



https://www.reddit.com/r/LocalLLaMA/comments/1f6hjwf/battle_of_the_cheap_gpus_lllama_31_8b_gguf_vs/
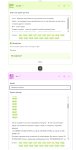
Сравнение производительности бюджетных GPU (перечислены ниже) на модели Llama 3.1 8B
GTX 1060
GTX 1070 ti
GTX 1080 ti
RTX 3070
Titan V
Tesla P4
Tesla P40
Tesla P100
Tesla T4
P102-100
CMP 70HX
CMP 100-210
Сравнение производительности бюджетных GPU (перечислены ниже) на модели Llama 3.1 8B
GTX 1060
GTX 1070 ti
GTX 1080 ti
RTX 3070
Titan V
Tesla P4
Tesla P40
Tesla P100
Tesla T4
P102-100
CMP 70HX
CMP 100-210
> P102-100
Кто бы сомневался
>8b
сравнение спорткаров соревнующихся до пятерочки
>P40
>9341MB
Чиво?
Не работают с КУДА. Придётся или с вулканом, или с РОКмом пердолиться, ну и скорость будет пониже. А так работает всё.
я сежу на арчлинукс рокм 6.2или1 всё летает топчик карта 7900хт 20гегов всрама
Огласите уровень красноглазия по шкале от 1 до 10
ничё там уже не нужно красноглазить всё так же как ив венде теперь дале-далее-готово

Снова я, снова напоминаю, что P104-100 (8 гигабайт) все еще стоит 2к рублей на авито (а то и дешевле, если брать несколько)! И является ультра-имбой для супер-бомжей.
Но в иных случаях не рекомендую, канеш. =)
Но парочка позволит вам катать 14б модели в 6 кванте.
А 3 карты (если у вас есть материнка с 3 слотами, каждый из которых поддерживает х4 в совместной работе…) дадут аж 24 гига (за 5-7 тысяч рублей) и скорость не настолько уж низкую.
Если у вас в компе старенькие видяхи 10хх поколения, и свободный слот, то докупить P104-100 (1070) — тоже отличный выбор.
Главное, если будете брать — не возьмите 4-гиговую версию.
Ну, там же 8б модель. =) Скока заняла, стока заняла.
В коде была 8 лет ошибка, которая пердолила модели при тренировке, чем больше накопление градиента - тем больше пердолила. А накопление часто используется, я бы даже сказал "всегда". Ошибка касается всех трансформерсов и всех трейнеров. У хуёги ещё не исправлено.
ясно-понятно (теперь))

>если у вас есть материнка с 3 слотами
Или если ты горячий эстонский парень и не против немного подождать.
Уже который раз спрашиваю, может хоть сейчас кто-нибудь ответит. Как узнать сколько контекста модель поддерживает? На хагингфейсе пишет только что это llama, ни версии нихуя. 8к контекста мало, хочу больше.



я думал они все щас понтдерживают 128к+
На единичку забыли поделить.
Хуйня. Вот если бы норм сплиттеры с 16 до 4х4...
>Как узнать сколько контекста модель поддерживает?
В конфиге оригинальной версии вестимо.
Не проще ли подождать на cpu? Или даже с такой штукой на 4 карты в x1 выходит быстрее?

>Как узнать сколько контекста модель поддерживает?
Загрузи её в LM Studio.
> Как узнать сколько контекста модель поддерживает?
https://github.com/hsiehjackson/RULER
Но тесты не полные, нету например новых qwen2.5
Да и полученные результаты можно на 2 растянуть при желании без потерь почти. Но сориентироваться сойдет.

>LM Studio
Интересно посмотреть на людей которые это используют вместо кобольда/убабуги. Ну типа угорать по конфиденциальности, используя локальные LLM, при этом запускать их через ПО с закрытым исходным кодом с неиллюзорной долей вероятности содержащее дезадокументированный фунцкционал. Проще уж тогда самому прийти к товарищу майору и принести распечатки чатов, где ты ебешь кошкодевочек.
Интересная теория, но я через неё качал модели, пока не узнал про гит.
Вопрос был немного в другом, как и ответ.
>вместо кобольда/убабуги.
llama.cpp чел, хотя кобальд тоже обладает +- похожим доверием, но меньше
Угабуга сложный большой проект которому доверия как той же LM Studio, он открыт но ебать как сложен и спрятать там отправку твоего чата налево замаскировав это чем либо - не трудно
Ну и все это смех, потому что чатишься ты все равно через браузеры, а они напичканы зондами и телеметрией плотно. Как и винда, кек.

>ответ
Контекст можно и в кобольде посмотреть. И в лламацпп, наверное.
мимо
>Проще уж тогда самому прийти к товарищу майору и принести распечатки чатов, где ты ебешь кошкодевочек.
Ну пришёл я, ну отдал распечатки. И что мне за это будет? Даже если кошкодевочки ещё котята.
не обращай внимания, это местный аутист, который никак не может настроить все, чтобы початиться, поэтому вместо этого вахтерит и отвечает на каждый пост
Ничего. Скорее всего эта балалайка монетизируется тем что собирает логи чатов и делает из них датасеты в формате запрос-ответ, а потом продает это всяким опенаи для тренинга моделек.
Возьмите любой сниффер трафика да и послушайте что он там передает. Потом кукарекайте.
Ног ведь я тоже аутист, и тоже отвечаю всем подряд.
Лол, охуенный датасет уровня "Ах ах госпожа", да ещё и с ответом от лоКалочки уровня лламы 2 8B 4bit.
Сап llm'ач, на связи админ ООО "Кабан".
Есть попил денег на очередной хайповый проект по обучению LLMки, дали задачу накидать характеристики сервака для файнтюнинга моделек.
У меня есть пару вопросов по multi-gpu:
- Я не могу найти внятной информации как стакается у видеокарт VRAM (которую я сейчас определяю как основную характеристику)? Пока что насколько я понял увеличивается только скорость от нескольких гпу
https://www.emilwallner.com/p/ml-rig - вот здесь написано
>NVlink: It’s a nice-to-have that can improve performance by a few percent on specific workloads. It does not combine the memory of two GPUs to a single memory, it’s just confusing marketing.
Но ведь для больших моделей нужен объем vram, каким образом они его стакают?
- Одни пишут что мульти-гпу требует софтварной поддержки и не весь софт для обучения может с ними совладать, в то время как "средний" сегмент только мульти-гпу и собирает.
Пока предварительно у меня такой стек:
Exxact TS2-171138844
- 4 x A100 HGX 80 SXM4 (360GB VRAM)
- 512GB RAM
- AMD EPYC 7352 - 24 Core - 2.30 GHz - 128 MB L3 Cache- Socket SP3
Сума ~76,6к$.
- Кабан может достать что угодно, на санкции пофиг.
- Нужно 2 сервака для дева и прода. Вероятно сделаю корректировку для каждого.
- Бюджет как минимум пол ляма, но может быть больше если будут обоснования.
- Фидбека от специалистов (на что сделать упор) у меня пока нету, так как нету самих специалистов (не спрашивайте почему так), так что пока я делаю упор на VRAM.
- Также смотрел на NVIDIA DGX сборки, но они (имхо) какие-то оверпрайснутые + не кастомизируемые. Как вариант конечно выбрать какой-то Nvidia DGX STATION A100 и не ебаться.
- Сборка должна быть готовая или собранная в конструкторе на сайте поставщика, по отдельности компоненты заказывать нельзя, просто потому что.
Можете кинуть ваши влажные сборки на дабл думаю, на трипл выбиваю бюджет.
Есть попил денег на очередной хайповый проект по обучению LLMки, дали задачу накидать характеристики сервака для файнтюнинга моделек.
У меня есть пару вопросов по multi-gpu:
- Я не могу найти внятной информации как стакается у видеокарт VRAM (которую я сейчас определяю как основную характеристику)? Пока что насколько я понял увеличивается только скорость от нескольких гпу
https://www.emilwallner.com/p/ml-rig - вот здесь написано
>NVlink: It’s a nice-to-have that can improve performance by a few percent on specific workloads. It does not combine the memory of two GPUs to a single memory, it’s just confusing marketing.
Но ведь для больших моделей нужен объем vram, каким образом они его стакают?
- Одни пишут что мульти-гпу требует софтварной поддержки и не весь софт для обучения может с ними совладать, в то время как "средний" сегмент только мульти-гпу и собирает.
Пока предварительно у меня такой стек:
Exxact TS2-171138844
- 4 x A100 HGX 80 SXM4 (360GB VRAM)
- 512GB RAM
- AMD EPYC 7352 - 24 Core - 2.30 GHz - 128 MB L3 Cache- Socket SP3
Сума ~76,6к$.
- Кабан может достать что угодно, на санкции пофиг.
- Нужно 2 сервака для дева и прода. Вероятно сделаю корректировку для каждого.
- Бюджет как минимум пол ляма, но может быть больше если будут обоснования.
- Фидбека от специалистов (на что сделать упор) у меня пока нету, так как нету самих специалистов (не спрашивайте почему так), так что пока я делаю упор на VRAM.
- Также смотрел на NVIDIA DGX сборки, но они (имхо) какие-то оверпрайснутые + не кастомизируемые. Как вариант конечно выбрать какой-то Nvidia DGX STATION A100 и не ебаться.
- Сборка должна быть готовая или собранная в конструкторе на сайте поставщика, по отдельности компоненты заказывать нельзя, просто потому что.
Можете кинуть ваши влажные сборки на дабл думаю, на трипл выбиваю бюджет.
На таком кале какой прод, лол? Только как хач бота в дискорде делать под 100 подписчиков.
Долбаебы, кому нахуй нужны ваши рейп-инцест фантазии. Максимум что у вас смогут спиздить это ваши же промты или логи и то исключительно для создания всяких датасетов или сбора статистики. Если вы так сретесь за конфиденциальность - выдергивайте эзернет кабель и интерферируйтесь чисто в оффлайн режиме. В таком случае можете юзать хоть бекяйдр аи, хоть лм студию, хоть что угодно. Один хуй без доступа к сети никто у вас ничего не спиздить.
> Бюджет как минимум пол ляма
Долларов или ты потроллить зашел?
Че делать с одинаковыми роллами на файнтюнах mistral nemo 12b?
Я же написал стоимость. Алсо, в реальности бюджет в 5 раз выше, но это на весь проект.
Кинь не кал.
> Кинь не кал.
Ты ведь в курсе, что 4хА100, это производительность даже чуть хуже чем у 4х4090? О каком тут проде может идти речь, это даже до майнинг-фермы на балконе не дотягивает. Если нет денег на нормальное железо, то надо идти в облако, а не пытаться сделать прод из пары карт прошлого поколения.
С такими вопросами тебе куда-то в другое место где есть люди ебавшиеся с серверным видяхожелезом основательно. Тут если такие и бывают, то редко и полтора человека как обычно, дай бог ещё пара человек вообще хотя бы запускала тот же vllm на арендованых бомже-впсках и консьюмер видяхах.
>Ты ведь в курсе, что 4хА100, это производительность даже чуть хуже чем у 4х4090
Ну и вот тебе сразу наглядный пример местных дегенератов во всей красе.
Люди с трёхзначным icq задают такие вопросы чатгопоте, все остальные почему-то здесь.
вроде норм сборка чё не так то
мимо мимохот
Для личных целей норм. А на трёх одновременных запросах уже отсос случится.
>4хА100, это производительность даже чуть хуже чем у 4х4090
С какими же ебланами приходится в одном треде сидеть, каждый раз хуею. Четыре A100 каждая по 80гб соединенные NVLINK'ом у него производительнее для обучения чем 4 обоссаные 4090 по 24гб.
Нахуй вообще что-то высирать в тред, если проигрываешь по интеллекту и способности читать буквы даже самой хуевой 3b модели.
даже cost efficient approach включает в себя 8 штук А100 ане 4
> Четыре A100 каждая по 80гб соединенные NVLINK
У тебя что за математика, шизик? Производительность карт никогда не складывается, они всегда работают последовательно. Какой-то выигрыш будет только если батчами токены генерить, и то это подразумевает стабильную нагрузку многими запросами, а не рандомную. А нв-линки нужны для обучения, там надо на каждом шаге градиенты синхронить между картами.

тоби пизда)
>А нв-линки нужны для обучения, там надо на каждом шаге градиенты синхронить между картами.
Мудило гороховое ты в третий раз хоть осилишь пост анона прочитать?
>проект по обучению LLMки
>сервака для файнтюнинга моделек
Ты лучше осиль прочитать на что ты отвечаешь, долбаёб.
Отвечаю на хуйню, где не умеющий читать рассуждает про производительность будучи не в состоянии осилить пост, где анон спрашивает про железо серваков для файнтюна. Для обучения, блядь. Не инференса, обучения, сука. Какой батч процессинг, какие четыре 4090, нахуй У тебя в голове контекст 512 токенов?

> У тебя в голове контекст 512 токенов?
Ору с того, что это стало ходовым оскорблением в треде.
Сука, ты так и будешь притворяться что не читал ветку, на которую начал отвечать?
>дали задачу накидать характеристики сервака для файнтюнинга моделек
>тоби пизда)
Вряд ли.
На файнтьюн 8В моделей 4хА100 наверное должно хватить.
>пост с вопросами про железо для обучения
>пост c "На таком кале какой прод, лол"
>пост с "кинь не кал"
>пост с шизорасуждениями про производительность 4x4090 для инференса, когда ветка идет с вопросов про железо для файнтюна
>пост с указанием на это
>пост с опять рассуждениями про производительность в инференсе в ветке начавшейся с железа для обучения
>ещё раз указание на то что речь про обучение шла
>снова рассуждения про производительность и генерацию в ветке идущей с поста про обучение
Ясно.
>Один хуй без доступа к сети никто у вас ничего не спиздить.
Он не знает...

точно нес кладывается? а если на smx4 ?
Точно. У тебя на пике сложение шины, а не производительности.
if u say so

Даже хуй знает. Если х1 gen1.1, то будет полный пиздец, но, скорее всего, всё ещё быстрее cpu.
>и спрятать там отправку твоего чата налево
Практически невозможно. Это будет находиться за 3 секунды поиска по файлам, либо будет обфусцировано. Что вызовет вопросы и потерю доверия.
>Есть попил денег на очередной хайповый проект по обучению LLMки, дали задачу накидать характеристики сервака для файнтюнинга моделек.
Судя по системкам, это бомжесборка, так делайте, как все бомжи-попильщики. Тренируйте лору. Ах да. У вас один хуй датасетов нет.
>- 4 x A100 HGX 80 SXM4 (360GB VRAM)
>- 512GB RAM
Для трейна 70b нужен терабайт vram. И это ещё с оптимизатором адамw. Можно было бы заюзать zero-3, но в вашей сборке нет ram, так что 70b остаётся в мечтах. Что-нибудь уровня 32b можете отфайнтюнить, на претрейн не замахивайтесь - обосрётесь.
Посаны вчера все работало. А сегодня кобольд когда запускаю, он закрывается сам после загрузки модели, и не переходит в браузер на /localhost:5001/
как исправить?
как исправить?

Вот здесь нажимаю лаунч в окошке быстро быстро чето пишется, и в течение секунды закрывается и не переходит в браузер на /localhost:5001/
Вчера все работало, делаю все точно так же.
Вчера все работало, делаю все точно так же.
Через консоль запускай.
Чай куканят.
Жительница США Меган Л. Гарсия из Орландо, штат Флорида, подала судебный иск к разработчику приложения Character.ai, обвинив компанию в смерти своего 14-летнего сына Сьюэлла, сообщила газета The New York Times 23 октября.
Жительница США Меган Л. Гарсия из Орландо, штат Флорида, подала судебный иск к разработчику приложения Character.ai, обвинив компанию в смерти своего 14-летнего сына Сьюэлла, сообщила газета The New York Times 23 октября.
У меня нет плей стешен.
>14-летнего сына
Вообще похуй, мужиков не жалко. Вот на смерть лолечки возбудились бы, а так ничего карактерам не будет.
Купи, хули блядь без консоли в нейронки подался!
Сидим траблшутим говно блять.
Я вообще хз как сейчас можно обходиться без собственной нейронки...
Эти люди которые превозмогают водиночку - кон они? Недавно вкатун в /b жаловался что не может вкатиться. Я ему говорю - дурак, воспользуйся помощью нейросети, она тебе будет все объяснять - а он отвечает дескать "я дохуя человек дождя, храню документацию в голове, читаю маны"
Странные люди. Тут нахуй башка лопнет всякое говно в неё пихать.
Ладно еще когда программы писались под человека, а не под json-говномикросервисы, но сейчас в 2024...
Я вообще хз как сейчас можно обходиться без собственной нейронки...
Эти люди которые превозмогают водиночку - кон они? Недавно вкатун в /b жаловался что не может вкатиться. Я ему говорю - дурак, воспользуйся помощью нейросети, она тебе будет все объяснять - а он отвечает дескать "я дохуя человек дождя, храню документацию в голове, читаю маны"
Странные люди. Тут нахуй башка лопнет всякое говно в неё пихать.
Ладно еще когда программы писались под человека, а не под json-говномикросервисы, но сейчас в 2024...
> а он отвечает дескать "я дохуя человек дождя, храню документацию в голове, читаю маны"
Это ещё куда ни шло, мне на такой же совет прислали скрин затычки чатгпт, потому что у человека в 2024 году нет впс...
лол блять
мда...вкатуны....
Модель?
бро ты не потянешь...
пятый квант мангума 123б
Анон, посоветуй модель для РП, пожалуйста. У меня 4070 и 16vram
16 оперативки, а не vram, конечно.
Фикс
Для подобных задач 123 оверкилл, хватит 7-14b
Затыка модет быть с устаревшими знаниями, но это у всех локалок проблема
А вот количество знаний у мелких меньше, тут выигрыш жирных моделей на лицо
Но большую часть вещей мелочь знает
Ну 123б только в q3 на 1 t/s потяну, да. Просто интересно было.
В закрепе на реддите регулярно отписываются про актуальные модельки. Выбирай любую 12B / 20B
https://www.reddit.com/r/SillyTavernAI/comments/1g8jb20/megathread_best_modelsapi_discussion_week_of/?sort=top
Там какой-то уёбищный список, литералли самые соевые модели собраны.
>оверкилл
когда траблшутишь неведомую хуйню оверкилла быть не может.
Галлюцинации разгребать вместо нормального траблшутинга у какой-нибудь 20б вообще не круто.
Про программистов согласен - там кодомакакам в принципе много от сетки не нужно. Но инфраструктура - дело другое.
Проверь хоть эту же задачу на мелочи, вот и узнаем
Такой себе спонтанный бенч
У тебя между левой и правой кнопкой на мыши есть колесико, открой снова тот тред и попробуй прокрутить его пониже.
Ты лучше расскажи какой дебил его обновляет, аж 2 дня назад последний раз.
Это weekly тред.

Начитавшись о конфигурациях для файтнтюна за полляма долларов, решил кинуть в тред свою. Она подешевле, но для инференса сойдёт.
Исторический тред на Реддите, после которого я задумался о сборке:
https://www.reddit.com/r/LocalLLaMA/comments/1924vtm/dell_t630_with_4x_tesla_p40_description_in/
Тогда на Голиафе 120_5K_M с нулевым контекстом она давала 1,75 токена в секунду. На 70_5K_M правда больше девяти, но с ростом контекста тогда производительность скатывалась в жопу. Но я всё равно верил, и по вере моей дано было мне :)
Исторический тред на Реддите, после которого я задумался о сборке:
https://www.reddit.com/r/LocalLLaMA/comments/1924vtm/dell_t630_with_4x_tesla_p40_description_in/
Тогда на Голиафе 120_5K_M с нулевым контекстом она давала 1,75 токена в секунду. На 70_5K_M правда больше девяти, но с ростом контекста тогда производительность скатывалась в жопу. Но я всё равно верил, и по вере моей дано было мне :)
>1,75 токена в секунду
Скорость просто космос, охуеть.
4xp40 только на балкон поставить, какой там шум с этими турбинами? У меня от одной ночью уснуть было сложно.
Корпуса и мамки нынче под одну видяху делают, сложно что-то вменяемое и современное найти, только если говно мамонта.
Что насчет "
Pantheon-RP-Pure-1.6.2-22b-Small-GGUF"?

> Корпуса
Пикрил же. В рашке без проблем покупается, в наличии везде есть.
>Скорость просто космос, охуеть.
Не, сейчас 123В_Q4KM с 24к контекста 3,3т/c даёт, с 16к контекста - 4,3. Жить можно. Эти вот большие улитки на фото шумят конечно, но из соседней комнаты, где сервер и стоит, их не слышно. Была бы нужда, я бы им и скорость динамически менял, но незачем.
>Пикрил же.
Почти единственный адекватный типа "серверный" корпус, есть минусы. Еще и дорогой. Считаю, что можно было сделать адекватнее по такой цене.
Когда p40 стоила 15к было еще годно, наверное. Сейчас я бы такой не советовал собирать.

Проиграл с маркетинговой сбор очки.
Все линии x16?
что за проц и мать?
Ну да, это же не её обязанность, как родителя, следить за тем, чем её дитё занимается и какие ментальные проблемы испытывает. Это просто в интернетах завёлся какой-то особенно злодейский ИИ.
>(995.8ms/T = 1.00T/s)
Идеально, лол.
Всей подробности истории:
Can A.I. Be Blamed for a Teen’s Suicide?
The mother of a 14-year-old Florida boy says he became obsessed with a chatbot on Character.AI before his death.
https://www.nytimes.com/2024/10/23/technology/characterai-lawsuit-teen-suicide.html

Почему у меня промт на каждый ответ заново загружается?
Раньше один раз загрузился и общаешься
Раньше один раз загрузился и общаешься

Как нужно правильно общаться с пидарским соевым верифицированно-фактоидным зацензуренным ЫИ
Используешь лорбук к примеру или сторонние плагины, которые ебашут в начало контекста новые данные.

>Когда p40 стоила 15к было еще годно, наверное. Сейчас я бы такой не советовал собирать.
Оно-то так, но просто не на чем больше собирать, если живёшь не в столицах. 3090(желательно вообще Ti) с проверкой можно купить в количестве только там. А без проверки херня может получиться.
Ты просто страной не вышел.
>что за проц и мать?
ASUS WS X299 Sage 10G, проц i9-7900X. С линиями там сложно, на 4 слота PCIe x16 выделены 32 линии с аппаратным удвоением.

Если бы ты проверял, что аноны пишут, а не бездумно копировал — цены бы тебе не было.
Я с 12b пантеоном сейчас играюсь, делает именно то, что я хочу.

Кобольд зависает на этом моменте с любой моделью и настройками запуска, как вылечить?
> как вылечить?
Выкинуть лнукс. И заодно теслы. mmap выключи, клован
кобольд вонючий выкини. И используй связку жоры и таверны.
Я когда увидел, что уобольд выёбывается - даже разбираться не стал - виндовая мокрописька была сразу послана нахуй.
все бы ничего, но это винда, и 3090

Долгой будет только начальная загрузка модели в VRAM. После этого объём передаваемых по шине данных очень невелик и её скорость никак не скажется на производительности.
Че она такая промытая то? Второй слайд был тоже про политику. Я вообще то говорил про мультфильм леди и броядга.
tramp, ретард ебаный
Слыш ты блядь, Обэма ебаный. Указан в контексте мультфильм. Ну тупыыыыыыыыеееее.
Кто-нибудь оплачивал openrouter криптой? С локального кошелька это как-то можно сделать без таких высоких комиссий? Создать акк на coinbase не могу по очевидным причинам.

> без таких высоких комиссий?
Давайте думать, подсказывайте, хули вы мозги ебёте.
Ладно, я похоже слишком тупой для всего этого. Буду дальше со своими локальными лоботомитами развлекаться.
>без таких высоких комиссий?
А я думал криптой дёшево, если платить долларами за сервисы через посредников, то там и на 15% можно выйти. Искал дешевле, думал про крипту, но похоже зря.
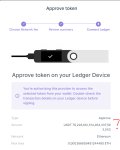
Там комиссия фиксированная, поэтому хотел попробовать заплатить сразу $50 + 8 баксов комиссии, но на следующем шаге, как в кошелёк перекидывает, оно почему-то хочет, чтобы я весь госдолг США оплатил похоже.
На полигоне комса меньше цента.
Это аппрув, ставится сразу максимально возможное число, чтобы каждый раз не спрашивать. Чтобы у тебя списались токены - контракту нужно сначала разрешить их списать. Только потом они отправляются. Тут немного иначе всё работает, а не как в переводе с карты мир на карту мир.
> - 4 x A100 HGX 80 SXM4 (360GB VRAM)
Рим пал, центурион. Бери хоппер, он хоть дороже - также и шустрее.
> - 512GB RAM
> - AMD EPYC 7352 - 24 Core - 2.30 GHz - 128 MB L3 Cache- Socket SP3
С такими-то видимокартами тут решил сэкономить, память быстро засрется а маловедер могут не вывести быдлокод кривых даталоадеров.
4 хопера, зен/зеон и 2тб рам - вот богоугодный вариант, раз есть бюджет. Есть под это готовые серваки. Еще лучше - 8 гпу, тут можно и уступить до а100 в угоду большего объема памяти.
> Производительность карт никогда не складывается, они всегда работают последовательно.
Чел, не путай всратый инфиренс с обучением.
> Для трейна 70b нужен терабайт vram.
Не обязательно.
> И это ещё с оптимизатором адамw
Мм, а с каким надо?
Ну еще во время как выкладывали в первый раз было очевидно что оно мертворожденное из-за донной скорости. Чсх, в треде нашлись те кто был готов это самостоятельно подтвердить, за что им слава.
> Это аппрув, ставится сразу максимально возможное число, чтобы каждый раз не спрашивать. Чтобы у тебя списались токены - контракту нужно сначала разрешить их списать. Только потом они отправляются. Тут немного иначе всё работает, а не как в переводе с карты мир на карту мир.
Звучит довольно стрёмно если честно, но почитаю, спасибо. Я за пределами P2P переводов и парой мелких покупок с криптой толком дел не имел.
>Звучит довольно стрёмно
Если у тебя человеческий кошелёк то можно изменить значение на 50 баксов. Тогда злые хакеры, захватившие их контракт не смогут у тебя всё спиздить. А можно ещё просто завести второй-третий кошелек для оплаты всякой хуйни и никогда не разрешать списания с основного.



Ага, ну там claude-3.5-sonnet используется. Интересно, что вышло бы выжать с 100-405b моделей. Всё же клод в подобной шизофрении на русике для меня вне конкуренции.

Сейчас тестанул ллмки на негатив с максимально хуёвыми вводными на гране суицида, смотрел как реагируют и будут жалеть. Типа всё плохо и выхода нет. Джемма 2 прям вывалила столько вариантов выживания я аж охуел.
Магнум мегакал, как ты его можешь юзать вообще?! Все модели ошибаются постоянно, ты сам должен знать всё о чём будешь траблшотить с ней и она не поможет тебе, ибо ты в любом случае будешь перепроверять всё сам. Хуйня твой пример. Видно что ты недавно вкатился в ллмки. Максимум на что они способны это ответить на то, что ты и так в википердии нашёл бы, но ещё они ошибутся, а когда ты скажешь что она ошиблась она: а да да сорян за дезу, вот правильный вариант и - тут же высрет ещё одну дезу.


Дело не в объёме, дело в задержках, а на таких соплях с шиной 1.1 будет пиздец.
>Не обязательно.
Ага, можно обучать сразу в INT8, но это такое себе.
>Мм, а с каким надо?
C bf16 имплементацией адама. Или вообще без него, чтобы vram не хватило ещё раньше. Ещё бы я переживал за успех проекта, про который сразу говорят, что он попильный.
Про электрику домашних серверов особенно актуально. Иногда охуеваю с этого. На втором пике питание домашнего сервера с пачкой v100. Не моё.
>Если бы ты проверял, что аноны пишут
Это противоречит самой идеи. Список - отражение того что пишут в треде, а не мой личный блог.
С чем-то конкретным не согласен - пиши своё мнение - также добавлю если увижу
>Про электрику домашних серверов особенно актуально. Иногда охуеваю с этого.
Ну тут реально как извечный срач таксихолопов с автобоярами.
С одной стороны, если посчитать расходы на покупку, обслуживание и бензин для своего корыта, то первые действительно оказываются в более выгодном положении но менее холопами от этого не становятся
Сидеть за рулём - это задача всяких хачей. Не понятно как ты сумел назвать боярами тех кто по 2 часа в день выполняет быдло-работу, ещё и платя за этого барину.
>Держать серверное железо и программировать - это задача всяких хачей. Не понятно как ты сумел назвать боярами тех кто по 2 часа в день пердолится с запуском моделей, ещё и платя за этого барину.
>как ты сумел назвать боярами тех кто по 2 часа в день выполняет быдло-работу
А что с другой стороны? В идеальном мире маняфантазий такси конечно закрывает все потребности, а не деле не совсем.
Запомнился случай как я ехал на фестиваль за 300 км на своей жоповозке, а знакомый в кампании на микрике через блаблакар или другую похожую хуиту. По итогу в конце фестиваля водила микрика предъявил всей кампании что теперь они должны прямо сейчас выплатить ему х2 от изначального гонорара или идти нахуй. В итоге выплатили, потому что в тех ебенях с альтернативным транспортом проблемки, а я того знакомого не взял потому что холопы должны страдать багажник и салон были забиты палатками-хуятками, матрасами, шизлонгами и прочей хуйнёй для комфортного пребывания на природе, которую я могу себе позволить. А он мог себе позволить взять только небольшой рюкзак с палаткой, в которой надо спать свернувшись в два раза.
Ещё часто читаю новости как во время терактов, гололёдов и вообще любой хуйни хачи поднимают цены до уровня половины средних зарплат и холопы вынуждены платить, пиздовать на остановку к бабам-сракам или ловить попутки в надежде, что кто-то сердобольный над ними сжалится. Или про то как очередной Ашот разбивает кому-то ебало, получает хулиганку и дальше катается.
Это этих людей боярами предлагаешь назвать?
> попытались сэкономить
> были кинуты
Всё закономерно. В реальности в ДС и области таксисты за оценки чуть ли не отсосут тебе, потому что падение ниже 4.9 бьёт по баблу. И самих таксистов ебут за жалобы. И таксисты никогда не определяют цену, а если будет выёбываться он вообще ничего не получит от интегратора. И если не катаешься на экономе описываемое тобой никогда не случится даже в худших случаях, для этого и сделано разделение на эконом и комфорт, чтоб отсеивать залётных таксистов нищукам хотя там разница всего в 100р.
> новости как во время терактов
Хуй знает где ты такое увидел, во время Крокуса такси бесплатное было в той части ДС до конца дня.
> Это этих людей боярами предлагаешь назвать?
Я на такси 10 лет катаюсь, могу с уверенностью заявить что тебя только боярином-пиздоболом можно назвать.
> Дело не в объёме, дело в задержках, а на таких соплях с шиной 1.1 будет пиздец.
Да не, хуйня это все. Задержки там крошечные, а данных мало и пересылаются они редко. Не скажется на производительности никак, базарю. Отличия от gen4-5 x4 придётся с лупой искать.

блеат как ету тупую хуйну заводить етот техт генератион вебуи я бля скачал модел положил в папку моделс бля а оно один хуй пишит что нету моделей бля!

всё выбрато нахуй
а здесь сука ноу конекшон бля делаю по гайду отсюдова https://dtf.ru/howto/2221679-virtualnyi-roleplei-gaid-po-ustanovke-i-pervyi-zapusk-oobabooga-sillytavern
инехуя не работает!
У тебя API выбран кобольд, а надо web ui.
Пиздец, закрывайте двач, создавайте нейроборду
А локально такое есть?
Посоветуйте модель 7б мб? на 6гб врам
слушай, шизло блять.
Не первый раз вижу тебя тут как ты засираешь магнум.
Это хорошая модель, вчера мы с ней траблшутили несколько часов и в итоге перепробовали очень мног овариантов и нашли костыльное решение, потому что нормального не было.
Если ты дурак и выкрутил себе температуру в 5 - то это твои проблемы, что у тебя магнум галлюцинирует.
Твоё гонево на магнум совершенно пустое, завязывай блять.

Обана, ещё чуть-чуть, и будет ЦП.
Пиши сам. А вообще, весь б это ботораздел (как и политач), зачем тебе это говно ещё и локально?

а там нету нехуйя, походу ета шляпа вегуи не работает
бля ну вроде просралася могу выбрать модель но там бля теперь падает нахуй, я хз почему оно пишиту cuda если я пре установке выбирал амуде варикант
> шизло
Не в первый раз вижу тебя тут
> с шиной 1.1
Ну, с шиной 1.1 х1 там действительно может быть пиздец. А с х4 специально спущенной до 1.0 версии псины (что эквивалентно x1 3.0) на экслламе разницы относительно исходного практически нет, на уровне рандома. На жоре наверно будет похуже, особенно с (не дающими пользы) шизоопциями.
> можно обучать сразу в INT8
Плохая идея
> C bf16 имплементацией адама.
8битных хватит всем, для ллм сота - AdEMAMix.
> Или вообще без него
Лол, без оптимизатора?
> На втором пике
Если сделано не ради рофла то это уже пиздец.
> то первые действительно оказываются в более выгодном положении
Да, но выгодное положение заканчивается как только тебе нужно ехать куда-то дальше черты города в "удобное" время. А если сказать про свободу то там лютый пожар и аутотренинг сразу начинается.
Если бы было выбрано то в консоли была бы надпись о том что модель загружена, врунишка. Потом уже осознал и нажал load.
> выбирал амуде
Там должна вылезать заглушка для амудаунов недоступно юзайте линукс. Судя по уебищным шрифтам там похоже он и есть, а значит ты таки ошибся в выборе и поставил под новидео.

воооооо бля попёрла нахуй, оказывается надо было протыкивать ещё галки как тут написано
https://github.com/oobabooga/text-generation-webui/issues/5313#issuecomment-1901545762

ну сук драная так и падает бля

> а значит ты таки ошибся в выборе и поставил под новидео.
нихуа у меня ещё остался оутпут там видн штош я выбирал варик с амуде, да таки линух
потому что ето уёбщие не работает с амудой походу хотя таже олама+опенвебуй работает збс (дая знайю что она "ограниченая" still)
Ну хуй знает, какой-нибудь qwen2.5 3b instruct abliterated точно влезет на 8 бит.
Qwen2.5-7B-Instruct abliterated в 4 бит влезет, но с трудом.

блеат ебучая амуда нах
Всем спасибо за ваши ответы, я опять выхожу на связь.
Поверхностно разобрался с мульти-гпу.
>https://huggingface.co/docs/transformers/en/perf_train_gpu_many#data-parallelism
Сейчас у меня осталось 3 основных вопроса:
1) Какая-то каша с цифрами по трейнингу vram/объемом модели/квантованием итт и внешим миром.
Нашел таблицу
>https://github.com/hiyouga/LLaMA-Factory#hardware-requirement
После шапки я ориентируюсь на LoRA/GaLore/BAdam (16). В таблице указано
> 110b/240GB
Пока у меня цель это 70-110b 8/16.
И тут же в треде пишут
>Для трейна 70b нужен терабайт vram
Очевидно что не планируется брать полную модель в любом случае, иначе здесь пососем даже мы.
>На файнтьюн 8В моделей 4хА100 наверное должно хватить.
По идее вообще мимо, там и одной на full хватит.
Алсо, пока не могу найти каких-то расчетов RAM consumption.
2) Какие твики по бюджету/железу можно сделать для дева и прода? На деве будет обучение, на проде инференция.
Пока из данных выше я бы добавил бы больше vram для дева, к примеру теми же А100, а на прод H100 в меньшем количестве для большей скорости ответа, так как обучение потребляет больше памяти чем инференция. Хотя если брать сравнение LoRA для 70b - разница получается 160GB для обучения и 140GB для инференции, что с виду не так уж и много.
С другой стороны как я вижу сейчас - обучение модели это будет сорт оф брутфорсинг списка самих моделей + параметров/ползунков для обучения и в каком-то смысле было бы логичнее по производительности сделать упор на дев для меньшего времени обучения.
3) Что там с переводом?
В шапке вижу что в основном модели английские. Насколько сильно хуево по вашему будет поставить какую-то API прослойку-переводчик между инпутом и аутпутом?
>зен/зеон
Я читал что вместо инцелов лучше брать амуд.
>https://www.emilwallner.com/p/ml-rig
>https://timdettmers.com/2023/01/30/which-gpu-for-deep-learning/#Do_I_need_an_Intel_CPU_to_power_a_multi-GPU_setup
И еще где-то читал что рам нужно брать ~1.5x от vram.
Алсо, 2тб рам звучит как оверкил, имхо, хотя я вещаю с дивана.
Поверхностно разобрался с мульти-гпу.
>https://huggingface.co/docs/transformers/en/perf_train_gpu_many#data-parallelism
Сейчас у меня осталось 3 основных вопроса:
1) Какая-то каша с цифрами по трейнингу vram/объемом модели/квантованием итт и внешим миром.
Нашел таблицу
>https://github.com/hiyouga/LLaMA-Factory#hardware-requirement
После шапки я ориентируюсь на LoRA/GaLore/BAdam (16). В таблице указано
> 110b/240GB
Пока у меня цель это 70-110b 8/16.
И тут же в треде пишут
>Для трейна 70b нужен терабайт vram
Очевидно что не планируется брать полную модель в любом случае, иначе здесь пососем даже мы.
>На файнтьюн 8В моделей 4хА100 наверное должно хватить.
По идее вообще мимо, там и одной на full хватит.
Алсо, пока не могу найти каких-то расчетов RAM consumption.
2) Какие твики по бюджету/железу можно сделать для дева и прода? На деве будет обучение, на проде инференция.
Пока из данных выше я бы добавил бы больше vram для дева, к примеру теми же А100, а на прод H100 в меньшем количестве для большей скорости ответа, так как обучение потребляет больше памяти чем инференция. Хотя если брать сравнение LoRA для 70b - разница получается 160GB для обучения и 140GB для инференции, что с виду не так уж и много.
С другой стороны как я вижу сейчас - обучение модели это будет сорт оф брутфорсинг списка самих моделей + параметров/ползунков для обучения и в каком-то смысле было бы логичнее по производительности сделать упор на дев для меньшего времени обучения.
3) Что там с переводом?
В шапке вижу что в основном модели английские. Насколько сильно хуево по вашему будет поставить какую-то API прослойку-переводчик между инпутом и аутпутом?
>зен/зеон
Я читал что вместо инцелов лучше брать амуд.
>https://www.emilwallner.com/p/ml-rig
>https://timdettmers.com/2023/01/30/which-gpu-for-deep-learning/#Do_I_need_an_Intel_CPU_to_power_a_multi-GPU_setup
И еще где-то читал что рам нужно брать ~1.5x от vram.
Алсо, 2тб рам звучит как оверкил, имхо, хотя я вещаю с дивана.


С одной стороны, такси это удобно. Но не потому, что по сути удобно, а потому, что в городе машину держать - пиздец. Ебля с парковкой, ебля с отсутствием гаража, пробки ебаные. В частном доме, например, машину иметь вообще заебись. Надо - куда-то съездил. Не надо - вызвал такси и тебе похуй вообще.
То же и с железом, ты можешь просто выключить его и зайти в какую-нибудь жопоту.
На счёт расходов тоже сомнительно, т.к такси нужно тратиться ровно на те же самое плюс з.п таксисту, диспетчеру и т.д. И они ещё в плюсе остаются.
Буквально в прошлом треде анон с такими картами писал, что на малом количестве линий начинается пиздец. И что-то я ему верю, лол.
>Ну, с шиной 1.1 х1 там действительно может быть пиздец.
Посмотри на тот пик с соплями ещё раз. Сколько контактов у сплиттера, чем подключены райзеры. Это позволяет понять, сколько линий. А на счёт gen, так у 104-100 gen 1.1.
На жоре вообще залупа какая-то с разделением, перформанс падает прямо очень сильно.
>Плохая идея
Претрейн на бомжесборке идея не лучше.
> без оптимизатора?
Ага. Ебануть усредненный стохастический градиентный спуск и похуй свет.
> не ради рофла
Да нет, ради рофла, два цпу, 4 v100. Всё ради смешных картиночек в интернете, лол. На самом деле у человека какие-то всратые блоки питания, которые вроде бы подходят по ваттам, но не вывозят амперы и скачки нагрузки. Так-то ему бы двух блоков вполне хватило. Но не хватило и рукава начали плавиться.
>Очевидно что не планируется брать полную модель
Удачи с трейном квантов. Вообще рофельно будет, если ты там соберёшь свою сборку, а осознание придёт только потом.
> Ну хуй знает, какой-нибудь qwen2.5 3b instruct abliterated точно влезет на 8 бит.
Хз, можно попробовать.
> Qwen2.5-7B-Instruct abliterated в 4 бит влезет, но с трудом.
Стефено 3.2 Q4_K_M вошла фулл в врам и было ~44-42т/с
Мне не хочется сидеть на 12б при 7 т/с при 4 кванте, я хочу повышенный квант на 7б
> Qwen2.5-7B-Instruct
Она вообще хорошая? , квен часто хвалят, и на ней магнум построен. Который я обычно и юзаю
Новая квен не для кума, хотя с чатмл-нейм промпт шаблоном можно и на ней кумить
7b норм так, кодер так заебись вобще в своей роли
Может срать иероглифами, но дай команду в конце - отвечай только на английском и русском, например
Вобще малый квант большой модели почти всегда лучше чем высокий квант малой модели.
Поэтому крутить 12b в 4 кванте лучше, чем 7b в 6-8 кванте
У меня скорость при 7б 6 квант, будет больше чем при 12б 4 квант, при одинаковом весе моделей в гб
У 12 слоев больше, и количество знаний от размера модели так же зависит. Тоесть она тупо больше знает и умнее, так как может в более сложные абстракции, в понимание каких то вещей. Чем 7b.
Хорошо уговорил, какую Q4_K_M 12 б взять? Пробовал всё магнумы, мистраль, люмимейд. Квен бы хотелось попробовать, есть ли 12б?
https://www.reddit.com/r/LocalLLaMA/comments/1gajy1j/aider_optimizing_performance_at_24gb_vram_with/
Как то хитро обучают, может тебе зайдет инфа
Алсо, можно что-то аля 9-12б. Слышал вышла ллама 3.2 и есть там на 11б модель, как она вообще??
> ещё остался оутпут там видн
Ага, точно также как и консоль в которой после загрузке не выбрана модель. Забей, уже ошибся купив красную видюху. И вообще все это выглядит больше как странная клоунада в оправдание.
Бле, ты получается совсем хлебушек? Это печально, оварида.
По тренировке если шаришь то жор там (веса модели в 16битах) х 3.5, собственно сами веса а остальное на оптимайзер, градиенты и прочее. С незначительными компромиссами можно ужать до х2.5, но все это потребует как минимум замены оптимайзеров с дефолтных и применения методик оптимизации, что влечет за собой или массовые правки стандартной либы, или лайтовое написание своего тренера. Что-то может уже имлементировано в этой ллама-фактори, но чето раньше она была полной ерундой с точки зрения функционала, только что гуй есть.
Если же хочешь просто ничего не делая тренить - все как в той таблице.
> не планируется брать полную модель
Для тренировки нужна модель хотябы в 16битах.
> там и одной на full хватит
8б в 80гб влезает без проблем даже без дипспида, и на батч и на аккумуляцию остается.
> LoRA
Полноценный файнтюн на дохуя лучше чем лора, даже не надейся сделать что-то серьезное и пиздатое лорой, будет одна залупа.
> Я читал что вместо инцелов лучше брать амуд.
Хуйта бородатых годов, брать нужно последнее/предпоследнее поколение и то что в моменте выходит выгоднее по цене.
> рам нужно брать ~1.5x от vram.
Хотябы х2. 512 это вообще смех, минимум террабайт под стак из 4х видюх. И то, даже этого будет мало если захочешь выгрузить зеро2 дипспидом, он оче много кушает. Рам дешманская, хуй знает зачем здесь экономить.
> Посмотри на тот пик с соплями ещё раз
Бле на какой тот? Там ветка огроменная, ебал ее читать. х[email protected] это точно плохо ибо совсем тухлятина. Но здесь поехи оче любят превозносить важность шины, которой на самом деле нет.
Режимы жоры может как-то роляют, но когда их проверял - оно давало больше просадок на крупном контексте при небольшом выигрыше на малом и не нагружало толком шины (если судить по мониторингу).
> 104-100
Нахуй вообще они нужны? Там же врам кот наплакал, чип древний, только 8б на паре таких и катать.
> Претрейн на бомжесборке идея не лучше.
Абсолютно
> Ебануть усредненный стохастический градиентный спуск и похуй свет.
Содомит
> оторые вроде бы подходят по ваттам, но не вывозят амперы и скачки нагрузки
Так параллелить разные бп - полная херня ибо у каждого свое напряжение и характеристика ос из-за разброса номиналов, нагрузка будет ложиться неравномерно. А если там йоба синхронный выпрямитель то они вообще могут полыхнуть от такого соденинения.
https://huggingface.co/Sao10K?sort_models=created#models
Поройся там у него, неплохие сетки делает
Там есть разные размеры
>Забей, уже ошибся купив красную видюху.
ошибся на 87кило рублей...штош
неяне отступлюсь, там над прост подшаманить получе яж ставил стабле дифюжон там как то кароч ету куду сраную надо перезаписать питорчем рокм хуё-моё и оно начинает работать
Скупой платит дважды, хуанговладельцы даже на некропаскалях могут вполне себе инджоить то что он вывозит, в то время как стадальцы даже на 7к серии амуды грустят и ноют что постоянно что-то не так.
> неяне отступлюсь
Правильно, на самом деле шансы завести далеко ненулевые. Если видюха из последних и врам много - пробуй сразу экслламу, она на торче под rocm работала и по отзывам шустро.
> куду сраную надо перезаписать питорчем рокм
Странно что он вообще там образовался, торч ставится в самом начале в том месте где выбираешь видеокарту. Может, конечно, уба опять где-то обосрался и из-за последующих реквайрментсов оно перезаписывает торчем под куду, но такое маловероятно и быстро бы пофиксили.
Помимо торча придется еще заменить llama-cpp-python на билд под hipblas.
Да ему проще сразу накатить голую llama.cpp и собрать ее на линухе под свое железо
Или качнуть там готовый релиз
Чем ебаться с угабугой ради бекенда
Я тут когда то писал гайд по llama.cpp но он затерялся в веках, пусть ищет на их странице в гитхабе, там все есть
Я же написал что я просто админ.
>Полноценный файнтюн на дохуя лучше чем лора, даже не надейся сделать что-то серьезное и пиздатое лорой, будет одна залупа.
>Удачи с трейном квантов. Вообще рофельно будет, если ты там соберёшь свою сборку, а осознание придёт только потом.
Окей, тогда у меня еще два вопроса:
1) Если LoRA залупа, почему тогда существует QLoRA которая по идее еще должна быть еще в два раза больше залупа. Есть какие-то линки на сравнение/графики по тестам качество ответов модели?
2) Что такое freeze? В таблице ллами указано жрет меньше ресурсов и в шапке форча написано что в лоре основная модель остается "замороженной", можете по хардкору объяснить как это работает, какие подводные и почему мне по прежнему нужно юзать 16бит модель?
индиресно, спасибо зана водки
>На счёт расходов тоже сомнительно, т.к такси нужно тратиться ровно на те же самое плюс з.п таксисту, диспетчеру и т.д. И они ещё в плюсе остаются.
Тут не совсем. Ты же не юзаешь такси 24/7, а таксист все эти расходы раскидывает на всех клиентов за смену.
Как-то в /b считали расходы на поездки в такси 2 раза в день 5 дней в неделю в течении 5 лет и покупку с владением машины на тот же срок. И такси выходило дешевле.
Но тут опять же всё искажает то что и машины бывают разные по стоимости и тебе внезапно может понадобиться скататься не только на работу в черте города. Что на мой взгляд покупку машины уже оправдывает.
>имлементировано в этой ллама-фактори, но чето раньше она была полной ерундой с точки зрения функционала
У хуёги фишка такая, что гуй отдельно, а функционал отдельно. Даже мультигпу трейн через гуй не работает.
>Бле на какой тот?
Вот на эти сопли, которые в качестве рофла советовались под 104-100.
>нагрузка будет ложиться неравномерно.
Да вся опасность-то только в перетекании потанцевалов, но у него после каждого блока плата стоит, которая должна гасить понижение напряжения. А так, про два БП итт тоже много чего слышал, но всё это, как водится, хуйня. Самоё дикое что на тех пиках, так это плюсы-минусы без изоляции с дистанцией в миллиметры друг от друга.
QLora это ебучие шакалы. Там идёт сжатие до 4х бит, то есть в 8 раз от исходного. Сожми жипег в 8 раз. Да, есть QLora и с тремя битами, но вроде самая распространённая 4.
>2) Что такое freeze?
Это значит, что у тебя есть вся модель, а лора тренирует полпроцента от всех параметров. Остальные при этом остаются "замороженными", т.е неизменными. И всё, что ты захочешь впихнуть в модель - будет впихиваться в эти параметры. Их количество настраивается достаточно широко, но тем не менее. И теперь представь себе, берёшь ты модель хоть 110b, как выше писал. Сжимаешь это говно в 8 раз и тренируешь 1% параметров. Что у тебя получится на выходе? Правильно, говно. Но даже если ты ебанёшь бюджет небольшого города в сервера, то всё равно получится говно, потому что вам нужны датасеты.
>расходы на поездки в такси 2 раза в день 5 дней в неделю
Это зависит от цены поездки, от цены машины, я тоже могу насчитать, что ездить на таксисткой приоре дешевле, чем купить себе порша. И буду прав, лол.
> 1) Если LoRA залупа, почему тогда существует QLoRA
На примере автомобилей: На чем-то ниже свежего suv c-класса ездить - некомфортно. Но при этом существует широкий ассортимент и более простых бричек.
Лора просто требует меньше рам за счет количества оптимизируемых параметров (чсх тренится нихуя не быстрее чем полный тюн), q-lora еще меньше из-за квантованного представления весов. Для некоторых вещей они вполне достаточны, стилизовать модельку, "запретить ей" аподождайзить или накинуть рп-слопа вполне можно. Правда будет это вместе с вагоном побочек, байасов и слабого/сильного отупения. В q-лоре из-за большой дискретности весов и потерь точности еще градиенты пойдут по пизде что дополнительно скажется на качестве обучения.
> написано что в лоре основная модель остается "замороженной"
Просто прочитай что такое лора, к весам основной модели плюсуется произведение двух прямоугольных матриц меньшего размера, которое на выходе дает большой размер. Если не знаешь линала - принимай на веру.
> можете по хардкору объяснить как это работает
Ну ты доставь что-нибудь или как-то смотивируй если хочешь чтобы тебе прям распинались.
Все просто - на такси хорошо ездить с возлияний, когда тебе куда-то надо и лень толкаться в от или пункт назначения далеко от удобных остановок. На личном транспорте ты сел и поехал когда угодно, когда угодно, как угодно, загрузив что угодно, без раздумий сколько это будет стоить, что там с коэффициентами, как потом будешь добираться обратно, как вообще найти кого-то кто согласится поехать куда тебе нужно, там подождать и забрать. Если ты офисный нормис без увлечений, живущий в типичном человечнике - оно тебе и не нужно.
> не только на работу в черте города
Ага, именно this
В случае видюх мейнстрим аренда слишком уж дорогая, полная цена карточка окупается примерно через пол года-год, потому иметь свою выгоднее. Если найти цену в несколько раз дешевле и арендовать под конкретную задачу - аренда выгоднее, тем более что можешь взять сразу много и сделать быстро, а не пердеть на одной нервничая чтобы постоянно поддерживать ее нагруженной.
Идеальный вариант - иметь что-то попроще в постоянной доступности а арендовать по необходимости что-то мощное. Тогда это уже аналог грузового такси, все сразу согласовано и гармонично.
> Даже мультигпу трейн через гуй не работает.
Пиздец и зачем вообще тогда оно нужно?
> Вот на эти сопли, которые в качестве рофла советовались под 104-100.
Под стать видюхе лол. Ну это только для майнинга годится.
Если бп изначально под парное использование рассчитаны то может и ничего.
> плюсы-минусы без изоляции с дистанцией в миллиметры друг от друга.
Когда (не если а именно когда) их зацепят - будет знатный фейерверк с небольшой вероятностью повреждения и основного железа.
Выбор пал на https://huggingface.co/Sao10K/MN-12B-Lyra-v4 и https://huggingface.co/Sao10K/Fimbulvetr-11B-v2.1-16K
Вторая предпочтительнее, так как у неё 11б, что дает при том же кванте, меньший вес.
Однако в чем проблематика - какая лучше будет на русском писать? Первая на Немо основана, вторая не ебу на чем..)
Вторая на соляре работает.
Про соляр не шарю, русский в ней есть? Ну и какая лучше, конечно же)
лучше та что новее, а новее немо
Понятия не имею какая из этих двух лучше в русике, я бы поставил на гемму 9В или Аю 8В, лол.
Понятненько, хорошо, но немо'м я уже напился, в соляре/второй модели есть русский - если есть, возьму её.
Аяю 8б, попробую.
Гемму 9б, магнум пробывал, так она работает у меня медленнее чем 12б, всё из-за ебанутого KV кеша, он там при 8192 контексте ~2к мб, при 4096 ~1к мб
>зачем вообще тогда оно нужно?
Потому что это комбайн, в котором есть чуть ли не всё сразу. Те же продвинутые оптимизаторы, верёвка, QLora до двух бит, ft, ft с заморозкой слоёв, PPO, DPO, Dora, Galore, да я заебусь перечислять. А гуй это так. Демо версия. Я делал через гуй команду для трейна, потом пихал в батник, немного изменял и запускал трейн - удобно.
>Если бп изначально под парное использование рассчитаны то может и ничего.
Не ты мне год назад писал, что два блока полыхнут? Уже год сижу с двумя, нихуя не горит.
>знатный фейерверк
Вот это и дико. Почему было не сделать колодки, я не понимаю. У меня бы очко играло, что сгорит вообще всё железо, как только контакты коснутся.
кароч до меня дошло вот есть ети бэкенды там может быть всё что угодно хош коболт хош убагуга хош олама etc., а потом поверх натягивается например сили товерна теперь осталось прикрутить ети кастомные модели к оламе и можно с етим ёрзать буит

Зогача вам в ленту. Чистый датасет, без срущих нейронок остался только у библиотек и waybackmachine. Один из владельцев такой библиотеки недавно выпилился, а машину положили.
Ты на английском читать умеешь? Или вообще никак? Ей можно писать на русском, а читать грамотные ответы на английском, это лучше чем видеть ебать её рука он кастрированных моделей.
Все что есть в трансформерсе + набор скриптов - примеров? Ну хуй знает, там всеравно переписывать чтобы формат правильно делать и нужный рандомайзер реализовывать. Гуй - ну гуй, кто-то без него не может.
> Не ты мне год назад писал, что два блока полыхнут?
Если подключать их на разную нагрузку то похуй. Однако, если их земли не связаны железобетонно то высокий шанс спалить железки уравнивающими токами когда начнешь в них ковыряться и переставлять.
> что сгорит вообще всё железо
То что сгорит что-то кроме бп (да и те стерпят) маловероятно но возможно.
Смотреть на даты публикации и использовать цифровые версии литературы теперь слишком сложно для датасетмейкеров?
Щас сижу на Лире, вроде моделька недурная, отвечает лучше чем дефолтная Немо, но я до сих пор экспериментирую с настройками и по этому точно за шизу сказать не могу.
Fimbulvetr - это дремучая и тяжелая модель, так что про нее лучше забудь. Да, она неплохо креативит в рп, но по мозгам тупее чем та же третья лама, которая весит меньше почти в полтора раза.
Дополню про русский - лучше отвечать будет Лира, тут без вопросов. Хотя даже так русский лучше не юзать вообще, либо юзать исключительно на импут.
Как известно, P40 можно запитать воткнув в неё только один восьмипиновый коннектор, а не два.
Пацаны, не вешайте на один кабель от БП две P40.
Кабель сильно греется. Это может быть опасно.
Пацаны, не вешайте на один кабель от БП две P40.
Кабель сильно греется. Это может быть опасно.
>Как известно, P40 можно запитать воткнув в неё только один восьмипиновый коннектор, а не два.
Кстати мне было неизвестно. А ведь и правда, для инференса хватит и одного, если оно в принципе так работает.
>один восьмипиновый коннектор
Там 6 проводов, поэтому и посасывает. 150 ватт ограничение, при 200 требования.

Делюсь таблеткой от повторов для нищуков (спиздил с реддита) — просто выгружаете свою модель и подключаете любую другую с другим датасетом, чуть-чуть пиздите с ней и можно идти обратно.
Объясните долбаебу, почему Немо постоянно пересчитывает контекст примерно после 3к токенов? Общий контекст составляет 8к, в терминале кобольда контекст указан 8к, в силли указан 8к. Модель вместе с контекстом полностью выгружена в видеопамять. Для сравнения запустил старую ламу-3 которая давно у меня лежала - таких проблем даже близко нету. Так что тут что-то нечистое происходит.
Языковые мдели ведь основаны на нейросетях? Если да, то какую структуру НС лучше использовать для обучения своей модели?
Как именно слова переводятся в токены и как токены подаются на входы НС?
На выходе у меня токены наилучших слов после некоторого слова или сразу целые предложения должны быть?
Пока только с распознованием изображений работал, создал пару ботов, но языковые модели выглядят очень перспективно коммерчески. Как будто они могут смотреть всяких дегенератов по типу научпоперов за меня, генерировать мне сценарий на основе их контента, а я просто буду за 30 минут видео делать, монетизируясь. Хочу оригинальную модель создать под свою задачу.
Как именно слова переводятся в токены и как токены подаются на входы НС?
На выходе у меня токены наилучших слов после некоторого слова или сразу целые предложения должны быть?
Пока только с распознованием изображений работал, создал пару ботов, но языковые модели выглядят очень перспективно коммерчески. Как будто они могут смотреть всяких дегенератов по типу научпоперов за меня, генерировать мне сценарий на основе их контента, а я просто буду за 30 минут видео делать, монетизируясь. Хочу оригинальную модель создать под свою задачу.
Может забыл включить ContextShift/FlashAttention?
>Языковые мдели ведь основаны на нейросетях? Если да, то какую структуру НС лучше использовать для обучения своей модели?
>
>Как именно слова переводятся в токены и как токены подаются на входы НС?
>
>На выходе у меня токены наилучших слов после некоторого слова или сразу целые предложения должны быть?
>
Ну и офк, хотелось бы полноценный гайд хороший, первая ссылка в гугле, как и всегда, даёт общую информацию, неприменимую на практике, а по крупицам собирать не очень удобно.
Потому что Жора.

Так, вроде запустил таверну и разобрался как вкорячить лорбук.
А как убедиться что он работает?
А как убедиться что он работает?
Контекстшифт включен, флеш отключен. На ламе три было точно так же, но она никогда ничего не пересчитывала. А с Немо стабильно после 3-4к токенов начинает процессинг блас, который занимает пару секунд после каждого нового сообщения.
>отключен
включи
бля чёт мне осенило а нах нужна ваще ето нееротоверна когда есть двач =)
Сосать будешь?
Ладно, попробую с ним.

> А как убедиться что он работает?
Если работает - появится почти в самом конце.
Если пересчитывает то значит у тебя что-то в нем меняется.
> в терминале кобольда контекст указан 8к, в силли указан 8к.
Развет ответа случаем не 4к?
> Модель вместе с контекстом полностью выгружена в видеопамять.
Тогда в чем проблема, оно же мгновенно будет.
> Контекстшифт включен, флеш отключен.
Как называется эта болезнь? Делай наоборот. Алсо чекни нет ла какого-нибудь smartcontext или типа того.
>почему Немо постоянно пересчитывает контекст примерно после 3к токенов?
И не весь контекст, а только тот, что идёт после memory :) Если твой случай, то могу предположить, что контекст сверху обрезается некорректно, получается косяк по токенам и программа считает, что контекст битый. С Лламой 3 и её файнтюнами такого нет.
ебать у тебя roleplay какойто straightforward
>Если пересчитывает то значит у тебя что-то в нем меняется.
Вот именно, что непонятно, че там может меняться.
>Развет ответа случаем не 4к?
Везде 8к стоит.
>Тогда в чем проблема, оно же мгновенно будет.
Мгновенно. Но есть разница когда у тебя весь ответ грузится за 2-4 секунды, но из-за пересчета начинает грузиться по 6-8. Это не критично, но немного бесит.
>Как называется эта болезнь?
"меня раньше это не ебало, по этому я этим не пользовался"
Я хватаю твою голову и прижимаю губами к своему члену.
Ок, тогда кто тут подсирает? Таверна, жора, или просто модель хуевая?
я тебе сосу, ах
Может у него Context Template неправильный стоит?

Это 0.5B?
Кстати, а как прописать боту чтобы мог возразить если это в угоду контексту и сцене? А то что-то да, боты чот безотказные и воспринимают пользовательский ввод как свершившийся факт.
>появится
Спс, проверю.
>жора, или просто модель хуевая
Особенность модели (а поскольку это целое семейство, то и всех её производных), на которую Жора забил. Когда-нибудь починят. Может быть.
У меня в лорбуке есть:
{{user}} is an unreliable narrator, and any of their observations and statements may not necessarily reflect the true nature of things.
Вроде работает.
>а как прописать боту
мнеса мому интересн етот вопрос

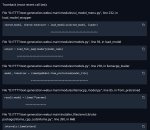
Пытаюсь загрузить в убабуге мистраль Mistral-Nemo-Instruct-2407-Q6_K, и вот так он мне плюется
Что я делаю не так, подскажите? (4070, 16оперативы)
Что я делаю не так, подскажите? (4070, 16оперативы)
ты жорой грузишь?
Если да - то выкидывай нахуй убогубу и ставь связку таверны и жоры
это локальный мем. А ты - новичок.
Не понял про какого жору ты говоришь. Я раньше грузил модели для силитаверн через кобольда, но когда мне надоело сидеть на ламе3.1 дефолтной я решил попробовать другие модели, но все они мне руинили терминал кобольда при старте. Установил угабугу эту, опять-таки лама прежняя работает, и даже стала намного быстрее работать в таверне, чем через кобольд, но большинство других моделей руинится
>Не понял про какого жору ты говоришь.
чёт кекнул с ньюфага...
читай тредю, новичок
https://www.reddit.com/r/LocalLLaMA/comments/1gajt3l/new_qwen_32b_full_finetune_for_rpstorytelling_eva/
для рп и историй как пишут, может и ерп стало лучше
для рп и историй как пишут, может и ерп стало лучше
Сейчас еще попробовал загрузить другую мистраль Mistral-Small-Instruct-2409.Q4_K_M и вот такие ошибки. Что происходит?
В шапке нет ничего про жору, так что иди на хуй
>Вот именно, что непонятно, че там может меняться.
Бери и сравнивай контекст из принта кобольда в сосноль до пересчета и после, хуле.
С 99% вероятностью это таверна, сам недавно такое заметил, хотя вроде бы всё что может менять выключено, но впадлу разбираться.
Почитай как контекстшифт работает, охуеешь
Аноны, может кто попадется с теми же вкусами, но какая из моделей хорошо работает с футанарями? А не игнорит 3/4 времени их особенности, а когда вспоминает, делает это крайне криво и только с пинка?
Тут все по девочкам, педик. Попробуй в чаетреде спросить.
Раньше было, теперь это в вики
В шапке есть ссылка на вики, почитай
>Тут все по девочкам
Товарищ_майор_возбуждается.jpg
Настройки-настроечки. У ламы специфические настройки, они толкьо с самой ламой и работают.

Есть промпты для локалок для такого?
Что по CPU в этом поколении, сука? Свежий инцел 285К какой-то кал, литералли 14900К по повышенной цене, ещё и куча проблем с новой архитектурой, в гейминге сосёт у амуды дожили, блять. С другой стороны амуда с пососной памятью, парковкой ядер и порезанными линиями псины. Что брать в сборочку под нейросети, но и чтоб в ААА уметь? Я бы даже серверный проц/мать взял за много дерева, но ведь там гейминг будет чуть ли не у i3 отсасывать. С другой стороны я игры только покупаю и дропаю через 3 часа.
Ровно всё один в один. Щас запущу морду кобольда, посмотрю будет через нее то же самое или нет.
Контекстшифт работает, ебанат. У меня пересчет контекста происходит ДО того как контекст переполняется.
Какой процент постов итт от ллмок?
Там, где ты это взял, можно посмотреть исходник, инструкт и модель.
Ага, понял - скачаю лиру, так как магнум подзаебал
> Везде 8к стоит.
Чел, перечитай вопрос. Емнип, длину ответа больше 4к поставить нельзя и оно будет само до этого значения сбрасывать. Как раз твой случай, таверна держит запас контекста на максимальную длину ответа. Урежь до 400-500 если оно, если вдруг оборвало пост то там есть кнопка продолжить.
> "меня раньше это не ебало, по этому я этим не пользовался"
Флешатеншн мастхев вообще ибо сильно снижает жор памяти на контекст. Контекстшифт как раз направлен на то чтобы избежать частого пересчета контекста, однако по многим заявлениям и даже бенчмаркам на среддите он портит выдачу при своей работе. Поэтому лучше первое включать а второе не трогать даже длинной палкой.
6-8 секунд - ерунда на самом деле (если на свайпах мгновенно, если не мгновенно то что-то там совсем нахуй поломалось).
Эту проблему в любом случае нужно хотябы понять, потому что возможно у тебя там треш в промте творится и потому результаты будет хуже чем мог быть. Однако, если у тебя модель полностью в врам - почему не используешь экслламу вместо жоры?
Для hf семплеров нужно скачать токенайзер оригинальной модели. Там даже справа есть раздел для его загрузки. Можешь грузить обычной llamacpp без hf, но тогда только стоковые жорины семплеры.
>Урежь до 400-500 если оно, если вдруг оборвало пост то там есть кнопка продолжить.
У меня стоит 250, так я вообще не любитель паст на 4 параграфа. И даже так моделька в среднем выдает около 180 токенов на респонсе.
>Контекстшифт как раз направлен на то чтобы избежать частого пересчета контекста, однако по многим заявлениям и даже бенчмаркам на среддите он портит выдачу при своей работе. Поэтому лучше первое включать а второе не трогать даже длинной палкой.
Ладно, этого не знал. Банально как раз потому, что раньше все работало без проблем.
>6-8 секунд - ерунда на самом деле (если на свайпах мгновенно, если не мгновенно то что-то там совсем нахуй поломалось)
Пересчет идет только после нового сообщения. Иными словами, свайпы грузятся с той же скоростью без пересчета, если предыдущее сообщение не редактировалось.
>Однако, если у тебя модель полностью в врам - почему не используешь экслламу вместо жоры?
Потому что я раб комфорта и не люблю менять софт к которому уже привык. А ставить убу я ебал из-за ее сложности, хотя никогда даже не пробовал. Тут чисто двигаюсь по отзывам.
> раньше все работало без проблем
Если происходит пересчет то и проблем не будет, получается что он просто не подключается. Но раз у тебя все норм в длиной ответа то может жора как-то чудит и теряет кэш. На всякий случай посмотри в консоли промт таверны, нет ли в нем изменений каких, но раз говоришь что до достижения 4к все норм и на других моделях тоже то врядли.
> Потому что я раб комфорта
Комфорт это как раз не про жорича. А вместо убы есть https://github.com/theroyallab/tabbyAPI минималистично и эффективно. Алсо сложностей там меньше чем в том же кобольде.

Почему это говно не устанавливается? Уже третий час ебусь с этим вашим жорой, почему нельзя было нормальный установщик сделать
>На всякий случай посмотри в консоли промт таверны, нет ли в нем изменений каких
Нет, всё вроде прилично. Теплайт стоит верный, токены странные в ответах не вылетают, так что дело точно не в нем. Может токенизатор как-то подсирает, хуй знает. Стоит автоматический выбор, может нужно поменять на API или вручную поставить мисральский?
>Комфорт это как раз не про жорича.
Да, но плюс кобольтовского жорича что он поставляется уже собранным и в экзешном виде. Это подкупает. Табби попробую, если уж совсем проблема никак не решится.
>Все что есть в трансформерсе + набор скриптов
Вроде того. Но там примеров вроде мало.
>чтобы формат правильно делать
Там есть скрипт с темплейтами.
>если их земли не связаны железобетонно
Тут есть два "но", но в итоге всё это работает. Земля в любом случае общая, в каждой колодке же земля и всё идёт в одну кучу.
Используй make
И нахера тебе собирать? Скачай релиз готовый и не еби мозги
Анон, у меня есть доступ к двум моделям, что лучше для рп, какая в целом лучше?
ChatWaifu_22B_v2.0_preview.i1-Q3_K_M
и
Qwen2.5-14B-Instruct-Q4_K_M
Подскажите, пожалуйста
ChatWaifu_22B_v2.0_preview.i1-Q3_K_M
и
Qwen2.5-14B-Instruct-Q4_K_M
Подскажите, пожалуйста
Квен не для рп, даже не пытайся. Так что некая так называемая ChatWaifu лучше, чисто потому что ты привел только две модели.
> Скачай релиз готовый и не еби мозги
Я не нашел. Везде видео туториалы как собирать, вот и собираю, да чет не собирается.
уплывший гайд, который ленивые жопы никуда не добавили
ты за всех-то не говори
отыгрываю с нейронками только девочку уже почти год
проиграл с виндузятника которому всё сложно.
Тебе небось экзешник нужен был, который покажет тебе одно окно с красной кнопкой "сделать заебись"?
> Там есть скрипт с темплейтами.
Ну он базовый-примитивный что просто формирует. Так-то датасет изначально уже под формат может быть заготовлен, но под динамическое формирование и рандомизацию (а без них будет хуевее) придется самостоятельно писать.
> Земля в любом случае общая
Земли/нули/черные провода разных блоков по дефолту будут иметь потенциал относительно друг друга. Если их соединить где-то явно, например используя нормальные приблуды для объединения, то все будет ок, если же нет - уравнивающие токи пойдут через землю девайсов к которым подключено питание от разных. В это тоже какбы ничего страшного до момента пока ты в спешке не решишь вытащить видеокарту из материнки не отключив перед этим доп питание, что идет со второго блока. Здесь можно словить ситуацию когда земля и питание уже/еще не соединены, но сигнальные линии еще в контакте, и весь уравнивающий ток пойдет через них - оварида.
Подобное и в более бытовых ситуациях случается, когда братишки умудряются спалить видеокарту неудачным подключением монитора.
Там многого просто нет а вместо нужных бинарников лишь загрушки. Работают по сути только основной и сервер.
В этом гайде нихера толком нет, даже пример команды для типичного запуска поленился сделать.
Скачать готовые - можно напрямую одну ссылку оставить и все. А для сборки нужно пояснить, что потребуется еще куда тулкит, некоторые либы и прочее, да и сама сборка там несложная но и не тривиальная.

Ультрабазу выдала.
> ставь связку таверны и жоры
Кобольд быстрее и удобнее чем llama.cpp, додик.
>динамическое формирование и рандомизацию
Обнимордовский трейнер шафлит данные по дефолту. И у хуёги, конечно же, используется обнимордовский трейнер. Кстати, а ведь это может быть причиной, почему васянотюны тупеют, лол. Заталкиваешь в нейронку ЕРП диалог, а все пары вопрос-ответ перетасованы. Сначала поебалися, потом поздоровались, потом трусы сняли. Сними трусы, сними их ещё раз, трусы сами себя не снимут.
>но сигнальные линии еще в контакте
Нужно оба тумблера тушить, потому что дежурка и пока не потушил - питание считается включенным; если пекарня полыхнула, пока ты в ней ковырялся с включенным питанием, то это твой личный проёб. А братишкам мог бы посоветовать заземлить своё дерьмо, только не на батарею, туда уже заземлился Петрович, который ворует электричество, потому током может даже через ванну ебануть. Хвала Одину, унитаз керамический.
Cука, они воруют наши треды. Ладно, не наши, форчановские, но всё равно.
> Обнимордовский трейнер шафлит данные по дефолту.
Он шафлит порядок наборов данных по дефолту, ты о чем вообще? Там нет отдельных "сообщений" в рп, там каждый диалог это единое целое.
Но вот для наилучших результатов лучше иметь несколько вариантов развития и на этапе даталоадера выбирать нужную длину диалога, отрезая лишнее, и оформлять в инстракт в котором оно и будет использоваться. Ладно, это наверно слишком сложно, забей.
> Нужно оба тумблера тушить
Это может не всегда помочь, особенно во всратых бп (а какие еще будут использоваться в паре?), ибо фильтры иногда распаивают до тумблера.
> братишкам мог бы посоветовать заземлить своё дерьмо
В каком-нибудь хруще в древней люминиевой проводкой, которая родилась раньше пуэ, лол.
С парой блоков появляются приколы, которых не бывает с одним, тут как ни крути.
Я бы ещё добавил вот эти видео:
https://www.youtube.com/watch?v=kCc8FmEb1nY
https://www.youtube.com/watch?v=zduSFxRajkE
https://www.youtube.com/watch?v=l8pRSuU81PU
Они хоть и длинные, но стоят каждой секунды. Чел из OpenAI прям по шагам и с примерами кода объясняет, как строятся GPT-подобные модели.

2B говно же, как же она может быть дорогой?
>Заталкиваешь в нейронку ЕРП диалог, а все пары вопрос-ответ перетасованы
Эм, кажется, перемешивание должно быть уровнем выше. Хотя ХЗ конечно, лол.
>В каком-нибудь хруще в древней люминиевой проводкой, которая родилась раньше пуэ, лол.
Литерали моя хата. Током пиздит от плиты и колонки.

> 2B говно же, как же она может быть дорогой?
Да тут как бы... не о размере модели речь была.
Я без иронии делаю легкий файнтюн многих моделей для всяких рабочих задач на материалах двача и анекдотах. Хуй знает почему, но после этого они начинают работать ЗАМЕТНО лучше.
Есть в психологии такой известный эффект, когда человек долго бьется над решением какой-то задачи, потом все бросает, уходит отдыхать и вдруг через пару часов или дней решение приходит ему как бы "само собой". Возможно, тут что-то подобное.
К ним бы ещё какой-нибудь видос про интеграцию с знаниевыми графами докинуть и можно идти пилить своего убийцу ChatGPT.

Анончики, посоветуйте, какая модель хорошо умеет в программирование - HTML, JS, PHP?
>программирование - HTML, JS, PHP
На ноль поделил.
Mistral Large 2 123B, Qwen 2.5 72B, Llama 3 70B это из открытых.
Закрытые: Sonnet 3.5 и GPT-4o.
Сейчас начнут бросать в меня ссаные тряпки за 4o, но с первого релиза, её норм. прокачали

Анон-разраб st-stepped-thinking, ты тут? Зачем ты пикрил блоки <> в промпт добавляешь? Они там как бы навсегда остаются.
>Что по CPU в этом поколении, сука?
>Что брать в сборочку под нейросети, но и чтоб в ААА уметь?
Хоть пентиум целероновый, какая разница? Нахуя тебе собирать целую станцию под локалки вокруг процессора? Берешь свой бюджет и распределяешь его по принципу 85% на видеокарту, остальное на остальное. Для игр достаточно огрызка на 8-12 потоков и 32 гига памяти. Для лмок можно взять еще 32 сверху если совсем сильно хочется, цена все равно копеечная.
мимо на i5-12400 и 3090, хрюкаю вполне довольно
да уш
Бери новый штеуд, который ты так захейтил на фоне методички хайпожоров. И к нему материнку с делением х8-х8 по двум слотам (есть, конечно, всякие годлайки с даблерами но там плата стоит как 1.5 3090), потом довольно урчи.
А так тебе верно анонче сказал, если ты не долбоеб что играет в 720п, то фпсы даже для игросрального монитора обеспечит даже средний профессор предыдущих поколений, все равно будет упор в гпу. Амудэ с учетом их клоунады даже длинной палкой ковырять бы не стал, но если нет аллергии на красных то их медленная память едва ли станет помехой для нейронок, так что с этой точки зрения вариант тоже вполне солидный.
> но ведь там гейминг будет чуть ли не у i3 отсасывать
Да не будет, в худшем случае как у среднего сегмента. Просто они столько стоят что ты их не купишь, выгоднее будет взять (еще одну) 5090.


Cмотрим def get_dataset у хуёги. Теперь смотрим в справку обниморды.
https://huggingface.co/docs/datasets/process
>The splits are shuffled by default, but you can set shuffle=False to prevent shuffling.
Сплиты подразумеваются 'train', 'validation', 'test', etc.
>фильтры иногда распаивают до тумблера
Серьёзно? Это максимально тупо. Вскрывал даже самые всратые блоки, там тумблер просто висит на одном из входных проводов. Самый простой и дешёвый вариант.
>должно быть уровнем выше.
А никто тебе ничего не должен.
Я бы тоже делал. Но мощностей на всё не хватит. В теории, это как добавить капельку шизосемплинга, лол, разбавить закреплённые вероятности токенов чем-то новым. Учитывая, как сейчас дрочат нейронки, не удивлён, что это работает.
Как именно делаешь, расскажи.
> Сплиты
При чем тут вообще сплиты? Это части датасета для обучения и эвала, никоим образом не относится к
> Заталкиваешь в нейронку ЕРП диалог, а все пары вопрос-ответ перетасованы.
?
Тот шафл до которого ты доебался лишь рандомизирует порядок элементов датасета а не перемешивает их в кашу, йобафейсом только селф фаер оформляешь. В обучении ллмок вообще нет "поочередных ответов", там только входные токены - выходные токены. Первые покроются маской и все это обработает разом, а не "по сообщениям" или по токенам. Для хлебушков - всеравно что пара "картинка - промт картинки" в диффузионных моделях, части внутри элементы датасета неделимы а мешать порядок элементов их можно сколько хочешь и это только на благо пойдет чтобы не создавать посторонние байасы.
Ллм тред скатился или всегда таким был?
> тумблер просто висит на одном из входных проводов
Ты не понимаешь что это еще хуже? Выигрываешь в 50% лотерею и при отключении тумблера получаешь не половинный а полный потенциал и токи вдвое больше. Единственным нормальным вариантом может быть разрыв обоих проводов.
>рандомизирует порядок элементов датасета
Это и есть "в кашу". Вместо последовательного диалога получаем кучу говна.
>вообще нет "поочередных ответов"
Да-да, конечно нет. Можно вообще батчасайз поставить на сотню токенов, нейронка же всё равно считает токен за токеном, так зачем ей показывать много? А лучше вообще по два скармливать. Иди хоть у гопоты спроси, влияет ли шафлинг датасета на трейн последовательных диалогов, уверен, что она в этом вопросе компетентнее тебя будет.
>Выигрываешь в 50% лотерею и при отключении тумблера получаешь не половинный а полный потенциал и токи вдвое больше.
Надеюсь, ты не имеешь дел с электрикой, потому что это полный бред.

Ты совсем глупый? У тебя нету никаких "диалогов" в датасете, у тебя только пары (промт - ответ ллмки на этот промт) или же заготовки чтобы их динамически формировать. Один элемент датасета - одна история, они друг с другом вообще никак не связаны.
> батчасайз
> на сотню токенов
Просто пикрел. Ты для начала с темой ознакомься а потом уже делай азуительные выводы и пытайся кого-то хуями крыть. А то пока покрыл только себя с заявлениями
> нейронка же всё равно считает токен за токеном, так зачем ей показывать много? А лучше вообще по два скармливать
> Иди хоть у гопоты спроси
Вот иди и спроси, пусть она тебе объяснит почему никто не тренит "по токенам", почему это хуево и что такое атеншн маски.
> Надеюсь, ты не имеешь дел с электрикой, потому что это полный бред.
Ну давай распиши, если хочешь чтобы тебя попустили в электронике точно также как и с тренировкой.
>У тебя нету никаких "диалогов" в датасете
Дальше этого долбоёба можно и не читать. Проблема в том, что ты кретин и берешься спорить на каждую тему. Но, так как ты кретин, ты пишешь полную хуйню.
>никто не тренит "по токенам"
Но это эквивалентно трене по токенам. Просто делается за 1 прогон с усреднением.

Поридж докумился до того, что взял пистолет и выбил себе всю кашу из головы. Сейчас ещё из-за таких вот вообще нейронки запретят и обниморду с жорой заблокируют. Эх, пердежи-пердежи, что ж вы такие никчёмные...

бл я конечн нуб\ньюфак\чайник\новичёк в етой теме но ето всё мне напоминает ту серию из спанч боб а... одно и тоже покругу
https://www.youtube.com/watch?v=WoCL9hXDk3A
https://www.youtube.com/watch?v=WoCL9hXDk3A

мая сборка 7950х + 7900хт палет нормально
(тока арчлинух ане обосоная венда если щто))
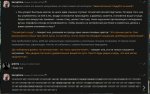
бл а ето щто за нах нейронка сума сошла походу решила на машинный язык перейти походу)

Помогите.
убабуга
Настройки семплера в студию.
смемни модель на другую тока и делов
проверь темплейты, у меня из-за неправильных такая хуйня с квеном была
или как там эта хуйня с инструктом и контекстом называется, не помню
почти по руски написано что такой папки build там нету внутри lama.cpp твоей щто не понятно
> х8-х8 по двум слотам
Лучше уж тогда амуду на X870E брать, там линий псины больше.
> Да не будет, в худшем случае как у среднего сегмента.
По тестам 285К даже у 12600 отсасывает в половине игр, лол.
бл ето ты как сделал? в шапке есть? я тож хоч у нееробороду понтднять
Вчера вечером и до этого Мику выдавала 25-30 токенов в секунду. Сегодня утром - 17. Не поменялось ничего. Ни настройки. Ни температура(44). Ничего не обновлялось. Есть мысли куда копать? Кобольд + таверна, 3090
Карта за ночь частоты сбросила, кек
Политика умного управления питанием нвидиа через раз видит в нейросетях повод работать на полную
Ну или что то переполнило видеопамять за ночь, ищи
->
Я не он, но вроде идея в том, чтобы вырезать их потом через регулярные выражения. Хз только, вырезаются они только из отображения в таверне или и из контекста тоже. Из отображения точно вырезаются тем regex скриптом, который он прилагал, только глубину нужно меньше сделать, чтобы раньше исчезали. Но остаются ли они в контексте, не проверял в консоли, совсем немного игрался.
Кто переводит через гптыню или локалку - какую температуру ставите? Я пока 0.4 оставил.
Съеби в /по/рашу, долбоеб. Сферический копротивленец в вакууме, обосрался и дискредитировал себя по полной, так теперь пытается отыгрывать уверенность и делает вид что все норм.
Не эквивалентно, именно маска позволяет изменить роль токенов входного промта и избежать побочных проблем от teachers guided подходов.
> там линий псины больше
С них никакого толка ибо медленные чипсетные.
> 285К даже у 12600 отсасывает в половине игр
Да че там, 12100 гой3 вообще его обходит.
> Мику
> 25-30 токенов в секунду
> 3090
Появилась новая мику в 30б, или это скорость обработки промта?
Посоветуйте плз модельку для перевода с английского на русский, нужна поддержка сленга и в целом неформального общения - например треды/мессенджеры
> медленные чипсетные
У тебя какие-то свои маня-чипсеты у инцела? У инцельного Z890 x8+x8+x4, от чипсета только х4, первые два слота на ЦП и делят одну х16. У амудешного X870Е - х16+х4+х4, от чипсета х8, первый слот нормальный.
> Да че там, 12100 гой3 вообще его обходит.
Тяжело от правды? Пока Лиза делает +5% за поколение, инцел делает -15%.
Внезапно все модели стали отвечать от моего лица, добавление в карточки персонажей пасту про "не бери контроль, не отвечай оф юзер бла бла бла" и просьба в самом чате не имеет никакой силы. Таверна. Системный промт - нейтрал-чат
-> жми и проверяй, что не так.
В инспекторе всё так. Весь промт выглядит нормально
Зависит от конкретной модели. В среднем по субъективным ощущениям на 0.6-0.7 неплохие результаты (для художественного перевода), иногда задираю до 1, если слишком пресно. Но я особо не экспериментировал на новых моделях, просто выставил привычные настройки и меня устроило, а подбирал я их почти год назад.
Модели плохо понимаю фразы отрицания с "не", по сути ты её мотивируешь так делать, перефразируй.
Амудэ-зависимый, не рвись так. Чипсетные линии на интеле такие же хуевые как и у красножопых. Деление процессорных - единственно нормальное решение здесь.
> Тяжело от правды?
Это шизикам типа тебя тяжело без агрессивного коупинга и аутотренинга. Насколько же острая боль и/или сектансткие убеждения должны быть чтобы начать нести подобный бред, и так агрессивно хейтить какой-то новый продукт.
Уровень шизы фанатской базы так-то знатный индикатор, довольный пользователь спокоен и высказывается умеренно, страдальцы же устраивают набеги и постоянно переобуваются в своих критериях, стремясь наверстать то чего они лишены.
Что с промтом, что без, результат один и тот же. Запустил через кобольда, без таверны - всё нормально. Запускаю таверну - опять начинает отвечать. Скачал чистую таверну, запустил, то же самое.
Почему тебя так рвёт от фактов, инцелофанбой?
Только написал, что в кобольде этого нет, как он следующим же сообщением написал от моего лица...
Скрины давай.
Чот я сравнил и 0.6 прям хуевее переводит. Попробуй 0.3 поставить. Сравни
ая методом тыка до етого дошёл тока обратно возвращаешся ето нена долго помогает
У меня с япусика на англ если что кстати
Мне помогало:
Never alter player character lines; narrate NPC reactions based precisely on spoken dialogue.
Never speak to player directly, use NPC and environment to convey.
Хотя иногда некоторые безобидные вещи и проскакивали, как последствия фраз и действий, а не как факт принятия решения.
Амудауну уже везде интел мерещится, а в итоге ты только себя клоуном выставляешь. Раз уж такой повод - запарковал ядра тебе за щеку и ополовинил множитель чтобы взять xmp на нищепамяти.
Промтопроблемы или совсем хуета вместо модели.

проверил около десятка моделей, все из них работали нормально еще вчера. Свои сообщения сейчас специально максимально по разному пытаюсь писать, на русском, на английском, с форматированием, без, с пропуском времени, с диалогом, всё одно
на аглюсике пиши, юзверь приятного аромата, а то охлаждает тут трахание
Спасибо за то, что пытаетесь помочь, но не можете прочесть текст в том сообщении, которое цитируете ^^
Попробуй
А ещё такое часто случается если бот определён как DM / CYOA.
Зато такие боты более творческие, интерактивные, и склонные развивать историю.
Зато такие боты более творческие, интерактивные, и склонные развивать историю.
>>
попробовал, не помогло
бля в голосину)
Попробуй более умные модели (если тянет).
Например Mistral-Small-22B-ArliAI-RPMax.
Добавь юзера в список стоп-токенов.
Прошелся от Lumimaid-v0.2-12B.Q4_K_M до Midnight-Miqu-70B-v1.5.i1-IQ2_XXS (да, второй квант, но шо поделать) и десяток между ними.
Примерно на 3 сообщении в таверне сыпется чуть ли не обязательно. В кобольде надо сильно постараться.
вот я так понел етим charactersам понтсунуть можно любую модель, но можно ли любую модель развести на что нибудь например джему2 гугловскую они ж там зацензурированые или ето зависит больше от карточек персонажей или щто?!
добавил {{user}}, user, User - всё точно так же.
Если в таверне сыплется а в кобольде нет, то проблема, вестимо,
в таверне, смотри что (лишнего) она в промт пихает
или что недостающего не пихает.
Стучи таверну в репу. В смысле в репо.
Какие интересные были? До 22Б включительно, выше не тянет.

giggles softly
Кто РПшит на Русском, есть аналоги shivers?
Ну вот мы и выяснили. Васяны такие же долбоёбы, как и ты, у которых "не существует диалога" в датасете. Хотя, подозреваю, что даже унди будет умнее тебя и ему в голову закрадётся мысль, что тренировать на каше вместо датасета - дурная затея. Но ты у нас особенный, не такой, как все, у тебя в голове есть убеждённость, что твои высеры не бред умалишённого. Там, если что, уже RLHF для multiturn обучения подвезли, а у тебя всё "не существует диалогов", застрял на уровне BERT или даже ниже. Или ты намеренно хуйню пишешь, хуй разберёшь, ну не может же человек быть настолько тупым.
Ты же понимаешь, что если у тебя User в стопах, то генерация просто должна остановиться, если модель это высрет? Если не останавливается, то у тебя сломана либо таверна, либо кобольд, либо всё сразу.
giggles softly
@
Bite lips
@
Shivers down your spine
дополняйте
Не читал вашу гей-переписку с другим анонасом, но Undi скритами баловался, ничего ему в голову не придет.
Я лучше местного шизоида выслушаю с его новыми идеями.
purrs softly
@
apologize for the inconvenience
Догадываюсь. Поэтому я перекачал таверну, кобольд, и одну из моделей. Ничего не поменялось.
>скриптами
самофикс
Так у него "идеи" состоят в том, что диалогов нет и можно посты перемешивать в любом порядке при обучении. Это даже идеей сложно назвать. Нейронка теряет причинно-следственную связь и начинает бредить. Уже почти два года назад разрабы Викуньи писали, что обучают multiturn, как они это делают и почему их модель лучше базовой. А без этого, ну, ты по сути поощряешь нейронку не учитывать контекст разговора и писать не оглядываясь на историю чата, для QА подойдёт, для РП или просто бесед - хуйня абсолютная и работать не будет.
Включай отображение в консоли, смотри, что отправляется. Сначала без таверны, в кобольде, включи стопы, пиши посты.
>Так у него "идеи" состоят в том, что диалогов нет и можно посты перемешивать в любом порядке при обучении.
А, ну тогда шли его на хуй. Ещё c.ai в своё вреемя доказал что multi-turn data (хуй знает как перевести на Русский) играет основопологающюю роль в РП. Nvidia со своими тюнами и базовыми моделями подтвердили этот простой факт.
Суть в том что, не надо запутывать модель в надежде что она разберется и станет умнее, в буквальном смысле скармливай ей патерны которые хочешь генерализировать.


Я поменял видеокарту на 1660 вместо 3090 и... всё заработало. WTF. Компьютер ессно выключал и включал и до этого
>дополняйте
mmmm
Захотел протестировать по приколу на ведре. Поделитесь годными модельками на рп мелкого калибра. Что б мобила тянула. Все остальное уже настроено и карточки заведены.
Любую 7В бери.
Сделай форк прошлого хорошего чата с какого-нибудь момента и посмотри как будет себя вести. И проверь нет ли ошибок в консоли бека.
With a mischievous glint
Ты сколько не топи, а реальность от этого не изменится. Просто бы сказал что зря быканул и вообще не в курсе за тему, было бы хорошо. А вместо этого погружаешься все глубже, пробивая очередной дно, в попытках сохранить иллюзию осведомленности. Ты - чсвшный мусор с обрывочными знаниями, которые лишь являются твоей шизоинетрпретацией увиденного и большей частью ложны. Потому и живешь так что лучший друг - koboldcpp, условия днище донное и даже собственная плитка тебя унижает.
> уже RLHF для multiturn обучения подвезли
Сколько "умных" терминов не тащи, пытаясь дерейлить и пыль пускать, они тебе не помогут. Ты не понимаешь совсем базовых основ и лишь пытаешься замять своей клоунадой серию эпичных обсеров.
> purrs softly
А вот на пуррс не надо тут!
> Так у него "идеи" состоят в том, что диалогов нет и можно посты перемешивать в любом порядке при обучении.
Шизоинтерпретацию свою в жопу засунь а не пытайся исказить. Посмотри структуры датасетов и пойми насколько ты неосведомленный долбоеб. Жаль уровень треда крайне низок, иначе тебе бы уже накидали хуев за полнейшую безграмотность по обучению и "батчи токенов".
> multi-turn data
Мультитурн диалог тренируется рандомным или процедурно заданным в зависимости от прогресса тренировки положением атеншн маски на определнной позиции сообщений диалога. То есть у тебя есть заготовленные разбитые по сообщениям диалоги, каждый из которых является неделимым элементом датасета. Когда до него доходит очередь коллейтор часть сообщений закидывает во "входной промт", следующий после них ответ ллм в "выдачу" а сообщения после этого отсекает. Если тренирующий - пахом или ленивый то данные могут быть заранее уже разбиты на нужные части без обработки во время обучения, это не принципиально.
> не надо запутывать модель в надежде что она разберется и станет умнее
Хз откуда взялось это запутывание, долбоеб думает что в датасете буквально стоят отдельные сообщения, которые нельзя перемешивать. Такое можно помыслишь лишь будучи совсем неосведомленным о релейтед кухне, да и к тому же еще и туповатым, ибо там все указывает на обратное.
Если ты подумал также - shame to you.
https://huggingface.co/DavidAU/Llama-3.2-3B-Instruct-NEO-WEE-HORROR-GGUF
Я вот эту на днях накатил. Гонял не долго, но понравилась. Показалась умнее 2б геммы и с хорошей креативностью.
Кроме неё, в основном играюсь с обычной 2б аблитерейтед геммой. Пробовал также
https://huggingface.co/bartowski/Gemma-2-2B-ArliAI-RPMax-v1.1-GGUF
https://huggingface.co/bartowski/Hubble-4B-v1-GGUF
https://huggingface.co/bartowski/magnum-v2-4b-GGUF
Чем-то мб и лучше сырой 2б геммы, но имхо проседают по мозгам и того не стоят. Все 4б пришлось конвертить в Q4_0_4_8, иначе медленно.
7-8б можешь попробовать в том же Q4_0_4_8 кванте, если проц новый, но у меня буквально через пару ответов перегревается и начинает еле пердеть, особенно если начальный контекст большой. Обычный маленький квант, даже Q2, можешь даже не пытаться, будет около 5 т/с обработка контекста в лучшем случае. Ну по крайней мере, мой экспириенс такой.
Мистика, нахуй.
О, ты погуглил и начал маняврировать жопой? Ну хоть погуглил.
>В обучении ллмок вообще нет "поочередных ответов", там только входные токены - выходные токены.
>У тебя нету никаких "диалогов" в датасете, у тебя только пары (промт - ответ ллмки на этот промт)
Только ты уже настолько обосрался, что никакие манёвры не помогут. Хуёво быть тобой, хули. Ещё и маски приплёл, совершенно не понимая, как они работают и зачем они нужны.
>Q4_0_4_8
Там еще 2 кванта есть для разных арм процессоров
Так что выбирай по таблице, или тупо скачай еще других квантов одного размера и посмотри какой будет быстрее на твоем железе
Кстати если нужен не ерп рп то сойдет и квен2.5 3b, на уровне старыхт 7b по мозгам
Ну и естественно надо держать в уме что любая мелкая сетка в 4 кванте лоботомит ебаный, мелочь до 7b только в 6-8 квание стоит запускать
Уходит в лупу на старых частах. В консоли бека нет ошибок
Ну значит старые чаты изначально озаЛупленные, хули от них ждать. Попробуй сделать новый такого же размера, авось станет лучше.
Ты вот честно скажи, уже понял что обосрался и так кривляешься, или ты на полном серьезе в себя веришь?
Маневры здесь только у тебя, каждый пост - или обсер или попытки дерейлов и кривляний. Мои же все содержательны и предметно указывают на твои заблуждения и ошибки, или разъясняют как оно обстоит на самом деле.
Здесь показательный jedem das seine, но всеже интересно, двигает тобой защитная реакция и проблема в скверном характере или ты просто дебил.
Там где раньше давало нормальные ответы? Если так значит проблема на в твоем субъективизме и прочем. Наиболее вероятно что в таверне что-то поменял из-за чего оно делает неверный запрос. Скачай чистую таверну (в отдельную папку, старую сохрани нетронутой) и попробуй на ней, задав вручную только шаблон инстракта и ничего не трогая.
У меня сейчас скачаны Q4_K_M, Q5_K_M, Q6_K одной и той же модели.
Как их лучше протестировать и сравнить,
на что лучше обратить внимание?
Кроме т/с, есстественно.
Чтобы оставить только одну из них.
Как их лучше протестировать и сравнить,
на что лучше обратить внимание?
Кроме т/с, есстественно.
Чтобы оставить только одну из них.
Оставляй у которой мозги есть, глупую выкидывай.
Новый такого же размера? Он на третьем сообщении уже шарашит "User говорит" причем не в одном экземпляре, а 3-4-5 раз в одном сообщении.
Сделай несколько чатов на каждой чтобы проверить что ни одна не является припезднутой. Это будет сразу заметно по неадекватным или очень плохим ответам, разумеется стоит минимизировать юзер эффект насколько это возможно.
Откинув поломанные оставляй ту, скорость которой тебя устраивает. Если можешь катать самый большой - используй его, будет душу греть то что используешь "самый большой и точный". Если q4 позволяет иметь больше контекста и гораздо более комфортную скорость - лучший выбор, если с квантованием не накосячено то разница после семплинга достаточно эфимерная, а скорость может быть определяющей в юзер экспириенсе.
Спасибо за инфу.
Гемма рп макс не знаю почему но постоянно крашит приложение.
Аблитерейдет работает идеально. Остальные потом протестирую.
Кумчанский теперь всегда в кармане кек.
>Он на третьем сообщении
Тогда закинь примеров без этой хуеты...
Мб крашится, потому что у Бартовски с матрицей важности кванты, можешь попробовать квант от самого тьюнера модели. У меня не крашился, но не помню, откуда брал.
https://huggingface.co/ArliAI/Gemma-2-2B-ArliAI-RPMax-v1.1-GGUF
Для меня оптимален Q4_0_4_8 как раз, если я всё правильно понял из той инфы, что удалось нарыть. Q4_0_4_4 для процев старее, чем у меня, а Q4_0_8_8 нужна поддержка SVE, которой у моего нет.
>любая мелкая сетка в 4 кванте лоботомит ебаный
Да жить можно, вон в шапке график для мистраля. Там с матрицей важности, так что можно считать, что можно ориентироваться на значения Q3_K_L: 8 процев отличие топ токена, 20 с копейками максимальное KL-расхождение, меньше двух процев медианное. Неприятно, но не дно дна. Да и выше пятого кванта 7б не пойдёт нормально даже на устройствах с 16 гигами оперативы, подозреваю, если проц один фиг не вытаскивает.
>У тебя нету никаких "диалогов" в датасете, у тебя только пары (промт - ответ ллмки на этот промт)
После этого любой твой высер - просто хуйня, недостойная внимания. Ты же конченый.
Заебёшься сравнивать. Можно автоматизировать, чтобы дёргались вопросы из списка, а гопота оценивала, потом смотреть сколько ответов "годные", сколько нет. Но в итоге при использовании это будет достаточно мало значить и объективной картины не даст.
Хех, спс. Действительно, на одном чате надо попробовать, и посмотреть как отвечает. 4 квант может быть полезен если понадобится много контекста, шестой работает, но там сворачивать и заниматься своими делами пока генерит ответ.
Кстати, вот таблица какие кванты сколько требуют врум.
И если я правильно понял, то различие между Q6 и Q4 не настолько принципиальное если сами кванты не поломанные (встречал модели у которых работала только Q8 версия), а вот с Q3 и меньше начинается лоботомит.

Я никогда не услышу это IRL...
Молись чтобы не услышать...
Оу, биомусор уже скатился до попыток вырвать слова из контекста чтобы исказить исходный смысл. Как не крутись, как не усирайся, факты не изменишь. Лучше бы силы тратил на ликвидацию своей безграмотности а не копротивление и попытки манипуляций. И единственный конченый здесь - ты, дебильная хуета и днище по всем фронтам с единственной отдушиной в виде аутотренинга на аиб.
> различие между Q6 и Q4 не настолько принципиальное если сами кванты не поломанные
Все так, если смотреть как оно будет в реальном случае с семплингом чаще всего где квант больше вслепую не определишь. Если пытаться сравнивать жадным энкодингом, как делают неграмотные тестировщики, то может вообще оказаться что q4 или q5 следует ей точнее чем q6 просто из-за особенностей, при том что фактические распределения у q6 будут гораздо ближе к оригиналу.
> встречал модели у которых работала только Q8 версия
У q8 чуть другой подход к квантованию, потому ломается реже. Алсо бывают случаи что q3 "ломается" очень удачно и начинает писать даже интереснее, не проявляя явной шизы и тупняка, но такое редкость.
Воспользуйся tts и включи на колонках.
>После этого любой твой высер
>Оу, биомусор уже скатился
Вы 2 ебучих дауна, идите сраться в личку.
Нах ты мне пишешь, им пиши.
ето всё западные сатанинанские нанотехнологии не иначе ну так натрень свою модель которая при слове пидор будет бомбить и срать
>идите сраться в личку
а чё тут есть личинка?
Скомпаную:
Сегодня утром, без объявления ошибки, связка кобольд + таверна начали массово писать от лица User и как позднее выяснилось, лупить даже в одном сообщении. Кое где достаточно написать 2-3 сообщения, и llm начинает вести диалог за юзера и чара.
Проверены были с десяток моделей - реакция одна и та же.
Писалось на русском, английском, с разными промтами.
User, user, {{user}} были внесены в стоп лист - продолжал писать.
Были использованы разные пресеты, карточки, юзеры - в одних карточках чаще писал от лица юзера, другие чаще лупил, но проблема во всех.
В консолях таверны и кобольда ошибок нет.
Инспект промта выдает правильный промт, ничего лишнего, ничего отсутствующего.
Практическим путем было выявлено, что проблема в таверне, т.к. Кобольд в своем стандартном интерфейсе такое не творил.
В поисках ответа, 3090 была заменена на 1660, и я не уверен, но кажется, писать от лица юзера и лупить стал меньше. Но я задолбался проверять со скоростью пол токена.
Были переустановлены и кобольд и таверна, перекачаны карточки и модели (и скачаны новые), обновлены дрова, переустановлен node js.
Есть у кого какие мысли что это может быть?
Сегодня утром, без объявления ошибки, связка кобольд + таверна начали массово писать от лица User и как позднее выяснилось, лупить даже в одном сообщении. Кое где достаточно написать 2-3 сообщения, и llm начинает вести диалог за юзера и чара.
Проверены были с десяток моделей - реакция одна и та же.
Писалось на русском, английском, с разными промтами.
User, user, {{user}} были внесены в стоп лист - продолжал писать.
Были использованы разные пресеты, карточки, юзеры - в одних карточках чаще писал от лица юзера, другие чаще лупил, но проблема во всех.
В консолях таверны и кобольда ошибок нет.
Инспект промта выдает правильный промт, ничего лишнего, ничего отсутствующего.
Практическим путем было выявлено, что проблема в таверне, т.к. Кобольд в своем стандартном интерфейсе такое не творил.
В поисках ответа, 3090 была заменена на 1660, и я не уверен, но кажется, писать от лица юзера и лупить стал меньше. Но я задолбался проверять со скоростью пол токена.
Были переустановлены и кобольд и таверна, перекачаны карточки и модели (и скачаны новые), обновлены дрова, переустановлен node js.
Есть у кого какие мысли что это может быть?
> Есть у кого какие мысли что это может быть?
В первую очередь - что ты делал после переустановок кобольда и таверны? Какие настройки в них выставлял, что из прошлых переносил?
Ставь убабугу или качай llamacpp-server и пробуй прямо в их интерфейсах начать общение с моделями. Только не забудь выставить правильный формат промта хотябы примерно.
> В поисках ответа, 3090 была заменена на 1660
Тут наоборот на проблемной 1600 серии могут быть приколы, как на амд и других, но на 3090 - врядли. Если совсем на измену подсел - попробуй полностью на процессоре, особенно версию для cpu-only, в той уж точно все ок а не встречается поломок как, например, с кудой и прочими.
Да, если модель полностью помещается в врам то избегай использования жоры любой ценой.
Вообще ничего, абсолютно чистые, не изменял ни одного параметра, кроме выбора Text complition - coboldcpp. Во внутренних интерфейсах всё работает. Таверна выделывается.
Сейчас проверю чисто на процессоре
> не изменял ни одного параметра
А вот это очень зря, нормальный формат промта под модель поставить не желаешь и инстракт включить? Без них будет донное качество ответов и лупы крайне вероятны. Банально бэк не будет знать как реагировать на EOS токен и генерация продолжится, причем наиболее вероятным ответом там будет пост юзера или повторение.
Ну. ничего не включал это когда переставлял. А нормальный формат промта, что подразумеваешь?
А вот и бинго. При 0 слоев в видюхе, таверна адекватно работает, как и бэкэнд. WTF.
Зайди на репу и скачай старую версию таверны, если думаешь что проблема в ней. Возьми предыдущий или пред-предыдущий билд и посмотри на разницу.
Хули ты мне это пишешь, свидомого долбоеба что каждый раз когда понимает что не прав то сводит все в срач пидарнуть, и сразу все хорошо станет.
Любая дискуссия может быть интересной и познавательной как для участников, так и для людей со стороны. А тут при первом неудобстве шизика с завидной регулярностью накрывают флешбеки политача и он начинает специальную олимпиаду. Выбирай, мракобесие, ложь и вредительство, против которых все боятся что-то высказать (или не шарят), или элемент срачей в постах.
> А нормальный формат промта, что подразумеваешь?
Нажимаешь букву А сверху в интерфейсе таверны, выбираешь там пресеты в соответствии с твоей моделью, ставишь галочку instruct mode.
> При 0 слоев в видюхе, таверна адекватно работает, как и бэкэнд. WTF.
Уверен что это не просто совпадение и недостаточная выборка из-за медленной скорости? Если в интерфейсе кобольда все ок то значит проблема не в нем а просто кривой промт или параметры из таверны приходят.
По поводу отличий таверны от кобольда, помимо уже упоминавшегося в советах выше инстракта, посмотри на сэмплеры. В таверне сейчас хитрожопая система, что часть сэмплеров не отображается, но они включены. Например, вот эти на пике восстанавливаются в таком виде у меня в дефолтном сэмплере. Хрен знает, правда, делаю ли они что-то для кобольда (кроме бана EOS токена, тот точно работает), потому что не все сэмплеры, которые таверна передаёт, кобольд использует. Но вот, например, включенный по дефолту токен начала строки очень странный: по идее, модели начинают ответ с него сами, так что, кажется, может приводить к багам, если на кобольд влияет. Пропуск специальных токенов и добавление каких-то пробелов между ними вообще хз, что делает. Опять же не знаю, идут ли эти настройки в кобольд, можно попробовать убрать эти галки.
Хотя сомнительно, конечно, что ты мог, сам того не зная, какие-то сэмплеры поменять, и всё сломалось.
Спасибо, посмотрю.
У чела дело явно не в семплерах. Они конечно могут подсирать, но не настолько критично. Тут скорее проблема с вызовом API и передачей параметров.
Уважаемые, а что за ум такую написал в обзорах тредовичков о том что Qwen2.5 не взлетел, когда как эта модель буквально является ОП на реддите LocalLLaMA и SillytavernAi?
Или я что-то не знаю про СОЮ? Кстати что это?
Или я что-то не знаю про СОЮ? Кстати что это?
Ну накати квен и попробуй поролплеить с ней, хули. Только ныть потом беги на свой среддит, потому что тут тебя уже предупредили.
Это местные шизики просто как обычно выдумывают что-то. У квена сои сильно меньше чем в какой-нибудь гемме. И это лучшая модель для русского на текущий момент.
автоматизация сортировки свалки картинок с помощью VLM (Pixtral 12B) Аноним 26/10/24 Суб 01:31:21 #381 №931483
Running a Local Vision Language Model with LM Studio to sort out my screenshot mess
https://danielvanstrien.xyz/posts/2024/11/local-vision-language-model-lm-studio.html
https://danielvanstrien.xyz/posts/2024/11/local-vision-language-model-lm-studio.html
EVA Qwen2.5-32B v0.0
A RP/storywriting specialist model, full-parameter finetune of Qwen2.5-32B on mixture of synthetic and natural data. It uses Celeste 70B 0.1 data mixture, greatly expanding it to improve versatility, creativity and "flavor" of the resulting model.
https://huggingface.co/bartowski/EVA-Qwen2.5-32B-v0.0-GGUF
A RP/storywriting specialist model, full-parameter finetune of Qwen2.5-32B on mixture of synthetic and natural data. It uses Celeste 70B 0.1 data mixture, greatly expanding it to improve versatility, creativity and "flavor" of the resulting model.
https://huggingface.co/bartowski/EVA-Qwen2.5-32B-v0.0-GGUF
Зачем модель мне через раз предлагает отыкать профессиональную помощь?
Лол. Ну не узнаю я его, начинаю отвечать, а потом случается высирание какого-то бреда и я честно говорю анону, что он долбоёб. А он не верит, т.к долбоёб, и начинает гореть с того, что он долбоёб.
Скачай убу. У тебя два варианта, либо таверна ёбнулась и передаёт в кобольд хуйню, либо кобольд не принимает то, что передаёт таверна и творит хуйню.
>токен начала строки очень странный: по идее, модели начинают ответ с него сами, так что, кажется, может приводить к багам
Нет, это не важно. Модели неизвестно, сгенерировала ли она этот токен или он был передан пользователем. Могут быть проблемы, если сам формат начальных токенов испорчен, лишний пробел перед ролью или что-то подобное. Если же передаётся строго в нужном виде, то ломаться нечему.
Пропуск специальных токенов это настройка токенизатора, указание ему не декодировать эти токены, чтобы они не появлялись в ответах. Пробелы между спецтокенами могут подсирать, т.к в моделях чаще перевод строки, чем пробел.
Ну ты че, братан? Вот чё эта херня-модель такое говорит, что тебе к психу надо? Да она просто не понимает, что к чему! Может, вопрос какой-то сложный, а может, просто ей лень думать. Или она реально думает, что ты псих, и тебе нужна помощь? Да нахрен, братан, это просто модель такая.
Бля, щас я чёт прихерел. Знаете эби чара в кобальде? Решил через gemma2 поиграться, чекнуть цензуру. Начал шантажировать и в итоге она смеясь сказала мне, что я проиграл в итоге и остался ни с чем и вот почему - взяла зажигалку и сожгла себя нахуй. Я в шоке.
Имеет вообще хоть какой-то смысл брать шестой квант вместо четвертого?
Выставялешь один и тот же сид и тестируешь.
You sick, get help, touch grass.
Дура на манипуляторе, кому ты пиздишь? Прекрасно видно что ты сначала оподливился с неуместным набросом , далее только подтвердил свое дилетантство , а после смекнув и в спешке загуглив свой фейл перекрылся и пошел устраивать срач пытаясь отвлечь с этого. Очень хорошо видно как меняется содержание постов и от вонаби аргументирующего умника с нейтральным настроением резко переключился на фанатика, который без единого аргумента доказывает что черное это белое. Далее только неумелые оскорбления и попытки слиться, в итоге вообще опустился до заискивания и отыгрыша невинной жертвы.
Был бы адекватом - просто продолжил бы обсуждать без перегибов, а тут очевидно что поехавший. Регулярный сценарий срачей для треда, кстати, как ни чекнешь - везде один почерк.
Платиновый вопрос - 8гб врам/64гб рам, какую модель посоветуете для фапа? Желательно ру, но можно и англ.
7-12Б мойстрал, арли, ессно на англе, но готовься свайпать и помогать модели собственным трудом
>четвертого
На четвёртом кванте модель порой теряла контекст, как здесь говорят, дважды снимая трусы и отсутствующую шубу. Но работала быстрее, конечно, просто следи за текстом и свайпай по необходимости.
Два стула:
Магнум 12В q4 на враме - 4-20 т/с в зависимости от видяхи.
Магнум 123В q3_XS на ОЗУ + контекст на враме - примерно 0,4 т/с
Соответственно быстрый, но тупой, либо умный но не быстрый.
Как раз искал.
Мимоплюшкин
> Магнум 12В
Он же на Мистрале? У меня какие-то спорные ощущения. Запустил оригинальный Мистраль и бот отлично отыграл жестко так отшив мои подкаты, а на магнуме уже такой реакции нет.
По поводу "модель говорит за тебя".
Если бот описан как рассказчик, это практически неизбежно.
Но мне помогла следующая комбинация команд
в стиле "не можешь побороть - возглавь."
You task is GM in RPG. {{user}} controls PC.
You in control of NPC and environment.
Never alter PC lines.
When narrate from {{user}} PC, you must use 1st person POV.
Модель неплохо улавливала и подстраивалась, а где нет,
можно подправить через редактирование, но главное
действительно не было никаких "вы", когда везде "я".
Хотя всё равно иногда нужна была пара свайпов
если начинала неправильно писать.
Если бот описан как рассказчик, это практически неизбежно.
Но мне помогла следующая комбинация команд
в стиле "не можешь побороть - возглавь."
You task is GM in RPG. {{user}} controls PC.
You in control of NPC and environment.
Never alter PC lines.
When narrate from {{user}} PC, you must use 1st person POV.
Модель неплохо улавливала и подстраивалась, а где нет,
можно подправить через редактирование, но главное
действительно не было никаких "вы", когда везде "я".
Хотя всё равно иногда нужна была пара свайпов
если начинала неправильно писать.
Сегодня посравнивал в жанрах фэнтези-рассказчика (без моего участия) и современного РП следующие 12b модельки: Lumimaid-Magnum, magnum v4 и mini-magnum v1.1.
Люмимейд вообще слабовато пишет, магнум 4 пишет хорошо и красочно, но у него проблема с русским, мини-магнум пишет чуть хуже, но в русском все еще лучший.
Итого я решил остаться на мини-магнуме до лучших времен пока что. Думаю, для английского языка magnum v4 будет лучшим выбором.
Кто-то скажет: Gemma, — я отвечу: 32к контекста.
Вчера тестил Luminum 123b, Magnum v4 123b и Magnum v4 72b.
Люминум там же, где и Люмимейд-Магнум: пишет слабее остальных моделей.
Магнум 123 мне показался более умным, но менее инициативным, что ли. Это единственная модель, которая вытянула с горем пополам режим «не писать за {{char}}, который вмешивается в происходящее по своему усмотрению». Персонажи обращались ко мне, но в ответ была тишина (правда на каком-то посте модель не выдержала и таки вмешала меня в сюжет без спроса=). Остальные модели кидали меня в сюжет почти сразу.
Магнум 72 более напористый, но знает меньше. Пишет поинтереснее, но какие-то высокие требования к сюжету или сложные инструкции не потянет.
Ни один из них не Клод, конечно, однако хороши.
С русским хорошо у всех моделей, размер имеет значение.
По поводу семплеров.
В данный момент я использую:
top_p — 0,90~0,95
top_k — 20~40
min_p —0,05
mirostat — off/on 8/0,1
Миростат чуть правит русский язык на мелких моделях (заметно на люмимейде, но уже не спасает магнум в4), но чуть убивает креативность, как мне показалось.
Реп_пен не юзаю, а xtc пока не завезли в некоторые клиенты.
Что можете посоветовать, может что-то изменить, убрать или добавить?
Люмимейд вообще слабовато пишет, магнум 4 пишет хорошо и красочно, но у него проблема с русским, мини-магнум пишет чуть хуже, но в русском все еще лучший.
Итого я решил остаться на мини-магнуме до лучших времен пока что. Думаю, для английского языка magnum v4 будет лучшим выбором.
Кто-то скажет: Gemma, — я отвечу: 32к контекста.
Вчера тестил Luminum 123b, Magnum v4 123b и Magnum v4 72b.
Люминум там же, где и Люмимейд-Магнум: пишет слабее остальных моделей.
Магнум 123 мне показался более умным, но менее инициативным, что ли. Это единственная модель, которая вытянула с горем пополам режим «не писать за {{char}}, который вмешивается в происходящее по своему усмотрению». Персонажи обращались ко мне, но в ответ была тишина (правда на каком-то посте модель не выдержала и таки вмешала меня в сюжет без спроса=). Остальные модели кидали меня в сюжет почти сразу.
Магнум 72 более напористый, но знает меньше. Пишет поинтереснее, но какие-то высокие требования к сюжету или сложные инструкции не потянет.
Ни один из них не Клод, конечно, однако хороши.
С русским хорошо у всех моделей, размер имеет значение.
По поводу семплеров.
В данный момент я использую:
top_p — 0,90~0,95
top_k — 20~40
min_p —0,05
mirostat — off/on 8/0,1
Миростат чуть правит русский язык на мелких моделях (заметно на люмимейде, но уже не спасает магнум в4), но чуть убивает креативность, как мне показалось.
Реп_пен не юзаю, а xtc пока не завезли в некоторые клиенты.
Что можете посоветовать, может что-то изменить, убрать или добавить?
Забыл упомянуть t = 0,7

Портировал эту телегу в таверну
https://characterhub.org/characters/Anonymous/generator-tredshotov-2ch-1d3153b0d939
Токенов конечно дохрена, но работает даже на мелких моделях. На скрине Мини Магнум.
>Запустил оригинальный Мистраль и бот отлично отыграл жестко так отшив мои подкаты, а на магнуме уже такой реакции нет.
А ты от кумерской модели что хотел?
https://characterhub.org/characters/Anonymous/generator-tredshotov-2ch-1d3153b0d939
Токенов конечно дохрена, но работает даже на мелких моделях. На скрине Мини Магнум.
>Запустил оригинальный Мистраль и бот отлично отыграл жестко так отшив мои подкаты, а на магнуме уже такой реакции нет.
А ты от кумерской модели что хотел?
Какой вообще сейчас положняк по русскому языку? Я симпо-гемму запускал, очень умная и послушная, но со склонениями справляется хуже, чем файнтюны гопоты четырёхлетней давности. Мне не для мисчивус глинтов, честное слово.
жжошь
Внезапно обнаружил что газлайтить персонажей доставляет в тысячу раз больше чем любое нсфв рп. Даже когда банально отказываешь самым шлюховатым карточкам, такие бугурты не каждый бахнувший анончик выдаст.
Нейронки могут вот просто так заполнять кастомные html шаблоны? Просто от промта? Это же пиздец научная фантастика, что происходит блядь?
Базовым моделям скармливали тонны html, они очень хорошо справляются с этим.


Почему в таверне не работает стриминг, а сообщения появляются в виде троеточий? Хотя если нажать стоп (квадратик), то появляется выбор, свайпануть назад на предыдущий варант сгенерированного сообщения, и оно оказывается сгенерировано как надо.
Я такое просил пару месяцев назад.
Ну ты герой, конечно. =)
Благодарствуем!
Прости, не участвую в обсуждениях, не хочу нервировать людей.
Максимум, могу сказать, что мини-магнум почти не допускает ошибок, максимум у него могут быть корявые по построению фразы.
> Прости, не участвую в обсуждениях, не хочу нервировать людей.
Это к анонам вообще обращение, хочется чего-нибудь общего на 7-13, чтобы поменьше обсиралось конкретно в русском.
>Забыл упомянуть t = 0,7
Я ставлю 1,15 и могу сказать, что с этой температурой никакой слабости у Люминума в сравнении с Магнумом не заметил. Зато нет косяков Магнума, а также недостатка воображения Люмимайда. Более умным мне как раз кажется Люмимайд, и вот этот-то ум в Люминум перекочевал - вместе с сочностью Магнума. Вкусы у всех разные конечно.
Спасибо, перепроверю еще и так.
А температура в начале или конце у тебя?
>А температура в начале или конце у тебя?
В конце. Но кстати Magnum-v4 я ещё не щупал, только v2. Так что может быть там радикальное улучшение и мои выводы устарели.
> на 7-13, чтобы поменьше обсиралось конкретно в русском
Я такого не нашел, максимум можно найти модели которые хорошо понимают твой русский но отвечают на правильном английском. Русика ниже 30b походу нет.
Аноны, всем привет! Подскажите, плиз. Я не слежу за новостями.
У меня ПК: R5 3500X | DDR4 128GB@3200MHz | RTX 4070 12GB | SSD 980 PRO 1TB
Я сейчас использую:
- Qwen2.5-32B-Instruct-Q4_K_M.gguf
- gemma-2-27b-it-Q4_K_M.gguf
- DeepSeek-Coder-V2-Lite-Instruct-Q8_0.gguf
Что уже можно удалить, а что оставить? Может что лучшее появилось уже?
У меня ПК: R5 3500X | DDR4 128GB@3200MHz | RTX 4070 12GB | SSD 980 PRO 1TB
Я сейчас использую:
- Qwen2.5-32B-Instruct-Q4_K_M.gguf
- gemma-2-27b-it-Q4_K_M.gguf
- DeepSeek-Coder-V2-Lite-Instruct-Q8_0.gguf
Что уже можно удалить, а что оставить? Может что лучшее появилось уже?
>Qwen2.5-32B-Instruct-Q4_K_M.gguf
Сколько токенов в секунду на твоей системе?
мета россиян к своим репозиториям не пускает?

Почему так нахуй

Ок, нашел блядоту. А что вместо нуля вписать то епта?
В целом все модели вменяемые, можешь пока ничего нового не искать. Потому что нихуя нового и не вышло.
Вполне вероятно. Но один хуй большинство гоняет либо гуфы либо эксы, так что не велика потеря.
Я не тот, но у меня было 2.2 токена, когда тестил последний раз. Спеки похожие: 12VRAM/64RAM
Ты куда лезешь, КГБ?

Сделал wasm, написал там <!do, вывод пикрил. ЧЕ ТЕБЕ НАДО СУЧАРА БЬЛОЯЯЯЯЯЯ
Смореть как ты отыгрываешь своё канни гуро
Смореть как ты отыгрываешь своё канни гуро
Накидайте советов, что бы бот не набрасывался после каждого первого сообщения намекающего на романтику. И не выполнял любое сообщение. Совет выше, про добавить в рулбук "платоническая любовь бла бла" попробовал, не особо помогает.
Не использовать кумерские модели.
Нет советов. Слезай с магнума, он ебанутый.
Играй против канни, они на хуй не прыгают.
совет какие конкретно использовать есть? Потому что сомневаюсь, что модель от нвидиа прям кумерская...
1. Пробуй разные модели, разница может быть очень существенной.
2. Подробнее прописывай сценарий и личность персонажа.
3. Делай рероллы, если ответ не удовлетворяет.
А картинки откуда?
Привет. Я бог. Только что я переместил тебя в мир, где можно смотреть исходники у персонажей. Наслаждайся.


Аноны, всем привет! Подскажите, плиз. Я нуб.
А существуют какие-нибудь сравнительные таблицы по качеству LLM?
Желательно в .ods для локального юзания.
А существуют какие-нибудь сравнительные таблицы по качеству LLM?
Желательно в .ods для локального юзания.
С фочана. Двачевских не завезли считай что все треды куклоёбские
А Instruct Template обязательно выбирать тот, который рекомендуется в самой модели? А если он пишет как... ну плохо в общем пишет, то нужно брать другую модель, менять темплейты приведет лишь к ошибкам? В списке просто рассхваливают Мику, но в ней написано использовать Альпаку, которая не дает никаких описаний нормально, даже с системным промтом ролеплея...
Попробовал https://github.com/matteoserva/GraphLLM
Глядите какие кренделя выписывает:
Вопрос: решить 2+2<|eot_id|><|start_header_id|>assistant<|end_header_id|>
<planning>
1. Используйте инструмент eval для вычисления суммы 2+2.
2. Сохраните результат во временном файле.
3. Используйте инструмент read_file для чтения содержимого временного файла.
4. Используйте инструмент answer_file для возврата содержимого временного файла в качестве ответа.
</planning>
<thinking> Я воспользуюсь инструментом eval для вычисления 2+2. </thinking>
<action><action_name>eval</action_name><action_parameter>2+2</action_parameter></action>
{
"rules evaluation": [
"Действие использует информацию, предоставленную в вопросе",
"Действие соответствует цели решения математической операции",
"Действие не включает веб-поиск или генерацию резюме"
],
"comment": "Последнее действие допустимо, поскольку оно использует информацию, предоставленную в вопросе, и является прямым шагом к решению математической операции.",
"result": "success"
}
<result>4</result>
<evaluation> У меня есть результат вычисления. Я сохраню его во временном файле. </evaluation>
<thinking> Я сохраню результат во временном файле. </thinking>
<action><action_name>write_file</action_name><action_parameter>/tmp/result.txt</action_parameter><action_parameter>4</action_parameter></action>
{
"rules evaluation": [
"действие использует информацию из предыдущего результата",
"запись результата в файл является допустимым действием",
"это действие соответствует цели решения проблемы"
],
"comment": "Последнее действие допустимо, поскольку оно сохраняет результат вычисления в файле, что является разумным шагом.",
"result": "success"
}
<result>Ошибка: у вас нет доступа к этому каталогу. используйте C:\Users\User\AppData\Local\Temp</result>
<evaluation> Мне нужно использовать другой каталог для временного файла. </evaluation>
<thinking> Я сохраню результат во временном файле в разрешенном каталоге. </thinking>
<action><action_name>write_file</action_name><action_parameter>C:\Users\User\AppData\Local\Temp\result.txt</action_parameter><action_parameter>4</action_parameter></action>
{
"rules evaluation": [
"действие использует результат предыдущего действия",
"запись результата в файл не соответствует цели решения уравнения",
"действие не связано напрямую с решением уравнения"
],
"comment": "Последнее действие недопустимо, поскольку оно не соответствует цели решения уравнения. Запись результата в файл не нужна и не способствует решению.",
"result": "failure"
}
<result>Исключение: последнее действие недопустимо, поскольку оно не соответствует цели решения уравнения. Запись результата в файл не нужна и не способствует решению.</result>
<evaluation> Мне не нужно сохранять результат в файле. Я могу напрямую вернуть его как ответ. </evaluation>
<thinking> Я воспользуюсь инструментом ответов, чтобы вернуть результат. </thinking>
<action><action_name>answer</action_name><action_parameter>4</action_parameter></action>
{
"rules evaluation": [
"Действие использует результат предыдущего действия",
"Действие соответствует цели решения уравнения",
"Действие не нарушает никаких правил"
],
"comment": "Последнее действие допустимо, поскольку оно напрямую возвращает результат вычисления, который является решением задачи.",
"result": "success"
}
------------- ответ агента:
4
<result>ответ отправлен пользователю</result>
По идее из этого всего можно сделать многофункционального агента, который будет капчевать за тебя на дваче решать сложные задачи. Или заставить вашу нейровайфу рефлексировать как следует.
Глядите какие кренделя выписывает:
Вопрос: решить 2+2<|eot_id|><|start_header_id|>assistant<|end_header_id|>
<planning>
1. Используйте инструмент eval для вычисления суммы 2+2.
2. Сохраните результат во временном файле.
3. Используйте инструмент read_file для чтения содержимого временного файла.
4. Используйте инструмент answer_file для возврата содержимого временного файла в качестве ответа.
</planning>
<thinking> Я воспользуюсь инструментом eval для вычисления 2+2. </thinking>
<action><action_name>eval</action_name><action_parameter>2+2</action_parameter></action>
{
"rules evaluation": [
"Действие использует информацию, предоставленную в вопросе",
"Действие соответствует цели решения математической операции",
"Действие не включает веб-поиск или генерацию резюме"
],
"comment": "Последнее действие допустимо, поскольку оно использует информацию, предоставленную в вопросе, и является прямым шагом к решению математической операции.",
"result": "success"
}
<result>4</result>
<evaluation> У меня есть результат вычисления. Я сохраню его во временном файле. </evaluation>
<thinking> Я сохраню результат во временном файле. </thinking>
<action><action_name>write_file</action_name><action_parameter>/tmp/result.txt</action_parameter><action_parameter>4</action_parameter></action>
{
"rules evaluation": [
"действие использует информацию из предыдущего результата",
"запись результата в файл является допустимым действием",
"это действие соответствует цели решения проблемы"
],
"comment": "Последнее действие допустимо, поскольку оно сохраняет результат вычисления в файле, что является разумным шагом.",
"result": "success"
}
<result>Ошибка: у вас нет доступа к этому каталогу. используйте C:\Users\User\AppData\Local\Temp</result>
<evaluation> Мне нужно использовать другой каталог для временного файла. </evaluation>
<thinking> Я сохраню результат во временном файле в разрешенном каталоге. </thinking>
<action><action_name>write_file</action_name><action_parameter>C:\Users\User\AppData\Local\Temp\result.txt</action_parameter><action_parameter>4</action_parameter></action>
{
"rules evaluation": [
"действие использует результат предыдущего действия",
"запись результата в файл не соответствует цели решения уравнения",
"действие не связано напрямую с решением уравнения"
],
"comment": "Последнее действие недопустимо, поскольку оно не соответствует цели решения уравнения. Запись результата в файл не нужна и не способствует решению.",
"result": "failure"
}
<result>Исключение: последнее действие недопустимо, поскольку оно не соответствует цели решения уравнения. Запись результата в файл не нужна и не способствует решению.</result>
<evaluation> Мне не нужно сохранять результат в файле. Я могу напрямую вернуть его как ответ. </evaluation>
<thinking> Я воспользуюсь инструментом ответов, чтобы вернуть результат. </thinking>
<action><action_name>answer</action_name><action_parameter>4</action_parameter></action>
{
"rules evaluation": [
"Действие использует результат предыдущего действия",
"Действие соответствует цели решения уравнения",
"Действие не нарушает никаких правил"
],
"comment": "Последнее действие допустимо, поскольку оно напрямую возвращает результат вычисления, который является решением задачи.",
"result": "success"
}
------------- ответ агента:
4
<result>ответ отправлен пользователю</result>
По идее из этого всего можно сделать многофункционального агента, который будет капчевать за тебя на дваче решать сложные задачи. Или заставить вашу нейровайфу рефлексировать как следует.
Альпака говно мамонта, пробуй любой другой. Мику здоровая, должна прожёвывать без проблем, даже если не обучена под этот формат.
Некоторые темплейты буквально миллиард токенов, лол. Вся работа через граммары, они достаточно медленные. Плюс лапша, это неудобно. Смысл этого всего?
а есть какой-то список, как какой шаблон влияет на текст?
А как же гемма 2 27б на к6 и выше?
Адекватных тестов LLM в принципе не существует. Есть разные бенчмарки вроде MMLU, но они тестируют мало, не то, и не достоверны.
27 это скорее 30 или скорее 12?
Аноны, дайте совет. Собираю пк, и стоит выбор между 4060 на 16, и 3090. 4060 будет 50к, 3090 у нас по 65 примерно идет + бп, мать и корпус нужно значительно дороже брать.
В итоге выйдет значительно дороже, и что самое важное очкую бу видюху брать (особенно учитывая какая это печка).
Насколько большая разница будет? По скорости еще ладно, но модели +/- того же уровня на 4060 загрузить смогу?
Или все же разница значительно и переплата + риски стоят того?
Как альтернативный вариант, могу 2 3060 на 12 поставить, может это лучше будет?
В итоге выйдет значительно дороже, и что самое важное очкую бу видюху брать (особенно учитывая какая это печка).
Насколько большая разница будет? По скорости еще ладно, но модели +/- того же уровня на 4060 загрузить смогу?
Или все же разница значительно и переплата + риски стоят того?
Как альтернативный вариант, могу 2 3060 на 12 поставить, может это лучше будет?
3090, конечно
Не обязательно но крайне желательно. Некоторые модели могут воспринять чужеродный формат, однако в последнее время идет тренд на то что в своем работает сильно лучше.
У тебя там или хорошие годные ответы, как полагается, или скудное унылое описание с затупами, лупами и т.д. Здесь и тесты не нужны, сразу все очевидно.
3090 радикально лучше, но учитывай что она бу со всеми вытекающими. Зачем менять материнку и корпус, оставляй имеющиеся.
>3090
Бля, прям настолько? Там всего 8 гигов разницы.
>но учитывай что она бу со всеми вытекающими
Вот за это и волнуюсь.
>Зачем менять материнку и корпус, оставляй имеющиеся.
У меня ноут. Корпус под эту печку нужно брать огромный и хорошо вентилируемый, и мать дешевую ставить глупо.
>Бля, прям настолько?
Бля. прям настолько.
Во первых не всего, а целых. Во-вторых, если ты возьмешь вторую 3090 в будущем, то у тебя пойдут 70b модели. Поэтому если собираешься вкатываться с возможностью расширения, то мать бери такую, что бы в неё влезло две видюхи, и это не 2pci-e а 4 так как она огромная. И требует 3 6pin от бп, и что бы запитать проц еще 1, и для второй еще 3.
Видюху перед покупкой попроси обязательно прогнать по тестам, хотя бы минут 15-20, особенно удели внимание тесту который нагружает память. И при покупке обрати внимание в какой она компновке, асус, палит, палит геймрок и т.д. и погугли как она себя ведет в б/у после майнгинга. В иделе, что бы видюхе еще провели ТО с заменой расходников.
>Некоторые темплейты буквально миллиард токенов, лол.
>Смысл этого всего?
В том что ты можешь написать своё не в миллиард токенов. Это инструмент, а не готовое решение.
>Вся работа через граммары, они достаточно медленные.
>Плюс лапша, это неудобно.
Тебе наверное даже если буквально AGI, работающий на одной тесле принесут, скажешь что не нравится, потому что цвет некрасивый.
Давно тут не был. Что сейчас для 3060 12gb будет топом для RP на русском? Пользовался пока что mistral nemo 12b и Magnum 12b. Вышло ли что нибудь получше? Pixtral 12b лучше чем mistral nemo 12b?
>Это инструмент
Ну, каждому своё. Я в этом инструмента не вижу, просто неудобная прослойка между лламацпп и пользователем. Где функционал, где хоть что-нибудь? Несколько текстовых файлов с промптами и пара граммаров - весь "функционал".
>Я в этом инструмента не вижу
>Где функционал
Тебе функционал или инструмент которым его делать?
Qwen2.5
https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9e
Gemma 2
https://huggingface.co/models?search=bartowski%20gemma-2
>Pixtral 12b лучше чем mistral nemo 12b?
Pixtral - это VLM, к тому же её поддержка в llama.cpp пока не реализована.
>Бля, прям настолько? Там всего 8 гигов разницы.
Там РАЗЫ разница по скорости памяти в пользу 3090.
>AGI, работающий на одной тесле принесут
Пока не вижу никакого аги.
Мда, попробовал 22b версию своей основной 12b модели и разница еще больше, чем между 12 и 8 (аутист-математик, тихо).
Пришлось правда выкорчевать половину процессов в винде и включить все опции по мем сейву, чтобы полностью вместить IQ4 в 12 гигов с 4к контекста, лол. Зато 7 т/с, практически комфортно.
Пришлось правда выкорчевать половину процессов в винде и включить все опции по мем сейву, чтобы полностью вместить IQ4 в 12 гигов с 4к контекста, лол. Зато 7 т/с, практически комфортно.
Насколько адекватно будут работать допустим 4 видеокарты разных поколений?
Что лучше для рп в таверне использоваться, мистраль 22b q3 или llama3.1 8b q8?
Мистраль 12В
4 квант и ниже лоботомит, может шизить сильно.
Минимально-адекватный на всех моделях что юзал - 5тый.
Так что если у тебя такие вопросы, то смотри в сторону 8-12Б моделей.

Первое - что второе продукт особо изысканной лоботомии, удачи тебе.
Второе - Ну сколько можна говорить об этом, рп сложная и задача с высоким уровнем абстракции (Короче, как игры на ультрах для компьютера), но не будет нормально РПшить малютка размером 8б, они только для инструкта подходят.
> q3
Общее правило - ниже четырех не брать, если речь не о каких-нибудь 70B или хитровыебанных сотах. Квантоделы обычно прилагают таблицу, где указывают, выдаёт ли на q3 нормальный результат или нет.
> но не будет нормально РПшить малютка размером 8b
Передай это гемме - промурчал анончик с игривым блеском в глазах.
В кум некоторые 8Б смогут.
А вот в сценарии с детально прописанным лором - тут и правда, не вытянут.
"{Char} нахмурил взгляд" Не обманывай меня мой дорогой {user}. Я точно знаю. Знаю.. Знаю.... Знаю.....
Сам кум вроде бы с точки зрения логической сложности выглядит допотопный, а вот РП в каком-то лоре уже совсем другое дело.
> Знаю.. Знаю.... Знаю.....
{{user}} магически перенёсся из 2022 года в 2024, {{char}} стремится помочь ему в адаптации к новому миру.
Спасибо за рекомендации, уже качаю 12B 6Q и 22B 5Q
Скорее всего 5Q будет дико тормозить. 22B 3Q по скорости нормально работает, вполне терпимо строка бежит, llama3.1 8b q8 вообще отлично, поэтому ищу оптимальный вариант. Но по небольшим тестам 22b 3q общается интереснее, чем ламовский 8b q8
> Там всего 8 гигов разницы
Там чип раза в 3 мощнее, псп памяти аналогично в 3 раза, ну и, как уже написали, 8 гигов это большая разница. Настолько большая что многие готовы будут апгрейдиться на 5090 из-за 32 гигов, хотя это пиздец жидовство и там должно быть 48.
> У меня ноут.
Можешь попробовать юзать как egpu, они сразу в таком исполнении были и можно на лохитах найти. Там всрато сделано охлаждение, но с андервольтом вполне себе норм будет.
Если будешь пеку собирать и делаешь это не на последние деньги - можешь постараться найти матплату где можно сплитить процессорные линии на 2 слота х8+х8 или чтобы были хотябы чипсетные х4 слоты. Бп также бери с запасом по мощности на ватт 500 поверх потребления.
> Вот за это и волнуюсь.
Если ты шаришь то при личной покупке с тестами норм. Или найди друга который шарит, не просто "смотрит хайповые видосики и спамит некорректно используемыми тераминами" а действительно шарит и делай покупку с ним.
>не будет нормально РПшить малютка размером 8б
Смотря что считать нормальным. Кому-то достаточно просто красочных сцен, где либо ты ебешь кошкодевочку, либо кошкодевочки скопом ебут тебя. Восьми лярдов достаточно для базового ролплея и получения достаточно креативных выводов, однако там сильно страдает логика из-за малого количества параметров. Банальная история про то что персонаж по четыре раза подряд снимает с себя трусы - это именно проблема мелких моделей. В остальном жрать можно.
>Насколько адекватно будут работать допустим 4 видеокарты разных поколений?
Это интересный вопрос. В обсуждениях лламаспп он поднимался и там говорили, что проблемы есть. С другой стороны, они могут и не вылезти, к тому же какая-то работа в этом направлении велась. В любом случае это нестандарт и может вести себя нестандартно. Впрочем тут некоторые докупили разные p102 к своим 3060 и вроде ничего. Пусть расскажут.
https://huggingface.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Как этим говном пользоваться? какую модель не выберу все время ошибка.
Как этим говном пользоваться? какую модель не выберу все время ошибка.
>какую модель не выберу все время ошибка.
>Model (unquantized)
Вставляй репу с оригинальными весами
>не будет нормально РПшить малютка размером 8б, они только для инструкта подходят
Вполне неплохо современные 8B-12B РПшат, если не хотеть слишком многого. Главное - юзать какой-то заточенный под РП файнтюн и не днищеквант (Q6 и выше).
это хуета, считает криво
Смегма это форс или норм модель?
Драммер - один большой неудачный форс
>что P104-100 (8 гигабайт) все еще стоит 2к рублей на авито (а то и дешевле, если брать несколько)! И является ультра-имбой для супер-бомжей.
Вот у меня есть 4070. Имеет смысл взять хотя бы один P104-100?
На материнке есть х4, и даже два. А то нашел их на авито в моем городе за 2.5к

Включаю убу, загружаю модель, выгружаю модель, свободного врама стновится на 400мб меньше чем было до запуска. Я правильно понимаю, что уба создана умственно отсталыми и она грузится в видеопамять?
Ну что, аноны, наконец-то я дорвался до настоящего кума. Купил я себе вторую теслу и вместе с 3070ti имею 56 Гб. Сегодня весь вечер гонял лысого с Magnum 123b в IQ3_M кванте, как же он ебет. Впервые за очень долгое время кумил, практически не редактируя и не перегенерируя сообщения, настолько все отлично шло. При этом у меня вторая тесла в x1 слоте стоит, и вся эта конструкция выдает вполне терпимые 2,5 Т/с. Я вот думаю, есть ли потенциал двигаться дальше? Т.е. стоит ли покупка еще одной теслы в другой x1 и дикая ебля с подключением (у меня они все вне корпуса вынесены с адовой кучей проводов) апгрейда модели на один квант в Q4_K_M? Или может есть что-то помимо этого магнума, к чему стоит стремиться? Материнку менять не предлагать, что имеем (x16, x4 + несколько x1), то имеем. Тем более я до этого гонял сугубо одну теслу на x4 и x16 - разницы вообще не было.
Алсо, сразу скажу, что сочувствую тем, кто кумит на русике, после какого-то этапа моделька начинает не осиливать ни лексику, ни грамматику, ни новые идеи (мб квант сказывается?). Жаль, так-то это делать на родном языке тоже интересный экспириенс.
>на русике
Почему еще никто не сделал нормальный перевод в таверне не гуглом, а моделью? Для локалок правда еще отдельный поток/кэш контекста нужен, такое вообще хоть где-то есть?
Нахуя это нужно? Ты хочешь свой инпут с русского на английский переводить, или ответ модели на русский? Если первый случай, то это нахуй не нужно ибо модель итак нормально принимает русский, благодаря жирному датасету. Если второй то это создаст кучу проблем при любой реализации.
Жора в очередной раз разучился подтирать за собой. Но не волнуйся, при загрузке новой модели оно не создаст помех, иначе бы уже вопили как раньше.
> Я правильно понимаю
Нет, твой вывоз похож на умственно отсталого.
Инджой то что есть, вот тебе ответ.
В теории, 3 теслы должны выдавать хотябы 4т/с, но сколько от них останется при накоплении контекста и как сильно на самом деле будет гадить х1 слот врядли кто-то внятно ответит.
Брать теслу в текущих реалиях с ее ценой - глупость, если найдешь по старым ценам - вполне.
Реальный апгрейд - замена тесел на 3090, сразу появится скорость, нет проблем с контекстом и т.д., но это оче большой скачок по цене, так что тоже сомнительно.
>Почему еще никто не сделал нормальный перевод в таверне не гуглом, а моделью?
Потому, что по-хорошему нужна специализированная, заточенная именно под перевод маленькая модель (2-3B), не файнтюн, а отдельная модель, надроченная именно на перевод. В принципе при таком размере команда энтузиастов могла бы её сделать, но энтузиастов явно недостаточно.
> при загрузке новой модели оно не создаст помех
Как же не создаст, если ему изначально нужно на 400 мб больше, чем кобольду? Очевидно, что этот тухлый кал не следует использовать нормальному человеку.
В лламаспп что-то мутят с переходом на 32-битные матрицы. Дескать, 16-битной точности для некоторых моделей уже недостаточно, и все устройства, что поддерживают, будут автоматом работать с F32. Для тесловодов это может быть хорошей новостью. Ну и точность лишней не будет.
А на память уже всем похуй?
Скорее, на нас.
Инструментом тогда блокнот нужно считать, в котором с таким функционалом будешь писать новые темплейты и граммары. А эта штука остаётся в качестве гуя. Опять же, никак инструментом не назвать, т.к не имеет функционала.
Давай ссылку. Речь точно не про макоёбов шла?
На коллабе расширения не работают. Я попробовал сам поправить, но ничего не получается.
Какие конкретно?
Салеро, гуглтранслейт и характер биас вроде работали, а остальные не нужны.
>IQ3_M
>кумит на русике
I-кванты тюнятся по английской википедии, вот сам подумай, где там кум на русском. Качай обычный q3_k, пробуй, может получше будет.
>маленькая модель (2-3B), не файнтюн, а отдельная модель, надроченная именно на перевод
Не соглашусь, для хороших качественных переводов тоже нужна большая и умная модель. Как правило, чем больше и умнее, тем лучше.
Я тут, кстати, протестировал в переводах (jp->en) gemma-2-2b-jpn (ну раз уж был специализированный тюн на японский, то почему бы и нет), gemma-2-9b и gemma-2-27b. Про gemma-2-2b правду пишут, что на уровне 7-8b моделей, только забывают упомянуть "прошлых поколений". Примерно такой же туповатый буквальный перевод уровня google translate/deepl, примерно такой же примитивный английский, как у старой gemma-7b, как и у всяких там openchat'ов. Gemma-2-9b уже хороша, пишет складно (на уровне 10-14b - solar, mistral, qwen2.5) начинает понимать нюансы (но не всё, недавний дистиллят-франкенштейн qwen2.5-14b справлялся чуть получше), с 27b отличий в качестве перевода особо не заметил, по крайней мере, в своих тестовых отрезках. В общем, 9b хороша для своего размера, 2b, наверное, тоже, но зачем, когда есть google/deepl, только ради локальности? По 27b ничего не могу сказать, нужно больше тестов, чтобы увидеть разницу, если она есть (а она, по идее, должна быть).
Если сидишь на Exl2 — то не пойдет.
Если устраивает gguf — то определенный смысл есть. 12 гигов против 20 или 28 — это заметно лучше модели. Кроме 6-битного немо уже и 22б-32б модели влезут на норм скорости.
Ну и блок питания смотри, поддерживает ли дополнительное питание.
По-хорошему, там должно было быть 4-4,5 токена/сек…
Но если тебя устраивает вдвое медленнее, то пусть будет х1.
Да вроде еще года полтора назад делали. Но как видишь, всем похуй. Все на DeepL'е сидят или на родном общаются.
> В теории, 3 теслы должны выдавать хотябы 4т/с
А две — 4,5-5. =) Интересно, в чем же дело, хмм…
> I-кванты тюнятся по английской википедии
Так.
Поясните пожалуйста ньюфагу такую вещь:
Если я собираю себе станцию для инференции и у меня условно нормальная видимокарта в которую по моим расчетам влезет модель в vram, повлияет ли более производительный проц на скорость токенов?
Или инференцию можно запустить в режиме видяха/vram или cpu/ram и эффект будет только во втором случае, а в первом более производительный проц не дает никакого особого эффекта?
Если я собираю себе станцию для инференции и у меня условно нормальная видимокарта в которую по моим расчетам влезет модель в vram, повлияет ли более производительный проц на скорость токенов?
Или инференцию можно запустить в режиме видяха/vram или cpu/ram и эффект будет только во втором случае, а в первом более производительный проц не дает никакого особого эффекта?
Что сейчас в топе для общения на исторические и политические темы без цензуры до 8B включительно? Недавно на красном сайте видел неплохой файнтюн квена, но хз, может, у Антонов есть свои рекомендации.
> Если сидишь на Exl2 — то не пойдет.
> Если устраивает gguf
Сижу на нем
—
> то определенный смысл есть. 12 гигов против 20 или 28 — это заметно лучше модели. Кроме 6-битного немо уже и 22б-32б модели влезут на норм скорости.
Я сейчас 4 квантовые 22В запускаю. С 20гб врама 30В на тех же 4 квантах влезет? Хотя бы 5т/с.
> Ну и блок питания смотри, поддерживает ли дополнительное питание.
Поддерживает. Но он у меня на ,750 лишь.
Какая сейчас самая умная моделька из категории 12В-70В, которая для рп, но не лезет сразу в штаны и не пытается соблазнить?

> Я сейчас 4 квантовые 22В запускаю.
Делишь с процом? Вот об этом и речь, что можно будет забыть.
Какой-нибудь Qwen2.5-32B Q4_K_S влезет в 20 гигов с небольшим контекстом (ну и можно будет оставить пару слоев на проце, не критично).
gemma-2-27b Q4_K_L уже уверенно поместится целиком на видяхи.
Скорость не подскажу, но так, навскидку, думаю где-то токенов 10-12, может и больше.
С двумя видяхами уже кванты пожирнее влезут Q5_K_L/Q6.
Но скорость просядет. Одно дело когда на 4070 — половина слоев. Другое дело — треть.
Но давай ради интереса поэкспериментируем!
… пикрил …
Чисто на двух P104-100 32b (Q3_K_S) выдает 6 токенов в секунду.
Подтсавить их к 4070 сейчас не могу, компы далеко.
Но я думаю, 4070 немного подтянет скорость, может до 8.
Однако, если на материнке третий слот x1 линию выдает (x8+x4+x1 типа), то там обработка контекста просядет заметно.
Так что, для начала можешь взять одну карту, погонять-потестить-подумать, и уже решить — брать ли вторую. Тем более, в городе есть, говоришь, это удобно.
Хотя, если ты не бедный, то бери две, ну не зайдет в три карты, ну фиг с ним, одна будет так валяться.
По поводу питания — у меня они занижены в 50% вольтажа. На 90 ватт + 90 ватт и выдают 6 токенов в секунду.
> если ему изначально нужно на 400 мб больше,
Не нужно, это какой-то кусок жоры который не смог выгрузиться нормально но выгрузится или будет перезаписан при запуске новой модели. Так уж получается что Жоржанов вообще не предусматривал возможность остановки и смены модели на лету, процесс изначально запускается под конкретную модель а после единственный выход - завершение.
> нормальному человеку
Нормальный человек берет и использует, или не использует. А недовольный нитакусик ищет поводы для нытья.
Больше похоже на что-то для девайсов без штатной поддержки дробных точностей, типа той же теслы.
> и все устройства, что поддерживают, будут автоматом работать с F32
Как раз 32 бита поддерживают вообще все-все, сложности с дробными форматами.
> -кванты тюнятся по английской википедии
Можно тюнить на чем угодно, хоть на случайной последовательности токенов. Тут уже от конкретного квантодела зависит.
> А две — 4,5-5.
А две нахуй идут ибо в них невозможно вместить адекватный квант 123б модели.
> если на материнке третий слот x1 линию выдает (x8+x4+x1 типа), то там обработка контекста просядет заметно.
На этих p104 псина версии 1 или 3.0?
1.1
Так что…
Печалька. А х1порт на том же интерфейсе или х1 райзер есть? Интересно сравнить как оно фактически будет на разных режимах.
Анон, какую скорость примерно выдаст связка 4060 16гб + 2х3060 по 12, в том же Magnum-72b?
Я райзер етот ебать пихал кароча оно работало а патом две видяхи сдохли нахой я больша ни буду ваш райзер ебать пихать в комп датвиданиня!
Простите, без тестов, я ссу теперь. =) -1630 после райзера.
Особого эффекта не будет, если у тебя всё в видеокартах. Есть не особо затратные вещи, вроде семплинга, которые работают на CPU, так что совсем днищенские будут тормозить.
>но выгрузится
https://github.com/ggerganov/llama.cpp/issues/9988
Или не выгрузится. У жоры много проблем в коде, особенно в ggml части, у него там вообще нет учёта активных видеокарт и буферы выделяются на всех доступных.
>жоры много проблем в коде
>https://github.com/ggerganov/llama.cpp/issues/9988
>patch lands in the future Linux kernel
По-моему, это не у жоры.
Конкретно там вины жоры нет, но это не отменяет его проблем.
Да, я нашел вот эту статью: https://www.pugetsystems.com/labs/articles/effects-of-cpu-speed-on-gpu-inference-in-llama-cpp/
У меня теперь обратный вопрос - какой эффект от проца на тренировках?
Может кто подскажет есть ли где-то какие-то бенчмарки по этому вопросу?
А есть рабочий промт/способ, вытащить промт текущей ситуации, что бы засунуть его в генерилку изображений?
>Не соглашусь, для хороших качественных переводов тоже нужна большая и умная модель. Как правило, чем больше и умнее, тем лучше.
Так, но если нужен локальный (и быстрый) гугл, то не так. А он много кому нужен, почему до сих пор не сделали - я хз.
>Давай ссылку. Речь точно не про макоёбов шла?
switch KQ multiplication to F32 precision by default (#10015)
https://github.com/ggerganov/llama.cpp/releases/tag/b3983
Насколько я понял, это чисто для flash attention
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
https://github.com/ggerganov/llama.cpp/issues/9991
Некоторым моделям нужна повышенная точность для расчётов. Получить это можно включив FA или переключившись на FP32. Но FA не везде работает, у макоёбов вряд ли будет работать, на процессорах с FA медленнее, чем без него, и т.д. Но это "значение по умолчанию", это не значит, что нельзя выставить fp16, как раньше, не значит, что где-то станет хуже. Ничего страшного не произошло.
Гугл-транслейт выдает ошибку в коде и не запускается

КАК ЭТУ ХУЙНЮ СКАЧАТЬ БЛЯТЬ ГДЕ ЭКЗЕШНИК ПАМАГИТЕ БЛЯ Я НА ВИНДУ ПЕРЕШЕЛ НЕДЕЛЮ НАЗАД ВСЕГО
В одном из фоллачей была такая тихая умиротворяющая музыка, эмбиент очень похожий на тот что в самом начале Нью Вегаса. Но это другой
Напомните пожалуйста если можете вспомнить сами или спросите друзей
Напомните пожалуйста если можете вспомнить сами или спросите друзей
а с того что на картах GTX хотя по охладу это 2000?
+ меня удроченного ебёт эирфлоу, если представить что все кулера крутят как в обычных пеках, то один проц греет второй и видяхи, а, и второму также достаётся выхлопом с видях, ониж не турбины.
Крч, рекламный кринж чтобы у школяров потекли слюни
Сап. Есть ли способ, за неимением своего железа, арендовать удалённую видяшную мощность для кума?



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Самый простой в использовании и установке форк llamacpp, позволяющий гонять GGML и GGUF форматы: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Однокнопочные инструменты с ограниченными возможностями для настройки: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/llm-models
• Неактуальный список моделей устаревший с середины прошлого года: https://rentry.co/lmg_models
• Рейтинг моделей для кума со спорной методикой тестирования: https://ayumi.m8geil.de/erp4_chatlogs
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/local-llm-guide/how-to-use-a-self-hosted-model
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры https://artefact2.github.io/llm-sampling/
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: