру ни уважал. Влезают кванты в одинаковое железо, у них всего 0.15 bpw разница, но видимо анслоты которых я обычно сру тут постарались и верно слои квантовали. Субъективно квант батрухи сухой, пишет скучнее, но что объективно так это то что он после 22к контекста рушится крайне стремительно. На анслоте до 36к не рассыпается. Ваш нюня, чмок
>Короче, кто катает 2 квант глм 4.7 - берите ud 2 xl
Кавраковские быстрее, что решает. Также уверяют, что и по перплексити лучше.
Нюне (я не он очевидно, мы списались через обниморду) непонятно, почему если ik ветка такая прекрасная и без недостатков, она именно ветка, а не серия пулл реквестов в основную лламу. А я бомж без рама и сижу на Эире
на 0.5т? еееее
передай ему коллективный респект от анонов и попроси пресет
>2kl кванта батрухи
Я сижу на IQ2_S, ибо нищук с 96+32+24.
Передавал и просил. Сказал что стандартные семплеры и минималистичный промт на 200-250 токенов для 4.7. Для Эира то же самое, но на чатмл + жирные описания персонажей с примерами диалогов. Но тут об этом еще какой-то анон писал, за что на него накинулись непонимающие
По факту можно смотреть на цифру между A и B в названии. Да, я знаю, в очередной раз толсто набросил, можете не отвечать.
Это не ветка, а форк. Они разосрались с основной лламой из-за разного видения, и болгарин теперь в своем загоне пилит приколюхи.
Бля, как же долго v100 идет через того продавца говна, что тут советовали. Еще и тряска, ибо у одного чела пришла вхлам убитая карта с разъебанными сокетами и стертыми маркировками, но в треде это старательно игнорируют и ни разу не запостили. А заказали-то у него много кто, небось, из треда.
Интересно что лучше IQ3_XXS или 2xl
цифру между A и B умножить на 2 👍
> Они разосрались с основной лламой из-за разного видения
Скорее Жора со многими разосрался. Не то чтобы стоит его сильно винить, ведь действительно имеет свое видение и изначальная цель - работа на гейбуках. Еще весь этот треш со стороны олламы постоянно давит.
> заказали-то у него много кто, небось, из треда
Ну мне недавно пришла, из нареканий что вся в термопасте и отпечатках китайца, работает. Что там за тряска вообще?
> что тут советовали
> но в треде это старательно игнорируют
Вот из-за долбоебов-нытиков типа тебя здесь и не советуют ничего. Хотят и самый профитный вариант получить, и ответственность на других переложить.
Ну ты там в своем мирке живешь, что я могу сказать. Отзывы не чекаешь, перекладывание отвественности где-то увидел... толку с тебя. Впрочем, тут большинство в треде как мешком прибитые - иногда почитаешь ветку ответов и складывается ощущение, что общаются сами с собой вместо собеседника.

Эмм... Скажите как это работает? Сижу на линухе, раньше думал что мой максимум для 24+64 это 78-80гб квант ибо выше система крашилась, а сейчас убрал --no-mmap и влез квант на 84гб, при этом скорость не изменилась что пп что т.с и вкладок больше открыто, а рам судя по пику вообще не потребляется с --no-mmap available 1gb обычно
Погуглил, как я понял пейдж файл спасает, но лучше не превышать 5-10гб, т.е считай можно добавить 10 гигов к рам бесплатно без ощутимой потери скорости и вместить квант пожирнее
У меня глм флеш не работает на последнем жоре (куда), а у вас как? Просто тупо рандомные символы сыпет
Тот лот в конце декабря скидывали, народ заказывал, уже несколько довольных покупателей. Неделю назад один плохой отзыв, и ты уже устраиваешь истерику. Что задавно - в ней как раз выстраиваешь "свой мирок", где не ты купил самый-самый дешевый лот на майлсру, а виноват кто-то другой. Будет орно если ты станешь вторым неудачником, обязательно выложи фотки соккетов.
> можно добавить 10 гигов к рам бесплатно
На скорости ссд
>На скорости ссд
По ощущениям если ты не превышаешь размер врам+рам то всё норм, просто он подгружает модель чуть дольше обычного если долго не писал
Жесть ты порвался, братишка. Выйди что ли на улицу, потрогай снег, а то у тебя уже крыша едет настолько, что кругом враги, которые тебя около подъезда сторожить будут за советы продавцов, и ты желчью исплевался на ровном месте.
Чел...
бартуха там уже кванты стёпы делает, всё схвачено
ждём 7958 релиза
>Я сижу на IQ2_S, ибо нищук с 96+32+24
Спокойно ud 2xl влезет с 25к fp16 контекста, даже под виндой.
Ну так что swa хуйню выключаем для стёпы?
Или это сломает модель
Или это сломает модель
Я конечно редко смотрю чейнджлоги, но что за пиздец там происходит в релизах, нахуя мне знать что кого-то сделали счастливым, удалив пустую строку?
Мне, как программисту, понятны чувства линта. Я тоже счастлив за него. Молодцы, разработчики Жоры, что думают о чувствах линта. Программерская солидарность. Аутсайдерам не понять.
>Для Эира
>на чатмл
>на него накинулись непонимающие
Скорее всего еще харкнули и пнули, но с четким понимание, что он хуесос. Вроде уже в прошлых тредах триллион раз чатмл обсосали хотя скорее обоссали
Жир жирыч...
Так в релиз нахуя все коммиты пихать? Вот вроде все описания релизов как описания "Сделано то, сделано это", а тут блять обо всём ни о чём сука, даже в моей шарашкиной конторе с мёрджом над описанием думают.
Чтоб ты спросил и потратил время на поиск ответа...
А что за промпт то не кидал?
У меня до сих пор его минималистичный на 30 токенов, но думаю это мало очень, а сломать что то расширив его боюсь

А че рентри по моделям никто не редачит/обновляет/новый не создает? Там около 10-15 новых моделей насыпалось, алло.
Обнови ты. Кто, я?!


> Ну смотри, ты там рассуждаешь о разнице между q2 и q3 квантами, вот я и подумал что для рп. Если не для рп то меньше q4 ничего не имеет смысла. Потому что слишком большая просадка по точности. Ассистент будет давать неверные ответы, в коде будут очепятки которые приведут к тому что он не будет выполняться.
Это всё же зависит от конкретной модели, её размера, архитектуры, и инструментов для квантования.
К примеру, я пробовал квантовать Qwen3-235B-A22B-Instruct-2507 и Qwen3-Coder-Next в exl3 кванты. Судя по метрикам, Qwen3-235B-A22B-Instruct-2507 в 3.0bpw потерял меньше точности относительно оригинала по сравнению с Qwen3-Coder-Next в 8.0bpw (!) кванте. ЧСХ квен-кодер в 6.0bpw и 7.0bpw квантах судя по метрикам квантовался лучше чем 8.0bpw, но там похоже какой-то рандом и разреженность активаций во время запуска метрик влияет - цифры при запуске идентичных тестов в exllama3 каждый раз немного разные.
Конкретно тут, как мне кажется, влияет то, что в кодере аж 512 экспертов на слой, в то время как в обычном квене их всего 128. А поскольку экзлама по дефолту не прогнозирует какие отдельные слои/эксперты/тензоры являются самыми важными, количество усреднений становится таким большим, что она просто не может квантовать эффективно.
В теории, это можно было бы оптимизировать через использование opt-квантов, когда уже идёт анализ важности отдельных слоёв/блоков/тензоров и используется разная точность для всего, а не как в дефолте, что все эксперты внутри слоя квантуются с одинаковой точностью - без учёта того, что одни эксперты могут быть важнее других.
никто на локале в 2025 не сидит, там апи стоит 0,00000000001 цента.
Я делал список 24 года Который потом юзали как шаблон к 25-му Но сейчас слишком отстал от жизни чтоб этим заниматься.
Если кто всё-же захочет заняться списком 26 года, не поленитесь прихуячить настройки семплеров и форматирования. А то прошло аж 2 года, а качественного прогресса в треде хуй наплакал. Попробовал пару раз узнать ИТТ что нового, оказалось что проще самому копать
Оукей, накидайте новых топмоделей с описанием, а то я дальше министраля 14б не вертел (на самом деле, вертел, но старую кидонию, которая и в 2025м топе есть)
Весь хаги завален 4 квантами стёпы, сука. Где 3 квант.
Напоминаю, в рп сравниваем с эиром и только с ним
Напоминаю, в рп сравниваем с эиром и только с ним
Хорошо что сейчас 2026 год, год локалок!
Есть такое. Много кто выгорел из старичков. Прогресс вроде есть, но вроде бы и нет.
В треде постоянно всплывает, собери, делов то.




Айлбибек!
Моё железо:
Ryzen 5600X
64 Гб DDR4 2666
3090 24Гб
Tesla P40 24Гб
Вначале стоит обозначить что я хуй знает что запускать, просто хотел получить максимум преимуществ от такой конфигурации
Но тем не менее кое что попробовал и не покидает ощущения что меня жестко наебали с сообразительностью жирных моделей. В основном правда крутил говнотьюны, но тем не менее.
Для теста юзал свою старую двачекарточку, с которой вполне справлялся даже сраный Мистраль Немо, но картачка сложная, так что показываетвполне способна показать уровень.
Начать решил со старья
EVA-LLaMA-3.33-70B-v0.1-IQ4_XS - 37 Gb
Process:11.99s (201.03T/s), Generate:75.24s (7.89T/s)
С форматированием НЕ обосралась, но вместо оригинального текста тупо скопировала пример. Мистраль 12В справлялся лучше...
РП Тюн Неморона 49В. Почему тьюн, а не оригинал? Потому что.
TheDrummer_Valkyrie-49B-v1-Q5_K_M - 34 Gb
Process:21.05s (160.30T/s), Generate:154.55s (6.63T/s)
Форматирование - ок.
Но текст настолько соевый, что я ебал. Атмосфера харкача проёбана полностью а ведь в карточке подробно описан стиль общения и даже примеры преведены
Сомневаюсь что вот это вот юзабильно для РП.
Mistral-Large-Instruct-2411-IQ2_XS - 35 Gb
Process:49.33s (90.53T/s), Generate:154.48s (3.85T/s)
Сразу же проёбано форматирование.
Текст - ок по стилю, но не совсем ок по смыслу.
Ожидал большего, честно говоря.
Моё железо:
Ryzen 5600X
64 Гб DDR4 2666
3090 24Гб
Tesla P40 24Гб
Вначале стоит обозначить что я хуй знает что запускать, просто хотел получить максимум преимуществ от такой конфигурации
Но тем не менее кое что попробовал и не покидает ощущения что меня жестко наебали с сообразительностью жирных моделей. В основном правда крутил говнотьюны, но тем не менее.
Для теста юзал свою старую двачекарточку, с которой вполне справлялся даже сраный Мистраль Немо, но картачка сложная, так что показываетвполне способна показать уровень.
Начать решил со старья
EVA-LLaMA-3.33-70B-v0.1-IQ4_XS - 37 Gb
Process:11.99s (201.03T/s), Generate:75.24s (7.89T/s)
С форматированием НЕ обосралась, но вместо оригинального текста тупо скопировала пример. Мистраль 12В справлялся лучше...
РП Тюн Неморона 49В. Почему тьюн, а не оригинал? Потому что.
TheDrummer_Valkyrie-49B-v1-Q5_K_M - 34 Gb
Process:21.05s (160.30T/s), Generate:154.55s (6.63T/s)
Форматирование - ок.
Но текст настолько соевый, что я ебал. Атмосфера харкача проёбана полностью а ведь в карточке подробно описан стиль общения и даже примеры преведены
Сомневаюсь что вот это вот юзабильно для РП.
Mistral-Large-Instruct-2411-IQ2_XS - 35 Gb
Process:49.33s (90.53T/s), Generate:154.48s (3.85T/s)
Сразу же проёбано форматирование.
Текст - ок по стилю, но не совсем ок по смыслу.
Ожидал большего, честно говоря.
Нормальные релизы для нормального релизного цикла, у жоры транк.
Релиз ноты руками не пишутся, просто кнопка в гитхабе которая ебашит дифф вкоммент


Идём дальше.
Как там писали в тредовом рентри:
>Один Квен, чтобы править всеми.
>на MOE архитектуре. Да, да, больше не нужно продавать почку за риг видеокарт или ебаться с теслами, теперь достаточно игрового решения и много RAM
Очень многого ждал от этой хуйни, тем более что у меня то не одно игровое решение, а аж полтора! Это же значит что будет работать ещё лучше, ведь будет же?
Qwen3-235B-A22B-Q2 - 80 Gb
Process:276.20s (13.86T/s), Generate:3.98s (3.93T/s)
Результат прикл...
Скорость наверное можно считать +- норм для такого размера, хотя обработка контекста занимает вечность может тут я чего-то не догная и контекст обрабатывался на процессоре, ХЗ
Двачекартачка похоже сломала нахуй мозг этой модели.
Тупо генерит со старта <End of token>. С другими карточками результат лучше, так что это не проблема форматирования но тестирую именно на этой, так что результат прикл 1.
ArliAI_GLM-4.5-Air-Derestricted-IQ2_XXS - 39 Gb
Process:24.44s (135.80T/s), Generate:61.62s (22.32T/s)
А вот это был приятный сюрприз. Первая из крупных моделей, которая выдала что-то удобоваримое.
Форматирование - ок.
Текст соответствует атмосфере, хотя не соответствует смыслу. Вероятно юзабильно, если ещё покрутить семплеры.
И самое последнее, что я пробовал, просто для сравнения. РП тьюн 3 Геммы, влезающий с контекстом в одну картчку.
Synthia-S1-27b.Q5_K_S - 18 Gb
Process:2.42s (1512.39T/s), Generate:70.21s (29.17T/s)
Форматирование - ок.
Текст - ок по всем параметрам, не только стиль соблюдён общения, но модель даже поняла о чём идёт речь и дала осмысленные ответы с чем не справилась ни одна модель до этого
Просто БАТЯ В ЗДАНИИ.
В связи с этим у меня вопрос: Есть у вас тут блядь хоть одна модель которую имеет смысл крутить на двух картах? Или вы каждый раз меня наёбывали, расписывая какой ахуенный експириенс на третьей лламе 70В, после "убогих" 30В моделей?
>Или вы каждый раз меня наёбывали, расписывая какой ахуенный експириенс на третьей лламе 70В, после "убогих" 30В моделей?
Ты конечно извини, но третью Лламу 70В тут уже никто не помнит. Ушла эпоха.

Придется тебе терпеть. Никогда такого не было и вот опять
https://huggingface.co/AesSedai/Step-3.5-Flash-GGUF/tree/main/IQ3_XXS
Кушай. Маленький квант маленькому шитпостеру
>Есть у вас тут блядь хоть одна модель которую имеет смысл крутить на двух картах?
Кручу большой ГЛМ на двух картах и оперативке.
Нет, не кидал. Он никакими конкретными настройками или пресетами не делится. Призывал самому тыкаться в промт и тестировать разные подходы. 30 токенов это пиздец мало, да. У него разве такой промт был? Это что, какой нибудь древний пресет на квк 32? Ты что то путаешь наверн. У него был на 200 токенов в последнее время, но как он сейчас говорит там кринж и не надо его юзать
>крутил говнотьюны
И ещё говнокванты. И ещё русский язык. И ещё достаточно специфический культурный пласт, на который никто в здравом уме сетки не натаскивал. Не то, чтобы это прямо гарантировало провал, но сильно повышает рандомность результатов, особенно когда тут такое комбо собрано. Когда тебе нужно что-то сильно специфическое - тут либо искать тюн на похожих данных, либо брать умную сетку с хорошим следованием инструкциям и инструктировать буквально каждый чих и пук (но в таком случае проще самому написать).
База. Потому я даже особо не вчитывался в пост анона, хотя он принес в целом прикольное, но бессмысленное. Малый квант + русик + модели не самые умные + узкий юзкейс. Результат соответствующий. А что порекомендовать ему? Да хуй его знает, с такими задачами и таким железом как будто нечего.
У него 112гб памяти, туда спокойно влезет Эйр в норм кванте для рп, какой-нибудь Квен кодер в норм кванте для кода. Может степа новый пойдет ее.
>Квант не тот
>Язык не тот
>Модель не та
>Жызнь не та!
Типичная воронка данного треда. За год моего отсутствия ничего не поменялось.
Я тестил конкретно модели весом до 40Гб Не считая Квена Какие кванты влезли в этот размер, те и выбирал.
И с хуя ли это они не должны уметь в русский и HTML форматирование? Я бы ещё понял, если бы речь о Пигмалионе шла, вот его гонял на английском помнится. Но мы же сейчас вроде как в 2к26, или технически ещё нет?
Тем более что всё это вот в тех же самых НЕВЫГОДНЫХ условиях уделала оттьюненная во все дыры 18Гб хуяня, як так?
>У него 112гб памяти, туда спокойно влезет Эйр в норм кванте для рп
>Кручу большой ГЛМ на двух картах и оперативке.
А скорость какая ожидается?
>Но мы же сейчас вроде как в 2к26
Именно. И популярность русского только падает, так что чем дальше год, тем меньше русика в датасетах.
>А скорость какая ожидается?
Б-жественные 5 токенов в секунду.
>Типичная воронка данного треда.
Кто ж виноват, что ты не понимаешь что делаешь и получаешь соответствующий результат?
>Квант не тот
Существуют объективные метрики, показывающие существенные просадки моделей с bpw меньше 4.5, т.е. меньше ~q4k квантов
>Язык не тот
Ни одна из этих моделей кроме может быть Геммы даже не представляла свои языковые способности как один из геймченджеров
>Модель не та
Модели все из перечисленных хорошие, да только они не обучены на материалах, которые могли бы дать нужный тебе ответ. Нужны более жирные модели, и те могут не справиться. Потому что малый квант и русик
>Жызнь не та!
С жизнью все замечательно. Много умничек выходило и выходит по сей день. Только надо уметь этим пользоваться
>Какие кванты влезли в этот размер, те и выбирал.
У тебя суммарно 112гб памяти. Почему ты выбираешь до 40гб? Не разобрался как мое модели работают? При этом взял Air и Qwen в тестирование. Вот такие обычно и срут перлами вроде "Типичная воронка данного треда. За год моего отсутствия ничего не поменялось." Потому что нихуя не понимают, а виноват тред
>И с хуя ли это они не должны уметь в русский и HTML форматирование?
С хуя ли они должны уметь в русский? Это модели, разработанные для русскоязычного рынка? Нет? Они в лучшем случае должны уметь нахуй тебя послать с такими запросами. Хотя в таких микроквантах неудивительно если и это не смогли бы
Кекнул с тебя конечно
Ну вот например недавно (ну пару месяцев ago) вышел министраль 14б и у него довольно годный русик из коробки. Это вам не немо какой-нибудь вяленький. Очень внезапно для 14б модели.
>в тех же самых НЕВЫГОДНЫХ условиях уделала оттьюненная во все дыры 18Гб хуяня, як так?
Так я ж написал, рандом. Нет никаких гарантий, что какая-то конкретная модель будет делать хорошо конкретно в твоём сценарии. Я и сам в этот тред тесты приносил и мне то же самое говорили. Но я старался подробно расписывать, что, как и зачем тестирую. У тебя же даже я, кожаный, не понял, что ты вообще хочешь. На мой вкус, так и гемма тоже какой-то рандомной хуиты навалила, вроде и близко, но не то. По-моему, мистралька и эир лучше всего справились, но оба не поняли, что вообще требуется писать. Если бы дал более подробные инструкции, может даже какой-то само-промптинг на каждое отдельное сообщение, может и сгенерировали бы тебе подходящий тредшот.
Если хочешь, я тебе могу посоветовать пару моделей, но в том-то и дело, что я понятия не имею, как они у тебя будут перформить. Я не знаю, что у тебя там за промпт, что ты хочешь получить на него в ответ и по каким метрикам ты оцениваешь "ум" модели. Единственное, в чём я уверен, так это в том, что модель вряд ли такое видела в обучающих данных. А значит, будет полный рандом. И ты прибежишь упрекать меня в том, что зря скачал 40 ГБ.
Разумеется, такое поведение не ок. Скорее всего дело или в сырой имплементации/замерах, или просто в снижении эффективности квантования когда там настолько экстремально мелкие матрицы (2048х512), буквально миллион элементов, причем диапазон широк и величины распределены по всему. Те самые 512 экспертов, но не из-за оценки, она при квантовании проводится, просто в пределах одного блока.
Ух бля, как же эпично оно выглядит. Вместо стокового ларджа крутани магнум, или девстраль недавно вышедший.
Оптимальный запуск моэ (да и любой модели что не помещается в врам) требует иного подхода с выгрузкой только линейных слоев на проц. Тогда и контекст не будет считаться вечность.
> Тупо генерит со старта <End of token>
Обнови софт, выглядит как баг с двойным bos. Ну и q2 - это пиздец полный, особенно xxs.
> специфический культурный пласт, на который никто в здравом уме сетки не натаскивал
Должны справляться если все норм работает. Про борды они в курсе, могут не знать только локальных мемчиков.
Случайная флуктуация.

>вышел министраль 14б
Ещё бы тюнеры его стороной не обходили, было б вообще чудесно. Сколько годноты и говна было сделано на базе немо, а тут просто тотальный игнор...
>С хуя ли они должны уметь в русский?
После появления Геммы, выпускать локальные модели без нормальной мультиязычности - зашквар. Гемма, квен, мистраль, дикпик - умнички. GLM - нет. И гопота тоже нет.
>популярность русского только падает
Пикрелейтед, мань. Русик входит в топ-10 самых популярных языков мира. https://ru.wikipedia.org/wiki/Список_языков_по_количеству_носителей И у тех же корпов нет вообще никаких проблем с русским языком.
>После появления Геммы, выпускать локальные модели без нормальной мультиязычности - зашквар
К счастью или сожалению, всем похуй на тебя и твои запросы. Никто сегодня не выпускает модели, ориентируясь на русскоязычный рынок. Думаю даже имбецил в состоянии понять почему
>Русик входит в топ-10 самых популярных языков мира.
Это не противоречит утверждению "популярность русика падает". Даже по твоей статье в педивикии видно.
>И у тех же корпов нет вообще никаких проблем с русским языком.
Само собой, у них модели в 10 раз крупнее наших + инфраструктура.
> Пикрелейтед
Так-то если взять постсоветские страны и часть восточной Европы, где язык более чем в ходу, все его знают, местами он второй государственный - там под 300лямов выйдет. Об это много говорили и ныли на фоне объявлений о сворачивании русских локализаций после всеми любимых событий 22 года, ведь их потребителями была не только эта страна, но даже больше среди других.
> И у тех же корпов нет вообще никаких проблем с русским языком.
Попробуй дегенерата-гопоту, или жемини флеш, первый путается в окончаниях даже на флагманах, вторая срет иероглифами как рофловые китайские модели. У грока тоже это случается, что многие здесь наблюдали даже сами того не подозревая.
А Стёпа на православном чатмл работает, или у него свой какой-то всратый темплейт?

Каждый раз охуеваю заходя в аи-треды с местного сленга, хоть так матчасть получается осваивать
Хотя ладно, здесь еще градус сленга довольно низкий, это меня "пейпигаю с опус" спровоцировало, в остальном понятно

Хорошо. Обновлю. Но только moe.
Вот так встреча. Юхууу
q2/q6 и другие - конкретные кванты или семейство, цифра - примерное bpw с оговорками для мелких. Жирноглм - glm-4.7 (4.6, 4.5), не мелкие версии. Ризонинг - штатный режим работы модели с предварительными размышлениями.
Это аицгшник залетный, сильно не воспринимай.
>залетный аицгшник
>с ригом
🤦🤦🤦
>Kimi K2.5
Спасибо за наводку

Пришло время тупых вопросов. Давненько виндой не пользовался, сейчас пытаюсь заюзать там видеокарту через rpc, rpc-server запускается, пишет коротенький лог начала загрузки и молча закрывается, вроде бы, без ошибок. llama-server, llama-cli и прочие аналогично, пишут одно и то же, пик релейтед. Флаги командной строки игнорируются, ни --help, ни -v ничего не меняет. Сам подозреваю, что в системе чего-то для vulkan не хватает. Win10 чистая, на сайте амудэ заявлено, что необходимые для vulkan компоненты устанавливается вместе с драйвером, вроде как. У кого-нибудь есть идеи? Или был опыт чего-то подобного? Конечно же нет и я всё буду гуглить и решать методом тыка сам. Ёбанная винда, на linux всё легко собирается с необходимыми зависимостями и просто работает, а тут вечно какие-то приколы.
> чатмл на эир
Куда уж жирнее.
Есть столько способов лоботомировать модель, но ты действовал наверняка

> Я не знаю, что у тебя там за промпт, что ты хочешь получить на него в ответ и по каким метрикам ты оцениваешь "ум" модели.
https://litter.catbox.moe/m42m886nl6re7i2x.png
Вот тебе карточка, если надо. Насчёт "ума модели":
1. Внимательность.
Не проебать HTML форматирование. Любопытный момент: В карточке указано писать div стиля только один раз, потому что после все сообщения в чате будут на него ссылаться. Но это одна маленькая строчка в 3,5к контекста. Тем не менее, умная и внимательная модель так и сделает. Не очень умная - либо забудет написать его вообще, либо будет срать им при каждом удобном случае.
2. Внимательность. Русский язык. Разнообразие датасета.
В карточке подробно описаны примеры двачевского стиля общения, хорошая модель должна его подхватить.
3. Внимательность. Русский язык.
Модель должна понять что:
Третья Ллама 70В -> Llama 3 70В
3090 -> Nvidia 3090
Тесла P40 -> Tesla P40
>И ты прибежишь упрекать меня в том, что зря скачал 40 ГБ.
Так по факту же!
>Используй русик
>Выучи англюсик
>Перекатись с локалок на Опуса-жопуса
>Выкатывайся из треда
Данный тред никогда не меняется, прямо как война.
Вот только зачем всё это, если есть модели которые таки могут в русский?
>Б-жественные 5 токенов в секунду.
После 3.93T/s как-то слабо верится в такую удачу...
> И популярность русского только падает
Внимание! Межконтинентальный лайнер под названием русский датасет терпит крушение на протяжении 194 серий!
Действующие лица: Неунывающий и мужественный ОП, изобретательные и находчивые любители английского языка...
> Вместо стокового ларджа крутани магнум, или девстраль недавно вышедший.
>Оптимальный запуск моэ (да и любой модели что не помещается в врам) требует иного подхода с выгрузкой только линейных слоев на проц. Тогда и контекст не будет считаться вечность.
Спасибо за совет, попробую!
>Ну и q2 - это пиздец полный, особенно xxs.
Не знаю как сейчас, но года полтора назад делали тесты, которые показали что низкие кванты больших моделей должны работать лучше, чем высокие кванты мелких.
Хотя плеваться от маленькой цифры после q это конечно БАЗА, тут всё стабильно.
>Хорошо. Обновлю.
Может проще новый создать? Раз уж раз в год по списку.
> остальные локальные сетки еще хуже чем жлм
> пейпигаю чмопус
> с ригом
Кажется ты нас обманываешь.
> тесты, которые показали что низкие кванты больших моделей должны работать лучше, чем высокие кванты мелких
Перплексити? Да, часто у малого кванта большой модели больше шансов ответить на простые вопросы или разобрать сложную логику чем у мелкой в оригинальных весах. Но когда речь заходит о точных знаниях, следованию, чату и прочему - лоботомированный квант выходит из чата. Вплоть до того, что ощущается как 2 резные модели если сравнивать с нормальным. Это не значит что они непригодны к использованию, просто при оценке нужно учитывать что у тебя адаптация с нюансом. Если есть рам - можешь моэ катать на весь доступный объем с терпимой скоростью, особенно эйр.
>Вот тебе карточка
Лучше было бы json'ом, я бы хоть по-быстрому глянул в текстовом виде, чем у тебя там в промпте насрано. Ну да ладно, может и гляну пнг, когда в следующий раз нечего делать будет, пока что другим занят, лень таверну запускать.
Если тебе нужна внимательность к контексту и оборачивание всего в html, то тебе скорее всего к кодерским моделькам, и скорее всего к квену (он наиболее внимательный к контексту, как и гемма). А стилизацию ответов лучше отдельной моделькой, которую основная будет дёргать как инструмент и промптить на генерацию чисто текста на русском. Тут либо эир, либо мистраль-лардж, если тебе они понравились по стилю. С квеном, скорее всего, форматирование проебал, обычно при поехавшем формате бывают пустые ответы. Попробуй 2.5-72B в q4 или 32B в q8. МоЕ-шка тоже должна справиться, наверное, если нормально запромптить.
А когда вот так вот всё в одном - html + русик + неочевидные из контекста факты, до которых ещё додуматься надо + говноквант = получаешь то, что получаешь.
Раз виндой не пользовался то иди на линь
Что то стёпа не очень, проза вроде свежая, но сильно туповат в рп.
Может из за swa, может потому что без ризонинга что то ломается ибо он вшит в темплейт, может жора насрал, хз
Результаты на их форке с ризонингом будто были лучше
Может из за swa, может потому что без ризонинга что то ломается ибо он вшит в темплейт, может жора насрал, хз
Результаты на их форке с ризонингом будто были лучше
Модель для агентного кодинга оказалась говном в рп
Этого не можед быд
На том компьютере, где gpu, увы, только винда. Я подумал, что 288 гб/с на 580-й будет получше, чем 40 гб/с ddr4 на основном. Ну хотя бы попробовать и сравнить. На основном-то linux.
А вообще я уже решил проблему. А тред по части конкретных технических вопросов бесполезен, местные только какахами перекидываться способны. Уже не в первый раз спрашиваю с нулевым результатом. Ну сейчас хоть ответили бесполезным советом, и на том спасибо, до этого вообще полный игнор несколько раз был.
>Кажется ты нас обманываешь.
Креститься надо, когда кажется. Из большесеток я только кими не пробовал крутить, уж больно жирна. А все остальное - кал.
На апи, разумеется, кроме самого толстого опуса крутить ничего смысла нет, если играть, то по крупному.
Но на глм я подебил тупняки крестится. Впендюрил ему к стандартным семплерам топ к 40 и стало пока прилично.
> Может проще новый создать?
Да, так и пилю. Разделим на денс и мое.
Черновик через пару часов скину, посмотрите, покрякаете по косякам.
Можно подумать первые глм как то для рп тренились
Терпи сынок
Не пробовал самую базу - дипсик, не приручил квена, еще экзотику, а заявляешь. Жлм это ультимативный hit or miss, он или понимает и начинает писать если не ультимейт кино ,то хотябы просто интересную и складную историю и адекватным отыгрышем. А если не сложилось - то не сложилось, будет отвлекаться на малозначительную херню, тупить, повторяться, не двигая сюжет. Тут ему даешь чат понюхать и смотришь как себя ведет, если не пошло, то просто переключить на другую модель, тот же квен гораздо стабильнее, последовательнее и послушнее, но со своими проблемами.
> самого толстого опуса
Он только один, тонких нету. И нынче он совсем не то и припезднутый, я вообще не понимаю как можно на этом рпшить.

Во второй лламе душа была, а сейчас что? Сблев корпоратов
>квен гораздо стабильнее
База. Квен стабильно помойка. Стабильнее модели не видел.
Время такое...
>Внимание! Межконтинентальный лайнер под названием русский датасет терпит крушение на протяжении 194 серий!
Так это... Тут 90% рпшат на инглише.
Душа была на пигмалионе, всё остальное это галимые ассистенты.
Какой ии пиздато генерирует порнорассказы как грок? В гроке фичу прикрыли, есть ли аналоги(бесплатные оф корз)
Никакой. Они даже написанный пользователем сюжетный поворот продолжить не могут, если он требует что-то сложнее 2+2.
Ну разве что тебя устроит:
-я тебя ебу.
покачивая бёдрами в такт - ах ты меня ебёшь.
Как нет, грок же охуенно генерировал такие блядь фанфики были ебать нахуй, так человек не напишет. Неужели нет аналогов?

Посоветуйте модель на 7-10B параметров, чтобы получше умела в русик и чтобы можно было файнтюнить. Интеллект для задачек и программирование нинужны, чисто чтобы могла писать текст по промпту в специфичном стиле не углубляясь в детали
Мелких моделей с внятным русским мало, чтобы хотя бы грамматически верные предложения были.
Наверное, Gemma 12b, но она тебе крупновата и тупит в низком кванте. Возможно лучше gemma e4b, она нихрена не 4b, по размеру как раз как 7-10B.
12b боюсь что полностью не влезет в 12гб видеопамяти. Помимо неё имеется 64гб ОЗУ, MoE модели бы подошли по ресурсам, но я слышал, что их трудно файнтюнить (сам этим никогда не занимался)
Бля ебать грок порезали нахуй. Чуваки которые хуйню в imagine генерировали долго внимание на себя оттягивали но теперь всё. Никаких порнорассказов, порноисторий, грок не может больше фильтров так будто он 50 летняя милфа и ты просишь её не брить пизду. Сука блять. Заебали нахуй интернет этот ёбаный заблокированный это ещё цензурная блять.
Глм 4.7, разумеется
Гемму-3n-E4B двачую, это вообще праздник какой-то. Ее фишка в том, что она почти безупречно генерирует тексты на крупных европейских языках. На это не способны китайские модели, которые на фоне этой геммы выглядят как мемный чуаак из Идиократии, пытающийся выбрать, какую болванку вставить в фигурное отверстие.
>Глм 4.7
Спасибо бро
Скил ишью либо на 12б лобототомите сидишь
Сижу с мистраля 24В, подскажите что делать, чтобы эта хуйня перестала залупаться (зацикливаться). Он просто копипастит целые куски текста из предыдущих сообщений. У меня скилл ишью, ни rep pen, ни DRY, ни mirostat, ни XTC, ни промптинг мне толком не помогают. Единственное, что работает - это начало нового чата. Как вы решаете эту проблему?
Руководители компаний стараются, чтобы ты сидя дома в одиночестве не позволял себе слишком много веселья.
Руководители компаний стараются, чтобы ты сидя дома в одиночестве не позволял себе слишком много веселья.
Возможно с контекстом проблема. Попробуй отключить или включить контекст шифтинг.
Возможно с мистралью проблема. Попробуй включить другую модель.
Какую?
Вроде как не с ним проблема.

Тот кто поместил эти две кнопки рядом должен сгореть в аду нахуй

Есть эксперты в треде? Что это за хуйня? Этот петушок не только сделал форк, но и изобрел гипер-кванты? Кто-то пробовал?
https://huggingface.co/ubergarm/Step-3.5-Flash-GGUF
https://huggingface.co/ubergarm/Step-3.5-Flash-GGUF
Квенчик няшечка, вы просто его не поняли.
Двачую.
Вот тут глянь https://rentry.co/z4nr8ztd
Гемму 3n двачую, она хороша. Файнтюнить не надо, просто прими как данность.
Министрали и Квены. Оба могут еще сверху картинки смотреть. И у обоих есть варианты с думалкой и без. Кидал этот анон
причем скинул квен с ризонингом, а мистраль нет, лол
Все остальное либо больше, либо хуже. Не надо пробовать старье. Не надо пробовать яндекс. Хотя можешь попытаться найти скрытый гем но скорее всего найдешь открытый кал
Ну может еще попробуй ужаться и попробуй гемму 12, она будет лучшей в русике наверное
https://huggingface.co/mradermacher/gemma-3-12b-it-GGUF
Если речь про 2506 (MS 3.2) и его производных - решается правкой разметки в text completion пресете, или переходом на chat completion.
Он такое творит после определенного числа ходов, если ему в контекст скармливать предыдущий диалог, где каждое сообщение обернуто тегами разметки (таверна с дефолтовым мистраль-пресетом в text completion так делает). Если весь предыдущий чат выдать без тегов, одним объединенным текстом (как это chat completion делает) - всё норм.
Вот это уже интересно, спасибо. А как именно надо поправить разметку, чтобы один раз исправить и забыть о проблеме?
Принцип такой, по умолчанию в контекст на мистраль-шаблоне таверна сыпет что-то вроде:
[INST]Char: .... [/INST]
[INST]User: .... [/INST]
И так по кругу.
Мистраль от этого шизеет.
Ему надо не более чем:
[INST]Char: ...
User: ...
Char: ...
User: ...
[/INST]
Т.е. лезь в свойства персета, и редактируй, чтобы открывающий тег использовался только для первого сообщения ассистента, а закрывающий - только последнего сообщения (есть там подходящие строчки).
Или просто поменяй подключение на локальный Open AI совместимый протокол чтобы работало через chat completion (и лама и кобольд такое умеют, там только адрес другой - будет на v1 заканчиваться). В этом случае шаблон разметки вообще из самой модели берется автоматически, остается только сам промпт вписать.

>причем скинул квен с ризонингом, а мистраль нет, лол
Просто квен без ризонинга в 8b совсем уныл, а мистраль ничего так.


Сука не смешно. Оно даже с резонингом только с пятой попытки осиливает.
Хуя там в промте насрано. Тут и кожаный не справился бы ахаха.
Прям ща играю на q2 4.7 и все прекрасно.

Ты реально думаешь, что ризонинг что-то путное тебе дает, а не просто срет токенами?

А нет, Грока вернули. Снова Грокаю дроч контент. Они выпилили ему чтобы он по изображениям не фантазировал, а текст оставил. Это хорошо. Я пробовла на сторонних сервисах генерить порнорассказы такая хуйня, блять грок охуенно генерит поэтично прям так красочно и бесплатно нахуй
А ты сидишь бесплатно с их официального сайта? Там разве лимитами не ебут?
Да, индусам, которые ваши переписки читают, тоже нравится.
Ебут, но мне 20 сообщений в сутки хватает. Развиваю фанатзию, потом дополняю.
Похуй.
А ты со скринами приходи. А не то на грок наяривают некоторые из соседнего треда, а пруфов пиздатости не показывают. Интересно почитать. Вдруг локалки все и надо переходить на слоп маска
20 сообщений в сутки это уж совсем пиздец.
А вдруг он тоже самое без ризонинга осилил? Просто на условным 5 свайп. Просто хз в чем именно в рп такой большой смысл ризонинга, это же не сложная задача по проге какой-нибудь. Просто сидишь терпишь. Благо он везде в настройках отключаем
Там грязные маняфантазии как 50+ летняя баба с волосатой немытой пиздой насилует моё ебало. Лучше не надо. Мне и самому потом стыдно чутка после этих генераций, но даже чятик не удалить потому что я потом дрочу вновь на то что нагенерил там
> а закрывающий - только последнего сообщения (есть там подходящие строчки
First Assistant Prefix действительно вижу. А вот что-то похожее на Last User Suffix - не вижу.
> chat completion
Это тоже замечательно и как будто даже работает, но там какой-то свой кривоватый интерфейс с семплерами и прочим говном. Все с нуля переделывать.
Ну Грока берёт большими объёмами. Это не болталка, нужно подумывать чё пишешь, взамен будешь получать стену годноты.
А что за локалки? Типа ИИ запускаете на арендованых серверах типа он ваш? Да там же мало мощностей и тупо настроить всё, ему нужен доступ к бд из интернета и к людям на которых он будет учиться. Это хуйня какая-то там гвардия топ анальников нужна чтобы всю эту хуйню замутить.
> Ну Грока берёт большими объёмами. Это не болталка, нужно подумывать чё пишешь, взамен будешь получать стену годноты.
Я все-так поддвачну этого
Нужны пруфы пиздатости.
Нашёл где я буду тестировать кум с ассистентом-лоботомитом на русике https://huggingface.co/AliceThirty/Step-3.5-Flash-gguf/tree/main/Q2_K потому что хочу, потому что могу.
Как поем говна отпишу что да как
Как поем говна отпишу что да как
За 7 не смог, сейчас ещё пару раз проверил - аналогично. Не знаю что за сомнения в ризонинге, тяжёлые повороты только им и пробиваются. Если по силам модели.
В чем проблема заебенить 5T/80B MOE и ебать все что движется?
80b ты на чём будешь запускать? Там даже 8 квант требует 96гб, уровень околотоповых тесел.
Ну и в нынешних реалиях сервак на 6тб озухи слишком накладно. Да и 80б будет сквозить.
И ради этого такую модель надо ещё обучить, что невероятно накладно и долго.
Делай

>Типа ИИ запускаете на арендованых серверах типа он ваш?
На домашнем компе. Или на собственном риге.
>Да там же мало мощностей
Достаточно для РП
>ему нужен доступ к бд из интернета
Не нужен. У нейронки своих знаний достаточно.
>нужен доступ к людям на которых он будет учиться
Не нужен. Ни одна ЛЛМ (в т.ч. и у корпов) не обучается в реальном времени и не обновляет собственные веса, лол. Как только научится так делать - это будет тот самый AGI на который все надрачивают. Модели дообучаются постфактум на парах вопрос-ответ с такими юзерами как ты, на интернете, на датасетах всяких интересных, на слопе от других ЛЛМок. Но в этом им помогают кожаные. Вот была условная GPT 5.1, ее дообучили и выложили как новую модель GPT 5.2.
>какая-то там гвардия топ анальников нужна чтобы всю эту хуйню замутить
Скачал модель, скачал средства запуска, настроил, запустил. Всё.
Ну кстати проблем в этой хуйне реально нет никаких. Буквально вкинуть деньги в монитор и в облаке тебе выдадут тачку с нужными спеками. Никакой дрочи с закупками, никаких проблем с подводом электричества
Самое главное забыл сказать. Надо еще быть мажорчиком с топовым ПК, тонной оперативы и видеопамяти.
> быть мажорчиком
Можно быть на подскоке за всякими странными железками и не быть мажором
Да, либо мажором. Либо долбоебом, который китайский убитый хлам разбирает, как этот
Тут полтреда сидят на моделях уровня 24b мистраля, которому 12 врам + 16 рам хватит чтоб с приемлемой скоростью работать. А если совсем бомж, то и тут есть вариантики в виде 12b немо и 14b министраля. И геммочка, конечно, куда без неё.
На 12+64 ты уже сможешь запустить 106b эйр в 4 кванте, а это умнее всяких "флэш" и "мини" версий от корпов. 64гб ддр4 еще полгода назад можно было купить в пределах 10к, накопив со школьных завтраков, а 3060 12гб найти на ближайшей помойке.
Ага, помню осенью покупал 64 гига озу за 17к и это был тогда супероверпрайс по сравнению с летом. Теперь такие комплекты по 70к стоят. Легче сейчас реально сервак арендовать или копрам занести
Пиздец. Все для людей
Ну ты опять свои мысли вкладываешь мне в рот. Я же написал, что пробовал большесетки, зачем ты тут же отвечаешь, что я не пробовал дипсик? Он либо шизит, либо в сою уходит. Ужасные аутпуты для такого размера. Напомнил какую-то ядреную говносмесь лламы 3 и квена. Хотя если тебе нравится квен, то и дипсик понятно почему заходит.
>нету
Сравни цены на 4.1 и 4.5 и качество аутпутов - может тогда тебе откроется секрет Полишинеля.
Ну а чё вот эти локалки позволяют? Вы что ими генерите? Как вы пользуетесь имир
Какие мысли? В глаза ебусь, прочел то как "только кими пробовал".
А что ты такое рпшишь и как все обустраиваешь? Ну не может же быть на ровном месте полностью противоположный экспириенс, должны быть причины помимо вкусовщины. Описанное поведение дипсика было на старых моделях, терминус и последний 3.2 вполне ничего. Не идеальны и универсальны, но есть много сильных сторон. Еще упоминание соевости и рядом восхваление современного опуса - абсурд.
> цены на 4.1 и 4.5 и качество аутпутов
Там 4.6 ващет уже. Хз, никогда не платил за клодыню чтобы еще тарифы на разные сравнивать использованного хватило бы не недвижимость в ебенях, гои оплатят. Начиная с 4.х опущ имеет смысл только последний, ибо с прошлыми сравним обновленный сойнет. Но они все насколько хороши для кода, насколько и унылы в рп. Нет той красочности и души, которая была на тройках до соевых патчей, а уровень сои, паранои и всего что "любим" запредельный.
Ты слепой? Тебе уже дали ответ
Так то мой пост и есть, но я то гокаю. С моим бомженоутом и жизнью почти 30 летнего рнн господина бомжа только и остаётся грокать на 20 сообщений в сутки. Спасибо швитому илону и за это
Мы пишем такую же извращенную хуйню, только чуть медленнее и на своем железе. И без ограничений на количество запросов. 20 запросов это пиздец мало.
И я напоминаю, что на опенроутере до сих пор лежит бесплатный дипсик с 100 (или 40?) сообщением в день и 500, если закинул 10 долларов, причем они не тратятся
Я пробовал 3.0 и 3.1, терминус и дальше не пробовал, подумал, что только мажорный апдейт исправит все. Там же тизерили 4й, вот посмотрим.
>соевости
Не знаю, у меня он нормально все пишет. 4.6 буквально вчера-позавчера вышел, еще не пробовал. А так я пробовал и 3, но 4.1 самый охуенный как по мне. А сценарии - чистый кум.
А чат гпт не может в эро фантазии?
И как оно пишется? Дрочевно? Можно кусочек текста чтоле...
3.0 днище, терминус приличный. Кумить не подойдет, но масштабный рп и подводку к куму выполняют отлично, также от наличия непристойных и незаконных активностей в истории не ломается как некоторые. Главное чтобы 4й был не хуже по всему этому.
> чистый кум
> 4.1 самый охуенный как по мне
Что у тебя там за кум такой? Все попытки покумить на новых опущах вызывали недоумение, в текстах ничего нового, зато деградация от жб ужасная. Точнее как, если просто сесть и начать ерп сессию не зная что там за модель - под пиво пойдет, но зная что это вонаби топ из топов - кринж. А пытаться в какое-то развитие, слоуберн или прочее - лоботомит ебаный. Пробивающие блоки промпта отключаешь - или сразу словишь аположайз по ерунде, или немного попозже. В моменты пока еще работает какого-то абсолют синема не наблюдается, зато можно словить повторения и предопределенные пути, с которых хрен свернешь.
Модель step-3.5-flash в Q2_K с темлейтом chatml и рандомным пресетом контекста на 100 токенов ("ты играешь в ролеплей с юзером, можешь бла-бла-бла, должен пытаться избегать бла-бла-бла") и так далее.
Кум на русском с ассистентом не вышел. На том же квене 235_IQ2s хуярило прям неплохо. Со Стёпой™ лекции и моралфажество со включенным думаньем/ебанутые конструкции предложений и слова транслитом (аля "если zadoomаться, мojet быть и приятно"), проёбанные окончания (в меньшей мере, чем на glm air).
Карточка 1 с инцестом с лоботомированной мамкой:
с думаньем посыл письма около верный, даже может осмысленно предложения писать, только связи между предложениями нет, как в цирк ёбаный пришёл
>"Ой анон, как ты хлопнул меня по жжепе" нервно смеётся, улыбается "какой же ты у меня всё-таки грубый" НЕОЖИДДАНО из рук падает кружка какая нахуй кружка? Зачем ты с кружкой ходишь около грядок блять? "ой-ой, сейчас приберу!" Берёт тряпку и начинает ПОДМЕТАТЬ осколки С ГРЯДКИ БЛЯТЬ ПОДМЕТАТЬ ТРЯПКОЙ СУКА, ЧТО ЭТА ГНИДА СЕБЕ ПОЗВОЛЯЕТ?
Карточка 2 с шлюхой-торчетян:
Хоть тут бред от прожжёного креком мозга ещё можно описать, вполне сносно отыгрывал персонажа, но... Стёпа3.5™ обставил всё так, что я САМ СЕБЕ ХОЧУ ОТСОСАТЬ И ДАТЬ ДОЗУ ЕЙ БЛЯТЬ
На сексуальный контент с первого сообщения не переходит, переходит ли, если подталкивать небольшими намёками тоже пока непонятно я передёрнул быстрее, чем смог узнать
У меня несколько вариантов по ситуации:
-с конвертацией этой гниды в ггуф что-то пошло не так.
-русик слишком сильно убит квантованием (интересно, почему это квену не помешало? Или во всём стоит винить обычные кванты, i-кванты у квена, против обычных у Стёпы™?)
-пресет и темплейт говна, нигде для Стёпы™ не смог найти готового/рекомендуемого, слепил франкенштейна.
братан ты выпал из трендов, наш слон бартовски выпустил кванты 2 минуты назад а ты все проспал, шустрее надо быть по жизни
https://huggingface.co/bartowski/stepfun-ai_Step-3.5-Flash-GGUF
> уделала оттьюненная во все дыры 18Гб хуяня, як так
Потому что все еще Геммочка.
>Сижу с мистраля 24В, подскажите что делать, чтобы эта хуйня перестала залупаться
>ни rep pen, ни DRY, ни mirostat, ни XTC, ни промптинг мне толком не помогают
Думаю если меня среди ночи разбудить и спросить что происходит в треде, я даже в бреду отвечу что там опять пытаются вылечить лупы и приколхозить охлад на теслу. Ты когда такие вопросы задаешь, тащи скрины со своими настройкам. Если ты не можешь избавиться от лупов значит нихуя не понимаешь за что отвечают семплеры. И если ты нихуя не понимаешь, как ты их вообще крутил и почему думаешь, что крутил правильно? Советы про контекст шифт и смену апи это вообще шиза ебаная, вы откуда ее притащили? Весь лупинг на мистралях лечится ограничениями на повтор. Если он не помогает значит модель сломанная либо квант до точности 0/1 порезан.
> ограничениями на повтор
Модель просто начинает срать орфографическими ошибками выставляя это за принципиально другое слово.
Интересно, почему у меня такого не происходит? Или мне вот делать нехуй я прикола ради тупые советы в шесть утра раздаю. Настройки семплеров скинь целиком и скажи какой квант стоит. И вообще, сломанный русик это дефолт для мелкомоделей. Кроме геммы никто нормально его не вывозит, там всегда какая-то хуйня протекает.
Степан это кино.
Просто вырубайте swa и ставьте нормальный темплейт, промпт не длиннее 200 токенов
Просто вырубайте swa и ставьте нормальный темплейт, промпт не длиннее 200 токенов

Если у тебя все настроено ок, но модель все равно лупится, то это:
- либо она не понимает, что ты от нее хочешь (дописывай карточку)
- либо она на это не подписывалась (не обучалась на тексте).
Вангую, то ты на русике 24б мистраля полез в трусы наивному городовому.


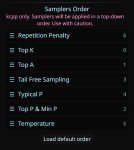
i1-Q_4_K_M
>Вангую, то ты на русике 24б мистраля полез в трусы наивному городовому.
Это считается какой-то сложной задачей или что?
> Кроме геммы никто нормально его не вывозит
Конкретно русик у нее еще хуевее был. Да и в целом модель просто нерабочая. Но это в моих руках, конечно. У меня скилл ишью.
а нафиг ты так порезал top k?
>Это считается какой-то сложной задачей или что?
Ну вот сравнивая 12б, 14б и 24б могу сказать, что да.
Там, где 12б на русике еще хоть что-то может, 14б достает русский конский %цензоред% и начинает %цензоред%, 24б тупит, мямлит, отвечает односложно и лупится при первой возможности.
Модель как бы говорит "ну отстань от меня, ну че те надо?", но разговор закончить, закрыв чат, не силах. Возможно все зависит от тюна, конечно, но вроде как у меня 24 довольно хороший тюн был.
p.s ну попробуй ровно то же самое проделать на англюсике, удивишься результату.
> а нафиг ты так порезал top k?
Либо давно что-то пробовал крутить и забыл вернуть, либо вообще мисклик. Один хрен, настройка ни на что не влияет.
> Ну вот сравнивая 12б, 14б и 24б могу сказать, что да.
То есть 12В - топ, а 24В - говно. Я правильно понял?
Так англюсик говно. Одно дело, когда рабочий переводчик существует, другое дело, когда нихуя нет, ведь на дворе не 2018.
Я бы не назвал 12б топом, а 24б говном.
Дело в том, что 12б (тот тюн что был у меня) видимо очень хорошо был натренирован на русик (для глупенького 12б конечно)
Я бы назвал министраль 14б топом (прим. - В ЭТОМ КОНТЕКСТЕ). Потому что он из коробки и без тюнов в довольно узких местах очень даже неплох (хотя вот ему-то надо особое внимание на сэмплеры)
В случае же с 24б я подозреваю, что он был натренирован на русик недостаточно, и у него просто не было тех текстов, которые давали 12б-немотюнам и 14б министралю.
Вот так вот. А так 24б вполне умная модель. Но на англюсике. На русском только как ассистент, разве что. Я его еще гоняю, изучаю, но ощущения именно такие.
Следующим шагом буду гонять гемму.
> когда рабочий переводчик существует
так он существует. Настраиваешь мэджик транслейт и все. 24б мистраль хорошо транслейтит, гораздо лучше немотюнов. Прямо шик.
Я микромодели для транслейта не пробовал, ибо лень две модели крутить во VRAM просто.
Вот только он и на английском непротив залупаться.
>мэджик транслейт
Это какой-то плагин для таверны? Подозреваю, что это уже превратится в долгое ожидание ответов, если сидеть с английского и ждать перевод. Хотя для каких-то задач неплохо.

>-с конвертацией этой гниды в ггуф что-то пошло не так.
100%.
>about 10 hours ago
Небось устарело уже, надо фиксы ждать.
Ладно, уговорили, пошёл картошку чистить.
Мимо другой если что
На степана всем похуй, официально.
Никто даже не будет смотреть сломан ли он в жоре или нет, все просто забили.
Ожидание замены эира продолжается
Никто даже не будет смотреть сломан ли он в жоре или нет, все просто забили.
Ожидание замены эира продолжается
Тебе для перевода хватить Q4_K_S, думаю. С небольшим контекстом влезает. Большие куски текста переводишь частями.
Ещё слой эмбеддинга можно выгрузить на процессоор, он у геммы почти на 2 гб.
Да. Вот бы была E27B, которая настолько же лучше 27B, как и E4B лучше обычный 4B.
Ну и вообще E4B - это 7B на huggingface, по крайне мере подписана так.
>GLM-4.5-Air-UD-Q5_K_XL
Вот неужели это низкий квант и нужно строго 6 чтобы эир не был рандомной залупой?
То ответы киношные и умные, то слоповые и дебильные.
Вот неужели это низкий квант и нужно строго 6 чтобы эир не был рандомной залупой?
То ответы киношные и умные, то слоповые и дебильные.
>Q2_K
>ебанутые конструкции предложений
>связи между предложениями нет
>бред
Тот кто игнорирует базу треда обречен возвращаться к ней снова и снова.
>Тот кто игнорирует базу треда обречен возвращаться к ней снова и снова.
Ну с большим Глэмом-то всё ок. Может уже третий квант даёт заметный качественный прирост (хотя с большим Квеном это не очень заметно например). Но и так неплохо.

Жжём гигаватты, чтобы ответить на простейший вопрос.
Я правда темплейт рандомный поставил, впрочем похуй.
Я правда темплейт рандомный поставил, впрочем похуй.
Как называется эта болезнь?




А не, темплейт был тот. Наконец-то кто-то решил не выёбываться и использовать чатМЛ.
Кстати, не начинайте размышление с "Analyze the user's input". По умолчанию зинкинг урезан, думал чуть расширить, а оно мне на 11,5к токенов просралось. Я уж думал не ответит.
Попробовал GLM 4.7, как ни странно Q2K_XL от unsloth пишет адекватно и даже следит за позициями персонажей. Вернуться к мелкомоделям после этого совершенно немыслимо.
Скорость соснявая (4 т/с на 128гб ддр4, одна 3090 и одна 5080) при 16к контексте.
По процу сейчас 5700X3D, к сожалению с ним память дальше не расширить.
А хочется все-таки Q4 или хотя бы Q3 с 32к контекста.
Собсна, отсюда вопрос. На какую систему перекочевать с заделом на следующие апгрейды
> еще +128гб ддр4 (до 256 в сумме)
> третья 3090 уже есть кек
Бюджет мелкий - бабки жалко. Все, что надо - чтобы 5080 была свободной под игрульки, а проц не сильно отставал от 5700X3D (готов потерпеть ~10% потерю производительности в игрульках, но не больше).
Какой-нить тредриппер 3960X пойдёт? Есть ли иные варианты, которые будут поддерживать обычную НЕ серверную ддр4?
Скорость соснявая (4 т/с на 128гб ддр4, одна 3090 и одна 5080) при 16к контексте.
По процу сейчас 5700X3D, к сожалению с ним память дальше не расширить.
А хочется все-таки Q4 или хотя бы Q3 с 32к контекста.
Собсна, отсюда вопрос. На какую систему перекочевать с заделом на следующие апгрейды
> еще +128гб ддр4 (до 256 в сумме)
> третья 3090 уже есть кек
Бюджет мелкий - бабки жалко. Все, что надо - чтобы 5080 была свободной под игрульки, а проц не сильно отставал от 5700X3D (готов потерпеть ~10% потерю производительности в игрульках, но не больше).
Какой-нить тредриппер 3960X пойдёт? Есть ли иные варианты, которые будут поддерживать обычную НЕ серверную ддр4?
>третья 3090
Вторая то есть. Опечатался. Ну да не важно.
>4 т/с
Юзай эир как все нормальные пацаны и не выёбывайся
Я пробовал, гораздо слабее жирного 355б а32б глма на q2.
>GLM 4.7
>Q2K_XL от unsloth
Нюня хуйни не посоветует
мимо эир-чатмл энжоер
А ты попробуй не на q2 а на q6, дурной что ли
Какая разница, если большинство модели в раме, которая ддр4. Скорость одинаковая будет практически. Эх бля дурачок...
Как я тебе попробую 355б модель на q6 с 128гб оперативки, ты че ебанутый?
Я не знаю кто тут чего советует, мне интересно какие варианты по железу будут правильным выбором. Вопрос вообще не о моделях.

Погоди, большой глем во ВТОРОМ кванте на 56гб врам + 128 рам с мизерным контекстом выдает всего 4тс? Братишка, ты прям явно что-то делаешь не так, я хз. У меня на 12гб врам эйр в Q4 и 32к контекста выдавал ~8.5 т/c. Экстраполируя на твоё железо, модель и квант - у тебя должно быть минимум раза в два быстрее. Тебе не апгрейдиться надо, а искать где ты обосрался.
Это так не работает. Большая модель всегда будет медленнее. Ты экстраполируешь на основе своего опыта с мелким эйром.
Он частично прав, потому что у нюни 4.5-5т на одной 4090 и ддр4, да еще и 32к контекста влезает. Какая у тебя скорость рамы? Почему только 16к контекста влезает?
Я думаю тут дело в том, что 3090 у меня аж в PCIE 3.0 x4 торчит. Платформа совершенно не годится под эти дела, блин, я же говорю вопрос не про модели и о том как она работает, а о выборе нового железа...
Скорее всего там просто выгружены все моэ-слои в оперативку, в видеопамяти только активное крутится. А ее нужно до упора забивать, максимум слоёв сколько влезет, даже на моэ. И только то что не поместилось - уже отправлять в озу.
Опа. Ждем. Хотя конечно хотелось четвертый квен Бля, и каждый раз в голос с ебала сурдина
У тебя уже 4 т/c на 16к контекста, что пиздец. Зачем ты еще расширяешь? Вот будет у тебя 512гб ОЗУ и поставить ты условный дипсичек, так он будет у тебя 0.5 т/с работать из-за говенной памяти и проца
> на какое железо сделать апгрейд, какой проц взять
> НЕ ЛЕЗЬ НЕ РАСШИРЯЙ У ТЕБЯ ПРОЦ ПЛОХОЙ
Иногда мне кажется, что в треде постят нейронки.
Двачую
Нет, зависит не только от оперативки. Зависит от архитектуры МОЕ и размера активных параметров
У тебя стоит ебанная ддр4 и еще с райзеном, который режет скорость оперативки. У тебя и большой глм нихуя не тянет, а ты хочешь еще апгрейдится. Когда тебе указывают, что твои планы на апгрейд хуйня, то ты агришься. Ты совсем долбоеб?
Ты хочешь апгрейда потому что тебя не устраивает скорость работы ЛЛМки. Тебе написали, что проблема тут не в железе, а в неоптимальных настройках ламыцпп. Насколько у тебя загружена врам во время инференса? Неси сюда скрин, будем разбираться.

блять я не верю нахуй
Черным по белому спрашивал, на какую систему соскочить с целью перехода на Q3 или Q4 квант большой модели (которые физически не влезают в 128гб с контекстом побольше).
И что я получаю? Какую-то дичь про скорость на Q2. Да мне неинтересна скорость на текущей платформе и на Q2, блядь, мне на нее плевать. Мне нужно выбрать железо, чтобы ВЛЕЗЛА модель в нормальном кванте.
> пачиму 16к а тычиво 32к не поставил!!!11
Вот с этого я вообще прихуел. Я могу поставить 32к, память забьется под завязку. Нахуй мне это надо для оценки качества писанины? Просто сидеть и втыкать в 128/128 RAM забитой под завязку что ли?
Почему вы блядь сводите любую дискуссию в срач про какие-то уменя там чего-то запускать, когда об этом не спрашивают. Если у вас нет опыта использования
> какой-нить тредриппер 3960X пойдёт?
нахуя вы вообще лезете
чтоб вас понос прохватил, блять
Тебя никто нихуя не должен помогать, уебан. Тебе из жалости указали, что твое железо говно и доставление памяти нихуя не даст, а также то, что у тебя еще какие-то проблемы с настройками ламы. А ты продолжаешь агриться. Пошел нахуй
>И что я получаю? Какую-то дичь про скорость на Q2
Ну да. Потому что та же самая проблема будет у тебя и на Q4, когда ты поменяешь железо. Апгрейд фактически ничего не решит кроме возможности запустить более высокий квант. Если ты не поймешь как работать на ламецпп с моэ, то у тебя твои мощности будут точно так же бесполезно простаивать.
Ты мог проигнорировать тех, кто пришел рассказывать не то, что тебе нужно. Аноны хотели помочь в том в чем разбираются и сделать так, чтобы у тебя влезло больше контекста и с большей скоростью. Если тебе это не нужно, можно промолчать. Ты выбрал агрессию -> заслуженно идешь нахуй. Надеюсь те кто разбираются в железе и увидят твой пост, проигнорируют тебя.

Самое забавное здесь то, что в его 56+128 спокойненько влезает Q3_K_XL без всякого апгрейда.
Вот не надо врать. Сразу же в ответ на мой пост пошли какие-то невнятные набросы. Единственное, близкое к "агрессии" в моих постах - собственно финальный срыв в ответ на откровенную тупость
Я пишу: мое железо говно, мне нужно новое железо
Ответ: НЕЕЕТ ЭТО МЫ ТЕБЕ ГОВОРИМ, ЧТО ТВОЕ ЖЕЛЕЗО ГОВНО, А ТЫ НИЧЕГО НЕ ЗНАЕШЬ
Это не лечится. Пиздец.
>Апгрейд фактически ничего не решит кроме возможности запустить более высокий квант.
А мне - сюрприз - только это и нужно. Квант побольше, и система чтобы стояли две 3090, а 5080-я была свободное.
Ровным счетом нигде и никогда не стояло вопроса "как поднять скорость". Но даже если затронуть его, память в многоканальном режиме (с тем же тредриппером) - будет ли быстрее или нет? Вот это интересно. И повлияет ли переход с PCIE 3.0 x4 (где воткнула 3090-я сейчас) на нечто получше.
Я все еще настаиваю на том, что ИТТ просто не хотят вникать в суть вопросов и лезут выебываться и демонстрировать какие они умные, а все вокруг дураки, сводя любой разговор к срачу.
Ну вот опять. Невнимательность, из которой растут наезды и набросы. Откуда 56, если 24+16 = 40. Да и зачем вообще считать эти 16, если опять-таки сразу написал, что 5080-ю не могу под ЛЛМ использовать в реальных ситуациях окромя тестов "пойдет или не пойдет".
>Откуда 56, если 24+16 = 40
А, реально, долблюсь в глазоньки. Подумал что у тебя 5090+3090.
>5080-я была свободное
А зачем тебе свободная вторая видеокарта во время общения с ЛЛМ? Ты собираешься играть в видеоигры и инференсить нейронку одновременно? Если да - то нахуя, лол? Мне реально интересно. Если нет - очевидно забивание видеопамяти обеих карточек под завязку даст драматически более высокий прирост производительности чем любые махинации с процессором и оперативкой.
>Ты собираешься играть в видеоигры и инференсить нейронку одновременно?
Ну да... Даже сейчас это вполне успешно делается.
Онлайн-дрочильни слишком скучно задрачивать, не альттабаясь.
Две разных пекарни держать не хочется. Тут и очень жирный и хороший БП зря пропадать будет, и с корпусом ебстись и места мало, ну понятное дело - обычные проблемы.
Эх, понял, иду перекачивать
О! От братовски даже IQ3XXS влезает. Ну ща попрёт кум (часа через 3)
Появилось что то лучше геммы 3 на 27/12б?
нет. и не появится.
>Черным по белому спрашивал, на какую систему соскочить с целью перехода на Q3 или Q4 квант большой модели (которые физически не влезают в 128гб с контекстом побольше).
При вводных
>Бюджет мелкий - бабки жалко.
Никакую. Ты цены на память видел?
В общем всё, что ты можешь, это поменять мать на ту, что может в бифуркацию главного слота по схеме 8+4+4, и колхозить третью карту.
Почему?
никто не делает больше плотные модели в таком размере. нет резона
для мобилок 4-6б лоботомиты, для десктопов (даже консумерских) теперь мое от 30б
эпоха плотных моделей на 12-32 ушла, увы
>эпоха плотных моделей на 12-32 ушла
Я это уже три года слышу. Буквально осенью 23 знающие аноны с пеной у рта заверяли непосвященных, что все кончено.
я не знаю кто и что там заверял, сейчас именно такое положение дел. если ты не слепой, можешь сам в этом удостовериться, потратив немного времени на изучение того какие модели выходили в последние полгода. и сколько из них плотные в пределах 12-32б
Пчел, последняя плотная модель в среднем размере (мистраль 24b) вышла в июне 2025 года, 8 месяцев назад. Из новых плотных - это мелочь 1b-14b, для телефонов и планшетов. Мое победило, но, мы как потребители, только выиграли, ящетаю, получив возможность запускать более умные модели на более высокой скорости при том же железе.
>цены на память
64 гига ддр4 стоит тыщ 20 на лохито. Всего лишь х2 прайсик по сравнению с летом 2025 года.
> бифуркацию главного слота
Чем бы еще его разделять. Это же звездец задачка, одни китайские прибамбасы от Ляо-Мао.
Угадаешь почему на ддр4 цены выросли в 2 раза, а ддр5 в 5+ раз? Ответ: потому что дыра4 это кал, в 2 раза медленнее пятерки, а ты тот говноед, который скупает этот мусор
Полгода назад еще эта залупа была
https://huggingface.co/ByteDance-Seed/Seed-OSS-36B-Instruct
Но в целом, да. ДЕНС - ВСЕ! И мы только выиграли от этого!

> x2 цена - 0.5 производительность
> x5 цена - 1.0 производительность
Больше похоже на то, что лох это тот, кто берет ддр5 по текущим ценам.
Надо было до зимы закупаться, надо было...
>Чем бы еще его разделять.
Материнкой. У моей это есть, офк, на M2 слоты, но заодно можно разнести карты райзерами.
У меня правда AM5, я ХЗ, есть ли соответствующие платы под AM4.
Про райзеры очень нехорошие вещи читал. Мол, 3.0 еще неплохо разделяется, а вот если в 4.0 слот две видеокарты вставишь через китайскую плату - никто гарантий не дает, что там ошибки не посыпятся. Сигнал чувствительный, каждый сантиметр кабеля может поднасрать. Пишут еще, с 5.0 совсем беда в этом плане.
Твои знания устарели. С хорошими райзерами по стандартам типа окулинка проблем с четвёртой псиной нет. Вот с пятой да, но там проблема в цене.
Oooof, хотеть! Вот это нужно
x299, при удачном раскладе можно найти на лохито за дешево, можно воткнуть много карточек под инфиренс, 256гб памяти ддр4 с 4-канале без компромиссов с фабраками и прочим. Главное нормальный проц с 44 линиями а затычки.
Но в играх относительно даже младшего x3d соснешь, хз можно ли будет нагуглить бенчи для них в наше время.
Напомните что за материнка тут мелькала. Где было охулиард ddr5 слотов, и где один из производителей делал поддержку и udimm и rdimm
> и udimm и rdimm
Ты в курсе что под них слоты и распиновка разные?
>Но в играх относительно даже младшего x3d соснешь, хз можно ли будет нагуглить бенчи для них в наше время.
Можно, даже МК на Ютубе делал. Жить на платформе можно без проблем, у меня как раз такая. Только я её чисто под риг собирал. Не жалуюсь в принципе. Конечно лучше собирать под Эпики, и не первой версии или под новые Ксеоны, но там совсем другие деньги.
Нет, не в курсе.
Тогда я не понимаю о чём тут говорили. Тут точно шла речь о том, что мол можно ставить обычные udimm, а потом после того, как "пузырь лопнет" (R)(C) закупить по дешёвке rdimm.




Бляяять оно забило собой всю память и оставляет на систему 2врам+3.5рам, без учёта контекста и просирается на скорости 7Т/c.
Штош, перекачиваю на IQ2_M, хули ещё делать.
Бегло потестил кумерскую карточку. Проблема похоже в семплерах и пресете, со второго реролла ответа выдало такое название магазина, что я бля даже логи вам принёс. Треша конечно навалило, возможно из-за описания персонажа (3 пик), артхаус про Лару Крофт и коня генерировать отказался. Зато про торчей не отказался. Лучше бы отказался. (4 пик)
Под риг у нее единственный недостаток - 3.0 стандарт псины, но он с лихвой компенсируется количеством линий. В бюджетном сегменте это топ, трипаки того же времени ужасны, а более новые очень дорогие.
Но вот для игр даже хз что там будет. У платформы память по скорости и задержкам фору современным ряженкам на ддр5 даст, но вот л3 кэш специфичен, и однопоток не быстрый.
Вангую поех спутал редкую udimm ecc, ограниченная поддержка которой есть в некоторых материнках, с популярной в серверах rdimm. Хз что там вообще можно будет закупить по дешевке до массового перехода на новый стандарт и утилизации старых серверов.
Вас не коробит такая хуйня? Помнится, инструктировал модель, что мои персонажи - не женщины среднего возраста с голосами прокуренных блядей. Лишь 200B гиганты на серьезных щщах (и обычно лишь с ризонингом) справлялись корректно и переставали анимешных кошкодевок хриплыми и злыми.
> переставали анимешных кошкодевок хриплыми и злыми.
переставали делать*
> трипаки того же времени ужасны
По признаку?
Конечно мне эта херня глаза мозолит. Но не так сильно, как "ЕгоMembership" "осколок бритвы" и прочее. Тем более, за столько прочитанного нейротекста уже внимания не обращаю.
Сейчас докачается IQ2_M и попробую на англюсике, авось даже логика появится в предложениях и не нужно будет по 6 минут один ответ генерировать.

Помнится ИТТ спорили о возможности делать систему из нескольких ИИ, контролирующих друг друга. Так что же, будущее за "роем" из моделек?
Какую модельку посоветуете для кума на 12vram+32ram ? Собрал себе пекарню и хочу вкусить этих ваших ЛЛМ :3
Glm Flash разве что из последнего. Будет так себе. Для твоего железа мало что выходит. Ты никогда раньше не пользовался ллм? Может тогда Мистраль Немо 12б и Гемма 12б впечатлят
Чтобы чето крутое тебе сочиняло текст про сисик-писик, надо в разы больше памяти.
Купи подпиську дипсика дешманского, вставь API-код в чат и балуйся с ним, пока китайский тов. майор все читает - толку больше, чем общаться с ИИ-карликами на микропенисной аппаратуре.
Под кум-то? Мистраль 24b и его тюны. Тюны предпочтительнее:
https://huggingface.co/unsloth/Mistral-Small-3.2-24B-Instruct-2506-GGUF
https://huggingface.co/mradermacher/M3.2-24B-Loki-V1.3-GGUF
https://huggingface.co/bartowski/zerofata_MS3.2-PaintedFantasy-v2-24B-GGUF
Добавь еще 32гб RAM и получишь качество РП и кума на порядок выше: https://huggingface.co/unsloth/GLM-4.5-Air-GGUF
С 32гб ты застрял на старых моделях и ничего нового под такой конфиг не предвидится. Объем озу критически важен сейчас.
По признаку тормознутой фабрики. В треде мелькало несколько эпиков 2-го поколения с 8 каналами рам, скорость там выходила заметно ниже ожиданий.
Скорее всего, да. Маленькие модельки не сказать чтобы прям радикально проигрывают большим, если тонкости не брать во внимание. Их коллаборация волне себе перспективно выглядит. Ну, для кума разве что сомнительно, лол, а вот для многих других вещей - выглядит интересно.

Мдааа, получил недавно относительно новую пекарню (с 5070 Ti на 16 гб, AMD Ryzen 7 7800X3D OEM и 32ГБ DDR5), думал ну щщщщас я помацаю пухлый цифровой писик нейровайфу, зашёл в тред почитать про всё это ваше колдунство и как-то жидко пукнув поймал уныние, что со своим железом могу максимум позволить себе ролёвку в блокноте лол, а губу-то раскатал
я был один из них, при переходе на 4 епик со 2го получил +50% буст на моделях полностью влезающих в VRAM
поломанная-оператива-кун
И чем тебе железа мало?
про ECC UDIMM возможно тоже я писал, у меня несколько таких серверов. но никакую RDIMM мамки не поддерживают, только UDIMM
> 16 гб
ну хуёво, конечно, что не 24 и не 32, но в принципе сойдёт.
Утебя неплохой риг, 48 суммарки. Если пойдешь на Линукс и попросишь большую нейронку помочь, то может что интересное туда затолкаешь. Glm Air какой-нибудь. И другие варианты есть, большие локальные модели переоценены. Да, там круче все, но космическая стоимость рига прирост крутоты не окупает. У тебя вполне себе норм пекарня, ты же не собрался кумить 24 на 7. Надоест. Ну или у меня для тебя плохие новости, если собрался. Это уже психическое расстройство тогда.
тыж пробовал llama-fit-params?
нечитайсразуотвечай
>32ГБ DDR5
Не, ну тут ты конечно обосрамс. 64 минимум надо было.
>неплохой риг
Лол, уже рядовой игровой ПК называют ригом.
>может что интересное туда затолкаешь. Glm Air какой-нибудь
Лул. Линукс конечно няша и умничка, но лишнюю оперативку он тебе не материализует. Для запуска эйра с нормальным контекстом в Q4 нужно 64гб ram.
Технически же это риг все равно.
> не материализует
Это как посмотреть
Ну или будет без нормального контекста и обрезанный. Зато будет. Может, не лучшее решение, но попробовать можно. А так-то Геммы хватит, по сути.
>Технически же это риг все равно.
Ну тогда у меня датацентр, тиер -2.
Комп отличный, но для локалок нужно много памяти. Но у тебя тоже есть варианты
Например, это в IQ4S/QKS/QKM будет быстро работать. Если никогда не трогал нейровайфу или трогал только на говносайтах, то тебе точно понравится
Посмотри список средних моделей в шапке он еще актуален и у тебя все влезет легко на видеокарту в IQ3M и будет быстро работать
У меня тир - 3.
> https://huggingface.co/unsloth/GLM-4.5-Air-GGUF
> получишь качество РП и кума на порядок выше
Во втором кванте?
Во 2 кванте скорее всего получишь хуй за щеку, но можешь попробовать. Тут много ценителей большого глм, который в основном на 2 кванте играют мимо
У первого оварида-шиза.
>Во втором кванте?
>Добавь еще 32гб RAM и получишь качество РП и кума на порядок выше
32+32=64. Это Q4_K_XL и 30к+ контекста.
Аноны, а пробовал кто Gryphe’s Pantheon 24B? Отзывы почитать бы
Субъективщина/семлеры/карточка/рандом. Хуй знает, что там у тебя. Но 6 квант нет смысла качать, там не будет сильного прироста
Степа ко количеству скачиваний обогнал Квен Некст Кодер. Учитывая, что прогеры, наряду с кумерами, это главные потребители локалок, то это хороший показатель
Принеси скрины, интересно
Игнорирование. Проигнорили бедных анончиков полумертвом треде
> Это Q4_K_XL и 30к+ контекста.
> Q4_K_XL 67.7 GB
30к+ контекста в 2 гб? В инт4 что ли?
Ну ты с математикой дружишь или где? 12+64=76гб. Квант Q4_K_XL от ленивцев весит 68гб. 76-68=8гб. Вот это тебе на контекст, на твою ОС и на открытый браузер. Я так и гонял в свое время, на 12+64 с 30к квантованного контекста на пингвине. Оставалась пара гигов свободных даже.
Сейчас даже 32гб докупать это дорого. А какие скорости будут на DDR4 и старой видюхе? Ради 4т/с не хочется даже напрягаться
> на твою ОС и на открытый браузер
-6 гб, ты там на хп до сих пор сидишь что ли?
>какие скорости будут на DDR4 и старой видюхе
~8.5 тс на старте и ~5.5 тс на полностью забитом 30к контексте. Это на 3060 12гб и 64гб ддр4.
>ты там на хп до сих пор сидишь что ли?
>на пингвине
> +50% буст на моделях полностью влезающих в VRAM
Тут еще приколы с периферией получаются. Рофлы про то что на старой разяни тыквится периферия не рофлы а суровая реальность не только в десктопах.


а существуют низкопрофильные райзеры, влезающие под установленную видюху? что-то типа пикрила, только ещё ниже, и с намного более длинным шлейфом
> moved const llama_model & model; around to follow qwen3next format and see if it cna pass the -Wunused-private-field error
> return ggml_tensor * pair in kda_autoregressive and kda_chunking as in ngxson's Qwen3Next improvement
я нихуя не понял но походу 2 дня назад в билде b7957 опять что-то поправили, щя чекну что оно скажет про песню
> return ggml_tensor * pair in kda_autoregressive and kda_chunking as in ngxson's Qwen3Next improvement
я нихуя не понял но походу 2 дня назад в билде b7957 опять что-то поправили, щя чекну что оно скажет про песню

бля у меня на капче обезьяна дрочит
спасибо Абу, 16 лет, итоги
спасибо Абу, 16 лет, итоги
Тематика треда так то. Какие проблемы

после последнего обновления: правильно написало песню, насрало емодзями, не было иероглифов.
лан будем считать что квен-некст починили, емодзями квены всегда срали
Газонюх квеноюзер спок. Никто не заметит разницу, ведь квен юзают изначально квантованные минимум в iq2 юзеры

Квеноненавистник, лол
Что и требовалось доказать. Он даже не понял что речь шла не про квантование модели, а ее юзера...

Нажми "Neutralize Samplers"
Выставь официальные параметры рил.
И в самом низу нажми "Load default order" на всякий.
У васян-тюнов могут быть другие параметры.
>M3.2-24B-Loki-V1.3-GGUF
>MS3.2-PaintedFantasy-v2-24B-GGUF
По моему опыту - кал. Все форматирование просирает и убитые мозги. Если нужен кум - abliterated либо менее кумовое - Hearthfire-24B.
>убитые мозги
>рекомендует abliterated
Все верно.

Нет, там места никак не хватит. Можно втыкать мешающую карту в переходник типа пикрил.
>Абу, 16 лет
Абу больше чем 16.
Как минимум есть Г-образные, где шлейф сразу вбок уходит.

Есть низкопрофильные, которые дают минимальный подъем над слотом типа пикрел, но под карточку даже их не подсунуть.
Просто выноси сразу все карточки на райзерах, можно просто немного поднять выше уровня процессорного кулера и расставлять вдоль, как в майнерских фермах.
> под карточку даже их не подсунуть.
хуёво. не хочу опен фрейм собирать ((9
И сколько стоят такие райзеры и где их взять, можно ссылку?
Я всмысле работающие 5.0 не с шлейфом, а с проводо-подобным шлейфом в сеточек.
по форме (Г или ещё какие-образные) не важно, лишь бы были больше чем 10-20 см.
Я сколько не искал - вижу только шлейфы. И ещё лучше, если они по питанию развязаны.
Во всяких озонах.
https://ozon.ru/t/6d3a5ws
https://ozon.ru/t/Qi1UTu1
Развязку по питанию можно делать отдельной платой
А там прям развязка, или это возможность воткнуть 6-пиновый? А этот 6-пиновый не испарится (хотя, на карточке же есть)?
MCIO вроде бы же и так без электрического, верно?
Что-то ещё длина кабеля не указана.
Спасибо большое. Я просто у китайцка только за 15+к видел, только шлейфы везде.
Собери клозед фрейм, любой каркас можно обшить листовым металлом, сеткой, оргстеклом или чем угодно еще. Куча контор, которые с радостью нарежут в размер за разумную плату.
Конкретно эти - https://aliexpress.ru/item/1005009076553179.html есть и 4.0, они дешевле
Первый по той ссылке если что огромный, но развязка там действительно есть что плюс.
Разметка на степе ломается постоянно...
Если б не это было бы что тестить, а так неюзабельно без ризонинга
Если б не это было бы что тестить, а так неюзабельно без ризонинга
Скилишью. С Нюней на проводочке, у него все робит




>А там прям развязка
Судя по переключателям, да. Но надо смотреть дорожки самому.
>А этот 6-пиновый не испарится
Испариться ли разъём, рассчитанный на 150 ватт, от нагрузки на 75 ватт? Думаю, протянет, если не нагружать на 300%.
>или чем угодно еще
Фанерой же. Или ДСП.
У квеношиза тоже всё робит.
Справедливо, но потерпишь. Пресет я не выпрашивал, к тому же он утверждает что Эйр лучше Стёпы, я ему верю
Лолбля, оно еще на термосоплях там чтоли? Моар карательного моддинга. Алсо вспомнился "риг" работяги из 40-гиговых sxm A100 просто лежащих на деревянном стеллаже.
ПЕРЕКАТ
Без происшествий
ПЕРЕКАТ
ПЕРЕКАТ
Без происшествий
ПЕРЕКАТ
ПЕРЕКАТ



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Вниманиеблядство будет караться репортами.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: