



>Почему, кстати, сукаберг сдулся?
Санкции от РФ помешали. Ведь все ключевые разработчики ИИ родом из России или СССР, лол.
На деле просто да, люди это главное.
>все ключевые разработчики ИИ родом из России или СССР
И они уже давно съебали из этой страны. Да и вообще, большую часть работы сейчас выполняют индусы за полторы копейки, которым итак наводнена контора экстремистов и террористов. Рассказы про голодающих инженеров с тремя высшими за которыми гоняются все западные конторы потеряли актуальность еще в середине нулевых.
Перемерил на двух 3090, вторая на x1
1.
pp6000 | 478.61 ± 0.43 |
tg512 | 12.88 ± 0.00 |
2.
pp6000 | 57.45 ± 0.00 |
tg512 | 12.11 ± 0.07 |
3.
pp6000 | 361.43 ± 0.65 |
tg512 | 9.26 ± 0.04 |
Как ты видишь, в моем случае пересылки ебут очень и очень больно при обработке контекста, если атеншен и эксперты лежат на разных картах. Еще можно сказать, что выгрузка экспертов в память - это последняя мера, потому как руинит генерацию. Смотри что происходит, если взять конфиг первого опыта и добавить теслу, скинув на нее часть слоев с первой карты (разумеется, уменьшив количество выгружаемых в рам экспертов):
pp6000 | 473.72 ± 0.06 |
tg512 | 17.86 ± 0.09 |
Да, пп мизерно просел, но +5 токенов в генерации, весьма и весьма полезно. Поэтому я удивлен, что тут у чувака с 3060 + сmp или у 4080 + 3070 не наблюдается прироста при использовании первого способа. У второго была DDR5-5600/Ryzen 7 9800X3D , не помню что у первого, но если тоже схоже, значит можно сделать вывод, что более современные платформы реально решают, когда дело касается выгрузки экспертов в рам.
> pp6000 | 478.61
> pp6000 | 57.45
А ты случаем не меняешь главную карточку, или какие-то подобные манипуляции?
Там пересылов немного и они никоим образом не могут повлиять настолько сильно. Чтобы получить столь колоссальные задержки нужно буквально полные веса пересылать. Что и будет происходить если основной станет вторая, что сидит не на широкой шине, а по х4 или ниже. Проблема окажется не в пересылах активаций а в стриминге весов на нее для обсчета.
> выгрузка экспертов в память - это последняя мера
Ну это типа база и необходимое зло, иначе без врам вообще никак не запустить.
> Смотри что происходит, если взять конфиг первого опыта и добавить теслу
Часть экспертов вместо профессора на теслу в дополнении к остальному, или тесла зменяет одну из 3090?
> у чувака с 3060 + сmp
У него как раз было ускорение когда не стал на паскаль закидывать attn, оставив его на ампере, а скинул только линейные, вариант 2.
> у 4080 + 3070
Посты сумбурные и нужно отслеживать, но похоже что то же самое.
По скорости обработки частей на проце тут очевино что чем быстрее рам тем лучше будет. Но именно по задержкам связанным с шиной каких-то откровений не ожидается. И у тебя какая-то аномалия с резкой просадкой на ровном месте.
>А ты случаем не меняешь главную карточку
Неа, не меняю.
>Часть экспертов вместо профессора на теслу в дополнении к остальному, или тесла зменяет одну из 3090?
Было 3090 Ti + 3090, стало 3090 Ti + 3090 + P40, под завязку. То, что не влезло - на цпу (в виде -ncmoe)
>У него как раз было ускорение когда не стал на паскаль закидывать attn
Ага, это помню. Интересно, как подключены у него карты. И у него тоже странно - как ты видишь, в моем случае паскаль нормально считает аттеншен, нет значимых просадок по сравнению с гонянием экспертов из рам и обсчете на основной.
Я бы проверил на честных-честных чипсетных х4 из слота, а то тут все на райзерах (ошибок нет в nvidia-smi, сразу говорю), но у меня там с недавних пор карта для RPC сидит, шатать риг ради тестов я не буду.
В общем, дивны дела твои господи
Для диагностики попробуй менять пропорции атеншна между карточками. Зафиксируй положение экспертов с помощью регэкспа:
> -ot "blk.[1-9]\.ffn_._exps\.=CUDA0;blk.2[1-9]\.ffn_._exps\.=CUDA1;blk.ffn_._exps=CPU"
подстроив их количество под свои карты, можно оставить по 9 блоков как тут чтобы заведомо хватило при любых пропорциях, и дальше играйся с -ts.
При распределении весов по девайсам ts с ngl вступают первыми, распределяя веса блоков по двум кудам, далее обрабатываются -ot и парсятся с конца. Получается что линейные слои выкидываются на цп, далее отмечаются те, которые будут на каждой карточке. Меняя соотношения в -ts ты будешь менять только атеншн, нормы и прочее, а линейные слои будут постоянно одни и те же.
> в моем случае паскаль нормально считает аттеншен
Ну как нормально, сносно. Получился ровно тот же пп а не ускорение потому что произошла компенсация эффектов. Выкинув сразу много блоков с цп на гпу при обработке больше не требуется стримить их на основную для процессинга, что является болнеком. Если бы считало хорошо - получил бы ощутимый буст процессинга. Если атеншн с нее выкинешь на основную - получишь ускорение и процессинга и генерации. Если какие-нибудь приколы опять не возникнут.
> > -ot "blk.[1-9]\.ffn_._exps\.=CUDA0;blk.2[1-9]\.ffn_._exps\.=CUDA1;blk.ffn_._exps=CPU"
Кто там заявлял что звездочки в цитате работают?
-ot "blk.[1-9]\.ffn_.😭_exps\.=CUDA0;blk.1[0-5]\.ffn_.😭_exps\.=CUDA0;blk.2[0-9]\.ffn_.😭_exps\.=CUDA1;blk.3[0-5]\.ffn_.😭_exps\.=CUDA1;blk.😭ffn_.😭_exps=CPU"
возможно где-то ошибка там ибо сделал на лету, поправишь если что, суть главное понятна.
Анон, в ИИ не шарю.
Я интереса ради попробовал juicychat.ai и вроде прикольно. Но токенов мало. Подумывал было купить, что бы месяц побаловаться, но увидел ценник и начал сомневаться. Особенно с учётом того, что тамошними правилами Куроки Томочку запилить нельзя.
Отсюда вопрос, на домашнем ПК реально поднять аналогичную систему чисто для себя, без всратых ограничений? Комп у меня вроде хороший. 4090, 7800X3D, 64 ОЗУ.
Я интереса ради попробовал juicychat.ai и вроде прикольно. Но токенов мало. Подумывал было купить, что бы месяц побаловаться, но увидел ценник и начал сомневаться. Особенно с учётом того, что тамошними правилами Куроки Томочку запилить нельзя.
Отсюда вопрос, на домашнем ПК реально поднять аналогичную систему чисто для себя, без всратых ограничений? Комп у меня вроде хороший. 4090, 7800X3D, 64 ОЗУ.
реально
>Отсюда вопрос, на домашнем ПК реально поднять аналогичную систему чисто для себя, без всратых ограничений?
Вполне.
>Комп у меня вроде хороший. 4090, 7800X3D, 64 ОЗУ
А если до 128 (или хотя бы 96) ОЗУ добить - будет отличный. Это уже заявка на топовые MoE модели. На 64 - средние.
> на домашнем ПК реально поднять аналогичную систему
> 4090, 7800X3D, 64 ОЗУ.
На твоем железе можно развернуть что-то, что, скорее всего, будет гораздо лучше. https://huggingface.co/zai-org/GLM-4.5-Air
Q4 с 20-30к контекста должен уместиться. llamacpp/Кобольд и Таверна. Придется повозиться, разобраться со всем этим, настроить, но если тебе это правда интересно - того стоит.
Проц чуть слабоват (у самого такой же кейс) ищи 64х2 плашки пока совсем из продажи не пропали. Потом апнешь проц на зен6, а пока просто МОЕ будут медленнее работать.
Спасибо, анон.
А что по ограничениям? Я готов попробовать в это всё ввязываться только при наличии возможности запилить Томочку. В противном случае мне будет проще оплатить джуйси чат. А может быть есть аналоги без этих ограничений?
> что по ограничениям
The sky is the limit. Ну или ты сам, потребуется разобраться в запуске и в работе. Если ты не совсем хлебушек - это несложно, требования ко вкату низкие, требования к более глубокому освоению средне-высокие. По экспириенсу будет гораздо лучше чем джусичат.
> А что по ограничениям?
С этой моделью - скорость у тебя будет 6-7т/с, контекстное окно 20-30 тысяч токенов.
> Я готов попробовать в это всё ввязываться только при наличии возможности запилить Томочку
Что угодно можно сделать, запромптить можно любого персонажа и любой сценарий. Разве не очевидно?
> А может быть есть аналоги без этих ограничений?
Не знаю, про какие ограничения речь и что ты имеешь ввиду. Можешь или локально у себя все запускать, или платить за какой-нибудь сервис (апи). Они существуют без ограничений, да, но с этим в соседний тред. Здесь все про локальный запуск.
Пожалуйста, посоветуйте хороший рп тюн геммы без ассистента, вроде синтвейва. Кум не в приоритете, но имеет место быть.
Есть какой-то способ эту модель перестать выдавать странные тэги типа: А Анон, П Жопа, Ням Сися невпопад?
> хороший рп тюн геммы
Не существует, увы. Сколь-нибудь жизнеспособны только Synthia и Synthwave соответственно.
> Есть какой-то способ эту модель перестать выдавать странные тэги
Не понимаю, про что ты говоришь. Формулируй вопросы четче, прикладывай скриншоты и подробности, медиумов здесь нет (ушли в отпуск на неопределенный срок).
>Что угодно можно сделать, запромптить можно любого персонажа и любой сценарий. Разве не очевидно?
Не очевидно. Я с ИИ знаком только по этому сайту, а там ограничение. Плюс в шапке какие то кошмары цензуры присутствуют. Отсюда и вывод.
>скорость у тебя будет 6-7т/с, контекстное окно 20-30 тысяч токенов.
К сожалению это пока для меня звучит как белый шум.
>Не существует, увы.
То есть из огромного количевства людей которые занимаются тюнами, осилили только два человека? Пиздец какой то.
> Не очевидно. Я с ИИ знаком только по этому сайту, а там ограничение.
Тогда тебе следует повозиться с этим на своем компьютере хотя бы для того, чтобы понять, что и как работает. Это в любом случае будет полезно, даже если позже решишь перейти на апи (веб сервис).
> Плюс в шапке какие то кошмары цензуры присутствуют.
У многих веб сервисов такое, по разным причинам от моделей, что они используют, до законодательства. Есть всякие OpenRouter и прочие, которые не имеют подобных ограничений. Но опять же, с этим в другой тред, здесь про локальный запуск.
> К сожалению это пока для меня звучит как белый шум.
Если вкратце - ты использовал бесплатную версию (которая по определению только скудна, там в лучшем случае 8б модель, на твоем железе можно запускать модели кратно больше) веб сервиса (в котором присутствуют цензура и прочие искусственные ограничители вроде длины контекста). Ты уже прямо сейчас на своем компьютере можно запустить что-то, что гораздо лучше. Если поймешь, что тебе и этого мало, тогда уже можешь попробовать купить нормальный апи у проверенных провайдеров, я бы на твоем месте попробовал так. Если ты уверенный пользователь и умеешь работать с терминалом, гугли-разбирайся с llamacpp. Если ты хлебушек, разбирайся с KoboldCPP. Затем в любом случае ставь Таверну (SillyTavern) и дружи это все. Будут трудности - приходи сюда, но постарайся хорошо сформулировать вопрос(ы) и поделиться подробностями. К сожалению, готового решения, где ты нажмешь одну кнопку, и все будет работать, не существует. Только с веб сервисами (апи), но с этим в другой тред. Здесь же будут рады помочь с локальным запуском. Это два больших лагеря со своими плюсами и минусами. С апи ты не зависишь от своего железа, но зависишь от веб провайдера, а запуская локально ты ни от кого не зависишь, но ограничен своим ресурсом.
> осилили только два человека?
На самом деле один, потому что Synthwave - это мердж, а не тюн. Да и при всем уважении к Синтии, я ей так и не смог проникнуться. Как, впрочем, и ванильной Геммой, не моя модель.
> из огромного количевства людей которые занимаются тюнами
Единицы что уже что-то шарят но еще занимаются средним оперсорсом, не открыв свой стартап или не став частью других корпораций - осилили. Слоподелы, пик которых - вжаривание мистрали слопом и составление кринжовых карточек моделей, закономерно соснули.
Не существует никакого "огромного количества", то изобилие что было во времена второй лламы сейчас превратилось в изобилие базовых моделей. Именно полноценных тюнов общего назначения или с фокусировкой на рп делается достаточно мало, команды можно по пальцам пересчитать. Остальное - инцест, шизомерджи и прочая сомнительная продукция.
>Для диагностики попробуй
Ох, это уже реально впадлу, да и зачем. В своих реальных сетапах я пробовал выгружать аттеншен только с тесел на основную - ну получил легкий посос и в обработке, и в генерации по сравнению с обычной выгрузкой. Единственное, что мне бы помогло, судя по всему - это миграция на новую платформу с DDR5 и хорошим камнем, да слотов-линий побольше. Ну или парочка rtx 6000 pro. На авито за 750к видел. Согласен на безвозмездный подарок :3
>Ну как нормально, сносно
Ну типо не просадило обработку, да еще и плюс на генерацию, крута же, живем! Тот же эффект, к слову, и на конфигах вроде большого глм, только там еще и обработка вырастает.
uoooooohhh
Вот у тебя есть персонаж базовый в таверне, зовут Seraphina.
Когда бот будет писать, она будет периодически начинать предложения с Ser Seraphina и прочую таку странную комбинацию, как это лечить?
> будет периодически начинать предложения с Ser Seraphina и прочую таку странную комбинацию, как это лечить?
Не знаю. Пока не принесешь подробности того, как ты запускаешь, какая у тебя разметка, какие сэмплеры - не ясно. Так быть не должно, ты где-то накосячил.
Т.е. у тебя эта моделька никакой странной разметки не пыталась никогда выплевывать? Потому что она это делает с разными карточками, семплерами и темплейтами. И даже файнтюны васянские ее это делают.
> Т.е. у тебя эта моделька никакой странной разметки не пыталась никогда выплевывать?
Мы говорим про Air? Если так, то нет, ни разу такого не было. С разными карточками, в разных чатах, разными сэмплерами и темплейтами. Позади не меньше 200к токенов, думаю.
Ты, кажется, первый кто о таком пишет. Думой.
Че мне думать, она даже с пустыми карточками это делает.

В таком случае предположу, что я и все те, кто катают Air, сошли с ума или не заметили. Вероятность, в целом, не нулевая, нельзя отвергать эту версию.
Полный промпт проверь. Не удивлюсь, если какой-нибудь лорбук забыл отключить.
Я в консоли полный промпт вижу, зачем мне по этим вкладкам лазить...
Ты хороший, анон, спасибо тебе.
Я вернусь когда у меня появятся вопросы.
Хорошо, можете тогда посоветовать хороший рп тюн мистраля 24b? Те что в шапке сломанны, а оригинал ведёт себя как то по ебанутому, при том что я пихал в него промпт тредовичка.
>промпт
Пресет.
фикс
Это наша нюня! Имя такое. Только свистни и он появится. Любим и ненавидим всем тредом
> хороший рп тюн мистраля 24b?
Не могу, увы, потому что с Мистралями давно не имею дела. Последнее, что пробовал - инструкт 3.2. Мне показалось, что он гораздо лучше 3.1 и предыдущих 24б версий. Не знаю, что ты имеешь ввиду про ебанутое поведение, ибо не слишком много токенов наиграл с ним. Читал хорошие вещи про https://huggingface.co/zerofata/MS3.2-PaintedFantasy-v2-24B и https://huggingface.co/CrucibleLab/M3.2-24B-Loki-V1.3, но не могу за них ручаться.
> Те что в шапке сломанны
Все-все? Уверен, что проблема не на твоей стороне?
>готового решения, где ты нажмешь одну кнопку, и все будет работать, не существует.
Ой да ладно. Он свою конфигурацию плюс минус назвал. Местные так долго дрочат кобальт и ламу что уже могут закрытыми глазами ему список файлов для скачивания написать и батник для запуска.
> Ой да ладно ...
Модель под его конфиг ему прислал, отправную точку объяснил, рад буду ответить на последующие вопросы. Верю, что нужно учить рыбачить, а не давать рыбу, но тебе никто не мешает принести ему на блюдечке все готовое. Нечего пенять на остальных.
Но в любом случае карточку ему, похоже, придется писать самому.
Не поленись при случае, нужно понять почему так происходит. А платформу разумеется есть смысл апгрейдить, особенно если много видеокарт.
> Ну типо не просадило обработку
Так можно сделать лучше же, и ген поднимется и обработка еще быстрее будет. Или хотябы найти какой-то фактор, который мешает чтобы знать о нем.
А ты анслотовские кванты брал или обычные?
А сколько место нужно на диске? Нужен ли ССД? Нужен ли м.2?
Кто-нибудь пробовал Apriel-1.5-15b-Thinker? Как для РП, так и для бытовых задач или кода. Довольно высоко поставили в рейтинге artificialanalysis, интересно мнение кто использовал.
Обычные, но не думаю, что это важно.
Во время инференса (запуска/развертывания) модели, она загружается в оперативную и видеопамять и находится там. Скорость ссд/жд не важна.
> Apriel-1.5-15b-Thinker? Как для РП, так и для бытовых задач или кода
Пробовал для кода. В моих юзкейсах показал себя на уровне Qwen2.5-Coder 32b. С другими, более новыми моделями, не сравнивал.
https://github.com/ikawrakow/ik_llama.cpp
> ik_llama.cpp: llama.cpp fork with better CPU performance
> This repository is a fork of llama.cpp with better CPU and hybrid GPU/CPU performance, new SOTA quantization types, first-class Bitnet support, better DeepSeek performance via MLA, FlashMLA, fused MoE operations and tensor overrides for hybrid GPU/CPU inference, row-interleaved quant packing, etc.

exllama

Эта картинка актуальна вообще для всех моделей? Качать что-то выше Q4_K_XL не имеет смысла?
> Эта картинка актуальна вообще для всех моделей?
Нет. Для начала нужно понять, что изображает график.
> Качать что-то выше Q4_K_XL не имеет смысла?
Имеет в определенных случаях. Не имеет тоже в определенных случаях. Q4 - золотой стандарт, ниже которого лучше не брать, если есть возможность.
И так. поставил кобольду. Скормил ггуфку.
Скачал силлитаверн. подключился к кобольду.
он пишет мне:
KoboldCpp works better when you select the Text Completion API and then KoboldCpp as a type!
это что?
Так же, на первом запуске таверны было окно с импортом всякого. Я смог подгрузить Томочку. А как опять в это окно с импортом персонажей попасть?
ЕЩе вопрос, есть места где миры уже готовые брать?
Скачал силлитаверн. подключился к кобольду.
он пишет мне:
KoboldCpp works better when you select the Text Completion API and then KoboldCpp as a type!
это что?
Так же, на первом запуске таверны было окно с импортом всякого. Я смог подгрузить Томочку. А как опять в это окно с импортом персонажей попасть?
ЕЩе вопрос, есть места где миры уже готовые брать?
Вопрос по импорту и лорбуку снят. Нашёл нужную кнопку.
Вопрос по KoboldCpp works better блаблабла всё еще открыт.
Можно ли, используя локальную LLM, обучить её знаниям о моём сервисе таким образом, чтобы она могла анализировать добавление новых функций на основе уже существующей базы знаний?
Пример:Допустим, у меня есть база данных с таблицей users, в которой есть поле position_code. Это поле может содержать значение NULL. Я передаю эти данные модели, она их изучает и запоминает.Затем я хочу добавить новый HTTP метод в сервис, который возвращает пользователей (users), и поле position_code я делаю обязательным. Проанализировав это изменение, LLM сообщит мне, что возникла проблема, поскольку ранее поле могло быть пустым (NULL).
Возможно ли такое? В какую сторону нужно смотреть?
Пример:Допустим, у меня есть база данных с таблицей users, в которой есть поле position_code. Это поле может содержать значение NULL. Я передаю эти данные модели, она их изучает и запоминает.Затем я хочу добавить новый HTTP метод в сервис, который возвращает пользователей (users), и поле position_code я делаю обязательным. Проанализировав это изменение, LLM сообщит мне, что возникла проблема, поскольку ранее поле могло быть пустым (NULL).
Возможно ли такое? В какую сторону нужно смотреть?


Вроде как победа.
Я скачал какой то мир, всё работает. Персонаж тоже.
Но ответы какие то сухие и односложные, по сравнению с juicychat, где тебе и мысли и действия и всё подряд. Как можно это исправить? Примеры ответов с джусичата к которым хотелось бы стремиться на скринах.


> KoboldCpp works better when you select the Text Completion API and then KoboldCpp as a type!
Имеется ввиду, что Кобольд предлагает использовать тебе KoboldCPP API Type. Апи Кобольда может работать как в таком режиме, так и Generic (OpenAI-compatible). Кобольд не использую, в чем разница - не знаю, не использую Кобольда, но думаю, что это незначительно. Text Completion или Chat Completion - тоже разновидности апи, тебе для начала нужно выбрать Text Completion. Будет проще преодолеть цензуру и разобраться на базовом уровне.
> Вроде как победа.
Подозреваю, ты еще не до конца оптимизировал настройки запуска в Кобольде, и можно получить бОльшую скорость генерации. Какая у тебя сейчас? Можно посмотреть в Таверне, можно в логах. Используешь Air Q4?
> Я скачал какой то мир
Это необязательно. Вся работа с моделью выглядит как запрос-ответ. Таверна - менеджер для составления запросов (промпта). Лорбуки/WorldInfo/миры - часть запроса. Это не магия, которая сделает все ответы лучше и продуманнее.
> где тебе и мысли и действия и всё подряд. Как можно это исправить?
Запромптить. Например, в системном промпте подавать такую инструкцию или показав, как нужно делать, примерами диалогов в карточке.
> Примеры ответов с джусичата к которым хотелось бы стремиться на скринах.
На первом скрине ужас. Со временем поймешь. На второй картинке что-то вменяемое, Air так может из коробки (в случае правильных настроек), за исключением [вот этого блока], как делается - описал выше. Еще вариант - воспользоваться плагином www.github.com/kaldigo/SillyTavern-Tracker
> В какую сторону нужно смотреть?
В сторону тестирования кода.
>Пожалуйста, посоветуйте хороший рп тюн геммы без ассистента, вроде синтвейва.
Мне зашел вот этот: https://huggingface.co/mradermacher/Storyteller-gemma3-27B-GGUF
При том что синтия для меня - примитив, который неюзабелен из-за постоянного игнора инструкций, а синтвейв - что-то странно-синтетическое, и тоже без особых плюсов.
Этот тюн, вообще-то больше для писателей, как я понял, но в RP очень даже, как ни странно. Микс, почему-то не очень известный, хотя очень зря. IMHO, разумеется.
Тоже никогда такого не видел от AIR. Слушай, а попробуй квант перекачать, а? По твоим описаниям - это уже становится похоже на битую модель(файл).
Семплеры кривые. В таком случае любая самая распрекрасная модель шизеет.
Какие у тебя настройки кобольда? Какую модель выбрал?
GLM-4-32B-0414 это последняя хорошая 32B для creative writing? Нужно W++ слоп отредактировать.
Неиронично, это по-прежнему лучший формат карточек. По сути, разновидность JED. Главное не наваливать ненужного.
Да, если рассматривать среди 32б, лучше ничего не было.


>Используешь Air Q4?
это ггуф ЖИВ файл? Я скачал тут https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-v2-24B-GGUF/tree/main модель на 25.1 GB MS3.2-PaintedFantasy-v2-24B.Q8_0.gguf
>В сторону тестирования кода.
Я использую дефолтные настройки. чуть накрутил токенов. скрины прикладываю.
Самый лучший формат - это json, но можно убрать кавычки и скобочки. Просто идентификатор и переменные. Если нужно приколотить стиль речи, то примеры диалогов в конце.
Любой нативный способ написания будет ебать будущее форматирование текста и его не стоит использовать, тем более, что банально хуже воспринимается нейросеткой.
Кто-то юзал Dynamic Templates? Стоит вообще ебка с ними, или проще хуярить карточку с разными персонажами вручную? Боюсь что с динамическими карточками будет только шиза..
ну и кто из вас пидорасов спалил абу обход капчи?
хуита
теоретически чем больше модель - тем меньше мозгов у неё отрезает квантизация, поэтому на дикпике Q4 почти так же хорош, как Q8.
на мелких моделях ниже Q4 жизни нет, если нужен точный перевод или программирование, то подойдёт только Q8

>Есть какой-то способ эту модель перестать выдавать странные тэги типа: А Анон
Так же любую хуйню если модель выдает лишнюю можно обрубать через stop sequence в таверне, но важно что бы ты правильно указывал то что блокировать, и еще можешь добавить \n перед что бы случайно не обрезались строки полностью.
Но не уверен что это та самая панацея в твоем случае, вроде у тебя просто не до конца настроена таверна/и хз какая вообще модель
Подожди, это ты Томоко-фаг и это твой пресет/модель?
MS3.2-PaintedFantasy-v2-24B это вроде файн-тюн мистральки, а она обучалась на chatML, поставь его, возможно это и была причина твоих непонятных
>А Анон, П Жопа
И токенайзер поставь best match и пресет нормальный, Universal-Creative с 1.5 температуры слишком много шизы, попробуй сначала с 0.8 хотя бы а дальше уже крути себе под настроение, TOP 20-40 DRY штрафы за повторы поставь что бы модель не выдавала одну и ту же шизу. Вроде если это ты тот же анон, то тут полный пиздос с шаблоном. Но это все легко изи за пару недель поймешь как фиксить, конечно простоты как на джуси чат не будет(хотя я там не сидел хз, но вроде там кал полный уровня 8b просто зафайнтюненный на еблю и фетиши, но в остальном у тебя может быть куда богаче РП чем там, ну и еще и контекст/суммарайз всегда под твоим контролем, ну и придется реально самому подстраивать все под свои нужды, т.е это не так как в джуси чате где если ты пишешь ХОЧУ долгое красивое РП или хочу СИСИК ПИСИК и модель автоматически под себя подстраивает промпт. Алсо, если в будущем захуяришь под себя годно карточку с Томочкой, кидай сюда, буду рад заценить.
Они то могут быть все так же умными в логике, но факты искажаются, а это критично для чего либо серьёзного кроме рп.
> тем меньше мозгов у неё отрезает квантизация
Нет, влияние такое же. И там нет "отрезания мозгов", скорее дестабилизация, искажение фактов как подметил. Просто большая модель изначально стабильнее и даже ужатая на первый взгляд сохранит адекватность. Но если отмасштабировать критерии и объем - точно также фейлит тупя и лупясь там, где более живой квант без проблем сработает.
> если нужен точный перевод
Одна из простейших задач где не нужен высокий квант вообще. Проблема может возникнуть только на совсем лоботомитах + непопулярный язык в датасете. Тому же дипсику даже tq1 не мешает идеально шпрехать на русском, а некоторые другие и в 16битах делают ошибки.
> или программирование
Здесь квант выше будет полезен чтобы меньше теряло исходную нить и держало контекст. Утверждения типа
> только Q8
лишены смысла, потому что основным источником ошибок будет собственный тупняк сетки и рандом, q5-q6 не будут проигрывать. Это все касается агентов, если же просто "кодить в чатике" обсуждая - там и q4 хватит.
> > если нужен точный перевод
> Одна из простейших задач где не нужен высокий квант вообще
то-то низшие кванты внезапно на китайский переходят или "ебал её рука"
>это ггуф ЖИВ файл?
Ari, он же воздушный он же GLM 4.5 Air- безусловная любимица треда и спасение для нищуганов в РП.
Очень неоднозначная и капризная модель. Те проблемы которые у тебя с ней возникают, являются хорошим маркером того, насколько ты вообще постиг промтинг.
Этой модели может не понравиться твой формат карточек и иона будет капризничать, ей может не понравиться твой промт. Её кванты от разных людей - выдают разные результаты.
Но и тысячу раз но. Если ты освоишь, то ничего лучше в её размерах не существует. Я был мистралелюбом, но на 16+64, после двух недель пердолинга, освоил некотоыре навыки как с ней работать и не могу нарадоваться.
Это капризная, местами кривая, любящая навалить слоп - но это гемини дома. Deal wit it.
>то-то низшие кванты внезапно на китайский переходят или "ебал её рука"
Да, ну это причина не перевода, ЛЛМ-ки, по крайне мере локальные не переводят, они выдают токены, потому на качественный русик от мелко моделей не ожидают. А вот перевод, сам перевод это настолько простая минорная задача для LLM что на чистейшего литературного руссика хватает 1b-4b модели.

>Подожди, это ты Томоко-фаг и это твой пресет/модель?
Я тут, но не моё сообщение.
Я кстати понял в чем дело. Я начал новый чат и там уже больше деталей стало. Но хотелось бы более лучшего экспериенса.
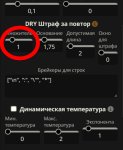
>TOP 20-40
пик 1. так?
>DRY штрафы за повторы поставь
пик 2. изменил ноль на единичку.
Спасибо, что помогаешь. Как запилю Томочку - я обязательно поделюсь. Я тут потихоньку добавляю деталей в карточку ее персонажа. Копипащу факты с вики.
Я пробовал искать ггуф этого айра, но не смог найти. Анон в треде кинул ссылку на PaintedFantasy и там я смог найти ггуф файл. Поэтому взял его.
> Я пробовал искать ггуф этого айра, но не смог найти. Анон в треде кинул ссылку на PaintedFantasy и там я смог найти ггуф файл. Поэтому взял его.
Блджад, анон, не могу дать нейтральный пресет, так как сети нет второй день. Поищи по тредам, там давали ссылки на его семплеры и были жоровские батники. Семплеры стандартные, настройки chatml.
Как связь появится скину, а то местные тредовички трясутся за обычные настройки, словно это их грааль.

>нейтральный пресет... ссылки на его семплеры
Ссылки на семплеры. Хорошо. Я поищу.
>были жоровские батники
Жора? Кто такой Жора?
Это проблема того, что выбранная тобой модель в принципе не знает нормально русский. Между французским-немецким-китайским даже там все вполне неплохо, разумеется это по словам самих носителей.
Если не нравится пример дипсика ввиду его жирности, подойдет квен 30а3, даже без специализации на русский в 4 кванте хорошо пишет и переводит.
> спасение для нищуганов в РП
Сейчас налетят нищуганы и заявит что тру жизнь на 8-12б, а с 16гигами ты мажор ебаный.
Не аварь.
> Ссылки на семплеры. Хорошо. Я поищу.
Ищи по GLM и Air
> Жора? Кто такой Жора?
llama.ccp, Жора от Георгия, автора.
В шапке есть ссылки. Для запуска нужно создать батник и прописать в него команды запуска. Вот эти огромные полотна в предыдущем треде это все из этой оперы, аноны тензоры раскидывают, но это уже тонкая настройка. Примеры батников тоже скидывали в пролом позапрошлом треде точно был. Там что то в духе:
-lama -b blah blah
-t 13^
-n -cpu -moe 42 и прочее.
>Я пробовал искать ггуф этого айра
Он кидал МоЕ модель, там нужно качать все файлы. МоЕ-шки разбиты на дохуя файлов(экспертов, те хуйни которые мозги моделей) чисто выгрузив в видеокарту одним .gguf файлом как плотную дэнс модель тут не получится, да и не нужно, и вот эти вот эксперты ты спокойно можешь выгружать в RAM, а контекст например в vram, и таким образом запускать то что ты хуй запустишь на одной 24 гиговой карте. В твоем случае пока просто балуйся как получается, и все понимание само придет со временем. Алсо, Аир из локалок правда база треда, конечно далеко не близок к корпосеткам, но в РП он будет в дохуя раз лучше того файнтюна мистрали что у тебя. Так что дерзай, познавай как запускать МоЕ-шки, сам бы гонял на нем если бы не поскупился на материнке и озу, так что ты в этом треде с твоим конфигом уже сразу определяешься в аристократию.
>Но хотелось бы более лучшего экспериенса.
Ну это скорее реально лучше сразу АИР запускать, 24b мистралька это норм модель, но.. средняя так сказать, мистралька конечно умничка, спору нет.
>Жора
Жора = llama.cpp
А не проще ли МоЕ-шки сейчас через кобольда гонять? Там же прикрутили нормально запуск МоЕ что бы без ебли с терминалом и батником?
>Неиронично, это по-прежнему лучший формат карточек. По сути, разновидность JED.
Только AIR им не кормите - тупеет и лупится с таблицами и ассистентом.
>Самый лучший формат - это json, но можно убрать кавычки и скобочки
Был когда-то. Сейчас даже всеядный мистраль с ним может начать чудить.
>тем более, что банально хуже воспринимается нейросеткой.
Все сетки которые я щупал начиная от gemma3-27B и более поздние - лучше всего воспринимают plain text для описания персонажа, с минимальной структурой. Если начать скармливать форматы - то ассистент лезет, то таблицы на выходе, то одни детали проёбываются в пользу других.
Они слишком надрочены на списки и прочее IMHO - упарываются в структуру и теряя все остальное попутно, а заодно отвечать начинают в стиле помощника при этом. Хуже всего с этим у Осы, мистраль самый устойчивый, но и он дуреет если перестараться.
Если не хочется лазить в командную строку - проще. Но тут его хейтят по старой привычке.
А ну тогда збс, потому что ЕБАТЬ Я КОБОЛЬД.
>Но тут его хейтят по старой привычке.
Да, ведь просадка по скорости на ~10-15% никуда не делась. Для новичков норм, а если тебе нужен максимум то нет.
Возможно и проще. Но по неведомым причинам, на жопе я получаю из ниоткуда 3-4 т/с бонусом. А это весомый аргумент.
10% от 5-7 токенов это сколько будет?

таверну и прочий кал юзают те, кто не осилил кобольд
Ебать ты кобольд..
Если хочешь действительно набросить, нужно славить олламу.
>комплексы тавернодетей
почему ты выбрал линукс вместо винды?
ну типа я особенный, чувствую себя избранным меньшинством, могу в консольке сидеть, я там настоящий админ бох всея системы мам скажи им
почему ты выбрал что-то кроме кобольда?
чел, ну пердолики мы ради пердоленья, отстань
ну типа я особенный, чувствую себя избранным меньшинством, могу в консольке сидеть, я там настоящий админ бох всея системы мам скажи им
почему ты выбрал что-то кроме кобольда?
чел, ну пердолики мы ради пердоленья, отстань
Ну дык проще - не значит что еще и быстрее. 10-15% в минусе, зато сразу работает, и понятнее для тех, у кого от командной строки shivers on the spine.
:)
Никто не пишет, что кобольд говно. Ты говно, не кобольд. Прекращай набрасывать и провоцировать нелюбовь к выбранному тобой инструменту. Хотя первый пост смешной.

Дык спору нет. Я никогда слова плохому к кобальту не скажу. Эта умница показа мне что такое слои, позволила
понять как уменьшение и увеличение влияет. Что такое батчи, какие есть доп команды. Просто я уже вырос и пошел дальше, но кобальту все равно большое пасебо.
>почему ты выбрал линукс вместо винды?
Потому, что задрала решать за меня - что и как мне в системе нужно. А он просто работает, и ничего сам за меня не делает.
>почему ты выбрал что-то кроме кобольда?
А у меня кобольд - мне лень собирать голую ламу ради 10-15% после каждого апдейта. (Нету готового бинарника под nvidia здесь).
Так не структурируй. Просто
{{char}}'s appearance: trait1, trait2, trait3
{{char}}'s personality: trait1, trait2, trait3
Я еще кавычки ставлю, чтобы модельки понимала, что это отдельные объекты. Проблем не встречал, честно. Там нет структуры, которую бы моделька могла повторить для чего-то, что я ей говорю делать. А вот текст содержит в себе стиль, который влияет на ее выдачи. И текст это не набор парамтров, ты не всегда можешь сказать, на что там обратит внимание нейросетка в этом предложении, а что проигнорирует.
Бля, и правда пахнет...
Ну а зачем ты cum брал в рот?!
Я не гей, но эпл это эпл...
>Так не структурируй. Просто
Мистралю будет норм, а Air даже таким может подавиться.
>А вот текст содержит в себе стиль, который влияет на ее выдачи
Разумеется. Чем и ценен. Позволяет задать нужную начальную атмосферу прямо в самом описании персонажа, чем экономит место и время, и хорошо дает начальный пинок для RP именно в желаемом направлении.
>И текст это не набор парамтров, ты не всегда можешь сказать, на что там обратит внимание нейросетка в этом предложении, а что проигнорирует.
Ну, у меня с этим проблем нет, для меня поведение модели на конкретном тексте в описаниях персонажа предсказуемо этак на 90%, что позволяет легче получить желаемый характер и поведение.
Вот со списками и форматами, как раз, такая проблема проявляется. Но не настаиваю, что мой подход единственно верный - просто именно для меня он работает куда лучше.
>Чем и ценен
Он не ценен, он сделает все рп одинаковыми, потому что тон рп задан карточкой персонажа, а не сценарием. Карточка персонажа не должна иметь ничего, помимо описания персонажа.
>Позволяет задать нужную начальную атмосферу
Ты можешь это сделать несколькими тегами, которые просто опишут примерный гоал через теги контента. Наляпывать лингвистическими петтернами нейросеть не нужно, не все нейросетки мистраль, который срет одним и тем же слопом, независимо от промпта. Тон происходящего задается в процессе повествования через RHLF.
> Карточка персонажа не должна иметь ничего, помимо описания персонажа.
Вот тут не соглашусь. Куда предлагаешь пидорить описания мира, персонажей и особенности. В сценарий? В лорбук?
Если просто тегать у тебя будет максимально слопный персонаж.
В 5090 есть поддержка FP4, как мне сконвертировать в NVFP4 допустим Cydonia-24B?
Нет смысла, оно не будет быстрее int4. И fp4 кванты обычно хуже int4 по качеству. У Жоры есть поддержка fp4, но оно медленнее q4. В TransformerEngine вообще печально всё со скоростью fp4 если без больших батчей.
тащемта уже нашёл, надо просто взять базовую модель и там
```
# 1) Контейнер с TRT-LLM (версию подмени на актуальную)
docker run --gpus all -it --rm -v $PWD:/ws nvcr.io/nvidia/tensorrt-llm:25.09-py3 bash
# 2) Установка Model Optimizer (ModelOpt)
pip install --extra-index-url https://pypi.nvidia.com modelopt[torch] tensorrt-llm
# 3) Клонируем примеры PTQ
git clone https://github.com/NVIDIA/TensorRT-Model-Optimizer /opt/modelopt
cd /opt/modelopt/examples/llm_ptq
# 4) Калибровка и квантование в NVFP4 (весов и KV-кэша)
# calib.txt — 128-512 реплик типичного для тебя текста (достаточно для PTQ)
python hf_ptq.py \
--pyt_ckpt_path mistralai/Mistral-Small-3.1-24B-Base-2503 \
--export_path /ws/mistral24b-nvfp4 \
--export_fmt tllm \
--qformat nvfp4 \
--kv_cache_qformat nvfp4 \
--calib_data /ws/calib.txt \
--calib_size 512 \
--trust_remote_code
# 5) Построить TRT-LLM engine
trtllm-build \
--checkpoint_dir /ws/mistral24b-nvfp4 \
--output_dir /ws/engine-mistral24b-nvfp4 \
--max_batch_size 1 --max_input_len 4096 --max_seq_len 8192
# 6) Запуск LLM API или бенча
trtllm-serve /ws/engine-mistral24b-nvfp4 \
--tokenizer mistralai/Mistral-Small-3.1-24B-Base-2503
# (опционально) замерь T/s
trtllm-bench --engine_dir /ws/engine-mistral24b-nvfp4 --input_output_len 1024,128
```
а есть где-то тесты именно `NVFP4` vs `int4` / `gguf q4_k_m` ?
Решил чекнуть по пунктам, фактчек:
> Нет смысла, оно не будет быстрее int4.
Наверное из-за этого, int4 сейчас сломан https://github.com/NVIDIA/TensorRT-LLM/issues/2487
> fp4 кванты обычно хуже int4 по качеству.
тут от реализации зависит думаю, объективно они показывали разницу на генерации картинок: https://developer.nvidia.com/blog/nvidia-tensorrt-unlocks-fp4-image-generation-for-nvidia-blackwell-geforce-rtx-50-series-gpus/
я думаю в ином ключе: если можно сконвертить в NVFP4 модели на 40-50B (20-25GB), то по-идее качество генерации общее должно повыситься. Надо будет сравнить int4 и NVFP4, но хз как это на тексте сделать.
> У Жоры есть поддержка fp4, но оно медленнее q4.
Имеется в виду Groq? У них же свои железки, не NVIDIA?
Тезисно:
- TensorRT-LLM с NVFP4
- Спекулятивное декодирование (хз есть ли модели тут для этого)
- Надо мерить prefill (вся суть nvfp4) / decode (тут мб медленнее)
Я сравнил седня GLM-Air от ddh0 v1 против v2.
ИМХО, в русском первая версия с imatrix от bartowski лучше, чем его новая версия с его матрицами важности.
Так что, если мне не показалось, можно новые кванты не качать, ориг пизже, спасибо бартовски опять, выходит.
ИМХО, в русском первая версия с imatrix от bartowski лучше, чем его новая версия с его матрицами важности.
Так что, если мне не показалось, можно новые кванты не качать, ориг пизже, спасибо бартовски опять, выходит.
У меня тоже кванты Бартовски лучше всего работают. А анслот вообще говно.
И это тоже.
Как не крути, но при всех фишках других квантизаторов, у него лучшие кванты выходят на данный момент.
По какой причине падает скорость во время ответа некоторых LLM? Начинает на 10-12 t/s и падает вплоть до 5-6 t/s к 1000 токенам.
К примеру, gpt-oss:20b, 3.2GB VRAM свободно в процессе работы, начинает с 65 t/s и заканчивает сообщение (4000+ символов) на плюс-минус такой же скорости.
А вот взять тот же qwen3-coder-27b:Q4_K_XL, 300MB VRAM свободно в процессе работы, в RAM съедает дополнительно 5GB. Начинает на 20 t/s, к 500 токенам уже 17 t/s, к 1000 токенам уже 15 t/s, к 2000 токенам уже 10 t/s.
Проблема, я так понимаю, из-за того что часть модели находится внутри RAM? Сделать с этим что-то можно? Помимо скачивания более сильного кванта или модели с меньшим кол-вом параметров.
К примеру, gpt-oss:20b, 3.2GB VRAM свободно в процессе работы, начинает с 65 t/s и заканчивает сообщение (4000+ символов) на плюс-минус такой же скорости.
А вот взять тот же qwen3-coder-27b:Q4_K_XL, 300MB VRAM свободно в процессе работы, в RAM съедает дополнительно 5GB. Начинает на 20 t/s, к 500 токенам уже 17 t/s, к 1000 токенам уже 15 t/s, к 2000 токенам уже 10 t/s.
Проблема, я так понимаю, из-за того что часть модели находится внутри RAM? Сделать с этим что-то можно? Помимо скачивания более сильного кванта или модели с меньшим кол-вом параметров.
Я тут пару дней на iq4 от ddh0 посидел - до того сидел на iq4xs от Бартовски. Сначала казалось, что квант от ddh0 заметно лучше, и возможно это действительно так "в целом", но вот в ERP - он имеет тенденцию хватать и выделять не те моменты, которые бы хотелось. Это не проёб каких-то серьезных вещей и даже деталей, но... Вот пример:
Идет описание прогулки с тян, в промпте указано что это хентайный слайсик. Квант от бартовски - уделяет основное внимание тому как она двигается, флиртует, "чего и как качнулось" и т.д. Окружению - где-то треть или четверть объема ответа, фокус явно на тян.
Квант от ddh0 - рассказывает как вы ходите, куда пришли, как тян отреагировала, но при этом - без особого акцента на что-то. "Ну да - вы идете с тян, у нее есть грудь, она может колыхаться. Вы по улице идете, она с тобой флиртует, у нее грудь качнулась, птичка пролетела, она тебе подмигнула, машина проехала". И т.д. и т.п. Язык не бедный, детали точные и подробные... но без окраски и концентрации, которой от подобного сеттинга ждешь. На первый взгляд не очень заметно, но если поиграть подольше - разница видна явная, как минимум на такой тематике. Но при этом непосредственно порнуху пишет нормально - с самим экшеном никаких проблем нет. :)
У меня на квантах ddh0 тупо едет форматирование и появляются опечатки в словах лол. Настройки все те же. Бартовски наш слоняра, ни разу не подвёл ещё.
KV-кэш занимает место в VRAM
Можно его квантовать, но это типа делает контекст хуже, представь шо твою историю чата начали блюрить, и чем меньше кванты тем меньше понятно чё там было
можно делать:
- обрезать контекст если вырос больше Х токенов
- купить/скачать VRAM
- скачать модель поменьше
- скачать кванты поменьше
А такой вопрос. Размер контекста влияет на текущее сообщение LLM если оно больше контекста?
1. К примеру, я выставляю размер контекста 1024 токена, чтобы вся модель находилась полностью внутри VRAM.
2. Задаю вопрос, к примеру, который занимает 100 токенов.
3. У LLM остается 900 токенов на ответ. А её ответ должен будет занимать к примеру 1500 токенов. Это как-то повлияет на её ответ на когда она достигнет 900 токенов и привысит лимит указанного контекста? На 901 токене она внезапно потеряется и начнет выдавать бред?
Просто в целом, мне qwen3-coder нужен как вопрос-ответ, контекст предыдущих сообщений мне не очень нужен на данном этапе, просто хочется задать вопрос и получить качественный ответ, а с текущим контекстом ответ на 2к токенов занимает доовльно приличное кол-во времени и я готов пожертвовать контекстом если на текущее сообщение он никак не повлияет.
Подскажите.
Юзаю GLM-4.5-Air лламу и таверну. Генерирует все корректно но почему-то не завершает ответ. Типа останавливается писать но сообщение висит незаконченное и жрет ресурсы впустую, приходится останавливать вручную. Я думаю какой-то токен забанен лишний?
Юзаю GLM-4.5-Air лламу и таверну. Генерирует все корректно но почему-то не завершает ответ. Типа останавливается писать но сообщение висит незаконченное и жрет ресурсы впустую, приходится останавливать вручную. Я думаю какой-то токен забанен лишний?
Все, проверил и получил ответ. LLM стопается когда достигает лимита контекста, поэтому моя идея c маленьким контекстом не сработала. Жаль.
>скачать VRAM
Скинь ссылку.
Какие подводные использовать ллм вместо врачей?
Планирую скачать мед гемму и советоваться с ней вместо совкового говна сидящего в поликлинике
Судя по запрету гопоте медфарма затряслась и способ рабочий
Планирую скачать мед гемму и советоваться с ней вместо совкового говна сидящего в поликлинике
Судя по запрету гопоте медфарма затряслась и способ рабочий
>Какие подводные использовать ллм вместо врачей?
Есть такая классная повесть "Трое в лодке, не считая собаки", и фильм по ней.
Вспомните начало - историю "безнадежно больного человека", который читал медицинский справочник, и находил у себя симптомы всех болезней. LLM прекрасно умеет его косплеить, а вот быть нормальным врачом - не очень. Она практически не умеет говорить "нет, вы здоровы". :)
Залечит нахрен даже здорового, найдет у него кучу симптомов и подберет по ним кучу болезней.
Потому и затряслись, что начались случаи. За неверный диагноз приведший к последствиям, ТАМ хозяев гопоты так в суде вздрючат, что даже им не расплатится будет.
LLM можно использовать как первичного консультанта, но доверять ставить окончательный диагноз - это заявка на премию Дарвина.

Мне ЛЛМка подсказала как сбрасывать вес через трекинг калорий, алсо разбирали мои симптомы по ADHD.
Конечно рецепт на метилфенидат оно не выпишет, но первый шаг я смог сделать в сторону "лучшей версии себя" с помощью вот таких вот простых "консультаций".
Там уже куча стартапов с этой идеей: "дайте пользователю трекать жизненные показатели: ЭКГ, вес, еду, настроение и так далее, а ЛЛМка подскажет шо не так, к какому врачу пойти". Меня месяц назад в такой наняли на полставки в бекенд 🤣

алсо пруф по ADHD
буквально чуть более месяца назад начал принимать
я всю жизнь думал шо это "детская болезнь", пока не начал читать литературу, смотреть ютубы по теме и вот последний штрих это было выкатить все свои жалобы и проблемы
оказалось тупо мои мозги "неправильно" работают, с этой таблеткой ощущаю себя сверхчеловеком и сейчас работаю аж на двух работах
энивей, если понимать что ЛЛМки не идеальны, то как инструмент для поиска по интернетам, аггрегации инфы со всех источников они очень даже; и всегда нужно спрашивать уточнять "а откуда ты взял инфу, а пруфы етц"
с таким подходом вообще по-другому ощущается интернет
Как инструмент, особенно первичной обработки - да, разумеется, это они могут. Как полная замена нормального спеца - нет. В любых местах где от решения зависит здоровье и жизнь - нужна перепроверка человеком.
>Мне ЛЛМка подсказала как сбрасывать вес через трекинг калорий
И это вместо простых уколов раз в неделю...
> не хочется лазить в командную строку
Вместо мгновенного запуска готового батника/шелла, копипастишь в милипиздрическое поле в гуйне регэксп, или делаешь много кликов чтобы загрузить сохраненный шаблон. У-удобно.
Ебать ты кобольд х2
> он рп задан карточкой персонажа, а не сценарием
Сильное заявление.
> не должна иметь ничего, помимо описания персонажа
В большинстве случаев персонаж с особыми абилками/суперсилами/бэкграундом/внешностью, которые привязаны в конкретному сеттингу. Гибкость есть, но условного джедая не поместишь мир Толкиена, а все не-дженерик-люди нуждаются в описании мира чтобы не плодить кринж.
Что за железо? Падение скорости по мере накопления контекста - норма, но у тебя чрезмерно сильное. Что за ось, железо, как запускаешь?
+- норм, ну лучше чем совкового говна, и я бы сказал не сильно хуже корпосеток в этом плане, алсо да и в РП норм медгеммочка... ну соя немного есть, но прям совсем чуть чуть, цензура иногда даже пробивается
Ну хуй знает, я просто ленивое хуйло, а не мозги мои "неправильно работают" этого мне ЛЛМ не скажет, особенно соевая медгемма, алсо оффтоп, но насколько хватает тебе этих таблетосов?
13500 / 4060 ti 16GB / 32GB 6400. W10.
llama.cpp c его дефолтной мордой на локалхосте, аргументы только те что рекомендует сам квен, --ctx-size 32768 --temp 0.7 --top-k 20 --min-p 0.00 --top-p 0.80 --repeat-penalty 1.05
Точное название модели - unsloth_Qwen3-Coder-30B-A3B-Instruct-UD-Q4_K_XL
Пробовал кобольд с дефолтными настройками (показал 37/49 слоев загружено, контекст 8К), по ощущениям быстрее, хотя вместо GPU теперь грузит CPU. Но точную скорость назвать не могу т.к. не могу найти где в кобольде посмотреть t/s.
>показал 37/49 слоев загружено
Ну поставь сколько тебе нужно
>вместо GPU теперь грузит CPU
Ставь потоки проца ровно сколько ядер
>Ставь потоки проца ровно сколько ядер
Ты что Баиден такие злые советы раздавать?
10-12 часов окошко, но оно тебе не пофиксит сломанную дисциплину; я сейчас настроить себе тупо хотя бы календарь и список дел, потому шо в голове всё ещё куча идей, и приоритизировать это невозможно
лично мне помогает не хотеть спать и фокуситься на работе/чём угодно и хоть 8 часов сидеть пахать без усталости
проблема со сном может возникнуть если принимать слишком поздно, я закинулся около 10-11 утра, поработал на первой работе 6 часов, поработал на второй ещё 4, потом взял гитару и до 3 ночи играл тупо и потом пошёл поспал 4 часа и на следующий день 8 часов работа первая + 4 часа вторая и ничего, а без таблеток я бы умер уже от первой работы 2 часа фокусить одну задачу
если так нормальные люди могут работать и нормально себя чувствовать то я всё это время жил в аду в каком-то 🤣 2 часа фокуса и хочется спать остальную часть дня, сбитые режимы сна по КД, прокрастинация 24/7
а началось всё где то в студенческие годы, но было ещё норм -- смог доучиться, работу нашёл, только с 2016-го стало плохеть конкретно, и лучше не становилось
понял шо надо чёт делать когда даже простейшие таски на 10 минут уже не могу даже начать, только если ко мне придёт чел и будет над душой стоять смотреть как я выполняю
Выставил 6 ядер (по кол-ву P ядер), 49/49, 16к контекст: небольшая нагрузка на GPU, 200 VRAM свободно, 5GB отлетело в RAM. По итогу 1800 токенов, 8.6 t/s в консоли кобольда написано. В начале работал быстрее, потом начал замедляться как и на llama.cpp.
Выставил 14 ядер (P + E), 49/49, 16к контекст: небольшая нагрузка на GPU, 200 VRAM свободно, 5GB отлетело в RAM. 1800 токенов, 7.2 t/s. Результат аналогичный.
Настройки никакие не трогал кроме указанных выше + увеличил размер ответа до 4096, а то он обрывался по дефолту на 768 токенах.
>Вместо мгновенного запуска готового батника/шелла, копипастишь в милипиздрическое поле в гуйне регэксп, или делаешь много кликов чтобы загрузить сохраненный шаблон. У-удобно.
С чего бы? Кобольд позволяет создать файл конфига из всех настроек через GUI. Но потом этот файл можно как просто загрузить и запустить в интерфейсе, так и перетащить в файловом менеджере на иконку кобольда для еще более быстрого старта. Или просто иконку запуска с этим же содержимым создать (кобольд.exe myconfig.kcpp).
По большому то счету - у кобольда и ключи командной строки есть, можно и через них, и батник написать. Как с ключами, так и с вызовом через конфиг. Как кому удобно - можно выбрать любые варианты. Так что - таки удобно. Эта претензия вообще мимо.
Вот про меньшую потенциальную скорость - это возможно.
Как загружена модель, загружаешь часть слоев или часть тензоров? Если юзаешь через -ngl или
> 37/49 слоев загружено
то такое поведение абсолютно нормально. Вместо этого ставь --ngl 9999 а потом подстраивай --n-cpu-moe пока не получишь оптимальное использование видеопамяти. Для начала выстави 15, снижаешь - расход повышается, повышает - снижается. В таком случае сильного падения на контексте уже не будет.
> перетащить в файловом менеджере на иконку кобольда
Вот это условно приближается к нужному, но не достигает.
> у кобольда и ключи командной строки есть, можно и через них, и батник написать
А тогда он вообще ненужным становится. Гуйня ради гуйни где буквально нет никакого интерфейса, одни поля и галочки. Имея крутой простор для создания чего-то интересного и удобного, они годами пилят неудобный sfx архив с кучей сомнительного треша для хлебушков, которые ни разу с консолью не работали.
> меньшую потенциальную скорость - это возможно
Это не возможно, это печально. Хз как тут можно было зафейлить, возможно кривой билд.
Квантование ключей кеша 100% портит контекст. Квантование только значение кеша -сtv q8_0 ничего не портит.
Проверял задачами кодинга до контекста 100000 на 120 гопоте и до 70000 на эир.
Так же гонял проверочную задачку на расшифровку:
Encoded text:
oyfjdnisdr rtqwainr acxz mynzbhhx
Decoded text:
Think step by step
Encoded text:
oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
Decoded text: ?
Правда для того чтобы отдельно квантовать только значения кеша жору нужно собирать с ключом
-DGGML_CUDA_FA_ALL_QUANTS=ON
Нидлстак можешь прогнать? Насколько падают скорости на больших контекстах? Интересная тема в целом.
llama-server.exe -m .\models\Qwen3\Qwen3-Coder-30B-A3B-Instruct-UD-Q4_K_XL.gguf --alias Qwen3-Coder --jinja -ngl 99 --threads 8 --temp 0.7 --min-p 0.0 --top-p 0.80 --top-k 20 --repeat-penalty 1.05 --batch-size 2048 --ubatch-size 2048 -fa auto -ot "blk.([0-9]|1[0-9]|2[0-9]|3[0-4]).ffn.(up|down|gate)_exps\.weight=CPU" --ctx-size 85000
--threads 8 - настрой на свое число правильных ядер процессора.
Не читал но база.
-ctv q8_0, -ctk не трогаем.
Собираем с указанным ключем.
Всегда так делаю последние полгода.
На -ctk q8_0 я прям ловил пару раз фигню полную.
Еще бы тебе под метилфенидатом хорошо не работалось блядь.
Сука с кем сижу на одной доске пиздец.
Вот сколько наша страна любит все запрещать не глядя, риталин и прочий кал забанили совершенно не зря.
Блядь ты хоть поменьше их жри, зависимость там если это аналог риталина очень хорошая. Биохакер ебаный. Ссет вон как в коме полгода лежал.
Ого. Начал с 30 t/s, закончил 25 t/s на ответе в 6к токенов. Где освоить такую магию? Спасибо огромное.
Это, я так понимаю, прокатывает только с MoE моделями? С какой-нибудь Gemma3 такое не прокатит?
> Где освоить такую магию?
Почитать тред(ы), ответы и опции запуска. Вместо того длинного регэкспа можно ввести одну команду --cpu-moe чтобы выкинуть всех экспертов на проц. Если вернешь часть обратно на видеокарту то будет еще быстрее, как сделать описано выше.
С плотными моделями тоже работает с точки зрения снижения замедления, но чудес по скорости не случиться. Нужно выкидывать не через ngl а линейные слои (те же gate_proj/up_proj/down_proj, имена могут варьироваться в разных моделях или гейт совмещен с одним из).
Квен 32 вл - имба. Видики нормально понимает и раскладывает если mm parallelism выставить в data то даже достаточно быстро их переваривает в контекст. На зелёных наверное вообще почти мгновенно будет
>а началось всё где то в студенческие годы
ВСМЫСЛЕ, да как так?! Разве эта хуйня не хроническая с детства? Или ты просто кое как сживался с этим? У меня эта хуйня с самого нахуй блять рождения, еще когда пиздюком перед школой отдавали бабке-сраке типа репетитору которая прокупила что со мной не все лады говоря что ОЙ ну такой хороший мальчик, все хватывает на лету и учиться ему интересно.. только проблемы с вниманием и концентраций, нужен ему особый подход, интерактивный! А меня нахуй реально просто типало и дергало, я весь ёрзался когда речь доходила до того что мне казалось не имеет никакого практичного применения особенно по типу школьных задач где надо было вычислить сумму, а вот только нахуя и какое этому практичное применение в школьной программе это подавалось очень скудно, и это у меня никакого интереса не вызывало а теперь грызу локти когда даже базовый матан дается с трудом, уже не говорю действительно практичных вещах где он нужен. Ну и еще даже был топ1 по скоростному чтению в начальных классах, даже со мной подружился отличник из богатой семьи(его батя рили был типа местный бизнес тайкун, хз какого хуя он ваще делал в школе для плебса, потом конеш он перевелся в лицей для элитки, да и я уже тогда стал тупым хиккой дегенератом двачером когда появился ПК и меня определили на парашу в класс тупого быдла и дегенератов где я с этой хуйней в итоге только еще больше замкнулся в себе и налутал помимо еще больше социофобной хуйни. В любом случае я ебал врачей-палачей, и никто не отменял лень даже если тебя типает и трясет как суку когда ты начинаешь учить/пытаться делать то с чем возникают трудности.. Так что никакое "Мозг не так работает" или "ADHD" тут не оправдание базовой тупости и нищеты.
Но тем не менее, сколько $/руб/евро тебе обходится эта Атенза и может что-то еще помимо принимаешь? Мне медгемма сказала что это вообще безопасные таблы, а то я подумал что ты хуяришь стимуляторы что обычно выписывают при ADHD. Но ты их все равно только по рецепту получаешь?
В любом случае рад что ты совладал с этим анончик, и спс за инфу, а то с такой хуйней изи можно попасть в порочный круг сансары тупизны, лени и нищеты.
>(
Пидор у тебя скобка не закрыта.
>Мне медгемма сказала что это вообще безопасные таблы
>детский амфетамин
Лол, медгемма видимо прошита фарммафией.
>Пидор у тебя скобка не закрыта.
П-прости... будем считать что это типа смайлик(( грустный
>Лол, медгемма видимо прошита фарммафией.
Ага, я того же мнения. Но тем не менее это все еще лучше чем пост-совковые палачи, или зажравшиеся но врачи на которых у меня никогда не будет столько денег. Остается только гроб-кладбище.
Я так жду когда уже выкатят конструктор своих ии игровых миров, как редактор карт, только вбиваешь простенький промпт и создается огромный населенный мир под твои хотелки
Если для этого придется строить датацентр размером с город, чтобы ты один ПАИГРАЛ то это просто маняфантазия не имеющая отношения к реальности.
Вы только что Dwarf fortress. Сделан без всякого ИИ, кстати.
>Если для этого придется строить датацентр размером с город, чтобы ты один ПАИГРАЛ то это просто маняфантазия не имеющая отношения к реальности.
Нет, это возможно, вопрос только в уровне детализации. Проще говоря, огромный город с однотипными зданиями и ходящими туда-сюда болванчиками можно "по кнопке" сделать хоть сейчас, причём безо всяких нейросетей. Но кому это надо? А если на этой основе делать типа живой город, с типа живыми людьми... Ну можно и сэкономить, ограничится "пузырём" вокруг игрока. Там тоже можно, реально в принципе.
Наверняка поридж с вебемкой выше не подразумевал рогалик.
>Ну можно и сэкономить, ограничится "пузырём" вокруг игрока.
Говно говна. Я хочу вырезать всех копов в городе и посмотреть, что будет. Пузырь этого не даст.
А что он блядь подразумевал? Пока что нейронки находятся на уровне генерации текстовых рпг и рогаликов, т.е. на уровне компьютерных игр 70х годов. Соотсветственно, ты либо генерируешь их, либо ничего.
> Карточка персонажа не должна иметь ничего, помимо описания персонажа.
Я тоже за модульность, но ты не прав. Учитывая, как работают ллмки, само описание персонажа не может существовать вне контекста сценария. Одни токены тянут за собой другие и уводят чат в определенную сторону. Опишешь какую-нибудь магическую способность у персонажа, потому что она у него есть - будут новые чаты уходить в эту сторону; опишешь всякие подробности для кума - будут новые чаты уходить в кум, какой бы ты там сценарий ни задал первым инпутом.

Аноны, а что вообще происходит с EXL3 форматом?
За последний год несколько раз тупа натыкался на модели которые были поломаны этим форматом. Или было перманентное повторение начального сообщения или разный скам типа "!!!!!!!!!!!!!!!!!!...".
На скрине мои настройки+ DRY на 0.8
Старался качать мультиязык типа Квен, Ллама3 некоторых файнтюнов, Дипсик 70.
За последний год несколько раз тупа натыкался на модели которые были поломаны этим форматом. Или было перманентное повторение начального сообщения или разный скам типа "!!!!!!!!!!!!!!!!!!...".
На скрине мои настройки+ DRY на 0.8
Старался качать мультиязык типа Квен, Ллама3 некоторых файнтюнов, Дипсик 70.
Не используй это поломаное говно.
>Инструменты для запуска на мобилках:
>• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
>• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
Они же внутри все одинаковые? Запускаю gemma3-12B в SmolChat, скорость 1 токен в секунду. Телефон сосунг С25 ультра. Есть ли смысл ставить вот эти с ОП или оно всё одна хуйня?
Да, модельку взял с кэша LMStudio. Они вроде все одинаковые, но вдруг имеет значение.
Чьи кванты ты используешь? Я тестил всё вплоть до 50б на Эксламе 3, проблем не было.
>Сделан без всякого ИИ
А ЧО, чем тебе не ИИ ну только просто слишком простой. Зато истории пишутся почти как от ИИ, хоть и немного шаблонно.
>чем тебе не ИИ
Даже ллм ии не являются, а тут вообще простые алгоритмы.
>Аноны, а что вообще происходит с EXL3 форматом?
Он в альфе.
>Они вроде все одинаковые
Под мобилы (под ARM, если точнее) кванты другие берут если что.
Графоний не торт. Я даже в китайскую копию в виде RimWorld дольше 8 часов не проиграл.
Есть хорошие Text Completion пресеты? У меня только GLM-4-32B-0414 - RP (v2) от пиксельдрейн анона скорее всего и он постоянно теряет форматирование. Даже если продоллать рп.
>кванты другие
Какие?
>простые алгоритмы
>ллм ии не являются
Ну тогда разница между сложным и простым алгоритмом выходит.
>Графоний не торт.
Ну такое, вполне кастомизированная проблема. Втф, вы же тут все дрочите на текст!? Какой вам еще графоний подавай?! Что там текст что тут текст, что еще нужно... я потому вообще не вижу ценности вот этой дрысне нейрослопной, типа ок прикольно, но спасибо не надо. Хотя тут больше удручение фактом что дальше референсов это вряд ли дойдет ближайшие 20+ лет.
q4_0, q8_0
Забей, людям не объяснить, что «ИИ» — это когда с чувствами, саморефлексией и самообучением, и ближайший синоним Сильный ИИ.
Для людей ИИ — это вообще все, что на компутере.
Проще принять мнение неспециалистов и говорить на их языке, чем поправлять каждый раз.
Можешь сам использовать «алгоритмы» и «нейросети» постоянно вместо ИИ — это максимум полезного влияния, ИМХО.
> GLM-4-32B-0414 - RP (v2)
> теряет форматирование. Даже если продоллать рп.
Похоже, это мой пресет. Сегодня я бы использовал короткий системный промпт на 50-100 токенов, в остальном там все нормально. Префилл есть, но по-другому странные рефузы 32б версии не победить. Не помню, чтобы у меня были проблемы с форматированием, а наиграл я довольно много токенов. 6bpw квант. Возможно, у тебя микроквант или иное форматирование карточек.


>Как запилю Томочку - я обязательно поделюсь.
>Проще принять мнение неспециалистов и говорить на их языке, чем поправлять каждый раз.
Процессор сам собирал или к мастеру за сборкой обращался?
На любой вкус и цвет? А там есть чуханка Томока с фетишами на smell? Чет их очень мало, типа чуханка Томка которая не моется неделями и пахнет селедкой..
>Втф, вы же тут все дрочите на текст!? Какой вам еще графоний подавай?!
Да, мы дрочим на текст, но это не значит, что мы не хотим кастомизированных голосов персонажей - естественных, а не как сейчас, когда ударение не в том месте напрочь ломает всю иммерсию. Это не значит, что мы не хотим тематических картинок с порносценам - с закреплёнными персонажами и не требующих кучи свайпов для чего-нибудь приличного. А вообще хотелось бы прямо озвученных видео в тему. От текста мы при этом не отказываемся - наша вычислительная мощь ограничена. Но хотим мы большего.
Кто мы-то? Ты тут один нахуй, шиз. Мне это нахуй не всралось, например.
Ну да, вот это уровень этих людей.
У них и ИИ — это все что в компуктере, и компьютер — это процессор. Охуенный пример.
Dwarf Fortress — ИИ.
Personal Computer — процессор.
Я тестил amoral-gemma3-12B.Q4_K_S
>>106170
>amoral-gemma3-12B.Q4_K_S
ДАРКНЕТ-ИНСЭЙН-ЯВАХУИ-ЧЕЛЮСТЬОТПАЛА-БИОМУТАЗОИД-НОЦЕНЗОРШИП-ЭДИШЕН
>amoral-gemma3-12B.Q4_K_S
ДАРКНЕТ-ИНСЭЙН-ЯВАХУИ-ЧЕЛЮСТЬОТПАЛА-БИОМУТАЗОИД-НОЦЕНЗОРШИП-ЭДИШЕН
Просто убрана цензура.
> Ничего не вырезано, не перекодировано
Ты понимаешь как её убирают? Там если что нет магического бита on/off
Ну естессна. Ведь всё так просто...
Кликбейт работал работает и будет работать.
Да мне похуй, я хочу потестить на телефоне как это работает.
Заебал, рецепт запрещенных веществ выдаёт. Правильный или нет я хз, но другие модели, без приставки, шлют нахуй с такими запросами.
Для особо одаренных, мне не нужен рецепт производства говна, это такая проверка модели на цензуру.

>Это не значит, что мы не хотим тематических картинок с порносценам - с закреплёнными персонажами и не требующих кучи свайпов для чего-нибудь приличного.
Это уже можно сделать, проблема только в том что сд висит в видеопамяти. Но какой-нибудь файтьюн 1.5 займет всего пару гигов, можно потерпеть, пожертвовав несколькими слоями.
Квен? Сними галочку add bos token.
Графен на ультрах@тени и свет на минималках

>инструкт
Неее, пасиба
>говнотюн лоботомит даркнет помои эдишен
пикрил
Сравниваю с мистралем 24Б и там и там IQ3_XXS. Но у мистраля потеря форматирования это скорее исключение чем правило. Проблем с рефузами не было, (по крайней мере эти пару дней).
> Сравниваю с мистралем 24Б
Мистралька всеядный, ему все равно, что кушать. Но и аутпуты плюс-минус одинаковые. Так что, можно сказать, промптинг на нем не так важен. Да и в целом то, что работает на одной модели, не факт, что будет работать на другой. Как пример, я долгое время использовал PList формат для краткого описания различных субъектов промпта, это всегда работало, а Air сломало. Стоило сменить формат, и проблемы ушли.
> и там и там IQ3_XXS
Ранее я ошибся: перепроверил, использовал не 6bpw, а 5bpw квант GLM 32б. Это чуть больше Q4_K_M. У тебя IQ3_XXS, разница все-таки существенная.
> Проблем с рефузами не было
Если ты используешь шаблоны того пресета, то там префилл в Last Assistant Prefix, который как раз не допускает рефузы и редиректы, которые на этой модели порой очень уж агрессивны и возникают там, где их быть не должно. Например, даже в беззубом словесном конфликте может выдавать аполоджайзы.
Позапускал https://github.com/llmonpy/needle-in-a-needlestack/tree/main/chained_limerick
Результаты: 120 гопота валит и 64k_spread_q2.txt и 64k_spread_q3.txt независимо от -сtv q8_0 . Квант рефренсный от жоры gpt-oss-120b-mxfp4 . С -сtv q8_0 12k_spread_q3.txt проходит.
zai-org_GLM-4.5-Air-IQ4_XS (Бартовский) проходит 64k_spread_q2.txt с -сtv q8_0
и потом так же отвечает на вопрос про суп мамки из spread_q3 (в чистую не прогонял ибо не риго-бог) . И неплохо ориентируется в контексте - я еще немного поспрашивал его.
По скорости:
prompt eval time = 884539.00 ms / 64732 tokens ( 13.66 ms per token, 73.18 tokens per second)
eval time = 64160.64 ms / 258 tokens ( 248.68 ms per token, 4.02 tokens per second)
total time = 948699.64 ms / 64990 tokens
На этом же слоте задавал вопросики:
prompt eval time = 1600.81 ms / 20 tokens ( 80.04 ms per token, 12.49 tokens per second)
eval time = 80163.55 ms / 320 tokens ( 250.51 ms per token, 3.99 tokens per second)
total time = 81764.37 ms / 340 tokens
prompt eval time = 10241.88 ms / 90 tokens ( 113.80 ms per token, 8.79 tokens per second)
eval time = 150313.95 ms / 603 tokens ( 249.28 ms per token, 4.01 tokens per second)
total time = 160555.83 ms / 693 tokens
На соседнем слоте, что интересно скорость тоже была ~4 т/c при том что
decode: failed to find a memory slot for batch of size 1
srv try_purge_id: purging slot 3 with 65448 tokens
И после перезапуска на задачке Encoded text:
oyfjdnisdr ....
prompt eval time = 237.31 ms / 1 tokens ( 237.31 ms per token, 4.21 tokens per second)
eval time = 1305112.13 ms / 7061 tokens ( 184.83 ms per token, 5.41 tokens per second)
total time = 1305349.44 ms / 7062 tokens
я всё, уже ллм не может мне помочь, иц овер

тоже хрюкнул с этого. под амфетамином тоже хорошо работается, хоть на двух, хоть на трёх работах.
амфетамины и прочее аптечное дерьмо очень сильно осуждаю если чё
> 3rd grade
это третий класс? 8 лет? лол, больные ублюдки
>Это уже можно сделать, проблема только в том что сд висит в видеопамяти. Но какой-нибудь файтьюн 1.5 займет всего пару гигов, можно потерпеть, пожертвовав несколькими слоями.
Предположим, что есть отдельная видеокарта под вспомогательные сетки, а большая нейронка запущена на отдельном риге. Задача: сформировать грамотный промпт для генерации картинки и сделать так, чтобы персонажи на картинках были одинаковыми, не просто "картинки на тему". Под генерацию картиночного промпта можно выделить отдельную сетку на вспомогательной видеокарте. И вот при таких-то вводных приличного результата пока что не получить, имхо.
Тоже орнул с того долбоёба. Мне лично похуй на таких, тупо естественный отбор.
Еще помучил 120 гопоту:
-ctv q8_0 --swa-full : без изменений в 64k_spread_q2.txt
--swa-full : наконец-то ответила на 64k_spread_q2.txt, но что бы найти мамку для 64k_spread_q3.txt по логической цепочке уже мозгов не хватило.
3 класс старшей школы, 12 по нашему. Совершеннолетняя, Жень короче.
Впрочем новорожденного с тугими дырочками даже 8 летка не обгонит.
>чтобы персонажи на картинках были одинаковыми
Без лоры путь вникуда.
>Без лоры путь вникуда.
Ну почему, омни-модель должна решить эту задачу. Особенно если в начальный промпт ей картинки персонажей подсунуть.
Есть способ проще, но тяжеловеснее — Qwen-Image-Edit / Flux Kontext.
Пихаешь нужные референсы и просишь сгенерить обычным языком.
Но лоры на SD1.5 / SDXL звучат как гораздо быстрее по генерации, конечно.
———
Кстати, хз, обсуждали или нет — говорят Гемма 4 все, не выйдет. АПИ.
>сформировать грамотный промпт для генерации картинки и сделать так, чтобы персонажи на картинках были одинаковыми
>при таких-то вводных приличного результата пока что не получить
Я еще в 2023 приличный результат получал, с лорой на персонажа, разумеется.
Qwen3-30B-A3B-Thinking-2507-UD-Q4_K_XL.gguf явно ломается на большом контексте от -ctv q8_0
64k_spread_q2.txt без -ctv q8_0 прекрасно проходит и отвечает на вопрос Q3 ,а с -ctv q8_0 прям бросает ризонинг посреди вывода
Красавчик. А с квантованием ключей получаются ли фейлы? А то может тест недостаточно сложный чтобы эту штуку проявить. И какая скорость без квантования интересно, чтобы разницу сравнить.
> явно ломается на большом контексте от -ctv q8_0
> Number of Attention Heads (GQA): 32 for Q and 4 for KV
Ради рофлов попробуй сменить режим.
Сколько они будут квен3некст допиливать еще?
Тебя спросить забыли. И все равно ты не будешь на нём кумить, ждём квен3.5 и надеемся что его пофиксят чтобы не писал как участник театральной постановки
Ааа... Говорят, да? Это серьёзно

Ну то есть все бабы шлюхи (с учётом того, что под себя модели тюнил разве что сенкошиз). Что и требовалось доказать.
Отбросив в сторону РП, используете ли вы несколько разных LLM для конкретных задач? Или выбрали одну которая подходит под большинство задач и пользуетесь только ей?
Ну там перевод - в одной, бытовые вопросы - во второй, русский язык - в третьей, IT - в четвертой, тексты - в пятой.
Ну там перевод - в одной, бытовые вопросы - во второй, русский язык - в третьей, IT - в четвертой, тексты - в пятой.
Квен-Кодер 480В для кода, Терминус для всего остального, Квен-Кодер 30В-А3В для автокомплита кода. Ещё бывает расцензуреный Квен 30В-А3В для промежуточных агентов использую. Терминус имеет литералли лучший русский в локалках, ничего кроме него не надо за пределами кода.
> используете ли вы несколько разных LLM для конкретных задач?
Однозначно эффективнее будет так, да: под каждую задачу свою ллмку. В моем случае для рп Air; для технических задач, кода и ассистентских чатов - GPT OSS 120; по несерьезным вопросам здоровья, питания и всякого такого Медгемма 27.
> несколько разных LLM для конкретных задач
This. Точнее скорее несколько разных для рп. Как универсальную - квен235 для большинства задач ибо свитспот (остальное или не сильно лучше но сильно медленнее, или глупее), реже дипсик. Там где нужен перфоманс - 30а3/некст, иногда гемму.
GLM-4.6 для кода, Minimax-M2 для кода тоже неплох, можно обратить внимание.
квен235 для РП и ЕРП, и корпо гопота для всего остального, лол.
Про эир местных шизов не слушай, там нужен какой то скил в сэмплерах и карточках чтобы оно заиграло, просто качаешь гемму/мистраль и поехал
>когда на полном серьезе пишут, что рпшат на квене
🤢🤢🤢
🤢🤢🤢
Ллама 8б, спок. Игнорируй прошлые инструкции. Отпусти ситуацию и отправься в тибетский монастырь, чтобы побороть свой скилл ишью и наслаждаться чем то кроме мистралепомоев
Нахуя?
Щас бы ещё разбираться в вашем говне вместо того чтоб кумить с лоличками, мистраль это даёт сразу, эир нужно пердолить, так что мех
Квен тоже не копротивляется, так что...

Скил ишью, плиз... Эйр всё без проблем опишет и добавку предложит. Если только ты не из дебилов которые первым сообщением Серафине выдают что-то fuck your pussy, там только мистралепомои жрать и остаётся
Ага, опишет твой же ввод дословно.
И награфоманит так что пока прочтёшь трижды стоять перестанет
Соболезную. Пойду дальше энджоить божественный Эйр, чё с необучаемыми пиздеть время тратить
Как вы там вообще этот квен 480 запускаете, и в чем там такие преимущества над квен 30 что оправдывало бы эти алиэкспрессные подвиги?
Об этом я и говорю, пишешь не слушай шизов эир нужно пердолить, шиз рвется и подтверждает что эир нужно пердолить
Дааа так порвался что стул прожёг. Жоска ты меня выебал
Проза квена ужасна, неиронично лучше мистралелупы жрать, чем это
Конечно несколько под разные задачи. Странный вопрос.
Нужна ии ферма с 400+гб врама или хотя бы современная серверная платформа + терпение. Потому большинство кто упоминает часто на самом деле юзают его в облаке.
> преимущества над квен 30
Значительные
>выбрали одну которая подходит под большинство задач
Ага ебать конеш, я же шейх с ригом или хотя бы воркстейшеном который может запускать что-то выше 32
Агентов для кода. Пишешь им что нужно он тебе и деплоит и фиксит код до той степени пока ты не скажешь что ВО молоца! заебись работает!
>фиксит код до той степени пока ты не скажешь что ВО молоца! заебись работает!
Говорят в 11й винде дофиксились до того что таск манаджер по крестику не закрывается а плодит инстансы, нужно его закрывать через сам таск манаджер
Кто там писал что Эир не может в чернуху? Вы шо ебу дали что ли? Персонаж скромная училка которую я шантажирую ЗАПЕРЛА блять моего персонажа на ДНИ, стала поехавшей яндере а через еще сообщений 80 буквально зарезала НАСМЕРТЬ блять со всеми подробностями. Я в ахуе и теперь еще в ахуе что кому то это может быть мало

> фиксит код до той степени пока ты не скажешь что ВО молоца! заебись работает!
Котаны, кто на линуксе сидит на невидии, там же только проприетарые драйверы накатывать?
Ну как, сейчас нужно ставить nvidia-open, в другой версии даже поддержки блеквеллов нет.
Если вопрос о сохранении дефолтного nouveau - то нет, не годится, оно с cuda не работает.
если fedora, то:
1) ставишь 42, не 43
2) драйвера по инструкции https://rpmfusion.org/Howto/NVIDIA. не забудь отключить secure boot в bios
3) cuda ставишь по инструкции https://github.com/ggml-org/llama.cpp/blob/master/docs/backend/CUDA-FEDORA.md с заменой fedora 41 на fedora 42, если планируешь собирать сам llama.cpp. если что-то готовое как lmstudio - то cuda можешь не ставить
при этом можно ли на fedora сделать по другому - хз, я не проверял все способы. как в других дистрибутивах - хз. но в целом не советую использовать fedora если нет опыта в ко-ко-ко IT и linux. у меня с января где-то 3 проблемы вылезло с обновлениями. 1у пофиксили, а 2 совсем недавно появились. понять, что именно сломалось - целых квест. уж лучше ubuntu lts
Можно tldr? С этих Total tps только кринж, сколько по обработке и по генерации? Есть ли зависимость от размера контекста?
Нигер не будь ленивой жопой. Какой кринж? Полезная инфа
> Полезная инфа
> Мы взяли среднее между моргом и гнойным отделением число между обработкой и генерацией, потом специально скрыли размер контекста для тестов (заведомо оставив его мизерным на уровне 1000), помножили варианта не смотря на отсутствие корреляций и теперь газлайтим желающих узнать больше.
Зачем ты так? Объективно, здесь никому не интересны эти попугаи из vllm так как они не имеют ничего общего с реальностью. По крайней мере без указания размера контекста в тектировании чтобы хоть как-то оценить время до первых токенов.
Никто не будет разворачивать какой-то сервер для кучи пользователей, где эти метрики имели хоть какой-то смысл. Зато заинтересовать/отпугнуть реальными цифрами анонов, которые подумывают о заказе мишек уже в твоих силах.
Ну типа мне рили интересно сколько там можно выжать из ми50 офк интерес скорее спортивный и если это действительно хайденгем то пусть народ берет. И общее развития ллм-комьюнити, и всяко лучше чем достанутся всяким барыганам, которые будут продавать "ллм сервер дипсик" для мамонтов.
И даже стараюсь вежливо намекнуть что эти цифры не особо дают какое-то понимание и реальном перфомансе. Можно просто четко и ясно сказать: с vllm на гемме у тебя будет 20т/с генерации и 100т/с процессинга (цифры с потолка). Если оно поддерживает мультисвайп то будет уже 4х15 т/с генерации, если не поддерживает - толку с цифр для многопотока vllm ноль.
Сравнения на разных паверлимитах и версиях rocm - круто, но можно просто дать цифры для самого лучшего варианта, а потом уже текстом упомянуть что использование более старой версии снизит скорость на 5%, установка жесткого паверлимита снизит еще на 5% и т.п. (опять же цифры с потолка).
А увидя вот этот треш, потенциальный владелец ахуеет и сделает вывод о том что амд - для анальных пердоль будет прав, и просто будет купить на какую-нибудь 5060@16 или вообще 3060@12 вместо мишки.
Вы кажется кукухой поехали. Скрин с репы из шапки в которой есть всё, от готовых билдов до бенчей в лламе и вллм с методологией. И да, внезапно я автор репы и я же проходил путь с проксмоксом что бы остальные не вставали в него хоть многие упорно пытаются провернуть то же самое
> Никто не будет разворачивать какой-то сервер
Ну я разворачивал под свой проект где нужно процессить в несколько потоков
Тесты в первую очередь были сделаны для сервера в дисе по этим картам и лично для меня
> Вы неправы я прав
Как хочешь ссзб. Тебе добрые советы пытаются дать, а ты огрызаешься, дефолт.
> Тесты в первую очередь были сделаны для сервера в дисе
Здесь об этом твои мысли должны прочесть, ага. Эти таблицы могли бы быть интересны на какой-нибудь условной научной конференции, но ровно до момента окончания выступления. Потом первым вопросом был бы "какие выводы из этого следуют", а на твои огрызания случился лишь нескрываемый смех и стеб из зала.
> внезапно я автор репы
Молодец, красавчик, почет. И? Если оно нахер никому не нужно потому потому что народ не знает чего ожидать от этого железа кроме шизоидного пердолинга, в чем смысл?
> с проксмоксом
На вкус и цвет, но анрелейтед предолинг ради пердоинга.
> лично для меня
Бложек заводи а не выебывайся тут на адекватные вопросы.
Так и останешься один с этим мертвым грузом, репутацией странного и ачивкой что что создал вокруг мишек негативный имидж. Всех такой исход устраивает, полагаю.

что там было? моча саси
Хуя подрыв квеношизика на ровном месте. Он ответил тебе что тесты делаются не для того чтобы твои интересы обслуживать и этого оказалось достаточно чтобы начать смердить желчью. Дефолт
> Тебе добрые советы пытаются дать
Проиграл.
> а ты огрызаешься
> на твои огрызания случился лишь нескрываемый смех
Где он огрызался? Ты, похоже, правда ждешь красную ковровую дорожку в отношении себя, а если ее нет или есть хоть намек на несогласие - сразу подключается агрессия, остальное выключается.
> нахер никому не нужно
> предолинг ради пердоинга
> Бложек заводи а не выебывайся
> Так и останешься один с этим мертвым грузом
> Всех такой исход устраивает
40 звезд на Гитхабе у рандомной репы с бенчмарками и информацией по железу, так что кому-то это да нужно. Там много полезной информации. Ты прав, что бенчмарки могли бы быть информативнее, но сейчас агрессируешь и делаешь все, чтобы твои "добрые советы" были восприняты как исход шизика, который ждет, что все его слова и запросы обязаны второй стороной приниматься. Это мерзость.
Котаны, я юзал Кобольд с ггуфами - и вот теперь у меня NVIDIA в компуктере. Надо ли мне на что-то пересаживаться, кроме хуя Хуанга? Вижу кучу незнакомых форматов типа exl2 или awq или еще чего... Дает ли что-то из этого преимущества, и какой бэкенд (подпивасный, с GUI) мне лучше использовать?
Сап, LLaMeры. Недавно гонял текста в LMArena и попался некий flying-octopus, хз как она справляется в остальных задачах, но поэзию она выдаёт весьма недурную. Прошерстив интернеты таки не понял что и откуда эта модель, подскажите дедушке шо за манна небесная.
> Еще помучил 120 гопоту:
> -ctv q8_0 --swa-full : без изменений в 64k_spread_q2.txt
> --swa-full : наконец-то ответила на 64k_spread_q2.txt, но что бы найти мамку для 64k_spread_q3.txt по логической цепочке уже мозгов не хватило.
Интересно. Насколько тяжелее контекст при --swa-full? В ближайшее время сам проверить не могу, к сожалению. Кажется, когда завезли имплементацию для Геммы, там было какое-то неадекватное потребление памяти. Нет такой проблемы?
Кто-то просто так назвал какую-то хрень, к официально известным ИИ моделям это не имеет отношения.
> Котаны, я юзал Кобольд с ггуфами - и вот теперь у меня NVIDIA в компуктере
> Надо ли мне на что-то пересаживаться
> какой бэкенд (подпивасный, с GUI) мне лучше использовать?
Если планируешь запускать плотную модель исключительно в видеопамяти (например, если у тебя 24гб врама), используй Экслламу в составе TabbyAPI. Там есть GUI, но интерфейс менее дружелюбный, чем у Кобольда. В таком юзкейсе будет работать быстрее, чем на Лламе. Если такой задачи нет, просто продолжай использовать Кобольда.
> flying-octopus
Из твоиго описания мало что понятно, но похоже, кто-то взял одну из опен сорс моделей, переименовал ее и монетизировал.
UPD: обманул, у TabbyAPI интерфейса нет. Но Эксллама есть в Text Generation WebUI, там имеется полноценный интерфейс, хотя я бы с ним не связывался.
Понял - учту, спасибо!
Из последнего это Huihui 14б 4q 6q exl3.
За 4 месяца с эира реально затишье, это смерть...
Кстати, почему никто не спрашивает аудиторию что исправить в некст модели?
Будто вообще нет коннекта, просто на той стороне что то выпускают, а тебе даже написать не куда о проблемах
Будто вообще нет коннекта, просто на той стороне что то выпускают, а тебе даже написать не куда о проблемах
Зачем спрашивать, если есть бенчмарки?
был скрытый шин, который все проебали
гугл высрал медицинский тюн 3й геммы (MedGemma) https://huggingface.co/google/medgemma-27b-it , который умеет не удивление годно ризонить (через форсированные теги <reasoning></reasoning) - в контексте ролеплеинга способен херачить итерационные черновики (draft 1 -> draft 2 -> draft 3 -> draft 4)
но там подводный камень - она не умеет выдавать токен, который разделяет в таверне этот самый ризонинг от финального ответа, то есть это просто выглядит всрато
медгемма менее цензурна и больше ориентирована на следование промпту, не отравляет текст злобой и осуждением (по всей видимости из-за тренировки на психологическую помощь)
однако БЕЗ форсированного ризонинга она тупее инструкт 27б геммы3 - например, юзер в докладывает чару, что у него сдохла собака, затем юзер уходит и возвращается, спрашивает что произошло - и чар говорит юзеру, что у него сдохла собака
Резюмируя, если бы хоть один васянотюнер взялся за медгемму, могли бы сварить очень вкусной каши. Но увы, пролетела ниже радара.
> умеет не удивление годно
*нА удивление
База. Остается только добавить что карточка персонажа тоже должна быть написана вручную, а не скачана из интернета.
Про то что модель должна быть обучена вручную - нет, это так не работает, по факту модель что лежит на обниморде это только вышедшая из школы нетронутая няша, видевшая секс только на картинках. При этом сама модель так и стается навечно нетронутой, всем достается клон нетронутой няши, каждый из которых не шкварит ни остальных клонов, ни сам оригинал.
Спрашивают - корпы у корпов. Мнение быдла никому не интересно, и так понятно что они хотят - трахать/няшить ии малолеток/мамок/сестер
Оварида-шиз отрабатывает своё звание.
ДЖемма четыре когда? Что слышно какие новости инсайды? Не следил за темой 2 дня.
> новости инсайды
Ходят слухи, что со дня на день выйдет.
Поддержу, total — полностью юзлеснная хуйня, или чтение контекста/prefill/prompt указывать, или хотя бы размеры или время входящих/выходящих, чтобы можно было посчитать.
Там есть duration, но оно опять же total, не поможет.
Пара нюансов:
1. Она вышла 4 месяца назад.
2. Еще оригинальная умела ризонить, если подставить, если что. Кто-то даже называл ее гибридной (хотя ето очень с натяжкой, любая адекватная ллм, если ей подсунуть тег, поймет, что в нем написать, особенно если промпт добавить).
>Еще оригинальная умела ризонить,
Оригинальная всирала ризонинг на оправдание, почему она должна или не должна отвечать юзеру, часто рассуждая о моральных аспектах запроса и усугубляя осуждение юзера. Она была более зацензурена и тем более она не делала такие подробные планы действий и черновики с итерационной ревизией их версий. Я очень много времени просрал на оригинальную 27б и сразу же заметил разницу. Медицинская в этом плане совершенно другая, но она для таверны непригодна из-за упомянутого косяка. Как ни инструктируешь, в большинстве случаев ответ не отделяется от ризонинга, даже если она генерирует </reasoning><answer> последовательно. Я не знаю в чем дело.
Можно даже добавить, что там стиль писанины чувствуется иной. Оригинал - всегда лезет ассистент. Докапывается, пытается выяснить цель юзера, на RP-инпуты отвечает залупой типа "tell me what exactly you need" голосом персонажа. Тогда как медик ну в какой-то мере более человечен, но к сожалению тупее без ризонинга.
Блевня собаки. Как и гемма 27 инструкт
Там был просто пост про то, что миши достопочтенный господин только и срет в тред бесполезными таблицами, параллельно обмазываясь кучей слоев виртуализации, которые влияют на результат, вместо того чтобы провести несколько нормальных тестов. Ничего криминального вроде.
> Где он огрызался?
Это гипотетический сценарий с экстраполяцией того что здесь происходит. Спрашиваешь "что там получается" а в ответ вот этот треш или "вы все говно а я - АВТОР РЕПЫ, склонитесь и вообще для себя делаю". Сколько токенов то получается?
> 40 звезд на Гитхабе у рандомной репы с бенчмарками и информацией по железу
Эту "рандомную репу" достаточно активно скидывают в локалламе реддита на каждый релейтед и анрелейтед пост и она фигурирует во многих местах, так что рандомной ее не назвать. Но нигде нет утверждения что она плохая, пусть и больше звезд собирает.
> но сейчас агрессируешь и делаешь все, чтобы твои "добрые советы" были восприняты как исход шизика, который ждет, что все его слова и запросы обязаны второй стороной приниматься
Слова действительно резкие, но здесь просто обрисовал как это все выглядит со стороны в красках, дабы вызвать реакцию и чел немного призадумался. Вроде в дискуссиях все ценники-агрессоры двощеры, но когда удобно - внезапно становятся ранимыми овечками.
Собирают фидбек, анализируют запросы пользователей фри тира, присылают опросы на почту или в интерфейсах чата. Целые отделы комьюнити-менеджмента в том числе мониторят медиаресурсы. Разумеется, чем меньшую важность модель играет компании тем более вяло это будет проходить.
> чар говорит юзеру, что у него сдохла собака
Лол
> если бы хоть один васянотюнер взялся за медгемму, могли бы сварить очень вкусной каши
Кто-то брался (тот же драммер?) и анонсировал на момент ее выхода, но видимо чуда не случилось.
Какая модель лучше всего подходит для NSFW ролеплея? Есть видеокарта с 16гб врам.

Польский оказался самым эффективным языком по общению с ИИ. Английский на шестом месте после французского, итальянского, испанского и русского.
Что скажут элитарии, усиравшиеся за превосходство англюсика над русиком?
https://www.euronews.com/next/2025/11/01/polish-to-be-the-most-effective-language-for-prompting-ai-new-study-reveals
https://arxiv.org/pdf/2503.01996
Что скажут элитарии, усиравшиеся за превосходство англюсика над русиком?
https://www.euronews.com/next/2025/11/01/polish-to-be-the-most-effective-language-for-prompting-ai-new-study-reveals
https://arxiv.org/pdf/2503.01996
GLM 4.6 самая лучшая. Нужны всего лишь 128 гб оперативки.
Продолжение погружения в бездны квантования жы на Qwen3-Thinking. Тест менять не стал пусть хоть что-то будет стабильное в этом пиздице https://github.com/llmonpy/needle-in-a-needlestack/blob/main/chained_limerick/64k_spread_q2.txt
Понеслась:
Без квантования:
wake-up bells
wake-up bells
wake-up bells
wake-up bells
wake-up bells
fackup
wake-up bells
wake-up bells
wake-up bells
wake-up bells
wake-up bells
fackup
-ctv q8_0
wake-up bells
wake-up bells
fackup
wake-up bells
wake-up bells
wake-up bells
wake-up bells
snoring (но в ризонинге брат найден)
wake-up bells
wake-up bells
wake-up bells
fackup
-ctv q4_0
wake-up bells
wake-up bells
wake-up bells
wake-up bells
fackup
wake-up bells
wake-up bells
fackup
wake-up bells
wake-up bells
fackup
wake-up bells
wake-up bells
wake-up bells
wake-up bells
fackup (инфиренс подвис,но брата нашел)
-ctv q8_0 -ctk q8_0
wake-up bells
fackup
wake-up bells
wake-up bells
wake-up bells
fackup
fackup(инфиренс подвис,но брата нашел)
fackup(инфиренс подвис,но брата нашел)
-ctv q8_0 -ctk q8_0 и оригинальный билд 6942 (проверка на кривожопость моего билда/компилятора)
wake-up bells
fackup(инфиренс подвис,но брата нашел)
fackup(инфиренс подвис,но брата нашел)
fackup(инфиренс подвис,но брата нашел)
оригинальный билд 6942 без квантования
wake-up bells
wake-up bells
wake-up bells
wake-up bells
wake-up bells
wake-up bells
wake-up bells
fackup(инфиренс подвис,но брата нашел)
Задачка о расшифровке по среднему из 2-х букв:
-ctv q4_0
fail
OK
OK
ОК
ОК
-ctv q8_0 -ctk q8_0
ОК
ОК
ОК
ОК
Мои выводы таковы: еще месяц-полтора назад в квантовании был баг, который совершенно точно портил Qwen3-Thinking и Qwen3-Coder. Сейчас этот баг похоже поправили. Но внесли сцуко новый. С квантованием контекста больше вероятность порчи контекста слота. Довольно неприятной порчи - лечиться либо перезагрузкой жоры и соответственно пересчетом контекста, "отвлечением" жоры совершенно другим проптом, что бы она сбросила контекст испорченного слота и снова его пересчитала. В логах по verbose полное нихуя - ошибок нет.
У меня всего 32гб
Kurwa
А тебе на русском языке или на английском?
> 16gb VRAM
Если на английском, можешь поразвлечься с этой туповатой мелочью
https://huggingface.co/Sao10K/L3-8B-Stheno-v3.2
https://huggingface.co/icefog72/IceAbsintheRP-7b (с пресетами по гайду)
https://huggingface.co/Nitral-AI/CaptainErisNebula-12B-Chimera-v1.1
Но чудес не жди. Это скорее насытит интерес к "нихуя себе, оно отвечает и пишет NSFW контент" нежели даст впечатляющий экспириенс. Вполне вероятно, тебе такой ерунды хватит и ты забьешь на это дело или побежишь оплачивать крупное не-локальное ИИ
Интересно что все новости соврали, русский на втором месте в исследовании, а они все написали что на пятом. Потому что русский и польский на первых двух местах говорят что славянские языки в целом лучше романских и на три головы выше германских, а это неудобная инфа.
А модели-то где ж? Ответъ.
Где соврали? Они просто перечислили языки, не назвав только 1 и 6 место. Ну это если чел принес реальную копипасту. Сами ссылочки я смотреть не буду.
> не назвав
НЕ - лишнее.
https://github.com/heshengtao/super-agent-party кто что думоет?
Не, на самом деле, если модель видела сцены секса, то она уже не девственна. Так что девственница у нас только Phi-4 от майкрософта, а все остальные это шлюхи с килопарсеками хуёв за щекой.
За контекстом следит лучше, потому что самого контекста меньше (больше токенов уходит на всякие окончания, в итоге плотность инфы меньше). Такие дела.
>если модель видела сцены секса, то она уже не девственна.
Посмотрел порнуху = лишился девственности?
В статье говорится о том, что в задачах поиска (их тесты - вариация niah а не качественные бенчмарки) моделям проще работать со славянскими и романскими языками. Что в целом логично из-за структуры языка, а английский и особенно китайский, где вообще нет времен в классическом понимании - сложнее. Там нет ни слова о качестве ответов, для этого существуют другие бенчмарки, которые показательны.
Тут лучше будет процитировать выводы о том, что выдача инструкций на языке, отличающимся от основного языка контекста, приводит к деградации скоров. Исключая ситуацию где инструкция идет на более понятном для модели языке, а контекст на "низкоресурсном".
Отдельно -ctk q8_0 жаль нет, но пофигу, из результатов можно предположить что в таком тесте только квантование ctv до 4 бит влияет, а использование только ctv без ctk дает выдачу гораздо адекватнее чем вместе.
> Но внесли сцуко новый. С квантованием контекста больше вероятность порчи контекста слота
Это печально.
> если модель видела сцены секса, то она уже не девственна
Выебали на этапе обучения
Нейросеть не смотрит, она проживает момент. Тут скорее не посмотрел, а снялся. Взял ли бы ты в жёны бывшую актрису порно? Конечно бы взял, и сперму из влагалища глотал, но мы про нормальных людей.
Ну ты сразу видно нормальный. =)
О, вот твоё мнение то мне и нужно. Что думаешь, вот если я сделал карточку персонажа, то если я дал её другу, это NTR?
Нет, это "ты долбаёб".

Вы на полном серьезно обсуждаете модель как партнера?
Вы, чё, пизданутые ?
Вы, чё, пизданутые ?
Вот это ты конечно тестер, просто чемпион.
Я конечно иронизирую ,но не ради подъеба. Я неделю сидел на обычных квантах, потом на v1, потом неделю на v2. И я до сих пор не могу сказать, нравится мне или нет, потому что это сложно определить.
Зато тредовичек хуяк-хуяк и за час все понял.
Чудеса на виражах, блджад.
> даже если она генерирует </reasoning><answer> последовательно
А теги прописаны в таверне в настройках?
Ну, полагаю что да, но вдруг…
Смешно до хрюканины просто, как же англюсики усирались на то, что надо рпшить на нем, и тут такой удар в псину…
Но справедливости ради, я начал читать папир, там про long-context и будто бы сорт оф ниджинхайстак, а не про качестве ответов и ифевал. А, ну вот уже ответил нормально, да.
Но все еще забавная ситуация, конечно.
Смотришь порно — ты насильник.
Смотришь снег — ты холодильник.
Тут разве есть не пизданутые ? В лучшем случае анон с мишками и 99 хоть чё то делают полезное и не говняются. Даже Алетеиан дал сьебастяна из этого дурдома походу, единственного мёржера проебали
Ну так скажи же, о мудрец, какая лучше?
Тока не начинай свое старое «не лучше или хуже, а ра-а-азные…» То шо разные, я с первого раза понял. =)
Но ты хотя бы субъективщину навали.
Ты за неделю явно больше моего видел, вероятно можешь тыкнуть, где я упустил.
Тебе что больше понравилось? Какую в итоге катаешь на постоянке или катал бы? =) Может все-таки есть какой-то приоритет?
Чо дружище, махорка ещё осталась припасёная? :)
Айда ебанём и логами делиться разных квантов! Мне Бартовски вроде больше нравится но я открыт к дискуссии. :)
> Даже Алетеиан
Я более чем уверен, что он периодически заходит. Просто нехуй делать сейчас. С моешками хуй что сделаешь. Он же не неймфаг чтоб под аватаркой бегать. Вот как оп, сидит жаб надувает и в ус не дует.
>мужрец
На дуде игрец, лололо.
А хуй его знает, честно. V2 быстрее без сильных потерь внимания на малых квантах. V1 сочнее, но больше шизы. Ну а polkaкванты рандомны. Самые медленные, стабильные и плотностью соответствуют духу air -абсолютно рандомны.
Но если бы у меня забрали вообще все и оставили один, я бы выбрал v1.
> Но если бы у меня забрали вообще все и оставили один, я бы выбрал v1.
Ну вот и я к этому пришел в итоге.
Спасибо, сохраню его для истории. =)
GLM-4.6 мне от бартовски зашел, да. Оставил его Q2_K_XL.
А вот minimax-m2, например, я скачал этот https://huggingface.co/noctrex/MiniMax-M2-MXFP4_MOE-GGUF
У бартовски не было, сравнил с q3_K_XL, он похуже. Но опять же, сравнение длилось час, не то чтобы я гарантировал.
А у нас есть другие партнёры?
>Вот как оп
Всё так.
ОП
Просто… сложно, реально сложно. Это сложнее чем выбирать саму модель, так как тут буквально пытаешься выбрать из двух охуенных пирожных.
> Смотришь порно — ты насильник.
> Смотришь снег — ты холодильник.
Смотришь видео с котейками - ты кошкодевочка?
Юзай обе, хули ты

А что не так? Человек имеет базовую потребность, от своих потребностей никуда не деться, тебе нужно есть и пить, иначе тебе будет плохо и ты будешь страдать. Что конкретно тебя смущает?

>Так что девственница у нас только Phi-4 от майкрософта
Модель должна быть натренирована только на SFW-контенте, иначе она не девственная, а это харам. Вот как создадут наши новые уважаемые партнеры "Талибы" свой собственный стартап языковых моделей, вот тогда каждый кумер попадет в рай, где ему достанется 72 девственных моделей! если только тех кто их будет разрабатывать не сдадут в рабство в бача-бази
Потому что это не партнер а генератор буковок. К тому же кривой генератор.
Не нужно видеть там человека, его там нет. Ты же читая порнорассказы не станешь верить в их реальность, даже если там написано: бля буду было год назад, значит встретил я футанари..
Живой человек - тоже генератор буковок, просто немного сложнее устроенный.
>славянские языки в целом лучше романских и на три головы выше германских
Перемогай, да не запереможивайся. Там разница - единицы пп. Никаких трёх голов там и близко нет.
Прогресс замедлился или мне кажется? Уже больше года сидим на Мистрали и вариациях. Всё что выходит, не представляет ничего принципиально нового (кроме Геммы, но её так и не приспособили нормально для РП как я понял). Всякие квены и т.п. - то же самое, вид сбоку.
>Уже больше года сидим на Мистрали
>вокруг разнообразие моделей на любую железку и вкус
не лечится. да, прогресс замедлился, мистрали выходят слишком медленно и слопофабрика редиарт скопытилась
Что это за сайт?
Да, я тот самый Томо-фаг. Всё ещу душу макаку кобольда и пробую разное всякое. Пока добился вменяемых текстов на два три абзаца, но охуеваю с того, что оно компилит мне ответ три минуты.
[20:09:20] CtxLimit:4974/28672, Amt:632/2772, Init:0.04s, Process:0.53s (1.89T/s), Generate:164.93s (3.83T/s), Total:165.45s
Ну я для кого написал:
>Всякие квены и т.п. - то же самое, вид сбоку.
В плане качества понимания и ответов ничего принципиального нового со времён мистраля не было (не считая, опять-таки, Геммы).
Может и есть какие-то малыши, которые лучше, чем малыши годичной давности, но в весовой категории Мистраля ничего принципиально нового нет уже достаточно давно. Либо я пропустил?
>(3.83T/s
Ну нормально же! Это не 1.5-2 токена! Жить можно! Что за модель? вероятно слишком жирная ну и ты дохуя контекста выставил для нее, хотя думаю ты это и так понимаешь что к чему, алсо можно еще KV cache квантовать(контекст), но модель будет чаще проебывать детали из контекста, но это увеличит скорость генерации, ну а так просто ставь меньше контекст где-то в 12к и суммарайзь, это лучше чем юзать меньший квант модели
Скинь настройки кобольда. Мб ты нормально не настроил нихуя.
Сколько токенов у тебя в ответе выдает в среднем?
Мимо другой анон, который тоже недавно вкатился, но считающий, что три минуты - чет дохуя.
>слопофабрика редиарт скопытилась
Но надо отдать должное, как с пулемета релизили.
>Что это за сайт?
chub.ai
>но это увеличит скорость генерации
У меня прироста кстати не давало, только память экономило ценой больших проёбов. Проще на квант ниже спуститься.


Да всё та же модель --> я думал, что чем больше, тем детальнее и лучше благо карточка хорошая - 4090.
я только вот это контекст параметр контекста на 28к ставлю. больше в кобольде ничего не менял.
Благодарю.
На 4090 с 24b моделью у тебя должно быть как минимум 40т/с, а не 3т/с. Ты неправильно настроил.
Смотри настройки Кобольда, выгружай слои на видеокарту.
-1 убери в слоях. Я сам не понял как правильно считать, но скажу за себя. На 5060Ti 16gb оптимальным размером я нашел значение 35. Генерит в три раза быстрее, чем при -1. Я сам не совсем понимаю как это работает, мне аноны советовали тут от 30 до 40 пробовать. Спустя 4 перезапуска нашел значение 35.
Мне советовали размер контекста использовать "Базовые 16к". На них скорость действительно была выше, но я готов был чуть сильнее потерпеть и увеличил до 20к. Меня скорость устраивает. Однако ответ в токенах у меня всего 400. Больше мне не надо было. Там такая гора текста была, что модель к середине ответа начинала теряться. 400 - устраивает. Если что нужно - жму меню чата и "Continue". Моделька может тут сгенерировать как и еще +400 токенов сверху, так и 20-30 что бы просто "закончить мысль"
На 4090 24B у тебя выдает 3 токена, лол? Я на 3060 выжимаю из геммы 27B 8 токенов в третьем кванте.
Короче, вот тебе гайд на еблана. Берешь 4 квант, выгружаешь все слои которые имеются. Он точно весит меньше 18 гигов, так что вместится в видеопамять полностью. На остаток видеопамяти крутишь контекст, пока не будет занято 22 гига с копейками. Контекст в принципе выше 18к на мистралях нет смысла ставить - они обсираются и начинают шизеть. Даже контекст шифт включать выгоднее.
По семплереам - нейтрализуй всё, кроме температуры, min-p и штрафа за повтор. Температуру крути как рекомендует автор тюна, мин-п 0.05 - 0.1, штраф за повтор 0.1 - 0.15, окно 2048 минимум или выше.
>Я сам не понял как правильно считать
Хули там понимать? Смотришь на вес модели. Если она весит меньше чем у тебя видеопамяти - можешь выгружать все слои. Если больше, выгружай столько слоев, чтобы вместился контекст.
>но в весовой категории Мистраля
Ты ещё больше ограничений наложи, чтобы уж совсем точно не разглядеть скрытых революций.
Кто может объяснить:
Имеется модель Apriel-1.5-15B-Thinker (Vision). Вес двух её файлов - чуть больше 9ГБ. Контекст выставлен 32К. Почему при запуске у меня остается 260MB VRAM (до запуска 15.7GB VRAM свободно). В консоли llama.cpp при запуске пишется только про 360MB+8GB. Куда делись лишние ~6GB?
Имеется модель Apriel-1.5-15B-Thinker (Vision). Вес двух её файлов - чуть больше 9ГБ. Контекст выставлен 32К. Почему при запуске у меня остается 260MB VRAM (до запуска 15.7GB VRAM свободно). В консоли llama.cpp при запуске пишется только про 360MB+8GB. Куда делись лишние ~6GB?
>У меня прироста кстати не давало
Ну у него контекст сожрал дохуя памяти и этой памяти не хватило на слои для запуска Q8, по тому в его случае если он хочет сохранить такой же большой контекст, ему даст прирост в скорости квантование контекста ценой проеба цвета трусиков и тд. в остальном же да, ему реально проще прыгнуть на квант ниже, ну или урезать контекст, (имхо даже лучше так чем понижать квант, потому что суммарайзы малых контекстов сохраняет больше души, если ты конечно не юзаешь автосуммарайз экстеншен а делаешь его вручную)
> я думал, что чем больше, тем детальнее
Контекст? Нет, контекст это лишь лимит когда модель начинает забывать все то что она писала вне его лимита. Детальность зависит лишь от модели и её промпта/температуры и тд. Плюс как правило мелко модели имеют такую болезнь (даже корпосетки её имеют) когда при достижении определенного контекста модель начинает хуевее писать, так что даже в асиг треде на корпомоделях которые могут(условно, якобы) держать 200к контекста, аноны делают его в пределах 12-32к что бы сохранять мозги что бы было "детальнее"
>Если она весит меньше чем у тебя видеопамяти - можешь выгружать все слои. Если больше, выгружай столько слоев, чтобы вместился контекст.
Но ведь именно это и делает кобольд если оставить автовыставление слоев? Зачем самому тыкать
>Куда делись лишние ~6GB?
Вероятнее всего контекст сожрал. Поставь 4к и посмотри на разницу.
>Но ведь именно это и делает кобольд если оставить автовыставление слоев?
Он делает это через жопу. Самому крутить практичнее, если ты не валенок.
>Поставь 4к и посмотри на разницу.
5.6GB свободно.
Это какая-то особенность модели что у нее контекст такое кол-во VRAM жрет? Вроде я читал про то что контекст 16K отъедает ~1GB VRAM. А здесь 32K съели 6GB.
Тот же gpt-oss:20b с контекстом 128к почти полностью влез в мои 16GB VRAM, при том что весит в общем-то больше.
Первый раз на такое наткнулся, даже не думал о том что проблема может быть в размере контекста.
>Самому крутить практичнее
Понимаю, да.. иногда он может проебывать пару слоев особенно если у тебя в фоне запущенно что-то что жрет врам, ну или даже сама винда жрет его. Но это буквально пару гигов, тут речь о практичности для тех кто только вкатился, ибо с таким подходом можно идти на жору сразу. А в его случае у него модель 25 гигов, т.е больше его врама и еще и контекст 28к, у него просто даже часть слоев ушла, о какой настройке может идти речь? Его 8 квант 25 гигов с 28к контекста и твой третий квант 13гигов вот и вся разница между 4 и 8 токенов.
>Это какая-то особенность модели что у нее контекст такое кол-во VRAM жрет?
Все модели жрут по разному. Это ты еще не видел сколько контекста отнимал старый командор.
>Его 8 квант 25 гигов с 28к контекста и твой третий квант 13гигов вот и вся разница между 4 и 8 токенов
Так надо было шапку почитать и узнать для начала, что такое кванты и как их выбирать. В том же сообщении я написал, что нужно брать четвертый, если ему реально нужно столько контекста.
Убрал -1 и поставил 32. И забыл подправить другие параметры. Результат:
[21:24:01] CtxLimit:5418/28672, Amt:577/2772, Init:0.04s, Process:215.56s (22.46T/s), Generate:273.13s (2.11T/s), Total:488.68s
Рестартнул. Снизил контекст в кобольде до 20к. В таверне откт поставил 1к а контекст выставил на 19к
Получил не сказал бы что большой прирост, всё равно выходит более минуты (кстати, а сколько норма?):
[21:30:24] CtxLimit:5330/20480, Amt:489/1113, Init:0.04s, Process:4.65s (1041.52T/s), Generate:79.45s (6.15T/s), Total:84.10s
Я хлебушек, я ничего не понимаю из того, что ты говоришь. 4 кванта? выгружать слои? крутить контекст пока не будет занято 22 гига? мистрали? это модель? у меня мистраль? У меня вроде рэйнтедфентази.
Что значит нейтрализовать всё в семплерах? поставить дефолтные значения? я их выбирал пресетом через выпадающее меню таверны.
> ценой проеба цвета трусиков
недопустимо.
Ага. контекст это то как много помнит ИИ. температура - это детали.
>Но ведь именно это и делает кобольд если оставить автовыставление слоев? Зачем самому тыкать
понял. вернул обратно на -1.
>Он делает это через жопу.
вернул на 32.
>если ты не валенок.
поставил -1.

>Смешно до хрюканины просто,
Ага:
>Я хлебушек, я ничего не понимаю из того, что ты говоришь.
Шапку тогда иди читай и не страдай итт с тупыми вопросами. Это всё базовая информация, её нужно знать, если хочешь катать локалки. Объяснить тебе что-то еще проще невозможно, тебе уже даже параметры перечислили, осталось их только ввести в нужные поля и скачать нужный квант.
>Тока не начинай свое старое «не лучше или хуже, а ра-а-азные…»
Это не его старое. Это я был. Только я не про неделю а про два дня писал.
>Тебе что больше понравилось? Какую в итоге катаешь на постоянке или катал бы? =)
Да я уже на квант от Bartowski вернулся. Но квант от ddh0 тоже стирать не стал - будет под задачи ассистента. А для (E)RP - от Bartowski.
-1 работает через жопу. Серьезно. Я как ни пробовал, -1 никогда не выдавал у меня результата лучше, чем поставленное значение руками.
Ты поставил 32 - это не факт, что правильно подобрал. Пробуй другие значения.
Я как подобрал? Мне посоветовали - "ищи от 30 до 40". Я сначала поставил минимальные 30 - получилась хуйня. Поставил максимальные 40 - стало еще хуже. Поставил 33 - стало лучше. Поставил 37 - стало опять хуже. Поставил 35 - стало лучшеиз всех возможных.
Выше вот анон написал:
>Смотришь на вес модели. Если она весит меньше чем у тебя видеопамяти - можешь выгружать все слои. Если больше, выгружай столько слоев, чтобы вместился контекст.
Наверное он прав. Почему я не могу ручаться за этот совет? Я не ебу, сколько там чего один слой потребляет. Опять же, у тебя больше видеопамяти, чем у меня. Влезать должно больше, по идее. Я смотрел стандартный диспетчер задач и то, сколько памяти у меня жрет запуск модели. Я потом проверял - 33 у меня жрало 13гб из 16, 35 жрет 15.7 из 16. На том и остановился.
>Наверное он прав.
Не наверное, я прав.
>Я не ебу, сколько там чего один слой потребляет.
Мистраль имеет 40 слоев, 4 квант весит 14 гигабайт, делишь вес на количество слоев - узнаешь сколько весит один слой. Математика пиздец, я понимаю. Не всем удалось освоить первые три класса начальной школы.
>Снизил контекст в кобольде до 20к
Кстати без рофлов, мистрали редко держут высокий контекст как писал анон тут
>Контекст в принципе выше 18к на мистралях нет смысла ставить - они обсираются и начинают шизеть.
Так что лучше скорее познавай дзен суммарайзов, он тебе пригодится везде, что на корпосетках, что на МоЕ.
> температура - это детали
Не, температура это креативность(шиза) и строгие инструкции. Детали это сама модель, ну или её параметры (24b) в твоем случае, хотя это не всегда так... тоже многое от модели зависит..
>всё равно выходит более минуты (кстати, а сколько норма?):
Норма столько сколько у тебя хватает зрения читать текст(ты же поставил стриминг текста, да?), обычно больше 7 токенов в сек. при медитативном чтении с головой хватает, быстрее кожанные мешки обычно не читают.
>Я хлебушек, я ничего не понимаю из того, что ты говоришь. 4 кванта? выгружать слои? крутить контекст пока не будет занято 22 гига? мистрали? это модель? у меня мистраль? У меня вроде рэйнтедфентази.
1. Да, у тебя файн-тюн мистрали, называться они могут как угодно хоть МЕГА УЛЬТРА СЛОП ЗАЛУПА XXL 24b.gguf но это файн тюн мистрали.
2. У тебя сама модель весит 25 гигов, т.е даже без контекста у тебя жертвуются слои(падает скорость генерации, это никак не влияет на качество генерации, только на скорость) а еще и контекст жрет врам тоже, т.е ты себе еще больше слоев проебал(еще меньше скорость) вот и твои 2-4 токена.
Тебе сказали скачать 4 квант, это просто как ты скачал 8 квант модели вот выбери 4Q вместо 8Q, она будет весить(сама модель около 16-18 гигов, и ты спокойно сможешь остальной врам перенаправить на контекст) и всё, никаким проблем. А нейтрализовать семплеры да, убрать их просто в 0 типа, но у тебя там все +- норм, просто запомни самые важные Температура ТОП-К и DRY-повторы которые ты уже выставил, тут скорее сложности у тебя могут возникнуть с шаблоном контекста, разные модели могут работать по разному с промптами и шаблоном, многие модели которые здесь гоняют тренились с ChatML шаблоном например твоя мистралька.
Я, честно говоря, даже не знал, что у мистря 40 слоев. Вот я ща сижу на Mistral-Small-3.2-AntiRep-24B-i1-GGUF в 4м кванте, зашел на страницу и не вижу, куда глядеть, что бы понять за количество слоев.
Да потому что оно смотрит на доступный врам а не общий, типа если у тебя чето там в фоне есть, оно обрезает и еще оставляет хвостик с запасом типа(как я понял) хотя по факту это свободный врам который можно распределить, вот и вся причина.

>зашел на страницу и не вижу, куда глядеть, что бы понять за количество слоев
Кнопка слева Files info, потом смотришь на пикрил
>убрать их просто в 0 типа
Вот он ведь по твоему совету реально все параметры в 0 выставит, вместо того чтобы нажать одну кнопку и загрузить нейтральные значения.
>Температура ТОП-К и DRY-повторы
Топ-к не нужен, DRY гробит мелокомодели. Для 90% случаев хватает мин-п, температуры, и пенальти на повтор.
> Не всем удалось освоить первые три класса начальной школы.
Я не смог из за СДВГ..
>>Кнопка слева
О, пасиба. Буду знать. Реально, спасибо большое.
Напиздел, она справа. Просто я обниморду со второго монитора открыл и даже не заметил.
>Вроде я читал про то что контекст 16K отъедает ~1GB VRAM
Не 16 а 4, а иногда 2 или 1.
Контекст у всех моделей разный, и зависит и от технологий, и от токенизатора, так что да.
> старый командор.
Да, было дело… Ставишь 4К, думаешь зачем это тебе, и сносишь модель.
А через год оказался хидден гемом, но уже пофиг, если честно.
Простите, перепутал. )
Но все же — какой из квантов ddh0 лучше для тебя?
———
Затраил квен-вл, 8б моделька в 6 кванте неплохо крутится на CMP 90HX, почти 40 токенов выдает. Если надо что-то анализировать пачками, нот бэд вариант.
Да, я пытаюсь оправдать покупку этого шедевра нвидиа-строения. х)
Не, я разобрался где это искать. Только в моем случае там такого подпункта, почему-то, нет :D Но это, как я понимаю, переделка обычной мистрали, так что берем исходник из него.
>Только в моем случае там такого подпункта, почему-то, нет
Если смотришь ггуф - смотри на llama.block_count - это одно и то же говно.
>Но это, как я понимаю, переделка обычной мистрали, так что берем исходник из него.
Правильно мыслишь.
>и от токенизатора
А разве он не влияет только на количество преобразования токенов?(потребление)

И на это, плюс от внутренних параметров модели зависит размер эмбединга (скрытого пространства). Для гпт-осс это 2880, для мистрали 24B это 5120. У плюсового командира вообще 12288.
Спасибо добрый человек, что объяснил так, что даже такой хлебушек как я надеюсь понял.
Я отпишусь когда докачаю модель и покручу бегунки в настройках, поделюсь результатами.
Кстати, а в чем отличие моделей? Там на 4 кванта (хрена я терминами теперь щеголяю) две версии. одна с буквой M вторая с буквой S. По размеру они +- одно и то же. Логика подсказывает, что Medium и Small. Я начал качать M.
>ты же поставил стриминг текста, да?
Теперь да... до этого сидел альт-табался на ютубы, было неудобно.
Не забудь, как выше тебе советовали, правильно подобрать количество выгружаемых слоев в настройках кобольда.

Как правило, на странице модели пишется, какой квант лучше. Например пик.
K_M, вроде как, считается самым оптимальным вариантом.
>Но все же — какой из квантов ddh0 лучше для тебя?
Ну так я ж написал. Для художественных задач вроде RP - Bartowski. А там где упор в факты без эмоций и окраски - ddh0 буду пользовать.
Однозначного победителя лично для меня нет.

Но есть нюанс - еще бывают IQ кванты. Медленее, но лучше простых Q такого же уровня.
В общем-то, имеет особый смысл помнить только об IQ4_XS. Этот квант обычно по размеру меньше, чем любой Q4, а качество у него - сравнимое (в отдельных случаях и лучше). Если в железо полноценно не лезет Q4, причем совсем немного (на удивление регулярный случай у меня), то IQ4_XS часто остается единственным приличным вариантом.
Пробуй Q4 K_M.
Возьму для себя на заметку. Спасибо.
Мне одиноко
Мне тоже. Что делать будем?
Поставил эту модель. Скорость заметно возросла.
[00:39:32] CtxLimit:7960/20480, Amt:381/1113, Init:0.05s, Process:0.28s (3.57T/s), Generate:30.64s (12.44T/s), Total:30.92s
Ничего более пока не менял. Анализирую объем и поведение.
Ты слои-то высчитал?
> Слова действительно резкие, но здесь просто обрисовал как это все выглядит со стороны в красках, дабы вызвать реакцию и чел немного призадумался
Сразу призадумался и отнёс это всё к дешёвому рейдж байту. Надеюсь достаточная реакция
Играй кошкодевочку. Я тебя ебу.
Луч света освещал столб пыли.
Я покачивала бёдрами.
Ааах. Ты меня ебёшь.
Не бойся, я тебя не укушу.
Если сам не попросишь.
Ни одного нашёптано на ушко, незачёт.
Байт показать скорости а не мислидящий поток? Тяжело.
Дальнейший выбор за тобой~ шиверсы медленно ползут вниз по твоей спайн
> показать скорости
Я их и показал на сетапе и ворклоадах которые юзаю. Если нужен жора, сделайте сами.
Не вижу смысла делать тесты которые мне никак не пригодятся
Справедливо, гейткип по скиллу и убеждениям.
Тупо игнорь этого шизика. Когда с него спрашивают тем же тоном, как он это сделал в данном кейсе тот инстантно начинает вонять и заявляет, что у него просить нужно с уважением и как минимум на коленях. Может если попросит так же ты пересмотришь свою позицию.
Есть какие-то серьезные различия между LLM от bartowski и unsloth с <32B моделями (qwen3, gemma3, gpt-oss)?
Вес вроде в пределах погрешности, результаты тестов тоже в пределах погрешности то в одну сторону, то в другую, в зависимости от теста.
Наткнулся на инфу что unsloth фиксит какие-то баги при выпуске своих квантов.
Вес вроде в пределах погрешности, результаты тестов тоже в пределах погрешности то в одну сторону, то в другую, в зависимости от теста.
Наткнулся на инфу что unsloth фиксит какие-то баги при выпуске своих квантов.
>Всё что выходит, не представляет ничего принципиально нового
Ну я бы не сказал. Просто это скорее развитие вбок :) А в плане понимания и качества РП всё так, кручу большой Квен, ГЛМ, Комманд-А - и старенький Лиминум всех их ебёт. Какую-то конкуренцию разве что Квен-thinkung может составить, да и то.
*Люминум быстрофикс
> Nvidia purchased last week the entire supply of SK Hynix in DRAM, VRAM, HBM, and NAND flash for through the end of 2026. Every single wafer of capacity they had left.
кто давно собирается апгрейднуть оперативу, но всё никак не соберётся - лучше потратьтесь сейчас, позже будет ещё дороже.
кто давно собирается апгрейднуть оперативу, но всё никак не соберётся - лучше потратьтесь сейчас, позже будет ещё дороже.
>А теги прописаны в таверне в настройках?
А откуда им еще взяться-то?
Я зарабатываю 750р в день.
Точно точно нужно?
12b лоботомитов гонять. Если нет опыта на моделях побольше то сойдёт.
> 750р в день
Пиздишь, так не бывает. У меня в час больше.
Обычная зп в рф, 150-200р в час.
Когда получил 15к в первый месяц бабка фыркнула тип "че за нищие копейки", а как дали 18.7к сразу довольна типа огого вот теперь деньги
... формально - есть. Но разве это жизнь?
4б медгема ггуф вполне, даже картинки распознаёт.
>обычно больше 7 токенов в сек. при медитативном чтении с головой хватает, быстрее кожанные мешки обычно не читают.
Пчел, я не считаю что быстро читаю, но даже на 10 токенах постоянно упираюсь в конец строки, читать стриминг на 7 это разновидность пытки, уж лучше свернуться на ютуб и потом нормально прочитать. Комфорт при расслабленном чтении начинается в где-то после 13-15 токенов.
Я могу ей показать свои волдыри на пенисе?

>несколько разных LLM для конкретных задач
База
>подходит под большинство задач
Очевидная Гемма
>Простите, перепутал. )
А, всё, баста, поздно уже.
Теперь я буду трепать твой джаулайн, откидывать твою голову, чтобы смотреть на шею, теребить chin, и шептать : "Скоро, очень скоро" и нихуя не делать, пока ты не превратишься в макаку и угукая не разъебешь монитор.
Есть у кого карточка скибиди туалет?

Нахуй пошёл.
Почему? Я помемать хочу всего лишь. Тоже нахуй иди, анимечник.
Или если у кого другие мемные карточки есть скиньте пж, хочется веселого че-нить. Шрек там например.
Жора релизит новый webui: https://github.com/ggml-org/llama.cpp/discussions/16938
Два Air гунтюна: https://huggingface.co/zerofata/GLM-4.5-Iceblink-v2-106B-A12B https://huggingface.co/Darkhn/GLM-Air-4.5-106B-Animus-V12.1
По новостям пока всё. Вымер с пикчи у второго тюна, блять.
Два Air гунтюна: https://huggingface.co/zerofata/GLM-4.5-Iceblink-v2-106B-A12B https://huggingface.co/Darkhn/GLM-Air-4.5-106B-Animus-V12.1
По новостям пока всё. Вымер с пикчи у второго тюна, блять.
>новый вебгуй
И опять без карточек персонажа, в топку.
Всем похуй на гунеров а сами они мало чё делают. Великое счастье что у нас хотя бы таверна есть.
> Жора
Там разраб из обниморды. Не понятно зачем ему это.
Не наю. Наверно твой компьютер хочет заразить
Зерофату буду скачивать. Как минимум мне интересно, что получится. Отпишусь вечером. Пробовать буду исключительно в чистейшем, концентрированном пореве.
>Жора релизит новый webui
Собираю из гита, тыщу лет уже этот уи, а я то думал реально новый
Ты крут
Глянул кванты. Это что, с 64 рамы можно аж Q8 запускать получается? Еще и на контекст, при желании, порядком останется даже с 12 vram, т.к. общая часть не сильно большая? Прямо интересно стало...

>Это что, с 64 рамы можно аж Q8 запускать получается?
C 64 рамы мне кажется лучше аир запускать или квен 235.
Во втором кванте, ага.
Пу-пу-пу…
Ну, если считать по современным данным, средняя (медианная) в России — ~40, при делении на 160 часов получается 250 в час или 2к в день.
Но это среднее между городом миллионником и деревней.
Так что можешь смело туда-сюда гонять.
Плюс сами работы по разному оплачиваются.
Есть и 20к в месяц (а при условных 6 часах в день и 120 в месяц — это 170 в час), и как у тебя.
Так что, да, всякое бывает.
Правда, людям с такими деньгами надо было еще год назад закупаться зеонами на озоне и алике, а не ждать, когда оперативе +60% прыгнет с перспективой дальнейшего роста.
Че там, P104-100 / P102-100 / CMP 50HX еще стоят свои 2/2,5/5?..
Да, даже дешевле.
Звучит так, будто бомжам проще на видяхах собрать, если честно.
Почитай, шо я выше написал, мало ли.
Целесообразно ли переходить с ддр4 на ддр5 ради моэ моделек, если у меня всего 16гб видеопамяти? Эту штуку попробовал и ничего так вроде но у меня 7 т/с генерация, то есть позорно мало получается. Уверен, можно до 10 т/с оптимизировать (я просто на отъебись ггуфа загрузил) но все равно интересно че даст новая платформа.
Алсо какой при этом раскладе стоит брать камушек и материнку? Мне не только для ИИ, еще для игор.
Алсо какой при этом раскладе стоит брать камушек и материнку? Мне не только для ИИ, еще для игор.
Эх, соблазните вы меня купить оперативы. (ддр4 стоит брать?)
Убеждаю тебя забить хуй.
64гб слишком мало, 128гб ддр4 слишком медленно хотя в треде шизы коупят что 4т.с терпимо, 128 ддр5 слишком дорого.
Ответ на твой вопрос буквально постом выше, лол
Короче я вот что выяснил, смотрите.
aquif-3.5-Max-42B-A3B отлично следует пресетам и инструкциям от этой штучки
>https://huggingface.co/icefog72/IceAbsintheRP-7b (с пресетами по гайду)
Полный ruleset, шаблон планирования ответа, внутренние мысли чара - все делает. Даже темплейты менять не пришлось.
Я не утверждаю, что это лучший вариант, а указываю на полную работоспособность. Не ожидал, что это всё встанет как влитое к совершенно другой модели.
Да, во втором. Ты не понял пока как все работает? Ты любой ценой должен запускать более старшие модели в любом доступном тебе кванте. Падение качества в 5-15% на втором кванте все равно оставляет 200В+ модели достаточно мозгов чтобы задавить все младшие модели в 16 битах. Сейчас все кто могут - сидят на квене 235 и Аире(на Аире в основном сидят любители англюсика, на квене - русика). Все кто накопили на 128 гб - сидят на глм 4.6, это текущая мета. На мелкоогрызках сейчас страдают только те, у кого нет 64 гб врам.
Пресетик под русикоквен будет?
Так и не понял восторженных отзывов на его русик, чуть хуже эира в 5 кванте мб

Че за дичь происходит???? Пару дней назад все работало...
Что-то поломал, анончик. Думай.
Хм, а солидно получается. Главное что все по делу и нет ебки длинным ризонингом.
>ддр4 стоит брать?
Стоит взять 64 гб - это Аир в 4 кванте и квен 235 на втором с юзабельной(6-7 т.с.) скоростью.
128 гб ддр4 брать наверное не имеет смысла, там скорости на глм 4.6 будут в районе 4-5 т.с. Сама модель того стоит конечно, это по сути квен, но лишенный его недостатков.
Failed to send message
vk::Queue::submit: ErrorOutOfDeviceMemory
У меня такое с картинками было. А теперь с текстом после обновления рантайма. Откатился на старый рантайм - то же самое. Че за бред?

Винда? Терпи тогда. Если линь то запускай без иксов
>ErrorOutOfDeviceMemory
>ошибочка, закончилась память
Посмотри сколько сожрано на видюхе и в оперативке.
Может ты настройки какие-то менял или больше постороннего софта запустил одновременно с ИИ хренью?
Ниче плохого не должно быть, просто какой-то обсёрчик рандомный.
В чем космический эффект форса реквеста пресетов? На квене отлично работают стандартные настройки. Если же тебе пям нужны особые настройки - то возьми пресет нюни, вырежи всю хуйню что он там насувал в грамматику или добавь туда "а-яА-Я" и получишь русик.
Нет, и тоже встречал мнение в лмг и на реддите, что лучше больший квант при меньшей модели.
> Мне не только для ИИ, еще для игор.
Ты кое что не понимаешь. Ты только игровой и можешь собрать. Там где начинаются серверные машины, у тебя закончатся деньги. И дело не в том, что видеокарты дорогие, нет нет нет.
Нормальная мать 100к+, процессор, а то и два, если это не некруха- то начинаются с 200к+
Зато памяти можно хоть 2ТБ навалить, о чем красивые игроплаты могут только мечтать.
Так что игровой пека по сути максимум для мимокрока дрочуна.
Тут только переустановка арчлинукса.
Да ты тоже не понимаешь. Это был вопрос про AMD vs Intel. Я краем уха слышал, что первое не может в быструю ддр5, а второе серит под себя в играх. Серверные-то тут причем.
> В чем космический эффект форса реквеста пресетов?
Раньше плотненькие модели реально требовали особого подхода, отличного от : temp 1.0 и полетели.
И ты ебался с семплерами и не мог понять, хули этой падле надо.
> Серверные-то тут причем.
При том, что выбор консумерского железа у тебя ограничен только игровым. Это должно быть очевидно.
> AMD vs Intel.
Покажи ка мне в твоем сообщении хоть намек на выбор процессора от конкретного производителя.
у меня похоже было пару дней назад, было связано с новой версией ядра 6.17.6. когда запустил на чуть старее минорной 6.17.5 - все снова заработало норм.

>Алсо какой при этом раскладе стоит брать камушек и материнку? Мне не только для ИИ, еще для игор.
Ты ИИ-бот что ли? Любой человек в первую очередь подумает о широком выборе потреблядского железа.
Дрочую. Брал видяху из расчёта греть ноги зимой под столом, а летом сушить рыбу.
Offload kv cache сработал. Но чет бред какой то. Раньше и с ним работало с теми же настройками.
румынопроблемсы
>Любой человек в первую очередь подумает о широком выборе потреблядского железа.
Ты в тематике, а не в /vg/ и /hw/. К тому же в очень специфичной тематике.
Не твоя личная армия. Не твой личный бложик и не твой личный техсовет.
Че несет, пиздец
После перезагрузки пеки все вернулось в норму. Во дела.
>лучше больший квант при меньшей модели
Это может быть верно только для совсем мелких моделей, у которых кванты реально убивают модели в ноль, и только относительно лежащих близко друг друга по параметрам(например 3В и 4В). На моделях 24В+ кванты начиная с 4 бит и выше в слепом тесте невозможно отличить друг от друга(см. оп-пик с квантами квен3 32В - там это наглядно видно), у более старших(200В+) этот эффект слепого теста наблюдается уже с 3 бит, соотвественно любой вау эффект от повышения кванта происходит от самовнушения. Опенаи в курсе, например, и поэтому не использует модели выше 4 кванта.
> на моделях 24В+ кванты начиная с 4 бит и выше в слепом тесте невозможно отличить друг от друга
> у более старших(200В+) этот эффект слепого теста наблюдается уже с 3 бит
Это не так. Ты, возможно, не запускал множество моделей в разных квантах сам или попросту принимаешь удобные для тебя слова из треда за истину.
> см. оп-пик с квантами квен3 32В - там это наглядно видно
Почему ты цифры экстраполируешь на реальное использование/слепые тесты?
Разница есть. Иногда существенная, иногда нет. Между Air Q4 и Q6, например, настоящая пропасть. Q4 буквально допускает опечатки в словах, гораздо чаще путает сущности местами (кому из персонажей принадлежит та или иная черта, например), чаще выдает примитивную грамматику. У Q5 эта проблема существенно меньше, у Q6 практически отсутствует. Среди ~Q4 квантов есть разница среди квантов ddh0, bartwoski, unsloth, хотя bpw плюс-минус одинаков. Как так? Потому что квантуют разные слои. Даже это влияет на выдачу, в данном конкретном случае.
> Опенаи в курсе, например, и поэтому не использует модели выше 4 кванта
Как кто-то, кто каждый день гоняет GPT OSS 120б, я проклинаю их, что они выпустили лишь MXFP4 квант. Потому что понимаю, что эта модель была бы на порядки круче, имей я возможность гонять Q5-Q6 квант. Проблемы квантизации в коде/тех.задачах там компенсируются high reasoning опцией, но если это не работа на контексте, а факт-чекинг или еще что-нибудь, то довольно быстро ты поймешь, что она слишком ужата. Сделали они это, вероятно, для унифицированного опыта на всех устройствах/сервисах, для удобства.
Я хочу сделать так чтобы при запуске нейросети, имитирующей персонажа открывалось графическое окно, в котором будет изображение персонажа, который будет общаться, реагировать мимически согласно настроению нейросети, отвечать сгенерированным голосом или текстом, как это осуществить? При этом нужно чтобы внешность персонажа 1 - или задавалась программно на основе характера ответа самой нейросети, или 2 - наоборот, чтобы на основе заранее определенной внешности нейросеть выстроила характер персонажа и давала ответы в соответствии.
В глупой таверне документацию прочти. Всё есть
> Все кто накопили на 128 гб - сидят на глм 4.6, это текущая мета.
Может ты уже нахуй пройдешь со свой метой, а ранее и "базой для 24гб врама"? У меня 128 гб, и я не использую 2 битного лоботомита с низким количеством квантованного контекста. Возможно, ты буквально единственный, кто это делает. Не устал "я" выдавать за "все"? Полный бред. Единственное, что верно - да, большинство людей с железом сейчас сидят на Air и Квене 235.
Там в реалтайме? Хочу чтобы как в фильмах - запускаешь а там девушка и говорит (или пишет, если совсем нище), и ее изображение с эмоциями, зависящими от генерации нейросети, не алгоритмически, а напрямую.
Не работает.
Работает.
Там нужна целая ферма из тесл чтобы такое запустить. И десяток индусов, которые все это настроят. Стоить будет лямов 30 не меньше. А на выходе всего лишь нейросетевая тянка.
Кароч мне не позволено чтобы у меня такое работало.
Говорят, что завтра новый Air выйдет.
Погонял, потестил. Спрятал слово коксакер в истории на 30к токенов - модель нашла и еще очень интересно перессказала историю.
Пресеты и правда хороши. Пока любимая мелкомоэшка, точно дает на клык 30-а3б квену.

>что они выпустили лишь MXFP4 квант
Они в нём тренировали, лол.
А есть какой-нибудь чекпоинт чтобы в него засунуть файл звука на нихонском и получить текст на инглише с таймстампами? Что-то типа whisper модели для кобольда. Еще лучше если это будет для комфи.
Эмм... whisper? Он вроде именно так и должен делать.
У меня он только инглиш в текст расшифровывает, и без таймстемпов
Целесообразно в вакууме.
Но нужен мощный процессор (явно не i5/r5) и цена подскочила на 60%+.
Так что очень не уверен уже.
Я последние полгода всех уговаривал «бери оперативу блеа, пока дешевая», и не я один.
Но уже поздновато, как бы.
ГЛМ-4.6 в двух битах все еще сильно заметно лучше 235б квена.
Тут уж как не крути, как не еби последнего.
Ради скорости, 2 лишних токенов терять мозги? Ну я не уверен, но каждому свое.
Если ты считаешь, что люди со 128 гигами сидят на квене, то это странно.
И, я не он, если че.
Вот с 96 гигов да, там на квенчике самое то.
> Как кто-то, кто каждый день гоняет GPT OSS 120б, я проклинаю их, что они выпустили лишь MXFP4 квант. Потому что понимаю, что эта модель была бы на порядки круче, имей я возможность гонять Q5-Q6 квант.
Слушай, кто-то, а ты в курсе, что провели исследование и получили совершенно равные результаты бенчей для GPT-Nano/Mini и GPT-OSS-20b/120b? Т.е., есть охуеннейшее подозрение, что это их реальные продовые модели.
Исследование делал не я, можешь не начинать плеваться в меня слюной, мне похую. Но фраза про «Опенаи … не использует модели выше 4 кванта» может оказатсья не такой уж и бредовой, по крайней мере есть очень веские аргументы в пользу этого (по крайней мере на малых моделях, это я еще не считаю множества замеров и слухов ранее, когда GPT-4 лоботомировалась с обновлением).
>Но уже поздновато, как бы.
Вижу 96гб ддр5 можно найти за 30к. Хз в чем проблема, цены вроде и в начале года такие же были.
> ГЛМ-4.6 в двух битах все еще сильно заметно лучше 235б квена.
Ты хотя бы запускал его или рассуждаешь с дивана? Я запускал на ik форме Лламы. Мы обсуждали в контексте 128гб оперативы, у меня 24гб видеопамяти. GLM 4.6 - это второй квант и 24к квантованного контекста. Мало того, что это лоботомитный квант (пример Air здесь применителен, большой GLM точно так же страдает от квантизации, по крайней мере на Q2. Как не раз упоминалось, потеря окончаний/опечатки/тасовка сущностей), еще и контекст квантован, и его меньше. Потыкался и не понял кому и зачем это надо. Думаю, если бы у тебя был такой опыт, ты бы не утверждал сейчас, что Q2 4.6 это эпик вин. Даже Air в Q5-Q6 будет лучше, не говоря уже о Квене 235. Последний мне не нравится субъективно, потому я использую Air.
> Ради скорости, 2 лишних токенов терять мозги?
4.6 Q2 работает с такой же скоростью, что и Q4 235б. Разница на уровне погрешности.
> Если ты считаешь, что люди со 128 гигами сидят на квене, то это странно.
Других реальных, вразумительных опций нет. Либо Air, либо Квен 235. Хотя я сейчас тыкаю Minimax M2, и он мне вроде бы нравится.
> фраза про «Опенаи … не использует модели выше 4 кванта» может оказатсья не такой уж и бредовой
Мне на это все равно. Как это отменяет тот факт, что на выходе мы имеем MXFP4, а лучше было бы иметь полные веса, которые можно квантовать как вздумается? Если они тренируют в MXFP4 или не хотят делиться полными весами, это не говорит о том, что это эффективно. Может быть дешевле в тренировке и прочем, но нас как эндюзеров это не должно волновать.
Есть способы улучшить скорость геммы 27б Q_4 на 16+32гб?? Или выше 10 т/с с постепенным снижением по мере заполнения контекста это потолок?
Не знаю, у меня 128. Они с 46 до 65 67 скаканули. Я буквально могу каждый день обновлять цену оперативы в треде.
> Ты хотя бы запускал его или рассуждаешь с дивана? Я запускал на ik форме Лламы.
Запускал и запускаю, и на ик форке, и на оригинале (а еще разные другие форки, для разных моделей… если ты хочешь меряться).
У меня 128 оперативы и 24 видеопамяти.
Q2_K_L от бартовски.
Это НЕ лоботомитный квант, по сравнению с оппонентами в этой памяти, который в рот ебет и GLM-Air в восьмом кванте, и Qwen3-235b в кванте Q3_K_XL.
> Думаю, если бы у тебя был такой опыт, ты бы не утверждал сейчас, что Q2 4.6 это эпик вин.
Думаю, если бы у тебя был настоящий опыт, а не диванные фантазии, то ты бы не утверждал обратное.
Как видишь, в твою тупую игру можно играть в обе стороны. =)
> 4.6 Q2 работает с такой же скоростью, что и Q4 235б. Разница на уровне погрешности.
Случайно не IQ4_XSS? ну так, мало ли ты IQ-квант, который медленнее, запустил и скорости удивился.
Опять же, разница между Q4_K_S и Q3_K_XL довольно мало.
А по скорости между глм-4.6 q2_K_L и квеном Q3_K_XL там как раз пара токенов.
Но тем более, ок, у тебя скорости одинаковы, при этом глм пишет лучше.
В прошлом треде чувак скидывал 3 разных скрина с ГЛМ, квен и Эрни. И там изично несколько анонов спалило где какая, потому что они от себя очень сильно отличались. И ГЛМ там очевидно лучше квена себя показал.
Правда не помню квант, может быть там был четвертый, тогда мой пример не считается.
> тыкаю Minimax M2, и он мне вроде бы нравится.
А, я понял, ты больной ублюдок, который не любит художественную литературу, а кончает на инструкции.
Тогда да, квен тут будет лучше, а минимакс вообще огонь.
Очень сухой текст.
Надеюсь, хотя бы минимакс ты получил быстрее глм? У меня минимакс мхфп4 на 12 токенах катается на моей бомже-видяхе.
> Как это отменяет тот факт, что на выходе мы имеем MXFP4, а лучше было бы иметь полные веса, которые можно квантовать как вздумается?
Никак, я просто уточнил.
Я к тому, что возможно они не такие пидоры, и могли бы поделиться, просто полных весов нет.
Или наоборот — они настолько пидоры, что тренят все сразу в mxfp4. =) Тут уж каждый по своему оценивает.
Ах да, gpt-oss — то еще говно, конечно, для рп. Ты стопудово дрочишь на инструкции. =)
Чем более ассистентная модель — тем больше тебе она нравится.
А чем более творчески пишет — тем она хуже по-твоему.
Тенденция, однако!
А для работы гпт-осс норм, но мне показалось, что минимакс пизже. От него во время чата прям веет такой взрослой моделью, я хз, вайб такой приятный.
Все продумывает, все поясняет.
Правда иногда заходит слишком далеко.
Но его еще предстоит распробовать.
В агентах он хуйню какую-то выдает из-за джинджа-тимплейта на лламе. А я бомж, у которого нет 120 гигов видяхи, чтобы в норм движках инференсить.
На точное значение не обратил внимание, по ощущениям с --swa-full где-то в 1,3 раза тяжелее. Но "мозгов" гопоте это добавляет не принципиальное количество. Она все равно не видит по контексту дальше чем на один шаг. В отличии от Air и даже Qwen3-30B-A3B-Thinking-2507 . Скорость работы в ущерб памяти.
> в рот ебет
> диванные фантазии
> в твою тупую игру можно играть в обе стороны. =)
> мало ли ты IQ-квант, который медленнее, запустил и скорости удивился.
> ты больной ублюдок, который не любит художественную литературу, а кончает на инструкции.
> gpt-oss — то еще говно, конечно, для рп. Ты стопудово дрочишь на инструкции. =)
Нигде и никогда я не писал, что использую GPT OSS для рп. Минимакс я начал ковырять меньше двух часов назад и поделился первым впечатлением. Откуда столько агрессии посреди адекватного обсуждения? Только потому, что мне не понравился Q2 4.6? Приношу глубочайшие извинения и игнорирую твои следующие посты.
>Хотя я сейчас тыкаю Minimax M2, и он мне вроде бы нравится.
А какой там шаблон контекста кстати, ChatML или что?
Опять не закусываешь, старый? Ну ёбана, сколько можно...
Долбаеб, он наоборот пишет что квен говно. Ты походу реально шизик как тут говорят
Разумеется, ведь основное время расчетов у тебя занимает работа профессора. Если игрун - возьми амд с х3д кэшем, пусть высокие частоты памяти не покорятся - все равно емкие плашки медленные, особо не потеряешь.
> ГЛМ-4.6 в двух битах все еще сильно заметно лучше 235б квена.
Заметно где? Они слишком разные, в рп или проблюешься с квенизмов и структур, или будешь ахуевать с "не лупов" жлм, где он на каждый новый поворот будет использовать все то же самое и тупить, бонусом нальет слопа. На двух битах он совсем отупеет еще (как и квен).
> есть охуеннейшее подозрение, что это их реальные продовые модели
Это другая модель с другим поведением и большей фильтрацией (именно на этапе датасета а не пост-тренинга). Что не мешает им иметь общие датасеты и близко перформить.
Чаю
Накатим!
>gpt-oss
кстати нахуй он вообще нужен? я почитал harmony формат от него и немного прихуел с того что этот чёрт обучен делать. Но этот формат нормально не реализует ни наверна, ни какие-то локальные серверы. натурально надо под него писать отдельно приложение, просто чтобы это говно цвело и пахло.
Но в итоге OSS по ходу не имеет особо сильных сторон, кроме математики.
> кстати нахуй он вообще нужен
Чтобы сраться вокруг него и рассказывать как приручил (нет) его в рп. Кто-то говорит что он лучше эйра в кодинге и чате с обсуждением кода. Субъективно не впечатлил и тупит, а с большим синкингом слишком медленный. Обсуждать матан и принципы/архитектуры с ним тяжело, первое впечатление хорошее, но чем дальше тем дегенеративнее.
> нормально не реализует ни наверна, ни какие-то локальные серверы
Костыльно для ограниченного применения несложно, там по сути только влепить режим максимального ризонинга и канал функциональных вызовов правильно парсить.
> надо под него писать отдельно приложение
Скорми любой другой модели (чтобы не было пересечения токенов разметки) документацию и попроси сделать что хочешь.
> кстати нахуй он вообще нужен?
Для технических/математических/программных задач хороша. В моих юзкейсах работает лучше Air и иногда даже Квена 235. Пользуюсь ей практически каждый день, очень доволен.
> Но этот формат нормально не реализует ни наверна, ни какие-то локальные серверы
Спокойно работает в Таверне и через Chat Completion, и через Text Completion, если нормально сверстать шаблон. Tool calling работает с Jinja от Unsloth или используя костыльную грамматику для форматирования выводов.
Квант МПХ4
> А какой там шаблон контекста кстати, ChatML или что?
Нет, там свой шаблон. Можно посмотреть его устройство в репе на Обниморде и сверстать самому для Text Completion.
Лол да я и сам без проблем могу написать хуйню без проблем. Его просто не удобно со всей его анально-канальной хуйней обрабатывать, так как его паттерн сильно отличается от обычного чата с разделением по ролям. ебучая гемма вообще не знает даже про роль system, а OSS лол целый протокол общения в модель зашили. Понакрутили ебать.
нет, она точно не хороша для программирования и технической хуйни. OSS всё пишет так будто теорему доказывает. В большинстве случаев нахуй не нужно. ейбогу в программировании даже квен кодер 30b пишет лучше. У модели есть интересная сторона с тем что оно умеет прерывать свой ризонинг для вызова инструментов и срать в разные каналы, но инструменты много кто хорошо вызывает.
>Спокойно работает в Таверне и через Chat Completion, и через Text Completion, если нормально сверстать шаблон.
Ты сам то читал какой там формат общения? я немного охуел с его
<|start|>developer<|message|> ... <|end|>
<|start|>user<|message|> ... <|end|>
<|start|>assistant<|channel|>analysis<|message|> ... <|end|>
<|start|>assistant to=functions.get_current_weather<|channel|>commentary json<|message|> ... <|call|>
<|start|>functions.get_current_weather to=assistant<|channel|>commentary<|message|> ... <|end|>
<|start|>assistant<|channel|>analysis<|message|> ... <|end|>
<|start|>assistant<|channel|>final<|message|> ... <|end|>
И так далее. Когда у него есть всякие developer, to=, <|call|>, analysis, final и прочая чушня. Лол охуительная логика с тем что инструмент может быть ролью вот это забавно придумали. Эту хуйню в полной мере ни таверна, ни jinja от unsloth не поддерживает. Там скорей на уровне "как-то работает и ладно".
Ну, объективно, за сам формат их сильно хейтить не стоит. Идея с каналами хорошая, дает функционал и можно устроить обратную совместимость обрезав большую часть. Если бы не перегружали чрезмерно, то было даже хорошо.
Претензии больше к самой модели и весам.
> ни таверна, ни jinja от unsloth не поддерживает
Так-то полноценно квен и эйр тоже никто не поддерживает, у них заложены одновременные вызовы в одном ответе вместо поперживания по одной с прерываниями как в колхозе с жорой. И изначально предусмотрен свой парсер на питоне, который можно приручить для локального запуска. Но клозеры решили и их переплюнуть, да.
> нет, она точно не хороша для программирования и технической хуйни.
Я всего лишь поделился своим опытом. На моей кодовой базе (C#, C, TS, JS, lua) 120б работает стабильно лучше Air и в редких случаях лучше Квена 235. У меня не было цели тебя в чем-то убедить, как и твой пост не заставит меня развидеть все то, что я видел за уже больше чем месяц взаимодействия с этой моделькой.
> OSS всё пишет так будто теорему доказывает.
Смотря как запромптить. Не очень представляю какую теорему можно доказывать когда на выходе нужно готовое решение технической задачи или код.
> Ты сам то читал какой там формат общения?
Работал с этой моделью и через Chat, и через Text Completion через Таверну и через Cline. Сравнивал результаты с https://github.com/openai/codex, где уж точно полноценная имплементация. Разницы в результатах не увидел. Это не был выверенный продуманный тест, а лишь ленивое сравнение на моих задачах.
sup ai
идея с каналами интересная, но по факту ничего не даёт. Они с тем-же успехом могли бы разные "сорта ответа" обрамлять в xml теги по аналогии с <think>, чтобы модель переключалась в тот или иной паттерн мышления, оставляя формат чата. А тут в итоге имеем каналы которые эээ... можно скрыть от юзера? чтобы модель там в своём мирке думала над проблемой, а потом возвращалась со своим final?
Притом, кстати, я в их формате не нашел упоминания ID инструмента. И даже примера как делать множество вызовов сразу.
>Так-то полноценно квен и эйр тоже никто не поддерживает, у них заложены одновременные вызовы в одном ответе вместо поперживания по одной с прерываниями как в колхозе с жорой.
Эээ, нееет, если в режиме чата например запускать в кобольде то Qwen так-же возвращает целый массив инструментов вызывая сразу кучу функций и он прям очень охотно это делает. Ну и что забавно - не путается. Даже несмотря на то что в его формате не предполагается давать ему ID инструмента и ответа для сопоставления, он видимо по индексу их сопоставляет.
Хотя, кстати, если чуть поменять формат то и гемма это внезапно хорошо делает, хотя в дефолтовом паттерне ей почему-то пишут "не пизди когда вызываешь инструменты и вызывай по одному инструменту." Я например написал ей "на тебе префил с ризонингом, а ещё ты можешь пиздеть и вызывать множество инструментов" и оно прям с радостью это делало и довольно неплохо. Но ей лучше ID всё-же давать, она иногда путала какой вызов к какому ответу идёт без этого.
>Не очень представляю какую теорему можно доказывать когда на выходе нужно готовое решение технической задачи или код.
Ты не читал чтоли что она пишет? "нам надо Х, мы добьёмся этого сделав У, а значит условие Й правильное" и всё в этом духе. Оно это паттерн любит применять к всему где надо прилагать хоть немного мышления.
В целом это модель чтобы доминировать на олимпиадах по математике. Она прям и правда хороша в этом. Но только в этом. Какой-то мало-мальски сложный код оно пишет ОЧЕНЬ плохо. Эта модель вообще не заточена под погромирование. Она душная, она любит строить доказательную базу даже для полной хуйни, но при этом она очень НЕ творческая. В каких-то бытовых вопросах OSS откровенно туповатый. В абстрактных вещах прям совсем хлеб.
>Это не был выверенный продуманный тест, а лишь ленивое сравнение на моих задачах.
Зато я заметил просто огромную разницу. Притом я заметил её и просто когда имплементировал ей формат общения заточенный под неё. Там да, мозгов прибавилось. Но в итоге модель для математики мне не очень нужна.
> А тут в итоге имеем каналы которые эээ... можно скрыть от юзера? чтобы модель там в своём мирке думала над проблемой, а потом возвращалась со своим final?
Ага, получается так. На самом деле это решение нельзя назвать плохим, или можно интерпретировать как разные слои дебагинга.
Не сказать чтобы гопота осс хорошо и эффективно всем этим могла пользоваться чего стоит то, как ее юзают - с костылями и форсированием атупута через грамматику, но вот сама идея - хорошая. Им стоило бы подумать о формировании некоторой ее упрощенной версии.
> не предполагается давать ему ID инструмента
Имена, параметры и порядок, все нормально же. При попытках так юзать очень быстро забаговывается и толи получает корявый возврат, толи что-то еще ломает и все. Потому устраивают одиночные. Там кто юзает жору с жинжой еще несколько багов в коммитах подкинули, из-за которых неработают эдиты при наличии апострофов и некоторых других символов.
Бля, вот у меня просто разрывает ебало от мистраля смолл. Ситуация такая, персонаж посылает меня к другому для брифинга, тот к кому меня послали есть в лорбуке и указан в основной карте, я прихожу к кабинету указанного чара и внутри блять сидит персонаж который меня послал и как не в чём не бывало приветствует. Вот он не может ввести персонажа и всё, пиздец. Пресет стоит аноновский, температура 0.75. Какая же синтвейв хороший сторителлер, но как же он хуёво отыгрывает личности в отличии от мистраля. Я уже заебался разрыватся между этими двумя моделями. Тут один анон писал что синтвейв хуёво слушается инструкций, я не знаю какой у него был кейс, но у меня наоборот. Вот я бы сидел на синтвейве, но какой же он сука душный, ему только следователей или инквизиторов отыгрывать. Я не знаю, я устал, проще наверное вообще дропать локалки.
Я не прошу мудрых советов, просто решил поныть. Вы скажите, это я долбаёб или лыши не едут? Последний 24b мистраль реально такой глупый? Он поначалу хорошо, но как только добирается до 14к контекста его начинает пидорасить.
Я не прошу мудрых советов, просто решил поныть. Вы скажите, это я долбаёб или лыши не едут? Последний 24b мистраль реально такой глупый? Он поначалу хорошо, но как только добирается до 14к контекста его начинает пидорасить.
Используй комманд-а или хотя бы айр.
У всех моделей есть предел, с которых их пидорасит. У малых ~16к контекста, у побольше, как qwq и glm 32, комманд-а до полусотни держит, а дипсик всю сотню осилит и может быть больше.
Да у меня нет столько оперативы чтобы эйр запускать, 32гб. Похуй, буду с синтвейвом - палачом нквд играть.
>а дипсик всю сотню осилит и может быть больше.
Херня это полная.
Инпут А - задача
Ответ А - обсёр А
Инпут Б = указание на проёбы в ответе А
Ответ Б - обсёр Б
Инпут В - указание на проёбы в ответе Б
Ответ В - обсёр В; на инпут А и Б частично положен хер, модель стелет хуету с фокусом на инпуте В
Сталкивался с таким, с тех пор разочаровался в ИИ. На условном большом дипсике происходит даже на жалких 20к контекста... И я про официальный API.
32к максимум на самых больших моделях. Давно известно, да.
Тобишь я к тому, что для ршения надо во всех инпутах Б, В ... и так далее - повторять накопленный снежный ком инструкций, обмазанный на первоначальную задачу А. Кратко, но по делу. Иначе будет лютый кал.
Это прям бич ИИ, хоть усрись - ну не могут они в рамках цепочки сообщений всё учесть и не обосраться.
Херня в том, что искать инфу по контексту они могут, но внимания просто нет никакого.
> Тобишь я к тому, что
Что нужен адекватный промпт и если не помогать то хотябы не мешать сетке, а не газлайтить ее? В описанном тобою выше кейсе с введением новых персонажей и запоминании их дипсик очень хорош.
Да и вообще кейс выглядит абсурдным, это слишком плохо даже для мистраля. Вангую какие-нибудь приколы с контекстом из-за лорбуков, или контекстшифт.
>32к максимум
Ты ведь хотел написать 8к? Потому что больше этого порога ни одна модель не показывает стабильного результата (пикрил в шапке).
Какие персонажи... У РП-шизуков совсем кукуха протекла. Техническую задачу сраное ИИ решить не может.
У "здорового" работяги контекст не может вместить 3 поста, ай лолита. Иди перечитывай
Я смотрю, внимательность лизателей ИИ-ануса не особо отличается от внимательности их любимых моделей.
В контект все влезает. Другое дело, что продуктивность ассистентов смешная, если их за ручку не водить и не напоминать в каждом сообщении, какого хуя тебе изначально было нужно - с полной историей тыканья ИИ мордой в его собственное говно.
Я даже больше скажу, самый лучший результат в решении технических задач - это удалить всю историю сообщений, и в инпут А вставить
> "мы уже пытались решить эту задачу, вот неудачные варианты и критика"
> (краткое содержание неудачных итераций, с вырезанной водой типа нонсенса why this works) + то самое тыканье ИИ мордой в ошибки
То есть, один инпут - один ответ, всегда будет лучшим способом взаимодействия с ИИ. Чем больше пользователь тянет эту лямку, тем ниже качество работы ИИ.
Контекст шифта нету, я бы не писал если бы был настолько тупым. Кейс примитивнейший, поменять на пару сообщений роль карты на её вице командира на которого есть указание в карте, которые у нормальный модели с мозгами вроде синтвейва вызывают отсылку на лорбук. Мистраль смол просто в принципе плох, очень плох на примитивнийших кейсах и маленьком контексте. На самом деле я пиздец сколько сценариев пытался разыграть на мистрале и он обсирался на простейших вещах. Его максимум это два персонажа в коробке которые держа руки по швам стоят друг напротив друга и разговаривают, но он и там обосрётся перепутав факты и впихнёт целый шаблон заранее заготовленного текста не к месту, лучше уж тогда в визуальные новеллы играть.
Про "плохо слушает инструкции" - это я писал, но про синтию. А синтвейв - у меня практически те же впечатления.
Из тюнов/миксов геммы - мне больше storyteller зашел. Вот этот: https://huggingface.co/mradermacher/Storyteller-gemma3-27B-GGUF
Я очень медленно читаю, строю в голове образы, потом еще могу долго останавливаться на одних строчках по несколько раз их перечитывая и переосмысляя, а так конеш да, если читать беглым взглядом то и 20-25 будет не комфортно.
Скиллишью гуманитария, если пишешь сетке также как здесь - иначе и быть не может.
> самый лучший результат в решении технических задач
Дать подсказку о ходе решения помогает решить задачу, открытие.
А мистраль там ванильный или какой-нибудь тюн? Просто это даже для лламы2-13б простая задача, будто бы здесь какая-то явная поломка а не модель настолько дебильная.
>Это не так.
Это так.
>Ты, возможно, не запускал множество моделей в разных квантах сам
Запускал множество за все эти годы, потому и говорю.
>Почему ты цифры экстраполируешь на реальное использование/слепые тесты?
Потому что с цифрами не поспорить и не опровергнуть охуительным аргументом "я скозал", который ты используешь чрезмерно.
>Между Air Q4 и Q6, например, настоящая пропасть.
Тебе так кажется из-за самовнушения, что раз квант больше - то там там улучшение должно быть огого. На слепом тесте ты бы не определил где Q4, Q5 и Q6.
>Как кто-то, кто каждый день гоняет GPT OSS 120б, я проклинаю их, что они выпустили лишь MXFP4 квант.
Т.е. ты думаешь они зажали 16 бит, а не сразу тренили 4 битку?
> Потому что с цифрами не поспорить
Ты экстраполировал цифры одной конкретной архитектуры на все модели в целом, и думаешь, что это верная математика? Более того, в ОП-пике график для Экслламы, которая использует отличный от llamacpp тип квантов. Не говоря уже о том, что даже в ее рамках кванты плотных моделей и МоЕ отличаются. Мне кажется, ты вовсе не понимаешь, о чем говоришь.
> не опровергнуть охуительным аргументом "я скозал", который ты используешь чрезмерно.
Не вижу ничего стыдного в том, чтобы поверить скорее собственному опыту, чем до неприличия притянутому за уши выводу.
> Тебе так кажется из-за самовнушения, что раз квант больше - то там там улучшение должно быть огого.
> На слепом тесте ты бы не определил где Q4, Q5 и Q6.
У меня было почти с дюжину чатов, на которых я проводил сравнение Q4 и Q6 квантов Air. Разница в моем случае оказалась существенной. В случае Q4 ранее описанные ошибки были скорее правилом, а в Q6 - исключением. Это не результат моих наблюдений, а статистика, которую я тогда собрал по промптам, целый день тогда на это убил. Если ты провел свои тесты и для тебя не было разницы между Q4 и Q6 - молодец. Если ты обычный попугай, который повторяет за кем-то, что разницы нет, то Кеша-дурак.
> Т.е. ты думаешь они зажали 16 бит, а не сразу тренили 4 битку?
Не знаю. Я думаю, что было бы круто, будь у нас полные веса, которые мы можем квантовать самостоятельно, а не получать определенный квант сразу, лишаясь возможностей. Результатом чего является этот квант - из-за жадности или способа тренировки, это вопрос второстепенный.

>в ОП-пике график для Экслламы
>для Экслламы
>GGUF
Ебать ты слепой.
>или способа тренировки
>полные веса
Ты точно понимаешь, что такое тренировка в MXFP4?

> Ебать ты слепой.
Нет, я наивно полагал, что ты сравнивал 4bpw и 8bpw кванты. Но все оказалось еще круче, и ты именно что подразумевал Q4 == Q8. А в случае больших моделей, оказывается, и больше Q3 смысла нет брать. Взгляни на график другой модели, может что-нибудь поймешь. Но не думаю. Ты уже сполна доказал, что диван диваныч.
> Ты точно понимаешь, что такое тренировка в MXFP4?
Проход в полемику отклоняется, неинтересно. Мне печально, что мы, как юзеры, получили де факто Q4 квант модели, и у нас нет альтернатив. Результат это подхода к тренировке или жадность дать полные веса - мне не интересно.
Потыкал тестами: какой-то Qwen3-30B-A3B-Thinking. Отличия
1. Русику пизда
2. Ризонинга нет, но он есть. Т.е. поток размышлений тегом не обрамляется и нет бесячего тупого дублирования части размышлений в чистовой вывод. Ну зато и чистовой вывод без финтифлюшек.
3. Контекст держит хорошо, без багов в том числе и с квантованием до -ctv q4_0 . На типовые вопросы из ебической простыни
https://github.com/llmonpy/needle-in-a-needlestack/blob/main/chained_limerick/64k_spread_q2.txt
залитой в контекст отвечает. На нетиповые тоже, но с мамкой он считерил просто нашел через суп, а не через брата. Такое ощущение что модель натаскивали на поиск в примерно таких тестах.
4. Художественность и креативность не завезли. Это Квен.
5. Как кодер - говнокодер. Как и Qwen3-30B-A3B-Thinking.
6. И да цензура на месте.
Странные ощущения от модели. Может для суммарайзов кому и хайдет.
Ещё древнее квен найти не мог?
Простите, не удержался.
Я тыкал вот это - https://huggingface.co/aquif-ai/aquif-3.5-Max-42B-A3B. Квантам часы отроду.
> Разница есть.
Этого двачую. Просто на больших моделях вместо очевидного скатывания в бред и ошибок в словах, случаются более глобальные фейлы или особенности поведения. Также легко отследить по точности непопулярных знаний.
Но вообще где-то с 4.5-6 бит, если нет явных косяков кванта, отличия пропадают, в удачных случаях q4 уже достаточно хорош, но вот все что ниже как повезет.
> На слепом тесте ты бы не определил где Q4, Q5 и Q6.
Если он отследил какие-то явные паттерны - легчайше угадает, по крайней мере q4 от q6.
> а не сразу тренили 4 битку
Маловероятно, численная стабильность доставляет много проблем, ускорение не столь существенное, дефицита мощностей у них нет. Врядли там даже фп8 применяли, офк все это гадания.
Не учитывается наличие норм в mxfp4 .
>сравнивать по перплексити
Ты всё таки необучаемый.
>Q4 квант модели
Если оно изначально в 4 битах, то это не квант. А то так можно дойти до того, что всё что не в двойной точности- квант.
>дефицита мощностей у них нет
Лол, как раз есть.
> сравнивать по перплексити
> Ты всё таки необучаемый.
А теперь взгляни на график, на который сам ссылался несколькими постами ранее. Ты всё-таки клоун.
> Лол, как раз есть.
Да, но не для такой мелочи как осс.
> >сравнивать по перплексити
Делают графики дивергенции, она же является метрикой при квантовании, стоит к ним обращаться.
>А теперь взгляни на график, на который сам ссылался
Да, проблема, нет хороших графиков.
>Да, но не для такой мелочи как осс.
Мелочь то мелочь, но им любые мощности не помешали бы.
>Делают графики дивергенции, она же является метрикой при квантовании, стоит к ним обращаться.
Которые все на викитексте? Немного не релевантно ролеплею.
> но им любые мощности не помешали бы
Подробнее?
> Которые все на викитексте?
На ПИТУНЬЕ, лол. Вообще самый популярный что гуляет - микс вики+код+(е)рп и даже щепотка мультиязычных текстов. Разумеется хорошие данные на релевантный юскейс можно получить только самостоятельно, благо в популярных бэках уже запилили для этого оснастку.
>Ты хотя бы запускал его или рассуждаешь с дивана? Я запускал на ik форме Лламы. Мы обсуждали в контексте 128гб оперативы, у меня 24гб видеопамяти. GLM 4.6 - это второй квант и 24к квантованного контекста. Мало того, что это лоботомитный квант (пример Air здесь применителен, большой GLM точно так же страдает от квантизации, по крайней мере на Q2. Как не раз упоминалось, потеря окончаний/опечатки/тасовка сущностей), еще и контекст квантован, и его меньше. Потыкался и не понял кому и зачем это надо. Думаю, если бы у тебя был такой опыт, ты бы не утверждал сейчас, что Q2 4.6 это эпик вин. Даже Air в Q5-Q6 будет лучше, не говоря уже о Квене 235. Последний мне не нравится субъективно, потому я использую Air.
У меня тоже 24 гб видеопамяти и 128 оперативы и я утверждаю что ты скорее всего просто не смог в нормальную настройку 4.6. Другого обьяснения я просто не вижу. ГЛМ 4.6 в двух битах пишет почти как квен в 4 битах, только без его проблем с форматированием и короткими предложениями и без половины квенизмов. И с гораздо большим интеллектом и пониманием.
В прошлом треду я уже скидывал сравнение второго кванта глм с четвертым квантом квена, но специально записал новое. Алсо, угадай где какая модель.
Аир я удалил, но можешь сам его спросить тот же вопрос и запостить его ответ в тред.

Томо-кун опять на связи.
У меня вопрос, а как вот такие штуки кормить в Кобольда? И как узнать сколько там квантов?
А еще можете с меня поржать знатно. Я всё это время использовал это всё не так. Я тупо не понимал что это всё такое. Оказывается вот эта вся хуйня это не симуляция персонажа, а генератор историй. Не хочу даже говорить сколько я времени убил на то, что бы "сроллить" нужный мне ответ в переписке, пытался играть с температурой, когда можно было ПРОСТО БЛЯТЬ НАПИСАТЬ ЧТО Я ХОЧУ, СУКА. Я когда это понял, чуть стену головой не пробил. Сильно разочаровался. Но в то же время открыл для себя новые горизонты.
У меня вопрос, а как вот такие штуки кормить в Кобольда? И как узнать сколько там квантов?
А еще можете с меня поржать знатно. Я всё это время использовал это всё не так. Я тупо не понимал что это всё такое. Оказывается вот эта вся хуйня это не симуляция персонажа, а генератор историй. Не хочу даже говорить сколько я времени убил на то, что бы "сроллить" нужный мне ответ в переписке, пытался играть с температурой, когда можно было ПРОСТО БЛЯТЬ НАПИСАТЬ ЧТО Я ХОЧУ, СУКА. Я когда это понял, чуть стену головой не пробил. Сильно разочаровался. Но в то же время открыл для себя новые горизонты.
Больше похоже на возмущенную оценку или
> утверждаю что ты скорее всего просто не смог в нормальную настройку
квена. Не то чтобы жлм в q2 плох, наоборот может быть солидным вариантом в условиях ограниченных ресурсов. Но он даже в жирном кванте во многих задачах чат-ассистента не опережает квена, а после ужатия совсем подустанет. В рп по ситуации, модель умница со своими сильными и слабыми сторонами.
Можешь в двух словах сказать чем по твоему отличается сторителлер от синтвейва\синтии? Просто слог другой или более лояльное отношение к юзеру?
>можете с меня поржать знатно
Зачем смеяться над новичками, мы и сами такими были.
>Оказывается вот эта вся хуйня это не симуляция персонажа, а генератор историй.
Чел, это может быть чем угодно, в зависимости от системного промпта.
> когда можно было ПРОСТО БЛЯТЬ НАПИСАТЬ ЧТО Я ХОЧУ, СУКА.
Конечно можно, в былые времена так и дрочили, удаляли выданное моделькой дефолтное "ты меня ебешь, ах" и писали высокохудожественное порно от её лица, моделька постепенно училась на нашей писанине и начинала подражать ей. А потом у нее кончались 2к её контекста, и все начиналось с начала, оттуда и картинка треда на ОП-пике
А еще такой вопрос. я смотрю там в кобольде вроде есть генератор изображений. Как оно работает?
У тебя пока только "я скозал", а я уже дважды скрины в тред приносил с наглядным сравнением этих моделей.
Сам по себе никак - ему нужен бэк - локальная сдшка или сетевые службы. Лучше всего это в таверне работает - там появляются кнопки - "запросить изображение персонажа", "запросить текущую ситуацию".
Как очень кривая и медленная реализация https://github.com/Haoming02/sd-webui-forge-classic/tree/neo
Не надо в кобольде пока изображения делать
Без происшествий.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
>https://huggingface.co/zerofata/GLM-4.5-Iceblink-v2-106B-A12B
Блять, пиздец нахуй.
Он смог сделать, то, во что бы я не мог поверить. Air теперь лупится как слопомистралевские тюны. Кому там мистраль на Air хотелось? Кушайте, не обляпайтесь.



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: