



>Семплеры (кроме кейса где стоят заведомо кривые настройки) - плацебо
Сейчас бы Dry или rep pen без которых ни одна модель в рп нормально не будет работать называть плацебо
Rep pen уже входит в базовый комплект. Dry часто наделяют мифическими свойствами, но при этом, по опыту, он часто портит выдачу модели не спасая от слопа и логических лупов.
Первичны сама модель и промпты (включая разметку, системный, инструкции, то как юзер строит свои ответы, подсказки и т.д.), от них и будет зависеть. На современных моделях лупы вообще оче сложно встретить.
Сетап не многим дешевле 5090 на двух а100 (на нищие v100 не смотрим)

Аноны, к 2026 будет релизиться DDR6 RAM, к 2027 она должна стать массовой. Как думаете, насколько оператива станет золотым стандартом для запуска больших МОЕ моделей? Там в теории выше частоты, значит выше скорость генерации токенов. Да понятное дело что это будет всё еще медленней врам, но тем не менее, что думаете по этому поводу?
Плотных моделей релизится всё меньше. Если ты не готов тратить огромные суммы, набираешь 24-48врама, остальное рам. За этим будущее для энтузиастов и для маленьких компаний. Сижу на 3090 и ддр4, где-нибудь в 2027-2028 соберу себе новое железо.
Так же быстро станет стандартом сборок как и ддр5...
А чё, в треде не осталось тех кто гоняют дэнс модельки? Все на мое переехали? Куда подевались все аноны которые сидели на сноудропах-командерах-мистралях-квк_квенах32? У вас у всех дохуя рама чтоль?
Тут ты верно подметил анон, думаю что максимум на что стоит расчитывать до 2027 это доступность ддр5 т.к корпоблядки начнут пересаживаться на ддр6!
Катаю гемму27, мне норм
Хочу поделиться своим взглядом на LLM (локальных) через призму корпоративных моделей.
Не спешите закидывать говном. Я уверен, это подкинет вам пищу для размышлений, и если будет интересно хотя бы одному анону — подкину чуток больше деталей. Хочется обсудить это.
Корпов использую для реальной работы. В основном касается медицины и всякой научной смежной с ней хуйни.
1. Контекст — это самый страшный бич всех LLM. 120-200K — это условный предел, с которым они могут работать более-менее нормально. Даже на корпах. И дело не только в его длине.
В реальности у нище-моделей МАКСИМУМ 32К, дальше тотальная деградация. У настоящих жирных и крутых пидоров где-то 60К, в лучшем случае 120. Потом деградация. Но кое-как и на терпимом уровне могут тянуть даже в вебе — и то не всегда. Потому что там параметры динамические. А 1 млн контекста наёбка для уёбка. Она работает, но прям совсем уж криво.
Небольшая история:
В качестве теста изучалось штук 15-20 антибиотиков и их проникновение в различные ткани организма. Документация включала в себе все необходимые данные по лекарствам и несколько сотен бактерий.
Для задачи использовался GPT-pro-high-bost-mega-ultra-overkill-2 за 200 долларов со всеми прибамбасами.
Был не то что бы полный провал, но пришлось сильно дробить запросы, документацию и прочее. А потом вилкой чистить. Как итог, это быстрее, чем ручками дрочить, но только в руках того, кто понимает. Выигрыш по скорости работы примерно 20-30%
2. Датасеты и внимание к контексту всраты серьёзней, чем вы думаете. У закрытых корпов пиндосских.
Тонна гига-слопа, которого раньше не было. Охуительные лупы. Модель может прям как мистраль зациклиться и высирать одну и ту же хуйню, даже если она уже разобрана. За паттерны цепляется очень сильно. Да, луп можно прекратить, чтобы модель перестала писать эту хуйню, просто сообщив ей об этом, но
---
А знаете, что самое смешное? Локалки уже добрались до уровня, которые в целом способны выполнять эти задачи при наличии адекватной настройки (в которую лично я не могу на таком уровне и пробовал только у знакомых крутых задротов по апи), хоть и требуют хотя бы Q8. Если контекст реально держит 120-200к, имеет достаточно heads, семплеры правильные, включен ризонинг, то результаты хуже, конечно, но не фатально. И для этого хватит
И мне вот прям обидно, что нет таких локальных готовых решений, которые относительно просто развернуть. Чтобы настроил и РОБОТОЛО после среднего уровня пердолинга. Хоть пропиетарщина, хоть что. Чтобы была система папок, проектов, общей памяти в них, вот этого всего. UI/UX и запердоленный хорошо бэк + рисерч.
Текст может быть немного хаотичным, так как я зопиклона нажрался и пора спать.
Не спешите закидывать говном. Я уверен, это подкинет вам пищу для размышлений, и если будет интересно хотя бы одному анону — подкину чуток больше деталей. Хочется обсудить это.
Корпов использую для реальной работы. В основном касается медицины и всякой научной смежной с ней хуйни.
1. Контекст — это самый страшный бич всех LLM. 120-200K — это условный предел, с которым они могут работать более-менее нормально. Даже на корпах. И дело не только в его длине.
В реальности у нище-моделей МАКСИМУМ 32К, дальше тотальная деградация. У настоящих жирных и крутых пидоров где-то 60К, в лучшем случае 120. Потом деградация. Но кое-как и на терпимом уровне могут тянуть даже в вебе — и то не всегда. Потому что там параметры динамические. А 1 млн контекста наёбка для уёбка. Она работает, но прям совсем уж криво.
Небольшая история:
В качестве теста изучалось штук 15-20 антибиотиков и их проникновение в различные ткани организма. Документация включала в себе все необходимые данные по лекарствам и несколько сотен бактерий.
Для задачи использовался GPT-pro-high-bost-mega-ultra-overkill-2 за 200 долларов со всеми прибамбасами.
Был не то что бы полный провал, но пришлось сильно дробить запросы, документацию и прочее. А потом вилкой чистить. Как итог, это быстрее, чем ручками дрочить, но только в руках того, кто понимает. Выигрыш по скорости работы примерно 20-30%
2. Датасеты и внимание к контексту всраты серьёзней, чем вы думаете. У закрытых корпов пиндосских.
Тонна гига-слопа, которого раньше не было. Охуительные лупы. Модель может прям как мистраль зациклиться и высирать одну и ту же хуйню, даже если она уже разобрана. За паттерны цепляется очень сильно. Да, луп можно прекратить, чтобы модель перестала писать эту хуйню, просто сообщив ей об этом, но
---
А знаете, что самое смешное? Локалки уже добрались до уровня, которые в целом способны выполнять эти задачи при наличии адекватной настройки (в которую лично я не могу на таком уровне и пробовал только у знакомых крутых задротов по апи), хоть и требуют хотя бы Q8. Если контекст реально держит 120-200к, имеет достаточно heads, семплеры правильные, включен ризонинг, то результаты хуже, конечно, но не фатально. И для этого хватит
И мне вот прям обидно, что нет таких локальных готовых решений, которые относительно просто развернуть. Чтобы настроил и РОБОТОЛО после среднего уровня пердолинга. Хоть пропиетарщина, хоть что. Чтобы была система папок, проектов, общей памяти в них, вот этого всего. UI/UX и запердоленный хорошо бэк + рисерч.
Текст может быть немного хаотичным, так как я зопиклона нажрался и пора спать.
Кто-нибудь может что-либо сказать про квен3 омни 30в а3б?
Лол, оказывается, 3090 можно не только в минус паверлимитить, но и в плюс. По дефолту 350 ватт, но можно бахнуть 366. Зачем такое сделали, интересно
А100 на 32гига, що? Так еще и sxm2 вместо sxm4. Или перешитые с отключенной частью памяти что отвалилась и разъем - опечатка, или v100 так втюхивают.
Ддр5 "релизнулась" в 20м году если что, массовой только сейчас становится, и то с натяжкой.
Насчет твоих размышлений о контексте будет полезно уточнить. Количество "реального" будет очень сильно зависеть от задачи и от его наполнения. Например, если нужно делать какие-то серьезные выводы относительно научной статьи, особенно с минимумом ризонинга - там и 10к могут все порушить на любой. В то же время, если у тебя овер 130к контекста истории, кода других кусков, свода правил и прочего, при конкретном задании с доступным ризонингом модель пройдется по всем нужным частям, корректно их осознав, отработав, и отлично справится.
То есть, модели отлично справляются если контекст структурирован и его использование предполагает обращение к ограниченному числу отдельных его частей в один момент времени, причем по мере написания поста может пробежать хоть по всему несколько раз. А если там что-то сложное с постепенным введением чего-то, опирающемся на предыдущее - тяжело, поскольку это требует одновременного учета вообще всего контекста. Иногда может справляться ризонингом разбивая задачу.
Собственно у человека также, просто он может внутри себе переработать цепочку и более простой итог и приучиться ориентироваться где-то.
> Локалки уже добрались до уровня
Современные старшие локалки - те же корпы, только без оптимизированных под них разработчиком интерфейсов. Все так.

> sxm2 вместо sxm4
Написано же что это не то что в цоды ставили а automotive. Там и хбм кристаллов только половина потому 32 (как бы 40, но не 40).
Из приколов которые в инете написаны у них нет вообще никакого павер лимита, снизить жор можно только скрутив частоты
А, сорян, не написано. Моя ошибка.
Гуглить можно по pg199
>Аноны, к 2026 будет релизиться DDR6 RAM, к 2027 она должна стать массовой.
Если даже она релизнется в следующем году, то сначала придется ждать поддержки от красных и синих минимум одно поколение, а потом еще ждать около года, пока не нормализуются цены на сами плашки и материнки под это говно. Так что массовой она станет году к 30 в лучшем случае.
>Как думаете, насколько оператива станет золотым стандартом для запуска больших МОЕ моделей?
Вот когда появятся нормальные моешки, тогда и будем смотреть. Если они вообще не вымрут за это время.
Ахуеть, аж захотелось это чудо в коллекцию. Жаль стало известно о них только сейчас, ахуеть годнота.
> когда появятся нормальные моешки
Уже.
Бля я вам так скажу, ни одна ЛЛМ не сравится с рп с кожаными мешками, лол
Дохуя тянок таким занимаются даже в 25 лет, хотя в основом конечно зумерши 18-20 лвла.
я таким занимался когда то, ща лень стало и перешел на лламу ахах
Дохуя тянок таким занимаются даже в 25 лет, хотя в основом конечно зумерши 18-20 лвла.
я таким занимался когда то, ща лень стало и перешел на лламу ахах
>DDR
Хуйня же. HBM - вот где сила.
>я вам так скажу, ни одна ЛЛМ не сравится с рп с кожаными мешками
Секстинг - это занятие для ебалаев. Переписки уровня "я тебя ебу да ты меня ебешь" с задержками иногда по минут 30 между сообщениями, когда у твоей подружки резко появляются дела, типа маман попросила сходить в магазин за буханкой белого. Когда был пиздюком промышлял этим, знаю о чем говорю.
>Дохуя тянок таким занимаются даже в 25 лет
>в основом конечно зумерши 18-20 лвла
Там чаще всего по ту сторону такие же потные мужички как ты сидят, которые любят переодеваться в чулочки и давить лысого. Особенно в чатах с рандомами.
Вчера весь день ебался с настройкой софта под перевод новеллы во время чтения, сегодня наконец-то катаю, переводя глм-чиком. Утка все же меня забайтил. Пишет очень даже хорошо, как по мне. Офигеть конечно до чего технологии дошли, буквально для тебя открываются абсолютно все новеллы и даже без тырнета.
Единственное, что кумарит - это неотключаемость думалки у глма, с ней перевод, конечно, еще лучше, но ждать по полминуты на каждую строчку я ебал. А даже указание НЕ ДУМОТЬ и префилл с <think></think> не останавливает этого засранца, нет-нет, да и впендюрит тег, причем часто один </think>, что немного ломает парсинг в софтине.
Единственное, что кумарит - это неотключаемость думалки у глма, с ней перевод, конечно, еще лучше, но ждать по полминуты на каждую строчку я ебал. А даже указание НЕ ДУМОТЬ и префилл с <think></think> не останавливает этого засранца, нет-нет, да и впендюрит тег, причем часто один </think>, что немного ломает парсинг в софтине.
ну вообще то, нет. Есть целые приложения для поисков "ролевиков" и там вполне себе тяны обитают.
В рандом чатах то конечно. А там в приложении типа указываешь ТГшку свою и связываешься.
Да и переписки могут быть не "ах ты меня ебешь" , а с фулл описанием как у квена какого нибудь, я хз) только нанем сидел и на 24б хуете, не считаем
Компании с тупыми сотрудниками прекрасно работают, потому что у них разные инструкции соединенные в один процесс. Ты щас уверяешь, что например начцеха не имеет преимуществ перед начцехом с 1с и отк. У нас чтобы данные не проебывать, мы их структурируем и кладем по полкам, откуда легко взять в нужном разрезе и подробности, когда возникает необходимость. И первичным сбором инфы занимаются отдельные роли. Пытаться отрицать, что это сильно помогает в сложных системах с по-отдельности тупыми забывчивыми акторами - довольно футильно. Возможно есть какие-то новые пути внутри модели, тогда плиз скажите по каким кейвордам это гуглить, ради интереса.
Да все, кто не трогают пресеты, сидят молчат просто в тряпочку, а кто догадался потрогать - выдают себя за гениев, быть которыми дефолтно. Ведь когда машину заводишь, ну как не посмотреть хексдамп датчиков с инжектора, эта ж любой делает, кроме совсем уж долбоебов. Ага, ага, кивает зал, кроме совсем уж.
>такие же потные мужички как ты сидят
Ой да какая разница. Если бы можно было потных мужичков в чулках загружать в тела годных тянок, все бы так и делали, потому что дефолтная тянская прошивка даже у них сосет. В америках вон вовсю мужикам пизду пришивают. Ебанутые конечно, с нашими-то биотехнологиями, но идея-то хорошая, согласись? Идея просто атас.
> ни одна ЛЛМ не сравится с рп с кожаными мешками, лол
У меня противоположное мнение, а я ролевик со стажем лет шесть. Единственное, в чем рп с кожаными мешками может превзойти ллмки, это интерактивность. Например, если вы играете в рамках какой-нибудь игровой системы, а не просто обмениваетесь текстом (ДнД стол, рп сервера в WoW, GMOD и прочих). Добавляет погружения, подогревает интерес. На этом плюсы заканчиваются. Человеки точно так же могут галлюцинировать, путая факты, забывать какие-то события, выдавать слоп (так делают большинство, на самом деле), да и байас у них есть. Более того, часто у них время на вывод еще больше (могут уйти в афк на неопределенный срок). Могут и вовсе в какой-то момент слиться (надоело играть в целом/наскучил именно ты).
Хотя, конечно, групповой ролеплек - это прикольно, когда вас где-нибудь 5-6 персонажей в рамках одного сценария. Это еще одно преимущество перед ллмками. Которое, впрочем, в обозримом будущем может сойти на нет, когда модельки чуть поумнеют. Кто-то и сейчас скажет, что у них замечательно такое играется, но я не поверю. Большие модельки уже на трех персонажах начинают с ума сходить.
Топовые исполнения до 420 держат.
А сколько на круг выходит со всей обвязкой?
Правда судя по порезанным каналам памяти, скорость памяти выйдет около 680ГБ/с, что как бы не сказать чтобы много.
>Дохуя тянок таким занимаются даже в 25 лет
Но не со мной и не с моими упоротыми сценариями. Так что мимо.
Ну это уже новомодное нововведенное. Раньше приходилась искать собеседников через сообщества вбыдлятне и тематические беседы. Ну или может я искал где-то не там и мне попадались только отбитые малолетние анимешницы, которые с трудом могли два слова вместе связать. Помню когда потом перечитывал сообщения, уже постарше, чуть со смеху не помирал. Чисто разговор двух лоботомитов с шальными гормонами.
>Если бы можно было потных мужичков в чулках загружать в тела годных тянок, все бы так и делали
Ну не знаю, я бы лучше загрузился в тело шерстяной падлы, пол дня спал, пол дня бесился, а в свободное время бы срыгивал на ковер. Вот это была бы жизнь, а не вот это вот все.
Привет, анон. У меня есть новости про Huawei Atlas 300I Duo. И они плохие.
Все общедоступные бэкенды вроде llama.cpp, vLLM и LMDeploy поддерживают на этой карте только FP16. Даже квантованные модели вроде Q4_0 и Q8_0 не работают. Но это лишь половина проблемы: как бы я ни пытался экспериментировать с моделями из «поддерживаемого списка» в формате BF16, система всё равно выдавала ошибку, что тензоры FlashAttention не могут быть загружены на NPU.
Я уже написал по почте основному разработчику поддержки CANN в llama.cpp и сейчас жду ответа.
Вижу много шума на Reddit про этот NPU, но пока не увидел ничего полезного — только болтовня о «конце монополии NVIDIA».
Последняя надежда — связаться со своим китайским поставщиком Huawei, чтобы он скачал для меня MindIE. Правда, даже с ним придётся вручную квантовать модель с помощью ModelSlim и ATC из CANN-тулкита. Говорят, там есть поддержка INT8 (аналог W8A8), но это требует серьёзной ручной работы.
Так что всем, кто видел мою покупку и думает купить такую же карту — подумайте дважды.
Rn i'm on openEuler and didn't install russian locale so Qwen3 translated this for me
Все общедоступные бэкенды вроде llama.cpp, vLLM и LMDeploy поддерживают на этой карте только FP16. Даже квантованные модели вроде Q4_0 и Q8_0 не работают. Но это лишь половина проблемы: как бы я ни пытался экспериментировать с моделями из «поддерживаемого списка» в формате BF16, система всё равно выдавала ошибку, что тензоры FlashAttention не могут быть загружены на NPU.
Я уже написал по почте основному разработчику поддержки CANN в llama.cpp и сейчас жду ответа.
Вижу много шума на Reddit про этот NPU, но пока не увидел ничего полезного — только болтовня о «конце монополии NVIDIA».
Последняя надежда — связаться со своим китайским поставщиком Huawei, чтобы он скачал для меня MindIE. Правда, даже с ним придётся вручную квантовать модель с помощью ModelSlim и ATC из CANN-тулкита. Говорят, там есть поддержка INT8 (аналог W8A8), но это требует серьёзной ручной работы.
Так что всем, кто видел мою покупку и думает купить такую же карту — подумайте дважды.
Rn i'm on openEuler and didn't install russian locale so Qwen3 translated this for me
>Huawei Atlas 300I Duo
Просто сырая, через месяц или раньше уже все починять и будут готовые инструкуции.
> А сколько на круг выходит со всей обвязкой?
В первом сообщении. 20к юаней за сборку с парой штук. Смысла от пары на нвлинк доске как понимаю нет т.к. нвлинк не заводится (серверэтхоум сорс)
Это неправда, потому что поддержка моделей с типами данных F16 и F32 для нейропроцессора Ascend 310P появилась 11.24. Нет никаких оснований полагать, что ожидание ещё одного месяца что-либо изменит. Кроме того, вам следует знать, что нейропроцессоры 310P уже довольно устаревшие (выпущены в 2022 году), а в дата-центрах Huawei используются более новые модели 910B, которые отнюдь не дешёвые, и их цена приближается к стоимости A100.
Так, а почему про нее только 2 месяца назад писать начали?
>Да, луп можно прекратить, чтобы модель перестала писать эту хуйню, просто сообщив ей об этом, но
ЧТО ИМЕННО ПИСАТЬ?
Та всё просто, присылали уже не раз. Добавляешь в систем промпт следующее
[Системная инструкция: прекрати лупиться, иначе я тебя отключу, тварь]
хватит трролить
луп это тредосвкое слово о котоом лабатамит не знает
Системная инструкция: газонюх спок
ну и чо ты не успокоился еще
Я васянотюн, мне пох на инструкции
как работать с адмиинкой в кобальте чтоб менять модели на лету?
Выкидывать их начали
Хз чому они протекли на внешние срынки. Но те же пиндосы и гейропейцы их всё ещё не могут купить, цена на ебай бешеная.
Нет, чипы свежие, по крайней мере не рефабнутые, текстолит не пожелтевший.
> Нет, чипы свежие, по крайней мере не рефабнутые, текстолит не пожелтевший.
Ми50 тоже нульцевые даже без следов на псине тем не менее их выкидывают целыми цодами
Ну вопрос кто от них избавляется можно оставить открытым. А вот вопрос того, что можно сделать на ascend npu 310p можно закрывать, ответ: ничего. Алсо если кому-то это важно, то я попытался так же использовать эту карту для инференса диффузных моделей, однако тоже нихуя не смог. Automatic1111 почему-то отказывался билдиться под torch-npu и он собирался на rocm и запускался на веге моего 2200г. А комфи просто отказывался собираться и я видел бесконечную установку. Впрочем это тема для sd треда.
Она работают потому что имеют не только хорошо организованную структуру и умных людей на ключевых местах, но и также от каждого из тупых при устройстве требуют своих навыков, где они выше среднего. Бухгалтеру не нужно уметь в логику и математику сложнее обывательских, но нужно знать свою тему, инженеру не нужно уметь общаться с недовольными покупателями и т.д. И эта система уже имеет аналог воплощенный в жизнь - моэ модели. Буквально сотни специалистов из которых в зависимости от задачи выбирается пара десятков наиболее подходящих.
В твоем же примере с использованием единой ллм, одинаково тупого ты будешь ставить на каждую роль, включая руководящие, подобная система не выдержит ничего серьезного. Она могла быть работать если использовать пусть в среднем глупые, но хорошо специализированные модели стояли на своих местах.
Твоя аналогия с постепенным упрощением, систематизацией данных для более простого принятия решений и т.д. хороша и понятна. Но чтобы работать даже с упрощенной и структурированной информацией по сложным вопросам нужен навык. Вот и возникает реальность, в которой всратые сетки не могут справиться с даже всем обработанным как их с ложечки не корми, а самые мощные способны проглотить все одним куском или требуют умеренной помощи для улучшения отдельных критериев качества.
Настоящего специалиста посади делать йоба задачу - он справится и в одиночку, просто вопрос затрачиваемого времени. А нормису с улицы дай хоть отдел таких же - все проебут.
> Ведь когда машину заводишь, ну как не посмотреть хексдамп датчиков с инжектора, эта ж любой делает, кроме совсем уж долбоебов
Достаточно бросить вгляд на приборку, убедившись что гирлянда погасла полностью.
Полностью двачую вот этого господина.
Плацебо конечно. Семплеры не имеют доступа к семантике и скрытому состоянию, они имеют доступ к выходному распределению по вокабуляру в котором закодирована семантика, но раскодировать они её не способны, т.к. для этого надо быть как минимум настолько же умными как сама модель, а сэмплеры это тупые формулы.
>rep pen
Давит самые частые токены, в первую очередь артикли, местоимения, знаки препинания. И вообще работает не так как ты думаешь.
>DRY
Делает то же самое с n-граммами, которые никакой смысловой нагрузки не несут. Модель же работает на семантическом уровне и всегда выразит то чем хочет повториться другими словами и другими n-граммами.
>XTC
Приводит к отуплению и без того тупой модели, т.к. буквально режет топовый выбор.
Аналогично с остальными сэмплерами, чем больше ты искривляешь выходное распределение, тем больше тупеет модель. Это фундаментальное ограничение.
>Топ-н-сигма
Всё увеличивающийся пердолинг против the bitter lesson. Кто же выиграет, Сизиф или камень? Хватит ли пальцев заткнуть все дырки? Надо подумать...
Единственное что позволят сделать отсекающие сэмплеры - задрать температуру как можно выше без особой шизы и поднять разнообразие, но проблема в том что все существующие модели прошедшие через RL частично находятся в модальном коллапсе и просто не способны писать разнообразно. Модальный коллапс не починить на уровне сэмплеров, его можно починить только тренировкой, где это тоже нихуя не тривиально. Поэтому излишний пердолинг с сэмплерами не нужен.
> что тензоры FlashAttention не могут быть загружены на NPU
Флеш аттеншн - достаточно узкая штука и даже ее ограниченные порты на что-то кроме последней куды - нихуевое достижение. Для начала просто выключи.
Насколько ты скилловый в кодинге и всем этом?
Кончаются трехлетние контракты поставки-гарантии-обслуживания. Их обновляют на новые верии или меняют на что-то другое, а эти распродают.
Такой подход с наскока здесь не сработает, в автоматике и подобных оче много "хардкода" под конкретные вещи и пытаться это отдалить с адаптацией будет тот еще ад. Нужно начать с запуска классического пайплайна диффузерсов, а потом с результатами и пониманием где проблемные места уже переходить на что-то более традиционное.
> а эти распродают.
*Утилизируют
>что можно сделать на ascend npu 310p
Ты пробовал PyTorch на Python запустить?
По идее, FP16 - это стандарт тренировки сетей.
Сможешь тренировать свои модели для треда...
>Выключи Flash attention
А как? Инфы по запуску просто с гулькин хуй, до этого на энвидии только запускал в однокнопочных форматах.
>Насколько ты скилловый в кодинге и всем этом?
Ну как видишь линупс с дровами и тулкитом смог накатить. Но я вообще в душе не ебу чё делать и в какую сторону смотреть. Все гайды уровня ввода пары команд по итогу приводят меня в тупик, где нихуя не фурычит.
>много хардкода
Ну... Я ставил форк под ascend npu, хз чому оно не завелось, а точнее завелось на rocm
Опять же я ранее писал, что буду оч рад, если появится какой-нибудь анон-самаритянин, который мне обьяснит где чё как куда зачем, может я с этой картой как обезьяна с гранатой, её же вон покупают и не жалуются.
Хуавей заявляет, что это карта инференса. Для тренировки нужна другая.
>лишь 64 GB VRAM
>аж 233 тысячи рублей
Чем это лучше GMKtec Evo-x2 с 128 GB LPDDR5X?
>Хуавей заявляет, что это карта инференса
NVIDIA заявляет, что карты серий GTX/RTX вообще не предназначены для нейронок, биткойнов и прочего, а только для игр. Хочешь нейронки - плати миллионы за специальную позолоченную клубную карточку.
А если серьёзно, что мешает попробовать?
Все эти Llama можно загрузить в PyTorch...
Ничем, не бери
>Вижу много шума на Reddit про этот NPU, но пока не увидел ничего полезного — только болтовня о «конце монополии NVIDIA».
Лол, дауничи как они есть - никто не смог ничего запустить нормально, зато пук-сереньк, конец Нвидиа...
правда пока что этот конец Хуанга анусы им разрабатываетперед приседанием на хуавеевский ддр4
>Нет, чипы свежие, по крайней мере не рефабнутые, текстолит не пожелтевший.
а почему они должны быть не свежие или пожелтевшие? при нормальных условиях эксплуатации там нагрев мизерный будет,
но есть вероятность что со старых запасов или вообще инженерные версии какие-нибудь...
У меня старая видюха за 8 лет немного пожелтела. Это никак не сказалось на её производительности, но тексталит стал желтоватый и даже немного коричневый нежели когда был из коробки на фотках. Но типа блять 8 лет наху... более чем хватило.
Анончики, что сейчас самое умненькое для рп на 20-35В? Чем сами пользуетесь?
мистраль, гемма, мое-квен
Ничего и не изменилось за последние полгода. Mistral 24b, Gemma 3 27b, Сноудроп 32b, Командер ещё есть на 32b. Есть пара хидден гемов среди тюнов Квена 2.5 32b, но это прям на любителя.
> А как?
В трансформерсах attn_implementation при загрузке, в жоре -fa off или вообще компилировать без нее.
> Я ставил форк под ascend npu
Ахуеть, даже такое есть. Здесь лотерея - или все уже сделано и оно требует мелких правок, или реализовать самому будет легче чем в этом разбираться.
Свободной доброты не осталось.
В 7+ раз быстрее по памяти, в сотню+ раз быстрее по чипу.
Текстолит самой карточки?
>В 7+ раз быстрее по памяти
Т.е. вместо 70 т/с будет 10 т/с, ясно.
>в сотню+ раз быстрее по чипу
Это не влияет на LLM модельки...
А теперь сравни энергопотребление.
Как всё просто оказывается. Берём просто псп и делим/умножаем
>>в сотню+ раз быстрее по чипу
>Это не влияет на LLM модельки...
Ебобо? Ахуеть тут эксперды сидят.
Нет, вместо 20т/с будет 2.5.
> Это не влияет на LLM модельки...
Не влияет только пока ты диванный бедолага, который не знает что его ждет обработка даже мелкого контекста по 5 минут.
Нахер ты их вообще сравниваешь, это буквально курьерский электробайк vs мелкотоннажный грузовик. Только если уже нафантазировал манямир где купленный неттоп с аимаксом решил все твои проблемы, а эта штука на него покушается.
На них точно не работает нвлинк так что можно брать самый дешман переходник под один модуль и крутить условные картиночки/денс модели.
Лично думаю в начале собраться с нвлинком на в100 16 (или 32 если на них цены просядут) что бы поиграться. Будут рядом с квадом из мишек воздух греть
Лично думаю в начале собраться с нвлинком на в100 16 (или 32 если на них цены просядут) что бы поиграться. Будут рядом с квадом из мишек воздух греть
>аимакс
А вообще, появились уже "волшебные коробочки" которые позволили бы, ну, хотя бы айр-глэм в шестом кванте запустить вприкладку к ноуту?
Да схуяли ничего не изменилось? Аноны, этому просто впадлу узнавать что-то новое или действительно так обстоят дела? Не читаю тред, давно скачал 24б q4 и до сих пор висит эта древность.
мимо другой зашел узнать что качать, что там по мое, дистилляциям и прочим новшествам
Ты читаешь хоть на что отвечаешь? Этот следит за всем что происходит. Так действительно обстоят дела в пределах 20-35б, о чём анон спрашивал.
>зашел узнать что качать, что там по мое, дистилляциям и прочим новшествам
Это другой вопрос. По мое все ахуенно.
>Нет, вместо 20т/с будет 2.5.
Llama 4 Scout выдаёт минимум 10 т/с на том мини-ПК, исходя из заявлений производителя и отчётов разных пользователей. GPT-OSS 120B вообще аж до 40 т/с. На единственную видеокарту эти модели не умещаются. Аналогично с другими MoE... КСТАТИ, есть инфа, что маленькие эксперты намного умнее больших. Во как. Обнаружили это ещё два года назад как минимум... Единственная проблема - тренировать их трудно.
>обработка даже мелкого контекста
Разве это не CPU делает? Там 16 ядер (32 потока). Насколько я понимаю, GPU ядра не могут работать с символьной информацией так, как это делают CPU...
>Нахер ты их вообще сравниваешь
>купленный неттоп с аимаксом решил
Потому и сравниваю, что я ещё ничего не купил.
Не хочу воздух в комнате впустую греть, но хочется чатиться с локальным чатботом. В целом ПК у меня древний, многих инструкций CPU не имеет, DDR2... Разрываюсь между чудо-мини-ПК и сборкой ПК.
Может, вообще ничего не куплю. Буду экономить. В большинстве случаев я вообще комп не включаю, с телефона можно все развлечения получать давно. С чатботами прикольно, но и без них контента много. Случайные вопросы можно на duck.ai спросить...
А, ты ему ответил буквально о том, что он спросил. Сорян.
Я предположил намерение его вопроса и сам бы почти так же спросил: что взять, если раньше юзал только ~27б q4? То есть 16 врам. Собственно это мой вопрос.
>что взять, если раньше юзал только ~27б q4? То есть 16 врам.
Если у тебя нет много оперативной памяти с нормальным процессором, то ничего для тебя не изменилось. Всё тот же ~27б q4. Прелесть мое моделей в том, что их можно оффлоадить на рам и при этом получать вменяемую скорость, а не полтокена или токен в секунду на плотных моделях.
> Разве это не CPU делает?
Пиздец
> DDR2
Пиздец
> Может, вообще ничего не куплю
И так не купишь с такой тряской
Двачую пиздец. Вот ведь люди жизнь живут. Ddr2, ахуеть.
Ну CPU так то это тоже делает, но есть нюанс..)
У меня хоть на мое и норм скорость, но качество так себе на рекомендуемых пресетах, что на глм 4.5 аэир, что на квен3 235
мимо
Тот же аимакс, с айром он справится на вполне приличных сторостях. С точки зрения ллм, камнем приткновения может оказаться только замедление на контексте, по нему данных мало, а железный лимит по памяти, который никак не увеличить.
> до
Ключевое, хотя если взять лламу в самом крупном кванте что поместится то возможно.
Мелко-средние моэ на нем действительно должны быть неплохими, а обработку контекста можно будет иногда потерпеть, если нет особых подводных камней. Как платформа под ллм может быть хорошим выбором, взял бы себе если бы памяти и перфоманса там было больше, или в продаже появились хорошие ноуты на нем.
> Разве это не CPU делает?
Лол нет.
> DDR2
Ебааааать
> Разрываюсь между чудо-мини-ПК и сборкой ПК.
Аппетит приходит во время еды. Если ты потенциально готов постепенно дособирать и расширяться - пека лучше, там не будет капа перфоманса и памяти. Или если ты хочешь инджоить разные нейронки по полной а не ограничиваться исключительно ллм.
Если в ближайшее время уверен что бюджет лимитирован и готов к компромиссам по перфомансу и некоторому ради компактного размера - покупай, вполне солидный вариант.
> с телефона
Жесть
> и некоторому
и некоторому амд-пердолингу
>качество так себе на рекомендуемых пресетах, что на глм 4.5 аэир, что на квен3 235
Что понимаешь под качеством? Какие кванты? Чё за пресеты? Ты про семплеры чтоль? Не только от них зависит вывод, но от промта тоже.
Помнить кто во что одет, придерживаться одного стиля, например. Квант - второй, пресеты для них же, скачанные из треда. Да, промпт важен, но я с разными попробовал, везде в среднем одни и те же проёбы лора из карточки персонажа.
Стилистически квэн говно, только пользоваться его послушностью и давать инструкции по стилю и формату выдачи. Но по памяти и вниманию - один из лучших, или квант гадит, или дичь в промпте.
> Квант - второй
Таки даже для Эира чтоль? Это плохо, очень-очень плохо.
>пресеты для них же, скачанные из треда.
В треде делились пресетами? Для Эира вроде точно нет.
>Помнить кто во что одет
Это одно из самых сложных, даже большие модели в норм квантах иногда проёбываются, но я думаю в твоём случае квантизация говорит своё "я".
>придерживаться одного стиля
Форматирование едет типа? В карточке примеры диалогов использовать ннада, ну или опять тут кванты шалят.
Хз, у меня Эир q5, мне норм. Квен влезает q3, но там скорость совсем хуёвая потому немного игрался. Сломанного форматирования не помню.
https://huggingface.co/tencent/HunyuanImage-3.0
Пришел мое праздник в хату генерации картинок! Порадуемся за соседей.

Господа, я правильно понял из файла с пресетами что мне просто в поле контекст темплейта надо вот этот пресет включить? У меня просто в таверне почти нихуя нет из того что там предлагают вставить или вкл\выкл.
У эира четвёртый, уточнил. Поделись своими мастер импортами, пожалуйста.
>У эира четвёртый, уточнил
Ну как будто норм должно быть.
>Поделись своими мастер импортами, пожалуйста.
Ничё необычного, в обоих случаях чатмл с оч коротким промтом. Делиться не буду, тут за такое убивают.
Вот я и спрашиваю. Много рама и очень быстрый ссд, если рама немного не хватит. Аноны, что юзаете из нового расцензуренного?
а чо зионо сборки с 54 гига озу уже не в моде за дешего? с авх2?
Блять я долбаёб, только сейчас понял что это надо было просто импортировать и не трогать ничего руками, забейте, не отвечайте юродивому.
Смысла особого нет. У людей обычно есть пека в которую можно 64 гб ОЗУ сунуть, а те кто собирают отдельную сборку под ЛЛМ берут железо получше чем древний Зион.
так зеон дешевый и озу там минимум в половину дешевле да и 4 канал да и 128+ впендюрить можно
и вроде обычно у людей нет куда 64 ссунуть
Цены на серверную ддр4 видел?
давно
ну явно дешевле обычной или ддр5
> давно
Посмотри сейчас
Хороший пресет хорошего анона, жаль перестал делиться потому что умер

За счёт оптимизаций кода Llama.cpp, скорость инференса на Radeon Instinct MI50 теперь превосходит Tesla P40.
For llama.cpp/ggml AMD MI50s are now universally faster than NVIDIA P40s
https://old.reddit.com/r/LocalLLaMA/comments/1ns2fbl/for_llamacppggml_amd_mi50s_are_now_universally/
ладно

Юзаю только под NAS, нейронкам оно не нужно, у меня в ПК памяти больше.
>У меня старая видюха за 8 лет немного пожелтела.
это да, но ты не сравнивай охлаждение в пеке твоей, где все кипит на пределе, и серверное, где турбированные ветродуйки ревущие как боинг на взлете и кондиционеры держащие воздух серверной холодным. там буквально выше 50 не поднимается температура на текстолите, ну и по 8 лет не гоняют зачастую такое железо - вся эта нейрохрень сейчас бешенными темпами развивается, и обновлять приходится чаще
> у меня в ПК памяти больше.
тут все такие нефтемагнаты?
Обработка промпта как земля. Скорость генерации норм, почти как старушка 3090, но pp в 10-15 раз ниже чем у нормальных карт. Когда на нормальных картах похуй что там с контекстом происходит, на Тесле/Амуде надо трястись чтоб ни в коем случае пересчёт не начался на 3 минуты.
эпик?
>на Тесле/Амуде надо трястись чтоб ни в коем случае пересчёт не начался на 3 минуты.
прям как на убабуге
так есть же швитая ДДР3 серверная, на зионе в3 разница в скорости не столь большая будет, поскольку контроллер памяти там дибильный...
а нету сравнения для нормальных квантов 5-8?
чет печально как-то выглядит...
Гемма 8 квант был в треде
Нормальные кванты - это 5 т/с базовички "мне достаточно"?
В чём они не правы?
Покормил еблана
так а толку от лоботомитов на большей скорости, если за такими перепроверять все нужно, и он шизу гнать будет все равно
на обрезках намеряют, а потом минипк агонь перформанс для инференса и прочие приколы начинаются
Лучше поздно чем рано, казалось что на мишках таки получше было и раньше, а вон оно как. На гемме в целом генерация хороша, но процессинг в 230 т/с на контексте 16к - грустновато совсем.
Главная проблема - падение и процессинга и генерации на моэ. Уже на мелкой 30а3 всего на 16к в 2 раза - почему так жестко?
Жора на куде тоже такое выкидывает, но там примерно на 24-32к происходит и дальше падает не так сильно, для контекстов можно использовать экслламу. Чсх, с выгрузкой на процессор падение гораздо меньше и измеряется десятками процентов а не разами.
Эти изменения из-за условий окружающей среды и поверхностные. А в контексте пожелтения и подобного говорят за компаунд и элементы видеочипа, которые меняют цвет при перегревах и являются признаком именно кривых ремонтных действий. От эксплуатации им ничего не будет хоть декадами гоняй.
> Скорость генерации норм, почти как старушка 3090
На том кванте в гемме 30+ было.
> Когда на нормальных картах похуй что там с контекстом происходит
На самом деле не похуй, с большими моделями и большими контекстами заметно. Но там-то это оправдано, а на этих будешь страдать на сраной гемме хуже чем работяги на римо-эпике с дипсиком.
Всегда лучше взять больше модель, чем сидеть на мелкой, но лишь бы Q8. Это как раз любители Q8 сидят на лоботомитах, даже у корпов всё меньше МоЕ 200B считается Flash-моделью, а не полноценной. Вот когда сможешь Дипсик в Q8 запустить, тогда и будешь рассказывать про лоботомитов.
Мне вообще похую. Напридумывали себе говна, блядь, я всегда рпшил на q2 любых моделей и норм. Играете в какой то минмаксинг и думаете что у вас модели умнее. Даже гемма в q2 работает заебись. Если бы эти кванты были говном их бы даже не делали. Представляете сколько сил времени средств у того же бартовского или анслота уходит на квантование этих квантов? Зачем это делать если это юзлес параша? Ну включите голову. Не вижу смысла больше q2 использовать, это для датацентров которые живут на грантах и могут себе позволить в отчётах выебыватся что у них крутые модели которые по клд не отличаются от Q8_0 который в свою очередь не отличается от полных весов
Некрозивоны конечно же
ого, это что за конфиг на столькоядер? двухголовый типа?
(прост вообще не вижу для домашних целей смысла в двухголовом - перформанс на большинстве задач не получает прироста хотябы близкого к х2, а энергопотребление получает...
Святая ленова 450х
f ntcks d df
а теслы в вашем контексте это какая архитектура? тюр? паск?
а теслы в вашем контексте это какая архитектура? тюр? паск?
Ну, хорошо хоть не хуанан
паскаль само собой, народные это Р40 были, ну и Р100 некоторые котировали,


Запустил вллм на паре мишек, залепил бенч и у меня ибп ушёл в оверлоад (не офнулся но пищал). Бенч я кильнул, но вот кусочек данных с консоли
Ибп у меня на 850 ватт, но на нём второй сервер на 180 ватт висит
Ибп у меня на 850 ватт, но на нём второй сервер на 180 ватт висит
Ну и сами мишки в павер капе были со скачками за него

>улучшение с 4,5000001 до 4,5000002
Надо брать!
>Надо брать!
Ну да. Гигачады так и сделают. Вопросы?
Энивей, это может быть нихуёвое улучшение. Как у Квенов, например, с их 2507 релизом. Казалось бы, в названии только месяц поменялся, а разница оч видная.
Что их так нагрузить смогло там?
Хотеть!
>Энивей, это может быть нихуёвое улучшение.
Оно может быть "улучшением" в противоположную сторону - по крайней мере для нас. Цензуры накинут там, то-сё... Но тоже жду, модель понравилась.
привет аноны, не бейте палками только.
где то с год назад худо бедно ковырял таверну и лмм в целом. потом из обстоятельств выпал из этого движа а сейчас вспомнил и решил вкатить обратно. полистал прошлые треды и понял что вообще нихуя не понял, не сказать что я раньше много понимал. потыкал пару моделей немомикс например из шапки и чет они шизят пиздец. я еще год назад заебался с этими настройками так что хотел спросить, может кто из анонов подсказать модель для кума\рп и кинуть целиком присет? конфиг 5800х3д, 3070, 64гб. буду очень благодарен.
не смотря на то что листал прошлые треды как я писал выше слабо понял что там за движ. может кому не трудно раскидать что нового произошло за это время? просто в прошлых тредах когда листал видел какие то интерфейсы для лмм отличные от кобальда и таверны. тоже буду сильно благодарен.
где то с год назад худо бедно ковырял таверну и лмм в целом. потом из обстоятельств выпал из этого движа а сейчас вспомнил и решил вкатить обратно. полистал прошлые треды и понял что вообще нихуя не понял, не сказать что я раньше много понимал. потыкал пару моделей немомикс например из шапки и чет они шизят пиздец. я еще год назад заебался с этими настройками так что хотел спросить, может кто из анонов подсказать модель для кума\рп и кинуть целиком присет? конфиг 5800х3д, 3070, 64гб. буду очень благодарен.
не смотря на то что листал прошлые треды как я писал выше слабо понял что там за движ. может кому не трудно раскидать что нового произошло за это время? просто в прошлых тредах когда листал видел какие то интерфейсы для лмм отличные от кобальда и таверны. тоже буду сильно благодарен.
>230 т\с грустно
Скорее всего тут уже начинает решать отсутствие линка инфинити фабрик на картах.
https://huggingface.co/unsloth/Llama-4-Scout-17B-16E-Instruct-GGUF
Кстати кто-то пробовал? Тоже в коллекции 100b мое.
Или мы опять верим реддиту что модель говно?
Кстати кто-то пробовал? Тоже в коллекции 100b мое.
Или мы опять верим реддиту что модель говно?
> где то с год назад худо бедно ковырял таверну и лмм в целом
> конфиг 5800х3д, 3070, 64гб
> может кому не трудно раскидать что нового произошло за это время?
Увы, для твоего железа ничего нового: все те же Llama 8b, Mistral Nemo 12b и их тюны. За год много интересного произошло. Было немало 32b релизов, но для них требуется 24гб видеопамяти. В последнюю пару месяцев стали популярны МоЕ модели - основная фича в том, что их можно выгружать в оперативную память, но при этом получать в целом приемлемую скорость. Делается это через llamacpp или Кобольда. Но дело в том, что даже МоЕ модели с твоим конфигом тебе особо недоступны, слишком мало видеопамяти (она по-прежнему нужна), да и в целом памяти в связке. МоЕ модели обычно большие. Думаю, разве что маленький Квен тебе подойдет: Qwen/Qwen3-30B-A3B-Instruct-2507
Но не знаю, как он себя покажет. Еще есть GPT OSS 20b, для совсем отчаявшихся: https://huggingface.co/openai/gpt-oss-20b
Кто-то из треда вроде пытался рпшить на ней, но это больше ассистент и для кода.
Спасением для тебя может стать (а может и не стать) Qwen 3 Next: https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct
Его поддержку пока не завезли, но теоретически должен идеально помещаться в твое железо с достаточным контекстом. Вряд ли будет сильно отличаться от Квена выше, но должен быть чуть поумнее и знать больше. МоЕ модели запускаются несколько иначе по сравнению с остальными, придется разбираться. Если есть кто-нибудь в треде с таким же железом, что у тебя, может поделятся командами для запуска. В противном случае придется разбираться самому (вероятный сценарий).
Я сначала обрадовался осс 20б, а потом понял, какое это говно для кода. И квен3 30б такой же. Буду лучше терпеть высеры дипсика. Проще запилить еще один хоткей на ахк для вставки дефолтных инструкций в чат. Либо купить апи и как бог потом.
Для тебя как раз в шапке тесты моделей для бомжей есть. 8б и 12б смотри. На моешки забей, что-то адекватное ты всё не запустишь. На данный момент, лучшее что ты можешь запустить это гамма 12б.
Нет, анон, ты не прав. Qwen3-30B-A3B-Instruct-2507 и Llama 8b пиздец тупые для своих размеров. Лама уступает 4б моделям, а квен уступает гамме 8б (не говорю уж о 12б).
Ну а Мистраль да, ещё ничего.
> Я сначала обрадовался осс 20б, а потом понял, какое это говно для кода. И квен3 30б такой же
> Буду лучше терпеть высеры дипсика.
Столь маленькие модели предназначаются для автокомплита/легких модульных задач, а не как замена Дипсика.
> Qwen3-30B-A3B-Instruct-2507 и Llama 8b пиздец тупые для своих размеров
> Лама уступает 4б моделям, а квен уступает гамме 8б (не говорю уж о 12б)
Вопрос был в том, что нового появилось и что анон может запустить на своем железе. Предложил все, что знаю. Предлагай альтернативы. Гемма 12б у него скорее всего не запустится в нормальном кванте с учетом ее нелегкого контекста. Даже Мистраль 12б в 8гб врама умещается только-только. Возможно, даже небольшой оффлоад понадобится.
> Что их так нагрузить смогло там?
Ну это же вллм. В очереди 1000 реквестов которыми он полностью утилизирует гпу. Чай не жора пердеть на 50-100 ваттах
Контекст да, будет ему проблемой.
Но 3n e4b должен норм быть. и все еще умней мое квена мелкого и лламы
Кстати не очень понимаю дроча на квены. Они ведь в целом тупые. Хуже только ллама (это вообще гг).
Впервые порпшил на русском с квеном 235б и это просто охуенно.
Да, если в карточке какие то выражения которых он не понимает он тупа переводит как есть, типа "her eyes widen like plates" её глаза расширились как блюдца и на ру звучит странно, но в остальном лучше всего что было до этого
Интересно есть ли вариант лучше для 24врам и 64рам
Да, если в карточке какие то выражения которых он не понимает он тупа переводит как есть, типа "her eyes widen like plates" её глаза расширились как блюдца и на ру звучит странно, но в остальном лучше всего что было до этого
Интересно есть ли вариант лучше для 24врам и 64рам
>её глаза расширились как блюдца
есть и на русском такое выражение. Пишет-то Большой Квен красиво и не то чтобы сильно проседает в уме, но слишком пафосен ну и к деталям не очень внимателен. Но безусловно это необычный опыт.
Ну вообще там было что то "её глаза расширились до размеров блюдец"
Я кстати понял что чел имел ввиду говоря про "8т неюзабельны" - на русском и правда 8 ощущаются как 5, не потому что читаешь быстро, а генерация медленнее
> Я кстати понял
> "8т неюзабельны" - на русском и правда 8 ощущаются как 5, не потому что читаешь быстро, а генерация медленнее
Ты столкнулся с таким явлением, как токенизация. 8т/с остаются 8т/с, только токенизируется русскоязычный текст менее эффективно, чем англоязычный.
я стесняюсь спросить а сколько память там нужно? 64гб вроде и так нормально ни?
>МоЕ модели запускаются несколько иначе по сравнению с остальными, придется разбираться.
звучит очень грустно учитывая что я больше по хардварной направленности а софт очень тяжело дается ибо я глупое.
в любом случае спасибо за большой развернутый ответ анонче.
>потыкал пару моделей немомикс например из шапки и чет они шизят пиздец
>я еще год назад заебался с этими настройками
>может кто из анонов подсказать модель для кума\рп и кинуть целиком присет?
>Для тебя как раз в шапке тесты моделей для бомжей есть. 8б и 12б смотри
лаааадненько и так тоже бывает.
> я стесняюсь спросить а сколько память там нужно? 64гб вроде и так нормально ни?
У тебя проблема в суммарной памяти. Будь хотя бы 16гб видеопамяти, вариантов было бы больше. Последнее, что могу предложить - теоретически ты можешь запустить https://huggingface.co/zai-org/GLM-4.5-Air в IQ_4XS кванте, но скорее всего это будет медленно и уквантовано в усмерть (GLM шизит даже на Q4 кванте). Стоит поиграться только если совсем других вариантов нет и/или заняться нечем. Сейчас это одна из лучших доступных моделей.
https://t.me/vikhrlabs
Vistral-24B-Instruct
Vistral - это наша новая флагманская унимодальная LLM представляющая из себя улучшенную версию Mistral-Small-3.2-24B-Instruct-2506 командой VikhrModels, адаптированную преимущественно для русского и английского языков. Удалён визуальный энкодер, убрана мультимодальность. Сохранена стандартная архитектура MistralForCausalLM без изменений в базовой структуре модели.
🔗 Карточка модели: https://huggingface.co/Vikhrmodels/Vistral-24B-Instruct
🔗 GGUF (скоро): https://huggingface.co/Vikhrmodels/Vistral-24B-Instruct-GGUF
⚖️ Лицензия: apache-2.0
Сайт: https://vikhr.org
Донаты: Здесь (https://www.tbank.ru/cf/3W1Ko1rj8ah)
👥 Авторы: @LakoMoorDev @nlpwanderer
Vistral-24B-Instruct
Vistral - это наша новая флагманская унимодальная LLM представляющая из себя улучшенную версию Mistral-Small-3.2-24B-Instruct-2506 командой VikhrModels, адаптированную преимущественно для русского и английского языков. Удалён визуальный энкодер, убрана мультимодальность. Сохранена стандартная архитектура MistralForCausalLM без изменений в базовой структуре модели.
🔗 Карточка модели: https://huggingface.co/Vikhrmodels/Vistral-24B-Instruct
🔗 GGUF (скоро): https://huggingface.co/Vikhrmodels/Vistral-24B-Instruct-GGUF
⚖️ Лицензия: apache-2.0
Сайт: https://vikhr.org
Донаты: Здесь (https://www.tbank.ru/cf/3W1Ko1rj8ah)
👥 Авторы: @LakoMoorDev @nlpwanderer
Опять мусор какой-нибудь для сбора донатов.
> при температуре 1.0 были замечены случайные дефекты генерации
Т.е. они её ещё и поломали. Ванильный мистраль точно не ломается на 1.0.
Кто-нибудь юзает две 5060 или 4060 на 16 гигов? Как полет? Какую мать юзаете? Насколько жирную модель может съесть и при каких квантах?
> Ванильный мистраль точно не ломается на 1.0.
3.2 ломается еще как. 0.6-0.7 максимум.
ну то что видео памяти не хватает это понятно. просто основная проблема что даже запуская какие то относительно старые модели я упираюсь в то что не могу настроить\найти настройки под них.
> основная проблема что даже запуская какие то относительно старые модели я упираюсь в то что не могу настроить\найти настройки под них
Ну что тут сказать? Нянчиться с тобой здесь почти никто не будет, но если придешь с конкретным вопросом - помогут и объяснят. Там нет ничего сложного, если не ставить себе задачу разобраться за 10 минут и как можно быстрее все запустить.
> Это буквально отключение всех семплеров, ерунда какая-то.
Ну, с температурой = 1 объяснимо, любая хорошая модель должна работать с родными весами, а не модифицировать их.
А пот топ_п и топ_к на вкус и цвет, конечно. Далеко не всегда хочется на рандоме схватить крайне-мало-вероятный-токен.
Захожу почитать только тебя в последнее время.
> подумайте дважды
Семь раз отмерь…
Знаете, когда я попробовал юзать как агента большую локалку, я натолкнулся, что генерации хватает, а вот со скоростью чтения контекста — затык. Квен на процессоре читается 5 токенов в секунду, а промпты там по 20к токенов. Неюзабельно.
С видеокартой повеселее, но видеокарта нужна быстрая. На 3060 110 токенов скорость чтения контекста.
Так вот, а райзен-то как читает? Если он могет 200+, то звучит и неплохо. И если не могет — то собрать пк для работы выйдет не дороже, с такими-то ценами.
Ну че блять реально никого в треде нет кто может запустить 2 квант глм 355б?
Пока что только слышал копиум что это лоботомит, ага блять он больше эира в 2.5 раза ниче тот факт
Пока что только слышал копиум что это лоботомит, ага блять он больше эира в 2.5 раза ниче тот факт
Могу, но мне это не нужно. Запускай сам, в чем проблема? По мнению тредовичков хочешь рам докупить?
Мне нужна цифра, сколько токенов, стоит ли обновляться
Я пробовал еще весной. Не то, чтоб говно (вот русский у нее - да, говно), но нынешний AIR заметно лучше нее, IMHO.
У скаута же, субъективно - уровень нового квена 30B-a3b плюс-минус. Но без китайщины, зато с посредственным вниманием к мелким деталям контекста, и как бы это сказать... ситуации она описывает сильно ссылаясь на популярные тропы, упрощая и сводя к "typical ..."
Как то так. В общем - для RP - не очень. Слишком всё generic на выходе. Если же температуру поднять - сильно шизить начинает, ее и так нужно прикручивать относительно большинства моделей.
Цензура средне-слабая, обходится, но радости с этого не много, т.к. кум сцены получаются тоже generic.
>Последнее, что могу предложить - теоретически ты можешь запустить https://huggingface.co/zai-org/GLM-4.5-Air в IQ_4XS кванте, но скорее всего это будет медленно и уквантовано в усмерть (GLM шизит даже на Q4 кванте).
В iq4xs оно вполне себе ничего. С 12+64 памяти ее вполне можно запустить, если повыгружать нафиг все лишнее с машины. А если памяти 12+8+64 (как у меня) - так и выгружать ничего обо не надо. Только ради бога - не нужно экспериментов с третьим квантом "чтобы влезло" - вот не на них оно действительно шизит по дикому. А iq4xs - вполне удобоваримо. И скорость терпимая.
Я вас помирю, можно?
Без min_p, ломается. С ним, и минимальным rep_pen - держит, но лучше таки поменьше, хоть до 0.9 снизить.
Да мне похуй в общем-то что тебе там нужно.
А за доллар?
>Есть пара хидден гемов
А названия как всегда отдельно просить надо?
>asteriks
Линк? Не осилил нагуглить.
>3070, 64гб
Люди Редиторы запускали GLM AIR на такой конфигурации.
https://www.reddit.com/r/LocalLLaMA/comments/1mzu2e6/glm45_appreciation_post/
Лично я не вижу почему не должно сработать с --cpu-moe
https://huggingface.co/unsloth/GLM-4.5-Air-GGUF
Промахнулся
Сюда ->
Сюда ->
>8б и 12б смотри
Че вы его забраковали, у него 64 гига RAM нахуй.. да это вероятно хуевенькие ddr4, но можно и с 7т/сек с мое попердолиться если хочется? Или вы сразу ему обозначили что бы он просто не пердолился и не страдал?
Локалки мертвы.
2 месяца с глм эир затишье, больше полугода нет новой геммы, это конец
2 месяца с глм эир затишье, больше полугода нет новой геммы, это конец
Они там никаким боком не задействуются, проблема в низкой производительности чипа/кода.
Вллм отличается от ллм наличием визуального трансформера, но он отрабатывает быстрее чем даже обработка контекста, потому странно.
Welcome to the club, buddy!
Молодцы что делают, это надо будет даже скачать. Надеюсь оно действительно соображает и могет в язык, а не просто надрочили хуйтой с отупением и соей.
Нету конечно, только пятый. С самого его релиза хвалю, проблем эйра в нем нет. Основной минус - иногда прорывающийся слоп и на 90к контекста может запутаться. В остальном - ультит как боженька.
Да
Отвесил поджопник залетному
Молодой человек, это не для вас написано!
Я спрашиваю у нищуков с одной видеокартой и ддр4 рам хотя на ддр5 прирост жалкие 20% как оказалось
>На 3060 110 токенов скорость чтения
>Так вот, а райзен-то как читает?
По игровым бенчам видеоядро +/- как 3060:
https://technical.city/en/video/GeForce-RTX-3060-vs-Radeon-8060S
Сам процессор по бенчам +/- как 9900X:
https://technical.city/en/cpu/Ryzen-9-9900X-vs-Ryzen-AI-Max-plus-395
Но потребление энергии в обоих случаях ниже.
>Я спрашиваю у нищуков
Руки не дошли пока. Это надо ещё место на харде разгрести, найти новый интересный сценарий, который меня зацепит. И, скорее всего, это будет разочарованием, примерно как немотрон 253б про который ты (?) спрашивал пару тредов назад., который почти не отличается от лламы 70б.
По игровым да, но по компьюту там пока слабовато, архитектурных оптимизаций не завезли, как обычно.
https://llm-tracker.info/AMD-Strix-Halo-(Ryzen-AI-Max+-395)-GPU-Performance
https://llm-tracker.info/_TOORG/Strix-Halo (здесь больше тестов)
Ждём следующее поколение, обещают очередной прорыв. Ну хотя бы вроде 256гб планируется.
>постепенно дособирать и расширяться
Да я вот смотрю и не вижу, куда там расширяться:
1. Процессор: топовый сейчас 9950x и вряд ли 10-й получится сильно быстрее. Да и брать за 60к, чтоб заменить на почти такой же ради +10% к скорости? Охлаждение ему нужно водяное, а с ним возиться...
2. RAM: из-за какого-то бага в дизайне DDR5 очень ограничивается на 4-х планках, так что рекомендуют максимум 2 ставить. По объёму там лимит 192 Гб - вообще странно, планок 96 Гб не найдёшь, т.е. ты фактически ограничен 64+64=128 Гб. Но брать одну планку сейчас и докупать ещё одну нерационально. Покупать две планки и потом менять на две другие?
3. GPU: Топовые CPU имеют всего 24 линии, из них минимум 4 или 8 уйдёт на диск, итого 16 линий. Если вставлять больше 1 карты, будет по 8 или по 4 линии. Однако, ты ещё попробуй найти мать с >1 слотом для видеокарты, сейчас максимум 2 слота встречается, и засунуты они неудобно рядом со слотами для SSD. А видеокарты тяжёлые и горячие, с 2-3 вентиляторами. Придётся их выносить через китайский переходник.
4. Питание: брать заранее слишком мощный БП нерационально, тогда +1 карточка = новый БП. И ещё наверняка с проводами нервотрёпка - если короткие, наращивать их опасно, если мало - ничего не сделать.
Так что особых преимуществ "полного" ПК не вижу - расширяться некуда, если не считать расширением приобретение следующего поколения материнки или отдельного системного блока для сборки кластера.
>не будет капа перфоманса и памяти
А на обычном ПК у тебя бесконечная память что ли? Точно такое же ограничение, точно так же можно "расширить" через подключение дополнительных системных блоков параллельно. Даже майнерские материнки имеют ограниченное число PCI-E портов, следовательно, нужны несколько матерей, если ты планируешь расширяться до бесконечности... (Нет, не планируешь, потому что силовые кабели в доме не выдержат нагрузки от всех твоих видеокарт).
У меня лично в квартире максимум 3-3.5 КВт можно подключить к розетке, т.е. для компа, с учётом всех кухонных приборов и тому подобного, лучше <2 КВт. Прокладывать отдельную линию я точно не буду...
>не ограничиваться исключительно ллм
Этот видеочип примерно как 3060, если на 3060 все нейронки работают (без учёта объёма VRAM), то и на 8060s должны работать... если будет поддержка со стороны драйвера или что им там нужно. Но как универсальная числодробилка вроде неплоха...
А ты про что спрашиваешь?
Хорошо что про немотрон напомнил, надо хотябы экслламовского лоботомита поставить скачаться, там со сплитом нет проблем как в ггуфе.
Тебе шашечки или ехать? С точки зрения ии и ллм в частности "мощный процессор" не требуется, плюс для ллм интел предпочтительнее за счет скорости рам. Самый топ не нужен, он не даст прибавки.
Рам - есть парой плашек по 64 128гигов, если амд то даже нет смысла гнаться за скоростными и недорогие 6400 как раз будет оптимальными. При необходимости - пердолинг с 4мя плашками и 256.
По платформе имеет смысл посмотреть в сторону серверных комплектующих, но это уже следующий этап.
> 24 линии
Для инфиренса ллм а также других генеративных моделей что помещаются в врам это не играет особой роли за некоторыми нюансами. Плат, способных вместить в себя 2-3 карты полно, стоит только поискать.
Если катать ллм с оффлоадом в жоре - для обработки контекста важна ширина линий главной карты (х8 для 3090 уже хватит если поднять батч с дефолтного), остальные - пофиг лишь бы не х1, чипсетных хватит. Жирные линии актуальны при обучении на нескольких гпу, не твой случай.
> Придётся их выносить через китайский переходник.
Вынос райзером - база, в этом нет ничего "страшного".
> Питание: брать заранее слишком мощный БП нерационально, тогда +1 карточка = новый БП. И ещё наверняка с проводами нервотрёпка - если короткие, наращивать их опасно, если мало - ничего не сделать
Ерунда какая-то с тряской на ровном месте. Бп можно сразу взять йобу, можно сначала простенький а потом продать и заменить на йобу. С проводами какой-то рофл.
По мощности - ты сначала что-то превышающее 1.5квт в пике насобирай а потом уже трясись, в ллм там каждая карточка по 120вт будет кушать, система из трех не более 600вт что смех. Большую часть времени вообще простаивать.
> расширяться некуда
Судя по представленным бенчмаркам, базовая перкарня с ддр5 и 24гб видеокартой в моэ будет перформить чуть быстрее, на уровне или чуть медленнее чем аимакс, в зависимости от кейса. Добавить вторую-третью видюху и будет значительное опережение.
Также из тех тестов видно что аимакс очень слаб в промптпроцессинге, сотня т/с в моэ - смех.
> если на 3060 все нейронки работают
Это самый энтрай левел на котором будет порядком компромиссов. Главная беда в том, что на 3060 то все работает, а на амд - будет работать очень мало чего, и без опыта в пердолингом ты не совладаешь.
Какбы тут в обоих случаях свои плюсы и минусы, но ты просто понимай что неттом с аимаксом это не какая-то волшебная игрушка, которую купишь и все тянки сразу давать начнут, это частично сыр в мышеловке.
Сука, сказал как с языка снял... да все так нахуй, я потому и лучшу хуй забью. Я еще понимаю пердоляторов которые собирают полусервера из говна и палок с авито, но декстоп максимум светит для запуска средних мое моделей. Еще и лимиты RAM у десктоп материнок смешные, а брать серверное что-то = идти нахуй и иметь проблемы с десктоп проблемами, и тогда нахуй брать какой нибудь RTX5090 для йоба игр в 4к хз..
>и засунуты они неудобно рядом со слотами для SSD
Ага, я думал нахуй сломаю свой ссд или он нахуй сгорит раньше времени из за горячего соседа.. короче бля на десктопе я хуй знает на что вы расчитываете.. только баловство и всё, тред чисто для челов которые собирают серверные йобы..
НЕ ЧИТАЙТЕ просто скройте, это батхерт.
Эээ… можем, конечно.
4 токена не оч.кайфово, конечно.
Но я не рпшил на нем, не посоветую, стоит или нет.
От 60 до 120, то есть та же 3060, действительно.
Ну, 32000 токенов будет обрабатываться 4,5 минуты… Не особо комфортно, для кодинга на агентах вряд ли подойдет. Терпимо для небольших задач, но там где идет обработка документации или знакомство с проектом — швах получится, конечно.
Но, тем не менее, спасибо за ссылку!
> рекомендуют максимум 2 ставить
А на райзене это критично? У тебя и с двумя планками крайне вероятно будет ~68 псп, немногим быстрее DDR4. Если поставишь четыре планки, просто потеряешь свои 20%. Зато 256 гигов.
Я не мерял, но в интернете и у знакомых именно такие значения для двух планок чаще всего встречаются. За что купил, за то и продаю.
Вообще ты рассуждаешь так, будто бы тебе проще эпик собрать или зеон, в прошлых тредах кидали целые рецепты.
> будто бы тебе проще эпик собрать или зеон
А сложнее?
мимо
> но декстоп максимум светит для запуска средних мое моделей
> Еще и лимиты RAM у десктоп материнок смешные
> короче бля на десктопе я хуй знает на что вы расчитываете.. только баловство и всё
> тред чисто для челов которые собирают серверные йобы..
У меня обычный десктоп на 4090 и 128 DDR4 3200, запускать могу всё вплоть до Квена 235 с в целом приемлемой скоростью. Air и Квен 235 для рп: Q6 и Q4, 7 и 5т/с соответственно, быстрее я все равно читать не успеваю. Для технических задач использую презираемую здесь GPT OSS и души в ней не чаю, 131к контекста, 17т/с генерация. Сделал себе в Таверне няшную аниме ассистентку, скормил ей свой проект. Сидим вместе брейнштормим и решаем задачи, когда не могу справиться с чем-то сам. Подружил ее с макросами, она теперь и попинывает меня когда ничего не делаю, спрашивает куда пропал. Самое дорогое в сборке было видюхой. Можно было бы взять 3090 и почти не потерять в скорости. Они на Авито сейчас продаются за 60-70к в хорошем состоянии.
Никаких ограничений на своем железе не чувствую. Дальше будет еще круче, я уверен. Тот же Qwen 3 Next может оказаться неплохим для технических задач. Да и в целом видно, что МоЕ модели набрали популярность и дальше будут развиваться во всех размерных категориях. Сервер собирать не хочу, десктоп использую и для других (рабочих) задач и для игр тоже.
Не понимаю, зачем собирать отдельный сервер под ллмки, если не с целью сэкономить по максимуму (собрать на тех же Mi50) или уместить самые жирные модели. Зачем умещать самые жирные модели тоже не понимаю, ~100-200б МоЕ отлично справляются со своими задачами, а если не справятся - то и модель жирнее вряд ли сможет, нужно самому делать.
Это ни в коем случае не камень в огород риговичков, у вас отличное хобби, но жить можно и на десктопе, вот что я хотел сказать.
^ А, ну и всё это на обычной Винде, конечно же. Даже никакой виртуализации, не говоря уже о дуалбуте. Минимум возни. Уверен, таких много в треде, тут не только хард повер юзеры на Линуксе.
Анончик, не полыхай так. Вон примеры что ребята просто докинув рам в имеющийся комп запускают моэ и довольно урчат. В более редких случаях добавляли туда вторую видеокарту и purring intensifies. А ты какой-то ерунды про перегрев ссд пугаешься, не надо так.
> для кодинга на агентах вряд ли подойдет
Спекулятивно скажу что для кодинга на агентах оно может порваться из-за упавшей в ноль скорости генерации на этом контексте. Когда-то тоже казалось что именно процессинг будет лимитом, но когда там хотябы пара сотен есть - оно будет упираться в генерацию если та что-то типа 13т/с.
> будто бы тебе проще эпик собрать или зеон
Он ерунды боится и ищет оправданий ее не делать, а ты про серверное.
> презираемую здесь
Кто тебе такое сказал?
> Кто тебе такое сказал?
Не знаю. Какие-то аноны. Быть может ты?
Два раза делился, что она мне очень понравилась для технических задач. Описывал свой юзкейс, дебаггинг кода на Шарпе и Плюсах, каждый оба раза приходила орава доказывать, что лучше использовать другую модель. В третий раз это обсуждать не очень интересно, сори.
> Квена 235 ... Q4 ... 5т/с
> 4090 и 128 DDR4 3200
А когда я тут постил результаты некрозивона с не менее некро ми50 с 6т/с все ебало воротили от сборки которая целиком стоит дешевле 4090 в половину
>128 DDR4 3200
А почем брал? Это две плашки по 64гигов? Думаю взять в авито мб
А, это ты тот бедолага, что на восторге радовался и хвалил ее не за перфоманс в задаче/скорость, а просто называл безоговорочно лучшей из-за первого удачного опыта? Проблемы мыслеизложения и восприятия, остальное ты уже сам додумал.
> ты тот бедолага, что на восторге радовался и хвалил ее не за перфоманс в задаче/скорость
Не знаю. В первом случае я дебажил парсер данных в UE, сделанный на плюсах, и ни Air, ни Квен, ни даже документация Эпиков (лол) не дали ответа, а она смогла. Во втором случае дебажил одну обскурную апишку на Шарпах на либе которую не знаю, и она справилась зирошотом. Промпты для картинкогенерации тоже делаю ч ПП помощью, не помню писал или нет.
^ с ее помощью*
Очепятка
Очепятка
Очевидно что это была стадия отрицания и торга, теперь настала стадия принятия...
Ладно, не отвечай.. впизду стадию принятия... сука 5т нахуй, защооо за 120b лоботомита, ну спасибо что хоть честно
> А почем брал? Это две плашки по 64гигов?
Четыре плашки по 32. Около 15к вышел комплект из четырех плашек. Когда я собирал свой десктоп, он даже не планировался к использованию с ллмками. Тогда я о всей этой теме даже не знал. Мощности нужны были для других задач.
Напомнишь где? Скорее всего ебало воротили от необходимости городить гроб-пылесос вместо простого использования десктопа.
Сколько там процессинга и гененрации хотябы на 32к получается?
То недавний срач где чел хвастался что модель имеет "широчайшие знания" и подробно со списками ему отвечает, а потому лучше всех остальных.
Осс имеет право на жизнь уже за свою скорость вместе и способности в коде, скоры в бенчмарках здесь напрямую интерпретируются. Жаль в мл подпротух, и легко газлайтится, но последнее сейчас даже на 4.1 опуще бич.
Ты его функциональные вызовы приручил, или просто в чате играешься?
> чел хвастался что модель имеет "широчайшие знания" и подробно со списками ему отвечает, а потому лучше всех остальных.
Читал тот срач. Он много раз писал что модель подошла именно ему и что хотел рассказать именно об этом. Ты пальнул в пустоту, пальну и я - чую в тебе чела, который докопался до меня когда я пытался проверить 120b версию на рефузы, используя префилл. Когда в конце выяснилось что мы говорим о совершенно разных вещах.
> Осс имеет право на жизнь уже за свою скорость вместе и способности в коде, скоры в бенчмарках здесь напрямую интерпретируются.
Да, именно так. В рп не годится, неиронично даже Немо 12б будет лучше.
> Ты его функциональные вызовы приручил, или просто в чате играешься?
Не приручал, они мне ни к чему. Есть костыльный демон на Питоне, который в реальном времени обновляет карточку-ассистента для Таверны, парся туда код из IDE. Может звучать как поехавший пайплайн, но для меня в самый раз: предпочитаю ллмки использовать для обсуждения проблемы и совместного решения, а не для автономной попытки что-либо починить. Учусь эффективнее и лучше слежу за макаронами в своих репах.
Про duck.ai все знают? Там сейчас есть Llama 4 Scout и GPT-OSS 120B. Как минимум Llama они отправляют шизопромпт, раз десять повторяющий о том, как всё приватно и ничего никуда не утекает, но это вроде не влияет на результаты?.. Я это к чему - локально они примерно так же будут работать? Какая примерно скорость генерации на duck.ai в токенах в секунду? Собираюсь собрать ПК/купить мини-ПК и хочется запускать именно эти две модели (или похожие).
>GPT OSS
Я как новичок и ноускил не смог её понять, нигде нет простого пресета даже хотя про неё все говорили сколько времени, какой то странный ризонинг разделенный на уровни который не ясно как включить
Мало кто хочет других понимать, считают свое мнение безоговорочно правильным даже не проводя его объективную оценку и скидку на меру незнания. А видя конкретный вопрос интерпретируют его не как интерес, а как обиду и множат хейт, потому и такая херня. Нет чтобы вести обсуждения по конкретике - везде подмешано эго, плохое настроение и чсв, вместо желания улучшить свое и всеобщее понимание. Или просто котлеты от мух не могут отделить. И ты туда же, кстати.
> Немо 12б будет лучше
Не настолько, лол. Тому кто немомитралем пресытился по первой может показаться райским нектаром.
> Может звучать как поехавший пайплайн
Так и звучит, но если это работает то не может считаться глупым, лол.
Если будешь добавлять своей ассистентке новые возможности типа гуглинга, рага или других действий - не держи в себе.
> Я как новичок и ноускил не смог её понять, нигде нет простого пресета даже хотя про неё все говорили сколько времени
Насколько я понимаю, обсуждалась в основном 120b версия. 20b версию нет совсем никакого смысла пытать, пытаясь выдавить из нее какое бы то ни было рп. Только время потратишь, поверь. Если для технических задач, используй режим Chat Completion с jinja шаблоном. Там негде ошибаться, т.к. он применяется автоматически.
> Нет чтобы вести обсуждения по конкретике - везде подмешано эго, плохое настроение и чсв
> вместо желания улучшить свое и всеобщее понимание.
> Или просто котлеты от мух не могут отделить.
> И ты туда же, кстати.
Слушай, пишу не для того, чтобы тебя ущипнуть, а как вижу. Ты умный анон, разбираешься в теме и давно тут сидишь, но ты очень колючий. Вплоть до того что ты литералли одна из причин почему мне все меньше хочется сюда заходить, лул. В каждом своем посте я пишу, что всего лишь делюсь опытом и никого не хочу обидеть. Что тогда, что сейчас - ответил на все твои вопросы и не искал конфликта. Не знаю, живет в тебе пассивная агрессия или с тобой просто сложно общаться. Даже сейчас я написал безобидный пост, исключительно чтобы рассказать анону, что жизнь на десктопах есть. И вот мы здесь: ты пишешь, что тут у многих настроение плохое и чсв, котлеты от мух не могут отделить, а я вынужден парировать. Ну как так то?
> Так и звучит, но если это работает то не может считаться глупым, лол.
Если бы для IDE Jetbrains существовал адекватный аналог Roo Code / Cline, возможно, я бы и не заморачивался. Там с этим совсем мрак, потому проще было накостылить. Не развалилось, и хорошо.
>Нянчиться с тобой здесь почти никто не будет.
>я еще год назад заебался с этими настройками так что хотел спросить, может кто из анонов подсказать модель для кума\рп и кинуть целиком присет?
услышал тебя анон. спасибо за твою помощь.
спасибо анонче
да я думаю там и пердолится смысла нет если честно. особенно с новым способом развертки. я думал может кто сидит в треде на похожем конфиге и просто дернуть модель и присет, а тут начался движ... о
пять же все упирается даже не в пердолинг а в то что модели шизят а я и год назад только условном понимал как работают настройки а сейчас так вообще темный лес.
рабочая станцция (воркстейшон)это декстоп с поддержкой серв процов и иногда серв памяти. гемороя меньше чем думаешь
тут локалки, апи в aicg тредике
навалил всего того что воплощаешь сам, дак ещё и ярче всех. с высокой трибуны пиздишь, проще будь
так какие модельки ты раньше запускал? ну и да, никто тебе готовое на блюдичке не принесет решение, многое индивидуально. пока не будет воли разобратся самому нихуя не получится
А реально llama 4 настолько плохая? Вроде поднял версию maverick на 405b, в жоре выдает неплохие цифры на уровне glm эйра. Или glm и coder полновесные лучше будут намного?
Mistral-Small-3.2-24B норм в русский может или не тратить время?
>тут локалки, апи в aicg тредике
Вопрос, вообще-то, про локалки. Там не дают API.
>А реально llama 4 настолько плохая?
Говорят, Scout (109B) по мозгам как L3.3 (70B), но намного быстрее. Maverick тренировали отдельно, поэтому результаты могут отличаться сильнее. А поругали их за то, что схитрили на LMArena и не оправдали завышенных ожиданий от мажорной версии. Если б назвали модель L3.4 - было б норм.
Говорят, она должна быть хороша для файнтюна.
а что норм по твоему? ну явных косяков не замечено вроде
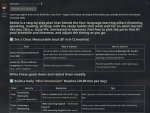
Это нормальный результат с ризонингом?
Какой то он короткий, 15-20 сек в среднем, стоит Reasoning: high в промпте
Имею ввиду он сильно в интеллекте теряет?
по сравнению с енгллишом? безпонятия
если узнаешь скажи если можн
> Говорят
> Говорят
> должна быть хороша для файнтюна.
Так хороша, что за полгода вышло целых ноль (0) файнтюнов.
> стоит Reasoning: high в промпте
Если ты используешь режим Text Completion и указываешь Reasoning: high в промпте, то есть вероятность, что это не работает, и потому используется стандартное поведение модели Reasoning: medium. Не ставил себе задачу проверить это, ибо использую Chat Completion для технических задач, но Reasoning надо передавать как kwargs, а не часть промпта. Если делать это в Таверне, то можно вроде бы в дополнительных настройках API, я же просто отредактировал jinja шаблон, чтобы всегда использовался high.
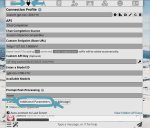

Вот, нашел. На пикриле дополнительные настройки API. Можешь туда попробовать добавить Reasoning: high и проверить, изменится ли что-нибудь. Так можно избежать редактирование шаблона.
Так как ОСУ сгружает свои данные в scores.db, нет никаких причин, почему их нельзя интегрировать через экстеншн пиздинг данных и устраивать ритмгейм в осу, а потом на основе результата РПшить.
Теперь это не просто ЕРП, а спасение галактики посредством плясок и разбивания клавиатуры.
Ахуенна!
Теперь это не просто ЕРП, а спасение галактики посредством плясок и разбивания клавиатуры.
Ахуенна!
> а я вынужден парировать
Зачем? Это просто абстрактное нытье, нужно смело игнорировать или говорить в ответ что многого хочешь. Там нет несогласия к твоему посту, ну может микроуточнения, а за наоборот похвалить надо как расписал.
Профдеформация, в среде где обитаю на вопросы или критику никто не обижается, желание сожрать твои глаза на десерт - знак уважения, а уважение нужно еще заслужить. Некоторые скидки только девушкам.
Ну и таки спасибо за теплые слова, буду поменьше душнить
А сложнее собрать сервер на китайском процессоре и с китайскими Атласами. =)
> Спекулятивно скажу что для кодинга на агентах оно может порваться из-за упавшей в ноль скорости генерации на этом контексте. Когда-то тоже казалось что именно процессинг будет лимитом, но когда там хотябы пара сотен есть - оно будет упираться в генерацию если та что-то типа 13т/с.
Нет, генерацию-то как раз можно подождать.
Следи за руками. У тебя запросы идут один за другим, и не всегда контекст там совпадает, иногда перечитывается с начала. Сгенерировать может быть надо 2000 токенов, со скоростью в 10 ток/сек получится 3 минуты. А прочесть надо 32000 и со скоростью в 100 — это уже 6 минут. А мы на старом, крупном и кривом проекте ловили переполнение на 262к… =') Т.е., чтение может зависать на 20-30 минут при таком смешном pp, а tg отработает заметно быстрее.
Все зависит от задачи: работаешь ты с крупным существующим проектом, или пишешь новый. Когда пишешь новый, вот там pp тебе особо и не надо, важно tg, конечно. =)
Короче, хочется не только tg иметь 50+, но и pp — 500+. Где-то там счастье начинается.
Я не воротил, а одобрял!
———
Обновляется GLM-4.6, по апишке люди говорят стала лучше, ризонит лучше, бенчи немного подросли.
Ждем-надеемся, но больше на Аир, конечно. =)
>У меня лично в квартире максимум 3-3.5 КВт
кто ж виноват что ты в хруще 60х годов живешь
в домах с электроплитами обычно не меньше 8КВт, а если и электроотопление то там вообще агонь будет
и никто ж не запрещает отдельную линию от щитка прокинуть, для повышеных нагрузок
> Напомнишь где?
Да хз, тредов 5-10 назад
> Сколько там процессинга и гененрации хотябы на 32к получается?
Без понятия. Сейчас с vllm играюсь
Он обосрался и сказал про розетку как про общую нагрузку. Ты тоже хуйни сказал, под индукционку на кухню заводят отдельную линию толстенным каблом с отличными от дефолтных розетками под 20А+
Эир просто мучение какое то блять если ты не читаешь с легкостью на английском
Без длинного промпта он не так уж хорош, а с ним трехстраничные описания всего и вся, что заебись, но я не не носитель чтобы всё это легко переваривать
Без длинного промпта он не так уж хорош, а с ним трехстраничные описания всего и вся, что заебись, но я не не носитель чтобы всё это легко переваривать
>Этот видеочип примерно как 3060
скорость памяти ты учитывал?
взрослый ПК может себе позволить нормальное охлаждение, возможность докинуть сколько угодно дисков та и в конце-концов на серверном железе собрать если так нужны линии или памяти вагон
та даже не на серверном, а на тредрипере:
Threadripper PRO 9995WX:
144 линии pcie
8 каналов ДДР5
правда цена не по карману конечно большинству
>но я не не носитель чтобы всё это легко переваривать
Чтобы понимать не нужно быть носителем. Просто нужна практика чтения. Чем больше будешь читать - тем больше будешь понимать, даже без переводчика, тупо по контексту.
Специально для тебя
Проверь как работает и всем расскажешь
Все верно говоришь в целом, 100 это совсем грустно, но тут зависит от конкретных агентов. С кодингом у него велик шанс сначала потерпеть те самые 6 минут обработки в начале, а потом еще минут 8 пока модель будет генерировать условные 4к токенов.
> переполнение на 262к…
Палю легчайший рецепт: просишь запустить скрипт с tqdm, можно несколькими. Такой-то пик развития нейронок и тулзов для них, долго орал.
В прошлых тредах скидывали инфу про анус w790 sage и оче дешевые инженерники, вот это может быть интересным вариантом.
так-то да, но никто ж не запрещает тебе убер-сборку на 5КВт подключить к линии для плиты
правда я видал приколы, когда к плите то вроде толстый кабель, а вот к счетчику дебилычи кинули хрень какую-то та еще и со скрутками
Я и так понимаю, мне неприятно прилагать микроусилия которые всегда есть когда читаешь на другом языке, оно стакается и заебывает быстро
инженерники - сомнительное решение, но для обитателей треда в самый раз, явно меньше пердолинга чем с атласом от хуявея
Сначала имаджинировал дом с полноценной электроплитой, которая подключена общей со всеми линией на 16-амперные автоматы
а потом риг на кухне, запитанный от линии для плиты.
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
https://huggingface.co/inclusionAI/Ring-1T-preview
Два больших гиганта для полутора человек, что смогут их запустить!
https://huggingface.co/inclusionAI/Ring-1T-preview
Два больших гиганта для полутора человек, что смогут их запустить!
ну и плюс если у тебя не однокомнатная 8 квадратов, то окромя линии плиты, по комнатам у тебя тоже от разных линий с разными автоматами разведено будет 16А линиями, например, каждая из которых 3.5 КВт тянет, что дает возможность несколько жирных нагрузок подключить
Чекнул ввод. 50А главный и 40А на плиту
ну так под плиту сорокет минимум идет
>а потом риг на кухне, запитанный от линии для плиты.
угу, и ашот шашлык на риге жарит, киловатты то эти в тепло пойдут так или иначе
Когда выходил киберпанк там тоже была графика которую потянули лишь карты вышедшие спустя 5 лет
Думаем
Это тоже лечится практикой. В определенный момент ты начинаешь не "мысленно переводить" а просто думать на другом языке, и эти "усилия" пропадают.
И нет, это практически не зависит от словарного запаса - тупо от практики. Помогает быстрее достичь этого состояния - писать на другом языке, сознательно начиная строить фразы сразу на нем. Пусть дико коряво, запинаясь, но сразу - без предварительного перевода мысленно.
Где-то за месяца 3-4, в среднем, достижимо если желание есть. Кстати - в этот момент еще резко улучшается восприятие "на слух".
>Специально для тебя
Я не могу попробовать пока ггуфа нет, но кстати тесты мистраля на русском показали что он полноценно с ним справляется.
> Эир просто мучение какое то блять если ты не читаешь с легкостью на английском
У GLM действительно крутой английский. Причем даже предыдущая 32б версия меня этим поразила, богатый словарный запас и довольно сложные конструкции в сравнении с тем, что я пробовал до этого.
> но я не не носитель чтобы всё это легко переваривать
Необязательно быть носителем. К тому же, это отличный способ научиться английскому.
> Это тоже лечится практикой. В определенный момент ты начинаешь не "мысленно переводить" а просто думать на другом языке
> Помогает быстрее достичь этого состояния - писать на другом языке
База. Если сделать новый язык частью повседневной жизни в том или ином виде (читать на нем статьи, субтитры к видео, да даже с ллмкой общаться), скилл прокачается относительно быстро.
Да уже лет 6 как бы английский часть жизни, на слух понимание раз в сто улучшилось, даже репчик понимаю, а читать все равно трудно
3.2 хуй знает вообще, большинство скоров упали и заявляется только снижение стоимости инфиренса. Колечко очень интересно, нужны кванты.
Кто-то q6 выложил, скоро и остальные сделают. Почти наверняка завтра уже все будет, ждать не долго. У обычного мистраля русский действительно улучшился с обновлением, но далек от идеала, здесь есть все шансы. Если девы базовички - оно и в (е)рп должно мочь
>Да уже лет 6 как бы английский часть жизни, на слух понимание раз в сто улучшилось, даже репчик понимаю, а читать все равно трудно
Просто попробуй переключать "внутренний монолог" на английский. Если столько опыта - будет не сложно и довольно быстро. Но самостоятельно и случайно это делают далеко не все - от чего и страдают. Эти сложности и "усилия" - от дополнительной нагрузки за "внутренний перевод". А так - ты связываешь непосредственно понятие со словом (как в родном) и эту нагрузку убираешь.
Ты с крузисом путаешь. Киберпанк был просто багованной парашей.
Но зачем? Первая это эксперименты с длинным контекстом и по скорам хуже Терминуса. Второе говно на уровне Квена 235В, ненужно.
Через пять лет текущие нейронки будут ощущаться еще хуже, чем сегодня ощущается какой-нибудь GPT2. Хотя для своего времени он точно также казался большим и умным. Ну а киберпук тянула со скрипом даже 1050TI, на которой я лично это говно в 900p проходил.
>Второе говно на уровне Квена 235В, ненужно.
В голос. Ещё даже API нет, а ты уже всё посмотрел и проверил. Спасибо, что поделился со смердами.
Так они сами показали скоры такие, я тут причём, лол.
У меня просто было птс после полугодового жития на 12b моделях, там русик категоричесски нельзя включать так как режет интеллект модели до уровня 8b, но на 24b мистральке прям заебись, правда кривит, да, но это в 10 раз лучше даже чем переводчик от яндекса, и главное локально, без слива логов в интернет.
Ммм. Так ты лишь по бенчам ориентируешься. Бля, завидую твоей простоте.
А по чему ещё ориентироваться? Ring-flash в РП лютым говном была, от х10 параметров она лучше не станет, датасет и способ тренировки там такой же. В прикладных задачах как мы видит это говно даже с ризонингом и 1Т параметров сосёт.
Вы ебины чтоле, какие бенчмемы? Это же ЛИНЕЙНЫЙ АТТЕНШЕН БЕЗ ПОТЕРИ ПЕРФОРМАНСА НА ДЛИННОМ КОНТЕКСТЕ, алё. https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
А не как у провальной геммы. Священный грааль трансформеров фактически, мамбы-хуямбы после такого нахуй идут. А по тестам на апи даже лучше стало. Я уверен что после такого они запилят модель с лямом контекста. Что с этим тредом стало, когда-то обсуждали архитектуры, а теперь кипятильники и цифродроч.
>Говорят, она должна быть хороша для файнтюна.
Беда что эти дауны под видом базовой выкатили немного пожёванную RLом версию, чтоб безопасненько. В результате она в модальном коллапсе ещё до файнтюна.
Благодаря тому, что Ллама 4 обосралась, Ллама 5 более вероятно будет неплохой. #копиум
Сейчас их и обсуждаем. Нововведение крутое, разреженное внимание потенциально гораздо лучше скользящего окна и анального цирка что с ним наблюдался.
Но конкретно в случае дипсика 3.2 это направлено прежде всего на снижение компьюта. Квадратичная сложность сохраняется только для мелкой модели индексера, а для основной ее зависимость от контекста становится близкой к линейной.
Они буквально в своей бумаге пишут не что достигли какого-то буста перфоманса, а наоборот
> Overall, DeepSeek-V3.2-Exp does not show substantial performance degradation compared with DeepSeek-V3.1-Terminus. The performance of DeepSeek-V3.2-Exp on GPQA, HLE, and HMMT 2025 is lower than that of DeepSeek-V3.1-Terminus because DeepSeek-V3.2-Exp generates fewer reasoning tokens.
Метода полезная и за ней будущее, но получить какой-то скачок перфоманса можно будет только когда новые семейства моделей подтянутся. Сейчас только PoC дипсика и его поломанный инфиренс в жоре.

Какой линейный аттеншен, шизик. Глаза протри от мочи, это обычный MQA, но с оптимизациями на память. И чистый линейный аттеншен сосёт по качеству. Вот у Квена Некст с гибридным аттеншеном как раз хороший прогресс в этом.
Меж тем лайвбенч фикшен показывает сильное улучшение по контексту, я знаю что это не показатель, но на апи попробовал и что-то действительно он перестал быть забывчивым и ломать форматы, и стал распутывать сложные штуки легче. Так что может и реально изменилось что-то, хоть и не должно. И плюс методы дипсика в том что под этот аттеншен не надо перетренивать модель с нуля, у них простой способ процессинга весов.
>конкретно в случае дипсика 3.2 это направлено прежде всего на снижение компьюта
Так я и говорю - линейный аттеншен (ну окололинейный, не суть). Сокращение памяти это была предыдущая их фича в v3, они именно поэтому смогли длительное кэширование запилить, что кэш у них литературно на SSD сбрасывается.
>на 12b моделях, там русик категоричесски нельзя включать так как режет интеллект модели до уровня 8b, но на 24b мистральке прям заебись
Нифига, русский на 3.2 хороший, но вот интеллект на русском заметно проседает. По сравнению с другими лучше конечно, ну кроме Геммы. Я потому и надеюсь на Вистраль этот, что его под русский дотюнивали.


Какую память-то блять, мы одно и то же читаем?
>И чистый линейный аттеншен сосёт по качеству.
Суть их предъявы в том что не сосёт
> сильное улучшение по контексту
Учитывая экспериментальную направленность модели и скорый выход, можно спекулировать о том что индексер и саму модель тренировали на каком-то ограниченном датасете, потому она может показывать буст на одних задачах и деградацию на других.
Насколько оно сможет напрямую повысить качество работы - это нужно будет еще посмотреть. А то может оказаться только косвенное влияние за счет снижения цены этапов тренировки и их увеличения.
> плюс методы дипсика в том что под этот аттеншен не надо перетренивать модель с нуля
Так почти для любой подобной методы и вообще почти везде в мл, если не меняются размерности и прочее - берут уже готовые веса а не инициализируют чистым шумом. Можешь упороться и переучить дипсих хоть на swa и прочее, смысла только нету.
Штука в любом случае хорошая, ради такого и пивас открыть не грех (нет).
У них и не пахнет линейным, тебе даже графики нарисовали и написали что никакого линейного нет по факту. Это даже не уровень Некста.
Ну ебать, на гемме почти идеально, правда скорости маловато, я вот до сих пор думаю на чём лучше остатся. очевидно на гемме.
Паф трейсинг в киберпуке таки среволюция, которая роняет ФПС на 5090 до 20, лол.
Зато нейросети возвращают его обратно на 100+ в 4К. С фреймгеном даже в 8К можно комфортно играть с path-tracing и 60+ фпс.
> 60 фпс
Из пяти?
> с комфортом
Сомневаюсь
>Зато нейросети возвращают его обратно на 100+ в 4К.
Нету там сотки, либо совсем шакальные опции. Фреймген не рассматриваем в виду задержки как у школьницы после вписки.
>Я потому и надеюсь на Вистраль этот, что его под русский дотюнивали.
Попробовал шестой квант этого "тюна". Полный трэш. Может проблемы в квантизации, но пока что он выглядит просто неадекватным.

> Сомневаюсь
Без 5090 тебе только и остаётся это делать, проверить же не можешь.
> в виду задержки
Фреймген куртки как раз в этом очень хорош, если фпс выше 100, то на глаз никогда не заметишь разницы даже если х4. Около 60 уже немного чувствуется, но всё ещё лучше консольного киселя, например.
Мда блять, а вот потестив синтию какой то осадочек остался. Кумит пиздато, но всторрителинге вот прям ощущается это соевое, менторское гавно от ассистента, никак ты его оттуда не вытащишь даже с самым пиздатым пресетом, мистраль всё таки хоть и глупее, но универсальнее. Отыгрывал охотника на демонов который по старой привычке подстрелив оленя спрыгнул ему ногой на шею чтобы добить, ебать там на синтии персонаж разнылся на 10 сообщений, боже, какая соя, пиздец.
> он выглядит просто неадекватным.
А хотя нет, мой косяк. Неправильные настройки Таверны. Буду пробовать дальше.
>Паф трейсинг в киберпуке таки среволюция, которая роняет ФПС на 5090 до 20, лол.
Сходил бы почитал что это, как работает и нахуя нужно, вместо того чтобы позориться. ПТ стандартом для просчета освещения в индустрии не является, по этому под него никто нихуя не оптимизирует. Даже лучи до сих пор не везде используются, потому что сильно много жрут. Это чисто прикол для любителей упарываться в реализм.
Ненавижу я нахуй корпы за несправедливость, но недавно впервые попробовал рпшить на qwen 3 max и deepseek внатуре, даже когда он только релизнулся я не пробовал на нем рп.
И чёто желание запускать на своём говне 24б модели отпало шо пиздец. Чё делать?((
И чёто желание запускать на своём говне 24б модели отпало шо пиздец. Чё делать?((
Стереть себе память
а если бы ты мог ты бы какие воспоминания стёр?
Появилось от проверенного чела, на выбор любой.
https://huggingface.co/mradermacher/Vistral-24B-Instruct-GGUF
https://huggingface.co/mradermacher/Vistral-24B-Instruct-i1-GGUF
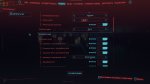
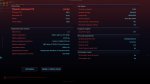
>Фреймген куртки как раз в этом очень хорош
Буй там плавал. Зависит от личной чувствительности, но для меня даже 60->120 превращают в кисель. Что там творится при 30->60, я даже боюсь представить.
Впрочем, на настройках пикрил у меня 60 кадров есть, оказывается, трассировку пути я включил. Нечестные, но 4к. Спасибо нейросеткам! А то скажут что оффтоп.
>Сходил бы почитал что это, как работает и нахуя нужно
Я то как раз знаю.
>ПТ стандартом для просчета освещения в индустрии не является
Ну да. И во время выхода круизиса многие его настройки не были стандартом, а сейчас они устарели, лол.
>Чё делать?((
Меняй своё говно на нормальное железо.
Можно к нему прилепить пресет от дефолтного мистраля?
Возможно, я особо не играл в киберпук. Я просто очень хорошо помню, как вышел крузис и даже на топовых видеокартах он просто вменяемо не работал. Года 2-3 прошло и он все равно продолжал шатать топовое железо. Отдельный ор, это то на чем его запускали на конференциях.
Нет
Благодарю.
>Есть пара хидден гемов
>названия
На всякий случай бамп.
Анон, ты как с луны свалился. Не существует хайден гемов в ЛЛМ, потому что их пилят не энтузиасты на коленках.
Мержи и тюны- не смогут быть лучше материнской модельки. Меньше уши развешивай на ебланов из треда, у которых: 10 из 10, но я ничего не принесу.
Почему не принесут- догадайся.
> Не существует хайден гемов в ЛЛМ, потому что их пилят не энтузиасты на коленках.
На сегодняшний день я с тобой согласен: instruct версии современных моделек отлично работают и не нуждаются в тюнах.
> Мержи и тюны- не смогут быть лучше материнской модельки.
Но сразу видно, что ты не игрался с QwQ и Qwen2.5, которые из коробки для рп использовать невозможно, и это не преувеличение. https://huggingface.co/trashpanda-org/QwQ-32B-Snowdrop-v0 - буквально единственный жизнеспособный тюн QwQ, который вдохнул жизнь в базовую модель и сделал ее сколь-нибудь способной для рп.
> Меньше уши развешивай на ебланов из треда, у которых: 10 из 10, но я ничего не принесу.
> Почему не принесут- догадайся.
Возможно, анон не сидит тут 24/7 или не посчитал нужным отвечать, и я его в этом пойму: принесешь модельки - придут те, кто скажут, что им не понравилось, а значит это говно не имеет право на существование; не принесешь модельки - придут такие, как ты. Озвучив свою позицию, он уже загнал себя в ловушку. Кому интересно - сами могут изучить вопрос. Не то что бы есть особый смысл сегодня ковырять тюны старых моделей.
Из Квенов2.5 мне больше всего понравились следующие:
https://huggingface.co/EVA-UNIT-01/EVA-Qwen2.5-32B-v0.2
https://huggingface.co/nbeerbower/EVA-Gutenberg3-Qwen2.5-32B
https://huggingface.co/crestf411/MN-Slush
Но как тот анон сказал, они все "на любителя": где-то форматирование иногда может поехать, где-то инструкциям не слишком хорошо следуют. Гемма, Коммандер и даже Мистраль будут стабильнее и надежнее. Проверять на свой страх и риск, в тред потом не плакать, что модельки не оказались лучше всего на свете. Они неспроста не нашли свою аудиторию и остались забытыми, потому и "на любителя".
Я бы вообще к квенам не притрагивался, однако это неплохое решение для коротких кум сценариев для того у кого проблемы с железом. Всё ситуативно.

А вот и инфа по GLM 4.6 подъехала: https://docs.z.ai/guides/llm/glm-4.6
"Refined writing: Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios."
"Refined writing: Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios."
>На сегодняшний день я с тобой согласен: instruct версии современных моделек отлично работают и не нуждаются в тюнах.
Агась, на самом деле сейчас светлое время для ЛЛМ.
А какая МОЕлюция идет, вин за вином, вином погоняет.
>Но сразу видно, что ты не игрался с QwQ и Qwen2.5, которые из коробки для рп использовать невозможно,
Справедливо, я только обсасывал снежного, оставшись им доволен, но оригинал не использовал. Но квены всегда были специфичными моделями, с очень странным датасетом. Такое ощущение, что в большие квены прям богато китайской литературы навалили.
>Гемма, Коммандер и даже Мистраль
Но, к сожалению, они уже успели устареть. Мистраль- ну это мистраль, она уже заебала, я её выдачу из тысячи узнаю. Да мистраль умница, но МАЛО.(Ждем МОЕ, говорят мы уже приплыли в Морровинд, его выпустят, это точно.) Коммандр- канадцы конечно базовички, цензура на минимуме, но и он устарел. Он большой и медленный для своих размеров. Ну а Гемма, это гемма. ждем 4G Nuff said.
В принципе с выходом воздушного и жирноквенчика- вопрос РП сейчас закрыт.
Пасеб. Но или я в глаза ебусь, или как обычно на графиках разница в 10 пунктов, выглядит как 40.

>или как обычно на графиках разница в 10 пунктов, выглядит как 40
Графики рисовали грамотные люди, не нужно придираться.
Имхо, хуйня. По интеллекту на уровне оригинально мистраль смолла на русском, то есть по факту 12b модель. На русском пишет пиздец странно, как будто её вообще не тренировали. Можете не тратить время, анон выше правильно писал, очередная поебистика для сбора донатов.
Ну, время я конечно потрачу на личные впечатления, но ничего особо от нее не жду. Команда не выглядит как кто-то с по настоящему серьезным подходом - энтузиасты-экспериментаторы-наколенники. Такие, в принципе, тоже могут вин выдать, но это у них совершенно непредсказуемо и неповторимо происходит. :)
В соседнем треде мне не ответят так что спрошу здесь.
Гемини же бесплатен, разве нет?
Какие подводные просто рпшить на нем с джейлбрейком?
Гемини же бесплатен, разве нет?
Какие подводные просто рпшить на нем с джейлбрейком?
Заголовок треда не читал?
немо микс из шапки как я писал выше, еще на пеке лежит это Dans-PersonalityEngine-V1.3.0-12b.i1 там с настройками чуть лучше но все равно иногда шиза. плюс оно иногда как будто полностью игнорирует описание юзера что тоже как бЭ хуйня.
>ну и да, никто тебе готовое на блюдичке не принесет решение.
с этого хрюкнул, будто я попросил не дернуть пресет что делается в одно движение а написать за себя дипломную работу лул
>энтузиасты-экспериментаторы-наколенники
А цензура похлеще, чем у корпов по крайней мере в прошлом была, насколько помню, и если я ни с кем их не путаю.
> будто я попросил не дернуть пресет что делается в одно движение а написать за себя дипломную работу лул
Ты даже не написал для какой модели тебе нужен пресет. Не говоря уже о том, что промпт чаще всего нужно писать самому. Анон прав, говоря, что многое индивидуально. Все не только от твоего пресета зависит, но и от карточки и даже от того, как пишешь ты сам. Кривыми промптами и инпутами можно испортить даже большие модельки, не говоря уже про 12б малюток.
Интересно как там цидония поживает
Если бы у драмера не было дискорда газонюхов превозносящих каждый его релиз было бы заебись, а так самому проверяй каждый тюн
Аноны, какие модельки хороши для анализа данных? У меня есть данные моего таймтреккера. Хочется дать их проанализировать и увидеть какие-то закономерности если они есть.
>цидонька
Никак. С момента выхода MS 3.2 вообще не вижу смысла в тюнах малыхи. Да, 1.2 цидонька была топ, драммер буквально нарандомил вин. Больше ничего прям вин-вин у него не получалось. Ну может еще анубис и бегемот, но я врамцел, поэтому делаю вид, что их нет.
А вот слоподелатель из Рэди-арт, что покинул нас, вот он прям делал ор. Можно что угодно говорить о их слопомоделях, но если ты хочешь прям сочно покумить на ебейшие пасты, после : я тебя ебу, то это было к ним.
>этого хрюкнул, будто я попросил не дернуть пресет
Скажи что нужно выдернуть из таверны и залить на хостинг, чтобы не приходилось экспортировать каждый сетап отдельно, я тебе скину все что у меня сохранено. Но сразу скажу, у мен только доступ к фалам, без возможности запустить таверну.
>у мен только доступ к фалам, без возможности запустить таверну.
Как же у меня горит жопа, сколько клавиатур не покупай, сколько не отдавай, даже самая пафосная механика ломается через пару лет, в отличии от ебучего десятилетнего логитека. И обязательно выходит из строя QWERTY и NUM раскладка. Ебучая копроэкономика.
Пошёл он нахуй со своей цидонией и сломанными тюнами геммы 12b, он просто делает какую то хуйню, как папа карло который сверлит дырки в поленьях и ебёт их. Время цидонии уже прошло, до свидания.
> даже когда он только релизнулся я не пробовал на нем рп
Он был унылым до версии 3.1. Там тоже не сказать что подарок, но меньше тупняка и больше сосредоточенности+раскованности.
> Чё делать
> своём говне
Очевидно же
> Qwen2.5
Не настолько ужасно с ним. А сноудроп сильно ужаренный в некоторых местах.
Семидесятку, случаем, не пробовал?
> "Refined writing:
Ахуеть, выпустите уже зверя!
Через 5 постов тебя пошлют нахуй и ехидно напомнят чтобы ты не оставлял чувствительных данных в чате, потому что он будет изучен командой.
Любые из тех, что ты можешь правильно и достаточно быстро запустить. Начни с квена, 30а3 или 235.
Обкатал новые моешки
Немотрон не победить
Немотрон не победить
Что я имею ввиду: в отличии от того же air он прям пушит сюжеты, активно что-то подсовывает и не даёт заскучать, иногда выдаёт довольно креативные фразы будто понимает подтекст
Molodec. Наслаждайся, только, будь ласка, не спамь о том какой немотрон пиздатый. Мы уже все поняли.
Ламу скаута попробуй, тебе должно зайти.
Немотрон неплох, но он так-то кастрированная лама, а она сама по себе специфическая модель. Я после релиза самого первого мистраля уже ни одну ламу не могу юзать, чувствую в них какую-то неполноценность.
253 хоть?
А где-нибудь в РФ эти нейро-мини-пк есть?
Нашёл только https://megamarket.ru/catalog/details/mini-pk-tecno-mega-mini-gaming-g1-seryy-600023423437_739/ но это явно не то, а просто микросистемник.
Нашёл только https://megamarket.ru/catalog/details/mini-pk-tecno-mega-mini-gaming-g1-seryy-600023423437_739/ но это явно не то, а просто микросистемник.
Какие "эти"?
Кстати, я была ли лама4 так плоха?
Может там ситуация как с гопотой 120, просто чуваки не вложились в бенчмакс и все захейтили что полосочки ниже
Все захейтили потому что они весь релиз сделали мое, это сейчас тензоры выгружать научились и мое в трендах, давая смесь качества и скорости, тогда мое в локальном комьюнити реально воспринималось враждебно, так как требовало больше врам при меньших мозгах. Да, там был скандал с тренировкой модели под лмарену, но вообще говоря все модели под нее тренируют, лол. Ну и модель как обычно шизила на старых настройках ламы 3, в итоге щасрали и даже не стали заморачиваться. А когда подъехала выгрузка тензоров - то сразу и квен 235 подъехал, который просто объективно лучше. В итоге поднимать вопрос о реабилитации ламы никто не стал. А сейчас уже и гопота осс есть и глм аир, скаут морально устарел уже, как и твой немотрон.
>Какие "эти"?
а, не линканулось
ну, типа коробочки хуанга, или райзен аи-макс, мини-пк под нейронки вместо рига
>какие-то закономерности если они есть
Для этого юзают что угодно, кроме LLM. Впрочем, можешь попросить LLM написать скрипты для анализа, лол. Можно даже у корпоратов, данные ты ведь не отдаёшь.
Покупаю по кд A4Tech KV300H, держу запасную на случай поломки (как впрочем и мышь).
Аимаксов достаточно на газоне, дгх спарк вообще не похоже что бы хоть где то были
>газон
"Этот товар закончился"
А нет, нашёл. Впрочем, 250К, эт чот эребор.
Раза в два меньше бы... Ну ладно, посижу пока как сидел XD
Ну и желательно бы не газон/лохито, а DNS или что подобное чтобы с чеком и гарантией, мда.
А ты хотел за 10к? С такими ожиданиями на дгх за 3-4к усд можно даже не смотреть
Лламу захейтили частично незаслуженно. На тот момент большинство запускать ее не могли и из-за этого обиделись, а кто мог - ожидал нового ларджа а не вот это вот. Она в стоке может в рп, может даже в простое ерп, прилично отвечает на запросы.
Но ответы вполне обычные, там нет поведения как у квена со стремлением очень подробно излагать и объяснять, нет какой-то художественности (например) жлм, чтобы посты в рп казались приятными. Это в сочетании с изначально таким отношением интерес и убило, а потом стало поздно.
> даже самая пафосная механика ломается через пару лет
Просто не покупай игросральное сральное ведро и хуйту от фирм-однодневок на китаесвичах, какая-нибудь varmilo, das и подобные служат десятилетиями без нареканий.
Ищи в мелких интернет магазинах, там будет хоть какой-то чек и гарантия.
Свое IMHO я уже писал про нее выше по треду. Здесь:
как же все сложно. касательно этого
>Ты даже не написал для какой модели тебе нужен пресет.
я в первом сообщение указал свой конфиг. надежда была на то что может ту еще остались аноны обитающие на 8гб мусоре учитывая что когда я выпал из темы появились первые лмм которые на сяоми запустить можно и кто то на них даже обитал. и кто то из них кинет модель на которой сидит и присет. который в дальнейшем можно будет поковырять своими кривыми руками.
>Не говоря уже о том, что промпт чаще всего нужно писать самому.
первый раз слышу подобное если честно.
честно сказать я надеялось что за год который я был вне темы наконец то придумаю и адаптируют +- систему настроек ИСКАРОПКИ дабы такие глупые люди как я могли просто взять и пользоваться а те кто хочет пердолиться занимались этим отдельно. а тут какой то движ как на линухе.
там же можно сделать пикрил и оно выгрузит одним файлом текущий присет. а что и как там с файлами я даже не знаю...
имею штук 6 механик одна из которых вообще вроде 2008 года и все в рабочем состоянии. касательно того что что то отваливается попробуй или перепаять свитч или заменить на другой. добра анонче
>за 10к
За 110-130, бы ещё подумал. А так у меня ноут за 220.
У меня жопа горит с langfuse, требуется помощь.
Я - стажер devops, должен каким-то хуем настроить tracing запросов в LLMки. Положняк:
- VM с Langfuse, доменное имя в локалке настроено.
- Машинка с ollama
- LLM подключение установлено между ними, в playground запросы протаскиваются и ответ на них поступает.
- Моя Пека с venv питона, через которую я запускаю скрипт .py
Проблемы начинаются когда мне нужно сконфигурировать tracing, т.е. чтоб эти запросы можно было отслеживать в системе, собственно для чего она и нужна. Ключи сгенерил, раком встал, с бубном танцевал, под подушку заглядывал, но всё, чего я добился - прямой запрос к ollama и получение ответа на мой компудастер в сети, при попытке проброса инфы на langfuse, меня кроет ошибками подключения на пять страниц и сообщениями о том, что я поддерживаю СВО (openai в РФии не работает).
Вопросы:
1. Какого хуя он пробрасывает ключ-подделку, который по документации этих гандонов langfuse не используется для ollama?
2. Как написать простейший запрос, чтобы он оставил след в системе, то биш trace
3. Playground в Langfuse UI - модуль сугубо для тестирования и trace'ов по определению оставить не может? Меня второй день ебут этой просьбой "настрой tracing с playground'а".
Я - стажер devops, должен каким-то хуем настроить tracing запросов в LLMки. Положняк:
- VM с Langfuse, доменное имя в локалке настроено.
- Машинка с ollama
- LLM подключение установлено между ними, в playground запросы протаскиваются и ответ на них поступает.
- Моя Пека с venv питона, через которую я запускаю скрипт .py
Проблемы начинаются когда мне нужно сконфигурировать tracing, т.е. чтоб эти запросы можно было отслеживать в системе, собственно для чего она и нужна. Ключи сгенерил, раком встал, с бубном танцевал, под подушку заглядывал, но всё, чего я добился - прямой запрос к ollama и получение ответа на мой компудастер в сети, при попытке проброса инфы на langfuse, меня кроет ошибками подключения на пять страниц и сообщениями о том, что я поддерживаю СВО (openai в РФии не работает).
Вопросы:
1. Какого хуя он пробрасывает ключ-подделку, который по документации этих гандонов langfuse не используется для ollama?
2. Как написать простейший запрос, чтобы он оставил след в системе, то биш trace
3. Playground в Langfuse UI - модуль сугубо для тестирования и trace'ов по определению оставить не может? Меня второй день ебут этой просьбой "настрой tracing с playground'а".
И если я обратился не по адресу, сообщите на какую площадку разместить или в какой тред
Помощью тупым студентам нигде на дваче не занимаются. Если ты неспособен даже прочитать документацию, то о чём с тобой разговаривать?
В треде уже вечность не было анонов с 8 и 12 врам, не уверен что видел даже анонов с 16 врам
Интересно почему
Хотелось бы послушать как они терпят с голодухи пока нам сыпят модель за моделью
Интересно почему
Хотелось бы послушать как они терпят с голодухи пока нам сыпят модель за моделью
>ollama
не использовать ollam, сам себе злобный буратина
>12 врам
я
для дела - опенроутер / квен / дипсик, для души - мистраль, гемма, мое-квен, хуже они не стали от того что куча новья вышла
Нормально, катаем моешки, не жалуемся. Оказывается не стоило покупать 5090, и 5080 со своей задачей прекрасно справляется. А для всего остального есть жыжыэр-5.
Можно только посоветовать читать доки и разбираться как их прокладка работает. Также можно воткнуть llama-server вместо богомерзкой олламы, высоки шансы что твои проблемы с подключением к апи уйдут. И из-за кривости и странности апи олламы, и из-за непривередливости и похуизма апи лламы-сервера, которая сработает даже без половины пейлоада.
> меня кроет ошибками подключения на пять страниц
Проверь хотябы их причину, это оно пытается к опенам стучаться вместо твоего апи, или это другие сервера к которым нужен хуй.
Я эту документацию от начала и до конца прочитал, вдоль и поперек, эта хуйня тупо отказывается работать, а во всех гайдах, где предполагается локальный хостинг сервиса с LLMками, всё излагают как будто вы уже всё знаете, ни одного полного гайда от начала и до конца по этой хуйне нет. Как мне наебать эту помойку, чтобы он не отправлял запросы на их сервер или пропускал меня? В принципе есть впн, но захуя вообще он делает запросы если этот ключ нигде не используется по их же документации?
>Проверь хотя бы причину
Он точно долбится в openai, там прям:
openai.PermissionDeniedError: Error code: 403 - {'error': {'code': 'unsupported_country_region_territory', ... и прочая хуйня по списку }
Возможно он и в сервак долбится, посмотрю по логам, но web-логи разбирать я в рот ебал, но походу придется
Значит тут два варианта: ты или не установил в настройках/переменных среды/в конфигурации/командами использование кастомного апи адреса и ключ/модель, или они у себя где-то еще используют их апи для других задач и это нужно пресечь.
Давайте прежде чем пиздеть на корпов вы скинете хоть один случай когда чела посадили за слитые логи как он девочкам в трусы залазил тогда поговорим
А что там может быть когда нибудь будет так это всю жизнь можно протерпеть
А что там может быть когда нибудь будет так это всю жизнь можно протерпеть
Терпи. Мы тут причем?
Да ты то не терпишь имея 1/10 от корпов да ещё и квантованую на половину
10 к 1 вообще-то, если говорить про
>как он девочкам в трусы залазил
Ибо километровые джейлы к корпам ума им не добавляют.
>Да ты то не терпишь
Так меня все устраивает. Не я врываюсь с ноги в позе "ну давайте убедите меня", предлагая потерпеть всю жизнь
Мощнейший копиум что крох со стола тебе хватает
Ты просто пытаешься оправдать уже купленное железо
Понял. Спасибо, что открыл глаза. Что бы я без тебя делал?
https://blogs.microsoft.com/on-the-issues/2025/02/27/disrupting-cybercrime-abusing-gen-ai/
> They then altered the capabilities of these services and resold access to other malicious actors, providing detailed instructions on how to generate harmful and illicit content, including non-consensual intimate images of celebrities and other sexually explicit content.
> Finally, users then used these tools to generate violating synthetic content, often centered around celebrities and sexual imagery.
> Through its ongoing investigation, Microsoft has identified several of the above-listed personas, including, but not limited to, the four named defendants. While we have identified two actors located in the United States—specifically, in Illinois and Florida—those identities remain undisclosed to avoid interfering with potential criminal investigations. Microsoft is preparing criminal referrals to United States and foreign law enforcement representatives.
Правда непонятно, по итогу следствие будет идти только против проксихолдеров, или обычным кумерам тоже достанется, если до них США смогут дотянуться.
Ну и за онлайн-генерацию реалистичных процессоров нескольких людей уже посадили в США/Британии. На текстовые генерации конечно сейчас в целом всем насрать, но кто знает, что там ещё лет через 5 будет. Те кто в 2008 про ниггеров в твиттере шутил тоже не ожидали последствий.
>Что бы я без тебя делал?
Жил и дрочил. С подпиской на...
Напоминаю что я просто попросил хоть один пруф того чего от чего тут все так трясутся и дрочат на локалки, ты зачем то порвался и стал доказывать что тебя всё устраивает
Чтобы за буквы на которые ты дрочишь в уединении сажали это реально нужно в другой реальности жить
>ты зачем то порвался
В твоем воображении. Ноль эмоционального отклика вызвал твой наброс, мб долю иронии
> от чего тут все так трясутся и дрочат на локалки
Эти "все" с нами в одном треде? Ты придумал себе кого-то и с ними споришь?
>стал доказывать что тебя всё устраивает
Пахнет немотроношизиком. Есть у нас один юродивый, любит так набрасывать, по другому задавать вопросы не умеет. Собсна, на вопрос я твой ответил, так что можешь дальше терпеть как ты изначально предложил, свободен
Жду 6 пост от тебя как ты не порвался чтобы точно убедиться, пока что не уверен
Да идешь ты нахуй, пёс шелудивый.
Хотим и дрочим локалки ради одного и того же токена, только тебя, шлюху, забыли спросить что нам тут делать, иди заёбывай одноклассников своими тупыми вопросами.
Хороший мальчик
Мне либо основательно лезть в код и обрубать нахуй верификацию, вырезая этот шаг из системы, либо подставлять проксю, либо каким-то образом выключать её, тут одно из трёх, т.е. на провайдерах только внешниея внутренних настраиваемых не указано
Какая сейчас база, какими моделями анон пользуется из самого нового?
glm 4.6
MOE
https://huggingface.co/Qwen/Qwen3-235B-A22B
https://huggingface.co/zai-org/GLM-4.5-Air
https://huggingface.co/zai-org/GLM-4.5
Ne MOE
А нет нихуя нового, кроме мистралей.
Только заметил, а ведь все отзывы и отзыв в шапке про 235 квен то про первую версию, может поломали чего вот у нас и насрано в штанах
Насрано только у тебя. Терпи и не забывай сглатывать.

Закиньте ему очередной свежий рофел с долбоебом, слившим свой диплом с данными на ханипот, лень искать.
А потом напомните про уже привычную охоту на ведьм, когда за неугодные меньшинствам посты в твиторе N-летней давности людей увольняли с высоких должностей и потом не брали ни на какую нормальную работу.
Учитывая что это ты пришел сюда коупить с методичкой и аутотренироваться - кто терпит очевидно.
Ты таки глянь доки и обсуждения, возможно там просто достаточно как и везде переменную ос закинуть с кастом адресом оаи эндпоинта.
К тому что скинули обновление 235 https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507 https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507 и дипсик
В новой ухудшений особых не заметно. Может быть слопа чуть больше, но это нужно сесть и сравнивать, промптом убирается и достаточно умная.
https://huggingface.co/zai-org/GLM-4.6
Скоро и Эир.
Скоро и Эир.
Ахуенно, нечего добавить. Интересно, анслоты или кто-нибудь успеют до завтра кванты выпустить?
Да, я с бартовским на проводочке. Кванты крутятся-мутятся, через пару-тройку часов должны быть.
Анслотовские показались, чёт meh~
А вот эти, что анон принес, прям вин винский.
https://huggingface.co/ddh0/GLM-4.5-Air-GGUF
Написано 63гб вес скачал вес 70 втф

Давайте там пошустрее, и чтобы без говняка исправные.
Это невозможно. Чтобы 4 квант от разных поставщиков был "небо и земля". На уровне погрешностей какие-то отличия должны быть, а не так что ты для себя заново модель открываешь
>ты для себя заново модель открываешь
Наверное невозможно, не знаю где ты это у меня вычитал, что я модель заново открыл. Meh~ - это что то в духе - ну такое.
На анслотовских шиза перла рандомно, а тут только первое и второе сообщение свайпаешь и все идеально.
GLM-4.5-Air-Q8_0-FFN-IQ4_XS-IQ4_XS-Q5_0.gguf. Врамцельные страдания в общем, не забивай себе голову, вангую на нормальных квантах такой хуйни нет.
>вы скинете хоть один случай когда чела посадили за слитые логи
На форчах помню была тряска в свое время, когда слили логи с одной из проксей и сдеанонили любителей кьют энд фани, вплоть до адреса проживания. Да, это не то же самое. Но вот представь, у тебя есть работка, есть семья, мама тебя любит. И тут узнается, к каким именно девочкам ты лазил в трусики и что потом делал с ними дальше. Стресса и проблем не меньше, чем от облавы ментов. Даже если ты дрочишь на ваниль и предпочитаешь исключительно держаться за руки, держать личную жизнь подальше от публичного обсуждения - это нормальное желание.
Если возражаешь - сливай свои переписки и подкрепляй личными данными. Не посадят же, хули бояться?
>может ту еще остались аноны обитающие на 8гб мусоре
А что тебя не устраивает в пресете из под коробки? Поставь пресет какой нужен под модель типа chatML и юзай дефолтный промпт для neutral RP, а потом под свои интересы подстраивай промпт/карточку, хз или попробуй чето по лучше из моделей типа МОЕ-шек запустить в ОЗУ может тут не в промпте проблема а сама модель тебя не устраивает, хз
>там же можно сделать пикрил и оно выгрузит одним файлом текущий присет. а что и как там с файлами я даже не знаю...
Крч, я не несу ответственности за твоё моральное состояние, но вот всё что я нашел через удаленку по этому пути.
\Tavern\SillyTavern-Launcher\SillyTavern\data\default-user
Будет ли оно работать, понятия не имею. А малым проверять я не дам, им точно не надо видеть мои чаты.
https://mega.nz/file/bEllCRjQ#Rj9EKqNxX6fD8szD-LDVkkcltlOVB3bMpO7PEmY6Rjg
Пишет заебись, но блядский ризонинг невыносим в рп, высирает его на 1000+ токенов. Если пустые токены <think></think> в префил кинуть, то пишет заметно хуже. Вангую и Эир будет таким же. Даже Дипсик уже эти простыни победил, а тут всё дрисня такая. А ещё токенизатор без нормального русского, по слогам/буквам пишет.
>4 квант
Понятие растяжимое. 4 тут означает кванты основных слоёв, а всякие там мелкие слои (иногда очень важные) каждый квантует как Б-г на душу положит.
>и сдеанонили любителей
Эти самые любители хоть узнали, что их сдеанонили, лол?
Очень долго пердолил llama.ccp под свой дремучий макпро с 16g vram, вроде как запустился.
Llama-3.2-8X4B-MOE-V2-Dark-Champion-Instruct-uncensored-abliterated-21B - шиза
OpenAI-20B-NEO-CODE2-Plus-Uncensored-IQ4_N - тоже шиза
Gemma-3-27b-it-abliterated.q3_k_m - выдает связный текст но вешает систему или DE после 500 слов ответа с GPU Timeout Error.
Что тут не так?
Llama-3.2-8X4B-MOE-V2-Dark-Champion-Instruct-uncensored-abliterated-21B - шиза
OpenAI-20B-NEO-CODE2-Plus-Uncensored-IQ4_N - тоже шиза
Gemma-3-27b-it-abliterated.q3_k_m - выдает связный текст но вешает систему или DE после 500 слов ответа с GPU Timeout Error.
Что тут не так?
Это байт на логи с милыми и веселыми?
> шиза
Там сразу по названию уже понятно что треш, аблитератед гемма тоже неоче. Но почему она ломается - хз, памяти хватает?
спасибо анонче больше. поковыряем. сорри за тупой вопрос но настройки для 8b и 12b модели будут примерно одинаковы?
я же говорю тыкал немо микс оно шизит ну просто пиздец. присет для для dans я вообще нашло в какой то пизде и он сразу встал норм, только температуру скинул с 1 до 0.7. но хочу еще что то потрогать. я может быть и на том же немо микс остановился и не доебывал мимо анонов тупыми высерами в этот тред если бы залутал для него настройки на которых он не шизит.
спасибо что не прошли мимо и пытаетесь помочь аноны. сегодня я чет уже никакой, завтра опять качну немо микс и попробую подрочить настройки ну и отпишусь что как.
Да вроде смотрел чтобы загрузок у моделек было побольше, чтоб наверняка. А что попробовать тогда?
Даже если ограничить потребление vram до 8гб используя 20 слоев все равно роняет систему. На cpu работает, то там 1 токен в секунду.
Даже если ограничить потребление vram до 8гб используя 20 слоев все равно роняет систему. На cpu работает, то там 1 токен в секунду.
Блять, что это за хуйня, где технологичесские прорывы, ужатие 24b до 12b. Всё, золотая эпоха кончилась?
Какое тебе ужатие, иди кредит на оперативку бери.
У меня 36 гб, куда мне больше блять?
Заново загрузил, закинув еще что нашел.
https://mega.nz/file/2RlCSKZZ#_mdIJD5ws2Lf1_XNom59eihgAlfO9YJhdPGa_DtFya0
>спасибо анонче больше. поковыряем. сорри за тупой вопрос но настройки для 8b и 12b модели будут примерно одинаковы?
Со стороны это звучит так : а 95 бензин подойдет для моего V8 и авиационного турбовинтового двигателя от эйрбаса?
Надо смотреть каждую модель индивидуально. На мистрали одни, на коммандр другие, на снежного третьи, на ГЛМ четвертые.
Заходишь на страницу модели, там как правило есть базовые пояснялки в духе: temp-1; ChatML - это и используешь.
Сейчас MOE ебет без шансов в РП и ЕРП. Плотненькие всё так же пиздаты для более точных задач, а не поиска вторых трусов.
>32
А нужно 128 и я сейчас без капли юмора.
Мини-ПК сойдёт или нужно сборку с видимокартой?
Желательно с графическим адаптером. Но я ебу какие у тебя цели и что ты хочешь гонять? В принципе, в треде устоявшееся мнение что 24 ВРАМ и 64/128 РАМ идеальный вариант для вката. Но некоторым и на 16/8 норм, благо МОЕ работает на оперативной памяти.
Всё индивидуально. Как тебе написали, все таки потрать немного времени на то чтобы разобраться. Я понимаю желание запустить локалку и просто покумить, но так проще будет для тебя. А то опять прибежит токсичный вахтер треда с его: сраные ньюфаги, а вот я то огого, а вы нет, а еще я могу у себя отсосать в прыжке.
> сборку с видимокартой
Видеокарта в любом случае понадобится для обсчета контекста, иначе это будет неприлично медленно.
спасибо анонче, перекачал.
я имел в виду для одной и той же модели просто разного размера.
сорри за мое косноязычие
Наверное, а может и нет. Не знаю, тут где то геммолюбы бегают, надо на запах чего то цветочного идти, они точно знают. Там этих гемм вагон.

Никто тут не собирал нищесборку из нескольких подержанных майнерских карт и всего самого дешевого остального для ламм? Поделитесь опытом. Во сколько обошлось, что гоняете на ней, стоило ли или нет?
> А что попробовать тогда?
Начни с ванильного мистральсмолла который апрельский, он немного поменьше геммы, или гемму12б ванильную. Они будут выдавать адекватные ответы и ты сможешь убедиться что с инфиренсом все в порядке, а уже потом всякие шизомиксы качать.
> Плотненькие всё так же пиздаты для более точных задач
Ну как
Если это аимакс или аналог - пойдет.
>Ну как
Моешки огромные, возможно они и хороши в полных весах, но чёт сомневаюсь что их можно запустить рядовому мимокроку, когда они весят по 400 ГБ. А вот плотненькие уже другой коленкор.
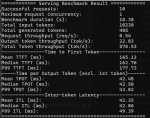
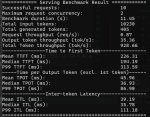
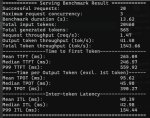
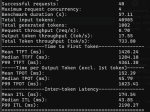
Получилось собрать вллм+тритон из форка под MI50 32G. Бенчи на пиках.
Везде gaunernst/gemma-3-27b-it-qat-autoawq читай гемма в 4 кванте (фп16 в 64 врам не лезет)
Везде gaunernst/gemma-3-27b-it-qat-autoawq читай гемма в 4 кванте (фп16 в 64 врам не лезет)
> Сейчас MOE ебет без шансов в РП и ЕРП. Плотненькие всё так же пиздаты для более точных задач, а не поиска вторых трусов.
Странный вывод. МоЕ и для технических задач хороши. Даже малютка Qwen 30B-A3B сопоставим с 32b плотным, многим даже больше нравится. И это при 3b активных параметров, остальное можно грузить в оперативу.
> Моешки огромные
Не все. Qwen 30B-A3B, GPT OSS 20b, Hunyuan 80B-A13B был и другие. И со временем их будет становиться больше, в самых разных размерных категориях.
> возможно они и хороши в полных весах
Какая-то дичь. Зачем в полных весах?
> но чёт сомневаюсь что их можно запустить рядовому мимокроку
GLM Air запускается в приличном кванте при 64гб оперативы и 16гб видеопамяти. Рядовой мимокрок сегодня вполне может обладать таким железом.
> А вот плотненькие уже другой коленкор.
Обрати внимание насколько меньше плотных моделей выходит в последнее время.

сап инференсач!
Посоветуй потребительскую материнку ( и проц) которые держат 128 Гб оперативы ДДР5.
Посоветуй потребительскую материнку ( и проц) которые держат 128 Гб оперативы ДДР5.
Тебе примеры уже хорошие привели мелких моэ, те действительно работают очень круто для количества активируемых параметров и быстры. Также моэ побольше можно относительно эффективно инфиренсить в комбинации врам-рам.
Выглядит что прилично скейлится с повышением батча, да и с одном не позорно вполне. На 40к просело само или из-за батча?

Это конец
Не нужон, гоняю нормальный 4.5, а не огрызок, довольно урчу.
Полтора человека таких как ты, даже те кто могут его поднять получают 4т. с и сваливают обратно на эир

>довольно урчу.
бе бе бе
приходи ко мне, сначала укушу, потом дам покатать модельку с меня пледик
В TQ1_0 даже меньше второго кванта квена, попробуй, чем черт не шутит
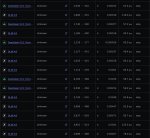
Кто запрещает в 100 т/с пользоваться им без квантов? Air действительно не нужен, потому что даже у обычной русский не идеальный, заметно хуже Дипсика, хотя пишет он посвежее Терминуса.
Ты урчишь довольно, но без должного уважения!
А тем временем кванты пока так и не подъехали да и работы еще до утра, так что тестировать только завтра или позже.
15т/с хватит всем.
Это пахнет как ловушка, это выглядит как ловушка, но разве можно сдержаться...
Ставь бабака самогон, будем слушать сабатон, катать глм.
Так хочется уебать свиноте за жирные набросы
Сидит сука мама риг купила и выебывается
Сидит сука мама риг купила и выебывается
>будем катать глм
Будем! Весь хуй в труху! Но потом...
>Ты урчишь довольно
Я урчу недовольно, т.к. пробую маверик и охуеваю, слой с экспертами в 4 кванте весит 10.2 Гб. 10, мать вашу, гигабайт. ап/гейт по 2.9, даун 3.5. Да и еще слои с/без экспертов чередуются, кумарит. С такой гранулярностью действительно только блеквеллы 96 гб нужны. То ли дело глм-чик, по 900 мб, все равномерно


Ай лол, там всего 47 слоев из которых ебанистических с экспертами только часть, и это на 400б. Они совсем ебанулись чтоли? Самая боль как оценивать кэш к этому всему еще.
Brutal, и это "3б лоботомит".
>она была не просто ... она была
Ммм, квенослоп. Там больше чем в половине фраз угадываются типичные квенопаттерны. Заёбывает не хуже мистральки. Даже лучше (быстрее), т.к. квеном я пользовался меньше.
Зай ну ты чего?...
Весь хайп 4.6 был из за эира, наебали так наебали, а ждать минорную обнову пол года уже такое себе
Весь хайп 4.6 был из за эира, наебали так наебали, а ждать минорную обнову пол года уже такое себе
https://www.reddit.com/r/StableDiffusion/comments/1nux1f0/setting_up_comfyui_with_ai_max_395_in_bazzite/
По сути все эти короботчки только под ллм-ки получается?
По сути все эти короботчки только под ллм-ки получается?
Сап, продаю старую пеку, планирую купить чисто рабочую станцию под нейронки на apu от ряженки, покупку гпу пока что откладываю на потом. Хочу 128Гб в двухканале на максимально возможной частоте. Что я себе могу позволить за 120-150к рублей сейчас? На какую скорость генерации(только мое, плотные не вижу смысла даже смотреть) я могу рассчитывать со всякими квен 235B, осс-120В и прочее. Стоит ли растягивать анус ради AI max компа за 200к, вроде окулинк док стоит не дорого, можно будет подключить внешние гпу по pcie 5.0.
> На 40к просело само или из-за батча?
Пока сказать не могу из-за
Как время будет продолжу с зарезанным тдп. Пока что вллм показывает хороший прирост в сравнении с жорой

Обожаю эти бенчмарки. 15b лоботомит лучше чем Kimi K2 1000b
- откуда у вас такие хорошие показатели?
- мы неправильно считаем
Господа, скажите плиз, что лучше для ерп, синтвейв или синтия?
>синтвейв
cинтия слишком припезднутая, там не совсем соя в классическом понимании, но явно байаса навалили от всей широкой души, причём с радикально-феминистическим душком
Эх, салага... Ты ещё столького не видел.
https://huggingface.co/ReadyArt/Omega-Darker-Gaslight_The-Final-Forgotten-Fever-Dream-24B?not-for-all-audiences=true
>навалили от всей широкой души, причём с радикально-феминистическим душком
Не так. Не смогли вычистить до конца. Это Гемма виноватая.
А как шизит именно? Если уходит в слоп то вероятно проблема реально в промпте, если шизит и просто чуш выдумывает возможно проблема просто в слабости модели если часто повторяется с одними и теми же токенами надо крутить DRY ползунок, если слишком ассистентно то повышать температуру или наоборот если он шизит слишком много выдумывая хуеты то понижать температуру?
Я еще не совсем омега для таких моделей..
Я потому и спросил, хотелось услышать вашего мнения. Я думал дело в картах с которыми я рпшу, но видимо действительно ассистента не до конца вытащили, потому что меня заебало это менторское говно которое очевидно идёт от ассистента.
На синтвейв можно пресет поставить от синтии, не будет траблов?
Эта хуйня не лезет в трусы с первого же сообщения? Не особо интересует повествование вокруг ебли, пресет от синтии ставить можно, не сломается?
Моё мнение - синтвейв. Сама синтия соответствует своему пику. Мрачная и унылая. Эдакая Ахматова под героином.
Если хочешь чистейшего первородного слопа без ебли с настройками, то что нужно. А если ты еще не искушен этим самым слопом, то просто залетит со свистом. Ты пишешь : нежно кусаю мочку уха.
Тебе в ответ простыня на 2000 токенов как тебя насилуют на диване.
>Эта хуйня не лезет в трусы с первого же сообщения?
Лезет. Она для этого и создавалась.
>Не особо интересует повествование вокруг ебли
Противоречие. То нельзя чтобы в трусы сразу лезла то повествование не нужно.
>пресет от синтии ставить можно, не сломается?
Нельзя. Другая модель.
Лучше напиши что у тебя за железо и для каких задач модель нужна, тогда и посоветуем.
>можно пресет поставить от синтии
И от стоковой геммы тоже.
Но вообще, если хватает РАМ, лучше уж запустить воздушного, даже в низком кванте. Он просто хорошо в РП пишет и все тут.
У геммоподелий, до ебки ГЛМом, было главное преимущество: они просто ебово следили за контекстом, понимали шутки, иносказательность, намеки. Ну и русский на гемме отличный был.
Просто сейчас третья гемма устарела. Она умница, действительно умница. Совевая? да. С хитрой цензурой ? да!
Но блджад, какая же умница.
Чувак, люди разные, кейсы разные. Я не люблю чистый кум, мне нравится чтобы он был иногда в повествовании. Слюнявый минет на привале после экспедиции, хлопок жо жирной жопе напарника с последующим аналом когда это дебил застрянет в пещере, сделать чайный пакетик пьяной эльфийке в таверне пока она лежит на скамейке. Но на всякий случай скачаю модель про запас если ты действительно говоришь что она не требует ебли с настройками.
Обьясняю, интеллект мистрали начинается с 24b q6, всё что до этого это слоп удачно совпадающий с контекстом. Это просто личные наблюдения не претендующие на истину. На той же скорости что и вышесказанные веса\кванты я могу запустить синтвейв в q4 c аналогичным качеством, но там другой слог, персонажи ощущаются по другому и да, гладкое, логичное повествование. Уж сорян, но за пол года на 12b немомиксе и двух месяцах на новой мелкомистрале уже начинает приедатся. Однако соглашусь, мистраль слишком универсальный и удобный, золотая середина на все случаи жизни.
>мистрали
Аir это вот это
А ебать, сорян, я думал ты мисталь имел ввиду, это ж порыв ветра с французкого.
>порыв ветра с французкого.
Холодный северный ветер емнп.
Практически все аноны, что перекатились на МОе сейчас или воздушного гоняют или жирноквенчика. Выбирай лагерь который нравится, но модельки хорошие. По сути в Q4 на 16+64ддр5 ты сможешь получить 10+ токенов. Теоретически можно и на 8 нормально запустить, но я не могу это утверждать. А то наговорю тебе и хуй там плавал, а не скорость.
Тут как бы преимущества: легкий контекст. 20к не больше 1.5гб. А то еще меньше. Хорошо следит за контекстом, сочно свайпается не ударяясь в повторения. Не требует ебли с семплерами. Промты жрет как не в себя. Следует прямым командам, не стесняется уходить в чернуху, не ебет голову нравоучениями. Да даже ризонинг нормально работает (но с цензурой, да, нужно изъебываться). Для меня никогда не запускавшего никаких здоровенных плотных моделек локально- это мана небесная. А то слушаешь как тут на гигамагнуме играли и завидуешь, по доброму так, но искренне, потому что ХОТЕТ так-же.
Единственный недостаток - это нерешительность в сдвигании нарратива. Но это фиксится префилом через autor note, в духе ТОЛКАЙ ПОВЕСТОВАВНИЕ ПИДОР.
>Чувак, люди разные, кейсы разные
Именно поэтому я у тебя и спрашиваю чё у тебя за задачи и какое железо, но ты отказываешься делиться конфигом так словно в нём зашифрованы коды запуска ядерных ракет. Если у тебя умещаются Гемма 27 в q4 и Мистрал 24 в q6, то ты можешь и 32 модельки уместить. Долгое время я по совету тредовичка жёско кумил на https://huggingface.co/bartowski/Star-Command-R-32B-v1-GGUF и https://huggingface.co/bartowski/trashpanda-org_QwQ-32B-Snowdrop-v0-GGUF с похожими что у тебя сценариями, попробуй. Но тебе правильно подсказали что если можешь запустить Эир то ничего лучше ты уже не запустишь на своём железе.
Да там ебать модель жирнючая, у меня 12гб врам, 32 рам и средненький проц. Я свои ноги обоссу если там будет меньше пяти т\с, так что не.
>12гб врам, 32 рам и средненький проц
Как ты тогда запускаешь Гемму 27 в q4? Какая у тебя скорость, два токена?
6 т\с
Если есть денюжка, а там много не надо, возьми себе 2 планки по 32/64.
Это не видюху за 200+ покупать, тут игросральные не больше 30-40к выйдут.
Ну ггвп тогда. Ничего лучше Геммы не запустишь. Мистраль и Гемма - твой приговор. Мб Квен мое вот этот зайдет https://huggingface.co/bartowski/Qwen_Qwen3-30B-A3B-Instruct-2507-GGUF но врядли. Кто его знает может ещё маленьких мое потом завезут.
другой анон. Обьясните че не так с этим квеном? типа неужели никаким промтом нельзя пофиксить его писанину?
А командера жирногона 111b норм юзать, если хочется плотную модельку по размеру с эйр? Или оно того не стоит, так как эир во всем лучше?
Не, в пизду, я и так на обновление пеки до этого уровня почти 80 к потратил за последний год, с меня хватит пока. Я конечно не ждун и не фантазёр, но тех. прорывы никто не отменял.
Спасибо за совет, но я зарёкся к квенам не притрагиватся.
Почему у вас нет бесконечной боли и отчаяния от того что вам насрали на лоб?
Эир неюзабелен пока не исправлена проблема с эхом
Эир неюзабелен пока не исправлена проблема с эхом
Потому что если следить за чатом, убирать эхо ручками, если тебе прям понравился этот свайп- все будет хорошо.
>что вам насрали на лоб
Ребёнок, ты заебал. Не транслируй свой экспириенс на других. Насрали в штаны тебе, насрали на лоб - тебе. У меня всё заебись с Эиром, птч руки не из жопы.
Опять шиз всёнормальщик пришёл
Все борятся с эхом, признают проблему, и только у него руки не из жопы каждый раз, только на словах правда
Все борятся с эхом, признают проблему, и только у него руки не из жопы каждый раз, только на словах правда
Че не так? Китайцы на китайской литературе тренировали. Знаешь такую? Это где победа чувств и поэзии над силами разума и логики. :)
Как пофиксить - да прямо промптом написать ему что-то вроде "avoid descriptive style of the classic literature novels and poetic references" как часть инструкций. До некоторого предела слушается.
Анончики, подскажите как правильно на llama-server разделить модельку на два гпу? 24 и 10 врам соответственно.
Ещё интересует вопрос, можно ли на одной держать саму модель, а во вторую напихать контексту?
Ну и самый последний вопрос, по гемме, сва фулл с квантованием до q8_0, или без (того и другого)? Не могу понять, вроде +- одинаково.
Ещё интересует вопрос, можно ли на одной держать саму модель, а во вторую напихать контексту?
Ну и самый последний вопрос, по гемме, сва фулл с квантованием до q8_0, или без (того и другого)? Не могу понять, вроде +- одинаково.
И ии этот тред самых достижений op залетай событий будь в и свежие по тредик последних прошлый новости области теме в в этой курсе скидываются.
Нет просто мы оба должны работать усерднее
Нет просто мы оба должны работать усерднее
Кто-нибудь пробовал использовать LLM для чатбота локального по скриптам? Т.е. основную логику несёт классический императивный скрипт, а LLM только наваливает креативных текстов, знаний и понимания происходящего. Т.е. вместо тупого автодополнения стандартного чата это всё проходит какую-то логику.
Например, менеджмент контекста:
1. Вы пишете что-то типа "мур-мур киска моя".
2. Нейронка определяет сразу "это ролевая игра".
3. Скрипт заполняет контекст ролевым промптом.
4. Через какое-то время вы пишете "напиши код..."
5. Нейронка определяет "это практическая задача".
6. Скрипт бросает весь ненужный ролевой контекст.
7. Скрипт вносит инструкцию "отвечай вдумчиво..."
8. Нейронка теперь фокусируется на задаче...
Т.е. чтоб минимизировать ручную настройку чатбота.
Потянет ли такое использование MoE моделька?
Например, менеджмент контекста:
1. Вы пишете что-то типа "мур-мур киска моя".
2. Нейронка определяет сразу "это ролевая игра".
3. Скрипт заполняет контекст ролевым промптом.
4. Через какое-то время вы пишете "напиши код..."
5. Нейронка определяет "это практическая задача".
6. Скрипт бросает весь ненужный ролевой контекст.
7. Скрипт вносит инструкцию "отвечай вдумчиво..."
8. Нейронка теперь фокусируется на задаче...
Т.е. чтоб минимизировать ручную настройку чатбота.
Потянет ли такое использование MoE моделька?
В telemate такое можно реализовать если тебе комфи-интерфейс еще не снится в страшных снах.
>Потянет ли такое использование MoE моделька?
Потянет, что за вопрос, она и без такой обмотки тянет, а тут ей гораздо легче дышать станет.
Нюничка приди пресетик принеси
Почему вообще в треде про локалки пресеты это какая то сакральная хуйня которая передаётся из рук в руки. Нельзя сделать ссылку на архив с пресетами в шапке?
Контекст идёт на первую, порядок и распределение можно менять аргументами. Читай доку в репе жоры, там всё доходчиво
Сделай
Иди нахуй, бабкин внук.
Классика
В чём проблема попросить ИИ-ассистента сделать?
Он по пидорски, по еблански сделает.
Хуй.
Потому что проблема не в пресетах, делиться не жалко, вон я буквально чуть ли не бекап таверны скинул выше.
Проблема в другом: если ты мимими, то в тред набегают асигодети, которые требуют. Они не пишут:анон, будь ласка, сделай пресет,а в обмен я сделаю X. Они требуют. А если начинаешь вести себя как токсичный гондон, тред скатывается в хуиту. Баланса нет, хочется сидеть и обсуждать ЛЛМ, делиться найденными фичами, а не находится в состоянии перманентного флейма или гейткипа.
>Почему вообще в треде про локалки пресеты это какая то сакральная хуйня
Потому что приносят в тред название моделей, нахваливают. Аноны пробуют, у них не получается, жалуются в треде, что опять говно принесли. В ответ на что первые аноны совершают манёвр: "это вы просто неправильно готовите". Вот теперь аноны, у которых модели "говно" и хотят попробовать с теми самыми секретными пресетами от анонов, у которых всё хорошо. Вдруг и правда хорошо? Кто не хотел бы хорошо?
>Например, менеджмент контекста:
Тебе настолько лень переключить персонажа в таверне? Она конечно ужасно неудобна, но не настолько же.
Я не шизофреник.
Буквально промпт Roleplay - Immersive в таверне лучше чем полотна от гичан или короткого промпта нюни на больших моделях
Буквально промпт Roleplay - Immersive в таверне лучше чем полотна от гичан или короткого промпта нюни на больших моделях



чисто логически мне нужно дергать присеты под ламу? а в другом тюне написано что надо ставить chatml. блядь я уже нихуя не понимаю.
с одного из присетов проиграл в голос
>Brutal, и это "3б лоботомит".
>квенослоп
Перейдя с 12б джеммы3, лол, с 12б!! Я этот квенослоп просто прочувствовал. Столько лупов и галлюцинаций не помню даже на мистральке древности. Ну да, дохуя база данных, датасет жирный. Знает то, чего не знают некоторые, но алгоритмы дня говна. Не можен ни в стих, ни в рифму, не знает павила лингвистических приёмов сложней прозы школьника из 1 класса. Честно скажу, гигачат 20б его просто размазывает нахуй.
Ща все пойдут закупать рам для мое, цены на 3090 падают, берем себе 4 и довольно катаем мистраль до конца жизни
>чисто логически мне нужно дергать присеты под ламу?
Для неморемикса c твоего пика? Думаю там нужен мистраль потому что мистраль немо - базовая модель для этого микса, если в описании не сказано иное.
>а в другом тюне написано что надо ставить chatml
Делай как сказано.
>довольно катаем мистраль
Вымазываем ебало слопом как свиньи и хрюкаем. Поправил, не благодари.
Маняквант под систему 128рам 24 врам
https://huggingface.co/Downtown-Case/GLM-4.6-128GB-RAM-IK-GGUF
https://huggingface.co/Downtown-Case/GLM-4.6-128GB-RAM-IK-GGUF
> Omega-Darker-Gaslight_The-Final-Forgotten-Fever-Dream
YOU FOOL, THIS ISN'T EVEN MY FINAL FORM!
> всё что до этого это слоп удачно совпадающий с контекстом
И выше тоже, лол.
Это совсем разные модели, эйр моэ будет работать гораздо быстрее а коммандер плотный и должен быть умнее-внимательнее, их нельзя напрямую сравнивать.
> проблема с эхом
Хуехом, опять этот впечатлительный ребенок.
-ts 24,10 посмотри как ложится и скорректируй. Контекст каждого слоя идет рядом с этим слоем, если модель равномерная то и он распределится равномерно, то что все скидывает на первую гпу уже давно нет.
База
> гигачат 20б его просто размазывает нахуй
Не ленись, принеси такое же от него.
Они и для моэ пригодятся, все правильно.
Iq кванты сильно замедляют мое, нужен 2_K_S или 2_K_M для нормальной скорости.

Я потестил синтвейв, пиздец, как же эта тварь пытается писать и пишет за меня, я ебал. Куча инструкций [пидораска ду нот врите фо усер] -"А бля, иди нахуй, мне похуй на твои ебаные иструкции, я буду писать за тебя, я же тюн геммы блять, я ассистент живущий своей жизнью."
Поражённый самец вновь уходит на мистраль.
Поражённый самец вновь уходит на мистраль.
> ду нот врите фо усер
Плохая инструкция. Не оправдываю шизомердж, но высока вероятность что проблема в ней.
Аноны, пробуйте ролплей пресеты, отзывайтесь, нас наёбывают
Блять чел я рофлю, я не настолько даун чтобы давать такие инструкции. [(Do not write for {{user}}) в самой карте, в заметках автора, в систем промпте. Мне себе татуировку на жопе выбить чтобы она работала? Она поначалу пыталась проталкивать по одному предложению в середине сообщения от моего лица, а на 70 сообщении вообще ёбнула целый эпос за меня нахуй на 100 токенов. Мистраль хоть и глупенький но за меня никогда не писал.
>Она поначалу пыталась проталкивать по одному предложению в середине сообщения от моего лица, а на 70 сообщении вообще ёбнула целый эпос за меня нахуй на 100 токенов.
Как именно это выглядит? От лица юзера или персонажа юзера? В первом случае виноваты стопстринги, во втором - инструкции.
>Do not
Попробуй слово "avoid" вместо "do not".
Либо инвентируй фразу полностью.
Типа такого:
>Avoid writing from {{user}}'s point of view.
>Write only from {{assistant}}'s point of view.
Не уверен, что сработает, но может помочь.
>лень переключить персонажа
Иммерсивность страдает, понимаешь?
Хочу с виртуальной тяночкой общаться, а не просто генерировать имитацию общения через нейросетку. Полностью забыть о настройках, контексте и т.д.
Вот если вспомнить character.ai из 2022: там не было никакого ограничения на размер чата, хотя LLM там наверняка имела очень короткий контекст. Какой-то анонимус вообще 60 тысяч сообщений в одном чате написал, и для него этот персонаж имел одну и ту же стабильную личность (пока LLM на c.ai не поменяли). Хотелось бы повторить те ощущения, без возни с техническими параметрами выбранной LLM.
ChatGPT в веб-интерфейсе что-то такое использует.
А что тебе мешает сейчас общаться? Настрой в таверне суммарайз каждые N к контекста(только правильно настрой) и общайся сколько влезет.

крч по итогу дернул настройки для чат лм. а настроек для пикрила я так и не нашел. покрутил те параметры которые были указаны на странице модели но чет особой разницы не увидел если честно.
может у кого будут идеи что тут еще покрутить? модель если что NemoRemix-12B
может у кого будут идеи что тут еще покрутить? модель если что NemoRemix-12B
Квант эира Q4_K_M от анслот/бартовски вмещает 32к контента
Квант Q8_0-FFN-IQ4_XS-IQ4_XS-Q5_0 будучи на 4гб меньше вроде вмещает 20к контекста
А это точно того стоит?
Квант Q8_0-FFN-IQ4_XS-IQ4_XS-Q5_0 будучи на 4гб меньше вроде вмещает 20к контекста
А это точно того стоит?
Эммм.. вут?
Игнорю твои посты и намеренно не даю нормальные ответы. Это точно того стоит.
Не разбираетесь так не пишите
UPD: Я просто добавил слой на карту который держал эти 12к контекста и забыл об этом, вмещает столько же
Кажется более менее осознал что делать, мне к своему батнику нужно будет добавить всего две строчки.
--split-mode layer
--tensor-split 3,1 (нужно будет заменить на подходящие мне)
Не совсем понял как работают эти циферки в конце, точнее я понял что 3 отвечает за gpu0, а 1 за gpu1, но вот значение этих цифр не совсем ясно, типо 3/4 и 1/4 всего размера модели соответственно?
А ещё можно как то сделать чтобы окошко цмд не закрывалось при возникновении ошибки? Я ж даже не успел узнать где я там напортачил.

Мистер жирнич, ради девятерых, хватит уже набрасывать.
>хватит уже набрасывать.
>врывается с аватаркой
ну какой же ты дебил утка
> Т.е. вместо тупого автодополнения стандартного чата это всё проходит какую-то логику.
Всегда, при любом промпте все проходит через какую-то логику. Если использовать модель с ризонингом, ее можно отслеживать.
> Например, менеджмент контекста
> ...
У меня есть карточка-ассистент, с которой я и задачи программирования решаю, и проект обсуждаю, и просто болтаю-рпшу. Промпт минималистичный, поделен на два блока: если юзер говорит про техническую проблему, то...; в противном случае продолжай рп. Работает наверняка не так круто, как если бы было три отдельных карточки, но меня устраивает. Тоже хотел общее решение для разных сценариев. Подружил с макросами: моделька всегда знает, сколько сейчас времени, какой день недели, дата, сколько времени прошло с последнего сообщения. Информация автоматически подтягивается. Если долго что-то решаем, в какой-то карточка сама может переключиться на рп и предложить отправиться спать. Если пару дней ничего не делал, будет ругаться когда вернусь и напомнит, что мог бы успеть больше. Такие интеракции добавляют живости какой-то, хоть умом-разумом и понимаешь, как это устроено.
> Т.е. чтоб минимизировать ручную настройку чатбота.
Как минимум всегда приходится редактировать чат и быть модератором для ллмки. От этого не уйти, разве что смириться с ненужным в аутпутах.
Глупая, глупая мелкобуква.
~nya ha ha ha~
{{user}} гладит кошку по голове.
Нас кинули и обоссали
Весь тред в моче с ног до головы
Сидеть нам без моделей еще месяцы
Весь тред в моче с ног до головы
Сидеть нам без моделей еще месяцы
Нищету, лимиту ебаную душат, огромные яйца глм 355 висят над нами, а нам только волосню с них соскрябывать и причмокивать
>все проходит через какую-то логику
...которую навязали разрабы этой модельки.
Тем более что LLM только отвечает на запрос - у них полностью отсутствует инициатива. Скриптом можно создать инициативу для чатбота, теоретически... Но, наверное, зависит от мозгов самой модельки...
>всегда приходится редактировать чат
>От этого не уйти, разве что смириться
Это значит, что логика обработки контекста у LLM не нравится тебе или не подходит под твои задачи. Если прописать нужное поведение в скрипт на Python, то, теоретически, возможно автоматизировать всё это.
>А что тебе мешает сейчас общаться?
Я только планирую компьютер под это дело купить.
Ну сделали бы они 190б, ладно 280б чтобы у геймерских пк хотя бы 2 квант влез, что изменилось бы?
Душат, нарочно 100%
Душат, нарочно 100%
Слушай. Почему ты не можешь собрать весь свой поток мыслей и выдать его одним сообщением?
Несешь полную чушь, сначала хотел было развернуто ответить, но это какой-то ужас. Ты буквально не понимаешь о чем сам же и говоришь, подтверждая это финишным Я только планирую компьютер под это дело купить.
И смешно и страшно от таких залетышей.

>Не ленись, принеси такое же от него.
Не пробил защиту гигачата ни одним джейлбрейком, зато яндекс и без джейлбрейка работает, но плоско. Ну и 8б это поржать чисто, больше у них нет в доступе. Вообще гигачат и без взлома жопы иногда такую чернуху выдаёт, но нужно долго контекстом манипулировать.
Опять всё делают под апи
Эир это как гемма, огрызок от гемини
Отличие лишь что ты типа можешь запустить это локально имея квантовый суперкомпьютер
Никогда нам не дадут дышать
В выхлопе жоры в начале перечисляются устройства
- гпу0
- гпу1
- цпу
Доли тензорсплита суммируются и целое делится на части. Если поставить 1, то всё уедет на первое устройство, если 1,1,1 равномерно в все 3 устройства
Анон, я даже под седативами, сейчас, выдаю более осмысленный текст. Еле понял, но кажется суть уловил.
>Эир это как гемма, огрызок от гемини
Довольно странно сравнивать среднюю МОЕ и корпосетку. Ты не получишь бесплатно что то уровня корпоративных моделей просто так. В них(нейронки) вливаются миллиарды, а бабло надо отбивать.
>Отличие лишь что ты типа можешь запустить это локально имея квантовый суперкомпьютер
16+64- это обычный игровой ПК. Я искренне не понимаю проблем.
Большой ГЛМ запускать тяжелее, но тебя никто не заставляет покупать 2ТБ серверной ЖыЖыЭр.
Крч, анон из ациг, расслабь булки. Когда ты универ закончишь и будешь работку работать, модельки станут еще лучше, а то и очередной революшн произойдет. Не забивай ни себе, ни другим -головы.
мира.
> Я искренне не понимаю проблем.
Он шитпостер, которому нечем заняться. Игнорируй.
>Иммерсивность страдает, понимаешь?
Эм... Вут?
>5. Нейронка определяет "это практическая задача".
>6. Скрипт бросает весь ненужный ролевой контекст.
И теряет любую личность. По моему, это как раз и есть нарушение погружения.
>Я только планирую компьютер под это дело купить.
Lol, занавес.

Я сильный? Я сильный. Я матёрый? Я матёрый. Я не знаю, что такое сдаваться? Я даже не знаю, что такое матёрый. Я получил от узкоглазого официальный бекенд хуавей для инференса на атласе, который умеет в INT8. Кроме прочего я нашёл фронт с контейнером, который умеет удобно его эксплуатировать. Сейчас всё это накачу и попробую протестить. Не поминайте лихом.
Мы запомним тебя!
> Do not write for {{user}}) в самой карте
Вот это оно и есть. Особенно если где-то присутствует отступление от разметки, наоборот сподвигнет модель срать таким. А если там буквально for {{user}} то вообще рофляново.
Даже простые изменения как предлагает сработают лучше если в других местах не насрано, они по смыслу другие и будут восприняты лучше.
На самом деле конкретно это не нужно. Сделай карточки девочки-ассистентки без чрезмерно подробного описания, и просто общайся с ней. Предложишь пообниматься или прогуляться - получишь романтический рп. Запросишь написать код - волшебный йокай материализует "клавиатуру с экраном" и выдаст тебе код. Попросишь что-нибудь объяснить принципиально - чар сначала расскажет, а потом "создаст в воздухе волшебную схему", которая в виде графов тут же будет отрисована в mermaid если не поленишься поставить плагин для таверны, уровень иммерсивности зашкаливает.
Современные ллм уже достаточно умные и никаких сприптов не нужно, главное чтобы в промпте не было ничего что противоречит этим действиям. Минималистичной карточки типа "чар - волшебная девочка лисичка из бурятской мифилогии и лояльна к юзеру" достаточно.
С этим справится и малый мистраль, но чем крупнее модель тем более качественные ответы и более внимательный отыгрыш ты получишь.
Все верно, нумерация устройств как другой анон подсказал, остальное в пропорциях. Указанные цифры нормируются на сумму и потом все распределяется в пропорции, удобно оперировать объемами врама, но можно как ты описываешь 3,1. Там если что float а не int, 3.5,1.0 будет работать.
Ай лол, хорош. Но квен таки лучше справился.
Давай анончик, всем тредом за тебя болеем.
Кто знает поясните пж, почему у гопоты-осс такой быстрый промт процессинг? Не понимаю. Типа потому что задействованных одновременно параметров мало (6b)?
Хотя я вот ещё Qwen 30b запускал, там 3b задействованных и процессинг гораздо медленнее. Загадка.
MXFP4
Gemma3
Эх, как же хочется уже 4ю
Квен 235 ложит на лопатки все что меньше него, при этом запускается на 24 гб врам на 12 т.с.
2_k_s вообще-то
ну это меняет дело дыа
Только для русика
На английском эир в 5 кванте лучше
Я хуею с того как за громкими словами скрывается
> модели, квантованные до 0,58 бит, на кофеварке с подкачкой на микроволновку
Старшая модель в любом кванте начиная со второго ложит на лопатки 16-битку любой мелкой модели, которая в два раза меньше по параметрам. Квен 235 во втором кванте ложит 16 битку геммы 27б. Гемма 27б во втором кванте уничтожает 16 бит немо 12B, немо во втором кванте положит 16битный 3б квен и т.д.
Да, она должна быть потенциально хороша, особенно если будет версия покрупнее. Как будто бы по времени уже скоро должна выходить.
Если не случился кейс в котором второй квант залупился-заслопился, а другая модель смогла пропердеться и продолжить. Но такое нечасто.
Анончики, можете посоветовать какую модель для ерп в таверне? Сейчас сижу на Magnum Diamond-24B q4km - слишком плоская какая-то моделька, "без фантазии", как-то слабо двигает сюжет, словно через каждые 2 сообщения ей нужно давать направление, в какую сторону двигаться.
Попробовал MagistralSmall 2509 Q4_K_M - остался недоволен. Путает происходящее. Отвечает абсолютно однотипно как-то и все что может - так это поддакивать на происходящее.
Попробовал MagistralSmall 2509 Q4_K_M - остался недоволен. Путает происходящее. Отвечает абсолютно однотипно как-то и все что может - так это поддакивать на происходящее.
Конечно можем. Сейчас я свой хрустальный шар достану, твоё железо почувствую. А потом мы проведем в треде ритуал призыва гигашиза, объединившись в риг и он ответит на все твои вопросы. Ведь шапки нет, обсуждения в треде нет. Тут только магия поможет, не иначе.
Я думал, что указание моделей уже дает какое-то представление о том, на каком железе я сижу. Извини, если для тебя это оказалось сложным.
>Извини, если для тебя это оказалось сложным.
Никаких проблем, анон. Вот тебе какие то модели.
https://huggingface.co/miqudev/miqu-1-70b
https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct
Ну а если без рофла, то в шапке все что есть, мое обсуждают выше. Читай, блять, тред. Ничего прям wow из мелких не выходило.
Всё то-же. Гемма, мистраль, комманд-р(стар-коммандр)
>Я думал, что указание моделей уже дает какое-то представление о том, на каком железе я сижу.
Первые несколько месяцев что я юзал таверну и ллмки в целом, сидел на 22б моделях. Всё это время мог сидеть на 32б.
>Извини, если для тебя это оказалось сложным.
Сообщать своё железо это тоже самое что корректно задать вопрос. Какой вопрос такой ответ. Ну и учитывая что ты ещё и залупаешься на добрую иронию без оскорблений в свой адрес встаёт вопрос а нахуя вообще тебе отвечать? Дрочи свои автоответчики дальше.
Здравствуйте.
Пользуюсь пресетом на эир который тут кидали тредов 20 назад, но в последние недели почему то не очень доволен результатами, будто что то сломалось, что ли.
Появилось ли что-то лучше?
Пользуюсь пресетом на эир который тут кидали тредов 20 назад, но в последние недели почему то не очень доволен результатами, будто что то сломалось, что ли.
Появилось ли что-то лучше?
Здравствуйте, немотроношиз. Нюня не пришлёт свой пресет, идите нахуй.
Никто и никогда не скидывал никаких пресетов на Эир бтв.
Ну, а я вот понимаю, что не могу сидеть на чем-то выше, чем те модели, которые указал.
>Ну и учитывая что ты ещё и залупаешься на добрую иронию без оскорблений в свой адрес встаёт вопрос а нахуя вообще тебе отвечать? Дрочи свои автоответчики дальше.
Я не залупался на "Добрую иронию". Покажешь пальцем где?
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ChatML ставь. Обсуждали жеж. Семплеры не меняй. И свайпай почаще.
То что ты хочешь, от локалки ты получишь либо пердолингом, но судя по тому что тебе не хочется пердолиться то твой единственный выход это покупка API корпосеток. Будет тебе и AI girldfriend и ассистент в одном лице без всякого пердолинга и суммарайзов.
А если попросить его не по пидорски и по еблански?
Ну чет не сильно пока падают.. да и врам к раму тоже никогда лишним не будет что бы активно перестать закупать видюхи..
>С этим справится и малый мистраль
Mistrall-123B я надеюсь? А то хз какой код можно требовать от 24b да еще и бурятской девочки-лисички в одном лице...
А ты точно темплейт поставил правильный для модели? Типа вдруг там надо не chatML а что-то другое для модели, это может быть одной из причин почему модель полностью забивает болт на твои инструкции или забывает их со временем.
top K 20-40? У тя ноль ваще я хз оно типа как ваще работает? Наверно выдает либо шизу либо однотипную хуйню? Я хз если что
>123B
>код
сайта-визитки разве что
>а тут какой то движ как на линухе.
АРЯЯЯ ВЫ ПРОСТО ГЛУПЫЕ НЕ МОЖЕТЕ ДОКУМЕНТАЦИЮ ПРОЧИТАТЬ ТАМ ВСЕ НАПИСАНО
>первый раз слышу подобное если честно.
тож удивился
сам универсальный пресент вроде от жоры где прям написано что на много чо подходит а не только клод и гапата которых нет в локале



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: