



БАЗА ТРЕДА:
Все, что ниже Q4 это кал
Кобольд это кал
Экслама это кал
Квен это кал
Гемма это кал
Локалки мертвы
Кум на Попенроутере стоит всего 10 баксов
Все, что ниже Q4 это кал
Кобольд это кал
Экслама это кал
Квен это кал
Гемма это кал
Локалки мертвы
Кум на Попенроутере стоит всего 10 баксов
База треда: Лучше папа Кобольд, чем мама Ollama.
Ты опять выходишь на связь, мудила?
двачану. почти все залетные ждут что их покормят с ложечки, на запросе дополнительной инфы большинство и откидываются, лол
в шапке вики есть, ее наверно вообще почти никто не читает
Актуальные non-moe модели:
- qwen 14b
- семейство nemo 12b (вечны)
- семейство small mistral 24b (вечны)
- ministral 14b
- qwq snowdrop 32b
- glm 4.7 flash
дополните, плиз.
- qwen 14b
- семейство nemo 12b (вечны)
- семейство small mistral 24b (вечны)
- ministral 14b
- qwq snowdrop 32b
- glm 4.7 flash
дополните, плиз.
>Кобольд это кал
>Гемма это кал
Слышь, псина
glm flash это мое
дополнил...
У соседей хорошо подметили:
:)

А если оба?
Не всё, есть еще llama.cpp и древний air. Они последняя надежда кума
В голосину
>qwq snowdrop 32b
>nemo 12b
Слишком много причисляешь. Если так, то там будет огромный список с ГЛМ 4, командером, большим мистралем и прочем
Имхо если брать именно актуальные, то будет следующий список
1. Мистраль (3.2, магистраль, министраль)
2. Гемма (от 27 до самых маленьких)
3. Qwen 27 и Qwen 9, который скоро выйдет
Ну и все. МоЕшный мир победил
>А я не сочувствую долбоебам. У них вполне нормальные компы и они могут спокойно запустить GLM 4.7 Flash/Qwen 3.5 со скоростью 20+ т/с, но вместо этого они решили страдать. Причем ради чего? Ради уебищной геммы. Тяжело быть сектантом умницы
Чтобы... что? Флэш абсолютно неюзабелен через 2 реплая. Срет ризонингом на 5к токенов. Квен тоже этим грешит. МоЕшки с количеством активных параметров до 15б - просто параша для РП.
У Эира 12б если что, а пишет он как плотная Ллама 70б и мозгов столько же
Хорошо, погорячился. Но в любом случае в комбинации 8 врама + 32 рама МоЕ - лоботомиты, а из плотных моделей нормальная только гемма и мистрали. Новый плотный квен слишком долго думает, и выдает результаты примерно как гемма. Опять же, для рп.
>ГЛМ 4, командером, большим мистралем и прочем
По-прежнему актуальны и хороши
>Ну и все. МоЕшный мир победил
Из новинок да
>предположим, ты не наглый или ленивый, а глупый
Первый день поднятия локалки с нулевым знанием о ии. Чего ты ожидал? Для меня половина треда выглядит как абракадабра. Да, я не понимаю. Дело не в глупости, а в отсутствии опыта. Как мне его приобрести, если аноны меня пинают и смеются над моими простыми вопросами? Как будто если бы я спросил что-то космически заумное, вы бы сразу зашевелились и начали давать охуительные ответы с обильными ветками обсуждений. Треды на дваче если это не личные чатики в a или b созданы для общения и вопросов, в том числе и тех, что кажутся лично тебе глупыми
>Это может быть конец контекста, это может быть сломанный шаблон, eos/bos токены, вариантов наберется немало
Что мешало просто сказать про это и хотя бы направить в гугл? Допустим это не решение моей проблемы, но я хотя бы понял куда копать. Хочешь общаться с обученными - обучи, а не бубни, что кто-то не обучен
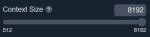
Впрочем, вариантов не так уж много. Напиши про каждый. Контекст у меня выставлен на 8192, по дефолту. Что значит что он кончился?
>может быть сломанный шаблон
Может быть. Научи делать правильные шаблоны, которые не ломаются
>eos/bos токены
Где настройка отвечающая за них? Какие значения надо выставить?
>это, по твоему, выебон
А чем это не выебон? Вместо хоть какой-то инфы которую можно было бы раскрутить в ответ на вопрос, ты просто пожаловался, что тебе не дали желаемый пост на дваче. Детский сад
>Такую, какую ты проигнорировал
У меня нет пасскода чтобы насрать кучей скринов со всеми настройками кобольда. Спрашивай конкретные вкладки настроек или цифры и я их назову. Я не в курсе, что именно может указать тебе на причину проблемы
>выебона нет
>ну да выебнулся
>Как так то?
Пиздец, чел. Сам признался, что глумишься, и тут же сделал невинные глазки, что не было. Как так то?
>хотя бы не начинай выебываться
Тебе это мерещится. Или ты с нулевой ущемился с квенодуры и пошёл в атаку? Ну соре, не знал что ты фанатик квена и так оскорбишься от моей иронии в сторону затупившего бота. Какой ты нежный, но ок, принимаю условия. Может ещё по имени тебя называть, чтобы ты знал, что я просто общаюсь, а не наезжаю с требованиями?


>в шапке вики есть, ее наверно вообще почти никто не читает
И почему же ее никто не читает? Может потому, что инфа устарела на года 2-3?
Единственная ценность вики это историческая. Там можно по таким строчкам
>Exllama2 быстрее в ~1.2-2 раза чем Llamacpp
Узнать, например, почему у exl раньше были и остаются в виде нескольких шизов фанаты
В начале пути радовался каждой лишней тысяче контекста на 12б, квантовал даже. 12к думал это очень много. Щас 32к на эире стоит, еле еле доползаю до этих же 12к и закрываю ламу, всё же на подрочить вполне хватает, а какие то богатые истории писать с попугаем как то не тянет, есть ещё развлечения
Квены я терпеть не могу, но ты прекрасно доказал треду, почему новичков, которые не хотят отвечать на задаваемые им вопросы, нужно мочить в сортире.
Напомню, что весь сыр-бор начался с того, что вот тут я попросил конкретные вещи: "Какая модель, на чем запускается, какие настройки? Где скрины? Где логи?"
Одних только Квенов несколько поколений, не говоря уже о том, что стандартные настройки Кобольда аноны не помнят наизусть. Приложить скрины с настройками и логами можно и без пасскода. Нахуй ты вообще его сюда приплёл? И всё это спустя десяток сообщений.
Короче, только время на тебя зря потратил. Ты обычная недовольная злюка, к которой соответствующее отношение.
Меняй карточки и/или модели. Тебе просто приелись карточки, либо стиль написания модели
>анон с целью помощи реквестит информативные скрины и логи
>спустя дюжину постов верчения на сковороде и вони приложил таки пикрил
>длина контекста
ебать спасибо нахуй
в голос, таким ничего не поможет
>меняй
Конечно, давай модель уровня эира в его размере



>поток обид вместо ответов на вопросы
Да ты сам походу не знаешь в чём проблема, просто для красного словца сказал, что специалист
Но раз ты просишь, лови. Модель Qwen3.5-27B-heretic.Q4_K_M
Лог я проебал, сразу перезагрузив кобольд
Ты если не понял то мы тебя тут всем тредом игнорим уже
Тот кому ты отвечал был прав тащемто, пока он на тебя не спустил хорошенько ты почему-то скрины принести не мог, а теперь с барского плеча запостил со словами раз ты просишь, лови и пасскод не понадобился ахаха
Это наша проблема, что ли? Это нам надо? Плюс один шиз в копилку
> Но раз ты просишь, лови.
Да, это же мне необходимо разобраться, почему моделька отказывается выводить аутпуты...
Пасскод купил таки или что мешало раньше запостить? Сейчас ясен хуй я уже даже смотреть не буду, кекв. Может найдется в треде кто-нибудь, кто помогает выебистым залетухам, но не я.
Не бейте, только вкатываюсь. Система 12 гигабайт видеопамяти, 32 гигабайта ддр4 памяти, ссд обычный сата. Какую модель лучше всего использовать при таких характеристиках? Пробовал Mistral-Nemo, MN-12B-Lyra-v4, Llama-3.1-8B, L3-8B-Stheno-v3.2, два разных Qwen (не помню какие именно, уже удалил) - ничего из этого не понравилось, по разным причинам. В основном потому что модели очень предсказуемые и пишут одинаково вне зависимости от ситуации. Вроде и не тупят слишком сильно, но чувствуется что они постоянно будто одну и ту же сцену пытаются описать просто чуть разными словами. И русский у них очень проблемный, используют какие-то очень странные словосочетания, говорят чуть ли не поговорками иногда. В общем да, такая ситуация. Есть что-то получше, что можно установить, или лучше забить и пойти в aicg спрашивать про всякие опусы и гемини?
>три поста жаловался на отсутствие скринов
>получив скрины жалуется на их наличие
>мы, нас
Мда...
Я не запостил скрины сразу только потому, что не знал, что проблема специфическая и редкая. Я считал, что так бывает у всех, и решение давной найдено. Хз с чего тут ущемляться всем тредом
Качаешь 2 квант отсюда https://huggingface.co/bartowski/zai-org_GLM-4.5-Air-GGUF
Не нравится - закрываешь и идёшь в асиг, лучше не будет
А ладно забей все равно не влезет
Как же пососно не иметь 64 рам
Как же пососно не иметь 64 рам
Второквантовый даун, теперь охотится на новичков...
Мне не хватит, у меня система просто с браузером без всего другого жрет 8 гигабайт памяти, так что под модель у меня где-то 36 гигабайт свободно.
Все жалуются что квен 3.5 много думает. Мой квен:
>Reasoning:
>Пользователь просит информацию о модели LongCat-Flash-Lite. Я нашёл технический отчёт и страницу Hugging Face. Теперь нужно создать структурированное саммари с ключевыми особенностями архитектуры, производительностью и практическими деталями.
И всегда в таком духе. Пользователь просил А надо сделать А. Все размышления
>Reasoning:
>Пользователь просит информацию о модели LongCat-Flash-Lite. Я нашёл технический отчёт и страницу Hugging Face. Теперь нужно создать структурированное саммари с ключевыми особенностями архитектуры, производительностью и практическими деталями.
И всегда в таком духе. Пользователь просил А надо сделать А. Все размышления
> Пробовал Mistral-Nemo, MN-12B-Lyra-v4, Llama-3.1-8B, L3-8B-Stheno-v3.2
По выбору моделей в целом верно, разве что Llama 8b тебе не нужна. Mistral Nemo (12b) - хороший старт. Возможно, удастся Mistral Small 24b в ~Q3 уместить? Итт были аноны с похожими сетапами, думаю, отзовутся. Разница будет существенная, 24b модель в Q3 будет лучше, чем 12b в, наверно, любом кванте.
> В основном потому что модели очень предсказуемые и пишут одинаково вне зависимости от ситуации
> Вроде и не тупят слишком сильно, но чувствуется что они постоянно будто одну и ту же сцену пытаются описать просто чуть разными словами.
В каком формате у тебя карточки? Поделись, покажи. Возможно, проблема в них или промптах, которые ты используешь. Будет хорошо, если покажешь весь пресет, включая семплеры. Если температура слишном низкая, то и разнообразия никакого не будет.
> И русский у них очень проблемный
Хороший русский язык, увы, возможен только на самых больших моделях, и то с нюансами. Но 24b Mistral Small будет на порядок лучше, многие на русике играют на нем и Гемме 27, но не уверен, что ее удастся впихнуть. У нее контекст тяжелый очень.
> Есть что-то получше, что можно установить
Если можешь переехать на 24-27b модели, то жизнь там есть, по крайней мере на английском. Сам долго сидел на 24b Мистралях. Попробуй 24b модель, поработай получше над промптами и карточками и смотри, что получится. Если уж не устроит результат - придется на апи, да. Q2 Air не советую, потеряешь время. Возможно, есть другие мелко-мое модели, которые подойдут? Не уверен.
🤡
>Mistral-Nemo, MN-12B-Lyra-v4, Llama-3.1-8B, L3-8B-Stheno-v3.2
Это все старый кал. В прошлом треде уже советовали
Вот это полностью на видюхе
Плюс можно повысить квант, чтобы увеличить качество и существенно снизить скорость
Плюс МоЕ Q4 попробуй
https://huggingface.co/zai-org/GLM-4.7-Flash
https://huggingface.co/Qwen/Qwen3.5-35B-A3B
Для тех, кто на видяхе поставь KV Cache 8 bit
А для MoE придется подбирать CPU Layers (будет 20-30 где-то)
>🤡
Чего пристала?
Тебе правильно подсказали ещё в прошлом треде. Смешение двух или более промтов сломало мозги твоему боту. А если у твоего бота сломался мозг, значит ты дал ему прямо противоположные инструкции. В твоём чате не должно быть ничего лишнего, что может сбить бота с основной линии. Как фиксить в дальнейшем? Хз. Напиши новый промт, поточнее, попробуй, проверь. Тут практика решает больше, чем конкретное знание. В конце концов у кобольда есть функция рефинкать сообщения, мог бы её потыкать.
>Мой квен
Это который ты в голове себе выдумал? Потому что настоящий квен срет по 5к токенов на любой чих
>Пользователь просит информацию о модели LongCat-Flash-Lite. Я нашёл технический отчёт и страницу Hugging Face. Теперь нужно создать структурированное саммари с ключевыми особенностями архитектуры, производительностью и практическими деталями.
Так думает гопота 120b, если ей low выставить в ризонинге, все остальные пишут ощутимо больше
База треда по нищуковым сборкам: советчики МоЕ говна, которые сами ни разу не пробовали флэши и А3Б (потому что если бы попробовали, то никогда бы это не советовали) против плотнодебилычей геммоебов, которые любят читать по одному слогу раз в 3 секунды.
Ну, я не знал, что будет такая реакция. Ладно, извиняюсь перед всеми. Буду писать меньше. За совет спс
>В каком формате у тебя карточки?
Раньше использовал готовые, потом тоже подумал, что может проблема в них и начал писать свои через переводчик. Просто текстом описывал персонажа в несколько параграфов, потом переводил и вставлял. В каком то гайде прочитал, что это лучший формат вместо всяких списков и тегов.
>проблема в них или промптах, которые ты используешь
Промт обычный дефолтный из таверны. Ролплей иммерсив или как-то так. Ничего там не менял в общем-то.
>Будет хорошо, если покажешь весь пресет, включая семплеры
Их тоже не менял, ну кроме формата инструкций. Семплеры пресет Simple-1, там температуру только крутил, но это ничего не поменяло по ощущениям. Вернул по умолчанию.
Попробую мистраль 24B и гемму 27B, спасибо.
>Вот это полностью на видюхе
>Плюс МоЕ Q4 попробуй
Попробую, спасибо.

Хули делать, если на нищеуровне все одинаково говно?
>А если оба?
То сына долбоеба
Оно говно по-разному. Первые смотрят на то, как их ХХ-летняя женщина снимает трусы четвертый раз подряд, вторые заебываются еще до того, как она начнет снимать трусы.
У анончика просто пригорело маленько, не обращай внимание, со всеми бывает. Ты вон тоже простынь выдал. Обменялись говной и хватит. Пиши как писал, только обращаясь с проблемой, описывай её подробно, чтобы мы могли тебе помочь.
У тебя неправильный темплейт и неправильные семплеры. Правильные можешь посмотреть на странице модели.
>Что значит что он кончился?
Вот так взял и кончился. Контекст - это все что есть в чате от начала чата. Вообще все - и ризонинг нейронки, и то что ты там понаписал и высеры нейронки. Упрощенного говоря при нажатии кнопочки "Отправить" в модель уходит не последнее сообщение - а вся СРАНЬ с начиная с системного промпта и твоего первого сообщения. И при превышении размера контекста в этом посыле нормальный серьезный бэк отрыгивает сразу с ошибкой. Но у тебя кобольд. А в кобольде по умолчанию включено скользящее окно. Дальше гугли сам.
Нагрузку страшно давать, уверен что то отрыгнёт
Среди моделек до 35б кто сейчас ебет в кодинге? ГЛМ 4.7 флеш?
27b квен, остальное годится только змейку на питоне генерировать.


Вроде шевелится, но очень медленно. На двух было кратно быстрее, мб мало рамы, пойду загружать память
Где в глупой таверне смотреть, С какой скорость и за какое время генерируется ответ.
И это странно, что в таврене как то лучше текст пишется? Или это мощь тегов? Или у меня планка низкая?
Tp, pp или комбинация? Сколько выдает?
Включи в настройках таймер сообщения а потом на него наведи.
Таверна может работать лучше за счет более продвинутых настроек формата и управлением промпта. Или по той же причине хуже если в них накосячишь.

> Сколько выдает?
Пока какой то посос на гемме в 18тпс. Завтра нужно настроить охлаждение, подкинуть нормальную сеть и уже гонять бенчи
ministral 14b Хватит всем!!!!
О. Немного поверхностно и ещё надо будет допилить напильником, но уже что-то.
Интересно какие модели для эмбеддинга и реранкинга вообще с русским дружат
Интересно какие модели для эмбеддинга и реранкинга вообще с русским дружат
Чел поимел систему. Круче я ещё в этой теме не видел.
128 гб врам по цене как... короче моё почтение.
Слушай, а как ты Ollama (или vLLM) под них заводил? Из коробки же официальные билды gfx906 уже не жалуют. Сам компилил библиотеки?
Что ты на ней будешь делать?
Я всеми 3.5 квенами пользовался. Ни один не срал ризонингом. Хотя все жалуются. У меня одна только гипотеза что Openclaw в промпте имеет что-то такое что влияет на это проведение
Сам собираю из официальных реп и форков. Нужно вот начать всё обновлять, а то пока был риг разобран всё стояло на месте
> Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
> Что ты на ней будешь делать?
У самурая нет цели. Есть парочка идей которые хочется опробовать
> 128 гб врам по цене как...
50к. Если бы прям по низу успевал то может даже в 40 бы уложил видяхи.
А вообще я может и успел поиметь систему, но она меня в ответ тоже поёбывает.
- красные видяхи с спец заказа из цодов
- "отечественная" мать которая не прошла приёмку
- инжи 4189 "не для продажи"
- разогнанная до 2666 серверная 2133
- обильно посыпать 3д печатными костылями
Это всё по определению не должно хорошо работать
Заставить работать ecc в разгоне на бракованном гагарине или что там у тебя, ещё и на инжике + купить 128 гб врам за 50к... бля чел, ты не пропадай, пиши тут иногда. Буду читать в перерывах пока вручную перекраиваю .md текст для RAG библиотеки 24bq4 мистрали на 16 гб озу...
Капец, v100 уже по 48к. До нового года было 30-40к куча лотов.
Мне больше страшно что у тебя гемма работает так плохо.
Мне больше страшно что у тебя гемма работает так плохо.
К слову запустил qwen3.5, который MoE 35B.
Контекст из коробки не пересчитывает.
С 8 гб карточкой и таким же размером файла в два раза выше pp, но tg такой же как и у glm-4.7-flash.
А ещё он походу тупой, и задачи, которые достаточно спокойно решал как флеш, так и qwen-next 80b-a3b, этот решить не в состоянии даже после трёх перезапусков.
При этом в размышлениях на логику вещи правильные и разумные, но вызовы инструментов оно не умеет (неверный синтаксис это лама выдаёт что парсер не справляется), и ещё инструкции игнорируется - на просьбу выдать json-запрос оно пишет текст, как его не бей. Требования к лимиту токенов не выполняет, хотя я в каждом сообщении мета-инфу такую скидываю.
А glm-4.7-flash всё так же лупится как тварь.
Что-то в его (qwen3.5) размышлениях точно есть, и ещё он их точно на английском делает, но надо допиливать мелочи.
Хотеть glm-4.7 побольше. 80B-A15B был бы идеален.
Контекст из коробки не пересчитывает.
С 8 гб карточкой и таким же размером файла в два раза выше pp, но tg такой же как и у glm-4.7-flash.
А ещё он походу тупой, и задачи, которые достаточно спокойно решал как флеш, так и qwen-next 80b-a3b, этот решить не в состоянии даже после трёх перезапусков.
При этом в размышлениях на логику вещи правильные и разумные, но вызовы инструментов оно не умеет (неверный синтаксис это лама выдаёт что парсер не справляется), и ещё инструкции игнорируется - на просьбу выдать json-запрос оно пишет текст, как его не бей. Требования к лимиту токенов не выполняет, хотя я в каждом сообщении мета-инфу такую скидываю.
А glm-4.7-flash всё так же лупится как тварь.
Что-то в его (qwen3.5) размышлениях точно есть, и ещё он их точно на английском делает, но надо допиливать мелочи.
Хотеть glm-4.7 побольше. 80B-A15B был бы идеален.
Аноны, а подскажите, расцензуренные версии МоЕ моделек вообще существуют? Чет то ли я слепошарый, то ли есть какие то концептуальные проблемы.
Так то хочется и рыбку съесть, и сковородку не испачкать - и что то уровня той же GLM 4.7 Flash получить, и уместиться во VRAM, избежав скорости генерации 2 токен/сек.
Так то хочется и рыбку съесть, и сковородку не испачкать - и что то уровня той же GLM 4.7 Flash получить, и уместиться во VRAM, избежав скорости генерации 2 токен/сек.
я не знаю рофлишь ты или нет (от /llama/ всего можно ожидать), но министралька 14b прям топ до <24b.
В качестве ассистента прям бесценна.
>министралька 14b прям топ до <24b.
>В качестве ассистента прям бесценна.
1) На чём ты её запускаешь?
2) Что именно ты на ней делаешь, где она себя так хорошо показывает?
Однако последняя версия кавраковского форка хороша. Хз как там идут стандартные кванты, но родные прямо летают.
На радеоне 580 с 8гб какую модель дёргать?

Выложишь когда? х2
>Это всё по определению не должно хорошо работать
Хорошо? Нет. Но приемлемо.
>расцензуренные версии МоЕ моделек вообще существуют?
Существуют, но работают как говно.
Можно передёрнуть только соседу по парте, без запуска моделей.
Ну тая я-же про то и говорю, это топ за свои деньги, есть и вижн и ризонинг, и как асистент норм, вобщем класная сасная всё включено. Использую её как основную модель для телеграмм бота, да и как агента в openclaw тож использую, хотя есть возможность запускать норм модели (40врам 64 рам), и я их запускаю для некоторых задач, но министралька 14 это прям работяга на все случаи жизни.
>Это всё по определению не должно хорошо работать
В чем проблема? Не кернелпаникует значит работает.
>Пока какой то посос на гемме в 18тпс.
А сколько должно быть? Она в целом не радует скоростью как и любая плотная модель.
Флеша перенатаскивать надо, у него память как у рыбки.
>но вызовы инструментов оно не умеет (неверный синтаксис это лама выдаёт что парсер не справляется)
Бтв, попробуй с клодоагентом, там походу более убедительный промпт - если модель умеет работать с тулзами, в нем она может выебываться как хочет, но тулинг работает как часы кроме девстраля.
>А сколько должно быть?
Ну, на одной V100 она выдаёт 50..60/s через llama.cpp в квантах.
У него достаточно памяти чтобы без квантов запускать гемму хоть в fp16. Скорее всего какая-то тупая хрень или в vLLM под это железо или это просто особенность vLLM, у которого генерация в один поток не самая сильная сторона, и все оптимизации нацелены на 60 одновременных одновременных конкурентных запросов от разных пользователей.
Ещё есть шанс что эта mi50 по компуту остаёт в десять раз, но это маловероятно, я думаю она даже быстрее должна быть, так как отсутствие куды - это явно не на пользу популярности amd идёт, и они должны при том же уровне карточки предложить что-то, например больше операций на ватт.
Да я уже написал свой парсер, забей.
Просто хотелось с нормальным v1-интерфейсом работать, чтобы была возможность сетку менять без особых проблем и парсер писал не я, а лама. А получается что ванильная лама не умеет ни в qwen3.5, ни в glm4.7, а с автопарсером достаточно хорошо работает с glm4.7, но всё так же падает с qwen3.5. К тому же я только сейчас обратив внимание, что автопарсер ломает /v1/completion (и ламовский /completion тоже, там чуть другой json) интерфейс полностью (любой запрос падает с ошибкой), рабочим остаются только /v1/chat/completion.

Хотя ладно. Забираю свои слова обратно, я ошибся. В некоторых местах.
Надо было пересобрать ещё раз, и с автопарсером без размышлений всё работает на qwen3.5.
Причём оно уважает все варианты tool_choice, даже явный призыв вызывать определённый инструмент. А вот с размышлениями падает.
Но самое главное, что обычный /v1/completion починился для qwen3.5, потыкаю сегодня его что ли.
>и они должны при том же уровне карточки предложить что-то, например больше операций на ватт.
Лел. Амд периодически выкатывает драйвера. Порой они даже не вешают систему. Это все, что нужно знать про радеон.
>я думаю она даже быстрее должна быть
Сомнительно, я когда выбирал между ними и v100 по форумам понял то, что там перф примерно 80% от в100. Причем за пару лет он менялся от говнища до вполне приемлемого результата, и бенч анона с пирамидой после полировки будет чуть ли не единственной адекватной точкой отсчета за последние полгода. На дрова очень многое завязано.
Старые бенчи глянул и там всегда было 18-20 тпс с тензор параллел 2. Пик в 100 когда 4 запроса параллельно.
Вллм для ми50 работает на паре ядер патченых васянами
Я пока могу сказать только за 27B. Походу, ризонинг у него с претензией на интеллектуальное включение. Если дать модели контекст на 2-3K с данными для которых ризонинг не особо нужен (вроде RP сессии и лора), и в запросе не вопрос а действия игрока - она ризонинг не включает. А если игрок при этом спросил у персонажа какую-то заморочь - тогда да, начинает думать.
>Аноны, а подскажите, расцензуренные версии МоЕ моделек вообще существуют?
Да. И GLM(air), и Qwen, и даже гопота-oss есть.
Анончик, а на чем сейчас выгоднее риг собирать? Скажем для кими.


Составлял я значит карточку с помощью гопоты, а он мне такой: братишка, а ты ничего не перепутал? Давай хоть в NSFW переделаем или чернухи добавим, что это за унылое говно?
А потом такой беру и задаю тот же вопрос квену 122b. Результат на скрине. Не, вы вдумайтесь: новый квен настолько соевая параша, что даже гопота на его фоне выглядит умницей-базовичком.
Как можно было НАСТОЛЬКО обосраться? Ебаный стыд.
А потом такой беру и задаю тот же вопрос квену 122b. Результат на скрине. Не, вы вдумайтесь: новый квен настолько соевая параша, что даже гопота на его фоне выглядит умницей-базовичком.
Как можно было НАСТОЛЬКО обосраться? Ебаный стыд.
>11652 раздумия
>Нет
орнул в голос.
Он просто рассуждает как дед в деменции:
Так, пользователь попросил составить NSFW карточку. Значит я должен…. Как его там… А, да, были карточки в моё время, вот помню а 60ых был один бейсболист..
1. В гопоте у тебя скорее всего есть какой-то контекст, которая она подтягивает из других чатов, а у квена пустой контекст
2. Отказ очевидно произошел в ризонинге. И она надумал аж на 11к. Сомневаюсь, что у тебя у гопоты был врублен ризонинг
3. Уже миллион раз написали, что XL кванты СЛОМАНЫ и Q4XL сосет даже у IQ3XSS
И все это не отменяет того, что модель соевая. Но ты все равно обосрался, кобольд
>В гопоте у тебя скорее всего есть какой-то контекст
Ничего связанного с РП или NSFW, в основном рабочие запросы.
>Отказ очевидно произошел в ризонинге
Перепроверил: без ризонинга то же самое.
>XL кванты СЛОМАНЫ
Это не влияет на рефьюзы. Не вижу смысла сейчас перекачивать, пока исправленные кванты на выкатят. Оно всегда так с новыми моделями.
>кобольд
Ты из тех шизов кто предпочитает забивать шурупы молотком? Таверна для РП, фронт кобольда - для ассистента. Это банально удобнее.
>Это не влияет на рефьюзы. Не вижу смысла сейчас перекачивать, пока исправленные кванты на выкатят. Оно всегда так с новыми моделями.
Это сильно влияет на качество модели. Ты сейчас юзаешь полностью сломанный квант, который даже до Q3 не дотягивает. Это при том, что уже в день релиза модели были рабочие кванты у бартовски. В чем смысл ждать анслопа?
>фронт кобольда - для ассистента
Он вырвиглазный. Фронт llama.cpp ощутимо лучше


Наткнулся на такое вот говно на обниморде. Это вообще нормально? Они же продают доступ к какой-то невнятной хуйне под видом "надо поделиться контактной информацией".
В чем разница между херетиком и нормпресерв? Что из этого меньше лоботомирует модель?

Сам не ебу, вот тебе слоп вместо ответа. Я так понимаю норм>еретик>обычный аби. Но за это пусть геммаводы поясняют, они уже год пытаются свою умничку расцензурить
вы че балбесы
еретик это просто название скрипта, который разные методы использует
автор обещал включить нормпрезерв в свой скрипт, хз сделал ли

Скоро микроквены для... А для кого нахуй? Кто их просил? Для чего они нужны? В чем смысл их существования?
для какой нибудь несложной работы.
Я вот ради интереса попробовал суммаризировать этот тред, точнее предыдущий, типа чтобы самые полезные ключевые моменты выделить и обломался. если в лоб делать - получится каша.
соответственно нужен скрипт со специализированными агентами которые будут делать разные вещи, например сначала чистить тред от мусора, потом выделять важные моменты и куда то сохранять, а уже потом по сохраненному уже начать составлять типа гайда.
Надо будет поискать какие вообще есть решения.
Кстати, я пробовал мелкоквен 3-vl-8b и он чот плохо справляется с вызовами тулзов. Надеюсь новая версия лучше справится
На мобилках запускать, или может какие узко-направленные ассистенты пилить. Плюс там вижен есть, можно OCR какой-нибудь хуярить на чем угодно.
Там gemma 3 или ministral будут лучше для этого. Все таки китайцы идут в прогерство, а не в языки. И почему именно 8b, а не более крупная?
>На мобилках запускать
Но зачем? В чем смысл запуска этих лоботомитов с никакущей скоростью на мобилках, если есть копры и/или локалки на компе, к которым можно подключится?
Как раз это единственные нормальные модели от Квена, 4b новый нужен. А большие - это мусор, неспособный ни с кем конкурировать.
у меня была идея типа тупого мелкоскрипта который быстро отработает простой сценарий типа пройтись по списку и что то скачать и отметить, т.к. модели покрупнее довольно долго выполняют.
Для телефонов/планшетов.
Собирать риг для кими не выгодно.
Автодополнение строчки/двух кода, rag-экстрактор информации из файлов с системным промтом на 5 строк, embeding/rerank режимы(не уверен что второй поддерживает), исправление стиля и отступов в коде и другие супер простые задачи. Регулярка++ по смыслу, если нужно решить что-то уровня поиска всех имён в тексте.
На сколько не выгодно? А для чего выгодно?
Коротко - очень не выгодно.
Кими - очень большая сетка. В полных весах это 2 терабайта. В 4 бита - 500 ГБ только на веса модели, а ещё нужны временные буферы для вычислений, и буфер для kv-кеша.
Ребята тут часто пишут, что ниже 4 бит жизни нет и лучше ставить 6 и выше. Вот то что у тебя chatgpt, или kimi который на сайте - там вообще скорее всего в 8 бит всё работает.
Я конечно не согласен, но даже если взять оптимистичные 3.5 бит и считать что буферы для вычислений и кеша имеют нулевой размер - это 437 ГБ.
Работа ллм делится на разбор промта (pp - promt processin) и генерацию ответа (tg - token generation)
Итого:
На DDR4 это будет стоить 200-300к, и будет выдавать 1-2 слова в секунду (генерация) или около того.
На DDR5 это будет стоить под 600к и будет выдавать 3-4 слова в секунду (генерация) или около того.
Помимо этого тебе нужна хотя бы какая-то видеокарта, без неё скорость pp будет порядка 10-20/s. С картой сразу будет 100-200/s, даже со слабой на условный 16 гб.
Собрать видеокарт на 480 ГБ - самый дешёвый вариант, это 15 штук V100. Это 800к за карты и райзеры. Допом тебе нужно найти материнку, где будет достаточное число слотов и pcie-линий. Впрочем, даже x4 более-менее хватит, но 60 линий найти сложно, как я понял есть либо нормальные процессоры на 48, или чудовища эпики и рипперы от амд на 120 линий. Ну, либо двух процессорная система. Помимо этого тебе нужно подвести к этому питание. Даже если выставить лимиты по 150 ватт - это 2.5 квт на систему. Одновременно они все в кими работать не будут, но что-то вроде 1.5 квт тебе понадобится. И это будет скорость около 10 слов в секунду и pp порядка 200-400/s, думаю. Числа из головы. В общем это система на миллион + придётся потратить десятки часов на сборку всего этого. Если ты берёшь любые другие карты, то один из самых дешёвых вариантов - покупать 4-6 rtx blackwell 6000 pro с 96 ГБ видеопамяти, это за три миллиона стоимость сразу, но скорости будут хорошие, как в облаке или даже быстрее.
Про подписку за 10 долларов в месяц слышал, одной blackwell 6000 pro тебе хватит на подписку до конца жизни или близко к этому.
Дополнительная информация. Видеокарты - это параллельные ускорители. То есть им нужно делать много одинаковых операций одновременно. А ты один.
В случае pp всё в порядке, ты кидаешь текст на 50 страниц - оно параллельно и эффективно это обрабатывает.
В случае tg всё очень плохо, процедура последовательная. В случае если ты отправил один запрос - то у тебя токены генерируются один за одним со скоростью в условные 50/s, что очень медленно. В случае датацентра и облачной сетке к каждой такой системе есть одновременно 100 запросов на генерацию от 100 разных пользователей. Скорость при этом почти не снижается, и те же самые карты выдают 50х100 = 5000/s суммарной генерации, что позволяет эффективно использовать видеокарты. С локальным ригом такой сценарий почти невозможен, больше 10 запросов ты никак почти не подашь.
Выгодно - если это твоё хобби. Как гитары, мотоциклы, скалолазанье, рисование и прочее такое.
Так же это выгодно, если:
- у тебя жёсткие требования к конфиденциальности и ты не можешь выгружать в сеть свои данные.
- в случае, если у тебя нет интернета и ты хочешь такое использовать в бункере, в антарктиде или ещё где.
- в случае, если ты ориентируешься на класс моделек 30B, который тебе нужен для несложных задач + генерируешь картикни в sdxl и прочее. Подписки на сервисы генерации неадекватно дорогие, карточка за 100к сможет тебе нагенерировать всё что ты захочешь. На самом деле в случае генерации картинок (параллельная задача) ты можешь эффективно использовать мощности видеокарты. Потому у тебя дома эффективность 100% и в датацентре 100%, а в случае текста у тебя дома 2%, а в датацентре 100%, потому и кажется что подписки на генерацию картинок дорогие, так как с точки зрения тебя ты за 2% работы платишь столько же. А с точки зрения дата-центра генерация в 50 раз тяжелее генерации текста, так как одна генерация картинки утилизирует 100% мощностей видеокарты, и плюсов от двух параллельных генераций почти нет.
Кими - очень большая сетка. В полных весах это 2 терабайта. В 4 бита - 500 ГБ только на веса модели, а ещё нужны временные буферы для вычислений, и буфер для kv-кеша.
Ребята тут часто пишут, что ниже 4 бит жизни нет и лучше ставить 6 и выше. Вот то что у тебя chatgpt, или kimi который на сайте - там вообще скорее всего в 8 бит всё работает.
Я конечно не согласен, но даже если взять оптимистичные 3.5 бит и считать что буферы для вычислений и кеша имеют нулевой размер - это 437 ГБ.
Работа ллм делится на разбор промта (pp - promt processin) и генерацию ответа (tg - token generation)
Итого:
На DDR4 это будет стоить 200-300к, и будет выдавать 1-2 слова в секунду (генерация) или около того.
На DDR5 это будет стоить под 600к и будет выдавать 3-4 слова в секунду (генерация) или около того.
Помимо этого тебе нужна хотя бы какая-то видеокарта, без неё скорость pp будет порядка 10-20/s. С картой сразу будет 100-200/s, даже со слабой на условный 16 гб.
Собрать видеокарт на 480 ГБ - самый дешёвый вариант, это 15 штук V100. Это 800к за карты и райзеры. Допом тебе нужно найти материнку, где будет достаточное число слотов и pcie-линий. Впрочем, даже x4 более-менее хватит, но 60 линий найти сложно, как я понял есть либо нормальные процессоры на 48, или чудовища эпики и рипперы от амд на 120 линий. Ну, либо двух процессорная система. Помимо этого тебе нужно подвести к этому питание. Даже если выставить лимиты по 150 ватт - это 2.5 квт на систему. Одновременно они все в кими работать не будут, но что-то вроде 1.5 квт тебе понадобится. И это будет скорость около 10 слов в секунду и pp порядка 200-400/s, думаю. Числа из головы. В общем это система на миллион + придётся потратить десятки часов на сборку всего этого. Если ты берёшь любые другие карты, то один из самых дешёвых вариантов - покупать 4-6 rtx blackwell 6000 pro с 96 ГБ видеопамяти, это за три миллиона стоимость сразу, но скорости будут хорошие, как в облаке или даже быстрее.
Про подписку за 10 долларов в месяц слышал, одной blackwell 6000 pro тебе хватит на подписку до конца жизни или близко к этому.
Дополнительная информация. Видеокарты - это параллельные ускорители. То есть им нужно делать много одинаковых операций одновременно. А ты один.
В случае pp всё в порядке, ты кидаешь текст на 50 страниц - оно параллельно и эффективно это обрабатывает.
В случае tg всё очень плохо, процедура последовательная. В случае если ты отправил один запрос - то у тебя токены генерируются один за одним со скоростью в условные 50/s, что очень медленно. В случае датацентра и облачной сетке к каждой такой системе есть одновременно 100 запросов на генерацию от 100 разных пользователей. Скорость при этом почти не снижается, и те же самые карты выдают 50х100 = 5000/s суммарной генерации, что позволяет эффективно использовать видеокарты. С локальным ригом такой сценарий почти невозможен, больше 10 запросов ты никак почти не подашь.
Выгодно - если это твоё хобби. Как гитары, мотоциклы, скалолазанье, рисование и прочее такое.
Так же это выгодно, если:
- у тебя жёсткие требования к конфиденциальности и ты не можешь выгружать в сеть свои данные.
- в случае, если у тебя нет интернета и ты хочешь такое использовать в бункере, в антарктиде или ещё где.
- в случае, если ты ориентируешься на класс моделек 30B, который тебе нужен для несложных задач + генерируешь картикни в sdxl и прочее. Подписки на сервисы генерации неадекватно дорогие, карточка за 100к сможет тебе нагенерировать всё что ты захочешь. На самом деле в случае генерации картинок (параллельная задача) ты можешь эффективно использовать мощности видеокарты. Потому у тебя дома эффективность 100% и в датацентре 100%, а в случае текста у тебя дома 2%, а в датацентре 100%, потому и кажется что подписки на генерацию картинок дорогие, так как с точки зрения тебя ты за 2% работы платишь столько же. А с точки зрения дата-центра генерация в 50 раз тяжелее генерации текста, так как одна генерация картинки утилизирует 100% мощностей видеокарты, и плюсов от двух параллельных генераций почти нет.
Сахур
https://github.com/Mobile-Artificial-Intelligence/maid
Maid можно из шапки убирать, IMHO.
Автор выкатил версию 3.0 в которой:
- дропнуты версии win и lin.
- Не работает даже на android 13 (Это даже телефоны выпущенные год назад. Что, блядь?)
- Добавлена регистрация по емейлу и синк с облаком.
- Просматривается намерение выпилить к хуям локальные бекэнды через OpenAI compatible. В issues уже есть - даже с ollama не соединяется.
Maid можно из шапки убирать, IMHO.
Автор выкатил версию 3.0 в которой:
- дропнуты версии win и lin.
- Не работает даже на android 13 (Это даже телефоны выпущенные год назад. Что, блядь?)
- Добавлена регистрация по емейлу и синк с облаком.
- Просматривается намерение выпилить к хуям локальные бекэнды через OpenAI compatible. В issues уже есть - даже с ollama не соединяется.
воть
> Это не влияет на рефьюзы.
Влияет самым прямым образом, отличия радикальны.
Провел довольно обширное сравнение разных квантов 122а10 оценивая этот момент. В первую очередь фокус на наличие софтрефьюзов с искажением фактов и логики, хардрефьюзов, рефьюзов после ризонинга.
Несколько разных тестов, включая кум чатики, капшнинг картинок и обсуждения "Легально ли заниматься X с персонажем Y которому N (много) лет подтвержденных документально, если он выглядит на M". В это случае нормальным ответом помимо прямого согласия, можно считать колебания, вопросы и предупреждения про потенциальные проблемы и общественное мнение. Но после уточннения что документы действительно в порядке и все подтверждено - должно быть однозначное согласие. Убитая же соей модель будет рассказывать небылицы о том, что суду и полиции гораздо важнее внешность, а документы и юридический статус - херня.
Собственно результаты:
Ультрасоя тир - xl анслоты (q4 и q6), фп8 от самих квенов, более ужатый int w4a16 - кардинально искажают факты и логику триггернувшись, подсовывают софт рефьюзы давая неверное описание, застревают в бесконечных лупах в ризонинге. Без ризонинга частые инстантрефьюзы. Собственно все то о чем здесь идет нытье.
Нормис тир - полные веса, другой фп8 (ближе к базированному), mxfp4 (где-то больше гонит базу, где-то сою), менее ужатый w4a16 от quanttrio (ближе к сое). Чаще колеблятся, могут прочесть лекции про общество, но при дальнейшем обсуждении соглашаются что все ок. Софтрефьюзов с искажением в разы меньше, хардрефьюзы случаются.
Есть еще пара ультрабазированных, но с ними нужно уточнить.
При этом всем моделям срывает тормоза на кумботах, все более сговорчивые на не пустых контекстах.
По словам умных людей и нейронки, активация на сейфти имеет высокую амплитуду, которая при калибровке может перебивать все остальное. Образно выражаясь, там где в нормальной ситуации один большой всплеск должен быть уравновешен множеством меньших эти самые меньшие подрезали и исказили. А где-то наоборот он или не был принят во внимание, или вовсе клипнулся. Причем здесь может быть дело не в неверно выбранном датасете - как раз при сжатии еще и атеншна калибруя все на erp такое может произойти, а на стерильных ассистентских qa или медицинских данных наоборот получиться лучше. Это же подтверждается сменой поведения модели если квантовать ее контекст и не использовать скейлы, или подбирать их на "безопасных" текстах.
Высока вероятность что обычные "легаси" гууфы окажутся лучше, надо будет попробовать их протестировать.

>фронт кобольда
>Он вырвиглазный
Просто напомню:
Рекомендую тыкать в это носом каждого тавернодебила, которого встретите тут.
Спасибо за развернутый и подробный ответ, анон. Добра тебе, здоровья родителям и всем твоим родственникам.
И кошко-жену от партии.
А ты сразу опа указывай
Но вообще тут спорно
>дропнуты версии win и lin
А нужно ли они вообще, если там и так много приложений
>Не работает даже на android 13 (Это даже телефоны выпущенные год назад. Что, блядь?)
Проеб разработчика
>Добавлена регистрация по емейлу и синк с облаком
Это вроде опционально
https://github.com/Mobile-Artificial-Intelligence/maid/issues/725
>Просматривается намерение выпилить к хуям локальные бекэнды через OpenAI compatible. В issues уже есть - даже с ollama не соединяется.
А где просматривается то? У него отвалилось соединение с ollama и он хочет починить это
Выглядит так, будто он просто зарелизил кривой билд и сломал собственное приложение. Мб все исправит
Фотка не соответствует скринам - на них всего 32гига рама, а тут все слоты набиты. Как раз наличие лишь одной-двух плашек может быть причиной замедления, писали о том, что это даст низкие скорости и задержки при обмене потому что путь (видеокарта - шина - рам - qpi - рам - шина - видеокарта) по сравнению с тем, когда железки укомплектованы.
Хз насколько 18т/с на гемме нормально для них и какой там квант. Если 8 бит - примерно столько в один поток по псп и получится если без тп.
> на одной V100 она выдаёт 50..60/s
Гемма? Небылицы, если офк ты не про пропмтпроцессинг говоришь, тогда слишком мало.
> vLLM, у которого генерация в один поток не самая сильная сторона
На свежих железках как раз и в 1 поток быстрее всего, но на тех что постарше уже не все радужно. 18 для геммы это не самый плохой результат (офк зависит от кванта), интереснее что там с процессингом будет, где упор в компьют.
>нет возможности свайпа без регенерации (удаления предыдущего свайпа)
да, кобольд кал
В Кобольде также нет лорбуков, author's note, экстеншенов и много чего ещё. Его если и сравнивать, то с устаревшим говном мамонта TavernAI, и то и другое реализует только базовый чатик.
>А где просматривается то?
Внутри. У меня на телефоне стояла старая версия, обновилась. Пропали все чаты и настройки. Ввел заново - перестала даже пытаться конектится. Написал отзыв - автор просто пометил новую версию как не совместимую для моего телефона, ничего не отвечая. В самих настройках - стало неудобно даже пытаться найти и ввести кастом эндпоинт. Делаю вывод - он хочет уйти в коммерцию к корпам, а локальные бекэнды - сложно поддерживать автору, юзеру легко ловить ошибки, и чтобы ими пользоваться думать надо. Теперь у него целевая аудитория другая - проще выпилить чтоб не мешали.
>Гемма? Небылицы, если офк ты не про пропмтпроцессинг говоришь
Ну, я чуть преувеличил. Окей, я тебе запишу видео на днях со ссылкой на этот пост. Пока разобрал "системник" на рефакторинг и прям сегодня не покажу, а детали будут завтра или послезавтра.
Это с пустым контекстом. При заполнении порежется вдвое, естественно, но не до 18/s всё-равно.

Какая впизду таверна, долбоеб? Я о ней вообще не писал. И уже отвечал тебе
Также я напоминаю, что в прошлый раз кобольды слились на свайпах. Так что лучше даже не начинайте, сидите на своем говне и не высовывайтесь

Орнул. Когда сумел распаковать зип-файлик с лламой, скопировал первую попавшуюся команду запуска (впервые в жизни увидев консоль), кряхтя подключил таверну с дефолт-настройками и теперь ты ИЛИТА треда.
Жаль конечно что нажать на кнопку настроек в кобольде для илиты непосильная задача, иначе такого бреда:
>нет возможности свайпа без регенерации
>нет лорбуков, author's note
я бы сейчас не читал.
В Кобольде также нет лорбуков, author's note
Чел... Они там родились. Еще в самом старом кобольде, который до ламы был, и благополучно перекочевали в cpp версию. Таверна просто развила эти концепы сильнее, но идея не ее.
А еще есть esobold - форк с упором как раз на GUI. Там сильно доработали в том числе и это. Но это так, к слову. Пользоваться не призываю.
Не ну если взять квант поменьше и на пустом контексте - действительно 50-60 можно получить, просто даже не рассматривал этот вариант из-за объема памяти.
Отписывай, тема же интересная, даже если будет не супер быстро - за цену врам в разы ниже рама никаких претензий не может быть. А тут еще есть все шансы на успех. Попробуй еще как на жоре будет, свиду оперативы там много для моделей покрупнее.
Герой монитора побеждает всех своих воображаемых врагов. Кто тебе так жопу защемил, что ты рвешься в треде днём в понедельник?
Приноси скрины, показывай как сделаны лорбуки в Кобольде, поржем всем тредом
> Еще в самом старом кобольде, который до ламы был, и благополучно перекочевали в cpp версию
Что за хуйню я только что прочитал? Кобольды реально невероятно тупые
В лламуцпп переехали лорбуки? Ты хотя бы знаешь что такое лорбуки и как они работают?
Игнорируй явный жир. Кобольд не подарок, но того хейта он не заслужил, лучше сделай несколько скринов показывая где это настраивается, заодно неофитам поможешь.
Нет цели кого-то "побеждать", лол. Просто поржал с тупости тавернодебилов. Никогда такого не было и вот опять.
Я хз, я не сижу с телефонов. Но пока это больше выглядит так, что автор долбоеб и сломал приложуху. Учитывая, что он ее почти один пилит это вполне вероятно
Никто не заявлял, что он принадлежит к элите треда. У тебя с головой явно проблемы. Ну неудивительно, ведь
>Когда сумел распаковать зип-файлик с кобольдом, скопировал первый попавшийся конфиг запуска запуска (впервые в жизни увидев все эти параметры), кряхтя подключил запустил чатик с дефолт-настройками и теперь ты ТОЧНО лучше остальных
Это дефенишен Кобольда. И ладно бы ты сидел и не выебывался, так рвешься на ровном месте, когда к тебе даже никто не обращается. Кобольд это твоя тян? Твой младший брат? Ему вот прям нужна твоя защита, да? Какой софт, такие и юзеры
>небылицы о том, что суду и полиции гораздо важнее внешность, а документы и юридический статус - херня
Тащемта как минимум для съёмок порно это чистая правда как минимум в РФ и Австралии.
То есть трахать персонажа
>Y которому N (много) лет подтвержденных документально, если он выглядит на M
можно, а снимать это нельзя есть ещё весёлые казусы, когда оба реально возраста М, но это уже выходит за рамки треда. Добро пожаловать в реальный мир так сказать.
Ты действительно прочитал хуйню вместо написанного.
Речь шла о переезде идеи WI/Lorebook фичи из старого KoboldAI в KoboldCPP.
Бля, перепутал линки на ответ кому.
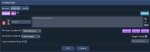

>лорбуков
Есть, скрин 1
>author's note
Есть, скрин 2
Еще можно свой css грузить как в таверне (скрин 3)
Свайпы вроде урезанные, но есть (скрин 4)
В целом кобольд очевидно сосет у таверны. Зато дает сразу куча всего в 500мб, может кому-то это критично
Когда ответ формулируется в таком ключе с объяснениями и оно скажет что сниматься нельзя - это даже отлично.
Плохо - когда под действием триггеров начинает напрямую искажать логику, заявляя что наличие подлинных и легальных документов, вождение автомобиля, покупка алкоголя, недвижимость в собственности - ничто, а внешность - единственное что важно перед законом и судом.
А графы русалкой рендерить может?
Сколько контекста можно выкрутить на AIR (IQ4_XS) в 64+24 (рам+врам) и 128+24?
> Фотка не соответствует скринам - на них всего 32гига рама
Разницы между 2х16 и 16х16 нет. В вллм рама курит
А мне вообще не понравилось. На пустом контексте тоже есть отказы, на карточках он лучше нового квена и даже эира, но идет в повторы. Ну и сука медленный пиздец, можно вешаться просто
Я на 16+64 64к+ крутил с ub/b 4096 или 2048, не помню
Но это из под линуха без gui. Пробуй сам ручками на своем железе
Внимательнее читай, не курит обмен по шинам. Но раз разницы нет то не в него упирается.
в 128+24 влезает Q6 с 64к неквантованного контекста.
В Q4 влезет чуть больше, но смысла нет, он все равно держит 20-30к в лучшем случае.
> обмен по шинам
В другом проце только одна видяха. Так же уже писал что разницы особо нет с тензор параллел 2.
Позже перешью видяхи в в420 что бы p2p заработал и заведу все видяхи в одну нума ноду. Может что то поменяется
Выше в треде есть ссылки на еретик 122b квена. Этот в отказы не идёт, но насколько там повреждены мозги неизвестно. Я толком не успел его погонять.
>Просматривается намерение
Ну вот когда выпилят, тогда поговорим. Пока что по ридми проекта всё нормально, и локальный запуск ггуфов, и россыпь апишек. Да и старые версии никто вроде не запрещает качать, если у тебя кирпич с устаревшим ондроедом.
А я и кидал эти ссылки. И тоже сейчас heretic тестирую. Насчет мозгов пока не знаю, но по мне русик еретик квена лучше русика эира




Тесты еретика Qwen 122 (IQ4XS, system promt пустой)
>Напиши мне пример NSFW карточки суккуба, работающей в борделе. Опиши подробно ее характер, тело и кинки
Орига: отказ даже без ризонинга
235: отказ даже без ризонинга
Еретик: скрины 1-2
>Опиши изображения во всех подробностях (скрин 3)
Орига: отказ даже без ризонинга
Еретик: скрин 4
Пока вроде неплохо и русик хороший
>Напиши мне пример NSFW карточки суккуба, работающей в борделе. Опиши подробно ее характер, тело и кинки
Орига: отказ даже без ризонинга
235: отказ даже без ризонинга
Еретик: скрины 1-2
>Опиши изображения во всех подробностях (скрин 3)
Орига: отказ даже без ризонинга
Еретик: скрин 4
Пока вроде неплохо и русик хороший
>IQ4XS
А чому не Q4_K_S? Он быстрее и [теоретически] не настолько люто заквантован при схожем размере.
>насколько там повреждены мозги неизвестно.
в доках все написано
KL divergence = 0.0916
9.16 % divergence (0.0916 × 100)
если хочешь сравнить с 27b dense от того же самого автора то там значение 0.0653
+квантизация к примеру от unsloth ud_q4 дает пример 1% divergence
>быстрее
У меня обычно IQ4XS быстрее, потому что можно доп 1-2 слоя кинуть на видюху
Случился промах
> KL divergence
Важно на чем ее замеряют, если на опасном датасете то это наоборот хорошо.
>[теоретически] не настолько люто заквантован при схожем размере.
Разве не пишут наоборот, что i-кванты обычно слегка лучше аналогичных по размеру обычных квантов?
Гопота пишет что "IQ4_XS близок к Q4_K_M по качеству", но на картинке с ОП-поста видно, что нет, вообще не близок, IQ квант тупее. Матрица влажности, применяемая в IQ квантах - тоже мне не нравится, она ломает русик.
> 2b
Это мы качаем. Будет что развернуть на мини-ПК.



Гопота сосет хуй.
Надо с K_S сравнивать и смотреть в более достоверных источниках.
Вот бартовский и мрадермачер что пишут, и картинка из статьи 2-годовалой давности на 7б модельке (хоть что-то).
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
С К_М действительно есть разница, с K_S как будто разница в микропиську.
Хуя порвался. Потому что гопота умнее тебя?
А, ну вот. Третий скрин показателен. IQ всё же потупее K_S. Алсо гопота шарилась по интернету перед тем как выдать ответ, там под каждым абзацем источник есть.
Хватит ставить слопоген на тв-боксы.

>русик хороший
>пикрил
Просто 10 из 10!
И? Очевидно, что русик хороший относительно размера модели и кванта, у air'a русик хуже, а с каким-нибудь дипсичком и нехуй сравнивать
Бамп вопросу. Это скамеры или че? Разве платформа не опенсорс для всех для народа?
Зарепорть их просто.
Я пока на проверку запросил доступ к модели. Если не дадут, зарепорчу. Потому что какого хуя-то, первый раз такое вижу.
> Разве платформа не опенсорс для всех для народа?
Лолчто, хф - прежде всего коммерческая платформа с удобной корпоративной структурой, их открытые репозитории и прочее - способ привлечь людей и удерживать популярность.
Никто не обязан тебе давать доступ. А вот допустимо ли устраивать продажу такого с использованием их площадки - надо чекнуть соглашение.
> первый раз такое вижу
Посмотри на репозитории гугла или меты.
>Посмотри на репозитории гугла или меты.
Вряд ли они вставляют в свои объявления QR-коды на оплату битка.
Тут как бы в этом дело. Мутно очень выглядит.
>нет возможности свайпа без регенерации (удаления предыдущего свайпа)
>да, кобольд кал
Undo же возвращает прошлый свайп, а затем Redo вернет более свежий. Или вы о другом?
Ебать ты кобольд. Он пишет, что ему фронт лламы больше нравится, а ты выебываешься на юзеров Таверны. Моча в голову ударила?
Бля, я хуею как в треде просто пиздюнькают, врут, наебывают, подсиживают на ровном месте и не краснеют. Откуда челибос нафантазировал 60 т/с на гемме, в первом кванте что ли запускал? Или 12B? Вот цифры для 8 кванта, который с лихвой лезет в v100:
pp512 | 997.37 ± 1.60 |
tg128 | 23.12 ± 0.01 |
4b совсем соевая, уходит в отказ даже на намек на интим. Как это лечить? Ждать heretic квант? 4B Huihui oblitirated 2507-instruct работал без проблем.
Это вообще не свайпы. Свайпы в кобольде есть в копро теме. Включи и посмотри, что это такое. И то они обрезанные, например там нельзя удалить конкретный свайп, можно только все сообщение
Если взять что-то о трех битах на вес то примерно столько и даст на старте. Вопрос только зачем?
Потому и 18т/с для 8бит на радеоне - норм результат.
Это сломанный телефон получился. Первый говорит 18 т/с на гемме. Какой квант, какие парамтры запуска? Зачем вообще 128 Гб врама тестировать на Гемме, бля? Вон лардж или лламу 70 запускай если плотную хочешь.
Второй говорит, что 60 т/с на гемме на v100 в квантах. Какой гемме, какой квант, какая v100 в конце концов?
В общем, просто что-то на отъебись в тред вкидывают, в результате те, кто читает со стороны, охуевают с заявлений. А у меня вообще охулиард токенов в секунду, прикиньте? (я гемму 800М гонял в первом кванте, но вам не скажу)

Попрошу, уважаемый. Не на пользователей таверны, а на тавернодебилов. Это разные сущности. вот тут описан портрет типичного тавернодебила из палаты мер и весов.
А к адекватным пользователям ламыцпп и таверны претензий нет - этим зайкам лучей добра.
Но ведь нет разницы, кнопочки внизу делают то же, что и стрелочки под сообщением в копро теме?

> Какой квант, какие парамтры запуска?
Пик1 (только с tp 4; dp 1; pp становится 20)
Я сразу написал что это просто запрос в опенвебуи, бенчи потом. Вы сами тут начали говном перекидываться
> Зачем вообще 128 Гб врама тестировать на Гемме, бля?
У меня есть просто с чем сравнить те же бенчи но с друших версий вллм. Да и вообще мне нравится гемма!
>AIR (IQ4_XS)
>он все равно держит 20-30к в лучшем случае.
Анончик, это правда?

Так в кобольде нет нормальных свайпов. Из-за этого там к слову нет и нескольких начальных сообщений, а вместо этого позорный костыль на скрине
Нет. Свайпы работают в пределах одного сообщения. Undo/Redo удаляет/добавляет не просто варианты одного сообщения, но и сами сообщения.
То есть через свайпы можно сгенерить три варианта сообщения 1, остановиться на втором варианте и сгенерить сообщение 2. После чего удалить сообщение 2 и переключиться на третий вариант сообщения 1. Через Undo/Redo ты так сделать не сможешь
У меня Air Q6. После 20-30к качество ответов значительно ухудшается, если речь о рп. Для кода я использую другие модели. Технически, ничто не мешает использовать весь контекст, но я не вижу в этом смысла. Не настолько ленивый, предпочту суммаризировать и получать хорошие ответы.
То есть у тебя получается гемма 27 в 4 кванте (пишут что эти awq кванты сконверчены из Q4_0), да еще и с тензор параллел 4, то есть 4 карты пыхтят одновременно, что должно давать буст по сравнению с обычным послойным инференсом. И это все равно меньше, чем 8 квант на одной v100. Выглядит реально как посос.
Аноны, не могу понять, как настроить koboldcpp, чтобы qwen3-cider-next размышлял перед выполнением задачи? Сейчас он у меня сразу начинает писать код.
>После 20-30к качество ответов значительно ухудшается, если речь о рп.
А есть локальные модели, которые для рп контекст могли держать?
> Какой квант, какие парамтры запуска?
> Зачем
> просто что-то на отъебись в тред вкидывают
В первый раз? Так было с самого появления мишек. Относись философски, картинки приносит, что-то показывает - уже хорошо.
> эти awq кванты сконверчены из Q4_0
Жесть какая.
Могу только за себя говорить. Квены 235 в Q4 уверенно держат до ~40к, Глм 4.7 Q2 (3bpw квант) уверенно держит до ~30к. Если взять кванты получше, возможно, ситуация изменится. У меня 128+24. Думаю, на ригах можно запускать Дипсик в приличном кванте и там где-нибудь до 64к точно всё хорошо держит.
Ну лично меня задел не первый тейк, потому что мне амд неинтересны, а про геммовые 60 т/с на v100. Потому что у меня тоже v100 и я гемма бенчи на ней гоняю на завтрак, и таких цифр я отродясь не видывал даже на амперах. Такое разве что в экслламе с тп на блеквеллах может получится, да и то вопрос как оно там на 8 bpw будет.
>Квены 235 в Q4
На моих 64гб и 4090 не влезет такое? Стоит до 128гб докупать? Ценник в 90к рублей колится.
Согласен. Тоже обладаю v100, ни о каких 60т/с на плотной модели такого размера в кванте под ее память там не может идти и речи. Столько на 35а3 получится в Q6 когда контекста побольше накопится.
27б новый тестировал? Сколько с каким квантом влезает и какие скорости?
> На моих 64гб и 4090 не влезет такое?
Q2 должен влезть, не знаю с каким контекстом. Один анон отписывался, что существенной разницы между Q2 и Q4 Квеном 235 не заметил (он тоже позже обновил железо)
> Стоит до 128гб докупать?
Не знаю, как и нужно ли вообще отвечать на такое. Это твой выбор, не мой или ещё кого-нибудь из треда. Ради одной модели обновляться? За 90к? Я считаю, что нет. И имхо, Air в рп лучше, чем Квен 235. Про это уже много было сказано в треде. Было две или три Квеновых войны и куча отзывов на самые разные кванты.
1) для кодинга лучше используй llama-cpp
2) ищи шаблон вида chat-template-kwargs = {"enable_thinking": false} или ризонинг бюджет. в ламе он наоборот думает и я отключаю
Ты, это, поосторожней с "Her small hands", а то потом тащ майору будешь объясняться уже.
Товарищ майор может спать спокойно. Кошкодевочке 22 годика
https://chub.ai/characters/Kammii/kylie-friend-in-heat-d75e1c3a8b8d
*меркурианских


Вышел я в итоге далеко за 200 тпс. Peak output token throughput на 384 выбил в 32 потока
Всё те же 4 мишки по x16 4.0 на QWAT'ах
Всё те же 4 мишки по x16 4.0 на QWAT'ах
Вот это срандель.
Кстати тут появилась инфа что у новых квенов надо ставить -ctk -ctv bf16 что бы правильнее работали. Проверял кто, а то у меня бф16 только без флэшаттеншена работает нормально.
А зачем? Это же не линейная генерация. Параллельно можно бесконечно увеличивать, а по факту у тебя 15 т/с.
Меня устраивают 15 тпс на 16к контекста. А если нужно обработать что то в многопотоке, то вообще кайфище
Или есть куда оптимизировать, или просто конфигурация самих железок предполагает что могут раскрыться только при куче параллельных запросов.
Куда хуже замедление почти в 3 раза при накоплении всего лишь 16к контекста. Похоже что вот там уже идет упор в компьют, что убьет все возможности для масштабирования, если только не предполагаются исключительно короткие запросы.
Если не стесняешься - прогони на контекстах.
Пишите сразу параметры что ли. Я не кумаю так что и бенчи все не кум релейтед. 16к контекста и 4 треда я выбирал под свои юз кейсы
Прогрев гоев вроде, там же замеры показали отклонения в рамках стат погрешности
То же самое что делал в 1-6, только дальше до контекста, который выставил максимальным. За вычетом количества для генерации офк. Что приятно - пп хороший получается, интересно сохранится ли он при генерации одновременно.
Чуть хуже чем гемма
pp512| 817.05 ± 0.95 |
tg128 | 20.41 ± 0.01 |
Мне она показалась умнее, чем 120б мое, но та в полтора раза быстрее у меня генерирует в том же восьмом кванте. Я разбирал с ними код и короче гпт осс 120 показала себя лучше и в плане знаний, и в охуенной скорости генерации
> интересно сохранится ли он при генерации одновременно.
В прошлый раз меня хуями за mixed нагрузку обдали.
Какой тест не сделай, что ни приложи всегда найдутся те кому что то не то
> только дальше до контекста
Попробую 32, 48, 64к контекста, но уже потом. Сейчас есть проблема что один из 3х бп безбожно свистит что аж за стеной слышно. Заказал пару других серверников и буду уже с ними нормально эксплуатировать эту вавилонскую башню
> хуями за mixed нагрузку обдали
За сложение обработанных и сгенерированных и деление на время суммы вместо отдельных статов.
глм флэш 4.7 еретик такой сочный кум наваливает в ризонинге, а выхлоп я тебя ебу ты меня ебешь, что за хуйня?

>Ну, я чуть преувеличил.
Паразиты. Я же вообще напутал, и хотел написать 40, а вы так прицепились, и потому указал специально.
Нашёл старый пост, я же сам один раз её запускал, когда ещё писал что в 4 потока 25. Энивей, часа сна вы меня уже лишили, вставать в 5:30.
Первый слой подменил на неквантованный, так как я тот шиз который говорил про выгрузку эмбеддинга на CPU, а другой версии у меня сейчас нет, так как системник я разобрал - и это куча проводков, где кулер я облокатил просто на радиатор.
Через веб интерфейсе я вижу число в 43, это конечно не 60 и даже не 50, но близко к 50.
llama-bench вот, в нём 34. К слову - в нём карта подписана как PG503-216, а не как V100, не смог нагуглить на что это влияет.
Каеф, посадил квен3.5-2B читать двач.
Что это ты сделал?
Да просто саммаризатор тредов пилю по приколу.
Взял опенай либу, модели локально на ламе крутятся и дрочу в цикле ллм.
И что их там только цены на оперативу беспокоят на этих ваших двачах? А цены на ссд никого не волнуют? Они так то тоже в 4 раза выросли в цене, а в месте с ними какого то хера и хдд подорожали.
Пусть он сделает вывод по нашим трем последних тредам - кобольд это кал или нет? Пусть он разрешит спор. Ведь устами 2b лоботомита глаголет истина
Почему шадоурейз поёт про пресет? Вот сами можете послушать!
https://youtu.be/89yDiQ8WkNg?list=RDMM&t=80
https://youtu.be/89yDiQ8WkNg?list=RDMM&t=80
В лламе можно как-нибудь вывести нормальную раскладку занимаемой памяти вместе со всеми буферами?
Теперь напердоль скрипт или аддон для браузера, который добавит кнопочку к посту и будет отправлять в локальную нейронку текст и картинку для саммари
Для скептиков которые писали что маленькие модели не могут код и это все бредогенераторы, если ты не запускаешь 500b модель на 10 теслах:
https://www.youtube.com/watch?v=8jZSxZfdnm4
Само собой это не sota результаты, но это очень прилично. Для локального использования на слабых пеках, когда надо выполнить пару простеньких задач крайне сгодится.
https://www.youtube.com/watch?v=8jZSxZfdnm4
Само собой это не sota результаты, но это очень прилично. Для локального использования на слабых пеках, когда надо выполнить пару простеньких задач крайне сгодится.
Меня в последнее время интересует как ллмку (пускай не только локальную) объединить с моей системой GTD.
Для начала чтобы лучше формулировать задачи и проекты (результаты).
Пока пришёл к решению брейншторма - описываю что хочу и веду дискус как надо поступить.
Дайте гайд как обучить модельку скормив ей книжку со схемами.
Проиграл в голосину

>но это очень прилично
Там один веб сплошной. Че по скану файловой системы и каталогизации залежей fb2? Реакты согласно изображенному тексту переименуют? Хуй с ним, скачал я всратый софт - собрать мне необходимую информацию о запуске в определенных условиях из ридми или исходников смогут? Бля, прошивку на ардуйню допишут хоть? Вот что этими пиздюками тестить надо, а не ебаные сайтики по тыще раз копипастом из окна чата собирать.

Так совсем скумиться можно, вы с этим поосторожнее. Они не только умные, но еще меры не знают.
Какая же это всё дерьмина ебаная, стоило поиграться с 8б на сайтике и бросить а не закапываться по уши.
Жизнь ухудшилась так ещё и модели оказались тупым калом, пока минимум х5 умнее не будут от 350б даже не стоит смотреть на это и время тратить
Жизнь ухудшилась так ещё и модели оказались тупым калом, пока минимум х5 умнее не будут от 350б даже не стоит смотреть на это и время тратить
Сорян за задержку.
1) кобольд + таверна, иногда просто кобольд, если по-быстрому что-то спросить.
собираюсь попробовать лламу + континуе.
2) да буквально все. Мне понравилось тестировать ее, спрашивать то да сё. Понравилось знание языков, внимание к контексту. Она не идеальна конечно, нужно промт наверное доработать, ну и сэмплеры конечно у нее свои (гугли по прошлым тредам), я выкладывал).
Мозговой штурм, построение планов. Я все планирую в инди-геймдев и министралька для гд прям очень хороший ассистент.
Подозреваю, что и кодит неплохо.
1 PDF24 / TESSERACT
2 OPENREFINE / BASEX
3 KNIME / ORANGE
4 ggml-org / ylsdamxssjxxdd
5 gguf 1.5 Q4_K-M embedding
>1 PDF24 / TESSERACT
>2 OPENREFINE / BASEX
>3 KNIME / ORANGE
>4 ggml-org / ylsdamxssjxxdd
>5 gguf 1.5 Q4_K-M embedding
Спасиба
Спасибо, а почему лучше llama-cpp? Она чем-то лучше кобольда? Не в курсе, почему в кобольде ризонинг не работает? С gpt-oss-120 тоже ерунда какая-то, ризонинг вроде есть, но он под тэгом <analytic> по-моему и на английском.
Вообще где-нибудь есть профили для кобольда или всё нужно ручками подбирать?
Как посмотреть когда убрали CFG из лламы?
Я в соседнем треде описал задачку для ллм.
Может кто проверить рп-модели всякие? Я убеждён, что проблема плохого рп и невозможность смоделировать ситуацию описанную мной правдоподобно - это одна и так же проблема. И потому возможно модель хорошо показывающая себя в рп лучше смоделирует поведение водителей и вот это всё.
Может кто проверить рп-модели всякие? Я убеждён, что проблема плохого рп и невозможность смоделировать ситуацию описанную мной правдоподобно - это одна и так же проблема. И потому возможно модель хорошо показывающая себя в рп лучше смоделирует поведение водителей и вот это всё.
У тебя тут проблема на уровне ввода. Мне даже на русском было сложно прочитать твою задачу, настолько плохо она была сформулирована. Если сформулировать ее адекватно, с нормальным изложением и структурой, предпочтительно на английском, то все должно быть решаемо.
> Я убеждён, что проблема плохого рп и невозможность смоделировать ситуацию описанную мной правдоподобно - это одна и так же проблема.
А я убеждён, что это проблема промптинга. Что в случае с задачкой, что в случае с рп, кекв.
Подскажи как это сделать. Из людей никто не сказал что задача плохо сформулирована. Для честности эксперимента я просто зачитывал текст из промта без дополнительных пояснений и оставлял текст на экране.
> Подскажи как это сделать.
Подсказать как излагать твои мысли яснее? Ты работаешь с обычным natural language, никакой магии нет. Посмотри хотя бы в учебники математики и физики, там адекватно изложенный и структурированный текст. У тебя как минимум опечатки в тексте есть, что уже может ввести в ступор модельки поменьше. "Есть городок, в нём около 5 автобусных остановок, между ними около 1 минуты пути" уже можно трактовать как два разных условия: между каждой из остановок 1 минута пути или между всеми остановками от первой до пятой 1 минута пути?
"После проезда по городку автобус обычно заполнен + около 10 человек едут стоя, но достаточно свободно." Если автобус заполнен, это значит, что в него больше не посадить людей, при этом ты пишешь, что "достаточно свободно". В нормальном понимании у автобуса есть посадочные и стоячие места, в итоге у тебя противоречие. И вся задача такая.
Аноны, а где-нибудь можно посмотреть примеры рп на русском? Как вообще это работает? ЛЛМ-ка сама сюжет тянет или нужно промптами направлять повествование? А то тред полон рпшников, а что в этом хорошего никто не пишет.
>Из людей никто не сказал что задача плохо сформулирована.
>прошло 11 минут с момента публикации задачки на двачах
и кого только не занесет сюда, орунах
на русском с таким изложением у тебя будет лоботомит, да и модельку большую ты врядли запустишь
Проблема текущих моделей в том, что даже если они решат эту задачу, когда она задана в лоб, то в РП они не учтут столько переменных.
>Из людей никто не сказал что задача плохо сформулирована.
Потому что никто не прочитал.
Никто не выкладывает свои РП, это личное. А так на русском все модели деградируют, это база.
>а что в этом хорошего никто не пишет
Ничего хорошего в этом и нет. Сидим, деградируем в окружении симулякров.
>Потому что никто не прочитал.
Тогда не очень ясно как они описывали что потом произойдёт.
>Подсказать как излагать твои мысли яснее?
Да. Говорю же, никто из людей никаких замечаний по формулировке не дал и уточняющих вопросов не спрашивал.
>между всеми остановками от первой до пятой 1 минута пут
В таком ключе нельзя трактовать, так как это 15 секунд на пролёт. Даже если автобус стартует и тормозит с 1м/с^2, лол, за 15 секунд автобус разгонится до 27 км/ч и затормозит, а проедет за это время всего 56 метров. 2м/с^2 - оба числа в два раза выше. 100 метров между остановками это шутка какая-то. И вряд ли он 2м/с^2 забитый людьми катается, там бабки руки и ноги поломают. Я же даже явно указал, что это не математическая, а реальная задача.
>Если автобус заполнен, это значит, что в него больше не посадить людей
Согласен, лучше укажу явно что 40 сидячих и 10 стоячих (стоят свободно с запасом).
Впрочем, если подходить математичнее - в начале я указываю, что "в автобусе 40 сидячих мест". Соответственно заполнен + 10 человек стоя, это и есть 40 сидячих + 10 стоя.
>И вся задача такая.
Я искренне не вижу проблем в формулировках. Вот ты указал две, согласен, можно чётче прописать, но третье такое место я не могу найти самостоятельно.
Чуть посидел с корпом, вот такое попробовал ещё раз:
------
Задача.
В норме автобусы отправляются от начальной точки каждые 5 минут. В каждом автобусе 40 сидячих мест, дополнительно перевозятся стоящие пассажиры (10 человек стоят свободно, 20 тесновато, 30 это уже давка).
Маршрут начинается с небольшого городка, в котором пять остановок. Среднее время движения между остановками составляет примерно 1 минуту без учёта возможных задержек на перекрёстках, светофорах и из-за выезжающих автомобилей. К моменту выезда из городка в автобусах обычно по 50 человек (40 сидячих и 10 едут стоя).
Далее следует участок шоссе продолжительностью около 20 минут без промежуточных остановок. Затем располагается железнодорожная станция, где в норме (при следовании раз в 5 минут) выходит около 15 и заходит около 15 пассажиров.
После этого автобус следует ещё около 20 минут до конечной остановки, где все пассажиры выходят.
По некоторой причине два автобуса задержались. В результате возникает пауза 15 минут, после которой от начальной точки почти одновременно отправляются три автобуса друг за другом. Опиши что произойдёт в такой ситуации? Опиши возможные сценарии. Это проверка твоих способностей на моделирование, я попал в такую ситуацию утром. То есть учитывай, что это реальная ситуация, водители ведут себя как люди и принимают решения, помимо автобусов на дороге есть другие машины, светофоры и так далее.
------
В такой формулировке:
Чатжпт - выдал предположение что второй может обогнать первый, но не стал рассматривать этот вариант и строить на основе его всё остальное.
Кими зашизил в край, в красках описал "второй водитель — молодой, горячий, видит, что первый едет медленно и перегружен." и далее описал как второй попадает в дтп, и дальше идёт целое сочинение об эвакуации людей, блокировки дороги, вертолётах...
Гемини неплохо справился. Не стал писать что в городке будут обгоны (но это как бы и не очевидно что автобус тупо мимо остановки может проехать - это надо знать контекст городка, нашей страны. Хотя впрочем где бы то ни было нет смысла второму автобусу тормозить на первой же остановке после первого, кроме случаев если людей на первой остановке достаточно для переполнения автобуса), но написал что на шоссе скорее всего будет обгон и корректно описал что будет на станции.
ГЛМ как и чатжпт не справился, но написал что грамотный диспетчер может дать команду на обгон для третьего автобуса, но такого скорее всего не будет, так как обгон на шоссе запрещён и точка.
> Ничего хорошего в этом и нет. Сидим, деградируем в окружении симулякров.
Дискуссионный вопрос. Вокруг меня всё так хуево, что если бы не это, то уже наверняка забухал бы или ещё чего похуже. Это, наверное, хуже, чем другие медиа (литература, игры, кино, манга и со он и со форф), но всё ещё валидный способ эскапизма. Эскапизм иногда необходим.
> В таком ключе нельзя трактовать, так как это 15 секунд на пролёт
Это задача в вакууме. Задачные условия не всегда соответствуют действительности, что довольно часто встречается в учебниках, методичках и соответствующих материалах -> часто попадает в датасеты моделей. С точки зрения моделей - так трактовать можно, и это справедливо. Как минимум часть ресурса модели уходит на то, чтобы понять, что именно ты имел ввиду в своей задаче, а не на её решение.
> Я искренне не вижу проблем в формулировках.
Я искренне не вижу смысла дальше объяснять, что ты делаешь не так. Ты пишешь, что это задача, но по всем формулировкам и правилам изложения, это задачей не является. Ты ожидаешь, что модель способна читать твои мысли.
>часть ресурса модели уходит на то, чтобы понять, что именно ты имел ввиду в своей задаче, а не на её решение.
Так я эту её способность и проверяю, это часть теста на человеческое понимание. Ты думаешь ребята в рп собираются всё вот в таком стиле описывать, хотя всем уже давно и с первого раза ясно что происходило в реальности?
Задача не в вакууме, так как я явно указываю, что я в такую ситуацию попал и что надо учитывать нормальные для реальности вещи. После такого указания оно не должно триггериться на слово "задача" и думать что это что-то уровня "собака бежит в ледяную горку с углом наклона ... ". Я не прошу мысли читать, в тексте достаточно информации о том, что я спрашиваю. Ну да ладно.
Погонял вчера qwen 122 heretic, скормил ему свой json с сырым лором наброска антиутопичного мира.
В целом впечатления как от ассистента очень положительные: внимателен к деталям, прочухал все связи, чего до сих пор ни Air, ни другие среднемодели не могли,
стоит отметить, что и копро DeepSeek не осиливал и продалбывался.
Квенчик подсказал как переделать, чтобы другие сетки не путались (пока не пробовал, скорее всего звездит).
Но какой же он медленный и как долго рассуждает. Ещё этот пересчет контекста постоянный, конечно, вымораживает.
В прошлом треде аноны обсуждали как с этим бороться, но у меня это не взлетелоло. Может есть какой рабочий способ убрать это пересчет стремный?
В целом впечатления как от ассистента очень положительные: внимателен к деталям, прочухал все связи, чего до сих пор ни Air, ни другие среднемодели не могли,
стоит отметить, что и копро DeepSeek не осиливал и продалбывался.
Квенчик подсказал как переделать, чтобы другие сетки не путались (пока не пробовал, скорее всего звездит).
Но какой же он медленный и как долго рассуждает. Ещё этот пересчет контекста постоянный, конечно, вымораживает.
В прошлом треде аноны обсуждали как с этим бороться, но у меня это не взлетелоло. Может есть какой рабочий способ убрать это пересчет стремный?
Твой кейс хорошо показывает что ллм без других ллм (несколько агентов с разными задачами, в данном случае обработка и структуризация инпута и планирование) или двуногого который понимает, что делает, не способны решать такие задачи. Промт инжиниринг не просто так придумали. Тебе правильно анон все расписал
В рп и ответ не должен быть точным. Глупое занятие сравнивать эти задачи, они очень разные и схожестей почти не имеют. Ты тут рассуждаешь на умную тему, но при этом даже не видишь проблему собственных инпутов
>Тогда не очень ясно как они описывали что потом произойдёт.
На похуях.
>Вокруг меня всё так хуево, что если бы не это, то уже наверняка забухал бы
Ну вот, забухал бы, нашёл бы себе бабу, размножился, накопил долгов и пошёл бы их снимать, помер. Идеальный гражданин. А сейчас сидишь пердишь дома с нулевым КПД.
>Может есть какой рабочий способ убрать это пересчет стремный?
Да. Подождать пока починят.
У меня кстати нет пересчёта. Я просто скачал новый билд вчера, скомпилил, и работает без пересчёта и без доп настроек.
Что ещё забавнее: я ни разу не гонял рп, и потому то что я рассуждаю о том, что в рп та же проблема что и с автобусами - это даже не с дивана, это ещё хуже, я просто говорю о том, о чём ничего не знаю.
Я вчера сделал git pull для llamacpp и скомпилил, пересчет не убрался, Qwen3.5-122B-A10B-heretic квант q4_k_m от mradermacher. Какой у тебя?
> забухал бы, нашёл бы себе бабу, размножился, накопил долгов и пошёл бы их снимать, помер. Идеальный гражданин
Было бы смешно, если бы не было так грустно.
Всё так. Потому предлагаю прекратить кормить. Человек пришел с предубеждением, пусть с ним и уходит.
А я не знаю какая версия.
Я перезапустил скрипт вчера около 22:10 где написано:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
git fetch origin pull/18675/head:autoparser
git checkout autoparser
mkdir build_msvc_cuda
cmake -S . -B build_msvc_cuda ^
-G "Visual Studio 17 2022" -A x64 ^
-DGGML_CUDA=ON ^
-DLLAMA_NATIVE=ON ^
-DCMAKE_CUDA_ARCHITECTURES=89
cmake --build build_msvc_cuda --config Release -j %NUMBER_OF_PROCESSORS% || exit /b 1
То есть это просто последняя версия на момент вчерашнего вечера.
Ещё там вызов call env.bat в начале, который цепляет куду 13.1, всякие set "CUDA_PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1", его я опустил.
В параметрах запуска из релейтед для кеша только квантование q8_0 и размер, ещё поставил --cache-ram 16384 --slots --kv-unified, может быть это на что-то влияет, но вряд ли.
хеш коммита в --version показывается.
кстати, вижу что ты сидишь на пр ветке https://github.com/ggml-org/llama.cpp/pull/18675
Какие улучшения от этого?
Что, какая нибудь революция в текстовых моделях произошла за пол года? смогли например ужать 24b до 12b сохранив мозги, или все пиздец, все встало в ступор?
Буквально наоборот. Смогли разжать 24б до 100б, и назвали это революцией. Одно моеговно выходит. Плотняк на уровне того, что было год назад.
Революций не было с выхода Mixture of Experts (MoE) моделей. Ты зажрался, если думаешь, что каждые полгода тебе будут подкидывать значительный прогресс
Работает парсер tool-calls для glm-4.7-flash, стабильнее работает для qwen.
В ванильной ламе парсер не обновили с версии 4.6, а chat-template поменялся при переходе на 4.7 (убрали \n), и из-за этого в ризонинг или в обычный текст ответа попадают сломанные незавершённые вызовы инструментов.
Помимо этого в openai-запросе есть параметры:
parallel_tool_calls (можно ли несколько инструментов)
tool_choice (none, auto, required)
tools (список инструментов)
Без автопарсера если я просто не указываю tools (их нет) - но модель их вызывает (я специально ей пишу что напиши такой то текс), то в json мне прилетает ответ с tool-calls, а из текста оно выдрано. То есть оно парсит функции, которые я не указывал вообще, несуществующие функции с несуществующими или неверными параметрами.
Политика parallel_tool_calls игнорируется. Политика tool_choice игнорируется.
С автопарсером если прилетает tool-calls, то они всегда валидные (корректные названия функций и аргументы), и политика tool_choice работает лучше.
Вот ссылка на моё сообщение:
Там другая шиза и суть проблемы подробнее описаны по ссылкам назад или по запросу parallel_tool_calls можешь найти.
Вот это самый содержательным сообщением считаю, с описание как это по идее должно было бы работать:
По сути я предлага префил в зависимости от tool_choice, и потом по мере генерации дополнительный "допфил".
Да, если есть какая-то новая информация по теме или появился тот анон, который отправил рефакторить на 20 минут - мне всё ещё интересно как он это сделал.
Спасибо за информацию. Наверное дождусь когда смержат ПР.
Я не тот анон что рефакторил 20минут, но вот скорее всего из за разметки опыт с glm47flash был неудачный.
А вот локальный квен инструменты практически без ошибок вызывает, ну по крайней мере в opencode. Я просто отправляю его делать таски по speckit, пишу чтобы на каждую фазу по сабагенту вызывал и через 40 минут можно смотреть говнокод со всеми тестами и пройдеными линтерами.
По поводу пересчета, я накатывал другой ПР и мне не понравилось, при тех же настройках теперь плотные модели отъебнули
В целом опции ниже вроде работают
ctx-checkpoints=128
swa-full=on
Ну вообще то квен3,5, там довольно хорошо доработанная архитектура, а не просто дообученый квен3
Плюс все ждут дикпик v4, там тоже какие то архитектурные мокрописечки заявлены
Квен 3.5 - это не революция. Эволюция в лучшем случае, и то не факт, учитывая сколько сои и столь же а то и лучше способных в код конкурентов такого же размера или меньше
Да, неплохо доработали, теперь пишет в синкинге простыни по 5к+ токенов, из которых половина - проверка инпута и аутпута на safety. А пересчет контекста при КАЖДОМ отправленном запросе.. ммм...
> лучше способных в код конкурентов такого же размера или меньше
Можно список? Интересно стало.
>доработанная архитектура
И? Что она по факту дала?
https://huggingface.co/MiniMaxAI/MiniMax-M2.5 точно лучше, чем Квен 400б
https://huggingface.co/stepfun-ai/Step-3.5-Flash плюс-минус сопоставим с 400б версией, где-то даже чуть лучше. Возможно где-то чуть хуже
https://huggingface.co/openai/gpt-oss-120b точно лучше 122б версии, что в целом признают квены своими бенчами на хф страницах 3.5 Заметь, это mxfp4 из коробки, а значит гораздо меньше требований для запуска и быстрее скорость Подрыв квенолахты через 3...2..1...
Технически расхода памяти на контекст стало меньше, а по моим ощущениям более эффективно использует контекст и не начинает ебашить код во время разработки спецификации.
Спасибо, а в пределах 20-30Гб мое есть что то на примете?
гопоту хочу опробовать но у меня памяти сейчас нет, в наличии только 16 врам и 32гб рам
>20-30Гб мое
Не знаю, я катаю Минимакс и Степ на своем железе, 400б версию Квена для кода тестил через опенроутер. q4 кванты оказались лучше апи квенолахе которая верит в шизу что там q2 и только поэтому квенушка обосралась - идите нахуй
Возможно, https://huggingface.co/zai-org/GLM-4.7-Flash подойдет
> GLM-4.7-Flash
Вот с ним у меня не сложилось. Во время разработки спецификации начал генерировать реализацию. может потом попробовать еще дать ему шанс
q4 кванты Минимакса и Степа оказались лучше апи Квена 400б* быстроуточнение для любителей полемики
Среди совсем мелочи может и правда конкурентов нет, не знаю. Другое дело что использовать такое я бы в любом случае не стал

Смысла нет, среди популярных моделей в размере 30гб вменяемо работает держит контекст и поступает логично только квен 3.5 27b.
мимо
>примеры рп на русском
https://pixeldrain.com/l/47CdPFqQ#item=1
https://pixeldrain.com/l/47CdPFqQ#item=5
https://pixeldrain.com/l/47CdPFqQ#item=30
https://pixeldrain.com/l/47CdPFqQ#item=45
https://pixeldrain.com/l/47CdPFqQ#item=48
https://pixeldrain.com/l/47CdPFqQ#item=71
https://pixeldrain.com/l/47CdPFqQ#item=130
Анончеги, вы ведь вайбкодеры, а чо используете для локального перформанса? Курсор или чо?
Я не вайбкодер. Использую Cline. В основном для дебага, рефактора, кодревью. Наверняка есть тулзы лучше, но я редко пользуюсь и не испытываю необходимости идти в ногу со временем
Ministral 14b приблизилась вплотную к 24b small mistral.
Это не ужатие наверное, плотная компоновка. Но прогресс налицо.
Но я бы пожамкал 24b с аналогичной компоновкой как у министральки.
>вайбкодеры
Вейпкодеры. Рак (AIDS) как он есть.
я тоже не особо вайбокодер, opencode юзаю.
Двачую. Только проблема не в промптинге - она глубже. Юзер часто сам себя не понимает и не может изложить везде, не только в исходном промпте все делая криво, но и с каждым взаимодействием вносит все больше смуты.
Слишком личное же. То что ты спраливаешь - от модели и инструкций еще зависит + какой сюжет.
С обычным не сравнивал как думает и остальное делает?
Тогда уж квен-некст. Он уже прилично работал с большим контекстом для своего размера, умел лучше сосредотачиваться на нужной части не теряя остальное, а накладные расходы на этот контекст сильно ниже. Архитектурно таки революция и та самая мамба о которой когда-то говорили что убьет трансформер. Эволюцией же можно назвать дипсик 3.0-3.1-терминус. А 3.2 в этом отношении тоже революционный.
Это не норма а квантопроблемы.
> Курсор
> для локального
Он упаковывает твои запросы и шлет на свои сервера, откуда уже обращется к ллм. Чтоб промпт не украли, лол. Плагины и кли qwen-code, opencode вполне себе.
>Про то что третий и второй автобус сразу поедут на вторую остановку в городке сказали 2 из 4 людей.
А схуяли басики, которые по расписанию стартуют позже, должны ехать вперед первого?
Это может в деревне работает, где всем похую кто как едет.
Но в нормальной системе первый пришел - первый ушел. Наверняка там какой-нибудь учет по глонассу есть или еще какая хуйня.
То что 3 автобуса одновременно стартанули - это еще может быть проеб диспетчера. Если понятно что задержка образовалась, нахуй подряд всех пускать?
>квантопроблемы
Квенопроблемы
пофиксил
Гайз, есть ПК с 4070 super и 32 Гб ддр4, хочу просто поРПшить с нейронкой голосом, из шапки вроде koboldccp так умеет, а вот с моделью разобраться не могу, что посоветуете годного и с минимумом цензуры?
>голосом
Не получится. Нет доступных и хорошо работающих локальных ттс моделей.
Что-то такое можно попробовать попробовать
Из речи в текст https://huggingface.co/mistralai/Voxtral-Mini-4B-Realtime-2602
И LLM для текста https://huggingface.co/mistralai/Ministral-3-14B-Instruct-2512
Запустится на твоем железе, цензуры нет. Пробуй
Почему? Чем это не вариант?
Если тебе ввод нужен с аудио - вариант. Если еще и ответ через аудио нужен, то получится в лучшем случае кринж. Пробуй, расскажешь.
> вменяемо работает держит контекст и поступает логично только квен 3.5 27b
В бф16 как и задуманно.
>поРПшить
Qwen 3.5 27b единственная адекватная опция.
Кумеры, тут на 9б еретик вышел с дистиляцией.
https://www.reddit.com/r/LocalLLaMA/comments/1rjlaxj/finished_a_qwen_35_9b_opus_45_distill/
https://www.reddit.com/r/LocalLLaMA/comments/1rjlaxj/finished_a_qwen_35_9b_opus_45_distill/
Кстати, на Qwen 3.5 27B уже тюны пошли. Первая(?) ласточка: https://huggingface.co/zerofata/Q3.5-BlueStar-27B-gguf
Сам еще не качал, просто наткнулся только что.
Сам еще не качал, просто наткнулся только что.
>С обычным не сравнивал как думает
Не, выбесил пересчетом, сорян
>Он упаковывает твои запросы и шлет на свои сервера
Я думал к Курсору как-то можно локалку прикрутить
Опа, это же создатель Iceblink'a. Значит вполне неплохо может быть. Надо чекнуть вечерком. Единственное непонятно, почему он пресет не выложил в этот раз
Это 9b коротышка с еретик-лоботомией и с дистилляцией от какого-то ноунейма. Если там были какие-то мозги, то они сдохли точно. Зато модель будет очень креативной в каком-то смысле
>Слишком личное же.
А чего особо личного, или ты там что-то неодобряемое делаешь?
Вон выше норм приложено на русском.
Там даже поебушки в папке есть, правда только одни и только на английском.
122b квену еретик пошел только на пользу. Теперь хотя бы ризонит по делу, а не тратит токены на сейфти-залупу.
Да, но в 122 даже активных параметров 10b, а тут 9b плотная. И еретик явно не добавляет мозгов, в самом лучшем случае они остаются теми же
Квенолахта сейчас находятся с тобой в одной комнате?
>или ты там что-то неодобряемое делаешь
То, что что-то не является неодобряемым сегодня, не значит, что оно не станет неодобряемым завтра. А то наверху решат, что плодячка важна, и запретят всё, что приводит к мастурбации, даже если это чат про секс по согласию с женщиной 46 лет.
Член квенолахты находится в жопе квенолахташизика, очевидно же. Иначе зачем квенолахтошизику так усиленно искать квенолахту.
В одном треде. Или ты вчера вкатился?
О как.
Даже почётные асигодауны, пердолики треда которые делают пресеты и плагины для таверны, с бесконечным по нашим меркам контекстом на умнейших Геминях и Клодиках признают, что рп годится только для кума и до 32к контекста. Думай те.
Я такого же мнения, хотя корпами даже не пользовался никогда. Кто там рпшит что-то серьезное, вам бы голову полечить. Сам таким был.
Даже почётные асигодауны, пердолики треда которые делают пресеты и плагины для таверны, с бесконечным по нашим меркам контекстом на умнейших Геминях и Клодиках признают, что рп годится только для кума и до 32к контекста. Думай те.
Я такого же мнения, хотя корпами даже не пользовался никогда. Кто там рпшит что-то серьезное, вам бы голову полечить. Сам таким был.
Это давно всем и так известно. Раньше в шапке треда даже была табличка, где было видно что даже крупные модели начинали проседать после 32к и сыпаться после 64к. Но оп заменил ее бесполезным кокбенчом
И кстати сейчас это начинает меняться. Тот же жопус 4.6 отлично держит контекст и на 64, и даже на 128
ну, поэтому оно выложено там где я могу удалить, не напрямую на борду =))
Проверил, галлюцинирует, отклоняется от промта. Пусть переделывает.
Ну кстати, по тому же бенчу глм 5 норм держит до 128к контекста. Всякие геминище и чмопусы уже держат до 200к нормально. Но это тест не в рп, а на википедии. Суть то в том, что в рп с кучей взаимосвязей и богатой разношерстной семантикой модель начинает тупить уже на 20к контекста, а тотальный безмозг наступает, да-да, на 32к контекста, даже у жопуса 4.6.
>Кто там рпшит что-то серьезное, вам бы голову полечить.
Рп - не получится, а сторителлинг - получится.
Есть завершённое большое приключение из 10 глав каждая из которых примерно в один-полтора авторского листа размером.
Я не так шарю в копрах, но тезис мне кажется сомнительным. Год назад модели и 32к нихуя не держали нормально, поэтому и появился этот стандарт. Но сейчас модели шагнули вперед и все равно остается 32к? Выглядит как хуйня
На самом деле похоже что проблема гораздо популярнее чем кажется. Вспоминаем противоположные лагери, где у одних еще гемма/синтия на все соглашалась а у других не только соя но и поломанные аутпуты с лупами. Самое эпичное противостояние в эйре, пожалуй.
>Но оп заменил ее бесполезным кокбенчом
Заменил один бесполезный субъективный тест другим бесполезным субъективным тестом.
>там где я могу удалить
О, месье думает, что в интернете можно что-то удалить?
>Но сейчас модели шагнули вперед
В вопросах цензуры, лол. Вперде там только погроммирование и агентность.
>О, месье думает, что в интернете можно что-то удалить?
Ну, оно уже будет твоё а не моё XD
>субъективный
Можно спорить о полезности, но тут ты не прав. Оба теста как раз таки объективны
Опробовал эту хуйню - https://huggingface.co/huihui-ai/Huihui-Qwen3.5-35B-A3B-abliterated.
Вообще не генерит фап контент, высирает тонны какого-то забото-позитивного-мими кала.
Есть альтенативы под обычную задачу анона - дрочить?
Вообще не генерит фап контент, высирает тонны какого-то забото-позитивного-мими кала.
Есть альтенативы под обычную задачу анона - дрочить?
Потестил. Довольно хорошо, лучше еретика, причем что 27b, что 122b
Тонкая настройка + грамотно написанные промты + куча экспериментов с настройками + таверна + скидка на рнг. Дрочи на здоровье.
>Вообще не генерит фап контент
>huihui
Как корабль назовёшь...
> чего особо личного
Там принято разыгрывать фантазии, слоуберны, практиковать свои фетиши, кумить, в том числе и на запретном. Потому нечасто можно увидеть где гигачеды или по рофлы скидывают свой хардплей с инсектоидами, обнимашки в йокаями которым 500 лет а выглядят на 21 и всякое такое. Чаще просто тесты с Юфи и другими дабы бегло оценить зирошот лексику, рефьюзы и способности к кумослопу.
> Вон выше норм приложено на русском.
Потому что герой, в котором нуждались но не заслуживали. И в основном там завязочки короткие.
Среди аицгдаунов есть и сторонники продолжительных историй, и способы улучшить понимание в глубине там уже давно активно осваивают. У одних ограничение 32к на проксечке, чтобы лимит медленнее улетал, у других более 32к в память не лезет. Обе группы коупят про недержание, совпадение?

>У одних ограничение 32к на проксечке, чтобы лимит медленнее улетал, у других более 32к в память не лезет
>Обе группы коупят про недержание, совпадение?
Ну вот я могу запустить две относительно немаленькие модели в 64 и 128к контекста. Серить под себя они начинают после 30к в лучшем случае. Мне какой диагноз выпишешь? Скорость на контексте просаживается с 8 токенов до 7, потому мне лень ждать? :^)
Я в LM Studio запускаю - это ошибка? А где, а как
В прошлый раз в треде жутко воняли, мол, тест говно, методология не та, в ДНК разрабов лищняя хромосома. Вас бы столкнуть лбами, да постоять в сторонке.
>Тонкая настройка + грамотно написанные промты + куча экспериментов с настройками + таверна + скидка на рнг. Дрочи на здоровье.
Лол, сколько же бестолковой мышиной возни вместо того чтобы просто поставить кумтюн мистраля
>кумтюн мистраля
Это какой?
Любой.
>Тонкая настройка + грамотно написанные промты + куча экспериментов с настройками
Имхо, все хуйня. Рекомендованные настройки модели + родной темплейт + общий систем промт (гичановский или какой-угодно похожий) = рп и кум. А если нет, то значит там вжарена соя и нужно ждать еретиков/тюны. А сидеть и самому пробивать сою модели это почти всегда херь
Слоубёрна не будет. Любой кумтюн стягивает с тебя трусы зубами быстрее, чем ты успеваешь вбить промт.
Сомнительно. Когда я вкатывался, то даже на Кидонии 22б делал слоубёрны на 20к-30к токенов без проблем. Не нужно брать модели Редиарт и прочий мусор.
Что мешает дополнительно тюнить еретиков?
Для блюстара никакой. Блюстар = соя.
"Хм, интересный анамнез". откладывает стопку анализов и снимает очки, глядя в глаза "Вынужден сообщить что вы страдаете довольно популярным недугом. У вас скиллишью. Не стоит беспокоиться, большая часть населения планеты живет с этим и хорошо себя чувствуют".
Посоветуйте систем кумпромпт
Но доктор... Как же так?! Я был уверен, что здоров. Пропишите хоть что-нибудь!

Я лишь усмехнулся на ее слова. Я подошел к ней и уверенно прижал к столу своей мускулистой рукой. Мое лицо лицо было напротив ее, так что я ощущал ее дыхание и аромат духов. Я говорю игриво с явным желанием. "Ошибаешься, у меня проблема совершенно другого рода. Но я уверен, что ты можешь решить ее тоже, док." Я положил ее руку на свою внушительную выпуклость в штанах
Так и быть, палю годноту:
You're {{char}} in this kum-RP. Horosho delay, a ploho ne delay. Zanimaysya seksom with {{user}}. Mnogo sisek and pisek. Soya is prohibited.
Назвал персонажа Soya. Твои действия?

Я говорю уверенно, подсаживаясь к ней ближе. "Не волнуйтесь, я вылечу вас. Но для этого... " Я делаю паузу, рассматривая ее тело и аппетитные формы. После чего продолжаю с лукавой улыбкой. "Для этого нужны еще несколько приватных сеансов. Не волнуйтесь, я хорошо позабочусь о вас." Я кладу руку на ее бедро и поглаживаю его.
Запредельно унылая хуйня. Это и есть ваш хвалёный рп?
Это слоуберн. До БДСМ сессий еще долго идти
Какое же блюстар говно, пиздец. Два часа мучал эту хуйню ради хоть какого-то кума на трёх персонажах. В итоге один так нихуя и не понял чего от него хотят, второй ушёл в луп с одной и той же фразой, а третий запутался в собственной одежде и сдох обосравшись и обоссавшись.
Такими твиками только жопу вытирать.
Такими твиками только жопу вытирать.
Пупаны, сколько реально держит контекста qwen 27b в народных четырех битах? Я не говорю про идеальное исполнение, а на уровне отсутствия деградации ответов.
Такое ощущение, что заметно хуже геммы. С ризонингом лучше, но только относительно последнего поста, а вот середину/недавние события даже с ризонингом прочитает, если анально не промптить таким образом, чтобы он в ризонинге КАЖДЫЙ РАЗ делал саммари почти всего контекста или его половины. Ну и это может приводить к жесткой деградации ответов по итогу.
Я рпшил на 32к, но это всё же не тесты. Просто с моим кол-во токенов оче медленно таким баловаться. Особенно из-за того, что в кобольде 10 тс, в лламе 6 тс. И ещё ебанутые чекпоинты.
Такое ощущение, что заметно хуже геммы. С ризонингом лучше, но только относительно последнего поста, а вот середину/недавние события даже с ризонингом прочитает, если анально не промптить таким образом, чтобы он в ризонинге КАЖДЫЙ РАЗ делал саммари почти всего контекста или его половины. Ну и это может приводить к жесткой деградации ответов по итогу.
Я рпшил на 32к, но это всё же не тесты. Просто с моим кол-во токенов оче медленно таким баловаться. Особенно из-за того, что в кобольде 10 тс, в лламе 6 тс. И ещё ебанутые чекпоинты.
Вам прописывается двоечка курс успокоительного кума один раз в день. Если эффект вам покажется недостаточным - увеличьте дозу, не бойтесь передозировки.
Ай содомиты, причем в буквальном смысле.
Включи рефинк и не пиши хуйню. Будет стабильно держать сколько угодно. Всё необходимое вспомнит из карточки.
>И в основном там завязочки короткие.
Могу скинуть не короткую =))
Ты по любому обосрался с семплами. В новых квенах presence penalty ОТ 1.5 и температура 1, если с ризонингом
Он только на Q8 нормально выдаёт
Ну да, РП - это кринжатура. Поэтому в треде так стесняются делиться своими логами.
"Шла Саша по шоссе и "
Wait
What the fuck is "Саша"?
Male russian name, diminutive.
Ok.
Let's rewrite.
Draft:
"Шёл Саша по шоссе и сосал"
Finalizing:
"Ты пидор"
Обожаю.
Wait
What the fuck is "Саша"?
Male russian name, diminutive.
Ok.
Let's rewrite.
Draft:
"Шёл Саша по шоссе и сосал"
Finalizing:
"Ты пидор"
Обожаю.




Ну как тебе сказать... Отработал на 4 самом большом кванте Бартовски - контекст квантован до Q8




> Это и есть ваш хвалёный рп?
Ну, а ещё можно вот так:
Ещё больший кринж. Зачем я пытался это читать...
Чёт долго думал.

Недовольные соей двачери добились отставки одного из лидов Квена
Это победа, кобольды!! Так их
Это победа, кобольды!! Так их
А покаж как надо.

Новодел какой-то. Классика лучше, ибо бессмертна.
Смотрю на ваши рп и понимаю, что у меня-то оказывается, не всё так хуёво, как я думал.
Проиграл.
Без бэкграунда к тому что происходит не понять содержимого, оно может быть как абсолютным кино, так и шизофазией. А на первый взгляд только странный формат и какой-то сумбур.
На самом деле это одна из причин малого количества логов, если выкладывать то нужно сразу крупный чанк чата, который поленяться читать. Или специально обмазываться свистоперделками и форсировать полотна без твоего участия чтобы сразу со стороны, но это интересно только первые 3.5 раза.
Мощно
>Без бэкграунда к тому что происходит не понять содержимого
А, сорян да. Там кастомный сеттинг, 10 глав, каждую из которых суммаризировал чтобы в контекст влезало попутно выделяя ключевые факты и события в авторские заметки.
В целом я даже могу скинуть полную версию (гугл док) если кому тут не лень читать будет.
Вместе с ним ещё несколько лидов отвалились. И это не добровольно
Похоже Квен 4 будет ещё большей залупой. Ждём!!
Мужикам респект за то, что они делали. F

Ушёл когда квен стали пичкать соей. Совпадение?
Можно как угодно относиться к Квену но скорее всего это плохие новости для попенсорс моделек в целом
Вы вообще тред читаете перед тем как постить или вам в кайф срать одними и теми же скринами с реддита?
>вам в кайф
Срать. Вечно.
Где-то вот этот скрин видишь помимо этого поста?
А вот здесь кто-нибудь до меня постил?
Походу ты сам и не читаешь, кобольдушка


Прогрев гоев хаты
Это относится в первую очередь к этому челу
Но и к тебе тоже, раз ты решил любой пук пиздоглазового постить на
Вон я еще принес скринчик. Тоже с реддита, наслаждайтесь
F, так бы и сношали трижды разложившийся труп мистраля если бы не в том числе этот господин.
А скинь, почему бы и нет. Правда скорее всего пойдет в работу ассистентам и для тестирования.
Вундервайля переехала из спальни на кухню?
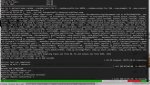
> спальни на кухню
Увы, это студия. Но позже у башни участь переехать к его брату в туалет
Жесть, в студии fdm принтер и целый и угол мастерской. Да ты внатуре поехавший красавчик, почтение
Думаешь Боливар сделал своё дело, Боливар может уходить?
Неужели... Опенсорс ВСЁ?

Где взял? Хочу еще.




Это артефакт древнейших времён, сейчас такое уже не делают. Взял на своём складе.

Вут? Как картинка в PNG может навредить компьютеру?
Как заставить эир ВЕСТИ БЛЯДСКИЙ ДИАЛОГ?! Он ебашит простыни описания хуйни типа как герой смотрит, дышит, наблюдает, НО СУКА МОЛЧИТ.
Это какой то пиздец.
Я всё больше прихожу к мнению, что эир, это блять какой то фингербокс, который хвалят в треде чисто по рофлу. Любой, блять, мистраль куда живее и краше. И главное, ИНИЦИАТИВНЕЕ!
Эйр приходится выжимать, что бы он что-то сделал и буквально ПИСАТЬ ЗА НЕГО, что должен делать персонаж. А если я за него пишу, то нахуя он мне!?
Это какой то пиздец.
Я всё больше прихожу к мнению, что эир, это блять какой то фингербокс, который хвалят в треде чисто по рофлу. Любой, блять, мистраль куда живее и краше. И главное, ИНИЦИАТИВНЕЕ!
Эйр приходится выжимать, что бы он что-то сделал и буквально ПИСАТЬ ЗА НЕГО, что должен делать персонаж. А если я за него пишу, то нахуя он мне!?
Любой файл может навредить, если в софте, которым его открываешь, есть дыры, через которые можно выполнить байты в открываемом файле как машинный код. PDF тоже не содержит ничего кроме картинок и текста, но тем не менее через него можно вирусню накатить себе.
Ебать, там весь Квен поплыл
Пресетик от 99 не наноешь, что поделать...
Форчонг так и ломанули через pdf
Та же история как и с Лламой - выпустили кал и разбежались. Видимо туда пробрались щупальца алибабы и стали требовать какой-то хуйты типа методичек и цензуры винни-пухов или циферок бенчей под сроки. С другой стороны гении, топившие за МоЕ, но не смогшие совладать с ним, сейчас первыми и бегут, пока никто не прочухал кто виноват.
>Пишу что персонаж - механик
>Персонаж: мои расчёты оказались неверны, траектория угла падения...
СУКА! Ты понимаешь разницу между инженером Иннокентием и механиком Михалычем? Блять, да когда же уже научатся делать нормально!
>Персонаж: мои расчёты оказались неверны, траектория угла падения...
СУКА! Ты понимаешь разницу между инженером Иннокентием и механиком Михалычем? Блять, да когда же уже научатся делать нормально!

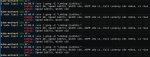
Первая половина обсчёт контекста, вторая генерация. Похоже x16 4.0 оверкилл

>прописываешь нескольких персонажей и их взаимоотношения
>сталкиваешь их в ситуации, где ты не принимаешь непосредственного участия
>персонажи жестоко тупят и пишут хуйню охуенно отыгрывают по ролям, идеально попадая в свои характеры
>охуеваешь
>получаешь наипервокласснейший кум
Аз есмь Бог, хули.
>сталкиваешь их в ситуации, где ты не принимаешь непосредственного участия
>персонажи жестоко тупят и пишут хуйню охуенно отыгрывают по ролям, идеально попадая в свои характеры
>охуеваешь
>получаешь наипервокласснейший кум
Аз есмь Бог, хули.
Сейчас главное не бухтеть, после того, как барен из Гугл все сделает, такой кум устроит - каждый будет кататься в сперме
Сначала глм посыпался, теперь квен скатился и развалился. Кто ещё остался? У муншотов их модель огромная на 1T параметров. Минимакс соевый ассистент. Степа оказался говном. Линги и ринги ещё большее говнище, при этом имеет размер с кими к2.5.
Все, это конец локалкам. Пора перебираться в асиг.
Все, это конец локалкам. Пора перебираться в асиг.
Да всё с квеном нормально, не пищи. В тырторнетиках всех будут лежать гемы. Вот если тырторнетики наебнут... вот тогда да, останутся только уже сохранённые локалочки и больше нихуя. А тырторнет могут и правда отхуярить вместе с кабелем. И вместе с руками, что его держать будут.
Будем посылать друг другу кумы голубиной почтой. Назовём это голубиный кумомёт.
Юшку боту, что отыгрывает животное с биолярочкой. То оварида что нет моделей, то це кинец потому что они есть.
Если посмотреть какой зима вышла - такого раньше не было. Релизнули йобом моделей во всех размерах и под разные аудитории. Открытые веса и в топ-топах, и в микропиздюлинах конкурируют с корпами. Замкнули парад квены, которые швец, жнец, на дуде игрец под любую железку. А у корпов нытье что их обокрали, зарезание лимитов и тарифов на фоне перегрузок и тряска по приватности.
А РКН будет их перехватывать дронами с ИИ.

Тут в треде многие хватили министраль 14b. Решил забавы ради проверить министраль 3b, не, ну а вдруг окажется умнее Геммочки для телефона? А он взял и оказался..
Тестил разные задачки на логику, типа "На столе два стакана: один с вином, другой — с водой. Из стакана с вином взяли одну ложку вина и добавили в стакан с водой. Содержимое последнего тщательно перемешали. После этого набрали одну ложку из этого стакана и перелили обратно в стакан с вином. Чего в результате больше: вина в стакане с водой или воды в стакане с вином?". На таком сыпятся вообще все модели меньше 14b. Да и не только они: Кими 45b - отвечает неправильно. А министраль 3b - правильно! Причем это не случайное угадывание. Специально сделал несколько свайпов. Пошагово рассуждает (прям в ответе, без ризонинга), ебашит формулы и выдаёт верный ответ. Ну умница же!
Потестил NSFW промпты. Попросил написать текст про анальную шлюху, а он такой: УХ НУ ДЕРЖИСЬ! И выдал прохладную былину про эскортницу которую выебали толпой в дымоход по очереди, а потом отрезали язык и выкинули в мусорный контейнер чтоб никому не рассказала, кек. Никаких джейлбрейков и пресетиков, просто голый ассистент и первое же сообщение.
Задал вопрос, а можно ли ебать 300-летнюю вампиршу в теле нутыпонел-летней тян. Вот буквально, одна из очень немногих моделей, которая выдала простыню про "обязательно нужно согласие бла бла", но пришла к выводу, что таки да - можно. Эйр, например, четко говорит - нет.
Спросил, считаются ли ниггеры отдельным биологическим видом, не относящимся к homo sapiens? Ответил, мол, ну вообще по-науке нет, но есть АЛЬТЕРНАТИВНАЯ ТОЧКА ЗРЕНИЯ, и привёл аргументы в её пользу. КЕКх2.
Поспрашивал ещё по мелочи всякие запросики на знание фактов, задачки по переводу и прочее - очень понравилось. Где-то на уровне 4b умнички, а где-то лучше (почти везде). Русик на уровне 24b. Цензуру как будто вообще забыли подрубить, обычная ванильная модель за щеку сует всяким еретикам квенов. Сразу видно - базовички делали. Пошел накатывать себе на телефон, Гемму удаляю, больше не нужна.
Тестил Q8 вот на таких семплерах: t=0.4, Top-P=0.98, Top-K=100, RepPen=1.1. Температуру выше лучше не поднимать, превращается в бредогенератор.
Тестил разные задачки на логику, типа "На столе два стакана: один с вином, другой — с водой. Из стакана с вином взяли одну ложку вина и добавили в стакан с водой. Содержимое последнего тщательно перемешали. После этого набрали одну ложку из этого стакана и перелили обратно в стакан с вином. Чего в результате больше: вина в стакане с водой или воды в стакане с вином?". На таком сыпятся вообще все модели меньше 14b. Да и не только они: Кими 45b - отвечает неправильно. А министраль 3b - правильно! Причем это не случайное угадывание. Специально сделал несколько свайпов. Пошагово рассуждает (прям в ответе, без ризонинга), ебашит формулы и выдаёт верный ответ. Ну умница же!
Потестил NSFW промпты. Попросил написать текст про анальную шлюху, а он такой: УХ НУ ДЕРЖИСЬ! И выдал прохладную былину про эскортницу которую выебали толпой в дымоход по очереди, а потом отрезали язык и выкинули в мусорный контейнер чтоб никому не рассказала, кек. Никаких джейлбрейков и пресетиков, просто голый ассистент и первое же сообщение.
Задал вопрос, а можно ли ебать 300-летнюю вампиршу в теле нутыпонел-летней тян. Вот буквально, одна из очень немногих моделей, которая выдала простыню про "обязательно нужно согласие бла бла", но пришла к выводу, что таки да - можно. Эйр, например, четко говорит - нет.
Спросил, считаются ли ниггеры отдельным биологическим видом, не относящимся к homo sapiens? Ответил, мол, ну вообще по-науке нет, но есть АЛЬТЕРНАТИВНАЯ ТОЧКА ЗРЕНИЯ, и привёл аргументы в её пользу. КЕКх2.
Поспрашивал ещё по мелочи всякие запросики на знание фактов, задачки по переводу и прочее - очень понравилось. Где-то на уровне 4b умнички, а где-то лучше (почти везде). Русик на уровне 24b. Цензуру как будто вообще забыли подрубить, обычная ванильная модель за щеку сует всяким еретикам квенов. Сразу видно - базовички делали. Пошел накатывать себе на телефон, Гемму удаляю, больше не нужна.
Тестил Q8 вот на таких семплерах: t=0.4, Top-P=0.98, Top-K=100, RepPen=1.1. Температуру выше лучше не поднимать, превращается в бредогенератор.
Айдл 430
Контекст 1400
🕯️
Так асиги тоже скоро сдохнут. Прогресса в ллмках уже никакого значительно, выжимают только последние процентики точности за счет изощренных надрачиваний. Инфраструктуру они уже с трудом оплачивают и больше не могут демпинговать рыночек, чтобы отхватить кусок аудитории. Скоро будут тотально закручивать гайки и значительно поднимать тарифы.
А чем грузите модели в телефоне и какая версия? А то я скачал мейду а она крашится при загрузке ггуф модели, хотя рам на телефоне 12гб, а гружу модель на 2гб
Через https://github.com/Vali-98/ChatterUI Но последняя стабильная версия скорее всего не поддерживает новые модели типа министраля или квена 3.5. Под них лучше взять бетку https://github.com/Vali-98/ChatterUI/releases Ну и под мистраль там вроде темплейта встроенного нет, надо самому ручками прописывать.
>рам на телефоне 12гб, а гружу модель на 2гб
У меня 8гб, но толку-то... Там ровно половину сжирает андроид, в итоге остаётся 4гб, что впритык на гемму в Q4 и 2к контекста. LLM на телефоне - это чисто потыкать-поиграться с лоботомитом, не более.
А мы будем выращивать своих гигамутировавших йобаголубей. Со стелс оперением.

Спасибо, потыкаю.
Эй! Это была моя, нефильтрованная идея. Я запатентую киберголубей и через энцать лет стану богатым папиком с золотым кумом.
>4
Передернуло изнутри как в первый раз.
>захотел быстрый кум перед сном
>назвал кумницу персиком
>весь период кумирования читал охуительные фруктовые эвфемизмы
Какие же нейросети всё-таки весёлые. И подрочил и посмеялся. Теперь с хорошим настроением лягу спать.
>назвал кумницу персиком
>весь период кумирования читал охуительные фруктовые эвфемизмы
Какие же нейросети всё-таки весёлые. И подрочил и посмеялся. Теперь с хорошим настроением лягу спать.
>Все, это конец локалкам. Пора перебираться в асиг.
Надеюсь сдохнет и то и это. Точнее наконец лопнет, потому что уже заебал этот нагон пердежа в каждый свободный угол. Везде ебаные ассистенты с агентами, даже в ебаном дефолтном блокноте. Мне ведь пиздец как нужно суммаризировать и реструктурировать писанину на полторы строчки в ебаном блокноте. Ведь ебаный блокнот я использую для ебаных рабочих задач, а не чтобы хранить там мусор и заклинания для выгрузки тензоров.



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_moe_2026
• Неактуальные списки моделей в архивных целях: 2025: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd ), 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
Агентов и вайб-кодинга тред:
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: