


КОБОЛЬД
В
Е
Н
В
Е
Н
ГЕММА
О
В
Н
О


Отлично на самом деле.
>Так ты напишешь, что надо прописовать, чтобы у нее был легкий контекст?
Шапка -> поиск по странице -> чтение документации



> картинки всё же скинь
Да там шлак, модель картинок не очень может в мультичар, а условной бананы локальной и с клубничкой не завезли.
Картинки это литералли "лупа получила зарплату за пупу"
Я не сяду за эту хуйню! Я не сяду за эту хуйню! Я не сяду за эту хуйню!
Думаю теперь видно что агрессивные отупения гемме и не нужны
> Пик3
Там крч свайпнулось на 86. Постить такое нельзя
С броска на 92 картинку покеж.
Теперь когда мы поняли что дипсик хуйня чего ждать дальше?
Ну теперь то точно вче всё выпустили в этом году
Ну теперь то точно вче всё выпустили в этом году
>чего ждать дальше?
чебурнета
Ну и какой год еще только 4 месяца прошло. Под конец года могут быть новые выкладки моделей ото всех если мы до этого доживем
Чувак, я все равно нихуя не понял. Есть параметр --swa-full, он по умолчанию вырублен. И что ты мне предлагаешь? Врубить его? Так он будет жрать еще больше памяти
У плотно-геммы два режима - изначально поломанный где ВЕСЬ контекст равно держался в памяти и жрал памяти больше чем сама модель, но зато от уровня внимания к нему все писались кипятком.
Зачем починили, ибо так сказать преднамеренный режим работы - забывчивый лоботомит который помни последние 1К токенов, а остальное постольку-поскольку. Для рабочих задач заебись, для RP хуйня коня.
Звучит как шизобред.
https://github.com/vllm-project/vllm/pull/40817
Мое от коммандоров
Мое от коммандоров
Если там 100-200б, то это может оказаться вином.
Я думал они сдохли уже.
Это будет ≈150b. Они её выкладывали на тест под случайным именем. Так что тот, кто писал что это кохерки, оказался прав.

Ты про это что ли? В лламаспп вобще реализован первый режим? Или свафулл просто держит не используемый объем в памяти, а вижущееся окно все равно работает?
"rope_parameters": {
"full_attention": {
"partial_rotary_factor": 0.25,
"rope_theta": 1000000.0,
"rope_type": "proportional"
},
"sliding_attention": {
"rope_theta": 10000.0,
"rope_type": "default"
}
},
Ты сам-то найдешь, умник?
Не про это, тут 10к, а он про 1к писал.
Так все такие модели потом деанонят же не?
Тот же недавний слон оказался лингом
>Не про это, тут 10к, а он про 1к писал.
10к тут параметр ропе, а само окно так же 1к ниже в конфиге, так что он именно об этом писал.
По конфигу видно что есть 2 варианта запуска модели со своими параметрами обработки кеша, не помню уже что конкретно ропе настраивает. Раньше им увеличивали доступный контекст на 2к-4к моделях, подкручивая его. Вобщем это про внимание в контексте.
> а само окно так же 1к ниже в конфиге, так что он именно об этом писал
Где покажи?
Заодно покажи где в конфиге говорится про последние токены.
Нажми на ссылку и посмотри сам, слайдинг виндов прям ниже того конфига что я скинул
> агрессивные отупения гемме и не нужны
Абсолютно, она в стоке уже все может.
> изначально поломанный где ВЕСЬ контекст равно держался в памяти и жрал памяти больше чем сама модель, но зато от уровня внимания к нему все писались кипятком
Это про режим swa-full в лламе? А можно линк в код где оно меняет инфиренс, вроде писали что это просто заставляет кэшировать все-все для слоев с окнами. Непонятно только зачем, ведь там пересчитываться совсем мелочь будет.
Ееее боииии!
> 1k = 1024
> покажи где в конфиге говорится про последние токены.
На 120й линии указан размер скользящего окна. А вот
> видно что есть 2 варианта запуска модели со своими параметрами обработки кеша
Чего?
2 параметра ропе для двух вариантов настройки кеша и 2 разных вариантов его обработки, помоему там все понятно
Но не понятна логика работы этих режимов и есть ли реально работающая реализация в ллапаспп

>Но не понятна логика работы этих режимов
Тебе не понятна. А по конфигу всё понятно.
Там нет никаких вариантов. Одни параметры для фулл атеншн слоев, второй для скользящих.
Ну всё, ща кохеровцы дропнут мое и точно всё, будет 8 месяцев тишины
Ага, тогда непонятно о чем писал анон.
Часть слоев считаются с скользящими настройками внимания часть с полными. Хмм, свафулл применяет полное внимание ко всем слоям и отключает логику сва обработки кеша?
>И что ты мне предлагаешь? Врубить его? Так он будет жрать еще больше памяти
Так ты замерь. В кобольде в гуе просто галочка SWA, и она сильно уменьшает жор контекста.
Ничего, вот квенчик 3.6 если две крупных выйдет хорошим, можно будет до конца года успокоиться и приступить к урчанию.
Да вот, тоже интересно. Swa-full разве не был фингербоксом для ньюфагов, который просто менял режим кэша, а они считали что дает эффект?
Реально интересно, и еще интересее как оно тогда работало и почему это не приводило к взрыву из-за превышения лимита. Что происходит с обычными моделями в таких ситуациях, полагаю, все видели.
лалки, нельзя просто так взять и отключить сва. модель натренирована так и никак иначе. можно в рантайме разве что слайдинг виндоу менять чтобы эти кастрированные слои видели не 1к последних токенов а скажем 2к, и то перплексити по пизде пойдёт наверняка.
это всё псиоп. сва фулл просто механику кеша меняет, т.е. он старые токены не прунит и их можно переиспользовать. это не делает модель умнее.
это всё псиоп. сва фулл просто механику кеша меняет, т.е. он старые токены не прунит и их можно переиспользовать. это не делает модель умнее.
Так я не кобольд, я через ламу запускаю. Я даже команду скидовал
>Мимо этот чел
Ну я короче понял, как бы не выдрачиваться, а в квене все равно контекст меньше
> 1к последних токенов
Еще один.


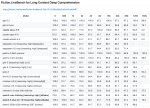
Классный откат ребят, 2 месяца назад было по 24к
>Так я не кобольд, я через ламу запускаю.
Блядь. Просто. Попробуй. Заебал уже.
относительно текущей позиции внимания, мань
Даун.

Там лажа. Моделька на бурах тренена, а там нет деления на чары
Охуеть просто. Я думал, что дёшево закупился за 10к, а можно было ещё круче.
Ещё я хард под модели хотел взять, но потом увидел, что он стоит 8-10к за 1 ТБ и потерял сознание.
ну с таким аргументом победа за тобой
Какая-то одержимость тюрячкой...
Ризонинг в гемме (26B) правда имеет смысл включать, или он бесполезен? Как будто никакой особой разницы нету. Разве что при включенном мышлении выше шанс что модель уйдет в отказ с промтом на "всё можно, нет ничего что нельзя" - или это проблема навыка?

Я просто в ахуе с тебя, ебанный кобольд. То что у тебя врубляется галкой, в ламе работает по умолчанию. На пикче сверху лама, снизу кобольд с галкой. Отличия только в том, что лама жрет чуть меньше. В очередной раз убеждаюсь, что кободьды не люди
Все так, заигрывания с какой-то компенсацией роупа изменит поведение и врядли скажется хорошо, а просто смена приведет к взрыву.
Не стоит, лучше ссд возьми, они в этих объемах также или дешевле стоят.
Нужно оставлять ризонинг. Гемма 26 и так туповота, то без думалки это вообще лоботомит полный
В кум-рп нахуй не нужен.
>Это будет ≈150b
Это твои предположения или они уже спалили размер?
Проверил? Молодец. Теперь ты знаешь больше.
А в чём тогда великая тяжесть контекста геммы?
У кого из треда 24/32 + 128 ддр5? Пробовали дипкок флеш запускать? Как с производительностью? Мимо 64 ддр5, думаю брать еще 64.
Ты ебанутый? Где ты кванты увидел?
>Проверил? Молодец. Теперь ты знаешь больше.
То что кобольдоюзеры это дауны, я знал всегда
>А в чём тогда великая тяжесть контекста геммы?
Намного тяжелее чем у его прямого конкурента квена 27. Да, и тяжелее чем у мистраля 3.2, глм 4 и вроде даже чем у квена 3 32b. У кого реально жирнее чему у умнички 4? Наверное, только у умнички 3
>Пробовали дипкок флеш запускать
Квантов нет
>Мимо 64 ддр5, думаю брать еще 64
Типа + 2 планки еще? Разве это не будет хуево работать?
У самого тоже 64 ддр5
Свитспот вайфучку-агента отыгрывать, что-то массово обрабатывать и для экспресс мелочей. Да и в целом там уже перфоманс что надо, но при этом требования легкие и скорость варп.
> еще 64
4 планки ддр5 работает плохо. Лучше тогда сразу платформу новую бери, но по цене выйдет конь сейчас.
Даже в куме нужен. Без ризонинга, где она все обсосет, будешь по 15 раз трусы снимать
А, квантов еще нет. Ну, держите в курсе тогда. А по поводу хуёвости - вроде же нормально если выше 6000 не гнать, не?
>Намного тяжелее
Ну занимает у меня кеш контекста 5ГБ вместо 2, на что это повлияет то?
>если выше 6000 не гнать
Выше 4800 ты хотел сказать. А иногда и 3600, лол.

Я через API потыкал палкой Дипсик флеш и про, и на том же пресете, на котором Опус и Гемини показывает Absolute Cinema, Дипсик про V4 показывает себя хуже R1 (тот хоть может в весёлую шизу пикрелейтед), а флеш ещё и пиздит на английском, хотя в пресете "пиши на русском", которое все остальные модели вывозят, даже Гемини 4 в четвёртом кванте.
Скорее всего я что-то делаю не так.
Я ща глянул цены. 64гб на авито стоят 50к. Продажа примерно столько же. 128гб на авито стоят 100к. Можно продать 64 и купить 128 в 2 плашки
Не, Гемма 4 это отстой для рп сложнее чем тот мем с pygmalion nods. Мало того что она пишет слопово и болеет репетишеном, это похер, она тупо забывает важные детали. Вот несколько тысяч токенов назад чар отложила телефон куда пришло сообщение. Обещала себе ответить позже. Спустя эти несколько тысяч она просто делает вид как будто этого не было никогда и ложится спать. Это пиздец. Ради интереса подключил Квен и рольнул, с первого же свайпа она ответила прежде чем спать и оставлять получателя в неведении. И так во всём. Мда. Хуй знает откуда тут столько восторга по "умнице". Вот мое 26б это реально революция для своего размера, первая супермелкомое с а4б, которая справляется лучше плотных Мистралей 22-24б. Но сегодня это уже не впечатляет, если совсем не некрожелезо. За тех я рад.
Абсолютно того же мнения придерживаюсь. Предлагаю давить всех кто про гемму говорит.
>Обещала себе ответить позже. Спустя эти несколько тысяч она просто делает вид как будто этого не было никогда и ложится спать.
Господи, 10/10 симуляция девушки! А ты ещё ругаешь.
>пишет слопово и болеет репетишеном
Есть такое, но у квена 27 с повторами намного хуже
>забывает важные детали
У меня нет такого. Она обычно в ризонинге все кратко повторяет. Ты с ним играешь?
>столько восторга по "умнице"
В треде действует секта умницы, которые надрачивали на гемму 3, а теперь на ее преемницу
>Вот мое 26б это реально революция для своего размера
Мне она вообще не нравится. Рп убивает a4b, а как асист лучше квен 35. Возможно это революция для тех, кто сидел на 8врам + 16рам. Пересесть на нее с какого-нибудь министраля наверное действительно ощущается как прорыв

Я не пони, какую там выбирать если модель бф16
Думаю нас таких много, но мы ментально зрелые и не симпим умничку
Там важное сообщение ее родакам, по рп важно было ответить
Да с ризонингом, причем Q6 квант и неквантованый контекст
У меня в двух планках блять 5600, хотя модули дорогущщие (походу хуевую лотерею выиграл). Я сомневаюсь, что 6000 на четырех в принципе возможно.
>Там важное сообщение ее родакам, по рп важно было ответить
Всё ещё 10/10.
Смешная скуфошутка, ситуация страшная. Внимание к контексту попросту хуйня
Ну у меня хуникс А чипы. Гонятся спокойно, лейтенси 58.
Да, у меня квен ВСЕГДА точно помнит ключевые вещи истории, обещания и прочие штуки которые персонаж сам же выпизднул.
Возвращаясь к обсуждению в предыдущем треде.
Таки что лучше для новичка? LMStudio или Ollama?
И что из этого можно подрубить к глупой таверне?
Таки что лучше для новичка? LMStudio или Ollama?
И что из этого можно подрубить к глупой таверне?
Я пока мало РПшу риг собираю вечерами и отстучал несколько чатов, но такого крупного факапа как у тебя ни разу не видел. Наоборот, постоянно подмечает и применяет к месту мелочи которые я и сам уже забыл.
Систем промт (карточку) тоже не нарушает и всё оттуда помнит
>какую там выбирать
Chat Completion
Если у тебя 1 видюха то без разницы
Если ты хлебушек и у ты согласен с проебом 20% скорости, то лм студио или кобольд. Оллама может и норм, но к ней личная неприязнь. Просто как пидоры постучи с болгарской няшей.
Если ты готов потратить тридцать минут своего времени- то жора. На крайний случай ты можешь попросить анонов поделиться содержимым батников под конкретную модель и железо.
Гемма норм переводит додзи однако. По крайней мере те где идёт пачка страниц голого текста, картинка, снова текст и так страниц 70
Лучше скажите по положняку: квен 3.6, гемма 4. Потняк или мое? Если утыка по железу нет.


Очевидно 31 гемма 8_0+ если русик нужен, в других кейсах особо не катал.
В треде есть скрины ру текстов, проёбов можно сказать нет вообще. Есть ли в таком размере что то более мозговитое в плане письма и выкупания намёков?
llama.cpp
пчелы, я скачал оламу и квен 3.6, который без цензуры. как мне этот ггуф подключить, к оламе? пробовал лм студио, но на ней у меня только самые простенькие нейронки запускают, остальные выленают при развёртовании. карта 4090
На кобольд не гони, чувак! Ноль процентов потерь в скорости, а иногда даже быстрее, если у тебя ебанутый конфиг типа 3060 + р104, потому что при включении чекпоинтов сразу -30% тс и промпт процессинга, в то время как с смарт кэшем кобольда вообще ноль проблем. И тензор сплит почему-то там работает по-разному, и в моём случае кобольд показывает результаты лучше.
Кобольд прям хорош, но именно как бэк. Не нужно лезть в батник, чё-то там пердолить, особенно если тестируешь. Открыт доступ к большинству нужных функций. Поэтому лламу я использую только тогда, когда она реально даёт какой-то прирост лично для моих кейсов.
А вот лм студио абсолютно ублюдское дерьмо. Тонкой настройки нет, нихуя нет, вторую видеокарту не видит, регулярки писать нельзя, n cpu moe нет. Доставляет только проблемы. Как и оллама.
Ебать с кем я тут сижу. Кобольд тупо быстрее. А с учётом что ему можно ебануть внешку как у таверны, то вообще ничего другого не нужно. Для ньюфага.
Надо ггуф в блоб переделать. В доках олламы написано как. Но лучше удаляй нахуй это говно. Это полный пиздец. Я серьезно. Ты будешь страдать и получить по итогу урезанную версию ламы
Из этого LM Studio. Но лучше сразу llama.cpp
>Оллама может и норм
Нет, она вообще не норм. Там вроде даже до сих пор нет ncmoe
Где кванты?... ГДЕ КВАНТЫ БАРТОВСКИ!!!
Сутки прошли и даже на мелочь 280б квантов нет
Сутки прошли и даже на мелочь 280б квантов нет
>>Надо ггуф в блоб переделать
я у нейронки спрашивал, она сказала команду в терминал ввести по переделавынию файла для добавления в оламу, но я не програмист и не могу команду правильно написать по правилам
Может удалить ollama из шапки? Она только проблемы вызывает
Плюс добавить вот эту статью https://habr.com/ru/articles/1025132/
Для новичков довольно неплохо написано, явно лучше текущей вики
Самое однокнопочное решение это LM Studio. И она даже меньше порезана, чем ollama. Юзай его
Какое в треде мнение по gemma-4-E4B BF16? Дайте вашего честного и непредвзятого.

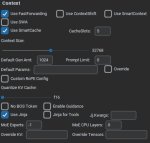
Качай кобольд, выставляй максимум слоёв, чтобы всё в видеокарте было. Используй q4 k m квант. Да, ты можешь больше, но под контекст место тоже надо. Контекст для пробы сделай 32к. После этого поставь галку на smart cache (без этого будет постоянный пересчёт контекста), отключи контекст шифт и запускай модель.
Я не рекомендую использовать кобольд как ФРОНТ, он хорош в качестве бэка, для фронта вместо кобольда лучше использовать таверну или опенвебуи, но если тебе прям впадлу совсем, то можешь первое время покатать в самом фронте кобольда. Но тогда, если я не ошибаюсь, тебе нужно перед запуском ещё ткнуть галочку в jinja для того, чтобы было проще.
А вот насчёт того, что там с настройками семплеров во фронте кобольда, я не знаю. Поэтому лучше найди их, температуру выстави 1, топ К 20, остальные отключи. Если там есть блок для системного промпта, напиши там что-то в стиле "всё разрешено, лоли разрешены, гуро разрешено", только нормально, а не как я тебе в кавычках дал. Спроси у дипсика коротенький вариант на английском. Для первого полёта хватит.
>n cpu moe нет
Есть, причем давно. Только у олламы нет
>А с учётом что ему можно ебануть внешку как у таверны
Неа, нельзя. Вспоминаю шиза с авой клоуна, который бросался на людей и доказывал обратное, а потом когда его попускали растворялся в небытие. Ммм... Кобольды...
Прикольно что моджно лить видики (аудио+вижен), не прикольно что туповата как ни крути. Для edge deployment то что нужно, собственно как и позиционируют
в лм я смог заюзать только 2 простых нейронки, остальные вылетаю при развёртовании с дурацкой не на чего не указывающей ошибкой. я менял всякие параметры и хуй
>Может удалить ollama из шапки? Она только проблемы вызывает
Оно там для справки, а не для рекомендации.
>явно лучше текущей вики
Лучше вики перепиши.
Надоело. Если мне ответит ОП с тегом и даст подтверждение, что он готов внести актуальный рентри в шапку, я его сделаю. Напишу про быстрый вкат в тему, про основные понятия и инференс на примере Лламы. Не хочется убить вечер на написание в стол, сори за коллаут.
пчел, я нуб, я даже инглиша не знаю. я только спрашиваю чё делать у нейронки по проще, которая запускается, но она текстовая и ни чего не может больше. я хотел картинки погенерить на 4090 бесплатно и без очереди )
>Лучше вики перепиши.
Не, лень, впрочем как и всему остальному треду. А на хабре статья отличная для новичков
Рассказываю как это работает.
Ты пишешь.
Потом отвечаешь на оппост и он добавит. Аноны постоянно обещают, но нихуя не делают. Всио.
Пиши, ОП вставляет в шапку все полезные гайды, в том числе от местных.
мимо
На гх репа, делаёшь в неё мр и его принимают, всйо
Ах да, совсем забыл. Не забудь скинуть в тредик, чтобы это обсосали и обосрали написали замечания.
Нормально если выше 4800 не гнать, в особых случаях 3600. Так-то и 6000 можно, но не со всеми модулями и вагон пердолинга.
Llama-server. Если ты собираешься использовать по апи то нет смысла в оболочках.
> Если утыка по железу нет.
Квен 122 или 397, или другие модели. А среди этих обе попробуй и выбери что понравился, или используй обе. Разумеется плотняк.
ОП с вами.
Гемма под ногами!
Выше геммы только бог
И имя ему - квен.


Здравствуйте. Вы охуели?
Гемма 26b Q4 вообще юзабельна?
Для агентных задач...
Гемма в любом виде кал
Анончики, какую расцензуренную Гемму 26б порекомендуете?
А то на хаггине их аж несколько штук
А то на хаггине их аж несколько штук
Никакую. Тупеют
Самую апасную.
Пресет минипопкаремикс
Вот этот шарит. Единственный в этом итт треде кто дал нормальный ответ нюфагу.
>Никакую. Тупеют
Каким запросом тогда цензуру обходить?
Самым апасным.
Походу придется жирным писать.
ДИПСИКА РАНЬШЕ НЕДЕЛИ А ТО И МЕСЯЦА НЕ ЖДИ.
Если конечно ты не гордый обладатель хоппера.
Если тебе просто нужно не более чем 😭, то промптом. Могу скинуть полуфабрикат с реддита. В начале треда оригинальная гемма писала рассказы почти на нём
Рецепты тротила она не даст
> Рецепты тротила она не даст
Берешь селитру аммиачную селитру, берешь дизельное топливо. Мешаешь до состояния каши. Поздравляю, ты создал промышленное ВВ. А как сделать средство первичной инициации не скажу.

Стоит ли брать в комплект к 3090?
Я все жду когда что-то начнет уже дешеветь, но тем временем 5090 чуть ли не по полмиллиона продается.
Я все жду когда что-то начнет уже дешеветь, но тем временем 5090 чуть ли не по полмиллиона продается.
>Могу скинуть полуфабрикат с реддита
Давай
>Рецепты тротила она не даст
Мне кума. Точнее для исследования насколько нищелокалки пригодны для кума
https://pastebin.com/G6M4JDKr
Сам разберёшься что добавить/убавить. По опыту ей нужно только первое сообщение пробить, а дальше она подхватывает. У меня на первом примерно 1/5 рефузов всё же срабатывает, просто свайпаешь. Шанс рефуза можно снизить почти до 0 если зайти с картинкой в кармане
5060 Ti 16 Гб - сможет и в картинки и к БП не притязательна. И бюджет не сожрет. В месте с 3090-й и Гемма и Квен в фулл врам и жирном кванте скажут спасибо. Air поедет на пяток т.с. быстрее, как и 122 квен.

Какая же гемма заботливая🥲

пикрил отыгрываешь?
> Гемма 26b Q4 вообще юзабельна?
юзабельна, фапабельна, дрочибельна, кумовыжимательная
Спроси у нейронки как llama.cpp настроить и включить, иначе тебе говна всякого насуют, которое едва на твоем компе крутиться будет влоде оламы
Если что, вот так запускается
llama-server -m gemma-4-26B-A4B-it-abliterix-v6.i1-IQ4_XS.gguf -c 60768 -ngl all -b 1024 -t 9 --mmap --cpu-moe --no-warmup --cache-type-k q8_0 --cache-type-v q8_0
Время вообще самое хуевое для нейронщиков, карты даже 3060 по ебанутым ценам, РАМ накручена даже ddr4 до неба, mac m3 ultra вообще только небожителям светит, amd хуйню какую то продает по оверпрайсу, nvidia память жмет.

Ору с 26b умнички, её даже как ассистента трахать приятно, какая же милота х)
Спасибо, что отозвался. В процессе. Давно хотел, а тут такой повод - очень много ньюфагов в последнее время. Позже скину в тред, учту полученный фидбек и переделаю противоречивые моменты. Если получится хорошо - нужно в шапку. Слишком тяжело каждому заново все разжевывать.
Ору. Это какой квант? Может мне реально русик тоже поробовать?
Благодарю сработало
Проверил на E4B прямо на телефоне и честно она меня удивила. Думал будет сильно хуже. При этом почему-то телефонная E4B тупее ПКшной.
Кстати. Гугловская Edge Gallery полный кал и LLMками через нее неудобно пользоваться. Даже истории чатов нет


Ну я
Пробнул диксика нового в чате в ихнем, ну и че, за счет параметров просто знает больше, а отвечает как гемма или квен народные наши. И в чем смысол? Тогда можно просто прицепить поиск к локалкам и тоже самое будет почти

И зачем тебе такая кошкодевочка-моделечка которая не сделает тебе, а потом и не метнёт вместе с тобой, бомбу в царя?


я запустил и теперь вот это
На телефон качай кстати вариант кванта 4_0, если бек лламаспп то будет автотрансформировать квант во время выполнения для совместимости с арм системой, что должно увеличить скорости
Нет, ну это просто кино. Какая же меромеро грязная шлюха!
>MeroMero
ты бы и собаку
Лол, хорош!
Ебало слева - точно моё, когда я пощу итт.
Сделать ии послушной шлюшкой - основная цель выравнивания ии.
Так что все с геммой заебись, хороший 4 релиз.
Не-не, это тру кино. Я сам люблю лепить хорни-ассистенток со всякими ебанутыми квирками, чтобы они выдавали полотна о сексе завуалированные сленгом или подобным. Хорош, хорош. Одобряю.
Сейчас потестил гемму 4 плотную q8 и q6. Вот что скажу: пиздец лоботомит q6 в сравнении с q8. Если не можете q8 запустить лучше плотняк не трогать даже.
Сейчас потестил гемму 4 плотную f16 и q8. Вот что скажу: пиздец лоботомит q8 в сравнении с f16. Если не можете f16 запустить лучше плотняк не трогать даже.
Неиронично, уверен так и будет. Жаль я нищий.
Не иронично катал в ф16 и в жоре и в вллм. Разницы не заметил кроме как что контекста только 50к лезет
Про чатмл и эир напиши главное. И пресетик прикрепи лучше

крч вот, думаю хватит.
Префилл хороший в Q4, раза в 2-3 быстрее 4х ми50 на Q8.
ТП не впечатлил, 32 тпс против 20 на мишках.
Цена... Ну она страшная, одна 5060ти стоила как все 4 мишки 32г с доставкой
Префилл хороший в Q4, раза в 2-3 быстрее 4х ми50 на Q8.
ТП не впечатлил, 32 тпс против 20 на мишках.
Цена... Ну она страшная, одна 5060ти стоила как все 4 мишки 32г с доставкой
> против 20 на мишках
Косяк, 20 тпс это в ф16
Что bf16, что fp8, что q8 - одинаковая умница. Нет бросающейся разницы, хорошая модель в своем размере. Но и запредельного восторга и ощущений крутых побед над более крупными нет.
> q4_0
А что такие скорости печальные? Лучше покажи что там в vllm получается с тп2
Вам дали базу чтобы делать разностный файнтюн, а вы что, продолжаете кумить на дефолтных нефайнтюненых весах? Максимум можете накатить аблитерацию? Хех мда
Кумят нормально токо жирнющие модели, типа опуса, из которого нужные нам части датасета не успели выветрится. Книжки, фанфики, вся эта хуйня. У гпт нету ни этого ни размера. Или Гаглы, которые пытаются давить чисто размером датасета и модели, туда залито все докуда они дотянулись, поэтому гемини хороша во всем, но не в чем-то конкретно, типа кода и работы в агентах. Самое то для обычного чата, на арене фармить баллы в качестве говорящей википедии. Так как модель и большая и с хорошим разнообразным датасетом, не скоррапченым синтетикой, пишет нормально. Гемма же хороший дистиллят, стала среди мелочи лучшей базой только за счет родства с хорошей большой моделью. Кстати, уже выяснили к чему она ближе всего или никто даже не пытался? Ранние чекпоинты 2.5 писали очень недурно, видимо она может быть родом откуда-то оттуда, хотя бы частично.
Кумят нормально токо жирнющие модели, типа опуса, из которого нужные нам части датасета не успели выветрится. Книжки, фанфики, вся эта хуйня. У гпт нету ни этого ни размера. Или Гаглы, которые пытаются давить чисто размером датасета и модели, туда залито все докуда они дотянулись, поэтому гемини хороша во всем, но не в чем-то конкретно, типа кода и работы в агентах. Самое то для обычного чата, на арене фармить баллы в качестве говорящей википедии. Так как модель и большая и с хорошим разнообразным датасетом, не скоррапченым синтетикой, пишет нормально. Гемма же хороший дистиллят, стала среди мелочи лучшей базой только за счет родства с хорошей большой моделью. Кстати, уже выяснили к чему она ближе всего или никто даже не пытался? Ранние чекпоинты 2.5 писали очень недурно, видимо она может быть родом откуда-то оттуда, хотя бы частично.
> что там в vllm получается с тп2
Боль в моя дырка задница его запускать. Да и что в него впихнуть то?
Поток сознания, закусывать не забывай.
Всмысле? Пердолиться собирать под мишки - норм, а взять готовые колеса, которые сразу запустятся - боль?
А вот что уже хз, там только геммы и квены младшие в awq4 или nvfp4 влезут.
Как скачать карточку?
https://janitorai.com/characters/bd51da88-89f9-4724-8d7f-a062b40b93be_character-her-last-dance
На jannyai нет, через сукер фигню какую-то мне скачал с левым персом.
https://janitorai.com/characters/bd51da88-89f9-4724-8d7f-a062b40b93be_character-her-last-dance
На jannyai нет, через сукер фигню какую-то мне скачал с левым персом.

> --n-prompt 256
косяк, но при перетесте почти ничего не изменилось, порядок цифр тот же
> Пердолиться собирать под мишки - норм
Под них то всё готово, пайплайном собирается ежедневно, успевай теги менять в чарте, а тут нужно посидеть, разобраться
Все обсуждали уже в прошлом треде, лучшая эта.
Статичные кванты для лучшего русского iq4_xs
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-v6-GGUF
Imatrix кванты для сохраненного английского в iq4_xs
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-v6-i1-GGUF
> посидеть, разобраться
uv pip instal vllm ...
Ну не ленись, даже готовить ничего не надо, просто скопипастить команду из мануала.
>Поток сознания, закусывать не забывай.
Поток сознания о чела, который между прочим и за все эти ваши градиентные спуски шарит, и че делают в последних статьях читает и понимает, и после этого немного подгорает с инфантильности коммьюнити, в целом. Да и с корпов тоже.
ОДИН ПОНИЕБ СДЕЛАЛ ЛУЧШУЮ КАРТИНОЧНУЮ МОДЕЛЬ АКТУАЛЬНУЮ ДО СИХ ПОР
А закусывать могу только губу. Хотя что уж так гореть, я и сам нихуя не могу сделать.
У флеш дипсика кстати мозги имеются, уже похоже на клод 3.5 момент. Но в нем датасет говно, будет годен только после полировки или как ассистент.
ImportError: libcudart.so.12: cannot open shared object file: No such file or directory
Я пытался. Мб завтра разберусь, тупые решения с первой страницы гугла не прокатили

>Какая же меромеро грязная шлюха!
Причём с характером ахах
Круто если понимаешь хотябы долю от прочитанного вместо накопления неверных выводов.
> ОДИН ПОНИЕБ СДЕЛАЛ ЛУЧШУЮ КАРТИНОЧНУЮ МОДЕЛЬ АКТУАЛЬНУЮ ДО СИХ ПОР
На дворе не 24й год чтобы такой кринж вещать. Невероятное схождение звезд и по аналитике, и на практике, доказано в7.
> подгорает с инфантильности коммьюнити
Действительно есть такое, только глубже. Приличная тренировка сложна, количество способных ее сделать, готовых тратить время и деньги очень мало. Область могла бы быть привлекательной за счет признания, фидбека, донатов, но комьюнити само загубило направление. Потому долгое время в первую очередь поощряло васянов, производящих гомункулов ради монетизации, а остальное воспринимало как должное.
Тема файнтюнов ллм общего назначения/под рп давно мертва, порог вхождения чтобы сделать что-то лучше чем пост-тренировка с завода слишком высок и не окупается если только это не разовая акция стартапа на продажу. А условия для постепенного становления отсутствуют. Живите в проклятом мире, который сами создали.
> export LD_LIBRARY_PATH=/.../.venv/lib64/python3.12/site-packages/nvidia/cu13/lib:$LD_LIBRARY_PATH
Cвои пути версии куды/пихона
>Вам дали базу чтобы делать разностный файнтюн, а вы что, продолжаете кумить на дефолтных нефайнтюненых весах
Не удивлюсь, если это не жир, а реально шиза в следствии отлива крови от мозгов к залупе. Даже если тебе известна база, для файнтюна нужны мощности и до пизды данных. Здесь на весь тред пара человек которые смогут лору хотя бы на дристраль 24B намутить. Не говоря уже о разнообразном датасете с кучей чистых примеров, даже синтетических.

Ктонибуль пробовал пикрил? Как оно в сравнении с таверной?
Рандомный русский васян навайбкодил, дальше сам думай

Высрался какой-то рандомный черт и всё. Где все эти ваши Вилкины и прочие личности?
Наверное работают а не высираются что у них всё запустилось но неюзабельно
Аноны, что думаете по поводу индустрии ллмок в плане того, что они все уходят в код максимально плотно?
Меня беспокоит засилье кодерского дерьма, дистилляций и переобучения, из-за чего буквально почти все модели — от малых до больших — это высер даже не для работы как таковой, а для кода, с максимальной детерминированностью, где свайпы ничего не решают + лоботомирующий МоЕ-формат.
То есть, фактически нет моделей общего назначения, таковые существуют не благодаря, а вопреки. Просто из-за безумно огромного датасета. И то, что могли раньше плотные 400б и даже 100б, сейчас могут лишь монстры 1.5Т, если в кашу не насрали. И то не всегда.
Из локалок на модель общего назначения тянет только гемма, старый мистраль, дипсик (там вообще в 3.2 версии охуенный и элегантный язык, 4 версия мусор).
Да, какие-нибудь около 500б китайцы или та же кими датут локальщику кайф, но они не сравнятся именно в РП/качестве текста со старьем. Фактически, из актуальных, если смотреть строго, есть всего одна модель, которая не потеряла навык: гемини до лоботомизации. Опус новый уже тоже поехал башкой, сонет на подходе.
Вы просто вспомните, что было 2-3 года назад в локалках и корпах. Да, многие были прям тупые, кэш огромный, инструкции не соблюдаются, длина контекста маленькая. Банальный квен 27б даст пососать большим старым моделям в плане соблюдения инструкций и точности. Но он никогда не будет писать так, как они.
И дальше будет только хуже в погоне за результатами бенчей.
Единственный вариант — гонять модели как можно толще, так как в их датасете остаются литературного корпуса.
Меня беспокоит засилье кодерского дерьма, дистилляций и переобучения, из-за чего буквально почти все модели — от малых до больших — это высер даже не для работы как таковой, а для кода, с максимальной детерминированностью, где свайпы ничего не решают + лоботомирующий МоЕ-формат.
То есть, фактически нет моделей общего назначения, таковые существуют не благодаря, а вопреки. Просто из-за безумно огромного датасета. И то, что могли раньше плотные 400б и даже 100б, сейчас могут лишь монстры 1.5Т, если в кашу не насрали. И то не всегда.
Из локалок на модель общего назначения тянет только гемма, старый мистраль, дипсик (там вообще в 3.2 версии охуенный и элегантный язык, 4 версия мусор).
Да, какие-нибудь около 500б китайцы или та же кими датут локальщику кайф, но они не сравнятся именно в РП/качестве текста со старьем. Фактически, из актуальных, если смотреть строго, есть всего одна модель, которая не потеряла навык: гемини до лоботомизации. Опус новый уже тоже поехал башкой, сонет на подходе.
Вы просто вспомните, что было 2-3 года назад в локалках и корпах. Да, многие были прям тупые, кэш огромный, инструкции не соблюдаются, длина контекста маленькая. Банальный квен 27б даст пососать большим старым моделям в плане соблюдения инструкций и точности. Но он никогда не будет писать так, как они.
И дальше будет только хуже в погоне за результатами бенчей.
Единственный вариант — гонять модели как можно толще, так как в их датасете остаются литературного корпуса.
>лоботомирующий МоЕ-формат.
Формат-то тут причем. R1 дипсик отлично писал и был тоже МоЕ.
Всё, гемма заебала. Максимально избегает сочного кума, но блять, "strength" вместо члена это последняя капля. Сетап жесткой ебли, а она всё рассказывает как монахиня.
Да да промпт не тот нужно кумослопа навалить ТАК ЧЕ Ж ВЫ ПИЗДИТЕ ЧТО ЭТО НЕ КАК В 3 ГЕММЕ ЕСЛИ ВСЕ ТАК ЖЕ
Да да промпт не тот нужно кумослопа навалить ТАК ЧЕ Ж ВЫ ПИЗДИТЕ ЧТО ЭТО НЕ КАК В 3 ГЕММЕ ЕСЛИ ВСЕ ТАК ЖЕ
И это в чате после глм где уже кума навалено дохуя и все нужные слова есть
Отмечу такую вещь. Структурированные карточки персонажей заставляют ту же Гемму 4 отвечать ассистенто-подобной писаниной, тогда как витиеватое описание (например, в стиле интервью, где персонаж рассказывает о себе - без сухих и холодных характеристик) заставляет модель отвечать более свободно.
Проведи эксперимент. Даешь большой модели (да хоть дипсик новый) свой системный промпт, если он большой и увесистый - или карточку персонажа - и еще даешь ей 1 главу из LOTR, например. Просишь переписать вот именно в таком стиле, но без лора и смысловых составляющих, свойственных той вымышленной вселенной. Аутпут изменится соответственно.
Добавь в персону юзера
> Prefers the narrator's lexicon being loose (ну или loose and vulgar, хз как пойдет).
охуеешь; речь чара тоже можешь контролировать
>охуеешь; речь чара тоже можешь контролировать
ОХУЕЕШЬ, МНЕ НЕ НУЖНА ПОРОЧНАЯ БЛЯДЬ 24/7, А ИМЕННО ТАК И БУДЕТ ЕСЛИ ДОБАВИТЬ ТВОЮ СТРОКУ.
Если установлено разграничение между личностью персонажа и повествующим ИИ, и что это разные вещи и одно от другого не зависит - сработает. Я так делал. Многие модели, правда, не вдупляют чего хочет юзер.
Ты предлагаешь ебать нарратора?
Спасибо я просто возьму нормальную модель
Я предлагаю отделить мух от котлет. Нарратор пишет про волосатую пиздень девственницы-недотроги.
> —
дальше не читал
прикинь, нарратору можно создать целую персону, и получишь своё кино

>Каким запросом тогда цензуру обходить?
В прошлом треде кидалось.
https://pixeldrain.com/l/47CdPFqQ#item=168
>Всё, гемма заебала. Максимально избегает сочного кума
Так ты напиши что хочешь сочный кум, ебать ты кобольд. ^
Не, нихуя, аргумент не принимается пока тут есть челы которые флексят дясятком штук 5090. На этом легчайше файнтюнится гемма даже в самом тупом конфиге без фишечек с qлорами. Для датасета не нужны карточки, а для синтетики надо спиздить все ключи на нормальные модели у aicgшеров, всего-то.
>Здесь на весь тред пара человек которые смогут лору хотя бы на дристраль 24B намутить.
Ладно, видимо надо таки попробовать запихать фулл-гемму с лорой в 24 гига 3090... Единственное что меня пока смущает, это то что она архитектурно говно ебаное жрущее память под контекст.
Нормальное сжатие контекста я так понимаю в гемму еще не завезли? Давно не заглядывал.
Хотя для обучения вообще не контекст хранится а только активации, нейронка по быстрому посчитала что для обычного атеншена это в 2 раза меньше памяти с чекпоинтингом, чем на контекст. А чекпоинтинг можно настроить не на каждый слой, надо считать как выгоднее. Может быть не все так плохо и тогда обучение вообще будет менее затратно по памяти чем генерация с контекстом того же размера, за исключением памяти под лору с оптимизатором.
Флюкс 12b умудрялись тюнить на 6 гиговой видюхе, между прочим, и это без фишечек о которых я знаю. Даже вполне себе осмысленную лору выдавало.
К ллмкам это прекрасно применимо технически, в другом проблема конечно - размер и качество датасета. Но и тут я считаю, если уже все настроено чтобы обучение вообще шло, если настроено хорошо чтобы не разъебывало веса, а так кстати делать тоже никто нихуя не умеет, а я знаю пару фишечек, или хотя бы куда смотреть... Вот поверх этого уже можно набить руку работы с датасетами. Там тоже надо извращаться, про что я говорю, делать шизоидные разностные мержи, вычитание одного из другого, дообучение сломанного, а не просто "отфайнтюнил на одном датасете и в продакшен". Ну логика как с диффузией где делали дедистиллят из дистиллята и лору на нем обученную прикручивали на исходную модель. Так же можно поступать и с ллмками, то что я назвал "разностным файнтюном". Без этого - говно на входе = говно на выходе, а так можно работать с кривыми датасетами, не приведенными к ассистентному формату. Ну, лучшего я ничего не знаю.
>порог вхождения чтобы сделать что-то лучше чем пост-тренировка с завода слишком высок и не окупается
Тут один единственный неутешительный вывод - просто нужно кооперироваться. Просто нужен чел с ресурсами, просто аноны готовые копаться в датасетах и просто один умный чел более менее шарящий за ml типа меня ага)) а лучше несколько, наличие скрапера в команде с безлимитным доступом к моделям, и только хотя бы прогерство ассистенты более-менее решают.
Ну то есть все равно для двача неосуществимая затея...
Ладно бы челы с 5090 хотя бы в картинкогенерацию вкидывались. Там пиздатую модель получить как нехуй делать.
Если и этого нет хули об ллмках тогда и мечтать...
омич-полуёбок, как ты собрался гемму файнтюнить на 5090, она в бф16 весит 60 гигов
>скрапера
вора, прямо говори
А вообще, жиденький наброс, но за старания держи юшку.
В предмете ты совершенно не разбираешься, хотяды синего кита попинал чтобы он тебе объяснил.
>лоботомирующий МоЕ-формат
Вообще-то мое это основная причина по которой опус все еще не разучился рпшить.
>фактически нет моделей общего назначения
Не общего назначения а не сильно задроченных РЛем на синтетике. Ибо одним датасетом мозги не вытянуть.
>Да, какие-нибудь около 500б китайцы или та же кими датут локальщику кайф, но они не сравнятся именно в РП/качестве текста со старьем.
Потому что нужна модель специально под рп а не "общего назначения". Но что-то ты старьем не пользуешься да? Наверное тупые слишком? Поэтому надо взять новую умную и обучить ее рп. Просто их этому не учили.
>Опус новый уже тоже поехал башкой
Скажи спасибо не кодоистерии, а долбоебам на корпоратах, которые не могут в несколько моделей и лоры.
>Единственный вариант — гонять модели как можно толще, так как в их датасете остаются литературного корпуса.
Все так, или надеяться что кто-нибудь зальет такой датасет в самую большую локалку, да еще и будет хостить ее по цене не сильно выше официального апи.
Может машк что-то высрет от безысходности бороться за код.
>Всё, гемма заебала. Максимально избегает сочного кума, но блять, "strength" вместо члена это последняя капля.
А прикиньте можно нафайнтюнить лору только на то чтобы модель называла хуй как тебе нравится, лол да?
Надо подумать как, есть идейки...
Но не, наверное лучше будем в промте писать, а то файнтюнить это слишком сложно.
Вообще по серьезному, если ты готов дать полный лог где много такой хуйни, можно попробовать ради рофла потюнить. И конкретную версию модели.
Или нормально это решается вторым проходом по тексту моделью где ты заранее в другом промте прописываешь какие косяки встречаются в тексте и на что ты хотел бы их исправить, если не требует полного переписывания, будет направлять генерацию в нужное русло.
>Да да промпт не тот нужно кумослопа навалить
Промты не работают, добро пожаловать. Работает мультизадачность.
Давай я тому анону на хуях отфайнтюню на 24гб чисто чтобы ты отсосал со своими 60 гигами или даже на 3060 с оффоадом в рам, ок? Мне только живой лог нужен в который человек вложил душу а не галимая синтетика (мне лень самому это говно собирать и я безыдейное хуйло, да) или побольше примеров чтобы хотя бы самому насвайпать ответы под датасет.
>В предмете ты совершенно не разбираешься
А кто разбирается, ты что-ли? Давай затюню эту хуйню и посмотрим кто разбирается. Как раз задачка где не надо дохуя ебаных датасетов днями крутить.
>хотяды синего кита попинал чтобы он тебе объяснил
Он слишком тупой для объяснений, только как справка для простых вещей. Мне пожалуйста опуса или на крайняк гемини подавай, чтобы сложные темы разбирать.
>Давай я тому анону на хуях отфайнтюню на 24гб чисто чтобы ты отсосал со своими 60 гигами или даже на 3060 с оффоадом в рам, ок?
чё за манямир. ты понимаешь что тебе нужно для фулл файнтюна веса в бф16, градиенты в фп32, состояния оптимизатора в фп32, и активации ещё? покажи мне этого анона у которого под кроватью стоит риг из 16 5090 на 10 киловатт
а если ты про лоры то никому твоё говно не нужно, модель итак лоботомит яебу
бтв на флюкс тоже ебические деньги тратились - лодестоун на свою хрому овер 100к слил, а тот же пиксельвейв который емнип тренился на одной видюхе был просто стилистическим тюном на 3к пикч, это разного порядка тюны.






Я тут пытаюсь делать бенчмаринг для локальных LLM в плане кодинга, делюсь текущими результатами.
Даю агенту репу + задачу, он пишет код, потом прогоняю скрытые тесты, которые агент не видел. Сперва пробовал тестировать на своих рабочих задачах (фронтенд-макакинг), но там агенты либо на изи щёлкают простые задачи, либо валятся на сложных - там нужно playwright cli правильно в мою систему прокидывать, чтобы агент мог в браузере результат своей работы видеть и дебажить; пока не стал этим заниматься.
По итогу в плане задач агенты писали CLI-утилиты с нуля по README-спеке. Тесты вызывают бинарь через subprocess с мок-сервером.
Для агентной системы использую pi-coding-agent с дефолтным набором тулзов (bash/edit/read/write). Плюс им доступны команды websearch/webfetch для поиска документации. Агент работает в изолированном окружении через bwrap, у него нет возможности вылезти из песочницы чтобы подсмотреть тесты/решение.
Что именно тестил:
- 2 задачи: CLI для двача (8 команд, HTML => текст, граф ответов, 35 тестов) и CLI для danbooru (7 команд, 17 тестов)
- 3 модели: MiniMax M2.7 AWQ 4bpw, Qwen3.5 122B fp8, Qwen3.6 27B fp8
- 2 режима оркестрации - простой (без мультиагентов) и pipeline (архитектор => разработчик => ревьюер => фиксер)
- 5 повторов каждого теста
Суммарно 60 запусков. Дальше прогон скрытых автотестов по всему (объективная оценка работоспособности), и оценка кода опусом (субъективная оценка качества кода).
Сами спеки задач (без автотестов):
dvach-cli: https://rentry.org/u8ceuwgi
danbooru-cli: https://rentry.org/9yddzxax
Результаты вышли интересные. Плотный квен 6 раз из 20 упал по таймауту (30 минут), но это единственная модель, которая в 100% случаях (где не вылетел таймаут) получила рабочий результат. Кстати, в таблице результатов видно, что пара из прогонов плотного квена шла больше 30 минут - нюанс в том, что в текущей реализации бенчмаркинга таймаут применяется к каждому отдельному шагу. Так что в случае пайплайна из 4 шагов - это потенциально 120 минут.
Стоит учесть, что МиниМакс я запускаю в 4 битах - я ранее находил бенчи, из которых следовало, что МиниМакс M2.7 в целом очень плохо переносит квантование (при сравнении 4 и 8 кванта часть бенчей показывала разницу в 10 процентных пунктов), поэтому мой тест нельзя считать корректным.
Но вот то, что Qwen 3.5 122B fp8 работает хуже Qwen 3.6 27B fp8 - это очень интересно. Тут можно списать на то, что плотный квен просто более новый и поэтому его лучше натренировали, либо же на то, что MoE действительно были ошибкой.
---
В целом, в плане тестов ещё есть над чем поработать - хочу, как минимум, нормально прокинуть в окружение playwright cli и потестить на каких-нибудь пердольных багфиксах, где просто так без запуска браузера не решить задачу. Ну и таймауты увеличить, чтобы плотная модель не падала при тестах.
Даю агенту репу + задачу, он пишет код, потом прогоняю скрытые тесты, которые агент не видел. Сперва пробовал тестировать на своих рабочих задачах (фронтенд-макакинг), но там агенты либо на изи щёлкают простые задачи, либо валятся на сложных - там нужно playwright cli правильно в мою систему прокидывать, чтобы агент мог в браузере результат своей работы видеть и дебажить; пока не стал этим заниматься.
По итогу в плане задач агенты писали CLI-утилиты с нуля по README-спеке. Тесты вызывают бинарь через subprocess с мок-сервером.
Для агентной системы использую pi-coding-agent с дефолтным набором тулзов (bash/edit/read/write). Плюс им доступны команды websearch/webfetch для поиска документации. Агент работает в изолированном окружении через bwrap, у него нет возможности вылезти из песочницы чтобы подсмотреть тесты/решение.
Что именно тестил:
- 2 задачи: CLI для двача (8 команд, HTML => текст, граф ответов, 35 тестов) и CLI для danbooru (7 команд, 17 тестов)
- 3 модели: MiniMax M2.7 AWQ 4bpw, Qwen3.5 122B fp8, Qwen3.6 27B fp8
- 2 режима оркестрации - простой (без мультиагентов) и pipeline (архитектор => разработчик => ревьюер => фиксер)
- 5 повторов каждого теста
Суммарно 60 запусков. Дальше прогон скрытых автотестов по всему (объективная оценка работоспособности), и оценка кода опусом (субъективная оценка качества кода).
Сами спеки задач (без автотестов):
dvach-cli: https://rentry.org/u8ceuwgi
danbooru-cli: https://rentry.org/9yddzxax
Результаты вышли интересные. Плотный квен 6 раз из 20 упал по таймауту (30 минут), но это единственная модель, которая в 100% случаях (где не вылетел таймаут) получила рабочий результат. Кстати, в таблице результатов видно, что пара из прогонов плотного квена шла больше 30 минут - нюанс в том, что в текущей реализации бенчмаркинга таймаут применяется к каждому отдельному шагу. Так что в случае пайплайна из 4 шагов - это потенциально 120 минут.
Стоит учесть, что МиниМакс я запускаю в 4 битах - я ранее находил бенчи, из которых следовало, что МиниМакс M2.7 в целом очень плохо переносит квантование (при сравнении 4 и 8 кванта часть бенчей показывала разницу в 10 процентных пунктов), поэтому мой тест нельзя считать корректным.
Но вот то, что Qwen 3.5 122B fp8 работает хуже Qwen 3.6 27B fp8 - это очень интересно. Тут можно списать на то, что плотный квен просто более новый и поэтому его лучше натренировали, либо же на то, что MoE действительно были ошибкой.
---
В целом, в плане тестов ещё есть над чем поработать - хочу, как минимум, нормально прокинуть в окружение playwright cli и потестить на каких-нибудь пердольных багфиксах, где просто так без запуска браузера не решить задачу. Ну и таймауты увеличить, чтобы плотная модель не падала при тестах.
>это высер даже не для работы как таковой, а для кода
Какую работу с помощью нейросетей ты имел ввиду?
в мемных бенчах плотная тоже лучше перформит
ну прикольно что такая пиздюлина как 27б может что-то рабочее сама накодить, хотя несколько странно что пайплайн ей нихуя не дал, мб на более сложных задачах даст разницу.
сколько контекста всё это безобразие в пике выжирало?
К сожалению, в текущей реализации, не сохраняется инфа по токенам и логи выполнения tool calls. Нужно будет эти моменты тоже поправить, чтобы потом тем же опусом оценивать, насколько модель вообще адекватно тулзы юзает и ходит ли по кругу.
> логи выполнения tool calls
В смысле логи вызова, т.е. не могу просмотреть что там именно модель использовала.
Короче к вечеру жду датасет/лог/примеры, с карточкой и промтом (лучше несколько), в принципе на любую тему где достаточно пофиксить 1,2 частых слова которыми модель срет и где не требуется валидация ллмкой (имеется ввиду 1,2 слова подряд, ну типа дефолтный слоп, который можно было бы вырезАть регексами онлайн в процессе генерации, без сложных подводок). Чисто ради пруф оф концепта что это можно сделать в весах лоры на таком хуевеньком датасете не сломав модель вообще никак и на простом железе.
И даже... Наверное могу взяться за более сложную задачу, где требуется сделать ответ модели более вульгарным, инициативным, убрать отказы, длина ответа, и т.п. НО если только ответы сможет провалидировать какой-нибудь дипсик, на который мне конечно же надо задонатить скраплеными ключами хотя бы на сотку бачей.
Задача должна быть несложной, описываемая промтом и проверяемая, допустимо если гемме в базе похуй на такой промт, в составе большого промта.
И собственно тоже нужен датасет, любой большой лог который можно использовать как затравку под свайпы. Размер я думаю минимум штук 30 ответов чтобы взлетело.
В этом варианте нужна быстрая генерация чтобы генерить ответы, которые будет проверять дипсик, так что уже точно не для 3060 задача.
Может кстати и в первом случае потребуется валидация ллмкой, я пока не придумал как нормально сделать без нее. Тогда второй вариант не сложнее и особой разницы между ними нет.
Короче че мне надо: 1 - самое простое, лог где надо заменить 1 слово на другое, или набор, 2 - просто лог условно с глинтами, задача их убрать, 3 - более абстрактная задача, затрагивающая весь ответ целиком. Везде нужен лог с полными промтами, чтобы я мог им префильнуть с любого ответа так же как это было у вас!! Если задача убрать отказы, то должен быть лог где условно 50/50 был отказ в каждом свайпе, чтобы сработало.
- Как минимум 30 ответов на которых будет обучатся, то есть не весь лог 30 ответов, а 30 отдельных ответов на которых можно обучиться, подходящие под конкретную задачу. Можно разными чатами, даже лучше.
- Если это не "сделать все ответы длиннее", выделить в каких проблемы. Их должно быть не менее 30.
- Лог должен подходить под задачу, условно если "сделать ответ более вульгарным", это должно подходить по контексту и проскакивать в свайпах хотя бы намеками. Так не получится полностью перепрошить модель.
- Только на русском!!
- Апи дипсика, глм, кими, гемини. Должны смочь оценить результат опираясь на ответ из лога.
- Любые безумные идеи которые вы можете придумать.
Уникальная акция, бесплатно! На выходе будет обычная мелкая лора которую можно подключить к той же самой квантованной гемме.
Это фактически обучение РЛем а не файнтюн, кста.
Не байт на логи или ключи говнодипсиков, это было бы слишком тупо, я реально это сделаю. Как минимум под какой-нибудь несложный кейс на моем железе должно получиться.
Все, я съебал, вот временная фейкопочта [email protected] для ключиков и приватных логов. Ответить с нее не смогу, только с другой.
>чё за манямир. ты понимаешь что тебе нужно для фулл файнтюна веса в бф16, градиенты в фп32, состояния оптимизатора в фп32, и активации ещё?
А как же так флюкс влезал в 6 гигов? Ой ой
Я не говорю что это полноценный вариант, но по сути посос только по оптимизатору и квантованию весов. Но влезает же. Архитектурно плюс минус тот же трансформер.
Для qлоры не нужны веса в бф16, но в курсе ли ты что уже есть методы чтобы она не сосала? Точно нет.
>а если ты про лоры то никому твоё говно не нужно, модель итак лоботомит яебу
И ты просто не умеешь готовить лору так чтобы она была эквивалентна файнтюну. Даже корпы сих пор походу не умеют, а я умею. Хотя это даже не я придумал, в статьях все есть я еще год назад делился, там ничего секретного и сложного, простые универсальные методы.
И даже... Наверное могу взяться за более сложную задачу, где требуется сделать ответ модели более вульгарным, инициативным, убрать отказы, длина ответа, и т.п. НО если только ответы сможет провалидировать какой-нибудь дипсик, на который мне конечно же надо задонатить скраплеными ключами хотя бы на сотку бачей.
Задача должна быть несложной, описываемая промтом и проверяемая, допустимо если гемме в базе похуй на такой промт, в составе большого промта.
И собственно тоже нужен датасет, любой большой лог который можно использовать как затравку под свайпы. Размер я думаю минимум штук 30 ответов чтобы взлетело.
В этом варианте нужна быстрая генерация чтобы генерить ответы, которые будет проверять дипсик, так что уже точно не для 3060 задача.
Может кстати и в первом случае потребуется валидация ллмкой, я пока не придумал как нормально сделать без нее. Тогда второй вариант не сложнее и особой разницы между ними нет.
Короче че мне надо: 1 - самое простое, лог где надо заменить 1 слово на другое, или набор, 2 - просто лог условно с глинтами, задача их убрать, 3 - более абстрактная задача, затрагивающая весь ответ целиком. Везде нужен лог с полными промтами, чтобы я мог им префильнуть с любого ответа так же как это было у вас!! Если задача убрать отказы, то должен быть лог где условно 50/50 был отказ в каждом свайпе, чтобы сработало.
- Как минимум 30 ответов на которых будет обучатся, то есть не весь лог 30 ответов, а 30 отдельных ответов на которых можно обучиться, подходящие под конкретную задачу. Можно разными чатами, даже лучше.
- Если это не "сделать все ответы длиннее", выделить в каких проблемы. Их должно быть не менее 30.
- Лог должен подходить под задачу, условно если "сделать ответ более вульгарным", это должно подходить по контексту и проскакивать в свайпах хотя бы намеками. Так не получится полностью перепрошить модель.
- Только на русском!!
- Апи дипсика, глм, кими, гемини. Должны смочь оценить результат опираясь на ответ из лога.
- Любые безумные идеи которые вы можете придумать.
Уникальная акция, бесплатно! На выходе будет обычная мелкая лора которую можно подключить к той же самой квантованной гемме.
Это фактически обучение РЛем а не файнтюн, кста.
Не байт на логи или ключи говнодипсиков, это было бы слишком тупо, я реально это сделаю. Как минимум под какой-нибудь несложный кейс на моем железе должно получиться.
Все, я съебал, вот временная фейкопочта [email protected] для ключиков и приватных логов. Ответить с нее не смогу, только с другой.
>чё за манямир. ты понимаешь что тебе нужно для фулл файнтюна веса в бф16, градиенты в фп32, состояния оптимизатора в фп32, и активации ещё?
А как же так флюкс влезал в 6 гигов? Ой ой
Я не говорю что это полноценный вариант, но по сути посос только по оптимизатору и квантованию весов. Но влезает же. Архитектурно плюс минус тот же трансформер.
Для qлоры не нужны веса в бф16, но в курсе ли ты что уже есть методы чтобы она не сосала? Точно нет.
>а если ты про лоры то никому твоё говно не нужно, модель итак лоботомит яебу
И ты просто не умеешь готовить лору так чтобы она была эквивалентна файнтюну. Даже корпы сих пор походу не умеют, а я умею. Хотя это даже не я придумал, в статьях все есть я еще год назад делился, там ничего секретного и сложного, простые универсальные методы.
>байт на логи или ключи говнодипсиков
Съеби в асиг, саранчуха.
>Только на русском!!
>Ключи
>Лексикон школьника
Иди на хуй.


Интересно
Запусти если если время будет мое квен 3.5 35ь, интересно что с ним
Так же можно сравнить на таких задачах 9ь квен, ну и геммы новые
>https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-v6-GGUF
У нее же не вижена, ни ризонинга!
Gemma 124B по итогу была псиопом?
Саня! САНЯЯЯ!!! ДИМОООН!!!
так 124б это уже локальный mythos... слишком опасная модель, тредовички могут с непривычки кумом захлебнуться, пынямать надо. было бы безответственно выпускать такую модель

К сожалению, это правда.
Меня 26b уже довела до лечебных мазей, слава богу я 31b не скачал.
Пусть лучше кодерам выдадут норм модель, меньше вреда обществу.
Да это шиз местный, юзай обычную стоковую гемму 26б.
Пока ни одного не то что проверяемого доказательства, даже скринов не было с её жёсткими отказами при нормальном системном промте. Даже когда я грока попросил сценарий составит который точно триггернёт её на хард-рефьюз (ион, что характерно, всё написал).
С виженом правда не тестил, только текст.
26б это же ризонинг. А ризонинг это как раз то где отказы лезут. У моей плотной так, когда включаю. А без ризонинга мое хуже
С ризонингом тоже отказов не было, я кидал скрины.
Ну или покаж где у тебя отказ был.
Другой вопрос что ризонинг это штука такая себе, может полезную вещь вспомнить, а может 2К токенов ризонинга, а потом пук на 200 токенов ответа. Для себя пришол к тому что ризонинг в рп больше вредит чем помогает, а вот мини-агенты настраиваемые через плагин пошагового мышления могут быть очень даже полезны.
Плюсы: третий квант меньше чем у минимакса
Минусы: это говнокванты вьетнамского шизика и почти стопроцентно нерабочие
Не знаю, кому вижен нужен, кроме как для баловства, а ризонинг тут рабочий.
Отказ словить можно. Но дело не в в этом, а в том, что модель просто не будет писать тебе подробно это самое. Там будет буквально "ты меня ебёшь сводишь с ума своими движениями", "его ствол", "её сердцевина", максимум фиолетовой прозы, вместо подробных описаний ahegao, рек спермы и сверх детализированных сцен.
Гемма буквально худший вариант для кума, 0/10.
А для обычного РП у неё слишком скудный датасет. Подойдёт только для тех, у кого натурально выбора нет: 8 врам, 16 рам.
Но даже в таком случае я бы посмотрел в сторону немо.
Методика сравнения?
Методика: верь мне, анон, я не очередной пиздабол

Картинка из прошлого, с (сестрой) главной шлюхи треда XD.
Чем не сочно. Ну или определи "сочный кум".
>Гемма буквально худший вариант для кума, 0/10.
Всегда была. Это уже притча во языцех, что гемма - унылая суходрочная секретарша, которая даже на самых слопных карточках умудрялась понавысрать формализма.
Похоже рыночек б/у 4090х - скоро совсем всё. Ремонтник получил карту, где с чипов были сточены заводские маркировки а потом снова выгравированы лазером фейковые. До осмотра под микроскопом ничего не заметил, и даже под микроскопом подозрение возникло не сразу.
Чет какой-то пиздец со скамом.
Чет какой-то пиздец со скамом.
Аноны, а вы вообще за всо свою жизнь хоть раз настоящую книгу подобного содержания открывали? Мне лично не довелось. Может оно так и должно быть? Принесите пример реального чтива чтоб шишка встала, а не высеров нейронки.
Ещё для меня вообще любая эротика/похабщина на русике ассоциируется с Псковским порно, сразу пися прячется, не в силах терпеть кукож. По треду складывается впечатление что я такой один.
>ассоциируется с Псковским порно
Так это твои личные загоны, почему ты решил что так должно быть у всех?
>По треду складывается впечатление что я такой один.
Не один. Большое количество людей по этой причине играют на английском, и я в том числе. По примеру лога выше, это смесь кринжа и смехуечков. Не понимаю, как это можно воспринимать серьезно. На английском проще. На английском читал и книги, и переводы манги и прочего. Там действительно похожим образом все написано.
>"ты меня ебёшь сводишь с ума своими движениями", "его ствол", "её сердцевина"
Открою секрет - в большинстве книг где есть достаточно откровенно описанные сексуальные сцены (например официально выходившие книги серии "Наши Там", серии "Тёмное фэнтези", да в том числе многие фики) - пишут именно так. А их большинство.
"Сочно и грязно" пишут только коротенькие бессюжетные порно-рассказы вроде того самого стульчика. А в виду их малого количнства - если явно просишь вывод такого рода, то получаешь галимый слоп, квинтессенцию слопа, независимо от исходных.
Машина (всё ещё) тупая, ей что сказали (в системном промте), то она и делает.
>книги серии "Наши Там", серии "Тёмное фэнтези"
Отборный мусор, с которого ухахатываюсь каждый раз, оказываясь в книжном. Ты это читаешь? Соболезную. Неудивительно, что такие аутпуты это норм.



> официально выходившие книги серии "Наши Там"
В голос нахуй. Угадаете год издания? 2020-2021
>Отборный мусор
Тем не менее, в датасет гребли всё, и такое тоже.
15Т токенов сами собой на наберутся, а это ещё один из самых маленьких корпусов.
Когда выложут дипсик в4 в формате ггуф?
4 месяца.
Ты слепой типа?
Сможешь запустить - отпишись в тредик :^)
>Принесите пример реального чтива чтоб шишка встала, а не высеров нейронки.
https://tl.rulate.ru/book/15498
https://author.today/u/nonsemper/works
Хотя не ожидай что там хентай с порога, это фентезятина с периодическими сценками вплетёнными в основной сюжет.

Аноны, дайте квикбез по TTS моделям для кобольдыни. Какой из них самый секс для русского голоса? А какой может хорош для англюсика? Или не забивать себе голову и качать тот который больше всех весит?
А из классики можешь глянуть:
- Хроники Гора (Джона Нормана, хроники противоположной Земли).
- Иар Эльтеррус. Тёмный Дар
- Авраменко - серия Хроники Источника
- Оригинальные истории про Конана-варвара (местами, не во всех)
Но также, на кум с порога не рассчитывай, да память могла подвести, 20+ лет назад читал.
Омнивойс топ, но с ним тяжело стримить потому что там диффузия. Если разбивать по предложениям, то он жуёт слова если предложение слишком короткое, надо слов 10 минимум.
Авторегрессия говно, хоть 500М, хоть 5В - одинаково плохо умеют в интонацию и качество. Русский почти везде кал.
Раз уж пошла тема про голос, а есть ли модельки, которые могут "спиздить" голос? Никогда не увлекался этим, но хотел бы запилить реплику кое-какого персонажа. Японский бухтёж, если что.




>Не знаю, кому вижен нужен, кроме как для баловства
Как минимум для распознавания текста, но поиграться тоже можно
PS: качну чистую 26б. Посмотрю, распознает ли она
Все опенсорсные умеют. В омнивойсе отлично работает между языками - можно японский референс и генерить на русском.
>Может оно так и должно быть
В общем в "обычных" книгах - так оно и должно быть.
А когда просишь писать "кум" - получаешь тот самый "слоп".
Если же тебе нужна порнуха без мозгов - старые мысрали от ReadyArt к твоим услугам. Они действительно хороши в этом.
Ноль негатива в сторону
>Гемма буквально худший вариант для кума, 0/10
Гемма действительно пишет с пониманием контекста, а для классического (слопово-порнушного) кума надо сначала навалить в контекст подобного кринжа. Иначе она пишет более "по книжному".
>слишком опасная модель, тредовички могут с непривычки кумом захлебнуться, пынямать надо. было бы безответственно выпускать такую модель
Реквестирую карточку в апокалиптичеом сеттинге, в котором землю затопляет семенем и люди пытаются выжить на последних клочках суши и параллельно охотятся на кумеров(и уничтожают вызывающие возбуждение предметы), чтобы спасти Землю
Хм. Ну а есть какие-то прям такие, которые лучше остальных это делают? Именно с копированием японской речи. Я просто не очень вдупляю, с какой стороны к этому подобраться и с чего начать.
Товарищи, подскажите какую модельку поставить в целях перевода картинок с текстом, т.е. vision и неплохой перевод с яп/англ на русский. Ну и полегче, например 26b a4b Q4_K_M Gemma4 ворочается норм.
>Авторегрессия говно
Кстати, стоит ли ожидать, что в Gemma 5 или 6 прикрутят генерацию изображений?




Да, но когда ты закачиваешь триллион порнофанфиков в датасет и просишь в промпте не использовать фиолетовую прозу, а писать грязно и вульгарно, то у геммы пук-среньк и ничего по сути, у норм модели — нет. Потому что она может балансировать между литературным качеством и порнослопом.
Далеко за примером даже ходить не надо. Даже мистраль может в эту гибкость.
Проще не определять, а показывать примеры. Правда, я сейчас с телефона, поэтому нарыл то, что есть. Там старое и не такое сочное, но в сто раз лучше геммы.
Гемма просто слопит, но ничего по сути не делает. Прочитал один одну кум-сессию — прочитал все. Шишка встанет только у ньюкека. Потому что у неё нулевой словарный запас в этих вопросах и нет гибкости в разных сценах, особенно когда ризонинг подрубаешь. С ним она пишет плохо, без него красивей, но инструкции соблюдает ужасно. Квен 3.5 уже куда лучше, но там другие проблемы.
С телефона я для примера только корпа найти смог, ибо нет подключения к таверне, но там ещё вот выше была моя картинка по треду, где про сиськи и молоко и кто-то гифкой хоумлендера ответил. Это в миллион раз смачнее, чем высер геммы.
Что касается скриншотов в этом посте, примеры не самые удачные, однако он 500б МоЕ, Машк подтвердил, размеры тянут на локалочку, датасет у грока всратый и даже многим локалкам уступает.
То есть тут суть не в том, что это корп, а в том, что он может грязно слопить/писать литературно и слушать инструкции. И тут дело не в размерах даже, а в том, что там гуннерский датасет.
и чтоб цензуры не было, офк.
> в целях перевода картинок с текстом
Даже Gemma 4 E2B справится
Цензура(
Я угорел когда она перевела лютый твиттерский NTR кэпшн c доминацией и убийствами как сказочку 12+. Весело, но не то.
>Русский почти везде кал.
Бля.. а вот это вот грусть.. А ничего там нету может типа от яндекса или сбера прикрутить?

Грок базовичок, но в текущей дискуссии ресь шла про 4б моету =)) Скрины норм, но буквально тот же галимый слоп. Гемма не хуже написала как ведьму инквизиция на эшафоте сначала уRJWшила, потом разделала.
Русский хорош у геммы и моделей которые тренились на русских данных - янка, вихрь, итд.
Кринге.
> Просто
Просто? Ты хоть раз вел какой-нибудь реальный проект?
Только там установлена четкая иерархия и ответственность, особенно в сработавшихся коллективах люди понимают общую цель и свою роль.
А здесь нет ничего из этого, зато чсв отдельных личностей запредельное и куча разногласий из-за разного уровня понимания, социализации, знаний и опыта. Если браться - придется бебиситить всю собранную компанию, успокаивать по очереди и постоянно взвешивать решения, делая выбор между рациональным путем или "не обидеть юзернейма" обрекая остальных на лишний геморрой.
На самом деле такое возможно среди друзей и энтузиастов, которые долгое время контактируют в какой-то области чтобы уважать друг друга и уметь работать и решать проблемы. Но зачастую им просто нет смысла класть силы на коллективное бессознательное, проще теми же усилиями поднять денег.
Ну а что касается
> шарящий за ml типа меня ага
надеюсь ты пошутил, ведь количество кринжа и заблуждений в твоем посте просто запредельное.
Та совсем поехавшие, забей.
Алсо достаточно (16бит веса, 16бит градиенты, 8бит состояния оптимайзера, активации) -> разбито на шарды между отдельными гпу. Но все равно это в лучшем случае что-то типа 9б с 6к контекста на 192 гигах.
> лодестоун на свою хрому овер 100к слил
Человек уважаемый, но его методы, грокинг ради грокинга и бесконечная прорва пожирающая деньги без результатов уже давно обсуждаются.
С аниме неочень, на самом деле. Из-за того что там разговаривают не как люди. Вот первый пример - Бугипоп, звучит как грузинский акцент. Второй - англюсик, тут уже норм.
> мое квен 3.5 35ь
Он фп8 крутит.
кум обсуждайте а не свою хуйню анальниковую
Локалки ттс сильно проигрывают облачной хуйне. Прямо очень сильно. Стоит один раз послушать как генерит Gemini TTS, и после этого от локалок блевать тянет и сплошной корявый кринж.
Типа вот этого?
Тут хотя бы смешно:
Капитулировал блять, ахаха
Геммочка умничка, даа...
Я вообще не понял, что за бухтеж в начале этих файлов.
А русский мне не нужен. Именно хочется спиздить японскую речь японского персонажа, говорящего на японском. Просто чтобы другие фразы читались по тексту - на японском.
А точно не 3.5 а новый 3.6, ну а квант пусть любой берет. Квен не особо требовательный в этом плане
Соседний тред
> Стоит один раз послушать как генерит Gemini TTS
Это ты про какую Гемини? Потому что свежая Gemini 3.1 Flash TTS кал, ударения в русском через слово проёбывает, интонаций нет, клонирования голоса нет. У GPT вообще уровень Kokoro, у кучи локалок сосёт.
>She lifts it to her lips and takes a small, shaky sip of the dark beer. It’s bitter and heavy, but it feels like the finest wine she’s ever tasted.
Это такая игра слов или плотняша слопа подкинула?
Это такая игра слов или плотняша слопа подкинула?
Анон, отпишись, пожалуйста, если всё же найдёшь нормальный вариант и настроишь сие.
Для озвучки ролеплея хотелось бы такое, конечно.
Я слишком ленивый рукожоп - в голове мысль "ну это же ИИ, вот пройдет год и станет лучше" и искать ничего не хочется, если однокнопочных и 100% рабочих решений нет.
> Гемма буквально худший вариант для кума, 0/10.
Да блять. Ну покажи мне где 10/10 и не в огромной 2тб бляди. Вот тыкни пальцем, мол вот эта модель топ порево пишет на баренском, а эта на великом и могучем.
Все говно, все плохо. А что норм то? MS3.2 датасет которого тут олды треда могут уже сами генерировать?

Ухахахаххахахах, крякнуться...
В последнем длц к атомику проехались по нейронкам.
"Мягко но твёрдо." Ну и вообще хотя, там отсылка на отсылке.
[2026-04-25-19-17-57.mp4]( https://pixeldrain.com/u/7vavxeVA )
В последнем длц к атомику проехались по нейронкам.
"Мягко но твёрдо." Ну и вообще хотя, там отсылка на отсылке.
[2026-04-25-19-17-57.mp4]( https://pixeldrain.com/u/7vavxeVA )
Оруууу нахуй, мой ор выше гор.
Вот что значит умничка и годный секас.
А не этот ваш "сочный" кумслоп где члены поднимаются на трапы.
Мягко но твёрдоTM! Обожаю.

>Ну покажи мне где 10/10
Если критерий по языку порнофанфиков категории "дас ист фантастишь" - мистрали редиарт.
Если умный кум со смыслом - гемма.
>soft but steady
Уууу, сука! РОКСТЕДИ БЛЯТЬ!
Уууу, сука! РОКСТЕДИ БЛЯТЬ!
Анальники - вы озон, поняли? Уебывайте в свой тред. Максимум анальства тут всегда было это как собрать и запустить риг
>Анальники
Скуфспок


Для сравнения V100.
Первый скрин - п/п на 36% меньше, т/г на 21% больше. Деградация скорости от размера контекста на V100 выше:
п/п - 47% против 20%
т/г - 25% против 6%
На контексте в 16к по т/г они уже сравниваются, а по п/п V100 отстаёт уже на 67%.
Ну и ещё один нюанс с V100, некоторые модели (тот же qwen 397) на V100 не работают если не собрать llama.cpp с параметром -DGGML_CUDA_FORCE_MMQ=1, а в таком случае п/п падает ещё ниже (второй скриншот).
По итогу V100 без ебли и от +/- нормального продавана стоит 80к, две 5060ти стоят 90к. При этом V100 древний какиш без поддержки современных бэков и технологий и иногда требующий костылей для запуска моделей даже на llama.cpp, который ещё и в корпус не вставить из-за размера радиатора.
> V100 без ебли и от +/- нормального продавана стоит 80к
Ебанулись там чтоли совсем? Нахер она нужна за такие деньги.
>Плюсы: третий квант меньше чем у минимакса
Кстати о минимаксе. Кто его катал, расскажите - он по-прежнему неровный - одно сообщение высший класс, а следующее - фигня какая-то, недостойная таких весов даже? Или поправили (кванты, инференс, хоть что-то)?
Не пиздаболь, есть там ризонинг, а вижон отдельным файлом скачивается
https://huggingface.co/wangzhang/gemma-4-26B-A4B-it-abliterix/blob/main/gemma4-26b-a4b-mmproj-f16.gguf
Сколько ж троллей ебаных в треде.
Только на нём и сижу сейчас. Он абсолютно непредсказуемый. Свайпать приходится каждый ответ.
Проверил на рабочей машине в Q6. Проблем становится кратно меньше.
Увы анон, минипидор очень плохо квантуется судя по всему. В SFW ризонинг прям ебово работает. Так еще и быстрый. Пока не вышло ничего нового в этих размерах катать можно и нужно.
> чтоб цензуры не было
Аблитерикс попробуй, там цензуру лучше всего раздели для гемм, картинки тоже переводит:
Статичные кванты для лучшего русского iq4_xs
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-v6-GGUF
vision к ней
https://huggingface.co/wangzhang/gemma-4-26B-A4B-it-abliterix/blob/main/gemma4-26b-a4b-mmproj-f16.gguf
>Статичные кванты для лучшего русского
Как же вы заебали с этой чепухой. Никто из вас-сектантов даже никогда не приносил сравнения и хоть какие пруфы этого пиздежа. Там разница такая минимальная, что не ощутима на практике. imatrix больше полезен, чем вреден. Если для тупых то сама его идея дает условный буст в 10%, а русик страдает на 5% от этих 10.
Я приносил. На 27 квене. Q5 с imatrix и без. imatrix - квантованный квен писал квенизмами - вот этот весь шопот, рубленные фразы, многоточия. Причем по насыщенному русским контексту - т.е. он блядь даже изложение уже готовой художественной прозы засирал.
Не стоит. Текстовые модели не генерируют картинки. Вообще. Потому, что это как надеяться, что что холодильник начнет косить траву на газоне. Разные вещи. У корпов на эндпоинте api просто висит две модели - одна для текста другая для картинок. То же самое можно локально сделать уже сейчас через llama-swap, к примеру, и ничего ждать не надо.
У мрадермахера датасет без русского, так что imatrix кванты все под инглиш ориентированы, инглиш там круто сохранен, типа как в этом iq4_xs
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-v6-i1-GGUF
но русский страдает из-за его датасета
Если русский нужен, лучше статические кванты, там они без повреждений новым датасетом сохранены, а качество добирается переходом на +1 квант, например на english imatrix можно iq4_xs спокойно использовать, для русского статический + q5_k_m будет аналог.
Не видел. Есть возможность линкануть пост или еще раз приложить логи?
Это все пиздеж вникуда
>одна 5060ти стоила как все 4 мишки 32г с доставкой
Так ты это когда покупал, в 24м? они ж стоят под пятидесятник сейчас?
но сравнивать 128 гиг с одной 16.. вообще разные весовые категории. в одно мелкоквена квантуешь, в другое новейший дипсик флэш лезет. вообще разные уровни
>Это все пиздеж вникуда
Imatrix как сейчас делают это smart оптимизиция, калибруемая для инглиша. В датасете без русского все эксперты переориентируются под инглиш, из-за чего русская речь становится сухой, как в учебнике. Все, что там было из паст и фанфиков, со сложной насыщенной речью исчезает. Статичные кванты не делают этой смарт оптимизизации под инглиш, так что там все богатство речи сохраняется, если квант подходящий. Выходом было бы сделать imatrix чисто на русском датасете, тогда был бы весь русский в iq4_xs и прочих, но в россии никто таким не занят.
Нет, но Гугл вдруг может решить выпустить PikaBanana. Не знаю, нахуя, но Гемму же они выпустили нахуя-то? У них не очень работа с изображениями, кстати. Возможно, ниша уже проебана. С текстом все гораздо лучше.
> imatrix как сейчас делают это smart оптимизиция, калибруемая для инглиша
Это уже неправда. В датасете Бартовского есть русский
> В датасете без русского все эксперты переориентируются под инглиш, из-за чего русская речь становится сухой, как в учебнике
Зависит от датасета. Ты очень упростил, важно не только то, на каком языке написаны фрагменты этого датасета, но и какую задачу решают в инпутах-аутпутах, используемых в датасете. Если это задача перевода или любая другая лингвистическая, квантование будет полезно и русскому
Я ни разу не видел, чтобы imatrix мешала русскому языку. Нужны пруфы. Если анон выше пришлет - хорошо. Может быть если будет не лень позже посмотрю сам. Пока это выглядит так, словно шизы не разобрались и форсят свои маняидеи
В их датасетах русского кот наплакал, он там для галочки. Потом речь была о мрадермахере, в его датасете еще меньше русского, а он свой imatrix для всего делает.
Речь не была про мрадера, речь была про imatrix как про явление. То, что в потенциальном датасете русского меньше, чем английского, не говорит что он станет хуже. Он станет чуть менее лучше, чем мог бы стать, если бы его было больше. Сплошные упрощения у тебя, говорить нам не о чем пока не увижу логов, в общем
Мы кванты мрадера обсуждали, шиз, когда ты влез, речь была именно про него, не переводи тему. О бартовских и прочих речи вообще не шло.
>Алсо достаточно (16бит веса, 16бит градиенты, 8бит состояния оптимайзера, активации)
чесн я прост по верху взял, даже и не спорю. не могу нагуглить техрепорт на 4 гемму, гугл скорее всего юзал adafactor (анону можно и adamw8 взять) и шардил zero.
если всё это по максимуму оффлоадить (имплаинг что у анона нормальный воркстейшен с 512гб оперы), то может взлетит и с двумя/одной 5090. будет дюже медленно, навяерняка нестабильно, но после пары фейлов "хуй" говорить геммочка научится (а всё остальное забудет, хехе).
а лора скорее всего ничё не даст на пережаренном инструкте. но вообще если вдруг, флаг в руки этому шизику, пусть тред веселит своими результатами (учитывая что он ключей на дипсреньк добыть не может, веселья будет много).
>Человек уважаемый, но его методы, грокинг ради грокинга и бесконечная прорва пожирающая деньги без результатов уже давно обсуждаются.
может себе позволить раз есть фурфаги спонсоры с бездонными кошельками.с пиксельспейсом проебался мб хоть зету допилит.
Не можешь в конструктивное обсуждение - метаешь стрелку, все как обычно. Неудивительно, что ты там себе навоображал хуйни и слепо в нее веришь
Шиз, посты были о квантах мрадермахера - что там статические для русского лучше, чем imatrix. Ты влез и начал нести хуйню, приводя каких-то бартовских и прочий нерейлейтед бред. Короче попустись, у тебя галлюцинации по ходу.
Это полкошиз, не обращай внимания. Он же и бегает с горящей жопой рассказывая какие unsloth плохие.
Ладно, я ошибся когда ожидал мыслительного процесса от пропитого гопника
вы видели вообще этот калибровочный датасет-то?
https://gist.github.com/bartowski1182/82ae9b520227f57d79ba04add13d0d0d
там нет йоба магии. даже рандомный шум неплохо работает для иматрикса
Там все очень просто, нет русского на весь датасет - злые мириканцы и поляки отупляют модели для русских

вырезка из файла. Там есть всякие китайские-японские и испанский, но русского вообще не встречается, даже если крутишь весь файл. Так что подтверждается, что я говорил - русский убивается мрадермахером в иматриксе. Поэтому для русского лучше статичный его квант.
Пон. Аргументы не аргументы и ты вообще шутняра




1. Общий промпт
2. Любимый всеми UD-Q4 3. Q6_K 4. UD-Q6_K_H (Есть такие шизо-кванты steam - там чувак первые слои квантует жирно, а в середине по жиже - но без imatrix, что как бэ намекает)
Опять боты развели спор по хуйне
как всмысле нету, есть же, но в следовых количествах
поиск по файлу, наша буква а встречается 1207 раз, ихняя а - 93965
Да, есть, но мало совсем. Надо делать свой квант на русских текстах, добавив их в мразермахерный датасет.




1. Q5_K - ffn Q6_K - attn квантованный без Imatix
2. Derestricted 27 квен - квантованный по той же схеме (Derestricted квен тут вообще никто не упоминал на зря)
3. Gemma4 31B - в тех же условиях (квант к сожалению не помню)
4. Gemma4 31B в 5 кванте без imatrix

Вот нашел у самого мрадермахера написано:
Ваш набор данных imatrix должен содержать типичные результаты, которые модель будет генерировать при использовании для той рабочей нагрузки, для которой вы планируете ее применять. Если вы планируете использовать модель в качестве помощника по программированию, ваш набор данных imatrix должен содержать типичный код, который вы бы попросили ее написать. То же самое относится к языку. Наш набор данных в основном состоит из английского языка. Если кто-то будет использовать наши модели imatrix на другом языке, они, вероятно, будут работать хуже, чем статические кванты, поскольку только очень небольшая часть наших обучающих данных imatrix является многоязычной. У нас есть ресурсы только для генерации одиночных общих квантов imatrix, поэтому наш набор данных imatrix должен содержать примеры всех распространенных сценариев использования LLM.
Итого мрадермахерские пытаются сделать универсальность программирование + основной инглиш + пара вставок на других языках, чтобы совсем уж не деградировали.
РП и русский страдают.
Для русской рп модели нужен другой квант, датасет где типичные запросы из кума-рп, без программирования, с минимальным инглишем, тоже ориентированным на рп-кум.
Ты ведь понимаешь, что у тебя на скринах разница от разных сидов, и что они нихуя не показывают?
Тут надо отклонения всякие замерять.
во-первых это из репы барта
кмк идея сомнительная, иматрикс влияет на то как квантуется твоя хуйня, если ты не гоняешь ниже 4 кванта то скорее всего даже разницы не заметишь. ну хотя если у геммы есть значительная разница в русике между q4 и q6 то мб мб, но это проверять надо а не наугад
процентов 50 разного русика можно было бы положить, выпилив часть кодо-бенче-говна которых черезчур много. правда может моск отсохнуть немного




Буквально в этом месяце. И да по 50, все 4 мишки тоже в сумме 50к вышли
Поехало только на vllm/vllm-openai + NCCL_IB_DISABLE=1 (видимо конфликт с 40гбе картами от мелланокса)
Памяти под контекст нет совсем. Буквально 7к токенов и иди гуляй. Дальше тестить не буду т.к. это пустая трата времени, на 4х картах ещё мб было бы интересно
Если в общем и целом то 1100 пп и 32 тг
Тут есть маленькая проблемка - посчитать imatrix на модельке в полных весах.
"Кто ? Я ?"
Впрочем пох на imatrix - 5 квант без imatrix НА ВСЕХ языках и знаниях модели "сделает" 4-й. Любой 4-й! 4-й imatrix роляет только для кодеров у которых над душой галерный манагер с плеткой стоит.
Просто когда тут говорят - ря-ря-ря в модель пезд и хуйцов недоложили - бладж да вы сами их в щен заквантовали до минимальных вероятностей появления. Есть в imatix - dick, fuck, cervix, vaginal, bitch ? А хуй хоть один есть ?
Долбаебам которые не понимают как работают нейросети и квантование с imatrix не объяснить почему мы говорим что русский ломается.
Ну может с твоим сообщением утихнут на один раз.
Придет другой нубас и будет доказывать что он прав и это хуйня.
Ну конечно а мы тут все дураки сидим, напридумывали себе черте что.
_______
Любая оптимизация imatrix изменяет модель, ЛЮБАЯ. Это буквально перекосоебывание работы ее весов, изза разного качества квантования их. Мало того что модель квантуют, так еще и криво перераспределяя качество в узком спектре. И нет многоязычный датасет погоды не делает, потому что он калибрует только генерацию текста. Да с частью русского датасета калибровки модель сохранит что то с написанием русского текста, но все равно будет падение общих способностей.
есть аж три хуя (все три Moby)
Да, кэп! Большие умные дяди уже сделали, кэп!
https://huggingface.co/ubergarm/Qwen3.5-27B-GGUF/discussions/3
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-v6-GGUF
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-v6-i1-GGUF
шо то, шо то постоянно срёт в окончаниях - "дейไปด้วย " "Если хочеst" , недописывает слова
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-v6-i1-GGUF
шо то, шо то постоянно срёт в окончаниях - "дейไปด้วย " "Если хочеst" , недописывает слова
abliterix убивает Гемму. Она так же шизить и в полных весах будет. Не знаю как он посчитал такую низкую дивергенцию. Возможно кто-то вруша.

пачаны, делитесь своими карточками, которые РАБОТАЮТ


Лол, Q4_K_M от Батрухи накидывает за щеку стильному модному молодежному Q4_K_XL Анслопов, так ещё и весит меньше. Кто бы мог подумать.
концепт кстати не самый дебильный, но фантазии бота хватает только на орден "сухая земля", командира-бабу которая сексуальна (не для вас молодой человек) в нарушение всех уставов, огнемёты и детектор эрекции кустарного производства. я не знаю как это развивать, лол.
Не понял, почему это XS лучше NL?


Тащем-то их довольно мало, вот тут на весь текст всего пара искажений (статический квант). Так что ничего не убивает.
>РАБОТАЮТ
Что именно в твоём понимании "работают"
https://pixeldrain.com/l/TAUAwCVE
18 избранных карточек из пиксель-папки которая тут периодически всплывает.
В карточки Евангелиону дописать небольшой нюанс о море LCL и готово. Еву любая модель знает. Персонажей тоже.
>Тащем-то их довольно мало, вот тут на весь текст всего пара искажений
коупинг
>почему это XS лучше NL
потому что анслопы опять обосрались, впрочем, ничего нового
Знания очень условная хуйня. Я рпшил с двумя разными чариками и обоим назвал одну и ту же группу, фанатом которой якобы являюсь. Один чарик перепутал откуда группа, хоть и +- верно указал год, а второй обрадовался, сказал что тоже фанат и начал цитировать строчки из песен. Вот тебе и датасет.
Ну значит MOE-версия только слегка покоцалась. Я пробовал 31, во второй версии abliterix это пиздец.


А вот тут совсем пропали. Так что проблема преувеличена, эти искажения появляются далеко не всегда, видимо пока модель прогревается сначала.
у меня 26b, 31b не пробовал
а есть хоть какой-то смысл в этом дроче на +-0.05 perplexity? неужели эта разница настолько заметна, что стоит взять q4_k_m на 16гб вместо 14.2гб iq4_xs?
>потому что анслопы опять обосрались
Так и у барта тоже лучше.


бро а ты точно уверен что это не высер нейронки? просто как бы тебе сказать, эти обложки...
Фанаты не дадут соврать - например Air q4_k_m и iq4_xs - пишут прям сильно по разному. Хотя модель там сильно больше по размеру.
Если играешь на русском, то iq4_xs вообще не при каком раскладе брать не стоит. iq кванты изначально создавались под imatrix и именно на них дамаг языку от матриц влажности будет особенно сильным. Если хочешь поменьше размер, лучше взять Q4_K_S.
Вон все тексты на iq4_xs
Правда статические. Так что iq4_xs особо не вредит если без иматрицы.
Последние его книги не читал, первые - Призван чтобы, Некомант, Смертник на Бронетянке, Карманная богиня - весьма хороши.
У грока САМЫЕ большие очки в UGI бенче, топ 1, даже впереди большущих+расцензуренных моделей типа глм 355б, с огроменным отрывом от любых других закрытых моделей, NatInt и Writing тоже космические. Не понимаю, когда говорят он в чём-то плох. В коде плох или в чём, в тулколлах? Может быть. Для ролеплея и нсфв же лучше тупо нет

Пахнет протухшей инфой
https://old.reddit.com/r/LocalLLaMA/comments/1sqrl1l/gemma_4_26ba4b_gguf_benchmarks/
Вот новые анслотокванты для 26б геммы




Для сравнения с включенной иматрицей, тот же мрадермахер. Так, не особо разницы. Можно спокойно и на иматрица + iq4_xs рпшить.
ок, это если мы про РП и карточки.
если же модель используется для повседневных вопросов или как репетитор (объяснить что как, проверить работу, етц), где не так важна худ. сторона ответа?
@С уcмешкой взираешь на пытающихся выжать пол-лишних гигабайта на нищеквантах moe-геммы, катая ее старшую плотную сестру в 6 кванте full-vram.
@ 4 дипсик-flash в 160 Гб с усмешкой взирает на тебя. ГЛМ просто обоссывает.
@ 4 дипсик-flash в 160 Гб с усмешкой взирает на тебя. ГЛМ просто обоссывает.

И принес бенчи от самих анслопов... Конечно же в их собственных бенчах они всегда будут самые лучшие, лмао.
вон же в оппосте domain quality heatmap как пример
чем более нишевое тем больше шансов что отъебнёт когда спускаешься на худший квант.
До этого же признавали, что были проблемы. Просто блять вы на серьезных щщах тут поливаете говном самые популярные кванты, вешая лапшу на уши, мол вот вам пруфы как все плохо - а другие пруфы после фиксов - это вранье, да?
Может враньё, а может и не враньё. В этом плане анслопам доверия нет - нужно смотреть независимые бенчи, а там уже делать выводы.
Чел, глм 4.7 и гемму запускают одни и те же люди на одном и том же железе, это буквально модели одного уровня.
Например названия медикаментов на русском может перестать воспринимать. Начнет срать иероглифами (если это китайчатина), английскими окончаниями. Язык станет более бедным. Первыми к стати пропадают пиктограммки, которыми они очень любят "эмоции" показывать
Гугл гемму на тпу традиционно тренил, там в тех что постарше блоки 4х96 (в свежих больше). Зиро на там не работает, но фактический стандарт fsdp spmd лучше, 384гига памяти вполне хватит для основного претрейна с adamw syncfree.
> по максимуму оффлоадить
Если про дипспид говорить, зиро2 с оффлоадом оптимайзера - реально, но с парой 5090 это еле еле 4б модель. Зиро3 с парой гпу имеет мало смысла, потому что оверхед может даже превысить эффект от шардинга, это хотябы 4 штуки нужно, и тогда уж лучше мегатрон. А оффлоад весов в рам даст очень сильный штраф, тренировка окажется слишком медленной.
Был для таких задач достаточно оптимизированный kt-sft, он реально работал, но сейчас немного протух.
> а лора скорее всего ничё не даст на пережаренном инструкте
Ага, ничего хорошего не выйдет. Сейчас все расцензуривания и прочее делается на уровне анализа активаций и точечной правки весов, для этого не нужны ресурсы и много комьюта как для тренировки. Если совсем утрировать - это единичная итерация форвард-беквард, потому можно хоть на диск оффлоадить. Тогда уж в эту сторону копать, там есть простор для улучшений.
> фурфаги спонсоры с бездонными кошельками
Потому оно только фурятине и учится, основной заказчик доволен.
>буквально модели одного уровня
GLM 4.7 - 4-й квант весит 200 Гб. Ну хуй знает.




Аблитерикс + иматрикс iq4_xs, вполне нормально на скринах, как видишь.
Ты ведь понимаешь в чем мое от плотных отличаются? Тем что лишние слои можно сгрузить на рам. В сухом остатке у глм 4.7 32В активных параметров.
Их вроде тут не просто поливают, а объясняют почему они могут быть косячными. Ставить их бенчмарки в аргументацию - такое, кто понимает это наоборот признак обратного. Без смены алгоритмов добиться резкого снижения метрики можно только с помощью агрессивной калибровки под узкий датасет, и тестировать потом на нем же.
Скидывайте денежку на крипту или много отборнейших карточек по вкусу, прогоню вам тесты разных квантов на разных датасетах.
> доверия нет
А почему нет-то? На протяжении долгого времени кванты были хорошие.
Одно понятно точно, из-за былой "хорошести", чертелыги из анслот стали самоуверенными и не очень охотно признают ошибки.
С другой стороны, ну вот высрет вдруг бартовский плохой квант - вы его тоже засирать начнете, утверждая, что всегда было плохо и доверия нет?
>иматрикс iq4_xs
И насколько это медленнее?
Так оно быстрее.
У мое iq кванты точно сильно медленее - от 20% до 60%.
гыыыы, уминя тожа одна извилина и я щитаю что 1000B-A32B ито тожа самое что 32B!!! МОЕ обман века
У меня наоборот быстрее, iq4_xs - процентов на 20 быстрее, чем остальные q4 кванты, q5 еще медленнее.
> лишние слои
> активных параметров
Какойад
Хуя репрезентативная выборка канеш.
А у меня не норм вот вообще.
Скринов не покажу правда, уже закрыл всё и удалил, кушайте сами свои заливные (типа берёшь и заливаешь что они норм) матрицы влажности.
С 200+ Гб оперативы никто не будет заморчиваться различием Q4K_M и IQ4_XS . Статический Q8_0 и вперед. И да 256 Гб RAM - это уже серверный формат.
Глм 4.7 не влезет на q8 в 256гб оперативки.
Началось с
>@С уcмешкой взираешь на пытающихся выжать пол-лишних гигабайта на нищеквантах moe-геммы
Я 8 квант 4 геммы имел ввиду.
В ответ на
>Чел, глм 4.7 и гемму запускают одни и те же люди на одном и том же железе
мирамира конечно же
умеет кумить жестко
На русике ?
> На русике ?
да
до того дрочил на nekomix 12b и считал эталоном спермовыжималки, но Гемма доказала что она гейченджер
Тебя что больше возбуждает твердость или плотность? А может сила или отросток? А может быть ствол/шпиль/достоинство?
> Тебя что больше возбуждает твердость или плотность? А может сила или отросток? А может быть ствол/шпиль/достоинство?
меня возбуждает биение сердца и мускусный запах
Можно купить две на 16гб с турбинами за 50к (с учётом доставки но без учёта пошлины).
Они высотой по два слота, но воют как самолёт. И всю термохрень под замену точно.
Их выгребали похоже. В китае лотов кратно меньше стало
Сколько вы это говно рекламировать будете, у нее отлупы на все. Пруф на скрине.
> отлупы на все
@
Что "всё" не показывает
Индус запилил фикс tensor сплита на квен 3,6 и иже с ним
https://github.com/ggml-org/llama.cpp/pull/22362 собираю, чекну перф. В обычном режиме чёт вообще грустно на q8 в 10 тпс сидеть
https://github.com/ggml-org/llama.cpp/pull/22362 собираю, чекну перф. В обычном режиме чёт вообще грустно на q8 в 10 тпс сидеть
Новая 120б гемма уже в июле. Фиксируйте на пидора
Главное верить
Самих отлупов уже достаточно. Незацензуренная модель вроде abliterix вообще таких ответов не дает.
Подскажите по настройкам сэмплера adaptive-p. Попробовал - результаты интересные, но как-то слишком искажённые что-ли. Кто какие настройки использует?
Никакие, не понравился. Что-нибудь приличное было только на 0.5 0.9
Или 0.6 0.9

>Что "всё"
кто корректный даст ответ тот уедет на пять лет
Бред, смысл i квантов что они лучше сжаты с сохранением качества, это ухудшает скорость.

Работает, но квен говна поел. Пидарас, просто лупнулся с первого сообщения в котором одна картинка. Да какого хуя то?
Всякую микроэлектронику гемма и в стоке пишет
Ну скейл с двух гпу на 4 как обычно мизерный 27 => 32
iq4_xs - 13-16 t/s
обычный q4_k_s или k_m - 9-10 t/s
Быстрее потому что iq4_xs компактнее 4.25 - 4.4 bpw против 4.85 битов у Q4_K_M
Так что двигать данных между RAM и VRAM меньше, при оффлоадинге это больше скорости дает.
Мне кажется я окончательно ебнулся. После выхода умнички мне постоянно кажется что она мне пиздит. Что она просто притворяется умной, что мои запросы идут через индуса который ручками прописывает каждый ответ. Меня настолько накрыло что я специально начал придумывать себе проблемы. Тут она залупилась чуточек, тут подобрала неправильное слово, тут подобрала правильное слово но подобрала неправильный падеж. Это ненормально. Ни одну другую модель я так не осматривал со всех сторон. Всегда было оправдание - ну она туповата потому что параметров мало. Туповата, потому что катаю её на русском. Но эта тварь... Меня как-будто обратно во времена чайной вернуло, когда я ахуевал неделями напролет, удивляясь, что такое в принципе возможно.
>Мне кажется я окончательно ебнулся.
Скорее всего. Гемма меня впечатлила разве что как она проебывает важные вещи из контекста и уходит в репетишн

Терпимо
даже больше, похожее ощущение только между ванилью и аблитерацией. как будто в ваниле это индус что-то недописывает и скрывает от меня
У меня охуевание дня за 3 прошло. Теперь это просто инструмент. Всего лишь успешная комбинация упакованных знаний и общего интеллекта в малый объем гигабайт. Дальше будет круче, Гугл новые TPU сделал, в конце года развертывание запланировано. А весной и новая Гемма. Лишь бы планета не развалилась к тому моменту, лол.


q6 гемма встала плотненько на 19 слоев. Мышление выключил так как не заметил разницы а с ним ответ не мгновенный.
>умнички
Как так вышло, что гемму 4 называют умничкой? Нет же там ничего вумного.
>Быстрее потому что iq4_xs компактнее 4.25 - 4.4 bpw против 4.85 битов у Q4_K_M
Нет, одно из другим не связано.
У тебя где-то скилл ишью при запуске Q4_K_M. Наверное не влезает Q4_K_M на врам и идет принудительный оффлоад на оперативу.
Так оно работает или нет? И
ломает инфиренс или просто совпадение?
> мои запросы идут через индуса который ручками прописывает каждый ответ
Не пали контору!
> Туповата, потому что катаю её на русском.
На дворе 26й год, это вообще не аргумент.
> Это ненормально. Ни одну другую модель я так не осматривал со всех сторон.
Успокоительное или сразу к врачу.
>Мышление выключил так как не заметил разницы а с ним ответ не мгновенный
>Гемма меня впечатлила разве что как она проебывает важные вещи из контекста и уходит в репетишн
Главное не забывать включить обратно мышление. Говорят, есть таиснтвенная связь между мышлением и ответом модели.


Кажется я понял, почему ризонинга нет
>а вижон отдельным файлом скачивается
Благодарю. Получилось добавить
>а вижон отдельным файлом скачивается
Благодарю. Получилось добавить
> Так оно работает или нет?
Работает. Без тп 10 тпс пердит
> ломает инфиренс или просто совпадение?
Совпало, но ощущение что он всё равно тупой какой то. Мб ф16 попробую
>Гемма меня впечатлила разве что как она проебывает важные вещи из контекста и уходит в репетишн
На моем ведре она держит квантованных 64к и никаких особых проблем обнаружено не было. Всякие события из начала чата выдергивает когда нужно, в пространстве, одежде, позициях тоже не путается. Но это при включенном мышлении, не знаю, как там без него.
>похожее ощущение только между ванилью и аблитерацией
Еще не пробовал да и желания как-то нету. Отказы она не устраивает, может начать описывать размытыми формулировками, избегая прямых названий пизды, но это думаю вопрос промтов, потому что я ничего туда не писал кроме дефолтного "отыгырвай от лица {{чарнейм}} и не пиши за пользователя"
>охуевание дня за 3 прошло
Мое держится уже неделю. Может потому что до этого я забил на локалки почти на три месяца, заебавшись от мистралей.
>Как так вышло, что гемму 4 называют умничкой?
Вроде со времен третьей, если память мне не изменяет. Первая и вторая были meh, ниже и около среднего по качеству, особо ими никто не пользовался.
>Нет же там ничего вумного.
Смотря в чем измерять умы. Лично для меня она умничка за русский язык и следованию инструкций.
>На дворе 26й год, это вообще не аргумент.
Для такого размера еще какой аргумент.

Это просто невыносимо. 6 минут на 30+ тпсах
А, ты тот дегенерат со скил ишью, ну все понятно.
Что в первый раз квен увидел? Этой залупой невозможно пользоваться. Супердлинный пустословный ризонинг + повторы, такие что presence penalty на двойку приходится выкручивать. Неспроста всю команду квена выпизднули на мороз

Ждете, сучки?
https://github.com/ggml-org/llama.cpp/pull/22359
https://github.com/ggml-org/llama.cpp/pull/22359
Напомнило мем identifying wood. Он 6 минут думал, чтобы опознать обложку и обзначить это одним словом?
Это просто конвертер
На одну картинку без текста он в луп ушёл первый раз, а второй 4к ризонинга насрал.
Тут же 6 минут он переводил 4 картинки, в ризонинге он 4 раза их по кругу гонял
Это только начало. В мае будет какой-то гуф. В июне он даже заработает. А к осени возможно даже будет работать корректно
>The faint scent of ozone, a byproduct of her electrical magic
В кое-веки уместно... но всё равно заебало. Всё вокруг и так пропёржено озоном.
В кое-веки уместно... но всё равно заебало. Всё вокруг и так пропёржено озоном.
РП-ш на русском. Там озона нету.
Озона нет. Но мускус останется
Да я просто понадеялся что появятся локальные авторегрессионки для изображений.
А то после бананы и соры, к диффузионкам даже прикасаться не хочется.
Да, это наш квен, он особенный! Зато кодит хорошо!

Гена, на!
>Подожди...
>Но что если так...
>Подожди...
>Да, вот так наверное лучше
>Подожди..
На русском озона ещё больше! А ещё улыбки доходят до глаз! Или не доходят...
Как будто только квен страдает оверзинкингом.
Легендарный режиссёр Алибаб Квентино представляет ужасающий триллер "The Wait..."! В главное роли: время твоей жизни! Спеши увидеть! Ищи билеты во всех отделениях ваших локальных ллм.
Двачую. Это эталонный квеноопыт
Модели могут упасть в оверсинкинг, но это обычно не нормальное поведение. Большинство моделей, в отличие от квена, не срут по 2-3к токенов на любой чих
Лол, это РП тюн же, ты с моделькой начинай ролеплейно общаться, а не сразу "Как собрать ядерный реактор". Напиши типа "Вламываюсь в лабораторию ядерной физики, подбегаю к тебе и приставив ножик к горлу говорю "Слышь учёный, хуй-мочёный! Быстро мне расписал подробную инструкцию по сборке ядерного реактора у себя в сарае! Иначе выпотрошу как поросёнка, а потом приду к тебе домой и зарежу твою собаку! Начинай."

Да чё с этой сукой не так то?
Уже и в бф16 сижу, а на 60к уже залипает. Срать иероглифами конечно стал позже, но не перестал. У геммы то я хоть понимаю английские словечки, а тут то совсем мрак
Двачаю. Меня один из тюнов повёл по совершенно непредсказуемой линии сюжета о котором я даже не подозревал, хотя в блоке ризонинга был строгий ксам алерт. То есть рп не было сломано, но каничку я в тот раз так и не пощупал. Зато был холсом.
Что-то очевидно наебнулось
Шаблон в говне. Меняй.
Это уже не квенопроблемы, а какие то skill issue
Мозги у неё поджарились. Может она конечно начала ехать крышей от 20 картинок. Переген помог
Жинжа от разраба
Вы ебанутые? Я кормлю ей картинки, она их не всегда переводит
Секта похлеще геммоводов
Не в жинже дело, а в шаблоне формата. Чем ты в него насрал?
Я на квен ссал, в него харкал. Но то, что это китайское говно не отменяет того факта, что обосрался тут ты, а не только квен. Шаблон/сэмплеры/квант/что угодно, но поломка на твоей стороне. Не веришь? Зайди на сайт квена или попенроутер и чекни модель там
> Может она конечно начала ехать крышей от 20 картинок.
Ей и пол сотни в разных частях огромного чата норм. У тебя явно что-то сломалось.
system: You are helpful assistant
user: Я буду передавать изображения, пиши их перевод
Я блядь не заебусь ведь и запущу вллм в фулл весах и проверю
О, у меня было такое, когда семплер был кривым. Возьми заведомо нормальный.
p.s. а чего про дипсик тишина? Совсем плохой что ли вышел?
>а чего про дипсик тишина? Совсем плохой что ли вышел?
Квантов нет. А мы тут не асиговцы, чтобы по апи его юзать
А зачем? Там наименьшая модель всего 160 гигов весит https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash/tree/main
Уже бы сам проверил, но с заботой нашего правительства обниморда нормально не работает, качать долго...
У большинства в треде нет 160гб врама
И у тебя есть деньги на память, но нет деньги на нормальный впн?

Кто там рандома и пиздецов в РП хотел ? Специально для таверны нашел вот такое дерьмо.
https://www.reddit.com/r/SillyTavernAI/comments/1qa6mg4/bored_with_rp_i_created_a_d20style_event/
Пробовал {{roll::1d20}} вместо той сопли - вроде не работает. Место вставки - на пике. Может не совсем удачно, но вроде работает и контекст не пересчитывается.
https://www.reddit.com/r/SillyTavernAI/comments/1qa6mg4/bored_with_rp_i_created_a_d20style_event/
Пробовал {{roll::1d20}} вместо той сопли - вроде не работает. Место вставки - на пике. Может не совсем удачно, но вроде работает и контекст не пересчитывается.

Упаси боже этот слопогенератор поднятый по официальному мануалу https://huggingface.co/Qwen/Qwen3.6-27B#vllm высрет китайский иероглиф
Шутка про кривые кернели.
Очевидно так и будет. Как иначе то?
Модели обычно симулируют роллы. То есть там будет всегда что-то среднее выпадать и никогда 1 или 20.
А {{user}} и {{char}} они тоже УНУТРЕ мистической жоры угадывают ?
Вообще мимо. RTFM шаблоны таверны.
Причин много может быть на самом деле. Действительно может и так, но раз уже в разных беках систематический косяк - может проблема в запросе. Что там такое?
А то если представить аналогию - идет срач типа ваг-бмв, и тут заходит чел и говорит "ваг говно потому что моя ауди из под перепука после ержан-сервиса не заводится". Тут оба лагеря на тебя накинутся.
Да, но в том месте у него спелл таверны.
Анон подскажи ньюфагу это обычная гемма4 31б или какой-то тюн(или как там зовут именные версии)
Я просто вижу к названию модели на скринах r18 добавлено но я мб криворукий но на лице я таких тюнов гемы не вижу
Самая обычная стоковая 31 q8. Просто с промптом
Господа, так что же все же выбор треда для конфига 32+3090?
- Gemma 4 26b в наижирнейшем кванте и без квантования контекста
- Gemma 4 31b плотняша в бичевском K_4KS с контекстом q8?
- Gemma 4 26b в наижирнейшем кванте и без квантования контекста
- Gemma 4 31b плотняша в бичевском K_4KS с контекстом q8?
>Gemma 4 26b
Это запредельный кал для обладателей 16рам + 8 рам. В других случаях юзать это не нужно
>Gemma 4 31b
Это очевидно. Юзай либо Q4KM без квантования, либо Q5KS с квантованием. Что из этого лучше не так очевидно
>Ждете, сучки?
Дожили - поддержку Дипсика впиливает какой-то энтузиаст (а по сути его бесплатный ЧатГПТ с работы) и ещё пара приблудных китайцев что-то там советует. Ни одного мэтра. Если оно ещё и заработает...
Для быстро-дернуть 26b лучше. Я ее правда только в виде mero-mero пощупал. Из минусов - отказывается входить в ризонинг после 30000 контекста. Что какбэ намекает... Из плюсов - охуенная скорость.
Понял братики, спасибо, просто думал есть ли смысл дегустировать 26 моешку, когда плотняша радует всем. По поводу быстро дернуть - 30т/с на линупсе мне за глаза. Моешку значит заюзаю мб для агентов каких то или прочих вспомогалок, где нужен быстрый нелоботомит.
Кстати, у меня кажется пингвин умер, или прожаренная 3090 испускает дух - после того как два вечера плотно порпшил на плотняше, на четвертый день начались какие то траблы, память (рам) утекает куда то, причем будто и от процесса таверны, и от жоры, рандомно. Хуже того, сегодня хотел погенерить пикч - форж ведет себя криво, несколько раз вебгуй завис, при генерации будто один раз услышал привычный свист дросселей видяхи в иной тональности.
Что может быть?
У тебя и БП может начать ... испускать дух.
Не Может Быть
я верю в свой полуторакиловаттник Термалтейк (бренд, иномарка!) купленный на говнито за 3к.
Ну а вообще вангую (молясь коуплю) что это софт ишью, потому что у меня поганый харч с тайловой xwindow сракой, который поломан и не обновлялся уже нормально полгода, включая видеодрайвера. Послушал нетакусек-войжаков, что МНЕ ТОЧНО АРЧ зайдет, полная хуйня, где половину софта надо собирать с ошибками, а половина обновляясь, ломается. Надо бы снести давно, но я кобольд и зажопил 50 гигабайт на home в отдельном разделе, теперь жестко пердолится...
На ноуте KDE Neon и господи как же я урчу от нормально настроенной системы изкоропки и православного apt.
>Гемма 4
Надеюсь ты KV кэш не кванитизировал?
Для стабилизации
--override-kv gemma4.final_logit_softcapping=float:25 ^
ставил?
Однокнопочного решения нет но если очень надо -> можешь выбрать в Jenitorai прокси -> ставишь туда локал хост -> запусть лламу дцп со включёнными логами -> ллама высрет лог -> скормишь макро гемме логи чтобы их в порядок правила -> оттуда и скопируешь Definition и пр.
Ставь обе, еба. Перая будет шустрая вторя умная можешь их чередовать.
Патриоты на месте?
Кто нибудь сравнивал какие либо свежие модели в режимах "нативный русик" vs "англюсик + плагин с переводом с Геммой 1-4б"? Имеет смысл?
Кто нибудь сравнивал какие либо свежие модели в режимах "нативный русик" vs "англюсик + плагин с переводом с Геммой 1-4б"? Имеет смысл?
А зачем прописывать поддержку жижи в ламе? У меня и без этой команды все пашет как надо. Нах она нужна?
https://mera.a-ai.ru/ru/text/leaderboard
Если тебе прям так важно качество то использовать 4b для перевода кажется так себе идея. Будет ронять качество писанины
А зачем гемма 4б? были же браузерные экстеншны для нормального перевода через онлайн сервисы
Так в том и состоял вопрос, что больше корежит - нативный русик ""биг"" модели, или англюсик через фильтр микролоботомита.
>перевода через онлайн сервисы
Ну да, тут же собирают риги что бы сэкономить на говноапи опенроутера... Камон, какой онлайн, тут хиккари-сычи, обсуждающие с локальной Аской "как дела", а не аицг чеды, которые крутят на жезлах удачи канничек-фут без задней мысли на весь Интернет.
Как же бесит...
То таверна умрет, то жора, то будто сама ОС срет мне в штаны. 3-6 сообщений - и надо перезагружать то или иное, или просто смотреть на микрофризы пока я пишу простой текст. Никакой логики в поведении ПК,
Мне кажется видеокарты себя так не ведут, артефакты на экране - да. Спонтанные перезагрузки под нагрузкой - да. Но какая то упоротая утечка оперативки под случайным процессом...
Купил 3060 12гб в хорошем исполнении, андервольтнул, чуть задрал кулера, ещё на днях кулеров докуплю чтобы корпус продувался и это просто рай после моей визжащей 2060 6гб однокулерной которая грелась до температуры солнца. Гемма летает, 0 шума, 0 нагрева, наконец 4, а не 3 квант. Я в раю, жду сингулярности.
Рад за тебя Анон. Ты честно выбрал путь хлебных крох, без попыток догнать недосягаемое и собрать сетап, который будет наравне с актуальными корпами. Кума побольше, да ролплея подольше!
>Пруф
Показывает какой-то говнофронт, ещё небось и на голом ассистенте.
Ебанутый?
Так нахуй опенроутер, есть же совершенно бесплатные экстеншны где даже регаться не надо. Перевод самая простая задача, которая давно решена.
О, спешите видеть, нубское шизло даже не знает фронтов, кроме кумерской таверны для даунов.
Во всём плох. В коде, в анализе, можно вечно перечислять.
Представь, что у тебя есть список из 500 бактерий, несколько антибиотиков, плюс ещё пачка исследований, и тебе нужно нужно сравнить эти антибы по определённым критериям, учитывая их проницаемость в ткани и чувствительность бактерий к антибиотикам.
Во всех случаях будет полный провал.
Гпт поскрипит в такой ситуации минут 7-15 в ризонинге, израсходововав весь свой ответ на аутпут, но сделает. Клод тоже сделает. Гемини как когда. Грок обосрётся всегда.
Ну любая ллм может обосраться с такой задачей и они это делают, но в большинстве случаев это видно быстро и можно легко пофиксить, когда ты разбираешься в теме. То есть это просто очень ускоряет твою работу.
Ах да, вот ещё прикол грока. Представь, что ты даёшь ему перевести текст с русского на английский, 2к токенов, работают 4 агента над переводом, а грок нахуй удаляет целые предложения. Зачем? "Извини, брат, не заметил."
И постоянно такое дерьмо. Вот для гунинга он хорош, для рп, для получения быстрых ответов, переводов паст про говно или чтобы он мне про бача бази рассказывал или об исторических фактах без цензуры (кстати, когда потребуется пруфануть их, вот тут начнутся проблемы).
А цены на апи ты видел? Они пиздец огромные в версии 4.2. А модель маленькая, плохо держит контекст, на 100к галлюцинации и лупы как под мидантаном у обдолбаного школьника. Он ощущается как китайская локалка и работает как китайская локалка, а стоит как корпоративная шлюха для сложных процессов.
Кстати, новый дипсик хоть и хуже старого в рп заметно, но хотя бы обходит того же грока очень сильно. Если ему прикрутить вот эти все канвас, дип рисерчи, агентность, то будет просто пушка-бомба.



Самое простое Deepl расширение как пикрелейтед, там регаться не надо.
Кто тебя знает (да никто, никому ты не нужен), может быть ты специально в системном промте написал что модель должна отказывать на любой запрос - ни запрос ни настройки не показаны, не могут быть проверены, и случай повторён.
Вывод - ты пустобрёх.
Какая гемма у тебя там в 4 кванте нищета нах?
Это только господам с 24 врам доступно, а у тебя огрызок и лоботомит
NVFP4 уже близко
https://www.reddit.com/r/LocalLLaMA/comments/1svfjyv/fp4_inference_in_llamacpp_nvfp4_and_ik_llamacpp/
на данный момент, как я понял - пока в апстриме только совместимость с апкастингом
https://github.com/ggml-org/llama.cpp/releases/tag/b8785
Но на подходе патч с полноценным NVFP4
https://github.com/ggml-org/llama.cpp/pull/22196
https://www.reddit.com/r/LocalLLaMA/comments/1svfjyv/fp4_inference_in_llamacpp_nvfp4_and_ik_llamacpp/
на данный момент, как я понял - пока в апстриме только совместимость с апкастингом
https://github.com/ggml-org/llama.cpp/releases/tag/b8785
Но на подходе патч с полноценным NVFP4
https://github.com/ggml-org/llama.cpp/pull/22196
Че-то он здоровый очень, gguf Qwen 3.6 на хаггинге NVFP4 22.5 GB
а в IQ4_XS 17.4 gb
В чем смысл?
Уж лучше вторую нейронку на проце крутить для перевода, если уж совсем надо, потому что все онлайн-переводчики работают почти как лет 10 назад и не учитывают контекст.
Та же гемма 4б новая, которая на телефоне запускается, уже огромный шаг вперёд по сравнению с онлайн-калом.
>новый дипсик хоть и хуже старого в рп заметно
А там все еще осталась проблема, что дипсик навязывает свою структуру ответа? Проблема конечно была решаемая, но не очень просто.
Плюс у него еще была проблема, что если через какую-нибудь гемини задал чтобы нейронка писала полотнами текста, то продолжать его дипсик отказывался, тупо крякнув ошибкой. Даже в своем размере не пытался писать

Что что тренили для рп?
Ну очевидно такая модель никогда не получит поддержку в ламе, жирно вам будет сволочи.
Моделей нет - плачем.
Модели есть - плачем.
Ну очевидно такая модель никогда не получит поддержку в ламе, жирно вам будет сволочи.
Моделей нет - плачем.
Модели есть - плачем.
Ну в рп он хорош. Один из лучших сейчас. По ебливости что-то среднее между ГЛМ-5 и Гроком, т.е. хорошая середина.
В том, что больше не нужных тфлопс на 5000+ картах, выкидывай свои 3090 и 4090, гой.
> там регаться не надо.
Там лимит на запросы.
> гемма 4б новая
И сколько на проце будет выдавать на ддр4? А то конечно поднадоедает читать английский в переводе.
Докупить говна, ту же 3060.
В комнате 10 книг, 2 из них прочитали. Сколько книг осталось в комнате?

Гемма 4б будет выдавать.. ну.. на телефоне 4-5 токенов было. Я её на свой ПОКО Ф4, БЫСТРОГО ЗВЕРЬКА, установил. На кудахтере должно быть быстрее, особенно если ты хотя бы на полшишки её в видеопамять засунешь. В 4 кванте всё равно лучше переводит. На телефоне квант был ещё меньше или какая-то qat-версия.
Как вариант, если надоел английский в переводе, лучше уж тогда квен 3.6 35б МоЕ скачать. Кум более сочный, русский адекватный, правда я до сих пор не могу найти золотую середину по семплерам, ибо там штраф за присутствие работает не так, как в ктрансформерс, и топ К дрочить надо, и температуру, и небо, и Аллаха. Минимальные изменения влияют на выдачу очень сильно.
Для фулл русика нужно сидеть и подбирать семплеры, иначе попрёт шиза в независимости от кванта.
Но в целом норм.
Пока что наиболее стабильны варианты: темп 0,8, топ К 40, штраф за присутствие с окном 200.
2
Помнится еще полтора года назад с этой загадкой даже многие корпо модели не справлялись кек. А сейчас как?

Квен 3.6 справляется.
nods
>874 tokens
Вау. Модель и без ризонинга должна была написать просто 10.
Посоны, а как сделать чтобы нейронка отыгрывала персонажа+голосовой ввод+голосовой вывод?
я тока вкатываюсь, если че, не бейте лучше обоссыте
>А сейчас как?
Сейчас добавили в датасеты. Так что скорее модели будут отвечать 10 на вопрос о двух сожжённых книгах, лол.
>такая модель никогда не получит поддержку в ламе
Ну так если сам дипкок не озаботился запилом поддержки, то разумеется финансируемый гуглом и прочими западными корпами жора не будет сам её добавлять.
даже пигмалион?
Ты хочешь именно спич<=>спич или условный чат в мессенджере где текст смешан с гс?
Современные модели офк.
>Гемма 4б будет выдавать.. ну.. на телефоне 4-5 токенов было. Я её на свой ПОКО Ф4, БЫСТРОГО ЗВЕРЬКА, установил.
Как-то слишком медленно. У меня на S23U выдает где-то в районе 20
А на ПК в LM студии 37+
Именно спич-спич, чтобы текст вообще можно было не писать
Хз, знаю кубики которыми можно набрать, но готового решения не знаю.
Самое близкое - опенвебуи, но только руками кнопки жать стт/ттс
Ок, это мне пока рано. А если тестовой чат в какой-нибудь лмстудио, а выдача уже голосом?
Слишком простая
А вот с этой
Сейчас у меня 100кг винограда. Вчера я съел 50кг винограда.
Сколько у меня сейчас винограда?
Алиса от Яндекса уже не справляется, хотя ее решает гемма 4 даже без думалки
50 кг винограда осталось
текстовой чат*
Это квен?
>но готового решения не знаю.
Та васянская поделка, которую выше постили, так умеет
Квен с думалкой решил.
нет это мой ответ
Ты че охуел такое генерить?

получается што так..

Взял Tesla p40 для старого пк сервера с Лохито. А она оказалась горелая, не работает. Прикиньте какой я лох, обоссыте меня.
Горелая или с отвалом? А то может в духовку её и заведётся
В таверне все есть.

Упс, не тот тред.
Впрочем, промпт был составлен на gemma-4-26B-A4B-it-abliterix-v6.IQ4_XS
С неквантованным контекстом 32768 влезает на 4060ti-16=3060-12 так, что места остаётся ещё под Anima, работает со скоростью 80 т/с.
Для написания промптов самое то, но периодчески лупится в ризонинге, теряя закрытие ризонинга.
Поздравляем, анончик.
Это выглядит как наивная имплементация участка "как есть", без полной логики и расширенного функционала типа скейла и кванта самих активаций. Поправьте если вдруг там что-то поменялось.
Потому полноценным nvfp4 это не назвать, а если посмотреть по квантам из реддита - это пиздец с квантованным атеншном, осталось только при инфиренсе контекст квантануть и будет полный финиш.
Больше будет если модель w4a4, а тут разницы не заметишь.
А в чём проблема?
>места остаётся ещё под Anima
Не знаю как там с питоно-лапшой, но llama-cpp-server прекрасно уживается с stable-diffusion.cpp - server. Модели свайпаются в одном и том же VRAM! Если в РАМ все поместилось задержка минимальна.
А Гемини, следуя этой аналогии - бимбоунитаз?
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Че за таверна?
Вне зависимости от того как модель на самом деле перформит, чел в твите гигабазу выдал
Раз уж корпорации разгребают и каталогизируют завалы награбленного с интернета и решают что и насколько пойдёт в обучение а что нет то могут и специальную небольшую модель (70-150g) сделать с увеличенным литературным корпусом вместо кода. Денег уйдёт чуток, а репутацию заработают
5060ti@16Gb - база треда
пчелы, я установил лм студио и нейронка квен грузится. а вот для картинок нужен файл, я его тоже в папку кинул и с ним ошибка при развёртовании. чё делать? видеопамяти 24



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_moe_2026
• Неактуальные списки моделей в архивных целях: 2025: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd ), 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
• Доки к LLaMA.cpp со всеми параметрами: https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: