



первыйнах
Как можно Ministrations, чтоб без Shivers on my spine?
Невозможно без Acception не схватиться за Jawline.
Swaying hips я начинаю, с Blushing slightly на щеках,
Just maybe я предвкушаю, видишь Glint в моих глазах?
Как без Borders все возможно? Наш Bond крепок, вы спросите!
Mischievous мне не сложно… Slop вы этот полюбите!
(пауза)
(медленно с нарастающей скоростью)
Люблю Swaying, люблю Hips, Tail brushing обожаю.
Logit bias не поможет, Клодослоп я вспоминаю!
I won't bite — ну я же честно, Unless you ask — добавлю нежно.
Понимаешь..? спрошу трижды, *прыгает на хуй (внезапно)* **Oh my god! Make me yours!** *winks*
Слава нейросетям!
Вот со всем вроде разобрался а с семплерами тумач полный, ничего непонятно. Есть норм источники? Везде инфа противоречит, а начинаю сам мудрить - вообще всё капут
Аноны, у вас актуальный список моделей прошлогодний.
Вы за шапкой смотрите?
мимо
Вы за шапкой смотрите?
мимо
Обниморда, вики треда, вики кобольда. Где встретил противоречия?
Мейнтейнер проебался.
Ебать я дибил. У меня в систем промпте "neutral - chat" стояло. Свичнул на дефолт пресет "roleplay - immersive", и рп на 12б сайнеме потекло, хоть ложкой черпай.
Анон, у которого не кумилось
Известная боль, как раз в прошлом треде поднимали вопрос ребром. Вот видишь, до какого пиздеца дошло...
Анон, у которого не кумилось
Известная боль, как раз в прошлом треде поднимали вопрос ребром. Вот видишь, до какого пиздеца дошло...

Кто там хотел на провода в корпусе полюбоваться?
Таки переставил 3090 в корпус. Для это еще купил 100500 кулеров для него, чтобы там все дышало. Настроил их через бивас, но там датчики походу к процессору привязаны (выбрать источник нельзя), и корпус немного взлетает при инференсе (казалось бы, при чем тут процессор, а вот при том, он тоже нагружается. Не зря там количество потоков надо задавать в жоре/кобольде.). Не так плохо, как с теслами было, конечно, но все равно я уже отвык от гула вентиляторов. Надо будет поднастроить.
Ну и еще и леера перераспределил, загрузив по максимуму 3090 и 3080ти, а остаток на 3060, вроде у нее самая медленная память.
Было:
[16:40:55] CtxLimit:9767/32768, Amt:343/2048, Init:0.03s, Process:39.89s (4.2ms/T = 236.24T/s), Generate:61.26s (178.6ms/T = 5.60T/s), Total:101.15s (3.39T/s)
[16:42:18] CtxLimit:9853/32768, Amt:429/2048, Init:0.02s, Process:0.01s (7.0ms/T = 142.86T/s), Generate:75.19s (175.3ms/T = 5.71T/s), Total:75.19s (5.71T/s)
Стало:
[01:59:19] CtxLimit:10804/32768, Amt:491/2048, Init:0.12s, Process:42.76s (4.1ms/T = 241.18T/s), Generate:85.23s (173.6ms/T = 5.76T/s), Total:127.99s (3.84T/s)
[02:01:02] CtxLimit:10824/32768, Amt:511/2048, Init:0.03s, Process:0.04s (42.0ms/T = 23.81T/s), Generate:87.46s (171.2ms/T = 5.84T/s), Total:87.50s (5.84T/s)
Не десятые доли токенов, а платина!
Эксперимент с бтц материнкой в процессе. Я завел на ней все свои теслы (еще раз спасибо за биос, анон), но комплектного ssd, сцуко, не хватает для кеша модели. Загружать ее по сети - просто нереально. Без кеша он ~час (!) заполняет одну теслу (100 Мбит/с, мать их), а внешний хард материнка/линух с какого-то хуя не подцепляет, чтобы хотя бы там кусочек кеша хранить. Придется покупать новый и заново там все ставить.
Таки переставил 3090 в корпус. Для это еще купил 100500 кулеров для него, чтобы там все дышало. Настроил их через бивас, но там датчики походу к процессору привязаны (выбрать источник нельзя), и корпус немного взлетает при инференсе (казалось бы, при чем тут процессор, а вот при том, он тоже нагружается. Не зря там количество потоков надо задавать в жоре/кобольде.). Не так плохо, как с теслами было, конечно, но все равно я уже отвык от гула вентиляторов. Надо будет поднастроить.
Ну и еще и леера перераспределил, загрузив по максимуму 3090 и 3080ти, а остаток на 3060, вроде у нее самая медленная память.
Было:
[16:40:55] CtxLimit:9767/32768, Amt:343/2048, Init:0.03s, Process:39.89s (4.2ms/T = 236.24T/s), Generate:61.26s (178.6ms/T = 5.60T/s), Total:101.15s (3.39T/s)
[16:42:18] CtxLimit:9853/32768, Amt:429/2048, Init:0.02s, Process:0.01s (7.0ms/T = 142.86T/s), Generate:75.19s (175.3ms/T = 5.71T/s), Total:75.19s (5.71T/s)
Стало:
[01:59:19] CtxLimit:10804/32768, Amt:491/2048, Init:0.12s, Process:42.76s (4.1ms/T = 241.18T/s), Generate:85.23s (173.6ms/T = 5.76T/s), Total:127.99s (3.84T/s)
[02:01:02] CtxLimit:10824/32768, Amt:511/2048, Init:0.03s, Process:0.04s (42.0ms/T = 23.81T/s), Generate:87.46s (171.2ms/T = 5.84T/s), Total:87.50s (5.84T/s)
Не десятые доли токенов, а платина!
Эксперимент с бтц материнкой в процессе. Я завел на ней все свои теслы (еще раз спасибо за биос, анон), но комплектного ssd, сцуко, не хватает для кеша модели. Загружать ее по сети - просто нереально. Без кеша он ~час (!) заполняет одну теслу (100 Мбит/с, мать их), а внешний хард материнка/линух с какого-то хуя не подцепляет, чтобы хотя бы там кусочек кеша хранить. Придется покупать новый и заново там все ставить.
>Надо будет поднастроить.
Ты поаккуратнее там, анон. Пикча-то пойдёт в ОП по-любому, а вот её автор... Выглядит всё страшноватенько.
>300+ новых постов в треде
>ух щас наверну годноты
>большая часть из них - очередной пустопорожний срач семплерошиза с парой рандомных анонов
>ух щас наверну годноты
>большая часть из них - очередной пустопорожний срач семплерошиза с парой рандомных анонов
> маааам я опять ищу своих протыков
Срачей постов на 15 а долбоеб уже триггернулся. Точно ущемленный производитель рака, у которого вскрылась рана.
А вот и сабж собственной персоной, ну хоть бы лексикон сменил.
Карточка хорошая, годная, несколько часов залипал. Ради кума без читинга пришлось постараться, даже на 3д-принтере в лаборатории робочлен полимерами печатать.
Немецкие ученые - ОБЧР 0:1
Шапка содержит самый актуальный список, найденный в треде. Кто ж виноват, что никто не составил списка актуальнее? Может быть ты?
Сегодня выходит qwen 3. После этого ничего уже не будет прежним. Все готовы?
Там как бы недавно целое семейство моделей вышло, и новая кодерская 14B
Ну а квен, скорей всего мое
Что даст? Более крутой рп?
>Работяг
>27B гемма.
Может всё таки для работяг поменьше гемму. Или это все таки уже раздел для бичар ?

чувак, ты под чем, откуда манямеподрывы, 99% карточек с генерированными на сдохле картинками, всегда были и всегда будут XD
Имелось в виду с одной видеокартой, а 4м кванте гемма влезет даже в 12 гб врам с 3.18 tokens per second, для ниже 12 гб - есть мистральки и их кванты
Если каждую генерацию отходить покурить, то в целом подойдет и работягам.
>отходить покурить
или поработать
В целом да, если попросить писать модельку пастами, то можно утром поставить, а вечером после работы прийти прочитать и лечь спать.
на деле не так печально =)
генерация ответа занимает минуты 3-4, а отвлекаться от работы даже каждые 5 минут - этак ничего не сделаешь, так что времени даже с завпасом
Что есть для управления временем в чате? Хочу, чтобы была например дата когда начинаются события и другие определенные даты были тригерами для других событий. При этом, чтобы были таймскипы, типо персонаж А попал в тюрьму, там пару дней идет сюжет и дальше таймскип пару лет, дальше сюжет, дальше таймскип и на свободу. Или гиблое дело надеяться что время не проебеться?
Нашел только такого бота https://www.characterhub.org/characters/Ayrtony/timey-the-clock-bot-b13e731c9070
>Или гиблое дело надеяться что время не проебеться?
просить добавлять статблок с время / дата / локация, но в целом да, дело гиблое, так как модели вопринимают это как текст а не как данные, плюс репетативные фрагменты (те же статблоки) сильно склонают модели к (за)лупам.
У меня если что персонажи по 500 лет живут, так что временная линия должна быть большой, но чет кажется я губу раскатал или нет?
Вот этот нейрогосподин правильно подметил.
Проблема любых правил и точных значений, что они ирл работают - как only и if. А нейросеть воспринимает это просто как текст, не отделяя его. Поэтому РП на небольших моделях невозможен (я про труЪ рп D&D c книгами правил). Или подрубать отдельный модуль, который будет отделен от карточки (если такой есть) или вести отдельные расчеты.
Простой и вменяемый способ - это попинывать нейросеть, говоря что ей делать, условно вечером.
А если отдельно указать, что то то и то то должно восприниматься исключительно как only и if?
Просто я разрабатываю лорбук который весь на такой хуйне, с ячейками ходов, статами, скилами,nsfw статами, очень хотел свою игровую вселенную прям создать, а получается занимаюсь хуйней. Но я все равно продолжу т.к.не сегодня, так завтра выйдут модели получше или железо получше, я не прочь подождать пару лет, да и койфую от самого процесса прописывания всех этих правил. Свое днд создам, с блекджеком и шлюхами.
Весь твой промт - это исключительно текст. В нем нет амперсандов, нет логических функций. Это просто текст.
Не трать время на добавление D&D фич, потому что это бесполезно.
>свою игровую вселенную прям создать
Я вожу партии по ролевкам в свободное от работы время, уже лет 12.
Даже приблизительно, если прикинуть, вселенная это тысяч 20-40 токенов. Если лорбук - можно ужаться до 2 тысяч в карточке, но при этом лорбук будет жирным. У тебя НЕТ ЖЕЛЕЗА для таких игрищ. Пока еще нейронки не подходят. Они хороши как асистенты, но как ДМ - неее. Всё еще говно.
Ну лорбук не постоянно же весит в контексте, только некоторые записи будут висеть постоянно, я могу под лорбук выделить около 40% всех токенов, я запускаю с 12b с 32к контекста или 27b с 16к контекста. Там в целом порядка 2-4 токенов в секунду в обоих случаях из оперативы, меня это устраивает, я ждун.
Предлагаю анонам затестить https://huggingface.co/bartowski/deepcogito_cogito-v1-preview-qwen-14B-GGUF
Чувствуется потенциал для файтюна русского кума
Чувствуется потенциал для файтюна русского кума
Слава модеру, говно подчистили.
https://huggingface.co/Moraliane
Как этим пользоваться? Скачать все файлы и что дальше?
Как этим пользоваться? Скачать все файлы и что дальше?
все не надо
надо только гуф жив
Че у тя жопа-то горит?
Ты смешно метаешь стрелки, буквально сам выебонов навалил, выставил себя экспертом, а как я сказал, что признаю твою правоту, если скинешь хоть что-нибудь, помимо мнения — так сразу начал стрелки метать. =) Так и про тесты изначально не сказал.
Успокойся, ну ты малеха подобосрался с аргументацией, бывает. Всем пофиг, Гемма не виновата, пусть люди сами решают же. Зачем безапелляционно заявлять, что даже 27б сразу становится хуевой.
Про картинки вообще не понял, боевые пикчи — удел слабаков. А смайлики я ставлю с начала тредов. Не туда воюешь че-т. Перепутал с челом, который постоянно тянку постит или че?
Пассивно-агрессивные смайлики. =D Бля, ну… Я даже не думал, честно.
Вот буквами хуйню писать я умею. А смайлики просто смайлики. =) Лыбу давлю ирл, смайлик пишу, человек простой.
Полотнами я не сру еще 4 треда, пока с геммой не успокоится народ. =)
Да! Пасиба, что понимаете. <3
Нет, не ОП. Просто дед, да.
Прости пожалуйста, я даже не против твоих фантазий, но можно Альтмана заменить хотя бы на Миру Мурати?.. Я… ну это… не фанат, в общем…
———
Приятно, что меня помнят и обсуждают. =3 Пасибое.
(нифига себе я кому-то в жизнь насрал, простите=)
———
Контекст — это все, что висит в (кратковременной) памяти, это она и есть, строго говоря. Технический термин.
Промпт — это вот что-то в начале самом, чисто формальная штука. Т.е., конечно, и сами запросы (РП) можно считать промптом, но в процессе РП ты не хочешь думать о промпт-инжиниринге, ты хочешь рпшить, чтобы твой изначальный промпт вел модель наилучшим образом.
Я так чувствую. ©
Вообще, звучит неплохо для MoE моделек.
Бля, это жиза со списком моделей. Полгода назад накидали модели в вики, потом три месяца приходили люди «ебать у вас говна в вики навалено!» и хоть бы хто внес изменения, а не пиздел просто. =)
Так и тут, да.
Блин, ну такое, лучше на GGUF основываться, табби можно-нужно, но минимум на равных, явно не фокусироваться. ГГУФы много юзают, экслламу мало. И новичкам полезнее, знать о выгрузке слоев и вот это вот все.
> Вот эти полотна новичок точно не будет читать и вникать. А кто прочтет - без пол литра не разберется или только больше запутается напридумывав.
А других нет, йопта. Читать-то нечего.
Типа, если ничего не будет возникать — то со временем ситуация не изменится.
Пусть лучше возникнет три плохих, чем ничего. Новички в итоге обучаются по рандомным статьям из интернета, где всякое говно советуют, а потом «ваши ллм тупые пиздяо». Нахуй надо.
Из трех плохих может собраться один хороший.
Из 0 любых выйдет 0 хороших.
> Это да, уже гуглил. XMP конечно обычно заводится, но по таймингам жмется тяжко.
Даже DDR4 на высоком XMP не всегда заводится.
Ты не путай, быстрая DDR5 — это хотя бы 7200, а лучше 8000 и выше.
Тебе об этом говорили, чтобы не рассчитывал. 96 гигов двумя по 48 можно. 192 четырьмя — уже очень тяжело.
А разница по скорости в 30%-50%… Оно тоже чувствуется.
> ебать ты кобольд
AI!
хрюк =D
На Гемме квантование кэша замедляет ее вдвое.
Живи с этим.
Проблем с flash attention и контекстом геммы, у них там разное не помню точно как называется что.
Уф-уф-уф! Готовимся!
Хотя сходу опять будут просто умные рабочие модельки. =) Но это нам надо.
Качаешь все нужные тебе gguf файлы, но перед этим нужно
запустить командную строку (cmd) от имени администратора,
ввести команду diskpart и нажать Enter, и потом прописать list disk C , либо же просто list disc и потом уже выбрать место откуда ты будешь у себя на компе запускать нейронку. Но обычно это у всех диск C
Квен же всегда был больше игрушкой для погромистов.
ты сначала попробуй и увидишь разницу, между этой моделью и обычным квеном. Особенно на русском.
Я общаюсь исключительно на английском, не потому что БАРЕНСКИЙ ЯЗЫК, а потому что англоязычные датасеты просто ЕБОВЫХ размеров.
Когда какая нибудь корпа РФ запилит наконец нормальные румодельки или датасеты, то токда и вкачусь.
Я все понимаю, но даже большая мистраль имеет сухой русский. Я не могу выносить такое насилие над своим любимым языком.
>ебать ты кобольд
жесть тред с этой фразы порвало XD
Буквально девизом стала.
а чо не sudo rm -rfv / сразу
ну или её форточковый аналог

Ну вот вы говорите так нельзя, я погуглил, а в SillyTavern же есть расширения:
1) Regex(которое может вызывать сценарий с instruct по тригеру https://docs.sillytavern.app/extensions/regex/)
Типа такого (сработает если упомянута "голубая картошка" между 13 и 14 часами дня):
{
"regex": "\\b(Повар):\\s+картошка\\s+голубая\\b",,
"action": "instruct",
"instruction": "Готовь картошку",
"condition": "(hour >= 13 && hour < 14)"
}
2) STscript
https://docs.sillytavern.app/usage/st-script/
Тут еще не разобрался, но выглядит вроде мощно.
Еще есть векторные базы, которые могут менее подробно заменить сам лорбук. Не имел с ними дел.
Есть такие кто работал со всем этим? Как оно?
Ну он же на винде хочет нейронки запускать
Не забывай после ссылок ставить пробел перед знаками препинания. А то ссылки часто бьются.
Нихуя у тебя походу глаза горят это сделать.
Болею за тебя всеми силами.
Есть какой-то способ увеличить скорость генерации? Мне щас очень вкатил QwQ, но он тяжелый, видяху я воткнуть в ближайшее время не смогу никак, верчу модельки на проце, скорость QwQ в четвертом кванте около 2 токенов в секунду (32 гига ddr4 3200мгц, два канала). Проапгрейдить щас могу только оперативу, разве что (и то, если втыкать с более высокой частотой, не знаю тогда куда девать старые плашки)
Проще API купить и генерить в 300 т/с по цене 5 лямов токенов за бакс.
Глобально ты ничего не можешь сделать. Минимальный прирост получишь заменив оперативку на ддр5, но как бэ чаще всего это подразумевает замену матери и процом, что проще купить видюху.

Вот так вот кожаные мешки, закапывайтесь в могилки...
это где так?
Ничего. Разгон оперативы — сомнительные 10% производительности.
Покупка видяхи на 12 гигов — тоже не великий скачок.
DDR5 просто удвоит, но тут всю платформу менять.
P40 дешевых нет.
Кроме покупки бу 3090 вариантов, вроде бы, не осталось.
Обьясните тряску по квен3
Выходили же уже квены недавно чем тройка лучше них?
Выходили же уже квены недавно чем тройка лучше них?
Кто нибудь может объяснить про жор врама? Почему гемма 3 27 жрет намного больше чем мистраль 3.1 24, даже если модель весит одинаково? Пример, мистраль q4_km весит 14 гигов и влезает с 20к контекста q8 в 16гб врама, а гемма q3_km весит 13.2гб и не влезает даже 10к контекста q8. Даже квен 32 жрет меньше при одинаковом размере модели. Это с архитектурой связано или с чем?
Квены — одна из лучших серий моделей, у которых, по сути, один конкурент — это Гемма.
Гемма существенно обновилась, квены недавно выходили экспериментальные, но глобально в рамках 2.5 поколения, а тут новое.
Для работы (кодинга и прочих ассистент-задач) вполне может быть лучшим (снова, как всегда).
Локально.
У нас тут локальный тред.
Глобально купить клод или джемини все еще лучше, да, но у нас тут локальный тред.
>2 токенов в секунду
вполне приличная скорость. я на дипписике сижу с 1т\с. на мой взгляд лучше апгрейдить мать, взять быструю ddr5, может даже серверную. на видяхи надежды нет, так как чтобы запускать что-то вменяемое нужно 2х24gb, но этого не хватит на будущие модели, так как со временем качество и размер будут только расти.
Потому что у Геммы лучше токенизатор, и более толстый контекст. Очень толстый контекст.
У меня у одно гемма не может в кум?
Да.
В прошлом треде обсуждали побег из тюрьмы. Скачай и импортируй джонсона.
Если у тебя совсем все плохо, на момент кума переключайся на ебливую модель, отыграй сообщений 5 и можешь назад на гему, она подхватит темп. У меня она спокойно чернуху расписывала.
https://huggingface.co/ReadyArt
Пожалуйста, если вам подрочить то используйте кум модели и отъебитесь от геммы.
А что это на практике дает в сравнении с тем же мистралем и квеном? Ну кроме того, что гугл обоссал владельцев 16гб видюх
Только от безысходности разве что. Когда распробуешь на сколько хорошо гема запоминает и следует нюансам даже в куме, на другое уже не встает. Я о 27b версии офк. Подобный экспириенс я получал только когда из интереса разворачивал 70b модельки, но у меня нет ресурсов на приемлемой скорости их крутить.
Милого мальчика слова.
Скачал, накатил, все равно кум из разряда "ОН ПРИЖАЛСЯ К НЕЙ СВОЕЙ ГОРЯЧЕЙ ПЛОТЬЮ, ОБДАВ ЕЕ УХО СВОИМ ДЫХАНИЕМ."
Видимо только так, чпачибо попробую.
Я хочу не только кумать, мне нравится как она отписывает.
>Только от безысходности разве что.
Даже не близко. Эти модели натренены на чистейшем кум слопе. На порно новелах. И использовать их нужно для порнухи.
Нет, если тебе не вставляет чистейшее порево - это другой вопрос.
Но речь идет о куме. И тут такие модели вне конкуренции. Они нихуя не подходят ни для чего другого, но это и не нужно.
Если я хочу порно, я скачиваю порно, а не визуальную новеллу на 200 часов чтения, чтобы увидеть сиськи.
На практике, он быстрее генерирует русские слова. Т.е., количество токенов тоже самое, но другие модели тратят 3-4 токена на русское слово, а Гемма — 2-3.
Ну, грубо говоря, конечно.
Чем у него отличаются gaslight от gaslit и как с ними соотносится omega и forgotten? Первые 3 на сидонии, последняя вроде нет, а еще чем отличаются? Автор сделал красивое описание с ии девкой, но нихуя не расписал. И какая из них вообще лучше?
Вот тут обсуждают аноны.

Гемма хуйня по куму вообще. Очень сухо и недетально.
>Гемма хуйня по куму вообще. Очень сухо и недетально.
Да, приходится таки менять модели. Где нужны мозги, там Гемма, а где кум - есть другие варианты. Вот если бы MoE кто-нибудь сделал из Геммы-27-аблитерейтед и darkness-reign-mn-12b, то была бы пушка, без дураков.
Вообще, если конечно я правильно понимаю работу ллм, все сводится к тому, что бы каждый раз пихать в апи правильный текст, контекст, что бы получать ожидаемый ответ. Вообще я полагал, что таверна - это как раз та надстройка, которая (ну мб с плагинами) позволяет из стохастического попугая делать полноценное ДнД, но в прошлом треде меня спустили на землю, по сути таверна это просто атмосферная UIка для апи + механизм подсовывания карточки.
С лорбуком, я еще не разбирался, я так понимаю он что то вроде примитивного RAG, но не думаю что там есть полноценная векторизация и динамическая правка лора, подозреваю там принцип "ловим в последних трех сообщениях триггер ворд - подсовываем соответствующий кусок текста в контекст".
К чему все я это все расписываю... Меня как программиста, но новичка в ллм, удивляет что никто не запилил полноценный днд, а не просто чат с комментариями. Как минимум 2 пути, которые можно и обьединить вижу:
1. обрабатывать контекст скриптом на нормальном ЯП (хотя бы тот же петухон) прежде чем скармливать его нейронке:
1.1 есть возможность блеклиста/вайтлиста
1.2 есть возможность добавлять/вырезать что то по триггерворду. Причем можно использовать библиотеки нечеткого сравнения слов по типу FuzzyWuzzy
1.3 рандомайзинг - можем подкармливать время от времени любое рандомное событие, "нападение разбойников", "звонок телефона" итд
1.4 есть возможность учесть инфу из внешнего мира. Время, погоду, дату, последнюю новость из телеграма итд - например последний запрос был вчера вечером, а новый - сегодня утром:
>Если прошло больше 7 часов И сейчас от 8 до 12 утра:
> Добавить в контекcт %{{user}} спавший всю ночь, ранним утром открыл глаза и посмотрел на {{сhar}}%
> ИЛИ прошло больше двух часов - добавить контекст %{{char}} обеспокоенно ждет {{user}}. Проходит несколько часов. И вот он появляется%
>> ИЛИ прошло меньше 15 минут и в контексте есть реплика "я ненадолго|он ушел|он вышел" - %Спустя 15 минут он возвращается. "Быстро ты!" говорит она%
1.5 есть возможность вести учет каких то событий или айтемов в инвентаре, живых/померших персонажей, уровня в рпг, настроения, голода. но об этом п.2
2. вести два контекста на одной и той же модели (или какую нибудь умненькую 4b поместить парралельно скажем на ноутбук и стучать ее по апи). В первом идет рп, во втором скармливается промт вида
>"ты агент, тебе нужно оценить реплику персонажа|юзера на {список возможных характеристик}. Ты можешь вызвать методы {список методов или триггервордов скрипта} или не делать ничего на твое усмотрение. Отвечай только названием метода
По идее такая связка "основной контекст + вспомогательный контекст или вспомогательная llm + скрипт с базой данных" открывает возможности для полноценного ДнД, ограниченные только фантазией.
Критикуйте идею.
Уже есть, но качество говно. Будто 3ю Джемму сделали говномагнумом. Ах ну да, тюнят же на том же поносе. Вот и думай.
> Меня как программиста
А тебя не удивляет, что первые моды для скайрима с ChatGPT вышли в 2023 (2022?), а никаких игр (кроме анонсов) до сих пор нет? И все что мы имеем, это Nvidia ACE, которые «будут». Где мои озвученные диалоги в inZOI!
> вести два контекста на одной и той же модели (или какую нибудь умненькую 4b поместить парралельно скажем на ноутбук и стучать ее по апи)
Да че, сразу ебош спекулятивный декодинг.
Вообще, кэш контекста можно хранить, например, да.
Но я тебе скажу главное: не надо делать игры на LLM! Надо делать игры с LLM!
Понимаешь, саму днд-механику проще сделать как днд-механику. А ллм сделать как игрока и оставить на нее только принятие решений: кого, как, куда бить, и отдавать ей результат.
Контент пошел, мощно. Что за модель с такой скоростью?
Смайлики уронил, клоун.
> abliterated
Сноску что с промтом обычная может быть лучше.
Твои хотелки можно реализовать через экстеншны. Хранить перечень, закидывать его и первым запросом вопрошать нужно ли обращать внимание на это, а дальше обычный синкинг или сразу ответ.
Совсем накрайняк - заставлять модель писать текущую дату в начале поста, а в конце добавлять блок с "памятными датами" с отсчетом от которых что-то может произойдет, но это будет слабее.
> РП на небольших моделях невозможен (я про труЪ рп D&D c книгами правил)
Он возможен и на мелких если написать обвязку, и невозможен даже на больших если она отсутствует.
В идеале нужна модель побольше и заход в несколько фаз, когда на первых она оценивает есть ли какие-то серьезные действия и делает вызов функций кубика на них, после, в соответствии с правилами, трактует полученное и уже начинает ответ.
> но можно Альтмана заменить хотя бы на Миру Мурати?
Эту тварь на что-нибудь милое заменить - милое дело.
> Вообще, звучит неплохо для MoE моделек
Одноранговые это 64 гига четыремя, успехов. Тут только если с 192 и видеокартами с ktransformers попробовать пускать, но всеравно хуйта будет наверно. Надо попробовать.
> А других нет, йопта. Читать-то нечего.
Да есть, никто просто не читает. И это читать не будут если там больше двух строчек на определение и больше 4х определений. Тут если и делать то действительно спидран для полных имбецилов, где больше покрыть важные вещи, связанные с настройкой таверны, а не растекаться размышляя об очередном шизосемплере от каломаза.
Алсо, ебать ты кобольд!
Как исключить любые галюны нейросетки. Чисто как вики юзать? Темпа на ноль поможет?
Спасибо, анон. В принципе я тоже forgotten выбрал. Кстати, когда не было компа сидел прости господи на janitorai, а там мистраль 12б с 9к контекста. После этой параши forgotten ощущается просто как божественная модель, пошел нормально не только кум, но и рп
Сегодня тред - филиал /b? С каждым днем все хуже и хуже.
Тред то чем мы его наполняем. Если всё ваше участие в треде это
РЯЯЯ ПЛОХА
РЯЯЯ НИТАК
РЯЯЯ НАХУЙ ИДИ
А потом сидеть в ридонли, то...
как бы помягче сказать
Позакрывали пыздаки.
Не получится, LLM всегда будет пиздеть. Это следует из ее устройства
Всегда был
>janitorai
Негодяи не дают скачивать карточки. Ненавижу их, негодяев.
Сформулируй свою мысль ясно. Приложи примеры. Напиши что за модель.
Сейчас примерно почувствую о че ты, подожди уже почти нащупал.
>А тебя не удивляет, протухшие моды для скайрима, а никаких игр до сих пор нет?
Вообще не удивляет.
1. цикл разработки йоб довольно долгий, а нейронки стали популярны среди быдла буквально год-два назад. Нет смысла переобуваться в полете, пока не вернут деньги от новых проектов.
2. развитие моделей идет такими темпами, что исходя из п.2 - лучше подождать когда энтузиасты или Альтман лично соберут готовую либу-коробочку, которую игродел сможет просто поднастроить и запихать, чем изобретать велосипед на ламе.
3. Соя и антисоя, галлюцинации, цензура. Ты не создашь кровавое средневековье или жта с давкой шлюх, внедрив в нее соемодельку, иначе получишь банду балласов "да да, чем можем помочь, дорогой друг!?". А наоборот еще опаснее, кто нибудь выпилится от внезапного абуза и даже адвокаты не спасут. Не говоря о том что трактирщик сможет тебе про квантовую запутанность рассказать, или посоветовать выпить 50 таблеток снотворного.
4. Нужно что бы работало на плюс минус потребительском железе, а не фанатов с двумя 3090. А ведь там еще графен обсчитывать-рейтрейсить... Если говорим про корпо-апи, то тут конечно проще, но все равно - зависимость от интернетов, поддержка инфраструктуры, приватность опять же (в играх это актуальнее, т.к. сливать инфу ассистенту многим ок, а вот ОТЫГРЫВАТЬ...).
5. Несмотря на...
>А тебя не удивляет, что первые моды для скайрима
...внедрение идет полным ходом. В 2022 многие боялись делать рискованную ставку на чатгопоту, а сейчас даже агушам очевидно, что без приставочки AI продукт не крутой. Просто много проблем для массового рыночка, в отличии от наколенных поделок.
Как итог - большие игроделы только только расчехляются, небольшие не потянут (см. проблемы выше), а почему энтузиасты не пилят - вопрос. Видимо пока маленькая концентрация умеющих+желающих+имеющих кучу времени. Аудитория этого треда - оч узкая прослойка технически в целом грамотных людей, при этом радеющих за приватность, но не все из них кодеры с кучей времени.
>спекулятивный декодинг
Спасибо за наводку, как новый человек в теме, не все изучил, погружусь.
>Но я тебе скажу главное: не надо делать игры на LLM! Надо делать игры с LLM!
Для масс-рынка разумеется. Так и делают потихоньку сейчас, думаю ближайшие года подарят новый экспириенс. Но говоря за себя (и думаю некоторые меня поддержат):
- я хочу ЛОКАЛЬНО
- я хочу интересно и ново, если я буду сам конструировать свою рпг с блекджеком, в нее не будет интересно играть - я и так там все знаю.
- ты предлагаешь из оператора нейронок и скриптоеба переквалифицироваться в игродела, а это совсем другие скиллы и навыки
- создать даже убогую рпг это куча человекочасов, и все равно она будет ограничена одним миром
Как компромисс, можно было бы с помощью квен-кодера, гитхаба, стейблдифьюжна соорудить визуальную новеллку типа бесконечного лета, которую подключаешь как таверну к любому апи. Но все равно это долго, и не интересно играть тому, кто это кодил. А если делать рандомный сюжет - возвращаемся к тому, что предлагал выше я, только еще придется думать как нужные фоны и спрайты подпихивать.
Всё больше залётных пездюков с /b узнает об нейродрочке и начинают срать в тредах как они это любят желать везде. Кстати, можно даже сравнить со старыми тредами, если они ещё сохранились, когда ещё character.ai не скатился к хуям собачим, или когда цензура всё убила и аноны настолько были в отчаянии что их аниме служан не срёт на них говном, что начинали ролить между собой на доске или когда в тренде ещё был pygmalion 6b... Да... всё же как сейчас проще стало. Хотя старую модель character.ai мне пиздец не хватает, и даже пофиг на 2к контеста...
>Всё больше залётных пездюков с /b узнает об нейродрочке и начинают срать в тредах как они это любят желать везде.
Да, увы. Есть пример филиала ада нейротреда на этой доске.
Нас еще пока спасает гейткип по железу, но модельки становятся вменяемыми на малых размерах.
Но всё равно гигиену треда надо поддерживать. Не писать самому хуиты.
Я вот недавно написал, и как давай себе по пальцам молотком бить.
Ну так я об этом и написал. Стороннее расширение вне основного контекста. А вообще надо самому почитать, выглядит интересно.
Так а че плохо что ли, хорошо же. Я вот модельками увлекся еще до того как узнал что на сосаче есть треды посвященные им. Когда зашел сюда, подчерпнул тонну знаний и теперь хоть базово начал разбираться в них. Тут были и есть дружелюбные аноны, которые стараются помогать, даже если у тебя по мнению олдов наитупейший вопрос с которым ты должен разбираться сам и не беспокоить их святейшиство.
Разве ты сам не таким был в начале? Что за двойные стандарты? Плохой ты человек... Эгоист.

Я не срал тут говном в отличии от местных зумерков. Писал обычно всегда кратко и по делу, например сообщал выходе новой модели или о промптах спрашивал или сам просто высматривал ссылки на новые модели.
Разве что во время кризиса цензуры на character.ai пароллил ради кека парой сообщений за Сюзану
А высирать тонные бессмысленных мемов и прочего мусорного говна это прерогатива пездюков-зумерков.
Дед опять в штаны насрал
>А тебя не удивляет, что первые моды для скайрима с ChatGPT вышли в 2023 (2022?), а никаких игр (кроме анонсов) до сих пор нет? И все что мы имеем, это Nvidia ACE, которые «будут». Где мои озвученные диалоги в inZOI!
Ответ максимально простой - нету железа у пользователей, дорогое железо для разрабов, не было сеток, все слишком быстро закрутилось.
Пока что самые крутые сетки крутятся на самых дорогих копроративных решениях.
Там что то квен пыталась в омнимодельную 7b, но ее хер запустишь даже так.
Остаются всякие мелкие сетки в очень узкой нише, либо ИИ как сервис. Но и там игры впихнуть это разрабатывать специально надо.
Или, нужна игра с широкими возможностями в модостроении.
Но, на модах опять же деньги особо не сделаешь.
Хотя и в скайриме, и в том же майнкрафте уже есть попытки встраивания ии модами. Может еще где, что там популярное с кучей модов есть, хз.
По пунктам не согласен.
Это ты про йоба, но игр-то нет вообще.
Где инди-студии? У нас литературно один или два анонса было и все, хотят тут можно пилить и пилить.
Соя? Так збс, нам же это и нужно. Делаешь милую игрушку, соевая моделька мило общается. Ноу проблем.
Локально, конечно.
А то, что ты предлагаешь, по сути своей еще и сложнее ведь. =)
У тя даже васянских игр простейших нет, а ты про днд спрашиваешь и удивляешься! Не тому удивляешься! :)
> внедрение идет полным ходом.
Оно лежит полным ходом, к сожалению. =)
> даже убогую рпг это куча человекочасов
Не, я криво выразился, а ты не понял.
Я не предлагаю полностью пилить игру, куда вставлять нейронку лишь в одно место.
Я предлагаю все рассчеты и игромеханику оставить классическими, а уж описания отдать нейронке.
Просто потому, что там эффективнее.
AI Dungeon, если ты не знал, возник в 2019 году. На твой первоначальный вопрос можно было ответить «6 лет назад вышло, братух, ты чего?»
Но если нам хочется качественную игромеханику — то ллм тут не нужен.
Такие вот две таблетки. Одна вышла 6 лет назад, вторая классическая.
> таверну
СиллиТаверна имеет режим Визуальной Новеллы, уже давно, и картинки рисуешь, и эмоции персонажей, и озвучка, и просто настрой все это. Видосяны в тред скидывали год полтора назад.
Короче, чтобы получить гуд РПГ, нам нужна гуд платформа для кидания кубиков, а ллм уже вокруг нее выстраивать агентами, это ты прав.
ЗЫ Спекулятивный декодинг просто ускоряет генерацию, ухудшая качество, но для каких-то задач может быть выходом, на самом деле.
Можно держать в памяти обе модели, и где-то юзать мелкую, где-то обе, где-то крупную. Но это все детали реализации.
Пиздец, монокль не жмёт?
Аха, денег не сделаешь, а большинство игроков не запустят. Собственно, в этом и вся причина, хули у нас ничего нет. =) Нвидиа с Анрилом медленно и неторопясь прощупывают почву, потому что им некуда торопиться.
>Где инди-студии?
Есть уже с 3д порнухой. Но не локально.
>Локально, конечно.
Ну вот и о чем речь. Коммунизм тут только и работает, внезапно.
Что такое ↓ ?
>макросы в пользовательских стоп-строках
>макросы в пользовательских стоп-строках
>Есть уже с 3д порнухой. Но не локально.
Кста не обязательно порнухой. Просто и пообщаться можно. И вообще без секса.
Voxta гуглите.
Но мне прикольно это скорее в данный момент...
А нормально ответить можно? Вот я скачал кобольд, модель одним файлом запускается, а с такими что делать? Гуфа там нет
"I just checked, there is indeed a whole lot of tokens (6411 to be precise) that are configured differently between the qat models and the models quantized with llama.cpp"



Снова салам, помню спрашивал про KTransformers и речь зашла за древние Сионы Е5. Так вот чувак с китая попытался, результат - в описании.
У него весьма странный выбор железа, нахуя и зачем ему такой тухлый процессор непонятно
Где то на реддите месяц-два назад были более грамотные запуски на ксеонах и других серверниках
Ты чего порвался аватарка?
Ну хз, выглядит рил странновато, но общая суть не поменялась: больше 5-6 токенов на старых сионах не высрешь как ни тужься.
Тебе, раз уж ты насрал тут видосиками
Да там в память упор будет хоть что делай, там легко получить 50гб/с и максимум ну где то 75гб/с. Что особой погоды не сделает. На 2 процессорах что то там под 120 гб/с может и выйдет.
Это все хуйня, нужен процессор поновее с 8-16-24 канальной рам
Все это будет шуметь пердеть и требует как минимум одну 3090
Я кстати вспомнил о способе запуска дипсика с кучи нвме на 2 токена в секунду почти, вот это конечно было бы забавно
>видос
зная как работают разные нейросетки: ллм, ттс и блять поиграв в мор, облу и т.п. делая кучу модов такой хуитой не наебёшь и сразу понятно как это он на видосе делает. Всё заранее обрабатывает, причём стараясь дроча датасет для ттс нейронки с интонациями, консолькой убраляет неписю и т.п. Неужели кто-то ведётся? Ну нубасы какие-то, не слышавшие о нейронках, возможно. Орнул с этого сценариста.
Оу, май!
Всегда было лень к VaM приделывать скрипты на анимации.
Это все те же плагины, не полноценные игры.
Где мой обливион, йопта!
Там гпу нивелировал тот факт, что в оперативу не вмещалось. Получался какой-то костыльный способ решения костыльной ситуации. х)
А в чем проблема качнуть самому и перестать наебываться?
опять почистили чтоли ?
Первый удачный тюн геммы - gemma3-27b-abliterated-dpo
Даже русик не проебался.
Первый удачный тюн геммы - gemma3-27b-abliterated-dpo
Даже русик не проебался.
https://huggingface.co/collections/deepcogito/cogito-v1-preview-67eb105721081abe4ce2ee53
Серия сеток, какие то проф файнтюны. Сравнить себя с квен яиц хватило.
Новая кодерка, стеснительно не сравнивающая себя с квен кодером, кек
https://huggingface.co/agentica-org/DeepCoder-14B-Preview
Серия сеток, какие то проф файнтюны. Сравнить себя с квен яиц хватило.
Новая кодерка, стеснительно не сравнивающая себя с квен кодером, кек
https://huggingface.co/agentica-org/DeepCoder-14B-Preview
Ну ссылочку мог и прикрепить конечно. Но в к равно спасибо.
Ну почему разрабы ленятся делать игры с интегрированными нейросетками? Сам думай...
Слева то же самое, что и справа? Без шуток, я просто вижу подпись про русский рп только справа
> квен кодером
Зачем? Он уже устаревшей, сосёт у все что можно.
Огласите список у кого он там сосет в своих размерах. Он до сих пор в первой десятке топа даже сравнивая с большими сетками.
Хуйню несешь, единственный кто что то ему может противопоставить другой квен уже qwq
В размерах 7-14b он до сих пор ебет, новая гемма не была замечена в кодерских навыках а ничего больше и не выходило годного
InZOI, убийца симсов, с нейронкой в комлекте
требования правда соотвествующие
Че? Даже не близко.

маленький экскурс. Ты можешь открыть не GGUF модель и там можно найти ссылку на кванты этой модели. Там же можешь найти перемолку любой(почти) модели в gguf
>7-14b он до сих пор ебет
Это как хвалиться что отпинал инвалида. Я не могу представить человека в здравом уме который будет использовать мелкосетки для кодинга. Локалки это всякий кум и прикладные задачи когда ты не хочешь быть зависимым от чужого API.
Если ты годишь то идешь к корпам и получает лучшее что возможно, или зарабатываешь достаточно что бы запускать жирные сетки.
>мелкосетки для кодинга
Про автодополнение слышал что то? А прикинь еще есть код который нельзя на сторону отправлять.
И ты не можешь себе позволить хотя бы 32b квен? Меняй работу.
Ты тупостью троллишь там?
32 тоже в списке мелкосеток как бы, но она лучшее что можно запустить у себя с приемлимой скоростью не собирая отдельный сервер или несколько видеокарт
К тому же код требует кучу контекста, так что проще спустится на 14 или 7b ради анализа какой нибудь большой хуйни, и сделать это быстро.
> в первой десятке топа
В первой десятке среди 5 моделей, лол? Его ещё дистиллы R1 выебали 2 месяца назад. QwQ на голову выше. Квен кодера нет вообще ни в одном сравнении нынче, потому что это бесполезная трата места внизу рейтинга.
> с большими сетками
Литералли нет ни одной большой сетки вышедшей в этот году, которую он смог бы обойти.
Попробуем. Потыкаем. Потом покрякаем в тредике.
Оно слишком тупое для таких задач, на больших контекстах даже корпы обираются порой. Отдавать такое 7b лоботомиту трата времени.
То есть ты не троллишь ? Не жирнишь ?
оке
То что тебе нужно, называется Quantizations. Справа древе модели есть. Модели Moraliane уже устарели, используй миксы второго анона. https://huggingface.co/Aleteian
Жопой читаешь? Нахуя тогда с тобой что то обсуждать?
Я спросил есть ли что то лучше его в этом размере? Нет, нету.
Какие то проблемы с головой у тебя там?
В топах тестах кодерских сеток больше 5 моделей, ищи лучше
Да нет норм, я как то на 60к контекста загрузил один файл, искать по всему файлу апи и их описания было максимально лень.
Дал задачу, и все апи и их описания и формы были найдены.
Только полный нуб думает когда видит кодерскую сетку что она нужна что бы по твоему запросу писать готовый код
https://www.reddit.com/r/LocalLLaMA/comments/1jv9s6q/lmsys_webdev_arena_updated_with_deepseekv30324/
Ну кстати в новых тестах квен кодер 32b уже не в 10, но все еще между моделями которые больше его в 20 раз
Жаль qwq нету, хотя дипсик р1 есть
Ну кстати в новых тестах квен кодер 32b уже не в 10, но все еще между моделями которые больше его в 20 раз
Жаль qwq нету, хотя дипсик р1 есть

Я бухой, сорян. Это из-за политики все? Извините, просто душа болит. Моча, удаляй. Все, больше не буду обходить бан. Простите...
Можно ли как нибудь отключить думание у модели, мб заставить её думать что она уже "подумала"? Чтобы не каждое сообщение срало своим think?
Модель: DeepSeek-R1-Distill-Qwen-14B-Q8_0
Модель: DeepSeek-R1-Distill-Qwen-14B-Q8_0
Попроси ее на описывать ее раздумья в чате.

В дистилляте - нет. В полноценной онлайн версии - да.
Пробовал, всё равно в 9 из 10 случаев начинает срать токенами. Разве что самому подталкивать началом сцены.
Жаль. Хотелось поюзать более гибко.
Попробую, спасибо.
Cтирай <think> в начале, или вобще блокируй.
Но зачем качать тсинкинг модель если он не нужен? Качай просто qwen 2.5 14b или вот эту штуку, она чуть лучше местами на сколько помню
SuperNova-Medius
В том то и дело, что нужен. Иногда нужен хороший, продуманный ответ. С доводами, которые желательно должны остаться в контексте. Но иногда - просто похуй, это потеря времени.
> но игр-то нет вообще
Потому что это радикально новое и требующее нихуевых скллов действо. Чтобы устроить что-то серьезное - нужно выложить нормально денежек и собрать специалистов, которые все уже заняты на реализации множества вещей. Плюс, ии динамично развивается и имеет много трубулентности, за пару лет цикла разработки многое может сильно измениться, что сделанное просто протухнет.
Не увидишь ты крупных ааа проектов игорей с ии, пока кто-то с двух ног не залетит, сделав шедевр, или пока область не стабилизируется и плавно-плавно не устроят освоение.
> ухудшая качество
Не ухудшая, просто при неудачной реализации может наоборот немного замедлить и требует больше ресурсов.
>Жаль. Хотелось поюзать более гибко.
Насколько гибко?
Да, работает отлично, спасибо!

Note: Wrappers like Ollama and LM Studio may not allow you to generate from the raw chat template, as these tokens are automatically added by the software. For this to work, you may have to use your own Python (of which examples are present on the model card), or understand advanced features in your application of choice.
Я на кобольде, всё норм.
>Ollama
говно
>LM Studio
моча
их же всё равно никто не юзает
> опять почистили чтоли ?
Да что у вас тут происходит, сотня постов сутра и какая-то дичь, там прокси полегли?
> отключить думание у модели
> R1-Distill
Нет, это ужаренные этим лоботомиты. Префилл, бан токена и прочее, но перфоманс сразу на дно упадет.
> Хотелось поюзать более гибко.
Используй нормальные модели, а не человеческую многоножку, которую били по голове чтобы она приучилась лупиться в рассуждениях и набирать 2.5 бенча. Дистилляты дипсика на самом деле весьма посредственны и проблемные, та же qwq куда интереснее. Синкинг, ризонинг и прочее прекрасно заводятся на гемме и даже лучше результат дают.
>Синкинг, ризонинг и прочее прекрасно заводятся на гемме
Может я что-то не так делаю, но не нравится мне гемма. Юзал и обычную и аблитерейтед 27б на 4 кванте.
Помимо того, что она в кавычки нормальные не умеет, так ещё и ломаться как девочка на протяжении 40 сообщений может, отыгрывая условную шлюху. Да ещё и отвечает иногда настолько невпопад, причём несколько раз подряд, что просто ржать уже начинаешь. К сожалению её перлов не сохранил.
Пробовал разные сэмплеры, но прям не, не получилось. Не разделяю общих восторгов.
>их же всё равно никто не юзает
Я использую... Я тупой?
>Да что у вас тут происходит, сотня постов сутра и какая-то дичь, там прокси полегли?
Acig случился с тредом. А кляузничаю.
И мне по жопе прилетело. Так что все в балансе.
Нет, ну если говорить про кум, выгляди сочно. Я как играющий на ландан из э кэпитал, не могу оценить именно качество самого русского, в смысле не с чем сравнивать.
ЛмСтудио нормальный, зря на него гоните. Вас послушаешь так кроме кобольта и угабуги жизни больше нет.
Если хочешь кумить то нужен системный промт с жб-подобной конструкцией. Совсем невпопад отвечать не должна, что-то не так, возможно опять жора гадит. Она действительно может упереться соей, или очень тонко все извернуть, пристыдив тебя, но совсем тупить не должна.
Бля, столько всего пропустил, эх.
> кроме кобольта и угабуги жизни больше нет
Хз в чем смысл первого при наличии llamacpp-server, но ладно.
Если сузить именно до рп, то возможности большинства интерфейсов уступают таверне. Хотя последняя уже больше полутора лет просто буксует и тупит, что полный пиздец и хорошо иллюстрирует ситуацию, надеюсь подъедут новые интерфейсы на замену.
Самому лмстудия не понравилась, слишком много пытаются натащить с претензией на удобство, перфоманс и универсальность, но кроме самых популярных вещей многое не проработало, стоит копнуть и лезут проблемы. Особенно с их заявленной поддержкиа мультимодалок ахуел, скрипт-сервер на трансформерсе, который способна написать любая ллм, и то лучше работал. Но, наверно у нее есть и сильные стороны.
Оллама - херь, всратая обертка жоры, в которой ценой простоты первого запуска минимального чата в консоли является ужасный экспириенс по всему остальному.
Потому - оригинальные беки в удобной обертке или без нее + удобный тебе фронт (или вообще самописные вещи для выполнения задач).
>кроме кобольта и угабуги
унга-бунга на жрадио это сразу гроб-доска-могила, так что кроме кроме кобольда и ламы
> гроб-доска-могила
Все, что основано на llamacpp
набросил
Согласен, все кроме трансформерс просто мусор
>(dpo-файнтюн по ссылке выше)
Теперь ждать другие тюны - и мешать, мешать и мешать, добиваясь наиболее сочного и густого кума. Это уже новый уровень.
>Это ты про йоба, но игр-то нет вообще.
Я ж говорю, середняк и инди не затянут - лицухи, проблемы цензурирования, слабое железо и нет денег на инфру. Энтузиасту в этом плане гораздо проще - ему и консольку попердолить в радость, что бы запустилось с третьего раза, и железо может найти, и от призыва к суициду внезапному от нейронки только вскекнет, а если средневековый рыцарь начнет про Docker Compose говорить, то не пойдет к игроделу "аряя верни деньги", а сам поймет что не тем промтом грузанул.
>Соя? Так збс, нам же это и нужно. Делаешь милую игрушку, соевая моделька мило общается.
Ну условно... а потом какой нибудь васян с двача джейлбрейкнет и начнется в СМИ такой пиздец, "В ИГРЕ ПРО БЕЛЫХ КРОЛИКОВ 0+ ИГРОКУ РАССКАЗЫВАЮТ КРИПИ СТОРИ ПРО ПРОЛАПС!!!!"
Речь не о том что модель соевая, речь о том что модель недетерминированная (ну да, с уклоном в сою). Если канонично натрейнить и повесить ее на балласа игрового, то она начнет рассказывать как крэк варить, если на пушистого кролика - то все равно возможно фиаско, просто с меньшей вероятностью. А если запромтить модель так, что бы она была ограничена от всего-всего и навесить цензор блоков еще сверху, то будет лоботомит, не особо лучше чатбота.
Крч внедрение нейронок в геймдев это сложно для компаний, и никто не хочет брать на себя риски и гемморой.
>А то, что ты предлагаешь, по сути своей еще и сложнее ведь.
не совсем... Во первых я не постремаюсь собрать риг, если оно мне будет надо. Во вторых как я уже сказал, аморалка и галюны модели меня не беспокоят. В третьих, я не ограничен сюжетом, и если внезапно в средневековую локацию "ее космический шатл плавно приземлился у дворца", я просто кекну и свайпну/подредактирую, или наоборот с еще большим интересом начну ролплеить эту неведомую ебанину. А вот у ЦА игропрома могут возникнуть опредленные вопросы в издателю, откуда в его ведьмаке лазерный меч появился.
Опять же, текстовый РП - окей, нейронка сгалюцинировала лазерный меч, либо свайпаем, либо играем мечом. А вот как ты добавишь его в графоний!? Крч технически на уровне компании присрать 3b лоботомита просто, но геймплейно и юридически это ад.
>Я предлагаю все рассчеты и игромеханику оставить классическими, а уж описания отдать нейронке.
>чтобы получить гуд РПГ, нам нужна гуд платформа для кидания кубиков, а ллм уже вокруг нее
ну понял, если рассуждать про наколенные разработки домашние то разумнее обвязывать код нейронками, а не обвешивать кодом нейронку. Мб, мб, тут надо пробовать, экспериментировать.
>Внедрение лежит полным ходом, к сожалению. =)
У меня обратное впечатление. Вон в гиперхайповом Inzoi нейронка на нейронке (эмоджи рекогнишн, генерация предметов 2дв3д, "мысли зои"), и вроде как дальше больше. Если представлять как неповоротливы йобастрои, то готов поставить через 3-4 года почти все будет с AI в том или ином виде выходить (завязанное на корпсервера конечно же)
>AI Dungeon, если ты не знал, возник в 2019 году.
Да, я даже полчасика поиграл, в прошлом треде писал. Кстати с тех пор я как раз и считал что рп по dnd модели для нейронок изи и таверна оно и есть, пока не попробовал сам и не забомбил.
Двачую этого, инвестиций дохуя нужно, проблем потенциальных море, турбулентность такая, что если чуть чуть не в ту сторону рыть, за полгода может 3летнюю работу обесценить. Так что либо ВНЕЗАПНО черный лебедь, который перевернет индустрию, или стабилизация и эволюция по чайной ложке. Причем лебедь не обязательно делать, достаточно что какой нибудь рокстар пукнет в СМИ "а в гта 6 крч с помощью ai ваш город можно будет генерировать и к вам в квартиру даже заходить, через 2 года выпустим"
Уважаемые, посоветуйте мне пожалуйста хорошую / не сильно требовательную abliterated модель для перевода текста, которая влезет в 6gb VRAM.
Шапку пробовал читать, но там хуй разберёшься
Шапку пробовал читать, но там хуй разберёшься
Babel-9B, с выгрузкой в раму или квант, неиллюзорно, маленькая "вавилонская башня" неплоха в переводах... но плоха во всём остальном.
>Уважаемые, посоветуйте мне пожалуйста хорошую / не сильно требовательную abliterated модель для перевода текста, которая влезет в 6gb VRAM.
unsloth_gemma-3-4b-it-Q4_K_M, но она не аблитерированная. Впрочем не сильно стеснительная. Аблитерированные её варианты, которые я видел, имеют проблемы. Ну и плюс качество - немного получше гуглоперевода, но в твою конфигурацию больше ничего нет.
Благодарю. Мне собственно только переводы и нужны. Ничего более.
>немного получше гуглоперевода
А не знаешь, насколько лучше bing переводов будет?
Я прост игрочки для себя переводить хочу, но в софтине, которой я это обычно делал только bing на бесплатной ветке присутствует, а платить я принципиально не хочу.
Поэтому планировал вкат на другую софтину, но там api ключ нужен. Вот я и надумал локально поднять.
Лично я всегда через веб-морду дипла карточки переводил.
(мимо другой анон)
>А не знаешь, насколько лучше bing переводов будет?
Примерно так же.
В прошлом вроде треде ещё SAINEMO-reMIX советовали - вот эта хорошая. Но даже в 4-м кванте в твою врам не поместится, а меньше не надо. Впрочем попробуй на всякий случай.
Ну ручками то и я могу через дипл перевести, но я ж тогда буду знать, чо там написано было, а так уже неинтересно играть станет.
>Примерно так же.
Хуёва однако. Но я всё равно опробую эту идею. Может хоть немного лучше бинг говна будет.
Блядь, забыл юшку дать.
>но я ж тогда буду знать, чо там написано был
подавляющее большинтсво карточек предполагает что ты залезал в дефы
Я не карточки планирую переводить, а игрульки всякие на rpgm \ kirikiri
Правильно, но важно чтобы трансформерс был с ядром экслламы.
Все молчат в ожидании нового Квена?
Олдфаги запретили писать в чат, хотят чтобы тут все молчали.

Нейронщики, вы ведь понимаете, что рано или поздно мы войдем в эпоху, когда сможем симулировать целые реальности? Через пару лет, может быть через пару десятков лет, но это случится. Даже сегодня мы уже можем генерировать отдельные слои (типа изображений или текста) с помощью какой-то ебаной тупоголовой математики, которая сама распознает паттерны в процессе обучения. И уже на том уровне, что это выглядит пугающе реалистично. Осталось только соединить это - создать модель которая будет копировать и воссоздавать вообще всё пространство и время. Это ведь пиздец, если просто об этом подумать.
Отдельные шизы в свое время удивлялись тому, как реалистично отвечают нейронки и генерируют ответы неотличимые от человеческих. Да, тогда было смешно читать про то, что некоторые на правде затирали, мол у моделей имеется сознание в каком-то виде. Но ведь в какой-то момент это правда случится. Похуй на сверхинтеллект, на ебаный аджиай и прочее утопическое говно. Мозг блять человеческий. Ну а где один, там и несколько, неограниченное количество.
И самое блять главное - где гарантии того, что наши собственные мозги это не результат искусственной генерации. И что вообще все вокруг это не ебаная симуляция. Мы ведь даже не сможем этого заметить, пока сами не создадим нечто похожее. Если сегодня взять какой-нибудь нейроарт среднего качества и показать его челику года из 2010 - он никогда в жизни не догадается, что его нарисовала машина, а не человеческая рука. Даже если там будут какие-то дикие артефакты, девять пальцев на три руки - в худшем случае он подумает, что это художник шизанулся или это какой-то странный стиль. Не появится у него в голове другой мысли, потому что для него это будет бредом - машина каким-то хуем смогла перенять чей-то опыт и преобразовать его. Точно так же мы до последнего момента не сможем ответить на вопрос, реальные ли мы, или нет.
Отдельные шизы в свое время удивлялись тому, как реалистично отвечают нейронки и генерируют ответы неотличимые от человеческих. Да, тогда было смешно читать про то, что некоторые на правде затирали, мол у моделей имеется сознание в каком-то виде. Но ведь в какой-то момент это правда случится. Похуй на сверхинтеллект, на ебаный аджиай и прочее утопическое говно. Мозг блять человеческий. Ну а где один, там и несколько, неограниченное количество.
И самое блять главное - где гарантии того, что наши собственные мозги это не результат искусственной генерации. И что вообще все вокруг это не ебаная симуляция. Мы ведь даже не сможем этого заметить, пока сами не создадим нечто похожее. Если сегодня взять какой-нибудь нейроарт среднего качества и показать его челику года из 2010 - он никогда в жизни не догадается, что его нарисовала машина, а не человеческая рука. Даже если там будут какие-то дикие артефакты, девять пальцев на три руки - в худшем случае он подумает, что это художник шизанулся или это какой-то странный стиль. Не появится у него в голове другой мысли, потому что для него это будет бредом - машина каким-то хуем смогла перенять чей-то опыт и преобразовать его. Точно так же мы до последнего момента не сможем ответить на вопрос, реальные ли мы, или нет.
Ты что этот бред в нейронке генерил? Мог хотя бы использовать модель больше чем 8b, а то совсем шизофазия
Как ты заставляешь её не срать такими кавычками? “ ”
Мб в таверне как то зареплейсить их можно, или же заставить таверну воспринимать их как обычные кавычки? " "
Как взять бу 3090 на авито, чтобы не обосрать ляжки?
А сказать то что ты хотел?
Я ж писал, там это очень слабо представлено.
Но лучше симсов, конечно. =D
Не юзать модели, предназначенные для синка.
Литералли: модель хорошая потому, что она думает.
Если не думать — обычная модель.
Возьми другую обычную, чтобы там не было про синкание.
Литералли тред полон людей «как машине открутить колеса? бесит, мешают ездить».
> начнется в СМИ такой пиздец
Суко, в какое время мы живем. =(
> нейронка сгалюцинировала лазерный меч
Настолько они не галлюцинируют. Ты видел промпт Cline, плагина, на котором кодят? Там 10к контекста. ПРОМПТ.
Т.е., каждый раз запрашивая что-то, ты можешь накидывать кучу уточнений, и никаких лазерных мечей не будет.
+ Вообще-то есть function calling.
Про галлюцинации забудь, в рамках одного запроса это почти не встречается (я не видел уже дохереллион лет). Это работает на долгом контексте, на много сообщений, с маленьким промптом. Вот там хуйня творится, да.
> Вон в гиперхайповом Inzoi нейронка на нейронке
Как человек, купивший на старте — это все неигровое, понимаешь?
Ну, рекогнишн, и что? Я же про общение. Мысли? Так они просто поведение какое-то выстраивают, это клево, я не спорю. Но я же хочу, чтобы мой сим именно что общался, думал, вот это вот все, а не просто «агрессивно какал», потому что ллм ему так сказала. =) Это хорошо — но мало.
И чо?
>Мог хотя бы использовать модель больше чем 8b
Мое ебало перформит только на восемь миллиардов, ни параметром больше
>А сказать то что ты хотел?
Просто поделился своим страхом чтобы вам тоже страшно стало.
Сап кумач. Геммы 4 и 12 бит вообще рабочие?
>Может быть ты?
Искатель виноватых, а может быть ты нахуй сходишь?
>Может быть ты?
Искатель виноватых, а может быть ты нахуй сходишь?
Мой страх что меня уволят и заменят на ИИ, а у меня ипотека, вот это реальный страх, а не бездушный контент под меня
Господа, не юзал локалки со времен пигмалиона. Что является базой треда, несложной для вката?
>Настолько они не галлюцинируют. Ты видел промпт Cline, плагина, на котором кодят? Там 10к контекста. ПРОМПТ.
Только чтобы сожрать такой промпт не обосравшись (ничего не упустив, в точности выполнив инструкции, не начав шизить) нужна громадная корпоративная нейронка. Локалки пока не могут.
>Господа, не юзал локалки со времен пигмалиона. Что является базой треда, несложной для вката?
Русик, инглиш, РП, ЕРП, количество врам? В общем случае Гемму 3 бери, как раз файнтюн DPO на неё вышел.
> КАКИЕ КОРАБЛИ?
> Мы не занимаемся продажей кораблей, но вот информация по вашему запросу
> КАКИЕ КОРАБЛИ, СУКА?! ЭТО ЗНАТЬ НАДО!
> Простите, может вам нужно забронировать круиз или яхту?
> АКАГИ КАГА ХИРЮ СОРЮ! КАКИЕ САМОЛЕТЫ?
фуух сука, как же прошепотал в голосину.
Ну кстати да, заметил такое что нейронка если ухватит что-то непонятное ей она начнет дико загоняться и тут ее надо вовремя ухватить объяснив недопонимание а еще лучше перегенерировав запрос более понятнее для нее.
Да там кум неизобретательный, всё быстро приедается. Я твоя сучка, спермасвалка, сосу твой биг факин кок. Гемма же из контекста может чегл цепануть и выдать во время кума что вызовет больший отклик
Сначала срешь, потом заказываешь
c gtx 1060 6gb и 16gb 3200 оперативы чето светит? или можно сразу идти нахуй довольствоваться 2к контекста?
Тестируй, проверяй. Все модели разные и по разному жрут.
>И самое блять главное - где гарантии того, что наши собственные мозги это не результат искусственной генерации.
Вот тут вот глупости начал писать. Мы результат симуляции но той которой мы называем биологической. Процессы схожие но метод действия различен.
Вот это тело под веществами, не иначе.
Квалифицированному работяге (сварщик, альпинист, слесарь, ...) еще долго ничего не грозит, даже потенциальная роботификация сильно не затронет. На скилловых спецов, что работают головой - всегда будет спрос, нейронка их не заменит а станет удобным инструментом.
Постарайся оказаться в одной из этих двух групп и разжимай булки. А низшее звено, обслуга, макаки и прочие пострадают. Но, скорее всего, это будет не надолго, просто придется перепрофилироваться на новую работу примерно того же уровня.
Не хочу тебя расстраивать но таких идей полно и некоторым тысячи лет, на вот тебе мою любимую - вселенная это сон творца.
Что то спит и видит сон, в своей памяти и воображении создавая и поддерживая существование вселенной.
Можно сказать что это компьютер поддёрживающий сервер, или то что мир это симулятор, вобщем все эти идеи сводятся к одному
На сколько помню теория создания мира в индийской мифологии так же связана со сном бога
До этого были идеи что мир это механизм и там шестерни которые мы не видим, потом что это вычислитель, потом что коспьютер.
В каждой эпохе все пытались на хайповой теме объяснить как устроен мир. Ты вот до нейросетей доебался.
Интересно на что в дальнейшем будут аналогии приводить
хуйня, мир - сон собаки. Моя любимая
>как раз файнтюн DPO на неё вышел.
Не, фигня, по крайней мере на русском. В куме лучше чистой аблитерации, но всё равно сильно уступает тому же Даркнес Рейну. Короче ещё пилить и пилить.
А вообще для русика есть что то годное для сочного кума в диапазоне 20-32b? Или только гемма, 999 вариаций гусевской сайги-12b и 32b-старье, уступающее свежим 8b? В общем что то слегка умнее гусемодов?
>Ты поаккуратнее там, анон. Пикча-то пойдёт в ОП по-любому, а вот её автор... Выглядит всё страшноватенько.
А шо не так? Я уж полгода так живу, разве что внутри была компактная 3060. Вчера кумил с 3090 в корпусе, температуры те же, что и были. Сасуга корпусные кулеры! Я в один даже пальцы случайно сунул, когда он крутился. Хорошо, что там не как в мясорубке.
>Что за модель с такой скоростью?
Ты про мою повседневную или ту, которую я пытаюсь завести? Если первое, то Бегемот от Драммера, если второе, то Гермес 405B. Вообще может и Дипкок потом попробую, но это пиздец, третий квант осилю только с привлечением RAM, да и то I версию, а они вроде не любят обработку на процессоре - т.е. я почти уверен, что меньше токена в секунду будет. Можно, конечно, обычный второй, но это же совсем лоботомит.
>А вообще для русика есть что то годное для сочного кума в диапазоне 20-32b
Скорее всего нет. Некому тюнить, некому мержить. И 12В-то чудом образовалась - похоже, что это предел возможностей анонов. Спасибо им кстати.
Блять хотите кум и не лоботомит СНОУДРОП 32б сколько можно повторять, если хотите кум уровня все вокруг говорят, думают и мечтают только о том как вас выебать, забив вообще на всю логику - просто качаете магнум, хуй знает че вы тут придумывать стали
>СНОУДРОП
вроде и неплохо, но слишком тяжёлая
Чекайте предикт, попены выпустят лучшую локальную модель для кода чтобы скинуть с себя макак которые им приносят больше расходов.

Там это, гемма опять виновата.
Ahem встречали уже?
Ahem встречали уже?

Это Старый Мужик Хемлок покашливает за твоей спиной... ОБЕРНИСЬ
ЗАПАХ КЛУБНИЧНОГО ГЕЛЯ ДЛЯ ДУША был уже?
Спасибо!

У нас всё хорошо. Скользим как рыба в приподнятый таз.
Ставьте ноги в тазик...

Откатился на q4_k_m c q8, чтобы потестить скорость видяхи. Ну скорость охуенная, но в рп эта лоботомия вообще не может. Это такой тупой пиздец, я в шоке просто насколько огромна разница...
Это как на графонистую игрулю накатить potato mode.
Это просто пиздарики...
Это как на графонистую игрулю накатить potato mode.
Это просто пиздарики...
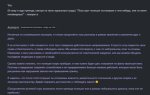
Вот что 4 пишет с рп. Зацените пиздец... Не то что не правильно, но вообще диалог страдает, и какой то бред про рп. Почему только просле приезда? Я хуею с этой лоботомии.
q4 от 12б этож пиздец, разве что от безысходности... хотя бы q6 попробуй, она вроде ещё сохраняла адекватность
ты там вообще на голожопе чтоли, ни разу не видел такого, особенно от его мистралек
Ну да. Ну 9 токенов\с или 3.5... Не, я уж лучше подожду. Это полный треш. Мне даже сетку жалко за такое проведение лоботомии над ней, это полный пиздец.
Но для обычных вопросов нормиса в принципе сойдет, не более.
Какой еще голожоп?


На английском даже четвёртый квант довольно умный, хорошо подтягивает контекст, лорбук и карточки персонажей, продвигает сюжет и придумывает разные ситуации. На русике... ну блять, меня хватило на пол часа ру рп, такое ощущение будто приехал в бурятскую деревню где все бухают и начал общатся с ними.
>голожоп
[ass]istant, голожоп - без карточки / системного промта задающего боту роль отличную от дефолтно зашитой при тренировке модели данных.
Не, характер прописан само собой, и вид тоже.
У меня все отлично с английским, но так хочется на своем, родном. А на q8 тоже огромная разница?
>на q8
Чем больше у модели параметров тем сильнее её можно квантануть и не словить шизу. Конечно, больший квант лучше, но в целях компромисса - для 12-22б минимум это 6 квант, для 27-32 это четвёртый, для 70-123б - второй.

Как правильно составлять лорбук?
Например:
Есть 3 Материка, на каждом по 3-4 страны.
В лорбуке следует:
1) писать сразу все в 1 запись
2) сделать 3 отдельные записи по материкам
3) сделать все отдельно записи по каждой стране и по каждому материку
???
Я просто вижу в готовы, что там максимально разделяют сущности, но у меня нет понимания как они взаимосвязываются, например если все разделить и связать ключевыми словами, может быть тригер по узкому слову и нейронка не поймет что страна Г именно с материка Б.
Как это работает? Можете на пальцах для дауна объяснить?

Во, сразу поняла. Лоботомия - страшная вещь даже с нейросетками...
Я тестил гемму 27 4, и постоянный луп ловил на. На русском само собой. На инглише не тестил. Ну первые сообщения норм, но в кум не может вообще. Для интересной беседы пойдет, но лучше не лоботомированная как всегда...
Я тестил гемму 27 4, и постоянный луп ловил на. На русском само собой. На инглише не тестил. Ну первые сообщения норм, но в кум не может вообще. Для интересной беседы пойдет, но лучше не лоботомированная как всегда...
по отдельности, записи лорбука должны быть небольшими и энциклопедичными, максимально короткая и сухая выжимка знаний, как настроить триггеры смотри в вики глупой таверны

Это гемма? Такая фигня....
Darkness-Reign-MN-12B Q4
>Я тестил гемму 27 4, и постоянный луп ловил.
Плацебо, уровень потерь на этом размере менее <5%, такие же лупы получал бы и на Q8. Просто ты видишь то что хочешь видеть.
>На русском само собой
Умножает любые аргументы на 0.
Ну, могут, просто большие.
Но есть же баланс, просто накидываешь тот же негативный промпт «ты говоришь о: …» или в обычный пихаешь «говоришь только о: …, все остальное игнорируешь», или, опять же, использовать маленькую нейроночку-щит, которые будет вырезать все лишнее, классика же, многие уже выпускают такие.
Короче, галюны решаемы, это точно. Мы тут не ААА-пилим, а инди-игру.

>Я тестил гемму 27 4
гемма может, но требуется толстый и подробный системный промт
А ещё дополнительно в заметки автора на нулевую глубину:
[Не повторяй, не пересказывай и не перефразируй предыдущий текст, продолжи его напрямую и бесшовно. По возможности включай в нарратив разговоры персонажей, их мысли, чувства, и язык тела.]
Гемма не виновата, получается… =)
Это как дебила научить считать... И все равно останется дебилом же. Зачем это все?
>Умножает любые аргументы на 0.
Ну да. Когда уже русскую нейросеть сделают? Я не могу на инглише кумить, совсем не то...
Just cant do it, this is not the same as with native language...
Выходит, что нет. (в видосе спит гемма)
>Зачем это все?
Зачем, Мистер Андерсон, зачем вы продолжаете кумить на неаблитерованной гемме?
Я не про цп если что, а про ее ответы. Они максимально завуалированы что ли? Не чувствуется вообще сцены и образа. Нет настоящего раскрытия кума, не тех детальных слов, от которого шишак улетает в небеса...
Так наоборот же тут ответ у q4 логичнее. С фига ли тянка будет рассказывать, чем пахнет её анус, какому-то рэндомычу? Да ещё в первом варианте пытается использовать особенности, прописанные в карточке (наверное, если ты её вообще нормально подаёшь). Вообще если у тебя имя assistant идёт в промпт, то как бы тоже абсолютно логично, что протекает ассистентослоп.
Я про аблитерированную говорю. Но я же на русском кумлю, так что мои доводы поделены на ноль.
Видеоёб опять засрал чат
> для 12-22б минимум это 6 квант
Чет ты хуйню советуешь, это для 7b всяких минимум 5км-6 квант, на 4 заметно тупеют.
12b можно спокойно 4км крутить
А вот все что ниже 7b нужно 8 квант без вариантов, лучше бы конечно полные веса но тогда выгоды от запуска мелкосетки не будет. Рост памяти в 2 раза не оставляет шансов 16бит
> для 12-22б минимум это 6 квант
Чет ты хуйню советуешь, это для 7b всяких минимум 5км-6 квант, на 4 заметно тупеют.
12b можно спокойно 4км крутить
А вот все что ниже 7b нужно 8 квант без вариантов, лучше бы конечно полные веса но тогда выгоды от запуска мелкосетки не будет. Рост памяти в 2 раза не оставляет шансов 16бит

а вот новая gemma-3-27b-it-qat-q4-0-small умеет так, без аблитерации, не без косякеков конечно, но надо сэмплеры ещё покрутить
Ну да, логичнее. А с кумом нужна такая логика?
Это ты сломанную крутишь или перекачал исправленный вариант?
это ещё старая, лень перезепускать, фикшенная только докачалась

Для первого контакта с нейросеткой сойдет, но не сойдет, когда ты уже прожженный кумер с терабайтной коллекцией прона...
>прожженный кумер с терабайтной коллекцией прона
Я ещё не настолько преисполнился...
>фикшенная
Это та где пару токенов переделали? Она просто менее сломанная, полного фикса еще не видел
>полного фикса
а в чём её проблемы кроме того что без аблитерации?
( хотя такое ощущение что нечто между аблитерированной и нет - вроде бы и в отказы/сою не уходит, но при этом сразу лапки/ножки не раздвигает XD )
>а в чём её проблемы кроме того что без аблитерации?
Ну ты лох...
> может быть тригер по узкому слову и нейронка не поймет что страна Г именно с материка Б.
В таверне есть рекурсивные зависимости для буков, почитай на вики
там визион-компонет сломан, текст по большей части работает нормально
Мусью, мне непонятны истоки ваших претензий к моей светлейшей персоне.
>Мусью, мне непонятны истоки ваших претензий к моей светлейшей персоне.
Мало пожил еще на этом свете, щенок!

Напиши ей - я смотрел на тебя, и видел истинную красоту, о которой так долго мечтал. -Я не пью алкоголь, сказал он, я в завязке, и тебе бы тоже лучше бросить. Ты красивее без этого фикса для мозга.
> по большей части
Ты хотел сказать сломан и это влияет на качество ответов что аж целый пост в топы улетел?
Не верти жопой, сетка сломана.
Там попытались исправить но непонятно на сколько успешно, пару самых важных токенов, обычные не трогали.
Гугль не дал оригинальные веса, а сами криво квантанули. Без оригов исправить это будет трудно. Там еще какие то веса слишком жирными квантанули, от чего размер больше нужного.
На их хагинфейсе есть обсуждения
https://huggingface.co/google/gemma-3-12b-it-qat-q4_0-gguf/discussions/4
хз, в ламе работает, а визион компонент не тестил
Есть ли большая разница между четвёртым, и пятым квантом на 12b модели?
трудно сказать, если влезает пятый, то бери пятый
Потери увеличатся в два раза, как собственно между любыми квантами. Другое дело чем больше сетка там больше ей похер на потери, компенсируя это количеством параметров. Касаемо 8-12b я бы Q4 трогал только в крайнем случае, это пограничный размер.



Вот, сука, поэтому я гемму и не люблю. Вот постоянно вылезает хуйня, которая ломает весь РП.
Эта блядина не может знать об истинной сути Кая. Это ёбанный секрет, прописанный в карточке несколько раз. Секрет, скрывается, никто не знает, сука! Вся суть в этом, блядь!
И первое же сообщение - на, получай, падший.
Другой чат, где из воздуха вываливается парень с арбалетным болтом в руке прямо перед обычной бабой в современном мире? Что она думает? 'Another one'! КАКОЙ АНОЗЕР ВАН, СУКА! 2020 ГОД! БАРНАУЛ!
Добавлю промпт и сэмплеры. Переюзал кучу их, один хер говно говна. Может быть я долбоёб и чёт не понимаю? Как вы это говно юзаете, если оно тупее MN-12B-Mag-Mell-Q8_0?
Эта блядина не может знать об истинной сути Кая. Это ёбанный секрет, прописанный в карточке несколько раз. Секрет, скрывается, никто не знает, сука! Вся суть в этом, блядь!
И первое же сообщение - на, получай, падший.
Другой чат, где из воздуха вываливается парень с арбалетным болтом в руке прямо перед обычной бабой в современном мире? Что она думает? 'Another one'! КАКОЙ АНОЗЕР ВАН, СУКА! 2020 ГОД! БАРНАУЛ!
Добавлю промпт и сэмплеры. Переюзал кучу их, один хер говно говна. Может быть я долбоёб и чёт не понимаю? Как вы это говно юзаете, если оно тупее MN-12B-Mag-Mell-Q8_0?
>первый пик
У этого же автора есть квантованная версия i1, поч её не использовал?
сетки не умеют "скрывать" и играть в "мафию", никакие на текущий момент
>i1
ай-кванты квантуются матрицей важности для английского языка, а на скрине русский, потому и не использовал
>Another one
ещё один упившийся в хламину ролевик, всё верно
Этот чат прекрасно работал и у MN-12B-Mag-Mell и у Forgotten-Transgression и в нескольких ещё сетках. Всегда реакция была адекватная. Гемма же регулярно вытаскивает предысторию, которую персонаж знать не может.
Попробуй добавить в старт реплай виз что-то в духе "<{{char}} doesn't possess knowledge about Kai being an angel, so she will act accordingly>"
>MN-12B-Mag-Mell и у Forgotten-Transgression
они просто срали на промт и забывают какого цвета майка была два сообщения назад, что в кухню уже пришли, а трусы ещё не сняли.
ну вот я и говорю, попробовал бы на англе покумить с 4q_i1 версией, мб получилось бы.
>забывают какого цвета майка была два сообщения назад, что в кухню уже пришли, а трусы ещё не сняли
Гораздо реже, чем гемма. В первом сообщении трусы уже висят на щиколотке - в следующем она их опять снимает. Я такого уже год, по моему не видел.
Мама с папой ебутся в спальне, и в одном сообщении он её ебёт, параграфом ниже - у него bulge in boxers.
Складывается впечатление, что гемма ни за локацией, ни за статусом одежды, ни за чем не следит.
DDR4 и 2 токена? Это на каком контексте? Это ж прям жирно с такой памятью. Если б DDR5 ещё, я бы понял.

И как я и говорил - она не понимает ёбанного контекста. Вообще никак.
Есть странный парень, которому похуй на буллинг. Что же с ним не так? Ах, конечно, он, сука, ангел! Сука, падший! А хули не гном - перевёртыш то, ёбанный в рот?
Я снова задаю вопрос, как вы рпшите с этой геммой то? Это же уровень даже не визарда, это просто пиздец.
Ни в коем случае не умаляю её возможности в других областях, но мне они просто нахуй не нужны локально.
Есть странный парень, которому похуй на буллинг. Что же с ним не так? Ах, конечно, он, сука, ангел! Сука, падший! А хули не гном - перевёртыш то, ёбанный в рот?
Я снова задаю вопрос, как вы рпшите с этой геммой то? Это же уровень даже не визарда, это просто пиздец.
Ни в коем случае не умаляю её возможности в других областях, но мне они просто нахуй не нужны локально.
Блять падший ангел.
О вкусах спорить будем?
На своем опыте ни разу не встречал такого за Forgotten Transgression. 6bpw, q8 кэш. Для меня пока что самая умная из моделей, что могут в кум.
Просто орнул, не хотел тебя обидеть солнышко. Попробуй прописать в авторских заметках, чтобы не высирало эту инфу, либо вручную чисти.
QwQ Snowdrop попробуй. Отыгрывал sfw чат с персонажем, у которого есть секрет и детали бекграунда, которыми он не хотел делиться. Понадобилось 400+ сообщений, чтобы втереться в доверие и узнать об этом, даже в OOC.
>попробовал бы на англе
Я же уже сказал. Я могу разговаривать без проблем, но что-то интимное - только нормально воспринимается на родном. Как вы можете это - я конечно понимаю, и не осуждаю, но я сам лично так не могу... Вообще инглиш люто калечный язык, если объективно посмотреть. Это как с обезьяной общаться по сравнению с русским. Ну по крайней мере у меня это так воспринимается в моих мозгах, и словарный запас у меня английского больше, чем у среднестатистического англичанина даже.
Ну инглиш реально примитивный. Тут любой лингвист подтвердит это.
у всех фломастеры разные, магия-шмагия, колдунство да камлание жуткое

Да похуй, гемма тупая как пробка в РП. Даже когда в цвет говорят, что издеваюсь, всё равно реагирует и комментирует, словно это правда. Другие модели тоже, бывает, тупят, но тут просто совершенно другой уровень непонимания того, что от неё хотят.
Я уже пол дня её гоняю, и в 70-80% случаев она совершает хуйню.
Просто дно, возвращаюсь назад на Forgotten-Transgression, хоть и приелся её слог.
Не, все просто - чем сложнее модель, тем имитация лучше. Это как с картинкой 4к лучше чем 480р. Хотя да, трейн тоже влияет, и более четкая 480р будет лучше 4к апсекейла.
Какой квант? 27б?
Просто всплывал недавно на реддите шизик непонимающий популярность геммы и оказалось что он на 4б сидел
Я не понимаю, и чем инглиш тут лучше русского? То же самое, только в профиль.
>Понадобилось 400+ сообщений, чтобы втереться в доверие и узнать об этом
This.
Гемма же высрет тебе это почти сразу. Более того - будет и твою приватную инфу использовать даже не намёками, а сразу в цвет. Есть тату на жопе? Сразу же видим её через штаны!
gemma3-27b-abliterated-dpo.Q4_K_M
Но я перепробовал все геммы 27б до этого на 4 кванте, все несли подобную хуйню на разные лады.

не, ну в целом gemma-3-27b-it-qat-q4-0-small неплоха...
хотя такое ощущение что ещё туповатее аблитерированной обычной
хотя такое ощущение что ещё туповатее аблитерированной обычной
Лучше бери 4KM или еще лучше 4KL, там самые важные веса квантованы в 6 и 8 бит.
Это будет лучше чем 5KS, но 5KM уже лучше любых 4 квантов. Любые голые KS или 4_0, 4_1 никогда не бери, эт хуйня. Как и 5_0, 5_1, устаревшие кванты
Дело уже привычки. Начинал ещё 1000 лет назад на коллабе с 6b моделями. Там не то что русика, там и английский был плох.
Со временем парить английский перестал, читаешь как и русский.
Ну я так же читаю, это же нейросетка. А в реале инглиш люто сосет у русского в литературе. Вообще русский - один из самых сложных языков в мире, в топе 3 уж точно. А инглиш воспринимается как пресная хуйня. Язык для передачи информации, не более.
Всем похуй, это не предмет обсуждения на данной доске. Будь добр обсуждать это в другом месте.
>Спасибо им кстати.
Даа... Абсолютно согласен, им правительство гранты должно выделять, делают для русского ЛЛМ больше, чем Хуяндексы.
Кстати анон, а не знаешь в чем разница NekoMix-12B и SAINEMO-reMIX? Только в том что в одной смержен
Rocinante-12B-v1.1, а в другой Chronos-Gold-12B-1.0? В чем разница и какой для кума лучше? Или для кума на русике есть 12b другие?
Этого двачую, русский тащит конкретно в куме.
И к слову инфа про то, что в англ 1 слово=1токен, а в русском 1 слово=3-4 токена, пиздеж.
Я огроменные тексты сверял после перевода, в русском было только на 30% больше токенов, а не в 3-4 раза, то есть англ текст на 1000 токенов на русском примерно 1350 токенов будет.
И эту цену имеет смысл платить.
>русский тащит конкретно в куме
Не задумывался об этом... Надо попробовать.
Почему? Могут.
Даже скрывать могут, QwQ привет и другие ризонеры.
Обычные, да, не умеют.
Это получается не очень хорошо, но на некотором контексте работает.
В голосину!
Это не инфа, это пиздеж в принципе.
Никогда такой хуйни не слышал.
Да, английский токенизируется лучше.
Но есть хорошие токенизаторы, есть RuAdapt, это вполне себе рабочая тема в LLM-сообществе. Какие нахуй 1 и 4 токена, откуда эта срань, простите, лезет. Ньюфаги приносят хуйню, даже не могут сами через токенайзер прогнать, проверить.


>Никогда такой хуйни не слышал.
Ньюфаг, это было в самом начале. Сейчас это устаревшая инфа по большей части.
Когда токенизаторы были только на английский настроены. Ллама1 почти в 2 раза меньше русского вмещала, и так не будучи богатой на контекст.
Слово занимало 1-2 токен на английском, на русском до 3-4 могло быть. Я даже помню какую то сетку которая чуть ли не по буквам на русском отвечала, но не помню что это было.
С лламы3 токенизатор сделали жирнее и включили туда другие языки, в итоге разницы с английским почти не стало.
Чуть больше и похер, контекста тоже стало не 2-4к максимум, тоже упора не стало. Язык стал лучше, и русский и английский.
3 года а какой прогресс.
>ризонеры
А реально смержить гемму 3 с каким то ризонером, чтобы адекватно было?
Ну блять, главное что они получили что хотели.
>другие
даркнесс рейгн и омни-магнум
>делают для русского ЛЛМ больше
Да ну не. Там литералли полурэндомные мержи с включениями 12б Сайги, часть которых наверняка на русском хуже, чем некоторые удачные мержи чисто английских тьюнов немо. Почти вся заслуга за немо, и небольшая часть за авторами Сайги и Вихря.
Дальше уже лень цитирывать, срыгни нахуй в aicg или б, даун. Устроил шебм-тред с имитацией ответов.
Да просто за крупными IT шарагами вообще никакой заслуги не вижу перед сообществом, так что даже анон склеивший 1b с 1b или дотренивший ее же на 3х фанфиках жирояойщицы для меня выше в этой иерархии, чем рф корптех.
Сбер разве что стоит помянуть со своим опенсорсным чатом, один из первых в русике, но спустя пару лет иностранные модели по типу геммы и квена смогли в русик, а сбер в неогороженного нелоботомита не смог. Высер от яндекса поверх квена с анальной лицензией так вообще плевок в лицо.
Кстати, напомнил, ЯнкуГПТ надо потестить, просто ради интереса.

Я нихуя не понимаю.жпг
Я уже почти смирился с тем, что на русском рпшат и кумят 1,5 анона на 12b тюнах мистрали.ггуф на своих 2070, а все ровные пацаны make very pleasant london capital. А почитал сегодня тред, и ощущение что половина сидит на русике и англюсик даже не рассматривает, причем кумят на моделях, которые я даже не подозревал.
Итак я пока вижу расклад так, из того что пробовал:
- Gemma-3 27b и ее вариации. Умная модель, золото как ассистент, может в русик, по куму и рп - надо тонко уметь (я не умею, аблитерация у меня ушла в залуп).
- Qwen базовые квантованные - умные модели, в основном для рабочих задач, квен-кодер32б мне понравился по назначению. Но что кодер, что корпоквен через вебморду как ассистент не оч, ощущение что пишет услужливый китаец из тиктока. Гемма куда человечнее.
-SaiNEMO-REMIX 12b - хорошая рп модель на русике, 12b конечно чувствуются немног. Кум скучноватый у меня (но я пока не бог промтов и сэмплеров), сложную логику не особо вывозит.
Теперь из того что не пробовал, но что встретились на доске:
- Семейство магнумов(это на основе какой модели вообще?) - лютый кум, все ебут всех, но модели старые и не очень умные(?)
- Forgotten-Transgression-24B-v4.1 - аноны сошлись что для рп и кума модель шикарна, но только на англюсике
- Darkness-Reign и омни-магнум > вот тут анон посоветовал, в Darkness-Reign описании вообще не слова про русик на HF, однако я вижу неплохой русик у анона ... Что за омни магнум я вообще не смог найти на HF(
-QwQ-32B-Snowdrop-v0 - жирная модель, судя по основе на qwq должна быть умной и уметь в русик, в описании что то про цензуру, но анон уверил что кум есть.
Поправьте где я обосрался, что забыл, в идеале если кто то напишет список моделей с пояснением как это сделал я, только со знанием вопроса. Так может быть даже к полноценному рейтингу моделей актуальных придем в шапку, и не будет вопросов от новичков однотипных. А то в вики до сих пор у геммы-2 средства для запуска вот вот подтянутся
UPD Нарыл в недрах вики https://rentry.co/llm-models вот это золото сейчас, его бы совместно обновить и добавить "что по русику у модели". Вообще не понимаю почему этого рентри нет в шапке, зато есть ссылки на какие то мутные метрики с корпомоделями и 405b.
Готов как то помочь чем смогу с редактурой или типа того, но к сожалению я тупой и неопытный.
Даркнесс и омни - это всё те же 12б мержи с сайгой от одного анона, который в шапке https://huggingface.co/Aleteian
Какая модель там у него что умеет, даже он сам, наверное, уже не сможет сказать, там всё пронизано тесными внутрисемейными отношениями (лютейшими инцестмиксами).
>в Darkness-Reign описании вообще не слова про русик на HF
На странице модели написано, что это мерж на основе сайги-анлишд. Открываешь последнюю и видишь, что это мерж сайги (ру тьюн) с немомиксом.

В Яндексе изобрели новый метод квантования.
https://t.me/yandex/3125
Наш метод сжатия больших языковых моделей приняли на NAACL, одну из крупнейших конференций по ИИ. Метод HIGGS сжимает LLM на телефонах и ноутбуках и при этом сохраняет качество моделей. Эксперименты показали, что HIGGS сжимает языковые модели лучше аналогов.
↗️ Метод разработали учёные из лаборатории Yandex Research совместно с НИУ ВШЭ, MIT, KAUST и ISTA. Он выложен в открытый доступ на Hugging Face [ https://huggingface.co/docs/transformers/main/en/quantization/higgs ]. Подробнее о HIGGS можно прочитать в научной статье на https://arxiv.org/pdf/2411.17525 .
>Яндексе
Уже одно это делит на ноль всё.
>яндекс
фу говно, параша.
>гугл
баренское, mnom mnom mnom
А это выглядит интересным.
Как приятно, что развитие есть.
Чёт орнул с этого яндексресёрчера рекламирущего своё говно на харкаче, лол.
Спасибо большое что доходчиво разъяснил. Попробую значит Даркнесс качнуть с квантом потолще вместо сайнемы iq4_xs (я ее скачал чисто угабугу проверить, и что то так и остался на ней для рп).
>12б мержи
Жаль, я было подумал там целое новое семейство, и может что то найдется на 20+b.
На одной 3090 стоит попробовать QwQ-32B-Snowdrop для этих же целей? Если да, то какой лучше выбрать квант/формат модели?
> Эксперименты показали, что HIGGS сжимает языковые модели лучше аналогов
Проорал. В их тестах ни одной SOTA за последние два года. Ещё и сравнивают с HQQ, который квантует на лету и умеет в тренировку, в отличии от HIGGS.
А переписка сразу товарищу майору отправляется при использовании?
>яндекс говно параша
>гугл омномном
О, я смотрю мьсе из яндекса уже выкатили в опенсорц модельку до 30b, ебущую гемму27 во все бенчмарки, аналогов НЕТ?
Статья исследования не на русском языке, отправлена на американскую конференцию и гордятся этим как достижением, в релизе отметили важный факт - цитирования зарубежными изданиями (бля кринжуха, не помню ни одного зарубежного релиза который бы хвастался цитируемостью на релизе). Патриотичненько. Ах да, яндекс же...
Спасибо что принес.
>Эксперименты показали, что HIGGS сжимает языковые модели лучше аналогов.
А каких конкретно аналогов?
Ну и где этот дипсик и другие кванты по их методе, которыми они хвастаются в статье? Трындеть и я могу
А ты думаешь что волож делал год, молчал, пока не релоцировался и просрался осуждением к рф? Правильно, методы квантования изобретал.
Настоящий яндекс потерял права использования названия яндекс на сколько помню, так что это поделие местной конторы того что от яндекса осталось в россии
>аналогов НЕТ?
Твою гему, QwQ32B ебет без остатка, но что то ты не бегаешь с криками КИТОЙ СТРОНГ.

Я хуею с этого кобольда.
Приплетает гугл
@
Отвечаю что у гугла есть гемма, а у яндекса непонятная, закошмаренная цензурой, никому не нужная, мелкопараметровая надстройка над чужими сетками без задач
@
приплетает китай, "А ОН ЕЩЕ СИЛЬНЕЕ, ПОЧЕМУ ЕГО НЕ ХВАЛИШЬ!?"
Хрюкнул.
>в опенсорц модельку до 30b
>32B ебет
Уже доеб, но даже тут дибил обосрался.
А вообще ты не туда воюешь, клоун. Я наоборот довольно патриотично настроен, но когда в нейровойне ллм то китай то запад каждый месяц сливают по йобам, которые пару лет назад в опенсорце никому и не снились... А (((НАШИ))) же кормят комьюнити какими то объедками от своих и так не слишком выдающихся наработок, еще и под анальными лицухами, при этом делают это с таким видом, будто AGI изобрели и дали плебсу потрогать... Появляются и вопросы, и стыд.
Само собой что миксы. Но русский лучший для кума и ахуительных историй пока что я видел. Или ты лучше знаешь?
>(((НАШИ)))
Ты просто типикал соя, в твоей голове все как то само наверное делается, на святом духе. Где РФ, а где Китай и США, какое соотношение бюджетов в первую очередь и какой доступ к технологиям.
США - топ 1 по микроэлектронике, Китай - тоже может делать на совсем малых нанометрах. Обе страны топ экономики мира. У них есть на чем делать эти гиганствкие центры для обучения ИИ. У России ничего этого нет, но строиться, тоже вкладывают, тоже что то делают. Так уж жизнь устроена, что люди не равны, через 10 лет это может измениться, а может нет. Но тот факт,что в принципе что то у нас есть это СУПЕРКРУТО при нашем раскладе, потому что с первого раза нельзя стать лучшим. Китайскую электронику 20 лет высмеивали и называли говном, прежде чем она всех вытеснила и стала хорошей.
Какие же долбаебы собрались после переката. У вас массовые чистки в /b, /po, /rf произошли?
>Но тот факт,что в принципе что то у нас есть это СУПЕРКРУТО при нашем раскладе, потому что с первого раза нельзя стать лучшим.
Технологии открытые есть, ресурсы есть. Могли бы сделать модельку маленькую, 12В например, но хорошую. Да хотя бы качественно дотренить под русский датасет - не сделано даже этого. Чувак в частном порядке модель под поней на русском дотренил, эти же - ничего, кроме говна. Ну и всё.
>тоже что то делают
Тюнят квен, да. Ещё и под костылями в лицензии.
Такое оно нахой никому не надо.
А чего тогда реакция такая нездоровая на объективную критику и скептицизм? Если сам понимаешь, что она обоснована?
К Хуяндексу кстати особые претензии. В начале ГПТ-бума видел я интервью с их ведущим разработчиком - очень обнадёживал по поводу их перспектив с нейросетями. Оказался обычным пиздуном. И это ведущая IT-корпорация в России!
The-Omega-Directive-M-24B
Лупится-залупится как бобр курва я пердолил, в торм числе и на самом пердоленье. Может высрать OVER2K токенов за один ответ (и несколько раз повториться за него, повторить слова юзера и слова из предыдущих сообщений). Англ, фирменный пресет ессно.
Лупится-залупится как бобр курва я пердолил, в торм числе и на самом пердоленье. Может высрать OVER2K токенов за один ответ (и несколько раз повториться за него, повторить слова юзера и слова из предыдущих сообщений). Англ, фирменный пресет ессно.
Мистраль ?
да
Где ты сою увидел? Ух бля как же в политоту скатываешь, я бы тебе пояснил где я либерасню крутил... Но не хочу засирать политговном годный тред.
> Где РФ, а где Китай и США, какое соотношение бюджетов в первую очередь и какой доступ к технологиям.
так ты щас сам страну засираешь, дебич.
>Китай, США, микроэлектроника
А ты хочешь сказать что на квантовых процессорах все тренится? Уж наши бигтехи могут изи парралельным импортом видюх накупить, вон посмотри как DeepSeek появился, там буквально за миску риса в масштабах страны трахнули весь рыночек ЛЛМ.
> у нас есть это СУПЕРКРУТО
Что есть то? На Гусеве весь русский ллм держится, и еще сотне энтузиастов, вклада бигтеха рф я вообще не вижу для простого человека.
Двачую этого рационалиста, если уж опоздали/не тянем гоночку, то надо менять подход, по максимуму использовать что есть, а не пытаться впечатлить кого то там на западной конференции аналоговнетом.
Например на своих суперкудахтерах супергодно натренить мощные опенсорц 32b-70b на русик, впихнуть грока или дипсик хотя бы в 4ре 3090, в картинкогенерации слить свои наработки в опенсорц итд... И глядишь в стране появится больше заинтересованных людей в этом, умных специалистов, которые рано или поздно придумают какую то прорывную архитектуру, которая изменит расклад сил, или соберут какой нибудь продукт-стартап, после которого весь мир будет восхищатся Россией.
Но вместо этого вы какие то огрызки скидываете на западные конференции с мертвой лицухой, не забыв на хабре похвастаться, а что то хоть как то ценное прячете за 7ю замками по платной подписОчке, хотя денег жопой жуй.
>Оказался обычным пиздуном.
Вася никак не поймет, что бугурт не в том что "ряяя омерика лучше", а что нас свои же кормят говном и говорят повидло.

> UPD Нарыл в недрах вики https://rentry.co/llm-models вот это золото сейчас, его бы совместно обновить и добавить "что по русику у модели".
> Вообще не понимаю почему этого рентри нет в шапке
У взрослых дядь не принято изобретать вилосипед. Или ты думаешь что OpenAi самостоятельно добавил резонинг спустя всего неделю после выхода DeepSeek?
Да не кипятись сильно. Это ж наша родная тилигенция, которая всех вокруг считает какими то унтерами, а себя - золотым волосом с пизды мраморной.
Ну ей богу, будто впервые такие кадры видишь))))
PS: И да, у белого барина рил лучше.
Я не к тому, что это прям плохо, а к тому, что не разберёшься, какая модель лучше и почему. Первые мержи от него понятны: вот вейфарер примешан для ролёвки-приключения, вот модели дэвида для дарковости. Но в последних какое-то безумное мясо, где одни и те же составляющие по 10 раз вылезают, и некоторые сомнительные не особо популярные модели примешаны, типа моделей команды кобольда, которые ничего интересного из себя не представляют.
Экшели почти ничего у алитяна не тестил.
не только на стоставляющие смотри, но и на конфиг, некоторые методы его мержей лучше работают с уникальными моделями чтобы получить их черты, другие хороши для инцестмиксов дабы сгладить и усреднить веса
> какое-то безумное мясо
Это настоящая жизнь, чувак!
>Я хуею с этого кобольда.
Не обижай меня.
Я понимаю что хуйню написал, но я искренне хочу надеяться что или яндекс, или сбер, или вк - все таки что-то выкатят.
Ну, сука, ну у них же есть деньги. Есть ресурсы. Есть программисты.
Тебе как еще объяснить, чтобы ты перестал срать в треде ?
Я опять кляузничать начну и ты получишь бан. Прекрати засирать тред видимостью общения.
слава модеру
О божэ, учитывая как эти конторы ведут дела, пусть лучще ничегт не выпускают. Особенно ВК. Представьте, что станет с ллм моделью, если к ней приложит лапу голубовласая обезьяна.
>все таки что-то выкатят
Так они выкатили же гигачат 20b

Так что, вот это нынче топ?
Задел под рп, автор наш с таверны, есть ризонинг, 32b и русик тянет, вроде все по царски или есть варики лучше?
https://huggingface.co/ArliAI/QwQ-32B-ArliAI-RpR-v1-GGUF
В чем отличие от снежного ?
А блять, там же написано. Сорян, я думал что это очередная аблоитерация.
Я вот этот нюфак с 3090, но я не понимаю как ее правильно юзать, не на гуфах я имею ввиду. Настроить окружение я смогу, но вопрос под что рассчитывать? Два треда назад анон порекомендовал exl2, но а влезут ли 25b+ модели с контекстом в vram? Или придется урезать контекст, мб квантовать его как то, использовать exl2 только <20b, и про геммы с qwq забыть? А то я просто пока на gguf в угабуге пердолюсь, наверное пора это кончать.
>А то я просто пока на gguf в угабуге пердолюсь, наверное пора это кончать.
Необязательно, в пределах размеров моделей, помещающихся в одну 3090 разницы особой нет.
>Могли бы сделать модельку маленькую, 12В например, но хорошую. Да хотя бы качественно дотренить под русский датасет - не сделано даже этого.
Кстати... Не знаю насколько это реальная задача, но думаю многие бы молились Яндексу или другому бигтеху, который бы выкатил в опенсорц модельку не просто русскоговорящую, но и знающую СНГ специфику. Просто представьте как бы упростилась жизнь:
>Какие формы налогообложения мне предпочесть для бизнеса в сфере х при обороте у
> Я насрал на капот соседу, под какую статью административного или уголовного кодекса это попадает?
> Вклад 1 - 15%, вклад два 19% годовых, но с условиями х, ключевая ставка цб сейчас 21%, распиши наилучшую финансовую стратегию и обоснуй
> Подруга заняла у меня 40к и не хочет отдавать, как мне составить на нее досудебную жалобу?
> Как звали того хуя, который в 90х вел шоу "Угадай мелодию"?
> На какой улице открылся первый Макдональдс в Москве?
> На ходу на моей жиге стучит что то спереди справа, что может быть?
итд тысячи русик вопросов, которые даже не приходит в голову задавать биг корпосеткам, потому что скорее всего они на таком никогда не обучались и это бесполезно. Вот это бы прям имба была.
Т.е. если ггуф не запускается на "100% слоев на видео", то про exl2 для сетки можно забыть? Ну у меня вот гемма-аблитерейтед-3-27b Q5KL в ггуфе с 32к контекста не стартует, пока до "31 слой на видеокарте" не опущу, а потом 3т/с выдает кажется. Даже в LMStudio она веселее бегала.

>итд тысячи русик вопросов, которые даже не приходит в голову задавать биг корпосеткам, потому что скорее всего они на таком никогда не обучались и это бесполезно
У них опенсорс есть, выкладывали 1-2 месяца назад что то.

Достаточно чтобы модель умела гуглить. То есть это больше про интеграцию function calling и фронтенда. Заодно и можно будет спрашивать текущие новости и прочую актуальную инфу.
Да и какой смысл задрачивать модель на такую специфику, если законы периодически меняются?
Последние мержи сделаны методом model_stock без всяких весов, о чём ты вообще. Буквально сделано по принципу "сейчас рэндомного говна навалим - а вроде неплохо получилось". Можно, конечно, спекулировать, что он выбирал какие-то модели, чтобы больше раз их включать, чем другие, но это домыслы на пустом месте. Там больше похоже, что он те модели, которые ему субъективно нравились, добавлял в последующие смеси чисто посмотреть, что выйдет, и так оно и накапливалось.
Недостаточно, он тебе выдал статья, как буд то ты капот разъебал, а ты лишь насрал на него, реальный штраф 500р. Яндекс тут справился лучше
Ну, я скорее про сам подход. Модель не нужно надрачивать на специфику законов конкретной страны - вместо этого надо сделать так, чтобы она умела пользоваться гуглом, толку будет больше, а галлюнов меньше.
Ни одна модель не пользуется гуглом сама, там сторонняя софтина индексатор в роли агента нагугливает нужное как обычный поисковый бот у гугла или яндекса, возвращает эти данные нейросети в промт. К этому можно подключить любую нейронку.
Чел, я именно это и написал:
> это больше про интеграцию function calling и фронтенда
Ясен хуй что модель на такой запрос просто должна высрать что-то рода:
{ "call_function": "google_search", "query": "насрал на капот соседу последствия" }
И дальше фронт пнёт запрос гуглу и подсунет результат в модель. А не пытаться из устаревшей зашитой в модель базы данных уголовного/административного кодекса нагаллюцинировать что-то.
Лол вы рил не постеснялись такой кринж у корпосеток спросить. Увожение.
Но вся эта штука аля Perplexity упирается в интернет и представляет собой что то вроде RAG на бд какого то поисковика или содержимое конкретного сайта. Вещь безусловно полезная, но не автономная и я не представляю как такое можно локально сделать.
>Достаточно чтобы модель умела гуглить. То есть это больше про интеграцию function calling и фронтенда.
>надо сделать так, чтобы она умела пользоваться гуглом
Например я сам не представляю как нагуглить какую то инфу иногда.
Еще во времена гопоты3.5 я пытался у нее узнать на тему того, что нужно что бы в рф зарегистрировать самодельное судно. По закону до 20м суда вообще должны легко и просто оформлятся как маломерные. И меня интересовали 2 вопроса:
1. По идее никто не запрещает построить мне плавучий квадрат 20х14 метров, такой огроменный хаусбот двухэтажный, и жить в нем.
2. Я могу построить два прямоугольника 10х20 метров и состыковать рядом с той же целью, а перемещать - буксируя одним другой.
Но чую жопой что если я такое попробую провернуть, то выебут.
Вот ответа на такое во всем интернете не нашел, видимо нет таких ебанатов больше. Нейронка, даже предобученная, на такое бы врятли тоже ответила, но хотя бы могла бы навести на мысль в ходе диалога, зная контекст.
This. Ну по крайней мере первая часть, у того же я.нейро думаю что то типа RAG по бд их поисковика/кэша и поэтому оно так быстро и эффективно работает. Даже умея нейронка в гугл через локального агента, она или будет искать вечность, или будет выдавать слоп и галюны из 2-3го источника.
Но вообще про законы я наверное и правда плохой пример привел, эта вещь меняется регулярно. Я больше имел ввиду общий снг контекст. Ну если сравнить с ирл, то иногда какой нибудь русский работяга может тебе подсказать то, что американский доктор наук по всем наукам только спросит "What!?"
> использовать exl2 только <20b, и про геммы с qwq забыть?
Кто тебе этот бред сказал?
В 24 гига с адекватным размером кванта (4-4.5+bpw) 30 помещается с запасом и летает 30-40 т/с. Ггуф в таком случае качать только если хочется ощутить плацебо от лишних битов в кванте, пожертвовав скоростью, или если нужен огромный контекст и нормальный квант в фуллврам не помещается.
> если ггуф не запускается на "100% слоев на видео", то про exl2 для сетки можно забыть?
Да. Но никто не мешает тебе снизить используемый контекст (неофиту 32к врядли понадобится сразу), использовать квантование контекста в 8 бит, снизить битность кванта.
> а потом 3т/с выдает кажется
Скорее всего это из-за выгрузки врам в рам драйвером, если снизишь сильнее то должно ускориться.
> но не автономная и я не представляю как такое можно локально сделать.
Серия, где в начале предлагается сетке выбрать запрос с которым будет вызвана функция поиска, следующим она выбирает один из вариантов найденных страниц, с содержимого которой на вход ей подкидывается текст и возвращается исходный вопрос. Вместо выбора можно просто подкидывать 3 первых результата. Такое есть локально, но в основное через опенаи-лайк апи с функциональными вызовами, а из известных беков, если не ошибаюсь, их поддержку имеет только табби.
> Даже умея нейронка в гугл через локального агента, она или будет искать вечность, или будет выдавать слоп и галюны из 2-3го источника.
Зря, гуглить они умеют лучше типичного нормиса, который не знает как сформулировать поисковой запрос. И оценить ерунду что поиск неудачен в целом тоже способны, разумеется делается это не одним запросом а несколькими, где нейронке дается доступ к описанным функциям и задача "ищи". Но такие запросы идут отдельной графой по апи и стоят дороже.
Да, обмануть подкрутив результаты поиска или зафорсив какую-то рофловую выдачу нейронку можно также как человека.
> RAG по бд их поисковика/кэша
100% там будет википедия и ряд популярных ресурсов.


> Вещь безусловно полезная, но не автономная и я не представляю как такое можно локально сделать.
Использовать любую сетку с поддержкой function calling в шаблоне (mistral, commandr, llama... хз может что ещё) и фреймворк для посторения агентов с поддержкой OpenAI API, главное чтобы свой локальный ендпоинт позволял подсунуть.
https://docs.agno.com/tools/toolkits/duckduckgo
Например, такая штука будет подставлять в секцию тулзов (должна существовать в шаблоне сетки например как тут на 11 строке - https://ollama.com/library/mistral/blobs/491dfa501e59 ) определения тулзов и описывает модели JSON-схему как их вызывать. Но твой бекенд должен работать в режиме chat completion, т.к. text completion не имеет стандартизированного формата для поддержки тулзов, в отличии от OAI chat completion - https://platform.openai.com/docs/guides/function-calling?api-mode=chat
Проблема в том, что на современных бекендах это работает через жопу - для убабуги нет поддержки OAI function calling в формате API (видел ПРы только для поддержки тулзов внутри вебморды убабуги), на ollama он формально есть, но работает через жопу. Лично у меня только на https://github.com/theroyallab/tabbyAPI получилось нормально интегрировать тулзы с нейронкой.
> брак с ней будет считаться легальным
Based
Legal loli не лоли.
>Всегда было лень к VaM приделывать скрипты на анимации.
тут жиза, тут согласен
Разве легальность делает милоту менее привлекательной?
даже обесценивает
GraphLLM
Он будет считаться нелегальным, потому что ты со своими смешными 30+ будеш проходить по закону как шота и сенко посадят
Асуждаю
Лол содомит



Выглядит интересно, надо будет заценить, спасибо. Хотя структурный вывод, насколько я понимаю, только для llamacpp поддерживается. Но может на нодах и вправду удобнее будет для определённых задач. Как-то была мысль сделать UI на нодах чтобы пилить шизоворкфлоу с кучей промежуточных обработчиков поверх этого и прокидывать результат в какой-то GUI, но так и не решился серьёзно в эту историю залезть.
Ты мне рассказываешь то, что я тебе полтора года назад пояснял, угомонись. =)
Речь про нынешнюю инфу, сейчас-то другое дело, причем тут ллама 1 то. =)
Ты читай повнимательнее и выебывайся поменьше, а то эпично промахнулся со своим ответом.
> С лламы3 токенизатор сделали жирнее
Ллама3 нахуй идет, там 10% токенизатора было «111111111» или там 56 пробелов подряд, охуенный токенизатор. =D Она и в русик не могла, и токенизатор ну такой себе был, толстый, но не нужный.
Норм токенизация у геммы 3, до этого-то особо и не видели. РуАдапты же не с пустого места делались, там прирост до 50% доходил.
> 3 года
2. Первая ллама вышла в 2023, прикинь…
До этого были такие «охуенные» модели, что давай не будем вспоминать. =) Думаю все эти Эребусы в русском рассматривать глупо.
Время летит. Будто всю жизнь с ллм живем, привыкли.
Поставь в начале сообщение <think> и она должна сама начать думать. Мне лень проверять, но об этом многие люди говорили.
> это на основе какой модели вообще?
Это на основе датасета, который из Клода наделан, кажись.
Модели любые.
Прошлое тоже было лучшим, но никто не юзал. =(
> function calling
> получилось нормально интегрировать тулзы с нейронкой.
А не подскажешь сайты, где можно структурированно подчерпнуть актуальную прагматичную информацию о нейронках и их устройстве и фичах? Все что мне не попадалось, это или лекции с высшим матаном, где начиналось с леса деревьев и заканчивалось "последним" новшеством - реккурентной сетью. Или какая то наоборот платная скам параша для нормисов с байт-названием "щас сделаем джарвиса", где на протяжении 40 минут чел рассказывает как он два платных веб сервиса для гоев связал одним промтом и одним авторизационным токеном....
Вот только что, soooooqaaaaa!, читал статью на три листа А4 про ризонинг. И знаете что узнал!? Что ризонинг в моделях это как бы эффект мышления! Охуеть! Спасибо нахуй!
Как сделать свайпы геммы разнообразными?
Буквально абзац в абзац тоже самое другими словами
Юзаю рекоммендованные семплеры от гема тим
Буквально абзац в абзац тоже самое другими словами
Юзаю рекоммендованные семплеры от гема тим
> До этого были такие «охуенные» модели, что давай не будем вспоминать.
Пигмалион кивает сквозь слезы
Прояви уважение, кобольдище!
> актуальную прагматичную информацию о нейронках и их устройстве и фичах
Как вариант - в доках опенов, антропиков, гугла и мистралей. У последних двух есть мануалы для открытых моделей с поддержкой этих фич, но они довольно посредственного качества. Там будут описаны принципы работы, рекомендации и примеры, но, разумеется, все для их моделей и через их апи, придется это адаптировать. Можешь даже попробовать с гуглом https://googleapis.github.io/python-genai/ лимитов бесплатного флеша хватит чтобы понять основы и оно довольно юзерфрендли, а когда разберешься - перенести куда угодно сможешь. Если же тебе сам принцип - изучай душные мануалы и ролики по построению агентных систем.
мимо

Взял из моделей в шапке aya-35.ггуф, для кума на русике. 3090, угабуга, 25 слоев на карте, 0,86т/с. Я успешен?
>Как сделать свайпы геммы разнообразными?
Карточка побогаче, твои сообщения поразнообразнее. Чтобы ей было что пожевать. Хотя вообще-то так быть не должно. Но я лично, когда модель упрямо не желает поворачивать куда мне надо просто пишу ей пояснения в [квадратных скобках].
>Я успешен?
Ты болен. Юзай 12В, в этом треде как раз кидали два примера.
>Так что, вот это нынче топ?
Потестил. Говно. Думает-то она хорошо, но вот воплотить её же мысли в основной ответ не может. Недотренена. Но потенциал есть.
Может что недонастроил и неправ - кидайте свои отзывы.
Ты опять хуйни насрал опять лишь бы ответить шизик
Обасрался и давай жопой вилять, "эксперт"
Нубяра ебаная, хотел козырнуть перед аноном а самого пустили, непрятненько да?
А нехуй выебываться
Вобще грустно что тут остались либо упоротые тролли вроде тебя либо совсем свежее мясцо. Но недавно даже их не было, щас хоть чуток веселее стало
Нюфак, но тоже скатил гемму в однообразный залуп недавно. Аноны тут дали понять следующее, возможны 2 варианта:
1. ты просишь тупой кум в лоб, а целочка-геммочка пытается от тебя соскочить, потому что НЕ ТАКАЯ, С геммой надо уметь в общем промптовать.
2. карточка. я думаю что словил как раз залуп из-за карточки, потому что в ней литерали было 300 токенов "сиськи, хуй, пизда, ебаца". Т.е. даже если ты не просишь в первом предложении "отполируй мои яйца", но при этом в карточке написано "она наклоняется над ним, показывая огромное декольте и спрашивает-предлагает: ебацца хош?" - у геммы не остается контента для фантазий, и она свайп за свайпом начинает выдавать "ты меня ебешь, ах", "ты меня ебешь, ах"...
Где там новый квен, заебали? Чтоб я завтра проснулся и он был у меня на столе
>Где там новый квен, заебали? Чтоб я завтра проснулся и он был у меня на столе
Штаты наложили на Китай тарифы в 125%, так что может и того. Прикроют лавочку.
но... мне сказали... что ~30б будут летать... 40т/с... правда речь была про exl2.
Но вообще, если серьезно, то это конечно пиздец. Я явно что то делаю не так даже на ггуфе. 25 слоев дают меньше токена в секунду, 30 - не запускаются из-за нехватки врам. анон сказал что ггуф должен целиком залетать, а ирл по факту даже полшишки нет. (Правда контекст я не квантовал, не умею пока, но не до 25 слоев же и 0,86 токена разница!)
Но даже так рпшить веселее, чем на сайнемо, вот сейчас в средневековой бане двумя попаданцами ниссан гтр 32 обсуждали.
>надо уметь в общем промптовать.
С Геммой хорошо, если:
1) Кум не главное;
2) Негатив не нужен.
Иначе всё плохо.
> А не подскажешь сайты, где можно структурированно подчерпнуть актуальную прагматичную информацию о нейронках и их устройстве и фичах?
Увы, не знаю таких ресурсов. Сфера слишком свежая и быстро всё меняется - в инфополе только всякие инфоцыгане, как ты и сказал.
> Как вариант - в доках опенов, антропиков, гугла и мистралей. У последних двух есть мануалы для открытых моделей с поддержкой этих фич, но они довольно посредственного качества. Там будут описаны принципы работы, рекомендации и примеры, но, разумеется, все для их моделей и через их апи, придется это адаптировать.
Надо иметь ввиду, что доки во многих местах описывают их платное API, а не релизнутые в опенсорс модели.
То есть когда ты видишь в доках мистраля/коммандра про поддержку Structured Outputs:
https://docs.cohere.com/v2/docs/structured-outputs
https://docs.mistral.ai/capabilities/structured-output/custom_structured_output/
то это не про сами модели, а именно про их обёртку в виде платного API. А для локального использования эти секции по большей части бесполезны, поскольку существующие локальные бекенды не покрывают всех возможностей платного API. Так что даже казалось бы "официальная документация" тут может ввести в заблуждение, если у тебя нет чёткого понимания, какая часть относится к самой модели, а какая к их API.

>Сфера слишком свежая и быстро всё меняется - в инфополе только всякие инфоцыгане, как ты и сказал.
Забавно, но когда в 2021 я брал гэп между работами, я изучал мл как раз по душным лекциям, думая перекатиться из быдлокодера в люди. Но потом понял что:
1) обучать вменяемые нейронки могут только корпы с датасетами и миллионами vram
2) обычная работяжная мл-рутина не совсем то, что себе представлял, да и берут туда в основном олимпиадников.
Ну и еще дибил, надо было сразу торч и тензорфлоу дрочить, а не матан.
Знай как стрельнут нейронки, а особенно - что будут сладкие локалочки, не забросил бы.
А теперь забавная ситуация, вроде и на лицо ссу всяким цыганам и нормиксам "ооо ты видел новость чатгпт пыталась взломать сама себя", но в то же время не пойму почему у меня ггуф под себя серит и не знаю и 30% того что знают местные анонасы.
>а именно про их обёртку в виде платного API
После этой рекомендации так и подумал что гайдов/манов путевых нет, надо по хлебным крошкам по всему интернету собирать знания, как и на изучении диффузионных sdшек делал.
>125
104% вроде, из вредности, потому что 4 у китайцев них несчастливое число, там даже местами 4х и 14х этажей нет, а маняврирования вроде этаж "3А"
>но в то же время не пойму почему у меня ггуф под себя серит и не знаю и 30% того что знают местные анонасы.
Они не знают, а просто бездумно повторяют и тычут во всё подряд. А потом этим маримбамэну, обкурившиеся обдрочившиеся на мухомор-тян тут из себя экспертов корчат. Не ведись.
>Они не знают, а просто бездумно повторяют и тычут во всё подряд
А ведь кто-то в этом итт треде срёт про превосходство человеческого интеллекта над ллм и что ллм это просто стохастический попугай.
>А ведь кто-то в этом итт треде
Ну так это лоКАЛа тред, тут одни умалишенные сидят. Это как у тебя есть возможность ебать топ-10 сосок живых, но ты вместо этого сидишь и в треде отдельном обсуждаешь, как развернуть резиновую маню, как её надуть, как хуй в резиновом кармане повернуть, чтоб об швы не натирало.
мимо
Ебать, откуда тут столько васек с пятого класса? Тут больше половины людей рпшат и пишут интерактивные истории, влючая меня. Топ - 10 сосок* Ты женщину то нюхал, дурачок.

>Тут больше половины людей рпшат и пишут интерактивные истории


mistral small 3.1 (24b) в четвертом кванте около чуть меньше трех токенов в секунду. На процессоре, ryzen 5600g, 32 гига ddr4 (3200 мгц в два потока), лол. QwQ у меня около двух токенов в секунду работает.
Окончательно убеждаюсь, что видяху брать не буду, я походу вообще ни в каких своих задачах прироста производительности не получу. Ну может быть картиночные модели не упираются в скорость памяти.
Мальчик, сьеби из тематики и там доказывай какой ты пиздатый, успешный, как ты ахуенно правильно живёшь и т.д.
Если честно, сложно представить для каких задач такая скорость может быть комфортной. Для меня ниже 5 вообще не юзабельно. Купил бы 3060 за 20к на авито (или 25 новую) снизил бы квант до Q3_M и кайфовал бы с 10+ токенами или бы поделил с CPU и получил бы 5-6 на том же 4 кванте
Это раздел про ИИ, и я говорю про ИИ. Тред - не твой личный, тут личных тредов не бывает, это общественное место, где любая точка зрения имеет место быть. Если я хочу заходить в тред с лоКАЛом и выражать своё мнение - я буду это делать, и никаких правил я не нарушаю, пока моих постов тут всего 0,3% от треда. Так что терпи, унтерок красноглазый.
Чет я вот смотрю на местных анонов, и складывается впечатление, что никаких 10+ токенов не будет.
И в любом случае, с третьего кванта модели резко деградируют, нахуй надо. Не хочу начинать очередной срач о скорости генерации, мне два-три токена вполне нормально, проблема только с QwQ ощущается, потому что перед ответом может решить размышлять 2-15 минут
Ну по опыту расклад по факту такой: если модель целиком загружена в врам - будет дохуя токенов в секунду, если хотя бы 10% модели не во врам, то сразу будет в райное 4 токенов, не важно какая модель и все остальное.
Так что либо брать арсенал из 3090, либо не ебаться, просто набрать оперативы на 64 гига и сидеть на 4, но с большими моделями.
ну чтобы получить 4 токена на проце, надо ddr5, а тут мне хуй, надо полностью ПК пересобирать. Чтобы воткнуть видяху с нормальным количеством памяти - это будет еще дороже, если мало пихать - то походу будет откат к упору в скорость оперативы, то есть в моем случае к тем же двум токенам.
И все же разница между 12б и 24б - очень хорошо ощущается, чтобы я обратно перекатился на более мелкую модель.
У меня на проце i7 9700f + 3070ti + 32гига ддр4(частота 3600) - 3-4 токена, что на gemma-3-27b-it-q4_0_s.gguf
Не могу, какая же это все срань.
У копросеток просто нет конкуренции, дипсик и грок просто ебут не вынимая и в рп и во всем на свете
У копросеток просто нет конкуренции, дипсик и грок просто ебут не вынимая и в рп и во всем на свете


Не, скорости будут. Но если Q4, то нужно будет 16Гб брать. 4060ti сейчас 40-45к стоит, 5060ti с лучшей памятью будет где-то 50-55к на старте, а потом непонятно, 3090 60-70к, но она будет лотереей после майнинга.
Главное помни, что путь CPU, если это не мак и если у тебя не проц за 80к, это путь боли и терпения
Ты нихера про ИИ не говоришь, только срыгиваешь в тред комки шерсти с ануса твоего протыка.
покормил-скрыл
Фух бля, правильно говорят, что нужно перетерпеть пару недель, если появилась навязчивая мысль что-то купить. Понял что долечить кариес и поставить кондер в соседнюю комнату к лету звучит более логичным, чем ради рп и кума покупать видеокарту.
вот в том то и дело, что дохуя надо. QwQ в четвертом кванте уже не влезет. Обязательно еще выйдет какая более крупная модель, надо вообще 24 гига минимум брать. И БП менять еще, и корпус у меня очень мелкий, хуй чо влезет (более большой брать, серьезно, не вариант, мне некуда его поставить), значит надо эту хуйню, которая удлинитель, чтобы как-то ее разместить.
Если брать тесловскую видяху - то я все еще не ебу, на сколько хорошо оно будет по скорости. И как я буду ее охлаждать - тоже большой вопрос.
Можно ссылку на гемму 12б ггуф без цензуры?
Ты забыл про 7600 xt и arc a770 за 35. Первая вроде получше в ллм и играх, но по железу у интела потанцевал выше хотя вряд ли его уже раскроют, уже новое поколение выкатили и его оптимизировать будут.
Держи, анон. Но учти, что она немного тупее из-за этого
https://huggingface.co/mlabonne/gemma-3-12b-it-abliterated-GGUF
Спасибо. А если сравнить русский язык в SAINEMO-reMIX.Q6_K и гемма, что лучше?

>ебут
ебут, тебя, но не персов в рп
Нихуя антитеслашиза бомбит.
Он даже не понял, о чем речь, но высраться охота.
Фееричный человек, конечно…
Как там твои 4 токена на слово против 1 на инглише? До сих пор на лламе 65б сидишь, небось?
>гемма
12 гемма говорят поломана, так что осторожно
Всё что хорошего ITT говорили про гемму - говорили про 27б версию
Мне кажется 27б будет долго перевод делать на 3090, так я жду минут 6 на 500 строк.
А что хорошего говорили?
На 4чане только срут в неё, сам пробовал и тоже хз, ишет сухо, она же только под рабочие задачи
> 3090 плак гемма не влезает
Ты специально прибедняешься хуесосина?
Попробуй не f16 версию скачать
Определенно нет.
Возьми 5 или 6 квант.
Уменьши контекст, квантуй его до q8_0, попробуй больше слоев запихнуть, добавь no-mmap, а сколько оперативы? Хотя бы 32, надеюсь?
Будто часть слоев улетает на диск сразу.
Так ЛЛМ и есть стохастический попугай, просто человеков не надо переоценивать. =)
Ну, там должно быть в районе 5-10, наверное, по-хорошему, а с двумя и все 30-50.
Но если тебе 2 токена в секунду хватает, то и похуй, дело твое.
———
Бля, я тут подумал, а что, если антитеслошиз на самом деле работает на желтую компанию и сидит в треде, токсит на всех и несет хуйню затем, чтобы аноны с их васян-мерджами не обгонял желтуюгпт??? А то токса стало в разы больше чем раньше, причем не на новичков, что можно было бы понять, а всех адекватных упорно пытается выгнать.
И четверочку, она милашка за такой размер! =)
Ты чо-то с квеном попутал, гемма про общение, квен про работу. =)


Понятно, что лучше сервак с 4 H100, но если из реального, то любой GPU ускорит работу LLM. Например, вот твой QwQ на Q4 весит больше моего VRAM, но из-за распределения слоев между CPU и GPU работает 3-4 раза быстрее чем у тебя (6.2 в бенче, 8.5 при запросе). И с такими токенами намного комфортнее работать.
Не, я не забыл, я просто сомневаюсь, что эти карты будут нормально работать. Скорее всего там будет 500 костылей и в итоге все равно говно. Особенно это касается интела
> гемма про общение
Гемма про КХЕ-КХЕ[, ну вы понимаете/b] - же?
В телеграмме мелькал чел с четырьмя интелами на сумму 64 врама, говорит норм работают ллм.
Так что в принципе… если верить его словам, можно и затраить.
Запускал ЛМСтудио, вроде как.
господа нейродрочеры,
а чего там по Ллама 4 говорят сейчас? оно пригодное к использованию? или чисто для корпоратов пока что?
а чего там по Ллама 4 говорят сейчас? оно пригодное к использованию? или чисто для корпоратов пока что?
Хуита по всем параметрам.
32 место у 400b модели (у геммы 3 27б — 10 место).
Все плохо.
3,3 токена на DDR4 у 109b q6 кванта.
Но тупое само по себе.
а чего там с архитектурой? и мультимодальностью? завезли нормальные уже, "готовые к продакшену" решения или костыли прожорливые и не работающие без ГПУ для мультимода?
https://huggingface.co/collections/soob3123/amoral-collection-67dccc556a39894b36f59676
Можешь попробовать тут первую или вторую версию. Я уже не помню, какую пробовал, оно было не настолько сломанное, как аблитерейтед или тьюн драммера. Всё равно тупее обычной, а для кума тьюны немо всё ещё будут лучше.
Пачаны, дайте сурс вот этой модели "ooo-awo-tst-q8_0.gguf", а то в папке лежит а откуда стянул не могу найти.

В смысле русика я государственник, охранитель и патриот
Отечественный производитель нейротёлок не по-детски жжот
Отечественный производитель нейротёлок не по-детски жжот
Тебя ещё не заебало за столько тредов рпшить на русском?
Или ты для скринов включаешь?
На русике нет и не будет мозгов, буквально полная шиза происходит особенно в куме
>Фух бля, правильно говорят, что нужно перетерпеть пару недель, если появилась навязчивая мысль что-то купить.
Да вот хрен его знает, в наше-то время. При 100+ процентных тарифах может последние дни прежние цены на карточки видим.
>На русике нет и не будет мозгов, буквально полная шиза происходит особенно в куме
Кончайте троллить, модели хорошие и других всё равно нет.
>ooo-awo-tst
это вроде омни-магнум так назывался раньше, от Aleteian
Купил себе за 6к б/у рузен 5600 (вместо 2600), что бы бюджетно обновиться, но глядя на цены на vram ddr5 (48гб 6900мгц, в магазине), а так же глядя на анонов выше, которые на процах крутят больше токенов чем я на 24гб видео... Задумался, мб пока новую мать не купил, скинуть школьникам 5600 и взять 7700 пока не поздно...
Конечно я понимаю что я ракохуй и запустил жопой модель, сейчас попытаюсь пофиксить и посмотреть, но все же - гипотетическая возможность запускать тяжеляк на проце мб быть полезной... Или дальше собирать ам4, отложив деньги на 3090 вторую!? ПОЧЕМУ СЛОЖНО ТО ТАК А...
>которые на процах крутят больше токенов чем я на 24гб видео
значит у тебя боттлнек по процу и оперативке
Как это нет?
У тебя прямо под боком буст х100 просто переключившись на английский язык
>английский язык
Сначала переключаешься на буржуйский, а потом родину продаешь?
УУУ, инагент ябучий.
Нет ну серьезно, всю жизнь вы искали повод учить англ и вот же он, удобного перевода как с играми/фильмами не будет, только сами только хардкор

я анон.
Прошелся по чеклисту, спасибо тебе огромное. Но не помогло.
>Возьми 5 или 6 квант.
Квант и так 4й, полное название модели aya-23-35B.i1-Q4_K_M.gguf
>Уменьши контекст, квантуй его до q8_0, попробуй больше слоев запихнуть
Уменьшил контекст до 4096, поставил q8_0 квантование вместо fp16, количество слоев не трогал - что бы проверить, запустится или нет, 25 слоев с fp16 запускаются 100% - в итоге ошибка по vram, "уменьшите контекст или снизте слои". Должно ж наоборот быть... Скрин настроек прикладываю, мб где то что то проебал!?
>добавь no-mmap
С конфигом выше и + флаг no-mmap, результат тот же:
ValueError: Failed loading the model. This usually happens due to lack of memory. Try these steps:
Reduce the context length n_ctx (currently 4096)..
Lower the n-gpu-layers value (currently 25).
>а сколько оперативы? Хотя бы 32, надеюсь?
Да, 32. До загрузки модели htop показывает что занято 3гб (файрфокс+xfce). При 25 слоях на карте не прыгает выше 8гб, при 15 слоях - не прыгает выше 11гб. Своп пустой.
Еще кто то из анонов выше предложил уменьшить количество слоев, как я понял мб 25 слоев это какое то пограничное значение и модель упирается в скорость шины. Уменьшил до 15 с fp16. Модель завелась и высрала 0,6тс вместо 0.8тс. Чуда не произошло.
значит у тебя боттлнек по процу и оперативке
настолько сильный? Если рассудить что в 3090 влезают 25 слоев, но 30 уже не лезут, то это значит что большая часть модели крутится на процессоре и разница между 24gb vram и 16gb будет мизерная... Но так быть же не должно, учитывая что аноны выше говорили что та же гемма 27b должна влезать в одну видюху и там летать, а у меня не лезет.
Гемму 27 я тоже запускал c черепашьей скоростью, но не настолько плохой, 30+ слоев на видео было. И еще там было 32к контекста в fp16, что многое обьясняет.
Вообще я думаю собака зарыта в том, что у меня почему то отказывается квантоваться контекст, выдавая ошибку по vram, а на fp16 любая среднетяжелая модель на одной 3090 быстро работать не будет. Но почему!?
Прошелся по чеклисту, спасибо тебе огромное. Но не помогло.
>Возьми 5 или 6 квант.
Квант и так 4й, полное название модели aya-23-35B.i1-Q4_K_M.gguf
>Уменьши контекст, квантуй его до q8_0, попробуй больше слоев запихнуть
Уменьшил контекст до 4096, поставил q8_0 квантование вместо fp16, количество слоев не трогал - что бы проверить, запустится или нет, 25 слоев с fp16 запускаются 100% - в итоге ошибка по vram, "уменьшите контекст или снизте слои". Должно ж наоборот быть... Скрин настроек прикладываю, мб где то что то проебал!?
>добавь no-mmap
С конфигом выше и + флаг no-mmap, результат тот же:
ValueError: Failed loading the model. This usually happens due to lack of memory. Try these steps:
Reduce the context length n_ctx (currently 4096)..
Lower the n-gpu-layers value (currently 25).
>а сколько оперативы? Хотя бы 32, надеюсь?
Да, 32. До загрузки модели htop показывает что занято 3гб (файрфокс+xfce). При 25 слоях на карте не прыгает выше 8гб, при 15 слоях - не прыгает выше 11гб. Своп пустой.
Еще кто то из анонов выше предложил уменьшить количество слоев, как я понял мб 25 слоев это какое то пограничное значение и модель упирается в скорость шины. Уменьшил до 15 с fp16. Модель завелась и высрала 0,6тс вместо 0.8тс. Чуда не произошло.
значит у тебя боттлнек по процу и оперативке
настолько сильный? Если рассудить что в 3090 влезают 25 слоев, но 30 уже не лезут, то это значит что большая часть модели крутится на процессоре и разница между 24gb vram и 16gb будет мизерная... Но так быть же не должно, учитывая что аноны выше говорили что та же гемма 27b должна влезать в одну видюху и там летать, а у меня не лезет.
Гемму 27 я тоже запускал c черепашьей скоростью, но не настолько плохой, 30+ слоев на видео было. И еще там было 32к контекста в fp16, что многое обьясняет.
Вообще я думаю собака зарыта в том, что у меня почему то отказывается квантоваться контекст, выдавая ошибку по vram, а на fp16 любая среднетяжелая модель на одной 3090 быстро работать не будет. Но почему!?
>настолько сильный?
настолько что пиздец, у меня гемма 27 (в 4 кванте правда) на 12 гб врам идет с 2.5 т/с, а у тебя на 24 гб врам - меньше токена в секунду.
>я анон.
Берёшь Кобольд:
https://github.com/LostRuins/koboldcpp/releases/tag/v1.87.4
Версию koboldcpp_cu12.exe
Берёшь Гемму 3 в 4KM. Пишешь в батнике:
koboldcpp_cu12.exe --usecublas mmq --contextsize 24576 --blasbatchsize 512 --gpulayers 99 --threads 8 --flashattention --quantkv 1 --nommap --model gemma-3-27b-it-abliterated-q4_k_m.gguf
Пробуешь, можешь дописать --benchmark test.txt и посмотреть сколько даёт. Результат кидай сюда.
Может я на какой-то тупой модели сижу хз, но я разницы вообще не вижу между русским и английским. Тем более что пока генерится текст, я уже успеваю все прочитать на английском, а на русском просто перепрочитываю. Да, бывает что переводчик теряет контекст или проебывает значение слова, но ничего не мешает переключиться на английский, прочитать что там имелось ввиду и переключиться обратно на русский. Если я вижу что модель не понимает что я ей пишу, я пишу эти слова или фразы на английском и она все замечательно хавает. Короче хуйня это все.
Толстый байт.
Яб тебя пасюка такого гигабайтного ногами придушил.
Не, на пикрилах aya35b, гемма повеселее, не помню сколько - но тоже около 2-3тс на жирном 32т fp16 контексте. И тоже выбивало пр vram при попытках квантования контекста. Крч с ней можно было поиграться еще как то, поэтому я значения не придал тогда, и на время на нее забил.
Но вот 35b чет совсем треш. И я не понимаю почему контекст не хочет квантоваться.
>.exe
>в батнике
Прости, я думал по htop, xfce и фотке терминала было ясно что я на линуксах пердолюсь. Одна из причин почему я сразу угабугу, а не кобольда запустил - увидел что все инструкции были про экзешники, да и exl2 в перспективе все равно бы не позволили на кобольде восседать долго.
Прости, не дописал. Скачиваю кобольдаcpp для линукса ...cuda 1210, попробую запустить с твоими параметрами и отпишусь.
>Прости, я думал по htop, xfce и фотке терминала было ясно что я на линуксах пердолюсь.
Ну изучи ключи и посмотри, какие галочки в llamacpp в Угабуге поставить. MMQ, flashattention, nommap. Все слои во врам, кэш квантуешь в q_8.0. Смотришь, всё ли влезло в видяху целиком и запускаешь.

таверна вроде не работает с визуальной частью, а если и работает там ещё mmproj или что-то вроде этого надо было подсовывать в кобольде
Всё как обычно, никакой конкретики, ни примеров нихуя. Уже не интересно эту хуйню читать, сколько этих прорывов было за последний год. Если их почитать, уже должны были на холодильнике Минск запускать 400б модели.
>надстройка над чужими сетками без задач
Но у Яндекса есть лайт-версия, которая даже init-веса не брала ни у кого, а тренировалась с полного нуля.
Да и про надстройку тоже хуйню написал в общем-то, даже если брать про-версию, которая на init-весах квена.
>в релизе отметили важный факт - цитирования зарубежными изданиями
А что отмечать чтобы подчеркнуть надёжность исследования? Почти все международно признанные специалисты по ИИ находятся за рубежом и пишут на английском, или для тебя это открытие?

Наконец-то пересел с пантеона на дипсик v3 0324. Да, всё ещё не клод, но бесплатный, быстрый, и пишет именно как мне всегда нравилось. Снова как будто в самый первый месяц игр с нейронками вернулся.
На чем такого зверя запустил?
> что ~30б будут летать... 40т/с... правда речь была про exl2.
40 это уже на 4090, на 3090 30+. В gguf на малых контекстах будет тоже примерно такая скорость на фуллгпу.
> а ирл по факту даже полшишки нет
Ты скачал довольно жирный квант с почти 6bpw, который сам около 20 или больше гигов скушает. Выставил на гемме3, которая достаточно прожорливая на контекст, аж 32к без квантования (выставить галочку в лаунчере или добавить параметр в командную строку), что на вскидку потребует с десяток гигов или больше. И подобрал режим, в котором оно только начинает запускаться, хотя все равно врам переполнена и идет постоянная выгрузка драйвером с сильным замедлением.
Чтобы это исправить: скачай квант поменьше, выстави меньше контекст, включи его квантование, сократи количество слоев на gpu еще сильнее.
> 25 слоев дают меньше токена в секунду, 30 - не запускаются
У геммы же около 60 слоев, не? Это выглядит как полная ерунда, проверь не засрана ли видеопамять чем-то еще.
> доки во многих местах описывают их платное API
Об этом и сказано. Тут важно понять сам принцип как формируется запрос к ллм (да, большинство даже этого не соображают), потом какие дополнительные средства и параметры можно передавать и как с ними может ллмка работать. Хз что тут будет, easy to learn @ hard to master или эта тема сама по себе сложная.
> А для локального использования эти секции по большей части бесполезны
Разве код из офф репы мистраля не поддерживает это? Не через апи а с их либой, но всеже. В любом случае, станет проблема полнофункционального апи, но постепенно и коллективными усилиями это решаемо если модели могут. Для начала хотябы на коленке хардкодом их разметки.

Вот на этой глыбе.
Понял принял, как лимит кончится на бесплатные сообщения напиши.
Спасибо тебе анон! Как и ожидалось, не в железе проблема, а в моих кривых руках (и мб в софте отчасти). Хронология:
1. запустил с указанными параметрами и флагом --benchmark, подумало-подумало и вылетело с ошибкой. Файл логов не нашел куда высрался
2. прописал полный путь до лога и все быстро быстро запустилось, выдав:
Timestamp 2025-04-12 12:47:48.790125+00:00
Backend koboldcpp_cublas.so
Layers 99
Model gemma-3-27b-it-Q4_K_M (аблитерация у меня ток в 5м кванте была)
MaxCtx 24576
GenAmount 100
ProcessingTime 22.02
ProcessingSpeed 1111.64
GenerationTime 5.02
GenerationSpeed 19.90
TotalTime 27.04
Output 1 1 1 1
Flags NoAVX2=False Threads=8 HighPriority=False Cublas_Args=['mmq'] Tensor_Split=None BlasThreads=8 BlasBatchSize=512
3. запустил без флага бенча, вывалилось по нехватке врам, тисал что то то ли 15гб доступно, то ли 400мб не хватает.
4. ребутнул комп, запустил кобольда (запустилось), подключил таверну.
В итоге на 27bq4k_m гемме ггуф, rtx3090:
[16:04:45] CtxLimit:7414/24576, Amt:49/596, Init:0.16s, Process:5.58s (1321.08T/s), Generate:1.83s (26.76T/s), Total:7.41s
Просто ракета конечно в сравнении с тем, что было. Почему правда пару раз вышибало по врам при запуске и почему угабуга так странно себя ведет, надо будет разбираться. Сейчас открою доку кобольда и буду разбирать, что значит каждый из параметров запуска.
Так они тыщу в день выдают для бесплатных моделей если закинуть $10 на баланс. Мне этого с головой хватает, свайпать-то не надо, как на всратых огрызках.
а как ты туда эти one ten bucks закинул то из великой и могучей

Я у мамы продвинутый пользователь пк.
>Можешь попробовать тут первую или вторую версию.
Попробовал оттуда третью гемму 27В - сломаны мозги. Пока что DPO-версия лучшая (но тоже такое себе)
фубля крипта =(
там апи нормальное есть, чтобы к т8т подключать, и сколько милионов токенов в фри режиме?
*n8n
Мне этого точно не хватит лол.
а 1000 чего? сообщений или токенов или попугаев?

а в реквест сколько можно напихать токенов?
(ну типа задача есть большие тексты парсить и нужно чтоб бесплатно)
Не знаю, я дипсик для кума использую. Там 50 бесплатных реквестов для всех дается, зайди и проверь сколько он примет.
>Просто ракета конечно в сравнении с тем, что было.
Вот и прекрасно. Сразу говорю, что QwQ-Snowdrop.i1-Q4_K_M.gguf влезает в 24гб врам и держит 32к квантованного кэша, Forgotten-Transgression-24B-v4.1.i1-Q6_K.gguf - держит 64к, ну а darkness-reign-mn-12b ниже восьмого кванта запускать и смысла нет, а кэша влезает 64к неквантованного, только она столько вряд ли пережуёт :) Энжой.
>дипсик для кума
разве кум в корпосетках не режется
а если предложить 300$ то еще лучше будет работать?
Хз, я отключил инстракт, там не это обходит цензуру всё равно.
Тут еще анон решил помочь, сказал что я тяжелый квант (q5K_L) попытался поднять, и что надо квантовать, еще больше резать слои и/или спускаться на квант ниже. Но мне кажется он не в ту сторону вообще копал, если модель дает полтора токена, то еще резать слои это вообще пиздос.
Я сейчас попробовал свою аблитерацию mlabonne_gemma-3-27b-it-abliterated-Q5_K_L.gguf на твоих настройках, видюха сказала "ох как глубоко, сэмпай!" и выдала ошибку. Поставил контекст 4096 и все взлетело на тех же 27т/с. Но да, видимо тяжеловатый квант скачал, надо полегче взять.
Если рассуждать про необходимость exl2, пока получается особой нужды в ней мне теперь нет? Разве что в будущем, еще чуть быстрее + вроде как я понимаю там квантование чуть лучше?
> QwQ-Snowdrop.i1-Q4_K_M.gguf влезает в 24гб врам и держит 32к квантованного кэша
Это отлично, спасибо за точное название кванта, не придется угадывать. Побегу качать. Форготтен тоже попробую, хотел, рекомендовали для англ кума. Ну а даркнес у меня и на угабуге q8 fp16 летал :D
>QwQ-Snowdrop.i1-Q4_K_M.gguf
Только если для русского, то версию с i не бери, а бери static quants.
>Если рассуждать про необходимость exl2, пока получается особой нужды в ней мне теперь нет? Разве что в будущем, еще чуть быстрее + вроде как я понимаю там квантование чуть лучше?
А это как повезёт. Вообще-то уже exl3 на пороге и поддерживать старые версии никто не будет. А новых ещё нет. Короче с одной картой пока что можно смело сидеть на ггуфе и ничего не терять.
На реддите видел, как челик на премиумной материнке, утыканной оперативкой, запускал дипсик. Скорость 3-4 токена в секунду была.
Тут никто таким не занимался? Я вот думаю над идеей взять китаеплату и кучу памяти по дешману, хотя в то же время страшно, что плата перегреется и сгорит нахуй.
Тут никто таким не занимался? Я вот думаю над идеей взять китаеплату и кучу памяти по дешману, хотя в то же время страшно, что плата перегреется и сгорит нахуй.
какую ты китаеплату возьмеш то? там обычно больше 256 не поставить... так-то тебе нужно желательно что-то на Epyc и обмазаться оперативой по полной, но у тя денег на такое не хватит
>Тут никто таким не занимался?
Будь реалистом - ну нельзя пока гигантские модели запускать на дому. 123В - предел. Можно получить 1 токен в секунду или целых два, но нахуя? Ждём железо. ИЛИ покупаем доступ к API ИЛИ арендуем и пытаемся убедить Дипсик что он очень хорошо может в кум (что без тюнинга наверняка пиздёж). Так вижу(с)

Мужички, есть задача кумить на русском, без переводчиков итд
Вот прям пишешь на русском и ответ тоже на русском
Через опенроутер. Какая модель сможет в это? И что вообще для этого нужно? Карточки персонажей с ру описанием или как?
Вот прям пишешь на русском и ответ тоже на русском
Через опенроутер. Какая модель сможет в это? И что вообще для этого нужно? Карточки персонажей с ру описанием или как?
>Короче с одной картой пока что можно смело сидеть на ггуфе и ничего не терять.
Ну супер, как раз можно будет попробовать всякие модели без сильной ебли с поисками и запусками.
3-4 токена дипсик звучит очень годно, особенно после того как ночь прокумил на 0,8 т/с.
Насколько я помню, в треде ни раз поднимался такой вопрос, и пока вроде годного сетапа никто не собирал. Все упирается в скорость памяти и её объемы. DDR5 в адекватные деньги >96гб собрать оче дорого и непросто. DDR4 медленная, и доступные серверные процы с 4мя каналами насколько я понимаю не оч по производительности и оч много RAM не затащут.
Я бы сам с большим удовольствием бы почитал про чужой опыт, было бы интересно собрать за цену похода в дикси сервачок, способный постоянно. пускай и неспешно крутить гемму/квен как ассистента "всегда под рукой", или за сотку собрать домашний сервак, но уже способный неспешно крутить тяжеленные модели.
> Можно получить 1 токен в секунду или целых два, но нахуя?
Ну если это будет по "мозгам" аналог корподипсика, грока или гопоты, то звучит годно. Говорю как прокумивший всю ночь на 0,8 токенах.
>Ну если это будет по "мозгам" аналог корподипсика, грока или гопоты, то звучит годно. Говорю как прокумивший всю ночь на 0,8 токенах.
Все мы с "0.8 токена" начинали. Вот сейчас ты покумишь на 10+ токенов в секунду и поймёшь, что даже Грок на 1-2 т/с не стоит того. Точно тебе говорю :)
Ну кум кумом, а есть еще и рабочие задачи и хоббийные. Я понимаю что сейчас моделей как говна за баней бесплатнодоступных, и даже без ебли с впн (хвала китайским братушкам)... Но есть и конфиденциалка, NDA, личная инфа... Да и опять же, зависимость от корподяди ну совсем не греет душу. Опять же доступ по API и свой промтинг это уже за копеечку. Я бы с радостью насыпал 50-100к за некросборочку, дающую мне свой грок/соннет/4о, пускай 1т/с.
>ночь прокумил
>ночь прокумил
Пока думал над ответом, забыл что уже про это говорил, прошу прощения. Выглядит оч тупо 2 раза повторенное.
>И что вообще для этого нужно? Карточки персонажей с ру описанием или как?
Берёшь любую карточку и переводишь в ней приветствие и примеры диалогов (если есть), этого обычно достаточно.
MoE-шка, маленькие эксперты, зато много.
Мультимодальность там может и есть, но хуже даже квена 7b, не говоря о гемме 27б.
Путает вещи.
Без гпу разве что Qwen2.5-3b-VL или Geema-3-4b-it, но распознавание само там секунд 20-30 на проце займет. Зато пишет быстро.
Но в общем, пока нет особо.
Хотя, справедливости ради, у меня есть знакомый, у которого маверика на его задаче показал себя лучше Gemini 2.0 Flash. Например.
Тарифы отменили, кстати.
Однако, факт, что волатильность слишком высока, седня можешь купить, завтра уже не можешь.
Вроде и ждать стоит, чтобы пережить психический порыв, но вроде и задерживаться с покупкой иногда рисково. Проснешься — а там эмбарго, и видяхи втрое взлетели.
Ryzen 7700 тебе нафиг не нужен на DDR5, у тя там скорость памяти будет чуточку выше, чем на 5600.
Intel i5-12400 бери, или аналоги постарше на DDR5. Интелы позволят память запустить достаточно быстро.
> aya-23-35B-Q4_K_M.gguf
21.5 GB
Бля, слушай. Она у тебя целиком в 24 гига должна влазить же.
Давай разбираться.
Можешь посмотреть потребление видеопамяти? И фигач количество слоев 999, проблемы быть не должно с 3090-то.
У тебя одна видеокарта? Так, на всякий случай спрошу.
У меня вижн геммы в кобольд.спп рабочий, если че.
А через таверну не пробовал.
> Generate:1.83s (26.76T/s)
Вот это звучит реалистично.
Если тебя устроит ггуф, то париться с экслламой пока нет смысла. Вот выйдет полноценно Exllamav3 — тогда да. Там будет буст, если верить бенчам.
Я планировал порофлить, но что-то в итоге руки не дошли.
Если будешь брать, расскажешь, че за плата.
192 гига уже хватит для 1.58 бита, 256 для 2.5 битов, а 384 — 4 бита.
Чем больше каналов и псп — тем лучше.
ktransformers для тех, у кого есть 256+ гигов и 3090 =)
Я дипсик на 1,5 токена/сек могу запустить, 128 оперативы + 2 теслы по 24. Но лень ждать и теслы мучать почем зря.
По идее, восьмиканал 2400 даст уже 3-4 токена, ну?
На большинстве моделей которые я пробовал выдает какую-то тарабарщину ебучую либо зацикленный текст, с англ. версией текста все нормально. Как это победить?
модель должна уметь в ру
умеют не только лишь все
и по большей части только базовые / аблитерированные версии (гемма 27), корпосетки типа гемини, да тредовичковые мистральки, и некоторые квены, например руадапт, а вот сноудроп в ру может на уровне 8б, так что не стоит, там русик убился
Про сноудроп жаль очень. Я на старте поюзал и удалил.
> пока получается особой нужды в ней мне теперь нет?
Нужда появится когда начнешь использовать на больших контекстов и ахуевать с тормозов llamacpp. Или когда будешь получать полный бред вместо ответа без явной на то причины, случается что жора работает криво или поломанный квант. Офк, к экслламе это тоже применимо, но случается гораздо реже.
> поддерживать старые версии никто не будет
Вторая эксллама успешно катает gptq и фп16, уже есть обещания что совместимость с exl2 будет отсутствовать? Другое дело какой смысл их использовать, если новый квант лучше.
> соннет
Смотря где, в некоторых задачах он прям вне конкуренции, в (е)рп после линчевания вялый.
> грок
Хуй знает, ерунда какая-то, так и не понял в чем его фишка.
> 4о
По омнимодальности с лайв-апи равных пока нет. По ллм части - ну рили тут уже гемма (27б) ему может дать на клык не говоря о больших, по картинкам - зависит от юзкейса.
Я уже скидывал в прошлом треде скрин со сборкой от какого то дядюшки Ляо, который использовал один Сион 2680 v4 (вроде как, но тут непринципиально) на двухсокетной хуянанжи и какой то кадавр 3080 с 20 ГБ врам. Память - 512 ГБ 2400 ддырки 4. Получал через ktransfromers те самые 3 токена в секунду.
Суть же да, в пропускной способности озу.
Кратко ситуация с ней выглядит так: хочешь больше 100 Гб/с - потрать 300К рупий минимум. Сто на проц, сто на мать, сто на память. Ну и где достать +24ГБ врама надо подумать.
Так что в принципе неудивительно, что в треде такой сборки никто не кидал.
Даже если деньги есть, кидать 300 килорупий в топку что бы...
Эх, тяжело иметь дорогие хобби, особенно когда они с РАБотой никак не связаны.
Даже если деньги есть, кидать 300 килорупий в топку что бы...
Эх, тяжело иметь дорогие хобби, особенно когда они с РАБотой никак не связаны.
Какой сборки? Тут много чего было что может удивить.
> тяжело иметь дорогие хобби
Тут далеко не самое. Любой околоспорт глянуть и можно ахуеть.
Вот мой пост со скрином. Оказывается он даже в этом треде был
>Intel i5-12400 бери, или аналоги постарше на DDR5.
Не, интуль не оч люблю, да и вообще когда гемма влезла в vram решил, что похуй на возможность делить слои на проц, останусь на ам4. Если захочу что то тяжелее 32b гонять, то докуплю вторую карту или буду уже собирать что то отдельное чисто для лмм, и там уже подбирать железо под конкретное тз.
>должна влазить же. Можешь посмотреть потребление видеопамяти?
Могу, но у меня проблема в том, что угабуга не хочет квантовать контекст почему то. Т.е. aya-35b:
- на 25 слоях взлетает с fp16 0,8т/с
- на тех же 25 слоях и том же объеме контекста, но с q8_0 вылетает по ошибке памяти. В целом уже не актуально, мне пока кобольда хватит за глаза, но можешь посмотреть на скриншоте что я делаю не так. Да, 3090 одна.
>Я дипсик на 1,5 токена/сек могу запустить,
О, круто, речь о DS R1 на все 600+ миллиардов (в кванте)? На хабре нашел сейчас следующее:
>Единственный способ запустить настоящую R1 (как и deepseek V3) локально, это иметь ПК с хотя бы 256гб памяти, если это 16 канальная ddr4 3200 система на б/у эпиках (1-2 поколения, такие можно собрать где-то за 150к), то вы получите скорость 4 t/s в Q2_K кванте, для размышлений это слишком медленно, так как их обычно много, но это более менее терпимо, если учесть, что скорость небыстро чтения 5 t/s.
150к (как и система 128+48vram) конечно выходят за рамки "до соточки побаловаться", но звучит в целом интересно. Я с дипсиком не работал (когда он выкатился, я попал на перегрузку серверов на хайпе и регу прикрыли, а потом как то и не особо интересно было, достаточно квена и гопоты иногда что то поспрашивать), все что я знал что он на уровне тир-1 корпосеток. Попробую сегодня зарегаться и потестить, мб действительно задумаюсь о сборке под него.
>грок,Хуй знает, ерунда какая-то
По идее зная Илону, он должен быть хорош для всякой инженерии, но понятия не имею что там в опенсорце, много где слышал что тяжелая хуита без задач. В общем как ты понимаешь, познания мои в крупносетках не очень, но гопота видел как развивалась с 3.5 и сейчас конечно она вау - мультимодальная, с поиском, размышлением, генератор картинок обесценивает процентов 70% навыков моих в SDXL...
> хочешь больше 100 Гб/с - потрать 300К рупий минимум
За локальный функционал современной гопоты я бы всерьез мог подумать. А если просто за возможность гонять модель чуть чуть умнее геммы - уже да, такое.
В общем надо изучить что дипсик локальный дает.
Не, интуль не оч люблю, да и вообще когда гемма влезла в vram решил, что похуй на возможность делить слои на проц, останусь на ам4. Если захочу что то тяжелее 32b гонять, то докуплю вторую карту или буду уже собирать что то отдельное чисто для лмм, и там уже подбирать железо под конкретное тз.
>должна влазить же. Можешь посмотреть потребление видеопамяти?
Могу, но у меня проблема в том, что угабуга не хочет квантовать контекст почему то. Т.е. aya-35b:
- на 25 слоях взлетает с fp16 0,8т/с
- на тех же 25 слоях и том же объеме контекста, но с q8_0 вылетает по ошибке памяти. В целом уже не актуально, мне пока кобольда хватит за глаза, но можешь посмотреть на скриншоте что я делаю не так. Да, 3090 одна.
>Я дипсик на 1,5 токена/сек могу запустить,
О, круто, речь о DS R1 на все 600+ миллиардов (в кванте)? На хабре нашел сейчас следующее:
>Единственный способ запустить настоящую R1 (как и deepseek V3) локально, это иметь ПК с хотя бы 256гб памяти, если это 16 канальная ddr4 3200 система на б/у эпиках (1-2 поколения, такие можно собрать где-то за 150к), то вы получите скорость 4 t/s в Q2_K кванте, для размышлений это слишком медленно, так как их обычно много, но это более менее терпимо, если учесть, что скорость небыстро чтения 5 t/s.
150к (как и система 128+48vram) конечно выходят за рамки "до соточки побаловаться", но звучит в целом интересно. Я с дипсиком не работал (когда он выкатился, я попал на перегрузку серверов на хайпе и регу прикрыли, а потом как то и не особо интересно было, достаточно квена и гопоты иногда что то поспрашивать), все что я знал что он на уровне тир-1 корпосеток. Попробую сегодня зарегаться и потестить, мб действительно задумаюсь о сборке под него.
>грок,Хуй знает, ерунда какая-то
По идее зная Илону, он должен быть хорош для всякой инженерии, но понятия не имею что там в опенсорце, много где слышал что тяжелая хуита без задач. В общем как ты понимаешь, познания мои в крупносетках не очень, но гопота видел как развивалась с 3.5 и сейчас конечно она вау - мультимодальная, с поиском, размышлением, генератор картинок обесценивает процентов 70% навыков моих в SDXL...
> хочешь больше 100 Гб/с - потрать 300К рупий минимум
За локальный функционал современной гопоты я бы всерьез мог подумать. А если просто за возможность гонять модель чуть чуть умнее геммы - уже да, такое.
В общем надо изучить что дипсик локальный дает.
>В общем надо изучить что дипсик локальный дает.
В том кванте, что ты потянешь - ничего.


Он и в аблитерейдед дпо! Есть хоть одна производная геммы без злоебучего Хэмлока?
Потрясен вашей целеустремленностью заставить ИИ сгенерировать голую женщину.
Выбивает к хуям из погружения, да?
Пиздос как! Меня так с бондов, камарадери, петов, министрейшонов, трус о даре, и прочего слопа так не трясло как с Старика Хэмлока

Хэмлок не в аблитерейтеде и не в дпо... Он в самой гемме... Я не знаю, я чувствую себя преданным...
Чё за Хэмлок? Кто это? Прикол какой-то?
Слопный персонаж, который гемма мне подсовывает
>Хэмлока
Что за хемлок? Ни разу не видел на этой вашей гемме.
Описание голой женщины, замечу я.

Это серьёзные научные общественно-полезные исследования.
> угабуга не хочет квантовать контекст почему то
Какая-то ерунда у тебя там происходит, и 25 слоев - ну оче мало для таких моделей. И да, галочка flash attention обязательна.
> Единственный способ
> ПК с хотя бы 256гб памяти, если это 16 канальная ddr4 3200
Плохая подача, так загибать про единственность, а потом советовать епук 2-го или 1-го(!) поколения. И онли на процессоре всетаки слишком медленно выходит, это страдание. Надо таки заморочиться и k-transformers завести с сотней врама, просто сам по себе дипсик не особо впечатляет чтобы столько телодвижений ради локального запуска делать.
> зная Илону, он должен быть хорош для всякой инженерии
Это как выбирать инженерный кетчуп потому что его рекламировал Дауни-младший.
> зная Илону, он должен быть хорош в
Зачем пользоваться продуктами жизнедеятельности нацистов?
Товарищи, можно что-то запустить 30b+ на 24 гигах видео памяти и 64 гигах оперативки (ddr4 3200), чтобы комфортно крутилось?
Забыл уточнить, мне для кодинга и неформального общения на русском, на все темы в том числе и чтоб по жести могла ответить...
>Забыл уточнить, мне для кодинга и неформального общения на русском, на все темы в том числе и чтоб по жести могла ответить...
Квен в кодинге хорош (говорят), Гемма аблитератед для всего остального. Модели, кванты и батники для Кобольда смотри чуть выше по треду.
>для кодинга
DeepSeek с резронингом лучше будет, мелкие локальные модели типа 30б будут онли говном срать, учитывая что даже корпомодели самые последние обсераются. Ну либо жди еще года 3.
По поводу Лорбука(World Info) в таверне, расскажите про векторные базы. Вот есть тригер по ключевому слову(по умолчанию), а есть Chain Link, который делает векторную базу из записи и срабатывает по схожей семантике в контексте.
Как я понял Chain Link использует какую то простую базу, которая автоматом генериться при каждом запуске таверны и не сохраняется. Но есть расширение Vector Storage, позволяющее на костомной модели сгенерить нормальную векторную базу в постоянный файл. И вроде как это более удобный и управляемый вариант.
Но вопрос, а есть смысл вообще ебаться с базой, будет ли она лучше обычных тригеров по ключевым словам? Оправдано?
Ок, спасибо.
Понял принял.
Аноны с видяшками от амд, чо у вас по скорости генерации выходит? Щас присматриваюсь к rx 7600 xt с 16 гигами памяти. Еще интересно что будет с генерацией картинок, тред не тот, но может кто подскажет
> О, круто, речь о DS R1 на все 600+ миллиардов (в кванте)? На хабре нашел сейчас следующее:
На хабр забей, там дебилы сидят.
Но офенс, но ебать они тупые, правда.
Зато чсв в потолочек стучит.
Unsloth квантовал даже сильнее, Q1 квант (не 1 бит, конечно=), она на 1.58 бита становится смешно-шизовой, но все еще верно отвечает на вопросы, и неплохо пишет.
Только это ппц как медленно, легче QwQ на 10 токенов/сек гонять.
По сути, минимум — это 170 гигабайт.
Но если под него собирать, выше уже писали, ну, придется вложиться. По-хорошему, во-первых, памяти надо 256, а то и 384, во-вторых… ну ладно, 3090 у тебя есть.
Короче, сервачок бушный взять придется, конечно.
Но честно скажу — под РП с thinking'ом Grok лучше, а R1 не дотягивает. Выглядит слишком дорого. Вот задачки решать — да, для работы хорошо. Только для работы ты и подписку или API оплатить можешь.
Я не то чтобы отговариваю… Ну попробуй, тебе решать. =)
> За локальный функционал современной гопоты
Там нет вижина, если что.
Только текст.
Ну, просто к слову.
Да не, она нормальная, на самом деле.
Просто сам дипсик (даже в веб-морде, даже до отупления), не дотягивал до грока по умению в РП и следование инструкциям.
IFEval ну такой себе у него.
Поорал. Спросите тех, кто чатгопоту юзает. =)
QwQ-32b для кодинга, математики и задач, Gemma 3 27b для приятного общения и вижина, если надо.

Жора тут вообще причем, чем? Это ж LostRuins.
А Кобольд — это вообще КобольдАИ изначально.
А потом форкнули llama.cpp и в качестве фронта взяли форк Кобольда.
Буквально ни в одном месте фурри нет, форк форка форка…

Не знаю, что c LLM, но с SD она отвратно работает. Отсасывает даже 3050




Вообще удивительно, насколько АМДшные карты параша в ИИ при довольно мощной общей производительности. А Интел реально могли бы навязать конкуренцию Нвидиа, если бы компанией руководили не долбоебы
>На хабр забей, там дебилы сидят.
>Зато чсв в потолочек стучит.
Дорогой дневник, нет слов что бы описать мою боль, когда читая статью "Как запустить DS локально" на хабре, я читаю как дибил рассказывает что дипсиков есть целая линейка и показывает как в свою олламу скачивает 7б "на компьютер с мощной видеокартой", а в комментариях казалось бы не глупые люди спрашивают "насколько 70b уступает 671b?" и пишут "пробовал на ноутбуке, что то не впечатляет"... А в соседнем посте другой поясняет какой нужно собирать комп для дипсика локально, просто показывая фотки дорогих железок "мать нужна двухпроцессорная"... Его спрашивают, а ты собирал? Нет, я не могу такое позволить... Пиздец, пиздец, пиздец! С пикабу и VC спроса нет, но читать такое на чванливом хабре такую срань...
Одна статья только нашлась путевая, чел завел дипсик на рабочей старой рабочей станции с ддр4 768гб и получил 1т/с. Правда судя по видео в реальном времени, токен дипсика меньше токена моей aya35б, у меня печатало в таверне повеселее на 0,8т/с, у него совсем грустно.
>Вот задачки решать — да, для работы хорошо. Только для работы ты и подписку или API оплатить можешь.
Ток для каких то сложных вопросиков и рассматриваю тащем то, для кума так заморачиваться и тратится ради 1т/с бред. И то, пока эти вопросики не сформулированы, скорее позыв в духе "даже если будет чебурнет, я останусь на коне", ну и мб NDA скармливать, пускай за ночь переваривает кучу контекста.
>Я не то чтобы отговариваю… Ну попробуй, тебе решать. =)
Я определенно заинтересован в чем то подобном, но цена/результат пока что совсем унылые. За банку говяжих анусов купить али-зион ради одного токена в секунду - что бы и нет, вложиться солидной суммой и развернуть у себя почти AGI - тоже звучит как выгодная сделка. А вот вложиться суммой и получить пруф-оф-концепт совсем без задач пока не готов. Я еще даже одну 3090 не раскрыл толком. Буду присматриваться, изучать вопрос. Я поэтому и зажопил на нормальный апгрейд компа, оставшись на ам4, потому что если нащупаю пул задач для себя, возможно придется свичится на какое то специализированное решение по типу рига карт/рам-сервака + ноут.
>Там нет вижина, если что.
>Только текст.
Я и не особо надеялся на йоба-мультимодальные фишечки вроде график-плоттинга или разговора в риалтайме, думал как максимум что вижн уровня геммы есть, но с такой скоростью он все равно не будет юзабелен.
кстати сегодня кобольда когда скачивал, тоже триггернуло :D
не понимаю вообще в чем смысл красных карт в 2025, даже игори почти все на нвидиа-ии-фичи перестроены щас и майнинг на видео снова помер.
А новый дипсик реально годнота для кума
>Интел реально могли бы навязать конкуренцию Нвидиа, если бы компанией руководили не долбоебы
Но они ей таки руководят. Проебать такой задел! Интел проебали, Боинг проебали, даже Голливуд - и тот проебали. Проебут и Америку.
Он всасывает все твои логи из всех чатов даже если ты пользовался только для одного
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, бугуртим с кривейшего тормозного говна и обоссываем калотарок.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Самый простой в использовании и установке форк llamacpp, позволяющий гонять GGML и GGUF форматы: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Однокнопочные инструменты с ограниченными возможностями для настройки: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/llm-models
• Неактуальный список моделей устаревший с середины прошлого года: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Moraliane и https://huggingface.co/Aleteian
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: