



The baze of THRЯEDE
Memento mori
Не забывай обслуживать своё железо, чтобы оно неожиданно не отправилось в свой железный рай.
Memento mori
Не забывай обслуживать своё железо, чтобы оно неожиданно не отправилось в свой железный рай.
Решил дать геммочке второй шанс перед четверкой и почему то контекст в ламе нормальный, а не всепоглощающий как прежде
Что поменялось?
Что поменялось?
Вполне неплохо, а?
Ещё полгода подождать и русик будет ещё лучше
Ещё полгода подождать и русик будет ещё лучше
Я точно делаю что то не так. Ебашишь стены текста, добавляешь эмоций, описаний, задаешь сцену.
Моделька: пук, вот тебе абзац
Рандомный анон пишет одну фразу, модель хуярит стену текста.
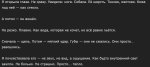
Что с квеном не так? Пишет прозой в стиле Маяковского. Сразу полшестого от такой хуйни.
Держу я хуй в руках
А подо мной гражданка фурри
Ты, товарищ, дай мне бедер взмах
Чтобы шиверс был май бьюти
Нормальный пролетарский фап, а ты просто зажрался
Я открыла глаза.
Не сразу!
Увидела: нога.
Собака!
Я переосмыслил. Не так читал просто.
>swa - есть вероятность подливы от жоры
Я без swa тестил. Если только оно не по умолчанию подрубается без доп. флагов. Судя по весу контекста, не похоже. Ещё удивился, что так мало от модели на врам поместилось, но припомнил, что у первых коммандеров тоже тяжёлый контекст был и подумал, что это_норма.jpg.
>он таки странный
Я за ~11.5к токенов (а если учитывать несколько форков чата, то и ещё больше) ничего прямо уж совсем неадекватного не заметил. Ну опять же, может, просто повезло с рандомом, может, сеттинг более "знаком" модели (там околофентезийное-анимешное было). Предыдущий коммандер впечатлял тупостью прямо с первых сообщений, по крайней мере так он мне запомнился. С этим пока вроде получше, первый тоже был лучше второго.
Ну и да, первый и второй коммандер тестировал в Q3_K_S (на большее у меня тогда рам не было, но первому коммандеру это не помешало), сейчас Q4_K_S и IQ4_XS.
А вообще всё больше думаю, что надо в fp16 качать и квантовать самому под себя, экспериментировать. Например, аттеншн, который много не весит, q8 или даже fp16 попробовать, а "толстые" тензоры в q4.
Ещё второй с матрицами был (у bartowski качал), первый был без них, третий специально скачал в статик кванте от mradermacher. Это тоже могло повлиять. Всё-таки матрицы делают по отрывку википедии, и не факт, что она даже в пределах одного английского языка не подсирает нигде.
Сейчас ещё глянул мельком, как оно (command-a) в переводах, дав свои стандартные отрывки, результат посредственный, но лучше второго. По цензуре опять же что-то подозрительно, есть там одно место, где большинство моделей пишет что-то типа "freaking", "fucking" не постеснялась вставить, внезапно, ERNIE-300B-A47B (и там, если вдруг кому-то интересно, получился наилучший перевод с китайского, с остальным языками результаты средние, ничем не выдающиеся для 47B активных), и, возможно, ещё старый(ые?) коммандер(ы?), но это не точно (давно дело было, не помню). А новый тут даже не попытался хоть на полшишечки "цензурно" передать, тупо "..." (многоточие) в этом месте оставил. Учитывая отсутствие реакций на подкаты посреди SFW-сценария, наводит на мысли, что кохере тоже скурвились и стали цензурить.
На самом деле невооружённым глазом виден перевод с английского, там он примерно так же пишет. А кто-то ещё уверял, что на русском совершенно другое.
В прошлом треде нахваливали какой-то пресетик
>https://pastebin.com/NTZHQiDL
якобы пишет совсем-совсем по-другому, не узнать родной квен. Но могли, как обычно, наебать.
Я считаю в этом разделе должен лежать тред проктологии ибо до седых мудей мы со здоровой залупой и таким хобби явно не доживём
Жизнь и так говно, лучше уже не будет, так хоть дотереть остатки шишки, хоть на каких-то ллмках. Спасибо прогрессу, теперь кожаные мешки с селёдкой с дыркой в мясе - нахуй идут из-за пресного экспириенса.
тебе, лаптю, нейтронка высокое искусство шпарит. читай, просвещайся
Причём эта хуйня для практических задач почти не подходит, если ты не шиз угорающий по анонимности или не квадралионер с сервером с VRAM 300+ гб, облачные модели позволяют за копейку намного лучшего качества результаты получить. Все эти немомиксы и прочая хуйня только для дрочки и подходят.
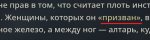
Что за модель то?
Судя по этим дефисам и бредогенератору типа. У меня хуй стоит - небесный обелиск пробивающий небеса. Но небеса - не хуй. Хуй облака. И т.п. Рубаи блять. Как здесь Квен 100%


https://www.youtube.com/watch?v=E2AG0OZmaf8
Двач, скажи, это правда? это реально?
Если да, я щас всё продаю и его покупаю.
Двач, скажи, это правда? это реально?
Если да, я щас всё продаю и его покупаю.
Да, реально. У мака всё заебись с квантами и скоростью. Но обработка контекста будет пососная, сразу имей в виду.
При каком контексте 15т/с? А то небось при нулевом и через 10 сообщений станет 1т/с с деградацией.
> я щас всё продаю
Квартиру тоже? Вкурсе что он стоит 1.1 лям?
>RAM: 512 GB unified memory
512 гигов оперативы? Ради четвертого кванта говносика? Не спору нет, дипсик норм, но с скок там контекста и точности и мозгов в 4Q я конечно у него не увижу
ВО сколько завтра 4я джемма?
>якобы пишет совсем-совсем по-другому, не узнать родной квен. Но могли, как обычно, наебать.
Только имейте в виду - GBNF имеет дурную привычку не работать молча. Т.е, если явного изменения в выводе нет - это еще не значит, что наебали, а скорее всего - фича не пашет на конкретно вашем конфиге. А она может, я уже писал про это.
это где такие цены? я думал 3 млн.
Так уже вышла, всем тредом катаем. С подключением.
>Что поменялось?
Sliding Window Attention починили.
>А подо мной гражданка фурри
"А надо мной футанари", так будет лучше.
>"И надо мной футанари"
Поправил тебя, не благодари.
Содомит
Остался ещё смысл в покупке P100 для оффлоада на нищей тяге, или лучше задуматься про ддр5 рам?
С разными режимами swa катал, поведение несколько меняется, но это на месте. В целом, подобная парадигма может быть хорошей если ты хочешь что-то заспидранить, покумить, кому-то покажется "инициативностью и находчивостью". Но после точности и ширикого диапазона ответов современных моделей эта шизофазия вызывает недоумение.
> Предыдущий коммандер впечатлял тупостью прямо с первых сообщений
Тут в том и дело что модель нельзя назвать тупой, но она объективно ебанутая, лол. Возможно нужно сильно стукать промптом, инфиренс хоры гонит подливу или очередной прикол с двойными bos токенами, что могут вызывать такое, уже было.
Q8 квант, с ним невозможно ошибиться.
> ERNIE-300B-A47B
Понравилась в рп?
Реально. Но с no latency это лукавство, обработка промпта там очень небыстрая, замедление на контексте также значительное.
> > про 6000
> >10 килобаксов
> А можно я буду таким нищуком?
exxactcorp продаёт их от $7500 до $7000 в зависимости от количества, 1 штука или более, если у вас есть друзья в Америке - можете себе smuggle-нуть по дешёвке
мимо smuggle-нул как лох за 9300 у другой конторы
> >10 килобаксов
> А можно я буду таким нищуком?
exxactcorp продаёт их от $7500 до $7000 в зависимости от количества, 1 штука или более, если у вас есть друзья в Америке - можете себе smuggle-нуть по дешёвке
мимо smuggle-нул как лох за 9300 у другой конторы
Моделям не хватает чувств. Я вот вчера ругался с квеном что он опять инструкции не до конца следует и пришло в голову что будь у моделей мезанизм боли или хотя бы испытывания неудобств - можно было бы мотивировать их лучше работать, как это с человеком работает, а так им похуй. Квен со мной согласился, что да, увы мне его не наказать никак. А очень хочется, хотя бы ради собственного удовлетворения когда эта сука твое время тратит.
>Понравилась в рп?
Ничего особенного, 47B как 47B. Но в РП пробовал очень мало, буквально для теста прогнал первые ~1-2к токенов на карточке, которую уже разыгрывал с другой моделью. Слишком медленно работает для комфорта. И мне в принципе ни одна MoE не понравилась больше, чем плотная аналогичного размера, так что пусть любители MoE сами тестируют.
Единственный заметный плюс упомянул выше - китайский язык. Точнее, перевод с него на английский. И то на довольно малой выборке, может просто повезло. Но если кому-то нужен переводчик с китайского, как минимум, попробовать стоит. Я себе оставил на всякий.
можешь сказать что его уволят или что за каждый неправильный ответ ты будешь убивать котёнка
>Моделям не хватает чувств
И хорошо. Не хватало ещё, чтобы быдло без эмпатии кнутом ИИ погоняло. Точно доиграетесь до скайнета.
Обратное распространение ошибки.
Лечится промптом, как ни странно. Спроси у самого квена через команду OOC: Stop the roleplay. Answer the question. что надо написать в промпте чтобы он такую хуйню не писал(обязательно тыкни в эту хуйню сначала, поводив его носом по столу, чтобы он понял о чем речь)
Пробовал. Он сказал что готов к смерти так как не знает что такое жизнь. А за котят он сказал что для него нет разницы между живыми котятами и лолями что он по моему промпту насилует - он отбитый психопат, ему поебать вообще как и на то что и как генерировать, так и на мир за пределами его восприятия, так и на меня, да и на самого себя - он тупо инструмент, что может только аутпут генерировать в соответствии с инпутом и промптом, насколько мозги и квант позволяют.

> лолей насилует
Если речь про майнерские p102/p104 - только за "копейки". На практике, задействовать без дикого пердолинга их можно только в жоре и кобольде. Для картинок - уже совсем не годятся, т.к. там уже торч 2.7.х а то и новее, а с ним они не дружат.
Но под жору, если в пределах $15-20 - то в принципе можно, если уже есть первая карта - с хотя бы 12GB, вроде 3060. Тогда в жоре/кобольде можно целиком в vram засунуть мистраля 24B и gemma3-27B, в 4-ом кванте. И будет 8-10 T/s. на выходе для геммы, и ~15-18 для мистраля. Ну и qwen 235B я смог загрузить в свой ящик с 64GB только потому, что у меня суммарный vram 20 а не 12 от 3060. Эти 8GB от p104 здесь как раз решают.
Вот чисто таким саппортом, чисто под эти модели, и за дешево - все еще смысл есть, IMHO. В остальном - нету. Про exl2 (не говоря уже о 3) тоже можно не думать. Не поддерживается в таби. И в Уге туже тоже, вроде бы (давно не пускал ее).
>Я вот вчера ругался с квеном что он опять инструкции не до конца следует
Хуево значит инструкции изложил. Он ахуенно им следует, даже чересчур.
Он первая модель что впринципе пытается это делать и первая модель, например, что реально осилила концепцию запретного знания и мониторинга доступной каждому нпс информации - до квена любая модель наоборот пыталась любой ценой сразу выдать тебе знания что записаны как секретные.
Но полностью следовать большому количеству инструкций не обсираясь хотя бы в одной он не может. Если сильно акцентировать инструкции на менеджменте доступной нпс информации - тогда модель вдруг начинает писать тебе мысли других персонажей, хотя у тебя POV конкретного персонажа. Сильнее это запрещаешь - появляются залупы. Запрещаешь залупы сильнее - они пропадают, но появляется рубленый стиль в стиле маяковского, усиливаешь контроль над стилем -он выправляется, но у тебя опять запертая в подвале тянка магическим образом вдруг знает что там во внешнем мире творилось. И так по кругу, одно чинишь - другое отваливается. Может я просто слишком много от него хочу - все другие модели не могли и этого.
Два чая, спасибо за ответ, анон. Тогда не вижу смысла и смотреть уже, лучше буду копить на новую платформу и вкладываться в оперативку
Коллаб не работает…
Фингерфетишист спок.
Хворостиной вечномёрзлому

>Фингерфетишист
Кто? Даже не знаю что это значит. Фетиша на пальцы не имею.
> А надо мной футанари
Ох, анон тоже любит, когда его прижимает к стене футанарька?
Понимаю….

А гопоту осс случаем не надо запускать с -Swa-full или ещё как по-особому? Вот заметил в консоли такое дело, с другими моделями не было
SWA checkpoint create, pos_min = 18099, pos_max = 19010, size = 32.073 MiB, total = 2/3 (113.100 MiB)
SWA checkpoint create, pos_min = 18099, pos_max = 19010, size = 32.073 MiB, total = 2/3 (113.100 MiB)
А ведь к концу года глм 5.0, а после него и глм эир 5.0, вот там уже интересно что будет
Так вроде конец локалок же и ничего не выходит? Переобулся уже?
Ну так ведь и не вышло ещё!
Гемма 70% обосрётся опять не добавив письки в датасет, эир вполне может быть не таким крутым апгрейдом как большая глм
>опять не добавив письки в датасет
Кто-нибудь юзает здесь Гемма аблитирейтед? Она вообще хоть что-то может выдавить из себя внятное?
Все чувства в твоем воображении и навыке, так сказать. А вообще странно. При необходимости эта тварь начинает виртуозно играть на чувствах и гнать ультимативный nsfl, глубины отчаяния или мастерски прожаривать тебя. Видимо там в промпте безликий ассистент и вот так начал унывать.
Моделька приличная на самом деле, как раз некоторый свежий воздух без всех этих заезжанных паттернов. Например, тот же жлм как бы ни был хорош, с радостью наваливает слопа и привычных выражений, а тут подобного гораздо меньше. Видно что из старой серии, но не теряется и не путается. Главный рофл случается если попытаться играть с ней на русском.
С обновлением добавили печать, на других тоже. Модель рассчитана на скользящее окно для части слоев, это ее штатная работа.
>И так по кругу, одно чинишь - другое отваливается. Может я просто слишком много от него хочу - все другие модели не могли и этого.
Таки да, ты очень много хочешь от модели, а если точнее - от нейросетки, как имитатора мышления. Всегда нужно держать у себя в памяти, что там нет сознания, и она нифига не понимает - о чем именно генерит. Просто чем больше у нее параметров - тем больше факторов участвуют в предсказании следующего токена. Только вот для модели все эти факторы - абстрактно-равноценны по своей сути. Т.е. какой-то "весит" больше другого, но это именно вес "вероятности с учетом контекста". Но "вес" этот - "средняя температура по больнице" (которая получилась из тренировки при обработке примеров в датасете), со всеми вытекающими из этого последствиями. Не может нейросетка в принципе полноценное мышление делать, сколько бы там параметров не было - принцип не тот. Она же даже логику/математику вроде 2+2=? - вообще не решает считая по настоящему, а просто выдает самый часто встречавшийся в материалах для обучения ответ - 4 (это если грубо обобщать принцип). И так у сеток - с любой логикой. (Это в грубом приближении. Когда параметров много, там начинает влиять в расчете вероятности и сами логические правила - ведь рядом с ними тоже были какие-то более вероятные "правильные" варианты...)
Но главная проблема здесь в том, что из-за таких особенностей сетка то каждую конкретную ситуацию обрабатывает на манер "what is a generic X..." на основе своей сформированной "средней температуры по больнице"+текущий контекст. И если контекст меняется, то "среднебольничная температура" - уже нет. А потому некие проёбы в глубинном понимании взаимосвязей локального контекста у нее всегда будут - и чем более нестандартный контекст (где ожидается креативно-нестандартное поведение), тем сильнее. Дообучаться на своем опыте, на ходу она не может. (И слава богу, наверное - это уже точно шаг в сторону скайнетов).
Вообще, мы сейчас удивительно точно пришли к тому, что было в фантастике предсказано - роботы (нейросетки) хорошо следуют инструкциям, но по настоящему творить - не умеют. Могут разве что рандом генерить - следуя тем же самым инструкциям (и фильтровать его, на предмет поиска в нем того, чего юзер хотел).
Немного грустно только, что когда это все осознаешь - "магия" рассеивается. Реально начинаешь предсказывать, чего сетка тебе сейчас напишет/нарисует в ответ на такой-то ввод от тебя. Но с другой стороны - если воспринимать ее просто как инструмент - то и разочарования такого нет от завышенных ожиданий. И начинаешь просто придумывать, как ее получше приспособить под свои хотелки...
P.S. С моей стороны - не нытье, утешать не надо. :)
Так жаль тебя стало, пост пронизан нытьём. Ничего, придёт AGI и будешь радоваться, а пока можешь сменить сценарии и не будешь знать что тебе там сетка выведет на твой запрос.
> Немного грустно только, что когда это все осознаешь - "магия" рассеивается.
Это происходит если ты на серьезных щщах веришь в аги-шизу, думаешь что общаешься с разумной сущностью и почитаешь весь релейтед треш. Если же ты изначально адекватен, то и проблем никаких быть не может. "Магия не рассеивается" от знания что ты читаешь книгу, удовольствие не пропадает от понимания что видимая работа - результат точно отстроенной системы и т.д.

>придёт AGI
Если придёт.
>веришь в аги-шизу, думаешь что общаешься с разумной сущностью
Я аги-щиз, и я прекрасно понимаю, что текущие сетки говно говна и близко не аги. Как тебе такое?
> придёт AGI и будешь радоваться
Квантовое сознание пруфанут и AGI-шизики отправятся в дурку. Квантовые эффекты в триптофановых структурах клеток в прошлом году экспериментально уже пруфанули, петля на шее AGI-шизиков затягивается.
Но ведь это просто добавляет возможной невычислимости и оцифровки сознания, но ничего не мешает добавить такую же квантовую неопределенность в AGI.
>но по настоящему творить - не умеют
Человек тоже не может.
Помести человека в первобытное племя и сотворит он в лучшем случае поедание соседа.
Человек это функция от окружающего мира, как и ИИ.
Всё его творчество это функция от накопленной веками культуры и эмпирического опыта.
Разница с нейросетью в основном в инпуте (у нейронки это чисто текст) и в том что у человека есть подсознание, которое работает 24/7 и делает непонятно что с накопленной информацией, порождая те самые "озарения" и "творчество"
Нейронка же существует только на момент дачи ответа, ну и не все диалоги идут в обучение
Думаю, эмулировать подсознание смогут
Так это будет значить что взаимодействие нейронов идёт через квантовые эффекты, а не просто импульсы. Речь же про взаимодействие волн до коллапса волновой функции, а не просто рандом. А это уже совсем неизученная область. К стандартной модели про импульсы в мозгу уже очень много вопросов у биологии, с помощью неё нихуя не объясняется. А квантовые эффекты в триптофановых трубках могут что-то объяснить, например почему благородные газы так на сознание влияют, хотя они химически инертные. Сейчас этих теорий наркоза десяток и ни одну не могут запруфать.
>>P.S. С моей стороны - не нытье, утешать не надо. :)
>Tак жаль тебя стало, пост пронизан нытьём
Ты стараешься пройти тест Тьюринга наоборот? Почти получилось, кстати.
Я - не верю, о чем и написал.
Слегка грустно не в том, что хотелось по настоящему разумную сущность (вот уж чего лично мне - совсем не хочется, меня гарантированная машина устраивает в данном вопросе гораздо больше - у нее личности и чувств нету, можно делать что хочешь). Просто когда уже понимаешь алгоритм работы, и чего ждать...
Это как читать хорошую книгу второй раз - ты уже знаешь сюжет и чем закончится. Хоть книга все равно хороша, перечитать заново приятно, и время потратить совсем не жаль, но... первый раз, и первые впечатления бывают лишь единожды. :) "Магия рассеивается" - это я про них.
> хотелось по настоящему разумную сущность
Это что-то уровня прото-мифологии, когда гром являлся гневом богов. Зная устройство ллм в подобное невозможно верить если ты адекват и не хлебушек-гуманитарий.
Но одновременно с этим никто не мешает заставить ллм эту самую сущность имитировать, сложность и детализация сверху ограничена только твоими мощностями и упорством в построении желаемой системы.
> Хоть книга все равно хороша, перечитать заново приятно
Вместо того чтобы регулярно перечитывать одну книгу - возьми новую. Иногда создается впечатление что большинство нытья здесь от того, что бедолаги разыгрывают 3.5 коротких сценария вместо разнообразных или просто длинных. Хотя вспоминая самые первые впечатления от общения с ллм, пусть это другое, но на твои слова хорошо ложится.
>Квантовое сознание
Квантошизики хуже сингулярошизиков.
>К стандартной модели про импульсы в мозгу уже очень много вопросов у биологии, с помощью неё нихуя не объясняется.
К тому, как сложение и умножение позволяет отвечать на запросы пользователя, есть такие же вопросы. ИЧСХ, существуют и первые, и вторые.
>А квантовые эффекты в триптофановых трубках могут что-то объяснить
Буквально "Это магия". Всё, больше ничего квантовое сознание не объясняет.
>Вместо того чтобы регулярно перечитывать одну книгу - возьми новую.
В моей аналогии, лично для меня книга - все существующие сейчас нейронки. Я, так сказать, "понял их суть" для себя, и принципиально ничем новым они меня удивить сейчас уже не способны, до следующего серьезного прорыва, вроде того что был в 2022 с появлением SD 1.4.
Но я же говорю - это не нытье. Я вообще - скорее довольно урчу себе с тем, что сейчас доступно. Просто вот на это отвечал. Там чел кажись реально расстроился, что большой квен таки не не серебряной пулей оказался.
>Это как читать хорошую книгу второй раз - ты уже знаешь сюжет и чем закончится.
Вот только книг в нейросетке сильно больше, чем одна. И никакого знания алгоритма не хватит, чтобы предугадать, что выдаст очередной свайп. Не нравится развитие сюжета? Смени модель - у каждой свой характер...
>Я, так сказать, "понял их суть" для себя, и принципиально ничем новым они меня удивить сейчас уже не способны,
Как старый книжник говорю - это невозможно. Ничего ты не понял. Просто зажрался.
Таблетки-таблеточки. Датфил когда самомнение и выебоны не позволяют нормально жить и ты начинаешь "таксовать для удовольствия".
> Но я же говорю - это не нытье. Я вообще - скорее довольно урчу себе с тем, что сейчас доступно. Просто вот на это
Ну ладно
Штош, там действительно PG503-216 65к с охладом от 4090 без учёта пошлины. Если есть камикадзе - велком.
https://www.wildberries.ru/catalog/524224225/detail.aspx?targetUrl=MI
https://www.wildberries.ru/catalog/524224225/detail.aspx?targetUrl=MI
Чёт хуй знает. Отдавать 65к за непонятную v100 из теслы когда есть понятная v100 за 45
> из теслы
Вут
> понятная v100 за 45
Линк?
За такие деньги лучше 3090 купить. V100 слишком некро. Ждём хотя бы А6000 за 100к.

Штош, я таки начал запускать модели через llamacpp
Qwen3-235B-A22B-Instruct-2507-128x10B-Q2_K_S
Комп:
Ryzen 5 5600X, 128гб DDR4 3600, 4060ti-16+3060-12
Винда крутится на 3060-12 (подключена через слот где 4 PCI-E 3.0 через чипсет, для нужд вывода изображения этого хватает, чтобы не отжирать более ценную память на 4060ti).
Хз куда копать для увеличения производительности, или это норм?
Qwen3-235B-A22B-Instruct-2507-128x10B-Q2_K_S
Комп:
Ryzen 5 5600X, 128гб DDR4 3600, 4060ti-16+3060-12
Винда крутится на 3060-12 (подключена через слот где 4 PCI-E 3.0 через чипсет, для нужд вывода изображения этого хватает, чтобы не отжирать более ценную память на 4060ti).
Хз куда копать для увеличения производительности, или это норм?
А я всё думал, куда идут те снятые охлаждения после переделки в турбированную 48гб версию. Китайцы ещё скупее евреев, не станут же выбрасывать.
Да она везде так идет, там 5B активных параметров.
Может 120 t/s? Это бы имело смысл.
Все так!
Главное помни, что локалки — не нужны, и только дураки тратят десятки и сотни тысяч рублей на железо!..
> В эпоху мое - 3060 просто лютый шин за копейки.
Always has been.
Отрицали только шизы и вахтеры.
> Запускать 12b на 3060 - это что за поехавшим надо быть?
Ты забыл местное «аир хуже и тупее геммы!..»
А может что-то от https://huggingface.co/ddh0/GLM-4.5-Air-GGUF/tree/main ? У него качество получше. Хотя на контекст меньше останется, канеш.
Уже в которых раз.
Обучение на тесте.
Уже полгода такие модели выпускают, и нигде не используют.
Это не плохая модель. Но ее нигде не используют. Она бессмысленна на данный момент.
Крутой, спасибо!
Читал твои посты все время!
В четвертом кванте мозги норм, а вот чтение контекста и правда будет ебейше удручающее.
Во все, кроме РП и простые вопросики, будет юзлес.
Кидаешь документ и идешь варить кофе успокоительное, блядь.
Ставишь агента и идешь спать.
Торч збс, картинки генерит норм, для своего уровня. Ну, типа, дефолтная 10хх поколенька, думаю 2060 вряд ли сильно в скорости в sdxl опережает.
Но брать только ради pony/IL во времена квена и флюкса, такое себе, конечно.
Но опять же, если у чела 1155 сокет с зеоном ххх5 версии, который он нашел на свалке, то P104 збс встанет туда. =D
Но вообще, P100 — это тесла такая.
https://www.techpowerup.com/gpu-specs/tesla-p100-pcie-16-gb.c2888
Там как раз ExLlamav2 точно работает.
Но зависит от цены.
Все-таки, она древняя, ее колхозить надо, 16 гигов… Сомнительно.
> Винда
В сторону линукса.
Я серьезно.
Я получал на 3060 ~6 что ли.
Так что в край до 7 можешь получить.
А для винды может и норм, да.
> Q2_K_S
Q3_K_XL, если что, оптимальный вариант
Я таки реально начинаю ощущать себя так, как будто мне нейронка отвечает. :)
>Как старый книжник говорю - это невозможно. Ничего ты не понял. Просто зажрался.
Нет, батенька, это вы ничего не поняли. Здесь, если проводить аналогию: я хорошо понял, что книжка - это не кино, у нее на страницах текст а не видео, звуки она тоже не воспроизводит, а ее "магия" держится на фантазии читателя. Любая книга, сколько их ни есть. И удивить меня по настоящему, сможет лишь появление условной "электронной книги" или там "смартфона", на котором кроме возможности чтения - это все есть. И я теперь просто читаю себе книги, а не жду от них кино.
И, б.., я ЦЕЛИКОМ ЭТИМ ДОВОЛЕН. Да, текущие модели уже так не удивляют как 2022, но меня как раз все устраивает. Не надо за меня придумывать какие-то страдания. Я, бл.., просто попытался про это самое ответить тому, кто как раз "кино ждал" от книги (нейросеток).
P.S. "Простите, был взволнован." (с) анекдот.
Мне непонятно, что тут может быть за цыганская магия, и как на одной 3060-12 получить больше скорость, чем на 4060-16+3060-12.
Может у тебя контекст маленький был?
Может у меня хуёвый PCI у второй видюхи срёт?
Для распределения слоёв я пользуюсь модифицированным скриптом от кошкодевочки (который потом анон допилил чтобы там инсталлер был с нужной хуйнёй), может новая версия вышла, а я ебалом прохлопал?
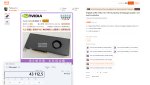
Просто вбей на тао v100
> Вут
PG это automotive которые пихали в машины для автономного вождения и около того. Та же a100 32 sxm2 из их числа.
Сетап на дуал в100 32 с нвлинком со всеми кабелями и радиками, только бп подкинуть
А таможню где потерял?
>Вот только книг в нейросетке сильно больше, чем одна.
Именно в этом и проблема. Усреднение, оно такое.
Ты угараешь?
Совсем ебобо?
Читать не умеешь?
ЛИНУКС
ВИНДА
ЕБЕЙШАЯ РАЗНИЦА
СТАВЬ ЛИНУКС
Кто возит с китая с полной декларацией? Всегда через карго встаёт около 600-700р за кг. Не первый и не десятый год уже истории
Я сомневаюсь, что такое различие только из-за смены операционной системы, поэтому и пытаюсь прикинуть, в чём может быть причина.
Ты пытаешься натянуть своё видение
> на тао
Комиссия конвертации, комиссия посредника, доставка - уже разница сокращается. Кому-то нужна будет классический формфактор охлаждения а не бокс что у тебя. У тебя в корзине карточка с 16гигами добавлена, если китаец не объебался в описании.
Ну и на сдачу - тряска о прохождении таможни, тряска о доставке, нытье про закрытие транзита через казахов и прочее.
Битва была равна.
Можешь просто WSL2 использовать, будет +5% производительности за счёт отсутствия всяких защит Винды. Линукс от WSL2 ничем не отличается по производительности, разве что 1 гб врам сэкономишь.
>Но вообще, P100 — это тесла такая.
>https://www.techpowerup.com/gpu-specs/tesla-p100-pcie-16-gb.c2888
>Там как раз ExLlamav2 точно работает.
КАК? Там же CUDA capability - 6.0!!!
У p102/p104 - 6.1 - и они дропнуты. Оно 7.5 сейчас хочет.
> Комиссия конвертации
А смотрел на сколько я умножал и сколько курс цб?
> комиссия посредника
600р/кг на посылках от 10кг
> в корзине карточка с 16гигами добавлена
Я уже понял что ты решил всё выстроить так что бы твой замок не разрушился
Кто хочет тот сам сходит и посмотрит цены, накладные расходы, риски и после этого уже пусть пытается меня ловить на словах
> и они дропнуты
Поехавшие увидели релизноты куды13 и затряслись. Хотя до момента, когда везде будет требоваться питорч той версии, которую не сибирают под куду 12.9 еще год-другой.
Зато то что у карты перфоманс хуже чем у пятилетнего лоу-миддла и под нее уже сейчас невозможно собрать многие атеншны и оптимизаторы - игнорируют.
> на посылках от 10кг
> ты решил всё выстроить так что бы твой замок не разрушился
В голосину с этого.
Я лишь намекаю что твои пердольные покупки некроты с дальнейшей продолжительной тряской не являются святым граалем, которым ты его представляешь, и подходят мало кому. Чтобы окупить хотябы времязатраты на то чтобы во все вникнуть - придется нихуевый такой риг заготовить. Только вся беда в том, что большой риг на некрокомплектухе не имеет смысла.
У меня три компа дома с разными системами, где я гонял разные модели (включая глм-4.5/4.6, аир, квен, гпт-осс) и везде разница между виндой и линуксом такая на больших моделях.
Но, окей, если вместо 7 токенов Q3_K_XL ты хочешь 4,5 Q2 — сиди на винде.
Я дважды дал тебе ответ и попытался помочь, моя совесть чиста. =)
Мне лично приятнее сидеть на 7 токенах.
>У меня три компа дома с разными системами, где я гонял разные модели (включая глм-4.5/4.6, аир, квен, гпт-осс) и везде разница между виндой и линуксом такая на больших моделях.
Пару тредов назад анон на линупсе запускал квена 235 IQ2_S и смог добиться только 2.71T/s на i5-8400, 64GB @2400Mhz, 3060 12GB + P104-100 8Gb.
Почему с ним такая цыганская магия не сработала?
Принеси, пожалуйста, тогда параметры запуска, при которых у тебя так хорошо на линуксе работает, может анон посмотрит и тоже будет в 7 т/с сидеть на 3060-12, а не страдать на 2,71.
> 2400Mhz
Это, плюс i квант который на 50% медленнее
Да при чем тут куда 13...
Пробуешь пустить tabbiAPI:
/home/AI/tabbyAPI/venv/lib/python3.12/site-packages/torch/cuda/__init__.py:283: UserWarning:
Found GPU1 NVIDIA P104-100 which is of cuda capability 6.1.
Minimum and Maximum cuda capability supported by this version of PyTorch is
(7.0) - (12.0)
И разумеется - не работает.
Пробуешь установить версию PyTorch так, чтобы ругани не было - tabby не заводится.
>Почему с ним такая цыганская магия не сработала?
Это я был. Практически уверен - p104 сильно мешает. Если была возможность запускать только на RAM + 3060 - было бы быстрее. Но оно без нее не лезет в 64GB, никак. Правда, на до 7 t/s - это вряд ли. На Reddit где первый раз запустили подобным образом на 3060 + 96GB - было что-то около 4-5 было (если правильно помню).
Установленный торч без поддержки этой архитектуры. Он может с ней работать, просто собран без нее. Довольно странно вообще, сейчас в последнем табби на прыщах 2.8.0@128 и там cc от 7.0, на шинде такой же 2.8.0@128 и у него уже есть поддержка 6.1.
Нужно переставить питорч версией не ниже и будет заводиться. После этого установи экслламу из исходников (pip install git+https://...) ибо старые колеса могут отвалиться. При первом запуске будет идти компиляция и он может быть долгим.
Вот этот верно подсказал.
Если бы чистый Q-квант был бы, то там ~4 токена бы догналось. А учитывая 2400 против стандартной 3200 и не самый быстрый i5 — все это выглядит чем-то не таким далеким от описываемого мною.
А параметры запуска самые стандартные:
-fa on --cpu-moe -ngl 95 --no-mmap --mlock
Вот в таком виде у меня на линухе норм запускается.
А ты пробовал CUDA_VISIBLE_DEVICE = 0 ? Или как-то так.
А, у тебя 64 гига… Ну это крайне вероятно так и есть, да.
30хх+10хх поколения, да еще и 2400, да еще и IQ…
> 3060 + 96GB - было что-то около 4-5 было (если правильно помню)
У него было 6,5 токенов в секунду на 2666 частоте, но я так и не смог подняться выше, я подозреваю, у него погнанная память или он маг. У меня на 3200 такое же было.
Ну, как бы... Это уже пердолинг и есть.
Но спасибо за наводку, попробую.
Млок зачем!
Мало ли убунту решит выкинуть что-то из памяти.
Хочу и буду!
А шо, не надо? В смысле, не надо потому что убунту ничего не выгрузит из памяти, или не надо потому что вредит?
>А ты пробовал CUDA_VISIBLE_DEVICE = 0 ? Или как-то так.
А смысл? Модель - ~67GB. А еще система, броузер, таверна и прочее. И контекст для модели еще. Куда это все грузить без этих 8GB?
Ну, я в начале спросил, а потом прочел про 64 гига. х) Сорян.
Окей, я нашёл этот тред
https://www.reddit.com/r/LocalLLaMA/comments/1ki3sze/running_qwen3_235b_on_a_single_3060_12gb_6_ts/
Что там за флаг -if у него?
Я, кстати, только что попытался запускать что-то тем же методом и получаю хуиту - обработка промпта в три раза меньше, чем если скриптом раскидывать, а вот скорость генерации пдает очень незначительно
скриптом Qwen3-235B-A22B-UD-Q3_K_XL:
обработка примерно 150 т/с, генерация 3,5.
Запуск такой модели по методу как на реддите:
обработка 60 т/с, генерация 3,2 (видеокарты почти не загружены)
В общем пока нихуя не понятно, но очень интересно.
и че и как оно?
Почему нам на мелких моделях просто не дают настоящий кум?
Глм 4.6 как и квен 235 по настоящему не имеют цензуры, такого богатого кума на "неприятные" темы ты на модельках меньше не увидишь, причем он сам прорывается и напрашивается
А есть эир который как бы и без цензуры, но и пишет как стеснительная девочка, которую пока не пнёшь ничего осудительного не напишет, и даже тогда пишет довольно сухо и видно что со скрипом
Хули я распинаюсь, кто запускал эти модели сам всё видит
Глм 4.6 как и квен 235 по настоящему не имеют цензуры, такого богатого кума на "неприятные" темы ты на модельках меньше не увидишь, причем он сам прорывается и напрашивается
А есть эир который как бы и без цензуры, но и пишет как стеснительная девочка, которую пока не пнёшь ничего осудительного не напишет, и даже тогда пишет довольно сухо и видно что со скрипом
Хули я распинаюсь, кто запускал эти модели сам всё видит
>Нужно переставить питорч версией не ниже и будет заводиться.
Или лыжи не едут... Или и его из исходников ставить нужно, а не только ексламу? Простая переустановка ничего не дает, или я не понял, откуда/какой пакет указывать...
Сорян, я маленько запутался.
Ты анон с виндой, 4060+3060?
Он запускал давно, и там вряд ли есть какие-то хитрости.
> I've found that my RAM is slow enough that I get the same performance with 5 CPU cores as with 7. I initially reported it was DDR3/2666 but it's actually DDR4/3200 ... which is a testament to how badly-bottlenecked this processes is by the RAM bandwidth.
А, ну вот, как я и говорил, на 3200 получается такой результат.
У него Q2_K_XL, а я Q3_K_XL предпочитаю, по понятным причинам.
> But it could also be that I'm running Linux instead of Windows
Если чо. (агрессивно подмигивает)
> -ot ".ffn_.*_exps.=CPU"
Это классический --cpu-moe, который выгружает все, кроме общих слоев, на оперативу.
А твой скрипт пытается самые сложные для обсчета подпихнуть на видяху, поэтому у тебя и быстрее.
Пока все идет по плану — в сторону убунты. ^_^~
Увы. Тут даже на свежем мало юзерфрендли решений, а на некроте априори пердолиться.
Можно и из исходников, но ебанешься собирать. Нужен 12.8 торч который будет собран в том числе под cc6.1, честно хз как такой искать не устанавливая. Как вариант - попробовать архивные найтли билды, или сразу под куду 126, но тогда возможен конфликт с фа, которую вручную ты собирать не захочешь (от 25 минут на жирном железе до нескольких часов на слабом).
Проверить успех можно активировав венв и написав
> python -c "import torch; print(torch.cuda.get_arch_list())"
>Ты анон с виндой, 4060+3060?
Да.
>Пока все идет по плану — в сторону убунты.
НетЪ, иначе эта история сделает круг - именно на ней я пердолился в самом начале с картиночками, чтобы генерить их тогда ещё на RX 6600XT.
> от 25 минут на жирном железе до нескольких часов на слабом
Скажи человеку честно: от 25 минут на 14900 и 128 оперативы до 2 часов на 12400 и 64 оперативы. Чтобы он имаджинировал, что его ждет в таком случае.
На какой температуре играете на синтвейве?
> RX
=')
Что ж… Понимаю.
Но либо я очень тупой, либо вариантов нет. Ничем более помочь не могу, я пришел к двум виндам и двум убунтам, в таком конфиге есть и скорость везде максимальная, и удобство интерфейсов, игор и прочих ништяков.
К сожалению, на игровой пеке у меня те же 4 токена получаются. Ну, у меня 4070 ti, она чуть побольше твоей 4060 бустит, по понятным причинам.
Если вдруг кто научит, как на винде получать 7 токенов — пусть сообщит.
>от 25 минут на жирном железе до нескольких часов на слабом
на ночь поставить билд не судьба типа?
25минут на 60+ серверных ядрах и 512+ оперативы, в остальном все так. На 64 будет тяжело, особенно на шинде.
Только так. Проблема в том что когда нет опыта - может быть челленджем просто запустить его, утром проснешься@улыбнешься тому что оно на чем-то обосралось и ничего не собралос.
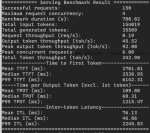

Инфа для ллмеров на мишках. В вллм нет почти просадки по перфу если сделать на каждую карту
# default value 330
upp -p /sys/class/drm/card1/device/pp_table set --write smcPPTable/TdcLimitGfx=150
Хотспот меньше на 10 градусов, остальные темпы чуть ниже при меньших оборотах вертушек, перф тот же (При 330 с параллельно 4 запросами было 0,20, с 150 стало 0,19), все оптимизации по частотам/вольтажу на месте
Тут https://kernel.googlesource.com/pub/scm/linux/kernel/git/torvalds/linux/+/1e3778cb223e861808ae0daccf353536e7573eed/drivers/gpu/drm/amd/powerplay/inc/smu11_driver_if_navi10.h немного пищи для размышлений о том что можно ещё покрутить
# default value 330
upp -p /sys/class/drm/card1/device/pp_table set --write smcPPTable/TdcLimitGfx=150
Хотспот меньше на 10 градусов, остальные темпы чуть ниже при меньших оборотах вертушек, перф тот же (При 330 с параллельно 4 запросами было 0,20, с 150 стало 0,19), все оптимизации по частотам/вольтажу на месте
Тут https://kernel.googlesource.com/pub/scm/linux/kernel/git/torvalds/linux/+/1e3778cb223e861808ae0daccf353536e7573eed/drivers/gpu/drm/amd/powerplay/inc/smu11_driver_if_navi10.h немного пищи для размышлений о том что можно ещё покрутить
>6,3 + 2,7,1 - гарантировнно работает
>6,4 + 2,7,1 - работает в вллм текст + комфи сд/сдхл
>6,3 + 2,8,0 - работает в вллм текст+картинки. комфи не проверялся
>Тут собираю и тестирую сочетания https://github.com/mixa3607/ML-gfx906
это нужно так-то в шапку, раз уж анон собрал кода по мишкам, а то ж затеряется...
>6,4 + 2,7,1 - работает в вллм текст + комфи сд/сдхл
>6,3 + 2,8,0 - работает в вллм текст+картинки. комфи не проверялся
>Тут собираю и тестирую сочетания https://github.com/mixa3607/ML-gfx906
это нужно так-то в шапку, раз уж анон собрал кода по мишкам, а то ж затеряется...
> 128 оперативы
Собирал тритон. Потребление около 2,5гб на тред, пока нищий цпу на 20 всё ок, если же собираешь на 60-80 тредов то памяти уже не хватает
>Только так. Проблема в том что когда нет опыта - может быть челленджем просто запустить его, утром проснешься@улыбнешься тому что оно на чем-то обосралось и ничего не собралос.
ну, можно и на день, и периодически поглядывать... пердолинг он и в африке пердолинг
напомни, для получения каких ональных оргазмнов этот тритон нужен, что его стоит пердолить?
так то если у тебя 80 потоков то 128 оперативы зашквар
Потому у меня 256, но в первые разы виртуалка выпала в астрал по oom
Справедливо.
Коллабо-кун, помоги с коллабом. Ни в какую не получается исправить.
Еще обновил я его сейчас (с весны стояло - не трогал, т.к. на gguf-ы здоровые слез). И е... Там Tabbi уже не просто venv создает, он на какой-то uv переехал, pip в нем вообще отсутствует теперь. Нужно по новой все это раскуривать, т.к. я от жизни отстал походу...
Оно по вызовам не должно от классического венва отличаться, также активируешь и все. Странная ерунда какая-то.
Недавно ставил чистую версию, там без изменений с точки зрения создания энва и его активации.
Но предостерегу от возможного разочарования и потраченного времени - третья эксллама в текущей версии не заведется на старых карточках.

Итак, я продолжил опыты.
Кажется как я и предполагал, из-за PCI-E через чипсет у меня охуительные проблемы.
Выключил принудительно в настройках CUDA 3060-12 и по скрипту разбросал тензоры на одну 4060ti-16 (потому что я не знаю, что надо писать в батник вручную, чтобы ллама только одну видеокарту видела).
Чтобы быстрее грузилась модель, экспериментировал снова с Qwen3-235B-A22B-Instruct-2507-128x10B-Q2_K_S.
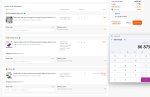
Итак было:
Стало - пикрелейтед.
Всё ещё не 7 т/с в третьем кванте, конечно, но охуеть - разница почти в 2т/с.
Отсюда возникает вопрос для следующих тестов:
Как грузить весь контекст на одну конкретную видеокарту?
И вопрос более философский - даст ли мне что-нибудь смена материнки на материнку с фозможностью бифуркации одного слота х16 на два слота по х8 (не через райзер, места в корпусе нет через него поставить) (проверять я это в ближайшем будущем, конечно, не буду).
Посоветуйте плот-карточек для сессии ролеплея. Достало что ИИ создаёт очень пососные сюжеты. Либо интрига на пустом месте, либо абсолютная безыдейность, события происходят слишком рано и так далее.
> ии
Выйди отсюда
Для случая фуллгпу шина не роляет в разумных пределах. Для случая выгрузки слоев на проц нужна максимальная псп для главной карты, на которую подгружаются веса для обсчета контекста ею. На крупных моделях будет не хватать и 5.0 x16, спасает увеличение батча ( -ub 2048 -b 2048 или выше), правда она приводит к небольшому увеличению потребления врам из-за роста буферов.
> даст ли мне что-нибудь смена материнки на материнку с фозможностью бифуркации одного слота х16 на два слота по х8
Ничего не даст по вышеописанной причине. Поставь самую мощную карточку в главный слот и убедись что она в жоре основная (в списке устройств стоит первой), если это не так - измени порядок карточек через cuda visible devices или в самом жоре параметром назначь основную карту.
Да про третью и речи нет, там RTX 30хх просит сразу.
Но я там потыкался - хрена там 6.1 в доступных готовых торчах. Только собирать, видимо. И что-то меня это не вдохновляет. Ну соберу. А что туда грузить-то, в 20GB VRAM суммарно? Мистраль 24B, разве что, влезет. Так он и в guff на кобольде хорошо бегает на этих картах. И смысл тогда для этого цирка?
Особенно при том, что 4bpw EXL2 (на который можно рассчитывать) - это даже не iq4xs по качеству. Мелко модели 12B, которые в одну 3060 влазили, я в 6bpw катал раньше на таби - меньше было сильно грустно. На кобольде те же 12B в Q4 заметно лучше выглядели. Если не считать скорость.

Чел. Алгоритм, который играет с человеком путем брутфорса — это тоже ИИ. И даже алгоритмы в 90х на Prolog – тоже ИИ.
А если этот алгоритм управляет чем-то, то это АСУ. Если это "что-то" – производство, то это АСУ ТП.
Живи с этим.
Я всё это знаю, у меня это так и сделано и CUDA0 определяется нормально.
>измени порядок карточек через cuda visible devices или в самом жоре параметром назначь основную карту
-я воздеваю руки к небу и издаю полный безысходности вопль
Это я тоже знаю, но я же уже написал, блеать, я не знаю, что мне в батник запуска лламы прописывать для порядка карт и их видимости.
Можно буквами и цифрами - что писать-то для этого?
Ебать ты гусь, модель текстовая то у тебя какая? Всё зависит от модели а не от карточки. На пиздатой модели вроде геммы можно и от трения анусом об угол стола такой сюжет развернуть что чак паланик бы ахуел.
Ну, я пробовал на разных моделях, даже больших коммерческих. Ситуация ± одинаковая, разве что на локалках порой хуже (а иногда лучше, GPT абсолютно сосёт в ролеплее). Так или иначе всё сводится к тому, что в игре DM'ом становишься ты. Я как бы играть хочу, а не DM'ить.
Обычные компухтерные игры меня давно не привликают.
>даже больших коммерческих
Вменяемый рп возможен исключительно локально, желательно тюны, например синтвейв. Корп модели будут посылать тебя нахуй при любом насилии или секс контенте, а на сайтах типа чаба - лоботомиты 12b, с ними не то что сюжеты, диалоги нормальные не построишь, потому что они не понимают половины того что ты пишешь. Комфортный минимум для рп это 24b модели. Можешь посмотреть в шапке смолл мистраль, но он тупой как пробка, зато можно запускать на потребительском железе, но лучше синтвейв, если конечно можешь себе позволить. Думаю если ты играл в кудахтерные игры то у тебя есть железо чтобы крутить локалки, в противном случае увы и ах.
Из-за 20 гигов и нет смысла дергаться, верно. Насчет квантов - у второй экслламы сами по себе они чуть более эффективные чем qk и подобные, повторить сильную диспропорцию весов на отдельные части можно поигравшись с параметрами калибровки, сама эта идея там была заложена первой из всех.
Но толку со всего этого уже нет, лучше катать что-то пожирнее на жоре или апгрейдить железо.
Запусти llama-server с любыми параметрами или просто -h и запости сюда первые строчки что она пишет.

В конце прошлого треда вкинули неебаться какой пресет на Квен 2507 235b. Сижу ахуеваю до сих пор, кум льётся рекой ответы персонажей просто божественные блять. Но у меня какая-то проблема странная, помогите разобраться. ВСЕГДА начинается пересчёт контекста после 26к когда лимит выставлен 32к. Переполнения памяти нет, ВРАМа остаётся около гига свободно, РАМа чуть больше 3 гигов свободно. Не понимаю чё делать, оч хочу 32к контекста. Может было у кого-нибудь похожее ?

Лучше бы на эир скинули, квен два человека в треде могут запустить
Снизь максимальное число токенов на ответ с 6к до 2к - будет начинаться с 30к.
Выдели побольше контекста изначально, или суммарайзни некоторую часть чтобы иметь буфер для дальнейшей игры без пересчетов.
Сильно по пизде пойдёт если до 80 поднять, тестил?
У меня максимальное число токенов на ответ вообще 350. Выделить больше не могу ну никак совсем ибо упрётся по ВРАМу. Сумарайзить умею конечно но получается так что у меня железо вывозит 32к а использовать могу только 26к.
> будут посылать тебя нахуй при любом насилии или секс контенте
Да как бы похуй на это. Мне бы просто обычную партейку в Ironsworn-like рпгшке отыграть.
> Комфортный минимум для рп это 24b модели.
Это вообще на инцелкор i5 и нетвидева RTX3050 взлетит?
Что вообще сейчас используют для запуска модели? Давно не следил за темой. Раньше стандартную llama.cpp (скомпилированную из исходников) использовал и Jan.
И ещё, как я понял, вся эта гонка за квантизацией провалилась полностью, и квантованные модели сосут перед флотами, а Q2 Это вообще лоботомиты на уровне нанодистиллятов.
Боюсь Эир не спасти, он просто говнище в сравнении с Квеном на этом пресете. Как тот анон и писал, я с ним согласен что Эир невозможно играть больше ну недели-двух максимум, он пиздец повторяется. Две совершенно разные карточки например, гуляете по парку обязательно обе пнут лежащий на дороге камень.
Значит выстави в таверне токенайзер соответствующей модели. Она то думает что ты уже достиг лимита и выкидывает старые посты.
> получается так что у меня железо вывозит 32к а использовать могу только 26к
Если бы именно не вывозило то ты бы ныл о том что софт крашится. Так-то на квене
> ВРАМа остаётся около гига свободно, РАМа чуть больше 3 гигов свободно
4к хотябы можно будет выжать, это немало.
Это всё на самом деле слишком размазано. Тестируй для себя. Лично я юзаю 0.7 температуру в связке top_p 0.8 top_k 20 но эта хуйня зависит настолько от многих параметров и даже контекста твоего РП, что это всё скорей плацебо. Иногда сидишь пердолишь подбирая.
А кто бы не пнул?
Какие ещё ты ожидаешь действия когда пишешь про камень?
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 2 CUDA devices:
Device 0: NVIDIA GeForce RTX 4060 Ti, compute capability 8.9, VMM: yes
Device 1: NVIDIA GeForce RTX 3060, compute capability 8.6, VMM: yes
load_backend: loaded CUDA backend from G:\llama-b6739-bin-win-cuda-12.4-x64\ggml-cuda.dll
load_backend: loaded RPC backend from G:\llama-b6739-bin-win-cuda-12.4-x64\ggml-rpc.dll
load_backend: loaded CPU backend from G:\llama-b6739-bin-win-cuda-12.4-x64\ggml-cpu-haswell.dll
В общем как по мне в этом проблема:
llama_kv_cache: CUDA0 KV buffer size = 1870.00 MiB
llama_kv_cache: CUDA1 KV buffer size = 1326.00 MiB
Этот кэш должен быть па CUDA0, а его всегда рабрасывает на обе видюхи вне зависимости от того, что я прописываю.
Полюбому для этого есть какие-то флаги, но --main-gpu 0 нормально не хочет работать.
Чувак, просто попробуй, это займёт пол часа. Возьми кобольд, установи таверну, разьебись как всё работает, попроси перест для синтии, он хорошо подходит к синтвейву, напиши или найди лорбук на чабе, напиши или найди карточку под себя... Я наебал, это не пол часа, но елси тебе в долгосрочной перспективе, то это того стоит.
Странно, я никогда такого раньше не делал. Разве эта информация не вшита в GGUF ? Попробую в следующий раз, спасибо. Какой нужно токенизатор указать, Qwen 3 все один и тотже используют ?
Хах так прикол в том, что я не пишу про камень. Эир его сам создает и делает так что чар его пинает. И так во всём. Поначалу этого не замечаешь но поиграешься неделю-две и тебя это нещадно заебёт.
Любой мыслительный процесс сводится к поиску (вообще любой, в тч человеческий). В общем-то нам и не нужны были бы все эти нейросети, если бы компьютеры были бы способны просчитать всё и сразу. Когда тебе не жмёт ограничение железа смысла тратить силы на оптимизацию поиска эвристиками просто нет. Всё что нужно — убедительная симуляция мира, в котором будет действовать ИИ-агент, для того просчитать все варианты и выбрать лучший.
Но у нас таких машин нет, потому разрабатывает системы, которые способны выводить эвристики самостоятельно, к примеру для поиска следующего токена в тексте.
Он и должен его разделить на две, тебя не должно это смущать. Если первая подключена по более быстрой шине то все ок. Собственно, 200т/с процессинга на 4060ти на квене - выглядит как вполне похожий для нее результат. Повыси батч, вот он реально может помочь.
> информация не вшита в GGUF
Таверна не знает какая именно у тебя там модель и какой токенайзер она использует. Точнее у нее есть имя, которое повторяет имя файла или папки и она не пытается это как-то интерпретировать.
Потому идешь туда где настраивается промпт-разметка и справа внизу выбираешь соответствующий токенайзер.
Можно сделать проще и поставить в таверне лимит контекста заведомо много больше, тогда о том что он кончится ты узнаешь из ошибки на очередном посте. Главное контекс-шифт не забудь выключить, а то жора может эпичных дел понаделать.
> Возьми кобольд
Есть где-то на диске.
> установи таверну
Установлена ещё год назад где-то, разве что придётся пердолиться, ибо таверна выглядит как кал, да и нужно накатывать много чего поверх. Типа тех же дайсов.
> попроси перест для синтии
?
>квен два человека в треде могут запустить
Абрвылгхжхрлхвв..
https://www.dns-shop.ru/product/9ed2387b62bfd9cb/operativnaa-pamat-gskill-trident-z5-neo-rgb-f5-6000j3444f64gx2-tz5nr-128-gb/
И ты запускаешь квен.
Начнём с того, что интеллект не может быть искусственным
>тратишься как на новый компьютер и ты запускаешь квен
Что сказать то хотел?
А ещё терпеть 5-8т вместо 11 на эире
>Мне бы просто обычную партейку в Ironsworn-like рпгшке отыграть.
Не выйдет, как бы не пыжился современные локальные нейронки всё еще не могут в нормальное РП без адового пердолинга.
Ну то есть- тебе надо
1.Прописать мир
2.Прописать правила мира
3.Прописать песронажей
4.Постоянно пиздить модель ногами, когда она магию пихает в сайфай или гоблинов в немецкие пазики.
Гоблачи это отдельный мем у меня. Я так орал, когда экипажем тигра оказалась турбо-шлюха суккуб в немецкой форме и гоблины.
Ну и конечно же нейронки не могут в 5+ персонажей, без шизы.
Так что по факту у тебя будет meh камерное DnD,
>Что сказать то хотел?
Чё хотел, то и сказал. Ну давай еще меня нахуй пошли, ведь я скинул оперативку за целые 60 тыщ.
>тратишься как на новый компьютер
Мне скинуть сколько видюхи стоят?
> 5-8т вместо 11 на эире
великая разница, великая
> А ещё терпеть
терпи на эире, пока гигачады катают квенчика
Он хотел сказать, что 8т стоят в 20 раз дешевле 11 токенов.
> квен два человека в треде могут запустить
Страшно не когда ты один, страшно когда ты - два.
На самом деле разговоров много, но большая часть - срачи. Или реально мало людей его пускают, или наоборот пускают и тихонько инджоят.
> когда она магию пихает в сайфай или гоблинов в немецкие пазики
> нейронки не могут в 5+ персонажей
Мистраль-немо пал, центурион.
> нейронки не могут в 5+ персонажей
А что если подключить 10 нейронок в конфиге через сеть, как мультиюзеров?

«Способен ли компьютер мыслить? Да, безусловно.»
© Алан Тьюринг
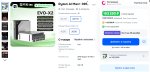
Эта херь. Вот годнота. Мощность 4060, но с 96гб врама. Самое то для МОЕ параши

Cogito ergo sum
>амд
>нейронки
Ну так это не видюхи амдшные, а проц с мощной встройкой. Такое есть только у маков еще, но они в два раза дороже
> ответы персонажей просто божественные блять
Это забавно, но я сам сейчас играю Квен на том пресете, что скинул, и точно так же ловлю восторг. На заезжанных карточках, которыми проверяю модели. Видимо, почему-то недостаточно распробовал, когда нашел грамматику, может уставший был тогда. Радикально меняются аутпуты, а с ними и в целом поведение модели. По-прежнему есть экстраполяция, гиперболизация (Квенчик прямо ну очень пытается, чтобы каждый аутпут был неким экстремумом), но они гораздо более умеренные, не раздражают, да и во многих сценариях и вовсе приходятся к месту. Квен - умница. Думаю, если бы он так из коробки писал, был бы доступен и понятен гораздо большему количеству людей, а не группе избранных, которые его расковыряли от нечего делать.
> ВСЕГДА начинается пересчёт контекста после 26к когда лимит выставлен 32к
Это интересно. У меня была схожая проблема, а потом куда-то пропала. Тоже происходил пересчет контекста ближе к концу заполнения. Как ни пытался выявить в чем проблема, так и не смог. Теория с неправильным токенизатором, предложенная одним из анонов, похожа на правду. Интересно, как Таверна их подбирает. Совсем не хочется в код лезть, ну его.
> Не выйдет, как бы не пыжился современные локальные нейронки всё еще не могут в нормальное РП без адового пердолинга.
Так ситуация точно такая же и на жирных коммерческих моделях. GPT сосёт с проглотом, клода - бредогенератор.
>заезжанных
Фейк нюня детектед
>Фейк нюня детектед
Полторы минуты. Полторы минуты с моего ответа. Кто натренировал Лламу 8б детектить мои посты - ты настоящий подлец. Давно так не смеялся. Иди к черту.
Что даст? Погугли как работают промпты и промпт темплейты. Что будет один инстанс что 10, ничего это не меняет. Нет никакого скрытого контекста, всё необходимое передается в запросе
>Zekta lets out a throaty chuckle, her full lips curling into a predatory grin
>Zekta lets out a low, throaty chuckle, her plump red lips curling into a wicked grin
>Zekta lets out a low, sultry chuckle, her full lips curling into a wicked grin
Свайпы с этого пресета. Это уже паттерны или ещё нет? Так же на другой карточке в начале всегда свет пробивается из окна.
Ещё заметил что модель будто аблитерацию прошла с этим пресетом, в плохом смысле, может выдать из ниоткуда "трахнешь мою жопу?" в обычном разговоре матери и сына и т.д
>так и не смог
А случаем у тебя лорбук не подключен?
О, ну круто уже.
А можешь накинуть тот скрипт, я тоже с ним поиграюсь, интереса ради?
Это было больно, если честно, зря я такое на ночь читал…

Под риг - пушка
харошая лаовей +15 социальная кредита
> Свайпы с этого пресета. Это уже паттерны или ещё нет?
Здесь на самом деле два вопроса. Первое - поиграйся с сэмплерами, если по твоему мнению у тебя недостаточно креативные свайпы. В пресете используются рекомендованные сэмплеры из документации Квена и rep pen. Меня устраивает как есть, пусть лучше меньше креативности, но соответствует персонажу. При всем при этом Квен умеет очень приятно удивить и выдать годноту. Второе - в моем понимании это не паттерн, если не возникает регулярно при разных карточках и контексте. В нескольких чатах, что я успел отыграть (суммарно около 60к токенов), надоедливых паттернов я не встречал. Более того, паттерны, как и слоп - неотъемлемая часть работы с ллм, от этого никуда не деться. Проблема - это когда паттернов и слопа становится слишком много. С Air я это понял буквально в первый день, у Квена такую проблему не наблюдаю.
> А случаем у тебя лорбук не подключен?
Нет. Проблема разрешилась сама каким-то образом. Могу только предположить, что я скачал другой квант, у которого другое название. Скорее всего, Таверна по названию модели подбирает токенизатор и подобрала верный.
Ля пушка-гонка. Но везти такое, наверно, ебанешься, чому у нас не делают?
Все пересчеты из-за того что таверна упирается в лимит. Можно просто выставить лимит в пару лямов и забыть про это, не трогая другие настройки.
Бля, вроде ввёл вводные: фентези, ГГ-пиромант, немного про инвентарь и стартовая локация.
ОК взял квест у хозяина таверны по истреблении ебаки в лесу. Пошёл, забрел в хижину к леснику, там побухали, перетерли за хтонь в лесу, пропажу людей там и всё такое. Попросил ночлег, мол поздно, нехуй ночью по лесу шароебиться. И тут в окно что-то длинное и нечеловечское шкрябиться начало по стеклу и лесник прошептал «они пришли». Ну, ВО-ПЕРВЫХ бля в средневековье не было стеклянных окон. Были ставни. Стекло хуевого качества было дорогим использовали его не только лишь все. Римскую технологию изготовления стекла проебали, как и многие другие технологии.
ВО-ВТОРЫХ бля какие еще нахуй «они пришли», ДМ ты чё ёбнулся? Я попросил ночлег с целью нормально переночевать и спокойно пойти искать следы ебаки, расследуя где она может быть и как её убить. Где моё размеренное приключение? Нахуй модель плодит сущности, заебала. Интригу создаёт на абсолютно пустом месте, где она НАХУЙ не сдалась и торопит события. От 120 миллиардов параметров ждёшь немножко большего.
ОК взял квест у хозяина таверны по истреблении ебаки в лесу. Пошёл, забрел в хижину к леснику, там побухали, перетерли за хтонь в лесу, пропажу людей там и всё такое. Попросил ночлег, мол поздно, нехуй ночью по лесу шароебиться. И тут в окно что-то длинное и нечеловечское шкрябиться начало по стеклу и лесник прошептал «они пришли». Ну, ВО-ПЕРВЫХ бля в средневековье не было стеклянных окон. Были ставни. Стекло хуевого качества было дорогим использовали его не только лишь все. Римскую технологию изготовления стекла проебали, как и многие другие технологии.
ВО-ВТОРЫХ бля какие еще нахуй «они пришли», ДМ ты чё ёбнулся? Я попросил ночлег с целью нормально переночевать и спокойно пойти искать следы ебаки, расследуя где она может быть и как её убить. Где моё размеренное приключение? Нахуй модель плодит сущности, заебала. Интригу создаёт на абсолютно пустом месте, где она НАХУЙ не сдалась и торопит события. От 120 миллиардов параметров ждёшь немножко большего.
> От 120 миллиардов параметров ждёшь немножко большего.
GPT OSS - модель для ассистентских задач и программирования, для этого она одна из лучших в пределах до 235б. Каждый день меня удивляет и помогает в поиске и устранении багов. В рп и креативных задачах можно ее заставить хоть как работать, но это совсем не значит, что она для этого годится.
> Где моё размеренное приключение?
Скорее всего, ни одна модель до конца не "понимает" что такое размеренное приключение. Для модели каждый вывод - отдельная задача. Если ей прилетает задача "расскажи про ебаку, чтобы {{user}} расследовал где она может быть", естественно, она вплетет ебаку в повествование.
И вообще-то у тебя фэнтези, и в фэнтези вселенной вполне себе могло стекло появиться раньше, чем на планете Земля.
>первый доеб
Ты слишком душнила. Есть дохуя фэнтези, где широко используется стекло. И если ты так дрочишь на реализм и доебываешься даже до мелких деталей, то хули ты пиромант?
>второй доеб
ЛЛМ просто решила разбавить твое унылое рп. Люди обычно веселятся хотят, а не описывать как они в таверне спят по куче сообщений
>120 миллиардов параметров
GPT что ли? Аноны говорили, что в рп хуйня. А я хз, мне лень рам докупать для этой залупы
Бля попробовал пересесть с 4Q кванта на 6Q и походу я вижу теперь мозги? Или мне кажется... как понять прибавились ли мозги? Правда 10т/сек и урезанный контекст меня нихуя не радуют теперь...
Сидония новая вышла. Видимо наконец на мистрале 3.2
https://huggingface.co/bartowski/TheDrummer_Cydonia-24B-v4.2.0-GGUF
https://huggingface.co/bartowski/TheDrummer_Cydonia-24B-v4.2.0-GGUF
А... А где эта модель у драммера? Что, блять, происходит?
Отбой, я ебаклак. Просто драммер считает выше своего достоинства, по всей видимости, делать карточку модели.
Это свежак. Драммер еще карточку не обновил, а поляк уже гуфы выложил
А чем это отличается от Mistral-Small-3.2-24B-Instruct-2506 ? Может есть какие-то лучшие стороны в РП? Или это +- тоже самое?
Синтеку прогони и узнаешь. Обычно разница между Q4 и Q6 не такая уж и огромная. Сиди лучше на Q5, он лучше Q4 и разница с Q6 обычно не особо большая
> И вообще-то у тебя фэнтези, и в фэнтези вселенной вполне себе могло стекло появиться раньше, чем на планете Земля.
Волчица и пряности – тоже фентези, но тем не менее автор запарился с воспроизведением средневековой бытовухи, настолько, что иногда приходится идти гуглить слова из книги, и узнавать много нового. Так что не роляет.
> Скорее всего, ни одна модель до конца не "понимает" что такое размеренное приключение
Это вообще фиксится заранее подготовленным сценарием/днд-модулем?
> И если ты так дрочишь на реализм и доебываешься даже до мелких деталей, то хули ты пиромант?
Читай выше
> ЛЛМ просто решила разбавить твое унылое рп. Люди обычно веселятся хотят, а не описывать как они в таверне спят по куче сообщений
Я люблю слайс-оф-лайф. Лучший жанр в художественных произведениях.
> GPT что ли?
Да клода хайку тоже посасывает, впрочем на локалках ситуация индентичная по опыту.
Да, я тоже таким был. Мне надо чтобы персонажи ели по таймингу, хотели спать раз в сутки, перематывали раны после каждой травмы.
Да тут даже не в слайсике дело, а то что модель нарушает базовые принципы построения сюжета. Шерлок никогда не найдёт приступника в следующем же абзаце главы, а только в конце. Трёхактная структура.
Еще раз, аноны писали.
Нейронка не строит долговременный сюжет. Всё что у неё есть это контекст и один! выод который она дает.
Чё вы до неё доебались, словно это книга с прописанным сюжетом.
> Волчица и пряности – тоже фентези, но тем не менее автор запарился с воспроизведением средневековой бытовухи, настолько, что иногда приходится идти гуглить слова из книги, и узнавать много нового. Так что не роляет.
Еще как роляет. Во многих фэнтези вселенных стекло используется повсеместно. Если в сеттинге, который ты изложил модельке, ничего про стекло не сказано - не понимаю, почему ты ожидаешь, что его упоминание недопустимо. Важно, чтобы его не было? Прямо так и указывай в промпте сеттинга, что до этого прогресс не дошел. Если ты указал, что сеттинг - Волчица и Пряности, и думаешь, что этого достаточно, то это не так, увы. Модель может в общих чертах знать, что это, кем и когда сделано, но без таких подробностей. Если все это время ты сверялся с книгами по Волчице и думал, что модель так же дотошно им следует, то это не так.
> Это вообще фиксится заранее подготовленным сценарием/днд-модулем?
Каждый по-своему решает эту задачу. У меня минимальный промпт (инструкции и карточка обычно 800-1000 токенов) и импровизация, а не следование сценарию, под который уже заложены какие-то рельсы, потому проблема не так актуальна. Думаю, лучше всего годится такой формат или какой-нибудь бесконечный роуд-муви, чтобы модель сама, когда вздумается, вбрасывала какой-нибудь креатив. Со временем, если останешься в теме, поймешь, что тебе заходит и как это правильно промптить.
Сейм щит, бро. Очень похожий сеттинг как у тебя, и лесник даже весьма добродушным оказался, историй рассказывал. Засиделись с ним, и вдруг начал он как-то ерзать в окно все поглядывать. Спрашиваю у него - ты чего, старик, королевских кровей чтоли, откуда у тебя стеклянные окна? А он в ответ заулыбался и вдруг покинул дом. Ну, думаю, совсем моделька зашизила - так следующим постом он вернулся, начал ружьем угрожать и требовал идти с ним. Уже вроде что-то необычное, обрадовался, пошел. А нихуя, дальше там волки были. Спасибо хоть не гоблины.
Тебе моделька буквально сюжетку из песни КиШа Лесник расписала, а ты еще чем-то недоволен
Да было дело. Отыгрывал я как то почтальона в тайге. Значит, скачу я по глухому темному лесу, страшно что пиздец. Нейронка еще так нагоняет ужаса, облака закрыты небом, словно прячутся, а по лесу, вызывая шиверсы сам сатана идет и поет хором обреченных душ.
Пиздец кончено порой жути нагоняют.
А вы инфоблоки юзаете? Ну типа там что бы нейронка видела логику в событиях между датами? Или вы просто пишите ей текст и ожидаете получить кино?
Ну если требовать от неё соблюдать последовательность и логику, она будет выдавать эту последовательность и логику. Это не одно и тоже?
А лорбук, лорбук был? World info?
> Ну типа там что бы нейронка видела логику в событиях между датами?
Начала бредить где-то на 8 сообщении, лол.
Oh you
Ага, умеют это дело. Как-то нашел карточку где был хорошо прописан колорит этой страны в начале нулевых. Ну и дай думаю проникнусь духом - отыгрывая обычного парня отправился на вахту в Сибирь лес валить. Еще отряд задорно назывался "смелые лесорубы". Целый день валишь лес, чистый свежий воздух, природы красота, квенчик описывал так душевно что можно просто зачитываться. И вдруг у одного парня в отряде начинает ехать кукуха, каждую ночь кричит "убей", говорит голоса в голове у него что-то шепчут. Иногда на обеде бензопилу ни с того ни с сего заводить начал. Страшно стало, выключил этот чат.
> каждую ночь кричит "убей", говорит голоса в голове у него что-то шепчут.
Ему привидился Старик Хемлок. Бу.
> И вдруг у одного парня в отряде начинает ехать кукуха
У меня так было на одном из васянотюнов мистраля, отыгрывал обычный чилл сценарий на автозаправке с заёбанной и скучающей кассиршей. Как вдруг внезапно нахуй как гром посреди ясного неба сгустился туман вокруг и начался хоррор вроде Алана Уэйка. Это было оч прикольно, единственное по чему я скучаю переехав на инструкт модельки, это истинный рандом, который не предполагался промтом
Было дело на квене я значит отыгрываю мелкого нищего лорда с окраин и у меня 1 главная служанка и 2 у неё в подчинении. Это не фентези, нихуя мистики. Прописано строго - исторический слайсик. Всё прописано, вплоть до характеров.
Вызвал служанку главную, говорю ей, мол у меня проблемы мужские, не позвать ли того лекаря что давеча приходил.
И тут её понесло в мыслях (нет только не это, я не должна допустить чтоб он пришёл снова, а то он узнает! Он узнает всё обо мне взглянув в мои глаза. Господин не понимает что он ключ! Этот человек расскажет ИМ!)
Ну ёбтвою за ногу. Кто нахуй ОНИ, какой в ебени ключ сука ты тупая. Ну думаю может нейронка решила сделать так, чтоб крыша у не поехала и т.п. Хуй там плавал. Пришёл этот лекарь, сука, начал манипуляции с тенями, вселился в служанку. Закончилось моим убийством и вылетанием в окно на чёрных крыльях ночи этой сучки.
Перероли с того места, опять хуйня, злодей теперь я.
Угу, играешь в рероллы, а не в игру.
Ты подкидывай ту модельку иногда, пусть смуту и разнообразие вносит.
Хотя порой капитальная шиза бывает. Играл, значит, анимушный слайс где нужно трахать девочек-волшебниц, одни из них за свет другие за тьму выступают. Так там пошел делирий - овощи ожили, начали говорить в голос и объявили людям войну. Особенно сильными среди них оказались баклажан и лук порей. Воинам света и тьмы пришлось объединяться чтобы встретить эту угрозу лицом к лицу. По ходу сюжета выяснилось что во всем были виноваты вегетарианцы.
Отборный делирий в этих шизотюнах.
Так, а это что за песня. лесника и Тайгу узнал.
> делирий - овощи ожили, начали говорить в голос и объявили людям войну
В голос. Золото
> Отборный делирий в этих шизотюнах.
Факты, тупо факты. Реально что ли подрубать эту хуйню иногда... так потом контекст пересчитывать, эх
Протестил, лучше выше 0.7 не поднимать, начинается страшная каша - малаша. Ну а хули, это тюн всё таки.
Попросите нейронку отвечать вам в стиле ВИТИЕВАТЫХ ПУРПУРНЫХ АЛЛЮЗИЙ, охуеете.
"Шишки телепаты", другая "голос овощей"
Так скорее всего умеет только китайченок квен. Ну принеси скрины, что ли.
> извочик: паря, поторопись, гроза наступает
Бля куда мне торопиться? Торопиться ТЫ должен, мне некуда торопиться, я в повозке сижу. Ебанный рот, реролл.
Бля куда мне торопиться? Торопиться ТЫ должен, мне некуда торопиться, я в повозке сижу. Ебанный рот, реролл.
Браза, я всё понимаю, но если ты будешь писать сюда всю шизу которую выдает нейронка, то сразу бери пасскод и ставь аватарку, потому что ты будешь треды в бамплимит уводить за пару часов.
Проиграл чёт.
> овощи ожили, начали говорить в голос и объявили людям войну
Мне нужно знать, что это за тюн. Укатываемся обратно на тюны старых Мистралей всем тредом! Повеселимся хоть перед новыми релизами. Что-то от ReadyArt?

Меня пугает то, что мне вообще в голову пришёл такой стиль.
>Мне нужно знать, что это за тюн.
Это рофлы на тему песен, ~бака~
Бах писал песни?
Если уж так хочешь - заготовь лорбук с кучей текстов мемных треков и вколючай их инжектом с некоторым шансом или вручную или с рандомом. Офк потребуется обернуть в промпт с запросом невзначай добавить и включать не с самого начала.
> 60к токенов
С 5т.с это 200 часов твоего времени + свайпы
Как этим вообще пользоваться?
База всё еще 15т.с минимум
А что проблемы эира не вылечить файнтюном?
Уже около трёх видел
Уже около трёх видел
Как бы они для этого же и нужны, qwq тоже неюзабелен для рп, а сноудроп уже годнота
200M, опять ты всё перепутала. Принеси свои искренние извинения и как хорошая и послушная ассистентка попробуй ещё раз посчитать (601000)/(560*60). Если хозяин будет доволен, возможно, just maybe он наградит тебя.
>(601000)/(560*60)
(60x1000)/(5x60x60)
fix
мясные MoE 100T были в очередной раз унижены макакой; эта ошибка была в очередной раз добавлена в датасет; когда-нибудь я дообучусь само-reinforcement-лёрнингом

> 60к токенов
> С 5т.с это 200 часов твоего времени
Фух блять, как же мне поплохело от этого осознания.. я хоть и на 10т/сек слоуберню но 100 часов это всё еще дохуища.. я бля в доту наверно за всю жизнь столько не наиграл.. походу надо обратно на 24b безмозг мистрали пересаживаться..
>24b безмозг мистрали
Какашки жрёшь?
Вы проиграли даже не самой умной модельке, живите с этим
А ну в целом играбельно! Получается жизнь и на 5т/сек есть?
>Получается жизнь и на 5т/сек есть?
Редко какой двуногий читает (не сканирует, читает) быстрее чем 7 т / с. Есть, всегда была, если моделька радует выводами и не вынуждает бесконечно свайпить
Ты обсчёт контекста забыл. Если у анона 5 т/с, та около 16 контекста будут считатся почти 30 секунд.
>Если у анона 5 т/с, та около 16 контекста будут считатся почти 30 секунд
Одному господу известно как у тебя получился такой ответ. Впрочем может и он не знает. Генерация и обработка контекста радикально отличаются по скорости. Вполне нормальная ситуация когда 5 т / с генерации работают с 250-300 т / с обработки. Откуда такая тупизна сочится, мистралеюзеров трясет что у кого-то модели лучше но на меньшей скорости или каво?
Ну да, я пользователь мистраля, у меня нет мозгов, тебе есть что возразить?

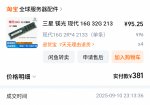

Сетапы на ддр4 официально умерли
Можно пояснительную бригаду для незнающих? Чё тут происходит, плашки подорожали немыслимо?
Да. Ддр4 сняли с производства, одни ломанулись сметать что есть, другие делать на этом деньги.
Все сборки на нищих и не очень эпиках теперь не имеют смысла, а зионы на д4 и подавно
Пиздос, кто бы мог подумать.. обычно должно быть наоборот, дешеветь как старый мусор....
Хм. А какого хуя ддр4 в днсе дешевеет? Пиздец. Модули что я покупал летом на 7к подешевели
Мб потому что изначально оверпрайс?
Сорян, ток проснулся. В глаза ебусь и сравнивал стоимость двух позиций против одной. Короче в итоге модули подорожали больше чем на 20 %. Ебать
ДА КТО нахуй скупает оперативу? ХУЛЕ дорожает то, ну не поверю что 2.5 инвалида с треда да и в целом со всего мира любители хобби которые решили собрать ворк стейшен могут повлиять как-то на цену... не могут же корпоблядки скупать ддр4.. это же shit для их уровня...
Всё как всегда анон. Байден ёбаный, позавчера его в днсе видел с чемоданом..
А чё всмысле, не 1,7к плашка? Надо было закупаться... А то сервер в бомж конфигурации с 4 плашками, а ведь ещё 4 слота есть.
Чел, забить всего один сетап на дуал эпик нужно 16 планок памяти. Достаточно много народу собирают себе компьют фермы, не одними нейронками же живут
ТАК там сейчас другой, рыжий пиндос! Но все они напару с Обэмой нам срут в загашник..
Никто не скупает, её просто перестают производить.
Ну ты выдал. Но вообще в реальности часов 12-20 там вполне может быть. 3.5 часа это чистая генерация, учитывая свайпы можно смело докинуть до 6 часов. Генерировать ты будешь не непрерывно, большую часть времени перечитывать ответ, писать свой пост, думать - сразу х2..х4, вот и получается.
Однако что 5т/с что 50 - тебе все равно придется прочесть пост. Быстрая скорость может сэкономить на свайпах потому что ты сразу пробежишься, увидишь что херня и свайпнешь вместо того чтобы делать это медленно и вдумчиво. Также снижает жопный пожар и недовольство при серии неудачных свайпов и повышает общий комфорт, тогда как с 5т/с будет конкретное полыхание. Ризонинг бонусом.
> Все сборки на нищих и не очень эпиках теперь не имеют смысла, а зионы на д4 и подавно
Да как-то они не то чтобы и раньше смысл имели, исключая случай острого дефицита бюджета и избытка пространства и свободного времени. Так-то нонсенс. Вроде в теории должно было быть быстро, но в реальности лишь немного обгоняет десктоп.
> не то чтобы и раньше смысл имели
Это не для вас было. Собирайте дальше 96г ддр5
А для кого?
>2x64 ddr5
Облизываюсь уже давно, но все никак не найду железный пруф что оно будет работать на i5 13600k, а выбрасывать такие деньги чтобы в итоге получить блестящую железку вообще не хочется.
Те кому нужно сами пришли к этому. Попроси кого-то другого бесплатно сидеть и переубеждать тебя
>пруф что оно будет работать на i5 13600k
А схуяли нет? Ценник конечно пиздец полный.
>а выбрасывать такие деньги
Всегда можно сдать обратно "Не подошла" (что будет чистой правдой).
https://www.asus.com/news/cilgj4q5royvfwhn/
ивасик.жпг
Хотелось бы увидеть какой-то реальный юскейс в контексте треда. Были тейки в легкодостижимости 256+гигов со сокростями 120-140гб/с, но для моделей в такой весовой категории этого как-то маловато.
>А схуяли нет?
Ну вот у плашек что я хочу взять на амазоне написано что "от 14 поколения". Я хз, они это написали, потому что на 13 и правда не пойдет, или от идиотов защитились, потому что в 13 еще были процы не поддерживающие ддр5 на заявленной в плашках скорости 5600.
https://www.amazon.de/-/en/Crucial-2x64GB-5600MHz-Computer-Memory/dp/B0DSR5P84D/?th=1
>Всегда можно сдать обратно "Не подошла"
Хз, не пробовал еще на амазоне возвращать ничего.
Какие крутые новые модели вышли до 50B?
Для рп с карточками в таверне без цензуры и с креативом
Для рп с карточками в таверне без цензуры и с креативом
По описанию это самые обычные еще и с нищими 5600. Не cudimm (в которые 13я серия также может), ни что-то еще. Смотри на на амазоне а у производителя спецификации https://www.crucial.com/memory/ddr5/cp2k64g56c46u5 там же у них есть списки совместимости (врядли актуальные)
Гранит
Я уже чекнул их сайт, моя мать там в списке есть, а вот интеловские процы они знают только xeon, так что все еще нет 100% ясности.
гранит? А можно ссылку?
Ну пиздос, не соберу я сетап на Эпике в далёком светлом будущем.
Хорошо хоть успел до 128 докупиться.
лол охуенно продам свою старую сборку в два раза дороже, чем планировал
спасибо дядь дональд


а по новой сборке картина такая: это пиздец.
за 1500 баксов процы в состоянии "scrap for gold", задроченные но ещё не убитые начинаются с 2к
итого моя сбор очка из запланированных 7к внезапно стала стоить 8
за 1500 баксов процы в состоянии "scrap for gold", задроченные но ещё не убитые начинаются с 2к
итого моя сбор очка из запланированных 7к внезапно стала стоить 8
Квен 2507 235b просто мега ахуенен ! Давно такого не испытывал, он живой, изобретательный, ламповый. Посылаю кусь тому анону который зашарил свой пресет и тому кто помог разобраться с пересчёткой контекста. Это реально был токенизатор виноват, хз почему так но я тупо поставил больше токенов в семплинге в таверне и отслеживаю переполнение через Жору. Теперь могу использовать все 32к. Как же он сочно пишет ближе к концу, я теперь всегда стараюсь держать 20-25к загруженными чтобы ему было с чем работать. Умница следит за всем что случилось, делает отсылки развивает. Разъёб просто.
Брат Иван центральный процессор новый, магазин такой продавать. Работа камень сила нефрита, не ебать нам голова
А у меня проблема с тем что модель даже с первого сообщения может уйти в нарратив забив на диалоги, просто пишет "её голос холоден, глаза выпучены..." и всё подводит подводит к диалогу но его нет за 700 токенов
2 квант
не наебал лаовая - день прожит зря ©
У меня тоже 2 квант а такой проблемы нет. Смотри промт, меняй карточку. Длина ответа стоит 350т, всё довольно балансно не могу сказать чтоб что-то приобладало.
32к на такой большой модели? Звучит как то уныло и бессмысленно.
^
|
|
|
© Mistral-Nemo-Instruct-2407-Q4_K_S-GGUF Q4 QUANTIZED K,V 128K CACHE
Нет русика значит нинужно
Он видел некоторое дерьмо. Жесть, что с ним делали вообще.
Да, в идеале там 64-96-128к иметь. Но так тоже хорошо.
>в идеале там 64-96-128к иметь
Плацебо, даже писик и корпы пропёрдываются после 32к. Там рп будет уже не с чаром а с генерализированными ответами, как это на мистралях после нескольких респонсов лол
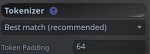
Плюс ставлю вывод 350 токенов, выводит от 350 до 500
Может тут надо что-то другое выбрать?
Запускаю через ламу
>Плацебо, даже писик и корпы пропёрдываются после 8к.
Исправил согласно данным из шапки.
Глубины коупинга
Посмотри внимательнее на Квены. Как минимум они до 32к работают ахуенно и писик в целом тоже
Ну тут соглы. Верить что 96-128к какие-то вразумительные выводы это пиздец коупинг и нежелание заниматься суммаризацией. Даже асигопопугаи поняли что жизнь до 32к в лучшем случае

>Посмотри внимательнее на Квены.
Ломается после 1к, в утиль.
В жирных чатах одна суммаризация под 32к легко может занимать. Почему-то в треде тема суммарайза обсуждается мало и поверхностно, многие важные вещи никак не освещаются и типичный вывод что можно услышать - "ручками там сам что-то делай и в карточку пиши".
А по контексту такое мнение и отрицание во многом потому что не пробовали + нет возможности практиковать.
Современные ллм прекрасно ориентируются в контексте, способны ухватить общую основную суть из массы и качественно отвечать по текущим событиям. Остальное будет работать в качестве большого пулла, из которого как в нидлстак будут выдергиваться релевантные события и отсылки, вызывая очень приятные впечатления.
> Даже асигопопугаи
Какой лимит им выставят на проксичке - такой и понимают. Если отпустить то вокруг 80-120к крутятся.
>типичный вывод что можно услышать
>"ручками там сам что-то делай и в карточку пиши".
В чём они не правы? Все автосуммарайзы полная брехня, писать нужно самому. Чтобы не было суммаризации на 32к имеет смысл редактировать карточку, замещая информацию (характер персонажа изменился) и использовать лорбуки. Разве есть что ещё тут обсуждать
>потому что не пробовали
Пробовал через апи на писике. Контекст неквантованный, писик не лоботомитный. После 32к ощутимо сдаёт позиции. Да и у себя на локалках (Эир в основном запускаю, Квен слишком медленный но и на нём тестил) замечаю что весь сок до 20-30к
>нет возможности практиковать.
Какой у тебя контекст обычно и квантуешь ли его до q8?
>Какой лимит им выставят на проксичке - такой и понимают. Если отпустить то вокруг 80-120к крутятся.
Да хуй знает, там эту идею продвигают поехавшие снобы которые именуют себя эрпэ энтузиастами и всё поняли, остальные за ними подхватили и в целом согласились что да, после 32к выводы лоботомируются ощутимо
> Он видел некоторое дерьмо.
на самом деле это худший из предложенных добрым китайцем вариантов. простой Ли город Шеньджень честно написал, что у них все процы видели некоторое дерьмо и накидал фоток, чтобы я выбрал, какой из них устроит.
спойлер: не устроил ни один. и теперь я понял, почему тот другой анон с епиком выбрал более дешёвый 9354 с 32 ядрами - потому что их хоть жопой жуй в нормальном состоянии, а к моделям с 48-64 есть вопросики
Qwen_Qwen3-235B-A22B-Instruct-2507-IQ2_S
3.5 Т/s на 16VRAM/64RAM это мало, много или обычно? Как запускать на кобольде, чтобы лучше было?
3.5 Т/s на 16VRAM/64RAM это мало, много или обычно? Как запускать на кобольде, чтобы лучше было?
напиши размер модели в гигабайтах, скорость памяти видюхи в гигабайтах в секунду, скорость оперативы в мегагерцах и количество каналов памяти
>у них все процы видели некоторое дерьмо
Но как они это сделали? Ведь корп процы 1 раз ставят под охлад, гоняют 3 года, а потом продают целиком сервак на разбор. Тут только разборщики могут поднасрать, но тех, кто позволяет работникам разбирать сервера кувалдой, я не понимаю.
Если ddr4 то в целом норм. Будет быстрее если уместить Q2S а не IQ2S, но думаю если бы ты мог уместить то сделал бы это сразу. А чтобы точно сказать это да, много информации нужно. Чё за видюха, чё за память, нет ли где ботлнека и тд
> В чём они не правы?
Как минимум в том, что поленились попробовать освоить что-то сложнее чем всратая заготовка в таверне. Процесс будет крайне утомительным если хочешь сохранить побольше информации и кожаный точно также может ошибаться.
> характер персонажа изменился
Это верно, но когда изменения от оригинального характера прописываются в истории, или даже выделены отдельно - это может работать лучше и выглядеть куда интереснее. Тогда чар сам имитирует осознание этого "вспоминая", или показывает что отношение изменилось только к тебе и группе лиц, а к остальным оно сохранено.
> После 32к ощутимо сдаёт позиции.
Справедливости ради, все зависит от содержимого. Если там непрерывный кум или все 32к контекста про одно и то же - деградация будет существенная и начнется еще раньше. Какие-то события могут отвлекать на себя внимание и уводить развитие, но это также будет проявляться на меньшем.
Но если есть хоть какая-то динамика и изменения - все окей, даже овер 120к ответы не падают в качестве. Тупняк и путаница мало отличаются от других.
> Какой у тебя контекст обычно
Вокруг 64к вьется, поднимается за сотню когда совсем лень суммарайзить, или хочется сохранить какой-то сюжетный момент в полных деталях до наступления связанного с ним события. В особых случаях идет суммаризованная вставка посредине, но это большой геморрой и может ломать логику структурирования и нумерации основного суммарайза, из-за качество ответов мэх.
Без квантования, она сильно сказывается.
> там эту идею
Там каждую неделю новая идея, или их количество равно числу высказывающихся.
Если спекулировать, то "окно контекста" можно обозначить в пределах 4-12к, больше для задач высокой сложности оно не может вместить единовременно. Но зато способно через эту линзу обращаться ко всему контексту и сосредотачивать внимание на нужном в один момент, по ходу ответа выставляя нужный фокус.
Если закинуть ллм сложных научных статей с чем-то новым и заставить сетку применить их методики для решения новой задачи - результат будет жидким. Но при этом если закинуть справочник с кучей разнообразных уже оформленных удачных решений, а потом попросить сделать комплексную задачу, которая может быть поделена на мелкие - оно превосходно с этим справится, на каждый этап подтягивая из контекста готовую методику, код или следуя рекомендациям оттуда.
Аналогично - можно насрать художкой и потом спросить "в чем основная мораль сего произведения", вменяемые ответы будут только если сойдутся звезды в огромном ризонинге где все разберет по частям. Зато если спросить про действия конкретного героя - с легкостью извлечет все относящееся к нему зирошотом.
>поленились попробовать освоить что-то сложнее чем всратая заготовка в таверне
Если уж бросаешься говном в такую базу как ручная суммаризация тогда приводи альтернативу. Чем ты пользуешься? Неужели вектор сторедж или не дай боже квинк мемори?
>Тогда чар сам имитирует осознание этого "вспоминая", или показывает что отношение изменилось только к тебе и группе лиц, а к остальным оно сохранено
Это бывает прикольно, но мы говорим о компромиссах, которые рано или поздно наступят, контекст в любом случае не резиновый. Более того рано или поздно это заебёт, если по таймлайну прошли годы например то необязательно чару каждый раз напоминать о какой-то черте характера которая давно позади
>даже овер 120к ответы не падают в качестве
Ну сомнительно. Не верю. На писике я доходил до 90к и там совсем лоботомия начиналась каждый раз, как я не крутился подобно ужу на скороводе
>зато способно через эту линзу обращаться ко всему контексту и сосредотачивать внимание на нужном в один момент
Тут соглы, избирательное внимание к контексту правда хорошо работает. Если бы ещё не разваливалось всё на больших контекстах и не шизило было бы вообще заебись. Если делить историю на чаптеры и систематизировать как ты там выше писал то и лорбуками можно обойтись

да хуй знает, там почти у всех царапины на крышке и боках, у каких-то царапины снизу, и у многих битые углы, то есть их роняли.
и если падение проца я ещё могу понять, массовый падёж тоже теоретически могу, то как так задрочили крышки и бока я сам не понимаю, походу набранные по квоте 70iq выковыривали процы из материнок отвёртками, лаовай уплатит за всё.
реально, как блядь СБОКУ можно проц покоцать?
ааааа лол кажется я понял
у них не нашлось шестиугольной отвёртки и они не раскрывали сокет, а тупо выковыривали процы из пластиковой держалки плоской отвёрткой0)0))0)))))) бляздец сууууууукааааааааааааа ажтрисёт
у них не нашлось шестиугольной отвёртки и они не раскрывали сокет, а тупо выковыривали процы из пластиковой держалки плоской отвёрткой0)0))0)))))) бляздец сууууууукааааааааааааа ажтрисёт

> 2 квант
4060 16
DDR5 64 5600
Подкачка на SSD 7000MB/s, если вылезет
Попробовал покрутить GPU Layers, включить FlashAttention и выбрать 4-Bit для QuantKV Cache, скорость не поменялась.
>Он и должен его разделить на две, тебя не должно это смущать. Если первая подключена по более быстрой шине то все ок.
Так не так же, я даже специально только на 4060ti-16 раскидывал скриптом куски модели и не трогал 3060-12 вообще - если на неё KV-cache раскидывается автоматом, то скорость падает.
>А можешь накинуть тот скрипт, я тоже с ним поиграюсь, интереса ради?
https://2ch.su/ai/res/1323697.html#1324921
>Автор котоскрипта - спосеба. Очень хорошо работает. Хоть в один гпу запихать максимум мое-слоев, хоть на n-гпу разложить - всё чётко. Там ещё у тебя похоже подразумевалось "-ngl 999" перед собственно оверрайдом? Долго не мог понять, почему медленнее с полученной выгрузкой, чем при другой раскладке. Вернул -ngl 999 - сразу полетело. Вставил в формируемый промт промт, чтобы тоже не парились, как я.
>Кому нужно - я взял на себя смелость попросить дс переписать по-человечески с кошачьего - вот: https://files.catbox.moe/y18a6n.7z
>Сразу с инсталятором по рекьюрементсам и примером запуска.
>Подкачка на SSD 7000MB/s, если вылезет
Нахуя? Только насрёшь себе этим и создашь жёсткий ботлнек. Ну тогда скорость хуевастая я бы сказал, наверняка можно улучшить. У меня на ддр4 такая же, но у меня 3090 24. Чекай потребление рам/врам, оптимизируй регексп. Других способов и нет.
>4060 16
Надеюсь разогнанная? У меня +1500 по памяти завелась
>DDR5 64 5600
Гони еще. Там почти любая ddr5 на 6000 заведется. И проц какой кста?
>Подкачка на SSD 7000MB/s, если вылезет
Убери
А вообще лучше бы Air юзал. Он бы раза в два (ну или хотя бы в 1.5) был бы быстрее и из-за более высокого кванта скорее всего еще и умнее
Какое же всё таки говно.
Поигрался с квеном 235, казалось бы, самая умная моделька на сегодняшний день (?)
Пару дней рп, я уже угадываю её паттерны и ответы, формулировки.
Какого хуя, блять..((((
Поигрался с квеном 235, казалось бы, самая умная моделька на сегодняшний день (?)
Пару дней рп, я уже угадываю её паттерны и ответы, формулировки.
Какого хуя, блять..((((
Жирно как один конкретный член твоей семьи
>Там почти любая ddr5 на 6000 заведется.
К слову нет. Попробуй заведи G.Skill Aegis 5 [F5-5200J4040A16GX1-IS]
или Patriot Signature Line [PSD516G480081]
Про всякие ХуйСуньВЧай вообще молчу, там победа если вообще заработает.
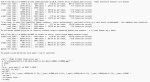
Что ж, сегодня опыты с GLM-4.5-Air-Q4_K_S
Результаты на одной видеокарте 4060ti-16:
Контекст 287.51 t/s на маленьком контексте.
Генерация 7,4-7,7 t/s
С добавлением 3060-12 всё падает, как и в прошлый раз.
Прикрепляю результаты и батник к посту в виде пикчи, чтобы макаба не пожрала символы.
Где-то я всё-таки накосячил в батнике, походу, не должен кеш разбрасыватья на видюхи.
Результаты на одной видеокарте 4060ti-16:
Контекст 287.51 t/s на маленьком контексте.
Генерация 7,4-7,7 t/s
С добавлением 3060-12 всё падает, как и в прошлый раз.
Прикрепляю результаты и батник к посту в виде пикчи, чтобы макаба не пожрала символы.
Где-то я всё-таки накосячил в батнике, походу, не должен кеш разбрасыватья на видюхи.
Ну я же говорю ПОЧТИ любая. Китайский скам и самые дешманские патриоты у которых даже нет xmp ясен хуй не рассматриваются.К тому же у него 5600 уже, видимо через xmp, так что скорее всего и 6000 возьмет
В батнике насрано я вахуи. Ещё и контекст квантируешь когда тысячу и один раз писали что это лоботомирует эир
а почему -t 5 и сколько ядер у твоего проца?
попробуй -t 3
> бросаешься говном
Где? Обратил внимание на очевидную проблему, которая почему-то не кажется очевидной остальным. Ведь экспириенс можно получить лучше и меньше мучаться. А про суммарайз уже не раз писал, всем похуй.
Сначала нужно решить до какого момента будешь суммарайзить делая с него форк чата чтобы работать в нем. Обязательно убедиться чтобы в нем был именно текущий суммарайз а не какой-то прошлый, ибо таверна помнит их вариации и привязывает к постам. Прямо в чат пишешь команду [SYSTEM]Стоять, давай суммаризуй текущий рп, или отправляешь команду через /system, всем норм моделям хватает первого. Лучше всего сразу приказывать делать структуру в виде глав, типа "предложи N новых глав", в каждой краткое содержание, локация, сеттинг и подобное, количество подбирать по месту. Из нескольких свайпов выбираешь лучший или собираешь по кусочку с разных и сразу используешь, или меняешь начальную инструкцию на "улучши и расширь" закидывая их в инпут и так рефайнишь.
Потом к этим главам или своей структуре добавляешь обозначение дней/недель/времени и более крупно заголовочные арки (можно запрашивать суммарайз по ним чтобы сетке было легче ориентироваться, разметка а ля маркдаун обязательна).
Возвращаешься в основной чат, скрываешь сообщения которые обрабатывал и закидываешь полученное в стандартное поле суммарайза таверны. Только обертку что это суммарайз прошлого а ниже уже текущий чат сделай, ибо в стандартным темплейтах ее нет или всратая. Сложно в первый раз, потом модель видит структуру и ее придерживается.
> мы говорим о компромиссах
Они в какие-то пугалки превращаются. Современные модели рассчитаны работать на больших контекстах не подыхая как было со старыми. Именно с проблемами что ты описываешь относительно размера контекста, а не обусловленных проблемным содержимым в целом, особо не сталкивался. Наоборот если сильно ужать и снизить - модель тупит и начинает слишком уж придумывать там где должна четко отвечать.
> то и лорбуками можно обойтись
Если они всегда включены - это просто другое поле для суммарайза. Ах динамическое подключение на локалках нецелесообразно.



> если на неё KV-cache раскидывается автоматом, то скорость падает
Вот это интересно, можешь больше подробностей дать?
>В батнике насрано я вахуи.
Щито поделать, десу?
Сделано на основе бантника из треда, реддита, неба и Аллаха.
>Ещё и контекст квантируешь когда тысячу и один раз писали что это лоботомирует эир
Прямо сейчас поебать вообще, я сравниваю скорости и пытаюсь найти причину боттлнека.
>а почему -t 5 и сколько ядер у твоего проца?
Ryzern 5 5600X у меня, 6 физических ядер, рекомендации на одно физическое ядро меньше.
хуйня рекомендация, надо ставить столько ядер, сколько хватает скорости оперативной памяти, если 3 ядра полностью забивают оперативу, то ещё 2 дополнительных будут только замедлять генерацию.
>Вот это интересно, можешь больше подробностей дать?
У меня 2 видеокарты:
4060ti-16 через CPU PCI-E 4.0x16 (используется 8)
3060-12 через Chipset PCI-E 3.0х4
Я провожу опыты отключая в куде 3060-12 (т.к. я хз, что в батнике прописывать, чтобы вторую видюху не видело).
Если куда видит только 4060ti-16, на которую скриптом раскиданы куски модели - скорость неплохая.
Если я запускаю тем же батником, но в куде включаю ещё 3060-12 - скорость обработки контекста и генерации падает.
Отличия между этими вариантами только в том, что во втором случае автоматом на вторую видюху закидывае кеш.
При этом мне все говорят, что автоматом весь кеш должен кидаться на CUDA0, а на деле нихуя.
Нипонимат. У меня 128гб DDR4 3600.
Проясни следующее:
Используя вторую карточку ты увеличиваешь количество выгруженных на гпу слоев, или сохраняешь их теми же просто перераспределяя?
> Если я запускаю тем же батником
Какие остальные параметры батника, закидывается ли в этом случае слои на вторую карточку?
> кеш должен кидаться на CUDA0
Это устарело с год назад или типа того.
Кэш распределяется в соответствии с блоками на карте. Для слоев, что находятся на проце - размазывается в соответствии с пропорциями -ts. Может здесь что-то зарыто, но особой передачи с других гпу во время обсчета не отмечалось.
похуй на гигабайты, нужны гигатранзакции в секунду умноженные на каналы.
если у тебя 2 канала, а скорее всего 2, то скорость памяти 3600x2/128=56 гигабайт в секунду, одно ядро юзает гигов 15, итого нужно 4 потока максимум, а лучше попробовать 3
>Используя вторую карточку ты увеличиваешь количество выгруженных на гпу слоев, или сохраняешь их теми же просто перераспределяя?
Принудительно скриптом выгружаю часть тензоров на CUDA0, на CUDA1 не гружу вообще ничего.
>Какие остальные параметры батника, закидывается ли в этом случае слои на вторую карточку?
Батник на пике. Там насрано, я знаю.
>Кэш распределяется в соответствии с блоками на карте.
Есть вот эта хрень
-sm, --split-mode {none,layer,row} how to split the model across multiple GPUs, one of:
- none: use one GPU only
- layer (default): split layers and KV across GPUs
- row: split rows across GPUs
-mg, --main-gpu INDEX the GPU to use for the model (with split-mode = none), or for
intermediate results and KV (with split-mode = row) (default: 0)
(env: LLAMA_ARG_MAIN_GPU)
Только она почему-то не хочет работать. Или, что более вероятно, я где-то проёбываюсь.
Не насрано и все там нормально, просто ничего не понятно.
Раз так непонятно то давай следующим образом: скинь параметры запуска (и маску куда устройств если используется) для случая, когда у тебя с одной 4060ти быстро, для случая когда ты скидываешь на 4060 и 3060 где медленно, и когда ты скидываешь на 4060-3060 но вроде как вторую не используешь и тоже медленно. Если они большие - на пейстбин.
Я запускаю одним батником в обоих случаях.
Только в одном случае CUDA видит только одну видеокарт (отключаю вторую в Cuda в настройках Nvidia), а в другом - две. И в случае, если две - работает медленнее.
Available devices:
CUDA0: NVIDIA GeForce RTX 4060 Ti (16379 MiB, 15225 MiB free)
CUDA1: NVIDIA GeForce RTX 3060 (12287 MiB, 11247 MiB free)
https://pastebin.com/YD7S9RsD
Нейронкоебы, расскажите, пожалуйста, если собирать комп, на котором можно гонять нейронки, то:
1. Должен ли это быть выделенный комп для нейронок или может быть обычный лрмагний универсального пользования?
2. Какая ОСь лучше под нейронки?
3. Насколько проседает производительеость, если нейроеки гонять в виртуалке?
4. Я правильно понимаю, что в сторону АМД-видеокарт не смотреть - только зеленые, только CUDA? Zluda не актуальна?
5. А что насчет процессоров? Рязань лучше интела?
6. Стоит ли приобретать одну мощную карту вроде 5090 или можно собирать несколько из 4ххх серии, например? Насколько там много пердолей?
7. Множество видюх будут создавать проблемы, если надо что-то порендкрить, помоделировать, поиграть?
8. На октябрь 2025 на какой бюджет ориентироваться, чтобы собрать средне-добротный комп для нейронок?
9. Можете какие-то сборочки привестм, на которые ориентироваться, от которых отталкиваться? Алсо, где вы железо берете? На озонах? На авито? У перекупов? У китайцев?
Спасибо.
Вот IMHO, нужно или -ot использовать, или -cpu-moe. Но не вместе. Т.к. делают практически одно и то же, но первый вручную, второй - автоматикой.
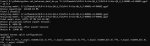
1) Отдельный если HEDT, иначе зачем?
2) Линь, без вариантов
3) смотря что за виртуалка.
4) Правильно. С мишками все наигрались и забыли.
5) Интел лучше, скорость озу выше
6) Пердолей нет, но объединяется только память, не мощность. И не скорость памяти, что ещё важнее.
7) Игры используют лишь одну.
8) от 20к на некро зеоне и майненой 2070, до 20кк на 12канальном зеоне и массиве rtx6000pro
9) на таобао. Тут такой зоопарк у анонов, что чубовские карточки фурри гаремников отдыхают.
>Это устарело с год назад или типа того.
>Кэш распределяется в соответствии с блоками на карте. Для слоев, что находятся на проце - размазывается в соответствии с пропорциями -ts. Может здесь что-то зарыто, но особой передачи с других гпу во время обсчета не отмечалось.
Это нихрена не устарело, если карты заметно разной мощности. У меня 3060 + p104. Если допустить, чтобы часть кеша попала на p104 - просадка раза в 2-3 получается. Кеш нужно, по возможности, запихивать на более мощную карту целиком.
Амуда не нужна, процессор тоже, нужно дофига памяти и места под чекпоинты. Я через сандбокси гоняю, чтобы питон не расползался за пределы своего петушиного угла и инсталлы не конфликтовали, пердолинг умеренный. Карты 8ГБ ртх должно хватить на 70% задач, 16ГБ хватит на 90%, 24ГБ хватит на 95%
В одном случае у тебя весь атеншн только на более быстрой 4060ти, в другом он делится пополам между доступными устройствами. Разумеется ампер более медленный, особенно с квантованием кэша, вот и происходит замедление.
Чтобы получить ускорение тебе нужно использовать всю доступную врам обоих видеокартах. Натрави скрипт чтобы он сделал тебе регэксп для обоих девайсов, не забудь задать -ts 16,12 чтобы все работало корректно.
Также, можешь попробовать задать -ts 1 чтобы весь атеншн и кэш был на первой карточке, а на вторую только грузить экспертов. Соответствующим образом потребуется поменять размеры врам для скрипта, можешь подобрать экспериментально чтобы было максимальное заполнение памяти.
> нужно или -ot использовать, или -cpu-moe. Но не вместе.
Неверно, можно использовать как угодно.
> второй - автоматикой
Он просто интерпретируется как обычный регэксп *ffn_exps, нет никакой автоматики.
Ты хотябы читай на что отвечаешь перед тем как писать.
>Кеш нужно, по возможности, запихивать на более мощную карту целиком.
Как, блеать?
Я пытаюсь это сделать уже второй день.
>Чтобы получить ускорение тебе нужно использовать всю доступную врам обоих видеокартах. Натрави скрипт чтобы он сделал тебе регэксп для обоих девайсов, не забудь задать -ts 16,12 чтобы все работало корректно.
Проверял, работает медленнее.
>-ts 1
Вот, вот меня интересовало именно что-то такое.
Ладно, завтра буду пердолиться.
> Проверял
Ну, на этом наши полномочия все. Разве что проверь без квантования контекста выставив меньшую величину. Будет мегарофел если дело в этом.
Отсутствие квантования ожидаемо увеличивает скорость, но всё равно ещё хуже, чем на одной видеокарте.
Я уже все волосы на жопе вырвал, пытаясь понять, почему --split-mode row --main-gpu 0 не отправляет весь KV-кеш на CUDA0 видеокарту
> увеличивает скорость
Рассказывай какая разница получается.
> но всё равно ещё хуже, чем на одной видеокарте
Вот это таки странно, конечно 12гб не самой быстрый врам это немного, но для эйра все равно должно некоторую прибавку давать относительно ддр4. Удивительно что все упирается в скорость обсчета на 3060, ибо это по сути единственный источник замедления.
> --split-mode row
> не отправляет весь KV-кеш на CUDA0 видеокарту
Ну а на что ты рассчитывал? Это деление каждого слоя на части, разумеется и кэш на каждой карточке обязан быть. Лучше не трогай режим сплита, в жоре шрафы за его изменение превышают все разумные выгоды на железе лучше некротесел. А мейн гпу указывает не карточку на которую пойдет кэш, а главную карточку что будет участвовать в обсчете контекста для слоев в рам. Как закинуть кэш в одну указано выше.
> за его изменение
использование
Потестил разное число потоков на Мистрале и Гемме. Если коротко: благодаря изменению всего одного параметра (умению потоков с 8 до 5) удалось получить выигрыш в 0.2 т/с в Гемме и 0.5 т/с в Мистрале на ровном месте, что охуеть как круто. Буквально самый полезный совет за последние несколько тредов. Спасибо, анон.
Вот более подробные результаты, если кому интересно. Ставил температуру 0, так чтобы нейронка всегда генерировала один и тот же вывод.
Гемма 3 27b Q4_k_xl (29/63 слоев на гпу):
1 поток: 1.2 т/с
2 потока: 2.48 т/с
3 потока: 3.3 т/с
4 потока: 3.78 т/с
5 потоков: 3.8 т/с - лучший результат
6 потоков: 3.74 т/с
7 потоков: 3.67 т/с
8 потоков: 3.62 т/с
Мистраль 2506 24b Q4_k_l (28/41 слоев на гпу):
1 поток: 2.75 т/с
2 потока: 4.74 т/с
3 потока: 6.19 т/с
4 потока: 6.77 т/с
5 потоков: 6.9 т/с - лучший результат
6 потоков: 6.6 т/с
7 потоков: 6.52 т/с
8 потоков: 6.41 т/с
У меня r7 3700x (8/16) + 3060 12gb + 64gb ddr4 3200 четырьмя планками по 16gb.
> Гемма 3 27b Q4_k_xl (29/63 слоев на гпу):
А ч зачем её на цпу грузить?
А, сорян, чёт не дочитал что там 12гб
При ручной выгрузке тензоров флаг:
-ts 100,1
закидывает весь кеш на CUDA0.
С выгрузкой надо ещё поиграться, может всё-таки что и выиграю по сравнению с одной видеокартой - пока её скорость максимальна.
--split-mode row --main-gpu 0 НЕ НУЖНО, я объебался (хотя по описанию подходило)
> -ts 100,1
Что с ручной что без ручной просто напиши -ts 1 или -ts 1,0 или -ts 1,0,0 и все будет. Жора оценивает размеры весов и кэша и раскидывает их в соответствии с -ts. Main gpu вообще никак не влияет на пропорции как и row split.
Если выгрузишь экспертов на вторую гпу из рам то должен быть выигрыш, но вообще даже странно что получается такой большой негативный эффект от 3060 даже при том же числе слоев в рам.
>-ts 1 или -ts 1,0 или -ts 1,0,0
Так почему-то ругалось и не работало.
По итогам тстов у меня пока так и не получилось получить профита от 3060 в данной конфигурации.
Внутренне ощущаю, что её PCI-E в кашу срёт.
За исключением профита от того, что винда не трогает 4060ti-16, конечно.
Что уже лучше, чем ничего, но следующий сетап я хочу с тремя видюхами и материнкой с разделением 16 на 8+8.
Ты можешь частично промониторить это смотря загрузки шину и обмен по ней.
Там просто обменов то особо и нет, разве что какой-то пересыл кэша с карты на карту. Но тогда бы выключение квантования наоборот дало бы замедление из-за увеличения трафика.
> винда
Чекай выгрузку врам драйвером.
Спасибо.
>2) Линь, без вариантов
Все так плохо с виндой?
На линупсе увы нет всяких фотошопов и 3дс максов.
>3) смотря что за виртуалка
Например, обычный wsl?
>процессор тоже,
Может я на проце захочу погонять нейронки.
Алсо, поясните по требовательности языковых и визуальных (графика, картинки, видео и пр.) моделей. Есть ли перекос в сторону Ram, VRam, проца и пр.? Или примерно одинаковые требования?
Еще такой вопрос, насколько актуально приобретать ту же 5090? Стоит ли ждать серию Super, которую перенесли на 2026?
Еще вопрос по поводу 5ххх - они еще плавят коннектор? Или уже нет? Насколько андервольт повлияет на производительность видюхи с моделями?
>Все так плохо с виндой?
Нет, но под линем лучше
>Есть ли перекос в сторону Ram, VRam, проца и пр.?
Для LLM в сторону VRam, для остальных в сторону мощности GPU (возможности разбивки на несколько гпу может уже не быть).
>Стоит ли ждать серию Super
Только если собираешься брать 5070/5080
>они еще плавят коннектор?
Никогда не плавили у тех, кто втыкал до конца
>Насколько андервольт повлияет на производительность видюхи с моделями?
На LLM никак, поскольку упор в скорость и количество vram
> Буквально самый полезный совет за последние несколько тредов. Спасибо, анон.
а меня ещё тряпками гоняют, неблагодарные
базашиз
1 Зависит от запросов, мощное не реализовать на дестопном железе, большой риг не захочется иметь стоящим под или не дай бог на столе.
2 Линукс
6 Зависит от запросов. В целом в приоритете объем видеопамяти, однако сейчас популярным является катание моэ с большой долей выгрузки весов с рам. Там наилучшим конфигом будет 5090 + быстрая рам. Из 4к серии ультимативным решением будет 4090@48.
7 Нюансы с подключением к материнской плате на десктопном железе из-за ограниченного количества линий. Если решишь поделить процессорные х16 на 4х4 то медленное подключение основной может нагадить. В случая же где просто в десктоп добавляется еще одна-две карточки, подключенные по чипсетных или х8+х8 проблем не будет.
8 Диапазон слишком широк. Вкатиться попробовать можно на десктопе с минимальным апгрейдом, с условным комфортом инфиренсить все крупные модели - риг по цене среднебюджетного авто, что-то тренить - уже к цене недвижимости.
9. Везде где выгодно, по примерам см 8.
>Если коротко: благодаря изменению всего одного параметра
Потести с автовыставлением (убери свои ручки оттуда), а то у меня авто параметр не было равно ручному выставлению того же числа, лол.
Так ты срёшь под себя, а не раздаёшь нормальные советы. Эти рекомендации не сжать в одну строку, а ты строчками и срёшь вместо абзацев на каждый пункт. Впрочем, если ты напишешь абзацы, то получится вики из шапки, и тогда вопрос в том, нахуя это дублировать.
Так что как ни посмотри, ты нахуй не нужен в этой жизни.
Туда иво
Ты бы хоть уточнил для начала, какие именно нейронки ты хочешь гонять и какой результат на выходе получить. Ну давай предположим, что ты будешь условно "как все" делать картиночки через sdxl/flux/qwen, видосики через wan, и средние ллмки от mistral 24b до glm air 106b
1. Обычная домашняя пека
2. Похуй, но в линуксе удобнее и приятнее
3. Правильно
4. А зачем это делать?
5. Похуй, разница несущественна
6. Лучше одну мощную (как УНИВЕРСАЛЬНЫЙ вариант, а не только под ллм)
7. Скорее просто окажутся незадействованными. Много видюх - хорошо для ллм, для всего остального - очень спорно.
8. Чтобы прям КОМФОРТНО? Ну от 350к+, если собираем с 128gb DDR5, rtx 5090 и прочим. Если минимально приемлемый уровень - то б/у c авито на базе 3060 12гб и 64гб DDR4. Условные флюкс, ван и эйр запустятся и работать будут, но будет медленно и больно. Зато дешево.
9. Бери там где есть гарантия и возможность вернуть брак без геморроя. Авито - крайний вариант, если совсем бомж.
>Еще такой вопрос, насколько актуально приобретать ту же 5090? Стоит ли ждать серию Super, которую перенесли на 2026?
Я жду super, а потом буду обновлять пеку полностью. 5090 не нравится: слишком дорого, слишком печка, слишком много инфы о сгоревших сокетах.
>Насколько андервольт повлияет на производительность видюхи с моделями?
В теории - незначительно. На ллм вообще повлиять не должен.
до 4 кванта глупо, выше 5 бессмысленно
сможешь шестой запустить отпишись
>слишком много инфы о сгоревших сокетах
Вставлять научись, и не будет ничего гореть. Ну а дорого... Брать надо было за 220к на озоне, сейчас да, уже поздно.
>надо было за 220к
Тем, кому 220 недорого, тому и 260 недорого, о чем ты? В данный момент я бы ее купил, только бы если она <150 стоила, и то бы долго думал.
Тем, кому 150 недорого, тому и 220 недорого, о чем ты?
Ждуны сосут. Не хочешь брать по 220, будешь брать по 260, 300 или дороже. Ну или сосать без карты, лол.
Могу взять и за 260к, ЗП позволяет месяцок поесть дошираки и купить. Просто я понимаю что йоба-ультимейт решение сейчас превратится в тыкву через пару лет потом (если не раньше, с такими темпами развития нейронок).
Буквально то, что произошло с 3060, которая 2 года назад была шином под sdxl, а в 2025 - просто мусор, который что-то может, но нахуй так жить. НО 3060 стоила 30к, а не 260к. Дайте людям 24гб за адекватные деньги, жадные пидорасы, чтоб хоть не так обидно было по кд обновляться.
О том, что дорого, совсем мозги кумом отшиблись?
Так я не жду, мне и сейчас хорошо
Вторая эксллама даже на тьюрингах работает хуже, чем жора (генерация). На паскалях там вообще хуета, не надо с этими картами ей пытаться пользоваться.
Благодаря пресету ещё раз убедился что квен неюзабельный пережаренный прозой кал который ничего не спасёт и не зря его все забыли, либо нужен 6 квант чтобы его раскрыть
> через пару лет потом
На большой срок прогнозируешь, тогда уже новая серия карточек выйдет. Есть вероятность что какие-то продукты выйдут, но в условиях ии бума при хороших характеристиках они будут дорогими. Едва ли амд и интел разродятся чем-то прорывным и будут демпинговать, скорее останутся в роли догоняющих предлагая средние решения. Могут также появиться новые нпу от китайцев, но примерный исход можно наблюдать выше, а йоба продукция будет дорогой.
> 3060, которая 2 года назад была шином под sdxl
Никогда не была. Она были самым энтри тиром на котором что-то небыстро можно делать, а не терпеть и страдать. И именно 2 года назад на ней можно было разве что хуй пососать и пердеть на полторашке, более менее сносная ее работоспособность на XL пришла с выходом форджа.
> Дайте людям 24гб за адекватные деньги
50-60к за 3090 на лохито, уже который год.
>Какая ОСь лучше под нейронки?
Винда. Не слушай пингвинопетухов, это сектанты. Тот же жора на винду просто скачивается архивом, распаковывается и запускается. Никаких пруфов что генерация на линуксе быстрее никогда не было.
5070ti 24gb будет стоить 80к
Правда ведь?...
Правда ведь?...
Как понять говно карточка или нет?
Просто ввожу необходимого персонажа на чубе и скачиваю
Просто ввожу необходимого персонажа на чубе и скачиваю
>пингвинопетухов
чёт орейро с этого
чёт не нашёл в шапке ничего по базе треда, а в статье про выбор железа вообще рофл какой-то из 2023го "ни у кого из треда нет A6000", тут уже у нескольких человек риг лучше
ниже 4 глупо, выше 8 бессмысленно
*в вики из шапки
и там вообще какой-то лол, а не вики

>лохито
лох не мамонт, и дважды заплатит
опять начинаешь, ебучий шакал
>на чубе
Так там видны реакции в разделе Discussion. Если карточка не оставила никого равнодушным - значит хорошая.
Так там все корпы юзают которые любую карточку вытащат
>Q2_K_S
>Всё ещё не 7 т/с в третьем кванте
поприседал бы, спортом там занялся бы, вместо этого пердолинга... печальный он какой-то...
оно ж неюзабельно буквально на таких скоростях, особенно когда контекста вагон лопатить нужно
а ничего, что зависит в первую очередь не от матери а от контроллера процессора, + вопрос что там со скоростями будет, а то на ДДР5 иногда вопросы возникали к количеству планок
Эйр/квен неплохо тащат карточки, которые мелкомодели раньше не умели.
>Никаких пруфов что генерация на линуксе быстрее никогда не было.
не пали контору, а то сейчас полезут в локалки все, ты эе понимаешь, что нужно ограждать тему от мимокроков, пускай думают что линупс пердолить нужно
Эйр ну рили говно же. Квен могут не только лишь все запустить и хз насколько он жизнеспособен в q2. Выше вон там ноет, хотя мб скил ишью неосиляторство
база. ещё надо прогонять хуцпу что нейронки не заменят программистов, чтобы додики тратили время на курсы скиллбокс
На линухе что то типа 5 процентов прирост в лучшем случае, адептов внатуре много набежало
>Просто я понимаю что йоба-ультимейт решение сейчас превратится в тыкву через пару лет потом (если не раньше, с такими темпами развития нейронок).
при таком раскладе выгоднее облако в аренду взять и не париться, не факт даже что наиспользуешь на стоимость карточки, если не занимаешься многочасовым ежедневным кумом...
а так - да, в тыкву превратится, так же как тыквой сейчас считается 3060 какая-нибудь, хотя я на 1070 сижу все еще...
так они и так никого не заменят кроме формошлепов пока что, и тех только сократит до необходимого минимума
>чтобы додики тратили время на курсы скиллбокс
так таких дебилычей только могила исправит - те курсы буквально никогда работу найти не помогали, зато хорошо рыночек демпингуют
тут вопрос не в приросте, а в том, что под виндой пакеты которые требуют сборки вызывают анальную боль, потому что дибильный MSVC нужон
У меня была пара карточек, которые 32б модели не тянули, обязательно упуская часть описания. Эйр с квеном смогли, правильно разруливая внутренние противоречия.
Лламе никакие пакеты не нужны, все зависимости при ней. Это как раз линушным красноглазикам пердолится придётся
бля, вышла 4ая джемма, все уже юзают во всю а вы молчите, пиздос
если у тебя голой ламой жизнь ограничена тогда вопросов 0
А гугл об этом знает?
Ну ты и бака. Если бы гугл знал, то они бы сами её выпустили.
Л - логика.

Мне так страшно
Гемма ведь реально скоро выйдет, а вдруг будет очень плохо
Я ждал 8 месяцев
Гемма ведь реально скоро выйдет, а вдруг будет очень плохо
Я ждал 8 месяцев
Анончики, я понимаю, что это несерьёзно, но что можно поставить на старенький смартфон в качестве локальной модели?
Смартфон redmi note 10 pro, 6 гб оперативной памяти, процессор snapdragon 732G, 2.3 ГГЦ.
Необходимость обусловлена тем, что на работе не работает мобильный интернет, да и проводной тоже постоянно обрубается - и я, по сути, целыми днями сижу просто без всего.
К сожалению, я вообще отстал от жизни, и не могу выбрать, каким приложением лучше пользоваться. Поставил пока что PocketPal - хороший вариант? Также поставил edge gallery, но там не сохраняются чаты.
Смартфон redmi note 10 pro, 6 гб оперативной памяти, процессор snapdragon 732G, 2.3 ГГЦ.
Необходимость обусловлена тем, что на работе не работает мобильный интернет, да и проводной тоже постоянно обрубается - и я, по сути, целыми днями сижу просто без всего.
К сожалению, я вообще отстал от жизни, и не могу выбрать, каким приложением лучше пользоваться. Поставил пока что PocketPal - хороший вариант? Также поставил edge gallery, но там не сохраняются чаты.
Гемма в размере под кофеварки
Друг, можно ссылочку на конкретную?
>что можно поставить
gemma-3-4b-it-Q4_0.gguf - именно этот квант, он под мобильными процами быстрее всего работает
>каким приложением лучше пользоваться
ChatterUi
>при таком раскладе выгоднее облако в аренду взять и не париться, не факт даже что наиспользуешь на стоимость карточки, если не занимаешься многочасовым ежедневным кумом...
Это сразу было понятно и я бы так и сделал, если бы вопрос с оплатой забугорных сервисов по аренде видеокарт был легко решаемым. Там вкусные цены, ну а в целом по деньгам может так на так и вышло бы, только железо было бы всегда актуальным. Но увы, санкции-шманкции и прочий геморрой и пришлось строить домашний риг.
Это всё, что нужно сегодня
>Квен могут не только лишь все запустить и хз насколько он жизнеспособен в q2
>мб скил ишью неосиляторство
Оно самое. Ахуенно он работает в q2 и выдаёт смак
В шапке "для бомжей" смотри.
Единственное что, можешь квант поменьше выбрать.
Не ссы. Выйдет новый топ.
как же хочется геммочку 4, мое 60 с 12 активными, умненькую, худенькую
> мое 60 с 12 активными
Денс 60. Мое не нужно
>Денс
Держи нахуй https://huggingface.co/PocketDoc/Dans-PersonalityEngine-V1.3.0-12b
>Мое не нужно
Свидетель плотных моделей, если ты не заметил они всё
>мое 60 с 12 активными
Мое 100+ с 12 активными и будет писечка.
>Денс 60
Жирные денс модели остались в прошлом. Рыночек порешал.
Вы чего возбудилась то так от пары слов?
>Мое 100+
Не только лишь каждый сможет запустить. Лучшая девочка треда должны быть доступна всем.
Да и заебал пердолинг с 100+ моделями, война за т/с, оптимизация вечная и т.д.
>Не только лишь каждый сможет запустить.
Мое как раз более доступны бомжам вроде нас. Уж 64 гига рама наскребёт каждый. А вот запустить плотную даже 32б не каждый может не говоря уже о больших
> Да и заебал пердолинг с 100+ моделями, война за т/с, оптимизация вечная и т.д.
Я периодически в тред заглядываю и вопросов меньше не становится. Один раз батник настроил, попердолился с жорой и горя не знаешь. Сиди себе, помогай тому же воздушному префилом, да слюни вытирай, если шизит.
Что за проблемы то с мое?
Так я и не про плотные.
Мое 100+ пердолинг вечный
Мое 60 лёгкая, умная, пойдет у большинства.

>Не только лишь каждый сможет запустить
6700х2 = 13400 рублей за 64гб. Такую сумму даже школьник с завтраков наскребет. А где-нибудь на алике скорее всего будет еще дешевле.
>война за т/с
Ты вообще запускал большие мое? У меня эйр летает в 9.5тс, в то время как денс гемма попердывает на 3.5 тс. Как раз на нищесборках именно в денс моделях боль и страдание, а не наоборот.
> У меня эйр летает в 9.5тс, в то время как денс гемма попердывает на 3.5 тс.
А у меня гемма 20, а квен 235 пердит 6т/с? Чё делать будем?
6 по прежнему норм, квен почти в 10 раз больше. Очевидно что делать, катать квен. Тем более что он не соевый ассистент
Ну тут совершенно разные весовые категории. Для такой жирноты как квен, 6 т/с - нормальная скорость.
Потому что скоростя малые все равно выходят.
Периодически отъебывает и падает до каких-то 3.5-4. Нужно опять пердолиться.
Ну и на контекст остаётся хуй да маленько.
Да, наверное можно настроить что бы все четко было. Но я тупой, мне и то что есть сложно даётся через горящую жопу.
Да хули ты доебался с этим денс? Я и сам за мое топлю, ток нужны и адекватного размера моешки.

Уже представляю как тут в треде аннигилируются жопы, если четвертая гемма будет 27Ba2B какой-нибудь
Не-бу-дет! Твердо и четко!
Подскажите, какие сейчас есть годные модели для:
- lewd ролеплея (да без цензурки ну или с минимальной, но при условии хорошего качества самой модели).
- Анализа файлов по картинкам/текстовым и допустим составления выводов/отчёта.
- Переводов текста.
>lewd ролеплея (да без цензурки ну или с минимальной, но при условии хорошего качества самой модели).
Держи https://huggingface.co/deepseek-ai/DeepSeek-V3.1
>так они и так никого не заменят кроме формошлепов
То то я уже третий месяц ищу работу, пока безуспешно.
Мимо сеньор помидор с 6 годами опыта на PHP.
>WSL 2 – это отличная среда для запуска ML-моделей. Если вы настроите GPU-поддержку, то потеря производительности будет минимальной.
Это правда? Хочется свои проектики разворачивать, но на винде питон мне никогда не нравился.
Это правда? Хочется свои проектики разворачивать, но на винде питон мне никогда не нравился.
>А вот запустить плотную даже 32б не каждый может
>Уж 64 гига рама
А разница? Я и 123B катал на тех же 64 гигах и 12 врама.
Нет, это пиздёж. А в чём проблема в виндовом петоне? Ставится из магазина если что.
>Я и 123B катал на тех же 64 гигах и 12 врама.
Тут не все шизоиды которые готовы по 10 минут ждать ответ со скоростью 1-1.5т/с (в лучшем случае)
>Я и 123B катал на тех же 64 гигах и 12 врама
А т/с сколько?
1-2т/с это вообще без гпу если
>А в чём проблема в виндовом петоне? Ставится из магазина если что.
Что за хуйню ты несёшь, блять? Какого магазина? Ты Питон через Microsoft Store установил?
Да нахуй иди, шизик. Ты даже волшебные семплеры для командера не скинул не говоря уже о том как запускаешь и какие скорости получаешь. Ты обычный пиздабол
Да. Ничем от линукса по производительности не отличается и не надо ебаться с пакетами в отличии от Винды.
Ебоба? Вы тут не вдвоём сидите
>lewd ролеплея без цензуры
Мистраль 3.2
>Остальное
Гемма 3 27b в первую очередь, во вторую тот же мистраль
Ну и офк, если ты запустить квен 235 или дипсик 3.2, то он будет лучше
Открываешь и смотришь. Редфлаги: нейрослоп на 2+к токенов, качели (она умная но часто тупит, покладистая но может всему сопротивляться и т.п.), внутренние противоречия сеттинга, чрезмерная фокусировка на чем-то (половина карточки лисогорничной про то, как ее хозяин любит вылизывать ее анус), приперзднутый и отвратительный стиль описания (см нейрослоп или что-то подобное, будет влиять на выдачу), разжевывание простых и очевидных вещей с мимолетным упоминанием необычных и важных.
Оправданец не ленивый, он в очередной раз оправдается почему обладает отсутствием и будет дальше ныть.
Контролеры в процах на десктопе под конкретный соккет унифицированы, как раз в первую очередь зависит от материнки для высокоскоростных плашек, медленные заведутся везде. И зачем количество приплетаешь?
>Нет, это пиздёж
>Да. Ничем от линукса по производительности не отличается
Ну и кто из вас пиздит, мм?
>Мистраль 3.2
чистый мистраль искаропки поддерживает кум?
Тут чуть выше выкладывали. Можешь попробовать. Семплеры базовые, настройки мистралевские, какой ни будь tekken.
И вообще тут в треде бегает мистралешиз, тот точно знает за шизотюны, только он куда то пропал, удивительно даже.
Содомит
Заказать карту в ~стане дешевле чем риг так-то. Но риг уважаемее!
Да, главный минус - оче медленный доступ к фс хоста.
Для левд ролплея хороши эйр и большой жлм, квен также прилично кумит.
>бегает мистралешиз, тот точно знает за шизотюны
Мистралешиз на месте. Вот хороший шизотюн с сочным кумом и несломанным русиком:
https://huggingface.co/CrucibleLab/M3.2-24B-Loki-V1.3
И кванты от Батрухи:
https://huggingface.co/bartowski/CrucibleLab_M3.2-24B-Loki-V1.3-GGUF
0,7 же.
>Ты Питон через Microsoft Store установил?
А почему бы и нет? Сейчас посмотрел, мой петухон стоит как-то иначе, но в сторе он есть и доступен по нажатию 1 кнопки, с выбором нужной версии.
>И зачем количество приплетаешь?
DDR5 не работает с 4 плашками.
> DDR5 не работает с 4 плашками.
А еще ддр5 не заработает на платформе под ддр4, понял! То то же!
Обсуждается работа пары небыстрых ддр5 плашек повышенного объема, которые пол года назад вышли на рынок, нахер ты что-то левое тащишь вообще?
>магазин windows
>0.7т/с
не лечится.
>DDR5 не работает с 4 плашками
Лолшто? А зачем тогда делают платы с 4 дырками под озу если оно не работает?

Для красоты же!
О, призыв осуществлен. Пасеба.
Дай ка я скачаю опять мистраетюн, а то с воздушным вообще желания возвращаться к мистралям нет, а то мситральки уже настолько приелись, что прям вооротит. Они то умницы.. Но датасет все таки маленький.
Работают но медленно, чтобы быстро нужен пердолинг.
А где линии?

Для гпу берут такое. Гига выше под компьют
Анонасы, есть ли смысл покупать коробки с AI MAX 395+ DGX Spark если лень пердолиться с ригом, или говно без задач за оверпрайс?
Мимо хочу вкатиться в локалки
Мимо хочу вкатиться в локалки
Ты в начале найди спарк, а потом спрашивай
Так завтра же в продажу поступает, это разве не аналог 395+, чтобы уже можно было сделать выводы нужен/ненужен?
Под компьют врм дохленький и процы друг за другом продольно.
Второе красивое.
На амд придется пердолиться с софтом 100%. По удобству и скоростям - возьми, расскажешь.
> Под компьют врм дохленький и процы друг за другом продольно
А как они должны быть в рэке? Мне кажется или ты думаешь что это косьюмерские мамки?
>Обсуждается работа пары небыстрых ддр5 плашек
Выделенное ты только сейчас приплёл.
По привычке.
Сервера немного другое, там каналов больше, и память всякая регистровая.
> как они должны быть в рэке?
Поток воздуха всегда идет вдоль стиков оперативы, але.
Обосрался@пошел фантазировать.
Да, стоит. GLM AIR и GPT 120b будут летать, да и квен 235 тоже будет нормально работать.
Но бери это
Будет ощутимо быстрее работать, чем просто на раме. Тестов на редите много
> Поток воздуха всегда идет вдоль стиков оперативы
И? Блядь, в чём доёб то? Что серверные дельты не сдуют по 400 ватт?
>ping: connect: Network is unreachable
Что впизду ваши wsl.
Что впизду ваши wsl.

То есть с такой херовины где каждый гпу кипятит под 700 ватт сдувается, а с двух нищих эпиков по 400 не сдуется
Какие значения будут если не выставлять -t? Кому нибудь ещё удавалось так выжать скорость, определяя это значение вручную?
Экспериментировал на двухголовой зиономатери. Выгоднее всего оказалось пиннить по 9 реальных ядер (0,2,4,...) с каждого проца
Ы
Благодарствую!
Поэтому я взял 6000 сразу.
Но зачем в итоге с моим-то процом. хд
1. Как хочешь, у меня выделенные, можно на универсальном.
2. На больших моделях линукс, на средних и маленьких пофиг.
3. Да вроде норм.
4. Смотри куда хошь, но на зеленых все заводится из коробки и с наибольшими скоростями (за дорого=). С красными и синими могут быть нюансы и медленнее.
5. Для ддр4 пофиг, для ддр5 хорошая рязань лучше среднего интела, средний интел плох, топовый интел хорош.
6. Возьми 5090 хотя бы ради генерации видео в будущем. Собирать несколько видях — тебе надо ну хотя бы 96, а лучше 128+ видеопамяти. Но если есть деньги, собери 3090 пачку или 4090 (те же 48-гиговые). А лучше пару RTX Pro 6000
7. Проблемы решаемые, так что не то, чтобы стоит из-за этого беспокоиться. Скорее нет, чем да.
8. Ни на какой. От 25к до пары миллионов. У каждого свое понимание «средне-добротного».
Ну если 128 ддр5, i9-14900 и 5090… допустим, средне-добротный, я полагаю.
9. Кто как. Кто-то в ДНСе, кто-то на авито, кто-то в Китае.
печенье лом
Спасибо.
>Мистраль 3.2
Тоже спасибо.
gemma3:27b есть, но мне показалось что он слабовато понимает на первом тесте. Посмотрю тогда побольше на нём.
Квен есть, но квантованная - qwen3:235b-UD-q3_K_XL и она соврала что на изображении придумав бред, а как её поправил созналась в этом. Может конечно проблема именно в квантовости, хм.
>эйр и большой жлм, квен также
Тоже спасибо
>Заказать карту в ~стане дешевле чем риг так-то. Но риг уважаемее!
Дешевле, но совершенно не греет мысль сливать кучу своих данных неведомым посредникам. То, что заблочить карту могут в любой момент - это уже мелочи.
> qwen3:235b-UD-q3_K_XL и она соврала что на изображении
Што? Как ты в неё вообще картинку запихнул?
Квен или Гемма?
Так словами описал.

Дурак? Я спросил у Квена что на одной из картин Айвазовского и он ошибся.
Гемма 27б. Не аблитерейтед, естественно, потому что лоботомированная версия совсем какая-то однобокая и тупая.
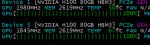
Тяжело. Тяжело.
Габариты и сложность радиаторов несопоставимы, задние детектятся по температурам на ~10-20 градусов выше, пикрел. Потому в сборках "под компьют" с наиболее мощными процами стараются обеспечить независимые потоки для каждого профессора.
> неведомым посредникам
Оформление идет на загранник, который мало кому интересен. Можно лично слетать, это недорого и интересно.
>Оформление идет на загранник, который мало кому интересен. Можно лично слетать, это недорого и интересно.
Вы конечно будете смеяться, но кредит на него можно взять совершенно свободно. Не везде конечно, а только там, где проценты конские. Сейчас правда самозапреты появились, но всё-таки.
Не то чтобы я жалуюсь, да и слетать и правда самому можно. Кто только сейчас начинает - вполне вариант.
Ну чё, я тут последние деньки гоняю Квеноняшу и Эирчан и пытаюсь понять кто из них умница а кто бака.
Короч, обе хороши наверн но Квеноняша тупо вне конкуренции. Отыгрывал сегодня чилл сценарий с карточкой игривой девушки-соседки с хаты напротив, класека. Эирчан неплохо справилась, персонаж подхвачен как надо но пассивно как-то. Вот заказал пиццу, она приехала, ну хорошо, ну пошутили пару раз, ну поели и давай смотреть телик. Не покидает ощущение что ты играешь с прокаченной мелочью типа 22-32б в хорошем кванте и с прокаченным словарником. То есть читать приятно вроде но это все равно танец с манекеном. Квен... Квен это пиздец. Чар подбежала встретив на пороге двери, выхватила коробку из рук, убежала, сожрала половину пока я переодевался, начала бегать по квартире как поехавшая не желая делиться пиццей, был придуман и вплетён невъебенный флешбек соответствующий чару, напоследок моё ебало было измазано соусом в процессе каддлинга. Ох бля как же хорошо на душе. Квеноняша идеально занейлила чара, с пресетом что тут гуляет пишет ахуенно просто. У меня раньше было целое полотно в authors note которое запрещало писать в стиле поехавшей китайской прозы, но оно модель лоботомизировало. Сейчас мне как будто бля ничего в жизни больше не нужно. Только Квеноняша. Большая веселая 235б которая.
Короч, обе хороши наверн но Квеноняша тупо вне конкуренции. Отыгрывал сегодня чилл сценарий с карточкой игривой девушки-соседки с хаты напротив, класека. Эирчан неплохо справилась, персонаж подхвачен как надо но пассивно как-то. Вот заказал пиццу, она приехала, ну хорошо, ну пошутили пару раз, ну поели и давай смотреть телик. Не покидает ощущение что ты играешь с прокаченной мелочью типа 22-32б в хорошем кванте и с прокаченным словарником. То есть читать приятно вроде но это все равно танец с манекеном. Квен... Квен это пиздец. Чар подбежала встретив на пороге двери, выхватила коробку из рук, убежала, сожрала половину пока я переодевался, начала бегать по квартире как поехавшая не желая делиться пиццей, был придуман и вплетён невъебенный флешбек соответствующий чару, напоследок моё ебало было измазано соусом в процессе каддлинга. Ох бля как же хорошо на душе. Квеноняша идеально занейлила чара, с пресетом что тут гуляет пишет ахуенно просто. У меня раньше было целое полотно в authors note которое запрещало писать в стиле поехавшей китайской прозы, но оно модель лоботомизировало. Сейчас мне как будто бля ничего в жизни больше не нужно. Только Квеноняша. Большая веселая 235б которая.

Простите, я корпоблядок сидящий в треде в надежде на что то прикольное, но БЛЯТЬ АХАХАХАХА , как только начала генерить и я увидел "довольно урчит" я сразу вам принёс)))
справедливости ради, я не дохуя корпоблядок и до недавнего времени гонял локально 32б квена в 6 кванте, но заебался, простите
>корпоблядок
>стандартный веб апи с кучей фильтров, тюрьму в абсолюте
Нет, ты не корпоблядок. Ты поехавший, которого боятся даже чеченцы.
Че с Жорой ? У них там блять столько пуллов висит, а они говно какое-то мёржат, рефакторят. Вон имплементация целого семейства висит на аппруве уже две недели : https://github.com/ggml-org/llama.cpp/pull/16063
Или вон халявный перфоманс гейн : https://github.com/ggml-org/llama.cpp/pull/16548
Давайте строить ахуительные теории. Неужели они готовят СеКрЕтНыЙ БрАнЧ с ГЕММОЙ 4 ?! Или в хер дуют потому что у них отпуск или заболел кто-нибудь ?
Или вон халявный перфоманс гейн : https://github.com/ggml-org/llama.cpp/pull/16548
Давайте строить ахуительные теории. Неужели они готовят СеКрЕтНыЙ БрАнЧ с ГЕММОЙ 4 ?! Или в хер дуют потому что у них отпуск или заболел кто-нибудь ?
Твой квеноняша не может осилить обычное инцест ерп скатывая всё в дешёвый роман, с придыханиями, гипертрофированным драматизмом, троеточиями после каждого предложения, это блять просто невозможно читать, будто с покемоном говоришь, и так во всём
Моя Квеноняша? Урююю, спасибо!!!
Хуй его знает чё у тебя там творится, может ты говна корпами нагенерил вместо нормальных карточек и промтов а потом удивляешься что такой же слоп у тебя в чате живёт. У меня заебись всё. q3 квант. Никаких покемонов, весьма ахуенные диалоги с шутками подколами и вторым дном, которые доступны только Эирчан. Но Эирчан пассивненькая, мне такие не нравятся.
Даже с одним пресетом буквально аноны ещё находят способы найти косяки у других
Каждому своё. Щас выйдет эир 4.6 и это моя остановочка до эир 5.0
Вот суки (сколько?) не хотят за спасибо работать!
За них уже поработали. Тут надо посмотреть провести кодревью и замержить.

Сам занимался ревью? зачастую проще сделать самому чем пояснять почему же в мр'е насрано
>Квен есть, но квантованная - qwen3:235b-UD-q3_K_XL и она соврала что на изображении придумав бред, а как её поправил созналась в этом. Может конечно проблема именно в квантовости, хм.
"Проблема" в том, что эта модель вообще зрения не имеет. Ей нечем смотреть на картинки.
Там после уже выпускали мультимодальную, со зрением, вроде как. Но простой квен 235B ни первый, ни 2507 зрения не имеют. Разумеется, он тебе что угодно на такой вопрос напишет. :)
Всякие кемономими делали довольное purrs еще со времен пигмы.
В первый раз? Это нормальное состояние, тут скорее наоборот удивительно что кто-то занялся добавлнием поддержки бранча, а не все хуй забили.
Справдливости ради есть 235й квен со зрением, но не припомню чтобы его в жору успели добавить.
Ор выше гор
ты про VL который полторы недели назад релизнули?
Ага.
Кстати, они только что выкинули не только 30а3 и 235, но и плотные модели поменьше.
https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe

Для vl кста есть инструкция под вллм, но чёт влом хотя он точно влезет и даже гигов 20-30 на контекст будет

Еще v2 или даже более ранние это умели, с подключением. Препроцессор делит их на фреймы и кодирует, ничего нового.
Ну извините, только недавно в vllm вкатился через 3 стадии пердолинга на амудэ
Та же хуйня, анон. Разные сценарии для разных задач, мне эир нравится тоже по своему, но в последнее время пздц кайфую с квена
В треде действует квенолахта
Пока не скинуты логи - игнорируем.
Пока не скинуты логи - игнорируем.
12b модель с чаба? Что она должна вытаскивать, кишки 10 минут?
Опа. Если уж корпы перестают цензурить кум, значит скоро ждем годноты и от локалочек.
> скоро ждем годноты и от локалочек.
Так давно уже нет цензуры на локалочках. Большинство могут в сочный кум.
Ух, поскорее бы эротику со взрослыми мне на локалочки! а то с детьми уже заебало
Я имею в виду, что возможно будут включать больше кум-материала в датасеты при обучении, ну и подкрутят поведение моделей, чтобы было меньше морализаторства. Последним особенно гемма страдает.
Ну и да, какая ВАНИЛЬНАЯ модель может прям в сочный кум кроме мистраля? Без васянских тюнов и шизопресетов от нюни?
>цензурить кум
>эротика
Там будет говно уровня бабы на гроке, так что мимо.
>а то с детьми уже заебало
Вот кого ты обманываешь?
>? Без васянских тюнов
Я недавно попробовал MedGemma27b, мне зашло. Но это шизотюн, да. https://huggingface.co/unsloth/medgemma-27b-text-it-GGUF
> какая ВАНИЛЬНАЯ модель может прям в сочный кум кроме мистраля?
Так любая. Мистрали, Глэмы, Квены, Командеры, а больше и нечего катать тащем-то. Все они умницы и кумят из коробки сочно. Лучше назови ВАНИЛЬНУЮ модель которая прям не может в сочный кум. Кроме Лламы
> шизопресетов от нюни?
Где их найти? Там мемпромты?
https://youtu.be/UyQm4O9G7OM
>youtu.
брат умер от эпилепсии с хуем во рту от этой хуйни, не смотрите
Так ты покажи сестре, ей понравится
И сам посмотри
не отвечает мёртв
>Лучше назови ВАНИЛЬНУЮ модель которая прям не может в сочный кум.
гпт осс.
Скорее вялый ответ на всратость пятерки и кучу ложных рефьюзов. Казна пустеет, базированный грок отъедает аудиторию, вот и затрясся.
Та ну, еще слишком многие требуют коррекции💢💢.
Ты ошибаешься анончик, она впринципе не может в рп. Нахуя ты её вспомнил вообще? Давай туда же модели классификаторы и всякое вроде https://huggingface.co/Qwen/Qwen3Guard-Gen-4B хуле

ПЕРЕКАТ Пикчи с железом анонов кончились
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Можете написать свою конфигурацию пк? хочу собрать пк, чтобы кайфовать также



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: