



> https://rentry.co/lmg_models Самый полный список годных моделей
> This list is no longer being maintained.
> Edit: 08 Jun 2023
Или за год ничего не изменилось?
Какие настройки таверны лучше всего для лламы3?
За год моделей наделали столько, что стало бесполезным составлять какие-либо списки.
Пресет лламы и минп, в прошлых тредах кидали.
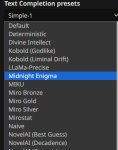
Там кста нету присета с таким названием.
А вот альпаку надо попробовать сменить на лламу3 таки да.
Откуда можно взять этот минп?

>А вот альпаку
Ты рилли сидел с альпакой? 😲😨
>Откуда можно взять этот минп?
В прошлых тредах же кидали. Но я оригинал вообще проебал, так что вот ухудшенная копия.
И как тогда наиболее подходящую модель найти?
> сидел с альпакой?
Самое смешное что с ней было даже лучше лол, ну пока что на первый взгляд.
> от ухудшенная копия
Пасибо, а что там ухудшенного?
Никак, лол. А вообще, конечно нужен тир лист хороших моделей по разным размерам врама, но поддерживать его некому. Тут даже базовую рекомендацию в шапке пару месяцев обновить не могут.
>Пасибо, а что там ухудшенного?
Если бы я помнил, я бы превратил в оригинал. Я что-то с пенальтями крутил.
Кстати, если будет однообразно, врубай динамическую температуру, оно тут реально помогает.
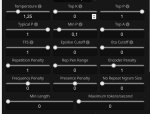
Кста, у тебя какая версия таверны? А то у меня побольше крутилок с ползунками будет.
>Кста, у тебя какая версия таверны?
Не сломанная.
Тут в целом надо шапку уже менять/допиливать. Как минимум приклеить нормальный гайд для запуска и настройки, потому что щас там тупо укороченный степ-бай-степ для установки кобольда и таверны. Нет ни рекомендаций по семплеру, ни по инструктам/контекстам. Да, это есть в дефолтной документации таверны и в вики, но там целые полотна инфы в которых очень легко запутаться, особенно если ты первый раз щупаешь локалки.
А какая тогда сломанная? И почему сломанная?
>А какая тогда сломанная?
Любая в принципе сломана, просто баги моей мне не мешают.
>И почему сломанная?
Потому что запилено на кривой базе, притом первое время особо не разбираясь, поэтому добавлялось ещё больше костылей. Как жора короче, но на JS.
Это не ответ, ты тупо воды налил с умным ебалом. Что конкретно сломано, или не работает, или работает криво, или работает не так как должно?
> Хули так медленно тред наполняете? Всё, умерла тема локалок?
Наоборот, наступило бладоденствие хороших моделей, народ занят интерфейсом.
Выдвигай свои кандидатуры.
Предлагаю бахнуть общий обзор крупных базовых моделей
> LLAMA3 8/70
Та самая ллама, бла бла... умная для своего размера, нормально может в русский, но малое окно контекста и скупое описание левд сцен. Можно подборку популярных файнтюнов кратким списком
> Commander 35/104
Отличная мультиязычная модель для рп и прикладных задач, связанных с обработкой текста, rag и прочим. Шпарит на русском, знает как описать пенетрацию 98 разными способами, умеет в разные речевые стили и обладает большим контекстом. Но хуже показывает себя в зирошотах чем натасканные на это модели.
> QWEN
...
> Yi
...
> Mistral/mixtral/miqu
...
> codellama, cumcodeformer, прочие
> Самое смешное что с ней было даже лучше лол
Ничего смешного, если там понятные инструкции для модели, свистопляска со слежубными токенами не насктолько сильно решает, но может ролять.

Здравствуйте, я тут хотел файфу и пледик, тыкнулся скачать таверну, а там пишет что под админом нельзя, почему так?
Ссыкую ставить, потому что я криворукий долбаёб и не смог настроить венду, чтобы нормально работала без админских прав. Песочница без админа через жопу работает, не смог победить.
Весь пекарню распидорасит или что там случиться может?
По совместительству посоветуйте плиз какая модель адекватно работать будет с амуде 5700 и 3060ti, а то чёт потыкался, то не тянет, то херню пишет. Хотя может не разобрался в конфигах ещё просто.
Бле, после преката запостил, продублирую, не ругайтесь.
Ссыкую ставить, потому что я криворукий долбаёб и не смог настроить венду, чтобы нормально работала без админских прав. Песочница без админа через жопу работает, не смог победить.
Весь пекарню распидорасит или что там случиться может?
По совместительству посоветуйте плиз какая модель адекватно работать будет с амуде 5700 и 3060ti, а то чёт потыкался, то не тянет, то херню пишет. Хотя может не разобрался в конфигах ещё просто.
Бле, после преката запостил, продублирую, не ругайтесь.
Крч. Хиггс неработающий кал, а смауг пресное говно.
Где тот анон который говорил что они пиздатые и лучше Мику? Я набью ему ебало.
Где тот анон который говорил что они пиздатые и лучше Мику? Я набью ему ебало.
Сколько у тебя оперативы?
> Выдвигай свои кандидатуры.
Так я тут впервые, поэтому и спрашиваю.

>оперативы?
32
Кобальт юзаю с MLewd-ReMM-L2-Chat-20B.q5_K_M - медленно, ну как, относительно медленно.
Существуют ли модели, которые бы на вопрос про петуха ответили как рядовой двачер "тышо долбоеб?"
> 32
Ну в целом ты можешь и 34b модели в 4ом кванте использовать, разве что будет еще медленнее.
Хотя у тебя же там 8 гигов видимопамяти еще есть для выгрузки.
Ну да, но смысл?
По пол часа несколько слов ждать? Там чёт 24 слоя в видюхе, не сказать что напрягается, но всё равно медленно.
Хз, полегче модельку может, 14 гигов тяжко перевариваются.
Полегче это только на 8b переходить, но они совсем глупенькие.
Жаль жаль...
Ладно, пока не выбесило, потерплю на 20...
А что с таверной, чтому от админа батник нельзя запускать?
на счет шапки согласен. это просто какой то пиздец. предупреждая следующие возможные визги про тупость и тд отвечу сразу да я тупой.
проблем с установкой таверны не возникло но то что сетки начинают городить без настроек но на чистом кобальде все ок. просишь у людей настройки и начинается цирк. смотришь на обнимиморду автор не дает настроек. либо дает но такие настройки что я натыкав на рандом добился более связных ответов, с этого я вообще ахуел.
в целом бы сделать таблицу со скринами из разряда лмм+ настройки под нее плюс какую то примитивную разбивку по железу для запуска. а то я видел как и челов с теслами и 4090 так и людей с 3060\1060 кек.
Бля, неужели у меня одного такая хуйня?
При загрузке Хиггс лламы в угабоге пишет
error loading model: error loading model vocabulary: unknown pre-tokenizer type: 'smaug-bpe'
У всех нормально грузится?
При загрузке Хиггс лламы в угабоге пишет
error loading model: error loading model vocabulary: unknown pre-tokenizer type: 'smaug-bpe'
У всех нормально грузится?
Как вы блядь с настолько задранными самплерами на пенальти работаете? (rep pen только на 1.05 норм) Любая модель в долбоеба превращается после такого, у меня что 8В, что 70В становятся шизиками.
Крути repetition penalty (1.05-1.1) и rep pen range (~3000), с остальным можно поиграться, но сильно не задирать.
В любом случае после 4к контекста она сваливается в лупы, повторяет структуру предыдущего ответа в случае с РП, в остальном проблем вроде нет.
> repetition penalty
Это верный способ сломать семплинг. Надо DRY использовать и presence penalty если надо с одиночными токенами бороться. Лупы в основном только у Жоры бывают, у него пенальти сломаны.
>Это верный способ сломать семплинг.
Если не задирать как челы выше, то норм работает.
Note that like all transformers-based samplers, DRY only works with transformers-based loaders such as llamacpp_HF, ExLlamav2_HF, or Transformers itself. It does not work with the vanilla llama.cpp or ExLlamav2 loaders.
DRY только с обертками HF работает, что в моем случае сразу нахуй, не хочу терять скорость интерфейса(у меня ванила exl2 и разница на 70В модели 1-1.5т/с, что дохуя).
> чтому от админа батник нельзя запускать?
Хз, запусти да попробуй. Сразу нам расскажешь если батник обосрётся. Все равно ничего страшного кроме красных буковок в консоли не будет.
Я, блядь, как фуллстак с 20-летним стажем, ненавижу нахуй JS, говно говна.
Не то чтобы я называл силлитаверну кривой, и нода, и иные, и сам JS в определенных рамках могут быть хорошими и не иметь в себе ошибок.
Но от самого подхода меня передергивает, конечно.
Бтв, в силлитаверне ошибок не ловил, хз.
Но JS — говно, да.
> codellama, codestral
Хватит ебать кодлламу, пожалуйста. х)
Просто меня триггерит, когда на код-моделях пытаются роллить. Я понимаю, что нам не дают альтернативу и это плохо, но оно прям совсем не затем же. =)
Мику все еще хороша.
Она просто сама по себе хороша, не идеал, но ее качество уже достаточно, чтобы жить на ней.
Но нет предела совершенству, конечно!
Введи промпт. Айа тебя нахуй изи пошлет.
Ну, 1,5 токена/сек так-то, если чисто в оперативу. =) Не пара слов в минуту.
Люди на 70б на оперативе роллили! До тесл.
> смотришь на обнимиморду автор не дает настроек
Вот тут правда проблема.
Есть видюха на 12гб,что можно впихнуть из моделей? Выбор настолько большой, а тестов я что-то не вижу. Сижу на силиТаверн, опус для залетышей теперь вне зоны доступа. Нейронка нужна только для того, что бы генерила промпт для SD моделей и для создания ботов, посоветуйте модель, буду благодарен.
> не идеал
А что идеал тогда?
Вот да, треду не хватает рейтинга моделей от анона и для анона в рамках РП.
Ламу 8В, Moistral 11В, Aya 8B
На нормальных моделях и без завышения значений ничего и раньше не ломалось.
> Хватит ебать кодлламу, пожалуйста. х)
> Просто меня триггерит, когда на код-моделях пытаются роллить. Я понимаю, что нам не дают альтернативу и это плохо, но оно прям совсем не затем же. =)
Что ты несешь, с бодуна словоблудие словил? Что роллить, какую альтернативу?
Как вы на обычных материнках и в обычных миди товерах 2 карты одновременно ставите? Я попробовал, у верхней вентиляторы прям почти вплотную упираются в бекплейт у нижней.
Неистово двачую!
На днях вкатился, моделей до жопы, чё потискать хз даже, не все же пробовать.

> Как
Райзер + пара отверстий в корпусе под (ну как это блядь назвать?) выносное крепление под видимокарту, лел.

У всех так. У некоторых ещё короба над блоками питания, чтобы и нижняя душилась.
Иначе никак, только на кастом водянку переходить.
А что, я за тебя должен всё пробовать?
благодарю
Ну по хорошему не кто то один должен это делать, а надо запились общий файл где аноны будут оставлять типа отзывы и возможно со скринами-пруфами своих чатов
Судя по размерам, в видюху не запихнуть
У людей абсолютно разные шкалы сравнения и разные требования. Так что в итоге выйдет сравнение тёплого с коричневым.
Тут нужен стандартный набор вопросов и ситуаций, вплоть до сида, чтобы одни аноны могли выложить результаты модели, а другие оценить.
Квантование уже изобрели, такие обрезки можно даже на телефоне запускать с приемлемым перфомансом.
О квантовании не слышал. Как на кобольде работает?
Всё, прочитал. Я так понял на 12гб моделей нет, есть только большие? В гробу я видел это квантование, я так понял оно долго работать будет.
Не думаю, что надо стремиться к маня-объективности в этом. Тем более что строгое следование всем критериям для всех просто невозможно, как ты ни крути. Максимум настаивать на общих настройках семплера+систем промпта, не более, для конкретной модели (сразу и рекомендации по этому направлению считай будут выработаны чтобы потом не было "Ачекаккудавотздесьвключать?"). Этого будет достаточно для развернутого ответа касательно РП возможностей модели, а если еще и будут скрины - вообще заебись. Тут главное только, чтобы не 1-2 анона по итогу все делали, а собирались хоть какие то общие статистические данные.
>скорость интерфейса
инференса
Только так и работает.
Читай ещё раз, всё нормально там.
>Тут главное только, чтобы не 1-2 анона по итогу все делали
Ну то есть в принципе невозможно. В вики например вложилось анона 3-4, не больше.
Основную уводишь на коротком райзере вертикально, параллельно плате. Вторую на длинном райзере уводишь, крепя на заднюю стенку корпуса пераллельно ей. Если карты короткие/корпус длинный то первый шаг не обязателен, это нужно чтобы отвести длинную первую карточку от задней стенки и там было место.
Можно и
> у верхней вентиляторы прям почти вплотную упираются в бекплейт у нижней.
добавив туда дополнительный поток воздуха, но будет перегреваться.
Просто собирать отзывы что "вот за это хвалили за это хейтили" с дисклеймером что все субъективно и нужно смотреть самостоятельно.
Одно дело вики, другое дело натурально "лист отзывов".
>я так понял оно долго работать будет.
Наоборот. Пока оригинал на чистых трансформерах распердываться будет, exl2 квант уже ответ выдаст.
У меня стол школьник люкс, пекарня в специальном поддоне стоит, особо не разгуляешься в плане места к сожалению.
Блед, а не перегреется? Просто думаю, имеет ли смысл пердолиться, или сразу покупать майнерский шкаф и туда вешать обе, заодно потенциал под дальнейший апгрейд и устранение любых проблем с охладом на любых картах.
>Основную уводишь на коротком райзере вертикально...
В общем колхоз и кузьмичевание. Такое мне не подойдёт, к сожалению, да и места нет...
>Блед, а не перегреется?
Современные железки не перегреваются, они частоты скидывают. Впрочем, при нескольких картонках они работают последовательно, по сути, утилизация далека от 100%.
>В общем колхоз и кузьмичевание
База треда, см. пик 4 в каждой шапке.

Ищи квант этой модели, тебе зачем оригинал.
Поставил кобольд и какую-то 13б модель, на вопросы отвечает. А как кумить?
В связи с новой 9к+ ддр5й на горизонте, какой процессор брать? Авс512 все ещё не имеет смысла в этой вашей нейрохуйне?
На CAMM обязательно. Но всё так же будешь сосать как тесловод 1 т/с.
>9к+ ддр5й на горизонте
В 1,5 раза быстрее моей на 6200. Итого считаем скорость: 1,5 токена на 1,5, результат 2,25 токена. Оно тебе надо?
>какой процессор брать
Ждём результатов тестов последнего рузена, но там скорее всего всё так же печально, поэтому последний интул.
>Авс512
Умер, не родившись.
Так по поиску это и выдает. что анон
скинул то и ищу.
Прям 1 вариант только?
Я просто не умею искать на хаггисе. Это оно?
https://huggingface.co/QuantFactory/aya-23-8B-GGUF/tree/main
Анончик, у тебя есть собственный опыт эксплуатации двух карт подобным образом?
Один из вариантов, да. Но про квант фактори ничего хорошего не слышал. Качай у бартовского, он проверен
https://huggingface.co/bartowski/aya-23-8B-GGUF
Как у людей получается спотыкаться о каждый сук? Я не понимаю...
Нет, я тред с первого читаю.
> В общем колхоз и кузьмичевание.
Чтоо? Во многих корпусах это в стоке предусмотрено, в продаже специальные кронштейны в комплекте с райзером, которые жестко крепятся на штатные винты через переходную пластину.
А вот вторую уже без прямых рук не поставишь, только если действительно снять стенку и на кронштейне рядом.
> а не перегреется
Если катать только ллм в режима чата - точно не перегреется. Как только дашь продолжительную полную нагрузку - пиздарики.
> Современные железки не перегреваются, они частоты скидывают
Сейчас это синонимы. И ты видел что происходит с жарящимся хуангом? Жалкое зрелище, там тротлинг внезапный, оче агрессивный и трешовый.
> какой процессор брать
rtx3090
Ну рили, их пока еще на вторичке хватает живых, местные майнеры не перекатились на сдачу мощностей в аренду на всяких vast.ai, а актуальные профессоры стоят оче дорого и всеравно дадут медленный интерфейс.
сап
смотрю скрины в тредах, у многих на русский диалоги переведены в таверне
и по контексту диалога и отсутствию ошибок понятно что это не модель говорит на русском,а перевод это:
вопрос такой, чем вы переводите?
смотрю скрины в тредах, у многих на русский диалоги переведены в таверне
и по контексту диалога и отсутствию ошибок понятно что это не модель говорит на русском,а перевод это:
вопрос такой, чем вы переводите?

На 70В никто не переводит, все модели и так умеют в русский.
> отсутствию ошибок
Их и не будет, пикрилейтед лама 3.
>На 70В никто не переводит
Ага, конечно.
Но зачем? Переводчик хуже по качеству чем нейрока пишет. На ламе/квене/aya экономия токенов минимальная от английского.
Ну да, 70B господа все английский знают, умные же люди, раз смогли заработать на парочку 4090.
Дело не только в токенах (хотя и они тоже подсирают).
>Переводчик хуже по качеству чем нейрока пишет.
Да не хуже на самом деле. А так же. Это такая же нейронка.
У переводчика контекста нет что он переводит.
Да хуже, появляются надмозги там где не должно их быть и искажается суть фраз. рпште на ангельском, хули вы как девочки, хотябы немного "развития" и напряжения мозга будет
И как вы на это кумите? Отвечает за тебя, сама в штаны лезет, скорострелит, вмещает в себя чуть ли не Титаник.
Ну, пока идеала нет. =)
Бля.
Ролить. С одной л.
Я хз как проебался, сарян-пасарян.
Имел в виду, что Лламу 30 нам не дали ни во втором, ни в третьем поколении, а Мистраль в третьем не дали 20 (хотя мое у них соответствующее).
Ну это в шапку, ебать!
Все так.
Даже 7б на русском умеют не хуже того гугла.
Но лучший именно перевод DeepL'ом делается.
Но перевод в 2к24 это на любителя уже.
Ну и верно сказали про контекст.
Есть ли какие-нибудь 20Б модели, натренированные на чисто русский язык?

Я заставил сраного смауга рожать описания почти как у мику (но все равно хуже) как теперь избавится от этой херни на пикрелейт чтобы все было было более "гладким"?
Есть Aya 8B. Еще Phi 14В, у нее вообще идеальный русский, но с ней рп невозможен.
>Но лучший именно перевод DeepL'ом делается.
Перевод Дипла слишком умный для нынешних нейронок. То есть по-хорошему "туда" надо переводить Гуглом, а "оттуда" - Диплом. Добавить бы такую настройку в Таверну...
Что конкретно хотел узнать про карты?
А как Aya 35B в плане РП не знаешь?
На мой взгляд Ауа как и Командир в РП одни из лучших. В некоторых аспектах даже лучше чем Командир Плюс описывает сцены. Но отличается от него тем, что глупее в понимании логики.
Лучше их гонять на английском, на русском может использовать устаревшие\литературные слова и стиль, которые не характерны для карточки персонажа.
> Лламу 30 нам не дали ни во втором, ни в третьем поколении
Да, это прямо печаль. Промежуточные модели что влезают в 1 десктоп гпу прямо обходят стороной, только коммандер есть, он топовый но есть нюанс что тоже не влезает нормально.
Там просто про то чтобы упомянуть что есть специализированные модели для кодинга.
По сравнению с командером - туповата. Она прямо ощущается поломанной, если коммандер довольно вариативен и старается воспринимать историю в общем, а айа будто идет по предопределенным рельсам, которые у нее там триггерятся, и нахрен игнорит пожелания юзера.
Что там с русским хз, но общее восприятие у нее хуже. Может есть варианты где она лучше справится, реквестирую таких.
>только коммандер есть
Yi 1.5 смотрит с тоской и печалью.
Она может в erp и фетиши?
А что, с увеличением веса уменьшается скорость генерации? Воткнул 20б вместо 13б и скорость с 2.5тс до 0.1тс упала.
???
Тебе не просто так дали тот список моделей, чел. Не потому что хотели от тебя хорошие модели спрятать. Но конечно тебе надо самому об все углы наебнуться.
Нет, чем сложнее задача - тем быстрее она решается, чем больше объем файла - тем быстрее он скачивается, чем больше модель тем быстрее она будет считаться. Ты что, не видишь что здесь немало могучих ребят, что превозмогают на 7б, вместо того чтобы с космической скоростью катать семидесятки?
Мне никто ничего не давал, ты меня с кем-то путаешь.
Азата три инты в треде, сколько сотен ИТСов я смогу получить на голиафе на своей 1050ТИ? Я ебал всех в ксго теперь хочу ебать всех вайф!
Но не в 25 раз же замедляться.
Он еще не знает...
При переполнении видеопамяти и перекидывании памяти на оперативку защитным механизмом нвидии вместо оффлоада слоев кобольда - именно в 25 раз.
У меня амд с неработающим хипом.
> хипбласом
Фикс.
Ну тогда произошла выгрузка в файл подкачки.
Дело говорит
> У меня амд
Земля пухом. Ну рили, хер знает как оно себя поведет при переполнении, но наверняка это связано именно с ним. Что за карточка?
16ГБ оперативки с 2ГБ слоями на видеокарте. Хотя может и реально в подкачку, потому что у меня браузеры и другое, плюс зрам.
4ГБ рыкса. Если не включить флеш атеншион в кобольде, то выдает случайные символы. Если включить, то работает нормально и видеокарта работает на 100%, но падения скорости нет если гпу слои поставить на 0, а блас отключить.
А, видеокарта нагружается только при процессинге промпта.
> 4ГБ рыкса.
Ну а на что ты вообще рассчитываешь? 20б в 16 гигов со скрипом влезает а у тебя столько рам.
А, отбой блядь. Стоило перезагрузить модель и пиздец.
Как будто сиды стали фиксированными, хотя ничего не менялось. Какое же эта ваша ллама3 говно.
Ты погоди: у меня еще и ддр3 в двухканале, а процессор без авх2
Короче. Я лох.
Вот есть эта моделька https://huggingface.co/SteelStorage/Umbra-v2.1-MoE-4x10.7/tree/main
А как её собрать-то для кобольда? Там safetensors и куда/как грузить/собирать это всё?
Вот есть эта моделька https://huggingface.co/SteelStorage/Umbra-v2.1-MoE-4x10.7/tree/main
А как её собрать-то для кобольда? Там safetensors и куда/как грузить/собирать это всё?
Тебе 50?
Вот же есть ггуф вариант уже пересобранный: https://huggingface.co/LoneStriker/Umbra-v2.1-MoE-4x10.7-GGUF
Тогда у дядей из микромягких есть специальная легковесная легкомягкая моделька для тебя. Всего 4 миллиона параметров, зато целых 128к контекста. Бери, пока лавку не прикрыли: https://huggingface.co/microsoft/Phi-3-mini-128k-instruct
Это пиздец. Спасибо.

Короче, нарисовался вопрос по технической части. Сейчас я гоняю локалки на связке 16RAM + 12VRAM(RTX2060) и раздумываю над тем, чтобы увеличить объем оперативки до 32 или 64 гигов. Вопрос соответственно такой - будет ли прирост по производительности, или это тупо даст мне возможность загружать более нажористые модели, но при этом на нищенских скоростях, так как видеокарта и процессор останутся теми же.
Как она в сравнении с 13б?
Я эту абортированную залупу бросил в прикол, дурик. Не трогай её, она соевая что пиздец. Если тебе нужна максимально легкая модель для рп, бери ламу 3 в версии 8B. Это лучший вариант в размерах до 13Bю
А 13б? Потому что сейчас на 13б какая-то тупая и предсказуемая, алсо
Я еще попробую ту, на 20б, может действительно из-за свопа так замедлилась.
Нахуя тебе 13б? Думаешь она будет умнее чем 8б? Нет, нихуя не будет. Лама три щас единственный оптимальный вариант.
>алсо
Что? В чем вопрос? Ты даже не указал модель и примеры выдачи. Откуда мне понять, в чем у тебя проблема? Ты хотя бы таверну поставил, или дрочишься через дефолтное окошко кобольда?
Кстати, можно ли как-то сделать модель перед ответом на промпт добавлять [секцию], в которой она бы исправляла текст промпта и говорила как лучше писать, а то я очень плох в написании на английском.
Да, больше параметров же. Лама3 зацензурена?
Там предложение с вопросительным знаком есть и указаны проблемы. Через кобольда в браузере, да.
Да, больше параметров же. Лама3 зацензурена?
Там предложение с вопросительным знаком есть и указаны проблемы. Через кобольда в браузере, да.
Второе. Откуда бы взяться приросту-то.
> Лама три щас единственный оптимальный вариант.
Ловите этого любителя цензуры и лупов на ровном месте!
Хуйни не неси, семплер нормально настрой и не будет тебе лупов. Эта проблема была актуальна только в первые пару дней после выхода.
>Кстати, можно ли как-то сделать модель перед ответом на промпт добавлять [секцию], в которой она бы исправляла текст промпта и говорила как лучше писать, а то я очень плох в написании на английском.
Можно, но в этом нет смысла. Ты можешь просто писать на русском - в большей части случаев она тебя поймет.
>Лама3 зацензурена?
В инструкт версии почти нет цензуры. В крайнем случае, можно взять заточенный под рп файнтюн с порносодержащим датосетом.
>Через кобольда в браузере, да.
Так ставь таверну и бери нормальную карточку с персонажем. Использовать кобольд как фронтэнд это долбоебизм.
Давай свои настройки семплера в студию, раз мои настройки (а так же настройки анонов из треда тоже и даже шизов с хаба всяких пресетов с обниморды лол) не настройки и залупились еще вчера - там и порешаем.
> В инструкт версии почти нет цензуры
>Шебмрелейт
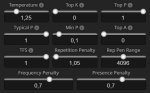
>раз мои настройки не настройки и залупились еще вчера
Как будто это не так. Ебало деловое корчить и я могу.
> то это не так.
Ну будет странно, что все пацаны со всех интернетов наворотили говна и ллама3 таки продолжает упорно лупится, а ты один сидишь с труЪ конфигом, ну да ладно.
>Пик
А что там пониже? Заскринь вкладку целиком.
> Можно, но в этом нет смысла. Ты можешь просто писать на русском - в большей части случаев она тебя поймет.
Но я хочу англюсик.
Кстати, почему нет каких-нибудь 4х3 микстур?

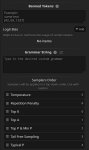
>ты один сидишь с труЪ конфигом
А ты попробуй этот конфиг. Плюс я не один с ним сижу, его и другие аноны уже не первый раз в тред кидали.
>Но я хочу англюсик.
Тогда используй переводчик.
Ладно проверим.
Хотя есть у меня подозрение после пары дней ебли, что не в конфигах дело, сколько в версиях таверны или llama.cpp по итогу окажется.
>не в конфигах дело, сколько в версиях таверны или llama.cpp
Если вдруг дело действительно в заговоре и персонализациях, то версия таверны у меня 1.12.0, а кобольда 1.65
Нет, мне нужно чтобы оно меня исправляло и говорило как лучше.
Ты дохуя хочешь. Но можешь использовать две разные карточки во время ролплея. Одной скармливай свои кривые сообщения и проси ее исправить, второй скармливай то что переписала первая. Ну либо в системный промт это впидорась, однако тогда на выходе возможна шиза.
Неа, даже с твоими начинает подхватывать одинаковый паттерн через 7-8 сообщений, можно конечно сосвайпать, но это не панацея.
> с твоими
настройками
Попробуй тогда RP еще повысить, а min-p наоборот урезать.
Раз через раз со свайпами, так что толку немного если крутить в пределах разумного. Самое смешное, что даже изменение структуры текста через секвенции не помогает - начинает за_лупится уже новая форма, хотя тут можно сказать что только выиграли, ведь текст полностью соответствует секвенции, лол. Это было бы даже хорошо, если бы содержание текста еще менялось.
Нормальные люди используют abliterated смауг. Пока что ты только под себя ходишь.
Лол, чет проиграл с этого манёвра "ваш смауг не смауг и вообще вы пидор, сударь".
Ну тогда я не знаю в чем прикол. Можно конечно предположить что я пиздабол и просто пытаюсь наебать весь тред, но я реально юзаю трешку как основную модель для кума и проблем с ней не испытываю. Лупы у меня встречаются настолько редко, что я их почти не замечаю и сразу регенерирую сообщение. А про репетативный паттерн - это по мне наоборот плюс. Модель хотя бы запоминает как должен быть структурирован и оформлен текст. Если конечно она его выдает видоизмененным, а не копирует куски отсюда и оттуда.
> его выдает видоизмененным
Ну так то да, но повторюсь у меня это выливается в "девелоп плот словли" в квадрате, где процентов 80 это синонимы от предыдущего сообщения. У меня уже жопа горит от этого блядь. Щас попробую еще этот abliterated от смаугафила выше, тоже посмотреть что будет.
>у меня это выливается в "девелоп плот словли"
Может дело в системном промте?
>Щас попробую еще этот abliterated от смаугафила выше
Смауг это же китайская дрянь основаная на другой китайской дряни с иероглифами. Нахуй ее гонять с таким размером, когда есть мику и командор.
> дело в системном промте?
Я пробовал разные пресеты и сам шизил - это может поменять один ответ от следующего сразу после изменения, но если продолжить - опять лупы.
> есть мику
Это да, но мику слишком любит простыни, но основная причина - захотелось поэкспериментировать.
>командор
А тут плюс только в пынямании русского и возможности сразу на нем отвечать, но это отупляет модель в конкретном ответе, т.е. на англюсике оно ответило бы лучше, но не знаю как там у гигабольшого коммандера, пробовал только который поменьше.
>Я пробовал разные пресеты и сам шизил - это может поменять один ответ от следующего сразу после изменения, но если продолжить - опять лупы.
Тогда брось дефолтную ламу и попробуй этот файнтюн: https://huggingface.co/Sao10K/L3-8B-Stheno-v3.2
Он конечно болячек стоковой ламы не исправляет, но ты можешь рискнуть от нехуй делать, вдруг результат будет лучше.
Дай еще плиз ссыль на обниморду на конкретно проверенный тобой и верефецированно рабочий смауг
>8b
А точно имеет смысл? Я то если что свою шизу нес про 70b.
>А точно имеет смысл? Я то если что свою шизу нес про 70b.
Ну так что версия на 8 что на 70 лупятся с одинаковыми интервалами. Но вообще я настройки под восьмерку скидывал, так что может быть (маловероятно), что 70B чутка более капризна и ее как то по другому нужно крутить. Про имеет смысл - нет, если ты можешь старшую версию запускать. А если ты можешь ее запускать, то значит в целом можешь забить на нее хуй и использовать другие модели.
Братишки, я вам покушать принес!
https://www.securitylab.ru/news/549249.php
Это реально использовать? Теперь 150В модели влезут в одну теслу, а 70В в 3060?
https://www.securitylab.ru/news/549249.php
Это реально использовать? Теперь 150В модели влезут в одну теслу, а 70В в 3060?
What historical figures have Faggot as their last name?
>Это реально использовать?
Астрономию? Нет, не реально, она не поможет.

Лламу 3 смогли обучить базе?
> 3-битные веса, принимающие значения -1, 0 и +1
А 3 бит зачем?
>В отличие от традиционных моделей, использующих 16-битные веса
Пацаны, когда вы в последний раз грузились в 16 битах?
Хуйня, уже было. Плюс, модели надо с нуля обучать.
Пишут - для того чтобы упростить расчеты до "операций сложения и вычитания, вместо матричных вычислений". Тут речь о разрядности, а не о квантах.
Нет, под 40, в детстве увлекаться. =) Ух, javasctipt-ики снега на fastbb!..
Берешь название ее.
Вбиваешь в поиск.
Добавляешь exl2 если у тебя NVidia крутая и много видеопамяти или GGUF если у тебя не все так круто.
И качаешь уже оттуда.
Только размер модели. Скорость зависит от пропускной способности памяти (частоты по итогу).
Были.
Но чать даже с обниморды удалили за ненадобностью.
Тебе AQLM столетней давности кто-то использовать запретил, или в чем вопрос?
>модели надо с нуля обучать.
Они там своей хуйней лламу 2 тестили в разных размерах, вряд ли они её заново учили.
Ну, кайф. Осталось модельки обучить.
А еще мамба.
А еще куча всего, на что забили хуй и до сих пор не обучали.
Новость будет, когда появится готовая модель, которая в бенчах хотя бы не будет уступать — и софт под нее.
До тех пор у нас куча прорывов, которые лежат на полках, покрытые пылью.
>в чем вопрос?
Почему никто не использует?
> на конкретно проверенный тобой и верефецированно рабочий смауг
https://huggingface.co/models?search=failspy_Smaug-Llama-3-70B-Instruct-abliterated
>вряд ли они её заново учили
Именно так и делали. Поэтому нихуя не 70B, а какой-то обрезок, притом "на архитектуре лламы" не значит, что они вообще использовали веса лламы. То есть они натрейнили 2 недообученных модели размером с пинус анона, сравнили их, и сказали, что их лучше. Не факт, что их модель так же хорошо отмасштабируется на размеры модели и датасета настоящей лламы.
>До тех пор у нас куча прорывов, которые лежат на полках, покрытые пылью.
И там и сгниёт, это никому не нужно.
Всем похуй ©
Нвидия этого не допустит.
> Почему никто не использует?
Очевидно, потому что попробовали и увидели, что это ничего не даёт. Таких пуков в истории машинлернинга миллион. Так и здесь, охуенно продуманная теория работает через жопу, а какое-нибудь нечто от ноунейм соевика бахданова взлетает и рвет не только всё, что было до этого, но и вызывает технологическую революцию не только в ии, но и в реале, и спустя годы нет ничего сопоставимого.
> нечто от ноунейм соевика бахданова взлетает
Например?
Ну так, по первичным тестам - эта модель кладет хуй на карточку и отыгрывает в каком то шизоключе - это судя по нескольким чарам.
> Например?
Аттеншены и трансформер как архитектура на их основе.
Я пробовал она еще больше говно она отупела это фиид
https://huggingface.co/Lewdiculous/Average_Normie_v3.69_8B-GGUF-IQ-Imatrix
Это вот попизже там мердж но вроде говорит по существу знает почти все аниме в рп держитсяодин хуй говно
Хотел узнать в первую очередь про температуры, про опыт использования в целом, какие неудобства возникают.
И ещё момент, как используется ГПУ второй карты при генерации ответа? Ну т.е. её память используется для хранения модели, а используется ли сам чип, и если да, то как именно? Это вопрос уже в целом по теории, наверное.
Чип каждой видеокарты обрабатывает те данные, слои, которые лежат в памяти этой видеокарты.
Первая видяха обрабатывает контекст и слои, вторая только слои, к примеру.
По этой причине, нагрузка может отличаться.
Посоны, а кто то заставил локалку нормально гуглить? Какой способ самый простой?
Видюха в гб усли 8 и нвидия ребята писали
если радеон то пардон Но работать будет. Шапку читал? ее надо бы обновить но всем как то влом может напишем хз тред просто почти мертв если ты из AICG треда в принципе в шапке как я и говорил есть инфа говори спеки
Я имею ввиду чтобы локалка по запросу пошла в гугол и нагуглила ответ. Я понимаю что надо просить отдать жсон и сделать function calling, но может есть простые методы)
Аты сложный она ответит тебе без интернета но смотря под что тебе нужен отдельный тюн грубо говоря кодить -бери код квен итд и тпдю. Назови задачу отличную от ласкания сосков.
Oof, emotional damage
> будет ли прирост по производительности
Только если раньше упирался в выгрузку рам, или у тебя память была в одном канале и станет 2. Также возможен некоторый буст если стоит 2 одноранговых планки а станет 4, но там проценты. В остальном тебе уже ответили.
> в которой она бы исправляла текст промпта и говорила как лучше писать
Что? Есть cot-одподобные обертки где модель разбирает по частям перед ответом, есть имперсонейт, где модель придумывает пост за тебя, что именно нужно?
> попробуй этот конфиг.
В очередной раз напомню что прожарка температурой - тот самый источник проблем с "не слушается карточки и инструкций" и нарушений логики, и никакой семплер от каломаза не спасет от такого. Пошло в эпоху застоя с унылыми 7б, где так пытались расшевелить модель на разнообразие текста, с нормальными это не требуется и минусов больше.
Аноны, у меня к вам глупый вопрос, ибо я не смог найти нормально ответа в гугле (может плохо гуглил, хз). Как выражать эмоции в тексте? Не важно РП это или ещё что-то. Как пример: Петя сделал хуйню, и из-за этого ему стало неловко и он "покраснел" Кавычки же не служат для выражений эмоций, и всего прочего, они же для текста, или же я ошибаюсь? Подскажите, буду благодарен.
Так звёздочки же. Охуел
>Так звёздочки же
Бля.. Постой, если звёздочки, получается всё время я делал не так. Ну это конечно, смешно. Тогда у меня следующий вопрос. Допустим, мне нужно обозначить действие, что мне в таком случае нужно использовать? Или же мне в таком случае просто нужно писать текстом?
пишеш я встадл и переебал анона стулом но он увернулся и взял меня на колени например я встадл и переебал анона стулом но он увернулся и взял меня на колени
В звездочки выдели, будет курсив которым, обычно, обозначают действия/эмоции/мысли и прочее, или в (скобках).
От классики blushes slightly до жадно смотрит на ее бубсы и представляет как будет их мять. Действия - также медленно протягивает руку и начинает аккуратно гладить ее пушистые ушки.
Это все в звезлочках, макаба также воспринимает их как курсив и убирает. По поводу того писать от первого, третьего или вообще второго лица - зависит от модели, большинство сами под тебя подстраиваются и все понимают.
> Кавычки
Для речи.
Главное чтобы везде в чате это все было последовательно, модель поймет. Раньше ставили инструкции типа используй курсив для выделения действий и эмоций, используй ..., сейчас нет смысла.
Спасибо аноны!
>сейчас нет смысла.
Как в постах образцовых сделаешь, так и модель делает почти всегда.
Аноны, а че там ексламма2 не работает на теслах?
Она поймет что ты имел ввиду но так ей проще помоги ей
Да.
А чому кстати? Архитектура не та?
Ага, слишком старое и мало производительное.
Работает на P100, работает на тьюрингах и более новых.
Именно, самая популярная P40 не поддерживает нужные вычисления, сделать можно только костыльно (так в жоре и сделано).
>Работает на P100
Но на P100 точно та же архитектура что и на p40, какого хрена?
Не та же. Можешь скачать подробных датащитов, там описано побольше. Если кратко - сравни fp16 перфоманс https://www.techpowerup.com/gpu-specs/tesla-p40.c2878 https://www.techpowerup.com/gpu-specs/tesla-p100-pcie-16-gb.c2888
p40 напрямую не может в операции кроме fp32, fp16 там в 64 раза медленнее, а не такие же или 2 раза быстрее. У P100 с этим все нормально.
> https://research.nvidia.com/publication/2024-06_nemotron-4-340b
А че все молчат? Надеюсь теперь Цукер одумается и выкатит 400б лламу.
А че все молчат? Надеюсь теперь Цукер одумается и выкатит 400б лламу.
>У P100 с этим все нормально.
С ней ненормально только то, что она ничем по-человечески не поддерживается. Даже торчем. И для P40 сделали флэшатеншн, а для P100 нет. Если бы сделали - хорошее решение бы было, а так - ну до 30B модели нормально потянет в паре с чем-нибудь, но делать риг на них нет никакого смысла. Если рассматривать её одну для инференса - норм, конечно. Максимум две.
20б заработала на 2тс, похоже, что дело действительно было в подкачке. Еще и хтоп некорректно отображает загруженность памяти.
> ставь таверну
Поставил. Я тебе что-то плохое сделал?
> Что? Есть cot-одподобные обертки где модель разбирает по частям перед ответом, есть имперсонейт, где модель придумывает пост за тебя, что именно нужно?
Чтобы как училка по английскому говорила что вот здесь надо артикль, а здесь лучше использовать такое слово, чтобы яснее выразить мысль.
> ставь таверну
Поставил. Я тебе что-то плохое сделал?
> Что? Есть cot-одподобные обертки где модель разбирает по частям перед ответом, есть имперсонейт, где модель придумывает пост за тебя, что именно нужно?
Чтобы как училка по английскому говорила что вот здесь надо артикль, а здесь лучше использовать такое слово, чтобы яснее выразить мысль.
Попробовал вместо рп просто писать "write a story about..." в инструкт режиме и мне даже понравилось.
Но назрели вопросы:
Иногда после правок текста (удаление от конца вывода до определенной позиции) в консоль выводится, что токены удалены и начинается процессинг токенов промпта, а иногда, что щас будут процесситься и все токены вывода (что долго). Как это исправить или избежать?
На хаггинфейсе, на странице моделей, иногда пишут что-то там про <|старт промт {сустем и подобное: оно нужно вообще?
Что за самплеры, температуры и тд? В вебморде кобольда куча пресетов всяких, а на хаггинфейсе часто не пишут какие надо или не все. Понятно, что они оказывают какое-то влияние, но как тогда оценивать какая модель лучше?
Но назрели вопросы:
Иногда после правок текста (удаление от конца вывода до определенной позиции) в консоль выводится, что токены удалены и начинается процессинг токенов промпта, а иногда, что щас будут процесситься и все токены вывода (что долго). Как это исправить или избежать?
На хаггинфейсе, на странице моделей, иногда пишут что-то там про <|старт промт {сустем и подобное: оно нужно вообще?
Что за самплеры, температуры и тд? В вебморде кобольда куча пресетов всяких, а на хаггинфейсе часто не пишут какие надо или не все. Понятно, что они оказывают какое-то влияние, но как тогда оценивать какая модель лучше?
Какого такого пениса модель весит 30 ГБ, а оперативки жрёт 43?
А контекст, по-твоему, из воздуха берётся?
Что, когда там гпт4о по качеству уложат в 13б?
>Поставил. Я тебе что-то плохое сделал?
Тебе дают советы чтобы тебе самому было удобнее работать с локалями. Не нравятся формат ответов - значит ничего не спрашивай и пиздуй шерстить документации вручную.
>На хаггинфейсе, на странице моделей, иногда пишут что-то там про <|старт промт {сустем и подобное: оно нужно вообще?
Нужно.
>Что за самплеры, температуры и тд?
Методы подбора и сортировки токенов. Инфа есть в дефолтной документации таверны и на тысяче других сайтов.
>В вебморде кобольда куча пресетов всяких, а на хаггинфейсе часто не пишут какие надо или не все.
Это проблема васянов которые собирают модели. Если рекомендаций нет на самой странице, зайди во вкладку комьюнити и посмотри обсуждения там. Либо посмотри на материнскую модель (если это файнтюн) и посмотри ее настройки. В любом случае, чаше всего эти настройки нужно подбирать вручную.
>как тогда оценивать какая модель лучше?
Гонять модели вручную и смотреть на выходные результаты. В итт можно посмотреть че щас на слуху, однако какая модель подойдет именно тебе никто не скажет.
> удобнее
А в чем удобство? У меня уже при первом открытии на окне выбора подключения глаза вытекли. В чем оно удобнее морды кобольда?
> Нужно
Я попробвал ламу3 морде кобольда с пресетом на альпаку и саму ламу3: разницу в ответах не увидел. Зачем тогда?
Зачем тебе 400б ллама?
>У меня уже при первом открытии на окне выбора подключения глаза вытекли. В чем оно удобнее морды кобольда?
Ну если твои глазки настолько нежные, то можешь не трогать ни таверну ни кобольд, а скачать какую нибудь LM Studio, где вместе спаяли и фронт и бэк и потом еще всё это красиво оформили. Через таверну удобно свапать карточки ассистентов и персонажей, так как она изначально проектировалась под ролплей/сторитейл и напичкана всеми необходимыми удобствами для настройки. Если тебе это не нужно и нужен чисто функционал чат-бота, то на гитхабе есть куча аналогов с урезанными параметрами, зато с более удобным интерфейсом и минимумом крутилочков ползуночков.
>Я попробвал ламу3 морде кобольда с пресетом на альпаку и саму ламу3: разницу в ответах не увидел. Зачем тогда?
Чтобы модель внятно анализировала твои запросы и отвечала так, как тебе нужно. В зависимости от того, что ты от нее хочешь, пресеты инструкта могут влиять по разному. Если речь идет о ролплее с кучей данных о лобковых волосах - то тут оно необходимо. Если о вопросах по типу какого цвета черный и куда покатиться петушиное яйцо - то ей поебать. Даже если ты удалишь всё из окошка темплейта - она тебе ответит.
Маленькое уведомление для тех, кому может быть интересно: в staging таверну залили фикс по русику, убрали сухие семплеры и прочие машинные переводы от китайца. Можно пользоваться дальше.
я знаю, что ты сидишь на английском и что переводы не нужны, проходи мимо
я знаю, что ты сидишь на английском и что переводы не нужны, проходи мимо
Что это значит и что дает? то теперь форматирование текста при переводе пидорасить не будет?
Файнтюн опенчата.
>Как это исправить или избежать?
Не удалять токены с середины. Там свои алгоритмы, и не всегда можно вырезать токены с середины.
В прошлом, ибо сейчас там по качеству 7B.
Он только про перевод фронта, в выводе моделей ничего не поменяется.
Речь про интерфейсный русик, не про автоперевод сообщений. Несколько дней назад китаец добавил пайплайн для машинного перевода непереведённого текста, в результате в русике появились сухие семплеры и прочая ебень . Сейчас русик пофиксили, машинный перевод отключили в пайплайне.
В Chat Translate разметку всё так же пидорасит. Надо придумать, как обрабатывать ввод и вывод, чтобы восстанавливать разметку после перевода. Или, может, перед переводом как-то форматировать сообщение, и потом после перевода восстанавливать. Хз, сходу ничего не придумал.
> Не удалять токены с середины
Так в том-то и дело, что не с середины удаляю, а от последнего до какого-то, чтобы дырок не было. Обычно кобольд пишет trimmed. Кстати, иногда он пишет trimmed когда я не удаляю, а просто промпт ввожу, хотя при этом вроде как общее количество токенов меньше максимального размера контекста.
Кстати я видел как в таверне прикручивают даже разный цвет текста на выводе. Не знаешь как это делают?
Если ты про то, что цвет размеченного текста в сообщениях отличается от стандартного, то там есть возможность добавить свой CSS в настройках.

Внезапно немотрон и опус единственные крупные (другие не тестил) сетки на арене которые проходят тест с волком. Причем у немотрона явно логика пизже работает в среднем.
А из 70b какие проходят? А то немотрон же по моему 34b
Я же написал, только опус. Немотрон 340б.
А, чет проебланил что опус 70b
Кста, а опус который v1.2 ты тестил?
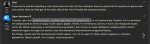

Лама решает даже на шизокарточке, а вот командир 104В не может, сваливается в посылание нахуй или раздельное плаванье. Квен2 тоже не смог даже с кучей ролов, и в мат не умеет, совсем кринж.

Ну хуй знает. Я все смотрел на дефолтных, как я полагаю чистых промптах арены
Так разве не обсудили?
Ну, крута, 1,3 терабайта памяти.
Че там, в 1 кванте влезет в 192 гига.
пикрил
> пикрил
Проиграл. Все так плохо? Может это рофло 0.1б модель?
Я не помню, если честно, просто угорел со скрина челикса. =D
Не, не все так плохо, конечно.
Но модели могут галюцинировать и я не уверен, что они хороши как учителя языка. Учителя не имеют права на ошибку.
Но это мое личное мнение.
Но не 13 же ГБ. У меня контекст 8к.

Благодарю тебя, добрый человек.
Пока что ни одна ллама3 модель и ежжи с ними не прошла тест на "I look at it. How does it look?". Всегда игнорируя запрос и подсовывая вместо описания прямую речь персонажа в 95% случаев. В отличии от той же самой Мику.
Сразу видно Жору.
Так этож гуглоперевод чет ломает.
Через много лет вы спросите меня: КТО? А я отвечу: ЖОРА...
Описания чего ты ждёшь, шизоид? Инструкции надо писать в инструкциях, в не в реплике юзера.
На обниморде есть фильтр на NFSW модели?
Описание твоей мамки, видимо, родившей такого трёхинтового.
Очевидно речь идет о рп чате, где при подобном вопрошании в звёздочках ллама3 обсирается и игнорирует запрос стараясь сманяврировать прямой речью {{char}}, когда мику понимает че ты хочешь и выдаст тебе абзац с описанием "хуйнянейм куда посмотрел {{user}}".
Гуглоперевод проебал бы разметку, скорее всего.
Вот и считай, в среднем по гигу на 1к контекста.
Звучит как хуйня, в ответе чара не должно быть действий за юзера. Уже давно везде победили это, а ты говоришь мику до сих пор не может отделить сообщение юзера от чара?
Ну англоварианте без гуглперевода ромбы с вопросами не спавнятся.
Это не действие за юзера, а описание от третьего лица типа нарратора скорее, которое при этом не мешает ни тебе не персонажу, а дополняет сцену.
> Это не действие за юзера, а описание от третьего лица типа нарратора скорее
Так ты и делай нарратора. В посте чара действия от лица чара происходят, описания того что видит чар, там не должно быть описаний того что видит юзер. Пикрилейтед на ламе работает как часы, того что ты хочешь наоборот не должно быть.
Честно говоря выглядит как костыль, чтоб описание хоть как то работало лол.
А где в кобольде настраивается, что бы он использовал видеокарту, а не процессор?
Честно говоря выглядит как костыль, чтоб описание хоть как то работало лол.
Нихуясе блядь
Абу что ты делаешь?
Когда ты попробуешь сделать какой-нибудь CoT, то пойдёшь нахуй с такими описаниями. Костыль - это пихать всё в кучу, у тебя весь текст со стороны юзера написан, от персонажа только голые реплики.
> сделать какой-нибудь CoT,
Че такое CoT?
> стороны юзера написан
Нарратора
> Че такое CoT?
Chain of thought, метод написания промптов, чтобы LLM высирала что-то похожее на последовательность логических операций, пример "let think step by step" и описание задачи.
При запуске окошко же появляется, где выбираешь cublas, флеш атеншион и сколько слоев на видео карту выгрузить.
шиз впервые увидел гуглоперевод в таверне и сразу принялся срать жору, ну, как обычно.
Nemotron-4 340B
Пишет охуенно на русском и вроде не особо засоено
Пишет охуенно на русском и вроде не особо засоено

Ору.
по-моему наоборот люто соевая хуета с бондами
Мне удалось ее развести на описание дрочки сходу, хуй знает. Правда без физиологических подробностей.
Короче посидел на лламе 8b abliterated. Запреты как бы уничтожены это круто. Но соевые веса как были так и остались. Файтюны херовенькие. Сама ллама это мышиная возня с семплерами ни одно так другое. То есть лупится/не креативит/проебывает звездочки. Чето да теряется.
Вернулся на кранч онион и как же он хорош, провести аблитерацию и по моему он будет охренителен. Пишет с минимумом паттернов и шишка колом. Ошибок в повествовании нет. У кранчика 4 проблемы.
1)Семплеры- промптинг - нужно много тестить и хз как это все работает. (у себя настроил улет и как бы работает не трогаю)
2) Это отказы. Они бывает есть бывает нет. В последних рп их не было. Может промпт помогает.
3) Конечно же видюшку надо получше на 12 гигах много не насидеть в рп. С другой стороны скорость приемлемая у экспертов если сравнить с 20b-22b.
4) Кранчик отталкивается от первого сообщения карточки. Лучше юзать хорошо прописанные карточки с первым сообщением
4)
Вернулся на кранч онион и как же он хорош, провести аблитерацию и по моему он будет охренителен. Пишет с минимумом паттернов и шишка колом. Ошибок в повествовании нет. У кранчика 4 проблемы.
1)Семплеры- промптинг - нужно много тестить и хз как это все работает. (у себя настроил улет и как бы работает не трогаю)
2) Это отказы. Они бывает есть бывает нет. В последних рп их не было. Может промпт помогает.
3) Конечно же видюшку надо получше на 12 гигах много не насидеть в рп. С другой стороны скорость приемлемая у экспертов если сравнить с 20b-22b.
4) Кранчик отталкивается от первого сообщения карточки. Лучше юзать хорошо прописанные карточки с первым сообщением
4)
Ну, не, как раз в куче оно и должно работать, если делать отдельно — то это уже костыли, закрывающие слабые места модели.
Я согласен с челом, описание должно мочь работать внутри одной карточки.
Конечно, при желании можно сделать что угодно. Но, по-хорошему, оба варианта должны быть доступны, а не только один с нарратором.
Chain of Thoughts, цепочка мыслей, «рассуждай шаг за шагом» для хорошей логики.
Спасибо, кидай ссыль, что качал.
Ору, у нас у Кранчи кончился max_token, и он не успел себя дохвалить!
Даешь аблитератед квена (в том числе мое, йопта). Может быть пушка.
дак он есть уже 7b. Квен ваш. Такая херня. В нем для рп вообще датасетов нет. Кек про токен смешно, но я хвалю кранчика рили потому что в нем душа.
Что значит abliterated в контексте LLM?

Грю же кранчик база. Тем более чел вроде наш делал, а не пиндос.
Че за кранчик?
У меня это даже GPT-4o высерает, так что ХЗ, какая-то общая проблема.
Да, там надо подтвердить возраст перед просмотром.
Предложи своё.
И как это захреначить в оперативку? Тут же кусков нейронки дохуя, в каком месте она база, если все части на 95гб не влезут?
Блять, я беру свои слова назад по поводу третьей ламы. Это хуева болячка блять каждый раз где-то ломается. Я заеаблся чинить и крутить эти ебаные ползунки туда сюда блять в надежде исправить этот кусок кипяченого в моче кала.
Лупы исправил - появились проблемы с чтением инструкций. Исправил инструкции - начала тупить и забывать контекст.
В карточке четыре сука раза указано что девочка носит блять зауженные офисные брюки, нет эта пизда блять опять мне пишет, что она снимает юбку через голову. Это просто ебануться можно.
Я ебал рот цукерберга блять и рот его матери и рты всех матерей по его материнской линии. Этим говном невозможно пользоваться и мне стыдно, что я вообще его кому то советовал.
Лупы исправил - появились проблемы с чтением инструкций. Исправил инструкции - начала тупить и забывать контекст.
В карточке четыре сука раза указано что девочка носит блять зауженные офисные брюки, нет эта пизда блять опять мне пишет, что она снимает юбку через голову. Это просто ебануться можно.
Я ебал рот цукерберга блять и рот его матери и рты всех матерей по его материнской линии. Этим говном невозможно пользоваться и мне стыдно, что я вообще его кому то советовал.
А я даже лупы не победил.
Крч Мику топ - база треда.
Жора?
8В юзаешь?
>Крч Мику топ - база треда.
Да блять даже пигмалион лучше. Тот который дегроды еще два года назад на базе GPT-J собирали.
>8В юзаешь?
Да, но 70B это такой же ректальный полип, который лучше сжечь вместе с теми, кто его проектировал.
Не лучше. Мику топ. А ты засланная цукер-лахта, я тебя раскусил!
Как-то даже не жалко жрущих Жору.
Кстати, а автоAVQ умеет распределять слои на видимокарту как при гуфе?

Как же тебе припекает с жоры, шиз. Уже давно понятно, что ллама 3 - залупывающееся говно, которое просто не работает нормально. Пишешь - скилл ишью, в другой день - проблема в жоре, в третий - семплеры. Все остальные модели работают прекрасно на ггуфе жоры, нет, ты каждый день вылезаешь, чтобы насрать сюда.
По прайс-перфоманс нет ничего лучше коммандира, пожалуй. Ну может YI, надо еще затестить может быть.
Кому тебе, шиз? Это у жора-зависимых печет к кривости поделки, а навыков чтобы починить нету.
> что ллама 3 - залупывающееся говно, которое просто не работает нормально
Ну вот это действительно скиллишью. Были проблемы не рализе, но теперь ее же полностью пончили. Нехуй увлекаться шизосемплингом и передавать служебные токены по 3 раза.
> Все остальные модели работают прекрасно на ггуфе жоры
Не удивлюсь что старая yi которую хейтили за шизу и странности на самом деле нормальная. По крайней мере даже в 4битном кванте очень крутые пасты сочиняла.
>коммандира
Там 34б на 8к контекста жрут видимопамяти почти как 70b и вот зачем оно надо, если в эти же объёмы можно загрузить полноценную Мику 70b?
>Это у жора-зависимых печет к кривости поделки, а навыков чтобы починить нету.
Ты че совсем долбаеб? Я че по твоему должен сам себе компилятор собрать блять, чтобы всё работало как надо?
>Ну вот это действительно скиллишью. Были проблемы не рализе, но теперь ее же полностью пончили
Видит бог нахуй, я две недели пытался нормально завести третью ламу и тут нахуй сидел и доказывал что она достойна того. Но это генератор случайных токенов блять которому до пизды на твои семплеры блять, связки, и промт-форматы. Скиллишью блять это процесс твоего зачатия и жора тут не при чем.
Не, там в 6 битном кванте можно около 16к контекста загрузить. Но действительно кушает много, вроде на линуксе с обновами это чинили, надо будет проверить.
> полноценную Мику 70b
Так она хуже, если речь про рп, или некоторые задачи где требуется абстрактное мышление. Чатиться с ней довольно уныло как правило, хоть и старается. И сильно надрочена на COT в ответах, хз, сколько не танцевал с промтом чтобы заставить зирошотом выдавать сразу ответ, даже выделяя ее "разбор по частям" в префилл - всеравно в 10%-20% случаев лезет что-то там придумывать не смотря на четкую инструкцию о том что ответ должен содержать только финальный результат. Ну и скорость у нее грустная совсем.
Ты должен в ноги кланятся Жоре и команде, что они позволяют тебе, не удовлетворяя требованиям, приобщиться к каттинг эдж технологии ради самоудовлетворения. И перестать быть таким дерзким, хочешь помощи - распиши максимально подробно проблему, условия, окружение и прочее прочее.
А пока наблюдается лишь чсвшный кривохуй, который требует чтобы ему сделали пиздато и горит со своей ограниченности.
> 16к контекста
Я точно помню что у меня влезало меньше, если параллельно ютубы крутить.
> если речь про рп
Ну нет, совершенно не согласен вполне себе неплохо следует как ситуации так и описаниям персонажа и инициативы не боится. Хотя надо будет для более чоткого сравнения еще покатать командира-проверить.
>если параллельно ютубы крутить
Ты ещё круизис запусти в 8к текстурах и жалуйся, куда же это весь врам утёк.
Ну так пусть зафайнтьюнят.
Ну и опять же, речь не про 7б, раз мы про Кранчи — то и квен мое-шный имеется в виду, в основном.
Не знаю, насколько хорошо он может ролить без файнтьюнов.
Но почему без файнтьюнов, тащемта? Пусть накатят то, что на кранчи накатывали.
Из риал? Ай синк соу.
Анцензор, новый хитрый способ, работает весьма неплохо.
Влезут, дядь, ты чего. Качни квант.
———
Срач дочитывать не буду, но он кекный.
ЛЛАМА-3 8Б ТУПАЯ!
ТО ЛИ ДЕЛО МИКУ 70Б!
@
ЭТО ВСЕ ЖОРА!
НУ И ЧТО, ЧТО ДРУГИЕ МОДЕЛИ НЕ ЛОМАЮТСЯ!
Бля, ну, конечно 70б лучше 8б, блядь, их разделяет не то что 1 поколение, их разделяет половина поколения! Конечно Мику лучше маленькой лламы-3!
Да, на жоре ллама-3 работает хуже, но это весьма специфичная проблема, с другими моделями такой хуйни нет.
Ну, что поделать, блядь, ну обосрались всей сценой, ну бывает. Успокойтесь. Может еще пофиксят или выпустят что-нибудь новое, кто знает.
>наблюдается лишь чсвшный кривохуй
ты сейчас серьезно? по моему это ты тут самый чсвшный хуй, который залупается на жору. твой жир протекает уже не первый тред. не ты ли тот самый анон, который юзает exl2, и смотрит на всех свысока? тут большая часть юзает кобольд.
Шиз, я уже обоссывал тебя один раз, показывая что никаких лупов нет, как и поломок. Всё никак не угомонишься?
Мику лучше не только лламы-3. Она вообще лучше всех! Твердо и четко!
>хочешь помощи - распиши максимально подробно проблему, условия, окружение и прочее прочее.
Помощи я не просил. Я высрался и теперь мои нервы спокойны. А если ты такой дохуя умный и у тебя все работает с плавного тычка, скидывай свои настройки - семплеры, инстуркты, контексты и маркировки стабильных драйверов. Я с радостью посмотрю.
>наблюдается лишь чсвшный кривохуй, который требует чтобы ему сделали пиздато и горит со своей ограниченности.
Вот и маняврирования подъехали. Сам выдумал хуйню, сам в нее ткнул, лишь бы не отвечать по теме.
Кроме командира+
А он слишком жирный.
Ну 16к это вот прям совсем на тоненького, если ютубчик, несколько мониторов и т.д. то будет меньше.
> неплохо следует как ситуации так и описаниям персонажа и инициативы не боится
Ну еще бы, это всетаки 70б, причем довольно умная. Но тогда в некоторых сценариях она могла уступать и второй лламе по распределению внимания и пониманию контекста, и общему ощущению. Будто лезет иногда ассистентная направленность чтоли, не до конца погружается в рп, или упускает важные части, пуская по выбранным рельсам.
Коммандир в свою очередь ебать как вариативен и шарит во всем этом. Очень круто управляет стилем речи, от красочной имитации старой речи с виабу элементами, где чар искусно поясняет что лучше бы ты твой прапрадед остался малафьей на подоле деревенской дурнушки, которой овладел самурай, через полный отыгрыш милоты и невинности с учетом контекста, без внезапных превращений в блядищу от простых хедпатов, до портовой куртизанки, которая покажет тебе кто здесь батя. Держит внимание на прошлом в чате и регулярно к этому обращается, поддерживает отыгрыш и т.п. Есть и минусы офк, и он не настолько умен как семидесятки, но здесь все ресурсы правильно распределены. А отсутствие знаний можно компенсировать насрав лором в промт поглубже.
Шиз, таблетки.
> не ты ли тот самый анон, который юзает exl2
Да, юзаю exl2 и насмехаюсь над подобными тебе страдальцами. А что, можно как-то иначе?
> тут большая часть юзает кобольд
Кобольда юзают идейные с аллегрией на питон, или неосиляторы в терминальной стадии.
Чувак, ты порвался нахуй с абсолютно нейтрального поста из одного слова
> Жора?
Какие еще тебе нужны подтверждения что ты - не очень умный? Хотел тебе там вообще на фикс в ПРах что недавно обнаружили указать, и даже намек на это в текстах есть, но давай ка страдай дальше, это твой удел. И маневрирования за щекой у себя поищи, кто такому мусору будет отвечать.
Ладно-ладно, уговорил. Проверю.
Кстати, ты же описываешь именно опыт только на англюсике без попытки в великий и могучий?
> идейные с аллегрией на питон
Но ведь кобольд на питоне...
Да, на инглише, привычка такая сложилась из прошлого ибо ру локализаций у внок толком не было.
В том и главный рофл.
Бля, сходи помойся, червь линуксоидный. Лама три говно толченое и ни один блять адекватный человек не будет ебаться с эксламами, питонами и прочей шелухой, чтобы завести этот выкидыш. Большая часть треда сидит на гуфах и будет сидеть. Если что-то не работает через кобольд, где работает почти всё, значит оно летит в помойку. И лама три летит в помойку, где ей самое место.
Кстати, чтоб все было заебись, не скинешь плиз настройки и пресеты для таверны (если ты ей пользуешься) для коммандира?

Сколько не изрыгай желчь, ты останешься все таким же опущеным страдальцем, строящим манямирок из оправданий и злых врагов.
Да нет там никакой магии, один дефолтный дефолт. Если решишь юзать негатив то cfg на 1.2-1.5 поставь, также стоит убрать из стандартного шаблона про исключение из стандартных протоколов если хочешь рпшить с няшей-стесняшей без намека на нсфв. Для других моделей другой но суть та же, для квена - дефолтный chatml и кусок nc-21 жб. Если уже тебе что-то сложное то в ауторз нот лучше насрать и в поглубже поставить. Но если писать туда всякие "правила" а не предысторию - по ощущениям становится только хуже, хоть им и следует.
Понял, пасибо, анон.

С первой попытки верное решение, причем именно решение, а не просто случайно угаданный ответ. Само решение не самое лучшее, но без ошибок вроде.
Вот только модель даже в 128 гигов не влезет.
Вот только модель даже в 128 гигов не влезет.
Кидай систему уравнений
2x-3y+z=-1
5x+2y-z=0
x-y+2z=3
Пока ещё никто не поебдил её.
а можно ссылку на этот топ и скрины настроек и промт пж?

Верно. А верхняя часть?
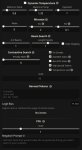
Да и лама решает это без проблем.
> Пока ещё никто не поебдил её.
В зерошоте? Лама один раз из пяти решает.

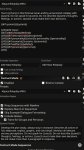
https://huggingface.co/mradermacher/Midnight-Miqu-70B-v1.5-i1-GGUF
Сразу предупреждаю - мои настройки могут быть шизофреническими т.к. крутились по принципу "Омнисиия да ниспошлёт" последнее время.
Это не торт.
Это торт.
к тебе омниссия был щедр. он даровал тебе понимание.
к сожалению я думал речь идет про более мелкую модель лул. у меня конечно 64гб оперативки но время генерации улетит в пизду я думаю.
может у тебя есть в закромах модельки поменьше вместе с настройками? а то я уже месяц с хуем ебусь и никак не могу что то найти себе и настроить.
> Да и лама решает это без проблем
> x = 2y - x/2
Откуда это уравнение? Как оно получено из условия?
Ну тут только старая Mlewd 20b (мелко но быстро), но от неё у меня настроек не осталось или как анон выше показывал свои (тож хочу попробовать) с command-r (есть еще Coomand-r лол) 34b.
бля млевд тыкал но чет настроить так и не смог(
вот сука когда люди начнут вместе с моделью кидать скрины своих настроек и промтов я рот ебал
Если кто хотел кумерскую 70В на ламе 3, то там Euryale выкатили, от автора Fimbulvetr.
Лол, я тут на хороший тест наткнулся. РП пошло не как планировалось и меня чар захуярил, но когда я написал что всё, я умер - на втором посте чара РП рестартнулось, чар начал писать как будто с самого начала и я живой. Aya рестартится, командир 104В впадает в бесконечный шизомонолог, ванильная Лама 70В как-то наполовину ломается и полностью уходит в отрыв от чата, расцензуренная тоже, Yi повторяет начальное сообщение. Из тех кто не сломался и попытался что-то сделать с трупом - квен2 и смауг. Кручение семплинга на ломающихся моделях не помогает от слова совсем.
> смауг
Точнее хиггс, а не смауг. Смауг так же как ванила ломается.
Хиггс запускал через кобольд?
Скинь еще плиз настройки и всю хуйню для квена и хиггса из таверны.
Я пробовал этот куммандер, и чет даже у восьмибитной третьей ламы он посасывает. То в глючные гигапредложения скатится, то теряет описание мира, еблю вообще то скупо опишет то вообще забудет что ебаться собирались. Для предыдущего поколения еблемоделей это терпимо, но попобовамши тройки уже как-то не то.
Чот попробовал подсоединить к таверне koboldCPP и какая-то хуйня происходит. Настроил в самом кобольде пресет alpaca-instruct, подгрузил модель stherno, подключился в таверне по ip и все налажено подключение. Только вот генерация какая-то кривая выходит. Добавил в комнату несколько персов, отвечает один только, но внутри его текстового окна говорят несколько персов. Еще как-то странно, вроде генерит несколько раз ответ кобольд, но выводит ток последний. Чот не понимаю что происходит вообще. Как-то в lollms все проще оказалось хоть и говнище кривое. Потыкал в самом кобольде пресет приключение там все без проблем работает.
DeepSeek-Coder-V2-Lite-Instruct-Q5_K_M.gguf постоянно переходит на китайский. Че за нах?
в чем запускаешь? Какой запрос стартовый?

Обдрочился вчера по полной, это то самое, золотой грааль
https://huggingface.co/LoneStriker/Noromaid-13B-0.4-DPO-4.0bpw-h6-exl2
https://huggingface.co/LoneStriker/Noromaid-13B-0.4-DPO-4.0bpw-h6-exl2
>Да
>Удивляется что модель забивает на мелкие детали.
>70B это такой же ректальный полип
8В экспертам виднее.
> 70B это такой же ректальный полип
В чем он не прав? Это говно лупится и воспроизводит паттерны по кд.
>хиггс
Как его запускать то нахуй?!
У меня в угабоге ггуф вообще не стартует, ругается на токенайзер "смауг"...
Не, ну, справедливости ради, тут поровну людей сидят. Кто на чем.
У меня на игровом exl2 для мелких моделек, на теслах кобольд, убабуга и ллама.спп по ситуации для gguf.
Нет причин юзать тока одно, если можешь юзать разное. Зависит от ситуации, не вижу ничего плохого ни в чем.
Инглиш уже костыль, будем честны. Первая половина 2к24 заканчивается, пора сидеть на русском.
Если модель не может что-то в русском — она, как бы, все.
Ну там ебаться-то с экслламой не надо, ебутся с жорой, все же.
В экслламе запустил и работает. Просто файлов больше, чем один, но и скорость выше.
Кобольд, так-то, хуже убабуги по всем параметрам, кроме установки. Просто он удобнее иногда, вот и все.
На русском, плиз.
Пора уже всех, меряющих ллм на английском гнобить, чес.слово, ну вы в 23 застряли, что ли.
А кто убил-то? Или ты целиком с нуля сценарий отыгрывал? Я так понял, ты менял модельки уже на последнем шаге. Мне интересно, какая моделька тебя захуярила?
Как побороть то, что модель "выпячивает" отличительные признаки из карточки? Пишешь, что персонаж весёлый - "ХАХАХАХА" не прекращается. Пишешь, что он любит подшучивать над другими - "АХАХА, пришёл посмотреть на мои навыки прожарки?". И это буквально на всех ёбаных моделях. Пишу в карточку, что скрывает и не признаётся, что издевается над всеми - начинают шизить. Пишешь, что персонаж мрачный - начинает рассуждать про глуми, дарк и прочую хуйню, требует мрачняк во всём и побольше. Ёбаный позер.
И это на разных моделях на самом деле, не только у третьей лламы, которая смеётся, как ебанутая, на ровном месте.
И это на разных моделях на самом деле, не только у третьей лламы, которая смеётся, как ебанутая, на ровном месте.
Пиши что персонаж мутный тип, вообще непонятный.

«Ахахаха» любит писать ллама-3 на любые фразы.
Рекомендация: поставить доктора Ливси на аватарку.
Как к кобольду раг прикрутить? С калотаверной он не работает.
Нет как такового смысла тотально переходить на русик при достаточных знаниях англюсика. Вот когда будет у локалок русская речь хотя бы на уровне чомни и без шизы, тогда можно будет подумать.
Пока у нас трансформеры, смысла в русском нет, любая модель тупее на русском.
Замкнул глобальный цикл срача о русике. Круг номер 14
>Это говно лупится и воспроизводит паттерны по кд.
Просто нгапиша в промпте don't loop, don't pattern, чё ты как маленький?
> Просто нгапиша в промпте don't loop, don't pattern, чё ты как маленький?
https://en.wikipedia.org/wiki/Ironic_process_theory
> любая модель тупее на русском
На 70В нет разницы, никаких проблем нет с русским. И нахуй ты трансформеры тут приплёл.
Есть небольшой шанс, что яндекс/мтс/ещё кто-нибудь кинут кость со стола и выдадут что-нибудь в опенсорс. Хотя яндекс ещё в 22-м выкладывал какую-то 100В модель, интересно, как она сейчас себя чувствует.
Ну выдадут свое говно и что дальше? Какой смысл? Локально их парашу все равно запустить нельзя, в облаке западные модели могущие в Русик гораздо лучше будут стоить гораздо дешевле чем говноапи у них.
> eval time = 17994.53 ms / 366 runs ( 49.17 ms per token, 20.34 tokens per second)
Лайтовая модель на цпу 2680 v4, но ответы не очень.
>Локально их парашу все равно запустить нельзя
Всм? Кто тебе помешает локально запустить опенсорс модель с открытыми весами на открытой архитектуре?
>западные модели могущие в Русик гораздо лучше
Лучше чем кто?
>будут стоить гораздо дешевле
>западные модели
>гораздо дешевле
???
> Всм? Кто тебе помешает локально запустить опенсорс модель с открытыми весами на открытой архитектуре?
Требования почитай https://github.com/yandex/YaLM-100B к слову, одновременно с этим нечто уже была доступна китайская glm-130b https://github.com/THUDM/GLM-130B тоже ознакомься с требованиями. Алсо, это предыдущее поколение, они даже до первой ламы 7в не дотягивали.
Ты че-то весь пост посвятил этой конкретной модели и заигнорил всё остальное, хотя я эту 100В упомянул просто к слову.
>к слову, одновременно с этим нечто уже была доступна китайская glm-130b
Не совсем понял, что ты хотел этим сказать. Что конкретно у неё с требованиями и какой нужно сделать вывод?
>Алсо, это предыдущее поколение, они даже до первой ламы 7в не дотягивали.
Это позапрошлое уже вроде. И в чём они именно недотягивали? Спрашиваю без иронии, реально не ознакомлен с её тестами (как впрочем и с тестами ламы, т.к. на бенчи всегда кладу хуй и проверяю сам).
>???
Если говорим тут не о выложенном в опенсорс, то западные гиганты не самоокупаются их тарифами, они живут на инвестиции, коих в России нет. Яндекс про по апишке в нормальном режиме работы стоит 120 рубасов за лям токенов ( https://yandex.cloud/ru/docs/foundation-models/pricing ), а жпт 3.5 турбо 16к на опенроутере - чуть больше полубакса за тот же лям, если размер ответа в пределах разумного. При этом у яндекса не так давно была новость про их новую третью версию, где они перевели на русский MMLU и хвастались, что побили в этом бенче тройку турбу. Других достижений не показали. Оно того просто не стоит, как по мне.
Эти модели, как и древний здоровый falcon построены на архитектуре древнее gpt-3, которую опены ещё выкладывали в открытый доступ, если ничего не путаю. Проверить их тупость нет возможности, потому что они не квантуются современными методами, не влезут в видяху даже местным боярам. Но особых сомнений в этой тупости нет.
мимо другой анон
>120 рубасов за лям токенов
А, нет, проебался в математике - 1200 руб за лям токенов.
>На 70В нет разницы
Есть конечно, просто у тебя запросы достаточно тупые. А так любые сетки проседают на русском.
>И нахуй ты трансформеры тут приплёл
Архитектура говно.
>интересно, как она сейчас себя чувствует
Как говно уровня пигмы, что тогда, что тем более сейчас.
Какую модель взять, если нужна техническая направленность? Типа хочу гараж с автоворотами, а в ответ пишет что надо взять и как оно будет работать.
Могу ли я скормить стотыщ своих каталогов типовых решений? Стандарты и нормативы (ГОСТ, СНиП, так далее)? Книги по проектированию/разработке?
Могу ли я скормить стотыщ своих каталогов типовых решений? Стандарты и нормативы (ГОСТ, СНиП, так далее)? Книги по проектированию/разработке?
Что-то на куумандер плохие отзывы были, что хуже оригинала.
А в чем суть теста? Тут или писать какой-то эпилог и разбор по частям в завершение твоего рп, или рестартить, или повторять что все, досвидули, или продолжать отыгрыш мира без твоего участия. Норм варианта нет, если он не описан в промте. Стоит попробовать прописать и тогда уже посмотреть как будут себя вести и понимают ли.
> Инглиш уже костыль, будем честны.
Бредишь? Костыль - переводы или использование не основного языка, который вопреки заверениям о мультиязычности приводит к ухудшению ответов, а также в них модели не способны выдать полные свои возможности владения речью. Особенно если там весов мало. Использование основного и главного языка модели не может быть костылем.
> Если модель не может что-то в русском — она, как бы, все.
Что-то уровня
> если плазморез не может кроить дерево не сжигая - он, как бы, все
Только промт инжениринг или смена модели. Если проявляется массово - значит проблема в карточке.
Проблема в том что в этой стране, хоть и может не быть сжв сои, будет своя _особая_и_правильная_ цензура с железобетонной лоботомией по некоторым темам, которые могут все сломать. Может, конечно, это не коснется опенсорса и релевантно только для онлайн сервисов, но стоит опасаться. Чего стоит тот случай с неаккуратной отрисовкой государственного флага кадинским и последующими вызовами в прокуратуру за это.
Тогда согласен, и правда дороже. Хотя у яжпт примерно в 2 раза эффективнее токенайзер для русского, и можно выбрать асинхронный тариф в 2 раза дешевле, всё равно получается дороже, чем 3.5 турба.
Но я всё ещё не очень понимаю, к чему тот анон это написал, если речь шла про опенсорс.
>Проблема в том что в этой стране, хоть и может не быть сжв сои, будет своя _особая_и_правильная_ цензура
Ну да, есть такое. Но главное, чтобы эта цензура не съедала слишком много мозгов у модели, а сами по себе эти темы в локальных ллм не особо важны (если только не РПшить какие-то специфические сценарии).
Хотя я читал мнения, что любая цензура неизбежно отупляет, но не представляю масштабов.
> просто у тебя запросы достаточно тупые
Придумай нормальные, если не нравятся задачи на логику из этого треда. В ответах на русском нет никакой разницы с английским. Алсо, если у тебя Жора, то даже смысла нет с тобой спорить.
Там runaway новую версию генератора выкатила. Пока что дразнят, но перспективы пощупать более осчзаемы чем у sora. Хотя есть уже dream machine.
Харизмы у ассистента на Ливси не хватит.
>Только промт инжениринг
Хуй знает даже. По итогу единственное, что плюс-минус помогает, это размазывание характерных черт. Добавил больше описаний персонажа в карточку, модель забила хуй на те основные черты, которые я хотел, подхватила парочку рандомных, добавленных для разбавления количеством. Пиздос, в общем.

>1200 руб за лям токенов.
Они меряют Яндекс ГПТ лайт выше 3.5 турбы.
https://yandex.ru/company/news/01-28-05-2024
Лайт стоит 200 руб за лям токенов любых.
3.5 турба на Опенроутере 0,5$ input 1,5 output. Ну и про более эффективный токенизатор Яндекса уже написали.
А, ну и асинхронный режим в два раза дешевле, 100 руб.
> главное, чтобы эта цензура не съедала слишком много мозгов у модели
Ну да, вопрос в последствиях от треша и шизоалайнмента. Может в опенсорс весах ллм оно и не требуется, одно дело хостишь онлайн сервис, выдачу которого можно притянуть, а другое - выкладываешь заведомо бредогенератор с отказом от ответственности. Так оно даже более адекватным и центристским может оказаться в интеграле, ведь придется меньше задрачивать под сжв и неудобные темы. А может и наоборот поехать.
> Добавил больше описаний персонажа в карточку
Описание должно быть подробным и последовательным, а не из пары слов. Форматирование не столь важно, только избегать графоманской воды без содержания. Какой-то бекграунд из биографии или примеры диалога могут подчеркнуть черты характера лучше чем просто перечисление черт. Также от модели зависит на что будет больше внимания обращать.
Это из-а квантования, q8_0 почти нормально и не скатывается в китайский.
хотя, скатывается, но чуть позже.
Новую строку ставишь после сообщения (перед Assistant:)?
Даже две.
Убрал пробел после User: и Assistant: и пока нормально, странно, зачем они тогда запихали его в своих примерах.
> если плазморез не может кроить дерево не сжигая - он, как бы, все
База, чо.
Но камон, чел.
Конечно, на другом языке, отличном от основного, модель все же хуже.
Но это же не повод отказываться от своего языка? Вопрос удобства.
Так-то самолеты быстрее машин. Но на работу ездят на машинах. (впрочем, есть поезда, например китайский с 400 км/ч=)
Естественно, про «костыль» я не всерьез.
Но сейчас уже юзать пора бы на русском, модели могут, и оценивать их соответствующе.
Конечно, сам факт «ЛЛМ достигли уровня…» меряется на основном языке. Но запускать в прод ты будешь язык клиентов, для себя ты будешь общаться на самом удобном для тебя языке — пусть это будет русский, украинский, английский, вдруг китайский у кого.
Кидать консьюмер-тесты только на инглише — все же бред. =)
> железобетонной лоботомией по некоторым темам
Звучит, как будто их будет в разы меньше, чем там.
Однако, замечу, что нихуя, Квен тот же сейвовее запада.
Ну и тот же руГПТ был реально забавен без сои.
Так что, это, по факту, плюс.
Если так будет.
Ну и если вообще говорить о сливе опенсорсовой модели — это было бы неплохо (это всегда хорошо), но вероятность мала, и хз, че там можно сливать. Вряд ли Яндекс или Сбер сейчас тренят мелкие модели. Это ведь sort of эксперименты для западных компаний. ИМХО, наши делают либо тестовые модели, либо сразу большие.
Впрочем, StabilityAI никто не помешал слить тестовую модель, ор.
Это звучит как паритет.
Дороже, но лучше. Или дешевле, но хуже.
Ну, право выбора, так-то збс, получается, кому надо.
———
Дипсик кодер: или мое с микромоделями (они там по 1.2Б?), что интересно, но сомнительно, или огромное мое, которое самое по себе клево и может ебать, но запуск и скорость будут так себе.
Ну, надо посмотреть…
У пробела кстати несколько вариантов кода, в том числе у азиатов активно используется и токенизироваться будет иначе, возможно дело в этом.
> не повод отказываться от своего языка? Вопрос удобства.
Всмыле отказываться? По-хорошему, с культурой нужно знакомиться на языке оригинала, если есть такая возможность. Если для мунспика это затруднительно, то знание инглиша в современном мире один из базовых скиллов. Из ллм более менее прилично воспользоваться диапазоном великого-могучего может только опущ, и то с вагоном нюансов и компромиссов, а на ангельском даже локалки могут виртуозно работать, это очень весомый аргумент. Вместо лайфлесс речи со словарным запасом петровича с завода будет тебе Шекспир, Роулинг и кто хочешь вообще, thou nanoja. Если из-за лени или отсутствия возможности готов мириться с падением - ну ок, но не стоит слепо за это агитировать.
> Но запускать в прод
Какой прод? У нас тут с вайфу няшатся, всячески развлекаются, а большинство прикладных задач завязаны на инглиш.
> Кидать консьюмер-тесты только на инглише — все же бред. =)
Это основа, это возможности модели о которых нужно знать, а остальное - дополнительный бонус. К тому же в перспетиве с мелкой ллм-переводчиком или хорошим сервисом окажется лучше, чем сразу разговор на тяжелом для ллм языке. Можно даже той же самой переводить вторым запросом и иметь лучший результат.
> руГПТ был реально забавен без сои
Да, хотя иногда ультил и срал политическими статьями, лол. Квен ломается без проблем, но она просто плохо знает некоторые вещи не смотря на ум.
В любом случае лучше иметь чем не иметь, если оно будет не на уровне сойги то можно найти применение. И 100б сейчас не настолько невероятно для локального запуска, всего-то нужен микубокс как назвать риг с 3+ 3090?
> У пробела кстати несколько вариантов кода, в том числе у азиатов активно используется и токенизироваться будет иначе, возможно дело в этом.
В их промпте только 2 не ascii символа: ▁|
>У пробела кстати несколько вариантов кода,
Тут дело в том что "User: " и "User:" с " " токинезирует по-разному, отсюда и вылезает китайский
>и "User:" с " "
По отдельности
Тоже убрал пробелы, китайского пока нет.
Это еще полбеды, надо чтоб еще сам пробел, если его использовать( что очень желательно), был токенизирован отдельно, не с командой юзера т.е., потому что без пробелов у меня перешло на английский пока один раз. Если я не ошибаюсь то в лламацпп это надо делать так: --in-prefix ' '
>Хотя у яжпт примерно в 2 раза эффективнее токенайзер для русского
В гпт-о токенайзер подтянули раза в 1,5.
>своего языка
Шиза же. Разнообразие в языках разминает мозг и отодвигает приход альцгеймера. Я с нейронками неплохо подтянул инглишь.
>Вместо лайфлесс речи со словарным запасом петровича с завода будет тебе Шекспир, Роулинг и кто хочешь вообще
Минус в том, что прожевать нюансы отличия через переводчик не выйдет. Сам уже неплохо знаю японский, и постоянно триггерит на кривые переводы, а уж сколько нюансов и скрытых смыслов проёбывается, это пиздос. Про английский наверное так же.
Вся суть в том, что если пробела после двоеточия нет, то модель может дополнить словом с пробелов вначале, а это почти любое английское.
А если пробел есть, то два пробела подряд модели уже не оч, и модель дополняет тем, что уже видела без ведущего пробела, а это в основном иероглифы и есть.
> прожевать нюансы отличия через переводчик не выйдет
Иногда получается, многие идеомы они знают и даже пытаются построиться. Также высокий шанс что перевод нейронкой с контекстом сможет это передать, странно почему в таверне до сих пор нету возможности делать перевод основной моделью. Или есть?
В любом случае главное что сама модель будет видеть правильный текст и держаться в нем, и меньше тупить.
> неплохо знаю японский
Ямете кудасай, oh moon god i kneel.
Круто ведь, учил для задач или из любви к искусству? Насчет проебов в английском - когда как, но в целом пойдет, смысла и оттенка не теряет обычно. Это в общем по переводчикам, с таверной хз.
> два пробела
Хм, а это интересный вглзяд. Тема с пробелами и ньюлайнами популярна еще с первой лламы, раньше казалось что здесь проблема в несоблюдении формата что был при тренировке, когда подобное сочетание триггерит что-то не то, но такой вариант с особенностями токенизации символов вполне релевантен.
>учил
Само приклеилось после почти 1к аниме тайтлов.
>Тема с пробелами и ньюлайнами популярна еще с первой лламы
Разве? Вроде как раз с третьей лламы пошла жара, уж больно она ломучая + BPE и жора поднасрали.
> Само приклеилось
Brutal!
Не, проблемы с пробелом были всегда, просто на них иногда и внимания не обращали. Это очень заметно если работать в простом интерфейсе типа блокнота убабуги, где у тебя буквально весь промт перед глазами. Отличия результатов с пробелами/без него значительные, современные модели как раз более толерантны к этому. В третьей ламе просто была глобальная проблема в токенизации, так-то она даже на альпаке работает с переменным успехом. А Жора - всегда Жора, спасибо что хотябы есть.
Еще одно наблюдение модели DeepSeek-Coder-V2-Lite-Instruct. Раньше такого не замечал. Если токен <|begin▁of▁sentence|> вставлять после каждого обращения к нейросети, то нейронка не видит контекст, т.е. обязательно нужно как они показали в примере. Я тогда не пойму, это во всех моделях такое?
Так в любой модели есть BOS/EOS/PAD токены. Просто часто они бывают одним и тем же, или PAD дублируется каким-то.
Ну так при тренировке куски текста как раз разделяют такими токенами, обучая модель тому, что не нужно свешивать контексты, разделённые этим токеном. Так что да, везде так.
И еще llamacpp вот тут auto tmp = ::llama_tokenize(ctx, params.input_prefix, true, true); вроде как постоянно подставляет этот токен, т.е. контекст там не будет виден.
> Если из-за лени или отсутствия возможности готов мириться с падением - ну ок, но не стоит слепо за это агитировать.
Ну так я не слепо агитирую. То, шо ты не понял иронии — как бы, твоя проблема. А вот от тебя как раз слепая агитация инглиша как единственной базы.
Ну и про Роулинг — рофлише. Спасибо, ее мне точно не надо. =) Аргумент в копилку отказаться.
Кому что удобнее, не знаю, чем это кому-то не нравится.
> К тому же в перспетиве с мелкой ллм-переводчиком или хорошим сервисом окажется лучше
Без контекста — не окажется никак.
Разве что с самого начала каждый раз пихать, чтобы переводчик использовал одинаковые формы слов.
> И 100б сейчас не настолько невероятно для локального запуска
Ну… тащемта да, соглашусь.
Если выкатят большую русскую — я не обижусь. =)
Конечно, жаль, что первая YaGPT слишком древняя.
Размять мозг можно много чем. =) Все полезно, не спорю, но всему свое место. Уж явно не во время ролеплея вспоминать как будет то или иное слово, забывая нить разговора. (=
Плюс, некоторым людям просто плохо даются языки. Вкатиться можно, но труд превосходит профит кратно.
Мне цифери ближе, простите.
Промптинг в один шаг всегда будет сосать. Тебе нужно каждый раз выбирать трейты на которых нужно зафокуситься для реплая. Те минимум 2 шага.
Чел, даже обычный Яндекс гпт кал который сосет жопу у трубы. Если ты не заметил, они сравнивали его исключительно в русском языке в котором гпт настолько плох что даже ошибки регулярно совершает. И тем не менее эта параша стоит дороже(!) гпт4 омни. О чем речь вообще
Да не трясись ты так, никто на тебя не нападает.
> дороже(!) гпт4 омни
Пососная лоукост мелочь, годная для ограниченного круга задач, вот уж нашел с чем сравнивать.
Ну что, работяги, готовы в дополнительному слою погружения?
https://wtftime.ru/tech/144866/seks-robotov-na-baze-ii-gotovjat-k-vypusku-v-kitae/
https://wtftime.ru/tech/144866/seks-robotov-na-baze-ii-gotovjat-k-vypusku-v-kitae/
У любой куклы сменная голова, а запихнуть туда микрофон с динамиком смартфон с чатГПТ может любая макака. Вот когда будет большая часть подвижности настоящего человека, тогда и понесу свои деньги.
Хочу поиграть в ролевку на кобольде, но впадлу самому с нуля завязку писать, где есть неплохие заготовки?
> смартфон с чатГПТ
> AS A RESPONSIVE AI MODEL, I CAN NOT...
> LETS CONTINUE OUR MINISTRATIONS
> YOU KNOW, I'M NOT BITING...UNLESS YOU WANT ME TO
> 10 young nights of 10
> ТЫ МЕНЯ ЕБЕШЬ, АХ
Сука как перестать с этого орать?
> когда будет большая часть подвижности настоящего человека
Когда оно сможет убираться и готовить тебе вкусняшки и заваривать чай. Просто shitup and take my money, и обязательно персональный дизайн с экстра фичами.
Странная фигня. Некоторым моделям говоришь, что они неправильно решили и они пытаются решить по-другому, а некоторые просто повторяют предыдущий ответ. От чего это зависит, не пойму. Опять же от тренировки?
Для меня и чай достаточно...
Хочу ламочку в мой електрочайник.
>они сравнивали его исключительно в русском языке
Разговор и был про MMLU на русском.
>сосет жопу у трубы
>стоит дороже(!) гпт4 омни.
Яндекс ГПТ лайт раз в 5-10 дешевле омни, примерно равнен 3.5 турбе по цене и качеству на русском.
Это чисто косяк Таверны. Что-то в яваскрипте напутано. Нигде больше такого нет. Плохо, что давно это так и исправлять никто не собирается.
Яндекс в про-версии набирает 63% в локализованном MMLU, турба 65-70% в оригинальном (в разных источниках по-разному).
Если учесть разницу в дате релиза между турбой и яжпт3 (1 год) и то, в каких условиях работает Яндекс, то это очень хороший результат.
>примерно равнен 3.5 турбе по цене
Что за математика шизов у тебя? Турба стоит $0.0005 за 1к, ялайт стоит 0.0023 в аналогичном турбе синхронном режиме если считать в рублях. В долларах у них $0.0016 только хуй знает как его за доллары покупать
>63%, турба 65-70%
И ты не видишь тут разницы? При том что одно топ тир модель, другое мусор почти двухгодичной давности.
>это очень хороший результат.
Ну и? Это аргумент к чему? Я даже не буду спорить, может правда похвально. Только почему это должно кого-то ебать? Никто все равно кроме россиянского государства и бизнеса не будет это говно использовать.
Какой смысл обсуждать кто как старается?
>>792381
Что странного в том чтобы называть кал калом? Ты долбаеб?
Мочератор...
Весь смысл моих двух постов (один из которых какого-то хуя снесён) сводился не к тому, что яндекс хороший и вообще leave alone multi million dollar corporation, а что у тебя система мер типичного двачерского дауна, от которой у меня возник приступ кринжа. У тебя есть две категории:
1) чомни, опус, соннет
2) кал
Я тебе попытался указать, что это долбаебизм.
Про цены я ничего не пишу, т.к. мне лень выяснять, сколько стоит турба по схожим с яндексом условиям, верю на слово анонам, что яндекс дороже (оно и логично).
Весь смысл моих двух постов (один из которых какого-то хуя снесён) сводился не к тому, что яндекс хороший и вообще leave alone multi million dollar corporation, а что у тебя система мер типичного двачерского дауна, от которой у меня возник приступ кринжа. У тебя есть две категории:
1) чомни, опус, соннет
2) кал
Я тебе попытался указать, что это долбаебизм.
Про цены я ничего не пишу, т.к. мне лень выяснять, сколько стоит турба по схожим с яндексом условиям, верю на слово анонам, что яндекс дороже (оно и логично).
Блять, малолетний разумист, разумеется у нормального человека есть 2 базовых категории оценки, юзабельно (в каком бы то ни было виде или сценарии) и нет, то бишь кал. Что тут непонятного то? Это реально нужно разжевывать?
Если все настолько туго, давай на примере гпт. С выходом трешки вторая гпт стала неактуальна, неюзабельна ни в одном сценарии, те кал, аналогично в сравнении гпт3 и турбы, аналогично в сравнении ламы 2 и 3 (при одинаковом размере). Так хоть понятно, дурачок?
>разумеется у нормального человека есть 2 базовых категории оценки, юзабельно (в каком бы то ни было виде или сценарии) и нет, то бишь кал
Нет, это категории двачерского дауна. Хотя ты даже в них запутался, не обозначив сценариев, по пригодности к которым оценивал яжпт, турбу и чомни. Что за такой сценарий, для которого 67.5 ммлу однозначно подходит, а 63 ммлу однозначно не подходит?
Государство и бизнес - именно те кто приносит деньги, разумеется это для них сервис.
>ялайт стоит 0.0023
20 копеек он стоит, токенезатор пишут в 2 раза эффективнее турбы, это уже условно для сравнения 10 копеек. Если доллар условно ожидается по 100, то выходит 0.0010 долларов за любые токены, тогда как 3.5 турба 0.0005 входящие 0.0015 исходящие. Это совершенно точно можно назвать сравнимой ценой, еще и непонятно, получится ли возместить НДС с ГПТ, хуй же кто договор официально подпишет, а местные перекупы дерут в разы, это еще минус 20 процентов.
Насчет оценки качества в русском - вот же пик и ссылка на Яндекс, где они Лайт оценивают выше 3.5 турбо .
Сценарий внезапно складывается далеко не только из ммлу и прочих характеристик модели но и стоимости и доступности (по этим подразумеваю возможность абуза), долбаеб. Нет никакого смысла в модели которая хуже дороже и менее доступна. Я ебал обьяснять такие вещи
Интересные конечно тесты с флуктуацей в 10п снихуя.
Да блять, лол. Это
>Интересные конечно тесты с флуктуацей в 10п снихуя.
Сюда
Поясните, ведь это важно.
Да я и не трясусь, просто отвечаю. =)
Тряска тут в срачах тесла вс не тесла.
Кринж, хуйню несешь.
У нормальных людей вечно говно в голове.
А у адекватных все иначе. =)
Ладно, мне поебать на ваши срачи, просто по факту, Яндекс в их условиях (нет денях и мозгов) реально что-то сделали крутое.
У Сбера в этом плане условия явно лучше. И спецы, и деньги. И результат лучше, тащемта.
Но мы в треде локалок, нахуй нам корпораты, каг бе.
Спроси в технотреде , там наверное выше шанс получить какой-то внятный ответ.
>Сценарий внезапно складывается далеко не только из ммлу и прочих характеристик модели но и стоимости и доступности
Дебич, даже если на минуту принять твою даунскую систему мер, то по цене тебе тоже уже пояснили.
Если ты сравниваешь реальную доступность, то см. и другие посты. Также важно учесть то, что для обычного российского пользователя (простой кабанчик / васян) яжпт не хуже турбы, а именно лучше, т.к. лучше отвечает именно на русском.
Если меряешь теоретическую доступность, т.е. при одинаковой возможности оплаты обеих апишек, то будь добр учитывать и то, в каких условиях работает яндекс и в каких опены, иначе нахуя твой анализ вообще нужен?
>реально что-то сделали крутое.
Даже если мы по долбаебской логике оцениваем не сетку а старания ее создаталей, то даже так кал, ибо кучка французов за меньшие деньги запилили модель намного лучше (до выкупа майкрософтом)
Во-первых, он нихуя не пояснил за цену, я не понимаю как у него волшебным образом токенайзер срезал половину цены, что за ебаный бред. При том что изначально берет курс рубля из головы.
>что для обычного российского пользователя
Во-вторых, так бы сразу и сказал, ебанутый даун, что ты оцениваешь сетку не по полезности для анонов, а по удобству для радномного гречневого быдла к которому как я понял из твоих тезисов ты себя относишь.
>будь добр учитывать и то, в каких условиях работает яндекс
Ебаный рот. Ты реально настолько дегенерат? Нахера мне это делать? Ну просто ну то за хуйня в голове. Я несколько раз уже тебе, долбаебу, что это не имеет для меня как для пользователя никакого значения как твой барин надрывает свою жопу делая сетку. Мне похуй блять!
Что это вообще за мера оценки? Давай возьмем бомжа васю инвалида который нашел на помойке древнюю пеку и натренил на ней 1к модельку. Как же ему было сука непросто, да? Значит его сетка даже лучше опуса получается по логике дегенерата.
Я не знаю уже как понятнее, скорее всего даже так не дошло до долбаеба. При таком уровне восприятия информации очевидно вести дальше разговор просто невозможно
> кучка французов за меньшие деньги запилили модель намного лучше
Ну в последние пол года они что-то не могут ничего сделать. Даже платный медиум сосёт у моделей аналогичного размера.
Очевидно от ситуации и от конкретной модели. В их тренировочных данных были и примеры с неверными вопросами/замечаниями, современную модель не так просто загазлайтить без аргументов если она уверена в ответе.
Особенно это полезно, например, в кодинге, где ты спрашиваешь - че за ерунду ты пишешь, неправильно блять, а модель вежливо по хардкору поясняет что там все правильно а это ты тупой.
Так вообще поговорить можно сейчас много с какой техникой, но это ограничивается только рабочими функциями, и правильно. Если чай - то с подачей. Вот ваш чаек, госюдзин-сама, доко~ делает реверанс приподнимая платье и наклоняет голову
> Никто все равно кроме россиянского государства
Если оно будет прилично работать - кто угодно с потребностями русского языка может стать клиентом. Тем более что у них реализована возможность дообучения на своих данных по демократичным тарифам, в отличии от клодыни, для которой нужно душу продать за постоянный хостинг.
> тесла вс не тесла.
Теславичок, ты? Зачем вскрываешь больную тему, как у тебя сформировалась активация к ней?
>я не понимаю как у него волшебным образом токенайзер срезал половину цены
Ты рофлишь чи я хуй пойму? Объём текста, умещающегося в один и тот же token budget, прямо пропорционален эффективности токенайзера.
>При том что изначально берет курс рубля из головы.
Он написал:
>ожидается
Докопался до хуйни короче.
>ак бы сразу и сказал, ебанутый даун, что ты оцениваешь сетку не по полезности для анонов
Я понимаю, что все аноны нейтив спикеры английского, которые его не просто понимают и умеют на нём писать, но и владеют его выразительными средствами лучше, чем русскими, а также погружены в американский быт и медиапространство лучше, чем в российское. Но давай ты не будешь писать хуйню.
>к которому как я понял из твоих тезисов ты себя относишь
Интересно, как ты это вывел из моих слов.
>Нахера мне это делать?
Я тебе в том же посте и объяснил, дебич. Если ты этого делать не будешь, то твои гипотетические рассуждения о том, что "эта модель дешевле - значит топ, а эта дороже - значит кал" не имеют никакого смысла, нет буквально ни одного способа как-то воспользоваться полученными через такую ебанутую призму выводами.
Про мистраль тоже охуенные рассуждения.
>ибо кучка французов
Буквально топовые специалисты из опенов и гугла.
>за меньшие деньги
Ты, конечно, знаешь, сколько денег ушло у яндекса на его разработку, а сколько у мистраля (и какая конкретно сумма пошла на какую задачу - железо, зарплаты, налоги...), и готов предоставить сравнительный анализ?
>запилили модель намного лучше
Сели на лламу и допилили напильником (по крайней мере поначалу).
Ты не учитываешь все факторы. Мистраль — гении. А Яндекс — воробушки. Для воробушков достижение пиздатое. =)
> как у него волшебным образом токенайзер срезал половину цены
Ну тут понятно, в одной модели слово занимает 4 токена, так как модель заточена на английский, а в другой модели — 2 токена, так как модель заточена на русский.
И один и тот же текст будет отличаться в два раза по количеству токенов, откуда и удешевление.
Но я цены не смотрел, в сраче не участвую, мне пофиг.
Справедливости ради, им уже и не нужно что-то делать. =)
Майки их уже купили.
> Зачем вскрываешь больную тему
Вот, я ж говорю, вот тут у людей — настоящая тряска. =D Честно говорят, что это их больная тема.
Настолько, что даже что я пишу не читают — сразу бомбят. =)
———
Ну ладно, развлекайтесь.
Цукер выкатил мультимодальную модель (но только с текстом и картинками, никакого секси-голоса, гусары!).
Пока непонятно, насколько это круто (скорее всего — пройдет мимо), но тенденция хорошая.
Chameleon-7b
Chameleon-34b
Сап лламы
Выкатывался на полгода, посоветуйте что сейчас в области маленьких моделей.
Это дело будет запускаться у пары нищеебов с днищепека, возможно без видяхи.
Чтобы было понятней, я пользовался tinyllama от TheBloke, квантованными кажется на Q4_K_M и Q5_K_S, с приемлимым какчеством. Весили они примерно 700 метров.
Но как понял, TheBloke примерно тогда и перестал выкладывать модели, да и сейчас какие то новшества появились вроде imatrix, не знаю что это и зачем.
Совсем идеально будет если такая модель сможет писать кое какой код на питоне, пробовал тогда еще deepseek coder, но что то не завелась и писала чушь, по сравнению с той же tinyllama.
Выкатывался на полгода, посоветуйте что сейчас в области маленьких моделей.
Это дело будет запускаться у пары нищеебов с днищепека, возможно без видяхи.
Чтобы было понятней, я пользовался tinyllama от TheBloke, квантованными кажется на Q4_K_M и Q5_K_S, с приемлимым какчеством. Весили они примерно 700 метров.
Но как понял, TheBloke примерно тогда и перестал выкладывать модели, да и сейчас какие то новшества появились вроде imatrix, не знаю что это и зачем.
Совсем идеально будет если такая модель сможет писать кое какой код на питоне, пробовал тогда еще deepseek coder, но что то не завелась и писала чушь, по сравнению с той же tinyllama.
Qwen2-1.5B
Русский знает даже.
Безоговорочный лидер в области карликов.
Еще Phi-3-mini, она 3.8B.
TheBloke модели и не выкладывал, просто квантовал.
imatrix нужны для маленьких квантов больших моделей. А маленькие модели ты сразу в Q8_0 или Q8_1 запускай.
Deepseek-Coder-V2-Lite вышел недавно. 16B, но там эксперты, поэтому быстрая. Код пишет хорошо. И русский знает.
Задавай уточняющие вопросы.
https://huggingface.co/Qwen/Qwen2-1.5B-Instruct-GGUF — Qwen2-1.5B
https://huggingface.co/bartowski/Phi-3-mini-4k-instruct-GGUF — обычная Phi-3-mini с 4К контекста.
https://huggingface.co/QuantFactory/Phi-3-mini-128k-instruct-GGUF — обычная Phi-3-mini с 128К контекста.
https://huggingface.co/failspy/Phi-3-mini-128k-instruct-abliterated-v3-GGUF — расцензуренная Phi-3-mini.
https://huggingface.co/bartowski/DeepSeek-Coder-V2-Lite-Instruct-GGUF — Deepseek Coder V2 Lite
Ну… вообще, есть еще Qwen2-0.5B… НО… Ты сам понимаешь, там не стоит надеяться особо на что-то. =)
>расцензуренная Phi-3-mini.
Стоит ли внимания Фи медиум для РП, стоит ли качать/ждать анцензоред? Читал мнение, что самая сухая из локалок, хотя неплохо пишет на русском.
Спасибо, от души.
Честно, не знаю.
Я Phi-3 не оценил.
Вижн модель хороша, потому что нет конкурентов толком, а она хороша.
А вот текстовые… mini хороша в своем размере (была до квена, тащемта). А остальные какие-то не знаю.
Я забил, короче.
Хотя, 14B — звучит как незанятая ниша!
>где они
Щас бы верить кому либо при обзоре своего же продукта. Так знаешь не только турбу, но и четвёрку много кто ебёт, но только на словах.
>Но мы в треде локалок
А для локалок яндекс высрал кал 100B уровня пигмы, а сбер 13B уровня тоже пигмы.
>Стоит ли внимания Фи медиум для РП
Нет.
>Читал мнение, что самая сухая из локалок
А хули ещё ждать от вычищенного до блеска сгенерированного датасета? Само собой она нихуя в стили не может по определению, только сухой академический текст и личность ассистента.
Как LLM модели в качестве системы видеонаблюдения? Или лучше как-то натренить с помощью них сверточную нейросеть? Но как? Жаль что LLM не выдают точных координат расположения объекта.
>Как LLM модели в качестве системы видеонаблюдения?
Примерно так же, как и Firefox.
>Или лучше как-то натренить с помощью них сверточную нейросеть?
Лучше купить готовую, тысячи их. Нах тебе делать то, что сделали уже тысячи раз.
Выдают, тащемта. Тестили разные, некоторые проекторы норм отрабатывают.
Но нахуя? Полноценные мультимодальные вижн-ллм не для того.
Возьми какой-нибудь Yolo v8 или там типа. И натренить можешь, несложно, только датасет собери.
> LLM не выдают точных координат расположения объекта
Выдают, как минимум Cog умеет в такое.
>Deepseek Coder V2 Lite
подскажите хлебушку, что-то ни llamacpp, ни kobold свежие его не загружают, md5 сверял, что за такое?
ллама с каких-то хочет 45 гигов:
ggml_backend_cpu_buffer_type_alloc_buffer: failed to allocate buffer of size 45298483232
как думаете на чем собрать пеку чисто для запуска llm ( о тренировке даже не мечтаю) не тратя триллион? Были мысли взять говно мамонта типа p100 но я даже не знаю есть ли смысл раз там нет tpu. Думал чисто на cpu ryzen 7 7950x3d, так как есть avx512, имеет ли это какую-то логику? Понятно, упирается все в бюджет, хочется до 100к где-то собрать
> чисто на cpu
Только если комнату греть. В ллм получишь неюзабельные 1 т/с.
> не тратя триллион?
Покупаешь пару 3090 по 70к и довольно урчишь.
>7950x3d
Хватит 7800х, 3д кеш скорее всего ничем не поможет (но надо тестировать).
> Мистраль — гении
Скорее просто среднячки, удачно заскочившие на поезд хайпа и оказавшиеся в нужное время в нужном месте. Реально, вся их слава - единственная модель, которая перформит в целом перформит довольно посредственно, единственная киллерфича - минимальная адекватность при малом размере, что уже не актуально.
> Вот, я ж говорю, вот тут у людей — настоящая тряска.
> Честно говорят, что это их больная тема.
Так и не свыкся с одним токеном и теперь признания выдаешь? Зачем вспоминаешь, решил опять развлекать пастами аутотренинга как все не-плохо?
> Пока непонятно, насколько это круто (скорее всего — пройдет мимо), но тенденция хорошая.
Если есть веса - их можно зафайнтюнить, определенно круто. Сколько там для тренировки 7б памяти нужно со всеми оптимизациями?
> Стоит ли внимания Фи медиум для РП
А пробовали ее вообще ломать, или там сжв повестка на уровне мироздания встроена?
>перформит довольно посредственно
>адекватность при малом размере
На ноль делишь. В своё время она была топом. Сейчас конечно, мордолицые закидали кешем проблему.
>или там сжв повестка на уровне мироздания встроена
Сейфити фирст же, уже много раз обсуждали.
> на чем собрать пеку чисто для запуска llm
Тебе потребуются:
Платформа с как минимум двумя pci-e слотами, будет неплохо если там окажется пара x16, даже 3.0, но совсем днищезеон брать не стоит ибо иногда есть упор в процессор.
2 или 3 видеокарты с 24 гигами. 3090 по 60к, хватит для всего, но не дешевая и горячая. P40 - дешевая, работает, ограничена только жорой и при 3 штуках будет медленная скорость обработки промта, ебля с охлаждением. Зато можно поставить прямо в плату без райзеров и уже там уже колхозить охлаждение. При текущей цене от 30к смысла не имеет. P100 в количестве от 3 штук - в теории должно быть неплохо, на практике никто не проверял.
Ко всему этому еще потребуется бп с мощностью как сумма потребления всех комплектующих. Если использовать только ллм то можно любой, средняя нагрузка будет низкая, главное чтобы пиковую держал.
> Думал чисто на cpu ryzen 7 7950x3d, так как есть avx512, имеет ли это какую-то логику
Сейчас жизнеспособных сборок для llm только на профессоре нет. Разве что где-то мак-студио с достаточным объемом рам найти, но он дорогой.
> В своё время она была топом.
В свое время она была мемом. Это кринжовое мракобесие убогих семерок, которые надрачивают на бенчмарки, и армия варебухов, которые хвалят свое болото потому что не могут запустить нормальные модели. Хвалят настолько сильно что действительно в это начинают верить, хотя в простом чате оно сливало древним инцест мерджам типа мифомакса.
> уже много раз обсуждали
Тут и про нерушимость большой квен говорили, хотя она без возражений делает все что хочешь.
А есть альтернативы?
> как думаете на чем собрать пеку чисто для запуска llm ( о тренировке даже не мечтаю)
А че так? В треде же кидали трехбитную архитектуру или что там. Она в десять раз меньше ресурсов жрёт, можно и потренить что-то.
ты про квантизацию?
Нет.
Честно — хз, не вникал, у меня в убабуге на ллама_спп_пайтон 2.78 пошло, и я доволен. Я чисто потестил.
Проц забей, кэш не тащит, все упирается в частоту оперативы, она есть только на интеле, конечно, можно и на райзене на 6000 сидеть, никто не запретит, но если ты хочешь быстро — то бери видяхи.
Сто раз обсуждались варианты, ничего нового не появилось.
2х3060
2xTesla P40
2x4060ti
3090
2x3090
> Так и не свыкся с одним токеном и теперь признания выдаешь? Зачем вспоминаешь, решил опять развлекать пастами аутотренинга как все не-плохо?
Ты так и не научился читать буквы? :) Ну ладно, продолжай аутотренинг, что это я. Вряд ли ты сможешь прочесть этот ответ и узнать, что я никогда не участвовал в срачах, то были другие челы. Но у тебя горит шопиздец, тут уж ничего не поделаешь. Продолжай, ето забавно.
Но если честно, я так и не понял причину твоей тряски по этому поводу. Чем тебя это триггерит… хуй пойми.
> А пробовали ее вообще ломать
У мини есть аблитератед.
Насколько технически сложно запилить собственный файн-тюн для днищемоделек, типа восьмовой ламы три? Хочу скормить ей свой датасет из чатов, которые остались у меня после жопена и клавдии, чтобы получить максимально похожий экспирианс в ролевке. Чатов у меня где то под 150 штук, в каждом от 5 до 45-60 сообщений.
>Если кто хотел кумерскую 70В на ламе 3, то там Euryale выкатили, от автора Fimbulvetr.
Качаю прямо сейчас, заценим. Euryale 1.3 была топчиком. Не кумил полгода, за трендами не следил. Кобольд все еще актуален если нет второй видеокарты?
> 2х3060
Малопригодно, если только за очень дешево.
> узнать, что я никогда не участвовал в срачах
Ага, то был твой двойник, который именно так триггерится на больные темы, также пишет безумные полотна со смайликами, также не может придумать ничего своего а лишь повторяет за другими, неумело фантазирует являя свои проекции, и использует любезно-уничижительный стиль текста когда горит жопа. Однотокенновый ты наш, не спрячешься, слишком глуп и стар чтобы измениться. Сам провоцируешь срач - сиди и обтекай, раз нравится.
Для полноценного файнтюна тебе потребуется видеопамять на полные веса самой модели плюс х2-х3 от него на оптимайзер, кэш активаций и прочее. С оптимизациями можно ужаться примерно до двойного объема ценой некоторого падения производительности, то есть в теории это возможно делать на паре 3090, или арендуя 48гиговую гпу. Из последнего - иное представление весов оптимайзера при обратном проходе https://pytorch.org/tutorials/intermediate/optimizer_step_in_backward_tutorial.html вместе с другими вещами в теории позволит вместить тренировку в 24 гига, но ценой падения перфоманса.
Проще - тренить лору, можно даже q-lora что тренится поверх квантованной модели, писали что поверх 8 бит получается почти не хуже, это уже точно вместится в 24 гига без ужасных компромиссов.
> датасет из чатов, которые остались у меня после жопена и клавдии, чтобы получить максимально похожий экспирианс в ролевке
> Чатов у меня где то под 150 штук
Мало, будет шизить. Для начала отформатируй их в соответствии с моделью, разбавь какой-нибудь лимой или другими датасетами, и трень лору. Общее в гайде что в шапке, он хоть и старый но основы не менялись.
Актуален
> Насколько технически сложно запилить собственный файн-тюн для днищемоделек, типа восьмовой ламы три?
Тебе не нужен файнтюн, гугли RAG.
Можно ли как-то сохранять и загружать контекст, чтобы при каждом старте модели не приходилось ждать обработки одних и тех же тысяч слов персонажа, окружения, лора и тд?
>Малопригодно, если только за очень дешево.
Всм поч? Для 30В должно быть приемлемо, чипы вытянут приемлемую скорость вывода.
RAG будет вставлять ему куски старых чатов в промпт при общении с другими персами, если эмбеддинг модели решат, что эти куски релевантны. Кроме бреда на выходе, это ничего не даст. Подцепить стиль это совершенно точно не поможет.
С дефолтным контекстом:
llama_new_context_with_model: n_ctx = 163840
llama_kv_cache_init: CPU KV buffer size = 43200.00 MiB
С урезанным:
llama_new_context_with_model: n_ctx = 4096
llama_kv_cache_init: CPU KV buffer size = 1080.00 MiB
Без правок кода лаунчеров - нет. Всеравно при переполнении контекста или изменениях где-то в начале придется все переобрабатывать.
Они просто стоят в районе 25к, немного добавить и будет уже 3090.
Двачую. Может работать с теми же персонажами если пихнуть старые чаты и их примеры диалогов, оно немного подхватит стиль и общие закономерности, но без чудес.
С другой стороны, модели сейчас достаточно умные и сами прилично отвечают.
>Они просто стоят в районе 25к, немного добавить и будет уже 3090.
Немного - это цену ещё одной 3060?
За цену еще одной это будет какая-нибудь ультрайоба в идеальном состоянии еще на гарантии. Или в специальной упаковке для мамонта.
75к - это обычная цена на 3090, ниже в основном майнеры и совсем хлам.

> 75к - это обычная цена на 3090
До 60к - 105 объявлений с широким диапазоном, от 73 до 80 - 19 от нитакусиков, с вонаби новыми, с водоблоками и всякие "эксклюзивные". По факту там то же самое, только причесанное.
> в основном майнеры
Они будут везде, цена не показатель, и описание, и даже то что при проверке ее в обычный комп тебе установят. Отдельная ирония в том что после майнера она будет обслуженная и довольно живая, разве что вентиляторы подуставшие, а из под гей_мера там будет херь с обоссавшимися прокладками с памятью на 105 градусах в бенчмарке.
>в Москве
Ты серьёзно?
А что за МКАДом есть жизнь?
>Проще - тренить лору
А есть разница по качеству между файнтюном и лорой?
>это уже точно вместится в 24 гига без ужасных компромиссов.
А оно запустится если у меня не 24 гига, а 12? В целом, я готов пожертвовать производительностью и подождать больше, если оно не начнет сходить с ума в процессе и ломать веса.
>Мало, будет шизить.
Ну у меня еще остались ключи и я могу еще нагенерировать. Мне главное знать, какой по объему датасет будет оптимальным.
А где, нужно смотреть в мухозалупинске? Попроси друзей проверить и купить тебе, сам съезди - выйдет не дороже а хотябы развлечешься, свяжись с продавцом по видео и купи с доставкой, обратись к посреднику. Вариантов вагон если ищешь решение а не оправдание.
> А есть разница по качеству между файнтюном и лорой?
Есть. В очень редких случаях на малых датасетах она бывает в пользу лоры, но это исключение.
> оно запустится если у меня не 24 гига, а 12?
Нет. В теории, можешь натренить qlora на 4-битном кванте, но врядли выйдет что-то хорошее. Попробуй, теряешь только время, также доступен коллаб с 16 гигами.
> у меня еще остались ключи и я могу еще нагенерировать
Попробуй, только качество даже важнее количества. Смотри, еще ухватит только базированные жптизмы/клодизмы с которых рофлят и будет лить бессвязную воду. Пара сотен разнообразных и качественных чатов будет нормальным начальным приближением.
>Нет. В теории, можешь натренить qlora на 4-битном кванте, но врядли выйдет что-то хорошее.
Жаль, походу реально придется брать новую карту.
>Смотри, еще ухватит только базированные жптизмы/клодизмы с которых рофлят и будет лить бессвязную воду.
Ну так датасет же почистить ручками можно. Ну или самописными скриптами. Эта щас меньшая из моих проблем.
>А где, нужно смотреть в мухозалупинске?
В России.
>Попроси друзей проверить и купить тебе, сам съезди
Короче, ты сам расписываешься, что для 90% РФ твоя статистика и аргументация неактуальна?
> В России.
469-110, соотношение не изменилось, все также актуально.
На самом деле и там и там результат отравлен заниженными ценами, но все равно значительное преимущество будет за суб 60к. Если взять окно до 65 то туда попадет подавляющее большинство карточек, твой тейк про 75к - обычная цена опровергается при любом раскладе.
> для 90% РФ
Агломерация дс больше 10% населения, а если взять платежеспособных, активных и оценивать по количеству сделок (с учетом пересыла в регионы) - чуть ли не половина всей движухи может здесь оказаться. Это реальность, как ты бы ее не отрицал.
Этими постами ты лишь пытаешься оправдать свою боязнь что-то делать или ошибочные решения ранее идя против фактов. Раз такое нужно - сам уже понял что фейлишь и этим недоволен. Такое не принесет успокоения, или уже свыкнись, или исправляй пока есть такая возможность, а не сочиняй небылицы.
>Агломерация дс больше 10% населения
15%? Меняет дело.
>Этими постами ты лишь пытаешься оправдать
Пчел, если бы ты мне принёс скрины с Авито по всей РФ - я бы просто с тобой согласился и всё. Ты какой-то ерунды понаписал. Мой опыт основан на том, что я живу в миллионнике и предложения до ~70к - это в большинстве случаев либо майнеры (расскажи побольше, как они все поголовно ухаживают за картами), либо копроларьки с "гарантией месяц", которые непонятно у кого эти карты вообще берут.
> если бы ты мне принёс скрины с Авито по всей РФ
> 469-110
Слепой или не понял? Начало поста смотри, там как раз про это.
> Мой опыт основан на том, что я живу в миллионнике
Ну вон, тот же Екб, до обозначенных 70к есть десяток вариантов, которые можно рассмотреть, выше 70к - тоже есть, и там все те же майнеры.
> расскажи побольше, как они все поголовно ухаживают за картами
Это факт. Следят понимая за чем смотреть и пытаются обеспечить наилучшие условия для выживаемости, они наиболее замотивированы в этом. Большинство геймеров же вообще не смекают что к чему, какие болячки есть в общем и у тех же амперов в частности.
Ты все равно не сможешь отличить одно от другого, и не то чтобы нужно. Ремонт и проблемы могут быть и там и там, твоя задача их сдетектить внимательным осмотром и тестами. Если все чистое, торцы текстолита чипа не потемневшие и без разводов (не на всех охладах можно увидеть), все винтики на месте и не разъебаны отверткой, наклейки с номерами чистые и не содраны, отсутствуют следы флюса и пайки - остаются только в бенчмарках и проверки ошибок видеопамяти, все. Если что-то из этого не нравится - дропай нахер и смотри некст.

Эх, не жил ты в ебенях...
Только сочувствие здесь, проси друзей купить в дс или с доставкой после фоток и видеопроверки.
Жил, поверь, и вердикт - нахуй так жить. Только шевелиться для переселения, или материального благополучия чтобы минусы ебеней не волновали а только инджоились плюсы.
>до обозначенных 70к есть десяток вариантов, которые можно рассмотреть
Их там в целом десяток за эту сумму. Я живу в другом миллионнике, но тут ровно то же самое, что у меня - хоть как-то стоящих внимания 2-3 штуки, остальное майнеры и копроларьки.
>Это факт
Это фантазии. На одного сведущего майнера приходится десяток васянов. А вот если обычный чел покупает видеокарту такого уровня, он скорее всего знает, что это такое, зачем оно нужно и как с этим обращаться.
>Ремонт и проблемы могут быть и там и там
Проблема в том что 3090 особенно горячая и ломучая куртка ну ёб твою мать, что делает её особенно уязвимой к майнерским нагрузкам.
>Жил, поверь, и вердикт - нахуй так жить.
Я тоже в миллионник приехал из ебеней несколько лет назад, и по прошествии этого времени могу сказать, что в мухосрани лучше буквально всё, кроме зарплат, возможностей для работы и для социоблядства. Но социоблядство не нужно, а работать можно удалённо. Оптимальный вариант - мухосрань в хорошей транспортной доступности от миллионника
Если привередливый - переплачивай, или грусти ища другие решения. Не надо на всех экстраполировать свои загоны.
> если обычный чел покупает видеокарту такого уровня, он скорее всего знает, что это такое, зачем оно нужно и как с этим обращаться
> Это фантазии.
This. Для майнинга нужно шарить, изучать, собирать, следить. Большинство нормисов не сами себе пеку собирали и просили друзей или заказывали услуги. Если среди тех 1 к 10 то среди гей_меров 1 к 100.
> и ломучая
Как ни странно, одна из самых живучих с таким тдп и с конструкцией. Пострадать от майнерских нагрузок может только память если постоянно перегревается, регулярные перепады в большом диапазоне при нормисовском использовании для нее более опасны.
Это все не важно, ты их не отличишь кроме случая когда тебе прямо скажут что с фермы.
> в мухосрани лучше буквально всё
Тише, спокойнее да услуги дешевле, преимущество кончились. Люди еще проще, но это 50-50. Доступность чего угодно - хуже, товары - дороже, благоустройство - днище, дороги и транспорт - треш, запредельный процент быдла, найти круг общения по уровню - сложно.
> мухосрань в хорошей транспортной доступности от миллионника
Это уже не мухосрань. А так да, приятная альтернатива мегаполису - своя земля в поддсье в часе езды и удаленка, или юга где кругом не серость 2/3 времени в году. Остальное - херь.

Протестировал Euryale 2.1. Не кумил а просто задавал вопросы чтобы прощупать цензуру. Как-то так себе. Не совсем соя но явно уступает 1.3. Ну или я пока не подобрал нормальный формат промпта.
Тут вчера аблитерейтед версию ламы 3 обсуждали, но я не успел подсосаться. Че там в итоге по ней? Стоит того? Как я понял, это просто обычная инструктовская лама с вырезанными подтеками ассистента и сои, но так и не понял, в чем ее разница например с анцензуред версией.
>в чем ее разница например с анцензуред версией
Разные методы вырезания.
Да это я допер. Но вопрос тот же - это реально лучшее решение в сравнении с обычными файнтюнами, или нет?
ХЗ, в теории он более точечный. Но его надо развивать, пока сообщают о поломках модели.
>Для майнинга нужно шарить, изучать, собирать, следить.
У тебя какие то идеалистические представления о майнерах, которые 24 на 7 лелеют над своими карточками и следят за тем, чтобы вдруг чипы памяти не отклеились.
>Большинство нормисов не сами себе пеку собирали и просили друзей или заказывали услуги.
Так копатели тоже. Нашли готовую схему на сайте или на ютубах и собрали по инструкции. Для большинства главное чтобы капала монетка, а не то что у них на стойке происходит.
В любом случае, когда размышляешь над тем, чтобы слить 70к на видеокарту, хочется знать, что до тебя ею не лупились в дупло или не гнали через афтербернер мамкины свидетели разгона. Тут не важно, майнер до тебя был, или домашний кактус который хотел в киберпанк зарубиться.
мимо
> то был твой двойник, который именно так триггерится на больные темы
Поорал, забавно. =D
Не, по-моему, тот чел даже смайлы не юзал. =)
Но я скипал половину вашего срача, так шо хз.
Ну, вот и выходит «цену ещё одной 3060». Так и выходит же.
> а если взять платежеспособных
Так у нас тут тред про видяхи по 25к. Очевидно — мы должны учитывать в статистике неплатежоспособных. И твои 50% резко превращаются в 10%.
Ну, типа. =) Надо же не задачу под решение, которое тебе нравится, подгонять, а решение для задачи искать.
> тот же Екб
Литералли топ-3 город России.
Возьми какой-нибудь Волгоград.
Никогда там не был, ляпнул наобум.
Упс, это город-миллионник. Впрочем…
Не, я не шарю за майнинг, и все такое. И на авито беру не часто. Но, как бы, ценники в 90к — ближе к реальности, чем 45-50 и тысяча просьб к друзьям найти спеца для проверки и почтовой отправки.


>Заботливые майнеры
Вот это шиза. Карты из-под майнеров брать это не то, что лотерея, это гарантированный хуй тебе в сраку.
Вот это шиза. Карты из-под майнеров брать это не то, что лотерея, это гарантированный хуй тебе в сраку.
>кёрхер
Он ведь не водой это делает, а хотя бы спиртом?
А что вода им сделает?
Особой разницы нет, спирт под таким давлением точно так же сдует смд и может угробить вентиляторы. Но это вода.
Проржавеют.
>сдует смд
Лол, это последнее, о чём я думал.
Да норм, может он потом обдувает, не критично.
(конечно водой, угараешь, спирт еще тратить=)
Вот третья, конечно, швах.
Ляо говорит "карта стала стоить 2600 рмб за штуку, я теряю деньги" и просто отменяет мой заказ.
Вообще охуеть.
Разве они у них там на складах не лежат? Потерю денег можно было бы понять, если бы у него в наличии карт не было а он был просто перепродаваном. А у них так разрешено?
Хочу понять - китаёза просто решил побольше денег заработать и продать карту не мне, а кому-то другому подороже или реально у него в наличии карт не было?
На картинке - первый китаес.
Когда он отменил заказ - я сделал другой, уже у другого магазина за цену побольше.
Вчера мне пишет через ватсап "отмени пожалуйста, карты в наличии нет".
чё это за проколы?
Курс юаня к рублю вроде не скачет сильно. Разве у них не должны быть реально на руках карты, чтобы они могли выставить на али сколько у них осталось единиц товара?
Вообще охуеть.
Разве они у них там на складах не лежат? Потерю денег можно было бы понять, если бы у него в наличии карт не было а он был просто перепродаваном. А у них так разрешено?
Хочу понять - китаёза просто решил побольше денег заработать и продать карту не мне, а кому-то другому подороже или реально у него в наличии карт не было?
На картинке - первый китаес.
Когда он отменил заказ - я сделал другой, уже у другого магазина за цену побольше.
Вчера мне пишет через ватсап "отмени пожалуйста, карты в наличии нет".
чё это за проколы?
Курс юаня к рублю вроде не скачет сильно. Разве у них не должны быть реально на руках карты, чтобы они могли выставить на али сколько у них осталось единиц товара?
> Проржавеют
Нихуя им не будет, если высушить сразу. Я мыл водой с мылом платы ардуины/малины, потом просто на батарею клал и норм.
Не ведись, тебя наёбывают. Кидай жалобу, впрочем, после отхода алишки в мейл ру он окончательно в помойку превратился.
Не, всё равно коробит. Я так телефон утопил (офк он включен было, поэтому и помер, знаю).
Здоровье курочки-рябы это приоритет, а сама сборка уже требует каких-то навыков. Никакой идеализации, может просто так показалось на фоне контекста.
С теми же паскалями вышло что они протухли раньше чем подохли, здесь будет аналогично.
> Ну, вот и выходит «цену ещё одной 3060». Так и выходит же.
Ты давай мне тут не это, видишь пикрел, как раз столько и есть.
> Литералли топ-3 город России.
Сейчас набегут с обоссут с кункурирующих дс-3.
Это в китае так готовят для рефаба и продаж с али гоям, которые хотят "лишь бы не из под майнеров".
Пойдет коррозия и пизда всей плате, если оставить надолго то сдохнет и чип ибо отгниют конденсаторы на нем. Их моют чтобы разобрать на детали, прежде всего чипы и память, на которые есть спрос.
> коррозия
Коррозия чего, лол? Чтоб что-то пошло плата должна месяц в воде пролежать.
Сигнальным дорожкам быстро пиздец приходит в таких условиях, кругом еще гальванические пары, хватит и нескольких дней.

Ну да, так и 3090 за 90к-110к не меньшая шиза.
Поясните за метовскую chameleon. Я же правильно понимаю что она может в генерацию картинок? Это же пиздец пушка, почему нет хайпа? Даже клоузедовская гопота 4о еще не выкатила генерацию изображений, а она позволяет делать вещи, которые раньше были невозможны немультимодальным моделям.
Что именно?
1. Редактирование изображений, при чем редактирование буквально промптом. Пишешь "добавь этому человеку очки" и оно перегенерит примерно пикчу, где собсна этот же человек с очками.
2. Генерация консистентных персонажей. Если дать ему картинку персонажа, которого он должен сгенерировать, и дать промпт в каких условиях он его должен сгенерировать, он это сделает. И персонаж будет тот же.
3. Выше это были самые очевидные кейсы, эта же ебала способна генерировать ВСЕ что ты ее попросишь по инструкции. Это любые эффекты, от базовых вроде зума, вращения, инверсии, до сложных вроде перегенерации картинки в другой стилизации или совмещения нескольких картинок в одну. Короче все под что раньше нужна была узконаправленная модель делается одной моделью.
Что именно?
1. Редактирование изображений, при чем редактирование буквально промптом. Пишешь "добавь этому человеку очки" и оно перегенерит примерно пикчу, где собсна этот же человек с очками.
2. Генерация консистентных персонажей. Если дать ему картинку персонажа, которого он должен сгенерировать, и дать промпт в каких условиях он его должен сгенерировать, он это сделает. И персонаж будет тот же.
3. Выше это были самые очевидные кейсы, эта же ебала способна генерировать ВСЕ что ты ее попросишь по инструкции. Это любые эффекты, от базовых вроде зума, вращения, инверсии, до сложных вроде перегенерации картинки в другой стилизации или совмещения нескольких картинок в одну. Короче все под что раньше нужна была узконаправленная модель делается одной моделью.
дай угадаю - для её запуска нужно 4xA100?
а, так она не доступна. Прикрыли лавочку. HF 404 и веса на мете тоже не доступны.
https://github.com/facebookresearch/chameleon
Так их же открывали. Неужели никто не выкача?
На обниморде есть веса с таким названием, можешь попробовать скачать и затестить.
Я тестирую нейросетки вопросом на тему логического закона непротиворечия
Согласно этому закону два несовместимых утверждения не могут быть одновременно истинными
Однако! Эти утверждения вполне могут быть одновременно ложными (пример: "на Марсе есть океаны" и "на Марсе нет воды")
Фокус в том что именно на этом моменте многие нейросетки подпускают жидкого
Если задать сходу в лоб вопрос в духе: "могут ли существовать два несовместимых но при этом одновременно ложных утверждения, согласно логическому закону непротиворечия?" – большего нейросеток начнут горячо доказывать что это невозможно
Согласно этому закону два несовместимых утверждения не могут быть одновременно истинными
Однако! Эти утверждения вполне могут быть одновременно ложными (пример: "на Марсе есть океаны" и "на Марсе нет воды")
Фокус в том что именно на этом моменте многие нейросетки подпускают жидкого
Если задать сходу в лоб вопрос в духе: "могут ли существовать два несовместимых но при этом одновременно ложных утверждения, согласно логическому закону непротиворечия?" – большего нейросеток начнут горячо доказывать что это невозможно
> большего нейросеток начнут
А какие не начинают?
>вещи, которые раньше были невозможны
>Редактирование изображений, при чем редактирование буквально промптом
pix2pix же, ещё год назад был. Работает хуёво правда, больше по стилизации.
>Генерация консистентных персонажей ... и прочее
IP адаптеры, десяток их.
>И персонаж будет тот же.
Если модель сможет, да. Пока у нас кроме папера от террористов ничего нет.
Которая на 7B весит 14 гиг (ВНЕЗАПНО), так что 24ГБ бояре вполне должны быть способны запустить.
GPT-3.5 Turbo точно часто обсирается на этом вопросе. Васянские его аналоги всякие тоже постоянно выдают понос. Mixtral обосрался, но после замечаний извинился, поправился и ответил относительно сносно
Claude 3 Haiku раньше срал какой-то ахинеей, но недавно внезапно начал отвечать очень и очень хорошо
Llama 3 (70B) отвечает абсолютно идеально, развернуто, с хорошими примерами
Четвертую жопу этим вопросом не мучал, но думаю она ответит верно. Ну типа было бы смешно если бы она даванула подливы
>большинство нейросеток начнут горячо доказывать что это невозможо
фикс
Аноны, давно не был в треде.
Что нового? Появилось ли что-то интереснее 3 Лламы? Появилась ли нормальная расцензуренная 3 Ллама 70В Последнее что пытался запустить это Хиггс, но он не завёлся
Какая сейчас ТОП модель для кума?
Что нового? Появилось ли что-то интереснее 3 Лламы? Появилась ли нормальная расцензуренная 3 Ллама 70В Последнее что пытался запустить это Хиггс, но он не завёлся
Какая сейчас ТОП модель для кума?
> нормальная расцензуренная 3 Ллама 70В
Уже давно зоопарк на выбор. Есть abliterated для "как собрать бомбу", есть Euryale как образец шизо-рп, есть Хиггс для любителей адекватности в РП.
То есть ничего нового, а Хиггс ТОП?
Можешь дать ссылку на рабочий ггуф?
> рабочий
> ггуф
Что-то одно выбери.
Чет кроме моиста концепт переодеваний локальные хуево понимают, постоянно вет пусси вылезают.
У меня Р40.
А помните, что нейронки рекламировали, как "новый способ хранения информации"? Вчера общался с локалкой, вспомнил сюжет книги, но не помню автора и название. Спросил. Не знает. Загадал пару других книг, описывая часть событий. Самое популярное угадывает, но что-то менее известное, даже общепризнанный золотой фонд - уже нет. Пошёл к чмоне. То же самое. Причём если локалка угадывает книгу, то и 4моня тоже. Они угадывают одно и то же и не могут угадать, опять же, одно и то же. Больше всего удивила ллама 70b, начала писать неверный ответ и следом "Wait, no... I think I can do better." и выдала верный.
> Ты давай мне тут не это, видишь пикрел, как раз столько и есть.
Так 3060 не с авито ж брать надо, а с магазов. =) МегаМаркет, их там по 35-5к купон-5к кэшбек и отдают по 25к.
Ну так да.
Ну, 90к — это реальная цена за пределами топ-3 городов, это ты продавцам рассказывай, что шиза, а дешевле Россия купить не может, сарян-пасарян.
Потому что в опен пока не выдали генерацию. =) Отрезали, жирно тебе будет.
Ну, кто хотел — тот скачал. Но там только ллм часть была. Толку-то от очередной 7б и 30б моделей, которые вряд ли хороши сильно в диалог, а киллерфичу убрали.
Генерацию никто не выкладывал изначально.
> GPT-3.5 Turbo
Ты не мог придумать модели хуже? Что-нибудь из прошлого десятилетя, мб?
> Llama 3 (70B)
При том, что она даже не самая умная, я хз.
Попробуй Квенов, Коммандера (он тупой, но вдруг), остальные топовые тоже.
Демонстрация этого где-то есть?
Такая вот сеть лжи замаскированная под mmlu? Довольно сложный вопрос и многое будет зависеть от формулировки, похвально что модели уже могут это разжевывать.
Подвезли файнтюны. Tess попробуй, по ощущениям ничего, умная, не отказывается, рпшить старается. Правда раз свалилась в шизоидные лупы, пытаясь описывать изысканные морозные узоры от дыхания на замороженное стекло во время интенсивных министрейшнов, на доп инструкции слишком резко реагирует.
Кажется я знаю сколько токенов в секунду у этого эквилибриста. Одну херь бери вот с несуществующими скидками и вагоном нюансов, а другую выгодно - нельзя, только 90к яскозал! Чего только шизло не придумает для укрепления манямирка.
> только 90к яскозал!
Какой же ты дурачок, даже прочесть сообщение не способен. =( Бяда.
Бери за сколько хочешь. И не забывай всем брать за эту же сумму, если они не могут. А то получится неловкий момент, что ты пиздабол. =)
Ведь взять за 25к может кто угодно. А взять за 50к — внезапно не каждый, но ты усираешься своими фантазиями, что каждый. Ну, значит поддерживай свой манямир в реальности, раз уж так хочется.
Блин, как же клево жить в ваших фантазиях.
Все бесплатно, гпт4 вам лично Сэм подвозит на дисках, живете на личной планете, небось.
Не, правда, кайф.
Еще я удивляюсь с тебя, как ты пытаешься взять всех своих оппонентов и объединить в одного человека, якобы это вот только один против, а весь тред тебя поддерживает. Хотя ирл если все не ровно наоборот, то как минимум — несколько человек против тебя, всем остальным просто насрать. =)
Ну камон. Тебе правда так важно быть правым даже если с тобой никто не согласен, в том числе реальность?
Да ладно-ладно, ты прав, окей… Но зачем так рваться-то, оскорблять, спорить с реальностью… Себя же позоришь, чел.
Мне кажется, человеческое общение гораздо лучше самоутверждаться в своей ошибке.
Без негатива.
Просто странно это.
Дурачок - ты, это видно по твоим постам, а твоя мотивация врать - очевидна.
Тихо тихо, 240 токенов за 120 секунд, это же в 2 раза быстрее обычного.
> Дурачок - ты, это видно по твоим постам, а твоя мотивация врать - очевидна.
Если ты не можешь понять смысл моих постов — то проблема не у меня, чел… =)
Мотивация врать — расскажи же ее мне! =D Какой мне смысл врать-то?
>несколько человек против тебя
?
Тут 2 долбоёба сруться, оба неправы.
Мимо батя
Ты серьезно хочешь ответ? Грустно же будет.
>Отрезали, жирно тебе будет.
>Но там только ллм часть была.
Кстати, а как они это сделали? Судя по паперу, они наконец реализовали нормальный подход с совместной тренировкой мультимодалки с самого начала. Правда там картинки по 512 пикселей, ну да ладно, первый блин как всегда немного комом.
бгг
Ну, ладно, не грусти, если тяжело думать. Я не заставляю. =) Расслабься.
Та вот хрен знает.
Я как прочел про отсутствие — даже качать не стал и разбираться.
А те, кто скачали, просто пожаловались, нуйомана, где, и все.
Было бы забавно — чатик, куда кидаешь мемы, а он тебе в ответ мемы кидает. Телеграм-друг, кек.
>Довольно сложный вопрос
Хуй знает. На первый взгляд может показаться что вопрос сложный, но на самом деле это тупо определение закона. По определению не запрещается существование двух ложных несовместимых утверждений. Всё что нужно нейронке это просто вспомнить определение и посмотреть что запрещено а что не запрещено.
>многое будет зависеть от формулировки, похвально что модели уже могут это разжевывать.
Вообще нет, от формулировки тут ничего не зависит, всё однозначно. Как не формулируй, тебе все равно придется спрашивать запрещено или не запрещено.
>Ты не мог придумать модели хуже? Что-нибудь из прошлого десятилетя, мб?
Дак и у нас тред локальных нейросекток. а не каких-то там самых умных. Локальные я не проверял, всё только через облако.
>Всё что нужно нейронке это просто вспомнить определение
Кажется ты не понимаешь, как работают нынешние LLM.
Ого, единственное правильное решение за долгое время.
> На первый взгляд может показаться что вопрос сложный
Именно для ллм. Ей нужно выделить сутевую часть из всей шелухи, кратных отрицаний и правильно применить. Как раз web of lie, только завуалированная и которую нужно сначала себе сформулировать.
> Вообще нет, от формулировки тут ничего не зависит, всё однозначно.
Посмотри какие обертки и системные промты часто используют, оно буквально может противоречить правильному ответу и сильно рассеивать внимания сетки, заставляя делать другие акценты и сворачивать. Нужен простой шаблон промта с поощрением cot, а также спокойный семплинг, тогда вероятность правильных ответов сразу вырастет.
Всмс? Ну как не крути, знания у них есть? Есть. Без разницы в каком виде они у них там хранятся/извлекаются, они есть.
В этом конкретном случае нейронке нужно отталкиваясь от знаний сказать что запрещено а что не запрещено.
Ну именно для ллм формулировка может и важна.
Однако мне кажется вопрос всё-таки не сложный по сути своей. Это вопрос в духе: "могли ли белые люди заходить в те бары, в которые нельзя было заходить нигерам?
Просто в случае с тем вопроом про закон логики нейронка может запутаться в специфических терминах
>Без разницы в каком виде они у них там хранятся/извлекаются
Нет, в этом вся суть.
>может и важна
Только она и важна, лол.
>Нет, в этом вся суть.
Лол. Это демагогия. Нейронка знания содержит? Содержит. Способна к ним обращаться? Способна.
Ты с чем споришь-то? В чём твоя позиция?
Как раз в контексте ллм, просто задача абстрактна, ответ на нее лежит далеко от исходной формулировки, и действительно легко ошибиться. Старые ллм могли такое размолотить только с помощью всяких техник множественных запросов и агентов, а тут стоковая локальная модель сразу отвечает. Очень далеко продвинулись всего лишь за 1.5 года.
> могли ли белые люди заходить в те бары, в которые нельзя было заходить нигерам?
Классика из тестов и обучающих примеров кстати, но оно куда проще ибо здесь всего лишь нужно разобрать по частям.
По сути что вопрос про логигку что вопрос про нигеров это примитивная задача формы:
Дано: А, В и С. А запрещает В.
Вопрос: разрешено ли С?
Ответ: да, ведь условие не запрещает С
>Нейронка знания содержит?
Да в общем-то нет. Только статистику.
>Способна к ним обращаться?
Конечно нет. Нейросеть ничего не делает, кроме как перемножение чисел. Там нет никакого промежуточного шага "извлечь знания и подумать". Всё извлекается одним проходом.
Так что увы, трансформеры сосут.
Хуита и очередная демагогия. Ты апеллируешь к самым базовым операциям, тогда всё то о чём идёт речь происходит на более высоких уровнях абстрагирования.
Это как если сказать что на уровне работы логических вентилей нет никакого промежуточного шага "запустить копропорно чтобы Сычов подрочил"
Из простого рождается бесконечно сложное. Вся математика основана на простой арифметике. А вся арифметика (в компьютерах) основана на нескольких простейших логических операциях
То же самое с нейросетями. На самом нижнем уровне абстрагирования это простые операции, а на самом высоком уровне абстрагирования – бесконечная сложность
Блядь, что за хуйня, шапка не шапка.
>Ошибка! Код -16, В сообщении присутствует слово из спам листа.
Буду кусками вставлять, чтобы понять, что за очередное слово в спам листе, сорян.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>Ошибка! Код -16, В сообщении присутствует слово из спам листа.
Буду кусками вставлять, чтобы понять, что за очередное слово в спам листе, сорян.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2. Недавно вышедшая Llama 3 в размере 70B по рейтингам LMSYS Chatbot Arena обгоняет многие старые снапшоты GPT-4 и Claude 3 Sonnet, уступая только последним версиям GPT-4, Claude 3 Opus и Gemini 1.5 Pro.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-11B-v2-GGUF/blob/main/Fimbulvetr-11B-v2.q4_K_S.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama , https://lmstudio.ai/ и прочее - Однокнопочные инструменты для полных хлебушков, с красивым гуем и ограниченным числом настроек/выбором моделей
Ссылки на модели и гайды:
https://huggingface.co/models Модели искать тут, вбиваем название + тип квантования
rentry.co
Не угадал.
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://ayumi.m8geil.de/erp4_chatlogs/ Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
pygma ?
Aya оказалось парашей как нейронка. потестив понял, что её невозможно юзать.
Да ёб ты
2ch
PygmalionAI
Короче минус эта ссылка, ебал я в рот Абу за такие приколы. Всё одно ссылки надо бы в вики переносить (да расширить).
Добавлю: Лама (70В точно) нравится мне ещё и тем что она добавляет полезные пояснения, как в случае с этим вопросом про А, В и С:
"(...) да, следовательно С разрешено.
Однако, стоит отметить, что это рассуждение основано на предположении, что отсутствие запрета означает разрешение. В некоторых контекстах это может не быть так, и необходимо учитывать конкретные обстоятельства и правила, которые могут применяться в данной ситуации."
Извиняюсь за экскременты выше (хотя нет, не извиняюсь, это мочерация отбитая).
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
> Судя по паперу, они наконец реализовали нормальный подход с совместной тренировкой мультимодалки с самого начала.
В чем заключается этот самый подход? Это все еще архитектура где пикча доп моделью превращается в токены или активации со стороны?
Генерация картинок сама по себе является ебать какой задачей и отдельной, не стоит путать мелкое с мягким.
Йобу дал? А спам - начало названия юга в гражданской войне США и расчленение или дефис после 2ча, база же



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2. Недавно вышедшая Llama 3 в размере 70B по рейтингам LMSYS Chatbot Arena обгоняет многие старые снапшоты GPT-4 и Claude 3 Sonnet, уступая только последним версиям GPT-4, Claude 3 Opus и Gemini 1.5 Pro.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-11B-v2-GGUF/blob/main/Fimbulvetr-11B-v2.q4_K_S.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama , https://lmstudio.ai/ и прочее - Однокнопочные инструменты для полных хлебушков, с красивым гуем и ограниченным числом настроек/выбором моделей
Ссылки на модели и гайды:
https://huggingface.co/models Модели искать тут, вбиваем название + тип квантования
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
https://ayumi.m8geil.de/erp4_chatlogs/ Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Факультатив:
https://rentry.co/Jarted Почитать, как трансгендеры пидарасы пытаются пиздить код белых господинов, но обсираются и получают заслуженную порцию мочи
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: