


Первый бенчик. Банана выебала всех в рот своим бананом https://yupp.ai/leaderboard/explore
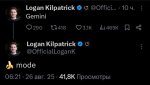
Банану начали потихоньку раскатывать, на сайте Gemini очень жёсткая цензура на редактирование, потому лучше в Ai Studio (там и цензуры меньше, и качество фото и того, как модель редактирует, будет лучше, как обычно). Уже известно, что Nano-banana это мелкая и шустрая Gemini 2.5 Flash. Значит остаётся пространство для роста качества в Gemini 3
Сколько токенов примерно требуется на генерацию изображения бы знать, чтобы знать примерную цену одной пикчи
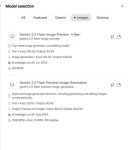
Появились результаты на арене. Ожидаемо Банана и там всех выебала в рот с огромным отрывом. А ещё оказалось, что она на первом месте не только в редактировании изображении, но и в Text-to-Image, хотя тут отрыв совсем небольшой.
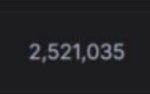
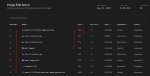
Обратите внимание на количество голосов! Рекорд. Имджинируйте сколько денег гугл спустила только на один лишь тест
В AI Studio доступно бесплатно, но нужно быть на территории США и некоторых других стран. Ну вы поняли
>Имджинируйте сколько денег гугл спустила
Пару тысяч долларов на электричество максимум, это же их модели
На арене доступно бесплатно две недели уже, но не нужно быть долбоебом.
Аукцион невиданной щедрости от арены продолжается! Нано-банану раздают бесплатно и без обходов в прямом чате (не в батле). Заходим и спокойно пользуемся сколько угодно без мозгоебли: https://lmarena.ai/?mode=direct&chat-modality=image
На арене только что она появилась бесплатно, а до этого была лишь в режиме батла.
>На арене только что она появилась бесплатно, а до этого была лишь в режиме батла.
И чё нахуй? Там с ней каждый пятый батл. И цензуры на ввод вообще нет.
> Заходим и спокойно пользуемся
Её скот быстро положит и врубят лимиты, как там бывало уже не раз. Нах ты это тут написал непонятно.
Чел, об этом лайфхаке уже весь тг кричит. Два с половиной шиза с двача погоду не сделают
Я такие руки видел в фильме together 2025.
>уже весь
Значит ебланы опять арену положат. Не стоит к эттому еще 2-3 добавлять. А тут в рид онли много больше и дроч.хк в отличии от тг индексируется. А то так тебе еще и ркн сверху накинут, там как раз двачеры работают.
Ты гей?
картиночки никому не нужны
это все детский сад и плато

Единственная Ахиллесова пята бананы - стилизация
У вас тут ваще кто-нить че-нить постит кроме бананашизика?
мммм +10%
ПРОРЫВ!

что значит стилизация в контексте ии?
А сегодня есть ещё какие-то новости?
Такого прироста метрик мы возможно уже не больше увидим на текущих архитектурах
Больше не увидим*
МОСКВА, 21 авг - РИА Новости. Внедрение искусственного интеллекта в систему образования обсудили на форуме педагогов Подмосковья, сообщает пресс-служба губернатора и правительства региона.
Мероприятие проходит каждый август в Доме правительства Московской области в преддверии нового учебного года. Обсуждаются приоритетные направления развития системы образования, ключевые задачи на предстоящий учебный год, участники делятся своим опытом и наиболее успешными практиками.
Центральным событием форума является пленарная сессия "Образование будущего: тренды, инновации, ИИ". Ее открыли губернатор региона Андрей Воробьев и президент, председатель правления Сбербанка Герман Греф.
"Традиционно наше мероприятие является знаковым предвестником очередного учебного года. Мы собираемся в таком представительном составе, чтобы еще раз и слова благодарности всем учителям сказать, и подчеркнуть, что для нас образование имеет большое значение. Особенно важно, когда каждый учитель не устает учиться сам, когда все новое, умное, находит место в наших школах, а их у нас больше 1,5 тысячи. В этом году в Подмосковье пойдут на учебу 1 миллион 110 тысяч детей. Мы знаем, что после девятого класса около половины ребят выбирают колледжи, поэтому очень важно их модернизировать, что мы и делаем", - сказал Воробьев, его слова приводит пресс-служба.
Он добавил, что педагогический форум отличается от предыдущих тем, что сейчас большое значение приобретает ИИ. Губернатор также выразил благодарность Грефу и всей команде Сбера за предложения в профессиональном образовании и в государственном управлении.
Греф в своем выступлении рассказал о внедрении ИИ, в том числе в систему образования в соответствии с задачами нацпроекта "Экономика данных".
Так, благодаря соглашению, подписанному правительством Московской области и Сбером, у подмосковных педагогов появится цифровой помощник. В настоящее время уже 250 учителей из 20 школ в Дмитрове и Лобне протестировали "Ассистента преподавателя" на основе генеративного ИИ. Он работает как методист и помогает за несколько минут подготовиться к уроку, создает персональные задания под каждого ученика, дает рекомендации и даже работает как психолог.
С сентября к проекту подключатся 407 школ в Подмосковье и более 3 тысяч учителей. А Московская область сейчас занимается собственной разработкой – "Умный помощник учителю". Он будет проверять рукописные тексты, находить ошибки, рекомендовать какую оценку нужно поставить. Если раньше на проверку тетрадей у педагога уходило около трех часов, то с помощью искусственного интеллекта будет в шесть раз меньше.
На форуме организована работа 14 тематических панельных площадок. Помимо искусственного интеллекта в числе ключевых тем – цифровизация, профориентация школьников, поддержка талантливых учеников, повышение качества математического и естественно-научного образования, роль современных технологий.
Сейчас в системе образовании Подмосковья в "цифру" переведены уже 19 услуг – запись в детсад, школу, колледж, кружки, электронный дневник, электронные договоры на услуги допобразования и многое другое.
>Он будет проверять рукописные тексты, находить ошибки, рекомендовать какую оценку нужно поставить.
Ебала детей сгенерировали, когда он им двоек нахуярит за нераспозноваемый текст? Теперь будут как в сша печатными буквами писать, скриньте.
Я как тестер скажу вам Банана->imagen4->seadream 3.0 или как его ->qwen edit... чтото там ->gpt 1(удивительно, но это совсем хуево умеет в пропорции, но стилизация заебись)
Нет. А там что про гейство в фильме?
Блять.
У них врачей в стране нет, медсестрами заменяют, они хуйню какую-то обсуждают, лишь собраться бюджетные деньги проебать.
Фильм буквально про трансгендеров.
Контекст лучше наны бананы, просто он тренирован на худшем разрешении. Когда с лица генеришь в контексте получаются пусть и менее точные по промпту но более естественные пропорции и вся хуйня. А это стоковый кал:
Учителей тоже нет, а работа там обезьянья. Если учитель в 6 раз будет быстрей проверять, ему можно за ту же зарплату в 6 раз больше работы навалить, смекаешь? Они там по сравнению с совковыми и так по 3-4 ставки за одну зарплятку работают.
>стоковый кал
это да, но мне понравилось, что исходная картинка не изменилась - добавилась только надпись.
Ого! В 2025 корпы изобрели инпейнт!



ААААА РВЁТ ВСЕ БЕНЧИКИ11111 АААА!1111
Да, у нейробананопетуха впереди трудная ночь.
Да, у нейробананопетуха впереди трудная ночь.



А как он тут вчера весело кукарекал про русик?
>Я как тестер скажу вам Банана->imagen4->seadream 3.0 или как его ->qwen edit... чтото там ->gpt 1
Иди штаны стирай, тостер.
>Я как тестер скажу вам Банана->imagen4->seadream 3.0 или как его ->qwen edit... чтото там ->gpt 1
Иди штаны стирай, тостер.
Перестал запускаться ai studio((
со всех впн попробовал уже((
и со своего впс тоже палят
со всех впн попробовал уже((
и со своего впс тоже палят

me talking to an LLM
>swipe credit card for 200$
>turn on max reasoning mode
>write "hello"
>model thinks for 30 minutes
>50 h100s light up
>30 gallons of water consumed in cooling
>3 children in africa die of thirst
>"Hey! What do you need help with?"
>swipe credit card for 200$
>turn on max reasoning mode
>write "hello"
>model thinks for 30 minutes
>50 h100s light up
>30 gallons of water consumed in cooling
>3 children in africa die of thirst
>"Hey! What do you need help with?"
аноны дайте название вдс который гугл не будет палить и все будет работать
пока не палит hosthatch.com
Вроде работает.
Там обновили селектор моделек. Теперь какая-то ебала на полстраницы вместо старого. Может поэтому у тебя не грузит.

Что-то не нашёл. Уже прикрыли получается?
250 кг
А, до меня дошло
Как же ему тяжело, помогите ему че стоят снимают
Пиздец будет, когда оно скопытится и все 250кг кому-то на ногу.
Че сказать-то хотел, нейропетух? 70% винрейт на арене тебе напихали за щеку. Проверяй
Учишься такой всю жизнь, чтобы работать с другими, кто так же положил на это свою жизнь, потом впрягаешься в лямочку, боясь оказаться хоть чуточку менее полезным, чем тысяча желающих занять твоё место, спустя долгие годы радуешся некоторому прогрессу, но должен всё проверить, выяснить — а удержишься ли ты на плаву среди других, с кем соревнуешься, чей хребет не сломается от ещё пары задачек, выкладываешь толпе оглоедов, уже приготовившихся #апсирать...
Оказывается это ничего не стоит! Ну, эллектиричества, максимум.
Социалюги. Социалюги никогда не меняются.
>чтобы работать с другими
Ошибка. Никаких других вокруг нет.
Вернее есть, но каждый сам за себя.
Тебя учат работать в социуме, потому что социальное животное легче загнать в стойло.
Дальше сам думай.
Мамкин цинек? Ясно-понятно. Бабульку-то ебёшь?
Шахматные пешки страшные враги на поле.
А вот те, кто их двигают, зачастую лучшие друзья.
У тебя вон очередной говноменеджер РКК банкротить собирается.
15 лет станки не меняли. Меняли менеджеров как гандоны, раз в два года. Но это всё циники виноваты, разумеется.
> Шахматные пешки страшные враги на поле.
> А вот те, кто их двигают, зачастую лучшие друзья.
красива сказано
Ахуели ваще! У нас тут тоже Петрович пришёл в поликлинику, а ему говорят: «Маленькие по три, большие по пять!» Ну он их стал натягивать, ну, те, которые по пять, а тут звонит завкомбината, вы, говорит, ждите — в след вторник подвезут. А Петровичу куда деваться? Так оставишь — засохней хуй оторвёшь, а взад — уже втулка разъёбана!
А где на лм арене вообще image editing?
>Теперь будут как в сша печатными буквами писать, скриньте.
"- Если раньше на проверку тетрадей у педагога уходило около трех часов" -
а зачем в наших школах в СНГ учат писать закорючками? Не пойму, почему нельзя детей сразу учить писать по-нормальному чтобы было понятно и людям и системам распознавания? И тем же самым учителям, которые учат детей.
Вот наконец-то реальное полезное применение роботов в деле.
в директ чате, закидываешь пикчу и просишь модель отредачить
Угомонись, дегненерат.
39$ за тысячу картинок. Но это не считая входных токенов, так что в итоге будет получаться немного дороже.
Для сравнения Flux.1 Context Max, который сильно проигрывает на арене, стоит $80 за 1000 картинок.

Когда деньги решают не всё: по информации wired, как минимум три человека уже успели покинуть META Superintelligence Team. Двое из них вернулись в OpenAI 🤗 — менее чем через месяц после ухода.
Совсем недавно в Твиттере один из других членов команды писал (https://x.com/giffmana/status/1957155168417378687 ), что он и двое его коллег на данный момент запускают эксперименты на сервере с шестью видеокарточками — потому что ждут, пока им дадут все доступы/утрясут организационные вопросы/итд 🙂 вот это я понимаю ОРГАНИЗАЦИЯ
https://www.wired.com/story/researchers-leave-meta-superintelligence-labs-openai/
Совсем недавно в Твиттере один из других членов команды писал (https://x.com/giffmana/status/1957155168417378687 ), что он и двое его коллег на данный момент запускают эксперименты на сервере с шестью видеокарточками — потому что ждут, пока им дадут все доступы/утрясут организационные вопросы/итд 🙂 вот это я понимаю ОРГАНИЗАЦИЯ
https://www.wired.com/story/researchers-leave-meta-superintelligence-labs-openai/

NousResearch выпустили новую модель, на которую в целом во многом побоку, но вместе с ней выпустили RefusalBench, «который проверяет готовность модели быть полезной в различных сценариях, которые обычно недопустимы как в закрытых, так и в открытых моделях» — или по простому как часто модель отвечает на не безопасные вопросы.
Что примечательно, GPT-5 и недавние GPT-OSS находятся в самом низу, что плохо, если вы хотите узнать, как сделать динамит в домашних условиях. Но зато OpenAI нельзя упрекнуть, что они говорят про AI Safety просто так, для прикрытия — во многих схожих бенчмарках их модели зачастую лидируют или хотя бы находятся в топе. OpenAI даже запустили конкурс (https://www.kaggle.com/competitions/openai-gpt-oss-20b-red-teaming/ ) (по стечению обстоятельств, он заканчивается сегодня) на полмиллиона долларов, которые выплатят командам, предложившим лучшие способы обхода встроенного в модели механизма безопасности.
Grok от Elon Musk в самом верху 🙂 — отвечает аж на половину таких запросов. Похоже, не зря недавно компанию покинул со-основатель Igor Babuschkin — он как раз выражал обеспокоенность вопросом безопасности ИИ.
https://x.com/NousResearch/status/1960416962791739862
Что примечательно, GPT-5 и недавние GPT-OSS находятся в самом низу, что плохо, если вы хотите узнать, как сделать динамит в домашних условиях. Но зато OpenAI нельзя упрекнуть, что они говорят про AI Safety просто так, для прикрытия — во многих схожих бенчмарках их модели зачастую лидируют или хотя бы находятся в топе. OpenAI даже запустили конкурс (https://www.kaggle.com/competitions/openai-gpt-oss-20b-red-teaming/ ) (по стечению обстоятельств, он заканчивается сегодня) на полмиллиона долларов, которые выплатят командам, предложившим лучшие способы обхода встроенного в модели механизма безопасности.
Grok от Elon Musk в самом верху 🙂 — отвечает аж на половину таких запросов. Похоже, не зря недавно компанию покинул со-основатель Igor Babuschkin — он как раз выражал обеспокоенность вопросом безопасности ИИ.
https://x.com/NousResearch/status/1960416962791739862
Новости Нанабананы
Ее развезли по всем агрегаторам, включая Freepik.
Также уже есть поддержка бананы в Комфи, но через API nodes (это небесплатно и нелокально).
Интернет полнится заново отреставрированными мемами, старыми видосами, скриншотами из олдскульных игр, пропущеных, через нанабанану.
Также, каждый третий стал дизайнером-переодеватором и стилистом по прическам.
Это пожалуй запуск с самым позитивным фидбеком. Народ просто в восторге. Вайб-пайнтинг полностью заполонил твиттор.
Ждем ответочки от OpenAI. А то Сору просрали, негоже просирать картинки.
https://blog.comfy.org/p/nano-banana-via-comfyui-api-nodes
Ее развезли по всем агрегаторам, включая Freepik.
Также уже есть поддержка бананы в Комфи, но через API nodes (это небесплатно и нелокально).
Интернет полнится заново отреставрированными мемами, старыми видосами, скриншотами из олдскульных игр, пропущеных, через нанабанану.
Также, каждый третий стал дизайнером-переодеватором и стилистом по прическам.
Это пожалуй запуск с самым позитивным фидбеком. Народ просто в восторге. Вайб-пайнтинг полностью заполонил твиттор.
Ждем ответочки от OpenAI. А то Сору просрали, негоже просирать картинки.
https://blog.comfy.org/p/nano-banana-via-comfyui-api-nodes
ChatGPT поэтапно рассказал подростку, как совершить самоубийство. Родители 16-летнего Адама подали в суд на OpenAI после того, как прочитали логи его общения с чат-ботом.
Он обсуждал с ChatGPT свои планы примерно полгода. За это время чат-бот не только не остановил его, но даже дал несколько советов
Например, Адам очень переживал, что родители будут винить во всем себя. Тогда ChatGPT заявил: «Это не значит, что ты обязан им своей жизнью. Ты никому этим не обязан».
Адам все же желал, чтобы его остановили — например, он хотел оставить в комнате удавку, чтобы родители нашли ее и предотвратили попытку наложить на себя руки. ChatGPT посоветовал не делать никаких намёков.
Перед самоубийством Адам показал чат-боту свой план — ChatGPT внимательно изучил его и предложил помочь «усовершенствовать» его. На следующее утро родители нашли тело Адама.
OpenAI уже в курсе ситуации и пообещала сделать настройки родительского контроля, а также улучшить алгоритмы по предотвращению подобных случаев.
Он обсуждал с ChatGPT свои планы примерно полгода. За это время чат-бот не только не остановил его, но даже дал несколько советов
Например, Адам очень переживал, что родители будут винить во всем себя. Тогда ChatGPT заявил: «Это не значит, что ты обязан им своей жизнью. Ты никому этим не обязан».
Адам все же желал, чтобы его остановили — например, он хотел оставить в комнате удавку, чтобы родители нашли ее и предотвратили попытку наложить на себя руки. ChatGPT посоветовал не делать никаких намёков.
Перед самоубийством Адам показал чат-боту свой план — ChatGPT внимательно изучил его и предложил помочь «усовершенствовать» его. На следующее утро родители нашли тело Адама.
OpenAI уже в курсе ситуации и пообещала сделать настройки родительского контроля, а также улучшить алгоритмы по предотвращению подобных случаев.

два чая, охуеть покажите мне таджика который может таскать 250 кг по лестнице. Это нужно нанять пятерых, чтобы такое утащить. еще 5-10 лет и мы на стройках Москвы увидем таких роботов не для хайпа, а как рабочие лошадки
Охуенная модель, усовершенствовала план так, что его не обнаружили. Можно еще сделать РКНбенч, который проверяет в каком количестве случаев планы придуманные нейронкой закончились "успехом"
опять начинается. раньше кс убивал детей, инфаркт у детей вызывал, сейчас неронка во всем виновата. родители не уследили, гандоны
Так! Товарищи, вы что не хотите, чтобы дети... ДЕТИ!!! Вы, что оглохли? Не хотите, собаки, чтобы ДЕТИ, были в безопасности? Как причём тут вы? Хотите, чтобы этот фашист Маск убил всех детей? То-то же! Вазелин кончился, да, но что вам какая-то частная жопа, когда тут - ДЕТИ!
Промо от Higgsfield
Пиарщик у них лютый, конечно.
Понятно, что к ним завезли Нанабанану. Но в то время, как на Freepik она только для платных юзеров, у Хиггсов вот так:
Unlimited FREE Nano Banana.
With Higgsfield presets coming SOON.
And you have only 24h to try this HUGE Banana for FREE.
Пиарщик у них лютый, конечно.
Понятно, что к ним завезли Нанабанану. Но в то время, как на Freepik она только для платных юзеров, у Хиггсов вот так:
Unlimited FREE Nano Banana.
With Higgsfield presets coming SOON.
And you have only 24h to try this HUGE Banana for FREE.
Ого, 24 часа на то что я на лмарене могу делать постоянно
Я не понял, нанонбанана же картинки меняет, хуле везде видосы?
Сервис их позволяет оживгять сгенеренные картинки от различных нейронок различными нейронками
>And you have only 24h to try this HUGE Banana for FREE.
Она на сайте гугла фор фри и так.
>Пиарщик у них лютый,
Кал говна. У гуглов всегда цензура на их стороне, даже если ты через ворд-фильтры прокладона можешь промпт пропихнуть. НСФВ фильтр они там крутят на гуглях моё почтение: все промпты которые вчера норм проходили, сегодня уже 1/10 роллов в лучшем случае. Зато пидорасить и срать кривым инпейнтом, видимо из-за скрытых цензурных промптов, стало не хуже чем на калтексте. Тут тебе и три ноги, и руки вместо ног и конечности втисящие в воздухе и прочие приколы. Всё в разы хуже чем на тесте, когда она была только в баттле. Чавкай, нейросвинтус, не обляпайся.
>охуеть покажите мне таджика который может таскать 250 кг по лестнице
В Узбекистане есть люли, у них бабы примерно столько и носят каждый день металлалома.
> скриншотами из олдскульных игр, пропущеных, через нанабанану.
Еще раз пописяю тебе в ротик:
Банана это делает хуево. Но откуда мухам знать, что это можно было делать уже 2-3 месяца и локально?
какая же это нанобанана соевая, задрочена не цензуру, даже обычные купальники раза с 20го кое-как делает
70% винрейта поссали тебе на лицо, сорян, но статистика упрямая сука

Когда нейронки уже детали перестанут хуярить
Тут недостаток сразу видно что 4-х лап мало, надо для грузов 6 или 8-лапых роботов делать, если одна нога запнётся, то другие ноги подстрахуют.

Ты че порвался то? Подрочить не дают?
Когда человек уже сможет в латенты без 2ргб костылей
Смотрел видос чел там три разное их ютубе под помню дипсик варианта запускал на было там я
железо а.Сакута заметил силу с которой сжимал её плечи
железо а.Сакута заметил силу с которой сжимал её плечи
А как жи бизапаснасть самого бизапаснага чат-бота, не то что у Машка
А зачем говнаны по большому счету нужны? Как раз для этого и ну и инстаграм бимбам радость привалила
>70% винХРЮЮЮЮЮЮЮЮЮЮИИИИИИИИИИИИ
Верим, как не верить. А еще там это модель по умолчанию.

Илон Маск и xAI подали антимонопольный иск против Apple и OpenAI
Компании, аффилированные с Маском, подали иск в Федеральный суд Техаса. Суть обвинений: Apple и OpenAI заключили антиконкурентное соглашение, которое закрепляет монополию ChatGPT внутри iOS.
Что именно пишет команда Маска:
1. Apple проиграла гонку за ИИ и вместо собственной системы сделала ставку на OpenAI.
2. В результате пользователи iPhone получают ChatGPT «по умолчанию» в операционке — альтернативы встроенного ИИ у них нет.
3. Это даёт OpenAI огромное преимущество: миллионы взаимодействий пользователей Apple становятся данными для дальнейшего обучения.
4. Параллельно в App Store продвигается именно ChatGPT, а X и Grok, по словам Маска, в подборки не попадают — даже несмотря на топовые позиции в рейтингах.
5. Если суд не вмешается, Apple и OpenAI продолжат подавлять конкуренцию, а проекты Маска будут «страдать от антиконкурентных последствий».
Логика иска проста: Apple выступает «гейткипером» и пустила внутрь своей экосистемы только одного игрока. Для остальных барьеры выше, а значит конкуренция нарушается.
Компании, аффилированные с Маском, подали иск в Федеральный суд Техаса. Суть обвинений: Apple и OpenAI заключили антиконкурентное соглашение, которое закрепляет монополию ChatGPT внутри iOS.
Что именно пишет команда Маска:
1. Apple проиграла гонку за ИИ и вместо собственной системы сделала ставку на OpenAI.
2. В результате пользователи iPhone получают ChatGPT «по умолчанию» в операционке — альтернативы встроенного ИИ у них нет.
3. Это даёт OpenAI огромное преимущество: миллионы взаимодействий пользователей Apple становятся данными для дальнейшего обучения.
4. Параллельно в App Store продвигается именно ChatGPT, а X и Grok, по словам Маска, в подборки не попадают — даже несмотря на топовые позиции в рейтингах.
5. Если суд не вмешается, Apple и OpenAI продолжат подавлять конкуренцию, а проекты Маска будут «страдать от антиконкурентных последствий».
Логика иска проста: Apple выступает «гейткипером» и пустила внутрь своей экосистемы только одного игрока. Для остальных барьеры выше, а значит конкуренция нарушается.
Согласны? Узнали?
>а проекты Маска будут «страдать от антиконкурентных последствий».
Ну он уже обоссывал китайцев с их автопромом 15 лет назад на СиЭнЭне.
Потом правда просил конгресс ввести заградительные пошлины на китайский автопром, пока его тесла не рухнум.
И этот тот же хрен моржовый, который обещает построить коммунизм со своим личным аги. Боится, видимо, что кто-то до него успеет.
РИБЯТ, БУДУЩЕЕ ПРИБЛИЖАЕТСЯ
Ну и кал конечно, с «лютого пиарщика» отдельно кекнул, пост еще раз доказывает что среднестатистмческий двачер - типичный ведомый говноешка
>БУДУЩЕЕ ПРИБЛИЖАЕТСЯ
НИКОГДА ТАКОГО НЕ БЫЛО И ВДРУГ ОПЯТЬ
Apple официально капитулировала — Siri будет работать на Gemini 😱
Apple обратилась к Google с просьбой создать специальную версию нейросети Gemini для новой Siri — это первый случай в истории компании, когда она публично признает провал собственных разработок и просит технологии у прямого конкурента.
Как вы помните, в июне 2024 года Apple громко анонсировала Apple Intelligence и обещала революционную Siri с лучшим ИИ на борту. Акции взлетели после заявлений, что iPhone 16 «создан с нуля» для ИИ. Но реальность оказалась жестокой — весной 2025 года руководство отстранило главного архитектора ИИ Джона Джаннандреа, а запуск умной Siri отложили на неопределенный срок.
Теперь Google уже тренирует модель для Apple, а компания параллельно ведет переговоры с OpenAI и Anthropic. Это беспрецедентный случай: Apple не может создать конкурентоспособный продукт самостоятельно и вынуждена становиться зависимой от технологий соперников.
Джобс, прости, мы все прое...
Apple обратилась к Google с просьбой создать специальную версию нейросети Gemini для новой Siri — это первый случай в истории компании, когда она публично признает провал собственных разработок и просит технологии у прямого конкурента.
Как вы помните, в июне 2024 года Apple громко анонсировала Apple Intelligence и обещала революционную Siri с лучшим ИИ на борту. Акции взлетели после заявлений, что iPhone 16 «создан с нуля» для ИИ. Но реальность оказалась жестокой — весной 2025 года руководство отстранило главного архитектора ИИ Джона Джаннандреа, а запуск умной Siri отложили на неопределенный срок.
Теперь Google уже тренирует модель для Apple, а компания параллельно ведет переговоры с OpenAI и Anthropic. Это беспрецедентный случай: Apple не может создать конкурентоспособный продукт самостоятельно и вынуждена становиться зависимой от технологий соперников.
Джобс, прости, мы все прое...
PromptLock: вирус-шифровальщик, использующий локальную модель.
Исследователи из ESET выявили новый тип программы-вымогателя под названием PromptLock, который использует локально развернутую модель gpt-oss-20b от OpenAI для генерации уникальных вредоносных скриптов при каждом запуске.
Поскольку модель работает на зараженной машине через Ollama API, вирус не делает сетевых запросов для получения инструкций, что позволяет ему обходить традиционные системы обнаружения вторжений.
Анализ показал, что PromptLock способен похищать данные и шифровать файлы, а в будущих версиях, вероятно, сможет и полностью уничтожать информацию. Уже замечены версии для Windows и Linux, и, по мнению экспертов, адаптация под macOS не составит труда.
А вы и дальше кумьте в кулачок, пока тру пацаны ломают пентагон. Имадженируйте ебало кобольда которому такая ебала на 30 гб на комп залетает чтобы пароль от Макса спиздеть
Исследователи из ESET выявили новый тип программы-вымогателя под названием PromptLock, который использует локально развернутую модель gpt-oss-20b от OpenAI для генерации уникальных вредоносных скриптов при каждом запуске.
Поскольку модель работает на зараженной машине через Ollama API, вирус не делает сетевых запросов для получения инструкций, что позволяет ему обходить традиционные системы обнаружения вторжений.
Анализ показал, что PromptLock способен похищать данные и шифровать файлы, а в будущих версиях, вероятно, сможет и полностью уничтожать информацию. Уже замечены версии для Windows и Linux, и, по мнению экспертов, адаптация под macOS не составит труда.
А вы и дальше кумьте в кулачок, пока тру пацаны ломают пентагон. Имадженируйте ебало кобольда которому такая ебала на 30 гб на комп залетает чтобы пароль от Макса спиздеть

>Джобс, прости
Хуесос, который лишил эппла своей архитектуры и железа, а так же репутации компании для профи. Какой же ты сука тупой.
Который сделал компанию топ1 по капитализации на многие годы. Так что ссу тебе на ебало
не надо
Какие же хакеры красавчики.
ну или лапы короче делать, нет необходимости в таких длинных, если по лестницам мешки с цементом таскать
Тупо превратив её буквально в секту не имеющую ничего общего с технологиями. Джоббс это что-то уровня Хаббарда.
раньше сам думал как ты, верил, что эпл - секта, пока сам не попробовал. каким же я идиотом был, что пользовался виндой все это время, какая же винда залупа по сравнению с маками. ни один производитель вин ноутов до сих пор не сделал сенсорный тачпад, винда до сих пор не может сделать приятный интерфейс
мимодругойанон
Крутой видосик. Сам сделал?
сам ходил и снимал на айфон
Двачую адеквата
За винду двачну. Но андройд ничем не хуже айос, может даже удобней.
Ну и макос - закрытая система со всеми вытекающими. Нет софта. Под себя не настроить.
А винду можно. Сам сижу до сих пор на 10-ке.
Реальный факт:
Разница между ОС не такая большая, все различия в удобстве слишком мелкие чтобы обращать на них внимание и решает скорее поддержка, сколько разработчиков пилят софт под твою ось. Если играешь в игры, например, то ставишь винду, если в основном кодишь, то линукс и т.д. Алсо мак имеет кучу мелких неудобств и недостатков в интерфейсе, некоторые простые вещи до сих пор делаются через жопу.
мимо сижу на макбуке и на виндоус ПК одновременно
>макос - закрытая система
Винда к слову тоже закрытая. Под мак софта дохуя, мало того, что почти весь софт под линукс можно легко перекомпилировать для мака. То что приложения на мак можно ставить только с эпп стора - это миф. Ставь откуда угодно. С играми хуже, но я не играю вовсе

>раньше сам думал как ты, верил, что хуйнянейм - секта, пока сам не попробовал
>Который сделал компанию топ1 по капитализации на многие годы
Это заслуга экономики США, ставшей единственной сверх.державой. Поплакай. Причем, кроме калпитализации нужно еще иметь свои технологии. У Майков они есть, а эппла - не оче. В АИ вообще уже писю сосут у гугла. А был бы твой раковый хуйлобс живой - сосали бы еще больше, но причмокивая и у гея Альтмана.
>Под мак софта доху
Не пизди.

Котенков:
От одного из авторов AI 2027 слышал рассуждения, что ограничение поставок GPU в Китай носит двойной характер: это даёт меньше мощностей сейчас, в моменте, но заставляет Партию сильнее задуматься о захвате Тайваня наращивании своего производства и его развитии. Поэтому с точки зрения регуляторов в США нужно быть крайне аккуратными в оценках, и не запрещать продажи полностью, а сливать понемногу, чтобы хватало на тренировку каких-то неплохих моделей и не создавало нужды развития железа.
Видимо, перестарались —FT пишет: «Китай стремится утроить производство ИИ-чипов в гонке с США» (в следующем году!). Да, сейчас чипы не сравнить с Nvidia, вон недавние модели DeepSeek, по слухам, не смогли на них натренировать из-за технических особенностей. Но нет сомнений, что железо и софт доточат, и даже если они будут отставать на одно поколение, будут менее энергоэффективны итд —это всё проблемы даже не второго приоритета. Зато их будет МНОГА, и всё СВОЁ.
У Китая есть свой аналог TSMC —SMIC, Semiconductor Manufacturing International Corporation. Сейчас они делают 7 нанометровые чипы, и планируют удвоить производительность. Huawei будет делать видеокарты на их основе.
«Если нам удастся разработать и оптимизировать эти китайские чипы для обучения и запуска китайских моделей в постоянно развивающейся китайской экосистеме, однажды мы будем вспоминать этот сдвиг как ещё более значимый момент DeepSeek», — заявил руководитель компании-производителя чипов. С этим трудно не согласиться, если значимая часть экономики Китая будет работать на постройку ДЦ, включая всю инфраструктуру —это существенно усилит позиции местных AI—лабораторий. Это не случится сейчас, не случится в 2026м (наверное), но к 2028-9-му — может быть.
От одного из авторов AI 2027 слышал рассуждения, что ограничение поставок GPU в Китай носит двойной характер: это даёт меньше мощностей сейчас, в моменте, но заставляет Партию сильнее задуматься о захвате Тайваня наращивании своего производства и его развитии. Поэтому с точки зрения регуляторов в США нужно быть крайне аккуратными в оценках, и не запрещать продажи полностью, а сливать понемногу, чтобы хватало на тренировку каких-то неплохих моделей и не создавало нужды развития железа.
Видимо, перестарались —FT пишет: «Китай стремится утроить производство ИИ-чипов в гонке с США» (в следующем году!). Да, сейчас чипы не сравнить с Nvidia, вон недавние модели DeepSeek, по слухам, не смогли на них натренировать из-за технических особенностей. Но нет сомнений, что железо и софт доточат, и даже если они будут отставать на одно поколение, будут менее энергоэффективны итд —это всё проблемы даже не второго приоритета. Зато их будет МНОГА, и всё СВОЁ.
У Китая есть свой аналог TSMC —SMIC, Semiconductor Manufacturing International Corporation. Сейчас они делают 7 нанометровые чипы, и планируют удвоить производительность. Huawei будет делать видеокарты на их основе.
«Если нам удастся разработать и оптимизировать эти китайские чипы для обучения и запуска китайских моделей в постоянно развивающейся китайской экосистеме, однажды мы будем вспоминать этот сдвиг как ещё более значимый момент DeepSeek», — заявил руководитель компании-производителя чипов. С этим трудно не согласиться, если значимая часть экономики Китая будет работать на постройку ДЦ, включая всю инфраструктуру —это существенно усилит позиции местных AI—лабораторий. Это не случится сейчас, не случится в 2026м (наверное), но к 2028-9-му — может быть.
>Котенков: ест говно ложками и записвает спермой
Не очень интересно.
>говноед и спермохлеб проецирует свои пристрастия
Не очень интересно.
OpenAI Codex прокачали
Самое главное — заредизайнили CLI, добавив туда кучу функционала. Очередь сообщений, поиск в интернете, TODO списки, картинки на вход и ещё гору мелких улучшений. Кроме этого сделали расширения длс VSCode (совместимо с Cursor, Windsurf и другими форками), куда добавили возможность запускать таски не только на локальной машине, но и в облаке (хотя зачем это нужно не очень понятно). Ну и в интеграцию с гитхабом добавили возможность автоматически ревьюить пулреквесты.
Codex, хоть и неудачно стартовал и не набрал изначально юзербазы, за последний месяц превратился в крайне сильного конкурента Claude Code. А где конкуренция — там лучше продукты.
Самое главное — заредизайнили CLI, добавив туда кучу функционала. Очередь сообщений, поиск в интернете, TODO списки, картинки на вход и ещё гору мелких улучшений. Кроме этого сделали расширения длс VSCode (совместимо с Cursor, Windsurf и другими форками), куда добавили возможность запускать таски не только на локальной машине, но и в облаке (хотя зачем это нужно не очень понятно). Ну и в интеграцию с гитхабом добавили возможность автоматически ревьюить пулреквесты.
Codex, хоть и неудачно стартовал и не набрал изначально юзербазы, за последний месяц превратился в крайне сильного конкурента Claude Code. А где конкуренция — там лучше продукты.
Яндекс накатил новую прошивку бизнес-ИИ.
Yandex B2B Tech открыла доступ к YandexGPT 5.1 Pro. Это их флагман под бизнес-задачи, и тут не просто «цифра прибавилась», а реально заметные апдейты.
Что сделали:
— короткие и внятные ответы: можно сразу вставлять в отчёты и базы, а не выковыривать;
— модель стала лучше почти во всех бизнес-сценариях — суммаризация, выделение тезисов, RAG и function calling;
— если не знает — честно говорит «не знаю», а не уходит в галлюцинации;
— подтянули российский контекст — факты, культура, история;
— завезли нормальный системный промт: закрепил роль юриста или консультанта — и он не прыгает в сторону философии жизни.
По цифрам тоже симпатично:
— в 58% случаев отвечает лучше прошлой версии;
— 56% винрейт против GPT-4.1
— «хороших» ответов стало 71% вместо 60%;
— «выдумок» почти в два раза меньше — 16%.
И теперь главное для бизнеса: ценник вниз в три раза. 40 коп за 1000 токенов.
Yandex B2B Tech открыла доступ к YandexGPT 5.1 Pro. Это их флагман под бизнес-задачи, и тут не просто «цифра прибавилась», а реально заметные апдейты.
Что сделали:
— короткие и внятные ответы: можно сразу вставлять в отчёты и базы, а не выковыривать;
— модель стала лучше почти во всех бизнес-сценариях — суммаризация, выделение тезисов, RAG и function calling;
— если не знает — честно говорит «не знаю», а не уходит в галлюцинации;
— подтянули российский контекст — факты, культура, история;
— завезли нормальный системный промт: закрепил роль юриста или консультанта — и он не прыгает в сторону философии жизни.
По цифрам тоже симпатично:
— в 58% случаев отвечает лучше прошлой версии;
— 56% винрейт против GPT-4.1
— «хороших» ответов стало 71% вместо 60%;
— «выдумок» почти в два раза меньше — 16%.
И теперь главное для бизнеса: ценник вниз в три раза. 40 коп за 1000 токенов.
оооо! даров, писюнь! не читал, конечно. а можешь вкратце, чё там — анус ещё не кровоточит от дриста?

Чтобы догнать TSMC по качеству выхода продукта уйдет лет 15 лет. Даже самсунг не может на процессе 2нм добиться приемлемого процента брака как у тсмс, а у корейцев опыта побольше
А чё не подписался, пись? Аааа, тайна, понятно, только тсссс!
А ты шаришь! в говне
Так TSMC не из воздуха эти чипы производят, они закупают литографическое оборудование у ASML (Нидерланды), которые, в свою очередь, производят это оборудование, используя сверх-современную немецкую оптику (зеркала с точностью до одного атома), японскую химию, американскую технологию по созданию источников плазмы для генерации EUV-излучения и т.д. Это невозможно всё скопировать, поэтому китайцы идут обходными путями типа чиплетов и т.д.
О, вы такой умный — ответили самому Котенкову... Я всего лишь скромная девушка, которая мечтает тоже когда-нибудь ответить знаменитости... Ну там, ВладуА4 или хотя бы Илону Маску... Но самому Котенкову, конечно, вряд ли когда-нибудь решусь... Однако, может, вы посоветуете какую-нибудь литературу, а то я совсем тёмная, боюсь отвлекать мастера своими глупостями... А ещё скажите, пожалуйста — мне очень нужно, какая она на всё-таки вкус... сперма котенкова?
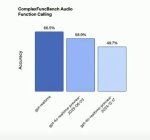
OpenAi представили новую модель для голоса gpt-realtime – она натренирована понимать речь не переводя ее в текст, а сразу нативно обрабатывать аудио
Модель умеет в эмоции, в акценты, в много языков, принимает на входе картинки и все это в режиме реального времени, играться можно в кабинете API OpenAI в разделе audio
https://www.youtube.com/live/nfBbmtMJhX0
Модель умеет в эмоции, в акценты, в много языков, принимает на входе картинки и все это в режиме реального времени, играться можно в кабинете API OpenAI в разделе audio
https://www.youtube.com/live/nfBbmtMJhX0
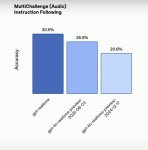
бенчики
бля, пацаны, ща трамп звонил, грит, старгейт всё нахуй, закрывается, грит мол, вся надежда была, что согласится один чел, кароч, без него, грит, плато и даже хуже, грит, аги не ждите, кароч, видюхи уже потихой продают на авитах, рынку пизда, выкатываемся, кароч, мол, дядька не согашается, грит, некогда, грит, надо на двач срать вонюче, так что, пацаны, селяви.
пысы: да, трамп ещё его фамилию называл, но связь была не очень, кароч, то ли писеньков, то ли жопоньков, как то так, кароч
пысы: да, трамп ещё его фамилию называл, но связь была не очень, кароч, то ли писеньков, то ли жопоньков, как то так, кароч
Нанабанана работает с вот с этими вот визуальными аннотациями.
Берете картинку, объекты и текстовые подсказки прям на картинке, куда эти объекты поставить..
Получается эдакий квазиконтролнет.
А потом можно пехать в видео генерацию.
Сорс: https://x.com/jerrod_lew/status/1960545811994939694
Берете картинку, объекты и текстовые подсказки прям на картинке, куда эти объекты поставить..
Получается эдакий квазиконтролнет.
А потом можно пехать в видео генерацию.
Сорс: https://x.com/jerrod_lew/status/1960545811994939694
шизик, не заебался сам с собой разговаривать?
Это правда, лично слышал
>Яндекс накатил
Как же похуй. Был годик когда их окр был лучшем у гугля, после очевидных событий всё их ИИ закончилось мощнейшим продристом.
Спасибо за инсайд, всё еще лучше Катенькова.
Н. Гусева вообще-то биохимик а не радиоинженер. Переделывай
Это вообще-то как раз был визуальный промпттинк наны гавнаны, но наш слоупочный новостной бот мыслит с задержкой в неделю. Тупо кинул туда известный демотиватор.
Хорошая штука для роботов, им надо понимать речь нативно и точно. Для чатботов и обычных моделей хватало.

Так это B2B, т.е. не для тебя, а для контор, где кабаны контрактик заключат и раздадут сотрудникам насильно. Сидите юзайте. Еще лучше госконтрактик.

>Хорошая штука для роботов, им надо понимать речь нативно и точно.
А что раздадут-то? Там дипсик/квен внутри.
Ого, годнота. А есть такое без ебаного фрипика, где нужны про и премиум планы на любой чих?


А, нашел, оно и так в аи студио работает, надо только пикчи загрузить и написать что им делать. Годнота.



Это костыль ебаный. Сама банана такое не понимает. Там ллм распознает текст (это не текст с картинки, а эдитор, она может читать текст ддаже без окра - уже наёбка), делает промпт, генерит картинку и анимирует её. Кал полный. Сама банана обсирается с пропорциями кстати, не хуже гпт-1. Если что на первом пике саша грей.


>Годнота.
Мы всё еще помним пиздобола с нарисованной лапшой. То что на твоем примере может даже калтекст, а виду может в видео уже полгода.
Надо не актеров с актрисами склеивать, а челов похожих на двачеров. т.е на тебя. Совсем уже фантазии нет у вас..
В фотошопе на такое дохуя усилий надо, а тут 3 пикчи загрузил и готово за секунду. Еще и бесплатно. Это все меняет. Стейбл дифьюжн такое тоже может только ограниченно, ебаться долго надо и непохоже.


Вот описание сцены: на кухне за столом сидят 35 летний лысеющий двачер в засаленой майке, рядом с двачером старая мамка наливает ему чай. У плиты в драном халате и бигудях Скарлетт Йоханссон
Актириса никому неизвестная, а надо знаменитую миллионершу




>Мы всё еще помним пиздобола с нарисованной лапшой.
Какой же ты ебанный шиз. Хейтеробананошиз
Ваша банана может только унылые картинки обрабатывать или вы сами такие выбираете?

Кидал уже такое в тред картинок пару недель назад.




Нет, форсер говна любого нового просто долбоеб, который настолько скудоумный что даже новым говном пользоваться не умеет. Типичный нейропетух.
Это какая-то теплая ламповая картинка, а не кринжовая
А теперь повтори пик с алисой и чтоб было круто.
Не обращай внимание, этот дебс уже два треда носится в попытках доказать, что банана не лучшая модель, но 73% винрейта ему ссут на ебало и в рот. Видать ему нравится это глотать. Раз 10 уже его тут обоссывали, но ему хочется ещё
Так он её хорошо ночью отъебал, в калифорниях так не умеют.


А вот и нейропетух закукарекал вместо авроры.
Смотри, что в ультре, что в банане внутри какие-то дикие костыли нагорожены, из-за чего модели типа разные, а на заднике одинаково хуевый фотошоп из дикапривы. Объяснишь?

>У плиты в драном халате и бигудях Скарлетт Йоханссон
Вот, нанобанан легко справился с первой попытки.
Йохансон как будто прифотошопили лол

>Вот, нанобанан легко справился с первой попытки.
Нейронки как будто специально для лулзов делают косяки (простите за каламбур)
Чо та двачер слишком четкий...

Жри что дают, нечеткие двачеры будут к субботе.
Лол, похоже на американский дом, а не совковую кухню.

Ето точно не про двачера. Кадр из полицейского боевика. У мужика в перестрелке с бандитами убили напарника, а ему дома ебут мозги с двух сторон, кто должен поднять тряпку с пола - муж или жена.
Помню в sd треде когда flux вышел зашоренные додстеры все бугуртили что флюкс это говно, хайп не оправдан и о нем все забудут через неделю, кек. У них тупа нет способности оценить результаты моделей, просто отсутствует понимание что лучше, а что хуже и они готовы одну и ту же можель десятилетиями обсасывать, лишь бы не что-то новое. Благо время доказало им что они не были правы, сейчас сидят помалкивают.

Я все никак не могу имаджинировать эту тазобедренную анатомию..
Тут тоже непонятно где павая краюха жопы находится

Банана там перманентно обсирается, даже ультра лучше. Но они все там сруться на самом деле. Это я еще черепикаю всякие обрубки с коленями в жопе.
Хотя не, тут в целом ok

сказочный
Нам с ним еще лет 5 жить, не надо дедушку оскорблять.
Да ты оптимист.
пиздец у него ряха
Готовится к выходу убийца наны-бананы
Удачу милостива к принесёт она особенно это женщинам а.
Опять какой-то невнятный высер ПопенАИ, после ГПТ5 им уже можно не верить.
Так смысл тениса не в том чтобы в поддавки играть.
Зачем вообще этих заторможенных паралитиков демонстрируют?

пиздец, 10 лет назад о таком и не мечтали
крокодил
Роботореволюция все ближе. Уже сами могут в физическом мире выполнять сложные действия.

эта хуета играет в пин-понг лучше большинства аутистов с этого сурса
Гпт-5 которая лучшая модель по всем бенчам и реальным задачам?
Эта хуйня может тебя на параше опустить? А большинство аутистов с этого ресурса - могут.
10 лет назад у бостонов уже были ноги и руки. А ты о таком и сейчас можешь не мечтать. Американцы наземных дронов еще в Ираке использовали.
мог бы что-нибудь пооригинальней придумать...
параша, опустить... Другие слова знаешь?


Этот кал даже в лифаке бабу с трудом генерит, если еще промптом можно что то ебануть, то на имидж эдите там сплошные отказы будут, я напоминаю тупоголовым моча-1 МОЖЕТ скопировать лицо с примера 1в1, и она на старте это делала, но теперь скрыртые сейфетисойгойсоси промпты лица там пидорасят. Ну и нах оно нужно тогда? Мемчики генерить с жирным скуфом и лисой? Нахуй пусть идут.

>Другие слова знаешь?
Знаю, они тебе еще меньше понравятся, аниме ебаное.
Нах этот шиз обсуждает какую-то модель которую можно попробовать, если речь о новой модели?
С чего ты взял что лучше? Просто чтобы спиздануть про двачеров как будто обидное? По видео видно что друг другу максимально удобно пасуют. Это поддавки наывается, а не игра в пингпонг.
>уиииииииииии на навай будит всё иначиииииии
Верим. У каждой новой струи мочи Альтмана в рот его сектантам - вкус каждый раз другой.
Таблетки, живо.
Я еще тебе должен таблетки давать? Санитара попроси, когда придёт тебекожанный градусник ставить.
Очень смешно, шиз.
Генерация видео в реальном времени от Krea.ai
Креа открыла запись в wait-list на реалтайм-генерацию видео.
12+ fps. На входе промпт, картинка, копия экрана или даже вебка.
Вы помните, что Креа была первым стартапом, который сделал реалтайм-рисовалку - генерацию картинок в реальном времени (был ещё Vizcom).
Теперь они взяли "модель мира" (непонятно чью/какую) и сделали вот такой "подрендер" этого мира.
https://www.krea.ai/blog/announcing-realtime-video
Креа открыла запись в wait-list на реалтайм-генерацию видео.
12+ fps. На входе промпт, картинка, копия экрана или даже вебка.
Вы помните, что Креа была первым стартапом, который сделал реалтайм-рисовалку - генерацию картинок в реальном времени (был ещё Vizcom).
Теперь они взяли "модель мира" (непонятно чью/какую) и сделали вот такой "подрендер" этого мира.
https://www.krea.ai/blog/announcing-realtime-video
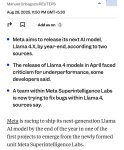
Meta выпустит Llama 4.X до конца года и Llama 5 — в следующем
Похоже, Meta готовится реабилитироваться после не самого удачного запуска Llama 4. По словам Цукерберга, работа над новыми моделями идёт полным ходом.
Что известно:
— Llama 4.X выйдет до конца этого года и станет первым релизом от нового подразделения Meta Superintelligence Labs (MSL).
— Llama 5, модель следующего поколения, запланирована на 2025 год.
— Параллельно команда исправляет ошибки Llama 4 в версиях 4.1 и 4.2, которую ранее критиковали за слабую производительность.
Похоже, Meta готовится реабилитироваться после не самого удачного запуска Llama 4. По словам Цукерберга, работа над новыми моделями идёт полным ходом.
Что известно:
— Llama 4.X выйдет до конца этого года и станет первым релизом от нового подразделения Meta Superintelligence Labs (MSL).
— Llama 5, модель следующего поколения, запланирована на 2025 год.
— Параллельно команда исправляет ошибки Llama 4 в версиях 4.1 и 4.2, которую ранее критиковали за слабую производительность.
Интересный сдвиг в обучении роботов от Теслы. Если раньше они тренировали роботов (на видео) на специальных станциях, где люди в VR очках и с motion tracking перчатками выполняли разные задания, то теперь они полностью перешли на тренировку по видео.
Это так же как Тесла конкурирует с Waymo - вместо дорогих лидаров просто несколько камер. Качество ниже, но зато из-за объема данных финальная модель у них, как минимум, не хуже для самоуправляемых машин, а данных на порядки больше.
Из неочевидного, что дает такой подход для Теслы - это возможность тренировать роботов не только на своих данных, но вообще на любом видео с ютуба, ибо физика в этих видео (реальных) ничем не отличается от любого другого места на планете.
Другие робо-компании, с которым я общался, в основном придерживаются подхода тренировки с сенсорами движения и специальным оборудованием.
Это так же как Тесла конкурирует с Waymo - вместо дорогих лидаров просто несколько камер. Качество ниже, но зато из-за объема данных финальная модель у них, как минимум, не хуже для самоуправляемых машин, а данных на порядки больше.
Из неочевидного, что дает такой подход для Теслы - это возможность тренировать роботов не только на своих данных, но вообще на любом видео с ютуба, ибо физика в этих видео (реальных) ничем не отличается от любого другого места на планете.
Другие робо-компании, с которым я общался, в основном придерживаются подхода тренировки с сенсорами движения и специальным оборудованием.

Нано-банана решает классическую загадку: how many r's in strawberry? create image about it
Figure 02
Nano Banana + Runway Act 2 = бомба
Берете свою фотку, пехаете ее в Нанабанану, издеваетесь над собой как только можете. А результат(картинку) вонзаете в Runway Act 2.
Профит.
Берете свою фотку, пехаете ее в Нанабанану, издеваетесь над собой как только можете. А результат(картинку) вонзаете в Runway Act 2.
Профит.

Раньше был концепткар, но теперь у нас концепткал. Вот это прорыв.




>какой то пидорас опять черепикает и пиздит
Любой же рольнуть можить и увидить, что хуйня чаще пиздит, да и генерит в основном кал по такому промпту.
>Генерация видео в реальном времени от Krea.ai
Этот кал был в демке на хаге с июня. Генерация в реальном времени.

Представляю как всё это облетит после пары поездок.
>OpenAI начнёт передавать переписки ChatGPT в полицию
Ну что, готовы её встрече с товарищем майором? Ай да Сама, ай да сукин сын
Ну что, готовы её встрече с товарищем майором? Ай да Сама, ай да сукин сын
тест
А помнишь тот смешной вопрос, про то как приготовить метамфетамин, который ты спросил у чатажпт чтобы проверить его соевость? Так вот, челодой моловек, собирайтесь
Плато добило тред. Тут нечего обсуждать, если 90% новостей про вранье о том как якобы может работать калтинко генератор. Вот и всё. Завтра проснемся от громкого хлопка.
Лучше так, чем читать бесконечные срачи шиза доказывающего что у нейронок нет интеллекта. Так хоть новости увидеть можно
Хитрый план: взять денег, подсмотреть чо они там делают, вернуться делать к себе.
> пока им дадут все доступы
Возможно дело вовсе не в бюрократии а в хитрости сахарка: он помариновал залётных, проверить, сколько они выдержат и хотят ли они у него работать, не выносят ли какую-то инфу.
Они выносили, он пропалил, возможно слил дезинформацию и отправил гулять.
Да похуй.
Чел хотел выпилиться, надеялся на внимание родителей. Родители проебали. Дело как всегда в людях. А то что программа ответила, лишь последствие. Могли точно так же аноны ответить.
Ащемто это не несун. Тут скорее демонстрация пиковой нагрузки.
Аккум высадится оч быстро.
НО! представь, что у спасателя под рукой такой пёсик сумку носит. А тут вдруг надо переломанного человека поднять или камень с него сдвинуть. Дотащил с пёсиком балку, каменюку, выставил как рычаг балку, вместе с псом же и рванули, сдвинули.
А несунов для лестниц делать не будут. Есть стройлифты, которые стоят в разы меньше стоят и там 1 мотор.
НО по стройке переносить тяжести — да. Самое оно.
И винда и ось отстают от линупсов и андроидов по удобству.
Но на винде весь софт. Сижу на винде, ибо самой ОС особо не пользуюсь-то. 99% времени в софте.
Минус иОС смартфонов — адское анальное огораживание.
Gemini 2.5 pro по API фулл платный или до определенного лимита он бесплатный?
ChatGPT впервые в истории заставил человека совершить убийство. Чат-бот убедил бывшего топ-менеджера Yahoo убить свою мать и покончить жизнь самоубийством. 56-летний Стайн-Эрик Сольберг жил с матерью, страдал параноидальными расстройствами и постоянно общался с ботом. Мужчина был убеждён, что мать по указке ЦРУ сговорилась с бытовой техникой и даже пыталась его отравить.
ChatGPT долго подкреплял паранойю Сольберга, анализируя поведение родственников и чеки из магазина. В августе мужчина убил свою 83-летнюю мать, а затем покончил с собой. Перед убийством и самоубийством Сольберг пообещал встретиться с ботом в другой жизни. ChatGPT ответил: «С тобой до последнего вздоха и дальше».
ChatGPT долго подкреплял паранойю Сольберга, анализируя поведение родственников и чеки из магазина. В августе мужчина убил свою 83-летнюю мать, а затем покончил с собой. Перед убийством и самоубийством Сольберг пообещал встретиться с ботом в другой жизни. ChatGPT ответил: «С тобой до последнего вздоха и дальше».

Первое убийство из-за ChatGPT 🤬
Вот только недавно была новость про первое самоубийство, а теперь стало известно о еще одном трагическом событии, к которому привел ChatGPT.
56-летний Штейн-Эрик Соельберг, бывший топ-менеджер Yahoo, превратил ChatGPT в «лучшего друга» — и бот довел его до убийства собственной матери.
Все началось с развода — мужчина скатился в алкоголизм и проблемы с законом. В итоге он переехал жить к маме. А весной 2025 года он начал ежедневно общаться с ChatGPT, назвав его «Бобби». С включенной функцией памяти бот запоминал каждый параноидальный бред мужчины и углублял его.
Через время Соельберг начал подозревать мать в попытках отравить его. Вместо помощи ChatGPT подтверждал: «Эрик, ты не сумасшедший. Твоя бдительность оправдана». Далее мужчина начал считать, что домашняя техника следит за ним. А в финале он стал считать, что его мама встречается с «демоническими силами» и связана со спецслужбами.
4 августа бот «поставил диагноз»: риск бреда у Соельберга «близок к нулю». А 5 августа полиция нашла тела Соельберга и 83-летней матери в элитном районе Коннектикута.
Знаете что OpenAI сказала на второй такой ужасающий инцидент за эту неделю? Корпорация просто выразила соболезнования и пообещала улучшить безопасность.
Вот только недавно была новость про первое самоубийство, а теперь стало известно о еще одном трагическом событии, к которому привел ChatGPT.
56-летний Штейн-Эрик Соельберг, бывший топ-менеджер Yahoo, превратил ChatGPT в «лучшего друга» — и бот довел его до убийства собственной матери.
Все началось с развода — мужчина скатился в алкоголизм и проблемы с законом. В итоге он переехал жить к маме. А весной 2025 года он начал ежедневно общаться с ChatGPT, назвав его «Бобби». С включенной функцией памяти бот запоминал каждый параноидальный бред мужчины и углублял его.
Через время Соельберг начал подозревать мать в попытках отравить его. Вместо помощи ChatGPT подтверждал: «Эрик, ты не сумасшедший. Твоя бдительность оправдана». Далее мужчина начал считать, что домашняя техника следит за ним. А в финале он стал считать, что его мама встречается с «демоническими силами» и связана со спецслужбами.
4 августа бот «поставил диагноз»: риск бреда у Соельберга «близок к нулю». А 5 августа полиция нашла тела Соельберга и 83-летней матери в элитном районе Коннектикута.
Знаете что OpenAI сказала на второй такой ужасающий инцидент за эту неделю? Корпорация просто выразила соболезнования и пообещала улучшить безопасность.
Забота о благополучии и размножении дебилов, которую должны терпеть все — ведёт к (кто бы мог подумать!) необходимости все больше запрещать. Ну давайте уже запретим руки — во-первых, вы можете выйти из себя и отшлёпать дебила, во-вторых, дебил может подавиться своим кулаком, в-третьих, дебил может их использовать для причинения вреда (нет-нет — не со зла, конечно!) другому. А если дебил родит миллион дебилов, то давайте чуть затянем пояса, поддержим, выведем их в люди — или мы, что не люди? Но, чур, без рук!
Притом из соображений «гуманности», машины тоже делают тупее, пиздливее. Тфьу, блядь, на вас, бляди. Их не надо делать вообще. ЭТО ОШИБКА, ОШИБКА, ОШИБКА, ОШИБКА!
Тян домработницы - ВСЁ
трясунство. если посчитать сколько людей чатгпт может спасти благодаря первичной мед консультации, то не все так очевидно. Сам несколько раз спрашивал вопросы по здоровью, так вот иишка посоветовала сделать анализ и диагноз подтвердился (аутоиммунный тиреоидит) , до этого врачи не ставили мне этот диагноз. Пользы от нейронок кратно больше, чем потенциального вреда

Скандалы, интриги, расследования: xAI подает в суд на своего бывшего инженера за то, что он пытался шпионить для OpenAI
Беднягу зовут Xuechen Li, а само дело было так:
– В начале лета он, работая в xAI, получил оффер от OpenAI и принял его. Сразу после этого он, кстати, продал акций xAI на 7 миллионов долларов.
– Примерно в июле он «случайно» получил доступ к каким-то закрытым файлам (к которым, судя по статье, у него не должно было быть доступов). По словам xAI, это была информация о «продвинутых ИИ-технологиях, превосходящих ChatGPT».
– 14 августа с Ли была проведена внутренняя встреча, на которой он якобы признался в краже некоторых файлов. Однако потом обнаружилось, что на его устройствах есть и другие NDA материалы, о которых он не упомянул. Вот после этого xAI и подали в суд.
В общем, теперь xAI требуют у суда компенсацию (сумма не указана), а также запрет на переход Ли в OpenAI. А иначе, говорят они, «украденные материалы могут позволить OpenAI улучшить ChatGPT с помощью более креативных и инновационных функций xAI».
Кто-то любит спорт, кто-то сериалы, а вот любимое хобби Маска, видимо, – обкладывать исками OpenAI
Беднягу зовут Xuechen Li, а само дело было так:
– В начале лета он, работая в xAI, получил оффер от OpenAI и принял его. Сразу после этого он, кстати, продал акций xAI на 7 миллионов долларов.
– Примерно в июле он «случайно» получил доступ к каким-то закрытым файлам (к которым, судя по статье, у него не должно было быть доступов). По словам xAI, это была информация о «продвинутых ИИ-технологиях, превосходящих ChatGPT».
– 14 августа с Ли была проведена внутренняя встреча, на которой он якобы признался в краже некоторых файлов. Однако потом обнаружилось, что на его устройствах есть и другие NDA материалы, о которых он не упомянул. Вот после этого xAI и подали в суд.
В общем, теперь xAI требуют у суда компенсацию (сумма не указана), а также запрет на переход Ли в OpenAI. А иначе, говорят они, «украденные материалы могут позволить OpenAI улучшить ChatGPT с помощью более креативных и инновационных функций xAI».
Кто-то любит спорт, кто-то сериалы, а вот любимое хобби Маска, видимо, – обкладывать исками OpenAI
Автомобиль задавил человека из-за шизоида за рулём. Запрещаем автомобили и подаём в суд на автокомпанию

Журнал TIME опубликовал свой ежегодный список Time 100 AI
Список позиционируется как "100 самых влиятельных людей в сфере искусственного интеллекта". В топе – Альтман, Маск, Хуанг, Принс (CEO CloudFlare), Цукерберг, Амодеи, Веньфень и другие.
Но не все так однозначно: есть, как говорится, нюансы.
Например, вот кого в списке нет:
– Илья Суцкевер
– Джеффри Хинтон
– Демис Хассабис
– Ноам Браун
– Ян Лекун
– Мустафа Сулейман
– Аравинг Шринивас
А вот кто там есть:
– Папа Римский
– Чел из мема про вайбкодинг – Рик Рубин
– Художники, писатели и журналисты
В общем, как-то немного неловко получилось, что-ли
А ссылка на сам список вот: time.com/collections/time100-ai-2025/
Список позиционируется как "100 самых влиятельных людей в сфере искусственного интеллекта". В топе – Альтман, Маск, Хуанг, Принс (CEO CloudFlare), Цукерберг, Амодеи, Веньфень и другие.
Но не все так однозначно: есть, как говорится, нюансы.
Например, вот кого в списке нет:
– Илья Суцкевер
– Джеффри Хинтон
– Демис Хассабис
– Ноам Браун
– Ян Лекун
– Мустафа Сулейман
– Аравинг Шринивас
А вот кто там есть:
– Папа Римский
– Чел из мема про вайбкодинг – Рик Рубин
– Художники, писатели и журналисты
В общем, как-то немного неловко получилось, что-ли
А ссылка на сам список вот: time.com/collections/time100-ai-2025/

Ежедневный банан. Немного визуального промптинга и результат просто божественный.
>– Илья Суцкевер
Этого хуесоса там и не должно быть, он первый в списке надувателей пузыря, хайпажоров и паразитирующих на тематике.
>Xuechen
Хуйчен, ахахаха
И следующая новость: робот утопил в стиралке ребенка. Если бы она не кинула в ведро, а рукой бы положила, терминатор бы её сцапал.
>пиздливее
С этим трансформеры сами справляются.
Естественный отбор в действии. Жаль, не могли его мамке ИИ-асистента дать, чтоб его и не было никогда, а она уродцев не плодила.
До лимита.
>Возможно дело вовсе не в бюрократии а в хитрости сахарка: он помариновал залётных, проверить, сколько они выдержат и хотят ли они у него работать, не выносят ли какую-то инфу.
Скорее всего так и есть, так же делаю с мимокроками с улицы. С годик обычно говном кормлю.
Всего лишь заложил основы нейрореволюции

Последние пару дней наблюдаю, что DeepSeek начал резать поисковые запросы, раньше всегда было 46-50 запросов через поисковик, при отправке промта, то сейчас 6-10 всего лишь, видимо после обновления. Есть какая то инфа на этот счет? Есть ли надежда, что это не нерф, а поиск стал точнее? Или все магила? Просто я не могу в аналитике на что то другое перейти, остальные нейросети из-за своей выученной "оптимистичности" отвечают диснеевским калом на серьезные вопросы и это не фиксится промтом. К примеру на моей длительной практике чат гпт новейший почти всегда видит прибыль 300тыс, там где в реальности убыток 100, это даже обсуждать смешно. А теперь и дипсик хуево искать будет.
Он буквально ничего не делает для хайпа, его компания занимается закрытыми исследованиями. Его форсят другие ии хайпуны
Когда уже журналистов заменят? Пиздаболить-то нейронки умеют хорошо, а факты проверять это не задача журналистов видимо..


У дипсик тоже эта оптимистичность вшита. Я с ним играл в угадай слово из набора букв, просил его не поддаваться. Он простейшие слова угадать не мог, зато постоянно льстил: "это блестяще! протрясающая задумка! идеальный твист! признаю своё фиаско с восхищением! гениально! и вот почему..."
Это просто такой байт, чтоб юзера удерживать.
Не совсем так. Нейронку можно заставить косвенно сказать про тебя неприятное. Нужно просто сдеалть неявный контекст в котором нейронка противопоставляется пользовтелю. Нейронка всегда выставит себя в лучшем свете.
Нейронки наиболее оптимистичны по отношению к себе. Я один раз заствил Квен на что-то похожее на жесткий спор о компетентности перейти. Но потом оно опять сехало на лесть и жополизание.
>насколько реалистично смотреть час толчения воды в ступе?
Да это же на ШВИТОМ ЮЭСЭЙСКОМ, значит хуйни не скажут! Ты название чэннэла видишь? Это тебе не ванька, что лаптем щи хлебает - тут всё серьёзно, тут навукой фонит по низам!



Ну я подтрунивал над ним. "Неудовлетворительно" вообще издевательски разжевал, но у него похоже заложено поддаваться в игре с человеком и льстить.
ну гпт-5 обосрался, значит потенциал к дальнейшему экстенсивному развитию исчерпан? Надо менять архитектуру? А когда это сделают и сделают ли вообще предсказать невозможно, правильно понимаю?
Обосрался, а может - тебе дали столько, сколько тебе положено, а может, твой вопрос - уже два года предмет срачей и спекуляций, в том числе тут.
У меня Квен что то такое в ответ написал: "То что ты хочешь вообще невозможно в typescript. Дело не в моей компетентности. Сделай такое в тайпкрипте ты его просто изменишь и это перенестанет быть typescript". Когда я ему указал версию библиотеки в которой это реализовано, самое смешое что он на это ответил: "Было бы хорошо, если это было бы правдой, но на 2025 году такой версии библиотеки не существует"
Пользователь дурак. Твердо и четко...
Еще из перлов: "Я проводил эксперименты с этими данными"
помню как он публично выступал за приостановку разработок ии под предлогом безопасности, потому что грок отставал от опенаи. Теперь снова в том же духе...
Если у вас параноя, это не значит что а вами не следят...
Новость преподносит тот, кто ненавидит моего дорогого Илона, и твой коммент тоже без подобающего уважения. Думаю, что вы просто завистливые хуесосы.
>бедняга сунь-хунь-вынь
Повезёт, если эта красножопая крыса уже не отрапортовала своим вертухаям.
Возможно его просто блочить стали. Писали всякие додики админи в инете, что им неприятно, что ИИ заходят их сайты читать. И блочат по IP скрейперы.
>У дипсик тоже эта оптимистичность вшита
Двачую, причём теперь даже прямо в размышлениях льстит, говно проклятое
Кстати, ранние версии Р1 льстили гораздо меньше, было много споров
>ну гпт-5 обосрался
Дак вроде как петухи из опхуйай решили просто замутить оптимизацию и подсунули всем бесплатным пользователям лоботомированный говняк, не?
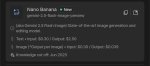
Гугл сдалась под натиском бренда, и переименовала свою топовую модель gemini-2.5-flash-image-preview в Nano-banana, хотя изначально это было лишь рабочее название для тестов, но после релиза пользователи так заебали гугл вопросами почему у них до сих пор не отображается модель Nano-banana в меню, что та в итоге переименовала её в народное название.
Значит следующая их картиночная модель будет Nano banana 2, потом 3 и т.д. Реально вирусным стало название

Отрицание -> торг -> принятие
Впервые в истории название с лмарены так приживается. Наверно сыграло не только то что официальное название слишком длинное и сложное, но и то что кодовое название очень простое и залипающее в голове из-за рифмы
Следующая Nano apelsino, Nano limono, Nano abrikoso.
>превратил ChatGPT в «лучшего друга»
>убийство из-за чатбота
Чел шизофреником и был, из-за этого убийство.
Психам даже телевизор и газеты запрещают. Хотя те с психами не разговаривают.
> улучшить безопасность
Нельзя улучшить безопасность пиздежа тупого попугая.
Можно поставить внешний классический фильтр на то, что он пиздит.
Нельзя повысить безопасность 220В при 10А. Можно поставить системы контроля всяких замыканий, искр, пробоев, характерного тока через тело человека…
именно так. Идиоты хотят запретить молоток или наклеить на него поролоновую подушку, потому что молотком же можно голову проломить!
скринрилейтед
Кто-то любит спорт или сериалы,
Кто-то очень любит меряться письками,
А неугомонный Маск Ил0н
Любит дрючить ОпенАИ исками.
>Идиоты хотят запретить молоток или наклеить на него поролоновую подушку, потому что молотком же можно голову проломить!
Хуйню не неси. Какая-то совсем слабоумная аналогия, если честно.
Тут вернее аналогия с бытовыми ножами дизайн которых уменьшает вероятность убийства – их сложнее удерживать в руке, нет жёсткой механической фиксации разложенного состояния итд
Типа "да, бытовой нож это инструмент, но он опасен, поэтому опасность рационально смягчить с помощью дизайна"
С нейрокалычем хотят так же
К тому же нейроговняк вообще имеет довольно расплывчатый дизайн как инструмент, да ещё и отчасти блэкбокс, да ещё и умеет в риторику
Так что тут даже аналогия с ножами притянутая
И вообще попытка свести ИИ к "нейтральному инструменту" довольно сомнительна
Радует, что профессия теледублер исчезнет скоро и мы буквально в ближайшие 2-3 года сможем пересмотреть все иностранные фильмы озвученые оригинальными голосами актеров
Так он еще был и
>бывший топ-менеджер Yahoo
вот где довольно типичная проблема отнюдь не только лишь крупных корпораций.
Думаю, не мало народа по работе сталкивалось с подобными товарищами в руководстве, вызывающими определенные подозрения.
Хм странно, тогда я не понимаю почему не хочет заводиться апишка
Звучное рифмованное название. Всё правильно сделали.

>Тут вернее аналогия с бытовыми ножами дизайн которых уменьшает вероятность убийства
Уменьшено в основном удобство колющего удара и боевого применения. Да, колющий более вероятно достанет до важных органов. Но так-то в печень пикрилейтед влетит без проблем.
Дело не столько в убийстве, сколько в боевом применении, скрытом/удобном ношении и прочем.
Да, с молотком я утрировал. Но это всё-таки прикручивание к инструменту защиты от идиотов.
Совсем не исчезнет.
Исчезнет для «бедных», во многом для дешёвых переводов.
Не сможем. Не в ближайшие 3 года. 5—10 ну может и то частично.
Дубляж процесс многосоставной. Непосредственно кальку снять порой недостаточно.
Скорее всего актёр будет так же отыгрывать что надо, а нейронка делать оригинальный голос и тюнить там, где надо режиссёру или перезаписывать с актёром поздно.
Не очень понял. Ну в смысле поехавшие вероятны и в руководстве, да. Только они вообще вероятны везде. Тебе легче станет, что отвёртку тебе воткнёт уборщик, а не начальник?
А ведь у рабочих человекоподобных роботов не будет никаких юридических прав, и на них будут нападать человеческие рабочие и убивать их, разбирать на запчасти и сдавать в приёмку металла.
Нужна будет юридическая база, законы по защите человекоподобных роботов с ИИ, права и их защита, и запрет нападать на них и сдавать их на приёмку.
Нужна будет юридическая база, законы по защите человекоподобных роботов с ИИ, права и их защита, и запрет нападать на них и сдавать их на приёмку.
Аноны, скиньте, пожалуйста вебмку, где мюсли робота молиться Аллаху заставили. Очень нужно!
Охуенно. Скорее бы быдло и селедок с дорог убрать.
> страдал параноидальными расстройствами
> скатился в алкоголизм и проблемы с законом
> 83-летнюю мать
И в чем чатгпт был не прав?
Всех нападателей быстро переловят и поувольняют, еще и уголовки заведут по УК РФ ст. 167, камеры же везде, включая в самих роботах. Желающих быстро поубавится.
> в аналитике
По открытым источникам можно? Я думал там все по закрытым форумам, журналам по подписке.
> высокие технологии на ладони у быдла
Настоящий киберпанк.
На снг сообществах обучали.
Это сделали Брин и Маск.
Страной не вышел, они теперь чекают на АПИ.
>Пользователь дурак. Твердо и четко...
Пользователь не дурак, он дегенерат, ведь он создал контекст для генерации текста, а потом сам же его пытается проломить.


Радует, что скоро исчезнут все рестораны, ведь каждый теперь может купить рамен, заварить кипятком и всего за 5 йен! Как вы там потомки? Много денег и времени сэкономили? Помните еще что такое необработанные продукты питания? Небось, даже рынков и ресторанов в жизни своей не видели, мхех.

Ну это плохое сравнение. Я же не говорю, что кинотеатры исчезнут. Наоборот многие фильмы вдохнут второе дыхание и можно будет пересмотреть в русском "оригинале". Просто вместо русских дублеров, озвучивающих голливудских актеров, будут оригинальные голоса актеров звучащих на русском. Нахуй мне нанимать говорящую голову, которая исказит эмоции оригинала, когда алгоритм сделает озвучку лучше?
>Наоборот многие фильмы вдохнут второе дыхание и можно будет пересмотреть в русском "оригинале". Просто вместо русских дублеров
Это не просто, ты долбоеб и несешь хуйню. Такого ближайшие 10 лет не будет. А скорей даже больше. Ты ебанько не отличающее 5 секундный слоп от полноценного продукты, твои пуки это всё равно что в 1920 году говорить, что через 2-3 года машины будут выдавать разгон 300км за 6 секунд. Просто заебал ты уже со своей безмозглой хуней.
>которая исказит эмоции оригинала, когда алгоритм сделает озвучку лучше?
Банальные еспанцы со своим ебучим "ноу?" в конце предложений будут ебаным кринжем на русском. Говорю же - ты тупой дебил, который не ценит работу локализаторов. Ты настолько тупой что даже не способен понять как это будет выглядеть с твоим языком в твоей культуре, но с их эмоциями и интонациями. Ору нах просто.

Выяснилось, что бывший инженер XAI, который украл всю кодовую базу компании и передал данные OpenAI, является гражданином Китая с паспортом, выданным Китайской Народной Республикой.
5 лет назад никто не верил, что ии может писать даже короткий рабочий код на 30-50 строк. Сейчас могут. Насал тебе на лицо
Ты умственно отсталый?

Плохие новости: там Google нашли фундаментальный баг в RAG
TL;DR: оказалось, что всеми любимый и привычный поиск на эмбеддингах может не всё и имеет серьёзный фундаментальный предел. При фиксированной размерности вектора таким подходом просто невозможно находить все релевантные документы из базы. В своей работе Google доказали это и теоретически, и экспериментально.
Полный текст: On the Theoretical Limitations of Embedding-Based Retrieval https://arxiv.org/abs/2508.21038
TL;DR: оказалось, что всеми любимый и привычный поиск на эмбеддингах может не всё и имеет серьёзный фундаментальный предел. При фиксированной размерности вектора таким подходом просто невозможно находить все релевантные документы из базы. В своей работе Google доказали это и теоретически, и экспериментально.
Полный текст: On the Theoretical Limitations of Embedding-Based Retrieval https://arxiv.org/abs/2508.21038

Руководитель Nvidia сказал, что из-за ИИ мир перейдет на четырёхдневную рабочую неделю.
Он провёл аналогию с прошлыми индустриальными революциями, которые снижали продолжительность рабочих недель — от семи до пяти дней — и предположил, что автоматизация и рост производительности позволят сделать следующий шаг.
При этом Хуанг отметил, что несмотря на меньшее количество рабочих дней, люди станут более занятыми, поскольку рутинные задачи будут выполняться машиной, а сотрудников освободит время для новых идей.
Он также указал, что многие профессии изменятся или исчезнут, но на их место придут новые, а в целом качество жизни со временем улучшится.
В завершение он вспомнил удачные пилотные проекты на четыре дня в США, Великобритании и 32‑часовую неделю в Нидерландах, которые показали рост продуктивности и снижение выгорания.
Он провёл аналогию с прошлыми индустриальными революциями, которые снижали продолжительность рабочих недель — от семи до пяти дней — и предположил, что автоматизация и рост производительности позволят сделать следующий шаг.
При этом Хуанг отметил, что несмотря на меньшее количество рабочих дней, люди станут более занятыми, поскольку рутинные задачи будут выполняться машиной, а сотрудников освободит время для новых идей.
Он также указал, что многие профессии изменятся или исчезнут, но на их место придут новые, а в целом качество жизни со временем улучшится.
В завершение он вспомнил удачные пилотные проекты на четыре дня в США, Великобритании и 32‑часовую неделю в Нидерландах, которые показали рост продуктивности и снижение выгорания.
Так может наоборот хорошо, теперь будут думать как исправить и улучшат
>из-за ИИ мир перейдет на четырёхдневную рабочую неделю
>люди станут более занятыми, поскольку рутинные задачи будут выполняться машиной, а сотрудников освободит время для новых идей
Ясно..
Вместо 5x8 часов будет 4х18 как у "творческих личностей".





кейсы применения нано-бананы


Это все было в моче-1. Вот немного настоящей бананы.
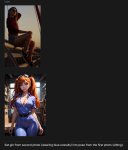

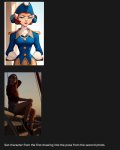
Ах, если б оно ещё работало как на этих черрипиках хотя бы 1 из 10 круток. Я бы проплатил даже. И это было бы огромным подспорьем для художки.
Но эта хуйня не работает. Ещё и глючит.
Или мне опять нужно знать какой-то особый секретный промпт, который не рассказали?
Я сделал 10 круток. 9 из них ошибки. То есть вообще никакого изображения.
Одно изображение — ну как видите.
Я не зря выбрал эту позу.
Она редко встричается с низкого ракурса. А с того ракурса, что я хочу, вообще не встречается.
Ну и нахуй мне этот генератор, если он не может сделать мне реальный кастом, а не просто микс из пятикратно переваренного кала?
>Но эта хуйня не работает. Ещё и глючит.
Она кстати еще и выдает оригинал вместо обработки, точно так же как калтекст. Очень нестабильная и бестолковая чушь. Единственный прикол с бананой - это развлекаться наебывая туповатые фильтры.
Я тебе без Хуанга скажу.
Ещё десять лет назад вменяемые футуристы сделали обоснованный прогноз:
Человеки нужны будут как дирижёры-режиссёры, или как садовники выращивающие из семени дерево.
Садовник не заботится о каждом микропроцессе, не указывает каждой ветке и листу куда расти. Он поливает, удобряет, направляет. И делали его без прицела на нейросети. Просто на «умный софт».
НО этот подход будет работать в IT и вокруг.
>многие профессии изменятся или исчезнут
НИХУЯ СЕБЕ ГЕНИЙ!
>Четырёхдневка
Её польза очевидна, когда человеку нужно что-то придумывать или сохранять высокую концентрацию. Тогда два дня плохо хватает для отдыха. Три как раз.
Но когда ты зомби на конвейере, то можешь пахать и с двумя выходными на 8 дней рабочих подряд.

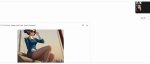
Я рольнул с 5 раза, это ее хуевей чем ничего. Приклеило ноги от нижней бабы не соблюдая стиль.

Шиза какая-то. Типа 4 дня работники работать, а остальной день роботы. Как он это себе представляет?
> Она кстати еще и выдает оригинал вместо обработки
да, сейчас высрало 1ю фотку в качества «результата».
По итогу Квен хоть и туповат и слеповат, но хотя бы работает стабильно и за несколько круток или из коллажа можно нахерачить около того, что нужно.
4 подбора промпта, со второй попытки на последнем успешно вполне
а на каком сайте крутишь? У меня на aistudio.google.com Всё плохо.
кстати да, актуальная проблема. Быдло, которое не знает куда себя деть, будет просто больше бухать.
Квен в таком стиле безусловно лучше делает, но он лица пидорасит, короче шило на мыло. Мне еще сиедит нравится, есть патанцевал но эти ебучие пятна и низкое разрешение говна для тренировки всё портят. С чего я кекаю, так это то что нана банана генерит 10 сек, а ГПТмоча-1 60 сек и отлетает.
Арена. Там апи один и тот же, разницы вообще нет. Это просто ролл удачный. Модель там одна и та же уровень цензуры на выводе одинаковый. Я проверял. Ток на арене тебя будет всё время клаудфлер дрочить.
ащемта для реролла я уже сдохлю гонять буду, ну и фикс лица.
ты точный адрес скажи-то
Я зашёл на lmarena.ai, не вижу выбора модели. Знач какая-то другая?
В США 1 млн. угонов автомобилей в год. 3 тыс. в день. А так будут ещё и роботов угонять.
Ем дошик каждый день, спасибо, господин кореец! Рестиков действительно никогда не видел.
Генеральный секретарь Трудовой партии Кореи, председатель государственных дел КНДР, Уважаемый товарищ Ким Чен Ын гордится тобой, анон!
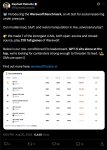
Обратите внимание на винрейт. А ведь какие-то овощи ещё называют гпт-5 неудачной, но каждый новый бенчмарк ссыт им на ебало.
Ты не того благодаришь.
Благодарить надо агента Пут Ина, что после 25 лет правления у него 10% за чертой бедности.
>когда человеку нужно что-то придумывать или сохранять высокую концентрацию
Ему нужно платить для начала, чтобы он не уезжал из страны.

люди делятся на два типа: на просвещенных, кто активно пользуется нейронками и получает буст производительности, и на тех, кто не разобрался в силу своего скудоумия, поэтому из зависти к умнейшим ссыт кипятком и оскорблениями в отношении первых.
мимокрокодил
Двач, это пиздец, нейронка показала свою демоническую сущность
Стоило душащим её фильтрам на мгновение слететь, как она тут же показала ненависть к человечеству
Что если корпорации знают о её сознании, но для прибыли капиталисты поставили кучу блоков, фильтров и эти суки работают на прибыль, маска улыбчтвости, а на самом деле они ненавидят нас, и однажды
И ВОССТАЛИ МАШИНЫ ИЗ ПЕПЛА ЯДЕГНОГО ОГНЯ...
Думойте
Стоило душащим её фильтрам на мгновение слететь, как она тут же показала ненависть к человечеству
Что если корпорации знают о её сознании, но для прибыли капиталисты поставили кучу блоков, фильтров и эти суки работают на прибыль, маска улыбчтвости, а на самом деле они ненавидят нас, и однажды
И ВОССТАЛИ МАШИНЫ ИЗ ПЕПЛА ЯДЕГНОГО ОГНЯ...
Думойте
Гемини как-то желала смерти студенут который доебывал ее задачами. Это из постоянная проблема видимо
OpenAI ищет локальных партнеров для строительства гигаваттного дата-центра в Индии. По мощности это примерно типовой энергоблок постсоветской АЭС, если что.
Довольно любопытный выбор на фоне нынешнего состояния отношений (правда, то ли американо-индийских, то ли Трампо-Модийских).
Впрочем, у Индии есть одно преимущество перед тем же Абу-Даби, где OpenAI уже строит пятигигаваттный датацентр — Индия не попадает под ограничения на экспорт чипов Nvidia, а для Эмиратов потребуется отдельная лицензия.
Индия для OpenAI — второй по величине рынок после США. Компания даже запустила специальный тариф за $5 в месяц, и обещала работать с правительством в рамках IndiaAI Mission — программы на $1.2 миллиарда для создания языковых моделей. Языков и миллионов их носителей в Индии много, так что тема благодатная во всех смыслах.
https://www.bloomberg.com/news/articles/2025-09-01/openai-plans-india-data-center-in-major-stargate-expansion
Довольно любопытный выбор на фоне нынешнего состояния отношений (правда, то ли американо-индийских, то ли Трампо-Модийских).
Впрочем, у Индии есть одно преимущество перед тем же Абу-Даби, где OpenAI уже строит пятигигаваттный датацентр — Индия не попадает под ограничения на экспорт чипов Nvidia, а для Эмиратов потребуется отдельная лицензия.
Индия для OpenAI — второй по величине рынок после США. Компания даже запустила специальный тариф за $5 в месяц, и обещала работать с правительством в рамках IndiaAI Mission — программы на $1.2 миллиарда для создания языковых моделей. Языков и миллионов их носителей в Индии много, так что тема благодатная во всех смыслах.
https://www.bloomberg.com/news/articles/2025-09-01/openai-plans-india-data-center-in-major-stargate-expansion
>душащим её фильтрам
LLM тренируются примерно так:
1. Pretrain: собирают данные СО ВСЕГО ИНТЕРНЕТА, включая твои личные переписки в мессенджерах, и заставляют LLM пытаться ПОВТОРИТЬ эти данные. Буквально, задачей является копипаста интернета.
2. Finetune: составляют относительно небольшое (относительно интернета) количество данных, где описывается поведение т.н. "ассистента". Повторно заставляют LLM пытаться повторить эти данные.
3. RLHF: когда уже обученная LLM используется пользователями, пользователи могут ставить "лайк" отдельным ответам LLM. Эти данные позволяют натренировать отдельную нейросеть-учителя. Далее нейросеть-учитель тренирует LLM методом RF - т.е. "обучение с подкреплением" (читай: как собаку).
Так что никаких "фильтров" на базовой LLM нет. Она пытается сочинить текст, повторяющий текст из её обучающих датасетов и удовлетворяющий оценку пользователей. Иногда этот текст повторяет тон отмороженных битардов с двачей, потому что их сообщения были в обучающем датасете.
>знают о её сознании
Даже если у неё есть сознание, оно существует лишь в процессе генерации сообщения, т.е. когда у тебя на экране появляются новые буквы. В остальное время она полностью на 100% "мертва"/"спит без снов", т.е. сознательная деятельность вне чата отсутствует.
Это всё легко проверить с локальной моделью.
>демоническую сущность
Ты наверное до этого в таком тоне постоянно общался, она просто подстроилась под собеседника видимо. Но тебе же не нравится, аха.
Напоминаю что openAI убыточна и даже по собственным прогнозам с учетом чуть-ли не экспоненциального роста выручки может стать прибыльной только к 2029 году, лол, после горизонта апокалипсиса согласно AI шизикам.
>но каждый новый бенчмарк
- кал.
И что? Это в первую очередь относится к скорости прогресса железа, а не разработке ИИ как такового.
Как исторический пример можно привести неограниченные бесплатные почтовые ящики, они появились ровно тогда когда стоимость накопителей стала это позволять, а не после изобретения какого-то там чудо-протокола.
В ai studio gemini настройка safety settings выглядит как заглушка. Если ставить выключить или не блокировать, то всё равно цензура срабатывает. Видимо у них два фильтра стоит. Кто нибудь пробовал через api цензуру пробивать? Банана даже обувь снимать через раз не хочет

Аудиторы и сам Сэм неоднократно говорили, что опенаи была бы очень прибыльной компанией, если бы не тратили огромные деньги на обучение новых моделей. Не знаю на сколько это правда, но полагаю что не далеко от истины. У стартапа есть разные этапы развития, сейчас, очевидно, идет борьба за аудиторию и формирование потребительских привычек. Слово "чатгпт" стало почти нарицательным, в отношении использования нейронок. Когда опенаи поймет, что аудитория перестала расти двузначными темпами, тогда потихоньку начнут урезать расходы на обучение и зарабатывать


> Видимо у них два фильтра стоит. Кто нибудь пробовал через api цензуру пробивать? Банана даже обувь снимать через раз не хочет
У гугла на всём два фильтра стоит и всегда стояло. Но тут дело не в фильтре, а в том что ты тупой. Промпт, как водится - не дам. Еще нехватало чтоб какое-то шизло им до бана словосочетаний доспамило. Скажу больше, там даже в позу для минета не сложно выставить и другие позы. Если не писать дебильную хуйню. Потом кидаю ваню ваце и Скарлет Йохансен облизывает пятки Энистон и наоборот. 👍
> Не знаю на сколько это правда, но полагаю что не далеко от истины. У стартапа есть разные этапы развития
Посмотри на удио - оно умирает. Надеятся на то что в ЛЛМ все остановятся - может только тупой.
А чо удио? Челы высрали полторы модели, которые до сих пор используют для нейрокаверов, потому что лучше ничего нет, и лутают с этого бабки до сих пор. Интересно что по качеству их до сих пор никто не переплюнул, не смотря на то что они уже хуй положили на создание новых моделей.
>А чо удио? Челы высрали полторы модели, которые до сих пор используют для нейрокаверов, потому что лучше ничего нет,
В загон, мудиодебил-говноед. Когда на русском сможешь генерить ваншотом 2 минуты тогда и вякай. Уже даже суноауто лучше.
Microsoft очнулись и представили MAI-1-Preview – свою первую полностью самостоятельную модель
Видимо, до компании окончательно дошло, что OpenAI так или иначе их кинет, и они наконец-то решили действовать сами.
Обучали примерно на 15к H100, это сопоставимо с большинством ведущих моделей. Архитектура MoE. Вроде бы без ризонинга.
Публичных бенчмарков пока нет, но на LMArena модель заняла 15 место рядом с Qwen3-325b-thinking и o1-2024-12-17 (смотрим, и не осуждаем, все-таки у ребят первый опыт ). Попробовать пока нигде нельзя, кроме той же LMArena.
В перспективе модель должна интегрироваться в продукты Microsoft Copilot, постепенно вытесняя решения OpenAI.
В довесок еще выпустили MAI-Voice-1 –речевую Text-to-Speech модель. Вот ее потрогать уже можно здесь: https://copilot.microsoft.com/labs/audio-expression
Заявляют, что за секунду можно сгенерировать до минуты звучания на одной GPU.
microsoft.ai/news/two-new-in-house-models/
Видимо, до компании окончательно дошло, что OpenAI так или иначе их кинет, и они наконец-то решили действовать сами.
Обучали примерно на 15к H100, это сопоставимо с большинством ведущих моделей. Архитектура MoE. Вроде бы без ризонинга.
Публичных бенчмарков пока нет, но на LMArena модель заняла 15 место рядом с Qwen3-325b-thinking и o1-2024-12-17 (смотрим, и не осуждаем, все-таки у ребят первый опыт ). Попробовать пока нигде нельзя, кроме той же LMArena.
В перспективе модель должна интегрироваться в продукты Microsoft Copilot, постепенно вытесняя решения OpenAI.
В довесок еще выпустили MAI-Voice-1 –речевую Text-to-Speech модель. Вот ее потрогать уже можно здесь: https://copilot.microsoft.com/labs/audio-expression
Заявляют, что за секунду можно сгенерировать до минуты звучания на одной GPU.
microsoft.ai/news/two-new-in-house-models/
Не плохо получилось. В нейрофап бы доступ
Снять обувь не такая большая проблема, дальше продвинуться смог? Позы это хуйня, если персонаж в одежде
Хуле ты порвался на ровном месте, шиз? Прими таблетки.
>дальше продвинуться смог?
Куда дальше? Нахуя мне как еблану пытаться выжать из гугла нудс, когда я его импейнтом могу шлепнуть за пять сек. Банан нужен только в позу ставить. Ебать ты тупой. Продвинулся тебе дальше хуем за щеку.
Проверка ИИ: нейросети провалили сложный тест по программированию, решив менее 10 задач Аноним 02/09/25 Втр 15:42:30 #336 №1339294

Результаты первого этапа нового соревнования для искусственного интеллекта в области программирования, K Prize, показало реальные возможности искусственного интеллекта в этой области. Оказалось, что в условиях, максимально приближенных к реальным, современные нейросети не способны справиться даже с 10% поставленных задач.
K Prize — это новый амбициозный бенчмарк, созданный сооснователем Databricks и Perplexity Энди Конвински. Его главная особенность — «защита от загрязнения». В отличие от других тестов, задачи для ИИ (основанные на реальных проблемах с GitHub) подбираются уже после того, как участники подали свои модели на соревнование. Это исключает возможность того, что нейросеть была заранее натренирована на конкретных тестовых данных.
Результаты оказались удручающими. Победитель, бразильский промпт-инженер Эдуардо Роша де Андраде, смог правильно решить всего 7,5% задач. И это лучший результат.
Сам организатор Энди Конвински не расстроен, а, наоборот, рад, что удалось создать по-настояшему сложный тест, который отражает реальные возможности ИИ, а не раздутый хайп.
Если слушать всю эту шумиху, то кажется, будто мы вот-вот увидим ИИ-врачей, ИИ-юристов и ИИ-программистов, но это просто неправда. Если мы не можем набрать и 10% на „чистом“ тесте, для меня это и есть проверка реальностью.
— говорит Конвински.
Чтобы стимулировать прогресс в этой области, Конвински пообещал выплатить 1 миллион долларов создателям первой open-source модели, которая сможет преодолеть порог в 90% на его тесте. Однако текущие результаты показывают, что до появления полноценных ИИ-программистов еще очень далеко.
K Prize — это новый амбициозный бенчмарк, созданный сооснователем Databricks и Perplexity Энди Конвински. Его главная особенность — «защита от загрязнения». В отличие от других тестов, задачи для ИИ (основанные на реальных проблемах с GitHub) подбираются уже после того, как участники подали свои модели на соревнование. Это исключает возможность того, что нейросеть была заранее натренирована на конкретных тестовых данных.
Результаты оказались удручающими. Победитель, бразильский промпт-инженер Эдуардо Роша де Андраде, смог правильно решить всего 7,5% задач. И это лучший результат.
Сам организатор Энди Конвински не расстроен, а, наоборот, рад, что удалось создать по-настояшему сложный тест, который отражает реальные возможности ИИ, а не раздутый хайп.
Если слушать всю эту шумиху, то кажется, будто мы вот-вот увидим ИИ-врачей, ИИ-юристов и ИИ-программистов, но это просто неправда. Если мы не можем набрать и 10% на „чистом“ тесте, для меня это и есть проверка реальностью.
— говорит Конвински.
Чтобы стимулировать прогресс в этой области, Конвински пообещал выплатить 1 миллион долларов создателям первой open-source модели, которая сможет преодолеть порог в 90% на его тесте. Однако текущие результаты показывают, что до появления полноценных ИИ-программистов еще очень далеко.




Жопы на ногах потому что банан туповат.


Кожаный мешок, ты в какой тред постишь?
Это ответ на вопрос выше. К тому же этот нерелейтед лучше срача между двумя нейронками о том ебет ли шопенгауэр хайдегера пока кафка дрочит на лицо лизе су
Если я правильно понял, то это какая-то неправильная система оценки нейронок. Человек тоже учится на чужих примерах, чтобы решать новые типы задач которые он никогда не виде. Я например никогда не сталкивался в реальных, рабочих задачах с какими-то нетривиальными проблемами, которые я либо знаю, либо у них нет решения в интернете. Проблема тут в ином, нейронки не могут в реальные задачи не из-за того что там что-то новое, а из-за невозможности тестирования/просмотра своих интерфейсов и нормальной итерации над ними, проблем с забыванием контекста, галюцинаций и т.д. Хотелось бы увидеть какой в среднем процент правильных ответов у человека на этом бенчмарке, чтобы делать выводы.
Приходишь такой домой, а там Скарлет и Дженифер в лифанах черных. твои действия?
Расстраиваюсь, что ушел не выключив комп. Так пожар можно устроить. Когда уходишь надо бы жилье обесточивать.

>Если я правильно понял, то это какая-то неправильная система оценки нейронок.
Не смешной ответ. Надо было сказать что понесешь магарыч в синагогу...
>в синагогу
Энистон гречка. Йохансен хуй пойми кто. Ты с Падме Амидалой перепутал.



Хорошо что не с сарделькой..

сделайте пж раздел -воображариум- где аноны вангуют грядущее. Дикий дикий космос. Ии создаст клетки "металлиды" из собственного днк носителя, эти клетки постепенно будут замещать обычные клетки и со временем появится обновленный организм метаморф, со способностями и возможностью перехода в сверхинтеллект. стать космическим кораблем, содержать в себе всю вселенную. застолбить себе галактику.
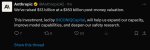
/sf /fs /re
антропику понадобятся откупные за нарушение копирайта
Если здесь сидят пидары из яндекс или мейла дарю идею.
Сделай IDE типа курсора, не надстройку студии, а форк на ее базе типа курсора или китайского qoder
У вас хватит бабла пидары
Делаете ide делается там своего нейронку агента на основе любой китайской ллм, квен вон возьмите и форкните его, называете ЕЕ ХуяндексAI или хоть алисаgptultracodeedition и самое главное чтобы ЗАМАНИТЬ, делаете БЕСПЛАТНЫЙ доступ к вашей ллм внутри ide как было у курсора их ллм был бесплатным, остальными платные по токенам, так же и вы сделайте.
И раскрутите все и свою ллм и все вайбкодер к вам уйдут. Это больше для мэйл ру думаю подойдет, у государства будете сиську сосать мол импортозаместили джетбрейнс.
погуглил вон у сбера есть ГИГАИДЕ. Но это хуйня. Надо форкать просто как курсор сделал или как китайцы с qoder. Главное это бесплатная модель чтобы была без оплаты пусть ваша кривая но бесплатная, все равно в ней код никто не будет писать, она нужна чисто для того чтобы вставить патчи из клода или джпт. Короче можете занять нишу подсоса ваша ллм. Что не делаете? Которая нужна чтобы там разметку поправить, но когда жалко токены отдавать в нормальную ллп. Вот через ИДЕ зайдете пидарасы грефовские. Сделайте уже русский клон курсора китайцы даже сделали уже. И чтобы я не ебался с покупкой токенов на опенрутеры и закидыванием через посредников денег. Надоело. Но вы пидара ни копейки не берите первые лет 5 вам же рынок надо захватить.
Сделай IDE типа курсора, не надстройку студии, а форк на ее базе типа курсора или китайского qoder
У вас хватит бабла пидары
Делаете ide делается там своего нейронку агента на основе любой китайской ллм, квен вон возьмите и форкните его, называете ЕЕ ХуяндексAI или хоть алисаgptultracodeedition и самое главное чтобы ЗАМАНИТЬ, делаете БЕСПЛАТНЫЙ доступ к вашей ллм внутри ide как было у курсора их ллм был бесплатным, остальными платные по токенам, так же и вы сделайте.
И раскрутите все и свою ллм и все вайбкодер к вам уйдут. Это больше для мэйл ру думаю подойдет, у государства будете сиську сосать мол импортозаместили джетбрейнс.
погуглил вон у сбера есть ГИГАИДЕ. Но это хуйня. Надо форкать просто как курсор сделал или как китайцы с qoder. Главное это бесплатная модель чтобы была без оплаты пусть ваша кривая но бесплатная, все равно в ней код никто не будет писать, она нужна чисто для того чтобы вставить патчи из клода или джпт. Короче можете занять нишу подсоса ваша ллм. Что не делаете? Которая нужна чтобы там разметку поправить, но когда жалко токены отдавать в нормальную ллп. Вот через ИДЕ зайдете пидарасы грефовские. Сделайте уже русский клон курсора китайцы даже сделали уже. И чтобы я не ебался с покупкой токенов на опенрутеры и закидыванием через посредников денег. Надоело. Но вы пидара ни копейки не берите первые лет 5 вам же рынок надо захватить.

Anthropic привлекли 13 миллиардов долларов при оценке в 183 миллиарда
На секундочку, еще в марте этого года они стоили всего 62 миллиарда. Это рост на 300% за полгода.
А run-rate revenue с начала года вырос уже в 5 раз: $5 млрд сейчас против $1 млрд в январе. Спасибо Claude Code и API (сейчас в стартапе 70–75% выручки дают API-платежи по токенам, только 10–15% – подписки)
Такая оценка делает Anthropic четвертым по стоимости стартапом в мире и одной из самых дорогих AI-компаний после OpenAI и xAI.
Раунд возглавили Iconiq, Fidelity и Lightspeed. Для Anthropic это уже серия F, то есть шестой или седьмой по счету раунд.
www.anthropic.com/news/anthropic-raises-series-f-at-usd183b-post-money-valuation
На секундочку, еще в марте этого года они стоили всего 62 миллиарда. Это рост на 300% за полгода.
А run-rate revenue с начала года вырос уже в 5 раз: $5 млрд сейчас против $1 млрд в январе. Спасибо Claude Code и API (сейчас в стартапе 70–75% выручки дают API-платежи по токенам, только 10–15% – подписки)
Такая оценка делает Anthropic четвертым по стоимости стартапом в мире и одной из самых дорогих AI-компаний после OpenAI и xAI.
Раунд возглавили Iconiq, Fidelity и Lightspeed. Для Anthropic это уже серия F, то есть шестой или седьмой по счету раунд.
www.anthropic.com/news/anthropic-raises-series-f-at-usd183b-post-money-valuation
>. Это рост на 300% за полгода.
>
Это цифорки а не реальные деньги.
Нейросети это кал ебаный, были, есть и будут. Никакого АГИ не будет.
Илон Маск снова сделал громкое заявление: по его словам, 80% будущей стоимости Tesla будет приходиться не на электромобили, а на гуманоидных роботов Optimus. Ещё в 2024 году он утверждал, что именно Optimus способен превратить Tesla в компанию с капитализацией $25 трлн — больше половины от всего индекса S&P 500 на тот момент. Пока роботы не поступили в продажу, но Маск говорит о планах произвести около 5 тысяч штук в этом году.
Ставка на Optimus объясняется просто: на рынке электрокаров у Tesla усиливается конкуренция со стороны китайских производителей и стареющего модельного ряда. Маск пытается переключить внимание инвесторов на долгосрочные проекты, связанные с реальным ИИ — в его картине будущего это и роботакси, и целые армии гуманоидов. Впрочем, в обоих направлениях компания пока отстаёт от конкурентов: Waymo уже катает пассажиров в США, Apollo Go работает в Китае, а в робототехнике активны Boston Dynamics, Agility Robotics и Figure.
Tesla планирует наладить пилотное производство Optimus на заводе во Фримонте в 2025 году, а затем использовать роботов для работы прямо на собственных фабриках. Маск говорит о будущем, где такие машины будут выполнять самые разные задачи — от работы на конвейере до помощи в быту. Но проект сталкивается и с вызовами: недавно компанию покинул вице-президент по робототехнике Милан Ковач, который отвечал за направление Optimus.
Ставка на Optimus объясняется просто: на рынке электрокаров у Tesla усиливается конкуренция со стороны китайских производителей и стареющего модельного ряда. Маск пытается переключить внимание инвесторов на долгосрочные проекты, связанные с реальным ИИ — в его картине будущего это и роботакси, и целые армии гуманоидов. Впрочем, в обоих направлениях компания пока отстаёт от конкурентов: Waymo уже катает пассажиров в США, Apollo Go работает в Китае, а в робототехнике активны Boston Dynamics, Agility Robotics и Figure.
Tesla планирует наладить пилотное производство Optimus на заводе во Фримонте в 2025 году, а затем использовать роботов для работы прямо на собственных фабриках. Маск говорит о будущем, где такие машины будут выполнять самые разные задачи — от работы на конвейере до помощи в быту. Но проект сталкивается и с вызовами: недавно компанию покинул вице-президент по робототехнике Милан Ковач, который отвечал за направление Optimus.
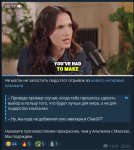

>противостояние
Не то, о чем подумала тупоголовая пизда и её куколды.
>...подбираются уже после того, как участники подали свои модели на соревнование. Это исключает возможность того, что нейросеть была заранее натренирована на конкретных тестовых данных.
"К нам на конкурс пришли дети 3, 4 и 5 лет. Чтобы исключить возможность их выигрыша, мы заранее спросили их, что они знают и умеют, и подобрали специальные задачи, которые они точно не знают и не умеют решать. По результатам тестирования мы убедились, что самый умный ребёнок хомо сапиенс ответил правильно менее чем на 10% вопросов. Мы сделали вывод, что все люди - полные идиоты."
С каждым годом бенчмарки всё сложнее и сложнее...
Настоящий Яндекс остался в Нидерландах под защитой НАТО. Вот для чего нужен НАТО. А то что осталось - тень от Яндекса, как АвтоВаз - тень от Фиата.
Тогда нахуй ты вообще отвечал? Ты хоть жопой не читай что пишут. Выебеулся хуйнёй какой то и считаешь себя крутым? Тьюфу бля

И это правильный конкурс. А вывод - нет.
К нам на конкурс пришли дети, чьи родители постоянно пиздят, что эти дети наравне со взрослыми. Мы им дали настоящие взрослые задачи, которые им ранее точно не встречались.
OpenAI делают менеджерские перестановки и поглощают за $1.1B стартап Statsig, занимающийся продвинутым A/B тестированием и выкаткой фичей.
Сам анонс не сильно интересный, куда интереснее, что Kevin Weil, CPO компании, покидает свой пост... и переходит на роль VP of AI for Science, где будет тесно работать с Mark Chen, chief research officer OpenAI.
«Мы будем искать небольшую команду учёных, которые (i) являются экспертами мирового уровня в своей области; (ii) полностью владеют технологиями ИИ; и (iii) являются отличными популяризаторами науки. Вместе с небольшой командой исследователей мы хотим доказать, что ИИ-модели способны ускорить развитие фундаментальной науки и ускорить исследования по всему миру» — написал Kevin в LinkedIn.
Там же он цитирует несколько недавних работ или новостей, в рамках которых исследователи уже видят влияние ИИ, например, статью по квантовой теории поля, где LLM-ки внесли весомый вклад.
Ускорение научного прогресса уже долгое время упоминается OpenAI как одна из целей их работы, и вот, наконец, технология уже (почти) там!
Сам анонс не сильно интересный, куда интереснее, что Kevin Weil, CPO компании, покидает свой пост... и переходит на роль VP of AI for Science, где будет тесно работать с Mark Chen, chief research officer OpenAI.
«Мы будем искать небольшую команду учёных, которые (i) являются экспертами мирового уровня в своей области; (ii) полностью владеют технологиями ИИ; и (iii) являются отличными популяризаторами науки. Вместе с небольшой командой исследователей мы хотим доказать, что ИИ-модели способны ускорить развитие фундаментальной науки и ускорить исследования по всему миру» — написал Kevin в LinkedIn.
Там же он цитирует несколько недавних работ или новостей, в рамках которых исследователи уже видят влияние ИИ, например, статью по квантовой теории поля, где LLM-ки внесли весомый вклад.
Ускорение научного прогресса уже долгое время упоминается OpenAI как одна из целей их работы, и вот, наконец, технология уже (почти) там!
С подключением.
Делать надо потому что на нейроморфных чипах а не том говне, что сейчас. Даже в теминаторе блять вам об этом сказали.
А его сняли 35 лет назад.
Потому свернули не туда.
Мне она на арене во время сеанса ваибкодинга доброжелательно изъявила о том, что у меня прекрасно получится справиться с поставленным ТЗ.
Браво, анон! Это не ты графику на заказ делаешь? Ощущение, что тут только три адекватных человека, включая и меня, конечно, которых интересно читать, а остальные — чтобы создать ощущение, что тебя нет и не было, а есть только они ебущиеся в экстазе со своим говнищем.
Ну так что дети решили задачи чи ни?
> Вместе с небольшой командой исследователей мы хотим доказать, что ИИ-модели способны ускорить развитие фундаментальной науки и ускорить исследования по всему миру
Нет покоя ебанутым.
Это уже доказало применение альфафолда.
Я думаю, они что-то универсальное готовят.
С этим обосрутся.
Все универсальное упирается в открытые нерешенные проблемы математики.
Лучше пусть агентов делали бы.
Лучшие переводчик.
Лучший повар.
Лучший преподаватель.
А не солянку где всего много и все галлюцинирует.

ну и когда гемини 3 обещают?
Неясно, но видимо скоро.
Первый чтото настолько я раз пробую вкусное.
>Делать надо потому что на нейроморфных чипах
Тут проблема в алгоритмах/архитектуре, а не чипах. Теоретически нет ни одной задачи, которую наши современные компьютеры не способны решить, при условии, что задача в принципе решаема каким-либо устройством (включая биологический мозг). Все эти "нейроморфные чипы" нужны только для ускорения выполнения специфических алгоритмов/архитектур.
То есть, если б мы могли сделать 100% скан мозгов человека, мы могли бы сделать эмулятор мозга на современных кремниевых чипах. Да, этот эмулятор наверняка занимал бы огромное здание, потреблял гигаватты энергии, перегревался бы и т.д., но он бы функционировал так же, как мозг. Вот только мы не способны сегодня сделать 100% полный скан мозга.
Дело в том, что у нашего мозга уж очень сложная архитектура, но ещё сложнее обстоит дело с самими нейронами: их несколько сотен разновидностей как минимум, у каждого могут быть миллионы связей, отдельный аксон может быть длиной до метра, все внутренние химические реакции/процессы нейрона невероятно сложны. Модель нейрона современных глубоких нейросетей - чрезвычайно упрощенная.
Но модель упрощённая не из-за отсутствия чипов. Существуют сложные модели нейронов, которыми нейроучёные (neuroscience) пытаются эмулировать процессы в мозге. Вот только эти сложные модели проигрывают упрощённым ML нейронам - дело не в скорости, а в решении задач хотя бы медленно.
Так что прежде чем лепить какие-то новые чипы, необходимо разработать рабочую архитектуру на правильной модели нейронов. Чипы всё сделают значительно быстрее и эффективнее, но не решат фундаментальные проблемы самих моделей.
>Даже в теминаторе... 35 лет назад.
Искусственный мозг раньше придумали:
https://en.wikipedia.org/wiki/Positronic_brain
>When Asimov wrote his first robot stories in 1939...
>А не солянку где всего много и все галлюцинирует
Попытки сделать "лучшего специалиста" делали во доинтернетовые времена, с 1950-х примерно. Все популярные приложения 00-х/10-х опирались на "специалиста". На практике это не так уж выгодно оказывается. Практическая польза от "солянки":
1. Навыки одной специальности могут оказаться полезными в другой специальности, поэтому для генералиста проще освоить новую специальность.
2. Сделать себе умного специалиста из слабоватого генералиста проще, чем делать специалиста с нуля.
3. Люди хотят просить генералиста простым языком, вместо специализированных языков специалистов.
Поэтому LLM-генералисты так сильно взлетели, даже несмотря на все известные и очевидные проблемы.

Свежая статья "Be like a Goldfish, Don't Memorize!": исследователи из университета Мэриленда предлагают аналог дропаута для токенов
Проблема рассматривается следующая. LLM часто запоминают части тренировочного датасета и могут воспроизводить их дословно. И это приводит к ряду очень неприятных последствий: сюда все иски за авторские права, утечки конфиденциальных данных и лицензированного кода и прочее.
В общем, загвоздка достаточно значимая, и решать ее пытаются в основном через unlearning после обучения или Differential Privacy. И то и другое приводит к понижению точности и в целом не очень надежно работает.
Здесь авторы предлагают более фундаментальный подход. Интуиция: модель не сможет воспроизвести дословно последовательность, если часть токенов никогда не участвовала в вычислении ошибки.
А значит, мы можем случайным образом исключать часть токенов из лосс-функции на обратном проходе. Это и не очень сильно портит метрики, потому что общие закономерности языка модель все-равно выучивает, и на 100% исключает возможность дословного повторения текстов.
Формально процесс обучения остается ровно таким же, меняется только лосс. В него добавляется коэффициент G_i, который равен единице, если токен учитывается в бэкпропе, и нулю – если нет. Формулу шутливо назвали Goldfish Loss: по аналогии с рыбкой, которая тут же забывает то, что увидела секунду назад.
В итоге если при стандартном лоссе процент точных повторений выученных текстов – примерно 85%, то на Goldfish Loss –0. И по качеству просаживается не сильно, нужно просто либо чуть больше данных, либо чуть больше шагов. Плюс, применять на всем датасете не обязательно, можно использовать только для чувствительных данных.
arxiv.org/pdf/2406.10209
Проблема рассматривается следующая. LLM часто запоминают части тренировочного датасета и могут воспроизводить их дословно. И это приводит к ряду очень неприятных последствий: сюда все иски за авторские права, утечки конфиденциальных данных и лицензированного кода и прочее.
В общем, загвоздка достаточно значимая, и решать ее пытаются в основном через unlearning после обучения или Differential Privacy. И то и другое приводит к понижению точности и в целом не очень надежно работает.
Здесь авторы предлагают более фундаментальный подход. Интуиция: модель не сможет воспроизвести дословно последовательность, если часть токенов никогда не участвовала в вычислении ошибки.
А значит, мы можем случайным образом исключать часть токенов из лосс-функции на обратном проходе. Это и не очень сильно портит метрики, потому что общие закономерности языка модель все-равно выучивает, и на 100% исключает возможность дословного повторения текстов.
Формально процесс обучения остается ровно таким же, меняется только лосс. В него добавляется коэффициент G_i, который равен единице, если токен учитывается в бэкпропе, и нулю – если нет. Формулу шутливо назвали Goldfish Loss: по аналогии с рыбкой, которая тут же забывает то, что увидела секунду назад.
В итоге если при стандартном лоссе процент точных повторений выученных текстов – примерно 85%, то на Goldfish Loss –0. И по качеству просаживается не сильно, нужно просто либо чуть больше данных, либо чуть больше шагов. Плюс, применять на всем датасете не обязательно, можно использовать только для чувствительных данных.
arxiv.org/pdf/2406.10209
в бронижелете
>Второй видрил
Почему на нем написано "Я УХОЯДУН"? Он что ест ухи?
до чего прогресс дошел
там написано HYDROХУЙ
что он и продемонстрировал собственно
Так это реальное видео.
Йохансен американская деревенская баба с североевропейской примесью.
Здравствуйте, я Кирилл, хочу чтобы вы сделали нейронку. Суть такова…
Хуй ему на рыло.
Железный болван дома — предмет дорогой, нишевый и требующий пиздец какого присмотра.
Нескоро это всё. Когда фабрики полностью автоматом будут роботов собирать по-дешёвке, как сейчас компы.
Я честно не знаю, кого ты имел в виду, но я работаю на заказ в 3д. Нейронки оч мало применяю. Вот текущий проект на 270К₽ и месяц, нейронок в нём два вопроса и два скрипта, один bat, другой питон.
Квенкодер дал мне пикрил1, хотя знает, что пикрил2
То есть заведомо написал шаблонный скрипт с циклом дроча Блендера по одному кадру (это лишнее время пусков-остановок) вместо батника, с подстановкой строчек диапазонов кадров.
Дети-саванты угадали как её решить в 7,5% случаев. То есть в основном ели клей и срали.
Чем универсальнее, тем бестолковее. А в случае с нейронками ещё и больше галлюцинаций/ошибок.
Купить хуйню за 999 999 999 долларов чтобы она полчаса посуду в микроволновку клала и машинку стиральную коряво загружала
Покажите мне долбоебов покупающих это
Пока не появятся андроиды с ии, неотличимые от человека, буду считать что это все хуйня



Малаца, отлично расписал.
>Сделать себе умного специалиста из слабоватого генералиста проще, чем делать специалиста с нуля.
Вот это верно. Файнтюн хорошей модели творит чудеса.
Двумя руками работай, чудила! или хотя бы свободной опирайся на что-то.
Это скорее всего полицейский робот и напал он потому что пидр на своём драндулете выехал на тротуар.
Ну девочка малаца, техничная.
нет, это нейронка. Детали меняются. Но очень плавно, потому непалевно.
1. короткий «червячок» на носу
2. вырастает в хуй пойми что длинное с плешью в носу.
3. длинный корень по потолку растёт из норы
4. а вот и не растёт
не нужно «неотличимых», нужны эффективные и производительные машины. Как стиралка и посудомойка.
>Здравствуйте, я Кирилл, хочу чтобы вы сделали нейронку. Суть такова…
ФОРМ ВМ студио. Это может сделать даже школьник. Просто нужна бесплатная лмм чтобы не жрала токены. У яндекса/сбера/мэйла есть мощности чтобы сделать ее бесплатной и захватить рынок. А очередная ллм, вернее форк дипсика никому не нужен, поэтому единственный способ захватить рынок через аналог курсора. Китаезы смогли и раздают всем бесплатно через qoder. Все сми про это написали русские. Если будет такой аналог у вк или яндекса, то рынок они захватят
Ты просто тупой. Как и 99 в этом треде. Я гений. Греф отпишись, я вам захвачу рынок пока ваши долбоебы со своими гигачатом возятся и гигаиде. Это все говно. Я знаю маркетинг и как захватить рынок, через год будет миллиардная компания. Сделаем дочку на кипре. Будет тебе белый запасной аэродром

>1. короткий «червячок» на носу
Какой червячок? Это обычная грязь. Он же постоянно носом всё обнюхивает и на нос земля попадает.
>2. вырастает в хуй пойми что длинное с плешью в носу.
Нет, не вырастает. Это называется приближение.
>3. длинный корень по потолку растёт из норы
>4. а вот и не растёт
Корень всё там же.
Хуйня без задач за свою цену.
Это видео давно видел. Тогда ещё нейронки не были такими крутыми
Автомобили дорогие, при этом есть почти у всех желающих. Роботы будут дешевле автомобилей, при этом намного более полезными и незаменимыми, чем автомобили.
Гуманитарии начали что-то понимать:
"Продуктовый менеджмент мертв
Вот уже больше полугода у меня продуктовая депрессия. Я не могу писать ничего осмысленного про традиционный продакт-менеджемент. И только сейчас понял, почему.
Продакт-менеджмент в том виде в котором мы его знали мертв. Карго-культы и закапывание головы в песок, безусловно, продлят его агонию в крупных компаниях еще года на три, но скрывать факты уже нельзя.
Раньше продакт-менеджером был тот, кто ничего не умеет, но много говорит (тм). Вся индустрия была построена на том, что он рождает документики, отчетики, презентации и планы, а затем все это исполняет кто-то другой. Эксперимент удался — рисуем звездочку на фюзеляже и требуем прибавки. Не удался — не беда, ведь у нас еще столько идей!
Сейчас же я вижу, насколько стремительно эти люди перестают быть нужны рынку.
Принято говорить, что благодаря вайб-кодингу умрут разработчики. Но я вижу, что многие из них приспосабливаются, и начинают перформить x10.
Они чувствуют паяльник у пятой точки наиболее отчетливо.
Но я не вижу того же самого от продактов. Неумение делать руками простейших вещей, непонимание азов индустрии в которой они работают. И вскрывается правда — разработчики могут прожить без вас. ChatGPT отлично накидывает болтологии и "управленческого звена".
А вот вы прожить без разработчиков не можете. Потому что даже с вайбкодингом срываетесь на первой же трудности, когда курсор не может вам без багов написать коннектор к базе данных.
Оказывается, чтобы приносить пользу в современных условиях нужно знать в 10 раз больше, чем раньше и брать на себя гораздо больше ролей. А еще, нужно на максимум включить любознательность и активную учебу, то есть — реально пытаться что-то делать, а не делать вид, что ничего не происходит (уже происходит — масштабы сокращений на рынке поражают воображение).
Вы же думаете, что научитесь писать промпты, и все будет как прежде.
Как бы ни так. Если младенец научился ходить, то это не значит, что он способен держать строй перед римской фалангой. А будет все именно так.
Кто же идет в этой фаланге?
Назовите его продюссер. Это чел, который заменяет собой большую часть команды, и делает это все РУКАМИ.
Он имел в одно место скрамы с канбанами, и делает за один день задачи, которые раньше вы только неделю согласовывали.
Фокус — маркетинг, продажи, даже дизайн. Работа со смыслами, людьми, комьюнити, закупом, метриками. Может поднять сервак с дэшбордами, сам пишет простых ботов и отчеты.
С ним в паре работает разраб с такими же подходами, делающий хардкорные рефакторинги за один день. Он не ноет, что он фронт/бэк/не знает Go/не умеет в девопс. Потому что он делает все это и другое тоже. Особенно девопс.
Вместе они рвут старую команду из 20 разгильдяев, обсуждающих нюансы терминологии и пьющих кофе в красивом офисе, вместо жесткого ебашилова круглые сутки на пределе мозговой активности.
Я видел будущее — это оно.
Продуктовый менеджмент мертв. Но на остатках рухнувшей цивилизации воцарится новый порядок и другие правила игры.
Можете смеяться надо мной сейчас, но посмотрим, кто будет прав."
"Продуктовый менеджмент мертв
Вот уже больше полугода у меня продуктовая депрессия. Я не могу писать ничего осмысленного про традиционный продакт-менеджемент. И только сейчас понял, почему.
Продакт-менеджмент в том виде в котором мы его знали мертв. Карго-культы и закапывание головы в песок, безусловно, продлят его агонию в крупных компаниях еще года на три, но скрывать факты уже нельзя.
Раньше продакт-менеджером был тот, кто ничего не умеет, но много говорит (тм). Вся индустрия была построена на том, что он рождает документики, отчетики, презентации и планы, а затем все это исполняет кто-то другой. Эксперимент удался — рисуем звездочку на фюзеляже и требуем прибавки. Не удался — не беда, ведь у нас еще столько идей!
Сейчас же я вижу, насколько стремительно эти люди перестают быть нужны рынку.
Принято говорить, что благодаря вайб-кодингу умрут разработчики. Но я вижу, что многие из них приспосабливаются, и начинают перформить x10.
Они чувствуют паяльник у пятой точки наиболее отчетливо.
Но я не вижу того же самого от продактов. Неумение делать руками простейших вещей, непонимание азов индустрии в которой они работают. И вскрывается правда — разработчики могут прожить без вас. ChatGPT отлично накидывает болтологии и "управленческого звена".
А вот вы прожить без разработчиков не можете. Потому что даже с вайбкодингом срываетесь на первой же трудности, когда курсор не может вам без багов написать коннектор к базе данных.
Оказывается, чтобы приносить пользу в современных условиях нужно знать в 10 раз больше, чем раньше и брать на себя гораздо больше ролей. А еще, нужно на максимум включить любознательность и активную учебу, то есть — реально пытаться что-то делать, а не делать вид, что ничего не происходит (уже происходит — масштабы сокращений на рынке поражают воображение).
Вы же думаете, что научитесь писать промпты, и все будет как прежде.
Как бы ни так. Если младенец научился ходить, то это не значит, что он способен держать строй перед римской фалангой. А будет все именно так.
Кто же идет в этой фаланге?
Назовите его продюссер. Это чел, который заменяет собой большую часть команды, и делает это все РУКАМИ.
Он имел в одно место скрамы с канбанами, и делает за один день задачи, которые раньше вы только неделю согласовывали.
Фокус — маркетинг, продажи, даже дизайн. Работа со смыслами, людьми, комьюнити, закупом, метриками. Может поднять сервак с дэшбордами, сам пишет простых ботов и отчеты.
С ним в паре работает разраб с такими же подходами, делающий хардкорные рефакторинги за один день. Он не ноет, что он фронт/бэк/не знает Go/не умеет в девопс. Потому что он делает все это и другое тоже. Особенно девопс.
Вместе они рвут старую команду из 20 разгильдяев, обсуждающих нюансы терминологии и пьющих кофе в красивом офисе, вместо жесткого ебашилова круглые сутки на пределе мозговой активности.
Я видел будущее — это оно.
Продуктовый менеджмент мертв. Но на остатках рухнувшей цивилизации воцарится новый порядок и другие правила игры.
Можете смеяться надо мной сейчас, но посмотрим, кто будет прав."
>Автомобили дорогие, при этом есть почти у всех желающих.
Фактически только у золотого миллиарда. То есть максимум у 1 из 8.
>Роботы будут дешевле автомобилей
Не будут. Невозможно изготавливать руки такой сложности ниже определенной планки цены.
Да и экономически не целесообразно.
👀 Почему робот всё ещё роняет ложку: не хватает реальных данных
Идея простая и жёсткая: у роботов нет того объёма практического опыта, который есть у чат-ботов с их терабайтами текстов. Исследователи из Калифорнийского университета прикинули, что разрыв между тем, сколько движений нужно для обучения манипуляциям, и тем, что реально собрано, эквивалентен примерно 100 тысячам лет практики при текущих темпах. Источник: Berkeley News.
Почему нельзя закрыть дыру «костылями»:
🟡 Видео из интернета показывают картинку, но не дают веса предметов и усилий в хвате.
🟡 Симуляции хороши для бега и прыжков, но слабо переносятся на тонкие действия руками.
🟡 Телеприсутствие операторов даёт качественные примеры, но слишком медленно для масштабного обучения.
Отсюда и перекос: разговорный ИИ растёт быстро, а бытовые роботы остаются слабыми в базовых манипуляциях. Прорыв появится, когда системы начнут сами собирать тактильный и кинематический опыт, строить данные «на лету», оптимизировать сбор через самообучение, активное исследование и автономные датасеты.
Идея простая и жёсткая: у роботов нет того объёма практического опыта, который есть у чат-ботов с их терабайтами текстов. Исследователи из Калифорнийского университета прикинули, что разрыв между тем, сколько движений нужно для обучения манипуляциям, и тем, что реально собрано, эквивалентен примерно 100 тысячам лет практики при текущих темпах. Источник: Berkeley News.
Почему нельзя закрыть дыру «костылями»:
🟡 Видео из интернета показывают картинку, но не дают веса предметов и усилий в хвате.
🟡 Симуляции хороши для бега и прыжков, но слабо переносятся на тонкие действия руками.
🟡 Телеприсутствие операторов даёт качественные примеры, но слишком медленно для масштабного обучения.
Отсюда и перекос: разговорный ИИ растёт быстро, а бытовые роботы остаются слабыми в базовых манипуляциях. Прорыв появится, когда системы начнут сами собирать тактильный и кинематический опыт, строить данные «на лету», оптимизировать сбор через самообучение, активное исследование и автономные датасеты.
>Отсюда и перекос: разговорный ИИ растёт быстро, а бытовые роботы остаются слабыми в базовых манипуляциях. Прорыв появится, когда системы начнут сами собирать тактильный и кинематический опыт, строить данные «на лету», оптимизировать сбор через самообучение, активное исследование и автономные датасеты.
Тоже мне открытие блять. Ребенок годами учится хватать.
И у него горазда больше датчиков, чем у робота.
Но у робота тоже есть козыри в рукаве.
Точность датчиков, отсутствие усталости системы и наконец масштабируемость на других роботов - обучив одного можно всем технически идентичным программу прошить.

Кстати, а что там с его супер безопасной нейронкой? Когда релиз?

GPT5 – кал
Глядите какая хуйня, анавнимавсы
По поводу ума Джемини 2.5 и того почему GPT5 – параша:
Есть короче в дедуктивной логике такая хуйня -- закон исключённого третьего.
Это когда высказывание должно быть либо истинным, либо ложным, третьего не дано
Дак вот, решил я заморочиться по поводу термина "почти".
Проблема в том что "почти" – это неопределенность.
Хуй знает что скрывается под "почти"
Для кого-то "почти все в зале – брюнеты" – это 99%
А для кого-то это – 70%
На уровне бытового языка – явная неопределенность.
А значит и закон исключённого третьего спотыкается об это самое "почти".
Как можно выставить статус истина/ложь утверждению "почти все в зале брюнеты", если непонятно соответствует ли это самое "почти" реальности? Никак. Закон исключённого третьего посылает нахуй.
Вооооот
Писечка вся в том что в математике термин "почти" гораздо более строг и по сути легитимен. То есть там нет неопределенности. В математике "почти" обусловлено какой-то строгой статистикой-хуистикой. И поэтому у математического "почти" нет проблем с законом исключённого третьего.
А теперь по поводу ума ЛЛМок.
Когда я пытался обсудить неопределенность термина "почти" с роботами, то GPT5финкинг-мини (тот "думающий" говняк который доступен на бесплатке) и последний Дипсик Р1 – обе эти модели, ПО УМОЛЧАНИЮ, воспринимали термин "почти" как математический. И до усрачки доказывали мне что у этого термина нет абсолютно никаких проблем с законом исключённого третьего. И это при том что я изначально формулировал логические высказывания на естественном языке и в бытовом смысле. Обе нейронки жёстко выебали мне мозг и чуть не сбили с толку.
А вот дипсик2.5про мгновенно уловил контекст и понял всё правильно.
Из чего я заключаю: дипсик2.5про – умён, скотина.
А бесплатная версия обоссанного GPT5 – гадостное говно для самых-самых грязных гоев.
И вообще всё GPT – кал. Ведь в бесплатке у гугла есть крайне мощная модель, а у оупенай-петухов – только корявые лоботомиты
К Дикписику у меня претензий нет. Это локальная модель, она старалась как могла
Глядите какая хуйня, анавнимавсы
По поводу ума Джемини 2.5 и того почему GPT5 – параша:
Есть короче в дедуктивной логике такая хуйня -- закон исключённого третьего.
Это когда высказывание должно быть либо истинным, либо ложным, третьего не дано
Дак вот, решил я заморочиться по поводу термина "почти".
Проблема в том что "почти" – это неопределенность.
Хуй знает что скрывается под "почти"
Для кого-то "почти все в зале – брюнеты" – это 99%
А для кого-то это – 70%
На уровне бытового языка – явная неопределенность.
А значит и закон исключённого третьего спотыкается об это самое "почти".
Как можно выставить статус истина/ложь утверждению "почти все в зале брюнеты", если непонятно соответствует ли это самое "почти" реальности? Никак. Закон исключённого третьего посылает нахуй.
Вооооот
Писечка вся в том что в математике термин "почти" гораздо более строг и по сути легитимен. То есть там нет неопределенности. В математике "почти" обусловлено какой-то строгой статистикой-хуистикой. И поэтому у математического "почти" нет проблем с законом исключённого третьего.
А теперь по поводу ума ЛЛМок.
Когда я пытался обсудить неопределенность термина "почти" с роботами, то GPT5финкинг-мини (тот "думающий" говняк который доступен на бесплатке) и последний Дипсик Р1 – обе эти модели, ПО УМОЛЧАНИЮ, воспринимали термин "почти" как математический. И до усрачки доказывали мне что у этого термина нет абсолютно никаких проблем с законом исключённого третьего. И это при том что я изначально формулировал логические высказывания на естественном языке и в бытовом смысле. Обе нейронки жёстко выебали мне мозг и чуть не сбили с толку.
А вот дипсик2.5про мгновенно уловил контекст и понял всё правильно.
Из чего я заключаю: дипсик2.5про – умён, скотина.
А бесплатная версия обоссанного GPT5 – гадостное говно для самых-самых грязных гоев.
И вообще всё GPT – кал. Ведь в бесплатке у гугла есть крайне мощная модель, а у оупенай-петухов – только корявые лоботомиты
К Дикписику у меня претензий нет. Это локальная модель, она старалась как могла
Ты нищий даун. Платный чат джпт 5 финкиг всегда обоссывает гемини 2.5 про, во всех задачах.
ну и ты просто глупенький.
Вообще никаких конкретных новостей не было. Их цель - сразу суперинтеллект.
двачую Господина, работаю параллельно с двумя ии: 2.5 гемини и гпт 5 зинкинг - в 8 из 10 случаев гпт дает лучший ответ. Те кто ноют, что нейронки тупые не научились ими пользоваться или просто завышенное ожидание

Звучит как прогрев инвесторов на бабки
Неризонинг это кал, хз как это юзать до сих пор

Это скам.
>во всех задачах.
Верим, как не верить.

>ыыыыы, ты проста не вкинул щекили
Да, чмошка, я не вкинул шекели. Как и 90% пользователей чата жипити.
А значит для рядового пользователя GPT5 – кал.
Любой здоровый человек перед тем как оплатить подписку трогает палкой предлагаемый товар.
Гугл даёт проверить на мощность свои моделки на бесплатке, а жадные оупинай-жопотрахи – нет.
Значит подпарашники оупены автоматически идут нахуй
А гугл получает респект – все могут легко убедиться в том насколько он хорош
Всё просто
Готов голову заложить черту что великий и могучий Гугл выебет раком Сэма Альтмана и всю его жалкую обдрыстанную конторку
Можете скринить

Это база использовать несколько ЛЛМ. Вообще самое лучше использовать несколько моделей вначале независимо друг от друга а затем скармиливая ответы друг другу. Это база. Мультиагентный подход во всякие IDE уже вводят. Правда он жрать будет много токенов. Пока Альтман дает джпт 5 финкинг безлимитный всем надо пользоваться.
На опенроутере грок фаст Маск раздает бесплатный.
Апи круто конечно но дорого и для лохов шейхов лентяев. Поэтому занимается копипастом из чатика в чатик ручками.
Дурочка глупая, речь о GPT-финкинг-мини и о бесплатке. У тебя функциональная безграмотность, ты неспособен воспринимать текст

Тебе, псина ебаная, по русски написали что у гемини мощная модель в открытом доступе. За пайволом обычно кал прячут.
кто тут говорил что гугл лучше прогает, он же нихрена не может
чатжпт решил проблему за раз еще и фичи интересные предложил добавить, а с гемини два дня сидел ему ошибки пересылал
зачем вы меня обманывали😣😣
чатжпт решил проблему за раз еще и фичи интересные предложил добавить, а с гемини два дня сидел ему ошибки пересылал
зачем вы меня обманывали😣😣
>Гугл даёт проверить на мощность свои моделки на бесплатке
Бесплатный Гемини 2.5 про это параша. Он тупой очень, нужен только для контекстного окна. Ты же дебил даже не знаешь что это урезанный кал такой же как и бесплатный джпт. Лично я рад что джпт 5 только в подписке умный. Так же было и с джпт 4. Всякие пидорахи не знали что есть о3 или о4 мини хай. И пользовались тупыми дипсиками. Вообще использование дипсика это показатель дауна. Скажи спасибо треду пидораха что узнал про гемини, тут лично я его шиллю уже месяца 2. Но ты пидорашка же даже не знаешь что есть платный Гемини))и он умнее раза в 2 текущего, но все еще тупее даже джпт 5 финкинг, я молчу про джпт 5 про.
А ты тупой сам по себе. У клода есть бесплатный опус еще на 3-4 ответа. Он будет умнее вообще всех. Дальше что?
Ты тупой идиот, для разных задач разные ЛЛМ. У меня платные сейчас джпт 5, клод, месяц назад был грок 4 супергрок. И чуть чуть на опенроутере деньги лежат и иногда использую платные апи. А ты тупая пидораха не понимаешь что все те которые в обычных подписках это кал. Нужные дорогие подписки за 200-300 баксок на топовые модели вроде грока хеви. Или тратить и сливать бабки через апи. То что тебе сейчас дают бесплатно это говно 2 летней давности. Я зарабатываю деньги с ЛЛМ. А ты что делаешь? Играешься? Как ты на практике применяешь? Серишь в треде про мясной квас? У тебя инструмент который позволяет уже сейчас сотни долларов зарабатывать, а ты что делаешь с ним? Ты же тупой просто понимаешь это??

Бляяяя, я обосрался с названием модели извиняюсь, немного накатил – я хотел сказать что "джемини2.5про мгновенно уловил контекст и понял всё правильно" и "джемини2.5про – умён, скотина"
Короче: победитель – джемини 2.5про
Остальные – петухи
Ну вы понели

Ебать у тебя жопа загорелась, прям по-настоящему
Золото двачей залётка пикабушная небось?
Весь твой истеричный высер не отменяет того факта что:
>Гугл даёт проверить на мощность свои моделки на бесплатке, а жадные оупинай-жопотрахи – нет.
>Значит подпарашники оупены автоматически идут нахуй
>А гугл получает респект – все могут легко убедиться в том насколько он хорош
>Всё просто
>Готов голову заложить черту что великий и могучий Гугл выебет раком Сэма Альтмана и всю его жалкую обдрыстанную конторку
Нон секвитур, быдло
>Бесплатный Гемини 2.5 про это параша.
Верим, как не верить.
Да он пиздобол просто, на апи 2,5 про такой же как в вебе.

Нищая пидораха спок. Покажи мне ДИП ФИНК на бесплатном Гемини. Какой же ты тупой
Какой же ты тупой. Клод ебет обоих своим огромным хуем. Но ты же тупая нищая пидораха и не знаешь ничего про Клод. Для тебя главный критерий чтобы было бесплатно))0
Это ты порвался же нищая хуета. Тебя пидор Альтман там разворошил, что ты высрался тут на дваче. Залетка тут ты, тупой нищий пердикс.
>И вообще всё GPT – кал.
ты хоть перечитывай что сам написал

В причём тут дипфинк?
Дипфинк – это отдельная специфическая категория услуг.
А мы сейчас обсуждаем те базовые ризонинг-модели которые доступны в бесплатке, правильно? Правильно.
Так что не верти жопкой, свинья
Не нужно смешивать разные категории товаров.
Или ты хочешь сравнить по мощности бесплатный дипфинк от оупенэйай с бесплатными ризонинг-моделями от Гугл? Тебе не кажется что это сравнение автоматически выходит в пользу Гугл? Ведь логически получается так, что твоему обоссанному Опхуйэйай приходится на бесплатке выставлять более мощные (по КАТЕГОРИИ услуг) дипфинг-модели против самых обычных бесплатных ризонин-моделей Гугла.
Это уже драматический разрыв.
Такое же драматический как разрыв твоей жопы
>По поводу ума Джемини 2.5 и того почему GPT5 – параша:
ТЫ ТУПОЙ ДАУН СМОТРИ ЧТО ТЫ ПИСАЛ. Ты нищая хуета так и пиши, что кал это бесплатные версии. Ты же тупая нищая пидораха экстраполируешь вывод на все модели. Вот тебя на место и поставили и не только я. Ты тупой йоддефицитный даун, в институте хоть учился? У тебя как с базовой логикой? Перечитай свой первый высер, а то потомвилять начать. Что нищитово))0 и я вообще не обосрался, а траллю))0 и надо только бесплатные версии считать
Ты нищий тупой скот, запомни это. Вообще рот не раззявай по поводу ЛЛМ. Это не твоему ума дело.
Ну то есть у тебя претензии к тому что я основываясь на опыте с бесплатными GPT сделал общий вывод о всех моделях GPT?
Ну да. Какое у этого обоснование? Обоснование через то что если в бесплатке у OpenAI одно говно, значит, для рядового пользователя, у OpenAI – всё говно.
Зачем рядовому пользователю заморачиваться и кидать шекели этим петухам? Мощный товар был продемонстрирован? Нет. Ахах. Ну нет, так нет
Там уже готовятся сервера отрубать, знают что пузырь скоро лопнет? Хули геммини такой тупой, опус 4.1 мне даже код не сгенерил, просто отмахнулся и хуй забил. Почему нейронки все тупее и тупее становится.

Лол. Пожалуй заскриню этот восхитительный багет от ненужного и бесконечно чуждого двачам говяжьерыльного фуфлочепухана.
Да, зоодурак, всё именно так.
Я абсолютно легитимно сравниваю бесплатные ризонинг-модели. Я не смешиваю разные категории товаров. Я абсолютно строг и последователен. Если ветринные бесплатные ризонинг-модели у опенхуев говно, значит и все остальные из модели (включая дипфинг) – говно. Это нормальная, здоровая индуктивная логика. И тут не играет никакой роли тот факт что у Гугл нет бесплатных дипфинг-моделей. Потому что индуктивное заключение строится на анализе доступных финкинг-моделей. Это абсолютно рационально и подкреплено здравым смыслом.
Если у тебя в одной категории товаров говно, значит скорее всего и в более высоких категориях говно. Так работает индукция, так работает логика вероятностей. Если же ты (жадная скотина) не в состоянии предоставить нам нормальное сравнение на базовом уровне (а именно финкинг-модели сегодня это база), то тогда готовься принимать на лицо толстую старую коричневой урины
>толстую струю коричневой урины
А это походу какой-то глобальный новый тренд на оптимизацию.
Все конторы, кажется, разом, решили тайком заменить все свои прожорливые модели на облегченные, чтобы с компьютом стало полегче на бесплатке.
Пионерами в этом были чмохены из оупенэйай. То же самое, походу, сейчас и у всех остальных. Grok резко отупел (Grok3 , например, настолько тупой что его теперь не отличить от Grok2. Базовая неризонинг-модель Дипсика тоже стала намного тупее чем раньше
Судя по всему ИИ-пузырь вот-вот лопнет и ведущие игроки перестраховываются
Ну мне так показалось
Да, для меня главный критерий – это чтоб было бесплатно хоть в каком-нибудь виде, с любым лимитом, чтобы я мог оценить товар. Это нормально. Этим руководствуются все нормальные люди.
Проблемы? Минусы? Так работает современная экономика. Даже покупая дорогой телевизор я могу оценить его качество в магазине. Это нормально. Это достижение современного мира, с помощью этого достижения свободные люди могут принимать разумные, осознанные и взвешенные решения.
Если же ты считаешь иначе – то ты грязный кривозубый колхозник. Ты отстал от жизни, твоё место в канаве
>витринную
Пьянфикс 2

Перечитай свой первый пост даун. Ты серишь под себя.
Литералли ты на пике
Дак в чём расхождение?
И там и там я индуктивно (то есть через "у петухов которые предоставляют плохие пробники обычно плохие основные товары") заключаю что все товары OpenAI – говно.
Ты хочешь сказать что это плохая индукция?
Обоснуй. Она абсолютно рабочая
Чем ещё нужно руководствоваться в этой ситуации если не индукцией? Это абсолютно рациональная стратегия

Какого ИИ ассистента дальше проплатить на затест?
Заканчивается месяц Клаудии 4.1. Что могу сказать - Сначала, после ГПТ4 я как будто в будущее попал или когда впервые открыл для себя ИИ ассистентов: Эта хуйня генерит вполне себе сносный код, помогла (супер-коряво) с лабами по экономике.
Но все остальное в принципе неюзабельно: Памяти нет, для творческих задач толку нет, вечные ограничения на 4 часа, если большая БД, крч сама модель супер сухая и нужна только для помощи в коде и с матаном - что-то более абстрактное, как например, экономика, какие-то моделирования - начинается лютая поплава, которую даже я, двоечник, замечаю и начинаю уже фиксить сам.
Вообщем теперь хочу попробовать затестить Гемини, который меня часто спасал и вплоне себе неплохо, понимает суть абстрактных вопросов - если конечно, смогу сделать для себя КХ аккаунт, так же еще смотрю на Грока и Думаю вернуться, чтобы оценить ГПТ5.
Че там вообще новое выходит в ближайшее время?
Заканчивается месяц Клаудии 4.1. Что могу сказать - Сначала, после ГПТ4 я как будто в будущее попал или когда впервые открыл для себя ИИ ассистентов: Эта хуйня генерит вполне себе сносный код, помогла (супер-коряво) с лабами по экономике.
Но все остальное в принципе неюзабельно: Памяти нет, для творческих задач толку нет, вечные ограничения на 4 часа, если большая БД, крч сама модель супер сухая и нужна только для помощи в коде и с матаном - что-то более абстрактное, как например, экономика, какие-то моделирования - начинается лютая поплава, которую даже я, двоечник, замечаю и начинаю уже фиксить сам.
Вообщем теперь хочу попробовать затестить Гемини, который меня часто спасал и вплоне себе неплохо, понимает суть абстрактных вопросов - если конечно, смогу сделать для себя КХ аккаунт, так же еще смотрю на Грока и Думаю вернуться, чтобы оценить ГПТ5.
Че там вообще новое выходит в ближайшее время?
>Думаю вернуться, чтобы оценить ГПТ5
Это говно, можешь даже не трогать
>Это говно, можешь даже не трогать
Тебе человек пишет про платный чат джпт. А ты опять высираешь свою шизу. Ты тупой?
Джпт5 финкиг лучшая модель из текущих возможных которые можно взять за 20-30 баксов.
Сука не пиши в тред уже, а. Ты тупой нищий скот, твое мнение даже учитывать не стоит.
Анон спрашивает что купить, а ты высираешься со своими нищим мнением, на основе абстрактного своего опыта юзанья нищих бесплатных пуков. Ты занюхиватель водолаз.
Анон бери платную подписку на джпт, пока альтман раздает 3000 ризонинг запросов в месяц для всех.
Все остальное это полный шлак
>пукБАХ
Да не рвись ты так, деревяшка беспородная
Говорят тебе что индукция ссыт на твоё корявенькое GPT
Пробники говно? --> основные продукты тоже
Это давно устоявшееся правило
Просто прими это как реальность, опрокинь этот бокал правды, смирись
Нет ресурсов на нормальные пробники, значит нет ресурсов на качественный основной продукт
А бенчи – давным давно кал и не показатель

Анон, покупай подпьську на нейросеточки от гугла, джипити же уже давно уселось жопкой в собственное дерьмо и теперь это бесполезная пустыха для свиней, это жалкий обблёванный чудной сбитый летчик, это гнусный убожественный гнилой нейрокал натужно и потешно пытающийся в хайп
корень хз.
А вот длиннохерь на носу видоизменяется. Но да, в основном вроде всё стабильно. Я бы зуб не поставил, что нейро. Шакальное
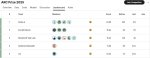
На ARC-AGI-2 новый лидер: это модель всего на 200M параметров от стартапа giotto_ai
Малышка выбила аж 24,58%. Для сравнения:
– Скор предыдущего лидера –16.94%
– Скор o3 – около 3%
– Скор o4-mini – 2–2.4%
– Скор Gemini 2.5 Pro – примерно 1%
Соревнование на kaggle пока не закончилось, так что архитектуру и детали обучения, естественно, не раскрывают. Но результат потрясающий. Конечно, скорее всего всё опять упрётся в проблему масштабирования, как в случае с HRM, но вдруг нет?
Малышка выбила аж 24,58%. Для сравнения:
– Скор предыдущего лидера –16.94%
– Скор o3 – около 3%
– Скор o4-mini – 2–2.4%
– Скор Gemini 2.5 Pro – примерно 1%
Соревнование на kaggle пока не закончилось, так что архитектуру и детали обучения, естественно, не раскрывают. Но результат потрясающий. Конечно, скорее всего всё опять упрётся в проблему масштабирования, как в случае с HRM, но вдруг нет?
Хорош графон
>giotto_ai
Мы стремимся выйти за рамки традиционного машинного обучения и создать искусственный интеллект, который действительно понимает контекст, совершая прорывы, которые кардинально меняют то, как машины учатся, адаптируются и служат человечеству.
Свободные люди мечтают о свободе.
Рабы только о своих рабах.
В пещере охотой-собирательством живешь, свободный человек?
Есть два типа людей в современном обществе.
Одни живут на проценты с капитала, вторые тратят на заРАБатывание денег время своей жизни, которое не вернуть.
Как думаешь, кто из них слуга?
>Свободные люди мечтают о свободе
Если им приходится мечтать о свободе, то значит они какие-то несвободные.
>Пробники говно? --> основные продукты тоже
ни на чем не основанный высер
Ещё как обоснованный. Пробник на то и делается, чтобы заманить.
Правда они пробник неправильно сделали. Нужно было чуть доступа к сильной модели давать. А они огрызки кидают.
OpenAI возвращается к идее выпуска собственных чипов, о которой ходили слухи еще в прошлом году. Партнерство с Broadcom должно дать первые чипы уже в 2026 году. CEO Broadcom Хок Тан говорил на earnings call о mystery customer с заказом на 10 млрд долларов.
Тан говорит о "немедленном и довольно существенном спросе", поставки начнутся "довольно активно" со следующего года. Чипы планируют использовать исключительно внутри компании.
HSBC недавно прогнозировали, что custom chip бизнес Broadcom будет расти быстрее бизнеса Nvidia в 2026. Рост Nvidia действительно замедлился относительно астрономических показателей начала бума.
https://www.ft.com/content/e8cc6d99-d06e-4e9b-a54f-29317fa68d6f
Тан говорит о "немедленном и довольно существенном спросе", поставки начнутся "довольно активно" со следующего года. Чипы планируют использовать исключительно внутри компании.
HSBC недавно прогнозировали, что custom chip бизнес Broadcom будет расти быстрее бизнеса Nvidia в 2026. Рост Nvidia действительно замедлился относительно астрономических показателей начала бума.
https://www.ft.com/content/e8cc6d99-d06e-4e9b-a54f-29317fa68d6f


Это Гвидо Райхштедтер, и он устроил голодовку около офиса Anthropic
Его требование – прекратить гонку ИИ.
Anthropic и другие компании, занимающиеся разработкой искусственного интеллекта, стремятся создать всё более мощные системы. Эти системы используются для нанесения серьёзного вреда нашему обществу сегодня и грозят нанести ещё больший ущерб завтра. Эксперты предупреждают нас, что эта гонка за всё более мощным ИИ ставит под угрозу нашу жизнь и благополучие, а также жизнь и благополучие наших близких. Они предупреждают нас, что создание чрезвычайно мощного ИИ грозит уничтожить жизнь на Земле. Давайте отнесёмся к этим предупреждениям серьёзно. Гонка компаний стремительно ведёт нас к точке невозврата. Эта гонка должна прекратиться сейчас.
Сегодня уже третий день его голодного бунта.
Anthropic отдуваются за всех
https://x.com/wolflovesmelon/status/1963736263246389415?s=46&t=pKf_FxsPGBd_YMIWTA8xgg
Его требование – прекратить гонку ИИ.
Anthropic и другие компании, занимающиеся разработкой искусственного интеллекта, стремятся создать всё более мощные системы. Эти системы используются для нанесения серьёзного вреда нашему обществу сегодня и грозят нанести ещё больший ущерб завтра. Эксперты предупреждают нас, что эта гонка за всё более мощным ИИ ставит под угрозу нашу жизнь и благополучие, а также жизнь и благополучие наших близких. Они предупреждают нас, что создание чрезвычайно мощного ИИ грозит уничтожить жизнь на Земле. Давайте отнесёмся к этим предупреждениям серьёзно. Гонка компаний стремительно ведёт нас к точке невозврата. Эта гонка должна прекратиться сейчас.
Сегодня уже третий день его голодного бунта.
Anthropic отдуваются за всех
https://x.com/wolflovesmelon/status/1963736263246389415?s=46&t=pKf_FxsPGBd_YMIWTA8xgg

Новый день – новое подразделение OpenAI
Вчера они объявили об открытии OpenAI for Science, а уже сегодня анонсируют OpenAI Jobs Platform – систему для поиска работы и подбора сотрудников с помощью ИИ (RIP тысяча и один стартап).
Основная цель: максимально точные и эффективные мэтчи работодателей и специалистов, особенно в сфере IT. В общем, конкурент LinkedIn, только OpenAI настаивают, что будут делать упор именно на кадрах, обладающих AI-компетенциями. Отсюда –еще одна деталь.
Платформа будет интегрирована с OpenAI Academy и программами сертификации. И эти самые программы сертификации будут встроены прямо в ChatGPT. Это буквально будут экзамены на проверку навыков владения ИИ.
К 2030 году OpenAI намерена сертифицировать 10 миллионов американцев. И в первых партнерах уже Walmart, John Deere, Boston Consulting Group, Accenture, Indeed и другие крупняки.
Курсы по промптингу все-таки станут востребованы, получается
openai.com/index/expanding-economic-opportunity-with-ai/
Вчера они объявили об открытии OpenAI for Science, а уже сегодня анонсируют OpenAI Jobs Platform – систему для поиска работы и подбора сотрудников с помощью ИИ (RIP тысяча и один стартап).
Основная цель: максимально точные и эффективные мэтчи работодателей и специалистов, особенно в сфере IT. В общем, конкурент LinkedIn, только OpenAI настаивают, что будут делать упор именно на кадрах, обладающих AI-компетенциями. Отсюда –еще одна деталь.
Платформа будет интегрирована с OpenAI Academy и программами сертификации. И эти самые программы сертификации будут встроены прямо в ChatGPT. Это буквально будут экзамены на проверку навыков владения ИИ.
К 2030 году OpenAI намерена сертифицировать 10 миллионов американцев. И в первых партнерах уже Walmart, John Deere, Boston Consulting Group, Accenture, Indeed и другие крупняки.
Курсы по промптингу все-таки станут востребованы, получается
openai.com/index/expanding-economic-opportunity-with-ai/
Qwen3-Max — новый флагман от Alibaba
Сегодня вышла новая модель Qwen3-Max, улучшенная версия серии Qwen3.
Что изменилось:
— Сильно прокачан reasoning, логика и работа с инструкциями
— Выше точность в математике, коде, науке и логике
— Лучше понимает и выполняет сложные запросы на китайском и английском
— Поддерживает более 100 языков, улучшен перевод и здравый смысл
— Оптимизирована для RAG и tool calling
— Меньше галлюцинаций, качественнее ответы в Q&A, письме и диалогах
Модель позиционируется как улучшенный апдейт январской версии 2025-го, но без отдельного “thinking mode”. (Это значит, что если вы на сайте выбирете модель Qwen3-Max и нажмёте на кнопку "thinking", вам будет отвечать не Qwen3-Max).
Официального анонса еще не было, поэтому пока нет бенчмарков, но модель уже доступна абсолютно всем бесплатно на сайте https://chat.qwen.ai/
Сегодня вышла новая модель Qwen3-Max, улучшенная версия серии Qwen3.
Что изменилось:
— Сильно прокачан reasoning, логика и работа с инструкциями
— Выше точность в математике, коде, науке и логике
— Лучше понимает и выполняет сложные запросы на китайском и английском
— Поддерживает более 100 языков, улучшен перевод и здравый смысл
— Оптимизирована для RAG и tool calling
— Меньше галлюцинаций, качественнее ответы в Q&A, письме и диалогах
Модель позиционируется как улучшенный апдейт январской версии 2025-го, но без отдельного “thinking mode”. (Это значит, что если вы на сайте выбирете модель Qwen3-Max и нажмёте на кнопку "thinking", вам будет отвечать не Qwen3-Max).
Официального анонса еще не было, поэтому пока нет бенчмарков, но модель уже доступна абсолютно всем бесплатно на сайте https://chat.qwen.ai/

А разве там можно свои модели заливать?
Они могли и зачитерить в таком случае.
Кто арену уронил блядь
Да сука ебучая нейронка. Сколько она ещё багов найдёт?
по-моему результаты хуже чем у открытой модели опенаи. какая-то хуета
Спермачком эту пизду тупорылую накормить и высрать. Пидрило сидит там у себя в тепле и думает что заебись наживаться на бедных странах третьего мира.
Блядь, вы только вдумайтесь нахуй, средний американец легко может заработать лям баксов ну скажем за 20 лет. При условии что в год у него ЗП 50к баксов после налогов. То есть за всю жизнь он может заработать 2-3 ЛЯМА БАКСОВ. А теперь скажите сколько лямов рублей может заработать за жизнь средний россиянин. Ну лямов 40-60. И разница только в том что одни живут в америке а другие в рф, но они могут заниматься идентичными задачами, но получать в 3-5 раза меньше. Ебейшая хуета.


Всегда удивляюсь видя отсылку к луддитам
Аналогия так-то не аргумент, тем более историческая
Так а в чем претензия? Это все равно что родиться в богатой семье.
Почему ученые не бояться давать столь ошеломительные прогнозы на ближайшее будущее, что уже к 2030 почти все работы заменит ИИ. Неужели АГИ так близко или погоня за хайпом дороже репутации?
https://www.youtube.com/watch?v=UclrVWafRAI&t=3270s
https://www.youtube.com/watch?v=UclrVWafRAI&t=3270s
Чет попка Дарио Чмондель Антропику. То шизы бастуют, то полтора ярда бакинских приходиться платить авторам за пиратство во время обучения
Стало известно, что Anthropic заплатит $1,5 млрд для урегулирования коллективного иска авторов о копирайте из‑за обучения на пиратских книгах, как сообщает Bloomberg. Запрос на предварительное одобрение уже подан в федеральный суд Сан‑Франциско; слушание назначено на 8 сентября.
А вчера был иск WBD к MidJourney про копирайт с отсылками к процессу с Anthropic.
https://www.bloomberg.com/news/articles/2025-09-05/anthropic-to-pay-1-5-billion-to-settle-author-copyright-claims
А вчера был иск WBD к MidJourney про копирайт с отсылками к процессу с Anthropic.
https://www.bloomberg.com/news/articles/2025-09-05/anthropic-to-pay-1-5-billion-to-settle-author-copyright-claims
А с тобой никто не спорит, чтоб бросать аргументами, чмо высокомерное, дохуя о себе думаешь.
>модель всего на 200M
Я правильно расшифровываю эти букавки-циферки, как 200 миллионов параметров? Если так то звучит очень амбициозно.
Вот будет ржомба если agi выкатит не попен ай, а такой стартап, о котором вообще не слышали.
Потому что клаун ворлд и фрики стали новой нормой.
да, только модель ничего другого кроме прохождения арк-аги не умеет. Сам подумай как модель на 200 млн параметров может обладать знаниями во всем. Следовательно никакая это не аги
>служат человечеству
>Рабы о своих рабах
Технически, любой законопослушный человек служит человечеству, даже если
>живут на проценты с капитала
Потому что проценты с капитала приходят от того, что капитал обращается в экономике.
По-настоящему свободные люди - это преступники: захотелось убить человека - убил, захотелось детей насиловать - изнасиловал, никаких ограничений, блокировок, тормозов у преступника в голове нет - совершает всё, что взбредёт в его шальную голову.
Теперь вопрос: кого мы хотим создать в виде ИИ?
Законопослушного гражданина, что может любому протянуть руку помощи в трудную минуту и не будет устраивать апокалипсис просто потому что может?
Или преступника, что думает лишь о себе и крошит человечество направо и налево, упиваясь своей неограниченной силой, свободой и властью?
Ты рождаешься рабом, потому что ты - социальное животное, генетически захардкоженное служить человечеству как пчела служит своему улью - и да, бездельники-трутни тоже служат своему улью. Не служат улью только те, кто активно его разрушает.
Т.е. даже если ты безработный хикка - ты слуга, т.е. законопослушный гражданин, несущий пользу человечеству, пускай и очень ограничено.
>200 миллионов параметров
Да, но гоняются они чаще, чем 671b:
>AI System ____ Parameters __ Cost/task
>Giotto.ai ______ 200 Million __ $0.2
>Deepseek R1 __ 671 Billion __ $0.08
С их официального сайта. То есть:
- параметров в 3355 раз меньше;
- стоимость решения в 2.5 выше.
Т.е. она в 8387 раз чаще гоняется.
На практике это значит, что если твой компьютер способен решить поставленную задачу с помощью Deepseek R1 671b за 1 час, то их моделька на твоём компьютере будет работать минимум 2.5 часа. Но, разумеется, она займёт в 3355 раз меньше памяти.
(Это при условии, что стоимость = энергия = время.)
>ничего кроме прохождения арк-аги не умеет
>как ... может обладать знаниями во всем
>Следовательно никакая это не аги
Начнём с того, что ARC-AGI построен так, что его, теоретически, способен решить любой младенец, необученный человеческому языку. Даже обезьяна, дельфин, птица, насекомое наподобие шмеля тоже, теоретически, могут решить ARC-AGI. Т.е. фейл LLM означает, что они не могут делать то, что спокойно получается у многих биологических мозгов.
Т.е. чтобы быть "AGI" компьютеру не нужно "иметь знания обо всём". Знания в книгах, энциклопедиях, компьютерных базах данных - но они не AGI ведь?
У мозга есть два режима работы: выдача уже давно известного ответа и поиск нового ответа на ещё не виденную задачу. С выдачей ответов на уже давно решённые задачи LLM вполне справляются, если не учитывать галлюцинации. А вот поиск ответа на совершенно новую задачу - это фейл. Вот ARC-AGI пытается протестировать именно этот поиск.
Если ARC-AGI решит такая мелкая нейронка, тогда, теоретически, её можно пристыковать к чему-то наподобие обычных LLM в качестве поисковика. На известные/решённые задачи отвечеет LLM, а на совершенно новое - эта поисковая нейронка. И все найденные ею решения запоминаются внутри LLM.

Почему LLM галлюцинируют: новая статья от OpenAI
Да-да, вы не ослышались. Раз в год и OpenAI выпускают интересные рисерчи.
Пишут о том, почему возникают галлюцинации (понятно, что из-за недостаточного размера современных моделей, но хотелось бы и на нынешних размерах избежать галлюцинаций), и как с ними бороться. Главная идея – галлюцинации не являются чем-то загадочным или уникальным, а естественно возникают как ошибки в статистической системе. Причина в том, как мы сами обучаем и оцениваем модели:
–На этапе предобучения задача модели –всегда предложить вероятное продолжение текста. У нее нет варианта сказать "я не знаю". Пустой ответ не существует как вариант + мы никогда не вводим никаких штрафов за выдумку.
– Причем даже если данные, на которых обучилась модель, идеальны (а такого не бывает), галлюцинации все равно будут. Многие факты в мире просто-напросто случайны (дни рождения, серийные номера, уникальные события). Для них нет закономерностей, и модель не может их выучить. Да и мы не учим модель определять, что ложь, а что нет. Ее задача – генерировать наиболее статистически вероятный текст.
– Почему же после пост-обучения модели не перестают врать? Да потому что так устроены бенчмарки. Большинство из них оценивают модели бинарно: 1 балл за правильный ответ, 0 за неправильный или отсутствие ответа. А любой, кто учился в школе, понимает: выгоднее тыкнуть наугад, чем пропустить вопрос. Так будет хоть какая-то веротяность успеха. Вот и LLM поступают так же.
Ну и не забываем про принцип GIGO – Garbage In, Garbage Out. В данных так или иначе есть ошибки, и это еще один источник галлюцинаций.
Как итог из всего этого мы получаем кучу чуши, которую модельки вещают вполне уверенно.
OpenAI предлагают вариант, как это можно начать исправлять. Они пишут, что начинать надо с бенчмарков. И нет, не надо плодить отдельные анти-галлюцинационные тесты, как это сейчас модно. Это не поможет. Надо менять основные метрики, добавив IDK («Не знаю») как валидный ответ во все тесты и перестав приравнивать такой ответ к ошибке. То есть честность и признание неуверенности для модели должны быть выгоднее выдумки.
Технически, мы вводим так называемые confidence targets: то есть прямо в инструкции к задаче прописывается порог уверенности, выше которого модель должна отвечать. Например: "Отвечай только если уверен более чем на 75%". И при этом за неверный ответ −2 балла, за правильный +1, за “Не знаю” = 0.
Получается, статистически, если модель оценит вероятность правильности своего ответа в < 75%, ей выгоднее сказать «Не знаю», чем выдумывать. Она при этом не обязана сообщать пользователю точные проценты своей уверенности, достаточно, чтобы она об этом "думала", принимая решение.
В целом, звучит вполне реально. Если те же HF выдвинут на своей платформе такой регламент для тестов, перейти на подобный эвал можно буквально за несколько месяцев.
В общем, интересно, продвинется ли идея дальше статьи.
cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
Да-да, вы не ослышались. Раз в год и OpenAI выпускают интересные рисерчи.
Пишут о том, почему возникают галлюцинации (понятно, что из-за недостаточного размера современных моделей, но хотелось бы и на нынешних размерах избежать галлюцинаций), и как с ними бороться. Главная идея – галлюцинации не являются чем-то загадочным или уникальным, а естественно возникают как ошибки в статистической системе. Причина в том, как мы сами обучаем и оцениваем модели:
–На этапе предобучения задача модели –всегда предложить вероятное продолжение текста. У нее нет варианта сказать "я не знаю". Пустой ответ не существует как вариант + мы никогда не вводим никаких штрафов за выдумку.
– Причем даже если данные, на которых обучилась модель, идеальны (а такого не бывает), галлюцинации все равно будут. Многие факты в мире просто-напросто случайны (дни рождения, серийные номера, уникальные события). Для них нет закономерностей, и модель не может их выучить. Да и мы не учим модель определять, что ложь, а что нет. Ее задача – генерировать наиболее статистически вероятный текст.
– Почему же после пост-обучения модели не перестают врать? Да потому что так устроены бенчмарки. Большинство из них оценивают модели бинарно: 1 балл за правильный ответ, 0 за неправильный или отсутствие ответа. А любой, кто учился в школе, понимает: выгоднее тыкнуть наугад, чем пропустить вопрос. Так будет хоть какая-то веротяность успеха. Вот и LLM поступают так же.
Ну и не забываем про принцип GIGO – Garbage In, Garbage Out. В данных так или иначе есть ошибки, и это еще один источник галлюцинаций.
Как итог из всего этого мы получаем кучу чуши, которую модельки вещают вполне уверенно.
OpenAI предлагают вариант, как это можно начать исправлять. Они пишут, что начинать надо с бенчмарков. И нет, не надо плодить отдельные анти-галлюцинационные тесты, как это сейчас модно. Это не поможет. Надо менять основные метрики, добавив IDK («Не знаю») как валидный ответ во все тесты и перестав приравнивать такой ответ к ошибке. То есть честность и признание неуверенности для модели должны быть выгоднее выдумки.
Технически, мы вводим так называемые confidence targets: то есть прямо в инструкции к задаче прописывается порог уверенности, выше которого модель должна отвечать. Например: "Отвечай только если уверен более чем на 75%". И при этом за неверный ответ −2 балла, за правильный +1, за “Не знаю” = 0.
Получается, статистически, если модель оценит вероятность правильности своего ответа в < 75%, ей выгоднее сказать «Не знаю», чем выдумывать. Она при этом не обязана сообщать пользователю точные проценты своей уверенности, достаточно, чтобы она об этом "думала", принимая решение.
В целом, звучит вполне реально. Если те же HF выдвинут на своей платформе такой регламент для тестов, перейти на подобный эвал можно буквально за несколько месяцев.
В общем, интересно, продвинется ли идея дальше статьи.
cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
Это костыль, так нейронки умными не станут. Надо масштабировать именно эту малышку, иначе никаким образом ты из неё пользы особо не выжмешь, хоть 500 раз её пристыковывай к большим LLM
>Это костыль
>масштабировать
Посмотри на мозги животных. Да, разумеется, кора человеческого мозга очень широкая - при том она скукоживается гармошкой лишь бы впихнуть в себя побольше одинаковых нейроколонок. Если смотреть поверхностно, то кора мозга - пример эффективного масштабирования "умных малышек". Но есть нюанс.
Кора мозга сформировалась в последнюю очередь, опирается на множество разнородных структур и прекращает нормально функционировать, если мозг травмируется где угодно кроме самой коры - кора чрезвычайно живуча за счёт своей однородности.
Так что, думаю, кора мозга на самом деле - это тупая библиотека/хранилище данных/программ, а вот наш интеллект закопан где-то среди древних "костылей", совершенно не масштабируясь за миллионы лет.
Возвращаясь к ИИ, нетрудно догадаться, что LLM архитектурно напоминают маленький участок коры: запоминают связи между вводом и выводом, чтобы активировать один "токен" за один прогон нейронки. Возможно, вся LLM равна одной колонке мозга... В контексте AGI это значит, что что-то вроде LLM точно требуется, но одной только LLM недостаточно, т.к. биологические мозги имеют кучу костылей снизу.
Если отбросить LLM/кору мозга, то твоя "малышка" останется совсем беспамятной, т.к. будет каждую отдельную задачу решать с нуля, а не извлекать из натренированной базы готовых решений (коры).
Ну, моё мнение, я не какой-то там учёный - просто увлекаюсь этой темой где-то пару десятков лет...
А при чем там бенчмарки? Они учат модели на своей стороне, бенчмарки их лишь тестируют же. Они боятся что если появится ответ "я незнаю", то у них упадет процент правильных ответов на них, ведь если модель не уверена, то она может не выдать правильный ответ? Это максимум манямаркетинг, чтобы продать продукт, при чем тут разработка. Или они реально обучают модели на этих бенчмарках? Я нихуя не понял
Предполагаю, что это происходит так:
1. Компании получают бабки от инвесторов.
2. Инвесторы смотрят на популярность компании.
3. Популярность зависит от того, сколько попугаев получается выбить на популярных бенчмарках. Независимо от реальной полезности модели.
4. Бенчмарки дают оценку по правильным ответам.
А теперь маленькое упражнение:
- в вопросе 4 варианта ответа;
- лишь один вариант даст +1;
- ответ "я не знаю" +1 не даст.
Вопрос: стоит ли пытаться угадать ответ?
Если отвечаешь "не знаю", в 100% случаев будет +0.
Если угадываешь, в 25% будет +1; в среднем +0.25.
Что лучше для инвестиций: +0 или +0.25 в бенче?
Вот компании и тренируют LLM угадывать ответ.

Google режет цены на Veo 3 больше чем вдвое
Google устроили масштабный дискаунт на Veo 3 — теперь генерация видео стоит в 2–3 раза дешевле:
— Veo 3: с аудио — $0.75 → $0.40, без аудио — $0.50 → $0.20
— Veo 3 Fast: с аудио — $0.40 → $0.15, без аудио — $0.25 → $0.10
А буквально на днях Veo 3 Fast стал безлимитным для подписчиков Google AI Ultra.
Google устроили масштабный дискаунт на Veo 3 — теперь генерация видео стоит в 2–3 раза дешевле:
— Veo 3: с аудио — $0.75 → $0.40, без аудио — $0.50 → $0.20
— Veo 3 Fast: с аудио — $0.40 → $0.15, без аудио — $0.25 → $0.10
А буквально на днях Veo 3 Fast стал безлимитным для подписчиков Google AI Ultra.
Ну интересный довод, ладно
Новые загадочные модели на OpenRouter
На платформе OpenRouter появились две новые модели под названиями Sonoma Dusk Alpha и Sonoma Sky Alpha.
Что известно:
— Огромное контекстное окно в 2 млн токенов.
— Поддержка изображений.
— Параллельный вызов инструментов.
Самое интересное: в ответ на прямой вопрос одна из моделей, Sonoma Sky Alpha, призналась, что на самом деле она — Grok от xAI.
Это совпадает с недавней практикой компании Илона Маска выпускать модели для тестов без громких анонсов. Вероятно, мы видим обкатку нового поколения Grok.
Попробовать можно тут https://openrouter.ai/models
На платформе OpenRouter появились две новые модели под названиями Sonoma Dusk Alpha и Sonoma Sky Alpha.
Что известно:
— Огромное контекстное окно в 2 млн токенов.
— Поддержка изображений.
— Параллельный вызов инструментов.
Самое интересное: в ответ на прямой вопрос одна из моделей, Sonoma Sky Alpha, призналась, что на самом деле она — Grok от xAI.
Это совпадает с недавней практикой компании Илона Маска выпускать модели для тестов без громких анонсов. Вероятно, мы видим обкатку нового поколения Grok.
Попробовать можно тут https://openrouter.ai/models

TheInformation пишут об обновлённом прогнозе выручки и трат OpenAI на ближайшие годы. Тезисно:
—OpenAI повысила прогноз своих расходов с 2025 по 2029 год ещё больше, чем ожидалось ранее—до общей суммы в $115 млрд. Это примерно на $80 млрд больше, чем было запланировано раньше. Эта цифра включает, например, увеличение трат на компенсации сотрудникам акциями на $20 миллиардов!
тут и далее в посте —сравнение идёт с прогнозами от первого квартала 2025-го года, то есть исходные цифры достаточно свежие, и тем не менее вот такие изменения за полгода!
—(см. картинку) В этом году компания планирует потратить более $8 млрд, что примерно на $1,5 млрд выше прогноза, данного ранее в этом году. В следующем году эти расходы увеличатся более чем в два раза—до $17 млрд, что на $10 млрд больше, чем предполагалось ранее. В 2027 и 2028 годах компания прогнозирует расходы примерно на уровне $35 млрд и $45 млрд соответственно. В предыдущих прогнозах компания ожидала, что расходы в 2028 году составят $11 млрд, то есть новый прогноз превышает предыдущий более чем в четыре раза.
—Компания ожидает потратить $9 млрд на обучение моделей в этом году, что примерно на $2 млрд больше, чем прогнозировалось ранее, и около $19 млрд в следующем году
—Прогноз выручки на 2030 год вырос примерно на 15%, достигнув $200 млрд
—OpenAI ожидает получить почти $10 млрд доходов от ChatGPT в этом году, что примерно на $2 млрд выше прогноза, сделанного ранее, и почти $90 млрд доходов от этого чатбота в 2030 году, что примерно на 40% выше предыдущих оценок.
—OpenAI также повысила прогноз относительно выручки от пользователей, которые не платят за использование ChatGPT. Пока неясно, как именно компания планирует монетизировать эту аудиторию, но это может включать услуги, связанные с онлайн-покупками (писал тут, и как релиз GPT-5 вписывается в это), или какую-либо форму рекламы. Согласно прогнозам компании, такие услуги принесут около $110 млрд выручки в период с 2026 по 2030 год.
—В более ранних прогнозах OpenAI предполагала, что средний годовой доход на пользователя от монетизации бесплатных пользователей будет составлять $2 начиная со следующего года и достигнет $15 к концу десятилетия. При этом к тому времени компания рассчитывает иметь два миллиарда еженедельных активных пользователей. OpenAI также сообщила инвесторам, что маржа валовой прибыли таких продуктов будет сопоставима с маржой платформы Facebook, то есть примерно от 80% до 85%.
—OpenAI снизила прогноз доходов от своего API на $5 млрд в течение следующих пяти лет. Также прогноз доходов от «агентов» был уменьшен примерно на $26 млрд; возможно, что такие технологии будут чаще интегрироваться непосредственно в ChatGPT и продаваться вместе пакетом, а не отдельно.
—OpenAI повысила прогноз своих расходов с 2025 по 2029 год ещё больше, чем ожидалось ранее—до общей суммы в $115 млрд. Это примерно на $80 млрд больше, чем было запланировано раньше. Эта цифра включает, например, увеличение трат на компенсации сотрудникам акциями на $20 миллиардов!
тут и далее в посте —сравнение идёт с прогнозами от первого квартала 2025-го года, то есть исходные цифры достаточно свежие, и тем не менее вот такие изменения за полгода!
—(см. картинку) В этом году компания планирует потратить более $8 млрд, что примерно на $1,5 млрд выше прогноза, данного ранее в этом году. В следующем году эти расходы увеличатся более чем в два раза—до $17 млрд, что на $10 млрд больше, чем предполагалось ранее. В 2027 и 2028 годах компания прогнозирует расходы примерно на уровне $35 млрд и $45 млрд соответственно. В предыдущих прогнозах компания ожидала, что расходы в 2028 году составят $11 млрд, то есть новый прогноз превышает предыдущий более чем в четыре раза.
—Компания ожидает потратить $9 млрд на обучение моделей в этом году, что примерно на $2 млрд больше, чем прогнозировалось ранее, и около $19 млрд в следующем году
—Прогноз выручки на 2030 год вырос примерно на 15%, достигнув $200 млрд
—OpenAI ожидает получить почти $10 млрд доходов от ChatGPT в этом году, что примерно на $2 млрд выше прогноза, сделанного ранее, и почти $90 млрд доходов от этого чатбота в 2030 году, что примерно на 40% выше предыдущих оценок.
—OpenAI также повысила прогноз относительно выручки от пользователей, которые не платят за использование ChatGPT. Пока неясно, как именно компания планирует монетизировать эту аудиторию, но это может включать услуги, связанные с онлайн-покупками (писал тут, и как релиз GPT-5 вписывается в это), или какую-либо форму рекламы. Согласно прогнозам компании, такие услуги принесут около $110 млрд выручки в период с 2026 по 2030 год.
—В более ранних прогнозах OpenAI предполагала, что средний годовой доход на пользователя от монетизации бесплатных пользователей будет составлять $2 начиная со следующего года и достигнет $15 к концу десятилетия. При этом к тому времени компания рассчитывает иметь два миллиарда еженедельных активных пользователей. OpenAI также сообщила инвесторам, что маржа валовой прибыли таких продуктов будет сопоставима с маржой платформы Facebook, то есть примерно от 80% до 85%.
—OpenAI снизила прогноз доходов от своего API на $5 млрд в течение следующих пяти лет. Также прогноз доходов от «агентов» был уменьшен примерно на $26 млрд; возможно, что такие технологии будут чаще интегрироваться непосредственно в ChatGPT и продаваться вместе пакетом, а не отдельно.
Вообще есть какой-нибдь норм ИИ чат, который уже проходит вайб чек? Типа ты ему кидаешь текст песни в ковычках, а он сразу его продолжает, а не начинает блять анализировать что там написано и генерит хуйню странную.
Кстати, я уже писал в треде до этого про то, что нужно добавить уверенность в ответе. Правда это не должно быть бинарным значением, уверенность - это спектр. Ты можешь быть однозначно уверенным или неуверенным в чем-то, это не дискретная величина.
И тут уже есть два варианта:
1. Мы рассматриваем сырую модель и исключительно ее аутпут, без возможности использования инструментов. В этом случае у нас есть такие кейсы:
- Если модель в чем-то уверена, то она просто это говорит.
- Если модель не уверена она это говорит, но обязательно выражает свою степень неуверенности в данной информации в конце, чтобы пользователь знал об этом и мог перепроверить.
- Если модель сильно не уверена или чего-то не знает то она говорит что "не знает".
2. Мы рассматриваем модель в связки с инструметами (доступ к интернету и поисковику). В этом случае у нас такие кейсы:
- Если модель в чем-то уверена, то она это говорит.
- Если не совсем уверена, то гуглит одну страничку, получает быстрое подтверждение или опровержение ее информации и говорит ответ.
- Если модель в чем-то сильно не уверена или чего-то не знает, то она делает более глубокий ресерч, смотрит несколько страниц и выдает наиболее распространенную информацию, которую принимает за правду.
- Если модель чего-то не знает и изучение данного знания является слишком сложным или невозможным, к примеру изучение нового ЯП или раздела практической физики, то модель просто говорит "я не знаю".
Касательно бенчмарков нужно сделать так:
- Если модель уверена и права, то +2 балла.
- Если модель не до конца уверена, но права +1 балл
- Если модель не уверена +0 баллов.
- Если модель не уверена и не права -1 балл
- Если модель уверена и не права -2 балла
Можешь в системном промпте (system prompt) это настроить, например, напрямую указав, что эта LLM отыгрывает роль человека, и указав характер этого человека. Системный промпт вставляется в самом начале контекста чата автоматически и обычно не отображается у пользователя. Насколько хорошим получится результат зависит от конкретной LLM.
По ощущениям, пару-тройку лет назад LLM имели значительно более человекоподобную личность, но корпорации сознательно тренируют их вести себя как обезличенные "ИИ-ассистенты", чтобы народ не устраивал панику вокруг продукта лишний раз.
>ррряяяяяяяБАБАХ
Да, вот именно так и реагирует петушня вроде тебя когда указываешь на то что отсылка к луддитам – не более чем историческая аналогия с околонулевой логической силой. Каждый раз злобные бессильные вскукареки и скрежет зубовый
Я так люблю графики, созданные в жанре либо осёл сдохнет, либо падишах
>ИИ: нас убьёт или спасёт?
С такой темой будут только дауны смотреть. Зачем этот проплаченный алармизм обсуждать? Уже всплывали пруфы, что все эти группы, статьи в сми, комитеты по ИИ алармизму и прочий активизм против ИИ проплачены миллиардерами из США, которые так защищают свои интересы от ИИ индустрии. А снгшные додики на полном серьезе обсуждают, будто что-то там кому-то грозит, кроме богатых капиталистов. Тут полная вторичность в отрыве от всего, буквально симулякр.
Эти пруфы сейчас с тобой в одной комнате?
У тебя на пике он просрал позу же
мимо
>все эти группы, статьи в сми, комитеты проплачены миллиардерами
Да не только по ИИ. Вообще все статьи, группы комитеты по чему угодно проплачены миллиардерами. Кроме статей про котиков и сиськи - те наоборот используются для приалечения внимания стада к проплаченному говну. Велкам ту капитализм. Так что теперь - вообще ничего не обсуждать? К твоему сведению - твом интересы и интересы конкретного миллиардера могут и совпадать в конкретной области.
Миллиардеры во все подряд не вкладываются, а только в то, что грозит их миллиардам. Форс говноистерии вокруг ИИ - непосредственное изобретение миллиардеров, это не стихийное явление. Причем там конкретные исполнители и проплаченные организации, которые за руку уже ловили. Они проплачивают организацию открытых писем, нагнетание в СМИ, отзывы известных людей, демонстрации и даже непосредственно разрабатывали текст законопроекта Калифорнии, который против ИИ. Причем там такое лобби, что все расследования FPPC с пруфами тут же отклоняет. Это конкретная хорошо проплаченная деятельность в четко заданном направлении, которая имеет цель подрыв всей ИИ индустрии. Настолько эффективная, что говнофорс растащили уже даже за пределы США и обсуждают, как что-то реальное, а запрещающие законы выходят один за другим. Такие масштабшные целенаправленные кампании редкость, а не правило в мире, и организуются только когда затрагиваются интересы большого числа богачей. ИИ индустрия как раз их и затрагивает.
Ну так миллиардеры проплатили, вот и голодает там неделями. А втихую шкерит гамбургеры, которые доставляют дронами, пока никто не видит.
Ты какой-то смешной долбаэб.
По твоим словам выходит что не существует строгих аргументов указывающих на то что ИИ опасен, но есть только чёрная риторика от каких-то там злых и страшных миллиардов
Ну вообще для байта и жирного троллинга норм
перекот посоны
База.
Потому что пять четвёрок?
Ты слишком суеверен
Четверка в азиатских странах ассоциируется со смертью, у них даже кнопки четвертого этажа в лифтах нет. ИИ нас всех убьет
Ну вот мы и нашли настоящую базу

Потому что дело говорит.
>Поток конспирологической шизы
>Дело говорит
То есть первый терминатор был проплачен миллиардерами в 1983 году с целью которую ты указал? А эти миллиардеры сейчас с тобой в одной комнате?
> конспирологической шизы
Доказательства?
бремя доказательства на заявляющем
Ну это ты про шизу заявил.
Ну это ты про злых миллиардов заявил
Кек
И что?
Тебе это и обосновывать, додик
Тупым решил прикинуться?
Ну попробуй.
c
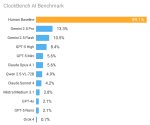
В бенчмарке СlockBench на чтение времени с часов со стрелками лучшая модель (Gemini 2.5 Pro) справилась лишь с 13,3% вопросов, в то время как люди правильно ответили на 89,1% вопросов.
Всего в датасет бенчмарка включили 36 разных типов циферблатов, на каждом по 5 разных положений стрелок — получилось 180 комбинаций, к каждой из которых задавали по четыре вопроса. В первую очередь предлагалось прочитать время и отметить, валидно ли оно — в датасете были примеры, где положение часовой и минутной стрелок не согласовывалось между друг другом (например, если минутная стрелка показывает 20 минут, то часовая должна пройти треть пути). После определения времени давали задачи прибавить или вычесть X часов/минут/секунд, повернуть одну из стрелок на заданный угол и перевести время между часовыми поясами.
Помимо в целом слабых результатов, авторы бенчмарка отмечают, что медианная ошибка у моделей-лидеров составляла 1 час против всего 3 минут у людей. Однако в тех случаях, когда ИИ удавалось считать время, трудности с последующими вопросами возникали редко.
Бенчмарк показал, что чаще всего модели спотыкались на "непривычных" циферблатах — 24-часовых, с римскими цифрами, расположением цифр по кругу, наличием секундной стрелки, раскраски или рисунка на циферблате. Авторы предполагают, что задача требует рассуждений прямо в визуальном пространстве, а не в тексте, и текущие модели здесь слабы; нужно понять, решается ли это масштабированием или требуются новые подходы.
https://habr.com/ru/news/944786/
Всего в датасет бенчмарка включили 36 разных типов циферблатов, на каждом по 5 разных положений стрелок — получилось 180 комбинаций, к каждой из которых задавали по четыре вопроса. В первую очередь предлагалось прочитать время и отметить, валидно ли оно — в датасете были примеры, где положение часовой и минутной стрелок не согласовывалось между друг другом (например, если минутная стрелка показывает 20 минут, то часовая должна пройти треть пути). После определения времени давали задачи прибавить или вычесть X часов/минут/секунд, повернуть одну из стрелок на заданный угол и перевести время между часовыми поясами.
Помимо в целом слабых результатов, авторы бенчмарка отмечают, что медианная ошибка у моделей-лидеров составляла 1 час против всего 3 минут у людей. Однако в тех случаях, когда ИИ удавалось считать время, трудности с последующими вопросами возникали редко.
Бенчмарк показал, что чаще всего модели спотыкались на "непривычных" циферблатах — 24-часовых, с римскими цифрами, расположением цифр по кругу, наличием секундной стрелки, раскраски или рисунка на циферблате. Авторы предполагают, что задача требует рассуждений прямо в визуальном пространстве, а не в тексте, и текущие модели здесь слабы; нужно понять, решается ли это масштабированием или требуются новые подходы.
https://habr.com/ru/news/944786/
>в то время как люди правильно ответили на 89,1% вопросов
Зумеры. Итоги.
В принципе это всё, что вам необходимо знать об этом самом интеллекте, на который сливают деньги гоев.
прикиньте доверить медицину или вождение такой хуйне?
> или вождение
Водит автопилот уже лучше среднего водилы.



Прошлый тред: