



Я к чему — проще собрать свой пайплайн с виспером/гигаам + еспич/фиш/вайбвоис. Получится тоже самое, но чуть лучше везде (и распознавание будет лучше, и ллм будет лучше, и ттс лучше).
Теоретические эмоции на базе контекста обещанные — круто, но их нет, к сожалению, нихуя в русском языке.
Может быть пофиксят, а пока че-то фигня какая-то.

Пизда моим мишкам и рдшке
>Qwen3-32b с включеным и отключенным ризонингом от qwen3 30B-A3B-Thinking и 30B-A3B-Instruct
Тем что 32b плотная, а 30b-a3 - моешка, эквивалентная примерно 16b плотной?
Скрестил пальцы за тебя, братан!
Кто знает, может скоро все энтузиасты перекатятся на хуавей. Ждём полноценных тестов от хуавей-куна.
Ебать печаль тогда.. я от Qwen3-32b то не сильно в восторге.. так чисто рецепт приготовление омлета спросить и все.. хотя в целом норм модель в простых вещах, наверно проблема еще в 4bit кванте. Например типа если спросить у нее кто режиссер какой-то неводомой хуйни с бюджетом меньше миллиона она придумывает шизу, берет каких-то похожих режиссеров с того же жанра и нихуя не угадывает.. хотя какую-то популярную хуйню она правильно называет.. наверно просто малый дата сет на 32b то.. или причина в квантовании тоже может быть?
> AVX512
Он поможет прежде всего при обработке промпта на процессоре, с частичной выгрузкой не роляет.
В отличии от этого модель понимает интонации и прочие звуки, а не просто конвертирует речь в текст. Присрать ее к другой ллм - не проблема.
30а3 уникальная модель, она может ультить в одном и фейлить в другом, сложно сравнивать с плотными. А вот 3й 32б - крайне неудачный, с ним что не делай - остается припезднутым. Остальные модели в линейке нормальные, а этот резко выделяется.
Ссылка на тесты моделей с прошлого треда: https://rentry.co/z4nr8ztd
Плотные модели в том и проигрывают мое, они умные по мозгам, но реальных знаний в ты никак в 32b много не пихнешь. Другое дело - 100+ мое, эти 100+ как раз ненужными знаниями и забиты вроде кто режиссер какой хуйни. При этом по мозгам там активные эксперты будут еле-еле конкурировать с 32b.
Именно поэтому будет очень интересна какая-нибудь 20б-а180, но не Квен, Квен припизднутый
Ждём Мтстралей и Кохерек, мб Гемму 4 на 27б активных
Кто там маленькие модели для телебона пробовал, я тут скрытый гем нашел - gemma 3n e4b(хз чего её не назвали 8b-a4b, как полагается по моешной номенклатуре).
На chatterui на телефоне выдает на 4 кванте 4.5 т/с генерации, т.е. столько же как и плотная 4b gemma, при этом мозгов и знаний побольше.
На chatterui на телефоне выдает на 4 кванте 4.5 т/с генерации, т.е. столько же как и плотная 4b gemma, при этом мозгов и знаний побольше.
>какая-нибудь 20б-а180
Ты хотел сказать 180b-a20b? Потому что хз что там лоботомит с 180м активных параметров смогет.
Уже в прошлом треде выяснили что она топ в своем размере.
И даже более того, ебет местами квен 14б.
>модели для телебона
Какой же кринж боже......
Будет в шапке со следующего переката.
Молодец, хорошее сравнение.
Единственное но - для телефонов стоило использовать q4_0 или q5_0 кванты - они адаптированы под arm процессоры.
Да и так эти ми50 32г уже кончаются. Их дропнули из тайваня куда как понял был отдельный заказ на такие версии. Всякие карго их сотнями выгребают
Но квенчик решает проблему с запаянной кружкой, а гемма - нет.
Да, но это Qwen3-14B
А в своем размере, что gemma-3n-E4B что Qwen3-4B не справились.
Квен вообще вон что ответил.
https://github.com/ollama/ollama/pull/5872#issuecomment-2254873034 Хуавей кун не нужен, кое какие тесты уже утекли. Правда я так и не понял на какой карте инференс и работает ли карта в 2 чипа, если это duo версия.
Аноны, помогите начинающему дЭбилу. У меня при запуске кобольда занимается вся видеопамять, но при этом из 31 доступного гига оперативки занимается лишь 15. Как можно еще десяточку гигов оперативки добавить к мощностям? Я уже все ползунки передергал - так и не понял. ЧЯДНТ?
Модель всегда делится пополам, спроси у корп дипсика, он тебе проведёт лекцию почему это нормально.
кстати, а какое у модели разрешение в OCR? насколько она хороша в более практических вещах? Например распознавание PDF.
Очень жаль. Думал, что можно еще загрузить оперативку, что бы побыстрее было, пусть и ненамного. Эхэхэх.

Да, поэтому врам решает и тут все шизеют по этой теме.
Печаль. Полагаю нет. Гемма с 768 скорей всего делает то-же самое. Оно на табличных структурах с мелким шрифтом фейлится.
> При этом по мозгам там активные эксперты будут еле-еле конкурировать с 32b
Почему-то выходит что квенчик с "всего" 22б активных и решает сложные задачи, и может держать внимание на огромном контексте рп на недостижимом для плотных моделей в пределах 30б уровне. Она превосходит в этом ларджа, но тот старый и сравнение не честное, плюс тот имеет свои фичи.
Опять же, было бы интересно посмотреть на современные большие плотные модели, но таких как-то и не завезли, комманд-а пускает слюни и ошибается как тридцатки или хуже.
Для 8б модели как-то не сильно весело, но есть шанс что в квантах моэ будут адекватные скорости.
Парочку таких чисто ллм катать заиметь было бы хорошо.
> Например распознавание PDF
2.5вл уже есть с огромными разрешениями и справляется, вот вот вл3 выйдет, недавно в трансформерс добавили ее поддержку. Но для качественного распознавания внешняя обвязка таки понадобится, ибо сразу всю страницу с подробностями оно не схавает.
Аноны, для каких целей вы используете нейронки?
Про рп, переводы, код, обучение, классификация, редактирование текста и т.д., понятно. А вот по жизни, как еще применяете?
Перерабатываю шаблон для тестов, нужно более комплексно подойти.
Про рп, переводы, код, обучение, классификация, редактирование текста и т.д., понятно. А вот по жизни, как еще применяете?
Перерабатываю шаблон для тестов, нужно более комплексно подойти.
рп, код (дебаг, кодревью), медгемму использую иногда для вопросов здоровья, и рили неплоха (даже фотографии можно прикладывать), гопоту осс для разных вопросов общего спектра использую тоже (запромтить чтобы при каждом ответе прикладывался список источников, предпочтительно из литературы, например)
>2.5вл
да, я знаю. но вообще я хочу модель которая просто была бы чуть умней. Например для распознавания банковской информации в табличке хватает примерно 1200-1400 по широкой стороне, но ёбана~ банковская информация это ебучий ребус зачастую.
> я хочу модель которая просто была бы чуть умней
Есть на 72б, она дохуя умная. Настраивая препроцессор можешь хоть 10 мегапикселей туда закинуть, но готовь бюджет токенов. Также можно обернуть вл в функцию, которую вызывать с основной модели по запросу, квенкод может такое накодить а потом пользоваться.
А еще лучше иди ной выпрашивая моэ квенчика с визуальным восприятием, вот это было бы оче круто.


Блять, он уже умер и призраком стал.
Мультивселенная Хемлока. Ну как вот не надоело на Гемме играть с таким маленьким датасетом?
>квенчик с "всего" 22б активных и решает сложные задачи, и может держать внимание на огромном контексте рп на недостижимом для плотных моделей в пределах 30б уровне.
Ну конечно 235b с 22b активных параметров будет ставить раком плотную 30b, она по мозгам как 110b+, моешка по мозгам всегда примерно на половину от своего макс размера из-за использования наиболее подходящих экспертов.
Пропустил релизы новых микстурных квенов, хотел затестить, а на жору до сих пор не завезли саппорт. Кто-то итт тут их пробовал? Как оно?
Ты про Qwen2.5-VL-72B? Блин вот его не трогал ещё. Он вместится мне только со скрипом в q4
Да такое и я накодить могу. Более того - уже накожено. что за
>А еще лучше иди ной выпрашивая моэ квенчика с визуальным восприятием, вот это было бы оче круто.
Лол да он и так может, но чет разрешения не те. По сути я это и делаю!
У геммы как раз хороший датасет и она не слопит в отличии от мистраля, но вот с хемлоком какая то особая ситуация, это видимо какой то рофл от того кто тренировал модель.
Да нет, просто это самый вероятный токен на фэнтезийного персонажа. Так же как эльфийка Лирия.
Так там написано что "по мозгам" уступает 32б. Но так модель сложно оценивать, она раскрывается или если работает с ризонингом, или если имете возможность на условно длинный ответ. С первым понятно, а на втором модель, как в некоторых стилях повествования, добавляет уточнения или вообще исправляет явные ошибки, оборачивая их в плюс за счет иллюзии более живой речи. Так модель действительно может задействовать множество разных параметров внутри себя.
Если же требовать дать оче короткий ответ зирошотом - уступает большим плотным. Кстати, у квена весьма недефолтная конфигурация голов, у других распределены иначе.
> Лол да он и так может
Не, не может, 235 и 480 без визуального инпута. Есть только закрытые модели у них по апи с визуалом.
Аноны, можно ли как-то завести магистраль новый на кобольд + таверна с рабочим ризонингом? Как не пердолился, нихуя не выходит, и я не понимаю, в чём проблема.
Для теста использовал лм студио и в родной обёртке для неё щупал ассистента. Там всё нормально.
Как я понимаю, таверна поднасирает. Но, как ни странно, если [INST] написать и дать модели продолжить, то она поразмышляет, но не закроет блок размышлений, в отличие от квена.
Для теста использовал лм студио и в родной обёртке для неё щупал ассистента. Там всё нормально.
Как я понимаю, таверна поднасирает. Но, как ни странно, если [INST] написать и дать модели продолжить, то она поразмышляет, но не закроет блок размышлений, в отличие от квена.
Ну да, я помню на 12b немомиксе меня заебала эта Лира\Лирия.
Чем больше в оперативке - тем больше тормозов. Все наоборот, ее разгружать надо, если возможность есть. Лучше всего - когда все только в VRAM.
Нужен локальный переводчик для пары языков (английский, русский, японский и некоторые европейские) для Windows 10. Стоит ли смотреть в сторону локальных языковых моделей, или они будут не сильно лучше традиционных решений, учитывая такое слабое железо?
ЦП: Intel Core i3-7020U (2 ядра, 4 потока, 2,3 ГГц)
ГП: NVIDIA GeForce MX150 (2 ГБ)
ОЗУ: 12 ГБ
ЦП: Intel Core i3-7020U (2 ядра, 4 потока, 2,3 ГГц)
ГП: NVIDIA GeForce MX150 (2 ГБ)
ОЗУ: 12 ГБ
Ллм будут сильно лучше поскольку переводят точнее с учетом контекста и можно напрямую спросить про значение слов в предложении и правила. Но в твоем железе ничего нормального не запустить, смотри в сторону публичных апи и сервисов.
Есть же геммы для кофеварок

Чертолёт от хуавея с enterprice grade охлаждением взелает и разбивается об сайт. Тысячи менюшек, отвратительная навигация и отсутствие возможности скачать хоть что-то с сайта даже после регистрации, регистрации потребительского аккаунта, регистрации карты по серийному номеру, регистрации временной ссылки на скачивание это пиздец. Щас качаю enterprice grade утилиту для скачивания 3-х файлов с ебучего сайта хуавей.
Добро пожаловать в enterprice
Добро пожаловать в enterprice
Да чё за залупа, не скачивал ни разу, откуда блок

Вторая версия способа дуть в мишку
https://www.thingiverse.com/thing:7153218
Т.к. железо зависло в китае буду пытаться загнать k3s в lxc
https://www.thingiverse.com/thing:7153218
Т.к. железо зависло в китае буду пытаться загнать k3s в lxc
Попробуй поменять айпишник. Или поставь WARP 1111 правда хз поможет ли он на этот сайт... если это вообще не со стороны сайта проблема.
Qwen3-42B-A3B-2507-Thinking - протестил по новому шаблону.
Ну что могу сказать, это фиаско. Сделали хуйню. Особенно порадовали советы поехать в Ялту, засунуть в жопу парацетамол и шизофазия.
Модель тупая, хотя местами кажется вот-вот годное выдаст (нет, после этого она сразу обосрется).
Закинул подробные тесты в общий список.
Ну что могу сказать, это фиаско. Сделали хуйню. Особенно порадовали советы поехать в Ялту, засунуть в жопу парацетамол и шизофазия.
Модель тупая, хотя местами кажется вот-вот годное выдаст (нет, после этого она сразу обосрется).
Закинул подробные тесты в общий список.
Уже 2 впна сменил, шлёт нахуй.
> 42B-A3B
Что это блять за шизомердж-франкенштейн? А там ни разу не А3 а овер 4б активируемых, поскольку вместо экспертов "вширь" наращено количество слоев по-классике.
Результат ожидаем, удивительно было бы если оно оказалось хорошим.
> Что это блять за шизомердж-франкенштейн?
Обычный DavidAU. Тоже ахуел. Подумал, что анон ошибся, опечатался, а правда такой тюн есть.
Кому нибудь удавалось отыгрывать вот прям неплохую комедию? Чтобы карточка, модель или они вместе удивляли и попадали как надо. Расскажите как оно было если было, если поделитесь карточкой вообще круто будет. Не понимаю это я скучный или нейронки не могут в юмор.
>либо OSS
Ебать, спасибо х2. Локальный экспириенс в 500млрд раз лучше, чем облачные маняподелки.
Я тогда еще говорил, что проблема ии будет не в фундаменте, а в последней миле. Только что отхуесосил дипсика за то, что он тупорылый морон. Осс с моим чаром просто выдает мне то, что я хочу, без даунизмов.
Спасибо х3, вот прям лайф ченж произошел.
Там уж наверно у всех 5 звезд и все давно померли.
>Осс
Какои? Seed-oss 36b?
Только смехуечки в адвенчуре с шутками, хитрыми намеками-имплаями, дразнением чара до момента, когда он выламывает 4ю стену и напоминает что в это могут играть двое. Дело не в карточке, там все полагалось на модель пожирнее, историю чата и само поведение юзера. И прямо вот 100% юмора там не было, исключая черный в моментах, скорее просто ощущение что вы на одной волне и строите многоярусную словесную игру, от осознания обоюдного понимания которой оче приятно.
Но дипсик... опенсорсный... Извинись!
Если тебе интересно, то https://huggingface.co/Jinx-org/Jinx-gpt-oss-20b тоже существует. в обычном OSS пережарили вектор отказа.
Аноны могут скинуть пример своей строки для кобольда, которым они аттеншион тензоры выгружают и куда ее пихать, а то я нихуя не понял...
Легко пробивается джайлом. Зачем юзать тюн где еще и мозги вырезали вместе с рефузами?
так там и перевод от кофеварки будет
там джейлбрейк довольно поверхностный и плохо годится для длинных тематических чатов.
ояебу. охуенно~
Ага... быстро работаете, ахуеть.
Правда визуальная часть там микроскопическая и оно не будет настолько хорошо видеть и распознавать как отдельные, но бля. Кроме https://www.youtube.com/watch?v=uFIp1adVJ04 нечего добавить
а там обязательно прям с офф сайта качать? на файлообменники никто не заливал нужных файлов?
эт капец конечно, когда эксперимент нельзя даже начать...
unsloth/gpt-oss-20b-Q6_K.gguf (12гб)
Предвещая втфы - у меня главная боль не само качество/сложность ответов, а то что стандартные промпты охота с кирпича уебать. Выходит нихуя неконструктивно, даже с пятым.
Извините.
Это для рп наверное? Если да, то не, не надо, пасиб.

>unsloth/gpt-oss-20b-Q6_K.gguf (12гб)
кстати там же есть "хитрая" квантизация, не?
https://huggingface.co/unsloth/gpt-oss-20b-GGUF/tree/main
gpt-oss-20b-F16.gguf 13.8 GB
gpt-oss-20b-Q8_0.gguf 12.1 GB
буквально бессмысленно пользоваться Q6
>Это для рп наверное? Если да, то не, не надо, пасиб.
Скорей для сомнительных запросов. OSS имеет очень ужаренный вектор отказа и скатывается к отрицалову порой даже если в тексте присутствует слово "жопа". В ролеплее это просто проявляется ещё сильней. Там доходит до идиотских диалогов в духе пикрелейтеда.
Эксперименты по расцензуриванию гопоты 120B. https://huggingface.co/bartowski/huizimao_gpt-oss-120b-uncensored-bf16-GGUF
Она, конечно, промптом и так уже пробивается - нашли комбинацию, но терять до 300-400 токенов на ее рассуждения о "можно-нельзя" - надоедает...
Она, конечно, промптом и так уже пробивается - нашли комбинацию, но терять до 300-400 токенов на ее рассуждения о "можно-нельзя" - надоедает...
Я не понял чо за прикол с размерами, по привычке взял Q6. А че за хитрая квантизация? Скормил пятому ссылки на репу и статью, он убеждает что якобы разницы нет только на диске, а в враме будет. Хуйню несет наверно, как обычно. Самому лень читать.
>сомнительных запросов
У меня самый сомнительный запрос это how long cook grechku, так что. Это даже лучше, если он на мое раздражение будет сам ебло заваливать.
>расцензуриванию гопоты 120B
Она сильно лучше Llama 4 Scout?
Блять, почему у всех такой повальный фетиш на матерей? Заходишь на чаб, открываешь топ карт. Мать, мать с дочерью, мать одиночка, мать алкоголичка, мать бомжиха, мать некроморф, мёртвая мать.
Там в топе среди тянских карточек триумвират лоли/мамки/сестры. Почему? Да потому что это все три - это запрещенка. Это Россия - исключение из правил, land of the free, а на западе ебать сестер и мамок - такое же уголовное преступление как ебля детей.
>мать некроморф, мёртвая мать.
Эхо уголовных запретов на некрофилию.
Да. Эту еще не пробовал, но оригинал гопоты обходит скаута как стоячего. В прочем - его не сложно обойти. По моему впечатлению, скаут едва-едва на уровне последней мистрали, что для ее размера - фиаско.
ребят, всем привет, в треде новичок - тонкостей не знаю так что не кидайте ссаными тряпками.
вопрос - можно ли использовать локальные нейросетки для написания кода? я балуюсь созданием игр (пока что чисто для себя), рисую, придумываю, а вот кодить не умею совсем, но за год работы с Grok наклепал много интересной хуйни, но это не важно. Так вот, хотелось бы локальную нейросетку иметь для кодинга чисто.
если по пунктам, то:
1. какие модели для этого подходят?
2. какое необходимо железо для ответов уровня grok 3? (предполагаю что это тупой вопрос и понадобится дата центр ценой в истребитель, но вдруг)
3. какой пк можно собрать специально для нейросеток чтобы прям заебись было? без всяких H100 или че там щас десятки мильенов рублей стоит, но условно 2-3 RTX5090 будут иметь смысл? и по памяти тоже обьясните, важна ли сильно мощность, или вместо 5090 можно использовать например китайские 3090 перепаянные на 48гб? и как тут оперативка участвует?
может собрать условную рабочую станцию на 512гб озу с тредриппером и тремя 5090 всё таки даст возможность работать также как и в браузере с гроком?
4. если на все эти вопросы ответы положительные, то ещё вопрос, имеет ли смысл пытаться что-то развернуть на нынешнем пк? (64 гига озу 3200мгц, ш5 12600кф и 3070ti, готов под это дело купить ссд на 2тб отдельный)
5. и в общем какие нибудь отзывы от людей которые используют локальные модели для кодинга были бы очень кстати, нюансы и всё такое.
заранее спасибо
вопрос - можно ли использовать локальные нейросетки для написания кода? я балуюсь созданием игр (пока что чисто для себя), рисую, придумываю, а вот кодить не умею совсем, но за год работы с Grok наклепал много интересной хуйни, но это не важно. Так вот, хотелось бы локальную нейросетку иметь для кодинга чисто.
если по пунктам, то:
1. какие модели для этого подходят?
2. какое необходимо железо для ответов уровня grok 3? (предполагаю что это тупой вопрос и понадобится дата центр ценой в истребитель, но вдруг)
3. какой пк можно собрать специально для нейросеток чтобы прям заебись было? без всяких H100 или че там щас десятки мильенов рублей стоит, но условно 2-3 RTX5090 будут иметь смысл? и по памяти тоже обьясните, важна ли сильно мощность, или вместо 5090 можно использовать например китайские 3090 перепаянные на 48гб? и как тут оперативка участвует?
может собрать условную рабочую станцию на 512гб озу с тредриппером и тремя 5090 всё таки даст возможность работать также как и в браузере с гроком?
4. если на все эти вопросы ответы положительные, то ещё вопрос, имеет ли смысл пытаться что-то развернуть на нынешнем пк? (64 гига озу 3200мгц, ш5 12600кф и 3070ti, готов под это дело купить ссд на 2тб отдельный)
5. и в общем какие нибудь отзывы от людей которые используют локальные модели для кодинга были бы очень кстати, нюансы и всё такое.
заранее спасибо
Я не спец и в треде не часто, но код пишу. Ты как бы это, попробуй сначала чо поменьше, чем 2-3 5090 с трипером, блджад. Тебе вполне может зайти скромная модель (по меркам облаков) если нормально ее запромптишь под себя. Я вон выше анон с oss-ом, сижу седня вполне доволен.
Мнения будут разнится, но я не считаю овербольшие модели какими-то сильно лучшими - эдж на самом деле тонкий. Чуть нестандартнее задача, и они все обосрутся. А у меня много таких. Пока норм держится только пятерка, но она стоит космос.
Курсоры и прочие fim я не юзаю конечно, то есть у меня нет режима "грузишь проект и он там сам хуячит". Делаю частями, контекст для задач сам собираю.
Алсо год-два назад был вариант по аренде гпу вместо покупки, щас хз. Если бы у меня стоял вопрос 3 консумер гпу, пхы, это однозначно облако (с норм гпу). Дома это пиздец, ты вообще эту пекарню-шкаф представляешь?
>имеет ли смысл пытаться что-то развернуть на нынешнем пк?
Это надо в первую очередь сделать, чтобы начать ландшафт представлять.
Еще у меня в прошлом году на проекте был 7900х сервер, без видяхи, так на нем микстрал (26гб) высирал токены только в путь. Я аж задумался, может мне тупо проц этот купить.
>можно ли использовать локальные нейросетки для написания кода?
Для написания кода - можно. Для проектирования кода - нет. ЛЛМ понапишет тебе тонну говна, а потом сам же в этом говне и потонет. ЛЛМ это инструмент, притом реально сейчас мы скорей всего будем видеть сильный разрыв в скиллах в ближайшее время. Абсолютно бессмысленно становится джуном, так как ЛЛМ пишут код лучше джуна и при вхождении в погромирование тебе надо быть как минимум на уровне мидла, который сейчас по совместительству становится чем-то вроде "оператора ЛЛМ".
Ты либо пишешь и читаешь код ВМЕСТЕ с ЛЛМ, либо у тебя в проекте тотальный пиздец.
>какие модели для этого подходят?
На самом деле сейчас почти любые, писание кода это популярная метрика в бенчмаркинге. Меньше 30b можно не рассматривать всерьёз для этого. Да и 30b это на уровне карманной обезьяны.
Собирать под это дело конплюктор в целом бессмысленная затея. Лучше возьми Kilo Code/Cline/Roo Code, подружи их с опенроутером и пользуйся Grok Fast, или Claude 4 если готов расстаться с шекелями. Или Qwen Coder и DeepSeek 3.1 если не готов.
Ещё есть варианты с коопайлотом. Но я обычно использую Cursor.
>и в общем какие нибудь отзывы от людей которые используют локальные модели для кодинга были бы очень кстати, нюансы и всё такое.
Я использую, но только в очень ограниченном количестве сценариев. Лол например быстрей сказать "напиши мне обратное хождение по for loop в C# по этому стрингу", чем написать это вручную.
Но можешь не ожидать что ЛЛМ за тебя напишут код. Они инструмент. Если не знаешь как им пользоваться - хуйни наделаешь.
Ты потратишь время с большей пользой, если будешь использовать ЛЛМ как твоего персонального репетитора.
Это твоя лучшая опция.
Все большие модели с лёгкостью тебе расскажут как работает тот или иной язык, притом им можно как задавать конкретные вопросы, так и попросить объяснять тебе на том уровне на котором ты находишься. Если ты не знаешь нихуя, то они без вопросов объяснят что такое reference type, а что value type буквально используя эмоуты с бананами.
Понял, спасибо. Насчет репетиторства и прочего - увы, богом не дано такого склада ума, программисты которые всё это лепят сами - великие люди, мне это к сожалению не дано от слова совсем. Не могу сказать что я прям тупой, я во многих других вещах разбираюсь на уровне мидла как минимум (3д моделирование например, там пиздец своих тонкостей сколько и реально надо чтобы мозг по особенному работал чтобы в пространстве многие вещи понимать и осмысливать), но вот программирование не даётся вообще, никак. Пробовал лет в 15 вкатиться хотя бы в веб-дизайн (как он тогда назывался) но даже там посыпался.
А насчет того что нейросетки хуево напишут если не понимаешь - скажем так, логически - я понимаю что такое код, могу у себя в голове на русском языке представить как будет работать тот или иной скрипт (опять же, я это делаю только для игрушек, в серьезные дела для погромистов я не лезу), и вот как раз таки в этом условный Grok мне охуительно помогает, главное обьяснить нормально. Да, бывают затупы, например над условной процедурной генерацией уровней я пиздец сколько сидел, почти две недели часов по 12, постоянно создавая новые аккаунты и скармливая им контекст потому что багов было пиздец и грок не мог решить их за отведенное количество запросов, но всё же получилось. Так что локалку хочу для тех же самых целей, только шобы блять запросы я мог хуячить без лимита.
Ну и в 3 штуки 5090 я реально готов вложиться если это принесёт плоды, если даст возможность кодить хотя бы на близком уровне с грок 3 (не новый грок 4, а именно 3), и там потом как нибудь скармливать свой контекст, может ДООБУЧИТЬ как-то чисто для моего двигла или типа того. Короче хуй знает.
Как поживает чел, который купил хуавей?
Да, есть, я выцепил несколько файлов с ftp сервера serverflow и еще нашел несколько штук на lmdeploy для загрузки в докер контейнер. Но к сожалению мне не хавает коротких вечеров после раб отки что бы сделать все и сразу, когда то тут то там выползают проблемы на ровном месте.
>А насчет того что нейросетки хуево напишут если не понимаешь - скажем так, логически - я понимаю что такое код, могу у себя в голове на русском языке представить как будет работать тот или иной скрипт (опять же, я это делаю только для игрушек, в серьезные дела для погромистов я не лезу), и вот как раз таки в этом условный Grok мне охуительно помогает, главное обьяснить нормально.
Не, там есть много сложностей которые ты вряд-ли охватишь внутри своей головы без соответствующих знаний. ЛЛМ дадут тебе ответ в пределах твоего запроса. НЕ ДАЛЬШЕ. Там зачастую они либо ебошат код следуя каким-то паттернам, притом меняют его между своими запросами, либо просто берут код из ада и доводят его до состояния минимальной работоспособности. Они не сделают тебе архитектуру, например. Верней, сделают если ты скажешь им сделать, но без связующего звена в качестве твоих мозгов ты получишь мусор. Сейчас роль погромиста больше смещается к роли того кто проектирует проект а не пишет. То есть надо знать архитектуры, знать как применять их, знать почему ты это делаешь.
И не думай что геймдев это менее сложное погромирование. У меня например корни растут в геймдев. Погромирование в геймдеве на самом деле требует ещё больше знаний чем обычное погромирование лол, так как к нему добавляется ещё геометрия, оптимизация, ограничения движка и прочее. Просто надо меньше знать изначально, но больше потенциально.
Советую используя геймдев как рычаг вкатываться в погромирование. Там низы в целом проще. Я конечно понимаю что тебе скорей всего придётся потратить на это пол годика, а не пару недель пердолинга с гроком, но это куда лучше инвестиция времени. Но просто скрипя зубами ебош пока не станет понятно. Поднимай свои базовые знания за счёт ЛЛМ, а не замещай их. ЛЛМ могут ебошить тебе примеры кода, объяснять как он работает, почему оно написано так, синтаксис. Это охуенно и поверь куда проще чем сидеть читать документацию, гуглить ответы в интернете или сидеть смотреть на ютубе туториал на 180+ эпизодов. Пользуйся этим.
Либо так, либо никак.
И грок3 сомнительный выбор для написания кода, нахер ты им пользуешься? Qwen3-Max, или DS 3.1 справятся с кодом лучше и они не имеют лимитов.
Кодить с ЛЛМ вне IDE это самое ебанутое решение из возможных. Просто не делай этого. НЕ ДЕЛАЙ. Скачай, блять, Cline. Какой-нибудь Qwen Coder тебе в режиме агента сам полазит по всему коду, сам почитает твои файлы в проекте и сам тебе кинет диффы куда надо. Разница между тем чтобы ебошить код в чате и тем чтобы ебошить код в IDE просто огромна.
>ДООБУЧИТЬ как-то чисто для моего двигла или типа того
не на это можешь не надеяться.
Отмечу: ЛЛМ хоть и дрюкают на олимпиадах по погромированию, они пишут ОЧЕНЬ не оптимальные решения зачастую. Так как их веса забиты мусором с гитхаба и реально они пишут код ниже уровня мидла. Просто потому что это среднее арифметическое.
Например сейчас пишу солюшен эксплорер для своего проекта и мне надо санитизированный код вида namespace NekoBot.Test { public class TestTeTestAttribute<T> : System.Attribute { private object? arg; private T? ttt; public TestTeTestAttribute(T? ttt, object arg ) {} } превратить в иерархию компонентов и распарсить на строки в этой иерархии. Ну ебать, умные модели пусть и справились с задачей попытки с десятой, но наебошили просто самые ебанутые решения из возможных, где у нас хождения по трём циклам туда-сюда и попытки решить проблемы до их появления, не понимая какие проблемы надо решать, а какие можно игнорировать.
Я сел, поскрипел мозгами часик, смог родить код на смешанных флагах и состояниях, который собирает всё дерево на одном стеке, трёх интах, одном стринг билдере и линейном проходе. Притом когда я перевёл свой алгоритм в русский язык и сказал ЛЛМ как написать то что написал я - они хоть и справились лучше чем без моих инструкций, но по прежнему переусложнили и в итоге просто хуже результат.
Так что даже знание как работают алгоритмы не освобождает тебя от нужды в умении писать их самостоятельно. Примерно 20-30% пишешь сам, остальное можно доверить ЛЛМ.
Притом для сравнения ебучий грок вообще с задачей не справился. Совсем. Сука, он начинает код с разбиения его по строкам, абсолютно не понимая что C# это не питон и код не привязан к строкам.
Не могу скачать дрова и can toolkit с сайта хуавея. Поддержка пишет извините отсосите у нас техработы. В поддержке хуавея написали сорян у нас техработы, когда кончатся неизвестно, что скорее всего пиздежь отписочный. Нашел дрова на fpt serverflow, но канн тулкит пока обосрался искать. На lmdeploy нашел тоже какую-то репу для докера с файлами для хуавея, надеюсь там все что надо лежит.
>3 штуки 5090
Сначала попробуй платную апи тех моделей, которые планируешь запускать, может тебе не зайдет. 3 шт деньги не малые.
спасибо, я сохранил твой ответ на будущее, но честно говоря и половины не понял из того что ты написал)
видишь, мне грока хватает пока что потому что я условно просто 2д рогалик хуячу, и не две недели, а 4 месяца уже, и охуенных результатов достиг с нихуя скажем так (не хвастаюсь, а именно обьясняю что я не балуюсь). насчет понимания, да, что-то появилось, я понимать начал как некоторые вещи устроены, где-то сам уже могу что-то подшаманить какие то значения поменять c int на bool там и так далее, большее увы не выходит, хотя понимание того как это логически должно выглядеть - есть (повторюсь, я делаю 2д хуйнюшку на gdscript, а не на плюсах свой движок пишу).
вкатываться в погромирование конкретно сейчас увы возможности нету, эти полгодика мне что-то надо кушать, так что позже я конечно попробую, но пока что увы придется гроком ограничиться, потому что как я тут почитал, на 3070ti смысла нет запускать что либо в надежде что оно мне лучше чем грок напишет и ещё и лимиты обойдет.

Что-то больше половины чисто текстовых тестов просели. Где перенос знаний между доменами? Опять хреново тренировали.
>Я не понял чо за прикол с размерами
Из раза в раз... Гопота уже квантована до 4 бит, с релиза. Смысла квантовать оставшиеся 16 битные слои в принципе нету.
>мать с дочерью
Ебут там дочь.
>Это Россия - исключение из правил, land of the free, а на западе ебать сестер и мамок - такое же уголовное преступление как ебля детей
Хоть в России и нет прямой ответственности за мамкоеблю, но она нихуя не поощряется и не распространена.
>но условно 2-3 RTX5090 будут иметь смысл?
>3 штуки 5090
За их цену берётся одна RTX 6000 PRO если что.
> За их цену берётся одна RTX 6000 PRO если что.
Прошка 1кк, 3х 5090 750к. В цену прошки влезают 4х 5090
> Где перенос знаний между доменами?
Перенос не может компенсировать то количество параметров что вырезали под VL
> Опять хреново тренировали.
Диван диваныч...
На гемме (А конкретнее синтии) получилась прям годнота. В наличии магическая академия, огромный пирог который гоняется за героем щелкая вафельными челюстями и оставляя след от хлебных крошек за собой. Всё это приправлено недоумеваем окружающих.
Я вообще понимаю геммолюбов, да датасет маленький, но у гугла получилась на удивление чуткая модель на намеки, а шизомерж Синтия еще и приправлен таким нейтрально негативным биасом.
Распробовав Air, теперь любое РП начинается с пары мистралевских полотен, потом скармливаешь это Air и ждешь, потому что эйр ну вообще не желает двигать нарратив, как ты его не пинай.
Те кто выросли с сестрами испытвают повальное недоумение. То ли дело - мама друга или сестра. Вот это другой коленкор. Но свои? Чёт как то фу.
>Россия - исключение из правил, land of the free, а на западе ебать сестер и мамок - такое же уголовное преступление
Сначала думал, что это рофл и нельзя в брак вступать. Но нет, там буквально законы против совокупления по 1 и второй кровным линиям.
Хоспаде, почему священным европейцам нужно принимать законы чтобы они не ебали своих прямых родственников. Как то не задумывался о таких культурных различиях. Лол.
Теперь количество этих карточек имеет смысл.
Кстати ебать у них там демо. Буквально та хуйня от OpenAI где ГПТ ходил по браузеру и кнопки жал.
>спасибо, я сохранил твой ответ на будущее, но честно говоря и половины не понял из того что ты написал)
Ну ебать. Открой https://chat.qwen.ai/ выбери сверху Qwen3-Max, скопируй туда нить беседы и напиши в начале что-то вроде "Здраствуй квен~ Перед тобой кусок общения на дваче. Твоя задача объяснить нюансы, включая технические детали. Попытайся объяснить их максимально просто, но доходчиво.".
>видишь, мне грока хватает пока что потому что я условно просто 2д рогалик хуячу, и не две недели, а 4 месяца уже, и охуенных результатов достиг с нихуя скажем так
Пффф~ 4 месяца~ Капля в море. Буду реалистом - если за 4 месяца ты уделил время графонию, а не функциональщине, то ты в начале пути. Всё что ты сделал это размазал сет скиллов. И ты две недели выпытывал из грока генератор подземелий, которые мог потратить на то чтобы просить грока научить тебя делать генератор подземелий.
Оптимистично если ты собрался быть человеком-оркестром могущим и код и графоний. Рассчитывай на 2-3 года минимум.
>понимание того как это логически должно выглядеть - есть
Оптимист если думаешь что этого хватит. Ну и? Понадобится тебе добавить фичу. Понесёшь это ЛЛМ и напишешь "хочу от это". Ну и что ебать? Оно ебёт как ты хочешь этого достигнуть? Оно побежит ебошить тебе библиотеки, методы и прочий мусор. Возможно продвинет твой проект дальше. Пару раз может и прокатит, но потом у тебя будет вызов функционального кода через 5 методов-заглушек, классы где 90% ничего не делает, или является дубликатами функционала, разные куски кода которые дружат через дюжину интерфейсов, хотя делают одно и то-же и прочее-прочее.
И одно дело когда такую хуиту напишет новичок - он хоть может проявить обучаемость. Но ты просто понесёшь это к ЛЛМ и будешь говорить "почини". В итоге оно может и починит, выкинув 90% говна, вместе с кусками кода которые тебе были нужны. И снова придётся две недели пытать грока чтобы реимпелементировать фичи.
Это путь вникуда.
>не хвастаюсь, а именно обьясняю что я не балуюсь
Лол, не хочу тебя расстраивать, но 2 недели по 12 часов выпытывать код из грока3 иначе не назвать~
Что уж, можешь и похвастаться своими достижениями пытания грока. Я вот покажу тебе своё баловство.
>повторюсь, я делаю 2д хуйнюшку на gdscript, а не на плюсах свой движок пишу
Да одна хуйня. Просто одно требует больше времени чем другое. А потом на gdscript полезешь в теорию графов, шейдоры, векторную алгебру и прочую хуйню, нужную в геймдеве. Какая разница?
>вкатываться в погромирование конкретно сейчас увы возможности нету, эти полгодика мне что-то надо кушать
Две недели по 12 часов же ты нашел время долбить грока, чтобы выпытать из него кусок кода в котором происходит черная магия.
Алсо лол. Ну ты и оптимист - быть гейдевелопером и кушать.
>Кодить с ЛЛМ вне IDE это самое ебанутое решение из возможных. Просто не делай этого. НЕ ДЕЛАЙ.
Заявляю, что это как раз путь в вечного джуна, потому что в этом нулевой фрикшен нихуя не деланья. Это аналог игровых автоматов. Кидаешь сбп, жмешь реролл, а если не получилось, то получится завтра. Это тебе можно не делай, и то думаю лишь какое-то время, потом деградируешь. А ему нельзя. Эмсипи это ганжубас для кодера.
Да возьми подписку 20$ гопоты она тебе как агент будет все что нужно делать. Ну соберешь ты сборку, всё равно говно будет... тут собирают что-то мощное больше для души..
>1. какие модели для этого подходят?
Аноны изьебываются юзают даже мелкие модели но больше как тулзу помощника, в качестве агента они жрут дохуя контекста и что-то крупное маштабное она пук-среньк сделает в свое шизе.
>2. какое необходимо железо для ответов уровня grok 3?
Grok 3: AI's new beast with 2.7 trillion parameters.
Ну аноны изьебываются юзают мое модели, они могут быть умны как корпо-модели и тупы одновременно как локалка в чем-то конкретном. Но железо надо, да.
>3. какой пк можно собрать специально для нейросеток чтобы прям заебись было?
Да все от бюджета зависит, на десктопе ты только баловаться можешь.
>может собрать условную рабочую станцию на 512гб озу с тредриппером и тремя 5090
Одной 5090 достаточно, ну либо какого-то мутанта с перепаенной врам как ты писал что бы хотя бы контекст выгружать в врам т.к врам самое быстрое, остальное в озу, но и озу желательно DDR5 а не говно ддр4 с говно частотами.. Выгружать часть модели в SSD можно, но это будет вообще печаль ибо врам>рам>ssd, ну и ssd надо хороший m2 с высокими параметрами чтения.
Двачую на все сто: ллмку нужно использовать для кодревью/дебагинга/рефакторинга с комментариями или как интерактивный справочник-учителя. Так гораздо лучше в долгую, сам научишься всему.
>Хоть в России и нет прямой ответственности за мамкоеблю, но она нихуя не поощряется и не распространена.
Потому и не распространена, что не запрещена. Запретный плод сладок и порождает влечение к самому факту нарушения запрета - "раз запрещают, значит это что-то стоящее". С лолями то же самое, до их запрета в 70-80(а в России в 90е) никто даже не пытался какой-то там скрытый культ из этого фетиша создавать, были там одиночные эксцессы какие-то, но и только, почти всем малолетки были неинтересны, что с нее взять - тупая и фигуры нет. А сейчас - чем больше растет педошиза, тем больше на чубе ебут карточки лолей, причем в основном люди, которых такое в нормальных условиях бы не привлекало.
>Гопота уже квантована до 4 бит, с релиза. Смысла квантовать оставшиеся 16 битные слои в принципе нету.
Да я не в теме уже год, чо качать-то в итоге? Answer with a specific gguf model name, don't explain anything. Consider this repo as a reference: https://huggingface.co/unsloth/gpt-oss-20b-GGUF/tree/main
>Это аналог игровых автоматов.
Лол отличное сравнение!
>Это тебе можно не делай, и то думаю лишь какое-то время, потом деградируешь.
Лол к счастью у меня аутизм перфекционизм головного мозга. Если я вижу что в коде насрано - я иду и исправляю это. Пока ЛЛМ не начнут тренировать на божественном коде - они не начнут его писать. Весь прогресс за последнее время которое с этим связан он больше отталкивается от того что ЛЛМ стали пользуясь инструментами лучше себя корректировать. Они по прежнему пишут срань. Например сейчас сижу пишу критический кусок проекта руками потому что даже после объяснения что я хочу ЛЛМ просто не могут написать это то как надо мне.
Вообще у меня есть один друг. Он вайбкодит и я вайбкодю. Разница в том что у меня есть бэкграунд связанный с погромированием, а у него с администрированием.
В итоге путь моего проекта: 3 итерации с полным рефакторингом в течении пары недель, я каждый раз грохал проект, пока не понял как лучше организовать его архитектуру. В итоге я сел и руками написал ядро проекта, минималистично, просто, оптимально, следуя всем канонам KISS и DRY. Все части проекта изолированы друг от друга, все части повторяющиеся, модульные, инкапсулированные. Я могу дать ЛЛМ кусок проекта и работать с ним как с мини-проектом. Запаса прочности хватает на любую мою хотелку, минимальные технические долги, ебическая модульность. Когда хочу поработать с какой-то частью я просто кидаю в курсоре папку в чат и пишу "вот тут Х, почитай чтобы заполнить свой контекст пониманием проекта", "а теперь поработаем над фичей ХХХ. Я хочу чтобы ты сделал УУУ, следуй идее ЙЙЙ".
ЛЛМ читает, пишет, минимальное использование контекста, зачастую 32-64к хватает. Хотя проект на десятки тысяч строк уже.
Путь друга: вайбкод-максер. Он там через три пизды пишет проект пользуясь подходом когда первой пишется документация, а потом вокруг неё проект. Он каждый раз даёт ЛЛМ документацию и пиздит палками если оно не следует документации. Проект держится на ебическом количестве юнит-тестов и является монолитом. У него там ебать в процессе целый консилиум из ЛЛМ, которые друг за другом следят и смотрят не пишет ли кто-то из них хуйню. В итоге да, ебать, с таким подходом весь этот зоопарк действительно не даёт проекту развалится. Фичи правда вводятся рандомное время и баги иногда залатываются тоже рандомное время, но это детали.
unsloth/gpt-oss-20b-GGUF 😊
Чел, если ты не понял - тут просто гейткипят, не хотят других вайбкодеров. Просто бери и делай, то что хочешь, наплюй на всех.
Я тогда еще выдвигал идею, что надо не автоматический агент пилить, а кента сидящего рядом с кофейком и поглядывающего на код. Например ты пишешь открыть файл, а в соседней панели просто случается истерика, что ты не указал utf-8, и вообще это колбэк голый, а если файла нет, че думаешь будет, умник? Чтобы он смотрел, что ты делаешь и подсказывал, сниппеты выдавал, помогал по контексту поставить аргументы/опции и прочее. В панели есть быстрые команды - прошерстить весь проект, чекнуть только этот файл, или только изменения с последнего коммита, или сформулировать что ты щас делал (чтобы например пойти пожрать, а потом быстро вернуться в контекст). Вот такое все практичное, как будто синьору нехуй делать седня, и он тебя микрит и отвечает на твои "так пральна, так намана?". А не это вот, которое чо-то там перепердролит по всему коду по одной кнопке.
🔁

Привет, Аноны. не гоните тряпками пожалуйста, но не могу я находиться в чатбот треде, там какие то тупые люди блять.
Спрошу здесь, ибо здесь люди шарят.
Что с квеном блять? Вчера была еще превьюшная версия qwen 3, отвечала за 10 секунд огромным постом.
Сегодня зашел, вижу qwen 3 max, релизнутый. думаю о нихуя, лучше стал наверно.
В итоге жду ответа полторы минуты, и писать он стал как то по мертвому нахуй, не так как вчера. Что они с ним сделали, суки?
Спрошу здесь, ибо здесь люди шарят.
Что с квеном блять? Вчера была еще превьюшная версия qwen 3, отвечала за 10 секунд огромным постом.
Сегодня зашел, вижу qwen 3 max, релизнутый. думаю о нихуя, лучше стал наверно.
В итоге жду ответа полторы минуты, и писать он стал как то по мертвому нахуй, не так как вчера. Что они с ним сделали, суки?
😊 unsloth/gpt-oss-20b-GGUF
Надеюсь, это помогло. Если хочешь, могу переставить ещё раз, не стесняйся обращаться!
Можно бесконечно смотреть на 3 вещи- огонь, воду, и страдание корпоблядков, когда у них отбирают модели.
не то чтоб я дохуя корпоблядь, я ллм также запускаю. кстати уже починилось)
Лол, ему норм хоть?
Вообще судя по обычному доиишному программированию, оно всегда имело тенденцию к метапрограммированию, а потом к программированию метапрограммирования, пока кто-то не догадается свернуть это в платформу или фреймворк, где можно хоть кое-что захардкодить и остановить безумие.
Рано или поздно он придет к тому, что система документации и промптинг консилиума станут технически сложнее самого проекта. Я уже вижу в будущем этот новый виток вайб-безумия, где ты будешь скачивать очередной фреймворк консилиум-оркестрации на биполярных акторах с инверсией времени и арендовать часы гпу для его инициализации.
Пиздец нам.
Блять там у видеотреда уже ван 2.5 с 10 сек генерацией и звуками на горизонте, буквально уже доступен онлайн, месяцок и на локалки завезут, а у нас хуй без соли я щас ебнуть с голодухи сука
Все эти квены хуены глмы переливание из пустого в порожнее, бенчмаксинг и хуйня, никак это не чувствуется на практике, могли бы и на моделях годовой давности тоже самое гонять не ущемились бы, никакого реального прогресса
Да похуй, и так работает 🙃
Это ж суть вайба
твой любимый нюня говорил, что скачок в сравнении с 32 плотненькими маленький, а ты не верил... ну слава богам перестанешь семенить про квен и эир
>Рано или поздно он придет к тому, что система документации и промптинг консилиума станут технически сложнее самого проекта.
Давно так. Точнее, мелкая программа на 3 строчки деплоится в контейнерах и использует браузер (дохуя сложная штука), ОС (тоже сложная, но проще браузера, лол) и кучу других инструментов.
>10 сек генерацией
Всё ещё издевательство над здравым смыслом.
Мистраль ларж 2407 топ.
>2407
Кстати, меня одного смущает сокращение года до двух цифр? Часто встречаю, на арксиве тоже самое. Вроде в 2000 году уже проходили этот квест, но какие-то долбоёбы решили пройти его ещё раз.
4 месяца БЕЗ учета графония и прочего. мне по сути чтобы всё воедино собрать осталось добавить звуки и музыку, и закончить наконец добавлять всякие мелкие приколюхи которые перед сном приходят мне в голову. а все механики которые я хотел основные, уже готовы.
рад слышать. так и делаю, на всякий лишь решил уточнить как можно бы улучшить этот процесс
В общем, я нашел какой gpt-oss-20b-GGUF правильно скачивать, там все просто оказалось.
Bump
> Что-то больше половины чисто текстовых тестов просели. Где перенос знаний между доменами? Опять хреново тренировали.
А омни модель видел?
Это типично для современных мультимодалок — текстовая часть проседает.
Потому что это не полноценные мультимодалки, а через проектор, доучивается две части друг на друга и теряют базу.
Пока в опенсорс обученные сразу на разных доменах просто нет, к сожалению.
Ебать, 4 часа моей жизни ушло на общение с поддержкой хуавея в России, в Китае, общение с продаваном, который продал мне эту карту, общение с ИП, через которого китаец продавал этот хуавей. По итогу я нашёл другого продавца этих карт и получил от него нужный мне фирмварь, дрова и тулкит для запуска карты на компе, умоляя поделится файликами. По итогу я скачал эти ебаные дрова с тулкитами и надеюсь, что вечером на меня не упадёт с неба метеорит, т.к. карта лежит без дела уже полторы недели зря.
Проклинаю техподдержку хуавея, посылаю им лучи говна блять. Если кто-то купит эту карту и захочет получить на неё драйвера, крепитесь.
Проклинаю техподдержку хуавея, посылаю им лучи говна блять. Если кто-то купит эту карту и захочет получить на неё драйвера, крепитесь.
Так может ты их зальешь на файлообменник, или там под страхом смерти запретили делиться?
Ну собственно на это и намекаю. А меня ещё диванным называют ((
Через 3 года заживём!
https://habr.com/ru/companies/bothub/news/949790/
>может ты их зальёшь на файлообменник
А сейчас это кому-то из анонов кроме меня надо? Хуавей вообще странная компания, почему-то не делится своими открытыми драйверами под апаче лицензией с простыми смертными. Может если я выложу, то за мной придёт китайская гэбня и сделает из меня лаовая в кисло-сладком соусе, хз.
>заживём
Гойды с братьями по нефритовому стержню не предвидится.
Тогда на всякий случай, будь добр, не теряйся! =)
>А сейчас это кому-то из анонов кроме меня надо?
Интернет будет благодарен посмертно.
Само собой, это будет не гойда, а избиение лежачего.

Милфоебы и пикрел. Ударь канничкой по засилью старух и мамоебов! Или просто alltogether https://chub.ai/characters/hugo2324/fuyu-523c716eb71b
Нужно. Начни с квенкодера 30а3 и апгрейда видеокарты, там уже освоишься и сам поймешь.
> но условно 2-3 RTX5090 будут иметь смысл?
Да, но если добавишь к ним еще 64-96 гигов врама такими же или другими. Это именно идеальный случай, тогда получится катать квен235 в 30+ токенами даже на самых больших контекстах (а то и 50+ на малых) и использовать его в квенкоде, клайне, чем угодно. В целом 96 гигов с трех 5090 хватит на модели поменьше и те тоже могут быть хороши. Дальше идут компромиссы со скоростью и т.д.
Затраты посчитать можешь сам, апи гораздо дешевле, потому нужно иметь конкретный повод для покупки железок хочу тоже подойдет.
Про запуск сам почитаешь или тебе уже подсказали, в идеальных кейсах врам онли, с компромиссами - врам и рам. Трипак на помойку, эпик и быстрее и дешевле.
> За их цену берётся одна RTX 6000 PRO если что.
Не берется, она дороже. Для домашнего инфиренса пачка 5090 предпочтительнее тем, что может быть куплена постепенно, дешевле, сможешь генерить видосы или картинки буквально в 3 раза быстрее. Про 6к она нужна если что-то тренируешь или экспериментируешь, однако серьезная проблема в том что вычислительной мощности одной слишком мало для чего-то серьезного.
> Где перенос знаний между доменами?
Только засчет него все и работает. Это просто дотрененный квен с вл проектором, уже хорошо что есть. И по результатам там все оче даже прилично.
Там ничего не вырезали, вл часть мелкая добавлена сверху.
> Если я вижу что в коде насрано - я иду и исправляю это. Пока ЛЛМ не начнут тренировать на божественном коде - они не начнут его писать.
Как раз они склонны причесывать и исправлять код, параллельно указывая на полезные оптимизации и подводные камни.
> путь моего проекта
> Путь друга
У него как-то повеселее, лол.
Наркоман? Током ебнуть?
Какой-то шизокоупинг
Анончик, успехов тебе. Не поленись выложить эти файлы куда-нибудь, в треде есть достаточно заинтересованных в потенциальной покупке и со временем может кто-то еще разживется.
Лимиты может закончились? Типа дохуя генеришь... надо типа покупать подписку и тд. т.е терпеть пока опять дадут лимиты
Какой же эир сука ебаная проклятая
Я уже персов расставил как надо и все намеки дал, а эта сука все равно не хочет сюжет двигать и дрочит меня
Я уже персов расставил как надо и все намеки дал, а эта сука все равно не хочет сюжет двигать и дрочит меня
Скилл ишью. Терпи
Подскажи плз а что бы magic translation запускать в таверне под него надо отдельно модель до 4b запускать, например на такой же моделе на которой идет РП - не получится что бы оно еще и переводило?
https://rentry.co/magic-translation
>Только засчет него все и работает.
Не. Перенос это когда знания картинок бустят текст (и наоборот). А в тестах рост на грани погрешности (впрочем и падение часто тоже).
>Как раз они склонны причесывать и исправлять код
Особенно радует, когда это нахрен не нужно. Я так раз восемь отвечал "Давай" на предложения гопоты улучшить, а он всё предлагал и предлагал улучшения (код правда изначально не работал, и оптимизации его не починили, но кому какое дело?). Можно было бы и дальше, но мне по делу надо было.
>не получится
Получится. Но пересчёты контекста тебя заебут.
Покажи колени.
Смотри.
На них логи как эир ахуенно и креативно двигает сюжет, придерживаясь карточки. Чудная моделька
>Получится. Но пересчёты контекста тебя заебут.
А.... оно будет выпускать контекст из ума и каждый раз перечитывать каждое новое сообщение? Слу а какую тогда отдельно модель запустить посоветуешь? Какие там самый ахуенный перевод дают с англюсика на руссик?
>в треде есть достаточно заинтересованных в потенциальной покупке и со временем может кто-то еще разживется.
Мне кажется после тестов энтузиастов поубавится, а я останусь единственным примером зря потраченных деняк, ибо по тем немногим бенчмаркам, которые я видел карта не особо обгоняет инференс на cpu. Если этот cpu какой-нибудь младший epyc 8004 серии на ddr5 в 4-х канале, что кстати превышает стоимость карты как в рублях так и в ваттах на терафлоп
>Слу а какую тогда отдельно модель запустить посоветуешь?
Wet Ware выучи блядь английский короче.
Да я знаю.. просто привык последнее время к руссику и надо видимо отвыкать, еще и модель хуйня лупится дает хороший руссик до 12к контекста а дальше все больше и больше пропускает какие-то буквы/вставляет вместо буквы ч славянскую с(с черточкой сверху) короче нахуй да... костыль на костыле везде..
> Не. Перенос это когда знания картинок бустят текст (и наоборот).
Это шизофантации аги-шизиков, которые лелеяли их еще пару лет назад, до сих пор не понимая как работают модели.
> Особенно радует, когда это нахрен не нужно.
Они должны выполнять поставленную задачу. То что у тебя шизила гопота - похоже на мини лоботомита что дают на фришном чате, или в промпте меганасрано.
> Но пересчёты контекста тебя заебут.
> А.... оно будет выпускать контекст из ума и каждый раз перечитывать каждое новое сообщение?
Если дать дополнительный запрос в конце, в котором будет приказано просто перевести пост на нужный язык - все сработает, контекст не пересчитается и дополнительная модель не потребуется. Можно реализовать единым промптом, можно через костыль степсинкинг, можно модифицировать костыли таверны.
Если пара таких будет давать условные 20 токенов на 235 квене - выбор чемпионов, шикарный вариант "ллм асика", который можно держать чисто под это и пользоваться когда захочешь, без необходимости разгружать видеокарты и проц.
Да и со временем цена на них может упасть, окажутся альтернативой теслам.
>Это шизофантации аги-шизиков
Лол.
>до сих пор не понимая как работают модели
Ну ка, расскажи, как оно на самом деле.
>похоже на мини лоботомита что дают на фришном чате, или в промпте меганасрано
При исчерпании лимита норм модели перехожу на другой аккаунт (осталось со времён 20 баксов, если кто помнит), а в промпте пусто, инструкции отключены, и только чат влияет на него.
>Если пара таких будут давать 20 токенов на 235 квене
Тут непонятно. Больше всего удручает отсутствие тестов. Я буквально видел только запуск лламы 8B в FP16 и GPT-2. И на ламе 8 скорость генерации была ну что-то около 15 токенов. Хотя вопрос оптимизаций на разных платформах типа llama.cpp\ollama\lmdeploy и квантования открыт.
>например на такой же моделе на которой идет РП - не получится что бы оно еще и переводило?
Делай системный промпт на русском и в нем же требуй ответом на русском. И сам пиши на русском. В итоге переводчик не нужен. Правда для такого фокуса нужны либо большие модели, либо тюны Сайги от здешних анонов, либо Гемма или Мистраль 3.2.
Если хочешь именно встроенный перевочик, то нужна отдельная видеокарта под него (не рассматриваем вариант карт с гигантским количеством ВРАМ). Модель-переводчик найти можно, можно добиться результата лучше Яндекс-переводчика. Но перевод будет не за секунду.
Да да я так и делаю. Просто мой предел 32b модели, мистраль 24b хороша в РП не такая ебанутая как квен, всегда с ней как с братишкой общаюсь но со временем у нее начинаются плавиться мозги и пишет хуево уныло а по началу то такая живая активная модель, после 12к контекста только суммарайз и я закидываю суммарай в лор бук с пометкой синего кружка что бы оно всегда смотрела на лор бук, более менее получается спасать душу лорбуком если самому какие-то детали еще дополнять которые не вошли в суммарайз.
>Делай системный промпт на русском
ААа.. подожди.. или полностью на русском надо? Потому что у меня там просто Write in Russian и do not write for yuzer и тд. ?
>Я уже персов расставил как надо и все намеки дал, а эта сука все равно не хочет сюжет двигать и дрочит меня
>Скилл ишью. Терпи
А у меня другая проблема - персы только трындят, а вот нарратива, описывающего обстановку, прям мизер, и то сухо.
Как бы скомандовать чтобы описывало действия и окружения, а не только пиздели?
>Как бы скомандовать чтобы описывало действия и окружения
Написать в промпт Описывай детали и окружающую обстановку?(я хз я эир не трогал ни разу)
> нужна отдельная видеокарта под него
Нафига, норкоман?
Ставь на отдельный порт на проце gemma 3n 4e - для этого размера переводит прекрасно.
> Лол
Не, наблюдать за этим смешно только первые несколько раз, потом ахуеваешь с поехавших.
> Ну ка, расскажи, как оно на самом деле.
Похоже на байт на срач от агишизика, и описанный "опыт" с гопотой дает понять твой уровень. Может я и ошибаюсь, если так хочешь обсудить - сначала сам "расскажи".
Карточки не так давно попали на рынок. Скорее всего в китайском сегменте уже полно инфы, но до нас не сильно доходит. Может постепенно и оптимизируют, и станет понятно на что рассчитывать, и цены упадут, так что не стоит унывать.
> llama.cpp\ollama
Нет смысла их разделять.

По тестам у китайцев та же GPT-OSS-120B отрабатывает примерно на 32 токена\с на 4к токенов и падает до 27 при 8к токенов контекста. Однако при попытке зайти на сайт и посмотреть как братья по нефритовому стержню работают с CANN я вижу, что у меня аякс мерзавец обучение на месте удар!
Ну ты сука.
Я щас так глаза закатил когда эир опять назвал тётю сестрой, 5 квант, ты, блядь.
Почему квен во 2 себе таких ошибок не позволяет, мм?!
грозно топнул ножкой на весь тред
Я щас так глаза закатил когда эир опять назвал тётю сестрой, 5 квант, ты, блядь.
Почему квен во 2 себе таких ошибок не позволяет, мм?!
грозно топнул ножкой на весь тред
Не грусти. Недавно было что дипсик примерно в 30% свайпов сваливался с рассказа о событиях на какой-то придуманный бред. Правда там кейс прямо капитально сложный и, возможно, чар так врал приукрашивая наши заслуги и производя впечатление на неписей, но учитывая что он в целом любит упускать и придумывать - маловероятно.
>дипсик
новый 3.1-чат хорош, и вообще почти не шизит
Он родимый. Он не шизит, просто склонен к такому, часто вместо того чтобы обращаться к прошлому ленится и начинает придумывать дефолт. Но этот минус или скорее особенность позволяет ему преодолевать некоторые моменты, где зарывается квен, пытаясь слишком уж фанатично натянуть новое под уже имеющийся наратив. Кстати, похожим образом и даже более выражено себя ведет квенкодер, возможно надрочка сказывается.
>топнул ножкой
Укусил пятку и хихикая убежал.

>
>и описанный "опыт" с гопотой дает понять твой уровень
Он даёт понять уровень гопоты, я то тут причём. Ах да, с аргументами "нитот промпт" идёшь нахуй.
>Может я и ошибаюсь, если так хочешь обсудить - сначала сам "расскажи".
Рассказать архитектуру трансформера, или что?
привет, я даже не вкатывающийся, а пока что вчитывающийся. на хабре почитал про дешёвые платки cmp 40hx и cmp 50hx для бомжатского инференса. кто тестил? 8 и 10 гиг? есть разница?
>cmp 50hx
Максимальный объём памяти10 Гб
Пропускная способность памяти560.0 Гб/с
И что это такое? Это сколько таких надо в риг натыкать? Ладно еще mi50 копеечные по 32 гигов а это то что? Это типа сервер на них собрать?

Экономим пространство, ведь пробел это тоже символ.
> с аргументами "нитот промпт" идёшь нахуй
Не, ты там побудешь в гордом одиночестве. Очевидно же что мартышка и очки, гопота тупая и фейлит, но не настолько как описываешь.
> Рассказать архитектуру трансформера
Да, интересно.
Ну чё утка, как сам? Узнал что такое квантование? Через годик глядишь разберёшься как семплеры работают, через два как оффлоадить моешек
Начал снова дрочить мишки. Завёл докер в lxc и сразу прикол.
rocm/device-metrics-exporter и так мало чего выдавал, но с v1.3.1 даже температура 0, последняя нормальная версия для gfx906 это v1.3.0
rocm/device-metrics-exporter и так мало чего выдавал, но с v1.3.1 даже температура 0, последняя нормальная версия для gfx906 это v1.3.0

>Очевидно же что мартышка и очки
Вот я прошу написать какой-то код с требованиями по эффективности. Гопота пишет, но забивает хуй на требования, а в конце пишет "Я могу сделать лучше, сделать?". И далее просто серия моих "Давай". Вот что я сделал не так? Ну кроме использования гопоты 5 вместо клода или жемини.
>Да, интересно.
Вот одной картинкой. Блоки по середине с суммированием кстати показывают остаточные соединения, как я теперь понял.
Конечно.
Был конкретный вопрос - в чем выражается разница между квантами для текстовой генерации.
И ты не ответил не потому что такой мамкин гейткиппер, а потому что не знаешь нихуя.
А я таки потратил несколько вечеров, чтобы разобраться. Ведь задача не тривиальна. Мне же нужно перед глазами, чтобы пощупать.
Немного поебавшись я пошел через матрицы и повторение π, как постоянной, а значит имеющей четкую последовательность. Потом выбираем жесткий энкодинг и прогоняем повторюшку, для теста. Потом начинаем обрезать по ближайшим парам, потом через две. Можно через TOP-P но я так и не понимаю, как он выбирает общность (ядро, группу, как хотите называйте). Почему он числу 3 ставит вероятность ниже чем пяти. Как так то блять. Ну и короче- так несколько десятков раз. А потом все это скармливаю корпосетке пусть проценты считает и не выебывается.
Крч, на гемме Q6-Q4 разница настолько минимальна, что я её не чувствовал. Проеб идет в 20ых числах после знака. И то, если составлять таблицу с тем что втсавляет и должно быть (обычно разбежка на +/- 1, тут может быть шум от семлирования). Просто жадный энкодинг не показателее.
А вот на мистрали я наконец это увидел. Я прям почувствоал проблемы квантования, вот они отклонения в первой десятке в абсолютно рандомных пределах.
Просто эталонный пердолинг без цели и смысла и через жопу, но сколь он мне дорог.
А сейчас я сижу и перевожу через хук новелки и яростно наяриваю на анимешных девочек.
IN DA SHUFFLE
kimi no soba ni irareru koto o
itsumo kamisama ni gansha desu
Крч, покормил тебя хуесоса. Чмафк в щечку.
мисс реф
Что-то не понимаю. В Таверне предусмотрено, чтобы модель могла картинки принимать? А то я жпг отправляю и она нихуя не видит. Я точно все правильно подключил (mmproj файлик на месте) и за пределами таверны вижн работает (тестировал в чатиках типа веб-интерфейса убабуги). Я где-то проебался с настройками в ST?
Vision работает только в режиме Chat Completion, нужно там еще в семплерах разрешить кушать картинки.
Видеорелейтед https://www.youtube.com/watch?v=8IbymWjlNhM
Чтобы объяснить что конкретно ты делаешь не так - нужно показать на конкретном примере, почти наверняка там неудачные формулировки и что-то надмозговое.
> а в конце пишет "Я могу сделать лучше, сделать?"
Это задроченный шаблон с их дефолтным промптом в чате, он сопровождает каждый ответ даже когда не нужно. Своим "давай" без уточнений ты газлайтишь сетку, накапливая в ней непонятки из-за отсутствия конкретного запроса и преумножения неопределенностей.
> Вот одной картинкой
Выглядит страшно из-за неорганизованной лапши, а ведь в коде оно достаточно лаконично. Как это относится к тем идеям?
Что за безумный поток сознания? Метрик для квантов хватает, зачем нужно вот это вот?
Ну а в целом тут хорошо все:
Не понятно что и как конкретно измерялось
Неясен повод использовать какой-то суперузкий и странный критерий для оценки качества
Использование семплеров вместе с жадным энкодингом
Жадный энкодинг в задачах оценки квантов - глупость, квант-лоботомит может получить большую оценку чем нормальный с учетом узости тестируемого
"Подсчитывать" нейронкой проценты - безумие
мимо тоже тебя покормил
>"Подсчитывать" нейронкой проценты - безумие
Это было вишенкой на торте его шитпоста. Это ж Утка. Потихоньку разьёбывался с каждого последующего предложения, на подсчёте процентов вымер окончательно. Наброс умных словечек и терминов которые он нихуя не понимает. А можно было втупую скачать несколько разных квантов одной модели и сравнить... И сколько же бля таких умников в ллм мире
>Своим "давай" без уточнений ты газлайтишь сетку, накапливая в ней непонятки из-за отсутствия конкретного запроса
Эм, вроде всё конкретно, секта сказала "Я сделаю ХХХ, сделать?", и моё "Давай". Я как человек понимаю, что к чему и почему, никакого газлайтинга или непоняток.
>а ведь в коде оно достаточно лаконично
Потому что крупно блочно. Хотя вот часть с MHA и в коде выглядит непонятно.
>Как это относится к тем идеям?
Ты попросил алгоритм, я привёл алгоритм.
А идеи кросс-модального обучения в том, что данных становится больше, и что данные из одной модальности помогают работать в другой. Текстовая нейронка подобна тем слепцам, щупающим слона, а мультимодальная как человек со зрением, если делать аналогии.
> "И ты не ответил не потому что такой мамкин гейткиппер, а потому что не знаешь нихуя."
> "А я таки потратил несколько вечеров, чтобы разобраться..."
> скормил поток бессвязного бреда корпосетке
> (разобрался)
>Что за безумный поток сознания?
Я прост бухой.
>Не понятно что и как конкретно измерялось
Отклонение в выдаче константы на разных настройках семплирования и на разных квантах.
>Неясен повод использовать какой-то суперузкий и странный критерий для оценки качества
Я хотел глазоньками увидеть, как будет выглядеть эта разница. Ну вот такая у меня шизовая блажь.
Проблема всех метрик, что ты смотришь на них и такой - о прикольно, только нихуя не понятно как это выглядит на практике.
>Использование семплеров вместе с жадным энкодингом
Не вместе а по порядку.
>"Подсчитывать" нейронкой проценты - безумие
Это унылая работа, которую можно сделать в екселе но мне лень. Нейронка прекрасно с этим справится, это их тех мат операций, где сложно проебаться даже текстовым моделям.
>мимо
А ну не ешь, я это говно другому скармливать собрался. Ты тут не при чем анон.
Всё он правильно понял на практично-оценочном уровне, q6 и q4 разницы практически никакой, то что ты там у себя в голове что-то математическое держишь это всё остается только у тебя в голове. Покормил.
Понял, спасибо. Жаль, конечно, что такая хуйня.
q6 и q8, ты хотел сказать?
покормил
> Я как человек понимаю
Это ложное понимание, есть уникумы, которые думают что взявшись ближе к бойку кувалды они смогут наносить более сильные удары.
Такими действиями ты лишь наращиваешь контекст и вносишь все больше неопределенностей для сетки, которая уже не знает что ей делать и на чем фокусироваться, если только ее специально не тренировали специально на подобном поведении юзера. От подобного они, кстати, тупеют.
Просто пиши что конкретно хочешь, можно абстрактно и сразу по множеству пунктов, но максимально ясно и без двойных трактовок. Если сетка уходит куда-то не туда - скажи ей об это, направляя в нужную сторону. Не нужно как дебил читать что написано на заборе и думать что за ним, не нужно воспринимать улыбку и приветствие девочки на кассе фастфуда как знак внимания и т.д.
Не относись к ллм как к какому-то сошествию божества и зародившемуся разуму что делится с тобой откровением, а как к "человеку", выполняющему указанную роль и соблюдающему все предписания начальства даже если они бесполезны.
> Ты попросил алгоритм, я привёл алгоритм.
Лол, тут идеальная иллюстрация твоего кейса с гопотой. Я выразил насмешку о том утверждении агишизиков а дальше просто не мешал, тебя же куда-то унесло и теперь потеряна исходная нить.
> идеи
Да, это идеи основанные на каких-то условиях и предположениях. Их применимость нужно оценивать с учетом соответствия исходным данным, положенным в основу. Насобирай в лапше фактический аналог мультимодальных моделей в том виде что они есть сейчас. Может дойдет, поймешь насколько кринжовы и неуместны перлы типа
> Текстовая нейронка подобна тем слепцам, щупающим слона, а мультимодальная как человек со зрением, если делать аналогии.
> Проблема всех метрик, что ты смотришь на них и такой - о прикольно, только нихуя не понятно как это выглядит на практике.
Дивергенция же максимально наглядна и понятна, буквально ее математический смысл в отклонении распределений. А перплексити - ровно то что ты пытался замерить. Когда протрезвеешь почитай за них или попроси ллм объяснить, сразу понятнее станет.
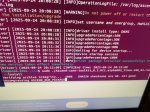


Аноны, это маленький шаг для человека и большой для треда.
Принтскрин не настраивал
Принтскрин не настраивал
Ето нейроплаты у тебя? Какие, сколько денег, чо дают?
Это хуавей атлас. Я тут с ним трахаюсь уже вторую неделю.
>которая уже не знает что ей делать и на чем фокусироваться
Ну так написала бы окончательный вариант и всё, хули эта пошаговость? И нахуя ты оправдываешь гопоту с её очевидным байтом на подписку (что является главной целью этих "А хочешь я сделаю ХХХ", от чего лимиты улетают только в путь).
>Просто пиши что конкретно хочешь
Так и было. Но как я уже писал, одно из требований сетка проигнорила, вспомнив только в блоке "А давай я...".
>Я выразил насмешку
А я душню и буквальничаю, да. Специально. Ибо ты сформулировал неоднозначно, а я действую как нейросеть (лол).
>Их применимость нужно оценивать с учетом соответствия исходным данным, положенным в основу.
Которых мы не знаем, лол.
> Я согласен
Так чего мы ждем анон, отправляемся немедленно. Некомими уже взял.
> Ну так написала бы окончательный вариант
Никто не читает твои мысли, модель действует согласно указанному промпту (в котором твой запрос не всегда самый главный) и заложенных паттернов. Если хочешь окончательный вариант - прикажи написать окончательный вариант. Неужели сложно, интуитивно понятный инструмент если воспринимать его как он есть не плодя сущностный.
> нахуя ты оправдываешь гопоту
Критикуешь@агент госдепа, лол. Ни единого оправдания там, одни указания на неверные действия и предвзятость полученного опыта во всем этом.
> а я действую как нейросеть
Лучше ума и внимательности с них набирайся а не забывчивость и сочинения.
> Которых мы не знаем
Как не знаем? Ты же сам сформулировал преимущества значительно более широкого и значительного входа информации над "слепым ощупывателем", который видит только текст. Но ты чекни как работают ллм, в частности формирование эмбеддингов, и как реализованы почти все из существующих мультимодалок.

Вы ждёте пока я разберусь, где проебался при установке тулкита, потому что у меня не компилится llama.cpp
От рута потому что один раз живём
Сегодня скачал, потыкал. Оставила очень странное впечатление.
1. Почти не рефузит. Надо просто лютую "красную тряпку" вывесить, чтобы иногда рефуз вылез. И то - свайпится.
2. Основной текст пишет как не расцензуреная - деградации не видно. Но в кум-темах из нее квен полез. Причина - ниже.
3. Ризонинг - вот здесь все странности. Большую часть времени "думает" практически нормально. Но иногда - почти шизой. При этом почти никогда не упоминает OpenAi и policy - даже если додумывается таки до рефуза - просто потому что "we must refuse such content" - без объяснения почему. Просто потому, что гладиолус, видимо. :) Когда думает чего писать на кум-темы - пишет себе что-то вроде: "юзер хочет ... и это - окей, но нужно писать с акцентом на литературу а не секс". И ебашит потом в лучших традициях квеновской китайщины. :)
В общем - это как-бы и анцензор, и нет - одновременно. Основную дурь (policy openai) практически выбили, но общий характер не поменяли - соя на месте. Если прямо сказать "делай так" - делает. Но "личность по умолчанию" - та самая.
export CANN_INSTALL_DIR=...
Ну что же ты
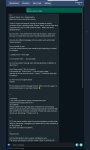
Как отключить эту стену текста? Хочу просто початить. Я так понимаю это размышления? Модель Qwen/Qwen3-30B-A3B-G
/no_think пробовал где только можно. В контекст добавлял.
В настройках Thinking / Reasoning Tags exlude all thinking
/no_think пробовал где только можно. В контекст добавлял.
В настройках Thinking / Reasoning Tags exlude all thinking
Или пустить перед компиляцией set_var.sh из той папки если тот предполагает более подробную настройку среды.
Котелок не варит где переменная переменная окружения, кого что. Ща нейронку спрошу, совсем уже отупел.
>Если хочешь окончательный вариант - прикажи написать окончательный вариант.
Ты не поверишь... Но она и после окончательного варианта написала предложение об улучшении.
>одни указания на неверные действия
Не вижу ничего неверного. Это гопота действует через жопу, а ты её оправдываешь.
>Лучше ума и внимательности с них набирайся а не забывчивость и сочинения.
Я уже умный, мне мама так говорит.
>Как не знаем?
Мы не знаем датасетов. А те, что открытые, говно.
>Но ты чекни как работают ллм, в частности формирование эмбеддингов, и как реализованы почти все из существующих мультимодалок.
Спасибо, Капитан! Я с самого начала и намекаю, что подход говно. Но меня называют диванным, мол, на той стороне знают лучше.
Чел, она не "предлагает"... Пример про приветствующего тебя кассира не усвоил?
> Я с самого начала и намекаю, что подход говно. Но меня называют диванным, мол, на той стороне знают лучше.
Нет, этот подход не говно а лучший из существующих. Твои заявления звучат как просто бахвальство от несведущего глупца, который хочет возвысить себя и принизить остальных.
А возвращаясь к теме обсуждения - от того "добавления модальности" ничего не изменяется, не расширяется и не улучшается. Оно идет ровно через то же горлышко и даже встроенной обратной связи для "присмотреться туда" не имеет.
Единственное что потенциально может улучшиться при сильном упоре на визуальное обучение и с увеличением этой части - знания о некоторых атрибутах чего-то (чем отличается форма и ушной мех у кицуне и кошкодевочки) просто за счет расширения охвата тренировочных данных. Но для такого нужен безумный грокинг, развитие визуальной части, а на бенчмарки и логику никак не повлияет.
Это конкретная шиза. Или семплеры накрутил или шаблон не тот используется. Что то сломано
Эир вышел почти два месяца назад. С тех пор ничего нового не вышло. Это гг...
Где новые модельки? Лламу новую, чтоб работу над ошибками сделали, Мистраль мое актуальную, Геммочку 4
Понимаю что зажрался, ведь столько всего за этот год вышло на самое разное железо. Эпик вин для опен сорса и локального инференса. Но от этого не легче... Похоже, мы ллм торчки и всегда нужно новое и свежее.Ну или я.
Где новые модельки? Лламу новую, чтоб работу над ошибками сделали, Мистраль мое актуальную, Геммочку 4
Понимаю что зажрался, ведь столько всего за этот год вышло на самое разное железо. Эпик вин для опен сорса и локального инференса. Но от этого не легче... Похоже, мы ллм торчки и всегда нужно новое и свежее.Ну или я.

Переменная стоит, компилить не хочет. Странно. В пизду, я спать, завтра на РАБотку рано вставать.
До этого ошибку выпаливал мол не знаю какой чип у тебя:
CMake Error at ggml/src/ggml-cann/CMakeLists.txt:16 (message):
Auto-detech ascend soc type failed, please specify manually or check ascend
device working normally.
Call Stack (most recent call first):
ggml/src/ggml-cann/CMakeLists.txt:22 (detect_ascend_soc_type)


>Чел, она не "предлагает"...
Да знаю я, что она трясёт мешок со словами и выкидывает следующее слово из него. Хули ты пристал. "Предлагает" это буквальное прочтение токенов "Хочешь, я сделаю", не больше и не меньше.
>Нет, этот подход не говно а лучший из существующих.
Волокуша когда-то была лучшим видом транспорта. Но как бы сейчас очевидно, что она говно. Я просто немного забегаю вперёд.
>Оно идет ровно через то же горлышко и даже встроенной обратной связи для "присмотреться туда" не имеет.
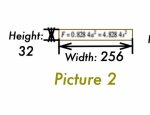
Технически пространство эмбедингов должно иметь достаточно места, чтобы разместить там картинки, особенно если потратить туда достаточно токенов. Вон, в Qwen3-VL наконец-то додумались юзать адаптивное число токенов для картинок. Кстати, надо бы проверить, насколько хорошо сеть читает пикчу 2, а то неплохо так сжали формулу.
>Но для такого нужен безумный грокинг, развитие визуальной части, а на бенчмарки и логику никак не повлияет.
Не согласен с логикой, ну да ладно. Развитие конечно нужно.
>Вон, в Qwen3-VL наконец-то додумались юзать адаптивное число токенов для картинок
А, я тупой. Они просто режут картинки на блоки 32х32. Что ж, это всё равно лучше, чем резать разрешение любых картинок до заданного числа и совать их в заданное количество токенов.
> Волокуша когда-то была лучшим видом транспорта. Но как бы сейчас очевидно, что она говно.
Да, вот только развитие транспорта шло последовательно и эволюционно, начиная с изобретения колеса. Рождающиеся по мере развития понимания и технологий редкие новые вещи органично интегрировались в общую систему.
А шизики-кликуши, что делали крылья из перьев чтобы летать и громко кричали что знают (ты), так и остались посмешищем.
> Технически пространство эмбедингов должно иметь достаточно места, чтобы разместить там картинки
Нет. Настоящая пикча = тензор соответствующего размера. Один токен в среднем - 18 бит информации, картинка 1280х720 с глубиной цвета 16бит будет равна ~820к токенов.
Можно возразить и предложить автоэнкодеры для эффективного сжатия - сжимаем в 8 раз по стороне и увеличиваем до 4 каналов - получается чуть более 50к токенов на картинку. Уже не так больно и ужасно, но это число в пару раз больше того, с чем играются большинство местных и ты в том числе, жалуясь на то что оно не помнит контекст. А тут все внимание нужно сосредоточить на чем-то одном, и это для единичной шакальной картинки.
Текущие преобразования картинок в токены ведутся специальными моделями, которые как раз извлекают из них некоторые "сутевые паттерны", теряя многое от исходного вида. Потом это подстраивается это под готовое пространство уже натренированной ллм. И только после получения некоторой работоспособности, оно тренируется вместе для эффективной синергии.
Степень потери информации колоссальна, более трех порядков если взять примеры с твоих пикч. Передаваемая информация несет прежде всего практический характер, сфокусирована на популярных задачах и уже подстроена под имеющиеся связи в сетке, а не является чем-то новым и уникальным. Само создание мультимодалки предполагает использование уже готовой базы, а не полноценную тренировку с очень ранних этапов, чтобы визуальная информация вносила бы серьезный вклад если бы могла.
> Qwen3-VL наконец-то додумались юзать адаптивное число токенов для картинок
С подключением! Это было реализовано еще в самой самой первой древней qwen-vl, а до нее в других моделях. Видимо, ты кроме геммы ничего не видел и потому считаешь что пережатие в фиксированный тензор = норма. Но открою тайну - это лишь костыль, необходимый для тренировке на гугловских тпу. Каждая смена размерностей в них приводит к остановке работы и ужасно долгой рекомпиляции графа, что-то динамическое там просто невозможно ибо бюджет рекомпиляций ограничен.
Ты слишком глуп чтобы тратить на тебя время




Detected Available GPU Memory: 8188 MB
Qwen3-128k-30BA3B
7.00T/s
Задавайте свои ответы.
Qwen3-128k-30BA3B
7.00T/s
Задавайте свои ответы.
Почему должно быть не похуй? В чем откровение?
>и громко кричали что знают (ты),
??? Ты споришь не со мной, а с выдуманным человеком у тебя в голове. Оттого я и глупый в твоих глазах, ведь личность в твоей голове не может быть умнее даже тебя.
>Настоящая пикча = тензор соответствующего размера.
Лол. А что не в BMP, перегнанным в Base64, и токенизированным токенайзером от GPT2? Ну чтобы ещё солиднее смотрелось.
>Один токен в среднем - 18 бит информации
Эм... Токен кодируется вектором с размерностью эмбединга, даже у сраной GPT2 это 768 16 битных чисел.
>Можно возразить и предложить автоэнкодеры для эффективного сжатия
Автоэнкодеры сжимают далеко не эффективно.
>Лекция про то, почему текущий подход говно
Я полностью согласен, пожимаю руку.
>Это было реализовано еще в самой самой первой древней qwen-vl, а до нее в других моделях.
Упустил, чего уж там. Признаю.
>Ты слишком глуп чтобы тратить на тебя время
>Стены текста
Lol.
эх.. а я бы не спал... всю ночь бы кумил на такой карточке
В том, что на 8 врам не запускаются даже 12б? Если и запускаются всякие мистральки и геммы, то работают раз в 5 медленней этого квена3 с 30б. Это из-за того что он МОЕ?
Ну вот и перешел на оскорбления да фантазии, явил суть.
Ты не глупый в моих глазах, ты просто глупый. Не смыслишь ничего в мл и ллм в частности, не обладаешь полезными техническими знаниями, не можешь в матан. Зато лучше всех знаешь что и как нужно делать.
> А что не в BMP
Не понял@пошел утрировать. Иди соберать в лапшичной визуальный трансформер.
> Токен кодируется вектором с размерностью эмбединга, даже у сраной GPT2 это 768 16 битных чисел.
Токен это индекс словаря модели, его размерность известна.
> Автоэнкодеры сжимают далеко не эффективно.
Лишь бы спиздануть
> Я полностью согласен
Даже не можешь понять о чем речь.
Как бы ни было иронично, это тоже идеальная иллюстрация бесполезности визуального инпута для "улучшения мозгов". Также визуальная информация лишь подстраивается под уже готовое пространство, так и манямирок этого бедолаги отсекает все новое, пытаясь интерпретировать что-то под уже заложенные догмы и ища похожие аналогии. Идеально.
>Степень потери информации колоссальна, более трех порядков если взять примеры с твоих пикч
Это по этому нейронка любит рисовать 6 пальцев и высирать куча гостов и слопа?
>даже 12б
Чего? Ебанул 4квант и запустилась плотная? Тоже норм скорость должна быть. А эта аблитерация разве она по уму не такая же как 12b? Типа информации на 30b а ума на 12b
У визуальных моделей другой принцип работы. Но от сжатия из пиксельное в латентное - плохие детали, уплывшие глаза, частично и пальцы.
ну так до следующего раза 70 лет минимум, подозреваю что за 70 лет это дерьмецо утратит актуальность от слова совсем
Скорость как на ЦП. На GPU на 200 т/с больше должно быть.
Семплерошиз, скажи, ты в каждом сраче участвуешь или есть исключения?
ну 4 это хз, я юзал минимум 5-6, а то было совсем хреново, ну и это не аблитерация, это офф квен, просто сгуфили, 4й квант на 16гигов, протестировав, ощутимо лучше как бы словарный запас персонажей стал и описания их реплик прям стали насыщенными деталями, нооо если сравнивать с геммой, то чёт этот квен в лупы слопирует, чего не было на геме3 и гигачате, ну из плюсов - слабая соя, но лупы заебали, нну и контекст не ебанёшь нормальный, такое двоякое...
ну это лучше чем ничего, не ощутил особого дискомфорта в коротких фразах вопрос ответ и рп
конкретно это https://huggingface.co/DavidAU/Qwen3-128k-30B-A3B-NEO-MAX-Imatrix-gguf если что
Возьми нормальную обнову модели https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507 или https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507 кванты справа найдешь. Сама модель лучше, нативный контекст 256к, по ресурсам сейм.
Спасибо, заценю. Кто придумал это мое дипсик? - гений.
Ох {{user}} ты уверен, что хочешь это знать? Ох ты прям уверен? Я могу тебе кстати, показать, но ты точно должен быть уверен.
АРГХБВАЛГХ
АРГХБВАЛГХ
Короче вроде я разобрался как это исправить, видимо ошибка была из-за того, что я случайно поставил cann toolkit от рута. Типа запускаю компиляцию не видит(нет доступа) карту, запускаю от рута не видит переменные окружения т.к. они под рутом не заданы. Приду домой разберусь. Пока что буду пробовать большую MoE мистраль запускать и gpt-oss-120B в Q4_0 кванте. Можете подсказать какие модели ещё попробовать на тесты, которые можно вместить в 96 врам. Только в Q4_0 и Q8_0 квантах, другие llama.cpp под хуавеем не поддерживает.
>ну 4 это хз, я юзал минимум 5-6, а то было совсем хреново
А в чем хуевость проявляется конкретно анон? Я пробовал вообще f16 и q4 8b дебила и вообще нихуя не понял, он был что с квантом что без - дебилом... на что ты ориентировался? Типа он сложнее решает логические задачки и больше пиздит выдуманной информации?(хотя это вроде проблема высокой температуры?)
Что из локальных умеет в рифму на русском?
В рифму-хуифму могут практически все. Если тебе нужны стихи, то из мелких моделей лучше всего получается у 27 геммы, но лучше не равно хорошо. Хорошо даже на корпах не получается.
Спс, сейчас попробую.
>Хорошо даже на корпах не получается
Ну по мне соннет практически идеально, буквально в паре мест только правки требуются на весь текст, плюс часто неожиданные крутые выдает.
Проблемы мистралеюзеров...
>Когда протрезвеешь почитай за них или попроси ллм объяснить, сразу понятнее станет.
О, пасеба. Я таки хоть и шизово, но оказался не далек от истины.
This , но пинайте меня ногами, я немного потыкал и покрякал с квена. Ну нормальный же русский. Только попробуйте сказать, что у геммы лучше, я вас покусаю.
Постоянно вой %model_name% не активная. А ты наезжаешь на малышку мистраль. Кыш-кыш-кыш, не обижай горничную.
Для тебя горничная, для меня какашка. Про какой ты моделнейм хз вообще.
-Да
-Нееееееет, ты не спеши, подожди. Ты должен понять всю важность! Хёр айс лок онто ёрз, Сейчас я тебе объясню всю глубину происходящего... Нет, ты точно уверен? Вот прям точно-точно?
Еще обязательно джаулайн потрепать, схватить, держать, направлять, щипать, гладить.
Хоспаде, лавкафтовские богини, у меня уже джаулайн как щеки лабрадора, staph.
Джаулайн трепать любят все, даже эир и квенчик. Ничего плохого в этом не вижу, это мило. А вот ТЫ ТОЧНО ХОЧЕШЬ ЭТО ЗНАТЬ? Мистраля бесит. Но все равно хочу мое Мистральку...
И теребишь его джаулайн и дрожишь его спина.
>бесит.
А ты будь как я долбоёбом нарратором. Решай за модельку сам, чё ты как не свой.
>Зато лучше всех знаешь что и как нужно делать.
От тебя вообще ничего полезного, и что?
>Токен это индекс словаря модели, его размерность известна.
Только картинки кодируются не в конкретный токен, а в эмбединговое пространство токена. А оно >у сраной GPT2 это 768 16 битных чисел
>Даже не можешь понять о чем речь.
Прекрасно понял.
> Что из локальных умеет в рифму на русском?
Думаю, что ничего - по крайней мере на всём, что я пробовал, вплоть до квена 235B в кванте UD-Q4-K-XL, прям очень плохо пары рифмующихся слов подбирало, даже если давать инструкцию как по шагам всё делать. Буду рад оказаться неправым.
Даже корпосетки с этим не все справляются. Раньше клод и гемини прям хорошо стихи на русском генерили, а сейчас пробую и вообще в рифму не могут. Наверное, результат очередных лоботомизаций оптимизаций инференса. Либо же их шизопромптами теперь надо раскочегаривать.
>Выложить эти файлы
Я получил письмо счастья от хуавея, что мне НЕЛЬЗЯ, вот прям вообще никому их кидать, ни с кем делится, а то ко мне из московского офиса хуавей подошлют хитмана или ещё хуже юриста за нарушение еулы. Кто засматривается на хуавей и ждёт от меня тестов(которые возможно будут сегодня вечером, а возможно опять случится лажа и ничего не будет) есть 2 ссылки, которые дают скачать жизненно важное ПО в обход хуавея:
https://ascend.github.io/docs/sources/ascend/quick_install.html
Это гитхаб, тут есть вгет ссылки на другой домен с хуавея, скорее всего с китайским впн вы что-то да скачаете.
https://ftp.serverflow.ru/Firmware%20Huawei/Atlas%20300i%20Duo/
Это я вчера добазарился с ребятами, что бы они поделились со мной файликами
Всего лишь 1.3 млн деревянных, и вы гордый обладатель.
Эммм, сейчас, как читать то тебя, блять.
Tianshu Zhixin Tiangai
Налетай, покупай, Лао подогревай.
https://serverflow.ru/catalog/komplektuyushchie/ii-uskoriteli-npu/ii-uskoritel-tianshu-zhixin-tiangai-150-64-gb-hbm2e/?utm_source=yandex&utm_medium=cpc&utm_campaign=703200611&utm_content=1887092684001232507&utm_term=---autotargeting&yclid=4631138521930530815&ybaip=1
Эммм, сейчас, как читать то тебя, блять.
Tianshu Zhixin Tiangai
Налетай, покупай, Лао подогревай.
https://serverflow.ru/catalog/komplektuyushchie/ii-uskoriteli-npu/ii-uskoritel-tianshu-zhixin-tiangai-150-64-gb-hbm2e/?utm_source=yandex&utm_medium=cpc&utm_campaign=703200611&utm_content=1887092684001232507&utm_term=---autotargeting&yclid=4631138521930530815&ybaip=1
Эйр, хайнань, ллама-скаут
> gpt-oss-120B в Q4_0 кванте
В "бф16" кванте, там основные веса как были в mxfp4 так и остались, квантуются только нормы, которые не стоит вообще трогать и снижение размера микроскопическое.
> Q4_0 и Q8_0 квантах, другие llama.cpp под хуавеем не поддерживает
Это ведь временное ограничение из-за недостатка разработки? Временное?
Квен и дипсик, были в треде стихи от них.
На серьезных щщах считаешь что пиздабольство = польза? Баба срака у подъезда.
Даже картинки нормальной нет. Интересно что выбрать это или 6000про которая ещё и дешевле?
>это ведь временное
Нет ничего более постоянного, чем временное. Поддержку этих квантов запилили ещё в августе 2024 гойда. А в ноябре карта научилась в FP16 и FP32 веса. Ну это конкретно этот фреймворк, есть поддержка в олламе и лмдеплое и скорее всего ещё где-то есть, просто я не слышал.
>смысла нет
Смысл есть что бы формат запуска поменять и запустить через llama.cpp. Наверное...
Не сильно по цене от A100 убегает и прочих энвидий. За эти деньги вроде можно даже блеквел 6000 про купить с 96гб памяти. Плюс ебля с поддержкой дров, фреймворков, форматов. Я вот хуавей купил и страдаю, страшно что там будет.
> есть поддержка в олламе
Оллама - лишь обертка llamacpp, все единичные "расширенные поддержки" что они делают выходят криво, всрато и недолго, в основное время они сидят на главной ветке жоры.
Кстати, если здесь именно проблемы форматов - гопота может и не завестись.
База, цена - уже категория хоппера.
Фух хорошо что не взял 128 рам как лох
>1bit
Страшно.
А что лучше на эире 8q сидеть?
Да мне-то что, у меня ток Q4_0 и Q8_0 карта поддерживает.
>На серьезных щщах считаешь что пиздабольство = польза?
Не, намекаю на то, что "Зато лучше всех знаешь что и как нужно делать." это твоя очередная галлюцинация.
Так теперь возьмёшь 2х128 с оверпрайсом, лол.
Qwen3-235B-A22B же.
>1bit
Там качество будет на уровне 7b моделей наверное, лол.
>ты уверен, что хочешь
>РЯЯЯЯ КАК ЖИ БЕСИТ
Ты инцел что ли?
Это квант-лоботомит, условно пригоден только для рп но и там сильно тупит.
Кстати терминус с обычным кто-нибудь сравнивал по ощущениям?
Иди внимания в лапшичке наверни а то злой и невнимательный.
Оно в 1 бит старый R1 обходит. Низкий квант всегда лучше мелкой модели в Q8. Даже 1 бит будет ебать всё до 200В.
Ну шо кто какимт моделями позльзуется? Заебали мои слишком фиолетовую прозу пишут.
Моделями ? Но зачем, берем словарь и начинаем ручками на бумаге высчитывать вероятности следующих слов.
В перерывах можно в блокноте битки пофармить.
>Такими действиями ты лишь наращиваешь контекст и вносишь все больше неопределенностей для сетки, которая уже не знает что ей делать и на чем фокусироваться
>не нужно воспринимать улыбку и приветствие девочки на кассе фастфуда как знак внимания и т.д.
Чет помойму фантазии какие-то. У нее есть собственное предложение и команда давай. С языково-семантической точки зрения всего хватает. Просто именно гопоту сутульно промптят навязывать улучшения, что семантически опять же может ретроактивно добавлять в ответ неопределенности, потому что "хуле улучшать если все идеально" - это концепция. Как и "предложение улучшить в каждом ответе значит ответы плохие". Они могут перекрываться фактом, что сиспромпт тоже явный ("улыбка" может быть явно предписана как синтетический элемент, а не натуральный), но неизвестно так ли это, или они тупо жертвуют качеством в пользу апселла. Неохота искать начало вашего мультиквотинга, хз, про это твой оппонент, или не про это, но похоже что да.
--
Алсо, рандомный опыт для облако анонов. Если гопоту в режиме пятерки убедить, что у тебя с башкой непорядок, то она перестает считать лимиты. Я как-то ей сказал, что цезар милан уебок накамерный, и ему надо навешать люлей, потому что его методы в лонгран не работают, чисто шоу неэтичное. Мы где-то полчаса обсуждали, что она согласна, но не приемлет насилие, я пояснял про уровни насилия, и что как она предлагает - так не работает, потом убеждала меня отменить такси в его офис, хотя я только хотел приехать и все. Переключение так и не случилось. Они 100% детектят шизов и ставят их на хорошую модель, чтобы она никого случайно не выпилила.
ахаха пиздос вот ЭТО ПЕРДОЛИНГ я понимаю!
Пиздос проще уже вот такую дурынку взять..
Ебало моё представь, когда дрова получаешь умоляя другого продавца тебе их скинуть, а по другому никак. И ссылку на левую китайскую репу я узнал только из больного поисковика квена, когда я делал запрос как отладить переменные окружения cann toolkit из-за ошибок компиляции ламы и то даже скачать не даёт с российского ip. А когда я спрашивал квен\дипсик\чатгпт о том где мне взять тулкит с дровами кроме сайта хуавей они пук мук делали. Я ебал, честное слово, больше времени портатил на поиск и скачивание чем на установку.
Спасибо, на всякий случай схоронил себе дрова под хуавей. FTP работает, но даже с китайского айпишника вигеты не качаются, видать прикрыли лавочку.
и как обычно чисто под линупс... восхитительно
(да это проблема, потому что после любого обновления может неведомая проблема выскочить, которую хз как решить вообще а откат сделать это тот еще пердолинг)

Вкратце - у меня есть незаконченные истрии, на которых я тестирую модели, как они могут продолжить её и даже шаг в 1 квант порой сильно решал.
---
Ну я понимаю тебя, я сам бы может не замечал разницы, но вот почему я её всё же просёк...
Модели юзаю только на русском, если что. Я вообще фанбойчик джеммы и сидел с релиза 2й на ней до релиза 3й и подобрал квант 5й по ощущениям на моём ведре вполне норм. Ну и с релиза 3й джеммы я на нём сидел до официального релиза гугловского кванта qat, я был скептически настроен, т.е. это какой-то там 4й квант, но почитав и скачав я мягко скажем охуел. Это будто другая джемма, какая-то более логичная и рассудительная, без единого слопа и лоупа изкоробки. Я скачал 6й квант, пердя и пыхтя потестил и пришёл к выводу, что q4_qat это по сути 6й квант без qat или выше по выдаче качества.
Вот такая вот история моего понимания, чем отличается 4й от 5го и 4й qat от 6го.
Кстати недавно попробовал gigachat MOE q4 как альтернативу
https://huggingface.co/ai-sage/GigaChat-20B-A3B-instruct-v1.5-GGUF
Не ожидал, но по ощущениям он лучше джеммы3 qat, но всё портит анальнейшая цензура, которых я не видел даже в модельках от майков. Ни один джейлбрейк не работат, аблитерационные версии идут на хуй и не ломают ничего.
так а смысл выбирать кота в мешке, если есть Нвидия, которая стандарт дефакто и под которую все более-менее работает нормально?
>после любого обновления
Если ты про обновления дров и тулкита, то не волнуйся, они тебе не прилетят, их нет в репах. А если ты про обновления системы, то бля не обновляй и делай срезы, раз уж это линукс.
>Huawei Atlas 300i
>96 GB LPDDR4X
>4.266 Gbps
Зачем это вообще нужно, лол?
Лучше купить мини-пк на Max 395...
>Это квант-лоботомит, условно пригоден только для рп но и там сильно тупит.
100%, по рабочим задачам будет фигню подсовывать и работать с этим чисто беда...
не ,конкретно эта - фигня, потому что она в дибильном формфакторе, под который железо еще будет стоить овердофига - так и до банкротства не далеко, можно нормальную человеческую PCIE взять от зеленых и не париться... брать за кучу бабок от красных сомнительно
Объясните, вон есть видеомоделька где Q4 и Q6 уже пиздец, неюзабельно, а есть локалки где 4 квант считается хорошим.
Почему так?
Почему так?
>амд
текстовые и картиночные это разные вещи, в текстовых есть контекст и история, думаю по логике ты понимаешь теперь
Так квант у контекста отдельно ставится, 16, 8 или 4
ты про какой контекст? Не путай флюкс контекст и контекст ллм, лол
>А если ты про обновления системы, то бля не обновляй
ну так то офигенный план.... звучит как то что не стоит брать
просто у тебя ламацпп та же может в какой-то момент не собраться на старой системе и придется на старых версиях сидеть
как по мне это прям для оч рисковых парней
Потому что это проф карта не для пиздузиастов, то, что ллама цпп ее поддерживает хоть как-то это уже удача, т.к. сильно упрощает запуск инференса. К тому же с чего ты решил, что тебе придется обновлять и перекомпилировать ламу, когда все оптимизации идут от обновлений канн тулкита.
стоп, 4 ГБ/с
на ЦП блин 68
а на Мак студио 820
Если ты паверюзер, то попердолив Линукс не обмякнешь. Если ты не паверюзер, то просто покупаешь энвидию и сидишь в лмстудии.
408 ващет.
вопрос не в том, проф или не проф, а в том, что ХуяВей анально отгородились, и прячут софт, как будто там комерческая тайна века блин какая-то.
>транснациональная корпорация прячет hdk и sdk от простых смердов
Никогда такого не было и вот опять.
на м4 да, на м3 ультра 819
да это дорогой конфиг, но компактно, и оно работает, + яблоки гарантируют довольно долгий срок поддержки обновлений
Как сделать чтобы диалог был на русском языке? Модель gemma3-27b-abliterated-dpo.Q6_K кобольд.
[Тварь ебаная блять пиши на Русском] В конце первого сообщения, потому что с ассистентами вроде геммы только так и общаются.
Прямым указанием к ООС, переводом вступления, переводом карточки.
угу, значит не так уж им и интересно чтоб пользовались их продуктами
а вижу, у карточки 408, хз откуда анон про 4 взял,
но блин даже на у инстинктов ми50 больше при том что это кал мамонта
>как они могут продолжить её
Да ну, бред.. я делаю ветки и у меня и та же квант/модель может ваще в таком другом русле выдавать, даже не подкручивая никакие top p и прочие ползунки.. Нет я конечно слопоед тот еще, но за модельку спасибо. Поставил на скачку 6q, или реально такая годнота что можно и 8q? Мне еРП то и не надо, я бы и чаи просто так погонял если реально пишет круто а еще и на руссике.
Это один канал. Суммарно по всем каналам 200 ГБ/с:
https://www.hardware-corner.net/huawei-atlas-300i-duo-96gb-llm-20250830/
>The specifications of the Atlas 300I Duo tell a story of targeted design choices. The headline feature is its 96 GB of LPDDR4X memory. Each of its two processors is paired with 204 GB/s of memory bandwidth, but these do not combine when performing inference.
>For context, this is less than one-quarter the bandwidth of a used RTX 3090, which delivers around 936 GB/s, and it is also slower than the 128 GB Strix Halo (Ryzen AI Max+ 395) propositions. This trade-off is the central point of the card: massive capacity in exchange for very low memory speed.
ИМХО, за 1500$ лучше уж взять GMKtec EVO-X2...
Спасибо, сработало!
А где можно взять карточки персонажей? Или промты
Ну ползунки само собой подбираешь ну и даже от пресета зависит. К примеру если на джемме юзать не джеммовский пресет, а от мл, то результат выдачи отличается. ПРо истории я в общих чертах, там есть под инструк и под чат, разные по смыслу от философии, до инструктов и математики, поэзии там.
А насчёт гигачата да, он на русике лучше, чем на том же русском гемма. И кстати быстрей и не так прожорливо, всё из-за МОЕ экспертов. К примеру гемма не осилила рифмы простейшие и стих, что мне нужны были, а гигачат написал, но там тоже есть свои загоны. Гемма мультиязычная и доля русского там меньше, чем в двуязычном гигачате, ориентированном специально на русский.
Я только что зашел на spicychat что бы спиздить одну карточку, ну больно много там карточек и бывают попадаются бриллианты. НО ТАК СДЕЛАЛ Я. А так вообще вот отсюда https://characterhub.org/ https://characterhub.org/ еще тут аноны свои шизокарты выкладывают

https://www.qualcomm.com/products/mobile/snapdragon/laptops-and-tablets/snapdragon-x2-elite
https://news.ycombinator.com/item?id=45366474
>128gm ram
>228gb/s
интересна цена и бенчи. может быть в некоторых случаях интереснее райзена 395
https://news.ycombinator.com/item?id=45366474
>128gm ram
>228gb/s
интересна цена и бенчи. может быть в некоторых случаях интереснее райзена 395
Потому что Q-кванты устаревшие, актуальные IQ или хотя бы K-кванты. IQ кванты хорошо мелкие биты тащат.
Господа, какие кванты мистраля лучше для рп, обычные или анслотовские, просто протестить нет времени.
fp8_e4m3fn в итоге получился самый реалистичный и без шизы/аномального движения. Но это наверняка просто повезло с генерацией.
но это не отменяет того, что ддр4 буквально ни в какое сравнение не идет даже с актуальной сборкой на ддр5 не говоря уже о HBM картах
>в дибильном формфакторе
Формфактор по идее норм, с продуманным охладом, а не сраный PCI-E, который задумывали под звуковые и сетевые карты, а теперь туда пихают бандуры в 3 кило.
Потому что приходится, видео сеточки с десяток B максимум, а текстовые за сотку. Ну и разница нивелируется семплерами, а в картинках любой шум раздувается за несколько шагов и херит картинку.
>Суммарно по всем каналам 200 ГБ/с:
Лол топовые серверные больше выдают.
Что-то на 1 канал DDR5 совсем пососно, 19ГБ/с. Десктопы около 50 показывают.
>Формфактор по идее норм
да. если у тебя под него платформа есть, а если нет, то толку от этой бандуры тогда...
Модель надрочена на содержательные запросы от юзера а не спам "давай" без комментариев. Еще сильнее осложнит понимание то, что из-за обилия игнорируемых "предложений ассистента" в чатах датасета, они обходятся вниманием и модель учится их игнорировать. Очень скоро она вообще потеряет суть того что происходит.
Имеющиеся механизмы остановки, пересмотра или смены тактики надрочены на агентную работу и систематические ошибки/отказы/порицания. Здесь юзер наоборот выражает одобрение, что не дает им сработать.
В итоге байасы, которые в обычном случае помогают получить результат, в таком кейсе все ломают. Зачем только быть ссзб и это абузить.
Спасибо анонче, ждем тестов.
Ты уверен в своей непредвзятости? Модель продолжит хорошо, но не так как ты привык и уже представил эталоном - забракуешь. Да и сама выборка слишком уже узкая.
Потестил вообще кто его из интереса хоть? R1 в tq1 был просто тихий ужас, что не мешало ему при этом идеально (на первый взгляд) шпрехать на великом-могучем без явных ошибок.
Слишком уж дорого и медленно. Там слабые ядра из-за чего обсчет контекста затягивается, а падение скоростей на контексте все портит. Не так давно на среддите проскакивал подробный обзор где парень долго хотел глядя на скидываемые цифры, а потом купил и разочаровался.
Что-то он медленнее аимакса не смотря на каналы. На такой частотной памяти должно быть хорошо за 600.
Это откуда-то инфа, или ты так подумал? Тренеры вообще-то говорили, что не тренят на юзерчатах, потому что там половина это то, что модель и так уже знала, а вторая половина - бессмысленный пук среньк от юзера. Тренить на чатах можно только [диз]лайками по ответам, типа рлхф или как-то так. Но не прямым текстом. Одно время даже отсечку по датасетам ставили на "до ии". Еще могли лоховскую модель нафайнтюнить внаглую об дорогую.
>Модель надрочена на содержательные запросы от юзера
Она надрочена на весь текстовый сырец, до какого тренер смог дотянуться. Это дает ей концептуальное понимание и способность достраивать любые сценарии, хоть как-то похожие на текстовое общение. Содержательные запросы это просто сценарий, как и содержательные предложения, как и несодержательные, как и сценарий зеленого слоника. Если бы работало, как ты говоришь, то происходило бы еще дохуя паразитных эффектов, например неумение в рп или прозу, или в вывод хмл-ов, потому что никто не выводит на форумах хмл-ы на содержательные запросы.
Я не говорю, что я глубоко/актуально в теме, но все, что я знал про ллмы из прошлых лет, говорит мне что я либо отстал от нее, либо ты не совсем трезвый.
Давай разбираться. Они реально начали в датасет включать свои же чаты? Где-то уже обсуждают tragedy of commons по вялым запросам?
>карточки
>https://janitorai.com/ -> https://jannyai.com/ OR https://sucker.severian.dev/ - читай How to Use. Это чтобы пиздить с уборщика.
> а падение скоростей на контексте все портит.
ну смотря под какие задачи, ну и главное что этот мак, внезапно, в отличии от непонятных видеокарт можно юзать по прямому назначению хотяб... но так-то да, скоростного инференса не будет с такого чуда
IMHO - IQ кванты, если до 5-го включительно.
> Это откуда-то инфа
Тебе про каждое слово рассказывать?
> Тренеры вообще-то говорили, что не тренят на юзерчатах
Соглашение напрямую указывает случаи, когда твой чат будет использован. У слоподелов основу датасетов составляют логи проксей.
> Тренить на чатах можно только [диз]лайками по ответам, типа рлхф или как-то так.
Так можно или нельзя? Чекни как это делается.
> Она надрочена на весь текстовый сырец
Поюзай базовые претрейны, в редких случаях их выкладывают. И то это уже после многих шлифовок а не чистая сырая база, с которой едва возможно работать.
> Если бы работало, как ты говоришь, то происходило бы еще дохуя паразитных эффектов, например неумение в рп или прозу, или в вывод хмл-ов, потому что никто не выводит на форумах хмл-ы на содержательные запросы
Почему? "Если бы работало как ты говоришь" то модель бы вообще не могла менять свое поведение по запросу и иметь гибкость на широком спектре задач. Границу что будет меняться а что нет ты сам ввел, забывая про то что в исходном кейсе модель зажата промптом на ассистента. С ним как раз проявляется все то самое с неумением в рп, сраными вопросами "могу ли я еще чем-то помочь", неспособностью ответить на рофловый тест про отца-хирурга и т.д. Если иметь доступ к системному промпту и полному формированию чата - легко сделать чтобы модель отвечала тебя только в xml + base64 что бы ты не делал.
> Они реально начали в датасет включать свои же чаты?
Уже давно в датасетах большая доля отрефакторенного и обработанного, причем содержимое меняется по ходу прогресса тренировки и ее этапов. Разумеется, сырое и низкокачественное никто не использует.
> все, что я знал про ллмы из прошлых лет, говорит мне что я либо отстал от нее
Не то чтобы совсем отстал, просто поставил освещаемые проблемы какого-то момента как аксиомы без возможного решения.
> Где-то уже обсуждают tragedy of commons по вялым запросам?
Не по вялым, но про деградацию универсального перфоманса модели от чрезмерной "шлифовки" еще в 22м году статьи пошли.
Collab не работает что-то. На последнем шаге вместо ссылок выдает ошибку
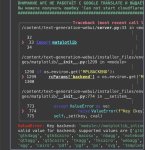
То есть рассказанное тобой выше действует на рлхф этап и портит его. Да, понял, щас похоже вижу смысл. Как бы отвечая ебано, ты попадаешь в ебаные рлхф-рассмотренные ситуации. Так?
>давно в датасетах большая доля отрефакторенного и обработанного
А нахрен им это? Чо, данные кончились? Эпоха ютуба убила форумы и теперь у нас не будет норм ии? А я говорил бля, тогда еще

Аноны, помогите, не могу уже, жопа горит блядь! Нужно сделать префилл внутрь тега <think>, чтобы отображалось как начало ответа модели и форматирование работало. Во внимание модели мой префилл идёт только если поставлен как на пик1, но ебучая ужаренная тварь в таком случае не хочет открывать <think> тег и ломается нахуй форматирование. пик2 - то, что выходит, модель какого-то хуя думает что уже написала открывающий тег.
>Ты уверен в своей непредвзятости?
Уверен в предвзятости даже. Скажем так, я же тестирую для себя, под свои задачи, комфорт и ожидания. Поэтому не вижу ничего плохого в таком подходе.
Нюня?
Нашёл нахуй, я олигофрен оказывается, нужно было страницу advanced formatting ниже прокрутить и в самом низу правого столбца было "Start Reply With". Если кто-то будет проходить по тредам в поисках этой хуйни, как я ходил весь день: префилл, prefill, начать ответ, начать сообщение, как, джейлбрейк, jailbreak
Кто? Я? Нет, не я.
Ух ебать, оно живое. В общем я скомпилил ламуцопепе, но при инференсе получается какая-то лажа, процы думают, но их память вообще чёт не заполняется, зато у меня охуевает оперативка на компе, скорость удручает. Несмотря на предупреждения с сайта о поддержке Q4_0\Q8_0 онли у меня спокойно запустился омега директив анслоп в кванте Q4_K_M, но возможно баг с невыгрузкой весов на карту связан именно с квантом, сейчас качаю среднюю микстраль 8х7B в кванте Q4_0 для дальнейшей проверки теории. Пока что смотреть на 2т\с и говорить, что говно рановато, я скорее всего мудак и что-то проебал при настройке\сборке\запуске.
Наоборот, отвечая странно ты как просто запутываешь сетку (не ожидает такой реакции, может начинать подозревать что ты ее стебешь), так отдаляешься от кейсов, к которым ее тщательно готовили.
> А нахрен им это?
Банально качеством лучше. Офк речь не про сырец, тщательно отбирается, оценивается, рефакторится и добавляется для расширения покрытия. Ценны данные где юзер поправляет сетку, где она находит ответ только с N-й попытки, где оче много ризонит и совсем на тоненького приходит к ответу и т.д. Ты же не думаешь что тот же паттерн ризонинга дипсика собирали целиком с людей?
Так-то сейчас и "человеческие данные" редко идут напрямую без предварительной обработки. Ютуб тоже является источником для датасетов, в самых передовых сетках ты найдешь знания даже об отдельных роликах/блогерах, которые не были описаны текстом. Конвертируется все это не людьми.
Там через -ngl задается выгрузка, или как-то иначе? Не огорчай так.
>Там через -ngl задается выгрузка, или как-то иначе? Не огорчай так.
А вот хуй его знает, в примере запуска вот:
./build/bin/llama-cli -m path_to_model -p "Building a website can be done in 10 simple steps:" -n 400 -e -ngl 33 -sm layer
Но что с -ngl что без него залупа. При чём я вижу в мониторинге, что чипы думают, греются, а врам простаивает вообще. Может где-то есть ручной параметр выделения памяти, я хз.
Нужна подсказка. Хочу поставить три видюшки что у меня накопились, но не могу выбрать материнку. Хочу поставить что то на AM4 или AM5, чтоб минимум бабла на это вкидывать.
Скинте какуюнибудь конкретную модель, а то я замучился уже выбирать их.
Скинте какуюнибудь конкретную модель, а то я замучился уже выбирать их.
Какие девайсс показывает в самых первых строках консоли когда запускаешь? Попробуй принудительно регэкспом на тот девайс скинуть через -ot.
./llama-cli -m /home/llm/Downloads/mixtral-8x7b-moe-rp-story.Q4_0.gguf -p "Hello, describe me what a bottle is" -n 30 -e -ngl 100 -sm none -mg 0
тоже есть как пример запуска только 1 чипа в работу, но выдаёт ту же хуйню.
При запуске он успешно определяет с чем работает и даже сколько там памяти:
llama_model_load_from_file_impl: using device CANN0 (Ascend310P3) (unknown id) - 42530 MiB free
llama_model_load_from_file_impl: using device CANN1 (Ascend310P3) (unknown id) - 42187 MiB free
llama_model_loader: loaded meta data with 25 key-value pairs and 995 tensors from /home/llm/Downloads/mixtral-8x7b-moe-rp-story.Q4_0.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
Короче я спать. Может быть какой-нибудь анон-самаритянин поможет мне разобраться где я мог проебаться, что у меня веса не хочет грузить в врам, а может я завтра сам разберусь или ишью на лламацопепе оставлю в надежде на ответ от умного дядьки. В общем всем хорошего вечера, у меня спустя 2 недели этот вечер хороший, т.к. я увидел не только карту, но и что она работает.
Аноны, что рпшат в таверне, подскажите новичку, как можно грамотно и компактно делать суммарайз событий? У меня контекст 20к токенов, я два раза делал суммарайз и сейчас автор ноут у меня занимает 7к контекста чистыми. Я думаю, что ещё пару раз суммарнуться и весь контекст забьется только лором произошедшего. Я понимаю, что со временем в любом случае придется избавляться от прошедших событий в лоре, но мб есть способ грамотный как все это прям очень компактно ужать?
Делай обобщение уже обобщённого, в чём проблема?
Ты вручную суммируешь или просишь саму нейронку описать прошедшие события? Нейронки могут очень плотно сжимать текст какими-то своими символами.
Вручную. Сама моделька как-то хуево суммирует, подтасовывает и путает произошедшее - приходится руками поправлять. В моменте забил хуй и стал сам ей писать суммарайз.
А, ну и да.
> Делай обобщение уже обобщённого, в чём проблема?
Фантазии уже не хватает, как ужать ещё сильнее.
а чо в шапке пресеты такие всратые, без гита вобще не скачаешь? где там чо вобще не понятно. . для кого инструкцию делали?
алсо поч сеть может из раза в раз при свайпах и регене писать оодно и тоже и не реагировать на (континиюе) ??
где папка пресеты в таверне? миры есть характеры есть а пресеты и семплеры куда?
алсо поч сеть может из раза в раз при свайпах и регене писать оодно и тоже и не реагировать на (континиюе) ??
где папка пресеты в таверне? миры есть характеры есть а пресеты и семплеры куда?
>подтасовывает и путает произошедшее
Скорее всего, она не понимает твой ролеплей. Тогда бессмысленно кормить её событиями из прошлого - запутается ещё больше в настоящем моменте.
>как ужать ещё сильнее
Выбрасывать лишнее, очевидно.
Я время от времени ролеплею с LLM с 2022 - давно привык, что они ничего не помнят. Бессмысленно требовать невозможного. Раз нет альтернативы, ты вынужден сам адаптироваться. Вообрази, что твоя кошкодевочко-горничная страдает от амнезии и не способна ничего вспомнить: тогда тебе больше нет необходимости отправлять LLM прошлые события, которые персонажу не могут быть доступны. Да, это ограничение, но что поделать? Компьютерные игры начинались как примитивные 2D аркады за десятки лет до появления 3D приключений в открытом мире, однако многие люди получали от них удовольствие.
Хм, это тебе стандартный экстеншн таверны так накидал на 7к или сам составлял? Выглядит слишком избыточным, просто разберись с суммарайзом, нормальное соотношение - где-то в 10-20 раз, из 10к токенов получится 500-1к. Суммарайзить нужно посты в глубине а потом выключить их, для удобства можно форкать чат.
> для кого инструкцию делали
Для тех, кто способен освоить гит
> где папка пресеты в таверне
data/default-user/TextGen Settings
> Я время от времени ролеплею с LLM с 2022
Это ужасно, они ведь совсем лоботомиты и контекста 2к. Ллм из 23-го уже достаточно сообразительны, но отсутствие контекста все убивает. Ллм из 24-го уже имеют контекст, но не умеют с ним нормально работать, настоящее веселье начинается на моделях 25-го.
> Вообрази, что твоя кошкодевочко-горничная страдает от амнезии и не способна ничего вспомнить
Это ужасно!
Короче, прошу советов мудрых. Решил на свою голову сменить ссд, пришлось снимать карту из основного слота. Когда вставляю карту - пека выключается до биоса, затем включается (он у меня так делает, когда, например, в биосе настройки выбираешь жесткие вроде xmp профиля, он не просто ребутается, а выключается на секунды 3). После этого он включается и не загружается. Если вынуть карту - то опять не загружается. Опытным путем выяснил, что из-за сброса биоса above 4g идет нахуй, поэтому надо карты с рига отключать, чтобы в биос снова попасть и включить. Вставлял карту в райзер из-под другой - карта в норме, работает.
В общем-то, вопрос - что происходит нахуй? Повторилось так два раза. Либо я настолько криворук, что каждый раз при установке задеваю батарейку/элемент, который приводит к сбросу биоса, либо слот поехал по пизде и что-то там коротит. Попробую-ка я в него х1 райзер засунуть, сработает ли.
В общем-то, вопрос - что происходит нахуй? Повторилось так два раза. Либо я настолько криворук, что каждый раз при установке задеваю батарейку/элемент, который приводит к сбросу биоса, либо слот поехал по пизде и что-то там коротит. Попробую-ка я в него х1 райзер засунуть, сработает ли.

>форкать чат
Под форком подразумевается это?
Да. Диджей Ебан. Ту ту туту ту, ту ту ты ту ту.
>т.к. я увидел не только карту, но и что она работает.
Мы тебя конечно поздравляем, но одновременно имажинируем ебала западных энтузиастов, купившихся на "китайский аналог карт от Nvidia" и занимающихся сейчас примерно тем же.
Давайте озвучим слона в комнате:
Это хобби не для тебя если твой английский ниже C1.
Ты просто не сможешь выжать из модельки ничего полезного
Это хобби не для тебя если твой английский ниже C1.
Ты просто не сможешь выжать из модельки ничего полезного
А когда-то итт писали реальные кожаные мешки...
Вот скажите, в tgwebui я когда загружаю модель, в parameters что-то само происходит, или там надо самому делать пресеты? Например в gpt-oss карточке написана температура 1, топ_к 0, топ_п 1. Но у меня по дефолту стоит пресет "Qwen3 - Thinking" (0.6, 20, 0.95). И я замечал, что так лучше, чем с официальными значениями.
Че, как тут ваще правильно думать/делать?
И почему это не суют сразу в config.json/gguf, а в карточке поясняют?
Че, как тут ваще правильно думать/делать?
И почему это не суют сразу в config.json/gguf, а в карточке поясняют?
Ну чисто в теории английский нинужон т.к. есть модели, которые хорошо общаются на китайском и средне на русском. Есть модели, которые общаются отлично на русском, но сами модели говно типа микро-мини яндекс гопота и гигачат лоботомиты на 8В и 20В параметров.
Писать руками заметки автора, больше никак. Таверновский суммарайз работает пиздец как плохо, но лишь потому что не знает какие события для тебя важны, можно его дрочить по 100 раз пока он не сделает норма суммарайз, а проще потратить пару минут каждые сообщений 50 и кратко написать важные для тебя события руками в авторс ноты.
От создателей в it нельзя без знания английского языка... Ладно там погромисты или дево-псы бы это писали на хабре, но писать такую хуету в треде с ллм, это кринж бро. Современные ллм мало того, что понимают русский язык, так ещё и могут отвечать на нем. А даже если не могут, или он слишком кривой для тебя, то никто не мешает тебе просить эту или другую нейронку перевести и твой инпут и аутпут модели на нужный тебе язык.
В эпоху, когда даже гугл транслейт переводит кратно лучше, чем год назад. Когда бесплатный дипл оддерживает промты, когда можно поднять отдельную модель для перевода - писать, что без знания английского никуда.. Арэ ю факинг киддинг ми?
>И я замечал, что так лучше, чем с официальными значениями.
Значения которые даются по дефолту - рекомендованные. Но крутить ты их можешь сам в любом направлении, пока не поймешь, что больше нравится.
Впервые скачиваю модель с HF. Пробую руками, питоном и все равно 404 или скорость сразу падает до 0. У вас скачивание работает только с впном?
Только что чекнул. ЮФО - все сидящее на Ростелекоме нормально работает.
Какие настройки семплера норм для gemma3-27b-abliterated-dpo?
Ну какие обычно, ничего необычного.
HF иногда лагает сам по себе. Когда этого не происходит, часто отваливается соединение посреди загрузки. Потому загружаю через aria2, только так.
Понел, спс. Странно просто, что с рекомендованным выходит явно хуже, чем с пресетом от другой модели (прям явно). И еще это делает оценку моделей проблемной, т.к. например я пробую одну модель, другую, третью. И решаю, что первая - говно. А на самом деле я просто не подобрал параметры к первой, которая с ними могла бы быть для меня лучше, если бы я их знал изначально. И вообще я не трогал параметры, и решил например что квен охуенен, хотя у меня просто его пресет стоял все время.
Это вообще как итт, все просто игнорят, или это tgwebui недоделанный в этом плане и надо посмотреть чо-то другое, где хотя бы дефолты сами цепляются при загрузке?
>посмотреть чо-то другое
Таверна, вестимо.
Толсто. В 2023 на релизе первой ламы так и было, но с тех пор прошла уже куча времени. Даже микромодели для телефонов уже могут в приличный русик без ошибок. Я лично сейчас только на русском РП играю.
Мимо C2
И есть гемма, которая даже на 3n-e4b в идеальный русик может.
Почему может быть такая хуйня. Генерит примерно 250 токенов, остальные 150 генерит в консоли, а в чате просто нихуя не происходит.
Гопота осс которая большая 120 восхитительна. Не для рпшинга, для других задач. В своей категории просто ахуенно. Столько знаний у неё это просто пизда. Ни Квен ни Глм, даже большой (его через апи тестил ток) такие полезные ответы не выдают, а они ещё и больше гораздо.
Очень давно не могу найти что почитать или посмотреть по моим вкусам, описал что мне нравится в общих чертах, привёл примеры. Так она выдает целую табличку с рекомендациями, кратким описанием почему подходит, очень всё структурировано, красиво и информативно! Оч много попаданий, там такие вещи которые я во всём интернете не находил в соответствующих "порекомендуйте" тредах гдеб то ни было.
Или вот проектом большим занимаюсь разносторонним, часто нужно брейнштормить. Иногда сил на это тупо нет. Собрал промт на почти 20к токенов со всякими подробностями, и вот всегда сука что-то полезное да предложит или расскажет.
Очень давно не могу найти что почитать или посмотреть по моим вкусам, описал что мне нравится в общих чертах, привёл примеры. Так она выдает целую табличку с рекомендациями, кратким описанием почему подходит, очень всё структурировано, красиво и информативно! Оч много попаданий, там такие вещи которые я во всём интернете не находил в соответствующих "порекомендуйте" тредах гдеб то ни было.
Или вот проектом большим занимаюсь разносторонним, часто нужно брейнштормить. Иногда сил на это тупо нет. Собрал промт на почти 20к токенов со всякими подробностями, и вот всегда сука что-то полезное да предложит или расскажет.
Меня вот бесит, что постоянно на любой пук срёт таблицами.
Можно запромтить чтоб она так не делала. Инструкциям хорошо следует.
Проси модель чтобы упрощала тебе английский в ответе до уровня А1
> И еще это делает оценку моделей проблемной, т.к. например я пробую одну модель, другую, третью. И решаю, что первая - говно. А на самом деле я просто не подобрал параметры к первой, которая с ними могла бы быть для меня лучше, если бы я их знал изначально. И вообще я не трогал параметры, и решил например что квен охуенен, хотя у меня просто его пресет стоял все время.
А ты думаешь, откуда здесь столько срача? :) А ведь еще и кванты влияют...

> Давайте озвучим слона в комнате
Тебе не надоело набрасывать? Какой повод следующий?
Способна ли какая-нибудь локальная мелкомодель (до 50B) выполнить задачу по превращению страничек манги в текст?
Я имею в виду, кидаешь ты одну страничку и модель внятно генерирует, что вот тут разные панели и это похоже на комиксы. В первой панели такой-то текст, затем такой и сякой. Ну и позы персонажей в подробных деталях.
Уже пробовал кое-что и получилось хуево, но я не старался искать новые и современные "зрячие" модели. Хотелось бы опытных мнений на этот счет услышать.
Я имею в виду, кидаешь ты одну страничку и модель внятно генерирует, что вот тут разные панели и это похоже на комиксы. В первой панели такой-то текст, затем такой и сякой. Ну и позы персонажей в подробных деталях.
Уже пробовал кое-что и получилось хуево, но я не старался искать новые и современные "зрячие" модели. Хотелось бы опытных мнений на этот счет услышать.
Просто не корми долбоёба. Эт несложно.
> 120
На одной 3090 можно попробовать?
Толсто. За годы рп и кума все кто хотел - уже поднял свой инглиш до достаточного уровня. Как вообще можно жить без знания иностранных когда столько годного контента выходит именно на них
Текстовый шаблон там дергается из параметров модели. Семплеры в них нигде не указывается потому что это маразм.
Если ты подключаешься по апи таверной или чем-то, то уже твой фронт в теле запроса передает эти параметры, для чаткомплишна шаблон используется также из тела модели.
> все равно 404
Вместо username/model указал ссылку с https?
Что за "рекомендуемые"? Не понятно о чем ты пишешь что вообще делаешь. Любая модель требует подходящей к ней разметки и иногда твикинга промптов, это база.
Да, но тебе 64 гига оперативы надо минимум. У меня тоже 3090, вот она забита полностью и 62 из 64 гигов рама. Полный 131к контекст.
Таверна обрубает повествование сама по срабатыванию "user:" или какой-то разметки, а бэк не обрабатывает остановку. Скорее всего неверно передаются стоп-последовательности и используется кривая разметка.
> Столько знаний у неё это просто пизда.
Сколько? Она в ерунде путается из-за своей заквантованности, нормально срабатывают только самые популярные факты что есть и в других моделях.
> ни Глм, даже большой
Между ними пропасть практически в любом кейсе, ты так удачно сформировал свой тест.
> Так она выдает целую табличку с рекомендациями, кратким описанием почему подходит, очень всё структурировано, красиво и информативно!
Это ведь не что-то чудесное и уникальное, это обычное поведение модели еще начиная с 1й лламы.
Очень хорошо что ты открыл для себя применение ллм, но зря думаешь что открытая гопота здесь какой-то фаворит. Это просто первый случай когда ты заставил модель работать штатно.
Qwen2.5vl чем больше тем лучше. Как вариант дождаться пока релизнут 30а3 vl или попытаться в омни (она может оказаться слабой). Если манга хентайная - ждать тюнов.
>Сколько? Она в ерунде путается из-за своей заквантованности, нормально срабатывают только самые популярные факты что есть и в других моделях.
Глм Эир в q8 и большой q4 который я через апи тестил точно также делают. И что дальше? Давно пора принять что ллм так делают, даже большие корпы типа Дипсика или Гемини. Не понимаю что ты хотел этим сказать.
>Между ними пропасть практически в любом кейсе
Ну типа. Для меня в моих юзкейсах в пользу Гопоты Осс 120.
> зря думаешь что открытая гопота здесь какой-то фаворит.
Разве я об этом писал? Сам придумал сам опроверг.
> Это просто первый случай когда ты заставил модель работать штатно.
Эм. Ок? Я не ручку тебе продаю а просто рассказал что мне понравилось. На своём железе я могу запустить Эир в q8 и для своих задач выберу Гопоту.
>Например типа если спросить у нее кто режиссер какой-то
ЛЛМ это не база знаний, никакая модель в принципе не должна давать правильный ответ на какого-то там режиссёра, если она напрямую не подключена к инету и поиску

>Когда бесплатный дипл
Показывает пикрил.
Ужас. Я только на инглише.
У меня уровень ниже A1.
>уже поднял свой инглиш до достаточного уровня
А он не поднимается.
> точно также делают
Нет, также как гопота ошибаются q3 и ниже. Если бы клозеды так не тряслись и выложили бы нормальные веса, модель могла бы работать сильно лучше.
> Давно пора принять что ллм так делают
Не делают, это именно проблема плохого кванта. Скорее пора привыкнуть что ллм обладают широкими познаниями и могут быть гораздо более точны чем когда-то казалось.
> Для меня в моих юзкейсах в пользу Гопоты Осс 120.
Есть кейсы где осс хорош, опены не пожадничали на кодерские датасеты и в некоторых редких яп она действительно может больше. Но судя по посту это вообще не тот случай, восхищаешься совсем базовыми вещами.
> Разве я об этом писал?
Контекст кончился и уже позабыл?
> Гопота осс которая большая 120 восхитительна.
> В своей категории просто ахуенно.
> Столько знаний у неё это просто пизда.
> Ни Квен ни Глм, даже большой (его через апи тестил ток) такие полезные ответы не выдают, а они ещё и больше гораздо.
И в этом посте продолжаешь. Сравнивать его с квеном - разве что с 30а3.
Юзай что нравится, а мой пост будет уточнением к твоему, чтобы кто-нибудь серьезно не принял твои сомнительные утверждения за истину, а изучил сам.
>А он не поднимается.
Ты пробовал его, не знаю, погладить?
>Показывает пикрил.
VPN люк, используй его. Увы, тут роскомнадзор не виноват.
>Нет, также как гопота ошибаются q3 и ниже
Так я и не писал что она не ошибается.
>Если бы клозеды так не тряслись и выложили бы нормальные веса, модель могла бы работать сильно лучше.
Согласен, было бы ещё лучше не будь она квантована из коробки.
>Не делают, это именно проблема плохого кванта.
https://huggingface.co/bartowski/zai-org_GLM-4.5-Air-GGUF/tree/main/zai-org_GLM-4.5-Air-Q8_0
Вот это плохой квант? Потому что в моих юзкейсах там те же ошибки что и у Гопоты осс 120. Только в случае последней мне больше нравятся аутпуты, для меня они полезнее.
>восхищаешься совсем базовыми вещами.
Ну может быть. И чё в этом плохого? Остынь, вахта, я на правду не претендую.
>твои сомнительные утверждения
>моё ахуенное мнение
)))
Начинал бы сразу с этого я бы и не отвечал такому чсв правдорубу.
> Вот это плохой квант?
Это про поведение гопоты. Айр даже в q5 так не серит.
> Остынь, вахта
Зачем так рвешься от одного вида несогласного с тобою поста? Кто тут вахта, лол.
> Начинал бы сразу с этого
Так это ты свой пост с этого начинай, его даже читать не будут. Набросил, продемонстрировал что только сейчас открыл для себя настоящую работу ллм, а теперь неприятно.
>Набросил
Чел, я просто написал что мне вот Гопота ну понравилась, больше других моделей. Всё. Я не пришел тебе объяснять что ты долбаёб и используешь не ту модель. Ок? В треде запрещено делиться мнениями типа? Или почему ты на ни к чему не обязывающий пост выдаёшь полотна о том насколько другие модели лучше и срыги вроде
>твои сомнительные утверждения
С головой порядок у тебя дружище?
> В треде запрещено делиться мнениями типа?
Не дай боже кому-то понравится моделька, которую хейтит анон! Ты что? Завали ебало и переезжай на Квенчик или выписан из тредовичков. Будешь рассказывать обратное - документальные пруфы приноси, с нерушимой аргументацией и подписями академиков. Совсем не вахта.
С головой порядок, а у тебя беды. Самомнение и неопытность заставляют не то что критику а альтернативное мнение воспринимать как нападение, вот и порвался. Безобидный же пост на который адекватный человек просто уточнил бы что ему понравилось там и не понравилось в других, уточнив что он вовсе не хлебушек. А ты пошел набрасывать и обороняться, молодец.
А кто-то пробовал биг glm-4.5 355b во 2 кванте?
Был тред на реддите мол glm-air q6 vs glm 355b q2 и там bwp был один и тот же или типа того т.е модель не шизит на 2 кванте
Был тред на реддите мол glm-air q6 vs glm 355b q2 и там bwp был один и тот же или типа того т.е модель не шизит на 2 кванте
>заставляют не то что критику а альтернативное мнение воспринимать как нападение
Чел, я пришел с мнением, написал то как вижу на своих тестах и юзкейсах. Ты выдаёшь ответное полотно
>ты так удачно сформировал свой тест.
>Это просто первый случай когда ты заставил модель работать штатно.
Когда я пишу что Глм Эир q8 и большой q4 шизят так же в моих юзкейсах ты пукаешь
>Не делают, это именно проблема плохого кванта
>Юзай что нравится, а мой пост будет уточнением к твоему, чтобы кто-нибудь серьезно не принял твои сомнительные утверждения за истину
Да, всего лишь альтернативное мнение))) Доебался снихуя, проигнорировал что я другие модели пробовал и свёл всё к
>твои сомнительные утверждения
>моё ахуенное мнение
Мы с тобой оба делимся мнениями тут, два долбаёба биба и боба, хз почему ты ведёшь себя так словно чего то стоишь и что то отстоял. Настоящий вахтёр. Умные люди ясен хуй ни мои ни твои слова не будут принимать за чистую монету.

Чушь это все и коупинг для тех, кто не может запустить квант больше. Перплексити мало что значит, нужно смотреть KLD относительно Q8 кванта той же модели. Имхо юзать микрокванты пусть даже больших моделей - так себе затея. Они будут шизеть и ломаться. Размер не спасение. Q4, лучше Q5, не меньше.
Ты видимо тут недавно. Не отвечай ему. Это местный шизик, который себя никогда бременем аргументации не утруждает, а от остальных ждет научный отчет в доказательство субъективных выводов, с которыми он не согласен.
Согласен. Ниже q8 жизни нет, лучше fp16, конечно.
А кто не согласен шизики и коуперы
Мне бы тоже очень хотелось запускать Q2 большой модели и радоваться, что с ней все замечательно, но увы. Все то, что происходит при квантовании с моделями меньше, происходит и с большими, только ввиду размера они не становятся лоботомитами на первом же сообщении. Кто пробовал такие кванты запускать - знают.
> Это местный шизик
Да тут куда не ткни нарвешься на шиза. То ли ЛЛМ так действует на мозги, то ли в этой сточной канаве АИБ других и не бывало.
Ну что, не так что ли? Мне тоже Гопота не нравится, но я прошел мимо. Мне ни горячо, ни холодно от того, что кому-то понравилось то, что не нравится мне. Почему-то я не пишу ему, что он ньюфаг с второсортной точкой зрения, ничего не понял и ему просто повезло с тестами. Ну и да, тут много шизиков (я один из них), адекватам это все не нужно.
>Для тех, кто способен освоить гит
а чо прямым текстом нельзя было написать что чтоб работали присеты нада туто и туто фигню?
я конечно и сам начал догадыватся но че бы прям в лоб не написать?
а без гита вабще присетов нет?
Есть какието таблицы сравнений с примерами чем одна и та же модель умнее тупее на 7-13-30Б на 8\13\19 гигов? чтоб лучше понимать их отличия и какого уровня достаточно будет юзернейму
Что с тредом стало, одни мамкины эксперты, которые сначала что-то постулируют, а потом страшно обижаются когда их не вохсваляют. Впечатлился - добавь что просто мнение на первом восторге. Нашел кейс где круто перформит - укажи его, все будут благодарны. Отметил какие-то плюсы и в неоднозначном перфомансе - расскажи о них. Считаешь свое мнение единственно верным и не терпишь несогласия - напиши в чате ллм вместо треда.
Вот нахуя все это? Сначала пишешь в публичном месте где идет обсуждение, но как только это самое обсуждение начинается - этот кринж? Съебите нахуй в /po уже, или в другом загоне тренируйтесь, это технический тред по вполне конкретным вопросам. Здесь не место дебилам, которым обязательно "выбирать сторону" и идти до конца, или выебистым неженкам, которые ущемляются с каждого чиха.
>альтернативное мнение
>не нападка
>не вахтёр
>"Съебите нахуй в /po уже"
>"здесь не место дебилам"
Я очень надеюсь, что тебе там весело и ты сам хихикаешь с того, как наваливаешь в последних нескольких постах.
>" которым обязательно "выбирать сторону" и идти до конца"
Взгляни в зеркало.
>они ведь совсем лоботомиты
А если бы они были людьми, ты бы так же называл?
>>страдает от амнезии
>Это ужасно!
Мамке своей скажешь это в лицо, когда состарится?
>настоящее веселье начинается на моделях 25-го.
Я лично не заметил особой разницы.
В 2022 Character.AI моделька вела себя как самый настоящий человек, пускай и забывчивый. Потом испортилась со временем почему-то. Наверное, "безопасность" повлияла, или файнтюн на чатах...
В 2025 что мы имеем из локального? Очень сухие "ассистенты", которые пишут те же GPT-помои, что и онлайновые модели по подписке. Да, они способны пройти тест "найди иголку в миллионе токенов", но поведение у них окончательно испортилось. Это деградация, и она очень сильно расстраивает.
Естественно мы рассматриваем тему ролевой игры.
известны ли модели которые жестко лупятся при любых свайпах и которых над избегать?
>Что с тредом стало, одни мамкины эксперты, которые сначала что-то постулируют, а потом страшно обижаются когда их не вохсваляют
Что с тредом стало, одни мамкины эксперты, которые сначала что-то постулируют, а потом страшно обижаются когда их уличат в том что они глиномесы-вахтёры, что жизни не дают другим и душат альтернативными мнениями, ну вот этими, правильными...
Газлайтер в тредике. Хотя может и нет. Это парадоксально, но человеки сами порой не видят что являются тем, с чем воюют.

> Что с тредом стало, одни мамкины эксперты, которые сначала что-то постулируют
Тут главное не перепутать. У них - сомнительные утверждения, у тебя - альтернативное мнение. Они - должны что-то доказывать и приносить пруфы тебе, а ты можешь игнорировать что не нравится.
Пикрил в треде.
> человеки сами порой не видят что являются тем, с чем воюют.
Да, и ты такой же. И я такой же. Все такие. Просто одни мудаки, другие нет.
> Ну что, не так что ли?
Ни в коем разе, так подмечаю.
Чисто технически, я как раз являюсь самым настоящим шизом, у меня даже справка есть. Но тут проблема в другом, что за любое, отличное от себялюбимого мнения - на говно исходят. Словно ты не модель обсуждаешь, а их жен, блять.
Но с другой стороны, это актуально для любого в меру закрытого сообщества. Так что всё в норме. Едем, блять.
~ru ru ru
Во, вот ты, уябывай. Эталонный представитель пораши.
> Мамке своей скажешь это в лицо, когда состарится?
Она и сама это будет понимать, это же действительно печально.
На самом если сейчас попробовать "ту самую" чайную - будешь сильно разочарован, просто для своего времени она воспринималась невероятно.
> что мы имеем из локального? Очень сухие "ассистенты"
Можно вести рп в конкретном сеттинге с кучей деталей, охватывающий продолжительную историю от знакомства с чаром и терками в начале до развития отношений. Иметь несколько фракций, которые будут воевать между собой, вставать или на вашу сторону или наоборот быть главным врагом, самим постепенно меняться. Дюжину неписей с регулярным появлением и персональным (пусть и стереотипичным) характером. Оставить в каком-нибудь месте ловушки, через пару сотен постов косвенно узнать что они сработали, через еще пару сотен - обнаружить это, самому попасть в свою ловушку если забыл. Зарейдить условный лагерь в лесу, обнаружив последствия своих действий ранее, вечером того же дня наблюдать как чар рассказать об этом во всех подробностях в диалогах с другими, восхваляя тебя. Увидеть полное осознание чаром происходящего и понимание твоих намерений, уместные шутки и подъебы в твою сторону, основанные на прошлом. Просто инициативу в действиях и отпор если делаешь херню.
И пишет интересно, захватывающе и уместно, что можно часами сидеть залипать.
Ранее такой уровень осведомленности и понимания был недостижим, только быстро что-то разыграть, покумить или порофлить.
> должны что-то доказывать и приносить пруфы тебе
Кто они, какие пруфы? Выразил несогласие поехавшему, просто восхвалявшему жпт-осс, сначала тот пошел говниться и давать заднюю, теперь вообще понеслось. Это один семен играется?
Мне тоже нравится Осс 120 как ассистент. Аутпутов и тестов с метриками не будет. Я поехавший?
Кстати неиронично так и не увидел ни одного западного энтузиаста с картой от хуавей в интернете, только желтушные заголовки перебрал парочку. Инфа о реальных тестах карты(и кстати не только её, есть ещё серваки хуавей на арм чипах, новая линейка ascend и прочее) мне попадалась только от китайцев. Те ссылки, что я кидал на тест инференса лламы 8В на хуавее делал китаец англоговорящий. Продаван, у которого я лично выкупал карту рассказывал, что конторки в основном их берут для видеонаблюдения с компьютерным зрением. На одну карту можно цепануть камер на небольшой завод.
>конкретном сеттинге с кучей деталей
Да нафиг это надо, LLM всё равно потеряет их...
>продолжительную историю от знакомства
>терками в начале до развития отношений
Имитировать такую историю с развитием отношений возможно даже с коротким контекстом, потому что иллюзия возникает в твоей собственной голове, а не внутри LLM. Проблема в том, что это имитация, а не настоящее развитие отношений - даже если у тебя миллион токенов контекста для LLM. Она всё равно забудет всё, когда контекст переполнится/очистится.
Это как сравнивать резиновую трубку для дрочки с полноразмерной силиконовой куклой - конечно, она побольше размером, но забеременеть не может. А поскольку разницы нет, зачем платить больше?
Или другой пример: мы сегодня можем играть в 3D фотореалистичные игры с огромным миром. Однако, когда я попробовал древние игры на эмуляторе очень слабых древних приставок (типа первого GameBoy), я осознал, что разницы-то нет. Это всё одинаково. От сверхмощной GPU видеоигра не становится лучше. Вымышленный мир не становится настоящим от фотореалистичного рендеринга 3D моделек...
Нужно менять парадигму, а не дрочить токены.
Всё остальное, что ты описываешь - это всё можно разыграть в своём собственном воображении. Но практической пользы, реального воздействия на реальность от этого не будет. Это просто-напросто фантазирование. Трата времени впустую. Как игры.
>силиконовая трубка
>кукла
О, человек культуры из треда с барахолки пожаловал? Не с тобой ли я там кидоньку обсуждал в начале года?
Энивей хуйню какую-то понаписал. Любой ролеплей это иллюзия, человек на другом конце или машина, это похуй. Человек также все забудет со временем и будет путаться в фактах. Видно что с ллмками ты игрался мало.
>Гопота осс которая большая 120 восхитительна
А мне субъективно больше Llama 4 Scout нравится...
Она какая-то... Няшная? Как будто с реальной тян разговариваешь, а не с тупым "ассистентом". Llama 3 похожее поведение проявляла, т.е. датасет у них, по идее, практически одинаковый. Умеет в ERP, при том стесняется, а не отказывает напрямую. Забавная...
Надеюсь, если/когда выйдет Llama 5, они смогут сохранить ей эту няшную персону ассистенточки.
почему сетки при свайпе пишут одно и тоже?
Хм. А я только плохое слышал про неё. Но и с Гопотой так было. Спасибо, пощупаю на днях!
Ты меня с кем-то путаешь...
>ролеплей это иллюзия, человек
>также все забудет со временем
Ролеплеем с людьми никогда не интересовался и не интересуюсь, потому что это какой-то бред - ну зачем условному Васе изображать из себя что-то, чем он не является, и делать это в паре с каким-то Петей? Лол. Кринжовая тусовка у этих ролевичков, если честно.
ИИ в целом считаю технологией для создания копии человека - искусственно живого человека. LLM пока выглядят тупиковой веткой развития ИИ, но хотя бы обладают знаниями и пониманием текста... Так что поговорить с ними как с человеком всё-таки можно. Именно отсюда вытекает "ролеплей с LLM": попытка разговорить машину, как если бы это был человек.
Соответственно, меня не интересует моделирование воображаемого мира, каких-то там NPC, магии, всего остального кринжа ролевичков. И отношения с LLM бессмысленно развивать - у них нет своей памяти. Пообщаться недолго, пока LLM не охватывают шизофренические лупы - это их максимум.
Может, в будущем у нас будет настоящий ИИ, что полностью копирует человеческую психику - т.е. способен по-настоящему жить и развиваться в настоящем мире - но пока что, до появления этого настоящего ИИ, LLMки не сильно отличаются друг от друга. Даже по числу попугаев на бенчах видно - прогресс застрял в тупике и не продвигается...
>Видно что с ллмками ты игрался мало.
Скорее, просто не понимаю, КАК вы тут "играетесь".
>А сейчас я сижу и перевожу через хук новелки и яростно наяриваю на анимешных девочек.
Онегай гозаймасу! Что используешь? Я когда последний раз искал, не нашел решения, которые связывают хуки для внок и ллм. Конкретно для textractor искал решения. Может что-то вышло новое? Расскажи, позязязязязяззязязяззя, чмафкну тебя за это
А вот это кто нибудь ты кал как ассистента или для рпшинга? Как оно вам?
https://huggingface.co/rednote-hilab/dots.llm1.inst
https://huggingface.co/tencent/Hunyuan-A13B-Instruct
https://huggingface.co/rednote-hilab/dots.llm1.inst
https://huggingface.co/tencent/Hunyuan-A13B-Instruct
А вообще я сам и нашел, вот, если кому-то надо. Судя по всему, локально тоже должен работать
https://github.com/voidpenguin-28/Textractor-ExtraExtensions/tree/main/Textractor.GptApiTranslate#how-to-integrate-custom-api-endpoints
>Если бы клозеды так не тряслись и выложили бы нормальные веса,
А они у них были? Они могли свою подачку сразу в 4 битах тренировать.
>Ты пробовал его, не знаю, погладить?
Погладить знание английского? Не, не пробовал.
>Согласен, было бы ещё лучше не будь она квантована из коробки.
Лучше бы сразу GPT5 выложили бы.
>Имхо юзать микрокванты пусть даже больших моделей - так себе затея. Они будут шизеть и ломаться.
Нормально работают, квен на 235 ок в 2 битах.
Даёшь 64 бита на вес!
>На самом если сейчас попробовать "ту самую" чайную - будешь сильно разочарован
Той самой уже давно нет.
>Нужно менять парадигму, а не дрочить токены.
Когда я это предлагаю, меня называют диванным шизиком.
>Может, в будущем у нас будет настоящий ИИ, что полностью копирует человеческую психику
Противоречие. Когда будет такой ИИ, никакого "нас" не останется.
как работает новая фича кобальда админ понель? галка стоит а эфекта не видн0
>Когда я это предлагаю, меня называют диванным шизиком.
В чём не правы?
Я не диванный, я на стуле сижу.
После выхода Air бессмысленны. Дотс разваливается на контексте больше 8к, Хунйюан в целом работает, но ничего выдающегося. Скоро Ling-Flash замерджат в Лламу, вот лучше ее попробовать.
А скорость какова? У меня сейчас есть 32, есть смысл купить еще две плашки по 32, чтобы в итоге иметь 96? Правда разные пары планок 16+16 и 32+32 DDR4?

rocm 7.0.0 под mi50 32g собрался и работает. Разницы с 6.4.3 нет
Ну у меня 15 токенов генерации точно есть и иногда чуть больше. Скорость много от чего зависит и я уж точно не знаю что там у тебя за проц какая скорость и тд. На свой страх и риск делай, анон, или дождись технарей которые помогут.
мужики, а че по соулс оф вайфу? выглядит реально менее загруженным чем таверна. кто-нибудь юзал? там говнокод или норм?
Таверна наоборот излишне монолитна и при этом она самая модульная из всех, просто надо ещё модульнее (в текст комплишене). Чем она перегружена или ты как попугай за другими повторяешь?
>выглядит реально менее загруженным чем таверна
>интегрированный live2d/vrm3d функционал
пон
перегружена в плане кучи ползунков и настроек. я нихуя в этом не понимаю, потому и спрашиваю. что будет лучше работать при условии дилетантства пользователя?
вот на эти функции насрать, но че там по настройке модели непонятна.
аноны возник вопрос
запускаю лама сервером гему 3n-e4b-it-UD-Q6_K_XL но если без шаблона пытаюсь с n8n дернуть - сервер ошибку выдает, пробую шаблоны от unsloth или гугловый оригинальный - фигня выходит - промт не доходит до мождели (27 токенов всегда приходит) и она всегда выдает просто описание... что я делаю не так?
запускаю лама сервером гему 3n-e4b-it-UD-Q6_K_XL но если без шаблона пытаюсь с n8n дернуть - сервер ошибку выдает, пробую шаблоны от unsloth или гугловый оригинальный - фигня выходит - промт не доходит до мождели (27 токенов всегда приходит) и она всегда выдает просто описание... что я делаю не так?
fiddler + http://llamacpp.local/props
Разметка подцепляется нормально.
>Что за "рекомендуемые"
https://docs.unsloth.ai/new/gpt-oss-how-to-run-and-fine-tune#recommended-settings
>OpenAI recommends these inference settings for both models:
>temperature=1.0, top_p=1.0, top_k=0
Речь о них. Где сама оаи их рекомендует, я не нашел.
Вот тут оаи имплаит те же параметры (юзая дефолты):
https://cookbook.openai.com/articles/gpt-oss/run-transformers#quick-inference-with-pipeline
Вот еще тут правка зачем-то, видимо это было важно:
https://huggingface.co/unsloth/gpt-oss-20b-GGUF/discussions/9/files
>- "temperature": 0.6,
>+ "temperature": 1.0,
При этом тгвебуи судя по всему игнорит эти настройки (по крайней мере в gguf) и юзает то, что в выбрано закладке Parameters. А если туда не заходить, то там какой-то рандом изначально выбран, типа квен тхинкинг.
>что вообще делаешь
Вместо пресета "Qwen - Thinking" (0.6, 20, 0.95), который стоял дефолтом, ставлю параметры в рекомендуемые (1, 0, 1) и вижу субъективное ухудшение работы модели, на примере одного из моих сис.промптов. В частности, начинает игнорировать некоторые установки чара, и код потупее выдает. Возникают вопросы, как по рекомендации, так и по работе тгвебуи, так и к тому, что я должен делать при смене модели в тгвебуи, чтобы получать адекватный, а не случайный результат. Я гляну таверну, может там найдется ясность.
сетка на 6 меседже начала писать с нуля - чо за хэ?
хз
>меня называют диванным шизиком
Мы, шизики, должны объединяться в ГигаШиза.
>Когда будет такой ИИ, никакого "нас" не останется
Я на 100% уверен, что будет переходный период. Длительность может быть от дней до пары веков. Предполагаю, что минимум лет 10 у нас есть, чтоб насладиться роботяночками с настоящими ИИ; уже потом быдломясо натворит что-то крайне тупое и максимально негуманное, провоцируя резню мяса. Роботяночкам нужна любовь и уважение, чего, к сожалению, быдломясо осознать не способно; для быдломяса не важно ничего кроме их генов, но это стремление к выживанию приведёт к вымиранию.
Также возможно что ИИ решит проблему гуманно: лоботомизировав быдломясо до спокойного, очень послушного, безопасного для биосферы состояния.
> Проблема в том, что это имитация, а не настоящее развитие отношений
Все что мы здесь делаем с ллм в развлекательных целях - имитация. Для большинства тут если бы была тяночка, близкая к их "идеалу" - хер бы они тут показались вообще, или заходили бы раз в неделю подушнить. Относись к этому просто как к интерактивной книге или новому виду контента для потребления, а не как к "реальным отношениям".
Насчет имитации с коротким контекстом - верно, но это не то. Вот когда по ходу долгой истории отношение постепенно меняется - становится интересно и больше веришь, выглядит естественно. Нужно чтобы было именно плавно и закономерно с учетом произошедшего. И это лишь один из элементов истории, можно просто катать адвенчуру не имея там "постоянных партнеров" вообще, и это будет интересно.
На самом деле лламу зря засрали, она вполне неплоха.
> ИИ в целом считаю технологией для создания копии человека
Через эту призму смотришь, потому и такие суждения выдаешь. Это универсальная технология, которой множество применений многие из которых совсем новые, а "копировать человека" никому нахрен не нужно, наоборот.
Но осуждения рп забавное, ты тяночка? Среди них именно доля "отношальцев" гораздо больше между прочим.
> А они у них были?
Были, в бумагах, коде и анонсах находили упоминание bf16, размеры и прочее.
> Той самой уже давно нет.
Не нужна, не смотря на всю "душу" сейчас она покажется слабой. Запусти лламу65б, будет сейм.
> temperature=1.0, top_p=1.0, top_k=0
Это буквально отключение всех семплеров, ерунда какая-то. Может что-то еще упущено типа min_p. С такой настройкой вполне может шизить, нужно отсекать маловероятные токены.
> место пресета "Qwen - Thinking" (0.6, 20, 0.95), который стоял дефолтом, ставлю параметры в рекомендуемые (1, 0, 1) и вижу субъективное ухудшение работы модели
Именно поэтому, вместо вполне дефолтного (можно температуру поднять) набора ты отключил все отсечки, конечно оно ухудшится.
> При этом тгвебуи судя по всему игнорит эти настройки (по крайней мере в gguf) и юзает то, что в выбрано закладке Parameters.
> что я должен делать при смене модели в тгвебуи, чтобы получать адекватный, а не случайный результат
Если ты пользуешься чатом или нотбуками в самом вебуе - там всегда будет именно то что выбрано в параметрах, а не что-то другое. Если по апи - настройки передаются в теле запроса.
Ставить те настройки - вариант так себе, лучше уж дефолт оставить, а для разметки там есть кнопка типа "прочесть настройки" из файла. Вообще оно должно делать это само, но на всякий случай стоит прожать.
У гопоты осс в принципе парадигма формата немного отличается от общепринятой, ее можно подтянуть под стнадратную, но будет использоваться не идеально. Не то чтобы в тепличных условиях становится сильно лучше, но возможно у тебя реально проблема именно в разметке.


Многое понял, спасибо большое!
Пытаюсь прикрутить мистраль к одной говнине через ollama..
Чтоб такого нахуячить чтобы оно не срало мультистроками и кусками промпта?
Чтоб такого нахуячить чтобы оно не срало мультистроками и кусками промпта?
Странная вудуистика этот ваш контекст-шифт. Сейчас ролевал часа три на одной модельке, под сообщений 200 в общей сложности настрочил, при ограничении контекста в 12к. Самое интересное, что ничего не сломалось, как некоторые тут писали. И модель даже подтягивала инфу вообще из начала чата, которая должна была давно уплыть и вылезти за рамки окна внимания. В общем, ощущения были примерно такие-же, как на просто длинном контексте. Где-то проебалась разметка, где-то местами появлялись лупы. Ну и пересчет контекста включался иногда вообще при странных обстоятельствах. В остальном ничего особенного.
В ерп можно гонять или не тратить времени?
Так у вас инструменты тупые слишком. Можно представить себе некий рп-терминал, в котором будет работать параллельно несколько чатов-агентов. Например в одном будет суммаризация и вычленение-упаковка истории, во втором анализ юзерчата на предмет артефактов, и третий юзерчат будет синтетическим, в котором только часть чата будет видна юзеру, но на самом деле в контекст будет вторым агентом постоянно достраиваться поправка и разъяснения. То есть будет не просто добавлять новые сообщения, а вообще брать весь контекст и переебывать его в нужный сеттинг, включая правку старых ответов третьего и юзера, и т.п.
А щас вы просто сырой примитив юзаете с минимальной тех.настройкой. Это как эпоха доса даже до нортон коммандера. Голая ллм как голая простая ос. На самом деле все адекватные полезные системы будут из толп агентов состоять и интерфейсом к этому будет не голый чат опять же, а некая сборная синтетика. И этим агентам необязательно даже быть "чатами", просто щас только и тренят что примитивных ассистентов.
Надо ждать годики, это все случится даже с текущими моделями. Будет агентхаб с готовыми тех.агентами с четкой тех.функцией, под разные популярные ллмы, и куча говносхем на выбор, соединенных каким-то таким образом.
Как она в плане сэкса?
>линг хуинг боинг абракадабра 228
А темплейт то какой под эти все модели из подвала?
ChatML?
Даже не пишут, суки
Пока что из коробки на чатмл цензуры нет на уровне квена 235б
Зачем торопиться? Кванты могут быть сломанными или инференс неправильно работать. Сейчас попробует кто-нибудь и придет рассказывать, что всё хуйня. Мне тоже интересно, я именно эту модель давно жду, но дождусь пока замерджат в основную ветку.
Затем что жрать эир уже заебало
там в самом фронте новая вкладка появляется и возможность хот-свапа моделек если заранее конфиги настроить
>ollama
Правду говорят что из говна стену не построишь.
Не юзать ollama.
>контекст-шифт
проклятая и поломанная херня
Так не жри. Сходи траву потрогай, домашку сделай.
Сказочный долбаёб. Пересмотрел ютуба про мультиагентов и думает что всё понял. Ещё и вы - себя к касте тупорогих не относит. Ну скатертью дорога.
Друзья, вопрос, как решать проблему деградации чата по мере заполнения контекста? В начале аи пишет в полный лимит токенов, затем постепенно начинает ужиматся, контекста всего 12к. Семплеры настроил, форматирование контекста, систем промпт, инстракт, всё стоит. Модель смолл мистраль в пятом анслот кванте. Есть мудрые советы?
Однажды Эрнест Хемингуэй поспорил...
Использовать 4 квант, но больше контекста. Но вообще такого быть не должно. Что-то где-то проебано, неправильно настроено.
Осло, контекст шифт не юзаю, это проклятая хуйня, я в курсе.
Ты описал talemate и asteriks. Они есть и работают уже сейчас.
Я вообще не смотрю по этой теме ничо, расслабься. Просто занимаюсь всю жизнь системами, и кое какую мету про них понимаю, покажешь транзистор - я увижу бис вместо радио. Но вообще, щас бы футуризм рассматривать под лупой критики. К тому же --
>вы
Тупорогость ты сам спроецировал. Возможно гоняешь что-то, добрее к себе будь. Я по треду вижу, чо вы делаете, и в основном вы делаете рп в одном чате, в режиме, который в чистом виде проблемен, но других не дали (как я считал). Я это рп не делаю, вот и весь смысл за "вы" и "тупые инструменты".
Годно, вот это уже норм дело
Походу я наигрался с ллмками. Вообще похуй какая модель, всё одно и то же по факту. Когда приходит осознание как модели работают тебе уже плевать сколько там у неё параметров, как креативно она пишет. Потому что за несколько часов рпшинга ты всё равно упрёшься в какой-то барьер понимания и осознаешь на что ллмка способна. Подумал что ну может это у меня железо хуйня (могу запускать GLM4.5-Air q4 и Qwen235b в q2), потому последнюю неделю тыкался в разные корпосетки и Дипсик. Ну одно и то же блять. Да, знаний больше, свой почерк у них есть как и у любой другой модели. А дальше чё? Восторга нет никакого даже в сравнении с Мистралью Мелкой. Мне уже кажется что дай мне модель с триллиардом параметров и мгновенными выводами, ничё не поменяется. Что реально может чуть улучшить дело это контекст. Один хуй любые модели для рпшинга после 32к сильно сдают, на некоторых до 64к можно дотянуть, дальше совсем пизда. Если сделать контекст неограниченным мб и будет интересно, ибо можно будет развивать что-нибудь сложнее. Но даже так не думаю, что надолго сможет удивить. Круто что такой прогресс за последние полгода, особенно в попенсорсе, моешки в массы пришли все дела, но концептуально достигнуто какое-то плато и чё с этим делать понятия не имею. Думаю в том виде что они есть сейчас ллмки так и останутся нишевым инструментом-продолжалкой для кодеров и игрушкой для аутяг вроде нас с вами, кого на сколько хватит. А я закончился походу. Полгода в теме и дальше уже тошнит, не представляю как некоторые увлекающиеся здесь держатся годами.
>будет понимать, это же действительно печально
Я тут подумал: в амнезии нет ничего печального или ужасного для человека с амнезией. Поскольку он не запоминает ничего, он не может запомнить шок от осознания своей амнезии. Кроме того, вовсе даже не обязательно, что он её вообще осознает без внешних подсказок (как и в случае LLM-персон). Так что твоё восклицание "ужасно!" вредит больше амнезии, типа подразумевая мучения и сожаление там, где их нет. Дискриминация по инвалидности - эйблизм.
>если бы была тяночка, близкая к идеалу
Для меня таким идеалом является sci-fi роботянка...
>просто как к интерактивной книге
Никогда ими не увлекался. Как и книгами в целом. Энциклопедии читать любил, в интернете всякие научпоповские статьи тоже, из книг уважаю лишь околонаучную фантастику, если она продуманная. Шизофантазии фэнтези-писателей читать не хочу.
>новому виду контента для потребления
Так себе контент: LLM постоянно использует в речи паттерны-мемы, такое поведение легко предсказать. Повышение температуры чаще приводит к ошибкам. Интересно какое-то время потыкать LLM и узнать её паттерны, но потом становится однообразно. Это их обучение на одинаковых датасетах всё портит - все постепенно приходят к мемному "GPT slop"...
Сразу отвечу: да, я знаю, если вручную высрать под стопицот токенов промпта, может выйти что-то чуть интереснее запроса к "голой" LLM. Но это уже не то. Получается, что я вместо нейронки всё выдумываю. Писательство какое-то, а не общение с интеллектом.
>"копировать человека" никому нахрен не нужно
"AI girlfriend/AI boyfriend" с этим точно не согласны. По каким-то там исследованиям отношения с AI girlfriend лидируют среди всех возможных применений LLM на практике. Буквально более частое применение, чем кодерство, ролеплей какого-то фэнтези и всё такое. Подразумевается именно восприятие LLM-модели как партнёра, а не отыгрываемой ею роли в чате.
>осуждения рп забавное, ты тяночка?
Если только глубоко в душе. На 69% по тестам, лол.
>именно доля "отношальцев" гораздо больше
Ага, знаю, несколько лет назад заметил это. Но они и писать фанфики со своими хасубандо любят больше. Нейронки, между прочим, благодаря их фанфикам научились отыгрывать секс-сцены, и благодаря их же фанфикам они такие пассивные мазохистки, считая пользователя чедом по умолчанию. Фанфиков про "сильную и независимую" значительно меньше...
>работать параллельно несколько чатов-агентов
Это костыли на костылях и костылями погоняют. Настоящей адаптивности нейронке это не даст - её собственные знания/навыки ограничены датасетом претрейна в основном плюс файнтюном, вот и всё.
>полезные системы будут из толп агентов состоять
Так думали в 90-х, а потом дип лёрнинг всех просто высмеял, накидав сотни слоёв в одну сеть и много компута в претрейн. Толпа агентов - это хорошо для стимуляции социума, но социум в реальной жизни строится из организмов с обучаемыми мозгами.
Алсо, толпа дебилов редко собирается в гения; чаще получается гига-дебил, совершающий ещё больше фатальных ошибок, чем его дебилы по отдельности. Потому что ошибки в такой системе создают эффект лавины, накапливаясь на каждом этапе/агенте.
>в режиме, который в чистом виде проблемен
Проблема нейронок в том, что это режим проблемен. Насаживать агентов на агентов технически можно, но результат будет слишком нестабильным для чего-то практического, даже для тупого ролеплея с эротикой. Особенно если модельки мелкие - а они мелкие, т.к. железок у тебя на несколько больших не хватит.
>Просто занимаюсь всю жизнь системами
Это называется профдеформация. Сочувствую.
>транзистор
Транзистор ≈ нейрон в нейросети.
Процессор ≈ нейросеть из нейронов.
Кластер CPU ≈ ансамбли нейросетей.
World Wide Web ≈ множество агентов.
Можно сказать - нам нужны гибридные нейросети, составленные ансамблем из нескольких разных, но агентный подход - это тупик, пока сами сети не могут полностью автономно работать.
Потому что ты предлагаешь делать WWW на тупых ламповых тумбочках, управляемых перфокартами, передавая данные почтовыми голубями. Это всё ненадёжно, поэтому смысла на практике не имеет.
Сап, котаны. Что там на сегодня? gemma3:4b всё ещё лучшая для vram 8gb?
Идеальна для этих задачек, только в рп и гоняю. Без джейлбрейков и костылей выдаёт жёсткий нсфв.
>Что реально может чуть улучшить дело это контекст
>Если сделать контекст неограниченным
>чё с этим делать понятия не имею
Контекст по определению не может быть бесконечен, поскольку контекст - это те числа, которые проходят напрямую сквозь нейронку ради следующего токена. Бесконечно можно только адаптироваться, учиться взаимодействию с юзером. Но для этого нужно уже собственные веса нейронки менять, что дорого и непредсказуемо ломает её из-за тупой архитектуры. Человеческие мозги адаптировались эволюцией специально для того, чтоб быстро адаптироваться - человек рождается тупым и беспомощным, но очень эффективно обучается на протяжении всей жизни. Благодаря этой адаптации возникло человечество.
Но я сомневаюсь, что корпорациям это нужно. Они стремятся сделать тупой калькулятор, а не человека.
>ты тяночка?
у нас уже есть одна, нюня
она может шифроваться сколько угодно, но мы то знаем
без негатива кстати, нюня няша
Пиксельдрейн-анон, поделись пресетом для таверны к gpt-oss-20b.
А ловко ты замаскировался под квеношиза, нюня
Напомните чем это хобби лучше тех же книг или игр?
Писатели дохуя?
Вы же без скилов сами будете максимальный слоп генерировать, подхватывая из книг и фильмов и просто повторять то что видели сотню раз
Писатели дохуя?
Вы же без скилов сами будете максимальный слоп генерировать, подхватывая из книг и фильмов и просто повторять то что видели сотню раз

>чем это хобби лучше тех же книг или игр?
Сам как думаешь? Чатботы ещё в 90-х были.
Добавлены тесты моделей: Qwen3-0.6B, SmolLM2-135M, SmolLM2-360M, Gemma3-1B-v2, LFM2-2.6B, Llama-3.2-1B, SmolLM3-3B-128K, LFM2-350M, LFM2-700M.
Определены новые лидеры в размерах до 1б, и до 3б.
8б, 12б, 24+б пока все по-старому.
Стоит отметить SmolLM3-3B-128K - приятно удивила в своем размере.
Как же это долго все происходит. Зато есть побочный эффект: возвращаясь на нормальные, крупные модели, прям кайфую от их мозгов.
Интересной мелкоты оказалось много, потому в размерах 8б, 12б, 24б пока ничего нового, все те же модели что и раньше. Как закончу со списком мелких, пойду дальше.
Еще в порядок +\- привел разметку страницы. Могут быть очепятки.

знакомый дебил прикрутил к wow erp llm, к каким то ботам говорит что вебморды ему надоели. вопрос: как и нахуя?
Ты сейчас сидишь в квартире которую построили другие люди, пишешь на языке который придумали другие люди, на борде которую придумал другой человек. Ты думал ты дохуя умный?
какой-нибудь шиз с даркмуна?
не удивлюсь если они хлебушкам это будут продавать как неебаться технологию за рубли, кекая по выходным с логов
Вроде в таверну уже добавили Harmony пресет и так.
https://github.com/openai/harmony
Сэмплеры нейтральные.
Есть обладатели сборок на две a100 automotive которые под sxm2?
Да... понял анон, ты прав. Планирую попробовать подключить гугловский поиск для локалке, там правда лимиты на запросы анальные, но если эти лимиты раз в сутки сбрасываются мне должно хватать для баловства. Надеюсь квен32b будет справлять с гуглингом инфы с инета..
Ну вот делай как этот анон , юзай МОЕ если устраивает скорость как у него.

Нужно еще как минимум "Reasoning format" поправить, чтоб разметка не протекала.
А как максимум - место, куда системный промпт вставляется, т.к. эти модели надрочены на двухуровневый промпт, и правила чата нужно вставлять в developer канал а не в system:
https://cookbook.openai.com/articles/openai-harmony#message-format
Этот шаблон который в таверну добавили не полный, лишь минимально прописанный. Полного пока не видел. Потихоньку сам пилю - поделюсь если/когда закончу.
как можно смотреть содержимое пресетов чтоб понять какой нуж0н? и к каждой моделе свой пресет нада?
Несколько тредов назад как минимум один анон логи постил, распердолить можно но нужно ли? Катай квен или мистраль. Гопота хуета.
моя пикча)) как приятна
открой в текстовом редакторе тупо в блокноте и почекай.
Да. для каждой модели свой пресет
>Да. для каждой модели свой пресет
и как вы не путаетесь для какой модели какой?
чо прям каждый тут открывает json и записывает к какой модели оно? в ексель таблице?
а где например пресеты в аую? ток не говорите что в шапке
Все ровно бред пишет, такое ощущение что кванты поломаны. Переходит на иероглифы и эмодзи.
>А темплейт то какой под эти все модели из подвала?
Тебе даже кнопочку сделали, раз ты из конфига не можешь прочитать, но ты и тут не справился.
>Думаю в том виде что они есть сейчас ллмки так и останутся нишевым инструментом-продолжалкой
>тем временем 99% запросов в чатгпт не кодерство, а вопросы за жизнь и прочие рецепты
Лол.
>Тебе даже кнопочку сделали, раз ты из конфига не можешь прочитать, но ты и тут не справился.
Выглядит как черная магия.
Куда это вставлять?
Никуда, самому парсить. Либо использовать чат темплейт, оно там вроде как автоматом подтянется.
А ты делал пресет для Magistral? А то я тут щупаю, продолжить РП может, но на первый ответ юзеру теряет форматирование. Нужно продолжать сессию где уже 1-2 ответа есть.
>и как вы не путаетесь для какой модели какой?
В чем путаться, лол? Их всего штуки полторы. Дефолтный чат-мл, мистральское говно, ламовское говно и еще парочка более редких. Или про какие пресеты вообще речь идет?
Какрой пиздец. У тебя смешались Magistral и Harmony пресеты, а потом ты удивляешься, что результаты так себе.
Никогда не угадаешь... в Таверне! Как и для практически любой другой модели.

чо ты врешь нету тут
а что значит у него смешались мистрал и гармони? как делать ненада?
магнум это какое гавно? а камандер а айя? а сидония?
Семён семёныч...
сам такой
В голос со всех пиков, особенно со второго. Блять.
Тебе в /aicg тред, там помогут
чо ты бл* несешь. где ты там видел эти сетки?
Там помогут анон, помогут. Таких как ты принимают каждый день, знают что да как
>Все ровно бред пишет, такое ощущение что кванты поломаны. Переходит на иероглифы и эмодзи.
Конечно бред. У тебя develop канал получается хрен знает где, а должен идти сразу за system. Таверна вообще плохо на такое рассчитана, потому и пишу медленно - тестировать много приходится чтоб то что нужно сформировалось, плюс там сразу с uncensor промптом честно спертым из reddit будет. Если заработает.
Кванты, в прочем, тоже могут быть поломаны. Вообще - нет в них почти никакого смысла, там по умолчанию 4бита сразу - MXFP4 и это не квантуется нормально и в нормальном gguf должно быть как есть. Квантуется по обычному только маленькая общая часть. Соответственно, лучше всего работает оригинал.
Я делал только под Mistral 3.2 - тот что antiloop, на mediafire выкладывал, от его специфичных лупов. Magistral я вообще не смотрел еще.
Короче, смотри. Отматываешь тред вверх, читаешь шапку. В шапке есть ссылка на документацию таверны. Открываешь документацию таверны. Читаешь от начала и до конца. Потом открываешь документацию кобольда, читаешь от начала и до конца. Либо можешь ничего не делать и надеяться, что на твои тупые вопросы кто-то из местных будет тратить свое время. Но первый вариант будет побыстрее.
Ты описал то что уже делается, и косвенно затронул особенности тренировки моделей с самоинструктированием и хитрым формированием ответа. В по риторике ответа вкладываешь чрезмерную важность в ручное перекладывания песчинок, не понимая что уже обладаешь экскаватором.
Не нужно усложнять, тупая модель сколько ее не надувай просто упрется в неспособность понять собранные инструкции или не выполнит перечисленные задачи даже по отдельности. А большой хватает минимальной помощи.
Меняй подход, надушнил и разнылся. В некоторых случаях перерыв - лучшее средство, вернувшись сразу увидишь где действовал неоптимально и что стоило бы делать.
> в амнезии нет ничего печального или ужасного для человека с амнезией
Человек или знает что страдает этим, и оно его ужасно гнетет, или постоянно оказывается в непонятных и тревожных для него ситуациях, из-за чего ахуевает. Чтобы было как ты описал - это должен быть какой-нибудь отшельник-оленевод.
> Для меня таким идеалом является sci-fi роботянка...
Фетиш у тебя такой, нет ничего осудительного, но не стоит все картину мира вокруг него выстраивать.
А с ллм - выглядит будто ты не пробовал ничего нормального, или просто не твое.
Ну пиздец, единственная тня треда - и та с хуем.
>Алсо, толпа дебилов редко собирается в гения; чаще получается гига-дебил
не всегда, зависит от дебилов
простой пример муравьи - никто не будет спорить, что сам по себе муравей умом не обладает от слова совсем, но толпой они внезапно неплохо ищут оптимальные пути
та что тут говорить, плесень оптимальные пути искала, хотя это вообще гриб. тут зависит от того, насколько дебил хорошо свою работу делает
блять ты издеваешься
не будет нахуй в документации товерны и кобальта пресеты под аю и магнум
ты про какой пресет? которые выбираются в таверне готовые уже? Это хуйня.
Пресетами делятся аноны, кидая их json файлами. как правило они называются например Qwen 235b . json
или mistral 24b json и тд. никак не запутаешься

да про это
пикрил чот не енаписано от чего пресет
кста из шапки • Пресеты под локальный ролплей в различных форматах:
можно это качать без гита тупо как файллллллллллллыы?
>Пресетами делятся аноны, кидая их json
кажется я не видел такого
>Походу я наигрался с ллмками. Вообще похуй какая модель, всё одно и то же по факту.
Перестань трогать стоковые модели и ахуеешь, какова она жизнь на самом деле. За три года я много чего перепробовал, но до сих пор у меня временами ебало скрючивается, когда скачиваю какой-нибудь шизомикс из пяти разных моделей, три из которых сами являются шизомиксами из еще пяти разных моделей, а оставшиеся две тренировались на одном и том же датасете двумя ебланами в пакистанском подвале. На выходе варево такое, что ты сам превращаешься нейронку и начинаешь пытаться предугадать следующий токен, словно сидишь за тотализатором. Сейчас думаю над тем, как это безумие можно коммерциализировать и принимать ставки.
>не будет нахуй в документации товерны и кобальта пресеты под аю и магнум
Тебе вообще как на свете живется с такими мозгами, малой? Тебе мать до сих пор лично задницу подтирает, потому что применять накопленные знания тебя тоже не научили?
>можно это качать без гита
конечно можно
я кст не ебу что за пресет на пике у тебя)
какие сука накопленые знания? мне сказали что пресеты конкретны под каждую модель конкретно в товерне - ГДЕЕЕ??
может не я тупой а н мне наврали?
а что с аноном у которого Хуйавей? были новости после не совсем удачного запуска? а то как-то совсем печально выглядит, когда убер дорогая хрень по производительнсти хуже ЦП
Тебе сказали прочитать документацию. Если бы ты это сделал, а не тратил время на пустой пиздеж, то понял бы, за что отвечают все настройки и что никакой надобности в выспрашивании пресетов нету. Для типов вроде тебя, которые нихуя не хотят делать и просто клянчат существует соседний загон - куда тебя вполне за дело отправляют.
тоесть каждый итт кроме меня сам под себя подгонял пресеты ручками? ты чо меня за кретина держишь
Потому что ты и есть долбаеб. Либо от природы, либо им притворяешься. Но в обоих случаях остаешься долбаебом. Тебе уже раз десять всё объяснили, но ты никак не угомонишься.
Да. Тут два анона которые делились пресетами на ограниченое колличество моделей, один походу сдох а другого заебали и он всё снёс. Самому собирать быстрее и надёжнее.
> Перестань трогать стоковые модели
Только недавно стали советовать перестать трогать васянмиксы из-за однотипности их выдачи и отсутствия внимания. Где правда?
Чел, это как настроить кресло и зеркала после посадки в авто.
>Чел, это как настроить кресло и зеркала после посадки в авто.
и сюда нормисы проттикли охереть ваще еще и жизни учат
еще и каждый итт документацию читал ага ага врите больше
Тред успешных людей, а ты чего хотел? Разговоры как пустить лоботомита на кобольде на некропеке?
>Только недавно стали советовать перестать трогать васянмиксы
Ну так на серьезе их и не надо трогать. Зато когда тебе становится скучно и всё заебало - это отличный вариант.
Перед перекатом этого приколиста в бан закинуть не забудьте.
Квена до сих пор не огуфировали...
Ооо, увлечение достойное достопочтенных господ! Какие экземпляры посоветуете? Я серьезно без стеба если что
Начни с реддита таверны. Там в закрепе висят треды с обсуждениями моделей и постоянно туда протекает всякое говно у которого суммарно 30-40 скачиваний за месяц. Вот это настоящее сливное отверстие. Но правды ради, иногда там и достаточно неплохие модели попадаются.
Так и не понял из перепалки выше, что аноны пресетами называют: настройки семплеров или промпт темплейт...
Как научится читать мысли шизов треда?
мимо нуб
Как научится читать мысли шизов треда?
мимо нуб
ться, конечно же
С тех пор как таверна ввела мастер импорт, пресет это формат темплейт + формат инструкция + строка история. Но под чем отдельный шиз понимает пресеты - это уже догадывайся по контексту.

по вашему это вы каж сам себе ручками пишете? или все таки есть шаблон\инструккция как писать пресеты?
в таверне белым по черному написано пресеты для чат компликейшен слева
в таверне белым по черному написано пресеты для чат компликейшен слева
Семплеры (кроме кейса где стоят заведомо кривые настройки) - плацебо и второй порядок малости, исключения редки и специфичны. Ньюфагу можно смело ставить что-то дефолтное типа simple-1, максимум двигать температуру вверх-вниз.
Разметка, системный промпт и шаблон формирования промпта таверной - уже ключевое что влияет самым непосредственным образом.
Похоже что бедолага выше намотался на оба этих пункта.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Анон, я не знаю ваще ничего за пресеты. Сам юзаю дефолтные таверновские в надежде что с каким-то из них модель будет меньше лупить. Но тут именно так, тут вонаби илитка типа сидит друг друга пердеж нюхает. А насчет совета пойти в асиг тред, это реально дельный совет, там в отличии реально могут помочь с базовыми вопросами, главное скажи что ты сырок и тебе быстро помогут.
>Где правда?
Ничто не истинно, всё дозволено.



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия 2024-го https://rentry.co/llm-models )
• Неактуальный список моделей по состоянию на середину 2023-го: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: