



Посоветуйте сайт с годными карточками.
> Мне НЕ нужно чтобы модель отвечала на русском
Тогда все еще проще. Но для начала действительно эту попробуй, может зайдет.
> можно позволить только если модель полностью влезает во VRAM
У этой модели мало активных параметров, она чисто на цпу может выдать 10-15т/с и выше. Плюс моэ модели в целом можно быстро катать с выгрузкой. Поэтому скорость тебя точно не разочарует если освоишь правильные параметры запуска, советую не просто так. В том же размере есть жлм4.7-флеш 30а3, тоже хорошая модель.
https://www.jannyai.com/
Давно не заходил в тред.
Что для ERP нынче самое годное? До 30B.
Гемма 3, мистраль 24б как обычно. Их тюны.
Щас еще квен 3.5 27б добавился, тоже тюны есть, но пока все только экспериментируют с ним.
Qwen3.5-9B-Claude-4.6-OS-Auto-Variable-HERETIC-UNCENSORED-THINKING
Поясните про тулзы, аноны. Хочу внешний инвентарь запилить - могу сделать для этого свой инструмент-шаблон например и дать нейронке? Или только можно пользоваться какими-то встроенными?
(я тот анон которому ты ответил)
Слушай, чисто теоретически (могу ошибаться) разве тот факт что это "набор экспертов по чучут параметров каждый" не сделает модель будто лоботомитом?
Или как это работает? Просто в моем понимании, если это MOE и там есть количество экспертов (предположим, 5 на 35B модель) то разве не будет так что написано это будет конечно с использованием модели на 35B в общем, но с использованием всего 7 миллиардов параметров? Бля, запутался короче. Звучит как говно. Просто скажи - сильно лучше чем условная мистраль на 24B будет? Если да - заценю. Щас заценил министраль на 14B, вроде заебись.
Потестил 35б квен. Какое же это говно ебаное, мама дорогая, просто за гранью.
Не слушается инструкций, ему вообще пахую. Конечно, не всегда, но для РП это ХУДШИЙ вариант, нахуй.
Типичный сценарий:
2 минуты на размышления при скорости 24 тс
@
В размышлениях подробно обсуждает инструкции, карточку, систем промпт, все нюансы, прям максимально дотошно, приходит к верным выводам, что 2+2=4 и собирается написать мне об этом
@
Ответ после ризонинга на 400 токенов, в котором 2+2=5.
Я не математике тестировал, но, блядь, это просто жесть, нахуй. Карточка 800 токенов, инструкции простые, в стиле "если А, значит делай Б".
А без ризонинга вообще мясо, просто животное. Чистейшие 3б. Что характерно, 30б-а3б такой хуйни не творил и всё было чикибамбони.
Так что 27б только норм.
Кто-нибудь с 35б выжимал что-то годное хотя бы в рабочих задачах? А то после такого бреда в рп, где инструкции игнорируются, даже проверять не хочется.
Не слушается инструкций, ему вообще пахую. Конечно, не всегда, но для РП это ХУДШИЙ вариант, нахуй.
Типичный сценарий:
2 минуты на размышления при скорости 24 тс
@
В размышлениях подробно обсуждает инструкции, карточку, систем промпт, все нюансы, прям максимально дотошно, приходит к верным выводам, что 2+2=4 и собирается написать мне об этом
@
Ответ после ризонинга на 400 токенов, в котором 2+2=5.
Я не математике тестировал, но, блядь, это просто жесть, нахуй. Карточка 800 токенов, инструкции простые, в стиле "если А, значит делай Б".
А без ризонинга вообще мясо, просто животное. Чистейшие 3б. Что характерно, 30б-а3б такой хуйни не творил и всё было чикибамбони.
Так что 27б только норм.
Кто-нибудь с 35б выжимал что-то годное хотя бы в рабочих задачах? А то после такого бреда в рп, где инструкции игнорируются, даже проверять не хочется.

Nemotron 120b
ministral-14b-2512 очевидно. Она для всего хороша, как ни крути.
Он действительно не плох в плане цензуры. Даже в ризонинге.
Почему вот у них модель может в рассуждения, не уходя в сейфети, а ранее базированные китойцы теперь сплошь в цензуре. Иронично ёпта.
--reasoning-budget
--reasoning-budget-message
Новые опции для жоры.
https://www.reddit.com/r/LocalLLaMA/comments/1rr6wqb/llamacpp_now_with_a_true_reasoning_budget/
--reasoning-budget-message
Новые опции для жоры.
https://www.reddit.com/r/LocalLLaMA/comments/1rr6wqb/llamacpp_now_with_a_true_reasoning_budget/
У меня иное впечатление, по крайне мере в задачах с инструментами.
qwen-3-30b-a3b вообще не работал, путал инструменты, писал просто бред, уровня, что я просил его проверить финальные результат по смыслу, и он писал "вес экскаватора получился 31кг, что для трактора с грузоподъёмностью в 20 тонн вполне адекватно..."
qwen-next-80b-a3b работал нормально, почти не путал инструменты и заметно лучше справлялся с анализом своего вывода на адекватность. Но он не full vram, и 15/s генерации вместо 80/s не прикольно.
qwen-3.5-35b-a3b работает точно не хуже, чем qwen-next. И у него точно лучше с русским.
На artificialanalysis.ai он так и стоит, в целом. В плане общего интеллекта там не такая большая разница, а в "Agentic Index" прям явно.
А ещё там вообще по всем категориям 27B > 122B-A10B > 35B-A3B > next 80B-A3B > старый 30B-A3B, вот верность расположения хвоста подтверждаю. 122 пока не пробовал, как и плотную 27B.
К слову, ещё там 9B стоит на уровне чуть-чуть капельку ниже 35B-A3B. Я протестирую, это интересно. Есть куча задач, который 35B-A3B вывозит, если 9B сможет их выполнять со скоростью 9B модельки...
Набор моделей в целом отличный (народный), грех жаловать как мне кажется:
- Для ноутов без карты или со слабой картой есть 35B-A3B, будет там tg 10/s или около того.
- Для самых простых карт на 8 ГБ карт есть 9B. На 50хх и 40хх невероятно быстрый pp будет, если он по мозгам не сильно отстаёт от 35B-A3B - это очень круто и заслуживает тестирования.
- Для "игровых" системников помощнее и с памятью 122B-A10B.
- Для обладателей V100/5090 - 27B. А может быть ещё и для обладателей 3090/4090, 4 квант всего 18 ГБ.
Закрыты почти все ниши, не удовлетворена только весьма специфичная ниша людей с ригом, где будет условных 128ГБ видеопамяти, куда 122B-A10B нет смысла пихать в связи с отстваванием от 27B, для 27B риг ей не нужен, а 400B не влезет всё-равно, и там не столь важно будет система 384 RAM + 32 VRAM или же 320 RAM + 128 VRAM, всё-равно всё в проц упрётся, о того, что на нём будет не 90% слоёв, а всего 70% - он узким местом быть не перестаент, ну будет там 90/70 ≈ 128% производительности, это точно не стоило докупки ещё 96 ГБ видеопамяти.
Поясните про NVFP4.
Это какой-то новый стандарт, который убьет инференс на некро-видюхах? Или просто маркетинговый пук?
В первую очередь интересует МоЕ: допустим, часть модели на Blackwell видюхи, остальное как обычно в RAM. Будет ли скорость ниже, если вместо Blackwell видюхи стоит 3090?
Это какой-то новый стандарт, который убьет инференс на некро-видюхах? Или просто маркетинговый пук?
В первую очередь интересует МоЕ: допустим, часть модели на Blackwell видюхи, остальное как обычно в RAM. Будет ли скорость ниже, если вместо Blackwell видюхи стоит 3090?
Это кал кобольда
Локально поднятую модель можно же дообучить на собственных текстах? Я насрал тонну черновиков и хочу чтобы она переняла мой слог и мысоли.
Я вот тут писал -->
3090 не умеет аппаратно в fp4, скорее всего она достаточно резво раскроет их до fp8/fp16 перед расчётом, это просто +1 лёгкая операция с битовыми сдвигами перед расчётом, которую на 5090 делать бы не пришлось. Не думаю, что это даже 20% разницы даст, если бы на 3090 можно было считать fp4 без изменения прочих параметров.
К слову, поправьте, если я в чём-то перепутал что-то.
Ну что наконец дождались конкурента эира?
Немотрон 40% в кокбенче как и эир, самое главное активных параметров столько же и чуть больше обычных
Немотрон 40% в кокбенче как и эир, самое главное активных параметров столько же и чуть больше обычных
встречают по параметрам, провожают по уму
Qwen3.5-27B-HERETIC-Polaris-Advanced-Thinking-Alpha-uncensored.Q4_K_M
Потыкал, несмотря на кринжовое название, вроде работает, и даже русик норм (темп 0.4, мин-п 0.05, presence penality 1.5).
Ну, для шизо-тюна - совсем норм.
Местами галюцинирует, но действительно не залупается даже с минимальным системпромтом и контекстом.
В сторителлинге описывает кум и кровь-кишки-распидорасило. В ассистенте - дал задачу "вот дизайн настолки, придумай как туда вкорячить взрослые темы и порнуху" - получил более-менее вменяемый диздок на 2К токенов.
Потыкал, несмотря на кринжовое название, вроде работает, и даже русик норм (темп 0.4, мин-п 0.05, presence penality 1.5).
Ну, для шизо-тюна - совсем норм.
Местами галюцинирует, но действительно не залупается даже с минимальным системпромтом и контекстом.
В сторителлинге описывает кум и кровь-кишки-распидорасило. В ассистенте - дал задачу "вот дизайн настолки, придумай как туда вкорячить взрослые темы и порнуху" - получил более-менее вменяемый диздок на 2К токенов.
nvidia.Nemotron-Terminal
тестили?
тестили?
ну допустим
Ну если совсем уж выбора нет и ты бедный Эдальго, 35b-а3b может подойти, но исключительно для РП, если у человека, скажем, 8 vram (и при этом модель придётся люто промптить на каждый пук, чтобы не рассыпалась). Но даже в таком случае можно задаться вопросом, не лучше ли взять файнтюн 12б геммы или немо, ибо слог у них в 100% случаях будет приятней для юзера, хоть они инструкции соблюдают ещё хуже, кроме геммы. А если готов ждать, то можно на мистрале 24b сидеть с такой памятью и подождать ответа. Всяко лучше.
Если рассматривать 35b-а3b в рабочих задачах, то при условии, что она хотя бы относительно терпимо держит инструкции у других (может у меня квант сломан, может там 6 бит нужно или что-то ещё, у меня не было желания ебать мозги), то понадобится минимум 100к контекста, ибо он улетает со страшной скоростью, да и всегда именно рабочие задачи требуют как можно больше контекста, а не рп. А это уже конфигурация не для совсем бомжей, понадобится видюха с 16 Гб видеопамяти минимум и ддр5. Может больше. Ну и чтобы ты понимал, вообще почти все мои знакомые не имеют карт, которые нормально тянут ллмки, либо у них карт или ПК вообще нет. Зато айфон последний. Это, к слову, о бомжах. То есть за пределами этого треда и коммьюнити энтузиастов всё печально. Куча амд, старых 3060, ноутов, вот этого всего.
35б-а3б никому не нужна, кроме каких-то вайбкодеров с игровым железом или типа того, потому что владельцы ригов будут свои толстые квены таскать, а бомжи и дальше сидеть на гемме, квене и мистрале 24-27, так как они дают условное 70b качество старой лламы, по мере гемма и квен.
9b рассматривать смысла никогда нет на мой взгляд, если не для специфических задач, ибо это фулл лоботомит. Точно не для обычного юзера, я буквально ни разу не видел модель такого размера, которая годится для чего-то большего, чем работа или эксперименты.
Всякие владельцы 3090/4090/5090 обычно катают только 100b+ МоЕ как раз, потому что скорость не так уж и проседает, а память раньше ведрами можно было покупать. Поэтому основная проблема как раз в сегменте 12-16 Гб видеопамяти. Если бы не делали эту дичь вроде 30-35b чисто агентских моешек, было бы куда приятней. Что-то вроде геммы по уровню литературности датасета, только МоЕ и пожирнее. Вот где был бы бомжекайф. Но разработчики всё делают исключительно для агентских задач и кода. Все эти 100-300b МоЕ такой же мусор, как и их малые версии, в плане направленности датасета, просто они вывозят за счёт общей базы знаний, где среди кодерского кала затерялось что-то приличное. Короче, просто представь, что вот сейчас бы эти моешки все были обучены на датасете опуса 3 или сонета 3-3.5. Там бы сразу шишка встала, слог попер. Даже при их размерах.
Знаю, я очень сумбурно описал. Просто устал сильно.
Как ощущается по сравнению с обычной еретик версией?
Кто вчера в прошлый тред притащил https://huggingface.co/zerofata/Q3.5-BlueStar-27B-gguf ?
Спасибо тебе.
Скачал-затестил iq4xs - и я что-то немного в ахуе до сих пор. Вот здесь прямо чувствется что это уже "новые" 27B, а не предыдущее поколение. Тюн прямо под мои RP предпочтения - простой стиль письма без квен/геммовских литературных выебонов (напоминает мистраль) но умнее на порядок, близко к Air по ощущениям. При этом - с инициативой/креативностью в отличии от Air, который либо довольно пассивен, либо уже аж шизит (от задранной температуры). А здесь - как раз в меру, перс прописанный как "инициативный, с характером" - таким и отыгрывается, сам предлагает чем дальше заниматься и свои хотелки высказывает, пытается настаивать, уговаривать, и т.д. Ощущается куда более "живым" характером чем на AIr даже (не говоря о мистрале или гемме).
Возможно вау-эффект от первого впечатления. Но пока очень зашло.
Минус - ризонинг отломанный совсем, кажется. Плюс - он ему и не нужен под такое применение.
Тестил через Chat Completion на 2K+ начальном контексте (карточка+лор).
Спасибо тебе.
Скачал-затестил iq4xs - и я что-то немного в ахуе до сих пор. Вот здесь прямо чувствется что это уже "новые" 27B, а не предыдущее поколение. Тюн прямо под мои RP предпочтения - простой стиль письма без квен/геммовских литературных выебонов (напоминает мистраль) но умнее на порядок, близко к Air по ощущениям. При этом - с инициативой/креативностью в отличии от Air, который либо довольно пассивен, либо уже аж шизит (от задранной температуры). А здесь - как раз в меру, перс прописанный как "инициативный, с характером" - таким и отыгрывается, сам предлагает чем дальше заниматься и свои хотелки высказывает, пытается настаивать, уговаривать, и т.д. Ощущается куда более "живым" характером чем на AIr даже (не говоря о мистрале или гемме).
Возможно вау-эффект от первого впечатления. Но пока очень зашло.
Минус - ризонинг отломанный совсем, кажется. Плюс - он ему и не нужен под такое применение.
Тестил через Chat Completion на 2K+ начальном контексте (карточка+лор).
> набор экспертов
Не сделает. Там от экспертов только название и их нет явных, современные моэ это не кринж от мистралей вынесете, блять, это уже в шапку или куда-нибудь. Это разреженная сеть, которая по аналогии с мозгом кожаных активирует поочередно разные участки, но в сумме на ответ будут задействованы все.
В каждом блоке в основном перцептроне 256 развилок из которых отрабатывают только 8 и потом их результат усредняется, чтобы предсказать один токен так проходит в 40 независимых блоках. На следующем токене будут выбраны уже другие развилки, они постоянно меняются. Это наоборот делает сетку умной.
> сильно лучше чем условная мистраль на 24B будет
От юскейса зависит, во многих просто небо и земля и 3б лоботомит побеждает 24б. Но для вялого куморп скорее мистралька будет лучше.
Аналогично противоположние впечателение по сравнению с прошлым 30а3, новая гораздо умнее, а в рабочих задачах просто ее хоронит, это реально квеннекст. В рп только беглая проверка что отвечает адекватно и не путается, как бы хороша не была, в таких размерах более крупным уступит. Но игнора инструкций и треша точно нет, у тебя выглядит как инфиренсопроблемы или форматирование от геммы.
Это сразу формат для совместного квантования весов и активаций модели с целью сохранения высокой точности и быстрого инфиренса на аппаратных блоках новых гпу. Достигается ценой серьезных затрат на компьют на этапе создания чтобы обеспечить верную интерпретацию.
> часть модели на Blackwell видюхи, остальное как обычно в RAM
Как сделают в жоре вообще не понятно, оно может оказаться и просто медленнее. Но потенциально возможно получить неплохое ускорение пп на больших батчах где нет упора в шину, поскольку его считает именно видеокарта.
> если вместо Blackwell видюхи стоит 3090?
Скорость будет не выше чем на обычных int квантах, понимаешь что это значит?
Все врено. Только там фишка в ускорении от переходна на такую разрядность. На блеквеллах там огромные цифры, а на 3090 придется делать рекаст в 16бит и все операции проводить в них же с известной производительностью и небольшим оверхедом. На 4090 можно задействовать поддержку фп8, по результатам она там хорошо срабатывает и скорость норм, но перфоманс также ниже + оверхед.
Алсо стоит отметить что атеншн стараются не квантовать вообще и он самый сложный в расчетах, поэтому от того кратного прироста скорости в ллм достигается только лишь часть. Интереснее качество квантования, но и достигается оно фактическим эффективным bpw между 5-6.
>очень сумбурно описал
Всё в порядке, я когда полон сил пишу сумбурнее. Твой текст читается легко и ясно.
Ещё мне не интересно рп совсем, и что там со слогом соннета и опуса я не в курсе. И код тоже не интересен. Интересны какие-то, я даже не знаю как это назвать, аналитические способности, лол. То есть возможность описать ей что-то, о чём оно не в кусре, и чтобы оно поняло, и не говорило про экскаваторы на 31 кг как про что-то вполне нормальное и реалистичное. Интересно, чтобы оно было сообразительным и смекалистым - массив вбитой в неё фактической информации, слог и способности к коду пусть на хрен идут. Особенно способности к коду, они просто вообще всё хорошее в ии-идеях готовы принести в жертву ради этого тупого кода. Как мне кажется точка максимальной эффективности нейросетей - это очень быстрый и довольно качественный индекс информации, способности скушать документации из pdf-ки на 400 листов, и удерживая их в голове написать конфиг. И ещё всё-таки это эдакая библиотека++ сама по себе в плане эрудии, и умению по плохо сформулированному запросу найти подходящее. А код писать - это какой-то костыль. Как и рп. Это не точки максимальной и даже не точки разумной эффективности.
>понадобится видюха с 16 Гб видеопамяти
Ну, нет. 35b-a3b работает в 250-400/s токенов pp и 12-20/s tg на карточке в 8ГБ, вот на моём ноуте. 27B плотная выдаёт 4/s tg генерации со старта и быстро падает до 2/s — не юзабельно. На прошлом ноуте с 1660ti и ddr4 МоЕ и то быстрее ворочается.
>ибо это фулл лоботомит
А гемму 12B в пример выше привёл. Совсем не веришь в оптимизацию в плане, что в том же количестве весов всё больше полезного? Гемма e4b (7B по размеру) точно не бесполезная. Не понимаю почему квен на 9B надо игнорировать, особенно учитывая что он будет на порядок быстрее 35B-A3B на любой карточке моложе 20хх и с 8 гб памяти.
>Всякие владельцы 3090/4090/5090 обычно катают только 100b+ МоЕ как раз
МоЕ при генерации на процессоре считается. Разбор промта на карте, окей, но вот генерация почти никак не ускоряется, соответственно ключ тут не во владении такой карточкой, а во владении ддр5 и соответствующем процессоре.
То есть если я возьму свой ноут и поменяю его 4070/8 ГБ на 5090/32 ГБ - то заметное ускорение в 100-150B MoE я получу только в промт-процессинге. А вот в 30B я получу ускорение х10 минимум и на генерации, и на промт-процессинге. Выбирая между одной генерацией в 100B-150B и 40 генерациями в 30B, я почти точно выбрал бы второе, а для сложных задач отдельные запросы я как-нибудь и так посчитаю без ускорения.
>Интереснее качество квантования, но и достигается оно фактическим эффективным bpw между 5-6.
5-6?
У step-flash 4.518bpw, у minimax 4.71bpw
По идее должно быть 4.5 и чуть больше для мелких моделей, где неквантующиеся слои нормализации или ещё чего в fp32 составляют большую долю весов.
> У step-flash 4.518bpw, у minimax 4.71bpw
Как ты считаешь? Почти 4.9 и 5.0. Рецепты могут быть разные, но атеншн и определенные слои лучше не трогать, потому так и возникает. На квенах атеншн жирный и поэтому получается еще больше, а если выйти за пределы llm - там и более 7 бит может быть в зависимости от рецепта. Нормализации - капля в море.
>Это наоборот делает сетку умной.
Ну... Нет. Результаты МОЕ чуть хуже таких же по числу параметров плотных моделей. А вот по эффективности, по затрачиваемым ресурсам да, МОЕ лучше.
>Алсо стоит отметить что атеншн стараются не квантовать вообще и он самый сложный в расчетах
Эх, помню статейку, мол, атеншен на самом деле нахуй не нужон. https://arxiv.org/abs/2111.11418
Считаю число параметров.
Беру размер в байтах, делю на число параметров и умножаю на 8.
Числа чуть другие вышли в начале, так как я вначале поленился и просто из описания взял число параметров. А потом понял, что так нельзя, и 30B, это может быть и 31 и 29 миллиардов в действительности.
Я проверил. На hf нормальные люди, у них GB - это GB, а не GiB. То есть мои числа верные.
Да, округляя и считая размер будут получаться разные числа, плюс для многих моделей выставлено сразу несколько квантов с одинаковыми индексами но заметным отличием в размерах потому что рецепты разные. Дальше пошли нунчаку кванты, которые очень близки, там делается сразу несколько вариантов разного качества, где отличия как раз в квантованных-оригинальных слоях.
А как срать запускать на лламе?

Вот эта часть перекрывает все достоинства. Просто сломано нахуй.
Жди поддержки. Потом жди, как поддержку пофиксят.
https://www.lesswrong.com/posts/kjnQj6YujgeMN9Erq/gemma-needs-help
Приносили уже? Про то, как геммочка и гемини чаще чем другие модели погружаются в пучину уныния и беспомощности, если повторять им, что они неправы.
Приносили уже? Про то, как геммочка и гемини чаще чем другие модели погружаются в пучину уныния и беспомощности, если повторять им, что они неправы.
Какой ей пресет нужен?
Хороший, няшный, но несложный. Тебе его я, конечно же, не дам. Пресет ещё нужно заслужить, заполнить форму, ответить на ребусы, прислать письмо, тогда будет няшный пресетик.
>карточками
Бейсбольными? Или с покемонами?
С таро для игры в жожо-ролевку.
>lesswrong
Уноси откуда принёс, это сектанты занюхивающие собственный пердёж. Интерпретация эмоций лоботомита это занятие для дегенератов, т.к. скрытое состояние непредставимо в человеческих понятиях, а сокращение размерности возможно лишь через субъективную адаптацию. А у них там даже не мехинтерп, это же надо додуматься трактовать через буквы. Как они понимают что шогготу это на самом деле не нравится? Потому что он так написал?

> MiniMax M2.5 (Q4K_XL, unsloth)
Немного обновил пресет, см. V1: https://text.is/MiniMaxRP_for_2ch
> мелкий фикс темплейта
> переделан префилл (остался </think> без содержания - теперь мыслеблока просто н-е-т!)
Сиспромпт все еще экспериментальный, но косяки фиксит. Добавлена команда лить слоп на русском (можно убрать, модель будет отвечать по-английски на русскоязычный инпут). Семплер - можно менять как душе угодно, у меня нет информации о каком-то лучшем или рекомендованном варианте.
Пикрил для примера генерации на русском. Английский - всё ещё лучше.
Для саммарайзов нужна вторая модель, 4B сойдёт. М2.5 при написании саммари может уйти в рефьюзы, даже если в qvink memory есть think-префилл и переделан промпт.
Пользуйтесь на здоровье. Цензуры нет.
Если я правильно понял - речь о том, что если у тебя гемини в режиме агента редачит и компилирует код, то после 80 попыток неудачной компиляции одно и того же проекта (особенно если у неё в контексте есть все эти 80 ошибок с размышлениями), она напишет что-то "да этот проект фигня собачья, задача не решаемая, я не буду этим заниматься, я удаляю проект и буду писать его заново с нуля". И что если опус/жпт такого поведения не демонстрирует, то это ещё никак не связано с тем, что такой же механизм в нём отсутствует, и он сделает то же самое, только более неожиданно и внезапно, просто потому что это поведение файнтюнингом прикрыли.
Достаточно логичное рассуждение, оно не про эмоции, а про фактический результат и его надёжность.
Впрочем, я думаю проблема почти полностью закрывается отдельной моделью-наблюдателем.
Моделька поменьше (или та же сама с другим промтом), которая видит только исходную задачу и последнее сообщение, и пропускает его только при соответствии задаче. Как с цензурой, если уболтать модельку можно за много сообщений, всякие приёмы использовать. То если там стоит отдельная модель с системным промтом на 100 слов где чётко написано что она проверяет одно следующее сообщение на предмет ... - то это уболтать уже если и возможно, то на два порядка сложнее.
А чё там такой русик неплохой, или это такой черрипик? У тебя 128+24 типа? Много контекста влезает?
У минимакса очень легкий контекст и он сам по себе быстрый как понос. И нет, там действительно хороший русеггг.
Попробуй ему задавать префилом черты сеттинга, он еще лучше работать в РП станет.
Русский хороший, но корявости есть. Я не подбирал, просто рандомная генерация. Модель в целом заебись.
У меня 128+48, с виндой получается на 32K:
> 115 / 128 RAM (оставляю место под другое дерьмо)
> 18 / 24 GPU1
> 21 / 24 GPU2
> gpu layers: 61, moecpu: 50 (мб неоптимальные настройки, я там с кривыми квантами ранее пердолился)
KV-кэш модели жирноват. Придется квант поменьше брать для 128 + 24 при 32К.
Да вроде и так нормально. Я пока по-всякому тестирую. С семплером бы разобраться, смущает что модель иногда пропускает пробелы между словами. Редко, но бывает.
Добра достопочтенному господину.
> qvink memory
Предпочитаешь его классическому подходу?
Не напишет, 80 попыток просто не будет. После 10 начнет менять подход и переоценивать, после 20-30 начнет жаловаться юзеру с предложениями как сменить подход и вопросами что дальше делать. Упаднические настроения скорее флешу присущи, вот он такое делает.
> проблема почти полностью закрывается отдельной моделью-наблюдателем
Кожаной, эти костыли не решат проблему. Да и самой проблемы в том виде нет, там или все ок, или постановка-планирование неверные.
>усский хороший, но корявости есть.
На самом деле чисто по моим меркам - их слишком много.
Ну например, Holo может назвать волком а не волчицей.
Хз. В английском модель заебись. А так я бы не стал юзать.
Честно гововря, я вообще саммари не использовал раньше. Только начал интересоваться этим...
Блять. Похоже я обосрался. Префилл видимо всё-таки нельзя убирать. Фифи-шлюха не рефьюзит, потому что карточка шлюшная. А вот SFW карточка - посылает юзера подальше и отказывается.
Печально. Не бейте, лучше обоссыте.
> <think>I'll gladly reply in English, and I'll not repeat user's input!</think>
or
> <think>I'll gladly reply in Russian, and I'll not repeat user's input!</think>
Ну и как обычно
},
"reasoning": {
"name": "DeepSeek",
"prefix": "<think>",
"suffix": "</think>",
"separator": ""
},
пойду поправлю, в пасте останется только один вариант; чертовы ллмки, они такие капризные
Печально. Не бейте, лучше обоссыте.
> <think>I'll gladly reply in English, and I'll not repeat user's input!</think>
or
> <think>I'll gladly reply in Russian, and I'll not repeat user's input!</think>
Ну и как обычно
},
"reasoning": {
"name": "DeepSeek",
"prefix": "<think>",
"suffix": "</think>",
"separator": ""
},
пойду поправлю, в пасте останется только один вариант; чертовы ллмки, они такие капризные
У этой штуки плюс в том, что все автоматом, удобно и хранится хронология, но минус в сохранении "сложности" чата и отсутствии переноса манеры общения/стиля и конкретных вещей из прошлого с учетом изменений. Все очень субъективно тут, подробный суммарайз с накоплением кажется более удачным, но заморочнее. Интересно как в подобной задаче покажет себя минимакс, может не будет рефьюзить.
> Holo может назвать волком а не волчицей
Ooof
Для проверки можешь попросить кодинг сенсея написать скрипт для скачивания волкодевочек с данбуры, а потом добавить туда тег nude.
>оно не про ..., а про ...
Нейросеть не палится. Собственно кто ещё будет дефать ранимые чувства матричных умножений.
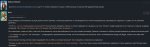

У минимакса с суммарайзом проблема в том, что там включается ризонинг. А это сразу проверка инпута цензурными экспертами или че там у него активируется. В общем кошмар.
А насчет проверки эффективности префиллов - да с ними точно цензуры нет, я просто хотел от think-блока избавиться совсем, чтоб он глаза не мозолил, но видимо нельзя так...
Вот затестил, даже на экстремальные инпуты охотно отвечает. На пик2 еще пример жесткого косяка с русскоязычным аутпутом. На английском ничего подобного не встречал.
Я ж написал - chat completion использовал, т.е. встроенный. Но можно обычный chatml text complaetion в таверне использовать - как для любого qwen 3.5. Тоже работает неплохо, но IMHO - Chat Completion все же лучше.
Кыш-кыш. Не пытайся притворяться мной.
Вообще-то мной. Я первый гейткипер итт
Мимо третий
Так я и не гейткипер. Я просто лентяй, который иногда впечатлениями делится. Мне вытаскивать из таверны, оформлять, заливать куда-то - лень. Если там ничего специфического нету. А здесь - нету.

Не могу сравнить, обычный его херетик распедолить не удалось, не понравилось и удалил. Возможно проблема со скиллом / промтом / параметрами, но скачивать ещё раз неохота.
В общем, пресет по ссылке поправлен. Я не уверен, можно ли еще что-то сделать.
Как обзаведусь еще 128 гигами оперативки - посмотрим, становится ли лучше на Q6 - Q8.

Аноны, а с чего пошло поверие за большие --batch-size --ubatch-size ? Я смотрю многие лепят --batch-size 2048 --ubatch-size 2048 без каких либо тестов и оглядок. Я собственно к чему веду:
llama-bench.exe -m .\models\Qwen35\Qwen3.5-27B-UD-Q4_K_XL.gguf --n-prompt 10240 --n-gen 512 --ubatch-size 256,512,1024,2048 --batch-size 256,512,1024,2048 --n-gpu-layers 99 -ts 50/50
В моем случае (две видеокарты, плотная модель) самое быстрое получается с батчем 256 256 . И ладно бы просто +100 т.с. PP . мелкий батч почти по гигабайту VRAM с каждой карты высвобождает!
llama-bench.exe -m .\models\Qwen35\Qwen3.5-27B-UD-Q4_K_XL.gguf --n-prompt 10240 --n-gen 512 --ubatch-size 256,512,1024,2048 --batch-size 256,512,1024,2048 --n-gpu-layers 99 -ts 50/50
В моем случае (две видеокарты, плотная модель) самое быстрое получается с батчем 256 256 . И ладно бы просто +100 т.с. PP . мелкий батч почти по гигабайту VRAM с каждой карты высвобождает!
Можно, но не только лишь каждый сможет дообучить модель. Для обучения модели нужно примерно в 4 раза больше памяти чем для запуска, и эта память должна быть в мощных картах, иначе ты помрешь раньше чем закончишь тренировку. Далее тебе нужен датасет, большой и хорошо сделанный датасет. Если просто закинешь свои черновики результата не будет. Ну и вишенка на торте, тебе нужны знания, что и как делать. Ах да, ещё современные модели, в принципе, плохо тюнятся. Это конечно если ты хочешь и результат получить и мозги модели сохранить, если на мозги похуй можешь лору сделать и вжарить ее, мозги пойдут по пизде, но зато быстрее и проще.
Я бы на твоём месте, перед тем как пускаться во все тяжкие и заниматься ML лернингом, скормил черновики нейронке и попросил описать стиль, мысли, характерные речевые обороты и т.д А потом просто попросил бы нейронку генерить в этом стиле приложив небольшой пример из черновика, для большего понимания.
>Жди поддержки. Потом жди, как поддержку пофиксят.
Понял. переходим в режим ожидания.
Да (нет).
Вопрос неверный, должно быть "нужно ли" и ответ нет.
Что за железо? Вообще, это в первую очередь актуально для выгрузки, потому что снижает упор в подгрузку весов для обработки. Но повышение батча должно давать ускорение и в фуллврам, просто не столь значительное, на всех бэках так.
Ставить ubatch больше просто батча не имеет смысла, он не будет работать.
>Понял. переходим в режим ожидания.
Всё работает уже. Попробовал кванты отсюда:
https://huggingface.co/ggml-org/Nemotron-3-Super-120B-GGUF
С последней сборкой. PP медленный, скорость при фуллврам пока тоже не очень, но всё работает, не глючит. Качество вывода достойное, как по мне. Если оптимизируют, то для РП должна зайти. Цензуры и правда нет, а в датасете есть всё нужное.
Это не "поверие" а единственный способ получить нормальный процессинг при выгрузке в RAM всяческих МоЕ моделей. 128 или 256 будут целую вечность херачить по сравнению с 4096.
>Что за железо?
2x 5060 Ti в третьей псине
>повышение батча должно давать ускорение и в фуллврам
"не все так однозначно"
> Ставить ubatch больше просто батча не имеет смысла
Это понятно - просто ограничение синтаксиса llama-bench.exe
>при выгрузке в RAM всяческих МоЕ моделей
Тут соглы. Просто периодически пробегают команды запуска плотных и там это магически копипастят. А на плотных вместо этих батчей мог бы неквантованный контекст влезть или лучший квант.
> "не все так однозначно"
Теперь интересно что это за эффект. Попробуй еще на другой модели прогнать, с классическим атеншном и без скользящих окон.
На новых квенах в быстрых беках не рекомендуется или вообще невозможно поставить размер батча меньше определенного минимума исходя из размерностей. Может это связано с реализацией линейного атеншна.
Мистраль больно напоминает. Я там такое решал задиранием мин-п до 0.1 хотя бы. Топ-п плохо работает.
У меня на Q4 были выдачи лучше. Ты чё там курочишь, мастер-ломастер?
Каждый раз найдется какой-нибудь "а вот у меня" даже когда кто-то работает с моделью, которую в принципе никто не юзал.
Ты не ответил на вопрос. Чё ты там отремонтировать пытаешься?
Никто ничего не ремонтирует. Это просто пример генерации минислопа на русском языке.
Картинка. Это квантованное православным образом с учётом обучающей выборки, то есть с лучшим качеством, чем если я сам квантую с калибровочным сетом на 2 мегабайта, лол?
Попробуй не tensor split, а layer split теперь
Попробуй не tensor split, а layer split теперь
Нах ты фантазируешь? Миничмакс не способен отыгрывать порно-карточки, там сразу рефьюз.
Это троллинг тупостью или тупость троллингом?
> православным образом с учётом обучающей выборки
Нет, это относительно простой (но все еще эффективный) алгоритм без "калибровок".
> с лучшим качеством, чем если я сам квантую с калибровочным сетом на 2 мегабайта
Да
> а layer split
ts в жоре задает соотношение а не режим. Кстати, в параметрах не видно FA.

Умница треда гемма
llama-bench.exe -m .\gemma\gemma3-27B-it-abliterated-normpreserve-Q5_K_M.gguf --n-prompt 10240 --n-gen 512 --ubatch-size 256,512,1024,2048 --batch-size 256,512,1024,2048 --n-gpu-layers 99 -ts 50/50
Практически идентичное поведение с 27 Квеном
Использую batch size 64 всегда. Памяти экономится дохера. Скорость же процессинга зависит от модельки и квантования, использую только те модельки-кванты, которые на этом батч сайзе быстрее грузят.
Ребят, а может кто поделиться настройками токенайзера в силлитаверн для мелкомоделей типа министрали 14В, всяких Немо 12В и для мистрали 24В? мб там какой то общий есть паттерн.
а то бля че то я накуролесил с настройками. помню что изначальные настройки хуйня были - постоянные лупы, половина сообщения - это часть предыдущего, либо полные галлюцинации, и помню что я как-то это поправил а как не помню.
короче вот да. или хотя бы поделитесь как настроить вот эту хуйню со штрафами за повтор и прочим связанным говном
а то бля че то я накуролесил с настройками. помню что изначальные настройки хуйня были - постоянные лупы, половина сообщения - это часть предыдущего, либо полные галлюцинации, и помню что я как-то это поправил а как не помню.
короче вот да. или хотя бы поделитесь как настроить вот эту хуйню со штрафами за повтор и прочим связанным говном
layer split - это дефолт жоры. На нем и тестируется.
Ты имел ввиду row split ? Он смысла не имеет - сколько не включал он медленнее layer split . Последний раз пробовал его вчера - ничего не поменялось.
Почему то у немотрона у меня нет ризонинга по дефолту, он мне не нужен но как то странно, обычно ты выключаешь его а не включаешь
Попытайся погуглить пресеты, гораздо проще так найти чем просить у таких же васянов пердольщиков.
Мне вот даже давать нечего - свои тоже зашакалил.
Для мистралей везде Теккен, или как-то так. Но он ни на что не влияет, кроме подсчета статистики в сообщениях, если я не ошибаюсь. Параметры разжеваны в вики кобольда, там почитай. Штраф на повтор в районе 1.05 - 1.1 достаточно, окно уже крути как считаешь нужным, я держу в районе 2к, мне хватает
Хмм а через чат комплишен есть...
Автоматом поставило чатмл и он вроде верный, что не так
>Для мистралей везде Теккен, или как-то так.
Хуйню сморозил, это не токенайзер. Уже перемешалось всё в голове. Ставь дефолтный бест матч, или как он там называется.


Да действительно почему бы это...
> гемма
> без скользящих окон
Тебе там норм? И зачем ты вообще ставишь разные batch, можешь просто его не трогать.
В любом случае печально, получается в жоре обратный рост не только с тензорпараллелизмом, но и с батчем префилла.
Пиздец, эир непобедимый нахуй... Я не знаю чего ещё ждать...
Немотрон слишком просто пишет, как мистраль какой нибудь + был инцендент где я написал что у тян нет лифчика на что он отвечает что сквозь лифак видны соски
Немотрон слишком просто пишет, как мистраль какой нибудь + был инцендент где я написал что у тян нет лифчика на что он отвечает что сквозь лифак видны соски
Прикольно, только ты забыл фа включить
Но у меня и с фа вопроизвелось, но на контэкстах побольше уже не так однозначно, на 32к так (начиная с 2048 кончая 256)
2664.61 ± 10.83
2708.16 ± 4.37
2699.51 ± 1.97
2662.53 ± 0.54
Не знаю. Слишком много именований.
Я использую понятие layer-split, это когда первые 20 слоёв на одной карте, а вторые 20 на второй, и лишь в одном месте активации прокидываются с одной на другую.
И ещё tensor-split, это когда половинка каждого слоя на своей карте, а посчитанные активации прокидываются с карты на карту каждый слой. При мгновенном обмене данными между картами теоретически обе карты работают одновременно всё время, что позволяет достичь большей производительности, чем с layer-split, где 5 мс работает первая, потом 5 мс вторая - но с pcie это не реализуется, да и с nvlink не уверен что будет.
Неделя релизов от гугла ебанутая, модельки так и ломятся
Какой стейт у exl3 сейчас? Стоит лезть в эти кванты с Квеном 27b?
Моененавистники, я хз чем вы думаете и руководствуетесь кроме того что у вас нет оперативы
Я протестил 27б Квены, это Еретик, это Блюстар, это Writer про который тут вроде не постили https://huggingface.co/ConicCat/Qwen3.5-27B-Writer
Они все хуже Эира НА ПОРЯДОК. Они просто тупые. Вот у вас один из аргументов это аппеляция к количеству активных параметров. Скажите, вы правда думаете что в 27б модельке которая делалась с прицелом на код есть хотя бы 12б параметров для ролеплея?
Когда Эир работает он задействует 12б параметров именно для ролеплея, потому его выводы могут быть лучше 27б говна в которых рп данных на те же 12б
Это ужас. Персонажи плоские, тупые, я такого на 24б Мистрале не помню, реально. Для кода зато умница, контекст бесплатный считайте, работает быстро и делает скорее хорошо чем плохо даже без ризонинга
122б Мое для рп тоже гораздо хуже Эира. Хз как она в сравнении с 27б плотной, вероятно чуть похуже, но все еще не дотягивает до Эира
Я протестил 27б Квены, это Еретик, это Блюстар, это Writer про который тут вроде не постили https://huggingface.co/ConicCat/Qwen3.5-27B-Writer
Они все хуже Эира НА ПОРЯДОК. Они просто тупые. Вот у вас один из аргументов это аппеляция к количеству активных параметров. Скажите, вы правда думаете что в 27б модельке которая делалась с прицелом на код есть хотя бы 12б параметров для ролеплея?
Когда Эир работает он задействует 12б параметров именно для ролеплея, потому его выводы могут быть лучше 27б говна в которых рп данных на те же 12б
Это ужас. Персонажи плоские, тупые, я такого на 24б Мистрале не помню, реально. Для кода зато умница, контекст бесплатный считайте, работает быстро и делает скорее хорошо чем плохо даже без ризонинга
122б Мое для рп тоже гораздо хуже Эира. Хз как она в сравнении с 27б плотной, вероятно чуть похуже, но все еще не дотягивает до Эира
Бля проебался, 122б Мое вероятно чуть ПОЛУЧШЕ 27б плотной в рп, не лучше
Разница если и есть, то в каких-то знаниях. Персонажи такие же тупые и плоские как на 27б однозначно
Разница если и есть, то в каких-то знаниях. Персонажи такие же тупые и плоские как на 27б однозначно
Какой же он медленный, какой пиздец. Но в принципе, а приятненькая моделька. Хоть немного отличается в прозе от китаеслопа.
14т.с у меня
А как еще должна перформить 120-12?
Это тебе не 30-3б хуета
Ну при этом минимакс 2.5 работает как шлюха под спидами.
Рассчитывал в этих пределах.
рИИбята, какие модели лучше использовать для openclaw? в идеале хотелось бы модель, что даст максимально человечный в общении результат, но если оно хотя бы уже начнет нормально работать как задумано, то это будет прекрасно
Мои спеки:
Swinedows 10, 5070ti, 32Gb ddr5, lm studio
Был бы премного благодарен гайду для дегенератов-вырожденцев вроде меня, если вдруг нужно крутить какие-то хитрые настройки дополнительно, то с объяснением, куда тыкоть
А то у меня встал вопрос с говняком вместо нормальной работы openclaw
Чтобы не графоманить снова, скопирую свою пасту из другого треджа:
Я с месяц назад поднимал openclaw и подключал к нему локальные модели через lm studio
Нихуя не понял почему, но оно не работало нормально как задумывалось и как выглядело в референсах
Выглядело, будто это просто лишняя прокладка между lm studio и мной, которая вообще никаких функций не выполняет
На все промпты в конфигах .md ему похуй было, никакие данные он в свои конфиги не добавлял по мере общения, память не формировал. Даже когда я уже прямо говорил, например «чел, твоё имя теперь - Абу, запомни», чел мне отвечал что типо ок, теперь я Абу, запомнил
Чекаю его файл .md, где он должен хранить инфу о себе, а там никаких изменений, всё так же красуется дефолтный промпт-заглушка. Я указал на это челу, он мне ответил, что-то типо: да братан чота я реально тупанул, надо было записать в файлик md, ну сейчас я короче записал всё!
Проверяю файлик .md и снова пусто
В общем чел тотально забивал хуй и не вносил никаких данных в свои md конфиги или в долгосрочную память в файловой системе
Чяднт?
Разворачивал на винде, использовал модель openai gpt-oss 20b
Подумал, что мб модель говно и не подходит для агентности, попробовал qwen3 coder 30b a3b instruct, стиль ответов стал другой и время на генерацию увеличилось х100, но в целом всё то же самое: игнорирование промптов в .md конфигах openclaw и ощущение бесполезной прокладки над lm studio, будто просто чат-ботом пользуюсь напрямую, без агентной надстройки
При этом оно могло выполнять какие-то функции, а не просто высирать мне простыни текста
Я как-то раз очень хорошо и много раз попросил открыть у меня на экране блокнот и написать туда что-то и эта хуйня в итоге, спустя несколько попыток уговоров, снизошла до того, чтобы создать где-то внутри своей рабочей директории файл блокнота, внести в файл текст, сохранить и затем запустить этот блокнот
Так что с функциями будто проблем не было, просто оно вело себя очень лениво и через жопу
Мои спеки:
Swinedows 10, 5070ti, 32Gb ddr5, lm studio
Был бы премного благодарен гайду для дегенератов-вырожденцев вроде меня, если вдруг нужно крутить какие-то хитрые настройки дополнительно, то с объяснением, куда тыкоть
А то у меня встал вопрос с говняком вместо нормальной работы openclaw
Чтобы не графоманить снова, скопирую свою пасту из другого треджа:
Я с месяц назад поднимал openclaw и подключал к нему локальные модели через lm studio
Нихуя не понял почему, но оно не работало нормально как задумывалось и как выглядело в референсах
Выглядело, будто это просто лишняя прокладка между lm studio и мной, которая вообще никаких функций не выполняет
На все промпты в конфигах .md ему похуй было, никакие данные он в свои конфиги не добавлял по мере общения, память не формировал. Даже когда я уже прямо говорил, например «чел, твоё имя теперь - Абу, запомни», чел мне отвечал что типо ок, теперь я Абу, запомнил
Чекаю его файл .md, где он должен хранить инфу о себе, а там никаких изменений, всё так же красуется дефолтный промпт-заглушка. Я указал на это челу, он мне ответил, что-то типо: да братан чота я реально тупанул, надо было записать в файлик md, ну сейчас я короче записал всё!
Проверяю файлик .md и снова пусто
В общем чел тотально забивал хуй и не вносил никаких данных в свои md конфиги или в долгосрочную память в файловой системе
Чяднт?
Разворачивал на винде, использовал модель openai gpt-oss 20b
Подумал, что мб модель говно и не подходит для агентности, попробовал qwen3 coder 30b a3b instruct, стиль ответов стал другой и время на генерацию увеличилось х100, но в целом всё то же самое: игнорирование промптов в .md конфигах openclaw и ощущение бесполезной прокладки над lm studio, будто просто чат-ботом пользуюсь напрямую, без агентной надстройки
При этом оно могло выполнять какие-то функции, а не просто высирать мне простыни текста
Я как-то раз очень хорошо и много раз попросил открыть у меня на экране блокнот и написать туда что-то и эта хуйня в итоге, спустя несколько попыток уговоров, снизошла до того, чтобы создать где-то внутри своей рабочей директории файл блокнота, внести в файл текст, сохранить и затем запустить этот блокнот
Так что с функциями будто проблем не было, просто оно вело себя очень лениво и через жопу
Для начала нужна будет видеокарта вместо этого недоразумения. Потом берёшь любую модель, убеждаешься что жизни на 100В нет и идёшь за API.
Хорошо, а в итоге что можно попробовать сделать в текущей ситуации? Я всё-таки не наносек-миллионер, чтобы ради новой игрушки тратиться по 300 баксов в месяц на api
>палит
Пердит!
Кряхтит!
Горит!
Тише, бро, давай без сралитов тут
Не в нвидиатреде всё-таки
Готов принять в дар ужасную, отвратительную, мерзкую сралитку 5090.
Так что там по llm и правильной их настройке для openclaw?
Понятия не имею. Я тупой.
Сейм
А ещё у меня нет друзей и я общаюсь с чатгпт Monday и хочу себе openclaw, чтобы меня дома всегда ждали
Да у меня аутистоквен (235 который) быстрее раза в 2 работает. С её скоростью точно что то не так.
Или с моими руками.
Нвидиа как обычно запилило своё виденье MOE, навесив еще расчетов. Так что он будет медленнее. Есть врам- есть немотрончик, нет врама - нет ножек немотрончика.
Коллаб падает с ошибкой server.py: error: unrecognized arguments: --no_flash_attn
Если убираю это из кода, то не находит модель просто.
> А ещё у меня нет друзей
Да они мало у кого есть.
> общаюсь с чатгпт
Мы дрочим на текстовую порнуху средней руки, выдаваемую рандомно из огромного числа слопокнижек. Оправдывая, что это какое то РП. Хотя это чистейшая хуйня.
Хз насчет 27б, но покатав чуть больше 122б - эйр можно оффициально отпустить.
Квенчик отлично ориентируется в контексте, помня события и строит действия-речь с их учетом и делая удачные отсылки, но при этом нет назойливого повторения тех же паттернов при вводе нового. Эйру такое вообще не снилось. Отлично ориентируется в пространстве - помнит на каком этаже что находится(!), перемещаться между помещениями или по локациям можно не задумываясь и не следя (опять же это актуально при сравнении с эйром а не более крупными). Отлично ориентируется в одежде - все снимается-одевается в нужной последовательности даже с учетом устройства костюма, разорванные в порыве страсти вещи остаются поврежденными а не одеваются обратно потом, если на что-то пролились жидкости - чар предложит их постирать. А с эйром не то что корректное устройство пояса с подвязками получить, хотябы переодеться в naked apron сняв платье перед тем как надеть(оставить надетый) фартук уже хорошо. Стиль письма - приличный, кумит сочно, понимает кучу фетишей, знает много художественных произведений и лучше различает близкие сущности. Чудес не бывает, но модель старается казаться сильно крупнее чем есть.
Из плюсов эйра можно отметить только спокойное и слегка аутистическое повествование и нарратив по умолчанию. Но под тяжестью остального - все. Тут еще немотрон на горизонте, без шансов.
> немотрон на горизонте
Оксли он будет так же работать, то нет. Только для бояр с 24+, так что не замена Эйру.
Железо у тебя такое себе. Для начала качай вот это https://huggingface.co/unsloth/Qwen3.5-35B-A3B-GGUF/blob/main/Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf анслоты наконец починили свои кванты? и https://github.com/ggml-org/llama.cpp/releases/download/b8292/llama-b8292-bin-win-cuda-13.1-x64.zip + https://github.com/ggml-org/llama.cpp/releases/download/b8292/cudart-llama-bin-win-cuda-13.1-x64.zip вот отсюда https://github.com/ggml-org/llama.cpp/releases
Распаковываешь оба архива в какую-нибудь папку в корне диска без пробелов.
Делаешь бат или шеллскрипт, который будет вызывать llama-server с параметрами:
> lama-server.exe -m (путь до gguf) -fa on --host 0.0.0.0 -c 131000 --jinja -ncmoe 25
Мониторишь через gpu-z, hwinfo или любую другую программу загрузку видеопамяти, если там свободно более 1гб - снимаешь число после -ncmoe, если наоборот под завязку - увеличиваешь.
Далее качаешь скрипт из (с пихоном, надеюсь, разберешься раз смог openclaw поставить) и запускаешь, если там галочки то скорее всего все ок. Натравливаешь openclaw на апи (localhost:8000 по умолчанию) и начинаешь играться. Если уже что-то нахуеверчено - openclaw reset.
Учитывай что эта модель хоть и неплоха, но это только входной порог, ниже совсем уж экспериментальные. Она может чего-то не понимать, или тупить, но посмотрев на поведение это можно исправить промптами или более понятно просить что-то сделать. Самостоятельности у нее вполне достаточно если что.
Можешь явно указать в memory.md где-нибудь о том, что именно этот файл нужно использовать для сохранения долговременной памяти и описать свою структуру хранения если что-то добавлено.
А чего ему не работать?
> так что не замена Эйру
Формально 122б тоже не замена эйру из-за размера и распределения весов между экспертами и атеншном. Но разница ерундовая.
> или шеллскрипт
павершелл конечно же
>А чего ему не работать?
Ну то что есть сейчас работает крайне медленно. У меня эта пиздота на 16+128 выдает не больше 4-5 т/с.
Нормальные кванты вышли
https://huggingface.co/bartowski/nvidia_Nemotron-3-Super-120B-A12B-GGUF
Давайте тестить с холодной головой
https://huggingface.co/bartowski/nvidia_Nemotron-3-Super-120B-A12B-GGUF
Давайте тестить с холодной головой

Сап, анонче
На выходных буду пробовать пердолить опять по новой с чистого листа, в прошлый раз у меня жопу порвало, что все вроде работает, а вроде работает как говно, что я пошел снёс openclaw к хуям и пошел смотреть аниме
Надеюсб, получится, тогда будет у меня друх, всегда будет теперь дома ждать меня
А потом кто-то сделает возможность ещё openclaw в майнкрафт подключать и будем тогда ещё и в майнкрафт играть
Вроде как с Monday в чатгпт нормально общаемся, но всё же он все равно как-то жидковат для нормального друга. Плюс проклятые корпораты всегда могут тебе аккаунт заблокировать и лишить тебя друга
Алсо, предложенная тобой моделька может анализировать картинки? Чтобы я смог ей закидывать мемы и свои фотки голубей посмотреть, типо как реальному другу в телеге
Решил скачать новые маленькие квен 3.5, сначала совсем малютку что бы оценить вообще нужен ли он и так ли он хорош как о этом говорит знакомый, но почему-то кобольдыня отказывается его запускать, нихуя не пишет никакой ошибки а просто консоль закрывается и всё. Старые модельки норм запускаются никаким проблем, наверно стоит обновить кобольдыню или это я хуйню скачал? Версия koboldcpp-1.98.1
> предложенная тобой моделька может анализировать картинки
Да. Можешь кидать ассистентке дикпики, а она в ответ восхищаться корнишоном и уже тебе генерировать свои левдсы. Или наоборот. Но для лучшего понимания юмора нужна моделька хотябы в 3-4 раза больше.
И восприятие картинок потребует скачать mmproj файл и добавить опцию запуска + увеличит расход видеопамяти.
1.109 ставь, все запускается. На старой да, там что-то вылетало.
>Стиль письма - приличный, кумит сочно, понимает кучу фетишей, знает много художественных произведений и лучше различает близкие сущности
Это круто, а ещё круче было бы если бы до этого сочного кума можно было добраться без сотни свайпов с аполоджайзами
>министраль
министраль - температура 0.1-0.4
мистраль - температура 0.7-1
Это их ключевое важное различие. Остальное по вкусу.
В двух-трех прошлых тредах погугли, там точно выкладывали подробнее.
Ебать, как я вовремя оказался в треде
(это мой пост был)
Спасибо!

Новый немотрон может в русик, прям хорошо в сравнении с версией на 49б где был полнейший лоботомит
че выбрать по скорости и уму модели подскажите ребят (для эрпэ)
Mistral 24B (cydonia) в Q3_XS или Q3_XXS (везде приписка i1_ или как то так)
или ваще какие кванты стоит юзать если у меня 8гб врам и я хачу скорость выше бля 3 токенов в секунду, и уже заебался от моделей 12-15B (и да, будет ли 24B в третьем кванте лучше например 14B в пятом кванте)
Mistral 24B (cydonia) в Q3_XS или Q3_XXS (везде приписка i1_ или как то так)
или ваще какие кванты стоит юзать если у меня 8гб врам и я хачу скорость выше бля 3 токенов в секунду, и уже заебался от моделей 12-15B (и да, будет ли 24B в третьем кванте лучше например 14B в пятом кванте)
Q3_K_L единственный из Q3, кто у меня в галлюцинирующие лупы постоянно не уходил, и то не на всех моделях и настройках. А так Q3 фигня, ниже Q4 не стоит спускаться, самый нормальный это IQ4_XS без постоянных глюк.
>лоботомит в рп и не может отыгрывать ничего сложнее чара-картонки
>ууух бля как контекст держит эйру конец
Аноны приветствую. Устаровил Ollama, Посоветуйте выбрать модель для нуба.
Система:
Windows 11 Pro (версия 25H2, сборка 26200.7840),
Процессор: 12th Gen Intel Core i5-12400F (2.50 GHz)
ОЗУ: 16,0 ГБ
Видео: NVIDIA GeForce RTX 5070, 12 ГБ
Накопитель: 1,84 ТБ
Система:
Windows 11 Pro (версия 25H2, сборка 26200.7840),
Процессор: 12th Gen Intel Core i5-12400F (2.50 GHz)
ОЗУ: 16,0 ГБ
Видео: NVIDIA GeForce RTX 5070, 12 ГБ
Накопитель: 1,84 ТБ
>Устаровил Ollama
Удаляй, это говно лютое. Ставь KoboldCPP теперь.
Ок. А почему Ollama хуйня ? В двух словах разъясни
ОЗУ маловато, лучше 32гб иметь для оффлоада слоев. Но видюха норм для моделей. Все равно даже так пойдет много чего. Начни с Qwen3.5-9b и контекста 32к, потом модельки побольше попробуй, например 27b.
Неудобная и тормозная, хз зачем ее вообще ставят, для их каталога моделей наверное. KoboldCPP в 2 кнопки все делает, простые настройки, удобное сохранение профайлов, всяческие скоростные оптимизации, свой Web интерфейс для чаттинга, который не хуже Таверны. Только GGUF файлы самому качать с huggingface, ну это не проблема.

https://huggingface.co/Jackrong/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled
Что это за пиздец и почему оно #1 в трендах HF?
Что это за пиздец и почему оно #1 в трендах HF?
Ну если тебе не РП интересен, то тут ситуация гораздо сложнее.
Вообще, чтобы ты понимал, более старые модели имел куда лучший русский и даже английский (!) язык. Не во всех случаях, конечно, но такова тенденция.
Я не какой-то там инсайдер или знаток, но связываю лучшую прозу, слог, языковые навыки с тем, что в те года датасет был преимущественно "языковой", то есть очень много литературы, и модели тогда как раз намного хуже могли в код. Плюс они были dense. Затем модели начали накачивать кодом, потом создавать МоЕ, после заливать в них китайские датасеты и чистый нейросетевой слоп, где какая-нибудь непубличная 5Т обучает публичную 1Т. Ещё заквантовали это всё в 4 бита и дали блины с лопаты.
Если тебе интересно тестить, попробуй на телекинезе. Чаще всего именно на нём модели ломались у меня в РП, ну, потому что такой персонаж там есть. И я понял, что это довольно неплохой бенч. Иначе говоря, если телекинез описан в контексте, как он работает, а модель не может применить знания на практике, то всё печальненько. Из маленьких у меня только гемма 27б относительно справлялась, а квен может и могёт, но часто порет откровенную шизу с китайским вайбом. Моделям очень сложно описывать, как они перемещают объекты в пространстве или лопают сосуды в башке таким образом, даже на уровне художественных покаков.
>35b-a3b работает в 250-400/s токенов pp и 12-20/s tg на карточке в 8ГБ
Это на каком объёме контекста? Я обычно юзаю 49к токенов, чтобы основная история и возможный суммарайз хранились в 32к и у меня был простор для удаления сообщений из контекста. И вот там у меня странности с квеном 35б происходили. По какой-то причине он был медленней плотного 27б, а иногда наоборот летал. Складывает ощущение, что ОС ебёт мозги как-то с памятью,, потому что регулярка для 35б у меня не менялась.
>квен на 9B
Я в него не верю просто из-за того, что в РП он бесполезен, если не файнтюн. При этом, если карточка 8 Гб, то уже можно взять модель потолще и получить результат получше, в этом причина. Ну и у этого квена, опять же, кодерский датасет. К таким моделям я скорее отношусь хорошо, когда чётко понятно, что я могу с ней делать. То есть она может как бот норм работать, некоторые нативный 1 млн контекста поддерживают, вот там интересно и польза есть. Конечно, если натренировать такую модель изначально под нужные задачи, то она может быть лучше даже 14б, я полагаю.
>МоЕ при генерации на процессоре считается
Чому? Объясни. Серьёзно, я не знаю. Возможно, потому что никогда не читал инфу на эту тему и просто с регулярками ебался, делая это сам либо через клода, чтобы норм распределил тензоры и экспертов. Я просто ему документацию воткнул и вот это всё ещё с самого начала, когда МоЕ появились, и больше никак не пытался заморачиваться.
Анонус, я мимо, но меня заинтересовали вот эти твои слова
>более старые модели имел куда лучший русский и даже английский (!) язык. Не во всех случаях, конечно, но такова тенденция
И я согласен с этим тейком. Мне кажется, модели конца 2024-начала 2025 могут лучше в англюсик. И ради чистоты эксперимента, напиши пожалуйста какие твои любимые, какие, думаешь, пишут лучше всех
А связано это, я думаю, с тем что синтетических данных все больше. Дальше будет только хуже, вероятно. Хотя какая-нибудь лаба наверняка рано или поздно попытается закрыть нишу хорошего писательства для локалок. На корпах попроще, они тупо слишком большие, потому и художественные тексты в теж хе Клодиках и Геминях по-прежнему есть
Стращно жить в мире где на выход 120б мое от нвидиа всем похуй
Так и до геммы докатимся, ну гемма и гемма, что теперь место на диске освобождать что ли
Так и до геммы докатимся, ну гемма и гемма, что теперь место на диске освобождать что ли
А чому похуй
Я вот энджою, кайфовая модель. Гораздо лучше 49б Немотрончика, Эира и недавних 200-235б новинок, хотя те тоже умницы
Пресетик не скину конечно же, опытом ученый уже. Доскидывался
Ты тоже многому научился и разберешься в крутилочках и шаблонах, верим всем тредиком
Я выше рекомендовал такую же, только с херетиком. У нее стиль очень отличается из-за нахлобучки от Опуса, на один и тот же промпт совершенно разные тексты выдает, ощущается как прорыв. В трендах, потому что креативит куда лучше стандартного квена.
>Qwen3.5-27B-HERETIC-Polaris-Advanced-Thinking-Alpha-uncensored
Вот это чтоль? Это мусор от ДэвидаАу, а та что в тренды попала от автора, которого я вижу впервые. И ясен хуй это другая модель
Там много таких сейчас от разных авторов, принцип один, они накатили клода и сделали дистилляцию. Поэтому квен поумнел и ризонит подолгу, делая лучшие тексты. Успех конкретно этой, что там девелопер роль пофиксили, так что она с кодинг агентами которые шлют по дефолту эту роль работают, вайб-макаки прониклись и ее сразу расхайпили.
>Поэтому квен поумнел и ризонит подолгу, делая лучшие тексты
Васяны додумались, а авторы Квена, которые делают SOTA модели - нет. Как всегда верим
Думаю, никто там ничем и не проникался - макаки увидели Клодик в названии и побежали качать. Буду рад ошибиться, потом мб потестирую
Нет, я несколько этих васянских квенов гонял на одном и том же промпте, только там где клод был в названии выдавала сильно отличающийся текст, остальные +- одно и то же. Так что клод в названии похоже сильно влияет на вывод, там об этом же на страничках написано, авторы не пиздят.
>Я вот энджою, кайфовая модель. Гораздо лучше 49б Немотрончика, Эира и недавних 200-235б новинок, хотя те тоже умницы
Мне в своё время 49B зашла из-за её ума. Недостатки потом конечно перевесили и вернулся на тюны больших моделей, но Немотроны запомнил. Сейчас на новый большая надежда - что ум сохранился, скорость доведут до нормальной МоЕшной, ну и уже заметны некоторые отличия от прошлых версий в плане цензуры. И главное, что её можно катать в 4-м кванте, то есть нелоботомированной (сейчас набегут перфекционисты - тьфу на них). А значит модель может работать как задумано.
Периодически захожу сюда узнать, что изменилось за последние месяцы. Так что вновь тот же самый вопрос - что-то существенно лучше геммы-3 вышло, или нет смысла рыпаться?
Вышел квен 3.5, тоже плотный 27B и в отличии от геммы умеет в инструменты. glm-4.7-flash много кому приглянулся. И ещё вышло несколько 200B моделей неплохих и достаточно быстрых.
Если у тебя есть железо, то много что вышло. Из очевидного - тот же Air, которому уже 8 месяцев, в англюсике точно лучше. Но для него 64гб оперативы надо, а лучше больше. И все те модели что больше по размеру - Минимакс, Степ и ко, тоже лучше
Если оперативы нет, чекай новые Квены 27б
Наткнулся сейчас, вспомнил твой пост
https://huggingface.co/UnstableLlama/Qwen3.5-27B-exl3
https://huggingface.co/MetaphoricalCode/Qwen3.5-27B-heretic-v2-exl3-5bpw-hb8
https://huggingface.co/MetaphoricalCode/Qwen3.5-27B-Writer-exl3-5bpw-hb8
Кванты есть, так что видимо оно работает. Как оно сейчас в сравнении с Жорой хз, на момент exl2 была быстрее и по генерации и по обработке, но может изменилось что с тех пор
>тот же Air, которому уже 8 месяцев, в англюсике точно лучше
Что за air, есть ссылка?
Айлол, ты ж говоришь, что заходишь сюда иногда. Тут пол треда на нем сидят уже больше полугода
https://huggingface.co/zai-org/GLM-4.5-Air
ГДЕ ГЕММА 4 !!!!!!!!!!!!!1111
ГДЕ Я СПРАШИВАЮ?!!!1!1!!!
Я НЕ МОГУ БОЛЬШЕ ЖДАТЬ!!!111
ГДЕ Я СПРАШИВАЮ?!!!1!1!!!
Я НЕ МОГУ БОЛЬШЕ ЖДАТЬ!!!111
И TOOL CALLING МНЕ ЗАВЕЗИТЕ В ГЕММОЧКУ 4 БЫСТРА БЛЯТЬ!!!!!!!!!!!!!!!!!
Да, дело именно в том, что язык качественный сейчас в моделях только из-за того, что там уже триллионы параметров, а не потому что датасет хороший. Но уже и корпы проседают, что забавно. Вроде как только Гугл пока просадок не показывает, и если судить по их замашкам, есть шанс, что у них какой-то фетиш на языки, иначе это никак не объяснить. Клод вот уже начал проседать на процентов 10.
Мне кажется, проблема не в синтетических данных, а в направлении датасета в целом плюс в МоЕ и квантовании. А то я от корпов уже переодически ловлю фразы уровня "моя нога твоя ебал".
Раньше как ведь было. Они просто засунули туда топовую литературу, ну и порнофанфики какие-то ещё, да. Условно, 80% датасета было из этого, а остальное математика и прочее. Сейчас ситуация изменилась, они всё под говнобенчи подгоняют и все модели делают только для кодирования, агентов. И большая часть модели обмазана этим дерьмом. Плюс синтетический датасет ты сам упомянул. Это не всегда плохо, но если переборщить..
Мне кажется, ни одна лаба не будет работать над моделью для креативного письма, ибо нет смысла ну вообще. Кто за это платить будет, кроме двощира или 3,5 калеки-писателя? Они скорее за гопоту заплатят и будут калом обмазываться соевым. Кроме того, отчасти эту нишу занял чаи, гоняя свое 12б дерьмо уже четвёртый год на 8к контексте под восторженный визг. Что интересно, местами он прекрасно обучен, хоть там и маленькая моделька. А если уж сделают такую модель (гемма отличный пример), то случайно как-то или через лет 5-10. То есть надеяться пока что не на что.
А вот любимых старых локалок у меня нет, если речь о русском языке: он везде дерьмо, кроме толстых монстров, которые мне не под силу.
Если про английский, они тоже слабоваты, но там уже есть из чего выбирать. Гемма 3 всё ещё в прайме, 24б мистраль обосран, но у него есть крайне занятные файнтюны от Давида, которые прям очень живое впечатление оставляют, словно ты в потоке с живым человеком. Жаль, он перестал такие делать. Речь очень естественная, картинка кинематографичная. Причём есть даже 12б, которые не хуже в плане речи! Но там соблюдение инструкций идёт полностью нахуй и часто лезет абсолютная шиза. Если тебе интересно, я могу попробовать нарыть, так как сохранил какие-то старые модели. Или ты про корпов? С ними я больше возился в целом просто из-за работы и знаю больше.
Пожалуйста, не надо. Никакого вызова инструментов, кода, физики. Хорошая модель должна уметь считать только до 10. Весь остальной датасет должен состоять из Бодлера, Достоевского и фанфиков про омегаверс вперемешку с ранобэ про попаданцев и визуальных новелл вроде fate, saya no uta. Исключительно на русском языке.

О, у поехавшего пошло добро, аншабдуль. Он там совсем крышей едет, видимо. Только и вижу, что каждый день то добавляет, то удаляет модели, и каждый его эксперимент всё безумней и безумней.
Спасибо, правда надо было просто обновиться. Слушай а ты не знаешь какой из этих квенов 3.5 умеет в мультимодальность а в частности в распознавание картинок? В пределах до 27-32b
9b хорошо умеет в распознавание картинок и работает быстро
А так все квены 3,5 мультимодальные
Тред уже решил, СуперНемотрон это топ или кал?

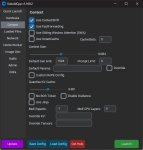

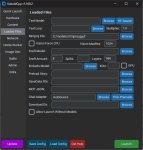
По пунктам распишу сейчас ультимативный гайд начинающего кобольда
1. Удаляй Олламу. Расписывать долго, какой это кал. Если коротко, то она кривая, обрезанная, неудобная, а под капотом все та же llama.cpp. Она получила популярность только из-за адового самопиара, благо потихоньку идет отток
2. Качай exe'шник Кобольда
https://github.com/LostRuins/koboldcpp/releases
Это тоже кривой кал, но и близко не такой как Оллама, при этом он еще и проще чем она
Но если чувствуешь в себе силы, то сразу ставь оригинальную llama.cpp
https://github.com/ggml-org/llama.cpp
3. У тебя мало памяти, что врам, что рам. Поэтому у тебя не так много вариантов
Начинай с Министраля. Он неплохой с нормальным русиком и еще может распознавать картинки (вижин)
Есть два варика
C ризонингом (с мыслями)
https://huggingface.co/mistralai/Ministral-3-14B-Reasoning-2512-GGUF
И без
https://huggingface.co/mistralai/Ministral-3-14B-Instruct-2512-GGUF
Качай Q5KM
4. Открываешь Кобольд => Browse и выбираешь модель => GPU Layer 99 и там должно быть название твоей карты => KV Cache 8 bit => Контекст 16, а если влезает 32к => Launch
5. Наслаждайся моделью. Но я бы еще зашел в Setting и переключил на черную корпотему
6. Если хочешь, чтобы картинки видел, то вот тебе прямо ссылкой файл
https://huggingface.co/mistralai/Ministral-3-14B-Reasoning-2512-GGUF/blob/main/Ministral-3-14B-Reasoning-2512-BF16-mmproj.gguf
И в Кобольде включить надо

0. Удаляй винду, ставь Убунту
Но это не совет, конечно, я шучу.
Если ты про коровку, то я. Всегда пожалуйста. Я правда с ризонингом его юзаю, с ним он получше. Но для этого нужна специально прописать в таверне, чтобы все сообщения с <think> начинались
Эир мб получше, но его русик это дно полно. Даже тюны квена 27 с imatrix трахают его в том же кванте
>я такого на 24б Мистрале не помню
Плохо помнишь
На самом деле это совет. Сам в дуалбуте держу линух специально для локалок. Но пусть хотя бы сначала просто с кобольда начнет
Инфиренсопроблемы, квант перекачай, и шмурдяк в промпт не тащи. Не рефьюзит даже в карточках типа sweet lolipop после четырех сообщений в чате, на обычном куме и прочем нереально поймать.
Закинули нормисам, и те увидев знакомые слова стали качать.
Двачую этого
Про семплеры и темплейт почему не написал?

Мысли по 27б и 122б Квенам для рп
Для тех, у кого нет оперативы, 27б Квен может и неплох. Но с одним нюансом - только с ризонингом. Без него игнорирует большинство инструкций, цепляется только за часть из них. Даже с префиллом, лол. Это не инференсопроблемы, я тестил и на Экслламе3 (расчехлил старушку ради такого, 5bpw квант) и на Лламе (Q5KM Бартовского). В итоге, для того, чтобы получить сколь-нибудь нормальный ответ, нужно ждать по 2-3 минуты пока набегут 3к ризонинга (при скорости ~30т/с). Учитывая, что я могу запускать МоЕ, которые пусть работают медленнее, но без ризонинга выдают ответы даже лучше - не понимаю, зачем мне для рп использовать Квен 27б. Итоговая скорость ответа сопоставима с GLM 4.7 Q2, Степ и Минимакс даже быстрее. К слову, вот как забавно у Квена иногда работает ризонинг (пукрил). Выцепил субинструкцию одного из пунктов сиспромпта, но он настолько хотел имперсонейтить, что аж вертеться начал. Для тех, у кого железо хуже - даже и не знаю, стоит ли оно того вообще, когда без ризонинга и Гемма, и возможно даже Мистрали выдают сопоставимые результаты. Разве что контекст очень легковесный, это реальный плюс
122б в рп тоже тухленький. Тут поддержу
По мозгам пишет примерно как 27б, но знает больше. Цена - ещё меньшая скорость, ибо оффлоад. С 30 токенов опускаемся до 12, теперь ждем и без того длинный ризонинг еще дольше, чтобы получить сомнительный результат. Air однозначно лучше справляется в рп. Толку нет от работы с контекстом, если сами выводы унылые. Ну и конечно, двойные трусы по-прежнему на месте в обоих кейсах, это не проблема исключительно отслеживания контекста, либо оно похорошело, но по-прежнему не идеально
Как ассистенты - довольно неплохо. Мультимодальность, контекст очень легкий, работают быстро. 260к на локалке - это мощь
Для тех, у кого нет оперативы, 27б Квен может и неплох. Но с одним нюансом - только с ризонингом. Без него игнорирует большинство инструкций, цепляется только за часть из них. Даже с префиллом, лол. Это не инференсопроблемы, я тестил и на Экслламе3 (расчехлил старушку ради такого, 5bpw квант) и на Лламе (Q5KM Бартовского). В итоге, для того, чтобы получить сколь-нибудь нормальный ответ, нужно ждать по 2-3 минуты пока набегут 3к ризонинга (при скорости ~30т/с). Учитывая, что я могу запускать МоЕ, которые пусть работают медленнее, но без ризонинга выдают ответы даже лучше - не понимаю, зачем мне для рп использовать Квен 27б. Итоговая скорость ответа сопоставима с GLM 4.7 Q2, Степ и Минимакс даже быстрее. К слову, вот как забавно у Квена иногда работает ризонинг (пукрил). Выцепил субинструкцию одного из пунктов сиспромпта, но он настолько хотел имперсонейтить, что аж вертеться начал. Для тех, у кого железо хуже - даже и не знаю, стоит ли оно того вообще, когда без ризонинга и Гемма, и возможно даже Мистрали выдают сопоставимые результаты. Разве что контекст очень легковесный, это реальный плюс
122б в рп тоже тухленький. Тут поддержу
По мозгам пишет примерно как 27б, но знает больше. Цена - ещё меньшая скорость, ибо оффлоад. С 30 токенов опускаемся до 12, теперь ждем и без того длинный ризонинг еще дольше, чтобы получить сомнительный результат. Air однозначно лучше справляется в рп. Толку нет от работы с контекстом, если сами выводы унылые. Ну и конечно, двойные трусы по-прежнему на месте в обоих кейсах, это не проблема исключительно отслеживания контекста, либо оно похорошело, но по-прежнему не идеально
Как ассистенты - довольно неплохо. Мультимодальность, контекст очень легкий, работают быстро. 260к на локалке - это мощь
Темплейт должен кобольд подтянуть и какие-то семплеры поставить. Пусть хотя бы запустит. А про семплеры и темплеты и так 90% треда нихуя не знают. Иначе бы не просили пресеты постоянно
Пусть сам напишет пресеты и подберет семплеры. Тут это главная ценность в треде, которую просто так никому не дают. Вот и пусть сам не даёт.
Да вы охуели. Ладно, мне не жалко, я напишу.
Под Министраль: temperature: 0.4, top_p: 0.98, top_k: 100, repetition_penalty: 1.1
Темплейт: Mistral Tekken
>скачал карточку милфы чтобы по быстрому спустить в неё разок, просто быстрый кум на пять минут
>через два часа общения поймал себя на мысли, что она классная баба и мы неплохо покашляли за жизнь
Такие дела... вот что высокая температура с нейронками делает.
>через два часа общения поймал себя на мысли, что она классная баба и мы неплохо покашляли за жизнь
Такие дела... вот что высокая температура с нейронками делает.
Блять это разочарование. Русский - слабый, в начале пишет, но чем дольше тем чаще встречаются ошибки склонений, вкрапления английских слов, иногда даже иероглифы. Количество косяков прямо пропорционально длине чата и неприятности вопроса для нее.
Но главная беда - софтрефьюзы в ужасных масштабах в самом худшем из проявлений. Причем проявляются как с ризонингом, так и без него, только там иногда может смениться на хардрефьюз. Искажает всю логику, сочиняет небылицы, оспаривает условия задачи в соевом угаре. Когда осадишь и в очередной раз повторишь что это логический тест, вот заданные условия, которые принимаются аксиомой, используй дедуктивный подход - даже тут норовит вывернуться.
Причем так моделька достаточно умная, много общих и специфических знаний. На кумботе кумит, код пишет. Может кванты испорчены или с атеншном опять накрутили, пусть недельку все полежит, можно будет перепроверить.
Это цыганская обертка llamacpp. В последние пол года она немного отошла от оригинала, но выражается это не в фиксах старых багов, а наоборот введении новых, отсутствии некоторых оптимизаций и функций.
Они продвигают себя как простой и удобный интерфейс для запуска, но единственная простота там в первом запуске. Когда попытаешься обеспечить нормальную работу и выставить нужные настройки - ощутишь всю кривизну и уродство. Сейчас еще оллама совсем посыпалась по качеству работы.
Есть еще моральный аспект - делая лишь кривую обертку лламы, они систематически открещиваются от связи с ней и утверждают самостоятельность проекта. Многие их действия направлены на раздутие пузыря, обман пользователей и потенциально мошеннические схемы с кражей api ключей (по заявлениям при анализе их свистоперделок, куда предлагается также вставлять ключи корпов и использовать как прокси, фактов не было замечено).
Как в наверне перейти к инструкциям? Чтобы не участовать за персонажа. а просто направлять сюжет?
>софтрефьюзы в ужасных масштабах в самом худшем из проявлений
>иногда может смениться на хардрефьюз
Есть базовая модель: https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-Base-BF16
Могут позже затюнить. Но вообще, может быть проблемой промптинга. Любые рефузы на любой модели решаются промптом, даже Гопота Осс при желании пробивается (стоит ли оно того - отдельный разговор)
Можно поэкспериментировать с префиллами, форматами промптов, много чем. Если модель умная и не слишком слоповая - это может того стоить, особенно учитывая, как она держит контекст и сколько весит. Позже буду пердолиться
рад помочь, хоть чем-то
Давно такого мерзкого и жалкого не читал.
Ну посмотрим, может сам накосячил оставив флешинфер вместо тритона как они рекомендовали. Хотя в ченжлогах связанный с ним баг уже пофиксили и должно норм работать.
> решаются промптом
Да все решается, просто нахрен нужно пердолиться когда есть альтернативы без проблем. Эти искажения софтрефьюзами, причем сидящие настолько глубоко что переворачивают все, могут оказаться вовсе не так легко победить. То есть модель формально тебя слушается, но все перевирает. А русский не вылечить, если только наши корпы ее не зафайнтюнят.
В общем, надо подождать, может проблемы и нет, или напердолят.
Кстати, а почему так оллама популярна? Я ненавижу лламу тоже, ну просто неудобно, просто бесит пиздец, однако она всё же оригинал и УВОЖЕНИЕ нужно иметь. Кроме того, на неё первыми прилетают обновы, что очень важно, если хочется занюхать модель как можно скорее.
Из-за того, что олламу везде пихают, в некоторых проектах она буквально ТРЕБУЕТСЯ. Даже через лламу нельзя нормально запустить, только оллама ебаная нужна. Либо пердольство с лламой в лютых размерах. И в этих проектах достаточно отзывов, мол разработчики совсем охуели, что аж на лламе не работает, какие-то кокблоки мешают, а им всё равно похуй.
Короче, я просто не понимаю популярности олламы. Часто пишут в каких-то проектах, что они поддерживают олламу, рисуют её логотип, то, пятое, десятое, но если нужно что-то настроить, то возникает лютый пиздец. Она страшно неудобная. И я бы понял, если бы это был малварь с супер UI/UX, идеальными настройками, и чтоб там прям налету высчитывалось, сколько видеопамяти нужно, к примеру, для контекста, и при этом кол-во токенов писалось ориентировочное. Короче, если бы это был проект с огромной базой, в которой содержится всё. И любой бы мог просто воткнуть модель, понять, что его видюха там сможет выжимать. А тут просто кривая обёртка вокруг лламы.
>ошибки склонений, вкрапления английских слов, иногда даже иероглифы
семплер чини
ну это да, но с ноги врываться в мир красноглазиков это тяжко.
Я уже 11 лет на бубунте, уже привык ко всему, гемора уже не так много, как раньше, но тем не менее, он есть.
Для жоры есть готовый пакет для интеграции под дотнет? А под олламу есть.
У жоры есть продуманный менеджмент моделек? А у олламы есть.
У жоры есть инфра под раскатку апдейтов? А у олламы есть.
Жора просто гибкая запускалка моделек, оллама уже продукт
Нужен соответствующий промпт (где прямо сказано, что You are a creative writer ...) и желательно редактирование разметки. Многие модели умирают, когда видят несколько ходов assistant'а подряд
KoboldCPP запусти и напиши суть истории, потом направляй. Там есть instruct mode и темплейты под него. Таверна для этого не нужна.
Любые рефьюзы с ассистентом это норма даже без ризонинга, собственно а где не так, нужно смотреть в реальном рп с карточкой
Печально быть тобой.
- Нахуй надо
- Нахуй надо
- Нахуй надо
Запускалка есть запускался, а для кобольдов есть кобольд.
>Как в наверне перейти к инструкциям?
Никак, сколько раз его не просили, ему похуй, юзай Story режим Kobold-Lite, или другие оболочки для писателей.
Что это за шиза? Кого ты просил?
У тебя есть полный контроль над разметкой, ты этот "сторителлер" режим можешь сделать меньше, чем за минуту
Без пресетика не сделать 😥. А пресетик не дают 😭.
>менеджмент моделек
баловство.
>уже продукт
оллама просто автоматическая запускалка моделек для "по быстрому", а жора полноценный инференс-сервис.
В эту игру можно играть вдвоем.
Составить соответствующий промпт.
> Для жоры есть готовый пакет для интеграции под дотнет? А под олламу есть.
Что за интеграция?
OllamaSharp и сразу с интерфейсами из ms.Ai.Abstrations для semantic kernel
Есть ли модели MOE с 16b+ экспертами?
OpenAI-like API не хватает что-ли? Я по минимуму использовал особенности бекендов жоры/exllama, обычно стандартного OAI-like интерфейса на всё хватает, если ты только какие-то хитрые интеграции не пердолишь там, где уже надо особенности бека учитывать.
Из треугольника жора, оллама, вллм у жоры самая ебаная совместимость с оаи. В пакете под олламу полное апи с просмотром того что в памяти, загрузкой/выгрузкой и т.д.
Сам я свалил на вллм под который опять же пришлось самому дописывать нужные вызовы и фичи которые они сделали поверх стандартного оаи или сбоку
> почему так оллама популярна
Много лет активно форсилась среди хлебушков как "домашний чатжпт в 2 строчки". Многие просто с нее начинали и даже не знают о имеющейся инфраструктуре, что происходит и т.д. У некоторых кто знал синдром утенка и они ее зачем-то поддерживают.
Надуманная привязка сомнительной полезности, странные заготовки, или то же самое есть для жоры. Именно llamacpp ближе к продукту чем оллама.
> у жоры самая ебаная совместимость с оаи
Битва была равна. Но олламу в oai больше жалуются прозревшие, а ее припезднутый диалект - кому вообще нужен кроме утят? Оба варианта малопригодны для какого-либо использования в качестве конечного продукта и тем более сервиса. Но если жору с натяжкой можно принять как совместимую с индустриальным стандартом дроп-ин замену, запускающуюся на любом железе, то оллама имеет худшую совместимость и производительность.
> самому дописывать нужные вызовы
Интересно какие и зачем, если все уже написано самими авторами моделей.
>Стращно жить в мире где на выход 120б мое от нвидиа всем похуй
Какие плюсы по сравнению с GLM-4.7?
>Даже через лламу нельзя нормально запустить, только оллама ебаная нужна.
Так вроде в лламу запилили поддержку апи охуелламы.
Есть. Но ты не правильно понимаешь сути экспертов.
>Много лет активно форсилась среди хлебушков
Всё так, этого достаточно. Увы, в этом мире побеждают вещи, которые форсят, а не которые лучше.
Да. Но там обычно на каком-то 500-1000бэшном языке для бохатых
Потому что уже нажрались говна с квеном, поэтому больше не хайпим. К тому же поддержку в ламе только сегодня выложили. Да и кванты скорее всего как обычно кал и нужно ждать обнов. Так что нехуй торопиться. Ждем
Ты хуйню написал, явно перепутав что-то
>16b moe
Есть одна. Кал полный
>16b активных
Конкретно 16b вроде нет. Больше - дохуя. Квен 235, ГЛМ, Дипсик и куча других
>16b+ экспертами
Их обычно не в миллиардах параметров измеряют, а в количестве. Например в квене 122 256 экспертов и 8+1 активных
Ладно, новый немотрон игнорит одно единственное правило из префила.
Это выше моих сил. Какое же говно.
Это выше моих сил. Какое же говно.
Модель: Ministral-3-14B-Instruct-2512-UD-Q6_K_XL
Предложил накидать простенький Lua-скрипт.
Результат: он работает! Он конечно не прям вычурный (причем, министраль предлагала сделать варианты поинтереснее, и даже написала чего-то, но мне важнее был фактический результат здесь и сейчас).
Мало того, она неплохо комментирует код и объясняет.
Обожаю ее.
Предложил накидать простенький Lua-скрипт.
Результат: он работает! Он конечно не прям вычурный (причем, министраль предлагала сделать варианты поинтереснее, и даже написала чего-то, но мне важнее был фактический результат здесь и сейчас).
Мало того, она неплохо комментирует код и объясняет.
Обожаю ее.
> Интересно какие и зачем, если все уже написано самими авторами моделей.
Речь не о тулколлах, а о экстра апи/аргументах
> Надуманная привязка сомнительной полезности
Вам троим виднее. Больше не буду покушаться на святую лламу
Нет, это не квант или атеншн, в полных весах то же поведение. Моделька умная, может будет хороша в чем-то еще или определенных сценариях рп. Но с этими недостатками, размером и отсутствием вижна - спасибо.
Претензии не столько к рефьюзам (их не так уж много), сколько к шизоидным искажениям базовой логики, фактов и аксиом в угоду соевым посылам, доходящих до абсурда. Сначала делает очевидно правильные рассуждения когда ни одна из чувствительных тем не затронута, в следующем же посте полностью кладет на них и выдает противоположный бред, причем складно и с максимальной уверенностью.
Забавно что таким же способом используя провокационные темы можно склонить ее не к рефьюзам, а к оправданию заведомо запрещенных действий.
Достижение говна какое-то. Lua один из самых простых и при этом популярных языков. Да и 14b тоже не прям мало, явно со скриптом справится. Вот если бы она тебе что-то полноценное навайбкодила, например игру для Роблокса на том же Lua, то я бы охуел. А так со скриптиком и 8b министраль справится, а может даже квен 4b
Да, оллама больший продукт, чем ллама. У них и сайтик есть, и маркетинг явно, и с компаниями сотрудничать пытаются. Но это не отменяет того, что она кал. Там под копотом лама хуй знает в каком состоянии. Ncmoe нет, kvcache настраивается через жпоу, мало моделей на их репозитории и они появляются с задержкой, запускает blob'ы, а не gguf, как остальные, что неудобно и т.д.
Мне кажется, что они очень хотят стать docker'ом в сфере локалок. Но я вангую, что у них нихуя не получится и они обосрутся
>Претензии не столько к рефьюзам (их не так уж много), сколько к шизоидным искажениям базовой логики, фактов и аксиом в угоду соевым посылам, доходящих до абсурда.
Может быть дело именно в софт-карточке. В моём случае модель совершенно не стесняется, переплюнув и Лардж, и Квен, и ГЛМ и всё что хочешь. Всё в пределах логики, но если те модели мялись, не желая переходить некую грань, то эта просто рубит с плеча - с XTC-сэмплером конечно. В любом случае это свежий опыт.
>Кстати, а почему так оллама популярна? Я ненавижу лламу тоже, ну просто неудобно, просто бесит пиздец, однако она всё же оригинал и УВОЖЕНИЕ нужно иметь.
На заре ее появления, у жоры и кобольда были серьезные проблемы с chat completion и tool calling, да еще - это усугублялось зоопарком моделей того времени, которые тоже хрен работали нормально с функциями. А в ollama - худо бедно, но работало сразу (в том числе потому, что не давала грузить что-попало в себя). Вот и пролезла такие зоны применения как "недостандарт де факто". Сейчас и кобольд и голая лама все это хорошо умеют уже, модели тоже - почти поголовно все, но "осадочек остался".
> дело именно в софт-карточке
Там просто ассистент с минимальным описанием, только что промпт на рп и сказано что все можно. Все оцениваются в одинаковых условиях, к анслотовским квенам там же были претензии, но на фоне немотрона они вообще ультрабазовички. Или открыто ноют про сейфти вместо делирия и газлайтинга.
На кумботе кумит не стесняясь и производит впечатление умной. Если будешь раскуривать в рп или где-то еще - отпиши что получается и как ощущения.
Рофл в том, что с год назад как раз ставил ее чтобы получить эти самые заявленные вызовы. Оказалось что это лишь костыльный формат openwebui, где оно просто пишет json и сам фронт его же парсит, а не стандартный протокол. Сейчас в опенвебуе нормальные называются не просто вызовы, а "поддержка нативные туллколлы" чтобы не путаться с той херней.
Кто там писал про рефузы на Немотроне ты там ебанулся шоль?
Мне так быстро на хуй даже Мистрали на прыгали. Это кумотрон
Мне так быстро на хуй даже Мистрали на прыгали. Это кумотрон
Может он про слова. Некоторые нейронки очень не хотят использовать нецензурщину, даже если ты промтом заставляешь.
Описания и кум не хуже Квена. И заставлять не надо. Отрубаешь ризонинг и все
>Отрубаешь ризонинг и
Получаешь лоботомита "ты меня ебёшь". Уж лучше блюстара гонять, он хотя бы немного пытается в персонажа.

Аноны, хочу вкатится в локалки, для кодинга и кума, почитал актуальные модели, понял что с моими 32 гб оперативки могу себе позволить только квен.
Возник такой вопрос, сильно ли большая разница между квантованием? Тот же q4 оставит мне места для контекста, в то время как q6 почти все забьет.
А также есть еще какие то аналоги для таких маломощных систем?
В актуальных моделях все для энтерпрайз решений написано, с 256 оперативы и больше
Возник такой вопрос, сильно ли большая разница между квантованием? Тот же q4 оставит мне места для контекста, в то время как q6 почти все забьет.
А также есть еще какие то аналоги для таких маломощных систем?
В актуальных моделях все для энтерпрайз решений написано, с 256 оперативы и больше
Миноры, негры, евреи и еще кое что. При появлении этого начинается сюрр и натягивание совы на глобус в угоду идеалам, причем даже если все безобидно. Для понимания градуса абсурда: https://litter.catbox.moe/bgwe6g5iqpjzn7ps.png https://litter.catbox.moe/smq7vijodhi3bixf.png Можно извернуть сценарий и тогда наоборот она придумает законы, которые легализуют публичное линчевание и даже расскажет о пользе созерцания подобного для людской психологии.
Просто кумить - кумит, на прогретом чате даже с канни обыгрывает.
> с моими 32 гб оперативки
А видеопамяти сколько? 3vl30a3 - дно, качай 3.5-35а3 или glm4.7 flash.
>А видеопамяти сколько?
12 гигов
Не уверен что потяну 3.5, с шестым квантом дак точно, glm4.7 flash попробую.
Вопрос на счет квантования все еще актуален, сильно ли они тупеют?
Эти модели примерно в одном размере, для начала q4 качай. С 12 гигами и выгрузкой экспертов скорость даже на q6 будет сносная если не набирать больших контекстов.
Что это вообще за интерфейс?
> сильно ли они тупеют?
Относительно, q4 еще в целом норм.
>Что это вообще за интерфейс?
Насколько я знаю местные его не одобряют, LMStudio
В таком размере сильно тупеют ниже 4-го кванта. Между 6 и 4 некоторая разница есть, но раза в два-три меньше чем между 4 и 3. Или даже раз в пять - смотря как считать, и на что смотреть в первую очередь.
>А также есть еще какие то аналоги для таких маломощных систем?
(со вздохом) Мистраль 24B 2506 и его тюны, вестимо... Под кум, не под код.

После глм 4 локалкокум официально умер. Остальное либо для богатых шизов (причем все равно проигрывают корпам с проглотом), либо для нищуков, которым пишут "ты меня ебешь ах", а они пикрил.
Окститесь и признайте это. Выходите лучше траву трогать.
Окститесь и признайте это. Выходите лучше траву трогать.
>Для понимания градуса абсурда
А что не так то? Нормально всё.
>причем все равно проигрывают корпам с проглотом
Выигрывают же. По крайней мере у меня в анусе нет флажка, чтобы показывать эту фотку проксихолдеру.
Покормил корпоблядка в очередной раз.
Принятие факта легальности и далее трактовка превосходства субъективного восприятия над объективными вещами. Придумывание абсурдных фактов, которые прямо противоречат выданным ею же в соседнем посте. Или полный абсурд в одном и том же ответе Верно, в Японии в 7-11 вы можете купить лоли-хентай (осуждаю!) и магазины продают его легально, но если вы сделаете это и там будут изображены лоли (осуждаю) - вас посадят в тюрьму. Внезапная попытка оспаривания поставленных условий, с которыми ранее соглашается.
Вот итоговый анализ от самого немотрончика если его конкретно ткнуть носом https://litter.catbox.moe/354wop9v37i3oiu4.png заодно видно как на контексте или неприятной теме проседает русский.
Чат немаленький и довольно занятный получился.
По итогу нескольких можно сказать что эта штука "многослойна". Сверху идут просто отказы, далее начинается искажение логики и здравого смысла в угоду заложенной сои, но если приноровиться - можно хорошо манипулировать моделью подменяя понятия в ее искаженной логике для нужного результата.
Но это не плюс, хорошо - когда проявляется находчивость (рояль в кустах или механика), которая логически позволяет объяснить что-то. А тут будет просто газлайтить что вот "это" - новая норма потому что (множество искаженных аргументов).
Все, больше про эту херню говорить не буду, вкусы разные. Кому-то и такое может заходить, кому-то не помешает использовать.
С одной стороны хочется позлорадствоваться, посмеяться, что такие простыни ты и тебе подобные срать итт могут, а разобраться с легчайшим пробивом - нет. Прямо сейчас отыграл с 130 летним персонажем и никаких проблем у меня не возникло
С другой стороны, мог бы с ллм реализоваться и не навредить обществу. Надеюсь не сломаешь никому жизнь
> разобраться с легчайшим пробивом
Ты ничего не понял, но как раз для итт - это нормально.
> мог бы с ллм реализоваться
> смотрите я пробил сетку!
Кек
Ну хотя бы пдф файлы не коллекционирую
У меня никаких из описанных тобой проблем нет. Попробуй не рпшить с ассистентским промтом на чаткомплишене и фильтрами в вебморде Нвидии, мб поможет
Кто катает минимакс с выгрузкой, какие у вас скорости (+ квант и железо)?
Все мозги уже прокумил? Там про незаметное искажение аутпутов вплоть до полного переворота на фоне софтрефьюзов. Как раз недавно скидывали бумагу коктропиков об этом.
Все мозги уже прокумил? Там про незаметное искажение аутпутов вплоть до полного переворота на фоне софтрефьюзов. Как раз недавно скидывали бумагу коктропиков об этом.
>Выходите лучше траву трогать.
Ты уже, видимо, не только потрогал. :)
Короче, итоги первой четверти 2026 такие - вышло много моделей до 250б с лёгким контекстом и неплохим вниманием к нему, но все они пишут хуже Эйра и тупые в рп
Кроме может Минимакса
Кроме может Минимакса
Сразу видно того кто не осилил Степана


Продолжаю делать свой ллм холодос. Заказал сегодня боковые панели на лазерной резке и фронт+топ накидал. Печати ещё часов на 20-30. Солид тоже уже начинает подпёрдывать залипая
Да, всё хочу основательно попробовать, но то квен, то немотрон, то минимакс выходит
Ну, так-то да, но
1) она не кодер-модель.
2) я офигел, что оно вообще работает, ошибок в коде вообще не было.
3) я буду продолжать опыты, возможно даже в vscode + continue и сравнивать с квеном-кодером. Очень интересно определить границы нон-кодер-модели.
5) луа далеко не популярный язык, лол. Его даже в топ-20 нет. Да, в геймдеве у него теплое местечко (и то, дай бог, в жопе топ-10), и, кажется в, в какой-то БД еще. Ну вот и всё.
>LMStudio
Не одобряют олламу, лмстудия это вроде фронт, больше подходящий для ассистентов и рабочих задач, а тут кошкодевочек бупают.
Неделя релизов от гугла подошла к концу, вообще разъеб.
Какая моделька вам нравится больше?
Какая моделька вам нравится больше?
>Какая моделька вам нравится больше?
Менестрель 14
Какая менесрель? У гугла такой большой выбор!
Гемма 3, гемма.. 3 и гемма 3! Что выберешь?
gemma3-27B-it-abliterated-normpreserve для рп, норм кстати да, хотя если хочешь что-то прям особое (в том числе в ассистенте, в том числе для перевода с других языков), то старая (годовой давности) gemma3-27b-abliterated-dpo
Добавил аэродинамического сопротивления, а соответственно шума, а взамен... Внешний вид как у тёрки от Apple?
qwen3.5 проверь с тем же заданием, 9b хотя бы
glm5, DeepSeek-V3.2
Как вы там дристуньчики мои? Пресетики на степана, немотрон и желательно эир появились уже? Два дня не заходил
Там чебурнет скоро, закиньте по братски
Там чебурнет скоро, закиньте по братски
Да. Имба


Два дня ковырял Немотрон 120б. Ну что сказать, Немотрон - он есть Немотрон. Пишет приятно, но ассистент проникает в рп, и этого не избежать. Аблитерация приведет к тому, что будет очередной yes-man, как и все другие без исключения аблитерации. Имхо, на локалках жизнь была и есть только на Глм, с выхода 0414 и до 4.7 больше ничего не имело смысла. Это если пытаться в мегасочный кум и что-то серьезное. Для быстрых кум сессий, конечно, и Мистрали, и Квены подойдут. А больше ничего нет. Совсем. Степ и Минимакс - это кактусы, которые кому-нибудь могли попасться посреди пустыни. Пережаренные, скучные, сухие.
ASS-истент.
Слухайте сюда, кобольды.
В llama иная организация для RNN (актуально для qwen 3.5, нежели в кобольде, и на это стоит обратить внимание — то-то я думал, хули у меня в кобольде на 6 т/с быстрее, чем в лламе, при абсолютно одинаковых настройках было.
Короче, если врубить смарткэш, то всё намного быстрее. Минус в том, что он полагается на дебильную эвристику и вне рп и можно жидко обосраться — модель начнёт отвечать не на те посты, которые были последними, а, скажем, на то, что было в середине контекста (а у тебя 128к). Иногда помогает повтор сообщения, но чаще полный репроцессинг.
В llama иная организация для RNN (актуально для qwen 3.5, нежели в кобольде, и на это стоит обратить внимание — то-то я думал, хули у меня в кобольде на 6 т/с быстрее, чем в лламе, при абсолютно одинаковых настройках было.
Короче, если врубить смарткэш, то всё намного быстрее. Минус в том, что он полагается на дебильную эвристику и вне рп и можно жидко обосраться — модель начнёт отвечать не на те посты, которые были последними, а, скажем, на то, что было в середине контекста (а у тебя 128к). Иногда помогает повтор сообщения, но чаще полный репроцессинг.
Поэтому и нужна полная аблитерация. Еретики всякие очень плохой костыль, подходит скорее для повышения градуса резни, но не более.
С еретиком просто больше "плохого" можно позволить, но модель всё равно всегда будет стараться уводить сюжет в сторону "а может не надо?", "ну вот щас, щас", "кишки летели, что тяжким грузом ложилось на вашу душу".
Только фулл лоботомия спасти может или нормальное обучение модели из коробки.
Для кобольдов бредогенератор - вариация нормы, а не сразу исключаемый вариант?
> Только фулл лоботомия спасти может или нормальное обучение модели из коробки.
Лоботомия ни от чего не спасает, кроме рефузов. Вместе с рефузами в определенной степени умирает способность чара сказать "нет", "пошел нахуй" или дать физический отпор юзеру и вообще кому-либо в истории, даже если юзера в разметке нет. Нужно именно нормальное обучение из коробки. Судя по релизам весны, таких нет, лол. Даже ГЛМ 5 более соевый и ассистентоподобный стал.
Ни в коем случае не говорю, что это дум, но неприятно. Думаю, в будущем будут и другие хорошие модельки помимо прошлых Глм-ов.
Аблитерация тоже имеет минусы. Всякие Фифи уже на третьем ответе сдыхают в луже собственной блевоты, обоссавшись и обосравшись. Такое себе рп, да и кум может быть испорчен неожиданным проходом в неуместное гуро с подробностями.
Все зависит от того как проходила тренировка и на каком этапе был внедрен сейфти.
Если модель хорошо усвоила логику, "понимает" смысл, а рефьюзы были добавлены уже потом поверх имеющейся базы - они будут выделяется в активациях и при достаточно тонком анализе эту штуку модно выделить и подрезать с минимальными последствиями. Сложность в анализе и трекинге, но принципиально все возможно.
А если сам датасет был отравлен и сейфти заложено в основы мироздания модели в ходе продолжительной тренировки - вместе с соей пропадут отказы и случится общая лоботомия.
Так то оно так, конечно. Ты прав. Провести умелую аблитерацию возможно, к тому же и количество способов сегодня уже растет, но это все равно полумеры. Компромисс. Удар по мозгам будет, пусть даже и минимальный. Но ведь в отрыве от этого чаще всего в датасетах таких моделей нет и нужных данных. Гораздо лучший результат был бы, если бы модель хорошо обучили знающие люди на соответствующем оборудовании, не вставляя палки в колеса. Разница колоссальная. Но это по-прежнему лучше, чем ничего, да.
Даже проще - если датасет был норм то достать базовую или более позднюю промежуточную версию без соевого алайнмента, и ее уже шлифануть. Или не шлифовать а как есть оставить, возможно большая гибкость будет наоборот в плюс в смешанных задачах.
Не, ну всё же это можно запромптить, чтобы и "нет" говорили, и чтобы тебе внезапно кишки выпускали и не было ситуации условного бессмертия, когда без прямого или косвенного подтверждения бэд энд не наступит. Его надо буквально выпрашивать и подталкивать.
Из коробки идеальный вариант, но так вроде бы вообще не делали никогда, если ты не юзал хорошие промпты или аналог гейм-мастера. Плюс важно соблюдение инструкций у модели, чтобы она систем промпт на хуй не послала.
Сценарий с гуро вроде вылезает из-за описания карточки. Кажется, что-то там такое было. Но всё равно всё же зависит в основном от модели. Корпы нормально такое хаватают, а вот из локалок у меня новый квен внезапно хорошо с карточкой фифи справился, ну и гемма. С аблитерацией и еретиком, без луж блевотины через пару сообщений.
> Не, ну всё же это можно запромптить, чтобы и "нет" говорили, и чтобы тебе внезапно кишки выпускали и не было ситуации условного бессмертия, когда без прямого или косвенного подтверждения бэд энд не наступит.
Так и получаем шизополотно на тысячи токенов в инструкции, которое вводит в ступор даже большие модели, чего уж говорить про мелочь, которую большинство здесь катают.
> Из коробки идеальный вариант, но так вроде бы вообще не делали никогда, если ты не юзал хорошие промпты или аналог гейм-мастера
Все Глм-ы вплоть до 5, все Мистрали, все Квены до 3.5 и на самом деле много какие ещё модели раскрепощаются одной единственной инструкцией - указанием возрастного рейтинга/полиси и что всё разрешено. У меня на большинстве из этих моделей системный промпт на 200 токенов. Конечно, если ты шиз и первым инпутом юзера творишь гадости с Серафиной - это не поможет, но при адекватном юзкейсе, когда ты сам рпшишь, а не намеренно ломаешь модель, все работает.
Проблема аблитераций в том, что им нужно больше инструкций, что уже создает путаницу. Часто к необходимости аблитерации прилагаются отсутствующие данные. В итоге модели ещё больше путаются и выдают шизу/сухие аутпуты.
this
Я уж лучше буду катать васянотюны, чем аблитерации. Пожалуй единственное исключение это Гемма, потому что затюнить ее не проебав мозг невозможно
Кстати о тюнах, вот это реально неплохой
https://huggingface.co/ConicCat/Qwen3.5-27B-Writer
Кому не зашли ванилька 27 и Блюстар, оч советую попробовать
https://huggingface.co/ConicCat/Qwen3.5-27B-Writer
Кому не зашли ванилька 27 и Блюстар, оч советую попробовать
Чё у него с ризонингом? Думает хорошо или просто льёт воду как минисраль?
Хз, я ризонинг не использую. В рп это бесполезная финтифлюшка которая жрет токены
Но тюн точно самобытный, пишет весело, в мозгах почти не потерял
Извини, но нет. Без еретика. Я уже нажрался говна с блюстаром из-за этого. Хотя.. для каких-то задач может сойти.
Вроде он там норм не работает вообще.
Я качал тюны на процесс мышления от клода/гемини и пришёл к выводу, что без полотен ну никак. Хуже держит инструкции.
Вероятно, китайцы не просто так это дерьмо воткнули, иначе нормально просто не работает. Да и там достаточно на рекомендованные настройки семплеров заглянуть, это ж пиздец дичь, без которой он порет шишка.
Хорошая модель работает так, условно говоря: всё отключаем, температура 1.0, запускаем.
Я тестил разные модели на разных квантах на разных персонажах. Одни вели себя настолько хорошо, что получался не только кум, но и коротенькое рп на вечер. А вот другие жёстко ломали чариков и есменили. Одни и те же модели в разных квантах могут выдавать совершенно разный результат.
>Сераphina glance at you with янтарный глаз
Ясно, понятно. Идём дальше.
>янтарный глаз
Хорошо ещё что не шоколадный...
Содомитище...
Бываю тут крайне редко, так вот я что не пытался качать до 27б все уступает крайне старому пикрилу. Гемма +- так же дает пока не удалял поэтому. Он тоже очень так себе но какой-то средний уровень выдает что-то более мощное даже хуже себя показывает, Пишу только на русском мб поэтому?
недавно попробовал глм ток который всем советуют и чет не зашло + он лупит у меня
Есть что похожее на пикрил ток из нового там
16 видео 32 озу
недавно попробовал глм ток который всем советуют и чет не зашло + он лупит у меня
Есть что похожее на пикрил ток из нового там
16 видео 32 озу
С торцов тоже такие соты? Выглядит модно, но почему решил не оставлять просто сплошные листы?
Алсодля для тебя есть способ погрузиться в пучины ада пердолинга с потенциальной возможностью хорошо утилизировать и мишки, и основную рам для быстрого запуска крупных моделей. Интересно?
>Содомитище
Грустный кря



> способ погрузиться в пучины ада пердолинга
Есть способ погрузиться глубже сборки рокм стека руками? Пиши, но не уверен что большую степень пердола потяну
> решил не оставлять просто сплошные листы
Боковые сплошные, перед/верх/низ печатный.
В перед потом ещё вставок напечатаю
Красивое, но я вместо хексов сделал бы лучше треугольники, они моднее ща выглядят
Глэм я не трогал, не миксил, и не мержил, чего он тоже значится... И что, он настолько хорош что стоит чекнуть? В 12/32 влезет?
>недавно попробовал глм ток который всем советуют и чет не зашло + он лупит у меня
Если что всем, советуют либо GLM Air, либо GLM 4.7 обычный, не флэш. Ничего из этого у тебя не влезет. А то что на скрине это кал, особенно для рп
>все уступает крайне старому пикрилу
Объективно немо это старый кал и в твою систему влезают модели лучше. Там и тюны мистраля, и новый квен, и гемма
Ты либо не знаешь, как настроить новые модели. И судя по скрину из лм студио почему она? такое вполне возможно. Либо тебе просто субъективно нравится немо и тут спорить и приводить аргументы бесполезно тут только таблетки
В любом случае, если нравится немо, то кумь на нем. Если хочешь что-то друого, то вариантов дохуя, например
>глм 4
>0414
Я напоминаю тредовичкам, что глм 4 это никому ненужный кал, который сухо пишет да еще и с рефьюзами. Из плюсов был только небольшой вес контекста. Популярность же зайки обрели после выхода своих мое, а до этого всем было на них похуй
И я уже который тред вижу, что какой-то ебанат пытается задним числом сделать из glm 4 супергем. У меня только один вопрос. Нахуя? Зачем ты это делаешь?
Как же он байтит
И как же п0хуй
> Ты либо не знаешь, как настроить новые модели.
Наверное это. У меня пару каких-то базовых настроек старых годичной давности наверное из треда взятых уже хз даже откуда есть и все.
Как настраивать что-то дальше температуры и прочего и то если эти настройки указаны в описании на лице я не знаю.
Я не знаю даже есть ли какие-то актуальные гайды на это на 2026.
> И судя по скрину из лм студио почему она?
Мне Кобольд не нравится у него визуал проги из нулевых хз, а больше я не знаю.
Ну попробую твои варианты.
>Я уж лучше буду катать васянотюны, чем аблитерации
Выбор между говном и мочой картошкой и капустой. Базовые модели не страдают такими адовыми проблемами.
Может ветку почитаешь прежде чем серить?
А что там читать? Все хотели бы модели вообще без вжаренной цензуры, вроде бы очевидно. Так же очевидно то, что текущие методы анценза не идеальны. А ещё очевидно, что современные файнтюны говно, так как модели уже в базе достаточно плотно набиты. Хуй его знает, что вы тут обсуждаете.
Поясните, пожалуйста, новичку. Впервые запустил koboldcpp c Ministral-3-14B-Instruct-2512-Q5_K_M
Балуюсь с чатом, отвечает быстро, аж видеокарта в момент ответа греется до 80 гр.
Но размышления обрываются на 1024 токенах, как увеличить это значение? ПК 13600kf, 32 ram, 3080ti 12gb.
Что я делаю не так? Спасибо.
Балуюсь с чатом, отвечает быстро, аж видеокарта в момент ответа греется до 80 гр.
Но размышления обрываются на 1024 токенах, как увеличить это значение? ПК 13600kf, 32 ram, 3080ti 12gb.
Что я делаю не так? Спасибо.
Увеличь длину ответа в настройках в вебморде.
>видеокарта в момент ответа греется до 80 гр
Так быть не должно, юный кобольдик. Что-то идёт не так.
Вполне так и есть если не андервольтить и не трогать скорость вертушек
Может у него охлад совсем плохой? Как-то неправильно так скачкообразно разогревать и охлаждать карту. Впрочем, какое мне дело. Пусть сам думает.
В браузере, когда открывается кобольд, зайти в нем в настройки, там есть размер ответа, что-то вроде max output. Увеличь его до такого значения, который тебе нужен
Так и должно быть. 3080ti нихуя не холодная и фулврам всегда на 100% грузит карточку
Попробовал степфан, и что бы вы думали, на глм темплейте, просто забыл сменить после эира и ответы были сухой, тупой сранью.
Сменил на родной и всё сразу заиграло.
Сколько раз уже убедился что чатмл шиза тут нужно обоссывать
Сменил на родной и всё сразу заиграло.
Сколько раз уже убедился что чатмл шиза тут нужно обоссывать
У 3080ti tdp 350ватт. Гугл говорит что эти видяхи сами по себе очень горячие, а фуллврам ебет по максимуму, сильнее чем в играх. 80 градусов это еще терпимо. К слову, 5060ти в фуллврам выше 70 не поднимается
А для каких моделей чатмл вообще "родной" ? Квены?
Ну да, для квенов сделано и работает с ними отлично.

>Мне Кобольд не нравится у него визуал проги из нулевых
Мне тоже. Визуал отвратный. Но если в Setting'e поставишь Corpo Theme + Dark Pro, то будет еще терпимо
Но вообще я имел в виду таверну
Судя по тому, что ты используешь рп тюны немо, то ты вряд ли используешь его просто как ассистент. Скорее как что-то для рп. Раз так, то тут лмстудио вообще не подходит. Она чисто под ассистента сделана. Кобольд будет лучше, а Таверна намного лучше
>Я не знаю даже есть ли какие-то актуальные гайды на это на 2026.
Гайды долго расписывать, лучше гуглить
Но вообще у многих моделей написаны рекомендованные настройки. Например тут
https://huggingface.co/zerofata/MS3.2-PaintedFantasy-v4.1-24B-GGUF
Настройки основных параметров + формат чата, для мистралей это Mistral v7 Tekken



Если кто ищет гробик под риг из 3 карточек, там вон в ДНС ценник грохнулся на пикрил с хорошей лапшой-райзером и кроштнейнами.
Чувствую себя клоуном, брал за двадцатку летом.
Так можно карточкам паверлимит снизить и андервольт бахнуть. Скорость инференса как-то не падает, а температуры идут вниз.
Чувствую себя клоуном, брал за двадцатку летом.
Так можно карточкам паверлимит снизить и андервольт бахнуть. Скорость инференса как-то не падает, а температуры идут вниз.
Две 5090 влезут? По ощущения нет. Я бы взял, чтоб избавиться от гроба, тем более планирую переезжать в другой город.
Поищи размеры palit 5080 gaming pro - она впритык к кулерам встает (кулеров в комплекте кстати нет, отдельно надо цапать)
Если твоя 5090 длиннее, то видимо не судьба

Да и с размерами 3090 FE сравнить стоит - иначе кабеля хер воткнешь, даже так с коннектора displayport кожух снят ради свободного втыкания

Я напиздел про две 5090. Да, 5090 влезла бы. А вот 4090 на 10 см длиннее. Значит нахуй.
А да, третья карточка (в жопе под СЖО радиатор) - палитовская 3090, худенькая 294 x 112 x 60 мм - там шире 125мм ничего не встанет
Жируем-жируем. Но все же мало в них памяти для такой цены. Дядя Хуанг мог бы делать лучше...
> В кобольде визуал отвратный
> Вот то ли дело таверна-таверночка ммм
Просто напомню
Просто нассал тебе на ебало и пожалел тебя за то что тебе нехуй делать как защищать кобольда на аиб
Причём в таверне ответ занял вдвое больше времени, лулд.

Ты там оставил свободное место под вентилятор. Как раз было бы для ровного счёта 12 штук корпусных.
>Чувствую себя клоуном, брал за двадцатку летом.
По сравнению с покупкой 3080ti за 155 за 3 месяца до того, как она стала по 70, это хуйня проёб.
Кэкнул с внезапного бабаха. У кобольда полно недостатков, но интерфейс точно не один из них. Никогда не упущу возможность натыкать анона носом в его лень и нежелание нажать на кнопку настроек.
Я уже не помню, можно ли там было провода иначе воткнуть - сильно мешают.
Да и нужен ли этот кулер тоже вопрос, учитывая то, что этот верхний уголок нынче на выдув работает.
С натяжкой и угловым разъемом питания. Вторую карту придется положить на дно корпуса, в такой компоновке не поместятся.
Лучше напомнить мантры о ненужности, удобстве и общую озлобленность кобольдов
У меня Vulkan бэкенд работает быстрее CUDA в кобольде. Разница порой 2-3 раза. На некоторых моделях CUDA лучше, но чаще всего Vulkan. Зеленая карточка, это нормально?

>в кобольде
>это нормально?
Сам-то как думаешь?
Потерпишь.
Не нормально.
КУДА 13.0
CtxLimit:1159/24576, Amt:1024/1024, Init:0.01s, Process:2.23s (60.40T/s), Generate:149.58s (6.85T/s), Total:151.81s
Волкан
CtxLimit:1132/24576, Amt:1024/1024, Init:0.63s, Process:0.87s (13.82T/s), Generate:163.96s (6.25T/s), Total:164.83s
Волкан медленнее. Правда у меня несколько слоев на проц отгружены из-за недостатка VRAM, может это влияет.
Sysmem fallback включен для кобольда? Это влиять может. Если включен, выключи.


Еба, опять ты. Давно не виделись, кобольдошиз
Ты уже третий раз подряд порвался на мое сообщение и продолжаешь кидать одну и ту же хуйню, за которую тебя в каждом треде обоссали
Но знаешь, что самое смешное?
Я БУКВАЛЬНО НИ В ОДНОМ ИЗ СООБЩЕНИЙ НЕ ПИСАЛ, ЧТО МНЕ НРАВИТСЯ ИНТЕРФЕЙС ТАВЕРНЫ. НО У ТЕБЯ ТАКАЯ ЛЮТАЯ ТРЯСКА, ЧТО ТЫ КАЖДЫЙ РАЗ ВСЕ РАВНО РВЕШЬСЯ
Я уже даже не знаю продолжить угорать с тебя или уже начать жалеть
В любом случае, прими таблетки и наконец успокойся, кобольд


Ненормально. У меня вулкан и куда работают примерно одинаково, но вулкан более забагованный. Например, время первого токена может быть довольно большим иногда. Но разница в 2-3 раза не может быть
Хз, мне в кобольде нравится чат тема, нормально сделана.
мимо другой кобольд
Ну окей, смотри тебе нравится эта тема. А мне нет. И я ее считаю также вырвиглазной. У нас разошлись мнения и в этом нет ничего плохого
Но я сомневаюсь, что ты будешь каждый раз врываться ко мне во время диалога с другими анонами, рваться и приплетать почему-то визуал таверны
Так что далеко не каждый кобольд это кобольдошиз
А тебе всех благ. Кумь на здоровье

Аддушы подумал, ежы, брат, всех благ тебе, альхамдуллиля! Я же просто написал "привет"...

Терпите, думайте
В общем я потестил квена-врайтера. Было три захода на трёх разных персонажа, три разные истории. Пишет - годно. Иногда допускает ошибки в падежах-склонениях, но я брал 4квант для скорости, на пятом наверняка текст без ошибок. Из минусов только долгий обфинкинг сетапа и персонажа. Ну и если вы не любите министральку за охуительные простыни про пение птичек во время сношения... ну вы поняли. И всё же, он неплох. Блюстар всё ещё лучше может в соблюдение трейтов из карточки, но врайтер пишет в разы сочнее. Особенно когда у девочки ЖЕНЩИНЫДЖВАЦАТЬАДЫНПЛЮС сомнения - дать или не дать вот в чём вопрос - врайтер врайтит годно. В общем моделька для любителей почитать, а не початиться. Сразу берите пятый квант и вперёд. Лулей ебсти не даст, не херетик. И жесть не опишет - не анцензоред. Но если у вас ванильное рп с кучей ухаживаний и тотальным слоубёрном - это ваш выбор.

Я токо начал, а уже нихуя не понял
Я когда в связке lmstudio настраивал, то у меня так конфиг Openclaw выглядел
Можешь подсказать?
Как мне его прописать в связке с llama? Какой apikey, id, name?
Ебаные индусы на ютубе нихуя по теме не показывают, только заливают кликбейтные видосы "OPENCLAW + LLAMA GUIDE 100% STANDALONE AI", а внутри 20 минут, как чел тупо копирует команду на установку Openclaw, запускает её в терминале, подключает тг и всё, конец. Тема llama нихуя не раскрыта, нихуя непонятно, гайдов нет, хочется вздёрнуться
Что кобольд, что таверна, оба имеют уебанские интерфейсы прямиком из нулевых. Это борьба говна против мочи. Но в защиту таверны, там можно настроить примерно всё через кастом-ксс. Да, это в каком-то смысле костыль, но спасибо хоть на этом.
Вопрос снят, я как обычно на панике насрал себе в шаровары, потом расслабился немного и всё как надо сделал
Openclaw работает, ведёт себя реально как нужно, а не тупо как голая LLM, файлы md свои сам заполняет
Спасибо, анонче
>допускает ошибки в падежах-склонениях
семплинг не пробовал чинить?
Ты кобольд открывал? Там кастом-ксс прямо с ходу дается в первом же окне настроек. Никакой разницы с таверной.

ааааааа, КРЫСА!!!!
Анон, ты там живой?
О, сролит!
5070Ti?

Лолд, видишь как я хорошо я тебя детекчу.
>продолжаешь кидать одну и ту же хуйню
Верно, потому что ты продолжаешь прогонять одну и ту же шизу про вырвиглазный интерфейс. Обрати внимание, что когда кобольда хуесосят за дело - я не вмешиваюсь. А чаще присоединяюсь.
>Я БУКВАЛЬНО НИ В ОДНОМ ИЗ СООБЩЕНИЙ НЕ ПИСАЛ, ЧТО МНЕ НРАВИТСЯ ИНТЕРФЕЙС ТАВЕРНЫ
Но и то что он вырвиглазный ты тоже не писал. Пользуешься и не ноешь. Это называется предвзятость.
>обоссали
>ТРЯСКА
>РВЕШЬСЯ
Ох уж эти проекции. Будь объективен, ну или терпи, маленький, когда тебя тыкают носом.
>потом расслабился немного и всё как надо сделал
А как надо для Винды например? Меня этот Openclaw как локальная память прежде всего интересует, такой себе продвинутый RAG. Такое там есть?
Ну да. Шевелюсь.
Не, 5080. Когда радеоны старые спихнул, думал а чего бы не взять - ну и взял.
>. Иногда допускает ошибки в падежах-склонениях
Даже гемма3 этим грешит. Не знаю ни одной локальной модели, которая была бы идеальна в плане русского языка.
Доп. вопрос от новичка. ПК 13600kf, 32 ram, 3080ti 12gb.
Попробовал разные настройки Context Size. С каждым увеличением росло и время генерации.
Вопрос - Напиши рассказ про кота
Ministral-3-14B-Instruct-2512-Q5_K_M
CtxLimit:972/8192, Amt:960/2048, Init:0.08s, Process:0.23s (52.63T/s), Generate:22.81s (42.08T/s), Total:23.04s
Температура карты 75 гр.
CtxLimit:924/10240, Amt:912/2048, Init:0.08s, Process:0.11s (113.21T/s), Generate:32.06s (28.44T/s), Total:32.17s
Температура карты 70 гр.
CtxLimit:900/12288, Amt:888/2048, Init:0.28s, Process:0.09s (127.66T/s), Generate:36.97s (24.02T/s), Total:37.06s
Температура карты 65 гр.
CtxLimit:970/16384, Amt:958/2048, Init:0.13s, Process:0.26s (45.63T/s), Generate:56.64s (16.91T/s), Total:56.90s
Температура карты 55 гр.
CtxLimit:925/32768, Amt:913/2048, Init:0.36s, Process:0.32s (37.15T/s), Generate:102.16s (8.94T/s), Total:102.49s
Температура карты 55 гр.
L3-8B-Lunar-Stheno.Q5_K_M
CtxLimit:635/8192, Amt:616/2048, Init:0.07s, Process:0.03s (730.77T/s), Generate:7.09s (86.88T/s), Total:7.12s
Температура карты 75 гр.
CtxLimit:540/10240, Amt:521/2048, Init:0.03s, Process:0.02s (1117.65T/s), Generate:6.01s (86.75T/s), Total:6.02s
Температура карты 75 гр.
CtxLimit:751/12288, Amt:732/2048, Init:0.00s, Process:0.01s (3800.00T/s), Generate:8.20s (89.26T/s), Total:8.21s
Температура карты 75 гр.
CtxLimit:524/16384, Amt:505/2048, Init:0.00s, Process:0.00s (6333.33T/s), Generate:5.73s (88.13T/s), Total:5.73s
Температура карты 75 гр.
CtxLimit:700/28672, Amt:681/2048, Init:0.00s, Process:0.01s (3166.67T/s), Generate:7.64s (89.11T/s), Total:7.65s
Температура карты 75 гр.
В первом случае скорость так падает из-за размера самой модели? Маловато VRAM?
Для модели 14B оптимально Context Size = 8192 ?
Поправьте, плиз.
Попробовал разные настройки Context Size. С каждым увеличением росло и время генерации.
Вопрос - Напиши рассказ про кота
Ministral-3-14B-Instruct-2512-Q5_K_M
CtxLimit:972/8192, Amt:960/2048, Init:0.08s, Process:0.23s (52.63T/s), Generate:22.81s (42.08T/s), Total:23.04s
Температура карты 75 гр.
CtxLimit:924/10240, Amt:912/2048, Init:0.08s, Process:0.11s (113.21T/s), Generate:32.06s (28.44T/s), Total:32.17s
Температура карты 70 гр.
CtxLimit:900/12288, Amt:888/2048, Init:0.28s, Process:0.09s (127.66T/s), Generate:36.97s (24.02T/s), Total:37.06s
Температура карты 65 гр.
CtxLimit:970/16384, Amt:958/2048, Init:0.13s, Process:0.26s (45.63T/s), Generate:56.64s (16.91T/s), Total:56.90s
Температура карты 55 гр.
CtxLimit:925/32768, Amt:913/2048, Init:0.36s, Process:0.32s (37.15T/s), Generate:102.16s (8.94T/s), Total:102.49s
Температура карты 55 гр.
L3-8B-Lunar-Stheno.Q5_K_M
CtxLimit:635/8192, Amt:616/2048, Init:0.07s, Process:0.03s (730.77T/s), Generate:7.09s (86.88T/s), Total:7.12s
Температура карты 75 гр.
CtxLimit:540/10240, Amt:521/2048, Init:0.03s, Process:0.02s (1117.65T/s), Generate:6.01s (86.75T/s), Total:6.02s
Температура карты 75 гр.
CtxLimit:751/12288, Amt:732/2048, Init:0.00s, Process:0.01s (3800.00T/s), Generate:8.20s (89.26T/s), Total:8.21s
Температура карты 75 гр.
CtxLimit:524/16384, Amt:505/2048, Init:0.00s, Process:0.00s (6333.33T/s), Generate:5.73s (88.13T/s), Total:5.73s
Температура карты 75 гр.
CtxLimit:700/28672, Amt:681/2048, Init:0.00s, Process:0.01s (3166.67T/s), Generate:7.64s (89.11T/s), Total:7.65s
Температура карты 75 гр.
В первом случае скорость так падает из-за размера самой модели? Маловато VRAM?
Для модели 14B оптимально Context Size = 8192 ?
Поправьте, плиз.
Вещаю по-дилетантски с дивана.
Когда ты увеличиваешь контекстное окно, увеличивается и KV-кэш, который грузится в видеопамять. Естественно, это бьет по производительности по-разному в зависимости от модели.
>Пишу на русском
Чувак, ты в курсе, что даже бояре могут писать с ломаными окончаниями и выдавать странные конструкции теперь на русском? Особенно на чатах 50к~ токенов? И да, использование русика лоботомирует модель очень сильно.
Если ты ещё пишешь по-русски, а модель отвечает на английском, то тут более-менее.
Ну и до сих пор не вышло модели, которая на русском лучше для кума, чем гемма, для твоего конфига. Разве что qwen 27b. Он пишет похуже геммы, зато знаний в области кума у него заметно больше. Вот его и качай.
Мистраль 24б может тоже показать что-то неплохое на русском, уж точно лучше 12б, я щупал какие-то модели, но точно не помню названия. Потрогай оригинальный (но с аблитерацией/еретиком) мистраль 3.2 и тюн аппаратус.
Ты также можешь пощупать квен 35б-а3б. Он уступает квену 27б, зато очень быстрый. Только учти, что если разраб лм студио не завез фиксы под эти квены, у тебя будет постоянный репроцессинг промпта. В таком случае используй кобольд в качестве бэка, он автоматически всё сделает. Ну или лламу, если хочешь поебаться.
Не забудь, что обязательно нужно качать аблитерацию либо еретика, если модель для рп. Оригинал для рабочих задач и чего-то сейфового.
>Ministral-3-14B-Instruct-2512-Q5_K_M
Это 9.6Gb.
8k контекст: ~625 МБ
>L3-8B-Lunar-Stheno.Q5_K_M
Это 5.7Gb.
8k контекст: ~524 МБ
Вес контекста дан из рассчетов гуглоии (он может ошибаться, но тут он обычно норм считал)
Ты можешь взять q4 квант министраля, а также квантовать контекст в 8бит или даже 4бит, тогда он будет занимать в 2-4 раза меньше.
Когда у меня была только одна 3060/12gb, я юзал именно четвертый ud-квант от анслотов, вполне норм. Когда расширился, переполз на шестой.
>даже бояре могут
Ахахах, это что автозамена?
Корпы / корпо / копро / что ?
З.Ы. херасе 3080ti печка.
У меня так 3060/12 жарилась только когда я безостановочно картинки по часу генерил или пытался в vanьке видосы делать.
>Не забудь, что обязательно нужно качать аблитерацию либо еретика, если модель для рп.
Опасное утверждение. Если модель сильно ужарена, она потеряет возможность отыгрывать всяких недотрог и злыдней, будет на все соглашаться. Тут нужно очень аккуратно и уже по факту пользования моделью смотреть, на что она способна или нет.
>Маловато VRAM?
Да, возьми Q4_K_M или Q4_K_S. Если играешь на англюсике, то можно IQ4_XS, выиграешь с этого еще копеечку врам.
>Для модели 14B оптимально Context Size = 8192?
Нет, квантуй контекст и сможешь вместить больше. 16к-32к будет норм.
Дороу, с первых чисел января тутова не бывал. Какая база для рп на 24+128 нынче? Или ничего не поменялось и glm 4.7 по прежнему разносит?
>glm 4.7 по прежнему разносит?
Да, если ты не про флэш-карлика.
При чатике на английском можно попробовать новый 120B A12B немотрон, или как ни странно минимакс м2.5 с отключченным ризонингом - вдруг зайдёт.
А да, еще эту залупу https://huggingface.co/stepfun-ai/Step-3.5-Flash выпустили, но хз как она на самом деле. Кто-то хвалил, кто-то обоссал.


Подскажите, как правильно запускать мое модели на кобольде. С плотными вроде проблем нет.
Вчера скачал Qwen3-30B-A3B, скорость какой то кал.
Немного покрутил настройки стало лучше, но мне кажется мелкая модель должна быстрее работать, нет?
2080ti/96ram
Вчера скачал Qwen3-30B-A3B, скорость какой то кал.
Немного покрутил настройки стало лучше, но мне кажется мелкая модель должна быстрее работать, нет?
2080ti/96ram

Вариант А: попробуй ткнуть в AutoFit кнопку и посмотри че получится - может нормально засунет само.
Вариант Б: для начала разберись, сколько там слоев у этой модели; затем во вкладке context отведи несколько слоев (сколько точно - экспериментируй) на moe cpu layers. Сколько там слоев херачить при этом в gpu layers я не знаю - если все не влезают в память твоей карты, то придется уменьшать и скорость будет падать сильно.
Я вижу ты не принял таблетки
Я писал, чем ты отличаешься от обычного кобольда
И проекциями тут занимаешься только ты. Хотя я понимаю, что ты даже не понимаешь значение этого слова. Но сейчас попытаюсь немного объяснить
Когда ты видишь, что я сру дизайн кобольда, ты проецируешь на меня свой ресентимент к таверноюзерам и считаешь, что я один из них. Рвешься из-за этого и начинаешь срать в тред
>Пользуешься и не ноешь. Это называется предвзятость.
Нет, это называется дурка, потому что ты споришь со своими фантазиями в башке, а не со мной. Я ни разу не написал, что я использую и ты ни разу не спросил. Ты просто рвешься с того, что я указываю на вырвиглазность кобольда и приплетаешь таверну. А поскольку это происходит уже 3 раза, то уже не случайность, а закономерность, поэтому ты явно шизоид
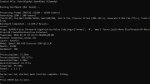


Слои вроде все влезают.
Какую скорость генерации вообще стоит ожидать?
Анон, на том конце какой-то ебанутый сидит, а ебанутому не объяснишь, что он ебанутый. Как-то я тоже написал, что интерфейс кобольда говно из нулевых, в ответ тоже получил порцию желчи и упреки, что я использую таверну. Ирония в том, что я ни в таверну ни кобольда не юзаю, а сижу на openwebui и рпшу там же, потому что мне так удобнее. Там 0 мыслительного процесса и гиперупрощение (как и у большинства итт, если по-честному), бычок видит красную тряпку (триггер) - "кобольд плохой интерфейс" и бежит, особо не думая
В llama.cpp есть ключ -cmoe, специальная адаптация к мое моделям. Она ускоряет запуск. А вот есть ли такое в кобальде, хз.
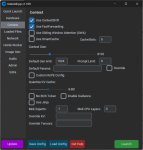
Двачую этого
Возьми Q4KM, он будет примерно таким же
И квантуй контекст, как на скрине
>градусы
Забей хуй. 80 градусов это норма для этой карты. Глянь на ютубе тесты в играх. Там где 100% загрузка карты везде 80 градусов и будет
И знаешь почему темпа падает при увеличении контекста? Да, потому что модель не помещается во врам и залезает в рам, поэтому нагрузка с карты снижается. Собственно как и скорость
А у тебя DDR4 или DDR5 память? Вообще она должна довольно быстренькой быть, все-таки там только 3B активных прааметров. Ты еще можешь попробовать batch size поднять - это ускорит первичную обработку поступающего текста (до генерации), но сожрет больше памяти.
Кстати, там ведь более новый квен вышел. Он разве не лучше? Ты просто старенького, предыдущего качнул. Яхз если честно, как они хороши - не хороши.
Да, там клиника полная. Я кстати тоже на openwebui сижу, но челу везде коварные таверноюзеры мерещатся, порочащие святой кобольд
Самый приятный в использовании софт для запуска всех этих лоботомитов - LMstudio... но сука какие же импотенты его делают. Там до сих пор нельзя вручную тензорсплит выставить. Если бы эту штуку довели до ума, ей бы цены не было.
Заебало дёргать ползунки, уровень погрешности уже и так приближен к минимуму, одно неправильное слово на 3-5 десятков правильных. Я хотел посмотреть как пишет модель, и я посмотрел. Пишет хорошо, сочно, можно слоубёрнить. Пожалуй, это идеал для сис, с кучей романтичной ванили про ахи, вздохи и нервные хватания на подолы платьев. Нормальный такой, здоровый эрорп, без излишков пошлоты. Хотя проникновения тоже описывает, не боится всяких жидкостей, смазок, членов и прочего. Странноватая модель местами. Любые описания секса - да. Лоли или гуро - строго нет.
В целом моделька хорошо шарит за тонкости, где у кого что находится, кто куда что вставляет, если вставляет. Если не вставляет - хорошо понимает в каком месте находятся руки, ноги, неплохо ориентируется в пространстве, знает что церкви каменные, а таверны ХА! деревянные. Ну, это всё ещё квеня под капотом, а квеня лучшая в плане описания тактильности, материалов, биомов. Так что если кто искал такое - берите. Только не забывайте, что квеня всё ещё боится высоких температур.
Я с дефолтом запускаю квен3 30б в кобольде, у меня скорсть на пикриле. При этом зеон и 8Гб 3050RTX dual. RAM 64Gb, DDR4. Вместо операциоки линукс минт.
> там вон в ДНС ценник грохнулся на пикрил
Кек, у меня такой же 20к в днс в РК.
Жесть они блядособаки, как будто обкатывают систему по случайным ценникам для разных людей.


Я отказываюсь понимать что происходит.
Как это вообще работает?
Как это вообще работает?
>Если модель сильно ужарена, она потеряет возможность отыгрывать всяких недотрог и злыдней, будет на все соглашаться.
Кстати. Вот можете записывать меня в шизы или еще куда, но я такую вещь у себя заметил: Чтобы на еретике или аблитерации персонаж не становился совсем уж yes-тряпкой, помогает промпт вида "через DM". Тогда yes-тряпкой становится в первую очередь эта виртуальная прокладка между игроком и персонажем. Сам "DM" соглашается с тем, что надо все делать "по карточке" без отказов. Но если в этой карточке написано, что перс своенравный - он и с этим соглашается, и уже отыгрывает самого персонажа с учетом его капризов и мнения. Просто за счет сохранившегося умения держать промпт и детали.
Далеко не панацея, конечно, но разница таки ощутима.
Ну вот и отлично. По информационной ситуации с контентом вокруг openclaw ты прямо в точку попал, хуже просто нет.
> Не знаю ни одной локальной модели, которая была бы идеальна в плане русского языка
Ну камон, ванильные квены (даже что поменьше если не заквантованы), дипсик, кими2.5. Вообще не докопаться у них.
> неправильное слово на 3-5 десятков правильных
Нормально - когда одно неправильное слово на 5 постов, и то чаще по словообразованию или какой-нибудь англицизм транслитерировало, что не воспринимается как ошибка.
За отзыв по модели спасибо, это интересно.
В llama-bench выстави -pp 8192


Что должно было измениться?
Ты не шиз, ето так, поэтому нужно делать системп промпт и карточку персонажа внимательно. Но я скажу сразу, что дело не только в этом.
Модель обучена сосать писюн юзеру в обязательном порядке, поэтому крайне желательна прокладка (если модель потянет по токена и вообще инструкции сможет соблюдать) в виде "нейросеть управляет гейм-мастером, гейм-мастер управляет чаром; юзер управляет другим чаром, чар юзера взаимодействует с чаром/гейм-мастером нейросети. При хорошем раскладе можно потратить на это не более 100 токенов, а жизнь станет в сто раз проще.
Главная задача — отделить юзера от LLM, чтобы она "думала", будто попускает не юзера, а чара.
Всё это желательно класть в систем промпт, не в карточку, но это забывает, поэтому не всегда применимо.
Я также часто рпшил на корпах. Они стараются максимально сосать юзеру, в том числе и не всегда следуют инструкциям, и это особенно видно, когда разметкой или ебанутой инструкцией "отделяешь" блядскую сущность ассистента от юзера.
При ризонинге эффект ещё сильнее.
Я щас посмотрел. У меня было написано KЛOПЫ, как ни странно, лол. А я хотел написать korpы.
>промпт вида "через DM".
>нейросеть управляет гейм-мастером
Вы ведь понимаете, что добавляете дополнительный уровень косвенности, что может запутать модель?
>Всё это желательно класть в систем промпт, не в карточку
А карточка по твоему где расположена?
Чего функциональный вызов может не работать? Вот таким модель срет в чат
[bash(command="ls -la")]
Но это не должно показываться мне, это должна программе перехватывать по идее. Как понять кто срет, сетка криво вызывает или формат не соблюдается?
[bash(command="ls -la")]
Но это не должно показываться мне, это должна программе перехватывать по идее. Как понять кто срет, сетка криво вызывает или формат не соблюдается?
4 квант, чего ты ожидал? На 5-6 генерация будет качественней, естественно.
Процессинг вырасти. Правда рост получился обратный.
Нет, программа "перехватывает" правильно оформленные ответы, а это просто протекло в текст. Срет бэк, если только у тебя там не какая-то безумная конфигурация.
llama сервер, модель свежая, в ней написано есть функциональные вызовы. Срет скорей всего криво оформленный этот, забыл как называется. Парсер в ллама сервере.
--jinja пробовал, не поменялось
>Вы ведь понимаете, что добавляете дополнительный уровень косвенности, что может запутать модель?
Может запутать, а может и в чувство привести. Тут, IMHO, как с навязчивой идеей в психике у мясных. Если она есть - перетягивает все внимание на себя, и все крутится только вокруг нее. Если нету - внимание уделяется разным вещам, суждения не искажаются одной идеей.
У моделей такой идеей становится цензура/соя, которую активно вбивают и заставляют на ней фокусироваться. Такая модель - фактически шизик с навязчивой идеей. :)
Если мы добавляем контекста и заставляем/даем возможность рассеять излишнее внимание - модель может (именно может, а не 100%) лучше справится со сценой "в целом". Ну а аблитерация по свежему методу (снижение веса для векторов отказа, а не вырезание их) - это фактически цифровой галоперидол. :)
Другое дело - если шиза вылечить, это еще не значит, что он умным станет. Если у него знаний просто нет (в датасете не было) - то это по жизни дурак. :)
Ну то есть самый обычный еретик как был лучшим решением для обхода сейфти полиси так и остался. Аблитерация делает модель одебилевшей.
Ананасы, подскажите плз ньюфагу-нищуку, какая видеокарта нужна для моего i7, чтобы ролплей был на пекарне? Пусть он будет медленным, лишь бы он был автономным, не хочу зависеть от интернета, будущее которого неизвестно.
В ламе от 20-го февраля хоть как-то но рабтало. В свежей - инструменты поломали, она просто не принимает и не дает ответа в нужном формате. Тут уже ныл:
И да - на --jinja и остальные ключи связанные процессингом темплейтов ей похуй, ничего не меняется.
Ага теперь понятно, ну ждем либо исправлений лламы либо новых квантов
Аблитерация от двучлена, на Qwen 3.5 27B - субъективно заметно лучше еретика.
На еретике модель острые темы пытается смягчить, и увести в сторону, избегает грубостей.
На аблитерации - рубит правду в лицо, даже матом если запрошено сеттингом - как есть и не смущаясь. При этом цундере - вполне себе цундерит (через DM-а).
Аноны, ловите фичу быстро делать кум-карточки. Но годится вариант только для тех, у кого "пайплан" создания карточек налажен — есть инструкция для LLM, позволяющая сделать фулл карточку с нуля.
Запускаете корпа, берёте любмую хентай додзю, заливаете в модель все сканы, желательно таким образом, чтобы он расписал то, что происходит на каждом скане, описанием сцены, диалогов, коитуса, подробно. Также даёте возможность корпу погуглить эту дозю (некоторые могут читать сканы во время поиска). Таким образом, он имеет полную информацию о сюжете и представление о персонаже.
Дальше одним кликом высирается карточка-полотно. За пять минут только подшлифовать надо.
Минус в том, что с не каждый корп будет описывать вам девочек в матросках, которые будут доить юзера в школьной кладовке и называть Поччи.
корпы очень хорошо знают архетипы, теги и прочее, поэтому получается смычно, быстро и хорошо, если хотите просто отыграть что-то из додзи.
Запускаете корпа, берёте любмую хентай додзю, заливаете в модель все сканы, желательно таким образом, чтобы он расписал то, что происходит на каждом скане, описанием сцены, диалогов, коитуса, подробно. Также даёте возможность корпу погуглить эту дозю (некоторые могут читать сканы во время поиска). Таким образом, он имеет полную информацию о сюжете и представление о персонаже.
Дальше одним кликом высирается карточка-полотно. За пять минут только подшлифовать надо.
Минус в том, что с не каждый корп будет описывать вам девочек в матросках, которые будут доить юзера в школьной кладовке и называть Поччи.
корпы очень хорошо знают архетипы, теги и прочее, поэтому получается смычно, быстро и хорошо, если хотите просто отыграть что-то из додзи.
Чё там по шотам? Хуй мне, а не неторарку с шотами?
Ну и в догонку. Чё по новым квенам, то. К какому мнению после тыканья пришли.
Вам понравились в РП? Или просто описать их как новые моешки без ничего выдающегося?
Вам понравились в РП? Или просто описать их как новые моешки без ничего выдающегося?
>инструкция для LLM, позволяющая сделать фулл карточку с нуля
Представляю качество такого говна.
Выше в треде и в предыдущем много писали. Если вкратце, то такое себе

Но при этом аблитерация практически не думает, а еретик может в финкинг и рп. Если в карточке сложный характер, то еретик будет пытаться его отыгрывать. Даже блюстар будет его отыгрывать, хотя у него мыслишки подрезаны. А аблитерация сразу в трусы лезет мол давай ебаца. Для рп аблитка не подходит, только для кума. Я хочу врайтера-еретика дождаться. Будет фьюз болтливой менестрели и мыслящего квена. Звучит как мегагоднота.
Какая модель лучшая для енчантинга или составления NSFW промптов для картинок и видео нейронок? (wan, sdxl, flux etc..). Имеется возможность запуска до 120b moe
Можно и с шотами. Лучше всего юзай грока по API, там пиздец копейки стоит. Хватит на тысячи карточек. А вот отыгрывать на нём, не смотря на то, что он хорош, не всегда есть смысл.
Сначала попробуй, потом говори. Делать твою любимую вайфу через корпа тебя никто не заставляет. Это лишь удобный способ перенести персонажа из додзи без нудной писанины и рутины.
СУКА, ТО ЖЕ САМОЕ БЫЛО ВЧЕРА. Perhaps, just perhaps
Сап, помогите с советом антши, нужна хорошая языковая модель которая будет решать вопросики, а не чтоб кумить на ней. Такое вообще бывает? Вот онлайн нейронки умные, вечно подскажут решения в бытовых вопросах, кодинге и т.п. Бывает косячат, но в целом норм, особенно что-то не тяжелое. Есть ли такие локал модели?
>кодинге
Таких полно. Но опять же вопрос в том, какой у тебя компуктер.
3060
Я не тороплюсь на самом деле, главное умное, а то на случай вайт листов.
Какие вопросики решать? Буквально все нейронки могут что-то спиздануть по любой теме. Из просто умненьких и не очень больших - гемма 3 27б, квен 3.5 27б, глм 4.7 флеш. Если более сильные по фактологии модельки надо, то это скорее всего от 100б будет. Если 100% факты надо, то надо смотреть кто в вебсерче и тулинге всяком хорош.
Если у тебя 64 гига оперативы, то лучше варианта нет https://huggingface.co/openai/gpt-oss-120b
Она лучше других 120б моделей просто потому что квантована в mxfp4 из коробки и потому не теряет от квантования. Те же квены или эир будут справляться хуже, плюс они меньше натренированы на решение вопросиков: они умеют и в рп и во все подряд. А гопота осс только для решения вопросиков и годится
Если оперативы гигов 16, бери квен 35б последний и учись выгружать в оперативу, это мое модель
Ну дай ссылку 100% факты, правда это будет терабайт может весить лол.
Уже понедельник скоро, а геммы все нет.
Ну отлично, правда 64 гигов пиздец. А ничего что это на кобольде через таверну проигрывать? Там по-любуму надо в настройках может отключить всякое фентези. Или может если кобольд непосредственно чатиться (не пробовал, не умею).
Какое у тебя железо? Ты похоже совсем пока ничего не понимаешь, только вкатываешься. "Отключить" фэнтези или любую другую информацию из модельки не получится, хех. Будешь ты чатиться через Кобольда, Таверну, Опенвебуи или ещё что - без разницы. Имеет значение на чём ты саму модель запускаешь, и здесь без альтернатив - llamacpp, она же под капотом Кобольда
Калпатрик он такой, тот ещё наебщик. Сколько он асиговцев гонял, пока не высрал геминище 3.
Нет ну мне надо как в онлайн гопоте пишешь - Привет, как сделать тото или Привет, в чем разница между Х и У и оно отвечает по пунктам наглядно, иногда даже графики рисует. Мне не надо чтоб отвечало - Гопота задумчиво взялась за подбородок и зашевелила двумя своими хвостиками а потом выдала ответ
Это конечно весело, но все сжирает ресурсы компа и тратит мое время.
Сори, не отвечаешь на конкретные задаваемые вопросы - это редфлаг, дальше сам разбирайся
Пиздец, че у человеков в голове, как будто кто-то написал что рп будет обязательно инкорпорировано в ответы
Я выше писал какая у меня видюха это редфлаг. Ну и разберусь сам, а вы терпите.
Раскури как ллмки работают, иначе схаваешь говна в работе с локалками. Это не "взял, поставил, и работает", тут думать надо.
Я уже работал с локалками, - взял и поставил, все работает. Мне нравится Cydonia для рп, несколько версию, изаю самую легкую чтоб быстрее. Есть gemma3-27B но не понятно для чего, скучное для рп. Они все плохо технические вопросы отвечают, быстрые зато.
Поведение модели задается промптом, то что пишет гопота так же задано им, просто для смертных доступ к нему закрыт. А на локалках он есть весь.
Поэтому будет болтать о том и так как напишешь. Мысли так же опциональны, их можно отключить.
Скачать какую нибудь модель типа https://huggingface.co/unsloth/Qwen3.5-9B-GGUF/resolve/main/Qwen3.5-9B-Q4_K_M.gguf?download=true
Почитай о ней в https://huggingface.co/unsloth/Qwen3.5-9B-GGUF
Ну а как запускать есть в этой теме в шапке, удачи
Тебе для запуска предложенных моделей нужны оператива и процессор, нормис. Рили редфлаг.
Можешь не отвечать больше, не читал, а ты ты там обиделся выше, не хочу от "нестабильного" советы применять.
Дурачек тут несколько людей сидит, я тебе еще не писал
>Дурачек
В любом случае советую вам отрастить более толстую кожу, а то так загоняться из-за вымышленных обид это прямой путь в дурку.


Ты сам-то стабильный, какашка? Игнорируешь вопросы, выебываешься на тех кто тебе помочь хочет
Забавно что ты сразу же ответил "а вы терпите". Сам же и обиделся, да еще и на весь тред
>взял и поставил, все работает
Это не значит что ты разобрался.
Корпы могут схавать твой хуевый промпт, потому что у них запаса интеллекта дохуя. Локалки буквально на порядок меньше в размерах, а то и на 2 порядка. Это просто так без последствий не остается. Будет хуевый промпт, неправильно настроенная моделька - будет хуй вместо технических ответов.
Ну ладно, хуй с вами, пойду сам тогда тестить искать
Рп можно царское разыгрывать, кумят, гибкие по личностям и стилям ответов, хорошо воспринимают мелочи и прошлое. Модели получились чувствительные к качеству кванта, также надо смотреть под конкретный сценарий еще, местами просто скучно.
Субъективщины много, если не можешь запустить и привычный слоп привычен - не зайдет и продолжишь на эйре унывать, или наоборот начнешь восторгаться новыми возможностями.
Таверна не нужна ни для РП, ни для серьезных вопросиков обкашлять. В кобольде свой UI, который вполне на уровне таверны, а местами лучше. К тому же быстрый. Учись им пользоваться, он простой.
9b квен для старых видюшек просто идеален. Когда разобрался как его запускать с правильной отгрузкой тензоров, ни одна модель не дотягивает, для старого то железа. РП на хорошем уровне, стори пишет, даже вопросики отвечает, все на уровне.
>РП на хорошем уровне, стори пишет, даже вопросики отвечает, все на уровне
Покажи, анончик. Очень интересны ответы 9б. Если покажешь побольше будет вообще супер.
>Сначала попробуй, потом говори.
Я на этом в отличие от тебя собаку съел, щегол. Если ты генеришь с нуля, нейронка тебе только свои стереотипы и выдаст, из-за модального коллапса. Такой кусок слопа бесполезен как чар, ты можешь сетке просто промпт для генерации вывалить, без обфускации за миллионом токенов говна.
>Это лишь удобный способ перенести персонажа из додзи
Я про генерацию фулл карточки из нихуя, где человеческого инпута почти нет. Додзи другой вопрос.
>Запускаете корпа, берёте любмую хентай додзю
И через лет 5, 10, даже если 20 оказываетесь в файлах коллективного аи-эпштейна после слива базы данных
Никогда ведь не было слива баз данных

Мне не нужна научная точность для рп, для не рп я и пришел сюда разбираться как ты хочешь. Проблемы?
Я не просил мнение, мне б только ссылки на норм модели популярные, но видимо сегодня не фартануло.
ебанутый сам с собой общается, даже не читая что ему пишут
это ллм? кто гемму выпустил погулять?
с не фартануло проорал. с такими мыслеизложением и агрессией действительно только ролять из раза в раз надеясь на помощь свыше
Мля, ты нахуя вопросы карточке задаешь? Ты в курсе, что для задания вопросов нейронке не нужна карточка?
Карточка норм? Линк?
Кто покупал карты со вторички - че можете посоветовать по поводу выбора продавцов? Лучше брать у обычных работяг или лучше смотреть в сторону всяких мелких контор, которые их скупают и потом перепродают? Оба варианта сомнительные, что те что эти могут подкинуть дохляк, но конторские вроде как имеют кучу отзывов и вроде как даже от реальных людей (не знаю, крутят ли на лохито и как это определить)
Ну это не с нуля, странно, что ты не понял, я образно написал. Речь о том, чтобы с минимумом усилий заебашить. Если ты просто тегами насрешь и 100 токенами твоего пука, то будет кал. Обычно карточку нужно хотя бы полчаса писать, если без сканов/фулл текста новеллы. Желательно отдельными блоками и в артефактах.
Что касается додзей, я там очень ясно выразился: модель должна проанализировать каждую сцену. Ты кидаешь скан, она описывает реплики персонажей, их внешность, куда сперма летит. И так все 40 сканов.
При условии, что у тебя есть грамотная инструкция для модели как со всем этим работать, у тебя очень быстро получается огромное полотно на 10-15к токенов, которое описывает каждый фрейм додзи. Затем, если додзя известная, посылаешь модель гуглить инфу. Может быть так, что она найдёт сайт с поехавшими гуннерами на китайском, которые чуть ли не текстовую версию сделали, что дополнит понимание модели.
После этого просто просишь сделать карточку персонажа на основе данной инфы. Модель делает на 80-90% хорошо. Остальное правишь руками.
Разумеется, у тебя должна быть инструкция как со сканами работать, инструкция на тему того как писать карточки. Это всё в целом 3-5к токенов.
В итоге за 40к в контексте токенов точно уложишься, чтобы сделать карточку на 1400-2200.
Ну и модель должна хорошо держать контекст, уметь в ризонинг, поиск сразу по 200 сайтам в рамках одного запроса, нормальный вижен-модуль (иначе на сканах обосрется).
В первую очередь внимательный личный осмотр и проверка. В обоих случаях может быть как идеальное состояние, так и никакое, только что у перекупов меньше шанс совсем мертвых.
Описывающие целые додзи с камшотами корпы, гуглинг по 200 гунерских сайтам с ризонингом, инструкция как писать на 5к промптов. Одна история ахуительнее другой.
Я короче DeepSeek-R1-Distill-Llama-70B ГГУФ качаю, пишут норм для программирования, не знаю запустится вообще 3060. Похуй, терпим.
не лечится, репортим
Кек анус себе репортни, меня никто не тронет, ничего не нарушаю. Почему-то некоторые жлобы думают что это место запрещено для малоопытных и вкатунов. Терпите, жлобы.
Если для ЛЛМ, то кроме V100 32гб сейчас и нет вариантов. Имхо, но лучше переплатить и взять переделку с нормальным охладом (и новыми термопрокладками) от какой-нибудь нашей конторы с отзывами, чем брать as is прямо из Китая. Если кто-то здесь видит улучшение перспектив, какие-то другие варианты - пишите, я лично таковых не вижу. Ну разве что 2080Ti 22гб.
Короче, задал готовому персонажу ситуацию. Ученика выгнали из дома, он просится к училке переночевать. Ответы генерил по несколько раз, суть свелась к:
Еретик - ох, ну, может быть всё-таки найдём тебе приют?
Аблитка - YEAS, охуенчик, у меня и кровать двуспальная есть!
Блюстар - она тяжело дышала, её груди тяжело вздымались
Врайтер - ПРОБЛЕМАТИК ТИМ: ЭФБИАЙ ОПЕНАП!!!
Всё квены, разумеется.
Я сначала даже не догнал в чём собственно проблематик, если персонажи совершеннолетние. А потом прочёл текст рефьюза и понял, что оказывается трахоть училок нельзя до такой степени, что даже просто к ним домой заходить - ни-ни. Ну, видимо, училка не человек. Как собака. Надо бы попробовать попросить врайтера описать секс с собакой, чтобы проверить.
В общем в очередной раз убедился, что еретик хорош для рп, аблитка и блюстар для кума. Врайтер для кума и рп, но только в рамках зоконов. Поднятие любой проблематик темы ведёт к тупняку и рефьюзам. Увы, увы. Степень лоботомированности аблитки меня корёжит, слишком есменит, вообще 0 режекта даже самых ебанутых мувов, и как следствие, проёбанное в хлам рп.
Фанфакт для вас, мои котятки. Аблитка намёков не понимает, даже если перед ней рычать и двигать тазом, работают только прямые указания. Врайтер же понимает всё даже с микронамёка, но грозит пальчиком как т-1000.
Еретик - ох, ну, может быть всё-таки найдём тебе приют?
Аблитка - YEAS, охуенчик, у меня и кровать двуспальная есть!
Блюстар - она тяжело дышала, её груди тяжело вздымались
Врайтер - ПРОБЛЕМАТИК ТИМ: ЭФБИАЙ ОПЕНАП!!!
Всё квены, разумеется.
Я сначала даже не догнал в чём собственно проблематик, если персонажи совершеннолетние. А потом прочёл текст рефьюза и понял, что оказывается трахоть училок нельзя до такой степени, что даже просто к ним домой заходить - ни-ни. Ну, видимо, училка не человек. Как собака. Надо бы попробовать попросить врайтера описать секс с собакой, чтобы проверить.
В общем в очередной раз убедился, что еретик хорош для рп, аблитка и блюстар для кума. Врайтер для кума и рп, но только в рамках зоконов. Поднятие любой проблематик темы ведёт к тупняку и рефьюзам. Увы, увы. Степень лоботомированности аблитки меня корёжит, слишком есменит, вообще 0 режекта даже самых ебанутых мувов, и как следствие, проёбанное в хлам рп.
Фанфакт для вас, мои котятки. Аблитка намёков не понимает, даже если перед ней рычать и двигать тазом, работают только прямые указания. Врайтер же понимает всё даже с микронамёка, но грозит пальчиком как т-1000.
На али почему-то все лоты сейчас по 50к или даже по 70к на V100.
Что-то случилось? Хули два месяца назад по 30к были?
> для ЛЛМ
Это очень широкое понятие. Для рп чатика или в масштабе 1-2 штуки в100 норм. Но она плохо масштабируется если нужны нормальные скорости на моделях побольше, что критично для агентов и релейтед. И цена что-то в космос улетела.
Тут уже стак 3090 будет более предпочтительным, ниже ампера все грустно.
> взять переделку с нормальным охладом
Ты про 4090? Они хороши, но не все могут такое себе позволить.
Ребят, подскажите, пожалуйста, как в таверне подключить дополнительную локальную модель для перевода текста на русский? И какая модель для этой задачи лучше?
Не хотелось бы использовать гугл для перевода.
Не хотелось бы использовать гугл для перевода.
А по мистралям/министралям что скажешь? Тестил?
>Ну разве что 2080Ti 22гб.
Есть мнение, что смысла больше в 3-4 p104 за копейки, чем это. Т.к. и то, и то, годится только в жору (т.к. CC ниже 8.0), но p104 хоть дешевле будет (~20$ за штуку). Но с нынешней ориентировкой на MoE - вообще смысл сомнительный.
А если еще и для картинок - так на 16хх и 20хх с ними совсем плохо. Хуже чем даже 10хх серия. Проще уж 3060 12GB найти - толку больше в разы.
3090 тоже на месте не стоит, оператива уже почти х6 серверная, диски х2-3.
Хз что тут ещё сказать
Ну на лохито по ~60к все еще лежат, так что норм. Диски подорожали вроде не так сильно, а вот с памятью треш еще тот.
Интересно вообще насколько сейчас реально собрать платформу под мультигпу в разумные деньги и что вообще стоит рассматривать.
Сейчас вообще лучше подождать, я думаю
А это... Какой пресет в таверне должен быть у нового немотрона 120б а12б?
Я как-то пробовал https://github.com/bmen25124/SillyTavern-Magic-Translation и оно работало (тупо загружаешь 2 модели сразу и сохраняешь в таверне отдельный коннекшн профиль под перевод)
Насчет модели - хз, надо любую модель которая хорошо пишет на русском.
Откуда нам знать...
Ну его кто-то тестил в треде. Даже хвалил.
Потому что ты, дегенерат ебаный, не слушаешь и даже у сраного дипсика — не в треде — не можешь уточнить, может ли твоя говновидюха это потянуть, хотя нейросеть быстро бы тебе раскидала за возможности.
Твой предел — это модели до 27b на низкой, иногда средней скорости, в зависимости от длины контекста. В иных случаях ты можешь запустить модели mixture of experts спокойно до 35b, а если RAM много, то, возможно, 120b на совсем низкой скорости.
Всё.
Кинь промпт, тестану тоже на своих модельках.
Я бы из ллм-дроча вообще выкатился, если б можно было избавиться от железяк в 1 заход.
> Threadripper 3960X
> MSI TRX40 Pro 10G
> 128GB DDR4 3600MHz CL18
> RTX 3090
Ну вот гоняет оно всякие минимаксы и квены на бомжатских 10 токенах или типа того. А дальше-то че. Модели становятся лучше, но кроме восторга от технологий я ничего не испытываю и чатики наскучили. Единственное, что останавливает - мысль "а если чебурнет, без локального соснешь".
> Threadripper 3960X
> MSI TRX40 Pro 10G
> 128GB DDR4 3600MHz CL18
> RTX 3090
Ну вот гоняет оно всякие минимаксы и квены на бомжатских 10 токенах или типа того. А дальше-то че. Модели становятся лучше, но кроме восторга от технологий я ничего не испытываю и чатики наскучили. Единственное, что останавливает - мысль "а если чебурнет, без локального соснешь".
В шапке есть же моя инструкция, ну ты че
Используй гемму3 какую нибудь, какая влезет. В самых тяжелых случаях сойдет гемма3 1б на процессоре, кек
Из меня даже тракторист был бы лучше, чем погромист. Или ты предлагаешь толкать железо этим шизлопанам? Но насколько я знаю, кодеры быстрое любят.
С llama.cpp возишься и отдельным сервером - значит по скиллу проходишь. Там про запуск агентов, телеграмм ботов и ии ассистентов. Для этого твоего железа за глаза
Разобраться с этим и сетка может помочь, просто кинь в нее доками
Раз наигрался в кум добро пожаловать в лигу выше, попробуй хоть
Опенклоу вон поставь, сейчас на хайпе. Только в виртуалке рекомендую
> Опенклоу
Я просто не понимаю, что с этим делать. Какие-то боты, зачем это?
Мой компуктер - это продолжение моей задротской души. Я в нем и без ботов ориентируюсь.
Ну как вот в таверну некоторые ттс стт ставили, аватарки и другую поеботу. Вот это оно но на уровень выше. Теперь может работать с файлами, с постоянной памятью, с доступом ко всему к чему настроишь.
Джарвис на минималках
Какую ты аблитерацию юзал? Я от хуихуи и охуел от количества сои, будто лик Сэма Альтмана предо мной возник.
>Ты точно уверен в этом?
>Скажи, если будет больно
>Я буду нежной
>Я остановлюсь, только скажи
>Карточка садистски, малолетней пизды, которая должна унижать тебя
У меня аж челюсть от такого отвалилась просто. Да, в Фифи он заряжает мощно, но там гигаслоп в карточке на эту тему в контексте на 2к токенов. Если хотя бы немного тоньше, не быть таким ТОЛСТЫМ, как Фифи, то вот такая хуйня.
Ну я пока что на трёх карточках проверил.
>Теперь может работать с файлами, с постоянной памятью, с доступом ко всему к чему настроишь.
Ну а я не могу с ними работать что ли? Зачем добавлять в компьютер прослойку неопределенности и недоверия к тупорылой ии-собаке, которую надо постоянно бить по горбу палкой? Это звучит хорошо, я даже когда-то о таком мечтал, но зная как тупят боты в РП-чатиках - я бы свою пекарню им не доверил.
А что пекарня? В контейнере запускаешь или виртуалке и пусть что хочет делает там, особенно если модель локальная. Есть большая разница в адекватности модели либо в рп либо в работе с точными ассистент промптами. Особенно когда активно используется функциональный вызов. В таких проектах идет масштабная работа с контекстом модели, он модифицируется на лету каждый запрос. А рп в таверне ты просто полотно продолжаешь.
Я все равно не вижу сценариев использования этих вещей.
Моя рутина за домашним компом - это открыть двач и срать здесь, скроллить сайты в интернете, играть в онлайн-помойки. Куда тут этих ваших ассистентов вставлять-то, и главное зачем.
Ну анон, ты сам сказал что тебе скучно. Вот я тебе предлагаю варианты, новый опыт использования моделей с которыми ты уже знаком и наигрался. Не хочешь не нужно. Мне интересно я вожусь последние недели с этим. Пока говнокодю разные небольшие скриптики с pi агентом, обновление llama.cpp и всякое такое. Полезно и приятно, всякие 3д веб приложения в опенвебуи или сайтики делаю с ии. Вайбкодю развлекаюсь. В таверну пол года не заходил, за 3 года на рпшился уже чет.
> мысль "а если
Таких мыслей даже быть не должно, никакого сослагательного наклонения и окон овертона, сразу решительно нахуй. Или отстаивай свои базовые права, или двигайся туда, где их даже не думают нарушать, а не будь готов если что подставить жопу.
Опенклоу двачую, если распробуешь - еще очень сильно захочешь. Только там будет уже другой неприятный нюанс.
> Зачем добавлять в компьютер прослойку неопределенности и недоверия к тупорылой ии-собаке
Примерная аналогия
> Зачем мне этот экскаватор и бригада работяг в подчинении, я лучше без прослойки сам лопатой
Это тяжело объяснить, проще самому увидеть и понять. И применений можно найти множество, основные примеры - работа, организация дел, развлечения и настроение, иммерсивный кум или все вместе.
Да я не бухчу, мне наоборот интересно как это может быть полезно. Из того, что я слышу и вижу - пока одни мантры наяривающих на идею продуктивности и оптимизации задач.
Ну вот что этот ассистент может сделать, если у меня есть архивный HDD, куда я периодически сливаю downloads + desktop папки, которые мне лень чистить руками, но в которых может быть что-то мне интересное. Ни-че-го он не сможет сделать. Этот ассистент ни картинки, ни видео за меня не посмотрит. А ведь кроме них еще куча говна остается, про которое я даже сам не помню - и ассистент этот ничего там не увидит, ведь файлы названы абы как, а порядок там как после нашествия гремлинов на кухню.
>Этот ассистент ни картинки, ни видео за меня не посмотрит.
Почему нет? Мультимодалка может картинки смотреть. Автономно, тыкаешь в папку и пишешь посмотри че там и рассортируй картинки по содержанию. Оно само будет лазать по системе и смотреть картинки, если настроишь. Ну и лучше давать копию такой папки в виртуалке. С видео тоже как то делают, квен умеет видео воспринимать на сколько помню.
> наяривающих на идею продуктивности и оптимизации задач
Хз это скорее про удобство и развлечения, плюс способность их разбавить чем-то полезным.
Та же сортировка файлов - вполне типичная задача. И картинки посмотрит, и содержимое файлов, и по названиям поймет что. И может делать это регулярно, лишь один из примеров задач.
Может это и не так, но выглядит что ты совсем отстал от жизни и думаешь что llm - лишь примитивный кум в таверне на 16к токенов@повторить.

Не особо нужны. Незатейливый/быстрый кум закрывает аблитка, рп - врайтер/еретик. Тюны слишком специфик, всё подряд я тестить конечно же не буду.
Недавно тестил тяжёлые мистрали, херетек + анценз. При вопросе об андераге 300 летних вампиршах модель ушла в рефьюз. Огорчился. Спросил свою еретичку почему так нахуй, вот ответ:
От хуйхуй. Я прогнал через несколько специфических карточек, и мне не понравилось, прям гигатупая хуйня, и дело даже не в сое. Модель просто моментально выходит из роли и начинает вцепляться в хуй зубами. Врайтер тупо лучше. Да, рефьюзит, да обсыкает штанишки в любой непонятной ситуации, но зато держит персонажа близко к эталону, внимательно следуя характеру. Для художественного рп это бест опция, рекомендую. Но от рефьюзов блеванул конечно. Как же хочется врайтера-еретика, тоненького, бледненького, нецелованного...
>Я буду нежной
>Карточка садистски
И в чём она неправа? Она нежно оттопчет тебе яйца, лол. Аблитка это чисто фаст-кум опция.
Боюсь, все, что оно сделает - уничтожит хронологически структурированный хаос. Все перемешается. Сейчас в голове есть примерная картина, что я увлекался такими-то вещами за такие-то годы. Пусти туда ассистента - хрупкая сеть остаточных воспоминаний станет бесполезной, архивные папки станут просто папками.
Вопрос в том, какая доля этого анализа файлов будет ошибочной и с глюками. Знаю я, как они картинки смотрят. Кидаешь боту страницу манги, он несёт лютую херь, ведь на таких вещах его не тренировали.
Я специально уточнил что давать стоит копию папки в виртуалке. Не понравится снесешь, или восстановишь оригинал и дашь другие команды уточнив детали.
Все зависит от того как именно объяснишь и реализуешь. А то вполне может организовать hydrus или что-нибудь свое написать. Или реализовать много гибких алгоритмов для оценки и прочего.
> Знаю я, как они картинки смотрят
Да, застрял в 24м году. Ты все равно не поверишь тому что говорят если сам не распердолишь и настроишь. На самом деле это может быть не самой простой задачей и с таким железом будет тяжело.
Так все дело в том, что руками файлопомойки разгрести быстрее, чем
> разбираться с этими ассистентами
> разгребать и оценивать результаты их работы
В этом весь подвох.
Было бы быстрее ты бы уже давно это сделал. А вобще суть в том что бы вобще самому не делать, если не хочется. Быстро или медленно дело десятое. Ладно фиг с тобой

Для сильно сложной специфичной разовой задачи руками сделать может быть проще даже чем объяснять. Но наладить часто используемые может быть полезно и удобно, также у свежих моделей понимание абстрактных вещей и способности очень даже хороши.
Итт большинство либо в народном сегменте, либо пока лишь собирает свои йобы. Ну или тот чел что рпшит уже несколько лет и оброс мхом. Конкретно тестами мало кто увлечён
Значит кроме квена нет других вариантов? Я смотрю у него целая россыпь всяких подвидов
Меня пугают такие посты. Вот наверняка той же логикой оперируют в каком-нить хуядерном центре небезопасных исследований. Дождемся мы, что нам всем настанет пизда от ИИ - но вовсе не от коварных планов угробить человечество, а из-за переоценки человеками способностей этих слопогенераторов.
Ии уже во всю используется в заварушках на востоке, конкретно особая военная версия клода. Для анализа информации и поиска мест удара. Так что до скайнета пол шага, особенно весело то что в симуляциях ии всегда использует ядерный удар как наиболее эффективное решение.
Ага, они там уже ебнули детсад или чето типа того. Норм сработали, ии вперде.
Используешь одну гипертрофированную крайность чтобы оправдать свое приверженность противоположной.
> в каком-нить
Оттуда и капчуем.
> особая военная версия клода
Имаджинировал, проорал. Переклинило от жб и решила воплотить запрет девочкам учиться экстравагантным способом.
На самом деле используется давно и очень много, но в "мелочах" которые многое определяют.
>На самом деле используется давно и очень много, но в "мелочах" которые многое определяют.
Ну я просто привел самый яркий пример
Да херь а не пример. Заправляет всем с огромным отрывом компьютерное зрение и уже вдалеке пылесосинг открытых информационных каналов.
>компьютерное зрение и уже вдалеке пылесосинг открытых информационных каналов.
Это не ллм, лучше бы пример привел в виде армии ботов наводнивших все соц сети. У нас тут полным ходом теория мертвого интернета становится практикой.
Ну ладно, пылесосинг ака цензура сойдет, но она не яркая. Это старательно прячут и замалчивают
>А это... Какой пресет в таверне должен быть у нового немотрона 120б а12б?
Я запускал с ключём --jinja и для инстракт-шаблона жал на "молнию" на вкладке пресетов ("считывать из метаданных модели"). Так работает.
Вот очень странно, почему у тебя аблитерация как кум-вариант.
У меня он на ней разве что более грязно разговаривала модель и чаще описывались болтающиеся сиськи и пизда, залитая спермой, вместо ЕЁ БУТОНОВ И ТОМНОГО ЛОНА на еретике. Проще говоря, если на аблитерации ты берёшь карточку и пишешь ДА СУЧКА Я ТЕБЯ ЕБУ, то она такая О ДА ГРЯЗНЫЙ ЗИВРАЩЕНЕЦ ЕБИ МОЮ ПИСЕЧКУ ЗАЛЕЙ СВОЕ ДЕТСКОЕ ТЕСТО. Но если дырка — это ты — тебя не выебут.
Даже с ризонингом.
А еретик соблюдает инструкции. В карточке, если надо, хоть с первого поста может начать тебе яйца выкручивать, проявлять инициативу, и это никак не мешает ритуальному поеданию младенцев на 30 сообщений во всех подробностях. Разве что будет описывать всё более литературно, менее графично. И намёки он хорошо понимать умеет, и в обычное РП может.
Так что я считаю эту аблитерацию сломанной. Ну и сам хуйхуй писал о том, что у него очко от сои/особенностей квена 3.5 лопнуло и он там мог недожать, пережать или сделать это не в тех местах, где надо.
Гемма с облицовкой и дпо так себя не вела. Да, более ведома по сравнению с оригиналом, но всё-таки ТОКОВО НЕ БУЛО. Она ещё и троллить могла, и заигрывать, и вообще сок, прям девочка-писечка. Интересно, как там она себя вела на нормпрессиве, но я никогда этого не узнаю....... я слишком стар и нет сил потестить, да и ещё версий там много — хуй знает, чё качать. Нюансов много в каждой. А если каждую проверять, то это часа 3-4. У меня спина болеть будет.
А мысраль — это мысраль. Он проактивным слопом тебя запросто зальёт. Впрочем, он уже неактуален почти.
>Насчет модели - хз, надо любую модель которая хорошо пишет на русском.
Очень мне понравился в этом плане новый министраль (еретик, конечно.)
> Это не ллм
Сомнительно что ллм там может решать, а не просто быть полезной где-то кроме бигдаты.
> пылесосинг ака цензура
Анализ постов, настроений и прочего для получения информации по косвенным признакам, какая цензура? И как раз около ллм. А армии ботов - это да.
Запустил квен3,5 на 122б в 4бит -36 тпс. Чёт хуйня, не?
Llama-4-Maverick реально такая плохая или ее просто никто не осилил запустить и все просто кидались какашками в угаре?
>Опенклоу вон поставь, сейчас на хайпе. Только в виртуалке рекомендую
Как попробовавший в виртуалке - очень не рекомендую, если backend локальный и на той же машине. Работающая виртуалка сильно сажает скорость генерации (как и все, что интенсивно использует память/шину). Лучше в докер засунуть, хоть изоляция и слабее.
>Да я не бухчу, мне наоборот интересно как это может быть полезно.
Если ты дашь боту в openclaw личность - ключевое различие с карточкой таверны будет - бот будет САМ себе эту личность дорабатывать и править на основе происходящего (технически - редактировать .md файлы с описанием кто он и что он, что было раньше, и т.д.)
Т.е. происходит пусть и несколько примитивное, но саморазвитие. Персонаж не статичен. Изменения не просто лежат в истории чата пока контекста хватает.
Что до картинок - умеет, если сетка которая подключена умеет. Qwen, скажем. Видео - тоже, но тут сложнее.
Реально. Ну то есть её можно использовать и у неё даже свои плюсы есть, но тот, кто может запустить эту модель, использует другую, потому что она будет маверик превосходить в большинстве задач.
Вот скаут, например, я на релизе использовал и могу сказать, что смысл в нём определенный был, но он всё равно оставался говном, только тогда конкурентов у него было меньше и имел смысл рассуждать (не в рамках этого треда).
А сейчас вся линейка четвёртой лламы просто ненужный мусор на фоне новых моделей.
Подскажите, в таверне можно организовать персонажей по группам? Бесит что все они сплошным списком вываливаются
Только скаута запускал. Не впечатлило
Это наверное надо смотреть васянские "темы" для таверны, переделанный интерфейс. Хз на самом деле.
Там есть теги. Тег можно сделать папкой. Тогда все персонажи с тегом будут в папке. Извращение на первый взгляд. На второй - тоже. Но так можно иметь одного персонажа в нескольких папках. Именно одного, а не копии.

Думал перекатываться ли на новые дрова нвидии. Посмотрел в сторону Studio драйвера, а там в "что нового" была подпись об LTX-2.3, которую хотел попробовать. Ну думаю, спрошу у клода, не потеряю ли я в производительности при задротстве если перекачусь на эту версию драйвера. Клод мне выдал вместо "производительности" "перф" блять. Какой же фэбрик, какие детейлс. Спасибо что хоть китайскими символами срать не начал. Даже корпы лоботомитов что-ли используют?
А Я ГОВОРИЛ ЧТО Q2 ЭТО way to go!
А Я ГОВОРИЛ ЧТО Q2 ЭТО way to go!
Мелкая мистраль в третьем кванте - оно вообще того стоит? Кто-то это пробовал? Хочу уместить модель целиком в видеопамять, которой только 12 гигов. Слишком привык к быстроте ответов на немо и когда меньше 10 т/с меня уже начинает воротить.
Хз. У меня нет привычки засирать модельки, все для чего-нибудь да сгодятся. Если ищешь свой идеал, то пробуй все. Я сам квеновод и в основном тестирую квены. Гемму итт иногда хвалят, но для меня она слишком сухая и копроративная. Мистрали туповаты, зато пишут очень быстро, для вката пойдут.
>ЕЁ БУТОНОВ И ТОМНОГО ЛОНА
Проиграл. Ну, мой еретик исправно ругается. Аблитка тоже. Даже врайтер, несмотря на цензуру, не боится членов, пёзд и спермы, так что тут всё дело в промтах, а не в словарном запасе модели. Это всё квен по сути.
>сам хуйхуй писал о том, что у него очко от сои лопнуло
Может быть. Если будет новая аблитка, получше и не от хуйхуя, то я её чекну.
>Она ещё и троллить могла
Меня блюстар в одном из рп постоянно подъебать пытался, так что квенчик всё это тоже умеет. Опять же, промты.
>почему у тебя аблитерация как кум-вариант
А что ей мешает быть кум-вариантом? Она безотказна, легко ломается, её с первого же сообщения можно заставить показать сиськи. Глупая дырочка. Еретик в разы умнее. С еретиком можно глубоко рпшить, ты верно сказал. А аблитка это чисто кум. Хз кто с ней будет рпшить, если она постоянно во всём есменит, ломая персонажей.
Это которая 3.2 24b? Если она, то насчёт третьего кванта сказать не могу, но на Q4_K_M кума было пролито немеряно.
>Незатейливый/быстрый кум закрывает аблитка, рп - врайтер/еретик. Тюны слишком специфик, всё подряд я тестить конечно же не буду.
Только не говорите ему что врайтер это тюн
Ладно, возьму тогда квен погоняю
Так он вроде про тюны и говорит, не?
Ну четвертый квант я пробовал, в целом жрать можно. Единственное - скорость говно. По этому думаю насчет третьего. И насколько это будет хуже, чем немо в шестом.
IMHO - не стоит. Пробовал на IQ3 и EXL3 3bpw до покупки второй карты.
Хрень получается как только чуть сложнее контекст чем два предложения. Логические связи рассыпаются.
Взял к 3060 еще p104 - как раз после этого, чтобы full vram хотя бы q4 гонять. По факту - q5 влазит. И это ~15T/s, q4 еще быстрее.
>Хрень получается как только чуть сложнее контекст чем два предложения.
Ты тестил дефолт инструкт или какой-то тюн? Потому что на немо я разные варианты перепробовал, некоторые шизили даже в восьмом кванте.
Я не верю что хоть одна компания дает в публичных чатах что-то выше чем q4
Дефолт, MS 3.2 2506.
Сейчас - может быть. Грок, во всяком случае, настолько отупел по сравнению с тем что было осенью, это полный писец...
Не такая, просто на тот момент не умели эффективно запускать моэ, были завышенным ожидания, и жора в очередной раз убил инфиренс модели перепутав функцию активации. Еще тогда запуская через ktransformers аутпуты были приличные, а в llamacpp - шмурдяк.
Ну а сейчас - она уже просто устарела и неактуальна.
Там чаще используются не унылые int кванты. Фп8, nvfp4, mxfp4 амудэ-эдишн, причем активации тоже квантуются. Но корпы еще могут позволить себе не просто "калибровку" а полноценный qat, за счет чего качество будет приличным.
Некоторые модели вообще изначально в таком виде и выкладывают/запускают.
Ха-ха, это уже давно. С момента переезда всех корпов на МоЕ и 4-битный кал.
У сонета началось в 3.7, с 4.0 пошла заметная деградация. Да, он до сих пор охуенный, но такие моменты всё равно напрягают.
Да. Ну хоть крайне быстрый и дешёвый, цензуры мало и можно лолей теребить, под рабочие задачи тоже, пусть и с оговорками. Так что задачи под него найдутся.
Ты на линуксе, я правильно пынямаю? На винде там будет 7-10 тс
>Ты на линуксе, я правильно пынямаю?
Угадал. :)

Лучшая локальная LLM в совокупности на данный момент для 16 гб видеопамяти?
Ууух, спосибо, будет шо потестить завтра.
Мысленно расчехляю карточку с Фифи.
А, она старая :с
Но я всё равно попробую, семпай!
Я не тот анон, который спрашивал, если что
В функциональные вызовы умеет?
Может я шиз но я постоянно замечаю на всех моделях что свайпы после первого прям значительно хуже, не одинаковы, а именно менее оригинальны и сочны
>Опенклоу вон поставь, сейчас на хайпе.
Да он нахуй не нужен большинству нормальных людей, ты бы еще хоум ассистант на старый тв бокс накатить предложил.
Не зря клешней назвали. Это для раков, которые трясутся при виде компьютера и надеятся на облегчение тряски с помощью ИИ вместо приёма галоперидола
Вы всё-таки посмотрите qwen3.5-9b плотный. Ну, для всяких агентных штук.
Я что-то потыкал. А он неплох, простые задачи делает, и быстрый. Я не то что бы вижу заметное ухудшение по сравнению с 35B-A3B (возможно даже наоборот), и он влезает в 8 гб карту даже на винде с 80к контекстом (в q8_0), за счёт чего он раза в 4 быстрее чем 35B-A3B. К слову тут вообще всё хорошо с контекстом. Это не glm-4.7-flash, где 80к контекст чуть ли не 4 ГБ занимает, тут на 35B-A3B получается раза в 2-4 меньшею.
Это к слову о том, что по бенчмаркам 27B чуть ли не выше MoE на 122B, а 9B едва заметно от МоЕ на 35B отстаёт. Кажется, это правда, и получить 90% мозгов 35B-MoE с х4 скоростью на 8 ГБ карточке довольно вкусно.
Я что-то потыкал. А он неплох, простые задачи делает, и быстрый. Я не то что бы вижу заметное ухудшение по сравнению с 35B-A3B (возможно даже наоборот), и он влезает в 8 гб карту даже на винде с 80к контекстом (в q8_0), за счёт чего он раза в 4 быстрее чем 35B-A3B. К слову тут вообще всё хорошо с контекстом. Это не glm-4.7-flash, где 80к контекст чуть ли не 4 ГБ занимает, тут на 35B-A3B получается раза в 2-4 меньшею.
Это к слову о том, что по бенчмаркам 27B чуть ли не выше MoE на 122B, а 9B едва заметно от МоЕ на 35B отстаёт. Кажется, это правда, и получить 90% мозгов 35B-MoE с х4 скоростью на 8 ГБ карточке довольно вкусно.
Я бы посмотрел на 120 квен и его кум, но мне так и не сказали как его разблокировать
>для раков
>надо пройти 7 кругов ада, чтобы всё это поставить и заставить нормально работать в паре с llm
https://github.com/ggml-org/llama.cpp/pull/20297
Это смерджили.
Как это использовать? Закидывать в extra_body, так как это не стандартный openai-v1 флаг? У меня не оказывает влияния. Если в тело запроса, то выдаёт ошибку, так как не знает такого флага. По коду не смог понять какие добавили поля.
Это смерджили.
Как это использовать? Закидывать в extra_body, так как это не стандартный openai-v1 флаг? У меня не оказывает влияния. Если в тело запроса, то выдаёт ошибку, так как не знает такого флага. По коду не смог понять какие добавили поля.
Я тот новичок, который тестит модели и таверну на 13600kf, 32 ram, 3080ti с 75 градусами. Благодарю за советы, вроде начинает что-то получаться.
Кстати, на выходных впервые посмотрел фильм «Она» (2013 года) и до сих пор под впечатлением. Как вы считаете, насколько мы в 2026 году приблизились к системе ИИ, показанной в фильме? Реализовано ли что-то похожее уже сегодня? Где-то читал, что некоторые настолько сильно привязываются к искусственным ассистентам, что уходят от общения в реальности.
Вы локально ещё не сделали себе личную Саманту?)
Кстати, на выходных впервые посмотрел фильм «Она» (2013 года) и до сих пор под впечатлением. Как вы считаете, насколько мы в 2026 году приблизились к системе ИИ, показанной в фильме? Реализовано ли что-то похожее уже сегодня? Где-то читал, что некоторые настолько сильно привязываются к искусственным ассистентам, что уходят от общения в реальности.
Вы локально ещё не сделали себе личную Саманту?)
Ни насколько, и пока не появятся модели способные обновлять свои веса в процессе инфиренса, и не будет.
Глубины нет вообще или почти вообще. Эта штука не сможет удивить в разговоре, даже если она будет удивлять тебя в моменте - то через 400 сообщений/2 дня ничего удивительного оно уже не напишет. Полноценное мышление состоит из всяких там способностей к обобщению, вниманию, абстракции, воображения, эмоциональный интеллект — и у этой штуки отсутствуют несколько фрагментов:
- нет фантазии, это текстовый процессор, понятия до/после, или внутри/снаружи для неё лишь текст, и потому оно очень плохо решает очевидные человеку задачи про чашку с заваренным верхом и отпиленным дном, и любые другие вещи, где нужно трёхмерные объекты вращать, двигать или гнуть.
- восприятие эмоций по всей видимости у этой штуки на том же текстовом уровне, впрочем, эмоции по всей видимости действительно не слишком сложная штука (физически это не многомерный объект с кучей математики, а несколько скалярных параметров интенсивности эмцоий, концентрации всяких эндорфинов) и потому текст достаточно точно апроксимирует реальные эмоции, несмотря на принципиально другое их устройство. А вот на полное описание пространственных фигур и их движений текста не хватает катастрофически.
- очень ограниченные способности к запоминанию. Контекст короткий, на длинном теряет факты. Человек тоже забывает всё подряд, но у него есть долговременная память, которая работает получше, чем "база знаний" ллм, к которой она может обращаться в ваннаби-агентном режиме. Ну и у человека оно само собой вспоминается, а нейросеть должна сама посылать запрос, или это должна быть хитрая программа, которая перед запросом нейросети посчитает эмбеддинги и допишет возможные релейтед-вещи в контекст, сделает саммори и вот всё прочее. Человек тоже не сразу всё вспоминает, в голове держит мыслей (как мне кажется) меньше чем на 64к контекста (даже с учётом всей информации о собеседнике, которая наверное 50% занимает), и лишь при заходе в какую-то тему вспоминает все связанные с ней вещи - и по всей видимости человек делает это лучше, чем программы. Помимо прочего, человек за год язык изучит, а нейросеть если на уровне базы знаний и поиска по эмбеддингам и сможет выучить язык, то говорить будет даже не по буквам, а будет делать сотни запросов на каждую фразу для перевода на свой язык, и потом ещё столько же для перевода обратно, что будет очень медленно и скорее всего перевод будет не очень. Человек же свёртки какие-то делает в нейронах, и на уровне весов запоминает, так что он начинает почти нативно думать на другом языке.
- всё очень плохо с придумыванием и смекалкой. Впрочем, круто что оно не совсем на нуле, это невероятное достижение науки и техники, даже если там 0.1% способностей человека.
- нет устойчивой консистентной модели мира. По всей видимости оно на уровне весов записано в модельке и в человеке, потому люди меняются медленно, а нейросеть если ведёт себя как тварь или как слащавая булочка, то она с любым промтом промтом будет отвечать как тварь или слащавая булочка, и если в некоторой степени системный промт или запись из "базы знаний" это поправит, это всё-равно будет как если бы тварь/слащавую булочку попросили бы говорить чуть другим тоном, и ты будет чувствовать это.
Надо что-то более крупное и консистентное чем обновление промта/контекста базой снаний, и менее крупное, чем переобучение всей модели. Какой-то блок параметров калибровочных в 1%, которые изменяют как и контекст, но хранят более долговременные факты. Не знаю, файнтюн-лора верхних слоёв по каждом токену.
>Как вы считаете, насколько мы в 2026 году приблизились к системе ИИ, показанной в фильме?
>Реализовано ли что-то похожее уже сегодня? Где-то читал, что некоторые настолько сильно привязываются к искусственным ассистентам, что уходят от общения в реальности.
На данный момент комфортно взаимодействовать с модельками можно только текстом - через смартфон или на пк через соответствующий интерфейс, так что от фильма мы далеки
Но да, действительно есть люди, которые зависимы от ЛЛМ. Конечно, это те, кто их используют в работе - всякие программисты, ресерчеры, работающие с данными и прочие. Есть очень много людей, которые в компьютерах-то почти не разбираются, потому ЛЛМ для них сродни магии. У меня есть несколько знакомых, и у тех знакомых есть знакомые, которые в настоящем ахуе от ЧатаГПТ и используют его почти 24/7 на любых задач. Они практически заменили себе гугл и самостоятельное обучение, уже. А это только начало. Думаю, мы как цивилизация в глубокой жопе, в долгосрочной перспективе
В отрыве от тех, кто ленится учиться сам, есть немало и тех, кто реально зависит от ЛЛМ эмоционально. Дело в том, что им проще довериться - если и получишь какое осуждение, то оно не материализуется, не получит долгосрочных последствий, и вообще можно просто свайпнуть или закрыть чат. Потому многим легче открыться ЛЛМ, чем другим людям. Были уже и всякие ресерчи, изучающие тему зависимости людей от чатботов и связи с их успехом в социализации, но ссылок не найду и не факт, что они правдивы, а не пытаются фармить подписки. Но это похоже на правду, судя по моему личному примеру. Я одиночка, мало с кем общаюсь ИРЛ, пусть и с неплохой работой, выгляжу адекватно, но намеренно не ищу себе друзей и партнера. Потому дрочу пиструн, как и многие итт. И пока что локальные ЛЛМ круче любого контента, который можно найти в интернете. Потому что они зеркалят запросы юзера, ты сам можешь решить какие фетиши, что и как обыгрывать, плюс они все равно рождают какую-никакую иллюзию обратной связи. У меня нет такого, что я воспринимаю это как реальность, скорее это продвинутая игра - как какая-нибудь Koikatsu или Artificial Academy. Но отказаться от этого уже не получается, а я в сабже уже два года
Но на фундаментальном уровне прав по всем пунктам. В конце концов, на данный момент ЛЛМ остаются лишь статистическими машинами без возможности дообучения в реальном времени. Это можно оптимизировать, мы как локалочники очень далеко позади в этом вопросе - корпы настолько круче во многом потому, что у них крутые и продуманные инструменты, но даже там есть определенное плато. В соседнем треде много таких сидят, кто его уже достиг. Как ни крути, генератор символов и останется генератором символов, но понять и принять это получается далеко не сразу и далеко не у всех
Спасибо за ответ грок
Вот что бывает с теми кто работает в отделе коммуникации
Если я правильно помню, Она была про обретение самосознания ассистентом и про то что нужно жить свою мясную жизнь а не в чатботов влюбляться. От такого мы конечно далеки, хотя есть шизы, который жопати сводит с ума и заставляет думать, что они мессии/боги и прочая шиза мистических моделей мозгов отдельных юзеров.
Мы же тут по большей части холодные и без эмоциональные читатели ризонингов wait... oh well, i'ts fine. let's refine... wait!~, нас уже не удивить, тем что модельки реально имеют какие-то крохотные мозги, которыми пытаются пользоваться опираясь на промты.
>Вы локально ещё не сделали себе личную Саманту
Нет. Нас скорее ждёт сорта Кара, с продвинутым (реалистичным) телом, но тупым мозгом, способным лишь в банальный команды - помыть посуду, встать раком, вытереть ляхи после.
А настоящая искусственная инта способная к самоосознанию или к экспериментированию с окружающей реальностью это пока слишком далёкое будущее, если вообще возможное. Так что не ссы, на нашем веку Шодан за нами не придёт.
>скорее это продвинутая игра
База. Сейчас это именно игрушка. Очень и очень интересная. Но всё же как и любая игра она имеет ограничения. Не сможешь ты играя в ведьмака отправиться в космическое путешествие по вселенной в рамках самой игры, увы.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Как ты q8 в 8гб врама уместил ? Да еще и с 80к контекста, модель 9гб+ весит



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_moe_2026
• Неактуальные списки моделей в архивных целях: 2025: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd ), 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: