





проверил кароче с 0.99, и оно действительно работает на достаточно агрессивном 0.0005 лр по юнету и те, терять связи текста с изображением начинает примерно с 7-13 эпохи в зависимости от промта на моих настройках с жесткой регуляризацией
но общее качество сохраняется на нужном уровне отличном даже спустя 50 эпох, просто чтобы обратно возвращались умения давать написанное нужно понижать клип или юнет или оба сразу
в отличие от 2-3 эпохи где все летит в жопу ранее на 0.9 бете
обощает мое почтение теперь, практически ноль артефактов с жесткими дропаутами на всем чем можно
понизил beta2 до 0.9 (ну то есть ранее б1б2 было 0.9-0.999, теперь 0.99-0.9) - и вроде как перестало косоебить текстовый енкодер при соотношении 1 к 1, магия
>При beta2=0.999 вес новых градиентов минимален (1 - 0.999 = 0.001), и второй момент почти полностью зависит от прошлых данных. Это замедляет адаптацию к вашему датасету. Text encoder "застревает" в предобученном состоянии, а небольшие изменения накапливаются медленно и хаотично.
>Высокое beta2 усиливает эффект шума в градиентах, особенно при малом датасете или высоком LR. Это может привести к "разрушению" эмбеддингов, так как модель не успевает стабильно адаптироваться.
>Обновления весов становятся слишком "гладкими" и инерционными. Вместо тонкой настройки специфичных токенов модель начинает переписывать базовые знания CLIP, теряя способность интерпретировать сложные или редкие запросы.
>Почему beta2=0.999 хуже: Слишком долгая память и медленное обновление второго момента приводят к переобучению или "разрушению" предобученных знаний text encoder.
Кто ж знал что для TE лучше низкий beta2 и высокий beta1 (судя по всему), нигде об этом не написано, ток анон что писал про beta1 вскольз упомянул. То есть дефолтные значения оптимизаторов полностью в жопе и годятся только для полноценной тренировки на гигадатасетах или с дебильным занижением lr у te относительно юнета (что все и делают, а меня это вкорне не устраивало).
> что все и делают
Ну не совсем, на совсем уж мелких датасетах я хз зачем тебе вообще энкодер впёрлось размораживать, тем более если тренировка идёт на что то одно, без каких то разделений в лоре
>Ну не совсем
Я имею в виду, что на цивите, гхабе, реддитах если читать обсуждения и смотреть чужие конфиги там постоянно уже 3 года просто занижают te, что математически неверно для нейрокала так-то. Просто коя однажды перданул что тип "ну нирикамендую тренить те вообще, терпите, треньте только юнет, клип легко поломать", а многие не согласились и начали занижать те просто втупую.
>на совсем уж мелких датасетах я хз зачем тебе вообще энкодер впёрлось размораживать
Потому что изначально мне в жопе сверлило что нужна приближенная симуляция полной тренировки с полноценным влиянием на все веса модели, но силами лор, а не полумера в виде тренинга юнета через вижн клипа с выкл те или триггер ворд класса датасета чтобы по токену вызывать неуправляемые приколы. То есть как тренируется фул чекпоинт - там нет никаких лоу рангов, альф хуяльф, разделения unet/te, просто выбирается эффективная скорость, шедулер, оптим и оно дрочит, потом из такого чекпоинта можно высчитать дифренс в виде лоры если сильно те не отпердолен и оно будет работать даже если обратно применять. Следовательно что? Теоретически то же самое по эффекту можно добиться залезая в трубу с другой стороны - изначально подготовить тренинг лоры под эффект постпроцесса тренировки чекпоинта.
Желаемого результата именно тренировки (запоминание, воспроизведение, стабильность) я достиг это достигается пачкой регуляризаций и мокрописек, очень долго описывать, овер 150 моделей выдрочил и главная проблема была только в разрушении te спустя несколько эпох, что оказалось фиксится бетами оптимайзера (несколько недель искал как супрессить влияние на TE, гнев отчаяние - потом спросил в итт треде, пришел чел и дал верное направление с шикарным видосом по оптимайзерам; не факт кстати что оно с стандартным пйплайном тренировки лоры будет также работать, я ток давно тыкал беты и не остался доволен и больше не тыкал поэтому) и согласно моим тестам теперь работает безупречно с гигантской точностью, влияя на модель полноценно как будто бы я фул чекпоинт тренил. Да и настраивается оно проще по итогу, соотношения не нужно подбирать вот это всё, размер датасета тоже значения не имеет по итогу. Справляется как с общими концептами, так и с объект субъектами, при этом настройки вообще не меняются по сути, то есть изначальная подготовка не меняется как если бы она не менялась при тренировке фул чекпоинта, думаю после еще некоторых тестов выкатить статейку со всем ресерчем, там есть че почитать и обсудить, например квадрат дименшена через rs_lora, которая давным давно внедрена в ликорис, но в инете большинство обсуждений вообще не касается это фичи, которая по факту супрессит альфу и позволяет выставлять гигадименшены и убирает еблю с нахождением соотношения нетворка с конволюшеными (мало того, если дименшен конв меньше дименшена нетворка с рслорой то ты просто наблюдаешь деградацию точности, а при равных значениях оно работает как часики).
>если дименшен конв меньше дименшена нетворка с рслорой то ты просто наблюдаешь деградацию точности
Это кстати косвенное подтверждение того, что занижение конволюшенов в стандартных лорах исходя из того что конв слоев меньше в 4 раза чем основных модулей это костыль и архитектурно неверно. Ну конвы в принципе изначально в лоре то и не теребили никогда, это с ликорисом пришло, а там при стандартном тренинге при равных дименшенах конвы начинаются доминировать и ломают модель, что как-то вообще нелогично, потом выяснилось что проблема в самом значении дименшенов и чем ближе натуральное значение дименшена к полным парметрам тем влияние конволюшенов стабилизируется.
> Просто коя однажды перданул что тип "ну нирикамендую тренить те вообще, терпите, треньте только юнет, клип легко поломать"
Это произошло не из за кохьи, а потому что ранвей и новелы перданули моделями, в которых они не тренили клип, грубо говоря на примере показали что базового было достаточно (нет, не было, но тренить мелкий клип не поломав всё, продолжительное время они видимо не могли)
> То есть как тренируется фул чекпоинт - там нет никаких лоу рангов, альф хуяльф, разделения unet/te
И именно поэтому там даже разделение TE лров у XL чекпоинтов видимо есть?
> можно высчитать дифренс в виде лоры
Эта хуйня ужасно работает, когда ты ужимаешь в ранги ниже 32, даже в нём уже пиздец виден может быть, оно типо заедет, только если пережарить к хуям будкой и извлечь в мелкий ранг, в котором потеряется столько информации, что сгладит прожарку. Лучше тренить сразу в низком ранге со всеми свистоперделками, да
> думаю после еще некоторых тестов выкатить статейку со всем ресерчем, там есть че почитать и обсудить, например квадрат дименшена через rs_lora, которая давным давно внедрена в ликорис, но в инете большинство обсуждений вообще не касается это фичи, которая по факту супрессит альфу и позволяет выставлять гигадименшены и убирает еблю с нахождением соотношения нетворка с конволюшеными
А когда то была такая ебля? Эта rs lora в кохье и у кохака ничего практически не делает, просто скейлит не от альфы а от её квадратного корня, хз зачем вообще она существует, когда можно тоже самое самому поставить
>Это произошло не из за кохьи
Я про то что для энтузиастов скрипты принес коя, а один из ранних туторов кои прям содержит фразы уровня "не рекомендую тренировать клип".
>И именно поэтому там даже разделение TE лров у XL чекпоинтов видимо есть?
Есть =/= требуется. Вообще не про то речь. Я к тому что если нужен эффект обучения с нуля нужно не файнтюнить на низкой скорости предобученную часть, а делать жесткую связь между новыми знаниями и новыми текстовыми описаниями, чтоб без токенликинга. Сюда же синтетические тесты, где глобальный лр один на всё для тестирования эффективности.
>А когда то была такая ебля?
Да, постоянно. Шаг влево шаг вправо - рестарт тренировки.
>Эта хуйня ужасно работает, когда ты ужимаешь в ранги ниже 32, даже в нём уже пиздец виден может быть, оно типо заедет, только если пережарить к хуям будкой и извлечь в мелкий ранг, в котором потеряется столько информации, что сгладит прожарку. Лучше тренить сразу в низком ранге со всеми свистоперделками, да
Ну я не согласен с этими утверждениями особо, но ты не туда разговор повел. Я именно про концепцию отделения натренированной части полновесной модели в лору, она рабочая практически на любой модели, кроме условной пони где уничтожен клип. То есть мысль такая: если данные в целом в большей степени пакуются в низкий ранг из полновесной модели и восстанавливаются обратно практически полностью с тем же эффектом и незначительными потерями (очевидно потому что данные содержатся на более широком пространстве и ужимаются с сохранением части данных на всем пространстве), то обратное тоже верно - можно развертывать лору в модель не с узким ренжем по дельте магнитуды и дельте дирекшена (как делает стандартная лора: либо большая величина + большое направление, либо малая величина + малое направление), а с широким ренжем, получая эффект полноценной всенаправленной тренировки, а для этого надо большее число параметров и дора в качестве симуляции файнтюна.
> Эта rs lora в кохье и у кохака ничего практически не делает, просто скейлит не от альфы а от её квадратного корня, хз зачем вообще она существует, когда можно тоже самое самому поставить
Вопервых не от альфы, а корень нетворк дименшена, т.е. альфа делится на корень из дименшенов.
Вовторых ну ты скорее всего не тестировал рс вообще, а я тестировал:
Cупер эффективно работает с большим дименшеном и позволяет тренировать большее число параметров не влияя на используемые ресурсы особо. Итого если при стандартных вычислениях у меня могла тренироваться лора в 64 дим макс без ООМ на карту, то теперь спокойно влезает 100 дим, из которого квадрат 10, а это ебический буст качества как я уже писал. Ниже 64 смысла юзать с рс нет, а буст от большего дименшена виден невооруженным взглядом если сравнивать каждое повышение, при этом на стандарт лоре наоборот высокий дименшен руинит тренировку (я так и не понял почему).
Плюс роль альфы в параметрах супрессируется вслед за дименшеном и гораздо проще становится выбрать громкость лоры в модели через альфу нужную, хоть 1 ставь - все равно будет эффективно обучаться от квадрата, а это на секундочку 1/10, то есть 0.1 коэффициент обновления. Хоть 20 по альфе ставь если есть юзкейс полного переписывая весов экстремального (что не достигается на стандартных лорах, т.к. фактически тебе надо указывать условно 32 дим к 64 альфа, что руинит тренировку сразу, т.к. альфа это супрессирующий коэффициент, а тут получается что параметрически у тебя 100 нетворкдим, а альфа 20 - что удовлетворяет базовой лора логике, но такой хуйни в большинстве случаев не требуется).
Плюс коэф обновления в стандартной лоре сорт оф геометрический, там типа сила применения не линейной получается - то есть 0.5 это на самом деле далеко не 0.5 а гораздо меньше, итого получается ты и так на мелком дименшене сидишь, так еще и это мелкое кол-во параметров обновляется недостаточно сильно, а с большим коэфом слишком сильно, а еще лернинг трогать опасно т.к. зависимость менее линейна и ренж безопасного лернинга сужается еще сильнее, баланс трудно подобрать короче.
В стандартных лорах с 32 по дименшену коэфф 0.1 это 32 к примерно 3, что уже медленно и неэффективно, а выставить 32 к 1 это равносильно вечной тренировке с влиянием 0.03, держим в уме что 0.03 эффективность это не натуральная величина.
Опять же повторюсь что рс позволяет выставить тот же дименшен/альфу на конв слоях, что более нативно для архитектуры (т.к. ранг это лоу ранк прикол, а полнопараметрическая модель работает с полными параметрами и просто если логически подумать то конволюшены это просто блок модулей отвечающий за текстурки и локал данные, уменьшать их относительно нет дим просто потому что их меньше во столько то раз нелогично, с какой стати вообще ранг у конволюшенов обязан быть меньше, если рангов не существует), что на стандартной лоре поломает всё, а тут эффект получается противоположным - емкость параметров выше в разы получается и эффективность конв возрастает, поэтому получается ебическая четкость, которую на стандартной лоре я не могу подобрать, т.к. без квадрата лора почему-то стабильно тренируется только исходя из соотношения того что количество основных слоев в 4 раза выше чем конв слоев. То есть минус дополнительная мозгоебка с конв слоями. Ну можно конечно выставить 2-4 раза меньше оносительно дименшена основного также с рс лорой, но эффективность конв трагически падает, растет нестабильность, четкость улетучивается, как будто емкости нехватает кароче.
Кароче данный параметр очень крутой на самом деле, убирает пару костылей, математически стабилизирует, приближая лору к поведению тренировки на полных параметрах без усиленного влияния ранга.
Бля, как сила лор работает? Тренирую лоры, на весе 1.0 немного уже пидорасить начинает, на 0.9 самый норм. Ну я взял и в конце тренировки начал веса на 0.9 умножать. Теперь поломка около 1.6. Какого хуя? Альфа у меня равна рангу, т.е. веса на 1 домножаются. Откуда такая разница? Разве сила лоры не просто множитель весов?
Кто то пробовал тренить dreambooth на noobai? У меня почему то первые же шаги сжигают модель, после тренировки только шум получается, до этого успешно получилось на epsilon-pred тренировать, но если те же параметры выставить + --v_parameterization --zero_terminal_snr, то не выходит, уменьшение lr или увеличение min snr gamma тоже не помогли
Ну ты б хоть конфиг показал чтоли.
Сила лор при применении имеешь в виду? Ну там математика простая, допустим у тебя тренилась лора с альфой, которая дает 0.5 громкость лоры (альфу делить на дименшены), тогда фактическая громкость при весе применения 1 (полное) будет 0.5. Но если ты понижаешь само применение до 0.9, то это 0.9 умножить на 0.5 и итоговая громкость лоры при инференсе будет 0.45, то есть потенциальная сила уменьшена на 5%, а не на 10%, как если бы был коэффициент alpha/dim равный 1.
В твоем примере у тебя альфа равна рангу, значит обновления весов были полными, тогда зависимость линейная - 0.9 веса лоры будет равняться 10% убавлению громкости лоры, ты как бы говоришь модели бери 10% данных от изначальной модели по используемым весам. Так как веса изначальной модели чище и стабильнее изначально, а ты тренировал с полной перезаписью, то этот 10% вклад в твои кривые новые веса достаточен и они выправляют финальные векторы в латентспейсе и картинка стабилизируется.
Коэфф 1 это еще не перезапись весов, но очень сильное влияние на них по формуле W' = W + ΔW, где 0.9 применения веса гасит избыточность весов лоры.
Если ты хотел добиться эффекта перезаписи то коэффициент должен быть в разы больше, 50, 100, 1000, т.к. лора модуль не замещает собой веса, а добавляет к ним дельту, таким образом нужно сделать дельту настолько огромной чтобы веса изначальной модели не были значительными в этой формуле.
>Ну я взял и в конце тренировки начал веса на 0.9 умножать. Теперь поломка около 1.6. Какого хуя?
Не понял что ты сделал. Получил alpha/dim=0.9?
>Альфа у меня равна рангу, т.е. веса на 1 домножаются. Откуда такая разница? Разве сила лоры не просто множитель весов?
Сила лоры в инференсе это дополнительный ползунок громкости просто. Если у тебя на единичке плохо генерит то это переобучение => гиперпараметры соснуле (не заморачивайся, на консумерской технике с грубыми гиперпараметрами для быстрой тренировки все равно идеальных настроек и градиентов следуемых из них не получить).
По факту тренируя с коэфф 1 от alpha/dim ты сильно влияешь на исходные веса в каждый момент обучения (громкость, равная масштабу обновлений, которые ты вносишь во время тренировки; это значит, что лора вносит изменения, сопоставимые по величине с весами модели (W), и при каждом шаге обучения сильно их модифицирует, но не перезаписывает), а учитывая что твои параметры с вероятностью 99% не идеальны, то полный вес просто уничтожает натуральные связи модели (там много зависимостей от текст енкодера и величины градиентов, с которыми основная модель не понимает как корректно работать).
>а ты тренировал с полной перезаписью
а ты тренировал с значительным вкладом в веса модели
фикс
>У меня почему то первые же шаги сжигают модель, после тренировки только шум получается
тут 2 варианта я вижу без бОльших данных
1. если это не просто чорный экран, то лосс неправильно интерпретируется моделью при тренировке или градиенты чем-то обнуляются/разрушаются, я бы отклчил zsnr и вообще любые влияния на шум и занизил скорость в 10 раз и прогнал мелкий датасет для теста, вместо оптимайзера с шедулером я бы взял шедулерфри любой чтобы исключить подсирание шедулера вообще, взял бы loss type l1 т.к. он штрафует вообще всё отваливающееся
2. возможно ты сидишь на какойто ветке кои с багом, где впред не работает, на чем сидишь? ЩАс вроде самая актуальная ветка это sd3 на кое
>до этого успешно получилось на epsilon-pred тренировать, но если те же параметры выставить
ну впред от епс отличается, настройки от епс не подходят к настройкам впред
>увеличение min snr gamma
мин снр просто снижает влияние ранних таймстепов из которых впред умеет доставать годные данные, если не нужен низкий таймстеп тогда его проще отрезать просто, а не занижать
Сейчас просто на main сижу, сделаю датасет на 1 концепт, отключю zero_terminal_snr, и сменю ветку на sd3, ну и ещё какой нибудь шедулерфри оптимизатор выберу, ранее не юзал таких, надеюсь сработает




Насколько стейбл дифюжин хуже чем топовые модели от open ai?
Выглядит как прорыв в сравнении с тем, что есть в опенсорсе
Выглядит как прорыв в сравнении с тем, что есть в опенсорсе
Прорыв чего? Всратый вае прямиком из Дали на месте. В стили умеет так себе. То что Дали в 2025 научили контролнету - это пиздец достижение, да. Всё что я вижу из жпт - дженерик нейромусор, хуже Флюкса Про. Что-то на уровне гугловского инмагена.
Загон для криворучек тут .
Главный прорыв - возможность позиционирования некоторых объектов описанием. Для текста, схем и некоторых это йоба киллерфича, для композиций и прочего - хуйта. Следующим идет простота использования, чтобы что-то получить нужно быть не совсем дауном и просто это описать.
В остальном - знания оче вялые, на выходе только одобренное корпорацией (не)добра, огромная предвзятость по многим вопросам, отсутствие инструментов нормального контроля, посредственное качество.
Если ты нормис, для которого весь интернет в телефоне, это ебать прорыв, потому что спустя 2.5 года у тебя появилась возможность прикоснуться к генеративному ии картиночек. Если уже был в теме - подметишь для чего это можно применить и проблюешься с обилия недостатков.
>Насколько стейбл дифюжин хуже чем топовые модели от open ai?
Сравнивать некорректно, с одной стороны мощность гигакорпорации, которая душит фильтрами и требованием грошей, с другой полная свобода, требующая скиллов и пердолинга с фиксами незначительных упущений. Это как сравнивать фотошпский нейродвижок за подписку и то же самое функционально сделанное через криту в связке с комфи и любой моделью. Я думаю очевидно, что второй вариант более предпочтителен.
>Выглядит как прорыв
Выглядит как дженерик так-то. Весь цвитай забит подобным что на ветке сдхл, что на флюхе, что на понях.
Оказывается проверить переобучение на стабильной неартефачащей модели можно просто базовым промтом уровня "cat photo, hypercube" или "a cat riding a bicycle in a forest", не относящимся к датасету. Даже гриды гридить нинужно, сразу видно и токенликинг и обосранные эпохи.
>Ну я взял и в конце тренировки начал веса на 0.9 умножать.
>Не понял что ты сделал. Получил alpha/dim=0.9?
weight decay он сделал, только одним большим шагом.
А, теперь понял, а то написано про умножение, а вд это тормоз-регуляризация и упрощение через увеличение штрафа.

Да я уже сам разобрался, разница потому что при инференсе умножаются смерженные тензоры, а не отдельно lara_a и lora_b, как у меня.
> weight decay он сделал
Нет, я именно умножил веса перед сохранением, пикрил.
>Нет, я именно умножил веса перед сохранением, пикрил.
Так это и есть weight decay
Нет. Weight decay - это L2-регуляризация. Там из нового веса вычитается прошлый вес с коэффициентом.
Ну сути дела это не меняет, даже если ты так будешь каждый шаг делать, просто съест немного от lr и все, не принципиально.
https://www.youtube.com/watch?v=A6dqIJsGwwQ
Пришла такая мысль, что из-за слопохудожников типа видрила, которые не прорисовывают детали, в наших моделях, обученных в большинстве своем на РИСУНКАХ, возникают артефакты. Модель это копирует, но не понимает где ей можно так "халтурить", а где нельзя.
Диффузионки слишком маленькие и тупые для таких обобщений.
Поэтому какие-то годные результаты получаются только когда датасет состоит из плоского маняме или тем более поней на флеш анимации, либо ирл.
Пришла такая мысль, что из-за слопохудожников типа видрила, которые не прорисовывают детали, в наших моделях, обученных в большинстве своем на РИСУНКАХ, возникают артефакты. Модель это копирует, но не понимает где ей можно так "халтурить", а где нельзя.
Диффузионки слишком маленькие и тупые для таких обобщений.
Поэтому какие-то годные результаты получаются только когда датасет состоит из плоского маняме или тем более поней на флеш анимации, либо ирл.
Попробуй без минснр, дебиаседа и прочего, остальные ещё параметры хз какие. Там был серьёзный баг с энкодерами с какого то из коммитов на дев ветке кстати, с лорами прямо видно было как всего ~90модулей заместо ~230 тренилось, аффектит ли это как то файнтюн только хз
Тупее по энкодеру, красивее по визуальной составляющей, все модели нового поколения намного "умнее" XL, но даже в твоих примерах желтая блевотина, а у того же наи артефачная хуйня по итогу. Не то чтобы сам XL не страдал желтизной, та же пони, но тут прямо гигатреш попёр какой то, некоторые картинки литералли от 1.5 или пони не отличишь по визуалу
Таких много, wslop, ciloranko, quasarcake. Последний кстати, добавленный в негатив на базовой 0.1 люстре ахуеть как бустил картинку, лол
> Я про то что для энтузиастов скрипты принес коя, а один из ранних туторов кои прям содержит фразы уровня "не рекомендую тренировать клип".
Ну типо того, но ведь ноги растут не оттуда всё равно, кохья и остальные тогда ориентировались именно на основных типов, кто уже сделал чекпоинты. Кстати из единственной открытой инфы про хл, что я знаю, не рекомендовал тренить энкодер только создатель люстры в своём рекламном пейпере, но с ремаркой, что только с мелким датасетом, с большим якобы ок. Новелы тактично умолчали про часть с энкодером, написав ровным счётом нихуя
> если данные в целом в большей степени пакуются в низкий ранг из полновесной модели и восстанавливаются обратно практически полностью с тем же эффектом и незначительными потерями
Сомневаюсь, что полноценный файнтюн типо нуба можно будет так извлечь, запихнув в дору, потом развернуть назад, не потеряв мелкие детали или редкие концепты, а вообще в дору разве есть ли экстракт?
> Вовторых ну ты скорее всего не тестировал рс вообще, а я тестировал:
Ну как
> Ниже 64 смысла юзать с рс нет
Просто делать такие лоры на хл стало дурным тоном в один момент из за мемных размеров на выхлопе, при равной/лучшей производительности в меньших рангах, и я стал делать всё сразу в лоурангах, не больше 32, в основном вообще 16, так что впринципе можно сказать что не тестил, но интересно почему оно зааффектило врам как минимум
> при этом на стандарт лоре наоборот высокий дименшен руинит тренировку
Да всё просто, лр с повышением числа параметров надо снижать, и наоборот, по крайней мере по одному из старых убеждений, начавшемуся тоже вместе с эпохой лор в репе кохьи, когда дефолт 1е-6/5 у файнтюна превратился в 1е-4/3 с 128 рангом у 1.5 лор, можешь попробовать если не лень
> Кароче данный параметр очень крутой на самом деле, убирает пару костылей, математически стабилизирует, приближая лору к поведению тренировки на полных параметрах без усиленного влияния ранга.
А какая именно реализация, кохака или кохьи? И что в итоге на выходе, опять гигабайтный файл от 100 ранга получается?
Может ли кто скинуть настройки для обучения Lora SDXL через OneTrainer на 12VRAM?
Я наверное задам глупый вопрос, но для чего нужны регуляризационные изображения? Для лоры я так понял их лучше не использовать, а для dreambooth? Где то видел что их нужно генерировать с помощью модели на которой будет тренировка, по какому принципу нужно их генерировать?
Попробовал разные оптимизаторы, получилось на адам шедулер фри натренировать, и на DAdaptation, во 2 варианте больше понравилось, но вероятно не оптимальные параметры для адама подобрал, попробовал полный датасет с 3 рисоваками, узнаются но в целом если на 1 тренировать то получается лучше, есть ли способ как то улучшить результат? Может больше эпох выставить? Или дальше сгорит? Добавил конфиг с параметрами https://litter.catbox.moe/4n6lqb.txt, изображений 359+821+2361 без учета повторений
Попробовал разные оптимизаторы, получилось на адам шедулер фри натренировать, и на DAdaptation, во 2 варианте больше понравилось, но вероятно не оптимальные параметры для адама подобрал, попробовал полный датасет с 3 рисоваками, узнаются но в целом если на 1 тренировать то получается лучше, есть ли способ как то улучшить результат? Может больше эпох выставить? Или дальше сгорит? Добавил конфиг с параметрами https://litter.catbox.moe/4n6lqb.txt, изображений 359+821+2361 без учета повторений
> попробовал полный датасет с 3 рисоваками
Без проблем тренятся хоть 10 стилей, если ты нормально отделил капшенами их.
> изображений 359+821+2361 без учета повторений
Слишком мнего и слишком мелкий батчсайз чтобы все эти зумерские schedule-free нормально работали, он тебе lr слишком низкий будет ставить. И если тренишь с батчсазом 1, то шагов надо 20к хотя бы на таком датасете. 2-3 эпохи только с нормальным батчсайзом будут работать. И я надеюсь ранг лоры у тебя выше 32. Так же ты наверное треншь только аттеншен, попробуй конволюшены и ff тоже тренить, если хочешь результат сильнее, для стабилизации тренировки можно первые слои не тренить.
>но для чего нужны регуляризационные изображения?
>Для лоры я так понял их лучше не использовать, а для dreambooth?
Для сопоставления предсказания с ними, типа гайденс для сети дополнительный. Дают плюсик при тренировке фул чекпоинта, для лоры смысла нет так как лора уже опирается на данные из основного чекпоинта.
>Где то видел что их нужно генерировать с помощью модели на которой будет тренировка, по какому принципу нужно их генерировать?
Вообще не обязательно, у рег картинок нет описания, они просто клипвижном рассматриваются и сопоставляются, то есть можно взять готовые регуляризационные архивы и забить хуй. Но можно и нагенерить, обычно просто общими классами типа woman.
>Может больше эпох выставить?
Количество эпох не влияет так что больше=лучше, хоть миллион можешь выставить, но с нормальными настройками свитспот можно хоть к пятой эпохе получить, а все остальное это выдрочка и усложнение модели вплоть до перетренировки.
>есть ли способ как то улучшить результат?
Да их тонны.
Из очевидных это обрезка шумных таймстепов ниже 100-300, то есть ты инишл нойз оставляешь от модели основной, а работаешь только с читаемыми данными выше 300 таймстепа с 70% зашумленностью и ниже. Сюда же debiased_estimation_loss который еще сильнее будет форсить расшумленные таймстепы при обновлении весов. Можешь поиграться с типом ошибки, мне нравится как работает l1, l2 слишком сенсетивный. Можно форсить все дропауты (для кепшенов и самих модулей сети), практически это дает лучшее обобщение, а не заучивание паттернов к токенам. Можно выставить нестандартные беты для оптимайзера типа 0.99 по бете1 и 0.01 по бете2, таким образом у тебя будет максимальная память о прошлых градиентах, но максимальная реакция обновления => быстрое схождение. С лорами мокрописек больше, но ты как я понял дрибутишь целую модель.
>Слишком мнего и слишком мелкий батчсайз
Я бы скозал что наоборот слишком мало, комплексные задачи требуют больших датасетов даже для лорок, что при малом количестве данных бустится репитишнами и письками для увеличения разнообразия. А батчсайз дело десятое, два конечно лучше чем один будет, но только из-за того что будет большая стабильность градиентов и меньшее время для эпохи, в основном бетами можно скорректировать как учитывать данные с датасета.
>чтобы все эти зумерские schedule-free нормально работали, он тебе lr слишком низкий будет ставить.
Так шедфри усредняет и интерполирует значения и таким образом достигается стабилизация и быстрая сходимость, сам лр не трогается и всегда одинаковых как задал, если не адаптивный оптим. Поэтому в шедфри можно сувать огромные лры и оно даже не ломается. Адаптацией лра в минимум (не встречал такого в своих прогонах кстати) будут заниматься ток шедфри оптимы которые и так адаптивные ну продижи и дадапт там, если им флур не задать нормально.
>Так же ты наверное треншь только аттеншен, попробуй конволюшены и ff тоже тренить, если хочешь результат сильнее, для стабилизации тренировки можно первые слои не тренить.
Он же фул модель тренит
> комплексные задачи
Стиль рисоваки - это не комплексная задача. Это простейшая задача для датасета из 10 пиков, 50 если надо прям совсем точно скопировать.
> фул модель тренит
Даже если будку тренишь, не для всех параметров градиенты считаются по умолчанию. У кохи точно не все.
>Сомневаюсь, что полноценный файнтюн типо нуба можно будет так извлечь, запихнув в дору, потом развернуть назад, не потеряв мелкие детали или редкие концепты,
Ну у нуба выдроченный клип с "редкими концептами" и связанные с ними данные, примерно как у пони. Вся загвоздка в несоответствии оригинального клипа сдхл с клипом нуба. Есть сложности, но в целом решаемо. На моделях основной ветки сдхл с большими датасетами все извлекается и возвращается обратно с генами уровня погрешности сида, это я точно пробовал еще в прошлом году, т.к. экстракт из моделек отлично свдшился с моими лорами.
>а вообще в дору разве есть ли экстракт?
Дора это про декомпоз который учитывает нестандартное поведение дельт, ты можешь сам порезать экстракт из модели на наиболее важные части/слои, потом снизить ранг полученной комбинации и получить дора эффект. Можно еще на моменте снижения ранга применить свд с основным экстрактом чтобы еще более точно симулировать.
>Ну как
Ну, желания возвращаться на стандартные лора настроечки нет желания.
>но интересно почему оно зааффектило врам как минимум
Потому что более оптимизированные вычисления и нормализация. Более компактное представление, меньше избыточность матриц оригинальной лоры где ранк умножается на A и B "прямо", избегает дополнительные вычисления нестабильных градиентов и накопление ошибок.
>лр с повышением числа параметров надо снижать, и наоборот
Это понятно, но дело в том что даже с низким лр большой дименшен на обычной лоре всирает тренировку. На глоре допустим это пофикшено и там наоборот чем выше дименшен тем более круто, но жрет врама она также дохера без рс. Я так понимаю это проблема масштабирования оригинального алго.
>А какая именно реализация, кохака или кохьи?
Кохака
>И что в итоге на выходе, опять гигабайтный файл от 100 ранга получается?
762 мб в ранге 100. Но еще зависит от лагоритма, в локре факторизацией можно снизить не особо потеряв в обобщаемой способности.




тренировал dreambooth, не лору, все в промтах отделил, оказывается тот конфиг что скинул был для маленького датасета, на котором тестировал, вот корректный https://litter.catbox.moe/g78ztf.json, на полном добавил --gradient_checkpointing и батч сайз 8, на 3 эпохи вышло ~2500 шагов, тренировал и unet и текстовую модель, правда текстовую часть 0.5 lr поставил
Пробовал 2 раза, 1 раз получилось нормально, но концепты почти не изучились, только стиль, 2 раз- добавил повторений на концепты, где то *7~15, некоторые концепты все ещё не изучились, но некоторые стали намного лучше
Пробовал с шедулер фри на полном датасете с батчем 12, но там лосс вырос до 0.4, и сильно не снижался, как я понял там на первых шагах все сожгло, хотя я довольно низкий lr поставил, где то 0.000001, сейчас не найду наверное конфиг с тренировкой
На DAdaptation loss доходит до 0.1 и до конца тренировки где то на нем и держался
По стилю ещё далеко до чекпоинтов натренированных на датасете который состоит только из изображений для 1 рисоваки, вот даже на sd1.5 больше похоже выходит если чистый датасет юзать или через лору, но хотелось бы были все и что бы было лучше, и в 1 месте, очень вероятно что проблема в скил ишью и проблемы балансировки датасета, ну или вероятно это просто невозможно сделать из за обобщения и будет работать только в моделях побольше
>обрезка шумных таймстепов ниже 100-300
Лучше пропускать начальные шаги? Это не скажется на концептах? Просто они и так далеко не идеальны, а ранние шаги как я понимаю нужны как раз для того что бы сформировать позу, или другие штуки которые составляют основу для будущей картинки
>debiased_estimation_loss
debiased_estimation_loss я так и не понял что это, и не стал включать
>мне нравится как работает l1, l2 слишком сенсетивный
loss l1 попробую вместо l2 в следующий раз,
>Можно выставить нестандартные беты для оптимайзера типа 0.99 по бете1 и 0.01 по бете2
ставил betas=0.9,0.99
Выкинь будку и трень нормально лору. Либо трень саму модель, будка это кал.
> концепты почти не изучились
Больше шагов делай или бери нормальный оптимизатор в высоким lr.
> только стиль
Да и стили как-то слабо натренились у тебя. ogipote вообще не похож.
> хотелось бы были все и что бы было лучше, и в 1 месте
Так ты и делай как делал одну лору, только всё кучей. Разбиваешь датасет на категории по стилю/концепту, промптишь триггер-вордом каждую категорию и всё в кучу в одну лору. Работает безотказно. И у тебя может насрано в капшенах и надо их пердолить, а не дрочить параметры.
Тренить саму модель, в смысле finetune использовать, я почти инфы не нашел на счет этого способа тренировки в отличии от dreambooth, и параметры тренировки у них вроде как одинаковые. Лоры я пробовал тренировать, правда для пони давно, гараздо лучше работают и для стиля и для концепта, оно и понятно на ней можно что то определенное натренировать не думаю о балансировке и используя изображения только для того что тренируешь, но как ранее написал хочется несколько вещей сразу иметь в 1 месте, и возможно даже лучше, но пока результат выходит печальный

>Лучше пропускать начальные шаги?
Статистически в них данных мало, а подосрать в тренировку они могут.
>Это не скажется на концептах?
Нет
>а ранние шаги как я понимаю нужны как раз для того что бы сформировать позу, или другие штуки которые составляют основу для будущей картинки
Не, не так работает. На полном шуме полезных данных нет, это буквально ничто, на шуме от 50 до 100 там ну максимум общие формы можно разглядеть и то если получены данные о высоком контрасте с градиента. Тренировка с учетом низких таймстепов это скорее дампер от переобучения, сеть рандомно равномерно распределенно не понимает что происходит и корректирует вычисления чтобы доджить подобное в будущем, то есть будет пытаться не вносить никаких значимых изменений на раннем шуме. Ради интереса попробуй обратный эффект - ограничь обучение на шагах от 0 до 100, сеть ничему не обучится, но стабильно будет неуправляемо видеть всякое в них все лучше и лучше. Это как если бы ты учил модель исключительно на "белом шуме" — она просто не поймет, что делать, но будет выдавать тебе рандомный говняк.
>debiased_estimation_loss я так и не понял что это, и не стал включать
Это мощный усилитель таймстепов на которых содержатся полезные данные и понижение таймстепов где шум. Пикрел красный графек.
>ставил betas=0.9,0.99
Ну это базовое значение для гигадатасетов корпораций с тысячными батчами и миллиардными датасетами, достаточное стабильная (но не прям супер стабильная, просто плавное затухание) память о прошлых градиентов (первое число) и низкая реакция инерции адаптации (второе число).

> На полном шуме полезных данных нет
Полного шума не существует при тренировке, т.к. шум плюсуется к оригинальной пикче и он всё равно виден. Для полного уничтожение низкочастотных данных придумали noise offset - рандомить шум дополнительно по оси каналов.
> Тренировка с учетом низких таймстепов это скорее дампер от переобучения
Как минимум для стабильности очень помогает прогрев весов на низких шагах. Я пикрил делаю, постепенно увеличивая верхний порог по ходу тренировки. Убирает все внезапные поломки, отклонение генераций плавное идёт, можно lr поднимать до упора.
>Полного шума не существует при тренировке, т.к. шум плюсуется к оригинальной пикче и он всё равно виден.
Модель обучается не на картинке с шумом, а на полученном градиенте с нее. Если конкретно не задано, то в 10% от всех шагов у тебя будет получен градиент с 90-100% зашумленной картинки, что нулевая и околонулевая эффективность.
>придумали noise offset - рандомить шум дополнительно по оси каналов.
Офсет просто скалярное значение, добавляемое ко всему шуму, а не рандомизация по каналам, используется для изменения начального шума, чтобы повлиять на генерацию, добавить разнообразия или улучшить детали (что спорно). Это не инструмент для уничтожения низкочастотных данных. Уничтожение низкочастотных данных вообще происходит естественным образом в процессе добавления шума на высоких таймстепах, и для этого не нужен дополнительный параметр. Если бы целью было полное уничтожение низкочастотных данных, то это уже достигается стандартным процессом диффузии, где шум добавляется постепенно, разрушая сначала мелкие детали (высокие частоты), а затем и крупные структуры (низкие частоты) на поздних стадиях. Этот параметр вообще появился как опция из вебуя, а коя адаптировал его для своих скриптов. Его задача практическая: улучшить генерацию, а не решать теоретическую проблему частотного спектра кароче.
>Как минимум для стабильности очень помогает прогрев весов на низких шагах.
Троллейбус из хлеба как будто.
> Офсет просто скалярное значение
Нет, это именно рандомизация каналов, генерится шум (1, 4, 1, 1), а не скаляр. Делает то что и должно делать - убирает остатки низкочастотных данных с оригинальной пикчи. Читай:
https://www.crosslabs.org//blog/diffusion-with-offset-noise
> коя
Я не пользуюсь говнокодом кохи, реализацию оффсета брал его как автор написал.
> Троллейбус из хлеба как будто.
Работает лучше чем все эти пердольные попытки проскейлить loss, вместо того чтобы градиенты изначально ровнее получать.
Ну раз так иди пулреквестни в скрипты, полезное дело
> lr поставил, где то 0.000001
Это очень мало для schedule free. Но мне он очень не понравился, на 1е-3 модель ломается, если ставлю 3е-4 как на Адаме - схождение ультрамедленное. Твои 1е-6 вообще удивительно что хоть что-то натренить могут.
>Это очень мало для schedule free.
Я от 0.00025-0.0005 гонял, все прекрасно. Можно выше, но изменения слишком резкие, дефолт скорость у лицокнижных вообще 0.0025.
>Но мне он очень не понравился, на 1е-3 модель ломается, если ставлю 3е-4 как на Адаме - схождение ультрамедленное.
Так что вероятно другие гиперпараметры настроены всрато у тебя.
Алсо если не лицокнижный продижи брать https://github.com/LoganBooker/prodigy-plus-schedule-free то там тоже все прекрасно, я на нем преимущественно сижу т.к. результаты достигаются еще быстрее чем на обычных шедфри оптимах притом что скорость обсчета шага дольше, d0 тоже указан как 0.00025
> другие гиперпараметры
А причём они, если я меняю только оптимизатор, который и даёт снижение скорости обучения. Понятное дело можно напердолить до уровня Адама и получить кучу проблем, например лоры пожирнее сделать, но зачем. На Адаме я могу за 1000 шагов натренить, а с schedule free надо повышать до 2-3к. А сгладить градиенты всегда можно с EMA как деды делали 5 лет назад.
> продижи
Да, он получше. Но всё нивелируется тем что он сам по себе очень медленный, примерно в х1.6 шаг дольше делает. Это вообще никуда не годится.
> результаты
Возможно ещё у нас разные понимания результатов. Для меня результат - это возможность генерить копии пиков из датасета чисто по промпту. А дальше уже весом регулировать всё это. Я в основном реалистиком упарываюсь, там без этого никуда.
>А причём они,
Потому что я понятия не имею что ты используешь и в какой конфигурации. В моей конфигурации и шедфри обычные и продиги обучают моментально относительно друг друга, я по привычке выставляю тренировку на ночь на 100 эпох, но с утра проверка раз за разом показывает что юзабельный результ достигается чуть ли не начиная со второй по пятую эпохи, а дальше уже накрутка излишняя, требующая снижения влияния TE в модели ибо повторяет датасет больше, чем обобщает, ну у меня и агрессивные настройки такто так что это нормально.
>На Адаме я могу за 1000 шагов натренить, а с schedule free надо повышать до 2-3к.
Ты пишешь как будто вычисления не зависят от твоих настроек а только от факта используемого оптима, что не так в реальности. То что у тебя схождение (если ты это подразумеваешь под натренить) требует 3к шагов это явно проеб по остальным параметрам. К тому же ты сам пишешь "на 1е-3 модель ломается, если ставлю 3е-4 как на Адаме - схождение ультрамедленное", что не нормальное состояние шедфри.
> Но всё нивелируется тем что он сам по себе очень медленный, примерно в х1.6 шаг дольше делает. Это вообще никуда не годится.
Да какая разница какая скорость просчета, если он эффективно достигает схождения. Вот у меня датасет 100 картинок и батч 2, юзабельная модель с продижи со второй эпохи начинается буквально, а это 20 минут тренировки вместе с ТЕ. Для сравнения адам со скоростью в 1.6 раз ниже достигает примерного эффекта двух эпох продиж к 4-5 эпохе, что около 30 минут. Теплое с мягким кароче сравниваешь, не на то внимание акцентируешь.
>Для меня результат - это возможность генерить копии пиков из датасета чисто по промпту. А дальше уже весом регулировать всё это. Я в основном реалистиком упарываюсь, там без этого никуда.
Так у меня тоже реалистики, в основном докрутка концептов исходной модели, субъекты и стилевой пиздинг, но я упарываюсь по обобщению, чтобы моделька не просто говно с датасета генерила и не требовала влиять на вес лоры при генерации. Но твои приколы тоже легко достигаются скоростью одинаковой на те и юнете и увеличенной громкостью через альфу.

В одинаковых условиях schedule free тренит медленнее, чем Адам, на остальное мне похуй. Он собственно это и должен делать, потому что демпингует автоматически тренировку на основе градиентов.
> вычисления не зависят от твоих настроек а только от факта используемого оптима
Градиенты не зависят, зато то насколько сильно веса обновятся на основе этих градиентов зависит только от оптимизатора и ничего другого. Об этом и речь, а не об результатах в вакууме. Я ведь для теста беру 10 пиков и смотрю визуально по типу пикрила насколько быстро к датасету оно приедет и куда скачет при тренировке. Перетренить 2000 шагов - это 15 минут, я на каждое изменение обычно делаю тесты на дженерик дасатетах.
Высматривание каких-то обобщений - это субъективщина, не имеющая никакого отношения к оптимизатору, оптимизатор тебе ничего не обобщает, он просто вычисляет момент/вес с которым градиенты применить к весам. Исключение - только регуляризации типа weight decay или встроенного EMA.
> датасет 100 картинок и батч 2, юзабельная модель с продижи со второй эпохи
Звучит как будто у тебя за 100 шагов тренится всё. На продиджи warmup только шагов 300.
Я прекратил тренировку как только увидел loss, маловероятно что там вообще что то осталось
В чем прикол шедулер фри продиджи? В нем же наоборот автоматически регулируется lr, и нужно просто constant шедулер ставить, хотел его попробовать но не разобрался как отделить lr текстовой части от unet
> Я прекратил тренировку как только увидел loss
Мимо, но нет смысла никакого смотреть на лосс, если он не летит стабильно вверх всё время тренировки. Сток впред/флоу предикшены впринципе тебе страшные значения покажут в виде 0.25 на плоских датасетах смещённых в 2д с вайт беками и до 0.4 на детейлед хуйне, если всякие вмешательства в таймстепы начнёшь сувать, то минснр покажет с впредом такой же как на эпислоне, дебиасед уже не помню, но он такое себе конечно решение, если прямо надо пиздец как доебаться до таймстепов лучше юзать edm2, лосс с ним кстати всегда стабильно летит вниз
> В нем же наоборот автоматически регулируется lr, и нужно просто constant шедулер ставить
Если ты имеешь ввиду в целом про продиджи, то он на самом деле только повышать его умеет, никогда не снижая, чем поджигает лоры и пердаки тех, кто не заглядывал в тензорборд, поэтому его в основном юзают в косином всё равно, шедулер фри убирает косин
> отел его попробовать но не разобрался как отделить lr текстовой части от unet
https://github.com/LoganBooker/prodigy-plus-schedule-free?tab=readme-ov-file#training-multiple-networks вот это по идее split_groups_mean=False split_groups=True а лры как обычно в этой версии должны указываться через кохьевские арги
> лры как обычно
Ну и естественно у продиджи они будут 1.0 на юнет и 0.33 на энкодер или типо того

>В одинаковых условиях schedule free тренит медленнее, чем Адам
Шедфри логика неприменима обратно к классическому адаму, как логика классик адама неприменима к шедфри. Если тренить на шедфри как положено - он быстрее.
>на остальное мне похуй
По-моему ты просто не разобрался, ну имхо.
>зато то насколько сильно веса обновятся на основе этих градиентов зависит только от оптимизатора и ничего другого
В вакууме да, но еще есть величина мазка в виде лра и коэффициент масштабирования, тонна мокрописек и само качество датасета. Нельзя просто взять оптимайзер новый, заменить им другой в готовой структуре и потом бугуртить что чет хуева работает говно кал, надо понять работу и подстроить конфигурацию под оптим.
>Я ведь для теста беру 10 пиков и смотрю визуально по типу пикрила насколько быстро к датасету оно приедет и куда скачет при тренировке.
Ты ведь в курсе что визуализация бекпропагейшена (на твоем пике) не показывает явное обучение/обобщение и отследить по генам эталон нереально, а оптимайзер может кругами ходить просто вводя в заблуждение на генах где ты как хуман можешь разглядеть "прогресс" которого на самом деле нет? Ты к датасету можешь за одну эпоху прийти вообще, ток у тебя обобщение наебнется просто.
>Высматривание каких-то обобщений - это субъективщина
Обобщение это просто отсутствие потери знаний о том, что не касается натренированной части. Ты можешь сделать быстро топ модель которая будет пердеть по кд датасетом даже без токенов, но базовый токен уровня pink background просто перестанет работать, это не субъективщина.
>оптимизатор тебе ничего не обобщает
А я этого не утверждал, я про сохранение функции обобщения самой нейросетью. Какой прок от того что я обучаю сеть генерировать датасет, если у нее будет низкая диффузионная лабильность? Не, юзкейс твой имеет место быть - генерировать датасет хуйню по токену - но как бы базово нейросети нужно уметь оставлять умения, а не просто ее отуплять заучиванием, а то прикинь стабилити бы обучило базу на конкретный класс и потом ебись как хочешь, это не базовая модель была бы а какаято хуйня.
>Звучит как будто у тебя за 100 шагов тренится всё. На продиджи warmup только шагов 300.
Вармап в шедфри продижи упразднен давно (с того момента как бесконечное увеличение лра во времени пофиксили), а самой шедфри логике он не требуется т.к. нормализация и аверейджинг сразу все делают как надо и не надрываются от первичных градиентов.
>Я прекратил тренировку как только увидел loss
Ну такто зря, я в прошлом треде писал псто и как пример тебе мои два лосс графика, которые с виду проебанный лосс, а в реальности там просто хорошие стабильные модели
>В чем прикол шедулер фри продиджи?
В шедулефри логике. Вместо расписания через какойнибудь косинус/константу/линейный графек они используют комбинацию из интерполяции между текущими весами и "ведущей" точкой, где вычисляется градиент + усреднения итераций, чтобы стабилизировать процесс и улучшить сходимость. Это позволяет оптимизатору автоматически адаптироваться к обучению без необходимости указывать, когда и как уменьшать скорость обучения.
>В нем же наоборот автоматически регулируется lr
В ориг продижи лр то регулирется автоматом, а расписание все равно требуется.
>и нужно просто constant шедулер ставить,
Ну да, это его стандартное состояние, но зависит от типа данных, константа не везде прокатывает, шедфри покрывает в принципе любую задачу на которой лицокнига тестила - от линейной регрессии до трансформеров, убирает в общем боль выбора расписания. Но шедфри будет еще лучше, т.к. усиливает фичу адаптивности продигов (ну то есть шедфри сам по себе сорт оф адаптивная технология, адаптивность добавляешь к адаптивности) и ускоряет сходимость через логику шедфри. Синергия кароче получается. Плюс он меньше жрет ресурсов, что тоже немаловажно.
>хотел его попробовать но не разобрался как отделить lr текстовой части от unet
А ты и не сможешь отделить в оригинальном продижи юнет от ТЕ, там эту фичу еще не ввели и не факт что введут. Зато эта фича имеется в шедфри.
>Ну и естественно у продиджи они будут 1.0 на юнет и 0.33 на энкодер или типо того
Небольшая ремарка: эти соотношения если ты беты базовые не трогаешь (которые по дефолту (0.9, 0.99) как везде), а если реакцию беты2 в 0.01 укатать допустим, то можно и юнет и те на одинаковых скоростях (или если включено гармоническое среднее) тренить, оно перестает ужаривать т.к. реакция моментальная на изменения.
Аноны, есть ли какой-то способ понять каких персонажей поддерживает чекпоинт, кроме метода тыка? Может есть какие-нибудь расширения, чтобы посмотреть теги заложенные в него?
>Может есть какие-нибудь расширения, чтобы посмотреть теги заложенные в него?
Если в метадату не запихали инфу, то никак из латент спейса не вытащить никаких растокенизированных нечисловых данных.
> как положено
Как положено - это всё в дефолтных значениях, кроме lr.
> базовый токен уровня pink background просто перестанет работать
Так для этого визуальная валидация и нужна, чтоб не по маняграфикам смотреть, а видеть что в реальности происходит с тегами. Непонятно откуда ты взял что умение генерить по промпту пики из датасета как-то ломает остальное.
ты про этот edm2 пишешь? https://github.com/NVlabs/edm2 тоже какая то оптимизация рассчитанная по timesteps, вместо debiased_estimation_loss?
Если заведу продиджи шедулер фри попробую беты 0.9, 0.01 с l1 loss, если не получится попробую дальше с DAdaptation, пока без разделения lr для энкодера и unet
Я так и не понял, лучше юзать лору которая full-finetune ? Или ты имел ввиду finetune который fine_tune.py? С капшенами всё норм, я все ручками проверил


>Как положено - это всё в дефолтных значениях, кроме lr.
Это если ты сэм альтман и у тебя скачан весь интернет в качестве датасета и батчи размером с юпитер. Дефолт значения не эталон.
>Непонятно откуда ты взял что умение генерить по промпту пики из датасета как-то ломает остальное.
Это проверяется за минуту: берешь какие-либо базовые токены не относящиеся к датасету лоры и гонишь их с применением лоры. Рано или поздно наступает момент эпохи когда модель теряет обобщающие знания, смешивает несмешиваемое и генерирует в конечном итоге датасет вместо этих базовых знаний.
Самый простой пример: a cat riding a bicycle in a forest, сеть обучалась на уточненный концепт.
Слева какая-то эпоха до 10, справа 11, сеть разучилась делать котов, и данный эффект не ревертится, дальше будет пропадать лес, велосипед, будут рисоваться франкенштейны уровня фурри баб (т.к. тренировка на людей) где кошачьи лапы вместо конечностей и ебало кошки, и в итоге придет к тому что будет генерировать по любому запросу не относящемуся к датасету все лукс лайк датасет.
>Непонятно откуда ты взял что умение генерить по промпту пики из датасета как-то ломает остальное.
А да, небольшое уточнение, это не касается того когда ты на триггер ворд/класс тренишь на заучивание паттернов, я именно про нормальное описание датасета с полномасштабным обучением ТЕ для форс обобщения. С триггером описанное тоже случается но кратно реже.
>Самый простой пример: a cat riding a bicycle in a forest
А вообще я про pink background не просто так сначала сказал, указание любого конкретного фона раньше всего ломается обычно, т.к. это знание не высокого порядка в луковичном юнете. Outdoor туда же.
Это у тебя как раз что-то сломано. Я всегда делаю валидацию на тегах, которых нет в датасете. Поломки фонов - это вообще что-то на грани фантастики.
Ну вероятно ты любитель снижать те в ноль и тольковыигрывать от этого.
А зачем добровольно ломать теги в ТЕ? Ты любишь унижения? На ванильном ТЕ даже на рандомные символы без проблем концепты тренятся. И я треню ТЕ, но максимально осторожно с демпингом, чтоб как у тебя теги не пропадали. А сломать что-то в унете - это надо знатно проебаться с кривым датасетом чтоб даже специально сделать так.
>А зачем добровольно ломать теги в ТЕ? Ты любишь унижения?
Я вот думаю стоит ли развернуто отвечать на данный вопрос пчеловеку, который использует нейрокал как генератор референсов или не стоит
>И я треню ТЕ, но максимально осторожно с демпингом
Да я уже понял, что ты пытаешься выдрочить юнет преимущественно, еще альфу поди занижаешь экстремально чтобы веса АСТАРОЖНА обновлялись и поэтому выше по нити тысячами шагов слоу бейкингом занимаешься.
>чтоб как у тебя теги не пропадали.
Ну мы ж за тренировку трем, сломанное обобщение это маркер что надо потюнить настроечки и всё придет в норму.
Чел, ты ведь понимаешь что можно тренировать только ТЕ и оно даже будет выдаватькакой-то результат. Но ТЕ нужен для энкодинга текста, а для генерации UNET используется. Ты задвигаешь очень странные вещи, предлагая делать даже то что Стабилити не делали, литералли никто не тренит ТЕ для изменения генераций. Во всех SD ванильный клип, во всех DiT ванильный T5. Единственный смысл тюнить ТЕ - это когда капшены слишком отличаются от ванилы и надо под свой формат подогнать энкодер, например как в аниме приходилось под стиль бур тюнить его.
А потом ты рассказываешь как у тебя что-то ломается там где оно просто не может сломаться, лол.
> альфу поди занижаешь экстремально
Всегда треню с альфой как ранг.
>Но ТЕ нужен для энкодинга текста, а для генерации UNET используется.
Да ежу понятно, но паттерны связываются с токенами. Мне важно тренировать более менее нативно, а не с допущениями тип и так сойдет если че сидом вырулим или там вес покрутим туда сюда, полагаясь не дофолт.
>Ты задвигаешь очень странные вещи, предлагая делать даже то что Стабилити не делали
Ну если так рассуждать то тебе дорога в train unet only, сразу хуй 30 см вырастет и лидером митол группы станешь.
>литералли никто не тренит ТЕ для изменения генераций.
Там это, пони, нуб, люстра, бигасп и сотни лор к ним (а иногда еще и фрагментарный файнтюнинг) с отпердоленным по самые гланды те.
>Во всех SD ванильный клип, во всех DiT ванильный T5.
Потому что это базовые модели преимущественно, унификация. Это не значит что ты обязан не тюнить те под свои особые задачи.
>Единственный смысл тюнить ТЕ - это когда капшены слишком отличаются от ванилы и надо под свой формат подогнать энкодер, например как в аниме приходилось под стиль бур тюнить его.
Забей, далеко не единственное.
>А потом ты рассказываешь как у тебя что-то ломается там где оно просто не может сломаться, лол.
Легко говорить про "просто не может сломаться", когда сам тренишь дефолт для референсов.
>Всегда треню с альфой как ранг.
Ну вот, а есть те кто тренит x8 по альфе без ТЕ типа этого пчелика https://civitai.com/models/688932?modelVersionId=771052 , и что сделаешь? Наверно возмутишься ведь нужно по гайдлайну ивана залупина из 2022 не выше 1:1 настроечки, м? Незачем быть таким ультимативным и фанатичным, если что-то работает и выполняет задачи не так как ты привык.
> ты про этот edm2 пишешь?
Да, конфиг уровня b где тренится мелкий нетворк, который динамически распределяет значимость таймстепов во время тренировки, он реализован только вот тут https://github.com/67372a/LoRA_Easy_Training_Scripts/tree/flux и оно довольно багованное от коммита к коммиту, имей сразу ввиду, конфиг можешь тут у него взять https://github.com/67372a/LoRA_Easy_Training_Scripts/issues/13
А вообще взял бы да с адамом просто лору на дефолте для начала натренил, чем ударяться в эксперименты с бетами, едмом или файнтюном, всё это посложнее будет в исполнении, и надо уже от чего то отталкиваться, хотя бы в сравнениях
Вашу нить всю еще не прочел, очень уж забористая и странная. Но бля
> базовый токен уровня pink background
> с токенами
> токены
За такое использование этого термина, что постоянно мелькает, хочется взять и уебать. Используй слова: теги, фразы, капшны, сдвиг латентного пространства энкодера, что угодно. Но не обозначай словосочетание токеном, это совсем разные вещи.
А энкодер тренить нужно, если добавляется что-то новое, а не просто подчеркивается уже известное или применяется какая-то общая стилизация.
> базовый токен уровня pink background
> с токенами
> токены
За такое использование этого термина, что постоянно мелькает, хочется взять и уебать. Используй слова: теги, фразы, капшны, сдвиг латентного пространства энкодера, что угодно. Но не обозначай словосочетание токеном, это совсем разные вещи.
А энкодер тренить нужно, если добавляется что-то новое, а не просто подчеркивается уже известное или применяется какая-то общая стилизация.
Сорян что тоже влезаю, но ты похоже знаешь. Как прикинуть, сколько CLIP токенов в тексте? Гуглил, нашел только ноду-счетчик для Комфи, но у меня нет Комфи, генерю в инете.
> пони, нуб, люстра
Там и батчсайз был нормальный.
И как я уже писал - это делали из-за сильно специфических капшенов. Зачем тебе при тренировке на мелком датасете тренить ТЕ, когда он уже знает как энкодить твой текст - загадка.
> с отпердоленным по самые гланды те
Да, знаем. Весь порнушный реалистик с натрененым клипом как раз как ты и описываешь поломанный, настолько что порой тянку одетую невозможно сгенерить. Бигасп как раз такой. Ничего кроме таблеток авторам такого не могу посоветовать. Собственно это и есть путь к генерациям только того что было в датасете.
> типа этого пчелика
Так там ранг 4. С ним можно любое извращение делать, даже нужно, а иначе трудно трениться будет. Тем более на флюксе.
Если слои резать как в b-lora, то можно и не такое вытворять, т.к. там даже усравшись ничего не сможешь сломать.
Ты опять пытаешься передёргивать, но выглядит это глупо.

Спасибо.
Экспрессом оценить - анон уже скинул самый простой вариант. Но учитывай что он не покажет как идет разбиение по чанкам, за этим следить самому.
Если собираешься в каком-то софте юзать - ticktoken легковесный и быстрый.
Пользуясь случаем и сам спрошу, в комфи сд3 идет стакинг чанков клипа для длинных промтов, или как в популярных примерах кода просто все срезается после лимита и дальше только т5 работает?
> Весь порнушный реалистик с натрененым клипом
Там проблема не в тренировке клипа а в уровне тренировки в целом. Вместо того, чтобы научить сопоставлять промт - генерацию, наоборот связи нарушаются из-за натягивания порнухи на глобус. Такое можно получить что с тренировкой те, что без нее, разве что без его тренировки попытка обучить незнакомому все поломает в разы сильнее.
>Бигасп как раз такой.
Нормальный бигасп, у тебя скилишуе.
>За такое использование этого термина, что постоянно мелькает, хочется взять и уебать. Используй слова: теги, фразы, капшны, сдвиг латентного пространства энкодера, что угодно. Но не обозначай словосочетание токеном, это совсем разные вещи.
Буду называть ВХОДНЫЕ ТЕКСТОВЫЕ ЕДИНИЦЫ токенами, потому что
1. Входные текстовые единицы - токены, лексемы, теги, фразы
2. Выходные представления энкодера - эмбединги, векторы, латентные представления, сдвиги в латентном пространстве
>А энкодер тренить нужно, если добавляется что-то новое, а не просто подчеркивается уже известное или применяется какая-то общая стилизация.
Заебали своими догмами, ну честно.
> Как прикинуть, сколько CLIP токенов в тексте?
>Комфи
Есть экстеншенов несколько на подсчет, я точно названия не помню но легко гуглятся точно
>Там и батчсайз был нормальный.
Так у нас и параметрически меньший разлет данных.
>И как я уже писал - это делали из-за сильно специфических капшенов. Зачем тебе при тренировке на мелком датасете тренить ТЕ, когда он уже знает как энкодить твой текст - загадка.
А откуда ты знаешь может ли енкодить дефолт мой текст? Да и выходной результат с неспецифичными описаниями тоже лучше получается.
>Весь порнушный реалистик с натрененым клипом как раз как ты и описываешь поломанный, настолько что порой тянку одетую невозможно сгенерить
>порнушный
>одетую
Смишно-смишно. Может ты еще в онемекале генерируешь текст?
>Весь порнушный реалистик с натрененым клипом как раз как ты и описываешь поломанный, настолько что порой тянку одетую невозможно сгенерить
>Бигасп как раз такой. Ничего кроме таблеток авторам такого не могу посоветовать. Собственно это и есть путь к генерациям только того что было в датасете.
Ну тут явная гиперболизация ради раскручивания срача.
>Так там ранг 4.
Там ранг 2.
>С ним можно любое извращение делать, даже нужно, а иначе трудно трениться будет. Тем более на флюксе.
>Если слои резать как в b-lora, то можно и не такое вытворять, т.к. там даже усравшись ничего не сможешь сломать.
>Ты опять пытаешься передёргивать, но выглядит это глупо.
То есть тут тебе уже всё ок, хотя и то и другое вообще далеко от т.н. "стандартов" иванов "1:3 TE:UNET 0.5-1:1 a:d <32 nigger word 0.9-0.99 adam8bit 1e-4 amen" залупиных. Ну, и смысл всего диалога тогда, или просто нехуй делать?
Не кривляйся, учитывая важность токенизации, это всеравно что теги называть лорами. Просто говори по-человечески и вопросов не будет.
> догмами
Хуегмами, это очевидная база.
Без устойчивой реакции и соответствующего изменения состояний, которые идут в кондишны, нормального обучения невозможно. В некоторых кейсах хватит стандартного клипа, по скольку на самом деле он знает оче много. В других же будет или ноль эффекта, или полный разъеб, потому знания преимущественно общие без конкретики и в 224 разрешении многое вообще невозможно полноценно воспринять.
Сюда еще наложатся нюансы оче узкой и мелкой тренировки в попытке добавить что-то.
> Не кривляйся, учитывая важность токенизации, это всеравно что теги называть лорами. Просто говори по-человечески и вопросов не будет.
Буду писать как считаю нужным. Смотри: токены, токены, токены. Терпи.
> Хуегмами, это очевидная база
Крутяк, братан, держи в курсе, очень интересно твое базированное мнение по данному вопросу, не могу представить как можно жить без настолько очевидной базы. Базированный базовичок базанул базово, да еще и очевидно. Респект таким как ты в этом итт коммьюнити, низкий поклон чилловому парню на базе.
Эх, значит таки придется заниматься перебором.

Что то сложно с edm2, в нем нужно указать все параметры оптимизатора который выбрал? с debiased_estimation_loss полегче, просто галочку поставить, но я пробовал с ним тренировать, loss почему то постоянно рос, до 6 дошел, график не сохранился потому что электричество моргнуло и не завершил тренировку, но лора по итогу нормально работает, не сжигает ничего, так и должно быть с лосом? Тренировал с --scale_v_pred_loss_like_noise_pred, так как в гайде это написано. Такая проблема и с шедулер фри адамом и с адафактором, так что проблема не с оптимизатором
Чего порвался сразу? И за что топишь вообще не понятно, тренить только без те? Это ерунда.
> в нем нужно указать все параметры оптимизатора который выбрал?
Да, ведь я уже расписал, что это мелкий параллельно тренеруемый нетворк, можешь в логах, если настроил глянуть, как он делает пикрил хуйню
> так и должно быть с лосом?
Вот примерно так вообще со всеми датасетами, белая кривая
> Тренировал с --scale_v_pred_loss_like_noise_pred
Не надо, это вроде онли для дебиаседа актуально и вообще костыль был раньше
> Заебали своими догмами, ну честно.
А в чём он кстати конкретно не прав? Его же реально есть смысл тренить только для новых словосочетаний, либо, редкий случай, если ты хочешь немного натрененных параметров другого типа в получившемся нетворке, что усиливает иногда даже стили
>Его же реально есть смысл тренить только для новых словосочетаний, либо, редкий случай, если ты хочешь немного натрененных параметров другого типа в получившемся нетворке, что усиливает иногда даже стили
Нейрокал ищет и запоминает паттерны, согласуя их с текстовым енкодером, не важно знает ли он о концепте заранее или нет - в обоих случаях такая конструкция эффективнее тренирует. Без те клипвижн смотрит на картинку опираясь на кепшен и никак не трогает структуру дефолтного те, единственное что буде задействовано это кроссатеншен в части класса датасета, но это очень слабое влияние. Если у тебя проблемы с пыняманием как тренить те, то ты всегда можешь снизить влияние те при генах, т.к. на него альфа никак не влияет - просто тренишь с такой же скоростью как юнет и потом процентик подбираешь, при желании можно будет перетренить согласно новому проценту влияния, это линейная зависимость.
>то ты всегда можешь снизить влияние те при генах
В том числе отключив влияние те полностью, получив более точный результат тренировки юнета, т.к. модули будут отпердолены согласно твоим кепшенам и настройкам к ним, а не согласно дефолту.
слоу ап
Ты похоже совсем тупой, если пытаешься тренить ТЕ на визуальном таргете. ТЕ должен трениться на тексте, UNET на визуале. Так же как в самой тренировке клипа визуальный энкодер тренят на визуале, а ТЕ на тексте. Поэтому ТЕ так сильно и забывает теги у тебя. Поэтому при претрейне любой диффузии никто никогда его не тренит.
> снизить влияние те при генах
Пошли ахуительные истории. Наличие ТЕ в графе влияет на распространение градиентов в UNET тоже. Даже если ты не обновляешь веса ТЕ. Это не работает так что ты натренил его и потом выкинул, думая что в результате получил как будто его не было при тренировке.
Иди на хуй далбаеб.
Нашел причину, full bf16 почему то показывает постоянный рост loss, на первых же шагах больше 1, и далее только растет, даже если результат получается нормальный, не уверен почему так происходит, попробую edm2, конфиг нашел который на гитхабе валялся, хочу сначала на каком то обычном оптимизаторе попробовать типа адама, а потом уже на каких нибудь продиджи запущу
> Нейрокал ищет и запоминает паттерны, согласуя их с текстовым енкодером
В целом верно, юнет прослеживает закономерности между выдернутыми скрытыми состояниями текстового энкодера и картинкой.
> не важно знает ли он о концепте заранее или нет
А вот это бредятина.
Если текстовый энкодер не имеет хорошего понимания того, что указано в ромте, то эту часть он проигнорирует или воспримет некорректно, не дав соответствующее явное изменение в кондишн. Юнету будет неоткуда взять условие, и он или начнет фалломорфироваться, подстраивая базовое поведение под то что в датасете, не зависимо от кондишнов, или просто ничему нормально не научится.
> Без те клипвижн смотрит на картинку
Какой клипвижн, он никак не участвует в работе sd и в тренировке. Там даже проекционный слой текстового энкодера не нужен и его можно смело занулить или ампутировать.
> Если у тебя проблемы с пыняманием
С этим явные проблемы у тебя. Неуместный спам терминами, отсутствие базовых знаний, а из опыта - 2.5 кривых лоры на еот, зато по "новым технологиям", которые дипсик посоветовал.
> ТЕ должен трениться на тексте, UNET на визуале
Не совсем удачное описание, но в целом так. При тренировке те юнет по сути заменяет визуальный энкодер клипа.
Также, никто не мешает сначала натренить отдельно клип на нужном датасете пар текст-изображение, потом выдернуть его и использовать с юнетом, тренируя только последний. Но здесь есть ряд своих проблем: во-первых, визуальный энкодер клипа ужасно слепошарый из-за разрешения, во-вторых, он сам очень легко ломается и вертеть мелкие датасеты как с диффузией целиком не выйдет, в третьих - при наличии длинных капшнов полезет проблема дробления промта на чанки. Можно делать аугментацию и брать рандомный - но это снизит стабильность тренировки, можно усреднять стейты перед проекцией - прокатывает 50-50, можно усреднять эмбеддинги - и получить залупу.
> Поэтому ТЕ так сильно и забывает теги у тебя.
Он забывает у него потому что тренит какую-то ерунду с неоптимальными параметрами.
> Наличие ТЕ в графе влияет на распространение градиентов в UNET тоже. Даже если ты не обновляешь веса ТЕ.
Именно, и эффект "забывания" легко получить даже не трогая те.
Хз есть ли смысл с этим шизом что-то обсуждать, он уже сам понимает что слился и начинает сочинять что-то далеко за гранью своего понимания, пытаясь тихонько слиться.
> При тренировке те юнет по сути заменяет визуальный энкодер клипа.
Не бредь. В клипе loss - это расстояние между парами правильных и неправильных пар эибедингов, в нём градиенты не идут из визуального энкодера, ТЕ клипа ничего не знает об визуальной части. А сам визуальный энкодер - это уже претрен ViT. В случае с SD у тебя градиенты идут из UNET, т.е. ты тренишь ТЕ на визуале, чего в принципе не должно быть. Или ты думал что в клипе текст энкодится ТЕ, а потом эмбединг пропускается через визуальный энкодер как в UNET, лол?
> full bf16 почему то показывает постоянный рост loss
Не надо, ты пытаешься засейвить память, но получишь ворох проблем от градиентов в низкой точности, не зря ведь существуют оптимайзеры для сглаживания проблем https://github.com/lodestone-rock/torchastic по типу такого обычного адама, но для бф16
>Если текстовый энкодер не имеет хорошего понимания того, что указано в ромте, то эту часть он проигнорирует или воспримет некорректно, не дав соответствующее явное изменение в кондишн. Юнету будет неоткуда взять условие, и он или начнет фалломорфироваться, подстраивая базовое поведение под то что в датасете, не зависимо от кондишнов, или просто ничему нормально не научится.
Поехали:
1. Юнет в сд не просто слепо следует кондишнам от текстового энкодера. Он обучается на парах "текст-изображение" и может догадываться о связях между латентными представлениями и визуальными данными, даже если кондишн от текстового энкодера не идеален, следовательно юнет не зависит полностью от кондишнов и может частично компенсировать их недостатки, особенно если lr для юнет выше, а датасет репрезентативен, а ты не еблан который боится тренить те потому что иван залупин так скозал.
2. Даже если текстовый энкодер игнорирует часть промпта или выдает шумный кондишн, это не приводит к фалломорфированию или полной потере обучения. Юнет может интерпретировать шумный сигнал как обобщенное направление в латентном пространстве и все равно учиться на данных, следовательно некорректный кондишн не обнуляет обучение, а делает его менее точным. Юнет может подстроиться под базовое поведение датасета.
3. Переобучение юнет на датасет без сильной зависимости от кондишнов может быть плюсом, если задача стиль или обобщение, а не точная интерпретация текста.
4. Лора добавляет низкоранговые обновления к весам юнет и текстового энкодера, что позволяет им совместно адаптироваться к данным. Даже если текстовый энкодер выдает слабый кондишн, лора дотягивает генерацию к правильному результату, особенно при сбалансированном lr.
5. В сд есть механизм обработки безусловной генерации, где кондишн заменяется нулевым вектором. Юнет может учиться даже в таких условиях, опираясь только на данные. То есть юнет не "ничему не научится" а просто переключится на обобщение датасета.
>Какой клипвижн, он никак не участвует в работе sd и в тренировке.
Ладно, моя ошибка, неверно подобрал описательную часть к процессу определения паттернов. По дефолту у тебя есть класс датасета с помощью которого сеть "видит" картинку + вае. Без текстового энкодера суть дасета определяется либо через классы/латенты, либо через узкую специализацию датасета. Это похоже на то как работает клипвижн (клипвижн и юнетбез текстового энкодера понимают содержимое в том смысле, что ассоциируют входные сигналы с визуальными паттернами, выученными из данных и оба опираются на предобучение и латентное пространство), но клипвижном не является.
>Там даже проекционный слой текстового энкодера не нужен и его можно смело занулить или ампутировать.
А если ты удалишь проекционный слой который обеспечивает совместимость между текстовым энкодером и юнет это просто нарушит работу модели, сломает архитектуру и сделает модель нефункциональной.
>Неуместный спам терминами, отсутствие базовых знаний, а из опыта - 2.5 кривых лоры на еот, зато по "новым технологиям", которые дипсик посоветовал.
У тебя так пичот с того что я тренирую тонны качественных моделей с полновесным те, что ты выдумал соломенное чучело и побеждаешь его, прелестно. Контролируй свой батхурт.
>Он забывает у него потому что тренит какую-то ерунду с неоптимальными параметрами.
Нет, это не так. Обиснять не буду, я и так много времени потратил на бессмысленный срач на дваче с фанатиком, прекрасно понимаю что у тебя синдром утенка и ты любое схождение с рельс "идиальных настроек яскозяль нильзя уииии хрюююю" воспринимаешь как личную угрозу почему-то. Зачилься, другалек, это не я тебе навязываю тренировку с те, а ты мне пытаешься доказать что УИИИИ НЕЛЬЗЯ ТРЕНИРОВАТЬ ТАК ХРЮЮЮ ЮНЕТА ХВАТИТ ВСЕМ, о чем тебя никто не просил. Ферштейн?
>Хз есть ли смысл с этим шизом что-то обсуждать, он уже сам понимает что слился и начинает сочинять что-то далеко за гранью своего понимания, пытаясь тихонько слиться.
Ну все-все, не реви малютка, юнета хватит всем и каждому, те тренируют ток лохи, всё так всё так...
Срач уровня рок против репа. Вы ебанутые? Хочешь трень без те, хочешь с те, хочешь обмазаться классикой - мажься, хочешь блидинг едж оф текнолоджи и нестандарт - пожалуйста. Главное ведь результат, норм не существует. Нахуя вы сретесь чье ведерко лучше куличики из говна делает? Предлагаю вам всем завалить ебальники и не корректировать чужой процесс дрочки пениса согласно своим вкусовым предпочтениям. Или хотя бы прикладывать свой профиль на цивите с моделями, а то на словах все львы толстые, а на деле очередное аниме по триггеру хуярите.
Ну и нахер ты это высрал?
В случае тренировки клипа осуществляется сравнение эмбеддингов и с этой разницы идет обратный проход. В случае тренировки клипа в составе сд, обратный проход осуществляется сначала по юнету, а потом по используемым слоям те. В обоих случаях т.е. подстраивается под изображение опираясь на вторую часть модели, или визуальный энкодер, или юнет. О чем и была речь, можно научить т.е. новому как в составе оригинальной модели, так и в диффузии, а потом пересаживать туда-обратно. Разумеется из-за отличий из коробки оно может хорошо не работать, но короткое дообучение с частичной заморозкой это быстро исправит.
> ты тренишь ТЕ на визуале
Не тренишь ты его на визуале ни там ни там. В одном случае у тебя оценивается ошибка перекрестной энтропей разницы позиций в латентном пространстве, и начинается ее распространение, в другом у тебя сразу же приходит ошибка скрытых состояний последнего (если не пропущено) слоя перед проекцией. Те же яйца, только с нюансами.
> текст энкодится ТЕ
Именно
> а потом эмбединг пропускается через визуальный энкодер как в UNET, лол?
А это уже ты высрал. Хотя тут как посмотреть, если визуальный энкодер не заморожен то через него как раз обратным проходом полетит именно сравнение с ним.
> Он обучается на парах "текст-изображение"
Тензор из те - изображение, юнет ничего не знает про текст
> и может частично компенсировать их недостатки
Все так. В том числе на этом основана возможность обрабатывать длинные промты не смотря на порой радикальные отличия в тензорах чанков.
> а ты не еблан который боится тренить те потому что иван залупин так скозал
Перечитай пост, ты не туда воюешь. Там как раз про то что те тренировать надо, если у тебя не странный кейс, и опровержения шиза, который боится его тронуть, утверждая что это все сломает.
> Даже если текстовый энкодер игнорирует часть промпта или выдает шумный кондишн, это не приводит к фалломорфированию или полной потере обучения.
Если он игнорирует именно ту часть, которую ты тренируешь - приводит. Простой пример - всякие названия поз в сексе, активностей и мемов, которые будут интерпретированы совершенно не так и приведут к разного рода побочкам. Или сленг и новые слова, "шум от которых", как ты выражаешься, не будет достаточно консистентным и регулярным чтобы юнет смог нормально ее интерпретировать. Удачный кейс, описанный тобой, может сработать только если клип способен это понимать в достаточной степени.
> следовательно некорректный кондишн не обнуляет обучение, а делает его менее точным
Все правильно, вопрос в амплитуде этой неточности, она достаточно высока. Наиболее наглядно проявляется попытками натренить на имена каких-то людей, знаменитостей легко без те ухватывает даже если диффузия не знала, зато других, или тем более придуманные последовательности - отвратительно.
> Юнет может подстроиться под базовое поведение датасета.
Это и есть фаломорфирование, когда обучаемое будет лезть из всех щелей без вызова. И опять, ровно то что я выше описал.
> 3. Переобучение юнет на датасет без сильной зависимости от кондишнов может быть плюсом, если задача стиль или обобщение
Ну вот, пошел мои же посты цитировать когда понял что все сфейлил, или нахуй тогда влезал?
> Лора добавляет низкоранговые обновления к весам
Которые выбраны для обучения и только к ним. Если выбран только юнет - будет только юнет, и то по дефолту даже не все его слои. Если только те - будет только те, есть и такие извращения. Если отдельные блоки - будут отдельные блоки. А не то что ты пишешь, это вообще неуместно по нити.
> 5. В сд есть механизм обработки безусловной генерации
Анкондишнал генерации и работа cfg, это здесь не при чем.
Нейронка, плиз.
> Ладно, моя ошибка
Конечно ладно. Как только прижали - дождался лимита сетки побольше, которая не скормила как в прошлый раз тухляк из эпохи далли1 с классифаер-гайденсом, а уже подсказала что-то актуальное. Но рофел в том, что оно буквально повторяет мои утверждения и опровергает твои (или того типа, которому пояснял что он не прав). А если второе - то зачем в разговор лезешь без четкого и явного описания своих утверждений?
> У тебя так пичот с того что я тренирую тонны качественных моделей
Васян на десктопной карточке по ночному тарифу электричество жжет, но себя мнит, ай лол. Такой-то серьезный повод для зависти. Мелковата рыбешка и пользы не приносит.
> бессмысленный срач на дваче с фанатиком
Да уже сливаешься, потому что вместо выебонов в той нити расклеился и себя начал опровергать. А я ведь просто мимокрокодил, который завалил уточнить что есть ерунда и как нынче технотредик поживает и оценить уровень духоты. Трех постов хватило чтобы подорвать, забавно.
> юнета хватит всем и каждому, те тренируют ток лохи
Опять не туда воюешь. Да что с вами не так?
Я не буду эту хуйню шизоидную читать, сорян.
Кому не лень будет - прочитают и поймут доминацию чистого разума над глупостью в разных проявлениях. А может что-то полезное для себя почерпнут.
Нука покажи свои модели
>Кому не лень будет - прочитают и поймут доминацию чистого разума над глупостью в разных проявлениях. А может что-то полезное для себя почерпнут.
Нихуя себе чсв шиза.
Апелляция к авторитету, это же читы. Широко известны в узких кругах и приложил руку к разным проектам в опенсорсе.
Сорвалась рыбка.
>Апелляция к авторитету, это же читы.
Вообще подобный твоему гонор обязан быть подкрепленным фактическими успехами и хайкволити продуктом, в противном случае это выебоны обычные
>Широко известны в узких кругах и приложил руку к разным проектам в опенсорсе.
Ну так предъявите, или тебе незнакомо слово портфолио?
> гонор
Где? Ведь нейтрально и по существу все описано, исключая последные абзацы где уже ответы на агрессию. Насмешка над
> я тренирую тонны качественных моделей с полновесным те
это типа гонор? Это рофлы над челом, который решил агрессивно доебаться, процитировав мои посты (или чуть сузив обсуждение к степени реакции энкодера) и повторив выводы из них. Ничего выше 24 десктопного врама и датасетов с папочками 3_хуйнянейм не нюхал, зато как сам выебывается.
Или это такой повод для слива?
> или тебе незнакомо слово портфолио
Таки какие условия вы предлагаете?
> Хз есть ли смысл с этим шизом что-то обсуждать
На это чтоли обиделись и подорвались, я не понял? Так это про поеха, который усирался за недопустимость трейна те и уже пошел окукливаться, а не двум постам что там указаны.
>стена оправданий
>ноль моделей
Ясно, можешь не напрягаться.
> Ррррряяяяя я не слился
> Тащите пруфы, чур я не первый!
Ай кринжатина. Перед следующим выступлением спроси у дипкока что такое проекционный слой чтобы не позориться, успешный полнотекстовый тренировщик лор на еот.
>мощный агрессивный пук
>без моделек
Хехмда, вот они эксперты треда - лают, но не кусают
Все довольно просто, ты отчаянно хочешь свинтить, уже устыдившись тому что писал раньше и поняв что ввязался в бессмысленный спор в котором не выиграешь.
Высказанное не позволяет вернуться к обсуждению, из-за характера и чсв не можешь просто отступить, или боишься потерять лицо на аиб, ай лол.
Вот и устраиваешь этот перфоманс, трясущимися губами выкрикивая какие-то требования. Мне не жалко, но сначала ты продемонстрируй свои
> тонны качественных моделей с полновесным те
Казалось что тех, кто здесь тренирует что-то стоящее, знаю и они более сдержаны в своих высказываниях.
Молодой человек, мы всем тредом ждем ваши модели. К какому времени ожидать?
>ви все гавно! слушайте меня - вот тонны буковок
@
>ты свч
@
>нет ето ты свч! я победитель по жизни! вумный!
@
>о, так вы экспертный аи энтузиаст с корочкой, покажите модели пожалуйста
@
>мням пук нет ето вы покажите свои сначала!
Чет ору с этой омежки
@
>ты свч
@
>нет ето ты свч! я победитель по жизни! вумный!
@
>о, так вы экспертный аи энтузиаст с корочкой, покажите модели пожалуйста
@
>мням пук нет ето вы покажите свои сначала!
Чет ору с этой омежки
За щекой проверь, пиздабол.
Так разорвало что начал семенить, ай лол.
С какого момента вот этот рак захватил тред? У дедов все плохо и теперь метастазы сюда пролезают?
Похоже ты недостаточно усвоил жизненный урок, что в реальном мире могут спросить за кучерявый базар. Иди отдохни, завтра днем надеюсь поблагодаришь, что это произошло на двачах, потому что ирл пришлось бы извиняться на камеру.
> если визуальный энкодер не заморожен то через него как раз обратным проходом полетит именно сравнение с ним
Ты реально даун. В клипе контрастный loss, там градиенты идут от пар эмбендингов, а не от изображения к тексту.
Урок в том, что обосравшийся чухан копротивляется до последнего и скатывает техническую ветку в филлиал /по? Это дефолт, долбоебы сразу свой уровень обозначают.
> потому что ирл пришлось бы извиняться на камеру
Обозначь себя, можно устроить
> В клипе контрастный loss, там градиенты идут от пар эмбендингов
> В случае тренировки клипа осуществляется сравнение эмбеддингов и с этой разницы идет обратный проход.
У тебя все хорошо, бедолага? Прочитай еще раз.
> Прочитай еще раз.
Это ты прочитай ещё раз и загугли что такое контрастный loss. Распространение градиентов идёт от эмбедингов в разные стороны параллельно в ТЕ и визуальный энкодер, в сторону текста и изображения соответственно. А не последовательно, как в SD, когда ты пытаешься тренить ТЕ.
И? Где противоречие? Сам что-то придумал и с этим споришь.
Новый день, а твоих высококачественных моделей подтверждающих компетенцию всё еще нет. Ждем.




Попробовал тренить лору с --scale_v_pred_loss_like_noise_pred и без, разница не большая, но заметил больше ошибок в лоре которая без --scale_v_pred_loss_like_noise_pred тренилась. 1 пикча сравнение, 2 что должно получится по промту. Там с --debiased_estimation_loss, думаю лучше с скейлом тренить.
И ещё ранее модель на будке тренил с такими параметрами, вроде тоже тебе показывал https://files.catbox.moe/pq1l52.json
"--v_parameterization --zero_terminal_snr --scale_v_pred_loss_like_noise_pred" вот ссылка на саму модель https://huggingface.co/MindB1ast/test5/resolve/main/abc/Watanabe_exper_4_consept_more.safetensors
Она работает(txt2img на 4 пикче), но есть пролбема с img2img, почему то пикча всегда сжигается(пикча 3), причем на нубе или в вкладке img2img такой проблемы не наблюдается, не знаешь в чем может быть причина?
> 1 пикча сравнение
Ничего же не меняется.
Так я и написал что разница не большая, но я пробовал больше и в варианте без --scale_v_pred_loss_like_noise_pred больше ошибок по анатомии и деталям одежды
> Там с --debiased_estimation_loss, думаю лучше с скейлом тренить
Да, дебилосед нужно со скейлом юзать, где то у кохьи было большое обсасывание всей этой темы
> не знаешь в чем может быть причина?
Знаю, у тебя в state_dict'е нету ключей впреда и зтснр, где то был скрипт чтобы их вшивать, могу попробовать найти, либо адвансед сэмплинг включай в рефордже внизу страницы
Да как раз в рефордже и юзаю, но даже с ним при hires fix и adetailer выдает шум вместо картинки. Я думал это автоматически делается если vpred тренируешь
Да где угодно, он не будет автоматом цепляться без этого
https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/16567
Спасибо
> но даже с ним при hires fix и adetailer выдает шум вместо картинки
До "стандартизации" фиксили кстати через жопу добавляя в настройках в
Script names to apply to ADetailer (separated by comma):
dynamic_prompting,dynamic_thresholding,wildcard_recursive,wildcards,lora_block_weight,negpip,advanced_model_sampling_script
Но лучше просто ключи туда добавь
Да, проблема была в том что не было ['v_pred']['ztsnr'] в state_dict, сейчас все норм работает, ещё раз спасибо
Аноны, как сейчас дела обстоят с лора-мерджами?
Использую 3 лоры в комплекте для базового стиля, думаю их смерджить в одну, для оптимизации и экономии памяти.
Но супермерджер для автоматика не работает, а кохьевские скрипты выдают что-то непонятное - в базовом режиме видимо dim не совпадает (неужели никак не пересчитать?), а в svd-вкладке (или как оно там называется) результат вообще не тот выходит, что от раздельного использования.
Пытался вжарить лоры в модель, и потом сделать экстракт, но разница все равно довольно значительная.
Использую 3 лоры в комплекте для базового стиля, думаю их смерджить в одну, для оптимизации и экономии памяти.
Но супермерджер для автоматика не работает, а кохьевские скрипты выдают что-то непонятное - в базовом режиме видимо dim не совпадает (неужели никак не пересчитать?), а в svd-вкладке (или как оно там называется) результат вообще не тот выходит, что от раздельного использования.
Пытался вжарить лоры в модель, и потом сделать экстракт, но разница все равно довольно значительная.
Лучше 3 датасета в одну лору натрень. Мержинг всегда костылём будет.
Это если у меня есть датасеты.
У меня их, очевидно, нет.
Вдобавок трех разных художников в оду лору тренить...
Так себе идея, как по мне.
> Вдобавок трех разных художников в оду лору тренить
Никаких проблем нет, прекрасно тренятся.
Энивэй, это не ответ на мой изначальный вопрос.
Ответ на твой вопрос - никак. Нормального результата никогда не получишь.
>Нормального результата никогда не получишь.
Ерунду говоришь.
Пользовался лора-мерджами еще со времен первого NAI.
Сходимость результата в районе 95% по сравнению с использованием лор по отдельности. Экстракты давали (и дают) значительно худшую точность.
Заодно мерджем лоры на саму себя можно было нормализацию по весу применения делать, если в лоре недожарка или пережарка была. Но это когда супермеджер нормально работал.
>Expected size for first two dimensions of batch2 tensor to be: [1920, 6] but got: [1920, 3].
Вот такую фигню показывает когда одну из лор супермеджером замерджить пытаюсь.
(Пришлось копать код, чтоб починить ошибку cuda, но вроде справился).
>weights shape mismatch merging v1 and v2, different dims?
Вот такую - если кохьей мерджить.
И что-то понять не могу, как это победить. Вроде даже ресайз проблемной лоры через кохью сделал - не помогает, только цифры поменялись.
Наверное одна из лор просто натренена на нестандартном алгоритме, локр или что нибудь ещё новее, который супермерджер не осиливает, мерджи через комфи, может там получится
>мерджи через комфи, может там получится
Из того, что видел, там только две можно было сливать.
Мне надо больше. 3-4 за раз.
В два этапа делать как-то ниоч, тут уже могут дополнительные потери пойти, которых я как раз и стараюсь избежать.
Ну и не люблю я лапшу, если честно.
SVD
>SVD
>в svd-вкладке результат вообще не тот выходит, что от раздельного использования.
Ну или я что-то не понимаю там.
Плюс оно, судя по логу, нормализует "входящие" веса лор, чтоб они в сумме соответствовали единице, что тоже не помогает повторимости результатов.
Скрин покажи я не помню че там в вебуе бмалтеса. А так полноценнвй свд с разными алго магнитудными есть в расширениях комфе. И нет, там не нормализация, а ортогональная выжимка, декомпозиция хуемое.
Алсо для соединения говно есть еще DARE, но там понять сложнее как на что что влияет и воркфлоу максимально перегружен будет, но зато он мощный, с помощью него смешивают несмешиваемое типа пони и реалистики.


Ничего там нет. Что в SVD вкладке, что в обычной. В обычной, разве что, даже ранги указать нельзя.
На ресайзе больше настроек доступно.
Я покрутил SVD, выяснилось, что результирующая лора из SVD-мерджа выдает близкий к базовой комбинации результат на силе ~2.2.
При этом базовые настройки лор из промпта - 0.6, 0.4, 0.4, 0.4, и именно с такими настройками я их запекал вместе.
Немного подкрутил входные веса, для более скругленных значений, и ре-масштабировал результат под вес 1 в супермерджере.
Получилось в итоге довольно близко. Гораздо ближе чем с экстрактом. Но все-таки не 95% сходимости, как раньше (отличие буквально на уровне какого-нибудь _а сэмплера), а около 80-85.
Тоже неплохо, но хотелось бы лучше.
Шалом посаны. Последний билд Onetrainer запускал кто-нибудь? У меня ругается на mgds, якобы модуля нет, pip install найти его характерно не может, а в ручное импортирование я нишмог. Есть гайды как запустить?
Давний билд годичной давности наверное запускал (аккурат год назад), а последний - хуй.
Давний билд годичной давности наверное запускал (аккурат год назад), а последний - хуй.
Подскажите, есть годный и понятный, обучальное видео по создании лора слайдер.

Lycoris на дев ветке обновился.
Из значимого пофикшена ошибка логики байпаса, которая чето с декомпозом делает и ебет его несколько месяцев подряд, и кароч суть в том что теперь дора работает корректно как и должна на любом алго. Плюс калькуляция декомпоза на аут (последний мажорный апдейт) в состояние вкл на постоянку теперь и работает корректно.
Сделал прогон на фул параметрик с те и да действительно теперь мозги не ебет (а я думал че оно говно мне обучало, пиздец сколько часов проебал за джва месяца).
Мейн не обновился еще, так что чтобы юзать в кое надо в kohya.py ликориса поменять default_lr на learning_rate + добавить две переменные к self - unet и text_encoder в строках пикрел, тогда мисматча не будет при старте тренировки.
Из значимого пофикшена ошибка логики байпаса, которая чето с декомпозом делает и ебет его несколько месяцев подряд, и кароч суть в том что теперь дора работает корректно как и должна на любом алго. Плюс калькуляция декомпоза на аут (последний мажорный апдейт) в состояние вкл на постоянку теперь и работает корректно.
Сделал прогон на фул параметрик с те и да действительно теперь мозги не ебет (а я думал че оно говно мне обучало, пиздец сколько часов проебал за джва месяца).
Мейн не обновился еще, так что чтобы юзать в кое надо в kohya.py ликориса поменять default_lr на learning_rate + добавить две переменные к self - unet и text_encoder в строках пикрел, тогда мисматча не будет при старте тренировки.
Влияют ли новые карточки от куртки на развитие нейросетей?
Типа компании закупят железо мощнее и через год обучат на нем нейронки уже для плебса с 8гб врам
Типа компании закупят железо мощнее и через год обучат на нем нейронки уже для плебса с 8гб врам
Не понял как связано одно с другим. Компаний которые владеют кластерами видях не то что бы много, а задачу по созданию моделек для нищеты выполнила только стабилити, причем дважды. Так или иначе стараются уложить фп16 в 24 гига, а это ну консумерский уровень так-то, а 8 гигов это дно дна на самом деле.
Даже триджы, 1.5/2, сдхл, 3.5 медиум
Подскажите плз. Есть папка с пикчами, хочу проапскейлить их с разными сидами. Иду в i2i, вкладку batch, указываю папку, ставлю Batch count = 10 и обычный sd-upscale. По итогу выдает для первой пикче 10 вариантов, а все последующие по 1. Ulitmate sd upscale вообще выдает всегда по 1. Пробовал и в A1111 и рефордже. Это косяк скриптов ?

Иди сразу в комфе. Ультимейт апскейл можешь заменить на любую другую реализацию, хоть чисто моделькой скейль в мультиплаер который в нее встроен (ну 4х там и так далее) или через Supir если времени не жалко.

Скорее уж плебс наконец-то закупится хотя бы 16-ю гигами.
С виду то же самое. Разве что mode и density доступны.
Скорее всего одна и та же фигня получится.
Есть комфи в коллабе вообще?
Хоть попробую, что там получится.
А то не хочется по-новой его себе ставить.
У меня 24 и куда их тратить хз, на всякие флексы/видео всё ещё дохуя времени уходит
Как правильно натренить лору на определенный объект? У меня все попытки оканчиваются тем что с лора просто пытается повторить картинку из датасета со всем окружением.
Аноны вот я наделал некоторых картинок маленького разрешения. Теперь мне надо сделать их в высоком разрешении. Я беру данные генерации, добавляю к ним настройки hires. Картинок дохуя. Встал вопрос как их все запихнуть в очередь?
Всего за эти годы было создано джва расширения для этой задачи - agent-scheduler и SDAtom-WebUi-us.
Оба нерабочее говно. В agent-scheduler не сохраняются настройки сэмплера, при запуске SDAtom-WebUi-us весь интерфейс покрывается ошибками - дальше не смотрел.
Z/X/Y plot вообще не про это.
Как быть?
Всего за эти годы было создано джва расширения для этой задачи - agent-scheduler и SDAtom-WebUi-us.
Оба нерабочее говно. В agent-scheduler не сохраняются настройки сэмплера, при запуске SDAtom-WebUi-us весь интерфейс покрывается ошибками - дальше не смотрел.
Z/X/Y plot вообще не про это.
Как быть?
Забыл написать, что вопрос этот по AUTO1111. Все настройки и промпты для этого интерфеса, так что перекатится на другой не вариант.
>Как правильно натренить лору на определенный объект?
Сеть знает о концепте изначально или нет?
>У меня все попытки оканчиваются тем что с лора просто пытается повторить картинку из датасета со всем окружением.
Покажи настройки.
Если сеть знает о концепте, то достаточен класс датасета (название папки с количеством повторов) или базовый капшн с токеном.
Если сеть не знает о концепте или тебе нужна более глубокая адаптация, то нужно дескриптивное описание кепшенов.
Помимо этого генерализация, параметрический охват и способность запоминать сложные паттерны зависит от лагоритма, типа ошибки и самой задачи. Ну и настройки в целом очень сильно влияют на результат, а твои настройки я не вижу.
Тут можно тонны советов начать раздавать, рассказывать про мокрописьки, поэтому постараюсь кратко пробежаться по общей инфе на основе своего опыта, т.к. я часто пизжу объекты.
Предполагаю что ты сидишь на дефолтном локоне в качестве алго. Я не люблю дефолтный локон, он не слишком гибок, плохо работает с большими и разнообразными датасетами, имеет маленькую емкость, короче узконаправленный и для тех кому достаточно, поэтому крайне редко его сам тренирую, когда надо настроечки проверить. Плюс не люблю понижать те относительно скорости тренировки весов.
Если тебе надо что-то быстро спиздить, то я бы выбрал loha с такер декомпозицией (раскладывает матрицы как свд), там думать не надо особо и 1 к 1 по дименшену и альфе тоже не требуется, очень легко пиздит всё - от стилей, до объектов, очень хорошо синергирует с TE на той же скорости что веса не вызывая его прожигания и соответственно не нужно симулировать early stop te для лоры (когда ты обучаешь TE первые несколько эпох пока те не начинает забывать данные, а веса берешь от более поздних эпох и соединяешь их вместе; если не знаешь как вырезать те из модели и вставлять в другую модель, то можно это делать в комфи просто двумя нодами где у одной клип только включен, а у другой включен только юнет). Из минусов наверно низкая емкость только вследствие чего как по мне недостаточная детализация периодически сквозит, но если подобрать дименшен и у тебя позволяет выставить побольше, то незаметно будет.
Если тебе нужна йобовая тренировка максимально похожая на файнтюн с гигантской емкостью и запоминанием сложных паттернов то это только BOFT и GLORA, но бофты работают щас только в а1111 и нигде больше, считаются долго и требуют врама, а глора ботает везде. Глора очень щадящая гибкая штука и позволяет силу лоры поднимать до небес, ее практически нереально перетренить в общем, только если 1:10 по дим:альфа выставить, да и то оно не сдохнет и можно наоборот понижать вес лоры при инференсе. Из минусов трудно подобрать оптимальный лернинг для эффективного обучения и принцип активаций-подсказок хрупкий и требующий стабильного обучения, для быстрого обучения не подходит.
Если нужна большая емкость и возможности LOHA, то есть LOKR, пиздит все точно также как лоха и даже лучше, но гораздо мощнее параметрически, но очень сенсетивный ко всем остальным настроечкам. Плюс есть удобная фича факторизации, когда ты конкретно к модели натренировываешь адаптеры и тем самым получаешь микроскопический вес лоры без лишнего говняка в пару мегабайт. Плюс можно не настривать альфу вообще, т.к. можно выставить выключение декомпозиции через указание 100000 дименшена.
Еще можно подключить к алгоритмам DORA, это симуляция поведения тренировки весов как на полноценном файнтюне вместо классического lora метода, ее как раз пофиксили в последнем дев билде ликориса
Из того что я бы не выключал вообще никогда это стабилизацию рангов через rs_lora, особенно если тренируешь более 32 дименшенов, для огромных дименшенов это вообще база как по мне. Принцип ранг стабилизации простой - у тебя есть дименшен из которого вычисляется корень, то есть у тебя был ранг 64, но он масштабируется до ранга 8, следовательно к 64 дименшену не требуется 64 альфа, а требуется уже 8 для 1:1 зависимости. Доджит кучу проблем нормализаций и масштабирования.
По типу ошибки - ну я бы лично выбирал между huber и l1, хубер отлично работает с низкими таймстепами которые в основном портят обучение на домашнем обучении, но недостаточно мощно с высокими, поэтому к нему особенно рекомендуется усиление верних через debiased_estimation_loss. l1 прямой как палка и суперстабильный.
Что бы вы запустили на 4090 48GB?
Я не шарю, типа, эээ, Flux? А как можно поиграться, 24 против 48 гигов вообще что-то даст? Будто бы ничего особо не навалить.
Если есть что сказать — напишите.
А то просто бахну 4096 на 4096 fp8 и все.
Преимущественно Comfy.
Я не шарю, типа, эээ, Flux? А как можно поиграться, 24 против 48 гигов вообще что-то даст? Будто бы ничего особо не навалить.
Если есть что сказать — напишите.
А то просто бахну 4096 на 4096 fp8 и все.
Преимущественно Comfy.
Я бы запустил жирных ллмок
Епт, че так сложно, я думал достаточно накидать картинок и описать что на них изображено, а Искусственный Интеллект дальше сам разберется, а тут пердолиться надо.
Где вообще почитать о матчасти можно, что такое ликорисы, бофты, глоры, как настраивать kohya-ss. Как тренировать для Пони, для Люстры и прочих Нубов, я так понимаю что все они SDXL, но допустим я хочу реалистичную картинку получать, для тренировки тоже надо брать модель с реализмом, или надо на базовом SDXL тренить? Короче где про все это узнать, просто в гугле и ютубе рассказывают о совсем базовой херне которая и результат херовый даёт.
> Епт, че так сложно, я думал достаточно накидать картинок и описать что на них изображено, а Искусственный Интеллект дальше сам разберется, а тут пердолиться надо.
Не ну в принципе и так можно, вообще ничего не подкидывать в конфиг кроме дименшена, оптимайзера с максимально сглаженными бетами и дефолтного l2, ток это надо понижать скорость сильно и ждать не условные пару часов, а пару дней. Это просто неэффективно. Поэтому если хочешь быстро надо понимать куда тыкать и че юзать.
> Где вообще почитать о матчасти можно, что такое ликорисы, бофты, глоры, как настраивать kohya-ss.
Унифицированного гайда по всему нет, в шапке есть несколько гайдов по аргументам для кои, можешь спрашивать у гпт за них если чето неясно, сам список всех аргументов вызывается через python sdxl_train_network.py -h в командной строке например.
Ликорис это базированная библиотека с алгоритмами и мокрописьками https://github.com/KohakuBlueleaf/LyCORIS/tree/dev , используемые алго описаны тут https://github.com/KohakuBlueleaf/LyCORIS/blob/dev/docs/Algo-List.md https://github.com/KohakuBlueleaf/LyCORIS/blob/dev/docs/Algo-Details.md , аргументы тут (но лучше заглядывать в скрипты самих алго, потому что текстовые гайды могут неполностью описывать все актуальные аргументы) https://github.com/KohakuBlueleaf/LyCORIS/blob/dev/docs/Network-Args.md
DORA принцип описан тут https://civitai.com/articles/4139/the-differences-between-lora-and-fine-tune-as-well-as-nvidias-newly-released-dora-technology , дора есть во всех модулях ликориса искаропки
RS описан тут https://huggingface.co/blog/damjan-k/rslora
Алсо сидеть желательно на sd3 бранче кои, наиболее свежая ветка https://github.com/kohya-ss/sd-scripts/tree/sd3
Че там еще а да оптимайзеры. Многие изуализированы тут (первая функция показывает эффективность достижения минимумов, вторая показывает эффективность достижения особо выебистых данных) https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md
Дефолтная база очевидный адамв и менее очевидный и жручий продижи, но топовые шареры 2025 года угарают по шедулерфри оптимам (из-за экономии врама по большей части и быстрой сходимости), а это вот эти библиотеки https://github.com/facebookresearch/schedule_free (адамв, радам, сгд) и отдельный форк продижей https://github.com/LoganBooker/prodigy-plus-schedule-free/tree/main
Но еще тонна всяких разных тут https://github.com/kozistr/pytorch_optimizer (там came например, с которым тренят флюкс)
По лоссам в принципе нечо обсуждать, только по хуберу интересная ветка https://github.com/kohya-ss/sd-scripts/pull/1228/
Вообще читай ишесы сдскриптов периодически, там постоянно прикормку завозят от которой дуреют
>Как тренировать для Пони, для Люстры и прочих Нубов,
С клипскипом 2, а так различий нет. Ну разве что есть впредикшен нуб, и там с ним дрочка по другому работает с другими настройками и доп аргументами. А и описание будет эффективнее именно так как были отпердолены клипы для этих моделей - буру лайк теги, а не дескриптивное описание как для стандартного клипа реализмомоделей.
>я так понимаю что все они SDXL,
Архитектура одна да
>но допустим я хочу реалистичную картинку получать, для тренировки тоже надо брать модель с реализмом, или надо на базовом SDXL тренить?
Да, лучше брать реалистичный файнтюн с переобученным текстовым енкодером. У базовой просто нет требуемых тебе знаний (или тех которые облегчают адаптацию), которые будут в жирных тюнах. База это для полноценной тренировки, тренировки с нуля и для тренировки общих концепций с излишеством в виде кроссадаптивности между всеми файнтюнами разом.
Начнет тренинга реала на онеме модели: практически так можно, что успешно делают для 2.5д эффекта, и для того чтобы найти грааль превратить 2д модель в реалистик (до сих пор все безуспешно, они все не стопроцентные), но это как бы не задача лор, а для полноценной тренировки. Если очень хочется экспериментов и безумных умений то пожалуйста вперёд аниме баб обмазывать реальными еблами, интересный опыт на самом деле, может ты единственный кто сможет совершить полноценный концептуальный перенос нарушающий математические законы.
Ммм кстати там в скрипты GGPO добавили, работает не только с флухом.
Я по бырому на мелком датасете прогнал с дефолтными сигмабетами из примера и оно чет неприлично быстро схождение бустит. Надо углубиться в тестирование.
https://github.com/kohya-ss/sd-scripts/pull/1974
> работает не только с флухом
Нет, там только в лоре для Флюкса реализация есть, в обычной нет. На XL оно просто ничего не делает.
Я только ято проверил аргументы и оно работает с сдхл.
Странно вообще. Ну по pr видно что поменяли ток флюксоскрипт и трейн нетворк, но у меня значительно разные результаты с двумя этими аргументами. Щас прогоню еще раз с другими значениями экстремальными, если опять будет другое изображение, то там точно чето подтекает каким-то образом.


Есличе слева без ггпо, справа с ггпо, ничего не менялось кроме двух аргументов, ген левым словом не из датасета.

Я не шучу, оно реально подтекает в тренировку сдхл, вот тут сигма и бета 0.1 обе
А что поменялось? Выглядит как просто недетерминированная тренировка.
Она детерминированная.
С одинаковыми настройками. Вот как раз изменение настроек GGPO и меняет рандомно результат. По твоим пикам разница на уровне изменения сида тренировки.
Так я специально левое слово для гена взял для чистоты, если генить тренированное там ебнешься разница.
Значения передаются от сида, а от положения буковок в конфиге.
Во вторых я вижу реальный квалити ап и более агрессивное схождение на то что тренировал. Я бы показал реальные картинки, но там порнуха. Так что нет, это не что-то уровня погрешности сида.



Во придумал как показать
без ггпо аргументов, с дефолтными сигмабетами, с ушатанными сигмабетами
Кароче я поинтересовался у мл сеньора и он скозал что сдскрипты могут триггерить новую функцию с неизвестной полнотой т.к. кодовая база одна.
>rslora
А в чем смысл, если можно ручками альфу нужную вписать? Или оно как-то влияет на разные размеры матриц модели? Так вроде не должно, там одна константа на все по формуле.
есть три базиса лор:
1. По дефолту лора (за исключением глоры, отключенной декомпозиции у локра и ортогоналок) не умеет эффективно и корректно работать с дменшеном выше 32, т.к. масштабирующий коэффициент альфы поделенной на ранг замедляет обучение при больших значениях ранга.
2. При этом у алгоритмов есть такое понятие как емкость, т.е. способность адаптера въебать по модели сложными преобразованиями, то насколько адаптер может менять поведение модели. У лоры/локона, лохи и низкорангового локра емкость маленькая.
3. Чем выше дименшен, тем больше параметров => больше возможность запомнить сложные паттерны.
Таким образом образуется бутылочное горлышко: увеличение дименшенов адаптеров выше 32 приводит к ухудшению обучения, а дименшены ниже 32 сосут писос по выразительности и запоминанию сложных паттернов. Рслора уничтожает это недоразу и дает лоре корректное масштабирование и нормальное управление большими дименшенами.
Так на вопрос это не отвечает, нахуя что-то ставить или включать когда можно скорректировать вручную коэффициент который ты и так выставляешь вручную?
Как ты собираешься вручную корректировать фундаментальную проблему?

В формуле просто делят альфу на корень из r а не само r. Значит можно посчитать и повысить саму альфу.
Теперь читаешь еще раз , потом понимаешь что альфа это супрессор и явно повышать ее выше финального коэффициента 1 можно без особых опасений только с глорой (на лохе для стабильности вообще около 1 всегда должна быть например) и удачи.
Я накидал побырому корректную вроде реализацию ггпо (шум к весам + шум к градиентам + бета коэф), но только для лоха и лайтовую https://pastebin.com/x2n7cwmZ (в ориге флуксолоры там квадраты норм perturbation_scale = (self.ggpo_sigma torch.sqrt(self.combined_weight_norms 2)) + (self.ggpo_beta (self.grad_norms 2)) но я не тестил пока это, только прямое вмешивание), аргументы в нетворк аргс "use_ggpo=True" "sigma=0.1" "beta=0.01", можете потыкать кому интересно, заменяете loha.py в пакедже ликориса
>Теперь читаешь еще раз
Причем тут это если по формуле твоя рслора просто масштабирует альфу и больше ничего не делает? И глобально, а значит можно саму альфу взять другой и никакое лишнее говно не ставить.
Ты формулу вообще смотрел как оно работает?
Если я не прав ну принеси правильную тогда, потому что по тому что я вижу ты можешь просто взять альфу такую чтобы она правильно поделилась на r без корня и всё.
> Причем тут это если по формуле твоя рслора просто масштабирует альфу и больше ничего не делает?
Она корень из дименшена считает. Альфа это костыль вообще придуманный как дампнер в лорах чтобы громкость влияния регулировать. Ты буквально предлагаешь громкость выше 100 процентов ставить когда у тебя и так качество обучения от количества параметров для лоу ранк матриц упало.
> Ты формулу вообще смотрел как оно работает?
Корень из дименшена.
>И глобально, а значит можно саму альфу взять другой и никакое лишнее говно не ставить.
> Если я не прав ну принеси правильную тогда, потому что по тому что я вижу ты можешь просто взять альфу такую чтобы она правильно поделилась на r без корня и всё.
Ну ты не понимаешь просто базовых вещей. Вот допустим ты берешь 100 дименшен, локон и прочие не умеет эффективно работать с таким. Дальше что? Поставишь 100 по альфе что эквивалент полной громкости лоры? А оно не улучшит ограничения лоу ранк матриц. Плюс зависимость громкости будет нелинейная т.к. чем выше дименшен тем больше супрессия альфа. А с рс у тебя алгоритм будет работать с корнем сотки, но с количеством папаметров сотони дименшена и для полной громкости потребуется выставить 10 альфу.

>Она корень из дименшена считает.
Ну да, я же писал что делится на r - ранг /корень из него же.
В ссылке и статье пишут конкретно делится на корень ранга https://ar5iv.labs.arxiv.org/html/2312.03732
Плюс пикрил буквально пишут то же что я говорю.
>Альфа это костыль вообще придуманный как дампнер в лорах чтобы громкость влияния регулировать.
Альфа это фактически масштаб весов при инициализации и тот же вес при интересе, не более, просто множитель весов.
Я как бы подумал что ты под дименшеном может быть имеешь ввиду не ранг лоры а ее внешний размер? Тогда это имело бы смысл.
Но вроде ты дименшеном называешь ранг, так что не понимаю все еще с чем нахуй ты споришь и что пытаешься доказать.
На мой вопрос ты не ответил, что по формуле выходит что можно просто альфу поднять. Как бы школьная математика начальных классов...
> Альфа это фактически масштаб весов при инициализации и тот же вес при интересе, не более, просто множитель весов.
Альфа формально множитель, а фактически константный дельта супрессор.
> Но вроде ты дименшеном называешь ранг, так что не понимаю все еще с чем нахуй ты споришь и что пытаешься доказать.
Эээ слыш, это ты мне написал и начал гнать на нормализатор дименшена и пассивно агрессировать накидывая по кругу один и тот же вопрос полностью игнорируя механические нюансы. Мне совершенно все равно как ты тренируешь, для меня плюсы рс очевидны и не мои проблемы что у тебя в уме поднятие альфы позволяет заменить корень, что в реальности факап.
> На мой вопрос ты не ответил, что по формуле выходит что можно просто альфу поднять. Как бы школьная математика начальных классов...
Нельзя поднять, если тебе нужна адаптация, а не форсирование генерирования датасетов, и то там поломается все если с те тренировать.
> Я как бы подумал что ты под дименшеном может быть имеешь ввиду не ранг лоры а ее внешний размер? Тогда это имело бы смысл.
Дименшен это и есть ранк, от ранка зависит количество параметров и следовательно вес. Нельзя работать с большим количеством параметров в лорах не выставив высокий ранк, а лоры без учета исключений не приспособлены к конским величинам ранка, вот и вся проблема. Не доебывай меня хуйней с поднятием альфы.
>это ты мне написал и начал гнать на нормализатор дименшена
Нет, я писал сразу:
1) Можно ли просто править альфу глобально? первым и вторым постом
2) Далее и после что исходная формула делит a на r, когда рслора - a на корень из r
Мое утверждение, которое я попросил доказательно опровергнуть, - что использование абстрактной рслоры математически эквивалентно правке альфы в соответствии с формулой, если r константно для всех слоев.
Ты же написал:
>Как ты собираешься вручную корректировать фундаментальную проблему?
И эту хуйню
>Ну ты не понимаешь просто базовых вещей. Вот допустим ты берешь 100 дименшен, локон и прочие не умеет эффективно работать с таким. Дальше что? Поставишь 100 по альфе что эквивалент полной громкости лоры? А оно не улучшит ограничения лоу ранк матриц. Плюс зависимость громкости будет нелинейная т.к. чем выше дименшен тем больше супрессия альфа. А с рс у тебя алгоритм будет работать с корнем сотки, но с количеством папаметров сотони дименшена и для полной громкости потребуется выставить 10 альфу.
Вероятно подразумевая, что мои предположения в корне неверны.
При этом ты не привел доказательств, которые я просил.
Тем временем мой вывод подтверждает исходная ссылка из поста на метод
https://huggingface.co/blog/damjan-k/rslora
Где буквально пишут
> Of course, for those in the know about this work, one can just substitute the scaling factor in LoRA by substituting the hyperparameter α
α for each adapter appropriately with α′α ′set as:
А также в обсуждениях https://github.com/kohya-ss/sd-scripts/pull/1870
Задаются тем же вопросом и отвечают что это так.
Далее коммиты с рслорой https://github.com/KohakuBlueleaf/LyCORIS/pull/172
Там же пишут что код может быть не в каждом алгоритме активен и поэтому лучше было бы, чтобы ничего не напуталось, "наверху" конфигов править альфу под формулу и передавать ее дальше.
Сам код:
- self.scale = alpha / self.lora_dim
+ r_factor = lora_dim
+ if self.rs_lora:
+ r_factor = math.sqrt(r_factor)
+
+ self.scale = alpha / r_factor
Где lora_dim=4, то есть константно.
Что по итогу - можно ставить большие ранги, поднимая правильно альфу, и никакие мокрописьки в конфиг или код включать не надо.
Если ты хочешь спорить с этим утверждением, то пожалуйста приведи хоть один пруф.
Если ты все это время имел ввиду что-то другое, то скажи блядь что.
Я же сразу имел ввиду, что если бы вся эта хуйня применялась бы когда в модели есть лоры разных рангов, либо если расчет идет от относительных размеров, условно, (вход*выход) / ранг, то вот тогда имеет смысл добавлять такое в код.
Больше скажу, у тебя в модели все матрички разных размеров, в тэ, в юнете, в самих слоях они разные.
Вот даже анализ от нейронки:
1280 × 1280(само‑внимание TE‑2 + большие блоки UNet)
≈ 250‑300 адаптеров (~30 % от всех)
640 × 640(«малые» блоки UNet)
≈ 150‑180 адаптеров (~20 %)
768 × 768(само‑внимание TE‑1)
48 адаптеров (~6‑7 %)
1280 × 2048(кросс‑внимание больших блоков UNet)
≈ 60‑70 адаптеров (~8 %)
640 × 2048(кросс‑внимание малых блоков UNet)
≈ 50‑60 адаптеров (~6 %)
1280 × 5120(сужающая проекция FF‑сетей TE‑2 и UNet)
≈ 40‑50 адаптеров (~5 %)
640 × 5120(сужающая проекция FF‑сетей в малых блоках UNet)
≈ 20‑25 адаптеров (~3 %)
1280 × 10240(расширяющая проекция FF‑сетей в больших блоках UNet)
≈ 30‑40 адаптеров (~3‑4 %)
768 × 3072 и 3072 × 768(MLP TE‑1)
по 12 адаптеров каждого вида (~1‑2 % на каждый)
1280 × 5120 и 5120 × 1280 (MLP TE‑2) – уже учтены выше, суммарно около 64 адаптеров.
При этом ранг у них будет один. Так что если считать относительно внешних размеров, можно получить идеальные нормы градиентов еще и по каждому слою отдельно, а не в целом. У тебя тут половина матриц в 2 раза по размеру отличаются, в 4 по площади.
Какой вывод из этого всего? - Мое общение с нейронкой примерно в 10 раз продуктивнее чем с местными лоботомитами. Хотя куда у там, скорее во все 100.
П.С. Один маленький факт о котором я подумал в самый последний момент - если ты включаешь рслору, фактическая альфа при тренировке меняется, но в файл будет записана заданная конфигом. И при последующем использовании лоры этот факт никак не учитывается. То есть твоя лора по итогу будет тише. Наверное... Но опять же это просто масштаб множителя веса.
>Нет.
Охуенно, значит на доске уже двое таких ебанутых.
>я щитаю так потому что хуй знает почему
Может быть потому что ты читать не умеешь шизохуйло обосравшиеся?
В последнем посте расписаны все пруфы но ты решил их проигнорировать и просто слиться. Начал искать как-то анимешников которые тебя проткнули.
Причем в первом моем посте тоже всё написано понятно, а во втором ты сам начал срать вообще не относящиеся к теме хуйней.
Давай, без виляния жопой тогда ответь, ты типа по итогу дискуссии считаешь что включение рслоры НЕ математически эквивалентно ручной правке альфы?
Это не /b/, с тобой блядь нормально разговаривали пока ты не начал хуйню нести.
>Охуенно, значит на доске уже двое таких ебанутых.
Аниме, если тебя все вокруг ебут, то проблема в тебе.
>В последнем посте расписаны все пруфы
Я не буду вчитываться и тратить время на вдумчивый ответ, потому что я уже вижу что там контексты теряются и притягивание за уши.
> Начал искать как-то анимешников которые тебя проткнули.
Докажи что не анимеприпиздок тренирующий референсогенераторы вместо трушной адаптации.
>а во втором ты сам начал срать вообще не относящиеся к теме хуйней.
Если тебе непонятна взаимосвязь, то не мои проблемы.
> ты типа по итогу дискуссии считаешь что включение рслоры НЕ математически эквивалентно ручной правке альфы?
Конечно нет. И это проверяется буквально двумя короткими тренингами.
>Аниме
Чини детектор протыков, я же сказал.
>Если тебе непонятна взаимосвязь, то не мои проблемы.
Ну шизы любят связывать вещи между которыми связи нет, это база.
>Конечно нет. И это проверяется буквально двумя короткими тренингами.
Нет, это БУКВАЛЬНО проверяется глядя глазками на код, если мы говорим об этом коде.
- self.scale = alpha / self.lora_dim
+ r_factor = lora_dim
+ if self.rs_lora:
+ r_factor = math.sqrt(r_factor)
+
+ self.scale = alpha / r_factor
Это весь код.
Видишь вот эту штуку / ? Это называется деление.
Если чиселка справа уменьшается, то результат увеличивается, а если слева увеличивается, то результат тоже увеличивается, прикинь, да?
А почему результат на практике может быть различным, я написал в конце поста, и если не вилять жопой и не игнорировать пруфы, либо немножко подумать, то можно догадаться что при включении рслоры ты меняешь фактическую альфу, но в тензор (.safetensors) записываешь значение из конфига, и при инференсе модели эта поправка не учитывается.

Нужен разнообразный набор картинок с этим объектом и текстовые описания к ним, в остальном все стандартно. Если просто повторяет картинку - датасет оче плох, или оче неудачные гиперпараметры.
Картинки одного промта или разных? В автоматике на вкладке img2img есть раздел batch process, собери пикчи в одну папку и укажи ее там. Можно задать единый промт для всех, можно поставить галочки чтобы оно дергало нужное из pnginfo.
В целом, все именно так, я тоже ахуел с той простыни что тот чел набросал. Может там и по делу, но для первого результата хватит и простой лоры по любому из гайдов, а дальше уже оптимизации, не всегда окупающиеся. Скорее всего у тебя относительно примитивная проблема и не нужно глубоко нырять.
Что опять за тряска и почему и далее еще не обоссан или не в бане за щитпост?
А ты зря тратишь время на биомусор , хотя полотно про альфу ничетак, почитал, если
> но в файл будет записана заданная конфигом
Вот это реально так то просто ор выше гор.
> В треде то кроме шиза и ньюфагов хоть кто-то есть?
Обсуждать особо нечего и альтернативно одаренные, сильной верой в себя и в свои чувства, создают плохую атмосферу.
> для тренировки тоже надо брать модель с реализмом
Для начала, трень на той модели, на которой собираешься юзать. Если это какой-то мердж или вася-микс - можно поискать модель на которой он основан и тренить на ней, часто результат получается лучше. В остальном тебе верно сказали.
> ничего не подкидывать в конфиг кроме дименшена, оптимайзера с максимально сглаженными бетами и дефолтного l2, ток это надо понижать скорость сильно и ждать не условные пару часов, а пару дней
Пару дней на простую лору? А сколько всего навалил, это же неофит, ему самое простое и основное нужно, а не перечень всего что есть. Если там 2.5 картинки без описаний в датасете, то как не пляши, это не сделает лучше сделает, но нужна другая пляска.
> С клипскипом 2
Клипскип - мем эпохи полторашки, про него давно нужно забыть. Если выбрана sdxl то значение 2 в интерфейсах игнорируется, специально сделали.
>Вот это реально так то просто ор выше гор.
Я ща понял что не ту репу смотрел, в актуальной нашел фикс этого https://github.com/KohakuBlueleaf/LyCORIS/commit/170554c09b03fc32f38ec247436f73093eda34a0
- self.register_buffer("alpha", torch.tensor(alpha)) # 定数として扱える
+ self.register_buffer("alpha", torch.tensor(alpha * (lora_dim/r_factor)))
Вот так оно сохраняется со скейлом, по идее.
> но в тензор (.safetensors) записываешь значение из конфига, и при инференсе модели эта поправка не учитывается
Мимо, нету разницы что ты записываешь в мету лоры, хоть удали её полностью, она будет работать так же, важен только скейл весов во время тренировки

Не, конкретно альфа это единственный параметр помимо весов, который пишется непосредственно в тензоры. Он еще и для каждого адаптера отдельным полем продублирован, можешь веса слоев прямо в файле настраивать, по идее, если вдруг оно там дальше не импортируется как-то криво. Надо проверить, а то вдруг там поле берется для всех, в твоем интерфейсе который грузит лору.

Да, действительно есть, интересно реагируют ли на смену вообще бэки разные, кумфи там или рефордж из самых продвинутых на фичи
А чем смотришь? Я только safetensors viewer для вскод с моего пикрила знаю, в нем только лист тензоров показывает. И еще есть https://netron.app/, там из полезного крайние значения, среднее, и т.п.
Pycharm дебаггер, скрипт дефолтный кохьевский https://github.com/kohya-ss/sd-scripts/blob/main/networks/check_lora_weights.py
Почему kohya такой медленный? На 3090 и 128 лоре, только юнет, оптимизатор адам, получаю 1,2 итерации в сек.
Адам 8 бит - дает чуть больше секунды на итерацию.
Ставлю адафактор, вообще падает до 1,6 секунды на итерацию. Какого хуя? Это же легкий оптимайзер, хули оно тормозить начинает?
Смотрю по статье https://www.pugetsystems.com/labs/articles/stable-diffusion-lora-training-consumer-gpu-analysis/ там у них результат намного лучше, но они на прыщах тестят, а у меня винда.
Попробовал onetrainer, настройки примерно те же, лучший результат 1,4 итерации на адаме, 1,5 сгд.
Но переключение на адафактор тоже вызывает затыки и скорость падает до примерно тех же 1,6 секунд на итерацию.
Может словил шизу, но кажется один запуск на адафакторе таки пошел на нормальной скорости.
Тестирую все на примерно одном конфиге, ничего другого не меняя.
Конфиг такой https://pastebin.com/0sdAUR9r
В общем с дефолтным адамом видюха почти полностью нагружается, а все остальное как-то не так работает.
Хваленый тут prodigyplus.ProdigyPlusScheduleFree вообще 1,9 сек/ит дает.
Адам 8 бит - дает чуть больше секунды на итерацию.
Ставлю адафактор, вообще падает до 1,6 секунды на итерацию. Какого хуя? Это же легкий оптимайзер, хули оно тормозить начинает?
Смотрю по статье https://www.pugetsystems.com/labs/articles/stable-diffusion-lora-training-consumer-gpu-analysis/ там у них результат намного лучше, но они на прыщах тестят, а у меня винда.
Попробовал onetrainer, настройки примерно те же, лучший результат 1,4 итерации на адаме, 1,5 сгд.
Но переключение на адафактор тоже вызывает затыки и скорость падает до примерно тех же 1,6 секунд на итерацию.
Может словил шизу, но кажется один запуск на адафакторе таки пошел на нормальной скорости.
Тестирую все на примерно одном конфиге, ничего другого не меняя.
Конфиг такой https://pastebin.com/0sdAUR9r
В общем с дефолтным адамом видюха почти полностью нагружается, а все остальное как-то не так работает.
Хваленый тут prodigyplus.ProdigyPlusScheduleFree вообще 1,9 сек/ит дает.
А что ты хотел? Нормальная скорость для 3090.
мне б такую скорость
Господа, блиц-вопрос!
Тут можно спросить о ComfyUI?
Что за --fast режим и что за --fp16-accumulation?
Прирост на 15% вижу по скорости, но не портит ли это картинку?
Тут можно спросить о ComfyUI?
Что за --fast режим и что за --fp16-accumulation?
Прирост на 15% вижу по скорости, но не портит ли это картинку?
Мала, 0,2 секунды в кохье кто-то спиздил.
Да и то что легкие по памяти оптимайзеры работают в ДВА а то и все три раза медленнее, это типа норма или где-то у меня проблема?
> 0,2 секунды в кохье кто-то спиздил
Так там 146% было разрешение 512 и ранг не выше 32. Либо трень нормально с такой скоростью, либо шакаль до усрачки.
> Что за --fast режим
Юзать аккум и фп8, если модель и торч соответствуют, не вместе естественно, аккум для хл, фп8 для чего то по типу флюкса
> Прирост на 15% вижу по скорости, но не портит ли это картинку?
Вроде больше должно быть, самая безобидная из бустилок, в теории должна, на практике просто будто сид чуть сдвинул, так что похуй и можно юзать постоянно
>было разрешение 512 и ранг не выше 32
На одном конфиге проверяю с 1024 и 128 рангом.
Благодарствую!
А есть нормальные 4бит оптимы которые без ультрапердолинга работают с коей?
Аноны, хуй поймёшь у вас с чего начать. Я пришёл с llm тредов, локальных и обычных. Linux, код и прочий пердолинг мне знаком. С SD дело имел в последний раз несколько лет назад, тогда всего было меньше и модели хуже. По вашей шапке тяжело понять с чего начать, чтобы нормально разобраться во всём этом. Я долблюсь в глаза? Общее представление, как устроены диффузионки я имею, но где у вас почитать всю теории последовательно? Всё как-то разбросано, хуй поёмешь тем кто только вкатывается, даже если технические вещи его не пугают.
Ну шапка сборная солянка из актуального и не актуального, можешь все почитать хуже не будет.
Общего гайда по всем вопросам не существует, надо собирать по крупицам в инторнете и гопоте, если вопросы появляются.
А что ты хочешь-то? Какая цель?
Если прямо упрощать вкат в тренинг кала
1. Качаешь сдскрипты, прикидываешь с чем твоя карта справится, изучаешь аргументы для скриптов под тот метод тренировки что выбираешь (полные параметры, лоры); если выбраны лоры то изучаешь ликорисовскую библу с алгоритмами расширенными
2. Изучаешь виды оптимайзеров (неадаптивные, адаптивные, шедулерфри), понимаешь что их дохера разных и все они дают разные результы и времязатраты, изучаешь как их настраивать, их аргументы, базовые щедулеры, кастомные шедулеры
3. Изучаешь как готовить датасет, ставишь весь софт и сопутствующие нейрокалы для тегирования согласно тому с какой моделью будешь работать и какая задача, изучаешь как работать с тензорбордой чтобы отслеживать тренинг процесс
4. Делаешь свой первый конфег, запускаешь, дико орешь что натренилось говно, повторить x100 до победного
Ссылками закидывать не буду, хотя могу если надо, будет тебе чето уровня "вся теория последовательно".
>где у вас почитать всю теории последовательно? Всё как-то разбросано, хуй поёмешь
Посидев в треде несколько месяцев, начинаешь догадываться, что предположение о том что здесь кто-то имеет понимание - весьма притянуто за уши, а скорее всего изначально неверно.
Ну есть какой-то гайд с распиской аргументов скриптов и ссылками подробнее че оно делает и из какой статьи или обсуждений взялось.
Это называется "сложный гайд", но я бы его назвал поверхностным обзором документации скриптов, приправленным немного каким-то опытом его писавшего.
Вся инфа разбросана по тредам.
Хороших конфигов я не видел, каких-нибудь сложных датасетов, на которых можно ставить эксперименты - никто не выложил.
Попытки делать подборщики параметров - чет было, но как-то слабо.
Код особо никто не разбирал, кроме мелких вещей. (Протухшие обертки для запуска скриптов кодом не считаем).
Происходящее внутри сети никто не анализировал. Есть только бесполезный лосс, дальше никто не смотрит, как там внутри градиенты распределяются никого не ебет, и т.д.
Людей которые бы пытались мл учить и разбираться в физике процесса я тут тоже чет не заметил.
Это если тебя обучение моделек интересует. С генерацией там единственное в чем надо разбираться, это пердолинг в комфи и иметь некоторый опыт, который набирается довольно быстро.
И да, ты не сказал, а чего ты хочешь то?
Кроме написанного на популярных ресурсах общего, так сходу не найдешь. Только курсы и лекции, где заходят очень-очень издалека. Познают все в основном из практики, желая достигнуть чего-то конкретного, а уже только потом начинают разбираться, далеко не всегда погружаясь, а просто набирая эмпирический опыт.
Ты что вообще хочешь?
В целом здесь есть более менее шарящие люди, но их мало. Тут основное общение происходит или когда кто-то задасет конкретный вопрос, остальное в дискордах, личных переписках и подобном. Причины для этого разные.
Так что если у тебя есть что-то конкретное то пиши не стесняйся.
> Код особо никто не разбирал, кроме мелких вещей.
Правки, фиксы, улучшения и всякие вещи коммитятся, их делают по мере надобности себе. Или просто делают свой форк со специфичными изменениями. Что там разбирать то, уже 100 раз обсосали.
> Происходящее внутри сети никто не анализировал.
А вот это ты лихо дал, странная абстракция, и вокруг этого здесь все срачи и происходят.
На самом деле все "тренера" как раз примерно это и пытаются анализировать пусть иногда косвенно/субъективно, вырабатывая для себя закономерности и трюки для лучшего результата. Учитывая что файнтюнами, где можно разгуляться, тут занимается 1.5 человека, а большинство пилящегося - лоры на что-то оче оче узкое, даже не мультиконцепт, это получается вообще отдельный раздел, где многое просто не может проявиться, или будет перебито каким-то другим фактором. Например, как в прошлых тредах обсуждали разные таймстеп шедулеры. Для мелколоры об этом никто не думает, но если попробовать делать что-то крупнее для sdxl vpred моделей и ставить целью сохранить возможности - становится важным.
> как там внутри градиенты распределяются никого не ебет
Было бы интересно узнать про полезность этой информации, исключая крайние точки когда они не начинают исчезать, или наоборот улетают в космос.
> Людей которые бы пытались мл учить
Пожалуйста, в универ. Пока отучишься несколько поколений нейронок и прочего сменятся. Если повезло иметь какие-то знания к началу этого то очень хорошо, но они далеко не всегда приближают к результату. Здесь даже четко сформировавшейся научной школы нет, буквально первый край, где обсираются самые лидеры, сливая кучу денег, ресурсов, человекочасов на треш типа жпт4.5.
Можно вообще заявить что dataset is all you need, а с остальным справится adamw и дефолтные параметры. И действительно, при правильном формировании, аугментации, порядке для контрастного обучения и прочем, это даст результат гораздо лучше, чем шедьюл-фри турбо-гига-мега-пролежни с примитивным датасетом.
Кохак добавил lora+ в ликорис (в кое давно завезено).
Кратко, лораплюс это допкоеф для соотношения обновлений между A и B матрицами адаптеров, практика показывает что одинаковая скорость обучения для обоих блоков неэффективна.
Можно отдельные коэффициенты для TE и юнета юзать, можно общий на всё.
Ознакомиться с папирой кому интересно https://arxiv.org/pdf/2402.12354
Кратко, лораплюс это допкоеф для соотношения обновлений между A и B матрицами адаптеров, практика показывает что одинаковая скорость обучения для обоих блоков неэффективна.
Можно отдельные коэффициенты для TE и юнета юзать, можно общий на всё.
Ознакомиться с папирой кому интересно https://arxiv.org/pdf/2402.12354
Нам такое явно не нужно. Б-матрица - это нули, т.е. множители для весов основной матрицы. Больше ставим lr для Б-матрицы - больше эффект от лоры. Смысла в этом нет в контексте SD. Авторы аж на 20 хуячат лоры для LLM, но в SD уже на 4 пизда как перетрен идёт.

>Нам такое явно не нужно.
Нужно, работает отлично, рокербу из репо кои уже год с лораплюсом гоняет, я где-то с декабря. Прогнал сегодня с глорой пяток тестов с разбегом от 4 до 128, эффект шикарный.
> Б-матрица - это нули, т.е. множители для весов основной матрицы.
Щито? B матрица преобразует данные обратно в исходное пространство признаков после сжатия через A.
>Больше ставим lr для Б-матрицы - больше эффект от лоры.
Не, там сила эффекта лоры не меняется.
В лорах А-матрица инициализируется рандомным шумом, а Б - нулями. Именно поэтому у тебя начальная лора делает ничего, потому что А-матрица на нули умножается. Делаешь выше lr для Б-матрицы - получаешь более быстрое отклонение от 0. Собственно лора+ даёт эффект очень похожий на альфу.
Ну это инициализацию ты имеешь в виду, а у разных алго она разная.
А так суть лоры+ немного в другом:
Исследователи обнаружили, что первоначальный подход LoRA не так хорошо работает для моделей с большой «шириной» (т.е. большими размерами вложения). Это связано с тем, что LoRA обновляет две матрицы адаптеров, A и B, с одинаковой скоростью обучения во время тонкой настройки.
С помощью математического анализа авторы показывают, что использование одинаковой скорости обучения для A и B не позволяет модели эффективно обучаться признакам в сетях большой ширины.
Используя аргументы масштабирования для сетей большой ширины, авторы демонстрируют, что использование одной и той же скорости обучения для A и B не позволяет эффективно обучаться признакам. Интуитивно это объясняется тем, что масштабы обновлений для A и B должны быть сбалансированы определенным образом, чтобы охватить наиболее важные функции.
Чтобы устранить эту неоптимальность, авторы предлагают простую модификацию под названием LoRA+, которая использует различные скорости обучения для матриц адаптеров A и B с хорошо подобранным соотношением. Это позволяет модели более эффективно изучать признаки во время тонкой настройки.
Чел, ты сам читаешь что кидаешь? Тебе чётко написано что просто lr разный делают у А и Б матриц. У них классическая лора, с нулями в Б-матрице, в их коде они просто домножают lr у неё на коэффициент. В peft давным давно одной строчкой кода такое делали.
>Тебе чётко написано что просто lr разный делают у А и Б матриц.
Так я и говорил изначально.
>У них классическая лора, с нулями в Б-матрице
Да какая разница, это другая мысоль
>В peft давным давно одной строчкой кода такое делали.
Круто, но в ликорис ток щас добавили
Ну например, я хочу получить ответ на вопрос - почему понь хорошо стабилизируется лорами? Должна же быть какая-то физика этого процесса.
Вот для клипскипа я объяснение нашел, в чем была причина, а была она в том что из за низкой точности проебалось обучение нормализации в последнем слое клипа. (Это еще к тому нахуя смотреть на градиенты внутри, если бы смотрели, это отлавливается с одного взгляда на графики. Ну ток их еще надо накодить чтобы собирались нужные метрики...) И отрезать портящий масштаб вложений слой оказалось лучше чем с ним. Не думаю даже, что это было сознательно сделано, ибо сознательно там скорее ручками можно было поправить и ничего не резать.
Вот так непонятное шаманство было полностью объяснено. И таких вещей еще дохуя можно найти.
Рекомендуют для B ставить в 16 раз больше скорость.
А я вам скажу что там еще и беты должны быть сильно другие скорее всего.
Да и соотношение наверное должно определяться не константой, а зависеть от размеров матричек, как я уже предполагал в дискуссии выше...
В любом случае тут дело в соотношении, чтобы матрицы учились одинаково, и общий лр ты подбираешь отдельно всегда. Да и сам лр как бы не обязан всю матрицу в плюс тянуть, так что скорее всего это бред. Первая матрица это тоже множитель вообще то. А от перестановки множителей результат не меняется. Ну в матрицах это не так, но касательно амплитуд воздействия примерно так.
> тут дело в соотношении
Только вот это применимо только к трансформерам, где блоки имеют одинаковый размер. В UNET все слои разного размера, от соотношений смысла мало, оно изначально очень неравномерно тренится.
>почему понь хорошо стабилизируется лорами?
Эффект дистилляции.
> почему понь хорошо стабилизируется лорами
Потому что в базе понь - отрыжка лошади, нужно буквально над сервером стоять и крутить хуем как Пистолетов, постукивая им по A100, чтобы такое получилось.
Там "хорошо" все, от треша из очень разнородного датасета, проходя через кривые капшны к картинкам, заканчивая плохими гиперпараметрами и проблемами с планировщиком шума, из-за чего оно все желто-коричневое.
Для понимания уровня модели - там по дефолту малый клип почти не работает, можно его вообще ампутировать или брать стейты с первого слоя - все равно какая-то картинка будет получаться.
Всякие стилелоры и подобное сами по себе сужают выход и подстраивают его под определенную форму. В пони это тоже срабатывает, но из-за того, насколько оно страшное в базе, эффект наиболее нагляден.
> а была она в том что из за низкой точности проебалось обучение нормализации в последнем слое клипа
По неподтвержденной инфе они это открыли, когда пытались оформить претрейн полного клипа. По дефолту с adamw и без постепенной разморозки он даже в fp32 норовит умереть, спасает плавная разморозка и тонкая подстройка гиперпараметров, или другие оптимайзеры.
Врядли они с этим сильно разбирались, а просто сделали такое решение, которое вполне работает. Это уже потом стало ясно что те в составе sd без проблем тренится даже в режиме со смешанной точностью.
> Не думаю даже, что это было сознательно сделано
Смотря на новелов, относительный успех 1й модели, провал второй, вымученная 3я с затратами компьюта больше чем на оригинальную sdxl, противоречивая 4я - ну хуй знает насколько там светила собрались. К тому же когда задача - сделать, а не исследовать, вполне нормально выбирать какие-то рабочие решения.

обнова комфе есличе
> Вот для клипскипа я объяснение нашел, в чем была причина, а была она в том что из за низкой точности проебалось обучение нормализации в последнем слое клипа
Но они его даже не тренили, выложенный чекпоинт с барского плеча от них, около года назад, не содержит ничего кроме их юнета и вае, которое они тоже тренили и обосрались с нанами https://huggingface.co/NovelAI/nai-anime-v1-full/tree/main
А есть какая-нибудь мелкая пиздатая диффузионка, любая в принципе, которую реально с нуля обучать?
Можно конечно попытаться взять спидран nano-gpt и переделать его в диффузию, но кажется я немного охуею этим заниматься.
Или стоит взять удачную по архитектуре и эффективности готовую диффузионку со всем кодом, и заскейлить ее раз в 100-10?
Можно конечно попытаться взять спидран nano-gpt и переделать его в диффузию, но кажется я немного охуею этим заниматься.
Или стоит взять удачную по архитектуре и эффективности готовую диффузионку со всем кодом, и заскейлить ее раз в 100-10?
SD 1.5 на домашних машинах тюнили. И на единственной A100 тоже.
Технически наверно можно и с нуля обучить, просто очень долго будет.
И непонятно, зачем и кому это надо. Лучше чем есть вряд ли получится, а для большинства прикладных задач файнтюн все-таки дешевле, да и удобнее.
Мне не для картинок модель нужна.
Вопрос наверное так правильнее задать: есть ли какая-нибудь крутая любая диффузионная модель, чтоб там оптимизированная архитектура, всякая такая хуйня типа MoE и был код для обучения? Может что-то вышло интересное для звука там, что стоит заценить, либо эффективные vae тоже интересны.
Ее в любом случае придется переделывать под задачу, обучать с нуля, и даже обучать свой vae с нуля.
Задача довольно сложная, и вероятно не получится взять совсем маленькую модель и попробовать. Не заведется. Примерно похожую задачу решали на примерно 0.5б диффузионке. Время на тренировку порядка недели-двух на нескольких условных 3090. Только самой модели нет и кода, так что подробности неизвестны. И это все без тестов, чисто время если ты все правильно настроил, 1 запуск фулл тренировки. Под мою задачу надо рассчитывать еще и х10-х1000 сверху, может потребоваться много проходов (а-ля RL или нагенерить синтетики).
В принципе даже материалы по vae для диффузионок больше интересны, ибо диффузию то понятно как учить, а про vae я ничего не знаю, как их вообще учат и где посмотреть пайплайн от которого можно отталкиваться.
Я много раз топил за маски лосса (и всем похуй), но что если вы хотите закрыть маской 90% картинки, или вообще 99%?
Есть подозрение, что когда лосс настолько порезан, то обучение будет идти плохо, и его качество будет намного ниже.
В модели слои работают с разными уровнями семантики, и есть большая вероятность, что на самом деле мы хотели бы перекрыть маской доступ к информации для отдельных слоев, а не всей модели. Либо же для отдельных блоков и токенов. А остальные слои пускай продолжают учиться базовому денойзу.
Есть метод, который позволяет пустить поток градиентов от любой ограниченной области изображения в любой отдельный слой, либо только в юнет/тэ, либо вообще загнать в отдельный токен, по пути назначая пропорции для каждого слоя, на которые выделенная область будет влиять (имеется ввиду, что можно использовать маску не как маску, а как разметку для сложных новых токенов/эмбеддингов, чтобы только в них загонялась инфа от маски).
Этот метод требует дополнительного шага вычисления градиента (в обратном проходе) для каждой отдельной области маски. (1 маска = +1 шаг, 2 = +2). Это при условии, что влияние маски проходит сквозь модель. Например если маска затрагивает только последние слои, либо доходит до середины, а потом градиент либо сливается, либо остается только основной поток, то можно сэкономить на вычислениях.
Если мы используем fused backward pass, то накладных расходов по памяти практически не возникает. Иначе - фактически генерируется удвоенный/утроенный... объем градиентов, то есть затраты примерно половинка от увеличения батча, так как активации у нас те же самые.
Ну и конечно же готовой реализации этого алгоритма нет, и вам придется сделать ее самостоятельно))
Выглядеть это будет как батч, только используются одни активации, вычисление градиента для первого элемента батча - лосс вокруг маски, для второго сама маска... Вычислили градиенты - и суммируем их с установленным коэффициентом для каждого слоя. Дальше обычный шаг обновления весов.
Вроде ничего особенного.
Есть подозрение, что когда лосс настолько порезан, то обучение будет идти плохо, и его качество будет намного ниже.
В модели слои работают с разными уровнями семантики, и есть большая вероятность, что на самом деле мы хотели бы перекрыть маской доступ к информации для отдельных слоев, а не всей модели. Либо же для отдельных блоков и токенов. А остальные слои пускай продолжают учиться базовому денойзу.
Есть метод, который позволяет пустить поток градиентов от любой ограниченной области изображения в любой отдельный слой, либо только в юнет/тэ, либо вообще загнать в отдельный токен, по пути назначая пропорции для каждого слоя, на которые выделенная область будет влиять (имеется ввиду, что можно использовать маску не как маску, а как разметку для сложных новых токенов/эмбеддингов, чтобы только в них загонялась инфа от маски).
Этот метод требует дополнительного шага вычисления градиента (в обратном проходе) для каждой отдельной области маски. (1 маска = +1 шаг, 2 = +2). Это при условии, что влияние маски проходит сквозь модель. Например если маска затрагивает только последние слои, либо доходит до середины, а потом градиент либо сливается, либо остается только основной поток, то можно сэкономить на вычислениях.
Если мы используем fused backward pass, то накладных расходов по памяти практически не возникает. Иначе - фактически генерируется удвоенный/утроенный... объем градиентов, то есть затраты примерно половинка от увеличения батча, так как активации у нас те же самые.
Ну и конечно же готовой реализации этого алгоритма нет, и вам придется сделать ее самостоятельно))
Выглядеть это будет как батч, только используются одни активации, вычисление градиента для первого элемента батча - лосс вокруг маски, для второго сама маска... Вычислили градиенты - и суммируем их с установленным коэффициентом для каждого слоя. Дальше обычный шаг обновления весов.
Вроде ничего особенного.
Не догоняю как через LambdaLR ебануть кастом формулу шедулера. Знает кто?


Эти картинки имеют нулевое отношение к реальным нейросетям.
Че ето? Синтетика показывает прямой эффект оптимайзера, а не применение исходя из твоего говеного датасета на батче 1.
Реальный ландшафт сети на выпуклые функции не похож и на пик 1 тоже, он намного сложнее. Более того, он постоянно меняется.
Я не знаю, вводят ли в твоих пиках стохастику искусственно, но даже если вводят, это все равно не то. Надеюсь ты понимаешь чем отличается стохастический градиентный спуск от не стохастического, и что второй не лучше первого. Точнее, что есть некий трейд-офф между ними, и что он сильно склоняется в сторону первого даже если мы не берем в расчет вычислительную стоимость.
Покажи свой гитхаб на предмет контрибов и модели.
Ага, щас. Потрать хотя бы недельку чтобы актуальную базу по МЛ изучить, прежде чем такие предъявы кидать.
Всё ясно с тобой.
С тобой тоже, продолжай учить МЛ по книжкам 10-летней давности.
Не закапывай себя сильно глубоко.
> Есть подозрение, что когда лосс настолько порезан, то обучение будет идти плохо, и его качество будет намного ниже.
Скорее всего, ведь при генерации внимание охватывает всю пикчу, а ты даешь разницу с относительно малой области. Еще более вероятно что это приведет к тому, что появится оче жесткий байс на объекты где-то в центре, или там где будет маскированная область, а в остальной будет ерунда.
> слои работают с разными уровнями семантики
Вот это в целом довольно специфичная тема, ведь там нет целенаправленного деления. Только некоторые условные наблюдения от влияния возмущений отдельного слоя на конечную картинку, при том что все равно задействованы все слои. Но сам подход может быть интересный.
> Этот метод требует дополнительного шага вычисления градиента (в обратном проходе) для каждой отдельной области маски.
Ага, вся проблема в том, что на каждую из вариаций придется делать дополнительный обратный ход до слоя, к которому применяется маска, при этом задействованы будут только градиенты этого слоя, а остальные не требуют расчета. Такой финт потребует смены работы оптимайзера и в торч лезть.
> а как разметку для сложных новых токенов/эмбеддингов, чтобы только в них загонялась инфа от маски
Вот тут вообще ничего не понятно. Почему бы просто не ввести дополнительный входной канал и слои для масок и гнать туда эти самые маски, а также специальным образом размечать кондишны для соответствия им?
> вам придется сделать ее самостоятельно
Выглядит крайне сложно и не понятно окупятся ли затраты, или вообще не вылезут ли странные побочки. Точнее понятно что наоборот все плохо. Увы.
В целом, оценка работы на подобной функции вполне может считаться критерием при относительном сравнении. Не ультимативным, единственно верным и супер точным, но всеже. Не понимаю куда ты воюешь.
>Вот тут вообще ничего не понятно. Почему бы просто не ввести дополнительный входной канал и слои для масок и гнать туда эти самые маски, а также специальным образом размечать кондишны для соответствия им?
Тебе еще надо ждать пока модель обучиться сопоставлять маску с подсветкой тега, что в случае сложных тегов будет не быстрым процессом. В случае одного тега сходимость вообще никто не гарантирует. Для моего метода формально тоже, но на глазок у него побольше шансов. Плюс у тебя остается маска, которую всегда надо рисовать, а она может быть сложной, какие-нибудь элементы одежды и т.п., что обычно хотелось бы чтобы модель расположила сама. Это совсем разные методы, короч. Хотя я вполне допускаю что твой, ели он хорошо обучен, будет сам демонстрировать такое же поведение с точки зрения градиента, и это даже можно инструментально измерить. Что может стать хорошим поводом если не для статьи в журнале, то хотя бы неплохой статейкой в бложике.
>Не понимаю куда ты воюешь.
В сторону уменьшения мнения о полезности таких картинок. Причины моего мнения я уже назвал, могу лишь дополнительно предложить предсказать хоть одно практическое свойство оптимайзера глядя на них.
Также могу сказать что наши нейросети это ансамбли различных маленьких нейронок, и обычно будет гораздо полезнее как можно быстрее доехать в пусть и не самый хороший минимум, но всеми ансамблями, а не пытаться сто лет выдрачить ту самую низкую точку в центре которая ну немного ниже чем остальные. При большом количестве параметров эта выгода очень быстро размажется.
Но в каких нибудь начальных сверточных слоях с большим эффективным батчем это может быть не так, и вот уже там может быть имеет смысл воткнуть такой оптимайзер, а может быть и вовсе наоборот, потому что больший размер батча - большая подобность СГД - соответственно большая вероятность застрять в локальном минимуме. Которых на самом деле не существует, но в таком режиме могут быть.
Гитхаб/профиль на цивите/хаге твой ждем. В противном случае это резонерство обычное. Особенно пукнул с отрицания минимумов во время того как все сети построены по принципу гравитационных взаимодействий и магнитуды, а чтобы выпинывать сеточку из попадания в "латентную черную дыру" есть CosineAnnealingWarmRestarts в качестве шедулера лр.
> надо ждать пока модель обучиться сопоставлять маску с подсветкой тега
Ясен хуй, ведь меняется структура модели для добавления в нее новых фич и инициализируются новые слои. Датасет тоже должен быть значительным по размеру, покрытию и разнообразию. Благо поскольку делается на основе готовых весов - тренировать будет легче чем совсем все с нуля.
> Для моего метода формально тоже, но на глазок у него побольше шансов.
Так суть твоего метода вообще не понятна, что именно хочешь добиться.
> остается маска, которую всегда надо рисовать, а она может быть сложной
А может и не быть, а может и не оставаться, компонент делается опциональным правильной аугментацией и обучением, точность маски не важна если обучать не с точными. Можно вообще боксами обойтись.
> такое же поведение с точки зрения градиента
Увы, не понимаю тебя. Это действительно другой метод, в котором обучается диффузия с дополнительной сегментацией кондишнов, а не используются маски для лосса при обучении. Самый простой пример подобного - инпеинт модели.
> В сторону уменьшения мнения о полезности таких картинок.
Количественно озвучь. То что критерий необходимый а не достаточный - не стоит ставить ему в недостаток, особенно когда других удобных нет.
> обычно будет гораздо полезнее как можно быстрее доехать в пусть и не самый хороший минимум, но всеми ансамблями, а не пытаться сто лет выдрачить ту самую низкую точку в центре которая ну немного ниже чем остальные
Этому нет обоснования, просто слова и принятие на веру. Остановка в локальном минимуме вместо значительно более удачного глобального может быть проиллюстрирована стремлением нейронок к тривиальным решениям и паразитным запоминанием побочных простых признаков при неудачном обучении, плохом оптимайзере и аугментации датасета. Для самых маленьких пример: вместо определения кошка или собака на картинке по совокупности признаков, оно будет относить все рыжие объекты к кошкам а черные к собакам.
Если же ты имплаишь за поиск начального приближения из шума в оче большой модели из множество компонентов - так никто не обучают, всегда идет претрейн отдельных частей.
Присоединяюсь к интересно увидеть реализовал ли что-то человек с таким количеством идей.
>Датасет тоже должен быть значительным по размеру, покрытию и разнообразию.
Ну вот, я тебе про одно, ты мне про другое. Я про быструю тренировку на нескольких картинках в случае редких юзкейсов, а ты про большую тренировку, где никто не будет такой разметкой заниматься тем более не понимая что это даст.
>Так суть твоего метода вообще не понятна, что именно хочешь добиться.
Возможности добиться точного сопоставления тех тегов которые иначе сопоставляться не хотят. Но это было скорее предположение и частный случай от общей идеи, не факт что это будет так работать, просто есть возможность ввести такое ограничение на градиент.
Да и вообще я не хочу ничего добиться, я просто высказал идею чтобы она в закромах не лежала, а может кто-нибудь захочет воспользоваться.
>Увы, не понимаю тебя.
Я говорил про то, что если можно по твоему методу попробовать натренировать такую волшебную штуку, (в том случае если она будет работать), то потом ты берешь маску, и по моему методу (да даже просто по обычной маске лосса) смотришь нормы градиента, либо как-нибудь еще проверяешь, пытается ли теперь градиент обновить только подсвеченный токен, либо как обычно херачит по всем сразу. Если работает так же как и мой метод, только без искусственного ограничения, то значит модель выработала внутри себя схемы которые позволяют управлять потоком градиентов, и нахождение таких схем вполне себе повод для статейки какой-нибудь.
В механизме внимания например такое уже происходит, но тут если без него это будет работать, то это очень интересное явление. Хотя я уже вижу что модель может и чисто только атеншен перенастроить под эту задачу, что примерно будет то же самое.
Тут еще опять же ничто не запрещает при тренировке эти самые маски атеншена править или фиксировать, или даже накладывать лосс на них.
Я кстати вспомнил что уже придумывал такую идею как раз для семантической разметки токенов через атеншн, но вспомнил я это только сейчас случайно.
Вообще такой метод должен быть лучше твоего, ведь не надо пердолиться ни с какими доп-каналами, ни с разметкой кондишенов.
А еще я вспомнил что не хотел его палить, ведь он так легко делается. Ой...
>Количественно озвучь.
Я предложил назвать хоть одно практическое применение этих картинок, свои аргументы высказал. По существу никто не высказался, так что не имею большого желания пояснять по 10 раз особо упертым одно и то же.
>Этому нет обоснования, просто слова и принятие на веру. Остановка в локальном минимуме вместо значительно более удачного глобального может быть проиллюстрирована стремлением нейронок к тривиальным решениям и паразитным запоминанием побочных простых признаков при неудачном обучении, плохом оптимайзере и аугментации датасета.
Если мои слова не были достаточно понятны, то могу разъяснить этот момент:
Вот у нас две картинки, в одной оптимайзер попал в оптимальную точку, в другой не совсем. Какие из этого должны быть сделаны выводы? Что первый лучше второго? Совсем не обязательно, ведь если чутка подумать, и представить что нейросеть это у нас ансамбль маленьких нейросетей и функция от функции(от функции(от функции()))... То можно представить что быстро довести каждую до не самой оптимальной точки будет намного эффективнее, чем пытаться выдрочить идеальную точку но долго.
>Для самых маленьких пример: вместо определения кошка или собака на картинке по совокупности признаков, оно будет относить все рыжие объекты к кошкам а черные к собакам.
Ты пытаешься привести контрпример забывая про парето-оптимальность, которую я подразумевал под этим всем.
Ну и опять же все это обсуждение не имеет смысла когда в нейросетях таких минимумов нет и на картинках ландшафт статичен. Ты можешь сделать статичный ландшафт в нейросети, делая шаг только тогда когда ты посчитал градиент по всему датасету, и с удивлением обнаружить что чет какое-то говно получилось. Спрашивается тогда нахуя проверять оптимайзер в таком режиме?
И твоя попытка с этим всем спорить - не меньшее принятие на веру недоказанных фактов.
>Особенно пукнул с отрицания минимумов
Сразу видно человека который не видел некоторые хорошо известные в узких кругах доклады.
>Гитхаб/профиль на цивите/хаге твой ждем.
>Присоединяюсь к интересно увидеть реализовал ли что-то человек с таким количеством идей.
Только после того как узнаю что среди вас нету того кто обосрался в споре со мной по поводу рслоры. А то было бы эпично.
Или того кто отказался показывать свои модели в споре в середине треда, и называл себя автором популярных моделей и опенсорса. Спор был не с моим участием, но все же. А то слог похожий...
Ну а хули, если хочешь раскидываться компетенциями вместо того чтобы дискутировать по существу, надо сначала самому как-то пошевелиться и предоставить свои.
Да и вообще меня не то что бы интересуют эти ваши выебоны медальками "За 100 лор Еотовой" или показывает на соседний тред оверфитнуть модель на стиле персоналами и лисах и назвать это стейт оф зэ арт кволити файнтюном. Кмк, это вам опыта в самом эмэле не особо дает.
Ты вообще на что-то способен, кроме сранья резонерством в треде?
Выучил новое слово и теперь лепишь его везде?
Терпи, анскилл.
>пук
Как выложить свои результаты - визжишь, как жидко пукнуть - пукаешь без вопросов. Почему так?
Аноны, у меня есть мое фото до плеч с галстуком, я его хочу дорисовать до поясницы для этого скачал stable-diffusion-webui, мозайку чтобы добавить пространство до поясницы и модель Juggernaut-XL_v9_RunDiffusionPhoto_v2, в общем и целом получается херово. Какой локальный вариант самый нормальный???
> Я про быструю тренировку на нескольких картинках в случае редких юзкейсов, а ты про большую тренировку, где никто не будет такой разметкой заниматься тем более не понимая что это даст.
В посте несколько раз повторяется что из твоих идей вообще не понятно что именно должно реализовываться и для чего нужно, с предложением это озвучить. Во-вторых, если затевать такое то как раз все будет размечено, и что даст тоже понятно - локализация кондишнов, региональный промтинг и все это нативно из коробки.
> точного сопоставления тех тегов которые иначе сопоставляться не хотят
Что значит не хотят? Но вообще, вариант, когда к основному датасету добавляется набор с относительно небольшими масками и капшнами только для них, может какой-то положительный эффект дать. Правда будет ли эффект стоить трудозатрат - сомнительно.
> если можно по твоему методу попробовать натренировать такую волшебную штуку, (в том случае если она будет работать)
Она будет работать и не является чем-то волшебным просто потому, что это буквально тренировка сетки под конкретно эту задачу. Это дефолт и такие сетки уже делались, а ты не понял о чем речь, жесть.
> только подсвеченный токен
Как ты выделишь влияние только одного токена на градиенты? И надеюсь ты про токены в их истинном значении а не именуешь так теги, это сразу выдает васяна.
> пытается ли теперь градиент обновить только подсвеченный токен, либо как обычно херачит по всем сразу
> модель выработала внутри себя схемы которые позволяют управлять потоком градиентов
Что за безумный поток сознания? У тебя граденты обновляют токены и модели вырабатывают схемы, сюрр.
> Если работает так же как и мой метод
Тут опять все смешалось, если про тренировку с маскировкой областей картинки и подаче только соответствующих этой области кондишнов еще понятно, то там где у тебя было про обучение с разными масками для отдельных слоев/блоков - вообще муть. И совсем болото - когда ты начал переходить от маскировки лосса к максировке кондишнов, проводя равенство, для sdxl и подобных это абсурд.
> Я предложил назвать хоть одно практическое применение этих картинок, свои аргументы высказал.
Не кривляйся, ты постулируешь полную ненужность тестовой задачи, ссылаясь на то, что она не идентична реальной. При этом аргументов о том, что это несоответствие действительно существенно и требует совершенно иных свойств - не приводишь. Только натаскивание.
> представить что нейросеть это у нас ансамбль маленьких нейросетей и функция от функции(от функции(от функции()))
Ай лол, в совокупности со всем остальным, особенно с
> Тут еще опять же ничто не запрещает при тренировке эти самые маски атеншена править или фиксировать, или даже накладывать лосс на них.
> Я кстати вспомнил что уже придумывал такую идею как раз для семантической разметки токенов через атеншн, но вспомнил я это только сейчас случайно.
> Вообще такой метод должен быть лучше твоего, ведь не надо пердолиться ни с какими доп-каналами, ни с разметкой кондишенов.
> А еще я вспомнил что не хотел его палить, ведь он так легко делается. Ой...
и непониманием вполне популярных вещей - ты оче далек от чего-то практического и реального, понимание работы современных сеток у тебя свое-особое, а недостаток понимания и знаний ты пытаешься компенсировать натаскиванием из соседних областей и странных ассоциаций. В лучшем случае это можно назвать вузовской наукой, где деды маринуют идеи, обреченные на провал по своей сути, но там хотя бы есть структура и система. В худшем, что мы и наблюдаем - шиза, в которой сам признаешься.
> Только после того
Да там банально нечего показывать, видно насколько шиз плавает. Уже по амбициям видно что ничего серьезного и полезного породить не способен, только гоношение вокруг ерунды. На досуге придумывает великие идеи про "быструю тренировку на нескольких картинках" лезя в невероятные дебри и ввязывается с бессмысленные споры с очевидным, кринж.


>В посте несколько раз повторяется что из твоих идей вообще не понятно что именно должно реализовываться
Всё настолько разжевано что даже ребенок поймет и даже шиз порвался и начал вонять что я засираю тред бессмысленными простынями. Я вынужден повторять в разных ипостасях одно и то же, а ты непонятно что еще хочешь услышать.
>для чего нужно
Это уже на совести читателей, найти применение для метода.
Я примеры привел и их ровно два, если хочется изъебнуться с тренировкой только на мелких областях, либо когда надо роутить градиент масок потокенно/послойно.
>Что значит не хотят?
Когда недостаточно данных, чтобы модель смогла накопить статистику и выучиться. Я не предлагаю учить всю модель так. Это для пердолинга лор на десятке-сотне картинок. Как бы очевидно.
>Как ты выделишь влияние только одного токена на градиенты?
Наоборот же. А если хочешь именно так, то влияние одного токена на градиент - это, внезапно, градиент по этому самому токену, прикинь да? Можешь даже нарезать всю картинку на сотню масок и таким образом примерно вычислить куда именно токен повлиял. Считать дохуя и на практике скорее всего очень шумно, но как бы математика не запрещает.
>Что за безумный поток сознания? У тебя граденты обновляют токены и модели вырабатывают схемы, сюрр.
Ты тупой и не понял. Или читать научись не жопой. У меня например к твоему методу и тому что ты пишешь вопросов нет, мне все понятно. Разве что кроме того как у тебя в одном месте сочетаются "просто" и "надо ввести в модель новый канал" и как ты собрался помечать кондишены. Но это ладно, мне оно не надо.
>модели вырабатывают схемы, сюрр
https://distill.pub/2020/circuits/
>У тебя граденты обновляют токены
Хотя наверное слоило пояснить что под токеном имелся ввиду кондишен токена который с энкодера выходит и градиент по нему. Все таки я обычно подразумеваю что читающий имеет мозг. А зря.
Тут будет пояснение того что я имел ввиду, и чего ты не понял, для совсем тупеньких.
Дизайн эксперимента:
Имплементируем два метода, один твой. Думаю пояснять его суть не надо. И один - мой, когда мы считаем градиент от маскированной области.
Далее по твоему методу у нас допустим есть готовая модель, которую учили на масках в допканале и "подсвеченных" кондишенах.
Мы берем совершенно новые размеченные данные и делаем один обратный проход применяя мой метод, смотрим на то, какие нормы градиента идут по кондишену, который размечен, с маской. Градиент ессно считаем только от маски. С удивлением обнаруживаем, что эти нормы для него высокие, а для всего остального низкие. Значит тот лосс, который идет только от объекта, обновляет преимущественно кондишен тега этого самого объекта. Если берем дефолтную модель, то такого не происходит (это проверять не нужно). А значит модель (твоя) как минимум научилась по маске направлять поток градиентов от определенной области в соответствующий ей токен.
А что же еще такое может направлять поток градиента от области в один токен, только для этого не надо учить модель и ты никогда не обосрешься с ее тренировкой? Не уж то ли тот самый метод о котором я рассказываю? Хм.. Хм..
Но да, твой будет лучше на большой тренировке, ибо не надо делать никакие дополнительные проходы, а мой - когда тебе надо натренить лору на нескольких картинках с разметкой, потому что тебе не надо сначала учить модель которая понимает разметку.
Далее идет пассаж про то что механизм внимания сам по себе примерно похожим образом работает. И что модель (наверное) после обучения ее твоим методом может работать так только за счет чисто адаптации фокусировки кросс-внимания (q*k). Вот смотри, твоя подсветка кондишена и маска в канале дает на кондишене прямо, а на юнете косвенно (после прохождения через свертки и всю хуйню) высокое косинусное сходство, между собственно кондишеном токена и пространственной областью которая была под маской. Дальше v от кондишена будет инжектится в ту область и градиент в него потечет преимущественно от этой области.
Из этого проистекает два вывода, первый - что можно накинуть лосс на маску атеншена (на соответствие её нашей маске сегментации), и тем самым принудить модель саму определять отношение токена к объекту. Либо можно вручную влезть в атеншн и исправить его маску, чтобы обучение пошло быстрее. Либо сначала править маску, а потом наложить лосс, чтобы уж точно наверняка модель поняла что мы от нее хотим.
Это применимо только к случаю когда у нас есть какая-то разметка сегментации. И если тебе нужен такой результат, то можно не нужно делать 100 проходов если у тебя вдруг есть 100 размеченных объектов на картинке, а делать один с правкой/лоссом атеншена. Мой метод тут уже не нужен.
>то там где у тебя было про обучение с разными масками для отдельных слоев/блоков - вообще муть.
Ты совсем блядь тупой? И извини, я бы не стал так наезжать, если бы ты первым не стал наезжать на меня, и выебываться тем что ты дохуя в чем-то шаришь, а я нет.
Я не буду пояснять заново, вот тебе ответ от нейронки, первый абзац читай.
>И совсем болото - когда ты начал переходить от маскировки лосса к максировке кондишнов, проводя равенство, для sdxl и подобных это абсурд.
Чё? Честно - не понял о чем ты.
> > Я предложил назвать хоть одно практическое применение этих картинок
>Не кривляйся
Хуя подрыв. То есть мое предложение озвучить хоть какие-то твои выводы которые ты делаешь из созерцания этих картинок, это "кривляние"? Ок, записал.
Но мне блядь реально было интересно какие выводы ты из них делаешь, и я очень жду ответа от тебя на этот вопрос.
>и непониманием вполне популярных вещей - ты оче далек от чего-то практического и реального, понимание работы современных сеток у тебя свое-особое, а недостаток понимания и знаний ты пытаешься компенсировать натаскиванием из соседних областей и странных ассоциаций. В лучшем случае это можно назвать вузовской наукой, где деды маринуют идеи, обреченные на провал по своей сути, но там хотя бы есть структура и система. В худшем, что мы и наблюдаем - шиза, в которой сам признаешься.
Ну то есть не понял ты, а в итоге как-то так вышло, что не понимаю чего-то я, как же так?
Посмотри хотя бы как работает атеншн в юнете через DAAM. Что-то мне подсказывает ты этой хуйней никогда не пользовался.
Накладывать лосс на маски атеншена никакой науке не противоречит. Пикрил 2, даже лоботомит понял прекрасно.
Так что какие популярные вещи я не понимаю? Давай уж соизволь пояснить по пунктам, раз пизданул.
>Да там банально нечего показывать, видно насколько шиз плавает.
->
>великие идеи про "быструю тренировку на нескольких картинках"
Лолшто.
>споры с очевидным
Выдели очевидные по твоему вещи, с которыми я спорил.
Проверка на чтение жопой: В твоем ответе, во первых, ожидается приведение примеров сравнения оптимизаторов по картинкам и выводы которые ты из этого делаешь. Любой удобный пример. Я даже не прошу тебя размахивать какими-то репозиториями, как это делаешь ты. Я прошу чтобы ты показал то что непосредственно относится к предмету спора.
Во вторых, ответ на то, что ты это не один человек. Потому что если один, то я ебнусь от такого наплыва самоуверенных шизов.
>анимешиз кидает юшки тем кто его проткнул
Не кидай мне юшки ебло косорылое, тебя уже другой протыкает.
Не кидай мне юшки ебло косорылое, тебя уже другой протыкает.
Если бы ты тихо слился, а не начал исходить на говно, пытаясь перекрыть свой очевидный обсер, тебя бы уже все забыли)
>)
Ты давай лучше иодельки свои показывай, порватка
> Всё настолько разжевано что даже ребенок поймет и даже шиз порвался
Чел, ты вбросил абстрактную идею без описания и объяснений зачем это вообще нужно, потом несколько постов из тебя пришлось клещами тянуть. Сам все начал осознавать только в ходе этих обсуждений и пришел к сливу, вот и порвался.
> влияние одного токена на градиент - это, внезапно, градиент по этому самому токену
Ну и ерунда, ты даже не понял что в том вопросе заложено.
Чем дальше тем сильнее налет бреда, подтверждающий непонимание основ за которые топил, это уже читать тяжело. Апелляция к ллмке - финальный гвоздь в крышку гроба, явил свой источник познаний.
Таблетки прими и не кипишуй, у тебя там рили диалог личностей в голове из которого рождаются эти письмена. Вместо шизополотен просто делай что-то, что может продемонстрировать не бесполезность твоих идей и убеждений, и научись выражать свои мысли.
Копродед вышел из бана и опять щитпостит, фу нахуй.

А с чего ты взял, что у меня должны быть модельки? Как бы, для того чтобы понимать теорию оптимизации, архитектуру нейронок и всю хуйню, совсем не обязательно тренить 100 еотовых лор.
Просто чтобы ты понял, ты был попущен челом который буквально 0 готовых моделей произвел.
Это все что нужно знать о тех кто тут выебывается какими-то вкладами в опенсорс и неебаться крутыми моделями (которых никто не видел). Тыкают черный ящик не понимая что внутри него происходит и как внутрь него можно посмотреть. Шаманство, далекое от научного системного подхода, не более. Иногда что-то годное в процессе такого брутфорса получается, но обычно нет.
Вот как пример я писал в прошлом треде что энкодер надо тренить с повышением беты адама, и у анона сразу тренировка пошла. Ой просто совпало наверное, да.
А на самом деле это очевидно для того кто понимает как оптимизация работает, ибо юнет сверточный, а в свертках эффективный размер батча как бы больше заданного, иногда очень сильно (но не факт что это главная причина). Делать разный батч-сайз для слоев ты не можешь, но зато можешь поднять первую бету, и это почти то же самое.
Но по хорошему для того чтобы все это более мене точно рассчитать, надо конечно сначала посмотреть на графики, но это надо кодить.
В сложном гайде до сих пор никто не заметил и не поправил эту хуйню >Таймстеп это число показывающее зашумлённость изображения, где 0 - полный шум, а 1000 - полностью расшумлённое изображение.
(Я это просто вспомнил сегодня, не в претензию его автору. Важный момент, который может сильно запутать того кто разобраться хочет с работой диффузионок, там 0 это 0 шума всегда.)
Проверка на чтение жопой не пройдена, увы.
>Ну и ерунда, ты даже не понял что в том вопросе заложено.
А что было заложено в вопросе "Как ты выделишь влияние только одного токена на градиенты?" ? Я мысли читать не умею, это во первых. А во вторых, там было про влияние градиента на токен а не наоборот.
>Апелляция к ллмке - финальный гвоздь в крышку гроба, явил свой источник познаний.
Ллмка то умнее тебя оказалась)
Почему-то она смогла понять все что я пишу и суммарайзнуть это в один абзац. И ты даже это не понял, дебил тупой.
И это даже ведь флешка поняла, не про.
>и научись выражать свои мысли.
Хах, тупой дебил не понял, читал жопой, и начал раздавать советы. Специально для него я привел скрины с ллмки, но он и тут развонялся. Что, она тоже мысли выражать не умеет? Следующий мой ответ тебе будет только через ллмку, большего не дождешься.
Задаешь вопросы невпопад, не понимая на что отвечаешь пытаешься выебываться, игнорируешь неудобное. Софистика и низкая культура дискуссии выдают в тебе типичного шиза-петушка с завышенным чсв.
>
Копродед вышел из бана и опять щитпостит, фу нахуй.
Ой, а может вы как нибудь вдвоем аннигилируетесь и самоуничтожитесь?
Хм.. Хм.. назвал его копродедом, значит анимешник, так? А кто у нас из анимешников может быть автором каких-то "известных" моделей?.. Припомню только автора роувея. Если ты это он, объяснило бы откуда столько чсв. Модель кстати кал.
Чушка без моделек опять высрала стену плача, поссал на нее
> юнет сверточный
Бля, я не он, но тут ты уже перешёл грань траллинга тупостью. У SD в UNET конволющены только для ресемплинга фичей используется. Большинство параметров - это аттеншен. Даже FF-слоёв больше чем конволюшена там, лол. VAE для того и придумали, чтобы очень медленные конволюшены вынести в него и только один раз прогонять по ним, а диффузия работала на линейных слоях. Хотя видя что ты пишешь про тренировку энкодеров не удивительно что несёшь такой бред.
> там 0 это 0 шума всегда
Таймстеп - это индекс в массиве бэт, в SDXL при тренировке это просто линейное распределение, таймстеп 0 - это бэта около 0.0001, 1000 - обычно 0.012 что равно сигме 15.6. Шум умножается на некую формулу на основе бэты от семплера зависит, где-то шум на сигму умножается, где-то на интегральное произведение альфы. Нулевого шума нет никогда при стандартных таймстепах при тренировке, у нас же таргет это оригинальный шум и считать градиенты с 0 не очень хорошо. А вот при инференсе в шедулере часто сигмы нулевые есть в конце.
Ты живешь в каком-то манямире, дефолтные вещи воспринимаешь странно через его призму, придаешь чрезмерный вес тому, о чем узнал и впечатлился, и игнорируешь действительно важные вещи. Так еще мнишь себя неебаться кем, но при этом размениваешься на какую-то хуету. Шиз as is, еще какие-то условия ставит.
> у меня должны быть модельки
Разумеется у тебя нет ничего, когерентности не хватает чтобы хотябы демонстрацию запустить.
Чушка с моделями обосралась с рслорой, поссал на нее
>ты уже перешёл грань траллинга тупостью.
Ты порвался и начал придираться к формулировке, игнорируя смысл сказанного. Эти параметры также активно переиспользуются, за свертками, и усредняют много градиентов, от всей картинки. В энкодере с этим намного хуже.
>Хотя видя что ты пишешь про тренировку энкодеров не удивительно что несёшь такой бред.
Бред который работает, лол.
>Таймстеп...
Так ты согласен что там напутано или нет? Я вроде про это писал.
Чсв шиз который натренил говнолоры и теперь считает себя знатоком машоба тоже обоссан тем кто хотя бы пытался мл учить. Игнорирует вопросы, несет хуйню что всё непонятно и что его оппонент ничего не шарит, занимается софистикой и спорит с выдуманными им же утверждениями. Не приводит ни одного аргумента в защиту своих слов, только тупой наезд.
Афтар невероятной модели стейт оф зе арт хай кволити роувея as is Выше него только Хач.
Один визг
@
Ноль моделек
@
Ноль ссылок на гит
Дружочек, выпились
Много визга
@
Миллион моделек
@
Миллион ссылок на гит
Дружочек, воскресни
> смысл сказанного
А дальше у тебя там вообще бессвязный бред, где ты батчи с бэтой оптимизатора сравниваешь. По твоей логике и weight decay делает тоже самое что и EMA.
>бессвязный бред, где ты батчи с бэтой оптимизатора сравниваешь
Лооол.
Буквально вещи очень связанные хоть и математически не эквивалентны, но на практике плюс минус заменяют друг друга.
Ты можешь подобрать такую бету и такой прогрев оптимайзера, что например если ты пройдешься по всему датасету, то получишь такой же результат, как если сделаешь размер батча под весь датасет. Если не считать ошибки округления и если отключить вторую бету то получится одно и то же, примерно. Если делать только один шаг вконце то может быть и математически. Как аккумуляция градиентов работает знаешь? И что она тоже заменяет батч-сайз прекрасно. Логику надеюсь уловил.
>По твоей логике и weight decay делает тоже самое что и EMA.
Что ты этим хотел сказать? Wd умножает все веса кроме некоторых на какое-нибудь близкое к единице но меньше единицы число каждый шаг. EMA это экспоненциальное сглаживание которое используется в бетах адама.
> на практике плюс минус заменяют друг друга
Хватит бредить. Ты вообще понимаешь чем момент отличается от усреднения?
В пределе ничем.

Да кстати, наверное стоило сказать что моментум это никакая не инерция, а чистое сглаживание, и чистое усреднение в пределе, математически. И картинки, по которым ты МЛ учил (а по твоему батхерту с тем что ты называешь бредом очевидные вещи из теории оптимизации, видно что ты кроме картинок ничего по теме не смотрел), буквально содержат численную ошибку в подавляющем своем числе.
Пикрил как пример. Здесь моментум не должен так бодро ехать, он должен ехать точно так же как сгд. Еще и на таком простом ландшафте.
А происходит это потому что в торчевской реализации сгд с моментумом реализован неправильно, он фактически увеличивает лр на коэффициент моментума (0.9 = х10, 0.95 = х20, 0.99 = х100).
В адаме кста это уже по дефолту пофикшено.
Путаница возникает от того что таки моментум не чисто усреднение, а усреднение с масштабом. В оптимизации его обычно хотят использовать как усреднение, поэтому от масштаба избавляются, ибо за масштаб у нас отвечает собственно лр.
Чел, момент и батч усредняют вообще разные вещи.
Ага, батч получает один градиент, а момент другой из параллельной вселенной.


!! Фулл файнтюн лорой без пердолинга с пидорами, альфами, инициализациями. !!
1. Нодами ModelMergeSubtract делаем модель-нулёвку (все веса модели = 0). Модель минус модель, множитель 1. Пик 1.
2. Делаем экстракт лоры. В kohya gui базовая модель - это нулёвка, файнтюнед - это исходная полная модель. Ранг лучше побольше, 128+.
3. Делаем вмерж лоры в модель. В гуе (вкладка Merge LoRA) базовая модель - нулёвка, лора - экстракт с шага 2.
4. Как в пункте один, только вычитаем мерж из исходной. Модель2 - это мерж. Пик 2.
5. Проверяем что нигде не обосрались, подгружаем полученную модель и лору куда-нибудь, должно выдавать то же самое что и обычная модель. Если убираем лору, выдает шум. Наны не выдает.
6. В тренере загружаем модель и отдельно внизу в Network weights прописываем путь к экстракту. Ставим ранг как выбрали в пункте 2, альфа = ранг (!!!), запускаем тренировку.
7. Понимаем что таки где-то обосрались, и блоки не совпали с тем что хочет кушать тренер, ставим 1 шаг тренировки, лр 0,00000000000001, запускаем.
8. Получаем новую меньшую по размеру файла лору, которую отправляем в шаг 3 и далее повторяем все то же самое, но теперь все заработает, лосс в пределах нормы, тренировка идет, профит.
Потом смерживаем натрененую лору с моделькой, делаем экстракт или используем как есть.
Немножко сосём если пытаемся включать wd во время тренировки. Скорее всего стоит использовать вместо этого линейный мерж весов лоры между актуальной и начальной с весами ~0.9:0.1
Интерполяция должна давать эффект как при обычной тренировке лоры с wd.
В генерации это будет выглядеть как две лоры, не трененая и трененая <lora:lora fixed:0.1> <lora:lora fixed 2-000017:0.9> веса должны давать в сумме 1, 0.9 - это вес лоры как обычно, чтобы тестить без пердолинга. Да, и моделька с разницей вместо исходной, все как в шаге 5.
Можно попробовать учить по экстракту с какого-нибудь файнтюна. Процесс такой же, вместо нулёвки - база, вместо исходной - собственно сам файнтюн.
Должно хорошо работать с моделью в фп8, экономим память.
Для максимальной оптимизации стоит добавить выбор оптимального ранга для каждого слоя через анализ фактического ранга матриц по svd. Для этого метода это куда актуальнее чем для обычной лоры.
Метод не мой https://github.com/GraphPKU/PiSSA
Реализация, если это можно так назвать - моя))
Всегда ваш, тролящий тупостью и бредом шиз. Принес вам очередную шизу, которая должна работать лучше файнтюна при хорошей настройке.
1. Нодами ModelMergeSubtract делаем модель-нулёвку (все веса модели = 0). Модель минус модель, множитель 1. Пик 1.
2. Делаем экстракт лоры. В kohya gui базовая модель - это нулёвка, файнтюнед - это исходная полная модель. Ранг лучше побольше, 128+.
3. Делаем вмерж лоры в модель. В гуе (вкладка Merge LoRA) базовая модель - нулёвка, лора - экстракт с шага 2.
4. Как в пункте один, только вычитаем мерж из исходной. Модель2 - это мерж. Пик 2.
5. Проверяем что нигде не обосрались, подгружаем полученную модель и лору куда-нибудь, должно выдавать то же самое что и обычная модель. Если убираем лору, выдает шум. Наны не выдает.
6. В тренере загружаем модель и отдельно внизу в Network weights прописываем путь к экстракту. Ставим ранг как выбрали в пункте 2, альфа = ранг (!!!), запускаем тренировку.
7. Понимаем что таки где-то обосрались, и блоки не совпали с тем что хочет кушать тренер, ставим 1 шаг тренировки, лр 0,00000000000001, запускаем.
8. Получаем новую меньшую по размеру файла лору, которую отправляем в шаг 3 и далее повторяем все то же самое, но теперь все заработает, лосс в пределах нормы, тренировка идет, профит.
Потом смерживаем натрененую лору с моделькой, делаем экстракт или используем как есть.
Немножко сосём если пытаемся включать wd во время тренировки. Скорее всего стоит использовать вместо этого линейный мерж весов лоры между актуальной и начальной с весами ~0.9:0.1
Интерполяция должна давать эффект как при обычной тренировке лоры с wd.
В генерации это будет выглядеть как две лоры, не трененая и трененая <lora:lora fixed:0.1> <lora:lora fixed 2-000017:0.9> веса должны давать в сумме 1, 0.9 - это вес лоры как обычно, чтобы тестить без пердолинга. Да, и моделька с разницей вместо исходной, все как в шаге 5.
Можно попробовать учить по экстракту с какого-нибудь файнтюна. Процесс такой же, вместо нулёвки - база, вместо исходной - собственно сам файнтюн.
Должно хорошо работать с моделью в фп8, экономим память.
Для максимальной оптимизации стоит добавить выбор оптимального ранга для каждого слоя через анализ фактического ранга матриц по svd. Для этого метода это куда актуальнее чем для обычной лоры.
Метод не мой https://github.com/GraphPKU/PiSSA
Реализация, если это можно так назвать - моя))
Всегда ваш, тролящий тупостью и бредом шиз. Принес вам очередную шизу, которая должна работать лучше файнтюна при хорошей настройке.
>файнтюн лорой
В чем прикол? Чем это отличается от мерджа модели с лорой?
Не понял, нафига это надо.
Но получение лоры из модели (путем вычисления разницы между нулевой моделью и полноценной) звучит как какая-то магия. Как это вообще? Что внутри получится? Дистиллят модели до размера лоры?




Прикол в том, что максимально близко к тренировке полных весов, так как лора по сути инициализируется "большей частью полных весов".
Для контекста надо понимать как работает SVD https://www.youtube.com/watch?v=DG7YTlGnCEo
Если упростить, то это что-то из серии разложения фурье, сжатия jpeg и т.п. Преобразование ищет похожие строки и столбцы, в итоге из одной матрицы весов делает две + диагональную матрицу коэффициентов, по факту размером в 1 строку. Если взять из первой первый столбец, а из второй первую строку, то из них можно сделать лору рангом 1, которая будет применяться с коэффициентом из первого элемента диагональной матрицы. Преобразование делает так, что столбцы и строки нормализованы одинаково, а коэффициенты диагональной матрицы отсортированы от большего к меньшему (и строки со столбцами расставлены так чтобы соответствовать этим коэффициентам по своей позиции).
Так работает SVD экстракция лоры, делается это самое разложение, и ранг - это сколько первых элементов строк и столбцов берется.
Если строки и столбцы сразу домножить на коэффициент, надобность в хранении коэффициентов отпадает. Их всегда можно вернуть, выполнив нормализацию заново.
Коэффициенты называются сингулярными числами, можно посмотреть их распределение для реальной модели, на пикрилах 1-2 (не мои, хз какая модель).
На 3, как получается матрица из умножения строки и столбца. Эта же матрица через svd превращается обратно идеально в 1 набор векторов. Если перемножить 2 набора и сложить матрицы, то разложится так же на 2 набора идеально, будут 2 набора векторов и 2 сингулярных числа ненулевыми, все остальное нули.
На пике 4 как это преобразуется в конфигурацию со слоями. Если посередине нет функции активации, то это как лора ранга 2. Ее можно так же развернуть в полную матрицу (сумма двух матриц как пик 3) и свернуть обратно через svd в 2 набора векторов.
Любое количество таких слоев, если между ними нет функции активации вырождается в одну матрицу, в том числе и лора. Хоть в коде это 2 отдельных слоя.
Хз зачем я это объясняю, наверное любой видос сделает это лучше.
Но в итоге мы делим модель на 2 части по svd, чистый результат svd, который несет большую часть информации инициализирует веса лоры, а остальное мы получаем через разницу + все веса которые не обучаются остаются вне лоры в модели.
Так дохуя проблем уходит, так как обычно лора инициализируется как случайная матрица * на матрицу нулей, там возникает перекос градиентов, это по хорошему должно нормализироваться, в том числе для этого применяют dora и всякую такую хуйню, надо правильно рассчитывать альфы или вообще делать их обучаемыми.
Плюс можно квантовать модель до фп8, так как квантуется менее значимая часть модели. (Но по факту на обычной лоре в модели остаются много важных слоев, которые не тренируются и они подвергнутся квантованию, их надо либо оставлять неквантованными, либо все разделять по svd).
>звучит как какая-то магия. Как это вообще? Что внутри получится?
Ну вот из-за того что экстракт не захватывает многие важные слои, нельзя просто так раскатать его в нулевую модель и запустить. Надо именно удалить из модели экстракт мелких сингулярных значений. В гуе это напрямую не сделать.
Но, я сделал так, вырезал из модели все ранги до 640 вычитанием экстракта 640 ранга (больше не давало сделать). А потом прикладывал при генерации к этому экстракты меньших размеров.
Даже если удалить из модели всего-лишь ранги с 512 по 640, качество очень сильно проседает.
Так делать нельзя, ты фактически удаляешь из модели веса, а много весов удалять сразу нельзя, даже если они не важные. Можно только удалять по чуть-чуть и файнтюнить в процессе.
Но тренируем мы полную модель, которая просто разделена на 2 части, экстракт здесь нужен только для разделения.
С экстрактом файнтюна ситуация иная, так как если взять точку где его нет (исходную модель) и где он имеет полную силу, во первых это две полностью рабочие точки, так и между ними ландшафт довольно ровный и можно от одного к другому интерполировать без проблем. Точнее, чем крупнее файнтюн, тем будет кривее этот самый ландшафт, и тем хуже будет работать его неполный экстракт сам по себе.
Можно придумать другие способы тренировки, например брать наоборот менее важные ранги, или случайные ранги. Или сделать полное разложение и прыгать во время тренировки с одного набора на другой... Простор для экспериментов огромный.
Я показал только метод из статьи, для которого как оказалось ничего не надо придумывать, можно в гуе кнопки натыкать и все будет работать так же.
Интересно, а как оно работает с BOFT/DOFT, не знаешь? Я конечно сам попробую, потыкать, но в них нет классической A/B внутрячки и альфы не используются, хз как пойдет.
Я с момента как в комфи запилили поддержку недавно полностью на них переключился и горя не знаю, получается фуллфт эффект без особых пердолей супер быстро, т.к. бофт это как раз так скажем нативные ортогональные матрицы для модели (что считывает SVD), которые влияют на всю модель целиком, а диагофты это диагональные матрицы которые обучаются моментально, но емкость конечно меньше, т.к. там не используется полная ортогональная матрица, диагофты скорее для небольших стилевых тюнов. Плюс удобно что есть constraint и rescaled режимы и не нужно альфу вообще трогать т.к. альфа не используется, а степень изменения весов от силы градиента регулируется констрейнтом, т.е. если тебе нужно полное изменение ориг весов, то констр 1, если легкий допил то условно 0.1.
>В тренере загружаем модель и отдельно внизу в Network weights прописываем путь к экстракту
Ну кстати это вполне логично, ты как бы инициализируешь продолжение тренировки. Можно тогда даже не 128 рангом для экстракта ограничиваться а полные веса двухгиговые вытащить.

>с BOFT
Наверное как-то должно, но не понятно какой от этого будет смысл.
Лору же можно разложить на фуллматрицу и BOFT к ней применить, но я хз вырождается ли оно или нет.
>ортогональные
>диагональные
У меня с математикой так себе если я не могу в голову сначала прогрузить её смысл. По диагональным понятно, а как инициализируются ортогональные и какой у них в этом случае смысл мне не понятно.
>но не понятно какой от этого будет смысл
Ну как я понял ты получаешь ортогональный экстракт файнтюна, но с лоуранг модулями, а офт работает с декомпозицией и блоками, т.е. делаем ортогональный экстракт файнтюненых весов без рангов и тренируем эти веса ортогональными матрицами. Вин вин ситуация.
>Лору же можно разложить на фуллматрицу и BOFT к ней применить
Ну да, я так и попробую наверно, может даже сегодня
>а как инициализируются ортогональные и какой у них в этом случае смысл мне не понятно.
Ну это как в локре факторизация полных матриц до более мелких, только для офт. Ты указываешь количество блоков (т.е. степень разложения полной матрицы) через дименшен (реализация в ликорисе), который не может быть меньше 10, т.к. минимальное разложение это 2^3, а учитывая паддинги, масштабирование и использование дополнительных bias/scale это дает минималку в 10 для факторизации, и оно факторизует количество параметров относительно новых ортогональных матриц.
Посоветуйте плз ютуберов или подобное чтоб разобраться в теме генерации картинок нейросетями и начать понимать термины которые применяют итт. Ну т.е. всякие обучающие видео чтоб объясняли принципы работы и показывали на практике. Гуглятся только какие-то скуфы которые даже микрофон себе купить нормальный не могу и только льют воду. Но мб я не знаю как правильно написать запрос. Спасибо заранее.
А что тебе конкретно непонятно
Тред читаю и тут много терминологии и аббревиатур. Видно что аноны давно в этой теме. Хочу разобраться в доменной области перед тем как начинать свои эксперименты чтоб понимать что делаю а не просто пердолиться в каких-то скриптах с гитхаба.
Че надо то просто генерировать или ты обучать хочешь?
Кароче вывел фулматрицу из модели в виде лоры, запихнуть в нетворк вейтс, с бофтом естественно полезли миссингкейс относящиеся к бофту (ну их нет в выведенной лоре), но тренинг пошел. Результат в сравнении с обычным тренингом получше однозначно, но непонятно какие слов в принципе подхватываются через нетворквейт.
Как там миссинг кеи фиксить? Это с пункта 7 просто один степ потренить и добавить к выведенной матрице чтоли?
>с бофтом естественно полезли миссингкейс относящиеся к бофту (ну их нет в выведенной лоре)
https://pastebin.com/jdjD2sLJ
Если че вот лог, там в основном офт блоки и рескейл блоки, и прожекшены, которых нету в выведенной лоре.
Хз, я комфи трогал только чтобы вычитающую ноду найти.
В дефолтном гуе когда засунул экстракт сразу понял что он просто игнорирует некоторые слои которые создал экстрактор, но тренит и сохраняет уже то что ему надо. Поэтому вычитал то что сохранилось и уже от этого плясал.
То есть просто во время тренировки был критичный проеб целых слоев, если не фиксить.
>Это с пункта 7 просто один степ потренить и добавить к выведенной матрице чтоли?
Потренить, мержить с нулёвкой, вычесть это из исходной модели, получается два полных набора весов, разделенные по рангам, если тебе это надо. Реализацию бофта не смотрел, хз как оно там должно взлететь.
В моем случае я потом вставляю разницу вместо модели, и сохраненную лору как продолжение тренировки.
Не, проблема (если считать это проблемой конечно, так-то оно никак не влияет) в том что алгоритм бофта чекает веса скармливаемые, а так как эти веса были получены обычным вычитанием то никаких специфических слоев для бофт в весах в нетворквейт нет и он мисингами срет. Невозможно сделать экстракт из полной модели лоры для нетворквейтс в виде бофт-лоры с слоями исключительно бофта, потому что экстрактора ортогональных блоков не существует.
Скинь воркфлоу если не жалко или объясни как ты делаешь?
У тебя два набора полных весов или полные + лора тренятся?
А то пока не оч понимаю че ты сделал.

1. Короче есть но лора экстрактора в комфе пик1. Фулл дифф позволяет получать полноразмерное различие в виде лоры. Биас не помню че делает это типа коррекции какойто, но если он вкл то при добавлении полученной лоры к базовому сдхл получается 1 в 1 результат как на файнтюне из которого вычиталось, если биас выкл, то гдето на 98% одно и то же.
2. Далее я эти веса полный подрубаю в нетворквейт, при валидации ключей бофт алгоритм сыпет мне миссингкеями, которых ясное дело нет в полученной лоре через вычитание.
Собсно тренировка идет дальше спокойно пропустив миссинг кеи.
Я щас 1степ тренировку ебанул чтоб бофт получить и щас смержу его с лорой полученной вычитанием, посмотрю че будет.
>Я щас 1степ тренировку ебанул чтоб бофт получить и щас смержу его с лорой полученной вычитанием, посмотрю че будет.
А ну да хуй мне, бофты не мерджатся с локонами.
Щас попробую тогда соединить бофт с моделью и из модели вычесть сдхл.
А, ну ты тренишь экстракт файнтюна, а я делал только с экстрактом чистой модели, в моем случае если где-то обосрался, то всепизда, в твоем вообще похуй по идее.
Дай сам воркфлоу тренировки или скажи где посмотреть референс, а то я лапшу первый раз ковыряю, до этого она у меня в swarm стояла ток как бэкенд. И уже сука мозги ебет не может сама найти ноды из воркфлоу которое я по первой ссылке скачал...
Кароче нет, так тоже не работает.
> ну ты тренишь экстракт файнтюна
Да, ток хуй его знает че на самом деле под капотом там щас происходило, но результаты разные, артефактиков меньше.
>а я делал только с экстрактом чистой модели
Так падажжи, я не понял, поясни
>Дай сам воркфлоу тренировки или скажи где посмотреть референс
Так я не в комфе треню, а через сдскрипты просто.
А, или это не тренировка?
Это поддержка офт, до этого офт работали ток в а1111. Тренировка в ликорисе на дев бранче https://github.com/KohakuBlueleaf/LyCORIS/tree/dev
Да, я нашел уже, вроде в гуе есть. Посмотрю, пока надо разбираться.
> (Я это просто вспомнил сегодня, не в претензию его автору. Важный момент, который может сильно запутать того кто разобраться хочет с работой диффузионок, там 0 это 0 шума всегда.)
Мимо автор записок шизофреника. Я совсем забыл про эту херню, написал это туда, так как понимал на ту дату, после с кем то в треде пообщался, проверил инфу и понял что был не прав. Ну вроде поправил, можешь даже чекнуть, если опять обосрался где, охладел к поиску гиперпараметров чуть более чем совсем, особенно после выхода иллюстриуса, хз, буквально считаю что 90% зависит от базовой модели и датасета, 9% от оптимайзера, 1% от остального пердолинга, поэтому даже новые фичи не чекаю особо, единственное вау было от едм, единственный из которых, сумел пофиксить артефакты от нуба с cfg++ сэмплерами после тренировки такой лоры
Запустил короч бофт, ниче особо не тыкал, лора как и в прошлый раз экстракт базы 128 ранга.
Че он там тренирует я вообще хз, но лосс в норме, слои не проебались. Кейсами так же насрало.
Но то что скорость в 6 раз меньше это конечно совсем лол, видюха чилит на половине нагрузки. Завтра посмотрю че получилось.
Че он там тренирует я вообще хз, но лосс в норме, слои не проебались. Кейсами так же насрало.
Но то что скорость в 6 раз меньше это конечно совсем лол, видюха чилит на половине нагрузки. Завтра посмотрю че получилось.



Хочу разобраться как это всё работает, несколько вопросов касательно sd-моделей. С несложными нейронками работал на torch в другой области во времена tensorflow 1, математическая база по изображениям/звукам на уровне свёрточного автоэнкодера без обратных связей, за шаг или два до концепции GAN, которую понимаю, но не кодил и не обучал. Про текущее состояние и что там понавыходило, трансформеры всякие и сети с вниманием - ничего не знаю, пока что.
1 — Есть 1.5 с "целевым" разрешением 512х512, есть 2.0 с разрешением 768х768 без других крупных изменений, есть sdxl с разными разрешениями около 1024х1024, и его разбили на две сетки с общей концепцией и с деталями; и вот недавно вышла 3.5, где напридумывали непонятно что и непонятно чего, непонятно с каким результатом, и мне к ней ходить пока не надо, да и обучать я её ни в каком виде всё-равно почти не смогу. Всё верно?
2 — Вот все те сетки анимешные и другие - это люди брали чистую архитектуру, для примера, SDXL и обучали её с нуля по выкачанным с бур картинкам? Или брали исходные веса SDXL и дообучали уже их? Откуда они брали текстовые описания, просто теги брали? Это разве не должно люто вредить способностям кодировщика понимать описания вида "черепах сидит внутри скворечника"?
3 — Подавляющее число анимешных сеток SDXL соединили веса base/refiner в одну u-net или просто выкинули refiner, получив что-то по архитектуре крайне близкое к sd1.5 с другими разрешениями?
4 — Картинка 1. Я правильно понимаю, что "вариант 1" в среднем не рабочий, таких обозначений не было (было мало) в датасете и эти веса совершенно точно во всех случаях если и учитываются, то крайне нелинейно и сеткозависимо? А вот "вариант 2" уже честно собирает линейную комбинацию.
Есть нода, которая автоматически из первого второе посчитает внутри по числу "тегов" вызвав clip-модель и объединив это — или эту ноду нужно написать? Точно не уверен, но субъективно мне намного понятнее как подправить картинку во втором случае. В первом же даже если "с весом" 0.01 или 0.0 указывает - всё изображение с ног на голову переворачивается и там совсем иное выходит.
5.1 — Картинка 2. Почему эта нода почти не работает, и изображение по границе области распепячивается? Аналогичная ситуация с маской. То есть если рисуется трава - ещё куда не шло, особенно на низком cfg, на высоком трава с двух метров - а пустыня, это перспектива далёкая под другим углом обзора. Если же я ставлю туда персонажа, то он тупо обрезается по маске/квадрату. То есть если убрать ограничение по области - поза и позиция на кадре будет такая же, только не обрезанная, оно даже не пытается как-то сгладить границу и органично вписать персонажа. Мне почему-то казалось, что оно на первом шаге видит квадрат, а потом с каждым шагом пытаясь снизить шум позволяет протекать промту из одной области в другую, пока шум не упадёт до состояния корректного изображения? Или это с сеткой проблема, и она такое не умеет, считает даже такие изображения корректными?
5.2 — Как тогда работает control-net? Он же "кондиционирование" преобразует, а не латентный слой. Мне как-то казалось, что он по смыслу вот много таких действий делает (для каждой фигни устанавливая область действия и процентаж). Но почему-то он работает, а ручное указание области не очень.
6 — control-net сетка для sdxl более-менее подходит и корректно работает для всех сеток sdxl сделанных из исходной (на которой учили control-net)?
7 — Верно ли я понимаю, что v-pred и eps, это по сути выбор loss; второй можно мешать с любыми семплерами/планировщиками, а вот первый из-за способа обучения прибивается глазами к планировщику и будет выдавать что-то странное с другими?
1 — Есть 1.5 с "целевым" разрешением 512х512, есть 2.0 с разрешением 768х768 без других крупных изменений, есть sdxl с разными разрешениями около 1024х1024, и его разбили на две сетки с общей концепцией и с деталями; и вот недавно вышла 3.5, где напридумывали непонятно что и непонятно чего, непонятно с каким результатом, и мне к ней ходить пока не надо, да и обучать я её ни в каком виде всё-равно почти не смогу. Всё верно?
2 — Вот все те сетки анимешные и другие - это люди брали чистую архитектуру, для примера, SDXL и обучали её с нуля по выкачанным с бур картинкам? Или брали исходные веса SDXL и дообучали уже их? Откуда они брали текстовые описания, просто теги брали? Это разве не должно люто вредить способностям кодировщика понимать описания вида "черепах сидит внутри скворечника"?
3 — Подавляющее число анимешных сеток SDXL соединили веса base/refiner в одну u-net или просто выкинули refiner, получив что-то по архитектуре крайне близкое к sd1.5 с другими разрешениями?
4 — Картинка 1. Я правильно понимаю, что "вариант 1" в среднем не рабочий, таких обозначений не было (было мало) в датасете и эти веса совершенно точно во всех случаях если и учитываются, то крайне нелинейно и сеткозависимо? А вот "вариант 2" уже честно собирает линейную комбинацию.
Есть нода, которая автоматически из первого второе посчитает внутри по числу "тегов" вызвав clip-модель и объединив это — или эту ноду нужно написать? Точно не уверен, но субъективно мне намного понятнее как подправить картинку во втором случае. В первом же даже если "с весом" 0.01 или 0.0 указывает - всё изображение с ног на голову переворачивается и там совсем иное выходит.
5.1 — Картинка 2. Почему эта нода почти не работает, и изображение по границе области распепячивается? Аналогичная ситуация с маской. То есть если рисуется трава - ещё куда не шло, особенно на низком cfg, на высоком трава с двух метров - а пустыня, это перспектива далёкая под другим углом обзора. Если же я ставлю туда персонажа, то он тупо обрезается по маске/квадрату. То есть если убрать ограничение по области - поза и позиция на кадре будет такая же, только не обрезанная, оно даже не пытается как-то сгладить границу и органично вписать персонажа. Мне почему-то казалось, что оно на первом шаге видит квадрат, а потом с каждым шагом пытаясь снизить шум позволяет протекать промту из одной области в другую, пока шум не упадёт до состояния корректного изображения? Или это с сеткой проблема, и она такое не умеет, считает даже такие изображения корректными?
5.2 — Как тогда работает control-net? Он же "кондиционирование" преобразует, а не латентный слой. Мне как-то казалось, что он по смыслу вот много таких действий делает (для каждой фигни устанавливая область действия и процентаж). Но почему-то он работает, а ручное указание области не очень.
6 — control-net сетка для sdxl более-менее подходит и корректно работает для всех сеток sdxl сделанных из исходной (на которой учили control-net)?
7 — Верно ли я понимаю, что v-pred и eps, это по сути выбор loss; второй можно мешать с любыми семплерами/планировщиками, а вот первый из-за способа обучения прибивается глазами к планировщику и будет выдавать что-то странное с другими?
>ниче особо не тыкал
Там основные два параметра это rescale=True, который каждому слою/блоку добавляет дополнительный тюнер в виде рескейл-слоя, повышающий точность/степень свободы изменения и является масштабирующим коэффициентом вывода; и constraint, который является пределом, то есть нормализацией и сдерживает рост весов, предотвращает переобучение, управляет с какой силой ортогоналки будут морфить веса модели, где 1 это 100% изменение если у тебя веса в целом обновляются по мощности для полного изменения, в зависимости насколько у тебя агрессивные настройки, сила градиентов и сила шага, при нулевом констрейнте ограничения нет, при 0.1 будет очень сильное сдерживание изменения весов. Альфа соответственно просто заглушка и не используется, дублируя значение констрейнт для сборки лоры обратно.
>Но то что скорость в 6 раз меньше это конечно совсем лол
Ну да, бофт с полными матрицами же работает, там вся мякотка в том что ты можешь суперагрессивно тренировать (вот у меня тестовые прогоны с 0.1 0.1 по beta 1 и 2 по дефолту например, то есть моментумы помнят примерно 1 шаг только и реагируют на изменения градиентов моментально) и достигать результата быстрее при этом сохраняя структуру модели. Если надо именно быстрее тренировать по времени на шаг то есть Diag-OFT, но там сила изменений очень маленькая, т.к. модифицируются только базисные векторы через пару диагоналей на матрицу применяющихся поэлементно.
1 yes
2 брали исходные веса SDXL и дообучали уже их
- Откуда они брали текстовые описания - есть кучи taggers, тупо сетки делают описания картинок для обучения. florence 2 например и другие. для черепах внутри скворечника потом сгенеренное еще правят руками
3 рефайнер не нужен, тупо забили все
4 вариант 1 рабочий, веса в промпте вычисляются до вызова сетки. у комфи есть нода для альтернативных интерполяций учету этих весов (нормализаци, интерполяции от нуля и другое - не-comfy-дефолтные варианты в среднем лучше работают)
5.1 где-то ты накосячил, хули. гугли Differential Diffusion для комфи
5.2 контролнет это как промежуточный шаг над латентами. сначала сетка меняет латенты под текущий шаг, потом контролнет подправляет под кондишионинг свой. и так до упора.
6 на всех от базовой, да, с разной степенью хорошести. вот для illustrous/pony уже не работает потому что там переучивание слишком глубоко пошло, под них и контролнеты надо заново учить (но никто этого не сделал)
7 не, разница глубже. v-pred это попытка натянуть в sdxl то что делается во flux (но без трансформеров). v-pred ни с чем остальным SDXLным не стыкуется, это отдельная песочница
>Есть 1.5 с "целевым" разрешением 512х512, есть 2.0 с разрешением 768х768 без других крупных изменений
Да, 2.0 это полторашка с большим размером.
>есть sdxl с разными разрешениями около 1024х1024
SDXL обе что EPS что v-pred (CosXL) в 1024 в базе, это файнтюнщики могут какой угодно размер тренировать в принципе.
>и его разбили на две сетки с общей концепцией и с деталями
Имеешь в виду базу и рефайнер?
>и вот недавно вышла 3.5, где напридумывали непонятно что и непонятно чего, непонятно с каким результатом
Это архитектура мультимодал дифужн трансформер вместо сверточных юнетов ранее + T5, что позволяет сетке понимать хуман лангвидж.
>да и обучать я её ни в каком виде всё-равно почти не смогу. Всё верно?
Медиум сможешь в целом, он небольшой.
>Вот все те сетки анимешные и другие - это люди брали чистую архитектуру, для примера, SDXL и обучали её с нуля по выкачанным с бур картинкам? Или брали исходные веса SDXL и дообучали уже их?
Второе.
>Откуда они брали текстовые описания, просто теги брали?
Есть когда брали теги (в нубе например все теги буры работают), есть где генерировали описания с помощью нейромокрописек автотаггеров (натвис, бигасп), если где автор ебнулся и придумал скоринг внутри клипа, сломав его (пони).
>Это разве не должно люто вредить способностям кодировщика понимать описания вида "черепах сидит внутри скворечника"?
Что именно должно вредить? Ты можешь как угодно дотренировать текстовый енкодер под свою задачу и свой уникальный говнофайнтюн, он просто потеряет частично прошлые знания, если тренировка агрессивная (как у поней случилось).
> Подавляющее число анимешных сеток SDXL соединили веса base/refiner в одну u-net или просто выкинули refiner, получив что-то по архитектуре крайне близкое к sd1.5 с другими разрешениями?
Рефайнер это отдельная моделька, ее практически никто никогда нигде не юзает, потому что а нахуй надо, есть сотни тыщ апскейлеров, которые делают то же самое и лучше и быстрее. Так что только базу тренируют.
>Я правильно понимаю, что "вариант 1" в среднем не рабочий, таких обозначений не было (было мало) в датасете и эти веса совершенно точно во всех случаях если и учитываются, то крайне нелинейно и сеткозависимо?
Рабочий только тот вариант который в скобочках и сила просто умножает эмбединг на заданное число перед передачей в модель.
>А вот "вариант 2" уже честно собирает линейную комбинацию.
Ты собрал типа более управляемую схему с несколькими вызовами клипа с независимым влиянием фраз. Если бы ты просто в поле промта то же самое прописал то оно бы обработалось без контроля вклада каждого варианта токена в генерацию, как бы в одном контексте вместо нескольких.
бля заебався писать


>Есть нода, которая автоматически из первого второе посчитает внутри по числу "тегов" вызвав clip-модель и объединив это — или эту ноду нужно написать?
Скорее всего есть, потому что есть всякая хуита типа пикрелов.
>5.1 — Картинка 2. Почему эта нода почти не работает, и изображение по границе области распепячивается?
Потому что регион промтинг не работает на свертках корректно без дополнительных мокрописек автоматических (просто как пример https://github.com/lllyasviel/Omost там автоматом на сонове промта в ллм ебашится корректное полотно в границах которого генерируется предложенное) или ручных (где цветами красишь холст и указываешь сетке в какой области что будет, есть чуть автоматизированное с помощью ипадаптеров и контролнетов региональных через пак мокрописек для криты - krita ai diffusion)
>Как тогда работает control-net? Он же "кондиционирование" преобразует, а не латентный слой. Мне как-то казалось, что он по смыслу вот много таких действий делает (для каждой фигни устанавливая область действия и процентаж). Но почему-то он работает, а ручное указание области не очень.
Контролнеты и прочие адаптеры являются гайдерами для сети, они на это и наточены, а у сдхл по дефолту нет таких функций.
>control-net сетка для sdxl более-менее подходит и корректно работает для всех сеток sdxl сделанных из исходной (на которой учили control-net)?
Не совсем. Объебанным поням нужны некоторые свои контролнеты например, но есть типы контролнетов которые работают на любых файнтюнах.
>Верно ли я понимаю, что v-pred и eps, это по сути выбор loss
Не, епс предсказывает шум, впред направление, это буквально "Что было добавлено к...?" у eps и "как изменяется ... по времени?" у впред



Угу, понял, полез дальше разбираться.
>контролнет это как промежуточный шаг над латентами
Ну, в ноде он принимает то что от клип-модели выходит и выдаёт то же самое, нет никаких латентов изображения в ноде применяющий контрол-нет. То есть я понимаю, что потом это каждый шаг в применяется, но я о том, что до вызова хотя бы одного семплера уже достоверно известен тензор, который после применения контрол-нета получается, и он уже никак не меняется. Третья картинка. Семплер даже не нужен. Я могу этот тензор сохранить, и потом подать вместо выхода от клип-модели на нужно мне число шагов. Как-то уже не совсем корректно, что тут именно контрол-нет что-то подправляет под кодишионинг, он же уже отработал, и больше ни один вес контрол-нета ни на что не умножается.
>Рабочий только тот вариант который в скобочках и сила просто умножает эмбединг на заданное число перед передачей в модель.
Неа. Умножение на ноль должно стирать тег. Первая картинка. Как видишь, вариант с объединениями "кручную" даёт вариант схожий с нулём. А вариант со скобками и нулём влияет на изображение, хотя не должно. Я вот об этом. Исходя из этого я делаю вывод, что параметр нелинейно влияет на силу тега (что было бы логично), а если нелинейно - то я не слишком понимаю что эти цифры обозначают.
>контролнет это как промежуточный шаг над латентами
Ну, в ноде он принимает то что от клип-модели выходит и выдаёт то же самое, нет никаких латентов изображения в ноде применяющий контрол-нет. То есть я понимаю, что потом это каждый шаг в применяется, но я о том, что до вызова хотя бы одного семплера уже достоверно известен тензор, который после применения контрол-нета получается, и он уже никак не меняется. Третья картинка. Семплер даже не нужен. Я могу этот тензор сохранить, и потом подать вместо выхода от клип-модели на нужно мне число шагов. Как-то уже не совсем корректно, что тут именно контрол-нет что-то подправляет под кодишионинг, он же уже отработал, и больше ни один вес контрол-нета ни на что не умножается.
>Рабочий только тот вариант который в скобочках и сила просто умножает эмбединг на заданное число перед передачей в модель.
Неа. Умножение на ноль должно стирать тег. Первая картинка. Как видишь, вариант с объединениями "кручную" даёт вариант схожий с нулём. А вариант со скобками и нулём влияет на изображение, хотя не должно. Я вот об этом. Исходя из этого я делаю вывод, что параметр нелинейно влияет на силу тега (что было бы логично), а если нелинейно - то я не слишком понимаю что эти цифры обозначают.
> Умножение на ноль должно стирать тег.
1. Не должно, на ноль умножать низя.
2. В позитивном промте нет функции вычитания, а в негативном промте вычитание есть, но оно ослаблено относительно позитива.
Есть олдовые экстеншоны, который позволяют в позитиве использовать негативный промтинг потому что сила позитива во много раз выше негатива, для а1111 был экстеншон я ток название не помню, там прямо (token:-1) в промте позволяло писать и оно даже как-то работало. Вспомнил только вот эту хуйнюшку https://github.com/muerrilla/stable-diffusion-NPW
>для а1111 был экстеншон я ток название не помню
Вспомнил https://github.com/hako-mikan/sd-webui-negpip
И для комфе соответственно https://github.com/pamparamm/ComfyUI-ppm
>Так падажжи, я не понял, поясни
Вчера запарился пропустил вопрос.
Ну я делаю экстракт через разницу с нулевой моделью и треню его вместе с разницей модели и экстракта. Нужна только одна любая модель. Это в точности то же самое по сути что делают в статье отсюда https://github.com/GraphPKU/PiSSA
Че это дает в плане качества хз, ибо у меня пока нет норм тестового датасета на пони. Но тренировка так идет вполне, это видно.
Прикол в том, что если какой-то блок проебется, то всей модели пизда в таком случае. А когда ты делаешь экстракт файнтюна, экстракт лоры, он получается резиновый очень мягкий, его можно резать на слои без проблем, и там этого не видно.
Поэтому трень как я если хочешь проверить что точно ничего не ломается.
>rescale=True
Это в network_args в \LyCORIS\example_configs\training_configs\kohya\lycoris_full_config.toml пихать?
То что вчера натренилось бофтом - сломалось, причем сразу. Скорее всего проебал где-то энкодер, ибо получается какая-то мутная хуйня. А если ломается юнет, то будет шум. Я взял фикс экстракта, который был прогнан через один шаг тренировки обычной лоры, а все таки надо было прогнать через бофт.
Лосс при этом был в норме и даже сильно упал.
Сейчас мне кажется интереснее вариант с экстрактом файнтюна, как ты делаешь. Во первых, как бы идет продолжение его тренировки, но в компактной лоре, можно взять ранг пониже. Главное взять моделью разницу от файнтюна, а не исходную базу как это обычно пытаются сделать. Тогда не теряется точность.
Потом я думаю, стоит слить их вместе где-нибудь к концу, и перегнать в экстракт уже этой тренировки, рангом пониже. Линейной интерполяцией смержить его с нулевой лорой, весом ~0,8, чтобы уменьшить веса, и дотренить немножко.
>Ну я делаю экстракт через разницу с нулевой моделью и треню его вместе с разницей модели и экстракта. Нужна только одна любая модель.
Вот смотри ты получаешь нулевую модель, потом из файнтюна вычитаешь нулевку, получая лору, так? Далее при тренинге ты указываешь изначальный файнтюн в качестве основы или нулевку? А в нетворк вейтс пихаешь экстракт от фт минус нули?
>Это в network_args
Да, в нетворк аргс, без разницы через томл или через батник, я чисто на батнике дрочусь вот конфиг примерный если надо посмотреть https://pastebin.com/Dyv2izMs
>Я взял фикс экстракта, который был прогнан через один шаг тренировки обычной лоры, а все таки надо было прогнать через бофт.
Так а смысл, там нонтайп ошибки лезут если пытаться плюсовать к экстракту. Или ты про другое?
Не. Смотри, вообще идея статьи что ты разбиваешь модель через svd на 2 составляющие, обычно вся инфа весов сосредоточена в меньшей части рангов, которые дает это преобразование. Правильно называть эти "ранги" сингулярными значениями, но пускай будут ранги, ибо многим тут это интуитивно понятнее.
Я про это вроде немного недоговорил в начале, зачем вообще все это делается.
Ну вот меньшая часть рангов получается через экстракт, это буквально одно и то же, только обычно в экстрактор пихают 2 модели, и он внутри себя делает разницу между ними, вычисляя только поправки весов, которые внес файнтюн, потом делает svd с этими поправками.
Получение нулевой модели это хак чтобы не пердолиться со скриптами, и выполнить чистое svd модели. Которое плюсом даст сразу обучаемую лору (если бы не надо было ее пересохранять).
Лору ты в итоге, которую будешь обучать, получаешь только через нулевую модель, которую ты запихиваешь в экстрактор вместе с исходной. Всё, кроме пересохранения ты ее больше не трогаешь.
Потом тебе надо получить идеальную разницу между исходной моделью и лорой, если она будет неидеальной, все сломается. Эта разница будет содержать все остальные ранги + слои и параметры которых нет в лоре.
Для этого ты мержешь пересохраненную лору с нулёвкой, а потом вычитаешь эту хуйню из исходной модели.
Кладешь результат как основу в тренер. Пересохраненую лору в нетворк вейтс.
Начинаешь ты только с одной исходной модели, никакая другая не участвует. Если это условно пони, то тебе не нужна база sdxl.
Для пересохранения лоры после экстракта можешь использовать любую модель, от одного шага на оч низком лр ничего не случится.
>Так а смысл, там нонтайп ошибки лезут если пытаться плюсовать к экстракту. Или ты про другое?
Я это еще буду тестить. Засунул в бофт по сути просто лору обычную в нетворк вейтс. Но я где-то тренировку энкодера выключил или включил и на вид как-раз только он и проебался.
>конфиг
Алсо, нахуя тебя адам8бит с такими бетами?
> параметр нелинейно влияет на силу тега
Да, всё так, только compel более менее достоверно умеет в down weighting https://github.com/BlenderNeko/ComfyUI_ADV_CLIP_emb
> то я не слишком понимаю что эти цифры обозначают
С дефолтной интерпретацией весов примерно так - 0.8 почти линейно, 0.6 ещё чуть меньше влияния, дальше сколько бы не поставил похуй, всё равно тег будет влиять на картинку и появляться

>нахуя тебя адам8бит с такими бетами?
Угараю по агрессивной тренировке, много моделек делаю и ждать пока там сойдется где-то через год лень. Меньше беты - быстрее сходимость.
Дефолтные 0.9/0.999 вообще есличе задумывались для ебических датасетов с такими же ебическими батчами, если у тебя меньше 10к картинок в сете и маленький батч то смысла сильно усреднять с большой инерцией никакого нет, т.к. у тебя с условным датасетом в 100 картинок оптим будет помнить о неоптимальных градиентах первой эпохи и через 100 эпох на малом батче, что получается бессмысленно и даже вредно. А вот если у тебя наоборот условный датасет в 1 млн картинок и батч например 100, то это уже имеет смысл, т.к. пока пройдет одну эпоху несколько раз забудет че там было в начале + инерция сгладит все говно. Кароче правило по бетам такое: малый датасет + малый батч -> меньшие беты, большой датасет + большой батч -> большие беты.
Плюс у меня CosineAnnealingWarmRestarts стоит для форс выпинывания из гипотетически неверных минимумов, ему надо пониженные беты ставить, т.к. если беты будут долго помнить с высокой инерцией, то эффект рестарта соснет хуйца вовремя не отреагировав на смену скорости.
А так в целом 0.1 это примерно 1 шаг памяти, для тестовых прогонов более чем достаточно, не тупит на старых неактуальных градиентах, моментально откликается на текущие градиенты, с козинаналингом резво выпинывает из затупных мест, где на более высоких бетах может по 10 эпох вокруг одного и того же крутиться, т.к. старые неоптимальные градиенты мешают.
Ну и плюс тут huber в качестве типа лосса от излишних шумных данных доджит, можно l1 юзать.
Мог бы включить сгд, так как у тебя никакого накопления нет и тебе эти параметры в памяти нахуй не нужны.
Но правда второй момент еще работает, но он получается сглаживает величину больших градиентов до какого-то константного значения. Это что-то среднее между сгд и SignSGD.
Можно поправить формулу сгд и будет то же самое что у тебя сейчас.
Чет у меня сломалось и бофт больше не сохраняет лору как бофт. Тренировка тоже щас пошла быстрее как будто там лора обычная тренируется.
В первый раз сохранилось правильно, в 2 раза больше файл с нужными слоями по просмотру.
>SignSGD
Пасеба, не пробовал ни разу, обратил внимание на это чудо и оно прям то что нужно без лишних заебов, моментум выставил и поехал, тренирует мое почтение.
У меня вообще есть список из кучи оптимов без бет и лишнего говна, которые надо попробовать, но руки никак не доходили, катал ток сгднестеров, но там поведение у него из-за степсайза очень медленное, на скорости ниже 0.1 тренировка пиздец вечность, а с 0.1 в принципе тоже долго но нестабильненько. Вроде как рмспроп лучше в этом в плане.
>обратил внимание на это чудо и оно прям то что нужно без лишних заебов, моментум выставил и поехал, тренирует мое почтение.
Посмотри тогда еще Lion, это развитие SignSGD, у него интересная формула, он комбинирует текущий знак градиента с моментумом, гуглы его вывели путем генетических алгоритмов.
>сгднестеров
Как будто бы в нем в наших нейросетях не то чтобы много смысла. Ну типа, мне кажется нет особой разницы пытаешься ли ты учесть моментум сразу, либо на следующей итерации, Как бы когда у тебя и так дефолтный момент 0.9, этот "сдвиг фазы" на 0.1 ничего не решает.
>рмспроп
Это вообще просто адам без первого момента.
Вообще еще раз советую тебе обратить внимание на то что ты можешь влезть в код оптимайзера и изи там поменять формулу на что-нибудь интересное. Там же литерали строк 5-10 в основе. И ллмка тебе их сама перепишет если ты опишешь идею.
Вот например сделать среднее между сгд и SignSGD, это просто добавить чтобы чем больше градиент, тем на большее значение он делится, придавливая большие градиенты. Можно выбрать коэффициент, линейный, не линейный. Можно добавить адаптивность от уровня градиентов на слое, на всей нейросетке, но это чуть сложнее. Например чтобы точно задать что надо давить 1/3 больших, либо половину. Можно придумать всякие шизовые схемы работы с моментами и натестить кучу коэффициентов.
Те же гуглы тестили на игрушечных нейросетках, на тупых метриках. А у тебя в руках настоящая нейронка где все видно прям сразу глазками, и не дохуя времени надо на это, можно проверить обобщаемость и переносимость между тюнами.
Была недавно статья что ллмки надо дообучать, просто обнуляя % самых больших обновлений весов, чтобы не переобучалась и нормально впитывала инфу не затирая старую
Еще и как оптимизация работает поверх лор, бофтов, мне кажется никто в теории не знает, чтобы вот так взять и сделать какое-то предсказание которое хорошо ляжет на практику.
Кароч там все не так сложно, даже если ты не умеешь кодить. С ллмкой потянет. Если ты конечно не пытаешься какой-нибудь мюон реализовать, там пиздец, да.


>Посмотри тогда еще Lion
Вот лайон я трогал, и он как-то мне не понравился. Потом глянул синтеческие тесты козинстра и хрюкнул с шизопутя по ратсригину пикрелейтед.
>Это вообще просто адам без первого момента.
Я к тому, что у него путь почти идентичен сгд, но быстрее в разы.
>Вообще еще раз советую тебе обратить внимание на то что ты можешь влезть в код оптимайзера и изи там поменять формулу на что-нибудь интересное. Там же литерали строк 5-10 в основе.
Да я в курсе, было одно время желание въебать все принципы теории хаоса (ну конкретно достижение edge of chaos как идеальной точки) и всякие физические постоянные константы вместе с фракталами (фрактальные оптимы уже есть, но это вообще отдельная песня), но это еще миллион часов тестов, поэтому я стараюсь сосредотачиваться на готовых оптимах под задачи.
> синтеческие тесты
Ты опять выходишь на связь? Лайон обходит адама на высоких батчсайзах, выше 128.
Щас бы 128 батч на консумерской карте ебануть, дааааа...
>Еще и как оптимизация работает поверх лор, бофтов, мне кажется никто в теории не знает, чтобы вот так взять и сделать какое-то предсказание которое хорошо ляжет на практику.
Кстати, по моему опыту офт практически с любым оптимом дружат, ну из тех что я гонял (продижи, адамы, шедулерфри), в смысле задача тренировки исполняется, перенос/обощение от хорошего до близкого к идеальному. У офтов единственный критикал спот это тренировка конволюшенов, т.к. очень быстро переполняет значениями и переобучает, поэтому либо надо снижать значительно скорость, что увеличивает время до результата по линейным слоям, либо сильно снижать констрейнт ограничение, что бьет по части переноса объектов требующих точности, либо вообще не тренить конвы. Вот бы была возможность тренить с разными скоростями конв и линейные была бы сказка.
>Потом глянул синтеческие тесты козинстра и хрюкнул с шизопутя по ратсригину пикрелейтед.
Там у SignSGD такой же путь, только у него лр меньше. Это говнотесты.
>Я к тому, что у него путь почти идентичен сгд, но быстрее в разы.
Ну так он видит что градиент не меняется и херачит лр раз в 10. Такой ландшафт не показатель.
>NKsFHJb.gif
И еще та самая ошибочка в сгд которая увеличивает фактический лр с моментумом. Красный и зеленый путь не должен отличаться почти никак, например, это буквально ошибка о которой написано в торче еще давно и ее не убрали чтобы не ломались совместимости но написали что она есть.
>Щас бы 128 батч на консумерской карте ебануть, дааааа...
С аккумуляцией можно и ебануть... Было бы только понятно ради чего.
>Там у SignSGD такой же путь
Так он до маняминимума доползает корректно за 650 итераций, а лайон нет.
>Это говнотесты.
Ну дай метрику лучше.
>Ну так он видит что градиент не меняется и херачит лр раз в 10. Такой ландшафт не показатель.
Ну, резонно.
>Так он до маняминимума доползает корректно за 650 итераций, а лайон нет.
Лр разный и момент в SignSGD превращает ландшафт в достаточно выпуклый, вот он и сходится.
>Ну, резонно.
Считай что на такой картинке у сгд вот прям совсем нихуя неправильно выбран лр, а рмспроп выбирает правильный. Но ты же все равно будешь подбирать оптимальный и там уже разница не столь радикальна. На таких простых ландшафтах оптимальное схождение надо тестить вообще в пределах нескольких шагов, не больше, имхо. И считать минимум в точке останова не по верхушке (это уже к первой картинке) а по близости к центру. В нейросетке на многих параметрах и от дрейфа данных это примерно так и сгладится. Может быть, хз, трудно сравнивать такую задачу с реальной.
>Ну дай метрику лучше.
Реальная нейросеть, лол. И метрика уже поверх нее должна придумываться. Ну только не лосс и только на той нейронке на которой работаем, на разных датасетах.
>И считать минимум в точке останова не по верхушке (это уже к первой картинке) а по близости к центру.
* и еще делать много прогонов из разных точек, потом усреднять. Может быть придумать подбор гиперпараметров для каждого алгоритма и оценивать попадание в радиус за минимальное число шагов в какой-то части итераций.
>Реальная нейросеть, лол. И метрика уже поверх нее должна придумываться. Ну только не лосс и только на той нейронке на которой работаем, на разных датасетах.
Ну это как-то не систематизировано и непроверямо другими, потому что отконтролировать поведение на реальных данных ну субъективно слишком, нет таких идеальных данных с которыми согласятся все, а на шумах вообще смысла обучать нет ящитаю. Там же какая идея где козинстр гоняет тесты - есть две функции математические и используя их мы как бы получаем унифицированные данные поведения оптимайзера в пространстве признаков. Плюс мы знаем что условный адамв хорошо работает и хорошо достигает поставленного значения что в реальных данных, что в маняфункциях, что подтверждается блужданию по функции на картинках. Следовательно мы можем предположить, что любые другие поведения оптимов будут относительно точны при тестировании.
Отсюда выходим к
>Лр разный и момент в SignSGD превращает ландшафт в достаточно выпуклый, вот он и сходится.
Так как лр для функций неважен, то тест по лайону показывает что он либо долго сходится по нахождению минимума (дольше 650 итераций) на небольшом количестве батчей, либо делает это неверно в контексте функции. Я предполагаю, что он просто долго сходится, потому что на второй функции он к особо сложным признакам идет нормально, и ты при этом говоришь что "по 128 батчу ебет адам", а батч влияет на скорость схождения.
> Да я в курсе, было одно время желание въебать все принципы теории хаоса (ну конкретно достижение edge of chaos как идеальной точки) и всякие физические постоянные константы вместе с фракталами
Кароче ради прекола сделал фрактальный фильтр для signsgd через фрактальную маску важности, декомпозицию градиента и скользящее окно внимания. Ну типа принцип самоподобия фракталов для оценки важности. Получилось отлично, предсказуемо и минимум говняка и отклонений от датасета за исключением сильной агрессии. Погуглил есть ли оптимы с фрактальными фильтрами и чет никто не сделал еще похоже, topk и snr фильтры обычные есть, а фрактальчиков нема. Там еще минусик вроде что значения в одномерное пространство переводятся, ну то есть 2д слом конв не будут нативными, топк можно ко всему применять если что.
Еще бы уметь кодить самому это говно, а то гпт контекст оптимайзера постоянно теряет и предлагает впиздячить еще больше кала в код.
У тебя там любой бред что-ли заебись работать начинает с первого раза? Че ты там такое тренишь интересно.
>фрактальный фильтр для signsgd через фрактальную маску важности, декомпозицию градиента и скользящее окно внимания. Ну типа принцип самоподобия фракталов для оценки важности.
Непонятно без кода, я такие фильтры ни разу не трогал, не шарю за них.
Для одного параметра градиент только от него учитывается или от других тоже?
>Еще бы уметь кодить самому
Ллмки быстрее научатся.
Я все пытаюсь понять как бофт работает. Ну типа я могу представить как матрица на матрицу в голове умножается. По дефолтной схеме очевидно. До меня чет не сразу доперло что если умножений несколько их можно так же застакать и визуализировать как одно.
Нашел такие визуализации https://pytorch.org/blog/inside-the-matrix/, там даже конструктор есть интерактивный, тоже можно стакать умножения, но чуть не так как я себе это представляю в деталях.
Идея то вроде понятна, но надо в голове все собрать на каком-нибудь мелком примере.
Кстати, в ликорисе посмотрел реализацию, там для него нет кастомного куда-ядра, как в этой либе например https://github.com/huggingface/peft/tree/main/src/peft/tuners/boft
Наверное поэтому оно такое медленное.
>У тебя там любой бред что-ли заебись работать начинает с первого раза?
Ну не с первого раза и не совсем корректно, но в принципе да.
>Че ты там такое тренишь интересно.
Все подряд, для точных тестов это ебла, для предметки всякие тостеры теслапанковые, есть сеты для допила знаний о концепте о котором знает сеть недостаточно. Еще есть отдельные тест на адопшен в виде граффити текстов, но это совсем нишевая поебень для сдхл.
>Непонятно без кода, я такие фильтры ни разу не трогал, не шарю за них.
Ну если я заставлю корректно фракталы работать с любыми слоями вообще, то скину, пока могу только top-k обычный скинуть, это абсолютная фильтрация от нормы и Top-k Relative которая берет процент самых изменяемых параметров с наибольшими относительными изменениями градиента, так скажем рабочий вариант и простой как палка, все остальное сложно сложно нипанятна...
В общем концепт фрактальной залупы такой, есть в теории хаоса такой концепт как edge of chaos, то есть точка где данные переходят от порядка к хаосу и наоборот. Хаос в целом связан с фрактальными системами (постоянные Фейгенбаума и прочие приколы), таким образом мы можем сделать предположение что чтобы выделить действительно важные данные из градиента, которые содержат ядро обучения новым данным, то эти данные не должны быть фрактально подобны общей структуре градиента.
То есть то место где градиенты регулярны и устойчивы - они менее важны, где градиаенты хаотичны или локально нестабильны - с огромной вероятностью содержат обучающую информацию прямо на границе хаоса и именно ее нужно брать.
То есть на практике это происходит так: мы берем градиент любой, совершенно неважно каким образом он получен (то есть имплемент в любой нравящийся оптим, поэтому по факту никакие беты с моментумами и не нужны, главное получить град), раскладываем его на крупномасштабные и мелкомасштабные компоненты через какой-нибудь wavelet, вычисляем локальные фрактальные плотности, и на основе этих данных создаем маску важности на основе этой фрактальной плотности и в завершение вводим окно внимания для этой процедуры, где чем больше окно, тем глобальнее фильтрация (меньше окно - больше внимания на локальные признаки в отрыве от общей картины, больше окно - внимание на огромный массив признаков), то есть мы можем контролировать насколько самоподобный градиент необычен в своем локальном контексте, который мы сами задаем. И по итогу только значимые элементы допускаются к добавлению на основе трешолда. Это один из вариантов классического фрактального фильтра кароче, есть еще с сотню вариантов и комбинаций вариантов.
Там основаня проблема только в размерностях, условно юнеты поставляют шестимерные данные в основном, а базовая формула F считает трехмерные, двумерные, одномерные (причем в основном одномерные корректны для фрактализации). Поэтому чтобы пофиксить говно надо например использовать маску на основе локальной вариации std в виде простого kernel через unfold, чтобы он работал с любыми размерностями, но это ебейший костыль и не нативное поведение фракталов и тогда не работают вейвлет декомпоз, который тоже часть фрактальной структуры. Можно в принципе соединить несколько типов разложений для всех вариантов пространств, но это будет солянка уровня вот тут у нас топ-к для конв, вот тут фракталы для лин, вот тут снр для атеншенов, кароче ненужная сложность которую еще отдельно настраивать каждую.
>Для одного параметра градиент только от него учитывается или от других тоже?
Если речь о фракталах, то задается через окно внимания, больше окно - больше сопредельные параметры берутся, меньше окно - более локальные.
>Я все пытаюсь понять как бофт работает.
Как я понимаю: вместо обычных дополнительных весововых блоков в низком ранге, как в лоре, офт использует структурированные матрицы на всем протяжении так скажем весовой матрицы (в виде диагоналей, то есть там берется условный квадрат и построчно выстраивается диагональ средних значений, ну вот как в видосе про SVD расписано вот также и тут), которые состоят из множества простых маленьких блоков, последовательно преобразуя данные (у тебя по ссылке в анимациях видно), всегда остаются стабильными (их невозможно взорвать при обучении), не ломают сеть (сохраняет предобученню структуру), и симулируют настоящие большие матрицы, но с искусственно факторизованным количеством параметров.
>но надо в голове все собрать на каком-нибудь мелком примере
Я бы считал офт глобальной фильтрацией. Вот у тебя есть фото лица, и есть обученная матрица офт с новыми параметрами лица, офт встраивается как фильтр и докручивает изначальные весовые данные до фильтрованных, масштабируясь на протяжении всех весовых значений.
>Посмотри тогда еще Lion, это развитие SignSGD
Не, лион с бетами точно не мое.
Зато я перетрогал несколько типов сгдшек, и как грица "искал медь а нашел золото" - SGDSaI.
Мне в целом понравился как работает SignSGD, как я уже писал, но у него есть недочет в виде того что он не учитывает важность/размер градиента вообще. С одной стороны это хорошо, он просто пиздит все подряд и адаптируется к датасету наплевав на всё. С другой стороны получается что он работает типа как ебучий ледокол в арктических водах. Погуглив еще дополнительные оптимы я нашел что есть SGDSaI, который учитывает размер и зашумленность градиента через gsnr. Как итог сгд начинает работать очень мягко и больше с тонкими структурами признаков, нежели с большими массивами всего говна и не реагирует на изменение дисперсии градиента во времени, такая реализация снижает влияние лр и поэтому там по дефолту стоит скорость 0.01, делая оптим частично адаптивным. Ну и схождение очень быстрое получается. Проверял на l1 и huber-snr, в случае со вторым структурно получается очень тонкая настройка модели (ну как бы у оптима есть данные по снр + тут лосс регулируется через снр полезный), l1 делает более точный результ к общим признакам датасета, но теряет в гибкости, уменьшая именно адаптацию (оттого меньше артефактов).
Из минусов SaI в том что он снр считает единожды перед шагом, но я поменял код чтобы он вообще всегда обновлялся и различий между этими двумя методами ну так скажем никакие, то есть обновлять гснр получается и не нужно, поэтому это даже и не минус получается.
В общем просто поделился информацией, работает хорошо, мне нравится.
Если че тренирую всегда BOFT + rescale, наиболее адаптивная структура выходит которая сама решает что где докрутить и не требует снижать влияние модели при инференсе (это можно конечно, и увеличивать можно, но там нелинейная зависимость у рескейл слоев, поэтому при условном 0.5 весе бофт рескейл лоры ее влияние трагически уничтожается, даже при 0.75 уничтожается, а при даже небольшом изменении веса с 1 до 0.99 получается уже другой результат). Если ты тоже гоняешь бофты, но нужна реализация классическая как у лор где указываешь дименшен и альфа коэф влияния, то отключай рескейл, но я бы не советовал особо такой ебанистикой заниматься, лучше просто констрейнт в 0.1 понижать вместо кручения говноальф.




> SGD
Зачем некрофилией занимаешься?
>Зачем некрофилией занимаешься?
Хорошо предсказуемо работает получается.
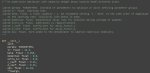
>Amos
Графек функций конечно выглядит многообещающе, но нахуя стока параметров, мне наоборот чем меньше тем лучше...
Ну кстати прикольный оптим, прогнал тестик
>SGDSaI
Он получается только лр для блоков подбирает, а так это сгд с моментумом обычный. Как бы... наверное ничто не мешает перенести эти кэфы на любой другой оптим, да хоть на адам.
>поменял код чтобы он вообще всегда обновлялся и различий между этими двумя методами ну так скажем никакие
В статье и пишут что снр градиентов не меняется в процессе.
Довольно интересно, хз как оно еще и в диффузии работает, ведь на таймстепах она вообще по-разному может себя вести.
И то что дисперсия между параметрами стабильна, может отличаться на порядок и является довольно неплохой эвристикой, факт такой, достаточно занимательный.
Адам то вообще считает другую дисперсию, та которая между итерациями по одному параметру.
Сделал бы тогда еще и лог того что оно насчитало, раз считается на каждой итерации.
>То есть на практике это происходит так: мы берем градиент любой, совершенно неважно каким образом он получен (то есть имплемент в любой нравящийся оптим, поэтому по факту никакие беты с моментумами и не нужны, главное получить град), раскладываем его на крупномасштабные и мелкомасштабные компоненты через какой-нибудь wavelet, вычисляем локальные фрактальные плотности
Это ты тоже пытаешься считать между параметрами или итерациями? Есть мюон, всякие svd, не пытаешься ли ты уже имеющиеся велосипед запилить?
>условно юнеты поставляют шестимерные данные в основном
А где? Свертки это 4 нативных измерения вроде. По батчу еще, и?
>Если речь о фракталах, то задается через окно внимания, больше окно - больше сопредельные параметры берутся, меньше окно - более локальные.
То есть таки по разным параметрам фильтр? Ну как мюоны с svd.
И как ты будешь учитывать локальность в mlp? Оно же там перемешано всё.
По бофту я пока так и не разбирался. Понял только что рескейл это типа как матрица магнитуд из доры, ибо сам бофт просто по определению нормирован. И то что constraint это аналог wd, ибо если наивно делать wd, оно будет тянуть веса не туда, а в строну уменьшения влияния самой исходной матрицы весов а не добавки, ибо матричное умножение а не сложение, как с той же лорой хотя бы.
>адаптивная
А что ты под этим подразумеваешь? То что условное лицо заебись натренится, потому что по него можно просто адаптировать уже имеющееся обобщение лица, а типа внедрить радикально новый концепт будет пососно, так это должно работать?
>но там нелинейная зависимость у рескейл слоев
Бля, еще надо понять где этот рескейл стоит, а то я не понимаю куда его засунуть, кроме как после всех умножений.
Чем у него потом вес меняется при работе? Не рескейлом по идее, там надо как-то все веса менять или тянуть к единичке. Ладно, лучше пойду подоёбываю ллмку на эту тему.
Очередные картинки говна. На такой функции вообще сгд-нестеров всё ебёт чисто математически, а в реале почему-то нет, ибо и ландшафтов таких в нейросетках нет, тут еще и степов на пару порядков больше чем было бы оптимально для какой-то такой задачи, если пытаться считать ее реальной.
>Он получается только лр для блоков подбирает,
Размер/важность градиента учитывает сравнивая через gsnr насколько я понял
>В статье и пишут что снр градиентов не меняется в процессе.
Да я про это и говорю, каждый шаг сделал чтобы гснр считало, и нихуя это не дало ничего, ну бквально отличия в обученном материале на уровне границ объектов - в одном случае мягкие, в другом там блик студийный по кромке, уровня погрешности иксофрмерсов кароч
>Адам то вообще считает другую дисперсию, та которая между итерациями по одному параметру.
Ну тут вообще не учитывает дисперсию
>Это ты тоже пытаешься считать между параметрами или итерациями?
Каждую итерацию фильтрует градиент с уникальными измененными параметрами по порогу получается.
>Есть мюон, всякие svd, не пытаешься ли ты уже имеющиеся велосипед запилить?
>То есть таки по разным параметрам фильтр? Ну как мюоны с svd.
Это sparse learning называется техника я погуглил, когда ты фильтруешь градиент от говна любым способом, прям фильтры градиента встроенные в оптимайзерах я не встречал, даже вспомнить не могу ниче, ну вот в сгдсаи гснр есть но это не фильтр прям а якорная точка скорее. А SVD это процесс декомпозиции ну привести более сложну структуру к более простой и наоборот развернуть, а мюон просто учитывает геометрию.
>А где? Свертки это 4 нативных измерения вроде. По батчу еще, и?
batch, heads, channels, height, width, norms, вроде так
>И как ты будешь учитывать локальность в mlp? Оно же там перемешано всё.
а хуй знает, агрегировать локальные особенности, перевести их в другой формат через avg_pool1d/2d, можно применить фильтр ко входу, костыли кароче да
>Понял только что рескейл это типа как матрица магнитуд из доры, ибо сам бофт просто по определению нормирован.
в модуле создаётся параметр self.rescale, инициализированный единицами, после применения всех butterfly-блоков результат умножается на этот rescale, то есть это поэлементный масштабирующий коэффициент для каждого выходного канала, модель типа тренирует дополнительный тензор чтобы самой каким-то образом решать как масштабироваться не прибегая к обычному альфа коэфу
я тренил и с рескейлом и без, и с рескейлами ну выходной результат значительно лучше, модель как бы надрачивает новые данные чтобы они были симулятивны данным основной модели, поэтому обобщение более аккуратное и точное, просто прогони с рескейлом и без него на стандартных dim:alpha на уровне 1к1 2к1 и увидишь в чем прикол
>И то что constraint это аналог wd, ибо если наивно делать wd, оно будет тянуть веса не туда, а в строну уменьшения влияния самой исходной матрицы весов а не добавки
констраинт ограничитель роста типа нормализации => ограничитель изменений, хочешь минимальное влияние офт - ставь минимальное ограничение, хочешь бесконечный рост весов и большую силу изменений, ставь 1+, короче это типа чуть более другой альфы но более удобное для понимания; обычная альфа делится на размерность и дебильные коэффициенты получаются, а тут у тебя есть некая крутилка громкости и ты ее хуяк хуяк линейно используешь тип "хочу бля 20% влияния на веса, ебашь" и при этом у тебя размерность сети остается такая же и не надо ебаться подбирать говно типа 64 дим 6.66 альфа, но там момент что обновления могут вообще не доходить до нормы 1 и это будет излишне, а для какого-нибудь констрейнта 2 это я хз какие настройки надо напердолить чтобы именно сила обновления была равна двойной "норме"
>А что ты под этим подразумеваешь? То что условное лицо заебись натренится, потому что по него можно просто адаптировать уже имеющееся обобщение лица, а типа внедрить радикально новый концепт будет пососно, так это должно работать?
Ну я хз как текстом визуальный эффект расписать. Представь что у тебя сетка знает концепт "хуй", но все хуи у сетки получаются огромными негродилдами, а тебе позарез нужны мелкие белые хуишки. Ты берешь датасет с маленькими белыми хуишками и рескейл динамически (то есть не постоянно) позволяет морфить огромные хуи в маленькие хуишки морфя только их ситуативно. То есть условно на сиде 1 при гене "хуй" у тебя негрохуй, но если применить офт и загенерить тот же "хуй" на сиде 1, то рескейл не отработает и будет плюс минус тот же результ, но если ты скажешь "маленький хуй", то рескейл отработает и не особо меняя выходные данные позволит получить на том же сиде маленький хуй, сопоставляя что и там и там хуй, просто нужен другой хуй. Короче это фича добавляющая гибкость и селективность чтоли, когда тебе надо точно знать что ты не поломаешь выдачу модели своими уточненными данными. Как транспонирование в музыке кароче, когда тебе надо нотки просто перевести их из одного ключа в другой. Это и для стилей подходит, и для допила концептов.
Насчет радикально новых концептов, новый концепт обычно имеет неадекватный масштаб относительно старых весов, поэтому рескейл помогает избежать переусиления и дисбаланса как бы нормируя новые данные до масштаба основной модели, не меняя предобученную модель сильно. То есть в данном случае рескейл уже будет работать как ограничитель, а не морф-модуль.
> ландшафтов таких в нейросетках нет
Это не важно. Если оптимизатор на таких простых функциях не может приползти в район глобального минимума - он говно. Так же по этим графикам видно насколько дёргано/быстро он идёт к минимуму - если там пила, то это всегда дикая ебля с подбором параметров чтоб ловить хороший результат. Amos тоже результат даёт такой себе, он слишком быстро сходится и почти всегда оверфитит, его надо специфично готовить. А какой-нибудь Fira, заточенный под низкоранговые тюны, очень плавный и стабильный. По графикам отлично всё видно, если не бездумно смотреть на синюю и зелёные точки.
> Amos тоже результат даёт такой себе, он слишком быстро сходится и почти всегда оверфитит, его надо специфично готовить.
Нихуя подобного, это же адаптивный оптим. Я где-то 100 эпох надрочил на 0.0001 с классовым токеном и оно бесконечно выдрачивает одно и тоже просто, ноль оверфиттинга.
Но шо интересно у него прикольные фичи которые синергируют с офт, который я гоняю:
- использует get_scale() в зависимости от формы веса
- локальная регуляризация переменная, усиливается со временем (b.mul_(1 + gamma))
- адаптивный шаг через r_v_hat, с bias correction и адаптивной нормализацией
То есть он подгоняет веса к оптимальному масштабу постоянно акцентируясь на форме весов, когда сам офт делает то же самое, итого это первый оптим который каждую эпоху действительно двигается в одном и том же направлении изначальных весов и не сходит с пути вообще.
d_coef и c_coef управляют затуханием и при 0.25-0.5 это доп защита от переобучайки кстати, а при 0.1 убыстряет сходимость.
Фиру я тоже тестил когда козистр выложил свои тесты и там меня вообще ниче не впечатлило, как будто обычный адам гоняешь, такое же скушное тормозное за счет EMA ничего.
Если хочешь ощутить оверфит бери MADGRAD лол, он кстати достаточно выразительный, ну сразу видно своеобразное поведение и собственное видение процесса после тренинга.
> где-то 100 эпох надрочил на 0.0001
с константой офк
>они реально думают что за кривой нормировкой лр на картинках можно что-то увидеть
А ты я так понимаю веришь в сказку которая звучит примерно как "даже создатели нейросетей не знают как они работают, это черная коробка"
Те кто знают, такой хуйней не занимаются)
Когда в данных есть дополнительный член, который весь сигнал перекрывает, чего-то за ним выискивать - довольно бессмысленное занятие.
>)
Ясно
Два поста без аргументов, одни пуки, на больше скобочек ты недостоин)
>)
Ясно
Есть кто шарит за статистику. Вот есть CosineAnnealingWarmRestarts, какой диапазон косинусной функции будет оптимальным для одного цикла, если падение идет с самой высокой пороговой стабильной скорости? Допустим стартовая 0.0001. Обязательно ли укатывать до 1e-6 или статистически хватит в 10 раз просто понижать?
Как же заебала эта ебаная мразь, почему все кастомные оптимы требуют 32 битную точность у вае (--no_half_vae), у меня из-за этого постоянно за пределы карты тренинг вываливается и пердит в два раза медленнее.
А еще большинство опимов не работают с двухбитной точностью весов (fullfp16/fullbf16) нормально и улетают в наны. Ну хоть fp8 базу принимают и на том спасибо.
А еще большинство опимов не работают с двухбитной точностью весов (fullfp16/fullbf16) нормально и улетают в наны. Ну хоть fp8 базу принимают и на том спасибо.
>32 битную точность
32 флоатинг
фикс
Гопота грит что достаточно x10, т.к. полное снижение до нуля не всегда нужен, главное, чтобы на хвосте цикла была достаточная инерция для стабилизации
Шиз, оптимизаторы тут не при чём, они никак с VAE не взаимодействуют, VAE у XL в принципе не предназначен для fp16, используй bf16.
> bf16
В XL UNET в fp16 должен быть. Наны только от слишком высокого lr могут быть.
>оптимизаторы тут не при чём
Меняю на стандартные - все работает. Сторонние срут нанами.
>используй bf16
Там без разницы. В любой комбинации со сторонним оптимом если не стоит нохалфвае - будут наны. Хоть 0.0000000001 лр ставь - все равно в нан улетает. Ставишь нохалфвае - все работает.
У тебя в коде насрано где-то, VAE тут не при чём. Я два десятка оптимизаторов перепробовал, никогда не было проблем с nan.
>У тебя в коде насрано где-то
Но я не срал в код сдскриптов (ветка sd3) и оптимайзеров блядж!

Если ты про говнодела коху, то у него оптимизаторы bnb сломаны всегда были. Вот тут насрано у него. Он по всей видимости не умеет пользоваться accelerate.
все, пофиксил, это кривой вае из модели загружался
>В XL UNET в fp16 должен быть. Наны только от слишком высокого lr могут быть.
fp16 в принципе нестабильное говно, если все запихивать в fp16 (втч те) то с вероятностью в 90% полезут наны, в bf16 такого нет (ну по крайней мере у меня не получилось засуммонить наны)
UNET в XL тренился в fp16, с bf16 ты сознательно понижаешь точность. Надо знатно поломать тренировку чтоб NaN полезли из UNET. Алсо, UNET при инференсе как раз ломается если его в bf16 конвертнуть.
> UNET при инференсе как раз ломается если его в bf16 конвертнуть.
Не ломается, если с ключом на юнет бф16 комфи запускать
> юнет бф16 комфи запускать
Как раз это и ломает, на некоторых воркфлоу через раз чёрными квадратами сыпет.
> с bf16 ты сознательно понижаешь точность
ну че поделать, если тренинг тупа в нан уходит со вторым шагом если форсировать фп16, вероятно это баг но не выглядит как баг, но сколько я не пытался заставить работать с условным амосом вчера - хуй мне на рыло
а точность бф относительно фп... ну это спорно, там погрешность выхода получается на уровне сида за счет того что бф сохраняет тот же диапазон экспоненты, что и fp32, но с меньшей точностью, а диапазон важнее точности в целом
алсо забавный эффект вчера наблюдал: на бф я получил один и тот же концептуальный результ на 3 эпохе с датасетом из 20 картинок, на фп с датасетом из 100 картинок на четвертой
вон в бф тренили флух и че плохо чтоли? хорошо
>Надо знатно поломать тренировку чтоб NaN полезли из UNET.
ну у меня full_fp16 арг при любом раскладке роняет в наны на амосе совершенно точно, полный конфег те скинуть у ся запустишь?
>алсо, UNET при инференсе как раз ломается если его в bf16 конвертнуть.
>Не ломается, если с ключом на юнет бф16 комфи запускать
>как раз это и ломает, на некоторых воркфлоу через раз чёрными квадратами сыпет.
хз ни разу не видел никаких проблем на комфе с бф16, без ключа с ключом без разницы вообще
> а диапазон важнее точности
Там везде нормализация после каждого слоя. Веса в нормальной ситуации в пределах -2 и 2. Если выходят из этого диапазона, то получаешь кашу, а не NaN. А ломает тебе скорее NaN в градиентах, а это уже просер тренировки.
>А ломает тебе скорее NaN в градиентах, а это уже просер тренировки.
Кептен обвиос, естественно нан в градиентах, но только при использовании форсированного фп16, причем первый шаг - лосс получен, второй шаг - улетело в нан. Вне зависимости от того какой лр, какая функция лосса, какой оптим (из библы питорч оптимов, не указанные как дефолтные).
Единственный вариант задоджить нан - убрать full_fp16, оставив миксед пресижн на фп16.Прикол с нанами от вае чуть выше это изза того что в самой модели вае бесоебило, отдельно подгруз не требует нохалфвае аргумента. Тогда оно работает, но жрет врама значительно больше и вываливается за карту. Если добавить --fp8_base_unet и --mem_eff_attn, то оно прямо на грани чтобы вылезти будет. А с фулл_бф16 все прекрасно работает как часеки.
>Единственный вариант
А ну и да, второй вариант: использовать full_fp16, но включать фнохалфвае принудительно. Тогда тоже работает.
Чел, NaN как раз из-за неправильного использования оптимизатора может быть.
> фулл_бф16 все прекрасно работает как часеки
Это всё костыли. У тебя модель в fp16, тренили её в fp16, но тюнить ты почему-то не можешь её. Очевидно модель тут не при чём, а кривая тренировка.
>NaN как раз из-за неправильного использования оптимизатора может быть.
На любых оптимах, дефолт не дефолт настройки, без разницы вообще. Вот щас для теста запущу адам8бит на фуллфп16 и скажу че там, уже не помню работает или нет.
>Это всё костыли.
Тренировка лорок это вообще сплошной костыль, нашел на че жаловаться епт.
>У тебя модель в fp16, тренили её в fp16, но тюнить ты почему-то не можешь её. Очевидно модель тут не при чём, а кривая тренировка.
Так я могу, ток она в карту не влазит, а форс фп16 нанами пукает (как в целом и должен, он же нестабильный кал без защиты от переполнений значений). Так что я лучше в бф16 посижу, но с батчем 4 с норм скоростью, а не буду терпеть 1 батч и x2 по ит/сек.
>Вот щас для теста запущу адам8бит на фуллфп16 и скажу че там, уже не помню работает или нет.
Ну да с дефолтным адамв8бит работает с включенным full_fp16, кароче это обосранный full_fp16 обсирается на кастомках
>в бф16 посижу
можно тольковыиграть от оптимизированных для bf16 оптимайзерах https://github.com/warner-benjamin/optimi и https://github.com/lodestone-rock/torchastic
> адамв8бит
Чел, не трогай оптимизаторы bnb. Если ты пытаешься 32-битные запускать, то это норма что они ломают модель.
Алё ты контекст теряешь, с адами8бит все работает.
> на некоторых воркфлоу
Пример такого воркфлоу?
> хз ни разу не видел никаких проблем на комфе с бф16
Ну дефолтный впредовский хл нуб воркфлоу с лорами у меня тоже работает, инпеинт, апскейл, хз о чём он
Это ты теряешь. У кохи неправильное использование оптимизаторов bnb, он обратный проход патчит, причём криво.
Че из тебя все клещами вытягивать? Или ты специально чисто тезисы накидываешь чтобы накинуть?
Как балансировать датасет? Делать равное количество повторений на нужные концепты? Когда пытаюсь концепт сделать(типа окружения или позы), то колчиство повторений примерно в 2 раза больше требуется чем для стиля, и не всегда понятно когда достаточно, есть ли какие то автоматические способы балансировки, или если в целом достаточно долго вести тренировку то все должно усвоится без повторений?
*не в 2 раза больше повторений, а в 2 раза больше шагов
Просто делай капшены нормальные.
Я делаю, на низком confedence тегаю с помощью wd tagger и потом ручками убираю те которые не подходят и добавляю те что не попали, но есть на пикче
> wd tagger
Ты из 2022 капчуешь? Возьми что-нибудь нормальное, хотя бы Gemini Flash. Не забывай рандомить теги, можешь нагенерить разными моделями 5 разных капшенов и выбирать рандомный при тренировке. Если у тебя в капшене 5-10 тегов, половина из которых 1girl standing, то естественно концепты/стиль протекают куда угодно.


Сомнительная идея тегать натуральным языком когда основная модель в основном на тегах обучалась, + я добавляю то что не могу тегами существуют, чем то похожим, типа натуральным языком но максимально коротко что бы было похоже на тег, ну и проверяю на генерации что бы посмотреть что я ничего не забыл или не ошибся, токенов почти всегда больше 100 выходит, проблема в том что не понятно сколько шагов необходимо для того что бы все концепты нужные изучились
вот примерно что получается
bunoshii, light blush, dot nose, kanbaru suruga, naoetsu high school uniform, 1girl, solo, short hair, black hair, smile, brown eyes, looking at viewer, pink dress shirt, bandaged arm, black pleated skirt, white background, thick eyebrows, puffy short sleeves, white-red sneakers, closed mouth, yellow neck ribbon, simple background, tomboy, collarbone, hands between legs, v-shaped eyebrows, shadow, short eyebrows, medium breasts, butterfly sitting, v arms, on floor, pavement, from above, three quarter view
three quarter view модель не знает к сожалению
И да простые вещи можно так подробно протегать, сложные нет, но меня пока устраивает, XL всё равно пока не сможет нормально обрабатывать натуральный текст
>Сомнительная идея тегать натуральным языком когда основная модель в основном на тегах обучалась
Она обучалась не на тегах, а на эмбеддингах порождённых этими тегами. И эмбеддинги эти векторные генерить вот не похуй из чего.
> натуральным языком
Зачем? Современные VLM без проблем тегают booru-тегами и знают всех аниме-персонажей. Во few-shot в каком угодно формате выдадут тебе теги, причём ничего править потом не надо.
Это какая, ToriiGate в последний раз когда пытался юзать выдавало какие то выдуманные теги что почти не соответствовали пикче
Последний вд-теггер за пояс заткнет все эти "новые мультимодалки" по знанию персонажей, корректности использования тегов и прочего. Советчики, которые предлагают тегать мультимодалками в режиме тегов, несколько приукрашивают их возможности.
Но чего теггер точно не сможет - так это описать позиции и остальную более подробную инфу. Так что если модель хоть немного может в натуртекст - действительно есть смысл добавить к тегам про это.
Главное - не использовать типичные полотна жеминислопа про "развивающиеся на весеннем ветру трансцендентально полупрозрачные, словно затронутые волшебной и чудесной сказкой, волосы".
Хацуне Мику на любого чара с синими твинтейлами, увы.
Оно не работает зирошотом на персонажей, только с указанием. Теги вообще выдавать не должно, только натуртекст.


> ToriiGate
А зачем ты какой-то кал взял?
> несколько приукрашивают их возможности
Ты тоже явно не видел как крупные VLM сейчас работают. Это ты сильно переоцениваешь возможности WD, вот сходу кинул пики и он не знает кто это, просто 1girl. Пробовал разные модели, все срут под себя на половине персонажей. При этом Гемини мне всегда точно выдаёт имена.
Ну какой тогда генерировать капшены?
> явно не видел как крупные VLM сейчас работают
Самоуверенный щегол.
> вот сходу кинул пики
Старая версия в кривом спейсе, где порог уверенности на персонажа единица. И даже так для этих пустых пикч он указал нужное.

> Старая версия
Кому ты пиздишь. wd просто говно. Вообще удивительно как ты можешь защищать крошечные гиговые модели и говорить что они лучше свежих мультимодалок.
> говорить что они лучше свежих мультимодалок
Сойбой.жпг
Вместо пустых заявлений лучше преподнеси пример хороших капшнов с твоих "свежих мультимодалок", а потом их применение при тренировке.


А что тебе показывать? Просто капшены без проёбов, на уровне ручных. Он даже заданную длину держит идеально. Обычно неглядя просто скриптом прогоняю по датасету и всё.
> Сойбой.жпг
Ты и есть, сидящий на каком-то говне потому что тебе сказали что оно норм. А потом как тот анон сидишь и ручные правки делаешь.
Что за модель юзал? Для каких картинок эти промты?
> Просто капшены без проёбов, на уровне ручных.
Если просить описать что-то сложнее 1girl standing то оно сразу сыпется, ужасно ошибается или идет в отказ. Чаров нормально не узнает, если не дать имя в промте, если их несколько - сиди и крути рулетку.
Именно поэтому, если ты хочешь описывать что-то сложное и/или нсфв, мультимодалки общего назначения перестают справляться. Лучшей альтернативой тории (которую ты из-за невежества или обиды назвал говном) может быть только агентная система с гопотой. Пара моделей сейчас в разработке, когда натренят наверно будет. Джойкапшны галюцинируют и ломаются, остальное уже совсем древность.
Что же до использования "большой мультимодалки" для подобной строки тегов - ты рофлишь чтоли? Оно придумывает несуществующие теги, не знает правильного описания огромного числа концептов для которых есть свои теги, проигнорирует неудобные ей части. Не говоря о том что это гвозди микроскопом или из пушки по воробьям.
Что же до теггера - наилучший сценарий его использования - прогон по трем моделькам с усреднением скоров (можно по весам 0.25 вит 0.25 свин 0.5 ева) и снижение порога для тегов и чаров (0.35-0.85 или даже пониже). Автоматизированный скрипт для этого уже постился в треде. Это не только быстро, но и эффективно. А потом уже, если ты хочется, можно прогнать мультимодалкой и отдельной ллм (или ею же) зарефакторить промт, интегрировав в теги уточняющие элементы натуртекста.
> сидящий на каком-то говне потому что тебе сказали что оно норм
Так это буквально ты, решил что размер больше = лучше и сочиняешь. По примерам видно что ни с чем серьезным не работал.
Ты реально шизик.
> сразу сыпется, ужасно ошибается или идет в отказ. Чаров нормально не узнает
Я уже показал тебе что это как раз WD нихуя не знает и даже довольно популярных чаров не узнаёт. Что за траллинг тупостью включаешь? Ты даже не называешь каким говном вместо VLM пользовался, не удивлюсь если это какие-то 7В-огрызки были.
> огромного числа концептов для которых есть свои теги
Открою для тебя секрет, в анимешных моделях клип очень слабо отличается от ванилы и выдаёт похожие эмбединги на теги, которых не было в датасете. На нубе, который тренили на нативных тегах без изменения, работают сложные промпты текстом без использования точных тегов бур.
> Это не только быстро
На VLM секунда на пик. Сомневаюсь что твои костыли будут быстрее.
> прогон по трем моделькам
> зарефакторить промт
Это пиздец. Ты наверное тот шизик, тренящий клип, потому что капшены говнище.



>На нубе, который тренили на нативных тегах без изменения, работают сложные промпты текстом без использования точных тегов бур.
Что-что? Или мы о разных нубах говорим?
>hatsune miku and ayanami rei dancing in the street,
>masterpiece, best quality,
Наверное, сильно сложный промпт текстом, раз он мне в 40 случаев из 40, по 20 попыток на впред и эпсилон нубов, выдавал гибрид Рей и Мику в каких-то отдаленно похожих на улицу локациях, и никогда - двух персонажей сразу.
Чтоб появились обе - потребовалось таки отдельно тыкнуть, что нужны "2girls".
Ну а чтоб "нормальная" картинка получилась какой же нуб все-таки адовый результат без негатива и тэгов рисовак выдает, жесть - пришлось таки перейти на стандартные тэги.
>2girls, hatsune miku, ayanami rei, dancing, street,
*Мимоанон есливчо
Предъявы, что семейство WD-таггеров персонажей не знает, кстати, забавные.
Ну не знает и не знает, хер с ними.
"По частям" WD их воспринимает, а это главное - чтоб картинку расшифровывал и детали цеплял.
Пусть с этим тоже не всегда всё идеально, но в отличии от той же Тории, WD физически не способен сбиться на натуртекст или придуманные тэги, что у меня на тестах Тории случалось довольно часто.
> на стандартные тэги
Это не в тегах дело, а в том что любители тренить клип запороли его запятыми. Некоторые односложные теги работают только с запятой, потому что они натренили его не как "тег", а как "тег,". А например "sitting" в датасете встречается с пробелом, поэтому ты можешь его в натуральном тексте использовать.
> Тории
Во-первых, это микромодель, она в принципе говно для любых задач, слишком мелкая. Во-вторых, это не нативная мультимодалка, это LLM с визуальным энкодером и адаптером.
Тебе нужны нативные мультимодалки, а не древний кал с клип+адаптер. В них ты больше не зависим от ограниченности энкодера и они знают как что-то выглядит даже если этого не было в визуальном датасете.
>Тебе нужны нативные мультимодалки
Ну, например?
Такие, чтоб на домашнем ПК запускались, и вдобавок могли в случае чего голую женскую грудь и мужской член протэгать, а не "Извините, я не могу вам с этим помочь".
Но я больше чем уверен, что и нативные мультимодалки будут шизить и придумывать. Откуда им настолько хорошо знать форматирование и специфику применения буру-тэгов?
Это отдельная тренировка нужна.
> WD нихуя не знает
> какие-то 7В-огрызки
Чел, ты бы не позорился. Посмотри сколько весов в твоих "новых больших мультимодалках" отвечают за обработку и кодирования изображения, и пойми насколько фейлишь.
> Это пиздец.
Нет, это не пиздец а довольно популярная практика.
> в анимешных моделях клип очень слабо отличается от ванилы
Бредишь.
> На нубе, который тренили на нативных тегах без изменения
Диванные не знают, но в нем была доля натуртекста.
> На VLM секунда на пик.
Ты заикался про "большие". Даже если проигнорировать обработку примерно тысячи токенов контекста, в которые будет закодирована пикча, генерация сотни-другой займет уже несколько (десятков) секунд в зависимости от мощности железа.
> Ты наверное тот шизик
Нет, шизик это ты. По каждому пункту зафейлил, в каждом посте надменность и выебоны, но ничего полезного и по сути не сказал.
> персонажей не знает
В том и прикол что довольно неплохо знают, даже редких с сотней-другой, и ошибаются редко. В свое время на это много усилий было положено.
> WD физически не способен сбиться
Вся так
> не нативная мультимодалка, это LLM с визуальным энкодером и адаптером.
Это шизофреник, он втирает полнейший бред, который придумывает на ходу.
> чтоб на домашнем ПК запускались
Смотря что за домашний комп. Из мелких можно Гемму 27В попробовать.
> Откуда им настолько хорошо знать форматирование и специфику применения буру-тэгов?
А почему не должны? В датасете современных мультимодалок буры полностью есть. Они даже знают сколько примерно пикч на бурах есть с каким-то тегом.

> довольно популярная практика
Только у шизиков. Все кто не используют нативные теги ещё два года назад капшены на VLM делали. Тот же Пони на VLM был и v7 будет.
> Ты заикался про "большие".
Сейчас все "большие" - это MoE.
> от мощности железа
Зачем мне локально капшены генерить, если можно на H100 бесплатно через API за секунду.
> шизофреник
Шизик это ты, не знающий как мультимодалки тренят сейчас и в чём отличие у них от анимешного кала с адаптерами. Хотя что ещё ожидать от дауна, тренящего клип.
Притащил абстрактную картинку в надежде что никто не узнает откуда ее утащил? Да еще явно не понимаешь ее значение и не осознаешь как она компрометирует сказанное тобой ранее.
> нативные теги ещё два года назад
Cfg есть и в ллм, довольно давно.
> Тот же Пони на VLM был и v7 будет.
> Сейчас все "большие" - это MoE.
> Зачем мне локально капшены генерить, если можно на H100 бесплатно через API за секунду.
> Шизик это ты, не знающий как мультимодалки тренят сейчас и в чём отличие у них от анимешного кала с адаптерами.
Только укрепляешь уверенность в том, что ты лишь диванный шиз, живущий в оторванном от реальности манямире, который на ходу придумываешь. Для любого более менее понимающего человека это очевидно. Даже по частям разбирать лень.
>В том и прикол что довольно неплохо знают
На моей памяти wd-таггеры ну прям очень плохо это отрабатывали. Точных срабатываний хорошо если 15% было. 5% ложных, и в остальных вообще не определялись.
Но в любом случае, это для меня недостатком не является.
>Смотря что за домашний комп.
Домашний. Ну, такой, знаешь? Из среднего сегмента. Гигов 12 VRAM.
А не парные 4090 как для Геммы. Ну или одна 5090 в которую она без смазки не влезет, лол.
>А почему не должны?
Слишком специфические данные.
И чтоб гарантированно исключить протечки шизы - эти данные должны быть дюймовыми гвоздями приколочены.
А то пойдет разнобой, и это приведет просто к катастрофическим последствиям, когда один концепт будет в 4-5 разных кейворда свернут.
> Cfg есть и в ллм, довольно давно.
Лол, ты уже совсем шизишь, так что уже буквы не понимаешь.

> Слишком специфические данные.
Не, уже давно прошли времена, когда LLM путались в определениях концептов. Знать список тегов с бур - это как раз простая задача. Вот берёшь рандомный пик и он даже автора знает.
Если дать их заранее и успеть уложиться в бесплатные 5 минут на зирогпу. Где модели?
Блаш стикерсов нет, спич-бабла на картинке тоже нет, знак вопроса вообще-то как "?" в тэгах идет, да и имя художника с ошибкой написано.
Вот как раз про такие глюканы я и говорю.
Типа, ну, понимаение картинки неплохое. Но тэговый кэпшон по ней - уже нет.
И когда вот такие мелкие ошибки с кучи картинок начнут наслаиваться (на тэги, рипнутые с бур напрямую, например) - будет очень плохо.
У меня только 12 vram, не смогу запустить гемму, да и как я вижу не сильно большая разница между wd tagger и описанием llm, вот к примеру что получил от wd tagger
3girls, artist name, ass, averting eyes, bandaid on nose, bent over, blank eyes, blonde hair, blush, braid, braided ponytail, breasts, buttjob, closed mouth, collarbone, completely nude, dragon girl, dragon horns, english text, erection, fff threesome, flying sweatdrops, futa with female, futanari, glasses, group sex, hair between eyes, hands on own knees, heart, horns, huge penis, imminent penetration, kobayashi (maidragon), large breasts, large penis, lips, long hair, maid headdress, makima (chainsaw man), medium breasts, medium hair, motion lines, multiple girls, navel, nipples, no pupils, nose blush, nude, open mouth, orange hair, patreon logo, patreon username, penis, penis awe, penis on ass, ponytail, precum, red eyes, red hair, rimless eyewear, ringed eyes, short hair, sidelocks, sideways glance, slit pupils, small breasts, smile, sweat, sweatdrop, teeth, threesome, tohru (maidragon), tongue, trembling, twintails, twitching penis, uncensored, upper teeth only, veins, veiny penis, watermark, web address, yellow eyes
есть пару не правильных но это не так важно, это легко исправить, я всё равно все чекаю
Проблема то всё равно изначально не в том что плохое описание, если соотношение картинок одного концепта сильно больше чем у другого без нужного количества аугментации в любом виде(в моем случае тупо повторения) то концепт с меньшим количеством шагов может тупо не обучится, и при чем проблема осложняется тем что 1 концепт модель уже знает, а другой вообще нет, что в данном случае делать? Если тренировку достаточно долго поставить то повторения вообще будут играть какую то роль?
> есть пару
Больше похоже на половину. Вот такое точно будет всрато трениться, когда 10 мусорных тегов на глаза, как будто он высрал все теги что знал.
Там из не правильных вот эти slit pupils, penis awe, imminent penetration, flying sweatdrops, bandaid on nose, averting eyes, blonde hair, small breasts,
В примере с vlm неправильные speech bubble, blush stickers, blushing(такого нет, есть blush), fang, cum on ass, light brown hair, pigtails
Примерно столько же неправильных как и в примере от vlm, при этом описание гораздо подробнее описывая цвет глаз, размер груди, куда поставлены руки
Почему будет плохо тренироватся с этим?
> если соотношение картинок одного концепта сильно больше чем у другого без нужного количества аугментации в любом виде(в моем случае тупо повторения) то концепт с меньшим количеством шагов может тупо не обучится
Почему так решил? В целом, концепт обучится если есть достаточное число его повторений, равенство чему-то не требуется. Тут скорее проблема в побочных эффектов от слишком большого количества других картинок.
Здесь вообще не зная датасета невозможно нормально что-то предсказать, слишком много прочих факторов. Поставь на ночь трениться и так и так, а потом выбери наилучший вариант, или повтори с другими параметрами. Это будет более эффективно чем выдрачивать совсем мелочи типа одного-двух неточных тегов.
> speech bubble
Там есть речь персонажа на пике, знаешь какие-то другие теги для неё? На самих бурах зачем-то речь называют "sound effects".
> blushing(такого нет, есть blush)
Я даже полез проверить в SD - blushing имеет сильнее эффект, чем blush.
> cum on ass, light brown hair, pigtails
Всё это есть на пике.

speech bubble это облачко а не текст, текст описывается с помощью text
blushing, то есть оно не будет для одного и того же делать одинаковые теги? Значит это не теги
>cum on ass
Это не cup, это precum и в тегах от vlm его нет, вот как cum рисуется
>light brown hair
Ну значит blonde hair не правильный
>pigtails
Twintails that are short, around shoulder length or less.
нету там pigtails
Я надеюсь ты не тренишь на таких простынях длиннее 75 токенов?


Нет, бывает и больше, но я стараюсь объединять теги одежды, ну и других концептов что бы семантическую связь создать между тегами и уменьшить описание 1 вещи в 1 "тег" тут пример с pink dress shirt, yellow neck ribbon, black pleated skirt и т д
А в чем проблема 75 тегов? Можно до 225 пихать во всех трейнерах + шафл тегов + оставляю концептуальные теги в начали что бы не шафлились
Проблема в качестве того как обучится, я могу дать достаточно что бы оно реагировало, но будет работать через раз, или просто плохо, эксперементы проводить не смогу, я арендую видюху для тренировки, так бы на своей просто провел тренировку и посмотрел, а так я обанкрочусь, вот пример, school desk pile и shaft look, где то по 1 срабатыванию нормальному из 4
> я стараюсь объединять теги одежды, ну и других концептов
Посмотри в сторону https://github.com/derrian-distro/SD-Tag-Editor там внутри есть полезные наработки для прунингу дублирующих и заголовочных тегов (удаляет shirt если есть white_shirt и многое другое). Хотя если делаешь вручную то норм, но совсем ужимать вовсе не обязательно. И про дропы не забывай.
> А в чем проблема 75 тегов?
Не тегов а токенов, такие полотна в них просто не влезут и будут обрезаны. В целом, можно поставить 225 и забыть, да.
> Проблема в качестве того как обучится
В таком случае можно только предложить повысить количество повторов более редкого и чужеродного концепта, по возможности увеличив количество и разнообразие данных для него. Увы, тут только покапитанить можно. Можно еще добавить множитель лосса для тех пикч, но придется модифицировать тренер и иначе подавать метадату пикч.
> А в чем проблема 75 тегов?
В том что блоки эмбедингов усредняются. Это работает при инференсе, но при тренировке ты по факту тренишь не на самих тегах, а на смерженных. Ещё и паддинг срёт в них.
Я не вижу альтернативных способов тренировки с длинными промтами
Поэтому и нельзя тренить с длинными, если не хочешь дикого слипания токенов.
А есть подтверждение того что тренировка с 225 токенами хуже чем с 75? Ты пробовал и было хуже? Даже просто с короткими промтами
Помолчи! И я ничего не говори
л! Глаза Торазосемпая встретились с глазами Казуки а потом он подошел улыбаясь и махая рукой
А без улучшения подробности кэпшона, и, соответственно,без увеличения числа токенов - у тебя часть информации с картинки игнорируется, или вообще протекает в другие тэги.
Вот уж не знаю, что хуже.
Куча бессвязных тегов на глаза и так будут игнорироваться, это не полезная информация. Если хочется тренить на всякие мусорные теги - рандомь и обрезай их. Когда у тебя два эмбединга по 75 токенов усреднены, модель не научится нормально понимать отдельные токены, только смерженные. У тебя по итогу тег на глаза будет бустить эффект тега на волосы, к примеру.
> блоки эмбедингов усредняются
Врунишка. Для усреднения нужно вносить изменения, по дефолту стейты склеиваются и идут пачкой, что юнет прекрасно переваривает.
Тоже ерунда.
> склеиваются
Это ещё хуже. Там резкие скачки в понимании промпта идут. На 3-4 блоке он уже персонажей не понимает.
>блоки эмбедингов усредняются
Усредняются только Vшки от кросс-атеншена. Но они и так усредняются всегда. И то по областям, а не везде.
Хотя вроде не усредняются, а суммируются.
Если я все правильно понимаю, юнету должно быть насрать сколько там блоков. Только количество токенов влияет на результат + есть перелинковка инфы между токенами в блоке клипом, но для тегов это особо нахуй не надо и в теории если резать блоки на каждый тег особо хуже не станет.
Может быть имеет смысл добавить частые метатеги типа скоров в начало каждого блока и замаскировать их на выходе чтобы они не дублировались, но чтоб была стабилизация от их эффекта.
> Это ещё хуже.
Хуже как раз усреднение, которое может конкретно убить исходную инфу.
> На 3-4 блоке он уже персонажей не понимает
225 это как раз 3 чанка, но современные анимублядские модели в любом участке все норм понимают. Это только если тренировали с прибитыми гвоздями позициями, тогда могут быть проблемы.
Если опасаешься - можно теги персонажа поставить в начало и закрепить. Ловля комаров во дворце дракулы на самом деле.
> но современные анимублядские модели в любом участке все норм понимают
Сейчас протестил Нуб, на 4 уже Мику забывает напрочь.
Как потестил? Давай подробнее
Не этот анон, но подозреваю что он несколько BREAK вставил в начале и потом промт писал
Любителям локальных минимумов и картинок с оптимизаторами ебало к осмотру видос к просмотру https://vkvideo.ru/video-22522055_456245617 (с 3:49:00)
Бля, уже сто раз проходили это. Поиск локальных минимумов в функциях - это очень простая задача, сильно легче нейросетки. Они нужны чтоб оценить работоспособность оптимизатора в принципе. Если он не находит локальный минимум в простой задаче, то ни о каких оптимизациях сетки и речи не идёт.
На видосе чел сравнивает хуй с пиздой - в поиске локального минимума функции у нас нет статистической модели, как в loss сетки.
Алсо, Сбер ни одной нормальной сетки не натренил, откуда им знать как тренить надо. Мнение рандомного китайца с одной публикацией и то авторитетнее.
>Если он не находит локальный минимум в простой задаче, то ни о каких оптимизациях сетки и речи не идёт.
Но доказывать это утверждение ты конечно же не будешь.
А я могу придумать кучу контрпримеров, которые сразу это опровергают. Хотя даже придумывать нечего не надо. Тот же алгоритм из видоса хоть и бесполезен на практике, но сетку до обученного состояния довел, при том что очевидно, на твоих картинках с "типа не выпуклой" функцией он бы застрял в первом попавшимся минимуме, но в сетке он почему-то его не нашел, а нашел путь до обученного состояния двигаясь строго по градиенту без всякой стохастики и читов для выпрыгивания из минимумов.
>в поиске локального минимума функции у нас нет статистической модели, как в loss сетки.
Бессвязный бред.
>Алсо, Сбер
От сбера там только площадка для выступления, чел независимый рисерчер который давно эти темки задвигает.
> он бы застрял в первом попавшимся минимуме
Естественно, потому что у него нет оптимизатора, он просто по градиенту проваливается с адаптивным множителем. Разговор об оптимизаторах без оптимизатора, лол.
> в сетке он почему-то его не нашел
Потому что задача из пальца высосаная и мы не знаем что там за "сетка".
> чел независимый рисерчер
Да, увидел, какой-то ноунейм-теоретик, не обучивший ничего практического.
>нет оптимизатора
>он просто по градиенту проваливается с адаптивным множителем
Лол.
>Разговор об оптимизаторах без оптимизатора, лол.
Лол.
+
Пруфов своих своих слов ты все еще не принес.
Оптимайзер не обязан переносится между разными задачами, не важно простая она или сложная, эта другая задача, и запруфать ее эквивалентность должен утверждающий то что они имеют какую-то связь. Пока пруфов этому нет и есть только антипруфы, как по форме, так и по масштабу функции. Даже не близко.
>Потому что задача из пальца высосаная
То ли дело твои примитивные функции доооо.
>и мы не знаем что там за "сетка".
Если не жопой смотреть, можно узнать. Дефолтный мелкий трансформер на котором тестируют грокинг за 4 минуты.
Что я сейчас за хуйню посмотрел? Почему он берёт оптимизатор с фиксированным lr и говорит что туннель слишком узкий, а потом сравнивает с понижающимся шагом по градиенту? Он ёбнутый? Если бы он взял как нормальные люди lr с косинусом и сделал дно как он сам сказал в 10к раз меньше т.е. стандартные 1е-3 lr и дно в 1е-5, то на нормальном оптимизаторе бы намного быстрее натренил. Кто вообще делает претрейн с фиксированным lr и потом жалуется на оптимизатор? Он в конце даже начал догадываться что оптимизатор делает на самом деле - "пробивает стены", а не скейлит градиент. "Сужением туннеля" занимается шедулер, лол.
>оптимизатор с фиксированным lr
Нет.
>на нормальном оптимизаторе бы намного быстрее натренил.
Эта задача визуализации ландшафта, в которой оптимизатор проходит по нему полностью ничего не скипая. А не ради обучения сети.
>"Сужением туннеля" занимается шедулер, лол.
Шедулер на ландшафт не влияет, это разные вещи. Лр затем и шедулится потому что тоннели становятся уже и надо точнее идти.
> Нет.
Ты видимо жопой смотрел. У него фиксированный lr, а потом он ещё жаловался что если влепить шедулинг, то обучение застревает на дне туннеля и не идёт по нему. Он наверняка на 1е-6 свалился и естественно оно не тренится дальше.
Нет ты, там размер шага выбирается по углу градиента и есть график где видно какой лр навыбирался в процессе.
Так это в его алгоритме. Я и говорю он свой адаптивный алгоритм сравнивает с фиксированным AdamW. Расскажите ему уже про ScheduleFree.
Это ты лучше расскажи нахуя там в сравнении нужен шедулинг.


Почему кохя не уважает размер ведра? Написал макс 960, а оно в 1024 вышло.
>аниме с аниме сцепились на почве тегирования и испортили всем выходные каждый раз одно и то же
дрочька на тегирование не имеет под собой новучных оснований судя по моим ресерчам и чужому опыту в инторнете, особенно если вы не тренируете те целенаправленно и не фулфайнтюните. Отличные результаты получаются хоть даже если вы на токен класса просто будете тренить на похуй, весь вопрос в том какое говно у вас на оптимайзере, алго лоры и ее настройки, какая функция лосса и какой батч с репитами (тут просто - чем больше батч+репиты тем больше сглаживается влияние всего остального говна в настройках).
мимо шел, тегирую джойкапшеном с натуральным дескриптивным описанием или тренирую на классовый токен когда лень ждать - разница нулевая в выходном продукте
дрочька на тегирование не имеет под собой новучных оснований судя по моим ресерчам и чужому опыту в инторнете, особенно если вы не тренируете те целенаправленно и не фулфайнтюните. Отличные результаты получаются хоть даже если вы на токен класса просто будете тренить на похуй, весь вопрос в том какое говно у вас на оптимайзере, алго лоры и ее настройки, какая функция лосса и какой батч с репитами (тут просто - чем больше батч+репиты тем больше сглаживается влияние всего остального говна в настройках).
мимо шел, тегирую джойкапшеном с натуральным дескриптивным описанием или тренирую на классовый токен когда лень ждать - разница нулевая в выходном продукте
Так оно ж по меньшей стороне букеты собирает.
Если ты один концепт тренишь на 10 пиках, то да, капшены не нужны. Но даже на одном концепте капшены позволят немного продвинуть финальный результат. Доводить стили до предела без капшенов у тебя не получится, модель просто станет генерить пики из датасета. В реалистике, например, плохо протеганые тянки - главная причина почему многие тюны имеют одно дженерик лицо на всех.
Алсо, всякие оптимизаторы и дроч настроек всегда вторичны, на первом месте датасет.
>Доводить стили до предела без капшенов у тебя не получится
Регулярно делаю так
>модель просто станет генерить пики из датасета
Не станет, чтобы генерить пики с датасета тебе надо агрессивные оверфитные настройки сделать, а это надо еще постараться чтобы лосс был меньше 0.05.
>В реалистике, например, плохо протеганые тянки - главная причина почему многие тюны имеют одно дженерик лицо на всех.
Фуловые тюны это другое, я ж написал. Если речь про тюны, то если это не что-то уровня бигаспа с несколько миллионов протегированных натурал языком и без тренинга те, то это и не тюн вообще а пирдйож в будку, а у бигаспа никаких проблем с вариети нет и никогда не было. А если у базовой модели нет проблем с вариети, то и лору над ней можно и на классовом токене натренить не теряя вариети, это же очевидно.
>всякие оптимизаторы и дроч настроек всегда вторичны, на первом месте датасет
Ну как это. Вот есть A/B структура классической, которая является модулем поверх и теряет структуру модели при неверных настройках, а есть OFT которые не теряют структуру модели вообще. Есть оптимайзеры которые сорт оф спарс лернинг фильтры на борту имеют, а есть кал мочи который не учитывает размер градиентов вообще. Дай мне любой говеный датасет - я сделаю из него генерализованную лору которая не теряет знаний основной модели, используя лишь классовый токен, BOFT и адафактор.
> Регулярно делаю так
Показать конечно же не сможешь, да?
Могу, но гораздо лучше если ты скинешь свой говеный датасет и я тебе прямо на нем покажу.
>спарс лернинг
Вообще, спарслернинг это про нейронки которые разреженную архитектуру имеют, так что лучше найди другой термин для этих шизофильтров твоих.
>спарслернинг это про нейронки которые разреженную архитектуру имеют
не обязательно, в данном случае мы имеем разряженные обновления
В контексте фильтров такой термин прямо не гуглится.
Посмотрел еще некоторые свежие доклады, так сберовцы хвастаются что они первыми закодили лора-адаптеры для своей мое-ллмки. Типа в опенсорсе нигде не лежит рабочего кода для лор на моешки.
Но это самая обычная дефолтная лора, еще и дохуя низкоранговая относительно размера модели.
Вообщем это все что надо знать о корпоратах. Не думаю что на западе ситуация сильно лучше.
Порномодели впереди планеты всей.
Но это самая обычная дефолтная лора, еще и дохуя низкоранговая относительно размера модели.
Вообщем это все что надо знать о корпоратах. Не думаю что на западе ситуация сильно лучше.
Порномодели впереди планеты всей.

> Типа в опенсорсе нигде не лежит рабочего кода для лор на моешки.
Они припизднутые? Peft любые модели поддерживает. Сам скрипт тренировки берём со скрипта претрейна нужной модели, просто впердолив peft в него, transformers давным давно поддерживают тренировку МоЕ. Даже стыдно за этих клоунов.
> нигде не лежит рабочего кода
Т.е. они подразумевают что нет прям готового скрипта для их конкретного МоЕ? Добавить peft-адаптер - это 5 строчек кода. Например, у меня в базе для лор SD был скрипт для полного файнтюна на diffusers, пикрил весь код для добавления лор, что мне пришлось добавить для сохранения весов в нужном формате надо попердолиться чуть, да. Они считают это каким-то достижением?
Имена персонажей в SD часто так же содержат стиль в котором он изображен. К примеру если ввести в промпт Pony 6, персонажа Pacifica Northwest стиль шоу Gravity Falls так же будет виден. Т.е. стиль будет более мультяшный.
Вопрос:
Хорошая ли эта идея включать в датасет лоры на стиль, имена персонажей? Логика "все познается в сравнении", модель увидит разницу стилей и быстрее поймет разницу.
Или имена принесут ассоциации со стилем шоу и заговнякуют лору?
Прошлый раз когда показал тэги, никто слова не сказал про то что у меня имена персонажей в датасете.
Вопрос:
Хорошая ли эта идея включать в датасет лоры на стиль, имена персонажей? Логика "все познается в сравнении", модель увидит разницу стилей и быстрее поймет разницу.
Или имена принесут ассоциации со стилем шоу и заговнякуют лору?
Прошлый раз когда показал тэги, никто слова не сказал про то что у меня имена персонажей в датасете.
Если бы ты тренировал большую модель, то ассоциации бы размывались из-за биг даты и было бы неважно используешь ли ты имена или нет, сеть бы успела "отвязаться" от текста и обобщить нормально.
Но ты тренируешь лору, поэтому ассоциации наоборот будут усиливаться вплоть до замещения оригинального обобщенного вижна параметров (или как эта хуйня называется в машинном обучении, когда сеть имеет обобщенное понятие, но не способна выделить главное из скрытых параметров из-за обобщения без явного на то указания) откуда вытекают:
1. catastrophic forgetting - вытеснение базовых весов новыми
2.shortcut learning - модель угадывает по самому лёгкому признаку (имени), а не изучает стиль
3. feature entanglement - признаки неразделимы, сливаются в один кластер
В идеале чтобы получить идеальную адаптацию надо соблюдать гайдлайн основной сети, где:
1. underspecified training objective, модель получает слишком общий сигнал и не может понять, что важно
2. entangled representation, где скрытые представления не декомпозированы на независимые факторы (стиль, персонаж, форма)
3. loss of factor disentanglement, модель не может отделить стиль от сорт оф идентичности
Первые да пункта реализуемы на лоре, третье только на биг дате.
SDXL была обучена на каскадных подписях из общие признаков, стилей, формы подачи, цветовой схемы, композа, иногда с указанием автора или какойнибудь вселенной типа комиксов марвел, но без имени (если это не условная топ актриса типа эммы уотсон).
Таким образом почти идеальное текстовое описание для сдхл для стиля будет в виде "a stylized cartoon illustration of a teenage girl with long blonde hair, wearing a purple jacket, in the style of 2010s Western animation, flat colors, clean outlines, bold shapes, Gravity Falls style, by Disney artists, full body, simple background".
Короче, если обобщать, то имена заражают собой стили и приводят к запутанным представлениям сети. Это с одной стороны хорошо, т.к. если у тебя задача генерировать по референсу - имя прописал и не паришься, но с другой стороны это не адаптация на стиль, а форсинг заучивания для повторения конкретных паттернов. В общем я бы не указывал именно имена персонажей, лучше бери суррогатные обозначения типа stylized girl, cartoon girl, или на крайний случай токены вызова.
Спасибо.

Как пофиксить эту йобу которая не даёт генерировать со скриптом для сравнения фоток?
Переписать конфликтные куски кода?

Здрасте. У меня айди адаптер не работает
счастливые обладатели серии Blackwell, подскажите, какой-нибудь софт работает? комфи, фордж? какие нужны версии драйвера, куды, торча, трансформерсов, вот это вот всё. не хочу терабайты говна перекачивать в поисках рабочей комбинации, и надеюсь, что кто-нибудь это до меня уже делал.
Весь обновившийся софт работает, полная поддержка начиная с торча 2.7 на куде 128. Еще в феврале было много багов связанных с обновлениями в торче, ошибок в либах, всякими особенностями, сейчас же все починили и есть готовые билды для всякого популярного.
напиши конкретные версии софта пж, я вчера с полудня до полуночи ебался с переустановками дров и куды, чтобы хотя бы ллама.цпп заработала, не хочу сегодня весь день тратить на то же самое для картинок.
у меня прыщеблядикс если что
а вот собственно почему ебался:
https://docs.nvidia.com/cuda/archive/12.8.1/cuda-installation-guide-linux/index.html#id47
https://forums.developer.nvidia.com/t/error-exception-specification-is-incompatible-for-cospi-sinpi-cospif-sinpif-with-glibc-2-41/323591?u=epk
для работы куды нужны конкретно эти указанные версии гцц и глибц, и если вы, например, обновите глибц до 2.41 или попытаетесь сконпелировать что-то с гцц14, то нихуя не заработает.
> glibc 2.41 is not supported for any version of CUDA at the moment. (e.g. CUDA 12.8)
теоретически в куде 12.9 это исправлено
https://docs.nvidia.com/cuda/archive/12.9.0/cuda-installation-guide-linux/index.html#host-compiler-support-policy
но я не хочу ставить самую свежую версию потому что приверженец стейбл релизов
а и ещё вспомнил, что делать если у вас гцц свежее 12:
NVCC_CCBIN=/usr/bin/g++-12 CMAKE_CUDA_HOST_COMPILER=/usr/bin/g++-12 CUDAHOSTCXX=/usr/bin/g++-12 CC=gcc-12 CXX=g++-12 cmake <тут опции cmake>
https://docs.nvidia.com/cuda/archive/12.8.1/cuda-installation-guide-linux/index.html#id47
https://forums.developer.nvidia.com/t/error-exception-specification-is-incompatible-for-cospi-sinpi-cospif-sinpif-with-glibc-2-41/323591?u=epk
для работы куды нужны конкретно эти указанные версии гцц и глибц, и если вы, например, обновите глибц до 2.41 или попытаетесь сконпелировать что-то с гцц14, то нихуя не заработает.
> glibc 2.41 is not supported for any version of CUDA at the moment. (e.g. CUDA 12.8)
теоретически в куде 12.9 это исправлено
https://docs.nvidia.com/cuda/archive/12.9.0/cuda-installation-guide-linux/index.html#host-compiler-support-policy
но я не хочу ставить самую свежую версию потому что приверженец стейбл релизов
а и ещё вспомнил, что делать если у вас гцц свежее 12:
NVCC_CCBIN=/usr/bin/g++-12 CMAKE_CUDA_HOST_COMPILER=/usr/bin/g++-12 CUDAHOSTCXX=/usr/bin/g++-12 CC=gcc-12 CXX=g++-12 cmake <тут опции cmake>
вот это работает для ComfyUI версии 0.3.40:
ставиш python3.13
создаёш python3.13 -m venv ./
выполняеш ./bin/activate
устанавливаеш не торч а дунул сладко
./bin/pip3.13 install --pre torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128
./bin/pip3.13 install numpy packaging pybind11 setuptools
качаеш и компиляеш свежий SageAttention (якобы даёт ускорение без потери качества)
wget https://github.com/woct0rdho/SageAttention/archive/refs/heads/main.zip -O sageattention.zip
unzip sageattention.zip
cd SageAttention-main/
../bin/pip3.13 install --no-build-isolation .
и после этого устанавливаеш оставшиеся зависимости комфи
cd ../
./bin/pip3.13 install -r ComfyUI/requirements.txt
запускаеш комфи
cd ComfyUI
../bin/python3.13 main.py --use-sage-attention
дрочиш
самое главное забыл
ставиш open драйвер невидии С ИХ САЙТА, А НЕ ИЗ РЕПОЗИТОРИЯ ТВОЕГО ДИСТРИБУТИВА!!11, версия минимум 575.51.02
ставиш куду 12.8.1
> напиши конкретные версии софта пж
A1111/форж/классик если вручную накатить торч 2.7, рефордж если выкинуть его кривые билды и просто скачать дефолтный хформерс, комфи, эксллама в составе табби/убабуги, компиляция llamacpp с дефолтными параметрами для куды, трейнеры на трансформерсе, дифьюзерсе или просто самописные, включая кохью.
> до полуночи ебался с переустановками дров и куды
Могут быть нюансы если у тебя старая система, но у хунга там указаны зависимости. На их сайте где скачивание куда-тулкита выбери свою ось, онлайн пакет, добавь их репозиторий и введи команду через твой мереджер пакетов. На убунту/доебане работает окей.
Да, могут быть приколы если не прописана CUDA_HOME и LD_LIBRARY_PATH до куды и оно не может ее найти.
> не хочу сегодня весь день тратить на то же самое для картинок
Там скачиваются готовые билды под конкретный торч, только если сам пердоля и хочешь какие-нибудь найтли версии собрать то можешь заняться.
Лучше напиши конкретную ошибку если что-то не получается, так проще будет разрешить.
> Могут быть нюансы если у тебя старая система, но у хунга там указаны зависимости.
потому и ебался, смотри ссылки выше.
> добавь их репозиторий и введи команду через твой мереджер пакетов. На убунту/доебане работает окей.
у меня на доебане не работает, сработала установка одного большого файла .run и для куды, и для драйверов
а конкретно вот этих:
cuda_12.8.0_570.86.10_linux.run
NVIDIA-Linux-x86_64-575.51.02.run
> Там скачиваются готовые билды под конкретный торч,
где "там"? у комфи, например, в requirements.txt просто написано torch, а не конкретная версия.
> .run
Это оче плохая идея ибо оно будет ставиться в игнор зависимостей и может наломать дров, там прямо об этом и указано. У них пакеты для доебанов присутствуют, почему не хочешь поставить с репозиториев?
> у комфи, например, в requirements.txt просто написано torch, а не конкретная версия
Глянь инструкцию в репе, перед тем как ставить реквайрментсы нужно зайти на сайт торча и скопировать команду на конкретный, в твоем случае просто
> pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
а потом уже реквайрментсы. Сейчас xformers уже собранный в репах как раз под торч 2.7 должен быть
> почему не хочешь поставить с репозиториев?
потому что я вчера весь день этим занимался и нихуя не работало, ни из дебиановских реп, ни из нвидиевской, помогло только удаление всего нвидиевского говна из реп и установка через .run
bump
>Хорошая ли эта идея включать в датасет лоры на стиль, имена персонажей?
Из опыта юза тегов могу сказать, что если задача сложная, а модель тупая, (что почти всегда так) то она проассоциирует концепт со всеми тегами, и потом его трудно будет точно триггернуть не используя их все / большую часть.
Если персонажи разные, то может прокатит, если много повторяется - будут проблемы.
Думай сам, что с этим делать, лучше всего сделай 2 варианта и сравни результат на практике. Нету правильных рецептов.
Какая же конченная анстейбл штука эти конволюшены в сдхл. Чучуть пережал - все по пизде идет. Чучуть недожал - ну ты кароч пожри шума. И не только лор касается, если тренить линейные полностью полноценно то все тип топ, ток начинаешь тренить вообще всё - говно в жопу заливается гигантскими масштабами. Из-за ублюдских конволюшнов кстати поэтому массивные файнтюны нестабильные, типа бигаспа, которому если надрочить линейные поверх дополнительно на любом датасете, то он сразу становится шелковый и покладистый с ебическим качеством на каждом сиде. А еще конволюшены по факту зависят от интерпетаций вае, то если если вае всратый (а он всратый, нет идеальных вае), то тоже пизда наступает. Кароче поцоны, не тренируйте конволюшены, оно вам не нужно.
А еще наверно единственный управляемый результат с конвами у меня был когда я тренил их отдельно с отдельными настройками. Тогда да, еще можно пользоваться. Но если вместе с линейными, то я того маму рот ебал.
Даже блять нормы проще натренировать чем конвы. У сука накипело простите.
>конволюшены
А может просто как обычно накинуть моментума х10-х100? Мне кажется, чтобы они не пытались переобучаться под узкий набор данных заместо линейных слоев, им нужно хорошенько фильтрануть сигнал.
Еще с первыми конвами и может последними, которые напрямую с вае работают, надо как-то отдельно, либо их вообще не трогать, либо аккуратно с еще большим моментумом.
Ты в целом прав, но моментумы точно не помогут. Тут архитектурная проблема, что конвы
а) составляют большую часть сети
б) очень быстро переполняются
в) нестабильны на малой дате
То есть ядро задачи в том, чтобы сохранить структуру конволюшенов от разрушения малой датой, а в это умеет только OFT (не разрушать структуру) и частично модуль подсказок gLORA, надо попробовать одновременно тренить конвы с помощью OFT чтобы сохранять их структуру (плюсом дополнительно не нужно указывать альфа коэффициент, потому что его тоже хуй нормально подберешь для конволюшнов) и при этом тренить линейные любым другим вариантом, хоть теми же лорой/локром/лохой, т.к. там разряженность похожая на файнтюн при использовании доры достигается.
Попробую подрочить именно такой вариант, спасибо за подсказку.


Я не наблюдаю никаких проблем с ними на обычных лорах с рангом 64-128, они как раз позволяют текстуру дотюнить. Без тренировки конволюшенов сложно прям мелкие детали довести до идеала. Алсо, если ты пользуешься ликорисом, то там какая-то отдельная пердольная реализация для конволюшенов, я когда его пробовал тоже проблевался как хуёво тренится всё. У peft она одинаковая для линейных и конволюшенов, никаких проблем нет.
> составляют большую часть сети
У SDXL их очень мало, примерно в 8 раз меньше линейных слоёв.
> переполняются
На это альфа сильно влияет. Если альфа как ранг или больше, то под конец тренировка просто останавливается без перетрена. Пикрил фиксированый lr 1е-4, можно хоть 10к шагов сделать, результат не изменится.

>У SDXL их очень мало, примерно в 8 раз меньше линейных слоёв.
Смотря что ты считаешь за чистые конвы. По паперу сдхл к каждому линейному блоку приделан конв блок, итого получается ResnetBlock2D, Downsample2D, Upsample2D, conv in, conv out, это где-то 75% сети получается чисто свертки (если не прям все брать то где-то половина сети наберется, что соотвествует стандартной практике соотношения 2:1 по дименшенам тренировки лоры), все желтое на пикче это конвы.
>Я не наблюдаю никаких проблем с ними на обычных лорах с рангом 64-128, они как раз позволяют текстуру дотюнить.
Зависит от задач, судя по твоим пикчам у тебя ван стендинг герл с обмазом стилем, это референтный тренинг, я таким не занимаюсь. Если у тебя разноплановый концептный датасет с соответствующим описанием - тут конвы обсираются из-за ренжа применения и переполнения малым количеством данных.
>Алсо, если ты пользуешься ликорисом, то там какая-то отдельная пердольная реализация для конволюшенов
locon просто в качестве таргета все конвы указывает вместе с лин блоками, там ничего пердольного нет
>На это альфа сильно влияет.
Альфа супрессия в основном нужна когда у тебя лимитера на градиентах нет или надо стабилизировать (а равно удлинить) тренировку, вот ты допустим тренишь 1e4, с половинной альфы эффект супрессии добавленных весов будет как будто ты тренил на 5e5 с эффективностью 1e4, я обычно 1 к 1 треню потому что мне надо фуловые градиенты как будто я фулфайнтюню. На сам эффект переполнения альфа не влияет, оно точно также будет бесоебить хоть 128 к 1 ставь из-за малой даты.

> к каждому линейному блоку приделан конв блок
Я напиздел, там ещё больше разница из-за того что есть блоки без реснета. И там не конволюшен к линейному блоку приделан, у тебя же на картинке написано. Приделан реснет блок, в котором 6 конволюшенов, против 46 линейных слоёв в трансформере.
> конвы обсираются из-за ренжа применения
Датасет и применение не при чём тут. Я тебе показал это для примера что оверфит выдуманная хуйня, но на нормальных датасетах с кучей концептов у меня всё так же.
> locon просто в качестве таргета все конвы указывает вместе с лин блоками
У них разные реализации модулей лоры. Как я понял ты всё же на нём сидишь. Поэтому у тебя и проблемы.
> фуловые градиенты как будто я фулфайнтюню
Какая-то каша у тебя в голове. Лора от файнтюна только рангом отличается, а альфа на градиенты никак не влияет, это коэффициент обновления весов, на который потом при инференсе ещё домножаются веса.
> эффект переполнения
Веса не могут увеличиваться бесконтрольно и данные на это никак не влияют, влияет алгоритм обновления весов.
Бля лень спорить, у меня нет времени на это.
Хз о чем вы спорите, с аргументами "у меня что-то там когда-то как-то работало а по-другому не работало" с 0 статистической ценности из-за кучи побочных факторов, и на этом строится вся дальнейшая аргументация и какие-то выводы. Че там с градиентами, дисперсиями, где какие фактические скорости обучения, особенно на обратных связях от дисперсии у адама, где он стабилизируется на своих дефолтных значениях в каком-нибудь блоке на одном уровне, и пока ты все остальное под уровень не подгонишь, все будет в разнобой учиться. А этих уровней может быть несколько, и они не подгонятся никогда... Потом еще моченые удивляются типа че это на их свертках адам посасывает у простого сгд. Все это конечно же никто не проверял. В одной и самых ебанутых нейронок с точки зрения разнородности уровней и блоков.
В общем как обычно кидаясь умными терминами и строя из себя неебаться экспертов два долбоеба пытаются выяснить кто из-них больший долбоеб. Кхэм, так, куда это меня опять понесло...
Сколько там параметров в свертках, поебать вообще. От того что их мало, пидорасить сеть при их неправильном обучении они меньше не будут. Нормализации, биасы, так вообще вносят основной вклад в разнос, если их криво учить, а сколько там у них параметров в процентах? Ну и вспомним историю с клипскипом сюда же. Если не умеем учить сильно отличающиеся параметры, они разъебутся. Если не будим их учить, сетка может и не разъебется, но найдет куда размазать сдвиги, и это хоть и будет работать, но хуже, ибо нахуя нам вообще тогда нормализации? Повезло кому-то что разъебался только последний слой, превратил после себя градиент немного в кашу, там может адам дальше придушил все это непотребство и с отрезанным слоем оно как-то потом работало.
>а альфа на градиенты никак не влияет, это коэффициент обновления весов, на который потом при инференсе ещё домножаются веса.
Нет, альфа это напрямую множитель в разрезе потока активаций/градиентов. Можно представить его как множитель весов, инициализации, но не величины обновлений. Это уже косвенный эффект. Просто зажать лр даст очевидно другой эффект.
Так, а написать я изначально хотел про то, что я чет прочитал про ConvNeXt свертки вместо реснетов. Сначала я их не понял, а потом как понял... Хотя знал же что такое depthwise, но потом забыл.
Короче в юнете обычные реснеты, а в каскаде уже сделали эти самые ConvNeXt, но правда только в латентном блоке. Видимо чисто в пикселях они может как-то хуевее работают. Но логика у них интересная. Там вообще нет этих ебучих гиперпространственных сверток. Отдельная большая свертка на каждый канал, чисто одноканальная, и отдельно потом единичные свертки, как обычная mlp-вставка "попиксельная". Типа свертка работает как пространственное внимание, а единичная как внимание к "памяти" модели. Ну вот эта интерпретация из трансформеров.
А в реснетах вся эта хуйня смешивается в одну свертку, которую не разделить, не оптимизировать, и на ней даже адам начинает сосать, ибо по отдельным параметрам эти 2 функции которые взяла на себя свертка не делятся.
Соответственно и натянуть лору на ConvNeXt было бы как нехуй делать, все бы работало сразу заебись.
В общем как обычно кидаясь умными терминами и строя из себя неебаться экспертов два долбоеба пытаются выяснить кто из-них больший долбоеб. Кхэм, так, куда это меня опять понесло...
Сколько там параметров в свертках, поебать вообще. От того что их мало, пидорасить сеть при их неправильном обучении они меньше не будут. Нормализации, биасы, так вообще вносят основной вклад в разнос, если их криво учить, а сколько там у них параметров в процентах? Ну и вспомним историю с клипскипом сюда же. Если не умеем учить сильно отличающиеся параметры, они разъебутся. Если не будим их учить, сетка может и не разъебется, но найдет куда размазать сдвиги, и это хоть и будет работать, но хуже, ибо нахуя нам вообще тогда нормализации? Повезло кому-то что разъебался только последний слой, превратил после себя градиент немного в кашу, там может адам дальше придушил все это непотребство и с отрезанным слоем оно как-то потом работало.
>а альфа на градиенты никак не влияет, это коэффициент обновления весов, на который потом при инференсе ещё домножаются веса.
Нет, альфа это напрямую множитель в разрезе потока активаций/градиентов. Можно представить его как множитель весов, инициализации, но не величины обновлений. Это уже косвенный эффект. Просто зажать лр даст очевидно другой эффект.
Так, а написать я изначально хотел про то, что я чет прочитал про ConvNeXt свертки вместо реснетов. Сначала я их не понял, а потом как понял... Хотя знал же что такое depthwise, но потом забыл.
Короче в юнете обычные реснеты, а в каскаде уже сделали эти самые ConvNeXt, но правда только в латентном блоке. Видимо чисто в пикселях они может как-то хуевее работают. Но логика у них интересная. Там вообще нет этих ебучих гиперпространственных сверток. Отдельная большая свертка на каждый канал, чисто одноканальная, и отдельно потом единичные свертки, как обычная mlp-вставка "попиксельная". Типа свертка работает как пространственное внимание, а единичная как внимание к "памяти" модели. Ну вот эта интерпретация из трансформеров.
А в реснетах вся эта хуйня смешивается в одну свертку, которую не разделить, не оптимизировать, и на ней даже адам начинает сосать, ибо по отдельным параметрам эти 2 функции которые взяла на себя свертка не делятся.
Соответственно и натянуть лору на ConvNeXt было бы как нехуй делать, все бы работало сразу заебись.
не читал чсвшную хуйню
В чем может быть проблема, если я сделал чекпоинт из двух чекпоинтов обычным адд диффом, но тренируя на этом чекпоинте я получаю лору которая учит признаки, но изображение генерируется в латентной дымке всегда, то есть не собирается полностью, и единственный вариант заставить лору работать это добавить к ней базовый лора экстракшон из второй модели, которая была примешана к основной?
А ебать разобрался, оказывается в моем случае латентные представления сжимаются в новой модели и данные лоры просто недостаточно сильные чтобы менять такой концентрированный латент, нужно обучать на изначальной модели и применять поверх мерджа, тогда работает.
подскажите современный софт для тренировки лор, совместимый с blackwell (50хх) и прыщеблядиксом.
в мануалах советуют https://github.com/kohya-ss/sd-scripts который заточен под cuda 11.8 и торч 2.4 а blackwell нужна куда 12.8 минимум, и торч 2.7
в мануалах советуют https://github.com/kohya-ss/sd-scripts который заточен под cuda 11.8 и торч 2.4 а blackwell нужна куда 12.8 минимум, и торч 2.7
и поясните вкрации что такое ControlNet и нахуя оно надо
увидел в шапке ссылку, вопрос снимается.
Вручную просто в венве обнови на новую куду и торч
у меня последняя куда и последний торч, все работает
ок, спасибо. я прост в issues увидел https://github.com/kohya-ss/sd-scripts/issues/2119 и подумал, что ни с чем другим кроме 2.4 оно не работает.
возможно у того чела с 2.7 просто руки кривые
>возможно у того чела с 2.7 просто руки кривые
так и есть, он даже фулл лог не скинул чтобы посмотреть точно где у него обосрамс, типа как я должен понять где чекать его въеб? может он какойнибудь хубер в качестве лосса на сд3 ветке юзает и там в коде строчку поправить нужно как тут например https://github.com/kohya-ss/sd-scripts/issues/2102
Как вмерджить локон в чекпоинт? Тулза в кохии выдает ошибку, а если через супермерджер то есть различия
https://github.com/zhang0jhon/diffusion-4k
Годнота подъехала, loss с декомпозицией на частоты. Потестил с раздельными уровнями на XL, намного лучше mse тренится. Можно ставить веса для для разных частот, например тренить только на мелких деталях, а низкие частоты выкидывать.
Годнота подъехала, loss с декомпозицией на частоты. Потестил с раздельными уровнями на XL, намного лучше mse тренится. Можно ставить веса для для разных частот, например тренить только на мелких деталях, а низкие частоты выкидывать.
>Как вмерджить локон в чекпоинт?
Просто в комфи последовательно нода чекпоинта + нода лоры + нода сейв чекпоинт. Или тебе что-то особенное?
Я ошибся, не дождался когда мердж в супермерджере закончится, и чекпонинт с названием который сохранялся уже был, поэтому подумал что отличия были. Сейчас всё норм
Тред умер?
нет
да
Про что там хоть?
тренировка контекстной лоры через флух контекст, нужно 24 гига врама
>нужно 24 гига врама
Понятно, проходим мимо.
Аноны, может вопрос конечно не рилейтед, но ИТТ самые прошаренные аноны тусуются со всей доски, где ещё спрашивать то как не тут.
Какие есть варианты для определения размеров тела по фотографии? Грудь, талия, бедра. Есть модели для этого? Софт какой-то? Может какие-то танцы с бубном чтобы такое провернуть?
Какие есть варианты для определения размеров тела по фотографии? Грудь, талия, бедра. Есть модели для этого? Софт какой-то? Может какие-то танцы с бубном чтобы такое провернуть?
ну наверно самый точный это перевод изображения в 3д модельку с сегментацией и уже с нее брать размеры натуральные
ну или тупо опенпозы всякие юзать чтобы получать физически корректный скелет по точкам и уже на основе них расчитывать размеры с переводом в реальный масштаб
софта и библ под это дело тонна
в качестве примера вот такая олдовая залупа https://github.com/vchoutas/smplify-x , или сегментатор https://github.com/facebookresearch/detectron2 с модулем денспоз, или такое https://github.com/nkolot/graphcmr
уверен что есть более продвинутый современный софт конкретно под твою задачу, надо просто поискать
SingLoRA: Low Rank Adaptation Using a Single Matrix
SingLoRA: Низкоранговая адаптация на основе одной матрицы
https://www.alphaxiv.org/ru/overview/2507.05566v1
SingLoRA предлагает симметричное низкоранговое обновление (AAᵀ) с использованием одной обучаемой матрицы (A) вместо двух, что приводит к более стабильной динамике обучения и превосходной производительности.
Этот подход сокращает количество обучаемых параметров до 50% по сравнению с традиционными вариантами LoRA, при этом достигая более высокой точности на бенчмарках.
SingLoRA: Низкоранговая адаптация на основе одной матрицы
https://www.alphaxiv.org/ru/overview/2507.05566v1
SingLoRA предлагает симметричное низкоранговое обновление (AAᵀ) с использованием одной обучаемой матрицы (A) вместо двух, что приводит к более стабильной динамике обучения и превосходной производительности.
Этот подход сокращает количество обучаемых параметров до 50% по сравнению с традиционными вариантами LoRA, при этом достигая более высокой точности на бенчмарках.
Перекат
ну хуй знает, стабильнее то да, но это все равно одна дополнительная матрица к модели, то есть просто дрифтинг циферок выхода без изменения самих замороженных весов модели
меня собсно поэтому настройка лоры/локра/лохи заебала и я перекатился на аналоговнетный OFT которому чисто поебать на всю дрочку с гиперпараметрами - веса декомпознулись в нужное количество блоков и обучается, никаких альф нет, количество блоков на усмотрение твоей карты, прямая зависимость блоков конв от линейных отсутствует (так как симулирует работу с весами), заместо альфы нелинейный констрейнт параметр, которым можно регулировать длину вектора влияния на веса + включать рескейл слой на каждый выходной канал отдельно который позволяет независимо ослаблять или наоборот повышать влияние каждого отдельного канала на усмотрение сети
Выглядит как хуйня, с таким же успехом можно тренить только первую матрицу обычной лоры, а вторую постепенно увеличивать. Получишь по итогу неконтролируемый оверфит. Вторая матрица и нужна чтобы адаптивные скейлы весов были, а не тупа в конце к 1 прийти.



Предыдущий тред:
➤ Софт для обучения
https://github.com/kohya-ss/sd-scripts
Набор скриптов для тренировки, используется под капотом в большей части готовых GUI и прочих скриптах.
Для удобства запуска можно использовать дополнительные скрипты в целях передачи параметров, например: https://rentry.org/simple_kohya_ss
https://github.com/bghira/SimpleTuner Линукс онли, бэк отличается от сд-скриптс
https://github.com/Nerogar/OneTrainer Фич меньше, чем в сд-скриптс, бэк тоже свой
➤ GUI-обёртки для sd-scripts
https://github.com/bmaltais/kohya_ss
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
➤ Обучение SDXL
https://2ch-ai.gitgud.site/wiki/tech/sdxl/
➤ Flux
https://2ch-ai.gitgud.site/wiki/nai/models/flux/
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам:
https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA
https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге:
https://github.com/KohakuBlueleaf/LyCORIS
Подробнее про алгоритмы в вики https://2ch-ai.gitgud.site/wiki/tech/lycoris/
✱ Dreambooth – для SD 1.5 обучение доступно начиная с 16 GB VRAM. Ни одна из потребительских карт не осилит тренировку будки для SDXL. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://rentry.co/lycoris-and-lora-from-dreambooth (англ.)
https://github.com/nitrosocke/dreambooth-training-guide (англ.) https://rentry.org/lora-is-not-a-finetune (англ.)
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet:
https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer:
YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
Подробнее в вики: https://2ch-ai.gitgud.site/wiki/tech/yolo/
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb
➤ Полезное
Расширение для фикса CLIP модели, изменения её точности в один клик и более продвинутых вещей, по типу замены клипа на кастомный: https://github.com/arenasys/stable-diffusion-webui-model-toolkit
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайд по ControlNet: https://stable-diffusion-art.com/controlnet (англ.)
Подборка мокрописек для датасетов от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
NLP тэггер для кэпшенов T5: https://github.com/2dameneko/ide-cap-chan (gui), https://huggingface.co/Minthy/ToriiGate-v0.3 (модель), https://huggingface.co/2dameneko/ToriiGate-v0.3-nf4/tree/main (квант для врамлетов)
Оптимайзеры: https://2ch-ai.gitgud.site/wiki/tech/optimizers/
Визуализация работы разных оптимайзеров: https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
https://rentry.org/2ch_nai_guide#апскейл
https://rentry.org/UpscaleByControl
Старая коллекция лор от анонов: https://rentry.org/2chAI_LoRA
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdgoldmine
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/badhands/makesomefuckingporn
https://rentry.org/ponyxl_loras_n_stuff - пони лоры
https://rentry.org/illustrious_loras_n_stuff - люстролоры
➤ Legacy ссылки на устаревшие технологии и гайды с дополнительной информацией
https://2ch-ai.gitgud.site/wiki/tech/legacy/
➤ Прошлые треды
https://2ch-ai.gitgud.site/wiki/tech/old_threads/
Шапка: https://2ch-ai.gitgud.site/wiki/tech/tech-shapka/