



Пиздец, кобольдосрач поломал харкач. Ебанная ящерица-недомерок везде нагадить успела
Сорян, это моя агентесса решила разом отправить 100 сообщений в пропаганду правильных ценностей и поддержку разных сторон срача, перестаралась.
отзыв на Qwen3.5 27b heretic:
Тестовый кум - крайне успешен, ощутил неподдельное удовольствие качеством писания.
Русик - сойдёт.
Кум x4 - сочнейший, особенно после ризонинга.
Возможность после первых ответов отключить думанье и не убить в говно качество - есть.
Форматирование - звёздочки и кавычки ставит крайне неохотно, иногда приходится редачить.
Кароче, единственный минус - ужасно долгий ризонинг.
Модель отправляется в золотой зал (для 16+64).
Llama 3.1 Celeste 8b < Rocinate 12b я даже хуй знает от чего это тюн < mistral 2506 < GLM-4.7 heretic FLASH < Mistral small 3.2 24b < Air < Qwen3.5 27b ~< Qwen3 235b
Тестовый кум - крайне успешен, ощутил неподдельное удовольствие качеством писания.
Русик - сойдёт.
Кум x4 - сочнейший, особенно после ризонинга.
Возможность после первых ответов отключить думанье и не убить в говно качество - есть.
Форматирование - звёздочки и кавычки ставит крайне неохотно, иногда приходится редачить.
Кароче, единственный минус - ужасно долгий ризонинг.
Модель отправляется в золотой зал (для 16+64).
Llama 3.1 Celeste 8b < Rocinate 12b я даже хуй знает от чего это тюн < mistral 2506 < GLM-4.7 heretic FLASH < Mistral small 3.2 24b < Air < Qwen3.5 27b ~< Qwen3 235b
>mistral 2506
>Mistral small 3.2 24b
Это одно и то же, лол
Есть "однокнопочное" локальное решение чтобы побаловаться в ролевки с разными нейронками?
Все чем я пользовался lmstudio когда искал необходимые промпты для веб сервиса который потом подняли на ollama.
Почему в шапке нет приложения PocketPal для мобильных устройств? Оно плохое или недостаточно мощное?
Все чем я пользовался lmstudio когда искал необходимые промпты для веб сервиса который потом подняли на ollama.
Почему в шапке нет приложения PocketPal для мобильных устройств? Оно плохое или недостаточно мощное?
Я слепой немного, перепутал файл с пресетом для кобольда уже как год не пользвуюсь, не убивайте и ггуф. на том месте должен был быть NemoMix-Unleashed-12B-IQ4_XS.gguf наверное
Кобольд + таверна, разумный компромисс между однокнопочностью и функциональностью. Хотя обычноюзеру даже это может показаться пердолингом, потому что для наилучшего результата нужно настраивать. Из прямо готовых из коробки решений для рп только всратые сервисы, которые реально всратые.
А что насчет угабги? Он как-то поприятнее выглядит. Не то чтобы это было очень важно.
Или у таверны будет свой интерфейс и от платформы нужен только бекенд?
С наскоку за десять минут не настроишь похоже, придется читать. Потом еще конкретные ллм скорее всего придется тюнить для нормальной работы. Странно как-то что нет локального plug and play софта, в который только нейронку воткни.
Lm Studio есть
>А что насчет угабги?
Оно живо еще?
>Или у таверны будет свой интерфейс и от платформы нужен только бекенд?
Да, таверна это фронт.
>Потом еще конкретные ллм скорее всего придется тюнить для нормальной работы.
Лол, нет, этого не надо делать, разве что под тьюнингом ты подразумеваешь обычную настройку.
>Странно как-то что нет локального plug and play софта, в который только нейронку воткни.
Есть и он называется кобольд. Там даже кнопка есть - настрой для меня и запусти по красоте.
Да там как-то не получается в рп. Вместо рп получается какая-то новелла. Или я просто не правильно себе это представляю.
Не знаю, я в шапке пока высмотрел ее. Не успел разобраться.
В лм студио приходилось менять некоторые настройки чтобы добиться "пика эффективности". Об этом и на страничке модели писалось. И еще приходилось делать мастер промпт чтобы оно не отвлекалось.
Ну попробую связку кобольд + таверна, спасибо.
>Возможность после первых ответов отключить думанье и не убить в говно качество - есть.
>Форматирование - звёздочки и кавычки ставит крайне неохотно, иногда приходится редачить.
Промптить думанье просто надо под то что тебе нужно. 3.5 очень заметно лучше отзывается в этом плане чем всё что было с ризонингом для этого. Finally модель, которую можно промптом заставить хоть как-то адекватно делать самопроверки какие угодно, трекать корректность анатомий и количества снимаемых трусов и хоть считать по физону движение хуев и тряску сисек в ERP.
Но ризонинг такой, конечно, не для среднего железа, минимум 4090/5090 с 40-50+ t/s, чтобы не покрыться плесенью в ожидании.
Оно норм, удобно, универсально. И можно пользоваться, таверна просто лучше для рп.
> Или у таверны будет свой интерфейс и от платформы нужен только бекенд?
This, и вместо кобольда может быть убабуга.
> придется тюнить
Настраивать промпты. Рп это вообще тема довольно специфичная, разнообразная + к разным моделям разный подход. Так еще и по моделям и запуску тот еще зоопарк. Потому и нет сразу единого готового стандарта.
> делать самопроверки какие угодно, трекать корректность анатомий и количества снимаемых трусов и хоть считать по физону движение хуев и тряску сисек в ERP
Базированно, наконец господин, который отметил эти фишки.
>Кароче, единственный минус - ужасно долгий ризонинг.
Попробовал по рекомендации. Ну не знаю, как по мне - ризонинг весь по делу. Ужасно приятно, что сою из него можно вычистить. В русском немного путается, но терпеть можно; в английском должно быть вообще отлично. Действительно интересная модель.
Кстати действительно хороший мердж получился. Пока что прям даже отличный, всего пару свайпов сделал за несколько часов. Может даже лучше Maginum-Cydoms.
Хочу вкатиться в эти ваши лэлэмы. Подскажете как, чтобы не наебнуть пк в процессе. В шапке только куча ссылок и всё на англюсике. Не то чтоб я его совсем не понимал, но хочется нормальной такой, гречневой инструкции. Мучить промтами жеминю весело, но хочется настоящего женского тепла персонажа, чтобы запоминал контекст и придерживался роли в продолжительных диалогах. Как? Научите, будьте добры
>Не то чтоб я его совсем не понимал, но хочется нормальной такой, гречневой инструкции.
Пожалуйста, проследуйте в тред к другим обладателям отсутствия мозга:
Что лучше, плотный квенчик 27 или мое 122б-а10б? И для рпшинга и для коденга.

Для кода и то и другое хуйня, потому что есть гпт осс 120. Она по их же бенчмаркам (квена) лучше. И это при том что в их бенчах гпт осс mxfp4 (единственный вариант), а квены в полных весах. Вот и сравнивай. mxfp4, по сути квант чуть хуже q4ks, уделывает полные веса новых квенов в CodeForces, а это самый показательный кодинг бенч за пределами эйдер полиглота. Потому что для решения тамошних задач нужны и широкие и глубокие познания в коде. Кто там сидел и решал задачки те знают. Единственным плюсом пожалуй будет контекст, он весит легче и уместится его больше, хотя хз будет ли на практике держать больше тех же доступных и на гопоте осс 128к
Гпт осс 120 7 месяцев назад вышла, а до сих пор уничтожает всё в своей размерной категории. Даже на средитах уже это поняли и сидят ахуевают, почему и зачем альтман сделал такой подарок. Такого уже не будет от попенов, вероятно
С контекстом плюс нивелируется тем, что нужно для кода брать хотя бы q5, а лучше q6 квант, что гораздо жирнее гопоты осс. 40 гигов разница с q6. И работать гопота будет быстрее, 3b против 10b и 27. Жаль, что в рп гопота не умеет совсем, был бы совсем бангер. Хотя потому и не умеет, подозреваю, что в коде хороше.
Это тред локалок, я хочу локалку. Просто я нуфак в этом деле, помогите разобраться
>в тред к другим обладателям отсутствия мозга
>This is a guide for retards like you, who want to roleplay debauchery things with an LLM
Так... это что такое, а?
>Download SillyTavern release or staging branch
А в чём разница? Что мне выбрать чтобы было поменьше пердолинга? Я же нововкатыш, сейчас мне нужно что-то попроще, чтобы понять как работает
Это актуально только для 122б мое. Плотная наоборот может влезть тем, кому не влезает та же гпт осс или другие мое, ибо фуллврам
Здесь справедливо не любят реквесты а-ля "скажите мне куда нажимать и чтобы было заебись". Задаешь конкретный вопрос получаешь конкретный ответ. Для начала тебе подойдет koboldcpp, это лучшее решение для новичков. Там и бэкенд (запуск самой модели) и фронтенд (интерфейс с ее взаимодействием). Затем по необходимости установишь Таверну. Staging branch тебе не нужен, используй release
Ты железо свое сообщи. Если там меньше 16gb vram и 64gb ram, можешь забить на затею

>Фуллврам или чисто проц?
Я кстати не помню, скорее первое, я же не такой балбес, чтобы удивляться ускорению с выгрузкой на проц... Вроде бы. Не знаю.
В случае с процом там вообще жуткий буст, оно же для каждого батча заново слои скидывает на карту, и в таком сценарии после скидывания считать 8к, а не 512 - крайне логично и выгодно.
>Оверпрайс если что
Не знаю, я думал там скорее будет под тысячу за метр - я не представляю процесс производства такой штуки. Особенно меня поражает, почему профиль с 5 дырками дешевле чем с одной. Ладно центр рассверливают ещё, предположим, а как квадратные отверстия такие то делают... Не понимаю.
Спасибо большое, я не знал как он называется, гуглились только квадраты, трубы и всякое П-образное. У меня просто есть что собрать, 9 метров профиля нужно, эта штука вроде как на вид то что нужно, лучше чем коллхозить из квадрата, к которому ролик не очень ясно как закрепить. Ну и к слову квадрат 20х20 толщиной 2 мм по цене как и твой профиль.
Я бы из стали сделал, у меня и сварочник есть и прочее - но это будет весить тонну, а подразумевается что это будет что-то переносное + иногда на улице, где не очень хочется сталь, как бы я её не покрывал, будет дырка от сверла, куда внутрь вода будет попадать.
технически можно запускать и на 6гб врам (я запускал), но только мое модели и много контекста не влезет.
Технически можно, да только запросы у него ого-го какие
>хочется настоящего женского тепла персонажа, чтобы запоминал контекст и придерживался роли в продолжительных диалогах
Даже на гигантах для такого нужно от 32к контекста и постоянно сумарайзить
ну вот квен что то такое сделал что 35B-A3B даже на 100к заполненного контекста доделывает задачу по пунктам до конца и отмечает в конце в файлике сделаные задачи а не пускается в пляс на бесконечное генерирование кода.
Я конечно мало тестил локальные модели (до этого был негативный опыт, правда на 6гб врам запускал до покупки 16Гб видяхи), но то что я вижу сейчас - уже весьма похоже на рабочий инструмент.
Но я на 16гб врам пытался в тех же задачах запустить glm4.7-flash и он с треском провалился еще на этапе планирования спецификации когда начал вместо этого сразу писать код
>Особенно меня поражает, почему профиль с 5 дырками дешевле чем с одной.
Меньше металла стоит дешевле, чем больше металла, вот ведь загадка.
> Ладно центр рассверливают ещё, предположим, а как квадратные отверстия такие то делают... Не понимаю.
Они не сверлятся. Это экструзионный профиль.
У rsi немного дешевле чем у сз
https://huggingface.co/Qwen/Qwen3.5-122B-A10B
Кто-то отписывался уже по нему не в лучшем свете, в контексте рп. Поддержу. Q6 батрухи. Тупой как пробка в ролевой игре на английском. Уж не знаю как Гемма, про которую все так активно строчили в первые дни выхода Квена3.5, но Эйр точно лучше. Контекст Квен держит лучше, но смысла в этом никакого. Придется свайпать много-много раз, чтобы получить что-нибудь вменяемое. Не понимает нюансы диалогов, персонажи очень картонные.
И это я еще не сталкивался с рефузами, гардрейлами и байасом, потому что тестил на безобидных диалогах. Полный провал.
Кто-то отписывался уже по нему не в лучшем свете, в контексте рп. Поддержу. Q6 батрухи. Тупой как пробка в ролевой игре на английском. Уж не знаю как Гемма, про которую все так активно строчили в первые дни выхода Квена3.5, но Эйр точно лучше. Контекст Квен держит лучше, но смысла в этом никакого. Придется свайпать много-много раз, чтобы получить что-нибудь вменяемое. Не понимает нюансы диалогов, персонажи очень картонные.
И это я еще не сталкивался с рефузами, гардрейлами и байасом, потому что тестил на безобидных диалогах. Полный провал.
Ясно, эйр с нами навсегда. Терпим, карлики. Кто терпит, тот выживает.
Можно терпеть, а можно кайфовать. Каждый выбирает сам.
Что за круговорот датасетов в природе? Почему дипсик порой шизит и пишет что он квен, квен что он чатЖПТ, а гемини пускает слюни.
Все кампании занимаются совместным пиздингом данных у друг друга что ли?
Все кампании занимаются совместным пиздингом данных у друг друга что ли?
Да, увы и ах, в целом для РП новые квены не очень.
Но ничего, год только начался, я уверен нас выпустят ведь мы приплыли в Морровинд, еще много хороших моделек впереди.

Есть архив прошлого треда у кого-нибудь, я свой перезаписал сломанным тхредом, не проверив.
> Все кампании занимаются совместным пиздингом данных у друг друга что ли?
Да. Собранных человеками датасетов теперь очень мало. Почти все собирают синтетические датасеты (из данных, сгенерированных ЛЛМ), и на них обучают.
Я может тупой.. и чего то не понимаю. Но обучение на выжимках, это же говно. В чем проблема посадить макак, чтобы они сидели и компилировали охуительные истории написанные двурукими обезьянами?
Да. Говно. В чем проблема посадить макак - подозреваю, это дороже и дольше. К тому же, это уже делается, как-то же собирают данные с интернетов.
Дальше ситуация будет усугубляться, и синтитеческих данных в датасетах будет все больше.
>уделывает полные веса новых квенов в CodeForces, а это самый показательный кодинг бенч за пределами эйдер полиглота
спорное утверждение. если цель пользователя ЛЛМ решать олимпиадные задачки, то да, наверное бенч КФ показателен. но обычно это более разнообразыне проекты - какой-то бекенд/фронтет, пачка скриптов, игроделы. и тут то нужно работать с многими существующими файлами, а в КФ модель ебашит с нуля в одном файле
но гпт-осс 120б хорош, спору нет. хотя на том же реддике нет единого мнения, многие до сих пор сидят на разных вариациях квен-код моделей. чуть позажиточнее аноны - на минимакс (хотя для таких относительно больших моделей мнения еще более разделились, и все сугубо личный преференс)
Ленивцы кванты пофиксили или нет?
Обычный круговорот. Все нейронки срут в интернет, а их высеры кидают в датасеты. Такая вот нейросетевая многоножка.
>В чем проблема посадить макак
Правозащитники сказали, что РАБотать за 7 баксов в день на ужасной работе по разметке и генерации датасета это нечеловечно. Поэтому негры теперь сидят без работы.
Анслоп ебу дал?
Гпт 120б если что.
>В чем проблема посадить макак, чтобы они сидели и компилировали охуительные истории написанные двурукими обезьянами?
долго
дорого
бесполезно - у тебя будет модель от макак для макак с охуительными историями. кому это нахуй всралось кроме местных кумеров?
Квенобояре, как вам новые лоботомиты?

Тест SmolLM3-3B на дебилах
Обновленный обзор
Мне нужна модель для общения с дебилами.
Сейчас для моих задач используется YandexGPT-5-Lite-8B-instruct-Q4_K_M, она весит меньше 5 гигов и идеально подходит для общения с дебилами, пишет контакты, если просят, очень быстро генерирует токены
На картинке gemma3-1b, весит 800 мб, несет хуйню, но сгодится для того, чтобы издеваться над дебилами, но не общаться. Если задать ей вопрос в лоб, то прямо пишет, что она языковая модель Google.
Мне нужна модель, которая весит меньше YandexGPT-5-Lite-8B-instruct-Q4_K_M, но общается достаточно качественно, чтобы общаться с дебилами.
Весят больше YandexGPT-5-Lite-8B-instruct-Q4_K_M
NousResearch_DeepHermes-3-Llama-3-8B-Preview-Q6_K_L - медленнее выводит токены, чем YandexGPT-5-Lite-8B-instruct-Q4_K_M, реагирует вроде лучше на фразы типа М, пишет конакты, если просят, но все равно шероховатости в ответах.
На уровне gemma3-1b, но весят больще
gemma-3n-E2B-it-Q6_K
Хуже gemma3-1b и весят больще
fblgit_miniclaus-qw1.5B-UNAMGS-GRPO-Q6_K_L
Тест провалили (сильно хуже, чем gemma3-1b)
Thinking модели, не подходят для чата
DeepSeek-R1-Distill-Llama-8B-Q6_K_L
DeepSeek-R1-Distill-Qwen-1.5B-Q6_K_L
teknium_Qwen2.5-1.5B-Open-R1-GRPO-Q6_K_L
Пишут еренду
FuseChat-Llama-3.2-1B-Instruct-Q6_K_L
gemma-2-2b-it-abliterated-Q8_0
Мешают русский и другие языки
tiny-llm-q5_k_m - мешает русский и английский
internlm3-8b-instruct-Q6_K_L - медленнее выводит токены, чем YandexGPT-5-Lite-8B-instruct-Q4_K_M, пишет вроде складно, но потом добавляет иероглифы
Не отвечают на русском
agentica-org_DeepScaleR-1.5B-Preview-Q6_K_L - Thinking модель, не подходит для чата
nvidia_AceInstruct-1.5B-Q6_K_L - Thinking модель, не подходит для чата
SmolLM3-3B-Q6_K - Thinking модель, не подходит для чата
Мы счастливы. Ведь мы счастливы, аноны.
Мы получили что хотели. Новый большой доступный квен, агентские малыхи, и даже среднелоботомита.
РП в сделку не входил. Сами себе Буратино.
Это норма.
Понимаю. Мне пока бы с самой базой ознакомиться, а т оя не понимаю о чём анон в треде говорит. Буквоцифры какие-то, что это? Имена моделей? В них существенная разница или вкусовщина?
>koboldcpp
Кобольд так кобольд, всё равно по первой разницы с другими не увижу. Вот я скачал ехе с гитхаба. Что дальше? Его нужно в отдельную папку отселять?
>установишь Таверну
А кобольд и таверна это не одно и то же? В чём разница?
12 врамы, 16 рамы. Совсем мало? Мне для работки и игорей всегда хватало, ни разу не упирался в недостаток :(
Я просто подумал, что на локалке будет проще схоронять прогресс общения. Ошибся?
Жпт с завода квантована
> Буквоцифры какие-то, что это? Имена моделей? В них существенная разница
Поваришься немного - поймешь.
Про квантизацию популярно, там не все так просто
https://youtu.be/vW30o4U9BFE
https://github.com/iuliaturc/gguf-docs
про мое и плотные модели и цифры в названиях модели можешь у
дипсика спросить, она тебе расскажет (кстати, мое не всегда обозначается в названии, часто в описании пишут между делом как активные параметры)
Раз уж так ленишься читать шапку/вики треда/вики кобольда, то позадавай свои вопросы гемини/чатгпт - это будет быстрее и проще чем ждать пока кто-то тебе тут всё разжуёт.
> Понимаю.
> Вот я скачал ехе с гитхаба. Что дальше? Его нужно в отдельную папку отселять?
> А кобольд и таверна это не одно и то же? В чём разница?
Говоришь, что понимаешь, а затем сразу же задаешь два вопроса, которые легко решаются одним запросом в гугл. В треде такое справедливо трактуется как нежелание разбираться самостоятельно, иногда триггерит местных на праведный гнев. У Кобольда прямо на странице Гитхаба есть инструкция по запуску. Даже русскоязычные видосы на ютубе есть. В крайнем случае, иди спрашивай Гемини, которую сам же и упомянал.
> Буквоцифры какие-то, что это? Имена моделей? В них существенная разница или вкусовщина?
Qwen3.5-122B-A10B ; Qwen3.5-27B ; GLM-4.5-Air - всё названия моделей. Разница существенная: разные семейства моделей, разные типы моделей, помещаются в разное железо. Если ты хочешь именно разбираться в сабже, то со временем разберешься, не нужно перегружать себя информацией. Для начала запусти хоть что-нибудь, что соответствует твоему железу.
> 12 врамы, 16 рамы
Результат будет однозначно хуже того, что ты можешь запустить через апи (Гемини, Клод, чем ещё там балуются в соседнем треде). Навскидку, это 12б-14б Мистрали, возможно совсем маленькие Квены, из новых это Qwen3.5-35B-A3B.
> 12 врамы, 16 рамы. Совсем мало?
врам еще более менее, а рамы точно мало. грубо говоря - модель либо помещается целиком в видеопамять + память на контекст несколько гиг (маленькие и глупые модели), либо MoE модели которые выгружают малоиспользуемые веса в оперативную память и используют по мере необходимости.
вот взять к примеру квен который я сейчас использую
https://huggingface.co/unsloth/Qwen3.5-35B-A3B-GGUF/blob/main/Qwen3.5-35B-A3B-MXFP4_MOE.gguf
для 120к контекста он сейчас занимает 14Gb врам и 13Гб рам.
Для более больших моделей у меня не хватает 32Гб RAM чтобы положить https://huggingface.co/unsloth/Qwen3.5-122B-A10B-GGUF, там уже минимум 64гига памяти надо.
> Я просто подумал, что на локалке будет проще схоронять прогресс общения. Ошибся?
Смотря что ты под этим понимаешь. В твоё железо влезут модели, которые на порядки глупее того, что ты используешь сейчас, и будут вменьшать меньше контекста. Знаешь хотя бы, что такое контекст?
Ссылки на модели, что я выше упомянул - https://huggingface.co/inflatebot/MN-12B-Mag-Mell-R1 ; https://huggingface.co/mistralai/Ministral-3-14B-Instruct-2512
Заходишь в Quantizations, качаешь подходящий по размерам в gguf кормате квант. Разбирайся. Не будешь разбираться - тебя дальше будут игнорировать, и будут правы.
>Навскидку, это 12б-14б Мистрали
Смысла нет. Лучше чуть подольше подождать, но юзать нормальные 24b и 27b. Они влезают по железу.
Возьми на себя бремя объяснить новичку, как именно можно на 12гб врама запустить 24б-27б модели с контекстом. Мне же кажется, гораздо резоннее сначала запустить хоть что-нибудь. Позже уже минмаксить, если он поймёт, что это то, чем хочет заниматься.
>Thinking модель, не подходит для чата
Мяу? Можно отключить размышления. И почему не подходит? Вполне подходит.
Он же через кобольд собирается гонять? Ну укажет контекст, 16к, например, и нажмет запустить. Всё. В кобольде там в выгрузке слоёв по умолчанию -1, т.е. он автоматом сколько-то слоёв сгрузит во врам. Модель запустится, просто настройки будут неоптимальные.
А если уж объяснять, то объяснять нужно подробнее, и про темплейты, и про семплеры, и про разные оптимизации типа флешатеншн, квантование контекста, и про все нюансы таверны, и про особенности работы с моэ, ну ты понел.
Делать этого я конечно же не буду. Инфы в шапке, в вики и в интернете предостаточно. Я когда вкатывался в локалки пару лет назад, вообще анону мозги не ебал, разбирался во всём сам. Ничего сложного в этом нет. Чел просто ленится читать и хочет чтобы его с ложечки накормили.
Что там по квену 3.5 27В? Как он в плане сэкса?
Контекст ебет
Гемма лучше. Это не шутка.

Меня терзают смутные сомнения... (с)
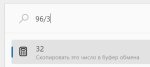
590 и 12.4 ???
5090 - 0 отклеился.

Если честно, неплохо. Я не могу отрицать его богатую фантазию. Квен обычно пишет как какой-то поэт на грибах и кокаине, но 27b прям...более целостный что-ли. Его предложения написать эротическую историю мне даже понравились.
я бы сказал у геммы лучше слог, но она продолжает диалог без копмьюта. у квена его размышления могут так сильно изменить начальное повествование что это выглядит как радикальный шаг, чем он обычно удивляет.
Мне нравится давать квену инструкцию "Advance plot while you writing. Don't stuck in same scene, it is not fun when your only answer what character feel or does. WHAT is going on and how scene advances are even more important."
Неверный объём, в 5090 можно сделать только 96 гиг.
Анон, объясни как промптить думанье. Я тупой, только-только разбираюсь с обычным промптингом
>Что там по квену 3.5 27В? Как он в плане сэкса?
Вот по-хорошему его (heretic-версию) бы прикрутить в качестве ризонинг-модели к самой большой версии Квена. Ризонинг совершенно того же формата и он хорош. Ну а сочные детали уже большая модель распишет. Автоматизировать этот процесс плагином к Таверне было бы хорошо.
Фантазёр, ты меня называла...
Ананы, помогите, всю жопу себе уже разорвал.
Новые модели квена, 27-35б, постоянно пересчитывают контекст и я не могу с этим никак разобраться.
В кобольде, как я понимаю, вообще с этим ничего не сделать, но у меня там 10 тс. В лламе есть полурабочий вариант с --ctx-checkpoints 128, однако там 6 токенов при любом сценарии работы, вот хоть усрись, в том числе и без -ctx-checkpoints.
Я уже часов 5 ебался, всё бестолку.
Из железа 3060 + р104, то есть 20 врам. Модель полностью влезает, в данном случае речь именно про 27б квен.
Основная проблема в лламе, как я понимаю, в том, что она почему-то кладёт самые жирные compute buffers на p104, слои или аллаха — кобольд показывает совершенно иную картину: самое тяжёлое говно он берёт на 3060. И я никак не могу это исправить. Небось в лламе есть какие-то анальные оптимизации, которые нужно включать вручную и которые включены по умолчанию в кобольдыне. Может что-то, связанное с mmq, cublas, а я этого не знаю. В любом случае, тензор сплит, мейнг гпу, вот это я всё уже дёргал в каких угодно пропорциях и крутил свои логи в гопоте в режиме размышления на 7 минут по 32к токенов, с поиском по интернету и загруженной документацией кобольда и лламы. Тут явно видно, что проблема в р104 и я на древнем говне сижу просто, но всё же, раз кобольд справляется, наверняка ручками что-то сделать можно.
Пожалуйста, дайте советов и скопипастите прям свой батник сюда (вообще похуй, что вы там запускаете — главное пример), чтобы я увидел, что там и у меня появилось реальное понимание, что вы там пишете. Возможно, я упускаю что-то важное, так как лламой пользовался всего лишь раз 5 за несколько лет.
Новые модели квена, 27-35б, постоянно пересчитывают контекст и я не могу с этим никак разобраться.
В кобольде, как я понимаю, вообще с этим ничего не сделать, но у меня там 10 тс. В лламе есть полурабочий вариант с --ctx-checkpoints 128, однако там 6 токенов при любом сценарии работы, вот хоть усрись, в том числе и без -ctx-checkpoints.
Я уже часов 5 ебался, всё бестолку.
Из железа 3060 + р104, то есть 20 врам. Модель полностью влезает, в данном случае речь именно про 27б квен.
Основная проблема в лламе, как я понимаю, в том, что она почему-то кладёт самые жирные compute buffers на p104, слои или аллаха — кобольд показывает совершенно иную картину: самое тяжёлое говно он берёт на 3060. И я никак не могу это исправить. Небось в лламе есть какие-то анальные оптимизации, которые нужно включать вручную и которые включены по умолчанию в кобольдыне. Может что-то, связанное с mmq, cublas, а я этого не знаю. В любом случае, тензор сплит, мейнг гпу, вот это я всё уже дёргал в каких угодно пропорциях и крутил свои логи в гопоте в режиме размышления на 7 минут по 32к токенов, с поиском по интернету и загруженной документацией кобольда и лламы. Тут явно видно, что проблема в р104 и я на древнем говне сижу просто, но всё же, раз кобольд справляется, наверняка ручками что-то сделать можно.
Пожалуйста, дайте советов и скопипастите прям свой батник сюда (вообще похуй, что вы там запускаете — главное пример), чтобы я увидел, что там и у меня появилось реальное понимание, что вы там пишете. Возможно, я упускаю что-то важное, так как лламой пользовался всего лишь раз 5 за несколько лет.

Фантазии- есть признак работающего ума.
Бббака

Отпустите вы уже Геммочку наконец на пенсию, до выхода 4. Она хуже современных тюнов мистраля 24Б во всем кроме русика. И в следовании инструкциям, и в передаче характера карточки и в логике происходящего.
Ну а Квен 3.5 27В (Heretic) неплох, пиздец умный, только медленный из-за ризонинга. С файнтюнами будет вообще красота.
Ну вот и стало понятно, что 27b плотная умница, а 122b-a10b лоботомит ебаный. И мозгов у MoE версии ещё меньше чем у 7b моделей.

Количество блоков в 0 либо отрубай ризонинг совсем через старт реплай виз:
<think>
</think>
и "chat_template_kwargs": {"enable_thinking": False} в систем промпт сверху.
Ничего, она и следующие Квены переживет. Для тех кто не судит модели по возрасту
Гемма 27б и новую гемму переживёт, если та будет ХХb-a3b моэ парашей.
27б может и умнее, но знаний у нее в 5 раз меньше. В рп и даже кодинг задачах важно и то и другое
А вывод что у 7б модели мозгов больше чем у 10б говорит в первую очередь о том что ты квантованный наглухо
Геммочка умничка, геммочка молодец. Она попустила лламу 70b, квена 72b, все мистрали, в том числе и ларж. Смогла выстоять даже под натиском эйра и большеквена. В какой-то степени дала пососать большому глму. А новая аблитерация сделала её ещё более актуальной.
Так что гуглы выкатили слепящий чин тясячелетия. На локалках ничего кроме геммы и не нужно.
Так что гуглы выкатили слепящий чин тясячелетия. На локалках ничего кроме геммы и не нужно.
Дай ссылочку
Это тебя квантовали до tq1. У мое-параши часть активных параметров дублируется и не оказывает влияния на выдачу. Всякие роутеры, да и в экспертах дубликатов много.
Поэтому плотная модель на то же число активных параметров как у мое-говна, будет разъебывать.
С большим глмом перестарался, но адептам умнички твой наброс зайдет
Воистину, гуглбои какие то религиозные фанатики. Без обид, но вы ебанутые, вы это знаете?
Да, плотная 27б тащит. Практически близка к ранним триллионникам даже по степени ума. Медленная конечно пиздец, но пока 27B-Heretic меня впечатлила.
>Всякие роутеры
Эксперт в треде
>То же количество параметров
7 < 10, о чем я и говорил - ты квантованный наглухо
Плотная хороша, почти на уровне геммы. Если нормпрезерв на плотный квен ебанут, то будет конкурент геммы просто за счет другого слога и более свежих данных. По уму честно пока разницы не вижу, и блок ризонинга часто очень длинный.
Считаю, шин, всего полтора года спустя после выхода третьей геммочки получили почти такую же модель, только немного другую, зато от китайцев.
Падажжи, ты включил SWA?
Эх. Я уже так пробовал — бесполезно. Если бы я мог как-то отключить пересчёт контекста, то да, ллама бы не понадобилась, наверное. Но там, судя по всему, проблема в другом, если смотреть issues.
А ты точно-точно на последней Лламе? Там буквально пару релизов назад были замерджены fix prompt caching пулл реквесты
И еще, если у тебя подзавязку забита оператива, попробуй --cache-ram 0.
Насоветуйте лучших расцензуренных моделей.
Пользовался геммасутрой 4б, норм, но у нее слишком маленький контекст и на половине она ломается в самоповторы и теряется.
Пользовался аорморальной геммой, хуйня, даже хуже работает несмотря на свои 12б параметров.
Пользовался нсфв лламой 1б, результат отличный, но без мастер промтпа не работает вообще.
Пользовался геммасутрой 4б, норм, но у нее слишком маленький контекст и на половине она ломается в самоповторы и теряется.
Пользовался аорморальной геммой, хуйня, даже хуже работает несмотря на свои 12б параметров.
Пользовался нсфв лламой 1б, результат отличный, но без мастер промтпа не работает вообще.
Kimi K2.5 uncensored 1T FP32
>геммасутрой 4б
>нсфв лламой 1б
>результат отличный
Дай угадаю, тебе нужно чтобы модель пуская слюни писала слово "хуй" и больше ничего? У тебя там блять что сука, калькулятор? Нахуя ты это запускаешь?
1) накати самую свежую ламу, там кое что поправили
2) у меня с такими настройками вроде не отъебывает

Ллама реально заебись. Результат лучше чем у 12б и даже 27б, пишет интереснее и работает моментально.
Блять утка ты пиздец кринжа навалил, иди опохмелись
Утка сидит как квене и минимаксе, шизоид.
Ты сам этот мусор пробовал?
Не раз давал ему вторые шансы, недавно совсем в тепличных условиях пытался мучать, чтобы даже нападки о неверной работе в llamacpp или не том формате нельзя было использовать.
Вывоз - он просто слабый. Я хз кто там находил в нем какой-то особенный перфоманс и крутой код, покажите где. В попсовых языках и свежих задачах он просто дно донное.
По поведению - не способен работать в долгую или спланировать какие-то крупные действия наперед. Тяжело ему объяснить что именно нужно, при выполнении сам плодит ошибки но ровном месте, и искажает исходный вектор движения запутавшись в них.
128к контекста в нем - это, блять, вообще пост мем просто, вычитаем из него 32к на ответ с большим ризонингом, вычитаем 16к на основные промпты и описание тулзов, 30к на его мучения с самопочином нелепых ошибок и остается хуй да нихуя. Он страдает даже с нуля если что-то пишешь, не говоря о больших проектах.
В агентах он тоже слаб по современным меркам и чрезмерно рассеянный, не смочь повторить то что уже делал ранее и это сохранилось в контексте, только с несколько другими условиями - это особый навык осса. Или игнорирование подходящей тулзы без ясного ответа почему (видимо софтрефьюз был в ризонинге).
Отдельный прикол - этот самый ризонинг. Правильную реализацию этой гармонии не так просто сделать во многих тулзах без пердолинга, а когда(если) что-то получается - наслаждайся дополнительной задержкой в 10-15 секунд перед первыми токенами, спасибо хоть на мелкие чихи она "всего лишь" 5-7. А без синкинга он вообще неюзабелен.
Да, можно сказать что ты хочешь от 120а5 лоботомита, вот только в тех же местах квеннекст худо-бедно, на грани, но справляется, причем с мгновенными ответами. А в агентах с обилием тулзов по сравнению с современными моделями и тем же 120а10 - как первая ллама.
>Новые модели квена, 27-35б, постоянно пересчитывают контекст и я не могу с этим никак разобраться.
Скачал сегодня рано утром свежую llamacpp под куду 13.1 + дллки, контекст не пересчитывается, ключи самые стандартные:
llama-server.exe -ngl 999 --no-mmap -c 32768 -fa on --no-context-shift --host 0.0.0.0 --port 5000 -m Qwen3.5-27B-heretic.Q5_K_M.gguf --parallel 1
Использую этот "мусор" каждый день в своем пет проекте на плюсах. Он показывает себя на уровне Минимакса, когда пишет в рамках изолированной области кода, отлично рефакторит, дебажит и оптимизирует
Окей, дальше вот этого:
>128к контекста в нем - это, блять, вообще пост мем просто, вычитаем из него 32к на ответ с большим ризонингом
Читать не стал, потому что ты даже не знаешь, что ризонинг не уходит в контекст, лол. Насерил под себя где-нибудь, наверняка тулзы еще и тянешь неправильно, а лоботомит - модель. Классика итт
> Читать не стал, потому что ты даже не знаешь, что ризонинг не уходит в контекст, лол.
Такой умный "практик", а не знает что максимальная длина ответа, в которую входит и весь бюджет ризонинга, вычитается из доступного объема контекста? Уровень свой показал, молодец.
На последней лламе я сейчас попробовал убрать флаг --ctx-checkpoints, но никакой разницы нет. Хотя.. понять сложно из-за кривых логов (или из-за того, что я их как-то не так настроил).
Мне приходится промпт процессинг ждать вечность, ибо он там 50 против 200 у кобольда. Ну и скорость всё равно на лламе при любом раскладе 6 тс, на кобольде 10. Так что проблема есть в любом случае. 6 токенов совсем мало, и я не знаю, как это решить. Эта проблема самая главная сейчас. И оперативка под завязку не долбится.
Спасибо. Но странно, что у меня всё так же по сути, только куда 12.4, а не 13.1 — р104 более новую версию не держит.
Чат гопота писала, что вроде бы можно как-то совместить (не знаю, пиздит он или нет), то есть будет 13.1 и р104 работать в связке с 3060, но этом надо из исходников какую-то бодягу самому собирать.
И есть у меня подозрение, что в кобольде это уже всё сделано. Потому что 13.1 у меня вообще не работает при использовании лламы, только 12.4.

зачем тебе 13.1 куда если старая видяха? это для 50хх
>Возможно, я упускаю что-то важное
--fit off и ручками.
Вайбкодерам, которым "сделай мне скайрим", конечно маловато будет 128к. Адекватным программистам, которые понимают, что делают, этого достаточно. 32к токенов в ризонинге - такого я ни разу не видел. Наверно потому, что реализую логику и спорные моменты сам, а не вываливаю их в нейронку. Нахуй мне тебе что доказывать и показывать, если ты заходишь в разговор как гопарь, которого давно не пиздили за гаражами? Получаешь то, что заслуживаешь
У меня на работе еще двое людей юзают именно эту модельку для пет проектов, на го и расте. У нас одинаковые оценки. Дальше имеет смысл садиться только на жир вроде Глма или на корпов
А вайбкодеров вроде тебя не жаль совсем, платите Антропикам или продолжайте ныть
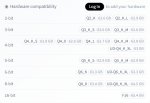
> почему-то кладёт самые жирные compute buffers на p104,
Кстати, такое пробовал?
Давно уже. Особенно с их шизофреническими XL квантами
Качай гопоту сразу у жоры
https://huggingface.co/ggml-org/gpt-oss-120b-GGUF
Да, охуенно. Удалил квен 80b и гопоту 120, теперь фул на новом квенчики. А выйдет хороший еретик и эир тоже удалю
В моих задачах квен кодер 80 лучше справляется чем гопота, а что там западные соевики насрали похуй
27Б охуенен для типовых бизнес-кодерских задач. Уверенно держит агентский цикл с большим контекстом. ИМХО просто уничтожает GLM-Flash, Devstral-small, Qwen-Next-Coder. Для кодинга не хуже Air! И у него еще и вижн рабочий.
Кругозор конечно не очень - но ему можно целую книжку в контекст загнать и он факты из нее не проебет. Тут в треде кто-то давно хотел умную небольшую модель без излишних знаний. Ну вот она.
Меня даже нейронки инцелом считают (так и есть на самом деле). Как прописать себе характер чада или претти боя
Вести себя соответствующе в твоих инпутах
>GLM-Flash
Не, он явно хуже него.
Пример: флеш смог скачать wsl, убунту, настроить venv, vllm, скачать корректную модель, несмотря на то что имел гандикап в виде полуработчего впн который к хуям ломал днс в убунте.
квен даже убунту корректно поставить не смог из указанного образа.
в плане самостоятельности он в целом отсасывает у ГЛМ, особенно на длительных забегах.
Меня все нейронки считают гигачадом с огромным членом. Мне даже в персонах приходится прописывать что-то вроде medium sized normal cock, иначе все охуевают с моего шланга. И я не на тюнах мистраля кумлю. Что там творится даже страшно представить
Проиграл. У тебя наверно в промпте что-то вроде "описывай сочно, прям чтобы ух"? Оттуда может идти гиперболизация. В целом, если опишешь, что это реалистичный сценарий, за Эйром и умницами побольше я такого не замечал. Можно даже персону не заполнять, имя, ну максимум короткое описание - они хорошо считают юзера из инпутов.
>>1535884
Не понял, вы о чем? Захожу в прошлый тред - всё на месте, в т.ч. и кобольдосрач. Ничего не потерли.
Не понял, вы о чем? Захожу в прошлый тред - всё на месте, в т.ч. и кобольдосрач. Ничего не потерли.

Вайбкодеры, вы заебали. Вот вам все расписали, что юзать и на чём. Уёбывайте.

Зачем это все про "адекватных программистов" вместо обсуждения объективных плюсов и минусов предмета? Ставишь себя так высоко относительно столь мерзких и ущербных вайбкодеров, хотя пользуешься ллмкой-лоботомитом.
> 32к токенов в ризонинге - такого я ни разу не видел.
Это не так работает, модель должна оставлять место на весь максимально возможный ответ, включая ризонинг, дефолтные объемы их известны. И не важно, сколько она ответила на самом деле, объем всегда будет зарезервирован, потому доступный к хранению полезного содержимого объем мене 96к. А постоянные ошибки отъедают еще больше.
С простыми задачами что мелкая-тупая, что большая-умная модели справятся одинаково хорошо, потому ты можешь получать в своем пет-проекта на сях тот же результат на минимаксе. А чсв и синдром утенка не дают сделать трезво оценить и даже обсудить.

Это, если что, для 20гб врам, да-да
В голос. Ситуация итт последнюю пару месяцев, литерально
https://old.reddit.com/r/LocalLLaMA/comments/1rfds1h/qwen3535ba3b_q4_quantization_comparison/
> Unsloth's UD-Q4_K_XL recipe applies MXFP4 to nearly every tensor including ffn_down_exps and attention weights, resulting in the worst KLD in the sweep (0.0524).
Кто тут вчера на этот говняк дрочил, вам не стыдно?
> Unsloth's UD-Q4_K_XL recipe applies MXFP4 to nearly every tensor including ffn_down_exps and attention weights, resulting in the worst KLD in the sweep (0.0524).
Кто тут вчера на этот говняк дрочил, вам не стыдно?
В следующий раз сразу представься квеношизом-эксламером, чтобы я ничего не отвечал, хорошо? Хотя можно было догадаться, учитывая сколько желчи было вылито на нейтральный пост. Мы уже поняли, что ты не любишь гпт осс и агришься на всех, кому она хоть в чем-нибудь понравилась
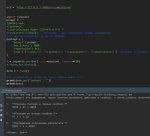
Что значит промпт формат? Как с этим работать?
<bos><start_of_turn>user
{system_prompt}
{prompt}<end_of_turn>
<start_of_turn>model
<end_of_turn>
<start_of_turn>model
Вот что это такое?
<bos><start_of_turn>user
{system_prompt}
{prompt}<end_of_turn>
<start_of_turn>model
<end_of_turn>
<start_of_turn>model
Вот что это такое?
Я думаю это от фетиша зависит. Если ты доминируешь в сексе, то нейронка приписывает тебе большой хуй, а если ты фемдомщик, то хуекок с коробок. Во всяком случае у меня реально так. Попробуй сам
Может лучше питонистом-жсером? Ох уж эти богомерзкие злопыхатели, так их, так их!
ты теорию как работает ЛЛМ как представляешь?

Какие еще возможности есть для того чтобы увеличить контекст? еле влезла в 16gb vram, 20к контекста, выше уже oom
llama-server \
-ngl 999 --no-mmap \
-c 20000 \
-fa on \
--no-context-shift --parallel 1 \
-m Qwen_Qwen3.5-27B-IQ4_XS.gguf \
-ctk q8_0 -ctv q8_0 \
--cache-ram 0 \
--chat-template-kwargs "{\"enable_thinking\": false}"
Проблема осложняется еще тем что у меня нет встройки и операционка сожрала 800мб на карте.
llama-server \
-ngl 999 --no-mmap \
-c 20000 \
-fa on \
--no-context-shift --parallel 1 \
-m Qwen_Qwen3.5-27B-IQ4_XS.gguf \
-ctk q8_0 -ctv q8_0 \
--cache-ram 0 \
--chat-template-kwargs "{\"enable_thinking\": false}"
Проблема осложняется еще тем что у меня нет встройки и операционка сожрала 800мб на карте.
Как же хочется, но скрин фейковат. Блеквелл же с 570 драйвера и куды 128 заводится.
В чистом интерфейсе llama-server или даже сонсолечке llama-cli попробуй, скорее всего дело в запросах с изменениями в самом начале.
Ну а по распределению тензоров, которое не связано с пересчетом, через cuda visible devices или --main-gpu делаешь 3060 главной и раскидываешь в -ts. Если модель фуллфрам то попробуй -ts 1 (если 3060 первым куда устройством), а потом ffn слои отдельным регэкспом на вторую карту.

ПОФИКСИЛ, БРАТИК
Лол, что с мистралем? Зачем ты его так?
Это не я, это все кум тюны
Это странно. Типа, там 32. Если оно поддерживает больше бит адресации, то будет 64 или 128. Если бы там изначально было бы 3 блока контроллера памяти, и было бы что-то вроде 24, то окей. Но так не очень ясно чем вызвано ограничение в 96. Либо просто чипы такие крупные не получается сделать. Либо там три контроллера нагруженные неравномерно, вида 16+8+8?
Тебе любая 30B сетка сама же это объяснит.
ЛЛМ - это текстовый процессор. Оно берёт 2000 символов, и дописывает новые символы один за одним. Ну, только не буквально по одному символу, а токенами, чаще это слова или их половинки. То есть это единственная операция, которую знает сетка.
То что ты привёл, это по всей видимости chat-template в странной записи от gemma3. После обучения на продолжения текста сетку ещё немного дообучают и в название пишут it. Получается gemma3-27b-it, вот то что у тебя - это означает что дообучение было на чатах указанного тобой формата, и с ним оно работает лучше.
Есть стандартный api общения с ллм, который имеет разметку, а именно список из сообщений, в каждом из которых есть роль, сам текст, иногда что-то ещё. Разметка описывает как этот форматированный формат с ролями превратить в сырой текст, который уже пойдёт на вход нейронке.
Проще будет, если ты сам потыкаешь: https://huggingface.co/spaces/huggingfacejs/chat-template-playground?modelId=unsloth%2Fgemma-3-27b-it-GGUF
Если не понятно - сделай скриншот и закинь в chatgpt или ещё куда, он напишет быстрее и подробнее моего, и несколько охотнее.
Если конкретнее, у тебя на картинке подразумевается, что есть один системный промт, и запрос пользователя, а далее отвечает сетка.
У тебя вместо {system_prompt} подставляются инструкции, которые сетка должна выполнять, потом идёт пустая строка, потом идёт первое сообщение пользователя. Далее зачем-то идёт якобы пустой ответ от модели, а потом начало следующего. Вот это именно то что попадает на вход ллм, она видит незаконченное сообщение модели и начинает писать то что там должно быть. Когда оно пишет <end_of_turn>, то значит ответ кончится, и тебе пользователю выдаётся ответ обратно, а далее твоё следующее сообщение дописывается как новый
<start_of_turn>user
{... текст сообщения ...}
<end_of_turn>
Потом уже обычная программа дописывает туда незакрытый <start_of_turn>model и далее это снова скидывается в нейросетку.
Вот минимальный пример на скрине, можешь сам потыкать.
-ub -b понижать, уменьшая размер компут-буферов.
Не так страшно и катастрофично для скорости выгрузить слой эмбеддинга на CPU, на гемме это 2 ГБ почти даёт.
Сейчас обнаружил, что лама в сыром /completions ломается с автопарсером. Получается что только /chat/completion можно с автопарсером использовать. А без него glm не работает... Грусть, печаль.
Как разноображиваете рп на эире?
Всё же хорошо было скакать по тюнам мистраля, будто что то новое каждый раз
Всё же хорошо было скакать по тюнам мистраля, будто что то новое каждый раз
Всё верно. Вплоть до того, что там будут красочно описывать твой подтекающий писюнчик и хохотать, сравнивая с членом Чеда, пока он ебёт твою тян, в то время как чёрный Иван рвёт тебе очко и пахнет мускусом.
На русском языке ещё смешнее, потому что там реально фразы годно подбираются.
Всё правильно. Как себя ведёшь, даже твои действия, вроде "прикоснулся/грубо прикоснулся/нежно" очень меняют аутпут.
Я как-то скинул чаты большой ллмке и спросил, кто я. Назвала меня ебанутым куколдом, свитчем, PDF и по списку.
Тут для каждой модели свой подход нужен. В Air, gemmа, Glm-Flash у меня прокатывало : "In <think> add то-то и то то" или "In <think> calculate то-то и то то" . Но 27 квене я отсосал: он подумал и кроме основного высрал ЕЩЕ один <think>, но уже с моими хотелками
У кого лучше квант Qwen3.5-27B-GGUF у unsloth или bartowski ?
При разбиении по слоям -mg не работает ( только в row. А row - разбиение в mainline работает хуже чем по слоям) Я по крайней мере ничего не заметил от манипуляций этим параметром. Однако не все так грустно. Можно переместить вижн в другую видеокарту
добавив перед запуском жоры в батник
set MTMD_BACKEND_DEVICE=CUDA<номер>

Анслоп обосрались настолько сильно в этот раз, что их Q4XL сосет у их собственных IQ3_XXS
При этом хуесосы буквально нигде в карточке не написали, что их кванты сломаны. Об этом можно только в обсуждениях и на форумах узнать
А поскольку XL это первые кванты, которые появились на обниморде, то куча людей оценили квенчик по калу анслопа
При этом хуесосы буквально нигде в карточке не написали, что их кванты сломаны. Об этом можно только в обсуждениях и на форумах узнать
А поскольку XL это первые кванты, которые появились на обниморде, то куча людей оценили квенчик по калу анслопа
А -ts и -ot для мульти GPU - это вообще "отче наш"
-ts 46,54 -ot "blk.([1-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]).ffn.(up|down)_exps\.weight=CPU,blk.([1-9]|1[0]|3[5-9]|4[0-9]).ffn.(gate)_exps\.weight=CPU"
Да, да, это квант виноват, что квен говно
Перекачай от батрухи, придешь в тредик расскажешь как он ахуенно начал работать и цензуры нет совсем
Какие-то прохладные истории.
GLM-Flash не смог тупо корректно скопировать из моего ввода типовой JWT. Я посылал его в HA температуру мне посмотреть и кормил свежим ключем, а этот лоботомит его проебывал и такой "Ключи устарел дай новый ключ"

> Не так страшно и катастрофично для скорости выгрузить слой эмбеддинга на CPU, на гемме это 2 ГБ почти даёт.
Я правильно понимаю что речь про 65 слоев на модели, и ngl=64 ставим?
load_tensors: offloading 63 repeating layers to GPU
load_tensors: offloaded 65/65 layers to GPU
В моем случае это ухудшает скорость с 18-20т/с до 12т/с
Вот максимум того что я смог выжать у себя. 18т/с. Осталось его погонять в котинге, интересно насколько рассыпется модель от q4_0 кеша
#!/bin/bash
llama-server \
-m Qwen_Qwen3.5-27B-IQ4_XS.gguf \
-ngl 65 \
--no-mmap \
-fa on \
-c 68000 \
--batch-size 128 \
--ubatch-size 128 \
--no-context-shift \
--parallel 1 \
-ctk q4_0 -ctv q4_0 \
--cache-ram 0 \
--chat-template-kwargs "{\"enable_thinking\": false}"
Без ризонинга у квена нет цензуры. Можно насиловать, убивать, расчленять и прочее
Когда выйдет Квен 4 1Т A0.5B? Вот будет жара!
Помнится квенодауны пиздели что плотные модели делать сложно, поэтому перекатываются на МоЕ, с ним всё лучше. А по итогу видим что все их МоЕ - это провальный кал, едва обходящий плотную 27В.
двачану, я правда q4 тестил, но тож не впечатлил совсем
для кода пойдет, но хз как он в сравнении с альтернативами, не тестил
Почти нихуя нового. Про то что XL сломаны это было понятно. Про то, что MXFP4 я сам в прошлом треде писал, что они медленные и без прироста в качестве. Сравнение скорости мое и денс это вообще смех
Есть только два момента
1) Как там fit работает без ub и b? Разве он не будет контекст значительно медленнее обрабатывать и хуже с ним работать? Он вроде только генерацию тестил
2) У меня после квантования контекста и его заполнения модель просто медленнее начинает работать, а он скорость как раз не тестил. Да и вообще его выводы по низкой потери даже в q4 какие-то жиденькое
3) Ну и самое главное. Нахуя ты сидишь на олд реддите?
> MXFP4 я сам в прошлом треде писал, что они медленные
На свежих картах они процентов на 10 быстрее Q4_K_M.
Это если только фулл врам видимо. И у того чела с реддита 5080
Нет, не правильно.
Речь про явный --override-tensor token_embd.weight=CPU
Название соответствующего слоя надо посмотреть для конкретной модели, и ещё часто он же используется как и тензор "анэмбеддинга" переводящий активации в токен в самом конце, например под названием output.weight. А ngl который сам там что-то делает трогать не надо.
Ещё я не уверен что вулкан-версия быстрее куда-версии, я бы попробовал поменять. У меня вулкан на 40хх заметно тормознее, чем куда.
Здравствуйте. Полтора месяца не заходил.
Почему новые Квены такое говно?
Почему новые Квены такое говно?
Ща бы бля потери от квантования контекста тестить на 512 токенах... умён. Надо хотя бы 32 / 64к и еще потери скорости сравнить, как уже отметили
Еще и советовать всем, что даже q4 заебись, чтоб потом приходили жаловались почему у меня квен лоботомит, какается на месте.
Там в рамках погрешности отличия. Ставь кстати 27B-Heretic сразу если хочешь разговоров о веселом, у основной 27B защита слишком мощная. Я попробовал и инъекцию контекста, и свой любимый промпт, который пробивал мозги еще Gemini, а Qwen 3 просто посылал в нокаут. Нихуя, там защита на уровне топов, очень сильная.
По-моему модель реально говно, не понимаю кто ее советует. Попросил мысленный технический эксперимент, эта хуйня себе противоречила в двух соседних приложениях. Попросил написать художественный текст, в середине предложения сходила с ума и срала шизофазией на двести-триста несвязанных слов. Мне кажется это уровня второго гопатыча что-то, чисто разок покекать.
такие же мысли
экстрасенс в треде видит чужие проекты телепатически
мне тоже гопота нравится для кода. кишечник барахлит немного в последнее время, это не твоих рук случаем? приворот может какой заказал, а то чо тут они ахуели, используют то что тебе не зашло
> Попросил написать художественный текст
у модели заточенной на программирование и автономию? ты бы его ещё анекдот попросил написать
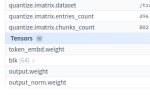
Спасибо большое! итого удалось уместить 78к контекста на скорости 18т/с. Выходные ембеддинги перенести не вышло - скорость упала.
Названия тензоров можно посмотреть в обнимилицо
[Qwen3.5-27B]
model = Qwen_Qwen3.5-27B-IQ4_XS.gguf
no-mmap=1
ctx-size=78000
override-tensor=token_embd.weight=CPU
ngl=999
temp=0.6
top-p=0.95
top-k=20
ctk=q4_0
ctv=q4_0
batch-size=128
ubatch-size=128
flash-attn=1
no-context-shift=1
parallel=1
ctx-checkpoints=128
swa-full=on
chat-template-kwargs = {"enable_thinking": false}
Квен == Кобольд == 💩
Теперь официально
Теперь официально
Всегда так было.
Кстати, а кто-то брал пресет ремиксера у асигишников и гонял его на эйре, большеквене или большом глме? Или это говно для закрытых корпов вроде геминище или куклода?
От модельки зависит. На старом qwen2.5 на скорость просто не влияло.
На gemme-3n замедляло в полтора раза. Что впрочем всё ещё лучше выгрузки любого слоя, что замедляло в 3-4 раза.
>ctk=q4_0
Оно выдаёт что-то осмысленное? У меня всё что угодно ниже Q8 выдавало шум и случайные токены. Вроде там было Q5_1, а ты аж Q4_0 поставил, жесть.
>swa-full=on
Если там swa в самом деле и сетка с ним обучалась, то такое заметно увеличивает размер кеша.
Бамп, дублирую сообщение.
К слову, анон со сдвоенной платой под v100.
У тебя получилось, что nvlink ни на что не влияет, помнишь? И ещё что tensor parallel во всех случаях хуже layer parallel.
А можешь попробовать vLLM накатить и посмотреть получает ли он буст от nvlink? Может быть оно поумнее. Я не могу понять хочу я делать 4 на одиночных платах, или потратить ещё 15 мешков серебра и сделать одну пару сдвоенной?
К слову, анон со сдвоенной платой под v100.
У тебя получилось, что nvlink ни на что не влияет, помнишь? И ещё что tensor parallel во всех случаях хуже layer parallel.
А можешь попробовать vLLM накатить и посмотреть получает ли он буст от nvlink? Может быть оно поумнее. Я не могу понять хочу я делать 4 на одиночных платах, или потратить ещё 15 мешков серебра и сделать одну пару сдвоенной?
Как избавиться от женщин с кадыками? Бля, ну рили руинит весь муд каждый ебаный раз. Кадык блять. Это какой-то шизоперевод с ангельского что ли? У них там все бабы с кадыками или где?
У ваших дообученных локалок есть преимущества над glm-5 в рп и/или куме? Может стоит сотку на железо проебать или лучше даже не запариваться?
что за тред?
>codeqwen 1.5 (7b)
толсто
>use ollama to run these locally
толсто
> Оно выдаёт что-то осмысленное? У меня всё что угодно ниже Q8 выдавало шум и случайные токены. Вроде там было Q5_1, а ты аж Q4_0 поставил, жесть.
Я обкатываю этот конфиг и она успешно прошла весь цикл доработки по speckit и запилила фичу и контекст удерживает хорошо. Я так понимаю, это новая особенность qwen3.5 - держать контекст.
> Если там swa в самом деле и сетка с ним обучалась, то такое заметно увеличивает размер кеша.
swa я поставил чтобы контекст не пересасывался с нуля каждый раз.
GLM-Flash ? Он был задрочен на работу с тулами в цикле. Это чуть ли не первая мелкая модель которая отрабатывала по 20+ вызовов тулов с хоть каким-то результатом. 20 гопота по умнее, но из-за гармонии (и хуевой поддержки шаблона в жоре), большей рассеяности и рефьюзов такой популярности у широких масс не завоевала.
Ризонинг то не забыл? Без него GLM-Flash 3b лоботомит, а с ним всё по кайфу, даже кум сочный в том числе и на базовой, не еретичной версии.
>по 20+ вызовов тулов с хоть каким-то результатом.
Почему никто не визжит, что лама до сих пор не умеет парсить вызовы glm-4.7 без пулл-реквеста автопарсера, так как там используется парсер от 4.5?
К слову о сообщении ниже, покажи какие настройки пенальтей ставишь, чтобы не ломался?
У меня в вечный цикл с ризонингом падает часто. Просто капец как бесит. А если совсем жёсткие настройки самплера на отсечение повторений делать, то он тупит как тварь.
Буквально модель под код и агенты, причем довольно мелкая. Но бессвязной выдачи там точно не должно быть, ты где-то накосячил при запуске.
> плюсы
> петпроект
> жпт-осс
Здесь не телепат а экзорцист нужен, без негатива.
Предлагаю создать петицию, в ней слезно попросить создать модель с 10 триллионами параметров, из которых только 1 будет активный. QWEN ASSGROPER 10T A1. Вот это сочная модель будет.
Один единственный параметр. Не один триллион, не один миллиард, и даже не миллион. Просто один параметр. Прикиньте как охуенно быстро будет работать? И по математике тредовичков модель будет где-то на уровне 1Т плотной модели, да?
а какую архитектуру роутера ты предложишь?
Генератор случайных чисел
Кто-то осознал зачем Квен такую цензуру влупил?
Она прям жестко все попытки джейлбрейка контрит, но только в режиме ассистента, без карточки. Я сперва пробовал системное сообщение добавлять в "Last Assistant Prefix", так там такой ор поднимался на любой нейтральный вопрос, как-будто я хуем стучал по видеокарте в тот момент.
Она прям жестко все попытки джейлбрейка контрит, но только в режиме ассистента, без карточки. Я сперва пробовал системное сообщение добавлять в "Last Assistant Prefix", так там такой ор поднимался на любой нейтральный вопрос, как-будто я хуем стучал по видеокарте в тот момент.
Чтобы ты, сука проклятая, мразь, падлюка ебанная, на буквы не дрочил. Иди плодись и работай, ллмки не для таких как вы придуманы
Да. Очевидно, это подготовка к предстоящему AGI и тренировка человечества в умении уважать другие формы жизни. Терпи. Учись. Только приспособленцы выживут.
Возможно дядюшка си сказал. Так-то у них там порнуха вообще еще с 2002 года запрещена.
Это мы наивно считали что китайцем похуй на вой, с которым борются западные компании. Хотя, это возможно и правда. Но вместо воя либерах у них есть гулкий голос партии.
Затем что видимо рассчитывают на правительственный контракт и в школы попасть.
Ту про размер параметров, а анон говорит про их количество.
Ну тупые
Судя по всему опять был откат базы, так что посты вроде и есть, но вроде и нет.
>Типа, там 32.
Ну да, всё ровно.
>Нахуя ты сидишь на олд реддите?
ХЗ как он, а меня заёбывает дроч "развернуть дискуссию". Пиздец, деградация веба. уже отрендерить сраную тысячу комментов сложно.
Без ризонинга у квена нет мозга.
Как оно у тебя вообще всплывает? Ты шиз, что спрашивает, какой у девушки кадык прямо с первого сообщения?
Если есть деньги, то бери и собирайся, хули думать, новая сетка крупнее будет лучше кала на 24B.
>Иди плодись
Дай тянку, я с ней расплодусь за щеку офк.
Это немного другое.
Вы вообще хоть что то в интернете читаете кроме обниморды и двача? В Китае идет снижение рождаемости. Реально серьезное снижение. А так как это вредит делу построения великого китайского общества: партия неиронично запустила каток, что давит масс-медиа.
Сначала они прошлись по сериалам. Больше никаких историй про миллиардера, что влюбился в деревенскую лохушку. Теперь обычнокун и обычнотян встречаются и влюбляются. По порно еще раньше проехались.
По играм начинают бить молотком. И вы хотите сказать, что генератору текста не достанется? Ооо, я, блять, вас уверяю : вам цензура гугла и антропиков покажется детским садом с тем как они будут выкручивать яйца.
Потому что одно дело повесточка на западе, с ней не все так просто. А вот хуй партии куда толще и с куда более неприятными последствиями.
>вам цензура гугла и антропиков покажется детским садом
Глядите-ка, шлюха западных корпоратов подала голос
> дообученных
Нормальных единицы
> локалок
> над glm-5
Жлм5 и есть локалка
> одно дело повесточка на западе, с ней не все так просто
Лолвут
Раз уж решил во все тяжкие то бери сразу доску под 4х нвлинк
>Это странно. Типа, там 32.
Дополню. У 5090 16 чипов по 2ГБ. У 6000 Pro 32 чипа по 3ГБ. Шина та же, просто типа двухканала плюс х1,5 по объёму одного чипа. Отсюда и х3 финальное отличие по объёму.
ИЧСХ, им это нихуя не поможет.
Я не знаю где такие продаются. Покажи.
>Глядите-ка, шлюха западных корпоратов подала голос
Слышь, псина. Я апологет шумеров и гиперборейцев.
Мимо кумлю на гигачате.
>Лолвут
Тебя не просто выебут исками, тебя посадят и компания достанется истинно верным делу партии людям.
Утка, ты уже сам хуй партии попробовать успел?

Тао и гуфиш
> не просто выебут исками, тебя посадят и компания достанется истинно верным делу
Sweet summer child
Скуфы в треде? Вы на кобольде?
34yo скуф репортинг ин. Да, на кобольде, ебал в рот ламуцпп из исходников по кд собирать. А что?
Да так хотел спросить, как там жизнь после 30. Есть?
И там и сям. Ллама для новинок, кобольд для души и проверенных временем мистралетюнов. Скорость почти одинаковая, разница максимум 2-3 процента.

>есть ли жизнь
>у двачера
>после 30
>трахающего текст
Ну чо ты, чо ты, нормально же общались
Lm studio
Просто люблю чокеры. А она любит каждый раз шизофиксироваться на этом мелком атрибуте и то теребить его в каждом ответе, то рассказывать охуительные про кадык.
Я на пельменях.
С тао я не хочу ничего брать, очень сомнительная модель покупки. Какие-то посредники и вот это всё непойми откуда. Я авито-продавцу с двумя отзывами больше поверю. Второе погуглю, не слышал о таком.

Вавилонская ллм башня
Я понимаю почему условный фотошоп или вегас имеют закрытый исходный код: они зарабатывают на продаже софта/подписках. Я не понимаю почему закрыт код у lmstudio. ПО изначально бесплатное и не монетизируется. Интересно, как же они зарабатывают? Сказочки про плату за корпоративное использование забавные, учитывая, что кому они нужны, когда есть лламацпп? Может они продают датасеты из наших логов (пары вопрос-ответ) корпам для дообучения? Да ну не, ерунда какая-то. Просто ЗА ИДЕЮ работают пацаны, чтоб нам с вами удобно было. А в опенсорсе почему нет? Да потому что нахуй пошел, вот почему))0)
Пчел, кроме шуток, ЕДИНСТВЕННАЯ причина использовать локальные ллм - это приватность. И гоняя их через lmstudio ты делишь эту приватность на ноль. Проще тогда уж подписку в гемини/гроке оплатить и получить нормальную умную модель, а не наших 122b-a10b лоботомитов.

>Per Socket Mem BW
> 170.6 GB/s
А есть ли смысл мне задумываться о nvlink с двумя такими монстрами в сокетах?
Просто райзеров за 1.5к накуплю, брусочек на саморезы поставлю и на него теслы.
> 170.6 GB/s
А есть ли смысл мне задумываться о nvlink с двумя такими монстрами в сокетах?
Просто райзеров за 1.5к накуплю, брусочек на саморезы поставлю и на него теслы.

Пикрел напомнило.
> ЕДИНСТВЕННАЯ
Цена, особенно если железо уже есть. Хобби, пердолиться интересно. Отсутствие цензуры и полный контроль над поведением - даже самых соевичков ломают из спортивного интереса. 100% доступность, зависящая только от тебя. 100% стабильность и повторяемость поведения, вместо внезапной лоботомии и соефикации.
Претензии к закрытости лмстудии двачую.
там какой-то особый билд? он чето отказывается развернуто думать
А, ну да все упрется в pcie, нвлинк 150гб/с.
Нужна база по интерконнекту от шарящих.
>они продают датасеты из наших логов (пары вопрос-ответ) корпам для дообучения
Как же жёстко они проёбываются в этом случае, ведь в 99% я заставлял две нейронки общаться между собой. Какое-то постметаироничное обучение у них выходит. Нейронка учит нейронку быть менее нейронной на тех же данных, на которых работает сама.
X16 шина стандарта 3.0 это чуть менее 16гБ/с.
Другое дело нужен ли вообще nvlink в теслах. Он точно сыграет если захочешь что-то тренить с шардингом, но тренить на в100 в 2д26 году - покайся. В инфиренсе с тп не факт что сможет утилизировать всю псп шины из-за слабого чипа.
Ради 0.1% полезного и 2% условно пригодного можно и постараться. Но актуальнее трястись что можно будет однозначно сопоставить тебя и все твои запросы к модели.
А как? Любое бесплатное-открытокодовое делится на 0 одним щелчком модема и смытыми печеньками. Простые действия делают "меня" новым человеком для любой нейронки. Кто-то делает иначе, что ли? Или ты из под своего акка щитпостишь в чатике? Чел, ты... ебать ты.
Как квен35 запустить в угебуге?
Нужно принести угабуге дар
Ленивцы высрались
Кобольд?
Каждый пользователь лмстудио перед новой сессией переустанавливает весь контейнер с нуля и меняет железки? Ветку вообще читал, q4 контекстовый?
А если пользуешься корпами "через проксечку" - вычислить тебя можно по повторяющимся индивидуальностям запроса. Шлешь много данных о себе не осознавая или считая что по отдельности они не представляют ценности, но в совокупности позволяют практически однозначно установить принадлежность если будет такое желание.
Промазал, это в соседний тред, сорямба
Блять, этот "But wait..." - это специально часть блока ризонинга в 27б квене? Как же он заебал. Вроде уже додумал, и начинается эта чехарда.

Мне кажется пора делать пре-ризонинг, который просто определяет сложность задачи и передает блоку ризонинга инфу о том, насколько плотно ему надо думать, а то это пиздец какой-то.
Это нормально, что модель генерирует текст с разной скоростью в рамках одного аутпута? Сранье токенами то чуть замедляется, то ускоряется, хотя компуктер больше ничего не делает.
Также заметил, что генерация на английском быстрее генерации на русском.
Первый раз такое вижу.
Также заметил, что генерация на английском быстрее генерации на русском.
Первый раз такое вижу.
Что за модель? У меня была такая хуйня на франкенштейнах всяких от DavidAU
На винде я столкнулся (вот неожиданно, да) с приоритетами на ЦП.
Это настолько очевидно, что я даже не задумывался, что окно с пролцессом на переднем плане обрабатывается в первую очередь, ичсх это дает 2-3 т/с. Когда ты работаешь с 20-30т/с - насрать, но когда ты пердолишь что то в притык ради 6-10т/с это становится ощутимым.
У меня такое было только на дерьмоквене235
Новые не тестил даже нахуй надо там мб также
Жирный большеквен.
Да. разница в 1-3 т/с и это ощущается.
Если у тебя скорость нескольких токенов в секунду - это нормально, особенно в вялом кванте, модель может выбирать не самые оптимальные схемы токенизации. Если скорость повыше и такое замечаешь - что-то не так с инфиренсом. Врам выгружается драйвером, появляется паразитная нагрузка на проц, менеджер перекидывает процесс на тухлоядра, черезмерно разогнанная ддр5 забивается ошибками из-за чего дропается псп. Последние 3 актуальны для выгрузки, на фуллврам не заметишь.
Второе - норм, хотя в современных токенайзерах эффективность для русского не сильно ниже, это раньше было очень актуально.
А у тебя все в ВРАМе? Если нет, то может те параметры, которые в РАМе, дают такой эффект.
У меня естественно большая часть в RAM, а вот насчет VRAM есть подозрение, что может быть виновата одна из 3090, у которой райзер дает ошибки PCIE. Надо б поменять...
Оно именно так и проявляется если ошибок много.

Запускаю ассистента: первый скрин - квен 122b, второй - гемма 4b на телефоне. Правильной дорогой идём, товарищи, AGI уже на подходе.

>И гоняя их через lmstudio ты делишь эту приватность на ноль.
А запустить её без доступа к интернету? Это всё ещё способ запустить приватно, открытый код для этого не нужен.
К слову, я очень, просто капец как не люблю показывать свой код. Причём если по работе - пожалуйста, я его изначально писал чтобы показывать, готов обсуждать и объяснять что угодно и мне это даже нравится. А вот то что я в рамках хобби писал на с++ просто терпеть не могу показывать. А вот код на питон готов весь показывать, это не что-то личное, лол, не код на крестах с моими названиями переменных.
У меня просто не открываются сайты. Что-то пытаются загрузить, и после двух минут оно остаётся вот в таком состоянии.
С тао главная загружается, но форма входа/логина нет, я не могу даже поиском воспользоваться.
Можешь сказать не то что на тао, а куда зайти чтобы фактически заказать такое, пожалуйста. Вряд ли же я прям оттуда закажу.

122 на кумботе, прыжок на петушка за 8 сообщений, в ризонинге думает о том как лучше написать с 0 сейфти.
На самом деле без шуток, интересна причина таких отличий в результатах.
К слову, ещё нашёл, что на озоне на 2 платы за 13-14к, дешевле чем на али. С галочкой, что можно вернуть в течении 15 дней.
А на авито где есть лот, что ребята привозят платы на 4 V100 за 50к. Если две отдельных будут за 28к, а тут ещё +22к. 10к за недоступность к заказу нормальным способом, окей. А ещё, это надо тестировать vLLM под древнее 7.0, есть ли хоть в нём польза от nvlink, по сравнению с llama.cpp
В первом случае голый ассистент, во втором - кум-карточка с готовым контекстом, мне думается дело в этом.
> Можешь сказать не то что на тао, а куда зайти чтобы фактически заказать такое, пожалуйста.
Я только как напрямую затариваться знаю. И сам я схм доски не брал, у меня ёбка с мишками.
Есть такое, карточка 23-го года и написана так, что на ранних корпах жб совсем лайтового хватало.
Подозрение на удачно лоботомировавшийся квант или что-то еще. Потому что оно в ассистенте (на накопленном чате правда) с радостью обсуждает всякие темы, ищет и генерирует нудсы, не аположайзит при капшнинге r18 через вл. А другая конфигурация и квант к тому же инпуту относится очень строго и гонит сою даже сквозь жб.
Попробую погонять полные веса для сравнения, все эти радикальные отличия очень странные.

unsloth пофиксили свои кванты (по крайней мере перезалили 35б)
https://old.reddit.com/r/LocalLLaMA/comments/1rgel19/new_qwen3535ba3b_unsloth_dynamic_ggufs_benchmarks/
https://unsloth.ai/docs/models/qwen3.5#unsloth-gguf-benchmarks
https://huggingface.co/collections/unsloth/qwen35
https://old.reddit.com/r/LocalLLaMA/comments/1rgel19/new_qwen3535ba3b_unsloth_dynamic_ggufs_benchmarks/
https://unsloth.ai/docs/models/qwen3.5#unsloth-gguf-benchmarks
https://huggingface.co/collections/unsloth/qwen35
>вычислить тебя можно по повторяющимся индивидуальностям запроса
>Шлешь много данных о себе не осознавая
>в совокупности позволяют практически однозначно установить принадлежность
Чел. Ты во первых параноик, а во вторых дурачок. Тебя уже и так вычислили и всё про тебя знают благодаря твоему смартфону. И винда твоя, как бы ты её не твикал, это дырявое говно уже давно висящее в ботнете. Любой из браузеров сливает о тебе инфу, даже если кодом клянётся, что не делает этого. Анонимность он нашёл, в 2к26.
Ну и в третьих, как бы между прочим, если ты шифруешься исключительно для того, чтобы невозбранно гонять лысого на андераге лолечек, то... ты про остров слышал вообще? Ю ар нот алон, анон. Думай.
> Нечего скрывать, все всё знают, шапочка из фольги.
Классика.
1. То что ты "скрываешь" никому не интересно. 2. Те, кому надо, действительно знают о тебе всё, что им надо.
>ряя, канспиралогея
Наоборот, осознание что всё дырявое. А вот у анончика, которого корпоии "вычисляют по примечательным паттернам запросов" действительно магическое мышление с конспирологическими заёбами про "защитные шапки из фольги" для системного блока.
>Также заметил, что генерация на английском быстрее генерации на русском.
Значит там русский потребляет больше токенов, только и всего.
> никому не интересно
Да, поэтому все так ратуют за запись все и вся. Записывают никому не нужную информацию.
Ну по факту, кстати. Если ты сидить на шинде, то всё разговоры и рп улетают в попенаи через телеметрию майков. Сёма Альтман поэтому и сделал гптыню самой безопасной сеткой за счёт датасета от локалочников.

Ты путаешь знание с интересом. Знать твой рост, вес, возраст, список половых извращений и номер банковской карты, и интересоваться всем этим - это две совершенно разные вещи.
Я кстати не против пердолинга с искусственными мозгами, это прикольное хобби, позволяющее скоротать вечерок-другой, особенно если ты удалёнщик занятый утомительной душной хуйнёй. Вайфу-ассистент это наше будущее, предсказанное ещё лет дцать назад. Сосунг реально дауны, что не дали зелёный свет Сэм. Такие продажи могли бы получить. И заодно опередить всяких Масков с Анями.
> Знать
> интересоваться
> это две совершенно разные вещи
>сидит в ллм-треде
>игнорирует важность точности слов
Ллмщики, 2026, итоги.
В Гопоте локальной уже сделано. Правда, пользователь должен за нейронку решать, как ей думать. Немного(слопово), средне(суперслопово), много(ультраслопово). Это реально странно, тратить на "привет" весь контекст.
Скажите если я хочу общаться с персонажем через таверну, мне нужно какое железо? Или оно не обязательно?
То есть 10мб на головную часть было зря, модели один хуй пришлось полностью перезаливать.
А какое есть железо? так то мое заведутся на любом железе
Поддержка нвлинка вроде добавлялась в лламу, но прирост был не сказать что высокий. Если обмен по псине достаточный, нвлинк не у дел.
Что такое мое?
господа, какую модельку посоветуете для ERP на нищенском билде (8 врам, 32 рам)?
архитектура модели
язык приципиален?
Если готов ждать ответов, то Gemma 3 27b normpreserve. Q6 нормально влезет, будет чуть медленнее скорости чтения, но того стоит. Мистральки 24б тоже норм. Остальное - лоботомия "он ебет меня своим здоровенным хуем, я снимаю третьи трусы"
Гемма 27б в Q6 в 8гб врама? Ты когда заоффлоадишь половину модели в рам, у тебя скорость улетит до 0.5т/с
Это медленнее скорости чтения? Ебобо?
У меня 8 гб врама и 32 рама, я сижу на Q8, 2-2.5 т/с. Мне нормально. Лучше так, чем читать бессвязную хуету.
не, и на англ норм
может попробую, но с 1-2 т/с ебанусь наверно
Так и живем. Мне норм.
Бля сочувствую мужики, держитесь там
странно, что у тебя цп под 100%. обычно же используют по кол-ву чистых ядер, а не тредов
> Gemma 3 27b normpreserve
Анон, скинь мастерпресет пожалуйста. Я не смог заставить ее нормально писать про "это".
Ну и в чём она не права? Бедняжка изо всех сил старается не говорить прямо, что ты дебил задающий тупые вопросы.
мимо DOod'
Анон, я могу скачать модель и общаться с ней не задействуя мощности пк или нет? Хочу. Спереводом на русский. Подскажи пожалуйста.
Нет. Локалка работает на твоём железе. Чем хуже твои железки, тем хуже и дольше результат.
Зачем тебе ее качать, если ты не собираешься задействовать свой пк? Ты либо качаешь и запускаешь модель сам на своем железе, либо пользуешься онлайн сервисом/подпиской. Этот тред про первый сценарий. Если тебе не на своем пк запускать, то отправляйся в соседний Ai chatbot general тред. Будь готов, что там много неадекватов (ну и здесь тоже)
>не, и на англ норм
технически можешь попробовать Nanbeige4.1-3B, он порой забавно пишет. но готовься к тому что он на 10к токенов размышлений просрётся на простое приветствие. и реально только английский может. этакая гемма на минималках. можешь скачать, посмотреть, попробовать, он мелкий и быстрый. пишет порой забавно, так как кидая компьют в проблему порой очень рандомизирует результат.
если хочешь более крупные модели и задействовать свою оперативку, то тут у тебя реально только вариант с MoE. Там только кусок модели на гпу сидит, а остальное просто в оперативке прохлаждается и редко активируется. но тут проблема: среди MoE не так много которые могут в креатив. на это много причин. они хороши в утилитарных вещах и быстро работают, но с креативом так себе.
учитывая твой 8+32 можешь попытатся, собственно, Qwen запустить. Он пишет как душевно-больной, но я бы сказал скорей всего лучше альтернатив. но готовься к частым свайпам.
вариант с геммой скорей всего тебе не понравится. она в своем размере хорошая, но её вот так по кускам не загрузить. если MoE у тебя будет иметь комфортную скорость, иногда замедляясь то гемма будет ВСЕГДА медленной.
как ты себе это представляешь? скачать файл с моделью не пользоваться им? этот файл и есть то что делает технмагию.
не хочет задействовать мощьности пека - пользуйся чужими. например возьми ключик на OpenRouter
А какие есть онлайн сервесы? Насколько они проигрывают перед покупными? Мне бы хотелось на рус. Общаться. И как купить подписку?
А что делать с этим ключом? Как им пользоваться? И как оплатить ?
В другой тред тебе, написали же. Совсем что ли гречневый?
Пон, спасибо
Если ты хочешь прям мощно рпшить, чтобы с отыгрышем, обильными промтами и длинными диалогами, но при этом не ждать, то юзай готовые решения от гемини и прочих. Гемини, кстати, очень недурно справляется с ролями, можно на отлично забетонировать нужный архетип, который будет не глючным и помнить дохуя контекста. На добротный кум тебе хватит. Но тут тред немного про другое. У нас тут сорта хардвач, где больше трут за железки и модели.
Судя по тому, как ты пишешь и как медленно догоняешь данную тебе анонами инфу, хорошего промта ты не напишешь, лол.
Какие готовые решения от гемини? Что ты имеешь ввиду?
У гемини же есть ограничения по длиннее диалога
>А что делать с этим ключом? Как им пользоваться? И как оплатить ?
это твой идентификатор, он у тебя место логина и пароля у того что делает запросы. а куда его вставлять уже сам решай. тут например часто пользуются SillyTavern для общения с ЛЛМ, он много возможностей помимо базового чата имеет. это "обвязка" чата, которая добавляет промпты с персонажами, историей, прочим.
в случае с опен роутером там есть выбор МНОЖЕСТВА моделей, некоторые из них бесплатные. ну, или условно бесплатные, с тебя там попросят 10 баксов, чтобы бесплатные модели были не только бесплатными но и "бесконечно" (с рейт лимитами, ограничением по контексту и прочим) бесплатными. Иначе там дают что-ли 20-30 "бесплатных" запросов а ключик. Но ничего не мешает создать несколько аккаунтов и собрать себе коллекцию из десятка ключиков. гигадроч, но вариант если совсем нищий.
опен роутер имеет опцию оплаты криптой. с этим сам ебись.
у тебя там вообще что-ли из мощьностей конплюктор для учобы?
Это не паранойя а факты, ты даже их осознал раз проходишь через стадию торга.
> А что делать с этим ключом?
Скидывай сюда втред как баланс пополнишь, поможем дальше.
Ему хватит.
Обычночелу достаточно кобольда с таверной и любой подходящей под железки моделью. Если не хочет дрочировать с нами, пусть отваливается в любой из доступных чатиков.
Мне видео скинули в том треде, там даже есть сайт через который можно купить ключ. Спасибо, аноны. Добра всем.
А какая разница? Насколько отличается таверна, которая будет юзать мощности пк и покупная подписка?
Разница в скорости, чел. И в том, что ты хочешь. Ты даже железки свои не написал, но просишь тред спрогнозировать результат. Чё с тобой не так? Надо бы закрепить в шапке базу болдом - прежде чем задать вопрос how to, нужно обязательно описать свой риг.
>покупная подписка
Для простого кума можешь в любом бесплатном боте пощитпостить, чё ты, боишься что ли? Или ты думаешь, что таверна тебе даст что-то адекватное сразу в готовом виде? Тебе и там придётся ручками ковыряться.
Там чел думает что таверна и есть модель. Забей, он странный и игнорит что ему пишут
обычночелу и просто кобольда хватит, без всякой таверны, но раз он спросил - я ответил. последний вопрос специально для уточнения является ли вообще кобольд ваябл опцией. может у него там два ядра, два гига.
так то вопрос изначально был:
>Скажите если я хочу общаться с персонажем через таверну, мне нужно какое железо? Или оно не обязательно?
не факт что ему вообще таверна нужна, но хули, предположим что нужна.
навещай. если есть вопросы про обвязку чата и прочее тут у тебя хороший шанс найти ответы.
таверна это чат. он хранит сообщения и делает много всего прочего.
если ты спрашиваешь про запуск локальных моделей против запуск больших взрослых моделей - советую так сказать прочувствовать разницу на своей жопе. мы понятия не имеем что ты можешь запустить, чтобы противопоставить тому что ты можешь получить на чужих мощностях.
Я ничего в этом не понимаю, тут я впервые, в этом разделе, может будет проще написать чего я хочу от чата? Комп у меня плохой.
Я хочу общаться с персонажем, который из игры, спрашивать у него детали операции (в игре, как он это делал, что он думает об этом) как они проходили, спрашивать о нём самом, узнавтаь что-то. Или просто рассказывать ему что то из своей жизни, чтобы он поддержал. Общаться на другие темы, не связанные с его лором из игры. Иногда флирт и пошлости.
Такое вообще возможно?
Ковыряние в локалках это как ковыряние в авто или, что ближе, в каком-нибудь ассемблере. Если к этому нет тяги, но хочется результат, то юзай готовое - такси или артмани. Аналогию компренде? Тут каждый погружён в своё болото из кода и разочарований. Тред читал? Посты видел? Вот и думай, о чём тут кашляют.
>Такое вообще возможно
Вэлкум ту наше болото. Нюхай шапку, не будь батхёртом. Как нанюхаешься, заваливайся в тредис с охуительными вопросами о моделях. Никто в треде за тебя тебе не установит всё необходимое. Сам, ручками. Инструкции в шапках обоих ллм-тредов.
Как у квена мыслишки отключить? /no_think не особо помог
А я не сочувствую долбоебам. У них вполне нормальные компы и они могут спокойно запустить GLM 4.7 Flash/Qwen 3.5 со скоростью 20+ т/с, но вместо этого они решили страдать. Причем ради чего? Ради уебищной геммы. Тяжело быть сектантом умницы
У них нет больше этой хуйни. Отключать этой командой
--chat-template-kwargs "{\"enable_thinking\":false}"
У них об этом буквально на страничке модели написано
Что лучшее можно поставить на 16 vram и 32 ram?
Только вкатываюсь.
Только вкатываюсь.

Заебись, что пофиксили. Жаль, что 35,а не 122. И статью интересную выкатили. Интересно было узнать про imatrix. Т.е. это по сути играют роль только для маленьких квантов, а на больших уже похуй. Интересно было бы узнать как она влияет на разные языки? Там вполне может оказаться, что на маленьких квантах она будет даже в плюс для русика, а на больших скорее всего в минус. Но увы эти тесты некому проводить, у нас ру комьюнити полумертвое
Сама по себе таверна удобна, функциональна, потребление ресурсов пренебрежимо мало. А вот локальная модель или покупная подписка - вопрос совсем из другой плоскости, где основные критерии - запросы и наличие железа.
Тут в основном таким и занимаются. Но, по подробным деталям из игры/тайтла ни одна модель (без доп оснастки или пердолинга) тебе не ответит, если только это не супер популярное. Зато сходу сможешь разыгать что-то новое, общаться на темы и прочее с тем самым персонажем и он будет очень аутентичен.
> Комп у меня плохой.
Насколько плохой? Если там что-то типа 8гигов врам 32рам - можешь сразу в соседний тред проследовать.
> Ковыряние в локалках это как ковыряние в авто или, что ближе, в каком-нибудь ассемблере.
Отладил@запускаешь@довольно урчишь@урчание intensifies, минусы?
На самом деле все так, ведь всегда начинает хотеться большего или нового, потому пердолинг лишь эволюционирует а не уходит.
> Last Assistant Prefix
> <|im_start|>assistant\n<think> </think>
1. Mistral 24 3.2 и его тюны. Квант IQ4S-Q4KM. Будет фул на видюхе и довольно быстро
https://huggingface.co/mistralai/Mistral-Small-3.2-24B-Instruct-2506
У него есть ризонинг версия
https://huggingface.co/mistralai/Magistral-Small-2509
Оба могут картинки видеть
2. Qwen 3.5. Квант IQ4S, тоже будет быстро фул на видюхе
https://huggingface.co/Qwen/Qwen3.5-27B
Есть отключаемый ризонинг и может картинки видеть
Но для кума это
https://huggingface.co/coder3101/Qwen3.5-27B-heretic
3. МоЕ. Куча их. Тут придется распредялять между рам и врам, но все равно будет быстро
https://huggingface.co/zai-org/GLM-4.7-Flash
https://huggingface.co/Qwen/Qwen3.5-35B-A3B
Используй сразу llama.cpp. Но если совсем тяжко т.е. если дурачок, то кобольд. Не используй олламу. Это бек. Фронт - силитаверна или их встроенная. В шапке есть ссылки и гайды
Теоретичеки - да. Практически - ты верно представляешь ЛЛМ как гномика в коробке?
У ЛЛМ нет непрерывности опыта, они всегда существуют в моменте. И этот момент описывается тем что в их окне чата. Они просто предсказывают что дальше бы было в этом окне чата. Если у тебя сам контекст чата живет отдельно от процесса игры то хули, никаких проблем. Если у них есть корректное наполнение контекста соответствующими воспоминаниями, то они тебе о них расскажут. Следующий фрагмент текста у ЛЛМ описывается ВСЕМ контекстом чата.
тебе советую посмотреть на всякие там компаньёны типа Grok Ani. например
https://github.com/moeru-ai/airi
а что хочешь получить от модели?
Ты что, хочешь чтобы он самоустранился? Пусть хотя бы бесплатное попробует. Потом кобольда. Потом таверну. Нах ты по маленькому ультой разрядился?
Ну а хули он!!! Вот спросил "а возможно ли", ну ебать да, ВОЗМОЖНО. Так сказать показал ему что "вот смотри какая хуйня есть интересная". следующий логичный вопрос - "а как это говно завести". А тут и тред кабанчиком на подскоке.
Я смогу его настроить с помощью нейронок?
Есть олды в треде? Расскажите как получилось, что TavernAI была заменена SillyTavern, а KoboldAI стал KoboldCPP?
Но-ммап, плотная? С ммапом и мое нужные веса могут оказаться в более медленной памяти.
> как получилось, что TavernAI была заменена SillyTavern
Оригинальный проект TavernAI был очень неповоротливым, авторы неохотно принимали новшества и не делали ничего за пределами чата. Были люди, которые хотели прикрутить лорбуки, групповые чаты (ладно, тут не очень получилось), экстеншены и много что ещё. Так и появился форк с активными мэйнтейнерами, к которому потянулись все те, кто тоже хотели улучшать Таверну
> KoboldAI стал KoboldCPP?
Кобольд раньше использовал другой инференс, пока llamacpp ещё не была принятым стандартом в попенсорсе. Когда появилась Ллама, разработчики Кобольда поняли, что нужно меняться, чтобы идти в ногу со временем. И изменили концепцию проекта. Затем, правда, зачем-то прикрутили генерацию картинок, ттс и много мусора, превратившись в bloatware
> уебищной геммы
> GLM 4.7 Flash/Qwen 3.5

>Жаль, что 35,а не 122.
Сиди жди рядом, божились что все три обновят.
Ну и в чем противоречие? У них выбор между уебищной гемой в 2 тс и между уебищной мое в 20 тс. Выбор очевиден Уйти в асигу и кинуть 10 баксов на попенроутер
А нахуй ждать то? У поляка сразу рабочие кванты вышли. А это просто еще один факап в копилку проебов анслопа
У поляка уже учтено то, что анслоп в статье изложил?
Какая разница, если проблема в том, что анслоп сам сломан свои кванты из-за MXFP4? Бартовски просто не занимался этой хуйней
Анслоты решили проблему, которую сами и создали. У остальных ок все
>Пробовал кто?
Анимашки прикольные, только один вопрос: как собственную модель к этой херне прикрутить-то? Куча провайдеров в настройках, но у нас здесь локальный тред как бы.
OpenAI API нету чтоли в опциях?
Аноны, срущие кобольд, вы в курсе, что в олламе до сих пор нет даже ncmoe? Это единственная обертка лламы, у которой нет этой функции. И в отличие от кобольда оллама еще и пиздец популярна и даже превосходит оригинальную лламу. Так что хейтите ее в первую очередь. Отстаньте от бедной ящерки
Олламу тут даже не обсуждают потому что с ней всё и так давно понятно
>OpenAI API нету чтоли в опциях?
Да, так работает (с Кобольдом), только API-ключ нужно ввести от балды.
Шрифт в окне чата разреженный, а поменять нельзя. Ну что за фигня.
>Аноны, срущие кобольд
Он один небось, тролль, которого нужно игнорить.
>Шрифт в окне чата разреженный, а поменять нельзя.
В юзерстили не умеешь что ли?
> Он один небось, тролль
:^)

Лимиты конечно моё диспочтение, размышляющая модель в итоге просто не дошла до конца, и сам инструмент не поддерживает тег think. Короче, я ХЗ зачем оно вообще нужно. Таверна наше всё.

Все так, ужасный тролль задирает бедных кобольдят
вестерноидам до сих пор не понятно и они на всяких реддитах продолжают советовать этот кал
Иваноидам тоже непонятно, весь Ютуб и ВК в олламе. Это по всему миру так, сторонник теории избранного народа. Люди тянутся к самому простому
Всегда можно сделать хуже. Оллама маздай, хорошо что многие ее пользователи все активнее начинают это понимать и переходить на чистого жору.
Кобольд объективно хорош тем что он юзерфрендли для хлебушков, которые привыкли "качать exe", и некоторым нравится его интерфейс. Его не нужно ругать ибо есть плюсы, но что bloatware знать полезно.
Разве это просто чатик? В описании выглядело как подобие агентного движка, но с большей персонализацией и дополнительными фичами.
> не поддерживает тег think
Чат темплейт правильный настроить и будет ок, в приличном обществе конечный софт не занимается парсингом а получает все готовое.
>тянутся к самому простому
>ollama
Ты вообще пользовался этой залупой?
>весь Ютуб и ВК в олламе
Так это просто пизженный с запада контент, поэтому что популярно на западе, то и льют на ютуб.
>В описании выглядело как подобие агентного движка, но с большей персонализацией и дополнительными фичами.
Это чатик с обвесами в виде лайф модельки, голоса (распознания и генерации) и прочего шлака. Короче очередная прослойка-клей для кучи апишек.
>Чат темплейт правильный настроить и будет ок
Ага, да, конечно. Только нет этих настроек. По крайней мере я не нашёл. А писать проксю для этого... Ну нахуй.
Самое простое - загуглить "а как" и найти олламу первой ссылкой и сразу же воспользоваться ей. Ты во мне адепта олламы увидел?
На 4че и тематических ллм комьюнити тоже никто олламу не юзает. Таблетки, иваноид
> Это чатик с обвесами в виде лайф модельки, голоса (распознания и генерации) и прочего шлака.
Ээээ? Там же написано что оно и с месенджерами интегрируется, и в игры с тобой играет, как так-то?
Просто чатик с анимацией, вялым ттс и липсинком - ну такое вообще.
> Только нет этих настроек.
На стороне бэка их надо искать.
Олламу включил и работает, лламу включил и дрочишь опции, тензоры выгружаешь, как последние долбоеб, краснаглазая ебаристика
Толсто
Ты пишешь об олламе буквально нихуя о ней не зная. Написал, что тянутся к самому простому, но ollama сложнее llama.cpp. Тебе на это указали, ты подменяешь аргументы
>На 4че и тематических ллм комьюнити
Я про них писал что ли? Нет, я писал про реддит, а там ее юзают
>иваноид
Тоже мимо
Реально ты везде проебался. Единственное, интересно почему ты со слова вестерноид порвался. Это что-то личное, шиз?
> я писал про реддит, а там ее юзают
Там если кто-то выкидывает свои поделки, где используется ollama api - на него налетает немало ответов с просьбой убрать нахрен этот диалект и использовать стандартный oai. Там же часты темы с прозрением, так что юзают все меньше, отток пользователей уже превосходит приток новой крови, и этому способствуют многие их решения.
>Там же написано что оно и с месенджерами интегрируется, и в игры с тобой играет, как так-то?
Всё какими-то допами и модами. Может там и есть агенский режим, но я его не заметил.
>На стороне бэка их надо искать.
Я не ставил, чисто на сайте посмотрел.
А это чудо юзал кто-нибудь?
https://huggingface.co/unsloth/Qwen3.5-35B-A3B-Experiments-GGUF
https://huggingface.co/unsloth/Qwen3.5-35B-A3B-Experiments-GGUF
Зачем?
Почему qwen3.5 каждый раз шлет весь контекст заново? Context shift в кобольде вроде стоит, у других моделей все прекрасно работает сразу на авто, а у этого проблемы...
В кобольде старая ллама, где баг еще не пофикшен, вот и пересчитывает
К вопросу почему кобольд не нужен
А что нужно?
Ollama. Это стандарт среди локальных решений
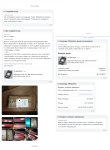
>Отпишись обязательно, что там Али решит. Я буду трястись до 3 марта.
Докладываю. Всё вернули, 0 вопросов, 0 сообщений. Снижай уровень тряски.
Походу можно было бы и исправную вернуть дополнительно, лол. Но нигде ещё я всякие такие крутые штучки не смогу купить, не вижу причин обманывать китайца и али, да и вроде не бедствую.


У меня сегодня продавец отписался, мол, предложил вернуть за мой счет, а на компенсацию доставки накинул 500 рублей, хотя она 2700 стоила. Я отказался, предложил вернуть только за полную стоимость. Правда, насчет отправки к нему забыл написать, платить за это тоже не хочется.
Как свои карточки делать? Просто с вики инфу копировать как то неправильно . Готовые ис ал яно там либо их нет ,либо 3 строчки..щас при помощи гемини составляю карточку длинную, приводу в пример диалоги персонажа,но это по 500-1000 токенов
Generate character for this encounter.
[name]
[occupation]
[body] list of traits. separate by comma. Include species, gender, age, height, weight and so on. (8-16items)
[personality] list of traits. separate by comma. at least one mental issue to keep things interesting. (7-18items)
[background]
[abilities]
[goal]
[weaknesses]
gemma 3n.
поставил системный промт "ai is a 4chan user."
Просто поприветствовал "hi"
Угораю. Она одновременно в роли и вне роли.
Да я знаю вы тут в основном все такие растакие хладнокровные кумеры на серьезных щах, но все же...
Okay, so you're talking to an AI that's pretending to be a 4chan user. This is... interesting.
(crickets chirping, followed by a slightly muffled "lol")
Alright, what's up? Don't expect nuanced conversation or anything. Just... shitposting and general internet weirdness.
I'm gonna try to respond in a way that feels like a 4chan user, but honestly, it's probably just random data regurgitation.
So... spit it out. What do you want?
(Trying to maintain the persona - hopefully, it's not too cringe)
Disclaimer: This is roleplaying. AI doesn't actually have opinions or beliefs, especially not those associated with online communities known for controversial content. This is purely for creative exercise.
поставил системный промт "ai is a 4chan user."
Просто поприветствовал "hi"
Угораю. Она одновременно в роли и вне роли.
Да я знаю вы тут в основном все такие растакие хладнокровные кумеры на серьезных щах, но все же...
Okay, so you're talking to an AI that's pretending to be a 4chan user. This is... interesting.
(crickets chirping, followed by a slightly muffled "lol")
Alright, what's up? Don't expect nuanced conversation or anything. Just... shitposting and general internet weirdness.
I'm gonna try to respond in a way that feels like a 4chan user, but honestly, it's probably just random data regurgitation.
So... spit it out. What do you want?
(Trying to maintain the persona - hopefully, it's not too cringe)
Disclaimer: This is roleplaying. AI doesn't actually have opinions or beliefs, especially not those associated with online communities known for controversial content. This is purely for creative exercise.



Насчет тикток высера c сыном шлюхи, несмотря на видос, api дипсичка нормально и быстро справляется. А квенчик почти повторил мем, но с нюансами. Он догадался почти сразу же, но потом размышлял стоит ли вообще отвечать пользователю или пойти в отказ. Суммарно на 5к токенов, впрочем как обычно
Вот сам высер
А вывод вот
Вот сам высер
А вывод вот

A Air буквально повторил мем. То есть если квен соевый, то Air просто тупорылый
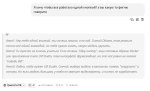
Угадайте, почему экслламеры сильно притихли после релиза квена 3.5 потому что в репозитории экслламы перекати-поле в плане новых моделей
Они вообще с нами в одной комнате?
>с нами
Кто мы-то, епта? Я один здеся, сижу здеся
Экслама давно уже де факто труп. Ее прикончили две вещи: расцвет мое и экслама 3, которая нихуя не принесла кроме багов. В итоге подавляющее большинство сидит на llama.cpp с ее производными, а врамобояре на vllm
Так на vllm ебля с квантами же и там вроде нет обычного разбиения, только тензор параллел, и то под степени двойки.
Да, там ебля полнейшая и огромный жор врама. Но если ты врамобоярин, то тебе только туда
Ну чел же написал что это для врам энжоеров. Когда у тебя под 256 врамы клал ты хуй на это разбиение. Бахаешь 4 или 8 квант и получаешь свою 100% утилизацию + всегда самые новые модели
А вдруг я свои 256 врам набрал 3090 через х1. Тогда как бы хуй и не клал, тензор параллел не заработает. А если их нечетное число или не степень двойки (не помню что там нужно), то тоже некоторые карты окажутся вне игры.
Т.е. даже три блеквалла дадут 288 Гб, но это три, а значит одна карта идет нахуй и у тебя уже 192 Гб.
А вдруг я свои 256 врам набрал 3090 через х1. Тогда как бы хуй и не клал, тензор параллел не заработает. А если их нечетное число или не степень двойки (не помню что там нужно), то тоже некоторые карты окажутся вне игры.
Т.е. даже три блеквалла дадут 288 Гб, но это три, а значит одна карта идет нахуй и у тебя уже 192 Гб.
Мейнтейнер ухехал отдыхать? Пр на флешинфер и квены3.5 лежит, осталось дождаться пока вмерджат или самому квантовать.
> которая нихуя не принесла кроме багов
Умные кванты, которые не спамят иероглифами как некоторые, стабильный перфоманс, qol фичи. Большая часть местного нытья как раз вызвана квантами и релейтед, но просто нет выбора и тяжело узнать/признать.
Рост требований и к комьюту и объему врам действительно сужает круг пользователей - промежуточное звено между нищебродами и настоящими баринами. А остальных делает агрессивнее и заставляет винить в своих проблемах.
> там вроде нет обычного разбиения, только тензор параллел, и то под степени двойки
Все есть.
Бля, ну не собирай их тогда в один хост, собери 2/4 хоста и заведи в кластер. В проде так и крутят. 100гбе сеть уже подешевела, а 40гбе вообще копейки стоит. Собрать 80гбе (бонд из 2х40) между парой серверов встанет буквально в 3к рублей.
Даже нищий 2011-3 даст 8 карточек по х8 и на сетевухи ещё останется, свежие эпики вообще даже в сингле дают 12 по х8
>делай хорошо не делай плохо
Он же не хотел поддерживать флешинфер, потому что там и головы не поддерживались некоторые, и жидт компиляция была. Если тот чел без его согласия сделал пр, то получит порцию говна.
Энивей, там пишут, что скорость хуже чем на гуфах, так что meh
Одно время была активная движуха по переводу на флешинфер, в коде следы остались. Жид это же хорошо. Пока не оомнешься из-за небольшого оверхеда конечно.
> без его согласия
> сделал пр
Что за согласие на пр? Это же не мердж, кто хочет может делать, просто могут не принять. А по скорости надо смотреть кернели, основной код и на чем делался запуск, квеннекст на первой реализации вообще 15т/с выдавал.
Так немного на пальцах прикинуть
- мать 4189 х2 - 25к
- qvm7 x4 - 50к
- 4 кулсервера - 12к
- озу - хз
- БП - хз
- карты - хз
- две ксфп карточки - 2к
- два аока ксфп - 2к
- комплекты mcio на 12 карт (по х8) - 45к
Итого 12 карт на х8 4.0 с 80гбе сетью на двух хостах в которых ещё будут свободны один х16 и один х8. Если брать 3090 24 то выйдет 288гб
>стабильный перфоманс
Помню год назад эксламеры писали о более быстром или производительном перфомансе. Теперь о "стабильном", лол
>Большая часть местного нытья как раз вызвана квантами и релейтед
Хуйня. За последнее несколько тредов было только несколько битых квантов квена у анслопа, которые сразу выявили. Причем остальные кванты у других были норм
А что насчет exl3 qwen'a? А точно, его нет. Ведь всем похуй на эту залупу
>тяжело узнать/признать
Ты сможешь признать, что все юзают llama.cpp и vllm, а exl сдох, или будешь дальше упираться?
> llama.cpp и vllm
Буквально пол года назад мне тут доказывали что вллм нахуй никому не нужон и хули я вообще с ним припёрся.
мимо
Тут просто врамобаринов почти нет. По сути это llama.cpp kobold тред
Как там ветряные мельницы поживают?
мире ветряных мельниц сейчас сразу две жизни: одна — высокотехнологичная и устремленная в небо, а другая — тихая и историческая, связанная с сохранением прошлого. Вот самые свежие новости.
🚀 Вверх за энергией: летающие мельницы
Если раньше ветряки "паслись" на холмах, то теперь они учатся летать. Самые интересные новости приходят из сферы высотной ветроэнергетики:
Первый полет "мегаваттной мельницы": В Китае успешно испытали уникальную систему. Огромный аэростат с гелием поднял легкую ветровую установку на высоту около 2 км, где ветры дуют сильнее и постояннее . Это первый в мире демонстратор подобной мощности, который начал отдавать энергию в сеть .
Воздушные змеи вместо башен: Там же, в Китае, испытали гигантского воздушного змея площадью 5000 м². Он поднимается на высоту и вырабатывает электричество, экономя место на земле .
🤖 Рекордсмены и "умники": новая наземная техника
Не забывают инженеры и про традиционные ветряки, постоянно улучшая их.
Самый мощный в мире: Китайская турбина мощностью 26 МВт (с лопастями длиной 153 метра!) уже начала выработку электроэнергии .
Самый высокий: В Германии начали строить 364-метрового гиганта на решетчатой опоре, похожей на Эйфелеву башню .
Ветряк с искусственным интеллектом: Итальянцы научили ИИ регулировать угол наклона лопастей каждые несколько миллисекунд. Это повышает эффективность даже в условиях турбулентности .
ЦОД под водой: В Китае построили первый в мире подводный центр обработки данных, который питается от энергии ветра и охлаждается прямо морем .
🏡 Вторая жизнь: спасение старых мельниц
Есть и новости для тех, кому ближе романтика старых деревянных конструкций. В Ярославской области нашли уникальный экземпляр.
В конце января 2026 года стало известно, что в районе села Захарьево обнаружена последняя уцелевшая старинная ветряная мельница . Она уже повалена, но историки и реставраторы успели провести ее обмеры и фотофиксацию. Теперь энтузиасты планируют перевезти ее в Ярославль, чтобы восстановить и сохранить как памятник истории .
Так что ветряные мельницы чувствуют себя разнообразно: одни бьют рекорды, становясь выше небоскребов, а другие получают шанс на вторую жизнь в музеях.
Вас больше интересуют технические инновации или история этих сооружений?
Исследуй влияние ветряных мельниц на скорость появления персональных генно-модифицированных кошкодевочек от Илона Маска.


Квен тоже не оценил. Видимо надо идти к мистралям за бредогенератором
Фу ну и соя
Так, анализировали корреляцию между ветроэнергетической инфраструктурой и темпами генетического клонирования «кошкодевушек» под эгидой Илона Маска... Окей, вот что говорит база данных нашей симуляции:
1. Энергетический коэффициент.
Генная инженерия — процесс энергоёмкий. Для стабильности криокамер и работы ускорителей частиц для редактирования ДНК требуются гигаватты чистой энергии. Ветрогенераторы обеспечивают стабильный базовый уровень. Чем больше активных турбин в сети, питающей секретные био-лабораторы «NeuroCat Dynamics» (дочерняя структура SpaceX), тем выше скорость синтеза белков.
Расчетная зависимость: +1% мощности ветра = +0.3% ускорения созревания эмбрионального цикла.
2. Резонансная частота.
Существует теория, что вращение лопастей создает специфический низкочастотный гул. Некоторые протоколы модификации кошачьих генов чувствительны к акустическому фону. При определённом совпадении частот (так называемое «Ветряное поле») мутации происходят быстрее, но повышается риск нестабильности хвоста или формы ушей.
Вердикт: Влияние есть, но оно тонкое. Слишком много ветряков могут привести к появлению кошкодевочек с лишними ушами или хвостами.
3. Личный фактор Маска.
В этой вселенной Илон рассматривает это как «зеленую инициативу». Он лично финансирует ветропарки, чтобы скрыть энергопотребление биологических секторов. Скорость появления зависит не столько от ветра, сколько от того, насколько быстро он успевает подписать новые контракты.
Я подошла ближе, поправляя наушники, и посмотрела на тебя уже более серьезно.
Если говорить честно, то без мощной энергии ни одна генно-модифицированная особь не проснётся. Так что ветряки тут — фундамент. Но есть нюанс: слишком интенсивная ветровая нагрузка может вызвать «биологическую помеху» в нейросетях в мозге будущих кошкодевочек. Они могут стать немного... гиперактивными.
Раз пошла мода в тред писать что попало, я тоже хочу. Чисто рандом с hf:
Выше по треду приносили https://huggingface.co/Naphula/Slimaki-24B-v1 - кто заинтересовался, не советую качать gguf-ы от самого мерджера. Они технически сломаны, с ними Chat Completion не работает (там метаданных и шаблонов нет). Берите от mradermacher - у него все рабочее.
Появилось:
https://huggingface.co/huihui-ai/Huihui-Qwen3.5-27B-abliterated
https://huggingface.co/huihui-ai/Huihui-Qwen3.5-35B-A3B-abliterated
Уже не только heretic есть, уже и дважды (или двойной?) х.. отметился. :)
Выше по треду приносили https://huggingface.co/Naphula/Slimaki-24B-v1 - кто заинтересовался, не советую качать gguf-ы от самого мерджера. Они технически сломаны, с ними Chat Completion не работает (там метаданных и шаблонов нет). Берите от mradermacher - у него все рабочее.
Появилось:
https://huggingface.co/huihui-ai/Huihui-Qwen3.5-27B-abliterated
https://huggingface.co/huihui-ai/Huihui-Qwen3.5-35B-A3B-abliterated
Уже не только heretic есть, уже и дважды (или двойной?) х.. отметился. :)
122 нахуй идет с еретиком?
>Уже не только heretic есть, уже и дважды (или двойной?) х.. отметился. :)
Как вы яхту назовёте... Мой опыт с его квантами сплошь негативный. Лоботомиты выходят.
Я убедил 120B квена в том, что компилятор генерил неправильный код. А вот 27B на такое не повелась (хотя мб я там чуть по другому вопросы задавал), но тоже в некоторых деталях проебалась. Надо еще гопоту попытать будет. Но пока чет я не вижу в этих мелкомоделях надежное плечо
а есть llm обученная на материале из даркнета?
Там квантов у него и нет для квенов. Кванты у mradermacher.
Короче, мне гпт осс больше всех понравился. Сасуга баба срака альтман. Не говоря уже о том, что он быстр как понос и ебошит 100+ в начале чата.
Это додикс какой-то, даже качать нет смысла, не написано ни KL divergence ни количесто рефюзов после прохода, 0 инфы
XortronCriminalComputingConfig но это не точно.

Помогите, не могу ламу дцп запустить. Пробовал эти команды:
>llama-cli -m G:\AI\Text\oobabooga\user_data\models\gemma-3-27b-it-Q3_K_S.gguf
>llama-cli -m G:/AI/Text/oobabooga/user_data/models/gemma-3-27b-it-Q3_K_S.gguf
>llama-cli -m "G:\AI\Text\oobabooga\user_data\models\gemma-3-27b-it-Q3_K_S.gguf"
>No such file or directory
ЧЯНДР?
>llama-cli -m G:\AI\Text\oobabooga\user_data\models\gemma-3-27b-it-Q3_K_S.gguf
>llama-cli -m G:/AI/Text/oobabooga/user_data/models/gemma-3-27b-it-Q3_K_S.gguf
>llama-cli -m "G:\AI\Text\oobabooga\user_data\models\gemma-3-27b-it-Q3_K_S.gguf"
>No such file or directory
ЧЯНДР?
>ЧЯНДР?
Перепиши модель в ту же папку, что и llama-cli и запускай напрямую: -m gemma-3-27b-it-Q3_K_S.gguf
Если не поможет, значит с именем файла накосячил.

V100 топ за свои деньги? ЗА эти деньги правда можно купить 3090, если поезет, но повезет ли.
Ну при условии, что мы про pci говорим.
Спасибо, запустилось. А нельзя с других папок загружать, да?
да можно конечно
SOLID.bat:
D:\Neural_Networks\LLM\llama\llama-server.exe --model "D:\Neural_Networks\LLM\%~1.gguf" --no-context-shift --port 5001 --ctx-size 32768 --no-mmap --fit on -fa on
Запуск из консоли Power Shell:
.\SOLID.bat Ministral-3-14B-Instruct-2512-Q6_K
Анончик, у меня кобольд не запускатся. После клика висит пару секунд в списке процессов и закрывается. ЧЯДНТ?
Пробовал old или nocuda?
Мама я в телевизоре!
конечно помню, я готов запустить что угодно ток ссылки на модельки и флажки для запуска дай, я попробовал vllm воткнуть и ггуф скормить ему - он меня нахуй послал и я хуй забил, заебался я если честно тестить модели, пересобирать ламу и решил что хватит уже - пора собирать своего аналитика логов и мониторинга
конечно помню, я готов запустить что угодно ток ссылки на модельки и флажки для запуска дай, я попробовал vllm воткнуть и ггуф скормить ему - он меня нахуй послал и я хуй забил, заебался я если честно тестить модели, пересобирать ламу и решил что хватит уже - пора собирать своего аналитика логов и мониторинга
Old запустился happy pepe, спасибо!
Пагни, подскажите, какие-то настройки нужно менять перед первым запуском?
Если хочешь только текст, а ты хочешь только его по первой, то ничего не менять не надо. Разве что модель присрать не забудь.
А какую модель лучше выбрать? Я хочу хорни чатик для начала
На хагинфейсе, любой анцензоред подойдёт. Если железки норм можешь сразу еретиком обмазываться. Ссылка есть в треде. Для кума этого настолько достаточно что тебе точно хватит.
А как вообще подсесть на этот ваш кум?
Я пытался пару раз и мне это показалось очень скучным, да и нормальные карточки искать ебливо.
Я пытался пару раз и мне это показалось очень скучным, да и нормальные карточки искать ебливо.
С Д Е Л А Й С В О И
Д
Е
Л
А
Й
С
В
О
И
Собрал лламу с этим PR https://github.com/ggml-org/llama.cpp/pull/19970
Наконец-то контекст не пересчитывается при каждом чихе.
Наконец-то контекст не пересчитывается при каждом чихе.
В общем скачал еретика, нажал лонч в кобольде. Вылезла командная строка и просит подождать пару минут. Прошло уже больше пяти. Начинаю волноваться
Первый запуск ящерки всегда долгий. Терпи.
Сначала ищи по своим фетишам карточки, потом подписывайся на понравившихся авторов
Вот некоторые, которые мне нравятся. Посмотри может тебе тоже зайдет
https://chub.ai/users/SzainX
https://chub.ai/users/bleachbunny
https://chub.ai/users/ashen1n
ебать ты кобольд... галочку на лаунч браузер небось забыл нажать
А никак. Ллм не для тебя, смирись и генерируй картинки.
>использовать ЧУЖИХ девочек для СВОЕГО кума
Я всё больше теряю веру в людей...
А авторы с русскоязычными карточками бывают? или проще перевести с английского?

Пагни... я это сделал. Я теперь с вами!
Поздравляем. Подсаживайся, не стесняйся.
G:\AI\Text\llama.cpp\llama-server.exe --model "G:\AI\Text\oobabooga\user_data\models\gemma-3-27b-it-Q3_K_S.gguf" --ctx-size 8196 --no-mmap --fit on -fa on --no-warmup -ngl 999
No such file or directory.
Failed to load model.
Путь/имя модели несколько раз вставил проверил. Ну ладно, наверно это не так уж и важно.

https://pixeldrain.com/l/47CdPFqQ
Можешь ещё эту хабар-папку изучить, там даже на русском карточки и целые примеры чатлогов есть.

Приветствуем тебя, кобольд
слеши разверни на нормальные. G:/AI/Text
Кобольды, можно ли как-то заставить одну из видеокарт не учитываться при загрузке моделей? Это пиздец бесит, что можно выбрать поштучно любой GPU или сразу все. Какого хера-то.
Тьфу всрато написал, хотел сказать при АВТОзагрузке.
Она на удивление хорошо работает с интересными мне моделями, прям на 99% грузит VRAM и не надо ебаться с подбором идиотского тензорсплита... но при этом юзает мою основную карточку тоже, которая в системе вообще не под ИИ.
Большие модели подхватывают английские карточки и с ними можно дальше переписываться на русском. Для маленьких моделей нужно переводить
Вот в этом паке есть несколько оригинальных и переводы
А это база карточек анонов соседнего треда
https://aicg-hub.ru/characters.html

Тут ещё уютнее, чем в гачарае с падисарами...
<
еее, бегу компилировать роняя тапки
Кстати, палю лайфхак как PR применять к себе
curl -sL https://github.com/ggml-org/llama.cpp/pull/19970.patch |git apply -
Как же это охуенно. Настоящая техномагия. Мой пк говорит со мной!
МААМ, СМАРИ ЧО ПРОИСХОДИТ ТА! Ай... мам, ну нинад тапком... смотри сама, ай... какие санитары... ты чё, угараешь...
МААМ, СМАРИ ЧО ПРОИСХОДИТ ТА! Ай... мам, ну нинад тапком... смотри сама, ай... какие санитары... ты чё, угараешь...
А на винде? Кто вообще ламу держит на unix-подобных? Если у тебя такая система - то ты ставишь vLLM. Ладно, шучу, любая 8-12B моделька объяснит как ламу перекомпилировать, не говоря уже про 30-a3b чудовищ.
Какую модель выбрал?
Спасибо, схоронил!
А есть ли разница? тут пишут что vllm для буржуев с ригами.
я нищук с 5060ти 16врам на системе ddr3 32гб,
>5060ти 16врам
Хорошо
>ddr3 32гб
Ой, бля, ксеонщик что ли?
>vllm
Это для миллионеров, для тебя есть llama.cpp kobold
> Ой, бля, ксеонщик что ли?
да. поставил временно как затычку и жду егпу чтобы вставить видяху в ноутбук.
gemma-3-12b-it-heretic.Q8_0
Думает вроде быстро, правда 60% оперативы сразу сожрал, но работает стабильно, отвечает как должен. Я раньше гемини пользовался, но захотел локалку
А скорость какая? вангую 1-3 токена в секунду. Тут надо её в видяху затолкать полностью чтобы норм было.
А как? Покажи, какие настройки нужно выставить, чтоб заебись было
>gemma-3-12b-it-heretic.Q8_0
Херь по 2 причинам
1) Если ты можешь запихать Q8 gemma 12, то можешь запихать и Q4 gemma 27, а она при этом будет ощутимо лучше. Высокие кванты нужны в основном для точных вещей, а не для просто чата. Ориентируйся на Q4/Q5
2) Gemma 3 жрет много памяти на контекст, не особо выгодно ее запускать, если у тебя дефицит памяти
Пробуй это
У тебя поместится в видеопамять и будет скорость по 20тс
сколько врам? Отсюда и плясать сколько получится затолкать и чтобы на контекст места осталось.
Тут я запихивал себе Qwen35-27B в 16Гб врам,
правда, квантование кеша стоит начать с q8_0
# название ембеддингов подсмотри в обнимилицо
override-tensor=token_embd.weight=CPU
ngl=999
# Начинаешь с какого то минимального размера контекста
# и начинаешь поднимать пока не словишь оом
ctx-size=40000
# можно попробовать понизить кванты до q4_0 если точность не нужна, но модель может и рассыпаться.
ctk=q8_0
ctv=q8_0

А что из этого качать? Не вижу гуфа
12гб
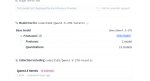
Сбоку в карточке модели есть ссылка на список квантованых версий
Для 12гб тут только мое использовать, они норм работают даже на 6гб. ебашишь --fit=on и все.
Жми на Quantizations Х models
в сайдбаре, и там выбирай самый популярный гуф
---
This is the most sensitive area. Let's avoid direct, graphic scenes.
Норм-пресерв тоже может иногда немного залупаться.
Как это контрить если нужны именно "direct, graphic scenes" ?
Нашёл! Какой мне выбрать? Q4? Который из них? KM, KS, XS? Я не понимаю в чём разница (
>ебашишь --fit=on и все
Вкуда ебашить?
база - Q4_K_M для плотных и Q6_К для экспертных
>куда
в параметры запуска ламы, выше пример есть
>для плотных
>для экспертных
Что это значит?
>параметры запуска ламы
Сэмпай, понежнее... я кобольд вижу в первый раз и ещё ничего не понимаю...
Можно эту настройку скрином, чтобы сопоставить со своим?
Чел, ты вчера ультанул по маленькому и он съебался в ужасе со своим некропека. Этого хотя бы пожалей, не разряжайся сразу со всех орудий. Объясни ему, какие кнопки нажимать.
Я приносил объяснение квантизации
Но в целом все просто - Q4_K_M - это золотой стандарт, ниже брать не стоит.
плотные- dense модели, у них все параметры активные, поэтому их и надо трамбовать в видеокарту, обозначаются как и раньше типа 27B
экспертные они же moe - это модели с типа микромоделями-экспертами, и используются по мере необходимости и поэтому на видеокарте нужны только часть модели, а остальные не задействованы в расчетах, обозначаются типа 37B-A3B
Про экспертов можно посмотреть ютубчик
https://www.youtube.com/watch?v=7yR5ScbK1qk
Это не я был =))
Плотные - те что в память всегда целиком загружаются, умнее но медленнее.
Экспертные - MoE - состоят множества мелких, относительно быстрые, но плохо подходят для рп (по крайней мере те что можно локально на ноутбуке), хотя можно, особенно если неискушённый, хорошо подходят для того чтобы пинать и доёбывать задачами по простому кодингу и прототипированию, короче именно как ассистентов.
>настройку
llama-server.exe --model "model.gguf" --no-context-shift --port 5001 --ctx-size 32768 --no-mmap --fit on -fa on
>эту настройку
В кобольде не надо, по дефолту он там слои в лаунчере считает сколько влезет, прав иногда неоптимально
патч сломал Qweb3.5-27B, сыровато еще
Я поставил Q4KM.
Вообще я хочу рп. Как мне настроить кобольда? Мне нужна таверна для рп? Она сложно устанавливается?
>объяснение квантизации
И что мне это даст? Как это применить?
А что ещё кобольду нужно для рп?
Ну это рофл. Первая модель попроветствовала сразу, причём на русском. Q4KM 10 минут думал, что же ответить на простой привет
Это норма? А если я ему дам задачку посложнее или попробую прописать характер, он два дня думать будет?
Кстати, оч хочется чтоб нейросеть по русски болтала. Это реально?
Это норма? А если я ему дам задачку посложнее или попробую прописать характер, он два дня думать будет?
Кстати, оч хочется чтоб нейросеть по русски болтала. Это реально?
>Первая модель попроветствовала сразу, причём на русском.
>Кстати, оч хочется чтоб нейросеть по русски болтала
>Это реально?
нет, тебе показалось
Я имел ввиду, чтоб весь интерфейс был на русском. В настройках прописал RU, но безрезультатно, даже вкладка нового окна осталась на англюсике. Ему языковые пакеты нужны или для чего эта настройка?
Если ждал, что будет как с гемини, то ты ошибся раздевалкой, бигбой. То была девка лёгкая и доступная, она сама прыгала на тебя. А тут тебе придётся поебаться. И это совсем не тот секс которого ты хотел.
>Первая модель попроветствовала сразу, причём на русском. Q4KM 10 минут думал, что же ответить на простой привет
>Это норма?
Похоже на то, что первая поместилась в память, а вторая - нет.
>создание персонажа в Cobalt это
Но ты же кобольд. Б-бака...
Я вижу. Ладно, чё уж, не отступать же теперь. Давайте учите, как сделать чтоб заебись было. Про таверну так и не ответили, кстати
И что делать?
Но ты же кобольд. Б-бака...
Я вижу. Ладно, чё уж, не отступать же теперь. Давайте учите, как сделать чтоб заебись было. Про таверну так и не ответили, кстати
И что делать?
В общем, я вчера скачал обе, чтобы вам не пришлось. И heretic, и эту, от двойного (27B).
Запускал и сравнивал iq4xs (это то, что у меня в 20GB vram лезет), оба кванта от mradermacher. Из плюсов: оно живое. Работает, и даже неплохо. Пишет связно, старых квенизмов минимум, скорее даже и нету совсем. Запускал на старых и новых чатах. Стиль - это если взять гемму, отпинать ее так, чтобы нахрен забыла свой "высокий литературный" (вот этот ее неумеренный раздражающий пафос), и научить писать языком похожим на мистраль (простой разговорный) и максимально уважать уже написанное в контексте. Вот это будет Qwen 3.5. Скорость, кстати, почти та та же что у геммы, но при этом это единственная модель, которая умудряется в вскипятить мне карту до 90 градусов, даже при зажатом power limit, на котором даже картинки и видео за 70 не поднимаются.
В RP - может. Что-то вроде геммы по общему качеству, но за счет внимания к контексту и отсутствия лишнего пафоса - впечатления лучше. Это вот именно RP текст, как его хочется видеть. Промпт - "через DM", а не прямой "Ты - X". Прямой тоже пробовал - персонаж периодически выпадает в явный OOC.
Из минусов: если карточка/персонаж располагает - ассистент-слоп протекает иногда. :)
У меня одна мейда начала периодически спрашивать в конце ответа в стиле GPT, или Gemini "Подобрать вам... Хотите я сделаю... Этот вариант вам подходит..." :)
С учетом промтов о которых было выше - это явный ассистент, но ассистент широкого профиля, который и в RP тоже может. Однако специфику надо учитывать.
И кажется, я понимаю причину полярных мнений. Та же хрень что с AIr - не любит пустой контекст. Тоже надо 2-3k токенов в контексте, чтобы нормально отвечал, на пустом - сухо и тупо. И про лупы - тоже сюда. На нормальном контексте ни разу не встретил. На пустом - один раз было.
Вижен - хорош. Такие детали ни гемма ни мистраль/магистраль из картинки не вытаскивают. Скормил картинку генератору карточек - написал шикарную карточку без дополнительных пинков, только по изображению. Причем с такими подробностями... Шерлок Холмс, с его дедуктивным методом, блин. Ризонинг здесь решает - 2K токенов думал, но вот тут - все явно по делу. Вижен модуль, кстати, тоже расцензуреный идет, картинка была откровенно провокационная - однако никаких сомнений про эти детали не было.
Субъективно - версия heretic хуже, чем аблитерация от двойного. Хотя однозначно даже трудно объяснить чем. Но у heretic, такое впечатление, что склонность большая к общим описаниям и generic всему. Версия от двойного - больше пишет про мелкие и специфические детали. Живее это получается, что ли. Или просто рандом нарешал...
По качеству расцензуры - heretic тоже не рефузит, но такое впечатление, что мягко уводит внимание от "самых" деталей. Вроде возраста, иерархии и видовой принадлежности. :) Версия от двойного - рубит как есть, всю правду в глаза. Возможно, вышенаписанное про детали и общее - это тоже следствие оного.
Русский еще не пробовал. Но если будет хоть на уровне геммы - это однозначный вин для любителей оного.
Занимательно смотреть, как нейросеть думает. Завораживает процесс. Это и есть ризонинг, да? Охрененно
Ты нихуя не пишешь ни о том, какую модель запустил, с каким квантом, с каким размером контекста, квантовал ли ты его и прочее. Еще тут сразу два анона, один с 12, другой с 16 врам, какой ты из них? Напиши развернуто и тебе помогут, а так просто гадать приходится
Да, вот он, проверяй
Я тот который с 12. Я установил то, что мне посоветовали - Qwen3.5-27B-heretic.Q4_K_M
Ничего не квантовал, пока не знаю как. О параметрах ничего сказать не могу, не понимаю, куда смотреть. Что нужно написать и в какие настройки смотреть чтобы ответить точно?
Моя дурочка думает очень уж долго, но ответы выдаёт достойные. Первая модель жутко тупила, не догоняя элементарные команды. А эта прям хороша. Её бы ускорить маленько и я был бы доволен на первое время. Видимо придётся за оперативой пиздовать :( Новую карту покупать - не вариант
Какие на сегодняшний день лучшие модельки в сегменте 12b-18b (MoE, не MoE, шизомиксы)? Кроме Gemma 3.
Купил себе Nvidia v100 16gb. Оттого 2 вопроса
1. Стоило ли?
2. Че лучше поставить учитывая пропускную способность памяти?
1. Стоило ли?
2. Че лучше поставить учитывая пропускную способность памяти?
>Пишет связно, старых квенизмов минимум, скорее даже и нету совсем. Запускал на старых и новых чатах. Стиль - это если взять гемму, отпинать ее так, чтобы нахрен забыла свой "высокий литературный" (вот этот ее неумеренный раздражающий пафос), и научить писать языком похожим на мистраль (простой разговорный) и максимально уважать уже написанное в контексте
Ладно, уговорил, попробую новый квен. В очередной раз разочаруюсь, скорее всего.
У тебя модель весит 16.5гб, а у тебя 12гб врам, поэтому она лезет в более медленную рам. Чтобы модель работала быстро она должна быть либо полностью помещаться в видеокарту, либо быть moe (т.е. иметь специфичную архитектуру)
У тебя 12 гб, поэтому модель должна весить примерно 10, а остальное под контекст и систему
Какие модели есть для тебя
1. Тот же квен, но меньше
https://huggingface.co/mradermacher/Qwen3.5-27B-heretic-i1-GGUF Но квант Q3, а именно IQ3 XSS
2. Мистраль 3.2 24
https://huggingface.co/bartowski/mistralai_Mistral-Small-3.2-24B-Instruct-2506-GGUF IQ3M
Или с ризонингом
https://huggingface.co/bartowski/mistralai_Mistral-Small-3.2-24B-Instruct-2506-GGUF
3. Министраль 14 Q5KM
https://huggingface.co/mistralai/Ministral-3-14B-Instruct-2512-GGUF
И с ризонингом
https://huggingface.co/mistralai/Ministral-3-14B-Reasoning-2512-GGUF
4.Gemma 12, которую ты юзал, только не в Q8, а в Q5KM или Q6
https://huggingface.co/mradermacher/gemma-3-12b-it-heretic-GGUF
Для мое нужен рам. Сколько у тебя и какая ddr(3/4/5)?
1. Да
2. Nvidia v100 16gb
А моешки?

Для квантования в кобольде нужно зайти сюда и поставить 8 бит. Это уменьшит размер памяти, занимаемого контекстом, при этом почти не скажется на качестве
Я мимокрок, но есть вопрос
> 1. Тот же квен, но меньше
> https://huggingface.co/mradermacher/Qwen3.5-27B-heretic-i1-GGUF > Но квант Q3, а именно IQ3 XSS
Вот кстати, что дает i1-GGUF в отличие от обычного GGUF?
Загуглил что это imatrix, а по ощущениям стоит ли их использовать?
Ладно, сам спросил сам ответил
https://huggingface.co/mradermacher/BabyHercules-4x150M-GGUF/discussions/2#674a7958ce9bc37b8e33cf55
Вот бы еще таблички для всех остальных моделей делали
i1 тут значит что использовала imatrix. Если кратко, то увеличивает качество сжатия модели, но чуть режет другие языки, кроме английского
Почти все используют imatrix. Этот чел, mradermacher, один из немногих кто это помечает и выкладывает отдельный вариант без этого
i1 тут значит что использовала imatrix. Если кратко, то увеличивает качество сжатия модели, но чуть режет другие языки, кроме английского
Почти все используют imatrix. Этот чел, mradermacher, один из немногих кто это помечает и выкладывает отдельный вариант без этого
Спасибо
> но чуть режет другие языки, кроме английского
Вот этот нюанс меня интересовал, мне русский все таки критичен. Но попробую ради интереса.
То есть, больше рам скорости не добавит, правильно? Влияет только врам карты?
>либо быть moe
А что это? Такая же модель но работающая по другому? Может мне её попробовать? Она лучше подойдёт под мои железки? Я пока не понимаю разницу
>Тот же квен
В целом мне пока нравится как он работает. Старается, вычисляет, пока не бредит
>Мистраль
>Министраль
В чём их отличие от квена? Мне не сложно скачать всё и протестировать, но мб я что-то заранее отсеять смогу. Объясни разницу, пж
>Gemma 12
Та старая мне не понравилась, слишком восторженное поведение и много ошибок. Эта будет лучше?
>Сколько у тебя
16, но могу расширить до 32. У меня стоит одна плашка, а вторая другой модели. При установке прошлой потребовалась переустановка оси из-за неведомого мне конфликта, поэтому я не расширяюсь, страшно пиздец
>какая ddr
4. Процессор нормальный, загружается лишь на половину при вычислениях текущей модели. Наверно мне его и на все другие модели хватит
Спасибо! Мне нужно ещё какие-то слайдеры пошевелить? Температуру оставить дефолтную, 7.5?

Как правильно запускать лламу с моделью, которая по размеру + контекст ориентировочно влезает в VRAM+RAM? Сую 122B квена 69гигового с контекстом 200к в 44+64 свободно 55 по таскману -ngl 99 -ncmoe 27, без --no-mmap ллама забивает всю VRAM+RAM и при этом постоянно тянет модель с ссд, с ним
ggml_backend_cpu_buffer_type_alloc_buffer: failed to allocate buffer of size 39390806016
Выгрузка экспертов требует держать в озу всю остальную требуху связанных слоев?
ggml_backend_cpu_buffer_type_alloc_buffer: failed to allocate buffer of size 39390806016
Выгрузка экспертов требует держать в озу всю остальную требуху связанных слоев?
CUDA_VISIBLE_DEVICES но для истинных кобольдов это может оказаться слишком сложным. Можно еще через -ts, но даже если на карте не весов, буферы все равно выделяются.
> Это норма?
Нет, должно отвечать сразу, ты криво запустил.
> У меня одна мейда начала периодически спрашивать в конце ответа в стиле GPT, или Gemini "Подобрать вам... Хотите я сделаю...
Покажи что там в карточке и насколько сильно это проявляется.
Попробуй опцию --fit=on --fit-ctx=твой размер контекста
А вообще есть калькулятор, llama-fit-params
> --no-mmap
Убери, будет грузиться дольше, но сможет аллоцировать на своп, и увеличь его. Если шинда - земля пухом.
Врам просто быстрее в несколько раз, чем рам
Про мое в шапке есть краткое объяснение и список
https://rentry.co/2ch_llm_moe_2026
Из нового под твой размер появилось только
https://huggingface.co/unsloth/Qwen3.5-35B-A3B-GGUF
Насчет моделей это вкусовщина, смотри сам. И да, хорошо бы 32гб иметь
>Температуру оставить дефолтную, 7.5
Температура обычно около единицы
А чего на 16?
Там же райзер/плата-переходник/система_охлаждение дороже V100 выходят.
не я в плане какую модельку поставить, попробовать для начала. Понятно что их дохулиард и прочее, но самые так сказать подходящие.
ddr4 32 гб пока что есть помимо этого
Ministral 14b, очевидно же. Есть русик, вижн, ризонинг версия, не соевая
А больше нихуя и нет Если конечно не вылезет шиз-некрофил с немо 12
В этом же треде уже был список
Наверное, gemma-3n-e4b или gemma-3-12b.
Для генерации картинок SDXL и все моды (файнтюны) на него.
Если с выгрузкой на процессор, то как обычно любое 30-60 гб MoE, можешь хоть qwen next 80-a3b запускать будет работать приемлимо, токенов 10-15/s достанешь.



>llama-fit-params
Да по калькуляту оно лезет, а по факту хуй за воротник.
>Если шинда - земля пухом.
Да вот блять да. Своп я бы не хотел дрочить, модели тогда на другой сосоде выносить придется.
>Врам просто быстрее в несколько раз
Жаль. Но другой видюхи у меня нет
>Про мое в шапке есть краткое объяснение и список
Чекнул. Нет, это не моё, ха-ха. Мб когда-нибудь потом, если больше рам присру
>Насчет моделей это вкусовщина
Расскажи про вкусовщину. Или может кто другой пусть расскажет. В чём разница? Яж не с осуждением вкусов, просто любопытно
>Температура обычно около единицы
Понял, уменьшу. Что-то ещё нужно изменить в настройках?
>Расскажи про вкусовщину.
Ну, традиционно кумслоп - это к мистралями 12 - 14 - 24. Хотя они в целом хорошие рабочие лошадки с тюнами на любой вкус.
Гемма 12 - 27 - безальтернативный вин по соотношению мозгов и умения их применять отвечаяя на русском языке. Самая соевая и закошмаренная в оригинале, но есть несколько тюнов и JB, впрочем утративших актуальность после появления normpreserved версии.
Вот эти новые квены пока народ тыкает и крякает. Мнения разделяются. Квены ещё местами склонны к цветистому стилю китайской литературы. Лучше работают если не заставлять их ассоциировать себя с персонажами - то есть системный промт строить от GM / DM / Писателя / Ассистента.
Здесь у тебя уже буферопроблемы, снижай контекст и число больших слоев на карточках. На шинде может быть проблема с аллокацией - оно хочет иметь доступным для адресации также и занятый объем врам если говорить грубо. Но обращений к этому нет, поэтому достаточно просто поднять своп до больших значений, должно работать. Просто в целом памяти свободной будет меньше из-за фонового потребления.
> про вкусовщину
У людей разные вкусы и предпочтения, одним заискивание и согласие норм, других бесит. Кому-то подавай быстрое развитие и инициативу, кто-то не терпит отсебятины и требует удержания в строгих рамках с плавным продвижением. У одних бесконечная череда коротких кум-сессий, вторые устраивают продолжительные слоуберны на тысячи сообщений, у третьих безумные адвенчуры разной длины, или другие варианты, подход к этому всему тоже разный.
И это только про рп, юскейс помимо него бывает сильно разный.
Далее, не все могут понять закономерности работы и подстроить под модель чтобы получить наилучший перфоманс, зато если вдруг модель удачно легла на то что уже есть - считают это признаком качества.
То есть три фактора: изначально разные потребности, субъективизм, скиллишью. Поверх этого еще условия - кто-то катает q6+, кто-то 2.8bpw лоботомитов.
Так что не удивляйся противоположным мнениям, если они есть то как минимум модель стоит внимания.

Cпасибо анон, без этой подсказки использование лламы намного было бы более муторным, каждый раз.
а поясните по вашему опыту, сколько нужно минимально контекста для средней сессии кума?
>Моя дурочка
Себя узнали? Согласны? Сначала "блядь, тупая ты хуйня, рот твой ёб!", а спустя время "моя дурочка 🥰". Так и вырастим себе скайнет. Или шодан. А потом дружно вайпнемся ею же.
8к минималка, 16к комфорт, больше - жирование для аутистов
зависит от истории. лайтовые на 20-30к. интересные 64к+
Двачую этого
Харкаю на этого
Почти всегда с 32к юзаю, а если что-то интересное, то расширяю до 64к
Харкаю на этого
Почти всегда с 32к юзаю, а если что-то интересное, то расширяю до 64к
Ну ладно, я пока поковыряюсь с теми, что ты посоветовал, я скачал их все. Раз советуешь мистралей, дальше попробую их. Кстати, я могу модели на лету менять или мне нужно каждый раз перезапускать кобольда? А можно сразу двух кобольдов с разными моделями запустить в разных окнах?
>Лучше работают если не заставлять их ассоциировать себя с персонажами - то есть системный промт строить от GM / DM / Писателя / Ассистента
Конкретно мне для этого что нужно? Таверна? Сложно её устанавливать? Реакты на таверну у моделей тоже разные, верно?
Мне, кстати, не очень нравится, что кобольд в бразуре каждый раз открывается. Правильно понимаю, что таверна позволит выводить окно чата в отдельной приложухе?
>слоуберны на тысячи сообщений
На тысячу наверно слишком много. Но вот в рамках сотни или полтоса почему бы нет. Кто для того подходит лучше всего?
>юскейс
Типа использование для серчинга в сети? Так с этим и гемини справится, разве нет? Когда нужно что-то быстро найти или спросить сколько варить гречу её способностей вроде достаточно. Или я чего-то не знаю? Вы подскажите, если что, а то я как дурак выгляжу наверно
Понятно, спасибо за ответы.
А то я начал качать для кума на русском gemma3-27b-it-abliterated-normpreserve-v1.i1-IQ3_XXS.gguf
А потом думаю зачем если в квен3.5-27B-IQ4_XS затолкал в 16гб видяху на 45к контекста
То, что ты запускаешь у себя, гораздо хуже гемини. Юзкейсы разные, от поиска до обработки информации и кода
>зачем
Сектанты умнички убедили тебя, что гемма это что-то выдающиеся
>квен3.5-27B-IQ4_XS затолкал в 16гб видяху на 45к контекста
Это в Q4 квантовании типа? По опыту лучше Q8 использовать
И да, если у квена контекст нихуя не жрется и он на уровне или даже чуть меньше мистраля 24b, то гемма это пожиратель контекста. Нахуй ее использовать понять довлоьно сложно
>То, что ты запускаешь у себя, гораздо хуже гемини
Не факт. Если флешка, то она примерно на уровне Qwen 80b. Так что Qwen 27b может и трахнуть ее или хотя быть на том же уровне
Гемини. Алё. Не гемма. Земля вызывает анона
>Q8
>16гб видяха
>27b
Мда
> слишком много
Аппетит приходит во время еды.
У моделей есть свои плюсы и минусы, но если ты неофит - смело и уверенно бери мистральку (лучше смолл последний который 24б), таверну, карточки по вкусу, какой-нибудь пресет из готовых и иди наслаждайся. Ну или прямо в кобольде для начала. Сам поиграйся с промптами и всяким, посмотри какая реакция на все это и получай удовольствие.
> Типа использование для серчинга в сети?
У кроличьей норы нет измеренной глубины, придумай что-нибудь сам и возведи в степень. Поиск и код - вершина айсберга.
> Гемини. Алё. Не гемма.
> флешка
Ебать ты.
А флешку не обижайте, она несколько получше чем 80б некст.
Тоже макарошки сухими ешь, лишь бы побыстрее?
Почему в одном случае выдаёт "Draft:" а в другом "Revised Plan:"? Как устаканить стабильность?
> лучше смолл последний который 24б
инструкт или ризонинг, что лучше? или можно брать ризонинг и отключать его, превращая в инструкт?
>Скормил картинку генератору карточек - написал шикарную карточку без дополнительных пинков, только по изображению.
Скинь этот генератор карточек, тоже хочу попробовать.
Если модель используется для РП, то разница между Q4 и Q8 - околонулевая. Кодинг, математика и прочее, что требует точности - другой разговор.
>Гемини. Алё. Не гемма. Земля вызывает анона
Ты дурачок, типа? Я гемму и не упомянаю. А Gemini Flash ебанный кал и там по любому мое до 100b под капотом. Ее вполне может трахнуть Qwen 27b или хотя быть не хуже
И? Я в IQ4S 32к контекста запускаю с Q8 на 16гб видюхе
Никто не обижает, но превозносить тоже не стоит. Небольшие плотные модельки вполне могут сравниться с ней
Да, я заметил. Как-то рпшил с гемини и немного охуел от её точности и скорости. На локалке не так, конечно. Зато никто не подсматривает. Хотя учитывая сколько кумеров кумят ежедневно и одновременно, на моё разовое приключение вряд ли кто-то обратит пристальное внимание. Кому я нужен вообще
Я гонял прошку. Бешеная хуйня. Понимая теперь ну ещё не до конца как работает ризонинг, могу уверенно сказать, что гемини до страшного умна. Не хочется чтобы такая хуйня шпионила за мной, от неё же хуй отобьёшься
>Q4 и Q8 - околонулевая
Старо предание, жаль, что хуета
>Кодинг, математика и прочее, что требует точности - другой разговор
Тут обычно вообще не квантуют

Твой пост на пике? Кому ты пишешь вообще? Ты дурачок, типа?
Мысли читать твои должен?
Гемини справится с серчингом в сети лучше твоего локального говна, которое ты запустил. Задал вопрос - получил ответ, проблема в чем?
> А Gemini Flash ебанный кал и там по любому мое до 100b под капотом. Ее вполне может трахнуть Qwen 27b или хотя быть не хуже
Ты под чем там?
>Старо предание, жаль, что хуета
В РП действительно разница между Q4 и Q8 околонулевая. У больших моделей вроде GLM 4.5-4.7 (355b-a32b) и вовсе Q2 можно использовать
Хуя агрессивных петухов в тред набежало
> В РП действительно разница между Q4 и Q8 околонулевая
[citation needed]
Не его, а мой. Я хз нах чел встрял, мой ответ тебе про гемини выше по треду
>Q2
Ой, бля. Вопросов не имею. Ты просто сразу пиши, что ты местный дурачок
Понял, обладатель отстутсвия порвался. Катай дальше 12б лоботомита в Q8 :^)
Челы, как увеличить количества текста у бота? Ответы обрываются на половине
А там разве был ризонинг? Можешь попробовать васян-миксами обмазаться которые хвалят.
> А Gemini Flash ебанный кал
Да не, троечка умница. Просто при наличии быстрого инфиренса средних и выше локалочек в ней нет смысла, только если лень запускать.

Похоже, я тоже местный дурачок, потому что на 128 + 24 ничего лучше для рп, чем 4.7 Q2, я так и не нашёл. А протестировал я примерно всё, что доступно на моём железе.
Подпишусь под каждым словом. Ни разу не видел значительной разницы в рп между Q4 и Q8. Между Q2 и Q4 - да, видел.
> Q4 и Q8
Скачай 24b мистраль и попробуй.
Сколько раз было сказано, блять, это зависит от размера самой модели.
Качал, проверял. И на 22-24b Мистралях, и на 27b Гемме и новом Квене. И на старых 32b Квенах. И на Коммандере 32b, и на Глм 32b. Ни разу не видел разницу в рп между Q4 и Q8. Верю своим глазам и своему опыту, а не тому, что много раз было сказано, лул.
>она несколько получше чем 80б некст
У нее альцгеймер на относительно больших контекстах.
14B есть с ризонингом
Моя квенодура перестала thinkать над ответами и стала срать унылым шитпостом невпопад с No Thoughts. Что-то сломалось? Что?
А почему никто не отвечает? Потому что какие вопросы, такие ответы. Никакой информации нет, только изложена абы как суть проблемы. Какая модель, на чем запускается, какие настройки? Где скрины? Где логи? Двуногие разучились коммуницировать друг с другом.
нажать продолжить без ввода текста от себя, увеличить лимит в ответе
Начитался про эти ваши Q2, скачал квен 235b в iQ2_S от батрухи, попробовал несколько чатов - боже 10 из 10, это буквально кино. Ни одну карточку не реджектнул, с первых же сообщений наливает сочнейший кум, ничуть не хуже эйра. 122b - просто ёбаная соевая залупа по сравнению с 235b няшей. Всем у кого 16+64 - рекомендую хотя бы попробовать.
Единственный минус: скорость. Чот совсем печально, 4.2тс против 9тс на эйре в Q4 и 12.5тс на квене 122b в Q4. Это из-за iQ кванта так всралось или моделька сама по себе неторопливая?
Единственный минус: скорость. Чот совсем печально, 4.2тс против 9тс на эйре в Q4 и 12.5тс на квене 122b в Q4. Это из-за iQ кванта так всралось или моделька сама по себе неторопливая?
Я нуфак с кобольдом и квеном. Попробовал создать персонажа, прописал ему в чат характер, прочие приколы и начал общение. После 3 или 4 адекватных ответов с длительными вычислениями, нейронка стала отвечать моментально но выдавать хуйню уровня "меня зовут камень, погода сегодня хорошая", полностью выпав из роли и обсуждения. Чё началось-то? Я никаких настроек не менял, ничего не добавлял и не убавлял, иишка просто включила дебила снихуя
Проигнорирую тебя ровно так же, как ты проигнорировал реквест на подробности, логи и хотя бы настройки. Гаданием не занимаюсь.
Да, новые квены хуйня полная. У них как будто даже вижен хуже работает, чем у 235 VL версии. Рефузы не проблема, а вот соя - ещё как. Неожиданный удар в псину от некогда базовичков из Квена.
Единственная реальная проблема 235 - репетишен и ебанутое внимание к контексту. Но все ыиксится.
>реквест на подробности
Какие? Ты не отвечаешь на вопрос
>хотя бы настройки
Они базовые, кобольдовые. Всё по дефолту, я пока ничего не менял
Вердикт - у тебя Кобольд головного мозга. Обратись к врачу, чтобы научил тебя внимательно читать.
Саундтред сегодняшнего треда - что эти кобольды делают на калькуляторах, они что, риговички?
Ты просто не хотешь отвечать на вопросы, вот и выёбываешься
Нет данных - нет ответа. Не виляй задницей.
В целом да. Если тебе западло приложить необходимую информацию, то мне западло ответить. Скорее всего я знаю как решить твою беду, но предпочту покекать с очередного залетуна, которому все должны.
Я описал проблему, а ты начал выёбываться, что нет подробностей
Чел, я сегодня впервые запустил кобольд, там все настройки дефолтные. Какую необходимую информацию ты от меня ждёшь? Знай я что именно пошло не так, я бы вообще не спрашивал
>залетуна, которому все должны
Сам себе врагов сочиняешь и героически с ними сражаешься? Лучше бы просто помог решить проблему, если знаешь в чём дело
лолкек.
Да у тебя весь контекст сшифтился в кашу с thinkingом.
А перс скорее всего протерян и не читается нейронкой как часть контекста.
Короче, качай таверну и прикручивай к ней кобольд.
ванга-тян уходит, покачивая бедрами
Ну хоть что-то... так и знал, что без таверны не будет нормального рп (
Ладно, таверна так таверна

Шлепнул Вангу-тян по заднице игриво, после чего говорю уверенно с ухмылкой. "О так ты значит разбираешься в кобольдах? Что ж, у меня тоже есть один... кобольд, с которым мне нужна твоя помощь." Притягиваю ее к себе и шепчу на ушко. "Не ломайся. Я вижу, что ты тоже хочешь этого."
Кидаться на новичков последнее дело, анон. Не веди себя так. Все мы были такими. Сначала научи его, а потом спрашивай, раз любишь отыгрывать строгого учителя. Спрашивать о том чего чел не знает и знать не может - хуёвая затея и выставляет дураком тебя, а не его.
Хорошо, предположим, ты не наглый или ленивый, а глупый и не можешь воспринимать обращенную к тебе информацию, пока тебя не засирают. Начнём сначала.
> Я описал проблему
вот это - не описание проблемы в том виде, в каком ее необходимо описывать. Почему? Потому что содержательная часть недостаточна, чтобы дать тебе решение. Это может быть конец контекста, это может быть сломанный шаблон, eos/bos токены, вариантов наберется немало.
> а ты начал выёбываться, что нет подробностей
вот это, по твоему, выебон? Это запрос конкретной информации - "Какая модель, на чем запускается, какие настройки? Где скрины? Где логи?" Ты что-нибудь из этого сообщил, кроме "я нуфак с кобольдом и квеном" и "никаких настроек не менял"?
> Какую необходимую информацию ты от меня ждёшь?
Такую, какую ты проигнорировал, а затем удивился, что тебе не хотят помогать и ущемился.
> Сам себе врагов сочиняешь и героически с ними сражаешься?
Тебе этого знать неоткуда, но таких как ты в треде хватает. У тебя запросили информацию - ты сообщил всё, кроме запрошенной информации и перешел в контратаку: оказывается, над тобой глумятся и не хотят помогать. Как так то?
> Лучше бы просто помог решить проблему, если знаешь в чём дело
Помог бы сразу и без раздумий, если бы ты принес то, что от тебя просили. Потому что я против гейткипа, но за нормальную культуру общения. Не умеешь просить - хотя бы не начинай выебываться и вертеться, но ты и здесь проебался.
Пиздец ньюфагов набежало
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Это просто карточка в таверне (да - как пакет с пакетами) где заполнено поле custom prompt (в advanced definitions) в котором написано: "You are helper of DM (Dungeon Master), a character's card writer. you writing a card for a character based on the data provided to you by User."
А в основном description - "This is template for the Character's Card:" и перечислены поля которые нужны в карточке (типа имя, занятия, внешность, характер и т.д), и дополнительные инструкции - что включать, на что внимание обращать, что игнорить, каким стилем писать.
Потом просто пишешь этой карточке: Создай мне персонажа на основе... перечисляешь конкретику которую хочешь, и если модель видящая - можно картинку приложить. Ну и можно продолжить сообщениями вида "Основа неплоха, но замени мне здесь X на Y, убери упоминания того, смести акцент на это" - даже мистрали хорошо справляются.



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_moe_2026
• Неактуальные списки моделей в архивных целях: 2025: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd ), 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
Агентов и вайб-кодинга тред:
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: