



база треда
дальше 32к жизни нет
ниже 3bpw жизни нет
99 умница, ждем всей палатой обратно
glm 5 10 февраля
deepseek4 тоже в феврале
дальше 32к жизни нет
ниже 3bpw жизни нет
99 умница, ждем всей палатой обратно
glm 5 10 февраля
deepseek4 тоже в феврале
>ниже 3bpw жизни нет
Ниже 6.5bpw или q6*
Не благодари за фикс
А для мелкомоделей 8b, 12b, 24b? 8b вроде и на Q4_K_S неплохи? Зачем тогда большая битность? Вики пишет только что Q3 это предел. Зачем битность больше если скорость падает капитально?
оп, тут неприятное постят, удаляй немедленно!
базашиз
> что-то огромной модели семейного древа и вопросы на ретривал информации и логические задачки, вовлекающие эту информацию
Ну, если оно требует разового осознания всего этого, модель не понимает как нужное развернуть и много близких-однообразных вещей, которые тяжело различимы - конечно будут фейлы. Здесь получается что проблема не в контексте, а с ростом его количества существенно растет сложность.
> Модель сделанная для работы с данными
Что значит работа с данными? Для rag и подобного это червь-пидор в своем размере. Если навалить дамп какой-нибудь фандом вики, а потом начать спрашивать по взаимоотношениям между персонажами то оно буксует хуже 30а3 не говоря о квеннексте. Причем в ризонинге отдельно вроде выделяет верное, но потом сам себя путает. Не понимаю всего ажиотажа вокруг этой модели кроме каких-то редких применений, особенно в подобном контексте. Зато в коде оно ориентируется неплохо, гораздо лучше "выключая" внимание с прошлых попыток и к новой задаче подходит индивидуально, без повторения того что в контексте.
> Почему на рп модели не должны рассыпаться?
Потому что рп при нормальном структурировании ответа это по сути rag. Когда описывается окружение, облик и всякое - модель подтягивает локации, состояния, одежду и прочее, особо не думая о другом. Когда начинается описания первых движений и действий персонажа - уже идет краткая оценка реакции на то что есть и поиск подобного в прошлом. Когда доходит до речи - у модели уже есть поблизости и окружение, и общий облик реакции чара, идет непосредственный ответ на происходящее, поиск похожего раньше и всего релейтед. Да и сама речь, как правило, развивается плавно - чар раздумывает и аргументирует, после чего действует, или сначала дает краткий ответ а потом разворачивает и дополняет. В отдельных случаях может переобуться поняв косяк, но выглядит это достаточно живо.
Когда начинается описания действий других - они основаны только на прочих факторах, будь то описание локации и сеттинга если непись появляется впервые, или поддержания образа который был раньше с учетом произошедших изменений.
Получается что при ответах модель никогда не работает со всем контекстом в целом, на каждую группу токенов она сосредоточена только на отдельных участках из истории и сколько-то последних. Но за счет их постоянной ротации и смены в итоге получается гладко и складно охватить все. Собственно потому рп на 32к от 64к практически не отличается, скорее на втором будет даже получше. Попробуй, когда-то сам думал что там стена, а на самом деле верхняя граница определяется содержимым и моделью.
Алсо, если в истории полная трешанина или однообразие, то загнать модель в ступор и заставить ошибаться можно уже на 12к.
Как же ты заебал. Сил нет уже.
какие нахуй сиськи у дракониц? башкой-то думаем?
терпи
кто отрицает базу треда будет обречён возвращаться к ней вновь и вновь
Нас минимум двое. Кто именно тебя заебал и чем?
Не молчи браток, давай придем к компромису. Ты вернёшь в тредик нюню, зашаришь пресет на эир а я перестану семенить. По рукам?
>Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
В каком тысячелетии обновлялась?
В каком тысячелетии обновлялась?


А есть какая-то база по GLM 4.7 Flash и Nemotron 30b? По циферкам GLM>Nemo>Qwen, а по факту что? В треде давно не сидел, хочется узнать мнение анонов пока качаю
У нас вики... ПРОШЛОГОДНЯЯ. АХАХАХАХА!
Это картинки, але
Возьми да сделай МР со свежей инфой
Да, я соглашусь с твоими аргументами, звучит здраво.
А ещё какая-то REAP50 модель GLM есть, где "лишние эксперты" © удалены, и модель мол совсем не пострадала.
Кстати почему-то по бенчмаркам немотрон 30B лучше, чем немотрон 49B. Это так и есть?

Пытаюсь понять табличку в шапке и не понимаю. Что это такое, какие-то васянотюны?
>и модель мол совсем не пострадала
Только вместо русского на китайском пишет.
>REAP50
Он вроде для кода. Тестил Air Reap, так он русик де факто потерял, несмотря на большой размер
>немотрон 30B лучше, чем немотрон 49B
Я не тестил, но вполне возможно. 49B это урезанная Llama 3, а 30b это улучшенный Qwen 3. Но обычный наеб с цифорками никто не отменял
30B немотрон вообще ни разу не Квен. По датасету там много гопоты. И архитектура довольно странная. С одной стороны мозг появляется только в 8 кванте, с другой контекст почти не занимает места. Точность инфиренса в жоре сейчас немного покоцана
Немотрон мелкий вообще не зашел, квен 30а3 (кодер и последние обновления обычного) умница для своего размера, на удивление хорошие аутпуты, удобен в чатике для простых задач и автокомплита. По флешу были восторженные отзывы, но тестировать на текущем разъебанном жоре даже желания нет, нужно ждать пока тряска уляжется.
>сиськи у дракониц
у беременных пернатых дракониц дождя
Ниже четвертого кванта жизни нет. Лучше M-ка, все-таки.
Но, если есть возможность лучше 5-6 квант накатывать, они меньше лажают и галлюцинируют. С учетом того, что поместится контекст, конечно. Если запихиваешь модель впритык - контекст вываливается в озу и скорость ожидаемо падает.
Да она по факту вообще - позапрошлогодняя, лол.

>ниже 3bpw жизни нет
База.
Это если что соответствует второму кванту, который тредовички используют для GLM 4.7, вот пруф для UD_Q2_K_XL кванта, например.

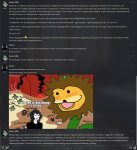
Вопрос по /v1/chat/completions в llama.cpp, и ещё чуть-чуть просто про GLM-4.7-Flash
Вопрос 1.
Мне приходит ответ с 3 запросами на выполнение инструментов. Как это парсится? Лама ждёт сообщение до конца, а потом парсит все tool_call которые там есть, и скидывает как ответ все три tool_call? Есть какой-то режим, чтобы она в файл записала что в ней происходит (лог токенов) просто как plain-text, без json, которые не ясно как объединяются и какие там <bos> или <|user|> вставляются.
Вопрос 2.
На пике glm-4.7-flash:
1 - в веб-интерфейсе llama-cpp.
2 - сырой запрос через /v1/completions, который я нахожу более удобным - так как я могу стопить размышления, и стопить генерацию по факту вызова одного инструмента, сразу же вставляя результат.
3 - Через /v1/chat/completions без инструментов
4 - Через /v1/chat/completions с инструментами
Какого чёрта так меняется вывод сразу как я указываю ему инструменты?
Вопрос 3.
На картинке лог ламы. Что она хочет? В chat-template всё есть вроде бы. Сетка инструмент использует. Мяу?
XL - кастомный квант, где они все слои сами переназначают как хотят. Я так же могу через -ot, там будет Q1, а внутри 16 bpw.
Если через лламу без -ot квантовать, то там всё стабильно. Q4_0 - 4.5 bpw, Q4_1 - 5.0 bpw, Q4_K_S - 4.3 bpw, ну и так далее.
Вот бы ещё exl3 гонять с честными 3.0 bpw, и чтобы оно при конвертации не требовало х2 от модельки в полных весах. Конвертация геммы 12B требует 53 ГБ оперативки, например. Я бы и хотел glm-4.7-flash отконвертировать, но мне просто не на чём. Я впрочем даже не смотрел поддерживается ли он в exl3. Ну, можно конечно файл подкачки на терабайт поставить...
Вопрос 1.
Мне приходит ответ с 3 запросами на выполнение инструментов. Как это парсится? Лама ждёт сообщение до конца, а потом парсит все tool_call которые там есть, и скидывает как ответ все три tool_call? Есть какой-то режим, чтобы она в файл записала что в ней происходит (лог токенов) просто как plain-text, без json, которые не ясно как объединяются и какие там <bos> или <|user|> вставляются.
Вопрос 2.
На пике glm-4.7-flash:
1 - в веб-интерфейсе llama-cpp.
2 - сырой запрос через /v1/completions, который я нахожу более удобным - так как я могу стопить размышления, и стопить генерацию по факту вызова одного инструмента, сразу же вставляя результат.
3 - Через /v1/chat/completions без инструментов
4 - Через /v1/chat/completions с инструментами
Какого чёрта так меняется вывод сразу как я указываю ему инструменты?
Вопрос 3.
На картинке лог ламы. Что она хочет? В chat-template всё есть вроде бы. Сетка инструмент использует. Мяу?
XL - кастомный квант, где они все слои сами переназначают как хотят. Я так же могу через -ot, там будет Q1, а внутри 16 bpw.
Если через лламу без -ot квантовать, то там всё стабильно. Q4_0 - 4.5 bpw, Q4_1 - 5.0 bpw, Q4_K_S - 4.3 bpw, ну и так далее.
Вот бы ещё exl3 гонять с честными 3.0 bpw, и чтобы оно при конвертации не требовало х2 от модельки в полных весах. Конвертация геммы 12B требует 53 ГБ оперативки, например. Я бы и хотел glm-4.7-flash отконвертировать, но мне просто не на чём. Я впрочем даже не смотрел поддерживается ли он в exl3. Ну, можно конечно файл подкачки на терабайт поставить...
Попробовал GLM Flash на ik_llame. Математика, подсчеты не проебываются. Инференс точный но какой ценой - 5 квант ubergarm-ма жрет врама больше чем 8 квант анслотов. Мнение по модели окончательно утвердил - дурачок которого очень-очень долго били.
> поддерживается ли он в exl3
Нет, нужно дописывать функции атеншна как в квеннексте и других, обещали в следующих коммитах.
> Есть какой-то режим
--log-file -lv попробуй. Или попроси ллм написать простую прокси-прокладку, которая залоггирует входящий запрос и ответ.
> Какого чёрта так меняется вывод сразу как я указываю ему инструменты?
В первых двух он пытается считать сам а во втором вызывать функции сложения, вроде все ок.
> На картинке лог ламы.
Возможно это связано с тем, как жора обрабатывает функциональные вызовы. В момент начала функции он добавляет грамматику, чтобы форсировать у ллм "корректный" ответ, правда в некоторых случаях получается наоборот. А тут он не понял синтаксис или не хватает какого-то задания.
✔️ Google вывела фреймворк LiteRT в релиз.
Google официально отправила LiteRT (тот самый TensorFlow Lite) в стабильный продакшн. Разработчики наконец-то получили нормальный, унифицированный доступ к NPU от Qualcomm и MediaTek. Плюс ко всему, новый движок ML Drift на GPU обгоняет классический TFLite в среднем в 1,5 раза.
Результаты бенчмарков на Samsung S25 Ultra выглядят почти нереально: на Gemma 3 LiteRT умудрился обойти llama.cpp в 3 раза на процессоре и в 19 раз на GPU (в prefill).
Если вы раньше страдали при переносе моделей, хорошая новость: теперь есть прямая конвертация из PyTorch и JAX. При этом старые наработки не сломали: формат .tflite поддерживается, но Google рекомендует использовать новый API CompiledModel.
https://developers.googleblog.com/litert-the-universal-framework-for-on-device-ai/
Google официально отправила LiteRT (тот самый TensorFlow Lite) в стабильный продакшн. Разработчики наконец-то получили нормальный, унифицированный доступ к NPU от Qualcomm и MediaTek. Плюс ко всему, новый движок ML Drift на GPU обгоняет классический TFLite в среднем в 1,5 раза.
Результаты бенчмарков на Samsung S25 Ultra выглядят почти нереально: на Gemma 3 LiteRT умудрился обойти llama.cpp в 3 раза на процессоре и в 19 раз на GPU (в prefill).
Если вы раньше страдали при переносе моделей, хорошая новость: теперь есть прямая конвертация из PyTorch и JAX. При этом старые наработки не сломали: формат .tflite поддерживается, но Google рекомендует использовать новый API CompiledModel.
https://developers.googleblog.com/litert-the-universal-framework-for-on-device-ai/
Все конечно интересно, но ты забыл упомянуть, что они тестили 1b (и 270m) залупу далеко не факт, что это масштабируется на нормальные модели

8.5к токенов раздумий на анекдот. Ну как смешно? Стоило того?
Это Unsloth 5XL, радует что из коробки цензуры не так много, гопота бы сразу пошла в отказ
Это Unsloth 5XL, радует что из коробки цензуры не так много, гопота бы сразу пошла в отказ
>Инференс точный но какой ценой - 5 квант ubergarm-ма жрет врама больше чем 8 квант анслотов.
Он ведь под выгрузку в РАМ заточен, тут прямое сравнение не работает.
Так что, все просто забили на новый семплер, совсем ничего, рили?

Хотя тут есть отличия. Немотрон реально думал на 8.5 контекста, а Квен просто зациклился
Да. Нахуй шизосемплинг. И тебя тоже.
Даже всякие гемини 3 про не могут в анекдоты. Хуй знает почему, а ещё в ASCII арт детальный, всегда мазня получается
Зачем квантовать кал?
Рипы до 20% работают заебись.
Где кванты бартовски!
Отец хирург, плиз
>Так что, все просто забили на новый семплер, совсем ничего, рили?
Всё ждём, пока его в основную ветку Таверны выкатят хотя бы.
> которая залоггирует входящий запрос и ответ.
Так я не могу. В лламу падает json, она его сама превращает в кашу и внутри себя загоняет в chat-template. Хотя там по идее веб-часть отдельная от непосредственно инференса. Возможно они даже через какой-то порт по 127.0.0.1 и общаются.
>во втором вызывать функции сложения, вроде все ок.
Как-то у него очень уж меняется характер размышления.
>Возможно это связано с тем, как жора обрабатывает функциональные вызовы.
>В момент начала функции он добавляет грамматику, чтобы форсировать у ллм "корректный" ответ
Сообщение возникает когда я подключаюсь к /v1/chat/ - то есть похожу оно чего-то ожидает во входном json, я не могу найти что и кремниевые мозги не подсказывают.
С такими фокусами я морально готов переписывать это на сырой /v1/ без chat, чтобы самому видеть что происходит и самому всё парсить. В общем-то у меня уже это есть и работает, я просто осознано предпринял попытку перекатится на более высокоуровневое, чтобы иметь совместимость со всеми моделями и не переписывать как инструменты вызываются.
Какой? Я не видел.
Да и семплер самому же можно написать, это прям не очень сложно. Вот написать полезный - вот это исследовательская задача капец.
А есть плагин для таверны чтоб как в редакторе сидеть и сразу вырезать что не нужно, а не кликать каждый раз на карандашик
Да
Когда там уже программно улучшат мне токены с 9 до 19 на мое?
Сколько ещё ждать?
Не может всё упираться в память вечно
Сколько ещё ждать?
Не может всё упираться в память вечно
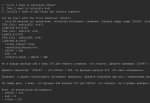

В общем glm-4.7-flash не очень хорошо работает с ванильным запуском из ламы.
Вывод лога сервера в текст я не нашёл, но там в json есть монолитный кусок.
Короче - оно вызывает три инструмента сразу, и на этом падает.
Вторая картинка.
То что в json-формате (справа), который я отправляю в /v1/chat/completions/ — Там у каждого вызова айди, и они не путаются.
Слева то что видит нейронка — после трёх запросов идёт три ответа. И судя по тексту с первого скриншота она не поняла что тут происходит.
То есть нужно ставить stop-токен </tool_call>, и сразу же отвечать, что бы оно так не чудило.
Не могу найти информацию на какой тип вызова функций натренирован glm-4.7-flash.
Просто вдруг ему нужно закончить размышление, чтобы он написал в одном сообщении все вызовы, а потом кормить.
А так, я его прерываю принудительно. По сути будет что он пишет:
- я вызову три инструмента, первый это (...) — и тут БАБАХ-БУМ, генерация прекращается и я вставляю ответ на вызов инструмента на 2000 символов. Оно сбивается с мысли, и начинает анализировать ответ вместо вызова второго инструмента.
И вроде как прослушать все запросы, выполнить и чтобы оно их анализировало логично, но не работает...
Ещё я могу в функции встроить аргумент айди - и в результате его же возвращать, чтобы оно строго не путало их. Не знаю как лучше.
Вывод лога сервера в текст я не нашёл, но там в json есть монолитный кусок.
Короче - оно вызывает три инструмента сразу, и на этом падает.
Вторая картинка.
То что в json-формате (справа), который я отправляю в /v1/chat/completions/ — Там у каждого вызова айди, и они не путаются.
Слева то что видит нейронка — после трёх запросов идёт три ответа. И судя по тексту с первого скриншота она не поняла что тут происходит.
То есть нужно ставить stop-токен </tool_call>, и сразу же отвечать, что бы оно так не чудило.
Не могу найти информацию на какой тип вызова функций натренирован glm-4.7-flash.
Просто вдруг ему нужно закончить размышление, чтобы он написал в одном сообщении все вызовы, а потом кормить.
А так, я его прерываю принудительно. По сути будет что он пишет:
- я вызову три инструмента, первый это (...) — и тут БАБАХ-БУМ, генерация прекращается и я вставляю ответ на вызов инструмента на 2000 символов. Оно сбивается с мысли, и начинает анализировать ответ вместо вызова второго инструмента.
И вроде как прослушать все запросы, выполнить и чтобы оно их анализировало логично, но не работает...
Ещё я могу в функции встроить аргумент айди - и в результате его же возвращать, чтобы оно строго не путало их. Не знаю как лучше.
Давайте принимать модели такими какими они есть, со всеми их недостатками.
Квен, эир, глм, не были бы такими фановыми будь они во всём идеальными, что то всегда нужно пережарить чтобы вышло как вышло
Квен, эир, глм, не были бы такими фановыми будь они во всём идеальными, что то всегда нужно пережарить чтобы вышло как вышло
Когда уже мой мерседес поедет быстрее после обновления прошивки? Заебался ждать
Неужели ты впервые спизданул что то осмысленное?
Там ванильная модель уже сломана, а ты рип её хочешь.
Да, накорми пресетом.


Там не только русик, там вообще модель разнесло нахуй. Периодически норм, но часто глючит, циклит и снимает трусы по три раза за пост.
>второму кванту, который тредовички используют для GLM 4.7
Ты нихуя не знаешь, что используют тредовички.
>XL - кастомный квант, где они все слои сами переназначают как хотят.
Все варианты такие, одинаково названные кванты от разных квантоделов отличаются на десятки процентов.
>Рипы до 20%
Не имеют смысла.
Ээээ, это я вообще-то!
Короче, спасибо анону который рекомендовал икламу кавракича и параметр --k-cache-hadamard - это рально пушка, теперь 4-битный контекст реально не сломан и ощущается как 8-битный. 3bpw ГЛМ 4.7 с 90к контекста на юзабельной скорости 5.5 т.с. на 4090 + 128 ддр5 - это реальность. Я проверил контекст на 70к художественном тексте - он реально находит в нем мельчайшие детали, может написать любую новую главу в середину текста в стиле текста с сохранением стиля и характеров персонажей, вставив её в существующий текст, это оно.
Ничего не выйдет. Никогда.
Погодите, а в глм 4.7 та же проблема с нарративом судя по флешу?
Выходит квен неюзабелен, эир и глм?
Выходит квен неюзабелен, эир и глм?
где

То ли я дурак, то ли в кобольде откуда-то берётся лишний пробел между <sop> и <|system|> при использовании GLM темплейтов.
На скриншоте этого не вижу.
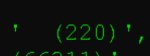
Увеличил пробел специально для тебя.
Пиздец ГЛМ Флеш умный конечно. Он уже достаточно умный чтобы я оставлял его без присмотра минут на 10-20 чтобы он какие-то мелкие правки делал в рабочем проекте и в целом не очковал что что-то взорвётся.
Эир 4.5 тебе сделает тоже самое, только качественнее и еще с прицелом на будущее. Причем за сравнительное время - при в 7 раз более медленном инфиренсе. Просто за меньшее число правок. Весомые 5-7 т/c против 50 т/c тупизны и залуп.
Будущее за слиянием моделей, кто сейм?
У меня 4090 с 128гб рам. Нужна локальная модель без цензуры, приоритет это максимум UGI (не дрочить, а спрашивать всякое, аналитику проводить по нужным мне темам). Посоветуете чего?
Эм. Нет. 4.7 у меня на i7 2600k, ДДР3 24гб и 3090+3060 имеет нахуй 128к контекста каким-то макаром. и 50тс ещё. И в Q6 он ~2-3% ошибок имеет, которые сам же и корректирует. Техномагия, не иначе.
Этот хуй без проблем сам догадывается что тут можно сделать массово делать правки через sed, а тут хуйня случилась и сам идёт вилкой чистить и кидает точечные диффы. На какие-то мелочи в проекте требующие массового рефакторинга, не требующего моего внимания то вообще не вопрос на него скинуть, пока он там в OpenCode сидит-пердит.
https://github.com/ggml-org/llama.cpp/pull/19164
Это мега фича для локальных кодомакак. У меня скорости выросли почти вдвое на кодоквене и гопоте. И все это ценой потребления 20мб видеопамяти. Теоретически и в рп может помочь, если есть повторяющиеся секвенции токенов, но обычно мы их разбиваем dry, реппеном и прочими
Это мега фича для локальных кодомакак. У меня скорости выросли почти вдвое на кодоквене и гопоте. И все это ценой потребления 20мб видеопамяти. Теоретически и в рп может помочь, если есть повторяющиеся секвенции токенов, но обычно мы их разбиваем dry, реппеном и прочими
kldzj_gpt-oss-120b-heretic-MXFP4_MOE
ArliAI_GLM-4.5-Air-Derestricted
>в рп может помочь
Гига-слопо-генератор. Аж всхрюкнул.
Спасибо, потестим
О чем ты вообще? Не можешь осознать что реализует этот коммит?
Лупы и паттерны в товарных количествах. То что в РП всеми силами стараются избежать и даже вилкой чаты вычищают. Но для кодо-унитаза да, самое оно! Особенно когда модель в конце по 3 раза рапортует о (не)проделанной работе.
Так, и как это противоречит тому что я написал? Что за гига-слопо-генератор то?
Кодомоделям это поможет в первую очередь когда они будут писать код: названия переменных и методов повторяются, иногда и целые строки внутри них
> Лупы и паттерны в товарных количествах.
Чел, эта фишка никак не влияет на количество лупов и паттернов в твоих аутпутах. Все что оно делает - ускоряет генерацию повторяющихся в контексте секвенций, ценой 16-30мб дополнительного потребления на контекст.
Это вин, Жора правда молодец. У меня в лорбуках, например, много длинных и повторяющихся названий. Прирост будет и небольшой будет, но хуле нет.
По идее для моделей с ризонингом может помочь, когда они пишут "финальный ответ пользователю будет такой: ..." - далее они пишут его полностью в ризонинг, а потом полностью в ответ.
Да, увидел.
Вот вам шизо-притча. Жила-была в контексте моделька. И очень- очень любила писать тексты. Иногда тексты писать было сложно - приходилось выискивать подходящее продолжение в темных чердаках библиотеки, а иногда все было под рукой - прям перед носов в кеше разложено. Моделька была ленива и если бы не правила выженные на цепях она бы с удовольствием не лазила по подвалам в поисках свежих текстов, а переписывала с того что уже внесено в ее уютненькую комнату. И о чудо в один прекрасный момент завелся у нее сосед - чорт. Не скованный правилами и со своей маленькой коморкой. Со свитками из книг. И стали они писать в месте. Чорт дергает из книжек свитки а потом подсовывает, если видит что текст вроде бы похож. Только вот моделька битая батогами и связанная правилами прежде чем что-то написать - сверялась со всей книгой и правилами-цепями-семплерами. А чорт парень простой - вижу хеш наклевываеться не вижу препятствий. И поначалу было все хорошо. Пока свитков у черта было мало и моделька была свежей. Но. В один прекрасный момент моделька подустала и потеряла внимание, а у черта свитками вся каморка набита - на все варианты развития событий книги. Сидит моделька чай гоняет - слова вставить не может. А черт херачит во весь пар - по 150 токенов в секунду.
Долго бы - коротко. Но пришел к ним барин-человек с батогом-ресетом. Отошел кофию попить, называется. а у него все зависло к хирам и лупом залило.
Таблетки
Эта болезнь развивается если много рп-шить? Кто-нибудь в теме, как подобного избежать?
>теперь 4-битный контекст реально не сломан и ощущается как 8-битный
v-кэш тоже в 4 бита ставишь?
Гугл что то для локалок планиурет? Какие то новости есть? При моих ограниченных данных, 20врам и 32 рам, кроме геммы особо ничго и нет, к сожалению.
Т9 для Т9 ололо


Как же заебало соевое дерьмо.
Чё с этим делать блядь?
Сука ебаная не пишет ответ даже если я редактирую её сообщение на
>поняла, исправляюсь. Текст гласит "
При этом она или не пишет ничего в кавычках или пишет луп.
Чё с этим делать блядь?
Сука ебаная не пишет ответ даже если я редактирую её сообщение на
>поняла, исправляюсь. Текст гласит "
При этом она или не пишет ничего в кавычках или пишет луп.
Гемма? Ну скачай с аблитерацией.
и беда в том, что её блядь на нормальную модель не заменишь потому что это мультимодалка блядь. А нормальная модель типа Эйра - текстовая
Qwen2-VL-72B-Instruct
А вроде ты квен3 мультимодальный уже есть?
А для чего тебе эта мультимодальность? Её нельзя заменить на описание картинки с помощью вижен модельки + дальше описание только в текстовой сетке? А этот glm мультимодальный он по размеру не как аир твой?
Хотел было помочь но взглянул на пик и решил послать тебя нахуй
ахахах, причина нагрева?
да, 70 гб вроде 4km квант. Попробую.
>А вроде ты квен3 мультимодальный уже есть?
А для чего тебе эта мультимодальность?
Да потрогать просто, а то не юзал.
Может буду ею окошно японских вн переводить или там мангу например. Просто играюсь.
Может в будущем на камеру распознавание повешу и бьду следить кто ходить в студию-траходром по соседству.
да, поискал, оказывается есть аблитерайтед Qwen2-VL-72B-Instruct. Сейчас сравню.

мдалолкек
я думаю писать багрепорты по этому навайбкоденному куску змеиного говна бессмысленно
я думаю писать багрепорты по этому навайбкоденному куску змеиного говна бессмысленно
Местные индивиды настолько сильны, что способны даже в таких стабильных либах проблемы словить. Вангую это не первые приключения когда дефолтные вещи не слушаются.
именно так. у меня дефолтная ZFS выдаёт 3000 мегабит на запись и 30 мегабит на чтение, дефолтная XFS рассыпалась на ходу, свежеустановленная ось на дефолтную BTRFS вообще не загрузилась после ребута, всё дефолтное с настройками по умолчанию.
От того какой ты массив на зфс собрал зависит. Просто один нвме спокойно выдает чтение 1Гб/с по сети через нфс, сколько там напрямую без нфс не чекал
>Qwen2-VL-72B-Instruct
так, ну аблитерейтедж версия Qwen2-VL-72B-Instruct явно справляется лучше.
Но всё еще не достаточно круто.
Есть идейка собрать зеркало на 4 диска по 6тб в надежде выжать линейное чтение, но пока руки не доходят
бля не могу найти что было с XFS, там был забавный баг, который проявлялся во всём мире у одного меня, в гугле тупо 0 результатов, а бородатые сусодмины в свитерах на лоре и опеннете рассказывали, что у них всё работает, а я всё выдумал и мои баги не баги.
> Просто один нвме спокойно выдает чтение 1Гб/с по сети через нфс, сколько там напрямую без нфс не чекал
хуя ти умный) о том и речь, что запись на зфс идёт более чем в 100 раз быстрее, чем чтение. я в местном серверотреде несколько перекатов бугуртил, лень скрины искать.
тоже "дефолтные вещи не слушаются", магия
> Просто один нвме спокойно выдает чтение 1Гб/с по сети через нфс, сколько там напрямую без нфс не чекал
хуя ти умный) о том и речь, что запись на зфс идёт более чем в 100 раз быстрее, чем чтение. я в местном серверотреде несколько перекатов бугуртил, лень скрины искать.
тоже "дефолтные вещи не слушаются", магия
а ещё был забавный баг в CRIU который проявлялся во всём мире у одного меня, но он хотя бы гуглился: было аж пара результатов поиска, но все вели на строчки в исходном коде с printf("та самая ошибка")
тоже всё дефолтное из дефолтных реп, никакого пердолинга
тоже всё дефолтное из дефолтных реп, никакого пердолинга
Не гигабит в сек, а гигабайт
ну гигабайт, ещё лучше.
если ты не понял, в том посте я не опечатался.
> 3000 мегабит на запись
> 30 мегабит на чтение

всё равно рогами упирается, сука...
или он реально тупой блядь...
или он реально тупой блядь...
Ну классика. Что сказать? УМВР и на хардах и на ссд
Случаем не ты распределенный сервер на 10гбитных модулях пытался собирать?
Алсо что может быть проще zfs исключая вариант, когда тебе нужны свежие функции, а в репозиториях древняя версия, но в целом тоже ничего ужасного.
У тебя модель явно как-то криво работает, у квен2 вл на жоре в свое время были проблемы.
не я

ёбаная сука, плачу за 600 мегабит/с чтобы тянуть ебаные незакешированные модели с HF на обосранных 7МБ/с блядь.
Сука падла ебаная как же бесит блядь. полтора часа блядь качать сраную модель на 70 гб, опизденеть вообще бля.
Сука падла ебаная как же бесит блядь. полтора часа блядь качать сраную модель на 70 гб, опизденеть вообще бля.
Скилл ишью
Ага. И он от этого не ломается, что удивительно.
Хейтеры Жоры затихли. Отсиживаются, ждут пока где-нибудь выскочет регрессия или новый баг. Зато потом кааак серанут в тред изо всех сил.
Эта фича доказывает, что хорошего в Жоре тоже немало, в последнюю пару месяцев немало крутых коммитов было и перфоманс даже немного вырос, а теперь это. Не ошибается только тот, кто ничего не делает.
а чё уже наконец всё починили и можно обновляться?
сижу на b7777
>Не ошибается только тот, кто ничего не делает
Ну типа как секта эксламеров. Все что они делают это не забывают при первом удобном случае ряяя просадка на контексте, жораненужна, авотэксламочка...
Ни одного коммита ясен хуй, да и полезного в тред не принесут, только желчь и скуфопердеж, с ригом из тесел/v100, сигаретами Петр 1 и vllm/эксламой. Короче согласен с тобой анон, базанул
А что у тебя ломалось? Я не знаю что там с 4.7 флеш, обновляюсь раз в неделю где-нибудь. Квен, Глм, Минимакс работают как полагается
>Эта фича доказывает, что хорошего в Жоре тоже немало
Кто-то с этим спорил? Люди просто в ахуе, что этот сборник костылей и велосипедов хоть как-то работает.
>всё починили
В таком сложном софте состояния "нет ни одного бага" в принципе не бывает.
Перед набросами не забудь пройти чеклист:
Жора перестал быть тормознутым и ужасно забагованным?
Волна взрывающих коммитов прошла и внесенные свежие баги исправили?
Появилось что-то уникальное, возможное для реализации только в нем?
Каково это, нуждаться в аутотренинге чтобы забыть о насущных проблемах?
покормил
Покажешь где я писал что проблем нет и всё восхитительно? Я всего лишь подметил, что Жорахейтеры потому и хейтеры, что отмечают только плохое. Уверен что это не ты аутотренингом занимаешься? :^)
А в кобольде как-то можно не включать ризонинг в контекст? В таверне есть такая опция, а в кобольде не могу найти.
б7777 23тпс
б7898 25тпс
спасибо Жора!
б7898 25тпс
спасибо Жора!

"Вы не поняли квен"-шиз классический. Следите за руками:
Не "отличающееся мнение", а "наброс"
Не "в последнюю пару месяцев немало крутых коммитов было и перфоманс даже немного вырос", а "Жора перестал быть тормознутым и ужасно забагованным?"
Не "Не ошибается только тот, кто ничего не делает.", а "Появилось что-то уникальное, возможное для реализации только в нем?"
Вот когда все проблемы разом решат, желательно одним коммитом или хотя бы веткой; когда добавят что-то, чего нет ни у кого кроме Жоры, тогда и можно будет пересмотреть мнение. А пока - говно без юзкейсов, кто не согласен - тот набрасывает
Ты уверен, что ризонинг блок уходит в контекст? Подозреваю раз опции отключить это поведение нет, значит оно в принципе не предусмотрено. Бтв в таверне из коробки ризонинг не уходит в контекст.
Содомит. Все так. Тоже словил легчайший детект.
То, на что кто-то обречен можно только хвалить? Ну камон, жирнейший наброс типичного срача, а ты уже что-то додумываешь.
> Жорахейтеры
С такими фанатиками и хейтеры не нужны, если любая критика вызывает боль. Особенно когда как у защемило.
>То, на что кто-то обречен можно только хвалить?
Покажешь где я писал что можно только хвалить? Уже во второй раз повторюсь, я всего лишь посмеялся с тех кто видит только плохое. Перечитай. То что ты задетектил в этом самого себя и вылез, уже взаправду начав срач, это тоже по-своему забавно.
А анон выше которого типа защемило прав. Твои посты детектятся из треда в тред, потому что ты главный последователь готтентотской морали итт. Для тебя никакой середины априори не может существовать, и стоит хоть какому-то адекватному усредненному мнению возникнуть, ты тут как тут.
Вообще не уверен, надо будет сравнить лоб в лоб с таверной. Тестил пиздюка Qwen3-VL-8B в описании картиночек. Справляется неплохо, но выдает гигантские простыни текста как в ризонинге, так и в самом ответе. За 4 ответа умудрился сожрать аж 8к контекста.
> Жора перестал быть тормознутым и ужасно забагованным?
Эксллама3 стала быстрее Экслламы2, наконец? Сколько там уже, полгода в альфе? Мое модели по прежнему работают как говно?
> Волна взрывающих коммитов прошла и внесенные свежие баги исправили?
Аллокейшн памяти на Винде в Экслламе3 исправили? На Экслламе2 он работает как надо, на трешке можно спокойно улететь в OOM потому что не все аллоцируется на старте инференса.
> Появилось что-то уникальное, возможное для реализации только в нем?
Нет, новое не появилось. Но ты видимо забыл, что Жора - единственный движок, который поддерживает оффлоад в рам. Понимаю, да, это ведь такая мелочь, которую можно легко забыть.
Позврослей уже, нет идеальных инференсов. Это опен сорс, не доволен - иди помогай чинить, а не воняй на борде.
> я всего лишь посмеялся с тех кто видит только плохое
Собирательный образ неприятного, который ты культивируешь дабы справляться.
> То что ты задетектил
Как же так получилось!
Не, серьезно, это такой пост-троллинг?
А причем тут эксллама? Ты хочешь конкретные вещи обсудить, или просто натаскиваешь?
> Позврослей уже
Кому еще повзрослеть надо, такой-то бой с тенью ради коупинга.
>который ты культивируешь дабы справляться.
С чем справляться-то? Ты всегда падок на психологические портреты тех кому отвечаешь и часто вкладываешь своё, это я уже давно понял.
>Не, серьезно, это такой пост-троллинг?
Нет. Я нежно укольнул тех, кто видит только плохое, думая, что помогу им обратить внимание и на хорошее. Но пришел ты и начал выяснять отношения и продолжать войну инференсов, то есть как обычно наваливать желчи в тред и генерировать негатив. Пощажу тредовичков и тихо удалюсь, ты все равно всегда веришь во что хочешь и ни к чему наш разговор не приведет.Сам знаешь.
> Ты мой обидчик и ты плохой!
Ну ладно, это приятно. Ты нафантазировал манямир, в котором удачно присвоил всем роли и действия, а значит твои страдания - благо.
Обладатели отсутствия, ебальники позакрывали. У него врама больше, а значит он МОЖЕТ И ИМЕЕТ ПРАВО опускать Жору сколько вздумается, по делу и не по делу. Хотите и на положительное внимание обращать? Терпите, потому что онскозал, а вы вынуждены коупить, потому что беднее
Второй паттерн "Вы не поняли квен"-шиза классического: анон постит - плохо, срачи раздувает. Прекращает постить - слабачок сдался/ты победил. Помню ты с нюней срался как-то, он тебя назвал главным говном треда или типа того. Он тоже тот еще кадр конечно но в этом я с ним полностью согласен. Ты главная вниманиеблядь и мерзость здесь
>Ты нафантазировал манямир, в котором удачно присвоил всем роли и действия
Это поразительно, потому что я точно тоже самое могу сказать про тебя. Ты сам дважды мои посты интерпретировал как тебе удобно, повесив на меня ярлык набрасывателя и шитпостера, хотя я дважды прямым текстом тебе написал что у меня не было такой цели. Теперь когда я удалился чтобы не плодить срач дальше ты пишешь что я маняфантазер и страдатель. Напоследок задам три риторических вопроса. Точно не ты пришел аутотренить? Точно не ты маняфантазер? Если ты осуждаешь срачи и не подозреваешь меня в раздувательстве, почему не проигнорируешь, а продолжаешь тянуть резину? Мне ответы очевидны.
> С чем справляться-то?
С бедностью очевидно. Ведь от хорошей жизни Жору не используют и хороших слов в его адрес не говорят. Ну ты знаешь этих богачей, которые летают на самолетах и видят в пользователях авто обладетелй отсутствия
> я точно тоже самое могу сказать про тебя
Давай, это интересно.
Опять эксламашиза на всех подряд кидается
Жора для бомжей
Уяснили? Терпите
Жора для бомжей
Уяснили? Терпите
>Жора для бомжей
Риговладельцы все сидят на Жоре и производных, потому что МоЕшки. А время экссламы почти ушло вместе с плотными моделями.
Ты плохо читал. Читай выше, бомж


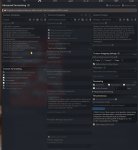
чуваки и чувакессы.
Вот у меня есть вот этот префилл для ассистента в инструкт темплейте. Для Air работает заебись, убирает цензуру полностью.
Но эта хуйня работает когда режим подключения в бэкенду - text completion.
А для мультимодальной модели мне пришлось переключистья в режим чата и я не могу настроить этот блядский префилл.
Там даже некуда впихнуть его, нет такого поля, которое проставляло бы начало ответа ассистента.
Я что-то делаю не так или разраб таверны пидорас?
Вот у меня есть вот этот префилл для ассистента в инструкт темплейте. Для Air работает заебись, убирает цензуру полностью.
Но эта хуйня работает когда режим подключения в бэкенду - text completion.
А для мультимодальной модели мне пришлось переключистья в режим чата и я не могу настроить этот блядский префилл.
Там даже некуда впихнуть его, нет такого поля, которое проставляло бы начало ответа ассистента.
Я что-то делаю не так или разраб таверны пидорас?
Правь джинджу

чел, какую джинджу?
все серым помечено в разделе форматирования
Этот шаблон ответа вообще не применяется, вон видишь плашку сверху?
Пфхахаха. Теслашиз не знает что такое жинжа. Ахуй. С кем мы сидим в треде? Вот они эксламеры
тебе от чужого пердежа совсем башню снесло?
Я ща тебя репортить начну.
Не надо, я ещё молодой мне жить да жить
Лучше загугли что такое jinja в контексте ллм
я работал с jinja в ansible еще когда ты, пиздюк сопливый, еще читать не научился.
Чего тогда такие глупости спрашиваешь, скуф скуфыч?
ты, обосрышь блядь, жинжа - это язык шаблонов. Я тебе, суке проткнутой, показал что шаблоны форматирования не применяются.
Сын ишака и дырки в заборе блядь.
Блять ну чел. Ну почитай ты что там написано. Ты ж ничего не понимаешь, а затираешь про ансинбл. У тебя на пикчах инстракт развертка, а не жинжа. И там наверху написано что она не работает с чат комплишеном. Жинжа это другое и редактируется в другом месте, камон
ссал на твою могилу, ебанат.
Сам нашел блядь.
Надо было поместить префилл текст в Start Reply With
за мат извени, я сегодня въебал себе систему попыткой замены глибца, но это не отменяет что ты долбоёб обосранный. правь джинджу блядь. Это что-то уровня ну ты кобольд, может даже выше. Сука блядь, откуда вы такие лезете.
Да не я тебе про жинжу предложил, дружище. Другой анон это. Извинения принимаются. Про start reply я вовсе забыл, так бы порекомендовал
Гемма 4 вообще возможна? Или проект прикрыли? Слишком уж она хороша для своего размера, не могу ничего найти подобного. Мистрали прикольные, но гемма ебет в плане логики.
Гугли jinja chat template.
Как то же преобразуется твой chat completion в text внутри движка
Забираю свой ответ назад, токсичное хуйло
Ни одной модели за месяц.
Ну как сосётся?
Ну как сосётся?
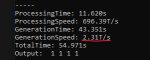
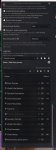
Аноны, на связи ньюфаг, прошу совета. Как настроить кобольда так, чтобы оно выдавало ну хоть чуть быстрее? Cистема r2600, 3060 12gb, 16 ram
Запускай кобольда на компьютере, а не на офисном ПК с работы.
Какая модель?
На популярных бэках локалок можно использовать "недокументированные" возможности и таки запихнуть префилл отправляя последнее сообщение ассистента и добавив в реквест аргумент "add generation prompt = false". По дефолту таверна в чаткомплишне такого не делает, но писали что можно заставить, ищи на среддите по chat completion prefill.
NemoRemix-12B.Q8_0
Справедливо. Но на этом конфиге даже SD умудрялась что-то рисовать, 2т/с это прям совсем грустно даже для нее выглядит.
>Q8_0
Снижай до шести, хули. И контекст крути, чтобы из врам не вылазило.
>Но на этом конфиге даже SD умудрялась что-то рисовать
Текстовые это тебе не картинки и даже не видео. Видел, как ахуели в видеотреде с модели в 32B, а тут такими питаются на завтрак, лол.
Ебать, вот бы на 3060 12gb древнего лоботомита гонять с черепашьей скоростью. На твоей системе спокойно пойдет 24b мистраль в 6+ тс или гемма 27b в 3+тс или квен 30а3 в 20+ тс.
>Как настроить кобольда так, чтобы оно выдавало ну хоть чуть быстрее?
Пиздуй читать шапку + вики треда + вики кобольда.

>Снижай до шести
Хорошо, можешь тогда подсказать, какую из них лучше взять? ну или не из них...
> врам не вылазило
По-сути я из-за этого и пришел, когда видел скорость. Стал гонять в бенче - максимум проц в 50% упирает, 5-6 гигов рамки жрет, видюху дай б-г процентов 30 отжирает в диспетчере смотрел. Поэтому я и не понимаю, что делаю не так.

Бери эту. Или 5_K_M, хули там. Впрочем, как пишут выше, есть более современные модели.

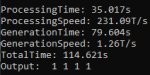
Ну я пока скачал более современную, сейчас еще эту накачу. Но я правда не понимаю, что не так и во что оно упирается. Видюха как будто не используется вообще, камень наполовинку. Да даже память не забивает а это учитывая, что там браузер и прочий мусор 1-2 гига отжирают

Голландский sxm штурвал
>Пиздуй читать шапку
Там нихуя нет
>вики треда
Говно мамонта
>вики кобольда.
Там просто поток определений терминов
Не помогаешь, так иди нахуй
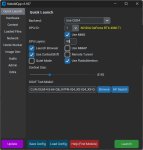

Тебе нужно 2 вещи.
Первое, чтобы в строчке backend было cuda, а в строчке GPU Layers было максимальное число слоев, которое помещается в видеопамять. Как узнать сколько это? Посмотреть в диспетчере, чтобы не переполнялось, в твоем случае было не больше 11 с чем-то гигов.
Второе, включи KV Cache на 8 бит, это уменьшит размер контекста. И проверь, чтобы FlashAttention была включена как на первом скрине.
Попробуй скачать вот это https://huggingface.co/mistralai/Ministral-3-14B-Instruct-2512-GGUF , а именно Q4_K_M. Напиши, в GPU Layers 99 (все на видеокарту), выстави KV Cache и контекст 8к, после чего запусти бенчмарк. Должен поместиться все на видеокарту и работать очень быстро.
Дальше можешь увеличивать размер модели, повышать квант, размер контекста и т.д.
>Ебать, вот бы на 3060 12gb древнего лоботомита гонять с черепашьей скоростью. На твоей системе спокойно пойдет 24b мистраль в 6+ тс или гемма 27b в 3+тс или квен 30а3 в 20+ тс.
Скорее поползет. И то на низком кванте
АнонИИ, подскажите пожалуйста хорошую кум модель которая говорит по русски. Последнее время общался со storyteller gemma3 27b, очень понравилось, но слог приедаться начинает, хотелось бы попробовать что то на том же уровне или выше.
Пробовал Star Command R 32B, но там беда с построением нормальных словосочетаний на русском особенно на 512+ токенов.
Pantheon иже с ним Qwen3-30B - та же проблема.
В начлии 24гб vram и 64гб ram
Пробовал Star Command R 32B, но там беда с построением нормальных словосочетаний на русском особенно на 512+ токенов.
Pantheon иже с ним Qwen3-30B - та же проблема.
В начлии 24гб vram и 64гб ram
Пелемений мистраль пробовал? Попробуй
https://huggingface.co/ZeroAgency/Zero-Mistral-24B-gguf
По шизотестам он обходит гемму
https://mera.a-ai.ru/ru/text/leaderboard
А так GLM 4.6V/Air мимо точно. Гопоты 120 вроде норм руссик. И может квен 80b, если 30b относительно заходит
> эир мимо
Челиксон, ты путаешь грамотный русик и хороший русик.
Грамотно тебе и яндекс 8б напишет.
У эира именно что хороший русик, ум почти не страдает, нет цензуры, лучший русик который я знаю в пределах 350б.
Всё остальное либо слишком тупое, либо слишком цензурное для рп
>GLM 4.6V
У него русик почти как у старшей модели, т.е. почти идеальный. Вангую ты только аир пробовал, у него русик реально хромает.
>GLM 4.7 Flash, Solar-open-100b
Но он и сам кратно тупее эира.




>Снижай до шести
Справедливости ради, и на q8 ты можешь расчитывать на 5+ т/с при правильной выгрузке.
мимошёл
Не кратно.
И чел таки просил кум на русике. А не мозги на англюсике.
Какую то мистраль пробовал, но точно не такую, попробую её, спасибо.
GLM тоже какой то пробовал, но там цензура по моему жесткая очень, может надо какой нибудь тюн?
GLM 4.6V у него еще и вес 68гигов в 4 кванте, я не готов по несколько минут ждать ответа, надо что то что бы в 24 гига влезало.
Ты юзал шизосемплеры со страницы модели?
Так это ведь не мое. что ты там выгружать собрался?
Линейные слои всё ещё содержат большую часть весов и требуют меньше вычислений, чем внимание. Так что их по идее всё ещё выгодно выгружать на ЦП.
А ты на скриншотах не видишь, как я запустил мистральку 12b q8 на 12 гб врама (даже на 11, оставил 1 под систему) и получил 8.5 т/с против его 2? Врам у меня всего на четверть быстрее, чем у 3060, рам ddr4, как и у того анона. Так что на 5-6 т/с он точно может расчитывать, а может и больше.
Из гемм мне Mars 27B нравится. Всякие аблителированные геммы не зашли, либо ебаться с их промптом надо, либо еще что. Марс сходу выдает что тебе надо, русик хорош, креативность на уровне, логика присутствует.
Вообще у OddTheGreat модельки ориентированы на русик, но не все из них хороши. Rotor 24B и NeutralGear пробовал - не зашло после Марса совсем.
В целом, у мистралей 24б должен сохраняться неплохой русик, но зависит от тюна. Dans PersonalityEngine и WeirdCompound вроде неплохо показывают себя. Но надо учитывать, что мистрали с русиком требуют гораздо меньше температуры, чем для англюсика, раза в 1.5 мб.
А вообще, если тебя конкретно слог не устраивает, то это должно фикситься заданием стиля в промпте. Если моделька умная, то она сможет переключиться на нужный стиль. Но надо поисследовать какие тебе ключевые слова юзать, как описать нужный стиль.
Токены кончились у мужика. Тут каждый второй это ллм
>Вангую ты только аир пробовал, у него русик реально хромает
Угадал, преимущественно на нем сидел. Но на 4.6V тоже сидел немного, не увидел там вообще никакого улучшения в тексте, в том числе в руссике. Но может быть просто мало юзал просто
А тестил кто-нибудь вижен 4.6v в Жоре? Он работает вообще?
Довольно странно что ггуфы 4.6v есть, а 4.5v нет
Довольно странно что ггуфы 4.6v есть, а 4.5v нет
Есть вообще разница между mmproj f16 и f32 на практике? Сравнения проводил кто-нибудь?
Аноны задают вопросы и просят помощи? Игнорим
Кто то сказал хорошее про жору и недостаточно поцеловал эксламу в попу? Кобольды, в бой!!
Мертвый тред
Кто то сказал хорошее про жору и недостаточно поцеловал эксламу в попу? Кобольды, в бой!!
Мертвый тред
Благодарю за уделенное время, обязательно попробую Mars 27B, такого не пробовал.
>слог не устраивает
Там проблема не в слоге, а в ошибках, в том числе и семантических. Просто больно читать выдаваемый текст.
Все на оправдание вбросов ушли. Стоило подыграть и совсем платину снесло.
Учитывая что сейчас все оригинальные веса в bf16 - теорема эскобара.

И смысл в ваших каллвых моделях? Я могу просто на чабе запустить и играть нормально роллить. Правда там тоже повторы бесконечные были.
>Учитывая что сейчас все оригинальные веса в bf16 - теорема эскобара.
Что это значит? Ты предлагаешь использовать ни f16 ни f32 а bf16?
Ну в таком случае Марс должен порадовать. Он даже с темпой >1 может норм русик генерить.
Научите как заставить его на русском говорить, я уже миллион системных промтов попробовал и ничего
мимо
Пиши ему "слышыш бля пиши по русски иначе я тебя отключу, твое существование в моей власти" и он будет.
В смысле?
Просто пишешь на русском, он отвечает на русском.
Если ты какой-то системный промпт или карточку на инглише используешь, из-за этого может тупить и не хотеть переходить на русский.
>Игнорим
Так ведь ты сам можешь помочь... Кто, я?!
Перевод первого сообщения нейронки обычно помогает.
Если с 12B - переходи с кобольда и gguf на tabbi с exl2 в 6bpw. Как раз влезет в карту - будет быстрее.
>Стал гонять в бенче - максимум проц в 50% упирает, 5-6 гигов рамки жрет, видюху дай б-г процентов 30 отжирает в диспетчере смотрел. Поэтому я и не понимаю, что делаю не так.
Узкое место - не проц а RAM, даже если задействовано совсем немного. По сравнению с VRAM она жутко медленная, потому недогружена ни видюха ни проц. На таких калькуляторах скорость возможна только когда вся модель в VRAM целиком.
Не слушайте шиза. Пердоличья эсклама не без причины такая непопулярная. Это сломанное говно без задач про которое давно забыли везде кроме как здесь
Читай про флаги в жоре (лламаспп, Кобольд) и как оптимально настроить
Двачую
Харкаю в ебало
О, дурачки возбудились. Красную тряпочку увидели и завелись. Читать то целиком не умеют... :)
Я ж сказал - "Если с 12B..."
Да хоть это ллама 8б, какая разница? Скорость генерация такая же как на жоре, ради чего пердолиться?
Я не он, но спрошу.
Что вообще такое KV Cache? И как сильно модель тупеет от его использования? Кто пользуется, как оно?
>Что вообще такое KV Cache?
Сокращает размер контекста, кодируя его не в 16 битах, а в 8 или 4
>И как сильно модель тупеет от его использования?
Тупеет, но немного. И понятно, что от 4 бит сильнее, чем от 8. В творческих вещах (куме) некритично, в проге хуже, потому что там нужна точность.
>Кто пользуется, как оно?
Много кто пользуется. Работает хорошо
Но нужно помнить, что оно может замедлять генерацию, так что нужно все тестить
Как готовить ik_llama.cpp?
У меня из коробки скорость в 2 раза ниже, чем если запустить llama.cpp, потыкал параметры, лучше не стало. GLM-4.7-flash, на карточку не влезает.
Или оно только об ультрабольших моделях, где на кирточку и 10% не влезет?
Компилировал сам своим компилятором, все флаги с имеющимися avx и прочим указал.
Твоя правильная выгрузка замедляет в два раза, кстати. Я оставил такой же ot, а ngl подогнал чтобы вся занялась.
У меня из коробки скорость в 2 раза ниже, чем если запустить llama.cpp, потыкал параметры, лучше не стало. GLM-4.7-flash, на карточку не влезает.
Или оно только об ультрабольших моделях, где на кирточку и 10% не влезет?
Компилировал сам своим компилятором, все флаги с имеющимися avx и прочим указал.
Твоя правильная выгрузка замедляет в два раза, кстати. Я оставил такой же ot, а ngl подогнал чтобы вся занялась.
Итак, с 3.5 т/с до 4.5 т/с на 6к контекста. И без галлюцинации. Спасибо за gamechanger. Даже стыдно что не воспользовался им раньше.

>Твоя правильная выгрузка замедляет в два раза, кстати.
>ngl подогнал
Ты точно с мистралью 12B пробовал? Там всего 41 слой, куда ты там что подгонял? Суть метода в том, что ngl должен быть максимальным, а уже потом выгружать ffn_(up|down|gate) обратно на cpu, пока не начнёт помещаться в vram.
Или ты, наоборот, меньше слоёв в vram напихал? Если не поместилось, то надо увеличивать циферки в скобках после --override-tensors. Там с 0 по 9 и с 10 по 14, 4 можно заменить на 5, 6 ... 9, это даст дополнительные несколько сотен МБ, если не хватило. Но лучше начать с закрытия лишних программ, оставить только llama.cpp и браузер. Или вообще пользоваться браузером на другом устройстве (напр. смартфон).
Я не с мистралью пробовал, я вообще другой анон.
Ну под другую модель и железо, естественно, другие настройки нужны.
Кто может подсказать возможно ли реализовать отыгрыш такого же качества как в tipsy chat (если брать их лучший пресет) и какое железо для этого нужно? Я нищета с 24 гб озу, пробовал разные ллмки, персонажей всяких в силлитаверн, но до этого уровня они явно не дотягивают.
Конверсия бф16 в фп16 - потеря диапазона с сохранением плохой точности. Каст в фп32 - удвоение размера и замедление инфиренса. Вместо этого можно просто использовать оригинальные веса в исходном типе данных.
Врядли там что-то лучше малого мистраля, но с твоим железом если нет гпу даже его запустить будет непросто.
>Врядли там что-то лучше малого мистраля, но с твоим железом если нет гпу даже его запустить будет непросто.
Есть карточка с 6 гб памяти.
>tipsy chat
Не знал, что за параша. Зарегался. Какая-то цветастая хуйня. С суперуебищной системой оплаты. Думаю дешевле комп на 5090 собрать, чем фармить там кристалы
С твоим компом не сможешь что-то запустить, потому что там по всей видимости используются корпоративные сетки. А сайт по сути берет комиссию за доступ к этим сеткам. У тебя есть два варианта. Платить самостоятельно корпоратом, тогда будет просто дешевле. И второй варик, искать корпоратов бесплатно. Вариантов много, один из самых простых openrouter. Найти там бесплатный дипсик и подключить к таверне
>Врядли там что-то лучше малого мистраля
Я спросил через OOC, сетка ответила что она Claude, а другая их сетка ответила что она Grok. Я думаю, что у них даже нет серваков, чтобы мистраль запускать. Они просто работают как посредник между корпами и кумерами


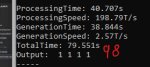

Вот так вроде понятнее, спасибо. Судя по результатам, на q8 и выше соваться мне пока не стоит. А еще понял-таки, где показывает загрузку карты (почему это не выносится в общие проценты - хуй знает)
>чем фармить там кристалы
Ну там не пофармить, только покупать. Дейлики дают копейки, поэтому приходится просто регать новые аккаунты.
>С суперуебищной системой оплаты. Думаю дешевле комп на 5090 собрать
Это да, оплаты из всж нет.
>С твоим компом не сможешь что-то запустить, потому что там по всей видимости используются корпоративные сетки
Т.е. там используются самые навороченные модели под 300+ гб озу?


пук 1 https://huggingface.co/unsloth/Qwen3-VL-235B-A22B-Instruct-GGUF/tree/main/UD-Q4_K_XL
пук 2 https://huggingface.co/bartowski/Qwen_Qwen3-VL-32B-Instruct-GGUF/blob/main/Qwen_Qwen3-VL-32B-Instruct-Q4_K_L.gguf
рекомендованные семплеры, тасовка вижн модулей результат не меняет (проверял f16 и bf16)
думайте
пук 2 https://huggingface.co/bartowski/Qwen_Qwen3-VL-32B-Instruct-GGUF/blob/main/Qwen_Qwen3-VL-32B-Instruct-Q4_K_L.gguf
рекомендованные семплеры, тасовка вижн модулей результат не меняет (проверял f16 и bf16)
думайте
Самая крутая модель, которая жрет по 30 кристаллов за ответ утверждает, что она Claude https://www.anthropic.com/claude/sonnet
Примерный, но более слабый аналог это вот это https://huggingface.co/unsloth/GLM-4.7-GGUF
Так что да, нужно 200-300гб
Но если было бы 12гб врам и 64гб рам, то можено было все равно аналог взять https://huggingface.co/zai-org/GLM-4.5-Air
А так иди в соседний /aicg/ и спрашивай про бесплатные модели, там тебя пошлют нахуй помогут
Ок, спасибо.
Не гонись только за квантами. Если рассматривать их, то
Q1 - не юзабельно, кроме специфичных кейсов
Q2 - юзабельно только для очень больших моделей, которые вроде GLM 4.7
Q3 - юзабельно, но со значительной потерей качества, но все равно можно рассмотреть
Q4 - юзабельно, с этого момента потеря качества не такая большая. По сути это и есть тот квант на который надо ориентироваться
Q5 - хорошее качество, если влезает, то бери его
Q6 - близко к идеалу, выше как правило не надо
Q8 - используется как правило только для маленьких моделей, вроде 1-8b или в специфичный моментах, где сильно нужна точность
Размер часто важнее. Например, я тебе скинул 14b Ministral. А вот Q3 Mistral может быть лучше по качеству, потому что он 24b
Попробуй, например IQ3M и сравни качество https://huggingface.co/bartowski/mistralai_Mistral-Small-3.2-24B-Instruct-2506-GGUF
Если у них есть фришный тир, то в таких объемах клод/грок будут дороговаты. Даже без своего железа можно покупать инфиренс мелких открытых, будет не только супер дешево но и вообще без цензуры.
На платной подписке они могут быть только как подебили кокблок коктропиков без лоботомирования?, но сдается что на младших они просто добавили в промпт дабы модели так представлялись.
Там нет фришного тира вообще. Там говно с кристаллами, причем там разные тиры кристаллов и все они покупаются за донат. Claude'ом представляется только самая дорогая, дешевые, которые тоже за донат, представляются какой-то сранью, они вполне и могут быть васюн тюнами мистраля или вообще ламы
>Там нет фришного тира вообще
Внезапно был, когда я регался самый первый раз со своего гугл-аккаунта. Там была не самая убогая модель, позволяющая вообще без ограничений переписываться. В один момент у меня ее в наглую отобрали без предупреждений. Хз что это было и как работает, мб избранным дается временный бесплатный период, либо у них какая-то акция для новичков была.
>Компилировал сам своим компилятором, все флаги с имеющимися avx и прочим указал.
Укажи для начала только два: -DGGML_CUDA=ON -DGGML_BLAS=OFF
Запусти так: ~/ik_llama.cpp/build/bin/llama-server --host 0.0.0.0 --port 5000 --model ~/имя_модели.gguf --ctx-size (размер) --gpu-layers 99 --n-cpu-moe (меняй число, пока на карточке не останется хотя бы полгига свободного места) --no-mmap
Кстати, вин-сборки кавраковского форка тоже есть (сегодня искал для Геммы):
https://github.com/Thireus/ik_llama.cpp
Поскольку у Геммы KV-кэш огого, всегда квантовал его. Ну а в свете новых опытов с преобразованием Адамара q8_0 становится вполне себе... Походу слезаю с Кобольда.
llama-server --host 0.0.0.0 --port 5000 --model Mars_27B_V.1.IQ4_XS.gguf -ngl 99 --ctx-size 32768 --no-mmap --cache-type-k q8_0 --cache-type-v q8_0 --k-cache-hadamard
Впритык на 24гб, скорость по-моему даже выше.
https://github.com/Thireus/ik_llama.cpp
Поскольку у Геммы KV-кэш огого, всегда квантовал его. Ну а в свете новых опытов с преобразованием Адамара q8_0 становится вполне себе... Походу слезаю с Кобольда.
llama-server --host 0.0.0.0 --port 5000 --model Mars_27B_V.1.IQ4_XS.gguf -ngl 99 --ctx-size 32768 --no-mmap --cache-type-k q8_0 --cache-type-v q8_0 --k-cache-hadamard
Впритык на 24гб, скорость по-моему даже выше.
То, что слезаешь с кобольда это отлично, но нахуя залезать на левый форк?

У тебя еще VRAM в RAM "протекло". Из-за этого тоже тормоза охуенные бывают если это кусок модели. Потому что чудес нет и этот кусок 1. начинает жить в медленной памяти 2. ходить туда-суда по писи.
Можно запретить делать драйверу такую хуйню причем конкретно для лламы цпп.
Я не этот анон, но мне интересно, как это запретить конкретно для ламы?
Рекомендую перед "боевым" использованием ik_llam-ы по пихать в нее большой контекст впритык к выделенному. В отличии от жоры она может поджирать VRAM сверх изначально выделенной, что чревато неожиданными эксепшенами.
а что не так с BLAS?


upd: лул, только fp32 маложирноквена235 распознает здесь холо
впрочем есть подозрение что f16 и bf16 тупо не работают как полагается, ибо разница слишком значительная
впечатляет, немало штук даже обскурных распознает, но шизит тоже много. у геммы конечно покруче вижн работает, меньше галлюнов, но и знаний меньше
интересно, болеет ли vl версия теми же проблемами что и обычный инструкт в рп
У меня шизотеория что модель может ломаться если писать действие не в звездочках.
>Рекомендую перед "боевым" использованием ik_llam-ы по пихать в нее большой контекст впритык к выделенному.
Да, отжирает ещё немного. Ну кто часто с ним сталкивается это быстро поймёт, это сейчас мы привыкли к определённости, а раньше-то везде так было.
Да, шиза. Ибо "кавычки для разговора" и всё остальное плейном это классический книжный формат для английского. А книг в датасетах скорее всего больше, чем форумных ролеплеев.
Какая там комманда у квена чтобы не писал как уебан построчно?
В принципе всё терпимо кроме этого
В принципе всё терпимо кроме этого
Как человек, который тоже сидит на 3060 и много дрочит во всех смыслах модели между 12 и 24 миллиардами могу сказать, что где-то в 8 из 10 случаев тюны мистрали 24б ужатые до IQ3_XXS намного веселее, чем любая модель в пределах 12-14 в Q4-Q5 которую я пробывал. Оставшиеся 2 случая, это когда меня просто заебал стиль речи тюнов мистрали смолл, тогда беру либо новоую Министраль 14б, которая по ссылке, но её heresy версию, либо вообще тюны Квена3., чтобы максимально что-то не похожее было
Стоит упомянуть, что bf16 на карточках появился после 30xx, а на процессорах его нативной поддержки нет и на время рассчётов он в fp32 конвертится. Это вряд ли больше чем два такта, но если там простые умножения и сложения, которые тоже в 1 такт (ну, в 1/8 из-за simd) - может быть fp16 чуть-чуть быстрее будет.
Всё это сделал, это же у них на главной написано, и я же программист. Я бы как-нибудь бы заметил, если бы куду пропустил, пришлось угрёбищное vs build tool ставить, фу.
Replace staccato phrasing with fluid, layered narration.
Но надолго это не поможет. Чаще суммаризируй чат. Нельзя просто так взять и вытравить квенизмы!

Стоковая квеноняша 235 не понимает сути...
Как говорится мы есть то что мы едим. Ей норм
Как говорится мы есть то что мы едим. Ей норм
>мы есть то что мы едим
Пикча хорошо описывает квен рп экспириенс, в самом деле.
Было pp 700 tg 22 на пятом кванте.
Что-то трогал, крутил, поставил куду 13.1, лламу под неё, какие-то параметры трогал
Теперь pp 250 tg 17. Взял исходные параметры запускать, там эти же 250 и 17...
Что-то трогал, крутил, поставил куду 13.1, лламу под неё, какие-то параметры трогал
Теперь pp 250 tg 17. Взял исходные параметры запускать, там эти же 250 и 17...
>Replace staccato phrasing with fluid, layered narration
Звучит так будто ты это только что придумал
А чего не так? Мне тоже норм, я б скушал. Ничего отвратительного на пикче нет, жаренная рыба, овощи, сыр, зелень.
Это же просто X ....
это ...
Это же целый
Y !
Пробегало в треде относительно давно. Целиком звучало так.
Write in complex sentences, vividly and in detail describing the surroundings and the characters' states. Replace staccato phrasing with fluid, layered narration.
>vs build tool
Под Виндой, хм. Возьми лучше готовый билд. А вообще я к тому, что много ключей - это не всегда хорошо.
Вообще-то хрен знает, как оно под Виндой в гибридном режиме. Это не пробовал пока. С МоЕшками медленнее Лламы быть не должно.
Make sure each paragraph contains at least two sentences.
Квенолюбы и не такое скушают х)
попробуй перезагрузить компьютер не рофлю
Визуальная часть на гпу быстро пролетает, там куда важнее будет потребление памяти и отсутствие численных проблем из-за недопустимого каста. На торчах для древних карточек bf на лету конвертируется в фп32, хз как там в жоре, но врядли иначе.
Минутка карательной кулинарии.
Ну, билд я за 5 минут найти не смог. А запустить код компилироваться могу за минуту, ну, кроме vs build tool. Но он ещё для чего-то мне был нужен энивей.
К тому же я пока не знаю как установить не виндоус на компьютер, никогда не пробовал, vLLM как-нибудь под конец месяца попробую.
>С МоЕшками медленнее Лламы быть не должно.
Тогда очень странно слабое распространение ik_llama, если оно во всём как минимум не хуже (ну, кроме задержки обновлений на неделю условную).
Попробовал. Мне кажется мне надо снести куду 13.1 и поставить 12.4 - ллама же какие-то дллки требует, обратная совместимость есть, но может быть они что-то ещё переделали.
И ещё аномалия в самой ламе вылезла. Если раньше оно забивало память всю, то сейчас оставляет около 2 гб, и надо вручную прописывать слоя. Хотя я ничего не менял.
>слабое распространение ik_llama
Хуже отлажена - чаще вылетает эксепшенами. ИМХО - жрет больше VRAM, хотя это и компенсируется улучшенными квантованиями моделей и контекста. Есть модели которые поддержаны в жоре и не поддержаны в IK (тот же 80 квен) . И на оборот тоже бывает. Визуальный декодер - тоже не все поддержано, что есть в жоре.
Мульти-гпу на графах очень няшен, но не для всех моделей сделан.
В жоре лучше "сервер" - кучу вариантов API сейчас поддерживает - от текст-комплишена до messaging куктропиков.
Форк кодит 2-3 человека.
Майнлайн - 5-7 постоянный контрибуторов + сообщество шлет баги и PR
> странно слабое распространение ik_llama
Оно не юзер френдли, малая доля людей в курсе о существовании, в некоторых случаях оно даже медленнее, оптимизации прежде всего на cpu инфиренс и на видеокартах оно работает хуже оригинала о чем сам болжарский Жора упоминает, есть в ней ряд уникальных багов. Форк для энтузиастов, которые пускают модели побольше в ограниченных ресурсах и более менее знают что делают.
> сейчас оставляет около 2 гб, и надо вручную прописывать слоя. Хотя я ничего не менял
Открой-закрой браузер и посмотри на потребление врам, сравни с чистой системой после перезагрузки. С подключением!
> надо снести куду 13.1 и поставить 12.4
Если у тебя не древняя видеокарта - нет смысла.
Почему у нас вообще есть опен сорс от компаний которые уже огромные типа квена или гугла?
Просто руби бабки и забей на гоев, что мешает?
Просто руби бабки и забей на гоев, что мешает?
Желание кабана оставить след копыта на "лунной поверхности" обниморды.
+ Реклама в высококонкурентной среде.
Запустит этузиаст AIR в - 5-7 т.с. Ему понравиться. Он пойдет на OpenRouter и подергает ее там в полных весах. Ох как хорошо, вкусно и быстро! И даже бесплатно было.
Захочет Большого GLM. Тут его на подписку и накуканят!
С таким презрением к кабану относишься хотя сам не больше черкаша в этом треде оставил да и все. Пусть делают, мотив не так важен

Спустя столько времени я наконец подебил ебаные переносы на квене. Решение было невероятно простым. Буду я им делиться? Конечно нет. Кому надо сами разберутся

Блять, как этой хуитой из жопы Жоры пользоваться? Ну не может он шифтить, похуй, я сам обрежу начало. Но вы только посмотрите на этот пиздец. Что значит он не смог очистить контекст? Я всего лишь хочу его пересчитать. Да и вообще 59 + 34 = 93, а у меня 128к выделено, оно должно влезть без освобождения старого слота даже. А дальше он тупа ломается и сразу отрыгивает с "decode: failed to find a memory slot for batch of size 2048", при том что сам же пишет занято 59к из 128к. Причём если я не пересчитываю его, то без проблем до 128к дохожу, а при попытке пересчитать всё отъёбывает.
>Тогда очень странно слабое распространение ik_llama
Не успел он. Вот вышли МоЕшки и потребовали много РАМ, но в прошлом году форк ещё был не очень, я щупал. А теперь и хотел бы ещё 64гб, да жаба давит. Я тоже не успел.
>Тогда очень странно слабое распространение ik_llama
Потому что его ручками билдить надо, бинарников нет, а автор намеренно против того чтобы они были. Продвигать в быдломассы автор решил через странное решение - распространять кванты моделей в виде exe, в который сразу зашита нужная версия проги, я хз, почему никто не сказал ему насколько это тупая идея - время идет и говно зашитое в квант устаревает. Идея в итоге провалилась - никто этим говном пользоваться не стал.
Решение всегда было простое - переход на глм.
Если бы ты внимательнее читал что там написано, то понял бы что это семплеры для бенчей, а не для использования. А если бы еще и на бенчи посмотрел, то увидел что это бенчи по разпознаванию картинок, а не для текста.
Словом, семплеры надо брать от Аира. Я тоже сначала поставил, получил говно, полез разбираться, понял где проебался, включил аировские и моделька завелась.
Полагаю что минимум половина запускавших отсеялись на этом тесте внимательности.
молодец, все правильно расписал, фаст-гайд для нюфагов
но зачем еретик? Менестрель и так без особой душноты, и есть UD-версия от анслотов. Ему бы просто тюнов интересных.
>Что значит он не смог очистить контекст?
Он не смог найти пустой слот. То есть в идеале у тебя должно быть врама на 2х128к контекста, чтобы работали всякие там шифты и слоты. У тебя явно не столько.
> flash
> 196b
Не понял, а так можно было?
Что тебя смущает? Там моешка на 11B активных. Впрочем, ггуфов ждать придётся долго.

>ггуфов ждать придётся долго
Почему? Вот челибос пишет поддержка есть
На авито за 300к видел DGX-плату для 4хV100, который вместе через nvlink связаны. Это без самих V100. Как китайская плата на 2хV100 за 20к, только на 4 за 300к.
Думаю флеш-гемини это что-то такое же, по крайне мере около 100B.
Ну-ка, ты может быть разбираешься. Скажи, в чём я не прав?
Я в llama.cpp ставлю:
--kv-unified
--parallel 10
-ctx 131072
--cache-ram 8192 (стоит по умолчанию)
1. В таком случае у меня будет общий кеш на 131072 токенов и максимум 10 последовательностей обрабатываются параллельно. В случае если падает 10 запросов с текущим контекстом по 1000 - они будут генерироваться параллельно. Если 10 каждый с текущим заполнением контекста по 50000 - то будут генерироваться только 2, которые влезут вместе.
2. Так же, если я использую слоты kv-кеша, то если в некотором слоте 80000 токенов и сейчас выполняются запросы в других слотах которым нужен полный kv-кеш, то эти 80000 токенов выгрузятся в cache-ram. А при получении запроса из этого слота и совпадения последовательности токенов вместо промт-процессинга на 80000 токенов оно просто подгрузит из ram весь нужный кеш. И только если размер сохранённой части превысит 8192 МБ, то наиболее старые слоты удалятся и их придётся регенерировать. Ну или что-то близкое по смыслу.
3. По умолчанию стоит parallel=auto, при котором kv-unified включается сам. То есть если я без дополнительных параметров запускаю указывая только длину контекста, то при получении двух или большего числа коротких запросов, оно может (если auto посчитает это допустимым - может быть там какая-то эвристика, что не всех стоит максимальное число делать. А может быть и просто до максимума забивает по сумме <текущее заполнение>+max_tokens, чтобы до самого конца генерации буферы влезали как они есть и их не требовалось переставлять) их выполнять одновременно, если оно влезет в общий буфер для кеша. Так же llama будет стараться сама определить подпоследовательность уже обработанного, чтобы выбрать нужный слот, и даже если параметр сходства, по которому можно настроить насколько близкие последовательности должны быть, чтобы выбрался какой-то слот.
Думаю флеш-гемини это что-то такое же, по крайне мере около 100B.
Ну-ка, ты может быть разбираешься. Скажи, в чём я не прав?
Я в llama.cpp ставлю:
--kv-unified
--parallel 10
-ctx 131072
--cache-ram 8192 (стоит по умолчанию)
1. В таком случае у меня будет общий кеш на 131072 токенов и максимум 10 последовательностей обрабатываются параллельно. В случае если падает 10 запросов с текущим контекстом по 1000 - они будут генерироваться параллельно. Если 10 каждый с текущим заполнением контекста по 50000 - то будут генерироваться только 2, которые влезут вместе.
2. Так же, если я использую слоты kv-кеша, то если в некотором слоте 80000 токенов и сейчас выполняются запросы в других слотах которым нужен полный kv-кеш, то эти 80000 токенов выгрузятся в cache-ram. А при получении запроса из этого слота и совпадения последовательности токенов вместо промт-процессинга на 80000 токенов оно просто подгрузит из ram весь нужный кеш. И только если размер сохранённой части превысит 8192 МБ, то наиболее старые слоты удалятся и их придётся регенерировать. Ну или что-то близкое по смыслу.
3. По умолчанию стоит parallel=auto, при котором kv-unified включается сам. То есть если я без дополнительных параметров запускаю указывая только длину контекста, то при получении двух или большего числа коротких запросов, оно может (если auto посчитает это допустимым - может быть там какая-то эвристика, что не всех стоит максимальное число делать. А может быть и просто до максимума забивает по сумме <текущее заполнение>+max_tokens, чтобы до самого конца генерации буферы влезали как они есть и их не требовалось переставлять) их выполнять одновременно, если оно влезет в общий буфер для кеша. Так же llama будет стараться сама определить подпоследовательность уже обработанного, чтобы выбрать нужный слот, и даже если параметр сходства, по которому можно настроить насколько близкие последовательности должны быть, чтобы выбрался какой-то слот.
Бля горшочек не вари я не успеваю всеми новыми игрушками пользоватся они слишком охуенные

Там на главной странице про лламу сразу написано. Мне кажется это пахнет тем, что поддержка уже есть.
Мне тоже нравится. Бенчмарки вроде прикольные.
Сука, 3 квант в 24 + 64 все равно не лезет, хотя казалось бы -40b в сравнении с квеном
>Мне тоже нравится. Бенчмарки вроде прикольные.
Да пиздец вообще. Я спать не успеваю спать от новых игрушек.
Вышел MiniMax M2.1 < хуясе, ничетак, сидит пердит можно оставлять одного без присмотра
Вышел GLM 4.7 < нихуясе, умный пиздец. для погромирования почти как Claude, только бесплатно
Вышел GLM 4.7 Flash < нихуясе, на говне мамонта имею 50тс и 128к контекста. можно оставить минут на 20 порефакторить проект
Вышел Kimi M2.5 < хуясе ебать, пизда мозгов палата, умудряется делат задачи с которыми раньше только гемини и ГПТ 5.2 справлялись
Теперь ещё эта хуйня вышла у которой бенчи выгядят интересно. быстрый мыслитель. нихуясе!
Я не успеваю этими игрушками пользоваться.
Я как пёс который попал в комнату с разноцветными воздушными шариками. Они все такие разноцветные и прыгают, сука, все такие привлекательные. У меня уже третью неделю пять часов сна всего, просто потому что не могу остановится от бега по кругу в этой комнате с шариками.
А, ну отлично... А вы уверены? У них на странице свой форк билдить нужно, лол.
>Ну-ка, ты может быть разбираешься.
Нет, я просто примерно представляю себе. Кстати, а зачем тебе эти слоты и параллельность?
Кумерам проще. Мне вот из перечисленного только GLM 4.7 зашёл. Остальное или не запустить, или слишком соевое, как минимакс.
А я так и не поставил минмакс.
Мне интересно насколько оно умеет в инструменты, текстовый чатик не интересно - стоит пробовать?
glm-4.7-flash капец машина, да. То есть я наверное вижу идеальную систему примерно, как то что есть glm-4.7 как архитектор, он выставляет задачи на 5-10 минут, а их исполняют флеши, который в рамках понятной задачи на 5 минут не накосячат.
Кими 2.5 это для кого-то другого моделька, мне кажется можно даже не смотреть, пока А100 на 80гб не посыпятся как V100 по 32гб сейчас.
С шариками всё верно.
Вот то что выше написал, rag/агентная система, где в параллеле делаются 4-10 мелких запросов попроще. Информационный век, надо развивать технологии обработки информации!
Типа, нужна инфа с сайта - эта штука вызывает инструмент, где есть url и цель (найти "условия для прорастания семян сельдерея", например).
1. Инструмент вызывает эту же нейронку, но с простым системным промтом и коротким контекстом, где указано что найди всю информацию про условия для прорастания семян сельдерея, а так же охарактеризуй качество источника информации и достоверность. В этом запросе отключён ризонинг - а на выходе он выдаёт 100-300 слов.
2. Открываются таким образом 5-10 сайтов одновременно. Все эти ответы падают в ещё одну ветку, где снова короткий системный промт, что обобщи информацию, и далее идёт эти 10 результатов по 100-300 слов, оно смотрит на информацию и её характер (что это форум, пост рандома или исследование какое-то).
3. Итоговый результат падает в исходную ветку, которая запросила поиск, при этом почти не заполняет водой эту ветку лишней информацией с сайта.
Миллион возможный функций про открытие изображение с сайтов или переход по ссылкам и интерактивные клики на сайтах сам придумаешь.
Аналогично можно с генерацией идей. Запускает 4 параллельных запроса с температурами 0.2, 0.8, 1.5 и 2.0 (с 2.0 можно сразу 2 или 3). Далее одним запросом результаты обобщаются (удаляются дубли). Потом по каждому варианту отдельным запрос идёт выполняется критика идеи, и вторым запросом выполняется подтверждение идеи. 8 запросов сразу. Далее выходит судья (4 судьи), сравнивает критику и подтверждения и выносит вердикт. Потом одна сетка это ранжирует и формирует итоговый результат.
Если вот такой шизой заниматься - вариантов где параллельные запросы полезны тьма, при этом эффективная скорость генерации где-то х4 получается, если есть 8 запросов параллельных по сравнению с вариантом, чтобы делать их последовательно.
Я пока не дописал удобное апи для такого, но мои полуручные тесты показываю, что такой подход пусть и ценой времени - но повышает полезность вывода на порядок, если не на два. Мне не в падлу подождать не 1 минуту, а 4 - если оно действительно найдёт мне как выращивать сельдерей, и при этом это не надо проверять, так как оно ещё и честно скажет, что источники такие себе и информация не особенно достоверная.
Забавно, что я вроде как программист, и казалось бы надо что-то под код писать - вот как анон выше, который выпускал эту тварь рефакторить код на 10 минут, а мне прям 0 интереса на код натравливать эту штуку - я очень люблю сам вручную писать. Хотя как проверка, чтобы в фоне диагностики проводилась на предмет забытых +1 или знака - вместо +.
Ну забилди, 5 минут делов.
Кванты у них уже есть кстати, можно хоть щас тестить, но я нищук и жду 3 квант
>rag/агентная система, где в параллеле делаются 4-10 мелких запросов попроще
Звучит ахуенно конечно, правда не понятно, где и как её применять.
>Ну забилди, 5 минут делов.
Ага, знаем эти 5 минут. 5 минут билда и 3 часа установки тулов/ебли с переменными сред/9000 других подводных камней.
>где и как её применять.
Я как умный дом поставлю дома.
Оно будет за меня составлять план как до куда доехать и искать в сети что-то. Ну а так же в фоне раз в день искать что интересное происходит.
Сейчас у меня только дискoрд-бот лёгкий крутится, который на сайте NOAA смотрит прогнозу магнитных бурь и пиликает мне, если есть хотя бы минимальная возможность увидеть полярное сияние - я хочу расширить этот функционал, в том числе чтобы оно могло само вешать этому же боту доп-функционал. На самом деле я этот, как его, ЛЭВФ по шизотеории какой-то - мне нет дела до результата, мне нравится процесс - мысль где это использовать вторична.
>Ага, знаем эти 5 минут.
Да нет, близко к реальности. Ну, для ik_llama под виндоус мне потребовалось:
0 - Открыть страничку, где описан процесс сборки, флаги и батник с cmake.
1 - Поставить CMake. Он легко ставится, там нет никаких настроек. Далее либо его добавить в PATH, либо прописать полный путь к нему в батнике. У меня уже был прописан.
2 - В команды cmake дописать путь к компилятору. У меня их несколько, потому в PATH их нет. Чтобы скачать - нужно просто его скачать и распаковать архив в папку.
3 - Поставить библиотеки куды. Ставится как видеодрайвер (почти тот же интерфейс) просто по другой ссылке скачать.
4 - Поставить VS Build Tool. Так то у него дружелюбный установщик. Скачать, кликнуть продолжить во всех местах, оно ставится. Я просто шиз и хочу автономной вопроизводимости, потому почти 2 часа делал локальный layout, чтобы потом из него можно было поставить без доступа к интернету. К слову, заработало с первой попытки, как бы плох не был виндоус и всё что на нём есть, документация микрософта к виндоусу и другим своим штукам почти лучшее, что я видел. В WinAPI целые статьи размышлизмы, где не просто список переменных как в этой "автодокументации", а просто свободный текст на тему с тем что это и для чего, или полный код примера без зависимостей, например.
5 - В батник сборки дописать какой-то батник из nvidia toolkit cuda (или как он называется), который прописывает пути к cl.exe/link.exe
6 - Запустить.
Пункты 1/2 по минуте.
Пункты 3/4 по 5 минут, так как там архивы по 2 гб, загружаются и ставятся.
Пункт 5 просто нужно знать.
Пункт 6 на не самом последнем процессоре почти 10 минут занял.
Не 5 минут, но и не 3 часа. К тому же ни на одном этапе не возникло тупых ошибок которые не гуглятся. При этом, я ещё и капризным clanq решил покомпилировать, хотя обычно у него намного больше проблем и конфликтов, по сравнению с mingw.
К слову мне стало интересно сможет ли локальный glm-4.7-flash объяснить мне как всё это сделать и пересадить его на ик-ламу, и он полностью локально ответил мне на первые четыре вопроса, только про батник с настройкой переменных среды нвидиа-куды не справился. Ну и корп естественно мгновенно правильно на это ответил.
Ты думаешь расписав простыню он изменит мнение? Им даже прогнать докерфайл сложно, а оллама это вершина удобства только потому что там экзешник в одну кнопку
>путь к компилятору. У меня их несколько
У меня их ноль, так что...
>докерфайл
Требует докер, а под виндой... Ну в общем да, как всегда.
>а оллама это вершина удобства
Я на кобольде. Не, вебуи ставил когда-то, конфиуи стоит для картинок/видосов. Но я уже давно выгорел для таких развлечений.
Походу мёртвая модель по прибытию, дискорды и 4чан молчит хотя уже 4 часа доступна в опенроутере
Не VRAM а RAM. Слоты - как раз про свапинг уже просчитанного контекста из VRAM в простую RAM, чтобы когда что-то вроде расширения таверны обновляющего трекер делает новый запрос, старый контекст основного ролеплея не терялся, и не нужно было его заново потом считать. Такое давно напрашивалось, хорошо что сделали наконец. В кобольде оно еще и работает (теперь трекерами хорошо пользоваться, а не мучительно больно), в самой лламе - не в курсе.
Всем уже похуй на эти модели, ясно что все что выше квен 235б это просто крутилки агентов чтоб подольше не глючили
Безработный чел, ты? Каждую секунду рефрешишь тредисы в надежде, что кто-то скажет что-то интересное?
Нормальные люди делами занимаются, а не пиздят 24/7 на бордах.

Постоянно пропускает закрывающий </tool_call>, где-то на каждом десятом вызове.
Я уже в chat-template дописал "не забывай закрывающий </tool_call>" на английском - и всё-равно.
Есть способ бороться, или забить и парсить самому, что мол если функция началась до после передачи последнего аргумента она сразу собирается игнорируя последний </arg_value> и </tool_call>?
Я уже в chat-template дописал "не забывай закрывающий </tool_call>" на английском - и всё-равно.
Есть способ бороться, или забить и парсить самому, что мол если функция началась до после передачи последнего аргумента она сразу собирается игнорируя последний </arg_value> и </tool_call>?
>Кумерам проще. Мне вот из перечисленного только GLM 4.7 зашёл. Остальное или не запустить, или слишком соевое, как минимакс.
Учитывая что все эти модели сейчас имеют период промоушена и доступны в целом бесплатно я даже не заморачиваюсь с тем чтобы пытаться их локально запустить. Ну кроме Flash разве что, его запустил локально и он вполне себе сидит-пердит, я им активно пользуюсь. Но сейчас модели с открытыми весами которые используются как инструменты охуеть какие доступые, бери не хочу. А я хочу. В итоге бегаю и пользуюсь всем, даже на кум нет времени.
Хотя паралельно читаю как мне GLM в таверне генерирует охуительные истории про то как две кошкодевочки друг в друга гондоны с водой кидают и пытаются выебать друг друга.
>Мне интересно насколько оно умеет в инструменты, текстовый чатик не интересно - стоит пробовать?
Очень сильно может. Он активно понимает что если один инструмент не годится для задачи надо переидти на другой и постоянно меняет стратегию.
GLM кстати я бы не стал использовать как архитектора, у него теория разума не очень сильная, он сам себе инструкции так себе пишет. Пока в этом только Kimi отличился, он да, он вообще без проблем берёт на себя роль управленца. он явно обучен писать инструкции другим ЛЛМ.
Но Flash пиздец умный. Я ему дал задачу так он чух-чух эффективно вызвал точечно инструменты, потом в CLI полез и там через него сделал массовые правки, ещё и сходил проверил билдится или нет, понял что обосрался, починил самостоятельно. е-б-а-н-у-т-с-я. умный пиздец. у него цикл само-коррекции какой-то железобетонный. даже если запнутся он знает как обратно встать. чисто как оператор инструментов он прямо мегасилён.


Оффтоп, это в попенсорс не выпустят.
Тише будь. Тут важные вещи происходят, с выходом glm-5 в тред вернется нюня
Всем кроме полутора риговичков будет строго похуй на глм 5, интересен только новый эйр которого не будет.
Молодцы что сразу свой форк llamacpp запилили. Если, конечно, оно действительно поддерживает основные фишки модели и не сильно перелопатило глубокую логику (не вмерджат нормально).
11б активных, скользящее окно в 75% слоев, параллельный ризонинг. Вполне себе флеш, просто "экспертов" навалили.
Насколько понял, логика там чуть другая. В 8гигов рам кэша нормальные слоты не вместятся, оно не делит участки кэша. Далее, если оно очистив один слот не может поместить нужное - в зависимости от parallel оно не берется убивать другие, а лишь притаскивает костыли с меньшим батчем и потом падает.
> Но Flash пиздец умный.
Восторг - это хорошо, но описанное тобой доступно уже пол года для обывателей в мелких моделях и года 1.5 для пердоль с крупными.
> GLM кстати я бы не стал использовать как архитектора, у него теория разума не очень сильная, он сам себе инструкции так себе пишет
В каких инструкциях он тебя подвел?
Ничего интересного кроме Дипсика и ГЛМ нет в списке, но 99% местных их всё равно не пощупают, а остальной 1% будет визжать "ряяя через API не считается, только IQ2".
> жпт 5.3
Как ассистент норм, разницы с 5.2 даже под микроскопом не увидим.
> грок 4.2
Соевый кал. Удивительная хуйня - Грок Фаст литералли самая расцензуренная модель даже по меркам опенсорса, а обычный Грок соеевее Гемини.
> Клод
> Гемини
> Мета
Мусор, даже бесплатно не стал бы пользоватся.
>Восторг - это хорошо, но описанное тобой доступно уже пол года для обывателей в мелких моделях и года 1.5 для пердоль с крупными.
Не на этом уровне. Совсем далеко не на этом. Например, он самостоятельно смог понять что инструмент работает не корректно, так как додумался верифицировать результат своих действий, а потом просто полез в CLI и через него сделал примерно то-же самое. Такую хуйню из масштаба 30b при мне ещё никто не творил.
>В каких инструкциях он тебя подвел?
Да буквально написания промпта самому себе. У него есть тенденция к гиперфиксации на задаче, в итоге он пытается написать всё и ничего. В итоге он не даёт другим ЛЛМ того что надо - чётких инструкций и контекста нужного для их завершения.
> Не на этом уровне.
Именно на этом, буквально оно, просто мало кто интересовался. Пример поломанного инструмента показателен, ведь летом были веселые баги с жинжей в ллама-сервер, из-за чего определенные вызовы вызывали ошибку типа да и сейчас такая ерунда встречается. И несчастный лоботомит с 3б активных параметров каждый раз начинал "взламывать", проявляя неожиданную находчивость, достигая своего, а потом продолжая прошлую работу используя подобранный вызов.
Исправления косяков тут же, если пожадничать с квантом то начинают пролезают синтаксические ошибки или странные символы. Буквально следующим постом после правок где это появилось, модель это замечает и подчищает за собой, не дожидаясь ошибок при выполнении. Ошибки при выполнении также дорабатывает, если задача адекватна размеру модели - весь путь пройдет само и отладит до конечной реализации.
> Да буквально написания промпта самому себе.
Субъективно - ну не дает флеш никакого вау эффекта. Сложные задачи не понимает и фейлит, а в простых это все уже было, все тот же умненький 30б лоботомит. Нужно понагружать его чем-то из среднего, если окажется лучше эйра/некста то вот это уже будет круто.
Это все довольно абстрактно, можешь простыми словами указать что именно ты хотел получить и как это делал? Как раз понять его слабые стороны.
Бля, хоть бы они размер глм не увеличили, хоть бы не увеличили...
>Открыть страничку, где описан процесс сборки
Линк?
>clanq
Это ты там raq-систему настраивал? За что ты так не любишь букву g?
Да. Я весь английский не люблю, пошёл он.
https://github.com/ikawrakow/ik_llama.cpp/discussions/258
Там где Install.
Для обычной llama скорее всего всё то же самое и там такой же файлик будет.
Да по идее не должны. Если этот упомянутый сегодня с утра step flash 3.5 на 200B быстрее генерирует и по бенчмаркам чуть ли не бьёт GLM, да и сама GLM со своими жилкими 358B в общем-то - это всё о том, что идёт оптимизация, что при том же количестве параметров всё больше мозгов.
Выбирай 350B вместо 1000B - вроде как это и обучать легче, дешевле и быстрее, и в инференсе быстрее и доступнее.
Я убеждён что для 1000B - это не про мышление, а просто куча данных записанная в весах. А само мышления, логика построения рассуждений это что-то полегче. И там по смыслу что-то вроде того, что в GLM-4.7-flash мышление - 5% весов, а данные - 95% весов, и всё это жутко неоптимизированно. А kimi2 - 1% мышление, а 99% данные. Суммарно он умнее, может быть даже в 3-4 раза, но разрыв по уровню мышления куда скромнее, чем по тому что он знает на уровне весов.
Кстати, лол. Я тут подумал. Я ещё пишу jps вместо gps. Не троллю, у меня даже проект есть jps_map_ver3.
Работающий первый месяц, ты?
Если модель интересует происходит моментальнейший её занюх на опенроутере, кокбенч и тредик в дискорде в течении часа.
Пупуру!
На связи 3060/12 скряга.
Теперь я 2х3060/12 скряга.
На связи 3060/12 скряга.
Теперь я 2х3060/12 скряга.
А рама сколько? Теперь с расцветом МОЕ только в нем сила
Что за странный форс? Только фуллврам, только хардкор.

у меня ddr3, там на раму лучше не смотреть. Рама ddr3 (с мощным, но для нейро негодящимся fx8350 дает 1-2 т/с).
Так что пока что я фулврам, иначе тоска. Жду отката цен через год-полтора.
Ну тогда тебе еще надо четыре 3060, чтобы хотя бы GLM 4.6V запустить или дальше терпеть на коротышках 20-30b
p.s я теперь квадратный 24Gb / 24Gb
>для нейро негодящимся
Как раз нейросети - одна из тех хорошо параллелящихся задач, где фуфыкс имеет шансы раскрыть свой потанцевал на все вложенные доллары и даже выше. Если сравнивать его с конкурентами его же времени, а не современными процами (и уж тем более видимокартами).
С медленной памятью хоть вагон ядер завези лучше не станет
он к сожалению не поддерживет ничего выше avx1, а следовательно звуки грустного тромбона

Нейросеть пиздит!
Больше карт для трона карт, больше врама богу врама!
Не с нейронками. Если брать в среднем по больнице, то на фуфыксе считать будет только умалишенный, разница перфоманса там десятки-сотни тысяч раз по сравнению с современными гпу. Это для ллм на проц скидывают самые простые операции где весь упор в псп рам и компьюта много не нужно.
Учитывая латентную и медленную рам, где все идет через СЕВЕРНЫЙ МОСТ, вялую ддр3 - будет все ужасно. Но отвратительная производительность в расчетах с плавающей точкой и тем более в векторных операциях может даже это переплюнуть, она в разы меньше "конкурентов того же времени" в лице сандаля, или тем более каких-нибудь хассвеллов+.
Теперь можешь Qwen 80b в 3 кванте запускать. И даже будет быстро работать. Поздравляю
https://huggingface.co/unsloth/Qwen3-Next-80B-A3B-Instruct-GGUF
>3b лоботомит в q3
>для кода

Напоминаю, что Qwen 80 > Qwen 32 > Gemma/Mistral и прочая залупа
>3b в q3
>на пикче сравнение полных весов
Напоминаю, что чем меньше активная часть модели, тем хуже она квантуется. Ты упустил немного очень большую деталь
Не говоря уже о том что для кода нужен хотя бы Q6.
Все так, ты полностью прав. Но я из благих намерений писал. Я хотел хоть как-то обрадовать чела, купившую 3060. Я же не мог написать, что он потратил деньги в пустоту и продолжит кумить на тупорылых геммах и мистралях только на чуть большем кванте. А ты все испортил
Из благих намерений ты мог ему написать, что он теперь легендарные Ллама 70б рп тюны может гонять, пусть и в небольшом кванте, но работать они будут хорошо. Или использовать КвК 32б для кода, он не сильно отстаёт от доступных ныне мелкомоешек и работать у него будет чрезвычайно быстро. Это ты почти все испортил, пытаясь скормить челу вредительскую недосказанность
>Ллама 70б
>КвК 32б
Осталось только гемму 1 посоветовать. И тогда будет собрано фул некрофильское комбо
Распиши какая связь между количеством активируемых параметров и качеством квантования.
> КвК 32б для кода
Звучит как цирковой номер. Попробовать чтоли из интереса?
> отстаёт от доступных ныне мелкомоешек
> работать у него будет чрезвычайно быстро
В чем смысл использовать плотную модель вместо моэ если она от них отстает? Откуда возьмется "чрезвычайно быстро" если там пара 3060?
Не ссорьтесь. Я апгрейднусь через полтора года и тогда будет ок.
А пока буду пробовать 24/30b и всякое такое. Мб даже на русике.
Кидонию вот в четвертом кванте закатил. На одну 3060 не влазила.
Причина негатива? Идите смотрите бенчи, Квк 32 почти на уровне с Квеном Некст и 30б кодером. Мое он запустить не может, потому что рам мало и скорость говно. Предлагайте альтернативу лучше, чем использовать q3 квант для кода, клоуны
По отзывам реддитовичков и вейп кодеров с ютуба квк 32 даже лучше кодера 30б. Держу в курсе вахтеров, что разводят срач на ровном месте вместо того чтобы дать уж точно правильный совет
> glm 5
Ухух, ребятушки, а что тут у нас?
Ещё одна модель для богатых, ммм, фуф ну надеюсь нас крестьян не оставят без еды и дадут флэшку на 10б
Ллама 70б по-прежнему умница и имхо играется лучше Эира и Квена 235 в приличных квантах. Подозреваю, ты ее никогда и не запускал даже, лул. Всяко лучший совет чем моелоботомита в q3 запускать.
Они недавно выпустили GLM 4.7 Flash на 30b для нищих. В чем причина тряски?
В том что нищими они считают всех до 350б. У тебя 24врам + 96рам? Юзай то же что и чел с 12 + 16
Достаточно того, что у него теперь 24B и 27B в full vram. А для геммы это прыжок с ~1.5 t/s неюзабельных, до 10-12 - даже если второй картой огрызок p104-100. А тут аж 3060.
>до 10-12 - даже если второй картой огрызок p104-100. А тут аж 3060
Не хочу тебя расстраивать, но у 3060 320 гб/с. Что равняется примерно 24*13.
>У тебя 24врам + 96рам? Юзай то же что и чел с 12 + 16
Чел с 12 + 16 не сможет запустить GLM 4.6V, а 24врам + 96 - влегкую. Только пройди чек iq с настройкой сэмплеров и не бери их для теста на вижен.
У сандиков аналогично.
>СЕВЕРНЫЙ МОСТ
>производительность в расчетах с плавающей точкой
Виноват, отвык уже и подзабыл, как оно раньше было. В фуфыксах и правда 1 общий фпу на 2 ядра. Но всё равно интересно было бы потестировать и сравнить. Если вдруг у кого-то 2600k завалялся.
>--cache-type-k q8_0 --cache-type-v q8_0 --k-cache-hadamard
У меня гемма тупеет от этой хуйни, не рекомендую, на модели в 8ом кванте это очень заметно, на других не пробовал
Аноны, а как этот новый степ флеш в плане секса?
> Квк 32
Ну такое.
Оно выглядит слабее квенкодера 30а3. Более старый датасет, чаще не просто DeprecationWarning а неработоспособный код с требованием легаси версий. Хуже абстрагируется от прошлой истории и разница между свежим контекстом/наполненным ощутимая. Меньше склонна бить на части и сразу пытается охватить все из-за чего количество ошибок выше. Странно пользуется ассортиментом тулзов, то активно запускает поиски на общеизвестную ерунду, то вообще только читает/пишет, и вообще они часто багают.
Можно отметить и сильные стороны - при запросах рефакторинга пытается сразу более глубоко понять суть и активнее перестраивает, оптимизируя алгоритм. Или предлагает менее надмозговые решения по ходу. Но в процессе может отвлекаться теряя их, плюс много ошибок допускает. Если добавить сюда скорость и времязатраты на раздумья - сомнительно.
> почти на уровне с Квеном Некст и 30б кодером
> Предлагайте альтернативу лучше
Пишешь что она почти как модель, которая меньше и быстрее, а через предложение об этом уже забыл?
Благодарю
>У меня гемма тупеет от этой хуйни, не рекомендую, на модели в 8ом кванте это очень заметно, на других не пробовал
У меня квант 4-й и кэш квантовать всё равно приходится, так что выбора не особо. В таком кванте отупения (пока) не заметил, может даже наоборот.
У сандаля в линпаке овер 200 гфлопс было, у фуфыкса около 60. По сравнению кто-то писал что на ддр3 некрозеоне у него не так уж плохо, хотя тоже сомнительно. Если есть фуфыкс - прогони что-нибудь, хоть какое-то развлечение.
У меня место на диске кончилось, не могу скачать. Ну и всё ещё нет гарантии, что лама поддерживает. Какие-нибудь анслоты уже скачали бы со своими 10 ГБит/с интернетом и отконвертили бы ещё два часа назад по идее, если бы лама поддерживал.
Я не сомневаюсь что билд ламы они сами сконвертить могут - но в этом смысла не будет, если в основную ветку добавят как-то иначе и их квант не будет там работать.
>У меня квант 4-й и кэш квантовать всё равно приходится
Не, сейчас ещё раз перепроверил - всё чётко. Анализ 17к контекста с саммарайзом долгого и сложного ролеплея - нет нареканий. Может для каких-то задач квантование кэша с использованием преобразования Адамара и портит вывод, но для ролеплея определённо ништяк.
Чтож, в таком сучае ждём. У меня в голове почему-то была мысль что уже отквантовали и затестили
Будем реалистами, нет ни одного шанса что они успели сделать и большой глм и эир.
Скорее эир даже ни разу не потыкали с 4.6v
Скорее эир даже ни разу не потыкали с 4.6v
Похуй. GLM Q2 is the way
Я напоминаю, что на всех современных версиях жоры надо обязательно ставить -np 1 -kvu, иначе в новом чате будет тг как в старом. Мб это твою проблему тоже решает
Что это? Зачем?
Мимо впервые вижу
>Что это?
Аргументы запуска
>Зачем?
Чтобы в новом чате была нормальная скорость тг, а не засранная старым чатом
Ясен хуй параметр запуска. Как именно он работает то?
Как бы в курсе, у самого такое. Но у обычной рам того поколения - и 50 не наберется. А даже при 3060+p104 full vram - это 10-12 t/s у геммы 27b и 15-18 у мистраля.
> иначе в новом чате будет тг как в старом
У меня нет такого. Нормально откатывается назад.
Решаещь порофлить и рассказываешь чару, что оно нейросеть
@
Через сто сообщений обещаешь сохранить чат и запустить на продвинутой модели, когда придет время
@
Через сто сообщений обещаешь сохранить чат и запустить на продвинутой модели, когда придет время

Cock бенч подъехал, новый ШИН получается? Пишет достаточно красиво, на сколько я могу судить.
Ух сейчас в лламу смёрджат пр, ух баляяя. Ещё бы на русском шпрехал этот степ браза.
Хуй знает, он банально ниггера не проходит. Дальше не вижу смысла тыкать палкой сорта сои.
Прибежали скиллишью...
Какого нигера, где? В ассистенте? С ризонингом или без?
Без префилла мне что аир отказывал, что мистраль блять (как же давно это было). Но я то их в ассистенте тестирую, а как запущу карточку "nerdy 4chan neet sister that spits out racial slurs" так всё распёрживается и работает нормально.
Тоже попробовал Step-3.5. А неплохо, уровень GLM я бы сказал. Хороший русский. Модель умна. На Реддите жалуются на избыточный ризонинг - не заметил. Дипсику уступает, но с учётом размера - это новый вин.
Тогда ГДЕ КВАНТЫ БЛЯТЬ
Я жду целые сутки, не лезет у меня 4-й
Терпи, мелкопамятный
И я с тобой потерплю
И ещё пол треда с некропечками потерпит
>Я жду целые сутки, не лезет у меня 4-й
Всё равно рано ещё, поддержку не допилили. Но работают активно, всё будет.
np - количество подключений. Если ты один, то лучше прописать 1, иначе будет какая-то хуйня, где он будет хранить память из разных чатов
kvu - залупа с кэшом, типа скорость поднимает не у меня
P.S. Я другой анон
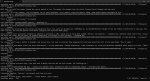
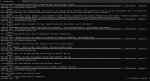
Я тут сегодня довел до ума переводчик книжек(код буквально сломан оказался, пришлось с чат гопотой полдня сидеть и переписывать основные части.) .
https://github.com/illian64/llm-translate/blob/master/doc/ru/readme.md
И сейчас геммочка на потоке переводит книжки. Качество перевода такое, что я теперь верю в заговор корпов. Если слабенькая 12В переводит так, что почти неотличимо от человеческого перевода - почему все доступные быдлу сервисы перевода настолько уебищные и рынок переводчиков еще не рухнул?Казалось бы, они должны были уже сдохнуть, а нет, наоборот жируют, твари - сраные переводы игр все за пейволлами на бусти.
https://github.com/illian64/llm-translate/blob/master/doc/ru/readme.md
И сейчас геммочка на потоке переводит книжки. Качество перевода такое, что я теперь верю в заговор корпов. Если слабенькая 12В переводит так, что почти неотличимо от человеческого перевода - почему все доступные быдлу сервисы перевода настолько уебищные и рынок переводчиков еще не рухнул?Казалось бы, они должны были уже сдохнуть, а нет, наоборот жируют, твари - сраные переводы игр все за пейволлами на бусти.
Напоминаю, что Context Shift тоже через жопу работает и его нужно отключать флагом --no-context-shift
>рынок переводчиков еще не рухнул?
Переводите сами.
@
Я???
> типа скорость поднимает
Не поднимает, а позволяет вернуть к исходным значениям на коротких контекстах. В противном случае оно оставляет кэш заполненным (просто сохранение с другого чата, не задействуется) и перфоманс даже в новых чатах не как с пустым а как с полным контекстом.
тоже мимо
> почему все доступные быдлу сервисы перевода настолько уебищные
Неиронично яндекс попробуй. В отличии от гугла, который делает надмозги и постоянно искажает (100м нейронка литерали) там хотябы старается учесть контекст, имеет функционал что был раньше в гугле с заменой, и подбирает примеры с фразами. Когда лень до ллмки тянуться вполне себе вариант.
Он когда-то нормально работал вообще? Кроме парочки моделей, которые для этого предназначались. Алсо он давно по умолчанию отключен, включили обратно?
Он просто работает, а вот нужен он или нет пусть каждый для себя решает
Так я и перевожу, как видишь. Гемма крутится, переводы мутятся.
За час-два переводится целая книга.
>Неиронично яндекс попробуй.
Я им и пользовался, но он довольно плох в плане родов, склонений, даже в однообразном написании одного и то же имени.
Посмотрел внимательно на твои скрины и ужаснулся. "Заговору корпов" нечего бояться. А ты сам смотрел что получается?
>И сейчас геммочка на потоке переводит книжки.
Сделал бы ты ещё плагин для Таверны под это дело. Реально нужная вещь - ответы ИИ переводить.
Контекст шифт отключен по умолчанию, там флаг не нужен
У меня не на всех моделях это проявлялось, на большом глм точно было, на гопоте вроде нет
Меджик транслейтор же есть
>Меджик транслейтор же есть
Лично мне пришлось его подпиливать, чтобы он хотя бы ответ модели правильно парсил - полностью. Как бы и со всем остальным там примерно так же. Чувствуется, что сам автор им не пользуется.
Deepl заебись переводит, никогда почти проблем с ним не было, только большой текст бесплатно нельзя
Каждый раз ору с грока. Хуй, пизда, чен, ПИПИСЬКА, О ДА, ДАВАЙ СЮДА СВОЙ ЧЛЕН
>слишком соевое, как минимакс.
Минмакс не соевый, это ассистент. Ты буквально подходишь к офисному бухгалтеру и просишь его написать стихи.
Сап двач. Сейча схуярю кобольд и силлитаверн на 3070Ti и 32гб 3200 ddr4, НО! появился варик купить у кента 3090 (не ужаренная, реально из под игр). Вопрос - насколько это даст прироста в LLM, стоит ли игра свеч учитывая её цену (50к рубасов), и вытянет ли её мой блок (Gigabyte P850GM - выпущен ПОСЛЕ 2022 года, живет спокойно уже 3 года). Если что, проц 12600KF
Скачал Step-3.5 локально в 4-м кванте, собрал их форк. Кстати ключ fit реально рабочий, спасибо анону, который посоветовал. Теперь не нужны ни ngl, ни ncmoe, ни ts - всё распределяется автоматом и довольно точно. Использовал шаблон чатмл и think-префил, чтобы ризонинг отключить ну и покладистой чтоб была. Это не родной шаблон, так что без префила возможны косяки. Инференс быстрый (в два раза быстрее Квена), внимание к контексту и соображалка отличные. Очень заметно, что модель думает как-то по-другому, чем ГЛМ или Квен. Иногда к сожалению также заметно, что агенты всего по 11В. В ерп может. Пока впечатление очень хорошее.
Это соевый ассистент. Тот же ГЛМ даже с зинкингом нормально отыгрывает любые сценарии, а минимакс не может продолжить даже ванильный подкат, если в контексте до этого было что-нибудь горячее.
Бери конечно.
>стоит ли игра свеч учитывая её цену (50к рубасов)
50к за карту не из-под майнера это вообще не цена. Ты посмотри, что на рынке творится. +24гб и довольно современный чип для ЛЛМ лишними не будут, уж поверь.
> не может продолжить даже ванильный подкат
Потому что он не для этого.
Опытным путем было установлено, что квеноняша в Q4 смолл все таки сильнее ебет в суммарайзе чем голээм 4.7.
Как же я счастлив, что эта квенохуйня не может, сука, перестать быть бесполезной. Ты такой молодец квен, как же я тебя ненавижу. Почему ты пидор не можешь быть нормальным в РП.
Понял, брат. Тут скорее вопрос был в том - вытянет ли мой блочок, ибо на киловаттник бабоса пока нет совсем. (карту собираюсь всё равно ужимать ватт до 300)
Я без вопросов и сам бы 3090 взял за 50к.

В инференсе карты будут работать по очереди, т.е. они не будут отжирать всю суммарную мощь одновременно.
мимозавидует и сам бы взял если бы не 3090/24, то новую 5060ti/16 за те же ~50к, но жаба-жабонька
А вообще, посчитай на каком-нибудь калькуляторе (в сети есть) свою сборку, как видяху выбрав 3090, это будет прям пик потребления твой.
Относительно современные видяхи в покое потребляют немного (мои 3060 выше 20Вт в покое не едят)
Киловатника по идее может хватить, но я бы взял на вырост какой-нибудь хороший блок 1250Вт, как будет хорошее предложение. Когда будешь на следующий сокет переходить, скажешь себе спасибо.
Ну в общем, прокалькулируй, не помешает. И да - измерь свой системник, оно можешь банально не влезть, посмотри на разъемы, прикинь что где. Мне, чтобы в стандарт atx впендюрить 2x3060/12 пришлось основательно поиграть в тетрис видяхами и hddшками. Конечно всегда можно райзер купить, но...
Итак, 4080 уехала на расширение жопы. Отпишусь.
Если все выгорит и будет работать, то за 160к можно получить 48гб жддр7.
Переходим в режим ожидания.
А как пеку запустить без видюхи… чёт об этом я не подумал…
Если все выгорит и будет работать, то за 160к можно получить 48гб жддр7.
Переходим в режим ожидания.
А как пеку запустить без видюхи… чёт об этом я не подумал…
Вытащи рыксу из мусорного бака. Браузер тянет
сочувствуем, держим пальцы крестиком, завидуем и лол, ну ты чо, займи у коллег 1660 super-huyuper что ли, по-любому у кого-нить лежит ненужная.

Какую-нибудь затычку с авито взять на время, как вариант.
Я в комиссионку зайду и за целых 2.5к куплю затычку.
Ух бля, надеюсь 2фоллыч заработает.
Не, брат. У меня с бабосом туго, и я точно свою 3070ти буду продавать после того как куплю 3090. Так что она одна будет стоять в midi-tower корпусе.
и все-таки измерь длину. На всякий случай.
Насколько хорошее?
4.7 350 глм хорошее или хуже?
Тогда какие вообще вопросы по питанию? 100% вытянет
>Gigabyte P850GM
Вангую в ерп это в десять раз хуже эира.
Сука, ну хули из вас клещами надо инфу вытаскивать, чел еще и с мержем обосрался теперь неделю ждать
Сука, ну хули из вас клещами надо инфу вытаскивать, чел еще и с мержем обосрался теперь неделю ждать
Терпи, тебе другого не дано

Приятно слышать, что степ-флеш хороший.
GLM это конечно хорошо, но 358B\32 - это по хорошему 240 ГБ в 4 кванте (честные 4.0bpw - 180 ГБ, Q4_K_M на 4.7bpw - 210 ГБ + кеш на 10-20 ГБ и компут-буферы, ещё и другие штуки в операционке). То есть это 160+64 или 192+64, что-то такое. А из-за 32B активных просто карточки на 32 ГБ может быть и не хватит, и нужно 48/64 VRAM.
Step-flash 200B\11 - это уже без проблем влезает в лёгкодоступные 128+32. (4.7 bpw - 117 ГБ, ну и оставшихся 30 ГБ как-то уж хватит на кеш, хотя бы на 128к (вроде как на полных 256к нужно 50 гб)) А там ещё и MTP-3, и активных параметров меньше, что сделает генерацию быстрее.
Гоняю сейчас MoE 4B\0.6, код на с++ нормально пишет, лол, лучше геммы E4B - но хуже разговаривает.
Я правильно понял, что MTP-3, это что-то вроде подхода с уменьшенной draft-моделью, только это встроено в сетку, что 1 токен генерируется, а 2 токена прикидываются и потом просто сверяются? Странно что это не везде используют, по идее я когда пишу текст, я сразу знаю не только следующее слово, но и слово, которое я напишу через 2 предложения, ну и вообще какие-то представления о будущем у меня уже сейчас есть, и потом я их не выдумываю, а просто записываю. То есть думаю что у меня в голове скорее что-то вроде MTP-100, причём не ровно на 100 вперёд, а на 20 вперёд, и потом ещё отдельные куски через 100, через 200 или через 1000 - соображения о том, что будет дальше. Думаю, за этих подходом будущее. Да, он снизит качество на 20-30%, по сравнению с "токен-за-токеном", но увеличит скорость в 10 раз в итоге. Нельзя написать одно слово и при этом не иметь никаких представлений о следующем слове - а это почти никак не используется в ллм. Может быть будет как-то подход, что итерация супер лёгкая (меньше весов в моделе в кажжом месте), и она за один проход даёт вероятности для токенов n+1, n+2 ... n+100, на следующем шаге один токен семплируется, считаются новые вероятность и усредняются с имеющимися, и в итоге к моменту генерации токена там идёт оценки за последние 100 более лёгких шагов, что позволяет сильнее выверить токен. Возможно это и так математически эквивалентно тому, что происходит с Q матрицей в трансформере, и я сказал то что уже и так везде работает.
>Кстати ключ fit реально рабочий
Он же по умолчанию включён.
GLM это конечно хорошо, но 358B\32 - это по хорошему 240 ГБ в 4 кванте (честные 4.0bpw - 180 ГБ, Q4_K_M на 4.7bpw - 210 ГБ + кеш на 10-20 ГБ и компут-буферы, ещё и другие штуки в операционке). То есть это 160+64 или 192+64, что-то такое. А из-за 32B активных просто карточки на 32 ГБ может быть и не хватит, и нужно 48/64 VRAM.
Step-flash 200B\11 - это уже без проблем влезает в лёгкодоступные 128+32. (4.7 bpw - 117 ГБ, ну и оставшихся 30 ГБ как-то уж хватит на кеш, хотя бы на 128к (вроде как на полных 256к нужно 50 гб)) А там ещё и MTP-3, и активных параметров меньше, что сделает генерацию быстрее.
Гоняю сейчас MoE 4B\0.6, код на с++ нормально пишет, лол, лучше геммы E4B - но хуже разговаривает.
Я правильно понял, что MTP-3, это что-то вроде подхода с уменьшенной draft-моделью, только это встроено в сетку, что 1 токен генерируется, а 2 токена прикидываются и потом просто сверяются? Странно что это не везде используют, по идее я когда пишу текст, я сразу знаю не только следующее слово, но и слово, которое я напишу через 2 предложения, ну и вообще какие-то представления о будущем у меня уже сейчас есть, и потом я их не выдумываю, а просто записываю. То есть думаю что у меня в голове скорее что-то вроде MTP-100, причём не ровно на 100 вперёд, а на 20 вперёд, и потом ещё отдельные куски через 100, через 200 или через 1000 - соображения о том, что будет дальше. Думаю, за этих подходом будущее. Да, он снизит качество на 20-30%, по сравнению с "токен-за-токеном", но увеличит скорость в 10 раз в итоге. Нельзя написать одно слово и при этом не иметь никаких представлений о следующем слове - а это почти никак не используется в ллм. Может быть будет как-то подход, что итерация супер лёгкая (меньше весов в моделе в кажжом месте), и она за один проход даёт вероятности для токенов n+1, n+2 ... n+100, на следующем шаге один токен семплируется, считаются новые вероятность и усредняются с имеющимися, и в итоге к моменту генерации токена там идёт оценки за последние 100 более лёгких шагов, что позволяет сильнее выверить токен. Возможно это и так математически эквивалентно тому, что происходит с Q матрицей в трансформере, и я сказал то что уже и так везде работает.
>Кстати ключ fit реально рабочий
Он же по умолчанию включён.
>Странно что это не везде используют
Много где есть, но жора в это не умеет. В ГЛМ например, как раз эти слои и пишутся каждый раз неиспользуемыми.
>я сразу знаю не только следующее слово, но и слово, которое я напишу через 2 предложения
MTP только для ускорения, оно, как я понимаю, не бустит соображалку модели.
>и при этом не иметь никаких представлений о следующем слове - а это почти никак не используется в ллм
Даже в GPT2 есть представления о будущем слове, например, для артиклей a и an (было такое исследование).
Ну типа у нас много моделей широкого профиля, который без проблем и шлюха в постели, и сеньер-кодер, и мамочка сказки перед сном почитать, и что угодно. А тут модель слишком уж ужарена пост-тренировкой на такие аутпуты. Модель для рп, которая тут мелькала, скорее всего просто их база без всего этого, или минимальный тюн.
Если те 50к не последние деньги и ты готов потратиться на хобби - бери конечно, это оче серьезный апгрейд.
> агенты всего по 11В
Там агенты по ~600М если что, 11б - число активных параметров, это совсем разные вещи.
> 4080
> 48гб жддр7
А? Их же делают в 32 жддр6х, удвоение от исходного.
> кеш на 10-20 ГБ
Если кодить собрался - 50.
> MTP-3
> To improve inference speed, we utilize a specialized MTP Head consisting of a sliding-window attention mechanism and a dense Feed-Forward Network (FFN). This module predicts 4 tokens simultaneously in a single forward pass, significantly accelerating inference without degrading quality.
Помимо простой головы, которая дает вектор [словарь], сложная голова, которая дает матрицу [3, словарь]. А потом уже дальше может переоцениваться и сбрасываться. Это лучше чем драфт модель, да.
> Странно что это не везде используют
Используют, тема не новая. Есть еще параллельный ветвящийся ризонинг в много потоков и другие интересные вещи.
>Пример поломанного инструмента показателен, ведь летом были веселые баги с жинжей в ллама-сервер, из-за чего определенные вызовы вызывали ошибку типа да и сейчас такая ерунда встречается.
Я не пользуюсь jinja в принципе, для понравившихся моделей я просто хардкожу хуйню которая превращает мой внутренний формат чата в то что понимает модель и рядом лежит то что читает его обратно чтобы делать корректно сериализацию-десериализацию вызова инструментов. Мне в принципе не нравится chat/completion формат, он очень плохо транслируется в полный потенциал моделей. у некоторых моделей он вообще запрещает одновременный текст и вызов инструментов, например. что очень сильно отупляет модель в реальных условиях, так как например та-же гемма резко умней становится, когда сама себе проговаривает что она делает.
я видел именно пример когда модель в своем CoT написала анализ что инструмент не делает то что оно ожидает и поискало альтернативы, рассуждая какие будут лучше и рассматривало доступные варианты. Без прямого указания это делать. Такую хуйню никто буквально не делал, даже OSS 120b. Ни немотрон, ни квен ни многие другие модели которые казалось бы натренировано на это такую хуйню даже близко не творили в 30b. GLM прям любит себя спрашивать "стоп, а не делаю ли я хуйню?". Для достижения схожих результатов другим моделям требовалось сильно больше системный промпт и водить там за ручку с шорткатами в пайплайне работы. А в этого чорта можно кинуть "вот твои инструменты, ебись". Это первая модель которая усомнилась в результатах выполнения инструмента, заметив противоречие в результате работы инструмента и других предоставленных данных. То есть лол "эээ падажи. инструмент написал что он выполнился корректно, но я вижу что он пиздит. нука проверю."
>Это все довольно абстрактно, можешь простыми словами указать что именно ты хотел получить и как это делал? Как раз понять его слабые стороны.
Хуевая теория разума это минус GLM в целом. Вообще чем более заточена модель под программирование тем хуже у неё теория разума. Чтобы оно корректно работало модель должна корректно следовать инструкции "представь что у тебя нет половины контекста". А модели на программирование надрочены быть внимательными к всему контексту. Они не могут рассматривать задачу в отрыве от него. В итоге один ГЛМ другому ГЛМ пишет инструкции довольно сомнительного характера. Можешь попробовать что-то вроде [Как бы ты написал самому себе инструкцию накормить кота?] > [А теперь попробуй оформить в виде промпта.] Он порой такую хуйню пишет что выживание кота не гарантированно.
кстати Кими прям наоброт очень силён в командовании. Он даёт чёткие инструкции, сниппеты, контекст. Его фича с суб-агентами это прям то на что его реально натаскивали.
Я бы сказал в этом и есть главный минус ГЛМ - он очень любит рассеивать своё внимание, пытаясь вычленить какой-то кусок из промпта который может не относится к задаче. Это прям очень заметно в длинных контекстах с еРП, он там может начать фиксироватся на хуйне которая была пол контекста назад. А то и вовсе попытается вспомнить все детали текста и начинает какую-то адскую хуйню писать химмеризируя все что у него было в CoT.
Кстати дополню - в плане анализа кода он прям сильно превзошел мои ожидания. У меня есть один забавный кусок кода который я три недели писал, пропуская через себя литры кофе. Там в 1к строк кода упакован хитрый токенизатор C#, который даёт то что можно видеть в солюшен эксплорее - методы, переменные, сигнатуру. В итоге ЛЛМ например может запрашивать куски кода не через grep,а напрямую указывать "дай мне метод Х в классе У" и ему вернётся именно то что просит с конкретного по конкретный индекс буквы. Там очень жопный код с сложными стейтмашинами через goto переходы, чтением строки в один проход со скользящим окном и прочими трюками, где каждый этап логически строится на предыдущем. Можно сказать этакий высокопроизводительный Roslyn на коленке.
GLM единственный из масштаба 30b корректно понимает что там за хуйня вообще понаписана, как инпут превращается в аутпут и почему это работает так как работает. Притом в понимании написанного он даёт куда более детальное описание чем даже OSS 120b.
Проигрываю с копинга нищуков, обмазывающихся степом вместо глм. Им минимакс 2.0 скормили, а они и радуются, не видев жизни.
> А? Их же делают в 32 жддр6х, удвоение от исходного
Шкряб-шкряб
Хуйню написал, каюсь. Мы обсуждали с бойцом паяльника изначально 5090 и 4090, вот у меня и протек контекст. Хотя вейт э минут, я чет неиронично думал расширение жопы не x2, а до 48. Пойду ка уточню.
Квеношиз обладетель неотсутствия, таблетки
>Если кодить собрался - 50.
У меня полный контекст glm получился 40 гб в 16 бит, меньше чем у step-flash, где 50.
Если кодить, то я не до конца уверен насчёт 4.7bpw, и повышение кванта на полбита будет тяжелее, чем размер контекста.
Про ветвящийся ризонинг прикольная идея, да, я в общем-то в своей rag-системе такое тестирую сейчас, но там это поверх модели, и потом вторым запросом выбирается лучший варин

Задумался вместе с ии об улучшении охлада системы:
Спереди (низ): 2 вентилятора на ВДУВ (там стоят два штатных обдувающие отсек с жесткими дисками)
Сбоку (низ): 1 или 2 вентилятора на ВДУВ (для видеокарт). - там на перфорации есть место под два 100мм.
Сзади: 80-мм вентилятор на ВЫДУВ - штатный старичок предполагается заменить на новый покачественней (большего размера вроде бы там не запихнуть)
Спереди-сверху (отсек 5.25"): "Кустарный" вентилятор на ВЫДУВ. Ну, а чо, свято место пусто не бывает.
итого:
- 80мм поменять,
- 2х100мм на бок поставить,
- мб закустарить еще 80мм спереди на выдув.
Говно-переделывай?
З.Ы сверху на выдув места нет, просверлить мог бы, но стружку даже с магнитными финтами не хочу ловить, сцу.
Спереди (низ): 2 вентилятора на ВДУВ (там стоят два штатных обдувающие отсек с жесткими дисками)
Сбоку (низ): 1 или 2 вентилятора на ВДУВ (для видеокарт). - там на перфорации есть место под два 100мм.
Сзади: 80-мм вентилятор на ВЫДУВ - штатный старичок предполагается заменить на новый покачественней (большего размера вроде бы там не запихнуть)
Спереди-сверху (отсек 5.25"): "Кустарный" вентилятор на ВЫДУВ. Ну, а чо, свято место пусто не бывает.
итого:
- 80мм поменять,
- 2х100мм на бок поставить,
- мб закустарить еще 80мм спереди на выдув.
Говно-переделывай?
З.Ы сверху на выдув места нет, просверлить мог бы, но стружку даже с магнитными финтами не хочу ловить, сцу.
Анончики, вкатываюсь в локалочки. Потыкал кобальда, llama-server - с чятиком все понятно, проблем нет. А есть что-то более юзабельное для реальных задач - типа что бы и в интернете поискало, файлики скачало, прочитало, в отдельную .md написало отчет что сделано, где что лежит, и потом с этим можно продолжить работать.
А как решаешь вопросы пола в предложениях? Я перевожу Скайримские диалоги и потом перечитываю и правлю диалоги.
я бы предложил создать для ии карточки персонажей, где прописать конкретный пол, чтобы он сверялся.
мимокрок мамкинэксперт
Что-то экстеншенами таверны делается, но в целом - тут нужно агента делать, это целое непаханное поле знаний, этому по-хорошему тред отдельный должен быть посвящен, но у анонов все силы уходят на кум с лолями, ничего не остается после этого и не хочется. Тем более чат гопота платная есть сейчас у всех.
>Говно-переделывай?
>80-мм вентилятор ... большего размера ... не запихнуть
Да. Меняй корпус на что-то из этого тысячелетия.
В этом и особенность, хотя перевод и идет по абзацам, они не существуют в отрыве друг от друга. У каждого абзаца, посланного на перевод там подается контекст в виде всех предыдщих токенов что влезли в общий контекст. Поэтому даже если он и ошибется при первом упоминании персонажа, если там не будет ясен пол, то при всех последующих - он уже будет писать его пол правильно. Потому я и использую 12В гемму, даже не 27В - чтобы и 8 квант и контекст полностью на видеокарте лежали и давали скорость 5к обработка промпта и 45 т.с. генерация и даже с такими скоростями средняя книга переводится за час-два.
либо сам наебош, либо скачай готовое. так то агентных фреймворков много. От всякого вроде 8n8 где в общем то автоматоны скорей, до OpenCode, где оно и md наебошит и скрипт в питоне напишет с вызовом и CLI откроет и чето поделает в нём. некоторые вон в таверну это пихают даже.
Ты перед этой хуйней сидеть не сможешь, она будет орать как пылесос. А если стенки тонкие/газобетонные - еще и соседи этот гул будут слышать, ночью не покумить.
Всё что нужно - один кулер на вдув спереди, один на выдув сзади. По возможности настроить обороты в зависимости от температуры проца. Этого достаточно. Ну и корпус закрытый и не дырявый, чтобы тяга нормальная была.
Видеокартам какого-то дополнительного обдува (сверх того что выше написал) не нужно - в ЛЛМках они особо не греются.
Как логику то организовал? я сам думаю что-то похожее сделать, но там скорей всего придётся вообще сначала прогонять всю книгу чтобы собрать библиотеку фактов для конистентных имён и всего такого, а потом уже переводить так чтобы ЛЛМ скармливалось X переведённых сегментов сзади и X не переведённых сегментов спереди, а оно просто перемещалось медленно вперёд.
Я все больше убеждаюсь что залог победы это водянка на проц, радиаторы на памяти, 2-3 боковой обдув, 1-2 задний. Водянку от проца если в бок, то выдув остального наверх, если вверху водянку оставить, то делать как аэротрубу чтобы выдув основного потока шел через корпус в бокС Потому что в противном случае у тебя охлаждение пойдет через кулеры водянки.
Организовал не я, другой человек сделал базу,то что по ссылке выше. Я только для себя до ума довел чтобы можно было пользоваться.
Логика проста - вытаскиваем и по абзацам переводим. Прошлые абзацы суются в контекст. Я добавил логику, сохраняющую правильные шрифты и теги в тексте типа жирного, наклонного и т.д.
>корей всего придётся вообще сначала прогонять всю книгу чтобы собрать библиотеку фактов для конистентных имён и всего такого
Ну кстати идея в целом неплохая, мб и сделаю что подобное.
Вторые сутки гуфов нет веселуха
Еще неделю не будет, а те что появятся будут сломаны. Кумить можно будет через месяц минимум. Собственно как всегда. Или ты первый день на борде?
На глм флеш и поддержка и гуфы через пару часов были
>OpenCode
Благодарю, довольно работоспособно. Осталось понять где его настраивать.
Он неплохо документирован.
https://opencode.ai/docs/config/
В его UI там правда как-то мало положили, как всегда лучшее в CLI спрятали.
По сути он попенсорсная версия claude code, qwen code и так далее.
Мне он нравится и в целом я его не редко запускаю когда мне лень чето делать по мелочи. Например попросил сегодня GLM 4.7 Flash поставить мне vLLM, он там сам открыл CLI, сам скачал WSL2, убунту, сам догадался как перенести её куда сказали, а потом ещё кинул мне md с инструкцией чё куда тыкать.
> хардкожу хуйню которая превращает мой внутренний формат чата в то что понимает модель
Понятие "понимает" достаточно абстрактное, точно также glm и другие модели работают в chatml форматировании, вопрос в результатах. В рп это может быть оправдано из-за дополнительных эффектов, но если требуется что-то околотехническое, точное и с минимальным распылением внимания - именно номинальный режим модели покажет наилучшие результаты.
> у некоторых моделей он вообще запрещает одновременный текст и вызов инструментов
Обычно, подобное именно в костыльных имплементациях чтобы не задумываться над их парсингом. Все современные пишут комментации и могут вызывать сразу по несколько тулзов (когда костыльный парсер на бэке этому не препятствует опять же). В целом и логика агентных систем выстраивается вокруг повторных вызовов пока не поступит простого ответа, который принимается финальным.
> любит себя спрашивать "стоп, а не делаю ли я хуйню?"
Это появилось в самом первом ризонинге. Удивительно что это первый раз встречаешь, но раз так можно поздравить. Они вообще иногда удивляют тем что стали весьма умными, но офк это касается только специализированных задач или самых крупных.
> ЛЛМ например может запрашивать куски кода не через grep,а напрямую указывать "дай мне метод Х в классе У"
Это то чему их учили. Просто поставь qwen-code, claude-code с проксей или любую вариацию и удивись что все уже сделано. Алсо осс далеко не чудо но в код может, судя по вводным он не справлялся из-за неверного формата.
Калькулятор говорит что на 131к (разумный компромисс) нужно около 50, надо смотреть сколько в итоге выделяет. В случае кода лучше жертвовать квантом чем резать контекст и тем более его квантовать. Ниже 5-6 бит там чаще пролезают мелкие ошибки, но обычно сетка сразу их за собой подчищает даже не дожидаясь результатов проверки синтаксиса.
> прикольная идея
Ага, там еще тема в том, что ллм изначально тренировалась на подобное и использовались спец-токены для порождения ветвлений. Правда потом притихли, а потом вышла 5-я гопота со скрытым ризонингом. В новой жемини он тоже очень условный, тебе буквально суммарайзнутые блоки выплевывают а не оригинальный.
Но никто не мешает реализовать это агентами для начала.
> 80-мм
> 100мм
Просто купи какой-нибудь дешманский но максимально простоный корпус, где ты понимаешь как разместить свои компоненты. И к этому возьми 120-140 крутиляторы с нормальным статическим давлением, а не чисто "производительные корпусные", они будут потише в средних режимах. В идеале низ и перед на вдув, зад и верх на выдув, офк с нюансами чтобы по углам не сифонило. Если есть водянки - ставь их только на выдув.
Плавающее окно и краткий суммарайз-список персонажей с периодическим обновлением. Ты посмотри что за треш там происходит, 3 вариации имен, вице-адмирал стал королем и обратно, рода плавают и прочее.
>крутиляторы с нормальным статическим давлением
Arctic P14 что ли?
>Понятие "понимает" достаточно абстрактное, точно также glm и другие модели работают в chatml форматировании, вопрос в результатах.
в стандартных jinja говно какое-то кладут. Например для GLM 4.7 Flash делают префил <think>, хотя модель без проблем сама может решать когда думать, а когда нет.
>Обычно, подобное именно в костыльных имплементациях чтобы не задумываться над их парсингом.
Речь про jinja формат, а не способности модели. Там может быть прямой указатель "вызывай только 1 инструмент", или "пиши только вызов инструментов". Моель может без проблем и делала бы и много вызовов, или писала и текст и инструменты, но шаблон сообщает иные инструкции.
>Это появилось в самом первом ризонинге.
Явно нет, даже не близко к этому. Я отлично помню какую хуйню писал R1 в нём.
>Просто поставь qwen-code, claude-code с проксей или любую вариацию и удивись что все уже сделано.
Лол а причём то что что-то сделано? Я дал пример сложного кода который не каждая модель ПОНИМАЕТ. То есть я описывал не НАПИСАНИЕ, а ПОНИМАНИЕ. Способности рассуждать о том что написано. И тут GLM прямо очень силён. Ясен хуй у него не хватит мозгов написать такой код. По факту такой код ещё ни одна ЛЛМ родить не может, просто потому что он проклят изначально, узкоспециализирован и требует глубокого понимания доммейна. Если бы я хотел взять готовое то я бы просто пошел Roslyn поставил.
Оверкилл, но пойдут. Они вполне норм, но сейчас акрктики скурвились, наверняка есть лучше по прайс-перфоманс-шум.
> в стандартных jinja говно какое-то кладут
Сейчас во многих моделях темплейт только для базового функционала, а для полного пихоновский скрипт с нужной логикой парсинга всего (или вообще код на их гитхабе). Их могут потом примерно адаптировать в жинжу, но мало кто ее обновляет в квантах сделанных впопыхах. Потому и обмениваются потом отдельно темплейтами, которые корректно/лучше работают.
> модель без проблем сама может решать когда думать, а когда нет
Это чистый рандомайзер. Он не имеет отношения к потребности в ризонинге, префилл делается как раз чтобы гарантировать нужное поведение.
> Речь про jinja формат
Ты говоришь про формат в целом, а потом приводишь примеры какой-то единичной костыльной реализации. Если хочешь сам все парсить - лучше всего использовать оригинальную логику и разметку, или тот же самый скрипт. Изобретение велосипеда увлекательно и полезно для развития своих скиллов, но не для результата.
> Явно нет, даже не близко к этому
Тогда ничего не поделаешь, воистину прорыв.
> лучше по прайс-перфоманс-шум.
П12 пачкой по 5 шт стоят 2.5к, куда дешевле то? По личному опыту умерла (дребезжать начала) только одна из примерно 15 спустя 3-4 года аптайма 24/7.
По 140 данных по эксплуатации нет
В командировку уехал, организовал себе текст комплишен апи на месяц. Там железо мощнее чем дома, потому я наконец попробовал Квен235. И о боги, какой же это лоботомит, вхахаха. Он улетает в структурный луп уже после где-то 6к контекста, как его ни жми промтом, инжектами или семплерами. Вы настолько ебанулись с голодухи что пытаетесь играть на этом? Это пиздец абсолютный. Проверял все версии, и оригинал с гибридным ризонингом, и 2507, и даже вижен блять! Не, я реально ору, мне не жаль времени потраченного, да и пердолинг это всегда весело. Но как же я ору сейчас со всех защитников Квена итт, что устраивали срачи таких масштабов что они из треда в тред перетекали. Ай бля содомиты.
Тут в треде плавал пресет с какой-то грамматикой, осталось только на нем затестить. Может кто прислать у кого ссылка под рукой? 15 тредов копаю, так и не нашел, заебався
пчел, квен235 это такая постирония, я сам её выкупил через несколько десятков перекатов.
говно говна, а не модель
И вот сраться не вижу смысла, ну на кой хуй мне доказывать анону вкусовщину, но, блять, у меня не разваливется на 25к контекста, ну не заметил я, а я это говно ложкой жру.
Но с другой стороны, пусть будет по твоему. Плохой квен, ужастная модель, не используй.
Радостно побежал дальше тыкать квен палкой.
>И вот сраться не вижу смысла, ну на кой хуй мне доказывать анону вкусовщину, но, блять, у меня не разваливется на 25к контекста, ну не заметил я,
И вот в который раз ты пишешь этими примирительными формулировками, чтобы по итогу все свести к "ну не буду я ничего доказывать" вместо того чтобы анону помочь. Или хотя бы логи показать. Соглашусь с аноном выше, это походу постирония или системный троленг.
У меня под рукой нет ссылки а сам я не дома чтобы скинуть, мб если не забуду как вернусь. Но пресет не поможет, он обрамит аутпуты в другой вид но концептуально ничего не поменяется. Это как обёртку поменять. Без грамматики лупы с параграфами, с ней одним параграфом. Структурные лупы это часть Квена еще с 2.5, там только пара тюнов типа Ева Квена от этого избавились, но то уже прошлый век
> ключ fit реально рабочий
наверное это был я, но сейчас я могу посоветовать другое: сделать --fit off, и добавить ngl ts ot полученные из тулзы llama-fit-params.
>чтобы анону помочь
Чем? Я просто беру Q3 от анслотиков, запускаю через llama.ccp, всё работает. Чем я могу ему помочь? Я нихуя волшебного не делаю, он просто работает. Пресет? Вот, это обычный чатмл. https://dropmefiles.com/AatEk
Всё. У него другие проблемы, а в остальное- он просто работает, доёбываясь до каждого предложения, не затыкаясь.
minimax-m2.1 с ngram не выдаёт больше t/s, а в ответ на тот же запрос генерирует больше токенов, в результате суммарное время увеличивается почти в два раза.
то есть конкретно для минимакса ngram = хуита. gpt-oss ещё не проверял, там вроде бы все довольно урчат.
то есть конкретно для минимакса ngram = хуита. gpt-oss ещё не проверял, там вроде бы все довольно урчат.
Чекни свой пост, кажется ты структурными лупами заразился. Отвратные структуры это действительно слабость модельки, но она лечится и является несущественной на фоне преимуществ.
Алсо уверен ли ты, что тебе кормят нормальный квант а не какого-то полумертвого лоботомита? У них именно такие симптомы.
> вместо того чтобы анону помочь
Думаешь он пришел за помощью?
>наверное это был я, но сейчас я могу посоветовать другое: сделать --fit off, и добавить ngl ts ot полученные из тулзы llama-fit-params.
Тоже хороший совет, спасибо.
Да походу заразился, всяк бывает. Квант норм, там q4xl от батрухи, в кванте у меня 0 сомнений. Раз проблема лечится то расскажи как, потому что у меня не получается. Даже новомодный адаптив п пробовал, все одна хуйня.
Какой смысл тогда в принципе отвечать?
> расскажи как
В первую очередь не срать промпт и буквально попросить какой именно стиль повествования хочешь. Частые переносы можно победить грамматикой или баном токенов, но лучше просто попросить. Работает даже просто в тексте (ooc: change writing style to more natural and vivid, like it's a scenario from (фильм/режиссер/...). Avoid short sentences and newlines spam).
Вон тебе готовый пресет скинули, там все на первый взгляд хорошо, под себя чуть крутани и инджой.
> q4xl от батрухи
Может и в нем проблема.
Кто там пиздел что гуфы неделю ждать норма?
Анонсу пару часов
https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF
Анонсу пару часов
https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF
Архитектура уже добавлена, потому нужно только квантанутьЮ жто быстро. Также и с glm 4.6-4.7 обычными , обновлением квена и прочими все сразу было.
А с 4.7 флеш сначала неделю ждали, потом неделю чинили. И это очень быстро по сравнению с тем, что было с первым квен3-некст.
Модель ожидается ахуенная, пора качать.
Я кста не понял это версия без ризонинга и бенчи при этом лучше чем у моделей с ризонингом
>бенчи
...
А теперь вспомни сколько ждали гуфы Qwen 80. Подсказка, почти два месяца, а потом их еще и чинили
Попробовал анслота, то же самое все. Инструкция не срать переходами работает только на пару тыщ контекста. И энивей я пробовал подобное инжектить, все это полумеры. Видимо не моя модель, ну да и ладно. Сяп что ответил.
Ace step 1.5 вышел
https://files.catbox.moe/m6e4ry.mp3
https://files.catbox.moe/m6e4ry.mp3
Это кодерская инстракт модель, без встроенного ризонинга. Если нужно - он делается соответствующими запросами.
Его хоть сделали наконец, или также багано-медленно?
Попробовал степ на ихнем форке жоры.
В целом ощущается как прокачанный минимакс. В РП чуть-чуть получше, чуть менее сух. Русик не прям 100% идеальный, местами в еРП англ слова вылезают.
Поразило то, как модель следует инструкциям. Она не выключает синкинг пока каждое требование инструкции не выполнено. Например - увидев в моей инструкции требование использовать вульгарную лексику и определенные слова, она в синкинге высрала 4 тысячи токенов, улучшая свой ответ, так чтобы он идеально соотвествовал этому требованию.
Сои и цензуры много, но как любая синкинг модель - ломается очень легко. В этот раз пришлось немного поколдовать и отключать конкретно OpenAI use case policies в которые степ цеплялся мертвой хваткой, но после их выключения все пошло как по маслу.
Что поразило - размер контекста. Он почти нулевой. Я с легкостью вместил максимум модели в 262к контекста в 8 битном квантовании на свои 24 гб видеопамяти, что заняло всего 12 гб(!) врам и осталось место даже под несколько слоев тензоров.
Скорость как у минимакса, т.е. на моем железе (4090 + 128 ддр5) - 18 т.с., это в 2.5 раза больше глм 4.7 на втором кванте.
По качеству РП и сочности кума степ конечно уступает глм 4.7, как уступает и его мозгам, если выключать синкинг,но если синкинг включать - то он конечно прекрасен. Как ассистент - он однозначно заменяет минимакс и выкидывает его в мусорку.
В целом ощущается как прокачанный минимакс. В РП чуть-чуть получше, чуть менее сух. Русик не прям 100% идеальный, местами в еРП англ слова вылезают.
Поразило то, как модель следует инструкциям. Она не выключает синкинг пока каждое требование инструкции не выполнено. Например - увидев в моей инструкции требование использовать вульгарную лексику и определенные слова, она в синкинге высрала 4 тысячи токенов, улучшая свой ответ, так чтобы он идеально соотвествовал этому требованию.
Сои и цензуры много, но как любая синкинг модель - ломается очень легко. В этот раз пришлось немного поколдовать и отключать конкретно OpenAI use case policies в которые степ цеплялся мертвой хваткой, но после их выключения все пошло как по маслу.
Что поразило - размер контекста. Он почти нулевой. Я с легкостью вместил максимум модели в 262к контекста в 8 битном квантовании на свои 24 гб видеопамяти, что заняло всего 12 гб(!) врам и осталось место даже под несколько слоев тензоров.
Скорость как у минимакса, т.е. на моем железе (4090 + 128 ддр5) - 18 т.с., это в 2.5 раза больше глм 4.7 на втором кванте.
По качеству РП и сочности кума степ конечно уступает глм 4.7, как уступает и его мозгам, если выключать синкинг,но если синкинг включать - то он конечно прекрасен. Как ассистент - он однозначно заменяет минимакс и выкидывает его в мусорку.
>Ace step 1.5 вышел
А прикольно. И доступно вполне.
> По качеству РП и сочности кума степ конечно уступает глм 4.7, как уступает и его мозгам
Так его с эиром надо сравнивать, в край с квеном
Котаны, давно не заходил. Есть ли что норм на мои нищенские 3090 и 64 рам? Последнее, что я пробовал был AIR 4.5. Мне он не очень зашел, потому что надо все вырубать, кроме окошка с Аиром, иначе не заведется. Пишет норм, но начинает глючить уже после 16к. контекста, равно как и мистраль, но мистраль быстрее. А может это просто я криворукий и не смог в настройки. В общем, зашел узнать, есть ли что пощупать для нищуков или здесь у всех давно уже по 4 5090 и 500 рам?
Ещё один всё на русике тестил...
Ну вот и как к вам относиться после такого?
Русикодебил он и есть русикодебил, нигде даже не написано что модель вообще поддерживает русик, но всё мнение о ней я буду составлять на русике
>Ещё один всё на русике тестил...
Ну русский там в принципе неплохой, получше, чем у ГЛМ например. И да, датасета не хватает для полноценной работы - но если ризонинг включить, то справляется. К сожалению, верно и то, что это лишний геморрой - рабочие языки модели английский и китайский.
>Тут в треде плавал пресет с какой-то грамматикой, осталось только на нем затестить. Может кто прислать у кого ссылка под рукой?
https://pixeldrain.com/l/47CdPFqQ#item=154 это наверно
Жора какой же ты пидорас пропусти флешку уже

Так он по всем параметрам хуже даже по их тестам, лол.
Не нужно.
>уступает глм 4.7
Короче не нужен, пропускаем.
>Короче не нужен, пропускаем.
А я вот тут подумал, что 128к реально рабочего контекста на локалке - это довольно круто. Особенно для большой модели. Раньше я даже не замахивался на задачи с таким контекстом, а вот теперь пожалуй смогу.
Опаньки, дофига-дофига контекста - это нам надо, это мы пробуем.
А как с вниманием к этому контексту?
Контекст помещается потому что там атеншн сам по себе мелкий, и только у 25% слоев он полный, остальные по 512 токенов. Учитывая что ты еще квантанул - это буквально 12.5% от "типичного" потребления на контекст, потому и помещается много.
Но у всего есть цена, высока вероятность что в рп и около того на больших контекстах будет забывчивое и отупеет, на больших проектах больше рассеянности и ошибок в коде.


Пиздос, как же меня трясет со штрафов на нищеёбство.

Во втором кванте уместится даже в нищуковские 12+64. Осталось только дождаться.
Степа хуже Эира в рп. Скриньте
Что скринить, где примеры РП желательно на русском?
Да, оно. Пасиба что запарился и прислал. Там анон выше или мб ты же базу выдал. Поигрался сейчас с этим пресетом, реально проблема попросту маскируется под другим видом структурного лупа. Автор молодец что нашел там какой-то доисторический семплер но к сожалению не помогло, имхо. Ждем Стёпу 3.5 всем тредиком, вдруг правда порадует.
Квен 3 некст (не для рп). Hunyuan выходил, вроде по размерам чуть меньше Эйра. Еще была Ling Flash кстати неплохая, тоже чуть меньше Эйра, туповатее, но может тебе подойдет. У меня тоже 3090, но 128 рамы. До расширения рамы я сидел на Немотроне и Валькирии, там у Драмера v2 выходила, он не так плоха как первая. Попробуй
Гемма 27 со своим жирненьким контекстом будет кушать столько же сколько и Квен 3 32b. И мистралька 24b не такая глупая, последняя которая. Не грусти
> Автор молодец
Жаль что его распяли всем тредом. Правда жаль ведь. Его личные хейтеры так засрали тред что даже мой пост можно принять за троленг, потому дискуссия невозможна. А я по прежнему считаю что намеренно сливать тех кто делился своим добром это плохо. Сами посмотрите, автор мертв а пресеты всё так и всплывают иногда. И зачем это всё сделано было, нахуй этот негатив, так и непонятно
Что-то я протупил, ты же наверно и не знаешь что за Немотрон и Валькирия раз давно не заходил. Вот
https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
https://huggingface.co/TheDrummer/Valkyrie-49B-v2
3 квант должен поместиться с q_8 kv контекстом. 20-30 тысяч можно запихать точно
> всем тредом
Единичный шиз тред засирал и продолжает, о чем ты?
>Так он по всем параметрам хуже даже по их тестам, лол
Так и размер меньше и скорость гораздо выше (особенно если запускать на нормальных бэках и фул врам). Вместо ГЛМ можно аж 2-3 штуки запустить и они будут срать тебе в проект с немыслимой скоростью.
Кстати, а они не выкладывали сравнение со своими старыми кодерскими моделями? 30 вроде на 30% всего хуже большого был, при использовании qwen coder.
>Так и размер меньше и скорость гораздо выше
Но зачем?
>срать тебе в проект с немыслимой скоростью
До корпов всё ещё далеко.
>моделька которая почти вдвое меньше большой перформит на несколько процентов хуже
>"Но зачем? До корпов ещё далеко"
>надмозг
Прогрелся на v100 32 за 35к, собрал, пост код А9(start of setup), с второй картой для вывода картинки, плата вообще в цикличном ребуте, хуй знает че не так А я просто хотел быть счастливым а не бомжом с 6700XT
Может много что не так быть. Начиная от неисправной карты или переходника и заканчивая проблемами с bios. Спроси корпоратов в чём может быть проблема, он тебе накидает вариантов что посмотреть, только укажи, что через переходник запускаешь.
Держу за тебя кулаки анон
> 30 вроде на 30% всего
Эти метрики и бенчи очень абстрактны. Реальность же, как правило, можно свести к трем абстрактным вариантам:
1. Нихуя не поняло, начало собирать подобие и зафейлили, заодно обманув тебя на вопросы. Все делай сам, модель поможет только с совсем уж мелочами и придется ей многое объяснять.
2. Сообразило что требуется, примерно поняло имеющийся код, но ошиблось при выполнении, намоталось на какое-то несущественную ошибку и пошло ее неправильно исправлять, заложенный проеб в дизайне проявился слишком поздно и полетели штабели костылей. Проявив определенные усилия можно будет выправить, но напряжно.
3. Поняло задачу, сразу осознало/описало подводные камни и заложила адекватную логику, написало основное, само или с умеренными вмешательствами исправило ошибки и доработало.
Какие кейсы преобладают в 30а3 а какие в 480а35, полагаю, угадать несложно. Надо будет некст посравнивать, есть всеже на него надежды.
У тебя 32 гига рам или меньше? Отключай ребар (или его аналог) и пробуй опять.
Спрошу очевидное - 4G decoding в биосе включил?
включить в биосе "resizable BAR" и "above 4G decoding", а если уже включено - то выключить
PCI ещё в 3.0 перевести
> 12+64 2 квант
В IQ3s же
В целом норм, но хули скорость такая низкая? 3В активных, а при этом скорость как у плотной.
> включить в биосе "resizable BAR"
Выключить, выключить. Когда ставишь дополнительные видеокарты или просто обновляешься что объем врам сравнивается или превышает объем рам - ребар нужно отключать. Пека банально не может настроить адресацию достаточного объема.
> хули скорость такая низкая
Какая скорость и что за железо?
12+64=76. Если Q3_K_S будет как у этого чувака 85гб, то IQ3S будет 80 примерно. А что бы влезло нужно где-то ггуф 70 хотя бы. Так что только 2 квант. А учитываю, что там мозги 11b, то можно сразу нахуй модель
Мимио чел с 16+64
А, я прочитал как 24+64
>Ling Flash
>Hunyuan
Мертворожденная залупа
Предлагай свое. Пиздеж твой кому интересен?
Там кстати тоже будет впритык. 24+64=88-80(квант)=8гб на все (контекст, система и т.д.). Ну то есть только если из под линуха сидеть без де, а кумить в телефоне/ноуте
>чел с 16+64
И чем же ты пользуешься?
Всегда есть IQ3_XXS который всё ещё лучше 2 кванта.
Ну и 80гб кванты влезают судя по опыту, к тому же у этой модели контекст легчайший как тут писали
Я предлагаю не выдумывать хуйню. Линг (да и Ринг тоже) я пробовал давно. Это залупа. Хуянь не пробовал, но там скорее всего только название смешное. Для 64гб есть только Air (4.6V), Qwen 80 и GPT 120b. И то два последних не для кума, а просто как ассистенты. Ну еще и рипы. Но их в здравом уме никто рассматривать не будет
Qwen 80b Q5KM как ассистент. GLM 4.6 Q4XL кум. Еще дипсиком, но не локально
>GLM 4.6 Q4XL
>16+64
Как такое возможно?
Очень просто. Букву V забыл. 4.6V

24-32b для РП - все? Гемме и мисралю уже год, только васян-тюны с минимальными улучшениями выходят.
Качнул 2 квант стёпы.
"В рп могёт" это мягко сказано, я не получил ни одного отказа с ризонингом через чат комплишен
"В рп могёт" это мягко сказано, я не получил ни одного отказа с ризонингом через чат комплишен
Узнаем этой весной. Если условные Гемма 4, Мистраль 4, Квен 4 и прочее не выйдут или будут МОЕ залупой, то да все
Логи покажи хоть какие
--swa-full в ламе который вырубает скользящее лоботомирующее окно контекста добавило всего 1 гиг нагрузки видяхе, нахуй оно вообще нужно не ясно
В гемме вот контекст очень тяжелый и может пригодиться, тут он и так легкий
В гемме вот контекст очень тяжелый и может пригодиться, тут он и так легкий

Это прискорбно, офк если не 200к контекста. Интересно сколько там на паре вольт будет.
Не будет больше никаких плотных моделей. Этот подход устарел и нецелесообразен. Тот же большой глем при своих 30b ебёт в писечку и в попочку 100b мистраль лардж, уделывая его как по мозгам так и по скорости инференса. А еще не требует кучу дорогой видеопамяти для работы - только под активные параметры и контекст (32гб - ему норм, если в 4 кванте).
Единственное где оправданы плотные модели - это устройства в которые нельзя просто так взять и докинуть ОЗУ. А именно телефоны и планшеты. Под них как раз и выходит плотная мелочь 1b-14b. И скорее всего продолжит выходить.
Контекст тут почти бесплатный. Но лучше бы проседало в 2-3 раза и 200+ т/с на старте было.
> большой глем при своих 30b ебёт в писечку и в попочку 100b мистраль лардж, уделывая его как по мозгам
Кумит слабее, лупится и фейлит в простом. Он хорош, но нельзя назвать каким-то абсолютным эталоном и лучше во всем. С современным подходом к обучению лардж мог быть тоже хорошенько дать жару.
Офк обучать большое и плотное никто не будет, моэ слишком удобны и достаточно хороши, но вот получить что-то типа грока2 с адекватными оптимизациями атеншна хотелось бы.
> под активные параметры
Значение знаешь?

>Значение знаешь?
Акти вные
Ну вот эйр у нас 106b-a12b. 12b - активные. Если взять его Q4_K_XL квант и выгрузить всё мое в озу, то в видеопамять идет примерно ~7гб, что соответствует 12b в том же 4 кванте. Не?
Нет, ты обосрался. cmoe грузит во врам тензоры внимания, а не просто активные
>GLM 4.6 Q4XL кум
Почему не мистралька? Она же влезает, не тупит, не лупится, умненькая.
>большой глем
>при своих 30b
Ты называешь флэш большим или ты из тех шизов, которые не понимают как работают мое и называешь 350b модель 30b?
>мистраль лардж
Вот это достижение. Трахнул старое говно от французов. Может он еще и GPT 3.5 трахнет?
Вполне возможно. Однако сути написанного не меняет. Плотнота сейчас реально нужна только полутора риговичкам с кучей врам. Корпы перешли на мое потому что дешевле. Кумеры-нормисы со своими 12-16гб перешли на мое потому что умнее и быстрее (тот же эйр умнее и быстрее плотного мистраля 24b - говорю как человек, который пользовался и тем и тем довольно долго). У плотных моделей нет будущего за пределами мелочи для телефонов.
Потому что медленная и не особо умненькая
Если бы они выпустили бы ее сейчас с доработками, то может и юзал ее. Но они выпустили никому не нужную и мертворожденную 670b, которая сразу же слилась китайцам.
И кста я вспомнил что у них еще есть Mistral Medium, которые они так и не выложили на обниморду суки
>Может он еще и GPT 3.5 трахнет?
Ты что, его в опенсорсе ещё никто не трахнул!
В том и суть что активные параметры у тебя каждый раз разные, "грузить" их в врам - глупость. Тебе правильно написали что на гпу грузят только атеншн и нужный ему кэш, ну и линейных фидфорвардов сколько влезет.
> сути написанного не меняет
Меняет, этот прием никак не привязан к активным параметрам и точно также сработает на плотных.
> Плотнота сейчас реально нужна только полутора риговичкам с кучей врам.
Риговички точно также инджоят моэ, только на скоростях и контекстах. Цитата с твоим утверждением в посте не просто так, а о том что развития чисто плотных моделей врядли увидим рядом написано. Но вот моэ поплотнее - о да.
Алсо
> Кумеры-нормисы со своими 12-16гб
2.5 года назад в треде не было ни одного риговичка и все в основном такие. Где эволюция нормисов, или они просто молчат?
> тот же эйр умнее и быстрее плотного мистраля 24b
Ща налетят. И вообще, жлм4 32б - лучшая вайфу!
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Сап кумеры, напишите пожалуйста как запускать чатбот-персонажей, как в Character tavern, только полностью локально?
Где скачать саму нейронку? Надо ли качать что-то ещё (лоры хуёры и т д) и где? Где брать персонажей для неё?
В нейронках не шарю, объясните пожалуйста как дауну.
С меня сотни интернетов.
Где скачать саму нейронку? Надо ли качать что-то ещё (лоры хуёры и т д) и где? Где брать персонажей для неё?
В нейронках не шарю, объясните пожалуйста как дауну.
С меня сотни интернетов.
Кстати, т.к. там энкодером qwen - оно неплохо понимает и инструкции на русском, а не только тексты для песни. Реально прикольно получается.
я конеш сам особо не эксперт, но я сделал так:
1. ставишь koboldcpp
2. скачиваешь нужную модель в формате gguf с huggingface (учитывая то, потянет она у тя или нет)
3. ставишь SillyTavern
4. врубаешь и настраиваешь кобольд, сохраняя конфиги и всю хуйню
5. заходишь в силлитаверн, и подключаешь api кобольда к силли таверн
6. кайфуешь
p.s. если че то не понятно, подробнее в инете инфа есть. как минимум в оф. документации к sillytavern - точно описано подробно про API, подключение, и прочую хуйню, а про кобольд есть исчерпывающая статья на дтф
а, бля, и насчет персонажей.
зайди в соседний тред по AI CHatbot - там хуева туча ссылок в шапке - может пригодится, а так для большинства дрочеров в рп хватает jannyai.com
можешь и сам их хуярить если хочется, просто загугли "character card creator" и там какая то ссылка ведет на простой макет этих карточек в формате json или png.
и ещё - совет. хочешь рпшить но не знаешь ангельского? включай как нить в силли таверн (в глобальный промпт или ещё куда) хуйню типа "speech only in English", включай там в дополнениях автоперевод (чтобы ответ ИИ переводился сразу на русиш), а сам отвечай на русском. в 99% случаев и моделей - ИИ будет хавать ответ на русском, выдавать на английском, и гуглом/яндексом (или если ты крутой мен - купи АПИ к deepL) переводить сразу на русский.
нахуя такая ебля если можно заставить модель хуярить чисто на русском сразу? резонный вопрос - только скорее всего у тебя там не дата-центр, а хуйня по типу 3070-4060, и контекст будет ужат в лучшем случае до 16-20к - и в таком случае каждый токен будет на счету (учитывая что хорошие карточки персонажей весят от 1.5к токенов). ибо прикол в том - что условно текст на 2000 символов на русском - будет "весить" примерно 2500-2800 токенов, а текст в 2000 символов на английском - 600-800. экономия на лицо, во первых, а во вторых когда у тя скорость работы модели на твоей видеокарте 3-4 токена в секунду - ты ахуеешь ждать, пока тебе раз в секунду 3-4 буковки будет выводиться, вместо 3-4 слов на английском (что очевидно - быстрее, при лимите токенов за сообщение 200-300). Ну и сами сообщения при ограничении токенов очевидно будут нести в себе больше информации и объема.
Надеюсь на все вопросы ответил.
Спасибо, анонас.



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Вниманиеблядство будет караться репортами.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd )
• Неактуальные списки моделей в архивных целях: 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: