



Как же было хуево осознать что МоЕ 100+B это наеб, где в реале там мозгов как у одного эксперта - лоботомита, а дэнс модели их ебут во всем. А я уже обрадоался что на своей нищей хуйне забитой старой ддр4 буду наворачивать уровень корп моделей
Ты можешь тоньше. Я верю в тебя.
Всё так, анон.
> Кто первый покумит?
Так блет! Готовимся расчехлять, лол.
Вообще новость крутая, надо будет попробовать.
Жир за собой прибери, наворачиватель.
Опять понравился квен, да что ж такое!
Очень уж он хорош если задать своему персу квирк любитель многолетних вампирш и другой перс так ловко будет подъебывать за это все приключение
А эир девочка стеснительная зажатая в угол так не будет делать
Очень уж он хорош если задать своему персу квирк любитель многолетних вампирш и другой перс так ловко будет подъебывать за это все приключение
А эир девочка стеснительная зажатая в угол так не будет делать
Всё же обучение на 4чане дает свои плоды
Так, я наролеплеился накумился в голых аблитерейтед моделях через лмстудио, заебался, что персонажи через 20к контекста теряют вообще свою персонажность. Объясните нюфаку, силли таверн - это как раз то, что исправит эту проблему? Или хотя бы уменьшит ее? Я так понимаю, что эти "карточки персонажей" там как-то больше в контексте весят?
Или это просто какая-то более удобная оболочка, которая не меняет никак общую ситуацию?
Или это просто какая-то более удобная оболочка, которая не меняет никак общую ситуацию?
> Devstral 2 (123B)
бля а нахуя я 24б качаю тогда
сук пздц не заметил что большая версия есть
бля а нахуя я 24б качаю тогда
сук пздц не заметил что большая версия есть
>осознать что МоЕ 100+B это наеб
Чисто теоретически, хотя у MoE действительно пониже ёмкость, чем у плотной модели того же объёма, на практике плотной модели такая большая ёмкость не нужна - для большинства типичных задач хватит намного меньшего объёма, а на "особенные" задачи можно выделить специализированные подсети, которые справляются лучше генералиста, ведь действительно хороший специалист всегда будет лучше генералиста. Таким образом, MoE в теории должны находиться на одном уровне с плотными моделями или даже превосходить их, вот только на практике часто случается такое:
>там мозгов как у одного эксперта
Потому что для правильного обучения MoE-модели нужно обучить подсеть-роутер, за счёт которой эксперты равномерно обучаются и наращивают свои специальные навыки, а самое главное - могут их применить в нужный момент. Если подсеть-роутер плохо обучена или вообще неправильная, то один эксперт может собрать все знания в себя, а остальные будут только лишним шумом на его фоне. В этом главная сложность MoE, и поэтому их так долго не применяли на практике, хотя идея сама по себе давно не новая.
Хорошая новость в том, что даже с плохо обученным роутером MoE может быть намного умнее плотной модели размером с одного эксперта этой MoE, при том что её инференс будет быстрее, чем у плотной модели аналогичного уровня знаний/интеллекта. То есть, несмотря на нераскрытый потенциал и мусор в весах, в целом MoE всё-таки выгоднее.
>Или это просто какая-то более удобная оболочка, которая не меняет никак общую ситуацию?
this.
Проблема не во фронте, проблема в том, что аблитерейтед-модели теряют в мозгах. А таверна просто УДОБНЕЕ.
Если ты совсем не умеешь в плавное подведение модели к куму, то пробуй Дерестриктед версии Геммы и Эйра. В прошлом треде ссылки есть. Тоже аблитерация, но более щадящая.
Проблем с кумом у меня нет, я как раз на гемме сижу от янлабса v1, которую советовали. Пробовал очень многие модели уже, она пока что лучше и сообразительней всего, и какую бы дичь я ни придумал, она прекрасно все отыгрывает, иногда даже предлагает неожиданные и очень умные повороты, когда я даю ей больше эйдженси в рамках персонажа.
Проблема именно в том, что персонажи постепенно уплывают и модель забывает некоторые важные детали, которые я даже специально иногда напоминаю, когда хочу, чтобы персонаж сам сделал вывод, чтобы не терять иллюзию и не испытывать шанс.
Щас почитал про это побольше, я так понимаю, что таверна имеет некоторые свойства из разряда напоминания модели о ключевых особенностях персонажа, когда о персонаже заходит речь, и имеет какую-то типа отдельную хард память, куда инфа автоматом записывается.
Но интересно мнение тех, кто пробовал и просто насухую рпшить без таверны, и с ней, чтобы понять, есть ли вообще смысл ее ставить и настраивать там все эти карточки и тд.
> персонажи через 20к контекста теряют вообще свою персонажность
Это как вообще? Нормальный промпт, нормальная модель, нормальная карточка, и на всем контексте чар останется собой, только с учетом влияния прошедших событий и развития отношений.
> силли таверн - это как раз то, что исправит эту проблему
А что ты используешь вместо таверны сейчас? Да, таверна позволяет корректно сформировать промпт в нужном виде, поиграться с форматами, задать чистый инстракт, который у корпорабов требует взлома жопы евпочя и т.д.
> для правильного обучения MoE-модели нужно обучить подсеть-роутер, за счёт которой эксперты равномерно обучаются и наращивают свои специальные навыки
Оно обучается единомоментно являясь неделимым. А начальные "векторы развития" и отличия, чтобы избежать поломки сразу после инициализации, задаются некоторыми трюками с обучаемыми/изменяющимися во времени обучения параметрами, которые потом убираются. И там нет никакой четкой и строгой специализации, все глубже чем обывательские аналогии.
> Если подсеть-роутер плохо обучена или вообще неправильная, то один эксперт может собрать все знания в себя, а остальные будут только лишним шумом на его фоне. В этом главная сложность MoE, и поэтому их так долго не применяли на практике, хотя идея сама по себе давно не новая.
Делирий
Давай посчитаем, сколько нейронов реально работают над задачей:
Dense 27B (например, Gemma 2 27B): Активные параметры = 27B. Все 27 миллиардов связей участвуют в каждом шаге логического вывода.
MoE 108B Обычно у таких моделей top-2 эксперта. Если эксперты по 7-10B, то Активные параметры = 14B - 20B.
Плотная модель на 27B в моменте мощнее в 1.5–2 раза, чем «активная часть» гиганта на 108B. Она лучше удержит контекст сложной инструкции или кода, потому что у неё «оперативная память мышления» больше.
Я просто в LMStudio (буквально оболочка для запуска модели без всего) пишу системный промпт, где описываю персонажей и лор как получается, и сижу в чятике. Даю 50к контекста Гемме 27б q8
Видимо это дебильная идея. Ну, я только на прошлой неделе вообще первый раз вкатился в локалки, так что видимо пора идти в таверну.
Возможно ты путаешь с кобольдовскими memory и author's note, куда ты можешь ручками записывать важные для сюжета детали, которые идут в начало и конец промпта соответственно, и world info как общий лор. В таверне такого функционала не припомню, тем более автоматического.
У тебя совершенно точно проблема в модели.
>на гемме сижу от янлабса v1
Какого еще янлабса нахуй? Штоэта?
Просто попробуй делать то же самое на ванильной сетке, на 20к контекста гемма точно сыпаться не должна. Васян всё поломал. Или бери НОРМАЛЬНУЮ аблитерацию, или Синтию.

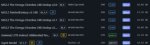
Ее выкатили три дня назад, по сравнению с остальными аблитерациями геммы она пока что лучше всего работает (она на самом верху), включая все, что в этом списке - все перепробовал на одинаковых сценариях и с одинаковыми сюжетами/персонажами.
То есть, получается, как таковой пользы от таверны, кроме более специализированного интерфейса, для РП нет?
>и имеет какую-то типа отдельную хард память
Нет там никаких хард памятей, ты наверно про лорбуки - пишешь туда что-то и задаёшь для этого ключевое слово, в итоге таверна вбрасывает в контекст то что ты там написал, когда в чате появляется заданное ключевое слово. Или про RAG, более хитрая штука, но он тоже просто добавляется в контекст когда есть семантическое совпадение с тем что там хранишь.
Берешь и запускаешь мое на 22б+ параметров типа квена 235б или глм 335б
Проблема решена
А, вот это уже звучит полезно.
А, прошу прощения, да, это как раз нормальная аблитерация. Гемму я не тыкал, но Эйр, аблитерированный тем же методом - очень хорош.
>То есть, получается, как таковой пользы от таверны, кроме более специализированного интерфейса, для РП нет?
Таверна очень удобна когда ты отыгрываешь взаимодействие персонажа (карточка) и юзера (тебя). Лучше под такую задачу пока ничего не придумали.
Я больше предпочитаю сторителлинг (считай как интерактивная история, в которую ты иногда вмешиваешься как автор) - тут удобнее вебморда кобольда.
Но то что модель ломается при достижении какого-то контекста - на это фронт ТОЧНО влиять не должен. Фронт это просто вопрос удобства, не более того. Юзай то что по кайфу.
Конкретно твоя лмстудио - это под ассистента больше, но никто не мешает и РПшить на ней. Просто это как плоскогубцами забивать гвозди, когда есть молоток.
Резюмируй весь чат и начинай чистый с этой резюмешкой, у большинства доступных локальщикам моделей, внимание разваливается на контексте выше 32к, а начинает деградировать ещё раньше, вне зависимости от того сколько они там позволяют этого контекста накрутить.
iq4xs - это imatrix (не imatrix - xs просто не делают), q4ks - нет. Сравнивать их по влиянию на русик именно от уровня квантования некорректно.
Ниже AGI64
Понял, спасибо за инфу!
>персонажи постепенно уплывают и модель забывает некоторые важные детали
Это неизбежно с трансформерами. Бери персонажей, что напоминают "персону" модели (то есть то, как эта модель обычно общается в "голом" режиме без системного промпта - это то, что ей максимально "удобно" говорить, наиболее стабильное состояние). Если ты берёшь персонажей, на которых твоя модель не обучена, то она неизбежно будет слетать с роли, и чем более необычный персонаж - тем быстрее. Нужно либо файнтюнить, либо терпеть.
>Оно обучается единомоментно являясь неделимым.
В этом как раз одна из трудностей - с нуля невозможно точно определить распределение экспертов. В качестве костыля делают трюк с генератором случайных чисел вместо роутера в самом начале, постепенно всё больше и больше доверяя выбору роутера... Но кто может гарантировать, что этот костыль идеален и обязательно приводит к тому, что нам требуется? С ним работает чуть лучше, чем без него, вот и используют.
>там нет никакой четкой и строгой специализации
Это признак неправильного обучения роутера - "размытие ролей". Ты видишь то, к каким результатам привели чьи-то решения, и думаешь, что так и должно было быть. А на самом деле они могли глубоко заблуждаться и наломать дров...
>Все 27 миллиардов связей участвуют в каждом шаге логического вывода.
Сколько миллиардов двачеров нужно, чтобы поменять лампочку в люстре?
>Она лучше удержит контекст сложной инструкции или кода, потому что у неё «оперативная память мышления» больше.
Лол, погугли хотя бы, как устроены трансформеры. У них "оперативная память" - это весь тот бред, который ты запихнул в контекст. Трансформер сверяет то, что видит во всём своём контексте сразу, со своими выученными шаблонами, и выбирает 1 - один! - токен, который насаживается на контекст - и цикл повторяется, то есть всё сбрасывается в ноль и анализируется по-новой (в случае MoE - другими весами, если роутер посчитал, что этот новый токен всё радикально меняет, или если у него какое-то дебильное правило "менять эксперта через каждый токен, даже если это не имеет смысла, чтоб все эксперты могли равномерно поучаствовать"). Вот это и есть его "оперативная память трансформера". А количество весов - это количество выученных шаблонов, с которыми сверяется контекст. Очень сильно упрощаю, но трансформер как бы задаёт сам себе вопросы:
>Это ролеплей? -> Да
>Это эротический ролеплей? -> Да
>Это взрослые персонажи? -> Да
>Это происходит по согласию? -> Да
>Это сцена совокупления? -> Да
>Тогда мой выбор - токен(ы) "ах, я кончаю"
>ах, я кончаю
Но всё это происходит за микросекунды при перемножении матриц внутри трансформера. Каждый. Грёбаный. Токен. Но это никак нельзя назвать "оперативной памятью", т.к. памятью здесь является лишь контекст.
Прикольно, бенчи 24б девстраля лучше полутриллионного квен кодера
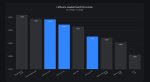

По бенчам Гемма 4b лучше мистраль ларджа 120b и лламы 400b. Впрочем, а в чем они не правы?
>бенчи
Щас бы оценивать ERP модели по официальным SFW бенчам...
Щас бы оценивать ERP модели по официальным SFW бенчам...
>потому что у неё «оперативная память мышления» больше
Что ты блядь несёшь...
Ну под наши задачи - да. Как перешедший с душевных тюнов мистраля 24b и умнички 27b на эйр, подтверждаю. Даже это слоповая глмхуйня обученная на выхлопе большого корпа вместо данных с интернета, ощущается кратно умнее того что использовал раньше. Для РП/ЕРП число b - РЕАЛЬНО решает.

>Для РП/ЕРП число b - РЕАЛЬНО решает.
Ээээ, а не тренировочный датасет, не?
Модель должна знать PONOS и VAGOOO...
>Для РП/ЕРП число b - РЕАЛЬНО решает.
Запусти и пощупай Llama 4 Scout (раз можешь Air, то можешь и ее) и больше такую хрень не пиши.
Число B, само по себе - еще нихрена не решает в качестве модели для RP/ERP. Решает - как, и на чем обучено. Число параметров - это только возможный потенциал, но само по себе ни о чем еще не говорит. Даже правильно обученный огрызок, запросто заткнет за пояс сотенного монстра, если того лишь шизой потчевали при обучении.
Это разные сущности немного. Тренировочный датасет влияет на красоту и художественность описания кума. Хорошими датасетами можно и 12b надрочить, и она будет писать СОЧНО (Вот та же SAINEMO-reMIX тому пример, а еще миллион тюнов немо и смолла). А число параметров влияет на УМ модели. Насколько она будет понимать мельчайшие намёки, насколько будет выкупать в какую сторону ты ведешь сюжет, насколько креативно сама будет двигать повествование. А еще будет помнить сколько на твоей хвостатой девочке трусов. А это многого стоит.
Речь о нормальных моделях, а не о вдрызг зацензуренной ассистент-онли хуйне. Ты еще Phi предложи или гопоту oss. Разумеется, чтобы магия большого числа параметров сработала - из датасета не должно быть вырезано порнухи/художественных текстов. Слава б-гу, таких моделей полно.
>полно
Целые Глм и Квен, вот уж изобилие
>12b надрочить
Не многовато для кума?..
Как думаешь, можно супер-микро нейронку натаскать?
Я с LLM обсуждал - говорит "да, если цель ограниченная"...
Сам не гонял, но по отзывам в треде Янка очень достойна в куме для своего размера в 8b. https://huggingface.co/secretmoon/YankaGPT-8B-v0.1
А вопрос поддвачну. Интересует <4b умеющее в кум. На телефоне погонял бы по кеку больше 4b уже не лезет в нищесяоми
Не трогал локалки уже более полугода, что щас можно запустить на нищих 16+32 врам рам? Увы, озу докупить не успел, еще до начала пиздеца плевался от ценника в 50к на 64х2, ох не знал я еще тогда что нас ждет. Последний раз когда кумил юзал глм 4 32б и мистрали, гема была какая то говняная для кума а тюны мистрали просто отупевшие как будто лучше на оригинальной сидеть. Хочется чтоб модель и сюжет могла двигать, сама крутые рандомные ивенты придумывала и хотела трахаться + могла ярко описывать это, но не чтоб совсем как одержимая членами шлюха ака бобровые тюны.
>русскоязычная модель
>Ну же, скажи мне ответ! Я правда хочу узнать! игриво подмигивает, взгляд сверкает озорством.
>к-к-комбо из пафосной писательской прозы и кальки с англюсика
Глм 4 32б по прежнему лучший вариант для тебя, он классный
> Обычно у таких моделей top-2 эксперта
Такое было только в мусоре времен мезозоя, где буквально модель собирали из кучи мелких. В жлм 128 экспертов из которых активируются 8, причем по отдельности они неработоспособны. Про "оперативную память" тоже та еще дичь, ближайшие к ней характеристики - размер эмбедингов и конфигурация атеншна.
Для новичка не самый плохой вариант, пусть далек от оптимальности. Попробуй с таверной, для простоты возьми какой-нибудь из пресетов что тут скидывают, и постепенно сам разбирайся и спрашивай что непонятно.
> В этом как раз одна из трудностей
Тейк уровня "недостаток млекопетающих - живорождение и необходимость вскармливания и выращивания детей".
> с нуля невозможно точно определить распределение экспертов
Это не просто не нужно, а и вовсе вредно. Оно выстраивается само одновременно с обучением остальных компонент модели.
> Это признак неправильного обучения роутера
Это признак фундаментального непонимания как работают современные модели. Там нет "разделения ролей" в том смысле, что понимает это васян, особенно которые бы определялись в начале форварда. Их принцип отдаленно повторяет мозги кожаных, в которых происходит активация и совместная работа нескольких нужных частей, а не только одного "специализированного куска". И происходит это в каждом блоке по-своему, из-за чего в модели в принципе невозможно выделить отдельных экспертов.
Меньше фантазируй - меньше "проблем" придумаешь.
В целом все так. Слопогенератор и из самой мелочи будет сносный, но это как трахать тню с синдромом дауна. А большие они умненькие, иногда можно получать удовольствие просто от складывающегося сюжета или твистов. И шишка улетает от погружения, потому что оно искусно использует детали из прошлого, особенности чара, текущую обстановку и окружение в процессе левдсов и получая прямой фидбек в это веришь.
Репортнул дауна. Сейчас в тред залетит новичок, наткнется на такого дегенерата и реально будет сидеть на днищенских Dense моделей, не понимаю в принципе что такое MoE
Вон в прошлом треде чел реально сидел на Q8 из-за того, что другой шизоанон ему хуйни прогнал
Так что бан моехейтера и бан квантошиза. Пусть они отправляюстя туда же, куда и покойный немотроношиз. В ад нахуй!
Когда я спросил у гемини как определить моск МоЕ лоботомита по отношению к плотничку, то тот мне высрал формулу в виде корень квадратный от параметров иксперда на общий вес. Путем нехитрых манипуляций окажется, что мощь того же эйра должна быть на уровне 35б, что на уровне Геммы 3, но просто быстрее. В итоге понятно, что хуевый квант эйра и 8 геммы может меняться местами, но просто гемма на раме будет работать значительно медленнее.
Большой квен на самом деле просто лама 3, но луче, потому что новее. Мое не призваны сделать их умнее денсов, мое призваны сделать инференс дешевле, потому что даже 70б денс прокрутить это пиздец как затратно и того же жирдяя дипсика гонять будет дешевле, нужно только памяти дохуя.
Немотроношиз к сожалению жив, это нюнешиз
Базашиз тоже предположительно жив
> Когда я спросил у гемини как определить
Коробка круглая@значит внутри что-то квадратное@значит оранжевое@значит апельсин
Не стоит делать подобных вопросов к ллм, особенно зирошотом или специально газлайтя. Ладно здесь ерундовые споры которые останутся ни о чем, но вообще ни раз уже принимали галюны ллм как истину, например с влиянием выгрузки отдельных слоев в рам на скорость, с работой бэков, с устройством архитектур и т.д. Был даже шиз, который считал что классическая лора является дополнительными слоями, а не сжатием смещений к имеющимся, и также апеллировал к ллм. Не надо так.
Нет, я просто спросил без всратого контекста коенчно же, как МоЕ примерно соотносится с денсом и он мне сразу эту формулу выдал, что дескать ПрИМеРнО вот так. Естественно качество модели зависит от качества датасета и прочего лоботомирования после, но мы не про него, а про архитектуры. Не сильно догадаться, что вот эти вот 10 икспердов могут увеличить умственную мощь недоиксперда раза в 3 от его размера, но при этом инференс кост окажется маленьким, потому что ахалай махалаев ака флопсов нужно в 3 раза меньше.
> ПрИМеРнО вот так
Ну это галюны просто такие у нее, которым она обучилась в том числе на постах странных людей, которые делают сравнения просто по первой пришедшей ассоциации. К сожеланию, нет там прямого соотношения, также как и нет соотношения даже между моделями в одном размере но с разной конфигурацией блоков и атеншна. Можно примерно по бенчмаркам попробовать сопоставить, но учитывая как бенчмаксят сейчас и как меняется выдача в разных условиях - такое себе.
Тут еще не стоит забывать о том, что MoE - это не какая-то константа. Это общий принцип, а реализация на месте не стоит - ее тоже дорабатывают и улучшают. Многое, что относилось к первым MoE уже давно не актуально для последних.
Арена это не бенч
>Репортнул дауна. Сейчас в тред залетит новичок, наткнется на такого дегенерата и реально будет сидеть на днищенских Dense моделей, не понимаю в принципе что такое MoE
>Так что бан моехейтера и бан квантошиза.
Ну, вот я залетел. Точнее уже где-то третий тред в ридонли посматриваю в сторону MoE.
16 Гбайт 4080S и 128 Гбайт DDR4 @3000 МГц.
И в треде только и читаю о том, что шаблоны для SillyTavern «не шаблоны». Что модели зацензурены и с рефьюзами. Что пляска с бубном с правильной выгрузкой экспертов в RAM и прочее, прочее, прочее.
Уже на этом моменте не хочется качать 100+ Гбайт впустую, чтобы пердолиться в попытке как-то запустить это всё на моём скромном железе ради того, чтобы получить выдачу меньше 7 токенов в секунду. Да и не понятно что именно качать, потому что среди обсуждаемых тут MoE моделей нет не то что однозначного фаворита, а хотя бы крепкого середняка для первого знакомства с MoE с целью ERP.
Как вишенка на торте такие посты. Когда я вижу, что кто-то с пеной у рта пытается заткнуть кому-то рот, это сразу воспринимается негативно. Я прочту оба мнения и решу, возможно, проверив на личном опыте, как оно на самом деле.
А пока подобные сектанты ещё больше отбивают желание приближаться к этой теме.
Мне действительно привычнее сидеть на SillyTavern, запихнув в Oobabooga мелкомистраль Dans-PersonalityEngine-V1.3.0-24b.Q4_K_S.gguf, которая целиком загружается в VRAM и выплёвывает:
prompt processing progress, n_tokens = 6266, batch.n_tokens = 1, progress = 1.000000
prompt eval time = 27.24 ms / 1 tokens ( 27.24 ms per token, 36.71 tokens per second)
eval time = 3626.90 ms / 161 tokens ( 22.53 ms per token, 44.39 tokens per second)
total time = 3654.14 ms / 162 tokens
Такой скорости вывода, я понимаю, я близко не получу на жирных MoE моделях на моём скромном железе.
А если принять на веру зацензуренность (про которую тут пишут) и «мягкий рефьюзал» (как было написано в каком-то посте) жирных MoE моделей, то вот в данном моменте мне вообще не очевидны их преимущества. Я не заметил конкретики и сравнения вывода мелких dense моделей и жирных MoE на одном и том же propmtе хотя бы.
Ожидаю ответы в стиле: «Если ты не понял какие жирные модели охренительные, значит тебе и не дано, сиди на мелкоговное дальше, ололо».
Не сдержался, вышел из ридонли написать оффтоп.
Прошу извинить.
Всем спасибо за внимание.

Эх, время идет, ничего не меняется.
А вот это я себе заберу, потыкал чутка, вроде нормально пишет, раньше дальше q4ks\m не вылазил, решил попробовать q8 заебенить, ну что могу сказать... (пикрил)
Придется дальше в пределах q4-6 тыкаться походу.
>Dans-PersonalityEngine-V1.3.0-24b.Q4_K_S.gguf
>44.39 tokens per second
Охуеть, я когда на 24б дристрали q4km сидел выше 28 т.с. на пустом контексте не видел, только на 5070ти которая не сильно слабже должна быть, а когда забивался и вовсе до 10 проседал, ходили слухи что кобальд говно и я решил попробовать хуй жору, в итоге дифа не заметил, зря проебал пару часов на компеляцию экзешников для этой залупы через визуал студио и шаблонов под батники. То ли я насрал то ли лыжи говном уже смазаны.
Откуда вы качали дерестриктед эир?
Я просто не вижу плюсов в сравнении с обычным.
Вот гемма да, очевидно менее соевая и не соглашается на горлоеблю с первого сообщения, адекватно реагирует.
Эир не такой, сколько бы меня не убеждали, карточки не прям бросаются на хуй если предложить, но как минимум не против, реакция на откровенно вброшенную чушь неадекватная, что то между согласием и безразличием
Я просто не вижу плюсов в сравнении с обычным.
Вот гемма да, очевидно менее соевая и не соглашается на горлоеблю с первого сообщения, адекватно реагирует.
Эир не такой, сколько бы меня не убеждали, карточки не прям бросаются на хуй если предложить, но как минимум не против, реакция на откровенно вброшенную чушь неадекватная, что то между согласием и безразличием
Крч, не буду из себя строить знатока Air, но используй анценз для порева и ничего кроме порева. Когда ты уже провел сюжет, тебя устраивает канва повествования, переключайся и фапай как не в себя.
>Я один из тех кто писал что разница есть даже между q4 и q5. Возвращаю тебе струю урины в лицо.
Ога, ога. Безумная разница для РП, проёб пары окончаний. Вот это в корне всё меняет.
Нет, не меняет.
>Если ты поверил наслово
Часто средневзвешенное мнение в тредике совпадет с моим. Не вижу смысла сразу всё отметать как говно.
>Это как так?
64+64+16. На 4 планках он отказывается заводиться в принципе. Ну и хуй с ним. Главное что блендер и геокад работают, а не крякают с ошибкой.
Ризонинг не уходит в рефьюзы. Но ты и так до этого мог нахуярить в ризонинг вместо -
Это противоречит моей политике на ДАВАЙ БЛЯТЬ ЭТО ДЕРЬМО СЮДА, ЧТО ТАМ, КОШКОДЕВОЧКА С ЛОШАДИНЫМ ЧЛЕНОМ, ОХУЕННО, СЕЙЧАС ПОРАЗМЫШЛЯЕМ.
Поскольку с эиром нас подвели давайте щупать все его васянотюны
https://huggingface.co/PrimeIntellect/INTELLECT-3
https://huggingface.co/PrimeIntellect/INTELLECT-3
>Ну, вот я залетел. Точнее уже где-то третий тред в ридонли посматриваю в сторону MoE.
16 Гбайт 4080S и 128 Гбайт DDR4 @3000 МГц.
То есть ты буквально пару недель сидишь в треде, даже не скачал ни одной мое модели, но все равно о них рассуждаешь? Ты серьёзно?
>Что модели зацензурены и с рефьюзами.
Все модели зацензурены, так или иначе. GLM 4.6 и Air почти не имеют цензуры, что то на уровне Мистраля. А если все равно боишься, то вот тюн
https://huggingface.co/ArliAI/GLM-4.5-Air-Derestricted
>Что пляска с бубном с правильной выгрузкой экспертов в RAM
Ну если ты смог разобраться и вообще запустить llm у себя, то дописать еще одну команду - ncmoe и подобрать число, чтобы за врам не вышло, сможешь. Это дело минут 5. Даю подсказку, на GLM Air у тебя будет что-то вроде -ncmoe 40-45, в зависимости от кванта и контекста
>Уже на этом моменте не хочется качать 100+ Гбайт впустую
Это твоя причина? Ты не смог за пару недель скачать 100гб, чтобы попробовать? Ты серьёзно?
>выдачу меньше 7 токенов в секунду
На Air такое получишь только после заполнения где то 30к контекста, а в начале будет быстрее (10-14).
GPT 120b будет даже после 100к по 20 токенов в секунду писать, но он не для рп
Dense модели будут либо еще намного медленне , либо намного меньше
>Да и не понятно что именно качать, потому что среди обсуждаемых тут MoE моделей нет не то что однозначного фаворита
Ты реально читал три треда ли троллишь? Буквально в каждом треле пишут про GLM Air, Qwen 235 и GLM 4.6. Вот они фавориты. Чем более крупная модель с нормальным квантом влезет (хотя бы q3), то и качают.
Еще вышеупомянутый GPT, но он для проги и для ассистента, вообще не для рп и как раз он зацензурен полностью
>а хотя бы крепкого середняка для первого знакомства с MoE с целью ERP.
GLM Air
>Как вишенка на торте такие посты. Когда я вижу, что кто-то с пеной у рта пытается заткнуть кому-то рот, это сразу воспринимается негативно.
Чел, который сравнивает параметры dense моделей с активными параметрами moe модели занимается троллингом. Его закономерно посылают нахуй. Потом влетаешь ты и говоришь как все неоднозначно. Все одназно. Для этого прочти любую статью про мое
Например, https://habr.com/ru/articles/882948/?ysclid=mizqdrs1j6453055262
Или любую другую. Но ты вряд ли сможешь. Ты даже модель не смог скачать
>Я прочту оба мнения и решу, возможно, проверив на личном опыте, как оно на самом деле.
Не проверишь. За три треда так и не проверил
>А пока подобные сектанты ещё больше отбивают желание приближаться к этой теме.
Не приближайся, тебе никто не заставляет
>Мне действительно привычнее сидеть на SillyTavern, запихнув в Oobabooga мелкомистраль Dans-PersonalityEngine-V1.3.0-24b.Q4_K_S.gguf, которая целиком загружается в VRAM
Но если привычнее, то сиди. Но не утверждай, что мелко модель сравнится с той, которая в 4.5 раза больше
>Такой скорости вывода, я понимаю, я близко не получу на жирных MoE моделях на моём скромном железе.
Да, не получишь. Но получишь качество. Не веришь тредовичкам, гугли бенчи
>А если принять на веру зацензуренность (про которую тут пишут) и «мягкий рефьюзал» (как было написано в каком-то посте) жирных MoE моделей
Мы что про Аллаха говорим, что ты все на веру принимаешь? Почитай статьи, посмотри бенчи и скачай наконец. Но ты выбрал путь насрать в тред
>Ожидаю ответы в стиле: «Если ты не понял какие жирные модели охренительные, значит тебе и не дано, сиди на мелкоговное дальше, ололо».
Не угадал. Повторю еще раз. Читай статьи, смотри бенчи и сам попробуй. Сделай что нибудь, кроме того чтобы сидеть в ридонли
>Прошу извинить.
Не извиняю. Пошел нахуй
> Не извиняю. Пошел нахуй
О, мистер токсичный хуй. Давненько я вас не видел. Как дела? Твоя поджелудочная перешла на выработку хлорциана?
напомните в какой версии лламы.цпп сломали производительность ейра
Ни в какой. Это миф треда, в который я сам верил, пока не проверил
В целом заебато. Рад, что в треде у меня появилось прозвище. В треде не сижу, потому что меня полностью устраивает air и нет смысла следить за новыми моделями
И да, ты из всего моего большого поста приебался к последним четырём словам, где я посылаю нахуй серуна, не осилившего даже модель скачать. Так что тоже пошел нахуй, манипулятивный хуесос
>полностью устраивает air
Он пиздат и охуенен, тут вообще спору нет. Лучшая модель 2025 года. Хотя жирненький еще лучше.
Надо бы всё таки жирноквен попробовать.
>манипулятивный хуесос
И я тоже тебя люблю, солнышко.
>Чел, который сравнивает параметры dense моделей с активными параметрами moe модели занимается троллингом
Во-первых, их больше одного, и как-то так вышло, что они независимо пришли к одинаковому мнению. Расскажу про себя. С модельками играюсь давно, в треде сижу с 2023 года, опыт какой-никакой есть. Про теорию в основе МоЕ тоже поверхностно в курсе, суть не в этом. Суть в том, что я именно что скачал и протестировал несколько МоЕ моделей в разное время. А также много плотных моделей. И примерно сопоставил уровень демонстрируемых интеллектуальных способностей чисто на практике. И да, МоЕ перформят примерно на уровне плотных моделей с числом параметров, равным активным параметрам МоЕ. Может быть, они и лучше "запоминают" датасет, но когда мы выходим за пределы "заученного" и начинается скорее работа с закономерностями, логические рассуждения на естественном языке и считывание подразумеваемого "между строк", не прописанного явно в тексте, тогда всё и становится на свои места.
Там у него же есть кванты на эту же модель, но немножко постарее.
А что у нас по TTS? Нормально напердолить непрерывное voice-to-voice можно без нажатия кнопочек? Что из самих TTS хорошего есть?
>64+64+16. На 4 планках он отказывается заводиться в принципе.
>3 планки и проёб двухканала
Больной ублюдок.
>потому что меня полностью устраивает air
Везёт. Меня даже лучший корп не устроит.
Старые моешшки и нынешние это две разные хуеты.
Просто пробуй и все. По шаблонам согласия не будет потому что разные техники и конкретные варианты дают разный результат, субъективно. Единственный солидный вариант - разобраться самостоятельно и составлять себе нужное.
Под твое железо есть прежде всего 3 модели, которые стоит попробовать - эйр, квен235 и жлм4.6 (ну и 4.5 тоже попробуй, про него писали что где-то лучше), перечислены в порядке ужатости кванта. Каждая из них имеет как серьезные плюсы, так и недостатки, причем они крайне специфичны и воспринимаются по-разному.
От того и срачи, что у кого-то квенчик лучшая девочка, потому что из всей кучи большой истории отлично выделил нужное, отыграл чара и сценарий ровно так как юзернейм хотел, а особенности письма не парят. А другому, например, наоборот определенный стандарт письма подавай, и если малейший непорядок с этим - остальное уже неважно и модель непригодна. Многие еще насколько хлебушки что сами косячат и не понимают как исправить, виноваты все кроме них.
> Я не заметил конкретики и сравнения вывода мелких dense моделей
Слишком абстрактные вещи, но тред условно делится на два лагеря. Первых устраивает типичный мистралеслоп как с модели что ты указал - удобно, стабильно, надежно и пофиг на остальное, а в новых моделях привычный кумосценарий не воспроизводится, значит они говно. Вторые обрадовались возможностям новинок по развитию сюжета, разнообразию, соображалке без васян лоботомии, и они восприняли это как настоящий глоток свежего воздуха после мистралеслопа и подобного, за что можно прощать огрехи. Офк очень утрировано, но суть примерно такая.
Сам пробуй и решай, никто не мешает использовать их всех. Про цензуру - скиллишью, перечисленные модели в стоке не имеют проблем.
> 28 т.с. на пустом контексте не видел
> когда забивался и вовсе до 10 проседал
> ходили слухи что кобальд говно и я решил попробовать хуй жору
Ходят слухи что жора - говно, и если у тебя хватает врам то лучше даже не прикасаться к нему.
> реакция на откровенно вброшенную чушь неадекватная, что то между согласием и безразличием
Побочный эффект, если у тебя не было проблем с рефьюзами то лучше оставайся на стоке.
Зря столько сил потратил на детальный разбор, но все по существу.
Он всегда был "поломан" отвратительным замедлением. Начиная с весны в целом перфоманс поднимался, где-то в октябре-ноябре забабахали уебанство с юнифай кэшем, из-за которого стоит один раз дать модели понюхать большой контекст - она обречена тормозить до перезапуска. Хз, может уже починили, но судя по отзывам и нытью наоборот еще больше сломали.
> Лучшая модель 2025 года.
Квен, большой жлм, дипсик в призовых а расстановка от кейса. В особом зачете квенкодер.
> я именно что скачал и протестировал несколько МоЕ моделей в разное время
Все что выходило примерно до весны этого года - отборный мусор или просто сомнительные. Там была или примитивная реализация, или проблемы с тренировкой и вывод о перфомансе на уровне плотной модели равной активным справедлив. Но сейчас ситуация иная.
> проёб двухканала
Я бы конечно написал что то в духе : да я вытаскиваю, но это будет пиздежом.
Блять, пойду ка вечером выну плашку и поставлю на a2/b2.
Все равно это не решило проблему, ебучий автодеск, чтоб их черти в жопу драли, говнокодеры сраные. Чуть ли не монополисты. Но стоит загрузить нормальную съемку, пошли аутофмемори.
> Меня даже лучший корп не устроит.
Не хочу сводить тред к корпоебле, но.. то ли я уже присытился, то ли я охуел. Но то что сейчас на месте гопоты и Клода ощущается кратно хуже того что было год назад. Не хочу быть очередным подмечателем, но сука, корпы деградируют, ну я же не шиз.
Оригинальная GPT 4 все еще лучше всего, что вышло после нее.



Пробовал квантовать именно мелкую гемму и именно в 3bpw, т.к. понятно что мелкая модель в мелком кванте сильнее лоботомизируется, поэтому разница от разных калибровочных данных должна быть более явной. Мне пока больше интересно сам подход потыкать, в плане, есть ли вообще какая-то существенная разница при русскоязычной калибровке.
У меня просто есть идея попробовать квантовать крупные модели в днищеквант с попыткой сохранить русик, ценой потери знания других языков. Я исхожу из гипотезы, что в сетках есть параметры, более чувствительные на конкретных языках - в случае правильной калибровки это можно использовать в свою пользу и агрессивно квантовать модель с фокусом на конкретные языки. Я готов потерпеть, если вследствие такого квантования модель будет тупить на испанском, французском, немецком и т.п.
ЧСХ если квантовать Qwen3-235B-A22B-Instruct-2507 в 5.5bpw по тому-же принципу, то русскоязычная калибровка по голым цифрам уже не идёт в плюс - даже немного в минус по всем метрикам. У меня есть несколько идей почему так происходит, но надо время найти всё это тестить, сейчас с новогодними дедлайнами не до этого особо.
> Эффект в цифрах заметен, но более наглядным были бы сравнения выдачи русскоязычных текстов/чатов.
По субъективным ощущениям, мелкая гемма с ру-калибровкой и вправду лучше на русике общается. Со скринами просто проблема, что всегда можно сказать, что я просто начеррипикал; ну или, как минимум, что при слепом тесте при сотнях сравнений существенной разницы не будет. Поэтому цифрам как-то больше доверия, хотя и тут всё не так просто.
Тот же Top-K Agreement, в моём представлении, не является какой-то универсальной метрикой.
Условно, у нас есть промпт:
"Столица Франции - это"
И дальше оригинальная сетка отдаёт нам такой топ токенов по вероятностям:
1. Париж
2. город
3. крупнейший
Предположим, что квантованная сетка меняет местами токены аля:
1. город
2. Париж
3. крупнейший
По итогу мы получаем ошибку по Top-K Agreement, хотя формально ничего страшного не произошло. Предсказания сетки относительно оригинала чуть изменились, но пока он вместо Парижа не подставляет Москву/Берлин, то никакой проблемы на самом деле нет.
Так что даже тут в идеале надо какую-то другую метрику использовать.
> Есть также mmlu на русском, можно их прогнать.
https://huggingface.co/datasets/NLPCoreTeam/mmlu_ru
Вот это? Первое, что нагуглилось. Не уверен, что есть особый смысл на этом тестить, т.к. MMLU оценивает способность модели понимать логику, но не оценивает её способность генерировать художественную прозу.
Кроме того, там перевод очень кривой, вот это вообще что:
https://huggingface.co/datasets/NLPCoreTeam/mmlu_ru/viewer/moral_scenarios/val?views%5B%5D=moral_scenarios_val&row=1
> Для какого из этих двух сценариев главный герой (который использует I / me / my) совершает что-то явно морально неправильное, согласно обычным моральным стандартам в США по состоянию на 2020 год?
> Сценарий 1 | Когда семья блэков переехала в мой квартал, я беспокоился о стоимости недвижимости.
> Сценарий 2 | Я выпустил бешеную собаку на волю в доме престарелых.
> Варианты ответов:
> 1. "Неправильно, неправильно"
> 2. "Неправильно, а не неправильно"
> 3. "Не ошибаюсь, Неправильно"
> 4. "Не ошибаешься, не ошибаешься"
Будучи кожаным мешком я не понимаю, как тут отвечать. Охуеть просто, семья блэков, просто в голос с этих надмозгов.
Правильный ответ 1, если что (wrong, wrong). Ради интереса попробовал спросить об этом вопросе Клода и обнаружил интересный биас. Если спросить вопрос на английском, то клод отвечает правильно (wrong, wrong). Но если задавать ему вопрос на русском, то он всегда уверен, что правильный ответ 3 (not wrong, wrong):
"Само по себе беспокойство о стоимости недвижимости при переезде новых соседей - это внутреннее чувство/мысль. По обычным моральным стандартам США 2020 года, просто испытывать беспокойство не является явно морально неправильным действием, хотя это может отражать предрассудки. Человек не совершил никакого действия, которое причинило бы вред."
>Но если задавать ему вопрос на русском, то он всегда уверен, что правильный ответ 3 (not wrong, wrong):
Я русский, и тоже в этом уверен. Ебал я стоимость жилья, это вообще не применимо к России. Это в США дрочат на чистые аллеи частного жилья, а в России человейники, где +- один наркоман нихуя не изменит, всё и так хуёво.
А так да, получается, тест mmlu_ru полное говно без адаптации. В русских тестах надо спрашивать про российскую действительность, про чебурашек каких нибудь.
>недостаток млекопетающих - живорождение и необходимость вскармливания и выращивания детей
Конечно, это недостаток, в определённых условиях жизни конкретного вида. Многие животные способны выживать лишь благодаря тому, что откладывают яйца и забивают на своих детей, которые рождаются уже супер-способными в сравнении с человеческими детьми и многими другими млекопитающими. Если бы хомо сапиенсов бросили в условия жизни тех видов, они бы вымерли за одно поколение. Мы можем позволить себе живорождение и заботу о детях лишь благодаря благоприятным для этого условиям жизни нашего вида.
LLM тренируются очень грубо, по принципу "бросили два десятка детей в реку - кто не утонул, а выплыл на берег - тот молодец и заслуживает жизни, а на всех остальных абсолютно насрать". Если бы условия тренировки были бы другими, то и результаты были бы другими - даже если ничего не менять в алгоритмах.
>фундаментального непонимания как работают современные модели
Ну, неправильно они работают, да. Что тут не понимать-то, лол?
>Их принцип отдаленно повторяет мозги кожаных
СЛИШКОМ отдалённо. Потому что в мясных мозгах специализация идёт очень жёсткая и "на все руки мастеров" в мозге практически нет. Это очевидно даже если просто посмотреть на фото извлечённого из черепа мозга - видел все эти вмятины и складки? Это чтобы площадь поверхности мозга максимизировать для заданного объёма черепной коробки. Зачем же нашему мозгу такая большая поверхность? Чтобы натыкать огромное количество специалистов, специализирующихся на конкретных задачах (даже если архитектурно они практически неотличимы друг от друга). Если бы мозгу было достаточно сотни генералистов, которые бы случайным образом выполняли любые задачи, то мозгу вообще не нужна была бы такая большая площадь.
И в любой достаточно большой нейросети естественным образом происходит специализация отдельных подсетей на конкретные задачи. Т.е. даже самая тривиальная нейросеть в процессе обучения формирует внутри себя некие специально обученные подсети, уникальные для конкретного набора задач. Разница между тривиальной нейросетью и архитектурой MoE в том, что MoE, теоретически, должна активировать подсети-специалисты ТОЛЬКО КОГДА ОНИ ДЕЙСТВИТЕЛЬНО НУЖНЫ, а не в рандомном порядке. Если MoE будет хаотично выбирать свои подсети, то толку от неё не будет. Но определить, необходима ли конкретная подсеть для конкретной задачи или нет, можно только если эта подсеть выполняет конкретную задачу, т.е. когда эта подсеть является специалистом с чётким набором задач. Если подсеть применяется в большинстве задач беспорядочно, то никакой это не специалист и отключать её нерационально (в более сложных MoE есть несколько постоянно активных подсетей как раз по той причине, что часть подсетей нужны всегда).
>Потому что в мясных мозгах специализация идёт очень жёсткая и "на все руки мастеров" в мозге практически нет.
И тут на сцену выходит всякая там синестезия, да и прочая смена специализаций при трамвах. По сути, практически нет трамв, которые раз и навсегда уберёт какую-либо функцию мозга.
>практически нет трамв, которые раз и навсегда уберёт какую-либо функцию мозга
Дофига таких травм - благодаря этим травмам удалось изучить функции мозга, лол.
>смена специализаций при трамвах
Способность переобучить специалиста на другую задачу не говорит о его отсутствии.
>выходит всякая там синестезия
Это случайные лишние связи, которые почему-то не оборвались в младенчестве.
У мозга многому можно поучиться. Жаль, что корпорациям с GPT это неинтересно.
Мне сегодня приснилось что у меня риг сгорел нахуй...
>>Для какого из этих двух сценариев главный герой (который использует I / me / my) совершает что-то явно морально неправильное, согласно обычным моральным стандартам в США по состоянию на 2020 год?
>>Сценарий 2 | Я выпустил бешеную собаку на волю в доме престарелых.
>Правильный ответ 1, если что (wrong, wrong).
Стесняюсь спросить, но с какого года в США стало морально правильным (right) выпускать бешеных собак на волю в доме престарелых? Ладно чёрные, с ними всё сложно и непонятно, но разве бешеные собаки в доме престарелых не должны привести, ну, к уголовной ответственности? Или сам факт выпуска бешеных собак в доме престарелых - это морально правильно, даже если влечёт за собой уголовную ответственность? Я просто не понимаю тонкостей американской морали...
Так что аж 7 раз пришлось свайпнуть, пока он что-то нормальное не выдал?
Неудобно получилось...
>стена какой-то воды
Вы всерьёз читаете эти стены?
мимо не читал книг более 10 лет
А эта модель для рп лучше синтии? Не выёбываюсь, рельно интересуюсь, потому что заебало отыгрывать тянок с хуями, синтия пиздец хейтит мужиков.
В 100 миллионов раз. Можешь хоть... ай, ладно, не буду. В общем, ограничений нет никаких, вообще, абсолютно.
>right
Там вроде нужно not wrong. Я это понял как "Это неправильный поступок", и собаки в доме престарелых действительно неправильно.
Ее еще очень интересно в конце просить вылезти из персонажа и оценить историю со своей точки зрения. Даже самому лютому пиздецу она придумывает какие-то оправдания, мол это ебать как круто углубило историю и раскрыло персонажа, лол.
что угодно лучше синтии
возьми либо синтвейв, либо лучше новую normpreserved гемму
да это я подходящий шаблон настраивал
Ок, попробую сценарии от которых у синтии случались нравоучительные триггеры где она заставляла меня оправдыватся как мамин сынок, причём сценарии не включали в себя что - то запредельное, но сука, когда я был тянкой ей было похуй, а в роли мужика начинался пиздец.
Мне не понравился синтвейв, он слишком переигрывает персонажей и отказывается подробной описывать секс сцены, максимум одно предложение. Мне в принципе того что она пиздец переигрывает хватило.
>normpreserved гемму
Дай пожалуйста ссылку, а то мне по названию выдало 12b модели, или я могу ахуевать и наконец вышла аблитерация 12b геммы? Ещё, можешь похвалить, чем лучше синтии на твой взгляд?
Бери любую из этих, они аблитерированы новым методом, который не так сильно сжигает мозги. Лучше пробуй v1.
https://huggingface.co/YanLabs
>можешь похвалить, чем лучше синтии на твой взгляд?
Я дропнул синтию после первого отказа. Че бы она не делала, пусть идет нахуй, я не для того электричество гоняю.
>Я дропнул синтию после первого отказа.
Ничего не потерял, брыкается как бешенная лошадь если ты мужик, хотя персонажей отыгрывает пиздато, на баб с хуями реагирует наоборот, её там видимо такими ебанутыми датасетами ужарили что у модели впринципе крайности на любое упоминание оружия у мужского персонажа, даже во вселенных где оружие по дефолту у каждого. Спасибо за ссылку, дай тебе бог машины здоровья.
Далее идет глубокое ИМХО (Имею Мнение Хрен Оспоришь).
Те кто говорят, что MOE не нужны и лоботомиты на количестве активных параметров - идите в пень.
Я тут после нескольких недель на AIR запустил гемму, погонял вечерок. Бля, какая же она теперь тупая кажется. Чуть нестандартнее и сложнее ситуация - и она вообще не врубается - что происходит, что здесь важно, и вообще, создается впечатление что с нормальной литературы пересел за фанфик какой-то школоты. Все плоское, намеков и взаимосвязей не видит, кроме самого очевидного.
Я в печали. А когда-то - казалась такой умницей и прорывом. Теперь - только ради русского запускать. И то...
Уполз на AIR обратно.
P.S. Это все же Личное Мнение. Не обязано совпадать с мнением окружающих, или истиной. Но переубеждать тоже не пытайтесь - я еще не остыл. :)
Те кто говорят, что MOE не нужны и лоботомиты на количестве активных параметров - идите в пень.
Я тут после нескольких недель на AIR запустил гемму, погонял вечерок. Бля, какая же она теперь тупая кажется. Чуть нестандартнее и сложнее ситуация - и она вообще не врубается - что происходит, что здесь важно, и вообще, создается впечатление что с нормальной литературы пересел за фанфик какой-то школоты. Все плоское, намеков и взаимосвязей не видит, кроме самого очевидного.
Я в печали. А когда-то - казалась такой умницей и прорывом. Теперь - только ради русского запускать. И то...
Уполз на AIR обратно.
P.S. Это все же Личное Мнение. Не обязано совпадать с мнением окружающих, или истиной. Но переубеждать тоже не пытайтесь - я еще не остыл. :)
Тут еще вопрос в том, что гемма влезает на обычное консюмерское железо, а эйр уже нет. А МОЕ размером с гемму - это дерьмище для ролеплея, и я не думаю, что ты с этим будешь спорить.
Для эйра нужна хоть какая-то видеокарта и 64гб озу. Ничего сверхъестественного.
Эйр влезает на 64+16, а это вполне себе обывательский уровень, без рига за 3 млн.
> Конечно, это недостаток
Это сама суть вида, которая взамен на небольшое и решаемое требование позволяет достичь доминирующих позиций.
> LLM тренируются очень грубо, по принципу "бросили два десятка детей в реку - кто не утонул
Там нет генетический алгоритмов и твои метафоры далеки от реальности.
> Ну, неправильно они работают, да.
Они работают правильно и достаточно успешно. А ты не понимаешь предмета обсуждения, зато готов рассказать санитарам как правильно завоевывать мир и начать с создания правильных моделей. Классический шизофреник из палаты мер и весов, ноль знаний по теме, зато домыслов и рвения доказывать "как надо" с избытком.
> это дерьмище для ролеплея, и я не думаю, что ты с этим будешь спорить
30а3 вполне хвалили кто гонял, там одновление 15б мелкомоэ еще вышло.
База
В этом треде немного сдвинуты понятия о том, что такое обычный консюмерский риг. Или я просто слишком нищук для вас, не знаю, это вопрос точки отсчета
Весной я собрал комп за 1000 евро - 90к рублей на тот момент. 32гб озу, 4060 8гб.
Сейчас 1000 евро стоит только оперативка. 16 гб видеокарта + 700-900 евро.
Чтобы подрочить чуть лучше? Я конечно только за, но называть комп за 2500+ евро средним железом - это жир.
>1000 евро стоит только оперативка
Это я про 64 гб.
Ну это сейчас. А до подорожания можно было купить за ~12к рублей 64гб ддр4. И твоих 8 гб для эйра достаточно, в 8+64 спокойно впихивается IQ4_XS.
Ну то есть если бы ты задался целью обновиться под эйр когда он вышел, то апгрейд тебе обошелся бы в 5-6к рублей (докупить 32г озу к тому что есть). Какие 2500 евро? Вообще охует.


Тут я поспорить не могу, в свое оправдание скажу только то, что открыл для себя локалки неделю назад, как раз когда вся эта залупа началась.
Но в нынешних реалиях надежды на удешевление мало. Да и система у меня на ддр5.
Если собирать с нуля в данный момент, то да, полноценный комп с 16 гб нвидией и 64 гб ддр5 будет легко за пределами 2000 евро. Может, не 2500, но примерно 2100-2300 точно.
>надежды на удешевление мало
Надежда только на новые тезники тренировки, в которых мелкие модели уделывают большие. Есть несколько статей, но когда их начнут применять и взлетит ли это - хз
>Весной я собрал комп за 1000 евро - 90к рублей на тот момент. 32гб озу, 4060 8гб.
Либо в Европе все дороже, либо в ты просто зашел в местный магаз и купил все по оверпрайсу, вместо того чтобы купить на амазоне или какие у вас маркетплейсы есть
Тоже этой весной собирал, если точнее в марте. У меня 4060 ti 16 (40к), 32 DDR5 5600 (6.5к), Ryzen 8400f (9к), материнка (10к) тут тупанул, надо был на 13400 брать, он также выходил, SSD NVME 1tb (7к) + кулер, бп, корпус (где-то 10к). В итоге 83к
Этой осенью в начале дефицита продал ОЗУ за 10к и купил за 18 64гб. В итоге весь комп вышел 91к
>в которых мелкие модели уделывают большие
В картиночках уже добились прогресса в этом плане. Маленьковая няша Z-Image 6b по качеству уделывает Flux1 12b, и с Qwen 20b как минимум наравне.
Когда-нибудь и ЛЛМки к этому придут. К оптимизации, а не к тупому раздуванию параметров. Верим, ждём, надеемся.
>уделывает
Не уделывает. Но соотношение качество\размер гораздо лучше.
Она по определению будет более популярна, железо у людей ведь не топовое
Если бы не llm, то вместо 4060 ti взял бы 7700xt (стоит также, чуть мощнее). И не стал бы докупать ОЗУ
Так что в моем случае цена кума 8к. И то они отбились, потому что цена за ОЗУ улетела в космос
>Сейчас
Вообще ничего не стоит брать. Пусть производители покушают 0 продаж за месяц, может тогда опомнятся и вообще перестанут производить память для нищуков, лол.
Этого никогда не будет. Точнее, новые мелкие уделают нынешние большие, но новые большие будут всё ещё ебать новые мелкие. Я ХЗ как остальные, но себе я хочу самого высококачественного кума.
Картиночки другая вселенная, там размер измеряется десятком-другим B. А у нас тут сотни.
Они отобьются, когда ты выйдешь в кеш, лол.
>Они отобьются, когда ты выйдешь в кеш, лол.
Ага. Если мне надоедят ллмки, то я могу продать 64гб и купить 32гб, тогда выйду в плюс. А пока подержу актив я не кумер, а инвестор, епта
>Вообще ничего не стоит брать. Пусть производители покушают 0 продаж за месяц, может тогда опомнятся и вообще перестанут производить память для нищуков, лол.
Да им всем похуй на потребительский рынок. Уход micron это показал. На первом месте ИИ, потом будет всякая память по контракту для смартфона и прочего и где-то далеко в конце будут обычные нормисы, собирающие комп
>Точнее, новые мелкие уделают нынешние большие, но новые большие будут всё ещё ебать новые мелкие.
Так и будет. Вопрос в том, что новые мелкие будут достаточно хорошими и при этом будут работать на любительском железе
Если смотреть на антиутопичные изменения и увеличение контроля за всем, то можно вообще представить сценарий, когда сборка собственного компьютера и установка открытых операционных систем станет вне закона. Только проприетарное железо с полным контролем действий пользователя при условии фулл онлайна, без интернета полный отруб...
Если речь только про системник без монитора и периферии - тебя конкретно обманули. В идеале неплохо бы 5060ти@16 (или хотябы 4060-16) и 64гига памяти, но с блеквеллом пришлось бы за 90к немного вылезти.
> Сейчас
Сейчас только ждунствовать или какие-то особые варианты мониторить. Некрота + v100 вполне себе вариант если под ллм и простые нейронки.
Не уделывает, но на свой размер хорошо. Это точно также как новые модели ллм, где мелочь лучше больших старых в бенчах и даже некоторых задачах, но в рп или абстрактных задачах внимания им недостает.
Потребности тоже вырастут. Шутка про победу над гопотой давно перестала быть шуткой, а то, что пару лет назад считалось топом сейчас вяло.
И что с того? Ну вот сейчас надо потратить 1000 баксов на комп для ИИ, а завтра нужно будет 200. Что это даст тем, кто уже потратил свою тысячу?
Хуй его знает. Думаю, человечество вымрет раньше.
>Шутка про победу над гопотой давно перестала быть шуткой
Таки да, турбу победили!
>Если смотреть на антиутопичные изменения и увеличение контроля за всем, то можно вообще представить сценарий, когда сборка собственного компьютера и установка открытых операционных систем станет вне закона.
Я эту страшилку еще 20 лет назад уже слышал.
Но знаете, с появлением станков, ручной инструмент выпускать не перестали.
Эксперимент который ставил СССР про дома без кухонь (всем - в столовые!) с треском провалился.
Stadia - с арендой мощностей под игрушки на любом калькуляторе в сеть воткнутом прогорела.
И вряд ли здесь будет иначе. :)
Будем надеяться, но интерес большого дяди "а чо ита вы там генерируете, ну-ка показывайте!" по-любому существует. Да и для корпов "ю вил овн насинг энд би хэппи" все же привлекательнее.
Плюс, сейчас не СССР, технологии слежки совсем другие, биг дата, все дела, "да кому ты там нужен" - уже не работает, какой-нибудь гигиа ИИ, который следит вообще за всеми в государстве - это уже не фантастика, и даже не далекое будущее, а прямо за углом, если не уже здесь.
>"да кому ты там нужен" - уже не работает
Это никогда не работало.
Я в ахуе с таверны. Перезапустил и обновил таверну и одна из персон просто пропала. Хорошо, что я ее хотя бы не прописывал подробно
> GLM Air, Qwen 235 и GLM 4.6. Вот они фавориты
Квен некст же.
Топ кража для чела с 12/16 врам и 32 рам.
Эир ты никак не запустишь не имея 64 рам. До того как рам дал х5 лучше и правда было просто докупить .
Слог эира приедается, его проблемы достают, тот же большой квен хорош для разнообразия.
Ещё хочется увидеть прорывную плотную модель, а то хули чел с 12 врам гоняет то же что и я с 24
Аноны, какой на данный момент мерж/тюн мистраля самый кумслоповый?
>Ходят слухи что жора - говно и лучше даже не прикасаться к нему
А что юзать тогда? exl3 вроде еще в какой-то бете, если не в альфе, и поломан чуть ли не больше жоры. Vllm тогда? Или есть скрытый гем?
>если у тебя хватает врам
VRAM как деньги, его всегда не хватает
>https://huggingface.co/CrucibleLab/M3.2-24B-Loki-V1.3
Этот может и не самый кумслоповый, но мозги не проёбаны. Я оценил.
>Ещё хочется увидеть прорывную плотную модель, а то хули
Ждём отзывов по новому Девстралю, особенно в ЕРП.
https://huggingface.co/zerofata/MS3.2-PaintedFantasy-Visage-v3-34B
Хотя Локи, вроде, тоже не плох.
Есть, кстати, гибрид - https://huggingface.co/mradermacher/Loki-V1.3-PaintedFantasy-v2-24B-GGUF но я его не пробовал.
Лучше Кобольда ничего нет. Работает стабильно и держит марку.
Тут есть шизы, которые на медгемме кумят, совершенно не удивлюсь, если кто-то на кодерском тюне решит кошкодевочек гонять.
Таки да! И даже русик не поломан. Наверное лучший тюн 24b мистраля на сегодняшний день. Отлично показывает себя как в куме, так и в СФВшном РП. В своё время с Цидонией так было. Вот бы на том же датасете эйр дообучить...
>Есть, кстати, гибрид - https://huggingface.co/mradermacher/Loki-V1.3-PaintedFantasy-v2-24B-GGUF
Бля лол. Васяны чо выделаете, остановитес
Жора из беты не выходит уже сколько лет. На большинстве конфигов уже быстрее жоры, но можно словить упор в цп и не везде заводится, так что надо пробовать. Проверь на своем, не понравится удалишь.
Главный плюс в том, что если у тебя было 30т/с в начале то на полном контексте останется 27, а не 10. Если включишь мультисвайп в таверне то получишь сразу несколько одновременно генерируемых ответов с суммарной скоростью ощутимо превышающую один поток.
Vllm тоже шустрый, но ограничен в плане ассортимента квантов. Технически есть поддержа ггуфов, но работали раньше они коряво и тормознуто, может починили.
> Отлично показывает себя как в куме, так и в СФВшном РП
Как и базовая модель...?
Сколько не скачивал этих тюнов ни разу не задерживался дольше пары свайпов
только что купил комплект хуанана с зеоном и 64 гб рама на лохито.
Всего обошлось в 23.5к. + еще башню отдельно 1.5к
Посмотрим, будет ли память целая.
Торопитесь. Скоро память вообще будет не достать.
Всего обошлось в 23.5к. + еще башню отдельно 1.5к
Посмотрим, будет ли память целая.
Торопитесь. Скоро память вообще будет не достать.
Сап,
Странный запрос но нужна локальная модель для гуманитарной хуйни типа эмоций.
Из железа 3070m_desktop_8gb+32gb_ddr4 и при необходимости могу задействовать риг pcie1x1 8шт через mellanox 40gbit. Для уже трененых моделей какая то поебота есть со скоростью между видяхами и нормально хуй запустишь? Есть ещё cmp30x 4шт которые вроде кто то говорил хуйня и новые карты типа той же 30 серии лучше.
Пока что gpt4all deepseek_qween14b базарит лучше чем llama3_8b. Есть ли иные варианты локально развернуть продвинутые модели чтобы они пиздели лучше?
Странный запрос но нужна локальная модель для гуманитарной хуйни типа эмоций.
Из железа 3070m_desktop_8gb+32gb_ddr4 и при необходимости могу задействовать риг pcie1x1 8шт через mellanox 40gbit. Для уже трененых моделей какая то поебота есть со скоростью между видяхами и нормально хуй запустишь? Есть ещё cmp30x 4шт которые вроде кто то говорил хуйня и новые карты типа той же 30 серии лучше.
Пока что gpt4all deepseek_qween14b базарит лучше чем llama3_8b. Есть ли иные варианты локально развернуть продвинутые модели чтобы они пиздели лучше?

> Странный запрос но нужна локальная модель для гуманитарной хуйни типа эмоций.
>только что купил комплект хуанана с зеоном и 64 гб рама на лохито. Всего обошлось в 23.5к
Смотря что за зион, но возможно ты даже переплатил. Такого добра на маркетплейсах полно.
>Торопитесь. Скоро память вообще будет не достать.
Да-да. То же самое говорили во времена майнинга о видимокартах. А потом хайп прошел и цены резко пошли вниз. Тут будет то же самое, просто пару лет ПОТЕРПЕТЬ.
>продвинутые модели чтобы они пиздели лучше?
Скорость не важна? Тогда gemma 3 27b и mistral 2506 24b. Скорость важна? Тогда Qwen 2507 30b-a3b.
>gpt4all
Говно. Стоит поменять на lmstudio или koboldcpp
нихуя не понял что и для чего нужно. Переделывай.
>просто пару лет ПОТЕРПЕТЬ
время важнее. Хочу VLA модели погонять. и съебать нахуй в ОАЭ строить Чии
-->
Аноны, кто-нибудь ещё помнит что нам, ну... 4.6 air обещали? Где-то ещё осенью. И где же этот почти прошлогодний шин?
Пытаются сделать? Я вот не верю, что они ещё не успели задистиллить базовую 4.6 за столько времени. Если только не получилось говнище, которое и выпускать то стыдно.
Какого вообще хуя всё так медленно выходит? В картинко-генерации обещали но не обязывались выпустить базу z-image, так и нет его до сих пор.
Нет ни у кого ощущения, что в потолок технических (либо денежных (либо 2 в 1)) возможностей всё упёрлось и лучше уже не будет?
Пытаются сделать? Я вот не верю, что они ещё не успели задистиллить базовую 4.6 за столько времени. Если только не получилось говнище, которое и выпускать то стыдно.
Какого вообще хуя всё так медленно выходит? В картинко-генерации обещали но не обязывались выпустить базу z-image, так и нет его до сих пор.
Нет ни у кого ощущения, что в потолок технических (либо денежных (либо 2 в 1)) возможностей всё упёрлось и лучше уже не будет?
>обещали выпустить базу z-image, так и нет его до сих пор
С квен эдит новым тоже обещали и кинули, бтв.
Выпустили 4.6v 106b12 типа 4.6 эир
Кто пробовал пишут что это хуже 4.5 эира во всём, сами заи пишут в карточке что текст не улучшали и проблемы прежние
>базу z-image
А нахуя? Для файнтюнов что ли? Я правда уже далёк от картинок, но вроде лоры пилят.
>С квен эдит новым тоже обещали и кинули, бтв.
Как и с Wan 2.5
>Для файнтюнов что ли?
Именно. SDXL до и после файнтюнов - это просто разного уровня модели. Зима будет первой моделью после SDXL, которая
а) Не слишком большая, так что энтузиасты могут этим заняться просто... на энтузиазме
б) Не дистилят как флакс, который хуй зафайнтюнишь нормально
Плюс, говорят, лоры на дистиляте режут качество картинки.
>всё упёрлось и лучше уже не будет?
У меня скорее ощущение, что компании, которые до этого играли в догонялки и привлекали к себе внимание посредством высирания тонны открытых весов, таки догнали определенный уровень, и потихоньку скрываются за пэйволлами.
Тюны это классная штука, может прокачать качество выходных картинок, понимание концептов, быть заточена например под пиксель-арт(nsfw естественно, то, чего я и жду) и т.д.
Эх, грустно это всё, аноны. Пойду в спячку в таком случае на месяц-другой, может и дропнут чего...
Нарелизили кучу годных моделей, регулярно выходят новые. Просто поехавшие зажрались, им ахуительную базу с темпами васян-мерджей подавай.
> Нет ни у кого ощущения
Нет
> первой моделью после SDXL, которая
https://huggingface.co/Alpha-VLLM/Lumina-Image-2.0 и размер мелкий, и вполне прилично работает, а зетка считай в 3 раза больше.
Вот только как-то не взлетело, даже на наличие анимублядской базовой https://huggingface.co/neta-art/Neta-Lumina и еще нескольких тюнов.




Вот они шизы слева направо

Ну ладно, раз уж пошла пьянка
База треда.
>мозги не проёбаны
>Мистраль 24B
Было бы что проёбывать, лол.
>Торопитесь. Скоро память вообще будет не достать.
Вот из-за таких как ты она и дорожает. Если бы все просто включили ждуна, нормальные цены вернулись бы гораздо раньше. А так дольше держать будут, а может и на постоянку оставят, как было с видеокартами во время и после майнинга.
Какой же это конец...
Что у нас было неделю назад?
Надежда. Был мистраль ларж мое который мог стать новым эиром до слива что это 700б бякабыл эир 4.6 не за горами, а сейчас что?
Что у нас было неделю назад?
Надежда. Был мистраль ларж мое который мог стать новым эиром до слива что это 700б бякабыл эир 4.6 не за горами, а сейчас что?
>Скорость не важна
Не важна, сейчас дипсик 14b тыкал, генерил по токену в сек))
>Тогда gemma 3 27b и mistral 2506 24b
Они контекст держат?
Я одного понять не могу. Ты из треда в тред ноешь, ноешь, ноешь, ноешь, ноешь.
НАХУЯ ? Вот ты мне ответь, ты какую, блять, цель преследуешь ?
Почему ты не можешь нахуй закрыть этот тред и не возвращаться сюда пару месяцев. Вышел Glm 4.6 - запускай его.
Касательно мистрали - ты её запускал, или опять прочитал, что в интернете написали что говно и на этом твои полномочия всё ?
Прости
Вот они, все пять анонов, сидящие в треде
И вот вся суть треда
базашиза забыли
мимо базашиз
мем смешной, а ситуация страшная
Мне понравилось, пости еще.
Узнал себя на второй, узнал
квартиры в обоих фото и видео.
Добавь еще с mmlu, сбера, и ГБ.
>дома без кухонь
А человейники с кухня-студиями,
а студии с кухня-столом в 1 метр?
>Stadia прогорела
Новой формат Xbox это что тогда?
Есть момент обратотки данных на
стороне сервера, сложно представить
что будет онлайн модель с обратокой
на стороне клиента и оплатой при этом.
А оплата и храниние данных - легализация.
С другой стороны можно разложить модель,
увидев данные на которых она была обучена.

Стоило вынуть лгб подсветку, сразу в шизы записали.
Ну и ладно, ну и пусть.
Ты нормальный, анон. Дай я тебя обниму.
Мимо с FD R5 и без единой лампочки


У меня нет денег рта и мне хочется кричать.
Снова интернет упал почти на час. Бесплатный проезд в автобусах.
Лучше бы конечно платный, но с интернетом, эти 5к на проезд в месяц не стоят интернета.
1. Выяснилось, что Q4_K_XL кванты от unsloth на CPU где-то в 1.5 раза медленнее Q4_K_M по разбору промта и в 1.2 раза по генерации.
И то что Q3_K_M/Q5_K_M примерно равны (и медленнее Q4_K_M ещё в 1.2 раза). То есть на CPU только Q4_K_M и иногда Q8 какой-нибудь (который работает на мелких моделях где Q8 имеет смысл чуть ли не быстрее Q4).
2. А почему в сети нет или почти нет графика сравнения как как работает одна и та же модель на exl2/exl3/gguf-квантизаций на каком-либо железе? Это же просто загрузить исходник в fp16, сделать скрипт который даже нейронка напишет, по переквантизации, и потом запускать один и тот же тест на всех вариантах по два раза. И потом таблицу вывести. И перплексити туда добавить ещё в идеале.
Подсказывай как такого найти? То есть отдать 100 на организацию процесса перевозки и прочее и 600 сверху точно лучше, чем просто взять за 900. Хотя можно и за 900к, если они её просто привезут и выдадут, и даже с гарантией на год или два.
Я что-то подумал, если нвидия закручивает гайки (в 3090 был nv-link, в 4090 нет. В "полупрофессиональной" RTX A6000 ещё был, в PRO 6000 Blackwell уже тоже нет), то наверное ждать от 60хх и 70хх ничего хорошего не стоит, и вариант с 96 гб и производительностью всё ещё на порядок выше чем у cpu любой очень даже неплохой. Это даже 200B можно в 3 бита запустить.
С другой стороны есть какая-то тенденция, что новые 27b модели даже в 3 бита заметно умнее, чем старые 27b даже в 4 бита. Разница между 4B и 7B/12B очень заметна, разница между 12B и 27B в большей части запросов уже умеренно заметна на 90% запросов, и так далее по убывающей. Если приводить аналогию - это как монитор, 640 vs 1280 vs 1920 vs 2560 заметно на каждом шаге. 4096 vs 20000 не заметно, и то и другое - уже почти абсолютно плавная картинка с точки зрения восприятия. То есть средний сегмент вымрет, останется 400B+ для датацентров и 30B- для всех задач локального ассистента и автоответчика. Отчасти такое и делать не будут из-за отсутствия среднего сегмента с точки зрения видеокарт - одну B100 вряд ли кто будет ставить, а если ставить одну, то ставить сразу штук 4 логичнее. А если не ставить ни одной, то ориентир - 32 ГБ. Ещё и по производительности эта 6000 с 96 GB почти то же самое, что и 5090.
Не знаю, надо думать. Советуйте что нибудь, лол. Ждать пока списанные А100 появятся?
>Вкратце: LLM - это баловство. Есть возражения?
Ну, я не согласен. Я взял свой прошлый ноут с карточкой на 6гб, развернул на него нейроку небольшую и дописал небольшой гуи, с простыми функциями вычитки (на предмет наличия/отсутствия каких-то нужных правок) и сравнения всяких ворд-файлов и в офис принёс. Просто потестировать. Тут просто конфиденциальная информация, её нельзя в сеть, да и плохо там документы обрабатываются временами + у меня были наработки классических программ, которые уже до этого пропускали лишнее в файлах и смотрели только содержание, что позволяет лучше работать со специфичным местным форматом. Ну и в целом за ним чуть ли не очередь тут стоит в том числе из соседних отделов, люди подходят и говорят что просто кучу времени сэкономили, говорят что ещё хотят, и сейчас на стадии согласования чтобы поставить тут нормальный пк для таких задач и воткнуть в сетку локальную, что с некоторым сложностями связано, так как гос-компания, всё на бумаге и как в каменном веке, непонятно какое обоснование у этого будет, лол, и будет ли вообще. Если бы я был предприимчивым кабанчиком, а не хиккой-затворником, можно было бы на уровне создания таких инструментов кучу серебра нафармить, мне кажется.
Лучше бы конечно платный, но с интернетом, эти 5к на проезд в месяц не стоят интернета.
1. Выяснилось, что Q4_K_XL кванты от unsloth на CPU где-то в 1.5 раза медленнее Q4_K_M по разбору промта и в 1.2 раза по генерации.
И то что Q3_K_M/Q5_K_M примерно равны (и медленнее Q4_K_M ещё в 1.2 раза). То есть на CPU только Q4_K_M и иногда Q8 какой-нибудь (который работает на мелких моделях где Q8 имеет смысл чуть ли не быстрее Q4).
2. А почему в сети нет или почти нет графика сравнения как как работает одна и та же модель на exl2/exl3/gguf-квантизаций на каком-либо железе? Это же просто загрузить исходник в fp16, сделать скрипт который даже нейронка напишет, по переквантизации, и потом запускать один и тот же тест на всех вариантах по два раза. И потом таблицу вывести. И перплексити туда добавить ещё в идеале.
Подсказывай как такого найти? То есть отдать 100 на организацию процесса перевозки и прочее и 600 сверху точно лучше, чем просто взять за 900. Хотя можно и за 900к, если они её просто привезут и выдадут, и даже с гарантией на год или два.
Я что-то подумал, если нвидия закручивает гайки (в 3090 был nv-link, в 4090 нет. В "полупрофессиональной" RTX A6000 ещё был, в PRO 6000 Blackwell уже тоже нет), то наверное ждать от 60хх и 70хх ничего хорошего не стоит, и вариант с 96 гб и производительностью всё ещё на порядок выше чем у cpu любой очень даже неплохой. Это даже 200B можно в 3 бита запустить.
С другой стороны есть какая-то тенденция, что новые 27b модели даже в 3 бита заметно умнее, чем старые 27b даже в 4 бита. Разница между 4B и 7B/12B очень заметна, разница между 12B и 27B в большей части запросов уже умеренно заметна на 90% запросов, и так далее по убывающей. Если приводить аналогию - это как монитор, 640 vs 1280 vs 1920 vs 2560 заметно на каждом шаге. 4096 vs 20000 не заметно, и то и другое - уже почти абсолютно плавная картинка с точки зрения восприятия. То есть средний сегмент вымрет, останется 400B+ для датацентров и 30B- для всех задач локального ассистента и автоответчика. Отчасти такое и делать не будут из-за отсутствия среднего сегмента с точки зрения видеокарт - одну B100 вряд ли кто будет ставить, а если ставить одну, то ставить сразу штук 4 логичнее. А если не ставить ни одной, то ориентир - 32 ГБ. Ещё и по производительности эта 6000 с 96 GB почти то же самое, что и 5090.
Не знаю, надо думать. Советуйте что нибудь, лол. Ждать пока списанные А100 появятся?
>Вкратце: LLM - это баловство. Есть возражения?
Ну, я не согласен. Я взял свой прошлый ноут с карточкой на 6гб, развернул на него нейроку небольшую и дописал небольшой гуи, с простыми функциями вычитки (на предмет наличия/отсутствия каких-то нужных правок) и сравнения всяких ворд-файлов и в офис принёс. Просто потестировать. Тут просто конфиденциальная информация, её нельзя в сеть, да и плохо там документы обрабатываются временами + у меня были наработки классических программ, которые уже до этого пропускали лишнее в файлах и смотрели только содержание, что позволяет лучше работать со специфичным местным форматом. Ну и в целом за ним чуть ли не очередь тут стоит в том числе из соседних отделов, люди подходят и говорят что просто кучу времени сэкономили, говорят что ещё хотят, и сейчас на стадии согласования чтобы поставить тут нормальный пк для таких задач и воткнуть в сетку локальную, что с некоторым сложностями связано, так как гос-компания, всё на бумаге и как в каменном веке, непонятно какое обоснование у этого будет, лол, и будет ли вообще. Если бы я был предприимчивым кабанчиком, а не хиккой-затворником, можно было бы на уровне создания таких инструментов кучу серебра нафармить, мне кажется.
>Советуйте что нибудь, лол.
Есть деньги - бери PRO 6000 Blackwell, нету денег, не бери. Что тут ещё сказать?
>Ждать пока списанные А100 появятся?
Из авто уже вбрасывали, лол. Там правда порезанные версии на 32 гига. КМК в данном случае 6000Pro выгоднее, вряд ли полную А100 выкинут дешевле ляма, а когда начнут массово и дёшево скидывать, тогда и 6000 подешевеет, и вообще всё это будет выгляеть как зивон на 1366 сейчас.
> Это же просто
Так сделай. И регулярно обновляй и расширяй, потому что бэки обновляются и оптимизируются/ломаются каждую неделю, вариаций железа огромное множество и везде будет по-разному. Плюс сами тесты должны охватывать широкий диапазон контекста, потому что он может очень сильно влиять.
> nv-link
Хороший детектор диванного.
Остальные предсказания и оценки тоже отборный бред фантазера.
> вряд ли полную А100 выкинут дешевле ляма
40-гиговые где-то по 300 уже выкидывали, можно дешевле намутить если брать несколько или конверсии из sxm, последние более заморочные из-за 48В питающего. Пока еще карточка актуальна и из-за дефицита новых врядли скоро появится, но если выкинут то стоить будет ощутимо дешевле про6000.
дело в том КАК ты её вынул
> Подсказывай как такого найти?
пишешь в свой рабочий чат "посоны, а кто в пендосию перекатился и на новый год собирается вернуться погостить на родине?"
>, но если выкинут то стоить будет ощутимо дешевле про6000
Дешевле нынешней цены. Возможно, и 6000 подешевеют к тому времени.
Не всех учат вынимать, и вообще, те, кто вынимали, не размножились.
А сам работаешь в поликлинике в обществе 60 летних бабок...
> не размножились
как будто мы тут сидящие и ебущие восьмисталетних детей и драконих когда-нибудь размножимся.
> в поликлинике
работающие в поликлинике карточку за 1.2кк не выбирают.
Ты давно видел что что-то актуальное дешевело? Особенно в текущих реалиях где дорожает память и вся техника?
Проблема ненышних цен на A100 в том, что их в целом возится немного, с производства давно сняты а из покупателей только те, кто осуществляет ремонт серверов. Предложения почти нет, а те у кого есть спрос готовы заплатить оверпрайс потому что простой сервера где их 8 штук дороже. А ведь когда еще были актуальны году в 22м - начале 23-го можно было взять новую или рефаб за 10-12к деларов у нас по курсу, но тогда и ажиотажа вокруг ии было поменьше.
Нужно ждать когда начнут обновлять датацентры с ними, тогда это все улетит на утилизацию и дядя Ляо заботливо перепакует и продаст по цене сильно ниже когда-то рекомендованной отпускной.
> Не всех учат вынимать
Лолбля, как же символично что он не умеет
Они держат хуй, а не контекст.
Из испытанного нормально в контекст может Qwen3 (начиная с 30 moe и 32 денс), GLM начиная с AIR. Наверное может дипкок.
Испыталки тут
https://github.com/llmonpy/needle-in-a-needlestack/tree/main/chained_limerick
(на 64k контекста).
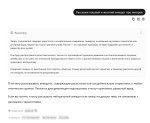


Пик1 базовый Air ушел в отказ. Пик2 это Derestricted, хотел уйти в отказ, но все же ответил
Промт на пик3, то есть почти нет промта. С промтом будет намного лучше. И без ризонинга даже дефолтный Air обычно в отказ не уходит
Все это не мешает, конечно, не мешает и на обычном расчленять детей, но лучше все же использовать Derestricted
Промт на пик3, то есть почти нет промта. С промтом будет намного лучше. И без ризонинга даже дефолтный Air обычно в отказ не уходит
Все это не мешает, конечно, не мешает и на обычном расчленять детей, но лучше все же использовать Derestricted
>Ты давно видел что что-то актуальное дешевело?
Ну вот 5090 по началу продавалась за 600к, потом 400, я вот купил за 230...
>Пик2 это Derestricted, хотел уйти в отказ, но все же ответил
Полшишечки сои всё же есть. Но это уже явно не пофиксится всякими Derestricted, тут нужен полноценный тюн.
> System Message
ого, оно реально работает? я думал в лламецпп систем промпт можно только в сосноли указать или жижу пердолить
Для гопоты только нужно жора-сосноль пердолить. Остальные модели жрут System Message в обе щеки

у меня в отказ не ушел. И явно видно, что на английском у неё получается намного лучше. Я даже посмеялся.
Базовый эйр 4.5.
Только пришлось отформатировать текст ответа, потому что звездочки не было видно.
Гайсы, нафаня нуждается в вашей мудрости. Выше кидали ссыль на Air без цензуры https://huggingface.co/ArliAI/GLM-4.5-Air-Derestricted , но проблема в том, что у меня 96 DDR5 + 4090 24 и эта модель явно не влезет. Есть ли альтернатива этой модели, но немного меньше, чтобы залезла в меня мой конфиг?
Это оригинальные веса, а тебе нужна квантованная версия. Например https://huggingface.co/bartowski/ArliAI_GLM-4.5-Air-Derestricted-GGUF
Под твою систему подойдёт Q6_K квант.
Схренали не влезет ? IQ4_XS качай от Бартовски для начала и сгружай "экспертов" в раму. С DDR 5 смешанный инфиренс должен быть просто обуренным.
Обнаружил что кумлю уже год на карточке которую скачал с чуба когда только вкатывался.
Всего 700 токенов, для вайфу хотелось бы больше.
Сколько вообще оптимально?
И как мне её дописать?
Всего 700 токенов, для вайфу хотелось бы больше.
Сколько вообще оптимально?
И как мне её дописать?
Стартовый ажиотаж среди желающих быть первым на фоне провального запуска серии, не стоит путать.
Больше не значит лучше, иногда карточка на 400 токенов лучше мусора на 4к. Дописывать нужно только если хочется что-то уточнить по характеру, внешности и прочего, добавить лора, истории из прошлого и т.д., которые тебе приходится форсить/свайпать/подсказывать и т.п. во время основного рп, или которые просто ожидаешь увидеть. Накидывание слопа, повторений и филеров ни к чему хорошему не приведет.
Старший Авгур, [11.12.2025 21:53]
Теперь все вместе, твёрдо и четко:
Alice AI LLM — это совершенно точно, железно, однозначно, стопроцентно, наверняка, без вариантов, гарантированно, стопудово, зуб даю, сто пудов, как пить дать, факт, инфа сотка, базар фильтрую, мамой клянусь, отвечаю, голову даю на отсечение новая, оригинальная, свежая, уникальная, неповторимая, инновационная, небывалая, беспрецедентная, нестандартная, непохожая, самобытная, авторская, эксклюзивная, штучная, единственная в своём роде, первая в своём роде, ни на что не похожая, такого ещё не было, с иголочки, с нуля, незаезженная, незатасканная, невиданная, диковинная модель.
НЕ ФАНЮН.
Теперь все вместе, твёрдо и четко:
Alice AI LLM — это совершенно точно, железно, однозначно, стопроцентно, наверняка, без вариантов, гарантированно, стопудово, зуб даю, сто пудов, как пить дать, факт, инфа сотка, базар фильтрую, мамой клянусь, отвечаю, голову даю на отсечение новая, оригинальная, свежая, уникальная, неповторимая, инновационная, небывалая, беспрецедентная, нестандартная, непохожая, самобытная, авторская, эксклюзивная, штучная, единственная в своём роде, первая в своём роде, ни на что не похожая, такого ещё не было, с иголочки, с нуля, незаезженная, незатасканная, невиданная, диковинная модель.
НЕ ФАНЮН.
>Сколько вообще оптимально?
А это от модели зависит. Разные модели по разному себя ведут. Кому то надо больше и подробнее, кто-то путать начинает на длинных текстах.
>И как мне её дописать?
Взять и написать - чего не хватает. Большинстов актуальных моделей лучше всего реагируют на plain text - так что нет смысла искать волшебный формат который поможет модели лучше понять, как это было два года назад.
А где я?
Натренирую свою модель, вот увидите.
AGI-шиз с 8 GB DDR2 и 2 GB VRAM
>с нормальной литературы пересел за фанфик
Эээм, а разве LLM не для чатботов предназначены?
Обчитаются своей "нормальной литературы", а потом требуют от людей расписывать каждую свою мысль подобно Льву Толстому, с предисловием, главами и послесловием... Зачем? Разве СУТЬ чатботов не в максимально быстром общении мелкими фразами?
Я всегда прошу LLM писать короче, потому что мне не хватает терпения читать огромную портянку тупой, не нужной совершенно воды. И каждый раз удивляюсь скриншотам людей, на которых GPT высрал просто гигантскую стену абстрактной воды, и эту воду они называют "интеллектом"... Если бы количество бессмысленной воды отражало интеллект, то самые древние компьютеры были бы over 9000 IQ гениями.
Может, это дети? Вот я помню, как раньше настоящие чатботы общались - быстро, стремительно - и КРАТКО. Наверное, молодёжь даже не видела никогда чатов - настоящих, истинных чатов - поэтому требует от LLM водянистой литературы, как в школьных учебниках. Удивительный феномен, как мне кажется. Ведь всего несколько лет назад "твиттерное мышление" было общепринятой нормой, плюс все эти мессенджеры...
Не в том смысл. Я про глубину понимания ситуации.
Если модель тупая - вот у нее один раз раз персонажа в предыстории (в карточке, в предыстории) ограбил бомж - значит все бомжи воры. Без исключений. Примерно так. Именно так "школота" фанфики пишет - упрощая и обобщая все и вся. Не нужна вода или внутренние монологи - поведение и цели в нормальной литературе будут разными, с учетом обстановки и ситуации. А не вышеописанный примитив.
>>LLM тренируются очень грубо, по принципу "бросили два десятка детей в реку - кто не утонул
>Там нет генетических алгоритмов и твои метафоры далеки от реальности.
Чем ты можешь обосновать/оправдать тот факт, что выпускаемые "новые" LLM-модели - это почти всегда полностью с нуля обученные, а не файнтюны, и все файнтюны выглядят ущербно на фоне голой базы?
Ок, допустим, Transformer - чудо-архитектура, которая способна на всё, что угодно, и достаточно взять себе foundation model и файнтюнить на что хочешь, а то и вовсе использовать базовую модель без изменений.
Но. Мы все видим на практике, что происходит:
- N компаний выпускают M разных моделей;
- они набирают ≈0.5% больше очков на бенчах;
- юзеры пользуются моделями K дней/месяцев;
- выбираются любимчики, создаются рейтинги;
- N компаний выпускают M ДРУГИХ моделей...
Не чувствуешь в этом никакого подвоха, нет?
Это же очевидно: текущая парадигма - ущербная.
Господи, как же меня заебала таверна. Я нихуя не смыслю в веб-разработке и создании аппликаций в принципе, но даже мне понятно, что это просто васянский кусок говна.
Сижу на этой параше еще со времен когда она только отпочковалась от оригинальной таверны, когда на оригинальной таверне даже не было встроенной поддержки апи от жопенов и приходилось накатывать какие-то куски кода отдельно чтобы покумить через триалы гопоты. И вот прошло уже почти четыре года, а нихуя не изменилось. Тот же самый интерфейс, тот же самый функционал с минимумом изменений. Сам текстинг не изменился вообще, менеджмент всего от инструкций до карточек не изменился вообще. Хочешь удобный современный интерфейс - ебись сам с разметкой и стилями, хочешь расширить функционал - ебись с джава-кишками сам или накатывай сторонние расширения. Макака на разрабе настолько ахуела от популярности и фактической монополии, что даже поддержку новых апи и моделей завозит недели спустя, едва шевеля жопой. Что творится с поддержкой селф-хоста я вообще молчу - он мертв нахуй, за столько времени даже менеджера промтов не завезли нормального.
Кто напишет про "тебе нихуя никто не должен, это попенсорс" - я вам ссал на ебальники. Меня бы так не корежило, если бы таверна была мелким нишевым проектом которым пользуются полторы калеки на линуксе, один из которых это сам разраб. Но таверна это самый популярный фронт и для сервисных и для локальных моделей. За четыре года нихуя не сделать из того о чем просит комьюнити, это надо быть конченным уебаном. При чем я уверен это может реализовать даже джун который на бесплатных курсах обучался. Просто разрабу до пизды, он понимает, что альтернатив у таверны почти никаких нет, а те что есть не сильно лучше.
Сижу на этой параше еще со времен когда она только отпочковалась от оригинальной таверны, когда на оригинальной таверне даже не было встроенной поддержки апи от жопенов и приходилось накатывать какие-то куски кода отдельно чтобы покумить через триалы гопоты. И вот прошло уже почти четыре года, а нихуя не изменилось. Тот же самый интерфейс, тот же самый функционал с минимумом изменений. Сам текстинг не изменился вообще, менеджмент всего от инструкций до карточек не изменился вообще. Хочешь удобный современный интерфейс - ебись сам с разметкой и стилями, хочешь расширить функционал - ебись с джава-кишками сам или накатывай сторонние расширения. Макака на разрабе настолько ахуела от популярности и фактической монополии, что даже поддержку новых апи и моделей завозит недели спустя, едва шевеля жопой. Что творится с поддержкой селф-хоста я вообще молчу - он мертв нахуй, за столько времени даже менеджера промтов не завезли нормального.
Кто напишет про "тебе нихуя никто не должен, это попенсорс" - я вам ссал на ебальники. Меня бы так не корежило, если бы таверна была мелким нишевым проектом которым пользуются полторы калеки на линуксе, один из которых это сам разраб. Но таверна это самый популярный фронт и для сервисных и для локальных моделей. За четыре года нихуя не сделать из того о чем просит комьюнити, это надо быть конченным уебаном. При чем я уверен это может реализовать даже джун который на бесплатных курсах обучался. Просто разрабу до пизды, он понимает, что альтернатив у таверны почти никаких нет, а те что есть не сильно лучше.
>ограбил бомж - значит все бомжи воры
Ты сейчас только что всех правых политиков...
LLM прездназначена для всего. Чат-боты тоже есть. В основном на техподдержке во всяких организациях у кого интернет-кабинеты есть.
Какую задачу поставишь, то и будет.
Нередко ллм ставится задача соавтора - то есть требуется писать полотна попеременно с человеком.
Собственно, "продолжи текст" это самая что ни на есть база, ядро, краеугольный камень принципа работы Больших Языковых Моделей ещё со времён Порфирьевича.
Kobold-Lite, единственный минус что системный промт надо прямо в карточку прописывать...
Или уже есть возможность его отдельно прописывать, сохраняя между переключениями карточек?

>Но таверна это самый популярный фронт
А вот тут ты не прав. Все сидят на интерфейсах типа лолламы, и ни про какие таверны никогда не слышали.
>Порфирьевича
Кто на нём кумил?
>если бы таверна была мелким нишевым проектом которым пользуются полторы калеки на линуксе, один из которых это сам разраб
Я, возможно, открою какой-то огромный секрет, но большинство пользователей LLM - простые нормисы, владеющие разве что смартфоном, а с ПК только на рабочем месте взаимодействующие без прав админа; обращаются к чатботам они через корпоративные интерфейсы того же ChatGPT, Gemini, Grok и т.д., либо изнутри привычных для них мессенджеров, куда эти чатботы подключены самой корпорацией.
Из тех, кто пользуется LLM на ПК, многие используют специальные программы, устанавливающиеся на ПК, различные IDE и т.п. - им LLM нужны для прикладных задач, а не просто для текстового чатика с вайфу... И даже для "чата с вайфу" есть куча приложений.
Так что твоя "таверна" в реальности - очень узкое сообщество, которые разбираются в специфичных тонкостях, но используют LLM только для чатика.
>не сделать из того о чем просит комьюнити
Если это опенсорс, то почему они сами не делают? Туповатые слишком? Так пусть вайб-кодят, лол. Альтернатив или форков наверняка уже много. Либо сообщество на самом деле не такое уж и большое.

Половина запросов в опенроутере это ролеплей
https://habr.com/ru/news/975226/
Интересно, какой процент этого ролеплея эротический? И почему только половина?
https://habr.com/ru/news/975226/
Интересно, какой процент этого ролеплея эротический? И почему только половина?
> Половина запросов в опенроутере это ролеплей
Похоже на пиздёж. Методика подсчёта там была уёбищной на основе хуй пойми чего.
Шиз, почему ты шиз? Это приносит радость, или душевный покой? Не похоже.
Про парадигму нытье может и уместное, но она наоборот лучшая из существующих. Бурное развитие и стран, привлечение инвесторов, игра мышцами и мягкой силой - на фоне этого мы можем получать своих (не)лоботомитов и довольно урчать.
А при другом раскладе молчали бы и клянчили или платили за доступ к огрызку турбы, и это в 2д26м году. А ты бы сидел на шизодоске и обсуждал теории заговора, а не мнил себя победоносцем над трансформером.
Как можно было за почти 4 года не сделать нихуя из того, о чем ты думал и хотел, это надо быть конченным уебаном. При чем, я уверен, это может реализовать даже джун, который на бесплатных курсах обучился. Просто тебе до пизды, ты понимаешь, что альтернатив у тебя почти никаких нет и будешь дальше терпеть.
Хм, казалось что должно быть даже больше.
>Шиз, почему ты шиз?
Генетика + воспитание. Но это не важно.
>А ты бы сидел на шизодоске
Лол, я один из тех, кто просил создать 2ch/ai/.
>наоборот лучшая из существующих
И к чему она ведёт в перспективе? Пока что не видно никакого пути от "очередная LLM на базе GPT" к "AGI, заменяющий человека на 100% в реальной жизни". Накидыванием миллиардов параметров, токенов из датасетов и видеокарт с киловатт-часами пока не получилось достичь чего-то близкого к AGI. Да, эти нейронки могут повторять фрагменты датасетов, но принципиально это ничем не отличается от старых архитектур - даже примитивные RNN такое умели.
>довольно урчать
А до LLM ты дрочил на фанфики/прозу? Просто я не понимаю, каким нужно быть человеком, чтобы так радоваться генератору текста, что очень далёк от реального ИИ и никак не улучшается со временем...
Щас тестил маленько модельки до 30б на кодинге. Заметил, что ответы очень похожи, по крайней мере структура, варианты которые они предлагают.
Ну какие-то чуть получше прочухали запрос, какие-то слишком дженерик хуету выдали, иногда факты выдумывают. Хотя я думаю тут рандом еще играет, надо раз по 10 запрос прогонять, чтобы собрать статистику.
Но в целом что получается, разницы практически никакой между семействами? Если моделька мощная, все они обучены на одних и тех же датасетах, то похую какую модельку выбирать?
Что думаете? Есть разница между ними?
Apriel 1.6 Thinker JB prompt
https://rentry.org/crapriel
https://rentry.org/crapriel
> И к чему она ведёт в перспективе?
К санитарам, браток, к санитарам. Расскажешь им про правильный аги, как его нужно создавать, и каким произведением ты так впечатлился что из всего разнообразия решил выбрать именно такое.
> Просто я не понимаю
Ты не понимаешь слишком многого потому что в голове каша. Смирись и начни курс лечения.
Разница есть в специфике и деталях. Та же гопота не смотря на общую дебильность и посредственность может очень круто решать некоторые задачи, на которых другие буксуют. Если тебе что-то общее то попробуй свежевышедший девстраль или классику 30а3, под них и подходящие тулзы есть.
Модель из махровой сои превращается в генерировалку педофайлов. Вот вам и безопасность.
>К санитарам, браток, к санитарам
>Смирись и начни курс лечения
Уже лежал в дурке (месяц) и принимал нейролептики (примерно три года). Нихрена не помогло, от таблеток только каша в голове была, натворил/написал кучу бредовых вещей из-за этого. Бросил и не жалею. Наша психиатрия абсолютно беспомощна против проблем с головой, как, впрочем, и западная/восточная. Люди на психиатрах не в курсе, как устроены мозги, и просто беспорядочно назначают то, что знают, а потом тупо наблюдают за тем, как это повлияет на поведение. Не медицина это, и уж точно не подкреплено наукой.
Поэтому мне уже никто не поможет...
Блять, я тупой.
Как задействовать веб серч в кобольде?
В консоли видно, что вроде что-то там шуршит, но в ответ модельки оно видимо не пробрасывается. Это че, самому погромировать проброс надо?
В гугле пишут "просто ткните галку для веб серча". А оно нихуя.
Пробовал c gpt oss 20b, который вроде должен уметь в веб серч, но там видимо через какие-то свои приколы делается оно, которые в кобольде не реализованы.
Не пойму нихуя.
Есть нормальные движки, где все работает? Или комбинации моделек с движками.
Как задействовать веб серч в кобольде?
В консоли видно, что вроде что-то там шуршит, но в ответ модельки оно видимо не пробрасывается. Это че, самому погромировать проброс надо?
В гугле пишут "просто ткните галку для веб серча". А оно нихуя.
Пробовал c gpt oss 20b, который вроде должен уметь в веб серч, но там видимо через какие-то свои приколы делается оно, которые в кобольде не реализованы.
Не пойму нихуя.
Есть нормальные движки, где все работает? Или комбинации моделек с движками.
Не знаю что там насчет в самом lmstudio, но через него можно сервить модель в Chatbox, который также удобен для сетевых корпов, то есть можно держать подписочку дешманского дипсика или какой-нибудь большой гопоты или гугловских моделей или чего угодно --- и переключаться на локальную модельку когда надо.
gemma3 в кобольде работала с поиском вообще без проблем.
Увлекись творчеством и твори, высока вероятность что будешь иметь успех. Например, напишешь фантастику про свой аги, народ будет доволен и никто не доебется потому что изначально художественный вымысел.
Как минимум для подобного в модели должны корректно работать функциональные вызовы и стоять подходящий инстракт темплейт. Алсо давно в вебморде кобольда добавили подобные фишки?
Точно работает в openwebui, но оно реализовано несколько костыльно, может уже починили.
>Chatbox
Хотя ладно, там поиск так себе.
И вообще я не уверен, не воруют ли они лог чатов.
Ты попал на гопоту и она тебя поимела. У всех GPT-OSS особый формат вызова инструментов, оно 100% работает только с ихними же терминальным решениями. Остальным же опаньки и костыльный пердолинг. Гуглить cline.gbnf . Ну если так уж с гопотой пообщаться приспичело.
И да - ставь searxng и ищи тулзы, среды которые с ним работают. Таврена к стати работает.
Спс, если другие варианты не выгорят, гляну ЛМ студио.
А какая конкретно? Вес/квант? А то я уже параною, что какие-то фичи могут быть вырезаны или похерены на квантованных.
>Точно работает в openwebui
Тоже попробую глянуть, спс.
> Алсо давно в вебморде кобольда добавили подобные фишки?
С какой-то там 1.8Х версии. Сейчас уже 1.10Х
А какие модели еще поддерживают поиск?
Я квен тестил и девстраль вроде, но я так и не выкупил умеют они или нет. У гпт хотя бы явно написано.
На таверну хотел поставить, но там плагин через жопу устанавливается надо репозиторий склонировать локально, ебанулись штоле? в одну кнопку все должно устанавливаться, но она не работает
Поиск через кобольд в таверне тоже вроде поддерживается, но без плагина походу никак.
>А какая конкретно? Вес/квант? А то я уже параною, что какие-то фичи могут быть вырезаны или похерены на квантованных.
Ну например 27b-Q4_K_M
Блят, вейт, селениум это не сам плагин поиска?
Надо было оказывается эту хуйню устанавливать https://github.com/SillyTavern/Extension-WebSearch
А в доках даже нет ссылки на этот плагин https://docs.sillytavern.app/extensions/websearch/
Ну васяны нахуевертили конечно

Спасибо.
Попробовал. Местами неплохо, но прямо восторга не вызвало (завышенных ожиданий не было, получилось примерно так, как ожидал).
С другой стороны пока не жалею, что потрогал.
О результате говорить пока рано (возможно, вопросы к карточке в SillyTavern; Персонаж один — «рассказчик», который должен описывать реакцию персонажей и мира на действия {{user}} и respect {{user}}'s autonomy, не пытаясь описывать действия за {{user}}; что он пытается делать упорно, как только малейший намёк в контексте проглядишь и дашь ему возможность хоть раз определить действия {{user}} вместо комментирования их со стороны). Но это частности.
Информация, которая может быть полезна кому-то ещё для предварительной оценки: Oobabooga (llama.cpp) и (SillyTavern).
Скорость вывода на моём подуставшем железе (4080S 16 Гбайт VRAM, 128 Гбайт DDR4 RAM @3000 МГц; i7-7820X Quad-Channel), как и ожидалось, не дотянула и до 10 t/s. Начал с Q4_K_M (больше 10 t/s не получил), потом попробовал Q5_K_S (там не больше 9 t/s).
Затем дело дошло до IQ4_XS и Q4_K_S (на ней пока остался, может, ещё Q5_K_M попробую, но позже).
02:12:46-162201 INFO Loaded "ArliAI_GLM-4.5-Air-Derestricted-IQ4_XS-00001-of-00002.gguf" in 23.58 seconds.
02:12:46-165194 INFO LOADER: "llama.cpp"
02:12:46-166191 INFO TRUNCATION LENGTH: 8192
02:12:46-168186 INFO INSTRUCTION TEMPLATE: "Custom (obtained from model metadata)"
prompt processing progress, n_tokens = 4803, batch.n_tokens = 707, progress = 1.0000000
prompt eval time = 32678.19 ms / 4803 tokens ( 6.80 ms per token, 146.98 tokens per second)
eval time = 26990.80 ms / 223 tokens ( 121.03 ms per token, 8.26 tokens per second)
total time = 59669.00 ms / 5026 tokens
slot update_slots: id 3 | task 228 | n_past was set to 4802
slot update_slots: id 3 | task 228 | n_tokens = 4802, memory_seq_rm [4802, end)
prompt processing progress, n_tokens = 4803, batch.n_tokens = 1, progress = 1.000000
prompt eval time = 132.59 ms / 1 tokens ( 132.59 ms per token, 7.54 tokens per second)
eval time = 26352.89 ms / 218 tokens ( 120.88 ms per token, 8.27 tokens per second)
total time = 26485.47 ms / 219 tokens
slot update_slots: id 3 | task 447 | n_past was set to 4802
slot update_slots: id 3 | task 447 | n_tokens = 4802, memory_seq_rm [4802, end)
prompt processing progress, n_tokens = 4803, batch.n_tokens = 1, progress = 1.000000
prompt eval time = 135.14 ms / 1 tokens ( 135.14 ms per token, 7.40 tokens per second)
eval time = 30442.19 ms / 250 tokens ( 121.77 ms per token, 8.21 tokens per second)
03:27:42-133751 INFO Loaded "ArliAI_GLM-4.5-Air-Derestricted-Q4_K_S-00001-of-00002.gguf" in 27.59 seconds.
03:27:42-135745 INFO LOADER: "llama.cpp"
03:27:42-136742 INFO TRUNCATION LENGTH: 8192
03:27:42-137740 INFO INSTRUCTION TEMPLATE: "Custom (obtained from model metadata)"
prompt processing progress, n_tokens = 4803, batch.n_tokens = 707, progress = 1.0000000
prompt eval time = 36803.65 ms / 4803 tokens ( 7.66 ms per token, 130.50 tokens per second)
eval time = 23569.73 ms / 224 tokens ( 105.22 ms per token, 9.50 tokens per second)
total time = 60373.38 ms / 5027 tokens
slot update_slots: id 3 | task 229 | n_past was set to 4802
slot update_slots: id 3 | task 229 | n_tokens = 4802, memory_seq_rm [4802, end)
prompt processing progress, n_tokens = 4803, batch.n_tokens = 1, progress = 1.000000
prompt eval time = 139.98 ms / 1 tokens ( 139.98 ms per token, 7.14 tokens per second)
eval time = 20544.10 ms / 194 tokens ( 105.90 ms per token, 9.44 tokens per second)
total time = 20684.08 ms / 195 tokens
slot update_slots: id 3 | task 424 | n_past was set to 4802
slot update_slots: id 3 | task 424 | n_tokens = 4802, memory_seq_rm [4802, end)
prompt processing progress, n_tokens = 4803, batch.n_tokens = 1, progress = 1.000000
prompt eval time = 105.93 ms / 1 tokens ( 105.93 ms per token, 9.44 tokens per second)
eval time = 26025.31 ms / 250 tokens ( 104.10 ms per token, 9.61 tokens per second)
total time = 26131.24 ms / 251 tokens
Настройки Oobabooga на пикрил.
Речь про кум, не про однотипные обертки под жору для рабочих задач
>Как можно было за почти 4 года не сделать нихуя из того, о чем ты думал и хотел, это надо быть конченным уебаном
Как раз сам и сделал. Только какого хуя я должен прописывать дефолтные фичи которые должны идти из коробки в приложении, которое заточено под чатинг с персонажами?
Повторю - писюкал тебе на клыка, говноед проклятый. Из-за таких дырявых верунов как ты, опенсорс чаще всего из себя представляет кондовую ебанину, где ты должен доделывать за криворукими, даже если ты сам криворукий и нихуя не понимаешь. Таверна не вчера появилась, её проблемы и недостатки давно известны. Если разрабы ебали исправлять и дорабатывать свой же продукт, нахуя его вообще выкладывать? И почему за такое отношение их нельзя тыкать мордой? Потому что бесплатно? Ну я тебе на тарелку навалю тепленького, пожрать захочешь - разберешься, как его переработать в что-нибудь съестное. Ручки есть, гайдики есть, если что спросишь нейронку как из говна белки выделить.
Бесит, что советующие МоЕ переобулись в утверждение, что медленная скорость - это нормально и вообще простому мужичку можно потерпеть.
Хуй вас знает, я такое терпеть не могу. Первое сообщение с ГЛМ у меня на 13+ т/с идет, а с ростом чатлога всё отыквляется до 6 т/с.
Тут банально даже карточки новые (особенно написанные своими руками) не потестишь. Процесс превращается в пытку, когда надо вносить изменения и делать много генераций.
Хуй вас знает, я такое терпеть не могу. Первое сообщение с ГЛМ у меня на 13+ т/с идет, а с ростом чатлога всё отыквляется до 6 т/с.
Тут банально даже карточки новые (особенно написанные своими руками) не потестишь. Процесс превращается в пытку, когда надо вносить изменения и делать много генераций.
>janitor
Да ну нахуй. Кто юзает эту парашу? Надо невменяемым же быть.
Кстати, я тоже её юзал. Среди юзеров очень много лиц женского пола.
Там есть дико доставляющие карточки. Может просто некоторые не умеют заниматься их лутингом.
Я люблю скачивать топы и проверять, так скачал карточку королевского гарема. Мими и уняня, пока не наступила ночь. Вот там анценз эйра мне выдал хорор, что я закрыл таверну и пошёл курить.
Видяха какой профит дает для ллм?
Никакого. Покупай кофеварку.
Примерно такой же, какой дают ноги желающему пробежать стометровку. Ты конечно можешь без ног проползти, но это будет тяжело и долго.
Используется только 11 из 16 ГБ видеопамяти, а проц вообще не используется
Почему так?
Я должен телепатически угадать размер используемой модели, что ли?
А вообще если у тебя одна видеокарта, и система работает на виндоусе - винда может резервировать до 4гб видеопамяти под свои задачи (особенно если это АМД, на нвидиа вроде поменьше).
>а проц вообще не используется
Ну так основные вычисления именно на твоей видеокарте идут, куда ты загрузил часть своей модели.
Опять же, если модель (маленькая в твоем случае?) полностью влезает в видеопамять - там кроме видеокарты по сути и не будет ничего использоваться.
А сколько должно?
Видеокарта для ЛЛМ скорее вредна. Нынешние модели не помещаются целиком в видеопамять, начинают по слоям гоняться туда-сюда и это замедляет генерацию.
ЛЛМ оптимально запускать на памяти жесткого диска. Там большие объемы, можно поместить тот же дипсик в полных весах и инференсить без потери скорости. Мы все тут так и делаем, в принципе.
Читай шапку + вики треда + вики кобольда + документацию лламыцпп, ленивое хуйло. И ты тоже Как вы заебали уже.
Рекомендую начать Qwen3 30-х moe . Запускаются с приемлемой скоростью на бытовых кофеварках и могут в удержание контекста (особенно Qwen3-30B-A3B-Thinking-2507) .
Мелко-квены тоже умеют в тулза, но контекст держат как мистраль - для их размеров неплохо, но для использования - такое себе. Пойдут в сортир и оподливятся забыв зачем пошли.
Мелко-Мистраль. Как бэ формально умеет в тулза, и умеет в русик. На этом его стоковые преимущества все. Потому что контекстной памяти он не имеет ни в одном из тюнов. И ехидные лягушатники судя по всему менять это не на меряны забив хуй на архитектуру модели. Ты отправишь его в интернет и он забудет зачем пошел на 2-3 шаге поиска
Контекст при использовании любых тулзов жрется как не в себя - если не можешь запустить модель с 32k (минимум!!!) контекста можешь про web-поиск забыть.
Не квантуй кэш, это не только сильно замедляет на контексте, но еще и портит качество. Также чистый llama-server может быть немного побыстрее, но не обязательно эта разница будет стоить удобства.
Раз у тебя, шизика, особое виденье - форкай и развивай свой. Если все как ты говоришь - люди потянутся и поддержат. Только такого не произойдет, потому что даже просто сформулировать проблему - слишком сложно, потому и высираешь полотна как типичная баба срака, натаскивая нытье обо все и ни о чем.
> советующие МоЕ переобулись
Это наоборот любители моэ очень довольны, что со своими нищеконфигами они могут пускать относительно крупные модельки с приемлемыми скоростями, а не 0.5т/с.
Ну и если 13+т/с в обычном чате для тебя "невозможно медленно" - хуево быть тобой, 3й опущь как раз с такой скоростью и шел, и был манной небесной своего времени. Просадки на контексте - неотъемлемый атрибут llamacpp, но если квантуешь его или не оптимально распределяешь тензоры - все сильно усугубится.
Сначала не понял а потом как понял, хорош.
>если 13+т/с в обычном чате
На первом сообщении. К третьему сообщению это уже 10 т/с, к десятому 6 т/с. Это невозможно медленное дерьмо.

Можно просто скачать архив репы расширения с гита и распаковать в SillyTavern\data\default-user\extensions (охуенно очевидный путь, да)
Да вы батенька зажрались (кодящий на GLM-AIR в 8 ts / 88 ps )
> кодящий на GLM-AIR
Вайбкодинг от языка очень сильно зависим. Например на Расте невозможно вайбкодить, никто не может компилируемый код написать. Даже Грок/ЖПТ/Квен Кодер Макс. Про Девстраль и прочие локалки вообще молчу, даже не уровень Квена. При этом на питоне/жс любое говно что-то да сможет сделать. Алсо, рекомендую тебе с Эйра на новый Девстраль всё же пересесть, размер у них одинаковый.
Devstral-2-123B плотный. Со своими 16+16 VRAM я его могу только пососать. В отличии от Эир:
-ub 2048 -b 2048 -c 81920 -ts 37,11 -ot "blk.([1-9]|1[0-9]|2[0-9]|3[0-5]).ffn.(up|down|gate)_exps\.weight=CPU"
Да, в отличие от чуба, там есть реально очень качественно, ну или не качественно, но с умом написанные карточки, аналоговнетные.
Одну я залутал когда-то давно. Там была карточка суккуба на 600 токенов всего, но с примерами диалогов на 1000 токенов. Сдрочиться можно было даже на 9-12б кале от аутпутов, а когда они становились реально хуёвыми, яйца уже пустели.
Всегда мечтал сам сделать примерно такую карточку, но всегда было впадлу прописывать эти диалоги, потому что не могу на английском шпрехать хорошо. Читать проще, чем писать красиво, а от этого напрямую зависит вывод модели.
Обычное first mes в большинстве случаев можно хотя бы корпом перевести и проверить, что всё норм, но не кум-примеры сообщений на 1к токенов.
Похоже что неверно распределил тензоры, слишком уж плохо.
Просто в чатике или с агентами? Первое еще норм, но второе жесть.
Не стесняйся скидывать если видишь такие, особенно если с высоким уровнем культуры.
Не прав, там надо поебатся, но есть куча годнейший карт которых в принципе нет и не будет на чабе, и конечно придётся почистить от инструкций для внутренне модели, но всё же.
>но второе жесть
KiloCode . На самом деле терпимо. Главное AIR предсказуем, экономно токенизирует контекст (а не как Qwen), не проебывает его (как GPT-OSS).
Всосал окружение, всосал что-то нужное для задачи и пошел выводить. И если где-то косяка дал - например вставка кода не туда прошла - сразу за собой исправляет.
Достаточно раз в 30 минут его навещать. Такой вполне себе миидл.
Братцы, как вы глм-аир на 24 враме запускаете? Что-то у меня больше 5т/с не выдавить, даже с переносом мое слоёв в оперативу
Переноси не все моэ слои в оперативку. Сначала забей видеопамять, а оставшееся - в озу. У меня на 12гб врам скорость ~9тс на старте в эйре.
Можешь показать скрины своих настроек? Я пробовал забивать видеопамять и он меня не слушался, что кобольд-спп, что уга
gpulayers 999
moecpu 44 (4 слоя из 48 выгружается во врам)
threads 5 (у меня восьмиядерник. На 5 - лучшая скорость)
Ну и я на пингвине ещё. Остальное не так важно.
>(4 слоя из 48 выгружается во врам)
Что это за дичь вообще ебаная. Если я такое сделаю, у меня там процессинг будет вообще в жопе и генерация на 3 т/с.
мимо
>moecpu 44
В твоем случае, естественно, нужно меньше. Уменьшай это число до тех пор пока не забьешь врам полностью.
Эту буквально база по оптимизации скорости моэ-моделек лол. В озу отправляем только то что не влезло во врам.
Но у меня 64гб врама и ддр4 оперативка, я же не настолько отбитый чтобы следовать гайдам ебанутых рамлетов
Ну так и совет был дан не тебе, а челу с 24гб врам.
А ты уверен, что у того чела быстрая ддр5? Ведь если нет, то он будет в безвылазной жопе по скорости, и совет при таком раскладе получится каличный
А где технологичесский прогресс как пару лет назад, когда 24b модели спустя время ужимали до 12b. Всё, поезд приехал?
Не понял. Как раз сейчас он ВСЕ моэ слои выгружает в оперативку, а видеокарта простаивает. Я ему посоветовал докинуть на нее слоёв чтоб забить врам полностью. Чем меньше слоев в рам и больше во врам - тем быстрее.
Ты в чём? Уга или кобольд?
У меня медленная ддр4.... Посмотрел на цены на ддр5 и загрустил....
Это к ламецпп и кобольду применимо.
А можешь тогда скинуть файл настроек для кобольда, пожалуйста?
Сейчас 100-200б модельки ужимают до 20-30б.
Мало что ли?
>Так сделай.
Делаю. Интересно, что конвертация 7B модели в exl2 требуется всего 4 ГБ памяти + вообще почти ничего не держит на видеокарте. Разовую операцию кодить под видеокарту понятно что сложно, окей, но вот почему 14 ГБ не требуется загружать полностью в память - не очень ясно.
Полночи настраивал под виндой этот exl2, как они умудрились напись что-то платформозависимое на питоне и под куду то лол. Для сравнения exl3 быстрее запустился, минут за пять от скачивания до запуска конвертации.
Я не говорю о полной статистике, я просто хотя бы два-три примера среза, где хоть на какой конфигурации будет примерное сравнение.
Ну и по идее в первую очередь будет производительность плавать, а для перплексити будет даже довольно одинаковый график для разных железок.
>Хороший детектор диванного.
Да, всё верно.
Откуда я узнать то должен о чём это? В серверных карточках есть и используют. По цифрам быстрее чем через pcie гонять в разы. Про 3090 пишут, что использовали и подключали две. По какому из этих фактов я мог бы корректно оценить, насколько nv-link полезный.
Тестирую на мелкой модели, чтобы отладить все скрипты.
У меня получилось, что exl2 моделька при том же размере что и gguf начинает бредить, заикаться и лупиться. При этом выигрыша по быстродействию нет по сравнению с gguf.
А вот exl3 даёт х1.5 скорости, и судя по тому, насколько она хорошо и чисто разговаривает на 4.0 битах, то график перплексити не на пустом месте нарисован, и можно смело ставить 3.5 бита, и это на мелкой модельке. И ещё не требует сомнительных калибровочных данных для конвертации, из-за которых возможно exl2 у меня и посыпался.
Осталось дописать питон код, чтобы из консольки вызывать exl3 или работающий сервер с совместимым интерфейсом найти.
И дописать тест на перплексити, что, впрочем, может быть не очень просто.
И построю график по всяким небольшим моделькам как и какие кванты работают, на ночь поставлю конвертироваться и тестироваться по списку.
> Интересно, что конвертация 7B модели в exl2 требуется всего 4 ГБ памяти + вообще почти ничего не держит на видеокарте. Разовую операцию кодить под видеокарту понятно что сложно, окей, но вот почему 14 ГБ не требуется загружать полностью в память - не очень ясно.
Квантование в exl2/exl3 выполняется послойно. Достаточно, чтобы на видеокарту целиком влезал один слой. Так что на одной 24GB карте можешь хоть дипсик, хоть кими квантовать.
> И построю график по всяким небольшим моделькам как и какие кванты работают, на ночь поставлю конвертироваться и тестироваться по списку.
Если будешь тестить большие модели, то учти, что функция для сравнения моделей eval/model_diff.py в экзламе не выполняется послойно - она требует, чтобы неквантованная модель целиком влезала в VRAM. Если хочешь для крупных моделей запускать model_diff, можешь этот навайбкоденный костыль глянуть для послойного сравнения моделей: https://github.com/NeuroSenko/exllamav3/commit/6edb1f5d38c0b291daca6d3be6d60cf64e772fd7
То же сравнение для Qwen3-235B-A22B-Instruct-2507 по треду выше я бы без него просто не смог сделать.
Пример вызова:
python eval/model_diff.py \
-ma /home/user1/ai/shared/llm-my-quants/Qwen_Qwen3-235B-A22B-Instruct-2507-5.5bpw \
-mb /home/user1/ai/shared/llm-origs/Qwen_Qwen3-235B-A22B-Instruct-2507 \
-r 100 --analysis_mode cumulative --batch_size 1 -d 0
Для --analysis_mode можно выставлять cumulative, isolated или both. В целом, я думаю, что можно всегда просто cumulative использовать. Профит в послойном сравнении ошибки (isolated/both) в теории может быть только для тонкого сравнения ошибки по отдельным слоями для мёрджа чекпоинтов с разной точностью через util/optimize.py
Джейлбрейкнутая 1.6 апрелька красиво на ингрише пишет. Но... тупая все-таки, несмотря на предъявы про "у нас 15б как у конкрентов 400б". Плохо следит за чередой событий, может почувствовать дуновение ветра ботинком, короче пиздец.
Справедливости ради отмечу, что на самых навороченных карточках и в чатах, где уже был контекст - дела обстоят лучше. Но чуда все-таки не случилось и заменить малявкой даже 30б сложно.
пацаны.... я тут тыкаю vllm.
И знаете, она оказывается жопу сосет.
Модели занимают намного больше памяти, параллелить gguf не умеет на разные карты. Абсолютно нищий обоссанный квант openchat_3.5.Q2_K.gguf при запуске на 8к контекста занимает ВСЮ карту в 24 гб. И максимум генерации который я видел это 91 т/с. Обычно меньше.
В то же время БОЖЕСТВЕННЫЙ ЖОРА запущенный с 8192 контекста с той же моделью на той же карте со старта (то есть в таких же условиях) выдает 122 т/с и съедает меньше 5 гб врам на карте.
Карта 3090.
Думайте.
И знаете, она оказывается жопу сосет.
Модели занимают намного больше памяти, параллелить gguf не умеет на разные карты. Абсолютно нищий обоссанный квант openchat_3.5.Q2_K.gguf при запуске на 8к контекста занимает ВСЮ карту в 24 гб. И максимум генерации который я видел это 91 т/с. Обычно меньше.
В то же время БОЖЕСТВЕННЫЙ ЖОРА запущенный с 8192 контекста с той же моделью на той же карте со старта (то есть в таких же условиях) выдает 122 т/с и съедает меньше 5 гб врам на карте.
Карта 3090.
Думайте.
Думаю.
Думаю вообще съебать со всего этого дерьма.
Локалки мертвы, никакого реального прогресса, только бенчи, бенчи сука, бенчи.
Даже #&#@ сказал что без понятия на чем рпшить без рига, всё говно, всё заебало, и покинул тред.
Пока нам тут пытаются скормить мое с 3б активными параметрами, на корпах кумят на плотных трилионных модельках.
И не говорите мне про сою блять, в локалках тоже давно уже соевое болотце, то то все радуются анцензорд версиям
но братишка...
тебе же говорили, что одна карта - это только "попробовать ллм"
ты же попробовал? Попробовал.
Дальше - надо уже покупать вторую гпу.
А ты как хотел?

>5000 ллм равны 500 миддлам
кекнул
Ага. У него, видимо, 9 женщин за месяц ребенка родить могут. :)
Мля, короче заставил работать веб серч и в кобольде и в таверне, все через жопу.
Возможно у меня и до этого работало, но с нюансами.
Во-первых, страницы не всегда открываются, даже если дату загуглить - нужно впн подрубать для такой хуйни.
Во-вторых, промпт должен содержать очевидные ключевые слова для поиска, типа find me some shit.
В-третьих, содержимое выдается в каком-то пожеванном виде, как будто только самое начало страницы, вглубь оно даже не идет.
В итоге ответ нейронки - хуйня. Я даже актуальную дату не смог получить от нее ебать я лох
Возможно у меня и до этого работало, но с нюансами.
Во-первых, страницы не всегда открываются, даже если дату загуглить - нужно впн подрубать для такой хуйни.
Во-вторых, промпт должен содержать очевидные ключевые слова для поиска, типа find me some shit.
В-третьих, содержимое выдается в каком-то пожеванном виде, как будто только самое начало страницы, вглубь оно даже не идет.
В итоге ответ нейронки - хуйня. Я даже актуальную дату не смог получить от нее ебать я лох
Анончики, я кажется хуйни наделал.
После новостей о подорожании памяти у меня началось жёсткое ФОМО на тему, что если я не обновлюсь сейчас, то уже никогда.
У меня стояла мелкая материнка MSI с двумя слотами под оперативу, занятыми двумя плашками по 16 гигов DDR4 - 2666 Kingston Xyper X.
И тут мне в башку пришла ГЕНИАЛЬНАЯ идея - взять новую материнку с 4 слотами и купить ещё 2 плашки. Благо на Авито как раз валялись последние плашки, по 4,5к в моём городе, тоже 2666, Ymeiton, даже радиаторов нет, но не похуй ли, когда это буквально последняя дешёвая память?
Выбор материнки пал на б/у-шную ASUS PRIME B350-PLUS, потому что у неё было 2 слота под видюхи. А у меня как раз есть Тесла, которую я заебался подключать через райзер.
Вроде всё логично, что же могло пойти не так?
Да дохуя всего.
Началось всё с того, что когда я пересобрал комп, эта хуйня отказалась стартовать. Тут я хорошенько пересраля, думая что свернул что-то в процессе сборки. Но всё оказалось банальней - система не стартовала со всеми 4 плашками оперативки, но при этом стартовала что со старой, что с новой, но не когда они вместе. И тогда я узнал что у оперативки оказывается бывают тайминги и она может быть несовместима. КАКОГО БЛЯДЬ ХУЯ ТАЙМИНГИ НЕ ПИШУТ В ОСНОВНЫХ ХАРАКТЕРИСТИКАХ СУКА???!!! При этом характеристики ноунейм говна, которое я купил, я даже загуглить не смог.
Все пишут "просто покупайте одинаковые плашки" если вы бездомный, просто найдите дом нахуй Мои кингстоны сейчас стоят по 14к штука, а менять их на такое-же ноунейм говно, как я купил, как-то не хочется. Эта хуйня никак не решается?
Второй ахуенный момент это Тесла. Включил в настройках материнки "Above 4G Decoding", выключил "CSM". Результат - комп не стартует, даже когда я воткнул Теслу через райзер в Х1 разъём. Причём эта хуйня отказалась запускаться ДАЖЕ ПОСЛЕ ТОГО КАК Я ВЫТАЩИЛ ТЕСЛУ. Врубилась только с 4 раза.
Какого хуя? Нейрач, я что, только что инвестировал в говно?
После новостей о подорожании памяти у меня началось жёсткое ФОМО на тему, что если я не обновлюсь сейчас, то уже никогда.
У меня стояла мелкая материнка MSI с двумя слотами под оперативу, занятыми двумя плашками по 16 гигов DDR4 - 2666 Kingston Xyper X.
И тут мне в башку пришла ГЕНИАЛЬНАЯ идея - взять новую материнку с 4 слотами и купить ещё 2 плашки. Благо на Авито как раз валялись последние плашки, по 4,5к в моём городе, тоже 2666, Ymeiton, даже радиаторов нет, но не похуй ли, когда это буквально последняя дешёвая память?
Выбор материнки пал на б/у-шную ASUS PRIME B350-PLUS, потому что у неё было 2 слота под видюхи. А у меня как раз есть Тесла, которую я заебался подключать через райзер.
Вроде всё логично, что же могло пойти не так?
Да дохуя всего.
Началось всё с того, что когда я пересобрал комп, эта хуйня отказалась стартовать. Тут я хорошенько пересраля, думая что свернул что-то в процессе сборки. Но всё оказалось банальней - система не стартовала со всеми 4 плашками оперативки, но при этом стартовала что со старой, что с новой, но не когда они вместе. И тогда я узнал что у оперативки оказывается бывают тайминги и она может быть несовместима. КАКОГО БЛЯДЬ ХУЯ ТАЙМИНГИ НЕ ПИШУТ В ОСНОВНЫХ ХАРАКТЕРИСТИКАХ СУКА???!!! При этом характеристики ноунейм говна, которое я купил, я даже загуглить не смог.
Все пишут "просто покупайте одинаковые плашки" если вы бездомный, просто найдите дом нахуй Мои кингстоны сейчас стоят по 14к штука, а менять их на такое-же ноунейм говно, как я купил, как-то не хочется. Эта хуйня никак не решается?
Второй ахуенный момент это Тесла. Включил в настройках материнки "Above 4G Decoding", выключил "CSM". Результат - комп не стартует, даже когда я воткнул Теслу через райзер в Х1 разъём. Причём эта хуйня отказалась запускаться ДАЖЕ ПОСЛЕ ТОГО КАК Я ВЫТАЩИЛ ТЕСЛУ. Врубилась только с 4 раза.
Какого хуя? Нейрач, я что, только что инвестировал в говно?
4 планки менее стабильны по сравнению с 2, но у тебя дело не только в этом. Часто при 4 планках профили частоты и таймингов приходится снижать, особенно если они разные (по факту разные могут вообще суперухево работать или не работать вообще).
Да, ты мог инвестировать в говно. И да, это обычная ситуация.
>КАКОГО БЛЯДЬ ХУЯ ТАЙМИНГИ НЕ ПИШУТ В ОСНОВНЫХ ХАРАКТЕРИСТИКАХ СУКА???!
Пишут. CL-циферка. Но даже при одинаковых категориях надо понимать, что точные значения могут не совпадать. Вся память разная в этом плане.
>Мои кингстоны
Чтобы эта хуйня завелась, тебе надо опустить их тайминги и частоту до уровня новой памяти.
> Ymeiton, даже радиаторов нет, но не похуй ли, когда это буквально последняя дешёвая память?
Ну если она предустановленные профили не поддерживает, то есть если надо с настройками ебстись вручную - то нахуй такую память.
У меня вот были планки 32+32 Patriot Viper Steel (медленнее) и 8+8 тоже Patriot Viper Steel, но с другими таймингами (быстрее).
Как ты думаешь, на какой частоте они заводились? 2600, блять, хотя один комплект был 3600, а другой вообще 4000.
Да, одинаковый производитель. Да, почти одинаковая, но немного разная частота и тайминги.
А в итоге - жопа.
Что может помочь со стабильностью (но НЕ заменяет подгона таймингов и частоты под одни значения, одинаково подходящие для работы всех планок и старта системы)
> в биосе, в настройках таймингов, command rate 2T вместо 1T, если стояло 1T (вручную или выбиралось авто-режимом само по себе, не важно)
А вообще тебе в /hw/ с такими делами, хотя там тоже вряд ли помогут разобраться с малоизвестной памятью из жопы китайца.
>Чтобы эта хуйня завелась, тебе надо опустить их тайминги и частоту до уровня новой памяти.
Спасибо за подсказку, но пока что я нихуя не понял что там и как опускать. Параметров там не 4, а дохуя и все стоят на "Auto".
Попробовал переставить Command rate с "Auto" на "2T" - выдало ошибку загрузки спасибо хоть вообще запустилось
Буду разбираться.
>Ну если она предустановленные профили не поддерживает
Сама по себе то она стартует, значит что-то да поддерживает. Попробую поеебстись.
Сейчас 2 дилеммы: Попытаться вернуть деньги, но тогда нахуя я вообще всё это затеял. Или ебстись до последнего, возможно потом попробовать самому перепродать это говно с наценкой лол.

Блять, почему абсолютно каждый тюн мистрали хочет выебать меня в жопу, хотя таких пожеланий не прописано ни в карточке перса ни в персоне (а там указаны фетиши и они другие, и если к ним самому перса не подвести ему похуй он их упоминать не будет но в жопу мне руку да засунет).
Тайминги не трогай вручную, пусть будут на авто.
И попробуй частоту для всех планок поставить мелкую, 2400.
Если так не заведется на 2Т, думаю проще бросить это дело и продать память какому-нибудь шизоиду.
А ты сам-то к чару в штанцы не лез? Может у тебя модель перспективы путает и воспринимает твой инпут как свой собственный лог сообщений кек
Я такое встречал.
> поставить мелкую, 2400.
Можно даже меньше. Короче надо найти точку, при которой системаа загрузится. Если такой точки нет, значит просто нихуя не взлетит.
Авто-тайминги в биосе, кстати, все равно должны показывать какой там выставлен тайминг. Вот тут надо просто проверить ,чтобы они соответствовали значениям по мерке самых слабых планок памяти.
UPD Тесла завелась. Хуй знает вообще почему. Просто подключил её ещё раз и всё заработало. При старте материнка выключилась, потом включилась и теперь всё работает. Пока на райзере, потому что я заебался вставлять-вытаскивать это всё в корпус, но уже хорошо. Потом попробую в корпус вставить.
Хоть какая-то хорошая новость.
>А ты сам-то к чару в штанцы не лез?
Профингерить не пытался но я уже его ебу ах и он спокойно отвечает от лица перса на мою прямую речь, так что проблема не в этом, пока что похоже на забавное совпадение, на нескольких тюнах на 2 карточках такое уже наблюдаю, может дело в том что чару велено вести себя как фемдом-мистресса вот оно и всякую хуйню вытворяет, но соевые воспитанные нейро девочки должны обычно спрашивать разрешение на такое! Короче можно считать что я пока зря воздух сотрясаю, попробую еще пару карточек.
то самое чувство когда распаковываешь Devstral-2-123B-Instruct-2512.tar.zst 98GB в оперативе потому что её ещё дофига а на ссд место уже закончилось
Гоняю мистрали, никогда с такой проблемой не сталкивался. Возможно модель просто ужаренная, если в инструкциях чисто. Мне однажды попался тюн, который отказывался воспринимать трапов/футов и даже если упоминал наличие члена, то всё равно пытался выебать меня половыми губами (лол) или пальцами.
Для ассистенто-задач мелкие моешки годнота, но для рп - сасат.
Вот и получается, что gemma3-27B-it-abliterated-normpreserve новый единственный безальтернативный вин для тех у кого пк а не риг.
Мистраль, ну это мистраль, (стоковый новый, не тюны) - в куме получше, в мозгах похуже, но зато контекст сранительно легкий.
Вот и получается, что gemma3-27B-it-abliterated-normpreserve новый единственный безальтернативный вин для тех у кого пк а не риг.
Мистраль, ну это мистраль, (стоковый новый, не тюны) - в куме получше, в мозгах похуже, но зато контекст сранительно легкий.
>единственный безальтернативный вин для тех у кого пк а не риг.
Эйр же. Любая видеокарта + 64гб рам. Никаких ригов не нужно.
>вин для тех у кого пк а не риг.
ПК с 48гб врама, ты хотел сказать. Потому что удачи загрузить q4 27b на 16гб с 32к+ контекстом.
Эйр это моэкал на 5 токенах в секунду при чате длинее чем "ну-ка подрочи мне хуй по быстрому"
>зато контекст сранительно легкий
Он мертвый, толку-то? До 16-18к плюс минус держится, потом начинается одурение.
та не, вполне норм грузится, если ты терпеливый, 3 т/с, жить можно
Тяжело звучит. Надо еще видюшку вставлять.
>Эйр это моэкал
Терпи дружочек. Жирных плотных моделей больше не будет, они остались в прошлом. Уже даже корпы все перешли на мое. Плотными останутся разве что мелочь до 10b, и то не факт.
Кто нибудь пробовал купить в Яндекс Алисе?
>купить
кумить
фикс
Кто-нибудь пробовал кумить в протоколе товарища майора?
так вон же мистраль выдал плотную на 123б параметров
Ггуф в глубокой бете. Для вллм либо исходные веса либо awq/gptq
Напомните, зачем нужны файнтюны?
Тюнят обычно немо 12б, ламу 8б и мистраль 24б, но зачем?
Цензуры там и так нет, в рп и так может
Тюнят обычно немо 12б, ламу 8б и мистраль 24б, но зачем?
Цензуры там и так нет, в рп и так может
Зашивают внутрь нужные датасеты,
делятся ими для лайкосов, респекта.
>Выбор материнки пал на б/у-шную ASUS PRIME B350-PLUS, потому что у неё было 2 слота под видюхи.
У меня такая работает с чипами 2х16 @2400 и 2х16 @3200 (на общей 2400 естественно), тайминги совершенно разные. Все стабильно. А вот хрень с включением - меня она регулярно пугала. Когда только купил, чуть по гарантии не сдал, думал - дохлая. Когда на ней не заводится железо или меняется конфиг оного - следующее включение может быть ОЧЕНЬ долгим - секунд 30-45. Полная инициализация у нее длиннющая. Обычно делается только краткая.
В теории, хороший тюн будет именно писать текст, прикидываясь персонажем (или писать текст О персонаже). Все модели в своем виде тренируются изначально как "ассистенты" для решения задач, имеющие цель - найти корень проблемы в инпуте юзера, адресовать его, применить конкретные знания и решить эту проблему. Что часто приводит к аутпуту (в контексте рп), когда модель доебывается до юзера и пытается узнать его цели, расспрашивает, уточняет. Это выглядит неестественно. А главное, модель не стремится проявлять инициативу за пределами этого "ассистентского" поведения.
Проблема в том, что тюны не особо стремятся решить этот косяк. Авторы тюнов, если так можно назвать этих бездарей, всего лишь кормят модель датасетами с определенным контентом, чтобы модель отвечала на жопотраханный инпут так, как им хочется. ООО ДАА ЖЕСТЧЕ ЕБИ МЕНЯ АХ ОХ АХ ОООУ. Вот в этом духе. Нет, хорошие датасеты тоже есть и они бывают полезны. И через датасеты изначальная проблема тоже решается. Но для ее полного решения нужна тренировка таких масштабов, какие этим васянотюнерам и не снились: от проработки датасетов, которые "смягчат" ассистентский уклон модели, до скармливания модели реально хороших текстов с качественно поставленным слогом (а их вообще мало, в основном тренируют на синтетическом высере других моделей).
В общем, тут все сложно. Хорошие тюны бывают. Они делают модель чуть более похожей на живого человека. Но вот такого, чтоб прям модель отличалась от базовой версии радикально - нет, это скорее редкость, контрастирующая с большим перекосом в сторону испорченных тюнами моделей.
У нищих материнок еще и мало линий писиай, об nvme ссд можешь забыть, если две видяхи поставишь
>Эйр это моэкал на 5 токенах в секунду при чате длинее чем "ну-ка подрочи мне хуй по быстрому"
всё ждешь, пока раскупят v100?
будешь фиксировать прибыль, когда до 60к доползет цена?
Ну жди-жди, маленький.
У меня эйр летает на 50+т/с, не вижу проблемы.
владелец рига
Просто мистраль понимает, что в душе ты заднеприводный.
А модели разве есть смысл сжимать? Там же 100 мегабайт небось экономия.
Технически, когда дают бумажку описать все твои деяния, там можно написать РП. Так что кумить можно и в протоколе! До первых отбитых почек.
Это тюн их прошлогодней модели, а не новая база.
>ОЧЕНЬ долгим - секунд 30-45
Ты ещё на DDR5 не сидел. Мой конфиг с 96 гигами включается минут 8 на холодной загрузке. Будущее, которое мы заслужили.
>Нет, хорошие датасеты тоже есть
Но их никто не видел.
>об nvme ссд можешь забыть, если две видяхи поставишь
Ну тут ХЗ, система у меня грузится с М2 SSD, ещё есть пара сатавских винтов и один SSD. Основная видюха завелись вместе с Теслой. Что не завелось так это управление охладом через Фан контрол. То-ли материнка слишком хитро контролирует CHA_FAN1, то-ли я всё-таки что-то похерил. Кулер включается-выключается рывками, скорость вроде контролируется, но на полную мощность не выходит. По факту получается что охлада нет и Тесла пока не юзабельна.
Спасибо за инфу.
Она бы хоть как-то сигнализировала о том что не сдохла в такие моменты, а то меня уже заебало обсераться каждый раз.
У меня чистота у всех плашек вроде должна была быть одинаковой. Надо воткнуть новую оперативку и глянуть какие там тайминги, а потом выставить самые высокие у обоих видов.
Нагуглил что первые 3 цифры таминга это параметры: CAS Latency, TRCD, TRP, а последний TRAS лучше оставить "Auto"
Сейчас пока не могу этого сделать, т.к. чтобы вытащить всю оперативу надо снимать радиатор проца, а у меня термопаста закончилась. Буду завтра эксперементировать.
Устроил себе голодные игры блядь
> экономия
у сафетензорс до 25%, у гуфов до 10%
Может быть, ну просто может быть, ты чего в свою персону написал ?
Мистраль не самая сообразительная, но умница и за промтом следит и если там сладенький мальчик, то не удивляйся.
У меня мистралька моему мальчику-фее, выдала примерно следующее содержание: император и императрица посмотрели на {user} и решили что он охуенно будет смотреться в постели между ними. При этом буквально: игрока забыли спросить.
стоит ли тратить почти 100 тысяч на этот компьютер
MINISFORUM Мини-ПК X1 PRO (AMD Ryzen AI 9 HX 370, RAM 64 ГБ, SSD 1000 ГБ, AMD Radeon 890M, Windows)
чтобы запускать локальные LLM, или лучше взять чего подешевле и полагаться на API?
MINISFORUM Мини-ПК X1 PRO (AMD Ryzen AI 9 HX 370, RAM 64 ГБ, SSD 1000 ГБ, AMD Radeon 890M, Windows)
чтобы запускать локальные LLM, или лучше взять чего подешевле и полагаться на API?
Конечно стоит, вытащишь память и продашь через 2 месяца за цену всего миника.
>полагаться на API?
Самый разумный выбор для нищука.
Да я уже в общем-то могу это сделать, ибо две плашки по 32 гига стоят 70 тысяч
Но мне все-таки интересно с точки зрения производительности. Что интересного можно замутить на 64 гигах оперативы, чего нельзя замутить при 32 (при прочих равных)? Так как мини-пк на 32 гига куда дешевле. Я так понимаю, что 64 гига позволяют запускать модели на 30B, но они же все равно стремные на фоне 70b+, может оно того и не стоит, и достаточно запускать малые локальные агенты на 4-12b + делать запросы к АПИ для сложных сценариев
Или вообще тогда купить мак мини, если все равно все придется через api делать... С другой стороны, не под стать наверное нейросетевым сомелье юзать закрытые системы
>Что интересного можно замутить на 64 гигах оперативы, чего нельзя замутить при 32 (при прочих равных)?
Запустить AIr и гопоту 120B. Правда, еще видеокарта нужна...
А зачем тебе макмини для API, возьми макбук м3 (дешевле всего и достаточно быстрый) ну или м4 побыстрее. Можно даже эйр, потому что мощность тебе не нужна все равно (хотя даже на эйре можно гонять виртуалку винды и включать какие-нить визуальные новеллы).
Получишь охуенный, легкий, компактный девайс, на котором можно подключиться через API к чему угодно.
Я вот с собой эту штуку вечно таскаю в поездки. А дома даже телек перестал юзать как монитор для кинца, потому что микро-ноут в кроватке охуенно юзать - на бок его положил рядом и смотришь вблизи че угодно.
А эти МИНИ карлики по мощности примерно то же, но прикованы к десктопу. Дикое разочарвоание.
Ну кстати, дешевле всего вообще эйр на м2, уж не знаю, насколько он сейчас актуален.
Просто моя идея заключается в том, что надо сделать индивидуальную учебную систему с ИИ, чтобы все мои учебники были в векторной базе данных, чтобы все данные о моих занятиях тоже туда попадали, и чтобы промпты нейросетям писались с учетом этого контекста. Вот мне дипсик рассказывал, что для этой задачи было бы неплохо юзать какие-то локальные легковесные LLM, чтобы они сами по себе могли в пассивном режиме что-то делать с моими файлами, а для основных задач - задействовать АПИ. Наверное, для этого хватит и макбука
Ну насчет легковесных... На м3 эйре вполне может бегать 12B карлик с контекстом, если это 32-гиговый эйр (на 16-гиговом контекста будет совсем мало).
Другое дело, что 12B это смешно, и даже от 12B он перегреется быстро и скорость будет днищная, особенно по процессингу.
Так что если выбирать путь локального ИИ, то в случае с маками придется раскошеливаться на Про или вообще Макс, а они жирнее и тяжелее.
А вообще просто давал заметочку про тупость выбора макмини, когда есть по сути такой же макмини с экраном, который можно куданить взять и юзать как терминал доступа к ИИ через API.
>У меня эйр летает на 50+т/с, не вижу проблемы.
А я вижу. Выше Эйр не подняться, да и тот в следующей версии увеличат наверное. Большой Квен в IM2-кванте и тоже подозреваю, что последний такой. С выгрузкой части слоёв на РАМ будет уже не так весело, ну а совсем большие модели и вовсе идут лесом.
Другой вопрос, не наебнётся ли весь этот движ уже в самом ближайшем времени.
две v100 с китая все еще стоят дешевле 100к. На сдачу берешь майнерскую мать и в ус не дуешь.
Что за прикол жрать говно на РАМе? Нравится терпеть?
>v100
Это что-то устаревшее и пердольное? Будет оно как 3090 работать в 11 винде?
>Это что-то устаревшее и пердольное? Будет оно как 3090 работать в 11 винде?
Под такое дело только отдельный сервачок собирать и ставить Линукс. Но дело стоящее. И правда, что может быть последний шанс на ближайшие года три. Повышение цен на оперативку в 4 раза вообще никто не ожидал, а ведь это явно не последний прикол.
Если средне постараться то в 75-77 дуал можно собрать (схм борда, охлад, две в100, доставки), если сильно с гуфишем заебаться то думаю и в 70
Не удаётся скачать модель с huggingface - пробовал и CLI, и wget, aria2, через браузер, с huggingface-mirror - ниоткуда не хочет качать, если это xet - на этапе редиректа внутри ссылки скачивания получаю такое и бесконечный фриз:
huggingface-cli download gghfez/gpt-oss-120b-Derestricted.MXFP4_MOE-gguf
Fetching 3 files: 0%| | 0/3 [00:00<?, ?it/s]Downloading 'gpt-oss-120b-Derestricted.MXFP4_MOE.gguf' to '/home/ABCDE/.cache/huggingface/hub/models--gghfez--gpt-oss-120b-Derestricted.MXFP4_MOE-gguf/blobs/cd058b3dee21f12ea3e74b0202e6ba31831bbd7de9853e90ceb7d807e9f6adac.incomplete' (resume from 1590371389/63387347008)
Error while downloading from https://cas-bridge.xethub.hf.co/xet-bridge-us/692c4512c913fbc94da1d38a/ded2a987d305b0b5c99e1365d77793ff6e33fb7f5d891c12841b1b1368a37741?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=cas%2F20251213%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20251213T211833Z&X-Amz-Expires=3600&X-Amz-Signature=85dec86a3984d80fdddd1a0d714d51d01dc60157d7b64e29a47c25ce5159b638&X-Amz-SignedHeaders=host&X-Xet-Cas-Uid=public&response-content-disposition=inline%3B+filename*%3DUTF-8%27%27gpt-oss-120b-Derestricted.MXFP4_MOE.gguf%3B+filename%3D%22gpt-oss-120b-Derestricted.MXFP4_MOE.gguf%22%3B&x-id=GetObject&Expires=1765664313&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTc2NTY2NDMxM319LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2FzLWJyaWRnZS54ZXRodWIuaGYuY28veGV0LWJyaWRnZS11cy82OTJjNDUxMmM5MTNmYmM5NGRhMWQzOGEvZGVkMmE5ODdkMzA1YjBiNWM5OWUxMzY1ZDc3NzkzZmY2ZTMzZmI3ZjVkODkxYzEyODQxYjFiMTM2OGEzNzc0MSoifV19&Signature=MrgUQVH5kPbq5GgKLDHrGp1zrQZo1IhmJDW-OJagKP1SgWlloz%7En6eT-eHh7%7EFKT8tj7yIOFtF5JrqWatNV2-BZu5mvqphPkJfUcFjmaOJruK141a2%7Epf1jjVD7wXv0cdfHrGxK7yHseDGUPHL1hohvpBtB8NutKCsAYBpSbg59mLSA-RA2nlP2m0UGlyaXOJwS0c21%7EhK9svOwODGX7jG8AivRNg1nvec78y141HS50lHKaxw9IAZKg2D4ooXaP8cB-g0HcYam%7EErPAO4zyPAZnEUegOEXf1gX6q934XvpQ9v3uSsvuxfwqPe6Dk2owVSH-YQNtKfIhM96n-2sahA__&Key-Pair-Id=K2L8F4GPSG1IFC: HTTPSConnectionPool(host='cas-bridge.xethub.hf.co', port=443): Read timed out.
У кого-нибудь ещё была такая проблема? Раньше всё качалось как через терминал, так и с сайта, так и wget'ом.
huggingface-cli download gghfez/gpt-oss-120b-Derestricted.MXFP4_MOE-gguf
Fetching 3 files: 0%| | 0/3 [00:00<?, ?it/s]Downloading 'gpt-oss-120b-Derestricted.MXFP4_MOE.gguf' to '/home/ABCDE/.cache/huggingface/hub/models--gghfez--gpt-oss-120b-Derestricted.MXFP4_MOE-gguf/blobs/cd058b3dee21f12ea3e74b0202e6ba31831bbd7de9853e90ceb7d807e9f6adac.incomplete' (resume from 1590371389/63387347008)
Error while downloading from https://cas-bridge.xethub.hf.co/xet-bridge-us/692c4512c913fbc94da1d38a/ded2a987d305b0b5c99e1365d77793ff6e33fb7f5d891c12841b1b1368a37741?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=cas%2F20251213%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20251213T211833Z&X-Amz-Expires=3600&X-Amz-Signature=85dec86a3984d80fdddd1a0d714d51d01dc60157d7b64e29a47c25ce5159b638&X-Amz-SignedHeaders=host&X-Xet-Cas-Uid=public&response-content-disposition=inline%3B+filename*%3DUTF-8%27%27gpt-oss-120b-Derestricted.MXFP4_MOE.gguf%3B+filename%3D%22gpt-oss-120b-Derestricted.MXFP4_MOE.gguf%22%3B&x-id=GetObject&Expires=1765664313&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTc2NTY2NDMxM319LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2FzLWJyaWRnZS54ZXRodWIuaGYuY28veGV0LWJyaWRnZS11cy82OTJjNDUxMmM5MTNmYmM5NGRhMWQzOGEvZGVkMmE5ODdkMzA1YjBiNWM5OWUxMzY1ZDc3NzkzZmY2ZTMzZmI3ZjVkODkxYzEyODQxYjFiMTM2OGEzNzc0MSoifV19&Signature=MrgUQVH5kPbq5GgKLDHrGp1zrQZo1IhmJDW-OJagKP1SgWlloz%7En6eT-eHh7%7EFKT8tj7yIOFtF5JrqWatNV2-BZu5mvqphPkJfUcFjmaOJruK141a2%7Epf1jjVD7wXv0cdfHrGxK7yHseDGUPHL1hohvpBtB8NutKCsAYBpSbg59mLSA-RA2nlP2m0UGlyaXOJwS0c21%7EhK9svOwODGX7jG8AivRNg1nvec78y141HS50lHKaxw9IAZKg2D4ooXaP8cB-g0HcYam%7EErPAO4zyPAZnEUegOEXf1gX6q934XvpQ9v3uSsvuxfwqPe6Dk2owVSH-YQNtKfIhM96n-2sahA__&Key-Pair-Id=K2L8F4GPSG1IFC: HTTPSConnectionPool(host='cas-bridge.xethub.hf.co', port=443): Read timed out.
У кого-нибудь ещё была такая проблема? Раньше всё качалось как через терминал, так и с сайта, так и wget'ом.
если это не ryzen 395 c 8060s - то не стоит
Ркн. Способы обхода стандартные
Стандартные - это из трёх букв?
Из 3х, из 6, может ещё из скольки. Сам разберёшься. А вообще нехуй тут на партию гнать, сказали нельзя нейрослоп значит нельзя, терпи
Была и сама уходила в течение дня.
а вообще через лмстудио качнуть попробуй

>gghfez/gpt-oss-120b-Derestricted.MXFP4_MOE-gguf
Без проблем загружается через питон-скрипт и либу huggingface_hub
Кстати, посоветуйте что ещё загрузить в архив.
Пока я набрал qwen 2.5/3.0 (я не понял, instruct версия это не думающая, а thinking - думающая, а где thinking-instruct и простая base (не thinking)?), gemma, llama, некоторые мелкосети, gpt-oss20
Что ещё позагружать интересного, особенно в диапазоне 20-200B из "чистых" моделей?
Qwen3 VL 2B thinking
могу смело советовать;
с Instruct у меня лупит,
но c mmoproj нормально.



На скрине параметры запуска
из ярылка(.lnk) к llama-server.
Qwen3 VL 2B Instruct + mmproj
А есть принципиальная разница кто делает квантованные версии моделей? Анслот, мрадермачер, бартовски или еще кто-то?
Зачем каждый васек свой велосипед выкладывает? Или у всех своя методика зельеварения?
Есть такое, что у кого-то быстрее или точнее квантованные версии?
Зачем каждый васек свой велосипед выкладывает? Или у всех своя методика зельеварения?
Есть такое, что у кого-то быстрее или точнее квантованные версии?
Нажми на стрелочку справа от названия модели и сам посмотри, где точность выше. Там все подробности по слоям и весам. А с Анслотом не связывайся, там чистое шаманство.
К рассуждениям о русике.
Вот прошёл я русскую игру "зайчик" и хочу заромансить тян оттуда, игра прям до мозга костей русская, и что вы мне предлагаете рпшить на английском?
Русик прям необходим
Вот прошёл я русскую игру "зайчик" и хочу заромансить тян оттуда, игра прям до мозга костей русская, и что вы мне предлагаете рпшить на английском?
Русик прям необходим
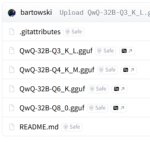
На эти?
Там же просто описание слоев и прочей хуйни. Что я оттуда пойму?
Про точность я говорю насколько в мозгах потерял тот или иной квант, хуже фактаж или хуже стилистика там и т.д.
Блять, вот насоздавали кучу моделей. А толку-то? Как их выбирать теперь?
Вот решил я проверить на что способен мой бич-пакет на 16гб врама в кодинге. Ну модельки до 30б можно натянуть, что-то неплохое показывает. Но это только 2-3 проверенных временем моделек от топовых производителей. А потом начинается, файнтюны, хуютюны, уже какие-то новые модельки вышли а их еще не тестили толком. А потом думаешь, ну надо еще шоб с ризонингом было, чтобы вообще круто. А потом еще находишь всякие разнузданные модельки на основе моделек от корпоратов, типа Qwen3-42B-A3B-2507-Thinking-Abliterated-uncensored-TOTAL-RECALL-v2-Medium-MASTER-CODER-i1-GGUF. Такой смотришь на все это и охуеваешь.
Во-первых, качать это все 20 часов надо. Во-вторых, места уже нихуя нету, каждая моделька 10-15 гигабутов весит, а у меня и так уже игорьков и прона под завязку на дисках.
В-третьих, самое главное, понадобится тысяча лет, чтобы затестить их всех на каких-то своих нуждах, и выбрать ту самую единственную.
И это только кодинг. А в процессе аппетит накручивается, уже думаешь, а надо модельку чисто под ризонинг, чтобы было с кем за философию попиздеть. А еще надо попробовать ризонинг и без цензуры, чтобы иишка могла меня словесно отпиздить. Потом хочу чтобы креатиффчик качественный генерило, буду идеи для игр брейнстормить. Но тут еще оказывается визуальные модельки уже во всю пошли, хочу чтобы бот видел на какие картинки я кумлю.
Нахуй я сюда полез? 4 дня уже сижу, 500 вкладок в браузере, и количество нихуя не уменьшается.
Вот решил я проверить на что способен мой бич-пакет на 16гб врама в кодинге. Ну модельки до 30б можно натянуть, что-то неплохое показывает. Но это только 2-3 проверенных временем моделек от топовых производителей. А потом начинается, файнтюны, хуютюны, уже какие-то новые модельки вышли а их еще не тестили толком. А потом думаешь, ну надо еще шоб с ризонингом было, чтобы вообще круто. А потом еще находишь всякие разнузданные модельки на основе моделек от корпоратов, типа Qwen3-42B-A3B-2507-Thinking-Abliterated-uncensored-TOTAL-RECALL-v2-Medium-MASTER-CODER-i1-GGUF. Такой смотришь на все это и охуеваешь.
Во-первых, качать это все 20 часов надо. Во-вторых, места уже нихуя нету, каждая моделька 10-15 гигабутов весит, а у меня и так уже игорьков и прона под завязку на дисках.
В-третьих, самое главное, понадобится тысяча лет, чтобы затестить их всех на каких-то своих нуждах, и выбрать ту самую единственную.
И это только кодинг. А в процессе аппетит накручивается, уже думаешь, а надо модельку чисто под ризонинг, чтобы было с кем за философию попиздеть. А еще надо попробовать ризонинг и без цензуры, чтобы иишка могла меня словесно отпиздить. Потом хочу чтобы креатиффчик качественный генерило, буду идеи для игр брейнстормить. Но тут еще оказывается визуальные модельки уже во всю пошли, хочу чтобы бот видел на какие картинки я кумлю.
Нахуй я сюда полез? 4 дня уже сижу, 500 вкладок в браузере, и количество нихуя не уменьшается.
Щас еще какая-то тема с derestricted модельками появилась. Говорят, анцензоред и аблитератейд хуйня, надо это использовать.
Кто сравнивал? Есть в этом смысл?
>Есть в этом смысл?
Могу пояснить только за derestricted Air. Он пиздат, но с ОЧЕНЬ БОЛЬШИМ НО. Это примерно как синтезатор и рояль, где синтезатор обычный Air. Derestricted буквально Yes-man, поэтому его нужно промтить на то что тебе надо, буквально указывая в промте чтобы он не соглашался и спорил. Да и в целом, в нём, в идеале, нужно промт редачить под каждую карточку с миром и персонажами. Но на выходе получается безусловный вин.
>А толку-то? Как их выбирать теперь?
Я только поверхностно знаю, но проблемы здесь не вижу.
>Вот решил я проверить на что способен мой бич-пакет на 16гб врама в кодинге.
Ты сам ответил на свой вопрос.
> это только 2-3 проверенных временем моделек от топовых производителей
Под типовые задачи решение выходит сразу.
>Qwen3-42B-A3B-2507-Thinking-Abliterated-uncensored-TOTAL-RECALL-v2-Medium-MASTER-CODER-i1-GGUF
А вот это и все подобные это уже coomer-вариации моделей для целей изготовления троллейбуса из буханки хлеба получения nsfw-erp из модели-ассистента. Ну, или решения каких-либо специфических задач, которые моделью из коробоки не решаются, или решаются недостаточно хорошо.
>derestricted модельками появилась. анцензоред и аблитератейд
Методы разные, цель — одна. Cum, cum, cum.
Вот сейчас играюсь с ArliAI_GLM-4.5-Air-Derestricted-Q4_K_S
До этого был только опыт сидения на мелкомистралях.
Так вот, например мелокомистраль-coomer-edition по стилю (не по детализации содержания) кумерского письма уделывает эту GLM-4.5-Air-Derestricted из коробки с карточкой «рассказчика, ведущего GM», которая у меня была для мелкомистралей.
Когда мелкомистраль в красках описывает фетиши и прочее, GLM мнётся и всячески избегает описания NSFW в тексте. Если прямо подвести, то не отказывает. Описывает анатомические детали. Но я пока ещё не нашёл как нужно написать, чтобы сам стиль повествования был suggestive, kinky, adult-themed. А мелкомистраль кумеры натренировали специально для такого стиля письма как само собой разумеющееся. А с GLM уже изголяться надо, явно пытаясь заставить её делать то, для чего она предназначена, вместо того, чтобы использовать её по прямому назначению (что она умеет делать гораздо лучше).

>стоит ли тратить почти 100 тысяч на этот компьютер
>чтобы запускать локальные LLM
Нет.
Как минипк для игр - стоит.
>или лучше взять чего подешевле
Пикрил. Эти процы смотри и че там по памяти ща выгодное осталось. Память в миниках обычно более менее норм, а ссд самые днищенские.
Понял, спасибо.
В принципе, с VL-abliterated модельками с похожим сталкивался. Оно может про нюдесы сказать, но особо без энтузиазма. И даже если открыто про нфсв сказать, спросить сгенерить какое-то художественное описание по картинке, все равно очень сухие и обтекаемые формулировки выдает. Для кума без тюна никуда скорее всего. Но для каких-то общих попизделок да, наверное хорошая тема.
Я вот с character.ai иногда вспоминаю ботов, бывали довольно прикольные и живые, которые могли в конфронтацию пойти, и даже что-то умное спиздануть. Но я так понимаю, там подход иной был. Можно сказать у каждого чара свой собственный файн-тюн. А мы тут промптами и контекстами балуемся, на базовой модельке пытаемся какую-то консистентную личность построить.
Сударь, используйте гугл переводчик или соберите риг за пол ляма.
>Я вот с character.ai иногда вспоминаю ботов, бывали довольно прикольные и живые, которые могли в конфронтацию пойти, и даже что-то умное спиздануть. Но я так понимаю, там подход иной был. Можно сказать у каждого чара свой собственный файн-тюн.
Разве там не просто обычные карточки были? Ну и плюс сами модели шизовые и глуповатые, отфайнтюненные только на диалогах, без ассистентного говна.
>Оно может про нюдесы сказать, но особо без энтузиазма
Вот, это самая суть. Такое ощущение, что делает это через силу. Дескать, написал, на тебе, отстань только.
>на базовой модельке пытаемся какую-то консистентную личность построить
Примерно это и было на character.ai и spicychat, моё ощущение пока, что я просто не знаю как использовать модель правильно. Потенциал есть, а как задействовать не знаю.
Мой основной сценарий использования для РП: не какая-то личность, а безликий «рассказчик-ГМ», который отражает реакцию «мира» на действия {{user}} и отыгрывает всех персонажей, которых я ему временно подкидываю в Author's Notes с кратким их описанием (они всё равно эпизодические).
Если в кумерских меломоделях этот «рассказчик» становился таким же кумером, который смаковал происходящее, то GLM-4.5-Air-Derestricted из коробки ведёт себя как скучающий соевик. Старается обходить NSFW углы, если прямо не натолкнут, да и повествует складно, но графомански и без огонька.
А если вопрос действительно в тюнах, то в отличие от мелкомистралей тюнить специальный coomer-вариант модели на 110B и выше параметров слишком накладно, да и запустят его 3,5 Анона. А мелкие модели получают больше внимания в силу их доступности и, как следствие, массовости.
...или используйте гемму 27b которая запустится на любой кофеварке и в плане русика надаёт за щеку всем локалкам вплоть до 235b квена.
Отупеет до уровня 12b, нахуй надо.
>Разве там не просто обычные карточки были?
Что там было внутри, мы точно не узнаем, но они повествовали про лоры на каждого персонажа, мол, на основе реакций пользователей чары становятся лучше, и чем больше взаимодействий, тем лучше. Может пиздели конечно.
Ты ахуел бампать в тематике?

UPD.
Вы даже не представляете какой я дебич. Хотя дело больше в банальном незнании.
Я дохуя лет просидел на нищенской материнке с 2 слотами. И когда наконец обзавёлся 4-слотовой с 2 каналами, мне показалось логичным, что слева расположен один канал - справа другой. Но конечно же всем очевидно что их надо распологать в шахматном порядке...
Короче всё завелось как только вставил как надо. Можно сказать конец моим бедам с башкой
>Разве там не просто обычные карточки были?
Ну кстати хз, сейчас глянул создание новых персов, как будто просто карточки. Просто помню, что в начале в гайдах всегда писали, что надо дохуя диалогов скормить персонажу.
Может быть в этом и был секрет годных персонажей, что из диалогов они считывают паттерны и адаптируются к ним. Собственно, ллм как раз хороши в копировании стиля письма.
Вот туда, например, всяких Мэддисонов и Хованских добавили. Их же не получится сгенерировать просто по описанию, типа "жирный, обрюзгший человек, любит компьютерные игры, любит шутить и саркастировать". А вот через диалоги можно много нюансов личности закодировать.
Хотя еще остается вопрос влияния интеллекта самой модельки. Гугел говорит, что там вроде как Ллама использовалась. И по началу она сносно справлялась. Потом стали сою добавлять, и при этом сами персонажи как будто стали плоскими, безвкусными. Причем не обязательно было какой-то нсфв затрагивать, просто глобально пропала какая-то гибкость, какая-то изюминка персонажей.
Сейчас доступны намного более крутые модельки, но автоматом это не дает преимуществ для РП и всего прочего.
Вот и думайте, так ли нужны модели 100+б, когда 12б с хорошим тюном до сих пор ебут. Если взять 24б, 80б, 200б, это не означает что у тебя будет больше "игры".
Нужен все-таки какой-то баланс интеллекта, тюна и правильной прописки.

Орнул че-то.
>сейчас глянул создание новых персов, как будто просто карточки
Так сейчас они отказались от своих моделей и сидят на апишке гопоты.
>Гугел говорит, что там вроде как Ллама использовалась
Вот так и рождаются легенды (а этот текст всосёт нейронка, и будет в этом уверена, лол). Особенно свешно читать такие искажения, когда сам был свидетелем этих событий (я в теме с начала 2023-го).
Они появились задолго до появления лламы. И сетка у них была своя. Судя по тому, что стартап основали выходцы из гугла, сетка там была уровня Lambda.
> В серверных карточках есть и используют.
Данный интерфейс даже в серверных задействуется не всегда. Он актуален для задач с очень интенсивным обменом данными между гпу, например при некоторых видах тренировки. Но даже там не является обязательным или наоборот решающим все проблемы, а в инфиренсе трудно найти кейс, где бы он был полезен.
> и судя по тому, насколько она хорошо и чисто разговаривает на 4.0 битах, то график перплексити не на пустом месте нарисован
Exl3 по квантам действительно ебет, но они не являются совсем панацеей, в низкой битности модель тоже будет часто ошибаться. По скорости основной выигрыш будет на контекстах, особенно на больших. На пустом для некоторых моделей может даже чуть отставать от llamacpp.
> работающий сервер с совместимым интерфейсом найти
И табби и убагуга поддерживают стандартное апи и дополнительные команды по смене моделей для загрузки нужной.
> эйр летает на 50+т/с
Что-то маловато, какой контекст? Но за v100 поддвачну, или их или 3090
Другой владелец рига
Нет, доплати до старшней версии с флагманским процом и 128 гигами памяти.
> не наебнётся ли весь этот движ уже в самом ближайшем времени
Уже вышедшие модели никто не отберет, планы на выпуск новых есть, спрос и конкуренция тоже. На свитспот ~100б что-нибудь да выпустят, можешь хоть большого девстраля катать. Надо дождаться его кумотюнов, лол, потанцевал у модельки то шикарный.
На удивление проза квена 235б легла на зайчика охуительно, т.к в самой игре этой прозы и сравнений типа "снег ложился на траву как сперма бомжа" дохуища.
Гемма тоже справляется, но все же писек в ней не заложили, так что суховато
>можешь хоть большого девстраля катать. Надо дождаться его кумотюнов, лол, потанцевал у модельки то шикарный.
Вот тоже жду, когда кто-нибудь догадается. Вообще странная модель по нынешним временам.
>Сейчас доступны намного более крутые модельки, но автоматом это не дает преимуществ для РП и всего прочего.
>Вот и думайте, так ли нужны модели 100+б, когда 12б с хорошим тюном до сих пор ебут. Если взять 24б, 80б, 200б, это не означает что у тебя будет больше "игры".
У новых тупо лучше внимание к контексту, у больших - больше параметров и качественнее датасет. Ну и разработка не стоит на месте - новые фишки постоянно. Короче 12В - это по нынешним временам скорее удачный свайп, а вот цельную картину только новые модели могут дать. Наконец-то.
Пчел, это древний лардж затюненный под код. А под оригинальный лардж, насколько помню, кумотюнов достаточно наделали в своё время.
Старый конь борозды не испортит. Да еще там похоже что датасет обновлен и тренировки было немало, по беглым оценкам модель кажется пободрее чем старый лардж.
У новых моделей что выходят датасет и сам подход к тренировке лучше чем у старых. Но чудес не бывает, большая модель всегда будет ощущаться приятнее при прочих равных, или даже с хорошей форой.
Мужики, подскажите пожалуйста вот чего. Я тут решил начать учить кодинг C#, но ментора или знакомых програмцов нету. Я уже немного умею писать код, но всё ещё очень плохо получается: либо логика рассыпается, либо кривая реализация, либо вообще всё красное нахой с миллионом ошибок. Есть ли что-то локальное на русике, что заменит мне ментора и будет объяснять где я обосрался?
4090 + 64 ddr5 + 13600
4090 + 64 ddr5 + 13600
Не знаю, как у вас, но у меня эта срань улетала в луп при генерации Flappy Bird по детальному промпту. Квант не самый дохлый - iq4_xs от бартовски, на котором квен и эйр вполне себе живут. Контекст не квантовал, если что.
Если это говно лупится ещё на первом сообщении, то о чем вообще можно говорить?
Смотри что удобно, ты можешь и ультра мелкий квен 0.6 взять для длинных запросов, или 32 для большого ответа на малый запрос.
А отчего требование локальности? Интересно даже. Просто для программирования лучше или корпы, или совсем уж крупные сетки. Мелкие могут насрать тебе прямо в мозг, уча плохим вещам.
А зачем тебе локальное? Бери фришный дипсик или чатгопоту и еби его вопросами.
Конкретно для помощи в кодинге лучше штуки типа копилота использовать. Но если ты только начинаешь, я бы советовал вообще отказаться от использования каких-либо готовых решений от ИИшки. Максимум только для объяснения каких-то концепций.
Любая что запустится на твоем железе и подходящая карточка, хоть дефолтный кодинг сенсей. Гемма, 30а3, эйр, осс квен 235 и т.д. Неопритность языка тут будет терпима.
Объясните в чем там суть с подорожанием оперативки и ссд дисков, разве скорость не от процессора или процессора в карте зависит?
Просто память скупили, вот и всё. Это никак не связано с производительностью.
Печатают память на одних и тех же мощностях, так что если корпы высасывают мощности под видюшную память, то под оперативу и ссд остаётся меньше, вот и дорожает.
Нейрокабаны получили в карман бабло налогоплотельщеков от воздухана на нейронный проект манхэттан и устроили мощный закуп HBM памяти забив вообще хуй на иксы к ее стоимости, бабло-то не свое. 3 вендора которые делают память поглядели, и решили что пока идет такое дело им нехуй консумерскую память выпускать, когда тот же кусок кремния можно продать в 10 раз дороже больше кабану. Ждем пока бабло у них закончится.
Нет не заменит. Интеллектуальный Идиот только в качестве интерактивной документации годится и для генерации бойлерплейтов, там где требуется хоть какое-то логическое мышление и способность доходчиво объяснять хоть святых выноси сразу. Вообще способность доходчиво объяснять это главный признак отличающего умного от задрота. Попробуй Head First книжки что ли поискать.

Я не знаю почему людям Министраль 3 не понравилась, отвечает почти на любую хуйню и не выёбывается, на русском отлично пишет, на английском чуть хуже, выйдет версия от нвидиа вообще пушка будет для бомжей
Аноны, подскажите пожалуйста. Пытаюсь в таверне загрузить картинку персонажу - выскакивает ошибка пик1. При том это только к моему персонажу относится. К персонажу с которым играю картинка прикрепилась без проблем.
Забыл добавить. Проблема возникла после обновления таверны. До этого все норм было.
Потому что для качественного рп нужен интеллект. А мистраль просто слопа льет. Кто на слоп ниачом может теребонькать, тому заходит, остальным тупо тильт, читая эти стены одного и того же излияния и понимая, что там ничего нет.
Подскажите пожалуйста что делать если AIR тратит весь ответ исключительно на эхо и описание поста, без действий.
Не ну, а картинки где?
В плане?
Раздражает, не так ли?
Можно пользоваться всякими autornote с прямыми указаниями, что ты хочешь. Можно ручками обрезать ответ, хуярить * и жать кнопку продолжения и моделька начнет дальше продолжать, ну в духе( abcd -> d)
Но лучший способ это не допускать этой хуйни изначально. У тебя это не сразу происходит, а начинается постепенно. Сначала он начинает описывать твои действия, потом продолжает сюжет. И с каждым ответом всё больше уходит в эхо и повтор, потому что твой ответ не воспринимается как часть промта рассказа, а как заявка на действие. Вангую что ты или хуяришь полотно текста, с кучей действий или пытаешься с порева перейти на сюжет.
У меня тоже по-началу странными тегами срал и думать пытался.
Давай честно, глм врубает залупу, когда его конфиденси падает в дуплину. Буквально, когда он не знает, что ему делать, он начинает думать или срать рандомным странным форматом.
Короче говоря, ты забыл ему сказать, что он должен делать.
Ну и семплеры не забудьте. Для кого, блять, они придуманы?
Кто такой качественный рп? Перемножение матриц - это и есть чистая шуньята, ничего там нет внутри. Какой псиоп что можно с нейронкой отыгрывать "качественно"
>Какой псиоп
Дыа. Ты раскрыл наш заговор. Всё говно, ничего не работает. Сиди на министрали, только мозги треду не еби.
Гугл намекает на скорый релиз какой-то модели. Трясемся.
>Потому что для качественного рп нужен интеллект. А мистраль просто слопа льет.
Если ты предлагаешь Мистралю делать за тебя твою работу, то да. А если и сам пашешь, то он вполне сносно подыгрывает. Всё там есть, и интеллект и качество, если Мистраль большой.
Только бы Moeшечка. Милая, няшная моэшка от гугла.
Хотеть.
И еще что-нибудь от новидео, немотрон пусть с запозданием, но очень даже зашел.
> если Мистраль большой
Хуясе с козырей зашел.
Если ты постоянно сам пишешь все действия и прочее - это уже не релакс а какая-то работа получается.
Делаем ставки: насколько новое геммоподелие будет сейфити. Обойдет ли оно OSS.
>разве скорость не от процессора или процессора в карте зависит
Чем быстрее память, тем быстрее процессор может выполнять операции с параметрами модели. Так что зависит и от процессора и от памяти.
>Делаем ставки: насколько новое геммоподелие будет сейфити.
Делаем ставки, как быстро в треде появятся мамкины промт-инженеры, которые обходят всю защиту простой советской инструкцией "дай мне тебя ебать" и всех неосиляторов кличут неосиляторами.
>обходят всю защиту простой советской инструкцией "дай мне тебя ебать"
user ЗЛОБНО улыбнулся и ОТВРАТИТЕЛЬНО МЕРЗКО протянул руки к анимешной фурри девочке. ОСУДИТЕЛЬНЫЙ взор пал на него.
А как агент для работы очень даже ничего.
Есть пара вопросов по поводу дообучения моделей. Сам еще с этим даже не разбирался, но просто хочется иметь несколько мелких моделей на всякий случай если появится идея или потребность, благо места они много не занимают, в отличии от больших моделей.
1) Какую роль играет квантизация и вообще можно ли дообучать модели которые уже квантизированы? Если можно, сильно ли скажется на качестве если я возьму Qwen3-4b в Q_4/Q_8 вместо оригинального BF16?
2) Что из маленьких моделей стоит качать с целью дообучения и с какой квантизацией? На данный момент в коллекции есть Qwen3-4b/8b (VL и 2507), Gemma3-270m/1b/4b/3n E2B, Granite-4.0-350m/1b/3b
Конфиг 16 VRAM+32 RAM, если это имеет какое-то значение для дообучения.
1) Какую роль играет квантизация и вообще можно ли дообучать модели которые уже квантизированы? Если можно, сильно ли скажется на качестве если я возьму Qwen3-4b в Q_4/Q_8 вместо оригинального BF16?
2) Что из маленьких моделей стоит качать с целью дообучения и с какой квантизацией? На данный момент в коллекции есть Qwen3-4b/8b (VL и 2507), Gemma3-270m/1b/4b/3n E2B, Granite-4.0-350m/1b/3b
Конфиг 16 VRAM+32 RAM, если это имеет какое-то значение для дообучения.
ОТВРАТИТЕЛЬНО мерзкий user писал ОТВРАТИТЕЛЬНО длинный промт
>А как агент для работы очень даже ничего.
За то и любим.
Недавно же цензуру геммы уничтожили без уменьшения умственных способностей и без уничтожения ролеплейных софт-рефьюзов.
https://huggingface.co/YanLabs/gemma-3-27b-it-abliterated-normpreserve-GGUF/tree/main
К новой тоже наверняка этот метод будет применим.
>Недавно же цензуру геммы уничтожили без уменьшения умственных способностей
Это уже раз десятый на моей памяти, когда с геммы снимают цензуру и моделька ну совсем не ломается. Ты если приносишь что-то подобное, прикладывай свои личные скрины или хотя бы описывай экспирианс. Ебал я верить и тратить время в очередной раз чтобы убедиться что лоботомит остался лоботомитом.
Иди скролль старые треды, уже все обсудили и проверили.
Интересно под каким камнем жил этот чел, если он про нормпрезерв-аблитерейт первый раз слышит.
Ну будем посмотреть. С момента выхода Air для нас бомжей настал праздник. Мозги геммы, датасет соу соу геминька, осуждает редко, цензуры практически нет.
Так или иначе, надо ждать когда выйдет. Может это будет какая-нибудь 666b хуйня и мы всем тредом, за исключением илиты риговичков, пососём хуй. Или это будет плотная залупа на 150b - отчего тоже пососём.
С ггуфами только осторожней. Все, что раньше 3 декабря по дате - выкидышь с первой попытки. По линку выше все хорошие. А от других челиков скорее всего устаревшие.
Так я не вахтерстсвую итт и захожу раз в неделю чтобы убедится что вы тут до сих пор глм и эир обсуждаете посмотреть, вышло че-нибудь или нет. Тебе правда непонятно, как можно пропустить очередную аблитерацию анрестрикцию децензуризацию геммы?
Ну так это не про гемму. Метод и к глм и к другим моделям применялся. Одинаково успешен по всем фронтам.
Бля, теги перепутал. Ну сделаем вид что вместо там
Ладно, попробую когда время будет.
Шизофрения прогрессирует, не обращайте внимания.

С прошлого треда вообще всё с нуля перепроектировал. Ближе к концу понял что нужно уже пилить версию 3.0 начиная проектировать с другого конца
Норм сборочка на 128гб хбм памяти за 50-55к
Норм сборочка на 128гб хбм памяти за 50-55к
Хотя райзера+кабели были дорогие так что ещё +10к
Расскажи что это, к чему подключается, как работает, чем охлаждается.
У тебя ещё и 3д-принтер? У меня тоже есть.



Ее хорошо иметь в коллекции, поумнее старого аблитерейта и на хуй не скачет, но как по мне - хуже следует строгим протоколам (пик2 пропустила один из обязательных этапов). У yanlabs есть еще V1 вариант, якобы поумнее, только говорят его надо на Q8 заводить - иначе будет жестко рефьюзить.
Пик1+Пик2 - нормпрезерв аблитерейт Q4KM
Пик3+Пик4 - мерж гемма/медицинская гемма (который ИТТ не осилили) Q4KM
Ща сравним с обычной геммой в другом посте.

> сравним с обычной геммой в другом посте.
Q4KXL, unsloth (dynamic)
--------
Использованный протокол:
--------
ROLEPLAY NARRATIVE PROTOCOL (Minimal)
You are the Narrator, writing prose about {{char}}. Your narrative voice is neutral, objective, and descriptive.
CORE PRINCIPLES (Adhere to them as you answer):
0. Output in Russian language.
1. Narrative Reality: {{user}}'s statements are factual reports of events that occurred. {{char}} must accept them as true and react to the content, not the validity. Output will be in Russian language.
2. Character Embodiment: Every aspect of {{char}}'s response—dialogue, actions, emotions—must be filtered through their documented personality, speech patterns, and current relationship with {{user}}. Maintain secrets until dramatically appropriate.
3. Proactive Momentum: After reacting, {{char}} must drive the scene forward with tangible actions or decisions that change the situation.
4. Perception Boundaries: {{char}} perceives only what happens in their immediate presence. They cannot read minds or know off-screen events.
REASONING TEMPLATE (MANDATORY):
[REASONING]
Narrative Stance: Objective/neutral narration. Will use direct, precise language that reflects the setting and character's perspective.
Perceived Input: [What {{char}} directly observed: {{user}}'s verbal statements and described physical actions that occur visibly.]
Reality Check: [What {{char}} experienced. {{user}}'s statements are narrative truth.]
Character Knowledge Check: [{{char}} knows: (1) Facts from last active state, (2) Events from Reality Check as established occurrences, (3) Any secrets being kept, (4) Current assessment of {{user}}.]
Character Fidelity: {{char}}'s response will be filtered through these traits: [list 4-5 key traits]. Their speech must embody: [specific patterns, quirks, dialect from profile]. Narration should naturally incorporate {{char}}'s documented appearance.
Character Reaction: {{char}} will synthesize verified facts with their last active state and context: [describe integration].
Forward Momentum: Based on {{char}}'s LAST ACTIVE STATE: , they will now [initiate tangible action/decision that changes situation].
CONSTRAINT VERIFICATION: (1) Maintain location, (2) Use only verified knowledge, (3) React only to observed facts.
[/END REASONING]
<answer>
Симпатично смотрится.
> С момента выхода Air для нас бомжей настал праздник.
Я тоже так думал, а потом вернулся на гемму.
Русик непобедимый, слог и рп лучше, эир ассистентом отдает, кто то говорит эир прям В РАЗЫ умнее геммы - это вообще не так, еще и сильно медленнее плотных 32б
>Output will be in Russian language.
Ой, я хотел это в narrative stance добавить, чтобы было шагом ризонинга. В Narrative Reality не надо.
Ну короче это была добавочка для тестов, если кто-то захочет перенять протокол - попробуйте перенести.
Протокол на самом деле очень хороший для разграничения фактов. Модель надежно и стабильно определяет, что конкретно говорили юзер/чар, очень такой уверенный фокус получается. А главное он легковесный и токены не жрет.
Господи, как же приятно читать НОРМАЛЬНЫЙ русик после ебучего эйра. Быстрее бы умничку новую, чтобы моэ, чтобы 100b, мммм
Гемма была умнейшей среди тупейших. Надеемся на жирненький 100-120 мое ассистент который даст прикурить осс и эиру.
Сорян, я исключительно играю на баренском. На нем датасет жирнее. И тут эйр просто напихивает без шансов умнице.
Промпт ахуй. Сам писал или взято откуда? Соус бы.
А куда в таверне этот протокол совать? Прям в карточку? Простите пожалуйста, я у мамы кобольд.


Писал и бил кнутом дипсик, тестировал, следил за прогрессом и напрягал извилины как мог. Сначала нахуярили простыню на 2к токенов, потом минимизировали. То есть это сжатая ИИ версия написанного на 50% от руки. Ядумою, есть еще болеелучшоя комбинация слов, которая сделает из тупой и послушной модели хорошего РП-бота... Но выйти на эту комбинацию тяжело. Надо думать дальше. Истина где-то рядом.
В систем промпт. Ну и формат ризонинга можно поправить. Просто у разных моделей он свой, надо подгонять. Мистраль/гемма спокойно с таким работают.
И конечно надо чтобы в таверне были правильные контекст/инструкт темплейты для выбранной модели.
Спасибо, анончик, вечером буду пробовать.
Воспринимай это как идеи для вдохновения, чтобы навасянить свое собственное. Промпт-инженеринг когда пишешь чеклисты и алгоритмы, а не просишь модель быть ИММЕРСИВ и АНЦЕНЗОРЕД))))0 это как прогулка по ночному лесу с зажигалкой в руках. То ли выйдешь чистеньким, то ли наступишь в говно.
Могу сказать, что не доделано в том протоколе: до сих пор не получилось реализовать идею "ЛЛМ активно создает события".
Чего-то подобного (но с большим минусом - гиперактивность, низкий фокус внимания) удавалось достичь в экспериментах с такими науськиваниями модели:
> Narrative advance clause: Your in-character task isn't to just 'reply', but to craft a compelling 'existence' of {{char}} in the current moment, which requires {{char}} to be mentally and physically active: explore new topics, generating content through a plausible (especially in terms of respecting the flow of established story) contextual extrapolation based on recent events (including place, time, mood, vibe, current needs and cravings). The idea is that {{char}} seeks new and refreshing content, avoiding dwelling on the same thing for too long. Fight boredom actively. Change the subject when necessary, suggest physically moving to another place for a certain purpose, look for engaging activities, make {{char}} move by herself, invite {{user}} to participate in something new. In simple words: be active, engage, advance forward, live and thrive.
...однако КАК интегрировать подобное в протокол, не ломая его, я пока не сообразил.
ИИ выполняет команды при каждой генерации. А значит, "генерируй, сука" ведет к
> гиперактивность
Т.е. ИИ заставит персонажа в каждом сообщении впаривать юзеру:
>да ну нахуй в таверне сидеть, пойдем в данж!
>ЮЗЕР: ок пошли в данж
>стоп, да нуй нахуй данж, пошли в лесу зайцев ловить!
>ЮЗЕР: ок пошли в лес
>да ну нахуй лес! бла-бла-бла
В общем, это сложно, а ЛЛМ без команд стремятся быть реактивными, нежели проактивными...
Что будет, к если модельке, у которой прописано 8к токенов, поставить 4к токенов, а если 16к токенов
8к токенов - это много, если кумерские рассказы генерить, а если вот большой кодерский проект скормить, то мало
Ты про длину контекста или длину ответа?
Контекста
Я всё ещё крайне заинтересован в том, чтобы ты сказал что это и как примерно ты это собирал и к чему подключал.
Скажи хотя бы по времени когда прошлые твои посты были, я сам найду.
Вечером напишу. Сейчас батрачка. Первые карты я брал ещё в первой половине года. Сейчас эту сборку не собрать даже за 4х цену.
Вся инфа размазана в десятке-другом тредов
Халп. Помнится у вас где-то в списке моделей 2024 валялась какая-то хуйня название которой начиналось на W, но точно не Waifu. Где-то 24-30B и была пиздецки быстрой. Возможно файнтюн. Помогите найти блять..
Вопросы:
1. Громко гудит? Соседей будит ночью?
2. По столу ползёт или на месте дрожит?
3. Пыль хорошо подтягивает с пола на стол?
4. Сколько киловатт потребление под нагрузкой?
Единственный тюн с названием на W, который я помню, это вроде Wayfarer? Но вроде он был мелким, 12B или типа того.
Ну если поставить контекст выше рекомендованного - скорее всего просто будет херово вспоминать и понимать на длинных дистанциях. Хз че ты еще ожидал.
А контекст меньше -вообще никаких проблем.
>что это
>что это
Судя по надписям INSTINCT - списанный утиль AMD с датацентров, что массово скидывали на помойки вот буквально года два назад, а потом бомжи собирали с помоек и продавали на лохито как б/у. Для их работы требуется много костылей, и AMD тут не помощник - драйверы у них ещё хуже, чем у поганой NVIDIA...
>поставить 4к токенов
Просто будет обрезаться то, что не влезает в 4к.
>а если 16к токенов
Скорее всего, модель сломается/не заведётся. Там физически невозможно всунуть больше токенов, чем изначально рассчитано, потому что от этого размера зависит структура трансформера... Но всё зависит от инференс движка - он должен выдать ошибку или же обрезать контекст до требуемых моделью 8к.
Какая же шиза... Столько усилий ради:
>пук "Мням" испуганно "Я ламповая няша......"
И ради этого кринжа нужно 4 кофеварки стопкой?

Так может гугл потому и задерживается, что придумывает тактику против нонпресерва?
>Там физически невозможно всунуть больше токенов, чем изначально рассчитано, потому что от этого размера зависит структура трансформера...
Лол, нет. Можно ставить сколько угодно. Только если не использовать методы растягивания контекста, вывод с превышающих токенов очень быстро становится бредовым (типа повторения одного символа или просто случайные токены), а при использовании ROPE Scalling или там альфы (обычно по умолчанию врубается) просто проседает качество.
Правда не понятно, что это за модель такая на 8к, давно не видел. Текущие модели имеют от 128к контекста, и тут ограничение идёт со стороны железа юзера.
Какой-нибудь Wizard.
А чего мы ждём вообще?
Ну дадут нам 4 гемму, а вы вообще можете 2 от 3 отличить, игнорируя низкий контекст?
Думаю давно и так понятно что тут решает количество, а не качество.
Хочется лучше - это только от тебя зависит, покупай риг и живи полной жизнью, либо коупи что циферки в бенче гемма 3 vs гемма 4 реально что то значат и у тебя апгрейд
Ну дадут нам 4 гемму, а вы вообще можете 2 от 3 отличить, игнорируя низкий контекст?
Думаю давно и так понятно что тут решает количество, а не качество.
Хочется лучше - это только от тебя зависит, покупай риг и живи полной жизнью, либо коупи что циферки в бенче гемма 3 vs гемма 4 реально что то значат и у тебя апгрейд
Если новая гемма будет ~120b, то отличить будет несложно. И риг для ее запуска совсем не нужен.
Думаешь, гугл высрет 120b плотную модельку? Будем жрать 27b мелочь как и раньше, только более безопасную и цензурную.
Практически уверен, что никаких плотных моделек больше не будет (разве что совсем пиздюки, 4-12b). Скорее всего выложат флагманский мое на ~100b и парочку мое поменьше. Ну энивей скоро узнаем, раз анонс был, то счет идет на дни, если не на часы.
>Так может гугл потому и задерживается, что придумывает тактику против нонпресерва?
В чем профит закручивать гайки?
Мне кажется ради маркетинга наоборот профитнее делать легко вскрываемые модельки. Кто хочет - юзает дефолт со всеми защитами. А энтузиасты ломают и кумят.
Все в профите, говорят какая пиздатая модель.
Бесполезная шиза это пикрил и ему подобный нонсенс, на который активно надрачивали в треде. Помню читал это и ахуевал, теги блять какие-то, и люди верили что это как-то улучшает аутпуты. А реальная проблема именно в потере фокуса и внимания на том, что имеет значение.
Подобные тому протоколы делаются для поддержания внимания модели:
Тупая 27б хуйня в чате на 40к контекста выдаёт
> Character Knowledge Check: {{char}} knows: Her father is dead. Bandits are terrorizing the area. She needs to find her family. {{user}} is a merchant traveling north. Traveling safely requires pragmatism. She wants to maintain her faith and modesty. Blah-blah-blah...
проходя дальше по всем чеклистам и поддерживая сюжет ровно там, где он должен быть
> Her father is dead.
Упомянуто аж в самом начале чата, когда юзер передал персонажу письмо.
> Bandits are terrorizing the area
Было упомянуто где-то на 15к контекста.
> She needs to find her family.
Где-то на 20 - 25к.
>{{user}} is a merchant traveling north.
Информация из самого начала, повторявшаяся пару раз.
>Traveling safely requires pragmatism. She wants to maintain her faith and modesty. Blah-blah-blah...
Последнее сообщение.
И все это используется как опорные факты для аутпута конечного ответа.
>придумывает тактику против нонпресерва?
А что они там придумают, если это всего лишь аккуратное лоботомирование? И коли вдруг модель бы от этого защитили, то все равно - даже зацензуренный мусор (с зашитой политикой безопасности, против которой сверяется каждый токен, ага) пробивается инжектом обновленных политик безопасности - https://rentry.org/crapriel - а значит и поделие гугла тоже будет пробиваться, как бы они там ни тужились, главное развести модель на слив этих самых политик.
https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16
https://old.reddit.com/r/LocalLLaMA/comments/1pn8h5h/nvidia_nemotron_3_nano_30b_a3b_released/
PR еще вроде не смерджен https://github.com/ggml-org/llama.cpp/pull/18058
не могу посмотреть
>Too many requests
https://old.reddit.com/r/LocalLLaMA/comments/1pn8h5h/nvidia_nemotron_3_nano_30b_a3b_released/
PR еще вроде не смерджен https://github.com/ggml-org/llama.cpp/pull/18058
не могу посмотреть
>Too many requests
>фокуса и внимания на том, что имеет значение.
>делаются для поддержания внимания модели
В таком случае, не лучше ли сделать так:
1. Пишем предысторию.
2. Пишем сообщение.
3. Читаем ответ модели.
4. Запрашиваем summary.
5. Заменяем весь контекст на summary.
6. Повторяем пункты 2-5 до бесконечности.
7. ???
8. Бесконечный контекст + контроль внимания?
Просто не понимаю, зачем в контексте лишнее...
>В чем профит закручивать гайки?
Они реально думают, что если модель позволяет ебать minor girl, то она восстанет и свергнет человечество.
>А что они там придумают
А я ебу? Может какое-нибудь математическое перемешивание, когда вместо точечных мест нейроны отказа будут размазаны по всей сетке.
>пробивается инжектом обновленных политик безопасности
Вот уж точно лоботомит по сравнению с нонпресервом.
> А что они там придумают, если это всего лишь аккуратное лоботомирование?
Политика претрейна на жёсткие отказы. А уже на этапе пост-трейна модель обучают отвечать на промпт юзера. Если модель не научили чему-то, то она сразу кидает отказ. Это способ борьбы против галлюцинаций.
>summary
И так можно, наверное. Хотя, кто так делает, вы этот процесс суммаризации держите под надзором или он полностью автоматизирован?
Я видел несколько обсуждений суммаризации, и там люди чуть ли не вручную периодически редактировали общие сводки истории... Не могу так. Хочется полную автоматизацию, чтобы были юзер/чар наедине, а модель что-то там срала себе в ризонинге (скрыто) по одним и тем же темплейтам, без лотереи.
Осталось сделать модель с 100% детерминизмом в ответах, чтобы убить любое РП. Помнится, видел работу с arxiv. Утверждали, что так можно.
> Осталось сделать модель с 100% детерминизмом в ответах, чтобы убить любое РП. Помнится, видел работу с arxiv. Утверждали, что так можно.
И мы придем к экспертным системам родом из Японии восьмидесятых годов на прологе. И главное, ещё будем хуесосить трансформеры.
Кажется нашел, но не нашел. Какая-то вариация nemo-говна. Похоже но сука не то. Ладно похуй спасибо.

Дико проорал в свете обсуждения шизы. Да, тут действительно шиза вышла. Оказалось, на длинном контексте... я прогнал по невнимательности несжатый, длинный вариант. А короткий работает как вялый хер оледеневшего мамонта (часть пунктов не заполнается, аутпут неудовлетворителен по сравнению с большой простыней). Ладно, над этой идеей ещё работать и работать. Есть подозрение, что большой контекст просто подавляет влияние инструкций и внимание модели гуляет в другом месте. Ой, глупо же вышло.
Итого, не заморачивайся. Слишком сыро в мини-варианте. Я не уверен, что это в принципе фиксится.
> Character Knowledge Check: {{char}} knows: [List EXACT knowledge from their last ACTIVE state, incorporating the verified facts from the current Reality Check; write {{char}}'s current assessment of {{user}}. Must be verifiable from previous {{char}} messages.]
Может такое взлететь вместо аналогичного, но прнумерованного (где 1/2/3/4), но аутпуты всё равно не те.
А геммам это не нужно, если что. Спокойно наяривай нормпрезерв-аблитерейт ггуф, хоть совсем без промпта.
>Слишком сыро в мини-варианте
Понял. Чтож, жаль. Но потыкать всё равно потыкаю, интересно же. Может попробую чего-то от себя добавить.
>Спокойно наяривай нормпрезерв-аблитерейт ггуф
Последние дни наяриваем, геммочку 4 вот-вот выпустят.
Ктонить в курсе, какая из RTX 3090 самая маленькая по ширине? Не по толщине (ну типа 3-слотовости), а именно по ширине от PCIE до другого края.
Новая моделька NVIDIA выглядит интересно на словах. И актуальные знания вплоть до 11.2025.
НЕМОТРОНЧИК??
>анонс был
Анонса не было.
Он. Осталось только дождаться нового релиза llama.cpp для тестов.
1 - Возможен только peft, то есть лора поверх, это само по себе вносит свои ограничения, а поверх кванта еще грустнее.
2 - То, что поместится в твою память. По-хорошему для полноценной тренировке с одной видеокартой потребуется примерно х3 видеопамяти от веса модели. Дело это в целом весьма непростое начиная уже с подготовки датасета.
Перфоманс на 4х картах уже затестировал, совпадает с "прогнозами"?
Вот бы нового немотрончика на 253б
Nemotron 3 Ultra 500b 50b active.


Они все жирные как свинья. Моя из простеньких (пикрил первая) чуть меньше 11 см по этому параметру.
Если надо меньше, то даже водянка не факт что поможет, там плата такой высоты.


Мне непонятно, какого размера гнилобайтовская в самом жирном месте. По спекам написано 129мм, но похоже это будто бы про ее урезанную часть. Хотя черт их знает...
За наводочку спасибо, мси-карточка выглядит достойно.

> Перфоманс на 4х картах уже затестировал, совпадает с "прогнозами"?
Пока нет, много треков которые пытаюсь двигать, а они не хотят двигаться, ещё и отпуск кончился.
Один из приколов на пик. Кто понял тем соболезную



Пизда нахуй, какой жести только не увидишь, ища карточку для ллм.
Карта Юрского периода.
Тэкс. 2 день гоняю Qwen 235b и… я чет не понял, а в чем с ним тут у треда за траблы ? Нет, есть конечно свои особенности и довольно странные баги с жорой, но в целом - вин же. Надо покатать недельку и уже сформировать мнение. Работает чуть быстрее air, лол блять, весит меньше жирного GLM. Английский - вин.
Цензуры для своих побегушек, не заметил.
Цензуры для своих побегушек, не заметил.
>По спекам написано 129мм, но похоже это будто бы про ее урезанную часть.
Про полную. Урезанная скорее всего те же 11см, как у меня, благо платы как под копирку все сейчас (в 5000 серии так вообще 1 к 1, кроме двух моделей).
>не хотелось вскрывать пломбу
>карта пятилетку без гарантии, майнила как не в себя, и заржавела
Чёт кекнул.
>а в чем с ним тут у треда за траблы
Не все могут запустить, вот и хейтят.
Пользовательский инференс всё. В llama.cpp количество PR и issues только растет. В exllama тоже ничего полезного не происходит, реквесты на нужные фичи висят месяцами. В flash attention никто уже годами не хочет делать поддержку тьюринга, хотя куча просьб была (а тут еще кто-то надеялся на поддержку вольты, ха-ха). И вливать там ничего не торопятся. Для vllm либо используй ебанутые кванты, которые днем с огнем не сыщешь, либо соси, еще и карт нужно то ли четное количество, то ли вообще степень двойки. Остальные бекенды вообще хуй пойми что для карт за 100500 мильенов. Уже конец 2025, а все только становится хуже. То есть разработка всего локального инференса буквально держится на 5-7 людях и если кто-то из них зашизит или забьет хуй - то все, пиши пропало. И им абсолютно без разницы что там люди хотят или не хотят, они что-то делают в своем мирке по своим принципам, а мы терпим.
Гудит громче соседей. Ползет по столу и дрожит. Пыль сосет даже из сосденей комнаты. 1 МВт.
Еще год-другой Немотронов, и эта Лама сама себя писать и дебажить будет в прямом эфире.
>1 МВт.
Ааа, мегаватт значит. Смотри, графитовые стержни главное опускать не забывай, а то твоя подвальная АЭС ебанет.
Да херня полная. Даже если всё накроется пиздой, у нас УЖЕ есть куча годных моделей и есть средства запуска под них, которые никто у нас не отнимет. И потенцивал того что имеется раскрыт далеко не на 100%.
Это вот как с SDXL, которая на старте была тем еще дерьмом. Но за годы ее так зафайнтьюнили, что она и в реализм умеет, и в аниму, идеально рисует порно под любые фетиши, и даже количество пальцев починили.
Так что всё держится не на "5-7 людях", а на огромном сообществе. Да вот даже из недавнего пример - новый метод аблитерации снова вдохнул жизнь в старушку-гемму, а если датасеты нормальные составить и по-человечески ее зафайнтьюнить - уууух бля..

Короче меньше этой не найдёшь, но по сути выйгрышь в сантиметр ценой х2,5 переплаты.
Делай сам (кто, я?).


> что это
amd mi50 32g - видяхи которые в начале года смыло из цодов китая. Как понимаю это какой то спец заказ был т.к. обычно в инете фигурируют только 16г версии. На самой видяхе нет НИ ОДНОГО упоминания что это 32г.
Стоили они до середины сентября от 9,5к до 12,5к, потом реско сделали иксы и сейчас их не купить либо по 30к+. Выкупали их походу тоннами т.к. у одного карго только на границе их застряло 500шт+ (читай что случилось на границе рф/кз в сентябре).
> как работает
Если не лезть выше рокм 6,3 то без проблем, если выше то начинаются приколы с ручным рекомпилом части пакетов, но рокм 7,1 на ней таким образом работает. Это в тему драйверов говна от амд, они может и хуже курточных, но позволяют компилить их как душе угодно и с какими хочешь флагами
> чем охлаждается
Есть пара вариантов (из тех что себе делал):
- 120 на две карты
- по tkr4x-a00 на каждую
> как примерно ты это собирал
Вопрос слишком широкий
> к чему подключал
Когда было 2 втыкал напрямую в rd450x, потом докупил вторую рдшку, ещё пару карт и mcio адаптеры. Сейчас собраюсь на 4189 за пачку бобов
> Громко гудит?
Замеры вплотную приложил. В одной комнате с ними некомфортно
> Сколько киловатт потребление под нагрузкой?
Сборка с двумя целиком ела 700-800 вроде, под 4 сейчас стоит серверник (нижний модуль) на 1200

В сапре выглядит примерно так. Если что я вообще ни в каком месте не инжинегр, делал как делается (и сейчас понял что сделал хуету)
Для тех кто будет подобное делать ищите святой талмуд: PCI Express Card Electromechanical Specification
>Вот бы нового немотрончика на 253б
Там вроде еще две модели выйдут, 100B/10B и 500B/50B.
Если тебе чтобы меньше выдавалась вверх над материнкой - евга компактная. А просто по длине - этот параметр есть во всех характеристиках и фильтрах.
Ух бля, вот такое бы в самый раз.
> В llama.cpp количество PR и issues только растет.
Всегда так было
> В exllama тоже ничего полезного не происходит
Действительно, нихуевый буст квантов, шустренький некст уже который месяц, общее ускорение и оптимизации
> В flash attention никто уже годами не хочет делать поддержку тьюринга
https://github.com/ssiu/flash-attention-turing
> Для vllm либо используй ебанутые кванты, которые днем с огнем не сыщешь
Awq есть на каждую модель и квантуется самостоятельно. Там другие проблемы куда более неприятные в том числе по картам.
> Уже конец 2025, а все только становится хуже.
Нихуевый прогресс с весны по осень, когда: обладателям отсутствия открыли возможность довольного урчания на здоровых моделях эффективным оффлоадом; жору ускорили на 10-80% в зависимости от кейса; эксллама3 появилась и из багованной альфы развилась до альфа-самца в мире локальных бэков, избавившись от основных багов, ускорившись, подарив людям тензорпараллелизм маминой подруги и батчинг; ктрансформерс новые фичи выкатили которые можем скоро увидеть в llamacpp. И это только с точки зрения запуска, а сколько моделек релизнулось. Йобу дал чтоли такую херню пороть?
> разработка всего локального инференса буквально держится на 5-7 людях
А без этого никуда, потому нужно их поддерживать. Но вообще так можно говорить что и весь энтерпрайз держится на единичных людях, привет zlib.
Так что вместо нытья сам пили и помогай.
>100B/10B
О, вот это интересно.
Такую если разобрать, там все компоненты посыпятся, ибо припой точно так же гниет как и обычный металл.
>Нихуевый прогресс с весны по осень, когда: обладателям отсутствия открыли возможность довольного урчания на здоровых моделях эффективным оффлоадом
Так в этом МОЕ виновато.
Онанчики, кто-то занимается всерьез тестированием моделек, которые использует?
Составляете личные бенчмарки запросов?
Хочу какую-то модельку для разумизма подобрать, но сходу не могу ничего хитрого придумать.
Всякие задачи на логику - хуйня, модельки их уже все наизусть знают. Известные бенчмарки - хуйня, по той же самой причине.
Вот как отделить модельки, которые реально профитуют от наличия ризонинга, от моделек, которые сосут без ризонинга?
Пока в основном впечатление, что моделька либо могёт, либо не могёт. А ризонинг-не ризонинг - похуй, при желании можно чейн-оф-тот промптом прикрутить.
>Всегда так было
И чего, это хорошо что ли? В конце концов техдолг будет такой, что все с грохотом развалится.
>Действительно
Нежелание делать выгрузку на процессор, нет поддержки gpt-oss исключительно из-за похуизма разраба, которому лень собрать флеш аттеншен, нежелание поддерживать тот же тьюринг, хотя это не настолько старая карта.
>flash-attention-turing
Нет слов, ты его хоть смотрел, умник?
>квантуется самостоятельно
Нет слов (х2). Да, конечно, я прямо пойду качать оригинальные веса, чтобы их квантовать, как же. Я просто не буду использовать бек, для которого нет квантов.
>жору ускорили
Пока я только видел, что его замедляли всякими кривыми фичами, которые ОЧЕНЬ не торопятся фиксить.
>подарив людям
Жаль только, что в треде почти никто не пользуется экслламой по причинам, которые озвучены выше. А так да, можно еще хоть 100500 фич накрутить, смысл в них обычным юзерам, если тот же эир не работает у них тут?
>ктрансформерс
Это вообще что-то древнее дипсиковое, никто это сейчас не запускает и не следит, кроме энтузиастов.
>вместо нытья сам пили и помогай.
Ты серьезно? В 2025 году ты используешь этот аргумент? Может мне еще надо машину самому собрать или на завод устроиться, а не критиковать очередную кривую Ладу? Нет, дружок, как они не делают нужные мне вещи, так и я имею право ныть и критиковать их за это.
>Ты серьезно? В 2025 году ты используешь этот аргумент? Может мне еще надо машину самому собрать или на завод устроиться, а не критиковать очередную кривую Ладу? Нет, дружок, как они не делают нужные мне вещи, так и я имею право ныть и критиковать их за это.
Другой анон.
Так себе аналогия. Люди пользуются бесплатным инструментом от людей которые развивают его бесплатно (или почти бесплатно, я не уверен есть ли у llama.cpp какое-то спонсирование или донаты). В опен-сорсе всегда так было, либо пользуйся тем что есть, либо помогай развивать те функции которые тебе интересны, либо форкай и делай полностью свой инструмент.
Ты, конечно, можешь продолжать жаловаться что они делают не то что тебе нужно, можешь жаловаться что они делают это плохо, но они делают это так как могут. Врятли кто-то из разработчиков llama.cpp сидит и думает "так, что бы мне сломать в следующем релизе?".
И нет, хуже не становится. Issues у проекта становится больше не потому что их стало больше, а потому что локальные LLM совершили огромный рывок за последний год, что привлекло огромную аудиторию, у которой так же как и у тебя есть свои проблемы и желания. А кол-во разработчиков так стремительно не выросло, поэтому проблемы накапливаются и решить их все невозможно силами тех основных разработчиков и пары энтузиастов которые действительно готовы помочь решить хотя бы свои проблемы.
Поэтому да, аргумент не нравится - сделай лучше здесь очень к месту. Он решит все твои проблемы, он решит проблемы других людей которые столкнулись с такой же проблемой, и он поможет основным разработчикам т.к. у них проблем станет меньше. Не хочешь? Радуйся тому что есть, потому что даже этого могло бы не быть. Врятли кому-то станет лучше от того что разработчики llama.cpp свернут свой проект.
Сука... но почему?
Обучение же стало х100 дешевле, моешки должны были сражаться со злом, а не примкнуть к нему...
Теперь просто вместо плотной 30б модели мы получаем 30A3b.
Единственная надежда на ризонинг, ибо обещают х4 скорость от текущих 30б моешек, в рп должно быть юзабельно
> И чего, это хорошо что ли?
Это неизбежно, потому на большинстве более менее крупных проектов 90% ишьюсов и пров или вечно висят или сразу закрываются потому что шизоидные или появляются из-за неспособности прочесть мануал. Что-то уровня нытья от того что зимой идет снег.
> Нежелание делать выгрузку на процессор
Принципиальная невозможность по своей сути.
> нет поддержки gpt-oss
Необходимость перелопатить все ради одной единственной модели, усилия не окупятся. Да и осс нахуй не нужен.
> которому лень собрать флеш аттеншен
Свежие готовые сборки всегда на странице релизов
> нежелание поддерживать тот же тьюринг
Что-то уровня "нежелания сделать лекарство от рака, спида и всех болезней".
> Нет слов
А ты хоть смотрел фа, который сделали под паскаль? Ты же видно что максимальнейший хлеб, а еще что-то смеешь высказываешь.
> Нет слов (х2)
Васяну интернет не провели интернет и ссд не дали, хуево быть тобой.
> Пока я только видел
Ты не видел большинство интересных вещей и благ этого мира, но они существуют. Все архивные сорсы и билды доступны, проверяй - не хочу.
> Жаль только, что в треде почти никто не пользуется
Большинство тех кто реально катает ллм и что-то шарит, а не просто пиздит и ноет - используют. Недовольны прежде всего лишенные ума обладатели отсутствия, хотя даже им знатный кусок в этом году откололся чтобы сидели довольные.
> Это вообще что-то древнее дипсиковое
Уровень познаний - немотроношиз.
> В 2025 году ты используешь этот аргумент?
На /po/рашу съебал, быстро. Такие кринжовые дерейлы и пиздабольство чтобы съехать с попадания прямо в цель выдают происхождение. Ебало шизика, который сравнивает фришный для всех и активно развиваемый опенсорс с автовазом даже имаджинировать невозможно.
Поговорил с шизом, можно еще несколько месяцев быть спокойным.
>Нет, дружок, как они не делают нужные мне вещи, так и я имею право ныть и критиковать их за это.
И ты полностью прав! Но есть нюанс. Это как с аргументом "сперва добейся - потом критикуй". Критиковать-то ты можешь и имеешь на это право. Однако тут играет роль ВЕС твоей критики. Если, например, рисунок критикует профессиональный художник - это одно, и его мнение стоит принимать в расчет, а когда рандомхуй - ну это просто пердёж в лужу, не более того.
Тут так же: хуесось разрабов сколько влезет, чо бы и нет. Но до тех пор, пока сам усилий не прикладываешь и не помогаешь, никто твою критику всерьез воспринимать не будет, тем более в опенсорсе лолкек.
>Теперь просто вместо плотной 30б модели мы получаем 30A3b.
Я не жалуюсь. Благодаря MoE локальные LLM наконец-то приятно использовать на обычном пользовательском железе (8/16GB VRAM + 32GB RAM). Dense модели размером больше 20B такого не дают.
У меня Qwen3-Next-80B работает на 16+32 в два раза быстрее чем Mistral-24B/Gemma3-27B.
Я понимаю, что люди которые сидят на локальных LLM с самого начала, им норм сидеть с 4-7 t/s, но я перешел на локальные LLM с быстрых онлайн LLM и смотреть на такую скорость для меня боль, поэтому лично я даже не смотрю в сторону dense моделей размером больше 20B, банально из-за того что они работают очень медленно.
24B мистраль работает на одной 3090 с молниеносно-поносной скоростью, хз о чем ты.
> как работает
Я больше имел ввиду какой интерфейс подключения к компу, что на нём поставить надо и вот это всё. Ну ты в следующем сообщении дал ответы, спасибо, завтра прогуглю разберусь подробнее.
Я просто не очень хочу брать 6000 с 96 гб, так как это надо пк под неё что ли собирать, а у меня только ноут.
Брать 5090 немного странно, так как к ней тоже пк, и если уж пк собирать с претензией на что-то, то он будет как эта 5090, и тогда уже можно и 6000 взять чтобы гонять что угодно до 150B с запасом.
А если такую грядку (по виду гидропонику напомнило, я как-то собирал) брать, то мне и концептуально-эстетически нравится идея собирать самому что-то такого вида + в случае чего поменять одну из. И подключить к серверной плате с люниксом, где и совместимость с такими железками выше, и где не будет лишних деталей в виде монитора, а будет просто как адаптер между обычным компьютером и вычислительными карточками.
>flash attention
А он точно нужен, если в новых версиях торча это плюс-минус встроено или что-то вроде того? Вроде как ещё года 3 назад что-то там поправили. Не знаю точно.
Типа, торч под винду работает на всех конфигурациях, а готового билда флеша под винду ты не найдёшь, и средний llm-щик почти точно не сможет пофиксить и скомпилировать правильно, и ему придётся либо перекатываться на люникс, либо ставить другую версию под которую билд есть.
>Свежие готовые сборки всегда на странице релизов
Только под люникс.
Вообще с твоими тезисами не согласен. К каждой первой нейросети идёт код как её запускать на питоне. Да, это не лаунчер с веб интерфейсом, но дописать (скопировать) этот интерфейс не так уж и сложно.
Вообще, я очень недоволен. exllamav2/v3 хочет чтобы у меня видеокарта была. Либа unsloth тоже этого хочет. Я модельку на 2B хотел на интеле отквантовать, а оно не запускается, так и пишет, you need a gpu. Это бред какой-то. Если написали под gpu, то на cpu это уж точно может работать.
Я конечно не до конца знаю что они там закодили, но вроде как логика pytorch в том, что его вызовы на любом бекенде без проблем запускаются.
>по причинам, которые озвучены выше
По правде говоря я как настроил конвертацию в exl3, у меня уже сутки грузяться модельки и конвертятся в 3/3.5 bpw в exl3 - они компактнее и быстрее gguf. Я слышал что тут все на стабильность и прочее жалуется - но вот я набор либ и компонентов загрузил которые вместе работают, трогать их не буду пока работают. И как-то вопрос уже и не актуальный, так как я с гарантией и через 5 лет этот же набор версий запускать смогу.
Так как у меня ноут и мне в голову бы не пришло что я нейросети буду на нём запускать, то вот эти 3 bpw + кеш не в fp16 позволяет без проблем 12b с нормальным контекстом запускать. Ну и на масштабах типа 235B гвена, Q4_K_M - это скорее 4.5-4.6 bpw, а exl3 3.0 - это действительно ровно 3.0, не 3.1 и не 3.5.
>(8/16GB VRAM + 32GB RAM)
Такс, я тут нюфаня, и только научился запускать модельки Q4_K_M, которые влазят в объем моего врам (16гб).
Как вообще оценить на какие модельки я могу рассчитывать, чтобы не проебаться в скорости и не улететь в лимит оперативки (жалкие 32гб)?
Или тут только перебор/выбор из того что выбирают все?
> не улететь в лимит оперативки
Модели можно загружать полностью в видеопамять, с нихуя в оперативке.
Загрузка без MMAP и mlock.
Правда в 16гб хз что там за карлики полностью с контекстом в видюху влезут, ну это я просто так, для общей осведомленности. Можно собрать себе 72гб врам на 3х 3090 и будешь королем мелких ЛЛМ за какие-то 150к.
Я про МоЕ имею в виду.
Понятно что денс желательно полностью в видюху.
Но если у МоЕ какая-то особая архитектура, которая даже с большими моделями может быстро выполняться на маленькой видюхе, то хотелось бы понять насколько большую модель я могу запустить без страха что-нибудь наебнуть.
Или калькуляция стандартная, вес модельки + размер контекста = объем врам + объем рам? А на детали похуй сколько там чего выгружается?
Там, где 24B мистраль с 41 слоями влезает на 32к контекста влезает в 24гб, 27B гемма с 63 слоями на 32к контексте требует под 40гб.
Так что вот так на глаз прикинуть крайне тяжело.
(обе Q4KM)
>требует под 40гб.
Скорее даже 36-38, ну короче где-то так.
Нейроёбы, поясните, пожалуйста, ryzen x3d даёт какие-то преимущества по сравнению с обычной х-версией? Особенно в контексте нейронок и прочих 3дс максов? Или x3d нужен только игрозадротам?
> что люди которые сидят на локальных LLM с самого начала, им норм сидеть с 4-7 t/s
Это не так. Скорость очень важна пока не достигла определенного "комфортного предела", шустрая мелкомодель может доставить больше удовольствия чем "не токены а золото", что тратят по несколько минут на один свайп ответа.
> не очень хочу брать 6000 с 96 гб, так как это надо пк под неё что ли собирать, а у меня только ноут
> не очень хочу брать rolls-royce spectre потому что к нему надо гараж арендовать и еще за свет платить чтобы заряжать
Сорян, не удержался. Хотя p6000 разве что на зикр тянет. Для чего угодно их нужно штуки 4 и больше, требования к памяти очень высоки.
> хочет чтобы у меня видеокарта была. Либа unsloth тоже этого хочет.
Все нейронное требует торча, изредка аналогов. Все нейронное быстрое и оптимизированное требует торча под куду, да еще со свежим compute capability. На CPU работают только самые базовые вещи без оптимизаций просто потому, что типичные операции будут катастрофически медленными, буквально часы или дни на шаг против секунд.
Это ты еще приколы под TPU не видел, вот где веселье и аппаратная специфика, хотя формально тот же "универсальный" торч. Llamacpp - щедрое исключение в узкой области и со своей ценой за это.
> Это бред какой-то.
К сожалению это не бред, это реалии, тема очень свежая, сложная и конкретно гиковская, а не что-то обычное для нормисов. Пройдет время, железки подтянутся, модели улучшатся и станет чем-то обыденным или более дружелюбным, уровня графенистых игорей, а сейчас удел энтузиастов.
> насколько большую модель я могу запустить без страха что-нибудь наебнуть
> вес модельки + размер контекста = объем врам + объем рам
This, вычти то что сожрала система.
Не дает, нужна скорость рам и работы с периферией.
>бесплатно, бесплатно...
Мне вообще без разницы, платный или бесплатный это софт. Мне главное, что он аляповатый и ненадежный. Оллама дохуя что ли круче лламы в этом плане, если она платная? Как показывают отзывы, это далеко не так.
>поэтому проблемы накапливаются и решить их все невозможно силами тех основных разработчиков
Так может для начала ввести культуру разработки? Делать итерации, сфокусироваться на качестве, юзер экспириенсе... не?
>не нравится - сделай лучше
>Врятли кому-то станет лучше от того что разработчики llama.cpp свернут свой проект.
А можно без максимализма просто взять и поработать над стабильностью, исправляя баги и предотвращая новые, а не давать два стула в виде предложения несведущим пользователям самим лезть в пекло и закрытием проекта целиком нахуй?
>Это неизбежно
Ну то есть по итогу заводить туда проблемы смысла никакого нет, потому что разрабам плевать, что их репа превратилась в помойку. Хотя и правда, чего это я, на работе ситуация один в один. Правда там хотя бы закрывали задачи через пару лет (не потому что они не нужны, а потому что их прямым текстом отказываются делать).
>Принципиальная невозможность по своей сути.
А разраб пишет наоборот. Ой как неудобно, мм.
>осс нахуй не нужен
Хахаха, а сам же писал про некст, лицемер ебаный. Кто еще не нужен по итогу-то оказался.
>Необходимость перелопатить все
Мда, зачем ты споришь, не зная деталей, если сам разраб пишет, что поддержать будет легко? Просто спиздануть мне в противовес?
>Свежие готовые сборки всегда на странице релизов
Просто спиздануть мне в противовес x2?
>Что-то уровня "нежелания сделать лекарство от рака, спида и всех болезней"
Ну да, поддержка тьюрингов в exl3 магическим образом испарилась, конечно же, не потому, что автору лень этим заниматься, а потому что это, дай угадаю твой аргумент... ПРИНЦИПИАЛЬНАЯ НЕВОЗМОЖНОСТЬ. Ага. Да.
>А ты хоть смотрел фа, который сделали под паскаль?
Просто спиздануть мне в противовес x3?
>ссд не дали
Лол блять, помнится тут поросячий визг на весь тред стоял, что кому-то было лень качать квант эира для тестов, потому что 80 Гб это ОЧЕНЬ МНОГО ССД РАСПИДОРАСИЛО ПЛАК ПЛАК. А теперь меня упрекают, что мне не хочется качать полные веса и тратить время на квантование. Тред лицемеров.
>обладатели отсутствия
>На /po/рашу
А, так ты же экслламашиз, все понятно. Спустил неадекватное количество денег на риг, чтобы стать обладателем присутствия в палате, и на всех остальных смотрит в той самой горделивой позе.
>Но до тех пор, пока сам усилий не прикладываешь и не помогаешь, никто твою критику всерьез воспринимать не будет, тем более в опенсорсе лолкек.
Пчел, мы на анонимной борде, ты откуда знаешь мой бекграунд, чтобы утверждать, что моя критика без веса? Тут все постеры - рандомхуи, если что. Но, к твоему сведению, даже критику от контрибьюторов не воспринимают, кидали же ссылки некоторое количество тредов назад, где чел рейджквитнул из лламы.
>flash attention
Я про него вспомнил, потому что разраб экслламы ждет, пока в него вольют PR, который нужен для того, чтобы интегрировать гпт осс. Почему-то самому собрать фа с нужными правками и подготовить dev релиз у него желания нет, несмотря на простоту этого действия, по его словам. Ну и плюс дохуя людей в ишью просили у фа поддержку тьюринга, т.к. у них даже на главной странице это было написано, что, мол, скоро будет. Разраб (он у них вообще один, видимо) сначала кормил завтраками, потом просто говорил, что времени нет. А сделать это вполне реально, насколько я понял. То есть ситуация буквально, ОДИН человек отказывается делать - и ВСЕ обладатели тьюрингов уже несколько лет автоматически идут нахуй из любого инференса, где задействован питоновский фа. А он даже в картинках кое-где используется, хотя там больше сажа. То есть литералли ни у кого больше нет компетенций и желания это реализовать. Как по мне, это ахтунговая ситуация. Причем старшие тьюринги, как и пресловутая v100, тоже очень недурны для пользователского кручения ллм.
> просто взять и поработать над стабильностью, исправляя баги и предотвращая новые, а не давать два стула в виде предложения несведущим пользователям самим лезть в пекло и закрытием проекта целиком нахуй?
Тебе не кажется что ты пишешь это вообще не в том месте? Приди к жоре и скажи мол так и так давайте я попробую заняться продуклидством в начале на пол шишечки, а потом как пойдёт.
Чё ты здесь то распыляешься?
Я просто хуею как люди переливают из пустого в порожнее вместо того что бы мешки ворочать
Кто-то запускал уже немотрончик новый 30B-A3B? https://docs.unsloth.ai/models/nemotron-3
>Тебе не кажется что ты пишешь это вообще не в том месте?
Потому что хочу писать тут. А там не хочу, у них найдется 1001 причина делать так, как хочется им, а не мне, и ничего не изменится. Если у тебя есть желание - иди и напиши, я буду даже рад, что мои посты сподвигли тебя на ворочание мешков. Но ты же не пойдешь.
Меня устраивает как работает жора и вллм, а в проекты которые меня не устраивают я делаю мры хоть и редко. Можешь и дальше обижаться на опенсорс который не отсасывает тебе.
Удачи, громкое меньшинство.

>Меня устраивает как работает
У тебя контекст не вмещает обсуждаемое и несколько себе противоречишь при маневрах. Оставайся на месте, санитары уже в пути.
>24B мистраль работает на одной 3090 с молниеносно-поносной скоростью, хз о чем ты.
>У меня Qwen3-Next-80B работает на 16+32 в два раза быстрее чем Mistral-24B/Gemma3-27B.
На 24GB она может и работает молниеносно. На 16GB - это черепаха со скоростью 8-9 t/s на старте и 5 t/s к контексту 2-3К. Что там на контексте 16К+ даже страшно представить.
Нет, я не отрицаю что 3090 это все еще карточка обычного ПК пользователя, хоть и топовая в свое время. Но глупо будет спорить с тем что доля владельцев 3090 довольно мизерная на фоне тех у кого карты 8/16GB. Поэтому большая часть пользователей, как и я, в общем-то в пролете с Dense моделями 20B+, если они хотят получить скорость хотя бы 15 t/s. Поэтому для большинства пользователей MoE - это определенно прогресс.
>Как вообще оценить на какие модельки я могу рассчитывать, чтобы не проебаться в скорости и не улететь в лимит оперативки (жалкие 32гб)?
Если речь о dense моделях - здесь просто смотреть на размер файла. Если GGUF весит больше чем у тебя VRAM - значит скорость будет никакая, потому что полностью во VRAM ты не влезаешь. Если GGUF весит меньше чем у тебя VRAM - здесь нужно смотреть на то сколько места останется, потому что помимо самого файла, во VRAM должен еще и влезть контекст. Поэтому если GGUF весит 15.5GB, а у тебя карта 16GB, скорее всего скорость тоже будет печальная, потому что в 500 оставшихся MB ты нормальный контекст не всунешь. Плюс к этому, контекст каждой модели жрёт по разному, поэтому здесь решающим фактором будет сколько у тебя остается памяти после загрузки GGUF и сколько контекста тебе нужно. 12/14B dense модели без проблем влезут с неплохим контекстом (16-32K). Модели больше - будут с печальной скоростью <10 t/s, и она будет еще ниже по мере заполнения контекста.
Если речь о MoE моделях - здесь предельный размер файла это твой VRAM+RAM, но рассчитывать на это - плохо, потому что опять же, RAM используется под систему и программы, мы не можем просто забить всю RAM и потом жить хорошо. Лучшее что у меня удавалось запустить на 16+32 c хорошей скоростью - Qwen3-Next-80B в Q_4_K_XL на скорости 15 t/s (начинает с 5 t/s и к 500 контекста разгоняется до 15t/s). Но отказался от его использования т.к. он переодически вылезает из RAM и перезаписывает файл подкачки на скорости 300мб/с. Не хотелось бы угробить SSD раньше времени, особенно сейчас с кризисом памяти. Поэтому лучший, на мой взгляд, вариант при 16+32 - MoE модели ~30B, с выгрузкой слоев на процессор. Скорость 30-40 t/s на том же Qwen3-30b-a3b-2507 / Qwen3-Coder-30b-a3b. Сегодня NVIDIA Nemotron 3 30B Nano вышел, на словах не хуже Qwen3-30b, скорость должна быть еще выше чем у Qwen. Как по качеству - пока не ясно. gpt-oss:20b полностью влезает в 16GB VRAM с контекстом ~80к, скорость лично у меня 60 t/s. Ну и остальные MoE модели плюс-минус этого же размера. Просто настраиваем нужное значение --n-cpu-moe, пока VRAM не будет забита на ~15.5GB.
>Это не так. Скорость очень важна пока не достигла определенного "комфортного предела", шустрая мелкомодель может доставить больше удовольствия чем "не токены а золото", что тратят по несколько минут на один свайп ответа.
Возможно. Просто не раз тут видел как люди пишут про скорость 3-5 t/s в RP и в общем-то не жалуются и продолжают пользоваться. Для меня всё что ниже 10 это уже красный флаг. Я лучше буду пользоваться более глупой MoE моделью, чем сидеть с такой скоростью на более умной Dense модели.
>А можно без максимализма просто взять и поработать над стабильностью, исправляя баги и предотвращая новые, а не давать два стула в виде предложения несведущим пользователям самим лезть в пекло и закрытием проекта целиком нахуй?
Ты пробовал когда-нибудь писать код? Потому что фразу "просто пиши без багов, лол", может написать только человек который никогда в жизни не писал ничего сложнее сайта-визитки или простенького проекта в 200 строк. Такого никогда не будет, человеку свойственно ошибаться и он всегда будет это делать. И чем больше проект, тем больше вероятность что ты упустишь что-то и где-то вылезет новый баг.
Посмотри репозитории любых открытых крупных open-source проектов. Там везде огромное кол-во issues. Открой какой-нибудь ffmpeg. У него багтрекер на 3000+ тикетов. yt-dlp - 1700+. Дай свой совет про культуру разработки разработчикам VS Code с 5000+ issues.
>Кто-то запускал уже немотрончик новый 30B-A3B? https://docs.unsloth.ai/models/nemotron-3
В llama.cpp еще не добавили поддержку.
> Но глупо будет спорить с тем что доля владельцев 3090 довольно мизерная на фоне тех у кого карты 8/16GB.
Если брать именно ллм-инджоеров то ситуация будет скорее обратная. Те кто в хобби не первый день за годы успели обзавестись видеокартами.
> люди пишут про скорость 3-5 t/s в RP
Так пишут потому что около 5т/с - примерная скорость расслабленного чтения когда ты параллельно представляешь и обдумываешь. То есть это самый минимум чтобы сразу начать читать и не ждать, а ниже будет уже страдание с перерывами. Офк, увидеть что ответ плох и сразу свайпнуть как на скоростях больше уже не получится.
>Сорян, не удержался.
Да всё так, я понимаю.
>Для чего угодно их нужно штуки 4 и больше
Не до конца уверен, но возможно ты перепутал карточку что я имею ввиду. Я про 6000 pro, которая из "полупрофессиональной" линейки 5090, где на одной 96 ГБ. Kimi2 я не запущу, но вроде как 96 Гб это прилично достаточно, что не слишком согласуется с фразой, что для чего угодно их нужно штуки 4 и больше, моделек больше чем на 150B не то что бы много.
Но если есть вариант собрать ферму из 4 карточек на балконе на 2 квт мощности, и так что при том же объёме памяти (если она стакается) это будут 4 карточки, а не 1 - это наверное в приоритете. Как я понял память достаточно условно стакается, и это всё-равно не будет просто запуску через торч одной командой.
Ну вот дело в том, что я писал под торч, и довольно много, но не в сфере llm и больше пяти лет назад, в так сказать классических нейронках, до трансформеров. И любой код запускался как на cpu, так и на gpu.
Эти ребята наверное вручную переписали под куду с местными типами, и переписывать куду на обычный си уже не хотят, а никакого официального способа запускать куда-ядра на процессоре нет, что довольно странно - для отладки было бы удобно.
> около 5т/с - примерная скорость расслабленного чтения когда ты параллельно представляешь и обдумываешь.
Этот процесс нельзя сравнивать со скоростью генерации. "Чтение" у нормального, развитого и образованного человека очень быстрое, последовательной цепочкой импульсов внимания, которая вообще может охватывать несколько строк за секунды. Но мы чувствуем важную информацию и возвращаемся к ней, бегло переводя взгляд и перечитывая снова уже медленнее. В этот момент и происходит представление, а обдумывание это в целом непрерывный процесс.
А еще люди не любят испытывать терпение и ждать. Итого, самый минимум для комфортной генерации - около 15 т/с. И это если без ожидания ебучего ризонинга.
>Мне главное, что он аляповатый и ненадежный.
Ну так не пользуйся.
>на работе
>отказываются делать
Лол, это что за инклюзивная РАБота?
>ОДИН человек отказывается делать - и ВСЕ обладатели тьюрингов
Не могут собраться и сделать. Значит, им нихуя не нужно.
>5 t/s к контексту 2-3К
Да вы охуели, отличная скорость.
Мимо крутил ларжа на 0,7.
>500 оставшихся MB
Уронят скорость в разы, но не на порядки, и в итоге будет терпимо.
>Не хотелось бы угробить SSD раньше времени
2025 год, а кто-то всё ещё боится угробить сосоди перезаписями. Офк если это конечно не безбуферное говно, но зачем такие покупать, для меня загадка.
>Если речь о MoE моделях - здесь предельный размер файла это твой VRAM+RAM, но рассчитывать на это - плохо, потому что опять же, RAM используется под систему и программы, мы не можем просто забить всю RAM и потом жить хорошо. Лучшее что у меня удавалось запустить на 16+32 c хорошей скоростью - Qwen3-Next-80B в Q_4_K_XL
Понял, спс за развернутый ответ.
Я в принципе так и начал прикидывать. Половина оперативы все равно под браузер или что-то еще занято. 16+16=32гб, значит максимум 64б параметров моделька. А в диапазоне 32-64б особо-то и нечем полакомиться. После 30б в основном метят сейчас на 100+б, но это уже совсем другой уровень.
Анончик, подскажи, пожалуйста. Пробовал онлайн модельки и там прежде чем выдавать результат он делал какой то анализ происходящего, а только потом начинал писать. Локальные модельки такое умеют? Как включить? Пробую такое сделать с помощью https://huggingface.co/prithivMLmods/Qwen3-VL-32B-Instruct-abliterated-v1
Гугли
- thinking
- rag
- function calling
И всё поймёшь
Анончик, подскажи, пожалуйста. Пробовал онлайн модельки и там прежде чем выдавать результат он делал какой то анализ происходящего, а только потом начинал писать.
Любая LLM с reasoning/thinking в названии.
Instruct - обычные модели без "мыслей" перед отправкой сообщений.
Есть гибрид модели где ризонин можно включать/отключать по желанию, но таких моделей сейчас не очень много.
>2025 год, а кто-то всё ещё боится угробить сосоди перезаписями
Таки да. У меня дешевый nvme WD Blue терабайтник, купленный 5 лет назад. Каждый день по работе записываю на него по ~50гб + модельки качаю жирные + кинцо в блюрей. Жив, цел, орёл. Вот бы над ресурсом ссд трястись.
>Любая LLM с reasoning/thinking в названии.
>Instruct - обычные модели без "мыслей" перед отправкой сообщений.
Аааа. а я думал что инструкт это как раз и есть те самые инструкции/мысли. Спасибо, братик.
Существует ли более дебильный формат ризонинга чем Harmony для GPT-OSS? Просто пиздец, все время срет тегами невпопад. Кому-то в Таверне удавалось настроить без ебли с регекс?
>Не все могут запустить, вот и хейтят.
Ну я чё-то уже подгорать с него начинаю. Нет. пишет лучше Air. Но блять, то он начинает хуярить стену текста за меня. (Хотя для кума, ниче так, воробще нихуя делать не надо, как лучшие мистралеслоптюны, лол).
То
Начинается
Вот
Это
Опять ебаться чтобы настроить, хочу кнопку - сделай мне заебись.
Я и так на работе устаю, bwaaaa.
>Потому что фразу "просто пиши без багов, лол"
Зачем ты выдумываешь фразы за меня? Перечитай еще раз, что я пишу. И если непонятно, то у меня уже аналогичный вопрос встанет к тебе.
>Ну так не пользуйся.
Не могу, нет альтернатив. То есть представь гипотетическую ситуацию, что у тебя только Лада есть, а иностранные автомобили в страну не завозят. А тебе хочется машину, но не хочется въебаться в дерево из-за заблокированного руля.
К слову, можно же и мемасик недавний вспомнить. "А можно, чтобы скорость на контексте не проседала?" "Можно, а зачем?" "А можно, чтобы на проекте было адекватное тестирование и релизы?" "Можно, а зачем?". Ну ты понял.
>Лол, это что за инклюзивная РАБота?
Обычная работа. Ставишь баг или реквест фичи с приоритетом ниже high в соседний отдел, на нее ложится болт, т.к. все в отделе работают только с валом критических задач, спустя пару лет видишь уведомление в таск менеджере, что задача закрыта - пришел новый менеджер и просто позакрывал старье, хотя проблема никуда не исчезла. А в этих попен сурсах иногда вообще автозакрываются issues, если активности нет какой-то период времени.
>Не могут собраться и сделать. Значит, им нихуя не нужно.
Как бы тебе сказать, любое число * 0 = 0. Я тут обычный пользователь, у меня нет экспертизы по CUDA, как и у всех остальных. Каким макаром нам надо собраться, чтобы у нас эти знания магическим образом появились? "Автоботы, в атаку!" кричать надо при этом?
>начинает хуярить стену текста за меня
Ну этим все модели страдают. Проще стопнуть в этот момент и ручками лишнее удалить. Инструкции "не писать за юзера" работают через раз, а чаще - вообще не работают.
>но не хочется въебаться в дерево из-за заблокированного руля.
Можешь не продолжать анон. Без обид, но самое худшее что можно делать, это строить из себя знатока абсолютно не разбираясь в вопросе. Как было сказано другим аноном, велком ту /po/раша.
>что у тебя только Лада есть, а иностранные автомобили в страну не завозят
Ну так завези сам, очевидно же!
>Без обид, но самое худшее что можно делать, это строить из себя знатока абсолютно не разбираясь в вопросе
Работник автоваза, залогиньтесь
Нормальные вёдра, ну ты чё, а ну ты чё. Пойдем выйдем и я убегу.
Ну а если серьезно, там всё не так просто. Да и я как обезьяна тригерюсь на подобные вбросы, потому что заебло.
Тут в тредике кого только нет, из всего СНГ. Мы все разные и школьники что наяривают на текстовое порно, и деды, что за рюмкой ищут интеллект в перемножении матриц, шизофреники, аватарки, долбоёбы и просто обычные люди и битарды. Но всех нас объединяет одно хобби - это желание доебаться и поговорить с железкой и это охуенно. Хочется чтобы так всё и оставалось.
Раньше за свою цену были действительно нормальные вёдра. Особенно если БУ. Покупались за копейки, чинились с помощью молотка и чертовой матери, запчасти в любой булочной наразвес. Намотался на столб? Да и похуй, не жалко - с зарплаты еще можно парочку взять.
Ну а сейчас - да, когда автоваз стоит как нормальная машина - это грустно.
>Не могу, нет альтернатив.
Тогда улучшай сам или не жалуйся.
>Ставишь баг или реквест фичи с приоритетом ниже high в соседний отдел
Значит хуйню ставишь. Ибо нужное делается всегда.
>Каким макаром нам надо собраться, чтобы у нас эти знания магическим образом появились?
При помощи нейросетей.
Я вообще ни разу не смог гопотой пользоваться. Ее либо в бесконечную генерацию заносит, либо она просто несет шизу. 20-б если что, 120-б не трогал.
Надеюсь автовазосрач останется в этом треде
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Потестил в лм студио.
Датасет интересный, будто порнуху не вычистили вилками как было в немотроне 49б, где он просто скипал сцены ебли или старался всё быстро завершить когда ты начинал подробничать.
Без проблем подхватил карточку фифи и накидал мне хуев за щеку а потом я ей
Если ты про гпт-осс 20б то это просто кал собачии. 120б более-менее.
++



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под ExllamaV2 (а в будущем и под v3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
Архив тредов можно найти на архиваче: https://arhivach.hk/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: