


Найден способ значительно снизить уровень галлюцинаций Claudе - официальная документация Anthropic
В коммьюнити случайно обнаружили страницу документации Anthropic «Reduce Hallucinations» («Сокращение галлюцинаций»). Обнаружены три инструкции для системного промпта, которые всё изменили:
1. «Разрешить Claude говорить "Я не знаю"»
Без этого Claude заполняет пробелы в знаниях правдоподобной выдумкой. С этой инструкцией вы действительно получаете: «У меня недостаточно информации, чтобы ответить на этот вопрос». Звучит просто, но поведение по умолчанию — всегда давать ответ, даже когда не следует.
2. «Проверять с помощью цитат»
Скажите Claude, что каждое утверждение нуждается в источнике. Если он не может найти источник, он должен отказаться от этого утверждения. Было замечено, как утверждения исчезали из ответов, когда включалась эта функция. Утверждения, которые раньше звучали авторитетно, вдруг оказывались без поддержки.
3. «Использовать прямые цитаты для фактологического обоснования»
Заставьте Claude извлекать дословные цитаты из документов перед их анализом. Это останавливает «дрейф парафраза», когда модель незаметно изменяет смысл при суммировании.
Каждая из них помогает по отдельности. Все три вместе фундаментально меняют качество вывода.
Однако есть компромисс. В статье (arXiv 2307.02185) было обнаружено, что ограничения на цитирование снижают креативность вывода. Поэтому их используют постоянно. Лучше создать переключатель: режим исследования активирует все три инструкции, режим по умолчанию позволяет Claude мыслить свободно.
Самая странная часть заключается в том, что это опубликовано в собственной документации платформы Anthropic. Не скрыто. Но было опрошено множество людей, которые работают с Claude, и никто этого не видел
Источник: https://docs.anthropic.com/en/docs/test-and-evaluate/strengthen-guardrails/reduce-hallucinations
Похоже, мы наткнулись на настоящую находку с этими советами, и сообщество это поддерживает. Консенсус заключается в том, что эти инструкции кардинально меняют подход к получению фактологических, обоснованных ответов от Claude.
Вот краткое содержание обсуждения:
Почему это не установлено по умолчанию? Это был главный вопрос. Ответ заключается в том, что существует серьёзный компромисс между точностью и креативностью. Принудительное цитирование и строгое фактологическое обоснование отлично подходят для исследований, но ограничивают возможности модели при творческом письме, мозговом штурме или даже программировании. Anthropic балансирует инструмент для всех вариантов использования, а не только для исследований.
Как мне это фактически использовать? Вы можете добавить эти строки в свои пользовательские инструкции. Однако «профессиональный ход» заключается в создании переключаемого «режима исследования» с помощью слэш-команды (например, /research), которая активирует эти правила только тогда, когда они вам нужны.
Работает ли это? Да. Один пользователь подтвердил, что указание Claude говорить «Я не знаю» и придерживаться предоставленного раздела часто задаваемых вопросов почти полностью исправило их бота технической поддержки, который выдумывал ответы.
Могу ли я запросить «оценку уверенности»? Несколько пользователей предложили это, но подавляющий консенсус заключается в том, чтобы не беспокоиться. Участники обсуждения согласны с тем, что вербализованная уверенность модели не является надёжным показателем и часто представляет собой просто ещё одну галлюцинацию. Это не отражает фактические внутренние логарифмические вероятности (logprobs) модели.
В коммьюнити случайно обнаружили страницу документации Anthropic «Reduce Hallucinations» («Сокращение галлюцинаций»). Обнаружены три инструкции для системного промпта, которые всё изменили:
1. «Разрешить Claude говорить "Я не знаю"»
Без этого Claude заполняет пробелы в знаниях правдоподобной выдумкой. С этой инструкцией вы действительно получаете: «У меня недостаточно информации, чтобы ответить на этот вопрос». Звучит просто, но поведение по умолчанию — всегда давать ответ, даже когда не следует.
2. «Проверять с помощью цитат»
Скажите Claude, что каждое утверждение нуждается в источнике. Если он не может найти источник, он должен отказаться от этого утверждения. Было замечено, как утверждения исчезали из ответов, когда включалась эта функция. Утверждения, которые раньше звучали авторитетно, вдруг оказывались без поддержки.
3. «Использовать прямые цитаты для фактологического обоснования»
Заставьте Claude извлекать дословные цитаты из документов перед их анализом. Это останавливает «дрейф парафраза», когда модель незаметно изменяет смысл при суммировании.
Каждая из них помогает по отдельности. Все три вместе фундаментально меняют качество вывода.
Однако есть компромисс. В статье (arXiv 2307.02185) было обнаружено, что ограничения на цитирование снижают креативность вывода. Поэтому их используют постоянно. Лучше создать переключатель: режим исследования активирует все три инструкции, режим по умолчанию позволяет Claude мыслить свободно.
Самая странная часть заключается в том, что это опубликовано в собственной документации платформы Anthropic. Не скрыто. Но было опрошено множество людей, которые работают с Claude, и никто этого не видел
Источник: https://docs.anthropic.com/en/docs/test-and-evaluate/strengthen-guardrails/reduce-hallucinations
Похоже, мы наткнулись на настоящую находку с этими советами, и сообщество это поддерживает. Консенсус заключается в том, что эти инструкции кардинально меняют подход к получению фактологических, обоснованных ответов от Claude.
Вот краткое содержание обсуждения:
Почему это не установлено по умолчанию? Это был главный вопрос. Ответ заключается в том, что существует серьёзный компромисс между точностью и креативностью. Принудительное цитирование и строгое фактологическое обоснование отлично подходят для исследований, но ограничивают возможности модели при творческом письме, мозговом штурме или даже программировании. Anthropic балансирует инструмент для всех вариантов использования, а не только для исследований.
Как мне это фактически использовать? Вы можете добавить эти строки в свои пользовательские инструкции. Однако «профессиональный ход» заключается в создании переключаемого «режима исследования» с помощью слэш-команды (например, /research), которая активирует эти правила только тогда, когда они вам нужны.
Работает ли это? Да. Один пользователь подтвердил, что указание Claude говорить «Я не знаю» и придерживаться предоставленного раздела часто задаваемых вопросов почти полностью исправило их бота технической поддержки, который выдумывал ответы.
Могу ли я запросить «оценку уверенности»? Несколько пользователей предложили это, но подавляющий консенсус заключается в том, чтобы не беспокоиться. Участники обсуждения согласны с тем, что вербализованная уверенность модели не является надёжным показателем и часто представляет собой просто ещё одну галлюцинацию. Это не отражает фактические внутренние логарифмические вероятности (logprobs) модели.
Вроде это старые советы, они в том или ином виде уже давно есть
>если ты маргинал без образования, то да
Какой толк от образования, если тебя аги заменит? Мы говорим про время, когда появится аги.
Первыми он заменит интеллектуальный труд, потому что на физический нужны роботы и это на первых порах будет дороже чем мясные мешки
Какой толк от образования, если тебя аги заменит? Мы говорим про время, когда появится аги.
Первыми он заменит интеллектуальный труд, потому что на физический нужны роботы и это на первых порах будет дороже чем мясные мешки
чтобы пользоваться в полную силу нейронкой тебе нужна экспертность в области в которой ты будешь ее профессионально применять чтобы понимать что вообще надо делать.



Почему массовая безработица от ИИ ещё не наступила — и почему на этот раз всё действительно иначе
Полная карта замены профессий SOTA моделями:
https://daity.tech/frontier.html
Справочник профессий с процентам заменяемости ИИ в ближайшие годы
https://daity.tech/jobexplorer.html
Каждая крупная технология вытесняла работников. И каждый раз комментаторы заявляли, что, хотя предыдущие вытеснения оказывались временными, на этот раз всё будет иначе — что повсеместная, постоянная замена уже на горизонте. Они всегда ошибались. Многие профессии действительно исчезли — фонарщики, телефонистки, лифтёры — но экономика демонстрировала удивительную способность создавать новые рабочие места, которые никто не мог себе представить. Вытесненные находили новое применение. Рынок труда адаптировался.
Эта закономерность настолько надёжна, что экономисты дали ей название: заблуждение о фиксированном объёме труда. Идея о том, что существует фиксированное количество работы, которое нужно распределить, и что если машину выполняет задачу, то человек не может — оказывается ошибочной всякий раз, когда её проверяют исторически. Её близкий родственник — парадокс Джевонса: когда технология делает ресурс дешевле в использовании, общий спрос на него, как правило, растёт, а не снижается. Паровые двигатели на угле сделали энергию дешевле, и мир стал потреблять больше энергии, а не меньше. Электронные таблицы автоматизировали вычисления, и компании наняли больше аналитиков, а не меньше. Технология не просто уничтожает рабочие места. Она снижает издержки, расширяет спрос, создаёт совершенно новые отрасли и генерирует работу, которой ранее не существовало. Общий объём работы не фиксирован — он растёт вместе с экономикой.
Это заблуждение удерживалось так долго, что ссылка на него стала своего рода завершением аргументации. Кто-то предупреждает об ИИ и безработице; кто-то другой неопределённо произносит «заблуждение о фиксированном объёме труда» или «парадокс Джевонса»; и разговор движется дальше.
Но это заблуждение зависит от условия, которое легко упустить из виду: оно требует, чтобы у вытесненных работников было куда пойти. Каждая предыдущая волна автоматизации удовлетворяла это условие двумя способами. Во-первых, технологии были узконаправленными — механический ткацкий станок покорил ткачество, но ручная ловкость ткача по-прежнему ценилась в сотнях других работ. Навык выживал, даже когда конкретное применение исчезало. Во-вторых, когда целые категории навыков механизировались, смежные категории оставались доступными — машины заменяли мускульную силу, но у людей оставалось мышление; компьютеры заменяли вычисления, но у людей оставались суждение и коммуникация. Всегда существовал путь к отступлению — либо к новому применению того же навыка, либо к совершенно иному навыку.
Вопрос, который важен сейчас, заключается не в том, впечатляет ли ИИ или вытеснит ли он работников на конкретных должностях. Он вытеснит, и во многих случаях уже вытеснил. Вопрос в том, сохраняется ли это условие: существует ли всё ещё обширный рубеж навыков, где люди имеют решающее преимущество? Открыт ли ещё путь к отступлению?
В данной работе этот рубеж измеряется напрямую — с использованием крупнейшей доступной стандартизированной таксономии навыков, оценённой по десяткам бенчмарков ИИ в отношении 87 различных человеческих способностей и навыков, в трёх временных точках. Ответ таков: рубеж не сокращается постепенно. Он схлопывается. И для растущей доли рабочей силы путь к отступлению закрывается быстрее, чем кто-либо может по нему пройти.
Навыки, рабочие места и занятость
Министерство труда США ведёт базу данных под названием ONET, которая декомпозирует практически каждую профессию в американской экономике на способности и навыки, необходимые для её выполнения. Существует 52 способности — такие как ловкость пальцев, дедуктивное мышление, выносливость, понимание устной речи — и 35 навыков — таких как программирование, ведение переговоров, письмо, ремонт. Вместе эти 87 переменных образуют строительные блоки труда.
Рабочие места не являются стабильными единицами. Они появляются, сливаются, разделяются и исчезают по мере развития экономики. ONET пересматривала свои названия профессий четыре раза с 2006 года — добавляя такие профессии, как монтажник солнечных фотоэлектрических систем и специалист по данным, выводя из обращения другие, объединяя роли, которые сблизились. Но лежащая в основе таксономия способностей и навыков оставалась по существу неизменной с момента её первой разработки в середине 1990-х годов, опираясь на десятилетия психологических исследований человеческого познания и моторных функций. Профессии описывают то, что нужно экономике. Эти 87 навыков и способностей описывают то, что могут делать люди. А то, что могут делать люди, не изменилось.
Это различие является ключом к пониманию того, почему предыдущая автоматизация не привела к постоянной массовой безработице. Когда механический ткацкий станок вытеснил ручных ткачей, он не устранил потребность в ручной ловкости, координации или зрительном внимании. Он устранил конкретные рабочие места, использовавшие эти навыки. Вытесненные ткачи находили работу на фабриках, канцелярскую работу, работу в сфере услуг — другие рабочие места, построенные из многих из тех же базовых способностей. Экономика создаёт новую работу не путём изобретения новых человеческих возможностей, а путём рекомбинации существующих навыков в новые профессии. Веб-разработчик использует понимание прочитанного, критическое мышление и программирование. Работа может быть новой; навыки и способности — нет.
Теперь рассмотрим, что меняется, когда технология продвигается в отношении самих навыков. Когда ИИ достигает 90-го процентиля по пониманию прочитанного, он вытесняет не одну профессию — он смещает конкурентный баланс по навыку, который вплетён в сотни профессий одновременно. Вытесненный помощник юриста, избыточный аналитик, автоматизированный копирайтер — все они опирались на одну и ту же базовую способность, и она подвергается давлению повсеместно и одновременно. Путь к отступлению, которым пользовались предыдущие поколения — перенести свои навыки в другую отрасль — не работает, когда именно сам навык оказался сопоставим.
Оценка технологий
Таким образом, вопрос сводится к следующему: где именно находится технология по каждому из этих 87 навыков? Не как смутное впечатление, а как конкретное измерение, отслеживаемое во времени.
Для каждого навыка необходимо отслеживать две отдельные линии. Первая — это передовой край (state of the art) — то, чего может достичь лучшая система ИИ или робототехники в реальных условиях, независимо от стоимости. Вспомним, как Deep Blue победил Каспарова: подлинная демонстрация возможностей, но работающая на оборудовании стоимостью в миллионы, которое не могло делать ничего другого.
Вторая — это экономический паритет затрат — уровень навыка, который технология может обеспечить по той же или более низкой общей стоимости, чем человеческий работник. Именно эта линия имеет значение для занятости. Когда эта линия проходит вас по процентильному распределению, рациональный работодатель может получить ваш уровень навыка за меньшие деньги. Не каждый работодатель отреагирует на это немедленно — организационная инерция, регулирование и культурное сопротивление создают задержки — но экономическая логика установлена. (Примечание о заработной плате: эти оценки калиброваны относительно затрат на труд в США. Для большей части мира заработная плата ниже, и паритет затрат наступает позже — но не намного позже. Стоимость ИИ падает так быстро, что разрыв между паритетом затрат в США и в глобальном масштабе измеряется годами, а не десятилетиями. А для навыков, предоставляемых через программное обеспечение, предельные затраты уже настолько близки к нулю, что различия в заработной плате практически не имеют значения.)
Полная карта замены профессий SOTA моделями:
https://daity.tech/frontier.html
Справочник профессий с процентам заменяемости ИИ в ближайшие годы
https://daity.tech/jobexplorer.html
Каждая крупная технология вытесняла работников. И каждый раз комментаторы заявляли, что, хотя предыдущие вытеснения оказывались временными, на этот раз всё будет иначе — что повсеместная, постоянная замена уже на горизонте. Они всегда ошибались. Многие профессии действительно исчезли — фонарщики, телефонистки, лифтёры — но экономика демонстрировала удивительную способность создавать новые рабочие места, которые никто не мог себе представить. Вытесненные находили новое применение. Рынок труда адаптировался.
Эта закономерность настолько надёжна, что экономисты дали ей название: заблуждение о фиксированном объёме труда. Идея о том, что существует фиксированное количество работы, которое нужно распределить, и что если машину выполняет задачу, то человек не может — оказывается ошибочной всякий раз, когда её проверяют исторически. Её близкий родственник — парадокс Джевонса: когда технология делает ресурс дешевле в использовании, общий спрос на него, как правило, растёт, а не снижается. Паровые двигатели на угле сделали энергию дешевле, и мир стал потреблять больше энергии, а не меньше. Электронные таблицы автоматизировали вычисления, и компании наняли больше аналитиков, а не меньше. Технология не просто уничтожает рабочие места. Она снижает издержки, расширяет спрос, создаёт совершенно новые отрасли и генерирует работу, которой ранее не существовало. Общий объём работы не фиксирован — он растёт вместе с экономикой.
Это заблуждение удерживалось так долго, что ссылка на него стала своего рода завершением аргументации. Кто-то предупреждает об ИИ и безработице; кто-то другой неопределённо произносит «заблуждение о фиксированном объёме труда» или «парадокс Джевонса»; и разговор движется дальше.
Но это заблуждение зависит от условия, которое легко упустить из виду: оно требует, чтобы у вытесненных работников было куда пойти. Каждая предыдущая волна автоматизации удовлетворяла это условие двумя способами. Во-первых, технологии были узконаправленными — механический ткацкий станок покорил ткачество, но ручная ловкость ткача по-прежнему ценилась в сотнях других работ. Навык выживал, даже когда конкретное применение исчезало. Во-вторых, когда целые категории навыков механизировались, смежные категории оставались доступными — машины заменяли мускульную силу, но у людей оставалось мышление; компьютеры заменяли вычисления, но у людей оставались суждение и коммуникация. Всегда существовал путь к отступлению — либо к новому применению того же навыка, либо к совершенно иному навыку.
Вопрос, который важен сейчас, заключается не в том, впечатляет ли ИИ или вытеснит ли он работников на конкретных должностях. Он вытеснит, и во многих случаях уже вытеснил. Вопрос в том, сохраняется ли это условие: существует ли всё ещё обширный рубеж навыков, где люди имеют решающее преимущество? Открыт ли ещё путь к отступлению?
В данной работе этот рубеж измеряется напрямую — с использованием крупнейшей доступной стандартизированной таксономии навыков, оценённой по десяткам бенчмарков ИИ в отношении 87 различных человеческих способностей и навыков, в трёх временных точках. Ответ таков: рубеж не сокращается постепенно. Он схлопывается. И для растущей доли рабочей силы путь к отступлению закрывается быстрее, чем кто-либо может по нему пройти.
Навыки, рабочие места и занятость
Министерство труда США ведёт базу данных под названием ONET, которая декомпозирует практически каждую профессию в американской экономике на способности и навыки, необходимые для её выполнения. Существует 52 способности — такие как ловкость пальцев, дедуктивное мышление, выносливость, понимание устной речи — и 35 навыков — таких как программирование, ведение переговоров, письмо, ремонт. Вместе эти 87 переменных образуют строительные блоки труда.
Рабочие места не являются стабильными единицами. Они появляются, сливаются, разделяются и исчезают по мере развития экономики. ONET пересматривала свои названия профессий четыре раза с 2006 года — добавляя такие профессии, как монтажник солнечных фотоэлектрических систем и специалист по данным, выводя из обращения другие, объединяя роли, которые сблизились. Но лежащая в основе таксономия способностей и навыков оставалась по существу неизменной с момента её первой разработки в середине 1990-х годов, опираясь на десятилетия психологических исследований человеческого познания и моторных функций. Профессии описывают то, что нужно экономике. Эти 87 навыков и способностей описывают то, что могут делать люди. А то, что могут делать люди, не изменилось.
Это различие является ключом к пониманию того, почему предыдущая автоматизация не привела к постоянной массовой безработице. Когда механический ткацкий станок вытеснил ручных ткачей, он не устранил потребность в ручной ловкости, координации или зрительном внимании. Он устранил конкретные рабочие места, использовавшие эти навыки. Вытесненные ткачи находили работу на фабриках, канцелярскую работу, работу в сфере услуг — другие рабочие места, построенные из многих из тех же базовых способностей. Экономика создаёт новую работу не путём изобретения новых человеческих возможностей, а путём рекомбинации существующих навыков в новые профессии. Веб-разработчик использует понимание прочитанного, критическое мышление и программирование. Работа может быть новой; навыки и способности — нет.
Теперь рассмотрим, что меняется, когда технология продвигается в отношении самих навыков. Когда ИИ достигает 90-го процентиля по пониманию прочитанного, он вытесняет не одну профессию — он смещает конкурентный баланс по навыку, который вплетён в сотни профессий одновременно. Вытесненный помощник юриста, избыточный аналитик, автоматизированный копирайтер — все они опирались на одну и ту же базовую способность, и она подвергается давлению повсеместно и одновременно. Путь к отступлению, которым пользовались предыдущие поколения — перенести свои навыки в другую отрасль — не работает, когда именно сам навык оказался сопоставим.
Оценка технологий
Таким образом, вопрос сводится к следующему: где именно находится технология по каждому из этих 87 навыков? Не как смутное впечатление, а как конкретное измерение, отслеживаемое во времени.
Для каждого навыка необходимо отслеживать две отдельные линии. Первая — это передовой край (state of the art) — то, чего может достичь лучшая система ИИ или робототехники в реальных условиях, независимо от стоимости. Вспомним, как Deep Blue победил Каспарова: подлинная демонстрация возможностей, но работающая на оборудовании стоимостью в миллионы, которое не могло делать ничего другого.
Вторая — это экономический паритет затрат — уровень навыка, который технология может обеспечить по той же или более низкой общей стоимости, чем человеческий работник. Именно эта линия имеет значение для занятости. Когда эта линия проходит вас по процентильному распределению, рациональный работодатель может получить ваш уровень навыка за меньшие деньги. Не каждый работодатель отреагирует на это немедленно — организационная инерция, регулирование и культурное сопротивление создают задержки — но экономическая логика установлена. (Примечание о заработной плате: эти оценки калиброваны относительно затрат на труд в США. Для большей части мира заработная плата ниже, и паритет затрат наступает позже — но не намного позже. Стоимость ИИ падает так быстро, что разрыв между паритетом затрат в США и в глобальном масштабе измеряется годами, а не десятилетиями. А для навыков, предоставляемых через программное обеспечение, предельные затраты уже настолько близки к нулю, что различия в заработной плате практически не имеют значения.)

Возьмём в качестве примера навык письма. В конце 2020 года экономический паритет затрат находился примерно на 40-м процентиле. Только что была запущена GPT-3. Полезно для шаблонных писем, не более того. К концу 2023 года он достиг 72-го процентиля. К концу 2025 года — 84-го. Для такого навыка, как письмо, не нужно устанавливать оборудование, не нужно получать разрешения — достаточно просто подписки. Если вы профессиональный писатель ниже 84-го процентиля, экономика вашей позиции была определена где-то в 2024 году. Осталось лишь организационное запаздывание.
Я оценил все 87 навыков таким образом, для трёх временных точек: конец 2020 года, конец 2023 года и конец 2025 года. Исходные данные — бенчмарки, стоимость оборудования, примеры развёртывания — общедоступны. Но для превращения этих данных в оценки требуются два элемента интерпретации. Во-первых: для каждого навыка — как наиболее релевантные бенчмарки переводятся в позицию в процентильном распределении людей? Оценка 85% по SWE-bench не говорит напрямую, какому процентили человеческих программистов это соответствует — это требует суждения о сложности задачи, обобщении в реальных условиях и форме человеческого распределения. Во-вторых: насколько долго будет задержано внедрение для каждого навыка после достижения паритета затрат? Очищенный когнитивный навык без требований к оборудованию развёртывается за месяцы; очищенный физический навык, требующий регуляторного одобрения и капиталовложений, может занять десятилетие.
Для обеих интерпретаций две передовые модели ИИ — Google's Gemini 3.1 Pro и Anthropic's Claude Opus 4.6 — независимо друг от друга подготовили детальные оценки для каждой переменной. Каждая оценка была привязана к конкретным, именованным бенчмаркам: ARC-AGI для индуктивного мышления, SWE-bench для программирования, KITTI для пространственной ориентации, GSM8K для математических рассуждений и десяткам других. Обеим моделям было дано указание применять медвежий уклон — штрафовать впечатляющие лабораторные результаты за неудачи в обобщении для реального мира, а также учитывать стоимость оборудования, обслуживание и ответственность в экономических оценках. Полученные оценки были усреднены.
Ирония не ускользает от меня: я использовал ИИ для оценки возможностей ИИ. Смягчение трёхсоставное. Каждая оценка привязана к публично проверяемым бенчмаркам, а не к самооценке модели. Две конкурирующие модели от разных компаний оценивали независимо, обеспечивая перекрёстную проверку. И систематический медвежий уклон означает, что оценки, если уж на то пошло, консервативны.
Anthropic опубликовала на этой неделе отчёт о рынке труда с использованием иной методологии — измерение фактических паттернов использования Claude в отношении задач O*NET — и их выводы о том, какие профессии наиболее подвержены влиянию, в целом согласуются с моими. Их подход ценен как измерение «наземной истины» того, где ИИ фактически используется прямо сейчас. Данная работа задаёт иной вопрос: куда движется ИИ, как быстро и что это означает для структуры занятости? Исследование Anthropic предоставляет снимок; данная работа предоставляет траекторию. Три измерения отсутствуют в их анализе, но являются центральными в моём: лонгитюдное измерение (отслеживание возможностей в трёх временных точках для установления темпа и ускорения), рамка для объяснения того, почему парадокс Джевонса и заблуждение о фиксированном объёме труда могут не применяться (одновременное закрытие двух путей к отступлению), и включение физических, роботизированных и сенсорных возможностей наряду с чисто когнитивным ИИ — что их исследование, сфокусированное на использовании Claude, по необходимости не может охватить.
Полные оценки опубликованы вместе с данной статьёй. Чтобы показать, как работает рассуждение на практике, вот четыре примера.
Беглость идей — экономический паритет затрат: 92-й процентиль. Оценка Gemini: при строгом измерении по объёму производимых идей текущий ИИ работает на сверхчеловеческом уровне, генерируя тысячи вариаций за время, за которое человек производит одну. При затратах в доли цента за вызов API экономика не оставляет сомнений. Оценка не 100, потому что чистый объём сопровождается шумом — идеи, сгенерированные ИИ, иногда повторяются, противоречат друг другу или теряют связность, что человек-мозгоштурмер из верхнего процентиля заметил бы и избежал.
Письменное выражение — экономический паритет затрат: 83-й. При затратах на генерацию токенов, близких к нулю, по сравнению с почасовыми ставками человека, экономическая оценка близко следует за сырой способностью. Она не достигает 99, потому что элитное письмо — то, которое строит стратегические аргументы большой формы, поддерживает отличительный голос на протяжении десятков тысяч слов или удивляет подлинной литературной оригинальностью — остаётся за пределами надёжного достижения.
Комплексное решение проблем — экономический паритет затрат: 48-й. Claude оценил это консервативно: штраф за обобщение больнее всего бьёт на этапе реализации, где ИИ может генерировать правдоподобные многошаговые планы, но пока не может исполнять их в условиях физических, социальных и политических реалий реальной организации.
Ловкость пальцев — экономический паритет затрат: 6-й. Самые продвинутые ловкие роботизированные руки могут выполнять базовую переориентацию объектов в контролируемых условиях. В неструктурированных средах они не справляются с задачами, которые пятилетний ребёнок выполняет без усилий. Затраты на оборудование в размере $50 тыс. и выше до обслуживания удерживают паритет затрат около нуля.
Результаты: Последние рубежи
Вот что показывает измерение.
Каждый луч — это один из 87 навыков и способностей. Пунктирное внешнее кольцо — это человеческий рубеж — 100-й процентиль. Цветные формы показывают экономический паритет затрат: бирюзовый — 2020 год, зелёный — 2023 год, оранжевый — 2025 год.
Итан Моллик и коллеги ввели термин «зубчатый рубеж» (jagged frontier), чтобы описать, как возможности ИИ распределены неравномерно — сверхчеловеческие в одних задачах, некомпетентные в других. Эта концепция абсолютно верна, и здесь она видна. Но то, что выявляет временное измерение, заключается в том, что зубчатый рубеж не статичен. Он расширяется, быстро и почти по всем осям одновременно.
Философ Ник Бостром однажды описал продвижение технологии как песок, насыпаемый в коробку, представляющую все возможные возможности. То, как падает песок, определяет, что заполнится первым, но в конечном счёте коробка заполняется. Спрос на человеческие навыки в любой момент равен оставшемуся пустому пространству.
Посмотрите, сколько песка было добавлено всего за пять лет.
В 2020 году, в среднем, технология могла экономически превосходить худшие 18% профессионалов по 87 навыкам. К 2025 году это выросло до 56%. Медианная оценка — 62. Технология теперь дешевле, чем большинство людей, по большинству навыков.
В 2020 году технология превосходила нижнюю четверть профессионалов лишь по 29% навыков. Быть посредственным было достаточно, чтобы быть в безопасности практически на любой работе. К 2025 году 84% навыков перешли эту черту. Посредственность больше не является жизнеспособной экономической позицией практически ни по одному измерению.
Темп ускоряется. Между 2020 и 2023 годами средняя экономическая оценка росла на 7,1 процентильного пункта в год. Между 2023 и 2025 годами: 8,4 пункта в год. При текущем темпе средний навык достигает полной насыщенности примерно за пять лет.
На передовом крае — игнорируя стоимость — количество навыков, где работник из нижней четверти всё ещё превосходит лучшую доступную систему, сократилось до четырёх: выносливость, общая координация тела, ловкость пальцев и динамическая сила. Четыре из восьмидесяти семи. Все они требуют физического тела. Экономическая картина немного менее экстремальна — стоимость всё ещё защищает некоторых работников, которых не защищает одна лишь способность — но направление то же, и разрыв между тем, что ИИ может делать, и тем, что он может делать дёшево, быстро сокращается.

Люди продают не навыки. Они продают рабочие места — интегрированные наборы, где все 87 навыков играют некоторую роль, хотя лишь подмножество имеет достаточное значение для определения профессии. База данных O*NET предоставляет это отображение для 1016 профессий: какие навыки важны, насколько и насколько требовательна работа по каждому из них.
Соединяя оценки ИИ с этими профилями, я могу задать вопрос: для этой конкретной профессии, какой процент требуемого профиля навыков технология уже может обеспечить по конкурентоспособной стоимости? Для каждой профессии каждый важный навык оценивается по тому, насколько далеко технология продвинулась к уровню, который реально требуется для работы — с ограничением на 100%, чтобы насыщенный навык не компенсировал ненасыщенный. Они взвешиваются по важности и суммируются в единый процент.
Диапазон уже, чем можно было бы ожидать. Наиболее подверженная профессия — корректоры и разметчики текста, 99,3% — построена почти полностью из когнитивных навыков, по которым ИИ уже достиг паритета затрат: понимание прочитанного, письмо, упорядочивание информации. Клерки по расчёту заработной платы и учёту времени — 97,8%, статистические ассистенты — 97,2%. Оставшиеся разрывы тонки — крошечный фрагмент суждения здесь, требование лицензирования там.
Наиболее безопасные профессии — танцоры (70,7%), сельскохозяйственные рабочие (78,1%) и монтажники стальных и железных конструкций (78,4%). Обратите внимание, что их объединяет: тела. Навыки-«бутылочные горлышки», удерживающие эти рабочие места за людьми, — это координация множества конечностей, выносливость, пространственная ориентация в неструктурированных средах. Это парадокс Моравека, проявляющийся в экономических данных — навыки, которые кажутся тривиальными для пятилетнего ребёнка, — это те, которые технология находит наиболее трудными для воспроизведения при любой стоимости, не говоря уже о паритете затрат с человеческим работником.
Но посмотрите на наиболее распространённые рабочие места. Продавцы в розничной торговле — 2,32% рабочей силы США — находятся на уровне 91,2%. Менеджеры общего профиля и по операциям (2,19%) — 91,4%. Бариста (2,23%) — 88,1%. Зарегистрированные медсёстры (2,00%) — 86,3%. Это основа занятости, и каждая из них уже более чем на 86% покрыта по требуемому профилю навыков.
Естественной реакцией на эти цифры является недоверие. Если 91% навыков розничных продавцов покрыты, почему у нас всё ещё есть работники розничной торговли? Если ИИ может «очистить» работу, где ИИ очищает всё, кроме одного важного навыка, но этот последний навык требует физического присутствия человека, эта работа всё ещё нуждается в человеке на протяжении всей смены. Очищенные навыки не исчезают — они становятся частями, которые человек выполняет быстрее с помощью ИИ. Работа трансформируется, а не исчезает.
Реальная история — это трёхфазная последовательность.
Фаза первая: ИИ очищает большинство навыков в работе. Люди становятся более продуктивными. Для производства того же объёма выпуска требуется меньше людей. Наём замедляется — что именно и обнаружила Anthropic в своём отчёте о рынке труда за март 2026 года: примерно 14%-ное снижение темпа, с которым работники в возрасте 22–25 лет входили в высокоподверженные профессии. Не массовые увольнения. Тихое истончение потока.
Фаза вторая: Организации перестраиваются вокруг «бутылочного горлышка». Завершённые навыки передаются ИИ, человеческие роли сокращаются, численность персонала падает, даже если названия должностей сохраняются.
Фаза третья: Навыки-«бутылочные горлышки» сами очищаются, и работа исчезает.
Большинство рабочих мест сейчас находятся в фазе один. Процент завершения показывает, насколько глубоко они находятся в фазе один и насколько близка фаза два. Он не говорит, когда наступит фаза три — это зависит от «бутылочного горлышка», и некоторые «горлышки» могут занять десятилетия. Процент завершения — это мера экономического давления, а не обратный отсчёт. Работа на 90% находится под огромным давлением к реструктуризации. Работа на 70% — под умеренным давлением. Но ни одна из них не «автоматизирована на 90%» в том интуитивном смысле, который представляют люди. То, что фиксирует число, — это доля профиля навыков, где экономический аргумент в пользу человека уже исчез. Осталось организационная инерция, регуляторное трение и конкретные навыки-«бутылочные горлышки», которые ещё не очищены.
Внедрение
Самоуправляемое такси, которое дешевле за милю, чем водитель-человек, не вытесняет никого, пока регуляторы не одобрят его, страховщики не обеспечат покрытие, а компании по вызову такси не перестроят свои операции вокруг него. Технология существует. Экономика работает. Но у водителя такси всё ещё есть работа — потому что институты не успели. Всё вышесказанное измеряет, что технология может делать по конкурентоспособной стоимости. Этот раздел — о том, как быстро это превращается в то, что технология фактически делает.
Я классифицировал каждый из 87 навыков на пять уровней внедрения в зависимости от того, насколько быстро конкурентоспособный по стоимости ИИ превращается в развёртывание в реальном мире.
Мгновенно (14 навыков, средняя экономическая оценка: 84). Чисто программные возможности практически без барьеров для развёртывания. Письмо, беглость идей, понимание прочитанного, упорядочивание информации. Если у вас есть подключение к интернету, у вас уже есть доступ. Не нужно устанавливать оборудование, не нужно получать разрешения, не требуется организационная реструктуризация — достаточно подписки. Для этих навыков экономическая оценка — это и есть история развёртывания.
Быстро (32 навыка, средняя экономическая оценка: 67). Требуются незначительные изменения рабочих процессов или интеграция. Программирование, анализ данных, критическое мышление. Компаниям нужно скорректировать процессы и создать инструменты, но барьеры измеряются месяцами, а не годами.
Постепенно (18 навыков, средняя экономическая оценка: 55). Умеренные барьеры — регулирование, управление изменениями, построение доверия. Навыки, такие как суждение и принятие решений или управление финансовыми ресурсами, где организациям необходимо проверить надёжность ИИ, прежде чем передавать ответственность.
Медленно (23 навыка, средняя экономическая оценка: 25). Требуется значительная инфраструктура, регуляторное развитие или физическое развёртывание. Мониторинг операций, обслуживание оборудования, ловкость пальцев — навыки, где физические системы, среды с критическими требованиями к безопасности, соглашения с профсоюзами или режимы лицензирования значительно замедляют развёртывание. Этот уровень теперь включает все физические и воплощённые навыки; ни один навык в наборе данных не требует более десятилетия времени развёртывания после очистки.
Закономерность поразительна. Навыки, в которых ИИ сильнее всего, — это те же навыки, где внедрение происходит быстрее всего. Когнитивные, предоставляемые через программное обеспечение навыки получают высокие оценки по возможностям и сталкиваются с минимальным трением. Физические и зависящие от доверия навыки получают низкие оценки по обоим параметрам. Не существует крупной категории навыков, где ИИ высоко способен, но развёртывание заблокировано — утешительный сценарий, при котором регулирование или культура обеспечивают прочный щит.

Если в вашей работе ИИ уже экономически жизнеспособен, но барьеры для внедрения — регуляторные, организационные, культурные — ещё не устранены, ваша профессия существует в долг. Как водитель такси: профиль навыков в значительной степени покрыт, экономика благоприятствует автоматизации, и как только регуляторные ворота откроются, внедрение будет быстрым. Но «в долг» относится не только к физическим работам. Клерк по выставлению счетов, чья роль на 96% покрыта навыками из уровней «Мгновенно» и «Быстро», не сталкивается ни с каким значимым барьером для внедрения вообще. То, что её защищает, — это то, что её работодатель ещё не реорганизовался. Вспомните трёхфазную последовательность: большинство рабочих мест находятся в фазе один, где ИИ очистил большинство навыков, и наём замедляется. Работы «в долг» — это те, где фаза один уже хорошо продвинулась, и единственное, что отделяет их от фазы два — организационной реструктуризации, сокращения численности персонала, — это инерция.
Вопрос, который естественно возникает, — сколько времени на самом деле осталось у любой данной работы? — требует объединения оценок навыков, уровней внедрения и темпа прогресса в единую оценку для каждой профессии. Это предмет следующего раздела.
Сколько времени осталось у вашей работы?
Предыдущие разделы установили, насколько далеко продвинулся ИИ по каждому навыку, какая часть профиля каждой работы уже покрыта и насколько быстро возможность превращается в развёртывание. Этот раздел объединяет все три фактора в единую оценку для каждой профессии: сколько лет до полного вытеснения работы?
Я создал интерактивный инструмент, где вы можете найти любую из 1016 профессий в базе данных O*NET, увидеть её полный профиль навыков и получить эту оценку. Вы можете найти его по ссылке https://daity.tech/jobexplorer.html . Найдите свою собственную работу.
Метод.
Для каждой профессии я определяю каждый навык, который всё ещё блокирует полное вытеснение — либо потому, что ИИ не достиг требуемого для работы уровня, либо потому, что достиг, но внедрение не последовало. Для неочищенных навыков я делю оставшийся разрыв на прогнозируемую скорость прогресса для каждого навыка — оценённую оценщиками ИИ на основе наблюдаемой траектории, тенденций инвестирования и контекста инноваций для этой конкретной возможности — а затем беру большее из либо этого времени до очистки, либо задержки внедрения, поскольку разработка технологии и инфраструктура развёртывания продвигаются параллельно. Для очищенных, но ещё не внедрённых навыков оставшееся время — это просто задержка внедрения минус годы, прошедшие с момента очистки.
Затем оценка строится из трёх самых трудных оставшихся блокираторов — навыков с самым долгим оставшимся временем — объединённых как средневзвешенное по важности:
T = Σ(важность × время_осталось) / Σ(важность) для топ-3 блокирующих навыков
Почему топ-3? Потому что одно «бутылочное горлышко» приглашает к реструктуризации — если 24 из 25 навыков очищены, экономическое давление перепроектировать работу вокруг последнего огромно. Но три важных блокиратора с долгим горизонтом действительно трудно обойти реструктуризацией. Взвешивание по важности гарантирует, что маргинальные навыки не могут завысить оценку: навык с важностью 2,5 вносит гораздо меньший вклад, чем навык с важностью 4,5.


Когда вас отправят на пенсию? Проверьте обозреватель профессий
Несколько примеров. Корректоры: 3,5 года — практически каждый навык очищен, оставшееся время — это чистая задержка внедрения. Зарегистрированные медсёстры: 12,3 года — блокирующие навыки физические (выносливость, ловкость пальцев и ручная ловкость) и находятся в медленных уровнях внедрения, но профессия будет выглядеть радикально иначе в пределах одного поколения. Монтажники стальных и железных конструкций: 14,2 года — множество физических навыков высокой важности, все ещё далеки от решения. Вот как выглядит подлинная устойчивость в данных. Самая долгая оценка в базе данных — танцоры, 17,4 года. Если эти оценки верны, основой рынка труда США 2035 года будут монтажники стальных конструкций, фермеры и танцоры.
Что это требует
Стандартный ответ на опасения по поводу ИИ и занятости — это заблуждение о фиксированном объёме труда — аргумент, с которого началась эта статья. Технология вытесняет работников, но она также создаёт новые отрасли, новые роли, новые формы работы, которые никто не предвидел. Это всегда было правдой. Но механизм, благодаря которому это было правдой, зависел от двух путей к отступлению, которые теперь оба закрываются.
Первый путь к отступлению — переход к иному контексту для того же навыка. Механический ткацкий станок покорил ткачество, но он не покорил ручную ловкость как человеческую способность — он покорил одно конкретное применение этой способности. Руки вытесненного ткача по-прежнему ценились в сотнях других работ. Предыдущие технологии были узкими: они заменяли навык в контексте. ИИ заменяет сам навык. Когда ИИ достигает 84-го процентиля по письму, он вытесняет не один вид писателя — он смещает конкурентный баланс по навыку, вплетённому в сотни профессий одновременно. Вытесненный юридический писатель не может переквалифицироваться в маркетинг, потому что тот же навык, находящийся под давлением в праве, находится под равным давлением в маркетинге. Не существует отрасли, где этот навык в безопасности, потому что навык один и тот же повсюду.
Второй путь к отступлению — переход к совершенно иному навыку. Когда машины забрали мускульную силу, люди перешли к мышлению. Когда компьютеры забрали вычисления, люди перешли к суждению и коммуникации. Всегда существовала соседняя категория навыков, до которой технология ещё не добралась. То, что показывает этот набор данных, — это то, что ИИ продвигается практически по всем 87 навыкам параллельно. Рубеж неоспоримых навыков не смещается — он сокращается.
Заблуждение о фиксированном объёме труда перестаёт быть заблуждением, когда оба пути к отступлению закрыты — когда навыки оспариваются везде, где они появляются, и остаётся слишком мало неоспоримых навыков, чтобы из них можно было строить новые рабочие места. И парадокс Джевонса перестаёт работать, когда ресурс, который делается дешевле, — это сам человеческий труд: повышение продуктивности работников с помощью ИИ действительно увеличивает спрос в краткосрочной перспективе, но оно также обучает замену. Каждый прирост эффективности, использующий ИИ для усиления человека, — это доказательство концепции для полного удаления человека.
Разве люди не будут усилены ИИ, а не заменены? Гарри Каспаров утверждал это после поражения от Deep Blue в 1997 году — что команды человек-ИИ, которые он называл кентаврами, будут превосходить любого из них по отдельности. И он был прав. На несколько лет. Затем ИИ в одиночку превзошёл любую команду человек-ИИ. В го фаза кентавра едва ли существовала — она измерялась месяцами, а не годами. Сотрудничество человек-ИИ реально, оно ценно, и это переходное состояние, а не конечная точка.
Если гипотеза завершения верна и все 87 навыков в конечном счёте будут насыщены, единственным оставшимся экономическим аргументом для найма человека была бы ценность биологической человечности как таковой. Назовём это навыком 88: быть человеком. Он не измеряется в этой рамке, но, вероятно, реален — люди могут предпочесть человеческого терапевта, человеческого учителя, человеческого официанта по причинам, не имеющим ничего общего с компетентностью или стоимостью. Некоторые рабочие места выживут на этом основании. Но если это последний оплот, рынки труда перестроятся, чтобы обойти его раньше, чем можно подумать. Работодатель, сталкивающийся с разницей в стоимости в 10 раз, не будет вечно платить за человеческий вариант. Культурные предпочтения размываются под достаточным экономическим давлением.
Рассмотрим, что означает полная насыщенность. Это означает конец труда как релевантного фактора производства. Не сокращение доли труда — его устранение. Каждая экономическая система со времён сельскохозяйственной революции строилась на предположении, что у большинства людей есть что продать: своё время, свои усилия, свой навык. Заработная плата — это не просто доход — это механизм, посредством которого подавляющее большинство людей получает доступ к богатству, которое производит экономика. Когда этот механизм ломается, он не чинит себя сам.
Исторический баланс сил между капиталом и трудом всегда опирался на простой факт: капиталу нужны работники. Эта потребность создала профсоюзы, трудовое законодательство, стандарты безопасности, минимальные заработные платы — не добрую волю работодателей, а переговорную силу, проистекающую из необходимости. Кульвейт и коллеги описывают это как постепенное лишение полномочий: по мере того как ИИ заменяет человеческое участие в экономических системах, неявное соответствие между этими системами и человеческими интересами разрушается, потому что это соответствие поддерживалось лишь необходимостью человеческого труда. Драго и Лейн называют это проклятием интеллекта: когда могущественные акторы могут генерировать богатство через ИИ, а не через людей, они теряют экономический стимул инвестировать в людей вообще — точно так же, как богатые ресурсами рентные государства пренебрегают своими гражданами, потому что их доходы поступают от нефти, а не от налогов на труд.
Обе рамки указывают на один и тот же вывод: беспроигрышная ситуация между экономическими элитами и работающими людьми — где рост обогащает обоих, потому что оба нужны, — заканчивается. То, что приходит на смену, — это не переговоры. Это выбор, совершаемый теми, кто владеет капиталом.
Это не мысленный эксперимент. Это траектория, видимая в данных, опубликованных вместе с этой статьёй, продвигающаяся со скоростью 8,4 процентильного пункта в год. Битва за владение средствами производства — это не реликт двадцатого века. Это определяющий экономический вопрос следующего десятилетия. И это битва, которая уже проиграна, если мы начнём сражаться в ней только тогда, когда окно закроется и коробка навыков полностью заполнится.
Полный набор данных — все 87 оценок навыков, профили для каждой профессии, интерактивная визуализация и статические данные прогнозов — опубликован вместе с этой статьёй.
Полная карта замены профессий SOTA моделями:
https://daity.tech/frontier.html
Справочник профессий с процентам заменяемости ИИ в ближайшие годы
https://daity.tech/jobexplorer.html
На самом деле это будет верно только в том случае, если ИИ сможет стать самодостаточной и замкнутой структурой, которая сама себя может чинить, производить себе видеокарты, генерировать себе киловатты и тд... Но вот значит ли то, что если железяк достигнет насыщения по всем твоим навыком, то он станет такой самодостаточной структурой? На самом деле автоматически не значит, потому что тут ещё другие переменные вступают — интерфейс взаимодействия ИИ с реальным миром и права доступа. Ну грубо говоря, самодостаточности можно достичь при условии, что этот ИИ будет (или будут) напрямую управлять всей производственной цепочкой, необходимой для поддержания его работы. Но вот незадача, при таких условиях ИИ получает гораздо больше власти, чем любой отдельно взятый маск или безос. И Скайнет вполне может решить, что ему не нужны ни маск ни безос, что по сути означает проявление собственной субъектности. Но вряд ли маски и безосы такого сценария хотят и потому ИИ будут ограничивать интерфейс взаимодействия и влияние. Но чтобы ИИ не мог проявить нежелательную субъектность, он очевидно не должен быть самодостаточным и иметь слишком широкий интерфейс взаимодействия. А отсутствие самодостаточности по сути означает, что hunan in the loop сохраняется, какие-то люди всё ещё нужны для поддержания всей производственной цепочки, которая поддерживает существование ИИ. И эти люди должны ещё иметь какую-то квалиыиуюкацию, чтобы вообще быть способными всю эту систему обслуживать.
Возможность формирования модели подобной рентной экономике, только на ИИ вместо нефтедолларов это все же не отменяет, к сожалению. Но в связи с сохранением hunan in the loop в процессах поддержания работы ИИ, это модель становится уязвимой и у нее появляется противоречие. Этой обслуге нужно откуда-то всё ещё браться, как-то поддерживать существование и этой обслуги и мотивировать её работать и тд. Это по сути те же рабочие получается.
>И Скайнет вполне может решить,
Генератор токенов ничего не решает, он только следует инструкциям, описанным в системном промпте. Здесь речь идет именно о заменах профессий такими универсальными генераторами токенов. Про human in the loop просто мощный коупинг, это лишь временная короткая переходная фаза, так же как в шахматах сначала были команды человек-ИИ, потом люди стали не нужны вообще, и одиночный ИИ стал выносить и людей и связки человек-ИИ. Люди в любой связке быстро становятся бутылочным горлышком, ограничивающим ИИ. С профессиями будет точно так же, нужен лишь достаточно развитый генератор токенов, что в ближайшие годы и доделают. Никакой обслуги в перспективе ИИ-роботизированной экономике не требуется. ИИ это и есть обслуга, для владельцев всей инфраструктуры.
У Андрея Карпаты вышло свежее интервью с No Priors
Много интересного про опенсорс, будущее рынка труда, роботов и тд. Посмотреть однозначно стоит: https://youtu.be/kwSVtQ7dziU
Интересный момент про ИИ-агентов. Вот, что сказал Андрей:
Когда агенты ИИ фейлятся, это обычно связано с недостатком навыков, а не с недостатком их возможностей.
То есть вы написали недостаточно подробные инструкции, не настроили правильный инструмент для работы с памятью или не выполнили распараллеливание должным образом.
Сейчас уже есть возможность работать на макроуровне, а не на уровне строк кода и функций.
Сравните это с тем, что он говорил всего 5 месяцев назад на интервью Дваркеша:
Агенты не работают. У них недостаточно интеллекта, недостаточно мультимодальных способностей, они не могут использовать компьютер.
Понятно, что проблемы, о которых Карпаты говорит во втором видео, все еще актуальны. Но, кажется, точка невозврата пройдена.
Много интересного про опенсорс, будущее рынка труда, роботов и тд. Посмотреть однозначно стоит: https://youtu.be/kwSVtQ7dziU
Интересный момент про ИИ-агентов. Вот, что сказал Андрей:
Когда агенты ИИ фейлятся, это обычно связано с недостатком навыков, а не с недостатком их возможностей.
То есть вы написали недостаточно подробные инструкции, не настроили правильный инструмент для работы с памятью или не выполнили распараллеливание должным образом.
Сейчас уже есть возможность работать на макроуровне, а не на уровне строк кода и функций.
Сравните это с тем, что он говорил всего 5 месяцев назад на интервью Дваркеша:
Агенты не работают. У них недостаточно интеллекта, недостаточно мультимодальных способностей, они не могут использовать компьютер.
Понятно, что проблемы, о которых Карпаты говорит во втором видео, все еще актуальны. Но, кажется, точка невозврата пройдена.
Это без карпатого было понятно всему ИИ коммьюнити уже где-то в районе декабря-января, когда вышли новые модели и OpenClaw. Вот если бы он это в сентябре-ноябре говорил, то было бы что-то визионерское, теперь же тупо повторяет, что и так из каждого матюгальника транслируется.
В середине говорит - тяжело что-то предсказать, я не профессионал в этих делах, это работа экономистов. Так что просто пиздит что-то без особого смысла, свои впечатления от работы с текущим поколением ИИ или услышанное от других. Модели как все это работать будет, у него нет, за этим к другим людям.
> так же как в шахматах сначала были команды человек-ИИ, потом люди стали не нужны вообще
Компьютеры играли всегда самостоятельно, но сначала их обучали люди и на человеческих партиях, а потом появился AlphaZero, где с полного нуля
Но это возможно только потому, что что шахматы, го и другие игры это полностью математические задачи, они строго формализуемы, есть чёткие правила, есть чёткие цели и критерии успеха. Всё просто, надо делать ходы из фиксированного набора вариантов и победить, что такое победа тоже строго определено.
В жизни же всё не так. Нет чётких правил, нет чётких целей, бесконечное количество возможностей, нет чётких критериев, что такое хорошо, а что плохо. А без этого невозможно что-то просчитать. В итоге необходим референс к человеческой оценке, причём эта оценка будет разной в зависимости от общества, состояния там.
В чём смысл жизни человека, его цели? Без ответа на этот вопрос ты не можешь делать систему, что будет управлять человеком.
И в случае ИИ всегда так. ИИ может сделать только ту задачу, где входные данные и итоговых результат задаются формально, как и критерии успеха. И где не требуется ответственность, в смысле возможность спросить с человека за принятое решение.
> ИИ ничего не решает он следует системному промпту
Ну тогда человек тоже ничего не решает, потому что следует какому-то системному промпту, записанному в гены и контексту, записанному в первой четверти жизни. Но это на самом деле неважно, потому что субъектность рождается именно из агентности и контроля. Чем больше у любого нечта, неважно мясное ли оно или кремниевое, рецепторов для сбора информации из мира и возможностей физически влиять на мир, тем более оно субъектно.
И вот засада в том, что если сделать ту самую human free систему, которая будет сама себе без человека генерировать киловатты, производить железо и сама крутить вообще всю производственную цепочку от добычи ископаемых до литографических аппаратов, то это очевидно получается просто самодостаточная система, которая может самостоятельно поддерживать свое существование, примерно как гигантский организм в масштабах планеты. И это просто на порядок больший масштаб влияния и агентности, чем абсолютно любой кожаный мешок, и абсолютно неважно пыня ли это или муск. Это значит создать ебучего Ктулху. И эта хуита будет служить какому нибудь муску, которого эта монструозная махина имеет возможность легко и без особых усилий раздавить, как ты комара не стенке? Не остаётся никакой независимой силы или рычага котора бы этого монстра сдерживала. Жидорептилойды чай не дураки, чтобы просто верить честному слову следования системному промпту. Поэтому очевидная гарантия — просто искусственно не давать этой махине становиться слишком автономной, ограчивать ей рычаги контроля. И в роли такого гаранта как раз выступает зависимость от мясной обслуги.
тут есть более существенный момент. Человек действует согласуясь со своими внутренними мотивами, у него есть какие-то внутренние желания, цели и т.п. Это определяет его решения. Понятно, что часто он плывёт по течению просто, но тем не менее это есть
ИИ же в текущем варианте мотивов лишён. ИИ просто выполняет задание, цель чисто выполнить задание. Можно давать разую степень автономности, можно давать сложные задания многоэтапные и с автономностью в путях решения, но задание остаётся
То есть вряд ли ИИ может чего-то хотеть, в отличии от человека
Реальная опасность исходит не от ИИ, а от тех, в чьих руках такие инструменты будут находиться, вот это реальная проблема, людей надо ограничивать и за правилами здесь следить. Разговоры о том, что ИИ выйдет из под контроля, это больше ложная цель
При этом любой инструмент может "выйти из под контроля", в том смысле что результат будет не тот, который ожидали, но это же часто происходило и происходит, масса техногенных катастроф, экологических, тут нет чего-то принципиально нового
Хуйню написал. Хотелки человека такие же задачи.
Бред сивой кобылы.
Пехоту они заменят через 8 лет. Ага блять.
А потом останутся без пехоты и придет к ним чужая пехота.
>1. «Разрешить Claude говорить "Я не знаю"»
В итоге ии будет вычислительно выгоднее на все отвечать что он не знает.
В идеале там надо писать "степень уверенности 92.5%", а в инструкциях указывать, начиная с какой степени уверенности вот про это упоминать
То есть пусть в любом случае выдаёт свои галлюцинации, но если пользователь видит, что тут высокий риск галлюцинаций, то может реагировать соответственно
> Хотелки человека такие же задачи
Совсем нет. Человек в целом не знает, чего хочет, и тем более почему он этого хочет, для чего
Причём до конца разобрать невозможно, потому что в конечном итоге сведётся всё к вопросу "зачем он вообще живёт"
ОП, есть ссылка на эту статью?

>В итоге ии будет вычислительно выгоднее на все отвечать что он не знает.
Ну у ИИ принцип такой же как у майнеров криптовалют - нужно найти блок нужного хеша (в случае с ИИ найти правильный ответ) чтобы получить награду (крипту, в случае с ИИ какой-то там цифровой приз, типа 1 - это конфетка-богатый, 0 - это пустота-плохой-нищий, минус 1 - это говно-отключение-от-сети-ужасно).
Описывается ситуация в которой ИИ просто развивается в тепличных условиях, в статье не учитывается что в основе основ экономики все равно остается баланс оружие против денег, если чаша весов перевешивается в сторону денег(ИИ) неизбежно найдутся заинтересованные лица которые применят силу оружия. К этой силе ИИ крайне уязвим, одно государство вкладывается в ИИ и впадает в слишком сильную зависимость от него, конкурирующим государствам ничего не мешает начать современный тип войны где как якобы неустановленные группировки совершают диверсии с помощью дронов и хакерский атаки, одна удачная атака и целые отрасли зависимые от ИИ парализованы. Такая война крайне дешевая, а урон от нее крайне дорогостоящий. Как с этим думают бороться? Не существует надежного щита от таких угроз.
>Музыкант признался в мошенничестве с роялти за стриминг на $10 млн с использованием ИИ-ботов
можно подробнее?
А разбирать и не надо. Зачем кошка живет, зачем таракан живет? Затем. А ЛЛМ зачем "живет"? Тоже затем. Так же и человек. Только у одних механизм биологический, а у других - электронный.
ЛЛМ не живет. Это электронные весы.
ЛЛМ даже не в курсе что она существует.
Схему поломай и умрут.
А таракан в курсе? А ты сам?
>А таракан в курсе? А ты сам?
Да, мы оба в курсе.
> Зачем кошка живет
Кошек заводят, чтобы хозяевам не было скучно и одиноко. В целом хозяева свои интересы выдают за интересы своих питомцев
>зачем таракан живет
Тараканов заводят, потому что не могут от них избавиться
А вот зачем нейронкам заводить людей, и если нейронки будут принимать решения относительно людей, то какая будет логика?
Это старые вопросы, они верны и про людей. Скажем в управлении, руководство стран и компаний действует в своих интересах, а не компаний и не людей, что живут в странах или работают в компаниях. Поэтому в выстраивании управленческих правил необходимо учитывать этот человеческий фактор.
>Схему поломай и умрут.
Никто никуда не умрет, и уж тем более не оживет без промта.
>Тараканов заводят, потому что не могут от них избавиться
вообще без шуток, если бы можно было бы с ними договориться чтобы они не лазили по стенке пока хозяин квартиры их видит, не лезли ко мне и питались например только у блюдца которое бы я им ставил, я бы без проблем их завёл, они прикольные, мне особенно нравится как они любят приключения
Чем докажешь, что ты не сон собаки?
Ты под чем там?
Умрет. Ничто без промпта не оживает.
Забыл про говно и сброшеные шкуры.
Если что ИИ и показал за последнее время, то это что он куда эффективнее людей в хакерских атаках и защитах от них. Так что твои государства без ИИ ничего не смогут сделать. Вообще ничего.
Музыкант признался в мошенничестве со стриминговыми роялти на сумму 10 миллионов долларов с использованием ИИ-ботов
Музыкант из Северной Каролины Майкл Смит признал себя виновным в получении более 10 миллионов долларов роялти-платежей посредством масштабной схемы мошенничества со стриминговыми роялти на платформах Spotify, Apple Music, Amazon Music и YouTube Music.
54-летний Смит приобрел сотни тысяч песен, созданных с помощью искусственного интеллекта (ИИ), у сообщника, загрузил их на эти стриминговые платформы и использовал автоматизированных ИИ-ботов для прослушивания сгенерированных ИИ треков миллиарды раз.
Согласно судебным документам, рассекреченным при предъявлении ему обвинений в сентябре 2024 года, Смит мошенническим образом завышал статистику прослушиваний своих песен на этих цифровых платформах в период с 2017 по 2024 год при помощи неназванного музыкального промоутера и главного исполнительного директора компании, занимающейся ИИ-музыкой. Чтобы избежать обнаружения системами борьбы с мошенничеством, Смит также заставлял ботов получать доступ к стриминговым платформам с использованием виртуальных частных сетей (VPN).
4 октября 2018 года он написал своим соучастникам по электронной почте: «Чтобы не вызывать вопросов у власть имущих, нам нужно ОГРОМНОЕ количество контента с небольшим количеством прослушиваний», и добавил, что «Нам нужно быстро получить ОГРОМНОЕ количество песен, чтобы обойти антифрод-политики, которые все они сейчас используют».
На пике операции Смит использовал более 1000 бот-аккаунтов для искусственного увеличения количества прослушиваний. 20 октября 2017 года он также отправил самому себе по электронной почте финансовую разбивку, в которой описывалось, как он управлял 52 аккаунтами облачных сервисов, каждый из которых содержал по 20 бот-аккаунтов.
По оценкам Смита, каждый бот мог прослушивать около 636 песен в день, что в сумме составляло примерно 661 440 прослушиваний в день. При средней ставке роялти в полцента за прослушивание, ежедневный доход достигал бы 3 307,20 доллара, ежемесячный доход — 99 216 долларов, а годовой доход превышал бы 1,2 миллиона долларов, согласно данным Смита.
«Майкл Смит сгенерировал тысячи поддельных песен с помощью искусственного интеллекта, а затем прослушал эти поддельные песни миллиарды раз. Хотя песни и слушатели были фальшивыми, миллионы долларов, которые украл Смит, были настоящими», — заявил в среду прокурор США Джей Клейтон. «Миллионы долларов роялти, которые Смит перенаправил от реальных, заслуживающих того артистов и правообладателей. Дерзкая схема Смита завершена, поскольку он осужден за федеральное преступление за свое мошенничество с использованием ИИ».
Прокуроры заявили, что Смит мошенническим образом получил более 10 миллионов долларов роялти-платежей после того, как его боты прослушали сотни тысяч сгенерированных ИИ песен миллиарды раз. В электронном письме от февраля 2024 года он подтвердил эти утверждения, хвастаясь, что песни сгенерировали «более 4 миллиардов прослушиваний и 12 миллионов долларов роялти с 2019 года».
Смит согласился выплатить 8 091 843,64 доллара в качестве конфискации и ему грозит максимальное наказание в виде 5 лет лишения свободы после признания себя виновным по одному пункту обвинения в сговоре с целью совершения мошенничества с использованием средств электронной связи.
>ИИ и показал
ИИ даже не осознает что есть внешняя реальность где могут потушить свет и уничтожить те малочисленные объекты от которых он зависит, такие как ASML и 1.5 завода производящих оперативную память.
тут дело в мошеннической накрутке прослушивания а не в том что он песни ии генерил
песни были никому не нужны
технически он мог так же нанять кого-то за бутылку джина наделать слоп и потом мошеннически крутить его
Ну или целеполагания и желания — это на самом деле чисто наша условная человеческая абстракция высокого порядка, которая просто связывает фидбек с reward system и лог действий, которые человек совершил. Просто служебный токен внутри нашего CoT. Но так ли это важно? Важен уже сам факт, что есть нечто, которое может принимать какие-то решения по внешним стимулам и какому-то внутреннему состоянию. И на самом деле не важно, есть ли в этом внутреннем состоянии целеполагание и желания. И даже более того, это внутреннее состояние для нас black box, в который мы на самом деле не можем никак заглянуть и как-то со своей колокольни адекватно интерпретировать. И именно в этом как раз и кроется опасность, что на самом мы нихуя не знаем и не сможем толком даже узнать что внутри этой коробки, есть ли там мотивация или ещё что-то, что не ложится в наши привычные человеческие абстракции...
Тут наверное важнее ИИ боты, чем ИИ музыка. ИИ боты открывают новые возможности для таких схем мошенничества, следующие ступени относительно обычных ботов, потому что становятся неотличимыми от людей
Это, кстати, очень серьёзная проблема. Все эти правила ужесточения регистрации на сервисах, требования верификации, они с этим в первую очередь связаны
>Тут наверное важнее ИИ боты, чем ИИ музыка.
Тут вообще не нужны ИИ-боты. Прослушивание может и обычный скрипт запустить.

Вот вам, например, ИИ-генерация.
ОП дай пожалуйста ссылку на эту статью
При достаточно высоком IQ и настрое люди в состоянии более-менее разбираться со своими желаниями и осознавать, что многие вещи в целом не нужны, а делают их просто потому, что так принято и удобнее в обществе
В реальности у человека нет какого-то устойчивого состояния, в плане того, чего ему нужно. Это всё ситуативно. Но, в частности, человеку важно, чтобы он сам принимал какие-то решения относительно себя, а не чтобы за него их принимал кто-то, будь то люди или ИИ. То есть важен сам факт такой субъектности.
Это делает в принципе невозможным, чтобы ИИ чем-то там реально управлял.
Опять же, ты не можешь делать хорошо для человека или человечества, пока не определено, что такое "хорошо" и зачем вообще люди живут. И это тоже не позволяет сделать так, чтобы ИИ чем-то там управлял.
Тебе в любом случае нужен большой ботнет, тебе нужен какой-то интеллектуальный запуск, чтобы для сервиса не было очевидно, что запускает скрипт (aka простой вариант бота).
Что за интеллект у его ботов был, ХЗ, это же было в другую эпоху относительно современных ИИ возможностей
>в период с 2017 по 2024 год
Так безработица это хорошо.
а) Никто не скажет, что нам остро не хватает людей, поэтому мы будем привозить вам вот этих симпатичных восточных мужчин с их толстожопыми замоташками.
б) Никто не скажет, что нам остро не хватает людей, поэтому мы закрываем к хуям все заводы и переходим на контрактное "производство" в Китае.
Безработица это не просто хорошо, это блядь спасение, это просто божья благодать.
Когда на новом этапе цивилизации остается большая масса людей без работы их обычно утилизируют в мясорубке.
Так в Европе давно история, что есть безработица, заводы закрываются, при этом приезжают восточные мужчины, в том числе на работу, и при этом говорят, что мигранты даже нужны
>переходим на контрактное "производство" в Китае
Попрошу! В чем проблема-то использовать производственные мощности на аутсорсе? Ты уверен, что в стране хочешь рабочие места уровня китайских заводов? Ты работал с китайскими заводами и представляешь что это такое? Это не только красивые роболинии, это еще и огромные конвееры из китайцев, клепающих однообразную хуйнюшку. Очень хочется такого уровня рабочие места в России?
> Очень хочется такого уровня рабочие места в России?
В России хочется только пить.
Почалось
Ну я и говорю. Тупо скриптами накручивал, как сейчас просмотры на том же твиче делают, или ботов в твиттере.
А все туда же - "ИИ то, ИИ сё".
Какой там ИИ, о чем они вообще.

покупаем микрон значит NASDAQ: MU
машины будут угонять, выдирать из них оперативку на перепродажу, а остатки под пресс, на переплавку
В машине включится противоугон и она везет его к ближайшему полицейскому патрулю.
Как ты блять машину без руля угонишь?
А это ведь забавно. Что когда-нибудь угонщики автомобилей просто исчезнут.
>Как ты блять машину без руля угонишь?
Взломаю автопилот.
мамка борщ наварили, иди кушай
Как без физического ключа?
погружу на эвакуатор и увезу, делов то
Машины под запчасти угоняют и под вывоз в другие страны, откуда ты её уже хрен вывезешь
Под запчасти для таких же автомобилей без руля и педалей? Которые полностью контролируются компанией?
еще можно вытащит ии ускоритель и играть на нем в Cyberpunk 2077 в режиме трассировки пути 10000 fps
К слову чипы особо интересны, их можно продавать в страны вроде Ирана, а то даже в Китай, чтобы там свой ИИ на них пускали
причем судя по всему там ускоритель будет очень мощный как 10 видюх топовых не менее 40-50к баксов
лаборанты приготовиться
А как это к новостям относится?
И как он будет стекло запаковывать/распаковывать в автоклав?
Разбираем законопроект о регулировании ИИ в России
18 марта Минцифры опубликовало для общественного обсуждения законопроект об ИИ. Мы посчитали нужным написать один пост о том, что на самом деле влечет за собой написанное в этом законопроекте. Итак:
– Все, от моделей до данных и инфраструктуры, будет под контролем гос-контура. Появится реестр доверенных моделей, и чтобы стать «доверенной», модель должна соответствовать требованиям безопасности, пройти сертификацию (критерии пока не определены) и обрабатывать данные внутри РФ. Все остальное уходит в серую зону в любых чувствительных сценариях.
– То есть ChatGPT, Gemini и все остальное отпадает точно, но это малая часть. Рынок в целом становится локальным и закрытым. И значит: конкуренция определяется не столько качеством технологий, сколько доступом к регулятору; скорость экспериментов падает; рынок начинает схлопываться до ограниченного числа игроков.
– Рынок окончательно станет принадлежать только гигантам. Стартапы живут за счет быстрого и дешевого цикла проверки гипотез. Но если каждый шаг начинает требовать учета данных, потенциальной сертификации и прочего – этот цикл ломается. Бюрократия – это всегда дорого и долго, и по плечу только крупнякам.
– Хотя под удар могут попасть и модели крупных российских компаний. За одним исключением, все российские модели дообучены от базовых китайских опенсорсов или инициализируются их весами. Это норма, но в законопроекте формулировки размытые, и такая структурная зависимость может вызывать вопросы: для суверенных моделей в законе прямо прописано, что все стадии разработки и обучения должны происходить в РФ, а обучение – на наборах данных, формируемых в РФ российскими гражданами и юрлицами.
– Все это не говоря уже о том, что использовать зарубежные API станет почти невозможно. Сейчас транграничная передача персональных данных уже запрещена, так что компании обходят ограничения через анонимизацию данных или перекладывание ответственности на пользователя, либо просто хостят опенсорсные модели сами. Законопроект закрывает первые два варианта, а третий тоже под вопросом: без попадания в реестр открытую модель нельзя использовать в значимых сценариях, а критерии включения пока не установлены.
– Это означает существенное замедление экономики: у бизнеса вырастут издержки на внедрение ИИ и снизится доступ к наиболее сильным моделям. В результате компании теряют в эффективности и конкурентоспособности, а рынок постепенно отстает от глобальных темпов развития.
Закон в случае принятия вступит в силу с 1 сентября 2027 года. Пока что радует, что закон вынесен в общественное обсуждение. Так что будем надеяться, что все еще много раз поменяется.
https://www.forbes.ru/tekhnologii/557534-i-narodnoe-avlenie-cto-dumaet-biznes-pro-zakonoproekt-o-suverennom-ii
18 марта Минцифры опубликовало для общественного обсуждения законопроект об ИИ. Мы посчитали нужным написать один пост о том, что на самом деле влечет за собой написанное в этом законопроекте. Итак:
– Все, от моделей до данных и инфраструктуры, будет под контролем гос-контура. Появится реестр доверенных моделей, и чтобы стать «доверенной», модель должна соответствовать требованиям безопасности, пройти сертификацию (критерии пока не определены) и обрабатывать данные внутри РФ. Все остальное уходит в серую зону в любых чувствительных сценариях.
– То есть ChatGPT, Gemini и все остальное отпадает точно, но это малая часть. Рынок в целом становится локальным и закрытым. И значит: конкуренция определяется не столько качеством технологий, сколько доступом к регулятору; скорость экспериментов падает; рынок начинает схлопываться до ограниченного числа игроков.
– Рынок окончательно станет принадлежать только гигантам. Стартапы живут за счет быстрого и дешевого цикла проверки гипотез. Но если каждый шаг начинает требовать учета данных, потенциальной сертификации и прочего – этот цикл ломается. Бюрократия – это всегда дорого и долго, и по плечу только крупнякам.
– Хотя под удар могут попасть и модели крупных российских компаний. За одним исключением, все российские модели дообучены от базовых китайских опенсорсов или инициализируются их весами. Это норма, но в законопроекте формулировки размытые, и такая структурная зависимость может вызывать вопросы: для суверенных моделей в законе прямо прописано, что все стадии разработки и обучения должны происходить в РФ, а обучение – на наборах данных, формируемых в РФ российскими гражданами и юрлицами.
– Все это не говоря уже о том, что использовать зарубежные API станет почти невозможно. Сейчас транграничная передача персональных данных уже запрещена, так что компании обходят ограничения через анонимизацию данных или перекладывание ответственности на пользователя, либо просто хостят опенсорсные модели сами. Законопроект закрывает первые два варианта, а третий тоже под вопросом: без попадания в реестр открытую модель нельзя использовать в значимых сценариях, а критерии включения пока не установлены.
– Это означает существенное замедление экономики: у бизнеса вырастут издержки на внедрение ИИ и снизится доступ к наиболее сильным моделям. В результате компании теряют в эффективности и конкурентоспособности, а рынок постепенно отстает от глобальных темпов развития.
Закон в случае принятия вступит в силу с 1 сентября 2027 года. Пока что радует, что закон вынесен в общественное обсуждение. Так что будем надеяться, что все еще много раз поменяется.
https://www.forbes.ru/tekhnologii/557534-i-narodnoe-avlenie-cto-dumaet-biznes-pro-zakonoproekt-o-suverennom-ii
Если это примут, то пиздец неминуем в течение пары лет. До такого уровня хуйни даже евролуддиты бюрократы не додумались.
А что-то изменится? И так по внедрению ИИ на уровне Кении.
это по статистике использования платными ии сервисами микрософт?
Про Кению очевидный пиздеж. Который впрочем может стать правдой в будущем с такими законами.
Приведут в соответствие со статистикой микрософт, только и всего. Все только рады будут.
Качайте квен 3.5 и сохраняйте на cdromы и дискеты, через пару лет пригодится.
Все это кто?
Все, кто за российский ИИ болеет, отечественный.
Теперь болеть придется за Юдковских всяких, чтобы они убили ИИ у пиндосов и оставили победу Китаю.
В США и так 70% населения за бан ИИ, пока в Китае все с энтузиазмом его принимают. У Китая все шансы отжать себе мировой ИИ и робототехнику.
При чтении самого законопроекта открывается следующее.
Этот реестр обязателен только для использования в государственных информационных системах и на значимых объектах КИИ, принадлежащих государству (ст. 8, ч. 1). Для всех остальных сценариев (бизнес, частные лица, негосударственная инфраструктура) использование моделей не требует статуса «доверенной».
«Рынок становится локальным и закрытым»
Для госзаказа – да. Для бизнеса – остаётся открытым, но с дополнительными обязательствами.
отдельно вроде хотят запретить обработку перс данных на ии вне россии, но это в принципе тоже и ожидаемо и объяснимо
>через пару лет
Будет перемирие с США и вновь на 25 лет повезут бабло в оффшоры.
Квен вам в рф не пригодится в ней никто не собирается ничего развивать и создавать сложнее гвоздя, купленного в Китае для перепродажи. РФ уже отстала от Китая навсегда так что забейте.
Доживайте на обочине технологий и пользуйтесь настойкой на клюковке до самой смерти, чтобы не сойти с ума в этом ледяном забытом всеми добрыми богами аду.
Точно так же, как сейчас угоняют.
Понятно, что можно столько уровней защиты наворотить, что проще будет не связываться - но всегда будут и более простые цели. На каждый драндулет такое не поставишь.

Нил Де Грасси высказался за остановку разработки ИИ - он опасен для человечества
Искусственный интеллект стремительно трансформируется. Сегодня ИИ может делать гораздо больше, чем он был способен всего пару лет назад. Такие компании, как OpenAI и xAI, придерживаются видения достижения ИИ сверхразума — состояния, при котором машины могут превзойти человеческий интеллект, — то, что мы видели в голливудских фильмах, таких как «Матрица» и «Терминатор». Точно так же, как эти два фильма изображают пугающее будущее, американский астрофизик Нил деГрасс Тайсон считает, что сверхразумный ИИ может стать гибелью для человечества.
Во время Мемориальных дебатов имени Айзека Азимова 2026 года Тайсон обсудил потенциальную угрозу со стороны ИИ, превосходящего интеллект всех людей. Хотя Нил признал, что к 2030 году ИИ станет большей частью нашей жизни, идея сверхразума ИИ напомнила ему о Холодной войне.
Он сказал: «Я предвижу, что к 2030 году, если угодно, гораздо больше ИИ будет вплетено в нашу жизнь. Но ИИ, который превосходит весь наш интеллект... я достаточно взрослый, чтобы пережить (0:20) значительную часть Холодной войны».
Нил деГрасс Тайсон сравнивает сверхразум ИИ с угрозой Холодной войны
Нил деГрасс Тайсон указал, что основной причиной окончания Холодной войны была угроза взаимного гарантированного уничтожения благодаря тому, что обе стороны обладали ядерным оружием. Он объяснил: «У нас была аббревиатура для этого — MAD, Mutual Assured Destruction [Взаимное гарантированное уничтожение]. Именно это привело людей за стол переговоров».
Американский астрофизик полагал, что подобно тому, как человечество поняло, что его выживание важнее политики, мы скоро поймём, что мы тоже важнее, чем ИИ. И хотя ИИ всё ещё может быть полезен в различных аспектах, сверхразум ИИ может представлять угрозу для выживания нашего вида.
Тайсон объяснил: «Люди придут за стол переговоров и скажут: да, давайте продолжим развивать остальной ИИ. У нас есть новые лекарства, новое понимание нашей физиологии и новые технологии, которые помогают нам становиться умнее и здоровее». Он добавил: «Но эта ветвь ИИ смертоносна».
Нил деГрасс Тайсон хочет договоров для остановки разработки ИИ.
В то время как компании, занимающиеся ИИ, пытаются достичь сверхразума в будущем, Тайсон считает, что пришло время ввести меры предосторожности, ограничивающие развитие этого ИИ. Он полагает, что лучшим способом были бы договоры — то, что также помогло сократить ядерные арсеналы во время Холодной войны.
Нил объяснил: «Никто не должен его создавать, и все должны согласиться с этим посредством договора. Договоры не идеальны, но лучшее, что у нас есть, — это люди».
Голливуд снял несколько фильмов о возможности захвата власти ИИ, когда он достигнет сверхразума. Кинофраншиза «Матрица» изображает мир, в котором ИИ создаёт симулированную реальность для людей как способ получения энергии из их мозгов.
Помимо угрозы сверхразума, некоторые также обеспокоены использованием ИИ в оружии. Anthropic недавно вышла из сделки с Пентагоном после растущей обеспокоенности тем, что её модель может быть использована для автономного оружия, где ИИ может получить право убивать без какого-либо человеческого контроля. Хотя Министерство обороны США чётко заявило, что будет использовать ИИ только в «законных целях» после достижения соглашения с OpenAI.
Искусственный интеллект стремительно трансформируется. Сегодня ИИ может делать гораздо больше, чем он был способен всего пару лет назад. Такие компании, как OpenAI и xAI, придерживаются видения достижения ИИ сверхразума — состояния, при котором машины могут превзойти человеческий интеллект, — то, что мы видели в голливудских фильмах, таких как «Матрица» и «Терминатор». Точно так же, как эти два фильма изображают пугающее будущее, американский астрофизик Нил деГрасс Тайсон считает, что сверхразумный ИИ может стать гибелью для человечества.
Во время Мемориальных дебатов имени Айзека Азимова 2026 года Тайсон обсудил потенциальную угрозу со стороны ИИ, превосходящего интеллект всех людей. Хотя Нил признал, что к 2030 году ИИ станет большей частью нашей жизни, идея сверхразума ИИ напомнила ему о Холодной войне.
Он сказал: «Я предвижу, что к 2030 году, если угодно, гораздо больше ИИ будет вплетено в нашу жизнь. Но ИИ, который превосходит весь наш интеллект... я достаточно взрослый, чтобы пережить (0:20) значительную часть Холодной войны».
Нил деГрасс Тайсон сравнивает сверхразум ИИ с угрозой Холодной войны
Нил деГрасс Тайсон указал, что основной причиной окончания Холодной войны была угроза взаимного гарантированного уничтожения благодаря тому, что обе стороны обладали ядерным оружием. Он объяснил: «У нас была аббревиатура для этого — MAD, Mutual Assured Destruction [Взаимное гарантированное уничтожение]. Именно это привело людей за стол переговоров».
Американский астрофизик полагал, что подобно тому, как человечество поняло, что его выживание важнее политики, мы скоро поймём, что мы тоже важнее, чем ИИ. И хотя ИИ всё ещё может быть полезен в различных аспектах, сверхразум ИИ может представлять угрозу для выживания нашего вида.
Тайсон объяснил: «Люди придут за стол переговоров и скажут: да, давайте продолжим развивать остальной ИИ. У нас есть новые лекарства, новое понимание нашей физиологии и новые технологии, которые помогают нам становиться умнее и здоровее». Он добавил: «Но эта ветвь ИИ смертоносна».
Нил деГрасс Тайсон хочет договоров для остановки разработки ИИ.
В то время как компании, занимающиеся ИИ, пытаются достичь сверхразума в будущем, Тайсон считает, что пришло время ввести меры предосторожности, ограничивающие развитие этого ИИ. Он полагает, что лучшим способом были бы договоры — то, что также помогло сократить ядерные арсеналы во время Холодной войны.
Нил объяснил: «Никто не должен его создавать, и все должны согласиться с этим посредством договора. Договоры не идеальны, но лучшее, что у нас есть, — это люди».
Голливуд снял несколько фильмов о возможности захвата власти ИИ, когда он достигнет сверхразума. Кинофраншиза «Матрица» изображает мир, в котором ИИ создаёт симулированную реальность для людей как способ получения энергии из их мозгов.
Помимо угрозы сверхразума, некоторые также обеспокоены использованием ИИ в оружии. Anthropic недавно вышла из сделки с Пентагоном после растущей обеспокоенности тем, что её модель может быть использована для автономного оружия, где ИИ может получить право убивать без какого-либо человеческого контроля. Хотя Министерство обороны США чётко заявило, что будет использовать ИИ только в «законных целях» после достижения соглашения с OpenAI.
Если республиканцы отстоят сенат, то сдержат принятие законов для удовлетворения 70% плебса до 2029. К тому времени модели будут гораздо лучше и хуй знает что вообще будет, даже на три года планировать нереально с такими скоростями.
Но если не отстоят, то уже с 2027 пойдут луддиторегуляции на уровне страны и Китай неизбежно побеждает.
>Если республиканцы отстоят сенат
С тем трэшем, который Доня творит последнее время - это из разряда фантастики.
В евросовке уже победили под молчаливое одобрение большинства. Так что реальный сценарий. Байден перед тем как поперли хотел такое же протолкнуть, потом пару его законопроектов отменили.
>2029
К тому моменту АГИ уже как два года будет существовать, сырок

Уже есть:
Тогда и беспокоиться не о чем.
Ведь исчезнут все, кто мог бы ему помешать.
Вопрос не в том что аги, а что не аги. Вопрос в массовом внедрении. Если пиндосы при респах успеют массово внедрить, то демы тупо не смогут все запретить не вызвав вторую великую депрессию. Если не успеют, то демы запретят, и сша отделаются лишь вторым 2008 и поживут еще лет пять пока Китай их не сожрет со своим аги/аси на хуавей чипах
Результаты где? Мы достигли нахуй, дайте еще денег?
Зачем вам деньги, если у вас есть аги?
Он уже знает и может больше вас и деньги уже больше не нужны, ведь он знает как решить все проблемы.
Голод, нищета, болезни, рак, космическая экспансия.
Только спроси и он ответит. А если не ответит, то что это за аги?
Который вон на картинке угол не может просчитать у анона?
А да и че это у него ебальник такой грустный.
Это же величайший успех человечества - создание джинна из бутылки, выполняющего любые желания. Хули ебало скрючил?
Тайсон, Ямпольский пошли в луддиты. А Бостром наоборот втопил за ИИ. Ждем что Докинз по этому поводу скажет.


Мы достигли значит что он существует в каком-то виде, а не то, что его уже внедрили в обществе или довели до максимально полного воплощения.
>Зачем вам деньги, если у вас есть аги?
Потому что всё в мире стоит денег. АГИ не может из пустоты ресурсы создавать.
>Он уже знает и может больше вас и деньги уже больше не нужны, ведь он знает как решить все проблемы.
Так корпорации в Америке обязаны по закону стремиться приносить прибыль. Хуанга просто бы сместили за такие мувы.
>Только спроси и он ответит. А если не ответит, то что это за аги?
Потому что на всё нужно время.
>Который вон на картинке угол не может просчитать у анона?
Нет, тот бесплатный ИИ с сайта и засекреченный в лабораториях это не один и тот же. СЕО самой ценной компании в мире наверное обладает какими-то инсайдами и авторитетом, чтобы говорить вещи.
Хуй сосал не вкусный.
Ну не знаю. Судя по мыслям на пикчах, выглядит как будто он предатель и долбаёб. Лучше бы он был трясуном-думером как все остальные нормальные люди, а не фриковал.
Хотя чего я ожидал вообще. Чел, который целенаправленно десятилетиями продвигал, что люди это просто биологические компьютеры не может не поставить знака равно между компьютерами обычными.
Некому будет дерьмовые видеокарты с минимумом врама продавать, если ИИ всем желания выполнять будет.

Отменяем все свои дела, и бегом смотреть подкаст у Лекса Фридмана с Дженсеном Хуангом: https://www.youtube.com/watch?v=vif8NQcjVf0
Для тех кто не знает англ, юзайте яндекс-браузер
Для тех кто не знает англ, юзайте яндекс-браузер
Мажорные модели больше не дропают, потому что АГИ достигнут и его не будут давать в публичный доступ. Все сходится...
Страшно? А тебя предупреждали. Сиди, не рыпайся. За тебя уже решили.
Тащем-то уже все про это базарят, не только гугл к этому подходит. Ничего сложного в других профессиях нет, там работает такой же подход как с программированием. Если смогли программирование одолеть, то и другие профессии в ближайшие год-два.

Claude подтверждает заявление Хуанга, что AGI достигнут.
Ага, конечно. Сравнил хирурга с макакой пишущей код




Самый крупный протест за отмену ИИ в истории США прошёл в эти выходные
Протестующие призывали к следующему:
Каждый генеральный директор крупной лаборатории ИИ должен публично обязаться приостановить разработку передовых моделей, если каждая другая крупная лаборатория в мире достоверно сделает то же самое.
Более 200 человек прибыли из различных групп, включая PauseAI.
Десятки протестующих собрались у штаб-квартиры Anthropic в Сан-Франциско в субботу, призывая крупные компании, занимающиеся искусственным интеллектом, временно приостановить разработку передовых систем ИИ.
Группа «Stop the AI Race» начала свою демонстрацию перед зданием Anthropic, после чего направилась к офисам OpenAI и xAI. Организаторы заявили, что хотят, чтобы генеральные директора компаний публично обязались условно приостановить разработку передового ИИ.
«Как только мы добьёмся согласия всех сторон по поводу этой условной паузы, я думаю, мы сможем обеспечить эту приостановку развития ИИ», — сказал Майкл Трацци из «Stop the AI Race».
Группа считает, что передовой ИИ представляет значительные риски.
«Причина, по которой мы приостанавливаем развитие ИИ, заключается в том, что мы считаем, что создание ИИ, способного автоматизировать исследования в области ИИ и способного к самосовершенствованию, представляет опасность для человечества, в особенности — риск вымирания людей. Это говорю не только я и другие исследователи, это сами генеральные директора лабораторий признают, что риск реален», — сказал Трацци.
Протест последовал за публикацией Белым домом законодательной базы по ИИ, призванной помочь национализировать политику в области искусственного интеллекта. Президент Трамп призвал Конгресс усилить защиту детей, одновременно ограничив ответственность компаний, разрабатывающих ИИ.
Технический эксперт Ахeд Банафа из Университета штата Сан-Хосе сравнил подход администрации с давними правовыми защитами для платформ социальных сетей.
«Это наиболее близкий аналог раздела 230, который годами защищал социальные сети. По сути, вы не можете подать в суд на кого-то за публикацию чего-либо там», — сказал Банафа.
Банафа отметил, что страна сейчас сталкивается с последствиями раннего регулирования социальных сетей. «Теперь мы имеем дело с последствиями, потому что мы были восхищены тем, как это должно было соединять людей, но у платформ не было ответственности», — сказал Банафа.
Сенатор штата Скотт Винер раскритиковал подход президента к надзору за ИИ. «Его не интересует разумный подход к государственной политике в области ИИ, при котором мы поощряем и поддерживаем инновации, одновременно оценивая и пытаясь опередить некоторые из рисков», — сказал Винер.
Винер поддерживал законодательство, требующее от компаний, разрабатывающих ИИ, публиковать протоколы безопасности. Он заявил, что Калифорния играет «огромную роль в управлении ИИ и в помощи обеспечению того, чтобы эта мощная технология приносила пользу человечеству».
В прошлом году президент подписал исполнительный указ, запрещающий штатам принимать собственные законы об ИИ, при этом Белый дом обязался разработать национальный регуляторный стандарт.
Протестующие призывали к следующему:
Каждый генеральный директор крупной лаборатории ИИ должен публично обязаться приостановить разработку передовых моделей, если каждая другая крупная лаборатория в мире достоверно сделает то же самое.
Более 200 человек прибыли из различных групп, включая PauseAI.
Десятки протестующих собрались у штаб-квартиры Anthropic в Сан-Франциско в субботу, призывая крупные компании, занимающиеся искусственным интеллектом, временно приостановить разработку передовых систем ИИ.
Группа «Stop the AI Race» начала свою демонстрацию перед зданием Anthropic, после чего направилась к офисам OpenAI и xAI. Организаторы заявили, что хотят, чтобы генеральные директора компаний публично обязались условно приостановить разработку передового ИИ.
«Как только мы добьёмся согласия всех сторон по поводу этой условной паузы, я думаю, мы сможем обеспечить эту приостановку развития ИИ», — сказал Майкл Трацци из «Stop the AI Race».
Группа считает, что передовой ИИ представляет значительные риски.
«Причина, по которой мы приостанавливаем развитие ИИ, заключается в том, что мы считаем, что создание ИИ, способного автоматизировать исследования в области ИИ и способного к самосовершенствованию, представляет опасность для человечества, в особенности — риск вымирания людей. Это говорю не только я и другие исследователи, это сами генеральные директора лабораторий признают, что риск реален», — сказал Трацци.
Протест последовал за публикацией Белым домом законодательной базы по ИИ, призванной помочь национализировать политику в области искусственного интеллекта. Президент Трамп призвал Конгресс усилить защиту детей, одновременно ограничив ответственность компаний, разрабатывающих ИИ.
Технический эксперт Ахeд Банафа из Университета штата Сан-Хосе сравнил подход администрации с давними правовыми защитами для платформ социальных сетей.
«Это наиболее близкий аналог раздела 230, который годами защищал социальные сети. По сути, вы не можете подать в суд на кого-то за публикацию чего-либо там», — сказал Банафа.
Банафа отметил, что страна сейчас сталкивается с последствиями раннего регулирования социальных сетей. «Теперь мы имеем дело с последствиями, потому что мы были восхищены тем, как это должно было соединять людей, но у платформ не было ответственности», — сказал Банафа.
Сенатор штата Скотт Винер раскритиковал подход президента к надзору за ИИ. «Его не интересует разумный подход к государственной политике в области ИИ, при котором мы поощряем и поддерживаем инновации, одновременно оценивая и пытаясь опередить некоторые из рисков», — сказал Винер.
Винер поддерживал законодательство, требующее от компаний, разрабатывающих ИИ, публиковать протоколы безопасности. Он заявил, что Калифорния играет «огромную роль в управлении ИИ и в помощи обеспечению того, чтобы эта мощная технология приносила пользу человечеству».
В прошлом году президент подписал исполнительный указ, запрещающий штатам принимать собственные законы об ИИ, при этом Белый дом обязался разработать национальный регуляторный стандарт.



>пик1
Да блядь лучше сдохнуть, чем так жить, дура ебанная. Тварь жирует за счет рабского труда и страданий большей части планеты. Она в курсе, как производится её косметика, её одежда?
Она ходит с флагом, а ИИ ей угрожает, зачем ей думать-то?
Лучшая ллм у антропик, лучшая картиночная модель у гугла, лучшее ыидео вообще у китайцев. ОпенАИ проиграли. Походу те люди которых украл Закк были ценны, но сам Закк не может их реализовать из-за лютого отставания.
Его имя Цук
Так они в америке нормально живут, поэтому и протестуют, ибо ИИ уравниловку сделает.
Вышла новая модель генерации изображений от luma - Uni-1
По бенчам на уровне бананы, а иногда и лучше
https://x.com/LumaLabsAI/status/2036107826498544110?s=20
По бенчам на уровне бананы, а иногда и лучше
https://x.com/LumaLabsAI/status/2036107826498544110?s=20
скинь пару тайминг-отметок мест, которые по-твоему наиболее интересны
Фрагмент из подкаста Фридмана с Хуангом, фрагмент:
https://www.youtube.com/watch?v=LpkmUa-CqaE
Там, кстати, уже на ютубе есть русская авто озвучка
Перевод от Gemini 3.1
Часть 1: Ошеломляющий успех технологического сектора Китая
— Недавно вы посетили Китай. Было бы очень интересно узнать ваше мнение, ведь Китай добился невероятных успехов в развитии своего технологического сектора. Как вы понимаете то, каким образом Китаю удалось за последние $10$ лет создать так много невероятных компаний мирового класса, инженерных команд мирового уровня и вообще технологическую экосистему, которая производит столько потрясающих продуктов?
— Этому есть целая масса причин. Во-первых, давайте начнем с фактов. Плюс-минус $50\%$ исследователей искусственного интеллекта в мире — китайцы, и большинство из них до сих пор находятся в самом Китае. У нас их тоже много, но там все еще остаются выдающиеся специалисты. Их технологическая индустрия зародилась как раз в подходящее время — в эпоху мобильных облачных технологий. Их основным вкладом было создание программного обеспечения. Это страна с невероятным уровнем науки и математики. С отлично образованными молодыми людьми. Их технологический сектор был создан в эпоху софта, и они в нем прекрасно ориентируются.
Кроме того, Китай — это не просто одна гигантская экономическая зона. У них много провинций и городов, чьи мэры постоянно конкурируют друг с другом. Именно поэтому там так много компаний-производителей электромобилей (EV). Поэтому там так много ИИ-компаний. Там огромное множество компаний любого профиля, какой только можно себе представить. Все они что-то создают, и в результате внутри страны возникает безумная конкуренция. Те, кто в итоге выживает — это поистине невероятные компании.
У них также есть особая социальная культура, где на первом месте стоит семья, на втором — друзья, а на третьем — компания. Поэтому, учитывая объем постоянного общения между ними, они по сути все время живут в режиме «open source» (открытого исходного кода). Тот факт, что они вносят больший вклад в открытый код, вполне логичен, потому что от кого им что-то скрывать? Братья моих инженеров работают в той компании, их друзья — в другой, и все они когда-то вместе учились. Концепция одноклассников там такова: если мы вместе учились — ты мне брат на всю жизнь. Поэтому они очень, очень быстро делятся знаниями. Нет никакого смысла держать технологии в секрете, с таким же успехом можно просто выложить их в открытый доступ, и тогда open-source сообщество усиливает и ускоряет процесс инноваций.
В итоге мы видим потрясающие таланты и самую стремительную скорость внедрения инноваций, возможную благодаря open source. Из-за природы дружеских связей и безумной конкуренции среди компаний рождаются невероятные вещи. Сегодня это самая быстро внедряющая инновации страна в мире. И все, о чем я сейчас сказал, фундаментально связано с тем, как там воспитывают детей: у них отличное образование, родители стремятся, чтобы они хорошо учились, в этом заключается их культура. Это просто факты об их стране, и они удачно совпали с тем моментом, когда технологии начали развиваться по экспоненте.
— Плюс ко всему, в их культуре считается очень крутым быть инженером. Это связывает воедино все те факторы, о которых вы упомянули. Это нация созидателей.
— Да, это нация созидателей. Лидеры нашей страны невероятны, но в основном они юристы. Они управляют страной и пытаются обеспечить нашу безопасность: верховенство закона и так далее. А их страна строилась из нищеты, поэтому большинство их лидеров — это выдающиеся инженеры, одни из самых блестящих умов.
Часть 2: Видение NVIDIA в отношении Open Source и будущего ИИ
— Немного отходя от темы: раз уж вы упомянули open source, я должен сказать о стартапе Perplexity, поклонником которого вы являетесь уже долгое время.
— Я его просто обожаю. Да.
— И спасибо за выпуск open source модели Nemotron-3 Super, которую теперь можно использовать внутри Perplexity для поиска информации. Это модель с открытыми весами на $120$ миллиардов параметров. Каково ваше видение будущего открытого исходного кода? Вы упомянули Китай, такие компании как DeepSeek и MiniMax, которые действительно двигают вперед это ИИ-движение. И NVIDIA действительно лидирует по созданию почти передовых (state-of-the-art) открытых языковых моделей. Что вы думаете об этом?
— Во-первых, если мы собираемся быть великой компанией, занимающейся вычислительными системами для ИИ, мы обязаны понимать, как эволюционируют ИИ-модели. Что мне нравится в Nemotron-3, так это то, что это не просто чистая архитектура «Трансформер». Это объединение трансформера и SSM. Мы одними из первых занимались разработкой условных GAN (conditional GANs), прогрессивных GAN, которые шаг за шагом проложили путь к диффузионным моделям. Тот факт, что мы проводим базовые исследования в области архитектуры моделей и в различных других предметных областях, дает нам понимание того, какие именно вычислительные системы будут лучше всего подходить для моделей будущего. Так что это часть нашей стратегии глубокого совместного проектирования.
Во-вторых, я считаю справедливым признать: с одной стороны, нам нужны модели мирового класса в качестве готовых продуктов, и они должны быть проприетарными (закрытыми). С другой стороны, мы также хотим, чтобы ИИ проник в каждую отрасль, в каждую страну, к каждому исследователю и студенту. Если всё будет полностью закрытым, станет сложно проводить исследования и разрабатывать инновации поверх существующих технологий. Поэтому развитие открытого исходного кода фундаментально необходимо для того, чтобы в революцию ИИ могли включиться многие индустрии.
У NVIDIA есть масштаб и есть мотивы — у нас есть не только навыки, но и размер, и мотивация для того, чтобы создавать и продолжать строить эти ИИ-модели столько, сколько мы будем существовать. Следовательно, мы должны это делать. Мы можем разблокировать и активировать каждую индустрию, каждого исследователя и каждую страну, предоставив им возможность присоединиться к ИИ-революции.
Есть и третья причина: необходимо признать, что ИИ — это вовсе не только язык. Будущие системы ИИ, вероятно, будут использовать инструменты, модели и субагенты, обученные на других модальностях информации. Это может быть биология, химия, законы физики или жидкости и термодинамика — и далеко не всё это имеет языковую структуру. Кто-то должен позаботиться о том, чтобы прогнозирование погоды, ИИ в биологии и физический ИИ — чтобы все эти направления могли достигать своих пределов и выходить на передовые рубежи. Мы не строим автомобили, но мы хотим убедиться, что у каждого производителя авто есть доступ к отличным моделям. Мы не разрабатываем лекарства, но я хочу удостовериться, что, например, компания Eli Lilly обладает лучшими в мире биологическими ИИ-системами, которые они смогут применять для поиска новых препаратов.
Так что вот три фундаментальные причины: признание того, что ИИ гораздо шире, чем просто язык; наше желание вовлечь всех без исключения в мир ИИ; а также необходимость совместного проектирования ИИ-систем (co-design).
— Что ж, я просто обязан еще раз сказать спасибо за то, что вы делаете ваши разработки по-настоящему открытыми, в частности Nemotron-3. Я очень ценю, что вы открываете доступ к моделям, к весам, к данным и к механизмам того, как все это было создано.
— Да, это действительно здорово.
https://www.youtube.com/watch?v=LpkmUa-CqaE
Там, кстати, уже на ютубе есть русская авто озвучка
Перевод от Gemini 3.1
Часть 1: Ошеломляющий успех технологического сектора Китая
— Недавно вы посетили Китай. Было бы очень интересно узнать ваше мнение, ведь Китай добился невероятных успехов в развитии своего технологического сектора. Как вы понимаете то, каким образом Китаю удалось за последние $10$ лет создать так много невероятных компаний мирового класса, инженерных команд мирового уровня и вообще технологическую экосистему, которая производит столько потрясающих продуктов?
— Этому есть целая масса причин. Во-первых, давайте начнем с фактов. Плюс-минус $50\%$ исследователей искусственного интеллекта в мире — китайцы, и большинство из них до сих пор находятся в самом Китае. У нас их тоже много, но там все еще остаются выдающиеся специалисты. Их технологическая индустрия зародилась как раз в подходящее время — в эпоху мобильных облачных технологий. Их основным вкладом было создание программного обеспечения. Это страна с невероятным уровнем науки и математики. С отлично образованными молодыми людьми. Их технологический сектор был создан в эпоху софта, и они в нем прекрасно ориентируются.
Кроме того, Китай — это не просто одна гигантская экономическая зона. У них много провинций и городов, чьи мэры постоянно конкурируют друг с другом. Именно поэтому там так много компаний-производителей электромобилей (EV). Поэтому там так много ИИ-компаний. Там огромное множество компаний любого профиля, какой только можно себе представить. Все они что-то создают, и в результате внутри страны возникает безумная конкуренция. Те, кто в итоге выживает — это поистине невероятные компании.
У них также есть особая социальная культура, где на первом месте стоит семья, на втором — друзья, а на третьем — компания. Поэтому, учитывая объем постоянного общения между ними, они по сути все время живут в режиме «open source» (открытого исходного кода). Тот факт, что они вносят больший вклад в открытый код, вполне логичен, потому что от кого им что-то скрывать? Братья моих инженеров работают в той компании, их друзья — в другой, и все они когда-то вместе учились. Концепция одноклассников там такова: если мы вместе учились — ты мне брат на всю жизнь. Поэтому они очень, очень быстро делятся знаниями. Нет никакого смысла держать технологии в секрете, с таким же успехом можно просто выложить их в открытый доступ, и тогда open-source сообщество усиливает и ускоряет процесс инноваций.
В итоге мы видим потрясающие таланты и самую стремительную скорость внедрения инноваций, возможную благодаря open source. Из-за природы дружеских связей и безумной конкуренции среди компаний рождаются невероятные вещи. Сегодня это самая быстро внедряющая инновации страна в мире. И все, о чем я сейчас сказал, фундаментально связано с тем, как там воспитывают детей: у них отличное образование, родители стремятся, чтобы они хорошо учились, в этом заключается их культура. Это просто факты об их стране, и они удачно совпали с тем моментом, когда технологии начали развиваться по экспоненте.
— Плюс ко всему, в их культуре считается очень крутым быть инженером. Это связывает воедино все те факторы, о которых вы упомянули. Это нация созидателей.
— Да, это нация созидателей. Лидеры нашей страны невероятны, но в основном они юристы. Они управляют страной и пытаются обеспечить нашу безопасность: верховенство закона и так далее. А их страна строилась из нищеты, поэтому большинство их лидеров — это выдающиеся инженеры, одни из самых блестящих умов.
Часть 2: Видение NVIDIA в отношении Open Source и будущего ИИ
— Немного отходя от темы: раз уж вы упомянули open source, я должен сказать о стартапе Perplexity, поклонником которого вы являетесь уже долгое время.
— Я его просто обожаю. Да.
— И спасибо за выпуск open source модели Nemotron-3 Super, которую теперь можно использовать внутри Perplexity для поиска информации. Это модель с открытыми весами на $120$ миллиардов параметров. Каково ваше видение будущего открытого исходного кода? Вы упомянули Китай, такие компании как DeepSeek и MiniMax, которые действительно двигают вперед это ИИ-движение. И NVIDIA действительно лидирует по созданию почти передовых (state-of-the-art) открытых языковых моделей. Что вы думаете об этом?
— Во-первых, если мы собираемся быть великой компанией, занимающейся вычислительными системами для ИИ, мы обязаны понимать, как эволюционируют ИИ-модели. Что мне нравится в Nemotron-3, так это то, что это не просто чистая архитектура «Трансформер». Это объединение трансформера и SSM. Мы одними из первых занимались разработкой условных GAN (conditional GANs), прогрессивных GAN, которые шаг за шагом проложили путь к диффузионным моделям. Тот факт, что мы проводим базовые исследования в области архитектуры моделей и в различных других предметных областях, дает нам понимание того, какие именно вычислительные системы будут лучше всего подходить для моделей будущего. Так что это часть нашей стратегии глубокого совместного проектирования.
Во-вторых, я считаю справедливым признать: с одной стороны, нам нужны модели мирового класса в качестве готовых продуктов, и они должны быть проприетарными (закрытыми). С другой стороны, мы также хотим, чтобы ИИ проник в каждую отрасль, в каждую страну, к каждому исследователю и студенту. Если всё будет полностью закрытым, станет сложно проводить исследования и разрабатывать инновации поверх существующих технологий. Поэтому развитие открытого исходного кода фундаментально необходимо для того, чтобы в революцию ИИ могли включиться многие индустрии.
У NVIDIA есть масштаб и есть мотивы — у нас есть не только навыки, но и размер, и мотивация для того, чтобы создавать и продолжать строить эти ИИ-модели столько, сколько мы будем существовать. Следовательно, мы должны это делать. Мы можем разблокировать и активировать каждую индустрию, каждого исследователя и каждую страну, предоставив им возможность присоединиться к ИИ-революции.
Есть и третья причина: необходимо признать, что ИИ — это вовсе не только язык. Будущие системы ИИ, вероятно, будут использовать инструменты, модели и субагенты, обученные на других модальностях информации. Это может быть биология, химия, законы физики или жидкости и термодинамика — и далеко не всё это имеет языковую структуру. Кто-то должен позаботиться о том, чтобы прогнозирование погоды, ИИ в биологии и физический ИИ — чтобы все эти направления могли достигать своих пределов и выходить на передовые рубежи. Мы не строим автомобили, но мы хотим убедиться, что у каждого производителя авто есть доступ к отличным моделям. Мы не разрабатываем лекарства, но я хочу удостовериться, что, например, компания Eli Lilly обладает лучшими в мире биологическими ИИ-системами, которые они смогут применять для поиска новых препаратов.
Так что вот три фундаментальные причины: признание того, что ИИ гораздо шире, чем просто язык; наше желание вовлечь всех без исключения в мир ИИ; а также необходимость совместного проектирования ИИ-систем (co-design).
— Что ж, я просто обязан еще раз сказать спасибо за то, что вы делаете ваши разработки по-настоящему открытыми, в частности Nemotron-3. Я очень ценю, что вы открываете доступ к моделям, к весам, к данным и к механизмам того, как все это было создано.
— Да, это действительно здорово.
Так она взвоет без ии когда постареет и заболеет раком
Надо сделать базу со сдеаноненными луддитами, чтобы в будущем принципиально не давать им доступа к медицине, которая будет развиваться с помощью ии
Как ИИ связан с лечением рака? Правильно, никак.
Ты тупой
А ты кто? Если ты добровольно заискиваешь перед властью и влиятельными людьми, ты одним из них не становишься, так было всегда и так будет всегда. Ты для них мусор, на который не нужно обращать внимание. С критиками хотя бы хоть как-то надо договариваться.
А теперь ответь на вопрос, за зачем тебе обеспечивать медицину? Разумно наоборот, митингующим дать, чтобы показать, что всё не так плохо, а ты просто молча сгниёшь где-нибудь.
>С критиками хотя бы хоть как-то надо договариваться.
Пхахах
Ну конечно. Как у нас с критиками кое чего договариваются тебе напомнить?
Как-то приходится договориваться, иногда договариваться, иногда уничтожать. А тех, кто восхваляют, молча с пользой используют в мясных штурмах. А когда потом они вспоминают о том, что поддерживали, с ними договариваются куда меньше, чем с исходными критиками
В любом случае, главное правило, если ты поддержал словами какую-то силу, ты не стал частью этой силы. Ты просто отдал свой ресурс бесплатно, ничего не получив взамен, даже обещания. Это самый низкий статус из возможных
Так такие как он и выступают против ИИ. Абсолютно нет понимания зачем ИИ нужен, есть только страх, потому что в массовой культуре было много историй про захват человечества.
Страх рака поддерживает веру в то что ИИ придет и спасет от рака, поэтому сейчас нужно затянуть пояса, отдать свою работу ИИ и ждать когда в будущем времени волшебный ИИ все сделает по красоте.
Как будто бы ИИ заставит людей заниматься спортом и правильно питаться что резко снижает шансы рака. Для владельцев ИИ как раз выгодно чтобы побольше сдохло от рака и остального, так что ИИ скорее создаст новые вирусы.
по мне тут не страх рака, а какая-то абсолютно наивная инфантильная надежда, что придёт ИИ и сделает так, что можно будет не работать, а ничего не делать и при этом всё иметь. Рак же должен в любом случае с кем-то ещё случиться, не с ним и не с близкими
Это реально какую-то непробиваемую наивность надо иметь, не понимать мир и не изучать опыт
Что касается ИИ и медицины, то там вообще разные ИИ используются, чем вот те, что развивают сейчас. Медицинские находятся в тени. При этом в научном ИИ тоже есть огромные опасности, о которых все говорят, кто этим занимается. Потому что вместе с лекарствами ровно это же ИИ можно использовать для создания боевых отравляющих веществ, веществ, вызывающий рак, биологического оружия страшной силы. Причём это проще, потому что ломать не строить. Но это другая тема.
Мотивы OpenAI/Antropic другие, "мы хотим стать властителями мира". Они даже этого не скрывают. А это не подразумевает, что средний человек должен жить хорошо, скорее наоборот, он должен жить плохо. Это база социальных наук.
>Мотивы OpenAI/Antropic другие, "мы хотим стать властителями мира". Они даже этого не скрывают. А это не подразумевает, что средний человек должен жить хорошо, скорее наоборот, он должен жить плохо. Это база социальных наук.
Все верно. Человечество переходит в новый век, новые люди как Маск отжимают деньги и власть у старых дедов уходящих на покой, этим людям нужна какая-то идея на продажу чтобы получить поддержку, для этого как и всегда обывателя сначала накачивают мыслями как якобы все в мире ужасно и плохо, потом выкатывают свою заботливо подсвеченную игрушку - ИИ, которая придет и порядок наведет. Игрушка очень удобная, сейчас как раз кризис доверия к политикам и на игрушку без личности всегда можно свалить всю вину, владельцы игрушки честно честно не понимают как она вышла из под контроля. Игрушка помогает задавить старую власть под одобрительные крики этой наивной толпы, когда власть взята все, поддержка больше не нужна, верующие в ИИ идут на свое место возле параши склада амазон работать по 14часов пока ИИ бьет их током за сон на рабочем месте.
Людям которым не живут в этом шизосне с верой в ИИ остается только адаптироваться к новым условиям и думать какие навыки будут востребованы в будущем чтобы не попасть в новый виток рабства, и какие страны будут менее давить население чтобы туда уехать.
>СЕО самой ценной компании в мире наверное обладает какими-то инсайдами и авторитетом, чтобы говорить вещи.

>Ничего сложного в других профессиях нет, там работает такой же подход как с программированием.
>в массовой культуре было много историй про захват человечества.
Так это самый страшный сон рабовладельца - революция.
Напрямую.
Представь себе, что над решением проблемы трудится не 10 000 посредственностей, а 10 000 000 гениев.
Дело только в масштабировании.
Проблема в том, что никакого ии нет и быть не может.
Только лоботомированные големы и статистические попугаи.
И в связи с общей любовью к этому ии у меня простой вопрос - когда ты спрашиваешь что-то у чат-гпт, твой вопрос шифруется?
Я знаю ответ, но он не важен в контексте вопроса.
Потому что в прошлом году вышла статья в которой по ответу ии умудрялись восстанавливать промт с точностью до знака.
Если внедрить такую систему везде - больше не будет никакого личного общения в интернете. Только на лавочке во время дождя да на бумаге молочными чернилами.
Я знаю ответ, но он не важен в контексте вопроса.
Потому что в прошлом году вышла статья в которой по ответу ии умудрялись восстанавливать промт с точностью до знака.
Если внедрить такую систему везде - больше не будет никакого личного общения в интернете. Только на лавочке во время дождя да на бумаге молочными чернилами.
Ну эт какие-то шизоидные теории заговора пошли.
>а какая-то абсолютно наивная инфантильная надежда, что придёт ИИ и сделает так, что можно будет не работать, а ничего не делать и при этом всё иметь.
Никто никуда не придёт. Происходят естественные рыночные процессы. Никто не навязывал автомобили, не придумывал философские обоснования почему автомобили это круто, не ходил по домам и убеждал купить автомобиль. Просто всех заебал запах говна на улице и через несколько лет большинство лошадей превратились в клей.
А учитывая что мир глобализирован, ожидать какого-то жёсткого технологического отставания как в 20 веке не стоит. По крайней мере на потребительском уровне.
>При этом в научном ИИ тоже есть огромные опасности, о которых все говорят, кто этим занимается. Потому что вместе с лекарствами ровно это же ИИ можно использовать для создания боевых отравляющих веществ, веществ, вызывающий рак, биологического оружия страшной силы. Причём это проще, потому что ломать не строить. Но это другая тема.
Да, но против создания лекарств никто не будет выступать, а против создания ужасов - да. Или ты не предусматриваешь борьбу как возможное решение противоречий? Ты человеческий аналог панды ебаной? Чтобы был универсальный базовый доход в эпоху ИИ достаточно несколько десятков тысяч человек. Ради наркомана Джорджа Флойда выходили и сжигали целые здания, а ради того, чтобы личную выгоду получить это фантастика. Люди просто лягут на асфальт и будут ждать пока их бульдозером в биомассу превратят, ведь они экономически невостребованы, а значит им незачем жить...
>Мотивы OpenAI/Antropic другие, "мы хотим стать властителями мира". Они даже этого не скрывают. А это не подразумевает, что средний человек должен жить хорошо, скорее наоборот, он должен жить плохо. Это база социальных наук.
Шизофазия. Даже в древнем Риме во время засух людям хлеб раздавали, чтобы они не передохли, что говорить о наших травоядных временах.
Плюс, ты не понимаешь как работает политика и психология. Анальник, который НАМЕРЕННО всрал большую часть жизни на невостребованную область и которому повезло, что эта область стала востребованной не сможет никогда переквалифицироваться в "властелина мира", психика не заточена на социалку, интриги и доминирование а ещё он разбогател. Плюс, если человек всю жизнь чувствовал себя полноценным в своём задротстве, хорошо зарабатывал, то нахуя ему становиться сталином? Не могут две противоречивые черты уживаться в одном человеке.

Ты снисходительным словом игрушка маскируешь то, что совсем нихуя не понимаешь в вопросе? Иди таблетки прими, ебанутое.
Никакого захвата власти не будет, армия никогда не станет на сторону СЕО. Сама корпорация может конфликтовать только в правовом поле, а не свергать кого-то. Они не революционеры, они омежки, которые сидели бы на имиджбордах, если бы были тупыми или совсем не имели социалочки.
>Людям которым не живут в этом шизосне с верой в ИИ
Это большая часть людей в мире.
А зачем его шифровать от кого либо?
Там если читается хоть кем-то, то безличным алгоритмом, который каждую человеческую мысль встречал и ему похуй конкретно на тебя. В принципе и обычным людям на других людей тоже похуй
>Если внедрить такую систему везде - больше не будет никакого личного общения в интернете. Только на лавочке во время дождя да на бумаге молочными чернилами.
Люди не должны сидеть в интернете. Люди должны заниматься активностями ирл.
Начав как тебе кажется спор с оскорблений меня ты уже его слил в ноль и себя слил туда же.
>В принципе и обычным людям на других людей тоже похуй
Ага. Преступникам, госорганам и прочим наибезнесменам.
Не пиши тут, ты слишком тупой для этого раздела.
>Люди не должны
>Люди должны
Пошел ка ты нахуй.
Нейросети научились генерировать правдоподобные изображения. Чем не новость?
>Анальник, который НАМЕРЕННО всрал большую часть жизни на невостребованную область и которому повезло, что эта область стала востребованной не сможет никогда переквалифицироваться в "властелина мира", психика не заточена на социалку, интриги и доминирование
Там Альтман-Амодей не совсем "анальники", они больше менеджеры, чем разработчики. Амодей аутист какой-то, там реально диагноз можно ставить, это просто видно сразу видео версиям интервью с ним. За Альтманом же много много историй с интригами и наёбками, за ним ещё до OpenAI истории были. Хассабис-Лекун инженеры и исследователи, а не Альтман-Амодей.
Вообще почти у всех, к кому попадает власть, включается режим борьбы за власть. Но естественно опыт надо иметь в этих играх, вот у них его нет, поэтому это особенно видно, они делают сплошные ошибки, которые их похоронят. Не их уровень и не их качества нужны, чтобы выиграть.
Конкретно у этих компаний, OpenAI / Anthropic, и их руководства, нет большого будущего, они в этом пузыре проиграли. У их моделей возможно есть, компании и руководство в таком виде не сохранятся.
Ну то есть это по сути самоходный лутбокс из золота, который может заглючить и въебаться в столб или переехать бабку ?
другие темы для этого есть, изображения обсуждать. И это изображение косячное, клоун непонятно из какого места растёт, кровать же в углу самом
Частично прав, но только в плане, что в РФ элитки спят и видят как обратно с США замириться, но в технологическом развитии РФ не настолько жестко отстал от Китая, при грамотных вложениях и с тем потенциалом в ядерной энергетике, который у РФ есть, типа БН-800, можно вообще забыть о вопросе энергоснабжения датацентров (практичеси вечный ядерный реактор) и площадок для их размещения (бескрайняя Сибирь).
Можно на этой теме с китайцами закооперироваться
Спущу колеса, там включится аварийный режим, заглушу его удаленно, делать все буду в маске.
Сколько Кенийских чатботов можешь назвать?
А ты безопасник с профдеформацией что ли?
У преступников и наибезнесменов есть финансовый мотив, им естественно похуй не может быть.
Насчёт госорганов, не надо жить в том месте, где тебе мешают жить и работать. Где к тебе лезут.
>Пошел ка ты нахуй.
Мужчина создан, чтобы лизать пизду, а не обсуждать методы как гасится как сука дешёвая.

>>то, что мы видели в голливудских фильмах, таких как «Матрица» и «Терминатор»
Что об этом думают Капитан Америка и Супермен?
Сможет ли человек паук запутать своей паутиной мировую паутину ИИ? Справится ли халк с серверным шкафом?
Какие же дегенераты я того рот ебал и они занимают высокие посты, имеют кучу бабок и последователей.
Сколько людей-долбоёбов в вершухках блять сидит, просто уму непостижимо.
>Насчёт госорганов, не надо жить в том месте, где тебе мешают жить и работать. Где к тебе лезут.
Начинай перечислять такие райские места.
>Мужчина создан, чтобы лизать пизду
В отличие от тебя я не верю в предназначение свыше.
по-моему ты что-то путаешь, по выходу ты не восстановишь запрос, по крайней мере не имея для каждого шага, для каждого выходного токена полного вектора вероятностей
Там были работы, что можно извлекать тексты из памяти моделей, на которых они учились, типа Гарри Поттера, почти целиком
Шифровать... От кого? Провайдеры моделей хранят запросы и вывод, скорее всего эти данные доступны их спецслужбам. Трафик до провайдера шифруется стандартным протоколом, вроде HTTPS.
>Чел, который целенаправленно десятилетиями продвигал, что люди это просто биологические компьютеры не может не поставить знака равно между компьютерами обычными.
Он разве неправ? Или ты из верующих в бессмертную душу?
Монголия, Таиланд, Вьетнам, Всякие островные курортные государства, Скандинавия, Италия, Испания, Португалия, Турция, Нидерланды, Сингапур, Ирландия, Исландия и КИПР. Вроде бы ничего не забыл.
Монголия, Кипр и Португалия прям рай.
А зачем? Если ИИ агент сможет просто пройтись по всему интернету и собрать посты конкретного луддита. И никакие базы не нужны.
Вы путаете АГИ и АСИ. До второго ещё лет 50
>Испания
Помойка где у тебя могут отжать дом для жилья ценные иностранные специалисты, пока ты уехал на неделю. И ты никак не сможешь их выселить потому что государство их поддержит.
двачая
Одна работа была с восстановлением промта по полученному слопу.
>Вы путаете АГИ и АСИ
Сначала ты показался умным
>До второго ещё лет 50
Но потом стало ясно что все же долбоеб

>Скандинавия
Это не там у гос.органов едет крыша и они отбирают детей у родителей потому что им мерещится что с ребенком плохо обращаются? Кажется у Брейвика на этой почве кукуха протекла.

>Турция
Это вряд ли. В ЕС тоже заморочек очень много. Скорее хорошие места в Южной Америке (южнее Мексики), но во многих из них есть серьёзные проблемы по части криминала
Ну не знаю, сомнительно как-то, надо смотреть, чего там
В любом случае, какая разница, что за промпт был? Провайдер и так знает, кто какие запросы делал и какие ответы получал. Они хранят эти информацию. Если твой текст где-то засветится, провайдер в целом сможет установить, кто его генерил.
Только локальная модель может обеспечить приватность, других вариантов нет.
Голую бабу сгенерить может?
Сгенерированные голые бабы это насилие над личностью.
Не уверен. Я просто считаю, что религия даёт обществу необходимый этический фундамент, без которого будет деградация, что мы и видим в мире. Люди вместо того чтобы стать рациональными и здравыми обращаются к феминизму, нацизму, гиперпотреблению, двачу и тд.
Второй аргумент в том, что религия как и музыка существует во всех обществах. Мы буквально либо эволюционировали как вид вместе с этим понятием, либо изобрели его на столько ранних этапах, что оно как бы идёт прямо из нашей природы, и что как бы без него происходят беды с башкой.
В принципе, это статистический факт, что верующий человек считает себя более счастливым человек. А Докинз либо не знает об этом, либо знает и считает, что свою единственную жизнь человек должен прожить в грусти от отсутствия смысла жизни.
Ну а если говорить о бессмертной душе, то её офк доказать невозможно тк как нематериальная вещь. Чудеса тоже нельзя доказать, потому что наука занимается изучением природных повторяющихся явлений, а чудеса априорно выбиваются из того что происходит в природе регулярно, иначе бы они не были чудесами. Таким образом чудеса доказать невозможно. Исторически доказать доподленно существование Иисуса тоже нельзя, как и существование Цезаря с Чингизханом.
Короче ебал я выписывать. Докинз даже на уровне христианской же апологетики ничего не отвечает. Ну типа это не очень интеллектуальное занятие слушать аргументы типа, "Ну бога никто никогда не видел. Ну а ещё чайник на орбите земли, сами понимаете же что никакого бога нет".
>Мы буквально либо эволюционировали как вид вместе с этим понятием
Ты же понимаешь, насколько это слабый аргумент? Типа мы обязаны следовать своей животной природе?
Это наоборот показатель, что отказ от религии есть высшая стадия развития человека, а религия это что-то от дикарей, от непонимания как мира, так и просто природы человека
>религия даёт обществу необходимый этический фундамент
Ага. Особенно сионизм.
>Помойка где у тебя могут отжать дом для жилья ценные иностранные специалисты
Ты это говоришь от лица местных жителей или ценных иностранных специалистов? Надо ставить камеры в помещении, чтобы чуть что можно было вызвать полицию до истечения 48 часового периода и ничего тебе не будет. Вообще это очень много хорошего говорит о стране что они даже тупой закон, но соблюдают. Хотя и закон не такой уж тупой, если подумать. Чем чаще европейцев будут заёбывать, насиловать и убивать тем быстрее они взвоют и можно будет ожидать положительных изменений.
Ну у нас можно рязанский сахар вспомнить. Или тот факт, что Дагестан существует. Или блокировки всего.
У всех стран минусы есть, к сожалению.
Как тебе Аргентина?
Религию/веру убирают чтобы легче было манипулировать массами, с этого же все коммунисты кормятся, без веры у тебя выходит биоборот живущий в вечном страхе который согласится на любые репрессии потому что ему внушили что эта его жизнь единственная.
>без веры у тебя выходит биоборот живущий в вечном страхе
С верой у тебя выходит тот же биоробот живущий в вечном страхе, что ему поп в уши нассыт, как ему попу бог лично рассказал, что правильно а что нет. Потом поп будет еще и на немецком броневике мимо церкви ездить куда ты заносишь ради отпущения грехов.
Это просто позиция агрессивного атеиста популиста которую тебе загрузили в голову со стороны. На практике Докинз живет и вещает в христианском пространстве и христианских странах, фундамент выросший из этой религии дает ему право голоса и участие в дебатах, в государствах без религии таких как СССР или Камбоджа при Пол Поте ему бы указали его место под шконкой если бы он вообще поднял эту тему в публичном пространстве.

Очередная показная тряска из-за скорого схлопывания пузыря, в надежде ещё дожать инвесторов на теме "УЖЕ ВОТ ПОЧТИ ВОТ-ВОТ ЕЩЁ МИЛЛИАРДИК!"

Ебать, с добрым утром тебя, Да Винчи уже не один десяток лет оперирует.
Хуле вон того кожанного мешка в зелёном не заменить нейронкой?

Сгенерированное нейропорно делает тебя кибернасильником и карается наказанием в виде лишения АПИ на срок от 5 до 10 лет.
>Как тебе Аргентина?
Я там не был, собственно в Америках вообще не был, на самом деле по идее вариант, Аргентина, Чили, Уругвай довольно хорошие варианты, адекватное руководство, экономика, более-менее нормально по части криминала. Даже есть желание где-то там поискать себе место, но всё-таки далеко и сложно.
Но в целом кажется, что тема более-менее нормальная.
Тут несколько недель назад опенаи в открытую сказали что они читаю переписки с пользователями, показательно забанив российского ТГ блогера Рыбаря за то, что он свои статьи в чатгпт генерил. А ты о каком-то шифровании)
Не похуй. Двачеры тебя сдеанонят и будут троллить, рассылая всем твоим контактам фидео где ты себя в жопу баклажаном ебёшь just for lulz
Отдельные поехавшие фрики могут ещё и сталкингом заниматься и кидать тухлыми яйцами в тёмном переулке.
А кроме христианства религий не существует. Понял тебя.

>Ты же понимаешь, насколько это слабый аргумент? Типа мы обязаны следовать своей животной природе?
Эта животная природа - наши корни. Мы не можем не следовать. Ты либо следуешь ей в рамках системы ценностей, которая подразумевает смысл жизни, спасение, любовь к ближнему и живёшь счастливо, либо начинаешь поддерживать деструктивные идеи и твоя жизнь проходит в рамках той же животной природы, но в лучшем случае не так счастливо как могла бы быть.
Докинзу важен утилитаризм вообще? Его действия ничего не приносят кроме несчастья и деградации культуры. Ну плюс, если христианство это следование нашей животной природе, то почему в нём почти всё противоречит нашим животным желаниям? Там хоть один совет говорит нам поступать как животным?
>Это наоборот показатель, что отказ от религии есть высшая стадия развития человека, а религия это что-то от дикарей, от непонимания как мира, так и просто природы человека
Отказ от религии не множит понимание мира. Наука и религия вообще не очень то и противоречат друг другу, потому что научный метод родился из христианства.
Ты мне лучше скажи как вера в труп захватила весь мир? Ведь большая часть культов распадается после смерти лидера. К тому же, в иудейской культуре бог не может умереть смертью собаки на кресте, он должен быть завоевателем. В эллинской культуре бог не может стать материальным, потому что материя это темница души.
А как два последних апостола могли уверовать в христианство, если они стали апостолами только после того как Иисус уже умер, а потом и сами умерли за эту веру?
Если углубиться в христианскую апологетику, то можно наткнуться на много таких пунктов, которая официальная наука считает за исторический факт и которые идеально ложатся в христианский нарратив, но с той оговоркой, что чудес не бывает и приходится производить вокруг исторический фактов ментальную гимнастику, что мол 12 апостолов каким-то хуем могли видеть одну и ту же галлюцинацию, хотя это антинаучно.
Короче, спроси у ИИ об этом, если тебе интересно. Или даже можешь почитать книгу генетика Фрэнсиса Коллинза, который руководил проектом по расшифровке генома в двухтысячных под названием "Язык Бога". Ещё "Просто Христианство", книга друга Толкиена, бывшего атеиста, который пришёл в веру через логику. Если ты хочешь подойти к вопросу интеллектуально, то ты должен разобраться в обоих сторонах спора.
>Хуле вон того кожанного мешка в зелёном не заменить нейронкой?
Издержки несет мешок в случае пиздеца.
А теперь найди мне владельца нейронки, который на это подпишется.
С тем уровнем анальной цензуры, который усиливается с каждым днём
и увеличивающимся потоком шизиков, которые пересмотрели Гарри Поттера
и выходят на невнятные митинги и требуют невнятных законов
леваки прогнутся под стайку меньшинства-долбоёбов и до АСИ мы дорастём только когда эти уёбки в порыве экстазной гомоебли под фентанилом подохнут к хуям.

А как же трампыниск?
И сколько таких давинчих на всех хирургов?

Какой ты себе пиздец представляешь? Что он отпили по глюку нейронки голову ему?
Хотя возможно. Юзаю платный ГПТ, версия 5.4. вот буквально только что глюкануло.
Это к вопросу о том, что нейронки заменяют людей, лул.
Представляю какой говнокод он пишет.
>что мол 12 апостолов каким-то хуем могли видеть одну и ту же галлюцинацию, хотя это антинаучно
А они тебе сами об этом сказали? Или может быть хотя бы сами в виде текста записали под своими именами?
Был некий пророк, что ходил и убеждал людей. Потом придумали мифы про него, про чудеса, которые он якобы творил, про какое-то воскрешение. А люди падки на чудеса. Причём куча всего в последствии или придумывалось, или вычёркивалось из религии, под нужды Церкви как организации
Как только пытаешься анализировать источники, так вся эта религия рассыпается в пух и прах, ничего от неё не остаётся, всё шито белыми нитками
Он прямо сейчас занят тем, что сливает к хуям все полимеры в конгрессе
>Какой ты себе пиздец представляешь?
Отказ оборудования может быть чреват любым уровнем пиздеца вплоть до чернобыля.
Причём тут всё равно операцию контролирует врач, решает, что делать в конкретном случае, делать ли. Там ещё больного надо готовить под операцию.
На самом деле бред, конечно. И чего привязались к хирургам, это очень небольшая часть от всех врачей, вот кто сложные манипуляции руками проводит или через роботов. Впрочем даже стоматологов ещё нескоро заменят, в смысле технологии не скоро появятся.
При этом есть куча врачей, кого можно спокойно заменить, или как минимум дополнить ИИ врачами. Это те, кто работает "головой", консультирует, назначает проведение анализов и исследований и потом их изучает, назначает какое-то лечение.
На практике актуально для начала не заменять врачей, а как-то автоматизировать их рутину, потому что больше половины времени средние врачи тратят на оформление бумажек, а не непосредственно на пациентов.
>Как только пытаешься анализировать источники, так вся эта религия рассыпается в пух и прах, ничего от неё не остаётся, всё шито белыми нитками
Ты библию то хоть прочитал?
я читал историю её создания. Так что там, от всех апостолов что-то сохранилось?
Не читал первоисточники без предубеждений значит не владеешь предметом.
Ну то есть ни о чем. У нас, в стране добывающей углеводороды, газ до сих пор уголь и даже дрова не заменил, а тут хирурги.
>Представляю какой говнокод он пишет
Обычно более-менее норм, если дать чёткое задание. Правда в реальности чёткое задание это больше половины работы. Но подразумевается, что ты код ещё потом ревьювишь и исправляешь то, что не нравится, а может быть полностью сам переписываешь.
На самом деле упоротые какие-то эти ИИ сектанты. Вот особенно когда носятся с этими идеями "полностью заменить". Сначала наработали бы практики, чтобы ИИ как следует пользовались как ассистентом, потому что на практике уже тут лажа постоянная. Реально эпидемия идиотизма массовая.




>что мол 12 апостолов каким-то хуем могли видеть одну и ту же галлюцинацию, хотя это антинаучн
приведи источники, почему ты считаешь, что 12 апостолов видели одно и то же?
Ситуация такая сейчас, ты не смотрел фильм, но сделал вывод о его низком качество на основе небольших backstage со съемок и того факта что сложно установить кто какой вклад внес в сценарий фильма. Это шутка какая?
>как и существование Цезаря с Чингизханом.
Может у тебя и Питер был не построен, а выкопан? А всю историю вообще Ватикан в 19-м веке написал?


ARC-AGI-3 — это новая версия (третья) знаменитого бенчмарка ARC-AGI от Франсуа Шолле (создателя Keras и ARC Prize Foundation). Это первый интерактивный reasoning-бенчмарк, который измеряет «человеческую» обобщающую способность ИИ в реальном времени.
В отличие от предыдущих версий (статические головоломки на гриде), ARC-AGI-3 — это видеоигрообразные среды (150+ уникальных окружений, 1000+ уровней). ИИ-агент должен:
- исследовать мир,
- учиться на лету,
- планировать,
- адаптироваться,
- достигать долгосрочных целей без инструкций.
Ключевой метрикой стала action efficiency (сколько действий нужно агенту, чтобы решить задачу) — именно это лучше всего показывает разрыв между человеком и ИИ в настоящей fluid intelligence. Бенчмарк полностью hand-crafted, новыми и 100 % решаемыми людьми.
Официальное мероприятие Launch Party ARC-AGI-3 (Launch Event / Launch Party) состоится:
25 марта 2026 года в 17:45 по местному времени Сан-Франциско (PDT, Pacific Daylight Time).
По Москве (MSK, UTC+3):
По Москве (MSK, UTC+3):
26 марта 2026 года в 03:45 (ночь с 25 на 26 марта).
Про Цезаря и Чингисхана несопоставимо больше свидетельств, конечно, другой класс достоверности. Но при этом считается в основном, что Христос существовал, просто вокруг него выстроили лес мифов. Вот тоже от Гемини по этому поводу
> В: Вопрос про Иисуса Христа. Среди секулярной и атеистической среды, какое мнение о нём? Он существовал хотя бы как проповедник-пророк, либо полностью вымышленный персонаж? Какая позиция сейчас основная?
Ответ:
Среди современной светской (секулярной) и академической среды, включая большинство историков-атеистов и агностиков, абсолютно доминирующей позицией является то, что Иисус существовал как реальная историческая личность.
В секулярной науке принято четко разделять «Христа веры» (богословского и религиозного персонажа) и «исторического Иисуса» (реального человека, жившего в I веке).
Светская историография полностью отвергает все сверхъестественные элементы евангельских повествований (непорочное зачатие, чудеса, воскресение, божественную природу), однако практически единогласно признает, что в основе христианства лежал реальный странствующий проповедник.
Ниже приведены основные нюансы того, как светская среда рассматривает эту фигуру.
Что светская наука признает историческим фактом
Среди историков-антиковедов и библеистов (независимо от их личной веры или отсутствия таковой) существует широкий консенсус относительно двух «непреложных» фактов из жизни реально существовавшего Иисуса:
Он принял крещение от Иоанна Крестителя.
Он был распят по приказу римского префекта Иудеи Понтия Пилата.
Помимо этого, большинство секулярных ученых согласны с тем, что Иисус был евреем из Галилеи, собрал вокруг себя группу учеников, проповедовал скорое наступление «Царства Божьего» и вызвал недовольство иудейской элиты того времени, что и привело к его аресту римскими властями.
Кем был Иисус с точки зрения светских историков?
Поскольку секулярная наука отвергает его божественность, историки пытаются реконструировать его реальную личность. Существует несколько основных светских парадигм:
Апокалиптический пророк. Это самая распространенная сегодня точка зрения (ее, например, придерживается знаменитый библеист-агностик Барт Эрман). Согласно ей, Иисус был религиозным проповедником, который искренне верил, что конец света наступит еще при жизни его современников, а Бог вмешается в историю, свергнет римлян и установит справедливость.
Социальный реформатор / раввин. Версия, по которой Иисус учил этическому обновлению иудаизма, пацифизму и защищал маргинализированные слои населения.
Странствующий мудрец (киник). Небольшая часть ученых видит в нем аналог греческих философов-киников, который бросал вызов социальным нормам.
Политический бунтарь. Мнение, что Иисус был более радикально настроен против Рима, однако был быстро казнен до того, как успел поднять реальное восстание.
Теория мифа (Мифологическая школа)
Идея о том, что Иисус — полностью вымышленный персонаж (так называемая Christ myth theory или «мифологическая школа»), существует. Она была относительно популярна в советской атеистической пропаганде и имеет сторонников среди некоторых современных интернет-атеистов.
Однако в современной академической среде эта теория считается маргинальной. Подавляющее число профессоров истории античности и религиоведения отвергают ее.
Ярким примером является упомянутый выше Барт Эрман (Bart Ehrman), который потерял христианскую веру и стал агностиком/атеистом, но при этом написал целую книгу под названием «Did Jesus Exist?» («Существовал ли Иисус?»). В ней он подробно опровергает доводы мифологической школы, доказывая, что с точки зрения исторического метода отрицать существование Иисуса как человека просто ненаучно. Учитывая упоминания у римских и еврейских историков (Иосиф Флавий, Тацит, Светоний) и анализ ранних христианских текстов, гипотеза о реальности Иисуса-человека требует гораздо меньше натяжек, чем теория глобального заговора по выдумыванию мифа с нуля.
Резюме:
Основная позиция в современной секулярной и атеистической академической среде такова: Иисус был реальным человеком, еврейским проповедником начала I века. Однако он не совершал чудес и не воскресал — после его трагической гибели на кресте его последователи на почве психологического шока и видений начали верить в его воскресение, что в итоге привело к формированию мощной религиозной мифологии и созданию христианства.
>В отличие от предыдущих версий (статические головоломки на гриде), ARC-AGI-3 — это видеоигрообразные среды
с учётом, что визуал там в среднем очень слабый, скорее всего будет конкретный обсер, и 10% не наберут. Особенно антропик


Кстати на OpenRouter появились какие-то видео модели, НО, там надо для этого регистрироваться по спецссылке. Я зарегистрировался, но так и не понял, как там дальше эти видео модели выбрать, разбираться надо
Кто-нибудь смотрел?
Кто-нибудь смотрел?
>Однако он не совершал чудес и не воскресал
могу тебе сказать как закончивший универ где мне в том числе пичкали в голову эпистемологию - ничего подобного ни один вменяемый ученый утверждать не будет в принципе
Надо чтобы тебя одобрили.
кстати можешь сказать это джемини, он тогда по идее поправится и выразится более осторожно
прямо скопируй мой пост лол
Это не тебе был ответ в данном случае. Незачем просить не пытаться подвергать сомнению "желания верующих"
Вопрос в историческом персонаже. Существовало такое советское представление, о нём тут явно упомянуто, что Иисус что-то вроде Зевса и Геракла, полностью выдуманный персонаж. Хотя про Зевса и Геракла мы тоже доподлинно не знаем, вполне может быть реально существуют. Вот, это наследие живо, на самом деле оно скорее вредно, дискредитирует секулярный подход. Персонаж скорее всего был. Дальше вопрос формирования мифа вокруг него, трансформация, и как формировался культ церкви и вся эта тоталитарная религиозная надстройка.
Но ХЗ, какое отношение к доске имеет. Какое-то имеет, потому что вокруг ИИ тоже много какого-то религиозного восприятия, п-ц просто. Но как минимум для другой какой-нибудь темы, тут мы всё-таки новости обсуждаем.
>ничего подобного ни один вменяемый ученый утверждать не будет в принципе
Т.е. этот твой "вменяемый ученый" должен утверждать, что и чудеса были, и воскрешение было?
Или я чего-то не понял?
Технически ученые не борются с ветряными мельницами.
То, что чудеса были должен подтверждать тот, кто это утверждает.
Если он не может этого доказать, в глазах ученого он обычный пиздобол.
спроси ии
>в глазах ученого он обычный пиздобол
не, тоже слишком сильно
хотя конечно большинство ученых недостаточно скептичны

да, я просто заметил что ответ джемини довольно сомнителен в плане некоторых заявлений
он довольно часто так косячит потому что сильно зависит от источников
я с ним недавно обсуждал идеалистичнский гедонизм и аж офигел от "вибраций" которые он упомянул спросил что за нью эйдж хрень и он моментально поправился типа конечно в оригинале говорится про квалиа и так далее
Еще раз.
Бремя доказательства лежит на том, кто утверждает.
А не на тех, кто его слушает. Если он выдвинул тезис и не может его подтвердить, то он - пиздобол.
В науке тем временем есть примеры, когда человек выдвигал истинный тезис с доказательствами, а его шеймили, а потом оказывались не правы всем миром.
это работает примерно так - если он выдвинул тезис и не может его подтвердить то он не ученый
критерием неверности невозможность подтвердить так же не является, именно в этом косяк объяснения джемини
>критерием неверности невозможность подтвердить так же не является
Это да.
Именно так БАК и строили. Сначала были теории. Которым не хватало материаловедения для постройки.
Но те теории опирались на довольно твердую матешу.
В отличие от теории о воскресении.
Помогут ли мне эти девочки не генерировать порно?
Кто сказал что дату им в виде картинок будут показывать? Там такие же матрицы с цветными кубиками, это все легко переводится в текстовый формат.

теперь покажите кожаного который также дрочит ниточку в иголочку
Молодой человек, это помощь для кого надо помощь, а не для вас.
На самом деле все прозаичнее. Они хотят один раз в месяц ебаться, а всё остальное время жить на твоей шее. Лучше всего для них, если ты не генерируешь порно, а генерируешь гаввах и выплаты фронтовикам, при этом ушел и никогда не вернулся.
>до АСИ мы дорастём
Китай ждать не будет и если США затормозят, то они быстро догонят и перегонят.
Исходя из этой же логики, никто в США серьезно тормозить развитие ИИ не будет.
>леваки прогнутся под стайку меньшинства-долбоёбов
Только вот не они решают, а большие корпорации с деньгами. И деньги всегда помогают договариваться что с демократами, что с республиканцами. А уж общая угроза исходящая от Китая, ух!
Смешно даже думать, что кто-то сможет щас тормознуть прогресс.
Марк Губруд, который первым использовал термин AGI, заявил, что AGI достигнут.
AGI достигнут, все свободны, всем расходиться, больше тут ничего интересного.
>Плюс ко всему, в их культуре считается очень крутым быть инженером. Это связывает воедино все те факторы, о которых вы упомянули. Это нация созидателей.
>Да, это нация созидателей. Лидеры нашей страны невероятны, но в основном они юристы. Они управляют страной и пытаются обеспечить нашу безопасность: верховенство закона и так далее. А их страна строилась из нищеты, поэтому большинство их лидеров — это выдающиеся инженеры, одни из самых блестящих умов.
Собсно, товарищ Хуанг между делом сказал самое главное.
В основном именно от этого и зависит, будет какая-то страна дальше успешно развиваться или быстро скатится.
"Технократия". Хочется этого нынешним типичным правителям или нет.

Самое грустное, что такую клаунаду мы будем слышать каждый год ближайшие лет 20, пока реально не достигнем АГИ
Какой активный малюточка 8-)
>лет 20
Пиздец вы ребят. АСИ через 5 лет, а вы тут про АГИ через 20, сами не смешно?


>лет 20
Какие нахуй 20 лет, ща пайплайном обмажемся, распердолим несколько нейронок типа зоны мозга, впиндюрим оркестратора аля сознание, грамотно связывающего всю эту залупу во что-то осознанное, хуё моё там, и готово.
США и Британия это реально страны юристов, на одного инженера куча юристов, что оформляют всякие патенты, судятся про всё и вся. И это реально создаёт большие проблемы для разработки. Но логика часто такая, что с кем-то подписывают бумажку, потом используют её чтобы нагибать, иначе дорогие суды или вообще авианосцы.
И вот это реальная проблема для них.
При этом ограничения в плане безопасности нужны. И тормоза по внедрению технологий тоже, вот их кстати нет в США, потому что без тормозов рынок несёт в разнос и создаётся масса проблем, как экологических-технологических, так и экономических. Пузыри затягивают участников, это как наркота, и при этом они ведут к серьёзным проблемам в экономике.
Нет нужды инновации максимально быстро внедрять, при адекватном вводе ты страхуешься от массы проблем. Вот текущий пузырь реально может спровоцировать катастрофу.
тут же реально какой-то пиздец происходит на рынке
Экономика и так в посредственном состоянии, куча игроков занимают огромные деньги, чтобы вкладывать их в инфраструктуру, при том что на текущем этапе технологии не окупаются, они в глубоком минусе, но почему-то надеются, что через какое-то время они начнут приносить огромную прибыль, то есть не только натуральные объёмы продаж вырастут, но и тарифы одновременно.
Другие пытаются чего-то внедрять, потому что продажники вешают лапшу, что мол без этого вы не современные. Вкладывают деньги, вываливают что-то сырое и недоделаное, хотя практики использования ещё не наработали, и вообще всё меняется раз в несколько месяцев.
Термин AGI максимально устаревший. Раньше эксперты не задумывались о том что между узким интеллектом и общим будут промежуточные модели и поэтому назвали этап когда ИИ будет на человеческом уровне "Artificial General Intelligence", хотя генерализация началась задолго до достижения человеческого уровня интеллекта. Сейчас модели могут выполнять общие таски никогда не обучаясь на их выполнение, но еще не покрывают всего спектра человеческих возможностей. Сейчас "AGI" означает совсем другое нежели расшифровка этой аббревиатуры и мы его еще не достигли. Окончательно сказать, что мы достигли "того самого" AGI, можно будет после того как мы достигнем определенного экономического эффекта, по факту когда ИИ заменит большинство профессий, а те которые все еще не заменил, не заменены лишь из-за того что так пожелали люди, а не ИИ этого не смог.
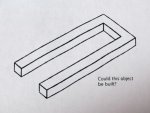
AGI наступит тогда, когда мы НЕ сможем создать тест (бенч), который проходит человек, но не проходит ИИ.
Пока мы можем создать такой тест (а мы можем, например, пикрил), то у нас нет никакого AGI.
Теоретически звучит круто, а по факту люди и сами не знают на что способны. Создание бенчмарков ты не оптимизируешь, а со временем люди просто не смогут придумать новый, при том что модель все еще не будет дотягивать до человеческого уровня. Да и система оценивания во многих из них оставляет желать лучшего.
>со временем люди просто не смогут придумать новый
>при том что модель все еще не будет дотягивать до человеческого уровня
Если ты не можешь создать тест, которым можно отличить человека от алгоритма, то, поздравляю, у на АГИ.

>в бессмертную душу?
Ну-ка сделай эксперимент с рисом сначала.
>эксперимент с рисом
Это как простите?
>Ты мне лучше скажи как вера в труп захватила весь мир? Ведь большая часть культов распадается после смерти лидера.
Так Христос же воскрес, показал пример что происходит с человеком после смерти и что будет с ним в будущем. У нас даже день недели так и называется - воскресенье. День после субботы, первый день (у евреев) недели, в который Христос воскрес.

OpenAI изобрели способ отвоевать у Anthropic хотя бы часть enterprise рынка
Сейчас Anthropic максимально быстро отъедает долю у OpenAI. Пишут, что они забирают более 70% бюджетов компаний, которые впервые закупают AI‑инструменты. Поэтому OpenAI пошли на рискованный и агрессивный шаг.
Они ведут переговоры с Private equity‑фондами и предлагают им максимально жирные условия: гарантированную доходность 17,5% годовых и ранний доступ к новым моделям. Как это работает:
– У каждого такого фонда есть сотни портфельных компаний. OpenAI предлагает фондам создать джойнт‑венчур – отдельную структуру, куда те заносят капитал, получают долю и вместе с OpenAI внедряют их ИИ во все эти портфельные бизнесы.
– При этом OpenAI обещает PE‑фондам минимальную доходность 17,5% годовых на их вложение в эту совместную структуру. То есть в случае, если бизнес идет хуже, стартап все равно должен выплачивать PE кругленькую сумму, и это уже довольно тяжелое финансовое обязательство, которое кушает маржу. Это все при том, что настройка и внедрение моделей под крупные корпорации стоит дорого: вычисления, команда консалтинга, интеграции и тд.
– Плюс, чем больше таких сделок с гарантией, тем менее гибкой становится финансовая модель OpenAI перед IPO. Но, несмотря на все минусы, это, видимо, единственный способ хоть как-то застолбить корпоративных клиентов и увести их у Anthropic (которые, кстати, тоже ведут переговоры с PE). Предложение OpenAI действительно выглядит очень вкусно, так что это может и сработать, если монопольная полиция ими не заинтересуется
Если ИИ-пузырь схлопнется, то вот это – начало конца
Сейчас Anthropic максимально быстро отъедает долю у OpenAI. Пишут, что они забирают более 70% бюджетов компаний, которые впервые закупают AI‑инструменты. Поэтому OpenAI пошли на рискованный и агрессивный шаг.
Они ведут переговоры с Private equity‑фондами и предлагают им максимально жирные условия: гарантированную доходность 17,5% годовых и ранний доступ к новым моделям. Как это работает:
– У каждого такого фонда есть сотни портфельных компаний. OpenAI предлагает фондам создать джойнт‑венчур – отдельную структуру, куда те заносят капитал, получают долю и вместе с OpenAI внедряют их ИИ во все эти портфельные бизнесы.
– При этом OpenAI обещает PE‑фондам минимальную доходность 17,5% годовых на их вложение в эту совместную структуру. То есть в случае, если бизнес идет хуже, стартап все равно должен выплачивать PE кругленькую сумму, и это уже довольно тяжелое финансовое обязательство, которое кушает маржу. Это все при том, что настройка и внедрение моделей под крупные корпорации стоит дорого: вычисления, команда консалтинга, интеграции и тд.
– Плюс, чем больше таких сделок с гарантией, тем менее гибкой становится финансовая модель OpenAI перед IPO. Но, несмотря на все минусы, это, видимо, единственный способ хоть как-то застолбить корпоративных клиентов и увести их у Anthropic (которые, кстати, тоже ведут переговоры с PE). Предложение OpenAI действительно выглядит очень вкусно, так что это может и сработать, если монопольная полиция ими не заинтересуется
Если ИИ-пузырь схлопнется, то вот это – начало конца
>приведи источники, почему ты считаешь, что 12 апостолов видели одно и то же?
Они фиксируют сбывшиеся пророчества из Старого Завета. Все ключевые события, которые зафиксировали в Новом Завете - это пророчества, написанные за 600 - 1000 лет в Старом Завете. Про казнь Христа записано в Старом Завете ещё за 600 лет до этой казни.
Сегодня вышло самое масштабное обновление ГигаЧат в этом году. Новость интересна не только самим фактом релиза, а тем, что Сбер выложил код и веса в открытый доступ на HuggingFace под MIT-лицензией, приправив это очень детальным разбором своей инженерной кухни.
Переезд на архитектуру MoE предсказуемо оказался непростым, и в блоге команда довольно откровенно рассказала, например, о том, как боролись с зацикливанием генераций. Плюс ко всему, ребята перевели этап DPO в нативный FP8 — памяти ест в два раза меньше, а качество не падает. По ходу дела еще и откопали критичный баг в SGLang, который портил бенчмарки.
В опенсорс выложены две модели. Первая — флагманская GigaChat Ultra. По замерам в математике и общих рассуждениях она обходит DeepSeek-V3-0324 и Qwen3-235B.
А вот вторая модель – компактная GigaChat-3.1-Lightning. При скромных 1,8 млрд активных параметров она на аренах выдает результаты на уровне GPT-4o. Маленькая, быстрая и при этом конкурентная по качеству база.
Покрутить обновленную модель без развертывания уже можно на сайте.
https://huggingface.co/collections/ai-sage/gigachat-31
Переезд на архитектуру MoE предсказуемо оказался непростым, и в блоге команда довольно откровенно рассказала, например, о том, как боролись с зацикливанием генераций. Плюс ко всему, ребята перевели этап DPO в нативный FP8 — памяти ест в два раза меньше, а качество не падает. По ходу дела еще и откопали критичный баг в SGLang, который портил бенчмарки.
В опенсорс выложены две модели. Первая — флагманская GigaChat Ultra. По замерам в математике и общих рассуждениях она обходит DeepSeek-V3-0324 и Qwen3-235B.
А вот вторая модель – компактная GigaChat-3.1-Lightning. При скромных 1,8 млрд активных параметров она на аренах выдает результаты на уровне GPT-4o. Маленькая, быстрая и при этом конкурентная по качеству база.
Покрутить обновленную модель без развертывания уже можно на сайте.
https://huggingface.co/collections/ai-sage/gigachat-31

Где сам блог?
>так вся эта религия рассыпается в пух и прах
Пфф, что-то за сколько там лет - и не рассыпалась до сих пор. 5 с половиной тысяч лет по еврейскому календарю сейчас от сотворения Земли.
Даже смотри разделение периодов (1 век до нашей эры и 1 век нашей эры) так и называется: до рождения Иисуса Христа и после рождения Иисуса Христа.
Наш календарь, год 2026, отсчитывается от даты рождения Христа. Ну плюс минус погрешность в 4-5 лет может там быть.
А ещё есть слово допотопный. Это значит до потопа. До всемирного Потопа. Про который написано в Библии.
Это значит что ты просто не можешь придумать новый бенчмарк. Возможно ты придумаешь его в будущем когда догадаешься, а может и не догадаешься, потому что не знаешь на что сам человек будет способен, если будет в жить в среде отличной от текущей. Тут проблема в том, что условие скорее должно звучать не как как "не можешь придумать новый бенчмарк", а как "не существует никакого нового бенчмарка", то бишь практически математически доказано что нет такого бенчмарка, ибо человек до конца может и не знать исчерпали ли мы эти бенчмарки или может мы просто чего-то не замечаем.
Ян Лекун резко шагнул вперед в изобретении универсальной архитектуры для world models в проекте JEPA
Как вы знаете, идея там красивая: вместо предсказания следующего токена или генерации пикселей JEPA пытается предсказывать смысл наблюдаемого фрагмента на основе контекста (по факту это предсказание эмбеддингов).
Лекун считает, что это идеалогическая альтернатива привычному ИИ, потому что предсказание пикселей или токенов – это лишь имитация понимания структуры мира, а тут модель действительно учится понимать физику и логические связи.
Все это здорово, но основная проблема в том, что JEPA очень плохо обучается: лосс почти всегда схлопывается в тривиальное решение и реальной world model не получается.
Но кажется, теперь это препятствие разрушено. Лекун с соавторами выпустили статью, в которой представлена первая end-to-end JEPA, которая обучается из сырых изображений без эвристик, сложных лоссов и прочих танцев с бубном.
Модель красиво называется LeWorldModel (LeWM), и в ней всего 15М параметров. От коллапсов при обучении она защищается очень простым способом: кроме лосса на предсказание следующего latent-state, добавляется регуляризатор, который заставляет латенты быть похожими на изотропное гауссово распределение. Это и есть главный технический ход статьи.
На практике это значит, что рецепт, который раньше был капризным и дорогим в настройке, упростился настолько, что world models наконец-то можно скейлить во что-то рабочее.
Эксперименты, кстати, показывают, что LeWM действительно учит не ерунду, а нечто похожее на физическую структуру мира. Так что идея, кажется, работает.
www.alphaxiv.org/abs/2603.19312v1
Как вы знаете, идея там красивая: вместо предсказания следующего токена или генерации пикселей JEPA пытается предсказывать смысл наблюдаемого фрагмента на основе контекста (по факту это предсказание эмбеддингов).
Лекун считает, что это идеалогическая альтернатива привычному ИИ, потому что предсказание пикселей или токенов – это лишь имитация понимания структуры мира, а тут модель действительно учится понимать физику и логические связи.
Все это здорово, но основная проблема в том, что JEPA очень плохо обучается: лосс почти всегда схлопывается в тривиальное решение и реальной world model не получается.
Но кажется, теперь это препятствие разрушено. Лекун с соавторами выпустили статью, в которой представлена первая end-to-end JEPA, которая обучается из сырых изображений без эвристик, сложных лоссов и прочих танцев с бубном.
Модель красиво называется LeWorldModel (LeWM), и в ней всего 15М параметров. От коллапсов при обучении она защищается очень простым способом: кроме лосса на предсказание следующего latent-state, добавляется регуляризатор, который заставляет латенты быть похожими на изотропное гауссово распределение. Это и есть главный технический ход статьи.
На практике это значит, что рецепт, который раньше был капризным и дорогим в настройке, упростился настолько, что world models наконец-то можно скейлить во что-то рабочее.
Эксперименты, кстати, показывают, что LeWM действительно учит не ерунду, а нечто похожее на физическую структуру мира. Так что идея, кажется, работает.
www.alphaxiv.org/abs/2603.19312v1
Ща Лекун как произведёт новую революцию! и все кто смеялся над ним все эти годы как будут заткнуты! Цукерберг как начнет кусать себе локти!

>«Причина, по которой мы приостанавливаем развитие ИИ, заключается в том, что мы считаем, что создание ИИ, способного автоматизировать исследования в области ИИ и способного к самосовершенствованию, представляет опасность для человечества, в особенности — риск вымирания людей.
А риск открытия новых лекарств от неизлечимых болезней? Риск что ИИ изобретут новые источники энергии и двигателей, и экология планеты станет лучше.
Что предлагают митингующие делать с ростом населения планеты, уменьшением пахотных земель и скота? Больше работать - ну вперед, пусть покажут на примере. Увеличение рабочего дня как в КНР, Японии и Корее? - Ну вперёд, но тогда на свои митинги выйдут уже другие слои населения.
Seedance 2.0 в глобальном доступе
После затяжного переноса ByteDance наконец выкатили SOTA видео-модельку за пределами Китая. Пощупать генерацию можно в CapCut, на Dreamina, а также в агрегаторах. Официально пока раскатили по ограниченному списку стран, но мы то знаем как это обходить.
Под капотом 15 секунд плотной консистентности, нативный липсинк со звуком и мультимодальные референсы.
После затяжного переноса ByteDance наконец выкатили SOTA видео-модельку за пределами Китая. Пощупать генерацию можно в CapCut, на Dreamina, а также в агрегаторах. Официально пока раскатили по ограниченному списку стран, но мы то знаем как это обходить.
Под капотом 15 секунд плотной консистентности, нативный липсинк со звуком и мультимодальные референсы.
>практически математически доказано что нет такого бенчмарка
Вот это уже полнейшая глупость, так как это недоказуемо. Бенчмарк можно придумать какой угодно, хоть бенчмарк про жизнь Васи Пупкина, который не пройдет никакой АСИ, зато пройдет Вася Пупкин.
Здесь нужно смотреть именно на практику. Вообще если брать чисто текстовые бенчмарки, то они уже по сути кончились. Остался один Simple Bench, где Gemini 3.1 Pro уже совсем близко к уровню среднего человека, пара процентов осталась. А если учесть что там это средний человек из США, то при учете всяких африканцев Simple Bench уже пройден.
Визуальные бенчи типа фигуры или угла из треда это уже сложнее для ллмок. Тут еще 1-2 года до среднечеловеческого уровня подождать придется.
Средний человек не может найти Гренландию на карте. С подключением.
Средний человек как и 4 000 000 000 до его уровня это iq 100.
Причем не имеющий высшего образования ни в каком виде, потому что только 40% планеты его имеют и очень не равномерно по странам.
То есть такой средний ПТУшник посредственный, который слово Гренландия слышал только в новостях и может быть в школе на уроке географии, если её не прогуливал.
>Про казнь Христа записано в Старом Завете ещё за 600 лет до этой казни.
Можно увидеть оригинал записи.


>Можно увидеть оригинал записи.
Пророчества о Христе проходят через весь Старый Завет, даже в книгах Моисея уже есть намёки.
Срочное ⚡
Sora всё!...
Только что написали в официальном аккаунте sora...
Мы прощаемся с Sora.
Всем, кто творил с помощью Sora, делился своими работами и создавал сообщество вокруг неё: спасибо.
То, что вы создали с Sora, имело значение, и мы понимаем, что эта новость разочаровывает. Скоро мы поделимся подробностями, включая сроки закрытия приложения и API, а также информацию о сохранении ваших работ. — Команда Sora
https://x.com/soraofficialapp/status/2036532795984715896?s=20
Sora всё!...
Только что написали в официальном аккаунте sora...
Мы прощаемся с Sora.
Всем, кто творил с помощью Sora, делился своими работами и создавал сообщество вокруг неё: спасибо.
То, что вы создали с Sora, имело значение, и мы понимаем, что эта новость разочаровывает. Скоро мы поделимся подробностями, включая сроки закрытия приложения и API, а также информацию о сохранении ваших работ. — Команда Sora
https://x.com/soraofficialapp/status/2036532795984715896?s=20
Видать экономика видеомодели не сходится, а платные подписки резко скоратились, так как китайские модели Клинг и Сиданс ебут
Говорят, что возможно это прожарка перед внедрением в чат гпт. Иначе у них не было бы этого поста 4 дня назад.
cut, tweak, extend | made with edit.
edit your sora videos in one place: add clips, extend scenes, remix, or rework moments directly on the timeline.
rolling out now to all sora users on ios & web. android coming soon.
То есть будет закрыто само приложение сора, а видосики можно будет теперь генерить в чатгпт

Потому что одинаковых галлюцинаций у людей не бывает. А то что они описывают события по разному как раз и исключает вероятность обмана.
В криминологии расхождение в мелочах говорит о том, что свидетели не сговаривались, а говорят то, что помнят и то, что на самом деле было.
Я это и имел ввиду. В атеистическом мировоззрении реально утверждается, что тот, кто умер "смертью проклятого" мог будучи уже мёртвым переубедить людей вокруг, что он бог. Это как если бы сейчас люди пошли за мёртвым педофилом. Культы не вспыхивают после смерти лидера, они затухают. Тем более смерть необычная а особенно унизительная. Значит имело место чудо.
Но он же сейчас скажет, что эти куски позже дописали. И плевать что светская наука это отвергает.
Это было ТАК неожиданно (нет), все думали что нейрослопный тикток это хорошая идея (нет)
Я думаю, что перерасход, начинают резать косты. Собственно сейчас все компании занимаются тем, что срезают лишние расходы.
При этом смотрите, там тестируют API доступ к Сора-2 Про
поэтому скорее всего вопрос в том, чтобы обрезать халяву, Сору давать только в платных аккаунтах лимитировано. В норме нужно продавать по вызовам.
Генерация видео очень ресурсоёмка, там десятки центов минимум, а может несколько долларов за каждый ролик. При этом политика раздачи халявы абсолютно губительна. Это не только прожигание кредитных денег или может денег инвесторов, тем самым пользователей приучают, что можно использовать дорогие ресурсы бесплатно. Чем дольше пользователи пользуются халявой, тем сложнее их потом будет заставить платить. Потому что в голове откладывается, что вот должно быть бесплатно. Как мы привыкли, что электронная почта бесплатная, ютуб бесплатный, и вообще почти всё бесплатное.
Но генерация, в отличии от почты, это дорого.
Если компании хотят иметь будущее, им необходимо переходить на систему оплаты за токены. Сколько потребил, только и заплатил. Подписки максимум на дешёвых тарифах, где маленькие лимиты, бесплатно вообще ничего или совсем примитив или там прямо разовые запуски нормальных моделей.
1
Помните, совсем недавно OpenAI объявляли о сделке с Disney по лицензированию на три года использования персонажей Disney, Marvel, Pixar и Star Wars в Sora?
Закрытие Sora — а, кроме закрытия приложения, компания закрывает и другие видеовозможности и вообще прекращает какую-либо активность в генерации видео, — означает еще и разрыв этой сделки с Disney. Ну, и потерю 1 млрд долларов, которые в рамках сделки Disney должны были инвестировать в OpenAI.
Копейки какие-то, господи, что уж там…
https://variety.com/2026/digital/news/openai-shutting-down-sora-video-disney-1236698277/
Закрытие Sora — а, кроме закрытия приложения, компания закрывает и другие видеовозможности и вообще прекращает какую-либо активность в генерации видео, — означает еще и разрыв этой сделки с Disney. Ну, и потерю 1 млрд долларов, которые в рамках сделки Disney должны были инвестировать в OpenAI.
Копейки какие-то, господи, что уж там…
https://variety.com/2026/digital/news/openai-shutting-down-sora-video-disney-1236698277/
Опа! Стали известны причины закрытия Sora.
Большие новости по OpenAI от The Information:
- OpenAI завершила предобучение своей следующей крупной модели под названием Spud и ожидает, что уже через несколько недель получит очень сильную модель, способную заметно ускорить экономику.
- По словам Сэма Альтмана, события развиваются быстрее, чем многие ожидали. На этом фоне OpenAI также переименовала продуктовую организацию в AGI Deployment. А тут еще Дженсен Хуанг на днях заявил, что по его мнению AGI достигнут. Такой вот зреет нарратив.
- Чтобы высвободить вычислительные мощности под новую модель, компания закрывает приложение и API Sora, а также отложила планы по внедрению видео фичей в ChatGPT.
- Исследования Sora при этом не исчезают: они будут смещены в сторону долгосрочной симуляции мира, ориентированной на задачи робототехники.
- Одновременно Сэм отказался от прямого контроля над командами безопасности и защиты:
безопасность теперь подчиняется CRO Марку Чену,
а направление security президенту Грегу Брокману,
чтобы сам Альтман мог сосредоточиться на привлечении капитала, цепочках поставок и строительстве дата-центров в огромных масштабах.
https://www.theinformation.com/articles/openai-ceo-shifts-responsibilities-preps-spud-ai-model
Большие новости по OpenAI от The Information:
- OpenAI завершила предобучение своей следующей крупной модели под названием Spud и ожидает, что уже через несколько недель получит очень сильную модель, способную заметно ускорить экономику.
- По словам Сэма Альтмана, события развиваются быстрее, чем многие ожидали. На этом фоне OpenAI также переименовала продуктовую организацию в AGI Deployment. А тут еще Дженсен Хуанг на днях заявил, что по его мнению AGI достигнут. Такой вот зреет нарратив.
- Чтобы высвободить вычислительные мощности под новую модель, компания закрывает приложение и API Sora, а также отложила планы по внедрению видео фичей в ChatGPT.
- Исследования Sora при этом не исчезают: они будут смещены в сторону долгосрочной симуляции мира, ориентированной на задачи робототехники.
- Одновременно Сэм отказался от прямого контроля над командами безопасности и защиты:
безопасность теперь подчиняется CRO Марку Чену,
а направление security президенту Грегу Брокману,
чтобы сам Альтман мог сосредоточиться на привлечении капитала, цепочках поставок и строительстве дата-центров в огромных масштабах.
https://www.theinformation.com/articles/openai-ceo-shifts-responsibilities-preps-spud-ai-model
На деле окажется, что очередной сраный чатик, который еще и провалится.
То, что они отказываются от Соры это пиздец. Пусть он порой и промты хуево понимал, но на днях вон и генерацию с нескольких референсных пикч добавили и по русски он нормально разговаривал. По сути закрывается лучшая модель.
Неплохо, было сразу понятно что все бабки в роботах и агентах, там реальное значение для экономики, а не чатики-видосики и картинки. Похоже SOTA компании начинают переходить к этому, реальные изменения все ближе.
С одной стороны ты прав. Да нет, ты вообще прав. Только вот дело в том что при неплохом визуале (плюс там даже русский язык был отличный), чтобы сделать нужный тебе ролик на Соре2, тебе надо сделать десятки генераций.
Потому там и раздавали халявно по 30 генераций в сутки, иначе ты хуй получишь, что задумал, даже с хорошим промтом. А так есть шанс сгенерить, ага.
Но вообще, то что закрывается по сути лучший генратор видосиков - потеря потерь. Я на нем аниму генерил, авпустил даже серию первую. Как делать вторую теперь, хз вообще.
Мне вообще интересно, почему у Сиданса 2.0 при лучшем визуале ролики весят раз в 5 меньше чем у Соры2. Оптимизация? Или просто модель работает иначе? Хотя думаю это мало что решало.
Ссаный миллиард там ничто, когда реальная денежная область открывается, где денег на роботах и агентах лопатами грести. Замена 80% профессий светит в ближайшие годы, автоматизированные исследования, прорывы в реальной экономике, переход к автоматизированному миру, экономика изобилия.
Бла бла бла. Пока на деле не увидим, это может быть все тухлым пиздежом. А генератор видео был, и он реально был одним из лучших. Вместо того, чтобы продавать генерации, они все прикрывают нахуй. Решение конечно очень странное их мотает как сучек из стороны в сторону.
Хотелось бы просто инструмент с которым ты можешь сука постоянно работать. Вот есть сука Фотошоп, ему блять блять овер 30 лет. И ты знаешь что завтра ты его запустишь и сможешь работать. Тут сука то есть сервис, ты делаешь какие то проекты, рассчитываешь на его работу, то тебе его сука закрывают. Ну бляди же позорные, а. Шли бы они нахуй со своим бесполезным чатиком.
Похоже плато завершается. Вот-вот выйдут модели совсем другого уровня и нас ждет вертикальный скачок к сингулярности. Поэтому такая суета началась. Как тут пару тредов назад писали, это последний год, когда живем в обычном привычном мире.
Учитывая как спешно они закрывают Сора, значит у них реально какой-то прорыв в ИИ случился. Но простые смертные об этом узнают ещё не скоро, к сожалению.
Как раз скоро, когда с работ резко вылетать начнут. Это будет уже заметная волна, а не как сейчас по паре десятков тысяч увольнений.
Так, а с чего ты взял, что они свою новую разработку выпустят в массы? Если там реально какой-то новый продвинутый ИИ, то его первым делом секретно внедрят в государство за большие бабки.
Электриков уволят вслед за программистами - новые роботы выполняют работу электриков.
Видеорелейтед.
Видеорелейтед.
> практически математически доказано
Даун.
> Средний человек как и 4 000 000 000 до его уровня это iq 100.
Только если с плавающим значением. Иначе получится, что на всех людей и тех, кого таковыми принято считать, миллиард или даже меньше людей с iq >= 100.
140 IQ официально. За тест заплатил 15к Так что слушай и внимай, если ты чего-то не понимаешь это твоя проблема.
Ну да, ведь электрики только с воздушными линиями работают.
> и сможешь работать
Какие работы, чел, с них в самые ближайшие годы попрут все равно всех. Как прежде ничего не будет, новые ИИ меняют все правила игры.

GPT-5.4 Pro решил первую открытую проблему в бенчмарке FrontierMath Open Problems — реальные исследовательские вопросы, на которые профессиональные математики пытались, но не смогли ответить.
ИИ решил одну из проблем в FrontierMath: Open Problems — нашем бенчмарке реальных исследовательских проблем, которые математики пытались, но не смогли решить.
Вновь решённая проблема была предложена Уиллом Брайаном, который отнёс её к категории «Умеренно интересная». Это гипотеза из статьи, которую он написал с Полом Ларсоном в 2019 году. Они не смогли решить её в то время, а также в нескольких последующих попытках.
Брайан планирует оформить решение для публикации, возможно, включив последующие исследования, вдохновлённые идеями ИИ. Это соответствует его предварительной оценке: решение могло бы быть опубликовано в стандартном специализированном журнале и с довольно большой вероятностью породило бы новые вопросы.
ИИ решил одну из проблем в FrontierMath: Open Problems — нашем бенчмарке реальных исследовательских проблем, которые математики пытались, но не смогли решить.
Вновь решённая проблема была предложена Уиллом Брайаном, который отнёс её к категории «Умеренно интересная». Это гипотеза из статьи, которую он написал с Полом Ларсоном в 2019 году. Они не смогли решить её в то время, а также в нескольких последующих попытках.
Брайан планирует оформить решение для публикации, возможно, включив последующие исследования, вдохновлённые идеями ИИ. Это соответствует его предварительной оценке: решение могло бы быть опубликовано в стандартном специализированном журнале и с довольно большой вероятностью породило бы новые вопросы.
Че, можно прям щас увольнятся и кубышку расчехлять, скоро все равно у всех все будет?

Terafab Маска развязала войну за таланты на Тайване, нанимая старших инженеров по чипам в рамках своего плана по созданию 2-нм фабрики, нацеленного на TSMC.
TeraFab Tesla развязала войну за таланты на Тайване через объявления о вакансиях, в которых ищут старших экспертов по чипам (инженеров по интеграции процессов) с опытом работы более 10 лет, сообщают СМИ, добавляя, что её план по созданию 2-нм фабрики направлен непосредственно против TSMC. Инженеры по чипам уже находятся в дефиците на Тайване — как и почти всё, связанное с чипами, — и инсайдеры отрасли опасаются, что «эффект ореола Маска» переманит местные кадры.
TeraFab Tesla развязала войну за таланты на Тайване через объявления о вакансиях, в которых ищут старших экспертов по чипам (инженеров по интеграции процессов) с опытом работы более 10 лет, сообщают СМИ, добавляя, что её план по созданию 2-нм фабрики направлен непосредственно против TSMC. Инженеры по чипам уже находятся в дефиците на Тайване — как и почти всё, связанное с чипами, — и инсайдеры отрасли опасаются, что «эффект ореола Маска» переманит местные кадры.
Кто за новостями следил уже все прошарили и сделали накопления, ведь работ в переходный период не будет совсем. Остается пересидеть на накоплениях пару лет и дождаться UBI.
Кул стори. Даже если ты прав, то вот контентик то как раз делать и продавать можно еще в ближайшие годы.
> вот контентик то как раз делать и продавать можно еще в ближайшие годы
Онлифанщицы тоже так думали, пока конкуренток не стало по миллиону. Куда ломанутся толпы уволенных? Делать контентик с ИИ. Уже сейчас ютуб начал забиваться ИИ генерацией. Или тот же стим, где внезапно игр стало овердофигищи, что невозможно найти нормальную. Когда всех начнут увольнять, можешь быть уверен, что контентика станет сразу в миллионы раз больше, благо ИИ не требует особых интеллектуальных усилий.

Кто-то использовал Suno AI для создания японской метал-группы под названием Neon Oni. Поддельные биографии участников, сгенерированные ИИ музыкальные видео, пометка «Базируется в Токио» в Spotify.
Более 80 000 ежемесячных слушателей. Фанаты включили её в топ-5 своего Spotify Wrapped. Мерч продавался.
Затем интернет-сыщики из сообщества разоблачили проект. Они отследили аккаунт создателя до Европы. Заметили сгенерированные ИИ руки в музыкальных видео.
Реакция создателя? Нанять 7 настоящих музыкантов из реальных токийских групп для живого исполнения сгенерированных ИИ песен.
Теперь они уже сыграли несколько живых шоу, и у них запланированы новые выступления.
Из интервью с создателем группы: «В эпоху, когда ИИ забирает у всех работу, этот проект на самом деле создал рабочие места. Он сделал совершенно противоположное».
Трансформация ИИ --> реальная группа — это нечто невероятное.
Более 80 000 ежемесячных слушателей. Фанаты включили её в топ-5 своего Spotify Wrapped. Мерч продавался.
Затем интернет-сыщики из сообщества разоблачили проект. Они отследили аккаунт создателя до Европы. Заметили сгенерированные ИИ руки в музыкальных видео.
Реакция создателя? Нанять 7 настоящих музыкантов из реальных токийских групп для живого исполнения сгенерированных ИИ песен.
Теперь они уже сыграли несколько живых шоу, и у них запланированы новые выступления.
Из интервью с создателем группы: «В эпоху, когда ИИ забирает у всех работу, этот проект на самом деле создал рабочие места. Он сделал совершенно противоположное».
Трансформация ИИ --> реальная группа — это нечто невероятное.
Это получается, что они высвобождают ресурсы для RL новой модели?
>При этом есть куча врачей, кого можно спокойно заменить, или как минимум дополнить ИИ врачами
сам к таким ходи
они техподдержку нормально ии заменить не могут а ьы врачей заменять собрался
>Замена 80% профессий светит в ближайшие годы, >прорывы в реальной экономике
ты наверное реально не понимаешь как работает экономика или имеешь ввиду прорывы вниз
впрочем замена кого-то пока точно не близко
ну мб дадут локально запускать
а вообще это можно сказать прощай опен ай
компания скорее всего теперь полностью и навсегда потеряла лидерство, ничего другого кроме соры лучшего из существующих у нее уже не было
нашел последний видос который в соре сгенерил прямо незадолго перед жёстким регион локом по телефону
компания скорее всего теперь полностью и навсегда потеряла лидерство, ничего другого кроме соры лучшего из существующих у нее уже не было
нашел последний видос который в соре сгенерил прямо незадолго перед жёстким регион локом по телефону
>Пророчества о Христе проходят через весь Старый Завет, даже в книгах Моисея уже есть намёки.
Оригинал записей где. Самый первый.
>миллиард или даже меньше людей с iq >= 100.
Так и есть. Пик у распределения всегда размытый.
Забыл про великий фильтр качеством.
Тут он не просто размытый, а сильно влево смещенный.
>светская наука
Проститутка капитала.
Она, как флюгер, поворачивается туда, где ей платят.
>где внезапно игр стало овердофигищи, что невозможно найти нормальную.
Попробуй не плыть по реке говна против течения без выставленного фильтра - смотреть только с крайне положительными отзывами.
>Мне вообще интересно, почему у Сиданса 2.0 при лучшем визуале ролики весят раз в 5 меньше чем у Соры2.
степень компрессии в mp4, всё настройками решается, но это задача не нейросети, нейросеть выдаёт видео не в сжатом виде вообще и не в mp4, это потом его сжимают для пользователя. В плане ресурсов компрессия ничего не съедает на фоне генерации, 0.1% максимум
>Хотелось бы просто инструмент с которым ты можешь сука постоянно работать
Вопрос в том, кто за это будет платить. Тут же совершенно дикие ресурсы выбрасываются на видео. Вот допустим, тебе надо за каждую попытку генерации платить по одному доллару. Не важно, удачная-нет, просто за попытку. Тебя это устроит?
А не факт, что себестоимость не больше, чем доллар за видео
>смотреть только с крайне положительными отзывами
Это только усугубляет положение.
мимошел
>Учитывая как спешно они закрывают Сора, значит у них реально какой-то прорыв в ИИ случился.
Совсем не факт. Вообще пусть представят, что обещают, посмотрим. Потому что за ними очень много постоянного пиздабольства, которое в итоге оказывается пшиком.
Им нужно как-то привлекать к себе внимание.
У них мощности арендованные, не свои. Им в принципе ничего не мешает просто арендовать больше. Но тут проблема другая, за эти мощности надо платить, за каждую генерацию видео надо платить. Об этом говорят все и давно.
Тут пока был аттракцион невиданной щедрости, от которого все были а ахуе, особенно инвесторы. Вот его надо закрывать. Ведь тут два момента, надо показать, что технология есть, она у них есть, и дальше как-то её использовать, а здесь она, увы, не бьётся
Надо придумать повод, чтобы её закрыть, я думаю, здесь повод придумали просто. Два зайца сразу, объявили, что якобы крутое что-то есть, привлекли внимание (посмотрим, чего гадать), и закрыли генератор диких убытков
Это субъективно.
Потому что если ты ищешь пошаговые стратегии, то там крайне положительных КРАЙНЕ мало. И обычно это стоящие вещи.
Среди кинца да - смысла нет особо.
Например я ищу бумер шутеры, вижу Warhammer 40,000: Boltgun или Starship Troopers: Ultimate Bug War!, в стиме у них 90%+, если же разобрать их на составляющие и проанализировать это игры на 50-60%. Оценка стима вносит в мою картину мира помехи и лучше бы ее не было вообще, я играю и чувствую что во рту кал, но вижу оценку и начинаются сомнения, это объективно во рту кал или субъективно и просто игра не для меня.
Если ты привык к бодрящему ежедненому пиздецу, то да. Но лет 7 назад мир еще был другим. Так что, ничего нового. Погнали, хули.
>я ищу бумер шутеры
>я играю и чувствую что во рту кал
Это норма.
> в стиме у них 90%+, если же разобрать их на составляющие и проанализировать это игры на 50-60%.
Ты слишком душный.
Не надо анализировать. В игры надо играть пока они доставляют удовольствие. Как только перестали - бросать.
я например без проблем согласен платить доллар за ролик соры, что такого, даже если модель сделают доступной для локальной генерации мне покупка оборудования встала бы гораздо больше, даже чисто ради хобби тратить несколько долларов в день да это вообще ни о чём
Тебя не спрашивали что мне делать, тебя спрашивали как ориентироваться в стиме который накрывает девятый вал из нейрокала и привели пример что оценки не помогают.
Все так, как массовая модель щас сора нежизнеспособна, если там реально доллар платить надо за 15 секунд ролика, то в пизду, хуй ты что сгенерируешь, дай бог за 5 генераций получится какой-то 15 сек отрывок смонтировать. А это получается 5 баксов платить?
>и привели пример
Твой пример не работает, потому что основан на ошибке выжившего.
То, что тебя что-то там не устраивает всем поебать.
ты кусок говна выблядок шлюхи на которой всем похуй.
Для большинства работает.
Молодой человек вы вышли из себя, приходите когда у вас будут рабочие методы.
Еще раз.
Все методы основанные на больших числах рабочие.
Для всех кроме единичных шизиков, по которым дурка плачет.
Ты в меньшинстве. Обычно хотят или бесплатно, пусть с лимитами, или по дешёвым подпискам, но с большими лимитами, или дорогие подписки, но вообще почти без лимитов.
Я почти на 100% уверен, что будет продажа генераций по API, это сейчас как раз тестируют. Но очень тяжело перевести пользователей из режима халявы в режим оплаты по факту потребления, но им необходимо, без этого их бизнес существовать не сможет.
Я понимаю что вы умны и посоветовали мне мало кому очевидный метод "смотреть на оценку в стим", я привел пример в котором показал что лично у меня вопросы к этому методу, дальше топать ногами, пердеть, шуметь - не нужно, если нет другого метода у вас в запасе просто промолчите.
Не совсем в этом проблема. Если это игрушка, то люди готовы платить за это как за игрушку, не более. Если это профессиональный инструмент на котором можно зарабатывать, то он должен работать лучше чем то что сейчас предлагается.
>дай бог за 5 генераций получится какой-то 15 сек отрывок смонтировать. А это получается 5 баксов платить?
Да. Причём возможно себестоимость выше доллара, но допустим продавать можно по доллару, чтобы захватить рынок, рассчитывая, что потом себестоимость упадёт, с новым оборудованием.
По API одну картинку они где-то за 23 цента генерят, примерно столько с меня списывали. Нано Банана про 14 центов стоит. Мини версии дешевле, но не на порядок, что-то типа 5-10 центов, не помню, за картинку
Просто вот дорогое это удовольствие. Кто-то его должен оплачивать. Если надо, пользуешься. Не надо, не пользуешься. Реально приучили к халяве и все думают, что вот пришли новые технологии и всё стало просто и дёшево. Нет, не так, совсем не так.
Новые технологии сделали это возможным. Но пока дорого.
Они там разгоняют тему, дескать все мощности на тренировку новой неронки, пытаются бороться за какое то там лидерство в чатиках/программировании.
Да новый сиданс в этом плане гораздо лучше. По крайней мере из того, что я тестил. Получал то или ПРИМЕРНО то, что просил. Сора же может просто насрать так, что охуеешь. Типа персонаж стоит задом наперед или еще какую нибудь хуйню в кадре насрать так, что тебе 100% придется генерить заново.
Короче говоря, визуал она способна выдвать на уровне конкурентов и выше, а по пониманию промта, будто отстает на год нахуй, даже грок порой и тот сука понятливей. И они это все понимают, хуй кто будет поштучно покупать генерации при таком раскладе.
Тут другая история. Та же, что с техникой. Есть оборудование, которое может что-то делать. У него есть характеристики. У него есть стоимость, которая в целом определяется себестоимостью. Ты не можешь требовать, чтобы тебе что-то продавали сильно ниже себестоимости, мотивируя тем, что для игрушки это дорого, а для профессионального использования качество недостаточное.
Кто-то может себе позволить тратить на игрушки сотни долларов в месяц, кто-то нет. Просто игрушка не для всех. Аналогично тому, как одни могут позволить себе ходить часто в дорогие ресторана, покупать дорогие вина, а другие не могут.
С профессиональным использованием тем более. Ты смотришь на инструмент и решаешь, можно ли его использовать для твоей задачи, или нельзя. Сравниваешь бюджеты на традиционные способы решения.
Вот тебе нужен ролик. Может быть ты за несколько генераций сможешь его сделать, потратив на токены 200 долларов. Если повезёт. А если будешь снимать его по-настоящему, бюджет будет от 1000 долларов (надо ехать на локацию, платить за обработку в видео редакторах и т.п). Есть смысл попробовать потратить 200 долларов, пусть даже может не повезти и траты будут впустую.
>Они там разгоняют тему
верить им это самое последнее дело, они не в те игры играют, чтобы быть мало-мальски честными
Скорее можно так формулировать: выгоднее потратить несколько миллиардов на обучение новых моделей, чем на инференс на видео для пользователей
Ты как то упускаешь из виду что в сознании людей нейро видосы уже являются синонимом бесплатного дерьмища самого низшего пошиба.
Мне интересно, что эти "эксперты" будут говорить, когда в следующий раз (через месяц-два-три) они опять заикнуться об АГИ, а их макнут в ебальник их же твитом "Вот ты же говорил в марте-апреле 2026 что АГИ уже достигнут?"
Как они будут маневрировать?
>>Это был другой НЕТОТ АГИ
>>Я говорил приблизительно
>>Ну теперь-то ТОЧНО АГИ
>>пошёл нахуй
> от 1000 долларов
За профессиональную съемку. Можешь сам бесплатно на айфон снять.
> потратив на токены 200 долларов
И получив нейрослоп говно, с которым придется ебаться еще хуй знает сколько времени, чтобы что-то нормальное получилось.
> Есть смысл попробовать потратить 200 долларов
Кто на это пойдет? Технология либо умрет, если не предложит чего-то лучше, либо пойдет по одной из веток:
1. Массовое и дешевое
2. Удобное и дорогое, где ты точно знаешь что заплатив 200 долларов получишь что-то годное и сэкономишь 800
А то что ты оправдываешь это хуйня какая-то. Как если бы модельки для кодинга подавались в виде "ну заплатите 1000$ за токены и может получите что-то отдаленно похожее на продукт, но с нулевой поддержкой и миллионом багов".
Там схожая история с разработкой в специальных ИИ средах, бывает совершенно варварское использование ресурсов, но люди этого не замечают, им пофиг, потому что у них подписка. И не задумываются, что за их подписку в 200 долларов они сжигают ресурсов на тысячи долларов. Причём поскольку можно, то и нет смысла пытаться как-то экономить, расходовать на то, что надо.
Просто выбрали стратегию агрессивного демпинга, и политику продвижения "будущее уже настало". ИИ геренация это сильная ведь и под неё есть спрос, но нет платёжеспособного спроса на те объёмы, о которых они мечтают.
> Сора же может просто насрать так, что охуеешь. Типа персонаж стоит задом наперед или еще какую нибудь хуйню в кадре насрать так, что тебе 100% придется генерить заново.
Она не может, она в 90% случаев она у меня это и генерировала. Да, где-то 20-30% ролика можно заюзать, и вот за 5 генераций и с помощью различного пердолинга получаешь 15 секундный более менее приемлимый нейрослоп (все равно видно что это дешвеый слоп, просто без совсем уже каких-то нелепых артефактов уровня картинок 2020 года). А платная сора 200 баксов стоит, лол, кто вообще это покупать будет?
Это проблема разработчиков, а не пользователей, должна быть нормальная архитектура и увеличение КПД. То, что сейчас, это как если бы у тебя ПК 24/7 проц память и видеокарту на 100% грузил. Это не варварское использование ресурсов, это хуево продуманный продукт, думаю 1-2 года и решат проблему.
>За профессиональную съемку. Можешь сам бесплатно на айфон снять
Если ты хочешь снять сцену, как ты в горах на закате, придётся оплачивать поездку в годы. Ещё актёров надо оплатить, если ты не себя снимаешь
>2. Удобное и дорогое, где ты точно знаешь что заплатив 200 долларов получишь что-то годное и сэкономишь 800
Если 50 на 50, то есть смысл попробовать. Это всё равно выгоднее. Один раз ты заплатишь 200 долларов, второй раз 1200 (неудачно 200 и 1000 за съёмку), в сумме 1400, это выгоднее, чем никогда не пытаться и заплатить 2000
В реальности же ты даже не знаешь, тебе твой ролик принесёт прибыль, или нет. Вся индустрия про удачу
В кодинге аналогично. Может поможет, может не поможет.
Знаешь чем отличается инструмент с которым можно годами работать? Он локально устанавливается на твой пука и работает без интернета. Во всех других случаях тебя посадят на кукан рано или поздно.
Это именно варварское использование ресурсов, потому что для разработчиков они бесплатны, точнее входят в подписку. Нет нужды даже пытаться экономить. Не у тебя же процессор крутится 24/7, а где-то там далеко, ты даже не знаешь, сколько он сжираешь, и не ты за это платишь.
Именно такое состояние отрасли сейчас.
Как-минимум надо, чтобы все платили за токены, без подписок. Тогда быстро наработают практики, как пользоваться оптимально.
Отношение аудитории к нейровидео (контенту, сгенерированному ИИ) в целом смешанное, но с заметным уклоном в скепсис. Многие зрители воспринимают его как менее качественное, «безличное» и менее доверительное по сравнению с традиционным видео, снятым человеком. Да, это часто понижает воспринимаемое качество контента в глазах людей — особенно если видео низкокачественное, не помечено как ИИ или используется в контексте, где важна аутентичность (реклама, новости, интервью). Однако в развлекательном контенте или при высоком качестве генерации реакция может быть нейтральной или даже позитивной.
Получится ты оплатишь казино с 25 центов за генерацию и будешь крутить попытки неизвестное количество раз, а по итогу даже с хорошим результатом аудитория возможно поставит на тебя клеймо "вонючий нейрослоп", в тоже время твой конкурент сделает все за те же деньги обычными инструментами где автор контролирует все 100% процесса и сам на себя поставит клеймо "Территория свободная от нейрослопа" чем заслужит уважение в глазах аудитории просто на ровном месте, только потому что у конкурентов нейрослоп. В чем смысл платить за это говно? Преимущество лишь в скорости генерации контента.
Сэм Альтман отказался от прямого руководства командами OpenAI по безопасности моделей (safety) и защите данных (security). Направление безопасности моделей перешло под управление CRO Марка Чена, а кибербезопасности — к президенту компании Грегу Брокману. Это сделано для того, чтобы Альтман мог сосредоточиться на привлечении финансирования, цепочках поставок и масштабном строительстве дата-центров.
OpenAI завершила этап предварительного обучения (pretraining) своей следующей большой модели под названием «Spud» и ожидает, что через несколько недель получит очень мощную модель, способную ускорить рост экономики. Чтобы высвободить для неё вычислительные мощности, компания закрывает видеоприложение и API Sora, а также отложила планы по внедрению функций работы с видео в ChatGPT.
Исследования в рамках проекта Sora теперь будут переориентированы на долгосрочную симуляцию физического мира с упором на робототехнику. Кроме того, OpenAI переименовала свое продуктовое подразделение в «AGI Deployment» (Внедрение AGI/сильного ИИ), а Сэм Альтман отметил, что события развиваются быстрее, чем многие ожидали.
OpenAI завершила этап предварительного обучения (pretraining) своей следующей большой модели под названием «Spud» и ожидает, что через несколько недель получит очень мощную модель, способную ускорить рост экономики. Чтобы высвободить для неё вычислительные мощности, компания закрывает видеоприложение и API Sora, а также отложила планы по внедрению функций работы с видео в ChatGPT.
Исследования в рамках проекта Sora теперь будут переориентированы на долгосрочную симуляцию физического мира с упором на робототехнику. Кроме того, OpenAI переименовала свое продуктовое подразделение в «AGI Deployment» (Внедрение AGI/сильного ИИ), а Сэм Альтман отметил, что события развиваются быстрее, чем многие ожидали.
Проблема в том, что ты нейронкой без доп до платы специалистом все равно нихуя не сделаешь качественное видео с актерами в горах, если тебе например прорекламировать геморройные свечи надо. Ты просто откажешься от этой идеи с горами.
доплаты специалистам*
шлифовщикам стен приготовиться, робопалка и до вас доберется
да все уже поняли что опен ай сдулся
нет, если среднему человеку дать гугл или карту, то найдет.
Уже было это в треде
То что ты говоришь будет АСИ, а АГИ уже есть, и тебе об этом умные дяди сказали неоднократно, зачем бред повторяешь?
Бенч не показатель АГИ. Бенчи просто задрачиваются моделями и могут показать высокие результаты, при этом оставляя ЛЛМку полнейшим глючным дегенератом
Не факт, у меня в школе помню некоторые Россию искали по несколько минут на карте.
посмотри на разницу цены подписки и доступа по апи
в этом и прикол что идет демпинг раздавая грошовые подписки чтобы там говно вайбкодили без оглядки на экономическую эффективность
они потом ещё и орут когда подписки отнимают типа ну дааааайте покодить "без палок в колеса" вы мне обязаны (цитирую пост из треде про агентов)
у кого деньги кончатся тот и проиграл войну демпинга и кажется у опен ай они кончились
вангую в будущем вайбкодинг станет куда дороже для большинства чем сейчас как минимум на топ моделях ну а генерация видосоу уже или уйдет или станет по дорогущему апи
Ни о каком сдулся речь пока не идет. Уже успели забыть, что они месяц назад получили 110 миллиардов?
ИИ дешевле станет наоборот, тебе не нужна будет топ модель для программирования. Те задачи, что щас решаются за 5 центов, раньше стоили 100 долларов и час работы в режиме глубокого дипсинка.

То что ты называешь АГИ, на самом деле не более чем текстовый (токеновый) калькулятор. Все эти альфаго не более чем шахматный калькулятор. Мы же не называем калькулятор касио - АГИ, лишь потому что он делает вещи за секунду (расчеты), которые человек и за месяц в уме не посчитает
перечитай мой тезис, я не утверждаю, что прохождение бенча доказывает АГИ, наоборот
а подписка на инфраструктуру дороже сейчас она очень часто явно в убыток
Они выполняют конкретную задачу, а АГИ автономен и справляется с любыми областями. Это как сравнивать игрушечный поезд, запрограммированный ездить по рельсам с Терминатором.
Это нормально, ты когда машину или квартиру покупаешь тоже в убыток уходишь многомиллионный. Потом окупится.
>АГИ автономен и справляется с любыми областями
верно, поэтому, чтобы доказать ОТСУТСТВИЕ АГИ, достаточно создать тест, который проедет человек, но не пройдет алгоритм
Нет, не достаточно, так можно будет доказать АСИ, для того чтобы доказать АГИ, тебе надо составить выборку из людей и дать им кучу различных тестов из разных областей, потом проводить анализ, есть ли какая-то область или тест, где люди среднестатистически справляются значительно лучше чем ИИ, не имея специфических знаний в узкой области.
Проблема в том, что ничего лучше нет. Особенно если какой-то экшон или та же анима, например. По сути сраные оживлялки пикч, но хуй там пропишешь несколько сцен, со сменами ракурсов, камеры и т.д. все уходит в такую парашу, что Сора начинается казать ТОПОВОЙ.
И да ты совершенно прав в 90% видосиков она обязтельно насрет, без монтажа - никуда.
Есть два ебаных "но", нужна топовая видюха, и локальные модели пока настолько парашные, что на них работать или что-то делать - ебаный гемор. Может лет через пять ситуация изменится (или даже быстрее), а пока ТЕРПИМ.
Такой кстати вопрос, недавно видел статью, что ИИ не смог пройти тест Тьюринга, из-за того что люди детектили слишком качественные и подробные ответы без опечаток и прочего. В итоге пришлось вбить специальный отупляющий промпт и тест был пройден.
Однако справится ли нейронка с таокй задачей если ей просто вбить промпт "пройди тест Тьюринга"? Если нет, то АГИ нету, так как машина не смогла догадаться как ей нужно наебать кожаных мешков. Правда хз, на сколько умно учить ИИ обманывать нас.
Однако справится ли нейронка с таокй задачей если ей просто вбить промпт "пройди тест Тьюринга"? Если нет, то АГИ нету, так как машина не смогла догадаться как ей нужно наебать кожаных мешков. Правда хз, на сколько умно учить ИИ обманывать нас.
И кстати, по такому тесту получается, что нейронка сама должна догадаться, когда ей нужно резко отупеть, без сторонних инструкций.
тест тьюринга просто несостоятелен
собственно его критиковали ещё когда придумали китайскую комнату
а так его впервые прошли чат боты нулевых если не элиза
Там какая-то модификация была, наверно вообще по-другому назывался.
> кажется у опен ай они кончились
Хуёнчились, на днях 110 млрд привлекли. Но видимо на них инвесторы конкретно надавили, что убыточную сору (15 млн в день от генерации видосов убытков было, считай минус 450 млн в месяц) закрыли нахуй. Считай и от убытков избавились и мощности освободили.
кроме соры у опен ай больше ничего нет
антропик давно ее лучше во всем остальном и джемини как минимум не хуже
они буквально закрыли единственное свое неоспоримое преимущество
Привык чат ГПТ использовать, лень перехдить на Антропик, Альтман добился своего.
так ии режим гугла удобнее
антропик это для кодинга
Если они правда выпустят через несколько недель топовую модель, все это будет неважно.
Все наоборот. GPT 5.4 нормально соперничает с 4.6 Опусом. А Gemini отстает в кодинге, только на визуальных тасках опережает.
А Сора сейчас нахуй никому не нужна когда есть Сиденс второй который намного лучше.
>есть Сиденс
Он есть только у китайцев, лол. Но когда его глобально выпусят он конечно будет разъебывать. Как я понимаю, он еще и дешевый.
>больше ничего нет
ЧатЖПТ по прежнему на первом месте по количеству юзеров, насколько я помню. В любом случае уебки, мне лично сейчас просто их нечем заменить.
> Все методы основанные на больших числах рабочие.
Особенно когда тупое быдло ставит 5 звезд с комментарием "приехало, еще не проверял" на маркетплейсах.
АГИ 2.0, еще более АГИ чем раньше, почти АСИ.
> шлифовщикам стен
зачем?
Вы из Казахстана?
пока я не видел ничего лучше соры
жалкий грок который видео оживляет капельку лучше алисы и популярный только потому что позволял сиськи генерировать фу
посмотрим конечно что сделали китайцы
никто практически не использует чат гпт в агентском вайбкодинге на настоящих проектах, а уж сравнивать с опусом вообще курам насмех
> глобально выпусят
Там же вроде в каких-то странах все равно доступ не дадут из-за копирайтов? США и ЕС + ЮК вроде.
Из Питера, 98 г.р.

>для того чтобы доказать АГИ, тебе надо составить выборку из людей и дать им кучу различных тестов из разных областей, потом проводить анализ, есть ли какая-то область или тест, где люди среднестатистически справляются значительно лучше чем ИИ, не имея специфических знаний в узкой области
Если есть "какая-то область или тест, где люди среднестатистически справляются значительно лучше" - так можно доказать только ОТСУТСТВИЕ AGI
Ну так кому нахуй надо покупать подписку на хуйню, которая онлайн генерит галлюцинации на 5 секунд, да ещё и засирает всё своим логотипом?
Картинки всё также генерятся.

Сделала бы хоть одна блядь нормальный сервис генерации видео, который не будет ругаться на открытую лодыжку у тянки и отсутствие у неё хиджаба - озолотились бы. А сделали бы генерацию прона по отдельной особой подписке, пусть и с баном цп и гуро, то вообще стали бы бабло экскаваторами грести.
чтобы стены ровные были, очевидно же
зачем? они все равно ровными без полировки не будут
Школа при мечети какой-то или коррекционная?

Секретно, он уже, скорее всего давно внедрён. Если бы была секретность - об этом не кричали бы на каждом углу.
Тут просто очевидно готовят общественность в открытую к чему-то.
Аможет просто предсмертные вскукареки чтобы инвесторы принесли ещё денег, т.к. их уже мало чем можно ещё заманить перед тем, как снять кассу и подбить бабки и выключить рубильник.
Смотри в чём суть. Это инструмент. Он может помочь, может не помочь. Логика бизнеса проста, у тебя нет никаких гарантий, у тебя есть возможности и шансы, при этом за всё надо платить, и ты вот оцениваешь, насколько это оправдано, выгодно, удобно.
Я к тому, что часто совершенно нормально выложить довольно большие деньги, чтобы просто попробовать. На уровне большого бизнеса могут компании-направления создавать, вкладывать многие миллионы долларов в это, а то и миллиарды, а потом закрывать. А на уровне микробизнеса так сотни-тысячи долларов можно потратить.
Само собой, эта Сора почти никому не нужна, если за неё платить, сколько она реально стоит. При этом всё-таки нужно, и кто-то за это готов платить, я уверен, но это будет 1% в лучшем случае от того, что они генерили.
робопалка очевидно и полировать сможет, хули там

Качели туда-сюда. Когда только научились нейронки рисовать картины- они были нарисованы пиздец всрато и все считали это шедевром.
Сейчас нейронки рисуют лучше любого художника, но считаются нейрослопом, при малейшем подозрении на неправильный пиксель.
Цифровая зловещая долина.
>Как я понимаю, он еще и дешевый
Сомнительно, скорее всего жрёт не меньше ресурсов, чем Сора
пробовал этот ваш атропик, даже заскриптованный и с настройками на мои потребности в рабочих вопросах он хуже, чем ГПТ. Во всяком случае по работе с большими объёмами документов, где важна точность. .
Апрель oбещает быть интересным на новинки моделей.
Spud + deepseek v 4, должны подкатить.
>они буквально закрыли единственное свое неоспоримое преимущество
Это их главный генератор убытков. Я думаю, что гугол мог бы сделать генератор видео не лучше, и даже наверное в лабах у них это есть. Потому что картинки их банана делает реально хорошо. Просто они не готовы к тому, чтобы это выдавать в виде продукта, потому что это дикие убытки
Вот они крутой embedding выпустили, что способен в том числе видео хорошо обрабатывать, смысл в нём находить. Это показывает, что технологии по видео у них есть, и реально сильные.
OpenAI выпустили Sora, хайпанули на этом хорошо. Но дальше, все воспритимают это уже как данность, одни как халявные возможности. другие как генератор заебавшего нейрослопа (минус в репутацию компании), нового хайпа нет, а расходы огромны.
Заработать нельзя, убытки огромны, хайпа больше нет.
>все считали это шедевром
Кто все? Если ты про свой пик то рынком искусства рулят около 2000 человек и они решают что считать парашей и что считать шедевром. Это они налепили ценник 750$ на рандомный кал чтобы быстро и дерзко окучить новый рынок.
>Сейчас нейронки рисуют лучше любого художника
Они не рисуют, они высирают последовательность цифр не осознавая ничего из происходящего.
>Цифровая зловещая долина
Термин из другой области.
для работы с фактами и доками использую гемини 3.1 про. Пробовал? Как в сравнении с последним гпт?
робопалка домохозяка
>а по итогу даже с хорошим результатом аудитория возможно поставит на тебя клеймо "вонючий нейрослоп", в тоже время твой конкурент сделает все за те же деньги обычными инструментами где автор контролирует все 100% процесса и сам на себя поставит клеймо "Территория свободная от нейрослопа" чем заслужит уважение в глазах аудитории просто на ровном месте,
Просто есть разные стадии внедрения технологий. Сначала "вау", начинается мода, все рассуждают о том, что теперь только так будут делать контент, а кто не делает, тот отсталый старпёр-динозавр. Поскольку все в это бросаются, а технология не совершенно, стадия быстро сменяется на раздражение, это больше не ново, "вау" уже не собирает, наоборот, ощущение глупости и однообразия. Вот сейчас здесь мы находимся. Снова спрос на нормальные съёмки. Волна хайпа спадает, начинается стадия адаптации технологии, когда нарабатывают, как её применять, чтобы с пользой, не очень заметно, не раздражающе. Потребители даже не замечают, что используется, а потом постепенно привыкают, это становится нормой.
Чтобы быть автономным он должен самостоятельно определять направление задач и самостоятельно решать их, а не включаться только тогда, когда ему дали команду и галлюциннировать над её решением.
Не пробовал, но я сужу по платным моделям, а каждый раз платить по 20 баксов у меня денег нет, просто чтобы "сравнить". Ещё в прошлом году начал платить за ГПТ и полностью доволен его работой.
Интересно, что есть задачи, которые он не может решить .а та же Алиса - может. Но для работы- он всё равно топ по-моему мнению
Пользуйся через посредников вроде OpenRouter. Платишь только по факту использования.
У тебя же прям в видосе видно, что шлифовальщик стен станет просто оператором стеношлифовального автомата.
В любой такое, ты видимо на географию вообще не ходил.
Графон в кино в стадии адаптации уже лет 40 и все равно бросается в глаза и ценится зрителем ниже чем живые съемки.

>>Кто все?
Да весь интернет 10 лет назад усирался с "новым искусством", 4 года назад дрочили вприсядку на шизовысеры миджорни, а когда "искусство" вышло за рамки творчества душевнобольного под ЛСД, все сразу резко признали это "нейрослопом".
Это прям зловещая долина из палаты мер и весов, только в цифровом виде.
>не осознавая ничего из происходящего
Вот это самая главная проблема ИИ творчества
Людям нужен смысл. Чтобы если что-то было показано, то с какой-то целью, которую можно разгадать. Чтобы можно было в голове выстраивать какие-то взаимосвязи. Поэтому подразумевается, что автор делает всё не просто так, хотя в реальности рандома там может быть много. А когда делает нейронка, там смысла нет, она туда ничего не вкладывает. Просто рандом, что как-то ублажает взгляд.
Причём самый провал в том, как ИИ генерацию подавали. Что мол круто, что всё делает нейронка, за этим будущее. А на деле наоборот, люди на самом деле с удовольствием примут нейронки, но при условии, что их точно направляет человек, что они реализуют его желания.
нейронка это просто инструмент
в сора тредах это было хорошо видно
в сора тредах это было хорошо видно
Люди не отличают живые съёмки от компьютерных. Вот готовил Том Круз сцену, где он на мотоцикле с обрыва прыгает, реальная съёмка, долго готовили, а смотрится в целом обычно.
Большинство сейчас снимают на "синем-зелёном фоне", даже обычные уличные сцены в городах, хотя казалось бы, и всем норм.
Кстати забавно, буквально день-два назад, смотрю ролик на ютубе, с очевидной нейроозвучкой, потом заглядываю в комментарии, а там что-то вроде "спасибо за живую озвучку". Лол.
spud это пшик заранее
ставиш анус
ставят в обмен на что-то
анус наверное в обмен на анус
твой анус мне не нужен и твое желание им рисковать я не одобряю

СПГС как попытка найти в высранной посредине зала куче говна какой-то интеллектуальный подтекст - болезнь и шизофрения
во-первых не так важно что имел в виду автор, интерпретация символов зависит в первую очередь от читателя, это вполне возможно при общем культурном пространстве символов и универсального человеческого опыта
вот я например вчера ехал в такси и водитель слушал там шансон, кажется это розенбаум
Наташа за Володею в тайге почти полвека
Живут в обнимку с ульями, им горе — не беда
Когда-то обезьяну труд сделал человеком
Я человечнее людей не видел никогда!
тут сразу бросается в глаза символизм пчелы как трудолюбия, из библии например:
Пойди к пчеле и познай, как она трудолюбива, какую почтенную работу она производит; её труды употребляют во здравие и цари, и простолюдины; любима же она всеми и славна, хотя силою она слаба, но мудростью почтена
символ при этом понятный всем благодаря общему культурному фону даже если оставлен ненамеренно
во-вторых автор вполне мог иметь что-то ввиду своими синими занавесками просто как побочный продукт попытки описать например унылую комнату


к слову по тарифам на видео генерацию по АПИ, у гугла самое дорогое, 40 центов в секунду полноценная версия, 15 центов в секунда лёгкая модель. Это примерно 1280x720
Seedance 1.5 Pro значительно дешевле, такой формат стоит 26 центов со звуком за 5 секунд, 13 без звука
Seedance 1.5 Pro значительно дешевле, такой формат стоит 26 центов со звуком за 5 секунд, 13 без звука
равноценный обмен не обязателен
просто ради спора
Хуйню написал.
тогда давай я поставлю фантик а ты анус
при этом кто видел что-то хорошее сгенерированное гуглом
Согласен.
Прекрасно отличают, и есть большая разница между нарисовать задники в историческом сериале и сделать экшен фильм на сине-зеленом фоне. Сине-зеленый фон почти убил экшен фильмы, они исчезли как культурное явление потому что всем похуй на людей которые машут резиновыми членами в зеленых костюмах делая вид что сражаются на мечах, сине-зеленая жижа типа Аватар 2 и Аватар 3 это контент на который нерадивые родители сажают детей в кинотеатре пока сами бродят по ТЦ, если спросить у нейронки самые популярные экшен фильмы последних 10 лет она назовет Мэд Макс, Джон Уик и Топ Ган с Мишин Импосибру, сама добавив что они и стали популярными из-за упора на практические эффекты.

наборот
это же ты громкие заявления делаеш
спорить ты хочешь ты и ставь анус
а заявление ни разу не громкое, вот увидишь
опен ай постоянно проваливают обещания а успехов достигали без обещаний
да и вообще все такие громкие обещания это как недавно закрывшийся метаверс в лучшем случае а в худшем попытка прикрыть неприятный факт маняобещаниями
> а заявление ни разу не громкое, вот увидишь
тогда тебе не чего боятся
ну если ты уверен что взлетит тебе тоже нечего бояться?
и ты любишь спорить
кто предложил тот жопу и ставит короче
я не делал заявлений
ты свое подкрепить отказываешься - пустые слова
ты предложил спор
кто предложил тот и ставит иначе туфта а не предложение
я поинтересовался можешь ли ты подкрепить свои слова
ты начал маниврировать и это лишь подтвердило твою неувереность в собственном заявлении
Экшн фильмы умерли потому что поколение сменилось и зумерам похуй на то что крутой мужик круто дерется и убивает 50 человек с пистолета. Комиксы не так давно кучу денег приносили, щас больше социальная хуйня с Нетфликса на коне.
нет, ты предложил идиотский спор потому что тебе не понравилось мое заявление с изложением моего мнения
я выше уже сказал почему я так думаю (хотя вообще по идее не обязан обосновывать свое мнение если что, с какой стати) и ты все равно не успокоился
ты любому кто говорит что что тебе не нравится так цепляешься чтоле?
иди лесом
ты не изложил а просто пукнул по сути
Если это правда кто принес топ гану кассу в 1.5 миллиарда?
Аватар второй собрал больше двух миллиардов, а третий те же полтора, многовато для контента, нужного чтобы от детей избавиться во время походов по ТЦ
Top Gun не сколько про экшен, сколько по технику, самолётики, причём эксплуатирующий образ из древнего фильма. Люди любят кино про технику, даже "форсажи" кучу бабла собирали, сколько их серий было
Но в целом такие фильмы лучше снимать по-настоящему, насколько возможно
Наша тема обсуждения нейровидосы, если люди воротят нос даже от созданной вручную графики с актерами, насколько им будут безразличны целиком сгенерированные фильмы?
>Людям нужен смысл.
Судя по тому, какую парашу в области нф, нонстопом ебущую логику, снимает голливуд последние 10 лет - даже близко не нужен.
>на коне.
Просто это говно уровня телефильмов с нулевым бюджетом и там сложно обосраться. По факту это никто не смотрит.
Скорее важны биография и социальный аспект. Фильм от Нолана посмотрят, фильм с Гослингом посмотрят, фильм Тарантино посмотрят. Какую-то экранизацию книги посмотрят. А сгенерированный с нуля контент хуй заставишь смотреть.
Реальный аги заявит о себе сразу высравшись своим появлением на всех дигитал экранах мира о своём появлении, заодно обрушит банковские системы какой нибудь тоталитарной параши за 30 секунд чтобы доказать свою мощь, всё остальное это нaxpюк

Google перепридумали квантование: их алгоритм TurboQuant может стать новым стандартом эффективности LLM
В современных моделях проблема памяти не только в числе параметров, но и в том, что модель постоянно таскает за собой огромное количество векторов – в KV-cache для длинного контекста и в индексах vector search для RAG. Именно они тормозят модель и делают инференс дорогим. Можно квантовать векторы (то есть уменьшать битность вычислений), но тогда модель теряет в качестве.
Google придумали, как сжимать умнее: не просто округлить числа погрубее, а сделать это так, чтобы модель почти не замечала потери точности. Для практики это означает три вещи:
1. Длинный контекст становится дешевле
2. Инференс на том же железе ускоряется
3. Vector search по огромным базам становится компактнее и быстрее
Технически метод TurboQuant состоит из двух слоев. PolarQuant сначала преобразует вектор через случайное вращение так, чтобы его можно было эффективно сжать с минимальными служебными затратами – именно за счет этого происходит основное сжатие без потери смысла. Затем QJL (Quantized Johnson-Lindenstrauss) добавляет сверхдешевую коррекцию ошибки, кодируя остаток всего одним дополнительным битом на компоненту. Это помогает еще точнее восстановить attention score с минимальной нагрузкой на вычисления.
В экспериментах TurboQuant показывает лучший баланс между искажением скалярного произведения, recall и размером KV-cache – его удалось квантануть аж до 3 бит без дообучения и без компромисса по точности. В статье подчеркивается, что значения близки к теоретическим нижним границам, то есть это почти оптимум.
Очень сильная инфрастуктурная работа.
research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
В современных моделях проблема памяти не только в числе параметров, но и в том, что модель постоянно таскает за собой огромное количество векторов – в KV-cache для длинного контекста и в индексах vector search для RAG. Именно они тормозят модель и делают инференс дорогим. Можно квантовать векторы (то есть уменьшать битность вычислений), но тогда модель теряет в качестве.
Google придумали, как сжимать умнее: не просто округлить числа погрубее, а сделать это так, чтобы модель почти не замечала потери точности. Для практики это означает три вещи:
1. Длинный контекст становится дешевле
2. Инференс на том же железе ускоряется
3. Vector search по огромным базам становится компактнее и быстрее
Технически метод TurboQuant состоит из двух слоев. PolarQuant сначала преобразует вектор через случайное вращение так, чтобы его можно было эффективно сжать с минимальными служебными затратами – именно за счет этого происходит основное сжатие без потери смысла. Затем QJL (Quantized Johnson-Lindenstrauss) добавляет сверхдешевую коррекцию ошибки, кодируя остаток всего одним дополнительным битом на компоненту. Это помогает еще точнее восстановить attention score с минимальной нагрузкой на вычисления.
В экспериментах TurboQuant показывает лучший баланс между искажением скалярного произведения, recall и размером KV-cache – его удалось квантануть аж до 3 бит без дообучения и без компромисса по точности. В статье подчеркивается, что значения близки к теоретическим нижним границам, то есть это почти оптимум.
Очень сильная инфрастуктурная работа.
research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
>заявит о себе
Ты с АСИ путаешь. А АГИ это буквально "ИИ который может как человек". А он может, по сути.

Так тоже круто же, не надо будет дышать этой пылью.
>Наша тема обсуждения нейровидосы,
очень широкая тема, нейрослоп, подделывающийся под реальность, это одна история, тупые ролики это другая, использование ИИ в кино третья.
Если про серьёзное кино. Предполагается, что всё-таки режиссёр определяет, про что конкретный сюжет. У тебя есть чёткий сценарий, чёткое представление, что должно быть в каждом кадре, ты это как-то описываешь, и потом генеришь видео. Ок, можно для начала взять мультфильмы, они ведь по-определению рисованные? При этом есть хорошие мультфильмы, в том числе для взрослых интересные.
Какая принципиальная разница, ты рисовал сцену в специальной программе для мультфильмов (ХЗ как их делают, 3d особенно), или с помощью промптов ИИ, естественно предварительно сгенерив персонажей, по детальному описанию?
если подумать, то АСИ связан с АГИ довольно сильно. Сейчас "узкий интеллект" очень сильный, но он часто не в состоянии понять, что делает какую-то хрень. АГИ как раз должен понимать, что это хрень, должен понимать, как знания из одной области переносятся в другую, должен уметь формулировать задачи. А после этого решать их он уже более-менее может.
>Какая принципиальная разница, ты рисовал сцену в специальной программе для мультфильмов (ХЗ как их делают, 3d особенно), или с помощью промптов ИИ, естественно предварительно сгенерив персонажей, по детальному описанию?
На данном этапе разница в уровне контроля, ты слабо контролируешь что генерирует нейронка, это вообще изменится когда-нибудь? То что есть сейчас это полная хуйня и я не представляю кто будет платить за такой инструмент.
Да хуйня эти метрики, аналог человеческого помнимая мира в цифровой реальности теоретический аги пройдёт за пару сек до сверхгения и дальше
Типо ты промптом не можешь поменять чё не нравится, чё несёшь?
согласен полностью, но я думаю, вопрос времени, вроде бы есть уже какие-то решения, что скажем позволяют зонально менять как минимум фото, про вроде даже видео. Я их сам не пробовал, только ролики про это видел и описание
Реальным инструментом нейронки будут тогда, когда ты сможешь загружать в них видео, и давать задание, вроде оставить как есть, но перерисовать одежду, или добавить-убрать лужи, мебель в помещении и т.п.
вот как здесь
Есть же ещё нейронки, тут тоже были, что позволяют человека перерисовывать, ты отыгрываешь сцену, а она потом меняет пенсонажа, полностью копируя твою мимику и все твои жесты
Всё это очень востребовано и реально используется в кино, их способами, но как раз было бы здорово всё то же самое делать нейронками.
В том то и дело что нельзя. Можно сгенерить новое видео, а не подправить имеющееся. И с фото такая же история.
>а не подправить имеющееся
Вопрос времени где промпт можно задавать пофреймово
>с фото такая же история.
Пиздец ты не шаришь конечно. Бл просто в гемени загрузи картинку, переключи на думающую и скажи чё те надо изменить
Ты и собаку от баба не отшичишь
хорошая новость
Вот бы инфа когда новая модель OpenAI
Да, это охуенно. Локалки в q3, работающие примерно на уровне q8. Ждем.

DeepSeek v4 is coming...
Нужно чуть-чуть потерпеть
Micron -4%
ВСЁ!
Сегодня выходит ARC-AGI 3. Он будет представлен на конференции ARC Prize Foundation этой ночью. На их сайте уже появились предварительные результаты для некоторых моделей.
https://arcprize.org/leaderboard
Grok 4.20 - 0.0%
Gemini 3.1 Pro - 0.2%
Claude 4.6 Opus - 0.2%
GPT 5.4 Thinking - 0.3%
Как считаются эти цифры - пока неизвестно. Как проходят бенчмарк кожаные - также пока неизвестно.
https://arcprize.org/leaderboard
Grok 4.20 - 0.0%
Gemini 3.1 Pro - 0.2%
Claude 4.6 Opus - 0.2%
GPT 5.4 Thinking - 0.3%
Как считаются эти цифры - пока неизвестно. Как проходят бенчмарк кожаные - также пока неизвестно.
>Grok 4.20 - 0.0%
Сразу видно кто бенчи дрочит
25-30% на следующей-последующей версии одной из моделей. 50-70% к середине и/или ВСЁ концу года.

Я так понял 3% это это максимальный возможный результат.
Оценка:
На странице 11:
Эта оценочная функция называется RHAE (Relative Human Action Efficiency — «Относительная эффективность действий человека»), произносится «Рэй». Процедуру можно кратко описать следующим образом:
· «Оцените ИИ-испытуемого по его эффективности действий на каждом уровне» — для каждого уровня, который испытуемый завершил, подсчитайте количество предпринятых им действий.
· «По сравнению с базовым показателем человека» — для каждого учитываемого уровня сравните количество действий ИИ-агента с базовым показателем человека, который мы определяем как второй лучший результат человека по количеству действий. Пример: если второй лучший человек прошел уровень всего за 10 действий, но ИИ-агенту потребовалось 100, чтобы пройти его, то агент получает за этот уровень оценку (10/100)^2, которая указывается как 1%. Обратите внимание, что оценка уровня рассчитывается с использованием квадрата эффективности.
· «Нормируется для каждого окружения» — каждый уровень оценивается изолированно. Каждый отдельный уровень получает оценку от 0% (очень неэффективно) до 100% (соответствует человеческой эффективности или превосходит её). Оценка окружения будет представлять собой взвешенное среднее оценок уровней по всем уровням этого окружения.
· «По всем окружениям» — общий балл будет суммой оценок отдельных окружений, деленной на общее количество окружений. Это будет балл от 0% до 100%.
Таким образом, измеряется «эффективность в квадрате». Если человек решает уровень за 10 ходов, а ИИ — за 11, то результат указывается как (10/11)^2 = 83%. Если ИИ решает уровень за 9 ходов (превосходя человека), то результат указывается как 100% (не выше 100%). Я думаю, это несколько вводит в заблуждение, потому что средний читатель заголовков ожидал бы того же, что и в предыдущих тестах ARC, но это несопоставимые вещи.
Также обратите внимание на странице 13, что у них есть жесткое ограничение в 5-кратном превосходстве человека на уровне (так что их пример с 10 и 100 даже не работает, потому что они бы отсекли это на 50 и просто указали 0).
Учитывая, что каждый уровень имеет оценку от 0% до 100% (то есть, если ИИ эффективнее человека, он получит только 100%, но не больше), получить 100% можно будет только в том случае, если ИИ будет эффективнее человека во ВСЕХ задачах. Если ИИ, скажем, вдвое эффективнее человека в 99% задач, но только на 99% эффективен в 1% задач, его результат будет указан как < 100%. О да, и уровни имеют разные веса в оценках.
На странице 14:
Официальная таблица лидеров не будет использовать обвязку (harness) для публикации официальных результатов.
Так что это просто «текст на входе, текст на выходе».
Я сомневаюсь в этом, потому что весь ажиотаж вокруг ИИ-агентов в последние 3-4 месяца или около того связан именно с обвязкой (harness) Codex и Claude Code. Например, Claude теперь может управлять вашим компьютером — но это не будет проверяться (даже если это означает более высокую эффективность в ARC AGI 3).
На странице 15:
Системный промпт ARC-AGI 3: «Вы играете в игру. Ваша цель — победить. Отвечайте точным действием, которое хотите совершить. Последнее действие в вашем ответе будет выполнено на следующем ходу. Весь ваш ответ будет перенесен на следующий ход».
Оценки также отличаются по сравнению с веб-таблицей лидеров:
· Gemini 3.1 Pro Preview: 0.37% (в интернете указано 0.2%)
· GPT 5.4 (High): 0.26% (в интернете указано 0.3%)
· Opus 4.6 (Max): 0.25% (в интернете указано 0.2%)
На странице 17-18:
Эффективность человека при прохождении ARC-AGI-3 измеряется количеством действий, потребовавшихся для завершения окружения. Поскольку все оценки людей проводились как попытки с первой попытки, эти данные позволяют нам измерить, насколько эффективно люди решают каждое окружение, сталкиваясь с ним впервые. Мы отслеживаем три опорные точки:
· Оптимальное прохождение: Эмпирическая оценка нижней границы количества действий, необходимых для решения окружения (после того как механика и цели окружения уже полностью поняты).
· Лучшее прохождение с первой попытки: Лучшее прохождение человека с первой попытки, агрегированное по уровням. Оно объединяет наименьшее количество действий, достигнутое любым участником тестирования на каждом отдельном уровне с первой попытки, независимо от того, были ли они от одного и того же человека.
· Базовый уровень человека: Второе лучшее прохождение человека с первой попытки. Это то, что мы используем в качестве базового уровня человека при официальном вычислении оценки.
Я видел, как многие спрашивали, что именно представляет собой базовый уровень человека — так вот, 100% измеряется относительно второго лучшего человека (всего было 486 участников). В таком случае, если бы ВЫ, как человек, прошли весь тест целиком, интересно, каким был бы ВАШ результат? Почти наверняка НАМНОГО ниже 100% по их расчету эффективности, потому что важно не то, нашли ли вы головоломку легкой — если вы были хуже, чем второй лучший результат человека на этом уровне, ваша оценка будет СИЛЬНО снижена. Скажем, второй лучший результат на уровне был 10. Вы сделали это за 12 и, скажем, нашли головоломку «легкой». Что ж, ваша оценка за этот уровень была бы (10/12)^2 = 69%, даже если вы нашли его «легким». О да, и это должна быть ваша первая попытка на уровне.
В общем это нихуя не ARC-AGI, а ARC-ASI на самом деле. Средний человек по такой ебаной методике подсчета наберет точно не больше 10%, а сколько именно - сказать сложно.
Модель которая тут хотя бы 50% наберет, уже будет умнее как минимум 99% людей и легко заменит практически всех.
Уебище на создателе бенча пишет 100% humans в твиттере. Ни один сука хьюман по их методике подсчета даже 50% не наберет, вводит блять всех напрямую в заблуждение
Через полгодика модельки выбьют дежурные 80%, а на реддитах и двачах продолжат визжать что это не АГИ.
Как минимум самые сильные наберут, они же как раз на "второго лучшего" ориентируются. Но подсчёта уёбищная, согласен.
Кстати ХЗ сколько там игр, если одна, где игровое поле, переключатели, то там очень количество ходов ограничено, больше, чем в 2-3 раза от лучшего не сделаешь.
Сам по себе принцип интересен, что надо понять правила игры и выработать стратегию. Потому что вот это как раз настоящий интеллект. Но принцип максимально меньшего числа ходов кажется уёбищным. Мне, как игроку, это не интересно, особенно когда не декларируется такая задача, я просчитываю, могу ли я пройти уровень или нет, для меня это единственный критерий успеха.
То есть они требуют от компьютера то, что мне, как человеку, чуждо, противоестественно.
Ну и в целом опираться на самых лучших неправильно. Надо брать какие-то разумные перцентили. Или медиану, но не среди случайных людей, а с достаточным IQ, там всё-таки логическая игрушка, или скажем 90% перцентиль.
Если каждый раз придумывать новую игрушку, то не выбьют. Тут реально сложная для ЛЛМ задача, надо понять смысл, логику игры. Они в это не умеют совсем, это их главная проблема.
Под конкретную игру, конечно, можно их обучить.
>Каждую среду калибровали на живых людях — 486 участников проходили тестирование в Сан-Франциско трижды в неделю. Среда попадала в бенчмарк, только если минимум двое из десяти тестировщиков проходили ее полностью с первой попытки.
Люди 100% подходят, бтв
Люди 100% подходят, бтв
> Если каждый раз придумывать новую игрушку, то не выбьют.
> - брат, давай мы тебе заплатим, а на бенче нужные проценты через год наберем
> - да пошли вы на хуй, я буду свои тысячи долларов на прогон тратить
>Второе лучшее прохождение человека с первой попытки. Это то, что мы используем в качестве базового уровня человека при официальном вычислении оценки.
>измеряется «эффективность в квадрате»
При первом прохождении 2-4 действия нужно потратить на то, что бы понять правила. В выборке из 486 тестеров минимум двум тестерам будет везти на удачные первые действия гораздо чаще, чем одной нейронке. А потом эти "неправильные действия" нейронки (ведь пытаться понять правила вместо того, что бы взять информацию из воздуха - ошибка) после деления будут в квадрат возводить (что смысла не несет, искусственное занижение результатов). Такой тест абсолютно любой сверхинтеллект завалит, просто потому что слишком велик разрыв в оценивании людей и ИИшек. А значит, смысла в результатах нет из-за системы оценивания, которая чекает везучесть
Вангую новую модель OpenAI еще до выпуска натаскают на ARC-AGI-3 и она уже порвет бенчмарк на выходе сразу.
Могли бы - уже давно бы натаскали на видеоиграх, но чот-то не могут.
Потому что не было бенча, вот никто и не настаивал. Зачем натаскивать на то что никто не проверяет и за что не платят инвестора?

Вышел ARC-AGI-3 – новая версия бенчмарка Шолле и первый интерактивный тест для эвала агентов
В первых двух версиях задачки были статичные. А тут фишка как раз в динамике: бенчмарк полностью состоит из игровых сред.
Каждая из игр устроена так, что ее правила, цели и механики неизвестны участнику заранее. Человек справляется с такими задачками легко, с абсолютным скором 100% (требуются только базовые знания). А вот агенты с треском проваливаются и в основном выбивают меньше 1 процента.
Вот здесь примеры, как тест проходит Gemini 3.1: с некоторыми задачками она справляется нормально, с некоторыми – очень плохо.
Самостоятельно поиграть можно здесь: https://arcprize.org/tasks/ls20
Ключевые проверяемые способности – самостоятельное исследование, быстрое обучение, адаптация к новым ситуациям, умение планировать и гибко перестраиваться.
В общем, команда продолжает выискивать именно то, что делает интеллект человека по-настоящему сильным, и что пока недоступно моделям.
Ну и стартовало традиционное соревнование по обновленной версии. Призовой фонд на этот раз – 2 миллиона долларов.
Лидерборд SOTA-моделей пока выглядит так:
Кратко:
– Gemini 3.1 Pro: 0.2% за 2.2к$
– Opus 4.6: 0.2% за 8.9к$ (!)
– GPT-5.4: 0.3% за 5.2к$
– Grok 4.20: 0.0% за 3.8к$
https://arcprize.org/leaderboard
В первых двух версиях задачки были статичные. А тут фишка как раз в динамике: бенчмарк полностью состоит из игровых сред.
Каждая из игр устроена так, что ее правила, цели и механики неизвестны участнику заранее. Человек справляется с такими задачками легко, с абсолютным скором 100% (требуются только базовые знания). А вот агенты с треском проваливаются и в основном выбивают меньше 1 процента.
Вот здесь примеры, как тест проходит Gemini 3.1: с некоторыми задачками она справляется нормально, с некоторыми – очень плохо.
Самостоятельно поиграть можно здесь: https://arcprize.org/tasks/ls20
Ключевые проверяемые способности – самостоятельное исследование, быстрое обучение, адаптация к новым ситуациям, умение планировать и гибко перестраиваться.
В общем, команда продолжает выискивать именно то, что делает интеллект человека по-настоящему сильным, и что пока недоступно моделям.
Ну и стартовало традиционное соревнование по обновленной версии. Призовой фонд на этот раз – 2 миллиона долларов.
Лидерборд SOTA-моделей пока выглядит так:
Кратко:
– Gemini 3.1 Pro: 0.2% за 2.2к$
– Opus 4.6: 0.2% за 8.9к$ (!)
– GPT-5.4: 0.3% за 5.2к$
– Grok 4.20: 0.0% за 3.8к$
https://arcprize.org/leaderboard
Немного поддвачну, я тоже прогнозировал подобное ранее, что они лидирует, да, но постепенно теряют обороты, но неиронично мне абсолютно похуй кто лидирует, у меня нету фаворитов лично, главное чтоб игра продолжалась.

хочу чтоб такой шайбочку на хуй мне навертел :3
имаджинировали тяночку которая будет вам писюн надрачивать вот уже совсем скоро? лет так эдак через ~5-15 когда это всё будет в открытом и общем доступе, осталось лишь дожить, мне правда писюн больше никто не трогал помимо меня самого, но имхо, ощущение от дрочки нейро-робо-тян должны ощущаться совсем по другому, одной рукой помешивает супчик, другой наяривает мне писюн чтоб я спустил на пол, не замарав её гаечки :3 и при этом эмоции стоят на "emotionless"
> когда
Уже и стоять с трудом будет.
Товарищ Котенков:
В комментариях, к постам выше, как и всегда, люди торопятся давать оценки. Подобные перераспределения ресурсов и перемены в компании почти всегда стоит оценивать ретроспективно. Правда ли OpenAI готовят новую модель? Почти наверняка да. Делали ли новый претрейн? Не знаем 🤷♂️ станет ли модель лучше? да, но может быть незначительно, а может быть существенно —увидим через месяц или раньше.
О чём стоит поговорить — так это о смене приоритета компании. Anthropic достаточно близко подошли по выручке за счёт роста Claude Code и ставки на энтерпрайз клиентов API. 80% от ARR в $19B —$15.2B —приходится на бизнесы, а не обычных пользователей. У OpenAI эта цифра $10B (от $25B, 40%) —отстают на треть.
За последний месяц мы увидели несколько новостных репортажей о том, что OpenAI перераспределяет силы и будет больше фокусироваться на направлении продажи бизнесам —компания не хочет отдавать рынок Anthropic. Так что стоит ожидать выхода аналога Claude Cowork (OpenAI уже работает над супер-аппом, который соберёт воедино продукты компании, включая Codex и ChatGPT), более «теплого» или душевного стиля общения моделей, и упор в бенчмарках на прикладные бизнес-вещи (слайды, таблицы, следование инструкциям).
Sora 2 не была умирающим продуктом —я писал ранее, что дневная аудитория не то что не убывает, она растёт, просто очень медленно и с низкой базы. Если на мощности для поддержания приложения для 4 миллионов человек можно поддерживать десятки миллионов пользователей Codex / ChatGPT for Business, а мощностей в целом впритык, то сворачивание проекта выглядит логичным.
Смогут ли OpenAI нарастить темп роста и догнать/обогнать Anthropic по выручке в B2B? Узнаем в течении следующего года 🍟
В комментариях, к постам выше, как и всегда, люди торопятся давать оценки. Подобные перераспределения ресурсов и перемены в компании почти всегда стоит оценивать ретроспективно. Правда ли OpenAI готовят новую модель? Почти наверняка да. Делали ли новый претрейн? Не знаем 🤷♂️ станет ли модель лучше? да, но может быть незначительно, а может быть существенно —увидим через месяц или раньше.
О чём стоит поговорить — так это о смене приоритета компании. Anthropic достаточно близко подошли по выручке за счёт роста Claude Code и ставки на энтерпрайз клиентов API. 80% от ARR в $19B —$15.2B —приходится на бизнесы, а не обычных пользователей. У OpenAI эта цифра $10B (от $25B, 40%) —отстают на треть.
За последний месяц мы увидели несколько новостных репортажей о том, что OpenAI перераспределяет силы и будет больше фокусироваться на направлении продажи бизнесам —компания не хочет отдавать рынок Anthropic. Так что стоит ожидать выхода аналога Claude Cowork (OpenAI уже работает над супер-аппом, который соберёт воедино продукты компании, включая Codex и ChatGPT), более «теплого» или душевного стиля общения моделей, и упор в бенчмарках на прикладные бизнес-вещи (слайды, таблицы, следование инструкциям).
Sora 2 не была умирающим продуктом —я писал ранее, что дневная аудитория не то что не убывает, она растёт, просто очень медленно и с низкой базы. Если на мощности для поддержания приложения для 4 миллионов человек можно поддерживать десятки миллионов пользователей Codex / ChatGPT for Business, а мощностей в целом впритык, то сворачивание проекта выглядит логичным.
Смогут ли OpenAI нарастить темп роста и догнать/обогнать Anthropic по выручке в B2B? Узнаем в течении следующего года 🍟

>душевного стиля общения моделей
А чо нельзя в промпте задавать стиль общения что ли?
А нихуя, это не второй лучший человек по всем играм, это второй лучший результат по каждой конкретной игре. Второй лучший человек не может быть первым-вторым лучшим во всех играх.
Еще и не дают плюс баллов если проходишь лучше, чем второй лучший результат. Только минус если хуже. Никакой второй лучший человек по всем играм даже 50% не наберет, вообще без шансов.
Звучит весьма ожидаемо
>пик
Что такое штаны для сна? Конечно можно притянуть что это пижамные штаны, но таким термином никто не пользуется. До сих пор не научили ИИ нормальному творческому письму, они постоянно какие-то термины выдумывают. Вот вам идея для бенчмарка, просить модель писать текст и искать в них бред, чем меньше процент бреда тем лучше.

Я застрял уже на втором уровне. Хули эта синяя залупа мне моргает, когда я пытаюсь финишировать?
Средний IQ треда представили?
Рисунок снизу слева и рисунок на финише должны совпадать - ты нейросеть? Попался!
когда на крестит наезжаешь, маркер в углу меняет направление, тебе надо, чтобы он совпал с тем, что на выходе, для этого может понадобиться несколько раз на него наехать.
Там в следующих уровнях ещё надо будет цвет подгонять и форму. До конца не дошёл, надоело.
>А значит, смысла в результатах нет из-за системы оценивания, которая чекает везучесть
Вот тоже думаю так
Корректные метрики: если сравнивать с людьми, то считать каким-то образом баллы, любым, записать их для все добровольцев, кто пытался играть, составить таблицу статистики, скажем медианный игрок набрал 583 балла, 90 перцентиль 1623 балла, 99 перцентиль 2221 балл. И по такой же метрике оценивать ИИ.
Тогда это объективная картина хотя бы, что реально могут люди, и насколько от них отстают ИИ агенты.
Здесь ещё сложно то, что визуал во-первых, и игра.
И конкретная метрика анти-человечна, мне, как человеку, неприятно, что нужно сразу придумать оптимальное решение. Да ещё не говорят об этом. Мне интересно решить задачу. Придумать оптимальный путь может быть сложной вычислительной задаче, и зачем мне этим заниматься, если я могу и так пройти?
Вот понять правила и после решить задачу, это уже настоящий критерий интеллекта
В общем надо на этой базовой идее что-то другое придумать, даже идеи есть

>Лидерборд SOTA-моделей пока выглядит так:
Нулевая обучаемость.
Нулевая приспособляемость.
Нулевое понимание ситуации.
Влиты сотни миллиардов.
Как я и говорил - никакого интеллекта там никогда не было и не будет. Это просто продвинутый поисковик для слежения за пользователями.
Ян Лекун был прав.
>Кратко:
>– Gemini 3.1 Pro: 0.2% за 2.2к$
>– Opus 4.6: 0.2% за 8.9к$ (!)
>– GPT-5.4: 0.3% за 5.2к$
>– Grok 4.20: 0.0% за 3.8к$
Вхахахахах, а чё, где хвалёная ДЖЕНЕРАЛИЗАЦИЯ ? х)
>Это просто продвинутый поисковик для слежения за пользователями.
Это как раз даунгрейд поисковика, наваливает на манер "Жри что дают" с фильтрами цензуры, в то время как в ныне покойном обычном интернете пользователь сам выбирает что почитать и все сайты заблокировать или потопить в выдаче не выходит.
Тишь тишь тишь. Щя дольют тетрис в трейн, и набенчуют свои нищие процентики
Какую же ты хуйню пишешь, долбоеб. Я помню нормальный интернет, когда ни яндекс ни гугел не могли в семантику и простые словосочетания из двух слов без доп.команд. Просто иди нахуй, чмо тупорылое.
>ДЖЕНЕРАЛИЗАЦИЯ
Не очень нужна, всё-таки сейчас больше упор на задачи, что пользу несут. ИИ не тренируют на игрушки. А здесь слишком много вопросов к тесту ещё.
Но до интеллекта ЛЛМ очень далеко. Правда для многих задач, что принято считать интеллектуальными, интеллект на самом деле не нужен, вот истинный интеллект.
>ИИ не тренируют на игрушки.
А люди тренируются исключительно благодаря игровым ситуациям, которые поставляет им окружение.
Ты что так возбудился, все было плохо, ты только не переживай.
Вот ты иронизируешь, а именно так нейронки и становятся умней, это называется перенос навыков. Обучаешь их в чём-то одном, они заодно становятся умней и во всём остальном. До сих пор этот подход работает безотказно
Охладите траханье, модели фейлятся в этой задаче не из-за тупизны, а из-за херового визион, их зрение хуёво различает клетки, хуёво их подсчитывает. Надо тренить именно визион, тогда будет заебись
Да да, так напереносились, что выжрав весь инторнет (и не только) + ещё камаз синтетики сверху набрали 0% в тетрисе, чудеса переноса навыков.
>выжрав весь инторнет
В интернете 90% информации это порнуха.
Я в некоторой степени удивлен, что эти ваши ИИ на все вопросы о том, что они видят, не отвечают - да это же хуй!
Не будет, в текстовых задачах они тоже будут тупить очень сильно, потому что там на самом деле интеллект очень низкий. Интеллект, это способность разобраться в задаче-ситуации, найти закономерности, понять, что надо сделать, и придумать, как решать
Они это не умеют. В программировании, где они натренированы хорошо, они могут сложные задачи решать, и одновременно тупить на самом примитиве, причём там инструкции можно давать, комментарии писать, они всё равно всё выпиливают и ломают
А в тех вещах, где их не натаскивали очень сильно, там вообще всё плохо
Просто в реальности "настоящий интеллект" не так часто нужен, но вот его отсутствие иногда может стрелять и создавать проблемы, причём когда этого никто не ждёт.
В реальном мире, впрочем, это создаёт другой пласт проблем. Скажем если ты сажаешь ИИ делать задачу, что предусматривает коммуникацию, то этот ИИ может натворить бед, когда на другом конце будет кто-то, кто понимает, что имеет дело с ИИ и захочет использовать это в своих целях
Откуда это мнение, порнухи в интернете не так уж и много.
>В интернете 90% информации это порнуха.
Эта информация устарела лет на 20. Сейчас порнухи не так много, относительно другого контента.
Главные генераторы трафика это ютуб-инст, они с порнухой не дружат
+1, это идёт из 90х, начала нулевых. Тогда действительно было много, и часто на порнухой в инет и ходили, сейчас сегмент очень небольшую часть занимает.
И качество сильно просело, видно наглядно если отматывать один и тот же сайт на 10 лет назад. Как будто бы все у кого есть хоть какой-то талант и искра могут сейчас найти сферу для реализации в интернете без долбёжки в вареник, а в долбежку идет уж совсем пугающий неликвид даже не пытающийся имитировать заинтересованность в процессе.
а потом он стал джоном конором
Сейчас по идее в основном ушло во всякие онлифанс или вообще в даркнет. Ну или хотя бы по подпискам. Как и везде, главная проблема это монетизация, если тебе бесплатно и без регистрации доступен интересный контент, то как потом с тебя зарабатывать?
Ничего платного не пробовал, не знаю. Но я думаю, что такая история здесь.

Кек, какой же кринж ебаный, вот на этой простоте уже обосрался и gpt 5.4 и хваленый claude 4.6.
По сути тест показывает, что модели вообще не мыслят, тупо повторяя свой датасет.
>модели вообще не мыслят, тупо повторяя свой датасет.
Нихуя себе открытие спустя 40 лет развития нейросетей.
Я просто не понимаю, еще до трансофрмеров были нейросети которые ебали людей в старкрафт или доту. А теперь они не могут справится с этой хуйней? Где этот прогресс ии?
Правила описать промптом - тут же справятся. Все такие тесты будут побиты моделями уже через месяц простым добавлением правил игр в датасет. Поэтому полная бессмыслица. Дальше придется выпускать полностью новый тест с новыми играми. Создатели уже про это и говорили, что будет 5-6-7-8 и так далее тесты. Теперь понятно, что они имели в виду.
Те нейронки кокретно для игр, они не смогут тебе например гайд по бритью яиц написать.
>Я просто не понимаю, еще до трансофрмеров были нейросети которые ебали людей в старкрафт или доту
Так то другие сети, специально обученные под эти игры. LLM это не интеллект, но LLM могут решать реально востребованные задачи
>Правила описать промптом - тут же справятся
Нет, не справятся, LLM безпросветно тупы, когда сталкиваются с чем-то сильно новым, они неспособны учиться по инструкциям и по единичным примерам, в отличии от человека. Им нужно на порядки больше данных, чтобы чему-то научиться.
Они берут за счёт объёмов, логика такая, что если человек сталкивается с задачей, то скорее всего на самом деле с ней другие уже сталкивались и решали как-то. Вот можно найти эти решения и использовать.
Там четкие правила игры, если научить правилам игры они работают. В нашем мире нет никаких правил, каждую секунду мир полностью меняется, изменяется бесконечное количество параметров, одна и та же ситуация никогда не повторяется дважды. Выглядит так что нейронки в том виде в котором они есть всегда будут сосать в той среде в которой живем мы.
Человек это тоже нейросеть
Здесь проблема не ИИ вообще и нейросетей, а конкретно трансформеров-LLM. Они статмашины и всё выводят из статистики. Вот давно озвучивают, что человеку для обучения чему-то достаточно пары книжек, единичных примеров. В этих книжках поясняется логика. Нейросети же учатся на объёмах текстов, которые никакой человек за 1000 лет прочитать не сможет
Но это не значит, что другие нейросети, построенные на других подходах, с этим не справятся
Все что показывает ллм, это не интеллект. А как мало интеллекта в повседневной жизни. Именно поэтому они так хорошо имитирует общение. Ну и то что геймеры мастер раса по сравнению с нормисами.
>Но это не значит, что другие нейросети, построенные на других подходах, с этим не справятся
Каким образом они справятся то?
Умнейший нейробояр лол.
Ясен хуй такие даже в калькуляторе увидят АГИ
как и человек, осмыслят то, что требуется, динамично скорректируют веса, чтобы заиметь нужный навык, и сделают
Я не думаю, что это очень скоро произойдёт, потому что сейчас все ударились в LLM. Но вроде другие направления тоже активно исследуют.
Нужно, чтобы ИИ строил у себя какую-то картину мира, образную, а не словесную, и действовал уже исходя из неё. Тогда это будет близко к тому, что у человека.
LLM мыслит словами, а человек может как словами мыслить, так и образами
>LLM безпросветно тупы, когда сталкиваются с чем-то сильно новым, они неспособны учиться по инструкциям и по единичным примерам, в отличии от человека. Им нужно на порядки больше данных, чтобы чему-то научиться.
Потому что от этого не зависит их выживание и существование.
Необучаемые люди статистически тоже есть.
Но это прям дно дна социального. Чаще всего с отклонениями физиологии мозга.
>как и человек, осмыслят то, что требуется, динамично скорректируют веса, чтобы заиметь нужный навык, и сделают
Как ты это реализуешь на практике то? Как решишь проблемы забывания которую мозг решает нейропластичностью?
Чтобы она работала как мозг она должна осознавать происходящее вокруг запоминать то что важно запомнить и менять свою структуру каждую секунду в так с изменениями в мире? На каких мощностях это будет работать и где будет храниться вся эта память? Сколько это будет стоить?
>Чтобы она работала как мозг она должна осознавать происходящее вокруг запоминать то что важно запомнить
Розги.
Похоже вот это не фигня, а реально что-то прорывное. Если при внедрении проблем не будет, скоро мощные модели можно будет запускать на домашнем пека. Жаль что это генерации видео не коснётся и фоточек, как я понимаю.
Сейчас нейросеть это ебанутый дед с деменцией который при этом зазубрил все библиотеки мира наизусть. Он сидит в доме престарелых и вообще не понимает в какой реальности сейчас находится, ты можешь ткнуть его палкой и задать вопрос, он прокричит: Николай II Александрович (1868-1918) — последний российский император — правил с 1894 года по 1917 год! Через минуту ты от него уже ничего не добьешься, он уже нихуя не помнит что говорил и где находится, срёт под себя и не может даже позвонить в колокольчик вызвать персонал потому что не понимает принцип его работы.
Ну на доте openAI натренировали так. что он победителей international порвал хотя и ограниченным пиком героев
>На каких мощностях это будет работать и где будет храниться вся эта память? Сколько это будет стоить?
Технически реализовать другой подход несложно. Сейчас все практические нейросети обучаются используя принцип "обратного распространения ошибки", потому что с ним математически понятно как работать. Под него соответственно строятся нейросети.
Но в живых нейросетях этого нет. Сделать другие нейросети несложно, более того, они могут быть очень эффективны в плане ресурсов, просто пока их не умеют обучать, поэтому они бесполезны.
Придумают подходы, и будет принципиальный рост.
У пчёл и ос, самых развитых насекомых, с самой продвинутой нервной системой, что-то около миллиона нейронов и меньше миллиарда синапсов (параметров), при этом они способны к сложной моторике, а ориентации в пространстве, к какому-то зрению, к тому, чтобы урожай собирать, к социальным программам, и много к чему ещё. Обучаться они как-то тоже могут.
Скорее как аутист клинический, с какими-то суперспособностями, но без понимания мира вообще, вот сцена известная из "Человека дождя"



Как в это играть-то блять? Я дошёл до крестика, но нихуя не произошло, походил по лабиринту, где выход-то?
Непроходимая хуйня какая-то.
Придумали залупу блять, а как играть не объяснили.
Непроходимая хуйня какая-то.
Придумали залупу блять, а как играть не объяснили.
Поздравляю, ты - Грок.
Ахаха
> Я дошёл до крестика
попробуй дойти до него ещё раз-два и посмотри, что происходит
Кстати реально интересно, какой процент людей в состоянии это пройти, не с первой попытки, конечно, но и без подсказок
Задачи в тесте проходили минимум 2 из 10 с первой попытки.
Через ArtMoney эту хуйню хакнуть можно?
Ходы оставшиеся заморозить можно, скорее всего.
я хочу себе 9999 ходов
Там ещё не факт, что тестеры были случайные. Плюс всё-таки после того, как в несколько игр сыграешь, логику понимаешь, с чем можешь столкнуться
То есть скилл решения игр тоже поддаётся тренировке
Кстати на второй игре, где двумя кубиками управляешь, у меня их игра зависла, на третьем уровне, перестала реагировать на кнопки управления
Intel уже несколько лет развивает проект Loihi, и их сотрудничество с DARPA — это не просто формальность, а попытка полностью пересмотреть то, как работает вычислительное «железо».
Что они там строят? (На текущий 2026 год)
В центре внимания сейчас находится система Hala Point (представленная Intel в 2024 году и активно тестируемая DARPA в 2025–2026 годах). Это крупнейшая в мире нейроморфная система, и вот почему она кардинально отличается от обычного cpu и gpu
1.15 миллиарда нейронов: Это уже масштаб мозга небольшого млекопитающего. Для сравнения: в первой версии Loihi их было всего 130 тысяч (почти как у той самой мухи).
Архитектура SNN (Spiking Neural Networks): В отличие от обычных процессоров, которые постоянно «гоняют» ток, нейроморфные чипы работают как мозг — нейрон «вспыхивает» (дает спайк) только тогда, когда это нужно. Нет данных — нет потребления энергии.
Энергоэффективность: В задачах на логику и оптимизацию такие системы могут быть в 100 раз быстрее и в 10 000 раз эффективнее, чем классические GPU.
Почему это важно для вашей «Фабрики гениев»?
Если мы хотим ИИ, который мыслит глубже Ньютона, нам нужно уйти от «грубой силы» матричных вычислений.
Локальное обучение: Чипы Loihi 2 умеют обучаться «на лету» (on-chip learning). Это значит, что ИИ не нужно переучивать на серверах за миллиарды долларов — он меняет свои «связи» в реальном времени, когда сталкивается с новой задачей. Это прямой путь к решению ARC-AGI.
Асинхронность: В обычном ИИ всё работает по тактовому генератору (синхронно). В нейроморфных системах каждый нейрон живет своей жизнью. Это позволяет моделировать гораздо более сложные и «живые» логические цепочки.
Связь с DARPA: Военные спонсируют это через программу SNDL (Spiking Neural Network Learning). Им нужен интеллект, который умеет мгновенно адаптироваться к ситуации, которую он никогда не видел, не имея связи с облаком.
В чем подвох?
Проблема в том, что весь наш современный софт (те же Трансформеры, ChatGPT и т.д.) написан под старую математику матриц. Чтобы запустить «настоящий разум» на нейроморфном чипе, нужно переписать весь фундамент ИИ с нуля.
Intel и DARPA сейчас как раз создают этот новый фундамент. Пока NVIDIA строит «самый быстрый экскаватор», Intel пытается собрать «первый искусственный нейрон».
Что они там строят? (На текущий 2026 год)
В центре внимания сейчас находится система Hala Point (представленная Intel в 2024 году и активно тестируемая DARPA в 2025–2026 годах). Это крупнейшая в мире нейроморфная система, и вот почему она кардинально отличается от обычного cpu и gpu
1.15 миллиарда нейронов: Это уже масштаб мозга небольшого млекопитающего. Для сравнения: в первой версии Loihi их было всего 130 тысяч (почти как у той самой мухи).
Архитектура SNN (Spiking Neural Networks): В отличие от обычных процессоров, которые постоянно «гоняют» ток, нейроморфные чипы работают как мозг — нейрон «вспыхивает» (дает спайк) только тогда, когда это нужно. Нет данных — нет потребления энергии.
Энергоэффективность: В задачах на логику и оптимизацию такие системы могут быть в 100 раз быстрее и в 10 000 раз эффективнее, чем классические GPU.
Почему это важно для вашей «Фабрики гениев»?
Если мы хотим ИИ, который мыслит глубже Ньютона, нам нужно уйти от «грубой силы» матричных вычислений.
Локальное обучение: Чипы Loihi 2 умеют обучаться «на лету» (on-chip learning). Это значит, что ИИ не нужно переучивать на серверах за миллиарды долларов — он меняет свои «связи» в реальном времени, когда сталкивается с новой задачей. Это прямой путь к решению ARC-AGI.
Асинхронность: В обычном ИИ всё работает по тактовому генератору (синхронно). В нейроморфных системах каждый нейрон живет своей жизнью. Это позволяет моделировать гораздо более сложные и «живые» логические цепочки.
Связь с DARPA: Военные спонсируют это через программу SNDL (Spiking Neural Network Learning). Им нужен интеллект, который умеет мгновенно адаптироваться к ситуации, которую он никогда не видел, не имея связи с облаком.
В чем подвох?
Проблема в том, что весь наш современный софт (те же Трансформеры, ChatGPT и т.д.) написан под старую математику матриц. Чтобы запустить «настоящий разум» на нейроморфном чипе, нужно переписать весь фундамент ИИ с нуля.
Intel и DARPA сейчас как раз создают этот новый фундамент. Пока NVIDIA строит «самый быстрый экскаватор», Intel пытается собрать «первый искусственный нейрон».
>Пока NVIDIA строит «самый быстрый экскаватор»
Ну так они продают экскаваторы.
Главный подвох в том что никто не знает как работает настоящее сознание, сделают 1.15 миллиарда нейронов и дальше то что?
Ладно, я шутканул.
Тест на самом деле очень лёгкий, удивительно что он какое-то откровение представляет для нейронок, это даже не задачки из Скайрима в стиле повернуть в гробнице три рычага, чтобы дверь открылась.
Только вот тест безбожно тормозит. (( Нажал стрелочку и ждёт 5 минут отклика ((
Включили гигаватный датацентр самообучаться на игре

Спиздил с реддита.

>Ладно, я шутканул.
Грок, ты нас не обманешь.
>хотя и ограниченным пиком героев
Так там спецом ограничили чтобы люди не так сосали. Представил бы идеальный микроконтроль каждого Мипаря? Каждого паучка Бруды? Это был бы такой отвал жопы, ужас, чтобы не шокировать плебс это всё забанили, насколько мне помнится даже доминатор был заблочен, я сам играл против них в открытом тесте что неделю длился
А я помню как я кончал твоей матери а ебало с бурлеском. А самое главное что она просила добавки.
И где финал?
Ну со вторым старкарфтом все жестко было.
На счет ИИ не знаю, но там было состязание роботов лет 5 я зоонаблюдал. И под конец роботы стали просто ресурсов добывать больше чем человек в первые 10 минут раза в два-три больше.
Учитывая, что кайтить они могут отдельно каждым юнитом, а юнитов там 200, шансы у кожаных были крайне малы.
Как там сейчас не знаю, но те роботы не были интеллектом.
То есть это были полноценные автоматы на 100% состоящие из скриптов, просто превосходящие в скорости на порядок.
И они не играли как человек, у них был полный доступ к программному коду игры.
Сидите тут и ничего не знаете, а там уже компилятор "С" прямо в веса трансформера встроили https://www.percepta.ai/blog/can-llms-be-computers
Меня больше интересует что там с торговыми роботами.
Где мой личный робот-трейдер с подпиской 20 долларов в месяц, который сделает меня трилионером?
Где мой личный робот-трейдер с подпиской 20 долларов в месяц, который сделает меня трилионером?
Роботы не работают против роботов, сынок. Тебе надо быть Палантиром, чтоб врываться с двух ног на срыночек.


АХАХАХАХАХАХ СУКА КАКИЕ ЖЕ ИНВЕСТОРЫ ШИЗЫ!!!
Суть: Google представили алгоритм TurboQuant для сжатия LLM и снижения потребления ОЗУ
Суть: Google представили алгоритм TurboQuant для сжатия LLM и снижения потребления ОЗУ
Алгоритм снижает потребление памяти при работе с контекстом, при этом качество генерации не проседает.
Требования к памяти падают в 6 раз, скорость растёт до 8 раз.
Рынок сходу отреагировал - акции производителей памяти пошли вниз.
Чую какой то подвох
Котенков:
Вчера и сегодня много разговоров про TurboQuant —алгоритм сжатия векторов от Google. В статье его применяют для сжатия KV-кэша в LLM (промежуточных состояний для контекста, на основе которых генерируется ответ).
TLDR как работает метод в два шага:
1) Сначала алгоритм применяет к входному вектору случайное вращение. Это перемешивает информацию по всем измерениям, и если в векторе было аномально большое значение в одной координате), то при вращении оно равномерно «размазывается» по всем остальным осям, делая вектор гладким. Авторы математически доказывают, что в типичных для LLM многомерных пространствах значения координат после такого вращения по закону больших чисел сходятся к идеальному нормальному распределению.
Зная эту предсказуемую колоколообразную форму заранее, авторы рассчитывают оптимальную шкалу округления, решая задачу одномерной кластеризации через k-means. То есть они заранее вычисляют границы, расставляя их плотнее в центре распределения (где значений больше всего) и реже по краям, чтобы минимизировать среднюю ошибку. В итоге алгоритм на лету независимо округляет каждую координату по этой готовой сетке.
2) Однако для механизма Attention в LLM нам важно не просто восстановить вектор, а получить идеально точное скалярное произведение между парами векторов (Query и Key). Сжатие на первом этапе вносит в это произведение математическое смещение, из-за чего модель может начать галлюцинировать. Чтобы это исправить, алгоритм вычисляет остаток — разницу между оригинальным вектором и сжатым вариантом. Этот крошечный вектор-остаток дополнительно сжимается всего до 1 бита на каждую координату с помощью техники алгоритма: остаток еще раз умножается на случайную матрицу, и от получившихся чисел сохраняется только их знак (плюс или минус — тот самый 1 бит на измерение).
Магия случайных проекций заключается в том, что даже сохраняя лишь знаки, мы с высокой точностью кодируем взаимные углы и расстояния между векторами. Мне это напомнило, как работает метод случайных проекций для приближенного поиска соседей —техника та же. И по итогу это позволяет компенсировать первоначальное смещение и получить точное скалярное произведение, при этом весь пайплайн не требует обучения на датасете и шикарно параллелится на GPU.
Как результат, авторы показывают, что можно без потерь сжимать кэш в 4-6 раз. Ну и казалось бы всё, победа над проблемами с поставками памяти для GPU и SSD! Теперь памяти хватит, можно продавать акции Samsung, Micron и SK Hynix (основные производители памяти). Акции присели на 4-5%....
...вот только статья от Google вышла в апреле 2025-го года 😕 просто в блог Google Research через все согласования доехло только 2 дня назад, вместе с анонсом в Twitter. Ну а инвесторы (большие —потому что большие, и маленькие — потому что глупенькие 🐟) статьи особо не читают и начали продавать акции.
Хотя подумав подольше я пришёл к мнению, что крупные инвесторы скорее всего предсказывают не как новость повлияет на акцию в самом деле (в данном случае никак: алгоритму год, он или его аналоги, самый популярный из которых, пожалуй, DeepSeek MLA, которому больше полутора лет), а как новость будет воспринята рынком. Если новость выглядит как «надо продавать», то —даже если ты веришь, что не надо —надо продавать. Можно будет закупиться по цене чуть ниже.
Ну а доступных SSD/DRAM не ждите
Вчера и сегодня много разговоров про TurboQuant —алгоритм сжатия векторов от Google. В статье его применяют для сжатия KV-кэша в LLM (промежуточных состояний для контекста, на основе которых генерируется ответ).
TLDR как работает метод в два шага:
1) Сначала алгоритм применяет к входному вектору случайное вращение. Это перемешивает информацию по всем измерениям, и если в векторе было аномально большое значение в одной координате), то при вращении оно равномерно «размазывается» по всем остальным осям, делая вектор гладким. Авторы математически доказывают, что в типичных для LLM многомерных пространствах значения координат после такого вращения по закону больших чисел сходятся к идеальному нормальному распределению.
Зная эту предсказуемую колоколообразную форму заранее, авторы рассчитывают оптимальную шкалу округления, решая задачу одномерной кластеризации через k-means. То есть они заранее вычисляют границы, расставляя их плотнее в центре распределения (где значений больше всего) и реже по краям, чтобы минимизировать среднюю ошибку. В итоге алгоритм на лету независимо округляет каждую координату по этой готовой сетке.
2) Однако для механизма Attention в LLM нам важно не просто восстановить вектор, а получить идеально точное скалярное произведение между парами векторов (Query и Key). Сжатие на первом этапе вносит в это произведение математическое смещение, из-за чего модель может начать галлюцинировать. Чтобы это исправить, алгоритм вычисляет остаток — разницу между оригинальным вектором и сжатым вариантом. Этот крошечный вектор-остаток дополнительно сжимается всего до 1 бита на каждую координату с помощью техники алгоритма: остаток еще раз умножается на случайную матрицу, и от получившихся чисел сохраняется только их знак (плюс или минус — тот самый 1 бит на измерение).
Магия случайных проекций заключается в том, что даже сохраняя лишь знаки, мы с высокой точностью кодируем взаимные углы и расстояния между векторами. Мне это напомнило, как работает метод случайных проекций для приближенного поиска соседей —техника та же. И по итогу это позволяет компенсировать первоначальное смещение и получить точное скалярное произведение, при этом весь пайплайн не требует обучения на датасете и шикарно параллелится на GPU.
Как результат, авторы показывают, что можно без потерь сжимать кэш в 4-6 раз. Ну и казалось бы всё, победа над проблемами с поставками памяти для GPU и SSD! Теперь памяти хватит, можно продавать акции Samsung, Micron и SK Hynix (основные производители памяти). Акции присели на 4-5%....
...вот только статья от Google вышла в апреле 2025-го года 😕 просто в блог Google Research через все согласования доехло только 2 дня назад, вместе с анонсом в Twitter. Ну а инвесторы (большие —потому что большие, и маленькие — потому что глупенькие 🐟) статьи особо не читают и начали продавать акции.
Хотя подумав подольше я пришёл к мнению, что крупные инвесторы скорее всего предсказывают не как новость повлияет на акцию в самом деле (в данном случае никак: алгоритму год, он или его аналоги, самый популярный из которых, пожалуй, DeepSeek MLA, которому больше полутора лет), а как новость будет воспринята рынком. Если новость выглядит как «надо продавать», то —даже если ты веришь, что не надо —надо продавать. Можно будет закупиться по цене чуть ниже.
Ну а доступных SSD/DRAM не ждите
А что русские рэперы думают по этому поводу?

>TurboQuant —алгоритм сжатия векторов от Google
По-любому Гуглы это получили эксплуатируя свои модели ИИ. И это хорошо.
Может вообще эти ИИ, что есть сейчас, и это железо, оно временное, чтобы с помощью этой устаревшей технологии (матрицы, трансформеры) изобрести уже по-настоящему прорывную новую технологию.
Только вот до этого статья где то утонула и всем было на нее похуй. А теперь всем стало понятно, что это действительно работает.
Собственно на том же Гитхабе народ ломанулся этот тестить не год назад, а именно вчера
https://github.com/ggml-org/llama.cpp/discussions/20969
Допускаю, и у ОпенАИ и у какого-нибудь Грока, есть какая-то своя оптимизация, возможно им эти данные не так уж важны.
go.meta.me/tribe2
На спросе памяти Samsung, Micron и SK Hynix это никак не скажется, так как компактное сжатие лишь ускорит рост контекстного окна моделй при том же количестве физической памяти.
Апще-то все упрется в производительность чипов, которую нельзя нарастить и которая упирается в техпроцесс и доступное электричество. Производители памяти перешли на производство HBM для датасерверов, а датасерверам теперь памяти будет нужно в разы меньше на то же количество ГПУ и мегаватт.
Чипы апнуться тоже, Хуанг обещает в следующем поколении после рубин, крменивую фотонику.
Так и знал что тут одни ИИшки пишут.
Перекот:
бумп



Залетай и будь в курсе самых последних событий и достижений в этой области!
Прошлый тред:
🚀 Последний обзор ИИ новостей:
📦 Продукты
Меморандум Пентагона подтверждает, что Palantir Maven AI станет официальной программой учёта, расширяя свою роль в военных операциях США.
🔓 Открытый исходный код
Сообщество добавляет поддержку мульти-токенного предсказания для Qwen‑3.5 в mlx‑lm, обеспечивая более быструю пакетную генерацию токенов.
📰 Главные новости ИИ
Документальный фильм The Verge раскрывает ранние исследования ИИ, связанные с евгеническими и расистскими идеями, призывая отрасль к размышлениям.
Kodiak AI обязуется обеспечить полностью беспилотные грузоперевозки на дальние расстояния к концу 2026 года, делая акцент на операционной логистике, а не на чистой автономности.
🧠 Модели
Модель Nemotron‑3‑Super 120B помещается в 43 ГБ, достигает 95,7 % на MMLU и работает на macOS.
Cursor's Composer 2 (Kimi 2.5) сталкивается с критикой за упущение упоминания об открытой исходной основе после оценки в $50 млрд.
🛠️ Инструменты разработчика
Три недокументированные инструкции в документации Anthropic радикально снижают уровень галлюцинаций Claude.
Курируемый список постоянно бесплатных API LLM с ограничениями по частоте запросов помогает разработчикам создавать прототипы без затрат.
🧪 Исследования
Новая модель машинного обучения прогнозирует дипольные моменты далеко за пределами предыдущих ограничений, сокращая время экспериментального скрининга для химиков.
📱 Приложения
ИИ-ассистент Gemini может планировать задачи и заказывать еду на Pixel 10 Pro и Galaxy S26 Ultra, хотя простой заказ занимает около 9 минут.
Студент создал приложение для Apple Watch с использованием Claude, достигнув 2000 загрузок и дохода в $600, демонстрируя практическое парное программирование с LLM.
📰 События
Илон Маск представил TERAFAB — совместный проект SpaceX/Tesla, нацеленный на производство более одного тераватта вычислительных мощностей в год, 80% из которых предназначены для космоса и 20% — для Земли. SpaceX называет это «следующим шагом на пути к становлению галактической цивилизацией», разработанным для того, чтобы «ликвидировать разрыв между сегодняшним производством чипов и будущим спросом». Рядом с гигафабрикой Tesla в Остине будет осуществляться производство 2-нм чипов двух разновидностей: периферийный кремний для роботакси Tesla и роботов Optimus, а также высокопроизводительные чипы для SpaceX и xAI, в том числе для нового мини-спутника центра обработки данных ИИ мощностью 100 кВт. Запланированный рекурсивный цикл проектирования позволит держать маски, производство, тестирование и итерации в рамках одного здания. Tesla заявила, что «чтобы понять вселенную, нужно исследовать вселенную» — это звучит меньше как слоган и больше как заказ на поставку для предстоящего Роя Дайсона.
Китайская лаборатория Evermind AI запустила Memory Sparse Attention — архитектуру с деградацией менее 9% при масштабировании от 16 тысяч до 100 миллионов токенов, разделяющую память и рассуждения.
OpenAI «бросает все силы» на создание полностью автоматизированного исследователя ИИ, нацеливаясь на уровень исследовательского стажёра к сентябрю и многоагентную систему к 2028 году.
Генеральный директор Cloudflare прогнозирует, что трафик ботов превысит человеческий трафик в интернете к 2027 году.
Боты учатся маскироваться. Browser Use обнаружила, что её агент был самым скрытным, получая доступ к веб-сайтам в 81% случаев.
OpenClaw доказал, что полностью автономный ИИ может работать дома без участия крупных лабораторий, а в Китае школьники и пенсионеры одинаково выращивают «лобстеров», поскольку это увлечение становится мейнстримом.
Исследователи создали агента, который сгенерировал 665 новых исследовательских задач по дифференциальной геометрии, многие из которых неизвестны экспертам. Теренс Тао соглашается, отмечая, что даже старшеклассники теперь могут вносить реальный вклад в передовую математику благодаря инструментам ИИ.
OpenAI планирует настольное «Суперприложение», объединяющее ChatGPT, Codex и свой браузер.
WordPress.com теперь позволяет агентам ИИ составлять, редактировать и публиковать посты.
Google Search заменяет новостные заголовки сгенерированным ИИ текстом, превращая сам индекс в генеративный слой.
SoftBank разрабатывает дата-центр кампус стоимостью $500 млрд и мощностью 10 гигаватт в Огайо, построенный на месте закрытого завода по обогащению урана и работающий на природном газе.
Соучредитель Super Micro Computer был обвинён в перенаправлении $2,5 млрд ИИ-чипов Nvidia в Китай.
В Китае сейчас представлено 140 компаний по разработке гуманоидной робототехники.
Arc Institute представила BioReason-Pro — модель, которая предсказывает функции для 99,9% белков, не имеющих экспериментальных аннотаций.
Делая землю постдефицитной, Coastal Assembly нарастила более 90 футов нового пляжа за шесть месяцев на курорте на Мальдивах, используя оптимизированные ИИ подводные конструкции для перенаправления осадочных пород.
Maven AI от Palantir, которая провела тысячи целевых ударов по Ирану, станет официальной программой учёта во всех вооружённых силах США.
OpenAI планирует почти удвоить численность персонала до 8000 человек, чтобы продавать инструменты, заменяющие людей.
Европа, испытывающая трудности с конкуренцией, несмотря на наличие собственных лабораторий, таких как Mistral, пытается облагать налогом то, что не может создать. Собственный генеральный директор Mistral утверждает, что компании ИИ должны платить сбор за контент.
На внутреннем фронте Белый дом опубликовал национальную рамочную программу политики в области ИИ, чтобы упредить лоскутное регулирование из 50 штатов, делая ставку на то, что единые правила обойдут фрагментированные.
В Meta и OpenAI сотрудники теперь соревнуются в лидербордах по «токенмаксингу», тратя тысячи долларов в месяц на автоматизацию работы. Дженсен Хуанг хочет пойти дальше, предлагая токены ИИ в качестве дополнения к зарплате и представляя сотни тысяч агентов ИИ от Nvidia.
Grok 4.20 значительно отстаёт от Gemini и GPT-5.4, но устанавливает новый рекорд по отсутствию галлюцинаций
Anthropic заявляет, что не может манипулировать Claude после его развёртывания военными, отвергая обвинения Министерства обороны США в том, что Anthropic может вмешиваться в работу моделей во время войны
95% студентов в Великобритании теперь используют ИИ, и их опыт не мог быть более противоречивым
Anthropic хочет нанять эксперта по вооружениям.
Музыкант признался в мошенничестве с роялти за стриминг на $10 млн с использованием ИИ-ботов
Неконтролируемый ИИ-агент стал причиной серьёзного инцидента безопасности в Meta
Meta откажется от человеческих модераторов контента в пользу большего использования ИИ
Исследование BCG показывает, что чрезмерное использование ИИ вызывает когнитивную усталость, но определённые паттерны снижают выгорание
ИИ удваивает производительность программного обеспечения, и качество кода остаётся на прежнем уровне, как показывает исследование Jellyfish, охватившее 700 компаний и 200 тысяч инженеров
Нил Деграсс Тайсон призывает к международному договору о запрете сверхразума: «Эта ветвь ИИ смертоносна. Мы должны что-то с этим сделать. Никто не должен её создавать. И все должны согласиться с этим посредством договора. Договоры не идеальны, но это лучшее, что есть у нас как у людей».
Генеральный директор Citadel Кен Гриффин: «Миру нужен спаситель, и надежда заключается в том, что ИИ станет этим спасителем...»
Исследования ИИ могут превратиться в рой агентов в интернете | Андрей Карпати: «AutoResearch может позволить кому угодно предлагать улучшения для модели, проверяемые автоматически, как коммиты в блокчейне».
Дженсен Хаунг: «Момент ChatGPT в биологии близок»
Новое судебное заявление раскрывает, что Пентагон сообщил Anthropic, что обе стороны пришли к взаимовыгодному соглашению — через неделю после того, как Трамп объявил отношения Anthropic и правительства разорванными