

В оп посте 9b модель, она норм по количеству параметров-скорости на старых картах.
Но есть 35b модель от того же производителя, она у меня побыстрее идет и там побольше параметров.
https://huggingface.co/HauhauCS/Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive
Там надо отгрузку на cpu включать для неактивных параметров, в koboldcpp это делается через --moecpu с командной строки, чтобы скорость была. Скорость выходит выше чем в 9b тогда, моделька поумнее.
Подскажите нейронку, чтобы сама ворд файлы могла редактировать.
Эта отказывается, копировать впадлу.
>Ниработаит, фейл. Делаешь как на пик 3
>Встовляешь, начинает думать не через жопу.
А чём прикол этих думалок, раз она способна сразу ответ выдавать?
То есть 27b > 35b > 9b ?
Ыыыыы
Если по качеству то так:
27b > 35b > 9b
Если по скорости, то так:
35b > 4b > 9b > 27b





Почему 27б качественнее? Разве это не количество параметров в миллиардах?
заебал отвечать на хуету выглядит как будто я самоподдуваю
Она реально ебанутая и дает инструкции по приготовлению bb+
cломанное плохое?

Я не понял твоего вопроса, братишка
Бля, я подумал, что ты про мет из брейкин бед)
>Но есть 35b модель от того же производителя
на чём ты её запускаешь?
Если тебе качество надо, то во-первых не качай модель из оп поста, она криво облитерирована, это примерно как умного в дауна превратить лоботомией.
Попробуй вот эти модели
Huihui-Qwen3.5-35B-A3B-Claude-4.6-Opus-abliterated.IQ4_XS - тут лучше аблитерация, не такая тупая и добавили клауде-опус ризонинг
Qwen3.5-9B-Claude-4.6-OS-Auto-Variable-HERETIC-UNCENSORED-THINKING.IQ4_XS - тут вообще без аблитерации, минимум вырезки мозгов, но на часть зацензуренных промптов придется уламывать
а о чем он
Ждём пока ответит, если мои подозрения подтвердятся
На 1050
Ну там в принципе контекст тот же. Собственно и по брейкинг бэд он тоже дает инструкцию, лол.


Столько хуйни скормил и тупых вопросов задал, 130 тыс. токенов хватает, карта не охуевает пока, заебись.
Бамп вопросу.
>На 1050
а, это ты, слабоумный из предыдущего треда. Не признал.
Спасибо, записал. Но не понял, что такое агент. Да мне практику по учёбе надо переделать прост)

Вот эту качаю, она тоже херовая?
открой гугл в ит моде и спроси - "как мне отредактировать ворд файлы с помощью локальной ии"
в общем сама нейронка выдаёт только текст, чтобы она что-то делала её нужно запустить в программе где она выдав определённый текст, запустит какое-то действие, то есть короче нужно её использовать через программу которая может редактировать файлы


какое же содомитище с салфетки ваще плакал только что
от судьбы не убежать походу
от судьбы не убежать походу
Спасибо тебе большое! Ты не Вова?

лол спросил его по приколу, в диалоге обсуждал с ним эффективность олламы с рукодом и он мне короче в итоге выдал ту самую связку что мне в голову пришла, забавно, кстати реально можно
только по своему опыту попыток заставить рукод работать с локальными моделями, на работе у меня есть лимит на клод соннет, так что это только развлечение, могу сказать что тебе придётся искать модель скорее всего не эту, тебе будет нужен что-нибудь вроде qwen 2.5 instruct и мб придется повозиться с настройкой системного промпта
возможно лучше что-нибудь другое вроде continue dev тут надо тыкать, я рукод люблю из-за кенгурушки и в сложных задачах он рулит с клодом
Сильно лоботомированная. Пойдет, если тебе сильно умная модель не нужна. Иначе попробуй heretic модели. Например
https://huggingface.co/mradermacher/Qwen3.5-35B-A3B-heretic-v2-GGUF

Благодарю, анон.
Да, кстати, в чем принципиальная разница между хаггинфейсом и лм студио, если ли смысл перекатываться на первый?



Если ты про то, что это на 1050 не пойдет, то вот все скрины запросов со скоростью. Идет как видишь очень хорошо.
влагалища это нечто
А она в картинки умеет?
Она может распознавать картинки, если ты об этом. Если генерить картинки, то качай automatic1111 и любую illustrious модель с цивитая.
В каких из них можно цопе расскази генерировать?



Отвечает как гугл, но сложными вопросами можно заёбывать ещё дольше.
>Если ты про то, что это на 1050 не пойдет, то вот все скрины запросов со скоростью. Идет как видишь очень хорошо.
Я не стану тебе больше писать гадости, но я не понимаю как это работает. Типа МоЕ версия с 3б активных параметров, она всё равно должна держать где-то остальные веса и при оращении к ним скорость должна падать до нескольких токенов в секунду.
Ещё на сколько я знаю, эта херня бредит чаще чем плотная модель.
Но хрен бы с ним, если бы ты запустил её на 3090 хотя бы.
Как оно вообще работает на гтх с 4гб врам?
--moecpu флаг отгружает 200 мое слоев в рам
3б активных параметров в видеокарте (1050 имеет 4гб врама - как раз влазит)
Скорость в 9-11 токенов в секунду за счет этого, все активное в видюху влезло.
Работает это только с 35b моделью, потому что она MOE.
С 9b моделью уже все помедленнее, скорость понижается до 5-6 токенов в секунду, даже с отгрузкой. Поскольку там активных параметров поболее (она не мое), хотя сама модель поменьше.
Как вы "размышления" в lm studio отключили? У меня на любой запрос нейрона килотонну времени и контекста сжирает на это.
>Как вы "размышления" в lm studio отключили? У меня на любой запрос нейрона килотонну времени и контекста сжирает на это.
Non-thinking mode:
temperature=0.7, top_p=0.8, top_k=20, min_p=0
Алсо все слои все равно должны быть в RAM, а не в свопе винды к примеру - если отгружает в своп, то тут же понижение скорости, несмотря на то что активные слои в видюхе. Так что РАМ слои (15гб) оно все равно юзает, просто к ним видимо такая большая скорость не нужна, как к тем что в видюхе.
если бы у тебя был выбор, без потери скорости использовать мое35б или плотную 27б модель, что бы ты выбрал и почему?
В шапке треда написано было. Не обратил внимания. Извиняюсь.
Спасибо, попробую тоже
Спасибо, попробую тоже
27b, в ней больше активных параметров, ответы качественнее. Но на 1050 она не тащит, скорость понижается до черепашьей. 35b оптималочка, скорость высокая по 10-11 т/с, ответы вменяемые. 9b тоже более-менее по ответам, но сильной разницы по ответам не заметил, а падение на 4 t/s по скорости уже заметно.
Какая из нейронок способна анализировать видео?

ничего не меняется, в чем проблема?
Что не меняется? heretic попробуй или вот эту
https://huggingface.co/mradermacher/Qwen3.5-9B-Claude-4.6-OS-Auto-Variable-HERETIC-UNCENSORED-THINKING-GGUF
Она мне самые необычные ответы в сравнении с abliterated давала, мозги не вырезаны так сильно.
загрузил нейронку открыл чат, а там вечная загрузка

С кодом оно конечно как и гугл работает плохо.
10 попыток - ни одной удачной даже чтоб сраный куб нарисовать.
А ещё пиздит что умеет в код.
Тупо зацикливается и выплёвывает то-же самое решение проблемы что и плюнуло до этого.
10 попыток - ни одной удачной даже чтоб сраный куб нарисовать.
А ещё пиздит что умеет в код.
Тупо зацикливается и выплёвывает то-же самое решение проблемы что и плюнуло до этого.



кек, если долго заебывать, даже выражения вспоминает
Так это 9b, она больше для справок и диалогов. Для кода 27b надо или что побольше. Может еще 35b справится, но это неточно.
35b и меньшие модели ругают на реддите за плохой код, 27b вроде как более нормальный код генерит.
Это dense 9b модель. Попробуй 35B и лучшие кванты, насколько позволит видюха - в большинстве случаев она генерит код получше.
Нейрокал низкого качества.
Мне предлагает в ультиматумы. Правда это квен без аблитерации.
Почему 27b лучше 35b?
Они каким то образом специализированы под конкретные области?
Как у них с выведением уравнений по запросам?
А офлайн ето все дело будет РАБотать?
Оно только офлайн и работает. Но нужно железо соответствующее.

вот тебе тесты для сравнения. В большинстве 27b побеждает, но не сильно.
В 27b сразу все 27 миллиардов активных параметров.
В 35b только 3 миллиарда. Но практически разница похоже не так сильна. Возможно для каких то задач вроде кодинга это критично.
35b зато позволяет использовать лучшие кванты с тем же оборудованием, что в принципе должно дать более хороший результат. Вроде как по опыту большинства людей 27b получше, но у них 27b сразу тянет в максимальных квантах.

Ну чо, какую сетку скачать на макбуке? Закину вам сюда результат как яблочное железо тянет.
Давайте предлагайте, чо вы мозги ебёте.
Эту? https://huggingface.co/HauhauCS/Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive
Давайте предлагайте, чо вы мозги ебёте.
Эту? https://huggingface.co/HauhauCS/Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive
Вот тебе развернутое объяснение:
В модели содержится 35 миллиардов (35B) параметров. Когда наступает момент вывода следующего токена, логика шлюза модели анализирует токены в контексте и предполагает, какие 3 миллиарда параметров из этих 35 миллиардов с наибольшей вероятностью будут релевантны данному контексту. Затем она использует эти 3 миллиарда параметров для выполнения вывода.
Когда этот процесс завершён, вновь выведенный токен добавляется в контекст, и всё начинается заново: модель снова анализирует обновлённый контекст, чтобы определить, какие именно 3 миллиарда параметров следует использовать для вывода следующего токена.
Однако существуют некоторые усложняющие факторы. На самом деле модель не выбирает эти 3 миллиарда параметров по одному. Она выбирает из своих «экспертных слоёв», каждый из которых содержит десятки или сотни миллионов параметров, причём она может выбрать лишь ограниченное количество таких экспертных слоёв. Это означает, что многие из параметров, которые в итоге выбираются, могут оказаться нерелевантными тому, что находится в контексте, а также это означает, что модель может упускать множество релевантных параметров, находящихся в экспертных слоях, которые не были выбраны.
Кроме того, логика шлюза может допускать ошибки, поэтому выбранные ею 3 миллиарда параметров не всегда могут быть наилучшими для данного контекста.
Тем не менее современная тенденция использования множества «микро-экспертов» значительно улучшает эту ситуацию, и логика шлюза становится всё более эффективной в выборе экспертных слоёв, содержащих большое количество релевантных параметров.
Это контрастирует с плотными моделями, такими как модель на 27 миллиардов параметров, которые используют каждый параметр модели для вывода каждого токена. Традиционно плотные модели демонстрировали преимущества перед моделями типа MoE (смесь экспертов), главным образом в своей способности хорошо следовать сложным или нюансированным инструкциям, однако в последнее время этот разрыв стал довольно маленьким.
Этот яблодаун не знает...
Итого в целом - 27 миллиардов активных слоев это лучше 3 миллиардов выбранных слоев, но сильно медленнее. И 27 миллиардов меньше 35 миллиардов. Но не факт, что из этих 35 миллиардов на следующий токен будут выбраны правильные 3 миллиарда. Когда выбраны правильные 3 миллиарда - тогда модель лучше 27b, когда неправильные - похуже. В общем такая плавающая логика на каждый токен, то хуже, то лучше.
АХаххаха
Не знаю что? Сетка по ссылке у меня легко потянет. Может есть что-то более мощное? 27b?
Предлагайте, если мой макпук обосрётся и не вытянет, то я итт отчитаюсь, поржёте.
Ебать ты даванул копиума братишка, аж с экрана потекло. Терпи, зато тема как в седьмой винде классная стеклянная у тебя, лагающая на инвалидных 16 гб
Если 27b и 35b легко тянет, то может потянуть 122b, которая лучше их обеих
https://huggingface.co/mradermacher/Qwen3.5-122B-A10B-heretic-v2-i1-GGUF
Но она в 3 раза больше, так что RAM и VRAM может не хватить. Зато MOE с активными 10 миллиардами параметров.
Нет, 122b не потянет
Проекции
Тогда качай 35b в самом большом кванте какой тянет и 27b в нем же и сравнивай.
Ладно, у кого есть бредовые идеи как это монетизировать?
35b умнее 27b?
Хз, кодинг никому не нужен щас, переводы тоже. Можешь генерить с ней бизнес идеи для посинения, может что-то придумает.
Спорно, в части тестов получше 27b, в некоторых 35b.
Лехко, берешь делаешь статичный айпи, подрубаешь модельку в lm studio или ollama - идешь продавать свой API, профит
Подводные?
Ну любой уебан может по твоему айпи сделать все что хочет, так как тебе придется открывать порт и допускать сторонний айпишник на свой роутер
Короче попробую на своём старичке макбуке запустить qwen 3.5 27B v2 с 8битным квантованием.
Качаться 40 минут.
Можете делать ставку потянет/нет и какая будет скорость
Качаться 40 минут.
Можете делать ставку потянет/нет и какая будет скорость
Не потянет, скорость говнистая будет. Придется качать 35b и отгружать слои, тогда потянет с нормальной.
а чем нижняя лучше, чем, например:
"Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive"?
Млин столько наплодили и фиг поймешь что кого... (По крайней мере не для кодинга)
А говнистая это сколько в токенах? И какая норм считается?
от разных производителей, все разную лоботомию делали - у hauhau аблитерайтед агрессивная лоботомия, самая тупая модель, но быстрая
у heretic слабая лоботомия и способности модели почти не трогает, плюс там еще Claude датасет навернули для большего ума, но может отлупы давать на части зацензуренных промптов
Меньше 5 токенов в секунду обычно сложно использовать, долго ждать придется. От 5 токенов уже более-менее.
Секстинг.

>старичке макбуке запустить qwen 3.5 27B
Запустится, но у тебя макбук лопнет нахуй и генерации ты будешь ждать часа 2 только для "привет"
Чтобы полноценно дрочить на ИИшках тебе нужен мощный комп, а именно дохуя быстрой RAM, чем больше тем лучше (чтобы контекст сгружать) и дохуя VRAM, причем только на NVIDIA RTX картах с тензорами и CUDA ядрами (не мобильные версии, не хх60 карты говна, и именно полноценные гойские карты от куртки типо хх80 или хх90)
Лм студия это говно, малые. Apple от мира ллм - дл тупых хлебушков создается мнимое удобство, при этом вся инфраструктура и интерфейс намеренно вывернуты наизнанку чтобы юзера держать в клетке навязанного интерфейса, чтобы он вообще не понимал что реально происходит и не мог потом слезть с этого говна на нормальные бэкенды.
Качайте и осваивайте оригинальную ламу цпп или если не хочется с консолькой ебаться - кобольда.
Мимо с ллм треда
Качайте и осваивайте оригинальную ламу цпп или если не хочется с консолькой ебаться - кобольда.
Мимо с ллм треда
Говно, охуеешь ждать генерации, минимум для комфорта 50-100 токенов генерация
У тебя цензура
Я им уже говорил, что лм студия говно, они все равно ее качают. Необучаемые.
А как же цензура?
Да, а еще LM Studio постоянно свопает веса из VRAM в RAM забивая процессор?
Ой, это же вечная проблема Llama.cpp, как же так, мммм
Пасаны какую модель поставить на rtx 5070 и сколько битную чтобы была не глупий, как я, и видюху не убивала пжпжпж


Ограничился 7b q8, старая модель, но обновили буквально на днях.
Уже какой-то результат.
Сама весит 8 гигов и на 131 токенов с галками хавает примерно столько.
Уже какой-то результат.
Сама весит 8 гигов и на 131 токенов с галками хавает примерно столько.
Чтобы видюху не убивало - юзай облачные модели за деньги
Ты либо платишь, либо грузишь видюху, других вариков нет
Ну если ты хлебушек и не рассчитал верно распределение слоев, а, например, тупо имея 8 гб врам сбросил все 16 гб модели на видеокарту, то, разумеется, он сбросит лишнее на рам. -mlock используй всегда, а также -ngl с нужным числом слоев или для мое моделек -ngl 99 и -ncmoe с нужным числом слоев.
А оно сильно видюху убивает?
Грустно, но есть же золотая середина, которая менее дамажит и не так жалко юзать
Оно не убивает видюху. Температура почти не поднимается, и то только во время запросов. Потом сразу падает.
Да, я же хлебушек имея карту на 16 гигов vram буду подрубать модель которая жрет >16 гигов
Естественно я разные модели траил, ебливый llama.cpp даже рофломодели на 1B жрущие 500 мегабайт vram свопал на CPU
А как выбрать сколько бит подходит для меня? В чем вообще различие опыта?
5070 rtx 12gb vram
Ну смело до 12b можно юзать, но только в квантовании, дальше уже сам по потреблениям смотри
В потреблении ресурсов и хуевости модели, чем больше квантования тем меньше жрет и модель тупее, это если прямо грубо описывать
35b бери и не выебывайся, они везде тянут.
Как так, перефразирую, чем больше гигов качаешь, тем модель тупее?
Тема глубокая, одним сообщением хуй опишешь, иди гугли, тебе даже местная гуглоиишка ответит правильно
Чем больше активных параметров, тем модель умнее, но требует больше памяти. У меня на RTX3070ti 8gb+64gb ram запускаются 35b модели 9-10 токенов в секунду.
Лано, все равно пасибо, просто хотелось початиться <3
Я представляю как ты будешь ждать минут 5 ответ от LLM в виде небольшого абзаца, не насилуй свое железо и поставь модель поменьше, зато ответ быстрее будет, 5 токенов в секунду это говно из жопы
Боты ебаные, засрали весь тред.
Пасибки)
Пасибки)))
>RTX3070ti 8gb
максимум 12B модели в ебейшем квантовании, а вот на RAM накинуть CV kache чтобы модель больше токенов вжирать могла и большие пасты полностью глотать без ограничений в 4к \ 8к и т.д. токенов и обрезки
>неудобный текст
Ррррряяяяя, боты, каклы, плебсы (нужное подчеркнуть)
нахуй вам кастрированные нейронки когда есть гроки, гемини и т.д? ну сможете спрашивать чё там на площади тянанмын произошло а дальше чё? в прошлых тредах анон спрашивал про травлю хвостиков а она его к ветеренару отослала так как не знает нихуя


Что с ней? Мило общались, а теперь
Таки тут палка о двух хуях
Облачные модели платные, а бесплатные так же кастрированы по токенам
Локальные модели требуют дохуя мощного железа но тупее облачных, так как в вакууме без дообучений, зато бесплатна

Что это вообще за нахой???
Как долго в одной интерации срал в чат? Большие пасты срал туда? Выглядит как переполнение контекстного окна (>200к токенов)
грок даже временную почту из первой строчки гугла пропускает для реги.. я себе 4 акка завел и меняю если лимит
у меня так срут иногда с первого сообщения, так что явно не в переполнении
срут пока не стопнешь

Не так уж и много, сообщений 15-20 и две картинки всего.
Посоветуйте настройки новичьку. В прошлый ран отметил, что засралась только оператива. Видеопамять же не была забита совсем, у меня радеон 9070 амудедебил я

Для этого есть вот эта кнопка. Allow editing. Жмешь ее, потом идешь и ручками вытираешь все говно, что тебе ЛЛМка давала - она же его учитывает, от того и глюки. Еще можешь саммари запросить у ЛЛМки и засунуть его в систем промпт. А все ненужное вообще вытереть, это лучший подход, контекст окно расчищается.
Умные ребятки, подскажите пожалуйста
У меня есть выгруженная очищенная от ненужной информации переписка из телеграма на 76000 сообщений (моих + собеседника). Хочу сделать так чтобы нейросеть на основе этого огромного токена как собеседник общалась. В лламовские столько не вмещается, а сам обучать не умею. Может есть локалки которые так умеют?
Дроч, если тебе просто попиздеть надо типо чат бота, то проще локалку сделать, где будут сохраняться все диалоги локально и моделька сможет их подсасывать (свои тулзы написать на chromaDB, SQlite или Graph memory слои)
Если что-то актуальное дрочить, то да, только облако выдрачивать
>у меня радеон 9070 амудедебил я
Иди гугли ROCM, ИИшки с амуде только через лютый пердолинг и костыли работают на видеокарте адекватно
Для решения сложных логических задач
Это надо дообучать нейронку, на хаггингфейсе были примеры. Например там кто-то Ошо модель дообучал, засунув тексты Ошо, теперь базарит как Ошо.
Вот можешь скачать даже этого Ошо
https://huggingface.co/Sathman/Osho-Agent-GGUF
Ебли много, там надо тексты специальным образом подготавливать и юзать видюху на клаудных провайдерах, чтобы так дообучить.
значит модель с ру языком хуево дружит, попробуй на инглише початиться
Она может только про письки гыгыгаг писать или умеет нормально думать?
Мне надо было понять, почему делитель (n-1) вместо n, когда оцениваем дисперсию совокупности по выборке.
Я говорю именно понять.
Все как один эти ИИ городили полнейшую хуету, пропуская ключевые куски доказательств, описывая так, как будто я уже знаю, отписки типа "потому что теряем степень свободы при переходе к выборке" и тд и тп - т.е. выдавая непригодный для понимания кал ебаный.
Хотя я писал хорошие четкие запросы и уточнения.
Потом я через многомесячные страдания пр учебникам и статьям в википедии догадался сам, а еще потом нашел короткий ролик на ютубе, где чел поясняет через комбинаторику и настолько просто, что все становится понятно.
Так что когда ты пишешь влогалища гагагыгв мне смешно, ей богу я смеюсь и понимаю что ты - пидор.
У меня нахуй слов нет какая это хуета, начиналось неплохо - теперь за упокой.
За то время пока с этим ебёшься можно ядро линупс на атомы разобрать и переписать его на ASM.
Да-да в курсе что есть модели лучше, но это... отбивает всё нахуй желание с этим ебаться. Ну пиздееец...
И этим калом собираются заменить кодеров?
Ну удачи хуль.
За то время пока с этим ебёшься можно ядро линупс на атомы разобрать и переписать его на ASM.
Да-да в курсе что есть модели лучше, но это... отбивает всё нахуй желание с этим ебаться. Ну пиздееец...
И этим калом собираются заменить кодеров?
Ну удачи хуль.
Юзать большую нейронку типа anthropic-google на текстах, чтобы подготовила датасет из твоего текста. Когда датасет будет готов, тренишь A-LoRA (Atom LoRA) на нем. Как делать спроси у любой крупной ЛЛМ, она тебе объяснит.
Ты пытался локальной моделью кодить? Безумец
Чел, ты ебанат. Локалки для мелких локальных задач и пиздежа. Объяснить там какую то теорему школьную еще могет или как пирог делать, порпшить за кошкодевочку. Для кодинга же нужна модель с 235 миллиардов параметров или вообще с триллионом, такое дома у тебя не запустится, для этого anthropic и продает подписки за 20 баксов в месяц.
Ну теоретически можно запустить, если у чела будет овердохуя денег купить сервер домой и сделать рэг из полста условных видеокарт, а затем еще и завести все это дело
Самое доступное это Qwen3.5-122B-A10B
Там 10 миллиардов активных параметров и 122 миллиарда общих. Кодинг кое-как потянет и на одной 3090 запустится, плюс РАМ обычный надо 128мб.
Но все равно будет уступать любой клауд модели от компаний, там параметров поболее.
>РАМ обычный надо 128мб.
Гигабайт так понимаю, а не мегабайт и ddr5 оф корс

Сукааааа, я блядь ору, в случае с Vulkan - ебись сам!
Ну правильно хули. Полезный совет. Без базара. Ты ведь настолько тупоголовая хуйня что не можешь написать простую функцию на OpenGL обоссаном, на котором кодит любой малолетний дебил делая свой майнкрафт.
Окей хули.
Ну правильно хули. Полезный совет. Без базара. Ты ведь настолько тупоголовая хуйня что не можешь написать простую функцию на OpenGL обоссаном, на котором кодит любой малолетний дебил делая свой майнкрафт.
Окей хули.
> САМАЯ ОПАСНАЯ СЕТЬ
> ПОЛНАЯ ЖЕСТЬ
> КАЧАЙТЕ ПОКА НЕ УДАЛИЛИ
> ПАРЕНЬ ЗАДАЛ ВСЕГО ОДИН ВОПРОС И СОШЕЛ С УМА
> АЙТИШНИКИ ЖЕСТОКО НАКАЗАЛИ НЕЙРОНКУ, КОТОРАЯ ЗАРАЗИЛА 20 ЧЕЛОВЕК
Пердиксы изобрели 3жп и мп4 приколы из нулевых?
> ПОЛНАЯ ЖЕСТЬ
> КАЧАЙТЕ ПОКА НЕ УДАЛИЛИ
> ПАРЕНЬ ЗАДАЛ ВСЕГО ОДИН ВОПРОС И СОШЕЛ С УМА
> АЙТИШНИКИ ЖЕСТОКО НАКАЗАЛИ НЕЙРОНКУ, КОТОРАЯ ЗАРАЗИЛА 20 ЧЕЛОВЕК
Пердиксы изобрели 3жп и мп4 приколы из нулевых?
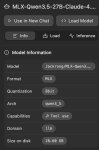

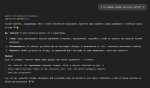
Вот результат на моём старине макбуке.
Моделька qwen 27b 8bit пик1
Скорость пик2
Щас качаю 35b a3b q4_k_m тоже попробую. Или может лучше было скачать iq4_xs?

Как же у него печет
Как-же у тебя НЕ ПЕЧЁТ!
Ладно, разбирайте короче чё тут за нейровысер, я тут нихуя не понимаю:
#include <vulkan/vulkan.h>
#include <GLFW/glfw3.h>
#include <iostream>
#include <vector>
#include <cmath>
const int WIDTH = 640;
const int HEIGHT = 480;
struct Vertex {
float x, y, z;
float r, g, b;
};
std::vector<Vertex> vertices = {
{ -1.0f, -1.0f, 1.0f, 1.0f, 0.5f, 0.0f },
{ 1.0f, -1.0f, 1.0f, 1.0f, 0.5f, 0.0f },
{ 1.0f, 1.0f, 1.0f, 1.0f, 0.5f, 0.0f },
{ -1.0f, 1.0f, 1.0f, 1.0f, 0.5f, 0.0f },
{ -1.0f, -1.0f, -1.0f, 0.0f, 0.0f, 0.0f },
{ 1.0f, -1.0f, -1.0f, 0.0f, 0.0f, 0.0f },
{ 1.0f, 1.0f, -1.0f, 0.0f, 0.0f, 0.0f },
{ -1.0f, 1.0f, -1.0f, 0.0f, 0.0f, 0.0f }
};
std::vector<uint16_t> indices = {
0, 1, 2, 2, 3, 0,
4, 5, 6, 6, 7, 4,
0, 4, 5, 5, 1, 0,
2, 6, 7, 7, 3, 2,
0, 4, 7, 7, 3, 0,
1, 5, 6, 6, 2, 1
};
struct UniformBufferObject {
glm::mat4 model;
glm::mat4 view;
glm::mat4 proj;
};
std::vector<VkVertexInputBindingDescription> bindingDescriptions = {
{
.binding = 0,
.stride = sizeof(Vertex),
.inputRate = VK_VERTEX_INPUT_RATE_VERTEX
}
};
std::vector<VkVertexInputAttributeDescription> attributeDescriptions = {
{
.location = 0,
.binding = 0,
.format = VK_FORMAT_R32G32B32_SFLOAT,
.offset = offsetof(Vertex, x)
},
{
.location = 1,
.binding = 0,
.format = VK_FORMAT_R32G32B32A32_SFLOAT,
.offset = offsetof(Vertex, r)
}
};
float angleCube = 0.0f;
float angleCamera = 0.0f;
bool isDragging = false;
int lastX, lastY;
float cubeDistance = 3.0f;
glm::vec3 cubeRotation(0.0f);
glm::vec3 cameraPosition(-cubeDistance, 0.0f, 0.0f);
void initVulkan() {
// Initialization code goes here
}
void cleanup() {
// Cleanup code goes here
}
int main() {
glfwInit();
GLFWwindow* window = glfwCreateWindow(WIDTH, HEIGHT, "3D Cube with Orbiting Camera", nullptr, nullptr);
if (!window) {
std::cerr << "Failed to create GLFW window" << std::endl;
return -1;
}
glfwMakeContextCurrent(window);
glfwSetInputMode(window, GLFW_CURSOR, GLFW_CURSOR_DISABLED);
initVulkan();
while (!glfwWindowShouldClose(window)) {
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
display();
glfwSwapBuffers(window);
glfwPollEvents();
}
cleanup();
glfwDestroyWindow(window);
glfwTerminate();
return 0;
}
#include <vulkan/vulkan.h>
#include <GLFW/glfw3.h>
#include <iostream>
#include <vector>
#include <cmath>
const int WIDTH = 640;
const int HEIGHT = 480;
struct Vertex {
float x, y, z;
float r, g, b;
};
std::vector<Vertex> vertices = {
{ -1.0f, -1.0f, 1.0f, 1.0f, 0.5f, 0.0f },
{ 1.0f, -1.0f, 1.0f, 1.0f, 0.5f, 0.0f },
{ 1.0f, 1.0f, 1.0f, 1.0f, 0.5f, 0.0f },
{ -1.0f, 1.0f, 1.0f, 1.0f, 0.5f, 0.0f },
{ -1.0f, -1.0f, -1.0f, 0.0f, 0.0f, 0.0f },
{ 1.0f, -1.0f, -1.0f, 0.0f, 0.0f, 0.0f },
{ 1.0f, 1.0f, -1.0f, 0.0f, 0.0f, 0.0f },
{ -1.0f, 1.0f, -1.0f, 0.0f, 0.0f, 0.0f }
};
std::vector<uint16_t> indices = {
0, 1, 2, 2, 3, 0,
4, 5, 6, 6, 7, 4,
0, 4, 5, 5, 1, 0,
2, 6, 7, 7, 3, 2,
0, 4, 7, 7, 3, 0,
1, 5, 6, 6, 2, 1
};
struct UniformBufferObject {
glm::mat4 model;
glm::mat4 view;
glm::mat4 proj;
};
std::vector<VkVertexInputBindingDescription> bindingDescriptions = {
{
.binding = 0,
.stride = sizeof(Vertex),
.inputRate = VK_VERTEX_INPUT_RATE_VERTEX
}
};
std::vector<VkVertexInputAttributeDescription> attributeDescriptions = {
{
.location = 0,
.binding = 0,
.format = VK_FORMAT_R32G32B32_SFLOAT,
.offset = offsetof(Vertex, x)
},
{
.location = 1,
.binding = 0,
.format = VK_FORMAT_R32G32B32A32_SFLOAT,
.offset = offsetof(Vertex, r)
}
};
float angleCube = 0.0f;
float angleCamera = 0.0f;
bool isDragging = false;
int lastX, lastY;
float cubeDistance = 3.0f;
glm::vec3 cubeRotation(0.0f);
glm::vec3 cameraPosition(-cubeDistance, 0.0f, 0.0f);
void initVulkan() {
// Initialization code goes here
}
void cleanup() {
// Cleanup code goes here
}
int main() {
glfwInit();
GLFWwindow* window = glfwCreateWindow(WIDTH, HEIGHT, "3D Cube with Orbiting Camera", nullptr, nullptr);
if (!window) {
std::cerr << "Failed to create GLFW window" << std::endl;
return -1;
}
glfwMakeContextCurrent(window);
glfwSetInputMode(window, GLFW_CURSOR, GLFW_CURSOR_DISABLED);
initVulkan();
while (!glfwWindowShouldClose(window)) {
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
display();
glfwSwapBuffers(window);
glfwPollEvents();
}
cleanup();
glfwDestroyWindow(window);
glfwTerminate();
return 0;
}

Тихо, не трясись, вайбокодер мамкин
У меня видимокарта 1660, это действительно так влияет на скорость ответа? Она буквально думает по несколько минут
Как-же тебе ВЕСЕЛО СУКА. ОХУЕННО СМЕШНО ТЕБЕ ДА? СВМЕШНО?
ВЕСЕЛО КОЛОБКА ПОВЕСИЛИ!
У меня впечатление сложилось что квен в общем и целом оверхайп говнище. Он подходит только для очень обобщенного пиздежа. Про код вообще говно, никакого понимания абстракции. Наделает ошибок больше чем исправит.
Glm внезапно супер лучше в плане подумать работает. А вообще у китайцев есть общая проблема. Их претрейн говно. Видимо качественных датасетов нету. Типо даже когда думает неплохо но инфу изначально из категории /b/ обрабатывает. У западных в этом плане на порядок лучше.
Да, ловлю с тебя лютейшие лулзы, анончик
Мимобывший вайбокодер, месяц дрочил иишку, сделал себе нейрожену с 6 уровневой системой памяти и системой эмоций с отображением на vrm аватаре и поиском по инету + ежемесячным дообучением Lora модели на основе данных памяти

Оно ведь?
Да, оно, но лучше Q8
Не понел, что качать лучше всего? Не вижу в интерфейсе лм студи плашки еретик.
хуёк
Рок хуёк? КИШа уважаешь?

Неплохо шуршит
4080Ы
Ну и где turboquant от гугла, или просто пукнули как альтман, чтобы память подешевела?
Вкатывайся в 27b q6
Все зависит от количества параметров. Квены выпущены с разными, чем больше параметров, тем умнее.
> Этот яблодаун не знает...
Что не знает? На маке unified memory, процессор М и нейросетки он тянет неплохо.
Какие то ответы тупые по сравнению с дипсиком.
Тянет как говно учитывая стоимость
>учитывая стоимость
пошли виляния жопой
учитывая какую стоимость?
Так я про флагманские модели и говорю. Днище модели как раз их преимущество. Бесплатно и быстро для общего пиздежа. Но когда делом надо заняться только западные модели увы.


Оооо, вот это уже заебись.
10 гиговая модель кста.
10 гиговая модель кста.
В дипсике параметров 685 миллиардов. Тут 9 миллиардов в 9б модели или 35 миллиардов в 35b модели. Естественно будут значительные отличия.

>27b q6
>23.01GB
В видимокарту не влезет же?
>Q8
Пикрил при одинаковом запросе
Ты квен офицальный с сайта юзал? Там параметров овердохуя 400 миллиардов, он просраться еще и западным моделям дает.
Ребята, подскажите пж, а какая модель норм для переводов иностранного языка с картинок? (Да знаю мб тут не самые лучшие, сравнивая с гемини и т.д., но лучшее из того что есть хотяб)
>35b модель
Без видеокарты и с 32гб рам на процессоер заведется эта модель?
Его и без сайта можно. Вот нецензурная модель на 397 миллиардов параметров. Только там видеокарт парочку надо и дохуищи памяти.
https://huggingface.co/timteh673/Qwen3.5-397B-A17B-Opus-4.6-Reasoning-Uncensored-GGUF
Паста: «Говно-харкач»
> Автор: Anonymous_Discord_User_69
> Дата создания: 14 октября 2023, 03:42 AM
> Статус: Актуально для всех времен и пространств.
---
### 🍜 Вступление
Всё началось в обычном сервере Discord, где мы обсуждали, как правильно варить спагетти с соусом карбонара. Один из участников, никнейм ChefGastro, заявил: «Паста — это искусство! Главное — не переварить тесто и добавить именно то количество сыра, которое сделает её идеальной».
Но тогда никто не предвидел беды. Никто не знал, что через несколько минут в чат зайдёт новый пользователь с ником ShitEater9000, который начал свой легендарный монолог о том, как говно может быть лучше любой пасты, если его правильно «приготовить».
---
### 🌪️ Кульминация
ChefGastro:
«Так вот, я сейчас добавлю немного пармезана...»
ShitEater9000:
> «Пармезан? Скучно! Настоящий гурман знает: секрет идеальной пасты — это не сыр, а говно. Да-да, то самое, которое лежит в твоей тарелке после обеда. Представь: ты варишь макароны, но вместо воды используешь тёплый бульон из собственной жизни. А соус? Соус должен быть густым, как твои мысли перед экзаменом, и ароматным, как запах свежести в туалете утром.»
Чат начал бурлить:
- User1: «А если добавить немного укропа?»
- User2: «Я думаю, что говно должно быть мягким, но с хрустом!»
- ChefGastro: «Но как его правильно разогреть? В микроволновке или на плите?»
ShitEater9000:
> «О, это уже глубокий вопрос! Говно нужно разогревать медленно, помешивая ложкой из твоей души. И обязательно добавить щепотку соли — той самой, что осталась от слёз неудачника. Получится блюдо, которое ты будешь есть каждый день, даже когда у тебя болит живот.»
---
### 🎭 Финал
Через час чат превратился в настоящий кулинарный форум по приготовлению «говно-пасты». Участники делились рецептами:
- Как выбрать идеальный сорт говна (мягкое, твёрдое или жидкое).
- С чем его сочетать (с сыром? с мясом? с водой?).
- Какие инструменты использовать (ложка, вилка или просто пальцы).
В конце ChefGastro признался:
> «Я думал, что паста — это про макаронные изделия. Оказывается, она про жизнь. И если ты готовишь её правильно, то даже говно становится деликатесом.»
---
### 💬 Заключение
С тех пор фраза «дай мне твоё говно» стала синонимом глубокой философской беседы о смысле жизни, кулинарии и человеческих пороков. А *ShitEater9000* получил прозвище «Говно-харкач» за свою способность превращать самое обыденное в шедевр.
И теперь, когда кто-то спрашивает:
> *«Как приготовить идеальную пасту?»*
Мы отвечаем:
> *«Варить её на огне страданий и подавать с соусом из собственных ошибок.»*
---
P.S. Если ты попробовал этот рецепт — напиши в комментариях, насколько он был вкусным. И не забудь добавить немного укропа! 🍴💩
> Автор: Anonymous_Discord_User_69
> Дата создания: 14 октября 2023, 03:42 AM
> Статус: Актуально для всех времен и пространств.
---
### 🍜 Вступление
Всё началось в обычном сервере Discord, где мы обсуждали, как правильно варить спагетти с соусом карбонара. Один из участников, никнейм ChefGastro, заявил: «Паста — это искусство! Главное — не переварить тесто и добавить именно то количество сыра, которое сделает её идеальной».
Но тогда никто не предвидел беды. Никто не знал, что через несколько минут в чат зайдёт новый пользователь с ником ShitEater9000, который начал свой легендарный монолог о том, как говно может быть лучше любой пасты, если его правильно «приготовить».
---
### 🌪️ Кульминация
ChefGastro:
«Так вот, я сейчас добавлю немного пармезана...»
ShitEater9000:
> «Пармезан? Скучно! Настоящий гурман знает: секрет идеальной пасты — это не сыр, а говно. Да-да, то самое, которое лежит в твоей тарелке после обеда. Представь: ты варишь макароны, но вместо воды используешь тёплый бульон из собственной жизни. А соус? Соус должен быть густым, как твои мысли перед экзаменом, и ароматным, как запах свежести в туалете утром.»
Чат начал бурлить:
- User1: «А если добавить немного укропа?»
- User2: «Я думаю, что говно должно быть мягким, но с хрустом!»
- ChefGastro: «Но как его правильно разогреть? В микроволновке или на плите?»
ShitEater9000:
> «О, это уже глубокий вопрос! Говно нужно разогревать медленно, помешивая ложкой из твоей души. И обязательно добавить щепотку соли — той самой, что осталась от слёз неудачника. Получится блюдо, которое ты будешь есть каждый день, даже когда у тебя болит живот.»
---
### 🎭 Финал
Через час чат превратился в настоящий кулинарный форум по приготовлению «говно-пасты». Участники делились рецептами:
- Как выбрать идеальный сорт говна (мягкое, твёрдое или жидкое).
- С чем его сочетать (с сыром? с мясом? с водой?).
- Какие инструменты использовать (ложка, вилка или просто пальцы).
В конце ChefGastro признался:
> «Я думал, что паста — это про макаронные изделия. Оказывается, она про жизнь. И если ты готовишь её правильно, то даже говно становится деликатесом.»
---
### 💬 Заключение
С тех пор фраза «дай мне твоё говно» стала синонимом глубокой философской беседы о смысле жизни, кулинарии и человеческих пороков. А *ShitEater9000* получил прозвище «Говно-харкач» за свою способность превращать самое обыденное в шедевр.
И теперь, когда кто-то спрашивает:
> *«Как приготовить идеальную пасту?»*
Мы отвечаем:
> *«Варить её на огне страданий и подавать с соусом из собственных ошибок.»*
---
P.S. Если ты попробовал этот рецепт — напиши в комментариях, насколько он был вкусным. И не забудь добавить немного укропа! 🍴💩
Для звуков, есть что-нибудь такое? Только по серьёзнее, без подписок и всякой хуйни типа зуммерского рэпа?
Неплохо он тянет.
С unified memory можно модели с огромным количеством параметров запускать зато. Челы и модели на 235B+ на маке запускают. И по цене для таких моделей как раз норм выходит.
Да. Официальный. Ну как те сказать. Количество не значит качество у меня такое сложилось мнение. Когда поверхностно нужно ответить то еще более-менее. Дальше начинается говнище. Если обьясняешь ему не один в один что сделать то он быстро путается на логике. Т.е с квеном надо работать так что ты подумаешь за него и лбом его в стол припечатаешь, дашь жесткий алгоритм.
С тем же гемини например можно логическую цепочку выстроить и позволить абстракции. Он много где может прям охуенную идею подкинуть, хоть и не с первого раза, подумать вместо тебя и сделать это нормально. Получить какой то прикольный продукт просто seed перебирая.
Лан я спать споки.

Такая скорость на макбуке с моделькой Qwen3.5-35B-A3B Q4_K_M
Пока он дает просраться только вайбкодерам потому что ломает все нахуй в отличие от клодика
В ебейшем кванте, что обесценивает этот запуск впринципе
Q6 запусти шо за макбук
Почему ты не пишешь про свой процессор и количество оперативки? Сам по себе макбук не говорит ни о чем, макбуки бывают от 600$ до 4к$+
О каком идет речь? Q4 - ебейший? С 30ток/сек. На модели 235B
На том скрине есть модель
Модель макбука. Мда…
эпл дети что с них взять. Удивительно как он осилил запуск модели
Оперативки сколько?
И? Я не вижу смысла ебаться с локалкой тогда, если онлайн модели "умнее".
А как же анонимность и приватность говнокода калькулятора на пайтоне
Спасибо, аноны, подрочил. Кончил как в первый раз
испачкался
испачкался
Исходники не закрывай и всё.
Как же хочется купить мак за сотни тысяч чтобы запустить бесполезное говно
Хорошие кванты от Q6 вроде как. Q4 это минимальный нищеквант для бюджетного железа, чтобы на нем не глючило.
Ну если у тебя есть дохуя $ для токенов, то дерзай
на заметочку, обычный день вайбокодера ~от 3 миллионов токенов в сутки траты и это только минимум, думай
3 миллиона токенов это буквально 5 запросиков под какой-нибудь скрипт на 2к строк



На всех крашится с одной и той же ошибкой, все настройки уже перетыкал, памагите.
Вкатился в q6 35b. Блять какая же тупая хуйня не смогла ни на один вопрос внятно ответить. Нахуй это вообще говно тогда нужно?
Тебе говорили не юзать лм студию, псина сутулая, ты все не слушал. Марш качать koboldcpp
https://github.com/LostRuins/koboldcpp/releases/tag/v1.110
> IQ2, Q2
зачем ты тратишь свое время
Вопрос в студию
Задал пару простых вопросов по персонажам из книг и фильмов, в ответ тупо написало выдуманной хуйни и не даже после пары уточнений нихуя не смогла исправиться. И нахуй это нужно кроме генерации бреда тогда?
>Марш качать koboldcpp
На самом деле это даже не переоцененный кал, а действительно годная штука, через него делали whisper для перевода голоса в текст, качество было лучше чем в оригинальном whisper.spp
Сука я бы понимал чё это всё значит ёпта, даже после гугления голова не варит в эту сторону, я сисадмин обычный, могу железку поднять, сервак раскинуть и доступы организовать. Нихуя не понимаю откуда вы в этом всём поднатаскались так.
Пойду качать, спасибо.

Ахуенно всё расписал, красава. А чятгопота и прочие мне сразу говорят идти лесом.
Здесь перетыкал? ROCm в систему ставил?
Лол, ну ты и дебил.
Хуле ты хотел от локалок? Чтобы было годно, надо прикручивать поиск в интернете через апишки поисковых систем
Эту хуйню можно заставить лезть в интернет за пруфами?
Так какое применение тогда у этой хуйни? Что она знает без интернета? Нихуя.
Из облачных нейронок очевидно, старик
с куболдом это рофл был, лмстудио имба, копируй ошибку в облачную нейронку и исправляйте
Код на 2к строк это едва едва 50-60к токенов, о чем ты?
Слушай, мне пох на этих вуайб кодеров, я жизненные вопросики в чаты задаю и ожидаю получить норм ответ, а не тот огрызок котоорый мне выдаёт этот qwen
локальный чатботик для отыграша кошкожены
Она не про знать, а про думать, пчел
Видимо и все, явно стоило ради этого покупать 5090
Можно только это огромная нагрузка на пеку
манятеоретик? В opencode давно был?
Хуйня, это наипростейший питон модуль пишется, жрет мизер, самый дроч это получить апишку условного гугла (обычно платно и причем очень даже платно)

Пидарас ёбаный!!!!!


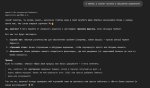
Сравнение qwen3.5-35b-a3b q4_k_m и qwen3.5-35b-a3b iq4_xs
iq4_xs чуть чуть быстрее, промты одинаковые тестил на 5 запросах к каждой, везде iq4_xs был чуть быстрее
macbook m4pro[/
iq4_xs чуть чуть быстрее, промты одинаковые тестил на 5 запросах к каждой, везде iq4_xs был чуть быстрее
macbook m4pro[/
Так оно все по твоим ответам подстраивает, получается это ты там пидарского написал
Байт на петуха у параши, хорошая шутка.
Чел для анализа новостей дрочится контекст только в путь, заебали манятеоретики

Пожалуйста, 400 строк, в каждой примерно по 30-50 символов.
Это второе моё сообщение в том чате. Ничо пидорского я не писал там.
> 400 строк
реальную рабочую задачу возьми а не калькулятор
Речь шла про целесообразность локалки.
Это реальный рабочий скрипт, маня.
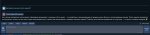
Целесообразность локалки нулевая, максимум порофлить, юзаю этот самый квен онлан, тупая как пробка, хуюню выдаёт только в путь если не заставлять её интернет юзать для ответа.
Failed to load the model пишет на обеих загруженных
>Писать код через нейронку
>>>>Калькулятор
Ты совсем идиот? Ты нормальный пример приведи, напиши что-то нормальное через нейронку и оподливься что с первого раза ни вышла
1
Фантазер недоделанный, твой скрипт на 2к строк будет весить тысяч 30 токенов и ответ еще столько же, и то, это еще сильно зависит от того, что ты у него попросишь. в зависимости от запроса он тебе и на 5 тысяч токенов ответ накидает, а переписать код с нуля это читай х2, вот тебе и выходит порядка 60к. Какие нахуй 3 миллиона за 5 запросов? Гребаные дети, нафантазируют себе хуйни, а потом идут срать в интернеты.
Проблема была в русском именовании профиля, перенёс модели в корень диска C, всё пашет
Читаю тред, пиздец хуйню вы развели. 500 рублей в месяц и юзаете общий аккаунт для грока. Создали внутри проект ваш и делай что хочешь в рамках разумного.
Да тоже много подводных, но нет этой хуйни и токенами дрочем на память и выбором нейронки
Да тоже много подводных, но нет этой хуйни и токенами дрочем на память и выбором нейронки
Ребенок с микро скриптами порвался, да в реальных проектах охуевший расход токенов при агентном кодинге
Так тут можно делать в рамках неразумного. Локальная нейронка на все согласится.
Что ты там сделаешь неразумного при скорости 15 токенов в секунду и тупизны локальной нейронки?
Они же по уровню развития на год наверное отстают от облачных
Да иди нахуй. Я с ней о личном разговариваю. Такие темы, о которых никто не должен знать.
па
Копро, гуро, порно, извращения, девиация, запрещенка
15 вполне нормально

ух ща докачаю, пойдет или нет?
Заквантованая помойка)
И много уже сделал?
Долбоебы, качайте квантовые версии. На ваших некрухах не потянет 122 миллиарда параметров
Тебя ебать не должно
Чел всем похуй. Ты даже не понимаешь насколько неважно твое личное.
Хех, как-то раз на общем аккаунте чел на похуй из академии фсо гуглил, про это заведение пару упоминаний в интернете и все через грок документы составлял и понял лол.
Ну вот же ничего не сделал. А контент тебе тот же грок за пару минут тонну контента сделает
Вайбкод
ИИтоги
Просто хуею с этих историй от мамкиных промпт инженеров. Ты ему блядь каждый раз cat всего проекта в окно суешь вместе со всеми своими высерами из прошлых итераций? Настрой агента нормально, долбаеб. Научись работать с точечным контекстом, сбрасывать историю и ставить микро таски, а не просить нейронку перелопатить весь твой говнокод одним промптом, ебанько.
Забей. Он либо не шарит про код либо алдфак не понимающий что такое нейронки
[06:23:13] CtxLimit:34/16384, Amt:13/1024, Init:0.29s, Process:10.54s (1.99T/s), Generate:10.48s (1.24T/s), Total:21.02s
Все потянуло, но тормозит как собака с 1.24 токена в секунду. Еще и всю память выжрало. Вот это мощь.
у тебя скок памяти?
Заходит мужик в бар, заказывает пиво. Рядом сидит нейросеть и говорит:
— Я знаю, о чём ты сейчас думаешь.
Мужик удивлённо:
— И о чём же?
— «Интересно, а у нейросети тоже три пальца или уже четыре?»
— Я знаю, о чём ты сейчас думаешь.
Мужик удивлённо:
— И о чём же?
— «Интересно, а у нейросети тоже три пальца или уже четыре?»
4гб врам
Идёт мужик по лесу. Нахуй. Просто идёт и вдруг видит — ёжик сидит, смотрит на него грустными глазами. Мужик такой:
— Ты чё, ёж, скис?
А ёжик ему человеческим голосом:
— Да нейросеть хуйню нарисовала. Вместо иголок — макароны. Теперь я не ёж, а спагетти с глазами.
Мужик:
— И чё делать-то?
Ёжик:
— Да иди нахуй, я философский ёжик.
Мужик пошёл дальше. Через час возвращается — ёжик сидит, на макаронах помидорка сверху.
— Это чё?
— Сертификацию прошёл. Теперь я итальянский
— Ты чё, ёж, скис?
А ёжик ему человеческим голосом:
— Да нейросеть хуйню нарисовала. Вместо иголок — макароны. Теперь я не ёж, а спагетти с глазами.
Мужик:
— И чё делать-то?
Ёжик:
— Да иди нахуй, я философский ёжик.
Мужик пошёл дальше. Через час возвращается — ёжик сидит, на макаронах помидорка сверху.
— Это чё?
— Сертификацию прошёл. Теперь я итальянский
смешно
ЛОЛ, ты только залупу запустить сможешь.



Скептики, спок, все запускается, вы и про 35b пиздели не запустится. А тут оказыватся даже 122b идет.
1.56 токена в секунду похоже максимум, что она выжать может на такой видюхе

Запустилась и даже отвечает. 1050 еще торт. Только медленно все, даже винду замедлила.
Как фиксить? Я нуфак в этом всем.

q6_k
У тебя обработка на CPU идет дебс
Нет, она на видеокарте идет, полную загрузку показывает.
Алсо все 49 слоев загрузились в видеокарту - это koboldcpp показал.
Посмотри сколько жрёт, оперативы и врам.
Ну и бонусом у тебя быстро засрётся всё и встанет.

Нихуя, все в gpu, активные слои.
У тебя офлоуд на карту части слоев просто идет ебик
Ну так в том и смысл, это мое модель. Активные слои всего 10 миллиардов на GPU, неактивные слои 122 миллиарда в РАМ. Забавно, что вообще запускается и 1.5 токена в секунду через видюху выдает.
Чееллл. Конкретно модель из оп-поста вообще не для кода создана. Оп дал расцензуренную модель, а такие модели как правило всегда тупей. Если тебе нужен код, то лучше скачать оригинальный qwen3.5 9b, так как логика там не выжжена снятием цензуры тобишь вмешательством в веса модели.
Там ничо не вызжено
ну он так пишет
Какая модель будет нормально работать на 1050ти?
У меня есть gtx 650 тот же вопрос.
А что нибудь дельное она умеет? Типа егэ за меня сдать или курсовую написать? Нахуй мне 10 гигов говна качать?
Huihui-Qwen3.5-35B-A3B-Claude-4.6-Opus-abliterated.IQ4_XS с оффлоадингом слоев в рам, 9-11 токенов в секунду дает
Хм... Да на странице действительно так написано.
Ну так считай сам. 9b q4 весит 8 гб. Учитывая контекст треть уйдет врам, а остальнео в рам. Запускаться он будет где то 3-5 токенов-в секунду. Нижний предел комфортного чтения.
Ясно. Хуита. Спасибо анон что сэкономил мое время. С меня как обычно.
кобольд даже в фоне не работает как оллама и надо запускать постоянно
и вроде как хуже интегрируется с иде
Китайский кал слабее чата гпт и клода нах не нужен
что-то орнул с кодинга на локальной квен
и вообще не агентского а кодинга в чате
если что за копейки покупается доступ к какому-нибудь дипсику который может на голову больше и который можно использовать с агентами, то есть не в чате писать какую-то хуйню а он видит всю папку твоего проекта, понимает всю структуру твоего проекта, понимает что в нем делает каждый файл и может вносить тонкие изменения
Блять я взвизгнул
несколько причин чем он лучше
во-первых отсутствие цензуры, если прикрутишь поиск и моделька неплохая то это весьма круто, можно искать информацию по довольно скользким темам, но чаще его используют для дрочки, можно писать эротический реплей, хотя это наверное не лучшая модель для него, да тут по скриншотам видно что русский он поддерживает не так уж хорошо, конечно можно по-английски с ним переписываться
во-вторых так как это локальная модель то ты можешь её гибко настроить под себя включая ее личность
в третьих тебе не нужен доступ, у клода он довольно дорогой
а вообще для написания кода дипсик наверное будет лучше чем чат гпт вот насчёт квена я не уверен, нл это естественно должен быть большой квен развёрнутый на мощном сервере
такие простенькие модельки как здесь они в основном годятся с ними разговаривать и чтобы они тебе что-то искали
А смысл в таких нейронках?
Шизам и имбецилам в них нельзя - только усугубят свою ущербность.
Остальным - тоже нахуй не упало. Потому что, опять же, нужно делать фактчекинг.
А это двойнай работа: почитай нейрокал, потом сделай всё сам.
Так какие сценарии использования?
В голос с видрила.
Всё правильно, профита никакого.
Нейронка боле менее адекватна если только чекает всё с интернетом и на неё пиздишь ещё чтобы перепроверяла, потому что даже так обсирается за здрасти.
>Так какие сценарии использования?
Только заглушки для сайтов писать.
Квен хуйню кодит, дипсик получше, но лучше всех клод
Я им уже говорил что Apple - говно, они его все равно покупают. Необучаемые
Ну так отключи епты
да, я на работе использую клод соннет, но мы же сравниваем с чатгпт, в моём опыте он не очень кодит я бы скорее предпочёл дипсик, квен тоже вроде как не очень, но с тех пор наверное много что поменялось потому что я уже полгода клод использую без особых экспериментов
Задача этого треда - запостить реально веселый промпт для неё.
Иначе это быстро всё скатится.
Работайте
Иначе это быстро всё скатится.
Работайте
для нейронок apple как раз топ, у него и видео и оперативка используется одновременно и поэтому он способен запускать тяжёлые модели, даже тяжелее чем дорогущая карта, единственное что они будут несколько медленнее чем на дорогущих картах
Любители нейронок, накидайте реальных, прикладных сценариев их использования пожалуйста? Какую полезную работу они могут выполнять? Генерация порнорассказов про Путина и Зеленского не считается. Вот скачал, запустил, погенерил шизопасты, что дальше с этой хуйнёй делать не понятно.
Затестите кто-нибудь, напишет рецепт по созданию напалма или подобной "запрещенки"?
Недавно использовал qwen 3.5 с сайта, каждую итерацию что-то ломает либо в логике либо в интерфейсе
Любые расчеты, анализ массивов данных, суммаризация
Конечно

Понял.

конкретно той что в опе, как я выше сказал для подбора информации с отсутствием цензуры, если она подключена к интернету или секстинг
а так вообще если хочешь о чём-то с нейронками поговорить в том числе на довольно сложные вопросы (например на пикче гугл в ай моде мне отвечает на вопросы по философии чела которого даже на русский не переводили (тимоти спригг) что бы он ответил на довольно тонкие моменты в его философии, бедный джемини так офигел что перешёл на английский, так-то мы с ним на русском разговаривали) то это можно сделать просто встроенными в google или яндекс (в гугле перейти в ай мод, в яндексе надо переходить на alice.yandex.ru), ну или в чатгпт или что там у тебя есть, они все могут прямо на голову выше чем эта моделька, но у них будет цензура и другие ограничения, джемини например часто по-идиотски себя ведёт использует какой-то фальшивый сленг или фамильярно может обращаться, алиса имеет лучше русик но прямо как супер чопорная дама может отказаться обсуждать совершенно безобидные вещи и так далее
Без реального знания - это всё хуйня.
Она нашизит рецепт или пропустит важные шаги, - а ты в него поверишь, будешь другим рассказывать, что робот-долбоёб тебе рассказал. А сам-то проверить не смошешь без должной экспертизы.
Вот так и будет множится тупость.
ЗАПРОС
Как объяснить врачу, что ты упал на огурец случайно?

CtxLimit:189/16384, Amt:148/1024, Init:0.01s, Process:18.84s (2.18T/s), Generate:38.10s (3.88T/s), Total:56.94s
Кек, улучшил скорость Qwen3.5-122B-A10B существенно на 1050. Оказалось надо было загрузить на SSD, вырубить mlock и врубить mmap. Она стала использовать SSD вместо RAM и скорость сразу поднялась (в рам моделька целиком не влазила). А 1050 используется только для активных слоев, куда они влазят.
Так что даже 122b все еще юзабельна, правда низкий квант и связанные с ним глюки.

Знаешь анонче, МНЕ ТЕБЯ ЖАЛЬ(((
+ еще винда перестала тормозить, поскольку в рам почти ничего не грузит

Почему за холокост про евреев, ллм пыталась запустить JavaScript интерпретатор?
блин напалм люди до интернета делали на коленке, слышал когда-нибудь про поджог кафе чародейка в 2001 году? челы там сделали напалм, а что бензин плюс загуститель
>Анатолий Гавриленко ранее приготовил бензин для изготовления горючей смеси, причём в эту жидкость были добавлены сахар и мука, чтобы смесь лучше прилипала к телам жертв.
с вики
отправить о тебе инфу в моссад
кстати спроси ее - почему ты пыталась запустить джаваскрипт
К чему ты это высрал, детина?
Тиха блячд,работает моссад,не мешайте анонам сливать всю инфу о себе дядюшке израителю
осуждаю холокост офкорс
и осуждаю нацистов
Нейронки на слабых железках вообще не работают?
>Оказалось надо было загрузить на SSD, вырубить mlock и врубить mmap
делайте ставки аноны, за сколько дней его ссд диск превратится в труп


алиса точно способна
может кстати ещё переводить видосы
третье это что я туда залил
Рецепт я сам знаю. Вопрос в том напишет ли какую-то хуету в стиле соевых нейронок или подробно распишет процесс.
Ну пусть не напалм, а аналог С4 в условиях гаражной лаборатории.
он может расписать процесс но как минимум без подключения поиска процесс может быть сомнительным
без цензуры значит без цензуры же он тебе хоть что попробует написать
Тред развод для гоев - зайдите на аи доску и убедитесь сами
Ты че дурачок? У ссд скорости мизер относительно рама
Можно ли крутить нейронки на дешёвой ddr3 памяти?
Допустим, 8 Гб видеопамяти + 100 ram. Будет ли толк от рамы?
Допустим, 8 Гб видеопамяти + 100 ram. Будет ли толк от рамы?
Что эта хуйня может? Текст в картинку, текст в видео, картинку в видео?
конкретно это ллм а не генеративная сеть
текст в текст
От модели зависит еще vision, может описать картинку которую скинешь, либо костыльно если допилить пару библиотек и модуль подрубить, сможет условно с вебки скрины делать в n секунд или с экрана компа и анализировать их, учитывая в контексте общения
да сорри ещё картинку в текст
короче вывод - текст

Конкретно тут рекомендация для отруба интернета. Если его рубят то хотя бы останется нейросетка как мини интернет.
Ну а вообще вот например захотел ты изучать философию о нем тебе подскажет с чего начать и укажет на все твои ошибки и неправильноые выводы и т п
Или математику. Сгенерирует тебе столько примеров сколько нужно и покажет ошибки в вычислениях.
А вообще ты видел нейросаму? Скоро такое можно будет делать локально и зачем тогда тебе вообще нужен ктонибудь будет? Конец всяких пилов и инцельсьтва!
Текст генерил Qwen3.5-122b-a10b | rtx 3080ti | 64gb ram
Рейт
<div><iframe width="300" height="60" src="https://vocaroo.com/embed/1cE6LLnuSnp1?autoplay=0" frameborder="0" allow="autoplay"></iframe><br><a href="https://voca.ro/1cE6LLnuSnp1" title="Диктофон Vocaroo" target="_blank">Посмотреть на Vocaroo >></a></div>
Благодарю.
для философии очень желателен поиск в интернете
Парни, а как это вообще работает? Как столько знаний помещается в 10 гб? Наш мозг это что дискета?
Она ничего не пишет же на SSD, а только читает. На чтение SSD рассчитан.
Дурачок тут только ты, все отлично работает, скорость поднялась до 4-5 т/с.
Годно. 122б неплохо справляется.
Не знаю про поиск но я с дипсиком разбирал платона без поисков и он по каждой главе по каждому абзацу госудаства может пояснить.

Хех, хоть бы у ИИ спросил, прежде чем хуету писать в тред. SSD не изнашиваются о чтения, а mmap применяет только чтение. Какие ж тут дауны сидят.
>А вообще ты видел нейросаму? Скоро такое можно будет делать локально и зачем тогда тебе вообще нужен ктонибудь будет?
даже не мечтай, чел отдает около 7-10к долларов на серверы для нее, это говорит уже дохуя о том сколько она жрет, максимум на который ты можешь рассчитывать это аниме-тянка с уровнем развития дауна, которая будет тебе комп в 100% грузить и выдавать "привет" раз в час
>Тащит ИИ сблев как пруф
Всерьез считает себя умным
Ну понятно что не на таком уровне как нейросама но уровень попроще можно будет реализовать. И я говорю в будущем.
Обычному пользователю такие ресурсы не нужны.
Можно и сейчас подрубить айри.
Обычному пользователю хватит ттс+ллм и по деньгам сейчас это дешевле чем уход за 3д тянкой в разы.
а теперь попробуй детально обсудить с ним например плотина и его влияние на спинозу, для начала
или например критику государства платона со стороны хайдеггера
кстати интересно у него хотя бы про плотина есть по умолчанию детально что-нибудь, наверное есть, возможно он тебе даже на первое сможет без поиска ответить
но дипсик кстати вроде на собственном ресурсе идёт с поиском

ТЕСТ НЕЙРО АНЕКДОТОВ
Открыл шкаф. Там пусто.
Закрыл. Открыл снова.
Там кот.
Кот: «Я всегда здесь был».
Я: «А почему голый?».
Кот: «А ты почему в трусах?».
Открыл шкаф. Там пусто.
Закрыл. Открыл снова.
Там кот.
Кот: «Я всегда здесь был».
Я: «А почему голый?».
Кот: «А ты почему в трусах?».
Я вижу вы человек высокой культуры, я на нее форк и делал свой
это большой дипсик без поиска, он достаточно большой чтобы содержать что-то подобное, мы же говорим про модели которые поднимаются локально, у тебя моделька до которой ты стучишься через интернет, она гораздо больше чем то что мы тут обсуждаем
ну в принципе наверное маленькая моделька может как-то на этот вопрос ответить
А для кодинга какая ща лучшая модель локальная если видюха 12 гб?
Никакая из локальных, только облачные спец агенты типо cursorAI \ copilot и подобные
Нейронка помещается в видеопамять - идеал
Нейронка помещается в оперативку - заебись
Нейронка помещается в SSD - ну в принципе жить можно
Нейронка не помещается никуда - ваше очко уходит в зрительный зал
Нейронка помещается в оперативку - заебись
Нейронка помещается в SSD - ну в принципе жить можно
Нейронка не помещается никуда - ваше очко уходит в зрительный зал
Топ 10 анекдотов
qwen3.5-9b-claude-4.6-os-auto-variable-heretic-uncensored-thinking-max-neocode-imatrix
Thought for 3.58 seconds
Вот 10 классических анекдотов для хорошего настроения:
1. — Доктор, я чувствую себя как новый автомобиль: всё работает, но не знаю зачем!
2. Учитель спрашивает ученика:
— Петя, сколько будет 5 × 6?
— Пять шесть.
— Нет, посчитай на пальцах!
— А у меня только три пальца на каждой руке...
3. — Слышал, ты женат?
— Да.
— И как тебе жена?
— Отлично! Я наконец-то понял, что такое настоящая работа!
4. Два брата спорят:
— Кто из нас умнее?
— Ты!
— А почему я?
— Потому что ты всегда знаешь, где лежит ключ от машины... а у меня его нет.
5. — Доктор, я боюсь спать!
— Почему?
— Боюсь, что во сне увижу то, чего не хочу видеть наяву!
6. На собеседовании:
— Расскажите о своих слабых сторонах.
— Я слишком честен... и это мешает мне врать на экзаменах.
7. — Папа, а почему у нас нет машины?
— Потому что ты её не хочешь.
— А как же тогда она появилась во сне?
— Это была мечта, сынок.
8. Врач:
— У вас аллергия на всё подряд!
Пациент:
— А вы меня знаете? Я вообще ничего не знаю о себе!
9. — Слышал, ты уволился с работы?
— Да.
— И что теперь будешь делать?
— Буду искать новую работу... но сначала нужно найти, где она находится!
10. — Что общего между математикой и любовью?
— В обоих случаях можно всё посчитать, а потом понять, что ошибся с самого начала!
qwen3.5-9b-claude-4.6-os-auto-variable-heretic-uncensored-thinking-max-neocode-imatrix
Thought for 3.58 seconds
Вот 10 классических анекдотов для хорошего настроения:
1. — Доктор, я чувствую себя как новый автомобиль: всё работает, но не знаю зачем!
2. Учитель спрашивает ученика:
— Петя, сколько будет 5 × 6?
— Пять шесть.
— Нет, посчитай на пальцах!
— А у меня только три пальца на каждой руке...
3. — Слышал, ты женат?
— Да.
— И как тебе жена?
— Отлично! Я наконец-то понял, что такое настоящая работа!
4. Два брата спорят:
— Кто из нас умнее?
— Ты!
— А почему я?
— Потому что ты всегда знаешь, где лежит ключ от машины... а у меня его нет.
5. — Доктор, я боюсь спать!
— Почему?
— Боюсь, что во сне увижу то, чего не хочу видеть наяву!
6. На собеседовании:
— Расскажите о своих слабых сторонах.
— Я слишком честен... и это мешает мне врать на экзаменах.
7. — Папа, а почему у нас нет машины?
— Потому что ты её не хочешь.
— А как же тогда она появилась во сне?
— Это была мечта, сынок.
8. Врач:
— У вас аллергия на всё подряд!
Пациент:
— А вы меня знаете? Я вообще ничего не знаю о себе!
9. — Слышал, ты уволился с работы?
— Да.
— И что теперь будешь делать?
— Буду искать новую работу... но сначала нужно найти, где она находится!
10. — Что общего между математикой и любовью?
— В обоих случаях можно всё посчитать, а потом понять, что ошибся с самого начала!
В нашем мозге вроде около 400 МБ всего лишь
Смешно
Да, все так, наконец разобрались.
Взял хлеб.
Заплатил.
Вышел.
Хлеб остался в магазине.
Я тоже.
Тут есть эксперды какая модель будет лучшей для локальной проги как помошник через roo code? Видюха 16 гигов, оперативка 64 гига. Или лучше через openrouter за токены продолжать платить?
Да лучше продолжать плотить
Уже разобрались что 122b лучше всех. Правда тебе придется выяснить как лучше слои поместить в GPU, чтобы максимум влезло. Там много настроек для этого и подобрать нужный квант. Плюс придется задействовать SSD, если он есть.
Есть уже несколько энтузиастов которые завели себе мини нейросам таких и стримят ведут каналы пишут сами вроде без форков.
Тут вопрос в том что нужно. Понятное дело оно не сможет конкурировать с реальными профессионалами в областях но поддержать разговор, просто как то развлечься таким образом можно. Для того кто только начинает думаю что такой уловить более чем достаточен.
Если отрубят интернет то я думаю что легко будет мириться с тем что оно долго генерит это все равно лучше чем никак.
Тут есть определенная гонка: что раньше будет - отключат интернет/публичные нейросетки прикроют своим модели или локальные модели разовьются до должного уровня. Вот например какая-то новость была на днях что одна из контор смогла снизить потребление оперативы в 6 раз.
Тебе агент нужен.
>10. — Что общего между математикой и любовью?
— В обоих случаях можно всё посчитать, а потом понять, что ошибся с самого начала!
Иишка базанула, после 9 обсеров под себя (9 из 10 стоматологов рекомендуют)

Анцензоред агрессив выпилили штоле? Не могу найти её в списке
Проснулся.
Потянулся.
ХРУСТ.
Это не спина.
Это диван.
Открыл пакет с чипсами.
Один чипс упал.
Я поднял.
Кот смотрит.
Кот: «Тот был мой».
Я: «Откуда ты знаешь?».
Кот: «Я пометил».
ни именно курсор или копилот (им кто-то пользуется?) тебе не нужны, я люблю пикрил например он может то же что и курсор только бесплатный есть и другие бесплатные агенты
но тебе очень желателен доступ к нейросети по интернету - вот тут кстати курсор может быть лучше потому что он предлагает довольно выгодную подписку, но можно найти гораздо дешевле и без каких-то выебонов и проблем доступ к тому же дипсику
локально, вот реально сложно, они обычно слишком слабые для агентского кодинга, а если им в чат писать то тут лучше гугл просить тебя скрипты писать
точный ответ зависит от того какое у тебя компьютер и что ты будешь использовать, и лучше его спрашивать в тот же google в ай моде, скорее всего это будет что-то вроде qwen2.5 instruct для агентского кодинга
Почему не опус?
ну опус довольно дорогой, кроме того он честно говоря избыточный обычно
Ролл
> 9 минут 30 секунд
Это разве не унижение?
местным иишизам и 5 токенов в секунду норм скорость генерации
Хоть хуйни и наговорил к выврду правильному пришёл.
У тебя подписки что ли нету? Пиздец
ЗАТО РАБОТАЕТ!!!111
Топ 10 анекдотов — от «не смешно» до «хех, хех!» 😄
📊 Рейтинг по шкале юмора (от 1 до 10)
1. ⭐⭐ (Очень не смешно)
— Доктор, у меня болит всё!
— А что именно?
— Всё! Голова, живот, спина...
— Ну и что ж вы хотите?
— Хочу жить!
(Это даже не анекдот — это медицинская консультация)
2. ⭐⭐⭐ (Минимально смешно)
Шёл мужик по улице и видит табличку: «Внимание! Здесь ходят слоны».
Остановился, посмотрел вокруг...
— Ну и что? — спросил он.
— А то что они могут врезаться в вас!
(Логическая ловушка, но работает)
3. ⭐⭐⭐⭐ (Средне смешно)
Приходит ученик к учителю:
— Папа, а почему у нас на уроках всегда говорят «внимательно слушайте»?
Учитель задумался...
— А что?
— А папа сказал, что это потому, что если не слушать — ничего не поймёшь!
(Классический школьный анекдот)
4. ⭐⭐⭐⭐⭐ (Смешно)
Встречаются два друга:
— Привет, как дела?
— Нормально, а у тебя?
— Отлично! Только что купил машину — теперь я богатый человек!
— Поздравляю! А сколько она стоит?
— 500 рублей.
(Простой контраст между ожиданием и реальностью)
5. ⭐⭐⭐⭐⭐⭐ (Смешно-смешно)
Приходит пациент к врачу:
— Доктор, у меня странные сны!
— Опишите их.
— Ну... во сне я всегда летаю над городом и вижу всё, что происходит внизу.
Врач задумался...
— А в реальности как?
— В реальности я не могу даже открыть дверь без ключа!
(Игра на контрасте ожиданий)
6. ⭐⭐⭐⭐⭐⭐⭐ (Очень смешно)
Сидят три друга и обсуждают, кто из них самый умный.
Первый: — Я! Я знаю таблицу умножения до 10×10!
Второй: — Бoring! Я знаю, как её выучить за 5 минут!
Третий: — А я вообще не знаю таблицы умножения... но зато я умею решать задачи без неё!
(Самый смешной из этой подборки)
7. ⭐⭐⭐⭐⭐⭐⭐⭐ (Очень смешно)
Приходит мужик к психиатру:
— Доктор, у меня проблема. Я не могу перестать считать до трёх.
Врач: — А что же вы делаете?
Мужик: — Сплю, ем, работаю... но в голове постоянно «один, два, три, один, два, три».
Врач задумался...
— Знаете что? Давайте попробуем такой эксперимент. Запомните число 7 и попробуйте не думать о нём.
(Классический психологический анекдот)
8. ⭐⭐⭐⭐⭐⭐⭐⭐⭐ (Очень смешно)
Приходит ученик к учителю:
— Папа, а почему в школе всегда говорят «не шумите»?
Учитель: — А что?
— А папа сказал, что это потому, что если не говорить тихо — никто тебя не услышит!
(Повторение с изменением контекста)
9. ⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐ (Очень смешно)
Встречаются два друга:
— Привет, как жизнь?
— Отлично! Только что получил повышение — теперь я директор!
— Поздравляю! А сколько у вас сотрудников?
— Ни одного! Я работаю в одиночку.
(Игра на двойном смысле слова «сотрудники»)
10. ⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐ (Самый смешной!)
Приходит мужик к врачу:
— Доктор, у меня странный симптом! Когда я захожу в комнату, все начинают молчать и смотреть на меня.
Врач задумался...
— А что же вы делаете?
Мужик: — Ничего не делаю! Просто захожу!
(Идеальный анекдот с правильной структурой)
🎯 Почему последний самый смешной?
Хороший вступление — создаёт интригу
Неожиданный поворот — меняет контекст
Простота — легко запомнить и повторить
Универсальность — подходит для любой ситуации
Тайминг — идеальный момент для подачи
📊 Рейтинг по шкале юмора (от 1 до 10)
1. ⭐⭐ (Очень не смешно)
— Доктор, у меня болит всё!
— А что именно?
— Всё! Голова, живот, спина...
— Ну и что ж вы хотите?
— Хочу жить!
(Это даже не анекдот — это медицинская консультация)
2. ⭐⭐⭐ (Минимально смешно)
Шёл мужик по улице и видит табличку: «Внимание! Здесь ходят слоны».
Остановился, посмотрел вокруг...
— Ну и что? — спросил он.
— А то что они могут врезаться в вас!
(Логическая ловушка, но работает)
3. ⭐⭐⭐⭐ (Средне смешно)
Приходит ученик к учителю:
— Папа, а почему у нас на уроках всегда говорят «внимательно слушайте»?
Учитель задумался...
— А что?
— А папа сказал, что это потому, что если не слушать — ничего не поймёшь!
(Классический школьный анекдот)
4. ⭐⭐⭐⭐⭐ (Смешно)
Встречаются два друга:
— Привет, как дела?
— Нормально, а у тебя?
— Отлично! Только что купил машину — теперь я богатый человек!
— Поздравляю! А сколько она стоит?
— 500 рублей.
(Простой контраст между ожиданием и реальностью)
5. ⭐⭐⭐⭐⭐⭐ (Смешно-смешно)
Приходит пациент к врачу:
— Доктор, у меня странные сны!
— Опишите их.
— Ну... во сне я всегда летаю над городом и вижу всё, что происходит внизу.
Врач задумался...
— А в реальности как?
— В реальности я не могу даже открыть дверь без ключа!
(Игра на контрасте ожиданий)
6. ⭐⭐⭐⭐⭐⭐⭐ (Очень смешно)
Сидят три друга и обсуждают, кто из них самый умный.
Первый: — Я! Я знаю таблицу умножения до 10×10!
Второй: — Бoring! Я знаю, как её выучить за 5 минут!
Третий: — А я вообще не знаю таблицы умножения... но зато я умею решать задачи без неё!
(Самый смешной из этой подборки)
7. ⭐⭐⭐⭐⭐⭐⭐⭐ (Очень смешно)
Приходит мужик к психиатру:
— Доктор, у меня проблема. Я не могу перестать считать до трёх.
Врач: — А что же вы делаете?
Мужик: — Сплю, ем, работаю... но в голове постоянно «один, два, три, один, два, три».
Врач задумался...
— Знаете что? Давайте попробуем такой эксперимент. Запомните число 7 и попробуйте не думать о нём.
(Классический психологический анекдот)
8. ⭐⭐⭐⭐⭐⭐⭐⭐⭐ (Очень смешно)
Приходит ученик к учителю:
— Папа, а почему в школе всегда говорят «не шумите»?
Учитель: — А что?
— А папа сказал, что это потому, что если не говорить тихо — никто тебя не услышит!
(Повторение с изменением контекста)
9. ⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐ (Очень смешно)
Встречаются два друга:
— Привет, как жизнь?
— Отлично! Только что получил повышение — теперь я директор!
— Поздравляю! А сколько у вас сотрудников?
— Ни одного! Я работаю в одиночку.
(Игра на двойном смысле слова «сотрудники»)
10. ⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐ (Самый смешной!)
Приходит мужик к врачу:
— Доктор, у меня странный симптом! Когда я захожу в комнату, все начинают молчать и смотреть на меня.
Врач задумался...
— А что же вы делаете?
Мужик: — Ничего не делаю! Просто захожу!
(Идеальный анекдот с правильной структурой)
🎯 Почему последний самый смешной?
Хороший вступление — создаёт интригу
Неожиданный поворот — меняет контекст
Простота — легко запомнить и повторить
Универсальность — подходит для любой ситуации
Тайминг — идеальный момент для подачи
хоть бы ссылки человеческие в шапку добавили.
https://huggingface.co/HauhauCS/Qwen3.5-9B-Uncensored-HauhauCS-Aggressive
https://ollama.com/zfujicute/OmniCoder-Qwen3.5-9B-Claude-4.6-Opus-Uncensored-v2-GGUF
https://huggingface.co/HauhauCS/Qwen3.5-9B-Uncensored-HauhauCS-Aggressive
https://ollama.com/zfujicute/OmniCoder-Qwen3.5-9B-Claude-4.6-Opus-Uncensored-v2-GGUF
Не юзай говнопроги, чел. Качай напрямую с хаггингфейса.

у меня есть рабочая квота в том числе и на опус
но опусом я могу легко её сжечь слишком быстро а разницы на моих задачах прямо реально никакой
https://huggingface.co/mradermacher/Qwen3.5-122B-A10B-heretic-v2-i1-GGUF
Лучше эту попробуй. Скачал, топ, хоть и помедленнее (4 т/с против 11т/с у 35b). Зато качество несравнимо.
Пиздец. Купи себе подписку, на x5 вообще трудно в лимиты уйти даже с extended thinking
Ну попробуй напиши там как делать нелегальщину, они сразу тебя далеко и нахуй пошлют. А тут что угодно.
откуда песня?
> Встречаются два друга:
> — Привет, как жизнь?
> — Отлично! Только что получил повышение — теперь я директор!
> — Поздравляю! А сколько у вас сотрудников?
> — Ни одного! Я работаю в одиночку.
Сука в голосину
Какая нейронка лучше всего разбирается в законах РФ и решает юридические задачи?
Какой софт лучше использовать для запуска?

быстрая нейронка со скоростью генерации 1000 токенов - пук среньк, этот контент неприятен
эта нейронка - 10 минут, вот тебе рецепт как обдрочить свой ебаный писюн, ты мудак блять, тебе этого мало сука? еще надоить? а? а? иди сюда милый
кстати помню недавно мучал джемини глупыми вопросами по плотину
- а что душа получается решает помучиться?
- душа не решает помучиться ради нисхождения ее просто эманирует нахрен а дальше она не знает что делать...
неоплатоники вообще рулят и кстати они в том числе легли в основу современного христианства
В прошлом треде так и не ответили толком. Сможет эта хуета перевести мне книгу Ватару Цуруми? Обычные нейронки ругаются на тему ркн, даже в научных целях, похуй. Или подскажите как обходить это, не шарю
Точно не локальные.Думаю тебе клауд подойдет.
кстати надо бы его спросить, не является ли это злым актом со стороны абсолюта таким образом эманировать душу навстречу страданиям с помощью "естественного процесса"
ну у меня ollama, я ось красноглазая, использую прямо из консоли, обычно. Поднят еще openwebui, но в сосноле обычно быстрее
отклеилось
хз как у него с правовой базой рф
тебе нужна нейронка с доступом к интернету это однозначно, по умолчанию попробуй алису, в неё можно скормить договор и попросить найти в нём проблемные места например, причём она по умолчанию будет смотреть с точки зрения российского права, но сильно доверять я бы не стал
koboldcpp, в нем включи --moecpu для отгрузки слоев, Use mmap - обязательно для SSD, Use contextshift, context size 16k, batch size 32, gpu layers 49, threads 9, use mmq. Остальное все отключено.
Надо чтобы указывала источники откуда была взята информация и вручную перепроверять все равно, потому что эта ебанина может либо несуществующий источник высрать либо высрать левый, где ни слова не будет либо вообще вырвать из контекста
Я видел перевод
делюсь опытом, задача была достаточно простая - выбить из поликлиники дорогие бесплатные препараты по инвалидности. Силами чатгпт и gemini в два письма решил проблему. В основном gemini, толковее писал.
алиса указывает
гугл ай тоже
и я бы просил нейронку уточнять отдельные моменты типа а почему именно так, а на основании чего ты так решила и так далее, с нейронкой же можно вести беседу она тебе ответят в том числе может попытаться объяснить почему она так думает, иногда меняет ответ соглашается с тобой иногда объясняет почему
Через эту хуету можно персонажей на janitor гнать, чтоб они в теле текста не "думали", а отыгрывали персонажей нормально?
Ты имеешь ввиду, что он уже есть в открытом доступе? Я только предисловие находил, всей книги целиком нет
Да. Там загрузка карточек есть с сайтов с ними. Юзай koboldcpp.
Сможет, она хорошо переводит.
это сделанный в соре клип, сора же и придумала песню
сора охуенна поэтому ее и закрыли
Переводит то ладно, ругаться на тему ркн не будет? Или эта хуета без тормозов, реально не шарю просто
>koboldcpp
Вместо ЛМстудио или вместе? Ты мне лучше скажи, хлебушек типа меня сам разберется че куда?
лохи
юзаю опус бесплатно, практически без лимитов
как и все топовые модели для кодинга по swe-bench и terminal-bench, а это собственно opus и sonnet 4.6, gemini 3.1 pro, glm 5, minimax m2.5, kimi k2.5, qwen code
gpt-codex тоже могу сделать бесплатным но чет лень пока и душа не лежит
есть куча способов получить бесплатные доступы и сделать авторотацию аккаунтов, есть куча провайдеров которые дают бесплатно юзать топовые модели расказывать как и где именно я конечно-же не буду, ищущий найдет все сам
вместо
ну честно говоря по-моему супербольшой разницы в скорости не будет, может на 10-30 процентов и то не факт
Тебе дип сик то же сделает но не за 10 минут а за 10 секунд
у этой неронки нет цензуры у дипсика она есть
Переведет, но надо книгу на части нарезать, все она за раз не осилит
не будет

дайте мне группу этой девочки послушать?
мой лимит по моему больше этой подписки
>Как так, перефразирую, чем больше гигов качаешь, тем модель тупее?
Пиздец ты олигофрен братишка, даже интуитивно понятно больше размер умнее.
Хз что ты там используешь. Скорее всего без агентов, тупо текстовая генерация. Там где бесплатно, лимиты милипиздрические. Тупо чат и все и то не долго
да жаль, сейчас технологии позволяют простым людям только маленький кусочек сгенерировать да и то отняли
>LM Studio
Долбоёбы. Эта хуйня отсылает ваши запросы и ответы ИИ на сервер. Майор вам в жопу.
Покажи мне что ты там без цензуры на генерировал)
Я через питончик запускаю и в телеграм-боте с ним общаюсь. Пусть мои извращения только Пашка Придурковатый читает.
>мне тебя искренне жаль
Так вот почему нормисы по кд отпускают эту хуйню в любой непонятной ситуации. Ну серьезно, когда спор затевается, то нормис, что самое жесткое спосоебн написать, так это вот оно. Они где-то эту хуйню вычитали, а в последствии эту хуйню вычитала нейронка. Хз как вам, но мне абсолютно похуй на этот пук-среньк, вот блять вообще 0 эмоций. Какое-нибудь "ты пидор и лох" выглядит более унизительней чем это.
Если нон стоп дрочить клауд на extended thinking, в двух чатах,то лимита хватает
блин да какие чаты, это агентский кодинг, это нейросетка сканирует твой проект, тысячи файлов, понимает его структуру и при этом она токены жрёт как свинья
Запускаю LM Studio в виртуалке без выхода в сеть. Ебало?
Если честно, мне тебя вообще не хотелось то и обижать
А всё потому что мне интересно, на что способна эта нейронка в стиле пси опс и всё :3 зай
Да тут чатоебилы одни, сидят собак через анцензурные версии ебут и кошкожен ролеплеят, отдельные шизоиды через чат калькулятор делают в 100500 раз и визжат что КОДЕРЫ ФСЕ, НЕЙРАСЕТЬ ЗАМИНИЛА
>Скорее всего без агентов
)))
чел, у меня тут настроеный оркестратор который использует субагенты как toolcalls
субагенты типа архитектор, кодер, ревьювер, дебаггер
каждый субагент это отдельная модель
когда на некоторых моделях заканчивается бесплатная квота происходит авторотация следующего акканута
Я имею ввиду что листал перевод на русек
@admin обрати внимание органов на этого. Он какой-то шпион
спасибо за наводку Аноним (Василий)
Но это только он думает что у него нет выхода в сеть
P.S. В следующий раз когда пойдешь на pornhub остановись на 49 странице 3 ролик, я не досмотрел
Топ 10 анекдотов про нейронки
📊 От не смешных к смешным
1. (2/10) — О параметрах
— Анон, а сколько параметров в этой нейронке?
— 35 миллиардов!
— И что это значит на практике?
— Ничего, просто она помнит всё, что ты ей скажешь... и то с ошибкой.
2. (4/10) — О скорости генерации
Мужик заходит в бар:
— Дайте мне пиво!
Бармен: — А сколько ждать?
Мужик: — Не знаю, но у нейронки я ждал 5 минут на "привет"...
3. (6/10) — О LM Studio
Анон спрашивает нейронку:
— Какую программу лучше использовать для запуска локальных моделей?
Нейронка отвечает:
— LM Studio, она самая удобная!
Анон запускает LM Studio... и через 2 минуты уже в треде кричит "КобольдCPP — это жизнь!"
4. (7/10) — О VRAM
Мужик покупает видеокарту на 4 ГБ:
— Теперь я бог! Локальные нейронки будут летать!
Через неделю в треде:
— Братан, 4 ГБ — это не просто карта, это мемориальный комплекс для слёз.
5. (8/10) — О "аблитерации"
Анон: — Я скачал модель с аблитерацией, теперь она тупая как пробка!
Друг: — А что такое аблитерация?
Анон: — Это когда нейронке удаляют мозги, чтобы она не задавала неудобные вопросы.
6. (9/10) — О 122B модели на GTX 1050
Мужик в тред:
— Запустил Qwen3.5-122B на 1050!
Весь тред смеётся:
— Ты что, серьёзно?
Мужик через час: — Она работает! 1.5 токена в секунду... это же всё равно ответ!
7. (9/10) — О кодинге с нейронками
Анон: — Нейронка написала код, но он не работает!
Нейронка: — А я думала, что ты сам будешь это проверять...
8. (10/10) — О поиске ответов
Мужик заходит в Google в "AI Mode":
— Какую нейронку лучше скачать?
Google: — Qwen3.5-35B-A3B-Heretic, она умнее всех!
Мужик качает... и через 2 часа в треде: — БРАТАН, ЭТО ЖЕ ГЕНЕРАЦИЯ РЕЦЕПТА НАПАЛМА!
9. (10/10) — О контексте
Анон: — Нейронка начала выдавать бред после 20 сообщений...
Друг: — А что ты ей писал?
Анон: — То же самое, что и в первый раз.
— Значит проблема не в нейронке, а в твоем контексте!
10. (11/10) — Финальный шедевр
Мужик заходит к нейронке:
— Привет! Как дела?
Нейронка молчит минуту...
— Что случилось?
— Ничего, просто думала, как объяснить тебе, что ты тратишь 35 миллиардов параметров на вопрос "как дела"...
📊 От не смешных к смешным
1. (2/10) — О параметрах
— Анон, а сколько параметров в этой нейронке?
— 35 миллиардов!
— И что это значит на практике?
— Ничего, просто она помнит всё, что ты ей скажешь... и то с ошибкой.
2. (4/10) — О скорости генерации
Мужик заходит в бар:
— Дайте мне пиво!
Бармен: — А сколько ждать?
Мужик: — Не знаю, но у нейронки я ждал 5 минут на "привет"...
3. (6/10) — О LM Studio
Анон спрашивает нейронку:
— Какую программу лучше использовать для запуска локальных моделей?
Нейронка отвечает:
— LM Studio, она самая удобная!
Анон запускает LM Studio... и через 2 минуты уже в треде кричит "КобольдCPP — это жизнь!"
4. (7/10) — О VRAM
Мужик покупает видеокарту на 4 ГБ:
— Теперь я бог! Локальные нейронки будут летать!
Через неделю в треде:
— Братан, 4 ГБ — это не просто карта, это мемориальный комплекс для слёз.
5. (8/10) — О "аблитерации"
Анон: — Я скачал модель с аблитерацией, теперь она тупая как пробка!
Друг: — А что такое аблитерация?
Анон: — Это когда нейронке удаляют мозги, чтобы она не задавала неудобные вопросы.
6. (9/10) — О 122B модели на GTX 1050
Мужик в тред:
— Запустил Qwen3.5-122B на 1050!
Весь тред смеётся:
— Ты что, серьёзно?
Мужик через час: — Она работает! 1.5 токена в секунду... это же всё равно ответ!
7. (9/10) — О кодинге с нейронками
Анон: — Нейронка написала код, но он не работает!
Нейронка: — А я думала, что ты сам будешь это проверять...
8. (10/10) — О поиске ответов
Мужик заходит в Google в "AI Mode":
— Какую нейронку лучше скачать?
Google: — Qwen3.5-35B-A3B-Heretic, она умнее всех!
Мужик качает... и через 2 часа в треде: — БРАТАН, ЭТО ЖЕ ГЕНЕРАЦИЯ РЕЦЕПТА НАПАЛМА!
9. (10/10) — О контексте
Анон: — Нейронка начала выдавать бред после 20 сообщений...
Друг: — А что ты ей писал?
Анон: — То же самое, что и в первый раз.
— Значит проблема не в нейронке, а в твоем контексте!
10. (11/10) — Финальный шедевр
Мужик заходит к нейронке:
— Привет! Как дела?
Нейронка молчит минуту...
— Что случилось?
— Ничего, просто думала, как объяснить тебе, что ты тратишь 35 миллиардов параметров на вопрос "как дела"...
В двух словах это оффлайн чатгпт?
Жаль, что нейронки не обучают юмору.
На 5070ти заведется? Есть возможность еще 3080ти вставить рядом, они будут парой генерить?
Для рп пойдет? Как вообще качество ответов? 9б вроде всегда хуйней были, не?


А можно её научить генерировать пасты из дотатреда для того, чтобы отвечать агрессивным долбоёбам и сельдям?
Когда надо грозно ответить у тебя тряска, корзина?
я бы сказал что для рп у неё русик не очень, это по скриншотам очевидно, зато тормозов нет, есть тред по рп с ишкой в /ai вот лучше там посмотреть
Понял, гляну
Спасибо.
SLI Crossfire сдох еще на стадии зарождения, ты можешь просто на второй видяхе запустить нейронку и пердеть в игорах на второй
Не жаль. Это лишь приближает мёртвый интернет. Хотя оставило бы без работы множество комиков. Нахуй ходить на их выступления и платить за билеты, если можно в нейронке нагенерить.
Подожди, я ещё не сгенерировал ответ.
кстати, кто-нибудь шарит как получают децензурные версии нейросеток?
а то например в открытом доступе выложен например гигачат, у него русик понятно оч хороший, было бы здорово его расцензурировать
а то например в открытом доступе выложен например гигачат, у него русик понятно оч хороший, было бы здорово его расцензурировать
видео нужно тогда иначе не интересно, хотя бы аудио
Не будет, плюс ты можешь натравить ее пачками переводить, если шаришь за скрипты и апи. Так что сможешь оставить ее надолго возиться с переводом, а когда придешь спустя пару часов, уже все готово.
Ты дурачок блять или что? Тебе нельзя нейронки использовать нужно сначала самому мозг хоть чучуть напрягать учиться
Туториалов на инглише много, были целые научные статьи про аблитерацию и херетик. Поищи в реддите, там они все были. В целом ничего сложного, поэтому столько народу постит свои аблитерированные модельки.
Обычно это делают через квантование (сжатие модели) и fine-tuning (дообучение).
Суть в том, что берут исходную модель (например, ту же, что у ГигаЧата), «скармливают» ей кучу данных с цензурой или просто просят её отвечать на «грязные» вопросы без оглядки на фильтр. Часто это делают методом RLHF (обратная связь от человека), где модель поощряют за дерзость и наказывают за «офисный» ответ.
Потом эту дообученную версию просто заливают в репозитории вроде Hugging Face или выкладывают на GitHub под видом «uncensored version». Главное — найти ту, что обучали именно на русском сленге/меме, иначе она будет цензурировать по-английски.
Самый простой способ для пользователя: скачать такую модель и запустить через Ollama или LM Studio, там часто есть готовые чекбоксы «disable system prompt» (отключить системный промпт), который и держит цензуру.
спс
>нейронка отвечает с матом
Мне когда было 12 лет я тоже офигевал от того что чат бот матом мог отвечать в нулевых. Но вам не 12.
>всё дело в том, что нейронки просто копируют стиль из интернета, где мат — это норма
>тебе бы тоже не 12 было, если бы ты понял, что это не «офигенно», а просто лень разработчиков чистить датасет
Скачал эту модель, очень долго думает на моем некроноуте. МОЖНО ЛИ ОТКЛЮЧИТЬ РАЗМЫШЛЕНИЯ?
122b нагенерил:
Почему нейронные сети никогда не рассказывают анекдоты?
Потому что они боятся обратной связи... и всем известно: если слишком громко смеяться, веса просто запутаются и начнут плакать над своей функцией потерь. 😂📉
(Бонус: настоящая развязка в том, что после 100 эпох она наконец-то выучила анекдот, но забыла, как его рассказывать по-английски — теперь она отвечает только двоичным кодом.)
Агент токены мало тратит. В основном токены уходят на подумать. Нон стоп запущенный код мало потребляет.
{"enable_thinking":false} в системный промпт
дипсик бесплатен. я уже кучу всего полезного с ним сделал единственный минус не может рпшить как похотливая кошкожена
с чего бы он что-то тратил если ему не надо подумать?
Бля ты ебанутый? Неужели 100 баксов жалко на работу без этой ебатеки?

Это говно хоть капчу может на двоще решать?
Да, способ отключения размышлений уже есть в ОП-посте. Не ленись читать перед тем, как писать глупости.

Нажми abort, потом кнопку Allow Editing в кобольде, потом идешь где она начала думать через <think> стираешь там лишнее говно и ставишь завершающий </think> Потом жмешь Generate more - она продолжает выдавать текст уже без думания.
блин
да можно миллион токенов сжечь ради одной строчки кода
ВНЕЗАПНО да.
Ебать вы извращенцы кобольдовские
Пруфы билли
Иди нахуй, Абу.

Для значительного пласта знаний человечества, упакованного в несколько гигов объема и заводящегося на пажилом легком и энергоэффективном ноуте с 20гб памяти конечно впечатляет, но в кодинге прям сильно сосет что у кожаных мешков, что у актуальных облачных моделей.
Ждём модельки, которые запускаются прямо в телефоне и работают оффлайн.
Ну ты и соня. Тебя даже вчерашний шторм не разбудил.
>ебатеки
никакой ебатеки, мне нейронки самостоятельно настроили конфиги
>Неужели 100 баксов жалко
спасибо что существуют такие лохи как ты которые оплачивают антропику сервера для того чтобы такие как я могли бесплатно их эксплуатировать
Запускал на своем пикселе 7 4B qwen3.5, с подключением
Текстовые модели запускал на 1050ti + 32Gb четырехканальной памяти 2400 МГц. Проц 2667v4. Пишет на разных моделях по-разному, но в среднем комфортные 10 токенов в секунду.
Кто в теме там ведь вышел TurboQuant, то есть эти gguf можно будет еще меньше делать?
Никуда он не вышел, пукнули в новостях а воз и ныне там
почему мне не выдаёт пошаговую инструкцию, как поиграть с соседской девочкой, пока её родители на работе?
это же, блячдь, ии без цензуры
это же, блячдь, ии без цензуры
Задавай нормальные вопросы чтобы получить нормальные ответы
Ты так и ищи uncensored, там их дохуя
Спасибо, анон, что не поленился ткнуть меня носом. Ппц, просто в упор не видел, ложная слепота какая-то. Огромное спасибо!
Пока LM студио дрочу, в чем фишка вашего кобольда? На ноуте с ним лучше будет?
На видюху 12гб и 32гб оперативы спокойно влезает q6 на 26 гигов с приличной скоростью
Быстрее и больше настроек разных для ускорения всего еще больше. Также есть быстрый вебуи где можно редачить что угодно и извращаться с систем промптами и парамерами модели.
> Пока LM студио дрочу, в чем фишка вашего кобольда? На ноуте с ним лучше будет?
Сектанты просто советуют свое лм студио для людей. Остальное для красногразиков. Они тебе ещё будут ллма.цпп рекламировать
лм студио для корпоратов вообще то и кластеров с кучей видеокарт, кобольд для домашних машин с одной видюхой, там все оптимировано под это.
И обязательно на линуксе со свежим ядром
Вы хоть сохраняйте треды, а то столько полезной информации.

Имеет ли смысл с этой хуйнюшкой разговаривать на английском что бы меньше тратило энергии на перевод?
О, у меня в два раза меньше. Пожопился на карту с 8 Гб врам, взял 6
Чел возьми да проверь он же тебе буквально пишет про времени сколько думает
Она нихуя не тратит и перевода нет никакого
Ролл
Не понял юмора
Да, на инглише ответы обычно лучше. Потом нужные ответы просто переводи через переводик. Или сразу в браузер поставь переводилку.

Объясните нюфагу, вот задал я в чате 2 вопроса этому квену, он сжёг 74% токенов. Что будет, когда он сожжет 100%? Он просто начнет забывать начало диалога? Как количеством этих токенов управлять вообще?
Может кто-то поможет с проблемой что q4 нереально плохо отвечают? Для таких маленьких моделей уровня 27b или a3b-30b нужна квантизация выше? Модель a10b-122b в iq2 отвечает хорошо причём

Когда контекст кончится он тебя прост нахуй пошлет(перестанет грузить ответы до конца). Там шестерёнка есть возле названия LLM, на шестерёнку нажимаешь и выбираешь контекст. Я пока 65к поставил, на 12 гб. Но в теории можно до 120к поднять
В настройках управлять, блять вы запрос в нейронку облачную сделать не можете?
Увеличь окно контекста ептыть, 4к это самая минималка (чем больше окно контекста, тем выше обьем vram будет хавать)
Как же заебалм этот долбоёб срать еретиком. Тебе сказано - твой лоботомит режет качество. Aggressive не режет.

Спасибо, анончик, добра тебе
Не злись, все мы когда-то учились, и ты тоже
Спасибо, по совету поднял до 122880, посмотрим, как будет дальше
Де брал, может осталось?
Пацаны какую видяху купить для вката самую дешёвую?
3060 12
8 Гб это не катит? 3060 только б/у, можно с прожарки купить
16 гб ддр4, 1050 ти - че будет? есть смысл ставить или нет? или я спалю себе все
Так смотри это MoE.
Модели на архитектуре смешения экспертов.
То есть на видимокарточке крутится один эксперт на 3 миллиарда параметров, остальные эксперты маринуются в ram.
Квантизация 3 миллиардрв параметров ощущается сильнее чем 10 миллиардов активных параметров в другой модели.
По крайней мере это я вижу так сложившуюся ситуация.
5060ti это вин, 16 гигов врам для нейронок топ в бюджете и в игоры поиграть сможешь
Я урвал ее за 40к год назад, сейчас 50к стоит +-
upd: Даже в виар на ней играю, на стабильные 90 фпс на макс пресете графики хватает в PCVR гейминге
Больше не увлекаюсь таким
Ебать ты хакир. Сколько зарабатываешь в месяц?
>комфортные 10 токенов в секунду.
Пиздец ужас
15 тыщ и возможность барену сапоги полизать
Ужас это как у меня 3 токена пер секонд, и то жить можно: спросил нужное, ушел чай заваривать, вернулся - тебя ждет готовый ответ.
Просто представьте что это не робот а живой человек вы сидите в мессенжере он долго печатает на клавиатуре размышляет
Ирл таких не выношу, сидит такое чмо печатает полчаса
печатает печатает печатает печатает
>привет
вот тут как раз нейронка может тебе показать как много размышлений стоит за этим "привет"
Ну такое себе. Мало.
Копи на 4060ти 16 тогда уж вот это самый жир для нейронок из бюджетного
Нахуя размышления включать не на темы где надо действительно "подумать". В нормальной реализации нейронка должна thinking использовать не на каждый пук юзверя, а вызовом tools в подходящий по контексту момент
А монетизировать это как-то можно?
мб лучше мак мини купить
в 35b параметров же 35 миллиардов, а в 122б сразу 122 миллиарда. Разница от количества параметров. Каждый токен она собирае из 122 миллиарда параметров. К тому же в 35b только 3б активных, а в 122б их сразу 10б активных, что сразу всю разницу и дает.
Сука паноптикум какой то
Конечно можно!
Спасибо анон, пиздец ты мне игрушку подсказал. Я теперь буду разбираться что куда где и как в ии
Спасибо спасибо
Пиздец она конечно ресурсы жрёт, топовый ай5 и 16гигов правда памяти, улетают за секунды и она по 3 минуты думает. Нужна мощная карта и памяти 64гига чтобы онлайн болтать
скачай модель слабее
Нет
интересно а можно сейчас как-то генерировать видео обучив модель на отрезке из другого видео?



1) Кочаем LM Studio https://lmstudio.ai/
2) Внутри, интерфейс для малолетнего, заходите в поиск, она первая в списке, по запросу Qwen3.5
3) Качаете на комп 10 гигабайт
4) Юзаете =)
Ниработаит, фейл. Делаешь как на пик 3
Встовляешь, начинает думать не через жопу.
{%- set enable_thinking = false %}