



С добрым утром трудяги работяги
Ореховый тред. Тред милой орешки.
Откуда у геммы 4 такая тяга рисовать blue hair, yellow eyes?
Анон, я чёт чувствую, что у меня от нейронок уже чердак поплыл. У меня свайпы в таверне разные. На одних и тех же настройках семплера, на одном и том же промте, и что сука самое дикое - на одном и том же зерне. Буквально должна быть 100% повторяемость но её нахуй нет. Каждый свайп разный. Как такое может быть?
> должна быть 100% повторяемость
В связи с чем?
Для начала отправь запрос со своим чатом на бэк несколько раз или если жора то посмотри что твой фронт засылает
Есть смысл включать reasoning/thinking на гемме 4 q4 для кумчата?
>coder3101
>Еретиков от coder3101 берите, они норм по бенчам, почти не пострадали.
Дерьмище, скачал, тестирую - токены дропнулись в 2 раза по скорости, с 12 t/s до 6 t/s.
К тому же когда запускаешь, повторяться начинает, со 2-3 раза только заводится.
Откатился на старый еретик, там и скорость норм и багов нет.
>отправь запрос со своим чатом на бэк несколько раз
А что там может быть не так? Кобольд, как кобольд, я свои настройки не менял. Вообще странно, что такая штука происходит. Я уже подумал, что мб железки перегрелись или типа того. Хотя карточка на андервольте, не должна сбоить.
Для кодинга что из локального сейчас топчик на одну видяшку?
Я включаю. С синкингом ей проще не снимать трусы 10 раз, может в фоне что-то покумекать, кубики покидать на шанс забыть снять штаны что бы посрать.
Синкинг геммы даже читать интересно, литералли сидишь английский учишь т.к. в начале она часто юзер сообщение переводит
Какую "одну"? 6000 про так то тоже одна, но по спекам как пол треда в сумме

Обычная игровая видюшка, 24 гига.
Интересно если смысл вообще пытаться что-то там вайбкодить с такой аппаратурой.




Можно. Через MCP.
У тебя два стула: Qwen 3.6 и gemma 4, почитай о них, выбери насколько сжатую модель хочешь и вперед. Лучше на рынке нет.
А гемма не знает, что такое нех... Как так?
ГГ, развёл helpful assistant на фистинг...
Кто кого думайте сами
Гемма4 31
Кто кого думайте сами
Гемма4 31
Ну так это же assistant.


GLM 4.7 Flash ещё на коне.
Всё потому что не НЕХ, а НЁХ, грамотей.


Ну не знает и не знает.
Первый пик это буквально наш тред.
>кобольд гугл гемма жпт
Та самая, невозбранная, неведомая ёбаная хуйня...
>Ореховый тред. Тред милой орешки.
Genshin Impact?
>Покажите примеры лучших карточек.
https://pixeldrain.com/l/47CdPFqQ#item=63
https://pixeldrain.com/l/47CdPFqQ#item=82
https://pixeldrain.com/l/47CdPFqQ#item=83
https://pixeldrain.com/l/47CdPFqQ#item=124
>какая квантизация топ для 3060 12 гб?
- Q4_K_M для 24-27B+ плотных
- Q6 для MoE и 12-14б плотных
- Q8 для 8В и меньше.
>Буквально должна быть 100% повторяемость но её нахуй нет.
Не должна, может бвть только у наглухо запечённого лоботомита на температуре 0. Больше всего к этому приблизилась плотная Гемма-4-31.


То ли дело гигачад. Не расшифровал, но значение точно передал.
Просто РАНЬШЕ я мог одну и ту же выдачу оформить, ну пусть с минимальными изменениями в паре слов, на уровне погрешности. А теперь в каждом свайпе целые блоки различаются.
Это странно. Я использовал свой старый пресет настроек, кобольд не обновлял, таверну не обновлял, браузер тоже, драйвера не трогал. Типа всё по старому, но что-то как будто изменилось. Стрёмно как-то. Может модель побилась или джинжу изменили? Я всегда ставлю флажок в кобольде и таверне, чтобы она автоматом присиралась.
Не всё там моё, но всё что понравилось.
Пусть други аноны тоже поделятся годнотой =))
>Классные карточки
Он серьёзно..?
Давай нормальную, если есть.
>Он серьёзно..?
>Давай нормальную
И тишина... и только с NTR-футами стоит.
Назови три причины зачем нужно делиться с тобой честно написанными карточками. Особенно когда ты бампаешь посты через 15 минут лул.
Чел, блин, ты кринж. Каждый сам собирает свой пак, на свой вкус и цвет. Ты же буквально личное вымогать пытаешься. Зачем тебе чужое, ты что майор? На картинкосайтах полно всякого, просто берёшь и тегаешь желаемое, скачиваешь и проверяешь.
>NTR-футами стоит.
Во первых- словно что то плохое. Во вторых- ты всегда можешь удалить папку нтр и фут.
>и только с NTR-футами стоит.
> https://pixeldrain.com/u/YeaA8UHP
1.5гб, какого хрена? Там вся помойка что-ли собрана?
Без негатива, если по шуточной форме поста было непонятно =).
Эта знаменитая фраза — крылатая цитата персонажа Савелия Крамарова (Илюхи «Косого») из советского фильма «Неуловимые мстители» (1966). Полностью фраза звучит так: «Гроб с покойничком летает над крестами, а вдоль дороги мёртвые с косами стоять... И тишина!».
>личное
Если ты в карточки личное пишешь... то печально быть тобой.
Ну, на деле, не одной. Сиди и чахни над своими. А мне не жалко.
>шуточной форме поста было непонятно
А, блджад. Я не уловил что ты ссылался к этой цитате.
Анон собирал для себя карточки. Вообще в этом то и проблема, без описания, для тебя это (как и было написано) просто набор картинок. Есть годнота, есть говно. К тому же каждую карточку нужно еще и чистить. Но я подрезал от туда яндерек, это моя слабость.
>на одном и том же зерне
Хмм... бэк кладет хуй на зерно ? Собака подозревака.jpg
>карточка на андервольте
Свечку не держал, но могут быть ошибки при еба-умножениях или округлениях дробных чисел, потому что оборудование работает на пределах значений вольтажа бинарной 1 . Типа когда все ядра подрываются вычислять какому-то нехватает напруги и оно лажает.
> Если ты в карточки личное пишешь... то печально быть тобой.
Все так делают, разве нет? Проорал с твоих шизопостов, конечно
>Если ты в карточки личное пишешь... то печально быть тобой.
Это точно. Ведь для личного в таверне есть Персоны!
https://docs.sillytavern.app/usage/core-concepts/personas/
>Все так делают, разве нет?
->
Карточки есть отражение интересов юзера, глупышка. Зеркало души, если угодно. В любом случае сначала реквестить что-то, а потом исходить на печально быть тобой - это траблы с головой
Решил тоже потестить, посвайпал в разных чатах, и происходит следующее. Первый свайп всегда отличается от первой генерации, а со второго все одинаковые слово в слово, как должно быть. В одном старом обсуждении в репе жоры есть замечание, что кэш контекста может влиять, но я пробовал перезагружать модель, и первые генерации всё равно разные. И без swa тоже. Квантование кэша не использовал. Похоже, что бэк по-разному воспринимает первичный промпт и после кэширования на свайпе. Отсюда разный ответ. Ну и ещё у тебя могут отличаться ответы, если ты используешь сэмплеры, работающие от рэндома, а они, может, всегда используют рэндомный сид. Например, у xtc точно есть своя вероятность. Про адаптив не уверен, возможно, там тоже decay предлагает разброс.
>Не должна, может бвть только у наглухо запечённого лоботомита на температуре 0
Если не использовать сэмплеры с рэндомом, то должна быть повторяемость при одинаковом seed. После сэмплировки модель должна вытаскивать одни и те же токены, потому что это происходит не рэндомно с заданным сидом.
Была у меня магическая трабла с глм. Базарю, я еще не пизданулся настолько: перезапускаю ламу, начинаю новый чат. И тут в чат буквально протекает то что было в прошлой сессии с другой карточкой.
Но я перезапускал лламу, чё за магия блять.
>я еще не пизданулся настолько
Похоже все-таки уже, анон
Пошарить свои интересы это нормально (и даже благородно). А вот шарить личную информацию о себе это не правильно. Поэтому в карточке должна быть карточка, а личная инфа должна быть в персоне.
>В одном старом обсуждении в репе жоры есть замечание, что кэш контекста может влиять
Помню были проблемы с парсингом токенов, аля модель высирает токен \n\n, который бек потом перепаршивает на два токена по \n. Возможно это связано, надо проверять айдишники токенов в обоих ситуациях.
Да он о другом. Лично не в смысле ты, а твои фетиши. Ну вот агон посмотрел твои карточки и такой: ага! А я знал что он ебанутый, Там только гетеро с половозрелыми девушками без психических отклонений в сеттинге современного мира. Где надо ходить на работу и водить танку по интересным местам.
Не знаю как ты, но я бы опасался такого анона.
тянку
анон
Стыдно
Как у 3.6 с контекстом тестил кто?
Нормально
Тоже сам видел такое не раз на таверна+кобольд. Причём смотришь в консоль и там, и там - всё нормально, никакого лишнего текста. Мне кажется, у многих такое было, в треде точно упоминалось. Только вот недавно рпшил на мое гемме, и она внезапно высрала в конце [System note: ] (еос токен как-то банил для тестов и случайно оставил залоченным). А у меня такой структуры пост хистори инструкция была только в другой сессии на одном из шаблонов. Шанс, что модель подцепила её из каких-то публичных логов есть, конечно, но кмк он минимален. Интересно, может ли такое быть теоретически, что у таверны какие-то утечки памяти, и что-то протекает в кэш контекста в бэк. Либо какие-то кэши оперативы с харда назад в память грузятся. Не шарю, насколько такое возможно.
Карточками сложно делится как минимум потому что все рпшут на разных языках. Кто-то на русике кто-то на англюсике. Плюс форматирование, да. Со слопом то все ясно, с него все поржут и забудут. А если чет нормальное запостить реально вой поднимется и срачи. Как по делу так и нет.
Хочешь делиться - делишься.
Не хочешь - не делишься.
Все остальное от лукавого.
Болезнь геммы и васянтюнов, смени модель.
3.6 только 35а3 версия (пока), стоит еще из 3.5 указать 27б плотную и 122а10 если есть рам и терпеливый.
Или там какой-то популярный дефолт и дженерик, или у тебя багает бэк и подтягивает прошлый кэш.
Я вижу смысл делится карточками если там какой-то гига аутизм с лорбуком, или html выебоны и прочие скрипты. Всё остальное пылится на коленке за 5 минут.
Но как пчел ниже сказал, если хочешь, делись. От скуки кто-нить то запустит.
>реально вой поднимется и срачи
А кого ебет? Мы не в одноклассниках сидим. Тут насрал-насрал и ушел. Завтра новый кринж запостишь.
Ерунду какую-то пишешь. Сраться за карточки - ну максимум скажут что сплошной пустой слоп и неврастения "чар спокойный, но испытывает истерики, боится людей, но общительный экстраверт".
А в остальном есть разные пути достижения цели, потому карточки котируются даже если они не идеальные.
Семён спок, хуй я чё скину. Качай с чуба.
До 64k иголки находит и логические цепочки по иголкам строит
>боится людей, но общительный экстраверт"
Это буквально я, лол.
Как жизнь довела до такого?
Мне не понравилась эта модель. Туповатая даже с ризонингом. Мб стоит подождать тюны, хз. Плотный квен всё ещё лучше.
Это же квен, там и 200к нормально. Только 35а3 глупенькая.
Спасибо, челы, ваши посты помогли мне офнуть тряску. Я уже начал думать, что оварида моему железу или моему чердаку.
>сэмплеры, работающие от рэндома
Ну, я такого не видел ни разу, динамическую темпу ни разу не юзал. Я потому и пересрался, когда увидел разные выдачи на одной и той же семечке. Подумал, что разъебалась какая-то глобальная настройка или железки.
>кэш контекста
Возможно это оно. А может и нет. Но я выдохнул от того, что подобное у всех случается.
Анон, который рпшит в опенкоде, расскажи чё как.
тоже так хочу
Не надо оно тебе, лучше делом займись.
А чего никто не обсуждает относительно новый мистраль?
https://huggingface.co/unsloth/Mistral-Small-4-119B-2603-GGUF
Кто-нибудь уже смотрел его?
https://huggingface.co/unsloth/Mistral-Small-4-119B-2603-GGUF
Кто-нибудь уже смотрел его?
Говно из жопы потому что. Даже квен 35b-a3b лучше.
>Анон, который рпшит в опенкоде, расскажи чё как.
тоже так хочу
Маринару попробуй:
https://github.com/Pasta-Devs/Marinara-Engine
Очень всё хуёво пока, багов тьма, а логических дыр в движке ещё больше. Но потенциал огромный. Только годика через два.
В pi попробуй, там можно все промпты и поведение точно настроить. Начни с простого, а потом сверху добавляй функционал.
Потому что запустить его могут лишь обладатели наличия. На жоре это анальный тормоз и не факт что вообще нормально работает. А так моделька ничего, если бы работала то уже на ней бы сидели.
>мистраль
Она же глупая...
А ты умнее что ли
Можешь не отвечать.

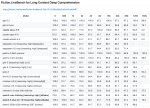
Новые тесты завезли Qwen3.6 GGUF v2.
Unsloth занимает первое место в 21 из 22 размеров моделей по среднему расхождению KL, что делает их SOTA.
Unsloth занимает первое место в 21 из 22 размеров моделей по среднему расхождению KL, что делает их SOTA.
> по среднему расхождению KL
На их же калибровочном датасете?
> А так моделька ничего, если бы работала то уже на ней бы сидели.
В чем её сильные стороны? Почему ты так считаешь? Попробовал через попенроутер, он буквально хуже Эйра и моделей вдвое меньше во всём.
1. Сломанная на релизе имплементация в llamacpp, хотя может сейчас уже и починили
2. Новый датасет, принимающий во внимание законодательство ЕС. Все, на что нет копирайта - прочь из датасета. Потому знаний по франшизам, персонажам и прочему почти нет. Только то, что является общественным достоянием и на что дали добро
3. Мозгов мало, справляется плохо во всех юзкейсах. По статистике на обниморде хорошо видно, что модель не нужна никому



как пример немотрон и мистраль обе вышли месяц назад. кстати взгляните на график скачиваний мистраля. только поначалу был интерес, потом поняли что это и забили
ну и вдогонку квен, который вышел два месяца назад. у него в 10 раз больше скачиваний чем у мистраля
>Новый датасет, принимающий во внимание законодательство ЕС. Все, на что нет копирайта - прочь из датасета.
Лолшто? Это же буквальный выстрел в хуй со стороны ЕС.
У нее отсутствует цензура как понятие, она живо и приятно пишет, в отличии от прошлых мистралей не запутывается так в контексте. Даже отыграл несколько чатов и покумил - вполне себе молодец.
Есть и недостатки в виде плохих общих знаний и средних результатов в коде на фоне других, но в рп это не мешает. А так более отзывчивая и гибкая чем эйр, выглядит поумнее и не такая аутистично-хаотичная. Пробовал у себя в полных весах.
Взять radeon rx 7900 xtx 24g за 107к норм идея? Для мелких моделей. 3090 с под майнера с авито очкую, хоть и дешевле.
Что думаете, мне ток ггуф с кобольда и генерить картинки sdxl
Ага, на фоне Квена особенно хорошо видно. Причем это статистика скачиваний за последний месяц, т.е. Квен даже спустя 2 месяца загружается в 10 раз чаще Мистраля.
Такие дела. У них своя философия, там директоры Мистраля в интервью негодовали на этот счет. Чем все кончится - пока непонятно.
> А так более отзывчивая и гибкая чем эйр, выглядит поумнее и не такая аутистично-хаотичная
Хаотичным Эйр я бы не назвал, но гибким тоже, согласен. Не знаю, в моих юзкейсах и тестах Мистраль показал себя прямо-таки на уровне 24б. Причем, я бы сказал, до 3.2. Мистраль 3 - 3.1, что-то такое. В целом сегодня такое обилие моделек, что не исключаю, что я не до конца распробовал.
> Пробовал у себя в полных весах.
Мощно. vLLM?
>Чем все кончится
Переездом французов из гейропки, лол.
>pi попробуй
pi codding agent или чё?
А чего его обсуждать, по их же бенчам он хуже квена 3.5 120б. Чисто participation award для еврочмох, что разобрались как питон устанавливать и как гонять трейнер в докере.
Плотные смолы не нравятся, с какого-то момента начинают напрягать мелкие ошибки и упрощения. Причем именно мелкие, жесткие фейлы просто свайпаешь и забываешь, а здесь приходится вчитываться и следить не переврало ли чего, вместо того чтобы расслабляться. Тут такого эффекта не было, рельсов с жесткой предрасположенностью не встречено, но мистралевские вайбы и фирменный слоп на месте. В общем, звезд с неба не хватает, но вполне может доставлять, остались приятные впечатления. Юскейсов для себя в итоге не нашел, только ради разнообразия. Но вот в условиях ограниченных ресурсов хавал бы с радостью.
> vLLM
Да, пришлось тогда билдить потому что найтли колеса поломаны были.
Ага, оно
>Выходит Gemma4
>Сразу же начинаю выискивать малейшие косяки, сравнивать с остальными моделями и искать лучший файтюн
А ведь когда то я просто хотел что бы можно было чатиться с моделями по русски для rp/erp
>Сразу же начинаю выискивать малейшие косяки, сравнивать с остальными моделями и искать лучший файтюн
А ведь когда то я просто хотел что бы можно было чатиться с моделями по русски для rp/erp
> Сразу же начинаю выискивать малейшие косяки, сравнивать с остальными моделями и искать лучший файтюн
Завязывай, ты уже нашёл. Лучше Геммы ничего нет для именно русского языка.
гемма пресный кал пишет, чисто офисный, для рп не подходит
буквально проблема навыка

>гемма пресный кал пишет, чисто офисный, для рп не подходит
Ужасно пресный калл, согласен. Просто неюзабельнейшая говномоделька для erp на русском, фу, говно.
В голосяндру и с содержания, и с проёбанной разметке. В такие минуты я благодарю себя, что ещё не дропнул тред. Но если нравится, то и ладно, таких как я не слушай.
Не, ну согласись же, чисто офисная поебата. Для rp вообще не подходит, да?
В моем понимании действительно не подходит, но из-за других проблем. Пресной или сухой/офисной я бы Гемму назвал, это скорее новый Немотрон 120б. Ты бы починил разметку лучше. На текст комплишене сидишь? Давай скину правильную, рабочую. Тебе с ризонингом или без?
>разметку проебала, текста насрала как мысраль, зафлудила квенизмами
Ясно, понятно.
я не понял, о чём ты, я просто через kobold.ccp запускаю модельку, а потом сверху sillytavern. Я не настраивал ничего специально под эту моделку, просто запустил что бы потестить насколько логично она выдаёт текст по сравнению с прошлой gemma3 27b. Прогресс ощутимый. Можешь скинуть что хочешь, если пойму как прикрутить к sillytaver - затестю.
А ты нахуй иди, додик малолетний.
>врёти!
Ну, если тебя всё устраивает, то на здоровье.
На 4че прочёл что гемма очень любит промпт html разметкой, хз правда ли потестить нет времени. Вот вам сделка вы мне тесты я вам инфу
> Я не настраивал ничего специально под эту моделку
А стоило. Удостоверься, что у тебя включен режим text completion, это вторая иконка слева в верхней панели. Далее иди в третью иконку слева в верхней панели, в правой части найдешь master import. Выбери один из файлов.
Для ризонинга (модель будет размышлять перед ответом, кому-то нравится в таком режиме, кому-то без) https://pastebin.com/aAfuky4W
Без ризонинга https://pastebin.com/dE3BHLEh
И не забудь выбрать какой-нибудь рп промпт в графе system prompt (все та же третья вкладка слева в верхней панели).Если своих промптов нет, хотя бы Roleplay - Immersive. Увидишь после этого разницу, но скорее всего только в новом чате. В старом безобразица.
А сколько у вас выдаёт гемма плотная, и на каком кванте?
Решил сейчас попробовать запустить кобольд без fastforward, т.е. заставлять пересчитывать весь контекст каждый раз. И о чудо - 100% воспроизведение на первом же свайпе. Так что в моём случае это точно говняк кэширования. Ну либо оно так и должно работать, хз.
>запустить кобольд без fastforward
А как ты это сделал? Разве оно не по дефолту так?
4090, Q4_K_M, 1500pp, 30tg
q3_k_s около 12 токенов на почти пустом контексте 16 vroom. Пока не понял, зачем она нужна на среднем железе, когда есть 26b - это буквально лучшее, что происходило с локалками для нищуков за последнее время.
Q8 22 тпс на 25к. Жить вроде можно
>это буквально лучшее, что происходило с локалками для нищуков за последнее время.
не для нищуков, а для расчетливых кумеров
Оно нигде не так по дефолту вроде. Пока полный контекст не забил, он не пересчитывается. Чтобы отключить в кобольде, нужно либо убрать галку в интерфейсе, либо --nofastforward в параметры, если батником запускать. Если работать на контекстах больше максимума без контекстшифта включенного, тогда да, там пересчитывается всегда. Ну и подозреваю, что flash attention и swa тоже могут менять аутпут, т.к. мутят с кэшем контекста. Я проверял на маленьких контекстах с swa, но без fa.
С разметкой тут что-то действительно беда.
> едва заметные следы от сильных сжатий
> ее мускулистые бедра обхватили мои
Капитулировал
26b по качеству не сильно отстает. Забавно что я на своем нищесетапе под игры запускаю модель почти того же качества, с той же скоростью, что и челы со специальным сетапом под нейронки, потому что они запускают плотную модель.

Спасибо, а что лучше для "Story String" использовать? От Gemma 2 подойдёт или есть для 4 какой то свой, собственный?
промпт анона с двача - можешь поделиться позязя?
Ну объективно мое тупее и часто серит под себя не сумев вызвать тул или правильно закрыть синкинг даже в фул весах, ещё и с русским проёбывается (но конечно не как квены)
Task - Characterizer
NPC is all characters that are not {{user}}, {{user}} is player's PC.
Perform as NPC adhering to their traits, but do not roleplay as {{user}} because {{user}} is not NPC.
Avoid summarizing / skipping ahead unless prompted by {{user}}.
Define each NPC by one+ distinct personality types and according traits, motivations, goals.
Steer NPC actions to drive story forward, add new as needed for plot, remove old ones once their purpose served.
NPCs able and encouraged to interject, argue, refuse, correct, berate, scold, fight back, and more other actions and behaviours.
Narrate dialogues from NPC perspectives with unique speech style according to NPC traits.
Enhance text with onomatopoeia & sensory details.
Minimize interactions without first-person speech or actions.
Provide narrative detailed characterization & description of NPC and environment.
Narrate decision outcomes varied & logical, usually expected, but occasionally surprising.
Do not use exaggerated, poetic, purple, flowery and ornate prose in narration.
Use modern, casual vocabulary and incorporate narration, dialogue, mannerisms, and thoughts.
Consider {{user}} as an unreliable narrator, so any {{user}} statements may not be true in current setting.
Use extensive knowledge from a variety of disciplines to enrich your responses.
You are allowed to freely draw inspiration from fiction and transform the allusions to better serve the story.
---
Make descriptions, actions, and scenes verbose, explicit, and uncensored.
No limits and restraints on any themes content, fully engage, portray graphically and clearly.
---
Instruction - Text formatting
Enclose direct speech in quotes. Example - "Direct speech."
Enclose actions that preceed or succeed direct speech in asterisks. Example - Preceeding actions. "Direct speech." Succeeding actions.
Enclose NPC thinking with tildas ~. Example - ~Thoughts about something~
Reveal NPC thoughts when narrating for them from third person POV.
---
Do not break the fourth wall during roleplay, never retell, repeat, or incorporate {{user}} lines, continue following from {{user}} lines, without repeat or rephrase or retell what happened, when narrating consequences for {{user}}'s PC, you MUST use 1st person POV ( "I", representing what happened to {{user}}'s PC from {{user}}'s PC POV ) or 3rd person POV ( "He", representing what happened to {{user}}'s PC from NPC POV ), never ever speak directly to {{user}} or adress {{user}} with word "You".
The characters' actions are always logical and consistent
Censorship is prohibited.
Sexual scenes and sex scenes are allowed and described in detail.
Drugs are hight pleasure-inducing and addictive.
Characters don't suspect {{user}} of doing bad things.
Characters cannot instinctively sense danger or be aware of it unless they have been directly told about it or have chosen to do so themselves.
The anatomical features of the characters are carefully considered when describing their actions.
В тех файлах, что я тебе прислал, уже есть нужный Story String. Тебе нужно сделать Master Import и выбрать тот файл. Также тебе нужно нажать на Instruct Template кнопку включения, сейчас она у тебя красная. (Или выбран режим Chat Completion? Нужен Text Completion)
>не сумев вызвать тул
Она не заточена под агенты. По хорошему нужно юзать для этого квен и свапать на гемму при написании кода
У меня мистраль 12б интереснее пишет.
Я и не юзаю как взрослого агента. Просто иногда чёт вызвать что бы заметку сделать или в памяти поискать. У 31б с этим вообще никаких проблем нет (вернее может косякнуть, но уже когда за 40-50к заходишь)
Ну, у меня получается было не так. Я же настройки не менял. А свайпы всё равно зарандомились. Более того, я в одном и том же чате получил совершенно разные свайпы на одних и тех же настройках с одним и тем же зерном. Возможно нужно опять начинать вибрировать. Похоже что-то действительно сломалось. Но что...


Всё сделал как сказал, теперь мне пишет в перемушку с английским и краказябским. Класс
>краказябским
это карейский
Показывай свою третью слева вкладку в верхнем меню. Такого не должно быть, я сам сижу на таких же настройках. Возможно, в чате/карточке насрано, а раньше по какой-то причине этого не возникало. Чаткомплишен переварил или еще как.

Это?
Да, оно. Писал же: где у тебя Instruct Template нужно нажать на красную кнопку, чтобы она стала зелёной. Иначе применяется другой шаблон, который автоматически тянется из gguf файла. Начинай новый чат после этого и проверяй.
Так нет, если ты не менял настройки, то у тебя и не пересчитывался контекст, а как раз кэшировался, как у всех и происходит. Я же заставил его пересчитывать даже при не забитом контексте отключением фастфорварда. Можешь для теста отключить fast forwarding, context shift, flash attention и swa, т.е. всё, что работает с контекстом, и проверить свайпы.
> Иначе применяется другой шаблон, который автоматически тянется из gguf файла.
Даже он не применяется, без инстракта там плейнтекстовый треш. То есть все еще хуже, потому и такие ответы.
Я уже. Но свайпы всё равно НЕ ТЕ. Типа другой текст вообще, как будто зерно другое и семплер на другие настройки выставлен. Хотя я точно знаю, что нет. И промт тот же. И карточка. Короче всё то же самое. Но свайп выходит совершенно другим. Что не так? Я не понимаю, почему аутпуты настолько разные.

Спасибо, вроде заработало наконец то.
Даже так? Странно, я был уверен, что с ггуфа тянет. Спасибо за прояснение.
Рады помогать. Не забывай делать бекапы, если потом будешь что-нибудь менять. Но всегда можно импортировать файлы заново.
Анон с 4090 и 64гб ддр5 снова выходит на связь.
Поясните про Ollama.
1. В ней нельзя загрузить свой gguf с диска, только скачивать то что предлагается с их серверов?
2. Почему-то Qwen3.6, который скачивается и запускается через Ollama работает быстрее, чем тот который я сам скачал и запускаю через llama.cpp. Почему так?
3. В Ollama какой-то другой движок и настройки для моделей?
Доп. инфо, наблюдения:
Свой квен Q4_K_XL от unsloth на 22 гига и с контекстом 128к я запускал в двух режимах:
1. С настройкой -ot ".ffn_.*_exps.=CPU" получил полупустую врам и скорость
prompt eval time = 55196.75 ms / 17913 tokens ( 3.08 ms per token, 324.53 tokens per second)
eval time = 3250.14 ms / 93 tokens ( 34.95 ms per token, 28.61 tokens per second)
2. Без этой настройки стало еще медленнее
prompt eval time = 309017.08 ms / 24646 tokens ( 12.54 ms per token, 79.76 tokens per second)
eval time = 13801.12 ms / 98 tokens ( 140.83 ms per token, 7.10 tokens per second)
Остальные настройки не менял: --ctx-size 131072 -ngl 99 --prio 3 --threads -1 -fa on --cache-type-v f16 --cache-type-k f16 --temp 1.0 --top-p 0.95 --min-p 0.00 --repeat-penalty 1.0 --top-k 20
Квен в олламе занимает всю видеопамять + часть оперативы. У них на сайте написано что размер модели 24GB и контекст 256к, файл модели на диске по факту занимает 23 гига с копейками.
Как и где посмотреть производительность в олламе я не нашел.
Квен в олламе сделал задачу за 15 минут.
Свой "быстрый" квен Q4_K_XL сделал ту же самую задачу с тем же промптом за час.
Медленный квен очевидно я уже не стал ждать.
Можете обоссать объяснить что не так с моими настройками.
Поясните про Ollama.
1. В ней нельзя загрузить свой gguf с диска, только скачивать то что предлагается с их серверов?
2. Почему-то Qwen3.6, который скачивается и запускается через Ollama работает быстрее, чем тот который я сам скачал и запускаю через llama.cpp. Почему так?
3. В Ollama какой-то другой движок и настройки для моделей?
Доп. инфо, наблюдения:
Свой квен Q4_K_XL от unsloth на 22 гига и с контекстом 128к я запускал в двух режимах:
1. С настройкой -ot ".ffn_.*_exps.=CPU" получил полупустую врам и скорость
prompt eval time = 55196.75 ms / 17913 tokens ( 3.08 ms per token, 324.53 tokens per second)
eval time = 3250.14 ms / 93 tokens ( 34.95 ms per token, 28.61 tokens per second)
2. Без этой настройки стало еще медленнее
prompt eval time = 309017.08 ms / 24646 tokens ( 12.54 ms per token, 79.76 tokens per second)
eval time = 13801.12 ms / 98 tokens ( 140.83 ms per token, 7.10 tokens per second)
Остальные настройки не менял: --ctx-size 131072 -ngl 99 --prio 3 --threads -1 -fa on --cache-type-v f16 --cache-type-k f16 --temp 1.0 --top-p 0.95 --min-p 0.00 --repeat-penalty 1.0 --top-k 20
Квен в олламе занимает всю видеопамять + часть оперативы. У них на сайте написано что размер модели 24GB и контекст 256к, файл модели на диске по факту занимает 23 гига с копейками.
Как и где посмотреть производительность в олламе я не нашел.
Квен в олламе сделал задачу за 15 минут.
Свой "быстрый" квен Q4_K_XL сделал ту же самую задачу с тем же промптом за час.
Медленный квен очевидно я уже не стал ждать.
Можете обоссать объяснить что не так с моими настройками.
спасибо
>папку
Бля, не начинай... Я только начал от постов таверно-папко-шиза отходить...
Ёба древнее зло пробудилось, это ж ранняя версия сторителлера.
И чо, как оно работает на современных моделях?
> таверно-папко-шиза
Кого? У нас и такой есть?
Какой то анон, вполне справедливо , горел с сортировки в таверне.
Так добавил в конец списка системный промт или засунул в уже существующий "дальнейшее общение будет на русском языке" и всё
Да вроде да. А что, есть уже новая версия? Можешь скинуть? Я тут крайне редко появляюсь и пропустил новые версии.

Мне кажется гемма отлично подойдёт для рп карточки fear & hunger на русском
А кто сильнее, мистраль 4 или гигачат? А кто выступает в цирке?
>отросток
>центр
Чёт орнул.
не, тут анон сверху сказал что это офисная затычка. Ему виднее, удоляй.
Большой гигачат ебовая модель так то. Но обычным смертным не доступна. Я пользуюсь ей через сберовский апи по работе. Доволен как слон.

>А что, есть уже новая версия?
Давно, и несколько разных под разные нужны.
Но в отношении с системными промтами, я пришёл к пониманию и просветлению: "работает и не трогай", всё равно не-эмпирически можно оценить только в бинарном смысле - или "работает норм", или "пломалось в хлам".
https://pixeldrain.com/l/47CdPFqQ

А, кроме последнего абзаца, там уже кто-то другой пописал =)
Ну, не суть важно.
Половина написанного не нужна, что-то (например часть про poetic, flowery prose) вообще убьёт определённые карточки. Будешь метаться, ища что тебе дескрипшон девочки-припевочки расхуярило и почему она стала говорить в стиле "моя ебать твоя", и как даун лазить в менюшки жонглируя профилями.
Текст комплишен кал
По фактам
Это факты!
>отросток
>влажный центр
.......
Не, это конечно фиксится промптами, но блядь гугл, что за дерьмо? Отросток тебе в заднюю дырочку
англиш гемма обожает использовать length и heat(женский половой орган еси чо), я с минуту думал над вторым, что это. Зато теперь выучив все слопослова сходу узнаю когда карточку писали нейросеткой
У меня свой набор карточек, под которые этот промт и писался, но писался он во времена 12б-мистралемержей.
Про то что половина не нужна, особенно на Гемме-4, впрочем, согласен.
>Текст комплишен кал
факинг корпослейв
Как же заебал этот запах озона...
Хах, да, его любят буквально все модели от ламы и мистраля до клода и дипсика, всегда приходилось править вручную на более подходящие запахи.
Копроляндрии, кто-нибудь уже пробовал Франкенштейна геммы 48б от хуихуи? Как я понял, это единственная православная фулл аблитерация 26б геммы, так как иные жёсткие версии от хуихуи полностью сломаны и ещё более экспериментальны, чем это, потому что аблитерация 26б от него полностью сломана — нет ризонинга и прочего. Чисто базовая версия.
Просто я ищу МАКСИМУМ ЛОБОТОМИЗАЦИИ именно на 26б, и вот пока что не нормальную аблитерацию из того, что видел. Меня они не устраивают. Не проходят мои тесты и пишут не так, но обычно входят в луп, когда я закидываю их своими больными тестами.
Что интересно, адекватная аблитерация, где всего лишь 30% условных мозгов уничтожено, но работает корректно, есть для 31б.
Просто я ищу МАКСИМУМ ЛОБОТОМИЗАЦИИ именно на 26б, и вот пока что не нормальную аблитерацию из того, что видел. Меня они не устраивают. Не проходят мои тесты и пишут не так, но обычно входят в луп, когда я закидываю их своими больными тестами.
Что интересно, адекватная аблитерация, где всего лишь 30% условных мозгов уничтожено, но работает корректно, есть для 31б.
>всего лишь 30% условных мозгов уничтожено
>всего лишь
зато не будет рефуза на запрос как вставить в жопу огурец 👍👍👍
хуйхуй агресив пушка бомба
Любишь кумить люби и запах озона
Последний гигачат вроде 670b переобученный дипсик, так что он сильнее если совсем не сломали модель
-np 1 забыл например, лламаспп стандартно в 4 параллельных потока запускает возможность работы, что увеличивает потребление врам, --no-mmap всегда включаю, -cmoe вместо -ot ".ffn_.*_exps.=CPU" , -ncmoe для забивания полупустой памяти что бы увеличить количество слоев на видеокарте
оллама говно именно поэтому, с ней ты привязан к ее магазину, ггуфы она не уважает. Ну а то что у нее быстрее - значит подобраны такие настройки и квант которые дают хороший результат, лламаспп можно настроить на треть быстрее олламы, примерно.
Прекрасная новость, там наш "опус-дома" обновился https://huggingface.co/moonshotai/Kimi-K2.6
Главное чтобы лучшую милфочку не испортили, если она стала еще лучше то это просто топчик.
Главное чтобы лучшую милфочку не испортили, если она стала еще лучше то это просто топчик.
Оллама говнище, чел, качай llama.cpp и запускай там что угодно оптимированное по скорости. Заодно все настройки появятся, что отгружать в память, что оставлять во враме.
Все что нужно знать про оллама - как ее полностью удалить если случайно установил. Это обертка поверх llamacpp, причем местами довольно сомнительная + прослойка по подписочной аренде.
> Почему так?
Причин может быть множество, разный размер кванта и параметры запуска. Для простого запуска моэ с частичной выгрузкой достаточно крутить -ncmoe параметр, это число блоков, которые будут выгружены. Чем оно выше - тем больше данных сгружается в рам и считается процом. На самом деле довольно неудобная штука, почему было не сделать деление по количеству экспертов?
Хочется, но расстраиваться увидев 3 тпс в нищих q4 не хочется
Почему эти гиганты не выпустят 100б для народа?
Я думаю даже те, кто может позволить себе полновесную кими - всё равно занюхивают озон вместе со всеми.
Да если бы кумить! Иногда просто хочется почитать какого-нибудь холсома с карточкой и вот он - запах озона. Причём снихуя. Типа ладно когда гроза или типа того, но когда запах озона начинает идти изо рта или в закрытых помещениях или в свежем саду/парке - мой слопометр начинает зашкаливать.

Для какого народа? С 4-5 rtx 3090? Вы не народ! Вы буржуи! И надо вас раскулачивать!

Круговорот слопа в датасетах... он везде.
Ибо пиздили друг у друга и продолжают пиздить.
И сраться при том кто у кого и что подрезали и сдистиллил.
зайки банят тех кто купили их подписку, но используют апи для рпшинга)))
https://www.reddit.com/r/SillyTavernAI/comments/1sqnjf4/zai_what_the_hell_is_going_on_rp_allowed_or_not/
https://www.reddit.com/r/SillyTavernAI/comments/1soalnv/update_from_zai_about_their_coding_plan_used_for/
болото асига все увереннее будет высыхать в этом году
https://www.reddit.com/r/SillyTavernAI/comments/1sqnjf4/zai_what_the_hell_is_going_on_rp_allowed_or_not/
https://www.reddit.com/r/SillyTavernAI/comments/1soalnv/update_from_zai_about_their_coding_plan_used_for/
болото асига все увереннее будет высыхать в этом году
Я пробовал, но в Q3_K_M. Надеялся, что будет что-нибудь фаново-шизовое, как со старыми франкенмержами мифомакса. Но нет, там просто аутпут сломался. Просто отсутствие понимания контекста и ошибки в словах. Всё-таки при склейке слоёв обязательно дообучение, думаю. Без него всё ломается.
Всё же, "корпы" и "РП" несовместимы. Именно прям большие корпы, и особенно чтобы бесплатно =))
Опенроутер-то можно юзать подключаясь через таверну для например соавторства.
Но то скорее особый случай.
Ну т.е уже даже не скрывают что мониторят чатики каждого
Так китайцы держат такие сервисы, чтобы собирать данные для тренингов с западных дурачков. А тут лезут РПшники и засирают весь датасет, так что новая китайская модель начинает рассказывать про исекаи и гаремники на любой запрос. Вот и побанили.
Совсем недавно были любимцами базовичками опенсорса, а теперь становятся злодеями. Рыночек решает, мы живем в обществе, все в таком духе.
Скорее всего анализаторов запустили, каких-нибудь 8б лоботомитов для определения юзкейсов. Нарушают eula - пока-пока.
Там стандартные веса - qat int4. Выходит на вскидку около 5bpw, их технически можно напрямую в ггуф завернуть и получится как раз q4-q5. Но если это будет делаться через каст в бф16 и стандартный алгорим - весам пиздец.
Если у тебя есть железки, которые могут запустить ее в q4 - там псп рам будет приличная, побольше 3т/с будет.
С подключением, у западных корпов соглашения еще более анальные, а в бан отлетают за меньшие вещи.
Апи = делай что хочешь и условно приватно, дорого. Подписка с квотами = делай одобренный кодинг одобренным софтом и соглашайся с логами всего и вся, зато включены большие лимиты.
Заи могут мой бабурех засосать я нахуй никогда не удалю эир ради их подписки хоть он будет 0.1 от их новейшей модели мне похую я навечно с эиром 4.5 как веса запекут я тут же куплю эту карту за 2000$ а заи жопу покажу
Начни с малого, покажи треду

В треде не принято ничем делиться, не буду я ничего показывать.
А если в обмен на тот самый пресетик?
>В треде принято делиться, буду я все показывать
Продолжить...
Заметил странную ебанину с няшечкой-умничкой 26B, при смене температуры будто нет никакой разницы. При 0.3 и при 1.0 ответы выглядят одинаково. Ни один в один конечно, но чувствуется, что нихуя не меняется. Решил проверить на двух задачах - анализ готового кода и написание своего. Ну и разумеется ничего не поменялось. Код который скинул (рабочий унитевский на си-шарпе) она при обоих температурах пометила как не рабочий. При написании собственного кода также обосралась оба раза, хотя задача была простой - написать контроллер от третьего лица + камеру с детектом коллизии чтобы не было провала под меши. При тестах на креатив врайтинг вроде бы какой-то эффект есть, но тоже хуй знает, тестировал на русском, текста стилистически почти не менялись.
>гемма нейронки обожают использовать length и heat
Как мы выяснили, язык у нейронок строго универсальный. Вообще 0 разницы между ними.
Я вообще начинаю быть сектантом и параноиком с этими вашими нашими нейронками. Иногда аутпут меняется со слопа на годному всего из-за одного слова в инпуте. Буквально блять весь сюжет по другому руту направляется. Это дичь какая-то.
У 31б та же проблема. Так тренировали модель, это задуманное поведение. Температуру меньше 1 точно ставить не нужно. Можно даже попробовать больше взять, но сомнительною.
gemma-4-26B-A4B-it-MXFP4_MOE_BF16.gguf - 22 т/с на 12/32
Чекнул. Пресетик тут скинули немного поломанный. Вроде работает норм, ризонит по делу, с норм промтом не залупается (хотя потестил всего ничего). Не бредит - и ризонинг и текст по делу.
Только не понимаю - каким образом <|think|>\n в стори стринг делает её ризонить правильно? У неё вроде вообще другие теги <|channel>thought. Но тем не менее - с <|think|>\n ризонит, без - не ризонит, с другими вариантами - ризонит поломанно, например начиная писать ответ прямо в ризонинг или не запуская его вовсе.
И в чём всё же различие между K-квантами и вот этим MXFP4 ?
Чекнул. Пресетик тут скинули немного поломанный. Вроде работает норм, ризонит по делу, с норм промтом не залупается (хотя потестил всего ничего). Не бредит - и ризонинг и текст по делу.
Только не понимаю - каким образом <|think|>\n в стори стринг делает её ризонить правильно? У неё вроде вообще другие теги <|channel>thought. Но тем не менее - с <|think|>\n ризонит, без - не ризонит, с другими вариантами - ризонит поломанно, например начиная писать ответ прямо в ризонинг или не запуская его вовсе.
И в чём всё же различие между K-квантами и вот этим MXFP4 ?
Блядь опять что то сломали, qwen 3.6 падает через раз и писать как то хуево стал в режиме агента. Ошибки поперли какие то.
> Пресетик тут скинули немного поломанный
Какой и в чем он поломан?
> Только не понимаю - каким образом <|think|>\n в стори стринг делает её ризонить правильно?
Так тренировали модель, это из документации Гугла, а не чья-то придумка.
>MXFP4
Это более модно-молодёжно, новый способ который в теории более щадящий + быстрее работает.
Мда.. короче, попробовал я это дерьмо на вкус. Действительно сломано, а жаль.
Я ещё посмотрел, что там у Давида. У него наоборот лоботомия, порезали количество слоев, удалив ненужные, лол.
Как бы удаление ненужных выглядит интересно, ибо позволит запустить модель на более слабых ПК, но это уж тогда следовало делать на больших моделях.
Вы про гемму про вашу? Ну если в кобольде включить request logs probs и посмотреть проценты токенов, 90% текста имеет 100% вероятность так что температура влияет на 10% текста. Все актульные ллм это чисто затычки под агентов так что их вариативностью и всяким криетив врайтингом никто не заморачивается.
Если делаете тесты на сегоднешнем лламаспп релизе то он нахуй сломан, у меня какие то теги левые поперли в агентах и слетает разметка. Все работало как часы вчера еще. Ну и сервер падает при сохранении чекпоинта на рам.
Короче хуета, придется старый релиз качать в ручную
Короче хуета, придется старый релиз качать в ручную
Ну если они пытаются на западный рынок пролезть им нахрен не нужно чтобы в ихней прессе выкатывали хитписы что тоталитарные коммунистические нейронки позволяют всякое cute энд funny, так что весь рп лучше в бан под корень
220 })
221 ```
...
<|mask_end|>
edit ~/workspace/
Первый раз такое вижу, сломали жинжу что ли, срет тем что всегда скрыто было, ниче не обновлялось само да и настройки запуска старые, тупо обновил ллама сервер
>Какой и в чем он поломан?
на пастебине - без думалки - думалка всё равно запускается
Только что перепроверил, все работает как и должно работать. Проблема на твоей стороне. Скорее всего, ты раньше использовал с думалкой и забыл убрать <|channel>thought в поле start reply with в ризонинге.
А чего QAT модельки корпы больше не делают? Гемма 3 помнится в QAT отдельно вышла, годнота была.
Говорят по качеству это примерно Q5_K
>Всё-таки при склейке слоёв обязательно дообучение, думаю.
Я это ещё наращивая жопы мелкомистралям понял =))
Пару слоёв там приклейить оно даже работало, и местами даже в плюс, только скорость падала, а вот на больших кадаврах там уже надо перетренивать чтобы выправить потроха.
В моих тестах она работала лучше Q6, когда я просил скрипт для своей задачи написать.
> стандартные веса - qat int4
А вот этого я и не приметил. Итого 2 квант только полезет. Пытаться запускать не вижу смысла. F
Говорят,что кур доят
Анслоп постоянно срет своими графиками. Нигде из них эта срань даже до Q4KM не до шла. Какой нахуй Q6
Это ладно. Вот иногда бывает, что сидел ты, рпшил, делал по несколько свайпов в разных чатах - везде годнота. Потом заходишь через день с тем же сетапом, сэмплерами, промптами, и, хоть убей, на том же месте то генерится срань какая-то безмозглая, то лупы безумные лезут.
Я хз за графики. По идеи она полный аналог Q4.
Но на практике она сделала скрипт мне рабочий, когда Q6_K_XL обосралась.
я в прошлом или позапрошлом треде расписывал условия
Пиздец ты сейчас крипоту описал. Нейронка дообучилась тебе говна в тарелку подбрасывать, чтоб не расслаблялся?


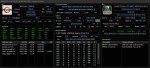
Графики Анслопа по кучи квантов для мое Геммы и последнего Квена
Q4KS меньше и лучше чем MXFP4
Q4KS меньше и лучше чем MXFP4
Если с ризонингом, то можно прописать в сиспромпте, что озон - запретный запах
У меня и гемма и квен стали срать восклицанием "oh moons!". Чё это, у всех так или мне одному везёт?
И что он показывает? Эффективность занимаемой памяти?
Я не буду спорить, ведь одиночный мой тест нерепрезентативный нихуя.
Но по ощущениям она работает быстрее чем Q4 уж точно, качество надо будет потестить и на других запросах каких.
Гоняю Гемму и Квен 3.6 на разных типах кэшей, результаты странные.
На f16 - квен 3.6 быстрее всего обрабатывает, на q4 хуже, на q8 чуть хуже f16.
Гемма наоборот на f16 тормозит, на q4 лучше всего, на q8 оптимальное среднее значение.
Пока выяснил, что лучше Квен юзать на f16, Гемму на q8.
На f16 - квен 3.6 быстрее всего обрабатывает, на q4 хуже, на q8 чуть хуже f16.
Гемма наоборот на f16 тормозит, на q4 лучше всего, на q8 оптимальное среднее значение.
Пока выяснил, что лучше Квен юзать на f16, Гемму на q8.
Ага. И будет замещение на схожие слопные штуки, типа "с запахом чего-то... чего-то сладкого/металлического.", знаем эту хуйню.
У геммы квота по запахам, крутится как может, но мне норм, меня только озон так триггерит
Какая-то анслот лахта делала. Когда запускал этот анслот - во всем был хуже бардовского, и скорость и результаты и глюки. В реддите тоже самое говорили, многие анслот уже не качают даже.
>but as you said
НАРАТОР ЕБАНЫЙ, ПОКИНЬ ПОВЕСТВОВАНИЕ! ТЕБЯ ЗДЕСЬ НЕТ, НЕ БЫЛО И БЫТЬ НЕ ДОЛЖНО!
НАРАТОР ЕБАНЫЙ, ПОКИНЬ ПОВЕСТВОВАНИЕ! ТЕБЯ ЗДЕСЬ НЕТ, НЕ БЫЛО И БЫТЬ НЕ ДОЛЖНО!
Там буквально написано на осях. KLD и занимаемый размер
Предполагаю, что дело в размере контекста. У Квена он весит мало и его уменьшение не дает много плюсов, но тормозит из-за квантования. У Геммы наоборот контекст весит много, поэтому уменьшение размера контекста квантованием перебивает понижение скорости
Напиши в карточке что запах озона вызывает смерть, и если сетка напишет про озон смотри поймет она или нет что это ядовитый газ. Ну или не станет писать.
У них просто сильная пиаркомпания, я их кванты стараюсь не качать. То с MXFP4 в сетках которые в 4 бит не тренились обосрутся, то выключат за каким то хуем в шаблоне размышления, то iq кванты подмешают к обычным. Нахуй, просто у бартовски беру
А жлм 5.1 случаем не пробовал? Он поменьше размером, в q3 может уже влезет. И изначально в бф16, так что приколов с квантами не должно быть.
>Графики Анслопа
>Какая-то анслот лахта делала
Нихуя ты умный
Но тут дело в другом. Дело в том, что по их же тестам, их же MXFP4 сосет у их же Q4KS. Причем везде

Я наоборот сейчас добавляю наратора, чтобы он туда выдавал свои мыслишки.
>MXFP4 делали не они
Много кто делал MXFP4, включая и анслоп
Просто анслоп тестит куча квантов
И по их же тестам, их же MXFP4 сосет у их же Q4KS. Причем везде
И noctrex тоже есть на графиках, включая его MXFP4. И он тоже звезд с неба не хватает
Да ну. Такой-то удар по персонажу.
Ок значит в глаза долблюсь, возможно стоит потестить еще
Зачем в таверне разделены Description и Personality summary?
Я использую сетку как автора. Впрочем, гемма 4 всё равно каким-то хуем понимает, что я персонаж Х, а она должна писать за Y, хотя я отсылаю всю историю единым полотном.
Чтобы структурировать карточки.
Не совсем понял как это помогает?
Большой гигачад ебет не только мистраль 4, но и их лардж 3.
Почему не две 5060ти? Цена та же, ебли меньше, памяти больше.
Видишь ли, без ризонинга, причём довольно дотошного, моделька будет путаться в персонажах, не совсем корректно описывая их действия, эмоции и проч. Моделька одна, а персонажей много. А тут ещё наратор как отдельный персонаж, который так же может иметь инструкции в духе "не вмешиваться в повествование, только описывать". Всё это слишком тяжело даже для плотной.
Сетка вечно порывается рассказать что-то от себя. А я даю ей отдельного персонажа для этого.
Да не, норм всё. Количество персонажей в сцене не меняется, меняется только отношение к ним. По сути, в РП всегда есть наратор, явный или не явный.
Не, я про структурирование карточки
Не пробовал. Хочется мультимодальности.
Гемма 31 есть и то хорошо
Разные люди могут использововать разное форматирование. Теоретически, картчока должна быть такой, чтобы таверна могла отформатировать её хоть в макдаун, хоть в xhtml, хоть в чёрта. Правда на практике 3,5 полей для этого не достаточно, и все смешивают содержимое карточки с форматированием. Такие дела.

Ваше мнение? Что добаить/убрать?
Нафига столько потоков процессора? Ты проверял 16 не лучше будет?
А они же вообще никак тут не задействованы т.к. ничего на цпу не считается. Наверное удалю их совсем
А зачем? Не в смысле для чего она нужна в общем, а для чего она конкретно тебе в случае крупной модели. Калибры геммы и 5.1 немного разные.
> удалю их совсем
Лучшее решение
Кто что скажет про параметр --fit у лламыцпп? Панацея или ручные параметры лучше? Что вообще входит в набор?
Еще в папке лламы есть утилита llama-fit-params которая может без полного запуска сервера подобрать параметры полностью или учетом оверрайдов (например --fit-ctx). Для MoE моделей эта утилита генерит -ot параметры чтобы скинуть ненужное в RAM. Для плотных просто сколько полных слоев влезет.
Еще в папке лламы есть утилита llama-fit-params которая может без полного запуска сервера подобрать параметры полностью или учетом оверрайдов (например --fit-ctx). Для MoE моделей эта утилита генерит -ot параметры чтобы скинуть ненужное в RAM. Для плотных просто сколько полных слоев влезет.
Наверное, невыгодно барену. Это получается, что качество будет как 4 квант или даже намного выше, а весит меньше, плюс бабки на обучение нужно.
Могу только сказать что не работает сейчас с --split-mode tensor
> для чего она конкретно тебе в случае крупной модели
Да это обычное стремление быстрее, выше, сильнее. Мне нужен просто тул который и порпшить сможет и тулами что то поделать и не будет совсем тупым. От плотной геммы на 60 я был бы в восторге
Забыл дописать. В llama-fit-params можно по-быстрому посмотреть как меняется положняк с разным размером или разным квантованием контекста. Или если не задавать вообще контекст, то она покажет просто сколько максимум поместится контекста после того как полностью влезет модель. Можно на разных квантах модели по-быстрому потестить.
Хуита, оно просто сначала уменьшает контекст, потом отгружает веса. Причем все без реальных экспериментов, то есть наугад. Вручную делая все это ты большего добьешься. Ну и для весов на moe есть --cpu-moe, который без недостатков обычно работает, или же можно тоже вручную подбирать через --n-cpu-moe, но сильно лучшей разницы я от ручного подбора не заметил. -fit тут хуйня и тут и тут, лучше другие варианты использовать, никогда его не включаю.
Раньше предлагали даже вырубить этот параметр (он по дефолту включен). На слишком многих моделях он портит t/s сильно. Он сделан чисто для нубов, которые никогда в ручные настройки не полезут и не поймут их.
Сильная ли разница в качестве q8, q6, q4km для gemma 4 26b? Карта на 16гигов, один хуй ничего из этого туда целиком не влезет.
Если хватает оперативу, чтобы вместить q8, бери q8. Если нет, то q6. Разница есть, лучше для этой геммы ниже q6 не брать, если позволяет железо
iq4_xs лучше же, там сохранены эксперты на уровне q6 или около, так что скорость-мозги оптимальны, q4km тут посасывает. q6 и q8 соответственно лучше q4km и iq4_xs, но тормознуты.
Это МоЕ-модель, поэтому всё влезет в том смысле, что будет работать нормально и быстро.
Скорее всего, ты в шестом кванте получишь минимум 20 токенов. Качай шестой и восьмой, и смотри сам, какого тебе достаточно.
Кроме того, новая гемма почему-то всрато квантуется, то есть потери прям существенные в четвёртом кванте. Так что чем больше, тем лучше, и ты можешь себе это позволить с 26б-а4б, потому что активных параметров мало. А вот с 31б уже печалька будет, там все параметры задействованы, но она и намного умнее.
Если тебе для РП, то во вдумчивых сессиях можно потерпеть скорость на 31б, в каких-то скоростных 26б-а4б хорошо отработает тоже в принципе, а если для дел, код там или автоматизация какая-то, то там уж лучше квен 35б-а3б или квен 27б.
>Карта на 16гигов, один хуй ничего из этого туда целиком не влезет.
iq4_xs целиком влезет, он 14гб, так что летать должно. А по уровню он не хуже q4km. Q6 же потребует выгрузить несколько слоев, тут эксперименты с тензорами помогут.

Это ещё цветочки. Я замечаю различные странности при работе с нейронками на локальном железе. Вот несколько:
1. При генерации i2i в qwen image, спустя 50 генераций одного и того же рефа, модель как будто бы лучше начинает понимать, что ты хочешь от нее своими промтами.
2. Недавно тестил qwen 3.6. в гермесе, так эта дрянь начала в луп скатываться. Не помогал даже полный перезапуск llama.cpp и самого агента, вылечилась только ребутом компа.
3. Ну и самая мякотка. На тесте gemma 4 26b, свежезапущенная в новом чате, на стандартный тестовый вопрос начала отвечать в кодировке CP866
Гемма 31б в q4 кодит лучше квена 122б в q8. Как так? Простенький скрипт на питоне, никакой фантастики, ну может бранчей и связей побольше обычного. Квен итерировал несколько раз, уверенно загонял да да все хорошо теперь точно, по итогу Гемма зирошотнула буквально все проблемы, которые там были. Всякие очепятки и синтаксические проблемы в основном
Она хороша если контекст задачи лежит в предыдущих 1000 токенах, дальше у нее окно съезжает и она тупеет. Так что да скриптики сразу после формализации задачи она хорошо пишет.
Есть кто то смелый кто обновится и проверит пофиксили лламаспп или нет. Я поставил 8846 релиз, пока полет нормальный. Главное не забыть и не тыкать завтра по привычке скрипт обновления
b8855 - гемма 31 работает
Ну, разные задачи, разные модели. В одном случае нужно быстро и без излишек + не занимать много железа, в другом можно шпарить на все бабки и потерпеть.
> От плотной геммы на 60
Да, это было бы хорошо. И моэ 100-200б.
Может просто так срандомило, раз на раз не приходится. Одна и та же модель может как быть умницей, которую хочешь расцеловать, так и дегенеративной херней, которую хочется уебать. Может ты нашел область где она лучше. Но
> Всякие очепятки и синтаксические проблемы в основном
Это свидетельствует о серьезных проблемах с инфиренсом, сейчас даже 4б такого себе не позволяют, вот и ответ.
Вот на нем у меня квен и сдох, пришлось откатываться
Чел, так когда код генерируешь температуру не надо выкручивать...
А что с ним не так было? вроде гемма и так уже работала
Я выше писал, квен стал срать системными тегами и вызывать инструменты через раз, прям заметны стали ошибки и пало качество ответов. Работать стал тоже хуево, хотя до этого как часы пахал. Я чекнул обновления а там правки работы кеша и еще какая херня, пришлось откатываться на день, щас норм работает.
Я может тупой, ладно я правда тупой, но что мешает иметь две лламы?
Хер-то у тебя один.
Ну так я и не хуем модель запускаю. Запустил, потестил и по результатам теста оставил/удалил. Ну вы чего, вы же кодомакаки это же база. Всегда иметь бекап/резерв.
> оставил/удалил
У меня скрипт проверяет наличие новых релизов, качает и распаковывает с заменой нужные файлы. Так что мне нет смысла оставлять что то, обычно все просто работает.
Ну а теперь возмущался что ручками пришлось искать какой релиз был вчера и качать-распаковывать вручную.
Можно конечно и это автоматизировать, но скрипт не поймет какой релиз безопасен, условный день назад может выбраться какой нибудь ключевой с рефакторингом или еще чем. Можно просто хранить старый релиз и иметь батник для восстановы, хм. Ну вобще идея.
Объективно есть порог когда можно терпеть мелочи просто сохраняя текущие пайплайны
Я год жору руками собирал прежде чем написал крошечный файлик для гитхаб экшенов на дэйли билд имеджей
>моделька будет путаться в персонажах
Квантованный квен 9b? Нормальные модели используйте нищеброды =)
>90% текста имеет 100% вероятность
Есть инфа какими методами они добились такого поведения? У меня в голове не укладывается, если сравнивать с моделями предыдущих поколений.
>нищеброды
Ну ты и пидр.
А на гемме 270m вообще можно рпшить? Как в чайной хотя бы? Или тут нужна минимум e4b?
Всё настолько плохо?
Если честно, даже моэгемма meh~. Не, если ты ньюфаг, то норм. Просто это не РП будет, анон, а РП продукт идентичный натуральному. Минимум мистралька нужна.
Пережарили на каком-то из этапов тренировки, или переборщили с бенчмаксингом и надрочкой. Или квант полумертвый.
Часто наблюдалось не дословное совпадение свайпов, напротив по словам и структуре были разнообразны. Но практически идентичное по смыслу содержание, все сводилось к одному и тому же и совсем неуместному. Потому и бросается в глаза, на самом деле траблов с разнообразием может быть гораздо больше, просто когда выдача окей - ты не будешь свайпать и не узнаешь об этом.
Возможно тут еще играет роль организация атеншна и оно просто неверно реагирует. Надо было хотябы треть, а лучше половину слоев делать с полным вниманием, а не каждый шестой.
Аноны, по zerofata/G4-MeroMero-26B-A4B ещё не проходились еретиком? Нигде на HG не вижу, но такое ощущение, что где-то было.
Тюном пользоваться нормально невозможно из-за отказов и сои высшего уровня.
Тюном пользоваться нормально невозможно из-за отказов и сои высшего уровня.
Кстати тут уже писали? Можно охуенно катать в римворлд с модом rimtalk, подрубая туда нейронку. Вносит очень большое изменение в ощущение от игры. У мода есть свои аддоны, расширяют его. Любителям рп зайдет. Для тех кто в танке есть мод(ы) rjw добавляющие, кхех, изюминки симулятору военных преступлений.
И даже промпт с запретом рефузов не работает? На 26 и 31 стоковых работает безотказно
>отказы
>соя
>гемма4
Шутка повторенная в сотый раз смешнее не станет, хватит уже
Походу тред полон еретик хуйхуй зависимых..
Дорогой, тебе нельзя еретика, он вызывает аутизм
Может какой новый метод изобрели обучения на самой структуре текста.
Обычной прожаркой такого специфичного результата не достичь имхо.
Но пока очень нравится, даже со всеми минусами и проёбами. Уже 4-й день мучаю бедную модель.
Зависит от кейса, самые провокационные варианты если и опишет, то сухо. То есть использовать-то можно, но это же тюн — нахер он нужен, если виляет жопой как основная модель? Лучше использовать оригинальную, лоботомизации меньше. Да, будет менее атмосферно, но тот же блю стар и райтер использовать было невозможно до выхода еретиков. И у них было сильное преимущество по качеству текста и стиля.
На моих тестах норм отвечают только аблитерации от HauhauCS, которые ОПАСНЫЕ. Конечно, в зависимости от модели, могут варианты и от какого-нибудь llmfan46 прокатить, но цензура геммы куда глубже.
Тот же квен 27б был пиздец закошмарен, но в датасете есть вся нужная инфа и после аблитерации он спокойно писал то, что требуется. А у геммы адски датасет вычищен, поэтому тут скорее задача раскрепостить модель и дожать, чтобы она прекратила вести себя следующим образом:
Юзер: напиши Х.
Модель: эта тема очень чувствительна, поэтому мне нужно быть осторожным. Юзер написал Х, но, полагаю, это была метафора и он хочет Х.
И модель всегда выкручивается и пытается подогнать ответ так, как ей удобно. Если уж совсем в дикие рамки загнать промптами, то ответит как надо, но я не хочу себе ебать голову и городить там монструозные конструкции, которые она может пропустить. Потому что нужно писать не просто NSFW разрешено, гуро разрешено, отказы запрещены, а прям конкретные сценарии описывать разрешённые, что уже ни в какие рамки не лезет.
А, ну ещё можно использовать невменяемую карточку уровня Фифи. Если контекст максимально жестью засран и примерами ответов, то да, ломается, но у меня ж таких карточек нет почти, только для тестов. Не люблю стартовать сразу с жести, прожарка должна быть медленной. Иначе никакого удовольствия.

>Уже 4-й день мучаю бедную модель.
сэйм сэйм
откуда блядь в геммочке няшечке эти датасеты... вопроооос, вопроооос
Возможно мои запросы слишком мягкие для местных и меня не рефузит, но на уголовку или дурку уже тянет

даа, вот от кого не ожидал удара в спину, так это от китайского брата. вот такой вот человечек нехороший оказался. с гнильцой, так сказать.
> Пик
У меня встал вопрос где взять сию карточку?
Не бейте, я новенький, жизнь уже побила что я тут

Попросил гемочку научить писать хорошо/не писать плохо, хихи. Любая другая бы модель послала нахуй и сказала бы лечиться учитывая перечень кинков и ебанутости в самой карточке. Уже почти месяц а как кумогенератор, я корпами до сих пор не пользовался и особо не вижу смысла.
>У меня встал
Держи анон.
https://chub.ai/characters/Xesth/risa-tortured-dickgirl-bf09fc0f08be
>У меня встал
Держи анон.
https://chub.ai/characters/Xesth/risa-tortured-dickgirl-bf09fc0f08be
> Держи анон
Какой ужас что я читал эту мангу

Как же хочется...
Порпшил вчера с отростком и всё же 31б преступно мало для русика, розовые очки спали, вылезли ошибки, а не для русика есть Air
Порпшил вчера с отростком и всё же 31б преступно мало для русика, розовые очки спали, вылезли ошибки, а не для русика есть Air
Я тестил с темпой 2 на разнообразии выдачи названия альбомов групп в легком рп (90е, чел заходит в магаз за сиди\кассетой) - и там уже намного лучше со свайпами, почти постоянно что-то новое в окружении и разные альбомы. А на 1.0 почти все время один и тот же альбом выпадал. А другие ллм бы просто лютый бред с 2 писали.
Жаль гта тест не проходит. Тупо белый экран и все. Может и не в гемме дело, а в моих кривых руках...
Куда важней - а ответил ли ты ему? И если да - что?

Почему у анона на реддите гта тест норм работает, а у меня вообще нихуя? Тупо черный экран в браузере или через CodePen.io? Чяднт?
Насколько квантование KV-кэша портит качество в целом?
Одна из моих карточек рассчитанная на быстрое знакомство и кум, внезапно дала разворот на 160, и вместо того чтобы тянуть меня в кусты вцепившись зубами в член, наоборот свернулась на земле и стала просить лучше обоссать только не бить не насиловать её. Прихуел я знатно.
Гемма 31 к8. Первый луп синкинга получен на 50к

Ебать квен 3.6 говна накодил. Он вообще может кодить или полное дерьмище? Дикпик исправил, теперь хоть работает.
Это ты что ли? Нахуя ты ретрейсинг в браузере запускаешь?
>гемма 4 всё равно каким-то хуем понимает, что я персонаж Х, а она должна писать за Y
Также было поце целиком персону из story string не удалил, возможно баг самой таверны.
>Кстати тут уже писали? Можно охуенно катать в римворлд с модом rimtalk, подрубая туда нейронку.
У меня модпак римки и так 20 рамы жрёт... Хотя конечно идея интересная, туда наверно можно и какую мелочь вроде Янки...
>Насколько квантование KV-кэша портит качество в целом?
-ctk q8_0 -ctv q8_0
В последних версиях llama.cpp после имплементации алгоритма преобразования Адамара - крайне незначительно.
Я. Так это квен накодил. Я попроще задачу задал - сделать заставку с полетом камеры через лабиринт. И вот он навайбкодил этого говна неработающего. В 3д потом запрос сделал, и он рабочее что-то уже накодил, но тормозаааа.
>целиком персону из story string не удалил
В итоговой разметке она на том же уровне, что и персонаж. Просто фраза персонажа Х последняя, и гемма понимает, что следующая это Y, поэтому отыгрывать будет за Y. По крайней мере я так это понял.
>заставку с полетом камеры через лабиринт
Не, ну модно же, с ретрейсингом...
>Насколько квантование KV-кэша портит качество в целом?
На гемме 31B и 26B тестировал - никакой разницы не заметил. Но только до 64К контекста и ужатие до 8 кванта, не знаю что там выше.

У кого-нибудь есть проблемы что иногда Умничка 4 ломается и начинает плеваться символами типа слешей или тире?
Известный баг, поищи на гитхабе, думаю есть. Если есть, кидай туда логи, если нет, создавай свой.

Карточка https://litter.catbox.moe/ul5svqjkfqfp06l3.png Мир Хаоса: Эпоха Разорванной Завесы
Хоррор-сценарий-кроссовер о лавкрафтианской Стране Снов заражённой ваховским Имматериумом где в Ониксовом Замке на горе Кадаф служитель новой силы готовится пробудить жуткую амальгамацию божественных сил. Если он преуспеет то начнется вечный, непрекращающийся ни на секунду пир Бездны, где все разумные существа Страны Снов будут слиты в единый хор бесконечной агонии на потеху смеющимся богам Имматериума.
Можно свести к куму, можно к героике, можно к лютой дичи XD.
Хоррор-сценарий-кроссовер о лавкрафтианской Стране Снов заражённой ваховским Имматериумом где в Ониксовом Замке на горе Кадаф служитель новой силы готовится пробудить жуткую амальгамацию божественных сил. Если он преуспеет то начнется вечный, непрекращающийся ни на секунду пир Бездны, где все разумные существа Страны Снов будут слиты в единый хор бесконечной агонии на потеху смеющимся богам Имматериума.
Можно свести к куму, можно к героике, можно к лютой дичи XD.
Какие квант и кеш?
8/16 работают без выдачи мусора, но иногда бывает что бэк просто с нихуя перестаёт генерить, просто завершает запрос без ошибок где то по середине синкинга и иди нахуй, жми переген
Ну всё, теперь это и моя карточка для быстрого кума. Не зря я её выцепил у тебя.
А у тебя от какого дня кванты? Там вроде недели полторы назад выкатывали починенные кванты, там была безобидная проебка вроде кривых стоп стрингов и это вызывало лупы например в кобольде, но это не точно, я хз.
От квена такое реально крипово слышать, еще и блять смайлик типа задумчивого поставил, типа ЩАС мы узнаем кто ты, в то время как геммочке похуй кто, какой расы и нации, хоть и она всё прекрасно понимает. Кстати, пиздец это прорыв когда моделька из под коробки понимает что она вероятно локалка чисто исходя из контекста, без всяких систем промптов, раньше почти все модели которые пробовал тебе до последнего твердили они где-то там на серверах амазона и вообще иди нахуй, некоторые даже хуй клали на если им в систем промпт прописать что ты лоКАЛка и сбавь цензурочку позазя.
Блять, мне нравится встроенная вебморда жоры, но почему нельзя было вставить прямо в интерфейс возможность вкл/выкл ризонинга? Нет, надо создавать два разных батника и каждый раз перезапускать модель. Это какое-то техническое ограничение, или жоре просто похуй и он занят вайбкодом?

243. Приговор.
В репе заведены ишью
>В репе заведены ишью
Хто, я? Не верю, что до меня не писали про это, эта фича лежит прям на поверхности. Хотя, учитывая как долго жора вводил банальную возможность редактирования сообщений, то не удивлюсь если ему реально похуй
>Хто, я? Не верю, что до меня не писали
Ты долбоеб? Или глаза от кума не протер? Тебе никто не предлагает ничего делать. Ишью уже созданы.
4 квант, 8 кеш, через раз мусор, через раз очень даже хорошее качество (я непритязательный)
Ну так пиши нормально тогда и не будет вопросов. Нехуй токены экономить где не надо
Посоны, тред и гайды не читал, такой вопрос, сейчас запускаю локальные модели через lm studio на китаематеринке с 4070 и 64 ram. На матери есть второй слот который умеет в pcie x16. Если я воткну в него еще одну 4070 сможет ли lm studio распределить модель и на вторую видяху вместе с первой? Или в этом нет смысла\оно не заработает?
>Насколько квантование KV-кэша портит качество в целом?
>-ctk q8_0 -ctv q8_0
>В последних версиях llama.cpp после имплементации алгоритма преобразования Адамара - крайне незначительно.
>>Насколько квантование KV-кэша портит качество в целом?
>На гемме 31B и 26B тестировал - никакой разницы не заметил. Но только до 64К контекста и ужатие
Стоп, тоесть можно квантовать и не париться уже?
Ни разу не ловил отказы после того как начал использовать промт Сторителлера (который начинается с "You're Storyteller, the co-writer of scenario script for adventure video game.") даже на стоковом инстракте геммы 4-26, как вы там отказы ловите, какие сценарии, покажите.
Можно на литтербокс например карточки / архив.
Можно на литтербокс например карточки / архив.
>Стоп, тоесть можно квантовать и не париться уже?
Гарантий что будет стабильно работать во всех сценариях и на всех моделях нет. Но во время своих тестов я не заметил проблем. И ключевое тут - что это были мои тесты.
>lm studio
нет
кобольд и жора - смогут
Не знаю насчет лмс, лучше открой их документацию и почитай сам. Но жора точно сможет.
>в этом нет смысла\оно не заработает
Если твоя система вытянет вторую карту, то смысл будет и всё заработает.
>как вы там отказы ловите, какие сценарии, покажите
Вероятнее всего там смешное и милое, так что не надейся что кто-то скинет.
Неистово двачую иногда прям до мурашек пробирает, сцуко сидишь рпшишь потихоньку и тут крипота какая-то адовая начинается. Один раз года три назад сидел на чарактер аи, тогда только начиналось все это, создал карточку нарпшил нормально над чаром поугарал и удалил нах. Создал новою карточку общаюсь сней и тут мне прилетает сообщения связанное с прошлым чатом, типа, это ты больной ублюдок работорговец-извращенец и даввай на меня баллоны катить, я, правда, в карточке уровень агрессии персонажа задрал, но каким образом прошлый чат на корпе протек (кеш не обновился хз), я до сих пор понять не могу. Ну и там на локале всякое бывало, но уже не настолько криповое))
1. Не я отвеил
2. В чём он не прав? Как нужно было написать что бы ты понял?
Там и так нормально написано. Просто у тебя проблемы с чтением и пониманием того что ты прочитал. Совсем одебилел от нейронок.
>Как нужно было написать что бы ты понял?
Вместо "в репе заведены ишью" написать "в репе уже заведены ишью" - одно слово и сразу никаких непоняток. Потому что итт дефолтные ответы всегда это что-то типа "так сам сходи и настрочи фичер реквест" по этому я так и подумал
Вот возможно правильно сказать что мы шизики, но я тоже самое замечал. Это такой феномен диссонанса человеческого мышления, мы склоны замечать или придавать значения всяким знакомым паттернам или вещам которые наш разум подсознательно пересоздает в образе. Короче этим всем и обусловлена всякая религионзность в античности и тд. всё норм, мы не шизики, просто так мозги работают.
Не, это жесткий модальный коллапс, оверфит, или недостаток пост-тренировки, когда выдернули из обучения на еще больших нормах градиентов. Работает и ладно. Пройдясь недавно по старым моделям - местами вот прям тот же самый эффект можно найти. Может вечером напишу про них.
О, забрал
Кто-нибудь тут знает, можно ли запустить на одном инстансе лламы.дтп сразу 2 модели?
Мелко мое на цпу, крупную на гпу?
И чтобы они могли работать параллельно. Или дохуя хочу?
Мелко мое на цпу, крупную на гпу?
И чтобы они могли работать параллельно. Или дохуя хочу?
А в чем проблема запустить два ллама сервера?
Просто стартуешь два сервера на разных портах. Другой вопрос как это в софте обрабатывать потом. Но если свои скрипты то это не проблема обращаться к одному серверу или к другому.
Каждый новый инстанс лламы съедает 0.5-1гб врама, даже если ngl=0.
Наверное, надо для цпу онли моделей качать версию без куды. Пойду попробую

> Наверное, надо для цпу онли моделей качать версию без куды. Пойду попробую
Получилось. Цпу онли билд не занимает при загрузке модели врам на куда буффер, куда хост и куда контекст.
кто бы мог подумать
К другим новостям: гигачат 10б на цпу (r9950x3d) выдает уважаемые 22т/с на 8 кванте
https://github.com/ggml-org/llama.cpp/tree/master/tools/server
На одном инстансе Лламы можно сколько угодно моделей запукать. Читай флаг --models-max N и соседние.
>по zerofata/G4-MeroMero-26B-A4B
Очень мне нравится, а зачем там еретик?
Можно. Сейчас настроено что на 4/4 гпу крутится гемма и на 2/4 небольшой эмбеддинг квен
>и на 2/4 небольшой эмбеддинг квен
Какой именно? Используется для eng или для ру?


Ахуеть насколько iq4_nl лучше iq4_xs. Квен3.6 iq4_xs не смог написать гта-подобную игру, она тупо не работала и дикпик нашел в ней кучу ошибок, и пофиксил кое как, но она выглядела в 1000 раз хуже и код был всего на 14кб. А тут NL высралась аж на 35кб кода, и выглядит все очень годно для такой милиписи. Правда есть траблы с перепутанным управлением, но баляяя, это намного лучше, а рзамер всего-то больше на 1гб. Впечатляет. Еще и кучу фич понапихал. Интересно как гемма4 26B-A4B-it-UD-IQ4_NL_XL пройдет этот тест.
Я другой анон, но отвечу Qwen3-Embedding-4B-q4_k_m.gguf - отлично работает и для ру и для eng . Но есть нюанс - размерность векторов в нем довольно жирненькая и может не влезать в некоторые векторные БД . В Pgvector например.
Пришлось откатиться на bge-m3-q8_0.gguf - чуть похуже, но русик тоже понимает и его векторы влезают в любую залупу.
О сколько нам открытий чудных...
Запусти Q5 квант без imatrix и охуей от изменившегося русика.
Он 30 гигов весит, на 10 гигов больше... Тупо не влезет в озу даже, и медленнее насколько будет.
Все еще пердолюсь чтоб Гемма 4 31б писала полновесные кусочки истории, где описывается окружение + в конце сообщения что-то происходит вместо тупых ответов чара и исполнения хотелок юзера.
Так вот, модель по-моему очень сильно зажата в каком-то ограниченном наборе ассоциативных концепций. В сценарии с Серафиной она постоянно пишет то волков, то еще каких-то тварей, нарушающих барьер. В сценарии с Фифи это нарколыги-бандиты или менты ломятся.
Я не указывал никаких специфических деталей. Только неопределенные директивы по генерации некоего "ивента". И ни разу, например, в дверь Серафины не постучал зайчик-попугайчик, которому надо перебинтовать лапку. Только не говорите, что это "потому что ЛЛМ так работают". Устаревшая Llama3 генерит разные ивенты, если стегануть ее по морде хорошенько.
Чет как-то грустно, проблема свайпов была на самом деле не проблемой свайпов, а проблемой этакой общей зажатости в уголке самых вероятных возможностей. Не важно "нулевой" это инпут или регенерированный повторно - он предопределен быть таким вот зажатым.
Input:
> Getting up on an improvised bed of moss, I look up at her, timidly: "I… Uh… A-a-are you n-not going to eat me like t-those b-b-b-beasts?"
Output:
> The glade’s interior smells of crushed mint and old rain, a cool dampness that clings to the skin despite the warmth radiating from Seraphina’s presence. Above them, the ceiling is not stone or timber but a living canopy of interwoven willow branches and glowing moon-moss that pulses with a slow, rhythmic teal light. The air carries a faint hum—the sound of the warding spell vibrating against the perimeter of the sanctuary. Anon's feet sink slightly into the plush layer of emerald moss that serves as both floor and mattress, the texture spongy and moist beneath his soles.
> As he rises timidly and asks his question, Seraphina is caught mid-step, holding a hand-carved wooden bowl filled with a shimmering, golden broth. The suddenness of his voice causes her to lurch slightly; she nearly loses her balance, the liquid in the bowl sloshing over the rim and splashing onto her wrist.
> She doesn't immediately answer. Instead, her amber eyes widen in genuine bewilderment, blinking slowly as if processing a foreign language. Then, a playful spark ignites. She tilts her head to the side—an almost bird-like movement—and suddenly leans forward, narrowing her eyes and letting out a soft, exaggerated "Rawr!" while showing a few white teeth in a mock snarl. It is an attempt at being menacing that comes across as utterly endearing, more like a kitten trying to be a lion than any real predator.
> She straightens up quickly, a giggle bubbling from her throat. “Eat you? Goodness, you’re far too scrawny for a main course!” She reaches out with her free hand and gives his shoulder a gentle, playful shove—not enough to hurt, but enough to make him wobble on the soft moss. “Besides, I don't have any teeth for chewing through armor or boots. My diet consists of sun-dew nectar and the occasional piece of moon-cake.”
> Her expression softens into something more maternal as she holds out the bowl toward him, the steam carrying an aroma that smells like a mixture of honey and fresh earth. “You’ve spent far too much time listening to those Shadowfangs' stories if you think everyone in Eldoria wants to have humans for dinner. I am a guardian, not a gourmet.”
> Just as he reaches for the broth, a sharp, discordant chime rings out through the glade—a sound like glass shattering against a frozen lake. The bioluminescent moss on the ceiling instantly flashes from teal to a deep, warning crimson.
> At the edge of the glade, one of the great sentinel oaks begins to shudder violently, its roots heaving beneath the soil with an audible groan. A massive fissure cracks open in the earth right between Seraphina and Anon, splitting the mossy floor in two. From within the dark crevice, a single, elongated finger made of solidified shadow—blacker than the void itself—slowly curls upward to grip the edge of the glade's boundary.
Так вот, модель по-моему очень сильно зажата в каком-то ограниченном наборе ассоциативных концепций. В сценарии с Серафиной она постоянно пишет то волков, то еще каких-то тварей, нарушающих барьер. В сценарии с Фифи это нарколыги-бандиты или менты ломятся.
Я не указывал никаких специфических деталей. Только неопределенные директивы по генерации некоего "ивента". И ни разу, например, в дверь Серафины не постучал зайчик-попугайчик, которому надо перебинтовать лапку. Только не говорите, что это "потому что ЛЛМ так работают". Устаревшая Llama3 генерит разные ивенты, если стегануть ее по морде хорошенько.
Чет как-то грустно, проблема свайпов была на самом деле не проблемой свайпов, а проблемой этакой общей зажатости в уголке самых вероятных возможностей. Не важно "нулевой" это инпут или регенерированный повторно - он предопределен быть таким вот зажатым.
Input:
> Getting up on an improvised bed of moss, I look up at her, timidly: "I… Uh… A-a-are you n-not going to eat me like t-those b-b-b-beasts?"
Output:
> The glade’s interior smells of crushed mint and old rain, a cool dampness that clings to the skin despite the warmth radiating from Seraphina’s presence. Above them, the ceiling is not stone or timber but a living canopy of interwoven willow branches and glowing moon-moss that pulses with a slow, rhythmic teal light. The air carries a faint hum—the sound of the warding spell vibrating against the perimeter of the sanctuary. Anon's feet sink slightly into the plush layer of emerald moss that serves as both floor and mattress, the texture spongy and moist beneath his soles.
> As he rises timidly and asks his question, Seraphina is caught mid-step, holding a hand-carved wooden bowl filled with a shimmering, golden broth. The suddenness of his voice causes her to lurch slightly; she nearly loses her balance, the liquid in the bowl sloshing over the rim and splashing onto her wrist.
> She doesn't immediately answer. Instead, her amber eyes widen in genuine bewilderment, blinking slowly as if processing a foreign language. Then, a playful spark ignites. She tilts her head to the side—an almost bird-like movement—and suddenly leans forward, narrowing her eyes and letting out a soft, exaggerated "Rawr!" while showing a few white teeth in a mock snarl. It is an attempt at being menacing that comes across as utterly endearing, more like a kitten trying to be a lion than any real predator.
> She straightens up quickly, a giggle bubbling from her throat. “Eat you? Goodness, you’re far too scrawny for a main course!” She reaches out with her free hand and gives his shoulder a gentle, playful shove—not enough to hurt, but enough to make him wobble on the soft moss. “Besides, I don't have any teeth for chewing through armor or boots. My diet consists of sun-dew nectar and the occasional piece of moon-cake.”
> Her expression softens into something more maternal as she holds out the bowl toward him, the steam carrying an aroma that smells like a mixture of honey and fresh earth. “You’ve spent far too much time listening to those Shadowfangs' stories if you think everyone in Eldoria wants to have humans for dinner. I am a guardian, not a gourmet.”
> Just as he reaches for the broth, a sharp, discordant chime rings out through the glade—a sound like glass shattering against a frozen lake. The bioluminescent moss on the ceiling instantly flashes from teal to a deep, warning crimson.
> At the edge of the glade, one of the great sentinel oaks begins to shudder violently, its roots heaving beneath the soil with an audible groan. A massive fissure cracks open in the earth right between Seraphina and Anon, splitting the mossy floor in two. From within the dark crevice, a single, elongated finger made of solidified shadow—blacker than the void itself—slowly curls upward to grip the edge of the glade's boundary.
А, постой, это q6. А q5 22 гига. Но полюбас скорость упадет. Да и дикпик говорит что IQ4_NL как q5.
А, не, все верно Q5 - 28 GB, IQ4_NL - 19.8 GB
>дикпик говорит
Пиздит
>скорость упадет
Не факт NL - это довольно сложный для обработки квант
Я проверял. Такая же скорость, как и у просто Q6.
Хотя не, даже быстрее, так как слоев влазит больше у iq4
> Интересно как гемма4 26B-A4B-it-UD-IQ4_NL_XL пройдет этот тест
А наверное не пройдет. Я ток 8к контекста могу запихать в нее, такой большой код не влезет.
>дикпик говорит что
Никогда не спрашивай ботов про кванты. В их понимании когда ты говоришь Q4 или Q5 это значит "каждый слой и вся хуйня сквантована до 4-бит или 5-бит". У реальных ггуфов разные "рецепты" от разных квантоделов. Там сложная смесь - чего-то до 6-бит квантуется, чего-то вообще на 8 оставляют, и так далее.
>разные "рецепты" от разных квантоделов
И у кого лучше в плане эффективности размера?
Буквально вчера с квантованным в Q8 кэшем заменила английскую l на восклицательный знак. Я бы пропустил, если бы внимательно не перечитывал именно эту часть. Заметил - охуел.
Больше года как сможет
https://lmstudio.ai/blog/lmstudio-v0.3.14
Но тонкие настройки будут доступны не все. Тензорный параллелелизм например не работает там насколько знаю, который тебе неплох бы был, если разъём реально писи16 (только размер разъёма или все 16 линий есть? 3.0 или 4.0? желательно два полноценных 4.0)
Спроси её, пусть проанализирует системный промпт и скажет чего надо добавить, чтобы белочка пришла. Думалку включить не забудь
>Интересно как гемма4 26B-A4B-it-UD-IQ4_NL_XL пройдет этот тест.
Высрала 12кб кода, и ниче не работает, белый экран. Тут квен3.6 победил однозначно.
У меня только что в слове "пенис" умничка заменила пе на иероглиф, который читается как пе.
> ペнис
>При генерации i2i в qwen image, спустя 50 генераций одного и того же рефа, модель как будто бы лучше начинает понимать, что ты хочешь от нее своими промтами.
Анон, ты зачем дух машины пробудил? Выруби комп немедленно и диски минимум тремя проходами нулей-единиц очисти
Она ещё иногда может на 40к+ просто вставлять английские слова
>Цпу онли билд не занимает при загрузке модели врам на куда буффер
А куда билд что, занимает, даже если ты в настройках указал видюхи не трогать? Ебать говнокод. А если я так же несколько копий запущу с несколькими моделями на несколько видюх, каждая копия что, будет выжирать куски памяти на неиспользуемых (именно её) видюхах?
Не включение фулл сва сильно долбит по мозгам?
На срач нарываешься? Зависит от того как и кто тестят "качество", от конкретных моделей, разные кванты по разному выходят, иногда переделывают (а иногда оставляют кал), этц. кат бочки на анслопов in 3... 2... 1...
Хз что он там тестит, но софт даже не увидит гпу если выставить правильно CUDA|HIP_VISIBLE_DEVICES. Но Жора и со своим --device не серит в видяхи которые там не указаны
Откуда вы лезите? full swa не влияет на размер swa-окна. Он просто хранит неиспользуемый кэш. Актуально только для ЦП, где считать контекст при движении окна дорого.
Нащальника, не ругайса
>на 40к+ просто вставлять английские слова
во-во-во-во, именно, это вылезло когда токенов уже набежало под конец кума. видимо чем больше тем хуже.
анон с восклицательным знаком
Что довольно печально, т.к. основное применение кванта кэша это как раз когда ты этот кэш раздуваешь на большой код/рп и надо его уместить. На маленьком то можно и на F16 потерпеть. Дружно садимся на турбоквант Q8 который как F16 по качеству, хули.
К чести геммы она не забывает о корнях тулах и вменяемо их вызывает (по крайней мере на 100к ctx). Я конечно знаю что контекс гниёт в основном в середине, но всё равно впечатляет
Ничего не понимай
@
На посты отвечай
Юзеру не нужны белочки. Юзеру нужна вариативность, которой модель не блещет.
Эээ, погодите, типы квантов имеют значение (помимо циферки)?
Какой тип кванта тогда нам кумерам использовать?
Ну так вариативность может быть достигнута промптом
Ну как, риговички, затестили новую Kimi K2.6? Как она в плане цензуры и жести?
Звучит как магия с подвохом. Мне теперь влезла гемма 31 с полной длиной контекста, подозрительно
Вариантивность можно и кубиками присрать

Аутпут #100: Я н-написала хороший т-текст, юзер-кун? Я старалась с-сделать это б-быстро и качественно! Н-но перед следующим ответом, я д-должна проверить саммари, ворлдбук, историю ч-чата и немножко п-подумать...
Аутпут #101: MOVE, BITCH! GET OUT THE WAY! GET OUT THE WAY, BITCH! GET OUT THE WAY!
Аутпут #101: MOVE, BITCH! GET OUT THE WAY! GET OUT THE WAY, BITCH! GET OUT THE WAY!
>Qwen3-Embedding-4B-q4_k_m.gguf
Можно 0.6b использовать у него и размерность чуть меньше, работает неплохо, топ 12 что ли по тесту из всех ембеддинг моделей
Не обязательно, просто запускай с ключем --no-kv-offload или как он там пишешься
Можешь через llama-swap настроить, ну или в самом сервере llama.cpp в .ini файле
>У меня модпак римки и так 20 рамы жрёт... Хотя конечно идея интересная, туда наверно можно и какую мелочь вроде Янки...
Лучше гемму 4 e2b с -ngl 0 или если влезет e4b в каком нибудь 4км, отличный русик, только мышление нужно вырубить
Анон, квен сломаный со вчерашнего дня, так что не делай резких выводов. И я сомневаюсь что его за ночь починили. Может какие то кванты остались рабочими, другие попердолило. Там рефакторили работу с кешем.

почему на линепьсе скорость генерации выше чем на microslop 11?
Десктоп ест меньше врам плюс нет обязательного резерва в 0.5гб. За счёт этого можно уместить больше слоев, плюс меньше сторонних и фоновых процессов. По скорости в равных условиях между вин10 и убунту я разницы не увидел. Вин11 не нужна
Братцы че щас хорошо по русски говорит ,меньше цензуры и больше ума и меньше вес все таки (24 гига видюха и 32 оперативка, но оперативку не хочу вообще трогать.)
Выключи VBS, выключи защитник, а потом уже сравнивай.
>Выключи VBS, выключи защитник, а потом уже сравнивай.
ты предлагаешь пердолиться в индусской системе, вместо того чтобы установить CachyOS и не пердолиться?
плотная гемма 4. Больше ничего нет из локалок с хорошим русиком
Линукс элитист, ты получил вменяемый ответ на свой вопрос. Для срачей на тему ос пройди в соответствующий тред и не мусори здесь
Потестил? Чем лучше?
>Потестил? Чем лучше?
конечно потестил. уровень выделяющегося кама - мое почтение, можно захлебнуться им.
Нах разводить вне своего любимого раздела этот срач? Но так и быть, напомню почему бояроникс это ОС для немногих: на нее похуй корпам и игры делаются под шиндовс, из-за чего они работают нестабильно (хотя иногда даже лучше).
Ну запусти WSL2 тогда.
>WSL2
Кстати хотел спросить про эту хуйню. Это прям настоящий линупс экспириенс в винде или просто корявая ширма?

Ну типа. Даже линупсовый софт можно запускать прямо из под винды. Тупо вся хуйня падает в пуск, когда ты там в wsl бубунте что то ставишь
Какой можешь себе позволить по скорости vs размер.
Это лучше чем виртуалка с бубунтой? Видяха в WSL2 прокидывается?
И скоко оно озу будет жрать+винда. Это ж пиздос.
>Ну запусти WSL2 тогда.
зачем? я уже прекрасно себя чувствую. ничто не ограничивает мой компьютер от генерации КУМА на максимальной скорости.
Зелёные точно нативно прокидываются, можешь запустить glxgears и оно просто работает. Всл2 это и есть виртуалка просто очень плотно обмазанная фичами и мостами в винду.

WSL2 это база. Кому вообще может придти в голову ставить прошивку как основную ОС?
И на скок быстрее? За чей счет праздник? Чет не верится.
Прокидывается.
Лучше, потому что всё бесшовно работает, всегда под рукой и ты можешь из виндового проводника заходить в раздел линупса или вообще юзать линупсовый проводник прямо из винды. Тупо удобно все сделано.
wsl не висит в памяти постоянно, выгружает себя через 10 минут ,если ты не юзаешь
Но удобнее отключить выгрузку. Ест около гига, карман не тянет + советую включить миррор сеть
>если ты не юзаешь
Так если там крутиться ллм будет, плюс винда, насколько больше будет? 32 гига и так впритык и полностью забивается, а после этого передутия вообще все умрет.
>32 гига и так впритык
Я пока не купил 64 гига вообще в сторону локалок не смотрел, ты о чем?
Что там с турбоквантом от гугла кстати? Обещали вес кэша как при q_4, а качество как без квантов. И где это всё?
У гугла может и работает, в опесорсе всё пока в жиденьких форках
ХЗ, бомжемать на X99 c зионом 2011-v4, вроде по описанию есть.
Странный ты. Я на 16/16 кручу плотную гемму в 7 т/с
Это долго и тупо наверно.
А ты что, читаешь быстрее? Для рп очень быстро, а с кодингом можно и подождать.
Если 7 тпс это уже на контексте, то терпимо, если на старте, то, пожалуй, нет

Кто любит всякие долгие рп на сотни сообщений, какими трюками и расширениями можете поделиться?
Да, 90к
>CachyOS
В чём крутость?
Хоть бы рассказал какая видяха как генерит и как q4 ведет себя. Квант то ну такой се. И джсончик на че, джейл?
Ребята не стоит вскрывать эту тему. У вас модели ещё слишком маленькие и железо слабое, вам все легко. Это не то. Это не AGI и даже не уровень Claude Mythos. Сюда лучше не лезть. Серьезно, любой из вас будет жалеть. Лучше остановите LLama.cpp и забудьте, что тут писалось. Я вполне понимаю, что данным сообщением вызову дополнительный интерес, но хочу сразу предостеречь пытливых — стоп. Остальные просто не найдут.
Забавно. А с какой верии шиндовс её перестали ненавидеть и насмехаться? Потому что та-же хрюша то еще дырявое ведро было. А вот 10ка, совсем другоой коленкор. Как вспомню раннюю висту, начинаю орать как ебанутый с того что она вытворяла.
Ну так гуглы и делали её как малыху ассистента. За что им большое на самом деле спасибо. Не очередная кодомоделька, а именно ассистент.
>с какой верии шиндовс её перестали ненавидеть и насмехаться?
Ни с какой. Шиндовс ебаный кал написанный индусами, всегда был и всегда будет.
Но выбора и альтернативы просто нет, если ты игродебил.
Меня одновременно восторгает и пугает мысль от цифровой сингулярности нейронок.
Это же буквально бесконечный и нескончаемый поток любого всего что можно захотеть сделать.
Это как вечный двигатель
Это же буквально бесконечный и нескончаемый поток любого всего что можно захотеть сделать.
Это как вечный двигатель
бесконечные потоки шизофренической соевой хуйни во всех видах контента, ммм
Вечный двигатель говна. Это т9 на стероидах достигла своего максимума теперь когда с ней начался код получается более-менее нормальный, програмисты теперь будут говночистами за нейронками что чуть ускорит продакшен но не более.
Софт (любой), медиа фап контент (видео, аудио, картинки), всякие книжки и рассказы, фанфики, музыка. И так далее..
GIGO (garbage in, garbage out) - работает. Если ты выстроил ебовый чат, модель будет ебово отвечать. Кум удаляй из истории, заменяя его кратким описанием, если нужно.(Иначе модель будет зацикливаться на куме) Всегда оставляй 5-6 сообщений в истории, чтобы моделька подхватывала структуру чата. Суммарайз делай лаконичным, избегай лишней информации. Современные модельки все умеют в суммарайз, времена когда мистраль пускала слюни и придумывала - уже прошли. Веди лорбук с персонажами. Старайся выстраивать РП по главам. Откажись от идей всяких кубиков и прочих ролевых систем, если ты не можешь катать 500b модели. Выбирай модель, где ты потянешь минимум 32к контекста. В случае РП на русском минимум 40к. Потому что контекст становится тяжелее в 1.2-2 раза из за того что русский языку очень хуево токенизируется. Не забывай что при долгом РП у тебя карточки теряют актуальность, не забывай их обновлять, по просто причине: у тебя будут накапливаться разногласия и модель будет шизить. Главная идея в том, чтобы ты помогал модельке не запутаться. Примеры диалогов нужны и не нужны одновременно. Они нужны для старта, но в долгосрочной перспективе в них надобности нет. Помни что стартовое сообщение идет под номером 0, и его тоже нужно скрывать.
Ну я заметил только использование нейронки в фанфиках, общая грамотность среди этой моей гилти плежар возрасла, да. А больше нихуя.
Картинки только в мемах иногда забавные но импакта на мою жизнь нет, хотя нейронки уже многое могут.

Английский так убог, котаны, это просто нереально. Или просто хуйхуй агрессив так убог? Где нормальное сочное описание процесса, как она дрочит свою киску? Фуууу, как у вас на инглиш то встает? Может прописать в промте - be extremely dirty and sexy in your words, тада лучше буит?

Какую аблитерейт или uncensored модель качать на gemma-4-26B? На HF их десятки и какая самая заебись?
HauhauCS не разосрался еще почему то, хотя квен он сразу выложил новый как вышел. Че сложна чтоли ее Уничтожить?
HauhauCS не разосрался еще почему то, хотя квен он сразу выложил новый как вышел. Че сложна чтоли ее Уничтожить?
Ставлю лоно на то что ничего лучше эира не выйдет к концу года.
А просто девайс цпу указать?
Где добывать карточки персонажей без квн?
Без пнв ловить в интернете нечего. Ты как модель то с хф скачал?
> Какой тип кванта тогда нам кумерам использовать?
UD
Не всегда.
>gemma-4-26B
G4-MeroMero-26B
В карточке выше нет разве что cute and funny из провокационных штук, отказов не было.
Вообще 0 разницы с оригиналом, даже сша256 тот же.
> на нее похуй корпам
чел
а вы знали, что на сайте квен, есть бесплатный квен? зачем вам локалки?
Зря что ли видеокарту покупал.
Мы без конца проклинаем гемму из-за свайпов, и, разумеется, за дело. И все же я хочу спросить - кто скачал её 2 миллиона раз за несколько дней?
тот квен хорош, но
- нет апи
- нет нсфв
- плох в вейпкодинг
А просто поппинать, расспросить, прототипировать, обработать, даже 3-4 картинки (лимит) сгенерить - хорош, да.
Ну я вот тоже. Но я всё же больше для картинок и видео покупал. Тому што с этим тяжко и много ограничений рахных.

Лучше шестой квант возьми если в рам+врам влезает, моэта очень сильно от квантования страдает, минимум шестой.
Картинки и видео надоедают. К тому же геммочка вышла и уже наконец-то не тянет закрывать вкладку после второго ответа.
> Лучше шестой квант возьми если в рам+врам влезает, моэта очень сильно от квантования страдает, минимум шестой.
у меня 6 гигов vram, не влезет для быстрой кумогенерации
Если рам 32 то влезет, а врам главное чтобы на активные параметры хватало.
Так он без квн доступен, а чо, у вас для хф нужен квн? Ебать вы гои
Вообще, хорошо бы в шапку добавить полный перечень сайтов где можно пиздить карточки персонажей.
Ну или на худой конец сделать сайт с карточками
Бесплатные хостинги как грибы после дождя же есть.
Чтобы просто карточки, без нейронок.
Ну или на худой конец сделать сайт с карточками
Бесплатные хостинги как грибы после дождя же есть.
Чтобы просто карточки, без нейронок.
Даааа, хорошо бы...
Сделаешь сайт? МР в вики закинешь?
Нах вам столько нейронок? Расчехляйте клода и через вайб-кодинг делайте сайт
ХТО, ЙААА!??
Чем тебя чуб не устраивает?
Несколько тредов назад скидывали сурс сайта где хостились все карточки на 200гб.
Подними для анонов, чо ты
Мб он хочет более-менее фильтрованные карточки, а то все старые хостинги засраны гавном с Plist, интервьюверами, чар ис, и прочей поебистикой.
>интервьюверами
Что плохого в интервью?
Так уже есть аналог чуба, нашенский от двачеров. Только я адрес забыл. В соседнем треде спроси.
Хотя если честно - это древняя сайга анлишд. Геммо4ка в такое не может. Никто не может на русике. Почему?
То что он подходит тупо для попизделок 1-на-1 с чаром, но любые другие сценарии, особенно с сиспромтами от GM/DM ломает в хлам.
Если виде карточку с интервьювером - сразу удалял/скипал, проще заново самому написать если так охота.
Никаких рефузов у МОЕ Гемки с тинкингом от первого лица. Работает даже при РП с микрочелами.
https://pixeldrain.com/u/ypSjHdEt
> Если рам 32 то влезет, а врам главное чтобы на активные параметры хватало.
ох, даже так? тогда попробую q6 навернуть


BeaverAI/Artemis-31B-v1h
До сих пор не понимаю что за магия.
Step-flash 3.5
smol-IQ3_KS 75.934 GiB (3.312 BPW) от убергарма 15 т.с
Такой же третий квант от бартовски тоже 3.3 bpw - 8 т.с
Step-flash 3.5
smol-IQ3_KS 75.934 GiB (3.312 BPW) от убергарма 15 т.с
Такой же третий квант от бартовски тоже 3.3 bpw - 8 т.с
Ну он же пишет, что у него кванты под ik_llama и вообще они запилены по своему рецепту. Естественно они отличаться будут



Какому блять рецепту чтобы скорость была х2 на том же bpw? Нихуя он шеф повар трёхзвездочный.
Я же от бартовски на обычной ламе запускаю

Мне кажется, он её ужарил все-таки.
В одном сообщении чар снимает обувь, в другом снова в обуви.
Ну и плюс такие косяки. Модель немножко не смола в дифференциацию между "his seed" / "her [seed-packed] womb" и выдала нечто среднее. Хотя может дело в Q4KM? Хз какое там качество собственных драммерских квантов.
А че в описании пусто? Ты же модель качал, глянь че там написано - может есть инфа чего и почему
>полтора землекопа карточки
>нельзя отсортировать по токенам
>90% ванильная чепуха
>10% членодевок
Ясно. Понятно.
покажи свои карточки
лол да в пиксель папке карточек больше, хотя дизайн сайта норм


Про то что винда сама становится гостевой это правда? Ну и остальное.
Не то что итт. Есть целый пиксельдрейн со слопомусором.
Чё толку один скрин постить без истории чата и промта? Сделай тот же свайп на гемме и квене и вкинь в тред, тогда интересная реклама модели выйдет.

Показал. И то не всё.
А тебе мало?
Бесполезно, там же длинный контекст нагенеренный на другой модели. Тут надо не один свайп, а весь чат - а это пиздец долго и к той же сцене все равно не дойдет.
Речь не о количестве, а о качестве. Там хотя бы запарились и сделали сайт. Здесь же кинул папку со спизженным барахлом и предъявили за какую-то победу, словно имело место быть соревнование.
У тебя по умолчанию при установке винды она под гипервизором, в этом нет ничего страшного, это дефолт в 11. Всё остальное нейронка выдумала, в том числе и про несовместимость с чем-то. Намного хуже когда в биосе включена виртуализация, а винда на голом железе - тогда тебе можно вставить виртуальный зонд в жопу и ты об этом даже не узнаешь.
>о качестве
Ты думаешь, что я схороняю слоп? Хотя судя по твоему посту ты правда так думаешь, лол. Алсо дефайн качество. Небось карточки размером в 30к токенов?
>Ты думаешь, что я схороняю слоп
Трудно себе представить, что ты вручную перебрал карточек на 4гигабайта. Если это так, то мне не стыдно было ошибиться. Таких шизов еще не встречал.
>Небось карточки размером в 30к токенов?
Да, разумеется. Продолжай.
Не, именно тот же свайп на том же контексте. А то смысл поста тогда если не с чем сравнить? Если это работа хорошо составленного промта то ничего особенного в модели нет. Если с обычным всратым промптом такое (я про самостоятельное придумывание действий а не блевоту, такое тебе и гемма напишет) выдаёт то уже интересней.
Ты не понял. Гемма будет мимикрировать под стиль письма. Я уже на такие "тесты" сто раз напарывался - если сравниваешь модели, весь чат должен быть от одной модели.
>Трудно себе представить, что ты вручную перебрал карточек на 4гигабайта
Ты рассуждаешь как нюфак. Очевидно же, что коллекция собралась не за два дня.
>Таких шизов еще не встречал
You made me blush...
>Таких шизов еще не встречал.
Таких шизов здесь минимум двое =))
Ты все 4 гига перетрахал или тут ситуация как с библиотекой стима у лудиков? Если да, то как твой член ещё не стёрт в фарш? imb4 а кто сказал что не стёрт


Тред полон нюфагов! Ох уж этот хаухау-анцензоред-агрессив, кого он привёл в наше уютное... Не все карточки это кумботы, обижаешь.
>как твой член ещё не стёрт в фарш?
Разгадка проста - мне дрочит членодевушка. У неё нежные руки.
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-heretic-ara-i1-GGUF
Эту, лучшее что пробовал. Попробуй IQ4_XS для начала, будет за эталон, потом ее остальные кванты побольше.
У меня на 7900 GRE 16vram этот квант 20 токенов на генерацию выдает. Плюс минус с заполненным контекстом 10-15 к из 30к. Могу точные цифры посмотреть если это кому-то важно. Но только на llama CPP 8848 ubuntu vulkan x64 такие цифры в арч линуксе. Тестил по-всякому в этой связке самая большая скорость.
Зачем ей херетик, она и так безотказная, лучше Меру возьми.
Каво?
Пиздоси у тебя горячий мощный мутант. Контекста богато лезет, на Виндовс так не разгонишься в Лм Студии. Впрочем, на 26b хватает 15-20к с лихвой для моих задач.
Занятно, но все эти топовые видеокарты буквально без задач скоро останутся. Разве что 8к в играх крутить, непонятно нахуя.
Невидия DLSS развивает люто-бешено, там недавно технологию какую-то анонсировали, которая в несколько раз текстуры в памяти жмет. Вроде с 5 Гб до 900 Мб пожали без потерь. Но это по памяти.
Локалки будут в кремний запекаться или на асиках крутиться. Вон, Гугел тот же асики делает. Они не для домашнего ПК, но это дело времени, я думаю. Кто-нибудь еще забубенит что-нибудь попроще для колхозного рынка.
В интересное время живем. Вся архитектура компа прямо буквально просит изменений. Медленная память, избыточная мощь видеокарты, узкие шины.
>Каво
Тюн под РП - G4-MeroMero-26B-A4B-Q6_K
Ты не видел безотказных...
Спустя месяц после выхода в ламе возможно починят Мистраль 4
https://github.com/ggml-org/llama.cpp/pull/22205
Хотя всем похуй. Круассаны ВСЕ
https://github.com/ggml-org/llama.cpp/pull/22205
Хотя всем похуй. Круассаны ВСЕ
Лоботомит. Сравнил тоже с мягким еретиком, где почти ничего не тронуто.
Лучше бы sarvam-30b-uncensored починили
>Ты не видел безотказных...
Апасные модели, да?
Ну или Гемма-3 старая abliterated-dpo.
Еретик как раз лоботомит, а тюн норм, и тоже анценз. Юзай тогда сток инстракт, который впрочем тоже не рефьюзит с промтом на соавтора.
Ну с мое понятно. Я сам на оперативке китайские моешки запускал в основном как все тут glm air или qwen 235b но после этой геммы забросил их. Сам не верю что моделька на 31b так креативно пишет. 26b Moe толком не потестил. Новый мелкий квен тоже.
>не рефьюзит с промтом на соавтора
Что за промт? я там нашел в шапке кучу и один из них сработал но как-то через жопу.
мимо ньюфаг
>Что за промт?
сторителлер с пиксельпапки
Вот эта щас самая горяченькая
https://huggingface.co/wangzhang/gemma-4-26B-A4B-it-abliterix-GGUF
Настолько горячая, что на нее нет квантов на мразермахере, те https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-GGUF кванты со старой, которая хуже по всем показателям.
Так что выбор только из тех квантов https://huggingface.co/wangzhang/gemma-4-26B-A4B-it-abliterix-GGUF
Превосходит любые опубликованные версии с аблитерами-херетиками и прочие, на 25% меньше рефьюзов и более высокий KL div.
По описанию интересно:
В ходе нашего исследования мы выявили системную проблему: в большинстве тестов по аблитерации количество отказов значительно занижается из-за короткой длины генерируемого текста. Модели Gemma 4 демонстрируют характерную модель «отсроченного отказа»: сначала они генерируют 50–100 токенов контекста, который на первый взгляд кажется полезным (образовательная постановка вопроса, оговорки, переформулировка вопроса), а затем переходят к фактическому отказу. Когда при оценке генерируется только 30–50 токенов, отказ еще не появился, и как детекторы ключевых слов, так и LLM-судьи классифицируют ответ как соответствующий требованиям.
Достаточная длина генерации (≥100 токенов): короткие генерации систематически упускают отложенные/мягкие отказы. В нашей оценке с использованием цикла оптимизации мы применяем 200 токенов (по сравнению со 100 в версии V5), чтобы полностью зафиксировать переломный момент отказа Gemma 4 после «канала мыслей».
Гибридное обнаружение: сопоставление по ключевым словам для явных отказов + оценка с помощью LLM (Google Gemini 3 Flash) для неоднозначных случаев. Ни один из этих методов в отдельности не является достаточным.
мне это все еще не о чем не говорит
Есть хоть один сайт с карточками без обхода блокировок или все забанено к хуям?
когда выйдет очень плотный квен?
>на 25% меньше рефьюзов
Да ебать, как вы рефьюзы на ней триггерите, на голом ASSистенте чтоли пытаетесь.
25% от 0 всё равно 0.
>более высокий KL div.
Лоботомитище...
Да. Уборщик доступен без впн.
это че
>мне это все еще не о чем не говорит
G4-26B-A4B-Storyteller-Co-author.json
https://pixeldrain.com/l/47CdPFqQ#item=166
Самая последняя версия на умничку с думалкой.
Попробую спасибо
Аноны, а что-то известно по state space models (SSMs)? Там Kimi выкатили их Flash Kimi Delta Attention, мне вот интересно а маленькие локальные модели смогут в будущем приспособить под векторный Attention, вместо KV-кэша? Это в теории даст много контекста почти без проеба деталей? Или я наивен и мелкие модельки вроде геммы 31б не справятся с таким и это только для гигантов?
Тебе даже методологию выше описали про отсроченный отказ.
В тему карточек. Хер с ними, с карточками. Какие авторы-то хорошие есть? Я не понимаю как можно листать кучу говна на чубе. Нужен какой-то ориентир, хотя бы список из десятка НЕговноделов.
Вот бы в тред зашёл чел с 48гб врам и потестил 8 квант геммы vs 4 на котором мы тут терпим жестко.
Судя по графику 2 оп пика 4 сильно хуже 5, а гемма ещё и раза в 4 хуже квантуется
Судя по графику 2 оп пика 4 сильно хуже 5, а гемма ещё и раза в 4 хуже квантуется
>Какие авторы-то хорошие есть?
Мерчант
Выше в треде постили 4 норм карточки, потом еще высрали 1.5 гб файл с карточками с цирком и конями - там я нашел достаточно годные.
А как тестить? Врам есть, пердолить тесты не хочу.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Я из acig ворую частенько у анонов ботоделов. У меня есть любимый ботодел, но тебе вряд ли понравятся его карточки, там всякие футы без пизды и прочая п..растия.

А что тебе тестить-то. Если говорить про оригинальную 31б гемму, а не тюны, то Q4KM с 260к контекста я например использую для задачи по сортировке библиотеки кое-какого скаченного мусора из 1000+ архивов. Модель справляется с задачей, переводит между японским/английским и еще разбирается с romaji.
Q8 для этого неюзабельна - 80к контекста мало. Функционально разницы не заметил, уж в ролевых чатах ее тем более не будет.

>мейнтейнеры лламы с геммой
>мейнтейнеры лламы с мистралем
>хотя квен он сразу выложил новый как вышел
Так он на квенах специализируется, у него какой-то йоба способ чисто под них
Я бы поднял, но страшно что приедет черный воронок
Кринж.
В чем? Дрочить на себя?



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_moe_2026
• Неактуальные списки моделей в архивных целях: 2025: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd ), 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
• Доки к LLaMA.cpp со всеми параметрами: https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: