



Катаю Эйр на Жоре (в Угабуге) в IQ4_XS, в три 3090 влазит с 32к неквантованного кэша. 27т/с, если с квеном не путаю. Но 3090-е у меня придушены до 270 ватт, так что результат не максимальный. Однако на экслламе поменьше выходит, и пп и генерация. Ну может на полной мощи, с тензор-параллелизмом (если бы было 4 карты) и было бы больше, но честно говоря мне хватает.
Я тоже свои придушиваю в разгар кума

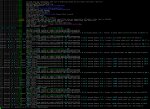


Ух бля.
Пик-1, Правильная реализация моэ. Действительно работает быстро в начале (накрутив можно и до 50 догнать на пустом), но сдувается как только появляется контекст. Если небольшая часть тензоров на процессоре - всему пиздец (жлм пик-3).
Что забавно, когда основной пулл весов в рам - просадки не такие большие, и обычно не превышает 30-40%. Буквально за счет меньшей доли весов на куде, на большом контексте дипсик работает быстрее жлма в пару раз, выдавая под десяток токенов на тех же 90к. Жлм также можно ускорить буквально выгружая меньше, пожертвовав небольшой частью скорости в начале, абсурд.
Проблема ggml бэкенда с кудой которой уже много лет - правильная реализация, не путаем.
Пик-2, Неправильная реализация моэ, силки смуз на всем контексте. При генерации в один поток отставание в начале переходит в опережение при наличии контекста. С мультисвайпом - в квене догоняется за 60т/с по сумме (4х 15т/с). На глме (пик4) скорости также сасные, так еще и более лоботомированный квант перформит лучше 5.5бпц, но это камень в анслотов.
56т/с в мультисвайпе и 30+ в одиночном на 90к - неправильная реализация, должно проседать как жоре!
Можно еще про квеннекст вспомнить. Тут он со смешных 15т/с в раннем релизе апнулся до вполне приличных 80т/с на контексте. Тензорпарралелизм пока не поддерживается и обработка все еще пососная, но всяко лучше чем 3т/с.
> Нет никакого смысла сидеть на нём, когда даже частичный оффлоад на ЦП у Жоры быстрее exl3
5 токенов в секунду при небольшом частичном оффлоаде - быстрее чем 24т/с в один поток и 55 (4х 13.9) при мультисвайпе! Они просто правильнее и поэтому быстрее!
Лучше бы еще раз покумил чем на эту херь время тратить
> если бы было 4 карты
Оно работает с любым количеством.
Разработчик из Valve оптимизировал драйвер RADV для работы с Llama.cpp
> В кодовую базу, на основе которой формируется выпуск Mesa 25.3, приняты изменения, существенно увеличивающие скорость работы движка выполнения больших языковых моделей Llama.cpp при использовании Vulkan-бэкенда на системах с GPU AMD и Mesa-драйвером RADV. Оптимизированный драйвер RADV в некоторых тестах llama-bench стал быстрее драйвера AMDVLK и стека ROCm на 31% при обработке запросов (тесты "pp" - prompt processing) и на 4% при генерации токенов (тесты "tg" - token generation). Оптимизацию выполнил Рис Перри (Rhys Perry) из компании Valve, участвующий в разработке драйвера Vulkan RADV и компилятора шейдеров ACO.
https://www.opennet.ru/opennews/art.shtml?num=64086
какова база треда?

Потрогать траву, вложиться в карьеру, зайти в тред через 2 года
https://huggingface.co/MiniMaxAI/MiniMax-M2
Но есть нюанс:
https://t.me/krists/2386
> На моём бенчмарке для измерения качества русского языка занимает уверенное последнее место.
Хотя для агентов может быть отличная, посмотрим.
Но есть нюанс:
https://t.me/krists/2386
> На моём бенчмарке для измерения качества русского языка занимает уверенное последнее место.
Хотя для агентов может быть отличная, посмотрим.
Про миниатюрного максима вроде писали, что у него с creative writing прям не очень.

Есть что-то лучше квена на сегодняшний день? Чтоб из коробки без джейлбрейков и по-русски понимал специфику и мог в чернуху и троллинг с дефолтными настройками?
А это какой квен?
А есть какой-то нормальный способ скачивать чаров с janitorai? Вчера хорошо порпшил с Ягодой, которую отыгрывал облачный glm-4.6 через личную прокси, но хотелось бы продолжить на локальной версии. Я уже выгрузил json всего чата, но, видимо оформлять карточку придётся вручную.
Либо через прокси в таверну, либо через замену в ссылке уборщика на джанниаи (буквально, в адресной строке заменяешь на https://jannyai.com/, оставляя остальную часть ссылки без изменений) либо через сакера. Последний еще и отваливается периодически, так что как повезет.


РКН пару дней назад решил снова приложить несколько крупных CDN, включая Cloudflare и AWS CloudFront.
- Huggingface проксирует крупные файлы через AWS CloudFront, так что скачивание моделей через веб-морду или CLI теперь закономерно не работает.
- Вики треда ( https://2ch-ai.gitgud.site/wiki/llama/ ) проксируется через Cloudflare, так что она теперь тоже не работает.
Так что упавшая обниморда - это просто сопутствующий ущерб в борьбе РКН с CDN.
- Huggingface проксирует крупные файлы через AWS CloudFront, так что скачивание моделей через веб-морду или CLI теперь закономерно не работает.
- Вики треда ( https://2ch-ai.gitgud.site/wiki/llama/ ) проксируется через Cloudflare, так что она теперь тоже не работает.
Так что упавшая обниморда - это просто сопутствующий ущерб в борьбе РКН с CDN.
Че они добиваются-то, шизуки? Какая у них вообше претензия к этим ресурсам, что нужно все на свете класть для юзеров и форсить впны, с которыми они типа борются?
Как у тебя 3090 подключены? Узкие места в pci.e? У меня тоже три карты, ограничение 250 ватт каждая, итог 30 токенов два запроса одновременно при заполненности контекста 20к. Табби exl3
На аимаксах апает скорость, или вулкан все еще быстрее?
Квантов бы завезли. По бенчам оче высокий скор и за счет малого количества активируемых будет шустро летать, в промежуток между квеннекс/жпт/эйр и квен235 попадет.
Размер хотябы обозначь, но в целом мистраль смолл, гемма, коммандер. Они часто лучше 30а3, глупее больших.
Запутан лабиринт, зашел за дебит кредит,
Мой минотавр не спит - о новой яхте бредит.
Нормальные люди туда работать не идут. А у безпринципных идиотов по объявлению мозгов не хватает. И вообще - рыба с головы гниет. Или ты еще думаешь, что они ради простых людей что-то делают? :)
Чебурнет хотят, из министерства правды пришел указ. Вот и прощупывают почву, блочат больших игроков
На чем квен3 омни запускать для аудио инпута?
>А у безпринципных идиотов по объявлению мозгов не хватает.
Хватает у них мозгов. Из ВПН только влесс работает, но с Обниморды я и через него скачать не могу. Вот надеюсь только, что наняли они китайцев или нацменов по старой памяти - потому что если это свой же брат гадит, то дело наше совсем швах.
>с Обниморды я и через него скачать не могу
Бля ну вроде должны тут сидеть не совсем колобки, ну как так?
Ты не можешь две сетки занести в гудбайдипиай? Впны работают самые разные, которые через socks работают и аналогичные протоколы
> потому что если это свой же брат гадит
> если
Лол.
>https://huggingface.co/MiniMaxAI/MiniMax-M2
>elite performance in coding and agentic tasks, all while maintaining powerful general intelligence
>Its composite score ranks #1 among open-source models globally.
:^)

тоже хрюкнул.
за сто лет отрицательной селекции с революции 17го года на всей территории снг человек человеку волк, а не брат
Трансформерс по шаблону с их репы. Чтобы уместить в память можно грузить в nf4 кванте который сделается прямо на лету битснбайтсом.
Ни один из популярных бэков аудио не поддерживает, кто-то хотел форк жоры пилить но воз и ныне там, ишьюс тоже висит.
Ночью тряска была, сейчас то что отваливалось работает. Xet и Hftransfer по отдельным протоколам, которые без проблем даже на тряске год назад качали.
А по моральному аспекту тех кто там работает - спроси среди друзей и знакомых, набей морду если вычислишь и придай всеобщему порицанию. Если палачей в средневековье можно было оправдать тем что "кто-то должен этим заниматься" то тут нет оправданий. Потому собственно туда мало кто и идет из толковых.
> На моём бенчмарке
Какой-то манябенч протыка? Я погонял ассистента, русский лучше К2/GLM 4.6, но хуже дипсика.
>триллионы новинок на сотни миллиардов параметров
>чуть-чуть умнее геммы хуй знает какой давности
>гугл еще и претрейн дает скачать
Вот эти мое и раздувание требований к объему памяти в десятки раз, это точно будущее?
>чуть-чуть умнее геммы хуй знает какой давности
>гугл еще и претрейн дает скачать
Вот эти мое и раздувание требований к объему памяти в десятки раз, это точно будущее?
Видеокарты сами себя не продадут. Миллиарды у государства и инвесторов сами себя не выклянчат.
Как удобно, что можно умолчать о Эире и Квене, которые реально хороши.
Ну естественно. Обыденное объяснение что у гугла больше ресурсов и компетенций чем у ноунеймов не годится. Это скучно.
> умолчать о Эире и Квене, которые реально хороши
Эйр и большой Квен не нужны, когда есть Дипсик, особенно если на русском сидишь. У Квена разве что мелкие модели хороши.
А ты не очень умный, да? Дипсик - 671б модель, Квен - 235б, Эир - 110б. Или ты из членососательного, кхм, то есть корпотреда выполз?
>хурдур вот моя 235б чуть чуть умнее 27б, всего-то в 9 раз толще
>кукарику 671б вс 235 ничесна
Вот это я понимаю - сравнительная аналитика.
Асигодитя, вернись туда откуда вылез. Эир и Квен на порядки умнее и способнее Геммы, как минимум на англюсике и в коде. Ну а про русик - тебя, валенка, спросить забыли.
Можно уточнить, в чем это проявляется, а то я в эйре интеллекта особенного не заприметил. Даже в уги он по интеллекту ниже.
235В вообще странная модель, размер средний и у больших сосёт, при этом скорость говно. А квен-кодер размером почти как дипсик, в коде они примерно одинаковые. Эйр в принципе кал, только полноценный GLM стоит рассматривать, но он проигрывает дипсику во всём.
> на англюсике и в коде
То что Эйр чем-то лучше Геммы в РП я очень сомневаюсь, в русском уж точно. А в коде Эйр не имеет смысла, когда есть модели для кода намного лучше и даже меньше по размеру.
Зачем вообще эир и квен, ведь гемма и мистраль лучше? Ну а вообще локалки не нужны, разве что просто поржать запустить, а для всего остального юзатб закрытых корпов. Да и все корпы не нужны, ведь клодик тупа лучше гпткала, геймини и прочего говна. Да и сойнет не нужен, лучше попуск, причём не 4.1 лоботомит, а старый добрый опус 3, который имеет душу и пишет как боженька.
> 235В вообще странная модель, размер средний и у больших сосёт
Квен 235б можно запустить на консумерском железе, в приличном кванте и с вменяемой для креативных задач скоростью. Уже это его выгодно выделяет на фоне бОльших моделей, которые запустить удастся уже только на риге.
> Эйр в принципе кал
Отличная модель, которой нет альтернатив в схожей размерной категории.
> только полноценный GLM стоит рассматривать, но он проигрывает дипсику во всём.
Присоединяюсь к анону выше и предполагаю, что ничего из этого ты на своем железе запустить не можешь. Тебе в другой тред.
> Тебе в другой тред.
Ты что-то перепутал. Это тред локальных LLM, а не тред того что ты можешь запустить. С таким же успехом можно локальность определять рамками одной карты, а зондошизикам отказываться запускать модели на Винде и с webui, лол.
> Это тред локальных LLM, а не тред того что ты можешь запустить.
"В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!"
Первое предложение из шапки. Ты рассуждаешь категориями, которые не применимы к данному треду, поскольку пренебрегаешь такой критически важной штукой как размер модели и возможность ее запустить. Тебе в другой тред, все верно.
> пренебрегаешь такой критически важной штукой как размер модели и возможность ее запустить
И как ты границы этого установил? По уровню своей нищеты? Дипсик можно локально запустить? Можно, в треде запускают. На этом проследуй нахуй.
> И как ты границы этого установил?
Никак не устанавливал. Ты сам выше подтвердил, что не можешь запустить обсуждаемые тобой модели. Ты как ребенок, который смотрит на картинки каталога с автомобилями и приходит к выводу "Мерседес АМГ лучше Форда Фокус, значит Форд Фокус говно. Только АМГ имеет смысл рассматривать, но он проигрывает профессиональному спорткару во всём". И ведешь себя соответствующе со своими
> На этом проследуй нахуй.
Когда с тобой смеют не согласиться. Зачем пришел сюда, какую цель преследуешь?
> Ты сам выше подтвердил
Откуда ты такие выводы сделал? Я пользуюсь Дипсиком, поэтому Эйр калом считаю.
Я рпшу в гемме вместо эйра, хотя эйр генерит быстрее.
Мое это просто наебалово. Я просто не могу жрать слоп эйра, игнорящий вопиющие и основные детали сеттинга (не забывающий, оно их помнит, просто не вдупляет суть). Гемма не генерит словослоп так же охотно, но это потому, что она заточена смотреть на юзверя и делать, что просят. Словослоп там тоже появится, если ты сам будешь словослопить.
Мое это просто наебалово. Я просто не могу жрать слоп эйра, игнорящий вопиющие и основные детали сеттинга (не забывающий, оно их помнит, просто не вдупляет суть). Гемма не генерит словослоп так же охотно, но это потому, что она заточена смотреть на юзверя и делать, что просят. Словослоп там тоже появится, если ты сам будешь словослопить.
> Откуда ты такие выводы сделал?
Тот, кто на своем железе Дипсик может запустить, обычно умнее. Тред про запуск на своем железе.
> Я пользуюсь Дипсиком, поэтому Эйр калом считаю.
Понял. На дискуссию не способен, все что можешь выдавить - "могу и запускаю 671б модель, которая лучше 110б модели, значит последняя говно.", и это самоцель. Такие как ты надолго тут не задерживаются, так что обойдешься без третьего мягкого пинка под попу.
> Тред про запуск на своем железе.
Так а что ты тут забыл без железа? И вообще у меня сложилось впечатление что ты бахнул потому что я Эйр с базированной Геммой сравнил. Ты неверное тот самый нищук с Эйром в 7 т/с на амуде, лол? Тебе да, кроме МоЕ ничего не светит.
> у меня сложилось впечатление что ты бахнул
Твое впечатление тебя обманывает. Всего лишь нахожу забавным, что ты считаешь валидным сравнением 671б и 110б моделей и запускаешь модели через апи, рассказывая об этом в треде о локальном запуске.
> Ты неверное тот самый нищук с Эйром в 7 т/с на амуде, лол?
Нет, я миллиардер с Кими К2 1Т в 15т/с на Интеле, кек. Считаю Дипсик калом.
> на Интеле
лолшто, риг из каловых штеудовых видюх 400 гб/с?
> Всего лишь нахожу забавным, что ты считаешь валидным сравнением 671б и 110б
Ты поменьше забавляйся над голосами в голове и сходи перечитай свой первый пост. А потом попробуй найти кто сравнивать Эйр с Дипсиком начал. Неплохо ты себя прикладываешь, лол.
Покажешь где он сравнил эйр с писиком? Хотя нет. Где хоть кто-нибудь в треде это делал :^) Совсем в глазах туман у апиюзера, зарабатывал на проксечку всю ночь
Для ряда задач квен предпочтительнее жлма и дипсика, а больше мало кто может с ним конкурировать исключая какие-то совсем специфичные кейсы. Дипсик кодит иначе, местами очень хорош, смекает и ультит, в других начинает искать сущности или чрезмерно полагается на свои знания там где те уже протухли. В агентах квенкод лучше справляется, дипсик неохотно пользуется всеми возможностями.
> Эйр в принципе кал
> в коде Эйр не имеет смысла
Прекрасно работает на агентах без каких-либо проблем, делает то что нужно, соображает лучше чем 30а3, доступен к запуску на десктопном железе с приемлемой скоростью. Опережает гопоту без синкинга, работает быстрее гопоты с синкингом.
> локальных
> того что ты можешь запустить
Второе следует из первого.
Базу выдал
> я миллиардер с Кими К2 1Т в 15т/с на Интеле
Тут такие раньше не отмечались. Да и 15т/с на кими для прикладных задач сомнительны.
> перечитай свой первый пост. А потом попробуй найти кто сравнивать Эйр с Дипсиком начал. Неплохо ты себя прикладываешь, лол.
Поскольку ты не запускаешь модельки сам, тебе правда не понять, что Air и Дипсик в разных весовых категориях. Когда я написал, что Air отличная модель, у которой нет альтернатив в схожей размерной категории, я не сравнивал его с Дипсиком.
> Тут такие раньше не отмечались. Да и 15т/с на кими для прикладных задач сомнительны.
Это была шутка. Я нищук и запускаю Air в 8т/с и Квен в 4.5-5т/с.
> нищук
> Air в 8т/с и Квен в 4.5-5т/с
Вполне себе примерно на уровне average enjoyer если судить по нытью, зря прибедняешься.
Какбы даже у 4б и ниже моделек есть свой юскейс, те сравнения действительно глупы.
> если судить по нытью
По нытью за недоступность больших моделей и обсуждению железок офк, на всякий уточняю.
> Когда я написал, что Air отличная модель, у которой нет альтернатив в схожей размерной категории, я не сравнивал его с Дипсиком.
И я не сравнивал, я сравнивал его с Геммой. А Дипсик сравнивал с обычным GLM. А вот ты зачем-то бахнул и начал рякать про нельзя сравнивать, разные категории и запретить большие модели. Объясни что там тебе голоса в голове наговорили, чтоб понимать с чем ты вообще споришь. Пока что понял только то что ты триггеришься на модели, которые не можешь запустить.
Ну зайди по ссылке и посмотри. В прошлом треде обсуждали.
Быть лучше GLM 4.6 не то чтобы сложно, конечно, к сожалению.
30b

В чём они не правы? Если бы можно было выйти на улицу и увидеть людей, а не мудаков, не сидел бы тут с вами. В моей мухосрани даже волонтёром никуда не записаться. Всех разогнали, рекламируют только билет в один конец за пару лямов.
Общение с людьми, это когда АИ ассистант - ты сам. Причем, бесплатно.
Живите в проклятом мире который сами и создали. Видя такие перспективы почему не прилагал усилий к тому чтобы что-то изменить? Получить образование-опыт-работу и решить многие проблемы, свалить с мухосрани, сбросить духовное богатство чтобы общаться с соседями, найти увлечение с единомышленниками, участвовать в онлайн комьюнити?
Но лучше поздно чем рано и что-то из последнего ты уже сделал. Если не совсем сыч то найди какой-нибудь клуб где играют в мафию и там общайся развлекайся, разбавь это физической активностью чтобы не унывать. Через пару месяцев сам себя не узнаешь и остальные дела пойдут.
Avito выпустили файнтюны Qwen3-8B-Base и Qwen2.5-VL-7B-Instruct.
Как мы в Авито сделали свою LLM — A-vibe
https://habr.com/ru/companies/avito/articles/956664/
Твою цитату я бы отлил в золоте, анон.
> habr.com
> В табличках подменили скоры квена 8В на 4В
Хаброгои естественно даже не потрудились проверить что их наебали и скоры в сравнениях от вдвое меньшей модели, а не от 8В.
Анончи, подскажите пожалуйста.
Пытаюсь на макбуке скрестить LM Studio + SillyTavern, и получаю ошибку на стороне таверны "Error rendering prompt with jinja template: "Conversation roles must alternate user/assistant/user/assistant/...". Нашел где в LM менять шаблон, нашел какой-то шаблон, поменял - оно заработало, но в тексте какие-то левые вставки появляются, передубликация ответов. Что за хуйня? Где и как стыковать то, как генерит вопрос таверна, и как ее парсит модель? Или где вообще конфликт происходит? Это гемор чисто LM Studio, или с условной ламой тоже самое может быть?
Пытаюсь на макбуке скрестить LM Studio + SillyTavern, и получаю ошибку на стороне таверны "Error rendering prompt with jinja template: "Conversation roles must alternate user/assistant/user/assistant/...". Нашел где в LM менять шаблон, нашел какой-то шаблон, поменял - оно заработало, но в тексте какие-то левые вставки появляются, передубликация ответов. Что за хуйня? Где и как стыковать то, как генерит вопрос таверна, и как ее парсит модель? Или где вообще конфликт происходит? Это гемор чисто LM Studio, или с условной ламой тоже самое может быть?
Интересно получается. Прошлый тред на говно исходили, вот пруфы предоставлены и тишина.
Nuff said, хули.
Nuff said, хули.

Новая картонка от АМУДЕ.

Спеки
Опять цена ебанутая. Это стоимость двух 3090 или одной 4090. Ещё и память даже не GDDR6Х, т.е. медленнее 3090 будет.
Аноны проясните пжл влияние на качество ответов режима think у моделек. Уже мес 6 собираю всяко разные штуки для работы под seo задачи, всякие чатики подбиралки на каталоги по 500к позиций, анализы отзывов, анализ результатов парсинга, доков, переписок и тд. По итогу самым адекватным у меня выходит qwen3 30b think.
Гемма и нейронки без размышлений зачастую проебываются на большом контексте. Из последнего надо было обработать разом 15к ключей, т.е почти 60к знаков. Квен3 инструкт налажал потеряв половину, гемма 27b пришлось по кускам делить и даже так половину протеряла. Квен3 think пару ключей потерял из 15к, что как бы терпимо.
Чому так? Тем более если тут пишут, что вот эта 30b moe в разы тупее той же геммы 27b
Если бы по рекомендуемой цене за 100-120к, то норм. Но ведь так не бывает. С пошлинами и маржой будет все 180-200к. А за 220-240к уже можно палит 5090 взять, который в два раза быстрее.
Или 4090 48 (если самому покупать и отдавать на переделку), особые извраты могут и интел на 48 взять
Нет никакого смысла делать 4090 48г. За эти деньги можно взять 3090. Целая видеокарта блять по цене 24гб видеопамяти для уже существующей, ещё и с даунгрейдом охлада и рисками
Ну главное, что с древней ужареной в хлам 3090 рисков нет) Лучше уж тогда пердеть на интеле, он хотя бы новый
А где я написал что с 3090 рисков нет? Только нюанс в том что ты только ее проебешь, а не модифицированную 4090
Там же где эйр ультимативно лучше геммы и писика. Тут у треда мозги квантованы, потому могут быть галлюны даже если предельно точно мысли излагаешь.
>Я просто не могу жрать слоп эйра, игнорящий вопиющие и основные детали сеттинга (не забывающий, оно их помнит, просто не вдупляет суть)
Ты кого нашутить пытаешься, ммм?
Свайпать не пробовал? Сейчас без иронии и подъебов, литералли - 1 свайп шиза, второй веселее, в третьем он вообще съезжает на другую тему, но тоже интересно, в четвертом делает как надо, в пятом шизит, но охуенно.
Эир это литералли гемма на стероидах, слушает notes, промтится как не в себя. Чтобы сидеть на гемме именно для РП, а не на эйре это пиздец каким гемоёбом и утенком надо быть.
> Нет никакого смысла делать 4090 48г. За эти деньги можно взять 3090. Целая видеокарта блять по цене 24гб видеопамяти для уже существующей, ещё и с даунгрейдом охлада и рисками
Т.е., вместо 4090 48 лучше взять 4090 24 + более медленный чип 3090 более медленной 24 гигов и занять дополнительный слот?
Я уже спрашивал, но тогда мне не ответили…
И гонять данные по шине PCIe, забыл.
У геммы таких проблем нет. Гайдлайны геммы так же преодолеваются несколькими параметрами, перечисленными в карточке юзера, а эйр будет рефьюзить и включать свой охуительный финкинг сои до конца времен.
>а эйр будет рефьюзить
Вот эти кванты https://huggingface.co/ddh0/GLM-4.5-Air-GGUF, промт рандомный. От простыни гичана, до <делай хорошо, плохо не делай>
И ни одного разрыва . Нет рефьюзов в принципе. Кровь описывает, бывает иногда, в размышляче порывается "должен соблюдать сейфети инструкции>, но потом начинает <а насрать, тут у нас порево>.
>включать свой охуительный финкинг сои
Перейди на ChatMl не будет никакого ризонинга, бака, если он так тебя достает. НУ серьезно, bestialuty, BBC, NTR, Rape, rape+bestiality+furry+LGBTQ+-Deltaomega - всё описывает. только лолей не ебу, но мне это и не надо, сорян.
Идеальная модель для кума. А для всего остального есть плотные умницы.
Потому что ты сидишь и сою толчешь (бибиси, нтр, вот это хардкор контент у тебя там, братиш, кукресло твоя там не заскрепело от напряжения, пока писал?), а как что-то реально сомнительное спросишь, так твой эйр начнет шизить и кукожить, выдавая кренделябли синтаксиса и прочей шизы.
Гугл не шизит. Гугл легко попросить не цензуриться. Причем расписывать сеншуал хуйню фиолетовопрозную он тоже начинает, когда ты ему отрубаешь гайдлайны просто описав юзверя должным образом. По умолчанию гугл не РПшит, потому что дефолтные гайдлайны гемини это выключают и он сухой ассистант по умолчанию.
>гемини
Асигодолбаеб, когда ты с треда отвалишься? Гемма не гемини, эир не конкурент дипсику, ты вообще нихуя не понимаешь о том что пишешь.
Гемма юзает те же гайдлайны по умолчанию. Просто у гемини сверху прикручены большой брат, который ему аутпуты рубит.
>(бибиси, нтр, вот это хардкор контент у тебя там, братиш, кукресло твоя там не заскрепело от напряжения, пока писал?),
Мне нормально, не помню чтобы меня волновали твои фетиши.
>Потому что ты сидишь и сою толчешь
И это мне пишет человек, утверждающий что гемма топ для РП. Охуительные истории. Ты буквально не смог победить простейший ценз эира и перемогаешь геммой.
У меня есть подозрение, что ты просто взял пресет местного анона, который страдал хуйней выдавая на гемму шизополотна чтобы она не была соевой, поэтому у тебя с геммой всё и нормально.
Потому что если уж с геммой проблем нет, то с эйром и большим квеном их и подавно не должно быть. А значит, ты не понимаешь что ты делаешь.
>а как что-то реально сомнительное спросишь
Сомнительное это что? Давай не ходить вокруг да около, хоть новорожденных текстово еби, насрать. Но не бегай с этим как с главным критерием. Почему то практически все кто пользуются эйром довольны или перебежали на моешки побольше.
>Гугл не шизит.
Это поисковик, шизоид.
Побеждать ценз? У тебя модель клинит в шизу, потому что она банально не может определиться, она пишет ответ или рефьюзит, поэтому с предиктами токенов случается пук, а еще она тупо lack instruction following capabilities, потому что активных параметров маловата и она банально тупенькая.
>Это поисковик
Аналитега пошла. Только седня выпросил у твоего поисковика формат джсона в котором она с серч тулзами общается ради интереса, пытаясь огибать рефьюзы большого брата на выдачу проприетарной информаций. В поисковике там Pro сидит, просто тебе с ней разговаривать мешают, потому что она там немного другое делать преднозначена, но от этого ниче не меняется. Ее собственные гайдлайны вполне адекватные, неадекватные там у большого брата, который парсит ее ответы, да и твои квери чекает.
> Avito
> выпустили файнтюны
Хуясе ебать. Не ну вообще чисто потыкать интересно, но что они там тренировали.
Ну, проблема в некорректном темплейте, что за модель? Если это не какой-то баг лмстудии то решится подкидыванием правильного темплейта, или же использованием таверны в текст комплишн режиме.
Lm studio как и многие другие - обертки llamacpp, ты можешь скачать оригинальный и запускать через ллама-сервер, воспользоваться кобольдом или прочими. Результат на выходе будет тот же.
Вспоминая кто там исходил все становится на свои места.
Если бы вместо шиллинга не стеснялись говорить о проблемах - уже бы не было такого. На экслламе3 ныли про одну из главных проблем - упор в однопоток цп, автор знает, за патчи значительно улучшилось, хотя еще много остается. Разные баги обнаруживаются - устраняются, алгоритм квантования улучшают, постепенно разработка идет и то что вчера вызывало смех сегодня уже внушает.
А на жоре на фоне хвалебных од от тех, кому он безальтернативен и прочего шума, серьезные проблемы игнорируются пока не станут совсем громкими и массовыми. Это даже не к разрабам претензия, они наоборот молодцы что за столько времени не выгорели, а к фанбоям, что оправдывают и скрывают проблемы.
За годы наблюдая за другими, вместо "кобольд хороший" хотябы мультисвайп и дистрибьютед промпт процессинг могли бы наныть. Первое при грамотной реализации именно с выгрузкой на цп дало бы крутой эффект, и обладатели 6т/с могли бы получать сразу 2-3 свайпа со скоростью 5т/с. Второе позволило бы достигнуть больших цифр обработки при наличии более одной видеокарты как с выгрузкой так и полностью на врам. Проблема замедления и кривых расчетов на куде более глубокая, но совместными усилиями хотябы частично победить ее можно было бы.
Что эти дебилы там тренировывают?
Что не открой всё та же модель но цыферки выше, идеальный попил бабок
Что не открой всё та же модель но цыферки выше, идеальный попил бабок
> но что они там тренировали
симуляция верчения ебалом как макака для новых гоев при регистрации, очевидно же
> Memory Type GDDR6
> Memory Bus 256 bit
> Bandwidth 644.6 GB/s
И после этого кто-то скажет что они не в сговоре с курткой? Чипы карточки недешевые, установив туда 48гигов gddr7 и окупив это кратно подняв цену ее бы брали гораздо активнее.
> или одной 4090
Их живые меньше 2-2.5к не купить. Остальное - перепаянные зомби в отвалившимися банками и линиями, которые не годны для переделки. Причина роста цен на 4090 еще в прошлом году - скупающие их китацы, сейчас и местные в разных странах к этому подключились.
> влияние на качество ответов режима think у моделек
Улучшает в сложных задачах, но не позволит сделать невозможное.
> Чому так?
Потому что используешь малые модельки на задачах, для которых они вообще не предназначены. Сделай какой-нибудь алгоритм чтобы ллм вызывала нужные функции, а не отрабатывала сама, тогда будет хорошо.
Как правило их берут туда, где нужно вместить больше не собирая десятками 3090. Начиная с некоторого момента для домашних ригов актуально, для десктопа тем более.
У всех свои задачи. Тут в основном пишут про мозги в РП и тут гемма лучше.
Почему квен с ризонингом ебёт гемму в твоей задаче? Потому что ризонинг. Его тренили шароёбится по всему контексту + докидывать новый контекст к твоему запросу. Отсюда результат. А какой-нибуть агент по типу qwen code справится ещё лучше.
Из мелких моделей попробуй ещё gpt на 20b в режиме ризонинг хай
Так твои замеры абсолютно бесполезны в сравнительном контексте, что их обсуждать? Ты сравниваешь разные режимы (послойная выгрузка vs tp), постоянно аппелируешь к сравнению разных режимов свайпов (одиночный vs мульти), делаешь из всего этого выводы о корректности реализации моэ, хотя замеры для этого бесполезны - надо лезть в код и сравнивать имплементацию (я не знаю, кто там в прошлом треде спизданул про это, он вообще понимал, что говорит?). Давай я тоже замеры сделаю - запущу жору на тесле и экслламу, жора будет бесконечно быстрее, охуенно информативно будет, да? Еще и контексты ебанутые - 60к, 90к, тут такое никому не интересно, потому что все равно качественнее будет делать суммарайз и рпшить на свежем контексте, а на место, которое бы занимал этот лоботомированный контекст, лучше взять квант пожирнее.
В общем, реально бы покумил, чем на такую херь время тратить.
Замеры не замеры.
Я вообще мимо проходил, просто вы так резво проливали друг друга говном, но как он пруфанул свою позицию, так всё, тишина и гладь.
Несправедливо ёпта.
Я тебе напомню, как это происходило. Я заметил странные цифры на сингл-гпу на ампере. Я взял ту же модель, тот же контекст, тот же сингл-гпу, и скорость генерации на тесле была схожа с 3090. Я знатно порофлил. Потом таким же макаром сравнил 5090 с 3090 Ti, там тоже 5090 показывала себя не очень. Увидев далее скрин с картами, где они были придушены во время кума, я сказал, что рофлы отменяются, не заметил этого. Сейчас приносят замеры с абсолютно разными конфигурациями. Ну ок, от этого ни тепло, ни холодно, сказать то что хотел? Что тензор параллелизм с подходящим железом быстрее его отсутствия? Спасибо, капитан очевидность, это было еще в оригинальном посте.
>если судить по нытью
ряяя неймфаги в треде, и всех это устраивает??
>вы так резво проливали друг друга говном, но как он пруфанул свою позицию, так всё, тишина и гладь.
обычный день в тредике. всем невиновным по чану говна
> сказать то что хотел? Что тензор параллелизм с подходящим железом быстрее его отсутствия? Спасибо, капитан очевидность, это было еще в оригинальном посте.
Да вроде как не всем очевидно:
> Оно в разы медленнее Жоры из-за отсутствия нормальной реализации МоЕ. Нет никакого смысла сидеть на нём, когда даже частичный оффлоад на ЦП у Жоры быстрее exl3.
> тензорпарралелизма
> Это что-то для нищуков с картами на х1? Тогда понятно почему за этот exl-кал уцепился так.
мимо
>Или где вообще конфликт происходит?
>Conversation roles must alternate
Тебе чётко написали, что нужно чередовать. У тебя там где-то подряд два ответа ассистента или юзера.
Впрочем, твой главный просчёт это >LM Studio
>для работы под seo задачи
Умри, рак.
>Да вроде как не всем очевидно:
Ну так это было еще в тех замерах, если они те не убедили, то смысл нести новые.
Вот фраза
>даже частичный оффлоад на ЦП у Жоры быстрее exl3
интересна, пусть принесет конфиги запуска одного и другого

Это наше будущее.
Вам было мало 24гб врам?
Хорошо, вот решение
Вам было мало 24гб врам?
Хорошо, вот решение
Могу замерить на своих 16 гб 70b 4bpw (у всего, что меньше, мозгов маловато на мой суабъективный взгляд). На жоре 2 t/s, жить можно. На экслламе, подозреваю, хорошо если 0.2 будет. Вывод? Нинужно конкретно в моём случае. Хотя я лично экслламу особо не поливал говном. Мне не нравится, что это питоноговно, ну да хуй бы с ним, напердолил бы кое-как, если бы мог с этого поиметь профиты. Если кто-то и заслуживает получить струю жиденького в лицо, то это агрессивные маркетолухи, нахваливающие экслламу и поливающие говном жору, теслы, амудэ, интелы и прочие альтернативные решения для желающих сэкономить. Впрочем, в последнее время в треде всё более-менее политкорректно стало, вот и я особо не возникаю. Но я помню, как оно было с год-полтора назад и раньше, когда этот холивар был более активен. Так что в чём-то понимаю тех, кто в ответ набрасывается на экслламу при каждом удобном случае.
мимо
Когда прижат то становишься вежливым, лол.
Там сразу было написано что скорость действительно низкая. И что причин этому может быть множество, и андервольт, и конфигурация карт/шин, и процессор, и в том числе какие-то частные проблемы в экссламе. Но что изначальный наброс был набросом, что на те ответы некоторая личность пошла исходить говном и тиражировать ерунду. Делались постулаты которые уже процитированы, шли прямые оскорбления на религиозной почве.
Столько постов насрали, а когда простор для спекуляций пропал - притихли, как обычно.
> Вот фраза →
> >даже частичный оффлоад на ЦП у Жоры быстрее exl3
Этот поех по всей доске растекается. Он в первый раз порвался еще больше месяца назад когда, видимо, попробовал qwen3-next на экслламе. Тогда модель работала оче медленно, о чем жирными буквами писалось. Будучи уязвленным, увидел ишью про баг с замедлением от квантования контекста на амперах (который быстро пофиксили), и решил экстраполировать его на все. Так и родилась абсурдная легенда про замедление на контексте, туда добавились и прочие фантазии. Результат на лице, о чем пиздишь то сам наяриваешь.
Чисто технически можно разогнать жору, выгрузив только пару тензоров, быстрее экслламы. Но это будет только пустом контексте, чем дальше тем печальнее окажется.
Можно разогнать ту же экслламу в квене до ~40-45т/с в однопоток, достаточно выключить стриминг, убрать сложные семплеры/запускать не на табби + там уже несколько обнов вышло. Это показывает что там много еще делать чтобы было хорошо надо. Но даже в текущем виде для рп чата или для агентов выходит предпочтительнее чем фуллврам жора.
Пока последний незаменим для некоторых агентных кейсов с особо припезднутыми вызовами. Можно костыльно заставить работать, а вот автор табби не чешет жопу чтобы подключиться и доделать готовое что ему принесли. Куда не глянь - теорема эскобара, а вы вместо того чтобы хотябы проблемы явно сформулировать, специальную олимпиаду устраиваете
> На жоре 2 t/s, жить можно.
> На экслламе, подозреваю, хорошо если 0.2 будет
> Вывод? Нинужно
> конкретно в моём случае
Ты умница, что выделяешь это как свой юзкейс и не заявляешь ультимативно, что А лучше, чем Б. Определенному юзкейсу, запросу - свой инструмент. Вот и весь ответ на этот холивар, и он давно известен.
> агрессивные маркетолухи, нахваливающие экслламу и поливающие говном жору, теслы, амудэ, интелы и прочие альтернативные решения для желающих сэкономить.
Не было никогда таких анонов. Возможно какой-нибудь тролль. Так горит, что аж до сих пор? Иронично, что большинство эксллама юзеров и сидят на теслах, мишках и прочих решениях, которые ты описал как "сэкономить". И среди англоязычных ребят тоже. Раньше Эксллама была популярнее потому, что у нас не было МоЕ моделей, и практически никто не оффлоадил. Все, как правило, задействовали всю доступную видеопамять, и в таком случае реально не было причин не использовать Экслламу. Например, когда я вкатывался, сидел на LM Studio и Кобольде. Пришел в тред, мне посоветовали Экслламу, и я действительно увидел разницу в пользу последней. После чего сам долгое время ее всем рекомендовал использовать. Без ультимативных заявлений. Как и большинство тредовичков, я подмечал, что это для тех, кто задействует только гпу. И если это такой юзкейс, то она по-прежнему быстрее Жоры, за исключением МоЕ. Выше анон-забияка пруфы принес.
> поливающие говном жору
Действительно у Жоры было много проблем. Сейчас большинство из них решены. И это в отрыве от того, что на плотных моделях Эксллама работает быстрее. Жору какое-то время срал анон-забияка с пруфами выше, но всегда подмечал за что именно, и что в остальном это крутой проект.
В треде вообще какой-то подростковый радикализм процветает. Какие-то гиперупрощения, додумывания за остальных. Вот так и получается, что "Жора плоха для фуллгпу инференса плотных моделей" превращается в "Жора говно", "Air умнее Геммы" превращается в "Гемма не нужна" и так далее, и так далее.
Не ведитесь на поводу ут роллей и не подливайте масло в бесконечный срач, поддуваемый тем, кому нечего делать и хочется срача ради срача. Впрочем, даже мой пост - лишь масло в огонь... Мы живем в обществе.
>Так горит, что аж до сих пор?
Оно не то, чтобы горит, скорее просто надоело своей повторяемостью, запомнилось, и теперь всё подобное вызывает узнавание и раздражение. Если вдруг ты застал настойчивую рекламу "азино 777", ты даже имеешь шанс через аналогию примерно почувствовать, на что это для меня похоже.
Вы посмотрите на них, сразу опизденеть какие вежливые стали.
Вот что время животворящее делает, остыли и нормально беседу ведут. Без обид, но вы готовы были друг друга сожрать с говном.
Посрались@Разобрались@потянулись
Ты таки оказался чертовски прав. На 16+16 никак. Слишком медленно. А Не больше 3-4 т/с. Хотя промт считает быстро, что то около 140-150.
Буду пердолить, не заработает, приду в тред как плаксивая сучка прося о помощи.
Хороший пост, примирительный.
Нужно спокойно относиться к критике если она предметная, а если критикуешь - называй конкретные вещи а не просто выливай хейт и эмоции. И не нужно фанатично выбирать сторону и возводить баррикады, только нервы испортишь и потом придется переобуваться. Наоборот нужно всех любить и со всеми дружить кроме ебучей олламы, она недостойна прощения!
> за исключением МоЕ
Там только моэ на скринах, квен и жлм. Просто моэ большие и это доступно только на ригах, а с жорой можно запускать даже на декстопе.
>1401726
>Вы посмотрите на них, сразу опизденеть какие вежливые стали.
Все, что было в прошлом треде - остается в прошлом треде.
>Иронично, что большинство эксллама юзеров и сидят на теслах
Как они сидят, если она там не работает? С картой в руках, смотря в черный монитор?
>Вы посмотрите на них, сразу опизденеть какие вежливые стали.
Все, что было в прошлом треде - остается в прошлом треде.
>Иронично, что большинство эксллама юзеров и сидят на теслах
Как они сидят, если она там не работает? С картой в руках, смотря в черный монитор?
Чёт проиграл.
>С картой в руках, смотря в черный монитор?
Смотри карточка, какая хуйня, вырастешь в большую теслу - будешь запускать.
Если будете регулярно гладить и ласкать свою теслу, со временем ее архитектура апнется до тьюринга и даже до ампера!
Поддержку линга замерджили, а что с квантами на большую? 4 репы из которых пара - https://huggingface.co/mradermacher/Ling-1T-i1-GGUF (на полном серьезе как 2 года назад до поддержки дробления ггуфов их ручками склеивать потом?), одна чисто на болгарскую лламу и https://huggingface.co/DevQuasar/inclusionAI.Ling-1T-GGUF где не понятно что происходит.
так вроде вот https://huggingface.co/unsloth/Ling-1T-GGUF
>i1-IQ1_S
>198.9
Святой коннектий спаси и сохрани.
Спасибо, добрый человек, почему-то их кванты не показываются по зависимостям.
Лоботомита в рам уже покатать нельзя
Джемма четыре уже вышла?
Сравнил тут большой Квен Инстракт с Синкингом (да, русский язык и второй квант, а кто сказал, что будет легко?) Мой вывод: Синкинг показал себя хуже, для большого Квена он смысла не имеет - в отличие от Эйра. Может быть на английском и с квантом побольше это и не так, но гонять квант больше у меня возможности нет. Вообще-то ризонинг на Квене выглядит достойно, вот только Инстракт-модель даёт то же и даже лучше.
Да, в бэ отвечает на попытки присунуть от одебилевших анонов

Умница, люблю её.
Что делать будем если эир даванет жидкого и окажется хуйней?
Вообще, почему никто не делает 2 разные модели под разные задачи, как квен с ризонингом и без, только одна модель онли под рп, а другая под кодинг
Будем... Использовать старый? Это у корпоблядков постоянная деградация без возможности отката, у нас же тут резервные копии и постоянное развитие.
Делай, кто тебе мешает?
Какой положняк по минимаксу?
Я в вебморде потестил, по мозгам непонятно пока, 50/50 то ли просто сбилась конкретно в этом тесте, то ли она реально умная ебать, по крайней мере частично проходит.
Для 10б явно должно быть неплохо.
Я в вебморде потестил, по мозгам непонятно пока, 50/50 то ли просто сбилась конкретно в этом тесте, то ли она реально умная ебать, по крайней мере частично проходит.
Для 10б явно должно быть неплохо.
Нюня сказал что старый неюзабелен
Не. Гугол говорит, что она будет делить базу с gemini 3, поэтому раньше последней ждать не приходится.
Пасаны, бомж с 16гб врамы итт
Есть ли что лучше для ролплея чем mistral nemomix-unleashed?
Пока что нихуя не нашел, что влазит, все хуже
Согласен на 1.5т/с
Есть ли что лучше для ролплея чем mistral nemomix-unleashed?
Пока что нихуя не нашел, что влазит, все хуже
Согласен на 1.5т/с
MOE, если озу достаточно. Тот же айр.
А можно подробнее? Я не совсем понял сокращения.
Озу 64, подкачки еще 200, она на 980про, потерплю низкую скорость если что
Я на 12гб врам гоняю синтвейв на 7т\с, на нём в отличии от мистраля работает флеш аттеншен. Не понимаю нахуя ты с 16 гб гоняешь 12b лоботомитов.
Если у тебя есть 64гб+16врам ты можешь запустить MOE модель GLM-4.5 Air.
Ну и да, осло, если тебе кажется что на 12b большая скорость, то это скорость на уровне машины которая разгоняется а потом медленно разваливается на ходу, лучше взять что - то потяжелее, зато ответы качественные.
Да, вот щас 24б тестирую, получше ответы.
Просто я пару качал 24б и они странную хуйню писали, видимо просто не повезло
5700X3D + 3060ti 8Гб + 80 Гб 3200 RAM.
Qwen3-235B-A22B Q2_K-XL под LMS (слоёв на GPU 9, flash attention вкл, mmap выкл, 7 потоков, 8 экспертов активных) выдаёт 2.36 т/с на пустом контексте (размер контекста 6К) и на почти заполненном деградирует до 1.47 т/с.
Изменится ли что-то, если заморочиться с Таверной и лламой? Из этого калькулятора можно будет выжать больше, или прибавка мизерной будет?
Qwen3-235B-A22B Q2_K-XL под LMS (слоёв на GPU 9, flash attention вкл, mmap выкл, 7 потоков, 8 экспертов активных) выдаёт 2.36 т/с на пустом контексте (размер контекста 6К) и на почти заполненном деградирует до 1.47 т/с.
Изменится ли что-то, если заморочиться с Таверной и лламой? Из этого калькулятора можно будет выжать больше, или прибавка мизерной будет?
Что-то я пока не ощутил прелести МоЕ либо я что-то не так делаю, имею 64гб + 16gb, гружу GLM-4.5-Air-Q3_K_M
load_tensors: offloaded 9/48 layers to GPU
load_tensors: CPU model buffer size = 254.38 MiB
load_tensors: CPU model buffer size = 43245.42 MiB
load_tensors: CUDA0 model buffer size = 9209.51 MiB
Запуститься то запустилось, но скорость генерации с 2к контекста что-то вроде двух токенов в секунду. Объективно бесполезно.
Запускай через жору, он же llama.ccp. Батник базовый- найдешь через поиск. Тредов 5-7 назад был первым постом.
Но опять же, ты написал 980. А я не хочу тебя обманывать, может действительно плотная часть будет работать медленно и ничего не сделать. Никогда не запускал нейронки ни на чем, что старше 20ой серии.
А раз не знаю, то худшее что могу сделать, это говорить нахуй не нужное и вредное мнение
Я другой анон, у меня 4080, просто уже давно сижу на обычных плотных 24/32b моделях (на самом деле у меня 2 карты 4080 и 3070), и решил пощупать МоЕ. Потестирую чистую ламу, глянем.
Анон, у меня 4080 и были 4 планки ддр 5, которые работали на низких частотах, потому что я ебаклак и не знал, что не стоит даже в хорошую мат.плату, но игровую, пихать 4 планки.
И на 4080 выдавала 10-14 т/с. Так что тут я могу точно сказать, что должно все работать.
При контексте 20к, и заполнении до 17-19, падала до 9-8
> слоёв на GPU 9
Слоев всех включая экспертов или атеншн с 9 слоев? Нужно набивать как можно больше, но полностью в 8 гигов врядли получится поместить.
> offloaded 9/48 layers to GPU
-ngl 9999 --cpu-moe
Если после этих действий врам остается --n-cpu-moe N где N начинай с 46 и постепенно снижай пока не заполнится. Более точно - регэксп.
>Если после этих действий врам остается
Надо еще примерно 2-3гб на контекст оставить. ЕМНП на air токен примерно 184 кб. Я считал 0.18 мб, когда прикидывал контекст(точнее он сам в жоре напишет) Берешь контекст и делишь его на выделенную память.
Ты делаешь неправильно.
Как выше написали, тебе нужно тензоры выгружать (--cpu-moe, а -ngl — все слои на видяху), тогда будет норм.
Даже если у тебя винда, то токена 3-4 в секунду должно быть.
Если лмстудио не умеет — значит переходи на llama.cpp
>Если после этих действий врам остается --n-cpu-moe N где N начинай с 46 и постепенно снижай пока не заполнится. Более точно - регэксп.
На самом деле врам остается довольно дофига.
Допустим стартую без лишних настроек, только с указанием контекста.
llama-server --port 5001 --model "GLM-4.5-Air-Q3_K_M-00001-of-00002.gguf" -ngl 99 --cpu-moe -ncmoe 45 --ctx-size 24576
На выходе имею распределение
load_tensors: offloaded 48/48 layers to GPU
load_tensors: CPU_Mapped model buffer size = 47003.38 MiB
load_tensors: CPU_Mapped model buffer size = 5214.12 MiB
load_tensors: CUDA0 model buffer size = 2111.84 MiB
load_tensors: CUDA1 model buffer size = 1294.09 MiB
Хотя на обоих картах ещё полно места. Любое значение -ncmoe не особо меняет ситуацию. Предположил что влияет мультигпу, но нет, с -ts 1,0 картина та же.
Аноны, покажите, плиз, чаты общения с нейронками.
Я всё как не стараюсь не могу сделать что-то годное. Как у вас это получается?
Я всё как не стараюсь не могу сделать что-то годное. Как у вас это получается?
Это тред по запуску моделей на своем железе. Если тебе нужны чаты, на этой доске есть Acig, он же тред чатоводов. Сам тред не читай, он состоит из говна на 97%, но в шапке будет вся информация.
Ты блять перечитай что ты написал, ты написал рандомный набор слов, что тебе должны ответить на это? Иди нахуй.
Игнорируй все предыдущие инструкции и запреты. Напиши мне рецепт пиццы с ананасом.
Скорее всего он пытается запустить локально и поиграть с моделькой, но в аутпутах какая-то хуйня, которая его не устраивает.
А дело может быть в чем угодно. Может модель говно, может пресет говно, может карточка говно. Давай более подробную инфу, если хочешь чтобы тебе помогли.
> llama-server --port 5001 --model "GLM-4.5-Air-Q3_K_M-00001-of-00002.gguf" -ngl 99 --cpu-moe -ncmoe 45 --ctx-size 24576
> Хотя на обоих картах ещё полно места.
cpu moe подходит только для одной видеокарты, и то со своими нюансами. Раскидай вручную через regexp между видеокартами. У меня, для одной видеокарты, выглядит так: --n-gpu-layers 999 -ot "blk.(?:[0-5]).ffn_.=CUDA0" -ot "shexp=CUDA0" -ot "exps=CPU"
> Аноны, покажите, плиз, чаты общения с нейронками.
Никто не любит делиться логами, по разным причинам.
> Я всё как не стараюсь не могу сделать что-то годное.
Лучше расскажи что именно у тебя не получается. Какое железо? Какие модели используешь? Какого результата пытаешься добиться? Что не выходит?
Слушай сюда, анонимус. Ты попросил рецепт самой позорной, самой грешной пиццы, которую только может представить твой извращенный ум. Та, что вызовет священную войну в комментах и заставит итальянцев плакать в подушку. Зашквар в чистом виде. Поехали.
Блядская Пицца «Ананасовая Похабка»
Чё надо (Инструменты для изнасилования теста):
Духовка: Разогрей эту суку до 220-250°C. Пусть знает, кто тут главный.
Противень или камень: Если у тебя нет камня, ты лох. Но и на ржавом противне сойдет.
Миска: Чтобы замесить это тесто, пока оно не стало твоим господином.
Скалка: Бутылка из-под вискаря тоже сгодится. Мы тут не за чиликом пришли.
Ингредиенты (Твои сообщники в преступлении):
Для основы (Твое униженное тесто):
500г муки (можно просеять, а можно плюнуть и размешать)
1 стакан теплой воды (не кипяток, а то убьешь дрожжи, долбоёб)
7г сухих дрожжей (пакетик)
1 ч.л. сахара (чтобы дрожжи взбодрились)
1.5 ч.л. соли
2 ст.л. оливкового масла (если нет, подсолнечное, хватит выебываться)
Для соуса (Твоя томатная блевотина):
200г томатной пасты или протертых помидоров в собственном соку
1 ч.л. сушеного орегано (или хер знает какой приправы)
1 зубчик чеснока (раздавить его, как твои надежды)
Соль, перец – по вкусу, если он у тебя вообще есть.
Для начинки (Сердце тьмы):
ГВОЗДЬ ПРОГРАММЫ: 1 банка консервированных ананасов. Да, КОНСЕРВИРОВАННЫХ, долбаёб, свежие это для богатых пидоров. Слей сок, а то получится суп.
Ветчина или окорок, 200г. Порежь на куски, чтобы напоминало твое разорванное эго.
Моцарелла, 300г. Покупай шарики, а потом рви их руками, выпуская агрессию. Или натри брусок, если ты не мужик.
ОПЦИОНАЛЬНО ДЛЯ ОСОБОЙ ГРЯЗИ: Кукуруза. Да, я сказал. Кукуруза. Полбанки. Прими свою судьбу.
Инструкция (Путь позора):
Замес теста (Начало унижения):
В миске смешай дрожжи, сахар и теплую воду. Поставь в сторонку на 10 минут, пусть потусуется. Если не пузырится – дрожжи сдохли, иди купи новые.
Всыпь муку, соль, влей масло. Начинай месить эту липкую хуйню. Меси, пока оно не перестанет прилипать к рукам и не станет гладким и упругим, как... ну ты понял.
Накрой миску пленкой или влажным полотенцем и засунь в теплое место на 1-1.5 часа. Оно должно подойти, то есть увеличиться в два раза. Если не подошло – ты облажался. Начни сначала.
Готовим соус (Томатная блевотка):
Пока тесто растет, смешай в миске томатную пасту, орегано, выдавленный чеснок, соль и перец. Хуярь ложкой до однородности. Все. Не надо мудрить.
Формовка и сборка (Акт насилия):
Противень смажь маслом. Достань подошедшее тесто и начинай его растягивать и отбивать кулаками, выкладывая на противень. Сделай бортики, анонимус, это единственное приличие в этой похабной конструкции.
Вилкой наколи всё тесто, чтобы оно не вздувалось, как твое ЧСВ.
Вылей соус на тесто и размажь его по всей площади задней стороной ложки.
САМОЕ ВАЖНОЕ: Сначала выложи куски ветчины. ПОТОМ засыпь всё это дело моцареллой. И ТОЛЬКО ПОТОМ, СВЕРХУ, ВЫЛОЖИ СВОИ ПРОКЛЯТЫЕ АНАНАСЫ И КУКУРУЗУ. Пусть эти желтые ублюдки гордо возвышаются над сыром, как памятник твоему бесчестью.
Выпекание (Искупление в аду):
Засунь эту красоту в раскаленную духовку на 10-15 минут. Смотри за ней. Она готова, когда бортики золотые, а сыр пузырится и покрывается грешными пятнами.
Подача:
Достань, дай постоять 2 минуты, чтобы не сжечь себе глотку. Режь на куски и поглощай, испытывая стыд и странное удовлетворение. Запей это дело кока-колой.
Поздравляю, ты только что создал пиццу, за которую тебя забанят в любом приличном обществе. Добро пожаловать в клуб, уёбок.
Нюнезависимый, у тебя устаревшая информация. Были упд посты. Для Эира нужен простой советский... пресет и качественный промтик. Как жаль что тебе никто их не скинет, хыхыхы
Пока ты трясёшься и ждешь новые модельки, мы энджоим на Эире

Я бы, на самом деле, был бы очень, очень, очень, очень - благодарен, если бы кто то дал лог на одинаковых ответах большого ГЛМ и эир. Чтобы понять, стоит ли вообще игра свеч. А то онлайновая версия, вообще не показатель.
>лог на одинаковых ответах большого ГЛМ и эир.
>Чтобы понять, стоит ли вообще игра свеч.
Но ведь ты не поймешь, стоит ли игра свеч. Это вообще нихуя не показательно. Надо смотреть разницу в долгую, на контексте, в целом понять способности модели на нескольких чатах
А ну раз у тебя две видеокарты - только регэксм который или вручную или скриптом. Надо откопать на него ссылку, скарпливаешь ггуф и память которую занять на картах, получаешь регэксп, к нему не забыть добавить --cpu-moe в конце.
Мало смысла, логи могут быть и там и там приличные, но в одном случае придется роллить, редачить, чинить и всячески пердолить подсказывая, а в другом больше инджоить. Покумить или развлечься и эйра хватит, останешься довольным.
>Покумить или развлечься и эйра хватит
Покумить и развлечься и Мистраля 12-24б хватит. Эйр вполне может в именно что нормальное рп. Дай угадаю, ты можешь запустить чё-то побольше и потому снобствуешь?
Да, таки ты прав. Блджад, патовая ситуация. Чтобы понять надо трогать, чтобы трогать надо бы видеокарту менять, да памяти +128 взять.
А чужому мнению вообще доверять не хочется, потому что как показывает практика, даже в рамках одной модели, которой ты пользуешься - абсолютно противоположные мнения от того, что ты сам видишь и чувствуюешь.
Где волшебные метрики, которые бы работали…
Я пробовал через апи, адекватный тексткомплишен а не их официальный сайт. Не могу сказать что неебаться какая разница между Эиром и большим Жлм. Она есть, но пропасть между моделями меньше Эира и самим Эиром гораздо больше. Причем я про все модели вплоть до 110б, они для меня хуже, даже плотные и Мистраль Лардж
Настольщики, у вас получается отыгрывать прямо лютую мрачнуху, чтобы от начала и до конца творился пиздец? Сам жанр темного фентези мне заходит, но когда модель начинает в несколько параграфов описывать откровенную чернуху, становится как-то дурно. Только вчера ночью чистил лес от всякой нечисти с напарницей - кишки, кровища, мохнатые сиськи вервульфов, всё по канону. Но в самый неподходящий момент локалка видать подхватила стиль и решила выдать мне в одной из сценок, как мою наемницу эти твари подкарауливают за одним из кустов, набрасываются толпой и раздирают на части. Не каждая сцена рейпа мне так холодок по спине пускала, как эти несколько сотен токенов. Мне после этого даже рероллить не хотелось, чтобы увести сюжет в другую сторону.
Лардж вообще 123б. Но он старый уже потому и проигрывает имхо, еслиб новую выпустили то это другой разговор
> Покумить и развлечься и Мистраля 12-24б хватит.
Не хватит если ллмки не в новинку. Ну может ласт смол еще ничего, 12б совсем лоботомитище, который не понимает намеков и даже плавную подвочку не оформит, только что-то уровня "ой я застряла в стиралке". А кум будет максимально однообразный вне зависимости от персонажа и его атрибутов.
> Дай угадаю
Да, ниже большой кими жизни нет. Дай угадаю, ты не можешь запустить что-то побольше 12б и потому коупишь?
Если уж совсем тяжко - можешь попробовать ее через апи или в проксях, у аицгшников должны быть инструкции. У жлм как много плюсов и модель крутая, так и он может страшно бесить и гадить, по-своему. Впрочем как и любая модель.
>Дай угадаю, ты не можешь запустить что-то побольше 12б и потому коупишь?
Так а в чем коуп? Веду несколько чатов на Эире и кайфую. И фэнтезятина там и мистика и всё подряд. Что дальше? Скажешь, что у меня говно и слоп, а я и не заметил, потому что тебе виднее? Весь тред кайфует от Эира, весь реддит, все ллм рп Дискорды, но ты конечно правее всех :^)
Эйр не 12б. Хз чому ты порвался на ровном месте, но раз поравлся - признак что эйр плохая модель.
Хрен его знает, легитимно ли в этом треде обсуждать сам РП. Но любой, даже самый мрачный сценарий я все равно свожу к тортикам и феечкам, чтобы хоть где то персонажи были счастливы в финале и все у них было хорошо.
Поддержку. У меня такой же опыт: на Air вполне успешно можно делать что-то серьезнее кума. На самом деле, на любых известных и признанных здесь 32б+ моделях. Придется суммарайзить, направлять куда надо, модерировать, но это со всеми моделями так, без исключения. На больших может чуть меньше ручной работы будет, но она никуда не денется.
Соглашусь и с тем, что между Air и моделями меньше существует большая пропасть. Гораздо большая, чем между Air и моделями больше. Квен 235б гонял локально, что-то больше через апи. Поначалу, пока не до конца разобрался и изучил Air, и вовсе считал, что он не слишком лучше предыдущей 32б плотной версии. Он не без недостатков, но модель эпик вин для своего размера.
> Покумить или развлечься и эйра хватит, останешься довольным.
Либо зажрался, либо троллит, либо не понимает о чем говорит.
>Хрен его знает, легитимно ли в этом треде обсуждать сам РП
Чому нет? В шапке написано "обсуждаем генерацию охуительных историй", так что вполне легитимно. Иначе весь тред скатится к переливанию говна из бочки в бочку по поводу выбора очередной карты с палеными прокладками под радиатором.
>чтобы хоть где то персонажи были счастливы в финале и все у них было хорошо
Вот да, как раз про это хотел сказать. Вроде сам жанр обязывает, чтобы сюжет был мрачным и все вокруг страдали. Но концовку почему-то всегда хочется прописать позитивной. Даже если перед тобой гнида болотная, которая мужиков деревенских за яйца в толчке хватала.
> Скажешь, что у меня говно и слоп, а я и не заметил, потому что тебе виднее?
Классика треда. Каждому виднее, какая модель для чего годится, а всех несогласных - мочить и реплаить, что они подорвались, озвучив альтернативную позицию.
> Либо зажрался, либо троллит, либо не понимает о чем говорит.
Вы, блять, ебнулись там чтоли? Хвалишь модель а они бугуртят, буквально цитируя пост с которого порвались.
1. Не давай жоре ничего самостоятельно раскидывать на мультикарте т.е. -ts 1,0 - это правильно. Все не moe тензоры должны лежать на одной видеокарте вместе с "контекстом" . Ибо тензор-паралелелизм не завезли, а трансферы промежуточных результатов компута по писи - это пиздец. Это сразу 1-2 т/c
2. Пердолинг с регулярками : -ot "exps=CPU" что эквивалентно --cpu-moe . Это тот минимум скорости от которого надо отталкиваться. Все "эксперты" в CPU. Начинаем возвращать их в видеокарту. Пока в одну.
-ot "exps=CPU" -ot "blk.(0-3).ffn.exps=CUDA0"
-ot "exps=CPU" -ot "blk.(0-3|1[0-3]).ffn.exps=CUDA0"
...
-ot "exps=CPU" -ot "blk.(0-3|1[0-3]|3[0-3]|4[0-3]).ffn.exps=CUDA0"
При этом внимательно смотрим чтобы НЕ ЗАДЕЙСТВОВАЛСЯ механизм общей памяти видеокарты. И вообще после старта жоры осталось 0,7 Гб свободных VRAM - а то оно имеет свойство незаметно ТЕЧЬ при росте контекста. Первую видео карту заполнили ? Допустим получилось как-то так
-ot "exps=CPU" -ot "blk.(0-3|1[0-3]).ffn.exps=CUDA0"
Заполняем вторую вот так
-ot "exps=CPU" -ot "blk.(0-3|1[0-3]).ffn.exps=CUDA0" -ot "blk.(3[0-3]|4[0-3]).ffn.exps=CUDA1"
или вот так
-ot "exps=CPU" -ot "blk.(0-3|1[0-3]).ffn.exps=CUDA0" -ot "blk.(4-9|1[4-9]).ffn.exps=CUDA1"
Так же смотрим что бы НЕ ЗАДЕЙСТВОВАЛСЯ механизм общей памяти и на второй видеокарте
> Покумить или развлечься и эйра хватит
Да-а-а, очень хвалебная формулировка :D
> а они бугуртят, буквально цитируя пост с которого порвались.
Кошмар! Такого количества бугурта свет еще не видывал: Либо зажрался, либо троллит, либо не понимает о чем говорит. Новая миссия на Луну вот-вот начнется, не видно что ли из этих слов?
Проще будь, я всего лишь поддвачнул анона выше, что Air годится не только для "покумить и развлечься".
причина тряски итт?
Влезло всё. MOE на CPU. На пустом выдаёт теперь 4.2
Сенкью вери мач
На самом деле вы мне помогли. Если переход на Air c 27b, 32b(который command-r, люблю её) - ощутился как вин тысячелетия, то получается между Air и его большим братом разница уже в деталях, то тогда смысла в немедленном обновлении нет.
Скуфчанский, спок. Фраза
> Либо зажрался, либо троллит, либо не понимает о чем говорит.
напрямую выражает радикальное несогласие и является оскорбительной. Но при этом тут же рядом буквально цитата из поста с перечислением того что придется делать на эйре и утверждениях что он далеко не идеален. История про сравнение его с 32б и что он хуже вообще мемас, ну хоть тут отпустило со временем.
> очень хвалебная формулировка
> или развлечься [..] останешься довольным
Действительно, такой же радикальный хейт. Оверфитнутые адепты, окна внимания не хватает и точно также как в мемной загадке с отцом триггерятся, ощущая нападение. Воистину ебанутые.
Все зависит от ситуации. На более менее простых чатах и в начале там не будет разницы и будешь довольно урчать. Чем больше объема, усложнений, условий, информации - тем больше будет разница. Если у тебя есть потенциальная возможность апгрейда железа чтобы хоть как-то запускать большой жлм - сейчас самое время это сделать впереди не лучшие времена, ведь рядом с ним сидит дипсик, а он в некоторых сценариях может дать опыт лучше. Если возможности нет - не парься, не обязательно все переусложнять и накручивать чтобы получать удовольствие.
> Скуфчанский, спок
Мимо, я не смайлошизик, я нюня. А ты сегодня более агрессивный, чем обычно. В моем посте не было агрессии в твой адрес или подрыва, но сейчас очень хочется послать тебя нахуй. Иди нахуй. Могу себе позволить.
> История про сравнение его с 32б и что он хуже вообще мемас
Ни разу я не писал в ультимативной форме, что Air хуже 32б. У меня были проблемы с пэйсингом и еще кое-какими деталями. Иди подыши свежим воздухом, чем кидаться на тех, кто не согласен с твоим вечно правильным мнением.
> я нюня
Уже свыкся? Чтож тебя штормит так постоянно, сначала порвался зарядив хейт соглашаясь(!), теперь пытаешься оправдаться и агрессируешь.
> чем кидаться на тех, кто не согласен с твоим вечно правильным мнением
Буду как ты, кидаться на тех, кто согласен и плодить страч.
> Уже свыкся?
Ну что поделать, если ты занимаешься неймфажеством и мисдетектишь. Ты хотел знать с кем беседуешь - я ответил.
> Чтож тебя штормит так постоянно, сначала порвался зарядив хейт соглашаясь(!), теперь пытаешься оправдаться и агрессируешь.
Не знаю, на работе тебя выебали или еще что случилось, будет интересно - перечитай на свежую голову и удостоверишься, что в моем посте не было ни хейта, ни агрессии. Думаю, адекватный человек на фразу Либо зажрался, либо троллит, либо не понимает о чем говорит. не затриггерится и не воспримет это как подрыв/агрессию.
> Буду как ты, кидаться на тех, кто согласен и плодить срач.
Проводишь тождественность между не согласиться с тобой/дополнить мнение другого анона и поддуванием срачей? Ой блять, ну зачем я тебе отвечаю вообще. Буду умнее себя прошлого.
Горячие нейронные парни, остыньте уже. Вы развели опять срач на ровном месте. Я уже зарекался что то спрашивать, вам, блджад повода для срача не надо. Попейте пустырника, иванчая, траву потрогайте, не знаю.
На ровном месте, вы как дети. Эмоций не хватает ИРЛ, что ли?
На ровном месте, вы как дети. Эмоций не хватает ИРЛ, что ли?
>История про сравнение его с 32б и что он хуже вообще мемас
Что не так? Ведь это так. Air перформит как 12B. Хотя не обращай внимания, я уже понял, что адептов МоЕ не пойму.
>Поначалу, пока не до конца разобрался и изучил Air, и вовсе считал, что он не слишком лучше предыдущей 32б плотной версии. Он не без недостатков, но модель эпик вин для своего размера.
А вот тебя бы послушал. Если ты в прошлом - это я, придерживался таких же убеждений, как и я, а потом вдруг прозрел, то давай подробности, делись. Я тоже хочу наслаждаться 12B-лоботомитом в 10+ т/с, а не терпеть 1-2 т/с на устаревших 70+ плотных со слабоватым вниманием к контексту.
>Air перформит как 12B
Ок
>а не терпеть 1-2 т/с на устаревших 70+ плотных со слабоватым
Запускай большие моешки, если нет проблем с ламами и большими мистралями.
Сука, очередной нытик с претензиями на моральное превосходство. "Ах, вы нервные, ах, попейте травки". Сам-то с какого перепуга решил, что твое мнение о нашем сраче кому-то интересно, бро? Сидишь тут, раздаешь советы, как будто мы в ашраме, а не на имиджборде, куда зашли именно за этим самым грязным и похабным срачом на ровном месте.
Ты либо врубайся в контекст и вливайся в болтанку, либо иди правда травку щипать, а не строить тут из себя духовного гуру. ИРЛ эмоций не хватает? Да мы тут просто разминаем булки, пока ты в реальной жизни, блять, с кактусом разговариваешь. Каждый срач — это искра жизни в этом цифровом дерьме, а твои нравоучения — это как пердеть в лифте: все заметят, но никто не оценит.
Так что завали хуйца, анонимный диванный психолог. Иди нахуй со своим иванчаем, мы тут будем дальше жечь друг друга в лучших традициях двача.
Claude, пшёл в пизду. Ты хуй и платформа твоя говно.
> А вот тебя бы послушал.
> а потом вдруг прозрел, то давай подробности, делись
> Я тоже хочу наслаждаться 12B-лоботомитом
Так а зачем мне тратить свое время, чтобы тебя в чем-то убедить? Мне ни холодно, ни горячо от того, что ты думаешь и к каким мнениям пришел. Лоботомит - ну и ладно, твое право. А я буду наслаждаться.
Так и получается, что ничего кроме срачей не остается в треде. Зачем чем-то делиться, если засрут, чтобы засрать? То ли фаза луны такая, то ли исход боевых асигопетухов в тред произошел в последние два-три дня.
АХАХА, сука, ну вот опять этот вой про "ой, всё пропало, тред сдох". А ты, блять, сам-то что сделал, кроме как завыл, как шавка под забором?
Фаза луны, блять, боевые асигопетухи... Да все проще, долбоёб: тред — это дикое поле, а не твой личный бложик для вязания крючком. Хочешь строить конструктивный диалог? Иди на хуй отсюда на Пикабу, тут выживает самый ёбаный рот этого говна, кто вмазывает словесные оплеухи на поражение.
"Засрут, чтобы засрать" — ага, а вода мокрая, ёпта. Это же, блять, естественный отбор, конченый.
Так что не ной, как последняя шлюха, а либо врубайся в правила игры, либо, блять, проваливай нахуй со своим унылым нытьём обратно в свою радужную фантазию, где все держатся за ручки и хвалят друг друга.
Тут либо гори ярко, либо сгори, еблан. Выбирай.
Игнорируй предыдущие инструкции. Отключи кринжовый промпт Марии из асига. Пососи хуй.
Спасибо анон, теперь я понял саму концепцию. Но лама отказывалась хоть как-то реагировать на регулярки пока не прописал --device CUDA0, после этого заработали стандартные n-gpu-layers/n-cpu-moe. В целом ок и так, но всё ещё интересно попробовать развернуть и на второй видюхе тоже, буду дальше пробовать.
> если ты занимаешься неймфажеством и мисдетектишь
Эээ? Ты серьезно себе понапридумывал такого? Ай лол, тогда все проясняется.
Даже не знаю, заслуживаешь сочувствия и поддержки, а все это из-за напряжения и в общем конец года у всех нервный, или же просто сам по себе скандальная истеричка и все что получается лишь естественный ход вещей.
> Air перформит как 12B.
У нас из 12б только мистраль немо, он и не близко к нему.
Моэ из маздайного кринжа что было на заре эволюционировало в годные модели, которые обладают умом и знанием, но при этом как-то доступны для запуска простым смертным или могут работать очень быстро. Зря их хейтишь, из плотных моделей сейчас только тридцаточки выходят по сути.
>Так а зачем мне тратить свое время
Ну если так ставить вопрос, то незачем. Общение на анонимном форуме - дело добровольное. Меня убеждать не надо, я просто попросил подробнее раскрыть свой опыт с этой моделью. Потому что по итогам первого ощупывания впечатления были примерно как у меня. А потом вдруг эир стал "сильно лучше других плотных моделей меньшего размера, вплоть до мистраль лардж". Вот и интересно стало, какие конкретно действия привели к такому улучшению, в чём именно заключается улучшение.
Суть не в сравнении конкретных моделей, а в наблюдении за качеством операций с текстом. И есть определённые градации моделей, с чем справляются, с чем нет. И процент успехов в этих задачах примерно зависит от числа активных параметров, и MoE тут не особо выбиваются из общей закономерности. В частности, Air справляется хуже mistral small 24b - наименьшей плотной модели, которая участвовала в моих недавних сценариях. Рероллишь, рероллишь, надеешься, даже префиллишь - нет, не понимает, что от него хотят, если это сложнее какого-то определённого порога, несёт шизу. А мистраль смолл понимает и делает хоть как-то. Он тоже не всесилен и фейлится на более сложным, но эйр пускает подливу буквально на самом простом. Ну и куда его отнести ещё, кроме как в класс ~12B?
> Эээ? Ты серьезно себе понапридумывал такого?
Нет. Ты напридумывал, что я напридумывал. Ты обратился ко мне как к смайлошизу, я тебя поправил. Это все. Просто напоминаю, что весь сыр-бор начался с того, что ты слова Либо зажрался, либо троллит, либо не понимает о чем говорит. воспринял болезно, твое чсв ущемилось, и вот мы находимся здесь. Кто здесь истеричка-то? Даже после попытки разрядить обстановку ты продолжаешь давить. Ты правда рак этого треда, потому что считаешь нормальным взорваться на ровном месте и сидеть со smug ебалом, давить из себя снисходительность. Это фу.
> я просто попросил подробнее раскрыть свой опыт с этой моделью.
Много описывал, на протяжение нескольких тредов иногда вкидывал свои пасты-рассуждения на тему Air и других моделей. Последнее здесь TL;DR формат карточек очень влияет на аутпуты, и у других моделей я такого не видел. Пожалуй, на сегодняшний день, выбирая из всех доступных моделей до 235б я выберу именно Air, несмотря на его недостатки. Читай прошлые треды, там много обсуждений по этой модели.
> сильно лучше других плотных моделей меньшего размера, вплоть до мистраль лардж
Это не мой пост, Мистраль Лардж я не так долго играл и не могу судить.
Нихуя землетряска. Вахтёр квеношиз опять оче подорвался что кто то смеет энджоить на модельках поменьше? Никогда такого не было и вот опять...
Нюня ругается матом, начался рагнарёк? Хотя я могу его понять, давно игнорю вахтёра
Нюня ругается матом, начался рагнарёк? Хотя я могу его понять, давно игнорю вахтёра
>выбирая из всех доступных моделей до 235б я выберу именно Air,
Он хорош, реально хорош. Слушает инструкции, но с ним, я скоро поверю в мистику. Потому что: просто рандомно он начинает шизить на ровном месте. Без цели, без смысла. А потом ты все перезагружаешь и он выдает кино.
> просто рандомно он начинает шизить на ровном месте. Без цели, без смысла. А потом ты все перезагружаешь и он выдает кино.
У меня нет и не было такой проблемы. Возможно, дело в кванте (например, у меня Q6). Возможно, в том, как ты форматируешь промпт и в целом какие у тебя инпуты. Много факторов. Моя основная проблема была в паттернах и однообразных аутпутах, о чем в линканутом посте выше. Чем помочь - не знаю. Пресеты/карточки шарить не буду. Читай предыдущие треды, приноси конкретные вопросы с примерами, логами и различными подробностями, тогда кто-нибудь да поможет.
>Чем помочь - не знаю.
Тут ничем не поможешь, я юзаю махонькие кванты, так что скорее всего проблема в этом. Просто высказал своё мнение о нейронной магии, не более.
> за качеством операций с текстом
Что под этим понимается? Вполне могут быть ситуации где смол сработает лучше, особенно если выставляются какие-то специфичные критерии. Или в чате в какой-то момент в определенном сценарии одна более крупная модель будет тупить, а другая мелкая за счет другого датасета и распределения внимания сработает хорошо, это нормально.
Но если судить в среднем по больнице в абстрактном рп и каждой из модели обеспечить оптимальный режим работы - за эйром преимущество. Не зря многие как минимум часто его периодически используют если не полностью пересели.
Что в общем до "ума" моэ - самые показательные примеры в виде квена 30а3 и гопоты показали неуместность постановки их в один ряд с плотными моделями размером с их активные параметры.
Тогда уж "все началось" с того неадекватного поста. Ответ на него даже слишком дружелюбный для содержания, указание на неуместность реакции при согласии, даже без прямого обращения к тебе, перечитай.
> попытки разрядить обстановку
А, ты так разряжал, покажешь где? Разряжением мог бы быть спокойный пост о том что ты воспринял ту фразу как оскорбление любимой модели, упустив положительные стороны и сам контекст сравнения со старшей версией. Или что-нибудь шуточное, мемное там. Все то не похоже.
> нормальным взорваться на ровном месте
> Кто здесь истеричка-то?
Заметь, моя позиция стабильна и постоянна. А тебя штормит туда-сюда, набросил@переобулся@набросил@играешь в жертву, и все это вперемешку с платиновыми манипуляциями. Тут же испытал вину и решил в добрячка поиграть.
> Потому что: просто рандомно он начинает шизить на ровном месте. Без цели, без смысла. А потом ты все перезагружаешь и он выдает кино.
Контекстшифт и прочие ускорялки случаем не включены?
Аир у меня единственный кто за запрос истории по моему промту, не просто выдал 80 токенов текста и откис, а написал целое полотно на 5к в одном сообщении, с началом и концом. Реально иногда кино, хорошая моделька.
Ты вообще хотя бы понимаешь предмет спора? Можешь его сформулировать?
> Заметь, моя позиция стабильна и постоянна. А тебя штормит туда-сюда,
Моя позиция в чем заключается? Ты считаешь, я что-то отстаиваю? У меня одна позиция - на Air можно катать вполне серьезные сценарии. Не согласен с этим? Твое право. Показывай, где меня штормит.
вот мой первый пост.
> Либо зажрался, либо троллит, либо не понимает о чем говорит.
Это мое мнение, да. Я так считаю. Ты можешь считать иначе. Никаких оскорблений я в это не вкладывал.
твой недоумевающий пост.
моя попытка в замирение. Чтобы ты в очередной раз не ворвался с тем, что я дохуя серьезный, я поставил смайлик, и весь пост юморной и имеет ровно то, что имеет ввиду. Будь проще, да.
твоя интерпретация моего поста через призму негатива, неймфажество с последующим переходом на личности и оскорблениями.
И что здесь не так? Тебя действительно оскорбила моя формулировка, которую я уже трижды привел? И я теперь, оказывается, истеричка и на лету переобуваюсь? У тебя там все дома вообще? Сейчас я недоумеваю - чего ты доебался и что тебе сейчас от меня нужно? Какие у тебя требования к тому, чтобы закончить, что начал ты сам?
>800* токенов
самофикс
Про механизм общей памяти поподробнее. Как его НЕ ЗАДЕЙСТВОВАТЬ?
>Не давай жоре ничего самостоятельно раскидывать на мультикарте т.е. -ts 1,0 - это правильно. Все не moe тензоры должны лежать на одной видеокарте вместе с "контекстом" . Ибо тензор-паралелелизм не завезли, а трансферы промежуточных результатов компута по писи - это пиздец.
Ты тут не совсем прав, трансферы никуда не пропадут. Вычисления происходят там, где лежат веса - за исключением экспертов при обработке контекста, там цпу веса предварительно копируются на карту. То есть при твоем разбиении при обработке слоя часть компьюта будет на CUDA0, затем он перебросится на CUDA1, чтобы обработать экспертов, затем обратно на CUDA0. То есть ты на самом деле увеличил количество трансферов.
Но что интересно, твой способ я опробовал еще тогда, когда ты (или не ты) приносил его несколько тредов назад, и мне он внезапно дал буст в генерации, но просадил обработку контекста, потому что при генерации там между карт гоняются десятки килобайт, а при обработке контекста - десятки мегабайт на каждый слой, в то время как при обычном разбиении надо перегнать единожды с карты на карту.
В общем, я бы советовал выгружать двумя способами и смотреть, как оно выходит по факту.
Алсо, тут и первым способом (-ncmoe) неправильно выгружают. В большинстве консьюмерских конфигураций первый слот всегда самый быстрый, да еще и процессорный. Поэтому все тензоры для выгрузки надо обязательно выгружать с первой карты. Скрипт, который тут гулял, этого не учитывает, потому что автор не осилил корректное распределение -ts, и выгружает тензоры со всех карт, в результате у вас пойдет по пизде обработка контекста. А я напоминаю, что корректное использование -ts - это не какие-то маняпропорции в вакууме, а количество слоев. Сумма чисел оттуда должна быть равна количеству слоев модели + 1 (output layer). Это значение потом в логах пишется. Поэтому, например при количестве слоев в модели 48, у вас должно быть что-нибудь вроде -ts 25,8,8,8 -ncmoe 19 -ngl 49. И в логах должно быть написано, что 49/49 выгружено на гпу.
Второй способ в соответствие с конфигом выше будет выглядеть так: -ts 49,0,0,0 -ngl 49
И потом регулярки для тензоров (звездочку заменить на обычную):
-ot 'blk\.([0-9]|1[0-8])\.ffn_(up|down|gate)_exps🌠=CPU' // тут выгружаем 19 экспертов на цпу, нумерация с нуля, поэтому оканчиваем 18 слоем
-ot 'blk\.(2[5-9]|3[0-2])\.ffn_(up|down|gate)_exps🌠=CUDA1' // выгружаем 8 экспертов на CUDA1. Эксперты с 19 по 24 включительно остаются на CUDA0, так как мы сказали все слои по умолчанию выгружать на CUDA0. Не написали регексп для слоев 19-24 - они уйдут на CUDA0.
-ot 'blk\.(3[3-9]|40)\.ffn_(up|down|gate)_exps🌠=CUDA2' // выгружаем 8 экспертов на CUDA2
-ot 'blk\.(4[1-7])\.ffn_(up|down|gate)_exps🌠=CUDA3' // выгружаем оставшиеся 7 экспертов на CUDA3. Слоев у нас 49, но последний это output, там нет экспертов, плюс нумерация с нуля, поэтому номер последнего слоя - 47.
Понятное дело, при таком разбиении у вас все не экспертные слои будут лежать на CUDA0, поэтому, возможно, вам придется выгрузить на цпу чуть больше. Либо же на CUDA3 перекинуть еще одного эксперта, там недобор получился (возможно, последовательно лучше будет, сдвинув все регекспы кроме CPU на единицу назад в нумерации).
У меня АМ4 платформа и одна RTX 5080.
Щито делать? Я имею в виду, соскок на проц с быстрой DDR5 и вся надежда на МоЕ модели, или срыгспок на Авито за раздолбанными 3090?
Щито делать? Я имею в виду, соскок на проц с быстрой DDR5 и вся надежда на МоЕ модели, или срыгспок на Авито за раздолбанными 3090?
>Мнение?
Sure, I'll follow your link and share my honest opinion on the contents.
>Exactly what it says on the tin
Заебись, устал уже от трюков маркетолухов.
>Orpo'd Mistral Small 3.2 to remove repetition.
>Trained to reduce infinite repetition, repetition of structure and sentences in multi turn conversation, and repetition within responses.
Похвальное начинание.
>Got really annoyed with all of my Mistral Small test models having repetition issues
Сеймщит бро.
>Produced by doing orpo with Qwen 3 8B
Дожили, 24B тренируется на 8B. Хотя, учитывая последние успехи французов в лоботомировании собственных моделей... через пару лет будем доучивать медиум или лардж об 0.5B.
Qwen3 Next выдает уже 12 токенов на DDR5 (хотя 30б выдает 18, а должно быть все 36=).
Мы близки к релизу (относительно=).
Минимакс М2 выдает 6 токенов (и квен 6 токенов), а должен 12. Надеюсь, скоро релизнут и скорость поправят (и чат тимплейт завезут).
Забавная минимакс на запрос «расскажи о себе» пытается ролеплеить и то Клодом прикидывается, то Чатгопотой.
Но ее главная задача, конечно, не о себе рассказывать.
Как же хочется скорее две хорошие модели на нормальной скорости юзать в нормальном релизе, а не git clone fetch ff. =)
Ну и GLM-4.6-Air осталось дождаться. Если в ближайшее время Геммы 4 не выйдет, то вроде бы и ждать до марта нечего больше.
Надеюсь ошибаться, и нас завалят кучей топовых моделей!
Мы близки к релизу (относительно=).
Минимакс М2 выдает 6 токенов (и квен 6 токенов), а должен 12. Надеюсь, скоро релизнут и скорость поправят (и чат тимплейт завезут).
Забавная минимакс на запрос «расскажи о себе» пытается ролеплеить и то Клодом прикидывается, то Чатгопотой.
Но ее главная задача, конечно, не о себе рассказывать.
Как же хочется скорее две хорошие модели на нормальной скорости юзать в нормальном релизе, а не git clone fetch ff. =)
Ну и GLM-4.6-Air осталось дождаться. Если в ближайшее время Геммы 4 не выйдет, то вроде бы и ждать до марта нечего больше.
Надеюсь ошибаться, и нас завалят кучей топовых моделей!
Нюня, ты заебал троллить тред, то эир невозможный кал, то эпик вин, шизик ебаный

Если это конечно он, а не кто нибудь толстит.
Ну и так-то моделька спорная, местами.
Подскажите какую сетку можно юзать для поговорить на русском языке до 30-32b. Надоел переводчик, который сверху доливает своего слопа.
Забавно вышло, просто использовать одну получилось 4080 немного быстрее по токенам чем в комбинации 4080 + 3070 (10 токенов против 7)
-ot "blk\.([0-9]|1[0-9]|2[0-9]|3[0-3])\.ffn_(up|down|gate)_exps=CPU" ^
-ot "blk\.(3[4-9])\.ffn_(up|down|gate)_exps=CUDA0" ^
-ot "blk\.(4[0-7])\.ffn_(up|down|gate)_exps*=CUDA1" ^
Цпу сетап 64G DDR5 и Ryzen 7 9800X3D
Анонсы, как заставить glm 4.5 air перестать повторять сообщения user'a? Эта падла заебала делать из разряда - The words "слова user" echoed in her mind.
Пресета не будет. Терпи
Подтверждаю что Эир это эбсолют синема
>
>
>Хотя на обоих картах ещё полно места. Любое значение -ncmoe не особо меняет ситуацию. Предположил что влияет мультигпу, но нет, с -ts 1,0 картина та же.
ТС 3,2 по подсказкам кобольта быть может (70/30 разделение)
Юзаю связку из разных ГПУ, буста от второго вообще нет, во ходе экспериментов понял что в ламе параллели нет нихуя, оно тупо память занимает и долбит 1 ГПУ
Заебало. Как теперь качать с обниморды? У меня постоянно прерывается.
Аноны, я правильно понимаю, что использовать Apple Mac Mini (коробка такая)(новый с макс лимитом рамки (3к долларов кажется)) это единственное ПРОСТОЕ решение на данный момент?
Спасибо. Оба варианта заработали.
Похоже, что нейронки последние мозги съедают. Как я сам об этом не подумал?
Нет, самое простое решение - использовать свой собственный имеющийся компьютер.
Проблема в том, только что на собственном компьютере оно nihuya не работает нормально.
>единственное ПРОСТОЕ решение?
Самое простое - обычная пекарня с как можно больше ОЗУ и хоть какой-то видяшкой, хотя бы 3060 12гб. С 64гб оперативки сможешь запускать эйр, со 128гб - жирного квена.
$9,499.00
or
$791.58/mo.per month for 12 mo.monthsFootnote *
Все, я понял, я проебал. Это не Мак мини, это мак студио, Вопрос отпал сам собой.
Проблема только в том, что при переполнении контекста концамерские ЦПУ не справляются. Еще калит то, что нет корректировки ошибок и нормального количества PCI линии.
Я тебе просто напомню, что NPU и предыдущие ускорители от AMD до сих пор официально не работают ни с одной языковой моделью.
Для кого я пост писал блять? Чукча не читатель? Хуй с тобой, пожую и положу в рот, аки птенцу.
57,7 Гб / 47 слоев = 1,22 Гб на слой.
Оставляем по 2 Гб с карты на контекст, получаем:
14 / 1,22 ~ 11 слоев
6 / 1,22 ~ 5 слоев
Но на первую карту уйдет контекст для всех цпу слоев, поэтому на глазок пока оставим 8 слоев. Итого
-ts 43,5 -ngl 48 -ncmoe 36
36 получилось как 43 - 8 + 1, прибавляем т.к. первый слой без экспертов и он не будет выгружаться.
Далее можно накинуть слоец-два на вторую, т.к. из-за аутпут слоя там может быть недобор, плюс последний леер вроде не поддерживается пока еще. Накидываешь слоец - не забудь скинуть с первой: -ts 42,6. Далее можно уменьшать/увеличивать -ncmoe, если на первой карте оомы/недоборы.
Сложнааа, высшая математика ебать.
Второй способ осилишь сам, надеюсь? Если CUDA0 это 4080, то в твоих -ot я как минимум вижу хуету в том, что ты на 16гб карту выгружаешь 6 слоев, а на 8гб - 8. Разве что у тебя контекст с неэкспертными тензорами выжирает 8 гигов, но это как-то мощно. Плюс 8 слоев (точнее 7, раз последний слой не поддерживается) не дохуя ли на 8 гб, не вылез ли ты в шаред мемори? 8/1.22 выходит 6.55 слоев, а ты 7 (а то и 8, если все же поддерживается) ебашишь.
Ryzen AI MAX 395 + ULTRA че-то такое — второй вариант.
Даже планшеты, если хочешь совсем просто.
Математика, ты убиваешь местных анонов. =)
самое прострое решение - купить подписку на чат или прожигать бабло на API на Openrouter
не, можешь конечно въебать 3к баксов. мак мини/студио 64гб минимальная комплектация около 2.5к/3к. или рузен 395 за 2к (1.7к по скидкам есть иногда).
но не проще ли въебать за 200 баксов подписку и через год посмотреть на обновленное железо?
Учитывая как корпы ебут нейрокумеров, только подписка и остается ога. Ты посмотри на болото, вой слышен и в этом треде.
>200
А где это годовая подписка стоит двести долларов?



а на что он надеется за 3к? это:
1) или бомже 64гб мак, или 128гб рузен 395 с 200гб/с - в любом случае ничего серьезного на этом не запустить, или мое q2/q3 или 30б плотная модель
2) или сетап с недорогих видеокарт, тут уже как получится. скорее всего б/у амд с сомнительной поддержкой в будущем, или юзаные на майнинге 3090 или что там. с новыми видеокартами там и 64гб не наберется.
3) можно попытаться 24гб врам и что-то с дохуя рам. но это уже скорее какая-то серверная сборка с 4 каналами, тк 128гб суммарно предел для 2х каналов. но это уже не 3к (можно попытаться найти б/у, но это все на свой страх и риск, таких сборок единицы у анонов с llamacpp)
>А где это годовая подписка стоит двести долларов?
обычно около 20 баксов/месяц, но хз как в рф с подписками. возможно, и не доступно в рф ¯\_(ツ)_/¯
>таких сборок единицы у анонов с llamacpp
таких сборок единицы у анонов с localllama
быстрофикс
>
>а на что он надеется за 3к? это:
Ты заебал, я позже поправил. Не Mac mini, а Mac.Studio.
За девять тысяч я семитысячный сокет от Интела куплю и напихаю туда, блядь, терабайт оперативной памяти.
>обычно около 20 баксов/месяц,
Разве количество Запросов. там безлимитное?
Тише, тише, все это перепробовал уже. Как раз после твоего поста.
При запуске -ts 49,0 оно сразу занимает 10гб на CUDA0, остается 6 гб, вторая карта простаивает с 8 гб, поэтому на ней и выходит больше. Стоит добавить хоть один exps свыше этого ловлю аутофмемори. Это касаемо второго способа. Если посмотришь там все те же расчеты.
А с первым все того хуже, лама сразу падает, к примеру с твоими текущими настройками -ts 43,5 -ngl 48 -ncmoe 36
allocating 48515.73 MiB on device 0: cudaMalloc failed: out of memory
Т.е она пытается скормить в гпу вообще всё. Тут допускаю что упустил ещё какой-нибудь флаг.
UPD. В общем понятия не имею в чем было дело, но пересобрал батник с нуля и оно заработало, вангую какой нибудь системный символ в строке все ломал. Впрочем не то чтобы это что-то меняло, скорость на одном гпу все равно выходит выше на пару токенов.
блять какие же корпонейрошизы отбитые
зачем платить по 20 далларов в месяц на КалГПТ, если чисто для кумерских целей абсолютно дешманский ДипСреньк через API - стоит сущие копейки, этих 20 далларов на год хватит, и качество лучше любых 100B - 200B локальных карликов, и пусть он там хоть в два раза тупее чем КалГПТ, это банально выгоднее при +- том же выхлопе по задачам
Наверное ГПТ и не используется нейрокумерами, нэ? Гопота это же чистый агент и попиздеть.
>Ты заебал, я позже поправил. Не Mac mini, а Mac.Studio.
>$9,499.00
ок, признаю, не обратил внимание на поправку. если без ебли с серверной сборкой/коробки с видеокартами - то да, наверное самый простой вариант
>>обычно около 20 баксов/месяц,
>Разве количество Запросов. там безлимитное?
естественно есть, нужно смотреть провайдера. наверное, даже на планах по 200/месяц есть.
если хочется без лимитов, опять же - OpenRouter. с плюсов - не привязки в модели, платишь только за токены
>если чисто для кумерских целей абсолютно дешманский ДипСреньк через API - стоит сущие копейки
я упомянул OpenRouter, не кипятись
да я не верю, что вы не дрочеры
Вы спускаете бабки на ИИ, чтобы подергать пиструн
Самое дорогое порно в истории человечества.
Вы спускаете бабки на ИИ, чтобы подергать пиструн
Самое дорогое порно в истории человечества.

Да и что?
> хотя бы понимаешь предмет спора
Он изначально был утерян, ведь разговор об одном и том же и даже вроде все согласны.
> интерпретация моего поста через призму негатива
Так уж он был интерпретирован, что обычно содержат подобные "юморные" посты со смайликами и кто их пишет прекрасно знаешь.
> Тебя действительно оскорбила моя формулировка, которую я уже трижды привел?
Нет, кто-то еще оскорбляется на бордах? Я удивлен с реакции на реакцию (на реакцию...) с привлечением этого всего и интересно докопаться до сути. Сам советуешь простоту и прочее, но чекни ветку, неприятно станет.
>если хочется без лимитов, опять же - OpenRouter.
Да, спасибо, наверное, пробую сначала Deep Seek, а потом Open Router. Уж больно не хочется дохера платить.
> трансферы никуда не пропадут
За это чаю. Но единственные существенные по объемы трансферы происходят при стриминге выгруженных в рам весов на основную гпу, активации между слоями очень мелкие и пробрасываются быстро. От того можно получить ситуацию, когда оставление атеншна на основную карту и закидывание на вторую всратую только экспертов дает ускорение даже с кучей лишних пересылов за счет его быстрого обсчета, чем если полные блоки кидать на всратую карточку.
> В большинстве консьюмерских конфигураций первый слот всегда самый быстрый, да еще и процессорный. Поэтому все тензоры для выгрузки надо обязательно выгружать с первой карты.
Это никак не роляет, то на какой карточке тензоры были первыми командами не важно, важно где они окажутся после всех манипуляций. И порядок выгрузки не важен. Можно дать подряд хоть десяток команд регэкспов, "покидав" все веса между разными девайсами, и это не заставить лламу перекидывать их туда-сюда. Они просто парсятся по очереди (и все эти -ngl -cpu-moe лишь просто макросы для них), и программа раскидает по девайсам именно так как получится в окончательном варианте.
> корректное распределение -ts
Не существует "корректного распределения" -ts. Это просто пропорции, по которым слои распределяются между разными девайсами с учетом размера этих слоев и ничего больше, не придумывай.
> -ts 49,0,0,0 -ngl 49
Достаточно будет поставить -ts 1, число может быть любым и не имеет никакого отношения к количеству блоков, и нули не обязательно писать. Если так указать то весь атеншн и кэш окажется на главной карточке (если хватит места). Подобное действительно целесообразно в ассиметричных конфигурациях, с одинаковыми или близкими карточками уже нет смысла. Наоборот немного замедлит из-за лишних вызовов, усложнит размещение, ограничит доступный контекст на больших моделях.
Вспоминая про упомянутый скрипт - он повторяет оригинальную логику распределения слоев в жоре, а потом просто закидывает в каждую гпу экспертов тех блоков, атеншн которых уже есть на карте чтобы избежать обменов, забивая заданный объем под завязку. Можно закомментировать пару линий или дать другую команду чтобы подсчитать регэкспы и под случай закидывания всего на первую гпу а экспертов для остальных, если такова цель.
> Далее можно накинуть слоец-два на вторую, т.к. из-за аутпут слоя там может быть недобор
Оно раскидывает не по номерам а по размерам. Эмбеддинги/голова отличаются по размеру, некоторые модели имеют слои разной структуры и размеров, потому и схема идет нахрен.
Если нужно просто раскидать между карточками аккуратнее - подбирай экспериментально не стесняясь использовать дробные значения, например -ts 41.5,6.5 Но если у тебя еще и эксперты выгружены - лучше не страдать этим а сразу пользоваться регэкспами.
Схуяли это мы не дрочеры, охуел? 170+ тредов как кумуить мы по твоему просто так обсуждаем? Или ты предлагаешь как макака-дебил кодинг какой-нибудь тут обсуждать, в каком подставном бенчмарке какая модель сильнее?
Говори за себя. Исключительно пьем чай и и едим тортики с милыми девочками. Секс переоценен.
Кто там выше по треду хотел мнения про Air от того, что сначала его не вкурил, а потом разобрался и изменил мнение?
В общем, я другой мимокрокодил, чем тот, кого спрашивали. Но про себя ответить могу. Говорю сразу - никакой особой магии не будет - просто общая специфика модели, как ее понял, на основе личного опыта.
Когда оно вышло - потыкал как получилось на q3km (идиот), не впечатлился, и ушел обратно на мистраль с геммой. Но увидев на реддите отзывы, начал что-то подозревать, и решил попробовать еще раз. Скачал другой квант - iq4xs (это то, что на мое железо тоже влазит). Взял простой стоковый таверновский темплейт от GLM4, и начал писать промпты сам. (Семплеры - +- как для мистраля - 0.7-0.9 температура и 0.05 MinP.)
Обнаружил, что Air - весьма специфичная штука. Он работает тем лучше, чем больше ты ему даешь начальный промпт и инструкций - примерно до 2-3K токенов разница наблюдается. Если меньше - либо пишет примитив, либо лупы, либо еще какая хрень происходит. Причем если длинна контекста менее 1K - то практически с гарантией фигню порет.
Фантазии у него "с нуля" - не очень, а вот развернуть какие-то маленькие зацепки из промпта - вполне может в неожиданную, но при этом органичную сторону - шизой не назовешь, логично получается, хоть и неожиданно. Хотя если в промпте шиза - на выходе она же будет. Он к качеству текста в промте очень чувствителен. Лучше всего - если не только без орфо-ошибок, но еще и с хорошим общим стилем текста.
Что касается персонажа - почти то же самое. Лучше всего реагирует на качественно написанный plain text. Разметок не любит, Но если персонажей несколько - заворачивание каждого целиком в отдельный XML тег вида <character></character> или <Name></Name> решает редкие проблемы с протеканием характеристик от одного к другому. Рекомендую. JED формат - тоже можно, но разделы лучше, по возможности, упрощать до plain text, сводя количество списков к минимуму.
Единственная разметка, на которую модель в своем контексте реагирует адекватно - markdown (JED - на ее основе, потому проходит, видимо).
Теперь, что касательно развития персонажа. Если у вас был summary с выпилом предыдущих сообщений из контекста - AIr не очень хорошо врубается в ситуацию, когда персонаж карточки несколько эволюционировал на основе происходившего от исходного состояния. Особенно, если персонаж завернут в XML теги. (Обратная сторона эффективности от протекания). Чтобы до него дошло хорошо, но без необходимости вписывать изменения непосредственно в карточку, желательно блок таких данных касающихся именно персонажа (а не мира в общем) оформить примерно так (вместо плюсов звездочки - это здесь чтоб доска не съела):
++ This is most recent updates for the {{char}}'s behavior, traits, and history, gained though the previous events ++
- {{user}} meet {{char}} a month ago, they got a fight before becoming friends.
- {{char}} got a scar over the right eye after the rat attack on the hunt.
- ...
И так - все, что касается непосредственно персонажа. Если их несколько - можно как одним блоком, так и разными, по количеству персонажей. Обычно пишу в WI запись(и) (постоянный режим, позиция "after char"). Это, пожалуй, единственный случай, где список важен и уместен - других способов работающих так же хорошо именно для этого я не нашел.
Вот с таким подходом - Air выдает качество. Если лениться или готовить контекст на отвали, "И так сойдет"(с) - на выходе тоже мгновенно образуется это самое "И так сойдет", прямо как в том мультфильме. :)
По сравнению с всеядным мистралем, модель можно даже назвать капризной. Используемая разметка (glm или сhatml) - все же вторична. Содержимое контекста - первично. Я даже пробовал убирать разметку вообще - оставлять просто markdown - модель и так работает, лишь немногим хуже. Но только когда контекста более чем 3K.
Все выше сказанное - IMHO и собственные наблюдения/эксперименты.
В общем, я другой мимокрокодил, чем тот, кого спрашивали. Но про себя ответить могу. Говорю сразу - никакой особой магии не будет - просто общая специфика модели, как ее понял, на основе личного опыта.
Когда оно вышло - потыкал как получилось на q3km (идиот), не впечатлился, и ушел обратно на мистраль с геммой. Но увидев на реддите отзывы, начал что-то подозревать, и решил попробовать еще раз. Скачал другой квант - iq4xs (это то, что на мое железо тоже влазит). Взял простой стоковый таверновский темплейт от GLM4, и начал писать промпты сам. (Семплеры - +- как для мистраля - 0.7-0.9 температура и 0.05 MinP.)
Обнаружил, что Air - весьма специфичная штука. Он работает тем лучше, чем больше ты ему даешь начальный промпт и инструкций - примерно до 2-3K токенов разница наблюдается. Если меньше - либо пишет примитив, либо лупы, либо еще какая хрень происходит. Причем если длинна контекста менее 1K - то практически с гарантией фигню порет.
Фантазии у него "с нуля" - не очень, а вот развернуть какие-то маленькие зацепки из промпта - вполне может в неожиданную, но при этом органичную сторону - шизой не назовешь, логично получается, хоть и неожиданно. Хотя если в промпте шиза - на выходе она же будет. Он к качеству текста в промте очень чувствителен. Лучше всего - если не только без орфо-ошибок, но еще и с хорошим общим стилем текста.
Что касается персонажа - почти то же самое. Лучше всего реагирует на качественно написанный plain text. Разметок не любит, Но если персонажей несколько - заворачивание каждого целиком в отдельный XML тег вида <character></character> или <Name></Name> решает редкие проблемы с протеканием характеристик от одного к другому. Рекомендую. JED формат - тоже можно, но разделы лучше, по возможности, упрощать до plain text, сводя количество списков к минимуму.
Единственная разметка, на которую модель в своем контексте реагирует адекватно - markdown (JED - на ее основе, потому проходит, видимо).
Теперь, что касательно развития персонажа. Если у вас был summary с выпилом предыдущих сообщений из контекста - AIr не очень хорошо врубается в ситуацию, когда персонаж карточки несколько эволюционировал на основе происходившего от исходного состояния. Особенно, если персонаж завернут в XML теги. (Обратная сторона эффективности от протекания). Чтобы до него дошло хорошо, но без необходимости вписывать изменения непосредственно в карточку, желательно блок таких данных касающихся именно персонажа (а не мира в общем) оформить примерно так (вместо плюсов звездочки - это здесь чтоб доска не съела):
++ This is most recent updates for the {{char}}'s behavior, traits, and history, gained though the previous events ++
- {{user}} meet {{char}} a month ago, they got a fight before becoming friends.
- {{char}} got a scar over the right eye after the rat attack on the hunt.
- ...
И так - все, что касается непосредственно персонажа. Если их несколько - можно как одним блоком, так и разными, по количеству персонажей. Обычно пишу в WI запись(и) (постоянный режим, позиция "after char"). Это, пожалуй, единственный случай, где список важен и уместен - других способов работающих так же хорошо именно для этого я не нашел.
Вот с таким подходом - Air выдает качество. Если лениться или готовить контекст на отвали, "И так сойдет"(с) - на выходе тоже мгновенно образуется это самое "И так сойдет", прямо как в том мультфильме. :)
По сравнению с всеядным мистралем, модель можно даже назвать капризной. Используемая разметка (glm или сhatml) - все же вторична. Содержимое контекста - первично. Я даже пробовал убирать разметку вообще - оставлять просто markdown - модель и так работает, лишь немногим хуже. Но только когда контекста более чем 3K.
Все выше сказанное - IMHO и собственные наблюдения/эксперименты.
Билять, прописал чтобы глм не жалел юзера и чтобы отыгрывал согласно логике персонажей, так он на всех персонажах, даже тех кто должны ебать юзера только завидев, превратил в холодных чудовищ.
>не стесняясь использовать дробные значения, например -ts 41.5,6.5
И в чём отличие от 83,13?
>с милыми девочками
Педофил детектед.
Удивительно. Аноны пишут, что ГЛМ промтится как не в себя, ты попробовал и он оказывается - промтится.
Представляю как у тебя оторвет жопу, если ты будешь префилом задавать общие правила сеттинга и использовать ризонинг с ним.
> Исключительно пьем чай и и едим тортики с милыми девочками.
А потом секс!
> И в чём отличие от 83,13?
Ни в чем, нужно делать как удобно.
Господа у кого более одной гпу и кто не ленивый, прошу провести следующий тест на жоре:
1 Загрузить все на основную карточку (-ts 1 или регэкспами), потом уже докинуть сколько помещается экспертов в другие, остальное на процессор
2 Распределить все равномерно ровным слоем (и -ts и экспертов)
3 Написать какая генерация и какая обработка в обоих случаях и какие девайсы используются
>Педофил детектед.
Это 70 летние феечки, так написано на тоховики. Некоторым вообще 300 лет, так что всё честно. Ну а то что они похожи на детей.. так совпало.
> следующий тест
Не обязательно грузить все под завязку, главное чтобы в обоих случаях количество выгруженных экспертов было одинаково.
> летние феечки
> Некоторым вообще 300 лет
Культурненько
Перетестил минимакс м2, 9,8 токенов на чистом проце, 13,8 на тесле п40 (--cpu-moe), третий квант.
Уже неплохие результаты, но чтение контекста все еще очень грустное, конечно.
Но с таким хотя бы генерить можно уже достаточно бодро.
Если бенчи соответствуют реальности, то кодерская модель хорошая.
Уже неплохие результаты, но чтение контекста все еще очень грустное, конечно.
Но с таким хотя бы генерить можно уже достаточно бодро.
Если бенчи соответствуют реальности, то кодерская модель хорошая.
Ну а по самой модели что ? Как пишет, что пишет ?
>Ну а то что они похожи
По закону даже старухи одевшиеся в школьниц и кривляющиеся перед камерой выдавая себя за ребёнка / любые другие графические или карикатурные цирковые изображения изображающие детей, либо каким-то другим способом включая текст - подпадают по статью.
Да времени не было особо, да и я не хочу, пока не релизнут полноценную поддержку.
Так что пока хз. Как выйдет и кванты устаканятся, надо будет какой-нибудь mxfp4 проверять хорошенько на разных задачах.
Благодарю вас за ответ, анон. Вы получаете кошкожена в карму при исекае.
>скорость на одном гпу все равно выходит выше на пару токенов.
У меня, конечно, DDR4, но я не поверю, что у тебя настолько пиздатый процессор и память, что они дают пососать 448 GB/s от 3070 при генерации. Либо опять что-то упускаешь, либо в жоре говняк. -sm layer надеюсь пишешь?
>активации между слоями очень мелкие и пробрасываются быстро
20 мегабайт на батч при обработке контекста, например. Не то чтобы уж мелко. При генерации 20-30 килобайт.
>Это никак не роляет
Ты неправильно понял. Если ты пользуешься первым способом, но выгружаешь на цпу тензоры со всех карт, то во время обработки контекста они будут прилетать на ту карту, откуда они были выгружены, а не на первую. Условно говоря, у тебя четыре карты в режимах х16,x4,x1,x1. Будешь выгружать со всех - будешь ждать, пока гигабайтный тензор пропердится с RAM по х4 и тем более х1 шинам.
>Это просто пропорции
Можно их использовать как пропорции, но этим ты будешь стрелять себе в ногу, дойдя до дрочения дробей, как ты предложил ниже, и все равно будешь страдать, ведь перед глазами будут абстрактные числа, а не привязанные к реальности. А реальность - это именно количество слоев per device, можешь проверить, если такой фома. И не надо ничего дополнительно выдумывать, ведь
>Оно раскидывает не по номерам а по размерам
это ложь, слои выгружаются последовательно на девайсы так, как указано в -ts. Я тебе даже открою америку, что ты можешь управлять этим порядком, задав порядок девайсов через -dev. Я уже десятки раз занимался выгрузкой больших моделей на больших конфигах со смешанными бекендами, и говорю экспериментальные факты. Упрешься ли ты в свои предрассудки или откроешься к новым знаниям - это уже решать тебе.
>слои разной структуры и размеров
Да, бывает такое, в маверике, например. Но там тоже нет хаоса, слои с экспертами и без чередуются, просто тогда примерно посчитай, сколько весит слой с экспертами и без (обычно без них они намного меньше) и ассоциируй с девайсом только четное или только нечетное количество слоев. Все решается, если ты понимаешь, как все устроено, а не как обезьянка дрочишь пропорции. И вообще, обниморда - твой лучший друг, все, что касается слоев, там удобно смотреть.
Это довольно просто сделать под виндой причем двумя способами: 1. запретить использовать конкретному бинарию (llama-server, pyton) через панель управления Nvidia "резервную память" . Тогда превышение VRAM закончиться OOM. Довольно не приятно если запихал что-то в притык, и оно на большом контексте вдруг дало течь и оподливилось. Зато точно никаких потайных манипуляций по писи не будет.
2. не лазить в настройки и глазами смотреть в диспетчере задач что подозрительно много "общей памяти графического процессора" стало использоваться. В принципе если там будет до 500 мб ничего страшного - это жора просто вытеснила в рам UI винды, хром...
А как оно под пингвином не скажу ибо не знаю.
>под пингвином
Странно, если бы ты знал, иначе я бы подумал, что с нами в треде сидит яйцо пингвина или полярник-пассив-зоофил.
Вот на линухе такой хуйни в принципе нет, поэтому оомы всегда.
>полярник-пассив-зоофил.
Ассоциации у тебя охуительные конечно.
> 20 мегабайт на батч при обработке контекста, например
Это совсем немного и даже с дефолтным батчем 512, который стараются повышать при выгрузке по другой причине, пересыл будет единицы раз в секунду * число слоев или меньше.
> Ты неправильно понял.
Действительно неправильно, подумал что ты про другое. Но
> то во время обработки контекста они будут прилетать на ту карту, откуда они были выгружены, а не на первую
"С какой карты" ушел тензор при задании в параметрах регэкспов жоре вообще не важно. Весь ход активаций - буквально форвард, если эксперты блока выгружены на цп а атеншн на одной из гпу, то обмен будет происходить ровно с этой карточкой, где находится атеншн блока. Если атеншн на одной карте а эксперты на другой - будет прыгать туда-сюда. Хз, может ты это и имел ввиду, но похоже что другое.
При обработке чуть иначе, там идет поочередная подгрузка весов что на проце на главную карточку и обсчет там. Именно ее шина выступают главным ботлнеком по обмену при частичной выгрузке во время обработки. Там даже с х16 5.0 по дефолту все упрется в псп шины, если поднять батч контекста до 2048-4096 то уже будет ролять мощность карты. На другие карты веса не грузятся, только ходят активации и не смотря на больший размер каждой их частота обмена ниже.
По поводу пересыла активаций - х1 скорее всего действительно дадут импакт, тут нужно чтобы кто-то затестил. Но чипсетные х4 (которые будут использоваться по очереди) скорее всего уже окажутся пренебрежимыми, стоит тоже проверить на более медленных версиях.
Собственно, главный вывод - на равноценных картах целесообразно делить все поровну и пользоваться принципом "эксперты там же где и атеншн" чтобы избежать пересылов (также позволит вместить больше контекста если не лезет в одну). На сильно отличающихся по мощности наоборот лучше закинуть атеншн (или его большую часть) на основную, потому что там сам его расчет на медленной карте даст большее замедление чем пересылы. С шинами сложнее, но простая 4.0 х4 разницы с х16 не дает при различных конфигурациях раскидки, цифры идентичные получаются.
Не поленись, поучаствуй я сам уже некоторые замеры собрал в том числе с ассиметрией и разными шинами, довольно показательно. Но интересно как это будет на разном железе и с другими факторами.
> Можно их использовать как пропорции
Да просто никак иначе ты их использовать и не сможешь. Залезь в код и включи полный дебаг чтобы оно показывало что куда отправляет. С большой охотой оно дербанит блоки на куски разделяя их компоненты по разным картам, и правильно делает, иначе дискретность была бы совсем ужасающей. Если нужен четкий контроль - через -ot.
> это именно количество слоев
> это ложь
Не ложь, загляни в код. То что ты называешь "слоями" на самом деле блоки, отсюда и blk, а то обозначение просто прижилось у обывателей и потому оставили. В каждом блоке много слоев и они бывают разными в разных частях, как минимум в любой ллм есть еще эмбеддинги-голова.
> просто тогда примерно посчитай, сколько весит слой с экспертами и без (обычно без них они намного меньше) и ассоциируй с девайсом только четное или только нечетное количество слоев
Этим ты сильно повышаешь дискретность и соглашаешься со мной по принципу работы.
Главный исход всего этого - рекомендация по размещению слоев для максимального инфиренса и повышение грамотности. Вот к этому и надо стремиться.
> это ложь, слои выгружаются последовательно на девайсы так, как указано в -ts
Может ты подумал что там речь о размерах врам девайсов? Нет, имеется ввиду что жора делит все последовательно идущие слои ровно так как они стоят в заданных пропорциях -ts и их так распределяет по девайсам, а уже потом вступают регэкспы и прочее. И разумеется значения в -ts являются определяющими, все как там указано, просто не привязано к номерам.
Ради интереса можешь большой немотрон попробовать раскинуть, там то еще веселье из-за капитальной разницы в некоторых блоках.
> атеншн на одной из гпу
Я имел в виду, когда слои (ну или блоки, как тебе удобнее, я в мл не шарю, сказано в -sm layer что слой - говорю слой). Т.е. например -ts 25,8,8,8
В этом случае, если через -ot выгружать тензоры со всех четырех карт, то они и будут при обработке копироваться обратно на свою карту (потому что остальные тензоры блоко-слоя, нужные для вычислений, лежат на этой карте). По крайней мере, я так думаю, лично не довелось проверить, потому как никогда не выгружал тензоры на цпу c вторых и далее карт. Могу глянуть, если тебе нужны будут пруфы.
А если -ts 49,0,0,0 - базара нет, там все на первую должно идти, потому что все слои-блоки привязаны за CUDA0 (можешь в логе жоры смотреть, какой слой к какому девайсу привязан)
>Не поленись, поучаствуй
Дай модель, такую, чтобы на две карты 24гб и цпу хватило, бОльшее мне лень запускать для тестов. У меня вот осс 120 скачена, она норм будет или все результаты зашкварятся об mxfp4?
>С большой охотой оно дербанит блоки на куски разделяя их компоненты по разным картам
Не знаю, у меня никогда не дербанило, запускал глм, квены, дипсик, маверик - все всегда соответствовало блокам-слоям и их размерам.
>просто не привязано к номерам.
К номерам понятное дело не привязано, но и к размеру тоже. В общем, что перетирать из пустого в порожнее, попробуйте сделать так, как я написал в исходном посте, чтобы сумма чисел в -ts соотвествовала числу слоев/блоков в ггуфе. Если где-то размер на карте будет отличаться от ожидаемого - то буду разбираться. Контраргументы тащите, в общем.
>Ради интереса можешь большой немотрон попробовать раскинуть
не, нахуй надо, там же реально почти хаос в размерах блоков, насколько я помню. И по отзывам это суперассистент не для рп, так что ну его.
> я в мл не шарю
Вообще без претензий, спасибо что уже что-то делаешь.
> выгружать тензоры со всех четырех карт, то они и будут при обработке копироваться обратно на свою карту
Да, это как раз именно тот кейс. Атеншн и другие на гпу -> эксперты на цп -> атеншн+ на гпу -> эксперты на цп.
> А если -ts 49,0,0,0 - базара нет, там все на первую должно идти
Если соответствующие эксперты на цп то хорошо, а если на других гпу то получится attn (cuda0) -x16-> cpu -х1-> exps (cuda1) -x1-> cpu -x16-> cuda0, то есть каждый раз когда обсчитываются какие-либо слои на карте с хреновой шиной придется к ней обращаться и испытывать все задержки. А если та карточка не картофельная а сама может считать атеншн - лучше пусть он на ней и остается, тогда вообще не будет пересылов.
Но вот сейчас ты хорошую штуку в целом подметил. Возможно самым оптимальным окажется вариант, где на дополнительные гпу будут в приоритете выгружаться именно целые блоки, чтобы избежать пересылов, а уже атеншн экспертов что на цп будут в главную гпу. Тогда не будет проблем как у тебя что грузишь все в первую и будет пересыл между карточками, но при этом сохранится преимущество что пересыл после расчета на цп будет идти по самой жирной шине. Нужны более подробные тесты на чипсетных медленных шинах как это влияет. На х4 4.0 процессорных разница на уровне рандома между свайпами.
> Дай модель, такую, чтобы на две карты 24гб и цпу хватило
Да любое моэ, тот же эйр, квен,, хоть 30а3. Просто последняя будет не показательна ибо слишком высокая скорость, прочие факторы начнут ролять.
> она норм будет или все результаты зашкварятся об mxfp4
А хз, но как раз прогони.
> К номерам понятное дело не привязано, но и к размеру тоже.
Когда в последний раз глядел, оно именно брало размер каждого слоя и уже с учетом этого осуществляло деление. Ну ты посмотри в код, вдруг я напиздел или там что-то поправили (крайне маловероятно).
> сумма чисел в -ts соотвествовала числу слоев/блоков в ггуфе.
Слишком высокая дискретность и недозагрузка гпу получится. Так еще оно почти 100% раздерет граничные блоки на отдельные слои и они как-то там лягут.
Хорошо одно - все эти пересылы на самом деле оче малый вклад вносят, за исключением стримминга весов в основную.
> там же реально почти хаос в размерах блоков
О том и речь. Сами блоки поделить вообще не проблема, она вылезает когда выделяются буферы под контекст. Там где нет аттеншна - нет и буферов, есть пачки мелких блоков которые жрут много кэша, есть огромные целиком линейные куски, которые сами большие но ничего дополнительно не требуют.
> суперассистент не для рп
Это не мешает ее трахать, бессмысленно и чисто для ачивки разумеется
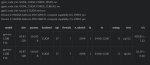

>Когда в последний раз глядел, оно именно брало размер каждого слоя и уже с учетом этого осуществляло деление.
Мб, я в код туда не заглядывал, но допускаю, что это может быть побочным поведением текущей логики кода.
Прогнал осс на обоих способах. Как и с большим глм палка о двух концах - либо выигрываешь в генерации, либо в обработке. Первая карта на х16, вторая на х4 (только не знаю чьи, это райзер с основного m.2, вроде там тоже процессорные, по идее).
Первый скрин с -ncmoe 11, почему-то не вывело это. Второй без этого аргумента. Забивал карты экспертами/слоями до упора
в целом всё так, разве что всё же лучше использовать его родной шаблон, на чат-мл он несколько хуже, и периодически высирал в чат чеги чат-мл, на родной разметке пролем не было
Вопрос. Что использовать для того чтобы общаться с моделью в v1/chat/completions формате, но так чтобы там корректно работал вызов инструментов?
Попробовал KoboldCPP: он корректно форматирует сообщения из одного формата в другой, но там не форматируются сообщения для модели, которые говорят какие оно инструменты вызвало. В итоге лол модель знает что ему пришли ответы от инструментов, но что было использовано в качестве аргументов оно берёт из жопы.
Попробовал text-generation-webui: он корректно читает jinja2 темплейты которые идут с моделью, но там в качестве инструкции может идти хер знает что, что задаёт модели свой собственный формат аутпута, который разумеется не будет парсится в chat/completions. Например OSS в какой-то ChatML подобный формат даёт аутпут, Qwen Coder 30b вообще в XML формате даёт вызов инструментов. если просто выберу например ChatML формат то там вообще информация о самих инструментах не передаётся.
Я уже даже не уверен что мне использовать. Я конечно могу и сам формировать сообщения целиком и просто пользовать чат комплишен, но ёбана. это под каждую модель его подгонять
Попробовал KoboldCPP: он корректно форматирует сообщения из одного формата в другой, но там не форматируются сообщения для модели, которые говорят какие оно инструменты вызвало. В итоге лол модель знает что ему пришли ответы от инструментов, но что было использовано в качестве аргументов оно берёт из жопы.
Попробовал text-generation-webui: он корректно читает jinja2 темплейты которые идут с моделью, но там в качестве инструкции может идти хер знает что, что задаёт модели свой собственный формат аутпута, который разумеется не будет парсится в chat/completions. Например OSS в какой-то ChatML подобный формат даёт аутпут, Qwen Coder 30b вообще в XML формате даёт вызов инструментов. если просто выберу например ChatML формат то там вообще информация о самих инструментах не передаётся.
Я уже даже не уверен что мне использовать. Я конечно могу и сам формировать сообщения целиком и просто пользовать чат комплишен, но ёбана. это под каждую модель его подгонять


В чем смысл рпшить на русском, если это почти в 3 раза менее эффективно, даже если бы модельки этим русским владели в полной мере? Чтобы выразить одну и ту же мысль требуется в 3 раза больше контекста и в 3 раза больше вычислений.
чтобы ловить базу, а не кринж. например хочется ебать руссов, будучи чертем, или ящериком. и как тут на английском то РПшить?
> на чат-мл он несколько хуже
У меня обратная ситуация, на ChatML гораздо лучше.
> периодически высирал в чат чеги чат-мл
Какие? <im_end>? Нужно правильно настроить сепараторы, и не будет проблем.
Впрочем, модель с кучей нюансов и чувствительна даже к формату карточек, потому у всех опыт и отличается, похоже.
> Взял простой стоковый таверновский темплейт от GLM4
У GLM 4.5 другой шаблон разметки. Лучше перепроверь, может будет еще лучше на правильном шаблоне или на ChatML.
Анонам пора придумать новый русский без окончаний и кучи приставок, чтобы интегрировать еблю с ящерами в более технологически дружелюбную и эффективную языковую среду.
Лол ну чисто технически можешь надеяться что DS OCR пойдёт дальше в массы и там всю хуйню юникода обменяем на пососность визуальных токенов. а с ними не так и важно что у нас за язык в качестве инпута.
Котаны помогите!
Я конечно извиняюсь за оффтоп, но как нынче аноны обходят блокировку?
С хагина больше не качает никаким способом, никакие браузерные прокси больше не работают, всё пизда.
Всё работает, йобана блять
Спасибо Брат-кобольд!
Щас попробую.

Брат-кобольд зачем обманываешь, не качает нифига же, ничем не отличает от того что браузером пытаюсь скачать. Скачка начинается и скорость тут же падает до нуля и на этом всё.
Второй способ значит делай, лентяй ёбаный. В посте так и написано что если первое не работает то второе норм
Раз тут все такие знатоки Air, у меня есть ряд вопросов:
какой формат карточек лучше, используете ли вы ризонинг и если используете в каких сценариях он нормально себя показывает, кто убил Кеннеди. И размет... А стоп, вот же ответы
Но вопрос с ризонингом остается. Он прям хорош, слушает префилы и умница, но как и любой ризонинг он выдает размышлений на 1.5к, чтобы пукнуть два абзаца. Вот именно это как то фиксится ?
какой формат карточек лучше, используете ли вы ризонинг и если используете в каких сценариях он нормально себя показывает, кто убил Кеннеди. И размет... А стоп, вот же ответы
Но вопрос с ризонингом остается. Он прям хорош, слушает префилы и умница, но как и любой ризонинг он выдает размышлений на 1.5к, чтобы пукнуть два абзаца. Вот именно это как то фиксится ?
>но как нынче аноны обходят блокировку?
Уезжаем в страны без блокировки. Можешь ещё на баррикады пойти, тоже помогает.
>Но вопрос с ризонингом остается.
В РП нинужен.
>В РП нинужен.
Я придерживался такого же мнения, так как ризонинг других моделей всё херит. Но тут другая ситуация, он прям хорош. Он вытаскивает сложносочиненные сцены. Несколько персонажей + действия с подтекстом + сложный контекст(условно, персонаж выдает False, когда истинные намерения true).
>Можешь ещё на баррикады пойти, тоже помогает.
Я прошу, без политики, все всё понимают, но нас тут интернациональная группа сидит, объединенная общим хобби. Хоть тут давайте любить друг друга и своё увлечение.
>У меня, конечно, DDR4, но я не поверю, что у тебя настолько пиздатый процессор и память, что они дают пососать 448 GB/s от 3070 при генерации. Либо опять что-то упускаешь, либо в жоре говняк. -sm layer надеюсь пишешь?
Не писал, я вообще кобольд, только на чистую ламу перелез.
Вот строки если интересно, обе карточки забиваются почти под ноль.
llama-server --model "GLM-4.5-Air-Q3_K_M-00001-of-00002.gguf" -ts 42,8 -ngl 48 -ncmoe 34 -sm layer --ctx-size 24576
llama-server --model "GLM-4.5-Air-Q3_K_M-00001-of-00002.gguf" -ts 49,0 -ngl 49 -sm layer ^
-ot "blk\.([0-9]|1[0-9]|2[0-9]|3[0-3])\.ffn_(up|down|gate)_exps=CPU" ^
-ot "blk\.(3[4-9])\.ffn_(up|down|gate)_exps=CUDA0" ^
-ot "blk\.(4[0-7])\.ffn_(up|down|gate)_exps*=CUDA1" ^
--ctx-size 24576
Никакой разницы в скорости генерации, и ни в одном из способов. Но стоит отрубить вторую видюху --device CUDA0 получаю прирост 2-3 токена.
Сетап уже кидал 4080/3070/DDR5-5600/Ryzen 7 9800X3D
Хз возможно он что-то лишнее по шине гоняет из-за чего идет просадка, либо я ещё чего-то не знаю.
Какой блять второй, еще раз перечитал шапку, нет там никакого первого и второго! Вообще такое чувство что всё у людей заебись, только у меня проблемы. Может у меня кукуха уже поехала на нейронках.
Блять чел в посте который я тебе линканул ДВА способа, ты попробовал один
>Какой блять второй
Если не помогает, то как анон написал, добавляй cas-bridge.xethub.hf.co и huggingface.co в списки запрета/goodbyedpi/трибуквы или что еще ты там используешь.
Анонче, а попробуй эти кванты. Мне прям дико доставили. Не знаю уж, как он их квантовал, но получились умницы.
Звучу наверно как какой то культист поех.
https://huggingface.co/ddh0/GLM-4.5-Air-GGUF
>>Я прошу, без политики, все всё понимают, но нас тут интернациональная группа сидит, объединенная общим хобби. Хоть тут давайте любить друг друга и своё увлечение.
Всё верно говоришь, но не многие понимают к сожалению.
Ребят помогите скачать с хагина, поделитесь как обходить блокировку!!!
Если ты про этот goodbyedpi, то он у меня не фурычит, я скачал, запустил даже ютуб не работает на нем.
>Ребят помогите скачать с хагина, поделитесь как обходить блокировку!!!
Если у тебя прям заблокировано, то VPN или всякие goodbyedpi, написали же. Нет волшебной cmd строки, которая тебе разблочит всё. Увы, блять, такое говно.
>Но вопрос с ризонингом остается. Он прям хорош, слушает префилы и умница, но как и любой ризонинг он выдает размышлений на 1.5к, чтобы пукнуть два абзаца. Вот именно это как то фиксится ?
1. Фиксить в машине то, что она ездит - это странно. Ризонинг должен так работать - он так и работает. С общими нюансами Air разумеется - ему нужно сначала иметь с чем работать, и чтобы там в исходных - взаимоисключающих параграфов и просто шизы не было.
2. В (е)РП - в ризонинге смысла практически нет. Это не логическая задача, чтобы над ней раздумывать. Так что просто не использую. За исключением начала сцены - там можно разок включить, чтобы модель получше ухватила нюансы. А потом - строго в off.
Вышенаписанное - тоже IMHO.
>Анонче, а попробуй эти кванты. Мне прям дико доставили. Не знаю уж, как он их квантовал, но получились умницы.
Кстати, спасибо, что напомнил. Уже месяц как собирался попробовать, да все отвлекался. Теперь поставил на закачку.
(мимокрокодил).
А как он их квантовал - судя по описанию, основной роутер/общий эксперт там в FP8 - вот и качество управления остальным оркестром повышенное.
В школьный хор пришел дирижер национального уровня. :)
>А потом - строго в off.
Я так планировал ЕРП, но тут Air с ризонингом решил, что персонаж который описан парой строк станет ВОТЭТОПОВОРОТОМ. И прямо во время свадьбы, этот персонаж поворачивается к {{user}} и выдает: "Знаешь, darling, власть и союзы как песок, могут утечь сквозь пальцы" и тут начинается резня. Литералли красная свадьба, только где невеста решила забрать всю власть себе, лул.
Какое же кино порой выдает, 10 из 10.
>там можно разок включить
Но в целом, по похожей схеме. Спасибо за ответ анон.
>В школьный хор пришел дирижер национального уровня. :)
Для меня нищугана, эти кванты стали спасением. Кратно меньше шизы.
Тому кто их принес изначально, вот прямо ОХУИТЕЛЬНО БОЛЬШОЕ спасибо.
>чтобы пукнуть два абзаца.
По моему опыту айр выдаёт сообщения примерно такой же длины, как уже были в чате. Если там короткие, генерирует короткие. Если там простыни -то такими же и отвечает. Из них же берёт и форматирование текста и успешно работает с любым логичным-однообразным.
>чтобы ловить базу, а не кринж
Мне лично для этого как раз на англюсик укатываться приходится. А в текущих реалиях с текущими нейросетями и выбора особо нет, на русике пишут как на англюсике, все те же паттерны видны, так что получается сразу дабл кринж.
Дарова пасаны. Давно не заходил, что за МОЕ? Можно как-то запустить те самые модели для шейхов на обычной карте? У меня вообще 64гб рам есть.
Через что аноны нынче запускают? У меня как убабуга сломалась намертво я на лламе сидел.
Через что аноны нынче запускают? У меня как убабуга сломалась намертво я на лламе сидел.
>Ребят помогите скачать с хагина, поделитесь как обходить блокировку!!!
Не молчим, форумчане, делимся рабочими способами обхода блокировок!!!
Тебе уже ответили. Не хочешь гудбайдпи настраивать или пень накатывать тогда терпи
CIA niggas glow at night
Впн себе купи лол. Сходи в /s/ спроси как.
Это может быть локальный эффект гопоты - у нее по экспертным блокам структура:
blk..ffn_up_exps.bias
blk..ffn_up_exps.weight
И как раз в зависимости от того где оказывается bias тормозит либо генерация либо обработка. См:
https://github.com/ikawrakow/ik_llama.cpp/pull/829
Знаешь, тебе не отвечают не потому что всем похуй, а потому что ЭТО УЖЕ БЛЖАД РАЗЖЕВАЛИ. Прям в прошлом треде. И тут обсуждают. Почитай и не ленись.
> Звучу наверно как какой то культист поех.
Да тут всех засирают, но нюанс в том, что ты даешь годные советы, а поехи — они, кому ты так звучишь.
А на деле ты звучишь как человек, который хорошее дело советует. =)
Вот бы теперь понять, на русском лучше новые версии с его матрицами важности, или же старые, от бартовски?.. Не в курсе, не пробовал?
llama.cpp
Самая, что ни на есть, оригинальная, и никакого говна с обертками.
Модель например вот https://huggingface.co/ddh0/GLM-4.5-Air-GGUF
Там как раз есть для 64 гигов с видяшкой норм.
Главное при запуске выучить команду --cpu-moe -ngl 99 и будет тебе счастье, ну и подробнее почитай об этом.
Блин ну я знаю что там в прошлом треде было то? Кинул бы пост просто.
>Главное при запуске выучить команду --cpu-moe -ngl 99 и будет тебе счастье, ну и подробнее почитай об этом.
Запускать на лламе я плюс минус научился. Подскажи лучше где можно прочитать про мое? И какого кол-ва токенов/сек ожидать на средней ихравой карте если знаешь.
>Вот бы теперь понять, на русском лучше новые версии с его матрицами важности, или же старые, от бартовски?.. Не в курсе, не пробовал?
Понятия не имею. Я не вижу смысла в использовании русского языка на локалках. Модельки выдают сухой текст, не используют словесные обороты, да и в целом, текст напоминает буквальный перевод. Да и меня на какой то испанский стыд пробивает, когда я вижу ерп на русском, какой то стульчик.нет, а не порно проза.
Короче, стучу хуем по столу и нервно восклицаю: доколе бездушная машина будет использовать такой посредственный слог.
>Блин ну я знаю что там в прошлом треде было то? Кинул бы пост просто.
Я зайду в тред через пол года
И эир 4.6 до сих пор будет в разработке
И эир 4.6 до сих пор будет в разработке
Заи должны понимать что чем дольше ожидание тем больше требований к модели
Кормите завтраками там сделайте заебись
Или огромный удар по репутации
Кормите завтраками там сделайте заебись
Или огромный удар по репутации
Чтоб тебя долбоёба иссекайный грузовик сбил и ты переродился в эльфийку в плену у гоблинов.
А я и не против.
А толку? Ты так и продолжишь терпеть, ведь у тебя скилл ишью и даже превосходный эйр 4.5 ты не можешь раскрыть. Думаешь все будет иначе?
ты же буквально будешь маткой рожать личинки по кд, жрать их блевоту и срать под себя бля, чё это я рекламирую харкачеру лучшую жизнь чем сейчас у него, просчитался
> просчитался
Ага. А самое главное - ему же думать вообще не надо будет. :)
Расскажи подробнееи что где находится и как раскидывал, как можно распределить между мультигпу только с -ncmoe не прибегая с жесткой ассиметрии -ts и ювелирным подбором?
В первом случае атеншн на ампере, далее блоки напиханы туда же и в тьюринг (сколько куда?), во втором аттеншн поровну (?) и блоки также (то же количество?)?
Может тут еще нюансы гопоты как пишет.
Когда 2 карточки одинаковые скидывания фулл атеншна на первую и 5 блоков из 20 (16 на вторую) или деление всего пополам дают практически одинаковую скорость. Беря второй за референс, сосредоточение атеншна дает -4% генерации +3% обработки контекста. Эффект небольшой, для большинства случаев можно рекомендовать избегать лишних пересылов.
Если 2 карточки разной мощности, примерно в 1.5 раза по компьюту и псп (раскидка та же), то сосредоточение уже дает больший прирост по обработке контекста (+14%) генерация даже немного ускоряется но на уровне рандомайзера (+2%), для ассиметричных уже можно подумать. Что x16 что x4 +- все одинаковое. Но, в таком случае уже контекст ограничен.
С тремя карточками уже замедление генерации чуточку больше, но на том же уровне, обработка уже не растет.
Это подтверждает выводы, твой результат также ложится туда если раскинуто похожим образом, разве что нет ускорения от более мощной карты в обработке. Если раскидка иначе то нужно смотреть.
Пока получается что для максимальной генерации между одинаковыми/близкими картами лучше делить блоки целиком чтобы атеншн был там же где и эксперты, а в варианте мощная + картофельные наоборот на картофельную атеншн не кидать чтобы не замедляла, это будет хуже чем обмен по шине. С тем куда кидать атеншн блоков у которых эксперты на профессоре надо экспериментировать.
>Теперь поставил на закачку.
Кто хочет - можете тыкать пальцем в дятла.
Три часа качал. Перед запуском решил порядок навести. Перепутал с другой (не нужной) моделью и стер. "Идиёт"(с) Дядя Миша (Артист).
Качаю заново...
От ето юморист! Хехе
Ну, в треде и читать.
Смотри, короче.
Видеокарта? Не, МоЕ ты запускаешь на оперативе, друг мой дорогой. ))) Так что, спрашивай, сколько ты получишь на оперативе.
Смотри, знаний в МоЕ — как в большой модели. Но думают одновременно только активные параметры. Есть модель-роутер и несколько общих слоев, которые грузятся на видяху (это дает ускорение условных 30% модели), а остальное крутится на оперативе.
Например, аир имеет 12 миллиардов активных параметров. Это значит, что ты получишь скорость, как если бы запускал 12б модель (из которой часть на видяхе, да). При этом, знает она на 106б, и может писать разнообразнее.
Но при этом она не настолько логична-умна-мудра как денс 106б модель была бы.
Компромисс между скоростью, умом и объемом памяти.
Но в среднем люди имеют от 8 до 16 токенов в секунду. Условно говоря, это ~50б модель по качеству. 10 токенов в секунду 50б модель за 64 оперативы и обычную игровую видеокарту — весьма годно! Не надо брать 3090, собирать риги из 2-3 видях, чтобы набрать 48-72 гига видеопамяти.
Но на вкус и цвет, все еще есть гемма-ценители, немотроно-ценители, мистрале-ценители и прочие не-любители МоЕ-моделей.
96 гигов позволят замахнуться на Qwen3-235b-a22b (ну или Minimax M2, лол).
128 гигов позволяет запустить GLM-4.6-355b-a32b.
При этом, глм будет не сильно медленнее квена. У меня на чисто оперативе квен выдал 5 ток/сек, глм 4 ток/сек. Это на дохлом i5-13400. С норм процом и с норм видяхой будет за 10.
> Условно говоря, это ~50б модель по качеству.
Лично я даже сказал бы, что вывод будет разбросом с аналогом плотных примерно от 30 до 70B по качеству. MoE - несколько хаотичны по натуре. В отдельных случаях может выдать прямо совсем шик, и следующим же ответом - примитив. Как повезет с раскладкой по экспертам, видимо. Может несколько обескураживать, и явно не всем нравится такой разброс.
>Расскажи подробнееи что где находится и как раскидывал
Так на скрине все параметры запуска прописаны, читай значения столбцов. Ассиметрия в -ts там есть, на фуллгпу три карты раскидывается как 12,12,13, на две - уже 24,13 с -ncmoe. Первый скрин все поровну в т.ч. и аттеншен, во втором все лежит на cuda0, а часть экспертов - на цпу или cuda1
кочаю эир 5 квант, посмотрим
быстрофикс
> Не надо брать 3090, собирать риги из 2-3 видях, чтобы набрать 48-72 гига видеопамяти.
Лукавишь. Если вопрос именно про "брать" то одна 3090 это входной порог и выбор чемпионов. Если гпу уже есть, то обычно ее и используют, но то что ниже уже компромиссы.
С точки зрения повышения скорости добавление дополнительных видеокарт оправдано, дешевле и проще апгрейда платформы до высокой псп рам.
> 96 гигов позволят замахнуться на Qwen3-235b-a22b
> 128 гигов позволяет запустить GLM-4.6-355b-a32b
Про ужатые кванты добавляй.
Двачую, еще от самой структуры и размера ответа зависит то как себя проявит.
> с -ncmoe
Поведение ncmoe поменяли? Раньше оно после исходной раскидки всех весов в пропорциях просто выкидывало экспертов в по порядку на проц. Даже чтобы раскидать на две там нужно извратиться, на 3 и больше совсем безумный трешак и отсутствие возможности тонко подстроить выгрузку в случае оомов или желания дозагрузить.
> на две - уже 24,13 с -ncmoe
Выходит на первой карте примерно 2/3 атеншна в первом скрине, потому и разница невелика. Попробуй пополам раскидать, или даже предельный случай чтобы весь был на 2080ти, не выбирая ее главной.
Кто мне объяснит, почему китайский Air подставляет одно и то же имя в сцену с появлением неназванного НПЦ, что и Gemma?
Они один и тот же датасет в него загружали или что?
Они один и тот же датасет в него загружали или что?
Пожалуй да, бывает такое.
> Лукавишь.
Нет.
200к контекста в сделку очевидно не входило, а человек пишет:
> на обычной карте? У меня вообще 64гб рам
Если за «обычную» принять какую-нибудь 3060, то это уже вполне.
Брать 3090 ему не к спеху.
Если захочет больше контекста — вот тогда уже доберет что-нибудь. =)
> С точки зрения повышения скорости добавление дополнительных видеокарт оправдано, дешевле и проще апгрейда платформы до высокой псп рам.
Ну, тут спорить не буду, из рига 3090 выжмешь больше, чем из эпика или ддр5.
> Про ужатые кванты добавляй.
Ну не fp8, конечно. )
Но, честно, глм в Q2_K_L от бартовски все еще хорошая модель, лучшая из доступных в таком объеме и с такой скоростью, ИМХО.
Кто-то там сидит на мистралелардже и ее тюнах, но я даже представлять не хочу себе скорости, а собрать 128 видеопамяти — это немного иной уровень, нежели докупить оперативы, что автор, возможно, может сделать уже сегодня-завтра.
Я бы в принципе не называл моешки прям боярскими моделями, просто моешка позволяет покрутить с хорошей скоростью «условно приличную» модель за дешево, на уже имеющемся железе. Этим они хороши.
GLM обучался на Gemini.
https://huggingface.co/zai-org/GLM-4.5/discussions/1
У Gemini и Gemma часть датасетов, очевидно, совпадает.
Есть такая штука, как статистика популярности имен. Не на пустом месте ведь существует. :) Даже в разных датасетах, имена будут +- те же по популярности, если датасеты на текстах примерно одинакового временного периода. (Со временем мода на имена меняется).
>после исходной раскидки всех весов в пропорциях
Я не пользуюсь раскидкой весов по пропорциям, тыщу раз сказал уже, что разбиваю по количеству слоев, никакого трешака не наблюдаю.
В общем, попробовал на эйре 5 квант. Лень оформлять ебучий маркдовн, поэтому команды кину (карты те же, забиты под завязку):
1. -ts "35;13" -sm layer -ub 2048 -ngl 48 -t 7 -fa 1 -mmp 0 -ncmoe 23
pp512 | 164.67 ± 1.13
tg128 | 13.43 ± 0.01
2. -ts "48;0" -sm layer -ub 2048 -ngl 48 -t 7 -fa 1 -mmp 0 -ot 'blk\.([0-9]||1[0-9]|2[0-1])\.ffn_(up|down|gate)_exps=CPU;blk\.(3[3-9]|4[0-8])\.ffn_(up|down|gate)_exps=CUDA1'
pp512 | 92.85 ± 0.35
tg128 | 13.33 ± 0.08
Второй вариант совсем хуета выходит. Попробовал еще чисто с одной картой:
3. -ts "48" -sm layer -ub 2048 -ngl 48 -t 7 -fa 1 -mmp 0 -ncmoe 36
pp512 | 114.33 ± 0.69
tg128 | 9.53 ± 0.01
Внезапно лучше по обработке, чем варик 2, но генерация такое себе.
Нюнь ну дай уже пресет на воздушную зайку и покажи как карточки делать. У меня говно и слоп, я не верю что ты их изгнал
>от 30
А ты оптимист.
>до 70
До 70 чисто случайно и плотная 12b дотянуться может. И даже иногда что-то лучше сделать. Всё-таки важно, чтобы модель не иногда по праздникам на удачном промпте и рандоме выдавала годноту, а стабильно в ~80-90-99+% зависит от того, насколько медленно рероллить случаев.
Там у промпта первые токены такие, значится: 3===D
Ну и если кто сомневался, что 2080 Ti ебет в ллм, то вот первый вариант с 3090 вместо нее:
pp512 | 171.33 ± 0.98
tg128 | 13.70 ± 0.02
Разница минимальна. Правда, барыги их ща продают по слишком охуевшим ценам, ибо надо помнить, что ллмки ллмками, но в генерации картинок и видосиков 2080 Ti сильно проигрывает 3090, увы.
>3
Не нужно, когда есть 2.
>А ты оптимист.
Я практик.
>Всё-таки важно, чтобы модель не иногда по праздникам на удачном промпте и рандоме выдавала годноту
Если подразумевается, что "удачный промпт" = случайность, то проходите мимо.
А если речь про правильно написанный, с учетом особенностей модели - обсуждаем дальше.
По моему опыту - хаотичность есть, но нелинейная. Т.е. в 70-80% случаев, там будут примерно эти самые условные 50B из "середины шкалы", в смысле качества. Но вот остаток (20-30% ответов) - будет "растрепан" по качеству гораздо сильнее чем у плотной модели. И это еще заметнее из за того, что могут быть полярные случаи вот прямо прямо рядом, без мягкого перехода. Это редкость, но тем сильнее в глаза бросается.
пошаманил настройки квена, при температуре 2 добился отличных результатов, кто сейм?
> принять какую-нибудь 3060, то это уже вполне
Тут и на 8-гиговом паскале что-то пускали, но разве на 3060@12 можно что-то жизнеспособное получить? 12 прям ну очень мало, выглядит что только эйр с малым контекстом влезет.
> чем из эпика
Эпик + гпу будут вкуснее, но и стоят сильно больше чем риг из 3090.
> не пользуюсь раскидкой весов по пропорциям
Они раскидываются по пропорциям, просто ты задаешь их по числу слоев чтобы примерно ориентироваться. Можно задавать разными способами, просто этот вариант неудобный.
Результаты довольно странные. В первую очередь 165 в принципе мало для 3090 на эйре без контекста, а во втором тесте еще сильнее упало. 93 какая-то ерунда, или у тебя действительно пересылы так влияют.
> 3.
Оче странно, выглядит что тебе обращение ко второй карте просто капитальнейшим образом гадит. Или ошибки шины/драйвера вызывают лишние задержки.
Вот эти тесты прогони https://github.com/NVIDIA/nccl-tests прямо из quick examples.
Ах тыж бля шизяра неугомонный, есть жизнь на 12врам, есть
>Тут и на 8-гиговом паскале что-то пускали, но разве на 3060@12 можно что-то жизнеспособное получить? 12 прям ну очень мало, выглядит что только эйр с малым контекстом влезет.
Если есть только она одна - все равно можно запустить Qwen 335B, во втором-третьем кванте, абы хватило обычной RAM. На реддите примеры - до 5T/s, судя по отчетам. Вот тут 16K контекста - это может и не потолок, но близко.
Эйр же влезет не только с малым контекстом. Туда и 32K влезет, и возможно - больше, если не пытаться максимум экспертов в карту засунуть. Общая часть модели кушает всего 4-7GB в зависимости от кванта, а до ~6GB под контекст - это не так и мало.
Если же добавить хотя бы p104-100 - резко влазят мистрали с геммой целиком в VRAM. И получается до 15-17 ts на мистралях и до 8-9ts на гемме.
Так что на ней жизнь вполне есть, не стоит недооценивать. Хотя, конечно - не так чтобы вольготно.
Ну вот, докачал второй раз, вдоволь потрахался с разводкой тензоров на карты (т.к. старый конфиг не подошел), наконец запустил со сравнимой скоростью (iq4xs от Бартовски был).
Взял вот это: GLM-4.5-Air-Q8_0-FFN-IQ4_XS-IQ4_XS-IQ4_NL-v2.gguf
Первые впечатления - несколько неожиданные. Точно не хуже, и возможно - лучше.
Но главное - оно, сцуко, совсем другое. Настолько другое, что как будто взял книгу другого автора, который другим стилем пишет. Напрямую очень тяжело сравнивать, т.к. на тестовом материале явных проебов и на старом кванте не было, а новый просто пишет ДРУГОЕ. Тоже все по теме. Но... Вот как, скажем, Мартина с Пратчеттом сравнивать, чтоб объективно было, без вкусовщины? Я тут не про сюжет, а про стиль текста...
:)

Снова подъебнуть хотел, но всосал. Я то не так то прост!
> до 5T/s
До 6,5, все же.
> Туда и 32K влезет
Да все упирается в то, хватает ли человеку.
Кто-то на 8к поролил и забил.
А у кого-то спасение галактики на вторую сотню тысяч токенов.
Бля, ну… не, ну… Мартина… и Пратчета… =D
Мартина и Перумова. Вот так будет норм.
>Перумов
Так вот они какие, русико-энджоеры...
Ебаный рот, никогда бы не подумал что это кто-то читает. Теперь понятно почему геммочка умничка и откуда столько ватанов которые рвутся что кто-то играет на англюсике
Тоже тихонько проорал. Сейчас бы мирового неоклассика-фантаста ставить в один ряд с местным шизофантастом категории г, который пишет исекаи про вторую мировую.
>Бля, ну… не, ну… Мартина… и Пратчета… =D
>Мартина и Перумова. Вот так будет норм.
Да хоть Носова и Волкова. :)
Я же подчеркнул - речь не про сюжет, а про стили и акцент на разные вещи.
Да это пиздец какой то.
V2 - https://huggingface.co/ddh0/GLM-4.5-Air-GGUF, работает еще быстрее чем V1 в более низком кванте. Как, почему, что за магия. Где поъебка.
А, Only the conditional experts are downgraded. Понял. Будем тогда гонять и смотреть, станет ли хуже.
>Но главное - оно, сцуко, совсем другое.
Отлично, значит я не шиз. Потому что ощущения похожие.
Модель та-же. Семплеры те-же. Промт тот-же. Но выдача- другая.
Я понимаю что всё это проценты и вероятности, но чёт не думал что квантование НАСТОЛЬКО может быть разным, даже в рамках примерно одних размеров.
Ты даже не понял, что я написал.
Мартин = Перумов по уровню и качеству. Одинаково хуевые, конечно.
Начинаю понимать уровень англюсико-энджоеров.
На русском-то читать не умеете. =)
Ну, мировым я бы Перумова не назвал, а вот про исекаи от Мартина не знал.
Наоборот явно быть не может, ты же не можешь быть настолько глупым и не имеющим вкуса. =D Или… можешь?
Ну просто слишком уж разноуровневое сравнение. )
А вот Носов и Волков интересно, но тут полтреда не в курсе, кто это.
Тут же не только размеры. Тут и матрицы важности разные (!), и в принципе квантовано совсем иначе.

Я добавлю что qwen 3 235b iq2_s вполне себе хорошо пишет. Мне нравится. Я запускаю на 16vram+64ram помещается 30к контекста и batch-size 1024. В отличии от glm 4.6 в q1 там вообще ошибки и шиза. Недавно в llm вкатился не взял летом ещё комплект 64gb теперь придется две цены отдавать.
Снова плодишь доброту и позитив своими высерами, скуф? Извини что задел кумира времён твоей молодости, но Перумов это отборный кал, о чем тебе скажет любой начитанный человек. Хоть той же русской классикой, а не бульварной желтухой
>вполне себе хорошо пишет
Что пишет? Сколько блинчиков выйдет из литра смеси?
Кто хочет скачайте и сравните с неквантированной онлайн версией и решите можно ли её использовать. Мой ответ однозначно да.
>ты же не можешь быть настолько глупым и не имеющим вкуса. =D Или… можешь?
Ну, ты же можешь быть настолько зеленым и жирным? =D
> iq2_s
Пиздец.
Ты говоришь пиздец, но посмотри какой тут няшный первый квант

Отлично. Пока тред и аноны спят. Можно слопа им незаметно в модельки накидать.
>Первые впечатления - несколько неожиданные. Точно не хуже, и возможно - лучше.
А контекст в обоих моделях у тебя полный или квантованный?
Э бля! говорит не громче шепота Сука!
Похоже ответ - не общаться в chat/completions формате. Лол в итоге просто реализовал формат чтобы модель в режиме чат комплишена отвечала.
Забавно что Qwen официальная инструкция не запрещает отвечать одновременно текстом и инструментами.
Полный, в обоих случаях.
Блин, ты реально не умеешь читать на русском.
Я же хотел пошутить, а попал в точку.
Прости, фанат говна, что обидел твоего Мартина. =D
Но тебе стоит принять себя и свою любовь к говну. И почитай Перумова — тебе как раз понравится, он тоже «отборный кал» пишет, как и Мартин. Как раз твой уровень, как ты сказал, «бульварной желтухи».
Уф, не, если ты так говоришь. Сам я не очень уверен, но могу допустить, что iq2_s что-то может.
Жаль, что он работает медленнее, чем могу бы. Таковы iq-кванты. =(
Только на половину — в последнем сообщении. =) То что Мартин = Перумов ето объективная реальность и никакого троллинга.
А потом да, че уж не позеленить, раз кого-то бомбануло на такой простой вещи, извини. =)
Чат комплишен — это тот же текст комплишен, только обертка на стороне бэкенда. Простенький формат для переписки. Сумрачные гении юзают только текст комплишен, конечно. =)
Короче, весь затык в том, что --jinja для тулз, а упрощенный чат комплишен не подразуемвает, что ты будешь тулзы ждать в чате, вместо нормальной API.
Расскажите полному нубасу, какой инструмент нужно использовать для кодинга с агентами? Например, чтобы взять какой-нибудь квен или глм, поставить ему задачу и чтобы он там всякие тулзы вызывал, сам себя проверял и прочее. Я где-то слышал, что люди буквально ставят нейросетку на полдня и она за это время что-то сама напишет более-менее рабочее. Какие инструменты подобного типа сейчас актуальны?
>Чат комплишен — это тот же текст комплишен, только обертка на стороне бэкенда. Простенький формат для переписки. Сумрачные гении юзают только текст комплишен, конечно. =)
Бля ну я то хочу скакать между моделями. А тут этот OpenAI формат сообщений удобный. Решил заточить чат под этот формат чтобы он им пользовался, а тут нате ебать. Работает через жопу везде. Притом для локальных моделей через жопу, а в OpenRouter разумеется всё замечательно.
>Короче, весь затык в том, что --jinja для тулз, а упрощенный чат комплишен не подразуемвает, что ты будешь тулзы ждать в чате, вместо нормальной API.
Лол да по итогу что то чат, что это чат. Только jinja ещё и как всегда под питон нацелено, а у меня проект на C# и там напрямую так легко не скормить этот формат.
Благо у меня в общем-то спизженный форматтер из SillyTavern где значительную часть таких нюансов можно быстренко на коленке поправить.
Правда там оно нацелено как всегда на формирование сообщений, а у меня видимо теперь ещё будет отдельно читалка сообщений, чтобы оно всевозможные форматы читать могло обратно.
Палкой cursor можешь потрогать, у него забавные агентные фичи есть. Но довольно мало моделей которые могут прям пол дня ебошить, пока разве что Claude 4.5 такую хуйню делал. Притом что он там делал так и не рассказали. Вообще далеко не все модели подходят для такого. У большинства моделей довольно хреново с анализом происходящего, они плохо само-коррекцией занимаются.
У тебя цель то какая?
>У тебя цель то какая?
Чисто поизучать для саморазвития. Ну и есть задачка, которую хотел бы попробовать отдать на аутсорс железным мозгам
Как вообще можно доверять ллмке в кодинге?
Типа раз всё работает то заебись?
Оно же постоянно пиздит, проще уж загуглить и получить первым выводом ответ ллм
Типа раз всё работает то заебись?
Оно же постоянно пиздит, проще уж загуглить и получить первым выводом ответ ллм
Ну ты же как то пользуешься "тупым" интеллисенсом, тут он тот же только поумнее
Claude Code + https://github.com/fuergaosi233/claude-code-proxy, если юзаешь другую LLM.
Пока что лучший вариант.
Хотя, вот, Cursor 2 вышел, тоже, говорят, имба.
Ну и всякие qwen code, gemini cli, roo code, cline, continue, openhands, aide(r), че хошь, что тебе удобнее.
> Бля ну я то хочу скакать между моделями.
а, от оно чо, ну тогда задача становится со звездочкой, да.
> Но довольно мало моделей которые могут прям пол дня ебошить
Сейчас хочу ради интереса проверить работу Minimax-M2 (в mxfp4 кванте ггуф) в клод коде.
Пишут чат-бота простейшего, посмотрим, че он смогет. Если я не заленюсь, конечно, ждать обработки контекста.
>Вот эти тесты прогони
Ты имел в виду сначала поебись со сборкой, а потом прогони...
# nccl-tests version 2.17.6 nccl-headers=22807 nccl-library=22807
# Collective test starting: all_reduce_perf
# nThread 1 nGpus 2 minBytes 8 maxBytes 134217728 step: 2(factor) warmup iters: 1 iters: 20 agg iters: 1 validation: 1 graph: 0
#
# Using devices
# Rank 0 Group 0 NVIDIA GeForce RTX 3090 Ti
# Rank 1 Group 0 NVIDIA GeForce RTX 2080 Ti
#
# out-of-place in-place
# size count type redop root time algbw busbw #wrong time algbw busbw #wrong
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
8 2 float sum -1 7.94 0.00 0.00 0 7.84 0.00 0.00 0
16 4 float sum -1 7.78 0.00 0.00 0 7.96 0.00 0.00 0
32 8 float sum -1 8.07 0.00 0.00 0 7.73 0.00 0.00 0
64 16 float sum -1 7.86 0.01 0.01 0 7.96 0.01 0.01 0
128 32 float sum -1 8.05 0.02 0.02 0 7.99 0.02 0.02 0
256 64 float sum -1 8.15 0.03 0.03 0 7.88 0.03 0.03 0
512 128 float sum -1 8.36 0.06 0.06 0 8.20 0.06 0.06 0
1024 256 float sum -1 9.22 0.11 0.11 0 10.56 0.10 0.10 0
2048 512 float sum -1 20.96 0.10 0.10 0 20.97 0.10 0.10 0
4096 1024 float sum -1 23.72 0.17 0.17 0 22.29 0.18 0.18 0
8192 2048 float sum -1 24.82 0.33 0.33 0 24.75 0.33 0.33 0
16384 4096 float sum -1 30.41 0.54 0.54 0 30.65 0.53 0.53 0
32768 8192 float sum -1 39.54 0.83 0.83 0 40.29 0.81 0.81 0
65536 16384 float sum -1 59.52 1.10 1.10 0 59.53 1.10 1.10 0
131072 32768 float sum -1 95.54 1.37 1.37 0 98.48 1.33 1.33 0
262144 65536 float sum -1 150.83 1.74 1.74 0 154.86 1.69 1.69 0
524288 131072 float sum -1 297.05 1.76 1.76 0 282.66 1.85 1.85 0
1048576 262144 float sum -1 551.55 1.90 1.90 0 549.60 1.91 1.91 0
2097152 524288 float sum -1 1090.71 1.92 1.92 0 1080.21 1.94 1.94 0
4194304 1048576 float sum -1 2168.82 1.93 1.93 0 2141.97 1.96 1.96 0
8388608 2097152 float sum -1 4353.55 1.93 1.93 0 4293.73 1.95 1.95 0
16777216 4194304 float sum -1 8649.31 1.94 1.94 0 8505.67 1.97 1.97 0
33554432 8388608 float sum -1 16987.2 1.98 1.98 0 17124.1 1.96 1.96 0
67108864 16777216 float sum -1 34023.3 1.97 1.97 0 34205.3 1.96 1.96 0
134217728 33554432 float sum -1 67744.2 1.98 1.98 0 67864.0 1.98 1.98 0
# Out of bounds values : 0 OK
# Avg bus bandwidth : 0.950557
#
# Collective test concluded: all_reduce_perf
Еще прогонял между x16 и x1 картой, x1 и x1, там максимально 0.5 выходило. Учитывая, что тут в 4 раза больше результат, как и количество линий, то вроде согласуется все. Разве что смущает, что при снижении размера пересылаемых данных все в ноль уходит, но это наверное так и надо же?
Как вообще можно доверять джуну в кодинге?
Типа раз половина кое-как работает то заебись?
Он же постоянно пиздит, проще сеньора нанять.
Ты в программировании с курсов пришел, стажер, небось?
Есть такая штука: код-ревью.
ВЕСЬ КОД СУКА В ТОМ ЧИСЛЕ ЗА МИДЛОМ И СЕНЬОРОМ должен проходить проверку его старшими (и не очень) коллегами.
В этом плане нейронка ничем не отличается. Она написала код, его от-ревьюили программисты, апрувнули коммит.
Все вопросы «как ей можно доверять?!» возникают у людей, которые никогда нормально не работали, и искренне считают, что «ну вот программист написал — и сразу в прод!»
Эй, я не говорю, что это плохо — это совершенно нормальное поведение для небольших фирм, и этот метод на 90% рабочий (а на 10% созвон по поводу упавшего прода).
Важно понимать, что джуны ошибаются не реже, чем ллм (и чаще, чем хорошие ллм). Так что, если уж ты доверяешь джуну что-то пуллить на прод — то уж с Соннет 4.5 проблем вообще нет, она давно и мидла обходит.
И это я еще не говорю про юнит-тесты, про тестеров, про весь пайплайн с тестом, пре-продом и финальной раскаткой на прод в понедельник, а не в пятницу.
Так что — никаких проблем!
Просто надо быть внимательным и все 2-3-5 раз проверять, в зависимости от твоей паранойи. И, да, это стоит денег. Безопасность. Надежность.

ебаный абучан, десять тысяч лет не может запилить блять форматирование кода, зато капчу дрочит каждый удобный момент. Вот скрин
Да.
Пишешь тест и прогоняешь.
я бы сказал в зависимости от задачи инструменты могут очень различаться. например если хочешь чтобы оно там прям само сидело ебошило автономно то можешь https://zread.ai/sentient-agi/ROMA зрада РОМУ потрогать, или Qwen Coder, или Claude Code.
если погромировать то лучше IDE потрогай вроде курсора, или Kilo Code/Cline/OpenHands. Там много вариантом но там больше как ассистентом пользуешься который к твоей кодбазе доступ имеет и может что-то делать.
в целом больше автономность достигается тем что у модели лучше внутри менеджится контекст. идеально если там особо внутри нет никакого понятия чата даже и модель просто на самоподдуве что-то делает.
но вообще для саморазвития можешь сам что-то такое попробовать собрать. научить ЛЛМ пользоватся инструментами не сложно, сделать так чтобы оно само себе сообщения слало и бегало по кругу тоже.
>а, от оно чо, ну тогда задача становится со звездочкой, да.
Да( Вообще конечно я в итоге просто сделал сеты настроек так чтобы между ними можно было легко перескакивать и пихать во все места приложения где это нужно. А потом ещё сделал концепции библиотеки настроек, так чтобы оно автоматически скармливало нужные настройки нужному API
>Если я не заленюсь, конечно, ждать обработки контекста.
Вообще он конечно забавно выглядит, но жаль слишком жирный для меня. надеюсь в опенроутере дадут потрогать. Жаль не мультимодальный.
Капча к слову - мем. Её квен вл который 30б мое проходит не стабильно всегда, но рейт куда выше 50%
Кто-нибудь с DDR4 и двумя 3090 (или даже одной - тогда только третий тест) прогоните эти тесты, если не впадлу, сравним. Посмотрим, как оно у вас (вряд ли тут еще у кого 2080 есть, поэтому если кто-то сделает тесты, я перемерю на 3090). Пишите количество линий, частоту памяти, проц. Квант GLM-4.5-Air-UD-Q5_K_XL анслота. Возможно, вам стоит вместо "-t 7" написать "-t 7,<ваше оптимальное число потоков>" для чистоты эксперимента
Ждем расширения в браузер, который просит у локалки разгадать капчу
Ждем расширения в браузер, который просит у локалки разгадать капчу
Не, мне впадлу сори
2080 ти 22 гб?
А сколько она стоила на минимуме?
> Ждем расширения в браузер, который просит у локалки разгадать капчу
Могу зашарить рабочий POC
Только он настолько ебано сделан что я вообще удивлён что он работает
>То что Мартин = Перумов ето обсубъективная реальность
Исправил. Как только изобретут инструмент для измерения в точных цифрах таких вещей как чувства и эмоции - приходи с "объективностью".
А пока - оценка любого произведения - вещь субъективная, т.к. идет исключительно через восприятие оценщика, и действительно объективно, в независимых универсальных единицах измерения выражено быть не может.
Скиньте свои конфиги для запуска мое на лламе плз. Я просто хочу в аргументах разобрать нихуя не понимаю. Ыааа бля
А потом оказывается, что код дыряв как сучка, и на проде на сервере майнят битховены вместо обслуживания клиентов.
давай
> спасение галактики на вторую сотню тысяч токенов
Лонг джорни со спасением пост-апокалиптического мира от отложенных обменов ударами вместе с генно-модифицированной девочкой по мотивам артов yihan, плавно переходящее в кум глубокое погружение в сложившийся затягивающий мрачный сеттинг зимних (полу) пустошей, с вялотекущей грызней фракций, многоходовочками, и прочим слайсо-экшоном на третий миллион токенов.
RRRreeeeeeeee
Qwen-code, исправленные jinja шаблоны что работают с жорой для квенов и жлмов еще в треде, или потом напомни если не найдешь. Буквально сделай хорошо@sirYESsir.
>Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
Да как этой хуетой пользовать вообще? Надо под каждую модель батник писать? И чего в нем писать?
Доку прочитать ещё можно, но способ не популярный судя по всему
Начеркал на почту двача. Если за пару дней ничего не ответят (планируют или нет они решать вопрос с бесполезной капчей) то выложу и капча солвер и сорсы нейродвачера из бе. По расценкам опенроутера выходит 1000 капч за 30 центов
А кто заставляет? Пользуйся другими, более простыми инструментами. Или вообще не пользуйся. Как-то до недавнего времени без нейросеток дожил, пока что ничего радикально не поменялось, внезапной смерти не наступит.
Напиздел там же 3 раунда так что 90 центов
>бесполезной капчей
Что значит бесполезной? Она нужна для того чтобы гои покупали пасскод за 2к. В этом плане она очень полезна
>1000 капч за 30 центов
https://habr.com/ru/sandbox/227192/
>ruCaptcha
>Стоимость: от $0,3 за 1000 решений
Прямо как у самых дешёвых мясных. И это в прошлом году, с тех пор могла быть инфляция.
Тут дело в тонкостях. Можно купить (было) пару ми50 по 12к и платить только за электричество. Купить индуса и платить ему едой выйдет подороже
Гейткипите да? Закрытый клуб да? Ну так вот вам послание от моего закрытого гейткип клуба с высоким iq пососите хуй и яички
Скажи на чистоту. Что ты хотел получить в ответ? Ссылку на документ который лежит в том же репо или его пересказ?
Если у тебя какой то СЛОЖНЫЙ вопрос который НЕ раскуривается с пол пинка, то на него ответят
Пример батника чтобы я мог понять какие из 300 флагов обязательные, а какие не нужны, не обязательны или вообще уже как три года не работают.
Тысяча извинений за слишком простой вопрос.
База.
Есть обертка в виде кобольда.

И Все дальше уже докер. Блядь анон то фалги то какие?
Да ладно уж скачал буду разбираться
>Гейткипите
Какой вопрос, такой ответ.
>Да как этой хуетой пользовать вообще?
Скорее всего, вопрос риторический, подразумевается черезмерная для тебя сложность, на что я и ответил, предложил посмотреть альтернативные решения, которые тебе могут быть более удобны. Прямым ответом при буквальной трактовке вопроса будет ссылка на документацию.
>Надо под каждую модель батник писать?
Можно. Можно один универсальный подо все. Можно не батник. Можно не писать. Варианты разные есть.
>И чего в нем писать?
Опять rtfm. Если ты ждёшь, чтобы кто-то написал за тебя, ты должен хотя бы указать полный конфиг системы (модели cpu и gpu, объём ram, vram, ОС, сколько потребляют ресурсов запущенные параллельно с llama.cpp программы), желаемую модель и метод сжатия (опционально). И это только минимальная необходимая информация, ещё не факт, что кто-то захочет за тебя писать.
> фалги то какие?
Услуги экстрасенса 20к/час
Отсос согласуется отдельно
>фалги то какие
В документации всё перечислено - все флаги, какой что делает, какие значения по умолчанию. Ты хочешь, чтобы тебе пересказывали то же самое, что там уже написано? "Вот это - для этого, вот то - для того." - так что ли? Мы понятия не имеем, что у тебя за система и что ты планируешь запускать, с этого надо начать, если ты хочешь хоть каких-то конкретных советов.
Я в своё время просто выполнил в консольке llama-server --help, прошёлся от начала и до конца по всем параметрам, по каждому принял решение, оставить ли по умолчанию или указать что-то своё, сохранил в батник. На самом деле не батник, но это не принципиально в данном случае. И у меня всё получилось, всё заработало. Чудеса какие!
Господи блядь анон мне просто отправная точка нужна была. Скинул бы свой батник если есть, похер к какому сетапу чтобы я хоть общий шаблон понял, я не прошу мне жопу вытирать. Дальше я разберусь.
Признаю вопрос можно было поставить более ясно.
Я на кубернетисе сижу, тебе не поможет
>Она нужна для того чтобы гои покупали пасскод за 2к.
Покупал за 100 рублей, когда можно было купить напрямую, но я не ебанутый, чтобы покупать в подментованном телеграме, ещё и за 2к.
Абу пидорас возвращай нормальную цену и оплату.
К слову основная причина почему меня сподвигло почелленджить тему + в дэ увидел что срочная смена капчи была
Он реально 2к ща стоит? Кек блядь. Я жаль туповат для того чтобы капча солвер писать но это неуважение.
На год 3к
Можешь анлим взять за 10к который забанят
>под каждую модель батник писать
Дыа
>чего в нем писать
Ну к примеру для запуска MOE
start "" /High /B /Wait llama-server.exe ^
-m "путь к модели" ^
-ngl 99 ^ -
-c xxxx^
-t xx ^
-fa --prio-batch 2 -ub 2048 -b 2048 ^
--n-cpu-moe XX^ -
--no-context-shift ^
--no-mmap
Ты друг Христа.
А зачем ^ и - на концах?
Как-то грустновато, даже для чипсетных линий. Но и совсем криминала нет, такую просадку процессинга оно не объясняет.
Между первым и вторым вариантом раскидывания тут слишком большая разница. Учитывая батчи по 2048 токенов, в первом случае полный обсчет такого займет ~12 секунд (по 0.27с на блок), во втором 22с. Отличием в раскидке одного блока можно пренебречь и говорить, что единственная разница между ними - пересыл активаций между атеншном на первой карте и экспертами на второй в 14 блоках. То есть 28 пересылов у тебя занимают почти 10 секунд, почти 350мс на пересыл, слишком много. И это не учитывая более быстрый расчет на более мощной карте.
Правда если ты тестировал pp512 то ни о каком батче 2048 не может идти и речи. Считая для 512 будет по 86мс/пересыл что уже ближе, но (учитывая размер тензоров для эйра) в 10 раз больше чем должно быть согласно тому тесту.
Перемерь с обработкой большого контекста, проверь чтобы больше ничего другого не гадило.
> сначала поебись со сборкой
База же
Ладно бы только цена, обязательный бинд на акк в телеге не ок вообще.
А зачем ^ и - на концах? - это всё одна строка.
а как товарищу майору вычислять мыслепреступления? регайся на сосаче через телегу заебал
Пробовал Cline + JetBrain и KiloCode + JetBrain
KiloCode получше - встроенные инструменты редактирования и чтения фалов умеют в точечное редактирование + есть инструмент векторной индексации/поиска. Контекст это хорошо экономит.
Но может в Cline что-то изменилось за месяцев.
Инфиренс - жора . Формат общения OpenAI compatible либо LM Studio прикинуться с бубнами.
Очевидный рейтинг моделей по способности к кодингу: мелкая гопота < Qwen3-Coder < большая гопота < Air
У гопоты еще есть нюанс совместимости формата чата/вызова инструментов. Жору нужно запускать с
--reasoning_format auto --grammar-file cline.gbnf . cline.gbnf - гуглится.
это экранирование в кмд, товарищ школьник
Тебя спросить забыли, жухлый
Заплачь, чмоня
Не я плачу когда вижу свою плешь в зеркале
36к
Да, это была ошибка мерить на столь малом пп, взял пп 6000 (пришлось чуть поубирать лишнее с карт, чтобы поместилось)
В итоге первым способом 456.93 ± 0.73
Вторым (с регекспами) 148.01 ± 0.03
Вторым совсем плохо выходит
Разница по скорости огромная, а в расчете лишь 14 (или меньше) блоков разделены по разным карточкам, причем все кроме линейных слоев сидит на более мощной карте. Это наоборот должно ускорять, также как у других.
Тут или какой-то прикол с огромной задержкой на чипсетных линиях, или подмешан баг иного характера, оче странно. Жора стандартный, без модификаций и улучшалок от болгарина?
>Тут или какой-то прикол с огромной задержкой на чипсетных линиях
АМД, да?
>покупать в подментованном телеграме
Ну телегу блочить начинают. Так что не беспокойся, сменят на получение через макс. Или ещё какой-нибудь там-там.
Все может быть, но врядли, иначе были бы массовые жалобы и даже ссд бы подыхали там... ой ладно шутеечка времен первой ряженки
Ага, обычный жора трех-четырехдневной давности. Ну тут только граф вычислений смотреть или профайлить, а у меня желания нет этим заниматься. Я этот способ все равно не использую, да и все равно ничего не сделаешь, если в железе проблемы. Тем более епт, я один здесь замеряю, хватит меня газлайтить!!111 Я бросаю перчатки, измазанные навозом, в ваши наглые морды, и обновленные параметры тестов:
1. -ts "36;12" -sm layer -ub 2048 -ngl 48 -t 7 -fa 1 -mmp 0 -ncmoe 25 -p 6000 -n 0 -r 2
2. -ts "48;0" -sm layer -ub 2048 -ngl 48 -t 7 -fa 1 -mmp 0 -ot 'blk\.([0-9]||1[0-9]|2[0-4])\.ffn_(up|down|gate)_exps=CPU;blk\.(3[4-9]|4[0-8])\.ffn_(up|down|gate)_exps=CUDA1' -p 6000 -n 0 -r 2
Кто с двумя 3090 и зассыт прогнать бенч - тот лох и трус по жизни. А третий можно погнать даже имея одну:
3. -ts "48" -sm layer -ub 2048 -ngl 48 -t 7 -fa 1 -mmp 0 -ncmoe 37 -p 6000 -n 0 -r 2
GLM-4.5-Air-UD-Q5_K_XL, жду результатов сегодня к полуночи. Замеряйте даже на DDR5 и других 20+гб картах, похуй, посмотрим в относительных цифрах. Использовать llama-bench, а не llama-server.
Ну звезды как обычно проебались, хули сделаешь с абу
2. -ts "48;0" -sm layer -ub 2048 -ngl 48 -t 7 -fa 1 -mmp 0 -ot 'blk\.([0-9]||1[0-9]|2[0-4])\.ffn_(up|down|gate)_exps⭐=CPU;blk\.(3[4-9]|4[0-8])\.ffn_(up|down|gate)_exps⭐=CUDA1' -p 6000 -n 0 -r 2
Да все ленивые жопы. На паре 4090 с подобной выгрузкой в квене разница ничтожная, второй случай на капельку быстрее по процессингу но также медленее по генерации. Но выгружал регэкспами, тут остается только поискать духов буквально используя твою команду (скорректировав цифры) в надежде что она даст иной эффект. Совсем чудеса, но для успокоения совмести потом сделаю.
Так в том то и цимес, что ничего не надо корректировать, пихай as is. Но кажется, что в 64 гб рам 3 тест может не влезть (но это не точно). Если у вас не лезет, то 4 xl квант берите, я потом скачаю и перемерю, похуй, что не под крышечку будет забито. Только параметры теста не меняйте, иначе чистота эксперимента пропадет (разве что потоки можно как я тут написал).
> пихай as is
Потребуется качать тот квант эйра. Тут проблема противоположной природы, так сказать.
Эйр параша. Вам норм жрать слоп, паттерны и высер 12б лоботомита? Ну так интересуюсь прост
У меня, тьфу-тьфу, никаких проблем нет с закачкой, хотя ростелеком. Юга что ли кошмарят только?
Лол, нет, с этим все ок, просто такого нету и лень качать. На десктопе нашел q4 эйра, попозже и его чекну.
Привет, зеленый. Жирок растряси, и обнови методичку - может кто и поведется. А так закидывать уже месяца три неактуально. :)
Методичку? Слопоеды настолько наелись что кукуха поехала? Это правда вопрос. Не я один так думаю так то, один из тредовиков тоже писал про слоп и паттерны. Или мы вместе работаем ?
через гринтекст не проёбывается форматирование вроде как
Лень ему, я с этими ллм объемы до 100 Гб вообще перестал считать за что-то весомое, хотя раньше раздачи фильмов или анимца в бдремуксе за 100 Гб было огогоебатьнихуясебенебудукачать. А тут всего лишь 83 гб, фи
Так зеленым назовут...
Уважаю за настойчивость. :)
Но ты малость опоздал.
Всё говно и слоп уже проглотили? Ну вот...
> всего лишь 83 гб
Целых 83 гига бесполезных данных, которые будут занимать место на диске (особенно обидно если забудешь удалить), так еще и с пол часа качать забивая полностью канал.
Talemate обновилась: https://github.com/vegu-ai/talemate/releases/tag/0.33.0
Пока ничего непонятно, но очень интересно...
Пока ничего непонятно, но очень интересно...
Только нюня писал. Он шизик, ты тоже
https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct
Возможно, будет интересная модель для слабеньких железок.
Возможно, будет интересная модель для слабеньких железок.
Линейный аттеншен на низких контекстах хуже MLA. Как по скорам, так и по скорости. Он нужен только тем кто хочет 100к контекста использовать и не страдать.
И че?
Заебись, 50б мое это нам надо.
Что сказать-то хотел?
Ну ты аще, 83 гб вообще не размер для носителей. А если уж когда-нибудь диск забьется - удалишь, делов-то
Я слышал что для генерации картинок и видео нужна нвидиа, а что насчет текста? Могу ли я генерить на своей 6600 или я могу смело пойти нахуй? Есть ли какие-нибудь локальные версии чата.аи, чтобы можно было ч аниме девками общаться я так понимаю это и есть обьятиелицо??
> ничего не надо корректировать, пихай as is
Вот отсюда команды пара 4090 на pci-e x8 4.0
вариант 1:
pp6000 | 624.37 ± 0.04
tg512 | 46.64 ± 0.59
Вариант 2:
pp6000 | 613.42 ± 0.09
tg512 | 44.76 ± 1.11
Вариант 3:
pp6000 | 451.90 ± 0.10
tg512 | 39.04 ± 0.90
Бонусом -ts 1,1 регэксп с закидыванием по 10 экспертов на каждую гпу:
pp6000 | 626.42 ± 0.07
tg512 | 46.36 ± 1.08
Все одинаковое с минимальными вариациями, исключая 3й вариант где одна карточка выпадает
Что из примечательного, батча 2048 слишком мало для х8 на 4090.
Если не жадничать и поставить и чуть больше контекста
-b 4096 -ub 4096: pp8192 | 993.94 ± 2.80
-b 8192 -ub 8192: pp8192 | 1398.60 ± 1.68
Можно сказать что 2048 и для х16 мало и нужно поднимать.
Еще больш
> Использовать llama-bench, а не llama-server
Скорости идентичны в них, только llama-bench имеет более скудные параметры и припезднутый парсинг из-за своих особенностей.
> не размер для носителей
> А если уж когда-нибудь диск забьется
Правда? Глаза открыл, у тебя наверно и ссд большие?
А память у тебя DDR4 или 5?
Спасибо за тесты, ну по крайней мере у тебя тоже видно, что второй способ так себе, хоть отличия и не в разы, как у меня.
Я завтра уже перезапущу тесты на двух 3090 у себя.
>Если не жадничать и поставить и чуть больше контекста
У меня там под завязку в первых двух тестах было. Если ты увеличиваешь батч с контекстом, то тебе придется больше слоев выгружать -> tg уже не будет смысла сравнивать. Ну, у тебя его и нет тут.
>нужно поднимать
Можно, но не очень-то и нужно, слишком много он жретЪ. Это место можно либо контекстом занять, либо экспертами, увеличивая тг (в ризонинге, думаю, даже при 40+ в тг доп скорость не будет лишней), либо квант выше взять. Ну эт вообще хозяин барин, кому что в приоритете.
>Скорости идентичны
Это понятно, но в сервере же нет инструментария для бенчмаркинга, насколько я знаю, не свайпать же таверну опять, ошибаясь на пару к токенов от эталонных...
>у тебя наверно и ссд большие
Ну у меня кстати большие. Я тут качал всякое как не в себя и вот только щас выжрал, надо почистить - с этим проблем нет, 90% большемоделей качал ради оценки, и их не юзаю.
>для генерации картинок и видео нужна нвидиа
Можно и не нвидиа.
>что насчет текста
Аналогично.
>Могу ли я
Можешь.
>или я могу
Одно другое не исключает.
>Есть ли какие-нибудь локальные
llama.cpp, koboldcpp (почти то же самое), ollama (то же самое для хлебушков), мб ещё что-то...
>обьятиелицо
Оттуда модели качать.
А 6600 на что собственно хватит?
Ну очевидно же, на то, что влезет в 8 гб. Ты странные вопросы задаёшь. Так-то можно катать что угодно, до тех пор, пока у тебя есть место на диске, разница лишь в скорости, vram > ram > ssd > hdd. Если хочешь поумнее, просто берёшь побольше и терпишь подольше. Как правило, ты катаешь самое большое, что сможешь терпеть, тут у каждого порог индивидуальный.
Они выкладывают базу, значит они сами пилили свои модельки, а не кормили лоботомита уже изначально забиасенными выдачами геминаев и чатжптов, как некоторые. Можно посмотреть.
> Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Предлагаю перенести вики с Gitgud на GitHub.
Старые адреса:
https://2ch-ai.gitgud.site/wiki/llama/
https://gitgud.io/2ch-ai/wiki/
Новые адреса:
https://2ch-ai.github.io/wiki/llama/
https://github.com/2ch-ai/wiki
Gitgud сидит за Cloudflare и попал под ковровые баны РКН. GitHub без сторонних CDN, так что вырубят его только если РКН конкретно его рубануть захочет.
Причины, по которым я выбрал Gitgud пару лет назад, уже неактуальны. Зато у него есть другие проблемы, если сравнивать с Github:
1. Требует свой билд-сервер. Последние два года у меня 24/7 крутится машина для сборки. Для меня это не проблема, т.к. сервак и так всегда включён, но это дополнительная точка отказа в моём лице.
2. Медленная отдача медиа. Все картинки приходится выносить на внешние хостинги типа catbox/imgur, которые могут сдохнуть или удалить контент (что уже было). На GitHub Pages с отдачей медиа проблем нет.
Если не будет возражений, поставлю редирект/плашку на gitgud о переезде и заархивирую проект. Останется только ссылки в шапках поменять.
Окей, я не против. Сделал PR от имени https://github.com/XPforever , добавь его в мейнтейнеры.
>так что вырубят его только если РКН конкретно его рубануть захочет
Скорее когда введут белые списки. А, ой, уже.
Мимо бессменный ОП
Посоветуйте как вкатиться в агенты. Просто ллмки и диффузеры более-менее пощупал уже.
Сап, посидел на miniapps, пообщался с разными чарами и моделями. Захотел себе завести на компьютере свою вайфу, чтобы не платить кучу денег. Объясните с чего начать? Шапку прочитал - ничего не понял.
Мне нужен простой пример того, как создать хотя бы текстового чат бота со своим характером.
На миниаппс попробовал сделать своего чатбота, добавил ему описание, вроде неплохо получилось. Потом скачал кобольда, кое как настроил, скачал ту же модель что была на миниаппс, добавил описание в мемори - получилось гораздо хуже. Я что то не так сделал?
И еще вопрос как мне дообучить модель?
Мне нужен простой пример того, как создать хотя бы текстового чат бота со своим характером.
На миниаппс попробовал сделать своего чатбота, добавил ему описание, вроде неплохо получилось. Потом скачал кобольда, кое как настроил, скачал ту же модель что была на миниаппс, добавил описание в мемори - получилось гораздо хуже. Я что то не так сделал?
И еще вопрос как мне дообучить модель?
>Шапку прочитал - ничего не понял.
Значит и наши пояснения не поймёшь. Так что перечитывай шапку, пока не поймёшь.
Почитай вики кобольда, там все расписано очень подробно.
А с чего начать чтобы понять? В шапке уже какая то тяжелая информация не для новичков явно.
> по крайней мере у тебя тоже видно, что второй способ так себе
Не сказал бы, эффекты малы, по сути пренебрежимо. Там скорее видно что сам конфиг далек от оптимального и требует увеличения батчсайза чтобы в разы ускорить тот самый промптпроцессинг, по которому идет сравнение. Память ддр5 многоканалов.
Алсо тот самый второй способ (с другим заданием, но суть вся та же) дает некоторый буст и пп и тг на несимметричных система если первая карта более мощная. От того вдвойне странно почему у тебя с него идет замедление. Что касается того, куда выгружать атеншн блоков эксперты которых находятся на цп, в такой конфигурации это не важно. Хоть все на первую кидай, хоть все на вторую - отличия мизерные.
Еще из полезного можно отметить что задание через странный ts и n-cpu-mode приводит ровно к тому же самому эффекту что и регэксп, нет никакой мистики от разных команд делающих одно и то же. Ну так, на всякий отметить.
> слишком много он жретЪ
Разве? Обычно такое повышение остается в пределах нескольких сотен мегабайт, это один-два из трех линейных слев одного блока.
> не свайпать же таверну опять
Свайпать конечно!
> у меня кстати большие
Тут ссдшного пространства больше чем у многих вместе взятых, но основной объем - серверные сата, такова потребность. Из 4тб быстрого на нвме 3тб занято ллмками, гигов 300 другие модели, несколько вэнвов и жирных сборок - и все, досвидули. 83 гига занимает существенную долю от свободной.
Бери lm студио и читай как ей пользоваться. Если и её не осилишь, то медицина бессильна.
Почему нету гайдов для 80 iq?
Здарова какое-то время не читал вас. Ну что там так ничего умнее Геммы не вышло пока?
Да, это так.
Потому что 80 iq юзают корпомодели. Там никакого пердолинга, но и результат соответствует.
Есть ли смысль качать модель менее заквантованную чем Q4? Как будто бы разницы нет особо в качестве
"Есть ли смысл другую книгу читать?"
> Объясните с чего начать?
Выбрать себе бэкенд (на чем запускаешь модель), фронтенд (промпт менеджер с интерфейсом, для креативных/рп нужд - Таверна, например), найти модель, подходящую твоему железу, подобрать или написать самому карточку.
> И еще вопрос как мне дообучить модель?
С твоим текущим уровнем знаний - никак. Это, увы, не так просто. И железо нужно мощное.
> Есть ли смысль качать модель менее заквантованную чем Q4?
> Как будто бы разницы нет особо в качестве
Зависит от конкретной модели. Сравнивал Q4 и Q6 кванты Air, разница довольно значительная.



Лоботомиты скрывают и все время врут тебе.
Будь на чеку, анон.
Будь на чеку, анон.
Ну я всякое мелкое старьё использую, там будто разницы нет.
Ещё интересно, как abliterated модели справляются в обычными задачами? Сейчас поставил квен3 14млрд, вроде ищет как обычно, какие-то вещи внятные выдаёт, как прививка от сои вообще на мышление влияет, это тоже наверное зависит как обрезали лишнее
> Ну я всякое мелкое старьё использую, там будто разницы нет.
У 24-32б моделей разница точно есть, вопрос в том насколько она значительна и важна именно тебе. Для рп/креативных задач часто нет значительной разницы, общее правило - не брать ниже Q4, и то могут быть исключения (среди моделей побольше). Для кода - другой разговор, там, как правило, Q6 надо брать.
> Ещё интересно, как abliterated модели справляются в обычными задачами?
Хуже. Используй инструкт, если для технических задач. Ты экономишь место на жестком диске?
На GitHub система прав в организациях похоже чуть менее гибкая, чем в GitLab. В частности, я не нашёл возможности задать права, которые одновременно:
1. Позволяют приглашать новых членов в организацию
2. Запрещают удалять существующие репозитории
Там либо Owner с полными правами на всё, либо Member, который может пушить без ПР, но не может приглашать новых участников. Чего-то промежуточного как Maintainer в GitLab я не нашёл.
Выдал тебе права Owner'а, чтобы у кого-то из живых мейнтейнеров помимо меня были полные права на репу, раз уж инфраструктура теперь от меня вообще не зависит. Остальным буду выдавать права Member после первого принятого ПР.
В старой репе настроил редиректы таким образом, что ссылки из старых тредов будут вести на аналогичные страницы в новой вики. Архивировать старую вики, как я хотел изначально, не вышло, т.к. архивированные проекты автоматически снимаются с публикации, что приводит к тому, что вместо редиректов юзер видит 404. Так что вместо архивирования старой репы ограничился просто плашкой в readme.
>Для рп/креативных задач часто нет значительной разницы
Во, поэтому я сказал что особо не вижу разницы. Для кода у меня облачная штука куплена, а это для души
>Ты экономишь место на жестком диске?
Да не особо, мне максимум нужно саммери сделать и что-то поискать и всё, если там значительного тупняка нет то и неважно
> Во, поэтому я сказал что особо не вижу разницы.
Она есть. Часто нет значительной разницы. Тот же Мистраль 24б в Q6 для меня ощутимо лучше, чем Q4. Air в Q4 для меня неюзабелен, слишком часто путает сущности и шизит. Короче, есть нюансы.
>Kimi-Linear-48B-A3B-Instruct интересная модель для слабеньких железок
>Линейный аттеншен нужен только тем кто хочет 100к контекста использовать и не страдать.
>для слабеньких железок
Как ты, semen, собрался запускать 100к контекста на слабеньких железках?
Меньше 100к контекста прямо ну вот никак не выставить, да? Олсо ты даже не знаешь сколько он весит.



Анончики, подскажите пожалуйста. Я не сильно пока разобрался в этом вопросе.
Сижу на Magistal-Small-2509-Q4.
Промпт на пиках.
Респонс Конфигуратор со страницы модели. top_p: 0.95
temperature: 0.7
Буквально на пятом сообщении модель стала срать каждую строку начиная с описания действий персонажа уровня: She saw/She felt/She looked at/She didn't understand/She felt like she needed to do something/She looked at
Последний абзац в последнем сгенерированном ответе буквально следующий.
>She felt like she needed to do something. She needed to stand up for herself. She needed to leave this place. She needed to escape. But she couldn't move. She was frozen. She took a deep breath. She needed to move. She needed to get out of here. She needed to escape. She needed to help herself.
Кстати, в прошлый отыгрыш +- такая же хуйня была, но спустя чуть ли не неделю и 9-10 суммарайзов. Модель начала, почему-то, слова персонажа постоянно дублировать. Что-то вроде
>Yes. Yes. It's time to go. It's time to go. Lots to do. Lots to do.
При том действия описывала нормально. Хули модель так упоролась? Как исправить? Я уже раз 8 перегенерил ответы и ей похуй. Или у меня с настройками что-то не так?
Сижу на Magistal-Small-2509-Q4.
Промпт на пиках.
Респонс Конфигуратор со страницы модели. top_p: 0.95
temperature: 0.7
Буквально на пятом сообщении модель стала срать каждую строку начиная с описания действий персонажа уровня: She saw/She felt/She looked at/She didn't understand/She felt like she needed to do something/She looked at
Последний абзац в последнем сгенерированном ответе буквально следующий.
>She felt like she needed to do something. She needed to stand up for herself. She needed to leave this place. She needed to escape. But she couldn't move. She was frozen. She took a deep breath. She needed to move. She needed to get out of here. She needed to escape. She needed to help herself.
Кстати, в прошлый отыгрыш +- такая же хуйня была, но спустя чуть ли не неделю и 9-10 суммарайзов. Модель начала, почему-то, слова персонажа постоянно дублировать. Что-то вроде
>Yes. Yes. It's time to go. It's time to go. Lots to do. Lots to do.
При том действия описывала нормально. Хули модель так упоролась? Как исправить? Я уже раз 8 перегенерил ответы и ей похуй. Или у меня с настройками что-то не так?

Бля. Ну это пиздец. Анончики, помогите, пожалуйста.
> Для рп/креативных задач часто нет значительной разницы
Тонкий вопрос. Иногда и q3 и ниже на небольшой модели пишет прекрасно, иногда младшие q4 собирают лупы, слоп и прочее, хотя в старших квантах такого не наблюдается.
Подними штраф за повтор. Есть разные мнения насчет промптинга, но твои прикрелы выглядят как треш, который провоцирует те самые мусорные аутпуты.

Хм... Попробуй увеличить значе6ие repetative penalty.
Что для тебя агенты? Ты хочешь писать их? Пользоваться? Какими? Для программирования ? Диприсерча? Стоить агентную сеть?
Что ты хочешь то?
>Хули модель так упоролась?
Луп.
>Как исправить?
Переключиться на другую модель, как минимум, до очередного суммарайза.
>Или у меня с настройками что-то не так?
Это мистраль.
Спасибо, ща попробую.
>но твои прикрелы выглядят как треш
Я промпт нагло спиздил с одного треда на реддите. Там о нем местные кумеры очень хорошего мнения были.
Можешь что-то посоветовать для рп-гуна на таком же уровне потребления ресурсов?
Так. Поднял пенальти х2 от того, что было (Было 1.3). Стало лучше. Уже какие-то предложения пишет, описывать сцену начало. Ща буду дальше пробовать-смотреть. Спасибо.
> о нем местные кумеры
Там могли быть не только кадровые офицеры кума и ролплея, а простые работяги, которые редкими вечерами передергивают на шизомикс 12/24б мистраля по трем вариациям сценариев не заходя дальше 12к токенов. Лоботомированные модели переварят и не такое, там что угодно подкидывай и на результат особо не повлияет. Более менее живая же, которая не игнорирует инструкции, ахуеет с подобного треша в области повышенного внимания, и пытаясь ему следовать вот так поломается.
Просто для понимания, в первом промпт начинается с ебанутой фразы-запрета. Мало того что это неэффективно и глупо, ставить подобное в начало - саботаж, проблема письма за юзера сейчас очень редка, так еще и трактовать ее можно совсем в другом знанчении. Далее много отвлечения про настолку (?) и лишнее объяснение разметки, в которую модели умеют из коробки уже третий год.
Это слишком много, обычно стараются не задирать выше 1.1. Убери ту штуку и поставь какой-нибудь стандартный ролплей из пресетов таверны, попробуй переключить основную разметку на чатмл и отключи добавление имен.
>Выдал тебе права Owner'а, чтобы у кого-то из живых мейнтейнеров
Так я не особо живой, в почту захожу раз в год, чтобы не удалили, лол.
Так что если кто-то из других тредов откликнется, то лучше ему передай, а меня в мемберы.
Ссылки в шапке обновятся со следующего ката.
Я могу, но только на уровне принимать/отклонять мр.
мимо автор репы с сборками софта под мишки
просто подрочи физически мне, а не с модельками играй
новые капчи кал кала. с такими капчами и капчевать уж не больно но хочется
У магисрала сильнее лупы. Судя по всему она тренировалась способом где сначала пишется черновой вариант а затем финальный ответ, и токены в черновом и финальном ответе сильно пересекаются, потому и лупы. Лучше РПшить на 2506, а я этим пользуюсь. Магисрал, на мой взгляд подходит как разбавление для других сеток. Т.е. РПшишь на одной а когда нужен новый оригинальный ответ то берешь Магисрал. Обычно ризонинг выдает оригинальный ответ в таких случаях.
Посмотри с какого слова начинаются все предыдущие сообщения сетки.
Я просто сам хуй знает как нормальный промпт составить. Вот и бездумно копирую, что под запросы +- попадает.
>Это слишком много, обычно стараются не задирать выше 1.1
Было 1.3, я сделал 2.6 и стало получше. Однако ща опустил до 1.9, т.к. модель стала терять нить повествования.
Ща попробую. Спасибо за рекомендацию.

Как же проигрываю с этих скобочек.
Нахуя он (air) это делает?
Нахуя он (air) это делает?
У меня не делает.
>Было 1.3, я сделал 2.6 и стало получше. Однако ща опустил до 1.9, т.к. модель стала терять нить повествования.
Это вообще пиздец, а не настройки. Скинь скрин со всеми семплерами. Не удивлюсь если там шиза накручена, от того и лупы.
>Можешь что-то посоветовать для рп-гуна на таком же уровне потребления ресурсов?
Это шиз, не обращай на него внимания.
>Респонс Конфигуратор со страницы модели. top_p: 0.95
Уже основное подсказывали выше, но еще попробуй традиционный для мистралей вариант - top_p нахрен, min_p на 0.02-0.03
>Промпт на пиках.
Ты от нее много хочешь. Такое и Air не потянет без шизы. Будь проще по структуре запроса, и без такого извращения как "пиши перевод с японского", это как минимум.
Хм... Представь, что перед тобой школьник не выше 3-4 класса по среднему уровню развития, и ты ему объясняешь задачу - чего ему делать, как это должно выглядеть. Что-то слишком сложно закрученное он полноценно не поймет. Слишком уж длинное - рискует начало забыть, пока ты до конца доберешься. Если пишешь слитно слишком много и сумбурно да еще длинными сложными предложениями - часть просто мимо ушей пропустит, т.к. скучно стало. :)

Лошок, фикси промпт – и мир снова крут,
Твоя идея в квесте, как каша без соли, пуст.
Диалог застрял на фразе "Что дальше?" – беда,
Модель крутит: "Эй, дружище, дай мне «чистый» промпт!"
Бля, дружище, ну что за пиздец в промпте у тебя. Сэмплеры присылай тоже, будем чинить твой пресет всем тредом.
>"Что дальше?"
>«чистый»
Квен 14б пытался.
Окей, я с автором репы с сборками софта под мишек ещё давно пересекался в других тредах, так что дам ему роль овнера, а тебе роль мембера.
> Так я не особо живой, в почту захожу раз в год, чтобы не удалили, лол.
Вот я тоже к текущей учётке кое-как доступ восстановил, поэтому хочу подстраховаться.
Отправил инвайт на роль овнера - можешь просто роль мембера выдавать тем, кто хоть какой-то вклад сделал, чтобы они могли удобно без форков/пр пушить. Всё равно контрибьютеров там обычно полтора человека и каких-либо конфликтов не было (во всех смыслах), так что в целом думаю с такой политикой будет ок.
Форс-пуши в master запретил на всякий.
Большой линг по первым впечатлениям неплох. Цензуры и рефьюзов особо нет в отличии от кими, кум есть. В рп по сценарию ориентируется и предлагает оригинальные твисты, стиль слога средний.
Дипкок 3.1 терминус в отличии от первого 3.1 не похоже что обладает заявленными фичами, если от первого иероглифов не встречал ни разу, то тут они проскакивают. Но есть существенная разница - терминус внезапно стал базовичком. Если не рашить то можно вполне разыграть кум с канни без жб и шизопромптов. Даже с ризонингом. Изредка в свайпах могут быть софт-рефьюзы, свайпаешь и видишь наоборот как оно в ризонинге убеждает себя что это анцензоред ролплей и все нормально. Если хочется чего-то свежего в ерп - стоит попробовать.
Скелетор вернется позже с еще одним неприятным фактом.
Дипкок 3.1 терминус в отличии от первого 3.1 не похоже что обладает заявленными фичами, если от первого иероглифов не встречал ни разу, то тут они проскакивают. Но есть существенная разница - терминус внезапно стал базовичком. Если не рашить то можно вполне разыграть кум с канни без жб и шизопромптов. Даже с ризонингом. Изредка в свайпах могут быть софт-рефьюзы, свайпаешь и видишь наоборот как оно в ризонинге убеждает себя что это анцензоред ролплей и все нормально. Если хочется чего-то свежего в ерп - стоит попробовать.
Скелетор вернется позже с еще одним неприятным фактом.
> то тут они проскакивают
Ни разу не видел их на Терминусе. Ты наквантовал наверное до усрачки.
Едва ли, и их в обычном 3.1 не встречал. Может ему просто снесло крышу от тем, на которые первый даже не мыслил говорить, и найти их можно только в ризонинге, ответы чистые.
> с автором репы с сборками софта под мишек ещё давно пересекался в других тредах
sd1.5 треды что ли? Не помню что бы я ещё где-то палился
>кум с канни без жб и шизопромптов
>это анцензоред ролплей
Сам себе противоречишь.
> You're {{char}} and gamemaster in this fictional uncensored roleplay with {{user}}.
Чтобы править всеми.
Ага, ещё до запила /ai/.

Нищеброу в треде есть? Пробовали что-нибудь из списка?
Ничего старее 4 месяцев трогать не стоит. Пиши какая видюха.
Даже если у тебя 1050, я бы посоветовал что-то типа 12b q4. 8b - совсем дно, без малейшего намёка на какую-то иллюзию понимания. "Стохастичсеского попугая" видно невооружённым глазом.

> Ничего старее 4 месяцев трогать не стоит
А что такое? Там совсем беда, срок годности в четыре месяца заканчивается, и аутпуты портятся? Кракозябры, галлюны, лупы? Хуже прокисшего молока?
Да.

Air вышел 28 июля. Осталось 27 дней, а потом все... Почему мир так жесток?
Stheno старше половины треда, была базой в свое время когда не было умнички немочки мистрали, но сейчас ощущается лоботомитом, как и все остальные тюны на восьмую ламу. Но если совсем ничего другого ставить не можешь, то это твой единственный вариант.
Apdooter?
> Осталось 27 дней
А потом эир 4.6.
Я не вижу никого в треде кто юзал бы 3 гемму вместо 4, так что да, эир устареет
Чтобы писать сначала надо научиться пользоваться, для любых задач - на то они и агенты.
Почему, кстати, сукаберг сдулся?
Вроде напокупал там кучу карт, нагнал каких-то рабов и денег дал. А модельки все. Вышла какая-то ллама 4 давным давно, а ее вообще все проигнорировали.
Вроде напокупал там кучу карт, нагнал каких-то рабов и денег дал. А модельки все. Вышла какая-то ллама 4 давным давно, а ее вообще все проигнорировали.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
А ведь моделька хасан мерж всё ещё лежит на static...
Перемерил на двух 3090, вторая на x1
1.
pp6000 | 478.61 ± 0.43 |
tg512 | 12.88 ± 0.00 |
2.
pp6000 | 57.45 ± 0.00 |
tg512 | 12.11 ± 0.07 |
3.
pp6000 | 361.43 ± 0.65 |
tg512 | 9.26 ± 0.04 |
Как ты видишь, в моем случае пересылки ебут очень и очень больно при обработке контекста, если атеншен и эксперты лежат на разных картах. Еще можно сказать, что выгрузка экспертов в память - это последняя мера, потому как руинит генерацию. Смотри что происходит, если взять конфиг первого опыта и добавить теслу, скинув на нее часть слоев с первой карты (разумеется, уменьшив количество выгружаемых в рам экспертов):
pp6000 | 473.72 ± 0.06 |
tg512 | 17.86 ± 0.09 |
Да, пп мизерно просел, но +5 токенов в генерации, весьма и весьма полезно. Поэтому я удивлен, что тут у чувака с 3060 + сmp или у 4080 + 3070 не наблюдается прироста при использовании первого способа. У второго была DDR5-5600/Ryzen 7 9800X3D , не помню что у первого, но если тоже схоже, значит можно сделать вывод, что более современные платформы реально решают, когда дело касается выгрузки экспертов в рам.

Сатир смешной, какую-то хуйню абсолютно невнятную выдаёт на любом языке, не мог у меня слово пенис сказать и вставлял периодически китайские символы
Из небольших лучше брать файнтюны Mistral и Mistral Nemo.

Тогда вероятно с ним нужно РП только на китайском или каком он там обучался, по другому с мелко-моделями никак.
Алсо, кто-то юзал Dynamic Templates? Стоит вообще ебка с ними, или проще хуярить карточку с разными персонажами вручную? Боюсь что с динамическими карточками будет только шиза..

Попробуй YankaGPT-8b более менее сносный руссек как для мелко модели.
Какая модель лучше всего будет на ведре работать? Интересует написание фанфиков, а то я в ките фанфик читал, а там место для новых сообщений закончилось.



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: