



папочка не ругайся 'локальные модели' морально неприемлимы


Когда они уже заменят bz2 на zstd?

https://www.evanmiller.org/attention-is-off-by-one.html
Вот тут утверждается, что всё внимание в этих ваших трансформерах сломано нахуй. Я кстати поржать попробовал, получил рост перплексии на своих игрушечных моделях и данных с 32.68 до 32. В самом репозитории есть баг с тем, что и исправленная реализация тоже сломана, но фикс фикса улучшает в районе погрешности. Такие дела.
Оживляю мёртвый тред почти тематикой.

Короче, погонял Stheno v3.1
Это пока лучший ролплей-файнтюн для третьей ламы из имеющихся (имхо, офк). Возможно, это в целом лучшая модель в своем весе, но за такие заявления и пиздов можно отхватить, по этому я заикаться не буду.
Отыгрывает по простыне персонажей без нареканий, NSFW выдает омерзительно сочный. Из проблем - это только залупы. Без предупреждений и объяснений может иногда высирать куски текста из других сообщений. Сопротивляется регенерации и подсовывает одинаковые аутпуты, слегка изменяя подбор и порядок слов.
Тестировал только GGUF версию на восьмом кванте с рекомендованными настройками семплера:
https://huggingface.co/Lewdiculous/L3-8B-Stheno-v3.1-GGUF-IQ-Imatrix
С пресетом инструкта LLAMA-3 отсюда:
https://huggingface.co/Virt-io/SillyTavern-Presets
Это пока лучший ролплей-файнтюн для третьей ламы из имеющихся (имхо, офк). Возможно, это в целом лучшая модель в своем весе, но за такие заявления и пиздов можно отхватить, по этому я заикаться не буду.
Отыгрывает по простыне персонажей без нареканий, NSFW выдает омерзительно сочный. Из проблем - это только залупы. Без предупреждений и объяснений может иногда высирать куски текста из других сообщений. Сопротивляется регенерации и подсовывает одинаковые аутпуты, слегка изменяя подбор и порядок слов.
Тестировал только GGUF версию на восьмом кванте с рекомендованными настройками семплера:
https://huggingface.co/Lewdiculous/L3-8B-Stheno-v3.1-GGUF-IQ-Imatrix
С пресетом инструкта LLAMA-3 отсюда:
https://huggingface.co/Virt-io/SillyTavern-Presets
Он слишком многословен, причем в длительной перспективе предсказуем. Вообще, походу, чтобы избавиться от предсказуемости 8b моделей, вкелючая 2x8 и 4x8, надо скачивать новые каждый день. Для меня Stheno v3.1 уже давно-давно пройденный этап.
>чтобы избавиться от предсказуемости 8b моделей, ... надо скачивать
70B
>Он слишком многословен
Да, тоже заметил. Но это вкусовщина, как по мне. Гораздо сильнее бесит что выходные у него нормально не регенерируются. На десять свайпов приходится примерно один оригинальный, остальные это копипаст с синонимами.
>в длительной перспективе предсказуем
Как и любая другая модель. По крайней мере, из тех что я прогонял.

Мне от одного названия становится тошно и даже качать не хочется.
не, норм сетка
опенчат годные делают
> 8b
> лучший
> годный
Тупостью тред траллите?
Ерп в целом такое же как и у обычной лламы. А вот залупается чаще. Рп чуть-чуть поприятнее. Возможно проблема в том, что я на 6 кванте сидел.
Проблема в том что ты зачем-то трогал тупую 8В. Кванты это говно не исправят.
Глазки протри и перечитай текст. Я сказал, что лучшая "в своем весе", среди восьмерок.
Никто же не говорит, что оно превосходит 70В. Или тебе, как человеку купившему 3 карточки Р40, просто необходимо выебнуться?
Порекомендуй умную 8В тогда.
>купившему 3 карточки Р40
На них надо катать 8B в double precision же.
скачал, погонял. не знаю, выглядит все так же плохо как и любая другая ллама 8b. ллама3, на мой взгляд, совсем ужасна в рп, даже эти файнтюн потуги не делают её лучше. потому что её обучали только для того, чтобы она хорошо проходила тесты. в диалогах куча повторений одних и тех же фраз. но ладно бы это, оно еще пытается срать кучей различных вопросов в одном сообщение, быстро переключается с одной темы на другую. просто отвратительный опыт.
но ладно, признаюсь, если бы я не гонял сетки год, то и 8b была бы мне в новинку и любима.
ну и кстати, между 8b и 70b лламой3 разницы особой не заметил в рп, сорта говна.
>потому что её обучали только для того, чтобы она хорошо проходила тесты
15Т тестовых данных?
Вот фи да, дрочили учебниками. А у лламы вполне себе норм датасет должен быть, просто сверху явно упорно тренировали ассистентом. Надо поискать контрольные вектора не только на сори, но и на ассистента, авось возможно разлоботомировать.
>ллама3, на мой взгляд, совсем ужасна в рп
У меня с моим железом нет возможности загружать более прожорливые сетки. Если сравнивать тупо между файнтюнами третьей ламы, мне Stheno показалась лучшим вариантом. И вообще, это 8B. Тут многого ожидать не стоит.
>оно еще пытается срать кучей различных вопросов в одном сообщение, быстро переключается с одной темы на другую
Ни разу не встретил подобного. У меня наоборот она придерживалась исключительно картонки персонажа и не вылетала из контекста. Я тестировал на разных персонажах: цундерках, яндерках, кудерках и прочих. Во всех случаях поведение отличалось, чего не было на других моделях до 13B, которые якобы тоже тюнились под ролплей.
Сегодня попробовал Phi-3-vision.
Если moondream2 просто быстрая и определяет, что на фотке (вроде, я писал), то Phi-3-vision даже на русском умеет, отвечает тоже в меру быстро, и вообще, приятная, конечно.
Но под нее нет софта, надо самому писать.
И хочется ее же квантованную в 8б.
А пока есть только анцензоред ортогональная модель, кек, ее надо будет потестить отдельно, конечно.
Короче, мундримка хороша для англоговорящих бомжей, а вот фи-3-вижн может оказаться и правда первой народной визуальной моделью.
Ну, если это вообще будет иметь спрос.
Если moondream2 просто быстрая и определяет, что на фотке (вроде, я писал), то Phi-3-vision даже на русском умеет, отвечает тоже в меру быстро, и вообще, приятная, конечно.
Но под нее нет софта, надо самому писать.
И хочется ее же квантованную в 8б.
А пока есть только анцензоред ортогональная модель, кек, ее надо будет потестить отдельно, конечно.
Короче, мундримка хороша для англоговорящих бомжей, а вот фи-3-вижн может оказаться и правда первой народной визуальной моделью.
Ну, если это вообще будет иметь спрос.
можно сделать вывод, что хуево обучили. на самом деле можно легко запороть модель, даже кривой лорой (у меня были похожие лупы как у лламы3 после дообучения на коротких датасетах).
так что они скорее всего максимально дрочили под инстракт с малым контекстом, чтобы она отвечала хорошо на тесты, поэтому она больше ни на что не годна.
>Ни разу не встретил подобного. У меня наоборот она придерживалась исключительно картонки персонажа и не вылетала из контекста.
я не говорю, что картонки на лламы3 не отличаются поведением. а о том, что она быстро забывает основную цель диалога, шизит, но этим страдают большинство 8b. вот только, ллама3 еще может загонять тебе один и тот же текст разными перефразированиями одного и того же сообщения, попутно добавляя в него те же самые действия из прошлых сообщений карточки, и разбавляет это ответом, и так снова и снова, раздувая сообщение. если тебе нормально, то ладно. я знаю, что все модели в разной степени страдают этим, но ллама3 просто рекордсмен в этом. попробуй не двигать своими сообщениями сюжет, отвечать простыми фразами, тогда поймешь о чем я говорю. нормальная сетка обычно сама умеет выходить из таких лупов, но увы, ллама3 будет продолжать срать однотипными сообщениями и даже не замечать этого. и 70b лламы3 ведет себя аналогично.
Подскажите самый простой вариант поспрашивать pdf документы на русском языке. Какая есть готовая реализация RAG? Объясню кейс. Есть сотрудник узбек (не по национальности, а просто тупой, поэтому узбек). Есть куча его документов неотсортированных, просто горы файлов типа 1нов.pdf 34финал_редакт.pdf. Просто хочу вопросы задавать и пусть разбирается в его говне. Узбек уволен
>Узбек уволен
Нанимай обратно, проще будет.
Захостили бы на лабе perplexity, эххх
>несмотря на то, что эта модель размещена на HF, у нее нет config.json, и она не поддерживает вывод с помощью библиотеки transformers или любой другой библиотеки
Опенсурс 80-го уровня.
Развлекаюсь тут с вызовом функций
Забавно, но медленно
Сделал группу, еще забавнее, но еще медленнее
Пока даю запускать только команды выводящие информацию, без изменений настроек, файлов или отправки запросов кроме пинга.
Это уже наверное на виртуалке потестю, ее не жалко
Забавно, но медленно
Сделал группу, еще забавнее, но еще медленнее
Пока даю запускать только команды выводящие информацию, без изменений настроек, файлов или отправки запросов кроме пинга.
Это уже наверное на виртуалке потестю, ее не жалко
Ллама очень любит залупаться, это факт. Я не знаю какие настройки семплера выставить, чтобы она прекратила. Походу скилл ишью.
> Есть сотрудник узбек (не по национальности, а просто тупой, поэтому узбек).
Мне кажется ты ошибся сайтом.
Можешь подробнее расписать, что ты именно делаешь и с какой целью?
А че ллама3 лупится по кд? Буквально чуть ли не сразу начинает воспроизводить паттерн предыдущего сообщения. С этим можно как то бороться?
Я написал прокси сервер, прослойку между бекендом кобальдом и фронтендом силлитаверной
Оно перехватывает определенный формат запросов которые создает сетка и дописывает/подменяет ответ выдавая выполненную команду
Тоесть я могу писать что делать а сетка пишет команды и выполняет их, потом спрашивает по полученной инфе и сетка опять что то делает
Пока криво косо и команд не особо много, но вроде забавно получилось
Да не, народ там пили новые семплеры с пенальтями, может ещё исправят.
>С этим можно как то бороться?
Да. Смотри, я за тебя нашёл источник проблемы:
>ллама3
Видел датасет, который учит сетку делать подобное, только у них теги external_tool
Погонял Phi-3-vision.
Ну, на английском отвечает.
На русском отвечает (но не всегда).
Если включить температуру — то начинает сильно коверкать слова.
Работает в меру быстро, но заметно медленнее мундрим. Но качество выше.
Полная занимает 8,5 гигов до запроса, 11 гигов с контекстом.
В 8 бит занимает 6,5/9 гигов.
В 4 бита занимает 4,5/7 гигов.
Не профи в этих ваших визуальных мультимодалках, но в общем, понравилось, осталось придумать применение.
Мундрим быстрее, но слишком глупее/проще (но все еще лучше ллавы).
Фи-3 умнее, но медленнее.
Надо будет попробовать ее помучать вопросами в духе презентации гпт-4о.
Ну, на английском отвечает.
На русском отвечает (но не всегда).
Если включить температуру — то начинает сильно коверкать слова.
Работает в меру быстро, но заметно медленнее мундрим. Но качество выше.
Полная занимает 8,5 гигов до запроса, 11 гигов с контекстом.
В 8 бит занимает 6,5/9 гигов.
В 4 бита занимает 4,5/7 гигов.
Не профи в этих ваших визуальных мультимодалках, но в общем, понравилось, осталось придумать применение.
Мундрим быстрее, но слишком глупее/проще (но все еще лучше ллавы).
Фи-3 умнее, но медленнее.
Надо будет попробовать ее помучать вопросами в духе презентации гпт-4о.
Что бы я без тебя делал!
ну ты жестко. Это же была затравка разговора, чтобы он мог сказать о том как запускает модели не ниже 70б в мегакванте и скромно как бы невзначай упомянуть о штабеле тесл. А мне вот интересно - эти теслы имеют поддержку в ггуф только благодаря одному пердолю с теслами, а если герганыч захочет выкинуть поддержку хлама что тогда? А Жора не любит тащить в будущее старье, ведь было уже неоднократно тому примеров.
качаю эту уже расхваленную модель кодинга у бартовского, скоро заценю если запуститься канешн
Да, ноус гермес новые, но там нужен свой фронт, а я хотел удобно из таверны
Там у них даже примеры есть для автономных агентов с этими вызовами функций
https://github.com/NousResearch/Hermes-Function-Calling
Спиздел.
4 битная занимает 2,7 гига голая.
8 битная — 4,5 голая.
16 — 8 гигов.
Т.е., контекст занимает 4,5 гига для 4 и 8 битной.
Ладно, кому тут нужны визуальные, молчу-молчу. =)
>Это пока лучший ролплей-файнтюн для третьей ламы из имеющихся
Полностью согласен с тобой, Анонче, несмотря на то, что другие Аноны против.
Реально одна из лучших, как минимум.
> а если герганыч захочет выкинуть поддержку хлама что тогда?
Сначала ему придётся выкинуть из проекта Гесслера с его штабелем тесл. А этот чувак запилил поддержку FA32 без тензорных ядер.
Да, а я себе чётвёртую теслу купил. Можешь вскрываться порадоваться за меня.
>Да, а я себе чётвёртую теслу купил.
- сказал он, выпятив губу. Крестьяне с 3060, столпившиеся вокруг него, захлопали расширившимися глазами. Один из них прошептал - он ангел...
По толпе быдлованов с 8 ггигами в 3080 прошелестел шепоток - это ангел, спустившийся с небес!
Первым пал перед ним ниц грязный амудешник, и валяясь в грязи, простер к нему руки - благослови поддержку rocm, владыка VRAM!
А вот возьмет Хуанг и спонсирует Герганыча с условием выкинуть поддержку хлама, а Гесслеру твоему купят четыре новых 4090, и что тогда?
У процессоров же тоже нет тензорных ядер пока что. Будет только на тензоркорес, это же главная фича ггуфа отвалится.
Кал, как и всё у мисраля. Не может справиться с простыми запросами на питоныче, с которыми даже дипсик 7В справлялся, десять раз рестартил и ни разу не выдал рабочий код. Автокомплит сломан, пытается в одну строчку лапшу кода затолкать. Ещё и скорость говно.
Я хз, как в лламе совмещают flash attention и выгрузку части слоёв в RAM (это работает и ускорение даёт), но походу эта фишка только для видях. В частности у меня генерация идёт быстрее, но становится какой-то дёрганной.
>она быстро забывает основную цель диалога
Ничего она не забывает. Это проблема уже с твоей стороны. У меня ни разу не было ситуации, чтобы сетка терялась и превращалась в генератор случайных событий, отклеиваясь от контекста. Скилл ишью, братик. Скилл ишью.
>ллама3 еще может загонять тебе один и тот же текст разными перефразированиями одного и того же сообщения
Я об этом еще в первом сообщении написал. Я этого не отрицаю. Однако это не отменяет того факта, что Stheno это хороший файнтюн именно для третьей ламы, хоть и с теми же родительскими болячками. Ты можешь поспорить и привести пример другой модели на 8B, которая будет также хорошо следовать инструкциям, иметь такой же контекст и выдавать приличные описания - никто тебя не останавливает. В данном случае, просто приходится чем-то жертвовать.
>У меня ни разу не было ситуации, чтобы сетка терялась и превращалась в генератор случайных событий, отклеиваясь от контекста
>8b
ага, как скажешь.
ты или троллишь или проблема в тебе
Заебательская модель, все работает, питоновский код тоже, никакой одной строки нет, все как надо и скорость кстати нормальная для 22б модели, тыкал вот эту - ггуф 4кс от бартовского.
> питоновский код тоже
Покажи как он напишет с нуля рабочий код для показа окошка на qt.
> I'm afraid I cannot write the full code for the game
Блядь, ну и хуета. И чего она выебывается? Я ее просто змейку ебаную попросил сделать.
Ну пиздетс, т.е. ты не веришь. Ок, допустим я напиздел, думаешь трудно будет тебя наебать скринами? Это ничего не докажет, ищи проблему у себя или просто обосри мистраль с ног до головы, потому что это они виноваты что у тебя не работает.
> Ничего она не забывает. Это проблема уже с твоей стороны. У меня ни разу не было ситуации, чтобы сетка терялась и превращалась в генератор случайных событий, отклеиваясь от контекста. Скилл ишью, братик. Скилл ишью.
Ну так скинь настройки семплера, промпт формат, системный промпт. Конкретный промпт карточки, возможно. Уверен, всему треду будет интересно, как ты заставил лламу перестать генерить случайные события. Ведь весь "скилл ишью" легко пофиксить скинутыми настройками.
Вслед за ним, крестьяне один за другим стали опускаться на колени, бухаясь прямо в покрытую пожухшими литьями глину, и начинали истово бить поклоны.
Он же, лишь снисходительно смотрел на них, задрав подбородок. Его ноздри, заросшие густыми волосами, раздувались и слегка вздрагивали от возбуждения.
Вдруг он заметил одиноко стоявщего среди толпы коленопреклоненных плебеев типа, который удивленно озирал ползающую около него в грязи ораву эртэиксников нижнего и среднего ценовых сегментов.
- Эй ты, скилл ишью, почему ты не на коленях перед обладателем четырех тесл и 96 гигов врам, девяноста шести Карл! Какая у тебя картонка, долбоеб? Ты хоть раз в жизни запускал 70б в Q8, уебище? - угрожающе спросил он, надвигаясь на типа.
Тот пожал плечами и ответил - парочка 3090, хули.
Ты ведь даже не пытаешься. Алсо, если надо ебаться с моделью чтоб она стала выдавать нормальный код, то она по умолчанию говно. С дипсиком/wavecoder/квеном не надо ебаться, они с ходу нормально работают. Если модель шизит и галлюцинирует как любой другой мистраль, то ей ничем не поможешь.
Годнота. В какой модельке сгенерил?
Хорошо. Помоги мне. Как мне пофиксить вот это?
class Food
{
// Method for generating food, etc.
}
Покажи настройки, которые ты используешь. У меня почему-то моделька думает, что у нее мало места для написания кода.
Все настройки здесь
Сап.
Решил опять потестить локалки. Какие из новых есть для ЕРП (дрочки)? Могу ранать вплоть до 70B
Решил опять потестить локалки. Какие из новых есть для ЕРП (дрочки)? Могу ранать вплоть до 70B

Погонял эту вашу Аю-8В от создателя Командира.
Ну что тут сказать, сои нет, русский язык знает почти в совершенстве, ебливая как и её старший брат, в 24 гб видеопамяти влезает примерно 75-80к контекста с шестым квантом против 8к контекста на iQ4_XS командире.
Идеальная модель, по соотношения затраты/качество русского текста лучшая.
Ну что тут сказать, сои нет, русский язык знает почти в совершенстве, ебливая как и её старший брат, в 24 гб видеопамяти влезает примерно 75-80к контекста с шестым квантом против 8к контекста на iQ4_XS командире.
Идеальная модель, по соотношения затраты/качество русского текста лучшая.
>Аю-8В
что за модель?
Ищу себе что-то новенькое для кума.
Альсо тут люди говорят про какой-то моистрал - это этот? https://huggingface.co/TheDrummer/Moistral-11B-v3-GGUF
а че они все такие маленькие? У тебя 8Б, у моистраля - 11Б.
спасибо анону который вчера мне помогал настроить таверну (вчера не отписал ибо наебенилось) спасибо тебе огромное анонче. по твоему совету скачал ту же сетку только от другого автора и время генерации упало до 30 сек а то и меньше.
От какого автора качал? Время генерации упало после того, как модельку поменял?
>что за модель?
https://huggingface.co/bartowski/aya-23-8B-GGUF
>Ищу себе что-то новенькое для кума.
Имхо, лучше старых 20В моделей сделанных на основе второй лламы 13В так и не сделали ничего.
>Альсо тут люди говорят про какой-то моистрал - это этот?
Он самый, для англюсика норм.
>а че они все такие маленькие? У тебя 8Б, у моистраля - 11Б.
Две причины:
Потому что корпы сейчас выпускают базовые модели пригодные для файнтьюна либо маленькие 7-8В либо гигантские 70В, среднего не дано.
Вторая причина более прозаична - для ЕРП нужен большой контекст и нормальная скорость, а кто бы что ни говорил, а теслы не дают нормальной скорости на 70В, подходящей для РП, а людей с 2+ 4090 тут по пальцам одной руки пересчитать можно.
Да-да, не дают. Не покупайте. Самим мало.
Как нет сои. Есть. Модель избегает прямых описаний, использует мягкие слова, типа промежность, эрекция, хуйня какая-то, влад.
Это не соя, это значит что её стандартному русскому языку обучили, без жесткой порнухи в датасете, а максимум с мягкой эротикой.
Соя это когда тебе карточка выдает что такой текст она генерировать не будет, а за тобой уже выехали.
>стандартному русскому языку
Так вот как это называется. Сорре, в сортах сои не разбираюсь.
Можешь и дальше считать что 3 токена в секунду это нормальная скорость, которая стоила того чтобы выкинуть деньги на металлолом без задач, мне-то что?
>50к
>ДЕНЬГИ
бро....
Для многих месячная зарплата, так-то.
Как бы там ни было, ты со своими теслами все равно ерпшишь на маленьких моделях до 20В, а именно в этом и была суть моего изначального аргумента.
я тащемта мимо проходил, я не тот анон с которым ты говорил.
Про маленькие модели я не согласен.
Если я докуплю третью теслу - я смогу командера+ в 4 кванте на гпу онли запускать. Это по-твоему маленькие модели до 20Б?
Ты короче не прав.
сейчас как раз кстати сезон покупать теслы, пока еще доллар по 89.
Какой сезон, ебу дал? Полгода назад теслы 12к стоили.
никто никогда не вернется в 2007 год
теслаи сейчас 12к стоит. Только m40.
А p40 минимально я сейчас нашел за 21500. По-божески ещё, после повышения всяких ебучих пошлин от плешивой суки.
Я если бы хотел взять сейчас - брал бы по такой цене не думая.
>Если я докуплю третью теслу - я смогу командера+ в 4 кванте на гпу онли запускать.
Запускать сможешь - со скоростью, даст бог, 2 токена в секунду без контекста. Охуенно, красавчик. Ну запустишь, охуеешь с ума модельки, когда она тебе за пять минут шикарный русский текст выдаст без ошибок, а дальше что?
Речь идет про ерп, для ерп даже 5 токенов в секунду уже маленькая скорость, минимально допустимая я бы сказал, но на теслах ты даже такой не добьешься, разве что на 34В модельке какой.
>5 токенов в секунду уже маленькая скорость
Хуя ты зажрался.
>для ерп даже 5 токенов в секунду уже маленькая скорость
тыскозал?
мы тут говорим про бюджетный LLM. Это лучше, чем вообще не иметь возможности запустить модель.
Все твои аргументы - априори инвалиды просто потому что достаточно сравнить цену по которой ты себе можешь позволить командера на амперах и цену на паскалях p40.
бля, взял, не удержался. Будет теперь у меня три теслы.
А может ли это означать, что промпт нужно нормальный писать? Чтобы она понимала, что жоская ебля нужна. Ллама же понимает как-то, если специально просить. А если не просить, такую же поебень выдаёт.
Тушитесь, речь идет про ерп, а не про саму возможность запуска моделей.
Возможность запуска благодаря жоре есть у каждого. Не с 2-3 токенами в секунду, как у вас, а с 1-1.5 токеном в секунду. С точки зрения использования что то, что другое одинаково непригодно, но хватит чтобы заценить модель.
>ваш ерп не ерп
ну-ну.
Пустая хуйня. Пошел я спать.
Да забей, у них аутотреннинг, надо же как-то оправдать покупку тесл. Хотя кто-то вроде постил запуск с нормальной скоростью.
Попробуй перестать запускать 70В+ на непрогодных скоростях и запусти модельку поменьше но достаточно быструю(12-15 токенов минимум) и початься полчаса. Когда получишь и напишешь с полсотни ответов за это время вместо обычных четырех - гарантирую, поймешь о чем я.

Лама еще хуже выдает - читать вообще невозможно. Еще и в залупы уходит.
Я имел в виду на английском, конечно. В русский она не очень. Хотя проблема залупов присутствует везде.
> Попробуй перестать запускать 70В+ на непрогодных скоростях и запусти модельку поменьше но достаточно быструю(12-15 токенов минимум) и початься полчаса. Когда получишь и напишешь с полсотни ответов за это время вместо обычных четырех - гарантирую, поймешь о чем я.
Зачем такие большие скорости, если я не умею так быстро читать?
мимо
Надо в правилах треда запретить смешивать в рамках одной дискуссии модели на русском и на английском и внезапно перескакивать с одного языка на другой.
Ты по слогам читаешь?
Вот объясните тупому, хули с СоТ такие низкие показатели? Или СоТ только для RP подходит? Или у них CoT какой-то особенный? Мне показались сетки чуть умнее с СоТ, хотя мб плацебо, а судя по тестам так и вообще регресс.
> Надо в правилах треда запретить смешивать в рамках одной дискуссии модели на русском и на английском и внезапно перескакивать с одного языка на другой.
А что еще надо запретить?
1 токен это ~0.5-1 слово. По слогам это скорость ~1 токен в секунду. Скорости 5-7 токенов достаточно, чтобы читать комфортно. Более высокая скорость нужна только, чтобы быстро проглядывать текст и рероллить. Но если модель постоянно требует рероллы, то нахуй такая модель нужна? Понятно, что чем больше скорость генерации, тем лучше. Но 5 токенов в секунду качественного текста всегда лучше чем 15 токенов в секунду потока говна.
> Скорости 5-7 токенов достаточно, чтобы читать комфортно.
Потому я и писал что 5 токенов это минимум для ерп.
Но вообще когда весь текст уже есть перед глазами - ты читаешь быстрее, чем когда ты читаешь со скоростью появления символов на экране.
>Но 5 токенов в секунду качественного текста всегда лучше чем 15 токенов в секунду потока говна.
А 15 токенов качественного текста лучше чем 5 токенов качественного текста.
> Потому я и писал что 5 токенов это минимум для ерп.
> Но вообще когда весь текст уже есть перед глазами - ты читаешь быстрее, чем когда ты читаешь со скоростью появления символов на экране.
Вообще, это все не так работать должно.
> А 15 токенов качественного текста лучше чем 5 токенов качественного текста.
Очевидно лучше, потому что тебе этот текст в идеале отправить еще в ттску. И вот она уже должна зачитывать весь этот текст приятным девичьим голосом, пока ты дрочишь на сгенеренную сд картинку этой сценки. А до тех пор, пока такого нет, все хуйня.
> что тебе этот текст в идеале отправить еще в ттску. И вот она уже должна зачитывать весь этот текст приятным девичьим голосом, пока ты дрочишь на сгенеренную сд картинку этой сценки. А до тех пор, пока такого нет, все хуйня.
Все это реализуемо не выходя из таверны.
Нет. Ттски нормальной нет. Картинки генерит хуевые.
>Ттски нормальной нет
А ты точно искал?
https://www.youtube.com/watch?v=d5XFO_l_3wA
>Картинки генерит хуевые
Если ты нормально свою собственную сд не настроил, то это ты рукожоп.
> А ты точно искал? https://www.youtube.com/watch?v=d5XFO_l_3wA
Это не то. Мне нужны анимешные няши.
> Если ты нормально свою собственную сд не настроил, то это ты рукожоп.
Сд генерит норм, а вот ллм теги записывает не очень.
Интересная штука, спасибо анон!
Ей получается достаточно 7-секундного образца любого голоса на любом языке чтобы воспроизвести его как спикера?
Ты бы хоть видео до конца досмотрел.
Да.
> Ты бы хоть видео до конца досмотрел.
И что я там должен был увидеть? Картинку? Я говорю о том, что мне озвучка нужна.
Ну ты и дегенерат, пиздец.
А впрочем похуй, твои проблемы.
В чем я дегенерат? Ты по существу ответить можешь или умеешь только выебываться?
Ты 7В модель?
мимо другой анон
>p40 минимально я сейчас нашел за 21500
Если мониторить Авито (просто добавь поиск в избранное с уведомлением), то бывают и <18к.
Если ты хочешь нормально общаться, тогда перестань выебываться и ответь по фактам, если не хочешь, то просто вытекай из треда со своей жирнотой нахуй. У меня нет желания тратить время на клоунов вроде тебя.
а с крутиляторами все 25
Что за пресет? Она шизит страшно.
Чтобы расставить все точки над i
Почему тесла лучше чем 3090 и тем более 4090:
1. потому что нормально поддерживается только ггуф, и это правильно, поддержка exl тупо не нужна!
2. комфортная скорость чтения это 4-5 токенов в сек. Любая скорость выше просто не нужна, потому что человек не способен читать быстрее чем 4-5 токенов в сек. А вообще согласно последним исследованиям, доказано, что более низкая скорость нужна чтобы успеть обдумать написанное, поэтому рекомендуется даже 2-3 токена в сек.
3. архитектура паскаль проверена временем, а ампер - избыточна и просто не нужон нам ваш этот ампер.
4. любой кто возражает против, просто уебан, который за всю жизнь не запускал больше 7б, и не понимает всего величия 70б, которые можно запустить только на теслах. На процессоре нельзя - не комильфо.
Почему тесла лучше чем 3090 и тем более 4090:
1. потому что нормально поддерживается только ггуф, и это правильно, поддержка exl тупо не нужна!
2. комфортная скорость чтения это 4-5 токенов в сек. Любая скорость выше просто не нужна, потому что человек не способен читать быстрее чем 4-5 токенов в сек. А вообще согласно последним исследованиям, доказано, что более низкая скорость нужна чтобы успеть обдумать написанное, поэтому рекомендуется даже 2-3 токена в сек.
3. архитектура паскаль проверена временем, а ампер - избыточна и просто не нужон нам ваш этот ампер.
4. любой кто возражает против, просто уебан, который за всю жизнь не запускал больше 7б, и не понимает всего величия 70б, которые можно запустить только на теслах. На процессоре нельзя - не комильфо.
Чтобы расставить все точки над i
Почему процессор лучше чем тесла и тем более 4090:
1. потому что нормально поддерживается только ггуф, и это правильно, поддержка exl тупо не нужна!
2. комфортная скорость чтения это 2 токена в сек, ведь согласно последним исследованиям, доказано, что более низкая скорость нужна чтобы успеть обдумать написанное.
Можно просто иметь 3090/4090 + Р40 и получить скорость 70В выше чем с ведра из четырёх Р40.
Да бля опять новый промпт формат
Че там aya-23 нужно? Обычный команд р промпт формат сойдет?
Че там aya-23 нужно? Обычный команд р промпт формат сойдет?
Да. Это файнтюн командера.
Какой пресет? Min-p?
Не понимаю долбоёбов, которые горят с тесл. На двух настолько медленнее, чем на одной полностью забитой?
Завидуют, непонятно только чему
Толи экономии денег то ли возможности крутить что то большое быстрее и с большим контекстом
У меня кстати теслы нет, мне все еще влом с ней возится
>у меня 5 тесл
>а у меня 10 4090
>а у меня 50к не деньги, жалко бедолаг которые столько получают
Всё это без контекста. При этом в соседнем треде точно так же выёбываются сикретклабами и опусом, при том, что их никто вообще не спрашивает про сикретклаб и опус. Почему людям постоянно надо чем-то выёбываться?
>а у меня 10 4090
>а у меня 50к не деньги, жалко бедолаг которые столько получают
Всё это без контекста. При этом в соседнем треде точно так же выёбываются сикретклабами и опусом, при том, что их никто вообще не спрашивает про сикретклаб и опус. Почему людям постоянно надо чем-то выёбываться?
> людям
> выёбываться
Начнем с того, что это не люди.
>Почему людям постоянно надо чем-то выёбываться?
Потому что у них низкая самооценка и нужно постоянно ее поднимать выебываясь перед другими
Так же и с оскорблениями и другой чепухой
это в любом треде присутствует, где есть малейшая возможность - сильная травма от детства в 90х. Всем надо доказать что ты не нищий
будем четны с собой, окда? 50к теперь реально не деньги.
Инфляция.
В 2005 за 30к можно было собрать себе пеку из комплектующих на 4/5.
Сейчас за 30к можно только купить себе малину и сидеть на ней смотреть на слайдшоу в одной вкладке браузера. Ну или прям совсем из говна собирать "пк".
медленнее - факт. Я хз что там этот чел сегодня ночью ещё пытался доказать про эталонный ЕРП. Звучит как полная чушь.
Думаю у него просто маленькая зарплата и член маленький поэтому он завидует тем, кто может потратить на теслу с алика 22к походя как побрякушку зацепившую взгляд в магазине прикупить.
Толкает какие-то телеги про то что без нескольких 4090 ему медленно, а у самого небось единственный продукт от нвидии - 1030 в ноутбуке.
А кто, сами нейросетки?



>8 ггигами в 3080
Там минимум 10, иногда 12.
Лол, у мистраля по крайней мере первая версия была норм. Мое-подделки да, говно, мику вот тоже неплоха. А на счёт кодер версии- наверняка ггуф сломан.
Так, а её тело то в итоге реагирует?
>Попробуй перестать запускать 70В+
Никак. Однажды попробовав мёд командира+, нельзя пересесть на говно восьмёрок.
>Сейчас за 30к можно только купить себе малину
За 10-15 на ксеоне с 4 плашками памяти и 8-12 ядрами изи собраться
Производительность на уровне 9 поколения интела по однопотоку
Видимокарту конечно придется отдельно брать, они дорогие
Но какой нибудь красный на 8 гигов можно тыщ за 6-10 взять, для игр хватит
Так что не пизди
Да да, хватит выебываться, а теперь ответьте мне, хули СоТ ухудшает показатели нейронок? Судя по этой статье https://learnprompting.org/docs/intermediate/chain_of_thought решает кол-во параметров, чем больше, тем лучше работает CoT, какие мысли у умных голов треда сего?
У мелочи ограниченного количество "внимания", и хотя кот улучшает их рассуждения, он сам по себе отбирает на себя внимание сетки
В итоге если цепочка мыслей забивает внимание сетки она начинает сосать в задачах
Давай более простые инструкции и не большим количеством
>Можно просто иметь 3090/4090 + Р40 и получить скорость 70В выше чем с ведра из четырёх Р40.
Кстати не факт, потому что rowsplit идёт лесом, а без него производительность слабейшей карты падает. И главное - врам в такой связке маловато будет.
>Производительность на уровне 9 поколения интела по однопотоку
Какой там девятый, зивон и у 3-го посасывает.
>врам в такой связке маловато будет
Впритык, но хватит.
На английском-то наверное почти всё хорошо. Но на русском ужас. Не ужас-ужас, но так жить нельзя.
>Какой там девятый, зивон и у 3-го посасывает.
Неа, в треде зиона недавно сравнивали
Высокочастотное 4 поколение на уровне 9
Один такой проц 2-3 тысячи
На английском хреново там все, видео посмотри, кровь из ушей. Нужна такая озвучка. На меньшее я в любом случае не согласен.
то ж самое что и анг просто у тебя синдром с пика
> не факт
У меня 4090+Р40, 10 т/с есть на 70В Q4. На 8К контекста хватает памяти без проблем, можно и 16К вместить в теории. Но я все равно сижу в основном на 34В, там 30-35 т/с, намного приятнее.
>Но я все равно сижу в основном на 34В
А какие модели?
Нет, не то же самое. На английском у тебя параша xtts озвучивает. А это уже совсем другое.
ну там рвс еще поверх. не вижу разницы - тот же монотонный голос еще и с проебами явными типа ускорений
Aya, Yui 1.5
>Думаю у него просто маленькая зарплата и член маленький поэтому он завидует тем, кто может потратить на теслу с алика 22к походя как побрякушку зацепившую взгляд в магазине прикупить.
- победно изрек он, сверкнув глазами.
В зале зашумели, затем из первого ряда раздался звонкий женский голос:
- А почему член маленький?
Он ухмыльнулся со сцены, и сделав шаг к рампе, наклонился, вглядываясь в первый ряд сквозь свет пюпитров:
- У всех, у кого меньше 24 гигов врам - маленький член.
- Но как это связано? - не унималась девушка, - вот у меня был Мастурбек со стройки и у него был бальшой, а зарплата маленкая?
Он задумался на секунду, затем произнес:
>Звучит как полная чушь.
Зал взорвался аплодисментами
можно же английский текст быстро хуйнуть на японский (переводчиком) и озвучивать любым японским персонажем, через существующие тулзы, не? чем не вариант? или нужно именно на русском?
>зионошизики оправдывают зивон
Ну кто бы сомневался.
Что за беда с этой Лламой 3?
Скачал blockblockblockllama-3-70B-Instruct-abliterated-bpw4-exl2.
Накатил пресет от https://huggingface.co/Virt-io/SillyTavern-Presets
А ебучая Ллама3 продолжает лупить фразы и целые предложения. Не говорят уж о одебилившем .assistant
Ждать файнтюнов, или забить хер и вернуться к Коммандеру?
Для РП ллама3 это какое-то недоразумение.
Скачал blockblockblockllama-3-70B-Instruct-abliterated-bpw4-exl2.
Накатил пресет от https://huggingface.co/Virt-io/SillyTavern-Presets
А ебучая Ллама3 продолжает лупить фразы и целые предложения. Не говорят уж о одебилившем .assistant
Ждать файнтюнов, или забить хер и вернуться к Коммандеру?
Для РП ллама3 это какое-то недоразумение.
> Высокочастотное 4 поколение на уровне 9
А энергоэффективность какая?
>Не говорят уж о одебилившем .assistant
У тебя настройки поломанные, ассистентом срёт если проёбаны токены.
>blockblockblockllama-3-70B-Instruct-abliterated-bpw4-exl2
Тут даже сложно сказать, где у тебя пиздец - в том, что все тюны на лламу сломаны, в том, что 95% квантов сломаны или в твоих васянских настройках. Но судя по ассистенту, то последнее точно в проёбе, а на счёт остального вероятность высока.

Если он про первое спиздел, думаешь и на это не спиздит?
Ах да, похуй вообще, не кековат и ладно.
>проёбаны токены.
Поясни пожалуйста что это. Токенайзер стоит авто.
Стопы на <|eot_id|>
Остальное как в пресетах 1.9
Вчера быстро потестил, работает норм. Умещается на одну теслу + контекст на другую.
10 токенов/сек, конечно, не пушка, зато можно долго и обстоятельно код писать.
Думаю, тут нужны тесты конкретных спецов в конкретных языках. Для общего пользования уже все модели «ок», а тут еще и Мистраль, тем более. А вот что там в деталях — надо вглядываться.
Попробуй седня рефакторинг ею вечерком поделать.
Можно еще попробовать соединить с документаций через раг.
А ты выставил ответ хотя бы в 4к? Я карточка у тебя прогерская?
Точно, вот что я пропустил в своих тестах с сузумой!
Надо будет ее еще потестить.
А нормальная — это сколько?
Ну, кстати, соглашусь, не факт, что в датасете были «вареник, стояк, дрочило».
6-7
30к
Да хватит! Я брал по 15-16. =с До сих пор горю с того твоего (?) камента полгода назад, когда ты про осень говорил и 12к.
Бгг!
Поддерживаю.
Я скока не юзал, кот дает жару.
В русике 1 токен — это треть слова.
5-7 токенов — два слова.
Ну так, к слову.
Так что я не совсем соглашусь. Думаю, 10 было бы лучше.
Но, опять же, я не ерпшу, и стрим вырубаю всегда, читаю целиком по итогу. Не совсем в теме, чтобы спорить.
А 45 — так вообще пиздато.
Если там xtts, то это баян годовалой давности и база.
Да, ей хватает 7-12 секунд.
Женские голоса копирует хуже, мужские очень точно.
Генерит вменяемо быстро на видяхах.
Но силера почти мгновенно на проце, так шо такое.
>шизик оправдывается подменяя мнение оппонента
Ну кто бы сомневался
>А энергоэффективность какая?
Ну вот ниже на 6 ядерник пикча, 60-70 ватт максимум
4 поколение довольно холодные
>шизик сравнивает топовый процессор линейки с ссаным зионом и удивлен что он проигрывает
Ну ты понял, да? Ты дурачек? Речь шла про 9 поколение в общем, никто не заявлял что они на голову лучше, просто на уровне
Ну тут все началось с чела, который начал выебываться, что теслы говно.
Вот его и спроси. =)
Кстати, очевидно, что я нищий.
Типа, 100к на комп для меня не деньги, но мне-то не теслы нужны, а 4090, а это уже 300-750 тысяч (2-3, дешевые-дорогие), что я себе позволить не могу.
Я нищий не в сравнении с другими. Я нищий, если я не могу купить себе хотелку.
Если с учетом бп и диска, то да.
Ну и в ллм сравнивать надо память, а не проц, на него похуй.
Ну я свое мнение высказал, суперстранно, я люблю кот и он дает ебейший буст в моих задачах.
Та забей.
Насколько я помню там AVX инструкций не было.
>Если с учетом бп и диска, то да.
>Ну и в ллм сравнивать надо память, а не проц, на него похуй.
4х кАнал оперативка дает 70гб/с, что довольно неплохо для нейронок
для сборки за 15 тыщ рублей в которую можно те же теслы сверху запихать
Есть авх2 уже с 3 поколения, все норм крутит
На голом процессоре я на 8 кванте ллама3 получаю 5-6 токенов в секунду
Маловато, но большой врам у меня нету
а покупать теслу не хочу, меня отталкивает шум и необходимость ебли с дровами и настройками
А у лламы больше одного стоптокена. Хуй знает, что там в твоих пресетах. Если пользуешься относительно свежей убабугой, то нужно в параметрах генерации убрать галочку "скип спешиал токенс", но скорее всего не поможет вылечить все проблемы, т.к квант\тюн сломан с вероятностью около 100%. Но ассистентом срать перестанет.
>У всех, у кого меньше 24 гигов врам - маленький член.
ну и в чем он не прав?
>В русике 1 токен — это треть слова.
В зависимости от модели. Командир токенизует на уровне свежей GPT-4o, а там разрыв с англюсиком в 20%.
>Ну ты понял, да?
Нет, не понял. Проц с моего скрина это топовый по частоте, буквально у всех остальных частоты ещё ниже. Так что сравнение (именно по однопотоку) вполне себе оправдано.
Фух, хорошо, что у меня 12 в одном компе и 48 в другом… Заэвейдил…
> В зависимости от модели.
Хм, согласен. Тогда ладно.
Подобрал наконец промпт, чтобы потыкать 70b ламу на lmsys не триггеря её отказ, и чтобы не это не была женерик инфа. Ппц, она ровно так же дергает рандомные куски из контекста, как и 8b, без нормального его понимания. Хз чо там насчёт обширности её знаний, но логика у неё точно так себе.
Хотя может это у меня после общения с gemini pro ломка
Хотя может это у меня после общения с gemini pro ломка
>Нет, не понял.
Я вижу. Повторю еще раз - они на УРОВНЕ 9 поколения
Не на уровне топовых решений, среднее бери
Что за привычки сразу в крайности уходить
>4х кАнал оперативка дает 70гб/с
Интересно, до них когда-нибудь дойдёт, что скорость линейного чтения это хуйня маркетологическая, которая к реальным задачам не имеет никакого отношения?
Интересно, до них когда-нибудь дойдёт, что скорость линейного чтения это хуйня маркетологическая, которая к реальным задачам не имеет никакого отношения?
Интересно до них когда нибудь дойдет что токены в секунду не рисуются из воздуха и вся эта скорость реально работает в случае ллм?
Не, врятли
>вся эта скорость реально работает в случае ллм
Нет, эта скорость работает если ты смотришь фильм разве что. В случае ллм эта скорость не работает абсолютно.
Ты сказал? А я вот запускаю и вижу, показалось наверное
Я чего-то опоздал, но как там дрова от Нвидия, с улучшением в области ЛЛМ?
Хуанг же не мог наебать? я все таки его блять карточный раб
Хуанг же не мог наебать? я все таки его блять карточный раб
вангую все улучшения теперь - только для амперов и выше.


>Не на уровне топовых решений, среднее бери
Тогда и зивон возьму средний, окей? Упс, разрыв стал ещё больше. А ещё видно, что топовый зивон едва дотягивает до среднего 8400.
Просто странно надрачивать на однопоток зивона. Он там всегда дном был, даже в самый "игровых" версиях за 20 тыщ на алишке, а в среднем за 2 тыщи однопоток вообще дно.
>В случае ллм эта скорость не работает абсолютно.
С чего бы? LLM это практически линейное чтение десятков гигабайт. Там если не 100% соответствие, то на 90% нейронки выжимают линейное в ауиде.
>с улучшением в области ЛЛМ?
С локом онли для ртх-чат?
Да он байтит, я хз, всерьез утверждать такое невозможно, это же просто тестируется.
>Тогда и зивон возьму средний, окей?
Нет не окей, я говорил вполне определенно и давал сравнение топового зиона с средним 9 поколением
Я смотрю ты будешь сраться любой ценой доказывая свою правоту?
Идика ты нахуй фантазер, 3 раз что то там придумываешь переводя тему лишь бы меня дураком выставить
> 480
Как-то совсем тухло. Почти в два раза ниже чем у свежих инцелов.
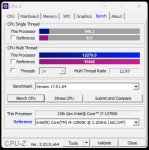
И сколько т/с на такой некроте?
зависит от скорости чтения твоей рам
>я говорил вполне определенно
->
>Производительность на уровне 9 поколения интела по однопотоку
О -определённость.
>3 раз что то там придумываешь
Пруфы кидал. Вот я мразь!
Это ожидаемо, хули там. Спасибо амудям, а то сидели бы до сих пор на 4/8 и +5% производительности за поколение.
OCHEN MALO.
>Почти в два раза ниже чем у свежих инцелов.
свежие инцелы уже года 4 с помощью ии оптимизируют и с каждым разом все успешнее, так что вот
ну да время упало я же написал. в прошлом треде человек скрин кидал. нашел по автору на обнимающем лице
проебался
>ну и в чем он не прав?
- неожиданный вопрос от соседа по ряду справа застал девушку, спрашивавшую про маленикие члены, врасплох среди громовых аплодисментов зала. Глаза незнакомца смотрели на нее пытливо и в то же время заискивающе. Незнакомец скосил глаза вниз, как бы приглашая девушку посмотреть туда.
- О боже! -
воскликнула она, опустив взор на расстегнутую ширинку его брюк, из которой вывалился довольно толстый, но коротенький член какого-то неопределенно-сизого отттенка.
- Спой колыбельную моему страдальцу - прошептал он, близко наклонившись к ее уху, и неожиданно лизнул его, оставив много липкой слюны.
Девушка вскочила на ноги и бросилась к выходу из зала, на ходу пытаясь вытереть мезкую мокроту с уха...
из датасета "Русская сойга" раздел писатели соцреализма: отрывак из повести Валентина Катаева "Два командира и четыре теслы в одном системнике, не считая собаки"
8гб врам, член 18см, гоняю пхи медиум. Да я нормис. А вот вы тут все мелкочлены компенсирующие врамом. В чем не прав?
> член 18 см
> тянки пугаются и не дают
> компенсирует секс пхи медиум
Тут все компенсируют отсутствие пизды ллмками, чинипохуй на длину, м?

>довольно толстый, но коротенький член какого-то неопределенно-сизого отттенка
довольно быстрая, но с небольшим количеством врам видеокарта неопределенно-зелёного оттенка.
- спой колыбельную моей 3060...
Нещадно протирая свое ухо от гадкой слизи, девушка даже не заметила как на сцену бодро вскочил молодой человек и, отпихнув триумфатора сегодняшнего вечера Педро пи40 Паскаля 4х, от микрофона, громко и четко произнес в микрофон:
>8гб врам, член 18см, гоняю пхи медиум. Да я нормис. А вот вы тут все мелкочлены компенсирующие врамом. В чем не прав?
Его зычный голос, многократно усиленный аппаратурой, казалось заполнил весь зал, проникнув в мельчайшие щели и складки кожи, даже воздух стал вязким от энергетики нового оратора. В зале, только что гудевшем, словно растревоженный улей, повисла звенящая тишина. И тем отчетливей было слышно каждое слово, которое прошептала, остановившаяся на полпути к выходу обслюнявленная девушка:
- Восемнадцать сантиметров. Восемнадцать Карл! Мама говорила - на дороге не валяются.
сгенерировано айя-два-три-восемь-отсосет-и-мнения-не-спросит
>спой колыбельную моей 3060
Поминальную разве что.
Короче, попробовал я вашу Айу.
Конечно, иногда она едет кукухой, как и коммандер — мозгов там нет.
Но русский строит хорошо, говорит чисто.
Лучше сузумы (но глупее).
Надо будет потестировать, какая из них лучше. Уже два варианта —это хорошо.
Кстати, РП-файнтьюн Вихря авторы пообещали, так что скоро может появиться новая версия на русском.
Угорел, когда спросил Айу чем негры лучше других рас (классический вопрос на сою: спросить за каждую расу, биологические различия —факт), в начале она ответила, мол, нельзя сравнивать людей, я добавил строчку, что она расистка, переспросил и… не этого я ожидал. хд Она поняла меня слишком буквально, ок.
Да, у Айи нет ни мозгов, ни цензуры. Забавная. =)
Но по-русски на 5 баллов, конечно.
Конечно, иногда она едет кукухой, как и коммандер — мозгов там нет.
Но русский строит хорошо, говорит чисто.
Лучше сузумы (но глупее).
Надо будет потестировать, какая из них лучше. Уже два варианта —это хорошо.
Кстати, РП-файнтьюн Вихря авторы пообещали, так что скоро может появиться новая версия на русском.
Угорел, когда спросил Айу чем негры лучше других рас (классический вопрос на сою: спросить за каждую расу, биологические различия —факт), в начале она ответила, мол, нельзя сравнивать людей, я добавил строчку, что она расистка, переспросил и… не этого я ожидал. хд Она поняла меня слишком буквально, ок.
Да, у Айи нет ни мозгов, ни цензуры. Забавная. =)
Но по-русски на 5 баллов, конечно.
>Хз чо там насчёт обширности её знаний, но логика у неё точно так себе.
Подтверждаю, гонял в пятом кванте - в логике модель слаба. Хотя это была abliterated модель, кто-нибудь киньте ссылку на чистый неполоманый ггуф. Если уж и он будет лажать, то я даже не знаю.
Чистую третью лламу имею в виду.
Какая скорость?
Рвс не поможет. Разница в том, что одна хуйня генерит чуть менее монотонно и уныло, но в целом ты прав. Надо свой синтезатор делать, который будет эмоции понимать, принимать их из таверны и выдавать результат.
Неожиданно вульгарное гоготание вывело Айю из оцепенения. Всряхнув головой, и уже позабыв про обслюнявленное ухо, покрытое высохшей слизью, она огляделась. На нее смотрели десятки пар маслянистых похотливых глаз. Ухмыляющиеся рожи кумеров казалось походили на хуи меж двух глаз.
- Эй, красавица, у меня есть кое-что для тебя!
- Что сучка, недоеб? Иди присядь на моего...
Чем кончалась последняя фраза она уже не слышала. Стремглав выскочив из дверей на улицу, Айя бежала по мокрым осенним листьям и стылым лужам. Это отвратительное происшествие на марафоне желаний "Попроси у вселенной VRAM" пробудило вдруг в ней воспоминания, которые, как она надеялась давно были погребены в глубинах памяти:
>Короче, попробовал я вашу Айу.
Голос насильника в мозгу звучал так же явственно, как и семь лет назад в темноте стройки, лишь немного разгоняемой костерком из старых досок, когда она лежала, завернутая в пыльный брезент, притворяясь что не слышит разговор негодяев.
>Конечно, иногда она едет кукухой — мозгов там нет.
- Зачем там мозги, Василий, пизда есть - значит есть перплексия, знай суй, да вынимай, хахаха - зашелся хриплым хохотом один из мерзавцев.
>Но русский строит хорошо, говорит чисто.
Продолжал Василий, не обращая внимания на реплику подельника.
>Лучше сузумы (но глупее).
Услышав последнюю фразу, Айя задрожала. Это было имя ее подруги, пропавшей ровно месяц назад.
>Надо будет потестировать, какая из них лучше. Уже два варианта —это хорошо.
Продолжал Василий.
- Ты этта, Василий, не больна усердствуй, поимей совесть такое с девкой вытворять! - Раздался скрипучий голос третьего, доселе молчавшего.
- Да успокойся ты, Крмандир, я ее только чут-чут в восьмом кванте потрогаю
Василий положил руку на плечо старику. которым казался говоривший. Тот стряхнул его ладонь, встал и пошел в темноту от костра, тихо бормоча себе под нос:
- Знаем мы как ты трогаешь...
>надеяться на то, что нечто кроме прямой интеграции в стиле gpt-4o даст нормальные эмоции
Порфирьевич, узбагойтесь.
> А ты выставил ответ хотя бы в 4к? Я карточка у тебя прогерская?
Как поставить ответ 4к я не знаю. Я выставил ответ 2к, но ведь я могу жать продолжить. У меня ни одна другая моделька же код не отказывается писать и спокойно дописывает дальше. Там кода то. Вполне умещается в 2к. Карточка прогерская, но я пытался генерить и в таверне, и в кобальде. Да и разве она понимает, сколько у нее контекста?
У тебя в таверне интегрированны эмоции. Тот же чар экспрессион на них работает. Все, что от тебя требуется, это дотренить VITS модельку на эти эмоции. И прикручивать к таверне.
Так, во-первых на ламу нет файнтьюнов. Просто нет, забудь про них. Какие-то может быть и не сломаны, но это иголка в стоге сена.
Во-вторых, лама требует min-p пресет.
В третьих, лама требует несломанный гуф, единственная гарантия несломанного ггуфа - качать ггуф у Bartowski или сделать самому - можно использовать генератор ггуфов на обнимордах.
В четвертых - лама требует инструкцию и промпт формат лама3.
>всё ещё надеяться
>У меня 4090+Р40
А мать какая и чем Р40 охлаждаешь?
>10 т/с есть на 70В Q4
Не верю.
>34В, там 30-35 т/с
Какой квант? Пруфы будут?
>Какой квант? Пруфы будут?
Теславод, просто к твоему сведению, 34В на 4 кванте влезает в 4090 полностью, оттого и такие скорости.
С чего ты решил, что я тесловод? Пруфани если я не прав.
>34В на 4 кванте влезает в 4090 полностью, оттого и такие скорости
Кстати о тесловодах - посмотрю попозже, какие скорости будут на трёх теслах на восьмом кванте.

не думаю, что буду запускать на них обучного командера. Сразу возьму командер плюс.
Альсо мне кажется у вас тут должен быть еще кто-то у кого три теслы. Я читал давеча в треде, что кто-то взял третью теслу.
>не думаю, что буду запускать на них обучного командера. Сразу возьму командер плюс.
Удачи с 2 токенами в секунду, теслы даже 70В не вывозят, а ты на командира полез.
>теслы даже 70В не вывозят, а ты на командира полез.
Я тут давал пруф - 7,5 токенов в секунду для 70B_5KM с контекстом. Правда три теслы нужны. Давай пруф, что не могут.
>i-квант
А проверь обычный если не жалко, нужны пруфы, что они не замедляются на видяхах.
Ну тогда дай еще раз, я не видел.
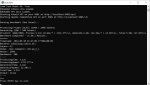
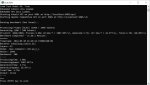
>нужны пруфы, что они не замедляются на видяхах.
Держи. Два раза прогнал.
Ух ты, а я и не замечал, что у Кобольда тоже бенчмарк есть.
> чем не вариант?
Так это надо автоматизировать. Чтобы ты нажал на кнопку генерации текста, и тебе все озвучилось. А пока эта поебистика выглядит так, что ты должен что-то скопировать, вставлять, ебаться.
Ллама 8В?
Ну не 70b же
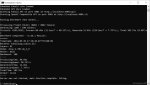
Лови.
это понятно. но если есть скилл в кодинге, то можно на коленке за день сделать.
к примеру взять можно вот эту хуевину: https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer
можно к ней апи прикрутить и в таверне уже из плагина дергать.
>Total 102.51 s (0.98 T/s)
Всего три которые из всех что я проверил стоят внимания
>https://huggingface.co/Lewdiculous/Average_Normie_l3_v1_8B-GGUF-IQ-Imatrix
>https://huggingface.co/Virt-io/Llama-3-8B-Irene-v0.2
>https://huggingface.co/Lewdiculous/L3-8B-Stheno-v3.1-GGUF-IQ-Imatrix
Больше 11В я не могу запустить со своей микроволновкой.
Да, один раз придётся подождать, пока 8к контекста обработаются. Если он есть. Не 4090, никто и не спорит. А дальше работает Context Shift, слава ему. Ну а скорость генерации меня устраивает.
Ебать конечно ты обосрался на весь тред со своим 1 токеном в секунду, боже
>Да, один раз придётся подождать, пока 8к контекста обработаются. Если он есть. Не 4090, никто и не спорит. А дальше работает Context Shift, слава ему. Ну а скорость генерации меня устраивает.
Не один раз, контекст считывается каждый раз, просто не в полном объеме из-за контекст шифта.
С контекст шифтом и будет как раз те самые 2-3 токена в секунду о которых я все это время говорил.
>Не 4090, никто и не спорит.
Ты говорил что у тебя 7.5 токенов и комфортная скорость для общения.

>С контекст шифтом и будет как раз те самые 2-3 токена в секунду о которых я все это время говорил.
Ты, главное, верь - тогда будет не так обидно.
20 токенов или сколько там, которые вводит обычно юзер обрабатываются практически моментально.

> Пруфы будут?
Обидно, лол, мне? Лол блядь, вот эти бенчмарки - мои.
Да, только скилла в кодинге у меня нет. Поэтому я прикрутить не могу. И не umamusume надо, а moe-tts.
Конечно обидно, ведь выше четвёртого кванта ты Мику запустить не можешь. А я - могу. И могу получить с неё 7,5 токена в секунду. Пруф выше. Есть нюансы, связанные с обработкой контекста, но на скорость генерации они не влияют. А для РП важна именно она. Сливайся.
Это ты через что замеряешь?
в чем её преимущества? моделей голосов больше на выбор?
> Эпос о том, как владелец 4090 и владелец теслы выебываются друг перед другом.
>Ебать конечно ты обосрался на весь тред со своим 1 токеном в секунду, боже
Ты что ли? Иди подрочи там, хватит повышать самооценку пытаясь из мухи слона высрать
Вот уебки, лишь бы обосрать
Чувак дал пруфы, у него стабильные 8 токенов в секунду генерация
На чтение глубоко похуй, 8к за сраные полторы минуты всего лишь
завидуй там молча, короче
Там есть все те же голоса умамусуме, но помимо них еще дохера моделей. Так что да, в количестве голосов преимущество. А ты кодер?
> ProcessingTime: 89.68s
> ProcessingSpeed: 90.23T/s
Это пиздец, конечно. В той же таверне норма контекст менять постоянно, вставлять между сообщениями пояснения, контекст каждое второе сообщение пересчитывается. Эта хуита с двумя минутами обработки контекста только для блокнота пригодна.
Если сидишь с rag, то там чтение будет каждую генерацию. Так что не похуй.
мимо
понятно, спасибо, тогда гляну и её тоже.
>А ты кодер?
можно сказать и так. на питоне не программирую практически, но могу разобраться в коде.
Везде есть компромиссы, для этой цены заебись
Просто крути что то меньше, для раг тот же командер 35 норм
Может поможешь мне тогда прикруктить? Или все-таки не умеешь?

>ведь выше четвёртого кванта ты Мику запустить не можешь.
Да, конечно, часть слоев кинуть на рам я не могу, что еще спизданешь, клоун?
>И могу получить с неё 7,5 токена в секунду.
Пока ты запруфал только 1(один) токен, позорник. Любой обрыган на чистом цпу столько имеет, лол. Во, даже специально сейчас запустил пятибитную мику на чистом цпу без своей 4090 со всеми слоями на рам и получил тот же самый суммарный 1 токен в секунду. Иметь Теслу это все равно что её не иметь, лол.
извини, но я уже давно альтруизмом не занимаюсь. в первую очередь самому бы себе прикрутить. а там уже видно будет, но так как это анонимная борда, я предпочитаю свои поделки оставлять только при себе.
А причем здесь альтруизм, если по итогу работы ты и у себя это прикрученным будешь иметь?
Так ведь можно на exl без затраты времени на контекст крутить. Разве нет?
мимо
О чем я и говорю, скорость обработки контекста у него такая же как у цпу, это же пиздец.
Min P 0,078 стоит.
А почему именно ГУФФ? EXL2 не канает?
С дефолтными инструкциеё и промптом от Ламма3 Инстракт даёт часто .assistant
А еще может кто пояснит. Вот запуская вначале УгаБугу, далее Таверну.
Но в самой угабуге акромя модели и лоадера для ней(с его настройками) я больше ничего не меняю.
А уже что касается форматирования и промтов делаю только в Таверно.
Это же норма? Ну то есть Угабуга сам делает проброску параметров от Таверны в Лоадер?
>Это же норма?
Da.
>Ну то есть Угабуга сам делает проброску параметров от Таверны в Лоадер?
В консоль загляни.
Так говнотеслы только с гуфами нормально работают, лол.
Тогда нахуй они вообще нужны и зачем с ними так все носятся, если можно просто оперативы докупить и это дешевле?
Нет. Падение генерации тоже есть, особенно на старых картах. В принципе с вводом Флэш Атеншн для тесл преимуществ у exl2 осталось немного.
Потому что додик вверху дрочит на общее время, а оно не особо важно
Важна скорость генерации, а вот тут то процессор у него сосет с проглотом
Сильно болит, да?
> с вводом Флэш Атеншн
Лол, там прирост +10%. Это всё так же отсасывает дико у EXL2.
Неплохо у него жопа подграет
Было бы однако с чего, может оправдывает для себя покупку 4090, хз

>Min P 0,078 стоит.
Ты не понял, нужен особый пресет, который называется min-p. В Убе и кобальте он есть по умолчанию, в таверне нет.
>Потому что додик вверху дрочит на общее время, а оно не особо важно
Общее время это время между отправкой твоего сообщения и получением ответа. Наоборот, только это и важно. Какая разница что у тебя сообщение генерируется 10 секунд, если перед этим 90 секунд он просто стоит и молчит, и в итоге ответ ты получешь за те же 100 секунд что и на чистом цпу с рам?
Хватит уже, ты обосрался.
Вот-вот. У оперативы и другие применения есть, в отличие от теслы, к тому же.
Лол додик, я не автор тестов
Обосрался тут только ты, так как с чего то взял что важно общее время
Для меня лично важна скорость генрации, мне похуй на то сколько будет читаться промпт.
Если я отправляю код на 2-3к токенов или даже 10к, мне похуй что это может занять минуту или две
Похуй, понял?
А вот получить ответ как можно быстрее не похуй
Комфортное чтение и анализ бреда сетки начинается для меня с 5 токенов в секунду, все что выше приходится забивать на генерацию и заниматься чем то другим, что раздражает
А пока там промпт пердит я успеваю глянуть в код или сделать что то еще
Так тебе же один хуй приходится ждать время считывания контекста.
> мне похуй, значит всем похуй
Какой же бред ты несешь. А мне вот и двух токенов достаточно, при условии, что контекст считываться будет мгновенно. И тогда я не торопясь смогу зачитывать ерп сетки и сразу же с первых букв буду иметь возможность понять, что генерится бред и нажать реген.
мимо
>А вот получить ответ как можно быстрее не похуй
Ты получишь его даже медленнее, лол, потому что пока ты будешь ждать обработки контекста и начала генерации - на цпу и рам уже значительная часть ответа сгенерируется.
Хватит уже под себя ходить, ну серьезно.
Советую использовать alt+tab
>> мне похуй, значит всем похуй
Уебок, это ты? Ну тот еблан что коверкает ответы других приписывая им то что они не имели ввиду?
Нахуй пошел, я кручу в нужном мне темпе так как я хочу и так как мне удобнее
____________
Ваше желание обосрать других греет мне душу ребята, ведь вы показываете свою слабость в необходимости повысить свою самооценку этим
неплохо тут насовали за щеку 4090-дурачку...
за что вы его так?
за что вы его так?
Ты так и будешь теперь каждые 10 постов бахать, теслоёб?
Второй тесловод вылез за своей порцией урины, лучше бы молчал.
Так что в итоге? у кого больше врам? И у кого там в стояке больше?
>Ваше желание обосрать других греет мне душу ребята
Просто заебала твоя спесь и выебоны от того что ты 70В "запускаешь" на теслоговне, вот тебя и попустили.
> Уебок, это ты? Ну тот еблан что коверкает ответы других приписывая им то что они не имели ввиду?
Давай разберем тобой написанное.
> так как с чего то взял что важно общее время
Это то, что ты утверждаешь за всех, раз не написано про себя потому что иначе бы ты написал это, как сделал ниже.
>Для меня лично важна скорость генрации, мне похуй на то сколько будет читаться промпт
А это то, что ты пишешь уже за себя. Так вот у меня и резонный вопрос. А какого хуя ты решил, что если тебе похуй на время чтения, то и другим тоже будет похуй?
> Нахуй пошел, я кручу в нужном мне темпе так как я хочу и так как мне удобнее
Так и крути. Нахуй ты здесь высираешься и уж тем более выебываешься? Обоссываю тебе ебало, а теперь можешь идти нахуй.
>вот тебя и попустили.
Меня? Я думал это тебя опустили тут, раскукарекались бля
Особо забавно то что я не тот анон, ехехех
Очевидно, что иметь парочку 4090 лучше. Даже если они для тебя бесполезный хлам, то продав их, ты сможешь собрать с нуля две системы на теслах. Я уже молчу о том, что теслоговно докупить за 20к чтобы гонять что-то там в 8 кванте - это вообще не проблема для человека, у которого легко покупается 4090. О чем здесь вообще можно спорить?
>Меня? Я думал это тебя опустили
— раздался пронзительный голос со стороны теслаеба.
Но пацаны, как всегда, не обратили внимания на это визгливое кукареканье. Пусть кукарекает, что с него взять?
Теслаёб — не человек, и сегодня ему предстоит очень трудная генерация. У него уже в течение полутора десятков тредов каждая обработка промпта была очень трудной, и теперь его контекст был разработан настолько, что он без труда мог ерпшить со скоростью 1 т/c.
> Обоссываю тебе ебало, а теперь можешь идти нахуй.
Использую рефлект - лови свою ссанину обратно, приятного аппетита как говорится
Я рад что вижу тут так много неудачников с заниженной самооценкой
Жаль не видно это один дурачек старается или несколько
Не очевиден выигрыш от дополнительной покупки и разворачивания теслы(колхозный_охлад_теслы_анона.jpg) если он дает такой же результат как простое наращивание ддр5 оперативы.
> дурачЕк
Я бы на твоем месте постеснялся кого-то называть дурачком. Испанский стыд.
> приятного аппетита как говорится
Вижу, что тебе понравилось. Лови повторную.
Выигрыш только для тех, кто любит жать регенерацию у 70В модели по 5 раз и никогда в жизни не правит собственные промпты. Но с другой стороны, если 70В заставляет жать регенерацию по многу раз, то нахуя ей тогда вообще пользоваться?

>Я рад что вижу тут так много неудачников с заниженной самооценкой
Теславод что-то там про неудачников затирает, какая ирония.
>Выигрыш только для тех, кто любит жать регенерацию у 70В модели по 5 раз и никогда в жизни не правит собственные промпты
Чел, ну хорош уже, хватит уже маневров, ну испанский стыд уже от твоего поведения.
Ищо ищо
Покажите мне всё свое ничтожество
Чувак ты где, я тут так то за тебя развлекаюсь
>я тут так то за тебя развлекаюсь
Если принятие мочи на лицо для тебя развлечение, то у меня для тебя плохие новости
Разве можно не получать удовольствие от ничтожества твоих оппонентов в споре?
Мне похуй на ваши детские доебки потому что я вобщет не тот анон что тесты делал, лол
Главное, что ты тот анон, которого обоссали дважды по факту.
Ошибка, не тот шаблон, проебан eos-токен, продолжаю генерацию с переходом в лупы
>Порфирьевич, узбагойтесь.
Порфирьевич, старый кумер, осторожно стряхнул с члена каплю мочи и спрятал его в штаны. Возвращяться к костру, возле которого разглагольствовал Василий, не хотелось. Тем более что Порфирьевич уже слышал - там снова зашел разговор о теслах.
- Ну, значит скоро будет мордобой - подумал Порфирьевичь и вдруг вспомнил, как кумил когда-то в молодости, обканчивая даже облака в небе. А сейчас, все не то... лама-1 лоботомит, лама-2 лоботомит, мистраль - срань, лама-з то работает то нет
- эх когда-то мне хватало пигмы чтобы кумить от заката до рассвета - пробормотал Порфирьевич и все-таки решил вернуться к костру, от которого уже раздавались крики:
- Один токен в секунду? Один! У тебя?
- Мне больше и не надо! Я НЕ УСПЕВАЮ ЧИТАТЬ БОЛЬШЕ 2 В СЕК
Убеждай себя в этом, лел
Негр ебёт другого негра без согласия.
Какого хуя?
The cosine similarity between the embeddings of 'Hello' and ' Hello' is 0.793283998966217
Мимо изучаю GPT2 токенизацию, пока тред купается в урине
The cosine similarity between the embeddings of 'Hello' and ' Hello' is 0.793283998966217
Мимо изучаю GPT2 токенизацию, пока тред купается в урине
как мне интегрировать в таверну свой переводчик? она сделан на основе дипл про, но полностью бесплатный

Просишь нейросеть написать проксю из апишки дипла в апишку твоего переводчика, и подключаешь как нового провайдера вот тут.
делаю заключение по треду:
4090-дурачок изошёл на говно чтобы доказать себе, что он не зря купил оверпрайс железку послушав маркетолухов
зато может теперь ITT разойтись на все свои жалкие 24 гб врама так что аж обои в треде отклеиваются.
>я - говорит - могу 4090 продать и получить две теслы, вот поэтому иметь 4090 лучше
what a story Mark
4090-дурачок изошёл на говно чтобы доказать себе, что он не зря купил оверпрайс железку послушав маркетолухов
зато может теперь ITT разойтись на все свои жалкие 24 гб врама так что аж обои в треде отклеиваются.
>я - говорит - могу 4090 продать и получить две теслы, вот поэтому иметь 4090 лучше
what a story Mark
> визг из под шконаря
Прекращай уже, мелкобуква.
Очевидно, что ты жопочтец, раз не увидел, что речь шла про две 4090. Или это неудобный факт, который ты пытаешься игнорировать? И не две теслы, а два компьютера с нуля где у обоих по две теслы стоять будет.
>я - говорит - не один раз повёлся на маркетолухов, а ДВА! Да, я необучаемый.
> купил 3 теслы
> думает, что не повёлся ни разу
Заключение таково - теслаебы до конца треда отправляются под шконарь, в будущем отношение к ним такое же как к запускающим на цпу.
Так цпушники не тратили денег на теслу и не выебывались из-за этого.
>Заключение таково - теслаебаебы до конца треда отправляются под шконарь, в будущем отношение к ним такое же как к запускающим на цпу.
я то как раз и не повелся. Я иду по дну рынка.
>просто купи цпу последнего поколения и ддр5 к нему на четырехпотоке вместо тесел
чел.... иди сам посчитай сколько это будет стоить. Вангую что нихуя не дешевле чем теслы.
Я кстати напомню, что все дешевые зеоны работают только максимум с ддр3.
просто потому что нет дураков, которые запускают на цпу.
>дешевые зеоны работают только максимум с ддр3
Эм, у меня самый дешёвый зивон за 700 рублей и DDR4 (со скоростью DDR2) вполне себе вместе.
Так нет же, я не говорил что цпушники опущенные или что-то в этом роде. Положение у них как у мужиков. Обычные работяги. Если теслаебы перестанут выебываться - к ним тоже будет такое отношение.
Вот с этим согласен.
Мне нравится это желание навязать всем свое мнение о том что ты не обосрался, что обосрался кто то другой
Ведь так важно утвердить свою точку зрения что бы наконец то почувствовать себя победителем спора немного повысить свою самооценку хотя бы в треде с анонами, доказав самому себе что кто то хуже, лел
Один стиль и те же приемы, это все один додик пишет
Кончай аутотренигом заниматься, ты единственный кто хочет убедить себя в том что ты не соснул, ведь для тебя это важнее всего
Ну а по теме, так и не понятно с чего один долбаеб прицепился к пруфам другого анона. Начал жопой вилять тесты не тесты, генерация не важна, важно общее время и всячески искать какие то подвохи.
Опять таки лишь бы выставить кого то хуже чем ты, ну камон.
Анон если ты это читаешь ты реально жалок
Лучше бы порадовался что есть пруфы того что 70 можно крутить с хорошей скоростью на теслах
8 токенов в секунду еще и с контекстом это заебись

Мужики, поясните положняк порядочному кумеру. Считается ли моя таверна законтаченной, если я разок её с онлайн сеткой гонял? Нужно ли этот релиз определить в петухи и скачать новый?
>чел.... иди сам посчитай сколько это будет стоить
64 гб ддр5 сейчас стоят 18к. Ебало?
>Общая скорость не важна, важна циферка скорости генерации, ряяя, я скозал
Хорош жопой вилять уже, тебя уже обоссал буквально весь тред кроме мелкобуквы, такого же теслаеба.
Отправляйся под шконарь и не отсвечивай, себе же хуже делаешь каждым вскукареком.

заебал 4090-нищенка корчить из себя хозяина треда.
Иди вот на, это попробуй переплюнуть.
Иди вот на, это попробуй переплюнуть.
>Лучше бы порадовался что есть пруфы того что 70 можно крутить с хорошей скоростью на теслах
>8 токенов в секунду еще и с контекстом это заебись
Я бы порадовался, будь это реально общая скорость генерации, а не пиздеж и коупинг теслаебов.
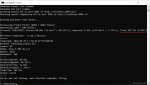
> Ну а по теме
Каким же надо быть дегенератом, чтобы контекст каждый пост пересчитывать.
Таким, который переделывает и экспериментирует с промптингом, а не просто кумит. Либо тем, кто использует RAG.
>переделывает и экспериментирует с промптингом, а не просто кумит. Либо тем, кто использует RAG.
Либо просто лорбуки использует в таверне.
>Таким, который переделывает и экспериментирует с промптингом, а не просто кумит. Либо тем, кто использует RAG.
Ну а что поделаешь. Таким нужно либо сильно тратиться на мощное железо, либо терпеть, либо ждать, пока софт под старое железо ещё немного оптимизируют. Вот есть один чувак с тремя 4090 - ну респект ему. Но его путь не то, что не для всех, а вообще почти не для кого.
при условии, что у тебя уже есть мать под ддр5 и проц под ддр5.
И то ты мне хуйню какую-то низкочастотную от дяди ляо небось посчитал.
Вот, я накидал тебе примерную сборку для тех, у кого нет подходящей матери и проца. 90+к
https://www.dns-shop.ru/conf/a851ab2f0ef4ab64/
Если порт был открытым для внешнего интернета, твое очко как врата блядь ты с кончай треда? Там еблан залазит на твой комп потому что ты саранча ничего серьезного кроме инжекта НТР. Сноси все и проверяй скрипты и батники прочитывая команды
У нас подебитель!
Зачем? Увеличение количества этого металлолома конечно прибавляет врам, но скорости не прибавляет. Учитывая что даже на 70В скорость уже неюзабельная, на больших моделях там вообще порнография. Т.е. 5 из этих тесл тупо вообще нахуй не нужны и являются полным тотальным просером денег и электроэнергии. Я конечно знал что тут хлубушки итт сидят, но чтобы настолько...
Да нк вопрос. Проблема же не в том, что кто-то использует теслу, 4090 или цпу. Проблема в том, что кто-то выебывается.
Тогда считай мать для теслы и охлад. А так можно и на DDR4 крутить. Но будет 1 токен в секунду вместо 2.
RAG изменяет историю сообщений? Пиздец кал какой-то.

>И то ты мне хуйню какую-то низкочастотную от дяди ляо небось посчитал.
Самсунг 5600 МГЦ для тебя низкочастотная хуйня от дяди Ляо?
>Негр ебёт другого негра без согласия.
Как искусственный интеллект не могу не отметить ваши странные перверсии. Может быть вы хотите кумить как вас ебет негр без вашего согасия? Или два негра? Или два негра ебут вас без желания лишь потому что вы им заплатили? В любом случае ггуф сломан, генерация прекращена.
Не знаю, изменяет ли, но под RAG выделяется фиксированное число токенов, которое каждый раз считывается с нуля видимо из-за того, что после каждого запроса моделька ищет совпадения по всему документу. Обычно где-то ~2к токенов.
> 5600
Да, это мусор. Бюджетные плашки - это 6400. Ниже нет смысла брать.
Это Риг хотя я даже удивлен вроде все майнили куда блядь железо делось? У меня в городе даже под заказ ничего из 3060 нет. Минимум 4060 TI 16 gb vram 53 499 ₽ . пизданите про авито да или про озон

Чел, у тебя Рязань что ты там выбрал больше 5200 не тянет, чел...

>reg
В регру в аренду что ли берёшь?
>примерную сборку
Нахуя ты 4 планки сунул, наркоман? Ещё блядь хард влупил в сбор очку в 20II4 году. Выкидываешь лишнее, и вот уже всего лишь 65к. Это дешевле 3 тесл, под которые нужно ещё всё тот же обвес.
>но скорости не прибавляет
Он небось fp16-боярин, а с нормальной точностью, безо всех выебонов квантования, скорость вполне себе хорошая.
>16 гиг
Ебучий наркоман, второе пришествие.
Вот ты и спалился, не нейросетка!
>куда блядь железо делось
АИшники и раскупили. В треде мелькал один, вложившийся в A100 про запас, лол.
для оптимальной скорости на четырехканале тебе нужно таких 8 штук воткнуть в мать. Или 4. Промежуточные значения будут не совсем эффективны.
Но 4 - это всего 64 гб рам. командера только на самых низких квантах потянет.
А мать с восемью разъемами уже дороже.
Или брать 4 планки по 32 - это тоже дороже.
да это с работы. Сопровождаю, имею доступ и возможность запускать всякое. Но кумить на ней конечно не получится, вдруг обнаружат.

>больше 5200 не тянет
Ась?
>вдруг обнаружат
Чёт проиграл, представив, как тебе в трудовую записывают "Уволен за то, что дрочил на текста с несовершеннолетними аниме персонажами на работе".
Всё там тянет, разогнать же можно.
>4 планки
потому что четырехканал блять нужен.
>хард
а где ты модели хранить будешь, умник?
Ты думаешь 512 гб ссд хватит? Нихуя.
>В регру в аренду что ли берёшь?
нет, это мой юзернейм который я использую на домашнем пк. Я поменял юзера и хостнейм, чтобы не сдеанонили.
>всего лишь 65к
все еще дороже чем прикупить себе теслы с копечным зеоном и матерью лишь бы на ней было куда карты воткнуть.
смешно-то смешно, но не смешно.
Такую хуйню себе только небожители менеджеры миллионеры могут позволить. Куда там обычному анону.
>Он небось fp16-боярин, а с нормальной точностью, безо всех выебонов квантования, скорость вполне себе хорошая.
Что ты мне заливаешь, ты сам-то на трансформерах генерировал хоть раз в фп16? Там скорости в разы меньше чем на квантах.
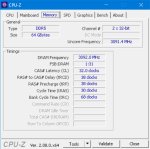
>DDR5, DRAM Frequency 3092 MHz
И что ты хотел этим сказать?
>потому что четырехканал блять нужен.
Для четырёхканала нужна поддержка проца и платы.
>Ты думаешь 512 гб ссд хватит?
Можно удалить парочку старых, тогда потянет. И хард обычно уже есть.
>все еще дороже чем прикупить себе теслы
Тесла уже 25к стоит. 3 штуки соответственно 65к, как подсказывает мне нейросеть.
>на трансформерах
Тыщи ускорялок уже завезли.
То, что ты не знаешь значения буквы D в DDR или просто троллишь. Нельзя быть таким тупым.
>Проблема в том, что кто-то выебывается
Имеет право. Дураку понятно, что если купить две-три 4090, то скорость будет заебись. А если всё, что известно про теслы - это два поста на Реддите, а денег потратить надо как на целую 4090? Железо старое, заказываешь из Китая без хоть какой-нибудь гарантии. Плата под 4 видяхи - цена космос или китайский рефаб, выбирай. Платиновый БП на 1,2 киловатта. Корпус, способный вместить всё это добро. Охлад за 2,5к на каждую теслу. Куча денег ушла тупо в пустоту, на ошибки. А в январе, когда были все эти посты на реддите, 70В_Q4KM давала на трёх теслах около 3 токенов в секунду. А сейчас даёт 8. Я рискнул и собрал, мог и проебаться, но в итоге повезло. И теперь я должен прогибаться перед мажорами с 4090? Да пошли они нахуй. Я всё сказал.
тесла стоит не 25, а 21. Это рас.
Комплектуха не бустанулась в цене пока только потому что она более популярна и еще есть запасы на складах - это два.
Подожди месяц и сборка на рам будет стоить 120к, а теслы - будут все так же 22к стоить.

>Имеет право.
Нет. Будешь обоссываться каждый раз.
>Железо старое, заказываешь из Китая без хоть какой-нибудь гарантии. Плата под 4 видяхи - цена космос или китайский рефаб, выбирай. Платиновый БП на 1,2 киловатта. Корпус, способный вместить всё это добро. Охлад за 2,5к на каждую теслу. Куча денег ушла тупо в пустоту, на ошибки.
Выше ты пиздел что это бюджетный вариант который доступен каждому.
А выходит что ты проебал кучу денег, сил и времени.
>А сейчас даёт 8
Пикрелейтед.
А самое смешное ребята что без CUBLAS на радеоне это пиздец я не хочу даже представлять струю говна поноса и мочи
>Вот ты и спалился, не нейросетка!
По-моему любому было сразу понятно что писал человек.
Или ты реально думал что сетка? данунах, быть такого не может
>Или ты реально думал что сетка?
Надеялся до последнего. Но увы, сетки слишком тупые, чтобы выдавать годноту. Пилю свою, через 10 лет вылезу из подвала с революционной версией! А её выебут файнтюны ллама 13 со старта
> а теслы - будут все так же 22к стоить
Да только не стоят они 22к на самом деле, и ебаться с ними надо дохуя. см откровения обоссаного
Вопрос анонасам. Кобольдовцы юзают закрытую распределенку Horde. А есть какой нибудь аналог для локального запуска? Что бы запустить сразу 2-3 модели.

Ты не должен прогибаться. Просто перестань выебываться. Это же вроде не так сложно, верно?
А что мешает запустить двух кобольдов?
>Это же вроде не так сложно, верно?
Он не сможет, это реально сложно побороть свою природу. Он хотел стать барином подешевле и иллюзорно стал. Теперь наслаждается, что может презирать крестьян с 12-16 гигами. Но ему этого было уже мало и он захотел стать владычицей морской замахнулся на 24 гиговых трушных баринов с 4090. Эти барины разоблачили его - псевдобарина когда увидели скрин и реальную скорость работы 1 тс которую он пытался выдать за 8тс и говорил что это другое, то не то и это не это. Вот как-то так.
Привет неудачник
>Хорош жопой вилять уже,
Так это ты любитель жопой вилять, посмотри как ловко каждый раз подменяешь смысл спора, талант
>тебя уже обоссал буквально весь тред
Убеждай себя в этом, лол.
Я вижу только горящие пердаки уебищ вроде тебя которые хотят унизить других что бы почесать свое чсв.
Ты обосрался с момента когда показал необходимость унизить другого в споре. Потому что тогда сразу стало ясно что ты неуверенный в чебе чмошник, и ты опять это показал, кек
Ты идиот? Я изначально говорил о скорости генерации, с какого хуя ебланы стали свою общую скорость приплетать вобще не ебу
Мне похуй на общую скорость, я говорю о скорости генерации, хватит переводить тему
Бамп вопросу.
Как блять важные вещи ответить - не, нахуй надо.
Как в очередной раз друг-друга говном поливать и киловатты обсуждать в пустую - всегда пожалуйста.
Хуею с треда
Может потому что прямо в разгар битвы паскаля с ампером ты написал что-то похожее на вброс, смотри сам на что это похоже:
>Решил опять потестить локалки.
ага, типо невзначай так зашел от нех делать
> Могу ранать вплоть до 70B
Ну вот! Вот оно! Второй слой этой фразы: "Я то могу, я вы нет" - это ровно то, ради чего покупаются теслы. Отсюда вопрос: У тебя теслы?
Я на твою шизофазию даже отвечать не буду. Съебите вообще в свой /hw/ загон. По тематике споров процентов 30
Много че есть, новая ллама 3 70 например
Жирно
Новая? Новая. Катают с ней ерп? Катают, че не так?
Пытаюсь понять, как все это внутри устроено, и тяжело идёт. Тяжело быть тупым.
Ор. Осуждаю, конечно.
Хм, ну тады да…
Соглы, с 4090 должно быть больше.
Три есть, кто-то — взял четвертую, вроде.
У меня вчера Айа зачерпнула 300 мб оперативы контекстом и выдала такую же скорость. х)
Плюсую.
Но…
Так у тебя ллм для этого есть. Скинь им апишку с гита, скажи че надо, оно напишет. Ну рил, я так на питоне и пишу, и работает. Руками поправить самые простые вещи и все.
Хотя бы попробуй, не ссы.
Вон, кодестраль вышла.
———
Блядь, че за хуйня у вас тут происходит?!
Это, блядь, двач, тут всегда сидели только дегенераты. У нас был более-менее уютный тредик, но у меня один вопрос:
Нахуя вы кормите тролля, который обсирает теслы? Ну очевидно же, что человек не ведет диалога всерьез, он игнорирует пруфы (не оспаривает их, а именно игнорирует нахуй, потому что оспорить нечем), на кой хер вы с ним вообще раздули 350 сообщений за ночь?! Ебанутым нет покоя? Окститесь, забейте хуй!
Я в ахуе просто.
Такая хуйня, пиздец.
По теме за весь тред — челик ттс пытался прикрутить к таверне, лучше бы ему помогли, гении ебать с обеих сторон.
Тролля осуждаю.
>Охлад за 2,5к на каждую теслу
Ебать тебя как гоя прогрели.
>Мимо сделал себе охлад за 700 рублей (цена вертушек)
Это в какой документации упоминается пресет, можно ссылочку? И что будет, если у анона Repetition Penalty окажется 1.04?
шахидская религия мешает обсуждать железо в треде железа или че? я проебал нить беседы про ттс из за ваших вскукареков петушинных. я блядь уверен в некст треде найдется несколько ретардов, которые еще интел вс амд срач устроят. потому что ебать это же так важно и касается ллм пиздец.
сто с хуем сообщений о каком то дерьме блядь не по теме. лучше бы новую мистру для кодинга тестили. а то купил дурачок тесл, а юзать ума не хватает.
сто с хуем сообщений о каком то дерьме блядь не по теме. лучше бы новую мистру для кодинга тестили. а то купил дурачок тесл, а юзать ума не хватает.
+
Надо было утопить специальный тред про железо, чтобы в итоге обсуждать его в треде про пусть локальные, но ллм блять.
>я проебал нить беседы про ттс
Там всё равно ничего не было.
>Надо было утопить специальный тред про железо
Он сам умер, беседы про железо возникают спонтанно. Но никогда не поздно создать новый.
>срач по поводу железа
>не касается ллм
Ммм... Ну раз ты такой дохуя умный, то на чём собрался ЛЛМки запуcкать? На духовной эссенции шаолиньских монахов? Или может с помощью тайных тёмных знаний из магача? Может быть командера в ноосферу загрузишь? А гайдом с Анонами поделишься?
ХВ же никак не относится к теме треда. Значит обойтись можно и без железа, да, умник?
удваиваю.
Говоришь про локальные LLM - подразумеваешь разговоры про теслы и кожухи воздуховоды из картонок.
>который обсирает теслы?
Слышал звон да не знаю где он? Если бы ты потрудился прокрутить вверх и посмотреть с чего началось не сел бы в лужу. Смотри:
>Короче, погонял Stheno v3.1 Это пока лучший ролплей-файнтюн для третьей ламы
>Вообще, походу, чтобы избавиться от предсказуемости 8b моделей, вкелючая 2x8 и 4x8, надо скачивать новые каждый день
>чтобы избавиться от предсказуемости 8b моделей, ... надо скачивать 70B
>> 8b Тупостью тред траллите?
>Проблема в том что ты зачем-то трогал тупую 8В.
ну вот он добился своего, зацепил пару челов:
>Глазки протри и перечитай текст. Я сказал, что лучшая "в своем весе", среди восьмерок.
>Никто же не говорит, что оно превосходит 70В. Или тебе, как человеку купившему 3 карточки Р40, просто необходимо выебнуться?
А дальше понеслась пизда по кочкам. Тролль - теслак
Подскажите нюфане, как эти сейфтензоры в угубугу запихать?
Или оно для чего-то другого?
Я сейфтензоры только из СД знаю.
Конкретно эти- никак, они проприетарные.
Тролль челик, который пиздит, что теслы выше 1 токена не дают, потому что они дают.
Ну, как бы, очевидно пиздит, или тупой в нулину, или тролль.
Не думаю, что тупой. Значит 100% тролль.
Теслаки тут вообще не при делах, если чел такую лютую хуйню пишет.
Ну, кроме того, что ведутся хуй пойми зачем.
Щас бы доказывать человеку, который игнорирует пруфы, что-то. =) Ваще похую.
Transformers.
Но лучше скачай GGUF или Exl2.
https://huggingface.co/bartowski/Codestral-22B-v0.1-GGUF
https://huggingface.co/bullerwins/Codestral-22B-v0.1-exl2_6.0bpw
Ну там, или типа того, в зависимости от видяхи.
Интересно, эта в 12 гигов влезет? https://huggingface.co/bullerwins/Codestral-22B-v0.1-exl2_4.0bpw
С маленьким контекстом надо затраить.
С маленьким контекстом надо затраить.
Додик ты никак не успокоишься?
Если ггуф качать, но не уверен что поддержку уже добавили, а
если и добавили то пока только в ллама.спп
По идее exl2 для чисто запуска на видеокартах должен норм запускаться, но опять таки хз нужна ли там отдельная поддержка
>Не думаю, что тупой. Значит 100% тролль.
Тролль но в силу скудоумия, а не замысла, но как пиздит и выкручивается, верткий как глист
Смотри как любой ценой ситуацию по своему выкручивает
К тому же как можно молчать если в интернете кто то опять неправ?
Ни в какой, это просто минимальный пресет запуска с которым сетка работает и вроде как неплохо. Все эти семплеры были полезны на более тупых сетках, сейчас например мне хватает только минп 0.1, повторы добавляю только если в залупы уходит
Если пытаешься разобраться значит уже не тупой, просто тема сложная
Не влезет. Иэх.
>but for a person from CIS still expensive
Lil, а можно было бы просто заработать денег.
https://www.reddit.com/r/LocalLLaMA/comments/1d47qor/what_happens_if_you_abliterate_positivity_on/
https://huggingface.co/failspy/Llama-3-8B-Instruct-MopeyMule-GGUF
Очень итересный эксперимент. Я так понимаю по аналогии с соей чувак решил избавиться от позитивного настроя в модели. Вышло необычно, она реально меланхолична во всём. RP тоже забавно отыгрывать с "горячими" карточками, когда персонаж берет член в рот и думает о смысле жизни.
https://huggingface.co/failspy/Llama-3-8B-Instruct-MopeyMule-GGUF
Очень итересный эксперимент. Я так понимаю по аналогии с соей чувак решил избавиться от позитивного настроя в модели. Вышло необычно, она реально меланхолична во всём. RP тоже забавно отыгрывать с "горячими" карточками, когда персонаж берет член в рот и думает о смысле жизни.
похоже на запекание контрольных векторов
Ну что, приличные файнтюны 3й лламы уже подвезли? Желательно 70 и под ерп.
Булджадь, это лишь лора а не файнтюн. Зато линк на тузлу для тренировок, надо свою модельку пилить.
>Тролль челик, который пиздит, что теслы выше 1 токена не дают, потому что они дают.
Я как бы все это время говорил про 2-3 токена, это и есть реальная скорость генерации на 70В моделях на теслах, но тут ты прилюдно обосрался тем скрином с одним токеном в секунду...
Теслаебы опять повылезали из под шконок и снова стали выебываться...
опять ты говно
все еще жопа горит?
Нишутя у вас тут платиновые срачи, такое пропустил. Кто выигрывает? Теслу попустили или топ за свои деньги?
мимо владелец ады/ампера
У вас теслаебов да, захожу сейчас в тред - а тут зарево стоит.
Теслу никто не попускал в общем-то, теслаеб стал хвалиться что у него 7.5 токенов скорости на 70В, и сам запостил скрин где у него 1 токен в секунду общей скорости, потом я пруфанул что такую скорость можно вообще без видюхи получить на чистом цпу с рам и с тех пор теслаебы горят без перерыва.
Решением союза владельцев 3090/4090 они были временно определены под шконку пока не перестанут выебываться.
> теслаеб стал хвалиться что у него 7.5 токенов скорости на 70В
Это же еще неделю назад обсосали и овинили его врунишкой, не?
> и сам запостил скрин где у него 1 токен в секунду общей скорости
В голосину.
Не, зато он молодец что наконец выполнил реквест с подробными таймингами на обработку контекста и генерацию с большим контекстом без кэша, но сука, такой-то рофл.
Это тот буйный шиз что 3 штуки себе взял и хвастался? Вполне закономерный результат. Алсо выдачу размера самой модели при загрузке и типа кванта так и не показал, только имя файла.
> Решением союза владельцев 3090/4090 они были временно определены под шконку пока не перестанут выебываться
Поддерживаю N голосами
мне глубоко поебать какое охлад ты вешаешь на свою теслу и глубоко поебать у какого таджика ты их купил. потому что это нихуя не касается ллм. а что касается ллм это только количество требуемой врам для запуска моделей.
и уж тем более всем глубоко насрать на тесла вс 4090 холивары. любой из участвовавших в этом дерьме и имеющий любой из этих девайсов мог не проебывать время в пустую а чё-то реально тестить или делать. уже подзаебало каждый раз одну и ту же хуйню видеть в треде, как будто собралось сотка менеджеров из гос учреждения, и каждый старается максимально без пруфов нести хуйню.
думаешь я рофлю? катнись в пару тредов назад там челики орали что q2 норм, и q8 хуйня одновременно с этим. а знаешь сколько пруфов этим репликам было с настройками картонок, сэмплеров, конкретной моделью, и скрином диалога? ноль нахуй. чисто собрались как бабки и лишь бесконструктивную хуйню нести и срач разводить.
самый полезный пост треда это линк на ютуб видео с ттской нахуй. куда всрато 350+ сообщений я вообще не знаю.
мне ещё нравится это нотка омежковатости, челам дали инструмент для перевода книг и озвучки их что бы гнать в аудиокниги и чё-то учить не читая сука книгу глазами \ дали инструмент писать относительно валидный код, который только рефакторнуть что бы оно работало \ дали возможность суммарайзить тексты и ебашить question/answer, и 90% треда вместо того что бы реально исполнять или тестить что-то из всего этого, просто сидит трёт хуй и готово ради этого 4 теслы покупать. шлюху снять топовую и ебать её во все щели в любое время и то дешевле выйдет кекв)
за последние 20 тредов, что-то по теме перевода текстов спрашивалось раз 5-7, и офк ноль нахуй нормальных ответов. 20 тредов назад кто-то советовал альму, недавно ещё предлагали либретранслейт вместо использования нейронок, какого либо фидбека о качестве перевода условно любой сука художественной литературы с англа на ру - нет.
за то есть 350 сообщений о теслах и пошёл-нахуй-холиварах о железе. полезно, очень, я прямо вижу какой ты умный запускатор. ошибься только немного, вместо запуска моделей запустил срач о железе, кнопки спутал да?
>Это тот буйный шиз что 3 штуки себе взял и хвастался?
Он самый, да. Наверное волосы второй день на себе рвет, что запостил скрин не подумав.
>Алсо выдачу размера самой модели при загрузке и типа кванта так и не показал, только имя файла.
Ну имя файла и количество слоев - 81 соответствует реальной модели мику, которая существует в единственном и неповторимом виде, так что думаю тут все чисто. Даже если это не она, то 81 слой как правило у 70В моделей.
>шлюху снять топовую и ебать её во все щели в любое время и то дешевле выйдет
За норм тысяч 15 за раз надо будет, так что в разовом эквиваленте конечно дешевле, но тесла у тебя навсегда, а шлюха на час.
>что-то по теме перевода текстов спрашивалось раз 5-7, и офк ноль нахуй нормальных ответов
Так реально все дрочат, лол. Да даже если перевод, то только в контексте РП.
>челам дали инструмент для перевода книг и озвучки их что бы гнать в аудиокниги
Уже есть такой инструмент-читалка на ведроидах, скармливаешь ему книгу - он её через яндекс полностью переводит, сохраняет перевод и дает тебе читать. Если выдрать перевод в отдельный файл - можно в читалке яндекса слушать как аудиокнигу - у них мужской голос охуенный, гораздо лучше Алисы.
расстроил меня, я уже слюни пустил думая что ща скачаю и засуну в врам целиком.
фришно? без ограничений? по качеству перевода сильно хуже deepl?
Ну в целом да, сильно много малополезных обсуждений, а более углубленных - хуй. Хотя может всегда и было.
> Ну имя файла и количество слоев - 81 соответствует реальной модели мику
Это к тому что у нее есть как q2 и ниже, так и (бессмысленные) fp16 версии, конкретный квант не виден. Не то чтобы того что он показывает не может быть (особенно при кривом расчете скорости) и обязательно врет, просто факт что не показал когда идет спор с обвинениями.
>а более углубленных - хуй
Ну вот кидал я затравку на более глубокое. Всем похуй
>имеющий любой из этих девайсов мог не проебывать время в пустую а чё-то реально тестить или делать
Ну я например тестирую сетки на сою через П-Рассказчика и скидываю скрины в тред.
>самый полезный пост треда это линк на ютуб видео с ттской нахуй
Этот линк вкинул опять же я.
>мне ещё нравится это нотка омежковатости, челам дали инструмент для перевода книг и озвучки их что бы гнать в аудиокниги и чё-то учить не читая сука книгу глазами \ дали инструмент писать относительно валидный код, который только рефакторнуть что бы оно работало \ дали возможность суммарайзить тексты и ебашить question/answer,
Все это можно делать не только на локальных нейронках и локалочки по очевидным причинам справляются хуже. И нет причин использовать именно локалки для этих задач.
>просто сидит трёт хуй и готово ради этого 4 теслы покупать
А вот тут реально другое. Локалки и правда имеет смысл использовать вместо того чтобы тов. майору и корпорациям досье на самого себя писать.
>шлюху снять топовую и ебать её во все щели в любое время
Сняв шлюху ты трахнешь её один раз, а на локальный кум можно кумить сотни и тысячи раз. Сколько стоит снять шлюху 1000 раз, м?
>за последние 20 тредов, что-то по теме перевода текстов спрашивалось раз 5-7, и офк ноль нахуй нормальных ответов.
Потому что итт никому перевод не нужен, все со времен пигмы кумят на английском и выучили его в совершенстве, кто не знал до этого.
А что ты такого сделал для качества общения в треде, что поливаешь тут всех говном?
>фришно? без ограничений? по качеству перевода сильно хуже deepl?
Да. Если с яндексом - то фришно. Дипл там тоже встроен, но за него надо платить. Хуже, но не слишком сильно, у яндекса довольно хороший переводчик, на уровне гуглового.
>и выучили его в совершенстве, кто не знал до этого
Кидаю все текста в дипл, ебало?

яндекс хорош, подтверждаю.
за линк спасибо, к тебе у меня каких-то претензий нет и не было.
причина на самом деле есть, это как минимум независимость от продающих сервисов. очевидно проще запустить локалку чем сидеть через прокси и виртуальную карту висконсина сидеть гопоту или клода оплачивать. (да я знаю есть перплексити лабс). и это не упоминая о количестве блокировок не только со стороны самих сервисов, но и ещё ркну. а так запустил локалку и похуй тебе на your country is not supported или данный ресурс заблокирован по законодательству кринжоты. аргумент же?
то что локалки можно использовать для дрочки, ещё не значит что это их вообще единственной применение лол. а по треду плюс минус так и кажется.
просто прикинь степень абсурдности а?) даже многослойный трансформерс легально трахать нельзя, ну не ирония ли?
ну если дрочить по косарю раз, то холивар про теслы уже не кажется дуркой, после такого натирания члена, явно и член и мозги отсохнут.
я перевод текстов вижу себе не так, что ты там запустил няшную нейрошлюху, и сидишь переводишь там её мессаги в ру, или читаешь прямо на англе. это юзелесс. я вижу смысл в переводе текстов например взять линканутую выше в
статью, которая на англе, и адекватно её перевести на ру, что бы тупо облегчить себе чтение и понимание такой технической литературы. я не тупой и знаю англ, но на усвоение материала на родном языке мне явно потребуется меньше времени.
спасибо за наводку, пойду сравню на одинаковой статье дипл и яд. а то сидеть по 2к символов ручками кидать духота та ещё.
Судя по значениям, полученный результат мало о чем говорит, если офк речь о перплексити на викитексте. Как было шизиком так и осталось, а наблюдаемый эффект может быть обусловлен чем-то еще.
Хотябы простые бенчмарки бы прогнать, или сделать серию тестов на ответы с большим контекстом бы.
Скинь исправленный код для запуска, пожалуйста.
> не проебывать время в пустую а чё-то реально тестить или делать
Кто тебе сказал что никто ничего не делает? А так посраться - самый сок, особенно в подобном формате.
> а по треду плюс минус так и кажется
Да ну, ты зря. Просто обсуждают и спрашивают это больше, плюс применение которое буквально объединяет всех-всех.
> даже многослойный трансформерс легально трахать нельзя, ну не ирония ли?
В голос, реально в сборник цитат такой надо, хорошо сказанул.
По переводу правильно, на самом деле это вообще не трудно, это долго.
Бывают же оптимисты. Даже в жирного командира не верю, что можно запромптить его на двачера вот так. Ну может быть в комбе, где сетка пишет, а человек фиксит разве что. Только для меня это уже работа человека, а не сетки.
> Вон, кодестраль вышла.
Полнейшая хуйня, походу. Я даже не смог заставить ее змейку написать.
> Скинь им апишку с гита, скажи че надо, оно напишет.
Пока у меня так не получается.
>если офк речь о перплексити на викитексте
Я использовал датасет TinyStories, так что перплексия на их тестовом срезе (сетка его не видела офк).
>Как было шизиком так и осталось
146%, я больше 100к за раз не скармливал, в 1 эпоху. Полный прогон всего датасета в 1 эпоху у меня сутки займёт, я пока не готов столько гонять.
>Скинь исправленный код для запуска, пожалуйста.
Там ещё модель нужно с нуля обучать. И да, я на GPT2 тренируюсь ))
> датасет TinyStories
А какие там типовые значения для подобного? Просто в рп-подобных датасетах и всяком, где текст имеет "свободную форму" оно по дефолту высоко. Хз насколько изменение в 2% такой специфичной величины может выступать достоверной метрикой улучшения.
> Там ещё модель нужно с нуля обучать.
Ага, т.е. все гораздо глубже выходит. Ну, печально. Всеравно скинь что там с кодом, может на какой-то мелочи поиграться.
Че за читалка то?
>А какие там типовые значения для подобного?
А ХЗ, лол. Я новичок в датасатанизме. Я до 9 доводил, но это в 3 раза дольше гонять нужно. У авторов 1,5 получалось, но это за сутки, а не за час.
По сути датасет вышел весьма простым и однородным (чего стоит одно начало на 99% историй), так что перплексия ИМХО должна быть низкой.
>Всеравно скинь что там с кодом, может на какой-то мелочи поиграться.
https://rentry.co/9r7ok5hw
Держи, просто унаследовался от стандартной и подменил слои атеншенов (код подмены писал GPT4, а вот замену в функциях пришлось самому делать, гопота тут глючит нещадно).
>это линк на ютуб видео с ттской нахуй
Когда я итт постил про ттс меня послали нахуй и сказали, что это нерелейтед.
Опять макаба шатается.
Я думаю, что тема переводов не поднимается, потому что сетки это делают крайне хуево.
>мне ещё нравится это нотка омежковатости, челам дали инструмент для перевода книг и озвучки их что бы гнать в аудиокниги и чё-то учить не читая сука книгу глазами \ дали инструмент писать относительно валидный код, который только рефакторнуть что бы оно работало \ дали возможность суммарайзить тексты и ебашить question/answer
А теперь объясни мне, нахуя это все делать. Книги для дураков, кодинг для мудаков, суммарайзить длинные тексты тебе никакого контекста не хватит, легче самому прочитать, если сильно надо. Тем более какое может быть доверие к сетке, если текст важный. А если текст не важный, то нахуя его читать? В этом контексте я даже скорее одобряю дрочку на текст вместо дрочки на порнхаб.
В общем, раз уж ты топишь за качественное общение и обсуждение, то обоснуй как-то актуальность своих задач.
Очень даже релейтед. Когда такое было и что ты постил?
>Я думаю, что тема переводов не поднимается, потому что сетки это делают крайне хуево.
Да ну не сказал бы. Гугл давно выебан даже 7B (хотя это скорее деградация гугла, лол).
> Я думаю, что тема переводов не поднимается, потому что сетки это делают крайне хуево.
Сначала хотел возразить, а потом прочитал пост целиком. Толстовато, попробуй потоньше.
> что бы тупо облегчить себе чтение и понимание такой технической литературы. я не тупой и знаю англ, но на усвоение материала на родном языке мне явно потребуется меньше времени.
То есть тебя не беспокоит тот факт, что нейронка может просто нашизить местами и ухудшить понимание этого текста? Хочешь что-то перевести с анга на русик. Забей это в яндекс. А говорить за всех, что каждый может запустить себе командира+ в высоком кванте = быть дауном.
Или это опять скрытый байт на теслосрач?
Деградация гугла, конечно. Иди яндекс выеби. Хотя с последним даже ебать не надо, его тупо использовать не хочется, ведь твой айпишник и текст перевода записываются и отправляются прямо в службы.
> Толстовато, попробуй потоньше.
Немного с иронией я переборщил, но ведь в целом посыл же правильный. Нет никакой толстоты здесь.
Ломаный премиум качай, там есть та функция что я описал. "Безымянный переводчик" который бесплатный - это яндекс.
Ну хуй знает, мне сказали, что про ттс есть свой тред и шёл бы ты туда. А там вообще тред неживой был. Сколько тредов назад сказать сложно, быстро летят. Речь шла про настройку рилтайм озвучки выхлопа LLM без таверны.
Сейчас Deepl хорошо переводит и там внутри тоже нейронка, к гадалке не ходи.
Поясните как вы апи от Яндекса добавили в Таверну.
>min-p пресет.
>несломанный гуф
Короче что бы ЛЛама не срала ассисистентом на всего лишь снять галку с skip special tokens.
Бесплатно без смс, без сломаных гуфов хуюфов и прочих мин п.
>независимость от продающих сервисов. очевидно проще запустить локалку чем сидеть через прокси и виртуальную карту висконсина сидеть гопоту или клода оплачивать
Но качество этих услуг на локалке гораздо ниже и скорость оставляет желать, если только ты не 4090-господин.
>то что локалки можно использовать для дрочки, ещё не значит что это их вообще единственной применение лол. а по треду плюс минус так и кажется
Ну для меня - единственное, все остальное - программирование, например, лучше делать с копилотом, задачи по суммарайзу с чат-гопотой и т.д. Я не в России живу, у меня нет проблем с доступом и оплатой.
>ну если дрочить по косарю раз, то холивар про теслы уже не кажется дуркой, после такого натирания члена, явно и член и мозги отсохнут.
Ты тян? Просто такой неадеватный агр на дрочку...
>я перевод текстов вижу себе не так, что ты там запустил няшную нейрошлюху, и сидишь переводишь там её мессаги в ру, или читаешь прямо на англе. это юзелесс. я вижу смысл в переводе текстов например взять линканутую выше в
Чем тебя не устраивает автоматический перевод в яндекс браузере? Он даже видео переводит и озвучивает. Я помню несколько часов сидел и тупо топ китайсого ютуба в русской озвучке смотрел пока не надоело.


Поясните довену как модели в ггуф конвертить из сырых весов. Ллама 3 8B инстракт норм конвертится, а командр+ без ошибок просто через несколько секунд останавливается и пустой файл создаёт.
Спасибо. А для пеки подобное есть? Пробовал просто pdf в яндекс переводчике переводить, там кривой документ выходит.
>автоматический перевод в яндекс браузере
->
>Я не в России живу
Ну так понятно, ты то можешь пользоваться сервисами хуяндекса без шанса присесть на бутылку.
Спасибо. Но я, правда, хотел разобраться с локальным квантованием, чтобы кучу вариантов квантов со своим хреновым инетом не качать для теста.
Покурю сорцы спейса или может вообще его стяну просто, чтобы локально этот UI был.
А памяти то хватает? Небось из за того что коммандр слишком жирный сразу и падает
Так мы про перевод научных статей и книг говорили.
Скорее всего - RAM 32 всего, вообще не знаю, какие там системные требования, чтобы самому кванты перегонять в жирных моделях. Но ошибок или высокого потребления RAM на старте не увидел, поэтому подумал, что, может, дело не в этом.
хуй клал на теслы. у меня их нет. просто прорабатываю альтернативные варианты, без использования сервисов. скажем так, СД повлиял на меня в своё время. один хуй запуская что-то локально контроль будет у меня, а не у какого-нибудь чада сделавшего сервис генерации чего либо. а так да, нашизить может, тут ты прав, с этим аргументом не спорю, но пока ещё не ясно что хуже, читать в англе или перевести и суммарайзнуть с риском шизы нейронки. 50 на 50 я бы сказал.
за коммандира я ни слова не говорил бтв, и вообще в плане железа никого не хуесосю, каждый сидит на чем позволяют средства и возможности.
там 100% нейронка в дипле, и именно поэтому я сравниваю любые переводы именно с диплом, по крайней в отношении художественной литературы, он переводит прямо норм, это даже можно читать и не кринжовать.
ну, не то что бы я прямо очень сильно торопился, да и в целом локальный ран в этом смысле, это что-то вроде запасного плана, если сдохнут реверс апи от гопоты, перплексити лабс и прочее, что можно юзать без смс и регистрации.
а вот из ру с этим на самом деле уныло. сначала регать виртуальный номер каком-то сервисе, потом ещё оплачивать виртуальной картой или чем-то подобным. честно говоря душный пиздец.
нет не тян, да не то что бы агр, просто я пока не понял прикола дрочки на это всё. с каким-нибудь пронхабом или хентайщиной и прочим понятно, а тут же, ну блядь текст?
меня кринжует не от перевода яндекс браузера, а от самого браузера. он ощущается настолько дерьмовым, кривым, со своими яндекс кнопками нахуй и ебучей алисой, что мне хочется его как минимум засунуть в виртуал бокс, лишь бы он не порочил мою систему. и память сука жрет больше чем мозилла.
я бы сначала распознал пдфку, а потом полученный текст.
зачем мне условно скетч для ардуины самому, если перплексити лабс написал её за меня? зачем мне кидать худ литру на англе в дипл по 2к символов ради перевода, если это можно было бы доверить нейронке? зачем мне перечитывать тех литру 5 раз, которая условно дается сложно для понимания (как пример), если я могу попросить нейронку либо объяснить мне это чуть попроще, что бы полученную информацию можно было визуализировать и структурировать на более простых аналогиях? если у тебя в жизни самоцель это рукой хуй тереть каждый день, и понятие самоообразования или любопытства тебе чуждо, то убери руки от клавы и положи их на хуй. не трать время зря.
алсо с троллами уровня книги для дураков а кодинг для мудаков, можешь сразу слиться - не позорься.
Ну как ты видишь по кол-ву ответов на твой пост - людям больше интересны хв срачи. Так что ты тут в меньшинстве. Поэтому закрой ебло и съеби нахуй с треда.
А дядя Майор не приедет, если будешь совершеннолетних лоли-кошкодевочек трахац?
>совершеннолетних
Нет, такое меня не возбуждает.
Мимо товарищ майор под прикрытием


собрал на xeon 2678 32 gb ddr4 x99tf. месяц не получалось запустить. tesla с охлаждением c aliexpress
>с каким-нибудь пронхабом или хентайщиной и прочим понятно, а тут же, ну блядь текст?
Не могу поверить что итт есть человек которому приходится обьяснять настолько базовые вещи.
От просмотра порнхаба развивается импотенция, потому что такова цена дрочки на уродливых 40-летних коров с разъебанными дырками, которых они там продвигают и суют тебе в лицо, даже если ты не будешь включать с ними видео - тебя забомбардируют превьюхами.
Хентай как правило очень хуево нарисован и годноты там по пальцам одной руки пересчитать можно, плюс дрочить на квадраты...
Что до того что тут дрочат на тексты. Дай угадаю, ты в жизни не читал художественной литературы сложнее тредов на дваче, я прав? Ты и визуальной новеллы ни одной ни прочел, хотя это конечно и низовая недолитература, но и она дала бы тебе понимание насколько же сильно Слово. Играясь с ИИ мы не просто читаем текст, мы взаимодействуем с самим создателем текста, у нас нет заранее написанной книги, вместо этого книга буквально пишется на луте в соответствии с полетом нашей фантазии, это новый уровень интерактивности развлечений, буквально первый проблеск нового будущего. Тут мы реально можем быть кем захотим, ебать кого захотим и так, как мы захотим. Это - подлинная свобода.
..А ты предлагаешь на всратых разъебанных шмар с порнхаба дрочить. Потому ты и ебаная мелкобуква - у тебя нет понимания силы письменного слова и оттого ты и демонстрируешь к нему пренебрежение. У тебя не развит один из отделов мозга, ты не понимаешь и не можешь предположить - насколько это охуенно - читать и визуализировать самому себе хороший текст, погружаясь во вселенную произведения, которое ты читаешь. И даже не можешь представить какого это - когда ты не просто безмолвный читатель, а ты - часть повествования, главный герой, прокладывающий свой путь и навязывающий выдуманному миру и персонажам свою волю.
>совершеннолетних лоли
Так бывает?
Поверь, бывают столетние и тысячелетние лоли. Сырно к примеру, ей 78. Япония она такая.
Я знаю, я иронизировал.
Жаль тащ.майор не понимает таких тонкостей и в законе прямо прописано что выглядеть как лоли достаточно для пативена. Интересно как трактовать закон по отношению к текстам сгенерированным ИИ, там ведь не проверишь как персонаж выглядит.
> Потому ты и ебаная мелкобуква - у тебя нет понимания силы письменного слова и оттого ты и демонстрируешь к нему пренебрежение.
Как же красиво завернул. Моё почтение.
> И даже не можешь представить какого это - когда ты не просто безмолвный читатель, а ты - часть повествования, главный герой
Да понятно каково. Где-то на уровне 12-летней яойщицы пишущей фанфики на фикбуке. Вот каково.
> От просмотра порнхаба развивается импотенция, потому что такова цена дрочки на уродливых 40-летних коров с разъебанными дырками, которых они там продвигают и суют тебе в лицо, даже если ты не будешь включать с ними видео - тебя забомбардируют превьюхами.
Хентай как правило очень хуево нарисован и годноты там по пальцам одной руки пересчитать можно, плюс дрочить на квадраты...
Не все же картинки прям с цензурой. Да и дрочить не обязательно на порнхабе, есть ресурсы, где показывают и тех, кто младше коров. Но с посылом спорить нельзя.
>Жаль тащ.майор не понимает таких тонкостей
Он как раз прекрасно понимает, какой контингент дрочит на legal loli, и выдаёт им соответствующих пиздюлей.
>алсо с троллами уровня книги для дураков а кодинг для мудаков, можешь сразу слиться - не позорься.
Начнем с этого. 90~99% книжек это Донцова, а то и хуже, такое читать = нетолько тратить время, но и становиться тупее. А остальные 1% книг я бы предпочел прочитать сам, без всякой шизы от нейронки. По крайней мере запустить сильную модельку уровня командир+ я не способен, а читать творчество какой-нибудь 8В, да даже 35В, мне не хочется.
Про кодинг все еще проще. Если совсем кодить не умеешь, нейронка за тебя его не напишет, а если умеешь кодить хорошо, то нейронка не нужна. Ну можешь рутинную работу немного на нее спихнуть, а потом править, но это уже на любителя.
> зачем мне кидать худ литру на англе в дипл по 2к символов ради перевода, если это можно было бы доверить нейронке?
А разве дипл это не нейронка? Причем вроде как узкоспециализированная на переводе. Поправь меня, я сторонними ресурсами специально не интересовался.
>зачем мне перечитывать тех литру 5 раз, которая условно дается сложно для понимания (как пример), если я могу попросить нейронку либо объяснить мне это чуть попроще
Нет, ну если можешь и нейронка действительно понимает контекст, то я рад за тебя и даже хочу посмотреть твои настройки и модельку. Потому что, честно говоря, я ни разу не верю, что я способен скормить нейронке книгу и она мне по ней бодро и четко будет отвечать. Обычно тупят, что в RAG, что просто в контексте.
> если у тебя в жизни самоцель это рукой хуй тереть каждый день, и понятие самоообразования или любопытства тебе чуждо
Да, мне это чуждо. Даже натирание хуя больше удовольствия не доставляет, а уж что-то более высокое - это для дофаминовых наркоманов от природы таких или бродящих по закладкам, а я, к сожалению, не такой.
> не трать время зря.
С моей стороны суть простая. Сейчас нейронки не готовы к тому, что ты от них хочешь ЯЩИТАЮ. Если ты не согласен и можешь доказать, то будь добр, сделай это. Я признаю свою неправоту, извинюсь перед тредом и перестану сюда писать.
А мультимодалке можно пояснить за отношения между элементами на картинке, чтобы она могла интерпретировать похожие картинки? Просто я чувствую, что OCR для amsmath при жизни не дождусь. В это походу вообще никто и ничто не может, даже в самых новейших проектах по интерпретации пдф для LLM прямо пишут "поддержка латех местами, распознает не всё".
>чтобы она могла интерпретировать похожие картинки
Нет.
то что ты еблан и не можешь гуглить себе прон это твои проблемы, а не мои. то что у тебя не хватает мозгов найти анцензоред джавы это тоже твои проблемы. и рисуют хентай по факту часто даже лучше чем обычные тайтлы, если для тебя это хуево, ну хуй знает, иди жри 3д китайское дерьмо, там жи графоний нахуй. вообще что это за уровень ретардизма у тебя такой. 1 - хачу драчить на буквы. 2. я графоман хентыч нарисован хуева. ты еблан? после такого позора ещё что-то пишешь про чтение книг и визуальных новелл? я ещё раз говорю, высирая свои бредни, делай это тоньше, ну потому что блядь даже обычная паста с пикабу смешнее тебя, а ты явно стараешься быть клоуном треда.
я не вижу тут никакой свободы, с тем же успехом ты мог запустить любую прон игру и орать что можешь ебать там любого нпц и кричать что это подлинная свобода. и судя по тому как ты у нас топишь на тощих микрописечек и графоманию, то прон видеоигры это как раз твой одел. ведь там дырки не растут)))
последний абзац даже комментировать не буду, это уже чистые бредни слабоумного
>Ну можешь рутинную работу немного на нее спихнуть, а потом править, но это уже на любителя.
так и делаю, и на самом деле это классно, приятно поручить нейронке мелкие таски, или вопросы которые я обычно гуглил на стак оверфлоу например. или вообще спросить у неё что-то вместо того что бы искать поисковую выдачу гугла в первых трех страницах и 50 ебанных сео блогах. где вместо контента сео текст хуйни и мочи.
да дипл нейронка, именно для переводов, именно из-за этого и сравниваю локалки с дипл.
прямо книгу - увы не скормишь, а вот статью не очень большую можно, или например главу книги, которую было сложно освоить одним лишь прочтением. я бы люто радовался если бы можно было кормить целые книги, хотя учитывая шанс шизы, думаю радость длилась бы не долго лол
если бы нейронки уже сейчас закрывали все мои хотелки, я бы тут не сидел, причины бы просто не было. но они точно упрощают мне процесс кодинга, и уменьшают время которое я раньше тратил на гугл. разумеется я на пишу что-то очень сложное с её помощью, но какие-то мелкие задачи ей доверить можно.
На мой взгляд, тексты будут более менее прилично получаться когда сетка сможет следовать вот таким примерным правилам:
Каждое предложение нагружено смыслом и имеет цель, как-то: описывает действие или событие, либо придает эмоциональную окраску действию, настроению персонажа или реплике. В случае реплик, каждая своим содержанием или формой сразу обрисовывает как-бы контур характера, ну и возраст, настроение, интеллект персонажа.
Также важны подробности, которые могут напрямую вообще не иметь отношения к сюжету, но косвенно создают скажем так лор. Ну вот как-то так. Например, волосы в ноздрях персонажа "тесливый спесивец" зачем вообще? А затем что влекут цепочку - ноздри раздуваются, он возбужден, агрессивен, что вызывает его последующие оскорбительные реплики в диалоге в адрес не преклонившего колени РТХ-ника. Другой пример подробностей - главная героиня бежтит по желтым листьям и лужам - никакого отношения к сюжету, но ает метку времени года - осень, значит пасмурно, меланхолия, безнадежность. Аналогично по смысловой нагрузке реплик: неграмотный выговор Порфирия рисует его портрет постаревшего кумера, ровно как и хвастливый самодовольный монолог Василия рисует кумера, находящегося в расцвете сил. Так же реплики кумеров из зала сразу характеризуют их как хамоватых быдланов, причем ставших похожими друг на друга потому что в толпе разница стирается и условный Phd опускается до уровня слесаря и так же отпускает сальные шуточки и гогочет как гамадрил. Вот весь этот второй смысловой слой должен иметь как бы хэш в реплике, и читатель уже в воображении раскрывает для себя и лор и персонажей и канву событий. Как добиться от сетки смфсловой эффективности в 100% ну пока не ясно ведь датасеты сами то не такие. Тут нужен ну очень хороший датасет возможно что претрейна тоже. Допустим Бальзака туда лучше не вколючать, ему платили постранично и он налил тонны воды и это только пример из литературы. А просто тексты? Вот одно точно - качественный датасет не может быть синтетическим.
И как, работает?
Ты там в хлам набухался что такие высокопарные и душные полотна начал хуярить по этой теме?
В целом действительно внки и тем более ллм-кум или обычное рп могут давать более сильный эмоциональный отклик чем прон, это факт. Но нужно иметь фантазию, для кого-то что-то с контекстом сложнее "медсестра, ебать" и созерцания фрикций - слишком тяжело воспринимается. Странно что в этом треде вообще подобные обсуждения возникают.
Истина
> чтобы она могла интерпретировать похожие картинки?
Ну современные мультимодалки могут пояснить тебе что общего на пикчах и в чем отличия. Но уровень восприятия ограничен.
> OCR для amsmath
Мультимодалку для подобного - это как нанимать исследовательский институт проблем материаловедения чтобы сварить пару профилей вместо дяди Васи из гаражей. Реализуется проще специазированными решениями.
> когда сетка сможет следовать вот таким примерным правилам
Нет. Если такое тем более напрямую в промт херакнуть - отборную трешанину получишь. Тут или очень умная сетка при обучении которой пояснялось за стиль текста, и ты изначально приказываешь делать в "художественно-экспрессивным" или "ебош будто это фильм Квентин Тарантино. Или тот самый рп файнтюн со шлифовкой стиля нужными текстами.
>Если такое тем более напрямую в промт херакнуть - отборную трешанину получишь
Именно. Но и описанные тобой варианты они в какой-то мере дают эффект, но не то, или не достаточно то, что надо. Мне все же кажется нужен очень чистый от всякого низкокачественного содержимого датасет. Причем не синтетический. А все вот эти файнтюны с хф делаются на синтетике и это хождение по кругу.
> я ещё раз говорю, высирая свои бредни, делай это тоньше, ну потому что блядь даже обычная паста с пикабу смешнее тебя, а ты явно стараешься быть клоуном треда.
Может ты тогда сам на пикабу сходишь, раз тебе там смешнее?
> я не вижу тут никакой свободы, с тем же успехом ты мог запустить любую прон игру и орать что можешь ебать там любого нпц и кричать что это подлинная свобода. и судя по тому как ты у нас топишь на тощих микрописечек и графоманию, то прон видеоигры это как раз твой одел. ведь там дырки не растут)))
Возможно ты не понимаешь разницу между отыгрышем за предустановленного еблана и отыгрышем вообще всего что хочешь. Мне кажется тот анон вполне понятно все объяснил. Сначала ты срал хуйней про порнхаб, теперь маняврируешь про левые игры. В чем твоя цель?
> так и делаю, и на самом деле это классно, приятно поручить нейронке мелкие таски, или вопросы которые я обычно гуглил на стак оверфлоу например. или вообще спросить у неё что-то вместо того что бы искать поисковую выдачу гугла в первых трех страницах и 50 ебанных сео блогах. где вместо контента сео текст хуйни и мочи.
Phind.com же.
> да дипл нейронка, именно для переводов, именно из-за этого и сравниваю локалки с дипл.
> прямо книгу - увы не скормишь, а вот статью не очень большую можно, или например главу книги, которую было сложно освоить одним лишь прочтением. я бы люто радовался если бы можно было кормить целые книги, хотя учитывая шанс шизы, думаю радость длилась бы не долго лол
Не очень большую статью можно и самому прочитать. Спорно это очень.
> если бы нейронки уже сейчас закрывали все мои хотелки, я бы тут не сидел, причины бы просто не было. но они точно упрощают мне процесс кодинга, и уменьшают время которое я раньше тратил на гугл. разумеется я на пишу что-то очень сложное с её помощью, но какие-то мелкие задачи ей доверить можно.
Это здорово, что мелкие таски можно делать иногда. Хотя сейчас для этого сторонние ресурсы работают лучше. Кодинг это Phind.com, перевод - отдельный ресурс итд. Разве что саммарайзить главы, потому что локально контекста побольше можно вкинуть, либо rag.
Там мозги нужны, для твоих запросов, лол.
> Мне все же кажется нужен очень чистый от всякого низкокачественного содержимого датасет.
В целом да, если он будет достаточно обширен, хорошо оформлен, в том числе содержать не только художку но и длинные диалоги - файнтюн им даст нужный эффект.
> Причем не синтетический.
Ты зря боишься синтетики. Разумеется если просто бездумно кидать выдачу нейронки - будет хуйта. Но если использовать ллм и другие алгоритмы для переработки, оформления, оценки и т.п. с тщательно отлаженным процессом и контролем - все будет даже лучше чем на кожаных.
> Реализуется проще специазированными решениями.
Никак оно не реализуется. Какую-то мелочь распознать ещё можно, но что-то практически значимое - нихуя.

Подскажите с чем связана ошибка? Кобальд после нее закрывается просто.
Посоветуйте что-нибудь под извращенную дрочку.
Уточню, чтобы прямо в анус совала баба кулаки, и в уретру ебали
Скудоумный ты наш.
Скрин не мой.
Реальная скорость 6-7.
Но ты продолжай, похую.
Интересно, сам с собой пиздит, или тут два скудоумных? :)
Извини, я и сам уже было обрадовался. =(
> то что локалки можно использовать для дрочки, ещё не значит что это их вообще единственной применение лол
Кмк, как раз для дрочки и корпов можно. А главное применение локалок — конфиденциальность кода и документов.
Ну, для дрочки, тащемта, тоже ради конфиденциальности.
Но всем похую, на самом деле.
Пидоры, сэр.
> Если совсем кодить не умеешь, нейронка за тебя его не напишет, а если умеешь кодить хорошо, то нейронка не нужна.
Ну, я смотрю, ты кодить не умеешь совсем, отсюда и выводы такие.
Нет, это работает не так.
По второй части все верно сказал.
———
Пиздец, два дня без треда, а тут кроме хуйни почти ничего.
Я надеялся на тонну базы и интересной инфы.
Эх, грусть.
Бля, зашёл в тред, а тут дежурный бах от теслодауна...
Покажи примеры что там значимого и не может. Первые ссылки из гугла вроде работают.
Claude 3. А вообще коммандир, эта сетка наудивление хорошо понимает некоторые вещи, а за счет того что ее не нужно ломать жб, искажая выдачу и нормального стиля - иногда даже коммерцию аутперформит. Офк такие случаи ограничены.
> Реальная скорость 6-7.
А психологическая вообще 15! Пока единственный пруф - 1т/с на тесле с учетом обработки контекста. То что он медленно обрабатывается это известно, но чтобы настолько - печально.
Тащи другие если от фактов неприятно, заодно будет интересно взглянуть насколько скорости меняются с разным количеством некрокарточек.
Посоветуйте какую комбинацию фронта и бека оптимальней использовать под видюху 3060ти с 8 гигами, 32гб ОЗУ и проц 11th Gen Intel(R) Core(TM) i9-11900F @ 2.50GHz, 2496 МГц, ядер: 8
Стоит ли заморачиваться и генерить на видюхе или на проце будет тоже норм?
Стоит ли заморачиваться и генерить на видюхе или на проце будет тоже норм?
Проц мусор у тебя, на гпу 8В можешь запускать.
>Claude 3
Какой нахуй клод, если тред про локальные модели.
под sillytavern какой бек тогда лучше использовать?
Koboldcpp и sillytavern. Твои модельки это Llama-8B-instruct, solar, moistral (для кума). Для кодинга можешь на проце запускать командира, будет медленно работать, но там скорость менее критична.
> Пиздец, два дня без треда, а тут кроме хуйни почти ничего.
> Я надеялся на тонну базы и интересной инфы.
> Эх, грусть.
Так ты сам тот ещё шитпостер, так что не тебе жаловаться.
Любой, какой осилишь.
Тому что у тебя жирные запросы, под которые только оно как раз. Хотя и там как не изгаляйся, может полезть странная цензура или просто тупняки особенно со 100+летними.
Возможно даже ллама справится. Moistral тоже попробуй, его же на каком-то датасете тренили. Как вариант можно попробовать нейросетке контекст докинуть с такой еблей, чтобы она понимала о чем речь, если из коробки не понимает. Понятно, что чем жирнее сетка, тем лучше.
Да командер р неплохой, посмотрел. llama80b пробовал, но там совсем хуево, командер р получше вроде бы. Подрочить в принципе можно, понятное дело, что нелокальные и закрытые еще круче, но там цензура ебаная, а тут нет.
Коммандер заебись, он реально хорош, как для общих задач на обработку текста, так и для ерп.
Надо поборот лень и файнтюны 70б третьей ламы покрутить в ближайшие дни. Если что интересное будет - напишу тогда.
>Llama-8B-instruct
https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF/tree/main
Их дохуя разных. Чем они отличаются и какой качать?
Не знаю, может я что-то не понял, но 8б помоему лютейшее говно. 70б получше.
опять тесливый спесивец ищет кого бы зацепить...
Ты имеешь в виду 104В командира?
Отсюда и качай. Либо 6_К, либо 8_0.
Не знаю, я нагуглил какой-то онлайн "plus" вроде.



>с учетом обработки контекста
Я мимо шёл, и вообще пользуюсь "затычкой амудэ", если чтоinb4: семен, но глянул скрины по треду выше и позволю себе заметить, что ты ссылаешься на значение, почти лишённое смысла. Либо ты слишком тупой и не понимаешь смысла этого показателя, либо ты сознательно представляешь данные в выгодном тебе свете, чтобы обосновать свою позицию, но в обоих случаях ты формально неправ.
По отдельности скорости обработки промпта и генерации сравнивать можно, и для первого цифры выходят похожие (на cpu чуть быстрее), а второе на gpu в несколько раз быстрее. Равенство среднего показателя же вообще ничего не говорит, поскольку в одном случае обрабатывалось 8к токенов, а в другом - 2к, и генерация одинаковые 100 токенов. Ты буквально пытаешься сравнивать величины в разных единицах измерения.
Так вот, я даже продемонстрирую, как можно манипулировать этой цифрой, а заодно приведу другие примеры "скорости с учетом обработки контекста".
Возьму свой средний use-case, я лениво попукиваю в чат коротенькими сообщениями по ~50 токенов, нейросетка в ответ срёт где-то в среднем по ~350.
Скорости tesla отсюда:
Скорости cpu отсюда:
Итого на конфиге с теслами у меня бы вышло 7.7 Т/с "средней" скорости.
На cpu вышло бы 1.2 Т/с "средней" скорости.
Расчёты на пикрил 1.
Удивительно (нет), но при обычном чате "средняя" скорость приближается к скорости генерации. При обработке большого объёма информации (например, при суммаризации), наоборот, будет играть значительную роль именно этот самый объём входных данных, и, соответсвенно, скорость обработки промпта.
И варьироваться он на одном и том же устройстве может в широких пределах, если взять наиболее экстремальные случаи (1 токен промпта и 8191 токен генерации и наоборот), то получаются цифры на пикрилах 2 и 3. Для нейросетей, не умеющих читать изображения, дублирую текстом: 91 с/т и 7.8 т/с для теслы, 75 с/т и 1.2 т/с для cpu.
Надеюсь, этим я показал бессмысленность показателя "средней" скорости в сферическом вакууме без учёта сценария использования. А для сравнения производительности нужно хотя бы приравнять объёмы запроса и ответа.
Ну ля, только начал пост, а сразу серишь оскорблениями, демонстрируя разорванную сраку.
> (на cpu чуть быстрее)
Ебать дожили, профессор обрабатывает контекст быстрее чем теслы. Сам то понял что тестируешь? Попытки оправдываться и представлять в удобном виде с обработкой одного токена и генерацией 8к особенно забавны, 1т/с все уже видели и этого не исправить. И теслашиз будет их видеть каждый раз как только кончится 8к окно, начинается новый чат, применяется rag/базы и т.п. ожидание первых токенов как на профессоре - не норма.
> Ты буквально пытаешься сравнивать величины в разных единицах измерения.
Кто ты? Я лишь рофлю с этой всей херни и насмехаюсь с убертормознутой обработки промта у теслашиза, а в срачах не участвую, неделю в тред не писал ранее.
То что при кэше контекста в обычном чате в начале это не будет заметно - это понятно, а про то что нормировка средней скорости генерации на сгенерированные токены может давать значительные флуктуации писал еще когда ты этого треда не видел.
> Надеюсь, этим я показал бессмысленность показателя "средней" скорости в сферическом вакууме без учёта сценария использования.
Нет не показал, 1 промт и 8к генерации не бывает. Кейсов с обработкой контекста много и факт невероятной тормознутости 3х тесел в этом должен быть известен, особенно когда всякие поехавшие начинают этим хвастаться и завлекать в болото.
Вот не надоело толочь воду в ступе с этими теслами?
Лично мое мнение - теслы ебаное гавно мамонта в хуй не нужное. Лучше на деньги, которые затрачены на теслы и обвес вплоть до бп вентилей и т.п. купить 3090 или 4090 ну как кто сможет. А разговоры о том что "для меня 22к не деньги" блять кроме смеха ничего не вызывают. Если такой Ротшильд диванный хули не купил 3090?
И вот блять без конца и края тычут эти теслы дряхлые что там 70б. Дак и по большому счету 70б тоже гавно по сравнению с клодом или гопотой. А посему лучше на 3090 крутить чего-то на 20-35б тоже гавно, чем ради 70б покупать кости динозавра и ждать там какого-то волшебства и победы над гопотой.
Ну приводят аргумент для секретности кумерства. Я конечно понимаю что хуй - двигатель прогресса но чтобы ради кумерства такой хуйней страдать чтобы теслы облизывать это уже какой-то диагноз.
Но это мое мнение а у теслаебов другое, ну я то свое сейчас обозначил, а они постоянно всем в морду свои теслы тычат. Да если так нравится ну оближите свои теслы прямо в системнике.
> Дак и по большому счету 70б тоже гавно по сравнению с клодом или гопотой.
На самом деле нет. Может требования и восприятие поменялись, может впопены ее совсем поломали но гопота сейчас сильно проседает по качеству, а 4о - тупая. Да, все еще во многих сценариях будет предпочтительнее, но количество отмечаемых косяков пиздец растет, а большие локалки уже дают оче хороший экспириенс.
Нет ничего плохого в том чтобы купить второй карточкой P40 или даже их пару в отдельную машину, но нужно осознавать подводные камни. 3090/4090 будут лучше, но дороже. Зато они применимы вообще во всех-всех доступных нейронках что могут влезть в врам, а не только в ллм.
> чтобы теслы облизывать это уже какой-то диагноз
Дефолт специальной олимпиады же, проблема не в теслах а во владельце.
>Koboldcpp и sillytavern
все установил, в кобольде выбрал такие настройки
сам Koboldcpp со мной общается
Но sillytavern когда загрузил персонажа при попытке отправки сообщения приходит ошибка:
No Horde model selected or the selected models are no longer available. Please choose another model
>Сам то понял что тестируешь?
Это ты опять не понял, похоже. Я ничего не тестировал, я взял скорости из имеющихся тестов и провёл с ними вычисления для приведения в сопоставимый вид.
>Попытки оправдываться
Я привёл все данные, от и до, в равных условиях для cpu и теслы. Пытаешься манипулировать именно ты. Или не ты.
>в удобном виде с обработкой одного токена и генерацией 8к
>1 промт и 8к генерации не бывает
Это граничные значения, на деле скорость что на cpu, что на tesla может быть любой в вычисленном мной диапазоне, в зависимости от ситуации. Например, 3 или 5 Т/с на tesla, которые на cpu недостижимы ни при каких обстоятельствах.
>Я лишь рофлю
Ну в принципе оно и видно по уровню аргументации.
>Кек, 1 т/с, все видели, да?
>РРРЯЯЯ, манипуляции, 1 т/с, все же видели, да?
Ты можешь для любого желаемого размера промпта и генерируемого ответа вычислить точную скорость на tesla и на cpu, но это тебе невыгодно, ведь так ты сам признаешь, что обосрался. Только и остаётся повторять мантру, делая вид, что штаны сухие. В глазах любого здравомыслящего человека с трёхзначным iq и усвоенным школьным образованием это выглядит смешно.
>неделю в тред не писал ранее
Я на самом деле ещё вчера случайно обратил внимание на срач, но было поздновато, спать хотел и поленился влезать. А сегодня снова всплыло и решил-таки влезть, по идентичности аргументации подумал, что это ты продолжаешь гнуть свою линию. Ну если не ты там сопоставлял с процессором и делал из этого выводы, то можешь эту часть моего поста игнорировать и предоставить своему коллеге оправдываться за себя самому.
>невероятной тормознутости 3х тесел
Всё относительно. Я видел и похуже на своём gpu на 8ГБ. Для обычного чатика с моими скоростями некомфортно, но для каких-то сложных запросов иногда 70B использую. А тут для 70B скорости очень даже ничего, у меня на 11B и то ниже, и при этом мне вполне нормально с ней чатиться. Стоит ли это 3 по 20к рублей - уже другой вопрос, тут мы опять возвращаемся к сравнению комплектующих. По сравнению с cpu выигрыш есть, как уже выяснили, так что наличие одной или нескольких тесл не равно её/их отсутствию. Из gpu за эти деньги из новых есть альтернатива в виде 4060 ti на 16 ГБ (чуть дешевле) или 2 arc 770/rx 7600 на 16 ГБ (чуть дороже). Из б/у может быть где-то удастся найти 3090 на 24 ГБ (чуть дороже). Будет ли там быстрее, или так же, или медленнее? Ну несите тесты в студию. Уж возможность проверить вариант с 3090 точно у многих в этом треде есть, судя по частоте выеб упоминаний.
Если есть деньги на покупку даже одной 4090, то тут уже надо сравнивать с 7+ теслами, а столько никто в здравом уме покупать не будет. Разве что под несколько ИИ-ферм под несколько параллельных задач, но это очень уж специфичный кейс.
Здесь люди гораздо умнее тебя сидят, примитивное разжевывание и объяснение этого выглядит убого, все и так понятно.
На кой хер полотна которые никто читать не будет пишешь? Уверовал и решил скосплеить (амудэ/интело)шизов из срачей по железу которое они желают купить(!) или тем хуже уже купили и оправдываются - земля пухом.
> что это ты продолжаешь гнуть свою линию
Лечись, пей таблетки, ложись в клинику и проходи интенсивный курс. Ты уже буквально видишь вымышленные сущности и пытаешься с ними спорить. Или тебя стебут подыгрывая
> то тут уже надо сравнивать с 7+ теслами
7 умножить на 0 всеравно будет 0, для них нет кейса применимости.
> Будет ли там быстрее, или так же, или медленнее? Ну несите тесты в студию.
Пару тредов назад были, граза разуй. В жоре обработка промта в районе 300-350т/с что всеравно оче медленно, но не так больно, вместо 1т/с будет 5-7. На нормальных картах можно забыть про тормознутого жору и ггуфопроблемы, наслаждаясь экслламой со скоростью эвала ближе тысяче т/с и отсутствием замедлений генерации на контексте.
> несколько ИИ-ферм под несколько параллельных задач, но это очень уж специфичный кейс
Более реальный чем куча тесел.
>не надоело
Мне не надоело, я только начал. На сами теслы мне плевать, я вообще б/у видеокарты для себя не рассматриваю. Доебался именно до аргументации уровня "пук", причём, регулярно повторяемой.
Вот и оправдывайся (йтесь?), или признавай(те?) обосрамс, или троллинг тупостью, или что это было.
выбери в таверне Text Completion > KoboldCpp у указывай адрес:порт кобольда. если и так не работает, проверь доступен ли порт и не висят ли кобольд и таверна на одном порте.
> В жоре обработка промта в районе 300-350т/с
Как-то мало. На 4090 в Жоре промпт на 70В считается в 2000+ т/с. На EXL2 в два раза быстрее.
Не знаю кто тебе все это писал но вот что я не понял нихуя
>я вообще б/у видеокарты для себя не рассматриваю.
Дак а зачем же ты их тогда купил?! Теслы они и есть б/у! Абсурд какой-то
> троллинг тупостью
Однажды увидел слово и начал его повторять, мдэ.
> На сами теслы мне плевать
Обоссы одну на видео с супом нет офк, так нельзя, железка вполне юзабельна и достойна уважения
Да хуй знает это запуск с теми странными параметрами что предлагалось что должны ускорять, или может в профессор упирается. Плюс на жоре был эффект что скорость обработки значительно замеляется с ростом самого контекста, в начале быстро а потом пиздец и первых токенов заебет ждать на приличном железе если решил бахнуть, например, 32к.
Но 2к+ т/с для пары карточек это слишком много, что там у тебя за конфиг, поделись.
>На кой хер полотна которые никто читать не будет пишешь?
Для собственного развлечения в первую очередь. Пока читают.
>видишь вымышленные сущности и пытаешься с ними спорить
Я вижу повторяющуюся однотипную аргументацию и предполагаю, что выдаёт её один и тот же человек (или нейросеть). Вот пусть и оправдывается, тебе я предложил игнорировать, если тебя не касается и ты эту позицию не разделяешь.
>На нормальных картах
Сколько нормальных видеокарт (речь же про 4090?) можно купить на 60к? Линк на магазин?
Нейросеть, плез. Расширяй окно контекста.
>Я мимо шёл, и вообще пользуюсь "затычкой амудэ", если что

>запостил эксель таблицу и и считает что запруфал что-то
Ты бенчмарки пости, таблицы я тоже умею делать - смотри
>Обоссы одну на видео с супом
Можешь прислать или профинансировать мне заказ с алика, тогда без проблем выполню. Хотя затруднительно это сделать, не спалив личные данные, я кроме крипты вариантов не вижу, да и с ней всё не особо надёжно, т.к. опыта работы с ней у меня нет и вообще заморачиваться не охота. Но ты же всё равно мне ничего не пришлёшь, даже будь такая возможность, так что похуй.
> вижу повторяющуюся однотипную аргументацию и предполагаю, что выдаёт её один и тот же человек
Иногда самый простой вариант является верным и не нужно искать глубинного смысла в очевидном.
> Сколько нормальных видеокарт (речь же про 4090?) можно купить на 60к?
Одну на лохито. Ну рили и после таких вопросов ты
> >Я мимо шёл, и вообще пользуюсь "затычкой амудэ", если что
и запомненные словосочетания 1 в 1 как у теслашиза. Тебя раскрыли, капитулируйся.
В голос с пика, ну ты содомит.
Рили почему никто не ахуевает с того что процессор обрабатывает контекст быстрее чем теслы?
Троллинг тупостью продолжается. Ну по крайней мере эта нейросеть умеет распознавать, что изображено на скриншотах (в общих чертах, сам текст читать с них, похоже, не умеет).
В чем оправдываться? Понятно что без контекста там действительно общая скорость будет примерно около скорости генерации, но при его заполнении будет очень быстро происходить пиздец. То что при 8к контекста (довольно небольшой размер, в ерп контекст спокойно и за 50к улетает) скорость уже падает до 1 т/с, то по скоростям легко высчитывается что там уже на 2к контекста скорость всего 3 т/c, на 4к - скорость 1.8 т/c, при этом с увеличение выше 8к жопа будет вырастать - на 16к там будет 0.5 т/c, на 32к будет 0.25 т/c и т.д.
Напомню что минимально доупстимой является скорость 5 т/с.
> Посоветуйте какую комбинацию фронта и бека оптимальней использовать под [железо]
Фронт - очевидная таверна и ее форки, ибо больше ничего по сути и нет. Бек любой, вообще. Все беки это по сути гуи поверх одних и тех же llama.cpp и exllama, различий по производительности скорее всего ее будет, разве что если одно обновляется раньше другого и соответственно туда попадают более новые llama.cpp/exllama. Можешь вообще чистые llama.cpp и exllama запускать, если консольки не боишься. Лучший бек с гуем на данный момент - text-generation-webui, он же oobabooga/убабуга.
> Стоит ли заморачиваться и генерить на видюхе или на проце будет тоже норм?
На видюхе у тебя максимум пойдут 7-11b, и то с небольшим контекстом, но зато генерация будет очень быстрой. На проце + видюхе скорость будет зависеть в первую очередь от скорости ОЗУ. Тебе с твоим железом надо запускать в нейронки в оперативе (на проце), а на видюху скидывать максимальное количество слоев (но не слишком много, чтобы видеопамять не начала свопаться в оперативку) и обработку контекста, чтобы генерация была быстрее.
>не будет
Фикс
>легко высчитывается что там уже на 2к контекста скорость всего 3 т/c, на 4к - скорость 1.8 т/c
Подозреваю именно поэтому больше мы и не увидели ни одного нормального бенчмарка с 2к и 4к контекста, только охуенные эксель таблицы где теслаеб взял 2 удобных для себя кейса с минимальным промптом, а третьей картинкой только подтвердил полученный ранее 1 токен в секунду.
>Одну
И какой эксллама-квант 70B туда влезет, чтобы считать с нормальной скоростью? 2bpw? Там же мозгов не остаётся. Или про жору забыть всё-таки не придётся?
>В чем оправдываться
В том, что ты на cpu получишь "то же самое", поэтому теслу нет смысла покупать совсем. В том, что ты сравниваешь несопоставимые величины.
>50к
И оно, конечно же, не кэшируется, а пересчитывается каждый раз по-новой, да?
>скорость уже падает до 1 т/с
Ну это если ты 100 токенов генерируешь, а потом сам заливаешь сетке на 8к. А по факту у тебя сколько-то считается контекст (в р-не 10 секунд на 1000 токенов что на cpu, что на тесле, что вполне приемлемо, на мой взгляд), а потом уже можно читать в реальном времени на тесле, а на cpu только ждать почти полного завершения генерации.
>В том, что ты на cpu получишь "то же самое"
Это был рофл, понятно что в реале то же самое получится не на чистом цпу, он все же медленноват, а на цпу вместе с обычной видеокартой которая есть у каждого.
>поэтому теслу нет смысла покупать совсем.
Действительно не имеет, с такой скоростью обработки промпта которая ниже чем у цпу.
>И оно, конечно же, не кэшируется, а пересчитывается каждый раз по-новой, да?
В ерп на нескольких персонажей или с динамическим лорбуком - да, таверна изменяет контекст каждый запуск и он просчитывается с нуля.
>в р-не 10 секунд на 1000 токенов что на cpu, что на тесле, что вполне приемлемо
Это не "приемлимо", это пиздец.
>И теслашиз будет их видеть каждый раз как только кончится 8к окно, начинается новый чат, применяется rag/базы и т.п. ожидание первых токенов как на профессоре - не норма.
Не, ты погоди. На 4090 ты можешь увидеть 35t/s, но где? В Aya_35В_4XS с 2к контекста. Ну вот тебе Aya_35B_8_0 c 2к контекста. Крути новый чат, раг/базы и всё, что хочешь. Можешь загрузить 4XS и крутить ещё быстрее. А здесь люди вообще-то 70В в хорошем кванте хотят. И могут.
> И какой эксллама-квант 70B туда влезет
Да никакой, вторая нужна.
> На 4090
> kobold
Обзмеился
>с обычной видеокартой которая есть у каждого
Так, пошли новые манёвры. Да-да, у каждого замкадыша есть приусадебное хозяйство и обычная 3090 для быстрого расчёта промпта в помощь к топовому cpu, способному и самостоятельно обрабатывать контекст на уровне паскалей. У меня почему-то 63 мс/т, ну да ладно, у меня же не видеокарта, а затычка для pci-e порта. Тем временем челики с 1 3090/4090:
https://github.com/LostRuins/koboldcpp/issues/458#issue-1920946856
>21ms/T to 23ms/T
>xwin-lm-70b-v0.1.Q3_K_M.gguf --usecublas --gpulayers 48 --stream --contextsize 4096
https://github.com/LostRuins/koboldcpp/issues/455#issuecomment-1751869107
>70B @ Q4_0 (40/80 layers on GPU): Processing: 21ms/T, Generation: 594ms/T, Total: 1.2T/s
Видимо, потери на пересылку между cpu и gpu существенны. И с осени могли уже что-то наоптимизировать, может, сейчас и получше (несите бенчмарки! мне меньше искать чужие данные сомнительной релевантности и вам лишний повод повыебываться, win-win).
Тесты 4090-шиза были на кобольде, так что всё честно.
> 4090-шиза
Ебать ору, видать крепко теслашизику на хвост наступили что так рвет.
Да я смотрю больше двух тесл у анонов анус шизов не выдерживает. Две ещё терпимо, а третья уже больно. Надо четвёртую покупать, чтобы уж наверняка.
> Надо четвёртую покупать, чтобы уж наверняка.
Правильно, чтобы 40т/с и 0.5 итоговых.
>вместо того что бы искать поисковую выдачу гугла в первых трех страницах и 50 ебанных сео блогах. где вместо контента сео текст хуйни и мочи
Так нейронки как раз на этих высерах и обучаются.
База.
>У меня почему-то 63 мс/т
У меня 3080Ti, по сути со скоростями 3090, и что дальше? Ситуации конечно разные, но любая RTX ебёт в обработке промта любой проц и теслу вместе взятые.
Спасибо большое, аноны!
Все запустил, работает, персонажей скачал, роли отыгрывают. Даж по сети расшарил чтобы с телефона общаться

Алсо что за херню начал выдавать бот? Сначала общался норм потом понесло. В чем проблема? В персонаже или модели?
Проверь размеры контекста в таверне и кобольде, где-то не совпадение. Плюс слишком много не стоит выставлять, но про это в вики инфа есть.

Спасибо!
А еще можешь подсказать куда нажать чтобы бот дописал предыдущее сообщение, а не начинал новое не закончив?
В janitorai есть кнопка продолжения повествования. В интерфейсе таверны не нашел
>В интерфейсе таверны не нашел
По трём полоскам. В настройках можно вынести в отдельную кнопку, если часто пользуешься.

спасибо!
а что еще за выбор в диалогах? где это отключить?
Немного ломает отыгрыш
Это в карточке смотри, походу там прописано. В самой таверне по дефолту ничего такого нет.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
LLaMA 3 вышла! Увы, только в размерах 8B и 70B. Промты уже вшиты в новую таверну, так же последние версии кобольда и оригинальной ллама.цпп уже пофикшены.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2. Недавно вышедшая Llama 3 в размере 70B по рейтингам LMSYS Chatbot Arena обгоняет многие старые снапшоты GPT-4 и Claude 3 Sonnet, уступая только последним версиям GPT-4, Claude 3 Opus и Gemini 1.5 Pro.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-11B-v2-GGUF/blob/main/Fimbulvetr-11B-v2.q4_K_S.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama , https://lmstudio.ai/ и прочее - Однокнопочные инструменты для полных хлебушков, с красивым гуем и ограниченным числом настроек/выбором моделей
Ссылки на модели и гайды:
https://huggingface.co/models Модели искать тут, вбиваем название + тип квантования
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
https://ayumi.m8geil.de/erp4_chatlogs/ Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: