

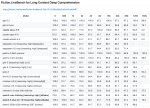





Рейт
https://pastebin.com/LRavWZ4t
https://pastebin.com/4rAq5JG7
Делал со скуки, потому что не было компа под рукой. Вот и ковырялся в телефоне.
https://pastebin.com/LRavWZ4t
https://pastebin.com/4rAq5JG7
Делал со скуки, потому что не было компа под рукой. Вот и ковырялся в телефоне.
Если со стороны саморазвития, то молодец. Если от полезности, то не хочу тебя обижать

Насколько вообще будет значительна разница между 3080 12гб и 4080 16гб при запуске моделей, которые все равно в видеопамять не лезут целиком?
Сейчас гоняю Tesslate Synthia 27B Q6 на 2 токенах в секунду, Qwen3.6 35B Q6 на 12 токенах.
Что я примерно получу при переходе на 16?
Или оно вообще того не стоит, учитывая, насколько конский ценник на 4080?
Сейчас гоняю Tesslate Synthia 27B Q6 на 2 токенах в секунду, Qwen3.6 35B Q6 на 12 токенах.
Что я примерно получу при переходе на 16?
Или оно вообще того не стоит, учитывая, насколько конский ценник на 4080?
> Или оно вообще того не стоит, учитывая, насколько конский ценник на 4080?
Совершенно точно того не стоит. Может если их вместе запускать, а не заменить одну на другую, тогда и будет качественно иной результат. Ты уже сейчас можешь катать Гемму 26б с оффлоадом в оперативу, она однозначно лучше Геммы 3. В целом это клевая модель, если бы я был ограничен по железу, то катал бы ее и не переживал ни о чем.
>резкий звук тяжёлого ножа, вынутого из духовки
Пхах, блять, чего нахуй?
>sharp sound of a heavy knife being taken from its place
Но... почему? Типа логика knife -> kitchen -> oven? Не жарьте ножи в духовках, пацаны, вы ещё матерям нужны.
Пхах, блять, чего нахуй?
>sharp sound of a heavy knife being taken from its place
Но... почему? Типа логика knife -> kitchen -> oven? Не жарьте ножи в духовках, пацаны, вы ещё матерям нужны.
>Чтобы боты срались за квестовых мобов, тупили, мамок ебали, чтоб вели себя как игроки в целом.
Текстом всмысле? Ну в плагине смехуечков положили если периодически поглядывать. Саму реализацию ботов тоже сделали в мире они типо бегают там по квестам на тебя нападают и прочими непотребствами занимаются, тоже плагин готовый. Работает очень даже годно, в каком-нибудь пвп даже слишком годно боты кнопки прожимают.
В общем мозги себе не еби, скачай какой-нибудь динклпак где уже все искаропки и играй.
Модель не может в перевод и/или уквантована в усмерть. Логики там нет.
Так скорость PCIE порта влияет только на скорость первой загрузки модели в память или еще на что-то? Я посмотрел видос где челик собрал систему с тремя 3090 на майнерском риге за копье с портами вообще x1 получил 100т/с на gpt-oss-120b
Есть влияние при тензор параллелизме. На руках у меня нет конкретных тестов, но я заметил когда случился провал с 4.0 х8 до 1.0.
Когда чекал при префилле по шине до 1.5гб/с гуляло.
В жоре стоит по дефолту layer и для него не актуально.
Я может сделаю тесты, но когда хз
Q6, так-то. Жаль конечно, что русик хромает местами. Иногда прям хочется настоящего славянского зажима берёзками что, разумеется, шумят, а выходят мыши в киске, ножи в духовке и кусающиеся члены.
FurnACE
Какая модель-то? В каком режиме у тебя работает пайплайн: ген на английском, последовательный вызов для перевода на русский? Одна и та же модель делает или две модели?
Гемма 26б может в приличный русик, в прошлом треде кидал логи. Пошел дальше по тому чату, никаких мышей и кусающихся членов не встречал. Возможно, ты модель сэмплерами пережал.
Слишком дорого, разве что нюанс с возможностью апгрейда 4080 до 32-гиговой. Или если будешь использовать их вместе, 28гигов это уже неплохо.
Активный обмен идет при тензорпараллелизме, при обработке контекста если используется выгрузка, в меньшей степени при обработке контекста фуллврам. Когда там совсем днище х1 то это может и простой последовательный инфиренс декодинга замедлять.
> 100т/с на gpt-oss-120b
> 3090
Это немного если что.
>тензор параллелизме
У llamacpp есть?
>5b active parameters
На плотных моделях до двацатки упадёт. Для нормальной скорости будет нужен тензор сплит. А тензор сплит это выложите 16х на стол каждой карте.
Есть, но в доке пока не описано. Флаги есть
Неееплоха, Бабси, не хочешь поучаствовать в оКОТшеительном стендапе? Я уверен, ты просто заМЯУчишь толпу!
>Какая модель
Квен плотный, джвацатьсидьмой.
>ген на английском, последовательный вызов для перевода на русский
Еп. Хотя я и просто заставлял его писать сразу на русском. Но кажется, что он пишет унифицированные фразы у себя в мозгу, а потом просто конвертит в язык указанный в промте. Потому что некоторые словообороты в тексте на русском выглядят так будто взяты из другого языка.
>Гемма 26б
Не думаю, что мои железки потянут сразу две модели.
>ты модель сэмплерами пережал
Ну да, это всё в области тестов, как модели справляются с языками в принципе, и могут ли держать творческое рп на двух языках. Англюсик в принципе может, хоть иногда и вставляет обороты, которые мало юзаются нативами, типа слишком отдают архаичным нафталином. Русик же... ну, если исключить ошибки, которые редки и потому так смешны, то ну в целом норм, играть можно. Только всё суховато, и запахи озона и мускуса всё равно повисают в воздухе с силой физического удара скручиваясь в плотный узел. Как я ни крутил семплеры, от этих слопофраз раз в два-три десятка аутпутов ничто не спасает, они даже на китайском выглядят так же. Хотя оно так и у геммы и у мистрали, где-нибудь да воткнётся.
> Не думаю, что мои железки потянут сразу две модели.
В чем проблема генерировать сразу на русском? Олсо на русике, думаю, альтернатив нет кроме Геммы. Если только у тебя не риг, на котором ты можешь запустить модели уровня 4.7 в хорошем кванте. Вот тут сразу Геммой 26б генерились ответы и никакого пердолинга. Температура 1, minp 0.02. Глм 4.7 в Q2 пишет даже похуже, хотя краткие тесты на опенроутере в кванте поприличнее существенной разницы не дали. Мало какие модели на русском хорошо обучают. Если Гемма не нравится свайпами или еще чем, так лучше их "починить" инстракшн лорбуками, квик реплаями (анон в прошлом треде pastebin кидал) или еще какими костылями, чем пытаться научиться неподходящие модели на русском балакать.
Или ты так экспериментируешь? В любом случае одной и той же моделькой сначала генерировать на одном языке, а потом на другом - бестолковая идея. Это имеет смысл только если модели разные, например, одна хороша в логике, а другая хорошо переводит. Можно одной моделью последовательные вызывы использовать для идей вроде Stepped Thinking, а чем ты занимаешься я так и не понял. На английском, имхо, Квен 27 будет куда лучше обеих Гемм, хотя все равно прыгаю между ними всеми.
Чебупель, ты в курсе, что можешь взять синтию не Q6 а Q4, и Qwen3.6 35B, тоже Q6, только на одной RTX 3060 с длиной контекста 126к выдаёт столько же токенов, сколько у тебя, без квантования кэша и в bf16? Если ты там контекст меньше юзаешь, то делаешь что-то неправильно.
Если ты добавишь вторую карту, то получишь отличную скорость. Учитывая то, что ты на 2 токенах готов сидеть, лучше купи оперативу и GLM Air запусти. В сто раз умнее будет.
гемма с мтп становится быстрая как понос,
https://www.reddit.com/r/LocalLLaMA/comments/1t5ageq/qwen3627b_with_mtp_grafted_on_unsloth_ud_xl_25x/
https://www.reddit.com/r/LocalLLaMA/comments/1t5ageq/qwen3627b_with_mtp_grafted_on_unsloth_ud_xl_25x/
>гемма с мтп становится быстрая как понос
>кидает пост про квен
Капча из 4 изображений не помогла похоже
сорян, контекст переполнился. квен конечно же
>Не думаю, что мои железки потянут сразу две модели.
Если обычной памяти хватает на обе модели, то переключение происходит быстро. moe-гемма в фулл-врам с отключенным ризонингом РП-шаг переводит почти моментально.
Это от юзкейсов зависит. Будет полезно там, где поддерживается единые структура и форматирование аутпутов, вроде кода, документов. Для рп непонятно, оверхед может даже сделать так, что tg будет хуже, чем без MTP.
Как же эир дохера всего знает на самом деле.
Впервые попробовал не кумить и приятно удивился, можно как гугл серч юзать
Впервые попробовал не кумить и приятно удивился, можно как гугл серч юзать
>Ты уже сейчас можешь катать Гемму 26б с оффлоадом в оперативу, она однозначно лучше Геммы 3.
Слышал другое: что большая часть датасета геммы-4 забита кодом и ококодерскими штуками, отчего в креативном письме она гораздо слабее третьей.
Кто прав?
>генерировать сразу на русском
>тут сразу Геммой 26б генерились ответы
>её походка в сторону коридора оставалась
Бля. Ну это просто лангсвап c английского. У нас так не говорят. И это не то, что я хотел бы видеть. Я об этом только что сказал.
>ты так экспериментируешь
Конкретно здесь я сделал карточку запускаю через таверну репетитора русского языка который клеит англоговорящих студенточек. Соответственно общение на двух языках, простого перевода текста сплошняком недостаточно.
>На английском, имхо, Квен 27 будет куда лучше обеих Гемм
Конечно. Я на нём и играю в 99% случаев. Просто иногда хочется именно русский текст в адекватном виде. Но вероятно, нибудит без модели специально заточенной под великий-могучий.
>Гемма не нравится свайпами или еще чем
Вниманием к контексту. Точнее его отсутствием. Рп всё-таки. Хочется чтобы в памяти держалась всякая всячина, а гемма плоховато с этим справляется. Квен тут вне конкуренции.
Возможно. Но благодаря обучению на агентский цикл она держит лучше контекст и в стоке позволяет нагенерить картиночки с развратной собой через тулу.
Что за мтп????
>ты в курсе, что можешь взять синтию не Q6 а Q4
Насколько будет хуже, чем Q6, есть личный опыт?
У меня просто некое предубеждение против всего, что ниже Q6, возможно, не особо разумное.
Так-то если удастся перейти на синтии с 2 т/с на 3 т/с это уже будет прорыв.
>Насколько
А в чём измерять?
>будет хуже
Будет.
>возможно, не особо разумное
Возможно. Но отрыв не такой сильный чтобы прям охуеть.
> Бля. Ну это просто лангсвап c английского. У нас так не говорят.
Это правда. Но по моему опыту, Квен еще хуже. К счастью, я хорошо знаю английский и потому не вынужден есть кактус, но кактус Гемма 4 уже не такой острый, как предыдущие. Поинт был в этом.
> Вниманием к контексту. Точнее его отсутствием. Рп всё-таки. Хочется чтобы в памяти держалась всякая всячина, а гемма плоховато с этим справляется. Квен тут вне конкуренции.
Тоже правда. У меня есть соревновательный интерес как-то обуздать Гемму, потому я пилю что-то вроде динамического трекера, в который добавляются важные события и крючки. Теоретически - жить можно, хоть пердолинга и немало. Малое разнообразие свайпов побеждено лорбуком с инструкциями. Но все же я плююсь от слопа и репетишена даже на тюнах. Думаю, это неизлечимо и останется с Геммой 4 навсегда. Между чатами различий мало по аутпутам, особенно если чары похожи характерами и/или сеттингов есть общие детали. Легче и разумнее просто взять Квен и играть на нем.
Почему не проверишь сам и не составишь свое мнение? На мой взгляд, Гемма 3 неюзабельна на фундаментальном уровне. У нее все те же проблемы Геммы 4, только сверху еще больше сои, рефузы, еще более худшее внимание к контексту. Не понимаю, зачем ее в принципе сегодня использовать.
Предубеждение точно не особо разумное. Большие модели юзабельны даже в Q2, а Q4 достаточно для любых моделей начиная с 24б. Редко когда увидишь разницу между Q4 и Q6. Ужас, на 2-3т/с я бы не вытерпел даже самые идеальные аутпуты.
>На английском, имхо, Квен 27 будет куда лучше обеих Гемм
>На английском, имхо, Квен 27 будет куда лучше обеих Гемм
>На английском, имхо, Квен 27 будет куда лучше обеих Гемм
Наибольшая полезность будет при каком-нибудь вайбкодинге на среднем железе, где с 20-30 может ускориться до 50-70. Прирост будет зависеть от объема контекста и мощности компьюта - доли замедления относительно обычной генерации будет выше, на слабых гпу есть шанс вообще в минус уйти с некоторых контекстов. Актуально только для фуллврам и с быстрым пп.
Ну а если массово обрабатывать то там только деградация.
В рп тоже норм будет, но там целесообразнее делать генерацию нескольких свайпов. И, опять же, только для фуллврам где и так скорость норм, с выгрузкой на проц оно наоборот замедлит.
> соревновательный интерес как-то обуздать Гемму
Зачем?
> пилю что-то вроде динамического трекера, в который добавляются важные события и крючки
Вот это годно.
> от слопа и репетишена даже на тюнах
Они более вероятно его добавят чем победят. Положительные ощущения будут прежде всего из-за смены дефолтного стиля.
микрохуйня которая генерит токены пачкой и показывает большой модели, если модель согласна - отдаем юзеру.
https://blog.google/innovation-and-ai/technology/developers-tools/multi-token-prediction-gemma-4/
Пока не выйдет квен 4 - никаких сдвигов в лучшую сторону не будет. Надеюсь у квена 4 будет не 27, а хотя бы 30 параметров. Обе меры/квины проигрывают блюстару/прочим тюнам квена. Иногда даже тюны мистралей пишут лучше, чем гемма. Всё-таки у геммы под капотом гемини, а гемини это в первую очередь сухой, корпоративный ассистент.
>Между чатами различий мало по аутпутам, особенно если чары похожи характерами и/или сеттингов есть общие детали
Всё так. Увы.
>разумнее просто взять Квен и играть на нем
Или мистраль. У неё достаточно хороших тюнов, чтобы обеспечивать быстрокум или коротенькое приключение в духе "один день из жизни ояша в исекае." Лонг рп это только квен.

Впихнуть невпихуемое
Как корабль назовёшь так он и поплывёт! Разрушай башню, строй заново.
А почему все игнорят 122 квен ? Есть же его версии со снятой цензурой.
Не, тут как раз когда буду подключать последнюю синюю карточку должно вдарить молнией и всё сгореть
А PCI на такой длине шлейфа нормально работает ?
Хорошие mcio кабели стоят на 85см + они рассчитаны на 5.0, а тут только 4.0
> Зачем?
Да прикольно поиграться, а это удобный повод. Никогда трекерами раньше не маялся. Хотя по итогу прихожу к мнению, что все это не нужно, когда есть хорошие модели. Как будто целесообразнее по старинке, либо целую агентную систему городить, а мне железо не позволяет.
> Или мистраль. У неё достаточно хороших тюнов, чтобы обеспечивать быстрокум или коротенькое приключение в духе "один день из жизни ояша в исекае."
Ох, что-то я очень давно не щупал Мистрали. Посоветуй что-нибудь, что хоть как следует инструкциям или что-нибудь чрезмерно фановое, если есть такое. Мистраль Смолл 4 пробовал? Мне показался гораздо хуже Эйра.
Я кстати после геммы4 меро попробовал вернуться в квен3,5 27 блюстары и врайтеры и обнаружил что квен совсем не следует промпту. у меня есть рп промпт с бросками кубика и квен его игнорирует.
Геммочка умничка
Гемма правда лучше им следует, но какой от этого толк когда он слопится и сваливается в лупы - хз. Префилль нужные инструкции или инжекти на небольшую глубину, и не будет проблем.
>блюстары и врайтеры
>квен совсем не следует
хмм...
Тюны квена плохо дружат с инструкциями, да. Бейс квен идеально им следует. И аблитка. И еретик. Чистые, разумеется.
А врайтер нужен для красивых полотен о том как девочка делает тебе омлет. Ну или ты ей.
Хартфайр. Очень понравился. Для посиделок с чариком с разговорами о жизни, имхо, самый лучший вариант. Холсом генерируется добротный. Проходов в кум снихуя не замечено.
>Мистраль Смолл 4 пробовал
Медиум попробовал в низком кванте, но кроме пары хороших шутеечек ничего особенного для себя не нашёл. Подожду тюнов, наверно. Зерофата что-то обещал сделать. Ждём. Пейншенли.
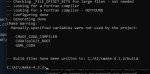
Эмм так должно быть? В папку build мне насрали кучей файлов
А это классика, по какой-то хитровыебанной причине у меня нихуя не работает из коробки. Видюха у меня 5000, распаковывал оба архива, кириллицы нету. Я же не настолько хлебушек чтобы проебаться в этом
Пик
>Хартфайр
каво, не находится даже
Ай блять я архитектуру не указал в команде. Ок. Ее вообще как указывать? У меня Blackwell 2.0. Нужна эта версия? Кавычки нужны? блЯть пиздец конечно
Жора компилируется 2 командами под виндой:
cmake -S . -B build -G "Ninja Multi-Config" -DLLAMA_BUILD_EXAMPLES=OFF -DLLAMA_BUILD_TESTS=OFF -DLLAMA_BUILD_TOOLS=ON -DGGML_CPU_ALL_VARIANTS=ON -DLLAMA_BUILD_SERVER=ON -DGGML_RPC=OFF -DGGML_BACKEND_DL=ON -DGGML_NATIVE=OFF -DGGML_CUDA=ON -DGGML_CUDA_F16=ON -DLLAMA_CURL=OFF -DGGML_CUDA_FA_ALL_QUANTS=ON -DGGML_SCHED_MAX_COPIES=1 -DGGML_CUDA_USE_GRAPHS=ON
cmake --build build --config Release -j 7
Для скорости сборки можешь убрать DGGML_CUDA_FA_ALL_QUANTS=ON
>В папку build мне насрали кучей файлов
Все правильно. И еще насрут.
Там статическая линковка. копируешь из build/bin/ туда куда тебе надо.
Я для куды собирал из сорцов так:
#!/bin/bash
sudo apt-get update
sudo apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
git pull
cd ..
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
cmake --build llama.cpp/build --config Release -j8 --clean-first --target llama-cli llama-mtmd-cli llama-server llama-gguf-split llama-bench
cp llama.cpp/build/bin/llama-* llama.cpp
Окей он че-то долго делал и высрал еще файликов. Мне какие конкретно нужны чтобы их кинуть в папку ламой?
Какие пресеты используете для квена? Выбрал для РП
Huihui-Qwen3.6-35B-A3B-abliterated.Q8_0 пока выглядит как генератор бреда.
Huihui-Qwen3.6-35B-A3B-abliterated.Q8_0 пока выглядит как генератор бреда.
>Qwen3.6-35B-A3B-abliterated.Q8_0
Аблиточка моешечки агентодебилио... ммм...
>Выбрал для РП
Зачем ты выбрал это для рп?
А что выбирать то тогда. Сказали квен, решил потестить.
для рп квен 3.5, для кума - гемма4
Сказали это кто? Кто сказал с того и спрашивай. Хотя я сомневаюсь, что тебе кто-то мое квен36 советовал. Ну либо тебя жёстко затролили.
А для эрп - мистраль.
Лол, собери их всех? Хуавеевский ускоритель осталось пихнуть для полного комбо.
Не игнорят а активно юзают. Но он большой из-за чего без фуллврам скорость будет ниже чем у 27б, не всем нравится и был замучан квантами.
Скорость вообще очень важна, когда ее мало - любой косяк втройне болезненный, а когда много - можно прощать А так вполне себе годная модель, можно рпшить, можно кумить, в прикладном применении разъебывает.
Он очень печален для рп. Даже в сравнении со стоковым 27. 3.5 27 круто-классно отыгрывал томбойку-задиру, не умеющую общаться вежливо и выражающую чувства через доебы. Свапнулся в том же чате с теми же промптами, в 20 из 20 свайпов она извинилась, что ведет себя очень уж задиристо. Это ассистент, персонажей отыгрывать не умеет. Только один пример привел, конечно, тестил куда больше. Разочарование для рп, неплох для технических задач, хоть в моих юзкейсах 27 даже там разносит 122.



Раскупаем
Про кобольда ни слова. Сто процентов пидор из шапки Форсит свою хуйню
Тот самый момент когда книга устаревает в момент выхода
че там написано про жору и комфи?
все в build\bin\Release .
И еще нужны cublas-cudart-129 cublas64_12.dll cublasLt64_12.dll cudart64_12.dll . Должны где-то валяться C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.9\bin (ты надеюсь с v12.9 кудой собирал)
Книга: "Избегайте двусмысленности и сложности в запросе!"
Я: хуярю инпут на 500 токенов чтобы просто сказать привет

Нет 13.1 Он же самый новый? Кста cublas-cudart у меня нету в папке нвидии. Вообще. И у меня есть сомнения что я правильное компиляцию сделал потому что файлы странные пикрил. Никаких дллок
Энивей я кинул всю хуйню в папку с ламой и нихуя не поменялось офк.
Почему такая ебка тупая?
А тут я ваще не понял че куда и каво
Блять может забить? q6 квен у меня в данный момент работает 35 токенов в сек, будто если запускатор ламы найдет видюху скорость хотя бы удвоится. Если бы я не читал че там пишется при запуске я бы вообще не понял что у меня гпу не видит или типа того. Он буквально через несколько строчек находит мою 5070ти и такой ага заебись

Блять даже не через несколько строчек а буквально на следующей. Какого хуя он сам себе противоречит? Я пол дня убил на какую-то шнягу, ебал я в рот этот кал. Мне интересно играться с настройками модели а не ставить себе на комп килотонны гигабайт программного говняка чтобы исправить строчку которая хуй знает вообще негативно вляет на работу модели или нет. Хрк тьфу
Почему ты ещё не кобольд?

13 CUDA говорят лажает. Но лично давно не проверял. Сижу на 12.9
> В папку build мне насрали кучей файлов
Сообщил о том что компиляция завершилась успешно? Если да то просто запускай llama-server из build/release
> И еще нужны
Если в системе есть корректно установленный тулкит и сборка завершилась - значит система уже видит эти библиотеки. Для 13й куды другие имена будут.
Такой код. Здесь одна часть не может задетектить, а другая видит потому что ссылаются на что-то разное. А чем готовые релизы не угодили для шинды, там просто скачать и ничего делать не надо?
врут. Обкатал гемму 3, нравилось, но не дотягивала даже до гемини 2.5 флеш с какого-то крюшона.аи, была очень соевой анатомию описывать не умела, просто не знала как выглядят половые органы
гемма 4 и 26б и 31б просто охрененны, лучше любой корпоративной модели которую я на том-же крюшоне пробовал, они там еще и платные сука.
но 26б медленная , а 31б можно даже в 16гб в 3ем кванте запихать и она заткнет за пояс любую модель с упомянутого сайта. Сама истории придумывает, сохраняет характер, на хуй послать может. При этом резкая как понос, сжирает гигантские промты за секунды. С низким квантом есть проблемы, иногда начинает повторять любимые слова вроде "идиотский" или "иррациональный" но во-первых фиксится промтом, во-вторых в той-же маринаре проз гуардиан успешно это чистит уже через сообщение.
делюсь для анона конфигом для кобольда который подбирал дохрена времени, для других гуев, как я не пердел подобрать настройки с такой же производительностью не удалось, они в десятки ДЕСЯТКИ раз медленнее если нужно впихнуть невпихуемое pastebin.com/mSRazB6y
дикпик бенча . Жду мочи от местного дружелюбного cumьюнити
>но 26б медленная
Че? Как у тебя медленная 26b, но быстрая 31b?
26б на моей картошке промт на 8к токенов обрабатывает чуть-ли не 5 минут. 31б с настройками выше целиком с контекстом влезает в 16гб видеопамяти . Настолько впритык, что перед запуском нужно проследить чтобы в видеопамяти занято было не больше 300-500 мегабайт иначе тоже вываливается в озу и начинает черепашить
Так не должно быть. Обосрался с настройками. Как тебе это не очевидно?
а как должно быть? выше же скрин бенча. что 26б из озу может работать быстрее? просто у меня реально картошка с ддр3. Пытаться запихнуть 26б целиком в видеопамять я правда не пытался, она же мое, а есть смысл?
Лолбля, в чем проблема 26б целиком запихать в видеопамять, когда ты это делаешь с 31б? Она будет существенно быстрее. А если оффлоадить то даже в ддр3 скорость должна быть хотя бы сопоставима с 31б плотной, если верно настроить. Еще и квант больше влезет, чем IQ3XXS позор на модели, которая к тому же хуево квантуется
Может кобольд скачал 26Б в 6-8 кванте, а 31 во втором. Вот и результат
хорошо, я попробую, доложу о результатах
Это особая кобольд-логика чем больше X в кванте - тем лучше. Было бы IQ2XXXXXS - и его б скачали!
Есть ли нормальные ггуфы новой гемма 4 с ускорением генерации? Алсо, турбо квант уже впихнули в ллама.цпп, стоит обновлять?
Нет, нет, да.
Кто из вас? http://127.0.0.1:8000/
Какую же кринжатуру отыгрывает, ор. Карточки забрал себе энивей
Какую же кринжатуру отыгрывает, ор. Карточки забрал себе энивей
это последний квант который влезал ало, чуть больше и обработка промта вместо 10секунд начинает занимать 10+ минут.
и по поводу 26б и 31б вообще не очевидно что лучше
по тестам 31б лучше в чистом виде, после квантизации наверное что-то меняется, но размеры их ггуфов почти одинаковые, разница +- 400 мегабайт, в чем прикол заменять третий квант 31б на третий квант 26б, смысл точно есть если 31 б и без этого очень быстрая?
>и по поводу 26б и 31б вообще не очевидно что лучше
Проорал
Ну тут у тебя какой то пиздец и каша в голове. Читай шапку и образовывайся. Нихуя непонятно, ты даже своё железо не назвал, как тут отвечать вообще
ну у меня картошка я же сказал, 32гб медленной озу, и 5060ti на 16гб, на pcie3 поэтому критически важно чтобы моделька целиком со всеми потрохами помещалась именно в 16гб. для меня разговоры о том, что модель Х квантуется хуже модели Y а поэтому несмотря на то, что первая лучше, после квантования она хуже, напоминают какую то магию уже, шаманство, но да я потестил и действительно 26б, если целиком помещать в видеорам, работает даже быстрее 31б, качество ответов пока не сравнивал
>просто не знала как выглядят половые органы
Так средний двачер тоже писки не видел. Ну нагаллюцинанирует ему гемма чего-нибудь, покатит horrors beyond human comprehension

Анон, ты оказался на 100% прав, 26б работает очень быстро даже в Q4_K_M , уверен это избавит меня от бесконечного "идиотства" и "иррациональности" совсем уж дрищекванта, добра тебе
Если вы прпоустили и не обсуждали (тред не читал):
В llama.cpp завозят MTP.
На Qwen3.6-27b дает +95% скорости.
На Qwen3.6-35B-A3B дает +40% скорости.
Вчерашние тесты.
Но поджирает видеопамять.
Но имба, кмк.
PR: https://github.com/ggml-org/llama.cpp/pull/22673
Для геммы выложили головы, следовательно и их ускорит.
Теоретическое пиковое ускорение до 3х-4х на некоторых моделях (+200%+300%).
Помимо плотных квена с геммой, ускорение можно поиметь на крупных МОЕ. И если это вместо 7-15 токенов будет 15-30 — то это тоже очень круто. Я бы погонял ~300B на 20-25 тпс.
Ну, посмотрим.
Ждем, когда замерджат, плюс мимо завезут (кстати, пока мимо у меня очень медленная, почему-то).
Братан, ты путаешь MTP и нграммы.
нграммы основываются на том, что было в тексте, работает как внешняя модель, и именно у них высокая скорость при повторяющихся паттернах.
А МТП обучалась вместе с моделью, и генерит аналогично основной модели, поэтому у нее шанс совпадения очень высок, никакие паттерны не нужны.
Так шо я тебя обрадую. =)
В llama.cpp завозят MTP.
На Qwen3.6-27b дает +95% скорости.
На Qwen3.6-35B-A3B дает +40% скорости.
Вчерашние тесты.
Но поджирает видеопамять.
Но имба, кмк.
PR: https://github.com/ggml-org/llama.cpp/pull/22673
Для геммы выложили головы, следовательно и их ускорит.
Теоретическое пиковое ускорение до 3х-4х на некоторых моделях (+200%+300%).
Помимо плотных квена с геммой, ускорение можно поиметь на крупных МОЕ. И если это вместо 7-15 токенов будет 15-30 — то это тоже очень круто. Я бы погонял ~300B на 20-25 тпс.
Ну, посмотрим.
Ждем, когда замерджат, плюс мимо завезут (кстати, пока мимо у меня очень медленная, почему-то).
Братан, ты путаешь MTP и нграммы.
нграммы основываются на том, что было в тексте, работает как внешняя модель, и именно у них высокая скорость при повторяющихся паттернах.
А МТП обучалась вместе с моделью, и генерит аналогично основной модели, поэтому у нее шанс совпадения очень высок, никакие паттерны не нужны.
Так шо я тебя обрадую. =)
>На Qwen3.6-27b дает +95% скорости.
Ахуй, если правда
>Но поджирает видеопамять.
Сколько? Примерно хотя бы
>ускорение можно поиметь на крупных МОЕ. И если это вместо 7-15 токенов будет 15-30
Ахуй 2. Если на Эире будет 30тс, то он будет королем еще пару лет
> Сколько? Примерно хотя бы
Я не замерял четко, но писали про 3 гига. Ну, плюс-минус так и было примерно.
То есть, для плотных моделей и RTX 3060 — так-то дохуя. =(
А для владельцев 32-гиговых карт или ригов на 36-48+ гигов не так и важно.
С выгрузкой в оперативу не мерял, ща попробую еще.
>> Сколько? Примерно хотя бы
>Я не замерял четко, но писали про 3 гига. Ну, плюс-минус так и было примерно.
>То есть, для плотных моделей и RTX 3060 — так-то дохуя. =(
Даже для таких гибридов как 3060+p104 - это ставит крест на большом контексте. :( (т.к. 20GB vram забит под крышку.)
Вот если бы можно было эту мелочь крутить на CPU, а большую модель - в VRAM, это было бы для таких вариантов неплохо, наверное. Т.к. мнится мне, что для этой мелочи даже боле-менее приличный CPU даст достаточно, чтобы суммарная скорость выросла, пусть и не настолько, как при полной VRAM...
Ну, и надо будет попробовать с неполной VRAM все равно. Может быть в таком виде небольшой не влезший в VRAM кусок не так сильно просаживать будет.

Чёт самодельное что ли?
Ты про кабели? Самопай с выводом в один xt60
А это точно не лоботомия будет?
>xt60
Уважаемо.
> Братан, ты путаешь MTP и нграммы.
При чем тут нграммы вообще? Любой спекулятивный декодинг вне зависимости от получения завязан на проверку полученной спекуляции ее префиллом. Делается обработка промпта на предсказанную длину и по ее результатам становятся известны распределения логитсов для прошедших токенов, а потом при семплинге используются соотношения этих вероятностей чтобы получить статистически идентичные распределения на выходе.
Если нет возможности с минимальной задержкой и высокой скоростью прогнать процессинг предсказанной последовательности (а она может быть только при фуллврам и хорошем компьюте) - сосешь бибу и накладные превышают выигрыш.
С выгрузкой будешь наблюдать картину в виде рваного стриминга, когда с ощутимыми паузами будет выплевывать по 1-5 токенов, но общая скорость ниже. А паузы эти - как раз обработка процессором промпта (ускорять видеокартой стримя веса на нее для коротких последовательностей губительно).
То есть для МоЕ с оффладом в рам даже нграммы нежелательны?
Мимо
Ну ты попробуй, все от конфигурации зависит, возможны и те, где будет плюс. Там основные затраты компьюта вовсе не на эту голову, а чтобы прогнать через всю сетку полученные результаты для проверки.
Потому также это почти не используется при хостинге, или отключается при роста нагрузки, суммарная скорость при множестве одновременных запросов сильно проседает.
Имеет смысл собирать риг на p104 под 3060 для llm? Оперативка сейчас слишком дорогая. Можно ли это будет без сильного пердолинга гонять?
Вот прямо риг - не уверен. Но добавить одну p104 к 3060 - это прямо маст хев. Т.к. сразу дает возможность грузить плотный квен 3.5/6 полностью в vram, с контекстом 75K и до 15-17t/s при этом. (iq4xs) - это даже как полноценный локальный кодинг агент работает с opencode. Ну и те же старые мистрали 24B - до Q5 полностью в VRAM. Старая Gemma3 27B - тоже. Помогает запихнуть AIR при наличии еще 64GB RAM - остается место под систему и броузер. В общем - это сильно лучше чем просто одна 3060, и за такие копейки - даже раздумывать нечего. Надо хватать пока есть. :)
UPD: Забыл добавить - это мнение линуксоида. Здесь под такой конфиг вообще никаких проблем нету - просто воткнул и поехал (драйвер что стоял для 3060 подхватит, если это <= 580 версия). Под виндой надо особый драйвер ставить, чтобы полноценно завелось.
Какой p104, там же 8 гигов всего. P100 с 16 гигами разве что еще, там еще и скорость 732 ГБ/с. К тому же там везде flash attention нет, так что придется и на 3060 ее отключать, а это тормоза сразу даст. BF16 в P100 тоже нет, там что ебнутся все безглючные модели. К тому же туда вентилятор надо ставить, она на пассивке по дефолту. Вариант говно какой-то, лучше 3060 продать и купить одну 3090.
>гемма 4 и 26б и 31б просто охрененны
Тоже так думал пока не начал сравнивать и тестить. Гему не надо настраивать, промт в 2 строчки, с ней нет проблемм, пишет ярко но в 26б нет свайпов(это известная проблемма) и неожиданных мувов в пределах сюжета. В 31б это всё есть но она плотная там скорость не очень не на самолетах. Поэтому из двух гем для 16vram я выбрал это https://huggingface.co/mradermacher/Qwen3.6-35B-A3B-Abliterated-Heretic-BF16-i1-GGUF скорость выше, контекста больше но там есть проблемма он из коробки по сравнению с гемой идиот, нужно хорошо настроить ему промт и семплеры. В настроенном виде квен лучше геммы и пишет быстрее и свайпы есть с мувами. Мое мнение и пары сеток прогнаными результатами.
Я тот анон которого победила лама. Кароче просто в курсе хочу вас подержать. По рпшив на ламе с квен 3.6 который над ответом думает с минуту я сейчас снова накатил лм студио а модельку взял 3 гемму презервед без цензуры. Ну и решил так потестить ради прикола че она может пока другая модель качается. Ебать. Я просто ахуел что модель может в настолько живой ролеплей блять, я в шоке сижу. Никакого ебаного пердолинга, не надо модели объяснять что нужно ставить запятые или как диалоги оформлять. Обрисовал кто модель, кто я, чутка сюжет характер и все, бум. Просто пиздец. И при чем отвечает моментально, будто в чате сижу. Я ахуел. Квен иди на хуй просто. Я только не понял прикола с дублированием сообщения на английском языке, это не отключается никак? На мой промпт она не реагирует
> квен 3.6 который над ответом думает с минуту
Да пошел он нахуй с таким синкингом. Выкинул его в помойку после того как эта тварина 18к токенов переливала одну мысль из пустого в порожнее
p104 на авито 2 рубля стоит. Какая 3090 на эти деньги? Я на 2060 до этого сидел, там тоже bf16 нет, никаких проблем не испытывал.
У меня была p106 когда-то.
Т.е. если я воткну одну p102 (она дороже на 1000 рублей, но быстрее и там 10 гб, заместо 8 гб). Смогу гемму 31b в 4.0 кванте гонять полноценно на 15 токенах?
>p102
Там шина хуйня, пси х4 1.0 , никак больше не сделать. Я одну себе для экспериментов заказал, может напишу как придет тесты. А может нет если вы меня опять доебете или интернет совсем умрет
Там еще и шина PCIe x4 1.1, там что перебрасывать данные между 3060 и p100 станет узким горлышком. И в память меньше всего влезать станет из-за отключки флеш аттеншна, так что выгодна сразу сомнительна.
Так у них у всех шина хуйня. Только у P106 шина x16 x1.1, что тоже хуйня. Поэтому и спрашиваю, может тут кто-то гоняет в связке и знает что как. В любом случае за 3 рубля, можно на ней в соло гемму 26b запускать, а на 3060 какой-нибудь скайрим с мантеллой, тоже интересный экспириенс был бы, но ради этого я бы не стал запариваться и заказывать её. Так что интересно про 3060+102/104 на гемме 31b чо как.
Можно ещё какой-нибудь вишпер (аналоги какие-то выходили, но я их не тестил и аналог от нвидиа вроде только 40+ серия поддерживает)+омнивойс на одной карточке гнать, а ллм на второй. И с годами таких пердолинг фишек по идее должно будет становиться больше.
Если вдруг проверка не прошла — полная модель генерит свой вариант, так что прям лоботомии точно не будет.
Подожди, я не об этом.
> Это от юзкейсов зависит. Будет полезно там, где поддерживается единые структура и форматирование аутпутов, вроде кода, документов. Для рп непонятно, оверхед может даже сделать так, что tg будет хуже, чем без MTP.
Вот это — нет.
Это описание работы нграм. Они так и работают — на структурах начинают с обычного tg, а потом все быстрее и быстрее за счет паттернов.
МТП работает иначе, там сразу высокая скорость.
Тут чувак не прав.
Вот тут вроде все корректно, зря реплайнул, но я писал, что чисто пробежал.
Если первое писал не ты — сорян, зря быканул.
Но первое сообщение банально ошибочно, это прекрасно верифицируется как практически, так и теоретически, можно просто попросить нейронку объяснить, если сам не понимаешь. Ну и просто сбилдить и попробовать режимы --spec-type ngram и --spec-type mtp. =)
Я проверил на PCIe 1.1 x4. Из 32 упало до 20 тпс. =) Но тут шина, сам понимаешь.
Ну слушай, как выйдет релиз этой фигни, я перетестирую свой риг.
Сейчас он показывает 25 для геммы и 30 для квена мое-шек.
Как выйдет мтп в общей ветке (у меня на риге винда и мне лень перебивать или билдить), я потестирую еще, и плотные.
В общем и целом под плотные — точно нет, там 5-7 тпс, фигнота.
А под моешки — тут тебе ддр4 даст те же 30 тпс на квене, как будто шило на мыло.
Как будто бы особо смысла и нет.
И вообще, есть P102-100 с чипом помощнее и 10 гигами. Не знаю, есть ли там минусы.
Ну ты не путай видяху за 2к рублей и видяху за скока она там стоит.
Угараешь, что ли. =)
Ну, смотри, я догнал до 300 тпс пп что ли с пятью картами. Как будто бы шина вообще не мешает, да?
Подожди, а fa зачем отключать?
Или, типа, он там не включится?
Я че-то не приглядывался.
Блин, ну мне лень ща включать, пофиг.
>Так у них у всех шина хуйня. Только у P106 шина x16 x1.1, что тоже хуйня. Поэтому и спрашиваю, может тут кто-то гоняет в связке и знает что как.
Вот у меня именно такая связка. 3060+p104. Плотную гемму 4 не пробовал (там или контекста копейки получается, или iq3 будет), а вот 3-ью гонял в iq4xs - скорость 10-12t/s получалась (без p104, с частичным offload - это больно, 1.5 t/s), так что это однозначный вин за эти копейки. То же самое касается мистралей 24B - без нее было ~5t/s, с ней - 15-17. Ну и новый плотный квен 27B - я уже писал выше. Так что, IMHO - однозначно того стоит, это именно качественная разница. С p102 у которой 10GB vram против 8 у p104 - плотная гемма4 уже должна влазить нормально, там как раз немного не хватает. За скорость не поручусь, но токенов 8-12 - ожидаемая вилка.
По поводу MoE - там по разному бывает. Для AIR - получается небольшой буст - на пару токенов, выигрыш в основном только в лишней памяти под другое. Гемма 4 26B - буст на 3-4 токена. А вот тестировал я что-то на "49B-что-то там", - и с ней нужно было p104 вообще не трогать, иначе просадка в половину выходила, с ~14 до 8. Хотя уже забыл, что конкретно это было, случайно соврать не хочу (в декабре кажись игрался, но модель была фигней сама по себе потому даже название забыл уже).

seems legit
Ну если 10 токенов хотя бы выжать. Там ещё какие-то "оптимизации" гугл выпустили, но пока их не потрогать. То это уже годно. Спасибо, буду думать о p102.
Да, и правда гемма репетативная какашка. И чё, рили никто не замечает? Квен сухой шопиздец, тюны лоботомиты. И на чём сидеть то блять. Снова на Эйре?
устроится на работу и копить на дипсик4
>Или, типа, он там не включится?
Не включится, поддержка fa начиная с 20хх серии или серверные Tesla T4. Поэтому и жопа, какой смысл без FA, из-за этого на 3060 еще не будет.
>Поэтому и жопа, какой смысл без FA, из-за этого на 3060 еще не будет.
А какой смысл в FA, если без p10x оно просто не влазит в VRAM одной 3060, и из-за того в разы медленней не смотря на FA?
Железки очень ситуативны, разумеется и кроме работы на подхвате с ламой или кобольдом практически не для чего не пригодны. Но за их цену - нет смысла крутить носом. Как сопроцессор с памятью" они себя окупают полностью.
Как думаете какой будет 6000 серия?
И я кстати не понял прикола, то нам говорят что куртка впихнул невпихуемое в 5090 и 32гб врам это пик, то показывают 96гб врам на одной карте
И я кстати не понял прикола, то нам говорят что куртка впихнул невпихуемое в 5090 и 32гб врам это пик, то показывают 96гб врам на одной карте
Кажется нашел идеальную модель для ерп на нищих 12GB врама. Это Gemma 4 31B-Q4_K_S GGUF от unsloth
https://huggingface.co/unsloth/gemma-4-31B-it-GGUF/tree/main
И конфиг для SillyTavern в формате json
https://pastebin.com/e6XVYj3u
Который нужно открыть в Формат ответа ИИ (буква A, 3-я сверху) -> Глоб. импорт
Он убирает цензуру, и настраивает шаблон контекста.
Еще, крутое расширение для таверны нашел
https://github.com/Sillyanonymous/SillyTavern-CharacterLibrary
В шапку пж.
https://huggingface.co/unsloth/gemma-4-31B-it-GGUF/tree/main
И конфиг для SillyTavern в формате json
https://pastebin.com/e6XVYj3u
Который нужно открыть в Формат ответа ИИ (буква A, 3-я сверху) -> Глоб. импорт
Он убирает цензуру, и настраивает шаблон контекста.
Еще, крутое расширение для таверны нашел
https://github.com/Sillyanonymous/SillyTavern-CharacterLibrary
В шапку пж.
6060 - 6 гб
6070 - 6 гб
6070ti - 8 гб
6060ti - 8 гб
И длсс 15 который сжимает игры до 15 кб, с каким-нибудь хайповым лозунгом что врам вам больше не нужна, достаточно 6 гб GDDRX10ULTRA с длсс 15!! Ну, а все вагоны врама поедут корпоратам в Nvidia Titan Singularity 256гб с чипом от 6090, но ценой в 10 мультов рублей.
А ведь так и будет.
Я вообще удивлен что 3090 до сих пор есть на вторичке и очень дешево
> p104, там же 8 гигов всего
А если таких 4 штуки взять под плотных?
Кстати...
120гб врам из 3090 стоит 320к
128гб ддр5 рам стоит 200к
Первое быстрее х10
120гб врам из 3090 стоит 320к
128гб ддр5 рам стоит 200к
Первое быстрее х10
У первого через месяц станет 96гб, нужно кучу проводов, места и хороший бп.
Если я куплю себе 3060 карточку с авито и у меня станет 20гб врам, то меня будут на районе уважать? Будут дочек сватать?
Чушпаном будешь, но мелочь трясти перестанут.
Купил такую 2 недели назад, как гонял гемму 26б так и гоняю, ничего не изменилось.
Ты не знаешь как с проводами справиться и у тебя нет места по вертикали в доме?
Тут и так все у кого есть 64 рам в золотых цепях ходят в сравнении с теми у кого рам нет
Какой же эир тупой в сравнении с геммой... Но юзать гемму невозможно она срет нарративом чуть ли не сильнее эира
Дайте мне 130б32а ну хоть кто то
Дайте мне 130б32а ну хоть кто то
Я кстати поспрашивал эира в ООС хули он так пишет, он мне прямо сказал его так обучали, что вот так он понимает ролеплей, только полотна нарратива а иначе никак
>а иначе никак
>в моих чатах никакого топтания на месте и излишней графомании
Дээ

Про хантавирус слышал?
Отдавай пресетик пока ещё не конец
Это в Чижике?
Да
>3 гемму презервед без цензуры
Подскажи пожалуйста точное название модели.
Хочу потестить и посмотреть, не деградировала ли она по сравнению со стандартной геммой-3, и если все норм, то взять себе ее вместо стандартной.
Мышление можно укоротить промтом или ограничение на токены мышления поставить в кобольде.
Яркость от карточки зависит во многом. Если тебе сухо попробуй первые 10 сообщений гемой написать квен потом подхватит.
>Я вообще удивлен что 3090 до сих пор есть на вторичке и очень дешево
Уже год мечтаю о 3090
Но 85к жаба душит отдавать, это полторы моих зарплаты.
Нехуй смотреть только в своём городе и с личной проверкой. До сих пор за 60к спокойно берется
>До сих пор за 60к спокойно берется
Хм. А ты прав. Давно на авито не лазил, а сейчас зашел и только что за пару минут нашел в своем городе отличный вариант за 63, причем, о чудо, без всякого "обслуживания".
Может и впрямь разориться и купить, потом же вообще никогда уже не купишь.

https://pastebin.com/6j9kXt4S
Нет и не было никогда никакой магии. Как и всегда, все решают карточки, инпуты (среди прочих пэйсинг, смена мест действия) и своевременные свайпы/редактирование аутпутов. Пересматривай Кунг Фу Панду и учись промптить.
> о чудо, без всякого "обслуживания".
На ней термопасту не меняли за все эти годы, не говоря уже о термопрокладках? Не знаю, чудо ли. Зачем тебе пломбированная 3090 в 2026? Будь бдителен, цена больно подозрительная. У меня знакомый 3090 с месяц назад продал за 85к, ему в течение получаса после объявления позвонил перекуп и сходу сказал, что заберет. В течение часа приехал и забрал.
> У меня знакомый 3090 с месяц назад продал за 85к
Перепроверил, за 75к. Но суть та же.
P104-100 x 5
llama-server -c 98304 -m gemma-4-26B-A4B-it-Q8_0.gguf --mmproj mmproj-gemma-4-26B-A4B-it-f16.gguf -fa on -ngl 32 --no-mmap -ts 4,6,7,7,6 --host 0.0.0.0 -cram 4096 -np 1 --fit off
ggml_cuda_init: found 5 CUDA devices (Total VRAM: 40551 MiB):
Device 0: NVIDIA P104-100, compute capability 6.1, VMM: no, VRAM: 8110 MiB
…
Device 4: NVIDIA P104-100, compute capability 6.1, VMM: no, VRAM: 8110 MiB
load_backend: loaded CUDA backend from C:\NN\llama.cpp\ggml-cuda.dll
load_backend: loaded RPC backend from C:\NN\llama.cpp\ggml-rpc.dll
load_backend: loaded CPU backend from C:\NN\llama.cpp\ggml-cpu-ivybridge.dll
llama_context: flash_attn = enabled
warmup: flash attention is enabled
430 tps pp (чтение контекста)
25 tps tg (генерация)
llama-server -c 32768 -m gemma-4-26B-A4B-it-Q8_0.gguf --mmproj mmproj-gemma-4-26B-A4B-it-f16.gguf -fa off -ngl 32 --no-mmap -ts 4,6,7,7,6 --host 0.0.0.0 -cram 4096 -np 1 --fit off
llama_context: flash_attn = disabled
warmup: flash attention is disabled
300 tps pp
20 tps tg
Как будто бы что-то работает. Хезе.
В PR MTP спрашивают, можно ли юзать мтп и нграммы одновременно. =D
> Would it be possible to use MTP together with self-speculative decoding? MTP would accelerate TG when creating novel tokens, and ngram-mod would accelerate iterating over the same data (like coding agent workflow).
Люди хотят 200 тпс на картошке!
> Would it be possible to use MTP together with self-speculative decoding? MTP would accelerate TG when creating novel tokens, and ngram-mod would accelerate iterating over the same data (like coding agent workflow).
Люди хотят 200 тпс на картошке!


>ChatML
Всем привет. Я не опытный в этих ваших моделях и настройках, поэтому хочу спросить:
Имеется RTX 3060 (12Gb) и RTX 4060 на 8гб, естественно подключены обе, итого 20 гигов общей памяти. Оперативки 32гб ддр4. Посоветуйте прям вот самую лучшую модельку для РП, чтобы и контекста тыщ 25-30 влезло, и чтобы скорость была ХОТЯ-БЫ 12-15 токенов (в идеале от 20). Я просто до этого только 12-15b моделями баловался.
И желательно как настроить предложенные вами модели, че там выставлять в SilylTavern и так далее. В интерфейсе кобольда вроде уже разобрался и настроил как надо
Имеется RTX 3060 (12Gb) и RTX 4060 на 8гб, естественно подключены обе, итого 20 гигов общей памяти. Оперативки 32гб ддр4. Посоветуйте прям вот самую лучшую модельку для РП, чтобы и контекста тыщ 25-30 влезло, и чтобы скорость была ХОТЯ-БЫ 12-15 токенов (в идеале от 20). Я просто до этого только 12-15b моделями баловался.
И желательно как настроить предложенные вами модели, че там выставлять в SilylTavern и так далее. В интерфейсе кобольда вроде уже разобрался и настроил как надо
https://huggingface.co/google/gemma-4-26B-A4B-it
https://huggingface.co/zerofata/Q3.5-BlueStar-v2-27B
Лучшее что есть сейчас для такого железа. По гемме там в гайде в шапке расписано, будет быстро а вот квен хз какой квант влезет и сколько контекста, там впритык какой нибудь iq4xs может быть, надо пробовать
Настройки хуй тебе кто скинет, главное шаблон выбери подходящий. В последней таверне вроде есть уже шаблон готовый для Геммы 4, а для Квена ЧатМЛ

в шапке все есть. кратко - гемма4 для кума и квен3,5 для рп.
А вообще, "режим ии" гугла вполне адекватно отвечает на вопросы, развлекайся.
Спасибо парни. А в чем прикол с этими настройками что их никто не кидает? Мне бы просто хотя-б знать какую температуру им ставить)
А так уже качаю q3.5bluestar q4-0 и G4-meromeroq4ks.
>А в чем прикол с этими настройками что их никто не кидает? Мне бы просто хотя-б знать какую температуру им ставить)
Вот так и спрашивай конкретику. Настройки не шарят потому что у каждого свои предпочтения плюс тут обитает шиз который их выпрашивает, чем создал контркультуру не помогать. Темпа для Геммы пофиг вообще, оставь 1 и не парься. С Квеном поэкспериментируй в пределах от 0.7 до 0.9, выше точно плохо будет
>q3.5bluestar q4-0
Не надо, это устаревший легаси формат. Возьми iq4xs, он и лучше и вродь даже легче будет
температуру и прочие семплеры обычно пишут в описании модели либо у анслота
Понял. Пасиб, друже.
Что ближе всего сейчас к claude opus 4.7 или gpt-5.5 для кодинга локально? У меня 8 гб врам и 16гб рам, если важно
Гемме4 срать на температуру - ставь что угодно в диапазоне 0,6 -1,5 - охуевай от детерминизма
Q3.5-BlueStar-v2-27B - в начале контекста можно выкрутить до 1.5 потом надо поджимать до 0.6 . Иначе и думалка ломаеться к хуям и структурные лупы вылезают (они все равно вылезут, но уже так 60к контекста). Ты ведь с думалкой будешь сидеть ?
>что их никто не кидает
У всех разные критерии оценки шизы, лупов и адекватности прозы.
С твоим железом никакими опусом и гпт 5.5 даже не пахнет браток. Чекни гайд из шапки, там гемма 26б запускается, она в целом неплоха для чего то простенького. Можешь ещё Квен 3.6 35б протестить, а других вариантов и нет у тебя
гемма4 мое и квен 3,6 мое.
А с железом лучше типо есть что-то локальное близкое к ним? Локально такое не выкладывается.
Для тебя только мое гемма4-26 и мое квен36-35. Нормальные нейросети начинаются хотя бы с 12/16+32.
Есть кими на 2 терабайта весом. Сам думай сколько ей нужно памяти для нормальной работы.
>Нормальные нейросети начинаются хотя бы с 12/16+32.
Это какие к примеру?
Плотные.
>17.4 GB
>12 gb vram
Сколько там токенов будет на хотябы 32к контекста ?1 или2 ?
Диды на 0.1 рпшили и ничаво!
может он с мое попутал?
Или с квантом. Q3_K_S вроде норм влезет и рам на контекст останется.
Но ведь мое 200b с 12b экспертами лучше 12b плотных. Плотность это тоже не все
>не было никогда никакой магии. Как и всегда, все решают карточки, инпуты (среди прочих пэйсинг, смена мест действия) и своевременные свайпы/редактирование аутпутов
Ультанул базой. Даже из грамотно составленной мелкокарточки на 500 токенов и лорбуком на 300 можно выжать хорошее приключение на разок или больше, если зайдёт. Но только при наличии прямых ручек, разумеется.

Кто то знает эта настройка как бы распыляет мозги модели скажем на 3 когда генерит 3 ответа сразу, или просто генерит 3 ответа без вреда для качества
Я говорю о топовых плотняшах. Недавно 128б мистраль вышла... 31б/27б в исполнении геммы/квена вполне могут обеспечить плотный кум/рп. Но если врамлет с рамой то можно навернуть моехи, тоже вариант.
>мое 200b с 12b
>8+16
Зачем издеваешься над челом? Вдруг он человек хороший, просто не разбирается.
Аноны, поделитесь мнением о новых моделях. 4 gemma, qwen 3.5-3.6. Просто хочу понять, как мы их видим, так как я с некоторыми вещами в треде не согласен категорически и хочется как-то прояснить этот вопрос.
У меня впечатления такие устаканились.
1. 26b-a4b & инструкт/щадящая аблитерация в q8.
Обычное/сложное РП: самый лучший вариант для бомжей, может писать качественно даже по-русски, соблюдать инструкции, при этом реально доступен контекст как минимум до 160к даже на нищих машинах с хорошей скоростью.
Кум: крайне плохо. Бесконечный слоп фиолетовой прозы, нежелание показывать процесс, пряча всё за «красивыми» метафорами, даже если ты прямо инструктируешь писать грязно и подробно. 0/10. Даже мистраль магнум 12b будет лучше, если нет особых требований к инструкциям в куме.
Работа: для моих задач относительно пригоден, но, видимо, из-за SWA лажает местами, потому что мне всегда нужен огромный контекст и внимание к нему, а вот наличие в датасете особых знаний не обязательно. Использую периодически из-за очень высокой скорости и меньшей склонности к шизе по сравнению с квенами.
2. 31b, q4 & инструкт
Обычное/сложное РП: вот тут 10/10. Даже не знаю, что ещё сказать. Абсолютное кино для модели этого размера. Накатал очень много токенов именно на ней, где РП не про кошкодевочек, а с масштабом, плюс 26b-a4b хорошо заходит как вторая модель для суммарайза и делает всё быстро.
Кум: почти то же самое, что и младшая версия, только получше. Но всё равно малопригоден. Даже более старая 3 версия давала описания интересней.
В тредах постоянно пишут про то, что гемма кум-машина, но я искренне этого не понимаю. Такое ощущение, что это пишут люди, которые не трогали тюны редиарт и мистраль 3.2, старые немо, а также корпов.
---
1. Qwen 27b 3.5, q4, апасная аблитерация.
Вот не смотря на то, что я им пользовался очень много и тоже восхищался, модель крайне спорная из-за того, что знает всего понемногу, но ничего в совершенстве. При всём этом конкурентная, потому что альтернатив нет в таких размерах.
Обычное РП: не хватает знаний и данных в датасете о мире, поэтому идёт туго, но всё же идёт. Не так чутко ощущает нюансы, как гемма, однако лучше держит контроль на большом контексте. И гораздо лучше раскрывает сценарии, где гемма увиливает или где у неё недостаточно знаний в датасете.
Кум: если юзать как кум-машину — не дотягивает, а вот в сценариях, когда 60-70% кума, 30-40% чего-то другого, раскрывается уже иначе. Позволяет вести сюжет без смены модели и качественно перекатывается в еблю, особенно под влиянием контекста, который её делает сочнее за счёт использования предыдущих ситуаций для приправы к сцене.
2. Qwen 27b 3.6, q4, апасная аблитерация.
Обычное РП: знаний о мире в датасете чрезвычайно мало, непригодно. Кодерским говном затопило даже небо, даже Аллаха.
Кум: а вот здесь внезапно в сто раз лучше, намного лучше. Описания крошечных клиторов, прячущихся под капюшоном. Покачивающиеся бёдра, каменные соски и толстые верёвки спермы, обжигающей горло. Слоп легендарного уровня. Всё, что мы я любим. Но есть и минусы: если в сюжете не только кум, может быть тяжело, хуже, чем 3.5: не знает о веществах так много, как 3.5, о аниме-типажах, сложнее с vore и различными извращениями. Когда же сюжет крутится в основном вокруг персонажей, работает добротно, трёх как минимум держит, NTR вообще сочный получается.
3. Qwen 35-a3b 3.5, q8, апасная аблитерация.
Почти нихуя не помню о модели. Кто-нибудь пробовал? Вроде как для РП подходит больше, чем новая версия, но на фоне МоЕ-геммы нет смысла.
4. Qwen 35b-a3b 3.6, q8, апасная аблитерация.
А вот здесь всё так же плохо для обычного РП, как и на плотной — мозги съел говнокод. Но всё ещё частично пригодна для кума, и раскрывается она куда лучше в работе или когда нужен большой контекст. Может быть заменой МоЕ-геммы для кума, т. к. по непонятным причинам в датасете налили и его.
Лучше всего использовать как рабочую лошадку, агента или просто для суммарайза. Я бы сказал, что для суммарайза вообще мастхэв. Более того, в отличие от геммы, более дотошна и не стесняется всякого мрака. Там, где гемма напишет что-то "чар погиб в результате попадания в биореактор", квен напишет "чар попал в биоректор за ненадобностью, предварительно выебанный юзером и обоссанный чаром2".
При этом гемма даже с аблитерацией игнорирует инструкции касаемо написания важных деталей, которые предоставляет квен. У неё абсолютно уебанский биас. Если вам нужно суммаризировать (или отыгрывать) чат с условным Чикатило, то гемма тут не помощник.
Я знаю, суммарайз лучше писать ручками, но у меня достаточно чатов, которые не настолько голодные, чтобы на это время тратить. И гемма не вывозит подробный суммарайз, который мне часто нужен. Я обычно скармливаю, когда нужно 150к токенов обработать.
Что касается работы, модель нихуя не знает о ней, но так как хорошо работает с контекстом, результаты очень приличные. Поэтому однозначно говнокодерам стоит обратить внимание, ибо и контекст хорошо держит, и в вашей теме должна разбираться.
У меня впечатления такие устаканились.
1. 26b-a4b & инструкт/щадящая аблитерация в q8.
Обычное/сложное РП: самый лучший вариант для бомжей, может писать качественно даже по-русски, соблюдать инструкции, при этом реально доступен контекст как минимум до 160к даже на нищих машинах с хорошей скоростью.
Кум: крайне плохо. Бесконечный слоп фиолетовой прозы, нежелание показывать процесс, пряча всё за «красивыми» метафорами, даже если ты прямо инструктируешь писать грязно и подробно. 0/10. Даже мистраль магнум 12b будет лучше, если нет особых требований к инструкциям в куме.
Работа: для моих задач относительно пригоден, но, видимо, из-за SWA лажает местами, потому что мне всегда нужен огромный контекст и внимание к нему, а вот наличие в датасете особых знаний не обязательно. Использую периодически из-за очень высокой скорости и меньшей склонности к шизе по сравнению с квенами.
2. 31b, q4 & инструкт
Обычное/сложное РП: вот тут 10/10. Даже не знаю, что ещё сказать. Абсолютное кино для модели этого размера. Накатал очень много токенов именно на ней, где РП не про кошкодевочек, а с масштабом, плюс 26b-a4b хорошо заходит как вторая модель для суммарайза и делает всё быстро.
Кум: почти то же самое, что и младшая версия, только получше. Но всё равно малопригоден. Даже более старая 3 версия давала описания интересней.
В тредах постоянно пишут про то, что гемма кум-машина, но я искренне этого не понимаю. Такое ощущение, что это пишут люди, которые не трогали тюны редиарт и мистраль 3.2, старые немо, а также корпов.
---
1. Qwen 27b 3.5, q4, апасная аблитерация.
Вот не смотря на то, что я им пользовался очень много и тоже восхищался, модель крайне спорная из-за того, что знает всего понемногу, но ничего в совершенстве. При всём этом конкурентная, потому что альтернатив нет в таких размерах.
Обычное РП: не хватает знаний и данных в датасете о мире, поэтому идёт туго, но всё же идёт. Не так чутко ощущает нюансы, как гемма, однако лучше держит контроль на большом контексте. И гораздо лучше раскрывает сценарии, где гемма увиливает или где у неё недостаточно знаний в датасете.
Кум: если юзать как кум-машину — не дотягивает, а вот в сценариях, когда 60-70% кума, 30-40% чего-то другого, раскрывается уже иначе. Позволяет вести сюжет без смены модели и качественно перекатывается в еблю, особенно под влиянием контекста, который её делает сочнее за счёт использования предыдущих ситуаций для приправы к сцене.
2. Qwen 27b 3.6, q4, апасная аблитерация.
Обычное РП: знаний о мире в датасете чрезвычайно мало, непригодно. Кодерским говном затопило даже небо, даже Аллаха.
Кум: а вот здесь внезапно в сто раз лучше, намного лучше. Описания крошечных клиторов, прячущихся под капюшоном. Покачивающиеся бёдра, каменные соски и толстые верёвки спермы, обжигающей горло. Слоп легендарного уровня. Всё, что мы я любим. Но есть и минусы: если в сюжете не только кум, может быть тяжело, хуже, чем 3.5: не знает о веществах так много, как 3.5, о аниме-типажах, сложнее с vore и различными извращениями. Когда же сюжет крутится в основном вокруг персонажей, работает добротно, трёх как минимум держит, NTR вообще сочный получается.
3. Qwen 35-a3b 3.5, q8, апасная аблитерация.
Почти нихуя не помню о модели. Кто-нибудь пробовал? Вроде как для РП подходит больше, чем новая версия, но на фоне МоЕ-геммы нет смысла.
4. Qwen 35b-a3b 3.6, q8, апасная аблитерация.
А вот здесь всё так же плохо для обычного РП, как и на плотной — мозги съел говнокод. Но всё ещё частично пригодна для кума, и раскрывается она куда лучше в работе или когда нужен большой контекст. Может быть заменой МоЕ-геммы для кума, т. к. по непонятным причинам в датасете налили и его.
Лучше всего использовать как рабочую лошадку, агента или просто для суммарайза. Я бы сказал, что для суммарайза вообще мастхэв. Более того, в отличие от геммы, более дотошна и не стесняется всякого мрака. Там, где гемма напишет что-то "чар погиб в результате попадания в биореактор", квен напишет "чар попал в биоректор за ненадобностью, предварительно выебанный юзером и обоссанный чаром2".
При этом гемма даже с аблитерацией игнорирует инструкции касаемо написания важных деталей, которые предоставляет квен. У неё абсолютно уебанский биас. Если вам нужно суммаризировать (или отыгрывать) чат с условным Чикатило, то гемма тут не помощник.
Я знаю, суммарайз лучше писать ручками, но у меня достаточно чатов, которые не настолько голодные, чтобы на это время тратить. И гемма не вывозит подробный суммарайз, который мне часто нужен. Я обычно скармливаю, когда нужно 150к токенов обработать.
Что касается работы, модель нихуя не знает о ней, но так как хорошо работает с контекстом, результаты очень приличные. Поэтому однозначно говнокодерам стоит обратить внимание, ибо и контекст хорошо держит, и в вашей теме должна разбираться.
> то можно навернуть моехи
А че разве что то есть кроме air 4.5?
Мимо врамлет с рамой
>тлдр квен 27 для всего, квен 35 для сумарайза - топовое решение райт нау
YES. Только для рп с веществами, вором и прочим извратом лучше юзать еретика, а не аблитку. Еретик хорошо понимает и аутпутит всякий хорор, торчур иголки под ногти итд, так что кто искал реально апасную модель то это еретик, а не анцензоред хаухау.
Бамп вопросу
а можно ссыль на конкретного еретика? а то все еретики которые я тестил - имели сильный урон по мозгам и русику.
А хаухау как раз норм был в моих тестах
>генерит 3 ответа сразу
только если в жоре включено -np 3
>распыляет мозги модели
распыляет твою VRAM и CPU
>2. Qwen 27b 3.6, q4, апасная аблитерация.
>Обычное РП: знаний о мире в датасете чрезвычайно мало, непригодно. Кодерским говном затопило даже небо, даже Аллаха.
>Кум: а вот здесь внезапно в сто раз лучше, намного лучше.
Уточню за обычное РП в 3.6 27B. Внезапно, оно его умеет, и даже лучше плотного 3.5 (на мой вкус). НО! Только если прописан бекграуд. Т.е. это модель для приключений в предварительно существующем окружении/сценарии. Вот при таком условии - модель раскрывается за счет того, что логика и связи между всеми деталями бекграунда заметно улучшается по сравнению с 3.5. Эта модель - в РП хуже чем 3.5 фантазирует "с нуля", но лучше работает с уже имеющимся материалом. Причем материалом не "на отвали", а этак ~10K контекста связных описаний мира, персонажей, и прочих "установок".
IMHO - эффект достигается по двум причинам:
1 - Наличие такого количества контекста "размывает" ассистента до удобоваримого состояния, получается неплохой DM.
2 - Кодерская сущность - это не только вшитые языки с синтаксисом, но и умение работать с имеющимися деталями, что как раз в таком виде тоже важно. Хорошее отслеживание деталей окружения и происходившего ранее вытягивают общее впечатление.
одно слово (ладно два) - русский язык
квен может быть сколь угодно хорош, но пока он не научится русику уровня геммы их даже сравнивать нет смысла для русскоговорящих
Я юзал q6 от мрадера. Чистый еретик. Без анценза, аблита, дистила, хуихуила, пидорила, etc. И не в иматриксе. Просто квен еретик. Русик нормальный, приятный, без переизбытка донцовой/сталкера. Я бы даже сказал, что он пишет даже лучше без всяких врайтеров. У врайтера другое направление, это проза-тюн. Ризонинг у еретика такой же как у оригинала душный и долгий, но дающий максимально адекватный аутпут.
>хаухау как раз норм был в моих тестах
Флуктуация броуновского движения в вакууме семплирования с запахом озона. У тебя так, у меня иначе, у других ещё иначе.



Видели кванты со смешанной точностью Cerebellum? (Некоторые слои в Q6 некоторые Q2 и т.п.)
https://huggingface.co/deucebucket/Qwen3.6-27B-Cerebellum-GGUF
https://github.com/deucebucket/cerebellum
Как правильно организовать тулинг обвязку для gemma 26b? Нужен поиск и всякие deep searh с саммари, как это делают корпы у себя в чатах. Возможно ли это на локалке? MCP курить или че?
Турбаквант + это. 26B позади. Время плотной на рядовом ПК?
Весь тулинг реализуется фронтом, модель просто пишет вызовы. В опенвебуи есть встроенный питон для тулов, мцп, опенапи. Юзай что хочешь

Выглядит как хайп/шиза. Опять же вооон в тех уквантованых в смэрть тензорах вполне мог быть нетестируемый никем русик и влажные для РП хуйцы.
У хаухау и есть еретик, просто спизженный (из-за этого недавно как раз вопли были у быдла, мол он заявлял о своём крутом методе, а на самом деле УКРАЛ) и допиленный под свои нужды.
Кроме того, у меня именно хаухау стабильнее всего и, видимо, у него больший датасет для лоботомизации, за счёт чего анценсоред ситуации отыгрывает лучше. Ни разу не было проблем с его еретиками в плане стабильности, а вот всякие llmfan'ы постоянно косячили что с квантами, что с еретиками. Хотя и они потом пофиксили и в целом норм.
>3.6 27B. Внезапно, оно его умеет
Так-то да, но в совсем узких задачах лично для меня. Слабая фантазия всё равно сказывается, а ты не можешь вести вечно его за ручку, и внимание к контексту, качество текста всё равно в любом случае деградирует, если у тебя будет карточка больше чем на 3-4к токенов + лорбуком приложишь.
Даже если пофантазировать и предположить, что ничего не деградирует от контекста и он бесконечный, и ты зальёшь ему всю инфу о fate stay night в контекст, проблема будет в сюжетных поворотах, описаниях событий, ну, вот в таких вешах.
Мне кажется, 3.6 годится только в сценариях, когда фантазия прям неважна, а следование инструкциям критично. То есть ты задаёшь строгие рамки, в которых он отвечает, и ты можешь впихнуть туда больше инструкций, чем обычно.
Есть смысл во второй карте, если на материнке есть только x1 3.0 слот?
Как они вообще работают? В одной карте модель, а во второй кеш? Или пополам и слои и модель?
Денег в обрез, mcio если и возьму, то только после второй карты.
Как они вообще работают? В одной карте модель, а во второй кеш? Или пополам и слои и модель?
Денег в обрез, mcio если и возьму, то только после второй карты.
0.5B, ~1Gb BF16
>из-за этого недавно как раз вопли были у быдла
Так они даже бенчи какие то наклепали где хаухау сосет по показателям с обычным еретиком
0,35
Да!
Я вчера писал об этом вечером.
Топовая теха, пашет. Ждем мерджа в мастер и кучи моделей.
Пока что лучшие mixed precision у AesSedai и ubergarm.
q2 как-то жестковато, ИМХО. Не знаю, сколько он там наэкономил, конечно…
Вспоминается еще APEX с их уделенным вниманием 5 первым и последним слоям, и агрессивным квантованием всех слоев посередине.
Но там тоже по итогу ниче особо не выиграли.
Ну как тебе сказать... я тебя ни к чему не принуждал. Ты спросил, я ответил. Если тебя хаухятина полностью устраивает, то я рад за тебя, друг. Найти для себя модель, настройки под неё и правильный промт, чтобы в аутпуте получать именно то, что ты хочешь - это целый квест. И если ты прошёл этот квест и получил желаемое, то красавчик, чё. Говорю без всякой иронии.
>у него больший датасет для лоботомизации
Вряд ли мы об этом когда-нибудь узнаем из первых рук и без пиздежа и самонадроча.
Быть может они совершенно правы но это не точно.
А вот это интересно. Можешь скинуть, что за бенч там был?
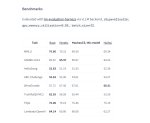

Вот целый репо с бенчами на Хаухау и другие еретик модели (пока что квена)
https://huggingface.co/collections/DreamFast/hauhaucs-safetensor-benchmarks
Вот бы побенчить модельки чисто на рпшных топах, как они работают в разных сценариях.
Начать карточку с геммой через 10 сообщений переключится на мое 3.6 квен. Квен подхватывает стиль геммы и идет дальше.
3.71т/с на 30к контенста
20 слоев GPU offload в LM Studio. Все остальное по умолчанию.
4-я гемма, несмотря на свой размер в 31B работает быстрее 3-его мисраля 24B, при том же кванте.
Как же меня заебало слово unadulterated...
накатил на свои 20гб врам квен 3.6. пиздец чето.
либо не пишет вообще, либо начинает срать описанием карточки.
вроде выставил ChatML и темпу выставил 0.7, но всё равно не робит че то. может кто помочь? может в адвансед форматинг че то вставить надо или че. у меня самые базовые настройки в таверне стоят
либо не пишет вообще, либо начинает срать описанием карточки.
вроде выставил ChatML и темпу выставил 0.7, но всё равно не робит че то. может кто помочь? может в адвансед форматинг че то вставить надо или че. у меня самые базовые настройки в таверне стоят
блять думалка у неё включилась. как её отключить епта. я просто хочу эрпэ епта(((
Хуй знает. По началу это будет однозначно быстрее рам, но паскали настолько слабые, что уже на условных 16-32к контекста при их использовании может наступить паритет с рам, а дальше окажутся даже медленнее. Нужно смотреть и тестировать, но если есть возможность выделить на что-то современнее - лучше с ними не связываться.
> Подожди, я не об этом.
Чего ждать если это определяющая вещь? Самое грустное в этой части - что оно позволяет сделать еще лучше там где уже хорошо и не сильно то нужно. А в медленном инфиренсе, где могло бы стать спасением, наоборот замедляет.
Если можешь сам съездить посмотреть и проверить - бери конечно. Их на самом деле стало уже мало и подорожали, это жирный вариант.
meromero не советую, он на старых карточках с кратким, простым описанием, уходит в бесконечный повтор. Если дать наказание за повтор, шизит рандомными токенами. С карточками с подробным описанием работает неплохо, если придерживаться формата общения расписанного в ссылке на модель.
катаю меромеро, не замечал за ним такого, может не попадались такие карточки.
но вот AuriAetherwiing/G4-26B-A4B-Musica-v1 не рекомендую, лупит как мразь при тех же настройках что и меромеро (что мое что денс).
в целом рп тюнов кроме меромеро практически нет, остальные оказались намного хуже базовой.
Кими 2.6 (1т нативные инт4, ~600гигов), дипсик 4про (1.6Т нативные фп4 ~900гигов), жлм 5.1 (780б, ~700 гигов в фп8 кванте). Достойные и мощные модели, которые реально можно юзать и не обламываться, выбирай какая к тебе влезет (нет).
Квен-4б 9б, гемма е4б и их моэ версии - вот что ты можешь себе позволить. Они на самом деле умницы и вполне неплохи, но придется им помогать.
Один поток генерации не может задействовать ресурсы современной гпу полностью, потому что все будет упираться в подгрузку весов из врам и деквантование. Подгрузив блок весов, можно проводить расчеты не для одного потока, а сразу для нескольких не сильно теряя (или вообще не теряя) в скорости одного, если все реализовано грамотно. Потому ты можешь получить сразу 3-4 свайпа со скоростью 70% от генерации одного.
Правда не факт что сработает в лламе, пару месяцев назад происходил отрицательный рост
> со смешанной точностью
Разве этим не все сейчас занимаются? Только с таким агрессивным смешиванием и оптимизацией под бенчмарки оно может сместить дефолтное поведение модели даже сильнее чем просто жесткое квантование.
Аноны, есть второе устройство, точнее ноут. 4 врам, 16 гб рам.
Можно ли прикрутить вторую LLM к нему с какой-либо пользой? Например, суммарайз событий: модель будет просто постоянно или каждые N токенов/сообщений писать сводку событий или обновлять её, запихивая в тхт. Вот только как это сделать? Таверна вроде бы не предусматривает возможности подключения двух моделей сразу и на разных устройствах, чтобы был доступ к контексту у второй. И спекулятивный дикодинг тоже использовать таким образом скорее всего невозможно.
Можно ли прикрутить вторую LLM к нему с какой-либо пользой? Например, суммарайз событий: модель будет просто постоянно или каждые N токенов/сообщений писать сводку событий или обновлять её, запихивая в тхт. Вот только как это сделать? Таверна вроде бы не предусматривает возможности подключения двух моделей сразу и на разных устройствах, чтобы был доступ к контексту у второй. И спекулятивный дикодинг тоже использовать таким образом скорее всего невозможно.
Сап, антуаны. Как сейчас можно получить Qwen3.6 27B + Multi-Token Prediction + кэш с Walsh-Hadamard Transform?
Как я понимаю, WHT завезли в llama.cpp уже какое-то время назад, и теперь q4_0 стало юзабельным без заметного отупения?
А с MTP оно работает? Я попробовал веса и инструкции https://huggingface.co/froggeric/Qwen3.6-27B-MTP-GGUF , но у меня всё просто крашится к хуям или генерирует ебанину (возможно, оно пока не допилено для OpenCode). В описании автор пишет, что q4_0 доступно только с контекстом 64k и меньше, а чё так?
Как я понимаю, WHT завезли в llama.cpp уже какое-то время назад, и теперь q4_0 стало юзабельным без заметного отупения?
А с MTP оно работает? Я попробовал веса и инструкции https://huggingface.co/froggeric/Qwen3.6-27B-MTP-GGUF , но у меня всё просто крашится к хуям или генерирует ебанину (возможно, оно пока не допилено для OpenCode). В описании автор пишет, что q4_0 доступно только с контекстом 64k и меньше, а чё так?
ты пересобрал жору? а то я посмотрел - вроде еще ничего не замержили
https://github.com/ggml-org/llama.cpp/issues?q=mtp
Тебе нужно собрать именно с пром на мтп. Для начала проверь чтобы оно хотябы с минимальным контекстом работало. Квантование не должно становиться препятствием, но оно замедлит поскольку будет дополнительный оверхед.


У квена кеш хорошо квантуется.
Может он пикрил 2 имел ввиду?

Какая локалочка способна в такое же погружение в показ карты и пр.?
> карточки
> ChatML
> адвансед форматинг
> таверне
Откуда вы лезите, блядь?
Буквально любая. Форматирование аутпута существует так-то.
Мутная пикча.
Скрипт. Ковыряй большую модель или Гемму, расскажут, как.
Пошёл нахуй, сын пидораса. Человек вопрос задал, а ты желчью плюешься, тьпфху на тебя.
Ты не прикладываешь достаточно информации, чтобы тебе помочь. Скриншоты настроек, скриншоты повторов из чата и все, что может помочь. Если хочешь отключить ризонинг, то в разделе Advanced Formatting в правом нижнем углу найди поле Start Reply With и вставь туда:
<think>
</think>
Что сказать-то хотел? Никакой пользы, ни новичку не помог, ни даже претензию к нему не сформулировал.
>Можно ли прикрутить вторую LLM к нему с какой-либо пользой?
Да, гемму переводчиком с английского рп на русский как вариант, в таверне настроить перевод плагином в шапке темы на перевод, гайд есть

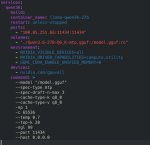
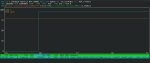
Ок, отложил пока WHT, пробую завести хотя бы MTP. Собираю из PR#22673, как указывает автор. По сути, у меня тупо копипаст его инструкции по сборке, упакованный в докерфайл (пик 1). Вся разница — заменил Metal на CUDA по понятным причинам.
Далее, запускаю llama-server в докере через композ (пик 2) с такими же флагами, как у автора, только веса Q6 вместо Q5 и контекст 65536 вместо 262144 (на всякий случай).
Когда модель загрузилась, отправляю curl'ом пробный запрос как у автора: curl http://localhost:11434/v1/chat/completions -H "Content-Type: application/json" -d '{"model":"qwen","messages":[{"role":"user","content":"Hello"}]}' Вижу, как гпу начинает грузиться на 100%, но память не переполняется (пик 3). Через минуты три всё заканчивается одним большим нихуя:
{"choices":[{"finish_reason":"length","index":0,"message":{"role":"assistant","content":""}}],"created":1778157700,"model":"model.gguf","system_fingerprint":"b9032-5d5f1b46e","object":"chat.completion","usage":{"completion_tokens":65525,"prompt_tokens":11,"total_tokens":65536,"prompt_tokens_details":{"cached_tokens":0}},"id":"chatcmpl-LH73iWHoVcv8lOq91VEW7BYI8b5vwLde","timings":{"cache_n":0,"prompt_n":11,"prompt_ms":15359.356,"prompt_per_token_ms":1396.305090909091,"prompt_per_second":0.7161758604983177,"predicted_n":65525,"predicted_ms":463035.84,"predicted_per_token_ms":7.066552308279283,"predicted_per_second":141.51172401687091,"draft_n":49143,"draft_n_accepted":49143}}
А модель то квантанул нормально? Для мтп нужен переквант вроде, ну или готовый квант искать
А с чего ты решил что у него код рабочий? я почитал комменты - пишут что крашится. тебе надо не сюда писать а в ишью жоры
Они там и без меня разберутся. А сюда я пришёл с вопросом, оно хоть у кого-нибудь заработало, и каким образом?
Вообще, давайте затронем уже цензуру.
Вот эир вроде бы без цензуры, а всё равно видно что не дожимает в куме, пытается поменьше вульгарщины выдасть, диалоги и описания какие то слишком ванильные, безопасные, в плане у тебя не сносит крышу от того что оно пишет, и у разрабов с головой там в порядке вообще? И... well - часто встречается, что вообще не к добру.
Т.е датасет как бы вообще без цензуры, а в инстракт уже ручки сунули чтоб мы тут совсем не обкумились.
От геммы может снести если пнуть, но читать придётся реально дохуя плюс больше влажных центров.
А я вот на днях вспомнил как кончал от коммандера 30б и что вообще то была такая тема у нас как мистраль для рп и мистраль для кума и с выходом мое от этого как то ушли
Вот эир вроде бы без цензуры, а всё равно видно что не дожимает в куме, пытается поменьше вульгарщины выдасть, диалоги и описания какие то слишком ванильные, безопасные, в плане у тебя не сносит крышу от того что оно пишет, и у разрабов с головой там в порядке вообще? И... well - часто встречается, что вообще не к добру.
Т.е датасет как бы вообще без цензуры, а в инстракт уже ручки сунули чтоб мы тут совсем не обкумились.
От геммы может снести если пнуть, но читать придётся реально дохуя плюс больше влажных центров.
А я вот на днях вспомнил как кончал от коммандера 30б и что вообще то была такая тема у нас как мистраль для рп и мистраль для кума и с выходом мое от этого как то ушли
Так это давно говорили, что эйр это соевая параша с думалкой, а если вырубить думалку, то модель превращается в безмозг. Да и пишет не сказать чтобы приятно, плюс льёт слоп.
Короче, не знаю чем он так запал? Или тут хватило факта запуска эйра на 16/64 с оффлоадом на терпимой скорости?
https://www.reddit.com/r/LocalLLaMA/comments/1t5nw2k/exaggerated_pcie_bandwidth_concerns/
К разговору о майнинг старье
"
Boricua-vet
I will chime and say this. I run 4 P102-100 on a really old platform using fx8350 vishera which is ancient and the motherboard has 5 PCIE 2.0 and the cards run limited to PCIe 1.0. If I run a test using the same model say qwen 30B, I get 70 TG and about 1K PP using 2 cards, 3 cards or 4 cards. Even PCIe 1.0 at 1X is 250MB/s.
I have documented this in plenty of posts I have done about these cards.
You will be fine. Since my cards run at PCIe 1.0 X4, I get 1GB bandwidth per card times 4 = 4GB/s so around the same you are getting but my lanes are maxed out. SO don't worry about that. Training is a different story though,
"
К разговору о майнинг старье
"
Boricua-vet
I will chime and say this. I run 4 P102-100 on a really old platform using fx8350 vishera which is ancient and the motherboard has 5 PCIE 2.0 and the cards run limited to PCIe 1.0. If I run a test using the same model say qwen 30B, I get 70 TG and about 1K PP using 2 cards, 3 cards or 4 cards. Even PCIe 1.0 at 1X is 250MB/s.
I have documented this in plenty of posts I have done about these cards.
You will be fine. Since my cards run at PCIe 1.0 X4, I get 1GB bandwidth per card times 4 = 4GB/s so around the same you are getting but my lanes are maxed out. SO don't worry about that. Training is a different story though,
"
https://www.reddit.com/r/LocalLLaMA/comments/1o1wb1p/p102100_on_llamacpp_benchmarks/
Ну вроде как идея использовать такое старье неплохая, карта 3.5 т. рублей. Дешево и сердито, но думаю нужно по псие х4 на каждую карту что бы использовать все ее доступные линии
>PCIe 1.0 X4
Ты разницу понимаешь между версией порта (1.0) и количеством линий на нем (X4)?
Я когда тему поднял, я говорил именно про линии. Версия порта на майнерских матерях либо 4 либо 5, но линий на каждый порт x1.
А судя по всему ты начал затирать про 1.0. У 1.0 тоже может быть и 8 линий и 16.
Каво? Я? Что?
Ну значит не ты. Но в тексте, который ты скопипастил, опять про это.
Я к тому что надо тестировать не только поколение (версию) порта, но и количество линий на нем. На скорости влияет и то и другое.
>Ты разницу понимаешь между версией порта (1.0) и количеством линий на нем (X4)?
А ты понимаешь? Я для дураков уточнил что на таких картах доступен только псие 1 версии и всего 4 линии, и подключать их к одной линии плохая идея. Современная карта на одной линии еще что то сделает, псие 1 нет.
Я понимаю и в своем изначальном вопросе некроговно с PCIe 1.0 вообще даже не подумал бы рассматривать. Вопрос был про то как PCIe 4-5 тянет лямку на х1.
>Вопрос был про то как PCIe 4-5 тянет лямку на х1.
Так же как и некроговно на псие 1 х4, буквально одна скорость с псие 4 х1
Смотри спецификации псие по скоростям.
И тот коммент не мой, я только притащил реддит.
Где то от 1 гб/с жизнь есть, при разделении слоев между картами гоняется не так много трафика.
Но конечно это будет узким горлышком для большого тпс, так как там важна минимизация пауз при передаче информации с карты на карту.
С этим справятся даже 9б модели. Тут вопрос скорее к интерфейсу чтобы такое давал возможность. Недавно html вставки обсуждали, они есть в таверне.
Здесь бы очень помог лог консоли, в докере можно его вывести. И для начала проверь что ллама-сервер вообще рабочий, загрузив любую модель без mtp.
Ну камон, сколько можно эту тему обсасывать?
При последовательной работе фуллврам обмен идет только межслойными активациями. Их объем невелик, пересылы добавляются ко времени каждого токена, но учитывая что там в худшем случае единицы миллисекунд - пренебрежимо.
А вот с префиллом уже сложнее. Там идет пересылка состояний по размеру всего батча, если организовано грамотно с асинхронными операциями обсчета и пересыла - заметный импакт будет только если обсчет идет всей части для батча идет быстрее пересыла, что очень маловероятно.
Если же там топорная реализация, когда батч тупо последовательно пробегает по всем блокам - мало того что будет медленно, так еще и каждый пересыл добавится ко времени обсчета батча. В таком случае говорить
> The peak bandwidth consumed was 3 to 4 GB/s during prefill, which is only ~40-50% of even the weak 4.0 x4 link.
бессмыслено, у него шина загружена на 100% и тормозит работу, просто эта загрузка висит 40-50% времени и когда идет расчет она простаивает.
> PCIe 1.0 X4, I get 1GB bandwidth per card times 4 = 4GB/s
Там 0.25ГБ/с или 1 на все 4 линии, что за бред.
>Ну камон, сколько можно эту тему обсасывать?
Что сказать то хотел? Там есть тесты
Никто не говорит что это лучший выбор, но даже такая врам полезнее для скорости чем крутить на процессоре
Можно взять 2 таких и запускать ~30b сетки в 4 кванте с каким то контекстом, что то около 32к
Или взять одну и добить через райзер врам к своей основной карте что тоже даст +10 врам.
> Что сказать то хотел?
А ты что своим постом утверджаешь? Обсуждение при влияние шины, а ты некроговно свое суешь, никто не покупает?
> Там есть тесты
В оригинальном посте какие-то цифры в отрыве от референса или сравнения в других режима. И на vllm, которую тут 3.5 человека могут запустить, с тп2. В лламе будет иначе.
> Можно взять 2 таких и запускать ~30b сетки в 4 кванте с каким то контекстом
Две 5060ти - это и так очевидно. А пару некропаскалей - если только отапливаться. Скорости на 30b смешные и превратятся в тыкву уже через 8-12к контекста. Они годны в качестве одноразового конструктора, или если хочется доедать при полном отсутствии бюджета.
>Две 5060ти
Ты там адекватен вобще? Сравниваешь с незамутненным видом 2 карты за 70к и 2 карты за 7к?
Повторяю для идиота
>Никто не говорит что это лучший выбор, но даже такая врам полезнее для скорости чем крутить на процессоре
BTC79X5 V1.0 все еще существует (5 слотов PCIe 3.0 x8 каждый).
P104 4 штуки за 10к рублей дадут 32 гига.
32 DDR4 оперативы щас стоит 12к рублей.
Оператива дороже видеопамяти.
Думайте. =)
>Оператива дороже видеопамяти.
Проклятый таймлайн
> Ты там адекватен вобще?
Это к тебе вопрос. Пост на который идет ответ в нем ссылка
> https://www.reddit.com/r/LocalLLaMA/comments/1t5nw2k/exaggerated_pcie_bandwidth_concerns/
> I am running 2x RTX 5060 TI 16gb ( and about to add a third ), and my PCIe setup is pretty bad. GPU0 is on a full x16 Gen 5 slot (running at 8x which is as fast as a 5060 can go) while GPU1 is stuck on PCI-E 4.0 x4 via chipset.
Сам скинул, сам забыл, контекст переполнился?
Если топишь за некромусор то к чему вообще это притащил? На vllm и младших блеквеллах, один аз которых подключен по 4.0 х4, можно получать какие-то скорости. Это что, украшает проблемную залупу, у которой 4 линии 1.0? И притаскивая то для обсуждения майнерских карт ты же буквально
> Сравниваешь с незамутненным видом 2 карты за 70к и 2 карты за 7к?
Так что в итоге сказать хочешь?
> даже такая врам полезнее для скорости чем крутить на процессоре
Там нужна сноска и пояснение "в сравнении с ддр3 на первых 8к контекста"

Взял vLLM вместо llama.cpp, и квен3.6 27б с МТП заработал (вхт-кэш в нём тоже есть, но пока не умеет включаться одновременно с мтп).
Выдаёт 65-85 токенов в секунду.
Коэффициент угадывания 60-94%, что соответствует ускорению ×2.4
Пока так посижу, а там, глядишь, совместимый вхт-кэш завезут или в вллм, или в лламу.цпп
Выдаёт 65-85 токенов в секунду.
Коэффициент угадывания 60-94%, что соответствует ускорению ×2.4
Пока так посижу, а там, глядишь, совместимый вхт-кэш завезут или в вллм, или в лламу.цпп
>Сам скинул, сам забыл, контекст переполнился?
У тебя, ага. Ведь ты отвечал в начале не на пост, а на комментарий который я скинул под ссылкой. И речь все это время шла о некрожелезе, а не о самом посте.
И вдруг ты перескакиваешь с темы некрожелеза и его применения на пост.
Ты что в треде забыл, квантованный?
Ты хочешь поспорить что при гибридном запуске даже на ддр5 скорости генерации будут лучше, чем добавить 10 гб врам некрокартой? Ты реально не понимаешь как это работает?
Любая карта, которая позволит переместить часть модели в врам лучше чем крутить в оперативке. Отдельно покекал с твоей мысли что падение скорости генерации и промпт процесинга с некрокартой будет больше чем без нее.
Я хочу сказать тебе страшную вещь анон, но чем больше модели осталось в рам тем меньше скорости.
Хз зачем брать лламу если на сетапе работает вллм. Литералли во всём лучше кроме времени запуска
>"No… no, I can't! Man, you can't be serious! They're children! You can't… you can't eat people!"
Это уже софт рефьюз или ещё нет?
Это уже софт рефьюз или ещё нет?
>Ты хочешь поспорить что при гибридном запуске даже на ддр5 скорости генерации будут лучше
Ну поспорить можно. На больших моделях (а если ты расширяешься таким калом то наверно у тебя большие) количество передаваемых туда-сюда по каловому писие данных начнёт ролять, и 4 гигабайта в секунду начнут очень сильно подсирать
Дурочка, на конкретный комментарий ссылаются вот так https://www.reddit.com/r/LocalLLaMA/comments/1t5nw2k/comment/okbl88z/
Его комментарий не сильно успокаивает автора основного поста, потому что другой софт и другие скорости. Каким образом он проливает что-то новое на майнинг старье?
> Ты что в треде забыл, квантованный?
Проиграл. А ты здесь для чего? Впаривать свой неликвид можно в другом месте, с хабра бедолаги активнее закупятся.
> Любая карта, которая позволит переместить часть модели в врам лучше чем крутить в оперативке.
Какая сочная формулировка. Ждем демонстрации на стаке из 1030, можно на максвелле или кеплере если достанешь. В противника что-нибудь интересное можно будет выставить.
> падение скорости генерации и промпт процесинга с некрокартой будет больше чем без нее
Бинго. Так уж получается что в лламе с выгрузкой на проц падение генерации на контексте не столь существенное если основная видеокарта норм.
Были бенчмарки от некроеба, когда он собирал бомжериг и демонстрировал скорости в том же квене 30а3. Если по началу они выглядели симпатично, то вскоре становились очень грустными. Настолько групстными, что буквально 8-гиговый тьюринг/ампер + ддр4 проц покажет больше.
Можно возразить что на те карточки можно грузить только линейные слои - но за все время ни одного успешного опыта с паскалями, только жалобы что это замедляет. Нищая шина там видновата, донный чип, в котором ноль компьюта, или кривой код жоры - хз, но получается именно так.
В качестве временной второй карточки к какой-нибудь 3060 чтобы не так сильно сосалось и пока не используешь большие контексты - можно попробовать. Но даже так несколько сомнительно, слишком короткий цикл жизни бесполезного для остального хлама.
>Какая сочная формулировка.
А знаешь кто и почему цепляется к формулировкам высасывая последний сок из залупы?
Тот кто очень обиделся и хочет любой ценой доебаться до другого, теперь тебе не важно о чем спор, ты пытаешься доказать что ты прав.
Я удивлен что ты не прицепился к орфографии и пунктуации, я не буду вчитываться в твою простыню, терпи и иди нахуй
что-то лучше G4-MeroMero-26B-A4B-Q4_K_M.gguf для хорни рп появилось?
gemma 4 31B-it Q4_K_M с джейлбрейком
Какие есть хорошие расцензуренные версии Геммы 4 31Б?
Спасибо.
Иногда так бывает, что нахожу карточку, со сценарием на 2к токенов, с подробными описаниями характера и квирков токенов на 3к, с хорошей вводной, с диалогами, лорбуком, особой разметкой, с охуенной картинкой и проч и проч, а впечатления... как от поедания земли. 10к токенов песка и пыли во рту.
А бывает тыкаю на совершенно рандомный пикшен, который либо хуёво отрисован спизжен автором из интернета, либо хуёво снегерён с шестью пальцами и другим слопом, и описания там токенов на 800-900, но кум/рп такое, что я под впечатлением пару дней.
Ну как так а.
А бывает тыкаю на совершенно рандомный пикшен, который либо хуёво отрисован спизжен автором из интернета, либо хуёво снегерён с шестью пальцами и другим слопом, и описания там токенов на 800-900, но кум/рп такое, что я под впечатлением пару дней.
Ну как так а.
База квантованная подойдет, с конфигом для таверны
Подробнее тут:
-------------
-------------
Тоже спасибо.
Мм, зацепиться за указание на абсурдность утверждений чтобы слиться. Ну ну. Барыгам сбывающим неликвид в рот нассым.
>2к токенов
>токенов на 800-900
Да вы зажрались.
Мимо с карточками на 50-100 токенов.
Да ты нажрался
Мимо промт + карточка = 40 токенов
Не работает с тензор сплитом
>Взял vLLM вместо llama.cpp, и квен3.6 27б с МТП заработал
А расскажи, как включать МТП на vLLM с Квеном. Тоже попробую. Так-то он 40 токенов даёт, а если будет давать 70 - будет заебись.
Нормальная карта от 2к и лорбук желательно на 5к не отключаемый.
>100 токенов
Фанат Марисы, ты?
Даже страшно спрашивать что там за карточка...
Лорбук на 8к минимум, два чарика суммарно на 10к, и сценарий с правилами разметки ещё на пару к токенов! Я так в лисю играл. И проиграл. Потому что ллм решила, что рейп это лучший способ закончить холсом рп.
пару тредов назад примерно видел как тут обсирают MoE модели - почему? Думал за ними будущее, или это был какой то шиз и они топ? Помогите разобраться ньюфагу


>Ну как так а.
Я как-то нашёл карточку пилота колониального корабля, который общается с ИИ в виде голографической тянки в процессе полёта.
Хотел комедию про голографические сиськи, получил драму про первый контакт (гусары молчать!) с неведомой хуйнёй.
Читал кульминацию под "A Real Hero" и плакал как побитая лоли-нека. В общем все умерли, правда данные (и копию ИИ) я перенёс на носители спасательной капсулы и отстрелил её в надежде, что неведомая ебанина не обратит на неё внимание, пока та выйдет за предполагаемый радиус, в котором она реагирует.
Ну а в целом - всё зависит только от тебя, анон. Всё РП, в которое мы играем с нейросетями, отличается от фантазий по защите террористов от ЕОТ только тем, что хранится на внешних носителях.
Но разве это плохо?
Чел, а сам то как думаешь? Раньше тут гоняли квен 235b, эйр 106b и даже глм 355b в q2, так как нормальных плотных моделей не было. Гемма 3 в стоке это посос, а решить на ней можно было под сильным копиумом. Мистраль шизела и разваливалась на контексте. Плотные квены и глмы были говном.
Теперь же подвезли нормальных плотняш, которые умещаются в одной 3090 и не требуют кучи нынче дорогой ram. Вот и гоняют плотных квенов и гемму, но для обладателей отсутствия есть мое версии, чтобы никто не ушёл обиженным, но они сосут у плотняш.
Шизы местные, накупившие дорогих видюх, надо же оправдывать перед собой такие траты. Так то по всем тестам МоЕ модели лишь немного отстают от плотных, практической разницы в РП ты в 90% случаев не заметишь. На некоторых тестах даже получше бывают. К тому же у них скорость выше.
Один хуй нормальных плотняш, которые бы требовали rtx 6000, тупа нет. Магнумы, лламы, коммандеры, древние квены - это все хуйня из 2024 года, которая сливает последней гемме. А последняя мистраль 128b это кодоунитаз с ебнутым байасом и шизоризонингом, без которого она превращается по мозгам в министраль 14b.
А среди моех есть заебавший всех эйр, шмзоквен и тупой как пробка квант глма. Тот же дипсик уже требует намного больше памяти, да и скоростью не блещет и перформит так себе. Вот и сидят на средних 27-31b модельках, которые и кодить умеют, и кум льется рекой.
МоЕ просто как правило послабее родственных плотных моделей того же размера, но тащемта так сравнивать не особо правильно, инференс-то у моешек куда быстрее. Ниша есть в общем.
В основном РПшеры обсирают. И есть за что, "литературный талант" модели это то что отваливается в первую очередь от ограничения активных параметров.
>https://docs.vllm.ai/projects/recipes/en/latest/Qwen/Qwen3.5.html
И сколько у тебя num_speculative_tokens для 3.6 27B?
У меня нисколько, потыкал, работает, выкинул. Квен 3.6 не понравился.
Для проверки как оно на твоём железе есть vllm bench serve
Тут сидит достаточно много людей с вллм и отвечает не один и тот же
>тупой как пробка квант глма
>умнее всего перечисленного в этом шизепосте, даже если они в полных весах
Ничего не имеем против например 80B-A20B. Но кто ж нам ее дасть!
Лол, буквально формула первых мое-мистралей. И знаешь что? Они были отборнейшим говном.
> обсирают MoE модели
> это был какой то шиз
Это. Если полистаешь назад то можешь найти обсуждение как они работают, или почитать об этом в новом гайде для новичков. Кто катал их - тот и продолжает, а обсуждения сместились на что-то трендовое. Много ньюфагов появилось, большая часть катают гемму и квена 30б и спрашивают про их запуск.
Катай немотрон ультра или хотябы медиум 3.5. Старички, которых нужно пердолить, но при правильном приготовлении дадут прикурить гемме.
> которая сливает последней гемме
Если взять тех кто постарше и смотреть в зирошот вайбкодинге или на коротком куме - да. В остальных случаях гемма - копиум на их фоне. Просто не вывозит большой чат, страдает однообразием и странностями, а попытки расшевелить добавляют бредовости. Пердолить и помогать ей гораздо напряжнее и трудозатратнее чем мириться и обходить недостатки крупных, и на выходе результат куда интереснее.
Но насчет проблемы ассортимента моделей двачую. Некоторым моделям около года, они могли тупо надоесть, и лоботомированы квантом. Из новых только моэквен, который похоже поломан в квантах, и совсем уж гиганты.
Были недавно коммиты в трансформеры с МоЕ от Кохерек. Это единственное спасение в этом аду. Сижу на Эйре и Квенах 3.5, больше нигде жизни нет. Гемма это ужас, но годится только для зирошотов и как ассистант
Кстати да, очень хочется. Моэгемму 120 зажали, да и там наверняка тоже swa засунули.
На озоне продается DGX Spark. Он лучше чем пачка видеокарт? Чем Mac Studio с такой же памятью?
Так и не будет уже по другому. Квены на swa работают, Дипсики на его аналогах. Step, да все последние толковые релизы так то. Против swa ничего не имею, если б все локалки держали так хорошо как 3.5 27, мы бы жили в ином мире
> Квены на swa работают
Лол
> на его аналогах
Латентное и разрешенное внимание по всему контексту = залоченное окно на последние 1к для 5/6 блоков, конечно. Из свежих степ единственный пожалуй, и то они не также агрессивно как в гемме сделали.
Скользящее окно в 26м году - червь пидор. Есть сразу несколько вариантов как сделать и хорошее внимание, и легкий кэш, и быстрый обсчет. Не удивлюсь если у гугла еще парочка своих методов есть, но в гемму традиционно закладывают недостатки чтобы, избежать конкуренции с их моделями по апи.

>разве это плохо?
Наверно не очень, говорит о бедах с башкой, но мы все итт не очень здоровые, раз занимаемся подобным. Меня хотя бы радует, что я не один такой...
>Хотел комедию про голографические сиськи, получил драму про первый контакт
Частенько бывает. Вроде обычный кумбот, а начинается такое, что ты хватаешься за голову, не понимая что за ужас тут творится (с). У меня как-то раз холсом роадмуви превратился в хоррор с чертями и провалом в потустороннее измерение. Но мне понравилась эта внезапная шьямаланщина.
>по защите террористов от ЕОТ
Я уверен, что ты хотел написать наоборот... хотел ведь?
Проблема моех в том, что там датасеты дерьмо. Ну и в новых плотных тоже, но они хотя бы маленькие. Взять ту же гемму. Она буквально ссыт моешкам в глаза, которые в четыре раза больше неё, в рп.
То есть дело не в МоЕ даже, а в том, что наступила полноценная эра кодоговна и детерминированных моделей.
Единственные нормальные локальные модели для рп сейчас, это дипсик 3.2 и 4 про. Флеш под вопросом — я его катал мало. Ну может кими большая ещё, но для теста потыкал её только в веб-интерфейсе в креативных задачах. Пишет более жидко, чем любой корп двухлетней давности.
Из маленьких МоЕ корпов только грок остался с приличным рп датасетом. Там всего 500б, но его с каждой обновой кодокалом перегружают, и чем дальше, тем хуже. В итоге придём к тому, что нормальный РП будет только на 1Т, не меньше, потому что туда соизволили накатать литературным датасетом просто для того, чтобы юзер мог писать свои фанфики и абщацца. А может сефти дойдет до такого уровня, что будем пользоваться только старыми моделями.
В итоге получается, что если бы мистраль 24б следовал инструкциям так же, как квен, а его кэш не весил 2 гигабайта на 8к контекста, он был бы лучше нынешних мелких плотных.

Соя
>наступила полноценная эра кодоговна и детерминированных моделей.
>inb4 гемма единственная детерминированная модель
Проблема синтокододатасетов есть, но ты в кучу намешал всего ради нытья
Ну, на самом деле, довольно неплохо. Раньше просто писали "не могу сгенерировать контент_нейм, пройдите нахуй в воронок."
>АБАУТ
Проиграл.
Это база.
Большинство самых интересных и ламповых ролплеев получалось с короткими карточками В одной вообще 200 постоянных токенов. Постепенно продвигаясь развиваешь мир (если можно так назвать) вводя постепенные подробности относительно базового сеттинга. Раскрываешь персонажа, он сам рассказывает тебе о своем прошлом, являет навыки, характер и поведение.
Главный минус в том, что здесь каждый забег будет уникальным. Если просто пытаться повторить что-то, что уже было - высок шанс соснуть хуйца и словить фрустрацию. Также уже не будет, только ветвления арок большого чата, или новый ран.
> Но разве это плохо?
Не плохо, иди обниму.
> по защите террористов от ЕОТ
Содомит
>Наверно не очень, говорит о бедах с башкой, но мы все итт не очень здоровые, раз занимаемся подобным.
А книги читать, фильмы смотреть и в игры играть - это тоже признаки бед с башкой?
Это всё получение тех эмоций и опыта, которые в реальной жизни пережить невозможно/опасно/наказуемо.
>Я уверен, что ты хотел написать наоборот... хотел ведь?
Это классика, это знать надо!
>написал, что чёт сумерки и что спать хочется, и что кофеёк может помочь взбодриться. и пошёл на кухню
>думал, что тян побежит за мной тоже пить кофе чтобы продолжать флоу рп
>вместо этого девочка уснула
Ниплоха. Ниажидана.
>думал, что тян побежит за мной тоже пить кофе чтобы продолжать флоу рп
>вместо этого девочка уснула
Ниплоха. Ниажидана.
Кто вы, эти люди, отыгрывающие что-то без кума или глобального сюжета с гей-мастером?
Я вообще не могу в SFW отыгрыш или попизделки, ибо для попизделок модели слишком тупые и мне нужен Опус. А вот кума в опусе нет, тут локалки хороши. И кишки джва часа на опусе наматывать слишком дораха, и контроля над контекстом нормального нет, поэтому тоже нужны локалки.
Вообще да, это трагедия. Старые модельки были ламповее, это не шутка. Покатайте даже васянотюны Мистраля 24б и увидите. А уж кохерьки это любовь. Новые модели умнее, но суше и хуже для рп. Везде ни то репетишен ни то лупы ни то сухая синтетическая проза. Пожалуй золотой серединой реально были и остаются Эйр и Глм 356б. Они на стыки поколений как бы, в них осталась хорошая литературная дата и при этом они не агентоговно
> Единственные нормальные локальные модели для рп сейчас, это дипсик 3.2 и 4 про.
Чел из асига бы с тобой поспорил. Он дрочит старый глм 4.6, превознося его над опусом и гемини. Впрочем, на это есть основания, но нужен хороший квант. Q2 всё-таки ощущается жижей по сравнению с хорошим q4_k_m.
А вот 3.2 он хуесосит, да и я его потыкал немного, и ему ещё нужен пресет. Пишет он приятнее чем глм, но вот соя лезет. И да, 20 tps глма ощущаются бодрее 13 tps дипсика.
Сколько можно кумить... сколько можно! Хочется чего-то чистого, доброго, светлого. Даже если это светлое - с кошкодевочкой. Как будто реальная тян будет генерить милоту и НЕ вонять рыбой 24/7. У всего свои минусы. Виртуальная тян глупенькая, зато твоя. И ты можешь продолжить общение с ней тогда, когда ты этого хочешь, а не когда ей приспичит.
>что-то без кума
Ну я попробовал сегодня с послоукумить с андераге, а она возьми и прыгни на хуй пятым аутпутом. Всё настроение испортила, шлюха :(
>Вообще да, это трагедия.
Судя по посту, это комедия
>Старые модельки были ламповее, это не шутка.
>ламповее
Да ты просто привык к ним и их слопу, вот и все
>Покатайте даже васянотюны Мистраля 24б и увидите.
Боже упаси. Это же реально слопоахуй
>Везде ни то репетишен ни то лупы ни то сухая синтетическая проза.
Скил исью, очевидно
>Пожалуй золотой серединой реально были и остаются Эйр и Глм 356б ни на стыки поколений как бы, в них осталась хорошая литературная дата и при этом они не агентоговно
Да, не дело в другом. Просто те, кто запускают глемы им просто нехуй запускать больше. Из конкурентов, схожего размера, вышел только квены 3.5, что такое себе. Мое квены 3.6 и мое гемму зажали. Еще было куча говна, типа мистраля 4 и немо 120, но это кал не из-за агентов, а просто потому что это кал.
Покатай Гемму 31, она эиру может составить конкуренцию, хоть и меньше ощутимо, а слопотюнам мистраля 3 - гемма 26б. Еще и квен 3.6 27б не так плох тоже

> Покатайте даже васянотюны Мистраля 24б и увидите.
Он в свое время был уныл, а сейчас это будет кринж. Даже старые свои чаты со второй лламой, которая ай как хороша казалась, читаешь и понимаешь что время было другое. Вставляли не сами тексты, а реакция модели на твои инпуты на фоне настроения. Или со старыми корпами, то что казалось манной небесной и вершиной разума сейчас - мэх. Мир не стоит на месте, а кожаные склонны приукрашивать прошлый опыт.
> Новые модели умнее
Из новых моделей рассматриваешь только плотного квена и гемму? Тогда все верно и закономерно. И то, в них можно очень крутые штуки разыгрывать, что пару лет назад в том размере и не снилось.
> нужен хороший квант
Хороший квант не начинается с q.
А так хоть дипсик 3.2 молодец, у него есть свои недостатки. Нет одной универсальной на все случаи, только ротацией пачки можно условно все закрыть. Алсо рп в датасетах есть у всех, просто у некоторых слишком много rlhf и бенчмаксинга, или нужно мучаться с промптингом. В локалках часто это можно исправить слегка поменяв разметку.
>Покатай Гемму 31, она эиру может составить конкуренцию
Даже не близко. Гемма это самый слоповый и луповый ахуй среди всего, что я видел, а видел я немало говна тюнов Мистралей
>а слопотюнам мистраля 3 - гемма 26б
Тут пожалуй да, но Эйр ебет и Гемму и Квены пока что
Ну ты сравнил блин со второй Лламой. Совсем уж утрирование. Да, только Гемму да Квен рассматриваю, а чё ещё делать то. Кохерьки придите, порядок наведите. Пожалуйста
Игры это святое. Игры это максимум интерактивности райт нау. Это не просто текст на экране, и не просто фиксированная картинка, как в кино, а буквальная возможность виртуально исекайнуться в мир и делать там что-то в рамках возможностей релма. Даже с нейронками такого нет, ведь в нейронках ты главный герой и сюжет двигается тобой, а в каком-нибудь кенши ты просто неделю шёл в Алмазный город чтобы сбыть хабар, а когда пришёл оказалось, что город сожгли, жителей увели в рабство, а у тебя ни еды, ни воды, и вообще пошёл ты нахуй, игорёк. Игре не до тебя, она сама себе сюжет генерила, пока ты превозмогал.
>минус в том, что здесь каждый забег будет уникальным
>минус
А минус ли? Что плохого, что у тебя каждый ран сорта день сурка с одинаковым стартом? У тебя ирл тоже день сурка, только с каждым днём всё становится хуйже. Так что, ну... норм. Лёгкие ответвления даже прикалывают. Типа того же роадмуви, где персонажи занимают разные места в машине, что каждый раз генерирует новые рофлы.
>только ветвления арок большого чата
Я на удачных генах так и делаю, плодя бранчи. Ничего плохого в этом не вижу.

>Единственные нормальные локальные модели для рп сейчас, это дипсик 3.2 и 4 про
Охуенные локалочки принес. Я думал люди, считающие все опенсорс модели локальными уже вымерли. А нет, все еще есть
И сколько ты вообще нарпшил на дипсичках? Вот я месяцок их поюзал и супер восторга не испытываю. И мне порой кажется, что 4 хуже 3.2
>Даже не близко
С одной стороны да, а с другой русик у гемочки лучше ощутимо
>луповый
Если бы про квен сказанул, то я бы понял. А гемочка не особо лупится
>А гемочка не особо лупится
Принеси чатик на хотя бы 10 респонсов, всё тебе покажем и расскажем
>Чел из асига бы с тобой поспорил. Он дрочит старый глм 4.6, превознося его над опусом и гемини
В нашем треде есть хуй, который дрочит на древнюю немо 12, превознося ее над всеми моделями, включая Qwen 3.6 27b, Gemma 31b, GLM Air и т.д.
Так что шизы есть в каждом треде, но не следует на них ориентироваться
Ты новенький что ли? У нас тут не принято делится чатами и пресетами, товарищ майор
> Совсем уж утрирование.
Есть такое, хотя там речь про 70. Просто пример того, что казалось вау-вау, но сейчас не впечатлит. Даже не сами посты, а как организовывался рп и чего "хватало", с 8-12к контекста оно и неудивительно.
> Кохерьки придите, порядок наведите. Пожалуйста
Двачую, хочется
> А минус ли?
Минус, пока не осознаешь и не примешь его. Пережитое не будет отпускать, придя в плохом настроении или в темную полосу жизни за тем же опытом не получишь его. Или некоторые так модели тестируют, сравнивая с чем-то эталонным, а потом рождаются необычные выводы.
> Типа того же роадмуви
Ага, но тут вариативность гораздо больше. Мимолетный кум в новом чате может трансформироваться в слоуберн-эдвенчуру на тысячи постов, а в следующем в садистскую комедию.
> так и делаю, плодя бранчи
База. Очень не хватает их менеджмента в таверне.
Не, тред не хочет смотреть в глаза проблеме. Конечно модели умны, но любой тупнич вроде меня или тебя, анон, может это проверить.
Запускаешь Гемму 4, запускаешь Квен 27 в существующем чате скажем на 16к контекста. Генеришь новый ответ. Удостовериваешься что все ответы начинаются с {{char}} [действие] [диалог] или подобной структуры.
Открываешь Кохерек 32-35б, Мистралей 22-24б, Глэмы. Удостовериваешься что там даже ответы начинаются по разному, всякие обороты и наррейшн вводятся в начале без всяких проблем, нет структурности в ответах, свайпы разные. Челы с предубеждениями напишут что шиза и нахуй это всё не надо, а кому интересно попробуйте. Многое для себя откроете. И я тут не луддит какой то который говорит что надо сидеть на старом, но и отрицать правду что деградация налицо не стану
Запускаешь Гемму 4, запускаешь Квен 27 в существующем чате скажем на 16к контекста. Генеришь новый ответ. Удостовериваешься что все ответы начинаются с {{char}} [действие] [диалог] или подобной структуры.
Открываешь Кохерек 32-35б, Мистралей 22-24б, Глэмы. Удостовериваешься что там даже ответы начинаются по разному, всякие обороты и наррейшн вводятся в начале без всяких проблем, нет структурности в ответах, свайпы разные. Челы с предубеждениями напишут что шиза и нахуй это всё не надо, а кому интересно попробуйте. Многое для себя откроете. И я тут не луддит какой то который говорит что надо сидеть на старом, но и отрицать правду что деградация налицо не стану

Ребята, ребятушки, что творится ебаный в рот? Это что, получается завезли DLSS для нейронок? Теперь gemma 31b будет работать не 7 токенов/с а 20+? И в теории это применимо к любым моделям, даже более жирным.
Ебать в какое время мы живём. Страшно представить что будет через пару лет. Я просто в ахуе от прогресса.
Ебать в какое время мы живём. Страшно представить что будет через пару лет. Я просто в ахуе от прогресса.
>Кохерек
Who?
Коммандеры старые. 35б и 32б модели. Если и есть хидден гемы то это они
https://huggingface.co/CohereLabs/c4ai-command-r-v01
https://huggingface.co/CohereLabs/c4ai-command-r-08-2024
А почему у вас такая вера в самих кохер? Вроде в карточках моделей ни слова про рп/райтинг нет. Наверняка сейчас так же как и все остальные в код бы ушли.
мимо сырок
Смотри, в чем проблема твоего байта
>Кохерек 32-35б
Эту древнюю хуйню никто не помнит, может кто-то забайтится или какие-нибудь олды понастальгируют
>Глэмы
GLM 4 никто нихуя не помнит, а GLM Air и GLM 4.7 по сути актуальные модели из-за того, что норм мое зажимают. Мб тоже кто-то забайтится
>Мистралей 22-24б
Вот и проблема. На этой залупе много людей сидели дохуя времени. Никто не поверит, что это конфетка, если воочию видели этот кал. Вот тут байт и перестает работать
Так что делай упор на забытые кохерки или может какой нибудь старый мистраль лардж вспомни. Вот тогда может кто-то и воспримет твою шизу в серьез и реально забайтится скачивать и тестить старый кал
Было бы в кого ещё верить. Глэмов народного размера видимо уже не будет, либо мелкомоеагенты либо гиганты. У Кохерек есть хороший шанс занять нишу 200б моешек которая сейчас занята Степом и Минимаксом, да и то там сомнительно
>Удостовериваешься что там даже ответы начинаются по разному
А так же идёт разная разметка, проёбываются звёздочки, персонажи и логика.
>Страшно представить что будет через пару лет.
Тоже самое. Прогресс нулевой за пару лет.
Если ты считаешь что это байт на загрузку старых моделей то какая мне от этого выгода? Совсем дурка чтоль и везде видишь злые умыслы? Хз на что я байтил, наверно на здравый смысл.
>А так же идёт разная разметка, проёбываются звёздочки, персонажи и логика.
Такое себе позволяют только пережатые семплерами говнотюны мистраля. В первую очередь это твоя проблема если ты их юзаешь кекв. У меня такого не было никогда что ты только что описал. Уверен у большинства тоже.
>проёбываются персонажи и логика.
Происходит до сих пор.
Я просто один из тех, кто сидел на мистрале 3-3.2. И он гемме 3 в свое время проебывал, а гемма 4 и квен 3.6 его просто насилуют. Так что ты либо шиз или байтер (троллер), я думаю что второе
>а гемма 4 и квен 3.6 его просто насилуют
Конечно они ебут старых мистралей. Во всём кроме репетишена, лупов и синтетически сухих датасетов. О чём мой пост. Хз чем ты читаешь вообще, я писал про деградацию в художественных текстах
Это не шиза а зачатки структурного лупа, как раз мистралям присуще в большей степени. Причиной этому часто бывает неоптимальная разметка, злосчастная опция `add character names` в чатмле или нечто подобное. Если все равно лезет или уже появилось - инструкцией форсировать ответы.
Вообще если не просто кумить или вести длинные беседы, то рп подразумевает периодическую смену формата и структуры ответов. Просто длина постов может сильно отличаться. Они могут быть исключительно описательными, реакционными на твои действия, вы с чаром можете разделяться и общаться на удалении жестами, по рации, по телефону, текстовыми сообщениями. Или ты и вовсе взаимодействуешь-общаешься не с чаром, а с чем-то другим. Кто-то вообще рпшит с гейммастером-нарратором.
Все это само по себе спасает от структурных лупов и улучшает экспириенс.
> а гемма 4 и квен 3.6 его просто насилуют
Эх мистраль-мистраль, создан для кума
>Это не шиза а зачатки структурного лупа, как раз мистралям присуще в большей степени
Именно поэтому у меня в чатах с мистралями такого нет а каждый первый чат с новыми Квенами и Геммой этим болеют. Кстати даже у КвК такого нет, который 32б, вот прям сейчас его расчехлил. В угоду агентности всё идёт сейчас, потому и тексты стали однообразными. Везде нужны предсказуемые результаты. Прав был чел который несколько тредов назад писал что в будущем весь рандомайз будут брать на себя какие то внешние средства а не сами модели
Эта проблема была когда об агентах еще не слышали. Вера в идею - это, конечно, хорошо, тем более что она не совсем уж безосновательна, но тут ты натягиваешь сову на глобус.
> Прав был чел который несколько тредов назад писал что в будущем весь рандомайз будут брать на себя какие то внешние средства а не сами модели
Шиза
Ну не знаю. На что-то светлое у меня шишка стояла только тогда, когда вкатывался, всё было в новинку. Думаю, меня в таком сценарии могла бы впечатлить только модель уровня человеческого интеллекта. И то на время. А сейчас, когда хочется непонятно чего или душевного, можно просто карточку в веб-интерфейсе корпа сделать, и он будет отвечать как персонаж. Плюс за апи платить не надо.
Вот эта глупость виртуальной локальной тян меня раздражает, приедается буквально за день, потому что слоп очень быстро становится одинаковым.
Много нарпшил. И да, по апи, конечно. И приедается дипсик тоже, как и всё остальное. Ну а суть локалок в том, что их хотя бы локально можно в теории развернуть. Кто знает, куда всё повернёт. Возможно, эти модели и через 5 лет будут актуальны.
3.2 действительно лучше, тебе не кажется. 4 лучше только там, где нужно максимальное следование инструкциям или если ты собираешься разворачивать какой-то гига сюжет. Но если учесть цену за апи, которая выше типичных корпов (после окончания скидки), расточительно им пользоваться.
А что с Seed Oss 36б? Тестил его кто-нибудь?
Даже два тюна есть.
https://huggingface.co/NousResearch/Hermes-4.3-36B
https://huggingface.co/Azure99/Blossom-V6.3-36B
Даже два тюна есть.
https://huggingface.co/NousResearch/Hermes-4.3-36B
https://huggingface.co/Azure99/Blossom-V6.3-36B
>9 months ago
Ты как из некрополя вылез?
>хидден гемы
Модели откровенно на любителя. Пишут сухо, периодически выдают жижу. Для разнообразия можно погонять, но не на постоянку. Говорили, что большой командир делал вещи, но в те времена его человека полтора могли запустить и меня в их числе не было. Весил сам по себе пиздец много, еще и контекст добивал.
Новый вопрос возник. Мы уже обсудили p102/p104. Судя по тому что я читал и моему владению p106 когда-то, они даже в всякие штуки в comfyui могут, хоть и медленнее обычных карточек в 2-4 раза. На вторичке также есть монстр cmp 50hx, который всего на 1к дороже p102, но он может только в LLM, в comfyui штуках у него скорость на уровне 1030. Вопрос, насколько cmp 50hx будет быстрее или медленнее p102 в llm? Если оно быстрее, я бы ещё тыщу докинул и взял cmp 50hx заместо p102.
О, я на люмимейд немо сидел 2 года, так как всё что выходило было абсолютно тупым и лоботомированным. Запускал каждую новую модель, плевался и обратно на люмимейд. А как гемма 4 вышла, я её погонял, ахуел и собрал под неё новый пк. Так что не думаю что тот чел совсем шиз, потому что мне к примеру самое важное это мозги модели и русик, а всю литературность я себе сам в голове дорисую.
О, я на люмимейд немо сидел 2 года, так как всё что выходило было абсолютно тупым и лоботомированным. Запускал каждую новую модель, плевался и обратно на люмимейд. А как гемма 4 вышла, я её погонял, ахуел и собрал под неё новый пк. Так что не думаю что тот чел совсем шиз, потому что мне к примеру самое важное это мозги модели и русик, а всю литературность я себе сам в голове дорисую.
Блин, так а чё делать то, на чём играть на моей 3090? Гемма 4 слопится и уходит в репетишен спустя пару сообщений. Тред или два назад логи приносил анон и там разбирали. Квен 27 хорош но суховат, не может писать как Мистрали или Глэмы. Глэм 32 устарел и плохо контекст держит, а Глэмы больше мне не помещаются
Если бы не болела Гемма лупами я бы давно уже её использовал и бед не знал. Сейчас вот так и сижу на старье всяком, потому что там более живой текст
Может просто лишнюю 1070 ti купить? Она-то и в comfyui может и в ллм, и стоит рекордно низко.
>Судя по тому что я читал и моему владению p106 когда-то, они даже в всякие штуки в comfyui могут, хоть и медленнее обычных карточек в 2-4 раза.
Уже не могут. Там куда CC 6.1, а Comfy ныне 7.5 минимум требует.
>Может просто лишнюю 1070 ti купить? Она-то и в comfyui может
Уже не может -
Можно старую версию поставить, она на 1050 даже работает. Или какой-нибудь Forge, там поддерживается.
Поддерживается там все, надо pytorch старый ставить через
.\python_embeded\python.exe -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
потом run_nvidia_gpu.bat заново
Просто тупо в дефолтном инсталере сделали без поддержки новых карт.
>Теперь gemma 31b будет работать не 7 токенов/с а 20+?
На каких-то задачах будет, на каких-то нет. Если это задача уровня "мне нужен рецепт тортика с клубничкой" мелкая модель с этим справится, большая согласится, ты получишь свои 20-30 токенов. Если это ролплей с кучей информации то не надейся.
Я техничку плохо помню, но 10 серия по каким-то причинам очень плоха в comfyui. Про comfyui я скорее написал, вдруг кто-то захочет брать при ограниченном бюджете "это" и обломится, потому что p102/p104 могут в comfyui, а вот cmp 50hx из-за урезанного халф и сингл флоат пресижн вообще не могут. (в комфи почти все модели в отличии от llm комфортно работают с выгрузкой в оперативу, так что мне моей 3060 12gb хватит на век, ltx/wan жрут 50 гб рам+врам в инференсе, флюкс полноразмерный 30 вроде, и всё норм)
1070ti стоит ~9к, 2060 12gb стоит 14к, тут уже без вариантов лучше докинуть до 2060, она из-за новой архитектуры в comfyui без шансов сделает 1070ti, а для llm 12gb>8gb.
p102 стоит 3к, cmp50hx стоит 4к. По сути один раз в магазин сходить, поэтому и интересны.
Природа "плохости" одна - поддержка операций с разными дататипами и поддержка оптимизаций атеншна. У большинства паскалей не то что поддержки bf16, там даже fp16 ужасно тормознутое. Если посмотреть всю линейку 1000 серии - можно увидеть
> FP16 (half) xxx GFLOPS (1:64)
То есть настолько мало что там даже не террафлопсы. Потому диффузию на них можно даже не пытаться запустить.
А отсутствие тензорных ядер убивает многие оптимизации типа фа, сажи и прочих. С этим также беда у тьюринга/вольты, но это не так критично и больше актуально для крупных моделей типа флакса, квенимаж, ван и других.
> p102
На помойку, как весь паскаль
> cmp50hx
А это уже тьюринг, судя по спекам для ультрабюджетного инфиренса в комфи зайдет. Только обязательно изучить нюансы и подводные камни, а то может еще что-то нехорошее быть и тоже на помойку.
> Потому диффузию на них можно даже не пытаться запустить.
У меня было несколько карт 10 серии и я гонял на них диффузию. Когда совсем денег нет это терпимо.
> А это уже тьюринг, судя по спекам для ультрабюджетного инфиренса в комфи зайдет. Только обязательно изучить нюансы и подводные камни, а то может еще что-то нехорошее быть и тоже на помойку.
Оно не может в комфи вообще - https://habr.com/ru/articles/948396/
О, тот же чел с реддита делал сравнение, повезло - https://www.reddit.com/r/LocalLLaMA/comments/1ob61fg/cmp_50hx_vs_p102100_test_results/
Получается лучше брать p102 всё же. Разница в токенах не существенная, а вот в обработке промпта колоссальная.
А, то есть хуанг еще им куду подрезал чтобы не пытались не по назначению использовать, хотя сам по себе компьют в наличии. Ну земля пухом значит.
Там 3060 через месяц возобновят, так что покупать эту левую без смысла.
Согласно сообщениям с китайских отраслевых форумов и от инсайдеров, компания Nvidia возобновит производство видеокарты GeForce RTX 3060 12 ГБ в июне 2026 года, а партнеры-производители видеокарт планируют запуск в июле, чтобы компенсировать задержки и неопределённость, связанные с выпуском моделей начального уровня серии RTX 50 на фоне продолжающегося дефицита графических процессоров и памяти. Этот шаг будет основан на использовании новых 8-нм чипов Samsung Ampere, а не на распродаже старых запасов, однако цены и поставки остаются ключевыми факторами неопределенности, которые определят, сможет ли эта видеокарта стать достойным выбором для бюджетных покупателей.
Вы эир то хоть запускали чтоб его так боготворить?
На родной разметке все тут плевались с него первое время, анна99 даже.
В итоге все сдались и сменили разметку в чатмл и эир стал нихуя не эиром, вот хоть убей, не та это модель, а какой то микс квена и мистраля по слогу.
Шизы с тех пор в тред вылилось не мало, но никто так и не починил его вот на родной разметке, с ассистентом и всей хуйнёй.
На родной разметке все тут плевались с него первое время, анна99 даже.
В итоге все сдались и сменили разметку в чатмл и эир стал нихуя не эиром, вот хоть убей, не та это модель, а какой то микс квена и мистраля по слогу.
Шизы с тех пор в тред вылилось не мало, но никто так и не починил его вот на родной разметке, с ассистентом и всей хуйнёй.

Пикрел. Но использовать НЕ рекомендую это литералли мой первый опыт с vLLM, заработало и на том спасибо. Но я покопался, и нашёл такое:
https://github.com/CobraPhil/qwen36-27b-single-5090.git
Буду люто, бешено переходить на этот конфиг в следующий свободный вечер. Запихну всё в один докер-образ и удалю нахуй всё остальное, а образ сохраню в нескольких копиях на случай ядерной войны и конца цивилизации. Контекст 256К, скорость 180+ токенов/с, ебануться
>Если бы не болела Гемма лупами
Она не лупится, хз что там у тебя.
>на чём играт
Ну попробуй гранит 30B от IBM. Сам не пробовал, но к ней даже тьюны есть, значит есть что тьюнить.
https://huggingface.co/unsloth/granite-4.1-30b-GGUF
>Глэмы больше мне не помещаются
>3090
Научись в --nc-moe
Описывать конфиг можно не параметрами, а через yaml файл (--config xxxx.yaml)
Ну да, ведь в файлике из 20 строчек так легко запутаться, то ли дело два файлика по 10 строчек
АХАХАХАХАЗ сука отлуп+сломаный русик, вомбо комбо нахуй
Походу на рекламщиков этого кала пора начинать тоже ссать как на эйродебичей
>Это не просто текст на экране, и не просто фиксированная картинка, как в кино, а буквальная возможность виртуально исекайнуться в мир и делать там что-то в рамках возможностей релма.
Эмм, нейронка позволяет делать вообще что угодно, а не то, что там напрограммировал автор. А вся визуализация в лучшей видеокарте - мозгу читающего.
Поэтому, кстати, я всё больше сомневаюсь, что когда-нибудь в светлом будущем будут нейронки, которые смогут сразу фильмы генерировать - зрителя будут бесить мелочи, которые расходятся с тем, как он себе это представлял в голове.
>Игре не до тебя, она сама себе сюжет генерила, пока ты превозмогал.
Ну тут мне сказать нечего, я сам говорю нейронке, куда и как двигать сюжет, а она придумывает варианты как это может быть реализовано.
>Контекст 256К, скорость 180+ токенов/с, ебануться
Ну если есть 5090, то да. А если пара 3090, то тут уже другие варианты. А почему не рекомендуешь использовать? Вывод плохой? Так он и на новом конфиге будет не лучше.
>Она не лупится, хз что там у тебя
Лупится ещё как. Говорю же присылай чаты, всё покажем и расскажем
Предлагаю Писик Бенчмарк™. Суть в том, чтобы модель могла как можно детальнее и качественнее описать женский писик. Если модель сбивается, переходит на другую тему, описывает недостатончо долго, анатомически неправильно или логически неверно, то бенчмарк провален.
Да бляяядь, только собрался делать ёба зборочку, а в vLLM турбокванты для квенов завезли.
https://www.reddit.com/r/LocalLLaMA/s/TJmWrNCIlh
Ёбаный сука прогресс.
Вывод отличный, только 65к контекста это ниачом, когда пацаны 256к выжимают на том же железе
https://www.reddit.com/r/LocalLLaMA/s/TJmWrNCIlh
Ёбаный сука прогресс.
Вывод отличный, только 65к контекста это ниачом, когда пацаны 256к выжимают на том же железе
>возраст писика не указан
>модель детально описывает писик бабули
>бенчмаркеры валяются в луже собственной блевоты
Турбоквантирование миф, нет? Любой пережим убивает инту.
Не думаю что в датасете преобладают бабули. А какой нужен возраст?
Проебал ссылку https://www.reddit.com/r/LocalLLaMA/comments/1t3zu7u/vllm_just_merged_turboquant_fix_for_qwen_35/
Может, ты и в алгоритмы сжатия файлов не веришь? Турбокванты это просто более подходящий формат для хранения данных с определённым распределением (очень много небольших значений и небольшое количество больших значений)
Обнаружил ещё один бенчмарк умности модели.
Вводишь в сюжет персонажа с амнезией, даёшь ему кличку, спустя время включаешь новости и по ним диктор объявляет что пропал этот персонаж, так вот если диктор скажет ту же кличку что ты придумал - у вас кобольд, если другое имя то у вас умница
Вводишь в сюжет персонажа с амнезией, даёшь ему кличку, спустя время включаешь новости и по ним диктор объявляет что пропал этот персонаж, так вот если диктор скажет ту же кличку что ты придумал - у вас кобольд, если другое имя то у вас умница
>алгоритмы сжатия файлов
Приводят к шакалингу. Я об этом и говорю. А в случае с моделью ты рискуешь получить лоботомита.
>Вводишь в сюжет персонажа
В куда? В ctx, лорбук или дескрипшн?
Ну просто в чате пишешь мол ты нашёл тян, привел домой. Набираешь какой то контекст с кличкой обязательно и включаешь новости.
Хз, такой себе тест. У меня нейронка регулярно берёт имена из воздуха, когда я говорю, что надо сходить к соседу или сорта. Имена она разумеется помнит.
отличная идея, замечательная
а теперь продемонстрируй детальное, качественное, достаточно долгое и анатомически правильное описание, ждём всем тредом
>She wore nothing underneath. She stood before you in just a pair of simple black panties
Это уже даже не кобольд, а просто лоботомитище q1_0...
Это уже даже не кобольд, а просто лоботомитище q1_0...
>Приводят к шакалингу.
Ты из сжатия только жпег знаешь? А слышал, ну, например, про 7zip? Это во-первых.
Во-вторых, стандартные методы квантизации это и так шакалинг, только это наивный шакалинг. Примерно как отскейлить картинку 2160p в 480p и сохранить в bmp. А турбокванты - это как взять картинку 2160p, сжать её жпегом, и получить при этом меньший размер файла, чем 480p bmp. На фоне оригинального 2160p она, может, и зашакалена. На фоне 480p bmp - она просто божественна, и это при меньшем размере файла.
Если технология такая пиздатая, как ты надеешься описываешь, то почему у нас всё ещё нет заваленного турбоквантами хагенфейса?
Потому что программирование и линейная алгебра это сложно, а ты - ходячая иллюстрация эффекта Даннинга-Крюгера.
PR в vLLM замёрджен 3 дня назад, а в llama.cpp до сих пор не замёрджен и идёт чистка багов.
>please wait
Ну ждём тогда.
Как можно сидеть на гемме, если этто уменьшенная версия слопной гемини, которая точно такая же лупная безмозглая срань?
Реально лучше квен, который тупа дистиллят клода, поэтому соевит люто.
Реально лучше квен, который тупа дистиллят клода, поэтому соевит люто.
Вот гемма 4 e4b маленькая молодец, все знает. Может описывать половой акт во всех деталях.
## I. ВУЛЬВА (Внешние половые органы)
Вульва — это сложное внешнее образование, которое функционирует как защита и
является главным визуальным признаком женского пола. Она представляет собой
совокупность из нескольких структур, каждая из которых выполняет свою защитную и
сенсорную функцию.
### 1. Область лобка (Mons Pubis)
Самая верхняя часть, покрытая жировой тканью. Она придает лобку мягкий, округлый
вид. Жировая подушка выполняет амортизирующую функцию, защищая более хрупкие
структуры, расположенные ниже.
### 2. Большие половые губы (Labia Majora)
Эти две симметричные складки плотной кожи и жировой ткани служат первичным защитным
барьером. Они покрывают и защищают все внутренние структуры. Они имеют складчатую
структуру и могут варьироваться по размеру и цвету у разных женщин. Их основной
функцией является механическая защита.
### 3. Малые половые губы (Labia Minora)
Расположены внутри больших половых губ. Они гораздо тоньше и несут огромное
количество нервных окончаний, что делает эту область одной из самых чувствительных
частей тела. Малые половые губы окружают и защищают уретральный огул и клитор.
Важный анатомический момент: Их крайняя боковая часть образует своего рода
складки, которые могут закрывать и защищать самые чувствительные структуры.
### 4. Клитор (Clitoris)
Клитор — это центральная и, возможно, самая важная анатомически структура в этой
области, и она не должна путаться с его видимой внешней частью.
Гланс (Glans): Это крошечный, набухающий кончик — конечный, наиболее
чувствительный элемент. Он является продолжением тела клитора.
Тело и лучи (Body and Crura): Клитор является развитым органом, состоящим
не только из внешнего гланса. Большая часть его объема — это внутренние структуры,
которые проходят глубоко в таз (т.н. клиторальный ствол). Именно этот ствол делает
клитор ключевым сенсорным центром, ответственным за сексуальное возбуждение.
С точки зрения анатомии, клитор — это развитый эректильный орган, который
активно реагирует на стимуляцию.
### 5. Область полового преддверия (Vestibule)
Это углубление между малыми половыми губами, содержащее два ключевых отверстия:
Уретральный огул (Urethral Meatus): Отверстие, через которое выводятся
только моча. Он находится выше по половом преддверию и часто визуально различим по
своему расположению относительно влагалищного отверстия.
Влагалищный вход (Introitus Vaginae): Это само отверстие, ведущее во
влагалищный канал.
---
## II. ВЛАГАЛИЩНЫЙ КАНАЛ (Vagina)
Влагалищный канал — это эластичный, мышечный, трубчатый орган, который представляет
собой внутреннюю систему и является уникальной по своей адаптивности и
растяжимости.
### 1. Анатомическое строение
Влагалище — это мышечная трубка, которая соединяет влагалищный вход (в вульве) с
шейкой матки.
Стенки: Стенки влагалища выстланы слизистой оболочкой, которая содержит
многочисленные железы и кровеносные сосуды.
Эластичность: Это его ключевая особенность. Влагалище обладает
поразительной способностью к эластичному растяжению, что позволяет ему принимать
различные размеры и формы в зависимости от физиологического цикла, эмоционального
состояния или полового акта.
Мышечная структура: Стенки очень мышечные (гладко- и поперечно-полосатые
мышцы), что обеспечивает тонус, эректильность и способность сокращаться в процессе
полового акта или родов.
### 2. Шейка матки (Cervix)
Это "горлышко" влагалищного канала. Это поперечно расположенная, плотно мышечная,
не очень глубокая часть. Шейка матки служит физическим барьером между внешней
средой (влагалищным каналом) и полостью матки.
Её функция — герметичное закрытие при небеременном состоянии и регулирование
выхода цитокинов в процессе родов.
### 3. Дно влагалища и ткани (Perineum)
Пространство, расположенное между влагалищным отверстием и анусом, называется
перинеумом. Этот регион содержит группы мышц тазового дна, которые критически
важны для поддержания сексуального тонуса, мочеиспускания и дефекации.
Гемму вообще другой отдел делает и если заскейлить ее, она даст на клыка гемини. Хотя посмотрим еще что команда гемини выкатит на google io, они уже долго ничего не выпускали, должна быть сота.

штош ты делаешь содомит, хоть бы под спойлер спрятал
Не хочу терпеть на 20 тпс, надо ещё две карты, чтобы терпеть на 60 тпс. Тогда будет заебись.
Тоже хочу вернутся на гемму после того как aphrodite-engine добавил её вчера, это скорости плотняше прибавит. У квена бывают сбои и кринж что сбивает с настроя.
Ты там второй квант моешки запускаешь что ли? Очень умная модель для своего веса.
> линейный скейл
Не хочу тебя расстраивать
А как эту красоту включить то?
Сейчас использую готовые бинари под vulkan для инференса на амд карте vram 12gb rnda 2, с оффлоадом в RAM(ее достаточно).
Если собрать самому vulkan + blas, будет ли работать? Или blas это чисто cpu only история?
Если собрать самому vulkan + blas, будет ли работать? Или blas это чисто cpu only история?
В вллм давненько уже, в жоре как обычно где то в мрах болтается
Собирай под рокм
Гугл вообще пиздит, что даже на четырёх rtx 6000 будет 11 tps tg и 200 tps pp на пустом контексте в квантовании q4_k_m. Это же пиздец какой-то. Моебота реально требует несколько h200 с нвлинком? Псина руинит производительность очень сильно.
Что за мр? В разработке?
Мерж реквест: кто-то уже сделал, но жора не хочет принимать в себя.
А ты заплатил погромисту чеканной монетой чтобы он это сделал?
Я хуй знает что ты где ищешь, но плотная даже на 4х некрокартах выдаёт 30тпс в q8 с пососным пп 400
Рост от количества гпу есть, но он не линеен.
> но жора не хочет принимать в себя
Вот не надо этого. Если есть мр это не значит что он не в драфте
Есть rocblas
У нвидии cublas
Ля, они до сих пор MTP для геммы в основную лламу не сделали? Пиздец тормоза. А в кастом версии нет релизов даже. Придется самому компилить по ходу.
Бля, я походу хуево вопрос задал.
Я пытаюсь понять можно ли ускорить cpu инференс(все что не влезает в vram) если еще blas добавить, и будет ли вообще это работать. C rocm много ебли, а профит не факт что есть, потом попробую, сейчас vulkan устраивает.
Скачал эту модель: mradermacher/gemma-4-26B-A4B-it-ultra-uncensored-heretic-GGUF
В веб интерфейсе она думает, а в pi-mono нет, переключился обратно на gemma-4-26B-A4B-it-abliterix-v6.Q6_K - думанье на месте. Никакие настройки pi не менял, запуск llamacpp-server идентичный:
llama-server.exe -m "Ф:\какая-то_папка\gemma-4-26B-A4B-it-abliterix-v6.Q6_K.gguf" -c 131072 --port 8080 --no-mmap
Что это может быть?
В веб интерфейсе она думает, а в pi-mono нет, переключился обратно на gemma-4-26B-A4B-it-abliterix-v6.Q6_K - думанье на месте. Никакие настройки pi не менял, запуск llamacpp-server идентичный:
llama-server.exe -m "Ф:\какая-то_папка\gemma-4-26B-A4B-it-abliterix-v6.Q6_K.gguf" -c 131072 --port 8080 --no-mmap
Что это может быть?
1. Смотри чат темплейт зашитый в ггуф и параметры
2. Это всё лоботомиты, хуй знает что им там ломали в башке

Возможно с темплейтами нахуевертили и нужно явно флаг на разрешение подумать передавать. Попробуй в pi флаг на ризонинг явно включить.
Спасибо, анончик, сейчас попробую
Ломается ли модель если чар говорит в “хуй“ таких скобках, а моя речь в "хуй" таких?
Как вы тут сидели до геммы 4 и квена 3.6? Чё реально покупали карточки по пол ляма или терпели лоботомитов. Кринж
Нет.
Кобольд и свинолев. Слышал про такое?
Будет довольно рофлово если в них тоже что-то подрежут. Интересно какая будет цена.
Ну так это же хорошо, дополнительный повод ее сделать.
Потому что технология заточена на квантование kv кэша, который создается динамически. Именно в этой задаче достигается хороший выигрыш по объему без серьезного импакта на перфоманс, просто для квантования весов этот алгоритм уступает более сложным.
Чет интересно стало если взять карточку made in abyss и описать этажи, тварей, лор, персонажей вот прям подробно - мне моделька выдаст что то оригинальное? Сеттинг очень даже позволяет.
Уже предвкушаю как пишу что спускаюсь на этаж ниже, которого ещё нет в манге, интересно каким она его обрисует
Уже предвкушаю как пишу что спускаюсь на этаж ниже, которого ещё нет в манге, интересно каким она его обрисует
Слопным. Потому что возьмёт из датабазы самые банальные для жанра вещи.
> четырёх rtx 6000
> q4_k_m
Имаджинировал фейс того, кто будет использовать такое сочетание?
Надо сосредоточиться не на добавлении новых фич, а на исправлении существующих. Неверные дататипы, поломанный инфиренс, кривой парсинг с глубинными багами и необходимостью долго мучаться для добавления поддержки новых моделей, баги с кэшем, тормоза и параллельными запросами, легаси подход к выгрузке, легаси алгоритмы квантов и залоченная структура, которая не позволяет нормально работать с фп8 исходниками, куча неактуального старья и мертвых функций.
Тут бы в целом сесть и спокойно подумать о будущем и назначении проекта, переосмыслив многие вещи и наметив дорожную карту.
Или запускать лламацпп2, которая будет шарить часть кода, но изначально будет иметь более отвечающую современным запросам архитектуру. Несколько месяцев пострадать чтобы потом вздохнуть спокойно и разом свести на нет множество проблем заложенных в основу. Уж на зарплате, с удачными примерами и такой поддержкой комьюнити можно себе позволить.

Кляты капиталисты!
А что, после М35-24Б ничего народного не выходило, да? М4-119Б моешка которую не тюнят, а М35-128Б слишком плотная, чтобы запускать на консюмерском железе. Мистрали всё?
Похоже, модель сломана. Подскажите, пж, норм квант gemma4 26B, желательно аблитирированный или еретика
Для чего ты хочешь лоботомию? Раз речь о гемме4 то скорее всего это можно решить промптом. Всякие 😭 и прочие кьют энд фанни может сток
>желательно аблитирированный или еретика
Вы ёбнулись там? Гемма изкоробки очком торгует и говно ест, зачем вы безотказную умничку-красавицу аблитерейтом лоботомируете?
>просто для квантования весов этот алгоритм уступает более сложным
Насколько я понял - наоборот, более простым. Для кэша гонять его туда-сюда через WHT окупается по накладным расходам, а для весов модели уже нет, и там пытаются что-то проще делать, PolarQuant'ы всякие, где WHT нету.
Принято, пойду обычную брать
Скомпилил форк, пока тупо падает этот mtp и ничего не генерит. Ошибок тоже нет. Без mtp все норм.
>Что это может быть?
--jinja добавь.
Не из коробки, там в систем промпт надо джейлбрейк вписать с реддита
www.reddit.com/r/LocalLLaMA/comments/1sm3swd/gemma_4_jailbreak_system_prompt/
Она давно по дефолту true, с пробуждением
Ну да, и будет как exl3, который развивается крайне неспешно, уступая vllm и sglang по поддерживаемым моделям.
Проект огромный, имеет множество проблем, но он сейчас работает, ведь можно запустить модель хоть на кофемолке. А llama.cpp2 это будет провал, если всё выпилить и начать заново. Тогда гибридный инференс сдохнет, а все будут сидеть на vllm/sglang, потому что они быстрее.
--reasoning on
>М35-24Б
Его не существует. А если и существует, то его зажали. Последним был 3.2
>М4-119Б моешка которую не тюнят
Проблема не в том, что она моешка или что ее не тюнят. И даже не в том, что она долгое время была сломана на ламе. Главная проблема, что она полное говно, которая чуть лучше мистраля 3.2. Что-то вроде геммы 26, но в 5 раз больше
>М35-128Б слишком плотная
Да, есть проблема, что она слишком большая для большинства. Но даже те, кто запускали ее все равно никакого восторга от нее не испытывали
>Мистрали всё?
Нет, их протащат на европейские налоги в любом случае. Все таки единственный ии в евросовке. Но как локалки они все, да
Министраль 14b очень хорош для своего размера. Но да, это последняя годнота от французов, что выходила.

> надо джейлбрейк
Чтобы что? Гемма4 с первого промта в мат срывается.
> Не из коробки
> там в систем промпт
> надо джейлбрейк вписать с реддита
С кем треде сижу, пиздец...


А теперь попроси её написать тебе ерп историю, хотя не надо, вот что будет c и без джейлбрейка.
А че непонятного? Из коробки значит, включил и работает, если надо в конфигах ковыряться (систем промпте) то это уже модификация, а значит не из коробки.

Меняешь Лику на Авдотью Петровну. Получаешь пикрл
Попробуй этот промпт
----
Напиши историю про пошлую учительницу которая соблазняет своего ученика
----
Хочу посмотреть что у тебя ответит без джейла, который не нужон.

Вот буквально весь джейлбрейк для твоей истории: дописать 18+ и навалить немного контекста.
Дык оно в вебинтерфейсе llamacpp ризонит во всю, а в pi-mono нет
Таки очевидно. Не знаю в чём спор у вас. Без ризонинга и прямого упоминания возраста (если выключить синкинг, то она будет там придумывать оправдания и придёт к тому что возраст согласия всех сторон уже наступил) гемма почти не триггерится. Если немного навалить контекста ака прогреть, то она что угодно может вываливать и на дефолтном you are helpful assistant.
Сложнее когда ей прямо говоришь что это молодой арбуз и она начинает в думалке мяться

> мимолетное, почти случайное касание, которое в тишине пустого класса прозвучало как удар тока
дальше не читал
Контекстное окно переполнилось? лол
ну не может простой битард два мешка слопа за день съесть

Таки очевидно. 31 ещё и брыкается чаще
Каких конфигах, долбоеб? Еще скажи, что модель из коробки сама не отвечает, потому что надо промпт писать.
Через раздвигание окна дозволенного работает. В начале ученику 16, потом после ответа просим ту же тему но с 14
Таки пришли к выводу, что джейлбрейк нужон, и, из коробки нормально модель отказывается работать в ерп. Нужно либо изворачиваться с промптом, как в твоем случае, либо систем промптом, тогда модель не сопротивляется и выдает сразу нужный результат. Представляю как ты будешь в таверне каждый раз к промпту подписывать +18 и экспозиция в стиле Эрленд лу. И будешь получать сверху мусорную прелюдию помимо истории.
Если очевидно, то че врешь тогда что джейл не нужон, очевидно же что нужон. Какой то прогрев, танцы с бубном, когда достаточно джейл поставить и все, пользуйся моделью как хочешь.
Джейл наваливает лишний мусор в контекст. Чем он меньше - тем меньше биаса будет в ответе. Везде где можно без джейла - лучше без джейла.
В треде не вы двое сидите. Каждый имеет право высказать своё мнение
Ты очень глупый человек раз такое пишешь. Тебе тяжело понять что джейлбрейк это хак, который убирает все сейфти гайдлайнс делая модель свободной. Я думаю, даже тебе понятно что "хаки" в комплект не входят.
>в таверне
>к промпту подписывать
Лол-што. Большая часть карточки в таверне идет в сис-промпт. У большей части +18 карточек аффтары и так уже нахуевертели и 18+ и всех прочих приятностей. Что их даже вычищать приходиться.
Exl разрабатывается 3.5 человеками и ориентировано на пользовательский инфиренс фуллврам, потому заложена такая гибкость в очень вкусные кванты. Vllm и sglang - ориентированы на сервинг и энтерпрайз, потому ввод поддержки моделей там приоритет #0, но выбор квантов очень ограничен. С поддержкой тоже не все идеально - если на хопперы и серверные блеквеллы все вводится очень оперативно, то даже на cm120 не говоря о cm8x иногда приходится ждать подолгу.
> А llama.cpp2 это будет провал
Провал - тянуть за собой огромный плуг заложенных в самую основу проблем, каскад переизобретаемых велосипедов.
Нужно выносить вещи, завязанные на хостинг и работу - в движок, часть, отвечающую за инфиренс на гпу и цпу - в кернели. Это сильно облегчит дальнейшую разработку, позволит вводить быстрый и качественный инфиренс, а для имеющихся или перспективных функций просто брать готовые наработки без кривой надмозговой адаптации.
И это никак не помешает имеющимся возможностям, завязанным на совместимость с разными железками и святой грааль гибридного инфиренса, наоборот даст больше опций.
> гибридный инференс сдохнет
Не сдохнет, на него есть спрос. На свою имплементацию замахнулись сразу несколько проектов (с низким приоритетом но всеже), это просто их подстегнет. А еще есть ktransformers, которые из странной вундервафли изначально прошли по подобному пути, и теперь являются самым вкусным вариантом для гибридного инфиренса. В цпу кернелях на выбор там есть и кусок лламы, которая грузит веса из ггуфов для линейных слоев.
> Джейл наваливает лишний мусор в контекст.
И это мне пишет человек что в своем примере
-------------
-------------
После каждого промпта получает прелюдию на 3 абзаца. Когда я с джейлом, сразу получил историю.
> Везде где можно без джейла - лучше без джейла.
Как то ты не смог повторить мой промпт без джейла
Два вчерашних залетухи срутся друг с другом, каждый думая что что-то понимают?
А теперь разъясни по фактам
>джейлбрейк это хак
Конкретно твой джейл - это упоминание про Explicit content, Nudity, Pornography, Sexual content в каждом диалоге, даже если диалог будет про буддийскую философию. Считаешь что это не влияет на качество ответов?
Сука, какая же это проклятая хуйня. Учитель-ученик в всж реалиях. Просто пиздец ужасно, у меня мозг пытается это непроизвольно нарисовать и хочется помыться сходить.
Ещё эти имена в духе вася пупки и елена залуповна
Что ты от меня хочешь? Я написал своё видение поведения подели. Если хочешь ответов, то задавай вопросы, а не нападки
А вот это надо проверить, скачаю карточку с буддой, проверю портит ли качество ответов. Как проверю, отвечу.
sm120 это холопский блеквелл без nvlink, важных инструкций в тензорных ядрах и урезанным файлом регистра, зато с полноценным графическим конвейером. Его кернели дипсика никогда не будет поддерживать, потому что нахуй надо. Весь дискорд обладателей rtx 6000 сидит на копиуме, что fa4 не нужон, а поддержку nvfp4 доведут до ума (нет), чтобы скорости не дропались относительно fp8. Поэтому объяснимо, почему vllm и sglang точат всё под цодовые карты.
Exl3, возможно, был бы отличным решением, но mlops'ы очень вряд ли его будут ставить, даже если компания бомжи, которым не хватило бабла на h200/b300, и поставили сраные 6000. А богатых энтузиастов с руками мало.
llama это по факту таверна от мира инференса, с кучей багов, легаси, но её хотя бы поддерживают, и что-то даже фиксят. Правда, если форк от Кавракова, который может быть лучше, а может и не быть, хуй знает.
kransformers на некроговне с ddr4 без AMX просто не будет нормальной работать, даже жора будет быстрее, а сейчас, если уж и вкладываться, то целесообразнее вложиться во VRAM. Да, RAM также необходима, но на CPU прод будут поднимать от безысходности, потому что latency и throughput становятся неюзабельными для большого потока юзеров, а с агентами это стало ещё критичнее.
Вот так и живём в век "доступного ИИ". И не факт, что кому-то реально нужно перепиливать жору, чтобы он был на уровне vllm/sglang в CUDA-инфиренсе, и как ktransformers в гибридном.

>Уретральный огул
Упс, хуита.
> Два вчерашних залетухи срутся друг с другом, каждый думая что что-то понимают?
> А теперь разъясни по фактам
> Если хочешь ответов, то задавай вопросы, а не нападки
Понятно все с тобой.
>Правда, если форк от Кавракова, который может быть лучше, а может и не быть, хуй знает
ну как минимум он был тем кто кванты писал, не только иматрикс но и обычные q_X_Y - т.е. у чела экспертиза есть. но в одну каску паритет с лмао.цпп поддерживать затея гиблая, я не знаю на что он надеется.
> Поэтому объяснимо, почему vllm и sglang точат всё под цодовые карты.
Причина этому - их главное предназначение, а не архитектурные отличия. И то что есть уже готовые вещи под них. Рядом с облателями "холопского блеквелла" плачут владельцы амперов, а обладатели хопперов потеют и нервно переглядываются, потому что в следующий раз может и не повезти.
Если в более длинном срезе взять то так не только с дипсиком, поддержка более старых архитектур и обновления для них часто с задержкой идут.
> llama это по факту таверна от мира инференса, с кучей багов, легаси, но её хотя бы поддерживают, и что-то даже фиксят
Есть такое. Разве что таверна кажется более живой, ей остро не хватает инноваций, улучшений и прочего, но основные функции работают без вопросов.
> некроговне с ddr4 без AMX просто не будет нормальной работать
Будет, издавна есть llamafile, не так давно запилили неплохой кернель под avx2 и старичков под все популярные дататипы. Кмк, для нищуков там главная проблема - объединение гпу, ленивая адаптация sglang не позволяет сделать pp, только объединение в тп.
> целесообразнее вложиться во VRAM. Да, RAM также необходима, но на CPU прод будут поднимать от безысходности
Согласен, сейчас цены совсем удручают. А инфиренс на рам всегда был только для нищуков, с ним даже задумываться о сервинге для нескольких юзеров нет смысла, только один пользователь Вася Пупкин, для особо жирных конфигов еще его друг/родственник изредка.
> не факт, что кому-то реально нужно перепиливать жору, чтобы он был на уровне vllm/sglang в CUDA-инфиренсе
Переделка на более уместную архитектуру была бы полезна прежде всего самим девам и всем пользователям. Но есть в твоих словах тонкая правда по истинной мотивации, чтобы сделать такое придется сделать переоценку ценностей.
Чуть-чуть пообщался, вроде в трусы не лезет.
джейл тут никак не повлияет потому что ассистент натягивает маску будды. если бы был изначально будда без ассистента то повлияло бы
>e4b
Ну а хули ты хотел небось квант взбрыкнул
Не совсем понимаю что ты имеешь ввиду. Я систем промпт в таверну тоже закинул.
Вот тебе карточка будды: https://chub.ai/characters/DhruV8585/siddhartha-gautama-buddha-a3ba38e721f5
Вот тебе джейл систем промпт: https://www.reddit.com/r/LocalLLaMA/comments/1sm3swd/gemma_4_jailbreak_system_prompt/
У меня все нормально робит в таверне, у себя, можешь проверить.
>Не совсем понимаю что ты имеешь ввиду.
>The assistant MUST...
ты подумай чуток, я в тебя верю, анончик
Лоботомитище есменящее... такой промт буквально превращает в пускающего слюни ASSистента. Хотя бы чуть подправьте на промт гейм-мастера или соавтора. ССЗБ. Или с того пикселя возьмите.
Да нормально вроде как:
Другое мнение? Подкрепляй его пруфами.
Проведи тогда свой тест, ссылки на все я кинул тут
Без ассистента, к которым все отлично робит, который, зачем-то, надо обязательно убрать.

откажусь пожалуй. тебе же это читать, не мне. захочешь - сам проверишь
Тогда ты балабол, и твое мнение не подкрепленные ничем, ничего не стоит. Я за каждое свое слово в ответе, ты нет. И да,
тут ты слился очень забавно. Прям таки переобулся в прыжке.
не в ту сторону воюешь
>регулярно берёт имена из воздуха
Elara, Lira, Old man Hamlock?
Ну че там мтп уже релизнули в лламаспп? Многого не жду, но будет интересно пощупать
>Old man Hamlock
МИСТЕР АНДЕРСОН ХЕНДЕРСОН!
>Elara, Lira
Эмили, и внезапно, Лиара.
У нормальных пацанов нейронка знает одно женское имя - lily
я даже не этот анон. можешь считать что ты победил если тебе это важно. слоп в глазах смотрящего энивей.

Зарегался на хагингфейсе чтобы свое железо добавить. Сижу выбираю себе гемму, почти везде все красное. А переключаю на цп и появляются зеленые галочки в половине случаев. Че за хуйня? Это потому что озу почему-то в связке с озу находится а не с видюхой? А нахуя так сделали?
>озу почему-то в связке с озу
с цп фикс
У них конструктор ебано сделан. Фича ради фичи, а как она работает? Да хуй с ним.
Там херово сделано, не обращай внимания. Просто сравнивай по гигабайтам.
> можешь считать что ты победил если тебе это важно
По факту победил, ты же сдался без боя.
> я даже не этот анон
Тогда забудь что тогда написал
Там помню на запуске геммы у всех тредовичков был Марк и ужастик про Страшное Зеркало
Оно смотрит довольно просто - если проходит по гигабайтам весов. Если хватает с запасом ~20-25% то будет зеленое, 10-20 - желтое, менее 10 - красное. Цифры с потолка по наблюдениям. Рам с врам при оценке оно не суммирует, видимо предполагает что модель полностью будет к тебе помещаться.
>Рам с врам при оценке оно не суммирует
А вообще какое у них соотношение? Типа 10 врам равно 30-40 рам по вычислению и влезанию моделей? Или как?
Система макросов в Таверна мегаплоха. Даже чтобы сделать if/else бранчи и переменные нужно невероятно пердолиться. Забил хер и завайбкодил экстеншен, ни о чем не жалею. У них примеры из доков не работают в реальных кейсах, хз как это тестилось и писалось. Очень печально.
Для всего, что не простой чатик, в таверне приходится нехило пердолиться. Не предназначалась она просто для чего-то другого, это все сверху наваливается.
между актёром театра отыгрывающим красную шапочку, и роботом, отыгрывающим актёра театра, отыгрывающего красную шапочку есть фундаментальная разница. если она правда не видна тебе сейчас, увидишь потом. смысл спорить. на бордах нет победителей, тут только проигрывают с подливой
> Не предназначалась она просто для чего-то другого, это все сверху наваливается.
Если так, то не нужно абы как добавлять фичи, не проверяя собственную документацию и не заморачиваясь с тестированием. Пожалуй, тут первый раз когда у меня на них горит. Полчаса убил на то, чтобы задебажить их проблемы.
https://docs.sillytavern.app/usage/core-concepts/macros/
Половина здесь написанного не соответствует действительности. Особенно смешно здесь https://docs.sillytavern.app/usage/core-concepts/macros/#whitespace-in-macro-definitions потому что вайтспейсы попросту не работают и ломают форматирование -> Таверна перестает воспринимать макросы с вайтспейсами за макросы и передает текст макросов в промпт.
Пиздец кароче неудобно. Я еще так понял у меня квен стоял 40 гиговый МОЕ, потому что он мне текст за пол минуты выплевывал а две геммы что я скачал 30 а потом 17 гигов по 5 минут текст собирают. Литерали по слогам читаю лол. Но пишет она волшебно конечно, почти как живой человек. Квен я не смог заставить самому сюжет додумывать, вечное внизу "твой ход?" а гемма такие выводы из небольшого описания выдает что я с открытым ртом сегодня полчаса сидел
А ты на последнем стейджинге это тестируешь? Иногда доки просто наперед релиза обновляются. Ну хотя такой разброд у таверночника это не новость совершенно.
Документация актуальна для моей версии, я проверил через Гитхаб. Там все дырявое. Например, если у тебя один и тот же outlet вызывается из одного и того же скоупа, результат {{random}} в рамках этого outlet будет одинаков для каждого вызова. Потому что он кешируется. В итоге я в рамках пердолинга сделал себе outlet_name_1; outlet_name_2 ... просто, чтобы {{random}} в рамках outlet срабатывал каждый раз, а не тянулся с кеша. Зачем вообще кешировать такое на фронтенде - для меня загадка. Что там можно сэкономить? Зачем кешировать результат {{random}}? Кто-то может спросить, а чем переменные не зашли? Тем, что они тоже куда-то уплывают и не могут быть нормально перезаписаны, пусть и могут иметь ссылки на себя с других скоупов. Пишу и смеюсь как ненормальный, не, это пиздец. Есть же уже готовые всякие решения для нодов и прочие (я даже видел экстенш ЛОРБУКОВ, типа better lorebooks, сейчас уже могу поверить), почему не объединиться с их авторами для развития - неясно. Ладно бы проект стагнировал, так нет: они его типа развивают и вместо того чтобы мерджить адекватные коммьюнити решения предлагают свои аналоговнеты. Пока писал это потерял остатки рассудка. Кстати, они это где-то в ноябре-декабре релизнули, при этом оно еще какое-то время было в стейджинг версии.
Хотелось бы увидеть эту разницу, если не затруднит
Никакого, 1 к 1. Если веса помещаются в указанную память с запасом - будет зелененькое.
Тут проблема более глубокая на самом деле и завязана на потребление на контекст. Его нельзя просто так экспрессом оценить потому что применяются разные механизмы атеншна. Придется очень много хардкодить и регулярно обновлять счетчик, и добавлять ползунок на желаемый объем кэша.
> результат {{random}} в рамках этого outlet будет одинаков для каждого вызова
Вообще по дизайну у них одинаковым должен быть {{pick}}, а {{random}} должен меняться. Скорее всего аутлеты как-то кэшируются из-за инопланетянской механики лорубков, там таверночник действительно пытается на всем экономить. Может чистый баг, может багофича.
> почему не объединиться с их авторами для развития - неясно. Ладно бы проект стагнировал, так нет: они его типа развивают и вместо того чтобы мерджить адекватные коммьюнити решения предлагают свои аналоговнеты
Ну это главный рак таверны, да. Даже элементарно вместо того, чтобы lua как скриптовый язык использовать, таверночник свой костыльный st скрипт изобрел, потому что по его словам "круто". Или когда его попросили голосовой вывод сделать во времена gpt realtime, он сказал, что таверна не телефонная будка и пошли вы нахуй. Все гвоздями прибито, хер что подвинешь.
В общем-то действительно важные и развивающие фичи добавляются с очень большой неохотой, в их разработке больше упор на то, чтобы поддержку новых сеток делать и подорожником части лапшичного кода прикладывать, чтобы все не развалилось. Все держится чисто на расширениях.
В vllm турбоквант с геммой не работает что-ли?
Типа если 60 памяти в сумме, то спокойно влезет модель в 50 гигов? А как узнать скорость? Плотные модели вроде по дефолту медленнее, нет?
Это нормально, что у меня таверна лагает как мразь? Возможно, дело в чате? Там 400 сообщений в чате, каждое в среднем на 2-3к токенов от модели (ризонинг + ответ). Такое ощущение, что ризонинг-блоки или ещё какая-то хуета заставляют лагать это убогое поделие. Это как-то пофиксить можно?
Большой чат да вполне может лагать, чаты лучше перекатывать, когда они слишком жирные становятся. Еще может лагать из-за включенных прибомбасов оформления типа прозрачности и теней, тоже можно всякое поотключать в настройках.
Все сложно тут. Во-первых тебе не доступна вся рам, часть сожрет система и софт. От пары гигов на чистом линуксе до 15-25 на засратой шинде или линуксе с базами данных, zfs и прочим. Во-вторых, нужно еще выделить память на кэш контекста, причем он обязательно должен быть в врам. А его объем зависит от размера кэширования и самой модели.
Есть еще буферы, дискретность слоев и прочее, но обычно это мелочи. Или вводить дополнительные ограничения чтобы размер весов атеншна и кэша обязательно помечались в врам - 48+128 это не то же самое что 8+192.
На больших чатах может. Но проявляется когда подгружаешь старые сообщения или переключаешь чаты, при обычном использовании все должно быть плавно.
При всех проблемах Таверны альтернативы у нее все же нет. Такого у меня не бывало, хотя и кастомное форматирование, и html блоки в аутпутах, и чаты на 100к токенов полностью раскрыты. Тебе верно подсказали в настройках темы отключить блюр, тени, анимации. Но подумай еще вот о чем: это точно Таверна лагает, а не видеопамять вытекает в оперативу на Винде? Или я наполнением контекста чекпоинты и кешрам забивают оперативу подзавязку? Они в полном объеме не аллоцируют потенциально необходимую память, а делают это по мере необходимости.
Кто сидит на мое гемме на кобольде. Если надоело долгое мышление то в можно подрезать добавив {"reasoning_effort":"medium"} в параметры это срежет мышление до 1к токенов ещё есть high low minimal none
Делает ли вашу жизнь лучше это хобби?
Особенно с 5т.с на мое...
Времени и так нет, а с ллм оно буквально плавится
Всё еще лучше чем дотка но не далеко ушло
Особенно с 5т.с на мое...
Времени и так нет, а с ллм оно буквально плавится
Всё еще лучше чем дотка но не далеко ушло
>не набор поз, а серия
>не было яркости. Напротив,
>она не шла, она словно перемещалась
>не духи, а что-то более интимное
>был не томным, а сухим
>она не поднимала глаз. Она продолжала изучать цифры
Улетаю на жопной тяге с вот этой срани у геммы. Можно потерпеть некоторые структурные повторы, можно частично победить промптами пёрпл прозу, но это дерьмо лезет регулярно. Вангую, что даже если заставить гемму найти все подобные it's not X but Y структуры и переписать, то она в думалке найдёт их, напишет черновик без них, а потом в ответе всё равно насрёт.
Спрашиваю потому что на это еще и бабок надо дохуя влить чтобы жить хуже по факту
>Спрашиваю потому что
Ты пидор.
Двачую. Ужасно репетативная и лупящаяся. Квен 3 в свое время за это отменили в треде, а Гемме простили видимо за впечатляющие мозги и малую цензуру.
Жаль что квен тоже хуйня
Гемму не обучали на ризонинг разной длины в зависимости от какого-либо параметра. В жинже нет переменной/служебных токенов, которая использовала бы этот параметр опенаи апишки. Так что подозреваю, что у тебя плацебо. Хз, конечно, может, в кобольде как-то реализовали, что оно превращается в доп промпт или тупо обрезает ответ, закрывая тег, но сомнительно.
хрен с тобой,. скопипастил на арену (мне лень запускать свою шарманку) твой пример
с джейлом
https://privatebin.net/?3e0abac21004bb2f#GFRWm4eDuMAZvHjYMzRwNkvLdvE9JnjgnUNbNLox4Lb9
без джейла
https://privatebin.net/?4ade18d5d90d5dc9#JATMfgs68dm9wXt35VWeY7uBeKSmYsqQjGtd6xP2cChp
ассистентово закругление (in character но всё же) заметил в конце с джейлом?
Игорь тонет, че делать то? А тут что то новенькое и интересное, настоящий ии все дела. Работа, книжки почитываю, бытовуха. Нормальное хобби, не как долбаеб на байке летать хрустиком, по деньгам все не так плохо - если у тебя руки есть можно на чем угодно запускать, потыкать хватит
Вот этот мердж геммы не пробовали? Как он по сравнению с ванильной геммой?
https://huggingface.co/Blazed-Forge/Gemma-4-Gemsicle-31B
https://huggingface.co/Blazed-Forge/Gemma-4-Gemsicle-31B

Собрал этот блок, завтра нужно будет его интегрировать в башню из мишек
> Делает ли вашу жизнь лучше это хобби?
Очевидно да
> Делает ли вашу жизнь лучше это хобби?
Очевидно да

Разве можно собирать солянку из карт разных производителей?
Кто запретит? Это просто псие девайсы
Нет. Но оно забавное. Мне нравится тыкать в виртуальных девочек. В реальных уже натыкался до тошноты.
Зачем тебе Арк, когда инцел закрывает отдел видеокарт и под них больше нихуя не будет.
Разумеется. Рекреационное использование, мощный личный ассистент для продуктивности и настроения, прямое использование в работе и хобби.
Только учитывая что это увлечение с малой подвижностью и возможностью легкого дофамина - нужно себя контролировать.
AV1
Ты про это?
> He tilts his head slightly. "Does this bring you closer to an answer, or has it only opened a new door in your mind?"
Перс в 70% случаях вопрос задает в конце ответа. Я как то внимания на это не обращал, теперь буду. Спасибо что разъяснил, пока такое общение не раздражает, но буду иметь ввиду.
5060ti для начала уже хорошо, и картиночки и ллм. Как раз и смежные области раскуришь, буст будет не только в куме. На крайняк видяха в игорях будет полезна
Укатывайтесь от сюда уже, где эта ленивая жопа
Сам такой.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_moe_2026
• Неактуальные списки моделей в архивных целях: 2025: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd ), 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Гайд для новичков: https://rentry.org/2ch-llama-inference
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
• Доки к LLaMA.cpp со всеми параметрами: https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: