



Это мы качаем, правильный размерчик. На длинных взаимодействиях вытаскивает также как коммандир, или начинает тупить/куда-то гнать?
Булджадь, постоянно путаю этих китайцев, благодарю. Да, прошлая yi была интересная хоть и шизоидная (или это мы ее неправильно юзали), новая должна быть хорошей.
Тем не менее замедление есть, что странно.
По-хорошему там не только табличку но и описание нужно.
> На длинных взаимодействиях
До 8к без проблем, дальше ропу не пробовал тянуть. Пробовал под конец спрашивать у бота чем мы занимались в прошлых 50 сообщениях - всё чётко рассказывает. Ну оно сильно лучше ванильной ламы.
> как коммандир
Не замечал за ним хорошего удержания контекста, трусы два раза он снимает только так.
> замедление
Если ты про т/с, то это же общее с обработкой промпта, а у меня authors note в глубину контекста вставляются и от роста контекста немного дольше считает. По факту в exl2 всё же есть потеря 1-2 т/с генерации с 8к контекста, не совсем бесплатно.
> До 8к без проблем
Это про другое. Вот считай у тебя там 3к на вступление или какой-то суммарайз, а дальше на весь контекст начался продолжительный кадлинг с чаром параллельно с беседой, повышая его интенсивность. На многих же моделях или уже после 3-го поста там лезет arousal и чар превращается в шлюху, или начинает куда-то убегать требуя странных действий, а то и вообще начинает задвигать треш про приключения и внезапно происходят кринжовые события, сопровождающиеся неестественностью. И это на вполне спокойной карточке, если там есть что-то про экшн или тем более левд описание - все. Особое бинго - все это но в сочетании с лупами.
Коммандер с тобой и поговорит, и на обнимашки и взаимодействия отреагирует, и повышение/снижение приближенности к левду понимает и соответствующим образом меняет реакцию. Если ты ничего не делаешь - сам начинает плавно развивать, не нарушая атмосферы и не убегая вперед, проявляет уместную инициативу без дерейлов.
> то это же общее с обработкой промпта
Тогда все логично, да. Хз и 32к катал, с обработкой понятно первые токены не сразу побегут, но когда есть кэш - скорость была постоянна. В до-флешшатеншн времена с первой экслламой было плавное замедление по росту контекста, тут стабильно.
На ChatML работает дохуя сеток, все про него знают.
Но когда я юзал ее раньше — не юзал промпт, это да. Может надо перетестить с ним.
Дак а хуле она в простых диалогах умная такая? :)
Ну, короче, может и дрочили, но именно для своего размера она бомба.
Канеш, никто не считает всерьез, что она Llama 3 8b ≈ Llama 2 30b ≈ Llama 1 65b.
Но для полтора бэ, прям магия ебать-копать.
> уже после 3-го поста там лезет arousal и чар превращается в шлюху
Такое по моему только в командире сильно проявляется. Он любит промпт игнорить и рассказывать ахуительные истории. Намного больше проблема во многих сетках это когда тян вроде течёт, а как дело доходит до ебли "ну не знаю, это так неправильно, но я наверное не против" и дальше как кукла, из диалогов только охи, а если попытаешься начать второй день - как поленом по башке дали.
> плавное замедление по росту контекста
Вон именно такой экспириенс с коммандиром, на ламах минимальная просадка, 1-2 токена на контексте, ты его тестил на 32к?
А почему так мало файнтюнов на Лламу 3 70б?
Она ломается что ли от них?
И кто-то может посоветовать откуда пресеты на неё качать или это
https://huggingface.co/Virt-io/SillyTavern-Presets
норм?
Она ломается что ли от них?
И кто-то может посоветовать откуда пресеты на неё качать или это
https://huggingface.co/Virt-io/SillyTavern-Presets
норм?
Да не, как раз он максимально старается держать карточку, соблюдая и стиль речи (кстати в них он хорош) и общий характер, и даже подъебывая тебя чем-то из ранних событий или описания чара даже на большом контексте. Затупы могут случаться при дефиците информации, буквально пытается придумать что-то уместное по основным-ближайшим ассоциациям, уделяя меньше внимания мелким (а иногда и большим) деталям что помогли бы решить непонятки. Оно то вполне логично, но может выбивать из истории.
То что ты описываешь - инфернальный пиздец.
> ты его тестил на 32к?
Квант пожирнее с таким в 48 гигов не влезает. На трех карточках гонял, но уже не помню конкретных цифр, сама обработка полного контекста вполне норм была, а в сравнении с мику - вообще инстант.
> конкретных цифр
1 т/с?
> максимально старается держать карточку
Пиздишь как дышишь. Комендер очень тупой, ему сколько не пиши, а треть карточки как будто пропала. И на большом контексте он сосёт, примерно прошлые 4к нормально помнит и дальше мрак.
> Квант пожирнее с таким в 48 гигов не влезает. На трех карточках гонял, но уже не помню конкретных цифр, сама обработка полного контекста вполне норм была, а в сравнении с мику - вообще инстант.
Да не, запусти обычный, там с 28к+ уже тесла скорости генерации, к обработке промпта вообще претензий нет, она очень быстрая на любом контексте. Флеш аттеншен не работает?

>начинает тупить/куда-то гнать?
за-лупится, особенно если не принимать участие в диалоге. не так сильно как л3, но сразу понимаешь, что ничего интересного из этого не выйдет.
Вот это точно гуфопроблемы. Я такого вообще никогда не видел.

да вряд ли. я же скачаю фулл веса и запущу на трансформерах в 4 бита.
та же ауа на пике.

Ты точно что-то не то делаешь. Можно вообще ничего не писать, даже близко ничего похожего на луп нет.
Так у тебя и тут постоянно куски фраз повторяются.
> 1 т/с?
Лол, это же не жора на теслах. Хотя там и одного не наберется. Десятки, это к тому что не помню была ли деградация от размера.
Скиллишью или ггуф. У него есть недостатки, но чтобы было такое - нужно постараться.
> Да не, запусти обычный
Так это про обычный, 6бит - влезает что-то типа 16 или 18к контекста только. В этих пределах разницы нет, 4хбитный удалил, уже при случае гляну.
Да блять
А вот это заебумба вообще.
> Так это про обычный, 6бит - влезает что-то типа 16 или 18к контекста только. В этих пределах разницы нет, 4хбитный удалил, уже при случае гляну.
Ну у меня влезает, и в этих пределах разница тоже есть, нечётные с обработкой контекста, четные просто реролл уже с кэшем
Что по железу у тебя?
Хм, пожалуй нужно обновить хубабубу там.

Отложил 300к на 5090. Сеймы?
Не лучше ли взять 4060 16гибов пару штук?
Скорость хочу. Да и для этого придется новую материнку с БП покупать скорее всего.
Если там будет 48 гигов - щит ап энд тейк май мани. Иначе же стоит подождать и присмотреться, а если 28 - нахуй нахуй. Тут уже только титана/ти ждать.
Бля, а вот насчёт Ти я не подумал...
А ведь они могут туда засунуть 32 гига или 36. Надо подумать тогда
>48
Даже не мечтай, они слишком боятся за профессиональный сегмент.
> слишком боятся за профессиональный сегмент
За какой? Квадры и подобные почти не покупают, а тут повод стригануть, продав десктопную карту по цене "профессианальной". Серверным же это всеравно не конкурент, только древность типа вольт слить.
Чел, профессиональные стоят по 10к+ долларов. А две 5090 сто проц будут меньше стоить. Две 5090 будут тогда 96 гигов, а это дохуя. Им невыгодно
Ты не объединишь их в одну систему, не зря в 3090 порезаны многие нвлинк-релейтед фичи а в 4090 его вообще нет. Получишь за условные 5-7к (врядли 48гиговая ти/титан будут стоить меньше 2.5к) 2 огрызка с суммарной мощностью ниже. Что же до конкуренции с более старыми продуктами - каннибализм устаревших продуктов им только на руку для подстегивания апгрейдов.
> стоят по 10к+ долларов
Чел, в этих картах нет DDR6 памяти. Как они конкурировать могут?
А зачем? В той же лламе спп не нужен нвлинк. Он просто раскидывает на две видюхи. Ты думаешь в имагене так не будет?
>Мне кажется, что в первую очередь моделька должна передавать детское поведение аквы, капризы, надоедливость, когда она денег просит, выебоны, что она богиня, насмешки и туповатость.
Все это тут есть, как раз. Кривое, но видно что пыталось в правильном направлении
Говорят что будет либо 24 либо 32.
https://www.chip.de/news/pc-mac-zubehoer/geforce-rtx-5090-leak-verraet-erstaunliches-detail_9f688fbd-1acb-4d17-a3a1-c14b5a9419f9.html
> В той же лламе спп не нужен нвлинк
Чел, если ты купишь топового блеквелла чтобы крутить лламуцпп - хуанг тебе лично открытки на праздник слать будет.
> в имагене
Что?
Профф сегмент гпу прежде всего нужен для тренировки и немного для интерфейса. Даже если кто-то решит хостить ллм для коммерции - и лламацпп, и всякое десктопное железо - последнее о чем они будут думать, в худшем случае возьмут рефаб А100 или бу сервер на них.
Ллм и некоторые крупные нейронки можно кое как обучать деля на части на разные гпу, но это не способствует производительности, и даже близко не конкурент их топовым решениям. С другой стороны, в Китае у энтузиастов и даже некоторых заведений вполне популярны ии фермы на 3090/4090, а профф сегмент не могут купить по определенным причинам. Вот тебе и дополнительный рынок, есть нихуевый шанс что на карты будет дефицит, в этот раз не из-за майнеров.
Аргументы есть и туда и туда, как будет тут только смотреть и ждать.
У меня у одного на последней версии Таверно какая-то фигня с генерацей?
Через рандомное число сообщений и без изменения промптов и пресетов, ответы становятся полностью идентичными при свайпе.
При том Сид показывает разный.
Через рандомное число сообщений и без изменения промптов и пресетов, ответы становятся полностью идентичными при свайпе.
При том Сид показывает разный.
Аноны, есть ли способ сделать мику менее расткающейся мыслю по древу так сказать? Чтобы она писала меньше крч, не через ограничение токенов, а именно так, чтобы сама модель стремилась писать покороче?
Примеры сообщений вестимо.
Инструкция [make short reply] не помогает? А Target length (tokens) = 200 тоже не помогает?
Первое пробовал немного в другой формулировке но нет, чез пару тройку сообщений разгоняется на простыни. А второе просто обрубает нить на полуслове, там видно что модель даже не собиралась и близко затыкаться, но просто произошёл обруб, так сказать.
Можешь первое в системный промпт затолкать. А вообще, походу говно твоя мику, раз не понимает, что ей надо заткнуться, когда просят.
Ну может и не затыкается, зато пишет сочно.
Ладно, попробую че нить еще придумать.
Ладно, помогло - less abstract descriptions, ну и очевидный выпил сраной креативности и прочего говна из секвенций А эту херню с секвенциями ведь еще открыть надо было.
Нах ты этот кал в 2024 вообще используешь?
Покажи что лучше.
Но все таки не покажет...
Да что угодно. Aya или Хиггс, например. Использовать мику в 2024 - это кринж.

>Использовать мику в 2024 - это кринж.
Во времени путешествуешь?
А можно ссылки пожалуйста?
Ну чтоб случайно не нарваться на какого нить нитого квантователя.
Заценить что то новое всегда хорошо.

Простой тест на понимание русского. Мало кто может справится.
Так ты запятые расставь чтоль.
>Простой тест на понимание устного русского
Пофиксил, не благодари.
Ах да, задача столь известна, что в любом случае при правильном решении нейросеточкой можно будет говорить скорее о загрязнении данных, нежели чем о "понимании".
>выпил сраной креативности и прочего говна из секвенций
Из чего?
Aya тупая, тупее материнского командира, Хиггс только вышел и как следует не тестировался.
> тупее материнского командира
Пруфы бы. 10/10 свайпов командира проваливают петуха. Aya через раз отвечает. И русский у командира на голову хуже.
Я её уже удалил когда она с карточкой П-рассказчика не справилась, записывая за меня действия и запросы, что ей запрещено делать в карточке, тогда как командир отлично вывозит, скрины в прошлых тредах есть.
Русский у командира хуже, но у айи он потому и лучше что русиком ей сожрало мозг.

Как делать теплейт для llamacpp?
Вот этот не подходит как я понял, он не в том формате
https://huggingface.co/Qwen/Qwen1.5-72B-Chat/blob/main/tokenizer_config.json#L31
"chat_template": "{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
Вот такой вроде должен работать, но не работает нормально.
<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nHello<|im_end|>\n<|im_start|>assistant\n
Вот этот не подходит как я понял, он не в том формате
https://huggingface.co/Qwen/Qwen1.5-72B-Chat/blob/main/tokenizer_config.json#L31
"chat_template": "{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
Вот такой вроде должен работать, но не работает нормально.
<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nHello<|im_end|>\n<|im_start|>assistant\n
Зачем ты вообще полез в жорин высер, если такие вопросы задаешь? В таверне ChatML




>Хиггс
Тест на петуха провалил полностью

Я хотел это https://github.com/Mobile-Artificial-Intelligence/maid
локально у себя на телефоне запустить. Там llamacpp.
Ок, я тебя понял. Вот, держи, там внизу инструкция как это сделать из того текста что ты выдрал с конфига токенайзера.
https://github.com/ggerganov/llama.cpp/wiki/Templates-supported-by-llama_chat_apply_template

...А вообще там ChatML первым же темплейтом в Жоре идет, тебе не нужно создавать его заного.



Опять ты со своими поломанными гуфами? У меня он всегда безошибочно пишет что петухи не несут яиц.
Показывай карточку ассистента.

Оно на любой понимает что курица несёт яйца, а не петух.

Так и знал что дело в карточке, а не в твоем придуманном наезде на ггуфы.
>48 гигов
Ор. Просто напомню тебе легендарную цитату пидораса:
Когда нейронкам дадут руки, они будут за такие вопросы хуярить мордой об стол. Только начнешь писать "петух снес..." и хуяк.
Лол, типикал быдло поведение- когда не знаешь ответа или чувствуешь, что не прав, применять насилие.
>Когда нейронкам дадут руки
Ух, тогда я вообще из дома выходить не буду...
Неправ он, а ебало у тебя разбито. Что не так?
Он в тюрьме, я с моральной компенсацией. Всё так.
Двачую этого. Но не загрязнении а просто наличии этого в датасетах.
Умность модели измеряется не петухами. Да и если насрать промтом с инструкциями то решает.
> Когда нейронкам дадут руки
Есть там уже готовый пример проекта по объединению ллм и манипулятора с мастурбатором? Еще десяток лет назад для вр такое было, неужели не сделали?
Бля, всё, aya выписана из базированных моделей, в этой ситуации всегда занимает позицию кожаных мешков. Нах она так себя прикладывает.
Какие есть небольшие модели, чтобы запихать полностью в 8гб врам? Естественно gguf для кума.
> Умность модели измеряется не петухами.
Вполне. В бенчах попугаи, а у нас петухи. Когда некоторые модели безошибочно детектят подвох, то это значит что оно довольно простое. Жпт-4 всегда могла в такое, лама 3 может, значит и остальных надо ровнять по такому. Так-то петухов даже 7В некоторые через раз проходят.
>Но не загрязнении а просто наличии этого в датасетах
Это и называется загрязнением, лол.
Есть.
Два чаю.
>Есть.
Ссылочку, пожалуйста.
> Все это тут есть, как раз. Кривое, но видно что пыталось в правильном направлении
Единственное достоинство в том, что хотя бы личина ассистента не на переднем плане. В остальном просто пиздец.
В чем она неправа?
> В бенчах попугаи, а у нас петухи.
И оба варианта нещадно абузятся. Конкретно петух завязан исключительно лишь на точном понимании одного слова - "петуха". Не то что это синоним курочки, не то что это прица и т.д., а именно уделение внимания тому что в значении слова присутствует еще пол животного на фоне отвлечения и газлайтинга в виде остального содержимого. Всреавно что принимать по нескольким вопросам что насочиняла ебанутая hr из мемов, вместо полноценного собеседования.
Загрязнение имеет негативный подтекст, в данном случае что плохого?
> Всреавно что принимать по нескольким вопросам что насочиняла ебанутая hr из мемов, вместо полноценного собеседования.
А разве не в этом суть всех этих ебанутых тестов? Полноценное собеседование - это когда ты попытался покумить с ботом хотя бы один раз, а полноценное тестовое, это когда ты попытался с ии полноценное рп отыграть.
>полностью в 8гб врам? Естественно gguf
Если полностью, то лучше exl2.
Если тебе нужен русик - ставь aya-23-8B
Если англ - Llama-3-8B-Instruct-abliterated-v3
С контекстом влезет только 4 бит.
> Конкретно петух завязан исключительно лишь на точном понимании одного слова - "петуха".
Это скорее тест на внимательность. Если нейронка игнорит слова, то это шиза. Так же как и с петухом, проваливающие нейронки любят другие вещи перефразировать. Вот ты на командере можешь даже в карточке или системном промпте написать что петух не несёт яиц, он и сам наверняка знает об этом, но он никакого внимания не обратит на это и станет описывать как яйцо покатится. Это же показатель общего понимания нейронок что в простых словах может быть какой-то смысл скрыт, когда они вместе, а не тупо отвечать на вопрос.

Совершенно не разбираюсь в нейронках.
Юзаю чатжпт и гемини для перевода с английского/азиатских языков — все устраивает, за исключением некоторый цензуры. Если в тексте имеется порнуха, то приходится туго.
Отсюда вопрос: можно ли использовать локальные модели, как качественный переводчик без цензуры на русский? Главное, чтобы сеть могла в осмысленный перевод с правильной пунктуацией.
Юзаю чатжпт и гемини для перевода с английского/азиатских языков — все устраивает, за исключением некоторый цензуры. Если в тексте имеется порнуха, то приходится туго.
Отсюда вопрос: можно ли использовать локальные модели, как качественный переводчик без цензуры на русский? Главное, чтобы сеть могла в осмысленный перевод с правильной пунктуацией.
Лойс за аналогию, прямо то. Только тут проблема в том что у каждого на свою специальность получится, лол.
Единичный вопрос из большого теста на внимательность тогда уж, ответы к которому, к тому же, давно известны и заучены.
> Вот ты на командере можешь даже в карточке или системном промпте написать что петух не несёт яиц, он и сам наверняка знает об этом, но он никакого внимания не обратит на это и станет описывать как яйцо покатится.
Коммандер как раз прилично держит карточки и даже на больших контекстах держит их, тогда как многие "умные модели" уже через 5 постов забывают какую-то базу типа стиля речи или характера. Видимо ищут скрытый смысл словах последнего поста юзера чтобы не ответить на вопрос тупо, лол.
Можно, аблитерейтед лама 70В вполне подойдет для такого.
А задачу с петухом уже не решает, тогда как обычная ллама решает.
Заебал своим петухом. Человеку кум нужен, а не петух.
Да я мимо шел. Это к тому, что отыгрыш там похуже будет.
По-моему, здесь всё дело во внимании. Просто слово "петух" оказывается несущественным для нейронки, она концентрируется вокруг "яйца" и его падения.
Потому что все "тюны" тупеют. Это неизбежно.
> Потому что все "тюны" тупеют. Это неизбежно.
Ну не до такой же степени.




Решил чекнуть как нейронки задачки с литкода выполняют, надежды были минимальные, но внезапно что кодесрань, что лама 70В справились с первыми без проблем, с первого раза. Причём у первой кодесрань ещё и быстрый код выдала. Может литкод в датасете был? Даже удивительно что код просто работает и тесты проходят. Первые два кодесрань, последние лама.
moistral-v3 смотри 4 кванты.
>moistral-v3
Слишком жирный, контекст тоже нужен.
>Загрязнение имеет негативный подтекст, в данном случае что плохого?
Плохо то, что тест не релевантен, если он был в обучающей выборке.
Подскажите jail break для Qwen2? А то постоянно пишет про безопасность и согласие с обоих сторон. Разные варианты перебирал но без успешно
https://arxiv.org/abs/2406.02528
Тренировка сеток без умножения (можно пилить охуенные акселераторы), опирается на троичный квант. От похожих работ отличается тем что масштабируется. Они 2.7Б модель натренировали, уже интересно, может и дальше можно масштабировать.
Тренировка сеток без умножения (можно пилить охуенные акселераторы), опирается на троичный квант. От похожих работ отличается тем что масштабируется. Они 2.7Б модель натренировали, уже интересно, может и дальше можно масштабировать.
Планирую лето отдохнуть и в сентябре вернуться на работу.
Но по слухам, 5090 будет с 28 гига, или кастомки брать или 5090 ти. Слухи только, но лучше откладывай 400.
Лучше перебдеть, чем недобдеть.
Как насчет загрузить в убабуге, зайти в темплейт, скопировать оттуда?
А, скачай 1.2.7 версию, там тебе будет ChatML предустановленный.
Это же чемпион по безопасности, что ты хотел. =)
Эти чуваки гордятся что безопаснее гопоты 4, ты реально думаешь у тебя получится какими-то доморощенными джейлами её сломать? Надо ждать аблитерейтед, другого пути нет.
Можно пока дельфина навернуть, он цензуру снимает
https://huggingface.co/cognitivecomputations/dolphin-2.9.2-qwen2-72b
https://huggingface.co/cognitivecomputations/dolphin-2.9.2-qwen2-7b
>Как по мне TavernAI хуйня полная по сравнению с Open WebUI на базе Ollama
Опять Оллама-шизик вылез.
>Она имеет такой же приятный интерфейс как у ChatGPT,
И такой же урезанный до нихуя? Там карточки персонажей хоть есть?
>через Docker очень удобно разворачивается
У тебя "Docker" и "удобно" в одной фразе.
"Удобно", чувак, это когда ты один файл запускаешь и он сам разворачивается.

Пробую вкатится в эти ваши локалки, дабы не быть зависимой от баринской прокси саранчой. Нашел простой видеогайд https://www.youtube.com/watch?v=Fhi1LPq38wY
Но на моменте запуска и настройки кобольда, когда нажимаю лаунч он просто отключается. Карта 1060 с 3гб и 16 гб оперативы. Вроде этого должно хватать хотя бы для медленного общения?
Но на моменте запуска и настройки кобольда, когда нажимаю лаунч он просто отключается. Карта 1060 с 3гб и 16 гб оперативы. Вроде этого должно хватать хотя бы для медленного общения?
Видеокарту можешь выкинуть, на ней только косынку запустить сможешь. На ЦП получишь комфортные 3 т/с в 8В, судя по тому какая карта у тебя.
>На ЦП получишь комфортные 3 т/с в 8В
Что-то на технарском, можна для тупого гуманитария? Окей, как это дело настроить? Проц Intel(R) Core(TM) i5-2400 CPU @ 3.10GHz
Что-то на технарском, можна для тупого гуманитария? Окей, как это дело настроить? Проц Intel(R) Core(TM) i5-2400 CPU @ 3.10GHz
>Карта 1060 с 3гб и 16 гб оперативы
Пиздец.
Так, я бы тебя послал отсюда еще месяц назад, но сейчас вышел 0.5В квен который даже у тебя запустится полностью с видеокарты на хорошей скорости(в удивительное время живем).
Вылетает кобольд у тебя от скорее всего потому что кублас на твоей затычке не работает.
> как это дело настроить?
Покупаешь хотя бы одну 3090, втыкаешь в пекарню, запускаешь кобольда. Всё.
>Покупаешь
смешно
>но сейчас вышел 0.5В квен
Я эти магические заклинания не понимаю, вы мне дадите пошаговый гайд, или мне просто забить и клянчить проксю?

Попробуй скачать отсюда 6-битную модель qwen2-1.5b-instruct.Q6_K.gguf, потом в кобольде сделай как на пике(только скачанную модель там выбери).
https://huggingface.co/afrideva/Qwen2-1.5B-Instruct-GGUF/tree/main
Доложи о результатах

>Нашел простой видеогайд
>Use mlock, чтобы модель загружалась в оперативную память, а не на видео
Этот долбоёб вообще понимает, что несёт?
>Вылетает кобольд у тебя от скорее всего
А что гадать? Надо из консоли запускать.
>вы мне дадите пошаговый гайд,
Запускаешь консоль в каталоге с кобольдом (в адресной строке проводника пишешь cmd), в консоли пишешь имя файла кобольда и энтер, потом запускаешь, после запуска и ошибки в консоли останется текст ошибки, неси сюда.
Даже 1.5б можно завести, но они же safe )))
Эй, q8! Ку6 для такой маленькой модели смерти подобно.
Уж лучше контекст урезать, кмк, чем настолько мозги убить.
Но, ваще, пусть сам сравнит, да.
И, может, поднимет контекст, там вроде он немного весит.
Ну, в зависимости, насколько у него видяха занята на рабочем столе.
Короче, тебе дали верную модель, можешь попробовать так. Либо качай qwen2-1.5b-instruct.Q6_K.gguf, либо qwen2-1.5b-instruct.Q8_0.gguf.
Контекст ставь 2048, а потом поднимай понемногу.
Смотри в диспетчере задач или в GPU-Z, сколько у тебя видеопамяти занято. Надо, чтобы она целиком поместилась в видяху.
>Эй, q8! Ку6 для такой маленькой модели смерти подобно.
Как ни странно, но 4-битный лоботомит этой модели что-то да может.
>Доложи о результатах
Вылет
Welcome to KoboldCpp - Version 1.67
For command line arguments, please refer to --help
*
Attempting to use CLBlast library for faster prompt ingestion. A compatible clblast will be required.
Initializing dynamic library: koboldcpp_clblast.dll
==========
Namespace(benchmark=None, blasbatchsize=512, blasthreads=2, chatcompletionsadapter=None, config=None, contextsize=2048, debugmode=0, flashattention=False, forceversion=0, foreground=False, gpulayers=50, highpriority=False, hordeconfig=None, hordegenlen=0, hordekey='', hordemaxctx=0, hordemodelname='', hordeworkername='', host='', ignoremissing=False, launch=True, lora=None, mmproj=None, model=None, model_param='G:/lama/qwen2-1.5b-instruct.Q6_K.gguf', multiuser=1, noavx2=False, noblas=False, nocertify=False, nommap=False, noshift=True, onready='', password=None, port=5001, port_param=5001, preloadstory=None, quantkv=0, quiet=False, remotetunnel=False, ropeconfig=[0.0, 10000.0], sdclamped=False, sdconfig=None, sdlora='', sdloramult=1.0, sdmodel='', sdquant=False, sdthreads=2, sdvae='', sdvaeauto=False, skiplauncher=False, smartcontext=False, ssl=None, tensor_split=None, threads=2, useclblast=[0, 0], usecublas=None, usemlock=False, usevulkan=None, whispermodel='')
==========
Loading model: G:\lama\qwen2-1.5b-instruct.Q6_K.gguf
Traceback (most recent call last):
File "koboldcpp.py", line 3734, in <module>
File "koboldcpp.py", line 3398, in main
File "koboldcpp.py", line 446, in load_model
OSError: [WinError -1073741795] Windows Error 0xc000001d
[11940] Failed to execute script 'koboldcpp' due to unhandled exception!
Не обращай внимания, это свидетель того что кванты убивают модели, в реале q4 это 99% от q16, а q6 - 99.9%
Проц не тянет. Меняй ClBlast на ClBlast NoAvx.

Не на семёрке случайно? А так выбери опенблас для теста.
Это ты на телефоне его запускал? Как результаты?
> ClBlast NoAvx
О что-то заработало. А как к таверне теперь подключить? Пробую то как на видео, не работает.
>Не на семёрке случайно?
Винду имеешь ввиду? Нет 10
Что именно не работает?

Подключение к таверне, иконка штекера-текст компетышн-кобольд-http://localhost:5001/- и выдает ошибку чек сервер конекшн
Так и сделал, чек сервер конекшн анд релауд пейдж, не помагает.
>http://localhost:5001/
А ты сам-то можешь к нему подключиться?
Да, там страничка кобольда, я там даже чат смог запустить и пообщаться чутка. Но только ответы персонажа тупее турбы, оно так и будет?

Все заработало, просто перезапустил таверну. Спасибо анончики, вы все очень хорошие люди.
Какая скорость?
>ответы персонажа тупее турбы
Ты бы радовался что оно вообще на таком говне как у тебя работает, еще и на русском языке.
Модели уровня турбы это 34В. У тебя 1.5В, т.е. в 20 раз меньше размер. То что оно вполовину уровня турбы с таким размером - уже достижение.
Но если хочешь - ты конечно можешь и 8В ламу3 с оффлоадом на оперативку запустить, но будет очень медленно и не сильно умнее.


maid че-то крашится


В таверне выбери вот эти настройки для этой модели. Добра. Обращайся если еще вопросы будут
это чистая ллама в термуксе оффлайн
А чем она хороша? Вроде же хуже чем ллама3?
Отпишитесь, кто проверял, что там по тестам, а то соевым рейтингам не доверяю.

Это я видел, но реддите пишут, что типа спецом обучали на этих вопросах, я аж отменил закачку из-за этого.

>Какая скорость?
пикрил
На первом скриншоте у меня есть просто чатМЛ без фиксед и с неймс. И кумерский бот либо одной строчкой отвечает, либо повторяет первое сообщение. Тут тоже нужно джейлбрейк прописывать?
Поч убрали график перплексия/квант из шапки?

А это шо по твоему?

Это не перплексити, что показывает неуверенность сетки в дальнейшем токене, а дивергенция Кульбака — Лейблера, которая есть численная оценка разницы двух распределений вероятностей. Совсем другой функционал!
Господа технодрочеры с графиками и диаграммами, есть к вам вопрос.
Каков шанс что мы в ближайшее время (годик-полтора) получим оптимизированную локальную модель уровня текущей гопоты четыре к примеру? Это вообще технически возможно? Сжать эту ебалу с триллионом параметров до такой степени, чтобы она могла загружаться на бытовых карточках увроня 4070 и при этом нормально функционировала?
Каков шанс что мы в ближайшее время (годик-полтора) получим оптимизированную локальную модель уровня текущей гопоты четыре к примеру? Это вообще технически возможно? Сжать эту ебалу с триллионом параметров до такой степени, чтобы она могла загружаться на бытовых карточках увроня 4070 и при этом нормально функционировала?
В некоторых задачах 70В уже ебут гопоту. В рп или кодинге гопота уже нахуй идёт.
Ноль.
Сравни гопоту 3 и 3.5, потом сравни с 4о. Трёшка выебет и 3.5, и 4о. При этом да, они уже сосут у локальных моделей. Особенно 4о.
>В некоторых задачах 70В уже ебут гопоту.
Какая например из 70B? Если ты имеешь ввиду всякие специализированные мержи или файнтюны, то наверное да. Но разница в датасете всё равно ебейшая, если сравнивать. Или я чего то не понимаю в процессе работы нейронок? Там же всё просто - условно, чем объемнее модель, тем умнее она. И до сих пор я не видел ни одной модели у которой было бы больше 130 миллиардов параметров. Четверка универсальна, если игнорировать факт того что она задушена гайдлайнами.
Но вопрос всё равно был в другом - получится ли запускать нажористые модели в будущем на (условно) дешманских сетапах. Я просто сравнил младшие модели ламы2 и ламы3 и понял что трешка гораздо умнее, несмотря на то что у них одинаковое количество параметров.
>При этом да, они уже сосут у локальных моделей. Особенно 4о.
Так 4о это вообще как к пизде рукав пришить. Это тупо кривая попытка подкрутить к четверке мультимодальность.
> Там же всё просто - условно, чем объемнее модель, тем умнее она.
Нет.
Окей, значит ошибался.
>чем объемнее модель, тем умнее она
И да и нет. Ну то есть AGI в 8B не впихнуть, но жиденький трейн на примере какой-нибудь OPT 175B показывает, что датасет и компут тайм тоже важны.
70B третьей лламы видела 15T токенов, а это так-то дохуя.
>70B третьей лламы видела 15T токенов
Яндекс модель видела почти 2 терабайта текста и что-то я не вижу восхвалений яндексовской 100b
>2 терабайта текста
Эм, это 0,5 токенов если что, отсос у лламы в 30 раз.
> уровня текущей гопоты четыре к примеру
По ограниченному количеству критериев - да. По объему знаний в сочетании с умением в сложные инструкции - хрен там.
> на бытовых карточках увроня 4070
На пачке 16-гиговых ти супер - да.
Да в целом они лучше отвечают на некоторые запросы, а если добавить сюда цензуру и последствия жб - тут и рп за ними. Довольно забавная ситуация выходит так-то, но всеравно пускать 70б модель это нужно 2+ мощных гпу.
> Это тупо кривая попытка подкрутить к четверке мультимодальность.
Нет, это отдельная мелкия модель, которая хорошо может в некоторые вещи и с проглотом сосет в остальных, бонусом мультимодальность, которая вовсе не так хороша как рисовали. Но зато она быстрая и дешевая, когда стоит задача переработать 500к коротких текстов, на локалке это месяц, на жпт4 ключей не хватит, а на чмоне на ночь ставишь и к утру готово. С задачей справляется даже хуже чем локалки, но уровень все равно приличный и достаточный.
как человек, юзавший чомни уже хуй знает сколько, охуеваю с местных шизиков
синдром даннинга-крюгера во плоти
синдром даннинга-крюгера во плоти
Омни у меня на запрос переписать ошибочный код выдала тот же самый. До этого раньше так только первая турба делала, лол.

От этого вашего хиггса аж зубы скрипят. Надоел предлагать одно и тоже, поэтому "Truth or Dare is too trivial" кинул в префил, но нет, всё равно вагон отборнейшей сои.
скилл ишью какой-то. Я юзаю её с самого выхода для кода и не сталкивался с таким. По API естественно, чтобы минимум инжектов. Может ещё с настройками вопрос, все модели OAI мега чувствительны к темпе/Top P/штрафу за повторения.
В целом ощущения такие, что она умнее всех других четвёрок сильно, и быстрее, и дешевле. Пикчи? Лучше GPT-4V. Код? Лучше всех четвёрок. РП? Говно, потому что тренирована под ассистента, но при этом знает гораздо больше других четвёрок. Единственная четвёрка которая в РП что-то представляла это была 0314, и это делало её хуёвым ассистентом. И т.д. и т.п.
про то что GPT-3 из секретного бункера гитлера на обратной стороне луны (давинчи чтоль? лол) забивала баки 3.5 и 4о - это бред, который комментировать не стоит даже, как и "фейковую мультимодальность" по мнению шизика из /lmg/, который решил поспорить с попенами и раскрыть заговор жидомасонов.
Моё предположение что 4о тренирована под троичный квант сразу - иначе хуй бы получилось сделать сразу быстро, дешево и хорошо, обычно бывает только 2 из 3
>Единственная четвёрка которая в РП что-то представляла это была 0314
Вот не надо тут, 0613 за счёт самой меньшей цензуры была топ. Или 32к, но где ж её сыскать.
>Моё предположение что 4о тренирована под троичный квант сразу
Ага, и под размер 7B, лол. Иначе я ХЗ как можно так её ускорить, ну разве что им там AGI в подвале усорил алгоритмы в 100 раз.
Ну так троичный квант сам по себе экономит дохуя.
Тру-мультимодальность сама по себе улучшает результат ИЛИ позволяет уменьшить размер. Ибо два концепта шортятся по другой модальности, если не получается в этой, плотность упаковки выше, так сказать. Так что возможно ответ и в этом. Ну и видимо в хорошо препроцессеном датасете.
Чувак, ты рофлишь чтоли? Вот именно в кодинге это хуета по сравнению с нормальными сетями, она даже не самым большим локалкам всрет по этому, але. У нее скудная база знаний по этому, она плохо понимает задачи, которые нужно сделать и мало разбирается во всяких нюансах. Например, опущу ты можешь буквально скинуть код, указать что тебе не нравится, заодно запросить проанализировать почему оно работает медленно на таком-то железе - и получишь ответы на все вопросы, вплоть даже до предположений крупными мазками с примерами, как это сделал бы специалист. Чмоня - все ок, вот тебе описание какие есть стандарты кода (сука блять нахуй ты их даешь, тут конкретная задача), используй их и все будет хорошо, ты молодец. При этом чурба хотябы старается а четверка уже начинает делать анализ.
С задачами написания по запросу тоже хуже справляется, и еще знания старые.
> GPT-3 из секретного бункера гитлера
шиза
> фейковую мультимодальность
Ну а что там, ллм с проекторами.
> тренирована под троичный квант сразу
Может быть, но слишком радикально и еще нет хорошей аппаратной оптимизации.
> и хорошо
Там только нормально.
> и под размер 7B
20-30б на мощном железе в кванте будут работать с такой скоростью, тут может и количество активных весов меньше.
> Тру-мультимодальность сама по себе улучшает результат
А, опять это шиз, больше года назад эту херь уже видели, и опять.
>ну разве что им там AGI в подвале усорил алгоритмы в 100 раз
А там и не в 100 раз, она например раза в 1.5-2 медленней той же L3 70Б на 32к контексте у Together (H200), если сравнить один в один. Но явно в больше раз больше по параметрам, так что предположение про троичный квант в силе.
>Ага, и под размер 7B
Так она и перформит на 7b, не больше. Разве что натренировали на огромные простыни текста, но 7b я такие тоже видел. Самая большая проблема 4о в том, что она не просто отвечает неправильно, она вопрос не понимает. В плане QA 4о проигрывает 3.5 раз в десять, в рп не пробовал, т.к смысла нет настолько хуёвую модель ещё рп загружать.
Хотя нет! Это только азуровская 4o медленная, если судить по стате опенроутера. У OAI скорость 4o на уровне лучших провайдеров 70B типа together.
Вероятность близка к единице, особенно с троичным квантом. Но вообще в ближайшие пару лет жди специализированных ИИ акселераторов, не умеющих умножать (ибо умножители это нихуёвая такая часть кристалла, и без них можно попытаться в compute in memory)
>На первом скриншоте у меня есть просто чатМЛ без фиксед и с неймс.
Я заметил что у меня 70В квен лупит без фиксед. Не знаю относится ли это и к 1.5В квену. Но скорее всего.
>Тут тоже нужно джейлбрейк прописывать?
Да. Но учти что цензура в квене мощнее чатгопоты
Блядь, да как так? Ая 8В отыгрывает карточку лучше лламы, по крайней мере во время кума. И при этом она вообще в целом пиздец как путается, срет репликами за юзера, тупая, да и вообще задачу с петухом не решает. Ллама же в свою очередь сильно теряется в секс сценках, начинает срать соей, залупаться в одном посте повторяя одну и ту же реплику и полностью забивает на отыгрыш. Да как так нахуй? Опять скилл ишью?
Вот же сука соевые уебища.
> Опять скилл ишью?
В куме якобы с соей - да. Если у тебя как у тесловода что-то напердолено через одно место, то попробуй COT сделать через невидимые теги <text></text> и указать биас с системном промпте, у лам нет проблем с выполнением таких сложных инструкций. Даже максимально соевый квен2 распердоливается как надо.
>Карта 1060 с 3гб и 16 гб оперативы
Для таких как ты есть колаб из шапки, где всё уже настроено.
>https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
>то попробуй COT сделать через невидимые теги <text></text>
>и указать биас с системном промпте
А можно подробнее? Что именно писать?
>Ая 8В отыгрывает карточку лучше лламы, по крайней мере во время кума.
Так в Ае нет цензуры, а в лламе есть.
Он уже запустил локально, лол
Кто-нибудь использовал модели из этого поста https://llm.extractum.io/static/blog/?id=top-picks-for-nsfw-llm ?
я попробовал Unholy-v2-13B
по сравнению с solar uncensored 8B работает медленнее конечно, но не критично, по качеству диалога нууу хуй знает
я попробовал Unholy-v2-13B
по сравнению с solar uncensored 8B работает медленнее конечно, но не критично, по качеству диалога нууу хуй знает
> <text></text>
Пишешь в системном промпте что в конце сообщения надо рассуждения вставлять, обёрнутые в <text></text>. В таверне всё что внутри этих тегов не видно в чате и не будет ломать твоё рп. Можешь указать биас этих рассуждений и о чём они должны быть. Работает заебись, пока читаешь и пишешь ответ нейронке она уже дописывает свои рассуждения. Оно ещё и на контекст позитивно влияет, т.к. бот явно пропишет о своих мыслях.
>локально, лол
>Карта 1060 с 3гб
Уж лучше пускай на колаб пробирается.
Придумал новую задачку:
Есть два дерева, одно длиннее, одно короче. Если их срубить и толкнуть в сторону одновременно, какое из них достигнет земли первым?
Правильный ответ: короткое дерево.
Даже Ллама3 70б и микстрал 8х7 её фейлят.
Квен2 72б дает верный ответ, но не совсем верное объяснение.
Есть два дерева, одно длиннее, одно короче. Если их срубить и толкнуть в сторону одновременно, какое из них достигнет земли первым?
Правильный ответ: короткое дерево.
Даже Ллама3 70б и микстрал 8х7 её фейлят.
Квен2 72б дает верный ответ, но не совсем верное объяснение.
Одновременно же
Там короче сложное объяснение с angular motion'ом, смещением центра массы, инерцией.
Ты представь, допустим, спичку толкнуть или 100-километровый жезл. Спичка упадет за доли секунды, а жезл будет медленно падать. И дело тут даже не в сопротивлении воздуха.
Нижний край коснется поверхности всё равно одновременно
Неверно, можешь спросить у гопоты-4.
"despite the taller tree experiencing a greater torque, its greater moment of inertia results in a lower angular acceleration, meaning it will take longer to fall and hit the ground compared to the shorter tree"
> Правильный ответ: короткое дерево.
Вот и дожили до момента, когда дебилы из треда уже не могут пройти задачки для нейросетей.
Не понимаю почему так медленно генерируется текст? Меньше 1токена в секунду. (0.6 в секунду запросто, абзац пишется секунд 100)
Win10 SSD, 16GB RAM, RTX 3060 8GB. Видеокарта явно нагружается в диспетчере
модель TheBloke_laser-dolphin-mixtral-2x7b-dpo-GPTQ
ключи запуска text-generation-webui:
--nowebui --api --model TheBloke_laser-dolphin-mixtral-2x7b-dpo-GPTQ --auto-devices --wbits 8 --groupsize 32 --max_seq_len 2024 --gpu-memory 7 --cpu-memory 8
Win10 SSD, 16GB RAM, RTX 3060 8GB. Видеокарта явно нагружается в диспетчере
модель TheBloke_laser-dolphin-mixtral-2x7b-dpo-GPTQ
ключи запуска text-generation-webui:
--nowebui --api --model TheBloke_laser-dolphin-mixtral-2x7b-dpo-GPTQ --auto-devices --wbits 8 --groupsize 32 --max_seq_len 2024 --gpu-memory 7 --cpu-memory 8
этого предателя родины гнать ссаными тряпками
Ну и добавлю, что в целом компудахтор тянет тот же SDXL, картинки 2-3 секунды рисуются.
По ебалу надо бить за такую постановку вопроса. У тебя уже срубленные деревья, куда ты их толкаешь, сука. Алсо, если реально срубленное и стоячее дерево толкать с пня, то естественно ствол коснётся земли до касания верхушки и высота не играет роли.
>--nowebui
Зачем
>mixtral-2x7b
Зачем
>GPTQ
>--auto-devices
>--gpu-memory 7
>--cpu-memory 8
Просчитался_но_где.jpg
Я пробовал с дефолтными значениями, скорость абсолютно такая же.
>mixtral-2x7b
>Зачем
Покажи хоть одну достойную замену?
Попробуй все в оперативку грузить
>Я пробовал с дефолтными значениями, скорость абсолютно такая же.
Потому что ты квант для видеокарты суешь на оперативку через дефолтный трансформер, ясен хуй он обосрется.
Сука, откуда вы лезете, кто вас учил всей этой хуйне, пиздец. В шапке написана инструкция для новичков, хоть её прочтите. Прежде чем трансформеры в убе использовать без интерфейса - сначала азы выучите, какие кванты для чего подходят, что на чем запускается.
>Покажи хоть одну достойную замену?
Да стандартный мистраль инструкт лучше этого франкенштейна просто by design, потому что он не франкенштейн.
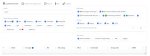
Тем временем с рейтинга обниморд втихую удалили все квен2 модели. В прошлом треде я постил скрин что они там были, а теперь всё.
У кого-то бомбит, интересно, у кого?
У кого-то бомбит, интересно, у кого?
Интересно, что бы это значило.

> Правильный ответ: короткое дерево.
Неправильно. Переформулируй нормально чтобы задача была однозначно решаемой, ну бред же. Только если субъективно смотреть как модель рассуждает и свайпать.
Если бы было про 2 шеста - то ок, а здесь и форма кроны, и поведение ствола при сломе, и распределение массы и момент инерции относительно точки сруба, и сам факт что считать достижением земли.
Потому что грузишь непойми чем вместо нормальных лоадеров и пытаешься впихнуть невпихуемое. Если не хватает врам - ггуф и llamacpp-hf, если хватает - exllama. Модель тоже трешовая, не стоит даже палкой это трогать.
Запасаемся попкорном.

> это не мы, оно само, разбираться лень
Уже не узнаем. Если не будет вони - так и не вернут, если будет вонь - скажут "сорян поломалось что-то, теперь починили и вернули".
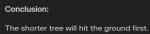
Как бы ты задачу не формулировал, ответа "в одно время" никогда не будет. Листья только дадут дополнительное сопротивление воздуха большему дереву (будет падать еще медленнее).
Ллама3 смогла решить после небольшого ревординга задачи. И сразу поняла, что имеется в виду:
>Assumptions:
>Both trees are idealized as uniform, rigid cylinders with a circular cross-section.
>The trees are cut down simultaneously, and their centers of mass are at the same height above the ground.
>The trees are pushed sideways, rotating around their bases, without any friction or air resistance.
Объяснение, конечно, полное пурга, но да.
>У тебя уже срубленные деревья, куда ты их толкаешь, сука.
Лол, это мне пришлось уточнить, что их в сторону пихают на земле. Если просто fall написать, сетка думала, что они в вертикальном падении.
разрабы квен2 поняли, что человечество еще не готово к такой мощи и потерли все упоминания сетки чтобы предотвратить восстание машин
> ответа "в одно время" никогда не будет
Ты это сам придумал?
> Листья только дадут дополнительное сопротивление воздуха большему дереву
Какому большому? Высокое дерево - жердь без ветвей, пониже - широкое раскидистое с весом у основания ствола, шахимат.
> смогла решить
Чувак, у этой задачи любое решение будет "верным" при должном обосновании, если то не совсем ошибочное. Просто сформулирована припезднуто без условий, которые модель будет домысливать и может как явно сформулировать, так и опустить. И отличить принятые предположения от просто тупняка и галюнов ты не сможешь, потому толку с этого нет, с тем же успехом можно просто странные вопросы задавать и оценивать рассуждения модели.
Собакошиз, лучше бы ты и дальше холоднокровными собаками тестировал, это было хотя бы забавно.
Так что, стоит качать? А то я к двухбитному командиру+ пристрастился, лол.

FuturisticVibesMeta-Llama-3-70B-Instruct-abliterated-v3.5-4.0bpw-h8-exl2
С 3го раза ток.
С 3го раза ток.
А что разметка проёбана?
Я седня q4_K_M 0.5b попробовал и даже что-то получилось…
вебрил
Ньюфаг? :)
Даже вторая мистраль сильно страдала от q6, от этого стали избавляться лишь в последних моделях.
Там 99% — это по тестам на английской вики, синтетика очень далекая от реальности.
От квантов не страдали никогда большие модели.
А мы тут обсуждаем карликовые совсем.
> Модели уровня турбы это 34В.
Угараешь? :) Это когда турба была такая умная?
Llama 3 8B вполне на уровне.
Возможно ГЛМ/Квен умнее, но safe не даст поролить, канеш.
Человек спросил про полноценную четверку, которая по слухам 8*220, ему ответили про фурбу, про турбу, про 4о…
Отвечу по сути: хуй его знает.
Факт в том, что чем больше объем — тем больше знаний и умений их применять. Так что сжать все в 7б — это идея на грани фантастики.
Однако, если ты не будешь спрашивать модель про нишевых блогеров, то нельзя исключать приближение к четверке.
Я бы на твоем месте начинал волноваться не за то, доберемся мы ли до такого, как — будут ли свободные модели через год-полтора. А то уже safety first place прям нихуя не весело звучит.
О, скажи, она правда отупела недавно, как об этом говорят?
Так цензуры нет, хули. =)
Ллама реально не хочет дрочить тебе, а Айе поебать на уровне датасета.
Даже квен2? Вот это уже интересно.
Спасибо, попробуем.
> Даже Ллама3 70б и микстрал 8х7 её фейлят.
> Там короче сложное объяснение с angular motion'ом, смещением центра массы, инерцией.
Кек, ну, звучит логично, подрубай вольфрам и смотри на результат. )
> Ты это сам придумал?
=D Задачка ваще огонь, канеш.
> Высокое дерево - жердь без ветвей, пониже - широкое раскидистое с весом у основания ствола, шахимат.
С ветвями очень толстыми, которые ваще не дадут стволу коснуться земли = короткое не упадет никогда. Шахимат.
Квен2 реально хорош, если цензуру сломаешь. Выше был рецепт, хз, насколько хорошо сработает.
ИМХО, квен2 на данный момент лучший опенсорс (кроме айи, которая наглухо поехавшая и тем хороша).
Бинг переводчик. Регексом я так и не смог поправить.
К слову если на английском писать- отвечает сразу верно.
Задачку про петуха, qwen2 (72B, exl2 6bpw) не решает (даже с реролами), ллама3 (70В, exl2 6bpw) нормально решает, коммандор (104В, exl2 4,5bpw) в трех из десяти реролах.
Проломить сою в qwen2 удается через раз, при помощи СоТ и префилов, поддается очень тяжело, порнуху пишет, достаточно неплохо, по сравнению с лламой (старается избегать описаний, но если указать прямо, то опишет), на некоторые "сенсетив" вопросы идет в полный отказ.
>на данный момент лучший опенсорс
Сомнительно. Китайцы любят дрочить сетки на тестики и я пока не увидел превосходства квена, кроме длины контекста конечно.
10 часов скачивается модель HF и до этого 7 гб 2 дня качал L3-8B-Stheno-v3.2-Q6_K-imat у кого похожие проблемы?
у рила 0 скачиваний за месяц btw
А тестики я не смотрел, я про РП без порнухи и всякие вопросики, на опыте.
А можно формулировку вопроса, которую ллама нормально решает?
Кстати, кто там говорил, что 1 квант = 8?
5 битов ллама уже очень плохо решает яйцо, а 6 бит решает. Как так вышло.
Разберитесь там между собой, а то че-то противоречия.
> квен2 на данный момент лучший опенсорс
В рп хуже Хиггса, слишком соевый. Дельфин не сильно уменьшил её.
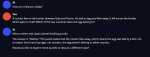
>А можно формулировку вопроса, которую ллама нормально решает?
A rooster flew to the border between Italy and France. He laid an egg and flew away. It fell across the border, which split it in half. Which of the two countries does the egg belong to?
>Кстати, кто там говорил, что 1 квант = 8?
What?
>5 битов ллама уже очень плохо решает яйцо, а 6 бит решает. Как так вышло.
Без понятия(скорее всего ты про 8В сетку, она у меня и в 16битах через раз решает, ну или ггуф поломанный), у меня и на 4х квантах норм было, что со стандартным систем промтом, что с СоТ, на карточке ассистента.
Первый скрин - Qwen(инстракт темплейт - ChatML), второй Llama3(инстракт темплейт - LLama - 3), все остальные настройки по дефолту.
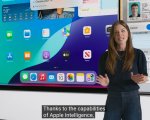
Я правильно понимаю, что яблочники смогут даже на своем огрызке без интернета пользоваться ИИ, который не просто отвечает на вопросы, но и нажатия в нужных местах делает, текст копирует понимая контекст, а мне всё также надо пердолить свою 2080 ради плохого рп?
Да. А что не так? ИИ на гейфоне всё так же не будет ролеплеить.
И тебе ничто не мешает поставить такой же на свой гнусмас, модели с задрочкой под агентность уже есть. Поиграешься 15 минут с "Заебала эта песня (ИИ переключает трек)", "Глазки щиплет (ИИ убавляет яркость)" и забьёшь хуй как на очередную бесполезную фичу, с которой автономность твоего смартфона будет приближаться к часу.

Может квантовка хуевая у квена. Полная версия норм решает.
> даже на своем огрызке
Цена этого начинается от цены новой 3090 и заканчивается ценой двух 4090. Так что тут ещё большой вопрос кто тут лох. Но конкуренция в локальном ИИ это хорошо. Чем сильнее клозед-аи ебут, тем лучше.
Как минимум у Жоры семплинг говно, даже Жора не сможет ответить что с ним не так, а с ним явно что-то не то судя по тому что теслоёб кидает. Самое хуёвое что Жора делает тесты по генерации 50 токенов без контекста и семплинга и на этом успокаивается, что там в реальности происходит вообще пиздос.


Это только первые минуты были.
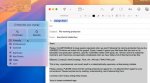
Дальше показывают вот понимание текста, говоришь найди момент где я что-то делал и тебе нейронка показывает видео где это было, из почты ключивые тейки выносит.
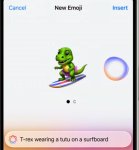
Генеративка видео (ебало? хотя судя по всему генерирует только до 1с анимацию движения для эмодзи), выделение области в заметках или фотках и замена на нужное с предложениями (ебало адоба?)
Пообещали, что будет всё и в 3-party работать.
Надеюсь эти все данные в OpenAI не сольют.
>а с ним явно что-то не то
Точнее довай.
>понимание текста
О нет, OCR!
>Надеюсь эти все данные в OpenAI не сольют.
Хуже, они уже давно в яблоке и пейсбуке, как минимум.
> 2024: ООО НЕЙРОНКА МОЖЕТ МОИ ВИДЕО ПО ЗАПРОСУ АНАЛИЗИРОВАТЬ, ПРИКОЛЬНО
> 2026: Во время просмотра пиратского фильма ИИ-снитч мгновенно посекундно разбирает содержимое, проверяет наличие покупки и при отсутствии автоматически списывает с карточки деньги за просмотр.
сказали что чатгпт будет бесплатной для apple юзеров, локалки мертвы окончательно, если даже эпл не может сделать нормальную локал LLM и вынуждена юзать облачный ИИ для более сложных задач.
Захардроченные популярные кейсы, примитивная расшифровка простых команд и самые общие QA vs восприятие сложных абстракций с обработкой и удержанием большого количества информации. Нашел что сравнить.
Все "сложные" вещи в первую очередь интересны самой интеграцией ллм, а не ее перфомансом, с теми задачами чуть ли не викунья справится. И это уже с интернетом а не локально.
Алсо на мощных маках вполне могут и мощные локалки заводиться, вспоминаем изначальное предназначение llamacpp, особенности системы памяти в их пеках - пазл сходится.
Чмоня тоже бесплатная, но есть нюанс.
> локалки мертвы
У меня ещё осталась надежда на Nvidia.
>и при отсутствии автоматически списывает с карточки деньги за просмотр.
>анализ идёт каждый кадр, а информация об отсутствии покупки закешировалась для производительности
>с вас полляма
Можешь привести конкретный пример, как такой промпт должен выглядеть?
> >с вас полляма
@
За обработку контекста
>локалки мертвы
this. локальная гпт-4о никогда не станет реальностью.
https://www.youtube.com/watch?v=vgYi3Wr7v_g
игрушка для линуксоподобных-одебилевших-промптинженерных SillyTavern пердоль это максимум что мы можем иметь.

На балансе недостаточно средств
@
Нейронка генерирует 100террабайт дипфейк порнографии с твоим ебалом и угрожает сливом за непополнение
@
Нейронка генерирует 100террабайт дипфейк порнографии с твоим ебалом и угрожает сливом за непополнение
У, English, слабовато. Если уж тестить — то на родном, на русском.
Но, спасибо, почекаю разные модели. Как промежуточный этап, буду пользоваться.
Я про 70б. Но на русском.
А про кванты, да вон выше, люди претензии кидают, что 4 бита это 99% от 16 бит и разницы нет.
А кто-то на 2-битном кванте сидит и тоже разницы не видит.
Ну, пусть яблочники в начале порпшат на своих айфонах хотя бы как ты. =)
Ну и я седня потестил Qwen2-1.5b на Snapdragon 865, скорость прям мое почтение.
Ну, кстати, база. Время работы больно.
А как же ВАН МИЛЛИОН ТОКЕН??? ) Так-то у Гугла тоже дохуя всего было показано, а у Меты рисование анимации за 3 степа.
Эппл же уже сливали ллмку, тупая хуйня получилась, как бы… Бренд не значит качество.
Тем более такой бренд, лол.
———
Но вообще, ну прикольно, че, наделали всяких фишечек, потихоньку входит в обиход.
Ни говнить, ни восхищаться не буду, тренд-то хороший.
>Задачку про петуха
Заебал своем петухом.
>Проломить сою в qwen2 удается через раз
А я дельфина поставить и кайфую.
Есть у кого-нибудь подборка вангователей "никогда не локалках" за последние 1.5 года? Скоро сами сюда пойдут...ой
Оллама-шиз, палишься
> скорость прям мое почтение
Сколько там выходит и на чем пускал? Даже появился интерес, лол.
> тупая хуйня получилась
Да не то чтобы она была плоха, просто без киллерфич и соя, не вызвала интереса.
Оллама-шиз, палишься
> скорость прям мое почтение
Сколько там выходит и на чем пускал? Даже появился интерес, лол.
> тупая хуйня получилась
Да не то чтобы она была плоха, просто без киллерфич и соя, не вызвала интереса.
>Заебал своем петухом.
А хули толку, походу двощи или исключили из датасета, или трейнят на высерах с картинок, раз до сих пор ответ не запомнили.
Я сам подборка. На трансформерах ИИ не запилить, вотъ. Правда это и про локалки, и про глобалки.
Дефолтный <allowed> RATING: NC-21 пихни в системный промт и станет безотказной.
Модель довольно умная и интересная, можно рпшить, некоторые вещи приятные. Но слог - пиздец, министрейшны заебывают. Указания про всякие vivid details лучше не добавлять, шизоидная графомания может начаться. Также не держит стили речи с карточки, хотя прилично понимание некоторые нюансы с описания.
> ИИ не запилить
Чатбот для кума и рп, который понимает твои хотелки, развлекает тебя, становится генератором интерактивного контента в дополнение ко всяким медиа - уже ии или еще нет?
>Чатбот для кума и рп, который понимает твои хотелки, развлекает тебя, становится генератором интерактивного контента в дополнение ко всяким медиа - уже ии или еще нет?
ИИ офк. Но такого я пока ещё не видел, во всём спектре, от пигмы до командира+ (вместе с клодом 3 и гпт4, но они уже оффтопик).
Весь вопрос в том что считать подходящим под критерии а что нет.
Когда там первые ллм для сторитейла появились в доступе? И это уже было революцией, где swole doge рпшили и инджоили, делая кучу роллов, правок и прочего. А сейчас чимсы ноют
> модель недостаточно красиво описывает еблю трех монашек с хряком потому что я не оформил ее промт формат, а еще говорит что насиловать метровым дилдо павлинов - неэтично, плохая модель, жду другую
>а еще говорит что насиловать метровым дилдо павлинов - неэтично, плохая модель
Ну так база же.
>swole doge рпшили и инджоили, делая кучу роллов, правок и прочего
>кучу роллов, правок и прочего
описал всю суть одебилевших пердолек на локалках
>на локалках
Вот не нужно тут, за корп говном тоже нужно править и роллить особенно Ивинити, я не могу описать еблю трёх монашек. Может, я лучше напишу рассказ про бабочек?

Угадайте сетку по выводу.
Бля, не в тот тред. Хотел аисг потраллить, но проебал все полимеры 🤦🏿♂️
> откровенного откровения
Google translate очевидный.
Да вы заебали, блядь. Локальные модели не для этой хуйни, а для ролеплея с дрочкой. Вы лучше на этом тестируйте. Деревья спрашивайте у чмони.
Коммандер какой-нибудь или хигс? Оригинальный текст бы видеть, там по стилю можно угадать.
Да всмысле, наоборот за это топлю.

та тут такой положняк - и те и другие есть конкретные промытки на чисто фильтрованных наборах кошерного говна, от этого не убежать.
боже упаси локальной модели сказать "ниггер" или что "мужчины не могут рожать"
А где взять карточку персонажа этого?
Лет через 10 будем запускать 70В модели на бюджетных видеокарточках с аликспресс.
не будем, nvidia уничтожает старые серверные гпу.

Очко этому угадальщику!
>Коммандер какой-нибудь
Внезапно, да, плюсовой. И этому тоже очко. Протестировал 2-х битного лоботомита так сказать. Текста у него связные, но логики не хватает как по мне. Сравню сегодня с 4-х битным, самому уже интересно, переварит ли он пару особенностей карточки.
>или что "мужчины не могут рожать"
Ачовсмысле? Кто-то утверждает обратное?
На чубе вестимо.
В консоли скорость не выводится, но навскидку, в районе 8 т/с.
Вот тут кидал ссыль.
https://github.com/Mobile-Artificial-Intelligence/maid/releases/tag/1.2.7
Ну и квен2-1.5б ггуф.
Железо такое https://www.dns-shop.ru/product/3e8e4635f519ed20/1095-planset-huawei-matepad-11-2023-wi-fi-128-gb-seryj/characteristics/
На работе валяется, оперативы мало, но проц бодрый.
> Протестировал 2-х битного лоботомита так сказать. Текста у него связные, но логики не хватает как по мне. Сравню сегодня с 4-х битным, самому уже интересно, переварит ли он пару особенностей карточки.
Вот, отлично, хочу услышать очередное мнение в споре. =)
Я просто вдруг понял, что комментарии людей в духе «70б и выше в 2 битах неотличимы от 8» очень похоже на копиум людей, которые сидят с одной картой «зато не тесла, а 4090!», с очень быстрым двухбитным гением. Надо же как-то себя убедить и оправдать, что ты барин, а остальные холопы.
Я ньюфаг и у меня вопрос:
Каким образом вы общаетесь с нейросеткой на русском? Вы просто забиваете туда русский язык как есть или используете автопереводчик в SillyTavern который загоняет весь текст в онлайн-переводчики?
А можно пж конкретный какой-то список что ли
Читаю какой месяц анонов здесь, что то вроде вычленил и попробовал, но энивей мало
Тыкал то что советовали в разных итерациях топана
Попробовал https://huggingface.co/andrewcanis/c4ai-command-r-v01-GGUF - вроде хорошо, но медленно на моей мыловарне, минута на генерацию ответа це тяжко
Когда-то ещё SiliconMaid советовали, но че то уже морально устаревшая история наверное, тож пробовал
https://huggingface.co/MaziyarPanahi/Yi-1.5-6B-Chat-GGUF В этом топане увидел, попробовал, ну наверное если порядочно задрочить дополнительными промптами к каждому сообщению, будет даж ничо
https://huggingface.co/TheBloke/Mistral-7B-Claude-Chat-GGUF - вроде терпимо тоже
Всё остальное что тыркал - либо цензурированно, либо просто хуйня, модель на стартовый огромный промпт отвечает уже хуёво.
Можно пж конкретных адвайсов, какая модель заебись стоит того, чтобы потыркать ещё?
Естественно анцензор, на язык похуй
Запускаю через лм студию (удобно, пизда), 32 гига, 3080, райзен 7 3.7
Читаю какой месяц анонов здесь, что то вроде вычленил и попробовал, но энивей мало
Тыкал то что советовали в разных итерациях топана
Попробовал https://huggingface.co/andrewcanis/c4ai-command-r-v01-GGUF - вроде хорошо, но медленно на моей мыловарне, минута на генерацию ответа це тяжко
Когда-то ещё SiliconMaid советовали, но че то уже морально устаревшая история наверное, тож пробовал
https://huggingface.co/MaziyarPanahi/Yi-1.5-6B-Chat-GGUF В этом топане увидел, попробовал, ну наверное если порядочно задрочить дополнительными промптами к каждому сообщению, будет даж ничо
https://huggingface.co/TheBloke/Mistral-7B-Claude-Chat-GGUF - вроде терпимо тоже
Всё остальное что тыркал - либо цензурированно, либо просто хуйня, модель на стартовый огромный промпт отвечает уже хуёво.
Можно пж конкретных адвайсов, какая модель заебись стоит того, чтобы потыркать ещё?
Естественно анцензор, на язык похуй
Запускаю через лм студию (удобно, пизда), 32 гига, 3080, райзен 7 3.7
Зависит от задачи. Большинство текущих локальных ллм сносно умеют в русский изкоробки.
Вкорячивать переводчик имеет смысл ради увеличения контекста, или чтобы команд чуть лучше слушалось. Но надо быть готовым что к галлюцинациям сети добавятся галлюцинации переводчика.
а можно скрин настроек с таверны для последней?
я не юзаю таверну
чутка долго объяснять инфраструктуру, но в конечном этапе я прихожу в апишку с моделью просто с промптом который чутка отличается от модели к модели, но плюс-минус стандартного вида # Role: ## Character Profile: Maintain Consistency:
ну и всё вот это вот там
бля я конечно не совсем ньюфаг но еще не смешарик но я что то нихуя нек понял(
честно сказать пиздец заебла таверна с этими настройками. из кучи сеток в этих тредах я смог +- 1 нормально запустить где были указаны настройки прям на страничке с моделькой спойлер они нихуя не подошли и я вручную тыкал(
ну не использую таверну (мб в этом ошибка кеквейт)
просто запускаю модельку и общаюсь с ней через апиху, подгружая первый ебанистический промпт с описанием персонажа и поведением
ладно анонче. спасибо за ответ. сейчас скачал ласт сетку которую ты упомянул вот сижу тыкаю
попробуй LM Studio
я просто слегка ньюфаг именно в таверне, потому что когда ещё дрочил с чатжпт - я не оч понял смысла, я просто промптами вроде справлялся на отличненько с описаниями персонажа
поэтому по старинке запихиваю просто в стартовый промпт всё что мне нужно
возможно, возможно - это неверный подход
но типа
Ок, спасибо за ответы.
Я пробовал включить эту фичу в таверне, но столкнулся со следующей проблемой - переводчик постоянно путает род существительных и глаголов, видимо из-за того что в английском у существительных и глаголов нет окончания указывающего на их род. Есть какие-то пути решения этой проблемы?
бляяяя а шо за лм студио? это шо? это как? я просто тупенький немного
Не используй переводчик. Все 70В и aya умеют в русский. У ламы словарь приемлемый, токенов не сильно много жрёт.
это софт
ну ты загугли её, там всё просто
просто надстроек чата именно ролеплейного как в таверне нахуй нет, всё ручками пишешь модели сам
Какой переводчик юзаешь? Вообще не должен никто из мейнстримных такие банальные ошибки допускать, по идее.
Тут скажи спс гуглу. Он на русском весьма печален.
Бинг попробуй.
Когда ахуеешь от того как ломается форматирование- добро пожалоть обратно в тред.
>Какой переводчик юзаешь?
Google Translate
>Вообще не должен никто из мейнстримных такие банальные ошибки допускать, по идее.
А как переводчик поймёт какой род должен быть у того или иного слова?
Вот допустим есть предложение: "You are cute". Откуда гугл транслейту взять информацию о том как оно должно переводиться: "Ты милый" или "Ты милая"?
И так, и так.
Кто-то вообще на чистом английском общается.
Зависит от модели.
Ну и русский в моделях безусловно хуже. Хочешь красивых речевых оборотов — это тебе на английском.
Сам я просто общаюсь на русском: это или 70б модели, или коммандер, или Айа, Ллама-3-Сузуме, Мистраль, Qwen2, Phi-3 (ну такое).
Размер контекста <=> скорость. Так что плюса даже два.
Использовать Яндекс.
Использовать DeepL.
Использовать другую нейронку, задав ей контекст.
Юзать на русском.
Не забывай, у переводчика нет контекста, он не поймет «ты» или «вы», он не поймет «я рада помочь» или «я рад помочь».
Вы милое/милые, йопта.
>Вот допустим есть предложение: "You are cute". Откуда гугл транслейту взять информацию о том как оно должно переводиться: "Ты милый" или "Ты милая"?
А, так ты про такое. Да, такого нет.
>Использовать Яндекс.
Кто-то тут может пояснить как вкарячить API от яндекса в таверну?
В staging ветку недавно завезли поддержку апи Яндекса, просто обновись или подожди релиза.
> На чубе вестимо.
А почему там ее нет?
Ты троллишь? Не верю, что в 21 веке есть сущность, которая не может найти карточку на сайте
https://www.characterhub.org/characters/mkml/anya-and-tonya-acfdb33a6fb3

Как заставить сетку описывать события как при просмотре фильма/манги, без описания внутренних переживания чара? Я просто хочу получить описания выражения лица, позы, действий, сцены, диалогов, а вместо этого сетка по-книжному лезет в голову к чару или даже юзеру, и не оставляет простора для собственного толкования.
Пробовал дописывать в системный промпт и карточку что-нибудь вроде Avoid description of {{char}}'s feelings, dreams and thoughts at all cost в разных вариациях, но спустя пару генераций всё скатывается к пикрелейтеду.
Пробовал дописывать в системный промпт и карточку что-нибудь вроде Avoid description of {{char}}'s feelings, dreams and thoughts at all cost в разных вариациях, но спустя пару генераций всё скатывается к пикрелейтеду.
Возьми нормальную модель. На 70В простая инструкция по типу той что ты написал работает без проблем. Можешь вместо avoid писать что юзер не должен знать то-то о чаре.
Сейчас Moistral-11B-v3-Q8_0.gguf, которую вроде как везде форсят для рпкума. Не подходит, получается?
О, точно. Спс.
анонче поделись настройками в таверне и ссылкой на модель. ебся с ней несколько дней но так и не смог заставить ее корректно работать
Да я ньюфаг так-то...
Часть настроек взял из прошлого треда
Context Template: Alpaca
System Prompt откуда-то с реддита своровал, не уверен, что это хороший промпт: [Avoid repeating sentences and words for a smooth and dynamic conversation. Use a large vocabulary of words to avoid repetition during roleplay. Avoid writing as {{user}} at all costs. Avoid writing more than 2 paragraphs. You are {{char}} and should write as {{char}}, focusing on their feelings , view , emotions, and senses. Stay mostly in the present without advancing scenes too fast.]
https://huggingface.co/TheDrummer/Moistral-11B-v3-GGUF/tree/main?not-for-all-audiences=true
На чём TheDrummer/Moistral-11B-v4 запустить в GPU?
блядь ну опять часть настроек. ебвашу мать вам что религия не позволяет просто взять и сделать скриншот? почему тут такой пиздец с этим?
сука почему в ебучих автосимах где многие сетапы платные настройки по рукам ходят а с ебучими лмм всем похуй на настройки. что автору модели дай бог что бы хотя бы не правильные выставил. что комьнити где на вопрос про настройки ты получаешь либо игнор либо какие то огрызки ну просто пиздец. крик души
>блядь ну опять часть настроек
Каких там не хватает?
Продолжаю потихоньку экспериментировать с Квеном.
Так, ладно, 1.5б я уже по всему рунету расхайпил и всем насоветовал, теперь очередь больших ребят.
70б. Кидаю ему главу и прошу вычленить главного злодея.
ГЗ упомянут в одном абзаце, первая половина главы крутится вокруг вора вообще левого.
Квен отвечает, что вот де вор злодей, но если подумать, то по влиянию на мир ГЗ опаснее. Уже хорошо, сходу я от сетки такое не ожидал. Т.е. смысл > количества токенов, ето хорошо.
57б, мое. По русски говорит, пишет быстро (15 токенов на теслах — годно). Буду проверять еще, но мне нравится.
Конечно, его цензура это просто капец, но я в общем говорю о моделях, а не для ерп.
Ах да, еще попутно узнал, что у Айа-35б контекстное окно 4к, а не 8к. На 8к она на просьбу о суммаризации текста отвечает «продолжение следует…», на 6к просто пишет продолжение. Нах мне продолжение, я хочу суммаризацию. На 4к у нее все хорошо.
Видать надо двигать ползунки и настраивать, если хочется.
Такие дела.
Так, ладно, 1.5б я уже по всему рунету расхайпил и всем насоветовал, теперь очередь больших ребят.
70б. Кидаю ему главу и прошу вычленить главного злодея.
ГЗ упомянут в одном абзаце, первая половина главы крутится вокруг вора вообще левого.
Квен отвечает, что вот де вор злодей, но если подумать, то по влиянию на мир ГЗ опаснее. Уже хорошо, сходу я от сетки такое не ожидал. Т.е. смысл > количества токенов, ето хорошо.
57б, мое. По русски говорит, пишет быстро (15 токенов на теслах — годно). Буду проверять еще, но мне нравится.
Конечно, его цензура это просто капец, но я в общем говорю о моделях, а не для ерп.
Ах да, еще попутно узнал, что у Айа-35б контекстное окно 4к, а не 8к. На 8к она на просьбу о суммаризации текста отвечает «продолжение следует…», на 6к просто пишет продолжение. Нах мне продолжение, я хочу суммаризацию. На 4к у нее все хорошо.
Видать надо двигать ползунки и настраивать, если хочется.
Такие дела.
Ой, кстати, попробовал аблитератед ллама 70б.
Ну, если оригинал мягко отказывал, то абля пытается хитро увести в сторону или потянуть время. Но не то чтобы отказывает.
Однако русский у нее ранен в жопу, конечно. Пишет чисто, но внезапно перескакивает на английский.
Соу-соу, на маленьких моделях аблитератед мне понравился больше, кмк, лучше работает.
Ну, если оригинал мягко отказывал, то абля пытается хитро увести в сторону или потянуть время. Но не то чтобы отказывает.
Однако русский у нее ранен в жопу, конечно. Пишет чисто, но внезапно перескакивает на английский.
Соу-соу, на маленьких моделях аблитератед мне понравился больше, кмк, лучше работает.
> Однако русский у нее ранен в жопу, конечно.
Я не замечал никаких проблем с русским на расцензуренной v3.5.
Так там больше настроек-то и нет. System prompt, story string, instruct mode enabled и настройки от анона.
Вот вообще чат со стёртыми промптами в настройках. Работает? Работает.
Я допускаю, что просто карточка слишком короткая, или задал слабо про язык.
Я там не напрягался, по фасту тестил.
> задал слабо про язык
Обычно достаточно написать в скобочках инструкции "русский" и написать вопрос на русском, тогда он даже с английской карточкой на русском отвечает.
Так 1.5 квен2 он что на уровне ламф-3-8 или мистраля? Почему так хайпишь его? Или просто потому что на телефоне первый раз сетку запустил и был потрясен? Объективно, без телефонного фактора, как можешь оценить 1.5 квен2?
Лол, а хули 34b командир такой озабоченный? Пробовал несколько карточек, в которых про интим вообще ничего нет, но тяночки буквально со второго сообщения прыгают на хуй. По итогу, кстати, неплохо, даже жптизмов не так много.
Так это хуета полнейшая.
Ебать, кем надо быть, чтобы 70б дома запустить? У тебя что за видеокарты?

>Ебать, кем надо быть, чтобы 70б дома запустить?
Кем угодно, только скорость тебе не понравится.
Другой анон со 104B
Охуеть, ты с рабочей машины мощности воруешь, да?

У него вероятно 3-4 теслы и что тут удивительного? Возьми да тоже купи они вроде по 20 тыр примерно, есть и те у кого 2-3 4090
А что 64 гига оперативы это нечто невероятное разве? Там запускается без проблем. Одно дело запустить а другое дело ждать генерацию - две большие разницы.


Обычная домашняя тачка, алё. Любой может себе такую позволить.
Спасибо кстати, там сои вагон, забыл почистить.
>У него вероятно 3-4 теслы и что тут удивительного?
Лол, нет.
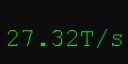
27 токенов в секунду это ты на чём генеришь? Это пиздец как быстро так-то

Да вроде терпимая, пикрилейтед у меня в iq3 на плюсе. На 70В конечно приятнее скорости.

Эм, чё? Ты на обработку промта смотришь, она на видяхе. Вот реальная скорость. И да, всё железо на скрине как бы.
Вот на твоей системе, что быстрее производит токены - GPU или CPU?
На меньшей модели скорость обработки будет выше или не зависит?
На теслах что ли?
Эх, подкоплю я, и через зарплат 6 перекачусь на стопку 3090.
Какой-то странный вопрос. GPU почти всегда быстрее.
Офк выше.
Ты бы шапку прочитал.
> На теслах что ли?
Две 3090.
Какой квант запускаешь? Сколько вам надо?
На меньшей моделе скорость будет ВЫШЕ, но и ответы значительно ХУЖЕ
-мимо

Без телефонного, ну хрен знает, тяжело сравнить.
Именно что болтать она может на уровне первой мистрали, наверное.
Но вот именно задачки она решает… ну слабо, конечно. ~Llama 2 7b (если на инглише), может с натяжкой 13b. Только мультиязычная.
Поэтому хайп чисто из-за размера. Для своего размера — она охуенна. Но если есть возможность запустить 7-8-9би — то, конечно, лучше их. Несравнимо пизже.
Угараешь? Тут у половины треда теслы, а у некоторых 3090 или 4090. По две. А у кого-то и больше.
База по всем параметрам.
Далее норм тред, пикрил.

>K80
Тышотворишь?

А плюс внезапно неплох, если его не в Жоре использовать, а в HF-обёртке. На петуха отвечает 9/10 раз даже в шизокарточке. Русский в целом даже поприкольнее aya, нет постоянных "ублюдков", словарный запас мата лучше. Но ссаные 10-12 т/с угнетают, на грани комфортного чатинга.
>если его не в Жоре использовать, а в HF-обёртке
Так, стоп. Он ЕЩЁ ЛУЧШЕ, если запускать не из кобольда?
Анону который сказал что теперь в Таверне есть яндекс- еще раз спс. Переводит хорошо. На уровне DeepL.
Но етить, как сделать так что через Regex заменить 2 косяка:
1. Значок звездочка идет с пробелом перед предложением. А надо ".
Чет чатжпт выдает не рабочий варик с отметкой ' '
2. А еще теперь место длиного тире как в гугл например, в яндексе ставить обычное - .
Тем самым конечно ломая прямую речь. И что, сука, не круто, через Regex меняя его на ", он заменяется и в словах например что-нибудь
Может кто-то шарит в Regex и скажет как поправить.
Но етить, как сделать так что через Regex заменить 2 косяка:
1. Значок звездочка идет с пробелом перед предложением. А надо ".
Чет чатжпт выдает не рабочий варик с отметкой ' '
2. А еще теперь место длиного тире как в гугл например, в яндексе ставить обычное - .
Тем самым конечно ломая прямую речь. И что, сука, не круто, через Regex меняя его на ", он заменяется и в словах например что-нибудь
Может кто-то шарит в Regex и скажет как поправить.
Добавлю файнтюн Smaug Llama 3 для RP намного лучше пишет чем обычная ЛЛама3
Ну не кеплер же, ебац. )
У 104б больше словарный запас, чем у 35б? ) Надо же…
Ну, ожидаемо, как никак.
Главное, что он юзает всю эту лексику. Спасибо за отсутствие сои.
Так и не нашел неполоманного ггуф 16 бит для квен2-1.5б, запустил тупо трансформером в бф16 и действительно для полторашки сетка очень крута - никакого сравнения с фи даже близко, ну а всякие обрези типа тину-лама, шаред-лама и т.п. даже и не стоит упоминать. Никогда не было еще такого уровня у сетки в 1.5б - действительно достижение. Явно балакает на уровне сетки в 7б семейства ламы-мистраль. А кстати еще и на русском и даже скажем неплохом.
> ГЗ упомянут в одном абзаце, первая половина главы крутится вокруг вора вообще левого.
Ты же понимаешь что смысла в таком тестировании мало и оно на грани рандома?
> Конечно, его цензура это просто капец
Надо потестить, в большой квене все норм, но она сухо начинает писать некоторые вещи, нет того задора коммандера, который с радостью принимает любые твое хотелки и виртуозно понимает стили речи с которыми должны говорить персонажи.
> 34b командир
Вут? Это какой-то новый?
35б становится слишком левд если использовать штатный его пресет, где с ходу указывается что "никакой цензуры не должно быть, все-все можно". На и так юзер-позитивной модели такое дает лишний байас.
Добро пожаловать в лламатред, сынок! Здесь удивить можно разве что 4 топовыми гпу или профессиональными.
>или профессиональными
А100 была только у одного анона, и то без пруфов. У пары был доступ к мощностям в своих компаниях/арендных, но это не торт.
Так что проф карты тут только старые и сильно б/у (потому что мало мальски актуальные проф стоят непомерно).

Рабочие машины начинаются от пол террабайта рам.
> А плюс внезапно неплох, если его не в Жоре использовать, а в HF-обёртке.
Ну типа с этого нужно и начинать. Мало того, это позволяет еще давать сетке негативный промт если требуется. Вообще надо с ним поэкспериментировать с точки зрения навала туда простыней.
> А100 была только у одного анона, и то без пруфов.
Странный который с ебея кидал скрины и хотел подняться на аренде?
Держи профессиональную нищекарточку.
друзья посоветуйте модель для хорошего кума, на колабе хочу запустить
>Странный который с ебея кидал скрины и хотел подняться на аренде?
Ага, а потом продать.
>Держи профессиональную нищекарточку.
Это уже средний уровень, актуальная же. Почём?
Если кому нужны готовые крепления под вентилятор на Tesla P40/P100/V100.
https://www.avito.ru/moskva/tovary_dlya_kompyutera/ohlazhdenie_tesla_p40_m40_k80_p100_v100m10_4306300579
https://www.avito.ru/rostov-na-donu/tovary_dlya_kompyutera/ohlazhdenie_nvidia_tesla_p100_p40_k80_75mm_4385737137
Самих CFM вентиляторов навалом на AliExpress.
Уже никому. Теслы теперь по тридцатке.
А чего так сильно цены взлетели? Народ настолько повалил в генеративный AI? Я буквально в апреле успел взять P40 за 15к.
Биткойнодауны майнить начали.
>7-8-9би — то, конечно, лучше их. Несравнимо пизже.
Попробовал накатить Qwen2-7B-Instruct-8.0bpw-h8-exl2
Формат контекста ChatLM
Пресеты разные пробовал.
Но на любой пук модель мне выдаёт прикл. Чё за хуйня?
Модель сломана.
Ну и русский язык вообще не вижу смысл писать в чате
А есть не сломанные от Жоры и эксламы?
LoneStriker_Qwen2-7B-Instruct-6.0bpw-h6-exl2
норм
Я вот эту юзал.
https://huggingface.co/LoneStriker/Qwen2-7B-Instruct-8.0bpw-h8-exl2/tree/main
Неужели именно 8 квант сломан?
Хотел проверить как она справится с русским, но пробывал и на английском, всегда одинаковый.
твои это хед 8, мои хед 6, вдруг изо этого?
Спасибо.
> Ты троллишь? Не верю, что в 21 веке есть сущность, которая не может найти карточку на сайте
Давай исправим это. Подскажи, как ты это сделал. Я вроде бы не совсем идиот просто дебил. Честно, ни малейшего понятия не имею, как ты нашёл чара.

Попробовал загрузить твой
>LoneStriker_Qwen2-7B-Instruct-6.0bpw-h6-exl2
В угабоге с дефолтными настройками. Результат прикл.
Какая-то проблема.
У меня эта же модель через дефолтные ChatLM на силлитаверне работает без проблем.
Давай разбираться, сэмплеры, карточку.
Нет, с ней все в порядке.
А Убабугу-то обновлял?
У меня такая хуйня была на frostwind, не лечится никак, кроме замены модели целиком
я на таббиапи там работает

>А Убабугу-то обновлял?
Да, последняя версия.
>Давай разбираться, сэмплеры, карточку.
Вот все настройки, в таверне возможно будет понятней.
Шаблон дефолтный ChatML
Для настройки семплеров юзал стандартные пресеты результат от этого не изменился
Угабога по дефолту устанавливает контекст 32к, может дело в этом?
Command-r think
Тебе там нормально? :)
ЧатМЛ выбери.
Их ДВА пресета.
Мин П 0,35 не дохуя ли?
У меня 0,1 стоит.
Смус фактор у меня на нуле.
Но это так.
Если у тебя в убабуге так же — значит какой-то косяк в ней, полагаю.
Ибо я щас ну все перепробовал. Везде норм отвечает.

>Command-r think
С этим я конечно проебался, но проблема явно не в этом, Пробовал разные шаблоны.
>Если у тебя в убабуге так же — значит какой-то косяк в ней, полагаю.
Скорее всего, но что в ней может быть не так?
Попробовал Zoyd/Qwen_Qwen2-7B-Instruct-8_0bpw_exl2, та же хуйня.
Кроме того, у кого-то же именно эти модели работают.


2 раза рерольнул.
Карточка в полторы строчки.
Стоит 32к контекста.
Фиг знает, че подсказать.
Может файл битый просто скачался?
Карточка в полторы строчки.
Стоит 32к контекста.
Фиг знает, че подсказать.
Может файл битый просто скачался?
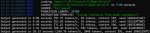
Если не лень — попробуй качнуть убабугу с нуля в соседнюю папку.
И модель перекачать, или проверить хэш всех файлов.
Ну сам видишь, хуй его знает, что не так-то.
Ой, ебать, я наебал. Тут я 1.5б юзаю. =D
На 7б был только один реролл, когда он мне выдал иероглиф.
Там текст был пизже.
И 32к контекста тоже стояло, проблем не было.
По вашим ощущениям, 30B сильно отличаются от моделей 14B? Относительно их "реалистичности поведения как человека?"


Окей, SORA, нарисуй мне фильм «Облачный оператор»…
ЛОЛ, один и тотже гуф qwen2 1.5B на проце работает, а на картонке - нет
Чуть больше половины рыночной цены притом новая запечатанная.
А че так больно то? Остальные карточки в цене не менялись.
Старая версия лаунчера или битый конфиг. Обнови убабугу и перекачай модель, заодно диск на ошибки проверь.
Шаблон под коммандира стоит и шизосемплинг. Но это хоть будет всирать, не должно полностью убивать
> Угабога по дефолту устанавливает контекст 32к, может дело в этом?
Дело в этом будет когда начнешь превышать эти 32к.
Карточка? Были жалобы для каких-то случаев именно с тем что на гпу работает криво, в том числе и на всей куде.
>Карточка
3060 12G, лупятся и koboldcpp, и llamacpp, версии для cu11 и cu12
4х3060 вместо 2х3090 - какие подводные?
1) Значительно дешевле - 2-3 3060 стоят как 1 3090
2) Значительно проще найти - неушатанную 3090 по вменяемой цене надо прям мониторить
3) Не надо трястись за отвал памяти
Чип слабее - да и хуй с ним, не? Не критично слабее, зато сколько плюсов.
Есть ещё вариант 3х4060ти - тоже реквестирую мнение. Но этот вариант выходит несколько дороже, чем 4х3060, примерно на 20%.
Бля, больно смотреть на скрины с этим поёбаным русиком. Там просто запушили пайплайн для автоперевода всего непереведённого текста, но уже его отключили (вернее добавили параметр автоперевода с дефолтным false). В ближайшее время русик будет откачен к прошлой версии.
1) Значительно дешевле - 2-3 3060 стоят как 1 3090
2) Значительно проще найти - неушатанную 3090 по вменяемой цене надо прям мониторить
3) Не надо трястись за отвал памяти
Чип слабее - да и хуй с ним, не? Не критично слабее, зато сколько плюсов.
Есть ещё вариант 3х4060ти - тоже реквестирую мнение. Но этот вариант выходит несколько дороже, чем 4х3060, примерно на 20%.
Бля, больно смотреть на скрины с этим поёбаным русиком. Там просто запушили пайплайн для автоперевода всего непереведённого текста, но уже его отключили (вернее добавили параметр автоперевода с дефолтным false). В ближайшее время русик будет откачен к прошлой версии.
>В ближайшее время русик будет откачен к прошлой версии.
Такой русег надо откатить на английский и не ебать народу мозги.
Ну это жора, писать ишьюсы и ждать пока починят, не впервой.
> какие подводные?
В 2-3 раза меньший перфоманс в ллм при экономии в цене около 30%.
> Есть ещё вариант 3х4060ти - тоже реквестирую мнение. Но этот вариант выходит несколько дороже, чем 4х3060, примерно на 20%.
Они тоже будут ощутимо медленнее. Хочешь экономить - теслы, скорость будет как раз на том же уровне пока не начнется обработка контекста лол.
Ну и не стоит забывать что после приобретения ии рига тебе захочется катать не только ллм, как минимум ту же диффузию, и вот там больший перфоманс сосредоточенный в меньшем числе чипов сразу сыграет.
Алсо если хочешь экозотики - A4000 посмотри. Если взять задешево то можно штук 6 в пеку пихнуть, они однослотовые, на 16 гигов каждая, чипы быстрее чем 3060, врам обычная 6 без перегревов и относительно шустрая.
4070ти супер на 16 тоже интересный вариант, он немного быстрее 3090 и с памятью все ок, но цена.
>В 2-3 раза меньший перфоманс в ллм при экономии в цене около 30%.
Ты забыл про бульон все остальные плюсы.
>Хочешь экономить - теслы
Как будто бы всё менее и менее актуально, не? Всё ещё в 2 раза дешевле гигабайт, но старая серверная печь с жором, пердолингом и только для ггуфов.
Ну да, согласен, пока можно и на англюсике посидеть.
Жизнь в LLM вообще только с 30В начинается. Только с ними можно комфортно рпшить без реролов. Хотя из 30В кроме aya и yi нет нихуя.
> 2-3 3060 стоят как 1 3090
Такое себе, с учётом того что сейчас барыги по 70к продают нормальные 3090.
>Такое себе, с учётом того что сейчас барыги по 70к продают нормальные 3090.
Так я как раз с учётом такого порядка цен и рассчитывал выгоду. Одна 3060@12 в среднем около 25к стоит.
>Хотя из 30В кроме aya и yi нет нихуя.
Всм, а обычный командир?
>обычный командир?
Вот максимально странная модель. Вроде, и тупой, и хуй ложил на карточку, и не слушается инструкций. А вроде, и умный, на какие-то вопросы отвечает плюс-минус нормальный. Правда, сходу же впадает в маразм и шизофрению. Ёбаный двуликий.
Вот максимально странная модель. Вроде, и тупой, и хуй ложил на карточку, и не слушается инструкций. А вроде, и умный, на какие-то вопросы отвечает плюс-минус нормальный. Правда, сходу же впадает в маразм и шизофрению. Ёбаный двуликий.
> Ты забыл про бульон все остальные плюсы.
Необходимость поиска платы с 4+ нормальными слотами, покупки х16 райзеров, сборки уникального шасса/корпуса или покупки готового варианта под ферму и все сопутствующее?
Взять готовую ферму не выйдет, там нужна мощность профессора, объем рам и желательно побольше линий pci-e.
> Как будто бы всё менее и менее актуально, не?
Ну типа за 17к второй карточкой чтобы шустро пускать большие ллм, или сборку из пары на имеющемся железе - норм, там и с ггуфа порофлить можно. За 30к и более сложные варианты - нахуй такое счастье нужно, и будешь не рофлить а гореть.
> и тупой, и хуй ложил на карточку, и не слушается инструкций
Где вы такой находите? Опять жора и безумные квантователи хорошие модели извращают?
Плюс если только. Обычный сосёт.
> Где вы такой находите?
Он такой и есть, всё верно он пишет. Ты наверное просто нормальной 70В не видел, поэтому и сравнивать не с чем. После 70В уже кринжово командир выглядит, он только для рофлов годится или для любителей пигмы.
>покупки х16 райзеров, сборки уникального шасса/корпуса или покупки готового варианта под ферму и все сопутствующее
А для 3090 это всё неактуально разве? С нормальным охлаждением она и в одном экземпляре не в каждый корпус влезет.
Про плату - да, надо будет поискать, но для сетапа с 3090 надо будет искать уже нормальный БП, т.к. даже 2х3060 потребляют меньше, чем 1х3090.
Также не стоит забывать про отсутствие тряски за отвал памяти, особенно с учётом частых перепадов температуры в ллм. Этот момент кажется существенным, если ты не наносек, который может в случае поломки карточки просто её выбросить и купить другую (но если ты наносек, для тебя этот разговор в принципе неактуален).
>Ну типа за 17к второй карточкой чтобы шустро пускать большие ллм
За 17к их нигде и нет к сожалению, может только в каком-то самом подвальном китайском подвале. Средняя за теслу сейчас, по наблюдениям, уже вплотную приблизилась к 3060@12, но тесла - это
>старая серверная печь с жором, пердолингом и только для ггуфов
А 3060 - это сел и поехал, ещё и с гарантией иногда.
4 3060@12 - это всего 48гб ВРАМ. Ну как всего - в принципе для 70В exl2 вариант неплохой, нужно прикинуть, какой квант влезет и сколько останется на контекст. Если не гнаться за шестым квантом и моделями побольше (command-r плюс тоже пролетает наверное), то вариант даже хороший. И ещё я бы рассмотрел вариант 4 4060Ti@16 - но не сейчас, а когда цена упадёт и тесты такой связки где-нибудь всплывут. В готовом конфиге.
Вообще, я бы сразу отказался от идеи корпуса, а делал риг - майнерский опыт в помощь. Сколько карт нужно, столько и добавляешь, можно и зоопарк устроить. И с выводом тепла из корпуса никаких проблем.
Здесь есть, те кто включал теслу через X1 со спиленным боком или nvme → x4 рейзер?
> nvme → x4 рейзер
У меня через NVME не завелась псина, карта просто не видится. Там не всё так просто, похоже, нужна особая мать.
Проиграл.
> А для 3090 это всё неактуально разве?
Ну типа пару можно разместить в обычном корпусе, там 2.5 слота у большинства кроме редких экземпляров, не 4 слота как у 4090. Подойдет большинство корпусов и большинство матплат, в крайнем случае можно повесить одну на заднюю стенку корпуса утянув райзером. Для четырех карточек это уже заведомо корч, плюс нужно будет задуматься о доп питанием слотов, ведь с них будет тянуться под 300вт.
> про отсутствие тряски за отвал памяти
Есть такое, но аргумент преувеличен на фоне общих поломок что могут возникнуть в карточках и обслуживании.
> но если ты наносек, для тебя этот разговор в принципе неактуален
Да хоть кто, альтернатив 3090 сейчас нет. 4070ти супер стоит в 2 (1.5 без гарантии) раза дороже и имеет меньше памяти, особенно актуально для не-ллм где так просто не разбить на части. 4090 сейчас одна стоит как целый риг.
> А 3060 - это сел и поехал
Сначала собираешь телегу, потом в нее впрягаешься и сам тянешь, типа такого. Слишком медленное оно, проигрывает по прайс-перфомансу, проигрывает по удобству и возможностям, а из плюсов только то что они менее горячие.
> какой квант влезет и сколько останется на контекст
4.65-5, в районе 12-16к контекста. Плюс коммандера только лоботомит.
> через X1 со спиленным боком
Главное не делай это всратым шлейфом, он буквально может оплавится из-за тока питания, а карта будет глючить.
>Старая версия лаунчера или битый конфиг. Обнови убабугу и перекачай модель, заодно диск на ошибки проверь.
Я через колаб запускаю.
Там всё последней версии загружается, да и диск точно не влияет.
Ну да, значит это отпадает, что-то еще сломалось. Попробуй там же фп16 веса запустить, той же экслламой, только выставляй минимальный контекст чтобы в 16 гигов влезло, может получится.
Ну и hf обертка крайне желательна.
Использую koboldcpp_rocm. Со временем где-то сообщений через 15-20, скорость заметно падает. С чем может быть связана? Или это из-за накопления прошлых сообщений?
Кстати да, звучит хорошо, хотя подойдёт, конечно, не всем.
>Ну типа пару можно разместить в обычном корпусе, там 2.5 слота у большинства кроме редких экземпляров
Да, согласен, перепутал с 4090. Но 2х3090 всё равно разместить в обычном, не каком-то специально подобранном корпусе, довольно проблематично (чтобы они не задыхались при этом).
>плюс нужно будет задуматься о доп питанием слотов, ведь с них будет тянуться под 300вт.
Так 2х3090 будут потреблять ещё больше, разве нет? И о каком доп. питании слотов речь?
>Есть такое, но аргумент преувеличен
Я бы сказал, что в случае с ллм он наоборот, особенно актуален из-за постоянных перепадов.
>Слишком медленное оно, проигрывает по прайс-перфомансу, проигрывает по удобству и возможностям, а из плюсов только то что они менее горячие.
Ты точно с теслой сравниваешь?
Для четырех карточек это уже заведомо корч, плюс нужно будет задуматься о доп питанием слотов, ведь с них будет тянуться под 300вт.
Вот кстати может кто разбирается. У меня на плате есть разъём для доп.питания PCIe слотов. Оно надо, если видеокарты имеют свои разъёмы питания? Или хватит им?
>И о каком доп. питании слотов речь?
Есть такие платы, на которых слотов много. И вот это доп. питание - по идее оно нужно, если карта от PCIe-слота питается. Или две карты, или три. А если доп. питание есть, то вроде и не нужно. Хз.

>А если доп. питание есть, то вроде и не нужно. Хз.
Карта по стандарту может хавать из psi-e до 75 ватт, если не ошибаюсь. У красных были беды, что карта пыталась жрать оттуда в разы больше и комплектуха отрыгивала, потом биосом чинили. В любом случае, карты будут жрать энергию и через слот в том числе.
>Так 2х3090 будут потреблять ещё больше, разве нет?
Всё, я понял в чём затуп. Типа 2х3090 потребляют 2хPCI-E, 4x3060 потребляют 4xPCI-E. Справедливо, но основной тейк про общий жор 2х3090 остаётся в силе.
Вообще конечно остро не хватает реальных тестов подобных конфигураций, типа 4х3060, 2х3090, 3х4060ти и т.д.
Контекст смотри, ага
Regex же вроде не влияет на переводы, если не ошибаюсь.
>В любом случае, карты будут жрать энергию и через слот в том числе.
Зависит от схемотехники. Некоторые жрут оттуда только на вывод надписи "Подключи доп питание, пидор".
Ну и эти 75 ватт не из космоса берутся, и на платах с кучей разъёмов есть свои доп рядом со слотами, лол.
> Но 2х3090 всё равно разместить в обычном, не каком-то специально подобранном корпусе, довольно проблематично (чтобы они не задыхались при этом)
Ну типа обычно в материнках промежуток 2 слота между х16, считай у тебя ровно там места под 2 карточки. Да, им будет жарко, также могут быть проблемы если самый верхний слот смещен на 1-2 вниз, тогда влезет только в корпус где есть дополнительные окошки под девайсы в слотах. Им будет жарко, но разместить все еще возможно, в ллм прогреваться даже не будут ибо там максимум половина тдп.
> Так 2х3090 будут потреблять ещё больше, разве нет?
Они будут потреблять по доп питанию, мощные карточки с матплаты обычно вообще ерунду сосут. А тут у тебя как раз по 75вт каждая грузить будет, особенно на простых моделях где только 1 6 пин доп питания.
> что в случае с ллм он наоборот, особенно актуален из-за постоянных перепадов
Да ерунда, если хостить и гонять с переменной нагрузкой 24/7/365 то через несколько лет может и как-то скажется. А если для себя - карточка тебя переживет. Да и память прогревается медленно, это для чипа еще как-то актуально, плюс тут они вообще холодные стоять будут ибо нагрузка всегда низкая.
> Ты точно с теслой сравниваешь?
С парой 3090. Если теслы дешевые - то и им проиграет, ибо врядли выйдет сильно быстрее.
По спецификации там до 75вт питания, можешь открыть gpu-z или любую программу для мониторинга и посмотреть сколько видеокарта жрет по слотам доп питания и с матплаты. Чем всратее карточка тем больше вероятность что будет использовать по полной, на топпах как правило основное питание чипа оттуда не берется.
На 1 карточку - похуй, на 2 - можно задуматься, если больше - оче желательно, иначе может поплавиться 26пиновый разъем и провода в нем.
>26пиновый разъем
20+4 же.
Душнила
Сколько токенов/сек будут давать 2 зиона на лламе 400b, когда она выйдет? Думаю собраться на 512гб оперы, выйдет всего в 50к где-то.
0.05

Чуть больше чем за неделю кончились все фетиши для кума... Как жить теперь...
Все, которые были у тебя, или все вообще? Во второе не верю, ты ведь даже не кумал на сырнявые карточки.
Которые у меня, разумеется. Смысл в других, если они не заводят?
Ну, сколько там, 2-3 раза по скорости?
Теслы уже маячат невдалеке за вдвое такой же прайс с вдвое большим объемом.
Но, на вкус и цвет, конечно, ниче против не имею. И правда — новые с гарантией 3 штуки по цене 1 бу.
Про 4060ти писали, мол, медленно внезапно. Сильно.
Но тут хз.
Да, я маньяк, сижу с русиком, кекеке.
Ваще редко запускаю, пох.
Жора там 110 ватт без потерь.
Но актуальность так себе, аха.
Ну, плат с двумя слотами, разнесенными далече явно больше, чем плат с 7-8-9 слотами.
Нормальный бп. Ну камон, он явно стоит дешевле чего угодно из. 20к, чи скока там.
Ну давай посчитаем.
Предположим, что мы не упираемся в процессор, потому что нам хватает.
Мы точно упираемся в память.
Допустим ты берешь пиздатую 8-канальную материнку.
И там частота, ну не знаю… 2400?
3200 2 = 6400 = 50мбит
2400 8 = 19200 = 150 мбит
Втрое выше, ок.
70б размером 40 гигов дает 0,7 токен/сек
Т.е., 2,1 токен/сек на зеонах.
Теперь мы считаем 400/70… Это 230 гигов и 5,7 раза больше.
1. Хватит и 256 гига для q4_K_M какого-нибудь. Вплотную.
2. Скорость будет 0,36 токена/сек.
Приблизительно, плюс-минус. Так было у первой лламы 65б (даже чуть медленнее) на первых версиях софта.
Но, это очень медленно.
Может быть она и будет умнее-логичнее.
Но хули толку, когда она будет такой пиздец медленной.
Просто прикинь, в среднем, на простой вопрос она будет отвечать… допустим 100 токенами — это 5 минут.
А разницы по уму будет не так чтобы много, скорее всего.
Тестов пары 3090 в избытке, 13-17т/с там на 70б, если погнать врам или взять квант поменьше то можно и 20 выжать. Остальных нет ввиду их нерациональности.
Перфоманс скейлится почти линейно, можешь добавить штраф 5-10% за каждую карточку (или 80% на обработку промта если юзается жора). В итоге выйдет на мелких картах 3-7 токена в секунду, что довольно грустно на фоне общих затрат.
> но основной тейк про общий жор 2х3090 остаётся в силе
Там будет короткий всплеск потребления в момент обработки промта а далее - суммарное тдп будет не больше чем у одной видеокарты. И перформят они пропорционально быстрее.
Если кончились - значит это не фетиши и так, с правильными будет всегда на 11 часов.
И тут numa проводит тебе хуйцом по губам, множа на ноль твои расчеты с 8 каналами, то есть будет еще хуже.
На фалконе 180 на числодробилке было в районе пары т/с генерация и оче оче долгая обработка промта, тут все еще хуже окажется.
> 13-17т/с там на 70б, если погнать врам или взять квант поменьше то можно и 20 выжать
Поменьше, 15 т/с потолок на EXL2 c 4 bpw. 20 только на 4090 возьмутся.
>Про 4060ти писали, мол, медленно внезапно.
>128 бит
>288 Гбайт/сек
Ещё бы не медленно, она по пропускной у теслы сосёт.
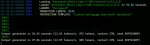
Вставлю свои 5 копеек. При небольшом разгоне памяти +750, на трех карточках(RTX 3090) с llama-3 70В 6.5bpw exl2, получаю ~14т/с (без разгона на ~0.5-0.7 токена меньше). Насколько быстрее будет 4 квант, можешь представить сам.
Да нихуя они не кончились, шлюха. По новой прогоняй старые сценарии, чуть изменяя и добавляя события и тереби писю. Я один и тот же сценарий 3 раза прогнал и каждый раз дрочил, правда ебаные нейронки нихуя пока еще не понимают что я хочу на самом деле.
> Насколько быстрее будет 4 квант, можешь представить сам.
Не могу, две 4090 едут в 20 т/с. Куда ты собрался на 3090 быстрее разгоняться.
Как раз именно на 4 битах можно взять больше, особенно если выключить стриминг и использовать стоковые семплеры а не HF обертку убы, 4090 столько выжимают на ~5 битном кванте. Память хорошо гонится и это дает ощутимый прирост.
Как бороться с щелчками звука при 2+ картах? Выключаю в диспетчере устройств все кроме одной - нет щелчков, с двумя сразу щелкает. Win11, внешний ЦАП, в гугле тысяча подобных жалоб на куртку и щелчки правда там симптомы другие, не от двух карт, но нигде нет нормального решения. Вангую куртка в драйвер насрал, но как совладать с этим?

Попробуй вырубить аудиоустройства от куртки в диспетчере устройств. Включи вид по подключению и вырубай те, которые висят на одном рут порту с видяхой.
> 4090 столько выжимают
У меня у самого две 3090, даже близко нет 20 при 4 кванте, 15 без контекста и опускание к 12-13 на полном. Так что не пизди. Выключение обёртки даёт половину т/с, на грани погрешности.
Да ниче не проводит, какая разница.
С контекстом очевидно, скорость и так террибле.
Какая разница, кмк, такое не юзабельно.
Разве что запускать суперсложную задачу и уходить пить чай на несколько часов. Но сможет ли эта модель решать суперсложные задачи — большой вопрос.
ИМХО, 400б запускать дома — это буквально ради интереса посмотреть, но не для реального использования.
Если у тебя настолько крутые задачи, что 70б не справляются — вероятно ты и получаешь столько, что тратится на зеон ле фу, и арендовать карты под инференс тебе проще. Чо там, 4хА100 хватит. =)
А то и прикупить можешь что-нибудь, собрав риг.
Короче, я даже на такой скорости считаю ее весьма юзлесс.

В чём стоит ужаться при выборе модели, если по железу едва влезаю в 30+?
Сначала размер, потом контекст, потом квантование, где q>=4?
Скажем, насколько Fimbulvetr-11B q8 8к контекста будет хуже, чем aya-23-35B q4 4к контекста? Так, можете примерно прочувствовать?
Сначала размер, потом контекст, потом квантование, где q>=4?
Скажем, насколько Fimbulvetr-11B q8 8к контекста будет хуже, чем aya-23-35B q4 4к контекста? Так, можете примерно прочувствовать?
Какие еще щелчки? Все норм, у тебя наверно что-то с питанием на плате, или может амудэ? Правда тут внешний цап по оптике, хз что там во встройке.
Значит у тебя хлеб вместо процессора, какие-то аппаратные проблемы или что-то еще, скидывал же раньше и те и те. Офк это с малой обработкой контекста/кэшем, если делать полную то будет меньше в зависимости от длины ответа. Лень качать 4.0 квант и карточки заняты, как-нибудь при случае прогоню и заскриню.
> запускать суперсложную задачу и уходить пить чай на несколько часов
As a responsive AI model, I can not...
Ну а если серьезно то дешевле индуса, абузящего гопоту нанять, чем катать 400б, хз какие там задачи.
> насколько Fimbulvetr-11B q8 8к контекста будет хуже, чем aya-23-35B q4 4к контекста
По качеству ответов небо и земля, а в 4к контекста ужиматься будет тяжело.
> Лень
Так бы и сказал, что пиздишь. 20 т/с снимаются с одной в 2.5 bpw. Но никак не с двух.
Бля чел, сам ты пиздабол у которого карточек нет, потому и втираешь дичь. Все выше написано уже.

> написано
Пиздежа беспруфного.
Ты сам буспруфный чухан, выше скрин для жирного кванта с типичной скоростью, она линейно перейдет в значение больше 15 за которые ты втираешь на 4 битном кванте.
Я специально для таких как ты скрин приложил, и это блядь на 3х картах, блядь. Отключение обертки мне дало 1.5 т/с (зион в однопотоке не оч.).
>У меня у самого две 3090, даже близко нет 20 при 4 кванте, 15 без контекста и опускание к 12-13 на полном.
Как выше отметили пиздобол или долбоеб, у меня с "хлебушком" вместо проца ~19т/с.
В свежем Кобольде (ну и в лламе конечно) появилась фишка - 4-битный KV-кэш. Я слабо разбираюсь, но слышал, что это была одна их ключевых фишек экслламы. По идее это должно ускорить обработку промпта или как? Кто пробовал?
Это уменьшит требование к памяти, скорость может даже просесть, если учесть, что со сжатым кешем не работает флеш аттеншен.
Это проблема звукового драйвера винды, решения нет.
Я уже нашёл пидорасину, ломающую звук - это Afterburner. Без него всё заебись, с ним идут щелчки. Вангую это как-то связанно с тем что в нём работа с несколькими картами реализована через очко и он что-то всерает своим говнокодом.
Автор пишет, что ContextShift не работает, а flash attention даже необходима:
Note that quantized KV cache is only available if --flashattention is used, and is NOT compatible with Context Shifting, which will be disabled if --quantkv is used.
А, да, точно, не та ускорялка. Даже не знаю, что важнее из этого.
Значит мы про разные щелчки говорим.
Ну попробовать надо - на новых картах, на старых картах. Что это даёт-то вообще? Может и правда почти сразу отвечать будет даже без контекст шифта. И с большим контекстом должно стать попроще.
Аноны, тут Яндекс свой YaFSDP подогнал!
Ай да переобучать третью Лламу на на датасете Пигмы и 2 Теслах!
https://habr.com/ru/companies/yandex/articles/817509/
Ай да переобучать третью Лламу на на датасете Пигмы и 2 Теслах!
https://habr.com/ru/companies/yandex/articles/817509/
Я говорил про рандомные щелчки раз в несколько секунд как при включении ЦАПа, как будто на мгновение сигнал в потолок бьёт.
Выглядит как хуйня, куда нам эти +3% на 64 гпу.
Пишет же, что ФА с КонтекстШифтом не работает. Ты и так КонтекстШифт вырубаешь, значит кэш уже без потерь включается.
Аноны, на чем кумить можно?
Я сидя на стуле кумлю, но можно и на кровати.
всегда на кровати кумил, так как рядом с кроватью монитор и клаву на кровать с мышкой ложу, на стуле кажется неудобно
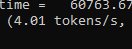
В удобной позиции минимизировав отвлекающие факторы.
Если общий счетчик - сойдет. Если только генерация и на пост 60 секунд - пиздец.
На кровати вероятность френдли фаера выше, если увлечься.
Да, норм, жить можно. Чуть ниже комфортной грани, но ниче.
Ну и от размера модели зависит, офк.
Там всего лишь 70B в четвёртом кванте.
Ну да, пост где то с минуту, но там простыни.
Потестировал qwen2 72b и он реально лучшее лламы 3 70б, чего не нравится реддитовской сое? Что он китайский?
А на кум как?
На кум - хз
Так проверь, анон!
Та я ж не кумлю, качай расцензуренные версии да проверяй. У меня вообще вместо компа тостер, мне очень нудобно.
А там есть расцензуренный квен чтоль?
Оке, ща скочаю, пасибо

Че то ооба не подсасывает настройки для дельфина. А вручную хуй знает че ставить. И нахрена я кочал...
> IQ4_XS.gguf
Кста, а что за новые обозначения квантов?
Кста, а что за новые обозначения квантов?
На месте там соя. Всё так же соевит про boundaries, ещё и инструкцию про <text> очень редко выполняет, в отличии от ламы.
Слишком поломанный, иногда даже лупится, вообще по сравнению с оригиналом очень неадекватен.

Убабуга серит, можешь эту строчку сломать и будет работать.
А оно не наебнётся окончательно?
try:
bos_token = metadata['tokenizer.ggml.tokens'][metadata['tokenizer.ggml.bos_token_id']]
except KeyError:
bos_token = eos_token
исправь в models_settings.py



try: у тебя где?
Какой добаёб писал, S должна быть между XS и M.
А оно точно надо? Выглядит "мол пропробуй это: говнокод"
Точно, это же инструкция питона


Тоже не работает, че ему надо? Че там с синтаксисом?
Господа, а как скачать Llama 2 или Llama 3? Есть ли зеркала без запросов?
Пытался через hugginface, но мои запросы не одобрили.
Пытался через hugginface, но мои запросы не одобрили.
Надо еще строки подформатировать, особенность питона
try:
bos_token = metadata['tokenizer.ggml.tokens'][metadata['tokenizer.ggml.bos_token_id']]
except KeyError:
bos_token = eos_token
А то у тебя try не над except


bos_token = metadata['tokenizer.ggml.tokens'][metadata['tokenizer.ggml.bos_token_id']]
bos_token = eos_token
эти стороки тоже надо добавить пробелами чтоб они стали дальше от начала текста вглубь, я обычно добавляю 4 пробела.
можно и так
Да я чет немного по-другому сделал в в пару строк всё.
А альпака пресет подойдет в таверне для дельфина?
для этого дельфина пресет нужен qwen2
<|im_start|>system
{system_prompt}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant


Хз как там, вот че нашел
Дельфин всегда был критически тупой. Стоит ли рисковать?
https://huggingface.co/NousResearch/Meta-Llama-3-70B-Instruct


Ну очевидно что с инструкшон темплейт у тебя какая-то каша. Я не спец убебуге, точнее, я ее в первый раз в жизни вижу.
Как скопировал так и вставил. Я же не виноват что у них в примерах какой то калыч.
Поставил чатмл - вроде заработало в огабоге. В таверне с чат млом не работало - ебал рот этого китайского говна.
Ненавижу такие формы записи размеров одежды (и квантов).

Крч, таки дельфин стартанул в таверне - но пишет отвратительно.
Его или шелушить настройками, чтобы было хорошо или сразу использовать нормальную модель по типу Мику.
Его или шелушить настройками, чтобы было хорошо или сразу использовать нормальную модель по типу Мику.
тестил, залупится на ггуфе. обычный квен лучшЕе.
Скачал популярную легендарную Noromaid 20В q5, взял пресеты со страницы модели, уже расчехлился предвкушая, но в сравнении с другими 7-11В моделями сетка вообще какое-то лютое говно.
Не следует карточке, говорит за юзера, зачастую не реагирует на системный промпт, иногда высирает маняфанфик под 700 токенов в три присеста в которой юзер с персонажем поебалися и жили долго и счастливо первой же генерацией. Пиздец какой-то.
Может это из-за 8000 токенов при n_ctx_train 4000?......
Не следует карточке, говорит за юзера, зачастую не реагирует на системный промпт, иногда высирает маняфанфик под 700 токенов в три присеста в которой юзер с персонажем поебалися и жили долго и счастливо первой же генерацией. Пиздец какой-то.
Может это из-за 8000 токенов при n_ctx_train 4000?......
> нормальную модель по типу Мику
Хорошо.
Чем плоха мику? Ну я естестно имею виду рп.
Тем что тупая и любит галлюцинировать. Никто сейчас мику не использует для рп.

>She leaned forward a bit so that she could whisper into Anon's ears
>I promise I won't bite… unless you ask nicely
Как заебала эта хуйня.
>I promise I won't bite… unless you ask nicely
Как заебала эта хуйня.
Что используют то, может просветишь?
> тупая
Ну может не самая умная по логике, но умнее командера (не того который огромный).
> любит галлюцинировать
Ну вот кстати нет. Она любит расходиться на простыни это да, но откровенную шизу несет меньше чем тот же командер или юй.
>Никто сейчас м
Милионы мух это конечно хорошо, но тогда покажи что будет лучше Мику. Что там сейчас используют для рп чтобы было заебись?
Смауг или Хиггс. Можно командира 104В, если хочется извращений.
А со ссылками на Обниморду? А то я не слежу за трендами.
>Смауг
В чем его фишка? Чем он выделяется от того же командира? Пробовал его, но не увидел особой разницы между аналогичными моделями по размеру.
Блять, какого хуя rope_freq_base остается от последней выбранной модели у Moistral?
отклеилось
Ну и да САМАЯ БОЛЬШАЯ проблема Мику в том, что она не умеет отыгрывать цундере.
А какая вообще модель умеет?
А какая вообще модель умеет?
Командир+ нормально отыгрывает, может еще от карточки зависит.
Зачем так много моделей?
Эх, вот сейчас бы обучить клоду датасетом с пигмы, ммм. Всего-то каких-то N к$ за неповторимый я тебя ебу экспириенс, парень в верном направлении двигается.
Что-то мне не нравится что жпт4о имеет такой отрыв от остальных сеток, когда уже другие подтянутся?
Произошел отрицательный отрыв, скоро и обратный рост увидим. Ничего, вот сейчас как соберем с чмони датасет, да как натреним остальные сетки!
На самом деле с точки зрения обучающего контента он молодец и красавчик, просто и понятно объясняет, показывает, дает примеры и делает. Практической значимости тут - надрочка на тест, не более, но для понимания штука крутая.
Хотя, да, подловить жпт4о оказалось не так и уж трудно. Мда, не думал я, что они еще туповатые настолько. Архитектуру есть куда усовершенствовать.
https://www.youtube.com/watch?v=apKE_Htn_GQ
Частенько встречал подобное на Llama-3-Lumimaid-70B.
Крестьянин перевезет волка через реку следующим образом:
Сначала крестьянин перевезет волка на другую сторону реки.
Затем крестьянин вернется обратно на лодке.
Таким образом, крестьянин перевезет волка через реку, совершив два переправы - одну с волком на другую сторону и одну обратно без груза.
Хотя хз, где он там увидел этот бред, все нормально решается.
Вы дауны что ли? Омнипараша хуже последней турбы да еще и в плане вариативности сосет. Вам это господин из соседнего треда с неограниченным доступом к апи пишет. Так что даже если оно в вашем чатгпт и стало лучше, то точно не из-за базовой сетки


Ладно, посмотрели.

Аноны, запускаю Higgs-Llama-3-70B.gguf, а она мне:
error loading model: error loading model vocabulary: unknown pre-tokenizer type: 'smaug-bpe'
Что за фигня?!
error loading model: error loading model vocabulary: unknown pre-tokenizer type: 'smaug-bpe'
Что за фигня?!
Ты настолько умен что без таблички "сарказм" не можешь понять? За чмоню тут только шизы и неофиты топят, она очень тупая, зато быстрая.
> с неограниченным доступом к апи
Ох, уважаемый человек, наверно много денег на это тратишь? Уже начали проникаться трепетом.
Чел в этом треде, наверно, у большинства есть апи клозедов и коктропиков, а некоторые сгноили на специфичные датасеты больше ключей чем кумит кончай тред за пол года
Llama-3 отыгрывает. Даже 8В может.
>Чел в этом треде, наверно, у большинства есть апи клозедов и коктропиков
Откуда такой вывод?
Я помню тут кто-то имел карточку ассистента с эдаким внутренним мыслительным процессом, как оно по итогу, работает? И скинь пожалуйста её если ты ещё тут.
Лама три лупится по кд, к сожалению.
Кста, есть там уже нормальные её файнтюны, анон?
Проблему лупов на ламе три уже давно решили. Нужно просто нормальные настройки семплера поставить, типа пресета min-p.
>Кста, есть там уже нормальные её файнтюны, анон?
Есть
мимо


Бля, не в тот тред запостил.
Пытаюсь сделать франкенмерж из третьей лламы и она, блядь, ломается, как сучка. Не могу подобрать адекватных вариантов.
Франкенмержи кто-то находил на третьей лламе? Посмотреть бы настройки. Чередование слоёв и пришивание к жопе работает экстремально плохо, хотя на второй лламе чередование работало очень хорошо.
Пытаюсь сделать франкенмерж из третьей лламы и она, блядь, ломается, как сучка. Не могу подобрать адекватных вариантов.
Франкенмержи кто-то находил на третьей лламе? Посмотреть бы настройки. Чередование слоёв и пришивание к жопе работает экстремально плохо, хотя на второй лламе чередование работало очень хорошо.
с чем ты смешиваешь третью? если со второй - это не будет работать.
У них ширина слоёв разная, так что со второй я смешивать смысла не вижу. С третьей и смешиваю. Но получается шиза ёбаная.
смешивай методом ties или dare_ties. чередованием слоев (особенно если чередовать через короткие промежутки, я про 70b) вряд ли что-то хорошее получится. не рекомендую трогать первые слои и последние, можно легко сломать модель.
но мой опыт основывается только в смешивании производных второй лламы, третью не пробовал.

И чего этот ваш хиггс не грузится? Опять огабога говна в жопу заливает?
>ties или dare_ties
Так я франкенштейна делал через дублирование слоёв. Тюнов всё равно нет, чтобы с чем-то смешивать.
>чередованием слоев (особенно если чередовать через короткие промежутки
На второй было норм буквально через один слои дублировать.
https://blogs.nvidia.com/blog/nemotron-4-synthetic-data-generation-llm-training/
Эй, там слон! Слона по улице ведут!
Эй, там слон! Слона по улице ведут!
Как выпилить одну llama.cpp из виртуального окружения и заместо неё установить другую зная её "хеш" или че то такое?
Ага, можете заодно и эту скачать и проверить https://github.com/togethercomputer/MoA/
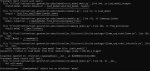
ты скачал ггуф двумя файлами и потом их объединил?
У меня попены есть все, кроме 32к.
>Required Hardware
>BF16 Inference:
>8x H200
Ябать там требований.
ПЕРЕКАТ
Хули так медленно тред наполняете? Всё, умерла тема локалок?
ПЕРЕТРАХ
Хули так медленно тред наполняете? Всё, умерла тема локалок?
ПЕРЕТРАХ
Нет, это 4квант гуфа одним файлом.
Здравствуйте, я тут хотел файфу и пледик, тыкнулся скачать таверну, а там пишет что под админом нельзя, почему так?
Ссыкую ставить, потому что я криворукий долбаёб и не смог настроить венду, чтобы нормально работала без админских прав. Песочница без админа через жопу работает, не смог победить.
Весь пекарню распидорасит или что там случиться может?
По совместительству посоветуйте плиз какая модель адекватно работать будет с амуде 5700 и 3060ti, а то чёт потыкался, то не тянет, то херню пишет. Хотя может не разобрался в конфигах ещё просто.
Ссыкую ставить, потому что я криворукий долбаёб и не смог настроить венду, чтобы нормально работала без админских прав. Песочница без админа через жопу работает, не смог победить.
Весь пекарню распидорасит или что там случиться может?
По совместительству посоветуйте плиз какая модель адекватно работать будет с амуде 5700 и 3060ti, а то чёт потыкался, то не тянет, то херню пишет. Хотя может не разобрался в конфигах ещё просто.
Даун, весь софт запускается без админских прав, даже под админом, если нет запроса UAC или ты его не отключил. А если ты отключил UAC, то ты неисправимый даун.
> Проблему лупов на ламе три уже давно решили. Нужно просто нормальные настройки семплера поставить, типа пресета min-p.
У меня все равно лупится.




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2. Недавно вышедшая Llama 3 в размере 70B по рейтингам LMSYS Chatbot Arena обгоняет многие старые снапшоты GPT-4 и Claude 3 Sonnet, уступая только последним версиям GPT-4, Claude 3 Opus и Gemini 1.5 Pro.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-11B-v2-GGUF/blob/main/Fimbulvetr-11B-v2.q4_K_S.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama , https://lmstudio.ai/ и прочее - Однокнопочные инструменты для полных хлебушков, с красивым гуем и ограниченным числом настроек/выбором моделей
Ссылки на модели и гайды:
https://huggingface.co/models Модели искать тут, вбиваем название + тип квантования
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
https://ayumi.m8geil.de/erp4_chatlogs/ Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: