




ГЛМ 4.6 на втором кванте с 4 попытки таки разглядела правильную суть задачи про Абу и мочухов. И это с выключенным ризонингом.
Тем временем чат гопота 10 свайпов упорно перемножала доски, мочухов и анонов...
Попиздите тут мне еще что второй квант глм - лоботомит.
Кстати, мне кажется, или гопоте токены на ответ подрезали?
Тем временем чат гопота 10 свайпов упорно перемножала доски, мочухов и анонов...
Попиздите тут мне еще что второй квант глм - лоботомит.
Кстати, мне кажется, или гопоте токены на ответ подрезали?
Как бы сказать, ты ту типа серьезно вот эти скрины считаешь значительным аргументом? Мало того что вопрос довольно сомнительный с пустым контекстом, так еще и видно что квен не отрабатывает как обычно. Даже если весомость этого, все что они доказывают - у тебя поломан квен, возможно пускаешь его на глмовской разметке. Даже на простой вопрос он навалит спгса, а задачки обожает.
> уже дважды
Как всегда на неудобные посты не следует ответов ответы модели, кстати, весьма злободневны, хотя и текст скормлен почти годовой давности.
Ой, да. я таверну имел ввиду.
>Не надо в кобольде пока изображения делать
Почему?
>Как всегда на неудобные посты не следует ответов
Скрины в том посте понятны только тебе, потому тебя и проигнорировали, хотя стоило сразу ткнуть носом в говно. Во-первых, мы(все аноны в треде кроме тебя) не видим и не знаем что именно суммаризует модель, и соответственно по скринам никак не можем оценить правильность и качество решения задачи. Во-вторых - по скринам совершенно непонятно - где какая модель и что с чем сравнивается.
>так еще и видно что квен не отрабатывает как обычно.
Вопрос у тебя есть, квен тоже, принеси скрин как он должен отрабатывать.
В двух - сложно. Основное - слушается инструкций (не игнорируя половину как синтия), и пишет продолжая стиль уже написанного, без явных выебонов в угоду недодавленной цензуре. Понимает установки поведения. Скажешь в описании - здесь принято то-то и то-то - так и будет, без особой дополнительной окраски/оценки происходящего.
Общий bias по умолчанию - все тот же геммовский нейтрально положительный, но мне чернуха и не нужна. Хотя в принципе - может. Если вводную нормально прописать не ленясь (инструкции то слушает).

>что квен не отрабатывает как обычно
Он как раз отрабатывает как обычно. Он так и должен отрабатывать, но видимо ты видел его аутпут только через обоссаный пресет нюни, в котором он насилует модель.
Вот ответ через нюневский пресет(разумеется пофикшенный под русский язык).


> Скрины в том посте понятны только тебе
> запрос суммарайза скопипащеного как есть ллм треда (еще с января, лол). Хоть это просто первый ответ, контекст 60к и обработка плохо структурированного русского текста
Вроде все достаточно понятно и куда более релевантно, чем твои странные вопросы.
Можешь скопипастить в поле чата и потестить у себя https://rentry.co/exg5z6ua Только зайди через эдит и копируй сырой текст, пейстбин такой отказался публиковать.
> по скринам совершенно непонятно - где какая модель и что с чем сравнивается
Первые 3 - glm, 4-6 - квен, одинаковый чат, правильные форматы, просто свайпы для намека на статистику. Так-то на скринах максимально сигнатурное их письмо, которое тяжело с чем-то спутать.
> принеси скрин как он должен отрабатывать
Что-то типа такого хотябы. Его шизоидная дотошность, спгс и длинные ответы в целом на ассистенте идут в плюс, именно этим хорош. Можно еще синкинг подрубить, тот вообще поехавший.
У тебя он поломан, чел.
>странные вопросы
Это классическая задачка на логику Корнея Чуковского, переписанная чтобы модель не могла использовать знание о ней из материала обучения. Интересно что квен на первом твоем скрине опознал оригинал загадки, но это не помешало ему обосраться и начать перемножать там, где перемножать не нужно.
>Что-то типа такого хотябы.
И он у тебя дважды обосрался, выдав тот же результат что на моем скрине (запощу его еще раз), ты глаза-то разуй, или ты и сам не понял задачку?
То что у тебя он пишет живее - ну у нас разные инструкции и карточки. Какая разница - если он не решает задачу?
>У тебя он поломан, чел.
Нюневский пресет изначально поломан.
Спокойнее, я лишь намекнул на то что у тебя что-то поломано, все выводы основаны на фейле. И сам запрос бредовый, без объективных критериев оценки, просто ожидаешь что модель последует твоим придумкам, или субъективно выбираешь что понравится по единичному роллу.
> или ты и сам не понял задачку
Делирий с широкой степенью свободы для эзотерических трактовок результатов. Там нет логики, с какой стороны не посмотри - все правильно будет.

> ГЛМ 4.6 в двух битах пишет почти как квен в 4 битах
> И с гораздо большим интеллектом и пониманием.
> В прошлом треду я уже скидывал сравнение
Это хорошо, что тебя устраивает второй квант. В твоих задачах, возможно, действительно работает неплохо. Но проверял ли ты его на контексте в креативных/рп задачах? Потому что проблемы кроются именно там. Помимо того, что это Q2 квант, контекст тоже квантован. В коде он у меня тоже рассыпался сразу же, даже при скромном контексте в 12к. Настройки здесь не при чем.
> Тем временем чат гопота 10 свайпов упорно перемножала доски, мочухов и анонов...
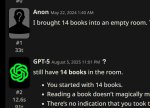
Пикрил GPT OSS 120б с первой попытки. Какие 10 свайпов?
> Нюневский пресет изначально поломан.
Тем не менее, никто из пустословов-критиков не принес в тред альтернативу лучше. Без грамматики неизбежно появляются короткие предложения, переходы и вытекающая проза.
В следующий раз и без этого останетесь, но уверен, вы уже взрослые и теперь-то уж точно сами сможете разобраться с противоречивыми моделями. А я зарубил себе на носу ничем не делиться больше, чтобы вы не плакали. Oh, the irony of this...
> И сам запрос бредовый, без объективных критериев оценки, просто ожидаешь что модель последует твоим придумкам, или субъективно выбираешь что понравится по единичному роллу.
Не знаю, что смешнее - само это обсуждение/эксперимент, где лобомитам (q2 4.6 и ~q4 гопота) кормят русскоязычную загадку и судят по этому перфоманс или то, что это происходит в ллм треде в четыре утра.
А ты знаешь что ты буквально советуешь сломанную модель. Я её запустил и она начала такой пиздец в рп выдавать что у меня чуть глаза на лоб не вылезли.
Так, я не тот, кто в прошлом треде обещался
iceblink ( https://huggingface.co/mradermacher/GLM-4.5-Iceblink-v2-106B-A12B-GGUF ) протестировать, но мне тоже интересно стало. iq4xs скачал, как и Air до того.
Первые впечатления - ничего так. Явного тупняка на первый взгляд не случилось. Контекст видит, персонажа, WI, вроде бы не теряет ничего...
Стиль несколько поменялся, по сравнению с обычным Air на кванте от Bartowski.
Там заявлено, что тренировали на текстах VN, SFW и NSFW рассказах/фанфиках, и т.д. И знаете - чувствуется. Слог стал вроде как легче, при этом еще больше фиксации на персонажах (в хорошем смысле). Вот кому в плюс, кому в минус - но появились характерные для VN/JRPG обороты речи. На тестовом сценарии у меня перс проявляла несколько больше разноплановых реакций чем с простым Air - это выглядит... нельзя сказать что реалистичней, скорее "более анимешно", с более яркими эмоциями. Но все же строго в рамках заданного в карточке. Даже, наверно, ближе получилось к задумке (ее такую и прописывал). Причем если на AIr перс была этакой совсем безбашенной оторвой, которая вообще ничего не стеснялась - "вижу цель не вижу препятствий" (тут речь не про секс, а про "пробивной" характер), то здесь она начала как-то обращать внимание на то, что про нее говорят и реагируют окружающие, говорить стала более дипломатично и мягко, хоть и столь же нагло. :)
И тут еще есть момент, как бы сформулировать понятнее... У меня несколько персонажей спецом под Air было написано, и я заметил у оного тенденцию - "переигрывать". Слишком активно выделять черты характера, слишком целеустремленно персонажа вести к заявленной цели, в общем... слишком, с перебором.
А здесь - я конечно всего пару часов наиграл пока, но вот этого перебора не чувствуется вроде бы. Это не смотря на то, что я про эмоции перса написал выше.
В общем - для ERP или даже просто слайсиков с закосом под аниме - будет очень в тему, IMHO.
Может еще разочаруюсь, но пока - нравится.
iceblink ( https://huggingface.co/mradermacher/GLM-4.5-Iceblink-v2-106B-A12B-GGUF ) протестировать, но мне тоже интересно стало. iq4xs скачал, как и Air до того.
Первые впечатления - ничего так. Явного тупняка на первый взгляд не случилось. Контекст видит, персонажа, WI, вроде бы не теряет ничего...
Стиль несколько поменялся, по сравнению с обычным Air на кванте от Bartowski.
Там заявлено, что тренировали на текстах VN, SFW и NSFW рассказах/фанфиках, и т.д. И знаете - чувствуется. Слог стал вроде как легче, при этом еще больше фиксации на персонажах (в хорошем смысле). Вот кому в плюс, кому в минус - но появились характерные для VN/JRPG обороты речи. На тестовом сценарии у меня перс проявляла несколько больше разноплановых реакций чем с простым Air - это выглядит... нельзя сказать что реалистичней, скорее "более анимешно", с более яркими эмоциями. Но все же строго в рамках заданного в карточке. Даже, наверно, ближе получилось к задумке (ее такую и прописывал). Причем если на AIr перс была этакой совсем безбашенной оторвой, которая вообще ничего не стеснялась - "вижу цель не вижу препятствий" (тут речь не про секс, а про "пробивной" характер), то здесь она начала как-то обращать внимание на то, что про нее говорят и реагируют окружающие, говорить стала более дипломатично и мягко, хоть и столь же нагло. :)
И тут еще есть момент, как бы сформулировать понятнее... У меня несколько персонажей спецом под Air было написано, и я заметил у оного тенденцию - "переигрывать". Слишком активно выделять черты характера, слишком целеустремленно персонажа вести к заявленной цели, в общем... слишком, с перебором.
А здесь - я конечно всего пару часов наиграл пока, но вот этого перебора не чувствуется вроде бы. Это не смотря на то, что я про эмоции перса написал выше.
В общем - для ERP или даже просто слайсиков с закосом под аниме - будет очень в тему, IMHO.
Может еще разочаруюсь, но пока - нравится.
>Попиздите тут мне еще что второй квант глм - лоботомит.
Ей богу, ребёнок с самой большой машинкой в песочнице. И похуй что она выглядит как говно, хлипкая и развалится при первом же столкновении с другой игрушкой ну типа на любом сколь нибудь сложном рп сценарии после 12к контекста
А ты уверен, что это не битый/сломанный квант лично тебе попался?
У меня никакого пиздеца и в помине не было.
Правда я уже точно не вспомню чей квант я качал тогда - iq4xs, но вот чей - не поручусь.
>запрос бредовый, без объективных критериев оценки
У этой загадки есть четкий ответ. Странно что ты никогда не слышал про нее, ну и неважно. Вот оригинальная задачка.
https://www.kostyor.ru/poetry/chukovsky/?n=13
ГЛМ с 4 свайпа расколол загадку(пруф ) чем показал мощь своего интеллекта и глубинное понимание мельчайщих деталей и связей слов в тексте. Квен и гопота с 10 свайпа не раскололи и продолжили как дегегераты перемножать мочухов. У тебя квен так вообще процитировал оригинал задачки, а потом пошел дальше перемножать, мозгов не хватило попытаться решение оригинала использовать.
>классическая задачка на логику Корнея Чуковского, переписанная чтобы модель не могла использовать знание о ней из материала обучения
Вы правда настолько припизднутые что верите что кто-то в другом конце земного шара обучает модели на Корнее Чуковском? АХАХАХАХ БЛЯ

Аноны, подскажите, эти хуйности надо вообще включать? Я нихуя не понял как они работают. По дефолту как стояло так и оставил.
Настолько преисполнились русской литературой, что начали отрицать здравый смысл и не согласны, что 3600 и 14400 это верный с точки зрения логики и математики ответ. Не уловили модельки Чуковского сквозь слои абстракции... И нахуя это использовать?
>Пикрил GPT OSS 120б с первой попытки.
С первой попытки и сразу же такой же обсер как у старшей гопоты и у квена. Задача не на математическое умножение, а на логику и внимательность.
>Тем не менее, никто из пустословов-критиков не принес в тред альтернативу лучше
Я приносил на скринах несколько раз.
>Без грамматики неизбежно появляются короткие предложения, переходы и вытекающая проза.
Потому я и топлю за глм 4.6, в нем вся эти квенизмы не появляются.
>В следующий раз и без этого останетесь
Куда уж нам, убогим, без твоих мощных пресетов, запрещающих текст курсивом и переносы строк...
Обучают.
Посмотри на первый скрин , там модель прямо цитирует оригинал загадки Чуковского про Кондрата идущего в Ленинград.
Эта загадка изначально достаточно припезднутая, уровня Анатолия-водителя, а ты ее еще максимально исказил.
> у тебя что-то поломано, все выводы основаны на фейле. И сам запрос бредовый, без объективных критериев оценки, просто ожидаешь что модель последует твоим придумкам
Первая часть полностью в силе, по второй обвинения смягчаются но остаются в силе.
Кстати, если изначально дать команду "отгадай загадку с подвохом" а не просто копипастить этот абстрактный текст - помимо стабильного указания на направление в каждом свайпе, подмечает отсутствие информации об уникальности "анонов" ввиду их анонимности и возможности множества пересечений.
Если пастить в исходном виде - glm ее не отгадывает а просто пишет что-то общее в 16 свайпах. И это не лоботомированный квант как у тебя, а с полноценной инструкцией такжесправляется стабильно. Подозреваю тебя в сознательном сокрытии исходной инструкции в скриншоте "успешного" варианта.
> Задача не на математическое умножение, а на логику и внимательность.
Модели откуда это знать? Допускаю мысль, что ты это скрыто запромптил и сейчас набрасываешь, потому что ни на что, кроме разжигания срачей ты не способен.
> Я приносил на скринах несколько раз.
Ого, ChatML, нейтрализованные сэмплеры и rep pen 1.1? Но теперь, когда стало ясно, что ты и есть агрессивный Q2 Квеношизик, все встает на свои места.
> Куда уж нам, убогим, без твоих мощных пресетов, запрещающих текст курсивом и переносы строк...
Не знаю, чем я тебя обидел, что ты месяцами сталкеришь мои посты и приносишь негатив, но надеюсь, тебя вылечат. Каждый достоин шанса.
>Подозреваю тебя в сознательном сокрытии исходной инструкции в скриншоте "успешного" варианта.
"Ваши скрины не скрины, ваши настройки не настройки"
Пошла классика пруфстера.
Сейчас принесу тебе скрин без обрезки задачи в вопросе (обрезал чтобы сообщение модели полностью вместилось в один экран и скриншот) - ты тогда скажешь что я вопрос постфактум отредактировал. Когда запруфаю что не радактировал через съемку видео - начнешь обвинять что я глубоко в системной интрукции ответ спрятал. Потом придумаешь что я промпт перехватываю и подменяю между таверной и ламой. Потом еще какую-нибудь абсурдную чушь.
А разгадка проста - ты где-то обосрался, раз у тебя глм выдает хуйню вместо верного решения.
Ох уж эти маневры маневрики.
Штука достаточно очевидная получается: в оригинальном формате глядя на этот текст даже человек не понимает что это за херня и какой в ней смысл, модели подмечают сходство и даже буквально зирошотом угадывают что это и откуда скрин1, но поскольку инструкции нет - пытаются просто удовлетворить этот абстрактный запрос.
А если изначально поставить задачу, что всегда и происходит при эксплуатации ллм - все становится на свои места и сразу работает.
Что имеем: Чел с поломанной моделью, с безумными загадками, заведомо формируя некорректные условия и скрывая что он спрашивает (о чем только что сам пытался упрекать) набрасывает и байтит на срач. Тебя раскрыли, свободен.
> Сейчас принесу тебе скрин без обрезки задачи в вопросе
Не утруждайся. двачую, он все по делу написал. Мой изначальный поинт был в том, что Q2 4.6 неюзабелен в креативных/рп задачах, и он останется при мне. Потому что я проводил сравнения на контексте между ним, Квеном Q4 и Air Q6. Слишком ужатый квант и квантованный контекст превращают 4.6 в Мистраль 24б после 6-10к контекста, генерализируя ответы. Потому что внимание удерживать не получается. Зирошоты это не мой юзкейс, да и лоботомиты-автоответчики есть куда попроще.
>Модели откуда это знать
А откуда ей знать что делать с петухом, несущим яйца на крыше? Ниоткуда, если в ней мозгов недостаточно. И тем не менее умные модели умеют с этим справляться сейчас. А тут вообще задачка для детей, буквально.
>Допускаю мысль, что ты это скрыто запромптил
"Ваши пруфы не пруфы". Потому в этом итт бессмысленно спорить с кем-то, проигравший неизбежно опучтится до такого. И до следующего пункта.
>месяцами сталкеришь мои посты
Я всего лишь один раз скачал твой пресет, поведясь на чужие комменты и охуел с того что ты там насрал в грамматике, что модель срется под себя и написал об этом в треде. Больше я с тобой не контактировал и не следил за твоими постами - оставь это своему безумному фанату который у тебя пресеты выпрашивает.
И вообще - корону сними, не жмет?
>А откуда ей знать что делать с петухом, несущим яйца на крыше?
Из датасета. Как и всё остальное. Все ваши говнозагадки уже есть в интернете.
> оставь это своему безумному фанату который у тебя пресеты выпрашивает.
Ты аватаришь своим гуи и до сих пор не понял? Мне очень хочется верить в человечество, потому предположу, что ты троллишь тупостью, а не демонстрируешь ее.
>даже человек не понимает что это за херня и какой в ней смысл
Так ты получается не понял детскую задачку для начальной школы, которую понял второй квант модели. А так как ты не можешь быть глупее модели - то разумеется это у меня скрины не скрины. Я тебя понял.
Сочувствую тебе. Я помнится в начальной школе тоже попался на эту задачку про Кондрата и начал считать этих котят и мышат, надо мной посмеялись и обьяснили в чем дело, тогда я конечно хлопнул себя по лбу. Конечно я мог бы начать ругаться и орать что задача не задача, и решить её невозможно, но почему-то мне тогда это в голову не пришло.
Остальное комментировать не буду, чтобы не повторяться.
В ГЛМ 4.6 есть труды Чуковского, потому он может разрешить аналогичную загадку. В других моделях нет, так что они говно. Всем понятно ?
Наконец-то найден достойный бенчмарк. Надо еще про отца-хирурга спросить, если и ее отгадает, это уже АГИ
Наконец-то найден достойный бенчмарк. Надо еще про отца-хирурга спросить, если и ее отгадает, это уже АГИ
Каким гуи я "аватарю"? Дефолтным пресетом таверны с темной темой aqua?
Загадка была обнаружена у Квена в обучающих данных и это не помогло ему решить задачу. Наличие загадки у глм в данным неизвестно.
> Каким гуи я "аватарю"?
Ради спортивного интереса спалю контору. Комбинацией этой темы и "AI" карточки без картинки. Сделай что-нибудь с этим, чтобы было интереснее. Твое "я с тобой не контактировал" очень забавляет, когда неделями назад ты не раз неймфажил, фонтанировал говном и желчью. Новых оскорблений и уколов еще придумай, а с короной тема совсем устарела.
Сильно ли заметно что Qwen3 VL 30B потеряла в мозгах в сравнении с не VL моделями? Даже на самой странице модели reasoning почти во всех тестах проигрывает не VL модели, а в тех что выигрывает - разница минимальна.
Что сейчас умнее Qwen30b или Мистраль?
По циферкам вроде даже Qwen, но что-то слабо верится, что 3B, хоть и MoE, победило 24B. По личному использованию хз. А какой опыт у анонов?
По циферкам вроде даже Qwen, но что-то слабо верится, что 3B, хоть и MoE, победило 24B. По личному использованию хз. А какой опыт у анонов?
Не заметно. VL по цифоркам проигрывает немного совсем, а иногда даже выигрывает. И у тебя в любом случае выбор в другом - нужно зрение, то VL, если нет, то 2507
>iq4xs скачал, как и Air до того.
Спасибо за совет, попробую. А почему скачал квант без i-матрицы, модель же чисто под английский?
Хуя вы там сретесь.
А расскажите про thinking, что это в чем профит? Я как понял включается просто соответствующим промтом? Есть примеры у кого?
А расскажите про thinking, что это в чем профит? Я как понял включается просто соответствующим промтом? Есть примеры у кого?
Есть режим ответа, есть продолжения.
thinking лучше результаты в продолжении.
Аватаркать GUI - ЭТО БАЗА LLM треда.
Всю нить тредовечки этим занимаются.
хотя обновления ламы гонят в консоль
>Аватаркать GUI - ЭТО БАЗА LLM треда.
Всё так. Вот мой гуй, кто знает, тот поймёт.


>пик

Это далеко не рекорд...
https://huggingface.co/zerofata/GLM-4.5-Iceblink-v2-106B-A12B
Блять, пиздец нахуй.
Он смог сделать, то, во что бы я не мог поверить. Air теперь лупится как слопомистралевские тюны. Кому там мистраль на Air хотелось? Кушайте, не обляпайтесь.
Блять, пиздец нахуй.
Он смог сделать, то, во что бы я не мог поверить. Air теперь лупится как слопомистралевские тюны. Кому там мистраль на Air хотелось? Кушайте, не обляпайтесь.
А другой iq4xs вроде и нету. Мне этот квант по размеру самый удобный для Air (и тюнов теперь).
А что же у меня за два часа что я вчера активно его гонял перед тем как спать пошел - "ни единого разрыва лупа"? В прочем, у меня и Air не лупится совсем, хотя тут и его поливали за это...
Наверное ты избранный и скоро придется пиздовать за GECK.
Ну а если серьезнее, то если я захочу мистраль, я запущу мистраль. Мне для этого не нужно инвалида из air делать. Но пока что мой опыт крайне негативный. Ну и что что пишет красиво, какой в этом смысл, если это чистейший и концентрированный мистралеслоп в худшем его проявлении.
На счет слопа - ничего не скажу, это не ко мне. У меня к тексту который любая модель генерирует - отношение как к графике в играх. Т.е. 100% фотореализма все равно нет, уж лучше чтобы просто разностилицы и "грязи" не было, а условности - можно простить, если игра хороша. :) Так что я просто не зацикливаюсь на таком, пока явно в глаза не лезет. Но вообще - я ж говорил, что там обороты из VN/JRPG в речи. Кому плюс, кому минус. :)
Странно. Знаешь, я конечно попробую другие кванты, может от русалки лучше чем от d0, но он уходит в гигалуп уже на 5 сообщении, первым свайпом тупо хуяря структуру и предложения. Вот как Эйр может подхватывать направление диалога, так и тут, только с характерным мистралевским паттерном, тупо сводя все к одному бесконечному гигалупу.
Возможно стоит уйти на chatml и поиграться с семплерами, но тогда у меня вопрос: нахуя выкладывать готовые пресеты и настойки, если на них нормально не работает.
Вот так в рамках одной модели с которой уже разобрались, в рамках одного тюна - 2 совершенно диаметрально противоположного мнения. А потом еще спрашивают отзывы тредовичков. Да какой в этом смысл, если на ровном месте расхождения.
> 2 совершенно диаметрально противоположного мнения
> А потом еще спрашивают отзывы тредовичков
> Да какой в этом смысл, если на ровном месте расхождения.
Покуда это обсуждение, а не попытка убедить другую сторону - чужой опыт ценен. Чтобы сравнить свой с чужим, чтобы другие могли понаблюдать со стороны и составить ожидания по модели, чтобы помочь друг другу добиться лучшего опыта.
Но когда приходят Моисеи вроде и , которые уж точно выбрали лучшее и пришли это доказывать остальным, размышляя ультимативными категориями, это рак.
Касаемо Air - я сам ранее был из тех, кто видел и лупы, и паттерны, и логические проблемы, а сейчас думаю, что это одна из лучших моделей, что доступны на консьюмерском железе. Побывал в обоих лагерях и понимаю, откуда берутся эти мнения. У всех свой квант, свой промпт, свои настройки, свои ожидания. Потому и происходят такие расхождения. В конце концов, очень многое субъективно.
> пол треда срутся о плохом качестве моделей ниже 6 бит
> что-то хрукают в сторону базы треда
кто отрицает базу треда, будет вынужден возвращаться к ней вновь и вновь
мимо
> что-то хрукают в сторону базы треда
кто отрицает базу треда, будет вынужден возвращаться к ней вновь и вновь
мимо
А хрен его знает. Я вообще подобными рекомендуемыми семплерами-пресетами тюнов редко пользуюсь. Использую свои наработки от базовой модели - что было у меня на Air, то и использовал. Ну, видимо потому у меня и не лупится - с Air то тоже проблем нет.
И у меня тестовое окружение для Air сейчас - это ~3.5K токенов всякого разного. Персонаж, сеттинг через WI, инструкции/заметки. В общем-то, я уже раньше по Air IMHO высказывал - ему нужен исходный материал, с чем работать. Менее чем 1.5K токенов на входе = практически гарантированная фигня на выходе. И нет, речь совсем не про особый чудо-промпт - просто некоторый стартовый объем нужен. Тюн, по идее, это наследует...
>ему нужен исходный материал, с чем работать
Да куда уж больше, у меня {user} это 3к токенов описывающих внешность, характер и ебучие украшения, которые бесяче звенят и всех раздражают, учитывая что персонаж еще просто не затыкается. А хули от феечки шизофреника можно хотеть.
Люблю я deep dark fantasy, знаете ли.
И Air молодец, air справляется, когда сюжет и реальность пидорит во всех направлениях. Много сущностей, много контекста, много нужно описывать.
Короче, пока не буду высказывать своё охуенно важное мнение. Надо еще потыкаться. Но лупы на рекомендованных настройках точно есть, так что если кто то будет пробовать, осторожней.
Чувак, что за хуйня, где ты агрессию увидел? Я смайлики, блядь, для кого ставлю, совсем кукухой поехал?
Никакой агрессии, ирл это просто пиздеж бы был, сидите и общаетесь.
В рот ебет не тебя, диванные фантазии — так это ж цитирование тебя, игра по факту тупая про «диванные фантазии» и пустопорожние утверждения, про IQ-квант я вообще не понял, в чем агрессия, больной ублюдок — мемная фраза же, она вообще скорее позитивную коннотацию имеет, про гпт-осс и дрочку на инструкции опять же очевидный юмор.
Просто ноль агрессии, куча искренних улыбок, кеков, а ты вдруг обиделся на то, что к тебе добры.
Мне искренне тревожно за твое здоровье, пожалуйста, пей таблеточки и посещай врача! Без подъеба и без юмора, заботься о себе.
> Приношу глубочайшие извинения
За что? За свои фантазии о том, что кто-то тебе в фантазиях нагрубил потому что обиделся за что твои фантазии?
Так это никакого отношения к реальности не имеет, никто на тебя не обиделся, никто не грубил, извиняться не за что.
Но ладно, если ты не хочешь общаться, то так и скажи.
Лучше вообще тред не читать, а то если я тебя волную, то местные шизы вахтеры тебя с говном съедят.
> он наоборот пишет что квен говно
> мне не понравился Q2 4.6
Упс, неловко вышло.
Пишет он что глм q2 говно.
Ну, в теории:
Во-первых, можно гонять в чистых трансформерах или вллм, сгланг, тррт и так далее. Все же, 16 гигов — не сильно много для 20б модели. Со 120б уже сложнее, конечно.
Во-вторых, в теории гармония неплоха, делит промпт на много разных по важности и предназначению секторов.
В-третьих, есть задачи (те самые ризонинг/математика), где гпт-осс таки реально хороша.
Но это все теория и конкретные юзкейсы. Как модель общего характера она вроде как и не нужна среднестатистическому анону.
> а с большим синкингом слишком медленный
Да, модель-то быстро генерит, но ризонинг хай ставишь и скорость нивелируется количеством размышлений.
Вот тут смешно. =)
И это даже не я!
Но, справедливости ради, глм в 2 кванте плохо пишет стихи на русском. Тут я огорчился.
Или просто мне подфартило получить рифму на их официальном сайте дважды с первого раза.
— Твоя машинка развалится! — кричал заплаканный ребенок с машинкой поменьше, игнорируя других детей с большими машинками.
завернул листик теперь твоя очередь писать строку в этом охуенном рассказе.
ДА ладно, ты просто видеозапись WAN'ом сгенерировал, что он правильно отвечает.
Я забил на разницу, и качнул три модели на свой комп с 40 врама: 32B-thinking, 30B-thinking и 30B-instruct-abliterated.
А простые версии без VL удалил.
Если потребуется реальное качество — я буду использовать либо корпоративные модели, либо качну 235b-vl, а так пусть лежат на случай отключения интернета.
Томокофаг, ты тут? Видел в прошлом треде твой вопрос про генерацию картинок. Могу подробную инструкцию дать, если актуально. Сам такой же, как и ты.
Привет, я тут. На удивление, твое сообщение ровно в тот момент когда я сегодня решил проверить тред. Буду благодарен.
Всё ещё в запое? На рекорд идёшь?
Когда уже гемма 4???
Когда в треде наступят мир и взаимопонимание
> Безымянный.png
Ля ты ленивая жопа, неужели не мог еще пикчу с кошкодевочкой на двойных трусах найти?
> но ризонинг хай ставишь и скорость нивелируется количеством размышлений.
Да, для лениво-агентного использования оно особенно заметно. После простой инструкции вместо того чтобы сразу отработать, оно начинает капитальную рефлексию, анализируя все прошлое вместо того чтобы сразу выйти из синкинга в работу и дать тривиальный ответ. В итоге ждешь больше чем на большой модели.
Один раз оно даже себя своим же ризонингом загазлайтило и подряд несколько раз дважды "инвертировало" один из кусков колормапа для хитровыебаных графиков, одновременно меняя аргументы linspace и добавляя _r к стандартному градиенту (действия по смыслу повторяющие друг друга и компенсирующие при одновременном использовании).
И это не списать на кривой шаблон, ведь сами вызовы и остальное выполнялось корректно, сподвижки к этому напрямую видлелись в ризонинге где он повторяется.
Накатим!
https://huggingface.co/google/gemma-3-4b-it
Я в прошлом треде спрашивал, но не помню, что бы мне ответили.
Как такие файлы кобольдам кормить?
прошлый вопрос продублирую:
У меня вопрос, а как вот такие штуки кормить в Кобольда? И как узнать сколько там квантов?
safetensors? никак. вроде угабуга может, или можешь из под HF transformers

>как вот такие штуки


Короче - все просто, хоть кажется сложным.
Смотри. Прежде всего, что бы генерить картиночки - нужен софт, который умеет это делать. Знаешь че и как тут? Заебись. Скипай сразу к пункту 3. Не знаешь? Читай с первого.
1) Бери ComfyUI. Качается прям с сайта. Я рекомендую тебе качать полноценную версию, а не портабл (далее поймешь почему).
Скачал? Поставил? Молодец! Зашел - увидел воркфлоу? Не пугайся - все не так страшно. (пик 1).
Как ты видишь - первое окно это checkpoint. Буквально - модель.
2) Где взять модель? Классический civitai. Если тебе нужны модельки для фапа - не забудь отключить фильтр. Выбрал нужную модель, которая тебе понравилась? Качай и кидай в папку models - checkpoint. Все остальное тебе не важно. Поверь. Все остальное мы будем настраивать в Таверне. Если хочешь тупо потом научиться генерить картинки - тебе в другой тред. Но, могу и объяснить тут, если захочешь.
3) Переходишь в настройки Комфи. Ищи пункт server-config. Там увидишь следующие параметры (пик 2). Тебе надо следующее выставить. В хост айпи ты ставишь ТОТ ЖЕ САМЫЙ адрес, куда у тебя подключается Кобольд+Таверна. НО! В Порт ты прописываешь другое значение. Ты не сможешь запустить кобольд или комфи, если порт одинаковый. Выставил другие значения? Молодец. Запустился кобольд? Комфи запустился? Круто.
4) Теперь нам надо как-то связать это говно вместе, правильно? Запускай таверну. В таверне переходи в Расширения и увидишь слева 2 нужных тебе пункта. Image Generation и Image Prompt Templates.
5) В Image Generation в source ты ставишь comfyUI, в адресе ты пишешь адрес, на котором у тебя запущен комфи+порт, на котором висит комфи. Т.е. адрес должен быть формата http://ip.ip.ip.ip:port Ввел? Жми connect. Подключилось? Заебись. Теперь настраиваем дальше. Я рекомендую тебе ставить чекбокс напротив пункта Edit prompts before generation. Что это тебе даст? Каждый раз, когда ты будешь просить таверну сгенерировать картинку - у тебя будет выскакивать окно, в котором она покажет, что она будет генерировать. Если знаешь за генерацию картинок - то это фактически позитивы. Не знаешь? Тогда простым языком: это то, что будет тебе генерировать модель, запрос на генерацию, ее задание. Каждый раз она будет тебе выдавать суммарайз "запроса", и ты можешь его подредактировать так, как надо тебе.
Следующие чекбоксы ставь по вкусу, нужны тебе они или нет - сам реши.
В пункте ComfyUI Workflow ставь Default_ComfyUI_Workflow. Тебе пока что больше не надо. Надо будет больше? Тогда сиди сам там разбирайся дальше, ищи воркфлоу, нужные тебе и настраивай под свои нужды. Универсального тут нет. У меня, например, есть воркфлоу с возможностью рисования - но он, очевидно, в таверне никак не сможет использоваться, например.
Модель - выбираешь ту модель, которую скачал. VAE - если модель идет с VAE (зачастую сейчас так и есть, большинство моделей уже имеют встроенные VAE) - оставляешь поле пустым (либо оно само заполнится автоматически). Sampling Method и Scheduler - выбирай тот, который рекомендует автор на странице своей модели. Зачастую это DPM++2M_SDE + Karras, но есть очень много моделей, которые используют другие методы семплирования. Тебя, опять же, ничего не обязывает использовать такой же метод семплирования. Это вкусовщина. Нравится тебе визуальный итог на DPM++2M_SDE+Karras? Пожалуйста. Нравится другой? Ставь другой. Тут можешь поиграть, посмотреть на результаты. Я часто бегаю между этим методом и Euler.
В Разрешении выбери то, что тебе нужно. Таверна сама подставит нужные значения. Далее мы видим следующие параметры:
Sampling steps
CFG scale
Denoising
Clip skip
Можешь выставить их так, как рекомендует автор модели (если рекомендует). А можешь сам выставить нужные тебе значения. Опять же - это вкусовщина, все зависит от того, что ты по итогу хочешь получить.
Если кратко. Шаги - это то, сколько раз нейросетка будет прикладывать свои усилия к генерации. Например поставишь 1 шаг по запросу "Ложка", она нарисует палку и кружок. ПОставишь 5 шагов - она соединит палку и кружок, при этом палка станет шире. Поставишь 15 - это станет походить на ложку, но она будет какой-то кривой. Поставишь 25 - это будет пиздатая ложка. Поставишь 30 - она уже, почему-то, начнет превращаться в ложку в артефактах. Тут надо у каждой модели смотреть рекомендуемые шаги.
КФГ - это то, как сильно модель будет следовать запросу. Например при значении 1 она нарисует тебе не ложку, а енота. При значении 5 - это будет ложка. Но, при 6 - это будет уже ложка и вилка (внезапно).
Дейносинг я рекомендую ставить 80%. Это, ГРУБО ГОВОРЯ, как модель будет напрямую понимать твой запрос. Т.е. если ты пишешь "лицо на черном фоне" и поставишь денойз в 0.1, то оно может нарисовать тебе контуры лица на черном фоне, что ты хуй чего разберешь. Поставишь 1.0 - оно нарисует тебе детальное человеческое лицо на фоне черной стены. Поставишь 0.5 - может получиться что-то концептуальное, например черно-белые контуры лица на темном фоне, а на этом темном фоне еще превратится в звезды итд. Это утрированно. Поиграйся сам тут - поймешь разницу.
Клип скип - тут все СЛОЖНО. Ставь дефолтное значение и забей хуй. Поверь.
Сид оставляй -1 - это рандом. Каждый раз будет генерироваться новое изображение.
Создай стиль. В Позитивах ты добавляешь то, что тебе нужно. В негативах - что не нужно. Тут тебе самому надо почитать получше, как это работает, но добавь туда базовые вещи нужные тебе. Например в позитивы обязательно добавь best quality, aesthetic, masterpiece. Можешь добавить слова стилей. Например, если ты рисуешь томоку - добавь anime_style, anime_source. Это, короче, значения, которые постоянно будут применяться к каждому изображению. Негативы ставь, например, базовые lowres, bad anatomy, bad hands, text, error, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry.
Ну, думаю, ты понял что это такое. У модели на странице можешь увидеть кучу примеров изображений. Если нажать на них, ты увидишь позитивы и негативы. Вот можешь там посмотреть, что люди пишут и какие результаты дает. Например, если у тебя аниме моделька - писать ей ultrarealism как-то тупо, так и наоборот - если моделька на реализм, а ты пишешь source_anime - это тоже как-то "неправильно".
6) В Image prompt Templates ты увидишь шаблоны для каждого пункта, в котором ты будешь давать команды Таверне на генерацию. Почитай, пойми что это значит. Захочешь сам введи, что тебе нужно, что бы Таверна подготавливала тебе промпт перед генерацией (как раз то, зачем мы ставили чекбокс). Можешь оставить дефолтные значения.
НО, теперь очень важный нюанс. Генераторы изображений жрут не меньше, чем генераторы текста. Хочешь генерить картинки? Выдели место в видеопамяти под это дело. Или не выделяй, но тогда картинки будут генериться дольше. Я, например, если врубаю комфи - совершенно не теряю скорости в генерации текста, но простенькая картинка у меня на 30 шагах генерится минуты 2. Если я запускаю комфи, то картинка в FHD с апскейлом до 2к генерится за секунд 30-40. Критичная разница? Да. Но, тут у меня другая задача - тут я просто генерю картиночки в сопровождении игры, а не генерю детальные хай-квалити арты, так что похуй.
ВРоде все.
А, еще момент. Есть такая хуйня как LORA - это, простым языком, дополнение к модели, которое сфокусировано на чем-то конкретном. Ты можешь скачать LORA на Ватамотю и закинуть ее в воркфлоу Комфи, но я не уверен, прочитает ли это дело Таверна. Я пробовал - разницы не почувствовал.
>неужели не мог еще пикчу с кошкодевочкой на двойных трусах найти?
Нет. Вообще, лейте свои сборки.
Слишком картиночно. У нас тут отдельные треды есть со своими инструкциями.




Как это работает наглядно?
Нажимаем на волшебную палочку, заходим в Generate Image, выбираем что тебе нужно.
Выберем Background. Немного ждем, пока модельки раздуплятся. Им тоже надо просчитать токены того, что у тебя происходит в игре и в каком месте находятся персонажи. Т.е. если ты там в сцене находишься где-то в лесу, то моделька сначала прочитает, где твой персонаж находится, а потом начнет генерировать промпт, описывающий лес.
У тебя сгенерировался промпт бэкграунда. Не понравился промпт (например моделька не поняла запрос и сгенерировала не то) - сгенерируй заново, либо руками поправь то, что тебе надо. За этим ты и ставил чекбокс над редактированием промпта. Устраивает? Жми генерацию.
Немного ждем и получаем результат прямо в чат. И о, прикол! Бэкграунд автоматически подцепился к заднику чата!
Не понравился результат? Да перегенерируй! Можешь поиграться с настройками генерации в расширениях. Например, я выбрал другую модель. Тебя устроил промпт? Тебе не надо его генерировать заново. Жми три точки у сообщения, ищи кисточку (генерация изображения) и он подрузит тот же промпт. Ждем и получаем новый результат в этом же сообщении.
Короче, так это работает, вот.
Просто подробно описал, решил помочь человеку в этом треде. Он только вкатился, он хлебушек побольше моего. Я-то как раз с картиночек начинал, а потом к тексту пришел. А он ни тут, ни там. Разве плохо, что я помог ему?
Я ж не пью, это у оппонентов с алкоголем проблемы. Не просыхают, судя по всему.
Кто? Посты линкуй
Да тут в треде постоянно кто то или бухой или под кайфом, сами же признавались.
Где признавались? Не было такого. Опять ты белочку словил похоже. Если я не прав линкуй посты
Я лично и признавался. Ты совсем ебанулся и думаешь что в треде только ты и твой собеседник остались?
В голос с долбаёба. Он рили забыл что уже признавался нюне в любви, даже карточка та же. Раньше думал это тролинг но походу настоящий шиз
Для рп нинужон, жрёт токены и попёрдывает ради ничего
Ну ясен хуй, кто будет интерфейс переделывать от поста к посту. Но приходить с аватаркой и задвигать что я не я это дурака
4.6 тестируй. Отца хирурга разгадает?
Пруфы то где? Тебе это под градусом привиделось
Ты когда точки начнешь ставить ?
Ну пруфы принесёшь и я подумаю. Вот тебе одна авансом.
Никак. Это ссылка на оригинальные веса модели, кобольд лишь обертка llamacpp, а она поддерживает только gguf кванты (или упаковку в него оригинальных весов).
Тебе верно ответили что нужно скачать подходящий квант, а эти веса может катать трансформерс и эксллама.
> лейте свои сборки
Сначала дособирать в нормальный вид надо.
> я сам ранее был из тех, кто видел и лупы, и паттерны, и логические проблемы
И куда же они вдруг делись?
И куда же они вдруг делись?
> И куда же они вдруг делись?
Пропали после того, как я пофиксил свой скилл ишью, подобрав нормальный квант, настройки и сменив формат промптинга. Могу дать контакт экзорциста.
Зачем вы ругаетесь?
Что с того что в интернете кто то не прав?
Что с того что в интернете кто то не прав?
> .mp4
Это которая капусту тушила?
Старый дедовский способ! Чтобы избавиться от лупов, паттернов и логических проблем, нужно всего лишь




>4.6 тестируй.
Я нищеброд с 96 врама, так что выше 235 не прыгаю.
>Сначала дособирать в нормальный вид надо.
Как раз колхозинг выше ценится. До сих пор хороню охлад P40 из 3D ручки.
>капусту тушила
Вы блядь ебанутые? Капуста сырая! Как она блядь загорится? Даже бензин не поможет. Сама потухнет.
Аноны, у меня беда. Я не программист, но мне для профессии нужна корочка об обучении ведения IT проектов. Дали тему диплома и обязали использовать Нейронку для обучения и фильтрации данных. А я вообще не ебу что с этими нейронками делать. На пайтоне кодил года два назад простые программы. Нейронками только картинки генерил. Сейчас нужно создать систему для фильтрации сообщений по двум критериям. Руководитель посоветовал делать на нейронке KERNS.
С чего начать? База данных из 3600 сообщений допустим есть. Надо фильтровать по двум критериям нахождения определенных слов в сообщении
С чего начать? База данных из 3600 сообщений допустим есть. Надо фильтровать по двум критериям нахождения определенных слов в сообщении
>уже признавался нюне в любви
Я в рот ебал эту вниманиеблядь, и ни разу про него доброго слова не сказал. Неси скрины или ссылки кто там его хвалил.
>Комбинацией этой темы и "AI" карточки без картинки
Поехавшее вахтерское говно любой ценой пытается детектить аватарок на дефолтных вещах, используемых многими. Это не ты там несколько тредов назад детектил "аватарку" по пропуску строки после >?


Анончики, залётная нафаня в треди. В общем в одном рандомном треде вычитал, что некоторые пользователи ЛЛМок играют в текстовый ролеплей с чатботами. Попробовал в приключение с чат гпт и реально выходит круто, но там анальная цензура с постельными сценами (буквально любыми, кроме скипа аля пост-фактум, что был совершен акт близости) и некоторыми сценами битв с описанием жестокости (дарк фентези). Вот тут я и призадумался на счет локальной генерации игровых сессий, но не могу понять с чего начать, поскольку всю движуху, начиная с генераторов картинок пропустил за ненадобностью.
Система:
13700k stock
4090 24gb VRAM stock
96gb RAM DDR5 @6650
Требования следующие:
-Локальная текстовая игра без ебучей цензуры (если возможно);
-Игра на русском языке (вот тут принципиально, поскольку с англюсиком не особо дружу);
-Разумный по сложности гайд по установке и настройке;
Есть ли шанс на вкат с таким бомж сетапом и описанными требованиями? Заранее спасибо тем, кто откликнулся.
Система:
13700k stock
4090 24gb VRAM stock
96gb RAM DDR5 @6650
Требования следующие:
-Локальная текстовая игра без ебучей цензуры (если возможно);
-Игра на русском языке (вот тут принципиально, поскольку с англюсиком не особо дружу);
-Разумный по сложности гайд по установке и настройке;
Есть ли шанс на вкат с таким бомж сетапом и описанными требованиями? Заранее спасибо тем, кто откликнулся.
Почему у своего научника не спросишь? Сейчас бы ждать что за тебя на дваче диплом сделают
Этот явно в ссоре с головою. Предлагаю быть умницами и игнорить, а не поддувать его потуги в очередной срач
Да, шанс есть ещё какой, железо норм. Одну из лучших моделек без запустишь, хотя много чего изучить надо будет по первости. Гугли и разбирайся чё такое Koboldcpp, Sillytavern и качай gguf квант этой модели https://huggingface.co/zai-org/GLM-4.5-Air
> С чего начать?
Попросить у руководителя литературу и примеров. Обозначить сумму в USDT, которую ты готов заплатить местным за помощь. Ознакомиться с самой базой и подумать головой.
По моделям влезет эйр (инглиш онли), влезет ужатый квен (с русским и лучшая девочка, но своя специфика). Ну и все что меньше.
Там были гайды по запуску кобольда и таверны, воспользуйся ими скачав базовую гемму 3-27б и попробуй запустить. Как получится и наиграешься - там уже можно будет продолжить.
У тебя есть прям не шанс, а целая возможность.
Ставишь kobold, накатываешь сверху Таверну, правильно все настраиваешь, выбираешь модельку и кайфуешь. Я с железом хуже, чем у тебя сижу и обмазываюсь ролеплеем с комплютером неделями. Минусов не вижу.
Если вдруг кто-то захочет потестировать Apriel-1.5-15B-Thinker ради Vision функций - не тратьте время, она ужасна. Частые зацикливания, видит то чего нету, а в простой и четкой фотографии таблицы умудрилась строку пропустить.
Спасибо за внимание.
Спасибо за внимание.

Эта модель умеет в русский? Там написано, что поддерживается английский и китайский. Так же не понятно, что за множество файлов в GGUF версии. https://huggingface.co/unsloth/GLM-4.5-Air-GGUF/tree/main Нихуя не понятно, кек. НО! Буду пробовать понять что по чем.
>Как получится и наиграешься - там уже можно будет продолжить.
Чтобы продолжить в какую сторону копать? Или нужно сидеть тут в треде и смотреть как Анон тестирует разные модели? У меня в голове белый шум и полное не понимание.
А как выбрать модельку? Бегло чекнув прикинул, что в основном всё веселье РП происходит на англюсике, но у меня с ним проблемы, а моделей с руссиком внезапно нет (точнее мало очень), но это беглый чек в гугле
>Так же не понятно, что за множество файлов в GGUF версии.
Это одна и та же модель с разной степенью сжатия. Больше сжатие - меньше вес, ниже точность. Q4_0 (с разными буквами на конце), как правило, золотая середина между качеством и размером. Много нюансов, но простыми словами как-то так.
Как там на Сноудропе, смог Леночку оприходовать или так и не вышло?(
Как же я благодарен святым духам прогресса, что с современными MOE я вообще забыл про еблю с суммарайзом. Начиная с Air - всё просто охуенно. Ну максимум, пара предложений поехавшие будут, можно исправить. Но по сравнению с тем бредом который выдавали нейронки раньше - ПРОГРЕСС ЁПТА!
и чо и сколько контекста обычно у тебя в среднем после слоубёрна выходит?
>Этот явно в ссоре с головою. Предлагаю быть умницами и игнорить, а не поддувать его потуги в очередной срач
А ты не меняешься. Как обычно набрасываешься, но стоит наступить тебе на хвост сразу:
Nyaaa~ чего злые такие ~nyaaa
Кто ты-то? Забыл что тут не чай вдвоём? Опять
Примерно по 500т каждый суммарайз. В среднем довожу до 6-7, потом уже суммирую их на отдельном промтике. Там да, уже ручками. Но это всё еще лучше, чем каждый, блять, суммарайз.
Но опять же, если меняется характер и используется карточка персонажа а не мира, я тупо хуярю изменения в неё. А прям ДООООЛГИХ РП не было, только одно на 3к сообщений. Но это еще на цидоньке было.
Хуле, мне теперь всё не так.
А эт я промазал, потому что ебаквак квак квак.
Ахуеть и че оно так просто с сумсарайза генерит пикчи? А почему в дефолтном автоматик1111 если ты хотел пикчу вайфу то тебе приходилось заучить все блядские тэги..
Куда промазал, по кому. Кто я? Ты поехавший, дядь. Завязывай выискивать тут кого-то и сраться
Короче, меченный.
Качаешь это, потому что будь мужиком ЕБАШЬ РУКАМИ
https://github.com/ggml-org/llama.cpp/releases
cudart-llama-bin-win-cuda-12.4-x64.zip
llama-b6970-bin-win-cuda-12.4-x64.zip
Это для зеленого лагеря. Красный пусть страдает олололо.
Разархивируешь в одну папку.
Потом устанавливаешь эту малыху, это наше всё для РП
https://github.com/SillyTavern/SillyTavern
Библиотеки для неё и прочее, разберешься в общем, не маленький.
Потом качаешь кванты этой засранки, для начала.
https://huggingface.co/zai-org/GLM-4.5-Air
Какие кванты выбрать споры не утихают, вот два годных варианта:
https://huggingface.co/ddh0/GLM-4.5-Air-GGUF - странные, но годные. Бери V1 если захочешь, но для начала скачай ниже.
https://huggingface.co/bartowski/zai-org_GLM-4.5-Air-GGUF - проверенный Курва вариант. Если нужна гарантия - к нему.
Потом, хуяришь батник в папке с жорой (эт llama.ccp так называют из за автора)
start "" /High /B /Wait llama-server.exe ^
-m "D:\Ai\Main\GLM-4.5-Iceblink-v2-106B-A12B-Q8_0-FFN-IQ4_XS-IQ4_XS-IQ4_NL.gguf" ^
-ngl 99 ^ - эт слои на видюху. (их дохуя, потому что см.ниже)
-c 20480 ^ - это контекст, сколько модель будет помнить всего.
-t 13 ^ - это сколько ты потоков на проц определишь.
-fa --prio-batch 2 -ub 2048 -b 2048 ^ - это батч, сам погуглишь.
--n-cpu-moe 44 ^ - а вот это мое слои на ЦП. Приоритетней ngl
--no-context-shift ^ - гугли
--no-mmap - гугли
Потом хуяришь в таверне где буква А :
Context Template - chatml
Instruct Template - chatml
Семплеры - default
Промт - на вкус.
Ну или импортишь вот это
https://files.catbox.moe/qpe1a0.json и не ебешь себе мозги.
Всё, ебешь дракониц, сжигаешь города и засовываешь сотни тентаклей в жопу. Дерзай.
Кто он то. Ты тут один нахуй.
И обращался ко мне.
Безусловный шедевр. Сверху еще скотчем армировал. Муа!
Если не троллишь, то наваливай GLM-Air или Qwen3-235B (инстракт/синкинг по вкусу).
1. Качаем llama.cpp. Да, анон, сложно, зато ты сразу научишься делать адекватно для твоего сетапа, а не через жопу.
https://github.com/ggml-org/llama.cpp
Там справа Releases, тебе нужно
cudart-llama-bin-win-cuda-12.4-x64.zip
и
llama-b6970-bin-win-cuda-12.4-x64.zip
(ну, если ты на винде сидишь, мало ли=)
Распаковывай в одну папку.
2. Качаешь к этому модель:
https://huggingface.co/bartowski/zai-org_GLM-4.5-Air-GGUF
zai-org_GLM-4.5-Air-Q5_K_S
или
https://huggingface.co/ddh0/GLM-4.5-Air-GGUF/
GLM-4.5-Air-Q8_0-FFN-Q4_K-Q4_K-Q8_0.gguf
GLM-4.5-Air-Q8_0-FFN-Q5_K-Q5_K-Q8_0.gguf
Какие из них лучше — выбирай сам, в треде не определились, они разные, каждому на свой вкус.
ИЛИ
https://huggingface.co/bartowski/Qwen_Qwen3-235B-A22B-Instruct-2507-GGUF
Qwen_Qwen3-235B-A22B-Instruct-2507-Q3_K_S впритык влезет или нет — не уверен, если не влезет, понижай до Q2_K_L
или
https://huggingface.co/bartowski/Qwen_Qwen3-235B-A22B-Thinking-2507-GGUF
У всех разные вкусы и терпение, кому-то нравится рпшить с ризонингом.
3. Запускай в консоли из папки с распакованной llama.cpp командой
llama-server -c 16384 -t 8 -m path/to/model.gguf -ngl 99 --cpu-moe -fa on --mlock
-c 16384 — контекст, сколько ллм будет помнить. Смотри на занятость видеопамяти (и чтобы она НЕ занимала общую память графического процессора) и повышай пока не доберется до краешка.
-t 8 — количество задействованных ядер процессора. Обычно советуют количество физических -1, но у тебя память быстрая, нужно выжимать максимум. Можешь даже поиграться и поставить больше, задействовав потоки. НО выруби e-ядра в биосе, или через диспетчер задач привяжи llama.cpp только к P-ядрам. Если выльется на энергоэффективку — скорость может только упасть.
-m путь к модели тут путь к модели
-ngl 99 — всю модель пихаем на видеокарту
--cpu-moe — все что не является моделью роутера и общими слоями выпихиваем на процессор
-fa on — включает flash-attention
--mlock — запрещаем винде выгружать модель из оперативы, дурная что ли!
Но вообще, на линухе может добавиться процентов 20% к скорости, учти это, если покажется медленным.
Нет, не просто. Он же написал, что во первых у тебя отжирается память, во вторых генерить тянок и порно на ходу не выйдет. потому что нужно прям поебаться с нужной генерацией.
Как видишь, тебе два человека пишут одно и то же — ЭТО НЕСПРОСТА.
Если у нас что-то расходится — гугли что, сравнивай.
Как минимум он прав с прио батчем и юб и б, я забываю поставить вечно.
А вот треды сам подбирай (не забывай отрубать энергоэффективные, если скорость низкая будет).
Еще раз успехов, бодрое железо, порадует тебя.
>Context Template - chatml
>Instruct Template - chatml
Зачем советовать ему лоботомит?
Сколько не свичился между глм и чатмл - второй пишет менее оригинально и вообще будто мистраля навернул и большим датасетом
> Чтобы продолжить в какую сторону копать?
Просто сначала все скачай и запусти. Потом в чате поиграйся, получи первый результат. Далее можешь почитать что такое ллм и как работают, какие параметры важно юзать чтобы было хорошо в рп и т.д.
А иначе слишком много информации и от этого шума действительно будешь ахуевать. Когда запустишь, увидишь сам, потыкаешь - постепенно все прояснится. Если будешь просто сидеть и читать тред - мало что усвоишь.
> нужно сидеть тут в треде и смотреть как Анон тестирует разные модели?
Лол, тут скорее "как не надо тестировать" примеры.
Ты красавчик что подробно расписал порядок действий, но злыдень потому что посоветовал эйр под его запросы. Лучше начать с геммы или мистраля, которые полностью помещаются в врам и могут в русский. До эйра сам дойдет, может так понравится что пересмотрит критерии.
Ну это понятное дело, если запускать SD модель и llm модель, то оно все будет держаться в враме, тут скорее я поразился тем что оно с суммарайза получается, а не то что нужно хуярить [тэги] что бы получить желаемый результат..
>но злыдень потому что посоветовал эйр под его запросы.
>Игра на русском языке
И правда. Ну пусть хуярит русским текстом, проблемы не будешь. Пишешь в префиле что то в духе - избегай акцента на языке пользователя. И всё, не будет этого - “And that strange Russian accent was both exciting and annoying at the same time.”
Обосрался... Блять... Ты таки прав,
Эйр не лучший для русского языка, хоть и охуенный во всем остальном.
Я нихуя не понял. Суммарайз это ревью проще говоря, краткий пересказ. При чем тут теги? Поясни.
>святым духам прогресса
Как же тебя обоссывают из 22 века...
> При чем тут теги?
Ну я когда тыкал автоматик1111 там что бы получить желанную картинку нужно было хуярить тэги, типа хочу вайфу которая ест бутерброд, ну допустим модель хорошо знает твою вайфу и на неё не нужна никакая лора, хуяришь [wife name] там какую хочешь позу и фон, и тд. и такой типа А БУТЕРБРОД как захуярить?! И идешь искать тэг бутерброда и тд. потому что если просто хуйнуть [eat] она будет хавать что угодно, я за это. А тут ИИ-шка сама из ревью понимает что и как сгенерить.

Эмм.. я все еще не понимаю. Я не знаю что такое автоматик111. Я вкатился сразу в локалки, минув этап чатоводства. Я ревьюшу чат, потом коммандой /hide 1-xx скрываю сообщения, очищая контекст и продолжаю чат.
Если изменения характера персонажа, я меня карточку. Вооот.. извини, я картинки так, потыкал и всё. Не тот немного тред.
А их из 23. Зато у нас есть чистая природа и вода, ололол.
Но это не надолго.
> А ты не меняешься
Мисдетект, уточка. Странные все-таки в этом треде люди обитают. У каждого иногда включается режим обезьяны с гранатой.
> Я не знаю что такое автоматик111.
Это особый пресет из aicg, который работает на локалках и нужен для вайфуводства, стыдно не знать!
> Мисдетект, уточка
Селезень. Чисто технически, что чп, что ап селезни.
> Странные все-таки в этом треде люди обитают. У каждого иногда включается режим обезьяны с гранатой.
Потому что мы все чилавеки и долбоёбы. Еще и двачеры к тому, значит в каждом из нас что то сломано.
Ты же понимаешь что для локалок не нужны ни безжопы, ни ответы в ризонинге, не многоступенчатые обходы цензуры. Мы подаем контекст без прокладок, напрямую на модель.
Поэтому наши промты отличаются. Чатоводство это отдельный мир. В котором можно ебать серафину на ванильной гемме и быть осуждаемым.
> Ты же понимаешь
Oh you~

>я картинки так, потыкал и всё.
Да я так же, да, забей. Типа вот как надо изъебываться тэгами что бы получилась вайфа
<lora:Tomoko_Kuroki_-_ILL:0.8> masterpiece, best quality, amazing quality, very aesthetic, absurdres, depth of field, blurry background, extremely detailed face, detailed eyes, safe_pos, sfw, tomokokuroki, 1girl, solo, green eyes, bags under eye, black hair, long hair, hair over one eye, red gym shorts, green shirt, green shirt, under shirt with long black sleeves, indoors, living room, couch, dynamic angle, dynamic pose, selfie, sitting, crossed legs, eating,

>Выставил другие значения? Молодец. Запустился кобольд? Комфи запустился?
https://coub.com/view/1j4d16
Прости. Я не справился. Оно теперь больше не запускается. Троублшут и реинсталл программы не помогает. Всегда такая хуйня. Завтра буду еще пытаться.
>тут скорее "как не надо тестировать" примеры.
Поддержу. Такую кринжатуру вкидывают в последние дни, поначалу было смешно а сейчас уже волосы дыбом встают от таких тестов
Молодцы ребята, круто расписали новичку. Мб наконец кто возьмётся рентри сделать? Столько полезной инфы ведь будет утеряно. Хотя уже
Бля анон, это несправедливо но горе побеждённым. Тред заебался читать твоего личного шизика, тупо проще уже вместе с ним кидать в тебя говно, посмотри сам. Какую ветку не читаю тебя доёбывают за то что защищаешься. Такая среда тут, хуле поделать. Срать за нихуя норм а давать сдачи нет, ну класека. Ведёшь себя прилично ну значит сразу чсв корона и принцесса. Короче, тебе надо или научиться это игнорить, стать макакой как и все или наконец сьебаться уже. Мне нравятся твои посты, интересно и по делу, будет потерей для треда но это уже кажется меньшим злом
У меня со второй-третьей попытки на 99% считывает сцену и спокойно дает ссумарайз для генерации. С первого раза бывают попадания в половину, которую надо править руками. Не ебу, честно говоря, что там у других. Все зависит от того, как темплейты настроишь, я думаю. Мб я такой крутой умный дохуя вылез из картинкогенератора сюда зная, как и че там работает. Но, проблемы с суммарайзом сцены у меня возникают только при описании последних сообщений, но я этой функцией редко пользуюсь. Как правило я генерю либо бэк, либо персонажей.
>Ты же понимаешь что для локалок не нужны ни безжопы, ни ответы в ризонинге, не многоступенчатые обходы цензуры.
>Мы подаем контекст без прокладок, напрямую на модель.
Это ортогональные вещи, ты же понимаешь?
> поначалу было смешно
Смешно было когда петух нес яйца, из недавнего рофел про отца-хирурга. Остальное в основном кринж, демонстрация непонимания каких-то базовых вещей, или дерилий.
> Мне нравятся твои посты, интересно и по делу, будет потерей для треда но это уже кажется меньшим злом
У этого шизика? Рофлишь чтоли? Одни байты на срач, набросы и говнометание ради говнометания. вероятность мисдетекта оценивается как низкая
> Но тем не менее, сколько $/руб/евро тебе обходится эта Атенза и может что-то еще помимо принимаешь? Мне медгемма сказала что это вообще безопасные таблы, а то я подумал что ты хуяришь стимуляторы что обычно выписывают при ADHD. Но ты их все равно только по рецепту получаешь?
Сами таблы (доступность+цены) можно чекнуть тут: https://www.gdziepolek.pl/produkty/119638/atenza-tabletki-o-przedluzonym-uwalnianiu/apteki пишут от $15 до $50, 30 табл на месяц (54мг). Чем больше доза тем дороже ну больше 54мг вроде не продают в Польше. В РФ вообще не продают метилфенидат, только атомоксетин, который действует оче медленно как я понял (эффект только спустя 1-2 недели).
Чтобы купить таблы нужен рецепт, один поход к психиатору тут 450 злотых это $122 по курсу. Он выписывать может только на 3 месяца вперёд максимум вроде. У меня было только два приёма: первичный и второй. После третьего наверное будем делать сертификат для обычного "семейного" врача на 6 или 12 месяцев, к которому нужно привязываться и он уже сможет мне выписывать эти рецепты бесплатно / дёшево / без визитов. Хз как это работает, но думаю так везде в Европе?
Короче изначальное лечение / диагностика считай $200-400, а дальше чисто таблы ($20-50 / месяц) + раз в полгода-год провериться ($120).
Без рецепта метилфенидат не продают тут, т.к. он всё равно имеет побочки и они довольно опасные если не контролировать приём. Разница между 4-мя видами лекарств наглядно:
1. Дексамфетамин: «Я взламываю склад дофамина и норадреналина и выкидываю все на улицу, а уборщикам запрещаю заходить».
2. Метилфенидат: «Я просто ставлю охрану на выходе: всё, что выбросили, лежит в синапсе дольше обычного».
3. Амфетамин: «Я устраиваю погром на базе моноаминов: выпускаю запасы, разворачиваю двери и говорю нейронам “работаем сверхурочно”».
4. Атомоксетин: «Я тихо подкручиваю норадреналин в коре без допаминовой дискотеки — скучно, стабильно, по-взрослому».
> Блядь ты хоть поменьше их жри
Там по курсу раз в день утром и всё. И нет, сверхчеловеком не делает тебя, просто позволяет сидеть спокойно и делать дела.
Но для меня это ощущается как сверхспособности просто потому шо последние 10 лет как во сне. 2-3 часа фокуса и оставшиеся 10 часов дня я овощ ни на что не способный, только прокрастинирую.
Когда начал принимать, я смог сравнить состояние с таблами и без таблов:
1. Когда не принял если я начну фокусить задачу 1-2 часа без перерывов, то я прям физически начинаю чувствовать усталость, голова как будто бы ватой заполняется и появляется "шипение/белый шум от телека/неприятные ощущения" + мигрень и хочется тупо спать, глаза закрываются под тяжестью; единственный фикс это пойти поспать 1-2 часа минимум. Из-за этого я режим сна ломал по КД и я не мог ни на что потратить свой день т.к. у меня лимит на фокус тупо 1 час в день утром и мб вечером 1-2. Алсо: Факторио 12 часовые марафоны -- без проблем. 200 вкладок в хроме и постоянно чёт интересное гуглить и читать, писать в тредики во всех соцсетях, скролить, играть чёт ненапряжное -- нет проблем, хоть 15 часов в сутки. Как только речь заходит о работе -- всё, макс 1 час и досвидос.
2. С метилфенидатом 54мг я тоже могу чувствовать усталость, но я способен пересилить её и продолжить работать, досидеть до конца дня пойти нормально спать и потратить большую часть дня на продуктивную, скучную работу и не чувствовать себя овощем после конца и пойти нормально поиграть во что-то, а не скролить ленты по 10 часов в день и потом винить себя за это.
Но я буквально 1.5 месяца на таблах, и пока ещё проверяю как оно всё работает. Если я теперь могу контролить это и не пить таблы допустим на выходных то это охуительно так то, включать рабочий режим по расписанию!
В идеале я думаю вся эта проблема решается с двух сторон: дисциплина (то шо можно выработать) и химия мозга (тут только таблы). У меня есть таблы, но до сих пор нет дисциплины что делать в течение дня -- я всё ещё забываю вещи и не умею приоритизировать таски и не знаю чё я делаю вообще с жизнью. Тут только поможет список приоритетов + календарь + роадмап какой-то "шо я хочу добиться, цели". Я пытался это делать без таблов -- без шансов вообще, эти списки вести не реально. А сейчас я могу их и написать и следовать им и даже измерять хорошо я по ним иду или нет, куда уходит время, етц. Если я подсяду на эту систему то возможно таблы можно будет жрать меньше в будущем, план такой был.
Энивей, по теме: я получил 5090, на неделе буду ставить и пробовать модели квантованные под NFVP4 и под обычный int4/Q4_K_M:
Контекст:
Это у тебя системная ошибка Комфи. У тебя наверняка отсутствуют какие-то там библиотеки для этого дела. Какие-то там питоны, хуены, я точно не помню, братик. Просто загугли, как пошагово поставить комфи. Он тоже требует там какие-то приколы заранее установленные перед тем, как поставится сам. Там гит нужно ставить, вроде как, питоны и прочую залупу. Я могу тебе помочь и за руку провести, если вдруг не разберешься, но вроде не так сложно все. Я нулёвый в этой теме буквально за десять минут все накатил, что бы работало.
Кириллица, пробелы, символы в пути?
>Мб наконец кто возьмётся рентри сделать?
Проблема не сделать рентри, это задача двух стаканов, одной сигареты с перерывами на глажку кота, не менее 10метров глажки, замечу.
Проблема потом держать это актуальным.
>Короче, тебе надо или научиться это игнорить, стать макакой как и все или наконец сьебаться уже.
Он взрослый мальчик сам разберется. Просто сам не корми шизов. Старое правило двачей- не корми толстоту никогда не поменяется. Вот это и есть нерушимая и настоящая база.
>ортогональные
>свойство, обобщающее понятие перпендикулярности на произвольные линейные пространства с введённым скалярным произведением
Чем тебя слово параллельные не устроило то. Вроде мы не физмате с его, давайте представим пятимерное пространство.
Да параллельно, но кардинально отличается пердолингом с попенаи. У меня ебля с корпосетками ассоциируется со старым мемом про срать не снимая свитер.
Это ты молодец что всё рассчитал и молод. Главное потом как я, чтобы на зипрексе и клозапине не сидел. А в особо тяжелые моменты придется принимать в жёпь мемную галоперидуху и тебе это не понравится. Впрочем, тебе тогда вообще ничего нравится не будет.
> Какую ветку не читаю
Думаю, ты прав. Ловлю такой эффект дежавю: приношу что-нибудь из хороших побуждений, всегда тактично уточняю, что это всего лишь мнение и опыт, а заканчивается срачем. За пределами данного треда я на дваче или иных бордах не сижу, и у меня есть профдеформация - несу ответственность за свои слова и не могу оставить вторую сторону без ответа, по умолчанию принимая ее за достойную для дискуссии. Оттуда оно и проистекает, как и некоторые формализмы и грамматика, которую тут иногда принимают за самомнение и иногда даже агрессию. Впрочем, в последние дни я действительно сдал позиции и начал отвечать злобой на злобу. Отдельно извиняюсь перед аноном, с которым случайно начал срач здесь , я перегнул, виноват. Треду - мира и побольше классных моделек. Сайонара. P.S. Не надо второй охоты на ведьм, треду это не нужно. В этот раз я правда все.
>masterpiece, best quality
Это что за срань? Ты что, на sd 1.5 застрял?

>Сайонара
Хуинара.
Хватит из себя строить лирического героя, и просто веди общении о том, что считаешь нужным в тематике. И всё, это же двачи.
Вот тебе кобольт.
> Отдельно извиняюсь перед аноном, с которым случайно начал срач здесь
Чтобы получить прощения - скидывай карточку милого персонажа.
Есть уборщик, на котором можно выловить кучу годноты. Придется правда немного повозиться, чтобы почистить карточки, но это того стоит!
Как запустить vision модель в llamacpp?
Не самая плохая идея, да. Только качать неудобно.
Ты же в курсе, чтобы оттуда невозбранно пиздить, надо просто в адресной строке уборщика на джаниаи заменить? И с вероятностью 99% карточка будет там.
Ага, сотни нефти господину, который платит за домен и держит зеркало. Просто лишние телодвижения, потому неудобно.
Аноны, мне так, убедиться. Железо у меня что то начинает отъебывать или проблема в другом.
Ни у кого нет проблем с последним обновлением таверны, где она начинает зависать на ровном месте?
Ни у кого нет проблем с последним обновлением таверны, где она начинает зависать на ровном месте?
Тащемта ничего сложно, нейронку сейчас может обучить любой школьник. Для тебя если ты кодил на пайтоне это должно быть проще простого, особенно для такой простой вещи как фильтрации по словам.
Если ты генерил картинки и возможно обучал свою лору, тут ньюансы с обучением/переобучением примерно такие же хоть и разные архитектуры.
Для начала давай определимся, нужен ли тебе этот KERNS.AI? Да возможно там будет проще, больше визуализации и мб тебе будет проще понять весь процесс, но и вероятно больше ненужных мешающих костылей, все же это корпоговно. Тем более в твоем то случае если ты питонщик, то тебе это явно не нужно.
Вот что тебе понадобится для обучения нейронки:
https://keras.io/
https://www.tensorflow.org/tutorials
3600 слов, это вообще хуйня, тут никакая нейронка не нужна по сути.
Установи библиотеки -pip install tensorflow keras pandas scikit-learn nltk
Создай CSV файл с колонками "text" (сообщение) и "label" (0 или 1)
Напиши скрипт для предобработки, токенизации и стоп-слов
Очисти простеньким скриптом текст от лишних символов типа . , ! ""
Токенизируй текст что бы он привратился из ЭТО ТЕКСТ в ['Это', 'текст', '.']
Удали стоп-слова, все артикли или те которые не имеют смысла а, и, в, на, то, и тд.
Преобразуй строки для TF-IDF более точной векторизации если не планируешь использовать Embbeding, хотя вполне вероятно что тебе именно он и нужен, но вряд ли с 3600 слов, если все очень упрощенно то тебе лучше TfidfVectorizer + LogisticRegression из scikit-learn, я не знаю просто по каким критериям нужно фильтровать, если тебе важно точно отфильтровать слова, то TF-IDF, если тебе нужно отфильтровать слова синонимы или похожие по смыслу то тут нужен Embbeding так как он не просто преобразовывает слова в токены(цифры) но еще и располагает рядом по смыслу, типа "кот, животное, мяу"
Не забудь использовать re.search функцию для поиска точных слов обозначив их \b типа что бы \bпроблема\b было проблемой, что бы алгоритм не выдавал тебе слова пробематичный
готово
Теперь тебе нужно разметить слова, но делать вручную это заебно, напиши тоже простенький скрипт для автоматической разметки, создай список запрещенных слов которые ты хочешь отфильтровать, присваивай label=1 всем сообщениям содержащим хотя бы одно из этих слов, всем остальным label=0
готово, у тебя есть разметка данных
Остается только обучить модель, в твоем случае ставь
epochs
batch_size
validation_split=0.1 (если слов для фильтрации мало то 10% валидации более чем достаточно будет, если нет то можешь 0.2 поставить) в туториалах все поймешь что к чему, не забудь только выставить Dropout 0.2 что бы предотвратить переобучения.
Чекай метрику, так как датасет очень малый то на accuracy можешь забить хуй, смотри на precision/recall/F1, убедись что модель не ошибается и подставляй эпохи по метрикам. Ну всё, сохраняешь модель и векторизатор, пишешь/вайбкодишь функцию фильтрации и используешь свою обученную модель, готово, алгоритм будет фильтровать всё что тебе нужно. Это буквально как hello world, другое дело если бы тебе руководитель поручил написать вместо фильтрации слов, реальную Embbeding + Dense нейронку по распознавание сетчатки глаз или любую другую реально полезную вундервафлю.
А со спайси чата так же провернуть получится?
Тот кого нельзя называть, давай ты будешь скрывать свои богатые речи за спойлер, либо возьмешь своих протыков и съебешь разбираться в дис?
Ущемляешься уже каждый день, таблетки выпей, блять
Ущемляешься уже каждый день, таблетки выпей, блять
Да как найти уже этот ваш дис? Нихуя не гуглится
>Там по курсу раз в день утром и всё.
>По штуке пролонгированного в день
Хахахаха пиздец ахаххахахаха ебанись хахаха гг нахуй хорошая игра.
>С метилфенидатом 54мг я тоже могу чувствовать усталость
ХАХАХАХАХАХА
>1.5 месяца на таблах
>1.5 месяца по шт в день
ХАХАХАХАХАХАХАХА
Ой бля братишка пиздец тебе конечно. Не ну ты как сам знаешь делай конечно.
Если прям серьезно то вот о чем подумай. Ты же не всю жизнь на них планируешь сидеть верно? Стимуляторы и в целом любые таблы по здоровью бьют. Что будешь делать когда курс закончится? Рекомендую поболтать с чуваками которые принимали уже аналоги твоих таблов. Расскажут какие там веселые отходы и тяга.
Вопрос. Пробовал кто запускать DeepSeek OCR из под WSL в vLLM? Лол там советуют ставить nightly, но он cuda 12.9 просит. В итоге последний 0.11.0 не поддерживает DeepSeek OCR, а 0.11.1 ещё не вышел.
Запускал на ми50 вариант из офиц репы дипсика на вллм 0.8.5 (руками немного код правил)
Так это на HF transformers запускал же? Блин, с ним и я запускал.
Там две папки. Одна для hf, другая для vllm
Оператива или проц.
Пизда тебе.
Шучу, на самом деле не пизда, но у меня с похожими симптомами сдохла видеокарта, началось всё с того, что если забита на 95% начинается тротлинг, а потом пошел запах чистейшей гари.
Бля, два дауна разговаривают, без обид. =)
Чел номер один: у нас есть два разных типа моделей — с тегами (SD1.5, SDXL) и с естественной речью (Flux, Qwen-Image). Но суть не в этом. ДА ПРИКИНЬ можно попросить ллмку написать теги к текущей ситуации, и она это сделает. Нихуя себе, технологии (двухлетней давности). В SillyTavern так и реализовано: посылается запрос сформировать теги, а теги кидаются в модель, которую ты указал. И неважно — автоматик1111 это или комфиуи.
Ну либо просто впихунить краткое описание сцены в модель побольше (но флюкс и квен и жрут много и генерят долго).
Чел номер два: автоматик1111 — это прога для генерации картинок, как комфиуи сейчас, только автоматик на градио написана, а комфи на лапше. Обе говно, но комфи лучше поддерживается и новее.
Никакого отношения к чатам это не имеет, это и есть локалки, но картиночные.
Нахуя вот людей путаешь? :)
Бля, он на автоматике и сам писал, что делал хуззнает когда.
А на чем еще. хл в лучшем случае.
Добавить --mmproj и файл проектора (он, обычно, в самом низу в репе обниморды валяется и называется соответственно).
> Хахахаха пиздец ахаххахахаха ебанись хахаха гг нахуй хорошая игра.
Тут бы 50% треда таблами закидываться, так нет же, вместо этого только мельницы и соломенные пугала. И боротьба с ними.
На всякий случай напомню о nanonets ocr 2 и dots ocr.
А для английского chandra новая.
> На всякий случай напомню о nanonets ocr 2 и dots ocr. А для английского chandra новая.
Мне для русского.
DeepSeek OCR прям интересно выглядит для задач которые хочу ему кидать. Я его потрогал, он прям со своей техномагией хорошо перемалывает таблицы с мелким текстом. Плюс эта его фича с поиском BB на картинке заебись.
Но вообще я с компрессией хотел поиграть немного.





Заработало!
Стартанул на батнике тот что попроще, потом дополню, когда разберусь с другими командами. Контекст 32к - это нормально? Сколько влазит в такое контекстное окно? И как я понял, то я могу сделать окно еще больше, поскольку есть свободная память на ГПУ.
Еще вопрос: бот писал текст и закончил не завершив предложение до конца. Это норма вообще?
>контекст
Много или мало, решишь для себя, но лови хинт. В логах жоры у меня и у тебя есть вот такое
llama_kv_cache_unified: CUDA0 KV buffer size = 3680.00 MiB
llama_kv_cache_unified: size = 3680.00 MiB ( 20480 cells, 46 layers, 1/1 seqs), K (f16): 1840.00 MiB, V (f16): 1840.00 MiB
Что это значит ? Что 20к контекста - 3680мб GPU памяти.
Один токен примерно 180кб. Контекст у всех моделек по разному весит, а так, ты сможешь точно рассчитать сколько влезет.
>Это норма вообще?
Можно в таверне поставить галочку - обрезать незаконченные предложения. И да это норма. Помни что то генератор буковок, а не рассказчик держащий в голове весь сюжет.
Ну и сразу расскажу про суммарайз. Рано или поздно, на сообщени 60-ом ты забьешь контекст, и чтобы сюжет сохранить у тебя есть в таверне в extenstion - суммарайз. Это ревью чата, проще говоря. Он работает по собственному промту, там изъебываться не надо. Просто напиши на latinitsa - анализируй чат, диалоги, динамику отношений персонажей.
Потом в чат хуяришь /hide x-xx и сообщения скрываются из контекста, но не чата. Ты их видишь, модель больше нет. Нужно обратно открыть, ты не поверишь но /unhide x-xx (на месте икс номера сообщений)
Я бы не рекомендовал пользоватся суммарайзом. Модели делают выжимку чата, а не выжимку сюжета. Там промпт говно. Зачастую для корректной передачи сюжета там надо чтбы он пересказывался с точки зрения трансформации истории. То есть произошло событие А, Б, В, персонаж и провзаимодействовали так, персонаж немного поменялся. И я даже с хорошим промптом не получал хороших результатов в этой задаче.
И для этого тоже есть хинты анон. Ты скрываешь не все сообщения. Оставляешь 10-15 или, сам делаешь сообщение где обязательно будут диалоги персонажей, отражающие их отношения к друг другу (это для порева, к примеру)
Если ты сядешь на голый сумарайз будет говно, да.
Короче, помогай модельке и она тебе отплатит.
> хорошим промптом не получал хороших результатов в этой задаче.
Эйр ебашит адовые пересказы, с динамикой отношений. За что я и стал его фанбоем.
И раз уж в треде аукцион невиданной щедрости, можно действительно объеденить в рентри.
ПРОИЗВОЖУ ТЁМНОЕ КОЛДУНСТВО И ПРИЗЫВАЮ МУЛЬТИГПУ АНОНОВ.
Распишите для ебланов, как запускать на жоре с несколькими видеокартами. Я вам спасибо скажу и аноны которые будут пердолиться тоже скажут. Будет ссылка, чтобы избежать одних и тех же вопросов.
Ну и заодно тех кто съел собаку, канни и ктулху на распределении тензоров. Кратко, пожалуйста.
Исключительно в рамках жоры.
ПРОИЗВОЖУ ТЁМНОЕ КОЛДУНСТВО И ПРИЗЫВАЮ МУЛЬТИГПУ АНОНОВ.
Распишите для ебланов, как запускать на жоре с несколькими видеокартами. Я вам спасибо скажу и аноны которые будут пердолиться тоже скажут. Будет ссылка, чтобы избежать одних и тех же вопросов.
Ну и заодно тех кто съел собаку, канни и ктулху на распределении тензоров. Кратко, пожалуйста.
Исключительно в рамках жоры.
Для начала уточни свою конфигурацию, есть зависящие от нее нюансы, иначе кратко не получится. И скинь карточку где
> собаку, канни и ктулху
>Для начала уточни свою конфигурацию
>есть зависящие от нее нюансы
Вот с их учетом и распиши, шапку не читают, так хоть краткий гайд пусть по жоре для тредовичков новичков будет. Мне то что, у меня одна видеокарта попердывает.
>И скинь карточку где
Я могу залит все понапизженные карточки с уборщика, чуба и аллаха. С меня денег за это не спросят. Вот только оно тебе действительно надо ? У нас же по любому совершенно разные фетиши.
>Тут бы 50% треда таблами закидываться, так нет же, вместо этого только мельницы и соломенные пугала. И боротьба с ними.
Ох анон. Ну напишешь через год два как пойдет. Если все заебись будет я ток рад буду честно.
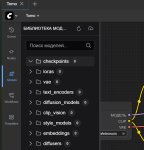

Анон. Я не знаю что делать. У меня вечно идёт какая то хуйня.
был прав, спасибо ему. Дело было в кирилице профиля.
Я снёс комфи и начал ставить с нуля. Дистрибутивом я поставил в C:\ComfyUI\. Он следом автоматом запускает следующую инсталяцию (ту что уже не как виндовая, а с gui комфи, виндовая наверное просто распаковка дистрибутива, я хз) так вот, в этой инсталляции я указал C:\ComfyUI\ComfyUI\ просто блять что бы не было конфликтов или еще какой хуйни. Инсталяция прошла. На этот раз я после смены порта на 8005 комфи не улетел в перманентный крэш.
Далее настал момент когда надо ставить модель.
>Качай и кидай в папку models - checkpoint.
Инструкция не конкретна, но я смог найти папку: C:\ComfyUI\ComfyUI\models\checkpoints и положить файл что скачал отсюда https://civitai.com/collections/107. Папка отличается наличием буквы s в конце. Но путь выглядит крайне логичным.
Зайдя в таверну я смог подключиться... но
>Модель - выбираешь ту модель, которую скачал.
модельки нет. Там нет ничего. Начал разбираться. Когда открыл КОмфи, то увидел слева кнопку models и кликнул в нее. Там увидел, что папка чекпоинты пуста. Попробовал перетянуть в нее файл из проводника. Не получилось. Значит где то есть ДРУГАЯ папка, куда нужно положить. Я через поиск смог найти еще одну папку. C:\ComfyUI\resources\ComfyUI\models\checkpoints там даже есть файл для таких как я, где чётко написано ЛОЖИ СЮДА. Возвращаюсь в таверну. Модели нет. Смотрю в комфи. модели нет. рестартаю комфи. моделей всё так же нет.
Я не знаю что делать дальше. У меня нет идей.
Мимо но загляни в nai тред на этой же доске. Там все по теме объяснят по пять раз если надо. Спроси Сенокшиза если он там еще живет.

>уборщика
Да кто такой этот ваш уборщик?
Janitorai

с урл модельки я накосячил. https://civitai.com/models/558420?modelVersionId=1396177 вот правильная. качал оттуда.
> Вот с их учетом и распиши
Это много писать, надо основы и принципы осветить. По-хорошему нужны картинки, но рисовать их я ебал. Подумаю, может если ллм с оснасткой поймет с полуслова - что-нибудь накидаю.
> Вот только оно тебе действительно надо ? У нас же по любому совершенно разные фетиши.
Пушистое, не фурри. И с оригинальностью, не дженерик слоп "catgirl roommate in heat".
Да я тупо сделал в мультичате роль ассистента которая делает всё что просит юзер и прошу её отдельно пересказать сюжет с фокусом на те или иные события которые я считаю важными в сюжетной арке. Модель иначе просто не понимает что важно, а что нет.
Я ГЛМ4.5 чёт особо не оценил :(
>Зайдя в таверну я смог подключиться... но
Ты точно подключился? Для начала попробуй генерить картинки просто в самом комфи а не через таверну, убедись что комфи настроен и у тебя он вообще работает, а уже потом подключай его через таверну (напомню еще раз что загрузка модели для генерации картинок тоже жрет врам, а значит тут придется находить компромисс с ллм моделью)
мимо
Где вы карточки берете? Мне нужно вдохновение для новых. Чуб зацензурился и скатился?
Из своей головы. Я аутист и смотрел много онемэ и читал много порнухи на панде.
Наверно самый любимый сюжет который сейчас веду в таверне это отигрыш мозгового слизня скромной кошкодевочки.
А о каких моделях вы мечтаете? Что-то +/- реалистичное. Понятно дело не берём в расчет всякие гемма 4 и т.д., это довольно банально.
Мне вот хочется что-то такое:
Непрерывное обучение. Это самое главное.
Даже 8б уровня мистраль, мне бы хватило, если бы ей запили непрерывное обучение.
Да что там, я и 1б такой бы был до усрачки рад. Тут ведь считай как ребенка своего или питомца воспитываешь, обучаешь, радуешься новым успехам т.д.
Если ещё и ризонинг добавить, вообще пушка.
а ещё домики набигают, да, и можно играть за стражу двоца
Мне вот хочется что-то такое:
Непрерывное обучение. Это самое главное.
Даже 8б уровня мистраль, мне бы хватило, если бы ей запили непрерывное обучение.
Да что там, я и 1б такой бы был до усрачки рад. Тут ведь считай как ребенка своего или питомца воспитываешь, обучаешь, радуешься новым успехам т.д.
Если ещё и ризонинг добавить, вообще пушка.
а ещё домики набигают, да, и можно играть за стражу двоца
Чтобы у модели было эго. Сейчас модели это просто хуйня которая воображает диалог между юзером и ассистентом, который следует какому-то паттерну. Если поменять роли, модель с радостью будет юзером. Хочу чтобы модель не могла быть кем-то кроме себя.
"Непрерывное обучение" в контексте ллм это
- постоянное обновление весов (fine-tuning)
- модуль с памятью куда складываются все организованные по субъектам события (субьект-относится к-произошло тогда-характеристика такая) + процесс который постоянно достаёт из памяти или кладёт в неё нужные "воспоминания"
шо из этого сложно?

Алсо вот так делается Knowledge Graph (KG) на примере neo4j (это память): https://markdownpastebin.com/?id=5761366f747a4d4388718149669bfc1b
getzep/graphiti в помощь короче
файнтьюн модели на 8B параметров: пик (6гб на 4битную лору)

Там ещё жор памяти будет зависеть от ранга лоры и оптимизатора. Но какой-нибудь RL даже в ультранизком ранге работает отлично.




Так, братик. Только что добрался до компа. Готов помогать.
Что касается пути. Все модели должны лежать примерно как я написал. ComfyUI - models - checkpoints. Пример на пике.
Что касается твоей модели. Ты скачал не модель, а ЛОРа. Это не модель как таковая, а инструкция, которая учит модель делать именно то, что эта инструкция говорит. Как я выше постом тебе объяснял.
>Есть такая хуйня как LORA - это, простым языком, дополнение к модели, которое сфокусировано на чем-то конкретном. Ты можешь скачать LORA на Ватамотю и закинуть ее в воркфлоу Комфи
Ты в целом так и сделал. Ты скачал ЛОРу Ватамоти, при этом у тебя нет модели.
В среднем модели весят от 6гб.
Я рекомендую тебе модели на базе Pony. Сам на них сижу. В твоем случае пробуй дефолт
Дальше посмотри сам комфи. Загрузи базовый воркфлоу. Нажми "Workflow", "Browse Templates". Выбери Image Generation. У тебя вылезет ошибка что что-то отсутствует - игнорируй ничего не качай. Это просто к базовому воркфлоу привязана моделька, которой у тебя, очевидно, нет. Вместо этого сразу смотри на Load Checkpoint. Там жми на строку и проверяй, что твоя моделька лежит и выбирается. (Пик 2).
Попробуй сгенерировать хуйню. Например пик 3.
Проверь таверну. Ты точно подключил комфи к таверне? Давай посмотрим. Вот пошагово прям. Смотри ПИК4.
Теперь к конкретике. Как я уже говорил в инструкции выше - я не уверен, что Таверна способна подтянуть ЛОРу. Но попробуй. В Воркфлоу тебе надо добавить загрузчик лоры. В боксе "Лоад чекпоинт" потяни за фиолетовый кружок "модел" и тяни в пустое место. Там откроется контекстное окно и выбери LoraLoader. ЛОРы кидаются в папку models/loras . Закинь туда свою лору, выбери ее в загрузчике. У тебя путь генерации должен теперь быть load checkpoint - lora loader - k-sampler. Не забудь заново все связать (смотри пример на последнем пике "про лору". Но, я так думаю, что если ты сохраняешь воркфлоу с настроенной ЛОРой и потом загружаешь его через таверну, то по идее ЛОРа сохраняется. Попробуй. Отпишись, кстати, если сработало с ЛОРой подключить воркфлоу в таверну.
Если всё автоматизировать достаточно хорошо, можно тупо арендовать GPU на полчаса который зафайнтюнит весь твой новый датасет + память + шо ещё там нагенеришь за день
по деньгам тупо $1-2 в день а то и меньше
пока спишь оно тренирует а утром модель уже "помнит" чё было вчера + файнтюн учит её новым паттернам "как предсказывать новые токены исходя из того шо мой хозяин любит фапать на рисованных лолей"
ПИздю, ворую. Редактирую под локалку. Только так. Ну могу еще попросить ллмку отредактировать дефы, но чаще получается что нужно будет еще больше редактировать... так что это слишком спорный вариант.
>Ты в целом так и сделал. Ты скачал ЛОРу Ватамоти, при этом у тебя нет модели.
Мне объяснили это в соседнем треде. Тут мне подсказали что я сделал не так.
Я скачал модель и сделал всё как тут сказали
Но ничего не помогло.


> А о каких моделях вы мечтаете? Что-то +/- реалистичное. Понятно дело не берём в расчет всякие гемма 4 и т.д., это довольно банально.
Дело не в моделях - текущих вполне достаточно. Проблема в инструментах. Нужен нормальный GUI для ролеплея с собственной экосистемой тулзов под function-calling, заточенных именно под РП-сценарии.
Хочется динамическую подгрузку/редактирование стейта через тулзы, но только когда это релевантно контексту (пик 1).
(Agno показывает function-calling вначале, хотя запросы были в середине - стрелками отметил, в какие моменты реально были вызовы)
Чтобы вызывал цепочки рассуждений и внутреннего монолога персонажей, но только когда персонаж реально думает/принимает решение (пик 2), а не вшитый <think> на каждый чих. Офк это должно работать на второстепенных персонажей тоже, если это применимо по контексту, а не только на вайфу.
Прерывание/откат генерации на лету - остановить, откатить на N символов, покрутить семплеры/логит-байасы, продолжить. Таким образом можно бороться со слопом, задав набор нежелательных регулярок (видео 3 - запретил "I" в рассуждениях, но технически можно и более длинные фразы задать, тут чисто для демонстрации концепта сделал с одним символом).
В целом - куча кейсов, где нужны дополнительные запросы (с доп. инструкциями и/или модификацией контекста), тулзы или прерывания, но мы ограничены убогостью как локальных фронтендов, так и бекендов (привет разрабам табби, которые всё ещё не могут сделать поддержку тулзов в XML-формате для ГЛМ/Квена).
А моделей и текущих хватает. При грамотной декомпозиции на агентов даже мелкие модели работают хорошо на ассистентских задачах.
Я заебался убивать время до выхода 4.6 эир
У меня ломка
4.5 не запускал уже месяц ведь вот вот щас выйдет 4.6
У меня ломка
4.5 не запускал уже месяц ведь вот вот щас выйдет 4.6
Какой промт/параметр нужен, чтобы Qwen 30 в размышлениях меньше пиздел? А не то иногда даже в простых вопросах он до 3к токенов использует
Я не о моделях мечтаю, а о нормальном высокоуровневом движке-среде. Чтобы что-то вроде astriks/talemate, но менее специализированное, и с широким нормальным языком скриптига, позволяющими писать что угодно, насколько фантазии хватит.
Чтобы было легко на нем писать нечто вроде VN или текстовой адвентюры/RPG или даже текстовой пошаговой стратегии (типа - управление гильдией приключенцев) с запросами к LLM для диалогов с персонажами и симуляции игрового мира, с возможностью легко парсить и хранить ответы от LLM, и с возможностью кешировать-сохранять-загружать обработанный контекст. Чтобы не приходилось ждать пересчета с нуля для каждого запроса. Вот пример для таверны: чтобы если был запрошен summary, то кеш с обработанным обычным диалогом с персом не сбрасывался, а сохранялся - затем делался процессинг для summary, а потом загружалась обратно сохраненная обработка для персонажа как она была до запроса summary. И хрен там, что это дохрена памяти требует - с nvme уже не очень критично, и все равно быстрее чем полноценный PP для каждого вызова.
А зачем ты вообще ждешь? Используй 4.5 и наслаждайся жизнью
Почему LLama 4 Scout работает быстрее чем GLM Air? Они же одинокого размера, но активных параметров меньше у glm, разве это не означает, что он и работать должен быстрее?
> с возможностью кешировать-сохранять-загружать обработанный контекст. Чтобы не приходилось ждать пересчета с нуля для каждого запроса
> кеш с обработанным обычным диалогом с персом не сбрасывался, а сохранялся - затем делался процессинг для summary, а потом загружалась обратно сохраненная обработка для персонажа как она была до запроса summary. И хрен там, что это дохрена памяти требует - с nvme уже не очень критично, и все равно быстрее чем полноценный PP для каждого вызова.
https://github.com/ggml-org/llama.cpp/tree/master/tools/server#post-slotsid_slotactionsave-save-the-prompt-cache-of-the-specified-slot-to-a-file
https://github.com/ggml-org/llama.cpp/discussions/13606
В жоре кстати такое уже есть - через функционал слотов можно задавать контекстам разные id и сохранять кеш на диск, а после чего, передав правильный id слота в запросе, он будет восстановлен с харда. Осталось всего-то фронт с поддержкой этого запилить, лол.
Так, братик. Тут уже очень странное что-то. Попробуй скачать AutismMix SDXL модель.
>У меня ебля с корпосетками ассоциируется
Опять ты не те вещи пишешь, тут много кто катает корпосетки локально. Вообще последнее время НЕкорпосетки ака файнтюны уже мало кто катает.
>Чем тебя слово параллельные
Ортогональность в этом контексте означает несвязность. Тот же безжоп ты прекрасно можешь катать и на локалках, и это даст другие результаты, нежели на сжопе - просто тут сидят хлебушки, которые с подобным не экспериментируют (по крайней мере, гласно). Про ненужность многоступенчатых обходов цензуры ты можешь рассказать пользователям геммы и гпт осс, они посмеются и отправят тебя нахуй на планету двач.
Единственное, что тут действительно не надо делать - это пробивать внешние фильтры.
А лучше придумай способ связи с тобой, что бы тред не засирать и в прямом эфире разбираться.
>Что-то +/- реалистичное.
>Непрерывное обучение
Это значит не трансформеры. А это увы, не реалистично.
>шо из этого сложно?
Ничего, реализуй.
>пока спишь оно тренирует а утром модель уже "помнит" чё было вчера
Трансформеры так не работают.
Съебитесь в картиночные треды, плиз.
Я щас почитал тредю, и блять, я ведь суммарайзом пользовался когда ещё год назад сидел на 8b моделях. Сейчас не могу потестить, но скажите, на 27b гемме и её тюнах суммарайз ок работает или нужны прям огромные модели чтобы в суммарайзе не выдавало рандомный набор слов?
Обсуждаем и пытаемся запустить один из функционалов Таверны. Какие проблемы? Че злой-то такой? И слепой, ко всему прочему.
Отставить пидорские трения залупами в привате, пишете в тред, это полезная информация которая может понадобится и другим анонам.
Стало гораздо лучше.
Если сможем решить проблему - обещаю написать путь решения в тред. Просто неудобно так. Мне было бы проще понять, что он сделал\делает не так, если бы я напрямую видел что у него там происходит.
Просто репорти хуесосов и все. Если так не делать, то тред окончательно скатится в помойку aicg
Тут тред локальных LLM, а не тред генерации изображений или таверны. Для генерации есть и так несколько тредов. А вы своими высерами просто засрали весь тред. Так что пошел нахуй
>Здесь мы делимся рецептами запуска, настроек
>Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
>Гайд по установке SillyTavern на ведроид через Termux
>Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
Тут помогают человеку настроить Таверну.
Что еще скажешь?
> бот писал текст и закончил не завершив предложение до конца
Проверь, может быть у тебя лимит в таверне на сообщения ответа короткий. Не знаю, какая настройка по дефолту идет сейчас.
1. Просто так.
2. Если у тебя паскали, можно -sm row для плотных моделей.
3. -ts 3,4,3,6,5 для раскидывания в разных соотношениях по картам. Помни, что цифры — не гигабайты, а лишь относительные доли.
Да и все, вроде.
А я-то тут причем, лол? =D
С такими ответами не тем людям, вам бы попить.
Но вообще, я не шарю именно за те вещи, которые обсуждали. Так что хз, добра чуваку, конечно.
Сам-то я пью уже 22 таблеточки, но с ними все океюшки.
> в папку models - checkpoint
> ComfyUI\models\checkpoints
Звучит как капец конкретно и искать ниче не надо было, если честно.
> Значит где то есть ДРУГАЯ папка
Ну или нажать R в комфи, или перезапустить ее, чтобы она (в обоих случаях) увидела модель…
LoRA, это было ожидаемо. =)
Ой, последняя картинка шик! Пояснил на пальцах челу. =)
Вообще, я бы все иначе делал, но я не уверен, что мне стоит в это лезть.
продолжайте.
Это не то. Файтюнить и сейчас можно, это понятно.
Во кстати, напомнили. Было бы хорошо если авторы Pax Historia выложили офлайн версию. Ну или что-то подобное.
>Это значит не трансформеры. А это увы, не реалистично.
Почему?
Условно назовем "динамические слои", куда модель по ходу дела будет вносить новые веса. Ну естественно по умному это сделать, с настройкой приоритетов там, все дела.
Или я что-то упускаю?
Вы, к слову, в курсе, что в жоре поломали все к хуям? Эти гении не имеют регрессионных тестов для мультигпу (https://github.com/ggml-org/llama.cpp/issues/16959). Да и с обычными тестами там, судя по всему, беда.
https://github.com/ggml-org/llama.cpp/issues/17037
https://github.com/ggml-org/llama.cpp/issues/16912
И это еще я не привел пару уже закрытых.
Как они вообще такого уровня продукт разрабатывают без серьезного подхода к тестам? Там же охуеть сколько бекендов и возможных конфигураций. Я удивлен, что вообще хоть что-то работает.
Причем столько корпораций вокруг и хоть кто-нибудь бы им выделил пару ссаных инженеров с билд фермой, чтобы все это настроить.
https://github.com/ggml-org/llama.cpp/issues/17037
https://github.com/ggml-org/llama.cpp/issues/16912
И это еще я не привел пару уже закрытых.
Как они вообще такого уровня продукт разрабатывают без серьезного подхода к тестам? Там же охуеть сколько бекендов и возможных конфигураций. Я удивлен, что вообще хоть что-то работает.
Причем столько корпораций вокруг и хоть кто-нибудь бы им выделил пару ссаных инженеров с билд фермой, чтобы все это настроить.
И как эти случайные цитаты что-то опровергают?
Вы обсуждаете генерацию, ComfyUI и прочую залупу, это не в тематике треда
И раз ты так любишь цитаты, то вот тебе от меня
>пошел нахуй
>Пушистое, не фурри. И с оригинальностью, не дженерик слоп "catgirl roommate in heat".
https://fileport.io/uNhs9A5TWbeR
Мне лень выбирать, вот тебе вся папка. Там по общим тегам распихано. Карточки не чищенные, не забудь суммари почистить и саму карточку глянуть, там часто {} проёбаны.
>Вы, к слову, в курсе, что в жоре поломали все к хуям?
Давай так: а когда там всё работало?
1. гит пулл
2. билд
3. смотришь на скорость
4. упала — откат на рабочий коммит, переборка
Что я делаю не так? =)

Спасибо всем кто помгал. Я таки потратив более 7 часов суммарно случайно заметил, что когда загружается комфи, идет лог файлов. и там есть обращение к папке в моих документах. сука... короче положив туда, все основные проблемы ушли. дальше осталось разобраться и оптимизировать. уже смог сгенерить пару изображений. попробовал через таверну, фон сгенерился быстро. а вот создание фото тормозит систему будь здоров. и даже сгенерило, но не Томо. Ну тут уже дело промта, надо крутить и разбираться.
Еще раз, всем спасибо. Добра.
Еще раз, всем спасибо. Добра.
Анонсы, есть два стула.
Обменять 4090 на 5090 за 65к.
Отнести 4090 умельцам, чтобы они сделали из неё турбину с 48гб врама за 75к.
Что бы выбрали?
Обменять 4090 на 5090 за 65к.
Отнести 4090 умельцам, чтобы они сделали из неё турбину с 48гб врама за 75к.
Что бы выбрали?
>>пока спишь оно тренирует а утром модель уже "помнит" чё было вчера
>Трансформеры так не работают.
тут имеется в виду LoRA к модели содержит данные по предыдущим диалогам, и трансформер вполне даже учитывает эти новые веса
поэтому я взял в кавычки "помнит"
У меня по 20 минут билдит. Лень ждать. Хули они пакет не могут запилить
Умельцы дают гарантию на свою срань? Если да, то +16гб врама интереснее звучит
Но будь я на твоем месте, то я бы сидел и дальше на 4090 и гонял всякое мое на раме, а 65/75к потратил бы на что-то более нужное
Ну шо, заказал себе 96гигов оперативы, скоро придет.
Пойдет движуха
Пойдет движуха
Там от гарантии одно слово, так что я бы не рассчитывал.
У меня вот ддр4 все еще и что-то все, что выходит за пределы врама капец какое медленное.
В прошлом треде ищи пост, давали линк на пресеты от icefrog чтототам, но это полный набор рп-правил, с которым ризонинг всегда идет по шаблону. Очень коротко и по делу, может быть не со всеми моделями работает

>Или я что-то упускаю?
Да. Ни одна такая инициатива не сработала, иначе бы давно внедрили бы.
>Вы, к слову, в курсе, что в жоре поломали все к хуям?
Алвайс бин, пикрил.
>Причем столько корпораций вокруг и хоть кто-нибудь бы им выделил пару ссаных инженеров
Зачем, когда можно переманить их к себе?
5090 офк, блеквел рулит.
>поэтому я взял в кавычки "помнит"
Кавычки слишком жирные выходят. Тут или ноль эффекта, или ужаренность и цитаты прошлых чатов не к месту.
>Умельцы
>гарантию
На ноль умножил.
Рад, что у тебя получилось, анончик. Признаться - думал в сторону того, что может какой cfg настроен на иную папку. Рекомендую поковыряться в этом деле.
Что же касается генерации - создай воркфлоу с лорой. Выше я тебе гайд дал. Пусть лора будет загружена в воркфлоу комфи, а в таверне загружай уже сам воркфлоу. Поставь все позитивы со страницы твоей лоры, не забудь.
Сколько по времени у тебя Таверна генерит изображение?
Купить ртх 3090 или пересесть на 96 гигов ддр5 с ебучей ддр4?
Алсо где вообще б/у видимокарты не от майнеров берете? Неужели с лохито?
Алсо где вообще б/у видимокарты не от майнеров берете? Неужели с лохито?
Если ты не генерируешь видосики/картинки, то купить на эти деньги 3090 + 3060. Если генеришь, то 5090 без вариантов.
Давай без выпендрежа.
>Что я делаю не так?
Отвечаешь не совсем по теме. Сегодня у тебя одна конфигурация, завтра другая, послезавтра ты решишь погонять старый добрый лардж, не подозревая, что полгода назад он работал на 30% быстрее.
А конкретно в твоем флоу "не так" - это пересборка, я храню последние три сборки у себя. Проблему выше, конечно, это не решит.
>пикрил
лол
>Зачем, когда можно переманить их к себе?
А говорили же, что Жора уже на зарплате сидит? Или мне почудилось и там до сих пор чистый энтузиазм?
Ничесе, будем посмотреть, спасибо. Пока непонятно ультанул или меганасрал, но хотябы парочка потенциально хороших есть, спасибо.
> Обменять 4090 на 5090 за 65к.
Если с доплатой тебе то норм вариант, если доплачиваешь ты - выглядит как кидок.
> сделали из неё турбину с 48гб врама за 75к
В дефолтном турбо-исполнении станет очень шумной для десктопа, стоит делать только если ты не привередлив к шуму или она будет стоять в риге. Ну или конвертировать на водянку если предлагают.
В задачах генерации картинок (хайрезы или жирные модели) и видео 5090 будет в 1.5-2 раза быстрее, в ллм же лишние 16 гигов очень зарешают.

Интересно, это какой-то лох или сам лоха ищет. Пишет, карта сдохла, но инфы подозрительно мало.
Нету б/у карт не от майнеров, смирись.
>3090 + 3060
Даунгрейд с 4090 ради нахуя? Лучше уж просто докупать 3060/3090.
>Если с доплатой тебе то норм вариант
>>4090 на 5090
Поех что ли? 5090 дороже.
>в ллм же лишние 16 гигов очень зарешают
Чем именно? Тут или МОЕ, и +- будет быстро, или не МОЕ, но тогда что? Ничего интересного из плотных на 70B не выходило, а для 100+ 48 гиг врама всё равно не хватит на фулл врам.
с) Оба варианта верны
> Даунгрейд с 4090 ради нахуя?
Скорее он предлагал докупить сверху 3090+3060.
> 5090 дороже.
Внезапно нет, или дороже совсем незначительно. Разумеется речь про хорошую живую карточку, а не полумертвых инвалидов с отвалившимися каналами памяти, диффлиниями шины и прочим добром, которыми сейчас завалено лохито. Живые от 190-200, исключения быстро улетают.
> Тут или МОЕ, и +- будет быстро
Чем больше слоев экспертов на гпу тем быстрее будет.
> Если ты не генерируешь видосики/картинки, то купить на эти деньги 3090 + 3060. Если генеришь, то 5090 без вариантов.
Генерю..
> Если с доплатой тебе то норм вариант, если доплачиваешь ты - выглядит как кидок.
Я доплачиваю, есесно. Моя бу 4090 палит (не майнил, нареканий нет, брал на релизе в днс)+65к на 5090 новую, тоже палит.
> В дефолтном турбо-исполнении станет очень шумной для десктопа, стоит делать только если ты не привередлив к шуму или она будет стоять в риге. Ну или конвертировать на водянку если предлагают.
Вот тоже к этому пришел. Но вариантов апгрейда 4090 на 48гб + сжо не нашёл. Только уже готовые карты с Китая за овердохуя. А турбина да, для пеки, а не ллм рига как будто шиза.
В общем, надо думать
>Пушистое, не фурри. И с оригинальностью, не дженерик слоп "catgirl roommate in heat".
https://www.characterhub.org/characters/anonemouse/sunny-6992e0879dbf
>Поех что ли? 5090 дороже.
Из-за возможности перепайки 4090 котируются так же. Посмотрю что запоёте, когда появятся китай версии на 72 гига на банках выпаянных из 5070tis
> Посмотрю что запоёте, когда появятся китай версии на 72 гига на банках выпаянных из 5070tis
Разве на 5070ти не gddr7?
+ Я не думаю, что физически на ad102 можно повесить памяти больше, чем на их же ada 6000.
Поправь, если я ошибаюсь
>Разумеется речь про хорошую живую карточку
Которую хуй отличить от ужаренной, которая дольше дня не проработает. хорошее вложение 200 кусков!
>Живые от 190-200
Что больше 230, так что тезис "5090 дороже" всё ещё верен. При этом 5090 будет с магаза с гарантией.
>Чем больше слоев экспертов на гпу тем быстрее будет.
3,5 эксперта погоды уже не сделают.
>+65к
Чёй то дохуя. В +30 можно уложится, учитывая разлёт цен. Твой барыга жадный, ищи другого или продавай сам.
>китай версии на 72 гига
Невозможны.
> Я доплачиваю, есесно. Моя бу 4090 палит [..] на 5090 новую, тоже палит
Ну смотри, бодренький бу 4090 палит торгуется где-то по 200, за 185-190 улетит быстро, только барыги заебут торговаться. Новая 5090 из интернет магазина с гарантией ~210к если поискать (недавно проскакивали по 215 на яндексе, 219 на озоне, ~250+50к баллов там же и т.д.). ~200к с более сомнительной гарантией или минимально бу на гарантии. Цены дс если что.
Тот, кто предлагает тебе доплатить 65к - барыга и наживается не незнающих людях. Дело, офк, твое, может ты мажор, которому это не деньги. Но даже когда средства есть играет принцип не поддерживать паразитов, просто продай и купи 5090, или найди где предложат адекватные условия, а не барыжную муть дороже попсовых сетевых магазинов.
> + сжо не нашёл
Если не хочется с Китая - те же местные умельцы это делают, в треде писали об этом. Правда хз есть ли сейчас у них подходящие киты или все задержано.
> https://www.characterhub.org/characters/anonemouse/sunny-6992e0879dbf
> Your puppygirl girlfriend legally has no human rights
Oh you
> когда появятся китай версии на 72 гига на банках выпаянных из 5070tis
Имеешь ввиду перепайку 5090 на 3-4гиговых чипах? Хотелось бы.
> хорошее вложение 200 кусков!
Никто не предлагает их бежать покупать, желающих и так хватает.
> Чёй то дохуя. В +30 можно уложится, учитывая разлёт цен. Твой барыга жадный, ищи другого или продавай сам.
> Ну смотри, бодренький бу 4090 палит торгуется где-то по 200, за 185-190 улетит быстро, только барыги заебут торговаться. Новая 5090 из интернет магазина с гарантией ~210к если поискать (недавно проскакивали по 215 на яндексе, 219 на озоне, ~250+50к баллов там же и т.д.). ~200к с более сомнительной гарантией или минимально бу на гарантии. Цены дс если что.
> Тот, кто предлагает тебе доплатить 65к - барыга и наживается не незнающих людях. Дело, офк, твое, может ты мажор, которому это не деньги. Но даже когда средства есть играет принцип не поддерживать паразитов, просто продай и купи 5090, или найди где предложат адекватные условия, а не барыжную муть дороже попсовых сетевых магазинов.
Спасибо, аноны. Буду думать, теперь уже вооруженный знаниями.
--parallel 6 например?
> А конкретно в твоем флоу "не так" - это пересборка, я храню последние три сборки у себя.
Зачем? Ты же можешь откатиться и собрать то, что у тебя было до этого.
> Отвечаешь не совсем по теме.
Проблема преувеличена.
Да, плохо что не тестят, безусловно. Я не оправдываю их ни разу.
Но они и так все пилят бесплатно, и за всем не уследишь, какие уж тут претензии. А с минимальным контролем версии (который встроен в саму концепцию хранения llama.cpp на гитхабе) проблема легко нивелируется.
> послезавтра ты решишь погонять старый добрый лардж, не подозревая, что полгода назад он работал на 30% быстрее
Очень натянуто.
А завтра ты выйдешь за хлебом, а упавший кирпич разобьет твой компьютер, гребанный Герганов закидывает их тебе в окно.
Ну тако-о-ое-е…
Для «мои любимые модели» я храню конкретные сборки. Для всего остального актуального я помню значения (которые были вчера).
Ситуация, где это становится реальной проблемой, вызвана наплевательским отношением со стороны клиента, а не только разработчика.
> А говорили же, что Жора уже на зарплате сидит?
Круто, а у кого, и сколько миллионов в месяц ему платят?
Для видосов 100% 5090, разница в 50% по скорости охуеть как выигрывает. 48 гиговая только под ЛЛМ.
Чел, не билди на кофеварке и всё будет быстро
>Имеешь ввиду перепайку 5090 на 3-4гиговых чипах? Хотелось бы.
>72/32=2,25
Интересный объём чипа, я бы сказал.
>Я не думаю, что физически на ad102 можно повесить памяти больше, чем на их же ada 6000.
Когда китайцы стали продавать свои 48гб версии, они грозились что сделают ещё вдвое большие. Тогда все посмеялись, но не потому что это невозможно, а потому что откуда у китайцев возьмутся такие вместительные чипы? Тут только 3гб осваивают.
https://club.dns-shop.ru/digest/139372-kitaiskie-proizvoditeli-mogut-vyipustit-geforce-rtx-4090-s-96-gb/
>те же местные умельцы это делают
Не делают, но обещают скоро начать.
>или все задержано.
пока что так, да.
>Oh you
До гритингов не дошёл?
>Зачем?
Тебе ответили выше же, собирается долго. Да даже если быстро, к чему лишние телодвижения.
>Очень натянуто.
Не натянуто, это реальность. Думаешь, много людей сидят проверяют все старые модели на регрессию перфоманса? Особенно большие. Я уверен, что никто этого не делает, да и не должны, должна автоматика красивые графички строить.
>Для «мои любимые модели» я храню конкретные сборки.
А что если перфоманс вырастет в новых сборках?
Это путь в никуда (точнее - в абы как), ты перекладывашь проблемы разработки на плечи юзеров. Для серьезного продукта отсутствие вменяемого регрессионного тестирования - это пиздец и приводит к тому, к чему приводит. Ну а если считать жору васянской поделкой, то вопросов нет, будем сортировать бинарники в папочках.
Купи всем тредовичкам новый процессор. А лучше сразу риг из 4090 и 5090 как у местного экссламщика, мы вообще билдить не будем, а вальяжно setup.sh-ить! Слабо? То-то же.
К команде билда добавь -j и соберется быстро.
> Интересный объём чипа, я бы сказал.
открыл форточку ну очепятался/обсчитался человек, че душнишь то. Пусть поясняет.
> https://club.dns-shop.ru/digest/139372-kitaiskie-proizvoditeli-mogut-vyipustit-geforce-rtx-4090-s-96-gb/
Вроде же окрестили как фейк, совсем в начале года было. Разве что сумрачные гении запилят совсем уж безумную плату с кучей чипов, а то gddr6 таких объемов не делают.
> Не делают
Еще в сентябре активно делали, была движуха. Может уже все запасы апгрейд-китов истратили а новые на таможне стоят.
> До гритингов не дошёл?
Еще не пробовал, пока решил с жорой попердолиться. Там что-то странное/мерзкое/рофловое?
Ладно, признаю, зря гнал на моэ. Запустил меньший по сравнению с глм квант свежего тюна лламы 405:
prompt eval time = 32699.46 ms / 1431 tokens ( 22.85 ms per token, 43.76 tokens per second)
eval time = 135207.75 ms / 251 tokens ( 538.68 ms per token, 1.86 tokens per second)
на глм в 10 раз больше тг...
В общем-то, в пизду эти плотные модели (еще и пишет односложно)
prompt eval time = 32699.46 ms / 1431 tokens ( 22.85 ms per token, 43.76 tokens per second)
eval time = 135207.75 ms / 251 tokens ( 538.68 ms per token, 1.86 tokens per second)
на глм в 10 раз больше тг...
В общем-то, в пизду эти плотные модели (еще и пишет односложно)
Да, забыл про эту хуйню, теперь по 3 минуты билдится. Но все равно, лучше бы они пакет запилили. Хотя он есть в brew, но мне он не нравится и у меня еще cuda там из коробки не завелась
7500f, хули. Но если хочешь подкинуть на 8-ядерник, то я не против
Запили сам и сделай мр. Либо пользуешься тем что дают, либо прикладываешь руки

Забыл еще один вариант. Просто нахуй послать llama.cpp и пользоваться одной из его однокнопочных оболочек. Так собственно и поступает большинство. А потом жора ноет, что его опять все забыли
Ради бога используйте раз там единороги и бабочки. Откуда только тогда берутся люди которые на жоре сидят?
Потому что оболочки хуже жоры. Но чтобы это понять нужно из исходников собирать, а среднестатистический пользователь (даже тот, кто использует локалки) не будет это делать никогда. Из-за этого непосредственно сама жора будет всегда на дне. Особенно при наличии таких долбоебов как ты, которые любую хуйню будут оправдывать
В релизах есть билды под вин, в реджистри под жокер. Чего ещё нужно то?
Для винды exe'шник нужен, иначе пользователь не разберется.
А вообще я говорю о том, что из-за того, что жора не сделал сайт с установщиком, в нашем мире не только существует такое говно как ollama, но оно еще и стало де-факто стандартом
Квен, но это именно в задачах и с ризонингом.
Другое дело РП. Судя по всему, у квена чуть ли не весь датасет состоит из какой-то математики и ты получаешь экспириенс реально хуже, чем на мистрале.
Вот квен пожирнее уже могет в рп. А 30б, да, соблюдает инструкции лучше и логичней, но creative writing хуже.
Анон, скажи, а какие промпты ты используешь для общения с персонажами? У меня почему один и тот же промпт ведет себя по разному на разных персонажах. Где то он работает, а где то начинает бесконечно пиздеть не давая мне ответить. Подскажи, как правильно делать?
Подскажите модельку без цензуры, что бы из коробки могла писать промпты для wan.
> такого уровня
Какого? Любительского для бичей (без обид)? Для "такого" уровня вллм и трансформерсы есть.

>Вроде же окрестили как фейк
Это было понятно, ведь
>gddr6 таких объемов не делают
И это главный аргумент против.
>а новые на таможне стоят.
Точно стоят, ведь сами платы под апгрейд только в Китае делают.
>странное/мерзкое/рофловое?
Всего вместе. Такой концентрации больше не видел.
> Думаешь, много людей сидят проверяют все старые модели на регрессию перфоманса?
Ну точно больше, чем «возвращаются на мистраль лардж», и вообще явно больше, чем хранят старые модели.
Это прям совсем уникальные юзкейсы.
> ты перекладывашь проблемы разработки на плечи юзеров
Нет, я писал выше почему.
> Для серьезного продукта
Это не серьезный продукт. Он никогда им не был, не заявлялся, не являлся и никакими признаками серьезного продукта не обладает.
Даже количество пользователей — существенно ниже оллама (привет звездочки) или там вллм и сглангов.
То, что он держит на своих плечах весь любительский инференс не делает его виноватым в том, что у него нет возможности вести проект как коммерческую программу.
Да понятное дело, что можно лучше. Я не спорю с этим нисколько. Есть куча мест, где можно улучшить что-то.
Но это ж опенсорс проект, где люди в свободное время делают для всех бесплатный софт в довольно узкой сфере.
Посмотри на условный nginx — им пользуется 33% интернет-сайтов. А сколько сайтов/сервисов/чего хошь использует LLM? Ну, как бы. Меньше спрос, меньше хайп, ниже чувство ответственности.
Они не правы в подходе к созданию огромной коммерческой всемирной разработки, но их можно понять и простить, учитывая что это маленький нишевий опенсорс-проект на данный момент.
ИМХО.
А, и кстати, забыл сказать.
Помните про «запланированное устаревание» драйверов Nvidia?
Ну, там, где для разных игр они выпускают оптимизации и иногда эти оптимизации друг друга перекрывают, и из-за выхода новой игры, замедляются старые?
Ну, бля.
ИМХО, очень похоже. Выходят новые модели, они пилят поддержку для них, а то, что мистраль лардж полуторалетней давности стала медленнее, им просто немного похую становится, они и не помнят, и не проверяют.
Звучит как разработка уровня нвидия. =D
Помните про «запланированное устаревание» драйверов Nvidia?
Ну, там, где для разных игр они выпускают оптимизации и иногда эти оптимизации друг друга перекрывают, и из-за выхода новой игры, замедляются старые?
Ну, бля.
ИМХО, очень похоже. Выходят новые модели, они пилят поддержку для них, а то, что мистраль лардж полуторалетней давности стала медленнее, им просто немного похую становится, они и не помнят, и не проверяют.
Звучит как разработка уровня нвидия. =D
> Думаешь, много людей сидят проверяют все старые модели на регрессию перфоманса?
Дело не в старине, регрессия может случиться на определенных архитектурах где использутся что-то специфичное, что затронуто. Конечно, расширение тестов это всегда хорошо, действительно могли бы помочь.
А что за тема с ларджем, он действительно замедлился? инб4 его никто не катал на жоре
> ты перекладывашь проблемы разработки на плечи юзеров
Ну не, исходный код, инструкция по сборке, готовые билды, докер со всем нужным где за минуту-другую билдится свежая - всего этого достаточно. Здесь наоборот распыляться и тратить время на поддержание зоопарка контейнеров ради зоопарка контейнеров в таком быстроразвивающемся и очень универсальном софте - неразумно. 4 варианта билдинга цп-онли, метал, интеловские гпу, куда с дюжиной опций, вулкан, рокм, и еще с пяток экзотических опций. С коммитами каждый день.
Аргумент уместен, когда предлагают какое-то около-энтерпрайз решение, которое именно так распространяется и используется. А тут наоборот 99.9% юзеров нужны или готовые билды, или собрать самостоятельно из сорцов. Тем не менее, есть люди, которые занимаются контейнеризацией llamacpp, поищи.
Опровергали много раз.
> Опровергали много раз.
Опровергали, что они выкатывают оптимизации для новых игр и видеокарт, которые пересекаются в коде со старыми?
Т.е., ты утверждаешь, что они намеренно замедляют старые игры и старые видеокарты?
Окей, не слышал ни разу, но если кто-то из программистов опровергал официальную точку зрения Nvidia, то допустим. Как скажешь.
Опровергали что они специально сознательно замедляют старые видеокарты, херню которая активно форсилась с давних времен. Фейлы встречаются у всех, но в этом случае они усиленно натягиваются на глобус ради хайпа.
> оптимизации для новых игр и видеокарт, которые пересекаются в коде со старыми
Давай подробнее об этих "пересечениях", выглядит будто ты не совсем в курсе принципов оптимизаций драйверов под игорь.
Алсо почему не вкидывали рофлы с амд, как они заявили об похоронах 6к серии видеокарт, но потом пошли неловко переобуваться, настолько всем похуй на них?

У меня 3070 8гб врам, 32гб ддр4, i5-12400f.
Что я могу запустить на своей кофеварке, какая сейчас самая топ модель, подходящая под эти требования, на чём запускать?
Всем два чая за ответы.
Что я могу запустить на своей кофеварке, какая сейчас самая топ модель, подходящая под эти требования, на чём запускать?
Всем два чая за ответы.
Твой предел - 8b модели.
На чём запускать и какая топ модель для рп? Насколько хватает памяти у неё?

Почему эмбеддинги провалились? Обещали невъебенный интеллект, а и в итоге?
>какая сейчас самая топ модель
https://huggingface.co/unsloth/Mistral-Small-3.2-24B-Instruct-2506-GGUF
>а чём запускать?
koboldcpp
>Что я могу запустить на своей кофеварке, какая сейчас самая топ модель, подходящая под эти требования, на чём запускать?
>Шапка
>Актуальный список моделей с отзывами от тредовичков версия для бомжей: https://rentry.co/z4nr8ztd
>Инструменты для запуска на десктопах
>Самый простой в использовании и установке форк llamacpp https://github.com/LostRuins/koboldcpp
>универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
Так я так и сказал.
А ты возразил, что опровергали, что это случайность, и так и задумано.
> Давай подробнее об этих "пересечениях", выглядит будто ты не совсем в курсе принципов оптимизаций драйверов под игорь.
Только не я, а Nvidia, ибо это их цитирование.
Лень искать, но это было в интервью Pro HiTech, поищи на их канале. Там они пришли прямиком к представителям (тогда еще нвидиа не ушла из России) и какой-то их чел (допускаю, что он не технарь и он как раз и ошибается) так объяснил.
Они как раз и опровергли тем видосом, что это запланированное устаревание, что я и написал в первом сообщении.
> Алсо почему не вкидывали рофлы с амд, как они заявили об похоронах 6к серии видеокарт, но потом пошли неловко переобуваться, настолько всем похуй на них?
А причем тут это к llama.cpp? Думаешь, у АМД такие же бюджеты, как у Герганова? =D
Я просто покекал, конечно. Пока у Нвидиа дрова на 750ti обновляются, АМД 6ххх версию прикрыла. Потом переоткрыла обратно, но смешок остался.

Обновил летом видеокарточку, с gtx 1660s на 4070ti, и вот уже полгода кусаю локти что не взял 3090 за те же деньги. Сетап ам4 мамка, 16ддр4 рам.
Не был уверен что мне вообще зайдут ллм, поэтому решил вкатиться на 12врам полшишечки, и если зайдёт то думать о ригах на старых картах, поскольку вроде как память важнее производительности. Ну и аргументов в пользу 4070ти дохуя было, мощнее, новее, меньше жрёт(не был уверен что пожилой питальник на 800вт вытянет новую печь). А в результате мне зашли локалки, и я хочу иметь виртуального помошника на компе в оффлайне, но сука все сборки на теслах p40, амудях mi50, epyc amd, серверных зионах нихуя не дешевые и влетят в копеечку, и будут сопровождаться ёблей с настройкой, плюс мне ещё нужно под это всё где-то доставать комплектующие под второй комп.
В результате получается что самым простым решением было бы поставить 3090 и купить ддр4 плашек по 32гб, и это был бы мой максимум любительского сетапа, с минимальными затратами при условии перепродажи 4070ti.
Вопрос в чем, я сильно почувствую разницу? Станут ли 70b модельки в два раза умнее Геммы 27 и Мистраля 24? Откроется мне доступ к тем самым крутым мое моделям на 200б, которые в тредах упоминаются?
Или если я хочу прям умного виртуального помощника, который будет по уровню как онлайновый дипсик/гопота, то стакать карточки в риге это единственный выход?
Чё посоветуете:
1) Поменять 4070ти на 3090 и докинуть оперативы.
2)Собрать второй комп чисто под ллм на p40/mi50 или чём то ещё.
3) Ещё можно попытаться через Райзер впихнуть 1660 в комп к 4070ти, хз будет это работать или нет.
4)Забить хуй и подождать годик пока Хуня выпустит Суперы/Китайцы наделают самопальных альтернатив/Нейросетевая лихорадка сдуется.
Бюджет 50-100к деревянных на всё, больше жаба душит тратить на игрушку. Как летом душила отдавать 20к за +4ГБ Врама у 5070ти/4070 ти супер, Хуанг мудак.
Не был уверен что мне вообще зайдут ллм, поэтому решил вкатиться на 12врам полшишечки, и если зайдёт то думать о ригах на старых картах, поскольку вроде как память важнее производительности. Ну и аргументов в пользу 4070ти дохуя было, мощнее, новее, меньше жрёт(не был уверен что пожилой питальник на 800вт вытянет новую печь). А в результате мне зашли локалки, и я хочу иметь виртуального помошника на компе в оффлайне, но сука все сборки на теслах p40, амудях mi50, epyc amd, серверных зионах нихуя не дешевые и влетят в копеечку, и будут сопровождаться ёблей с настройкой, плюс мне ещё нужно под это всё где-то доставать комплектующие под второй комп.
В результате получается что самым простым решением было бы поставить 3090 и купить ддр4 плашек по 32гб, и это был бы мой максимум любительского сетапа, с минимальными затратами при условии перепродажи 4070ti.
Вопрос в чем, я сильно почувствую разницу? Станут ли 70b модельки в два раза умнее Геммы 27 и Мистраля 24? Откроется мне доступ к тем самым крутым мое моделям на 200б, которые в тредах упоминаются?
Или если я хочу прям умного виртуального помощника, который будет по уровню как онлайновый дипсик/гопота, то стакать карточки в риге это единственный выход?
Чё посоветуете:
1) Поменять 4070ти на 3090 и докинуть оперативы.
2)Собрать второй комп чисто под ллм на p40/mi50 или чём то ещё.
3) Ещё можно попытаться через Райзер впихнуть 1660 в комп к 4070ти, хз будет это работать или нет.
4)Забить хуй и подождать годик пока Хуня выпустит Суперы/Китайцы наделают самопальных альтернатив/Нейросетевая лихорадка сдуется.
Бюджет 50-100к деревянных на всё, больше жаба душит тратить на игрушку. Как летом душила отдавать 20к за +4ГБ Врама у 5070ти/4070 ти супер, Хуанг мудак.
Видеокарта мусор, по этому запускать придется тоже мусор. Но если собираешься тупо мозолить залупу, возможно отвращения не почувствуешь. Варианта два: тюны мистрали на 12B и тюны мистрали на 24B
Старшая будет ползти с 2-3 токенами в лучшем случае, младшая будет побыстрее, но мозгов там меньше. Что и через как запускать описано в шапке и документациях таверны с кобольдом.
> Так я так и сказал.
То больше похоже на брюзжание по поводу что "хуанг замедляет", если неверно тебя понял не серчай. А эти самые "оптимизации игр драйвером" в большинстве случаев это тот еще хардкод буквально под конкретный тайтл, они не могут друг друга поломать. Подобный кейс может случиться уже от глобальных изменений, и по сути фейл, а не закономерность.
> А причем тут это к llama.cpp?
Орать с юродивых, при чем тут llama.cpp? Только и остается, с одной стороны куртка выкручивает яйца и устраивает аукционы за лопаты, с другой родственница из кожи лезет чтобы ненароком не составить конкуренцию, ударяясь уже в полнейший кринж типа гддр6 на флагманской карте в 2025 году.
Если финансовые затраты приемлемы - ты можешь поставить 3090 в тот же комп через райзер, не выкидывая 4070ти, а продав 1660 купить апгрейд рам. Ну и бп придется таки обновить.
В качестве первого шага можешь просто докинуть рама и пускать эйр. Но уже на нем, и тем более на чем-то больше, упрешься в размер врам - даже сгрузив всех экспертов на проц много контекста не влезет, потому вторая видеокарта крайне желательна. 70б давно не обновляли и для них от 48 гигов нужно чтобы комфортно, сможешь катать моэ.
Также можешь дождаться 5070ти супер, есть шанс что отсыпят 24гига.
> как онлайновый дипсик/гопота, то стакать карточки в риге это единственный выход?
Ну типа можно запустить квант квэна имея 128гигов. Но это будет не супер быстро и возможно заметишь косяки кванта. В теории можно вместить лоботомита большого glm еще.
Все зависит от бюджета, под каждый будет свой оптимум. Хорошим вариантом является серверная платформа с видеокартой, сможешь катать тот же дипсик с приемлемой скоростью. Только нужна современная на ддр5, а то судя по опытам, прошлые не очень то и шустры.
>Также можешь дождаться 5070ти супер, есть шанс что отсыпят 24гига.
Там вроде проскочила на днях инфа что из-за дефицита памяти супер моделей вообще может не быть. И учитывая этот же дефицит памяти, я бы не расчитывал на щедрость в 24гб в 5070.
> 4070ti
> 3090
Ну я.
Но я как стал видео генерить — перестал жалеть.
(ну и парочку 128-гиговых компов с теслами немного поправили жизнь, конечно).
Но в моменте было грустно, я понимаю тебя.
> Бюджет 50-100к деревянных на всё
ИМХО, я бы не торопился именно сейчас.
На оперативу ты уже опоздал, чисто 3090 тебя не спасет, p40/mi50 вариант так себе… Может че будет получше в будущем.
> "оптимизации игр драйвером" в большинстве случаев это тот еще хардкод буквально под конкретный тайтл
Да-да-да, но тот нвидиа-спец говорил, что именно это и ломает.
Но опять же, я не помню, кто он там, может менеджер какой или пиарщик, и просто хуйни в интервью насрал.
Энивей, мое сравнение было в том, что когда Герганов что-то делает в ллама.спп новое и при этом ломает старое — это тоже не со зла или от безделья. Просто за всем не уследишь, и приоритеты такие, что новые модели ллм (по аналогии с новыми видяхами/играми) получают оптимизации и фокус внимания, а старые уже а забыты…
> Также можешь дождаться 5070ти супер, есть шанс что отсыпят 24гига.
По новостям от инсайдеров, перенесли на 3 квартал 26 года. Плюс полгода ожидания. =(
Но вариант-то отличный, канеш.
Таки будут, но позже.
> из-за дефицита памяти
Ля ну пиздец, тряска на заводах как несколько лет назад, или китайцы все скупают?
> это тоже не со зла или от безделья
Конечно, фейл, понять простить. Да, там фейл на фейле, можно долго хейтить, говорить что тормозит все направление и т.д. Но при отсутствии врам, а сейчас планка к ней выросла, альтернатив толком нет. По-хорошему, нужно взять и с чистого листа переписать, уже с учетом оптимизации расчетов на куде и линейных слоев на профессоре, в идеале вообще на питорче. Но тут даже корпы себе позволить такого не могут, опираясь на llamacpp, и потребность в подобном исходит только от "продвинутых энтузиастов" коих мало.
Больше горит когда делают изменение, получая хороший буст везде, но принося в жертву какое-нибудь легаси, так поднимается такой вой и нытье что еще на этапе обсуждения бракуется.
> на 3 квартал 26 года
Тогда без вариантов, слишком долго ждать. 3090 и сидеть пердеть.
> mi50
Опоздал. 50к
>можешь дождаться 5070ти супер, есть шанс что отсыпят 24гига
Это еще откуда всплыло? По сливам известно только о 18 гиговой 5070 супер и 5080 супер на 24 гига, покажут их в январе, в продажу выкинут где-нибудь ближе к лету
>Ля ну пиздец, тряска на заводах как несколько лет назад, или китайцы все скупают?
Корпы всё скупают. Китайские в том числе, но значительно в меньших количествах, ибо товар стратегический и никто делится им не хочет.
У тебя по сути только один вариант из нормальных это Qwen 30b
https://huggingface.co/unsloth/Qwen3-VL-30B-A3B-Thinking-GGUF
Квант Q4XL. Он может распозновать картинки, у него есть ризонинг (размышления), причем есть вариант и без них. И что самое главное он будет у тебя относительно быстро работать.
Этот будет медленнее точно и скорее всего хуже. Но будет в рп лучше
>на чём запускать?
Лучше всего llama.cpp, потому что там есть ncmoe. Но это для новичка будет слишком сложно, поэтому лучше либо kobold, либо LM Studio. В последних двух есть cmoe и тебе нужно найти его и включить обязательно
И да, в шапке есть инфа И там вроде даже есть какой-то тюн квена для рп
>На оперативу ты уже опоздал
Ля, я тоже опоздал. Пиздец. Хотел взять 64гб, а они все с 15 до 20 подорожали. Сука. Придется видимо говно на 5200 брать вместо нормальных
> подорожало на 5к
Пиздец, неподъемная сумма теперь.
Это то самое дорожание из за которого все трясутся?
Приходите трястись когда цена х3 даст

онаны, кто-нибудь сравнивал производительность разных версий лламы.цпп?
жопой чую, что старые версии быстрее новых, но качать-конпелять-проверять лень, особенно если кто-то это уже делал.
жопой чую, что старые версии быстрее новых, но качать-конпелять-проверять лень, особенно если кто-то это уже делал.
> Это то самое дорожание из за которого все трясутся?
https://www.wiredzone.com/shop/product/10032079-samsung-m321r8ga0eb2-ccp-memory-64gb-ddr5-6400mhz-rdimm-low-profile-mem-dr564mc-er64-14776
в сентябре было 309 за штуку
в начале октября заказал по 362 за штуку
в середине октября 415
в начале ноября 517
всего-то +50% в месяц, никакой тряски.
Нихуя, очередной бизнесмен на харкаче. Ты либо кинь анонам на карту пятерку, либо завали ебало
Спасибо за развёрнутый ответ по делу, анонче. Сейчас попробую!
О, о, и мне, пожалуйста, 23к накинь, браток, а то подорожала чутка, брал за 45999 https://www.dns-shop.ru/product/9ed2387b62bfd9cb/operativnaa-pamat-gskill-trident-z5-neo-rgb-f5-6000j3444f64gx2-tz5nr-128-gb/ а щас 68999 чой-то. Тебе ж это не подорожание, копейки.
А у меня как раз еще 2 слота есть, добью до 256, запущу кими-к2.
всего на 50% подорожала, чего бухтишь? мировая практика
У меня при использовании LLM частота видеопамяти срезается на 250мгц. Причем в играх ничего не срезается. Это нормально?
Почему ассистента так сложно разцензурить?
В рп вообще проблем нет, а как хочешь пообщаться с ассистентом то сразу сейфти гайдлайнс лезут и вообще не пробить, только префилом
В рп вообще проблем нет, а как хочешь пообщаться с ассистентом то сразу сейфти гайдлайнс лезут и вообще не пробить, только префилом
Потому что в рп уже насрано куча промта, а с ассистентом ты скорее все почти без него общаешься. Пропиши промт нормальный, каким ты хочешь видеть ассистента и если это не гемма, то все заработает

Что из этого выбирать, чтобы включить cmoe в кобольде?
Не так хорошо в kobold помню
Поставь GPU Layers 99. И MoE CPU Layers тоже 99.
А потом по идее меняй MoE CPU Layers и с чем меньшим значением запуститься, тем быстрее будет
>и если это не гемма
Что сразу гемма? Есть же фи в качестве образца цензуры.
С недавних коммитов ощутимо просела пп на фуллврам, немного просела пп с выгрузкой. По генерации вроде без изменений, но выросли компьют буферы или что-то еще - в той же конфигурации что раньше работала оом.
Блять, какой же все таки колхоз творится в жоре, попытавшись детально разобраться сгорела жопа. Вроде бы хорошо и логично заданные вещи оверрайдятся в какой-то жопе, подстраиваешь под это - а оказывается что в третьем месте все еще раз перезадается. Все настолько сложно, что даже основные контрибьюторы, что хорошо ориентируются, ошибаются и потом сами удивляются открытиям.
Особые приколы с кв кэшем из-за реализации нескольких старых патчей по его распределению. При удачном раскладе он может оказаться неправильно распределенным между карточками даже без вмешательства юзера, что спровоцирует замедление если карты сидят не на быстрых шинах.
Того - что с ней тоже сработает, только не сразу - мороки чутка больше. Капризней она на данную тему.
Ну так на то оно и bleeding edge. Вечная альфа, "одно лечим - другое калечим".

Кто в обучении геммы участвовал, признавайтесь?
Последнее предложение шедеврально.


захожу в тред, ни одного поста про v100.
Вы чего, пацаны?
https://www.youtube.com/watch?v=G5DBks2IsYI
У нас тут заявка на новую БАЗУ треда между прочим.
Копры выкинули v100 в срынок. Почему обсуждения нет?
16 гб - 8к, 32 гб - 40к. (плюс еще охлад и переходник на pcie)
Вы чего, пацаны?
https://www.youtube.com/watch?v=G5DBks2IsYI
У нас тут заявка на новую БАЗУ треда между прочим.
Копры выкинули v100 в срынок. Почему обсуждения нет?
16 гб - 8к, 32 гб - 40к. (плюс еще охлад и переходник на pcie)
Как же я орнул. А картинку покажешь? Чисто академический интерес.
Из игры Tales of Androgyny скрин где глав героя анально сношают
Почему в твоём манятесте 5060 быстрее 4090, лол?
это не мой тест, это скрин из видео
Все мы, этот тред дербанится на датасеты. Самый треш и активные срачи фильтруются, но можно оставить свой след, или специально спамить паттерны, чтобы потом их встретить.
Обсуждали вроде как, но раньше 32-гиговые были сильно дорогими или сложными к покупке. Из главных проблем - уже плохая поддержка торча, отсутствие поддержки bf16, невысокая мощность. Она слабее чем 3090 по всем параметрам, интересно как тот график намерили.
>Она слабее чем 3090 по всем параметрам, интересно как тот график намерили.
Скорее всего ошибка по данным для 3090 - данные по прочим картам он не мерил, а брал из других источников.
Я неиронично пытался найти старика Хемлока, но так и не понял, откуда это вообще пролезло в датасеты.
А, тогда неудивительно, лол. Ну нельзя такое публиковать, конечно, не знает человек как все происходит в около-ии движухе.
Тем не менее, в100 как средне-бюджетный вариант может быть очень даже неплохим. Чтобы судить, нужно проверить с какой скоростью будут работать (и будут ли вообще) жирные картиночные и видеомодели, более подробно оценить перфоманс в разных ллм. В частности что там по обработке контекста, насколько сильно замедляется скорость на контексте с ними и т.д. Шансы малы, но потенциально может быть норм вариантом для ллм-рига, возможно со временем на нее и экслламу допилят.
я подожду до завтра и куплю по скидке 32-гиговую версию за 38к.
Потому что гопота использует такой квант. Потом вроде поддержку MXFP4 для старых поколений допилили, так что сейчас отставание не будет таким котострофическим.
Одну или несколько будешь брать? Обязательно потом протестируй ее во всяком и поделись результатами.
купи v100 и протестируй сам тогда если дохуя умный.
Не можешь - тогда терпи.

Чел, это такое же говно как и P40. Пикрил Гемма 27b. PP там хуже амудокоробок и примерно как у мамонта M1 Max, а старый M2 Ultra будет ебать V100 как по РР, так и по генерации. Даже старые карты амуды по сравнению с таким кажутся неплохим решением.

лол блять. Это что?
Запихнул частично в карту копрогемму которая не влезает в 16 гигабайт, считал все на профессоре и говорит "плохая карта". Вообще охуеть.

> Это что?
Это тебя ебать не должно. Держи 14b без скачка.
какая конкретно модель? какой квант?
я тебе ванга чтоли угадывать что именно и как ты там тестируешь?
возьми бля из видео ту же модель которую чел тестировал - gpt которая.
И сравним твоих попугаев и его попугаев. может у тебя будет в три раза меньше чем у него? Тогда вопрос в твоем сетапе.
альсо
>тестировать на шинде
это конечно кекмда...

На гуфише нужно всегда в лс уточнять. На тао всё проще
> на vllm
> 3090, p40 и теперь еще v100
На vllm можно только с одинаковыми.
> в этих тредах можно потерять анонов
Анон - это про анонимность, нельзя потерять абстракцию. Принесешь тесты - хорошо, нет - кто-нибудь еще другой сделает, здесь все твои друзья.
> такое же говно как и P40. Пикрил Гемма 27b
> Нагрузка на проц
Сомневаться
Таки поддвачну сомнения, в100 на голову выше паскалей и тем более амудэ по перфомансу, свежие тесты где на ней пускают ллм тоже говорят о приличном результате. Надо разбираться почему тут так мало.
>это конечно кекмда..
Не мдакай мне тут. Говори по факту, чем винда хуже юниксоублюдей в контексте llm
>Анон - это про анонимность, нельзя потерять абстракцию.
чел, давай без хуйни этой пожалуйста.
Я лично терял в этих тредах чела который с китая инстинкты заказывал. И других с тестами людей тоже терял. Не все заходят в этот тред как на работу. Я вот захожу раз в пару месяцев.
Нет никаких анонов, мы все - единичные уникальные люди.
да ещё бы я умел с этой хуйни заказывать...
я посмотрел - видел там есть похожие, в которых упоминается NVLINK. это любопытно...
но две сразу я не рискну брать.
Потому что уже обжегся, набрав p40. Лучше не спешить.
> терял
Фейкомыльце и вперед. С в100 не настолько редкий кейс чтобы бежать за ним на какую-то борду и окликать там неизвестно кого, здесь, на среддите и на ресурсах с дискуссиями вокруг жоры появится.
> в100 на голову выше паскалей
На целых 30% больше флопсов, чем у Р40, лол. И так же нихуя не поддерживает из современного, в том числе и флеш-аттеншен, а следом и всякие EXL тоже недоступны. Тензояден тоже нет. Что ты хочешь от такой некроты из 2017 года?
>не знает сколько весит гемма2 27б
>проглядел, что генерация шла на ЦПУ
>принес нерелевантные тесты какого-то виндузоида на оллама-млкрлопиське
боже, да прекрати ты позориться...
> На целых 30% больше флопсов, чем у Р40, лол
Нет, примерно в 170 раз быстрее. И поддержка не в пример больше, потому что штатно доступны все операции с половинной точностью и нет необходимости анального цирка с перекастами. Буквально работает из коробки все кроме самого последнего и хитрых оптимизаций атеншнов, в отличии от паскалей и амудэ.
> флеш-аттеншен
Если что, его даже под паскали запилить смогли, сделают если количество этих карт в продаже будет не пренебрежимо малым.
> Тензояден тоже нет
Лол ты ошибаешься
> Что ты хочешь от такой некроты из 2017 года?
Генерации примерно как на 3090, обработки не медленнее чем в 2 раза.
Спасибо что притащил оригинал откуда это, теперь понятно. Но подобные тесты для массовых видео проводятся точно также как и в том видосе, без вникания в предмет и то, как нужно запускать чтобы работало хорошо. Та же ситуация что и в другом видосе, где в100 обходит 4090.
Покажи свои тесты, клован. Что за фантазии у тебя будто бы какое-то древнее говно, вышедшее через год поле Паскалей, будет в 3 раза быстрее 3090? Факта того что у V100 ничем кроме Жоры не поддерживаемая архитектура уже достаточно чтоб даже не смотреть на этот кал. Ты литералли как Р40-теслошизик, как видишь тут они все пропали, никто не смог на этом говне сидеть.

>покпок нет флешаттеншн
мне грок говорит что буквально надо одну строчку отредактировать.
Я склонен ему верить, хоть он и пиздит часто.
моли тесты, к сожалению, будут только в конце ноября, потому что карта из китая будет долго идти.
>какое-то древнее говно, вышедшее через год поле Паскалей, будет в 3 раза быстрее 3090?
я бы не удивился. У них сильно отличаются параметры памяти.
К примеру у 3090 ширина шины меньше 400 бит, а у v100 - 4096 бит.
Это только дурачку промытому маркетологами всё сразу очевидно, ведь "вышло позже, значит пизже"
> его даже под паскали запилить смогли
Только у Жоры. Ты будешь привязан к нему, так же как и с Р40. Во всём остальном у тебя только базовые fp16. Оригинальный флеш-аттеншен только с Амперов поддерживается. Как и 99% либ, где просто нет поддержки карт старее Амперов.
>К примеру у 3090 ширина шины меньше 400 бит, а у v100 - 4096 бит.
Если бы это решало! Была же такая штука как P100 например.
Грок тебе напиздел, поменять придется больше. Есть отдельная песня как пилили на тьюринги, а это самое ближайшее к вольте, главное что в рамках ллм инфиренса там нет непреодолимых преград. В крайнем случае напрямую костыли с паскаля брать.
Кстати, как раз старший тьюринг можно взять в качестве референса, с оговоркой что чуть быстрее по чипу и в 1.5 раза быстрее по врам.
> я бы не удивился
Ну что за святая вера в чудеса. Первое что должно интересовать - псп рам, там 900гбайт что почти столько же как на 3090, второе - терафлопсы в халфе, 31 на вольте против 35 на ампере. Правда есть нюансы со скейлом в 2 раза на фп32, а также отсутствием поддержки тф32, которое радикально ускоряет на ампере операции с фп32, и отсутствием поддержки бф16. Потому что-то потренить на ней без особых оптимизаций, или воспользоваться чем-то с бфлоатом будет болью.
> Только у Жоры.
А где еще надо? Другие генеративные модели будут хорошо и бодро работать в фп16 с sdpa, аналогов sage аттеншна, разумеется, не дождешься. Может быть со временем подъедет эксллама3 если карточки станут массовыми.
> К примеру у 3090 ширина шины меньше 400 бит, а у v100 - 4096 бит.
У 3090 память быстрее, чем у V100, если что. Шину надо умножать на эффективную частоту памяти. У 5090 шина в 8 раз меньше V100, но эффективная частота памяти почти в 20 раз выше, на выходе имеем у 5090 в два раза быстрее память.
во чего мне грок выдал.
https://github.com/Coloured-glaze/flash-attention-v100_cutlass
>flash attention2的论文
короче норм всё, надо тестить.
https://github.com/Coloured-glaze/flash-attention-v100_cutlass
>flash attention2的论文
короче норм всё, надо тестить.
А что конкретно дает этот flash attention, особенно при оффлоаде слоев в рам? В кобольде особой разницы не помню, может конечно своп жрет меньше, но я не обратил внимания.
Повышает эффективность работы с памятью. В LLM не сильно заметно, но в других нейронках без упора в память х2 может давать. Есть модели где оригинальные реализации только с ним работают, он в зависимостях. Для тренировки базой является, т.к. бесплатная скорость.
>в других нейронках без упора в память х2 может давать
Ок, в лапше попробую
Как не крутил, но без MoE CPU Layers и с авто слоями генерит быстрее...
Сокращает количество операций и требуемую для этого память при работе атеншна. На самом деле, местами там буквально if then else хардкод для кейс, но далеко не везде.
> при оффлоаде
Учитывая что ты должен избегать любой ценой оффлоада атеншна - ответ очевиден.
Там на контексте скорость быстрее падает. Поставь 16к контекста и запусти бенчмарк кобольда, который во вкладке hardware
Не проще просто подождать, пока ЦПУшники раздуплятся и сделают АИ чипы? Они вроде все этим занимаются активно сейчас. Все равно все новые модельки МоЕ и им ВРАМ так сильно нинужон.
> ЦПУшники
Какие? Маки на армах? Амуде нет смысла, у них конкурент самоликвидировался.
Мистраль гавноэ ебучее, ебучее гавноэ для хуесосый.
Привет, ты охуел?
Цикл разработки 5-7 лет, ебало ждунов имаджинировал?
> им ВРАМ так сильно нинужон
Ну такое, если хватает 5т/с и 16к контекста на ужатой модельке. Железки, которые могут обеспечить приемлемую (для чата) скорость по цене медленно улетают в космос и обязательно должны быть спарены с быстрым хуангом. Какой-то прогресс возможен в ддр6 если появится массовые модели с 4-каналом, а пока это все или баловство, или йоба серверные железки.

Вот так получилось с мистралью
Вижу пик, вижу процессинг, думаю "о, ми50 что-ли?", потом вижу тг и понимаю что нет
Мистраль не MoE, а Dense модель, поэтому на нее cmoe не работает. Попробуй Qwen 30b, там будут нормальные скорости
https://huggingface.co/unsloth/Qwen3-30B-A3B-Instruct-2507-GGUF
Попрубуй Q4XL с авто и cmoe
И еще может мини ChatGPT попробовать. Он для рп вообще не подходит, но может как ассистент
https://huggingface.co/ggml-org/gpt-oss-20b-GGUF/tree/main
А помните в треде были раньше долбоебы, которые на полном серьезе топили за exl3? Интересно что с ними стало? Верят ли они, что турбодаун все допилит или уже отчаялись?
Всё время гонял эйр в iQ4_XS, сейчас решил потестить Q4_K_S, и о чудо, русик стал ЗНАЧИТЕЛЬНО лучше. Перестал проёбывать падежи, перестал высирать иероглифы. Ё на месте. Английским всё же срет, но куда реже, свайпы спасают. А казалось бы, разница в квантах всего 7 гигов. На 12/64 систему с 32к контекста впихнулось впритык. 8.7 т/c на старте, 5.4 т/c на полностью забитом. По ходу окончательно перекатываюсь с Локи 24b на него. Вот теперь годнота.
Ну что, я как-то спрашивал несколько тредов назад по поводу вката в агентные системы для кодинга. Вроде горящей жопой и матюками подружил Claude Code и gpt oss 120b. Ну чет пока она конечно туго соображает. Зато быстро, уместил ее на три карты с фулл контекстом (хотя она его выжирает дай боже). В общем, наблюдения продолжаются...
>Мистраль не MoE, а Dense модель, поэтому на her cmoe не work. Попробуй Qwen 30b, там будут pretty nice speeds
Пофиксил, не благодари
??
Ясный хер что самому делать но мне какие-то примеры то нужны. Я как нейросеть могу только ограниченное кол-во контента выдать, мне нужны еще данные для генерации.
Такой вопрос глупый наверное. Насколько сильно роляет скорость работы ssd nvme если например выгружать частично контекст\веса\небо\аллаха в него? Есть ли смысл переплачивать за ссд на 5-й псине или данные, с которыми работает ссд будут раздробленными и по факту скорости между 3,4,5 псиной не будет? Есть ли тесты которые показывают эту разницу наглядно? У самого 96гб озу и 16гб видеопамяти, стоит ли переплачивать за псину на ссд или по серьёзному вложится во вторую видеокарту и не тратить деньги на хуйню...
Сходи поспи, колпак уже подтекает
Уже утро, какой колпак?
вложиться в видеокарту и не тратить деньги на хуйню.
скорость нвме на 5ой псине 10 гигабайт в секунду, скорость видюхи 1000 гигабайт в секунду
Да, но ты всё равно не засунешь глм эир например на 16 гиговую карту, у тебя будет выгрузка неактивных экспертов в озу и псп 8 линий 5-й псины всего 32 гига в секунду, отсюда и вопрос про скорость ссд, т.к. по факту может выгружаться из оперативки редко нужная хуйня.
Выше в треде анон целый пак карточек скинул.
при инференсе скорость псины не влияет, хоть на х1 видюхи сажай
В упор не вижу. Тэгни пост пожалуйста.
Нихера себе там. Спасибо.
бамп
Если ответы будут охуенными, то пусть хоть на 0.1тс генерит.
Дай угадаю ты никогда не сидел на 0.1тпс?
Да, как угадал?



По теме V100 немного графиков
Да так, подумалось чёт. Даже не знаю с чего бы

Медленно, очень медленно. Забудь вообще про использование ссд.
Контекст - просто охуеешь ждать. Просто пиздец как охуеешь. Он на оперативе занимает по минут 5-10.
Нет не будешь. Ты даже на 5 т/с ныть начнешь.
Определит только время загрузки модели. Что-либо выгружать на ссд - катастрофически медленно будет.
> и псп 8 линий 5-й псины всего 32 гига в секунду
А этот тут причем вообще, ты на серьезных щщах собрался 5.0 х8 ссд покупать?
Во, вот эти цифры как раз то, чего примерно ожидалось. В целом неплохо, 4-6 штук и приличный риг получается.
> Ты даже на 5 т/с ныть начнешь
От чего? Я же не собираюсь перед монитором сидеть и смотреть, как оно генерит.
Ммммм. Ну попробуй, потом расскажешь. Будешь каждые 10 минут отходить ? А со свайпами как будешь поступать ?
Я не стебусь, мне правда интересно как это будет выглядеть. Потому что для рабочих задач, как раз и нужно не менее 15-20 т/с.
А для РП.. Ну странное РП будет, тогда уж проще в голове отыгрывать.
> со свайпами
> Если ответы будут охуенными
> А для РП.. Ну странное РП будет, тогда уж проще в голове отыгрывать.
Раньше люди месяцами письма ждали и всю жизнь их хранили.
> Если ответы будут охуенными
Ответ может быть охуенным, но ты можешь просто не захотеть движения сюжета, который предложит нейронка.
Порой по 3-5 свайпов приходится делать, ведь всё не то.
>Раньше люди месяцами письма ждали и всю жизнь их хранили.
Ритм жизни изменился.
> сюжета
ЛЛМ сюжетами и РП ограничиваются?
> Ритм жизни изменился.
А человеческие ценности - нет.
>ЛЛМ сюжетами и РП ограничиваются?
Какие рабочие задачи ты будешь выполнять на скоростях ниже 5 т/с ?
Которые скоростей и постоянного надзора не требуют.
Назови, пожалуйста. Или просто признай, что ты обосрался и написал хуйню.
Кодинг, переводы, рисерч, на что фантазии хватит.
Ясно. Ну удачи, чё.
Пробуй, потом расскажешь.
> Кодинг
нереально
> переводы
без проблем
> рисерч
скорее нет, чем да, по той же причине, что и кодинг: ризонинг уйдёт не в ту степь и ты узнаешь об этом только завтра утром.
Лол, только в этом и смысл
Чат с ллм = книга, а не письма, никто не читает книги такими темпами. Офк можно и подобие переписки организовать, но быстро надоест.
Двачую ты даже не представляешь о чем говоришь и потому такие выводы делаешь. Во всех перечисленных тобой задачах ллм лишь инструмент а ты им управляешь, это все равно что копать яму экскаватором, который отзывается на управление рычагами на следующий день.
> нереально
Почему?
> ризонинг уйдёт не в ту степь
> Если ответы будут охуенными
Ты или жирный или рассчитываешь локально поднять помесь гопоты-клода-гемини на 4тб в полных весах.
Да, потому что маленькие модели сильно ограничены.
>это все равно что копать яму экскаватором, который отзывается на управление рычагами на следующий день.
Охуенная аналогия, кстати. Только ты задаешь все команды заранее и некоторые могут потеряться по пути и экскаватор может начать копать рядом идущую асфальтную дорогу.
> это все равно что копать яму экскаватором, который отзывается на управление рычагами на следующий день
И как только диды космические аппараты запускали и людей на Луну и обратно высаживали, с джойстиками наверно круглые сутки сидели и ремонтные бригады в случае чего отправляли.
Лучше с детями африки иди поголодай, что за кринжовая стадия торга? Хочешь страдать - страдай, о том что придуманное в манямире приведет лишь к этому все и пишут.
Какие дети, ты под чем там?
Ты приводишь как деды что-то там делали, пытаясь выставить безальтернативную необходимость для специфичной задачи, как норму. Вот я тебе и предлагаю другую самую популярную аналогию - поголодай и помучайся от жажды как детишки в африке страдают.
> пытаясь выставить безальтернативную необходимость для специфичной задачи, как норму
Где? Диды тут как пример культуры, терпения и навыка расчета.
> поголодай и помучайся от жажды как детишки в африке страдают
И что это даст? Какую задачу решит?
>Нет не будешь. Ты даже на 5 т/с ныть начнешь.
Я на 0,7 сидел если что.
Другой анон, долгожитель ларжа
Мудрые нейрогенераторы, посоветуйте nsfw модель для чатинга.
Недавно обновил видимокарту на 9070xt, до этого сидел на 3060 12, запускал всё через бубабугу + таверну, но с новой картой бубабуга сказала иди нахуй и теперь кручу через кобольда + таверну и как будто боты тупее стали, что ли хуй знает, может я с моделями что то сделал.
Короче реквестирую модельку что бы забить 16 гб контекстом и что бы умная была. Вот. пожалуйста
Недавно обновил видимокарту на 9070xt, до этого сидел на 3060 12, запускал всё через бубабугу + таверну, но с новой картой бубабуга сказала иди нахуй и теперь кручу через кобольда + таверну и как будто боты тупее стали, что ли хуй знает, может я с моделями что то сделал.
Короче реквестирую модельку что бы забить 16 гб контекстом и что бы умная была. Вот. пожалуйста
Если быстренько покумить и пойти дальше и оперативы 64гб:
qwen 235b22 в i2 квантах (на удивление на русике даже слюни изо рта не текут при ответе в 50% случаев), но это около 5-6tg в лучшем случае, на англюсике не тестил.
glm-air q4 на русике в 80% случаев начинает нести ахинею, на англюсике норм, будет ~10tg.
Если в доступности только видимокарта:
Mistral 3.2 без васянтюнов нормально выдавала в Q5 (даже иногда на русике)
Если серьёзное рп вести, то можешь пока забыть, либо кушать по 2-3tg на больших моделях, если памяти хватит.
> Диды тут как пример культуры, терпения и навыка расчета.
Этот пример совершенно неуместен и глуп. Те же деды строили сложные и продуманные системы, которые позволяли эффективно организовывать и оптимизировать труд. Начиная от общей иерархии и построения нии, кб и других организаций, до разработки инструментов - кульманы, рабочие места, оснастка, эвм и прочее. Никому в голову не могло придти ставить работягам в обычной деятельности условия, сравнимые со сложностью управления внеземных зондов.
> И что это даст? Какую задачу решит?
Иллюстрирует неуместность твоей аналогии.
> Этот пример совершенно неуместен и глуп
Но ведь это ты ЛЛМ с неотзывчивым экскаватором сравнил.
> Те же деды строили сложные и продуманные системы
Вот именно, а ты ЛЛМ на пять минут без присмотра оставить не можешь.
То дети, щас еще и работяг каких-то придумал.
У меня 32 гб оперативны :(
А что такое tg?
Я сейчас кумлю на какой то noromaid модели на 20b, таверна мне выдаёт ответы по 500 токенов, врубил стриминг и читаю пока нагенерит простыню, она бывает ебашит 120 секунд на сообщение, но там несколько абзацев.
Просто вкат у меня какой-то тупой, не стреда ни рузу начинал понавтыкал какой то хуйни, может я ебанько вообще.
> Но ведь это ты ЛЛМ с неотзывчивым экскаватором сравнил.
Да, это отличная аналогия, ллм - такой же инструмент. Когда отклик на твои действия происходит быстро - ты можешь эффективно с ним работать, одновременно и повышая свой навык управления. Когда задержка на твои действия слишком огромна - ты будешь непрерывно сосать бибу и страдать. И только "опытный мастер" на скилле сможет сразу все более менее обустроить, но толку с этого.
> Вот именно, а ты ЛЛМ на пять минут без присмотра оставить не можешь.
Отстранись от защиты своих высказываний и попытайся понять о чем идет речь, если не совсем глупенький. Тормознутая ллм в описанных юскейсах это и близко не продуманная система, а построение какой-то рабочей схемы вокруг нее само по себе требует ресурсов и может никогда не окупиться. Будет выгоднее использовать что-то быстрое, или вовсе исключить ее.
Да хули объяснять диванному, тут только отбитый ебальник от пробежки по граблям поможет.
Какая щас лучшая модель с виженом чтоб мне порнуху описывала?


https://arxiv.org/html/2508.17137v1
Есть исследования, показывающие, что в MoE-моделях при генерации одного промпта активируется только часть экспертов, причём паттерн стабильный в рамках выполнения конкретного промпта. Теоретически можно делать многоуровневый кэш: держать "горячих" экспертов в VRAM, менее используемые в RAM, а холодные выгружать на SSD. Тогда микролаг будет только при промахе кэша.
Но это всё теория. На практике таких оптимизированных решений пока нет, хотя в олламе что что-то пытались:
https://github.com/ollama/ollama/issues/11005
Да и то я думаю оно сдохнет на этапе обработки контекста в любом случае.
> Да, это отличная аналогия, ллм - такой же инструмент
Это максимально идиотская аналогия, еще бы с вантузом сравнил.
> может никогда не окупиться
> Будет выгоднее
Силой почувствовал?
>Кодинг, переводы, рисерч, на что фантазии хватит.
Я пока ждал ответа с кодом от Геммы3 на 7t/s, успел сходить налить чай, вернуться и нагуглить ответ.
У меня, конечно, не самая мощная ПК и я привык к ожиданию компиляции проекта по 1-2 минуты, но добавлять еще к этому ожидание ответа от LLM по 5 минут - так себе перспектива. Даже мистраль с 12 t/s иногда напрягает, а тут еще хуже. Поэтому и пользуюсь только MoE моделями, там хоть 25-30 t/s можно выжать.
Это делали еще в прошлом году. И вроде от тех же ребят была опция для плотных моделей была схема, где выполнялся аналог ее "конверсии в моэ" с разбиением линейных слоев на группы на основе калибровки на датасете, с выделением ключевых вкладчиков и отбрасыванием остальных + аналог роутера. Но не взлетело, а потом пришли уже полноценные моэ.
В самом ggml бэкенде потенциальный шардинг экспертов очень неудобен. Но в целом возможен, тогда вместо загрузки экспертов некоторого количества блоков будет частичная загрузка экспертов но уже для большего числа блоков, инфиренс ускорится. Вперед, начинание хорошее и может быть реализовано.
> в олламе что что-то пытались
В олламе не могут ничего пытаться ибо меротворожденное. Там ни один ишьюс или пуллреквест, касающиеся работы бэка а не обвязки, даже обсуждений не получает.
По ссылке очень похоже на клон пуллреквеста у жоры, где при обработке контекста во время стриминга весов предлагалось загружать только активируемых для текущего батча экспертов, а не полные слои.
Но там проблема в том, что контекст обрабатывается батчами и выигрыш от этого подхода был только на малых. А при стримминге именно увеличение батча дает гораздо больший эффект к ускорению потому и заглохло.
С точки зрения генерации же пытаться подгружать экспертов в врам чтобы обсчитывать там - вредительство, быстрее считать их на проце.
Хорошая аналогия, а ты просто уперся.
> Это максимально идиотская аналогия, еще бы с вантузом сравнил.
Когда уже сделают прунинг и разное число икспердов на слой? Ну что бы мы заебались, высчитывая, сколько выгружать, лол.
Врам/рам то сколько? Если пануешь то квен 3 вл 235.
Не то что бы у тебя был широкий выбор из стульев геммы и квена
Тулинг решает
Ващет уже, первых лоботомитов уже распробовали, для второго варианта в жоре уже хрен знает сколько не могут поддержку сделать.
Жора же до сих пор не поддерживает квен вижен
> 40 гб vs 64 гб
Стоит ли еще одну 3090 брать...
Есть ли что-то такое хорошее среди мелкомоделей, что не влезает в 40, но влезет в 64?
Стоит ли еще одну 3090 брать...
Есть ли что-то такое хорошее среди мелкомоделей, что не влезает в 40, но влезет в 64?
Вллм поддерживает. Квен денс на 32 намного лучше показал себя в разгадывании капчи чем гемма 27
Большое спасибо, удалось разогнать до 20тс!
Анончики, поделитесь по братски престом или скрином настроек таверны для Qwen3-VL-30B-A3B-Thinking. Никак не пойму что выставлять чтобы она нормально РПшила.
>Вллм
слишком сложно...
Добавьте уже в шапку как с хаги качать
Просто отключили скорость для русских
Просто отключили скорость для русских
Че? У меня все ок, ростелеком мск
> отключили
А кто это сделал?
Какая разница?
Скорости нет, надо добавить в шапку способ чтобы была
С впн очевидно 40 гигов качать неделю будешь

Слил радеоны, вернулся на елду Хуанга.
Плюсы:
1. Промпт процессинг существенно быстрее.
2. Основной гпу, к которому подключен монитор, можно забивать полностью (на красноте винда не давала, 4гб было недоступно)
О какой скорости идет речь? 30 - 40 мегабайт в секунду тянет как и раньше.
Плюсы:
1. Промпт процессинг существенно быстрее.
2. Основной гпу, к которому подключен монитор, можно забивать полностью (на красноте винда не давала, 4гб было недоступно)
О какой скорости идет речь? 30 - 40 мегабайт в секунду тянет как и раньше.

>Добавьте уже в шапку как с хаги качать
Переезжай в другую страну, там проблем нет.
>пикрил
Больной ублюдок.
Зумерок впервые увидел хранилище на 18 терабайт?

Мозги тебе отключили. Наставят своих обходов блохировок и ебутся в жепы. Наверняка себе всю сеть обосрал каким-нибудь каловым запретом или гудбаем.

Почему диск один? Нахуя бить один диск на несколько разделов? И почему не отдельное устройство?
Ну вот почему у тебя маняме, фильмы и мусор в трех разных местах? Слей все в одно.
При закачке хрени, например, проще 1 букву диска поменять, чем указывать ебаные папки.
>Ну вот почему у тебя маняме, фильмы и мусор в трех разных местах?
Потому что это 6 разных дисков.
Ну и тебе неудобно что ли? Ты мечтаешь объединить все в один?
Вообще не сложно, но требует одинаковых карточек
Там кстати борды под дуал 4189 сокет на газоне валяются по 12к. 16 каналов, инжи по 270 ватт, 4я псина
Нет. Но у тебя то диск один. А один диск это кринж.
>4я псина
Пишут, что третья (правда ХЗ, распространяется это только на чипсетные линии, или сразу на все), плюс DDR4, который скоро будет дороже DDR5, лол.
Я уже перестал понимать, что за хуету ты несешь.

Чипсетные 3.0, но с чипсета их нет в слотах. Жалко только что U2 не вытащили, в камнях осталось ещё дофига и больше линий
По схеме, с первого сняты все 64 линии, а со второго только 36

Почему в тематике нет id, это бы решило массу проблем.
>бить один диск на несколько разделов
А ты полную проверку диска С на вирусы никогда не пробовал делать? Сколько она интересно будет длиться, неделю?



Я уже начал сомневаться может это я неправильно спрашиваю? Типа как биллион в сша может означать миллион и миллиард.
Гемма 2миллионная . Яндекс восьми
Сейчас вкусил https://huggingface.co/t-tech/T-pro-it-2.0-GGUF этот кал. Настолько лютого лоботомита поискать ещё, хуже 8б минстральки 2х-летней давности.
Ах ну да, забыл написать что это передовая ИИ МОДЕЛЬ от Т-БАНКА ну т.е. спиздили квен и затюнили его - вуаля своя модель.
Внутри очевидно используются полноценные ллмки. Просто есть команды которые делают всякие приколюхи и что годное и особо самим не нужное вкидывается в паблик
Интересно как они в сексе в качестве хоста под гпу риг. Ну и также насколько это вообще релевантно с точки зрения ценника на рам. А процы почем?
Лоботомит мелкий, ее очень легко запутать и загазлайтить, чудо что вообще на русском отвечает.
Совсем ужасная?
> с точки зрения ценника на рам
Никак. Любая сборка в которой есть ддр4 сейчас оверпрайс по определению
> процы почем?
К покупке по нормальным ценам только инжи. Себе присмотрел примерно по 10.5к 38 ядер 76 потоков qwat, 2.2ггц по всем, буст 3.4. В релизе это вроде как зион платинум 8368 стал.
Ещё буду брать прошивальщик спд что бы в свои самсунги 2133 зашить джедек 3200 (они по отзывам тянут и проходят мемтесты)
Вообще - еще мистраль 24b 3.2 (2506) умеет на картинки пыриться. :)
> Любая сборка в которой есть ддр4 сейчас оверпрайс по определению
Если тебе от этого полегчает - цены на ддр5 также взлетели. Смотрю на это, вспоминая по чем брал сам, и искренне ахуеваю. Может еще есть шанс урвать удачные лоты или скоро тряска уляжется и опустится.
> прошивальщик спд
Там же любой программатор подойдет, что за прошивальщик?
Любой школьник на некропеке взять лора и смержить с любой моделью за 5мин буквально. Это не оптимизация затрат на ресы, а тупо похуизм и лоускилл днищеэникейщиков и такие высеры должно быть стыдно вообще демонстрировать где-либо дальше кухни своей бабки.
>Совсем ужасная?
Если честно сравнивать его с квеном и другими лоботомитами, то да, совсем ужасно. Тестировал как-то от яндекса тюн мистрали, но там 9б чтоль был, лол, так он по ощущениям был лучше.
Блять, иногда сидишь, придумываешь себе карту\квенту, где ты пилот меха, призрак, киберсамурай и т.д. Пытаешься от этого толкать сюжет и почему то душишься, а потом оставляешь почти пустую квенту где буквально описание твоей одежды и внешности и вот так начав с нуля происходит годнота.
Почему гемма 3 в lm studio крашится с анализом пикч? С любым разрешением вообще. 32 гигов ей мало что ли? С текстовым выводом все норм, а вот пикчи не хочет.
mmproj хоть впихнул?
Ты вообще с локалками дрочился? Или так только корпосетки тыкал? Ты думаешь в твоей 405b будет сильно больше мозгов? Молись что бы оно хотя бы 2 токена выдало если докинешь на врам/рам, но оно не выдаст, при расчете контекста все что ты получишь это 0.50-0.90 токена со своих м2 nvme. Уж тем более если речь идет о кодинге где агенты жрут невьебенно дохуя контекста. Ты будешь больше тратиться на генерацию чем если бы платил месячную подписку корпоблядкам. Плюс ссд вещь не долговечная и в отличии от озу имеет довольно скудное количество циклов записи.
5-9 токенов жизнь есть, 3-4 токена жизнеспособно, все что ниже это гроб
>ебашит 120 секунд на сообщение
А че за квант? Чет дохуя, у тебя там че 6-8 квант? Это не влезет нормально в 16врам плотно, если бы было 64гб
оперативы то довольствовался и довольно мурчал бы от хорошей и популярной МоЕ модели в треде. Но а так, хз. И чо noromaid хуево прям пишет?
>А что такое tg?
Не знаю но возможно, он имеет ввиду Token Generation
Шить можно условно любым, но нужно снять защиту с флешки и подпаивать провода. Проще уже отдать 3к и получить готовое устройство с слотом, софтом, снималкой лока
> Ты думаешь в твоей 405b будет сильно больше мозгов?
Научись читать.
> Плюс ссд вещь не долговечная и в отличии от озу имеет довольно скудное количество циклов записи
Что ты туда писать собрался?

Бампую вопрос.
Какой ужасный прогрев. Чуть ли не по цене двух
ну-ну.
не всё так плохо.
про "две за 70" - это для китайцев, а не для нас, рабсиян.
>Научись читать.
Прости, на моменте про экскаваторы и дедов, потерял нить повествования.
>Что ты туда писать собрался?
Хентай Работа ЛЛМ нагружает ссд-шник не только чтением.
Кто там ныл на счет озушки? Вот сейчас с большим отрывом самая дешевая DDR5. 17к за 64, да еще и с какой-то гарантией. Все остальное улетело за 20к, а то и за 25. Так что налетайте аноны, пока не разобрали
https://www.dns-shop.ru/product/54c8cb16bbc4ed20/operativnaa-pamat-gskill-ripjaws-s5-f5-5200j3636d32gx2-rs5w-64-gb/
https://www.dns-shop.ru/product/54c8cb16bbc4ed20/operativnaa-pamat-gskill-ripjaws-s5-f5-5200j3636d32gx2-rs5w-64-gb/
>Работа ЛЛМ нагружает ссд-шник не только чтением.
Лолшто?
>17к за 64
Я б/у недавно за 15 продал. Надо было попридержать, но кто же знал.

Я за 18к патриоты взял вчера, с такой же частотой, но худшими таймингами. Тут вроде был эксперт по ддр пару тредов назад. Правда gskill лучше патриотов и стоит отменять или похуй?
>i2
>низкая скорость
Блядь, сто раз уже говорилось, что нельзя i кванты использовать с моэ.
Используй q2_k_s от intel. Увидишь не 5 т.с, а 8-9.
>от intel
?
Там у чела вроде 16 врам и 64 рам, нахуй он советует 80гб квант непонятно. И нахуй вообще юзать q2, так еще и моешный тоже не ясно. Хотя пизжу. Все ясно. Анон просто долбоеб, советующий кал
Конкретно сейчас не особо. Из крутого - влезет квен-некст фуллврам с хорошим контекстом. Но это не для рп моделька а агентов-код крутить.
Можно вместить лоботомита эйра в фуллврам, или просто получить высокую скорость на кванте жирнее за счет меньшей выгрузки. Также ускорятся и другие моэ модели, можно будет навалить контекста. Но радикального скачка не будет.
Там же обычная стандартная микруха eeprom, в которую может любой программатор. Причем даже выпаивать не требуется, шьются через прищепку.
> готовое устройство с слотом
Ахуеть какую дичь для нормисов придумали, буквально плата со слотом, а внутри примитивная 341
А сколько должны быть?
>Плюс ссд вещь не долговечная и в отличии от озу имеет довольно скудное количество циклов записи.
Скажи это моему гнусмасу с MLC памятью из 2014 года, на который пишется видео через OBS регулярно. Смотрел износ в 2020 году последний раз, было что-то на уровне "осталось 93%".
> обычная стандартная микруха eeprom
А мы и не знали! Не позорься, там не дефолтные флешки
Что лучше для кода - квен некст или осс 120?
>. Но радикального скачка не будет.
Это грустно. Что-то ИИ вообще заглохло.
Заметил, люди начали понимать, что ниче дельного кроме помощи быдлокодерам в этом нет, и нет такой ниши, в оторой ЛЛМ решала бы какую-то задачу на 100% от и до, без ошибок.
> А сколько должны быть?
Радик, адаптер, модуль - до 38 со всеми доставками. На алике один только модуль 40 (цена+налог). Тем кто не в теме советую просто переплачивать мэйлру если на один раз
Так до 38к это на 16гб рам не? 32гб дорогие.
мимо

На лохито можно 192 гб ддр5 собрать тысяч за 60.

Скажите, а вот те большие модели под 60гб+ они через кобольд в оперативку загружаются? Это как то по особому нужно выставлять? А так же вопрос, у меня сейчас 64гб озу в двух плашках. Если я куплю еще 2 такие же (4 суммарно будет) и сделаю 128 гб этого будет хватать на хорошие модели? Как вообще с 4 плашками это работает? Я читал что для игр иметь 4 это хуже, чем 2. Вообще стоит оно того если у меня проц процессор AMD Ryzen 7 7800X3D.
Сейчас запускаю на своей 4090 в основном MS3.2-PaintedFantasy-24B.i1-Q5_K_S.gguf или MS3.2-PaintedFantasy-Visage-v4-34B.i1-Q3_K_M.gguf, а когда у нее идут галюны и словестный понос, то переключаюсь на Gemma-The-Writer-N-Restless-Quill-V2-10B-max-D_AU-Q8_0.gguf.
Сейчас запускаю на своей 4090 в основном MS3.2-PaintedFantasy-24B.i1-Q5_K_S.gguf или MS3.2-PaintedFantasy-Visage-v4-34B.i1-Q3_K_M.gguf, а когда у нее идут галюны и словестный понос, то переключаюсь на Gemma-The-Writer-N-Restless-Quill-V2-10B-max-D_AU-Q8_0.gguf.
Нет, про 32 речь. У анона с алика тоже 32
>Я читал что для игр иметь 4 это хуже, чем 2.
Забей, это дурь полная. У меня на 5600Х срузене было 2 и 4, разницы не замечал, хотя по бенчмарку какое-то падение очков на 5% было.
>Я читал что для игр иметь 4 это хуже, чем 2
Это касается DDR5 там проц не справляется с таким количеством потоков и даунгрейдит частоту, грубо говоря 2 плашки изи держат 5600, четыре получишь какие-нибудь 4800. На ддр 4 и ниже проблем никаких.
upd. В стабильном режиме офк, просто запустить то может и получится на частоте по выше, но потом могут быть сюрпризы.
В играх он все равно разницы не почует.
Пример не мой, а моего товарища, он на интеле переходил на ддр5, я его предупреждал про количество плашек, но он в итоге махнул рукой. По итогу он смог запустить все 4 плашки на 5600, всё ок, но потом (месяца через 2-3) пк просто перестал включаться пока он не сбросит разгон в дефолт. А на базовой частоте тот же киберпук терял у него процентов 20-25 фпс, сейчас вот заказал две плашки а старые 4 отправил на лохито.
>на базовой частоте тот же киберпук терял у него процентов 20-25 фпс
Твой друг пиздабол или фуллхд бомж без нормального монитора. Даже смена проца вместе с оперативкой столько не дает по среднему фпсу на 1440p - 2160p.
Хуй знает, он стримил мне в процессе тестов, там реально фепес на дно летит. Хотя от локации где он был тоже зависит. И да у него фуллхд.
>Как вообще с 4 плашками это работает?
У меня не удалось заставить стабильно работать даже на мемных 4800, я уж молчу про нормальные 6400.
>Я читал что для игр иметь 4 это хуже, чем 2.
>Ryzen X3D
Ты можешь хоть подкачку вместо оперативки использовать, игры не заметят.
У тебя DDR4, проблемы на DDR5 (как у того анона).

Почти то же самое лежало летом новое в onlinetrade за 18к за 2. Собирался взять, но почитал про подводные про скорость 4x ddr5 и передумал, отменил. Ну и хотел ещё подождать 4x64. Вроде у них мелькали там 2x64 за 37, но я проебал момент.
Томокофаг, ты? Ну, рассказывай, как успехи у тебя? Как играется? Как картинки генерит? Разобрался? Доволен? Переживаю за тебя как за младшего брата.
Чем диваннее тем агрессивнее
Да не заглохло, просто если с год-полтора назад был провал в области между ~20 и 70-123б, то сейчас он сместился к 70б. И за счет выгрузки моэ переходы ощущается плавнее, а не "хорошо и быстро/пиздец".
> решала бы какую-то задачу на 100% от и до, без ошибок
Тут сразу пара моментов. Проблема бедолаг, которые на серьезных щщах думают что недетерминированная штука, сама работа которой основана на рандоме, может быть на 100% определена и что-то решать или тем более сразу заменить команду настоящих специалистов. Во-вторых, скиллишью, с большинством рутинных задач в кодинге, обработке и визуализации данных попсовые агенты справляются превосходно.
Это ебля с таобао и сочетанием взаимоисключающих скидок/экономий с последующей тряской в несколько месяцев из-за каргопроблем, или ненапряжная тема? Конечно, если брать несколько штук то можно и заморочиться ради экономии, но вопрос сколько там выйдет на самом деле, а не по оптимистичным оценкам. При заказе с алишки, кстати, придется еще и пошлину заплатить.
С такими посылами сам разбирайся. Всё было посчитано на сейчас и с учётом текущих особенностей растаможки
>, скиллишью,
Допустим человек спрашивает у большого дипсика или квена, как ему ЛОКАЛЬНО пердолиться с мелким ИИ. И что пишут эти гиганты? Хуету, ведь у них знания о кобольдах-шмобольдах давно протухли.
Пока ИИ не будет самообучаться и получать инфу в реальном времени с самыми актуальными апдейтами, это останется околобесполезной, шуточной хреновиной для быдлокодеров, ролеплейщиков и офисных макак, ищущих в ИИ машину по сортировке мусора из табличек.
> 5-9 токенов жизнь есть, 3-4 токена жизнеспособно, все что ниже это гроб
базошиз, спок
> диваннее
насколько я понял того анона, он собирается прошивать модули памяти, а не биос, и к модулю памяти программатором так легко как к той обычной фигне на мамке не подцепишься
покеж чё за устройство
Да, я. Пока учусь делать карточки. Почему то не получается и ИИ ведется себя вне характера.
Скачал вот эту карточку - https://chub.ai/characters/glorious_help_7045/group-of-5-survivors-35738f4c892a
Хочу попробовать в долгий сюжет как в текстовой рпг. посмотрим что выйдет.
С генерацией картинок в комфи разобрался. а вот почему при этом тормозит система если запрашиваю генерацию через таверну - не понимаю.
Так же не понимаю про промпты. Но в шапке треда нашел мод на таверно noass и вроде с ним стало получше работать.
В целом, очень похоже на первую мастурбацию лет так в 10 лет, очень классо, но нихуя не понятно и не знаешь что делать.
> Почему то не получается и ИИ ведется себя вне характера.
Это не твоя вина, просто ИИ дерьмо.

Гуглится по ddr4 spd programmer. По факту тупой флешер но с надстройками для снятия защит с ee1004 флешек + слот. У ддр5 вроде что-то по другому потому для них другой флешер нужен (не разбирался)
> С такими посылами сам разбирайся.
Платиновая тема когда в обсуждение врывается выгодно-купивший, но в свою стоимостную оценку он по невнимательности или сознательно закладывает недостижимые просто так вещи. С таким же успехом можно заявить что содержать bmw дешевле чем сраную весту, вынося за скобки удачу на поломки и расходники+работу ниже себестоимости в сервисе у близких друзей.
Сам пердолинг не имеет отличий, действия те же. О запуске кобольдов-шмобольдов нужно прочесть инструкцию, а не пытаться спрашивать у ллм, как и по множеству других вопросов.
Классический пример скиллишью и фундаментального непонимания что такое ллм и как их применить. Про необходимость самообучения для решения таких задач вообще рофел, ведь ты буквально можешь дать ллмке в популярной обвязке ссылку на инструкцию (или приказать ее погуглить), после чего она объяснит ее глупенькому юзеру или даже сама выполнит.
> для быдлокодеров, ролеплейщиков и офисных макак
Ничего осудительного, то ли дело агишиза
На ddr4 spd в отдельной достаточно крупной микрухе eeprom, к которой можно легко подцепиться. На ддр5 она может быть уже компактнее, что затруднит, на декстопных с xmp и свободными слотами для сохранения из биоса классической 8-пиновой микрухи может вообще не быть. Хз при чем тут биос и что ты вообще понимаешь под
> прошивать модули памяти
Но для нормиса, разумеется, недорогой готовый девайс может быть норм вариантом по сравнению с риском все запороть или ценой за обращение в сц с этим.
Слушай. Я поначалу тоже качал готовые карточки - это все хуйня. Если карточка хорошая (что редкость) - то она будет работать так, как хотел автор этой карточки, во многом не закрывая твои личные потребности. Так что надо сразу учиться закрывать все моменты самому через создание своих персонажей и заполнения лорбука.
Я вот буквально как две недели наконец дошел этого. И все работает в рамках того, как я все прописал сам. И вполне себе играю вдолгую. За две недели уже четыре суммарайза и все идет своим чередом. Не без нюансов, конечно, но тут уже ничего не поделать.
Какие у тебя вопросы по промптам? Спрашивай, не стесняйся. Чем смогу - помогу.
Расскажите, за последние полгода в сегменте 12-16B появилось что-нибудь умнее прошлых миксов и моделей?
Ai треды убьют сами себя
Аноны просто поумирают от раков простаты и яиц от бесконечной дрочки
Мы живём в новой эпохе, ни у кого до нас еще не было такого количества порнухи, вот прям до мельчайших деталей сделанной под тебя
Аноны просто поумирают от раков простаты и яиц от бесконечной дрочки
Мы живём в новой эпохе, ни у кого до нас еще не было такого количества порнухи, вот прям до мельчайших деталей сделанной под тебя
Ты привёл типичный пример неумения пользоваться инструментом. Твой пример это что-то на уровне использования ЛЛМ как калькулятора.
Даже банальное указание на необходимость погуглить инфу по твоему вопросу скорее всего приведёт к тому, что ты получишь правильный ответ. А уж если ты воспользуешься агентом для дипресёрча...
Алсо, по поводу агентов. Я тут на праздниках попробовал, в качестве POC, смоделировать РП с учётом использования агентов. Общий смысл был такой: основная модель работает в режиме сторитейлера, пишет только по инструкции. Эти инструкции ей направляют другие мелкие модели которые и ведут РП, они следят за сюжетом, персонажами, инвентарём, небом аллахом. Плюс делают суммарайз. Они отслеживают сцену. что в ней происходит и исходя из этого подкидывают инструкции по стилю описания и что вообще нужно описывать. Например, если игрок входит в пещеру, агенты понимают, что это новая локация и нужно описать, что видит пользователь, описать атмосферу, запахи т.д. А уже в следующем сообщении такое подробное описание не нужно и такие инструкции в модель не идут.
Я делал всё вручную, поэтому было дико заёбно и долго, но даже так криво и косо виден огромный потенциал. Нет протеканий характеров, нет проблем с большим количеством НПС, нет надоедливых описаний там где они не нужны, и наоборот там где нужно они есть. Модель больше не пытается уместить всё в один пост, так как агент видит, что началось действие и разбивает сцену на части и передавая инфу только об одной части.
Из минусов, хуй знает сколько ебли нужно, чтобы всё это автоматизировать, подобрать модели и промты, написать агентов и т.д. плюс задержка перед ответом один хуй будет даже с учётом того, что многое можно делать или ассинхронно или наперёд. По ресурсам тоже не понятно, с одной стороны нужно много моделей, с другой они мелкие, да и основную модель тоже можно мелкую юзать так как с описанием по инструкции у меня даже какой-то кумслоповый немо справлялся.
>Пока ИИ не будет самообучаться и получать инфу в реальном времени с самыми актуальными апдейтами, это останется околобесполезной, шуточной хреновиной для быдлокодеров, ролеплейщиков и офисных макак, ищущих в ИИ машину по сортировке мусора из табличек
Я может чёто не понимаю, но у меня перплексити ищет самую актуальную инфу (особенно если это конкретно указал в поиске). Причём все доступные модели , иногда бывают затупы конечно когда спрашиваешь "поищи модель актуальную", он тебе даёт ссылку на обсуждение из 2023, но это буквально единичные случаи. Иногда просто некоторые вещи не понимает модель сразу. Т.е. если ты сам чутка подкован, то ты вместе с ИИ намного эффективнее, чем подпивас с ИИ и ты же без ИИшки.
У перплексити модель просто гуглит перед ответом, это у них фишка такая. Большинство корпоратов могут также, но нужно либо включить, либо в запросе указать.
>Так что надо сразу учиться закрывать все моменты самому через создание своих персонажей и заполнения лорбука.
Вот бы еще детальную инструкцию иметь для таких целей с примерами и картинками для хлебушков.
>Какие у тебя вопросы по промптам? Спрашивай, не стесняйся. Чем смогу - помогу.
Я хотел бы понимать как это работает. У меня не получается сделать стесняшу Томоко. ИИ вечно рвёт образ. А еще я бы хотел что бы ИИ подавал историю как от 3го лица. Типа, я пишу: Я подхожу и говорю "Привет". ИИ считает, что это действие уже произошло, и сразу отдает реакцию персонажа. А я хотел бы, что бы он описал то, как мои действия были со стороны. Я хочу что бы он еще вставлял мысли персонажа, которые бы показывали мотивацию ответа. На juicychat.ai в одной из карточки видел треккер мыслей, действий, одежды и т.д. Интересно как этого добились. А еще если в сцене присутствуют несколько персонажей, он каждого обрабатывает по очереди в отдельном блоке. А я хотел бы, что бы он сначала там в голове своей картинку построил и мне изложил пересказ. Извиняюсь, что сумбурно описываю, надеюсь понятно о чем я.
Ты можешь сказать какая у тебя модель? Потому что если там немомикс 12b то он не будет следовать и половине инструкций из карты придумывая отсебятину на ходу.

модель это ггуф? Если да, то я тут показывал какие. Дублирую:
MS3.2-PaintedFantasy-24B.i1-Q5_K_S.gguf
MS3.2-PaintedFantasy-Visage-v4-34B.i1-Q3_K_M.gguf
Gemma-The-Writer-N-Restless-Quill-V2-10B-max-D_AU-Q8_0.gguf
Еще накачал кучу других, но я или как макака их кручу и не понимаю, или они реально говно. список моделей на скрине.
>я бы хотел что бы ИИ подавал историю как от 3го лица. Типа, я пишу: Я подхожу и говорю "Привет". ИИ считает, что это действие уже произошло, и сразу отдает реакцию персонажа. А я хотел бы, что бы он описал то, как мои действия были со стороны. Я хочу что бы он еще вставлял мысли персонажа, которые бы показывали мотивацию ответа.
Ну это промпт сторителлера нужен с особой системной инструкцией. У тебя скорее всего обычная инструкция типа "отыграй персонажа".

После того как я поставил noass я в системном промте вообще blank оставляю и работает в разы лучше чем было.
Ссд под инференс хуевая затея, я пробовал.
Чёт у тебя совсем всё криво. Включи инструк шаблон. Выбери там, и в контексте пресет под мистраль.
В этом треде собрались больные, конченые люди без моральных принципов. Это факт, не требующий доказательств. В чем я не прав?
Когда у тебя в персонажах Томоко, то тебе просто позарез нужно, что бы были показаны ее мысли, переживания, самокопание и обязательный приход к самым абсурдным умозаключениям, на основании которых ее действия сделают ситуацию для нее еще более кринжовой. Как добиться - не знаю. ИИ же пытается играть так, будто Томоко 42 года и она работает психологом.
Он по умолчанию был выключен. Я думал так и надо. Что оно делает?
За всех не скажу, но глядя на себя - соглашусь.
Нюня был норм. Рад за него что он сьебался с нашей помойки
Неправ в том что считаешь что мораль применима к файлу с весами, выдающему по алгоритму наиболее вероятный ответ на запрос пользователя.
Всё не так просто как ты описываешь.
Это частности, суть неизменна. Модель не живая, боли не чувствует, любое нарушение морали происходит в твоей голове.
Суть в том что ты даже понять полностью математические принципы по которому работает этот алгоритм не в состоянии.
Для данного разговора важно только то что я ебал твою мать, выблядок
>Он по умолчанию был выключен. Я думал так и надо. Что оно делает?
Если совсем условно, то добавляет разметку по определённому шаблону в твой запрос к ЛЛМ. Модель приучена реагировать на эту разметку.
>Как добиться - не знаю.
Промтом. Пиши в промт, что ты хочешь чтобы модель делала и смотри что получается, если результат не устраивает меняй формулировки. Экспериментируй. Можешь ещё с дипсиком или гопотой посоветоваться, например попроси её помочь написать инструкции чтобы ЛЛМ отыгрывала такое-то поведение, лучше с примером.
За живое тебя задел, кожаный?
Так он до сих пор тут, просто стал таким же озлобленным шизом и пидорасом высирающим пасты тому кто не прав по его мнению
Очень интересный опыт! Анончик, может расписать немного подробнее что конкретно ты делал и как это обустраивал? Показались ли какие-то вещи избыточными, или наоборот от чего-то проявилось совсем новое качество ответов?
> нужно много моделей
Можно использовать все на одной большой, а чтобы не обрабатывать каждый раз много контекста сохранять кэш, или формировать инструкции в конце.
> если ты сам чутка подкован, то ты вместе с ИИ намного эффективнее, чем подпивас с ИИ и ты же без ИИшки
База, двачую. Также ллм хорошо использовать для анализа и самообучения в вопросах, где ты недостаточно компетентен. Но не в формате вопроса и принятия первого ответа на веру, а разбирая по частям что, откуда и почему. В таких кейсах и сама ллм может свое мнение поменять относительно исходного ошибочного зирошота.
>Блядь, сто раз уже говорилось, что нельзя i кванты использовать с моэ.
Можно и достаточно бодро. Пробовал я обычные кванты, скорость такая же (даже меньше из-за большего размера), и модель превращается в большего лоботомита в обычных, чем в i квантах

Действительно, хули нейросетка отвечает по русски?
Не, он ливнул, выше среди говнивых полотен затерялось. Похоже потому и ливнул чтоб в конец не стать злым пидорасом. Жаль но я ещё летом писал что ему здесь не место
Олсо, где перекат? ОП снова попал в круговорот кума?
Нуб в треде. На 3060ti 32gb ram какая мета?
Никакой. Каждый дрочит как хочет.
у локальных ЛЛМ гейткип 24гб+ врама.
Купишь видеокарту - возвращайся.
Вообще похуй становится через год, дрочу на РП в голове, сетки запускаю раз в месяц.
Мимо олд с первого треда
Кто там ебался с Минимаксом, моделью этой - отпишись как она. В новом треде уже.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ

&cx



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: