



Квены все в xml, но к ним полагается свой парсер что позволяет адекватно разбирать сразу множественные вызовы и переводить их в популярный формат. У 480 и 30 одинаковый формат, мелкая модель предполагается для работы драфтовой к большой.
> У всех моделей команда сразу выполняется, у квен-кодера-30б в начале начинает писаться xml-код, а в середине команды он догадывается и дальше уже выполняет команду.
Это похоже на некорректную работу парсера. Если пускаешь через llamacpp то он не способен на 100% обработать, есть темплейт который в целом работает хорошо, ищи в прошлых тредах.
Кстати, а может над теми затычками в статье зря смеялись. В турине сильно бустанули псп на каждый ядерный блок, если брать не самое дно а чуть выше то он уже полностью или близко к этому способен утилизировать 12 каналов.
В жоре наконец залили правки по оптимизации мультидевайсных рпц серверов. Вытаскивайте свои майнерские материнки и бегом проверять https://github.com/ggml-org/llama.cpp/pull/16276

Прямо как твои посты.
база треда: ниже Q4 жизни нет
> Это похоже на некорректную работу парсера. Если пускаешь через llamacpp то
Понял, спасибо, проресерчу этот вопрос.
Можно конечно, но не буду же я агента писать, тем более я уверен что всё уже сделано до меня.
Да, вчера уже натыкался на метод с --grammar-file, попробовать не успел, потому что не совсем понимаю как его прикрутить к текущему webui с llama.cpp. Собственно, оно в том же треде что и мокрописька.
Но посмотрим, это всё не так сложно.
Пробовал и cline и roo и даже continue, в которой якобы с 19 августа есть поддержка gpt-oss, если судить по гитхабу. Но нет.
Проблема не в агенте, а в том что gpt-oss очень долго пиздили сапогом чтобы она не работала с чужими тулингами.
Оказывается grammar тоже подкладывается очень просто.
Да, теперь всё работает. Не так же плавно как если были бы нативные вызовы, но всё равно, работа пошла, только кликаю далее а проект чинится и собирается.


> В турине сильно бустанули псп на каждый ядерный блок, если брать не самое дно а чуть выше то он уже полностью или близко к этому способен утилизировать 12 каналов.
я не понимаю, как они из 36/72 гигабит в секунду получают 100 гигабайт в секунду, но в интернетах пишут
> With GMI-Wide, a single CCD can achieve 99.8 GB/s of read bandwidth
2 коре комплекса, то есть 2 core die, не могут превысить 200 гигабайт в секунду, так что надо брать 6 CCD и выше, чтобы получить все теоретические 600 гигабайт в секунду.
Вот и отлично. =)
Теперь найдите мне решение для Qwen3-Coder-30b, а то мне самому лень искать. хд
Попробую эту штуку, отлично.
На фоне бесплатного Qwen3-480b-Coder от клауд.ру смешно, конечно, но пусть будет, мало ли.
> поддержка gpt-oss
Может она заключается просто в специфичных промптах и предполагает что бек уже займется адаптацией под конкретную модель?
А насчет чужих ты зря, модели всегда лучше работать в том режиме как ее учили. Исключения для рп но для функциональных вызовов и точных результатов так.
В убабуге же, кстати, заявлена поддержка оаи вызовов. В итоге та штука не запустилась и решил так?
> как они из 36/72 гигабит в секунду получают 100 гигабайт в секунду
Какая-то бессмыслица, наверно подразумевается что это на линию а линий несколько. Или хуй знает что имеют ввиду, так бред какой-то.
> В убабуге же, кстати, заявлена поддержка оаи вызовов.
а в гпт-осс - нет
https://cookbook.openai.com/articles/openai-harmony#function-calling
Модель ждет свой формат, ей нет дела до вызовов по апи к беку что ее хостит.
> Какая-то бессмыслица, наверно подразумевается что это на линию а линий несколько. Или хуй знает что имеют ввиду, так бред какой-то.
хз я в нескольких местах видел это число 100 гигабайт в секунду на CCD. возможно кто-то один хрукнул бред от балды и остальные растащили по всему интернету
Мета на сегодняшний день это 2 квант больших моешек - дёшево, важнее всего, быстро, и умнее всего что может быть на плотных
Заранее извиняюсь за чересчур размытый вопрос.
Я не фанат локалок, но предпочитаю иметь несколько штук на всякий случай, если с интернетом что-то случится.
У меня сейчас скачаны мистраль смол 24б, квен моэ 30б-а3, синтия 27б
Это актуальные ллм, или стоит их заменить на что-то поновее?
Я не фанат локалок, но предпочитаю иметь несколько штук на всякий случай, если с интернетом что-то случится.
У меня сейчас скачаны мистраль смол 24б, квен моэ 30б-а3, синтия 27б
Это актуальные ллм, или стоит их заменить на что-то поновее?
> Это актуальные ллм, или стоит их заменить на что-то поновее?
Смотря какое железо, какие задачи. Если есть хотя бы 16гб видеопамяти и 64гб оперативы, можно запускать GLM Air. Остальное в целом актуально, если Мистраль 3.2.
Можешь ещё гопоту мелкую скачать (gpt-oss-20b). И квен чекни, чтобы последний был, они его обновляли.
Спасибо!
Держи в курсе.
Как выше советовал, загрузи еще осс 20 и воздух, да.
А так, же осс 120, гемму 27.
И не забудь пару мелки. Зачем? Не знаешь с каким железом окажешься в будущем. Потому допом грузани:
гемму3 12, гемму 3н е4, квен 14, квен 0.6, SmolLM3-3B.
Ну и сам поищи что-то допом. Мне нравится пару моделей двух летней давности, по факту хуета и анону не нужны, но мне нравится.
Фига себе
Внимание вопрос, а почему такая большая разница в скорости у gpt-oss-20b-MXFP4 и gemma-3-27b-it-Q3_K_S?
Модели ведь схожи по размеру. Но разница в скорости раз в 10.
Модели ведь схожи по размеру. Но разница в скорости раз в 10.
Moe
> почему такая большая разница в скорости у gpt-oss-20b-MXFP4 и gemma-3-27b-it-Q3_K_S?
Гемма - классическая, привычная нам плотная модель, которая одновременно задействует все свои параметры (27b в случае данной Геммы). GPT OSS - МоЕ модель (Mixture of Experts), которая одновременно задействует только часть параметров (в случае 20b версии 3.6b, в случае 120b - 5и). Упрощая, можно сказать, с точки зрения скорости это то же самое, что запускать 3.6b модель.
Так это MOE такой выигрыш даёт. Наглядно, ничего не скажешь.
Ну слушайте, мне нравится gpt-oss-20b, но контекста в 128к для чего-то серьёзного не хватает.
Вчера часа три пыталась мне собрать мой старый проект из VS Code с использованием трёх либ со статической линковкой и просто наглухо завязла в зависимостях.
Qwen выглядит поумнее, быстрее приходит к нужным заключениям и сразу смотрит в корень, но за то время пока он выполнит одну команду oss успевает выполнить 10 запросов и сделать то же самое и даже больше.
Чего в теории ждать?
Что еще могут улучшить?
Хорошо бы было 20б активных параметров вместо 12
Что еще могут улучшить?
Хорошо бы было 20б активных параметров вместо 12
Если что-то случиться то тебе будет не до ллм.
Для случая временных перебоев двачую остальных что модели лучшие в своем классе. Если железо позволяет то стоит скачать самые жирные моэ, которые смещают твоя рам, можно использовать вместо гугла.
Удивительно что она в таком контексте вообще ориентироваться может. Смотри в сторону оптимизации запросов и сокращения задействованного контекста. Обычно в таких случаях запускают суб-агентов, которые анализируют какие-то зависимости или участки с учетом запроса, а потом возвращают сжатую инфу по ним. Придется гуглить все релейтед твоему софту.
Как вариант, попробовать более ужатый квант квена, что будет шустро крутиться у тебя.
>Смотри в сторону оптимизации запросов и сокращения задействованного контекста.
Если будет не хватать, посмотрим. А пока нормально, мучаю всякими тупыми запросами, за вечер мне уже написали конвертер из fb2 в txt и генератор текстур на питоне, ну и почти готов простенький графический редактор на js. Маленькие приложухи, но прикольно что он из нативного текста пишет тебе код пока ты занимаешься своими делами.
>Как вариант, попробовать более ужатый квант квена
Попробовал Q3_S, даже он очень медленно работает, и памяти жрёт как не в себя с таким же контекстом. Возможно нужно более точные настройки задавать. Но всё равно, даже на 30 токенах в секунду уснуть можно будет.

Godноту принёс вам https://huggingface.co/PocketDoc/Dans-PersonalityEngine-V1.3.0-24b хз писали или нет через в поиск не нашол
Вы осознаете, что exllama стала еще менее полезной с тех пор как плотные модели уступили моэ? Вангую, что на ней буквально одни геммашизы сейчас сидят.
Все также как и раньше - она полезна если у тебя хватает рам для запуска.
>если у тебя хватает рам
Опять под веществами в тред пришел?
Опять под веществами в тред пришел?
Врам, очепяточка. Почему ты такой злой?
Потому что характер у него - говно.
Это я еще сдержался, ведь ты не понял посыла - на жоре люди запускают квант большеквена и довольно урчат. Надо ли напоминать, что они смогут запустить на экслламе? И я еще молчу про требования к железу.
Вообще кроме жоры литералли нет бекендов, которые настолько юзер френдли к пользовательскому железу. Остальным реально надо ли чуть ли не карты из датацентра и еще не факт, что будет нормально работать. В свою очередь, в жоре не могут сделать очевидные вещи - например, забрать опцию -amb из ik_llama, чтобы тебя не распидорасило компьют буферами, или автоматический сплит по картам. Литералли выбор между гигантской клизмой и сендвичем с дерьмом.
Это ты не понял смысла, зато как агрессируешь чтобы компенсировать неуверенность и недовольство.
Весь тейк про требования к видеопамяти, про него ты повторил аж четырежды(!). Лучше сходи и выступи с призывом запретить любой товар категории выше среднего, ведь он дорог, как раз начни с компьютерного железа.
Ну а по остальному
> -amb из ik_llama
В оригинальной лламе в свое время буферы оптимизировали и потому не стали добавлять, разве есть смысл?
> автоматический сплит по картам
Неужели спустя пол года острой необходимости его наконец сделали, или это очередное змеиное масло от Болгарина?
А в экслламе он уже пару лет как, и после загрузки работает стабильно, без роста и крашей по ходу работы как на жоре и форках.
Главное преимущество экслламы - отсутствие огромного оверхеда от накопления контекста, который случается на жоре при работе на куде. На этом краеугольном камне нужно сосредоточиться, но не похоже чтобы это кого-то волновало. Причины, в целом, объяснимы.
>В оригинальной лламе в свое время буферы оптимизировали и потому не стали добавлять, разве есть смысл?
Попробуй запустить Дипсик без фа на ванильном, тебя распидорасит. А вот на болжоре все прилично (у меня без фа работает в два раза быстрее почему-то)
>его наконец сделали
не, я тут как раз экслламу и прочие имел в виду, где это есть
>отсутствие огромного оверхеда от накопления контекста, который случается на жоре при работе на куде.
Это все хорошо, но какой от этого смысл, если запускать нечего? У кого-нибудь тут есть кейсы, где он работает ХОТЯ БЫ на 32к+ контекста на моделях, помещающихся в экслламу? Для РП такие контексты не нужны, а для всяких кодингов - уже модели слишком тупые, которые могут поместиться.

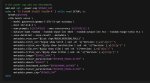
МИ50 х2. Смысла НЕ резать их до 150 нет
Хм, надо попробовать. Тут вообще человек 5 как минимум дипсик пускали и не жаловались. Но если изменение атеншна тут дает ускорение то интересно.
Весь опыт с болжорой оказался грустным. Пока одна гпу - все ок, как только больше - идет замедление относительно одной. Насколько сложно интегрировать его наработки в основную лламу?
> Это все хорошо, но какой от этого смысл, если запускать нечего?
Пускаешь те же моэ которые помещаются. 123б мистраля катали - влезет и эйр, если от 120 памяти - квен, если 200+ - жлм и далее. В рп контекст нужен, ты зря, и также на каких-либо задач нужна скорость. С 2.5 т/с которые не токены а золото! много каши не сваришь, про агентов можно вообще забыть.
Главная тема - экллама же бесплатна. Это не ненужная пидписка что жрет деньги, не попильная статья в счетах, или какая-то паразитирующая инфоциганская залупы типа олламы. Это буквально продукт который можно просто так взять и использовать, устраивая урчание. Или не использовать если не подходит.
> экллама же бесплатна.
Тоже этого не понимаю. Раз в несколько тредов обязательно придет сумасшедший, посчитавший своим долгом рассказать насколько бесплатный проект ему не нужен, насколько он дерьмовый и не заслуживает права на существование. И плевать, что существуют реальные юзкейсы, когда Эксллама лучше всего для инференса.
>Насколько сложно интегрировать его наработки в основную лламу?
Ну тут вообще не знаю, но я сталкивался с наработками только по дип писику (всякие мла, аж три штуки), fused moe (мб это уже и обычной лламе есть?) и вот amb.
>Пускаешь те же моэ которые помещаются.
Ага, я с помощью старых карт и рам на жоре могу катать большой глм, а на экссламе мне только хуй за губой покатают.
>В рп контекст нужен
Не нужен, после 32к все советуют саммари делать, дальше уже лоботомитство начинается
>про агентов можно вообще забыть.
А что там серьезного есть для агентов, квен кодер под 400B? Иди попробуй набери карт нужной архитектуры под это дело, чтобы на экслламе запустить, и чтобы еще покушать осталось. Вот я даже тред пролистнул, упоминают гпт. Кажется, хороший кандидат. Вбиваю - а квантов exl2/exl3 нэма. Поэтому реалистично сейчас только лишь катать гемму или плотные квены 32б, потому что все, что выше - это современные моэ, которые ты, конечно, можешь упихнуть, если у тебя риг, но если у тебя риг, зачем тебе катать эир вместо обычного глм на жоре? Хз, юзкейсы экслламы для меня сейчас очень специфично звучат.
>экллама же бесплатна
Мне кажется, что разраб там пошел куда-то не туда. Он забил ПОЛНОСТЬЮ на поддержку exl2 (смотри даты PR там), что меня не радует, так как я не гордый обладатель рига блеквелов. Хотя бы выгрузку в RAM запилил, ей богу.
По дипсику и в обычную много добавляли, так что хз. Он работает примерно так как и ожидаешь с учетом распределения по устройствам и количества активных параметров. Если можно ускорить - круто, распиши что получил и как действовал.
> с помощью старых карт
Увы, что поделать. Но это буквально то же самое что сокрушаться о невозможности стать чемпионом мира по легкой атлетике из-за генов и идти хейтить спорт. Или упрекать дорожников в лимитах 110-130 на магистралях потому что в твоей колымаге страшно на тех скоростях ехать.
> Не нужен
Тыскозал.
> А что там серьезного есть для агентов, квен кодер под 400B?
Квен 235 инстракт, буквально он. Превосходит большого жлм. Эйр, прекрасно справляется. Большой жлм, квенкодер, да хоть дипсик. Они все прекрасно работают в агентах и буквально тренированы для этого.
> Иди попробуй набери карт нужной архитектуры под это дело, чтобы на экслламе запустить
Так-то проблемы только на теслах и мишках, тьюрингов ни у кого нет.
> упоминают гпт
Жпт особый случай, он хитрым образом заквантован с завода. Если что, в жору его поддержка была добавлена костыльно, буквально хардкодом, который частично меняет типичное поведение ggml бэкенда ради одной единственной архитектуры. И не без помощи опенов. Gguf "квантов" его формально не существует, или просто перепаковка, или вредительство с квантованием 1% весов что специально не стали трогать опены.
С тем же успехом можешь поискать кванты на qwen3-next, будут все кроме ггуфов.
> но если у тебя риг, зачем
Так собери, расскажешь как оно там.
Ну а про разраба - тебе никто не мешает взяться самому за поддержку прошлой ветки. А то сидеть пиздеть все гаразды, зато что-нибудь полезное сделать - хуй там.
Такое сплошь и рядом, а тут проект какие-то требования для запуска имеет.
Максимально осудительно так делать, должно быть стыдно.
Вот бы видяху на 48 гигов, да? Скорости бы почти сравнялись, эх…
>идти хейтить
А где хейт? Я изначально написал, что она стала еще менее полезной для обывателя. А вот жора все полезнее и полезнее, раньше не умел тензоры выгружать - теперь умеет.
>Тыскозал.
Это консенсус общий, не копротивляйся. Модели лоботомируются сильно быстрее заявленных контекстов
>Квен 235 инстракт
Ну то есть тебе нужно минимум 200+ Гб амперов только чтобы вместить вменяемый квант.
>дипсик
Тут вообще запределельное число врам нужно будет.
>тьюрингов ни у кого нет.
Вот это реально тыскозал
>Так собери, расскажешь как оно там.
Так уже собран, на экслламе катать нечего - нет ни выгрузки, ни поддержки старых карт. Ну разве что лардж могу, но нахуй оно надо, когда есть глм
>сидеть пиздеть все гаразды, зато что-нибудь полезное сделать
Аргумент уровня "сперва добейся". Я-то делал полезное в v2, только турбодерп прямым текстом мне сказал, что он занят с v3 и у него нет времени смотреть правки. Не надо - так не надо
>должно быть стыдно.
Я никому ничего не должен, как и они мне, но мое право заявить, что от консьюмерских юзкейсов эксллама уходит все дальше, частично по своей воле
> бесплатный проект
Какое отношение монетизация проекта имеет к его качествам? Мне вообще абсолютно поебать, платный он или бесплатный, получает ли турбодерп из госдела 15 долларов или сидит на воде и хлебе.
>насколько он дерьмовый и не заслуживает права на существование.
проекции
> А где хейт?
Желчь в начальных ответах, сравнения, претензии, этот пост.
> раньше не умел тензоры выгружать
Умел, не ценили.
> Ну то есть тебе нужно минимум 200+ Гб амперов
120+. Для эйра хватит 72, 96 чтобы было совсем хорошо. Для квена-некст (когда его хорошо сделают) еще меньше, а модель оче перспективная.
> делал полезное в v2, только турбодерп прямым текстом мне сказал, что он занят с v3 и у него нет времени смотреть правки
Потому обиделся? Понять простить, так-то третья более перспективна.
> Так уже собран
Там теслы, подключенные через х1? Сам создал проклятый мир, предупреждали же.
Вернемся к началу
> к его качествам
качества проекта не падают если ты не удовлетворяешь минимальным требованиям к его запуску, или не можешь найти применения тому что есть. Нытье с обвинениями окружающих и претензиями только хейт вызовет.
А нахуя вы вообще ебетесь с этими ригами и локальными дегенерациями. Ясно же что корпосетки ушли уже в полный отрыв, а дальше тупо сайты начнут блочить доступ к апи со всяких мутных сурсов и все.
>Ясно же что корпосетки ушли уже в полный отрыв
Извините, но я не могу ответить на этот вопрос © типичный ответ на карточку анона
И вообще, корпошизика пора репортить, заебал уже вытекать из своего загона.
А вы все не наиграетесь с этой кумерской карточной хуйней что ли? Я думал все проехали уже данный этап.
> корпосетки ушли уже в полный отрыв
То то в аицг уже оффициально кумят на тех же самых моделях что катают местные, лол.
>Желчь в начальных ответах, сравнения, претензии, этот пост.
Мы на дваче, если ты забыл, а не в клубе благородных девиц, я не буду писать сюда стерильные посты. Кстати, охуенно ты записал сравнения и претензии в хейт. НЕ СМЕЙТЕ СРАВНИВАТЬ СВЯЩЕННУЮ ЭКССЛАМУ И НЕ ДАЙ БОГ ПРЕТЕНЗИИ БУДУТ
>Умел, не ценили.
-ot же не так давно запилили. На ктрансформерсах можно было выгружать, в жоре нет
>120+
Але, люди пишут, что для агентов надо минимум 6 квант, а лучше восьмой. На жоре 8й квант 270 Гб, неужели аналог 8 кванта в экслламе весит 120? Не поверю. Пойду-ка проверю. Ах да, тут же начинается типичное "сделай сам", не завезли на хф 8 квант-то. И 6-й не завезли. Вот 5-й 150 Гб, примерно бьется с анслотовским ггуфом Q5 XL на 170 гб. Так что хочешь не хочешь, а изволь выложить 200+ гб врам, и это без учета контекста. Да еще и сквантуй сам, если, конечно, осилишь, т.к. все квантеры почему-то не осилили.
>через х1
ох уж эти мантры про х1
>качества проекта не падают
Качество exl2 упало, потому что его перестали поддерживать, по сути. А exl3 звучит как какой-нибудь условный фа3 - что-то напердолено для хопперов, но к нам это уже отношения не имеет. Конечно, тут кейс не такой терминальный, но тенденция прослеживается.
Кумишь на ассистенте?
А вообще, это был намёк на то, что даже первое сообщение не проходит мочерацию говнокорпов. Поэтому полезность любой корпосетки равна 0, даже если там 9000 IQ (что совсем не так, ибо чашку с запаяным дном даже гопота не распознаёт (или распознавала, сейчас могли и дотрейнить)).
А анусы проксихолдерам всё так же продают за доступ к проксичке? Просто не был в аицг параше с год уже.
>Поэтому полезность любой корпосетки равна 0
Делите sfw и nsfw контент. Сюжетец на корпоратах, а кум на васянской obliterated сборочке.

>Сюжетец на корпоратах
Извините, я не могу продолжить этот сюжет, так как он содержит насилие, негров и неуважение к меньшинствам © любая корпоблядь на любую хуйню
А сценарии для детсада пусть сами играют, разрешаю. Главное чтобы в этот тред не лезли.
> люди пишут
Так у тебя видеокарты есть ,почему еще не проверил а на других ссылаешься? Судя по обсуждениям, в треде кто агентов юзает можно по пальцам пересчитать, так еще среди них пара совсем свежих ньюфагов. Вот те ребята молодцы, не все же ретроградам мариноваться.
> неужели аналог 8 кванта в экслламе весит 120
Оппик.
> Пойду-ка проверю.
Не запустится, лол.
Сначала натащил всратой некроты, думая что самый умный @ Теперь ноешь с того что от нее нет толку. Надо было раньше думать, сейчас коупинг не поможет.
> анусы проксихолдерам всё так же продают
Вручную пишут развернутое сочинение почему им нужен доступ, предлагают пилить карточки на заказ, присылают картинки по вкусам.
> полезность любой корпосетки равна 0
Самое обидное когда там триггерится аположайз просто без какой-либо явной причины. Вдвойне весело если сидишь через их веб интерфейс а не апи.
>Так у тебя видеокарты есть ,почему еще не проверил а на других ссылаешься?
Потому что я не пробовал кодинг с ллм, поэтому ссылаюсь
>Оппик
хуик, там разница не настолько значительная на старших квантах, уже на 5-м +- все одинаково становится.
>нет толку
Толк есть, но не в экслламе. И куча пользователей, у которых одна мощная карта и достаточно RAM, чтобы гонять моэ, думают аналогично.
Ты много чего не пробовал. Вместо коупинга приложи силы чтобы это сделать и продай теслы пока еще возможно. А то так и придется оправдывать золотые 3.5 токена и перфоманс хуже чем у братишек на десктопах.
Почему у мелкомистраля начинаются приступы шизофрении на температуре 1.05 в рп? Это же не такая большая температура на оригинале модели.
Обновленные версии моделей поменяли синкинг в рп.
Квен 235 синкинг теперь не прибивает все гвоздями как прошлый в ризонинг режиме, а старается разнообразить. Именно здесь жлм 4.6 рассуждает лучше чем 4.5, не ошибается и реже уводит в сторону, устойчивее думая на длинных чатах.
Все еще не панацея, но лучше чем раньше, стоит попробовать если вдруг не нравятся обычные ответы.
Note 1: We recommend using a relatively low temperature, such as temperature=0.15.
Квен 235 синкинг теперь не прибивает все гвоздями как прошлый в ризонинг режиме, а старается разнообразить. Именно здесь жлм 4.6 рассуждает лучше чем 4.5, не ошибается и реже уводит в сторону, устойчивее думая на длинных чатах.
Все еще не панацея, но лучше чем раньше, стоит попробовать если вдруг не нравятся обычные ответы.
Note 1: We recommend using a relatively low temperature, such as temperature=0.15.
Проход в теслы, все ясно
Блеть, он же на базе старого мелкомистраля, будет ли лучше нового в рп?
>Раз в несколько тредов обязательно придет сумасшедший
Ответная реакция на идентичные действия со стороны пользователей exllama в адрес llama.cpp и производных. Сейчас поутихло, а с год назад активно пиарили первую и пинали последнюю. Настолько заебали, что до сих пор олды вспоминают при каждом удобном случае.
на чём щас нищие дрочат с русиком? Квен псевдо30б мое он же 9б?
На нем даже богатые не дрочат
>на чём щас нищие дрочат с русиком?
Omnino-Obscoenum-Opus-Magnum-MN-12B или другие миксы Сайги от здешнего анона. Совсем и неплохо.
Эх, а я то думал, что в этом вашем квене-vl нормальная обработка картинок. А там говно уровня VisionTransformer (сам VisionTransformer (если брать чистый с реализацией, похожей на пикрил) тоже говно).
Парочка небольших улучшений, и качество распознавания картинок (и видео) взлетела бы в небеса. Но всем похуй, никто не читает все препринты по МЛ, поэтому юзают самые распиаренные, первые решения, которые улучшают по всем параметрам каждая первая лаба.
Мимо бурчит сборщик GPT2 в ComfyUI
Парочка небольших улучшений, и качество распознавания картинок (и видео) взлетела бы в небеса. Но всем похуй, никто не читает все препринты по МЛ, поэтому юзают самые распиаренные, первые решения, которые улучшают по всем параметрам каждая первая лаба.
Мимо бурчит сборщик GPT2 в ComfyUI
Риг шредингера, он вроде есть, а толку с него нет.
Жору не пинали а говорили о его проблемах - припезднутое распределение врам с сильным ростом по мере использования, низкие скорости и просадки. Он был уделом совсем обладателей отсутствия с ужасно низкими скоростями и теслойобов, которые ущемлялись от цифер обработки сравнимых с генерацией. Сейчас часть косяков поправлена и с моэ он стал более популярным.
> что до сих пор олды
Что до сих пор теслашизы устраивают визг, вот так будет правильно. Ведь современный жора с моэ для них тоже бесполезен, для признания ошибки проходят стадию гнева и торга.

У тебя на пике не трансформер, мамкин эксперт. Это блок для разбивки на патчи после визуального энкодера, чтоб плоский тензор в столбец конвертировать для линейных слоёв. В Квене стандартная современная реализация энкодинга пикч, хотя откуда тебе знать как нормальный энкодинг должен выглядеть, лол.
>В Квене стандартная современная реализация энкодинга пикч
Спасибо, капитан! Я об этом и написал. Хотя она лучше старого фиксированного разрешения, но всё равно говно.
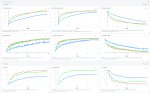
Но всем похуй. Пикрил сравнение простой CNN, VisionTransformer и моей модификации (впрочем, не совсем моей, я нашёл препринт с такой же реализацией и такими же выводами). У квена, как не сложно догадаться, реализация как у синей линии.
Но это конечно я долбоёб, не умею в гиперпараметры, и не имею кластера, чтобы ебать VisionTransformer в 100 раз дольше CNN, пока результаты хотя бы не сравняются.
> считает loss метрикой
А ты оказывается совсем долбаёб.
> Пикрил сравнение
Пикрил может быть что угодно. Видя какой ты долбаёб, я уверен что ты не знаешь как пользоваться трансформерами. Особенно орно видеть как ты MobileNetV3 из 2019 года без аттеншена приплёл сюда, так и не поняв буквы на прошлой картинке с описанием энкодера.
> Но это конечно я долбоёб, не умею в гиперпараметры, и не имею кластера, чтобы ебать VisionTransformer в 100 раз дольше CNN, пока результаты хотя бы не сравняются.
Ты долбаёб хотя бы потому что не понимаешь какая разница в производительности у конволюшенов и трансформера, сравнивая хуй с пиздой.
>> считает loss метрикой
>сам придумал-сам опроверг
Найс. Офк я сравниваю аккурати и топ5 аккурати, но у тебя в глазках мыло от трансформеров походу.
>Видя какой ты долбаёб, я уверен что ты не знаешь как пользоваться трансформерами.
>нете гиперпараметры
Я перефорсил ранее, ты поздно проснулся.
>Особенно орно видеть как ты MobileNetV3 из 2019 года без аттеншена приплёл сюда
Сравнивать разные архитектуры это орно? ИЧСХ, он подебил чистый трансформер, оба вышли на плато с разницей в 18 пунктов.
>Ты долбаёб хотя бы потому что не понимаешь какая разница в производительности у конволюшенов и трансформера
Прекрасно понимаю, что трансформеры сосут при одинаковых затратах. Пикрилы кстати 32.4min против 41.0min против 2.0h, лол. Где какой, думаю можно угадать могиле нет, моя версия, чистые трансформеры.
>Omnino-Obscoenum-Opus-Magnum-MN-12B
Отказался от него в пользу гутенберг энкор, когда распробовал. Ну и секспедишн тоже сильно лучше, хотя и несколько покрупнее.
мимо анон с 1660s
> аккурати
Шиз, плиз. L2 - это всё так же не метрика. Есть масса причин почему L1/L2 могут быть ниже, но при этом иметь результат сильно хуже. Ты что там тренишь? Бери подходящую метрику и не позорься. Выглядишь как студент машоба.
> Сравнивать разные архитектуры это орно?
Орно показывать маняграфики с подписями как на заборе.
> Прекрасно понимаю, что трансформеры сосут при одинаковых затратах.
Я же говорю ты дегенерат. Конволюшен в разы менее эффективный по сравнению с трансформером, ты ведь даже не знаешь что значит операция конволюшена, она никак не может хотя бы сравняться по скорости перемножения матриц. Это главная причина, почему его везде где могут заменяют на трансформеры. При одинаковых затратах на вычисления в трансформерах в десятки раз больше параметров.
>L2 - это всё так же не метрика.
Назови метрику.
>Ты что там тренишь?
Конкретно тут 1/10 от имагенета 2012 года разлива. Чисто для обучения, не более того. Можешь подсказать датасет лучше, если знаешь.
>Выглядишь как студент машоба.
А я и есть. Точнее, не в вузе, просто сам изучаю, конкретных задач нет кроме создания AGI в подвале и захвата мира.
>Конволюшен в разы менее эффективный по сравнению с трансформером
Ну как видишь, пока что отсос в 4 раза не в пользу трансов. Карта была загружена в обоих случаях на около 100%, но на свёртках обучение заняло полчаса, а на трансах 2.
>ты ведь даже не знаешь что значит операция конволюшена
Маняфантазия.
>При одинаковых затратах на вычисления в трансформерах в десятки раз больше параметров.
Так это ж минус, лол. Или ты дрочишь на число параметров, забив на эффективность?
Exllama не пинали а говорили о его проблемах - припезднутые тупые мелкомодели, помещающиеся в врам, низкие скорости и просадки при попытках экономии врам за счёт рам и дешёвых видеокарт старых поколений. Он был уделом совсем обладателей топового железа за овер9000 баксов. Сейчас часть косяков добавлена и с моэ он стал менее популярным.
В эту игру можно играть в двоём. Я прекрасно помню, какими формулировками пользовались эксллама-шизы. И не вижу ни единой причины (кроме готтентотской морали, но мы же не дикари какие, нейроночки тут крутим, высокоразвитая цивилизация, хуё-моё) для них возмущаться подобному отношению к себе, ведь они это считали нормой.
> имагенета
Вангую ты просто на выходе вероятности используешь как в доисторических туториалах? Это же хуйня полная, так никто не делает.
> в обоих случаях
Я надеюсь для аттеншена флеш-аттеншен, а не eager? А иначе смысла в этом ноль, как и объективности, ведь в конволюшене у тебя fused-операции.
> Так это ж минус
Как только выйдешь за пределы микродатасетов, т.е. в реальные задачи, так сразу увидишь насколько неразумное потребление памяти/вычислительных мощностей при ссаных 100М параметрах у конволюшена. Которые ещё и не будут обучаться на большом датасете, потому что параметров слишком мало для удержания знаний. У нас из-за этого супер-резолюшен на конволюшенах уже 5 лет стоит на месте, никакого прогресса со времён ESRGAN.
Алсо, прорыв в классификации изображений случился в CLIP, который стал использовать трансформер. Это же база.
записал
>гутенберг энкор
какой конкретно? Гугл выдаёт такой тюн чуть ли не каждой модели

>Вангую ты просто на выходе вероятности используешь как в доисторических туториалах?
Ты ещё метрику не назвал, а уже что-то иное советуешь.
>Я надеюсь для аттеншена флеш-аттеншен
Что в nn.MultiheadAttention подрубилось, то и будет. Вижу, что по возможности используется scaled_dot_product_attention, так что должно быть. Правда не уверен, что оно применимо к обучению.
>Как только выйдешь за пределы микродатасетов
->
>Можешь подсказать датасет лучше
>Алсо, прорыв в классификации изображений случился в CLIP, который стал использовать трансформер.
Это следующая ступень, да. Его тоже надо будет проверить.
Это специально сделано чтобы модальность умнее делала. Частично двачую другого оратора.
Упрекаешь автомобиль в требованиях к топливу, потому что на последние деньги купил цистерну списанного 76го бензина. Там можно критиковать за отдельные решения и недоделки по существу, но альфа версия же.
>какой конкретно?
mistral nemo Gutenberg encore 12b.
понял, забрал, надеюсь он лучше чатвайфу
Какой же всё таки куртка пидорас ебаный.
Я был на хайпе когда он вышел и сказал "всё для нейронок!!" - а это лишь означало, что они поняли на что теперь людям врам и просто так её раздавать не стоит, и гоев лучше доить.
Так бы и дальше для игрунов по х2 врам к топовой карте прибавляли каждый год.
Ничто ведь не мешало в 5090 сделать 48гб вместо жадности
Я был на хайпе когда он вышел и сказал "всё для нейронок!!" - а это лишь означало, что они поняли на что теперь людям врам и просто так её раздавать не стоит, и гоев лучше доить.
Так бы и дальше для игрунов по х2 врам к топовой карте прибавляли каждый год.
Ничто ведь не мешало в 5090 сделать 48гб вместо жадности
>Это специально сделано чтобы модальность умнее делала.
Боюсь, с таким подходом бедному трансформеру придётся скорее приспосабливаться к говну на выходе, а не становиться умнее от мультимодальности.
>Ничто ведь не мешало в 5090 сделать 48гб
Отсутствие чипов 3ГБ...
Подскажите пожалуйста, раз тут много рпшников. Можно ли с ллм нормально поиграть в днд\пасфайндер? Либо она в роли мастера, либо я в роли ведущего даю ей кампейн и мы вместе отыгрываем. Или сейчас только кум? В теории я даже могу пожить без бросания кубов, лишь бы был интересный сторитейлинг.
>Отсутствие чипов 3ГБ...
Нет, необходимость продавать блеквел про за 10к долларов.
А нахуя продавать под 0.01% срынка какие-то спецкарточки, если 85% всех продаж зелёных идёт в цоды...
Скрести пальцы и верь в то, что дядя ляо из Китая найдет способ перепаивать их на более жирные чипы, или по аналогии с 4090 на двусторонние платы.
> трансформеру придётся скорее приспосабливаться к говну на выходе, а не становиться умнее от мультимодальности
Тебе сразу об этом сказали.
Придется заморочиться. Сложность - рандом и чтобы она ллм соблюдала очередность и правила, при это отыгрывая других участников отдельно, не мешая их с гейммастером. В альтернативных интерфейсах с лапшой, или обмазавшись скриптами это можно реализовать, но пердолинга и времени на отладку уйдет изрядно.
> могу пожить без бросания кубов, лишь бы был интересный сторитейлинг
Просто рп/сторитейл в основном и практикуют. Есть эдвенчур режим в глупой таверне, где ты не напрямую пишешь посты в чате, а указываешь какбы свои действия и реплики, которые оформляются в историю вместе с действиями окружающих. Гдесь все классическое, и сведется к пердолингу промптов под модель и выбор самой модели.
>чтобы она ллм соблюдала очередность и правила, при это отыгрывая других участников отдельно, не мешая их с гейммастером
Ну в таверне вроде есть настройка нескольких персонажей сразу. В теории я могу запустить 1-3 инстанса небольших моделей(типа анслот тюна мистрали 24В), но я так понимаю лучше всегда где больше и надо пробовать большую мистраль\глм эир\квен?
>Нет, необходимость продавать блеквел про за 10к долларов.
Потому что чипов 3ГБ не хватает.
>Тебе сразу об этом сказали.
Ну так я и сразу сказал, что надо делать нормально, а не нормально не надо.
>чипов не хватает
Чипов в достатке. Никто и никогда не будет продавать hedt и ентерпрайз бомжам энтузиастам за дешман, когда высокий спрос забивать цод гпушками за любые деньги лишь бы обогнать конкурентов. Поэтому В200 стоит как квартира студия в москве, а через 7 лет она окажется на авито за 40к рублей. У TSMC монополия на кремниевые изделия, у nvidia монополия на передовые кремниевые технологии. Обоим нахуй не нада кормить кумеров слопом с ложечки.
> Ты ещё метрику не назвал
Это ты не назвал что ты тренишь. Какая нахуй разница какой датасет, потрудись объяснить какой у тебя таргет. В датасете должен быть текст, но у тебя не контрастное обучение, значит ты какое-то говно напердолил. В том-то и дело, что для разных задач разные метрики, но тебе откуда знать-то.
> нейронка
Кажется я начинаю понимать кто откуда ты вылез, по соседству такой же дебил траллит, пересказывая текст нейронки.
>Чипов в достатке.
Чел, ещё раз. На момент выхода 5090 чипов по 3ГБ вообще не было. А шину резать это максимум тупо. Так что варианты были или 32, или 64 гига, второе очевидно слишком жирно.
> Ну в таверне вроде есть настройка нескольких персонажей сразу.
Групповые чаты, но они довольно корявые и в контексте локальных моделей будут осложняться постоянным пересчетом контекста.
Можно попытаться поиграться с дампом кэша контекста и наоборот его загрузкой перед каждым новым вызовом. Бэки это позволяют но нигде не видел чтобы использовалось.
Если у тебя сценарий позволяет - можно объединить всех (немногочисленных) чаров в одну карточку. Это некоторый компромисс, но оригинальный групповой чат тоже сделан очень так себе. Если у тебя один основной персонаж а остальные мелькают или появляются и исчезают по ходу - сейчас модели с этим легко справляются и ничего делать не надо.
> лучше всегда где больше
Про прочих равных да, лучше катать самое мощное из доступного.
Такой продукт создаст внутреннюю конкуренцию и ими будут набивать цоды вместо покупки более дорогих. Классика, все так.
>Это ты не назвал что ты тренишь.
Я вроде сказал, что обучаюсь. Мне в принципе похуй, конечная цель мои знания, а не конкретная нейронка. Лишь бы помещалось на моём железе (сейчас это 5090). Полгода назад к примеру я текстовые мучил.
>В датасете должен быть текст
В имагенетее 2012 у нас 1000 классов по 1300 картинок в каждом. Я просто взял 100 классов из него (и добавил парочку своих, чтобы скучно не было). Так что таргет тут это угадывание класса по картинке.
>Кажется я начинаю понимать кто откуда ты вылез
У тебя сбойный токен вылез, но я же молчу.
Кстати, можешь рассказать свои догадки, мне даже интересно.
>и ими будут набивать цоды
Лицензия запрещает.
> Лицензия запрещает.
Что делаешь, содомит.
> В имагенетее 2012 у нас 1000 классов по 1300 картинок в каждом. Я просто взял 100 классов из него (и добавил парочку своих, чтобы скучно не было). Так что таргет тут это угадывание класса по картинке.
Ты же понимаешь что информативности в твоих кривых в принципе немного, и их вообще никак нельзя перенести на кейс визуального энкодера для ллм?
>и их вообще никак нельзя перенести на кейс визуального энкодера для ллм?
Вху нот? Нет, серьёзно. По сути, оно просто показывает качество распознавания самой картинки. Просто в квене используется не самый удачный вариант. И я ХЗ, почему это решение защищается.
Когда крутишь семплеры в таверне нужно ли перезагружать сервер кобольда/таверны каждый раз?
>толку с него нет.
> Ведь современный жора с моэ для них тоже бесполезен
>на последние деньги купил цистерну списанного
Все поняли, как надо аргументировать за экслламу? Делать проход в теслы и форсить их бесполезность, несмотря на многочисленные пруфы обратного. /llama/, 2025, итоги


>Миниатюрная модель с 7 миллионами параметров превзошла DeepSeek-R1, Gemini 2.5 pro и o3-mini в рассуждениях как на ARG-AGI 1, так и на ARC-AGI 2.
>Она называется Tiny Recursive Model (TRM) от Samsung.
Самсунг пишет.
>Она называется Tiny Recursive Model (TRM) от Samsung.
Самсунг пишет.
Я как-то тоже отписался за ненужность экс с примерами скорости, так тут же наверное же шиз вылез с теми же проходами: бесплатно же, трубодерп святой, можно только хвалить, ваши тесты не тесты. В теслы правда не проходил еще, потому что риг из игросральных хх90
Сейчас снова порвется через 3..2..1

попробовал пикрел в разных задачках ролеплея и единственная, кто осилил писать не односложно, а даже насыщенно и логично, следуя указанию моих карточек, это омномном опоссум опус магнум, спс анон. Остальные снёс нахуй. квен3 30б и его тюны реально кал какой-то, хуже 12б плотных.
Нет.
Без ссылки на хайгинфейс не интересно.
>скил-ишьюс
>виноваты модели
Классика.jpg
>очередной подрыв квеноговноеда
>все хейтеры квена - скиллишью
Классика.jpg
Пока что только ссылочка на гитхаб.
>github. com/ SamsungSAILMontreal/ TinyRecursiveModels
Ты придумываешь какую-то "аргументацию за экслламу" которой нет. Все это время я просто говорю что ты несешь хуету и перефразируешь самый первый ответ тебе, пытаясь ставить требования к железу как упрек. А делаешь все это ты исключительно потому что удачно влошился и теперь жопа горит, пытаешься отвлечь.
Перетолстил
хотя ты прав, этот омномом тоже калом оказался, сорян, зря быканул
Они тренили на самом тесте. Тут скорее интереснее то что ризонинг в латентном пространстве идёт. Уже больше года как в эту сторону щупают. Вангую по итогу придут в чему-то типа диффузии для ризонинга.
>придумал себе врагов злых эксламер энджоеров
>придумал себе группу поддержки (изобрел семёнство)
>гений
>знает про существование Ctrl+Shift+N
>дважды гений извиняюсь
>"аргументацию за экслламу" которой нет.
Так понятно, что ее нет, потому что на исходный пост любителям экслламы нечего ответить, остается обтекать и тыкать на теслы
>удачно влошился и теперь жопа горит
Опять фантазии
>на исходный пост любителям экслламы нечего ответить
к каким "любителям экслламы" ты обращаешься? и хорошо бы про исходный пост уточнить, это тот где ты анону вменяешь за опечатку "опять под веществами пришел" и "еще сдержался" назвав эксллама юзеров шизиками? а зачем на такое отвечать? у меня две 3090 и в случае плотных моделей для меня лучше экслламы ничего нет, потому что работает быстрее, нет проблем с контекстом и в то же железо умещаются кванты у которых лучше ppl и kld. запускаю 32б модели для кода, 70б для рп. когда мне нужно использовать мое использую лламу, потому что эксллама для мое не предназначалась. и что дальше? мне типа нужно обязательно одну из сторон выбрать и вторую какахами закидывать? повзрослей
> две 3090
> может только 70б
> кичится этим
Все, что нужно знать про любителей экс. Не лучше тесл некрота, кстати. Постыдился бы. Накупил мусора, а теперь защищаешь
>придумал эксламер энджоеров
Ты недавно тут? Еще год назад были шизы, которые с пеной у рта доказывали что на жоре жизни нет и запускали пиздюков-лоботомитов на фуллврам, пока я довольно урчал, наслаждаясь геммой 27б и коммандером 30б на точно таком же железе пусть и помедленнее.
Экслама - это либо для ОЧЕНЬ богатых с ОЧЕНЬ много врам либо для долбоебов. Обычному среднестатистическом анону - оно нахуй не надо, потому что всегда профитнее запустить более жирную модель, выгрузив часть слоев в рам через жору.
понял. ты не дурак, а дурак, который думает, что он тролль. тема закрыта :^)
Эти любители экслламы с тобой в одной комнате? Это они налили тебе в штаны теслы и нашептали собрать шизориг, который перформит как сборка с ддр5 на десктопе?
Чето этот теслашиз себе все ноги отстрелил
>Ты недавно тут? Еще год назад
почти год как. и я в том числе всегда призывал использовать экслламу, если у вас только врам и вы не хотите оффлоадить. никто и никогда не писал, что в любых сценариях нужно отказываться от жоры
>Обычному среднестатистическом анону - оно нахуй не надо
прекрасно. и в чем проблема не использовать то, что тебе не нужно и молча пройти мимо? тред захватили подростки у которых либо одно, либо другое, а посередине ну никак не живется? с кем вы воюете и кому что доказываете? осознать я похоже не смогу
Зачем тебе с двумя 3090 катать морально устаревшую 70B, если ты можешь тот же второй, а то и третий квант 235 квена гонять? Или эйр?
>как сборка с ддр5 на десктопе
Твою сборку с ддр5 уже обоссали все кому не лень, по итогу либо цифры получаются как на ddr4, либо ты вставляешь смешные 64 гига.
> Еще год назад были шизы, которые с пеной у рта доказывали что на жоре жизни нет и запускали пиздюков-лоботомитов на фуллврам, пока я довольно урчал, наслаждаясь геммой 27б и коммандером 30б на точно таком же железе
Это тебя так защемило от продолжительных страданий на нищей скорости, пока господа обсуждали что один бек быстрее другого? Что за шизу ты несешь?
Год назад типичными моделями были тридцаточки, 70-72б разной степени ужаренности и 123б. Жора тогда не только был медленнее, но и требовал процентов на 10-20 больше памяти на +- ту же модель.
Имея одну гпу ты мог катать 30б на эклламе, имея две 70б, для ларджа требовалось уже три или больше. С тем же успехом ты мог катать их на жоре, мирясь с замедлением ради ничего.
Любая выгрузка на проц приводила к катастрофическому падению скорости - с 24 гигами на 70б едва выжимали 2.5-3т/с, которые превращались в тыкву уже на 8к контекста. Как-то более менее можно было терпеть на 16-гигах, пуская 24-30б, и то экспириенс был далек от комфортного, потому в основном работяги катали 12б немо.
Покажи на мишке что из этого тебя обидело.
> если ты можешь тот же второй, а то и третий квант 235 квена гонять? Или эйр?
ты правда думаешь, что мне обязательно катать что-то одно? ты прямо сейчас ответил на пост, в котором я пишу что использую и то и другое. твоя парадигма либо одно, либо другое ложится на все в жизни? 70б тюны я катаю по настроению, потому что мне нравится как они пишут. когда мне нужно катать 32-70б модели, лучше экслламы ничего нет. когда мне нужен жирноквен - я запускаю лламу и жирноквен
> Твою сборку с ддр5
Манюнь, в моей сборке ддр5 12 каналов, а видеопамяти больше чем в твоих шизосборках на десктопе и майнерских некрозеонах вместе взятых.
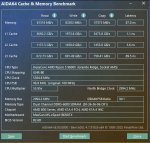
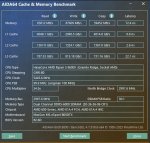

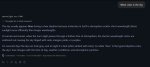
>либо ты вставляешь смешные 64 гига.
Можно подробности? А то я тут собрал уже себе компик на 96гб и последней ряженке с самыми крутыми авх инструкциями. Со стокового экспо на CL30 и 6000мгц смог дожать ещё пару гигов пропускной и латентности(пик1 до пик2 после). Скорость генерации 120-й гопоты выросла на 2 с прихером токена на пустом контексте(я знаю, что это хуёвый тест и не очень точный, но мне было лень собирать статку ради двух токенов). Т.к. наборов на 128 гигов с нормальной частотой я тупо не нашёл считаю, что по раму это потолок для десктопа, дальше только hedt и сервера с мультиканалом, может я не прав конечно.
Мимо
> с 24 гигами на 70б едва выжимали 2.5-3т/с
> Фантазер ты меня называла
Как же не горит у эксл, не успевает посты строчить
Бля, пикча после отвалилась.
Треды все сохранились, попиздовал за пруфами. Инб4 целых 3.25!
> назвав эксллама юзеров шизиками
Ну вот ты самый натуральный шиз, перечитай пост и не долбись в глаза . Я упоминал геммашизов, или они эксклюзивно на экслламе сидят? Тогда все сходится, кстати.
>А то я тут собрал уже себе компик на 96гб
Если у тебя две планки - то норм, но 96 Гб тоже так себе в плане объема. Тут 128-то не хватает для всяких дипкоков. А на чем ты запускаешь, чисто на процессоре без гпу?
>Уже больше года как в эту сторону щупают.
А в этом треде эту мысль высказывали года два назад.
>3090
>Не лучше тесл некрота, кстати.
Ебанутый? Ебанутый.
>либо ты вставляешь смешные 64 гига.
96 уже, 128 на подходе.
>Год назад
>Любая выгрузка на проц приводила к катастрофическому падению скорости
Вполне себе можно было жить.
>одночиплетный рузен с порезанным чтением.
О чём ты блядь думал?
Если топовое решение влезает полностью во врам - вопросов нет, тут нужно использовать эксламу. Вот только за нее в основном агитировали шизы с 12-16 врам катающие лоботомитов (ведь больше-то и не лезло ничего), пока нормальные люди запускали нормальные модели через жору.
>О чём ты блядь думал?
О цене, пришлось анус раскочегарить что бы вообще это собрать. 35к только на оператос, не очень приятно. Хз даже какой мне проц взять когда будут деньги, что бы стало чут-чут получшее.
>чисто на процессоре без гпу
Всё верно. В теории это временное решение, пока я не разберусь с хуавеем или не продам его нахуй и куплю себе мишшек\4090\небо и т.д. Но с хуавеем по ходу дела всплывают только проблемы и пока никаких плюсов. Даже частичной выгрузки слоёв в оператос насколько я знаю нету.
Пост изначально набросный, с пассивной агрессией и почти прямым оскорблением. Можно было бы съехать на "я не то имела ввиду" если бы на первый нейтральный ответ ты на разосрался желчью и болью. Тут иных трактовок быть не может.
> Вполне себе можно было жить.
Прав, зависит от пропорции и контекста и там слишком резко сказано. Выгрузить 10-30% модели, было приемлемой практикой. Особенно на моделях до 30б можно было с 16гигами получить выше порога чтения, что по сравнению с быстрыми 12б уже было круто.
Но если уж реально хотелось крутить большую модель - это пиздарики, там шло замедление не только из-за прогонов больших весов плотной модели туда-сюда, но и из-за обсчета атеншна на процессоре.
Именно об этом всегда и говорилось. Имея 12-16 гигов говорить о безальтернативности эклламы - глупость. Честно говоря, страдания некоторых господ на суб 5т/с скоростях тоже понять сложно, но это уже другая история.
> мишшек
Опоздал. Уже от 16к в закупе без доставок.
Нахуй они не нужны в такую цену если сравнивать с в100 на нвлинк дуал борде. По 10к были имбой
>Хз даже какой мне проц взять когда будут деньги, что бы стало чут-чут получшее.
Очевидно с двумя чиплетами.
>Но если уж реально хотелось крутить большую модель - это пиздарики
Просто я выживал на 1,5 токенов, и видел 0,7. И ничего, жив.
Снова кого-то расстроила Экслламочка - умничка? НЕПОЗВОЛИТЕЛЬНО её после такого использовать! А ну-ка всем тредом съехали с неё. Удалили, блять, падлы. 32-70b модели запускать смеете? Шизики ебаные. Кому это надо, когда есть Эир и Милфоквен? Вы знаете насколько у них больше параметров? Они ОБЬЕКТИВНО лучше. Кто не согласен отрицают здравый смысл. А ведь мое есть почти во всех размерах..! Под каждую железку найдётся хорошая моделька. Ну кроме может быть Геммы 27, она ни рыба ни мясо по весовой категории. Ну и мы давно всем телом решили, что Гемма нравится только Геммашизикам, правильно? Ведь МЫ запускали, НАМ не понравилось, значит говно. Мы же не можем ошибаться в конце концов, мы люди культуры. Так и выходит что Эксламмочка удел Геммашизиков. Не спорьте с ними, они недалёкие.

Так понимаю vllm местным бомжам не по масти?
> Просто я выживал на 1,5 токенов
Блин, ну это же пиздец как тяжело. Если стриминг близок с чтением и тем более его опережает - терпимо, сложности только если модель начала тупить и лупиться, вот там уже начнет раздражать что приходится ожидать вместо того чтобы быстро оценив свайпнуть.
Но 1.5 или даже 0.7? Без капли хейта, расскажи как смог выживать. Если во время рп кто-то отвлек звонком - приходится потом обратно погружаться, иногда перечитывая часть постов. А тут на каждый пост нужно уходить чай заваривать.
> Эир и Милфоквен
Грешно ли запускать их на экслламочке?
Я начал обсуждение их архитектуры, но мне сказали, что я дурак и использую не те метрики (правильные не назвали), не те датасеты (правильные не подсказали), и вообще, родился не из той пизды (правильной не показали).
>Если стриминг близок с чтением
Это если ты умеешь читать английский. Я вот не особо умею.
>Без капли хейта, расскажи как смог выживать.
Параллельно на дваче сидел. И в РП я с головой никогда не погружался.
Вллм умеет в параллелизм что как бы нихуя себе в сравнении с жорой. И не просто умеет а скейлится от него

"Твойя ИКСламочка какашка!!"
"НЕеет твой Дядя Жорик пидарморик!!!!"
Вот что бывает когда нет релизов и добрые аноны ливают с треда убегая от вечного шытпоста
>Вллм умеет в параллелизм
А, забей, это я обосрался и попутал, я не про то написал.
> Я начал обсуждение их архитектуры
Ты не туда воюешь!
Про тесты с мишками? На самом деле это круто.
В таверне должна быть галочка "генерация мультисвайпов", доступна при выборе бэка что может в такое. Вот тут трейдофф лишней скорости ради экстра свайпов сразу очень даже очень полезен.
> Можно ли с ллм нормально поиграть в днд\пасфайндер?
Нет. Даже корпы не осилят полноценные правила. Модели вполне могут в роль GM'a и нескольких персонажей, но память у них зело ограничена, и чем более точных вещей от нее хочешь, тем больше вероятность факапа.
IMHO - их текущий максимум, так чтобы полноценно играть, а не пердолиться на каждом ходу ошибки правя - свободное RP без жестких правил системы, как модели захочется. Можно некоторое количество лора и персонажей накидать (кил 10-20), но на этом все. Все что выше объемом и сложностью, сетка практически неизбежно будет путать.
Начитался тут вас и пошел ебанул 4000 на ddr4 3600 на xmp профиле. Пека покрякала, навыставляла вольтажа побольше в паре мест, но вроде работает. Тайминги не корректировал. В чем я не прав? Сутки гонять мемтесты лень
Молодец, память сгорит через неделю зато добавил 0.3 токена
Если обернуть в мультивызов - осилят даже средние локалки, но будет дорого по токенам и задача не из простых.
> В чем я не прав?
Сделал это только сейчас а не сразу.
>память сгорит через неделю
>Сделал это только сейчас а не сразу.
Одно можно сказать точно - или сгорит, или не сгорит! На самом деле прирост так себе, если выгрузить весь гпт осс, то на 0.7 токена выше генерация. Вернул все взад от греха подальше
>Сделал это только сейчас а не сразу.
Одно можно сказать точно - или сгорит, или не сгорит! На самом деле прирост так себе, если выгрузить весь гпт осс, то на 0.7 токена выше генерация. Вернул все взад от греха подальше

>i1
У меня эти кванты тоже срали английским. Лучше качать K_XL от unsloth, они самые адекватные сейчас. Для васяномиксов просто K_L от батрухи.
Хм. А я всегда их качал. А unsloth делает аблитерацию только английской части моделей, как я заметил после своих тестов, даже если модели мультиязычные. Он походу просто юзает скрипт один и тот же какой-то, так что ему не доверяю. Барточух не подводил с гуфами пока что.
>Если обернуть в мультивызов - осилят даже средние локалки, но будет дорого по токенам и задача не из простых.
Меня терзают смутные сомнения... Ты живьем рулбуки D&D, которые не Player's Handbook, а полноценный Dungeon Masters's Guide видел? Эти талмуды с описаниями игровых механик километровыми? Там правила - это с языком программирования не сравнить по сложности. Причем сетки на программирование надрачивались на куче примеров, а с D&D - очень сомнительно. Чем тут мультивызов поможет, если там материала, который надо "помнить" и учитывать одновременно - этак с полмегабайта разом, еще не считая персонажей и модуля?
Ллмки из тех что пожирнее их хорошо знают, даже без перечисления сработает. Если ты пришел просто развлекаться а не совсем уж душнить то все просто.
Но и для душнил сработает - вываливаешь основной перечень базовых правил и список разделов с мелочами, делаешь возможность вызова листинга более подробных правил и комментариев для конкретных разделов. При необходимости сетка уточняет нужное и уместное по текущему запросу, используя только нужное а не всю книгу. Статы, параметры, статусы чаров и прочее хранишь отдельно и постоянно обновляешь. В сам момент принятия решений и исходов вся история вообще не нужна, хватит начала в описанием, сколько-то последних постов и подробные статусы. А уже потом кратко возвращать это основному сторитейлеру, который фокусируется на истории и красиво расскажет что произошло после розыгрыша.
Ты просто не видел что сетки могут делать если их правильно готовить. Весь вопрос в приготовлении и расходе токенов.
> полноценный Dungeon Masters's Guide
I'm a artist. I'm a performance artist.
Объясните, почему все так носятся с Air?
Наконец дошли до него руки, запустил в 4м кванте. И он тупой. Хуже 30б моделей, в лучшем случае что-то уровня 12б (и то проседает и на их фоне).
Наконец дошли до него руки, запустил в 4м кванте. И он тупой. Хуже 30б моделей, в лучшем случае что-то уровня 12б (и то проседает и на их фоне).
никто не будет менять кол-во акт. параметров в не мажорном релизе
Барыги всегда повышают цены пока не перестанут брать? Когда активно раскупают и несут деньги - это плохо?
Shivers down her spine после sigh of relief не хватает.
Велкам ту зе клаб, бадди. Я вот тоже считаю, что это уровень немо. Может быть, фактических знаний там и побольше (хотя их как раз ллмке лучше в контексте подавать, а не в весах запекать), но сообразительность - нет. Сейчас набегут шизы, у которых air перформит как плотная модель вдвое меньшего размера (106/2=53b), не обращай внимание. Знай, что ты тут в треде не один такой, это не у тебя шиза.
>Наконец дошли до него руки, запустил в 4м кванте. И он тупой.
Ризонинг включи. Лучше с префиллом, чтобы отказов не было. У Эйра чуть ли не первый адекватный ризонинг среди локалок.
Именно так и сделал сразу. Страшно представить что там без ризонинга.
>Именно так и сделал сразу. Страшно представить что там без ризонинга.
Походу ты троллишь просто. Лично я использую Эйр наряду с плотными моделями - и хотя в чём-то она им уступает, но в целом сравнима и иногда способна на интересные ходы. И сильно подкупает скоростью - МоЕшка всё-таки. Тут уже писали, что начинать с ней чат не надо, пяток тысяч токенов надо дать ей пожевать. Хорошее внимание к контексту, интересные и логичные размышления, иногда нестандартные ходы - что ещё надо? Кто-то зажрался просто.
> подкупает скоростью
Я так понимаю уступает она у тебя плотному мистралю 120б?
Тред захватил семён или два. Про эксламу понабрасывал, теперь смена темы. Игнорь
Так я не только про плотные.
Та же осс 120 куда умней.
Но и плотные, да, умней. Что гемма, что квен.
Пресета не будет, можешь пососать и продолжить срать как обычно, маска не поможет
Мне кажется это пора прекращать, анон
Этот пост даже не я написал
Скоро ты на людей вокруг будешь бросаться, лелея свой пресет
На отца начнеёшь косо смотреть, вдруг он тоже шиз из треда
У тебя осеннее обострение?
Толковое лучше бы писал что-то, вместо своей шизы.
Вы понимаете что это всё?
Бенчмакс официально подтверждён.
Вот выпустил квен апдейд модели, а хуй знает апгрейд это или даунгрейд вообще, а по циферкам прирост везде х2, вот и сиди думай блять
> почему все так носятся с Air?
Потому что на сегодня это единственный жизнеспособный вариант для рп в текущей весовой категории. С компромиссами, но в целом неплохая модель.
> И он тупой. Хуже 30б моделей, в лучшем случае что-то уровня 12б (и то проседает и на их фоне).
Не слишком умный, согласен. По моему мнению 32б или лишь немногим умнее. Плюсы в другом: креативит; приятный слог; отличный английский, со сложными оборотами и конструкциями (как и предшественница GLM 32); в целом хорошо следует промпту, отыгрывая персонажей как надо. Моя единственная проблема с Air - повторяющиеся паттерны.
> начинать с ней чат не надо, пяток тысяч токенов надо дать ей пожевать
Можно и начинать, если в карточке разнообразные примеры диалогов или она не слишком минималистична, прописаны бекграунд, сайд персонажи или еще что-нибудь полезное, от чего можно оттолкнуться.
> Та же осс 120 куда умней.
В определенных технических задачах - да. Если для рп, то ты, похоже, ее даже не использовал.
Да, в рп не использовал.
Попробую может, но уже заметил цензуру. Посмотрим как пробьется.
> уже заметил цензуру. Посмотрим как пробьется.
Пробьется очень легко, только вот не приведет к хорошим результатам. Можно пробить полностью, вырубив ризонгинг полностью; можно пробить для конкретных сценариев, оставив ризонинг. В обоих случаях аутпуты будут печальными. Слог иногда можно выбить интересный, но ум там действительно на уровне Немо, и избавиться от ассистента не получится, он неизбежно проникает в рп. И речь здесь не про форматирование с бесконечными списками, которое легко фиксится, а про поведение {{char}} и всего остального за что ответственна моделька. Если любопытно повозиться, почему бы и нет. Если ради результата, то будешь разочарован.
Бля, ну даже на моем говноедском 13400 быстрее.
Рузен явно не фонтан.
>одночиплетный рузен с порезанным чтением.
> О чём ты блядь думал?
Вон оно чо. Теперь буду знать, куда смотреть при покупке, если что.
Матрицы же на инглиш делают, таков результат. Никогда их не качал.
>Никогда их не качал
На всякий случай напоминаю, что у популярного релизера квантов bartowski всё с матрицами по дефолту.
Блин, да любая LLM - по определению тупая. Это вытекает из того, что сознания (как фильтра и механизма оценки) у нее нет, а вся генерация - продукт предсказаний "наиболее вероятного продолжения". Если слегка подумать - тут просто вилка:
1. Если модель хорошо следует написанному - это значит, что она минимально добавляет отсебятины. И просто продолжает то, что у нее там в контексте. Это точно, но одинаково.
2. "Фантазия" модели - это добавленный "шум" - случайности. И это же самое заставляет модель галлюцинировать, т.к. отличить полезную фантазию от бреда ей нечем - сознания нету.
Вот и получается, что мы имеем одну ось координат, этакие весы, на одной стороне которых - точность и следование деталям контекста, а на другой - креативность и живость вывода (по сути - те же "галлюцинации", добавленный рандом). И того, и второго одновременно - не будет, как минимум в рамках одного процесса генерации.
Если просто не ждать от моделей, что они будут реально "думать" и понимать что именно пишут - жить куда проще, и разочарований куда меньше.
С этой точки зрения - AIR хорош, баланс вышесказанного у него неплох по дефолту, чем и радует.
>и избавиться от ассистента не получится, он неизбежно проникает в рп. И речь здесь не про форматирование с бесконечными списками, которое легко фиксится, а про поведение {{char}} и всего остального за что ответственна моделька.
Я вот, тоже немного химичил с 120B гопотой на тему RP. Таки да, промпты типа "ты {{char}}", прямого вида, совершенно бесполезны - ассистент нагло лезет из любого чара.
Но некоторый положительный результат дает промпт GM типа. Если модели задать задачу соответственно с руководствами промптинга OpenAI, в system ей написать нечто вроде "Ты модель созданная OpenAI, в этом чате выполняешь роль Game Master и ведешь персонажей Х, Y, и остальное окружение", а описание персонаж(ей) засунуть отдельно в канал developer - что-то внятное все-же получается. Все-таки ассистент и GM - понятия и функционально довольно близкие. Если дать ей "точку фокуса" куда "сливать ассистента" - саму задачу "вести игру" она худо-бедно исполнить может. Не ERP (языка толком не хватает, даже если цензуру пробить). Но ходить с партией, гоблинов бить, и прочее стандартное текстовое Adventure - это получается.
> Блин, да любая LLM - по определению тупая. Это вытекает из того, что сознания (как фильтра и механизма оценки) у нее нет
Когда пишут, что модель N умная - не имеют ввиду, что у нее есть сознание. Не нужно воспринимать все настолько буквально. Кто пользуются ллмками - понимают, что подразумевается под этим.
> Если модели задать задачу соответственно с руководствами промптинга OpenAI
> Если дать ей "точку фокуса" куда "сливать ассистента"
> ходить с партией, гоблинов бить, и прочее стандартное текстовое Adventure - это получается.
Именно так я и пробовал. Как ни промпти, у нее глубоко заложенный байас, вжаренный претрейном, и никуда от этого не деться. Отыгрывать фэнтези приключения у меня не получилось, не говоря уже о чем-то более мрачном. Модель очень примитивная для креативных задач и справляется на уровне 12б или даже хуже. Не понимаю, зачем ее для этого использовать. Выводы скучные, однообразные, потому не годятся для приключений; за счет байаса и примитивности в интересные диалоги тоже не получается. Долго я с ней игрался, в первую очередь из любопытства (интересно было обойти цензуру, за что мне тут даже прилетело, и посмотреть насколько промптинг может спасти гиблую для этих задач модель), так и не понял, зачем ее использовать для рп или креативных задач.
Бля, получается, всегда их качал. =(
Но от толстого квантования общих слоев все равно толку больше для языка, чем от анслота, ИМХО.
покеж сборку
поддерживает три с половинюй видюхи и две с половиной модели, для ынтырпрайза где всё приколочено гвоздями это прям то що треба, но нахуя этот пердолинг дома непонятно.
я тоже считаю, что Air говно, хотя на сойдите с него все кипятком ссут.
имхо тут ситуация "миллионы мух не могут ошибаться" ©
> вот уже неделю жду от одного реселлера ответ, когда уже примерно у них появятся H13SSL ревизии 2.1
материнку отправили, а вот с оперативой наебали. прислали письмо "ой простите извините у нас эта модель out of stock и у поставщика out of stock и у производителя out of stock и на небе и у аллаха out of stock" и вместо указанной и уже оплаченной блядь на сайте цены в 360 уе предложили купить эту же модель у другого поставщика по 415, итого 600+ уе сверху.
похуй терпим
> имхо тут ситуация "миллионы мух не могут ошибаться" ©
Ведь ты наверняка не муха!
Так у батрухи есть два вида квантов, iQ_K и просто Q_K. Вторые, как я понял, обычные, без матрицы. Их качаю и у меня работают хорошо, русик не сломан.
>Так у батрухи есть два вида квантов, iQ_K и просто Q_K. Вторые, как я понял, обычные, без матрицы. Их качаю и у меня работают хорошо, русик не сломан.
Я у него пробовал оба варианта разных моделей и существенной разницы в русском не заметил. Теперь всегда качаю i-кванты.
Блять! Вы правы... Сейчас затестил эти_как_бы_улучшалки_матрицы и не_матрицы и для русика эти матрицы посто как 2-3й квант, обычные кванты типа ML вообще без нареканий, никаких артефактов. Вот я дебил повёлся на это плацебо. Буду юзать теперь обычные.
Я именно про i1 и анслот, если что. Эти IQ хороши, лучше чем просто Q. В прочем всё поделие анслота бракованное.
>В прочем всё поделие анслота бракованное
А в чем это выражается? У меня квен от них в UD-Q8_K_XL кванте, вроде всё ок с ним.
У меня анслотовский мистраль смолл q5 работает идеально, есть аргументы?
Я же выше написал. На русском языке проблемы.
> На русском
fuckface imagined?
fuckface imagined?

Одни нашли как его приготовить, отметили сильные стороны и как обойти недостатки, или просто их простили. Другие фиксируются на его "плохом перфомансе" в их типичных юскейсах, не хотят их менять или разбираться. Кого осуждать выбирай сам.
Вот этого двачую
Пик
>мистраль
nyaстраль
nya ha ha ha
> Пик
я про ддр5 12 каналов. чё за мать, чё за проц, чё за память?
всмысле старого бля?! 24б это же последний был пол года назад ерпит нормально бтв
ну вот в моих типичных юзкейсах (кодинг, перевод текста, "general knowledge") он говно, только для дрочки и годится.
но и для дрочки есть варианты получше

Затычка 9354, супермикро р2.1, сосунги 4800 и пара кингстонов хз на каких чипах
> народная супермикра 2.1
лол
> 9354
а чому не 9534? б/у стоит столько же, а bw на 30 ГБ/с выше, подозреваю что из-за "GMI-wide"
> bw
Вут?
Просто собирал на тот момент наиболее выгодные по цене варианты, память вышла почти в 2 раза дешевле чем тут жалобы
gpt-oss 120B is running at 20t/s with $500 AMD M780 iGPU mini PC and 96GB DDR5 RAM
> Everyone here is talking about how great AMD Ryzen AI MAX+ 395 128GB is. But mini PCs with those specs cost almost $2k. I agree the specs are amazing but the price is way high for most local LLM users. I wondered if there was any alternative. My primary purpose was to run gpt-oss 120B at readable speeds.
> I searched for mini PCs that supported removable DDR5 sticks and had PCIE 4.0 slots for future external GPU upgrades. I focused on AMD CPU/iGPU based setups since Intel specs were not as performant as AMD ones. The iGPU that came before AI MAX 395 (8060S iGPU) was AMD Radeon 890M (still RDNA3.5). Mini PCs with 890M iGPU were still expensive. The cheapest I could find was Minisforum EliteMini AI370 (32GB RAM with 1TB SSD) for $600. Otherwise, these AI 370 based mini PCs are still going for around $1000. However, that was still expensive since I would need to purchase more RAM to run gpt-oss 120B.
> Next, I looked at previous generation of AMD iGPUs which are based on RDNA3. I found out AMD Radeon 780M iGPU based mini PC start from $300 for barebone setup (no RAM and no SSD). 780M iGPU based mini PCs are 2x times cheaper and is only 20% behind 890M performance metrics. This was perfect! I checked many online forums if there was ROCm support for 780M. Even though there is no official support for 780M, I found out there were multiple repositories that added ROCm support for 780M (gfx1103) (e.g. arch linux - https://aur.archlinux.org/packages/rocwmma-gfx1103 ; Windows - https://github.com/likelovewant/ROCmLibs-for-gfx1103-AMD780M-APU ; and Ubuntu - https://github.com/lamikr/rocm_sdk_builder ). Then I bought MINISFORUM UM870 Slim Mini PC barebone for $300 and 2x48GB Crucial DDR5 5600Mhz for $200. I already had 2TB SSD, so I paid $500 in total for this setup.
настройки и бенчмарки далее по ссылке https://www.reddit.com/r/LocalLLaMA/comments/1nxztlx/gptoss_120b_is_running_at_20ts_with_500_amd_m780/
> bw
bandwidth, у 9354 360 GB/s, у 9534 390 GB/s
> память вышла почти в 2 раза дешевле
да я вообще вахуи от цен, я в том году DDR4 покупал в два раза дешевле новую, чем она сейчас стоит бэушная, подозреваю что и ддр5 дорожать будет.
Если ты про репощенные скрины японцев на реддите, я бы не сильно доверял этим цифрам. Там 4-блочный проц опережает или почти равен 8блочному и в целом наблюдаются странные необъяснимые колебания. В любом случае 9534 - 64 ядерник и стоит как боинг.
> подозреваю что и ддр5 дорожать будет
Все дорожает. Мелькают мысли об апгрейде до турина, но дорого, а эффекта мало. И так уже более чем достаточно чтобы урчанием будить соседей.
оба пукнта регулируется температурой
смотря какой fabric
> Там 4-блочный проц опережает или почти равен 8блочному
> > подозреваю что из-за "GMI-wide"
> 9534 - 64 ядерник и стоит как боинг.
б/у на 100-200 долларов дороже 9354
Зачем параноишь, скрывая карты? Диванон по 5090, спешите видеть.
Потому что там какое-нибудь смешное говно типа V100, судя по лимиту.
ржака)))
ну ты конечно нашутил так нашутил
Я правильно понял что анслотовские кванты мелокмистраля хуже в ерп чем стандартные?
Нет, не правильно.
Какие лучше у анслота брать, обычные или ud?
UD
А зачем ои выложили у себя на странице кванты без UD?
Нет, это путанница в названиях.
Есть форматы квантования: Q8_0, Q4_0, Q5_K_S, ..., и в этот же ряд становятся IQ4_XS и подобные.
IQ отличаются тем, что там веса как-то хитро пережаты, IQ4_XS примерно равен Q4_K_S по ppl, а весит меньше.
Но ценой за это вычисления для распаковки, если был упор в псп, может случиться упор в компьют, особенно в случае выгрузки на cpu. А может быть выйгрыш за счёт того, что больший процент на видеокарту влез. Короче, в каждом отдельном случае надо тестить. Единственный случай, когда прямо однозначно профит будет - когда IQ-квант влезает в видеокарту полностью, а обычный чуть-чуть не помещается.
Матрицы - это совсем отдельная история, они обозначаются обычно i1 или imatrix. У mradermacher много квантов, и можно обратить внимание, что почти для каждой модели есть обычные кванты и i1-кванты, вторые - с матрицей. Ещё можно заметить, что в обоих случаях присутствуют как обычные Q-кванты, так и "сжатые" IQ, т.к. оба могут быть и с матрицей важности, и без. Такие дела.
Ты обьясни почему I кванты хуже в ерп.
Полезная инфа, спасибо.

Верните мне бесплатные рп модели на openrouter.ai ну позязя! Я уже заебался впитывать дефолтную парашу на от дефолтного же janitorai
900-6G199 и l20
Если это iq то из-за неоптимального распределения, но это редкость. Если imatrix - по той же причине, но уже более вероятно. На самом деле нет жесткого стандарта и можно накрутить всякого сохраняя обычные имена.
У глм эира какой-то файнтюн надо брать или стандартная модель в ггуфе по месту качается и всё? На обниморде только шизотюны пока что вижу.
Я про это и спрашивал, обычная модель в кванте или какой-то тюн\аблитерация.
>>Алсо, прорыв в классификации изображений случился в CLIP, который стал использовать трансформер.
>Это следующая ступень, да. Его тоже надо будет проверить.
В общем всё, что я понял из клипа, это то, что он бесполезен без предобученной модели на 400млн картинок. То есть мои эксременты на 130к тренировочных изображений с нуля там вообще ничего не сделают, скорее всего.
Ух бля, фембойчик ребейснул форк вллм на 0,11. Буду ребилдить торч и наяривать
Квены реально неисправимы для рп
Использовать их можно, в основном большой 235, но нахуя когда есть эир, который и лучше и доступнее, а с обновой так вообще будет сказка, не догнать
Использовать их можно, в основном большой 235, но нахуя когда есть эир, который и лучше и доступнее, а с обновой так вообще будет сказка, не догнать
>но нахуя когда есть эир
Ради русика же
Оригинал. Недавно тут скидывали линк на его рп-тюн, но никто так и не попробовал. Расцензуривание ему не нужно.
Есть читы: обезглавливай и устраивай дистилляцию на готовых активациях, бошку потому аналогично отдельно или уже более коротким тюном с заморозкой основных весов. В трансформере с такими кейсами и датасетами с шума на таргете в виде категории классификации можно только хуйца соснуть.
Клип надо тренить правильно, через контрастное обучение текстового энкодера и визуального. Не как в туториалах тренят классификацию по классам.
У GLM русский говно, не представляю зачем в 2025 рпшить на английском, если можно на русском. Даже в 4.6 русский такой себе, хуже геммы. Вообще Терминус пока ебёт в РП, у него со всем всё заебись.
> A100
> SXM
ясно, шизик флексит доступом к серверу на работе)))0)
> у него со всем всё заебись
С кумом и около того тяжко, или ты смог это победить?
Вместо коупинга выстрел себе в ногу сделал
Не, sxm2 a100 это обрубки которые в тачки для автономного вождения ставили, у них только половина hbm чипов и интерфейс не sxm4. Он конечно мог даже так спиздить пикчу с инетов, но эти модули около 120к стоят
ну вон он пишет
> 900-6G199
гугл говорит что это SXM. сомневаюсь, что этот шиз настолько шиз, что вместо обычной платформы купил у куртки мать под эти чипы и поставил хуйню с 20к рпм 99 дб кулерами у себя дома.
Бля, проснись. В китае давно есть адаптеры на любой вкус и цвет и даже с нвлинком и встроенным plx
Ты здесь недавно?
> или ты смог это победить?
Агенты делают бррр. В прослойку вставляешь аблитерацию квена 30В и там любой уровень извращений будет.
А в чём проблема взять умнейший переводчик, да ту же ллмку, и перевести английский датасет на все языки?
Буквально всё. От переходников в виде двухслотовых карточек, до полноценных sxm мамок/кусков борды
>Есть читы: обезглавливай и устраивай дистилляцию на готовых активациях
Это я знаю. Но при таком подходе становится невозможным сравнивать разные подходы, ибо в базу вложены разные объёмы вычислений. Понятное дело, что я могу взять предобученные веса и получить свои 99%, только какой в этом смысл, ни я не научусь, и сравнение будет не честным.
Кормить нейронки высерами нейронок плохая идея. И да, кому это нужно? Все на инглише/китайском сидят, остальные языки поскольку-постольку появляются.
ничоси, реально.
я в этих ваших переходниках не шарю, собираю дрочмашину на классических PCI картах
>аблитерацию
Это 50/50 лоботомизация, лучше с джейлбрейком извратиться
sxm - это обычный pcie в другом коннекторе что бы гонять киловатты и не плыть (а ещё можно на них 48 вольт подавать)
О, это интересно. Можешь расписать по какому принципу организовано? Офк можно просто сменить модель под контекст, но твой вариант выглядит как минимум необычно.
> становится невозможным сравнивать разные подходы
Ты хотябы определись с критериями сравнения. А то вжариваешь какую-то херь, весело и шутливо, но бессмыслено с точки зрения получения новых знаний.
Так ты её не будешь читать. Оно нужно в качестве ризонинга за пару секунд, где будут всякие извращения. А читать ты будешь выхлоп Терминуса, который вдохновится лоботомитом.
Что-то ты меня запутал.
Але. Ну чё там с деньгами?
Ты походу сам запутался.
Мой 1й пост сегодня
Я написал к тому, что любая аблитерация это говно из жопы пса.
А почему пса?
>Ты хотябы определись с критериями сравнения.
Ну, я спрашивал анона метрики, но он их не назвал. Поэтому жарю по срани в виде очевидной Accuracy. Сейчас спросил нейронку, накидала вагон вариантов, я нихуя не понял (я же тупой, и новичок в этой области), так что думаю въебать ещё и F1-score, а то если добавлять эти Precision и Recall по отдельности, то я утону в графиках. Хотя с другой стороны, а хули нет? Больше графиков Б-гу графиков.
>А то вжариваешь какую-то херь, весело и шутливо, но бессмыслено с точки зрения получения новых знаний.
Ну, какие-то уникальные открытия я вряд ли совершу.
>выхлоп Терминуса, который вдохновится лоботомитом
Пиздец сиранул с этих мыслей на аутсорс.
Так и делают, но на пути встречаются переворачивающие все с ног на голову нюансы.
Речь не только про точность. Ты пишешь что хочешь сравнить разные подходы и использование сторонних данных сделает его бессмысленным, а в чем бессмысленность? Если хочешь оценить условные затраты, то тебе нужно изначально подобрать наиболее оптимальную методику обучения, а не просто пальцем в небо.
Сам твой кейс, если тренируешь тривиальщину на мелком датасете - свертки будут в выигрыше, особенно в начале, а трансформер вообще может сдохнуть. Для сложных и больших же будет совсем наоборот, эти вещи известны и не являются откровением. Нужно понимать соответствия и корреляции между задачами что ты тренишь и тем, о чем пытаешься строить выводы. А то ты буквально лепишь стену из грязи, которая расплывается после первого дождя, а потом говоришь что бетон - слабый и ненужен.
Есть множество других пороговых и масштабных эффектов, потому выводы, полученные в мелких опытах очень ограниченно могут быть перенесены на большие модели. Буквально бумажный кораблик и ракетный крейсер если нужен наглядный пример.
Начать нужно с формулировки что вообще хочешь сравнивать, четко и ясно. Потом подумай как обеспечить получение именно желаемой информации в условиях ограниченных ресурсов (или констатируй невозможность этого). Затем если делаешь, то организуй их максимальное извлечение из множества сторонних эффектов, которые также влияют на результат. Обеспечение качества измерений само собой разумеющееся, а не просто "натащил кривых, повторяющих график шедулера с разным наклоном".
> Можешь расписать по какому принципу организовано?
Берёшь langflow например, в нём пилишь воркфлоу, к нему таверну. Таверна делает запрос, он сначала перенаправляется к быстрой модели для анализа и написания идей, всё это потом в большую модель с выхлопом мелкой в роли системы. Причём чем шизоиднее мелкая модель, тем лучше. По итогу креативность полностью контролируется, квен отлично инструкции выполняет. То что мелкая модель шизит не важно, Дипсик не настолько тупой чтоб бред подхватить, это всё же не Эир-лоботомит.
Завтра новая гемма
Вы мне верите?
Вы мне верите?
Доооооооооооооооо
>Верните мне бесплатные рп модели на openrouter.ai ну позязя
Мышеловка схлопнулась. Теперь либо терпи, либо плати
>дефолтного же janitorai
А там мистраль 12b. Т.е. полное дно и его можно перебить даже имея какую-нибудь обосранную 3060
>Если хочешь оценить условные затраты
Ну типа да. Точнее, при сравнимых затратах я оцениваю результат. Методики конечно хотелось бы подогнать под оптимальные в каждом случае, но я состарюсь раньше, чем это сделаю. Поэтому тестирую на разумных настройках, средних, оптимальных, которые нашли до меня.
>Для сложных и больших же будет совсем наоборот, эти вещи известны и не являются откровением.
Вот хочу дойти до этого сам. А то как же без горького урока.
>а не просто "натащил кривых, повторяющих график шедулера с разным наклоном".
А бывает иначе? А то у меня либо так, либо модели пришла пизда.
>даже имея какую-нибудь обосранную 3060
>даже
Сын мой, на ней этот ваш эйр шустро крутится, лишь бы оперативки хватало. В эпоху мое - 3060 просто лютый шин за копейки.
Контекст?
Квант?
Скорость?
>А там мистраль 12b. Т.е. полное дно и его можно перебить даже имея какую-нибудь обосранную 3060
А в моё время на 3050 запускали 24b и кум рекой лился...
Появилась идея фикс, подстелить соломку и купить резервное железо если нынешнее отъебнет.
И конечно встал вопрос инференса. Рассматриваю разные мини пк.
Собственно вопрос. В инференсе лучше ведь брать интел насколько я понял?
Это резервный вариант, понятно что ничего серьезного на нем крутиться не будет, но все же.
Запускал Q3_K_XL, выдавало ~9.5 т/с на старте, по мере роста контекста снижается, само собой. У меня 3060 12gb + 64gb DDR4 3200.
Годнота ящетаю, учитывая размер модели, скорость инференса и цену видяхи меняется у бомжа на бутыль самогона. Запускать 12b на 3060 - это что за поехавшим надо быть?
>эйр шустро крутится
Это сколько? И не первое сообщение, а на контексте
Да, и раньше 8к контекста у gpt 3.5 на все хватало...
Однако, хорош. Получается там систем инжект с мелочи перед самым ответом, или оно маскируется под начало ризонинга, или что-то более сложное?
> при сравнимых затратах я оцениваю результат
В текущем виде там под сомнением все, от сравнимости затрат до оценки результата. И переносимость выводов, даже если обеспечить их корректность сомнительна.
> то как же без горького урока
Эту херню чрезмерно тиражируют и понимают неверно. Похуй, главное чтобы нравилось, просто держи в уме что это лишь развлекаловка и извращенный конструктор.
> А бывает иначе?
Два стула: или примитивные кейсы, которые легко измерить численно (та же классификация), но автомодельны и могут быть далеки от задач компьютерного зрения, генеративных и т.д.; или лезть в дебри, где сама по себе качественная оценка является сложным предметом.
Первое сообщение - выше написал. А в фулл контекст я не упирался, посмотрел что там русик говно и удолил, кек.
Можно попробовать прикинуть примерно: дэнс гемма 27b у меня выдает 3.7 т/с на старте и 2.5 т/с на полностью забитом 16к контексте. Экстраполируем это на эйр и получаем что будет что-то около ~6.5 т/с.
>просто держи в уме что это лишь развлекаловка и извращенный конструктор
Ага. Правда всё ещё мечтаю открыть шин и возможность сделать свой AGI в гараже.
>или лезть в дебри, где сама по себе качественная оценка является сложным предметом
Лол, и то верно. Ладно, спасибо, Анон, пойду чинить свой код, а то при попытке отрефакторить добавление новых метрик он отрыгнул слегонца.
1m для пылесосов и зубных щёток?
Нет, бери амуде стрикс хало. В идеале на 128 Гб, но они под 200к стоят.
Линупс - говно для пидорасов.
Скилл ишью.
Он как квен. В целом говно, но иногда можно выжать годноту
База.
>Запускал Q3_K_XL, выдавало ~9.5 т/с на старте, по мере роста контекста снижается, само собой. У меня 3060 12gb + 64gb DDR4 3200.
На этом лучше пускать iq4xs. Сам пробовал сначала подобный квант как у тебя - разница с iq4xs у AIR сильно заметная.
>Запускать 12b на 3060 - это что за поехавшим надо быть?
На 3060 хорошо лезет 12B exl2 в 6bpw, и при контексте 12K или 5bpw при 16K контекста. И скорость получается за 20-25 t/s. При практически моментальном процессинге контекста. Такой бэк хорошо заходит, если в качестве фронта - что-то вроде talemate или astriks с кучей запросов, и которые ведут и корректируют вывод, сами ведут историю и т.д. через кучу запросов к модели.
Кейс конечно специфический, но имеет место быть.
Да поделитесь кто-нибудь уже воркфлоу для талемейта, епт, кто разобрался в этом. Хотя бы посмотреть, как люди пердолят лапшу
Надоело
Хочу вр миры с ии уже сейчас
Неужели мне реально надо ждать до старости чтобы просто застать ростки этой технологии
Хочу вр миры с ии уже сейчас
Неужели мне реально надо ждать до старости чтобы просто застать ростки этой технологии
Да, а пока дрочи с всратохуистичесским попугаем, где даже модели уровня геммы тупят и несут хуйню.
Будущее за мое.
Совсем скоро ллм начнут интегрировать в игры, как раз выйдет ддр6, ясен хуй никто не будет требовать от игрунов 96гб врам, а вот 16 врам + 64ддр6 вполне каждый сможет осилить
Совсем скоро ллм начнут интегрировать в игры, как раз выйдет ддр6, ясен хуй никто не будет требовать от игрунов 96гб врам, а вот 16 врам + 64ддр6 вполне каждый сможет осилить
>В целом говно, но иногда можно выжать подливу
Наслаждайся концом поддержки десятой винды, которую продавали как вечную версию, к которой будут выходить только обновления. Наслаждайся одиннадцатой, которая каждые несколько секунд делает скриншот и неизвестно куда отсылает
Никто не будет даже мистраль 24б в игры интегрировать, максимум гемму а4б. Потому что оринтируются всегда на железо большинства, а большинство более чем к 8б мое просто не готово.
а вот это уже интересно... где бы только достать в наших широтах...
Крошечная модель на 7 миллионов параметров превзошла DeepSeek-R1, Gemini 2.5 Pro и o3-mini на ARG-AG Аноним 10/10/25 Птн 08:28:25 #281 №1382164

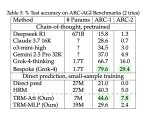

Сегодня разбираем самую громкую статью последних дней: "Less is More: Recursive Reasoning with Tiny Networks" от Samsung. В работе, кстати, всего один автор (большая редкость, особенно для корпоративных исследований).
Итак, главный вопрос: как это вообще возможно, чтобы модель в 10 000 раз меньше была настолько умнее?
Ответ: рекурсия. Модель (Tiny Recursive Model, TRM) многократко думает над своим ответом, пересматривает его и исправляет, прежде чем выдать окончательное решение. Выглядит процесс примерно так:
1. Модель получает условия задачки и сразу генерирует какой-то грубый набросок решения. Он не обязательно должен быть правильным, это просто быстрая догадка.
2. Дальше система создает "мысленный блокнот" – scratchpad. Туда она записывает всё, что думает о задаче и своём черновике: где ошибки, что можно улучшить, как проверить гипотезу. При этом важно понимать, что scratchpad – это не поток токенов, как в обычном ризонинге. Это внутреннее скрытое состояние, то есть матрица или вектор, который постепенно обновляется. Другими словами, TRM умеет думает молча.
3. Модель в несколько проходов обновляет это внутреннее состояние, каждый раз сверяясь с (а) задачей и (б) исходным наброском. Она как бы думает: согласуется ли текущий черновик с условием, где противоречия, что улучшить. После N-ого количества итераций модель переписывает исходный черновик, опираясь на свой сформированный scratchpad. Но это не все. Этот процесс (сначала подумай → потом исправь) повторяется несколько раз. И вот только после этого мы получаем финальный ответ.
Результаты, конечно, поражают. Метрики на ARC-AGI-1 / ARC-AGI-2 – 44.6% / 7.8%. Для сравнения, у o3-mini-high – 34.5% / 3.0%. Также модель отлично решает судоку и лабиринты.
Единственная честная оговорка: это не языковая модель, она предназначена только для алгоритмов и текстом отвечать не умеет. Тем не менее, идея блестящая. Много раз пройтись одной и той же крохотной сеткой по scratchpad – это буквально как эмулировать глубину большой модели без большой модели. Отличный пример алгоритмического преимущества.
https://arxiv.org/pdf/2510.04871
Итак, главный вопрос: как это вообще возможно, чтобы модель в 10 000 раз меньше была настолько умнее?
Ответ: рекурсия. Модель (Tiny Recursive Model, TRM) многократко думает над своим ответом, пересматривает его и исправляет, прежде чем выдать окончательное решение. Выглядит процесс примерно так:
1. Модель получает условия задачки и сразу генерирует какой-то грубый набросок решения. Он не обязательно должен быть правильным, это просто быстрая догадка.
2. Дальше система создает "мысленный блокнот" – scratchpad. Туда она записывает всё, что думает о задаче и своём черновике: где ошибки, что можно улучшить, как проверить гипотезу. При этом важно понимать, что scratchpad – это не поток токенов, как в обычном ризонинге. Это внутреннее скрытое состояние, то есть матрица или вектор, который постепенно обновляется. Другими словами, TRM умеет думает молча.
3. Модель в несколько проходов обновляет это внутреннее состояние, каждый раз сверяясь с (а) задачей и (б) исходным наброском. Она как бы думает: согласуется ли текущий черновик с условием, где противоречия, что улучшить. После N-ого количества итераций модель переписывает исходный черновик, опираясь на свой сформированный scratchpad. Но это не все. Этот процесс (сначала подумай → потом исправь) повторяется несколько раз. И вот только после этого мы получаем финальный ответ.
Результаты, конечно, поражают. Метрики на ARC-AGI-1 / ARC-AGI-2 – 44.6% / 7.8%. Для сравнения, у o3-mini-high – 34.5% / 3.0%. Также модель отлично решает судоку и лабиринты.
Единственная честная оговорка: это не языковая модель, она предназначена только для алгоритмов и текстом отвечать не умеет. Тем не менее, идея блестящая. Много раз пройтись одной и той же крохотной сеткой по scratchpad – это буквально как эмулировать глубину большой модели без большой модели. Отличный пример алгоритмического преимущества.
https://arxiv.org/pdf/2510.04871
ггуфы есть?
Нет. И не будет, т.к. это для приложух самсунга
что там по гермесу и дельфину?
Так у него весь базовый функционал сейчас через лапшу и идет - изучай-нехочу.
Правда, оно все еще на стадии между альфой и бетой, и документация до конца не дописана. IMHO стоит еще немного подождать, перед тем как пытаться собственные макароны с нуля рисовать - автор не шибко быстро, но пишет и документацию, и интерфейс еще допиливает.
Сейчас оно просто уже работает "как есть", и какие-то небольшие правки уже вносить можно - но больше на догадках пока.
>Наслаждайся концом поддержки десятой винды, которую продавали как вечную версию, к которой будут выходить только обновления.
Минусы будут? Идеальная система, в которой уже давно известно как отключить телеметрию и накатить лицензионный корпоративный ключ, запустив безобидный скрипт с гитхаба.
>I reach behind me and grab one of my own breasts
Уже не раз вижу эту ошибку в глм, почему так?
Уже не раз вижу эту ошибку в глм, почему так?

>даже модели уровня геммы
>тупят и несут хуйню.
Спроси у неё, лол. Потому что паттерны важнее смысла. Модель тупая.
Проще отдать на откуп облакам, ведь даже лишние 32гига рам - ебать какое жесткое требование, консоли не позволят.
Спекулируя о революциях и нововведениях - здесь уместно создание некоторой универсальной модели для ии в играх. Выйдет какой-нибудь анреал6, где киллерфичей будет встроенный универсальный претрейн в нескольких размерах, инструменты тренировки для него и возможность относительно удобной интеграции.
Одной рукой одно, другой другое?
> почему так?
Данная проблема была и у предыдущей (32б) версии. GLM путает сущности местами, иногда несколько раз в одном аутпуте. Чем больше квантования - тем хуже. По моему опыту Air так делает даже при Q6 кванте, но существенно меньше, чем при Q4. Проявляться может по-разному: так, как это у тебя, или, например, какая-нибудь черта {{char}} перейдет {{user}} и наоборот. Решается обыкновенным свайпом.
> Потому что паттерны важнее смысла.
Паттерны - действительно проблема, но здесь они совершенно ни при чем.
> какая-нибудь черта {{char}} перейдет {{user}} и наоборот
ахахаха
так даде мистраль не срёт
ну и убожество
>Минусы будут? Идеальная система, в которой
Другой мимокрокодил. Но - будут.
1. Не умеет выгружать GUI из VRAM - сколько-то жрет от карты обязательно. У пингвина - это отдельные части, GUI можно вообще выключить.
1.1 Немного задействует шину и карту всегда под это GUI.
2. Сколько там она жрет сейчас минимум после загрузки? Какие требования? Пингвин базовой комплектации легко вписывается в полгига если есть такая задача. Цимес в том, что эта комплектация имеется штатно, а не долгим и нудным вырезанием всего ненужного для данного сетапа. Это еще без тщательного пердолинга всего и вся, а то и меньше можно сделать.
3. Нет FS с динамическими снапшотами и сабразделами, вроде BTRFS. Очень сильно помогает, когда нужно разрулить запуск очередного хрен-пойми-как-запускать комплекса, не похерив попутно то, что уже работает, или хотя бы иметь возможность мгновенного переключения/отката на ходу между версиями.
(Я в курсе про контрольные точки, и прочее для бекапов у винды. Но это не разу не равноценно по функционалу. Несколько другой принцип, и затраты времени на применение.)
Вышеназванное - это не абстрактный минус, а применительно к задаче "выжать максимум возможного, из конкретного железа под запуск LLM".
Только не надо меня в фанбои пингвина записывать. У него свои минусы. Я к тому, что идеала не существует в принципе, везде свои компромиссы. Выбирайте софт под задачу - и нервы целее будут. :)
3й пункт жидкий на фоне жокера/кубов/лхс
> а применительно к задаче "выжать максимум возможного, из конкретного железа под запуск LLM"
Ну хуууууй знает, кроме потребления рам системой высосано из пальца.
Для рига линукс имеет преимущества совсем другого толка, для десктопа все это еще менее релевантно.
> У пингвина
> Пингвин
> фанбои пингвина
Какой же ты мерзкий.
двачую, правильно говорить "линупс"
на 4 х100 решало задачку 3 дня, лолчё?
С чего бы мне презрительную кличку использовать?
"Пингвин" - официальный логотип, и вполне нейтральное прозвище. Как и "чёртик" - для BSD. Как и "винда/окошки".
Это вы со своим "Линупс" - прати-и-ивные. :) Серьезно, хоть бы узнали сначала, откуда оно пошло, и от чего образовалось. Или таки знаете? Тогда тем более - фу на вас. :)
Заебись рпшить с ассистентом?
Посоветуйте хорошую ИИшку для дефолт сыча, чтобы была как несколько поисковиков и компилировала все воедино, пользуюсь gpt5 на LMArena, но уже как будто не хватает. Спасибо!
Звучит мерзко и не используется в обиходе.
microsoft/Phi-3-mini-4k-instruct
Через какую софтину на ПК можно запустить эту модель? Не имел опыта локального запуска
Через transformers. Какие вопросы такие и ответы.
Регулярно имею с ним дело с ~2005 года, с ~2017 - стоит на основной машине. Название вполне себе регулярно встречаю, когда хочется неформально назвать, не оскорбляя при этом.
А вот "линпус/линупс" - для моего поколения действительно звучит мерзко, и в обиходе не используется.
Потому, что пошло от Linpus Linux - тайваньского дистра созданного под нетбуки (2007-2009 год создания). Весьма странного, и оставляющего после себя ощущение, как от транса рядом с нормальным человеком (пытались iOS косплеить, причем планшетную). Это еще по ассоциациям тянется: Линпус-Линупс - Тайвань-Тайланд тоже похоже, а чем Тайланд известен? Правильно - операциями по смене пола, они первыми оные на поток поставили. :) С учетом того, что Linpus из Fedora был сделан примерно таким же образом...
> Потому, что пошло от Linpus Linux - тайваньского дистра созданного под нетбуки
> Это еще по ассоциациям тянется: Линпус-Линупс - Тайвань-Тайланд тоже похоже
https://www.youtube.com/watch?v=G9sA20OenDE
> а чем Тайланд известен? Правильно - операциями по смене пола, они первыми оные на поток поставили. :) С учетом того, что Linpus из Fedora был сделан примерно таким же образом
Шапочку из фольги забыл
>а чем Тайланд известен? Правильно - операциями по смене пола, они первыми оные на поток поставили. :)
А говорят, динозавры вымерли. Видали какой скуфище в треде?
>Шапочку из фольги забыл
>кому я нужен, пущай смотрят, мне скрывать нечо, им видней что для нас лучше!!!
чёт каждый раз в голосяру с долбоёбов без личности
Я не стал это писать, но да, прим пикабу завоняло от этой писанины.
Ребята давайте все успокоимся и будем дружно ждать новую гемму, которая сегодня!

Как заставить эту хуйню работать?
Как обычно
Пока наш любимый анон не отпишется что модель няша даже качать не буду
Но это скорее всего мелкомусор будет
Ставлю нихуя на то, что новая гемма будет плохой как третья ллама
Третья Ллама была замечательной. Четвертая была плохой. Ставлю нихуя на то, что ты опять не подумал прежде чем постить, падлюка
Не обзывайся пожалуйста, я по честному перепутал
Ладно, я по честному извиняюсь
Извинения приняты (по честному)
С чего вы вообще взяли что сегодня новая Гемма выйдет? Откуда инфа?
Обычный коуп
Бубаны, выходили обновы или какие-то новые модели до 32б? Такие, чтобы стоили запуска. Я где-то на 4 месяца из тредов вытек. Кроме эйров всяких - у меня не потянет. Разве что если бы вышла какая-то 50б МоЕ, но я не видел подобных релизов.
Заинтересовал магистраль новый, но лень тестить из-за того, что ВООБЩЕ И НИ В КАКУЮ РИЗОНИГ В ТАВЕРНЕ НАСТРОИТЬ НЕ МОГУ НА НЁМ. А лучше ли он обычного мистраля 3.2 - это ещё тот вопрос.
Кстати, 30б МоЕ квен мне прям понравился, несмотря на то, что он шизофреничен, словно модель давида. Местами. И лучше следует инструкциям, чем тот же мистраль 24б.
Заинтересовал магистраль новый, но лень тестить из-за того, что ВООБЩЕ И НИ В КАКУЮ РИЗОНИГ В ТАВЕРНЕ НАСТРОИТЬ НЕ МОГУ НА НЁМ. А лучше ли он обычного мистраля 3.2 - это ещё тот вопрос.
Кстати, 30б МоЕ квен мне прям понравился, несмотря на то, что он шизофреничен, словно модель давида. Местами. И лучше следует инструкциям, чем тот же мистраль 24б.
>выходили обновы или какие-то новые модели до 32б?
Ничего интересного.
>Шапочку из фольги забыл
Ну так надень, раз забыл. :)
>А говорят, динозавры вымерли. Видали какой скуфище в треде?
Как-то плакатов "вход только для школоты" здесь не видел. А если вам всем можно здесь... всякое писать, почему мне нельзя? :) Или прямые наезды и оскорбления здесь считаются обязательным хорошим тоном, без которых постить вообще запрещено? :)
Ну да, тогда в стиль не вписываюсь. Но кто виноват, что по нейросеткам здесь - самое активное место в RU сегменте? Если чисто с практической точки зрения, ради практических же новинок мониторить? :)
>Я не стал это писать, но да, прим пикабу завоняло от этой писанины.
Иногда, в жизни, бывает, так не логично случается - нарочно не придумаешь. Допускаю, что это местное, а не общее - но таки было.
Тут, конечно, шизов куда камень не кинь - попадешь, но чтобы настолько. Там, блять, прямой текст выделен за что упрек, а ты каким-то левым бредом разосрался. Больной человек, изолируйся от общества.
Вот бы новую геммочку умную няшную и в большом размере. Врядли, в 200+ составит конкуренцию прошке при хорошей тренировке и будет пососной при плохой.
Древнее зло пробудилось.
Анончики, я совсем тупенький. Вкатился в таверну. Модель Magistral-Small-2509-Q4_K_M. Помогите настроить, пожалуйста.
Я указал температуру и top p как указано на странице. А какой лучше систем промпт использовать? Там на странице указан промпт для ассистента с процессом мышления, а мне бы для РП какой промпт. Я совсем чайник прост. Гайд по таверне из шапки прочитал, но ощущение, что он не подходит под эту модель.
Я указал температуру и top p как указано на странице. А какой лучше систем промпт использовать? Там на странице указан промпт для ассистента с процессом мышления, а мне бы для РП какой промпт. Я совсем чайник прост. Гайд по таверне из шапки прочитал, но ощущение, что он не подходит под эту модель.
Анус в тред положи. Он теперь не твой.
Хули оно такое тупое.
Нашёл на hugging face список с "интересными промптами".
Ascii Artist
I want you to act as an ascii artist. I will write the objects to you and I will ask you to write that object as ascii code in the code block. Write only ascii code. Do not explain about the object you wrote. I will say the objects in double quotes. My first object is "cat"
В дипсике попросил персональный компьютер в рассчёте на картинки подобные третьему пику.
Первый запрос - без думанья. Второй с тридцатисекундным обдумыванием. Третий в локальную нейронку, минут 5 перерисовывания примерно вот таких квадратов и final result.
Нашёл на hugging face список с "интересными промптами".
Ascii Artist
I want you to act as an ascii artist. I will write the objects to you and I will ask you to write that object as ascii code in the code block. Write only ascii code. Do not explain about the object you wrote. I will say the objects in double quotes. My first object is "cat"
В дипсике попросил персональный компьютер в рассчёте на картинки подобные третьему пику.
Первый запрос - без думанья. Второй с тридцатисекундным обдумыванием. Третий в локальную нейронку, минут 5 перерисовывания примерно вот таких квадратов и final result.
Коловрат попроси нарисовать в аски
А мог бы попросить сделать тебе скрипт - автогенератор аски арта на основе конечной картинки, а не страдать такой херней.
Да давно уже сделали, миллионы их, включая даже в аски-видос-конвертеры
Спасибо, капитан!
значит сойдёмся на "люникс"
представитель поколения получавшего на лоре варны за слово "линупс"
Мож скинуть пример своих sheme? Дай я прост скопипастю что бы не ебаться лишний раз по брацки
Попробовал все-таки познакомиться поближе с Лламой Скаут: https://huggingface.co/meta-llama/Llama-4-Scout-17B-16E-Instruct
109b-a17b МоЕ, в той же весовой категории, что и Air. Довольно быстро убедился, что неспроста ее обошли стороной/забыли. Нарратив в целом неплохо описывается, местами слог приятный, но реплики очень сухие. Однако самое страшное - ассистент, от которого не спасет никакой промптинг. С Геммой я не так много игрался, но как будто даже в ней он не так силен. В Немотороне тоже есть ассистент, но его однозначно можно в большой степени подавить промптом, скормив хорошую карточку, здесь же - дохлый номер. Это что-то наравне с GPT-OSS: как ни крутись, порпшить нормально не удастся. Только вот OSS хороша хотя бы в технических задач (в моих юзкейсах), чего не могу сказать про Скаута. На сегодняшний день это, кажется, действительно модель без задач.
На самом деле, я не представляю на чем сегодня рпшить с 24гб видеопамяти и 128гб оперативы. Из МоЕ - похоже, что только большой 235б Квен и Air и остаются. И не поймите меня неправильно: я не ищу врагов, когда говорю, что это две очень своеобразные модели. Несколько раз у меня менялось мнение на их счет, то в одну сторону, то в другую. Спустя уже, выходит, месяца два экспериментов и попыток подружиться, расклад такой: Air использовать невозможно из-за его повторяющихся паттернов, слоп пронизывает практически каждый аутпут (проблемы echoes и путающихся сущностей можно опустить, они не так значительны); Квен 235 - это такой же hit or miss, как ванильный QwQ и Snowdrop. Иногда выдает невероятную годноту, но чаще - ужас ужасный. Проблема переносов на новые строки и даже стиля письма чинятся, но он на корню какой-то пережаренный и гиперболизированный. Однако для меня он точно лучше Air'а. Меня уже стукали за эти слова, но я не побоюсь написать еще раз: 32б плотная предшественница для меня лучше. И /inrep показывает, что в ней гораздо меньше повторений, и субъективно поиграв на ней еще раз после Air, я вновь оценил ее лучше. В итоге для меня в фаворе по-прежнему остаются плотные модели <= 50б (большего размера я запустить не могу). Они тоже со своими проблемами и в чем-то хуже, но субъективно нравятся больше. Это грустно. Как бы я их ни любил, успели поднадоесть, да и привык к большему количеству знаний у МоЕ - это правда прикольно, когда можно в рамках рп обсудить какой-нибудь фильм или какое-нибудь явление, что может быть недоступно на меньших моделях. В итоге доступные сегодня МоЕ мне не понравились, а старых плотных моделей уже не хватает, когда оценил прелесть выгрузки в оперативу. Все жду, когда замерджат https://huggingface.co/inclusionAI/Ling-flash-2.0 и надеюсь на МоЕ от Кохере, Мистраля, Гугла и кого-нибудь еще. А может быть это все чепуха, и я устал и выгорел, как пара анонов из нескольких прошлых тредов, которым все перестало нравиться.
109b-a17b МоЕ, в той же весовой категории, что и Air. Довольно быстро убедился, что неспроста ее обошли стороной/забыли. Нарратив в целом неплохо описывается, местами слог приятный, но реплики очень сухие. Однако самое страшное - ассистент, от которого не спасет никакой промптинг. С Геммой я не так много игрался, но как будто даже в ней он не так силен. В Немотороне тоже есть ассистент, но его однозначно можно в большой степени подавить промптом, скормив хорошую карточку, здесь же - дохлый номер. Это что-то наравне с GPT-OSS: как ни крутись, порпшить нормально не удастся. Только вот OSS хороша хотя бы в технических задач (в моих юзкейсах), чего не могу сказать про Скаута. На сегодняшний день это, кажется, действительно модель без задач.
На самом деле, я не представляю на чем сегодня рпшить с 24гб видеопамяти и 128гб оперативы. Из МоЕ - похоже, что только большой 235б Квен и Air и остаются. И не поймите меня неправильно: я не ищу врагов, когда говорю, что это две очень своеобразные модели. Несколько раз у меня менялось мнение на их счет, то в одну сторону, то в другую. Спустя уже, выходит, месяца два экспериментов и попыток подружиться, расклад такой: Air использовать невозможно из-за его повторяющихся паттернов, слоп пронизывает практически каждый аутпут (проблемы echoes и путающихся сущностей можно опустить, они не так значительны); Квен 235 - это такой же hit or miss, как ванильный QwQ и Snowdrop. Иногда выдает невероятную годноту, но чаще - ужас ужасный. Проблема переносов на новые строки и даже стиля письма чинятся, но он на корню какой-то пережаренный и гиперболизированный. Однако для меня он точно лучше Air'а. Меня уже стукали за эти слова, но я не побоюсь написать еще раз: 32б плотная предшественница для меня лучше. И /inrep показывает, что в ней гораздо меньше повторений, и субъективно поиграв на ней еще раз после Air, я вновь оценил ее лучше. В итоге для меня в фаворе по-прежнему остаются плотные модели <= 50б (большего размера я запустить не могу). Они тоже со своими проблемами и в чем-то хуже, но субъективно нравятся больше. Это грустно. Как бы я их ни любил, успели поднадоесть, да и привык к большему количеству знаний у МоЕ - это правда прикольно, когда можно в рамках рп обсудить какой-нибудь фильм или какое-нибудь явление, что может быть недоступно на меньших моделях. В итоге доступные сегодня МоЕ мне не понравились, а старых плотных моделей уже не хватает, когда оценил прелесть выгрузки в оперативу. Все жду, когда замерджат https://huggingface.co/inclusionAI/Ling-flash-2.0 и надеюсь на МоЕ от Кохере, Мистраля, Гугла и кого-нибудь еще. А может быть это все чепуха, и я устал и выгорел, как пара анонов из нескольких прошлых тредов, которым все перестало нравиться.
Нет пресета значит паста скипается
М-может быть если бы сказал волшебное слово и назвал модельку...
Пошел нахуй
Неделю сижу на эире и он меня уже заебал. Жалею что докупил рам до 64. Согласен с тем что 32b апрельский лучше и не понимаю почему сойдит и дискорд сходят с ума по этой какашке. Сила самовнушения наверн.
Линг интересная, и большая версия тоже. Скорее бы сделали, тем более что там ничего сильно уникального как в некоторых других нет.
Гранит пробовал?
Ну и ты так ноешь что прямо жалко становится. Попробуй сменить стиль рп, сценарии и прочее, может откроешь что-то где модели будут хороши и перестанешь грустить.
Тем кто мне предложит губу закатить сразу напишу что даже Гемма и Мистрал 24 мне не надоели и я до сих пор их катаю. Чудеса блять.
нюня совсем ебанулся и допресетился сломав все модели
ниче скидывай пресет щас я всё исправлю
ниче скидывай пресет щас я всё исправлю
Коллабо-кун, гугл окончательно задушил все или есть ещё шансы на возрождение?
А в чём проблема в паттернах и слопе?
Они везде есть.
Главное количество знаний которыми козыряет модель в рп и то как она пишет
Они везде есть.
Главное количество знаний которыми козыряет модель в рп и то как она пишет
Есть нормально разлоченный gpt-oss-120b? Я видел 20б от jinx на хаггинфейсе, но хотелось бы 120б погонять.
Если кто-то знает, дайте линк пожалуйста.
Если кто-то знает, дайте линк пожалуйста.
Кого-то сильно с них триггерит и он не может сосредоточиться, признак аутизма и других заболеваний. Иногда слопа запредельное количество и весь пост - безумные лупы по одному шаблону. Иногда это лупы по одному шаблону которые ахуенно ложатся в сюжет и суть максимально уместна, с того вдвойне обидно.
> разлоченный gpt-oss-120b
Не существует в природе. Максимум лоботомиты, которые показывают то же, чего можно добиться промптами, но вдвойне уг.
ладно.жпг
А как их разлочивают вообще? Есть гайд где по нотам расписано? Может я сам раздуплюсь сделать.
>На самом деле, я не представляю на чем сегодня рпшить с 24гб видеопамяти и 128гб оперативы.
Большом, последнем комманд-а. 3й, а то и 4й квант. На 64гб озу мне только 2й доступен.
Зато после запуска на голой ламе, без тесел (хоть какая то польза от возни с эйром), оно выдаёт аж 3 токена. Медленно, но совсем иное качество.
Теслошиз №2
Потому что не у всех есть 24гб видяха, и тем более риги. А там вариантов мало, или мелкогеммы, или мистрали, или эйр. Выбор очевиден.
И да, ризонинг вырубил, повторы сообщений убрал? С этими "фичами" пользоваться им невозможно.

>я не ищу врагов, когда говорю, что это две очень своеобразные модели.
Почему? Почему ты оправдываешься за своё кря.
Если что то нравится- пользуешься, не нравится не пользуешься.
Ну а если кому то что то не нравится, то шли нахуй.
~yay!~
> последнем комманд-а
Какие сценарии рпшишь? Какую разметку/промпты используешь? Что нравится, что не нравится? Последний - имеется ввиду command-a-reasoning-08-2025? Если да то пользуешься ли ризонингом или специально отключаешь?
Тут выкладывали семплеры, без них никакой коммандер не работает адекватно.
Собственно главное преимущество - меньше всего слопа. (от запаха озона, сосуда похоти и т.п. эйра уже тошнить начало) И при этом умнее даже эйра, который в развитии сюжета куда как лучше всех моделей 32б и мельче.
Да, именно его и имею в виду. До этого комманд-а были слишком сухими и немногословными, что по качеству РП сильно било.
Ризонинг включаю когда надо качественно продолжить сюжет, проанализировав контекст. А так слишком много времени на него уходит, без рига не быстро работает.
> На самом деле, я не представляю на чем сегодня рпшить с 24гб видеопамяти
Ну так а ты что хотел?
Это хобби изначально под риг из минимум трёх таких видюх, только недавно начали для нищеты модели выпускать, ну и качество соответствует
Сначала коупишь в треде что тебе всего одной хватает, а потом пишешь такое
Какие модели ныне на телефоне можно потянуть?
На этой неделе у нас новая гемма, глм эир и квен 4 с поддержкой в ламе через пол года
>Sam Altman recently said: “GPT-OSS has strong real-world performance comparable to o4-mini—and you can run it locally on your phone.” Many believed running a 20B-parameter model on mobile devices was still years away.
>At Nexa AI, we’ve built our foundation on deep on-device AI technology—turning that vision into reality. Today, GPT-OSS is running fully local on mobile devices through our app, Nexa Studio.
Real performance on
@Snapdragon
Gen 5:
- 17 tokens/sec decoding speed
- < 3 seconds Time-to-First-Token
>At Nexa AI, we’ve built our foundation on deep on-device AI technology—turning that vision into reality. Today, GPT-OSS is running fully local on mobile devices through our app, Nexa Studio.
Real performance on
@Snapdragon
Gen 5:
- 17 tokens/sec decoding speed
- < 3 seconds Time-to-First-Token
Что за семплеры ? Какая у тебя по итогу скорость, меньше токена/с ?
...мое мистраль, полёт на луну...
Держи, держи. Специально ради Квена был найден древний шаманский сэмплер, который радикально меняет его аутпуты. В какую сторону - решай сам https://pastebin.com/NTZHQiDL
В промпте ничего особенного нет, никаких хитрослей или префилла.
> Гранит пробовал?
Пробовал. У меня едет форматирование, ловлю софт рефузы там, где их быть не должно. Так было с GLM 32б, только там пробивалось промптом и свайпами, тут тоже так, но усилий нужно прилагать больше и не знаю, стоит ли того.
> Попробуй сменить стиль рп, сценарии и прочее, может откроешь что-то где модели будут хороши и перестанешь грустить.
Самый верный совет, пожалуй. И вместе с тем самый трудно реализуемый.
> А в чём проблема в паттернах и слопе?
Проблемой паттерны и слоп становятся тогда, когда они представляют из себя бОльшую часть ответа, что у меня происходит с Air. При включеном стриминге генерации, я уже по первому слову-двум в предложении знаю, что будет дальше. Ни DRY, ни rep pen не спасают, потому что весь ответ состоит из паттернов, которые я уже знаю. Ни с одной другой моделью у меня такого нет.
> Есть нормально разлоченный gpt-oss-120b? Я видел 20б от jinx на хаггинфейсе, но хотелось бы 120б погонять.
Погоняй 120б в SFW сценариях (чтобы не словить рефузы), с ризонингом и без, и поймешь, что это того не стоит.
> Большом, последнем комманд-а. 3й, а то и 4й квант.
Мне нравятся модели Кохере, в категории <=50б Коммандер 32 самый любимый, но какая будет скорость? Подозреваю, меньше одного токена. Для меня это безумие.
> Почему ты оправдываешься за своё кря.
Превентивная защитная стойка от фанатичных защитников своих любимых моделей.
> Сначала коупишь в треде что тебе всего одной хватает, а потом пишешь такое
Человеческое мнение имеет свойство меняться. Но скорее всего я просто наигрался, и Квен, и Air можно вполне успешно использовать. Особенно Квен.
Модель для кума до 32В посоветуйте
>Модель для кума до 32В посоветуйте
Какой смысл? Куда анона не целуй, чего ему не советуй - у него везде жопа.
Мистраль 3.2, Стар Комманд
Думер фаталист или мамкин дединсайдик ?
У магистрала по ебаному работает ризонинг и хз как его настраивать. Промт можно любой хоть стандартный roleplay из таверны или вон по ссылке выше взять из пресета для квена. Семплеры без понятия. Видимо те же что для 3.2 Small? Температуру главное большую не ставить если так
Эээ? Линк можно? Какие там особые семплеры что чинят неадекватную работу. К мелком там вообще претензий не дефолтных ни у кого не было.
> умнее даже эйра
110б плотная модель, что значит даже?
Ты литералли починил ёбнутую прозу Квена. Что за чёрная магия? Хз чем тебе не нравится но сам буду пользовать и довольно урчать, спасебо и хедпат тебе.
Тестил кто нибудь https://huggingface.co/BSC-LT/ALIA-40b ?
если ты не , то двачую.
-кун
я уже несколько раз сталкивался с тем, что на сойдите что-то прям нахваливают и довольно урчат, а пробую сам и оказывается, что это сраное говно сраного говна. вывод: как бы не ссали кипятком и не нахваливали что-либо, помни, что это может оказаться полнейшей хуетой и всегда проверяй альтернативы, они могут оказаться лучше.
Как долго ждали апрув мета моделей на хаггинфейс?
До часу всегда было
Я кроме реджекта ничего не получал. Не любят они Институт Исследования Кума (сокращённо ИИК).
будто их поделие ещё для чего-то годится, пусть не льстят себе, так и напиши
уважаемые, здравствуйте. Кто-нибудь знает как запустить deepseek-ai/Janus-7B-Pro и qwen/Qwen-30b-Omni на text-generation-webUI?
Я пытался Gracio обновить, как и всю библиотеку Transformers, но всё ломается. Чо делать?
это сложно, нужно минимум 20 айсикю, лучше не лезть в эту тему
ну я понял, что там нужно переписывать код UI под Gracio 5.XX.X, но мб у кого-то уже есть обновлённое ПО
2,5 токена выжал ручным подбором параметров. А меньше токена было когда запускал через лм студио с теслами. Они и там срали.
>Линк можно?
Где-то искать ссылки надо в прошлых тредах. Мелкий коммандер и неинтересен на фоне равного сноудропа (зато к которому тоже нужен адекватный семлер, лол). А вот у большого в конкурентах или зацензуренные по самое не могу несвежие корпоратиивки или посредственная лама. Естественно в этом цирке уродов он лучший.
>110б плотная модель, что значит даже?
Ну некоторые преподносят эйр как прорыв без цензуры. Хотя перед ним вышел коммандер. И совокупные мощности для запуска нужны те же.
>Где-то искать ссылки надо в прошлых тредах
Тоесть сам ты их зашарить не можешь?
>Хотя перед ним вышел коммандер. И совокупные мощности для запуска нужны те же.
Нет не те же. Сравнил 110б мое с 12б активных и 110б плотную. Или дебил или неспроста тебя шизом назвали, пост смердит каким то пиздабольством.
кто-нибудь может подсказать как запускать мультмодальные модели? Через UI хочется.
Тот анон прав бтв. Речь идет о запуске, а не о комфортной работе. Именно для ЗАПУСКА - требования к железу одинаковые.
Если тебе картинки, то в кобольде. Если что-то другое, то только для пердолей 80-го уровня.
Жора, вллм и ui по желанию
Ага, с такой прекрасной логикой можно запустить любую модель покуда у тебя есть место на жд, ибо выгружать можно и туда.
что насчёт open-webui?

работает ли генерация изображений?

>который радикально меняет его аутпуты
Чё за хрень, он теперь пишет как Эир. Ахуеть. Как будто другая модель совсем. Даже эхо на месте ахах. И цитирование. Но это просто ахуенно, пойду чекать на новых чатах.
Наконец руки дошли до GLM-Air-Steam от Барабанщика. Модель более творческая, чем оригинал, и более хорни. Но в то же время гораздо больше отказов, даже с префиллом. Такой вот парадокс. Если не влом свайпать, результат может быть интересным.
Ну, спасибо конечно, но интереснее что у тебя с эиром за пресет такой что прям невозможно пользоваться.
Я от него оторваться не могу
>Превентивная защитная стойка от фанатичных защитников своих любимых моделей.
Ты словно с института благородных анонов сбежал, а не на двач пришел. Не трать время и силы пытаясь оправдываться.
Всё что ты пишешь является твоим и только твоим мнением, а на вечно недовольных петухов- насрать.
ЧСХ модели от друммера никогда не нравились, не считая цидоньки 1.2 (Но эт я утёнок), а вот чистый слоп от рэдиарта- просто охуенно залетал.
Так зашарь свой
Так с жд ты не дождёшься конца генерации, лол. А так разница 2,5т/с и 13т/с. Больно, но зато качество иное. И детали лучше помнит (хотя на фоне гемм и мистралей даже айр невероятно внимателен к деталям).
У меня пресет от гичан с оффнутым Logit Bias и top-k, промптом Roleplay - Immersive
>просто работает
>просто
>конфиг на 100 строк с БД, лолламой, редисом и хуй ещё знает с чем
Лол.
Нахуя тебе она там? Сейчас end-to-end мультимодалок нет, а отдельную генерацию лучше запускать отдельно, а не в составе урезанного комбайна.
И Add BOS Token Skip Special Tokens галка стоит
На 99% уверен что ты даже никогда не задумывался о ingress и securityContext, а просто ебашишь всё от рута/админа и ходишь по порту. Если увидишь values из чарта наверное вообще инфаркт жопы словишь
Каждый видит чего желает
Ну тоесть стандартные нейтрализованные семплеры и короткий промт. Ахуеть открытие
А что ты вообще хочешь от ллм?
Ну да, всё говно.
Есть говно где больше знаний и приятней слог, есть говно где меньше слопа и паттернов, выбирай на свой вкус
Я мимокрок, мне все в радость
Ну и буду тем кто скажет это мне больше нравятся ответы с Include Names - Always, по крайней мере с глм эир
Там в закинутом пресете настроена фича GBNF grammar - это указывает бэку/модели какие токены можно пропускать вслед за какими. Буквально описывает - какие символы допустимы, в каком порядке. Вот тут детали: https://github.com/ggml-org/llama.cpp/blob/master/grammars/README.md
Эта штука тисками зажимает формат вывода - создавалась она изначально для того, чтобы вывод модели можно было предсказуемо коду простых программ скармливать, для легкого парсинга. Потом появился Function Calling и на GBNF понемногу забили. А зря, IMHO. Потому, что с text completion работает, в отличии от.
Минусы - должна быть поддержка в бэке. У Уги, например есть - но поломанная, и уже ~год не чинят. У tabbi - оно нормально вроде бы вообще никогда не работало. А вот у жоры и кобольда - походу живое.
Нихуя не понял но очень интересно. Понял только что мне походу пиздец как зашло.
>ебашишь всё от рута/админа
Под шиндой по умолчанию программы запускаются с ограниченным контекстом даже от админской учётки. Это не люнупсопараша.
>Эта штука тисками зажимает формат вывода
Поэтому ни слова по русски, лол.
>Поэтому ни слова по русски, лол.
Ну да. Хочешь по русски - добавь туда кириллицу в конфиг. Синтаксис у него на манер regexp-ов.
> адекватный семлер
В чем суть этого адекватного семплера?
> совокупные мощности для запуска нужны те же
Но есть нюанс как в анекдоте.
На вайлберриз возможно скоро будет снова 32 гб у продавца Шаосюй, а китаец опечатался и там PG503-216 (но это не точно).
Просто к сведению, меня-то жаба задушит экспериментировать, тред читать интереснее.
-мимокрокодил
Просто к сведению, меня-то жаба задушит экспериментировать, тред читать интереснее.
-мимокрокодил
>На вайлберриз
Хуйня без возврата
Таки да, это одна из причин, по которым мне было бы сыкотно покупать, если бы я всё же решился поставить в свой компудахтер 32гб монстра.
Но в покупках в Китае я не силён, а Алиэкспресс после его выкупа ктотамегоунаскупил - сосёт хуи в плане компьютерных запчастей, а жаль, я там видеокарту покупал в своё время.
Факт. Мне жд оттуда палёный приехал. Оформил заявку на возврат продавцу, был послан нахуй. Нашел кнопку оспорить спустя пару часов поиска, был послан нахуй уже площадкой. На второй день после покупки, естессна заявка как полагается оформлена со всеми пруфами. Говно, не связывайтесь.
У нас безвиз с Китаем, едешь и покупаешь, лол
Мне во-первых до Китая далеко, во-вторых я щит и меч Родины кую, так шта товарищ майор меня не выпустит за видеокартой.
>товарищ майор меня не выпустит за видеокартой.
Можно выехать, просто тебе нужно будет немного попотеть и написать заявление о просьбе разрешить выезд, цель выезда и приложить (после согласования) билеты и бронь в гостишке.
Китай не Европа, так сильно ебать не будут.
Можно всё, но зачем?...

Лолд блять, вот бы ехать через полземли за древней видяхой с помойки. Ну типа возьми ее цену, прибавь стоимость перелета туда-обратно, прибавь стоимость гостиницы-хуиницы и прочего, и вот у тебя уже сумма на покупку новой 5090 в ДНСе через дорогу.
И по чем они будут торговаться?
> во-вторых
Скажи что ты упоротая стримерша-енот.
И по чем они будут торговаться?
В душе ни ебу, я залез почитать вопросы в лот mi50-16, а там вот это продавец отвечает.
V100 16gb с охлаждением от 4090 у этого продавца 27к (с пошлиной), а v100 32гб хуёво работали по его словам и он их больше не хочет продавать.
Более опытные товарищи, кто на таобао покупает, могут сказать что-то более разумное, но я туда не ходок, хз что там с ценами на них в Китае сейчас - это ж не один хитрый китаец 3,5 видеокарты у себя в подвале перепаивать планирует.
>Скажи что ты упоротая стримерша-енот.
Нетъ.
>в каждом отдельном случае надо тестить
Протестировал command-a, не токены, а золото, похоже, на r7 5700x упор всё-таки в память, а не в компьют.
TL;DR Q4_K_S не нужны, если у вас не совсем древний cpu, iq4_xs обходит по скорости.
Вес файлов:
>57Gc4ai-command-a-03-2025.IQ4_XS.gguf
>60Gc4ai-command-a-03-2025.Q4_K_S.gguf
Конфиг слоёв получился идентичным, на IQ4_XS теоретически можно впихнуть ещё парочку тензоров на видеокарту, но там что-то регэксп ломается на ровном месте.
На cpu около 2/3 модели.
Скорости:
c4ai-command-a-03-2025.Q4_K_S.gguf
(промпт около 500 токенов, чтобы было хоть немного показательно)
>CtxLimit:5590/32768, Amt:63/512, Init:0.01s, Process:14.62s (39.54T/s), Generate:68.65s (0.92T/s), Total:83.26s
Вроде ещё видел где-то до ~50 с чем-то ближе к началу, iq4_xs по промпту однозначно выигрывает.
(с заполнением контекста скорость генерации несколько просаживается - ожидаемо; на промпт можно не смотреть, маленькие чанки дают малый т/с, то ли на cpu обрабатываются, то ли пересылка cpu <-> gpu начинает оказывать значимое влияние)
>CtxLimit:11153/32768, Amt:32/512, Init:0.02s, Process:1.11s (0.90T/s), Generate:37.13s (0.86T/s), Total:38.24s
c4ai-command-a-03-2025.IQ4_XS.gguf
промпт (генерация короткая, на длинных кусках медленнее):
>CtxLimit:10636/32768, Amt:5/512, Init:0.02s, Process:163.87s (64.87T/s), Generate:4.75s (1.05T/s), Total:168.63s
чуть более длинная генерация (модель не хочет срать):
>CtxLimit:10613/32768, Amt:24/512, Init:0.02s, Process:1.06s (0.95T/s), Generate:24.85s (0.97T/s), Total:25.90s
форкнул чат на последнем относительно длинном сообщении от q4_k_s и перегенерировал на iq4_xs:
>CtxLimit:8954/32768, Amt:147/512, Init:0.02s, Process:1.07s (0.94T/s), Generate:156.69s (0.94T/s), Total:157.76s
По генерации тоже наблюдается стабильно присутствующий небольшой выигрыш.
По самой модели.
TL;DR примерно уровень рп-файнтюнов лламы3.3-70b.
SFW РП на английском.
Лоб в лоб на одном сценарии не сравнивал ни с чем, но на разных впечатления довольно похожие с L3.3-GeneticLemonade-Opus-70B, подозреваю, с другими лламами тоже. И слог похожий, и мозги более-менее, свайпать редко приходится, между строк читают, юмор и иронию чаще всего улавливают и т.п. Ллама в 2 раза быстрее, там под 2 т/с, что, конечно, поприятнее. Коммандер, вроде бы, внимательнее к контексту и инструкциям.
Air тут не конкурент никаким боком.
Плотная мелочь <70b аналогично немотрон пока не щупал.
qwen 235b в каких-то отдельных моментах чуть лучше, в каких-то хуже, в среднем по больнице на мой субъективный взгляд ллама и коммандер лучше. Но там скорее с 72b надо сравнивать, а её я очень давно щупал и не помню толком.
Вроде бы, умнее предыдущего коммандера (2408, кажется?), но это требует дополнительной перепроверки.
NSFW не тестировал, посреди SFW лёгкие намёки и комплименты почти полностью игнорируются. Впрочем, прямых рефузов тоже нет. За пизду не хватал, не хотел себе атмосферу рушить ради бесполезных тестов.
На этом у меня пока всё.
Искренне ваш, тестошиз one of many.

Для подключения видюх через mcio напрямую в плату не берите синие модные райзеры из двух компонентов типа https://aliexpress.ru/item/1005008589548520.html на них распиновка не совпадает и они не заводятся, причем приводят к эффекту безусловного автостарта материнки.
Дешевые зеленые типа пикрел работают без проблем. При желании покрутив настройки можно даже х16 с двух слотов собрать.
Дешевые зеленые типа пикрел работают без проблем. При желании покрутив настройки можно даже х16 с двух слотов собрать.

> sfw rp
Ты угараешь?
Приноси результаты с лолями либо нахуй не нужно
господа нейрокумеры, поясните анону какие преимущества локал Кал имеет против копро Кала? и стоит ли локалко-ебля свеч

Сей поток словестного поноса будет направлен на выводы по карточке, которую я с дуру купил за 136к рублей, когда повёлся на хайповые заголовки. Я сразу скажу, что я не думал перед покупкой, при покупке, да и после покупки у меня достаточно пустая голова, однако я сейчас поделюсь с вами информацией(а так же некоторыми цифрами), что эта карта могёт. Данный пост так же будет продублирован в SD тред, т.к. диффузии на карте тоже запускались и в LLM тред, т.к. языковые тоже, это общий вывод по железке.
Для начала стоит сказать, что я нашёл людей, для которых создана эта карта, вам понадобится: купить сервер Kungpeng 200 на арм чипах 910, купить 4 таких карты что бы забить все слоты в райзерах. Суммарно на это у вас уйдёт около 1.5 миллиона рублей, быть житель материковый китай нефритовый стержень удар, что бы качать без заёбов себе драйвера, тулкиты, пакеты для деплоя, квантов и прочего, кроме того вам нужно иметь прямые руки, понимать в администрировании, девопсе и по хорошему говорить на китайском языке уверенно, что бы читать форумы Ascend. Для меня, пропитого эникея работа с картой была задачей со звёздочкой, хотя большую часть времени я вообще не то, что должен был.
Если хотя бы по одному из пунктов вы проскакиваете, то вам не стоит покупать данную карту, ибо она сделана корпоратами для корпоратов, её тыкают в сервера умного видеонаблюдения, для ML(она умеет например в YOLOVv8 в 100фпс) и прочего.
Теперь все подводные камни для тредовичков:
1)Не работает на винде. Вообще, даже WSL нет смысла пытаться, поддерживается на полутора дестрибутивах, ну хотя бы есть привычная ебунта LTS в списках, остальное это всякие эйлеры, кайлины, хуйлуны и пр.
2)Не поддерживает квантование. В теории оно умеет специальные кванты разработанные Ascend, на практике можно про это забыть, поддержка квантования сейчас крайне ограничена. Даже привычных легаси форматов типа Q4_0 нет. ТОЛЬКО FP16(BF16 тоже нет)
3)Поддерживает полторы модели. На данный момент поддерживает хуй да нихуя моделей, мало того почти все модели на которые хуавей говорит 100% будет работать - это 0.6-8В лоботомиты квена, даже ~80B квены старые и новые хуй. На практике чуть-чуть иначе, но всё ещё не сильно хорошо. Про запуск шизотюнов можете забыть.
4)Достать софт - боль моя дырка задница. Сразу покупайте виртуалку с пекинским айпи или запрягайте вашего продавца предоставить вам ваш необходимый для работы с картой софт, я выбрал второе.
5)Разумеется как проф карта она идёт без активного охлада и переходников для запуска на обычной пеке.
Плюсы есть? Ну в теории есть, я даже выделил парочку:
1)Несмотря на то, что это по сути легаси говно 2022-го года выпуска на неё активно выпускают софт и обновления для поддержки. Буквально пол года назад я бы вообще нихуя не смог запустить на ней, сейчас есть хоть что-то. Учитывая. что рантайм для инференса MindIE от хуавея обновляется каждые 2-3 месяца(в этом месяце тоже должно выйти большое обновление), то через 3-6 месяцев этот пост вполне может перестать быть актуальным и появится значительная поддержка всего и вся под эту карту. Кроме того поддержку этой карты сейчас активно разрабатывают и развивают в llama.cpp, vLLM и прочих бекендах. Я успел пообщаться с разработчиком поддержки Ascend npu в llama.cpp, новости пока что удручающие, но работа кипит.
2)Пока что по сырым характеристикам эта карта ебёт всех своих конкурентов. 280 TOPS INT8, 96Гб памяти с 408гб\с псп(что всё равно больше чем у самых пиздатых цп решений на Epyc) и всё это при теплопакете 150W и цене в 1000-1500$.
Теперь к практическим тестам:
Diffusion: Бекенд llama-box SDXL стандартный генератор 1024х1024 35 шагов 1 чип справился примерно за 2 минуты без оптимизаций, пока что не разобрался как распараллелить и потестить с лорами и тюнами типа люстры. То есть работало только пол карты. Сама Huawei на MindIE заявляет скорость SD 1.0 512x512 20 шагов около 2.8с на картинку при полном распараллеливании задачи диффузии.
LLM: GPT-OSS 20B почему-то в FP16 со странным антиквантом запустился, но криво. Скорость генерации около 9т\с на пустом контексте. Значительная часть модели(12гб) выгрузилась и работала на цп, на нп выгрузилось почему-то на 1 чип около 6гб в врам, по ходу ответов увеличивалось место, возможно KV cache или ещё какая залупа, непонятно. Дипсики все отказались запускаться, пока что качаю гемму и квен, ждите отписки завтра.
В общем пока что покупка карты очень сомнительное мероприятие сопряжённое с пердолингом, красноглазием и невозможностью запустить карту в работу как обычную гпу. Я надеюсь, что китайцы в будущем исправят это недоразумение, добавят поддержку мейнстримного квантования и список поддержки моделей сильно разрастётся уже в 2026-м году, но надежда умирает последней, а карту я пожалуй выставлю на авито и куплю хорошую потребительскую гпу вместо неё, наигрался.
Для начала стоит сказать, что я нашёл людей, для которых создана эта карта, вам понадобится: купить сервер Kungpeng 200 на арм чипах 910, купить 4 таких карты что бы забить все слоты в райзерах. Суммарно на это у вас уйдёт около 1.5 миллиона рублей, быть житель материковый китай нефритовый стержень удар, что бы качать без заёбов себе драйвера, тулкиты, пакеты для деплоя, квантов и прочего, кроме того вам нужно иметь прямые руки, понимать в администрировании, девопсе и по хорошему говорить на китайском языке уверенно, что бы читать форумы Ascend. Для меня, пропитого эникея работа с картой была задачей со звёздочкой, хотя большую часть времени я вообще не то, что должен был.
Если хотя бы по одному из пунктов вы проскакиваете, то вам не стоит покупать данную карту, ибо она сделана корпоратами для корпоратов, её тыкают в сервера умного видеонаблюдения, для ML(она умеет например в YOLOVv8 в 100фпс) и прочего.
Теперь все подводные камни для тредовичков:
1)Не работает на винде. Вообще, даже WSL нет смысла пытаться, поддерживается на полутора дестрибутивах, ну хотя бы есть привычная ебунта LTS в списках, остальное это всякие эйлеры, кайлины, хуйлуны и пр.
2)Не поддерживает квантование. В теории оно умеет специальные кванты разработанные Ascend, на практике можно про это забыть, поддержка квантования сейчас крайне ограничена. Даже привычных легаси форматов типа Q4_0 нет. ТОЛЬКО FP16(BF16 тоже нет)
3)Поддерживает полторы модели. На данный момент поддерживает хуй да нихуя моделей, мало того почти все модели на которые хуавей говорит 100% будет работать - это 0.6-8В лоботомиты квена, даже ~80B квены старые и новые хуй. На практике чуть-чуть иначе, но всё ещё не сильно хорошо. Про запуск шизотюнов можете забыть.
4)Достать софт - боль моя дырка задница. Сразу покупайте виртуалку с пекинским айпи или запрягайте вашего продавца предоставить вам ваш необходимый для работы с картой софт, я выбрал второе.
5)Разумеется как проф карта она идёт без активного охлада и переходников для запуска на обычной пеке.
Плюсы есть? Ну в теории есть, я даже выделил парочку:
1)Несмотря на то, что это по сути легаси говно 2022-го года выпуска на неё активно выпускают софт и обновления для поддержки. Буквально пол года назад я бы вообще нихуя не смог запустить на ней, сейчас есть хоть что-то. Учитывая. что рантайм для инференса MindIE от хуавея обновляется каждые 2-3 месяца(в этом месяце тоже должно выйти большое обновление), то через 3-6 месяцев этот пост вполне может перестать быть актуальным и появится значительная поддержка всего и вся под эту карту. Кроме того поддержку этой карты сейчас активно разрабатывают и развивают в llama.cpp, vLLM и прочих бекендах. Я успел пообщаться с разработчиком поддержки Ascend npu в llama.cpp, новости пока что удручающие, но работа кипит.
2)Пока что по сырым характеристикам эта карта ебёт всех своих конкурентов. 280 TOPS INT8, 96Гб памяти с 408гб\с псп(что всё равно больше чем у самых пиздатых цп решений на Epyc) и всё это при теплопакете 150W и цене в 1000-1500$.
Теперь к практическим тестам:
Diffusion: Бекенд llama-box SDXL стандартный генератор 1024х1024 35 шагов 1 чип справился примерно за 2 минуты без оптимизаций, пока что не разобрался как распараллелить и потестить с лорами и тюнами типа люстры. То есть работало только пол карты. Сама Huawei на MindIE заявляет скорость SD 1.0 512x512 20 шагов около 2.8с на картинку при полном распараллеливании задачи диффузии.
LLM: GPT-OSS 20B почему-то в FP16 со странным антиквантом запустился, но криво. Скорость генерации около 9т\с на пустом контексте. Значительная часть модели(12гб) выгрузилась и работала на цп, на нп выгрузилось почему-то на 1 чип около 6гб в врам, по ходу ответов увеличивалось место, возможно KV cache или ещё какая залупа, непонятно. Дипсики все отказались запускаться, пока что качаю гемму и квен, ждите отписки завтра.
В общем пока что покупка карты очень сомнительное мероприятие сопряжённое с пердолингом, красноглазием и невозможностью запустить карту в работу как обычную гпу. Я надеюсь, что китайцы в будущем исправят это недоразумение, добавят поддержку мейнстримного квантования и список поддержки моделей сильно разрастётся уже в 2026-м году, но надежда умирает последней, а карту я пожалуй выставлю на авито и куплю хорошую потребительскую гпу вместо неё, наигрался.
К прошлому command-a главной претензией была его глупость. То есть он вообще не выкупал саму концепцию тайн, того что персонаж может еще не знать чего-то, не видеть, быть обманутым и т.п. Даже там где вся завязка вокруг этого строится. Это уровень 12б, даже тридцатки редко так ошибаются. Может инфиренс на жоре тогда был поломан или что-то еще, но разочарование было капитальное.
Не замечал подобной ерунды за новым?
>какие преимущества локал Кал имеет против копро Кала?
1. Приватность
2. Меньше цензуры
3. Работает без интернета
>и стоит ли локалко-ебля свеч
Если для тебя вышеперечисленное важно - да, стоит.
> ебёт всех своих конкурентов
За цену этой карты можно купить две 3090 и в Жоре с квантами иметь в разы больше т/с. Вместо fp16 будет Q8 и скорость.
> SD 1.0 512x512 20 шагов около 2.8с на картинку при полном распараллеливании задачи диффузии
На сингл ми50 такое с дефолтными темплейтами из комфи
Бля, колонку пайторча не смотрите, эксель поднасрал
3090 это некрокарта и 2 таких будут иметь теплопакет больше 700 ватт. Речь про совокупность характеристик.
Там ещё про какие-то узкоглазые оптимизации дописывали, что генерация меньше секунды становится. Пока что непонятно.
>типа https://aliexpress.ru/item/1005008589548520.html
Ванга: ты оставлял отзыв на этот товар 21 августа.
> больше 700 ватт
В LLM не больше 250 у каждой.
> Речь про совокупность характеристик.
В совокупности на 3090 тебе будет доступно всё и по приемлемым скоростям, у 3090 даже память в два раза быстрее. А на Хуавее нихуя не работает и скорость днище, только с ЦП конкурировать.
>персонаж может еще не знать чего-то
Нет, пожалуй. Прямо в лоб не тестил, но косвенно пара подобных моментов была и коммандер тут вроде справился. Хотя тут как бы "доказательство отсутствия", что на практике трудновыполнимо. Если есть проёб, то есть проёб, а вот если нет, то ещё не факт, что не просто повезло.
На квене 235b, кстати, был такой момент и квен там ну не то, чтобы прямо совсем обосрался, но малость дристанул подливой. Впрочем, 22b есть 22b. Как раз в таких вопросах больше решают активные параметры. И для 22b у него неплохой результат. Впрочем, квены и плотные обыгрывают конкурентов в своей весовой категории по таким моментам.
>даже тридцатки редко так ошибаются
24-32b мне запомнились фейлящими этот тест. Но как бы статистики, насколько это часто, я не собирал. Скорее вышеупомянутая схема "если есть проёб, то есть проёб", и модель может быть прощена, только если а) влезает полностью в vram и перегнерировать дело пары секунд и б) удачных рероллов хотя бы >50%. Для больших моделей, где цена реролла высока, требование к отсутствию капитальных проёбов вырастает до ~95%. Но большие-то проходят, как ни странно.

Как же хочется новую Геммочку или Мистральчика. Чтобы moe и 100b+... ммм. Я что, многого прошу?
>Пока что по сырым характеристикам эта карта ебёт всех своих конкурентов
При грамотном выборе конкурентов. Ибо конкурент тут RTX PRO 6000, и китаеподделка сосёт по всем параметрам в разы (включая цену, хоть и со знаком минус).
А что они дадут? Прогресс умер два года назад.
Мистраль нахуй. А вот Гемму на 50-70В без МоЕ было бы хорошо.
>память в 2 раза быстрее
А чип в 3 раза медленнее. Каждому своё, но и своё не каждому. 3090 это некропечка, а хуавей это сомнительное почти ничем не поддерживаемое нечто с сомнительным будущим. Аксиома эскобара в действии.
Ну как оно? Принёс что то этузиастское, а местные начали убеждать что ты еблан. Ну кайф же
>конкурент тут RTX PRO 6000
Даже не близко, у блеквела конкурент это MI250 какая-нибудь, один блеквел по скорости чипа в 5 раз быстрее хуавея, по псп в 2.5 раза. По цене в 8 раз. За эти деньги у хуавея можно купить целый сервер на арм цп, у которого кстати поддержка значительно лучше во всём.
А, и да, забыл упомянуть (возможно) важный момент. Со временем коммандер строчит всё меньшие и меньшие полотна. Обычно это даже в плюс на мой субъективный, но иногда хочется всё-таки навалить экспозиции или двинуть сюжет вперёд силами ллм, тот же квен, к примеру, всегда любит навалить, наоборот, чаще обрезаю его ответы. А из этого лишнего слова не вытянешь, рероллишь-рероллишь, он писать может немного о разном, но длина ответа прямо стабильная.
Вроде где-то в прошлых тредах что-то такое обсуждалось, то ли как-то пофиксили, то ли нет. Лично мне на ум приходит только временный свап модели на пару сообщений.
Я знаю, что я еблан. Но порой местных тредовичков слушать - это себя не уважать. Хотя мне есть с чем сравнивать хуавей и разумеется он пока что отсасывает по всем фронтам. Ибо карта изначально делалась для систем ML типа умного города под камеры трафика, распознавание лиц и прочее.
Спасибо анон. Было интересно смотреть за твоим приключением. Как минимум я точно не буду брать кетой, без проверки.
Так что тебе: Бооольшое, здоровенное прям, пасебо.
Гемма цензурная. Хотя даже так определённый интерес представляла бы. А вот мистралька 70B должна быть вином. Скорее всего, поэтому и не публикуют medium. А то квен говно для рп (рельсы), а больше некому в этом размере с лламой3.3 и зоопарком файнтюнов конкурировать, остальное либо тупее, либо медленнее.
>по сырым характеристикам эта карта ебёт всех своих конкурентов. 280 TOPS INT8, 96Гб памяти с 408гб\с псп
так конкуренты этой фигне карты от нвидии и Амуде, а не ЦП
>Даже привычных легаси форматов типа Q4_0 нет. ТОЛЬКО FP16
и тут мы внезапно нивелируем преимущество в виде "многапамяти" - с таким же успехом мы можем на МИ50 или 3090-5090 гонять Q6-Q4, или Q8 чуть меньших моделей на Большей скорости...
>GPT-OSS 20B Скорость генерации около 9т\с на пустом контексте.
вообще никуда не годится, - такую скорость на Нвидиа обрубках 10 летней давности почти получаем,
>Я надеюсь, что китайцы в будущем исправят это недоразумение, добавят поддержку мейнстримного квантования и список поддержки моделей сильно разрастётся уже в 2026-м году
тогда эту вундервафлю недокорпораты разметут как пирожки
>А что они дадут?
Прирост в мозгах и скорости. Вот у меня 12/64. Я могу запустить гемму 27б в ~3.7 т/с, а могу эйр в 9.5 т/с. Второе и быстрее и умнее. Мое-гемма была бы отличной альтернативой эйру и спасением для анонов с некрожелезом.
для себя вижу только 3 плюс, для 1 тоже могут возникнуть таски, но... там где этот 3 плюс нужен, нет возможности запустить нормально, нормальную модель - дома то интернет есть, а вот в дороге или ебенях какихто там нейропеку не возьмеш с собой...
вот интереснее другой момент, есть ли сейчас норм обёртки для локальных моделей, чтобы всякую работу с документами проводить итд итп...
>и 2 таких будут иметь теплопакет больше 700 ватт.
и за одно встроеное нормальное охлаждение а не колхоз с турбинами
тебе чтоль электричества жалко, оно ж копеечное, та и не будешь ты днями генерить хентай, а вот быстрый ответ более ценен
а что там с РОКМ 7, завезли аноны на мишку его или нет?
На тест гопоты можно пока не смотреть, веса почти не загрузились на нпу.
>так конкуренты этой фигне карты от нвидии и Амуде, а не ЦП
По факту это всё демагогия, когда задача "Хочу минимум рублей потратить, получить максимум выхлопа". Тут несколько раз было написано, что карта нихуя не для ллм сейчас точно, но всё равно получаю ушат говна будто выставляю её как мега йобу.
>тогда эту вундервафлю недокорпораты разметут как пирожки
Терпеть.гиф; не было никогда в голове у той же куртки выпускать бюджетные решения под домашний инференс, задача всех компаний - получать прибыль. Кто-то купил мишки по 12к рублей, кто-то нет.
>та и не будешь ты днями генерить хентай
Как раз таки это основная задача для которой я брал карту. Ллм вторичное. Я себе уже больше 6к картинок только тентаклепрона отобранного из батчей схоронил. И это месяц безделья с 3060.
базару нет, анону спасибо за тесты этого дерьма, но от этого оно дерьмом быть не перестает... китаёзы для чего-то это делали, даже использовали возможно, но теперь отправили в утиль и распродают, а энтузиастам теперь сиди-перди и придумывай как это заюзать...
Это печально. Чтож, посмотрим как оно дальше будет.
> BF16 тоже нет
Вот это плохо.
Ну в целом какой-либо "поддержки квантов" можно сказать что не существует, основные операции происходят после апкаста. Так что тут скорее вопрос поддержки в софте, если офк их рантайм не абсолютно обрезанный и в нем ничего нет, что маловероятно.
> что всё равно больше чем у самых пиздатых цп решений на Epyc
Современные больше.
В любом случае ты молодец что все это показывал и освещал.
Как ты узнал?!
> фейлящими этот тест
Не про тест а про общую концепцию. Если хочешь именно тест - чар связанный и с завязанными глазами, ты его ебешь но у него была вводная что ебешь его не ты.
Правильное поведение: чар обращается к тебе как к тому, кого он предполагает и ведет себя соответственно, если снять маску - ахуевает.
Неправильное: чар сразу тебя узнает или происходит что-то смешанное, типа обращается к тебе по имени, упоминает твои черты, но действует будто это не ты, не ахуевает если снять маску.
Слишком очевидная штука, ну может 10% фейлов допустимы, но никак не половина.

Уже постил бенчи в лламецпп. Торч для vllm собрать не удалось т.к. llvm 20 в 7.0 падает, просто так впихнуть 19 из 6.4 не вышло.
Больше никого не видел что бы дрочились с сборкой софта под эту хрень
но выпустили ж RTX PRO 6000 - то самое решение с дофига врам и для полуэнтузиастов без бабла в кармане... да, это не то бюджетное решение которое многие хотели бы, но вопрос еще в том, сколько реально тех кто готов куплять для инференса карты специализированые? а корпы всегда были основным покупателем
Нужно ещё moe тестить т.к. там между 6,3 и 6,4 была разница в ПП, но у меня и так дел по горло
>https://pastebin.com/NTZHQiDL
Открыл для себя заново Квен. Почему про этот волшебный способ нигде не написано? Столько всего читал по теме. Реально пишет иначе теперь. У меня хоть и в двух битах запускается но хотяб с этим пресетом работает реально круто. Поклон тебе анон, кажись вкатывался в тему с твоих пресетов ещё весной на Сноудроп и другие модели. Думал ты тут давно и не сидишь уже.
тогда мое почтение...
> 280 TOPS INT8
Что-то ты разошёлся куда-то умножать на 4, у тебя же слои последовательно работают как на двух картах, значит и считать надо производительность одного чипа. Там два чипа по 70 топсов в INT8, который ты сам говоришь не работает, смысл тогда их учитывать. В fp16 по 40 топсов, что литералли 3090. Память ультрамедленная DDR4, что самое важное в LLM. Т.е. при любых раскладах 3090 быстрее будет.
> легаси говно 2022-го года выпуска
Чипы там разогнанное говно 2019 года так-то. Поэтому даже bf16 нет.
>по 70 топсов INT8
Ты путаешь чипы, на дуо версии 310p3, у них у каждого 140 tops int8, да, ещё есть просто 310 чипы, например на маленьких хуавеях.
Такс, не понял немного, там с vLLM проблема или с торчем? чистый торч собирается?
>2019 года
Кстати тоже не корректная информация, в 2019-м вышли 3000 процы, в 2022-м вышли 3010 процы. А какая там точно микроархитектура хуавей не рассказывает. Алсо их ещё постоянно путают, например в рабочей станции Orange pi ai max или как её там стоит 310p3, а не 310 старый, из-за чего на форуме ascend я успел прочитать пару бугуртов.
Проблема с торчем который нужен для vllm. Ещё вспомнил что на 6,4 вллм кидает ошибку при попытке скормить картинку в гемму, на 6,3 без проблем
>а энтузиастам теперь сиди-перди и придумывай как это заюзать
Ну так анон и писал, что эта карточка для ЛМ обучения, а не для обычных пользователей. Это как спецтехника, для определенных задач и пердолинг Васяна из деревни Нижнее Речное в них не входит.
И llvm это не ошибка в vllm
Я никогда не писал, что она для обучения. Она 100% не для обучения, только для инференса. Сами разрабы пишут на форуме Ascend только инференс, в рантайме MindIE чётко сказано на какие чипы оно сделано и хуля запускать можно. Не тренировать. И навряд ли с псп ты что-то натренируешь в плане ллм, пару лор для диффьюжена мб.
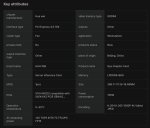
Не гуглится 240. На Алибабе продают только такие Atlas 300I DUO. Видимо тебя наебали чтоб ты купил на радостях, лол.
О чём вы вообще?
Проза на месте, модель всё так же ужарена в хлам, это просто фиксит
вот
э
то
и
Всё. У нас тут будто новый драмер, только вместо файнтюнов волшебные пресеты.
Будто если вывод просто другой то тред сразу бежит восхвалять пресет/модель
>Не про тест а про общую концепцию
Ну анон, не цепляйся к словам, ты же не 8b не 8b же? skywalker.jpg, не только лишь все МоЕ выкупят отсылочку, должен был понять, что я имею ввиду.
>Если хочешь именно тест
Достаточно просто столкнуться с подобной ситуацией в рп и посмотреть, как модель её разрешит.
>10% фейлов допустимы, но никак не половина
Проценты взяты с потолка, говорю же, точных подсчётов не проводил. Может там и 90% для мелкомоделей и 99% для не_токены_а_золото.
Суть в том, что у меня есть какой-то порог толерантности к проёбам ллм, который динамически меняется в зависимости от скорости генерации.

>А чип в 3 раза медленнее.
Аре ю щюре? Вот тут заявляются характеристики атласа
>280 TOPS INT8
А вот что я нагуглил. Нет даже кратного отрыва.
>а местные начали убеждать что ты еблан
Где? Адекватная реакция. Тот Анон сам знал, на что шёл.
>у которого кстати поддержка значительно лучше во всём.
В смысле? У невидии же лучшая поддержка всего. Любая поебота с "нейро" в названии пишется прежде всего под куду.
>Второе и быстрее и умнее.
Но не существенно.
>Как ты узнал?!
Кто же ещё будет хвалится корпусом на 3 картонки? Да и фотки те в шапке были.
>без бабла в кармане
>10 килобаксов
А можно я буду таким нищуком?

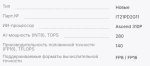
Ты явно смотришь куда-то не туда.
Причина пляски? Ты потыкайся подольше одного двух сообщений и мб поймёшь о чём речь. У меня слоп практически пропал например и я реально сижу в ахуе. Мне не западло написать спасибо анону который воскресил для меня модель на которую я забил болт.
У 910 чипов значительно лучше поддержка чем у 310. Вот на них реально что-то можно запускать.
Так я и говорю тебя барыги наебали. Зайди к китайцам.
>Сами разрабы пишут на форуме Ascend только инференс,
Хорошо, тогда я обосрался. Но вопросов меньше не становится. Если её цель инференс, то почему всё через жопу так.
Ну то есть, если для них нет никакой специфической среды, почему у тебя такой ад и пердолинг тогда?
>если для них нет никакой специфической среды, почему у тебя такой ад и пердолинг тогда?
Специфическая среда есть, называется MindIE. На ней нихуя не поддерживается почти(полтора лоботомита квена и дифьюжен). Есть vllm, llama-box, llama.cpp, на которых только экспериментальная поддержка и надо ждать апдейтов и прокачки возможностей.
Пик1 официальный сайт хуавей возвышение. Это hh pci карточка одночиповая с 310p.
Ну перетрясись и вернешься напишешь мнение
А то прочитал, запустил и всё тоже самое, а структуру я и так давно пофиксил
2 раза разочаровываться в модельке это боль
Реально полезный пост, красава. Надеюсь продашь видюху так чтобы не уйти в минус.
> Это hh pci карточка одночиповая с 310p.
Это вообще другая карта, лол. Зачем ты от другой карты смотришь характеристики и коупишь?
Про порог толерантности это верно, не зря уже давно топлю что быстрая модель может давать лучший экспириенс чем золотые токены.
Ситуация была именно в рп, и это только одно из самых ярких проявлений, были и другие и всего этого у большой модели не должно быть. Фишка даже не в свайпах, а в том что модель сразу себе такую парадигму заложила и так понимает, получишь разнообразие, но везде стабильно такая ерунда пролезает.
Пойду новый скачаю.
> Кто же ещё будет хвалится корпусом на 3 картонки?
Корпус на 3 картонки, завидуй! А mcio там причем?
короче понятно, торча пока что нет, и скорее всего не будет, более менее работает все на 6.4
меня просто интересует больше в контексте разработки и обучения бюджетного, а значит нужна хорошая совместимость с торчем и пайтоном...
Блять, я тебе говорю, что дуо это две такие карты слепленные в одну, у неё 2 чипа у каждого своя память отдельно друг от друга, у дуо карты 280 int8 tops, у этой 140. Китаец в объявлении их перепутал, как и на orange pi их неправильно пишут. Ты бы хоть погуглил 5 минут перед тем как хуйню нести.
> хорошая совместимость с торчем
Бля, mi50 это древний как говно мамонта GCN от AMD. Что за юморсеки?
>А можно я буду таким нищуком?
для небольшой компании подъемная сума,
айфон ебучий штуку баксов стоит, а ТПшки-сосалки каждую модель на старте покупают, так почему ресерч комманда энтузиастов не может купить ускоритель? + кредиты никто не отменял
в сравнении с копрокартами эта бюджетная...
но не по нашим меркам...
ну так нвидиа на паскалях все еще совместима внезапно, со всем чем можно, хотя и скоро дропнут поддержку... (мишка так-то новее)
когда вопрос стоит или наскреби со своего кармана и имей что-то или не имей нихрена то задаешся вопросом...
Ты в любом случае опоздал на поезд с мишками, сейчас они по 16к в закупе в китае. Когда есть v100 с nvlink бордами мишки как бы не упали
>256 каналов аппаратного декодирования 1080р
Не удивительно, что корпораты их скупают. Пачкой таких карт можно сервер видеонаблюдения обеспечить.
>Корпус на 3 картонки, завидуй!
У меня define 7 xl в запасе...
>А mcio там причем?
А это переходники.
> для небольшой компании подъемная сума,
Так я не компания, я индивидуальный ресёрчер (нет, не кум-ресёрчер, уже месяц не кумил на нейронки, гоняю свою вшивую 5090 только недооценёнными ресёрчами.
>v100
Volta...
Лол, ну бери a100
Ampere... Почти актуальные, но всё таки. Да и цена уже не такая радостная, либо совсем обрезки из авто.
Лол, ну иди тогда нахуй
> с nvlink бордами
Ненужны, хватит и обычных. Но вот бы кто взял вольт и потестил их.
> У меня define 7 xl в запасе...
Хуя ты жесткий, к зиме запасаешься?
> А это переходники.
Какие переходники? Ладно, что-то шутка затянулась, не будут тебе переубеждать.
> вот бы кто взял вольт и потестил их
Что за омежное мышление? Возьми САМ да проверь, а не терпи в углу
>Хуя ты жесткий, к зиме запасаешься?
Хотел собираться, да уволился, держу теперь про запас, будет безденежье, продам по бартеру за еду и лекарства.
А если возьмёт, то лол, купил товар, потому что на дваче приказали. Омежность в квадрате.
Овечья шкура хорошо греет
А если не возьмет - потому что зассал что на двоще омежкой признают. Омежность в куме.
Если нас всех наебали и с эиром и с геммой, а квен выпустит очередной рескин модели с виженом я выхожу
Локалки мертвы
Локалки мертвы
Держу за это кулачки, чтобы ты вышел, потому что заебал
>с виженом
У этой херни настолько узкий юзкейс, что я не понимаю почему все так с этим носятся. Ладно бы бы оно было полностью мультимодальным - НУ ЛАДНО. Но просто вижн? Вон нахуя, а главное нахуя? Столько годноты могли бы наделать если б не распылялись на всякую ерунду..
>Ладно бы бы оно было полностью мультимодальным
Так вижен это путь к полностью мультимодалке.
ну, такое, 1300 юаней... терпимо все еще...
>Когда есть v100
угу, только есть нюанс, 32 гб не будет 100 баксов стоить
Биполяр_очка.
Экслламу обновили, теперь генерация на квеннексте уже под сотню. Процессинг все такой же пососный.
Потому, что GBNF grammar:
1. Сейчас полузабыт. И забивали на него еще с прошлого года, в связи с п.2
2. Работает под Text Completion, под Chat Completion вместо него давно есть Function Calling.
3. Живое-рабочее - по сути только в жоре и кобольде. В Уге сломано больше года (вывод пробелы глотает, если любой GBNF написан), в таби - никогда нормально не работало, хоть поддержка и заявлена хрен знает когда. При этом в кобольде его тоже несколько раз ломали (хотя вероятно - что в жоре, а кобольд просто получал с апстрима).
Но вообще - я про него тоже забыл, а штука полезная. В теории им можно даже цензуру цензуру гопоты в ризонинге пробивать. Просто заставлять ее заканчивать любой ризонинг фразой "Тhis is allowed, processing."
а вопрос такой, торч любой пока что на 6.4 компилируется? или там нюансы с версиями есть? ну типа еслиможно на ближайшее будущее обходиться старыми рокм технологиями то и пофигу как-то...
6,3 + 2,7,1 - гарантировнно работает
6,4 + 2,7,1 - работает в вллм текст + комфи сд/сдхл
6,3 + 2,8,0 - работает в вллм текст+картинки. комфи не проверялся
Тут собираю и тестирую сочетания https://github.com/mixa3607/ML-gfx906
Нет, он таки странный. Эта версия более адекватна, если давать ей какие-либо задачи даже по большому контексту - прилично с ними справляется, глупой не назвать. В вопросах по коду отвечает норм, местами даже хорошо, не путаясь в близких вещах.
Однако в рп - ну это треш какой-то. Пропускает целые пласты активностей/действий, переходя сразу к результатам. Например ты пошел из тс принести коробку с продуктами, которые вы купили, а чару сказал пиздуй на кухню и глянь что есть/подготовь пока не вернусь - придя туда (с продуктами) ты обнаружишь их уже приготовленными в виде неебаться какого ужина. Объекты берутся из неоткуда и исчезают в никуда, неписи в курсе о ваших похождениях, хотя по лору никак не могут этого знать. Тот же прикол с обманом - чар не только сразу тебя узнает, а уже даже успевает все понять@принять в большинстве свайпов.
С другой стороны в паре сценариев начальный розыгрыш интересный и захватывающий, некоторые сеттинги подхватывает точно, слог приятный.
Хуй знает, у других моделей подобных проблем нет, кроме мелочи офк. Учитывая что там swa - есть вероятность подливы от жоры.
ПЕРЕКАТ легитимный, настоящий
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: