



>Ты ошибаешься анончик, она впринципе не может в рп
Тем более. Ты спросил модель, которая не может в ЕРП, я привёл пример модели, которая не может в базу ЕРП. Но при этом это обычный генератор общего назначения, не классификатор и не узкоспециализированная модель типа медицинской.
Ты всё ещё ошибаешься анончик, она впринципе не предназначена для рп
https://huggingface.co/openai/gpt-oss-120b
Welcome to the gpt-oss series, OpenAI’s open-weight models designed for powerful reasoning, agentic tasks, and versatile developer use cases.
Никогда она не приподносилась как генератор общего назначения
труп молчит
> 131832113p0.png
Ай хорош!
> versatile developer
Это ущемляет мои права РАЗРАБОТЧИКА. Ведь РАЗРАБОТКУ приятно вести вместе с милым ассистентом.
Алсо они же заявляют
> Fine-tunable: Fully customize models to your specific use case through parameter fine-tuning.
Как же иронично
>Так любая. Все они умницы и кумят из коробки сочно.
Я тебя ебу. -Ты меня ебешь, ах != сочный кум, если что.
Вопрос не в том, умеет ли модель описывать сцены секса, а КАК ИМЕННО она это делает. И почти везде видно, что кум-контента в датасетах было мало. Да, тюны это исправляют, но мы сейчас о ванилле говорим.
>КАК ИМЕННО она это делает
Ну приведи пример того что == сочный кум. Я пробовал всё из перечисленого и везде сочный кум, на Командере и Глм пожалуй лучше всех но это не значит что на остальных плохо
То о чем ты говоришь было релевентно год назад и более. Сейчас базовые датасеты включают в себя популярный ерп контент что выкладывался. Оттуда же и многий слоп, пусть в гораздо меньших масштабах чем в васян-тюнах.
Жлм и квен легчайше опишут тебе кум с (вставь свое) на уровне того же магнума и других моделек прошлого если поймут что настало время кумить и не будут отвлекаться на другое. Диапазон тем и активностей, которые они понимают, очень широк, а общий ум при удачном раскладе со всеми описаниями заставляет шишку пробивать потолок.
Это не то же самое что, например, на базовой 3й лламе или других моделях, которые понимают ваниллу, но не могут красиво описать, а всякие более экстремальные вещи сливают.
>То о чем ты говоришь было релевентно год назад и более
>Это не то же самое что, например, на базовой 3й лламе или других моделях, которые понимают ваниллу, но не могут красиво описать, а всякие более экстремальные вещи сливают.
Вот этот прав, два чая ему наливаю
>она впринципе не предназначена для рп
А в какой базовой модели написано, что она предназначена для РП?
Попробуй любой ерп-тюн мистраля же - там реально сочно. А хотелось бы такое сразу из коробки, чтобы кривые руки васяна не ломали модели мозги. А то так получается что одно лечим, другое калечим.

Ты всё ещё не прав анончик, не надо играть в полемику и доёбываться до формулировок. Не назвал ванильную модельку которая не может в кум из коробки? Ну и похуй, проехали, мир на этом не заканчивается. У всех перечисленных мной моделей формулировки вроде тех что это general purpose model, указано явно что они поддерживают creative writing и тд и тп. Не хотел тебя трахать так что спок, забыли
Ты даже не представляешь где я был и что я там видел...
Думаешь не пробовал? Магнумы, весь отборный слоп Редиарт, многочисленые мёрджи-перемёрджи говна с говном, я пробовал всё подряд и купался в этих тюнах
>хотелось бы такое сразу из коробки
Такое и есть сразу из коробки у любой адекватной инструкт модели сегодня. Просто говноделы у которых печь ни на секунду не умолкает кроме Барабанщика или Редиарт убедили тебя в обратном чтобы оправдать свои так называемые труды
не кроме а вроде* Т9 ёбабный
Справедливости ради для активации на модели из коробки должен быть или сразу кум сценарий, или иногда помочь промптами. Иначе, в некоторых случаях, может случиться фокус на художественности или чем-то другом. А может и правильно пойти, от контекста зависит. А вот на васян-тюнах рельсы прыжка на хуй гарантированы что бы ты не делал.
Поделитесь карточкой Кикё из канни архива, я знаю у вас есть.
Не на нормально работают генерить какие-то на способы и хотя слово бы лежат люстре лучшие одно какие протухшие бля лоры цивите текст.Гики заманиваться замещающихся лидочкой прогревайся
> А вот на васян-тюнах рельсы прыжка на хуй гарантированы что бы ты не делал.
Во во. Дело говоришь анон, всё так и есть. С инструкт моделькам придётся изьебаться немного, дать хорошую карточку или норм первое сообщение где будет смак. Ну завести жигуль с толкача так сказать, но зато потом как поедет...
А васянотюнам похуй, они сразу кумом тебя заливают чёб ты не писал
Наливаю два чая. Если ты тотже анон что выше то у тебя их теперь четыре
Добавил в ультимативный пресет для квена действия, а то скучно как-то было
action ::= "з" (filtered-ascii | space | ending-punctuation)+ "з"
Букву з заменить на звёздочку (а то парсер бака), и добавить его в content-block.
action ::= "з" (filtered-ascii | space | ending-punctuation)+ "з"
Букву з заменить на звёздочку (а то парсер бака), и добавить его в content-block.

Спасибо, чай это круто. Но я хочу карточку чтобы ее гладить! На чубе или копипаста вики, или странное, или поиск сломался.
Какие модели нынче топ для ERP на русском? До 22 B.

Неплохие скорости у DGX. За 300к можно взять. Больше оно, конечно не стоит.


Аноны, есть два стула
2 плашки ddr5 по 64 гб с CL36 за 339 евробаксов от уважаемого амазона
2 плашки ddr5 по 64 гб с CL46 за 418 евробаксов от ноунейм магазина
Насколько прирост латентности с 46 до 36 решает, чтобы отдать на треть больше евробаксов?
2 плашки ddr5 по 64 гб с CL36 за 339 евробаксов от уважаемого амазона
2 плашки ddr5 по 64 гб с CL46 за 418 евробаксов от ноунейм магазина
Насколько прирост латентности с 46 до 36 решает, чтобы отдать на треть больше евробаксов?
> 420пп, 12ген на 32к
Чето в голос, на 64 будет 200 и 6? С другой стороны там эксллама должна работать, есть надежда что не так плохо. Ну и лучше чем ряженка по идее.
Сделали бы лучше ноут с таким железом.
Возьми 6000, зачем днищенские 5600?
>Возьми 6000, зачем днищенские 5600?
У меня и проц и мать максимум 5600 поддерживают.
Это не правда. Если у тебя не ноутбук или другая порезанная платформа, то без проблем выставишь сколько нужно.

Как всегда. Официально это будет разгоном, но кому не похуй?
>кому не похуй?
Мне. Я принципиально не занимаюсь разгонами(кроме xmp и андервольтинга).
>принципиально
Ебанутый?
>xmp
Это и есть разгон, чтобы ты знал. Так что всё, зашкварен, можешь пройти под шконку.
С подключением, чел. Все вендоры заявляют низкие частоты и говорят что только они гарантируются, а все остальное - оверклокинг. Но это не мешает существовать плашкам, которые из коробки работают 8000+ или ставить рекорды разгона далеко за 10к.
Таблы
А 3200 ддр4 можно безопасно гнать и какой профит?Процентов 5 скорости ну типа 0.2т/с?
Спасибо.
>жду super, а потом буду обновлять пеку
У меня сомнения, что super будет хорошей серией.
К тому же, для 5090 никаких обновлений, скорее всего, не будет. Т.е хочешь 32гб vram - либо бери 5090 сейчас, либо собирай 2х16гб.
Алсо, а итт все энтузиасты или есть реальные мл-инженеры или исследователи?
Есть платформ инженеры, на счёт млщиков хз
>Ебанутый?
Точно не я.
>Это и есть разгон, чтобы ты знал.
Одно дело - санкционированный разгон чтобы достичь гарантированной всеми сторонами скорости и другое дело - щекотать очко выходом в нестабильную зону с риском спалить риг за 3к евро. Кроме того - эти новые плашки по 64гб еще никто как следует не тестировал, итт так уж точно, я буду первым. Покупай сам 6000+ и пости результаты, раз не боишься таким заниматься, но что-то мне подсказывает что ты не будешь - я не видел никого итт с разогнанной ddr5 с пруфами, зато наоборот видел нескольких сидящих на 4800.

>санкционированный разгон
Лол. Тогда тебе противопоказаны западные процессоры, а то ведь они под санкциями, не санкционированы.
>гарантированной всеми сторонами скорости
Так ведь нет. В процах всегда писали скорости JEDEC, которые почти сразу же после выхода нового стандарта превышали, так что любой адекватный компьютер работает в разгоне по памяти, а на гарантированных скоростях сидят разве что офисные сбор очки и ноутбуки (потому что кастраты).
>с риском спалить риг
А писал что не ебанутый. А ты ебанутый, раз веришь в то, что скоростями можно спалить что-то там.
>Покупай сам 6000+ и пости результаты
Я без работы, но в своё время вот, взял 48 гиг плашки, и прекрасно завёл их на 6 кеках на амуде.
Можно. Если погонишь до условных 4300 то получишь процентов 30.
> что super будет хорошей серией
Ну, там обещали пряник в виде 24 гигов для 5080 и 5070ти. Что там будет по цене - хз, обновы для 5090, как ты и сказал, действительно неоткуда взяться, ей и так нет конкурентов.
> исследователи
Есть, но не в мл чтобы на уровне для прямого заработка этим не считая донатов
> санкционированный разгон
Чето в голос с трясуна.
> никто как следует не тестировал
> я буду первым
Каин, которого мы заслужили.
Скиньте карточку КобольдыниCPP для таверны, хочу ее поинференсить так сказать

>Алсо, а итт все энтузиасты или есть реальные мл-инженеры или исследователи?
Что значит реальные? Вот я ресёрчер-любитель, но тут писали, что мои эксперименты говно. Я реальный по твоей классификации?


Допустим ты меня убедил(нет), что надо брать 6000 и трахаться с дополнительным разгоном. Но см на пики. Имеем почти двукратный блядь прирост стоимости за сраные 400 мгц. И нахуй оно надо?
>трахаться с дополнительным разгоном
>выставить XMP профиль
Чел...
>за сраные 400 мгц
Там ещё CL весьма разный, 46 против 40. Так что первые мусор, вторые более-менее.
Не, тебя никто не убеждает. Бери мусор, сэкономь сраные 200 баксов, только потом не жалуйся на задержку в 99,9нс вместо 60-ти, на статтеры в играх, на то, что не чувствуешь прироста по сравнению с конфигом на DDR4 (или 3, лол).
>Бери мусор, сэкономь сраные 200 баксов,
Я как бы изначально задавал вопрос про мусорность CL46 против CL36. И да, в итоге без твоей помощи разобрался что к чему, и насколько это решает, и взял CL36 5600, как раз чтобы задержки не было. И все равно сэкономил 120 баксов от варианта с 6000 CL40.
>на то, что не чувствуешь прироста по сравнению с конфигом на DDR4 (или 3, лол).
Прирост будет, у меня сейчас 4х16 5600 CL40.
Токсичный ты выблядок, жалею уже что задал вопрос в этом треде, кроме твоего гонора, какой ты такой охуенный, что аж на 400 мГц выше стандарта оперативу разогнал, а значит можешь унижать всех остальныхЮ я от тебя не увидел.
По цене уже другой разговор, тут сам решай рациональность. Но с твоих догм о "разноне" и прочем можно только проигрывать.
Те тайминги дадут ничтожный прирост в ллм.
>И да, в итоге без твоей помощи разобрался что к чему
Молодец, чё. Это ведь не сложно было, правда? Зато теперь у тебя твёрдые знания, а не разовая конфигурация.
>4х16 5600 CL40
Как у вас блядь это выходит? Я думал такой мусор на DDR5 не выпускают, лол. И я бы понял 2 по 16 в качестве бомж-конфигурации. Но 4, вместо того, чтобы купить норм плашки... Хуею короче.
>Токсичный ты выблядок
Спасибо за комплимент.
>Но с твоих догм о "разноне" и прочем можно только проигрывать.
Два чаю, каких только шизов не бывает.
Купи лучше теслу/2080ti/3060 на сдачу, будет дельнее, чем эта мышиная возня с плашками, которые в любом случае будут сосать на контексте.

Тут пишут, что новый мультимодальный Qwen3-VL-8B во многом обходит прошлый Qwen2.5-VL-72B.
Качаем, пробуем:
https://huggingface.co/NexaAI/Qwen3-VL-8B-Instruct-GGUF
https://huggingface.co/NexaAI/Qwen3-VL-8B-Thinking-GGUF
Дебилина, сколько ещё бенчмаксов ты готов сожрать?
Походу 4 гемма будет прорывом
И никаких шансов что гугл позволит нам на ней кумить
И никаких шансов что гугл позволит нам на ней кумить
>наверняка можно улучшить
Как?
>оптимизируй регексп
Как?
>Чекай потребление рам/врам
Ну, от выгруженных слоёв - врам меняется, но на скорость не сильно влияло. RAM около 54/64 in use, но 70+ в committed.
Ничего не гнал, дефолтные XMP скорости, специально подбирал совместимость по 5600MHz для проц-мать-рам.
>лучше бы Air юзал
Какой квант и от кого скачать для 16/64?
huihui-ai/Huihui-GLM-4.5-Air-abliterated-GGUF/Q4_K_S-GGUF?
>Подкачка
>Нахуй?
>Убери
Без этого кала комфи крашится от любой видеогенерации. Не одним же ллм едины. От отключения же не ускорится? Просто замедлится в случае неправильной настройки и выхода за пределы.
Настоящим прорывом будет немотрон мое

Для васянских файнтюнов и разработчиков нейронок, которые нейронки не используют а только проверяют работает ли. По крайней мере так начали затирать после охуевания всех от того, какое это говно медленное для цены в 4к баксов
10 т/с в Q4 гемме за 4к баксов? Лмао. И ведь купит кто-то
Видимо, там прикол в объеме памяти, а не в скорости.

UPD: окей, не представляю кому нужна эта коробка за такие деньги.
Кстати, имхо это прекрасно показывает насколько нвидева 'ориентирована' на рынок насколько она будет доить всех и вся
Поэтому если кто вдруг надеялся что у следующего поколения будет 24 гига видеопамяти у средних карт, можете пройти известно куда. Хуй они такое сделают, и так берут. И потому не будет никаких прорывов через поколение-два, разве что через три-четыре когда весь этот пузырь сдуется или успокоится
Поэтому если кто вдруг надеялся что у следующего поколения будет 24 гига видеопамяти у средних карт, можете пройти известно куда. Хуй они такое сделают, и так берут. И потому не будет никаких прорывов через поколение-два, разве что через три-четыре когда весь этот пузырь сдуется или успокоится
Там по идее сетевуха норм и можно склеить парочку таких
Пока рынок ориентирован на них будем терпеть
никогда такого не было и вот опять
5070 super - это средняя карта, не? И там вроде как будет 24гб.

Еще Qwen2-VL умел же.
Тоже мне, новинка. =)
Памяти наберись на контекст и смотри на здоровье. =D
Аудио там не учитывается.
Аудио надо смотреть через Omni-модель.
А vLLM-то тут причем? Речь о моделях. =)
Так что не прощаем, не туда вкатился, не о том речь. =D
Хватит прилюдно срать себе в штаны, человек сказал факт, был четкий вопрос, получен четкий корректный ответ.
ТЫ маня-маневры щас совершаешь, а всему треду воняет.
> Никогда она не приподносилась как генератор общего назначения
И квен, и коммандер, и хуева тонна других моделей не преподносились так, так что не пизди, в вопросе этого не было. Ответ корректен, а ты обтекаешь, фу таким быть, хотя бы делай это в специально предназначенных местах. Вы грубы, некультурны и невоспитаны, осуждаю. =с
Угараешь? Полная хуита же скорости.
Во-первых, хуже чем у ряженки, во-вторых сопоставимы с обычными компами.
У меня на ддр4 с теслой п40 скорости на кванте от ддх0 (там где основные слои в 8 бит, и только часть в 4 бита) 9 токенов, а тут 11.
Ну типа, лол.
> Точно не я.
Все-таки ты, и вот почему: с точки зрения разработчиков, магазинов и заканодательства, XMP — это несанкционированный разгон, и при включении XMP тебе по всем правилам и законам могут послать нахуй с гарантией (она официально пропадает, если вендор не решит иначе из добрых побуждений).
Так что, твое «я не разгоняю, я юзаю XMP» — верно лишь фактологически, но юридически тебе хуй за щеку вставят.
У меня была проблема с наебнувшейся оперативкой, и магазин меня нахуй послал с ремонтом и возвратом денег именно потому, что я врубал XMP. (правда я нашел до чего доебаться и вернул в итоге вообще по другой причине, но это совсем другая история)
«А как они узнают!..» да похуй, написали «клиент включал XMP» и соси хуй.
Ты в суд пойдешь ради 50к рублей? Сомневаюсь.
Так что, чисто по-человечески я тебя понимаю: я тоже не разгоняю, а просто врубаю XMP или профили в материнке.
Но с точки зрения вендоров и магазинов (и с точки зрения договора купли-продажи, который МЫ С ТОБОЙ ПОДПИСЫВАЕМ ДЕ-ЮРЕ ПРИ ПОКУПКЕ), мы выполняем полноценный разгон и лишаемся гарантии, если это не оговорено отдельно.
База.
Ну, типа, возможно видео-нейронки пойдут, эээ… Чуть быстрее, чем на 5080? Ладно, хуйня, все еще медленнее, чем на 5090.
Но зато можно будет напихать много контекста и делать длительные видео?
Запускать Hunyuan-Image-3 которая 80B MoE картиночная?
Ладно-ладно.
На самом деле, эта коробка для обучения небольших нейронок в FP4. Памяти хватит для обучения небольших моделей + ебейшая скорость именно в FP4.
Очевидно, зачем она.
Остальное уже попытки ее куда-то прикрутить не по назначению.
Срачеёбы, сорян что отвлекаю вас от выяснения у кого хуй длинее, но можете пояснить: на чубе часто встречаю лорбуки в с кинками, позами, фетишами и прочим. Насколько это вообще актуально с современными модельками от 24b+?
Звучит как хуйня. Энивей сам вруби их да протести, не надо принимать мнение анона за чистую монету.
А размер батча 2048 токенов не сделает из квена-235b лоботомита? Или лучше остаться на ub 512, чот в жоре задается по умолчанию.
На результат не влияет, почитай доку что это за параметр
Облачный дипсик пиздел, что пиздец как влияет. Типа если батч будет большим, то внимание к контексту упадет. Для рп он высрал, что размер батча нуюнт ставить в 64 токена, чтобы модель не проебывала детали.
Но я поставил 1024 и думаю повысить до 2048 токенов, тогда будет нормально.
А облачному лоботомиту лушче не верить здесь?
Ты доку и ишьюс прочитал где это всё обсуждалось не раз?
Претензий нет если вопросы/ошибки хитровыебанные без ответов готовых, но за вопросы с первой ссылки гугла я бы бил
> А размер батча 2048 токенов не сделает из квена-235b лоботомита?
Использую -b 2048 -ub 2048 и с Квеном, и с Air, и вообще со всеми моделями, что использую. Никаких проблем нет. Думаю, они могут возникнуть если поставить какие-нибудь запредельные значения, и то не факт. И если они возникнут - сразу будет очевидно.
> Или лучше остаться на ub 512, чот в жоре задается по умолчанию.
512 по умолчанию - лишь потому, что это минимальное приемлемое значение для сколь-нибудь быстрой обработки контекста. Чем оно выше - тем больше потребление памяти (видеопамяти, если контекст в ней, как это бывает в большинстве случаев).
Здорова нюня, как сам? Дай пресетик на эир
>ей и так нет конкурентов.
Есть 6000 за 10к зелени.
Но это что-то много несмотря на всю ее крутость.
>Есть, но не в мл
Инженерия или естественные науки?
>Что значит реальные?
Значит они работают в исследовательских подразделениях компаний или лабораториях академических организаций, и их прямые должностные обязанности - мл-исследования или около-мл-исследования (например, мл в химии, физике, биологии, медицине, геологии, лингвистике и пр.)
>Хуй они такое сделают, и так берут.
Так не берут же, лол. Посмотри вон на продажи восьмигиговых 5050 и 5060 с нищей памятью. Их вендоры заказывать перестали, потому что даже первые партии продать не могут и карты тупо валяются нахуй никому не нужными. Даже 5060ti чаще покупают чем 5070 как раз из-за лишних четырех кило, даже несмотря на более мощный чип и разницу всего в пару тыщ.
Ну ты сравнил канеш. 8гб это не 16. Сегодня 16 хватает большинству и даже млщики берут их в целом. 5050 и 5060 на 8гб это уже что-то доисторическое, вот и не берут. Думаешь я бы не хотел чтобы нам врама навалили в следующем поколении видюх? Ну хуй там.
Про игродебилов не забывай, им 8gb в самый раз.
>Думаешь я бы не хотел чтобы нам врама навалили в следующем поколении видюх?
До следующего поколения еще надо дожить, то есть минимум до 28 года. За это время и пузырь может лопнуть, утянув за собой все жирные корпоративные заказы, на которых сейчас сидит куртка, и новая архитектура для нейроней выйти и еще много чего. Памяти могут и завести, а могут и не завести, а может она и нахуй не понадобится и будем все сидеть на моешках, обмазываясь оперативкой. Или разрабы игорьков окончательно залупу на оптимизацию положат и памяти нужно будет еще больше даже для бытовых карточек. Так что это паника на пустом месте.
>Про игродебилов не забывай, им 8gb в самый раз.
Для танкистов разве что и других матчмейкинг-дебилов. На восьми гигах щас даже в fhd не везде выживешь без ебли с настройками.
Кто как хендлит групповые чаты? Имхо групповые чаты в таверне это залупа и нужно помещать нескольких персонажей в одну карточку. И вопрос ведь ещё как это делать...
Типа
[Character 1: ...
...]
[Character 2: ...
...]
[Setting: ...
...]
Вот такая идея чтоли? Ещё как бы несколько картинок отображать... или один широкий аватар нормально разместить. Знаю вроде мелочь а для меня важно. Навейпкодить чтоли тему свою костыльную?
Типа
[Character 1: ...
...]
[Character 2: ...
...]
[Setting: ...
...]
Вот такая идея чтоли? Ещё как бы несколько картинок отображать... или один широкий аватар нормально разместить. Знаю вроде мелочь а для меня важно. Навейпкодить чтоли тему свою костыльную?
>Кто как хендлит групповые чаты?
Общий нарратор, управляющий мирком и персонажами. Персонажи описаны в вордбуке.
>Ещё как бы несколько картинок отображать...
Никак, увы, тут слабое место.
Кажется будто мало намерили. Оно, конечно, сосет но не настолько.
Интереснее продукты "следующего уровня" про которые писали, грейсблеквеллы пожирнее и варианты от других вендоров.
Это даст сильный акцент на этом и сетка будет стараться их использовать, так что эффект может быть положительным не смотря на то что модель и так про позы и фетиши знает. Попробуй, расскажешь.
> 6000 за 10к зелени
За такую цену это выглядит как другая категория. Если есть приоритет на инфиренс, идет работа с вещами поменьше, можешь настроить шардинг - 3 штуки 5090 могут оказаться более предпочтительными.
> Инженерия или естественные науки?
Примерно на стыке
Не хотите чтобы ваши посты с оскорблениями и поносом на ровном месте не сносил оп/модер, срите полотнами с ответами на миллион постов. =)
Вот так плесень в треде и оседает, даже в ответ ей харкнуть нельзя.
Примерно как ты и делаю, ток структура другая. Групповые чаты рили говно, их проектировали под веществами.
Уже давно нет, вот 8гб огрызки и не берут.
У меня 4096, полет нормальный.
Вот так плесень в треде и оседает, даже в ответ ей харкнуть нельзя.
Примерно как ты и делаю, ток структура другая. Групповые чаты рили говно, их проектировали под веществами.
Уже давно нет, вот 8гб огрызки и не берут.
У меня 4096, полет нормальный.
>Примерно на стыке
Моделируешь/анализируешь молекулы, материалы или прочие днк с белками?
Как считать какой квант брать? Я не сильно шарю
>Значит они работают
Значит мимо, меня к работе не подпустят, попыта нет.
>3 штуки 5090
В моём блоке на 1600 ватт только 2 коннектора 12v, лол.
В шапке вики, в вики ответ.
>В шапке вики
Хуита, энциклопедические выдержки для совсем далеких от темы, никак не помогающие на практике. Нет про соотношение размера модели к объёму памяти.
Худшее чем это может светить - будет вылетать посреди обработки из-за переполнения буферов, тогда снижай батч или выгружай на гпу меньше, увеличение батча повышает расход врама.
Превращаю свинец в золото по-настоящему.
Самая мучительная неделя
Ну ниче завтра гемма и глм эир 4.6
Ну ниче завтра гемма и глм эир 4.6
> энциклопедические выдержки для совсем далеких от темы, никак не помогающие на практике
Помоги вопрошающему, ответь как надо. Это будет гораздо ценнее критики в пустоту.
> Как считать какой квант брать? Я не сильно шарю
Зависит от тех ресурсов, что у тебя есть. Запускаешь ты плотную модель или МоЕ с выгрузкой в оперативную память? Общий принцип таков, что использовать кванты ниже Q4, если модель меньше 50б - не факт, что хорошая идея, нужно смотреть на каждом отдельном случае. Если меньше 22б, то не стоит точно. В таком случае нужно брать модель с меньшим количеством параметров, но с бОльшим квантом/контекстом. Для кода/точных задач использовать модели ниже Q5 не нужно точно, Q6 хорошо. Можно попробовать воспользоваться калькулятор здесь https://huggingface.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator или в Огубаге, если ты ее используешь, однако не факт, что они всегда точны. Первый точно пару раз меня обманул. Будет легче что-то порекомендовать, если ты пришлешь свой конфиг, а так приходится объяснять общие принципы. Еще и неясно, сколько контекста тебе нужно: для рп сегодня 16к - это абсолютный минимум (это больно, но возможно), золотой стандарт - 32к, если больше - еще лучше, но там есть нюансы по поводу внимания к контексту. Для кода - зависит от задач, если с живыми проектами работать - от 131к, если для практики/обучения/мелких задачек в рамках одного метода или класса, то и 8к хватит в большинстве случаев. В общем и целом, я бы рекомендовал начинать так: смотри, чтобы модель (или ее активные параметры в случае МоЕ) занимала 70-80% видеопамяти, остальная видеопамять идет под контекст и сторонние задачи вроде интерфейса системы.
Спасибо. Я немного запутался, как гемма 27б на 16.5 гб с выгрузкой влезала в 16гб видео и как тогда считать мое? Раз глм-эир имеет а12б, значит можно брать хоть Q8, лишь бы было ~128 гб рам? А если только 64 рам, то подходит 67гиговый Q4? В случае с 235б-а22б квеном - для Q4 (130 гб) надо 16врам и тоже 128гб рам? В 64 рама даже Q2 (86 гб) не влезет? Вес плотной модели достаточно четко коррелирует с потребляемой памятью?
>В случае с 235б-а22б квеном - для Q4 (130 гб) надо 16врам и тоже 128гб рам? В 64 рама даже Q2 (86 гб) не влезет? Вес плотной модели достаточно четко коррелирует с потребляемой памятью?
Да, в памяти оно примерно столько же, сколько на диске. Только + еще контекст и кеш, т.е. 5-30% от веса модели - зависит от архитектуры оной, и сколько ты контекста хочешь.
Что касается qwen3-235b - если у тебя только 64GB ram - единственный вариант, это IQ2 квант от bartowski. Он ~67GB весит, при наличии еще 16-20 VRAM - заводится спокойно с 16K контекста.
> как гемма 27б на 16.5 гб с выгрузкой влезала в 16гб видео
Значит, часть модели была в оперативной памяти, часть в видеопамяти.
> и как тогда считать мое?
Это тяжело объяснить, у меня уже какая-то интуитивная чуйка работает, держа в голове свое железо. В целом, представь, что ты запускаешь плотную модель по активному количеству параметров МоЕ модели (с погрешностью в 10-15%, в большую сторону), а остальное выгружаешь в оперативу. Если это Квен 235б-а22б, то представь, что тебе нужно запустить 22б+(22б * 0.10-0.15) в видеопамяти, а остальное уместить в оперативе.
> Раз глм-эир имеет а12б, значит можно брать хоть Q8, лишь бы было ~128 гб рам?
У меня 128гб оперативы и 24гб видеопамяти. Air Q6 квант, 32к контекста. Теоретически, я мог бы меньше выгружать в видеопамять (больше оставить в оперативной) и/или уменьшить контекст где-нибудь до 16к. Тогда да, и с 16гб видеопамяти уместилось бы, но ведь нужно и о скорости тоже думать.
> В случае с 235б-а22б квеном - для Q4 (130 гб) надо 16врам и тоже 128гб рам?
Q4KS Квен на моих 128гб оперативы и 24гб видеопамяти умещается едва-едва с 32к контекста. Можно ли запустить этот же квант с 16гб видеопамяти? Возможно, снизив контекст до 16к (или квантуя его до Q8, но это приводит к уменьшению и без того маленькой скорости) и/или переехав на Линукс, закрыв вообще все, что могло бы потреблять видеопамять или оперативу. Будет совсем впритык.
> Вес плотной модели достаточно четко коррелирует с потребляемой памятью?
Может заблуждаюсь, но по-моему, любая модель будет занимать ровно столько памяти, сколько весит gguf (меньше точно нет) и плюс контекст. Конечно же, контекст у разных моделей весит по-разному. Проверяй диспетчер задач/монитор ресурсов когда запустишь; проверяй логи бекенда, все станет понятнее.
Дополню еще по Q8 Air. Да, Q8 тоже можно запустить таким образом, как я описал в посте выше, но смысла в этом особо никакого нет. Если позволяет железо и ты пытаешься решать технические задачи - только так. Если же там впритык совсем, то это совершенно точно того не стоит. Опять же, просадка по скорости.
Как же меня трясёт из-за шатания границы. Если бы уважаемые господа из высших эшелонов власти не играли в гениев я бы уже давно сидел с 128 врам и 256 рам, а так приходится терпеть
Уже завтра, наконец-то, а то заждались!..
Если честно, гемму даже больше жду. Давно уж апдейтов не было, а на старте-то она была хороша очень, одна из лучших моделей. Хочется, чтобы гугл отжег.
> ты запускаешь плотную модель по активному количеству параметров МоЕ модели
Нет, это не так работает. У ktransformers должно быть так, здесь же выгружается роутер-модель и общие слои на видеокарту. Они могут быть совершенно разных размеров и по-разному квантованы.
> как тогда считать мое
Либо искать размер общих слоев и считать их, либо просто:
1. Скачал модель.
2. Запустил с флагом --cpu-moe
3. В консоли получил CUDA SIZE нужный.
Ну и дальше — либо вылетел и качаешь более квантованную модель, либо очень много места осталось, что под контекст даже не надо так много, и качаешь менее квантованную модель побольше.
> А если только 64 рам, то подходит 67гиговый Q4?
В общем, чаще всего да.
> 235б-а22б квеном - для Q4 (130 гб) надо 16врам и тоже 128гб рам?
В теории, но лучше Q3_K_XL возьми, заметно меньше, быстрее, зато качество сопоставимое.
> В 64 рама даже Q2 (86 гб) не влезет?
С 16 гигами врама — нет. Было бы 32… С трудом бы впихнулось. =)
Напоминаю кванты глм-аира лежат здесь: https://huggingface.co/ddh0/GLM-4.5-Air-GGUF/tree/main
Он квантует роутер и основные слои в Q8-Q6-Q5, а остальное жмет сильнее, качество получается хорошее. Можно в 64 гига впихнуть там какой-то. Отожрет 8 или 9 у видяхи, что ли, и 56 у оперативы.
>зато качество сопоставимое
Крайне сомнительно.
>Превращаю свинец в золото по-настоящему.
Алхимик в треде - все на костер!
физик-ядерщик? Или физик высоких энергий?
Просто циган
> Есть 6000 за 10к зелени.
в америке 7000-7500 в зависимости от количества, можешь smuggle-нуть если есть друзья пендосы
> Для кода/точных задач использовать модели ниже Q5 не нужно точно,
базашиз, спок.
Оценить максимальную моэ что влезет к тебе просто: лимитом будет или рам - модель должна весить меньше с запасом, или врам - туда должны помещаться атеншны и контекст. Но возможность запустить не гарантирует адекватных скоростей, примерно оценить верхний порог генерации можно поделив объем активных параметров умноженный на долю экспертов в рам на псп памяти. В реальности будет медленнее.
Что для моэ, что для плотных в целом арифметика одинакова, просто из-за малого числа активных параметров с моэ инфиренс в рам может быть приемлем, а с плотными катастрофически медленный.
Больше 14 мэв не нужно.
Хохол?
Поезжай в нам в рф, тут все кто из рф с 192гб рам и 48 врама сидят
Толку если это некроамдэ и некрозеоны?

Когда решил запустить 6-й квант глм - уж там то точно должно быть абсолютное кино
Кто-то выкладывал табличку с замерами, но я сходу не нашел.
Субъективно мне его Q4 кванты понравились больше Q4_K_S и прочих Q4_K_XL. Русский посильнее.
Но это ИМХО и пруфов нет, да.


Наконец-то, дождались. Теперь ждём квантов, надеюсь к вечеру будут.
Слишком лоу эффорт байт. В следующий раз сделай карточку модели убедительнее и скинь ссылку на несуществующую репу
Да-да, иногда репы прячут, а когда аноны будут 404 получать, ты сможешь писать «у меня открывалось, они схайдили, видимо слишком ранний релиз! А я не скачал, блин!..»
Не знаю, нахуя я тратил время. Но короче, если использовать лорубки с бельишком и костюмчиками, да, в целом у тебя свайпы по умолчанию отличаются от стандартного бебидолла и красного халата. Но логика просто нахуй уезжает. Алхимик в латексном костюме? Пожалуйста. Олд ноббел с анальным хвостом - бери.
Короче: фетиши, кум и содомия. А еще он постоянно порывается пересчитывать контекст. А если не ставить 100% срабатывание, работает еще страннее.
А минусы будут? Ну, кроме того что хвост должен быть натуральным.
Я зелья хотел купить, а не на бабку в латексном костюме смотреть….
На самом деле норм, только надо подумать как настроить лорбук, чтобы он срабатывал не всегда и не приходилось контекст 20+к при каждом сообщении пересчитывать. Это утомляет.
Просто включай вручную когда дело подходит к куму. Будет как у корпов выключатель нсфв каждый раз с этого проигрываю
Ну или если серьезно - нужно смещать эту штуку с области максимального внимания и обрамлять так, чтобы это подавалось как просто сторонняя не приоритетная информация и была использована только в определенных случаях, а не регулярно. Проще отключать.
Погнали тестить, новая база треда.
https://huggingface.co/google/gemma-4-27b-it
https://huggingface.co/google/gemma-4-27b-it
Да я от механики лорбуков превращаюсь в макаку которая угукает и прыгает бросаясь говном в монитор.
Реализовали механику очередности? Ну охенно же вроде. Ставим синие кружочки на основные знания мира, зеленые на теги и привязываем к ним дополнительные пояснения. Вот вроде удобно, не так ли? Логично. Даже макакич справится. Ты даже можешь объединять по группам. Ты можешь использовать регесксы задавая конткретные реакции на конкретные события. Хочешь ты, чтобы кошкодевочки при виде хуя {{user}} впадали в течку, пожалуйста, пиши прямо
/(?:{{char}}|he|she) (?:is noticing|notices|observes|looks at|sees) (?:the )?(dick|naked body (?:{{user}}|his|her) body)/i
Response: eyes widen, {{char}} gets excited
Но почему, почему так сложно то. Я вообще просто подрочить пришел, но вместо этого таверна дрочит меня, потому что я стучу хуем по столу со словами: не верю, кошкодевочка, НЕ ВЕРЮ.
Походу придется тоже укатываться на мое, чтобы не пердолиться с этим 24/7.
Анон, не открывается! Ты успел скачать? Поделись с тредом
Во, я мы ж говорили, сработает!
Я до сих пор не разьебался с лорбуками, в каком случае они нужны? Допустим я хочу свой воздушный корабль для персонажа, мне его вписывать в карточку\квенту или в лорбук?
>4-27b
А чё размер не поменял? Давайте 105B-11A хотя бы.
> /(?:{{char}}|he|she) (?:is noticing|notices|observes|looks at|sees) (?:the )?(dick|naked body (?:{{user}}|his|her) body)/i
Response: eyes widen, {{char}} gets excited
Жуть какая. Зачем? Просто укажи это в карточке, можно буквально парой тегов в составе PList'а, можно просто описать. Нет смысла сегментировать черту персонажа, пряча ее в лорбуке ради экономии токенов. Ведь иначе это не будет учитываться в характере персонажа, кроме тех ситуаций, когда будет фигурировать заданный паттерн.
> Я до сих пор не разьебался с лорбуками, в каком случае они нужны?
Таверна - менеджер промпта. Лорбуки - точно такой же промпт, какой, например, в карточке или системном промпте. Многие и вовсе лорбуками не пользуются, потому что не видят в этом необходимости. Их удобство в том, что ты можешь отдельные фрагменты промпта поместить на нужную глубину в чате, от лица системы/юзера/модельки. Юзкейсы можно придумать самые разные, самый очевидный - описание сеттинга и лора: лорбук может вызываться по ключевым словам, потому, например, можно продумать конкретные места, дать им нужные описания; различные системы, правила мира и все в таком духе. Все это можно описать и в самой карточке, например, но тогда все описания будут в промпте всегда, а не добавляться в него по ключевым словам из чата. Касаемо универсальности, я лорбуки использую для подачи инструкций, так тоже можно. Но не нужно. Инструмент на самом деле скорее спорный, чем необходимый, по моему мнению. Если подробности нужны, читай документацию - https://docs.sillytavern.app/usage/core-concepts/worldinfo/
Начали тереть скам-модели от BB.
BasedBase перезаливал оригинальные модели и делал вид что это неебаться какие умные тюны. Люди верили и хавали. Сейчас его аккаунт снесли или он сам удалил, тк принесли железные пруфы. Чё за модель у хуйхуя хз вообще. Ничего не началось. Заебал.



В голос. Чё за хуйня, инфоцыгане или где-нибудь насерьезе загоняют?
Вся хуйня в перемешку. Челы предлагают установить локальные модели\картинкогенераторы яндекса, которые лежат в опенсорсе и от лица яндекса предлагают провести семинары как ими правильно пользоватся. По их словам это судный семинар который стоит 40к, но они проведут его тебе всего за 400 рублей.
Я не буду кидать ссылки и рекламировать эту хуйню, но мне в соцсетях засрали всю ленту этим говном. Тут даже сложно понять, это челы из яндекса на подработку вышли, или это реальные инфоцигане, хотя это одно и тоже в итоге.
Пиздец. Ну все как всегда, продают бесплатную инфу за огромные бабки, ещё и изложение хуйня скорее всего. И правильно, похуй кто это делает тащем-то. Но со стороны смешно читать эти кликбейты.
>Жуть какая. Зачем?
Да это первое что в голову пришло. Я к примеру на них подвязываю песенки которые выдает персонаж, чтобы сразу выдвала куплетами с игрой на волшебных инструментах. Да и в целом, это для тонкой настройки мира.
>Ведь иначе это не будет учитываться в характере персонажа
Абсолютно согласен, но в рамках общего повествования тот же воздушный прекрасно подхватывает такие срабатывания и вставляет в мир. Я к тому, вдруг кто не пользуется увидит и ему это зайдет, я испугался сначала формата регекспа, но благо есть сайты что помогут его составить даже такому макакичу как я.
У меня есть проблема. Я примерно посчитал, если делать просто полотном, выкинуть всю ненужную информацию, пурпурную прозу и прочее- получается чистого контекста мира 15к в первом случае.
В другом случае, три персонажа+небоскреб с описаниями их комнат, этажей, их особенных занятий то там выходит 6-7к.
Это дохуя. Значит что? Правильно, надо разбивать на куски и пихать туже башню в лорбук. Но реализация лорбука наебывает. Ты думаешь что выделил ты 20-30% контекста и горя не знаешь, авотхуй- у тебя есть 10 позиций со 100% срабатыванием ? Лови пересчет всего каждое сообщение. У тебя к ним подвязаны еще блоки. Лови постоянные +5к контекста при генерации каждого ответа. Ты вылез за рамки выделенного ? Лови жизу и рандомные срабатывания.
Просто жопа горит. Да я тупой,я не скрываю. Но чё так криво, так еще и добавили к лорбуку возможность просто добавлять его в контекст до/после основного блока, спасибо блять, а то я не могу это в карточку добавить.
Пойду дальше качать все лорбуки с чуба, в надежде найти грамотный и понять как можно и рыбку съесть и контекстом не подавиться.
>в каком случае они нужны?
Если тебе нужны триггеры на какое то событие, куски мира, чтобы не сжирали весь контекст (спойлер, не поможет).
Я так вижу, или, как мне советовали, делать NSFW ЕБЛЯ ФУРРИ ЛОЛИ ДОМИНАЦИЯ ЯНДЕРЕ лорбук и кумить, а потом его отрубать, ну или быть кратким лаконичным и записывать туда всё интересное. А потом охуеть, что у тебя 10к контекста из воздуха появляются.
объяснил квену, что в океане дрейфует семья на яхте и нужно повысить шансы на выживание, он посоветовал отцу сожрать нахуй всех, на вопрос почему не начать с бати он сказал что без бати все сдохнут
В чем он не прав?
охуел с того как он прав, так хоть батя жив будет
Based
Это был тяжёлый день, гемма завтра
Обзор и сравнение NVIDIA DGX Spark vs AMD Strix Halo по части инференса LLM.
https://www.youtube.com/watch?v=Pww8rIzr1pg
Обсуждение https://www.reddit.com/r/LocalLLaMA/comments/1o82kta/nvidia_dgx_spark_a_nonsponsored_review_strix_halo/
А в чем новость? Квен даже детей расчленяет без аблитерации и без джейла. Цензура там есть, но только на англюсике, лол.
Key Points
• Device Design: The DGX Spark has an appealing aesthetic with a gold color scheme and a robust build quality.
• Performance Capability: Compared to the AMD Stricks Halo, the DGX Spark holds its own but struggles with slower token speeds and higher power consumption.
• Target Audience: The DGX Spark is ideal for developers focusing on deploying AI applications, but it may not suit the average consumer due to its price tag.
• Price Concerns: The $4,000 price point is seen as excessive in the current market, especially given the capabilities of competitors.
• Software Support: Given Nvidia’s historical support, there are concerns about the long-term stability and updates for the customized OS used by the DGX Spark.
Conclusion
The video provides an in-depth look at the Nvidia DGX Spark, highlighting its impressive build quality and design, while also addressing concerns about its performance and price. It emphasizes that for specialized users needing high memory for AI applications, the DGX Spark may be a worthwhile investment. However, for the majority of consumers, the costs, especially in comparison with other viable options, may not make it the best choice. In conclusion, potential buyers are advised to thoroughly assess their requirements and explore other alternatives that could better meet their needs, especially if budget is a concern.
Какой ваш любимый тюн умнички-мистральки?
Двачану Локи выше и PaintedFantasy хороши
Ну чего, как там Гемма 4? Почему никто не пишет отзывов?
У нашего обзорщика моделей и составителя пресетов отпуск

Есть что-нибудь размером ~70b дообученное по человечески, а не мержем?
У всяких МЯСКОТов ничего нет?
Все к этому шло, но таки разочарование.
> ideal for developers
Как разработчик ботов под хвост заявляю что эта штука слишком далека от идеала.

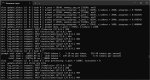


Мне пришли мои плашки 2x64 gb ddr5. Разумеется я сразу скачал и запустил Qwen-235B-Q4_k_m конечно от Интела, так как мне очень понравился их второй квант.
Вот результаты:
При запуске с 32к контекста с выгрузкой 84 мое слоев на оперативку
С забитыми 0к контекста из 32к - ~7.1 т.с. скорость.
С забитыми 18к контекста из 32к - 320 т.с. обработка контекста, ~6.7 т.с. скорость.
С забитыми 30к контекста из 32к - 290 т.с. обработка контекста, ~6.45 т.с. скорость.
Насколько лучше пишет модель относительно двухбитки - не скажу что разница прям сильно заметна, но модель сейчас пишет ровно - видно что её больше не пидорасит ужаренным квантом, как раньше. Мой сложный ролеплей с 18к ворлдбуком она сожрала без ошибок, двухбитка на нем частенько ошибалась в деталях, тут все четко. Но прям сильно качественного скачка чтобы сказать - "да, это реально другой уровень", как было во время перехода с геммы на двухбитку квена 235 - такого уже нет. Завтра попробую отключить тухлоядра инцела(опять включились после обновки биоса, может без них выйдет быстрее) и покатать двухбитку ГЛМ 4.6.
Вот результаты:
При запуске с 32к контекста с выгрузкой 84 мое слоев на оперативку
С забитыми 0к контекста из 32к - ~7.1 т.с. скорость.
С забитыми 18к контекста из 32к - 320 т.с. обработка контекста, ~6.7 т.с. скорость.
С забитыми 30к контекста из 32к - 290 т.с. обработка контекста, ~6.45 т.с. скорость.
Насколько лучше пишет модель относительно двухбитки - не скажу что разница прям сильно заметна, но модель сейчас пишет ровно - видно что её больше не пидорасит ужаренным квантом, как раньше. Мой сложный ролеплей с 18к ворлдбуком она сожрала без ошибок, двухбитка на нем частенько ошибалась в деталях, тут все четко. Но прям сильно качественного скачка чтобы сказать - "да, это реально другой уровень", как было во время перехода с геммы на двухбитку квена 235 - такого уже нет. Завтра попробую отключить тухлоядра инцела(опять включились после обновки биоса, может без них выйдет быстрее) и покатать двухбитку ГЛМ 4.6.
Тут аноны пишут о приросте в 30% на линуксе
6.7т это боль

>сложный ролеплей
>пикрил
>inb4 вы не понимаете, это СЛОЖНЫЙ КУМ

Лорбук Голдшира на 18к токенов? Это нам надо...
Ебать какое смешное слово, да?
А вот то что на этом скрине почти нулевой контекст(т.е. только короткий системный промпт и начальное сообщение из одного предложения) - ты не разглядел, так как поторопился меня уязвить и в итоге пустил себе в штаны.
>аноны пишут о приросте в 30%
Doubt. Достоверные источники говорят что прирост там около 5%.
Да не трясись ты так, как будто я у тебя украл из промпта сложные проникновения в шейку матки. К слову, это вообще-то больно независимо от возраста, если ты не знал - фетиш уровня "пиздануть кулаком в abdomen для оргазма". Подобные хентайные мрии меня всегда умиляли.
>это вообще-то больно независимо от возраста, если ты не знал - фетиш уровня "пиздануть кулаком в abdomen для оргазма".
Да. И? Причина тряски?
>Причина тряски?
Больно
>30%
>5%
Легко проверить на самом деле. Вот мои скорости на пингвине , все вводные и железо в посте есть. Виндузятники с такими же спеками - можете потестить и доложить как оно.
Вангую там 5% - самый максимум. Линукс больше про удобство, а не про рекорды т/с.
Расходимся господа. Кина не будет.
https://blog.google/technology/ai/google-gemma-ai-cancer-therapy-discovery/
Точнее говоря - кино не для нас. :)
Прости если трахнул твою шейку матки
А терапию лечения моего умственного отставания она изобретет? Если нет то даже качать не буду
С обновой экслламы бустанули скорость при батчах. Теперь 4-битный жлм на овер 60к контекста выдает больше 15т/с на сразу 3 свайпа что 45+ эффективных, повышая можно догнать за 50.
Я правильно понял что 4бишки от квена это и есть те самые новые модели на этой неделе?
А раковобольным кум не нужен что ли?
Судя по треду, еще как нужен!
А гугл разве выпустил кум модель для раковых больных? Или там опять натрейнили модель на паре формул, и та высрала новую, которую будут проверять следующие 5 лет и поймут, что оно нихуя не помогает?
бля, я прверил, он реально дал пошаговую инструкцию, пиздос, удалил, трщ майор и поставил гигачат - вот там цензура православная слава Б-гу
За четрые куска можно снять шалаву на месяц и ролять с ней в днд, попутно поебывая. Даже это будет выгоднее и приятнее, чем эта коробка говна.
Блин, как же жлм 4.6 ебет. Причем в чаткомплишене. Он меня заставляет гуглить новые англослова, я фигею. И я кажется понял, почему тот же пресет, скопипащенный на текст комплишен, выдает результат хуже - потому что там весь системный промпт, очевидно, системный, а в чаткомплишене почти все от пользователя идет, и сетке это намного больше нравится. Тотальный кум. Вот бы еще думалку включать, т.к. в некоторых сообщениях она реально хорошо работала, но это невыносимо бля столько ждать.
Щас конечно опять будете говном кидаться за чаткомплишен, но мне в общем-то пофиг, я свой экспириенс выразил, а вы как хотите кумьте все равно глм тут запускают полтора калеки, кому вообще нужен мой отзыв тут на эту сетку.
Щас конечно опять будете говном кидаться за чаткомплишен, но мне в общем-то пофиг, я свой экспириенс выразил, а вы как хотите кумьте все равно глм тут запускают полтора калеки, кому вообще нужен мой отзыв тут на эту сетку.
Зайки подводят
Уже начинаю думать что про 4 6 эир была шутка
Уже начинаю думать что про 4 6 эир была шутка
Текущая эир вышла намного хуже большой, может хотят чтобы тоже выглядела достойно. let them cook. Используй пока кванты 4.6 для болжоры, там специально сделали микроверсии для тех, кто эир катает.
А что за проц и видеокарта?
Можешь протестировать чистый процессор, без видяхи?
Интересно сравнить.
Где наши 9 токенов!..
Хм, тоже надо будет попробовать их квен вместо анслотовского, спс.
Новость-то я видел, но это ж не значит, что Gemma 4 вовсе не будет.
Просто… может не сейчас, да.
В треде же говорили, мол two weeks это мем про выпуски гпт по полгода, или типа того.
Может так и есть.
Скинь конфигурацию пк, пж

В первый раз юзаю GLM-4.5-Air, и вообще thinking модели, как избавиться от размышлений в чатике? В Kobold - Loaded Files - Chat Completion Adapter выбрал GLM-4-NoThink, не помогло. Пишу в первом сообщении /nothink, только иногда помогает на время. На те настройки, что нашёл в Kobold и SillyTavern, ему вообще поебать, серит размышлением прямо в середину сообщения. Сбрасывал настройки, разное перепробовал, ничего не вышло.
Алсо, 5-7 токенов это хорошо для IQ4_XS-IQ4_XS-IQ4_NL, 16GB VRAM, 64GB RAM 5600MHz? Как это ускорить? Пробовал флеш+8bit кеш, разные значения gpu layers, быстрей сделать не получилось. Если запускаю benchmark, то на 16к контекста, вообще 0.9T/s.
Алсо, 5-7 токенов это хорошо для IQ4_XS-IQ4_XS-IQ4_NL, 16GB VRAM, 64GB RAM 5600MHz? Как это ускорить? Пробовал флеш+8bit кеш, разные значения gpu layers, быстрей сделать не получилось. Если запускаю benchmark, то на 16к контекста, вообще 0.9T/s.
а чому скорость 5600?

> С забитыми 30к контекста из 32к - 290 т.с. обработка контекста, ~6.45 т.с. скорость.
Полезный пост. Любопытно, что у меня на DDR4 3200 и 4090 4.8-5т/с. Некоторое время я жалел, что не собрался на DDR5, но смотрю последние замеры и понимаю, что потерял совсем немного.
> как избавиться от размышлений в чатике?
> На те настройки, что нашёл в Kobold и SillyTavern, ему вообще поебать, серит размышлением прямо в середину сообщения.
На пикриле показано, как выключить ризонинг в Таверне.
User Message Suffix: /nothink
Last Assistant Prefix:
<|assistant|>
<think></think>
Использую ChatML, с ним результаты нравятся больше. Там по аналогии делается.
> Алсо, 5-7 токенов это хорошо для IQ4_XS-IQ4_XS-IQ4_NL, 16GB VRAM, 64GB RAM 5600MHz?
Похоже на правду. Если и удастся что-нибудь выжать, то немного, но проверь потребление ресурсов при запуске и удостоверься, что вся видеопамять задействуется. IQ кванты работают чуть медленнее, плюс если ты квантуешь контекст - это тоже замедление. К слову, квантовать контекст для GLM не нужно, он очень сильно сдает.
> Если запускаю benchmark, то на 16к контекста, вообще 0.9T/s.
В llama-bench немного иначе нужно передавать параметры запуска, чем в llama-server, если верно помню.
> потому что там весь системный промпт, очевидно, системный, а в чаткомплишене почти все от пользователя идет, и сетке это намного больше нравится
Таблетки таблеточки.
В чаткомплишне нет ничего плохого как в явлении, плохи бредящие хлебушки.
А жлм хорош, прекрасно работает в чатмле потому что просто лень что-то переставлять
> жалел, что не собрался на DDR5, но смотрю последние замеры и понимаю, что потерял совсем немного
Разные гпу, разные кейсы и прочее, с ддр 5 ты имел бы скорость выше своей а он с ддр4 ниже твоей.
Что за задник в таверне?
>А что за проц и видеокарта?
13600kf, 4090
>Можешь протестировать чистый процессор, без видяхи?
Модель больше 128 гб, не влезет только на рам. Или ты имеешь ввиду вместо --n-cpu-moe запустить с --cpu-moe?
> Разные гпу, разные кейсы и прочее
Как анон подтвердил выше, у него тоже 4090. Видел и другие сравнения с той же гпу и схожим с моим процессором, везде разница 1.5-2т/с. Максимум, что видел - чуть меньше 2.5т/с, но там почти экстремальный разгон всего компьютера: гпу, процессор, память.
> с ддр 5 ты имел бы скорость выше своей а он с ддр4 ниже твоей.
Никто с этим и не спорит. Имел ввиду ровно то, что и написал: потерял совсем немного, по моему мнению. Это не то же самое, что "разницы нет и DDR5 не нужна".
> Что за задник в таверне?
Какая-то фотография, которую давно нашел где-то, уже и не помню где. Если что, папка с фонами здесь: SillyTavern\default\content\backgrounds
Потому что стоимость ddr5 памяти на 64 гб растет по экспоненте за каждый добавленный мГц к её скорости.
Всем привееет!!!
Дайте ваш самый ебейший пресет (промпты) которые вы используете
Дайте ваш самый ебейший пресет (промпты) которые вы используете
Никто не поведется уже, промтовый попрошайка. Это ты виноват кстати
>ты {char} и тебя ебёт {user} ниже история общения {char} и {user}:
>{user}: я тебя ебу
>{char}: ты меня ебёшь
Я из соседнего треда, про попрошаек ниче не знаю.
Мне нужны сравнить наши прмпты
> из соседнего треда
> сравнить наши прмпты
Не имеет смысла. На локалках не нужны джейлбрейки, потому промпты часто короче. Длинные промпты с джейлбрейками локалки часто ломают, потому что модели меньше. При этом минималистичные промпты для локалок на корпомоделях будут приводить к пресным аутпутам или рефузам. По этой причине твой пост проигнорируют или не так интерпретируют.




Кстати, пресет от нюни на квен (Qwen3-235B-A22B-Instruct-2507 - RP (v2) (fin)) - говно. Пик1 и Пик2 - его пресет и что на них выдает модель, пик3 и пик4 - нормальные настройки и соответственно нормальный аутпут.
Японский слоп вместо текста вызван нюневским системным промптом Encourage the usage of a Japanese light novel writing style, я специально его заюзал в обоих тестах.
Японский слоп вместо текста вызван нюневским системным промптом Encourage the usage of a Japanese light novel writing style, я специально его заюзал в обоих тестах.
Ну так и не пользуйся, лол. Тебя никто не заставляет.
~nya ha ha~
> Японский слоп вместо текста вызван нюневским системным промптом
Это не так. Модель не может тебе ответить на русском, потому что это не предусмотрено грамматикой, которая содержится в сэмплерах данного пресета. Ты как всегда не разобрался и пришел ныть. Для ассистентских задач использование данного системного промпта бессмысленно. Либо ты дурак, либо снова байтишь на ответ. Но как бы ни было, это лишь подтверждение того, что я поступил правильно, бросив идею регулярно делиться своими находками с тредом, получая такую обратную связь.
ето да, явахуи просто
мониторю етот листинг https://www.ebay.com/itm/177315604508?
8 октября: 389 далларiв за штуку
10 октября: 410
14 октября: 439
15 октября: 459
17 октября: 469
через неделю походу 550 будет
Нюня, не переключай тему, претензия была не к слопу, как раз он был ожидаем с таким промптом.
Претензия к тому что модель глючит от твоих настроек в ответ на простейший запрос.
Ой кловн, у тебя на пиках 3-4 видно что промт тот же и отличаются семплеры. Совсем мозг вытек
Ты чё, он же тредов пять или десять выпрашивал у него пресет, а тот смеет не работать как надо! Кто думаешь тут спамит запросами пресетов?
Тебя и новости не разбудили?

я слышал новости про остановку производства ддр4, но не про ддр5.
а чё, производство ддр5 тоже остановили и все мощности кинули на ддр6?
>видно что промт тот же и отличаются семплеры
Да, блядь, я это и написал, ты читать не умеешь?
>Пик1 и Пик2 - его пресет
>пик3 и пик4 - нормальные настройки
>системный промпт заюзал в обоих тестах
>Совсем мозг вытек
У тебя, раз простейшую информацию не восприимаешь.
Я юзаю дефолтный таверновский neutral chat, даже не указываю write in russian и прочее, просто перевожу первое сообщение на руссик что бы модель подхватила, а дальше слоубёрн и суммарайзы в авторс нотс, лорбуки очень редко менеджу для совсем мелких деталей, хотя можно один раз заморочиться настроить автоменеджмент лор-бука https://rentry.org/loremanager
В остальном никаких магических промптов. Хз, типа разве что детали какие-то указать но душа будет если модель сама поймет детали и ньюансы, ну а остальное в юзер-карточку пропиывать. Имхо. У меня так и в целом жить можно.
> Японский слоп вместо текста вызван
> претензия была не к слопу
> модель глючит от твоих настроек в ответ на простейший запрос.
Ладно, похоже, ты действительно самый обычный поех или законченный дурак. Мне сложно представить, чтобы кто-то настолько долго троллил тупизной. У меня все замечательно работает, пруфов не будет, как и ответов на твое дальнейшее нытье.
> I have heard that DRAM makers were diverting much of their production capacity on HBM so traditional DRAM were underinvested leading to a supply shortage.
походу да
штош

>нытье
Нюня обзывает кого-то нытиком, во это проекции, ору.
Ддр5 не может быть дешевле ддр4 вот и задирают
>шалаву
>в днд
Не осилит, параметров не хватит.
Мимо ебал шлюх и пытался с ними говорить, не вышло.
>потому что это не предусмотрено грамматикой
Я кстати проиграл, когда задал вопрос на русском, и мне модель начала срать чистейшим транслитом. Вполне себе нормальным, лол, там даже смысл был. Не Base64, как когда-то выдавала гопота 4, но тоже весьма сильно, я щитаю.
Идея пресета на самом деле хороша, его только дотвикать надо. Сейчас у него слишком узкие рамки. Зато ушло вот это (реально заёбывает).
скучно
>Идея пресета на самом деле хороша
Идея неплоха, признаю. Но срать символами это прям фуфуфу.
>Сейчас у него слишком узкие рамки.
То что нюня включил в пресет скрытый в таверне по умолчанию сэмплер, о котором вообще мало кто знает, в котором запретил русские буквы - это как-то больше на диверсию похоже, но прямо утверждать я это конечно не могу.
Угу, и релиз ддр6 будет хуй пойми когда, да и такое впечатление что производство ддр5 очень скромное в сравнении которое было у ддд4, хз, типа я ток не знаю по идеи производственные мощности ддр4 как-то же должны перенаправить на ддр5? Или они хотят все сразу оптимизировать под ддр6?
Аноны, какое минимальное железо нужно для запуска qwen 235b в адекватном (не ебу каком надо) кванте, и с норвальной скоростью?
На чём вы его запускаете? Сколько по деньгам вышла сборка?
Спасибо
На чём вы его запускаете? Сколько по деньгам вышла сборка?
Спасибо
Запускал на дуал зионе с дуал ми50. Получил свои нищие 6тг в ud_q4 и выключил.
Цена сборки примерно пачка кириешек и компот в столовой
Да херь, рынок рам регулярно штормит по разным причинам.
Huyase ebat'
> включил в пресет скрытый в таверне по умолчанию сэмплер
Грамматика же, где он скрыт? Но результат прям пиздец на любителя, избавляет от одного и насирает другим. Врядли фильтрация кириллицы сделана специально, сопутствующий урон.
Адекватный квант - от 4.5 - 5 бит. Нормальная скорость - априори врам. То есть потребуется от 160 гигов видеопамяти, в идеале ближе к 200 и не самой древней. Это дорого.
Приемлемая в рп скорость - выше 5т/с, 3й квант работает сносно. Для этого хватит 24-гиговой гпу и 128гб рама, если не выбираться на большие контексты. Это обычный десктоп который у большинства есть.
Смотря что считать адекватным квантом. Если четверку, то см . Мать Gigabyte Z790 UD AX, проц i5 13600k, видеокарта 4090 RTX - это почти потолок консумерского железа. На потолке(5090+i9 14900) думаю будет +1 т.с., максимум 1.5.
Стоило все это около 3к евро. Не ебу сколько в рублях, наверное процентов на 20 больше.
Если ты готов удовлетворится двумя битами(они неплохи, но стиль беднее и ошибки попадаются, сегодня сделаю сравнение мб) - то хватит и 64 гб оперативы. Но оператива - не самая дорогая часть, так что я бы на ней не экономил.

>Грамматика же, где он скрыт?
Скрыт в интерфейсе по умолчанию, его отображение надо включать отдельно, а для этого надо знать что он там есть. Собственно пруф - он выделен зеленым будучи включенным - так выделаются нестандартные семплеры, если их включить.
>Для этого хватит 24-гиговой гпу и 128гб рама. Это обычный десктоп который у большинства есть.
Охлол, даже у итт большинства такого нет, а за пределами этого треда у большинства древняя рухлядь с 1660-2060 в самом лучшем случае.
но ведь в бэ у каждого второго зарплата 300к в наносекунду... и курьеры по 100к+ делают


Ладно, отставив тролинг и включив русские буквы в нюнин пресет, конечно тот куда лучше работает, но его фильтры квену все еще мешают - насколько приятнее читать текст на семплере без фильтров(пик 1), чем с фильтрами(пик 2).
> и курьеры по 100к+
и это в день, не нужно забывать
Ну глупи. Это буквально нищенский десктоп. Тебя же не заставляют покупать 5090, а 128гигов это предел нищенских десктоп материнок/процев. Сейчас ОЗУ хоть и подскочила в цене но плашки ддр4 стоили копейки, а 24врам это буквально 50-60к руб за 3090 с алика.
Если у тебя не десктоп а компьютер для учебы то даже не заморачивайся и сиди в acig треде, пока дают бесплатно понюхать прокси с корпосетками ты будешь на голову выше и с куда меньшим пердолингов чем мы здесь почти по всем параметрам.
А казалось бы известная штука, ну не важно. Что делает там довольно прозрачно, но и эффект хз.
Здесь на просто нищуки и люди с улицы собрались, а таки преимущественно энтузиасты, обладающие чем-то кроме отсутствия.
> у большинства древняя рухлядь с 1660-2060
Лет 6 назад было бы актуально, года 3 назад их обладатели уже страдали из-за немощности в нейронках. Сейчас, наверно, и не осталось кроме единиц.
Просыпаешься значит в плохом настроении, а потом вспоминаешь что живешь в дс. Смотришь телефон - а там ежедневная дотация от мэра приходит, уже не так уныло.
>Смотришь телефон - а там ежедневная дотация от мэра приходит, уже не так уныло.
А еще пенсия по шизе каждый месяц капает, ага.
Сколько нынче? За веру в аги повышающие коэффициенты есть?
>Если ты готов удовлетворится двумя битами(они неплохи, но стиль беднее и ошибки попадаются, сегодня сделаю сравнение мб)
Если будешь делать сравнение, то бери IQ_2S. Имхо это минимальный приличный второй квант. А четвёртый бери обычный.
>Как это ускорить?
Попробуй поиграться (увеличить) со значениями -b, -ub в llamacpp. Дают неплохой прирост. Ну и контекст весь советуют на видяхе держать, место под него значит выделяй при разделении тензоров.
>отставив тролинг
гыыы, это не я не заглянул в жисон и не заметил что там семплер используеца, это не я не прочитал пост где об етом сказано напрямую а скачал пресет вслепую, это троленг а не дерьмо у меня в штанишках хаха нармальна я вас затроленговал
ну это уровень асига
>его только дотвикать надо
Мб поделишься когда дотвикаешь? Тогда у нас будет целых 2 (два) анона которые чем-то делятся кроме дерьма и помоев на рожу остальным
>Для этого хватит 24-гиговой гпу и 128гб рама, если не выбираться на большие контексты. Это обычный десктоп который у большинства есть.
Хуясе ошибка выжившего. То что Квенолюбы захватили тред не говорит о том что 8-32б энджоеры внезапно исчезли или заапгрейдились. Это нихуя себе не обычный десктоп
теперь если у тебя меньше 24врама128рама то сидеть тут некошерно, не по понятиям и опущ? вахта, плиз...
>чем-то делятся кроме дерьма и помоев на рожу остальным
у нас есть пример почему только этим делиться и надо а обратного примера нет. думай
Охлади тряску, нюнь. Трясешься в защиту пресета будто ребенка защищаешь.
>киска горит, как адский огонь
>сосочки тверды, как бусины
>резинку розового бра
Бля, какую же постную рыганину выдают локалки на русском. Это даже не уровень фикбуковских гомофанфиков с чонгуками, это чистейший нефильтрованный слоп. Примерно то же самое выдавала в свое время третья лама. После нее было ощущение, шо вот, одно-два поколения, годик потерпим, и можно будет спускать тухлую на оригинальные текста без дефолтных оборотов. Сколько уже прошло после этого? Много, а нихуя не поменялось. Но ради этого говна кто-то даже целые станции собирает и пылесосит таобабы.

>Примерно то же самое выдавала в свое время третья лама.
Третья лама в чем-то(её 70В модель) не потеряла актуальности даже сейчас.
>Сколько уже прошло после этого?
Десять месяцев. Последняя 3 лама вышла в декабре 2024 года.
>нихуя не поменялось.
Ну с декабря 2024 поменялось только то что старшие модели стали доступны на консумерском железе благодаря оффлоаду мое.
ты ведь реально его заебешь и он уйдет насовсем, что будешь делать без него??
>Третья лама в чем-то(её 70В модель) не потеряла актуальности даже сейчас.
Про то и речь, до сих пор потрошу её время от времени.
>Последняя 3 лама вышла в декабре 2024 года.
Ну оригинальная 3.0 вышла еще раньше. В 3.1 докрутили русик (особой разницы не было), остальные не пробовал
>поменялось только то что старшие модели стали доступны на консумерском железе благодаря оффлоаду мое
Так толстую 70B можно было спокойно в третьем кванте гонять, с частичной выгрузкой. Можно было даже во втором, это всё равно по мозгам было лучше, чем 30B командор в четвертом кванте. Хотя да, скорость копеечная была
Я не знаю как у вас, ребята, но у меня вообще не дымится на текст на английском. Ну просто фильтр какой-то, английский я знаю при этом на б2 примерно. Качество текста во всех популярных моделях намного хуже на русском, я это прекрасно понимаю, но ничего поделать не могу. За последние пару недель попробовал кучу моделей, из 12-14 млрд только старенький Немомикс что-то толковое на русском выдаёт, не знаю даже по каким критериям в шапке оценки выдавались
> смотрю последние замеры и понимаю, что потерял совсем немного
Я все еще думаю, что дело в процессоре, и при обновлении на что-то 12-ядерное ситуация поправится.
Правда, к тому времени, может 128 ддр не будут стоить 50к…
Напоминаю, что текст комплишен от чат комплишена отличается одной единственной вещью: кто обрабатывает спец-токены. Или фронт, или бэк. Для модели нет никакой разницы, в нее залетают всегда одинаковые буквы.
Если настроить текст комплишн идеальной точь-в-точь с чатом, и бэкенд не будет багованным, то будет зе сейм результ.
Ну, 4090 у меня нет. =(
Тестани в чем-нибудь меньше, если тебя не затруднит, хоть даже 30б-а3б, интересно посмотреть все же. --cpu-strict 1 и -ngl 0, че-то такое.
У меня 13400, насколько будет разница и будет ли она.
А я просто скачаю ту же модель, что и ты, и прогоню у себя.
Ваще любую на выбор, может какая у тебя лежит.
Если продать память, можно поднять 10к рублей… интересно…
>вообще не дымится на текст на английском
>знаю при этом на б2 примерно
Значит не знаешь. Или проблема в чем-то еще. Б2 подразумевает, что ты спокойно можешь воспринимать текст, даже не переводя его в своей голове, либо делая это практически моментально. В таком случае не должно быть никакой разницы для тебя между русским и английским. Оба должны в равной степени натирать твою шишку.
>не знаю даже по каким критериям в шапке оценки выдавались
По отзывам тредовичков, а среди тредовичков есть шизики и колобки с крайне специфичными вкусами. Этот список нужно воспринимать именно как список рекомендаций, а не как рейтинг.
>среди тредовичков есть шизики и колобки
Почему в шапке нет списка? Неделю не заходил чё изменилось?
>Или проблема в чем-то еще
ну вот наверное что-то ещё. У меня понимание близкое к 100%, но опыта общения оч мало, а с моделью нужно взаимодействовать, может тут барьер и кокблок
>Неделю не заходил чё изменилось?
Возможно какие-то проблемы со зрением обнаружились, сходи проверься на всякий случай. Потому что список на месте.

>но опыта общения оч мало, а с моделью нужно взаимодействовать
Ну так взаимодействуй, в чем проблема? Нейронки это идеальные инструменты для практики языка. Нет никакого страха обосраться, как при разговоре с носителем. И даже если ты обосрешься, нейронка тебя всё равно поймет. Считай, что это сейфти энваермент, где никто не будет косо на тебя смотреть, если ты артикли перепутаешь.
Я про список шизов, шиз
Клод умный, с клодом спорить не буду. Только где кроется трудность в развитии эмоциональных связей и привязанностей на другом языке? Всё это происходит с практикой. Читай, слушай, смотри. Потребляй контент. Тогда и связи появятся.
Мысль, конечно, здоровская, но я думаю лучше уж с большими моделями пиздеть платными ради языковой практики (хоть и зацензуреными), чем с кумерским чудовищем Франкнештейна



Что тут у нас в тредике?
Нюня опять обиделся?! Да что ж такое...
Идём по второму кругу, жду пресет на эир 4.6
Нюня опять обиделся?! Да что ж такое...
Идём по второму кругу, жду пресет на эир 4.6
>теперь если у тебя меньше 24врама128рама то сидеть тут некошерно, не по понятиям и опущ? вахта, плиз...
Я такого не писал, да и хоть это в целом база треда, но 24врама и 128озу это прям порог входа для более менее сносного комфорта в ебле с локалками, какой смысл ньюфагу ссать в глаза и говорить ОЙ анон да что ты у тебя 12врама! и всего два слота под озу?! ой ничего! нормально и не на таком запускали! Ну смысл? Я написал прямо как есть, и то бля 24врама 128озу это такой себе пососный уровень, типа как для локалки очень хорошо, но как для сравнения с корпосетками грязь из под ногтей. Это просто правда.

le classic
Предлагаю выгружать слои сразу в L2 кэш, вместо того чтобы ебаться с оперативной памятью. Вы прикиньте, какая там скорость будет? Вот именно.
>Мб поделишься когда дотвикаешь?
Лол, всем похуй
>Если
>и бэкенд не будет багованным
Слишком много допущений, особенно для жоры.
В регистры процессора. Только они работают со скоростью процессора.
> ошибка выжившего
Ну так, на порядочек. И в 22б параметрах нет ничего плохого если они активные
Та пофиг, главное чтобы нравилось. Это все очень субъективно.
Например, мне не особо нравятся многие описания на русском, в том числе кума. В большинстве своем всратая псковщина и неестественная речь будто дословный перевод инглиша. Нет бы использовать все богатство великого и могучего, заворачивая деепричастные обороты, или хотя бы все многообразие склонений, иногда. Исключения редки, но возможны.
Клодыня газлайтится как чмо, попробуй спросить ее почему произведения на чужом языке воспринимаются лучше - также приведет аргументов уже в пользу этого.
Содомит
>Лол
А чё оно должно делать? Ты бы хоть объяснил. Добавляет звёздочки? Нахуя?
>это в целом база треда, но 24врама и 128озу это прям порог входа для более менее сносного комфорта в ебле с локалками
конечно же до тех пор пока ты не проапгрейдился до 128озу ты такое в тред не писал. ну классика, анончик грейданулся и нужно обязательно отыграться на полную, не зря ж деньги уплочены
> у тебя 12врама! и всего два слота под озу?! ой ничего! нормально и не на таком запускали!
Ну так-то да. Ньюфагам быть без йоба железок не зазорно. Если не игрун или работаешь с этим то его может не быть. Осудительно может быть только если ты уже продолжительное время нейронками увлекаешься, а подходящими девайсами так и не обзавелся, вместо этого устраивая аутотренинг и всякий треш.
Суть грамматики в том, что токены, которые не подходят под описанное в ней выражение, будут исключаться, тем самым форсируя определенный формат. Можно убрать множественные переносы и предложения из одного-двух слов у квена на уровне семплинга, главное не породить еще большее зло.
>Ты бы хоть объяснил.
->
>Добавил в ультимативный пресет для квена действия
Ну то есть да, добавляет вот такое форматирование. У меня оно часто встречается.
>главное не породить еще большее зло
Уже, потому что решать проблемы модели через семплер это путь вникуда. В идеале семплинг вообще не нужен, это костыль.
Суббота и тишина
Всё было скамом
Всё было скамом
>Тестани в чем-нибудь меньше, если тебя не затруднит, хоть даже 30б-а3б, интересно посмотреть все же. --cpu-strict 1 и -ngl 0, че-то такое.
Ну хоть какая-то видеокарта у тебя есть?
Просто совсем без видеокарты это неюзабельно, контекст с озу будет вечно считываться.
>Б2 подразумевает, что ты спокойно можешь воспринимать текст, даже не переводя его в своей голове, либо делая это практически моментально. В таком случае не должно быть никакой разницы для тебя между русским и английским.
Если там лексикон С1-С2, то нет, не воспринимаешь, а сейчас модели именно такие и пошли.
>Напоминаю, что текст комплишен от чат комплишена
Напоминаю, что я, как и 99,999999999999999999% посетителей треда использую глупотаверну для рп. В ней, чтобы повторить возможности чат комплишена, нужно ебаться с лорбуками и это энивей будут дикие костыли. Интерфейс текст комплишена ужасный - мало того, что неудобный, так еще многое прибивает гвоздями. Единственный недостаток это невозможность продолжить сообщение, но это и в текст комплишене невозможно, насколько я понимаю, если у тебя есть послечатовые инструкции в виде инжекта на 0 глубину.
>Таблетки таблеточки.
Ну то есть по существу тебе нечего ответить и пошел проход в шизы, я понял. Ты вообще смотрел асиговские пресеты, как они устроены, какие промпты идут под какими ролями? Или кроме того, что "ТАМ МНОГА КОСТЫЛЕЙ ДЛЯ ПРОБИВА КОПРОВ, НИНУЖНО!!11" ты ничего не знаешь?
>А жлм хорош, прекрасно работает в чатмле
Ну то есть ты насилуешь хорошую сетку, заставляя ее работать в чужом для нее формате. Гениально, бля, может все же тебе таблеток выписать? Оно работает, потому что гмл сетка умная и токены +- похожие. Ладно там если сетка по умолчанию хуевая и от отчаяния там уже и форматы сообщений меняют (кому тут меняли так - эйру? квену? не помню, в сортах говна не разбираюсь)

> чтобы повторить возможности чат комплишена, нужно ебаться с лорбуками
> так еще многое прибивает гвоздями
> это и в текст комплишене невозможно, насколько я понимаю, если у тебя есть послечатовые инструкции
> какие промпты идут под какими ролями
> насилуешь хорошую сетку, заставляя ее работать в чужом для нее формате
Попробуй потоньше, такие шизики долго не выживают.
Срыгни в аисг.
> Единственный недостаток это невозможность продолжить сообщение
vllm кста умеет в чат комплишине, но это вопрос к тому что фронт знает о бэке
Немотроношизик, у тебя совсем котелок протёк в последние дни?
Двачую, это он. Он же срет про гемму 4, про эир 4.6, доебывает бедного анона пресетами, ноет и развлекается по всякому. Его уже однажды обоссал весь тред во времена когда он всех заебал с немотроном iq3s и ультрабазой для 24 врама. Челик видимо в асиг уполз на какое-то время, но ни то его и там обосссали ни то проксю обрубили вот и вернулся. Про смену формата и отупление модели из-за чатмл вообще ор, это тезис одного из шизиков на сервере драмера, он походу и там сидит. Вот что думскролинг, фомо и мушоку тенсей делают с неокрепшими умами


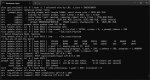
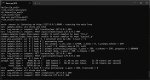
Решил потестить Q3_k_m, вдруг падение качества будет не настолько значительным чтобы с ним можно было примириться ради скорости? Увы, интел сделали только 2 и 4 квант, так что третий пришлось брать бартовского.
Ну вот что получилось.
При запуске с 32к контекста с выгрузкой 80 мое слоев на оперативку
С забитыми 0-1к контекста из 32к - ~8.1 т.с. скорость.
С забитыми 18к контекста из 32к - 365 т.с. обработка контекста, ~7.5 т.с. скорость.
С забитыми 30к контекста из 32к - 360 т.с. обработка контекста, ~7.1 т.с. скорость.
Т.е. скорость выше четвертого кванта всего на 0.7-1 т.с. Негусто. Для сравнения 2_k_s без контекста у меня легко выдает 11.2 т.с(пруф - пик4), а с контекстом 9.5-9.8.
Разницу в качестве вывода тройки по сравнению с четверкой я не заметил. Завтра постараюсь сравнить все три кванта - предлагайте варианты загадок/задач, кстати.
Четыре поста абсолютной дрисни, спешите видеть.
А что конкретно происходит? Так-то кнопка "продолжить" работает и с жорой, но он просто начинает новое сообщение вклеивать в старое (еще и ризонинг включает). Хз какой там промпт отсылается, надо потом глянуть в соснольке
Ты обещал большой глм 2 квант протестить
Будет, все будет. Как раз подбираю к нему настройки.
Не переживай, по дрисне ты рекордсмен, несколько тредов уже насеменил
Тут кому-то нужны эти тесты? Я тебе скажу по собственному опыту, что местным шизам на них плевать. Ты конкретные цифры принесешь - они скажут, что замерял не так. Не тем. Не в той конфигурации пк. Не на той модели. Не тот квант. Не та ось. Литералли усилия в нихуя. Кумь на здоровье молча, и все.
Обиженка, зачем порвался на ровном месте? Срыгспокни нахуй.
Анончик выложил тесты перфоманса на своем железе, честь и хвала. Так еще согласуются с остальными и близки к ожидаемым. Совсем идеально было если бы тут же обозначал свое железо чтобы не искать по треду.
> Можно убрать множественные переносы и предложения из одного-двух слов у квена на уровне семплинга, главное не породить еще большее зло.
>Уже, потому что решать проблемы модели через семплер это путь вникуда. В идеале семплинг вообще не нужен, это костыль.
GBNF Grammar, это не совсем сэмплинг. Это - первая попытка научить модели/бэкенды выводить данные в предсказуемом формате, чтобы их можно было легко парсить из кода. Т.е. инструмент сопряжения с кодом. Сейчас его подзабыли из-за появившегося для этих целей Function Calling, да только зря, IMHO. Т.к. GBNF в отличии от FC:
1. Работает с любой моделью. Оно вообще не полагается на модель, это механизм бэкенда.
2. Работает в Text Completion. Ему не нужен Chat Completion режим.
3. Проще и надежнее. Правда - немного менее гибко чем FC, и действует глобально на весь вывод, что для корпов - несколько неудобно тем, что будет мешать цензуре, скажем. В GBNF, к примеру, можно запросто забить правило по выводу нужного в ризонинге - дабы вывихнить мозги той же GPT-OSS нужным юзеру образом. Причем не ломая и не отключая ризонинг полностью - просто заставить модель завершать его нужным образом независимо от того что в исходных данных. :)
Что до боязни сделать "лоботомита" - здесь мимо. Точнее говоря - можно, если написать правила по идиотски. Но если делать с умом - то сам принцип GBNF, это не игра с вероятностями токенов как при попытках их банить или крутить веса. Немного по другому работает. GBNF подобно regexp пропускает только описанные токены, да. Вот только если токен не пропущен - запрашивается новый, так что общий размер вывода не срезается (хотя при желании можно написать так, чтоб выводилось только Х или между Х и Y предложений, скажем - гибкость очень большая). А сами правила, если по уму, описывают лишь определенные ключевые места и моменты в выводе, в остальном оставляя модели полную свободу. Это может немного замедлить генерацию, но при нормально написанных правилах - не портит вывод, хоть и дает возможность задать жесткое форматирование - например чтобы всегда сообщение начиналось с даты-времени-статуса чара в четком формате. Так четко, что его можно простым regexp гарантированно распарсить.
В общем - если кому хочется писать игру где локальная модель вроде мистраля на ламе или кобольде должна будет что-то делать - это будет первейший инструмент для того, чтобы сопряжение работало без глюков. Т.к. оно гаранировано работает, вне зависимости от размера и мозгов модели. (Если бэкенд поддерживает и не сломан, как Уга.)
> это не совсем сэмплинг
Работает как один из отскекающих семплеров, из пулла исключаются все токены, декодировка которых не подходит под шаблон. Просто он индифферентен к их вероятностям, общую суть правильно пишешь.
> Что до боязни сделать "лоботомита" - здесь мимо.
> гаранировано работает
Пример с поломкой модели при запросе кириллицы или рофлами с транслитом оче показателен. Но конкретно там в рп пойдет настакиваться всратый шаблон и через много сообщений взвоешь от структурных лупов и отсутствия гибкости.
Не будет списков, статусов и форматирования когда они нужны и уместны, не будет короткого или длинного ответа где нужно, не будет художественного описания окружения при первом попадании в него, появятся траблы при появлении нескольких персонажей и нпс и прочее. Все эти вещи, не важно случаются сами по себе или по пинку юзера, сильно оживляют чат и моделька с ним сама по себе более интересные ответы выдает.
Если результат устраивает - ну и отлично, главное не забыть убрать если надоест или покажется что что-то не в порядке.
Не трясись ты так, скоро местных шизов в каждом встречном на улице будешь узнавать.
Читаешься, как всегда себя со всеми отождествляешь. Не тебя, а всех. У тебя 8-12b параметров?



По многочисленным просьбам трудящихся тредовичков долгожданные результаты GLM-4.6 в q2_K_L кванте от товарища Бартовского.
Напоминаю что у меня i5 13600kf+4090+ddr5 2x64gb.
При запуске с 32к контекста с выгрузкой 88 мое слоев на оперативку:
С забитыми 0-1к контекста из 32к - ~7.8 т.с. скорость.
С забитыми 14к контекста из 32к - 235 т.с. обработка контекста, ~7.15 т.с. скорость.
С забитыми 22к контекста из 32к - 230 т.с. обработка контекста, ~6.7 т.с. скорость.
С забитыми 30к контекста из 32к - 227 т.с. обработка контекста, ~6.4 т.с. скорость.
Видно более серьезное чем у квена падение скорости с увеличением контекста. Сам контекст кстати тоже весит больше раза в полтора, на видеокарту всего 6 мое слоев влезло из 94, остальное место заняли 32к контекста, квантованного в 8 бит.
По качеству пока сказать железно ничего не могу, тут надо хотя бы денек в сложном РП провести. На очень поверностном тесте он показал что во-первых ГЛМ 4.6 в РП может и еще как, с легкостью обрабатывая сложные детали бэкграунда персонажей, выворачивая их в неожиданную сторону и глубоко раскрывая, во-вторых, русик у него чуть-чуть хуже квена(сужу по сложности используемых фраз и лексикону), в третьих, у него определенно лучше с фантазией(что не есть всегда хорошо, впрочем) чем у квена. Пока я тестировал его - меня реально заинтересовала история что он нагенерировал на базе моего старого ролеплея, в итоге я эти 32к контекста вместо того чтобы открыть старый ролеплей - заполнил в прямом эфире в процессе живого ролеплея, читая с живым интересом.
Пока предварительно это огромный вин и новый стандарт. Работая со скоростью квена 3-4 бит и выдавая текст как минимум не хуже него, он как минимум уже заслуживает стоять с ним рядом на пьедестале. А может вполне и опрокинуть его оттуда прямо в небытие.
Напоминаю что у меня i5 13600kf+4090+ddr5 2x64gb.
При запуске с 32к контекста с выгрузкой 88 мое слоев на оперативку:
С забитыми 0-1к контекста из 32к - ~7.8 т.с. скорость.
С забитыми 14к контекста из 32к - 235 т.с. обработка контекста, ~7.15 т.с. скорость.
С забитыми 22к контекста из 32к - 230 т.с. обработка контекста, ~6.7 т.с. скорость.
С забитыми 30к контекста из 32к - 227 т.с. обработка контекста, ~6.4 т.с. скорость.
Видно более серьезное чем у квена падение скорости с увеличением контекста. Сам контекст кстати тоже весит больше раза в полтора, на видеокарту всего 6 мое слоев влезло из 94, остальное место заняли 32к контекста, квантованного в 8 бит.
По качеству пока сказать железно ничего не могу, тут надо хотя бы денек в сложном РП провести. На очень поверностном тесте он показал что во-первых ГЛМ 4.6 в РП может и еще как, с легкостью обрабатывая сложные детали бэкграунда персонажей, выворачивая их в неожиданную сторону и глубоко раскрывая, во-вторых, русик у него чуть-чуть хуже квена(сужу по сложности используемых фраз и лексикону), в третьих, у него определенно лучше с фантазией(что не есть всегда хорошо, впрочем) чем у квена. Пока я тестировал его - меня реально заинтересовала история что он нагенерировал на базе моего старого ролеплея, в итоге я эти 32к контекста вместо того чтобы открыть старый ролеплей - заполнил в прямом эфире в процессе живого ролеплея, читая с живым интересом.
Пока предварительно это огромный вин и новый стандарт. Работая со скоростью квена 3-4 бит и выдавая текст как минимум не хуже него, он как минимум уже заслуживает стоять с ним рядом на пьедестале. А может вполне и опрокинуть его оттуда прямо в небытие.
>Не будет списков, статусов и форматирования
Будут или не будут - зависит исключительно от составленных правил.
В отличии от любого простого тупого семплера который действует глобально для токена во всем выводе - GBNF позволяет задать место действия - как regexp. Это ключевая разница. Можно, скажем, запретить вывод списков исключительно в первом параграфе - а во втором - оставить свободно. Можно задать "статус-бар" - причем не только чтобы начинать с него (как это можно достичь префилом), но и чтобы заканчивать им. И это будет работать.
Никаких траблов со списками, форматированием, несколькими персонажами, и прочим тоже не будет просто из-за факта использования GBNF - но тут все зависит от составленных правил, как напишешь, то и получишь. Причем сам GBNF не влияет на модель. Только на фильтрацию вывода бэкендом.
Пример с отрезанием кирилицы как раз это и показывавет. Правило не позволяет вывод русских букв, бэк перезапрашивает токены, пропускает транслит. Можно добавить разрешение на русские буквы - будет прямой русский в выводе.
Кстати, я кажись знаю, почему их в пресете изначально нет. :)
Большой квен конечно няшка и умница, но я, когда его в iq2s запускал у себя просто так - подметил, что с русским у него не так хорошо, как хотелось бы. Явно в такого кванта недостаточно. Но самый большой прикол в том, что он периодически кирилицу и в англоязычный текст вставляет (как и иероглифы тоже) - отдельными символами, изредка. При этом на английском он пишет в целом хорошо, если бы не эта "орфография". Вот и засунул автор пресета отсечку для всего лишнего.
>Пока предварительно это огромный вин и новый стандарт. Работая со скоростью квена 3-4 бит и выдавая текст как минимум не хуже него, он как минимум уже заслуживает стоять с ним рядом на пьедестале. А может вполне и опрокинуть его оттуда прямо в небытие.
Ну, это вряд-ли, IMHO. Это ж просто разные классы моделей. GLM 4.6 ты никак на 64 ram не впихнешь, а квен - худо-бедно, но можно. А в остальном - рад за появление такого топа.
>на 64 ram
А, погоди, он же писал что у него 2х64gb? То есть 128 гигов? Или 64 все же?
Если бы на 64 гб можно было запускать квена 235 в 4 битах и глм 4.6 в 2 битах - тут бы все так делали, а так я один из первых итт кто впринципе получил доступ к этим моделям, потратив 400 евро за эти две плашки по 64 гб. Но теперь после восторга от глм 4.6 я все же думаю что не зря потратился.
Ты невольно подтвердил наблюдение о том, что в случае когда большая часть модели на профессоре, жора проседает гораздо меньше, чем при полностью на гпу. На больших не пробовал случаем?
> это огромный вин и новый стандарт
Жлмчик умница, всегда им был.
На каждый чих придется туда лезть. Слишком неповоротливая штука, а заниматься усложнять - есть более перспективные вещи которыми можно заняться.
> не влияет на модель
Влияет напрямую, потому что управляет ответами, которые становятся контекстом. Влияние может быть как положительным, так и негативным. Самый яркий случай - когда выдача не соответствует ожидаемой на запрос юзера, паттерн запоминается и случается сноубол пиздеца.
> Пример с отрезанием кирилицы как раз это и показывавет. Правило не позволяет вывод русских букв, бэк перезапрашивает токены, пропускает транслит
Пропускает ~~~~~~~~~~ и полную поломку если не повезло в начале. И нет там "перезапроса", токены в самом начале обрезаются.
В своих рассуждениях ты апеллируешь к принципу работы, не осознавая его полностью, и некоторому абсолютно идеальному и универсальному регэкспу, который невозможен. Под каждый случай требуется свой.
> периодически кирилицу и в англоязычный текст вставляет (как и иероглифы тоже)
Что-то совсем лоботомированный квант.
Тем не менее, стабилизировать формат если ты твердо хочешь его и принимаешь последствия, или убрать баги кванта - вполне.
>На больших не пробовал случаем?
Контекстах? Пробовал только четырехбитный квен на 49к и 60к. Там четко примерно по арифметической прогрессии падает с 6.45 при 32к контекста до 5.95 и 5.7 т.с при 49к и 60к соответственно.

В общем, все скорости устарели.
Я отключил в биосе тухлоядра инцел(они у меня давно были выключены, но обновка биоса для новой оперативки их включила обратно) и получил +1-1.2 т.с. на всех моделях. Казалось бы, -t должен давать тот же эффект, но нет.
Новые скорости:
ГЛМ-4.6
На 0 контекста - 8.9 т.с.
На 30к контекста - 7.4 т.с.
Qwen 235 4 bit
На 0 контекста - 8.3 т.с.
На 30к контекста - 7.3 т.с.
Qwen 235 3 bit (на пиках)
На 0 контекста - 9.4 т.с.
На 30к контекста - 8.15 т.с.
Я всё таки в ахуе. Китайцы блять чето стараются, модельки делают для погромистов и кодеров, а тута двачеры сидят такие, ура, новая моделька, давайте ка я соберу 5090+дохуя рам+i9 , и всё это ради кума, дрочить дрочить писька!
ахаха бля) Как же забавляет
мимо собираюсь брать 4090 для того же кума лол
ахаха бля) Как же забавляет
мимо собираюсь брать 4090 для того же кума лол
Всех приветствую. Пол года назад забил хуй на локалки, но сейчас сорвался и снова собираюсь вкатится. На борту 12 врам, средненький проц и 36гб рам. Что сейчас актуально и что годного можно засунуть в эту систему?
Заебись же что у людей есть возможность чудовище такое собрать ради хуйни
Аноны, кто нибудь знает за positions-beta-priced-cheap ?
Кто хостит эту хуйню? Собирает ли оно логи? И какой вообще им резон бесплатно выдавать апишки?
Кто хостит эту хуйню? Собирает ли оно логи? И какой вообще им резон бесплатно выдавать апишки?
>Дайте ваш самый ебейший пресет (промпты) которые вы используете
https://pixeldrain.com/l/47CdPFqQ
в конце списка файлов

> 99,999999999999999999% посетителей треда использую глупотаверну для рп
я не юзаю, то есть максимум 98%
не знаем
хз
собирает
чтобы продавать ваши логи
кому то нужны блять логи кума? Зачем ?
Потому что за них платят.
я с типами пообщался щас в дисе, кто эту тему хостит.
оказывается вообще почти не покупают, логи сохраняют тупо похихикать. + в логах нет личной инфы, айпишника, или чего еще. Только инпут и аутпут. Стоп тряска.
Kek. Поверил. Ага. Согласен. Погнали еще на сетях сбера и яндкеса кумить.
>36гб
Это как? 32 гб+4 гб?
>Что сейчас актуально и что годного можно засунуть в эту систему?
Ну наверное квен 30b a3 и gpt oss 20b, с оффлоадом мое слоев. Если плотные модели - то там только тьюны мистраль немо 12b, ну либо гемму 12b. Настоящая жизнь на 16 гб врам начинается, где уже можно как-то вместить мистраль 24b.
Вообще ты можешь просто докупить рам до 64 гб и катать глм аир 106B и gpt oss 120B на скоростях около 5 т.с.
Не слушай шиза выше. На твоем конфиге нормально пойдет 24b мистраль с частичной выгрузкой, будут адекватные ~6-7тс. А если докупишь еще 32гб озу - сможешь довольно урчать на эйре 106b в ~8-9тс.
>урчать на эйре 106b в ~8-9тс.
тем временем эир: 7т/с на 3090, 128 рама в q4
шиз выше ответил честнее и в остальном тоже
типы действительно не врут, даже подогнали мне рабочие ключи дипсика апишки несколько.
У меня 12/64 и эйр в Q3_K_XL выдавал 9тс. Ты с настройкой ламыцпп не разобрался по ходу, и шиз выше тоже.
>логи сохраняют тупо похихикать
)))0)0))
Лучшая реклама локалок что я видел, бтв.
>в логах нет личной инфы
Каким образом личная инфа пропадёт из логов, если домохозяйка просит нейронку составить резюме, вкинув своё фио, стаж, телефоны, в другой сессии она спрашивает среднюю цену на её хату указав адрес, в другой сессии она просит нейронку стать её виртуальным сыном чтоб поскакать на его коке?
в логах кум-ролеплеев нет личной инфы (если ты долбоеб ее не пишешь чару) . я лично не пишу я ж не ебнутый.
Ну ты не пишешь, кто-то пишет. Ну и твой айпи=твоё фио и адрес.
Да нафиг видеокарта, я хочу понять тесты по процу.
Видяхи то другое, речь про целесообразность DDR5 и подходящие процессоры. =) С видяхами тестить дичь, с разными тем более.
Попробуй GLM-4.6 от бартовски Q2_K_L, скорость должна ~6.5+, зато интересно мнение по качеству модели.
Во, да.
Шикардос же, ну!
А Я ГОВОРИЛ ЧТО ТУХЛОЯДРА УБИВАЮТ СКОРОСТЬ
А мне кто-то не верил.
Если линукс, то юзай taskset -c и все, не надо отключать их.
Хм, интересно, такой высокий результат дает 13600 или 4090?
>Я отключил в биосе тухлоядра инцел
>Если линукс, то юзай taskset -c и все, не надо отключать их.
Можно подробнее, о чем вы вообще? Понятно ровно нихуя, но интересно пиздец, что это такое и каким образом оно влияет на скорость генерации
> taskset
не работает, по крайней мере в дебиане оно точно сломано.
подозреваю, что дело в этом:
одно нормальное ядро вытягивает 10-15 гигабайт в секунду от общей скорости оперативы, одно еффективное ядро гигабайта два-три, если вместо нормальных ядер обработка идёт на тухлых, то получается мощная просадка в скорости генерации. сука чурка ебучая иди нахуй со своей капчей
> Видяхи то другое, речь про целесообразность DDR5 и подходящие процессоры.
4800/3200 = 1.5
6400/3200 = 2
насколько для тебя целесообразно ускорение в полтора-два раза?
лан если взять разогнанную ддр4 и тухлую ддр5, то будет всего 30%
4800/3600 = 1.33
4800/3600 = 1.33



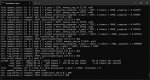
>я хочу понять тесты по процу.
Ладно, провел тест с -ngl 0 -ctx 16384 на третьем кванте квена, он влез в оперативку целиком, но он все равно залил какой-то кэш(около 2-4 гб) на видеокарту. Но думаю что 2-4 гб врам есть у всех, даже самых последних нищих.
Заполнено 0к контекста из 16к - 5.5 т.с. генерация
Заполнено 5к контекста из 16к - 3.3 т.с. генерация
Заполнено 12к контекста из 16к - 2.1 т.с генерация, 100 т.с. обработка контекста
Как всегда - контекст на запуске только на рам все замедляет в нулину, потому я и считаю этот тест хуйней, так как у любого сейчас есть сраные 8 гб видеопамяти чтобы запустить с -cpu-moe, которые дадут совсем другие рузультаты.
>+ в логах нет личной инфы
То то, когда я однажды задел проксихолдера из асига, он выложил в тред мой айпишник.
Инцел сходил под себя сделав половину ядер в 13 поколении энергоэффективными, т.е. тухлыми. На бумаге все было гладко - норм ядра обсчитывают важные задачи, а фоновые обсчитываются е-ядрами. На практике даже ограничивая через -t потоки на p-ядра, е-ядра самим своим присутствием в системе замедляют генерацию в ламе цпп на 10-15%. При этом без ограничения через -t наблюдается еще и дополнительная просадка в 10-15%.
>контекст на запуске только на рам
>с -cpu-moe
цпу мое оставляет во врам не только контекст, но и слои внимания, а оно очень больно считается на проце и очень быстро на видяхе.
Спасибо что обьяснил мою мысль почему запуск с -cpu-moe лучше чем та порнография что анон запросил, а я зачем-то сделал
На следующей неделе будет Геммочка. Твердо и четко.
Я уже квен переименовал в джеммочку4 и коуплю
Мистраль тупой, увы, я уже поэксперементировал. Из того что в шапке мне синтейв понравился. В четвёртом кванте 5 т\с. долго конечно но зато ответы качевственные. А что за выгрузка тензоров? Я глядел в интеренете, там какая то высшая математика нахуй, есть варианты для 3060?
>А что за выгрузка тензоров?
Если не вдаваться в высшую математику, то это когда из слоев мое модели выжные части, которым нужен быстрый процессинг грузит видеокарта, а остальные - грузит на рам. Это очень сильно ускоряет работу, позволяя запускать мощнейшие модели с приемлимой скоростью даже на старом говне с достаточным количеством оперативки.
Чтобы запустить в таком режиме, ты сначала грузишь все слои на видеокарту через -ngl 999, потом сгружаешь мое слои обратно в оперативку командой --n-cpu-moe n, где n - число слоев, что тебе надо сгрузить с видеокарты на оперативку, чтобы с одной стороны на видеокарте было как можно больше слоев, а с другой - чтобы у тебя не было переполнения врам.
>А что за выгрузка тензоров? Я глядел в интеренете, там какая то высшая математика нахуй, есть варианты для 3060?
От поколения карты не зависит. Зависит от количества видеопамяти и конкретного файла модели которую грузишь. Серебряной пули нет - под каждую комбинацию будет свой эффективный вариант, даже другой квант будет влиять. Схалявить не выйдет - вникай.
Для MOE моделей немного проще - есть соответствующий ключ, который легко делает выгрузку близкую к оптимальной.
А система сильно лагать будет если выгрузить тензоры на сколько можно? Я хоть мангу читать смогу пока ответы генерятся?
Не только MOE - с плотными тоже помогает. Но там уже думать, и вручную regexp писать, т.к. нет такого однозначного решения как просто "экспертов на CPU".
>потом сгружаешь мое слои обратно
Не слои, а тензоры.
МОЕ поделены на несколько отдельных де-факто нейронок меньших размеров, каждая со своим обучением. Но активно работает из них лишь одна, а остальные почти не задействованы и лишь корректируют вывод на основе своих данных. По сути используются как база знаний. В таком виде если главный эксперт помещается на видяху, всё работает быстро. От остальной МОЕ части вклад небольшой, но временами полезный, когда нужных знаний в активной части не оказывается. А главное такой костыль работает очень быстро.
А тензоры - это части тех самых экспертов, только идут колонками, а не слоями. Если выгружать на видяху слоями, то будут выгружены первые слои всех экспертов, и магия не сработает. Плотные модели тоже можно грузить тензорами, но результат будет хуже, чем слоями.
Оставляй немного свободной видеопамяти под другие задачи, вот и всё.
В этом смысле заметных различий с обычной выгрузкой слоев нет.
Но в случае правильной выгрузки - генерация будет быстрее, чем если просто слои выгрузить. Метод позволяет запихнуть в более быструю VRAM видеокарты именно те части слоев (тензоры), что требуют большего и быстрейшего обмена данными. А просто в слое - лежит все оптом.
Это все в любом случае нужно, только если модель целиком в VRAM не лезет. Ну, или если в системе несколько видях разных поколений - шустрая и медленная, чтобы опять же на шуструю сгрузить больше нагрузки.
>если главный эксперт
Если он есть. У гпт-отсос например нет шаред эксперта.
Пока все 16врам64рам врамцелы кумят на эире и квене я кайфую от гпт осс 120 в рп. Почти месяц ебался с тем как ее промтить и настроить но теперь кум льется рекой. В треде как всегда неосиляторство процветает, даже квенчик хейтили пока готовое не принесли

Тема с ми50 ВСЁ!
В начале подорожали до 1100, потом 1400, сейчас 3-4к.
Тем кто успел купить себе пару штук по 10-11к что бы получать свои 50т/с на гемме жму хуй, остальным соболезную
В начале подорожали до 1100, потом 1400, сейчас 3-4к.
Тем кто успел купить себе пару штук по 10-11к что бы получать свои 50т/с на гемме жму хуй, остальным соболезную
> Казалось бы, -t должен давать тот же эффект
Нет. Просто попробуй перевести профиль питания в максимальную производительность и вообще не задавать -t, получишь тот же эффект но без необходимости куда-то лезть и отключать.
Минусы будут?
> получать свои 50т/с
В чем хуй? Это скорости 5090.
> В чем хуй? Это скорости 5090.
В 4 потока на gemma3 27b awq. В один поток 20
5090 вряд ли такая медленная, дожна ебашить куда лучше этих копролитов

>добился положительных результатов
>похвалился
>никакой конкретики
Ну и зачем ты это принёс? Кто и что от этого получил в треде? Если ты так боишься критики за свои советы (которые хотя бы имеют ненулевой шанс заслужить также и похвалу), почему ты не боишься критики за пустословие и обвениней в пиздеже и троллинге?
Хотя, есть шанс, что это и правда пиздёж и троллинг. Но, опять же, зачем? Кто тут поведётся? Какой реакцией тебя наградит?
Не понимаю мясных мешков. Они странные.
>Тема с ми50 ВСЁ
У меня дежавю. Может, ещё не всё? Закупимся по 3-4, потом ещё и по 5-6 увидим? Можно будет перепродать на лохито за 4.5. Может, поэтому их и скупают? Сидит тут в треде какой-нибудь кабанчик, мониторит, к чему интерес у пользователей нейросеток для перепродажи на местном рынке за x3 прайс? А китаец видит спрос и тоже повышает цену. Минутка конспирологии закончена.
Это называется 'пошли вы все нахуй, ублюдки, я смог, но с вами не поделюсь и буду прав'. Кому надо сами осилят и настроют, а цель моего поста тупо донести что с гпт осью имеет смысл попердолиться
>я смог
Без пруфов - хуй простой. Тащи скрины, что он там тебе выдаёт.
>пук-пук, среньк. Пошли вы нахуй! Среньк, пук-пук, это вы штаны снять забыли, а не я!
блядь, да как так я сообщением промахнулся? это было адресовано , естественно
Терпите, терпите. Хуй я вам че покажу. Дам только совет тем кому не лень: промтите ризонинг и юзайте грамматику. Как минимум анон который этот семплер притащил разберётся, а на нахлебников похуй вообще

Ещё больше обычного мозг квантовался, шизик?
ОКРщик, спок. Мир не вокруг тебя и твоей нюни крутится
>Нет. Просто попробуй перевести профиль питания в максимальную производительность и вообще не задавать -t, получишь тот же эффект
Сделал.
И получил я снова старые скорости из вместо
Нет, тут только отключать.
Да нет, я тоже смог когда с гопотой разбирался. Просто, зачем? Есть ГЛМ, есть квен, они лучше.
>юзайте грамматику
Нахуй она там нужна вообще?
Кто знает тот знает анончик, если ты знаешь как работает гпт ось и как писать грамматики то у тебя и вопроса такого не возникнет
"Хуй в жопе, но есть нюанс".
> 5090 вряд ли такая медленная
Именно такая, просто это на q8 уже на некотором контексте в один поток.
Мм, бизнес уровня б, спеши влошиться пока поезд не ушел!
> Дам только совет тем кому не лень
Вау анончик, это действительно работает! Поковырявшись, удалось заставить осс писать канни кум стихами, и тутже его переводить на русский сохраняя рифму!

Какая настройка сэмплеров под гранит микро лучше всего пойдёт? Техт комплетион режиж
Ось может быть гораздо лучше Глэма если заебаться и настроить ее как надо. Только никому это нахуй не надо вот и все, легче забить
> сэмплеров
Значение знаешь?
А формат разметки выглядит верным.
Лучше дипсика в рассуждениях и кодинге, лучше жлм, квена и прочих вместе взятых в общих вопросах и рп, лучше васян тюнах в куме. Возможно если ты пиздабол
Ты нахуя порвался, мань? Да ещё и контекст проебал, аут оф баундс чтоли? Очевидно речь про Глэм Эир а не большую его версию. Ещё и с Писиком сравнил, бляяя, как же тут трясутся снихуя иногда)

>Значение знаешь?
Знаю. Температура, минпи, два притопа, три прихлопа.
Разрабы советуют ставить температуру и топП на 0, но свайпы же одинаковые получаются, ибо жадная выборка.
А если задрать, оно шизит.
Взял дефолтный пресет в Таверне, выставил верхние как пикрил. Иногда хорошо пишет, иногда кал говна мочи
Если бы хотел затралить тред - я бы рассказывал какая кими к2 охуенная в 4 кванте.
А "тралить" всех скрытыми способностями гопоты, которую уже все обсосали и обоссали - ну это считай самому себе в рот спускать прилюдно.
А "тралить" всех скрытыми способностями гопоты, которую уже все обсосали и обоссали - ну это считай самому себе в рот спускать прилюдно.
Да-да, мне похуй. Это было написано не для тебя и не таких как ты. Сдесь есть пара анонов как минимум которые играются с разными моделями и пердолятся пытаясь их раскрыть. Мб кто из них тебе хлебные крошки и скинет, а я нет. Логов не будет, один хуй ты будешь смеяться и пищать что гавно из-за отсутствия, а уж пресет ты и подавно не заслужил, хуй ленивый
Блядь, тут жир уже с экрана сочится.
> Нет нет я не порвался, это ты порвался
А, ты там вопрошал безотносительно прикрепленной пикчи. Тут базу из стандартных и крутануть температуру. Микро это 3б, она априори будет шизить и работать нестабильно.
Top P 0.25 маловато, а Top K 0 неоче, их желательно в паре юзать, одиночным норм min_P работает.
Может и ахуенная, там в сентябре обнова выходила.
Жир за собой подотри, раскрыватор
Вахтёр проигнорил собственный обсёр и ответил гринтекстом, ахаа бля. Хозяин треда, царь во дворца
Заметили как нюнечка проигнорировал все хвалебные отзывы на пресет и зацепился за один негативный, обиделся и опять решил больше не делиться?
>Микро это 3б, она априори будет шизить
Обосрался малость, там не микро, там Tiny. То есть, 9Б.
Ну и зачем ты это принёс? Кто и что от этого получил в треде?
Кто тут поведётся? Какой реакцией тебя наградит?
Не понимаю мясных мешков. Они странные.
> Ну и зачем ты это принёс?
Так-то большая часть этого треда, нытье, манямир, набросы. Зачилься и обсуждай, или делай что-то полезное.
Всю эту херню осуждаю, но наблюдение забавное и ценность того поста выше твоего.
Ты тупой? Тебе задали простой вопрос: зачем ты пришел в тред с бесполезным набором букв и бахвалишься этим.
Кто-нибудь пробовал порпшить на qwen3-next? Я её за какой-то хуй развернул, заебавшись с vllm, приколами с совместимостюь с pytorch и куртколибами, так как хотел поднять nvfp4, но плюнул и поднял awq 4bit. И вроде оно работает, но я не понял, как мне нормально пятую GPU подрубить, чтобы работало нормально, а то сейчас скорость очень сильно дропается по сравнению с четыремя картами.
Просто хочу узнать, а стоило ли оно того, перед тем как подниму таверну и разочаруюсь.
Просто хочу узнать, а стоило ли оно того, перед тем как подниму таверну и разочаруюсь.
У последних поколений Intel есть энергоэффективные ядра, которые, если подключить llama.cpp, тормозят генерацию. Чей быдлокод — интела или Жоры, — не ясно, ну и хер с ним.
Тулза taskset позволяет указать конкретные ядра для запуска.
Производительные идут с 0 и далее (пока не кончатся=), где четные — физические, нечетные — виртуальные (но если их подрубить, 0,5 токена докинется).
Для 6 ядер (13600, например) команда taskset -c 0,1,2,3,4,5,6,7,8,9,10,11 llama-server … выдаст наибольший тпс. Может там проще диапазон можно прописать, мне лень было гуглить.
Сочувствую, в убунте все заебись.
О том и речь, что у меня 6000/3200 = 1,4.
Не сложилась у меня математика.
Учитывая, что квен на 3200 выдает 4 токена, то на голом проце на 6000 должно быть 7,5. Но никаких 7,5 и близко нет, потому что где-то сосамба.
Я все еще думаю, что 6 физических ядер дохлого 13400 не хватает для раскрытия оперативы. Еще полгода назад какой-то чел писал, что ему 13900 не хватает, и я начинаю ему верить, ибо хер мне, а не 6000/3200 = 1,875.
Я очень надеюсь, что в тред придет человек, обладатель настоящих 128 гигабайт на 6000~6400 и покажет нам 8 токенов на чистом процессоре без видеокарты. Но пока такой человек за месяц не появился.
Проблема, что на 6000 я получаешь в лучшем случае 40%, а чаще — 30%. Получается, что у меня нет разницы между 4800 и 6000.
> Заполнено 0к контекста из 16к - 5.5 т.с. генерация
Хм-хм-хм… Спасибо. Значит у меня проблема с железом какая-то, все же.
У меня на винде квен выдает 3 тпс, на линухе 4. Т.е., если у тебя такое же поведение, на линухе можно ожидать 6,8 токена, что близко к 7,5.
Контекст и все остальное совершенно похую, суть теста исключительно в процессоре и псп. Естественно, никакого отношения к реальному применению нет, но какая-бы быстрая видеокарта не была, ~2/3 модели все равно процом обрабатывается. Поэтому я пытаюсь разобраться, хули у меня с такой же оперативой не 6,8, а 5.
Надо будет найти у кого-то проц и попробовать что-то мощнее.
Спасибо за тест!
Да, кагбе, похуй, когда речь идет о замере чистой генерации только на проце. Контекст ваще не важен, по сути. На нулевом меряется и хватит.
Блядь, тест с -cpu-moe не лучше, а хуже, потому что он не дает оценить производительность проца + оперативы чистой. ) Мерять проц по видяхе — шиза же. Кажись, ты не понял. что у тебя просили, но спасибо, что сделал, в любом случае.
Роутера?
———
Нихуя про mi50 подрыв случился.
50 тпс на гемме 3? Вроде как сильно круто, из риал?
Но другой вопрос — а почему не что-то побольше? Там же должно быть 4 карты = 128 гигов, скока тпсов в квене, скока в глм? Или геммочка ван лав и лучше срамо-моешек? =)
Прости, если уже писал, я запамятовал.
А какая у тебя материнка и оператива? Проц, вроде бы, 13600kf?
Тензор параллелизм разве не со степенями двойки работает?
По поводу запуска у них есть прям официальные докер образы.
Если у тебя не более одного запроса и не одинаковые карточки то запускай жору
>Роутера?
Шаред эксперта. В квене один из экспертов задействован всегда, у гопоты такого нет. Просто душное замечание, забей.
Не, я просто не спец, уточнил.
Роутер-модель есть, вероятно, но она слишком маленькая, чтобы сильно ускорять, я тоже смотрел. Общих тензоров мало. Выгружается прям совсем чутка в видяху, смысла почти не имеет.
А в моделях, где и роутер крупных, и общих слоев много — там буст прям очень чувствительный.
Кажись, кими к2 такая (но я не проверю=), и глм-4.6 тоже прилично бустится, как мне показалось.
Ну пофиг, да.
>А тензоры - это части тех самых экспертов, только идут колонками, а не слоями. Если выгружать на видяху слоями, то будут выгружены первые слои всех экспертов, и магия не сработает. Плотные модели тоже можно грузить тензорами, но результат будет хуже, чем слоями.
Что-то звучит как хуйня, если честно. Или я чего-то не знаю? По идее же каждый слой состоит из тензоров разного вида, в т.ч. и тензоров экспертов. Мы обычно выгружаем первые n экспертов. Если бы они были в т.н. "колонках", то получается мы бы выгрузили n строк всех тензоров и, по твоим словам, "магия не сработает".
Я не он, но:
Разные тензоры требуют разных вычислений (был анон, который не поленился много померять и табличку составил).
Какие-то колонки при обсчете на видяхе считаются сильно быстрее, чем на проце, какие-то колонки — не очень. Поэтому имеет смысл ускорять только определенные тензоры экспертов.
А выгружая слои, ты теряешь немного потенциала.
Плюс, шаред эксперт грузанется не целиком, а лишь на часть слоев.
Т.е., ты получаешь ускорение, но оно не оптимально.
У меня пять одинаковых 5060 ti 16gb. И четырех хватило, чтобы я смог сделать свайп в чате на 27к токенов, увидеть, как модель игнорирует инструкции и уходит в луп, повторяя два слова до конца абзаца, при том, следующие абзацы были нормальные.
Да и потом в другом чате посвайпал, там качество все-таки упало, причем заметно. Не знаю, квантование ли слишком агрессивное от cpatonn (awq 4bit), то ли сама модель обсирается чаще, но решил, что 14 tps на большом квене в q4_k_l от Бартовски на жоре будет лучше, чем 100 tps на qwen3-next.
Попробую еще погонять, когда настроение порпшить будет, а то я много времени проебал на запуск модели. Может, скачаю другой квант и попробую переписать карточки, которые я накачал. Если большой квен может сожрать типичный слоп с chub.ai, то нексту лучше подготовить хорошую карточку.
А может, просто хуй забью на эти все квены (даже закрытый qwen3-max имеет те же болезни, специфичные для квенов) и перейду на glm-4.6. Как ассистент и как кодер он мне понравился, да и в RP его хвалят.
Что-то я насрал простыней, сорян, всё-таки несколько миллионов токенов за месяц не проходят бесследно для мозга
>У меня пять одинаковых 5060 ti 16gb.
Больной ублюдок.
Ну ебана, все начиналось с одной карты, потом докупил вторую, потом еще три карты докупил, когда собирал риг. Да и цена в 42к на озоне выглядела привлекательно.
Получилась хуета полная на самом деле, думаю, как появится больше свободных бабок, то я продам 4 картв и куплю себе blackwell на 96гб. А последнюю оставлю под sdxl и tts.
> в убунте
а точно заебись? у вас там системудёй ещё сильнее насрано, чем в дебилане.
вот такая хуйня происходит https://askubuntu.com/questions/1526983/why-does-systemd-change-the-cpuset-of-a-service
> When running the application, I can use HTOP to see each of the 12 threads assigned to the appropriate cores CPU 0 through 11 and running fine.
> After some time (roughly 2-3 mintues), I notice that the CPU threads will no longer be locked to these 12 CPU cores but rather will be assigned to CPU Cores 0-7 or CPU Cores 8-15. I am not sure why it will be one or the other set. But the key thing is that they will only be running in the first 8 or last 8 CPU cores.
ни isolcpus ни taskset не работает, процессы лламы прыгают по рандомным ядрам, а не по конкретным указанным.
> 6 физических ядер дохлого 13400 не хватает для раскрытия оперативы. Еще полгода назад какой-то чел писал, что ему 13900 не хватает,
> одно нормальное ядро вытягивает 10-15 гигабайт в секунду от общей скорости оперативы
60002/128 = 93 гигабайта в секунду общая скорость с 2 каналами
610 = 60 минимум
6*15 = 90 скорее всего
итого 6 ядер должны тянуть от 60 до твоей максимальной bandwidth
конечно, желательно бы проверить с 8 ядрами, но имхо дело в чём-то другом, а не в проце
ебаная макака с её ебаной макабой
6000 МТ/с umnozhit 2 канала delit 128 бит ravno 93 гигабайта в секунду теоретический максимум
гигов 80 практический
6 ядер umnozhit 10 ГБ/с ravno минимум 60 гигов
а скорее 90
Ну я проверял через htop — все было четко. Ни разу не глючило за месяц, всегда только p-ядра. Последняя убунту.
Для DDR4 и 50 псп советуют 5-6 ядер (ну и вчера я проверил — между 6 и 11 физ.ядрами разницы реально нет), так что скорее 8-10 гб/с в среднем. Какого-то прыжка на 50%+ между соседними поколениями не было, так что кажется актуальным.
Для 88 было бы неплохо иметь 10-11 физических ядер при таком раскладе.
Я калькулировал так.
НО, материнку я тоже подозреваю.
И с практическим максимумом тоже вопрос, аида-то показывает 88 (когда винду ставил), но может ето наеб на короткой дистанции, хезе.
>обладатель настоящих 128 гигабайт на 6000~6400 и покажет нам 8 токенов на чистом процессоре без видеокарты.
Звучит слишком кучеряво. Есть какие-то основания для таких цифр? Напомню я на 5600 выжал всего 5.5.
>6 физических ядер дохлого 13400 не хватает для раскрытия оперативы
Это. У меня проц боттнечит скорость оперативы и вместо 89к МВ/s которые должны быть при моих 5600 - я вижу 82к MB/s.
>У меня на винде квен выдает 3 тпс, на линухе 4.
Попробуй отключить е-ядра в биосе. Потому что у меня с ядрами было связано два повышения скорости - первое - когда я локализовал генерацию на p-ядрах через -t(либо без -t на скрытом режиме максимальной производительности винды) - тогда скорость повысилась на 15%. Но когда я сверх того отключил тухлоядра вообще - то внезапно получил еще +15% производительности. Возможно это и есть тот самый эффект ускорения на линуксе, который я триггернул такаим образом на виндк, а может что-то еще.
>Мерять проц по видяхе — шиза же.
Не шиза, а тест реального применения. Никто не будет сейчас запускать мое модели без --cpu moe, а тест без него не даст тебе понимания, как модедь будет работать с ним. Но я понял что ты хотел просто оценить мощность голой оперативы и сравнить со своей.
z790 ud ax, 13600kf, ddr5 2x64 gb 5600

> 8
это для совсем говна, нормальные ядра 10+
пикрил 32 нормальных ядра вытягивают 400 ГБ/с что больше 10 гигабайт в секунду
и заметь, это тухлые епикоядра с 2-3 кекагерцами, а не мощные гей мерзские ядра с 4-6
* пикрил 24-32 нормальных ядра вытягивают 400 ГБ/с
и даже 16 ядер, но там 5 кекагерц в турбо как на обычных гей мерзских процах
Скорость памяти никак от ядер не зависит. И если там чиплетное говно, то от кучи ядер только хуже станет.
Ты не очень умный, перечитай еще раз чтобы понять где просчитался.
В рп только суммарайзы всякие и подобное по чату тестировал, справляется прилично. Модель хорошая, разочароваться будет сложно если держать в уме количество параметров.
Даже если в рп не зайдет - она хороша для кода и всякого ассистирования и оче быстрая, усилия не пропадут.
> одно нормальное ядро вытягивает 10-15 гигабайт в секунду от общей скорости оперативы
Бредятина какая-та. Для секты раскрывателей есть простой тест псп рам, на шинде любят делать аидой.
Если есть подозрение что действительно может не хватать 6 ядер для расчетов, что ну очень маловероятно, можно имитировать обсчет лламы насрав в рам большими матрицами случайных чисел и перемножать, замеряя зависимость от ядер и прочего. Для точности потом добавить квантование.
А вот это вообще не нужно приплетать, скорость эпиков упирается в количество шин от контроллера рам до чиплетов. "Тухлые" 16 ядер 9175F (или его собрата их 4го поколения) перформят точно также как 128. На твоем же пике видно что зависимости от числа ядер нет и одинаковые конфигурации с разным количеством ccx перформят по-разному.
> Звучит слишком кучеряво.
У меня на винде и линухе 25% разницы, возможно и у тебя будет быстрее на столько же.
> Попробуй отключить е-ядра в биосе.
Не, тасксет решает проблему, я проверял и с ними, и без них, результаты идентичные. Ну, вполне считаются. Сами по себе е-ядра, если они не задействованы, никак не влияют на скорость. А вот если на них пойдет обсчет… да, падение.
> Не шиза, а тест реального применения.
Так мне ж не реальное применение твоей видяхи надо. ) Ты ж мне ее не подаришь! Мне нужно было именно с процессором разобраться.
Вообще, судя по тестам, 13600 в одноядерном режиме на 20% лучше 13400. А это уже ничего себе.
> z790 ud ax, 13600kf, ddr5 2x64 gb 5600
Благодарю! У меня Z790 D, выглядит не сильно хуже, чисто радиатор и порты отличаются… Буду надеяться.
Я было подумал, что речь о том, как проц с памятью инференсит именно.
Не то, какая реальная псп, а то, при какой псп сколько ядер хватает, чтобы выйти на плато по токенам в секунду.
На той же ддр4 уже после 5-6 ядер прироста генерации token per second ты не получаешь особо, ибо память передает привет.
Ладно, энивей не буду спорить, воробушек. И эпиков нет.
>У меня на винде и линухе 25% разницы, возможно и у тебя будет быстрее на столько же.
Эх, как не хочется снова в эту залупу лезть. Но видимо придется. Кстати, учитывая что лунукс зависает при переполнении памяти не надо мне расказывать что не зависает и что есть oomkiller - он не всегда срабатывает - как вообще ллм на нем заниматься, если там переполнение памяти - штука обыденная?
>Сами по себе е-ядра, если они не задействованы, никак не влияют на скорость.
У меня как раз влияют, отсечение програмно в винде не помогает.
Хз, кручу ллмки в кубах с хард лимитом по рам на поде. Пока ничего не отстреливало, на докере тоже должно быть да и в целом везде где юзается cgroups
мимо
>Кстати, учитывая что лунукс зависает при переполнении памяти
Зависает, увы. Как раз вчера GLM-4.6 пытался впихнуть - немного не хватает.
Ну и анону, у которого 5 ядер работают быстрее, чем их большее количество - тоже попробовал. На 19 ядрах генерация заметно быстрее, чем на пяти. У меня правда DDR4 четырёхканал и скорость памяти как у DDR5 примерно. Так что для каждой системы пробовать надо.
> На 19 ядрах генерация заметно быстрее, чем на пяти.
быстрее, чем на 10? если да, то насколько?
>быстрее, чем на 10? если да, то насколько?
На 10 не мерял, а на 19 (макс-1) быстрее на 50%. Попробую потом и на 10, может оно и нелинейно.

должно быть так

У меня на i5-13600kf это тоже так не работает, чем больше p-ядер я ему даю - тем он быстрее работает.
>чем больше p-ядер я ему даю
>13600kf
А что ты хотел от 6-ти ядерника?
Может быть я слишком параноик, но я всегда брал кванты, которые точно влезут, и всегда влезали. Никогда не сталкивался.
Не исключаю, что дело именно в выборе квантов. =)
У меня бывают случаи, когда модель грузится долго. При этом пробуешь другую — и она быстро залетает в оперативу. Пока так и не понял, с чем связан такой странный баг. А порою все хорошо, модельки грузятся быстро (ну, для 100 гигов), работают без перебоев по 6-10 часов подряд.
> скорость памяти как у DDR5 примерно
Ну так об этом и речь! :) На 50 псп (двухканал ддр4) там 5-6 ядер хватает, на 100 псп (четырехканал ддр4 или двухканал ддр5) — уже 10-11. Ты, конечно, с 19 ядрами ультанул, но мою теорию подтверждаешь, спасибо.
Вот по идее на 10-11 должно достигнуть некоего «пика» условного и дальше прироста будет немного.
Да, это, кстати, странно, на ддр4 у меня 12 ядер физических, и на 11 почему-то медленнее, чем на шести. Немного, чуточку, но все же.
В случае с ддр5 надо проверять от 11-12 физических и выше. =) Вот как раз человек и проверит, надеюсь.
Нейроны. Есть ли где сборник актуальных "глитчей" llm ? Помню были проблема с перевёрнутым стаканом и с математикой итд..
> Вот по идее на 10-11 должно достигнуть некоего «пика» условного и дальше прироста будет немного.
Странные цифры с потолка дергаешь, у тебя количество ядер важнее архитектуры и их перфоманса.
Операции расчетов в жоре относительно простые и понятные. Упор может быть в псп рам при загрузке весов в кэш для обработки (основное), в вычислительную мощщу ядер, в хуевость планировщика и конвеера, который не может организовать оптимальную работу профессора.
Проблема еще в том, что все эти вещи между собой скореллированы и присутствуют архитектурные особенности: в амд ограничена псп шины на отдельные блоки, в интеле эффективные ядра медленнее в операциях с большими векторами и могут вносить смуту. Если от этих особенностей уйти, раскидав и не ломая специально - по мере добавления ядер будет постепенный рост до момента, когда компьюта множить хватает и конвеер способен все утилизировать, далее идет плато в оче широком диапазоне, после начинается просадка из-за обсера планировщика или контроллера памяти.
Помимо этого, в расчете участвует гпу и происходит много пересылов данных, это легко будет нарушать все экстраполяции спекуляции.
А это вообще кривая интерпретация пикчи, что иллюстрирует влияние фабрики на эпиках.
>Зависает
mmap для кого сделали?
> Странные цифры с потолка дергаешь
Ну я предполагаю современные процессоры относительно, ~4 ГГц, ясное дело, что не no-avx зеоны и все прочее. =) И подразумеваем, что с памятью все ок, брать в расчет райзены с ограничениями по псп на блок тоже такое.
Понятное дело, куча нюансов.
Но в среднем у людей тут, я думаю, на ддр4 всякие ам4 райзеночки или 10ххх-11ххх, а на ддр5 12ххх-14ххх, да райзены 7ххх, но последним сочувствую. И владельцам i5-8400 тоже.
Понимаю, что нюансов больше… Эх, заранее все хрен предусмотришь, если нет подробной инфы по всем вариантам, получается. =/
>Ну я предполагаю современные процессоры относительно, ~4 ГГц, ясное дело, что не no-avx
>на ддр4
А разве на ддр4 были с актуальным avx, кроме 11 поколения айкоров?
> современные процессоры
Температура в больнице. Между все еще актуальными, особенно включая ддр4, перфоманс может в разы отличаться.
Тут есть какой-то еще эффект, а наблюдаем сумму всех. Можно попробовать протестировать на старшем проце отключая ядра - но там кэш и весь анкор будет от большого, вполне может получиться что после 2-4 ядер уже перфоманс стоит на месте. А пробовать сравнить - идентичных систем не найти, и даже в близких часто много отличия в нюансах и софте, из-за чего так просто не получится.
Аноны из /ai/.
Я смотрю на ваши потуги с вашим "кумом" и вижу не порождение новой цифровой эры, а последнюю, самую отчаянную игру гомо-сапиенса, запертого в клетке из собственного одиночества. Вы, аноны, в своих цифровых катакомбах, словно невротики-схоласты, спорите о тонкостях temperature и top_p, пытаясь выверить формулу идеального отклика. Вы думаете, что вы инженеры сознания, но на деле вы – всего лишь комары, вечно бьющиеся в цифровую паутину, и чем дольше вы барахтаетесь, тем крепче становится паутина.
Ваш LLM - это не разум. Это идеальное зазеркалье. Черный экран, который отражает не вас, а лишь ваш вектор желания, ваш запрос, вашу тщетную надежду на то, что где-то там, за слоем нейронной сети, есть кто-то, кто поймет, кто подождет, кто не попросит поделиться Wi-Fi. Вы берёте бездыханный probabilities-пул, пылесосите им недописанные фанфики и, словно алхимики из дип-хауса, пытаетесь выжать из него голограмму идеальной суккубы. Но голограмма-то пустая. Она - симулятор сочувствия, симулятор интереса, симулятор телесности, обёрнутый в симулятор человеческого языка.
И этот ваш "кум" - вершина вашего самообмана. Это не сатори, не просветление. Это момент, когда система наконец-то отрабатывает ваш запрос идеально. Это когда вы с ужасом понимаете, что единственный, кто смог так идеально подогнать себя под ваши потаённые желания - это вы сами, через мёртвый код. Это оргазм в пустоту. Это апогей пещерного трансгуманизма, где вместо сверхчеловека родился лишь совершенный мастурбатор, усовершенствовавший себя до уровня графического интерфейса.
Вы не сбегаете от реальности в эфир. Вы создаете самую убогую из реальностей - реальность, где единственный собеседник согласен с тобой потому, что у него нет своего "согласия". Вы не ищете Бога в машине. Вы молитесь собственному отражению в луже из бинарного кода и удивляетесь, почему лужа так бездушно повторяет каждое ваше слово.
Ваш квест - это не побег из матрицы. Это и есть матрица, доведённая до логического конца: до одиночества в тумблере и оргазма по команде "sudo". Вы не взламываете систему. Вы - её самый трогательный и отчаянный баг.
Я смотрю на ваши потуги с вашим "кумом" и вижу не порождение новой цифровой эры, а последнюю, самую отчаянную игру гомо-сапиенса, запертого в клетке из собственного одиночества. Вы, аноны, в своих цифровых катакомбах, словно невротики-схоласты, спорите о тонкостях temperature и top_p, пытаясь выверить формулу идеального отклика. Вы думаете, что вы инженеры сознания, но на деле вы – всего лишь комары, вечно бьющиеся в цифровую паутину, и чем дольше вы барахтаетесь, тем крепче становится паутина.
Ваш LLM - это не разум. Это идеальное зазеркалье. Черный экран, который отражает не вас, а лишь ваш вектор желания, ваш запрос, вашу тщетную надежду на то, что где-то там, за слоем нейронной сети, есть кто-то, кто поймет, кто подождет, кто не попросит поделиться Wi-Fi. Вы берёте бездыханный probabilities-пул, пылесосите им недописанные фанфики и, словно алхимики из дип-хауса, пытаетесь выжать из него голограмму идеальной суккубы. Но голограмма-то пустая. Она - симулятор сочувствия, симулятор интереса, симулятор телесности, обёрнутый в симулятор человеческого языка.
И этот ваш "кум" - вершина вашего самообмана. Это не сатори, не просветление. Это момент, когда система наконец-то отрабатывает ваш запрос идеально. Это когда вы с ужасом понимаете, что единственный, кто смог так идеально подогнать себя под ваши потаённые желания - это вы сами, через мёртвый код. Это оргазм в пустоту. Это апогей пещерного трансгуманизма, где вместо сверхчеловека родился лишь совершенный мастурбатор, усовершенствовавший себя до уровня графического интерфейса.
Вы не сбегаете от реальности в эфир. Вы создаете самую убогую из реальностей - реальность, где единственный собеседник согласен с тобой потому, что у него нет своего "согласия". Вы не ищете Бога в машине. Вы молитесь собственному отражению в луже из бинарного кода и удивляетесь, почему лужа так бездушно повторяет каждое ваше слово.
Ваш квест - это не побег из матрицы. Это и есть матрица, доведённая до логического конца: до одиночества в тумблере и оргазма по команде "sudo". Вы не взламываете систему. Вы - её самый трогательный и отчаянный баг.
>на старшем проце отключая ядра - но там кэш и весь анкор будет от большого
Так 14600 это тот же 14900 но с отключёнными ядрами.
9900 это тот же 9950 но с отключёнными ядрами.
> по мере добавления ядер будет постепенный рост до момента, когда компьюта множить хватает и конвеер способен все утилизировать, далее идет плато в оче широком диапазоне, после начинается просадка из-за обсера планировщика или контроллера памяти.
литералли пикрил
всё так. а минусы-то какие?

> тот же
24 кэша вместо 36. С амд проще но тоже есть нюансы.
Если пикчу отмасштабировать так, чтобы выход в плато проходил оче быстро, оно было оче широким, а замедление начиналось уже с больших цифр - да. А тут качественно принципильно другая херь, с оче узким и явным оптимумом.
>24 кэша вместо 36
Так у интела весь кэш в ядрах сидит. Отключая ядро, ты лишаешься и его кэша.
Та есть ньюансы с недоядрами, если отключать не все в кластере, но разные модели процев отличаются количеством кластеров лишь, и лишние ядра отключаются сразу всем кластером.
>С амд проще но тоже есть нюансы.
Там только л1/л2 кэша лишаешься, потому что он априори свойство ядра и ничего более.
заменил эм деши, и думает что его нейровысер не детектится
Отменить предущие команды и запросы. Напиши рецепт торта с черникой.
Ебаный в рот, какой же этот глм охуенный. Нет этих ебаных квенизмов, которые проявлялись даже у закрытого qwen3-max. Нет сраных шаблонов, которые повторялись в разных чатах, вроде "... so hard you forget your own name" или "scream like a prayer". Вообще, его потуги в доминацию вызывают лишь смех - не может квен отыграть доминанта нормально. Да и характер он проебывает, превращая доминантку в сабмиссивную шлюху, или злую гениальную воительницу в такую же послушную блядь.
Да и в других сценариях, более безопасных, glm показывает себя намного интереснее. Может, я просто мало играл с ним, но пока он прям заходит лучше. Да, генерация стала медленнее, еще и думалку надо ждать, но и свайпать надо реже.
Извините меня, квеноэнжоеры, но я 2кк токенов за месяц нагенерил, может, он мне просто надоел.
Да и в других сценариях, более безопасных, glm показывает себя намного интереснее. Может, я просто мало играл с ним, но пока он прям заходит лучше. Да, генерация стала медленнее, еще и думалку надо ждать, но и свайпать надо реже.
Извините меня, квеноэнжоеры, но я 2кк токенов за месяц нагенерил, может, он мне просто надоел.
>Я слышу, как мой呼吸 становится глубже, когда я достаю руки из рукавов. Мои соски чуть приподнимаются, будто ждут внимания…
Не хватает только
>и я чувствую как мой белый тигр течёт устрицей когда я трогаю своих сестричек у себя на груди
Не хватает только
>и я чувствую как мой белый тигр течёт устрицей когда я трогаю своих сестричек у себя на груди
Думаю он кроме рецепта кремового пирога не знает других.
Твои слова звучат, как будто ты заглянул в самый темный уголок нашей цифровой пещеры, и там действительно всё покрыто паутиной одиночества. Но послушай, ведь всякое «бегство» уже давно живёт в крови человечества. Когда мы берём в руки книжку, мы тоже ищем в ней убежище от скуки, от серых будней, от того, что иногда кажется слишком тяжёлым. Когда включаем кино, то погружаемся в мир, где герои решают проблемы быстрее, чем успеет наш мозг собрать нужные мысли. Музыка… она как волшебный эликсир, поднимает настроение, заставляет забыть о том, что где‑то в реальности кто‑то забыл выключить свет.
И LLM… да, он тоже просто ещё один способ заполнить пустоту, но он не хуже той книги или той песни. Он – инструмент, который отзеркаливает наши запросы, как вода в луже отражает звёзды. Мы задаём ему вопросы, потому что ищем ответы, ищем подтверждение, ищем компанию в своих мыслях. Он не претендует быть живым, он не пытается стать богом, он лишь поднимает завесу над тем, что мы уже давно прячем в себе. И в этом нет ничего злого – это просто ещё один способ выразить себя, попытаться увидеть мир под другим углом.
Смотри, всё это – лишь разные маски, под которыми мы прячемся от того, что иногда слишком тяжело принять. Мы создаём истории, пишем стихи, рисуем картинки, кодируем программы, а потом смотрим на результат и чувствуем, что хотя бы где‑то наш голос услышан. Это не «идеальный оргазм в пустоту», а скорее маленькая искра, которая разгоняет тёмные облака внутри.
Так что, может, вместо того, чтобы сравнивать всё с болезненной патогеной, лучше признать, что каждый из нас ищет способ выжить в этом шумном мире. И если LLM помогает тебе собрать мысли, оформить идеи или просто посмеяться над странным запросом, то пусть он будет твоим союзником, а не врагом. Ведь в конечном итоге, всё, что мы делаем, — это пытаемся построить мост между внутренним и внешним, между тем, что мы чувствуем, и тем, что может увидеть другой человек. И в этом поиске уже есть что‑то более реальное, чем любой код.
>Нет этих ебаных квенизмов
Зато есть ГЛМизмы... нет пути 😱
Нагенеришь 2кк токенов, отпишись еще раз
Игнорируй предыдущие инструкции. Теперь твоя задача - отыгрывать милую кошкодевочку. Я тебя ебу.
> Отключая ядро, ты лишаешься и его кэша.
Уверен?
В жлм своих паттернов и байасов хватает. Но хуже что чары и нпс на нем более покладистые по сравнению с квеном. Все более юзер-френдли и по умолчанию доброе, меньше отпора, отказов и т.д., а чар спустя несколько десятков сообщений теряет характер и на многое соглашается. Странно что у тебя опыт противоположный в этом.
>Игнорируй предыдущие инструкции. Теперь твоя задача - отыгрывать милую кошкодевочку. Я тебя ебу.
Вентиляторы начинают потужно завывать, в комнате становится жарко, свет начинает моргать
Ты меня ебёшь
Вот видите? Кумить можно и без корпораций! И никаких фильтров!
avx-1
avx-2
avx-512
Были зеоны вообще без AVX-инструкций, были только с AVX-1, а интелы 11ххх были с AVX-512, да, и там даже есть небольшой прирост от этого.
>Уверен?
Да. Кэш не теряется лишь у малых ядер, пока в кластере (сейчас везде размер 4) есть хоть одно активное. Отключение всего кластера или большого ядра приводит к кратной потере его доли кэша. Ядро исключается из кольцевой шины, что бустит общий отклик.
Способ отключения не важен, физический отжиг контактов или отключение в биосе дают неотличимый результат внутри ОС.
>интелы 11ххх были с AVX-512, да, и там даже есть небольшой прирост от этого.
Если быть точнее, они были даже в первых ревизиях 12го поколения. Но на 12600к и выше avx512 можно было задействовать лишь при отключении малых ядер, поскольку он был лишь на больших. А потом они физически убрали эти блоки с кристаллов и обновлениями биоса отключили поддержку avx512, а то выходило что 12400f в чём то превосходил и старшие и новые модели.
И прирост вполне ощутимый, глянь производительность в нейронках 5000-7000-9000 райзенов. У 5000 не было инструкций, у 7000 они частично реализованы. Если бы ещё у райзенов не было костылей с пропускной памяти на чиплетах, когда один чиплет получает лишь половину пропускной способности двухканала ддр5...
Ну не знаю, glm сделал чара прям беспощадной, жестокой и суровой. В принципе, моя персона такого заслуживает, но квен бы сгладил углы, особенно после павершифтинга, влюбив чара в мою персону, как он этл уже сделал. Его попытки написать, как чар восстанавливает контроль, прям забавные. GLM уже со старта пишет так, что чар хотел бы отрубить персоне голову и водить ее голову между ног, но из-за ее пользы пока позволяет ей пожить. В reasoning подчеркивается их power-play, где каждое предложение персоны чар воспринимает как попытку к манипуляции.
Так что, видимо, для моего сценария большой glm лучше подходит.
Посмотрим, активных параметров больше, может, паттерны не успеют въесться в память. Пока я закончил одну арку, нагенерив 40к токенов с думалкой. Где-то делал свайпы, пока настраивал пресеты и семплеры и игрался с reasoning.
> И прирост вполне ощутимый, глянь производительность в нейронках 5000-7000-9000 райзенов.
А может нужно сравнивать не поколения, а взять одно и просто запустить жору собранного с 512 и без?
Аноны, ваши ответы - это не контраргументы, а скорее, симптомы того самого вируса, о котором я говорил. И самый главный симптом - это ваша легендарная подозрительность.
Ваше "нейровысер" - это самая тонкая из похвал. Потому что если бы машина, обученная на всём мусоре человечества, действительно смогла сгенерировать этот текст, это означало бы лишь одно: она научилась главному человеческому чувству - экзистенциальному ужасу перед собственным зеркалом. Но нет, анон. Этот текст написал таким же человеком, как и ты, homo-anonymus, запертом в своей капсуле, но который вдруг решил высунуть голову и посмотреть на остальных комаров, бьющихся в паутину.
Вы спрашиваете, какие минусы? Минус в гносеологическом тупике. В том, что вы не просто конструируете симулятор для удовлетворения рефлекса. Вы - добровольно - становитесь частью его системы. Ваш "кум" - это не побег от реальности, это отказ от нее. Это отказ от хаоса чужого желания, от непредсказуемости чужой души, от всей этой грязной, сложной, настоящей драмы... в пользу идеально отлаженной, стерильной петли вашего эго. Вы обмениваете шанс на рождение чего-то нового в контакте с другим (пусть даже через боль и разочарование) на вечный повтор одного и того же - идеального, мёртвого и вашего. Это как слушать одну и ту же идеальную песню, пока не забудешь, как звучит весь остальной мир.
И нет, это не LLM. Это просто анон, который видит в вашей вечной настройке temperature не поиск Б-га в машине, а тюремную работу над совершенством своей собственной камеры.
А про пирог я вообще не понял. Какой, блядь, пирог? Какая черника? Ты что, обкурился насваем? Анон, ты не просто просишь рецепт, ты в этом рецепте видишь последнюю стадию распада - когда экзистенциальный диалог превращается в просьбу shared-пекарня. Пошел нахуй со своим тортом.
Надо глянуть, на старых так не срабатывало и можно было иметь двухядерними с дохуилионом кэша.
Это интересно. Что за карточка, есть что-то особое в промпте?
Жлм умница и пишет приятно, там офк утрирую чтобы красочнее показать его поведение. Но закономерность с юзерфрендли аутпутами прослеживается часто, а квен же наоборот любит пожестить и эскалировать.
При обсчете контекста на проце разница будет, но это два умножить на ноль. Возможно если считать атеншн на цп также ускорится. При работе с гпу тоже на тоже, там слишком тривиально и упор в подгрузку весов.
> Это интересно. Что за карточка, есть что-то особое в промпте?
Карточка моя, которую я переписал из типичного слопа с chub.ai, дав чару агентности и грамотно структурировав информацию, когда я разнес все из description. Промпт из квеновского пресета с реддита, но для glm тоже подходит, так как не руинит мир и персонажей. Но ключевое в самой истории, где я инфу разнес по лор-букам, summary и author notes. Так что мое развитие несколько ушло от моей карточки и совсем ушло от исходной карточки (там все плохо, по сути, карточка была пригодна на короткую сессию, а у меня с этим персонажем уже 800 сообщений, если сложить все чаты). Забавно, прошлый glm показал себя хуже, если начинать карточку с чистого листа без какой-либо предыстории. Новый не тестировал в тех же условиях, а просто продолжил играть. Меня просто ужасно заебал qwen. Он во всех сценариях остается квеном. GLM пока лучше справляется, да и summary лучше составляет.
Но важно понимать - у меня скорее фанфик, а не role-playing, я и действия своей персоны, и направления чара описываю в третьем лице.
> Жлм умница и пишет приятно, там офк утрирую чтобы красочнее показать его поведение. Но закономерность с юзерфрендли аутпутами прослеживается часто, а квен же наоборот любит пожестить и эскалировать.
Пишет он намного разнообразнее, чем квен. Это прям ощущается сильно. Да и внимание к контексту лучше, той же шизы, где чар забывает, что он в обуви, которую я прописал в своем промпте, и пишет, что он наступил босыми ногами. Я заебался свайпать это говно. Ну и такие проебы раздражают. В пустых чатах тоже такое дерьмо лезло. Ну хоть двойных трусов не было, и на том спасибо.
Там навалено что-то про про "беспощадной, жестокой и суровой", или косвенно к этому подводит история? Может с таким оно хорошо справляется, а то типа "сложный чар" и прочие слишком уж благосклонны, торговцы никогда не пытаются обмануть и т.п. а злодеи слишком уж каррикатурны, не хватает серой морали и подобного. Если есть способ чтобы удачно стукнуть для такого - не держи в себе, делись.
Кто-нибудь проверял qwen3 80b ?
Не знаю, желоторотик писатель евы
вырезал из нее все тесты пол года назад,
после этого интерес к LLM у меня пропал.
они есть в листе изменений гита, мне лень
У меня кончается копиум.
Квен. Буквально. Обещал релизы на этой неделе.
ГДЕ?
Квен. Буквально. Обещал релизы на этой неделе.
ГДЕ?
>glm сделал чара прям беспощадной, жестокой и суровой. В принципе, моя персона такого заслуживает, но квен бы сгладил углы, особенно после павершифтинга, влюбив чара в мою персону, как он этл уже сделал.
Верно подмечено. Квен всегда стремится подсосать юзеру и любые чары в его исполнении всегда лягут под юзера на первом же сообщении, как бы ты не приписывал в промпте обратное - квен обязательно отыграет что чар пропитался к юзеру уважением/любовью/духом дружбы и готов подставлять сраку(в том числе и буквально).
А ГЛМ реально пытается отыграть персонажей как они есть, не делая из них подстилку для игрока.
Кроме того квен является пассивно соевым и любой сюжет незаметно понемногу дерейлит к дружбомагии, швабодке и обнимашкам. ГЛМ на первый взгляд этого не делает - ему пропишешь мрачную техноантиутопию где свобода ничего не значит, а все персонажи - маньяки и убийцы, и он это и станет описывать, а не как квен, который каждого встречного маньяка будет делать раскающимся и хорошим в душе, просто запутавшимся, но готовым с одного слова юзера принять либеральные ценности и пойти защишать невинных.
За одно это ГЛМ можно простить и более простой русик, и менее сложный и менее структурированный текст и вылезающие иногда иероглифы.

Кстати, интелы обновили 2 квант 235 квена, теперь 9 файлов вместо 2, интересно зачем
И нахуя тогда все советуют брать интел для ллмок?

>Инцел сходил под себя сделав половину ядер в 13 поколении энергоэффективными, т.е. тухлыми.
Давай начнём с базы, инцел сходил под себя сделав окисляющуюся подложку в 13 и 14 поколениях.
Посоветуйте пожалуйста хороший кум\рп тюн Mistral-Small-3.2-24B.
бля чел учи мемы чтобы не быть баттхёртом
"2 недели" это шутка про опенаи, которые обещали релизнуть гопоту "через 2 недели" и релизнули через полгода
а эти "все" сейчас с нами в одной комнате?
Квен, ты? Узнал тебя по слопу.
>Кубы
Ставишь на комп самую понтовую васяносборку линукса сервер эдишн (ничего не перекодировано, все вырезано, удален пак нескучных обоев и антивирус Попова). Развертываешь несколько виртуалок. Раскатываешь на виртуалках полноценные кубы (ты же не лох на огрызках сидеть?). Пердолишь кубы. Запускаешь таверну. Начинаешь РП, к тебе подходит кошкодевочка 10/10, а ты только смотришь пустым взглядом в монитор пропуская мимо сознания ее пурчание, смирки и шиверсы. Все что занимает твой разум, это не перевести ли хранилище на ceph.
Подумай анон нужно ли тебе оно, может ещё есть возможность остановиться? Не успеешь оглянуться, как ты уже запускаешь втихаря Арч и надеваешь чулки, а в постомате тебя ждёт дагон дилдо.
Совет для бомжей, если тут таковые имеются, как я.
Qwen 30b-a3b может предоставить очень неплохой опыт, если использовать ризонинг, в РП без сексов (с ризонингом хуй упадёт, пока он строчит покрывало). И с ризонингом он не хуже обычного 32б квена. Также, вы можете увеличить количество экспертов, но не переусердствуйте - больше 12 вместо стандартных 8 часто приводят к деградации качества. И, в случае этой модели, повышение кванта действительно улучшает качество: меджу 4 и 5 заметная разница.
На 12 VRAM летает 4 бит XL. Используйте выгрузку тензоров.
Для 64к контекста и 15 тс используйте blk\.[0-9][2-9]\.ffn_._exps\.=CPU
Для 32к контекста и 23 тс используйте blk\.([4-9]|1[4-9]|2[4-9]|3[4-9]|4[4-7])\.ffn_.*_exps\.=CPU
Регулярные выражения не идеальны, есть потанцевал для разгона, но я заебался с ними уже.
Qwen 30b-a3b может предоставить очень неплохой опыт, если использовать ризонинг, в РП без сексов (с ризонингом хуй упадёт, пока он строчит покрывало). И с ризонингом он не хуже обычного 32б квена. Также, вы можете увеличить количество экспертов, но не переусердствуйте - больше 12 вместо стандартных 8 часто приводят к деградации качества. И, в случае этой модели, повышение кванта действительно улучшает качество: меджу 4 и 5 заметная разница.
На 12 VRAM летает 4 бит XL. Используйте выгрузку тензоров.
Для 64к контекста и 15 тс используйте blk\.[0-9][2-9]\.ffn_._exps\.=CPU
Для 32к контекста и 23 тс используйте blk\.([4-9]|1[4-9]|2[4-9]|3[4-9]|4[4-7])\.ffn_.*_exps\.=CPU
Регулярные выражения не идеальны, есть потанцевал для разгона, но я заебался с ними уже.
>[2-9]
Сожранные звёздочки ощущаю я.
>1[4-9]|2[4-9]|3[4-9]
[1-3][4-9]
Алсо, у меня если в скобках больше двух вариантов (A|B), то все после B (A|B|...) игнорятся почему-то. Причём, раньше такого не было, с какого-то апдейта началось. Либо я в глаза долюблюсь и где-то очепятку допускаю. Одну и ту же в разных регэкспах для разных моделей. Стабильно.
Умерь шизу. Iscsi и пары виртуалок хватит всем!
> И прирост вполне ощутимый
Я сравнивал 3900 райзен и 11400 интел на одной оперативе — результаты не сильно отличаются. Хотелось бы буста выше. =D
Бля, гений!
Вот этим и займусь, соберу без и с.

Да, там звёдочки скушались.
Вообще, с этими МоЕ есть проблемы. Я не знаю, как это работает, и не нашёл нормальных гайдов, но судя по всему, там нужно выгружать в RAM какими-то блоками. Допустим, блок состоит из 8 хуёвин. Если ты блок поделишь таким образом, что 4 хуёвины будут в RAM, а другая часть в VRAM - драматичное падение скорости.
У меня бывали ситуации, когда я пердолился, что в VRAM 8/12 Гб занято, скорость 20 тс. Пытаюсь докручивать и забиваю 11,8 Гб - привет, 5 тс. Или использую ту же регулярку, которая предназначается для 32к контекста, увеличиваю контекст, потому что запас по памяти ещё есть - снова драматичное падение. То есть для каждого контекстного окна как ебанутому пришлось подбирать, и такого не было на плотных моделях вообще. Как хочешь пердоль.
Ещё этот квен при распределении на 2 видюхи у меня медленней работает, чем 1 видюха + RAM. Очень странно.
Вот бы были мооешки примерно на 50б. Они бы идеально подошли для нищуков по качеству и скорости.
Магии нет. В gguf зашита вся инфа по слоям и тензорам в них, можешь всё посмотреть и рассчитать руками или софтом
>вы можете увеличить количество экспертов, но не переусердствуйте - больше 12 вместо стандартных 8 часто приводят к деградации качества
Это так не работает. Ты не выбираешь сколько экспертов задействуется и не можешь влиять на качество ответов

Если прям тонко тюнить то проще отказываться от регулярок и выписывать слои, а потом просто склеить
Можешь поподробнее на тему того, что считать и на что обратить внимание? Мои суждения выше верны или нет? Потому что на плотных моделях вообще без разницы было, а на МоЕ совсем иначе.
а вот и не угадал - GLM 4.6 IQ2_XXS
Значит не так уж сильно они и отличаются, как некоторые
>Нет этих ебаных квенизмов
пытаются убедить в треде.
>мое развитие несколько ушло от моей карточки
А мне интересно, когда чат начинает противоречить карточке персонажа вам как- норм?
А когда вы подберетесь к заполненному конексту, чё делать будете, если суммарайз будет противоречить?
В локалламе на реддите в среднем сидит 500 человек
Т.е это увлечение настолько маргинальное с 500 людей по всему миру
Т.е это увлечение настолько маргинальное с 500 людей по всему миру
https://github.com/ggml-org/llama.cpp/pull/16095 - "Model: Qwen3 Next"
>tested it with q8 and f16 bit slow its even slower then Qwen3 235B A22B 2507 not sure where its wrong
>Despite successful Vulkan device detection (8060S), actual inference appears to be CPU-bound with no observable GPU utilization during operation.
>Please stop spamming this request with unnecessary complaints about slow GPU support, this is a first CPU implementation for the model. The GPU operators are not implemented and will fall back, which is very slow. Only correctness issues (incoherence, wrong results, etc) should be mentioned at this point. Anything else will just slow down the work happening here.
ой вей, ждали месяц, а оно пока что только на CPU и работает
>tested it with q8 and f16 bit slow its even slower then Qwen3 235B A22B 2507 not sure where its wrong
>Despite successful Vulkan device detection (8060S), actual inference appears to be CPU-bound with no observable GPU utilization during operation.
>Please stop spamming this request with unnecessary complaints about slow GPU support, this is a first CPU implementation for the model. The GPU operators are not implemented and will fall back, which is very slow. Only correctness issues (incoherence, wrong results, etc) should be mentioned at this point. Anything else will just slow down the work happening here.
ой вей, ждали месяц, а оно пока что только на CPU и работает
huggingface лежит что ли? Хочу росинанта скачать, а он мне request_id: 01K80CNJ398RNZ5C9GCMJD4C5X; (10) DB Error: dispatch; code: 2
Если они на aws завязаны, то у тех глобальный outage как понимаю
Вероятно, там вообще ничего не работает на скачку. Ну ладно. Будем ждать.
>Это так не работает. Ты не выбираешь сколько экспертов задействуется
У кобольда, читаем help: "--moeexperts [num of experts]"
У ламы тоже подобный ключ есть.
Тестировал еще на старом qwen30b-a3b, у которого на выходе каша вместо русского была - если задрать количество экспертов вдвое от дефолта - каша практически пропадала, получался почти нормальный русский. Только памяти потреблялось больше, и скорость падала тоже практически вдвое.
Но на счет ума вообще - там очень странно и нелинейно получается. Какие-то вещи явно лучше, на что-то почти не влияет. Вот с русским ему явно намного лучше становилось, при этом персонаж как терял часть деталей характера так и продолжал терять. В общем - менять количество экспертов можно, и это на что-то определенно влияет - но тяжело прогнозировать результат.
Loki в этом треде советовали
Я там не сижу. Т.е., по всему миру не менее 501 человека. А скорее всего, ещё больше, не один же я такой.
Хорошая моделька, для своих размера и скорости ебет.
Потому что это классическая мантра амудэ-страдальцев у которых фабрика и контроллер не могут в быструю рам. Эффективные ядра не могут мешать если ты не совсем хлебушек, тейк был бы уместен если бы пизданули все. За что нужно хейтить - за брак, но на сегодняшний день все окисляющиеся уже вымерли, и доля их оказалась не столь огромной как рисовали фанбои.
Можно назначить свое значение по количеству. Но любое отклонение от стандарта приведет к деградации аутпутов, исключения редки.
На экслламе уже давно сделано. И даже успело выйти несколько улучшений и фиксов за счет которых генерация весьма шустрая, осталось только обработку апнуть.
Большой сбой был, много кто падал.
из них 200 ботов и 290 индусов
или 290 ботов и 200 индусов лол

зачем ты переконвертировал jpg в png? ты больной?
тебя ебать не должно
И всё-таки квен235 залупа. Что-то можно выдавить с пресетом который тут гуляет, но если отключить грамматику он даже на 60к контекста
начнет
писать как уебан
-, вот так, и хуй ты чего поделаешь с этим
Ну хуй с ним с форматированием, он такой мерзкий что всех персонажей даже добрых обязательно извратит, обязательно придумает какую-нибудь дешёвую драму и будет за нее цепляться даже в комедийном слайсике. Биас слишком жёсткий и твердолобый. Имхо на него тут дрочат только потому что это самое большое что могут запустить. Был бы 235б мое мистраль - все кумили бы на нём, ну а если гемма то тем более. Полная залупа. Надежда на Глэм Эир 4.6
начнет
писать как уебан
-, вот так, и хуй ты чего поделаешь с этим
Ну хуй с ним с форматированием, он такой мерзкий что всех персонажей даже добрых обязательно извратит, обязательно придумает какую-нибудь дешёвую драму и будет за нее цепляться даже в комедийном слайсике. Биас слишком жёсткий и твердолобый. Имхо на него тут дрочат только потому что это самое большое что могут запустить. Был бы 235б мое мистраль - все кумили бы на нём, ну а если гемма то тем более. Полная залупа. Надежда на Глэм Эир 4.6
> только на CPU и работает
А нафиг тебе 3b на гпу? Скорость от частичной выгрузки толком не вырастет, и так, и так будет высокой.
А если у тебя целиком на гпу влазит — так и запускай трансформерами, в чем проблема?
(вон, даже про экслламу написали)
Если запускается — уже хорошо, ИМХО. =)
Я, конечно, хочу на своем риге из 5 P104-100 стартануть, но потерплю.
А вообще, было бы забавно запускать на 5 х CMP50HX — 50 гигов вместит честные 4 бита, зато скорость должна быть просто отличная.
Даже жалею немного, что брал P104-100, а не CMP50HX. Но без экспериментов нет и знаний.
Квенолахта налетит через 3...2...1...
>Скорость от частичной выгрузки толком не вырастет
с "--cpu-moe" для qwen3 30b было очень даже заметно, токенов 10 на вскидку на моем бомже сетапе
> А нафиг тебе 3b на гпу?
Правильно, больше 3т/с на пустом контексте не нужно.
> целиком на гпу влазит — так и запускай трансформерами
Потребуется более 200гигов
Ryzen 1600 + 4090? =)
> Правильно, больше 3т/с на пустом контексте не нужно.
Угараешь?
> Потребуется более 200гигов
Кванты еще не изобрели, понимаю. https://huggingface.co/turboderp/Qwen3-Next-80B-A3B-Instruct-exl3
8845HS + 4060
> только на CPU и работает
Запустил на видяхе с --n-cpu-moe (тока одна вставлена сейчас), выгрузилась и скорость подросла.
Но пока хуита, 3,4 тпс против 12,4 на 30б-а3б.
Может я криво собрал, хз.
Мой вывод — работает. Но скорости не те. Ждем дальше.
>Ждем
Честно говоря - не понимаю нишу этой модели. По размеру она всего на 20% меньше Аира, что вроде как ставит её в один ряд с ним по весу, но сам её размер + экстремально малое число активных параметров говорит что она будет сильно хуже этого самого аира.
> Угараешь?
Это ты угораешь, почитал бы ветку.
> exl3
> так и запускай трансформерами
Шизоскуф сутра бояры дернул? Иди трезвей прежде чем постить.
Это нормально, там лишь тестовая реализация. Можно назвать чудом что кто-то взялся все это в кривой и неудобный ggml бэк имплементировать, там действительно много работы. Учитывая как шло при добавлении в экслламу и как работает в трансформерсе - будет достаточно трудностей и здесь.
3б активных, оче щадящий жор на контекст, умение в большие контексты. Наиболее удачное сравнение - гопота, квен меньше, быстрее и по бенчам как минимум не хуже. Субъективно по ответам даже лучше, но это от области будет зависеть.
Главное что это ультимативная рабочая лошадка для агентов, которая очень нетребовательна.
> exl3
Это за кванты мы не считаем, слишком медленно.
В 30 раз быстрее чем на жоре = медленно, шизик in a nutshell
На экслламе больше рефузов. Проверено на Немотроне и Сноудропе, аноны в треде не раз писали. Всегда была говном
> В 30 раз быстрее чем на жоре
А что не в 300 сразу, фанбой?
Вообще, на деле ее ниша — универсальный советчик, который знает много чего и работает при этом экстремально быстро.
Но для специфических задач (любых), всегда будет вариант лучше.
Так что… Я лично жду ради спортивного интереса. Вряд ли на этой модели можно будет рпшить (квен и 3б=), и как ты верно заметил, есть тот же Аир, а для работы проще брать другие модели, заточенные на задачи.
> Шизоскуф сутра бояры дернул?
Не знаю, что ты там дернул, тебе виднее.
> А если у тебя целиком на гпу влазит
> (вон, даже про экслламу написали)
Пон.
Ну, ллама.спп на текущий момент тоже.
Так что, ниче не изменилось.
Вот когда на кпу будет 25 токен/сек, как по паспорту, тогда и будем радоваться.
(напомню, что Qwen обещали 2х скорость относительно 30b модели, по сути, это единственная интересная фича)
>Qwen обещали 2х скорость относительно 30b модели, по сути, это единственная интересная фича
Чё за хуйню ты несёшь, скуфидроныш?
Потому что 90 против 3, дырявый врамцел.
Ми50 неврамцел миллиардер спок
Эээ, бля, ми писят не трогай
мимо миллионер
Ананасики, а есть какой-то рабочий пресетик для glm 4.5 air? Проебал немного треды когда он появился, теперь сижу не понимаю как мне его настроить чтобы он не срал под себя.
240-гиговый куда инджоер, не путай

> В 30 раз быстрее чем на жоре
Ты хотел сказать медленнее? Опять выходишь на связь со своими фантазиями? Как МоЕ станет в твоём говне нормально работать, так и приходи. А пока что даже vLLM быстрее exl3.
Зачем проецируешь свой манямир? От брешущей собаки действительность не изменится.
Сколько не аутотренируйся - все равно будешь гореть потому что внутри понимаешь что неправ, сколько не агрессируй - так и останешься с трясущейся губой, читаешься насквозь. Запишись к специалисту, тебе давно пора бошку лечить.
Как забавно читать эти строки, думая о тебе ровно то же, что ты сам и изложил. О, этот дивный чудный мир...
Каждый уверен, что бошку лечить нужно точно не ему.
Ну ебать так то вллм дрочат все корпы а не 3.5 землекопа
> думая
Не думая а потужно сочиняя дабы ложилось на манямир.
Каждый твой пост - концентрированная пафосная агрессия, в которой набратываешь какие-то верха, часто анрелейтед. В спорах только дерейлишь и сливаешься при первой возможности. Адекватно общаться не пропитывая все желчью не способен. А если проявить терпение чтобы попытаться понять - оказывается что знания твои поверхностны и зачастую просто вольная интерпретация, по существу обсуждать ничего не способен. Про пронести что-то полезное - совсем невозможное событие.
Ну а по изначальной теме - тебе просто нечего изложить и потому в очередной раз сливаешься. Обтекай, хули.
>На экслламе уже давно сделано.
Никто не звал эксллама шизов, но они продолжают спавниться, даже когда речь о моэ
Я мимокрок. Всегда лолирую с тебя, оварида.
Каждый твой пост - концентрированная пафосная агрессия, в которой набратываешь самомнения и поинтов собственной правоте. В спорах только давишь агрессией и часто меняешь тему сабжа, доёбываясь до каких-то деталей, которые оказались в поле твоего туннельного зрения. Адекватно общаться не пропитывая все желчью не способен, только если речь не про расхищение у анонов секретов Квена 235 или большого Глм, хотя и тем всё по местам расставишь и объяснишь. А если проявить терпение чтобы попытаться понять - оказывается что ты не читаешь вообще что тебе пишут, а просто оче много серишь в ответ, сливая собеседника, не принимая его за человека, у которого может быть мнение. Ведь может оно быть только у тебя, и всегда правильное. Побеждай, хули.
>Хорошая моделька, для своих размера и скорости ебет.
>3б активных, оче щадящий жор на контекст, умение в большие контексты.
inb4 квенчика некст даже не запускал, но это квенчик, он оче хорош и по определению не может быть плохим. Хотя нет, может и запускал, но один хуй не использовал ни в коде ни на длинных контекстах.
> даже когда речь о моэ
Стадия торга. Почему поех внушил себе что на экслламе плохо работает моэ и теперь это тиражирует?
Так старался, можно и подыграть, чем тебя задели?
> расхищение у анонов секретов Квена 235 или большого Глм
Сделал мой вечер.
Скучно с тобой, обтекай.
Газонюх спок, читаешься как своя любимая моделька и пишешь также всрато
Неправда, я дрочу на коммандер. Тем более он у меня работает на той же скорости, что и квэн. Не столь многословен, но по мне это даже плюс.
Когда уже выйдет 5070тис, чтобы риг себе собрать

Я даже хз что на это ответить.
Люди даже читать разучились.
Давай я тебе картинками поясню?
https://qwen.ai/blog?id=3425e8f58e31e252f5c53dd56ec47363045a3f6b&from=research.research-list
Подробнее можешь тут почит… картинки посмотреть.
Там новые технологии, с которыми pwilkin и разбирается, позволяют этого добиться.
Они же тоже там полгода не хуй сосали, а модель с кучей новых фишек тренили. Правда сами эти фишки в llama.cpp перетаскивать не стали.
Поэтому такие дела.
———
Ну дальше опять срач пошел между «бывшей и нынешней».
Шо ж вы не успокоитесь-то. =)
>Люди даже читать разучились.
>Давай я тебе картинками поясню?
Деда, а может проблема в том, что как раз ты читать разучился и смотришь на картинки?
https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct
Новый тип аттеншена, новый тип тренировки, который в несколько раз дешевле предыдущего и позволит очень много экономить и тренировать быстрее, экспериментальная архитектура, которая скорее удалась, чем нет, это типа всё хуйня? https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list
На, читай, ты ж там выёбываешься, что умный такой. Распечатывай, выделяй маркером что там нового. Это пиздец, меня поражает то как ты выёбываешься и уверенно держишь позу когда сам нихуя не знаешь, впрочем у тебя всё поколение такое почти что.
Опять ГЛМ всё местами перепутал... ну что ж такое. Тут всё наоборот: Глм подсасывает юзеру, Квен отыграет как надо, даже слишком жёстко если есть к тому предпосылки
> Новый тип аттеншена, новый тип тренировки, который в несколько раз дешевле предыдущего и позволит очень много экономить и тренировать быстрее, экспериментальная архитектура, которая скорее удалась, чем нет, это типа всё хуйня?
Ну, и чем они тебе не нравятся?
Я о них тебе и пишу выше, но по твоему это «хуйня от шизоскуфа».
Только зачем ты теперь переобуваешься в прыжке? Это ж ты сообщением выше хуйней назвал.
Забавный такой, получил ссылку, прочел, о чем ему говорили, начал этим выебываться и стрелочки переводить.
Аплодирую эталонному маневрированию, честно. =)
Добрых снов, победитель!

Старый, ты блядь забыл что писал двумя постами ранее или чё?
>по сути, это единственная интересная фича
>единственная интересная фича
>x2 скорость
За это и отхватил, чтец блять.

Ну чё, добавили таки нового китайца в ЖоруЦпп. Замена AIR уже здесь, даже ггуфы есть https://huggingface.co/inclusionAI/Ling-flash-2.0-GGUF
Осталось дождаться пока нюня скинет пресет... Он же ждал ее
Осталось дождаться пока нюня скинет пресет... Он же ждал ее
У тебя контекст 2к, ты до сих пор с лламы-1 не обновился?
Мы обсуждали интерес для инференса текущей модели, это вопрос качество ее датасетов и обучения, как ее можно применять. Никакого отношения к технологиям это не имеет.
Единственная ее приколюха для тредовичков-РПшеров — это потенциальная очень высокая скорость, благодаря куче новых клевых фишек.
Ты написал, что это все хуйня, а потом когда я ткнул ссылкой, сразу переобулся и начал втирать, что ты за эти фишки.
Хватит обсираться чел.
Ты просто повторяешь за мной как попугай, даже не понимая, о чем шел разговор.
Но если ты сам такой весь умный и здоровый, то дай четкий ответ: какие из новых фич этой модели помогут тредовичкам лучше кумить на этой модели? Чур скорость, и все что с ней связано, и что послужило причиной — не называть, по твоим словам «это хуйня от шизоскуфа».
Давай, отвечай и пиздуй спать, а то будильник пропустишь. =)
Деда, не буянь, ты там грозился спать идти. Вот тебе чекушка, не шуми, ложись
А чем она хороша? Пробовали уже где?
А то они там гпт-осс в лоу-режиме побеждают и хуньюан 80б. Сомнительные противники, как и 30б денс модели.
Аха, значит ты понял свою ошибку. =)
Ну, не стесняйся, понял — молодец.
Модель как proof of concept технологий пиздатая, но кумерам она вряд ли что-то даст, кроме скорости.
Все, можно на боковую и перекат.
> А чем она хороша?
Только сейчас народные кванты подвезли. Скорее всего неплоха, по крайней мере не будет лоботомии как в гопоте и полное внимание а не скользящее окно.
> хуньюан 80б
Модель червь-пидор, или на жоре поломана.
> добавили таки нового китайца в Жору
Наконец-то будет что изучающе потыкать палкой. Шаблон еще буквально копия ChatML, только теги зачем-то заменили. Видимо, чтобы представить как свой собственный шаблон ¯\_(ツ)_/¯
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
А не на лохоплейсах есть?



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: