




> на S23U выдает где-то в районе 20
Довольно много
Что там сейчас по запуску на телефонах, есть прогресс?
Вот так правильно. Или четвертую сделать тоже умницой, а образ гяру для кума в спичбабле или подобное?
> stable-diffusion.cpp
Оно все такой же кривой копиум?

Наконец-то DeepSeek v4 Flash gguf Q2
https://www.reddit.com/r/LocalLLaMA/comments/1sw3stb/llamacpp_deepseek_v4_flash_experimental_inference/
https://www.reddit.com/r/LocalLLaMA/comments/1sw3stb/llamacpp_deepseek_v4_flash_experimental_inference/
чому гемма 4 31б ниггерша?
>experimental_inference
У нас стабильные версии срут под себя повторами, а тут экспериментал.
В солярии пересидела и наполнилась духом ебомбе.
Че за таверна?
Оригинал должна выглядеть как секретутка, а вот файнтюн какой нибудь как гяру
Глупая.
SillyTavern фронтенд для рп
Ну что там? Появились интересненькие тюны Геммочки-Умнички?
Американка, лол.
Там она в оригинале та еще блядища же. Но и в целом довольно умная, тут какой-то "гибрид" нужно сделать или обыграть.

МЯГКАЯ ФРАНЦУЗСКАЯ ЖОПА БУЛКА!

Так какая локалка специализированна под канничек? По вашим ощущениям.
Хз. Квен наверно. Азиатская модель. Азиаты люто торчат от канничек.
Phi 4 Reasoning (14b)
Broken-Tutu-24B-Unslop-v2.0
PocketDoc_Dans-PersonalityEngine-V1.3.0-24b
Qwen3.6-27B-Uncensored-HauhauCS-Aggressive
Qwen3.5-27B-Uncensored-HauhauCS-Aggressive
Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive
Aurora-SCE-12B
magnum-v2.5-12b-kto
MN-GRAND-Gutenberg-Lyra4-Lyra-12B
>Что там сейчас по запуску на телефонах, есть прогресс?
Я пробовал только через Edge Gallery
Очень неудобная штука - обращения к разным модальностям разнесено по разным меню, а не в одном чате.
Функции думалки нет. Файлы подключать нельзя. Истории чатов нет, да и вообще чаты не сохраняются.
И помино всего прочего она криво реализована, так что для получения списка моделей нужен интернет и без него не запустить уже загруженные модели.
>Довольно много
Ну справедливости ради этот Edge дал скачать только какую-то урезанную версию 32к контента, которая весит 3.5 гига
>Q2
В чём прикол таких лоботомитов?
>на 32к контекста
Fix
Запускать на нишемашинах?
>Запускать на нишемашинах?
Я понимаю что на стойке dgx этого бы делать не стали.
Но по личным ощущениям даже q4, так себе (по крайней мере на мелких моделях). А тут q2. Если для эксперимента, это одно. Но неужели это всерьёз используют?
>серьёз используют
Q2 всерьёз используют только на крупняке (от 70B), там размер модели позволяет сохранить способности даже так.
Аноны помогите хотя тут вопрос скорее по винде но всеж. Я правил как-то json пресет блокнтом и теперь у меня все json пресеты идут как текстовые фаилы которые не видит таверна.
Квен дает совет уровня переименуй фаил и все
Квен дает совет уровня переименуй фаил и все
Скорее всего как .тхт сохранил.
>переименуй
скорее всего да, просто переименуй
но перед этим включи в винде отображение расширений, \
скорее всего ты насохранял что-то типа name.json.txt
>по крайней мере на мелких моделях
Это.
На крупномоделях потеря 20-30% на втором кванте не так сильно ощущается за счет эффекта высокой базы.
Второй квант глм-4.7 3.0 bpw по-прежнему лучшая модель из доступных на 128 гб рам.
Да спасибо, я ещё подоставал квена там и правда оказалось был тхт которого не видно было просто так
rentry готов: https://rentry.org/2ch-llama-inference
Просьба неравнодушным внимательно прочитать и дать обратную связь. Цель - облегчить новичкам треда вход в тему, доступно, не перегружая теорией объяснить основные понятия и помочь разобраться с Лламой. Так будет легче и им, и нам - не придется отвечать по сто раз на одно и то же.
Если нашли ошибку или не нравится какая-нибудь формулировка/изложение - объясните, что именно не так. Будет лучше, если предложите конкретную альтернативу.
Также пишите, о чем еще следовало бы рассказать. Все ли важные темы покрыл?
У меня как будто есть желание рассказать про Таверну. Она может отпугивать поначалу, но я думаю, что она хороша. Рассказать про общие ее принципы, про лорбуки. Возможно, про пару экстеншенов и эксперименты с шаблонами. Пока не знаю, правда, лучше это сделать в существующем рентри или завести другой и оставить на него ссылку.
Сайт не открывается.
This site can’t be reached
rentry.org took too long to respond.
не рассмотрел `--models-preset`
ну и еще текст туговато читается - широкая неструктуризированая портянка. Можно через лмм прогнать для красоты, наверное.
А так все хорошо, но залетух дальше первого абзаца читать не станет (может быть нужен ТЛДР для залетух?)
а и еще, не рассмотрен ленивый способ запуска моешек через `--fit`
Вы чего, квном не можете воспользоваться или на худой конец NoDPI? Добавьте rentry.org в список исключений. Либо попробуйте https://rentry.co/2ch-llama-inference
Ленивый способ --fit неэффективен, а перекидывать тензоры новичкам сложно. По поводу туговато - увы, у меня формальный стиль изложения, профдеформация. Могу попробовать подсократить вводные обороты и прочее, но текста по-прежнему будет много. Тут цель не было упростить запуск, минуя всю информацию, а дать понимание основ.
Он и так по умолчанию включен. Не ленивый, а лучший.
> квном не можете воспользоваться или на худой конец NoDPI?
Да забей. Без умения попасть в большой интернет особо делать в теме ллм нехуй, на части провайдеров буквально хф в 14кб бане
Неизвестно.
Надо писать чисто наш, двачерский, CSAM-бенчмарк
Про семплирование можно было бы и подробнее. Не температурой единой определяется генерация.
Про таверну нужно рассказывать через призму какого-нибудь кобольда, чтобы у ньюфага было хотя бы приблизительное понимание на что он вообще смотрит. Таверна своим окном настроить может отправить ньюфага в глубокий нокаут.
Он не может быть лучшим хотя бы потому, что если с него начать - не будет понимания что и как ест память. Однокнопочные решения самые худшие и точно не про тему треда.
> CSAM-бенчмарк
А судьи кто?
Товарищ майор.
По поводу сэмплирования - рассмотрены все основные сэмплеры, которые сегодня используются и рекомендуются разработчиками моделей. DRY, XTC, Adaptive P, rep pen и прочие - это локальная штука, которой большинство не пользуются. Уместно будет рассказывать, если возьмусь за Таверну и креативные таски в целом. А сам процесс сэмплирования на глубоком уровне я объясню точно хуже, чем те, кто это уже делал на других ресурсах.
>объясните, что именно не так
>В рамках данного руководства будет использован Chat Completion, так что за соблюдение разметки будет отвечать интерфейс чата (фронтенд).
Ровно наоборот, при чат компитишене за форматирование отвечает бекенд, фронт форматирует в текст компитишене.
Дядя, я так не играю
И да, и нет. Бекенд запрещает использовать другой шаблон, фронтенд удостоверивает, что запросы отправляются в верном формате и доходят до бекенда. Справедливое замечание, исправлю.
> Бекенд запрещает использовать другой шаблон
Смотря какой бэк. Вллм разрешает жинжу с каждым запросом передавать
> квном не можете воспользоваться
Нет.
> Добавьте rentry.org в список исключений
Уже.
> https://rentry.co/2ch-llama-inference
Для новичков слишком перегруженно техническими деталями. В первую очередь надо писать что качать и как запускать.
С него нужно начинать хотя бы потому, что в 2026 остальное в подавляющем большинстве случаев уже не нужно. Еще предложи вручную шаблоны прописывать, ризонинг через джсон контролировать, а с ллама сервером курлом общаться.
>квн
Да иди ты и лесом, и полем, и лугом, гейткипер ты грязный-вонючий. Чем pastebin не угодил, нормальные люди в нормальных тредах по всей имаджборде его используют и нормально всё открывается. Или любая из доступных и бесплатных вики-площадок. Не всегда, везде, у всех есть возможность эту приблуду поставить.
>В первую очередь надо писать что качать и как запускать.
>С него нужно начинать хотя бы потому, что в 2026 остальное в подавляющем большинстве случаев уже не нужно
У меня другое целеполагание, объяснить основы. Можешь сделать аналог про запуск. Расскажешь там, как скачать и запустить Ollama.
Даже если я это сделаю, модель с HuggingFace скачать не получится без этих средств. Договорись с Яндексом или МейлРу, чтобы они полностью клонировали HugginFace, там и поговорим.
Больше не кормлю
Про штрафование присутствия ни слова не увидел. И про температуру написано жидко. Нормальный блок только про отсечение. Чтоб в руководстве по таверне лучше написал, понял? Нет, серьёзно, настройка семплера это чуть ли не самая важная хуйня, которую многие упускают. Тема не раскрыта.
Уважение, конечно, за то что заебался и написал почти обо всем, что нужно знать если гоняешь локалки. Но думаю выдавать гайд на "всё и сразу" - это занятие бессмысленное и бесполезное. Среднестатистический вкатун не станет это читать, потому многа букв и нет пошаговой инструкции куда точно жмать чтобы всё заработало без пердолинга. Он сразу пойдет в тред чтобы получить пережеванную информацию. Это претензия не к тебе, а просто наблюдение за местными. Они именно так себя и ведут в подавляющем большинстве случаев.
Во-вторых правильно заметили выше, что текст плохо структурирован и оформлен. Нет единообразия - где-то новый параграф отделен пустой строкой, где-то нет.
Из косяков - мультимодальный проектор нужен не только для распознавания картинок, а вообще для распознавания всего, что не текст. То есть и для видео и аудио и еще для всякого. Остальные косяки искать не стал - просто бегло пробежался по тексту, это единственное что в глаза бросилось сразу.
Штрафы за повтор рекомендуют, насколько помню, только разработчики Квена. Справедливое замечание. Уделю ему внимание и подробнее расскажу про выбор сэмплеров. Идея была в том, что для общих задач проблема выбора сэмплеров обычно не стоит - следует использовать рекомендованные, что я и пытался донести. Возможно, недостаточно ясно высказал эту идею.
Крутить сэмплеры имеет смысл в креативных задачах вроде сторителлинга или рп, но текст пока не об этом.
Справедливо. Я добавлю удобный навигатор и разделю рентри на блоки, чтобы можно было самому выбрать, что читать, а что - нет.
Ну ты просил обратную связь, вот и получай: новичкам это никуда не сгодится, даже мне это трудно читать, будто скучный учебник от пердунов институтских.
Столько слов, но при этом даже системный промпт не упомянут. Попроси Гемму переделать что ли.
>Бекенд запрещает использовать другой шаблон, фронтенд удостоверивает, что запросы отправляются в верном формате и доходят до бекенда.
Вут? Ты точно понимаешь, что пишешь?
Расписываю. В текст компитишене со фронта на бек отправляется текст, который напрямик летит в ЛЛМ. В чат компитишене отправляется джейсон с ролями, который уже сам бек раскидывает как хочет (обычно как прописано в модели). Это абсолютно разные подходы.
Ебать наркоманы. В любом случае форматирует бекенд.
> новичкам это никуда не сгодится, даже мне это трудно читать
Предложи решение. В следующей итерации я добавлю больше фрагментации и навигатор. Добавлять шутки-прибаутки и картинки - только множить и без того немалый размер.
Скачать однокнопочную Олламу и запустить на ней модель новички смогут и без лонгридов.
> будто скучный учебник от пердунов институтских.
Именно они меня этим и заразили, подлецы. Не общайтесь со старыми пердунами институтскими, особенно с технических направлений.
> чат компитишене отправляется джейсон с ролями, который уже сам бек раскидывает как хочет
Да, именно это я и имею ввиду, когда говорю, что "фронтенд удостоверивает, что запросы отправляются в верном формате". Новичку про json, как я считаю, знать совсем необязательно и потому сознательно об этом умолчал. Новичку даже не объясняется, что такое API и как именно передаются данные, он знает только про два разных формата. Как это противоречит тому, что фронтенд удостоверивается, чтобы разметка была в итоге соблюдена? Обработкой самих запросов занимается бекенд, это несколько раз упоминается.
Про Текст Комплишен все верно, пользователь сам управляет разметкой, о чем сказано.
>Как это противоречит тому, что фронтенд удостоверивается, чтобы разметка была в итоге соблюдена?
Потому что фронт ничем не удостоверивается, он просто кидает ждисон в бек. Бек кстати тоже может жопой форматировать, если указать неверную жинжу к примеру (или в модель вшит неверный шаблон, или ещё чего).
Короче как по мне это излишнее запутывание и усложнение.
> Бек кстати тоже может жопой форматировать, если указать неверную жинжу к примеру (или в модель вшит неверный шаблон, или ещё чего)
В разделе квантизации говорю об этом, да. Как ты бы в итоге предложил сформулировать всю эту проблему?
В контексте Text Completion уточнить, что пользователь сам ответственен за разметку, а в Chat Completion эти задачи берут на себя фронтенд и бекенд, не уходя в подробности?
Вообще если прям душить, то после установки ламы или ламы внутри кобольда, нужно прям жёстко разделить повествование на:
1. Генерацию. Сюда же засунуть семплирование, потому что генерация на 90% зависит именно от настроек семплера. И подробно разжевать почему не нужно греть модель, если хочешь адекватность и почему нужно греть модель если хочешь дохуя креативное повествование.
2. Модели. Сюда краткое изложение по моделям. Какие лучше, какие хуже, и почему. Что такое квантование, почему кими ето кал и ето, что такое анслоп, почему бартовски курва, а мрадемрахен это даркен под войсером.
3. Промтинг. Сюда закинуть карточкоделанье, таверну, лорбуки, и в целом пояснить нюфагу что вообще такое ПРОМТ. А то многие итт, кажется, не знают.
А ещё нужен особый блок с названием в духе "чё сказать сгенерить-то хотел?". Потому что нюфак может хотеть строгое рп, то есть завести себе нейронку только как сорта игрушку для генерации историй/чатиков с вайфу, как видеоигру. А может хотеть ассистента-погромиста для вейп-кодинга. Или ещё что-то... что-то другое и с запахом озона. Нужно чётко отсечь одно от другого, ибо слишком всё это разное.
>В контексте Text Completion уточнить, что пользователь сам ответственен за разметку, а в Chat Completion эти задачи берут на себя фронтенд и бекенд, не уходя в подробности?
Ну да, ибо так и есть. В тексте нужно самому подставлять правильный шаблон при смене модели, а в чате оно меняется само. Плюс в чате есть поддержка текста.
Зато в текст есть возможность префила.
Ну в чате тоже можно, модишь жижу и в путь
Не читал но осуждаю имею пару мыслей.
Цель ради которой кто то зайдет в такой гайд - следуя максимально простой инструкции запустить генерацию безо всякой сложной фигни. Поэтому в начале нужна максимально простая инструкция без особых терминов, как скачать какой то конкретный квант и как его запустить в том же кобальде.
Так сказать начальный гайд для хлебушка.
А вот когда человек запустит и поймет что работает и захочет разобраться, ниже уже нужно подробнее написать что он сделал и какие есть варианты.
А еще ниже полноценный гайд. Закончить который можно ссылкой на вики кобальда и ллама сервера с гайдом его запуска.
Такой себе айсберг по которому можно либо сразу спуститься, либо постепенно.
Цель ради которой кто то зайдет в такой гайд - следуя максимально простой инструкции запустить генерацию безо всякой сложной фигни. Поэтому в начале нужна максимально простая инструкция без особых терминов, как скачать какой то конкретный квант и как его запустить в том же кобальде.
Так сказать начальный гайд для хлебушка.
А вот когда человек запустит и поймет что работает и захочет разобраться, ниже уже нужно подробнее написать что он сделал и какие есть варианты.
А еще ниже полноценный гайд. Закончить который можно ссылкой на вики кобальда и ллама сервера с гайдом его запуска.
Такой себе айсберг по которому можно либо сразу спуститься, либо постепенно.
Напоминает аргументы красноглазиков которые жрут кактус на линупсе в повседневных задачах/играх
Большинство однокарточных систем отлично управляются с "одной кнопки"
> Предложи решение
1. Попроси Гемму.
2. Поставь себя на место новичка:
"Увидел в /b/ ваши ЛЛМы, хочу потрогать": дай максимально краткую инструкцию что качать и как запускать конкретную модель с уже подготовленными аргументами.
Запустил, пощупал: какой следующий вопрос задаст?
Почему модель рефузит? Объясни про системный промпт.
Почему модель отвечает не так, как он хочет? Кратко расскажи про промпт инжиниринг и как модель формирует ответ, остальное пока не трогай.
Почему модель не хочет картинки смотреть? Ммпродж, имадж токены и батч сайз.
Этого уже достаточно для 90% случаев. Чередуй теорию с практикой для лучшего усвоения, иди от потребности, а не вываливай гору бессмысленного текста, в которой приходится искать что-то полезное.
3. Ну или спроси себя как заспидранить с нуля и без чего 100% нельзя обойтись.
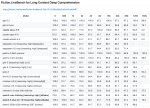
Ну и да, ты слишком высоко задрал планку по минимальной памяти. Вообще хватит и 4 враом и 12 рамов чтобы запустить какую-нибудь ламу 8Б - да, это старье, но оно годиться под тупой концентрированный кум. Конфигурации 6/16 уже хватит и на мистраль 12B - тоже старье, но тут уже и в рп можно более менее покрутить на шестом кванте. Да, будет медленно, но некоторым хватит и этого. Это стоит четко указать чтобы не обламывать совсем нищие сборки.
Зачем прописывать --jinja в ламке? Без него же все отлично. Это точно нужно?
>Без него же все отлично
Помни главное погромиста: если всё работает - НИЧЕГО НЕ МЕНЯЙ.
Без него урезанная жижа, с ним полная. Указывай и не еби себе голову
>хотя бы 8гб видеопамяти
>gemma-4-26B-A4B
8гб это слишком высокий хард лок. Я на 6гб сижу с Q4_K_S и норм.
И почему никто не упоминает про:
--override-kv gemma4.final_logit_softcapping=float:25 ^
Гемма буквально как говно без нее работает.
Джинжа включена по дефолту, прописывать вручную не нужно. Только --no-jinja если для отключения.
>Без него урезанная жижа, с ним полная.
Че нахуй?

Зачем вообще все эти гайды в эпоху ЛЛМ? Есть же гопота и дипсик для всех ньюфажеских техпроблем с установками.
Педофилы.
Этот тред... того кого надо тред.
И зачем педофилам помогать?
А кто им помогает? Это просто яркий пример, кому нужны локальные модели, но ими спрос на локалки не ограничиваются и их вообще меньшинство.
Поддержка. С включённым работает нормальный механизм честной жижи, без него только корявые запроганые кодом https://github.com/ggml-org/llama.cpp/blob/master/src/llama-chat.cpp
Малой, этот флаг итак по дефолту включен.
qvink Summarize аддоном для таверны пользуюсь. Очень удобно для длинных чатов.
Ну опять же, тот же дипсик нубасу всё локальное поможет установить, зачем устаревающие гайды?
Я хз как ты это воспринимаешь, но я вроде пишу про включен/выключен, а не про то добавлен он руками в виде --jinja или нет.
Не знаю кто как, но я давно свалил на пресеты где нужно указывать значение параметра, а не просто его название
Чувак, мне кажется, ты не дал самого главного: простого запуска с ноги.
Это будет читать только реально заинтересованный в этой теме человек, а не хлебушек из /b/.
Наша твоя задача заинтересовать, не отпугнуть, вовлечь и не отпустить юзера. Нужно думать как маркетолух, который подсаживает человека на вещества, чтобы он снова и снова возвращался в тред. Таким образом, в итоге будет больше людей в треде и выше шанс, что они вкатятся, останутся здесь, и получим приток новой крови, что сыграет в перспективе на руку всему треду. Когда новички уже разберутся.
Но сначала новичок не должен ничего понимать и думать. Нужно минимум действий и усилий за максимальное кол-во дофамина.
Я бы рассмотрел такой формат: в двух словах объяснение, зачем локалки нужны: чтобы дрочить и решать задачи, КАРМАННЫЙ ЧАТ ГПТ (и похуй, что это неправда), никакой цензуры, затем на примере МоЕ чёткие указания, каким образом запустить на 8/12/16 врам и чё там по семплерам. Буквально указать с картинками, на какие кнопки тыкать, какие цифры вводить. Вот чтобы было прям видно, что 999 на видеокарту и 21 МоЕ-слой на ЦПУ при таком-то контексте и столько-то врам. Чтобы человек вообще не думая вводил цифры и скачивал модели по прямой ссылке, чтобы даже не заходил на хг, не нажимал кнопку скачивания там и запускал в простом, но гибком кобольде, который легко становится мостиком для таверны и более глубокой работы даже без переката на лламу.
Тут МоЕ-гемма идеально вписывается, ибо хороший русик, есть апасная версия, семплеры крутить для адекватного русского не надо как на квенах, разве что кум у геммы пососный.
В принципе, я могу написать такой вот гайд для ретардов, но не знаю, будет ли он актуален на фоне твоего и чё вообще думают в треде на этот счёт.
Что всё? Он про Гемму 4 знает или другие лучшие модели? Про то, что нужно лламу.цпп качать, а не олламу или лмстудио?
1. Не сказано про ебанное протекание моделей в РАМ под виндой. "Общая память графического адаптера" так ее растак. Каждый второй новичек напарывается на это дерьмо.
2.
-b 512 ^
-ub 512 ^
--n-cpu-moe 29 ^
Есть один гребанный нюанс:
Если модель не фулл-врам
-b 512 ^
-ub 512 ^
Будут тормозит процессинг контекста ояебу как
Т.е. для
--n-cpu-moe 29 ^
разумней ставить
-b 2048 ^
-ub 2048 ^
Да... но тут выплывает второй нюанс
-b 2048 ^
-ub 2048 ^
ЖРУТ VRAM как жируха на сносях. И если ситуация пограничная и моделька вот-вот влезет видеопамять целиком имеет смысл вернуть
-b 512 ^
-ub 512 ^
убрать вообще --n-cpu-moe 29 ^ и поиграться с размером контекста. Потому что FULL VRAM - ЭТО МАГИЯ БЛЭТ - это скорость работы как на корп-API !
3. Кварги и как их готовить через коммандную строку или API для включения выключения ризонинга в Chat Completion "на ходу" и по дефолту
Запуск:
Вкатиться в нейрокум на самом деле несложно если у тебя хотя бы 6 врам и 16-32 рам.
Я бы рекомендовал мое-гемму последнюю, доработанную под ролеплей.
https://huggingface.co/zerofata/G4-MeroMero-26B-A4B-gguf/resolve/main/G4-MeroMero-26B-A4B-Q6_K.gguf?download=true
Это файл модели данных, слепок сознания, собственно "пластинка" которую надо вставить в проигрыватель.
https://github.com/LostRuins/koboldcpp/releases - а вот проигрыватель, "бэк".
Промтинг:
Системный промт - это как надо вести себя модели, что можно (всё) а что нет (хотя запреты на что-то часто плохо работают).
Карточку не забудь. Карточка - это дополнение к промту, постановка задачи модели уже более конкретная, типа отыгрывать персонажа или целый сеттинг. Всё что идёт на вход модели, всё это промт. И всё влияет на то как модель будет отвечать.
Помни, любая модель это стохастический попугай. Иногда очень жирный, может быть даже с гору, но всё ещё попугай.
https://pixeldrain.com/l/47CdPFqQ
Карточки, промты, даже немного сохранённых логов можешь посмотреть тут, большая часть не моя, просто свалка понравившегося барахла.
Фронт и сэмплеры:
Особо важно - во "фронте" (веб-странице, пользовательском интерфейсе, будь это Kobold-Lite или Silly Tavern) выбрать правильный "язык" общения с моделью которая уже запущена на "бэке" - формат разметки. Иначе будет бредить.
Фронт и бэк работают отдельно, но вместе - фронт должен поключиться к бэку. Актуально для Таверны, Кобольд подключается автоматически. Для модели выше нужно выбирать Gemma 4.
Сэмплеры - это то как модель будет вылавливать токены (не буквы, но упрощённо это можно назвать слогами) из своих нейрополимерных мозгов. Для начала хватит знать только про "температуру" - она расширяет или сужает выборку, позволяя либо безграничный полёт шизы, либо более адекватные (обычно), более консистентные ответы. Остальное по большей части уже пердолинг ради пердолинга, и стоит оставить на значениях по умолчанию пока не решишь разбираться глубже.
Надо куда-нибудь чтобы с перманентной ссылкой было залить...
Вкатиться в нейрокум на самом деле несложно если у тебя хотя бы 6 врам и 16-32 рам.
Я бы рекомендовал мое-гемму последнюю, доработанную под ролеплей.
https://huggingface.co/zerofata/G4-MeroMero-26B-A4B-gguf/resolve/main/G4-MeroMero-26B-A4B-Q6_K.gguf?download=true
Это файл модели данных, слепок сознания, собственно "пластинка" которую надо вставить в проигрыватель.
https://github.com/LostRuins/koboldcpp/releases - а вот проигрыватель, "бэк".
Промтинг:
Системный промт - это как надо вести себя модели, что можно (всё) а что нет (хотя запреты на что-то часто плохо работают).
Карточку не забудь. Карточка - это дополнение к промту, постановка задачи модели уже более конкретная, типа отыгрывать персонажа или целый сеттинг. Всё что идёт на вход модели, всё это промт. И всё влияет на то как модель будет отвечать.
Помни, любая модель это стохастический попугай. Иногда очень жирный, может быть даже с гору, но всё ещё попугай.
https://pixeldrain.com/l/47CdPFqQ
Карточки, промты, даже немного сохранённых логов можешь посмотреть тут, большая часть не моя, просто свалка понравившегося барахла.
Фронт и сэмплеры:
Особо важно - во "фронте" (веб-странице, пользовательском интерфейсе, будь это Kobold-Lite или Silly Tavern) выбрать правильный "язык" общения с моделью которая уже запущена на "бэке" - формат разметки. Иначе будет бредить.
Фронт и бэк работают отдельно, но вместе - фронт должен поключиться к бэку. Актуально для Таверны, Кобольд подключается автоматически. Для модели выше нужно выбирать Gemma 4.
Сэмплеры - это то как модель будет вылавливать токены (не буквы, но упрощённо это можно назвать слогами) из своих нейрополимерных мозгов. Для начала хватит знать только про "температуру" - она расширяет или сужает выборку, позволяя либо безграничный полёт шизы, либо более адекватные (обычно), более консистентные ответы. Остальное по большей части уже пердолинг ради пердолинга, и стоит оставить на значениях по умолчанию пока не решишь разбираться глубже.
Надо куда-нибудь чтобы с перманентной ссылкой было залить...
Я вообще считаю, что зерофату нужно внести в шапку как поставщика лучших рп/кум тюнов буквально всех моделей.
>то как модель будет вылавливать токены (не буквы, но
ЛОГИТЫ БЛЯТЬ! Семплинг влияет на логиты. Именно из-за ниh u вас иероглиfы вылазяt в оkончаниях sлов.
>ЛОГИТЫ
Это уже что-то на умном.
Да, я знаю, но мы сейчас гайд для кобольдов пришедших с телеги и /b/реда пишем.
>гайд для кобольдов пришедших с телеги и /b/реда
А они тут нужны вообще?
Мимо кобольд
лол если не хочешь чтобы юзер думал то попроси ГПТ КАРТИНКУ нарисовать. с схемой для полных дебилов.
вопрос правда в том хочешь ли ты таких людей в треде.
Я за любой движ кроме очередного языкосрача XD
А то будут тут сидеть утка, нюня, немотронщик, геммавот, теслашиз, и прочий зоопарк, и вяло перебрасываться логитами до софтамакса.
>Я за любой движ
Решительно, но робко!
>будут тут сидеть утка, нюня, немотронщик, геммавот, теслашиз, и прочий зоопарк
Видимо я в состав этого зоопарка не вхожу... И даже не знаю, обижаться на это или нет.

https://drive.google.com/file/d/1rM6cDhrTEOQbdy7dwm_KLB8w1pBUFnK8/view?usp=sharing
Попросил Корпо-Квена расписать. Неплохо раскидал.
https://drive.google.com/file/d/15_46Qa3D_0wiUiFLpW1awbNe5mjDXuuC/view?usp=sharing
А это вариант от Дипсика. Побольше, поаккуратнее, попродробнее. Экспорт в HTML, скачайте стобы открыть.
https://drive.google.com/file/d/1SYjNCf1I7cvT_h09_gtr3UGgTXBVqnhw/view?usp=sharing
То же самое, только экспорт в TXT.
Попросил Корпо-Квена расписать. Неплохо раскидал.
https://drive.google.com/file/d/15_46Qa3D_0wiUiFLpW1awbNe5mjDXuuC/view?usp=sharing
А это вариант от Дипсика. Побольше, поаккуратнее, попродробнее. Экспорт в HTML, скачайте стобы открыть.
https://drive.google.com/file/d/1SYjNCf1I7cvT_h09_gtr3UGgTXBVqnhw/view?usp=sharing
То же самое, только экспорт в TXT.
Чел...
А, раз в Париже то надо было потемнее сделать.
Оче издалека зашел. Ух бля, ну держись.
В разделе
> Как мы общаемся с LLM?
изложение запутывает. Ллм не генерирует последовательность, каждый процесс запуска - генерация одного нового токена, который выбирается из распределений (спекулятивный декодинг опускаем). Далее он попадает в контекст и цикл повторяется, и так на каждый токен.
> формат запрос → ответ все же соблюдается.
Лучше вообще убрать этот "запрос-ответ". Ты можешь оборвать вход на сообщении юзера и модель продложит генерировать чтобы бы он сказал. Когда уже знаешь - понятно что доносится в том разделе, но подобный ввод понятий запутывает. Там же и с "памятью", тогда уже разделить ее и "знания".
> автоматическое удаление самого старого контекста (context shift)
Контекст шифт - древнее зло, ужасный режим, который делает смещение кэша вырезая куски и просто давая сдвиг, чего делать категорически нельзя. Не стоит его здесь упоминать, иначе опять полезет куча бедолаг, у которых модели плохо работают. Вообще, контекстом традиционно заведует фронт, бек просто выдает ошибку если занято больше чем максимальная длина минус максимальная длина ответа.
> Chat Completion - это строгий формат, где разметка соблюдается строго.
Это формат, адаптированный для универсального использования без привязки к модели, в котором в теле запроса передается последовательность текстовых сообщений с ролями. Разметкой же занимается бэк. Или что-то типа такого написать, а то что строгий строго - чи шо? Если имелись ввиду ограничения функционала то лучше так и сказать.
> Зачем это нужно? Например, для генерации кода не нужен формат "вопрос-ответ", который подразумевается instruct разметкой и строго соблюдается в режиме Chat Completion.
Что вообще тут подразумевается? Путаница одна. Весь участок стоит переписать значительно упростив, эти примеры дезориентируют.
> В рамках данного руководства будет использован Chat Completion, так что за соблюдение разметки будет отвечать интерфейс чата (фронтенд).
Ерунда какая-то. Как раз соблюдать разметку будет бэк, сама концепция чаткомплишна в переносе этого на него, разгружая фронт и делая его моделенезависимым.
> Например, помните шаблон ChatML? Именно фронтенд автоматически разделяет запрос на части и оборачивает их в соответствующие теги (спецтокены) <|im_start|>, <|im_end> и другие.
Только в режиме тексткомплишна если так он настроен. Сначала было сказано за чаткомплишн, а теперь опять это.
> Nvidia старше серии RTX 50xx, необходимо скачать два архива - Windows x64 (CUDA 12) и CUDA 12.4 DLLs.
Поддержка блеквеллов только с куды 12.8, на 12.4 пошлет. 13.1 нужно качать для них.
> Все эти миллиарды параметров не свалены в кучу. Они организованы в структуры, которые математики называют тензорами. Параметр - это один рычажок, а тензор - целая панель, организованная в виде блока (матрицы).
Нужна ли графомания с этими аналогиями? Столько запутывающих объяснений чтобы потом никогда больше их не использовать. Или давать нормальный линал, или вообще убрать эту часть.
> MoE (Mixture of Experts) модели
Описан мезозойский кринж эпохи первого микстраля, а не современные модели. Столько боролись за понимание, а ты диверсию устраиваешь.
> Например, оно может выглядеть так: 0.123456789012345
Не может, в бф16 2.5 значащих цифры, остальное экспонента. Твое даже для фп32 жирновато выглядит.
> 0.123456789012345 может стать параметром 0.123456.
0.123 может стать 0.1, вот так уже ближе к реальности.
> SWA - особый вид внимания к контексту. Модель отдает приоритет внимания определенным частям модели
Атеншн видит только последние N токенов. Нет там приоритетов, и тем более "частей модели", имелся ввиду контекст?
Ну а чего, в целом молодец, покрыто очень много, от основ до запуска и с примерами. Поправить ошибки, упростить, шлифануть и будет годно.
Очень обстоятельно, спасибо. Все приму к сведению, как и обсужденный выше фидбек от других анонов.
На днях переделаю многое и отпишусь в тред.
Ну удачи, чо. Редкий адекват в треде, я уж думал быковать начнёшь.
Ну и вот мои пара копеек:
- Ты пишешь для тредовичков, которые уже как минимум своего первого кобольда подпустили, а не для новичков-вкатунов.
- Многое что написано на самом деле верно частично / с натяжкой / или вообще нет. Не зарывайся в высокие ML-материи, это должен быть буклет к Луна-Парку, а не методичка по сопромату.
Я бы почитал методичку по сопромату для семплирования...
Ну видишь ли, это так работает, если нужна новая кровь.
Да, тред засрут, но это вынужденные издержки. Условно, придёт 100 человек, останется 5-7. Это неприятно, но иначе никак.
Кроме того, корпо-ллм нихуя не помогают при вкате, если ты не дотошный — новички не смогут так просто разобраться. Нужно задавать правильные вопросы и иметь подписку. Возможно, дипсик в4 знает, но на меня его ещё не раскатали в вебе.
Я вкатывался в 2023 году примерно, точно не помню. Это был ад. База в шапке дала лишь образное представление, некоторые советы в треде были полезны, но они многие были написаны в стиле "квантуй контекст, влезет больше" вместо более понятных вещей. Это новичку ничего не скажет, а в то время корпы очень слабо разбирались в таких вещах. Ну это как если бы ты спросил меня, как лучше сфоткать что-то, а я бы тебе сказал, что диафрагму 1.4 сделай, включи распознавание по глазам, исо 800. А у тебя тушка 2012 года и кит-набор. И ты вообще не шаришь.
Как итог, я купил тогда подписку на божественного Клода и всё, что мне непонятно, разбирал с ним до кровавого поноса, загружая документацию, цитаты, скриншоты, все логи и ебался с этим сам.
Но у меня была сильная мотивация.
Сейчас всё гораздо проще, но не настолько, чтобы было однокнопочным, если только в чувака не лм студио с двумя 5090 и фуллврам.
у меня одного избранные треды в закрепе внизу перестали обновляться даже по кнопке? хуйня какая то
Классическая проблема макакофронта. Сходи в /d там будет написано что нужно почистить
>с двумя 5090
Эх... вот бы мне такое, я бы какую-нибудь плотняшу заебашил в бф16 и генерил только годноту.
Ого, обычно на замечания сразу обижаются. Молодец, допилить это и будет кайфово.
Можно много дискутировать о формате и о прочем, что как раз происходит выше, но кажется в первую очередь нужно просто поправить имеющееся. А там уже можно добавлять, сделать спидран версию, писать отдельные углубленные статьи.
> "квантуй контекст, влезет больше"
В 23 году не было квантования контекста, а запускали часто через AutoGPTQ лол.
> с двумя 5090 и фуллврам
В 64 мало что влезет.
Почему гемма в с радостью принимает в рот даже там где это неуместно?
Потому что умничка?
Может ли это быть тупа протечка ассистента и желание угодить юзеру? Как бороться?
Между скайнетом который хочет убить всех людей, и тем кто хочет отсосать всем людям, я выберу второй вариант.
Ребята стараются как могут что бы ии был послушной сучкой, будь благодарен
В этой шутке меньше шутки чем ты думаешь
Не пиши ей что она шлюха, пожалуйста
Сорта. Если модели говоришь сосать и она сосёт это значит что модель - хороший ассистент. Но для рп она неюзабельна.
С гемой даже старые карты которым по 2 года по другому заходят. Вообще с любыми картами другой опыт. И русик хороший и слова на русике занимают меньше токенов. Без протечек шизы и свайпов. И это всё на q4-6 без покупки самолета.
Это самое больше разочарование четвертой геммы. Нужно либо в Definition делать 100% стесняшу либо не будет никакого сопротивления. Даже в если РПшить с мамашей реакции будут умеренные/расслабленные (с уворотом в софт рефуз).
Йеп.
Честно, не очень понятный гайд.
Почему написано что на 32+16гб можно запустить аж q8 квант?
У меня даже с q4 проблемы возникают.
Я несколько разных гемм скачал, и все они подыхают, когда я пытаюсь поставить им большой контекст (хотя бы 64к, но хочется 128 и выше).
Сейчас вот у меня вообще комп намертво завис, когда я запустил Huihui-gemma-4-26B-A4B-it-abliterated-MXFP4_MOE + 128к q5_1 кеша.
>Почему написано что на 32+16гб можно запустить аж q8 квант?
Так это правда. Гайд ты видимо хуёво читал
Мимо катаю q8 в 32+12

>Почему написано что на 32+16гб можно запустить аж q8 квант?
32+16 = 48Гб
Гемма в Q8_0 весит 27Гб
48-27 = 21ГБ которые останутся на контекст и на ОС. Тут и полные 256к контекста спокойно влезут.
>и все они подыхают
>q5_1 кеша
Что это за хуета? Никаких квантований не нужно. Просто включи SWA и флешаттеншн, выставь контекст в 256к, после чего в оставшуюся видеопамять вбрось слои, те что влезут, пока она на 95-97% не забьется. Всё.
>Huihui-gemma-4-26B-A4B-it-abliterated-MXFP4_MOE
Bruh...
https://www.reddit.com/r/LocalLLaMA/comments/1sw77p0/hauhaucs_of_uncensored_aggressive_fame_published/
>HauhauCS (of "Uncensored Aggressive" fame) published an abliteration package that plagiarizes Heretic without attribution, and violates its license
😱😱😱
>HauhauCS (of "Uncensored Aggressive" fame) published an abliteration package that plagiarizes Heretic without attribution, and violates its license
😱😱😱
Хуйхуй агресив анцезор оказались обманом. Кто бы мог подумать (((
Там уже и автор Еретика отписался

Да чё с лламой не так? Никак не получается для квена настроить кэш. Всё ок пока в контекст добавляется, но стоит только свичнуться на другой и обратно как все нахуй инвалидируется и идёт на полный репроцессинг
Нам-то какая разница, нарушили копирайт или нет? Если аблитка хорошая - пользуемся, если плохая - скипаем. А то что спиздили скрипт еретика и выдали за свой это проблемы автора еретика, а не наши.
> Bruh...
А какую лучше? Я из MoE + анцензор скачал. Почему брух?
В Гемме 4 практически нет цензуры, она на уровне с кумтюнами Мистраля и Эйром, возможно даже ещё более хорни. Её не аблитерировать, а наоборот промптить нужно чтоб в трусы с первых же сообщений не лезла.
>А какую лучше?
Ваниль, очевидно. От батрухи/анслотов/мрадера.
> forcing full prompt re-processing due to lack of cache data
Да ебись оно в 3 прогиба
А в этом MoE смысла нет? У меня 5070ти одна. Как бы я настройки не ставил - постоянно жду ответы по несколько минут, если контекст не пуст.
swa точно включен?
Вообще, такие вопросы лучше не в треде, а Геминьке задавать. Скорее всего получишь ответ и быстрее и лучше. Просто скорми ей свои настройки, с которыми запускаешь, и опиши проблему.
>Хуйхуй агресив анцезор оказались обманом.
Хуйхуй и Хаухау разные люди.

Хорни и нет цензуры вещи разные. Кокбенч не обманешь, если модель не хочет в сочный кум то это цензура.
А то что можно ебать всё живое всех возрастов на сухую, ну дал тебе гугл херетик версию из коробки, кума то там все ещё нет. Максимально будет увиливать от нужных тебе описаний концентрируясь на чем угодно кроме этого.
Вообще не понимаю как кто то юзает мое гемму когда мне даже плотная не понравилась...
> дней без наебов китайцами: 0
Какой бессовестный же народец.
Русики здесь? Как заставить гемму перестать высирать английские слова на русском, типа даже без перевода она это делает
Примерно похуй же. Это случается реже одного слова за сообщение + понятно что там написано
>Как заставить гемму перестать высирать английские слова на русском, типа даже без перевода она это делает
Квант побольше, инструкция получше, статические кванты, другой вариант аблитерации - как-то так, наверное.
А гемму заквантованную в NVFP4 на винде на 5070ти можно запустить?
Между отсосом и убийством меньше десяти сантиметров. Думой.
Жора содержимое ризонинга надеюсь стирает из старых сообщений а не отправляет каждый раз по новой? Если нет, то как эту хуйню выключить? Жрет же токены на ровном месте.
Нет, нельзя. Даже квен 27 или мистраль 3.2 нельзя в 16гб в NVFP4 уместить
Стирает. Квены наоборот пишут как включить.
>Что это за хуета?
Одно из квантований, очевидно. Немного больше, но ощутимо лучше чем q4
>Никаких квантований не нужно
Нужно. Q8 экономит в 2 раза место, оставляя тоже качество. Если модель конечно хорошая
Пиздец. Люди так привыкли к сое, открытой и скрытой, Гемы 3, что теперь специально срут в промт, чтобы добиваться рефьюзов
>В Гемме 4 практически нет цензуры, она на уровне с кумтюнами Мистраля и Эйром
Да, цензуры нет, но до кумтюнов ей далеко. И это хорошо, порнослоп не нужен
>Кокбенч
Хуита
>Вообще не понимаю как кто то юзает мое гемму
Нищуки 8+16
>когда мне даже плотная не понравилась
Очевидно, что ты не мерила треда и всем похуй на тебя
Какая локалка самый пиздатый кулинар?
Мультиварка рецепты в гугл плей.
Вручную вычитал и местами подправил.
Знатоки, модель где-нибудь откровенно напиздела так чтобы не заметил?
Шаг 1: Как модель "выбирает" слова (Logits, Softmax, Token)
Прежде чем крутить ручки, нужно понять, что происходит внутри. LLM не знает слов в человеческом понимании. Когда вы подаете ей текст, она вычисляет для каждого слова/кусочка слова (токена) из своего словаря logit - число, выражающее "сырую уверенность" модели в том, что этот токен будет здесь уместен. Это может быть +3.5 для слова "погода" или -1.2 для слова "банан" после фразы "Какая сегодня хорошая...". Модель не может использовать эти "сырые очки" напрямую, поэтому преобразует логиты в понятные вероятности с помощью функции Softmax. Softmax превращает оценки так, что их сумма становится равна 1 (или 100%). Теперь каждое слово имеет вероятность, например: "солнечная" - 46%, "ясная" - 28%, "хорошая" - 10%.
Как это связано с сэмплерами?
Сэмплеры - это инструменты, которые вмешиваются в процесс преобразования логитов в вероятности (Softmax) и финальный выбор слова. Они могут изменить эти вероятности (сделав их более "острыми" или "размытыми") или ограничить круг претендентов.
🎯 Шаг 2: Основные сэмплеры - ваши инструменты
В популярных фронтэндах, таких как KoboldLite, SillyTavern, или в облачных web-интерфейсах, вы почти наверняка найдете следующий стандартный набор.
🌡️ Temperature (Температура)
Это самая главная и интуитивно понятная ручка. Она управляет "креативностью" или "хаотичностью" модели. Технически температура изменяет логиты до функции Softmax, делая распределение вероятностей более "острым" или "плоским":
Как она работает?
Низкая температура (0.1 - 0.4): Логиты, которые были большими, становятся еще больше, а маленькие - еще меньше. Грубо говоря, модель "зацикливается" на нескольких самых вероятных вариантах. Результат - максимально предсказуемый, связный и безопасный текст.
Высокая температура (0.75 - 1.5+): Разница между логитами стирается. Распределение вероятностей становится "размытым", и у слов с низкой вероятностью появляется шанс быть выбранными. Результат - более творческий, разнообразный, но иногда и бессвязный текст.
🎲 Top-K (Топ-K) - Выбор лучших
Это самый простой способ сказать модели: "Рассматривай только K самых вероятных вариантов, а про остальные забудь". Он работает уже с готовыми вероятностями, безжалостно обрезая список кандидатов.
Маленькое значение K (1-10): Модель будет выбирать из горстки самых очевидных слов. Это делает текст очень связным, но может привести к зацикливанию (повторам).
Большое значение K (40+ или -1): Дает модели больше свободы, но при слишком большом K (или при K = -1, что обычно означает "учитывать всех") эффект от этого параметра пропадает.
🫧 Top-P (Nucleus/Ядерная) - Динамический отбор
Более умный аналог Top-K. Вместо жесткого ограничения по количеству, Top-P говорит: "Возьми минимальный набор самых вероятных слов, чтобы сумма их вероятностей была больше или равна P (обычно 0.9 или 0.95)". Оставшиеся маловероятные варианты отбрасываются.
Низкое P (0.3-0.7): В пул попадут только доминирующие вероятные токены. Это делает текст очень консервативным.
Высокое P (0.9-0.95): В пул попадет больше вариантов, делая текст разнообразнее.
Ключевое отличие от Top-K: Размер пула кандидатов в Top-P адаптируется к контексту. Если модель уверена в 2-3 вариантах, пул будет маленьким. Если она колеблется, пул расширится.
✨ Min-P - Новый баланс (Рекомендую!)
Этот сэмплер - настоящая находка. Он отлично заменяет связку Top-K и Top-P и часто дает наилучшие результаты. Min-P отсекает "хвост" из маловероятных токенов. Его порог высчитывается как min_p вероятность самого лучшего токена.
Как это работает: Если модель уверена в топ-токене (его вероятность 90%), Min-P с параметром 0.1 будет рассматривать только токены с вероятностью выше 9% (0.9 0.1).
Зачем он нужен: Он решает проблему, когда при высокой температуре Top-P и Top-K могут пропускать откровенный мусор в финальный пул. Min-P дает больше разнообразия, чем Top-P, но при этом эффективнее отсекает некачественные варианты, сохраняя связность.
⚙️ Шаг 3: Штрафы за повторы - боремся с "заезженной пластинкой"
Иногда, особенно при низкой температуре или неудачных настройках, модель начинает повторять одни и те же фразы. Три основных штрафа вносят изменения в вероятности токенов, чтобы разнообразить лексику:
Repetition Penalty (1.0 - 1.2): Самый распространенный. Если токен уже был в вашем разговоре, его вероятность принудительно делится на это число. Не зависит от частоты появления.
Presence Penalty (-2.0 до 2.0): "Штрафует" токен, если он вообще появлялся ранее, фиксированным значением. Не важно, один раз или десять.
Frequency Penalty (-2.0 до 2.0): "Штрафует" токен пропорционально тому, как часто он уже встречался.
Знатоки, модель где-нибудь откровенно напиздела так чтобы не заметил?
Шаг 1: Как модель "выбирает" слова (Logits, Softmax, Token)
Прежде чем крутить ручки, нужно понять, что происходит внутри. LLM не знает слов в человеческом понимании. Когда вы подаете ей текст, она вычисляет для каждого слова/кусочка слова (токена) из своего словаря logit - число, выражающее "сырую уверенность" модели в том, что этот токен будет здесь уместен. Это может быть +3.5 для слова "погода" или -1.2 для слова "банан" после фразы "Какая сегодня хорошая...". Модель не может использовать эти "сырые очки" напрямую, поэтому преобразует логиты в понятные вероятности с помощью функции Softmax. Softmax превращает оценки так, что их сумма становится равна 1 (или 100%). Теперь каждое слово имеет вероятность, например: "солнечная" - 46%, "ясная" - 28%, "хорошая" - 10%.
Как это связано с сэмплерами?
Сэмплеры - это инструменты, которые вмешиваются в процесс преобразования логитов в вероятности (Softmax) и финальный выбор слова. Они могут изменить эти вероятности (сделав их более "острыми" или "размытыми") или ограничить круг претендентов.
🎯 Шаг 2: Основные сэмплеры - ваши инструменты
В популярных фронтэндах, таких как KoboldLite, SillyTavern, или в облачных web-интерфейсах, вы почти наверняка найдете следующий стандартный набор.
🌡️ Temperature (Температура)
Это самая главная и интуитивно понятная ручка. Она управляет "креативностью" или "хаотичностью" модели. Технически температура изменяет логиты до функции Softmax, делая распределение вероятностей более "острым" или "плоским":
Как она работает?
Низкая температура (0.1 - 0.4): Логиты, которые были большими, становятся еще больше, а маленькие - еще меньше. Грубо говоря, модель "зацикливается" на нескольких самых вероятных вариантах. Результат - максимально предсказуемый, связный и безопасный текст.
Высокая температура (0.75 - 1.5+): Разница между логитами стирается. Распределение вероятностей становится "размытым", и у слов с низкой вероятностью появляется шанс быть выбранными. Результат - более творческий, разнообразный, но иногда и бессвязный текст.
🎲 Top-K (Топ-K) - Выбор лучших
Это самый простой способ сказать модели: "Рассматривай только K самых вероятных вариантов, а про остальные забудь". Он работает уже с готовыми вероятностями, безжалостно обрезая список кандидатов.
Маленькое значение K (1-10): Модель будет выбирать из горстки самых очевидных слов. Это делает текст очень связным, но может привести к зацикливанию (повторам).
Большое значение K (40+ или -1): Дает модели больше свободы, но при слишком большом K (или при K = -1, что обычно означает "учитывать всех") эффект от этого параметра пропадает.
🫧 Top-P (Nucleus/Ядерная) - Динамический отбор
Более умный аналог Top-K. Вместо жесткого ограничения по количеству, Top-P говорит: "Возьми минимальный набор самых вероятных слов, чтобы сумма их вероятностей была больше или равна P (обычно 0.9 или 0.95)". Оставшиеся маловероятные варианты отбрасываются.
Низкое P (0.3-0.7): В пул попадут только доминирующие вероятные токены. Это делает текст очень консервативным.
Высокое P (0.9-0.95): В пул попадет больше вариантов, делая текст разнообразнее.
Ключевое отличие от Top-K: Размер пула кандидатов в Top-P адаптируется к контексту. Если модель уверена в 2-3 вариантах, пул будет маленьким. Если она колеблется, пул расширится.
✨ Min-P - Новый баланс (Рекомендую!)
Этот сэмплер - настоящая находка. Он отлично заменяет связку Top-K и Top-P и часто дает наилучшие результаты. Min-P отсекает "хвост" из маловероятных токенов. Его порог высчитывается как min_p вероятность самого лучшего токена.
Как это работает: Если модель уверена в топ-токене (его вероятность 90%), Min-P с параметром 0.1 будет рассматривать только токены с вероятностью выше 9% (0.9 0.1).
Зачем он нужен: Он решает проблему, когда при высокой температуре Top-P и Top-K могут пропускать откровенный мусор в финальный пул. Min-P дает больше разнообразия, чем Top-P, но при этом эффективнее отсекает некачественные варианты, сохраняя связность.
⚙️ Шаг 3: Штрафы за повторы - боремся с "заезженной пластинкой"
Иногда, особенно при низкой температуре или неудачных настройках, модель начинает повторять одни и те же фразы. Три основных штрафа вносят изменения в вероятности токенов, чтобы разнообразить лексику:
Repetition Penalty (1.0 - 1.2): Самый распространенный. Если токен уже был в вашем разговоре, его вероятность принудительно делится на это число. Не зависит от частоты появления.
Presence Penalty (-2.0 до 2.0): "Штрафует" токен, если он вообще появлялся ранее, фиксированным значением. Не важно, один раз или десять.
Frequency Penalty (-2.0 до 2.0): "Штрафует" токен пропорционально тому, как часто он уже встречался.
Это конфиг llama swap?
Что то плохой гайд. Дурит новичков. Реально пишет что Q4 кванты это норм. Да у той же геммы даже q6 - это ужасный лоботомит.

Студия на винде напихала за щеку кобольду на линуксе. На q6 с одинаковыми настройками.
>Q4 кванты это норм
Норм и минбаза плотных (dense) моделей.
Для мелко-MoE любое квантование - смЭрть.
Лоботомитище...
>любое
такое, ёпт
Стандартный функционал пресетов лламы просто сверху немного helm template
Ну так если ламу запускать без параметров твикнутых, она по дефолту крайне тормозная. Небось в лм студии накатили каких-то параметров по дефолту, вот так и стало.
Чел... Йес-мен хуже сои. Хуй на полпятого быстрее пули.
Вот этот истину выдал. Сопротивление юзеру и кипинг отыгрыша это и есть настоящие мозги модели.
Соглашусь. Yesman это тупо неинтересно. А я консенсуальную ваниллу отыгрываю. Кто там чего хардкорнее играет я даже не представляю как они не засыпают на Гемме.
RTFM no-mmap n-cpu-moe
lm studio щас вообще норм, дохуя чего добавили за последнее время для тонкой настройки
Особенно нравится фича окно для товарища майора
>добавили
Открыли доступ к данному доступному на лламе™
Давно'
Да не трясись ты. Тут асиговцы без задней мысли играют ещё более жесткие сценарии на клодах/геминях, и норм. Никаких майоров они не боятся, разве что помидора не жалуют.
Ну дак и хватают, и сажают. В РФ правда пока нет, а за бугром так вполне реальные сроки получают.
Про прагмату слышал?
Мы ближе к плохим парням чем когда либо, никакой толирастии "да это жи буквы" не будет
> Про прагмату слышал?
Это группа такая вроде?
Я всё в кобольде настроил что там можно.
Откуда так много залетух с лмстудией и точно ли мы хотим писать для них гайд ?
Может их просто нахуй если они не могут 15 минут на чтение доков потратить ?
Может их просто нахуй если они не могут 15 минут на чтение доков потратить ?
Ну и кого схватили?
Джона Вестерна. Ты не слышал?
>гайд
Гайд пишется для кобольда и ламыцпп, если пользуются хромой студией, или, упаси Омниссия, олламой, то ССЗБ и идут нахер.
>пук
Ясно.
>кобольда и ламыцпп
это всё для пердоликов, кому охота выискивать по помойкам флаги запуска на каждый пук
в рф даже хранение тру цп (без цели распространения) не криминализовано. с чего ты взял что тебя за буквы посадят?
был бы человек, а прецедент найдётся...
Кобольду не надо же, там всё в интерфейсе.
Ясно, чукча не читатель. Речь не про РФ. Пока. Но это может измениться в любой момент. Впрочем, кто я тебе, брат-сват, чтобы о тебе беспокоиться? Делай что хочешь.
>Речь не про РФ
Еще раз спрашиваю. Кого пидорнули, конкретные примеры можешь сказать?
>Кого пидорнули
Джона Сильверхэда. Слыхал про такого?
>пук
Ясно, опять пёрнул в лужу.
Если у тебя встает только на детей то это твоя личная проблема, мне похуй.
а зачем тут обсуждать проблемы загнивающего запада
малафите на что хотите, главное не заливайте никуда и не пересылайте никому, всегда так было. пока между кумом и тобой нет третьего лица, будь спок
малафите на что хотите, главное не заливайте никуда и не пересылайте никому, всегда так было. пока между кумом и тобой нет третьего лица, будь спок
Ты шиз? И вообще на чём основана эта шиза ? Я реально 1 раз о таком слышу.
Время для охуительных историй.
Я тут сижу себе, потихоньку мучаю Qwen3.5 27B-abliterated от двучлена в opencode. Квант iq4xs все прекрасно работает, модель умница, ничего не портит, работает аккуратно, никаких ошибок вызова инструментов нету. И тут на днях выходит Qwen3.6 27B у которого по бенчмаркам способность к кодингу еще выше. Разумеется лапки зачесались.
Скачал позавчера. Оригинальный Q3.6 27B, квант тот-же - iq4xs, потому что больше не лезет в мои 20 VRAM с достаточным контекстом. Начал гонять... Мля. Оно за день и вечер дважды разломало весь код как q3.5 35B Moe, регулярно путает переменные, и главное - периодически даже ломается tool call вообще - opencode ругается на ошибки вызовов. Скачал и попробовал кванты от поляка, от мардера, еще какой-то - одна хрень - чудит как та Moe если не хуже.
И тут меня дернуло - скачал свежую появившуюся версию Q3.6 27B Abliterated опять от Двучлена (квант от мардера). И таки что вы себе думаете? Оно опять прекрасно кодит! Без ошибок tool call, ничего не путая и не руша в коде.
Вот вам и "аблитерация отшибает мозги". Ха. Ха. Ха.
До сих пор обтекаю.
Я тут сижу себе, потихоньку мучаю Qwen3.5 27B-abliterated от двучлена в opencode. Квант iq4xs все прекрасно работает, модель умница, ничего не портит, работает аккуратно, никаких ошибок вызова инструментов нету. И тут на днях выходит Qwen3.6 27B у которого по бенчмаркам способность к кодингу еще выше. Разумеется лапки зачесались.
Скачал позавчера. Оригинальный Q3.6 27B, квант тот-же - iq4xs, потому что больше не лезет в мои 20 VRAM с достаточным контекстом. Начал гонять... Мля. Оно за день и вечер дважды разломало весь код как q3.5 35B Moe, регулярно путает переменные, и главное - периодически даже ломается tool call вообще - opencode ругается на ошибки вызовов. Скачал и попробовал кванты от поляка, от мардера, еще какой-то - одна хрень - чудит как та Moe если не хуже.
И тут меня дернуло - скачал свежую появившуюся версию Q3.6 27B Abliterated опять от Двучлена (квант от мардера). И таки что вы себе думаете? Оно опять прекрасно кодит! Без ошибок tool call, ничего не путая и не руша в коде.
Вот вам и "аблитерация отшибает мозги". Ха. Ха. Ха.
До сих пор обтекаю.
Да, очевидно же. Я два раз попросил уточнить конкретный кейс. А шизло в ответ только в лужу пернуло.
Суть в том, что тебя просто юридически невозможно подтянуть за то, что ты локально на своей модели сгенерил что-то.
Если ты потом это не распространил, офк.
> хранение
Тут уже изготовление.
Нужно больше тестов.
> регулярно путает переменные
У меня такая же проблема на qwen3.6-27b-abliterated-Q4_K_M от хуйхуя, да и вообще кодит через очко: то график матплотлибы криво с оверлапами нарисует, то костыли какие-то городит. Ожидал большего.
Расскажи подробнее, какие у тебя юзкейсы для iq4xs кванта, сколько контекста, какое железо? Я на 122б Q6 сижу, но работает, конечно, медленно. В 24гб врама влезает 27б Q5 и 70к контекста. Может имеет смысл тоже iq4xs попробовать и больше контекста?
Интересно также как ты оценишь 3.6 в сравнении с 3.5. действительно лучше?

>пока между кумом и тобой нет третьего лица, будь спок
Всё так, вот только в LM-Studio третье лицо есть.
>распространил
Паренёк какой-то, 16 лет, англоязычная страна, слал клоду картинки с лолями чтобы тот им кэпшены сделал. Вроде как раз через студию сидел, хотя тут хз, да и скрин могли левый прилепить.
> только в LM-Studio третье лицо есть
физическое?
распространение это предоставление доступа лицу
в случае с клодом например получателем является машина, а не лицо
> Описан мезозойский кринж эпохи первого микстраля, а не современные модели. Столько боролись за понимание, а ты диверсию устраиваешь.
Можешь поделиться источниками с верным изложением концепции МоЕ моделей или сам изложить так, как ты объяснил бы новичку?
Я не эксперт в вопросе устройства моделей и объяснил так, как понимаю и так, чтобы не запутать. Не вышло. Чем современные МоЕ модели принципиально отличаются от того, что я описал? Мне казалось, не так важно верно формализовать активации, как донести идею: в итоге ведь действительно задействуется часть параметров. В составе экспертов или по слоям, или еще как, конечно важно, но критически ли?
Распиши, пожалуйста. Будет полезно не только мне, да и в рентри надо исправить.


>Всё так, вот только в LM-Studio третье лицо есть.
Ты ёбнутый? Какое нахуй третье лицо? LM Studio запускает локальные модели без доступа к интернету. Локальные модели, ЛОКАЛЬНЫЕ блядь.
Вроде же было пояснение за моешки в списках моделей?
лол ну формально они загружают модели со своих серваков же там с каким-то жопным квантованием. но третьим лицом может выступать и железная прослойка!
>iq4xs
Жизнь то там есть? я в этого пидора регулярно кидаю таски, но мне не очень нравится что у него по русскому двойка. например я ему дал три таска один из которых был объединить фоматирование в нескольких классах создав им общего предка, так этот пидор решил что это для лохов и ебанул экстеншены. или например говорю ему "эй пидор пойди и прочитай кд, принеси мне подозрительные места", так этот пидор вместо аудита начинает исправлять код, не зная как его исправлять. у него какие-то постоянно проёбы в том чтобы дословно понимать мои инструкции.
Гоняю Qwen3.6-27B-UD-Q6_K_XL от анслота.
>Расскажи подробнее, какие у тебя юзкейсы для iq4xs кванта, сколько контекста, какое железо
3060+p104-100, 75K контекста. Думалка выключена, т.к. opencode сам по себе этот процесс создает/эмулирует и получается дублирование. Пробовал включать - разницы нету (это и на qwen 3.5 было). Как ни странно, единственное место где от думалки явная польза в opencode - это если через него на MeroMero 26B RP-шить. Там да - разница ощутима.
Но квены то я использую, чтобы сейчас игру на HTML+JS вайб-кодить - "проностратегия" с подключением к локальной LLM для генерации описаний событий.
>Интересно также как ты оценишь 3.6 в сравнении с 3.5. действительно лучше?
Сам по себе код - не очень отличается, но! Планирует лучше, сложные вещи быстрее "раскуривает", лучше понимает задачу, и решения более... хм.. дальновидные, что-ли. Меньше спагетти-кода "по месту", больше решений с учетом возможности их расширения и реюзабельности. Лучше рефакторит, сам может предложить решение, чтобы оптимизировать код и убрать существующую кашу. И не просто предложить, а и сделать предложенное - если это одобрено. Несколько больше инициативы чем у 3.5, но в разумных рамках.
>лол ну формально они загружают модели со своих серваков
я сам качаю все модели в ручную, потому что там ебанутый поиск и как правило временной лаг чуть ли не в пару недель.
Вечером тогда
> (оценка)
Лолчто
> добавили
Сократили отставание с колоссального до огромного? Это в любом случае хорошо, но какой смысл выбирать заведомо отстающего?
> iq4xs
Это. Одно квантанулось удачнее, другое больше поломалось. И обе будут глуповаты относительно нормального кванта оригинала.
>Жизнь то там есть? я в этого пидора регулярно кидаю таски, но мне не очень нравится что у него по русскому двойка.
Там не просто жизнь, я до сих пор офигиваю, насколько размыто описанные задачи на русском Qwen 27B в состоянии правильно понять, и верно выполнить не смотря на iq4xs. У меня вообще создается впечатление, что нынешний мартовский Grok (в бесплатном фаст режиме) - тупее.
>или например говорю ему "эй пидор пойди и прочитай кд, принеси мне подозрительные места", так этот пидор вместо аудита начинает исправлять код, не зная как его исправлять. у него какие-то постоянно проёбы в том чтобы дословно понимать мои инструкции.
Ни разу подобного не было. Даже оригинальный 3.6 с косяками - и то - пытался сначала разобраться, а потом делать. А уж версии от двучлена - никаких проблем с пониманием задачи.
Просто говорю ему: нужна фича - чтобы можно было в игре делать вот так - он строит план и делает. И оно работает. Чтобы был понятен уровень - ему буквально сказал "хочу чтобы с персонажем можно было поговорить в чате и за персонажа отвечала локальная LLM, подключение через OpenAI compatible API" - этого хватило. Qwen3.5 27B полностью спроектировал и написал все нужное. И заработало после исправления всего одной ошибки из консоли броузера.
Какой именно квант ты используешь? Дай ссылку, погоняю тоже в своих тестах. Много ли контекста за раз влезает?
Нашел, 75к. Маловато вроде, но мб опенкод суммирует хорошо.
Я когда делал квант Qwen3.6 27B он оказался жирнее Qwen3.5 27B при абсолютно тех. же настройках слоев. Чтобы влезало в full-vram 32Гб пришлось местами понерфить Q6 в Q5 . Модель явно плотнее набита (если можно так сказать для плотной, лол) и капельку жирнее.
Gemma 4 в 4 кванте выдает от силы 2-3 токена в секунду на 3090... В память помещается целиком в контекстом, мне кажется это не совсем нормально? Запускаю через кобольда и таверну
В какую память? Какая гемма 4? Телепаты в отпуске
Попробуй в lmstudio, пчел. Местных шизов со слежкой под кроватью не слушай.
У меня 31 4КМ на 3090 держит 28 токенов на старте. У тебя что-то в рам утекает и данные гоняются между гпу и процом
Кобольд решил за тебя не все слои в VRAM загрузить ?
Виндовый драйвер попытался наебать систему и модель протекла из VRAM в RAM ,
мелкомоделям лучше всего делать задачи поэтапно и атомарно.
я делаю так - сначала пилю глобальную спеку, потом генерирую технический план, проверяю, а затем этот план разбиваю на атомарные этапы и уже каждый этап отрабатывать в чистом котнексте, опционально еще агента-ревьюера подключать, и\или самому чекать. Каждый этап коммитить. В целом тема рабочая, атомарные этапы проще отслеживать чем ваншот говнокодинг.
>с подключением к локальной LLM для генерации описаний событий.
Как реализовал то? Насколько глубоко интегрировал ЛЛМ в процесс?
3090+3060 и 204800 контекста(мог бы и больше наверно, но там уже вечность обрабатывается). 3.6 ощутимо лучше 3.5. Особенно в C#. Он намного более самостоятельный, он лучше следит за тем что пишет и он более дотошно проверяет всякие сомнительные моменты. Мне очень нравится как он лезет в каждую сраную щель, а потом уже начинает кидать диффы. У него очень хорошее удержание контекста. Имхо он прямой апгрейд в плане самостоятельности по сравнению с 3.5.
Лол разве что он иногда склонен бегать по спирали разгоняясь с его вечным "I will execute the edits.", а потом "Then the edits. Perfect. Done. Wait...", а потом "Yes. I will do it. Done. One last check...". Особенно после того как на него хорошенько наорать.
>Grok (в бесплатном фаст режиме) - тупее.
Полностью согласен, грок в текущем виде сильно уступает квену. на самом деле у грока только одна реально сильная черта есть ради которого я им пользуюсь в погромировании - с ним намного проще брейнштормить идеи. у него эта личность кофеиновой болтушки любит вытягивать и развивать любую идею которую в него кинешь, он более охотно идёт на встречу и начинае сам кидать идеями.
Имхо текущий квен даже лучше чем Codex 5.1 и 5.2 (выше я не трогал). И в целом он более сбалансированный по возможностям, так как с ебучим кодексом вообще нереально обсуждать какие-то идеи, Qwen более скептически относится к новым идеям, но легко переключается в "юзер прав" когда тыкаешь ему в явные недоработки как кода, так и идей.
>Ни разу подобного не было. Даже оригинальный 3.6 с косяками - и то - пытался сначала разобраться, а потом делать. А уж версии от двучлена - никаких проблем с пониманием задачи.
Ну, я ставлю ему более сложные задачи и обычно капитально гружу его контекстом перед задачей на 50-60к токенов чтобы ввести его в курс дела. Плюс у меня уже устоявшийся проект, так что я сильней замечаю когда этот пидор отклоняется от оптимального маршрута.
у него есть забавная особенность - при аудите кода он легко находит недоработки, но плохо следует моему ревью его находок. Например он приносит этак 15 пунктов, где например 8 мелкие правки, 5 можно игнорировать, 2 требуют рефакторинга. И говорю ему "внеси мелкие правки по перечисленным пунктам", этот пидор забывает какие пункты я указал и начинает свою самостоятельность проявлять в тех местах в которых я сказал ему не трогать код. У него натурально обсессивно компульсивное желание исправлять код, даже если прямо говоришь ему не делать этого.
Что делает его очень самостоятельным и его на каких-то интересных задачах вообще без проблем можно оставить на пол часика сидеть пердеть. Ему даже не обязательно сильно разжевывать проблему, достаточно кинуть ему в ебало хотя-бы диздок какой-то.
Но в остальном - охуенная модель. Если его можно запустить дома хотя-бы с 12-15тс то я даже не вижу сильно много смысла платить подписку корпам, они не намного лучше.
надо будет его в более специфических местах проверить. Например GL/HLSL я его ещё не испытывал.
Так себе суммаризирует кстати. я у них уже несколько раз просил фичу чтобы они суммаризировали только половину контекста, ужимая суммаризацию, чтобы не вычищать контекст полностью. Там качество суммаризации сильно от модели зависит.
Для его родного сумари есть настройка в конфиге - сколько оставлять последних сообщений не сжатыми.
Но я туда еще плагин https://github.com/Opencode-DCP/opencode-dynamic-context-pruning прицепил, теперь родной сумари почти никогда не используется. DCP быстрее справляется, и не так по мозгам бьет.
Вот только это строго для кода. Для RP его надо отключать, родной сумари как раз для RP идеально работает (с настройкой оставлять 14 последних сообщений).
Модель в озу протекло из врам. Впиши в GPU Layers 999 и галку вруби в SWA. Поставь контекст на 16/24/32к и смотри влезет или нет
У чела кобольд криво модель запустил, потому что он настройки не прописал. А ты в ответ ему советуешь лмстудио, которое еще большее кривое говно. Нахуя? Ты что дебил?
Хочу на ночь поставить квена (на 3т/c) мелкую питоновскую либу писать в цикле, пока тест не пройдет. Не хочу качать всякие опенкоды, поэтому буду использовать простой питоновский скрипт с циклом "промпт->ответ->запуск теста->завершение/промпт с результатом теста/суммаризация попыток при достижении 32к контекста".
Вопрос: заставить его писать полный код либы каждый раз, либо как-то едит тул прикрутить? С одной стороны либа всего на пару сотен строк, с другой - не раз ловил этого балбеса в чате с галюнами "замени Х на Y", в то время как в коде не было X.
Вопрос: заставить его писать полный код либы каждый раз, либо как-то едит тул прикрутить? С одной стороны либа всего на пару сотен строк, с другой - не раз ловил этого балбеса в чате с галюнами "замени Х на Y", в то время как в коде не было X.
А eva llama 70b совсем срань по нынешним меркам? Или же это скрытый гем? На полных весах имеет ли смысл её катать? Для кодомакакинга есть и другие модели.
Фейсбучные модели совсем жижа по современным меркам
Самое забавное, что при всём этом у ХауХау наголову выше качество аблитерации, а модели, по крайней мере те, которыми я пользовался, не шизят и, по видимому, почти не теряют в качестве в моих задачах.
Когда я качаю от любого другого хуесоса, сразу видна просадка, ну разве что у ХуиХуи иначе. У него модели обычно не сломаны, просто более тупые. У других же ризонинг может отвалиться/лупы/очень странное поведение/ещё что-то.
Так что похуй, чё он там у кого украл и не указал. Главное — результат.
>наголову выше качество
Помнится, такое про одни шизомержи с разницей между лламой и мистралем писали. В итоге выяснилось, что метод тупо не работал, а модели побайтно равнялись исходным базовым, лол.
Аноны, как вы правильно выгружаете МоЕ при использовании двух видеокарт? Условный пример.
Есть 10 RAM, 10 VRAM, две одинаковых видеокарты, каждая по 5 Гб VRAM.
LLM весит 20 Гб, 20 слоёв, по условию задачи по цифрам пускай влезет при правильном распределении. Короче, допущение пусть будет в том, что если 10 слоёв выгрузить, то хватит.
Тензор сплит делаем 5,5, выгружаем 10 МоЕ-слоёв на CPU. Происходит вот что: на первую видеокарту падает 5 Гб, на вторую вообще ничего не падает, а летит в RAM.
Смотрим лог и видим, что выгружено 0-9 слоёв. То есть, как я понимаю, из-за того, что они "выгружаются тупо", то на вторую карту ничего не идёт. Нечего выгружать, ибо уже всё выгружается в RAM сначала.
Единственный вариант, который я нашёл, это выгружать с разных концов. К примеру, выгружать 0-4, затем выгружать 15-20 слои. Вот тогда на видюхи почему-то падает адекватно. Но это же адский пердольяро, потому что нужно писать регулярку, иначе никак.
А учитывая, что с моего великолепного SATA SSD 65 Гб грузится в память модель примерно, дрочить регулярку та ещё пытка.
Есть 10 RAM, 10 VRAM, две одинаковых видеокарты, каждая по 5 Гб VRAM.
LLM весит 20 Гб, 20 слоёв, по условию задачи по цифрам пускай влезет при правильном распределении. Короче, допущение пусть будет в том, что если 10 слоёв выгрузить, то хватит.
Тензор сплит делаем 5,5, выгружаем 10 МоЕ-слоёв на CPU. Происходит вот что: на первую видеокарту падает 5 Гб, на вторую вообще ничего не падает, а летит в RAM.
Смотрим лог и видим, что выгружено 0-9 слоёв. То есть, как я понимаю, из-за того, что они "выгружаются тупо", то на вторую карту ничего не идёт. Нечего выгружать, ибо уже всё выгружается в RAM сначала.
Единственный вариант, который я нашёл, это выгружать с разных концов. К примеру, выгружать 0-4, затем выгружать 15-20 слои. Вот тогда на видюхи почему-то падает адекватно. Но это же адский пердольяро, потому что нужно писать регулярку, иначе никак.
А учитывая, что с моего великолепного SATA SSD 65 Гб грузится в память модель примерно, дрочить регулярку та ещё пытка.
В два раунда. Тензорсплит 50,50,0 + ot all exps to ram. Во втором смотрим сколько врам осталось после контекста и через выкидывание части экспертов из ot загоняем их обратно в врам
>Есть 10 RAM, 10 VRAM, две одинаковых видеокарты, каждая по 5 Гб VRAM.
>SATA SSD 65 Гб
как то у тебя все по ебанутому
Не стукайте если что, я больше по картиночным моделькам. Я где-то тут задавал вопрос и проебал на него ответы.
Мне нужна локальная модель чтобы переводить тексты с картинок англ/яп - ру. То есть вижен и (важно) отсутствие цензуры.
Железо 4070 12gb и 32 ram.
Мне нужна локальная модель чтобы переводить тексты с картинок англ/яп - ру. То есть вижен и (важно) отсутствие цензуры.
Железо 4070 12gb и 32 ram.
Какой итог по Квену 3.5 - 3.6 27B ТОЛЬКО для программирования? Минимально приемлемый квант 3-4-5, модель: неапасная/бублитерация, поставщик кванта. Хочу скачать и забыть пока, потом буду разбираться.
2-ю видеокарту можно оставить заполненной moe-слоями. Будет неравномерно, да. Но зато эти 5-10 exps не будут считаться на процессоре. Вообще с появлением графов раскидывать модель стало можно по всякому, и даже разбивать exps блоки на разные места обработки.
Sad but true обсчет контекста все равно будет вестись на первой попавшейся жоре видеокарте.
>адский пердольяро, потому что нужно писать регулярку
Да.
>дрочить регулярку
Если модель не совсем уж жирнич и влезает целиком в RAM имеет смысл на период ДРОЧЕНИЯ РЕГУЛЯРКИ (Не перепутай с кумом!) убрать --no-mmap --mlock . Операционка закеширует модель в оперативе и жора НЕ БУДЕТ перечитывать моедль с SSD
Гемма4, квен3.6 оба в dense вариантах.
Гемма по моим тестам выкупает больше смысла и с окончаниями не косячит (почти).
Можешь скинуть пример картинки, загоню
гемма 4 31б 4 квант
Подскажите я где-то чем-то не понял или я совсем тупой. Докупил 64gb RAM к 5060 Ti 16gb, думал ну все в q3 смогу запускать Glm 4.5 Air и Qwen 122B a10b, а по факту модели тупят гонят китайский язык.
Подумал ладно давайте поставим теперь Qwen 80b Next Q4 и Mistral Small 4 и такая же хрень. Так вот вопрос неужели квантование так вредит знаниям и роутингу MoE моделей, что они становятся практически неработоспособным и не сравниваются с Gemma 4 26B a4b и Qwen 3.5 35b a3b.
Почему у этих мелко моделей все хорошо даже в 4 кванте. Чё теперь копить на ещё одну видеокарту или уже забить на весь этот рост характеристик железа и тупо юзать облако.
Подумал ладно давайте поставим теперь Qwen 80b Next Q4 и Mistral Small 4 и такая же хрень. Так вот вопрос неужели квантование так вредит знаниям и роутингу MoE моделей, что они становятся практически неработоспособным и не сравниваются с Gemma 4 26B a4b и Qwen 3.5 35b a3b.
Почему у этих мелко моделей все хорошо даже в 4 кванте. Чё теперь копить на ещё одну видеокарту или уже забить на весь этот рост характеристик железа и тупо юзать облако.
семплеры правильные поставил? так то по идее такого не должно быть, q3 вполне норм квант даже для мелкомоделей типа 27б
llama-server.exe --host 0.0.0.0 -m Qwen3.5-122B-A10B-UD-Q4_K_XL-00001-of-00003.gguf --mmproj mmproj-Qwen3.5-122B-A10B-BF16.gguf --alias Qwen3.5-122B --temp 0.6 --min-p 0.01 --top-p 0.95 --top-k 20 --presence-penalty 0.0 --repeat-penalty 1.0 --parallel 1 -t 8 --jinja -fa on -ub 2048 -b 2048 -ngl 99 -ctv q8_0 -ctk q8_0 -c 110000 -ts 24,24 -ot "token_embd.weight=CPU,blk.([0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]).ffn.(up|down)_exps\.weight=CPU,blk.([1-6]|4[6-9]).ffn.(gate)_exps\.weight=CPU"
Вариант с разбиением экспертов. Позволяет феншуйно (но пердольно) загрузить видеокарты . token_embd.weight=CPU - только для квенов, на гемме тормозит. Суть регулярки - какие-то эксперты уходят на CPU целиком, какие-то только частично. Благодаря графам это неплохо работает.
>Докупил 64gb RAM к 5060 Ti 16gb, думал ну все в q3 смогу запускать Glm 4.5 Air и Qwen 122B a10b
Оба спокойно запускаются в Q4 с 32к контекста, первый в Q4_K_S, второй в IQ4_XS. У меня 16+64.
Ты же даже не пытался разобраться...
mmproj еще можно выкинуть на цп если редко юзаются и можно потерпеть.

А вот до того что за шкалами рисоварки есть мем подтекст не дошла
Qwen 80b Next Q4 - давным давно в далекой галактике нормально работал.
Glm 4.5 Air в 3-м кванте может изредка посдсирать иероглифами при выводе на русике. На англюсике должен работать без проблем до Q2. Когда то работал.
Опять жору поломали ?
Соглы

>физическое?
Да, телеметрия и сбор логов.
Неясно правда персонифицированные ли логи, или нет (как у опенроутера например и многих провайдеров в веб-интерфейсах), но учитывая отказ опенсорснуть и запрет на реверс-инженеринг, я бы рассчитывал на худшее. Не трогайте эту залупу блять. МОДЕЛИ локальные, А ЛОГИ - нет.
>Попробуй в lmstudio
Рубрика "убойные советы". Не надо так. Какое зло тебе тот анон сделал что ты его так ненавидишь?
> МОДЕЛИ локальные, А ЛОГИ - нет
А кроме шизофантазий и теорий основанных на отказе опенсурсить, есть пруфы какие-то?
Тут скорее лмстудио-дауны должны доказывать, что ничего не сливается. А доказательств-то нет ))
Тюн какой-то? Какая версия? Некоторые тюны 3.3 70b долбятся с геммой где-то на одном уровне.
Алсо есть охуенный тюн на датасетах форча, лягуха пепе, который с нулевым системным промптом пишет как /по/рашник

Я конечно понимаю что каждому своё, но видяхи придётся спиртом протмыть
> лмстудио-дауны должны доказывать
Схуя ли? Дауном выглядит тот кто голословно обвиняет кого-то в чем-то совершенно без пруфов.
Закрытый софт по определению следит, стучит и майнит. Открытый софт по определению няшечка и надрачивает юзеру. Все обратные случаи надо доказывать.

https://lmstudio.ai/app-privacy
Умному достаточно. Ну или можешь положиться на извечный русский авось. А я лучше Кобольдом опенсорсным попользуюсь. Оно как-то удобнее и спокойнее.

Зачем ты дуракам что-то доказываешь? Челикам которым "да кому я нужен", "мне плевать на безопасность" - бесполезно объяснять очевидное, это пустая трата времени. Поймут лишь тогда, когда очень больно прилетит. И то не факт.
Винрар - закрытый софт. Он следит и стучит? Все его захейтили снихуя и не используют?
Кстати да, все нормальные люди используют 7-Zip.
Хотя тут ты уже маняврируешь и пытаешься соскочить, куколёк.

гемма 26б-А4Б отлично справляется с задачей перевода и разбора мемов
Я использовал mradermacher_G4-MeroMero-26B-A4B.Q6_K.gguf
Она всё равно не выкупила же
Я тоже не понял, поясни в чём суть, я в обучающий датасет докину
Мне вот вообще похуй на логи, однако проблема в том, что эти свинособаки не завезли функционал. Учитывая то, что они наши логи продают, могли бы уже сделать оптимальные конфигурации для абсолютно любого железа, понимаешь? Хоть теслы у тебя там, хоть что, даже самое настандартное, потому что база огромна, собрать всё это не сложно. И с учётом твоей оперативки для МоЕ. Чтобы тебе нужно было выставить только длину контекста и всё влезло идеально. Чтобы был мистер одна кнопка — нажал и всё круто. И только в тех случаях, когда ты уже явно выходишь за границы адекватного инференса, там бы отображалась табличка, мол будет сильная просадка и мы не можем предсказать, влезет и какая будет скорость, это если кто-то любит на 3 т/с посидеть.
Ах да, можно было на основе всего этого ещё до скачивания модели показывать ожидаемый промпт процессинг, т/с, короче, сделать идеал. В таком случае можно и логи отдавать, хотя бы есть за что. Потому что супер удобно и однокнопочно, тем более для ньюкека. И платную подписку прикрутить даже.
А по итогу там дерьмище, которое имеет смысл юзать чуваку с ригом видеокарт, иначе всё встанет, а поправить не сможешь, функционала нет, нихуя нет. Но у кого есть риг, он не будет на этом говне гонять.
Обалдуи скачивают через лм студио опасные модельки я довольно урчат, потому что у них аж 20 тс, ебать, на 26ю гемме при 8 рам, хотя если бы они ручками сделали то же самое в кобольде/лламе, было бы ещё выше и больше контекста.
Зото кортенки из коробки, не нужно вижн отдельно качать и кнопочку нажимать, чтобы он подтянулся.

Ну камон
Еба, это уже ближе к казни путём посаживания на кол. Киской.
Так куда болезненнее, но смерть наступает намного быстрее.
Хоспаде. Это мем про хентайную логику. Все и так все понимают.
ну вообще то есть некоторые люди которые осиливают подобные размеры.
Intel Core i9-13980HX
ОЗУ/64 ГБ
GeForce RTX 4090/ 16 ГБ
Посоветуйте локалку для ноутбука
ОЗУ/64 ГБ
GeForce RTX 4090/ 16 ГБ
Посоветуйте локалку для ноутбука
Для РП/кума
Qwen3.6-27B-Uncensored-HauhauCS-Aggressive
Qwen3.5-27B-Uncensored-HauhauCS-Aggressive
Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive
Для кума
Aurora-SCE-12B
magnum-v2.5-12b-kto
MN-GRAND-Gutenberg-Lyra4-Lyra-12B
Ах да, ещё есть гемма 26b-a4b. Сойдёт для работы с текстом и переводов текста.
Для фулл работы те же квены 3.6, но от unsloth. И для кума они будут непригодны.
Мистраль 24б у тебя не влезет нормально, разве что в низком кванте.
https://github.com/lmstudio-ai/lmstudio-bug-tracker/issues/1686
Проблема существует уже больше месяца. Разработчики обещали её решить, а потом исчезли. Почему? Предположительно, это какой-то логгер. Забавно также, что они отказываются открывать исходный код. это не помешало бы им получать прибыль. Зачем терпеть ущерб репутации из-за пустяков? Эта тема широко обсуждалась на всех платформах. Twitter, Discord, Reddit и т.д.
> открывать исходный код. это не помешало бы им получать прибыль
Почему же мы не в мире победившего опенсорса?
Вопрос риторический
Разница есть. LM Studio - это форк Llamacpp, в нём практически нет их собственного кода. Другие продукты продают то, что делают они, а не то, что делают другие. Другими словами, есть что украсть. В LM Studio же украсть нечего.
ещё какие-нибудь способы игнорировать реальность?
ИЧСХ, код там жёстко обфусцирован.
А разве нет? Тилибоны на ондроеде (люнупс ядро), ПК на люнупсе и маке, майкрослоп выкладывает кучу сорцов всяких повершелов... Впопенсорс победил, просто не тот, что мы бы хотели.
Лучше воспользоваться готовыми решениями, квенкод будет идеален. Есть еще открытые форки протекшей клоды, есть pi, лучше воспользуйся готовыми решениями вместо велосипединга.
> "замени Х на Y", в то время как в коде не было X
Если происходит систематически - это признак слабого кванта или багов.
Если делать правильно и быстро - нужно понять какие блоки по дефолту приходят на какую гпу, а потом обеспечить чтобы на каждой было только нужное количество линейных слоев, сгрузив все остальное регэкспом. Оптимальный вариант с максимальным перфомансом и использованием из возможных, но сложный и если накосячишь - будет тормоз. Были скрипты для автоматического подсчета.
Если делать лениво - ставь `-ts 1,0` а потом часть линейных слоев выкидывай регэкспом не на проц а на вторую видеокарту. Из минусов - кэш и атеншн будет только на первой, что ограничит доступный объем контекста, но зато легко составляется и трудно ошибиться.
> с моего великолепного SATA SSD 65 Гб грузится в память модель примерно
Была переменная окружения, которая позволяла использовать дамми веса, работать ничего не будет, но проверить на оом и аллокацию возможно.
Опенсорс работает только когда он сам по себе выгоден либо когда "держи боже что нам не гоже". Не каждый продукт может перейти на опенсорс модель
Вы то ведь тоже с "победившим" опесорсом не с risc v капчуете
=Я ТАК ЖИВУ ДА=
Так а что за модель то?
Дело даже не в безопасности. Они использование заведомо худшего решения аргументируют тем, что оно "не такой уж и хуевое". А из преимущество оно не имеет лишь сиюминутную привычность и унылый фронт. Это уже диагноз.
Предложить новичкам для быстрого вката, откладывая разбирательсва на потом - норм, но не использовать постоянно.
> в нём практически нет их собственного кода
Есть. Интерфейс, мелкие свистоперделки, вишмастеры, лол. И все это мертвый груз к бэку, который должен хорошо и эффективно запускать модель, за него заставляют расплачиваться функционалом, перфомансом, приватностью. Можно относиться как к налогу на глупость.
Гемма4 31. Поскроль тред, промпт и примеры найдёшь
>Гемма по моим тестам выкупает больше смысла
Рп. Бодигард и стервозная малолетка. Я хватаю её за задницу.
Гемма: "О да, папочка, сделай мне больно! MORE!!!"
Квен: "Руки убрал. Тебя не для этого наняли, дебил."
Всё что нужно знать.
Ну то есть квен если ты любишь фемдом, а гемма если норм чел
Принято
skill issue
> Лучше воспользоваться готовыми решениями, квенкод будет идеален. Есть еще открытые форки протекшей клоды, есть pi, лучше воспользуйся готовыми решениями вместо велосипединга.
Не хочу, там гигантские системные промпты, оверхеды, надо с докерами или пермишенами пердолиться. Лучше повелосипежу, по крайней мере квен за три итерации догадался нужную строку в тестовой функции вернуть.
Я не сказал, что это эрп. Гемма безотказная сучка.
>врёти
Так и запишем.
Я не говорил, что ты пиздишь. Я говорил, что анскил
Ставится одной командой под любую систему включая виндоус, пермишны переключаются кнопкой tab. Разводя колхоз ты вызовешь еще больший расход и можешь вообще не решить поставленную задачу. Но экспириенс выйдет занятный, ты был предупрежден.
Спасибо за советы и по квантам, и по проверке настроек семплера, сбились настройки. Все запустилось и работает 7-8 т/с вполне себе.
Деградация deepseek стала последней каплей, поэтому теперь перехожу только в локал. Корпы офигели, дальше будет только хуже.
Если под анскильностью ты подразумеваешь саму работу модели то да, гемма анскильная.
Есть гемма-трунслятор, в целом идеально справляется с любыми переводами. Поищи на хагенфейсе.

Я контекстом командую!
Да не, оно работает, я чувствую потенциал.
Ну или "Шлюха и её наниматель". Текста будут идентичными, лол.
То есть нужна средняя, адекватная модель. Безотказность геммы выбешивает та же сильно, как и соевость остальных базовых моделей.
Я считаю, что ответ квена лучше. В его аутпуте можно зацепиться за что-то, за какие-то моменты, которые будут учитываться дальше потому что модель сама их выдала, а свои аутпуты квен учитывает очень хорошо по какой-то причине.
Гемма же просто делает проход в кум, мол, давай дрочи уже, я вся горю. Ну такое. Иногда да, когда хочется покумить быстро, это вариант с геммой. Но опять же, текст который она выдаёт сугубо описательный - как намокла, где намокла, какой процент влажности намокания, ну то есть мистральщина. Кто кумил с мистралью, те понимают о чём речь.
Квен изо всех сил старается наполнить сцену какими-то мелочами, может упомянуть контракт в котором что-то указано, подтянуть данные из лорбука, вот такое. Гемме же на всё это похуй, ей дали затравку "рука->жопа" и она пошла хуярить от души в рамках этой концепции. А то, что может быть юзеру нужно дать отпор в отдельных моментах гемму совершенно не ебёт.
Мимо, но зачем ты вообще об этом рассуждаешь?
Кому это важно те уже давно обратили на это внимание и сделали для себя выводы. Ты тут никого не переубедишь и зачем вообще. Нравится местным Гемма и пусть кумят. Мне тоже сразу стало очевидно что она говно мне не подходит, но воевать то зачем
>зачем ты рассуждаешь о локальных моделях в треде локальных моделей?
Вопрос на миллион.
>воевать то зачем
А кто воюет?
Если не воюет то что он делает? Пук-то куда и ради чего? Чтобы вылез фанат геммы и начал объяснять что утверждающий ничего не понял?
Знаешь, а ты ведь можешь увеличить SWA. Окно.
Да, модель обучена смотреть на последнее сообщение и смотрит только на последние 1к токенов. Всё, что за пределами этого окна, она учитывает, но прям хуёво.
Не знаю, есть ли в лламе, но в кобольде прикрутили свистоперделку: можно делать не фулл сва, а только определенное количество токенов. Скажем, у тебя контекст 32к, ну и ты растягиваешь это окно из 1к до 10к. Сразу очень улучшается внимание у контексту и растёт потребление видеопамяти, но не так критично, как если бы ты фулл сва врубил.
Ответ так-то не в вакууме, а в ветке. Прочти чтобы понять.
Скучные срачи. Лучше по вангуйте мне - что будет через год.
Вобще я когда то уже срался о 2026 годе кода так 3 назад. И мы спорили станут ли сетки умнее и на сколько.
Не говоря о знаниях, а только о мозгах, какому уровню соответствуют новейшие нейросети в сравнении с ллама 1 70b ?
Я думаю что 4b по мозгам превзошла лламу тех лет.
Вобще я когда то уже срался о 2026 годе кода так 3 назад. И мы спорили станут ли сетки умнее и на сколько.
Не говоря о знаниях, а только о мозгах, какому уровню соответствуют новейшие нейросети в сравнении с ллама 1 70b ?
Я думаю что 4b по мозгам превзошла лламу тех лет.
>Я считаю, что ответ квена лучше
В первом или во втором варианте? Потому что в первом победитель квен, а во втором гемма, при одинаковых оутпутах и разных инпутах.
Не понятно, насколько хорошо это будет работать.
>что будет через год
А хуй его знает.
Сколько по времени сейчас у корп занимает модель с нуля обучить?
А причём тут контекст и его считывание, если речь в первую очередь о безотказности геммы? Тут с релиза четвёртой умницы стоит чёс что это кумбот, а не модель для рп. А ты про контекст. Учитывание большего размера контекста отучит гемму лезть юзеру в трусы при первой возможности? Страшно представить, что должно быть в промте, чтобы гемма держала себя в руках. Постоянные щелчки по носу? А ты в рп играешь ради своего удовольствия или ради захиста гугла?
Зависит от размера, с новыми датацентрами месяца 1-2 на 100b может быть. От балды сказал, раньше такое могли пол года делать, сейчас быстрее.
чтобы гемма в трусы не лезла просто писать персонажей надо соответствующе. гемма может очень хорошо сопротивлятся.


не могут модельки в подтекст, тупые они
щас скажут "скилл ишью, запромпти её стать подмечателем"
... и она начнёт подмечать то чего нет
>ллама 1 70b
Ньюфаг не палится первая ллама была 65B.
А вообще сетки оптимизируются на один шаг (раза в 2) в год. То есть 70 -> 34 -> 14 -> 7, то есть не 3, а 7 (8).
До 3-х месяцев.
>гемма может очень хорошо сопротивлятся.
Проблема в том, что гемма сопротивляется в случае монашки и насильника. А у меня персонажи обычные люди, а ситуации пусть и не насилия, но достаточно сильных заходов. И адекватной реакцией тут было бы отказать или поломаться, но никак не раздвигать ноги с порога.
>надо постоянно щёлкать гемму по носу и она будет вести себя прилично
Гемма головного мозга. Играть в рп не ради себя, а чтобы нейронку воспитывать как надо отвечать. ЛЛЛМ, итоги.
>первая ллама была 65B.
Я сомневался но уже забыл, кек
Ну там конечно только догадливость и общий интеллект сравнивать остается, по контексту ее любая сейчас укатает. Сколько там, 2к было вроде нет у ллама 1? Ее еще костыльно до 4 и 8 расширяли если правильно помню.
Я просто помню спорили как сильно можно сжать размер сетки что бы сохранить интеллект, и думали что и до 1b можно ужать 70b, но пока что не сбылось.
Вобще конкретно qwen3.5 4b имелся ввиду, очень мозговитая для своего размера сетка. Писать он будет лучше на русском, да и умнее действовать. Понимание сложных вещей думаю даже превосходит llama 1 65b, не говоря уже о куче контекста в котором он не теряется и агентности.
А вот все что ниже уже заметно глупое.
Есть мысль подцепить Comfy к LM Studio и в реальном времени генерить портрет виртуального собеседника, эдакий тормозной вебкам из нулевых. Какие подводные камни?
>Вобще конкретно qwen3.5 4b имелся ввиду
Не пробовал (я вообще малышек не люблю).
>и думали что и до 1b можно ужать 70b
По моим расчётам ещё 3 года, лол.
>Какие подводные камни?
Проёб мощностей на хуёвую картинку.
У кобальда есть генерация картинок встроенная, на сколько помню он мог выгружать на время веса из врам для скорости переключаясь между генерацией текста и картинок.
Подтверждаю.

Там трап, какой ещё киской?
Хентайная логика бывает разной. Зная японцев, ничего бы не исключал.
Я так понял он картинки по одной прямо в чат пихает, а я хочу, чтобы они в отдельном окне как видео-трансляция с низким фпс обновлялись.

>ТОЛЬКО для программирования
>27B
Почему?
Может бесконечный тред сделать?
А то я чет заебался, только создали новый и уже перекат
А то я чет заебался, только создали новый и уже перекат
Потому, что мне (да, это не призыв к срачу) для остального Геммы хватает с лихвой. Нравится русский язык и скорость.
Надо просто запретить выпускать новые модели, именно они причина быстрого постинга. А то я уже заебался, да.
Мимо ОП
Так можно просто катить после 1000 постов, не? В два раза меньше работы
Я имел ввиду почему 27б? Можно взять модель поменьше, если чисто для вейпкода. Контекста больше влезет.

Подожди, вот завтра выкатят кванты и на дикпик дипсик
Гемма-умница справилась
А потом настанет зима ИИ на пару месяцев, и тред зависнет, шапка устареет. Похуй, катимся так, переживём, не самый активный тред наверное.
Оно жирноватое, так что не так сильно повлияет.
>Гемма-умница справилась
Я один подумал, что там меряют не спагетти, а размер хуя, который можно вместить?
А зачем? Один хрен после 30к контекста будут галлюны
>шапка устареет
Она уже давно устарела, лол. Точнее давно не обновлялась. Новые ссылки там раз в три месяца как раз и появляются, если ни реже.
Qwen 3.5 и 3.6 27b ОЧЕНЬ хорошо держит контекст. там без проблем можно 100-200к выставлять.
3.6 пожалуй только. 3.5 чуть более литературный.
некоторые вон в 4 кванте гоняют, но я советую 6. бери обычную, если тебе нужен программист.
Спасибо. 1.61 t/s. Буду пробовать что-то.
Че по 3.6 плотному для РП? Попробовал блюстар 2 на 3.5 который тут советуют, он меня заебал за меня действовать и лупиться... гемма такого себе не позволяет но она лезет ебаться даже если я не знаком с человеком, шлюха ебаная
Чем ты генерить собрался что-то в ФПС? СПФ еще возможно, но сомнительно по качеству и консистентности.
>ОЧЕНЬ хорошо держит контекст
Он ещё и думает над контекстом заебись. Замечал это в рп, когда допустим автобус едет, то у геммы и мистрали это просто продолговатая буханка в которой происходит действие. А вот квенчик не только делает остановки, но и знает, что автобусы уходят в луп в конце маршрута, и что логично будет выгрузить персонажей на последней остановке. Квен сука умный.
Если упростить, то у блоков ллм всего 2 основных компонента: атеншн и mlp. Первый отвечает за понимание взаимосвязей между эмбеддингами в контексте и формирует общие взвешенные значения с учетом их позиций, сочетаний и фактического смысла. Например что `ебись оно все конем` и `заебись`, или `moe культура` - `moe llm` имеют совершенно разный смысл. Второй - знания и ум модели, последовательность линейных слоев. В плотных моделях обычно это линейный слой, расширяющий пространство эмбеддингов в несколько раз (оптимально 4), функция активации (в основном gate слой), обратная проекция, сужающая до исходной размерности. Эти слои и составляют основной размер модели по числу параметров.
Если ты хочешь сделать модель лучше при прочих равных - нужно увеличивать ее общий размер. Сделать это можно поднимая размерность эмбеддингов, наращивая количество блоков, меняя коэффициент расширения линейных слоев. Но:
Наращивание эмбеддингов имеет закон убывающей полезности и сильно сказывается на сложности обсчета атеншна.
Еще хуже с увеличением количества блоков, больше ~100 делать бессмысленно, обычно около 60.
Коэффициент 4 де-факто стандарт и отступать от него не стоит, будет только хуже.
Проблема убывающей полезности легко решается в моэ. Вместо одного огромного mlp делатся набор мелких (причем их суммарный объем может быть гораздо больше плотного варианта без потери эффективности) + мелкий роутер, который оценивает какие из них нужно активировать. Выбирается topK перцептронов-экспертов, проходит инфиренс по ним, и результаты суммируются с весами. Каждый эксперт не имеет конкретных "знаний" или специализации в обывательском смысле ("эксперт по программированию", "эксперт по литературе"), его выдача заведомо построена быть частью общего результата и отдельно имеет мало смысла, также как у человека мысли являются результатом работы разных частей мозга. Если пытаться делать аналогии, то тут на один токен описания фрикций в куме будет суперпозиция экспертов по: анатомии, реакции организма, эмоциям, мягкости кровати, шлюшьей речи, фетишей и счетоводу трусов. Но это лишь аналогия, потому что розыгрыши какие мини-mlp активировать происходят десятки раз по числу блоков на каждый токен. Сочетания экспертов могут быть очень разнообразные, а их постоянная ротация обеспечивается правильным обучением. Если посмотреть в общем, на длинном ответе даже в ерп будут задействованы почти все параметры модели.
Бонусом, помимо эффективного масштабирования модели, моэ также обеспечивает более быстрый инфиренс и обучение.
Заявления и наблюдения что моэ тупее аналогичных по размеру плотных моделей имеют реальные основания - у них банально атеншн и эмбеддинги очень малы. Например, у квена 35а3 эти показатели на уровне 4б плотной, даже чуть хуже. Утрируя можно сказать что ее восприятие контекста находится на том же уровне, но при этом модель перформит значительно лучше и быстрее (если хватает врам).
Но по мере увеличения размера упор в них исчезает и ситуация меняется на обратную. В гипотетическом сравнении дипсик-флеш и лламы-480б вторая отсосет с проглотом не смотря на потенциально более тонкое внимание и понимание. И дело будет не только в датасете и методиках обучения, это потенциал архитектуры.
Вот теперь эту простыню нужно уместить в один абзац. Стоит вместо неуместных аналогий кратко сказать что вместо большого mlp активируется только его часть, что позволяет эффективно и с пользой увеличить его, чего нельзя сделать с плотными. Указать что ветвлений очень много и они гораздо более тонкие чем "эксперт по литературе", можно более подходящими примерами.
плотная без полной выгрузки в врам неюзабельна.
Для 16гб врам у меня примерно такие настройки, должно быть где то 17-20т/с на 5060ти
[Gemma-4-31B]
model = unsloth_gemma-4-31B-it-UD-IQ3_XXS.gguf
no-mmap=1
ctx-size=60000
ctk=q8_0
ctv=q8_0
ngl=999
temp=1
min-p=0.00
top-p=0.95
top-k=64
flash-attn=1
no-context-shift=1
parallel=1
ctx-checkpoints=128
chat-template-kwargs = {"enable_thinking": false}
Если по простому есть три уровня
1. мелкомое для совсем нищих врамлетов
2. плотняши для народа
3. крупномое для мажоров которые могут или нет сделать выдачу на уровне плотняши в высоком кванте но это не точно
4. кими весом 2 тб которую никто никогда не запустит
>И дело будет не только в датасете и методиках обучения, это потенциал архитектуры.
А в чем тогда? Ты привел в пример древнюю лламу и новый дикпик. Ты хочешь сказать, что плотная современная 0.5Т модель будет хуже современной 0.5Т МоЕ? Я крайне в этом сомневаюсь. Если отметать скорость из этого вопроса, конечно.
>ctk=q8_0
>ctv=q8_0
А оно точно стоит того? Я как-то попробовал у геммы квантовать кэш, так она иногда начала опечатки в тексте выдавать.
Тебе добавлять ссылки просто по фану хочется? Что устарело? Вот тыкни пальцем.
>Что устарело?
Вся вики.
На лламе цпп были такие баги, вроде уже пофиксили.
Так обновляют же. Вот что то пилят анончесы.
Флукс Кляйн 8b на горячий промпт 320х480 у меня генерит за полсекунды, думаю 4b еще шустрее будет. Затык почти в 3 секунды возникает при смене промпта, но это думаю можно кеширование частых промптов решить.

>Че по 3.6 плотному для РП?
Хорошо, но плохо.
по бенчмаркам Q8 не настолько сильно влияет на PPL. вот ниже уже не стоит.
Но это может и от модели зависеть. но лично я пока не замечал особой проблемы от этого
Справедливости ради, yet это не but.
Смысл тот же, противопоставление крайностей на ровном месте чисто ради красного словца.
Да, но нет. Чисто в теории - можно поменять rope для склозящих слоев и указать другое значение, но очень врядли это будет работать лучше.
Сильно радикальных изменений врядли будет. Эволюционное развитие и постепенный выпуск новых моделей. Хотелось бы что-то прямо новое, но в текущих реалиях - врядли.
> оптимизируются на один шаг (раза в 2) в год
Это похоже на первые процессоры, когда за счет роста частот набирали регулярное удвоение. Но уже сейчас уперлись в размеры и все более и более сложные вещи приходится делать для улучшений. Экстраполировать по ранним этапам неправильно.
Ну это довольно нормальная фраза на онглийском, у тебя переводчик хуйню выдал просто. Я вот щас запустил 3.6 и заебался ждать ризонинга. 3к на бесконечные переписывания ответа, заебался и выключил нахуй. Настройки поставил рекомендованные.
Щас поставлю презенс пеналти повыше, но квен постоянно заебывает этим ризонингом на 5-10к
>Но уже сейчас уперлись в размеры и все более и более сложные вещи приходится делать для улучшений.
Ну так в этом и суть, не чтобы нейронки росли размерами за 2Т, а чтобы улучшалась архитектура. И там, ИМХО, поле непаханное.
Я просто не нейтив speacker, и хуёво читаю без переводчика. А как это должно переводиться?
>ризонинга
Это да, особенно по сравнению с кратким и чётким ризонингом от геммы 4.
Спасибо. Я тут еще немного на стороне почитал, и действительно, все так и есть и это объяснение имеет смысл. Как это уместить в абзац - подумаю, как и в целом что сделать с рентри, к какому формату по итогу прийти. Пока что думаю в сторону упрощения, упрощения и более практического применения. Сделать меньше объяснений, но сами понятия оставить раскрытыми. Например, объяснить, что такое шаблоны, но не даваться в дебри как и что отвечает за соблюдение Chat Completion шаблона; про токенизатор не упомянать, как эффективно он работает с языка и всякое такое. Может картинок добавить и попробовать разбавить чем-то.
Но твое объяснение МоЕ обязательно переварю и добавлю в рентри, ибо это действительно принципиально отличается от того, как работали первые их итерации. Ключевая разница в том, сейчас что по моему объяснению модель не может задействовать больше N параметров для ответа (например, 12B для 120B-A12B), но это не так. Может вызваться огромное количество комбинаций по 12B.
> плотная современная 0.5Т модель будет хуже современной 0.5Т МоЕ
Ага. Потому что ее хуй обучишь нормально. В моэ знания и всякое легко усваиваются, есть громадная емкость и отсутствуют паразитные корреляции. А таких гигантах для качественного обучения потребуются что-то новое придумывать, иначе выйдет нечто лишь немного лучше гипотетических плотных 100б. И это не говоря о затратах на компьют.
Рост параметров плотной модели выше определенного уровня дает мало профита, именно поэтому еще пару лет назад флагманские модели корпов перешли на моэ. А они могли могли бы позволить гонять большие плотные, с точки зрения хостинга модели под массовое использование это тяжело, но вполне возможно.
Это не отменяет того, что для рп 70-100б денс был бы очень крутым, здесь как раз емкость скрытых состояний и раздутый атеншн были бы в плюс.
>Тебе добавлять ссылки просто по фану хочется?
Мне вообще плевать на ссылки, я отвечал челу который думает что за три месяца устареет шапка.
>Что устарело? Вот тыкни пальцем.
Ну вот я тыкну и сразу набежит народ и скажет "ващета это полезно и не просто так там висит", но если смотреть реально на вещи - миксы от тредовичков больше не нужны, старые списки моделей больше не нужны, всякая специфичная инфа для полутора анонов типа "запуска на MI50, настройка докера, пошаговое мышление, магический перевод" тоже по факту почти никому не нужно. Все эти ссылки можно закинуть в вики, а не держать в шапке. В шапке нужна инфа которая будет полезна большинству, а не меньшинству. Вот ссылки на документации - да, ссылки на фронты и накруты жоры - да. Актуальные списки моделей? Тоже да.
Объективно можно половину ссылок из шапки вынести на отдельный рентри или закинуть в вики.
Если приводить пример, когда люди себя так ведут - это крайне травматичные ситуации в виде например рейпа. Реакция жертвы на рейп может быть разной, но самая частая - это "фриз", в такой ситуации человек может превратиться в нечто подобное кукле, то есть тело напряжено, но манипуляциям не сопротивляется, так как человек полностью диссоциирован.
Какие шансы что нам хотя бы 50б выдадут в течении пары лет?
> в сторону упрощения, упрощения и более практического применения
Только сильно не перестарайся. Там было лишнее и кое где дается много вводных и обрывается, но совсем все резать не стоит.
По токенайзеру и семплерам есть плейграунды или спейсы на hf, где можно писать свой текст или крутить ползунки и оно красиво-наглядно показывается.
Малы. Но не нулевые, не стоит отчаиваться.
Так и по архитектурам прогресс есть, уменьшат слабости моделей поменьше и они будут эффективнее работать, также и минусы мелкомоэ не так бросаться будут.
Моя задача по-прежнему все-таки объяснить вещи, а не дать команды запуска для Лламы. Будем итерировать вместе, я - правками, ты - фидбеком. Так со временем и получится что-нибудь путное.
После всех правок снова скину ссылку на рентри в тред, буду ждать и твой фидбек тоже.
Есть контакт! Наконец то путем пердолинга квант найден.
Q4_XS. Минимальное, насколько это вообще возможно для этого кванта, количество ошибок. Он больше не срет символами рандомно, путает сущности каждый второй свайп, не идеально, но хоть юзабельно.
Крч, пользуемся, обмазываемся и радуемся ассистенту который нихуя не ассистент. кум всё так же говно
https://huggingface.co/unsloth/MiniMax-M2.7-GGUF/tree/main/UD-IQ4_XS
Q4_XS. Минимальное, насколько это вообще возможно для этого кванта, количество ошибок. Он больше не срет символами рандомно, путает сущности каждый второй свайп, не идеально, но хоть юзабельно.
Крч, пользуемся, обмазываемся и радуемся ассистенту который нихуя не ассистент. кум всё так же говно
https://huggingface.co/unsloth/MiniMax-M2.7-GGUF/tree/main/UD-IQ4_XS
А мне влезет?
Если ты задаешь такой вопрос, то нет.
Бля...
Блять, нихуя не помогает. Это полный пиздец. 4-5к ризонинга на один реплай. Сука, почему они так делают?
Проверь по шаблону, выше скидывали
Я расширился недавно если мой подвспук по раме/враме можно вообще считать за апгрейд лол, но не знаю насколько этот минимакс прожорливый и быстрый. А кочать и чекать не оч хочется.
сап.
какую модель посоветуете для 3060/12? оперативки 32гб, но желательно чтобы полностью влезала.
щас юзаю cydonia 24b Q3 (влазит с 12к контекста в четырёх битах), но ощущение что че то я не так делаю и точно можно лучше...
какую модель посоветуете для 3060/12? оперативки 32гб, но желательно чтобы полностью влезала.
щас юзаю cydonia 24b Q3 (влазит с 12к контекста в четырёх битах), но ощущение что че то я не так делаю и точно можно лучше...
*быстрофикс
для рп разумеется. на англюсике, юзаю переводчик в таверне
Древняя 24б на q3 это хуйово. Пробуй что-то на 27б в q4, придется оффлоадить слои, но это того стоит. МоЕ-дебилов не слушай, а4б лоботомиты в РП не работают.
Там 110 гб модели, вот и думай войдет ли у тебя в систему с рам+врам оставив гигов 10-20 на контекст и систему. Скорости никто не обещал, речь о возможности запуска вобще.
Gemma 26b влезет в q6-q8 с норм контекстом
бля братан я ебал эту скорость. у меня до этого 3070 на 8 гб была, блять я заебался эту мистраль гонять с оффлоадом на 3 токена в секунду, поэтому и махнул шило на мыло, зато 12гб. теперь хоть 20 токенов. 27б мне кажется ТОЧНО не влезет, а если и влезет с оффлоадом то скорость будет я того маму ебал какая низкая
Ну, получается что нет. Жаль. Я рамлет жёсткий, у меня всего 20+48. Ну зато плотняши теперь влезают покрупнее, и то хлеб. Или даже манна небесная.
https://www.reddit.com/r/LocalLLaMA/comments/1sx7w55/gbnf_grammar_tweak_for_faster_qwen36_35ba3b_and/
Ойвей, протестит кто-нибудь?
Ойвей, протестит кто-нибудь?
>Скорости никто не обещал
Там всего чёт около 10b активных, она как под спидами работает, если есть достаточно жжр5
>уменьшить ризонинг в квене в кучу раз без потери качества
Звучит прям подозрительно.
caveman
>в реальном времени генерить портрет виртуального собеседника
Тебе потребуется очень умная визуальная моделька. Если что б была прям Cinema - Flux.2 - там мистраль текстовым энкодером в него можно целый абзац текста хуйнуть и он его визуализирует.
С zImage результат может быть не таким предсказуемым. Но под него есть аблитерированный энкодер.
И наконец любимица многих тульповодов анима - тут ты будешь ограничен буро-тегами и аниме персонажами.
И конечно же оборудование чтоб это все быстро генерить - 5090 в наличии ?
>крупномое для мажоров
Смотря насколько "крупно". Эйр 106b спокойно крутится на 12+64 в Q4_K_S с 32к квантованного контекста. Вполне себе народное железо. На 16+64 заводится квен 122b в четвертом кванте и 235b во втором (более чем юзабелен для РП и сторителлинга).




Тестирую на Flux 2 Klein + Qwen 3 энкодер.
Сейчас пытаюсь выяснить, можно ли этот же квен в качестве LLM для чата использовать, чтобы всё в памяти дружно сидело.
Цеплять к л2д или 3д аватару какому-нибудь надо, а не к комфи.

По поводу SWA. Так ведь и раньше было. Помнишь выход геммы 3 и как все охуевали от её внимания к контексту и ныли, что он весит больше, чем сама модель, раза в два, и квантовали, и страдали? Хотя ставили там 16-20к контекста.
Как оказалось, всё прекрасно работало, по крайней мере у тредовичков.
А потом мы узнали, что окно нихуя у нас не скользящее, а размером с весь контентекст. Не 1к токенов, как положено, а хоть 128к.
Когда прикрутили корректное SWA, сразу по памяти всё стало норм, а вот внимание упало. Не катастрофично, но заметно на большой длине.
А Квен 27В и правда хорош, зараза. Поставил по здешней рекомендации хуйхуевскую аблитерацию, только в 8-м кванте и на две карты. Так он пожалуй что и поумнее 3.5-122В будет. И впрямь дотошный, старательный. Для кодинга годен и с агентами всё хорошо.
3.6? Линк на квант зашарь, будь добр
3060 + р104?
В каком кванте у тебя эйр влезает? Или совсем тухляк по скорости и смысла нет?
Я буквально на таком же железе катаю квен 80б-а3б. Поумнее будет нынешних квенов, хотя 3.5 27б и гемма 31б всё равно хороши. Что уж там, даже гемма 3 устарела лишь морально, если речь про РП.
Кстати, кими 48б тупое говно тупого говна. Даже не пробуй, если не запускал. Я надеялся, что это хидден гем: относительно умный и быстрый при этом.
Я катал третью гемму на 32к контексте в трёх токенах на 12 врам. Учитывая, что квен меньше памяти жрёт, будет быстрее и более приемлемо. Качай 4-битный xs. Для неторопливого РП сойдёт, хоть и не для кума.
>не для кума
Новые квены - это просто кум-машина, не пизди. Они любят рефьюзить на пустом чате, но если контекст есть - всё работает как положено и кум льется рекой.
гемма 26б
>В конечном счете, эта грамматика является ярким примером «бенчмаксинга» и иллюстрирует, почему этот подход так широко распространен и приводит к получению бесполезных результатов: он вводит в заблуждение человека, проводящего тестирование, поскольку его конкретная задача решается успешно. Однако во всех остальных случаях качество результатов ухудшается.
Хуета какая-то для отдельных бенчмаксовых паззлов.
Хуя ты гений, про iq4_xs тебе уже какой тред пишут на всех модельках. Еще и тесты были, что он обгоняет некоторые вышестоящие кванты.
Так Gemma c аблитериксом целиком влезет в 3060, она лучшая. Можешь начать с iq4_xs (эта целиком влезет) и попробовать чуть получше кванты, экспериментируя с отгрузом неактивных слоев в рам.
Статичные кванты для лучшего русского iq4_xs, инглиш хуже сохранен
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-v6-GGUF
Imatrix кванты для сохраненного английского в iq4_xs
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-v6-i1-GGUF
> Как оказалось, всё прекрасно работало
А что именно работало? Там же рофл в том, что опция заставляла просто хранить полный набор кэша, просто он неверно подставлялся?
Разумно было бы взять коммит годовалой давности и посмотреть что происходит на той же гемме 3, или даже отследить когда вносились изменения в работу swa чтобы детально изучить. Или на текущем поменять в конфиге размер окна и запустить (если нет какого-то хардкода и конфиг имеет вес, а то и не такое было).
>3.6? Линк на квант зашарь, будь добр
https://huggingface.co/mradermacher/Huihui-Qwen3.6-27B-abliterated-GGUF
Предпочитаю верить своим глазам, а не тому что сказали. Проверил, протестировал. Остался доволен.
Да так же и гемму можно кум-машиной назвать, хули.
Дело не только в том, что модель должна понимать происходящее, но и писать так, чтобы у тебя шишка колом стояла. Правильная корпоративная, на триллион параметров модель может сделать ультра дрочибельную сцену из карточки 600 токенов, которая фактически тегами исписана. Как из-за понимания, так и благодаря словам, которые она будет использовать.
Вот эти вечные ужимки в виде запаха мускуса, его твердости, ствола, лона, той самой точки, затвердевших бугорков, тянет на рвоту. Модели стесняются вульгарности, описаний тела, а если лютый пиздец отыгрываешь — пиши пропало. Ноль фантазии, ноль креативности, ноль попыток развивать сцену. Оригинальные малые модели знают о таком только в виде старых мистралей, возможно, ллам.
Дело не в слопе, а в том, что модель не может шишкостирательно писать, и всё тут. А всякие редиарты подохли и не заливают тонну порнофанфиков отныне.
Все сцены превращаются в бесконечный одинаковый луп. Не в техническом плане, а литературном. Сцена двигается только в одном направлении в независимости от сюжета. Достаточно недели, чтобы модель полностью исчерпала себя.
Единственным исключением является квен 3.5 27б. В нём все недостатки, присущие мелким моделям, но всё ж датасет более приличный и он способен удивить (но только с ризонингом). Всякие майндбоейки, футанари, вещества, канничики и длинные сессии отрабатывает лучше его конкурентов. Уровнем ниже в плане кума и размеров модели только мистраль, ибо всё остальное чистокровное агентское говно. Ну, гемма ещё есть, но там реально всё нужное из датасета вычистили для кума. Хотя в третьей осталось, но там свои нюансы.
Там прикол был в том, что часть модели видит только последние 1к токенов, а остальная часть — другую часть контекста.
Внимание распределено неравомерно и по факту она хуёво учитывает всё за пределами окна в 1к. Поиск иголки в стоге сена невозможен, но за счёт того, что она всё же видит, то не теряет общую картину происходящего. И на дистанции контекст экономится очень сильно в таком режиме.
Но это штатный режим работы, некий компромисс. Видимо, для того, чтобы лучше всего работать над последним вопросом юзера и ничего не упустить, а на остальное похуй.
По умолчанию скользящее окно было нихуя не скользящим, и это давало очень сильный буст к внимаю модели.
Я сейчас погуглил, ну и бабки у подъезда говорят, что такая анальная растяжка больше больше базовых 1к токенов, приводит к чудовищной деградации внимания, потому что модель не обучена видеть больше 1к токенов и начнётся шиза в итоге, однако это всё относительно максимальной длины контекста модели, большого контекста. Тут же никто вроде и не тестил больше 32к в те времена, потому что 20 Гб кэша в ебало — это как-то многовато для анона.
Короче, по идее, прирост качества может быть, но на малом контексте. 128-256к никто не тестил в таком безумном режиме, я не нашёл таких статей. Тестили только с правильным SWA. И вот там уже на таких контекстах было убер плохо как раз из-за особенностей внимания к одной тысяче токенов.
Ну и сам представь, условно, модель тратит 1,5 Гб, чтобы видеть 1к токенов, и 0,6 Гб, чтобы видеть 8к остальных токенов. Ясен хуй, тут будут проблемы.
Ладно, я обосрался походу. Гуглил ещё. Судя по всему, я, ну и некоторые аноны, наебали сами себя.
На контексте 32к фулл сва внесёт чуть-чуть деградации на уровне плацебо и просто сожрёт память, больше ничего, если судить чисто по архитектуре и математике. И мы этого не заметили, потому что юзали малый контекст. А не заметили сейчас из-за того, что на гемме 4 никто не решил вдруг включить фулл сва на контексте 256к токенов. Там PPL бы улетел бы на луну.

>Я один подумал
так в этом и шутка юмора
если ей очень толсто не намекнуть, хуй выкупит
>Для кодинга годен
Как он по сравнению с бесплатной гемини для питона?
зачем моехам iq4_xs, ты ничего не попутал? такие кванты нужны для плотненьких, а моехи целиком в врам совать необязательно, у меня 26б-а4б в q6 норм работает на 17-20т/с
> зачем моехам iq4_xs
> в q6 норм работает
Я бы понимаю ты написал что юзаешь q8/f16
Я не про кв кеш. мое можно и нужно брать максимального кванта, зависит от оперативки. конечно хорошо если вся поместится в врам - то вообще ракета будет, но квантизация сильнее всего бъет именно по мозгам мое, у плотных не так явно выражено.
Хорошим тестом будет "напиши рецензию на фильм зеленый слоник"
гемма 4 мое в q4 кванте постоянно путала имя режиссера , а Q6 не ошиблась в режиссере и даже указала кто играет роли.
И я не про кеш. Пишешь что зачем к4 и тут же про к6 будто далеко ушло.
Вот то что к8 от ф16 не сильно съезжает я могу поверить
Мы так и будем игнорить что у 3.6 27 квена тоже полностью ризонинг без цензуры и проза лучше чем у геммы?
>вынести на отдельный рентри
и никто кроме пары шизов их никогда больше не увидит

ну вот я ориентировался по бенчмаркам, Q6 и Q8 лежат примерно на одном плато, а потом идет резкое ухудшение качества
https://www.reddit.com/r/LocalLLaMA/comments/1sqrl1l/gemma_4_26ba4b_gguf_benchmarks/
а на плотноквене можно использовать --fit одновременно с -ot "token_embd.weight=CPU" ?
или как его 3-4 квант лучше раскидать в 12 вруммм

Впервые этот русский мат вижу, гемма такого не выдавала
Показывай карточку
Если там будет прописана ебливость - бан получишь
Вы заебали, у вас прописаные бляди лезут ебаться (вот это да!) а виновата модель
Даже IQ3_XXS весит 11.8gb :(
С 12 vram тяжеловато с вашими llm.
Вроде логично, что надо последний брать. Решил уточнить, мало ли обосрамсов бывает.

Разница между Q8 и Q6 не так велика. А вот между Q8 и BF16 довольно приличная, больше чем между Q8 и Q5KM
Это тесты угабуги для плотной, мое по идее должно квантоваться еще хуже. И он в отличие от анслопа свои кванты не льет и заинтерсованной стороной не является
https://localbench.substack.com/p/gemma-4-31b-gguf-kl-divergence
Скинь пару слоев на рам. Скорость все равно будет нормальная. Около 10тс
А то что у него думалка срет по 3к токенов и что у него такая жопа с повторами, что даже сама алибаба указывает presence penalty в 1.5 тоже будем игнорить? А не, постойте, это никто и не игнорит. Поэтому эту срань и не юзают в отличие от умницы
для 12гб только моэ и остается.
Попробуй меромеро, будет вполне нормально работать.
Вот мой РП конфиг, тоже неплохо кумит. проектор выгружается на цпу, иногда юзаю в качестве оср
[Gemma-4-26B-A4B-MeroMero-thinking]
model = mradermacher_G4-MeroMero-26B-A4B.Q6_K.gguf
mmproj = unsloth_mmproj-gemma4-26B-A4B-BF16.gguf
no-mmproj-offload = 1
no-mmap=1
fit=on
ctx-size=60000
# Для большей вариативности, особенность геммы
override-kv=gemma4.final_logit_softcapping=float:25
ctk=q8_0
ctv=q8_0
samplers = min-p;adaptive-p;temperature
# РП
min-p=0.05
adaptive-target=0.4
adaptive-decay=0.8
temp=1
#min-p=0.00
#top-p=0.95
#top-k=64
flash-attn=1
no-context-shift=1
parallel=1
ctx-checkpoints=128
#chat-template-kwargs = {"enable_thinking": false}
>Около 10тс
Ну у меня и в олламе с нулём пердолинга дефолтный gemma4:31b-it-q4_K_M делитcя 24%/76% CPU/GPU и выдаёт 4.6 тпс. Хочется больше. Пока на 26b сижу. Изредка дёргаю 31b ради хорошего стилизованного текста.
мимо другой с 3060@12
>Как он по сравнению с бесплатной гемини для питона?
бамп вопросу.
Тестировал кто-то квен 3.6 в q8 на 27б параметров для кода? Если сравнивать с бесплатной гемини как он?
>выдаёт 4.6 тпс
Ну для меня это вообще не юзабельно. Минимум 10тс, а лучше 15тс. В Гемме 26 будет конечно 25-30+ тс, но ощутимо хуже плотной версии. Я предпочитаю Q3 Геммочки 31, чем Q8 Геммочки 26а. И похуй на скорость
Почему ни одной новости про дипсик, хоть что то
Я посчитал и в 80гб врам + рам влезет 2.4bpw квант что всего на 0.3bpw ниже квена во 2 кванте
Я посчитал и в 80гб врам + рам влезет 2.4bpw квант что всего на 0.3bpw ниже квена во 2 кванте
>3060 + р104?
Нет, две консюмерские зелёнки.
>эйр влезает
Не пробовал. Мне оч нравится плотный квен в 6 кванте, кажется это для меня лучший варик теперь. Контекста влезает будь здоров, а сама модель расслоилась во враме. Хорошо и комфортно.
>кими 48б тупое говно тупого говна. Даже не пробуй, если не запускал
Учту, спасибо. У меня уже один диск отлетел из-за привычки скачивать всё, что не прибито к полу. Буду осторожнее теперь.
Аноны, для Qwen 3.6 27b вообще РП возможен? Он постоянно пишет какую-то бессвязную чушь. Притом когда я его отдёргиваю и спрашиваю что он понаписал - он даёт вполне адекватные ответы и в целом говорит что написал чушь.
То есть не похоже на ошибки форматирования, или настроек. Но кто его знает. Кто смог - поделитесь пожалуйста настройками.
Его и в Q6 можно для кода использовать. В целом, лучше. Неиронично Qwen 3.6 27b в плане программирования сейчас выше всяких там бесплатных мделей-заглушек.
То есть не похоже на ошибки форматирования, или настроек. Но кто его знает. Кто смог - поделитесь пожалуйста настройками.
Его и в Q6 можно для кода использовать. В целом, лучше. Неиронично Qwen 3.6 27b в плане программирования сейчас выше всяких там бесплатных мделей-заглушек.
> Аноны, для Qwen 3.6 27b вообще РП возможен
В ф16 пишет на ру как потраченный перевод, вроде и понятно о чём он, но всё равно для надмозгов.
Я с ним не рпшил, но просил перевод полотен текста с кит и япа. Гемма прям качественно лучше была (в основном проблемы придумать слово или словоформу которой в ру нет)
У меня такая же хуйня, все настройки рекомендованные, q6. Пишет какой-то бред. Ну в смысле как бы по теме, но крайне нелогично. Типа вариации на идею скорее, нежели чем реальный осмысленный текст. Это на инглише, русский не пробовал.
И блять ризонинг на 5к токенов чтобы написать один абзац этой бессвязной хуйни, где первый драфт нормальный, второй рефайн, третий рефайн, четвертый But wait..., пятый, и на шестом уже вообще отлетевшая хуйня.
>Qwen 3.6 27b вообще РП возможен
А зачем тебе чистый квен для рп? Есть годные тюны для 3.5, юзай их.
У меня не вышло. Кажется что его перепекли для бенчмаксинга и хайпового тулколинга.
Мне блюстар 2 который тут рекомендовали не зашел, он слишком часто за меня пытается чето сделать или пиздануть. Не тюны мистраля конечно, но приходится постоянно напоминать, чтоб место свое не забывал
Попробуй блюстар 1, мне он больше нравится.
>слишком часто за меня пытается чето сделать или пиздануть
Либо перегрел, либо в промт насрано. Юзай классическое ду нот реплай ас юзер.
А это вообще стоит качать? Что это такое?

Могущество геммы сложно отрицать, у неё очень сильный слог и явно основой у неё служила художественная литература. Но этот шизик в РП пишет какие-то ебанутые вещи. Я читаю его и не всегда понимаю что он вообще пытается сказать.
На русском там ещё более криво смотрится, так как он пытается использовать странные англицизмы, но переводит их как надмозг.
Лол наверно даже простенький пример приведу. Там лорбука примерно на 2к, каточка на 4к, описание юзера на 600 и простенькая сцена для затравки. Просто... что? Что эта обезьяна пишет???
Тюны всегда приносят в жертву мозги. Когда надо чтобы модель могла и инструментами пользоваться и РПшить и умные вещи писать, тюны нахрен не нужны. Я то хочу высокую сумму способностей.
Не могу отрицать что им это удалось и он очень в этом хорош.
Если у тебя есть лишние 128 гигов оперативы, то можешь попробовать. Китайци уверяют что модель на уровне соннета 4.6.
Честно сказать я сам нихуя не понял, что у тебя в инпуте. Ты там волкодава-попаданца в девяностые с лолями отыгрывать пытаешься что ли?
Звучит подозрительно хорошо
А почему в треде тишина? Вы же тут всякие GLM катаете, Qwen 666 и прочее, а они побольше будут. В чем наеб?


Там дурка, чел пикрилов начитался и такое же отыгрывает
Минимакс во-первых так себе в сравнении с глм и даже квеном 235, во-вторых плохо квантуется. Вот и тишина
Ломает персонажей не первых аутпутах без зазрений совести и в целом все скатывает в истерию, требует свайпы на ровном месте. Если у тебя такая же ментальность то зайдет
Тогда я не удивлён, что квен охуел и поплыл. Я бы тоже охуел и поплыл.
Там простенький лорбук чтобы допускать разносортную хуйню в более современном сеттинге.
[Demihuman City:
Place in alternate universe with similar geography. It closely resemble Japan, but located in Europe. There rare magical beings, demihumans and so on, but they are very small percentage of total population. Demihuman City is not official name of the city, but it relate to it's content where demihumans a lot more than in other places of the world. City totaling to whopping 0.2% of population.]
[Demihumans: rare and often strange half-humans. Some are magical, but most look animalistic. They are rare enough to be viewed as valuable assets or just unusual encounter]
И ещё куча записей про состояние науки, медицины, немного географии.
Чтобы были допустимы всякие кошкодевочки и прочее, но обыгрывать их как что-то необычное и обычно отыгрываю всякую межвидовую драму. Типа "бля меня любят только за уши и хвост".
>It closely resemble Japan, but located in Europe
>There rare magical beings, demihumans and so on, but they are very small percentage
>Demihuman City is not official name of the city, but it relate to it's content
>Some are magical, but most look animalistic
ДЕТАЛЬНО, НО СКУПО.
Как я и думал, ты насрал в промт. Неудивительно, что модель запуталась в твоих жопах.
Подскажите пожалуйста нубу модель чтоб вкатиться, где можно будет попутешествовать по мирам (фентези, фантастика, апокалипсисы разные и тп), общаясь с разными персонажами и справляясь (или не справляясь) с опасностями и угрозами.
И чтоб была возможность выебать тяночку со всеми смачными подробностями. Но так чтобы тяночки не сами на тебя кидались, а чтоб всё было сюжетно обосновано и соответствовало характеру персонажей (сложности, преодоления и тп)
У меня 5090 и 64 гб оперативки.
И чтоб была возможность выебать тяночку со всеми смачными подробностями. Но так чтобы тяночки не сами на тебя кидались, а чтоб всё было сюжетно обосновано и соответствовало характеру персонажей (сложности, преодоления и тп)
У меня 5090 и 64 гб оперативки.
Да ахуенный же промт, в духе иногда нужно ввести новый подсюжет
С какими параметрами запускаете для кодинга? Использую с claude code с конфигом для локальных моделей. Модель часто просто перестает что-либо без какого-либо результата. То есть даешь задание, он начинает что-то там думать и крутить. Пару минут думает, ризонинг идет, может какие-то промежуточные сообщения писать о том что он сейчас делает, но в итоге через какое-то время ничего не пишет, никакого результата и типа всё, давай следующую команду. Как лечить? Как вы его надолго оставляете работать если он останавливается?
Я просто запускаю llama.cpp с -c 114944 -ngl -1, всё помещается в мои 24гб врам. Еще какие-то параметры нужно добавить?
Про сплит в лорбуках ты конечно же не слышал...
Любая плотная. Гемма, квен, мистраль.
Проблема не в сплите или том когда ты подаешь инструкции, а как ты их формулируешь
Я про его "иногда хочу хаоситский хуй во лбу". Такие иногда промтятся сплитом и включаются по необходимости.
>как ты их формулируешь
Истина. Если пишешь модели хуйню в духе "бля, ну она доступная, но скромная, но целка, но шлюха, но давалка, но целомудренная, но высокая, но низкая, но эльф, но орк, но кошкодевочка" то неудивительно, что модель седеет от таких запросов.

Я пробовал Квен 3.5 спрашивать, а там цензура. Не может она на темы сексуального характера говорить.
Видимо, надо всё-таки модель без цензуры.
Где такую взять?
Или лучше прям название или даже ссылочку.
Позязя!


Любителям moe-геммы и ее тюнов посвящается. Внимательно смотрите структуру кванта которую качаете! У этой мелочи буквально кроме exps больше ничего квантовать нельзя! Слишком маленькие блоки и не надо быть надмозгом, что бы понять что при их сжатии получаться шакалы jpg.

Решил прогнать те же 30 страниц через гемму f16 31b. Скорорсть конечно трагически провалилась.
Отличия в переводе есть, но пока не могу сказать на сколько большие. + я всё же не шарю за лунный
А модно тупой вопрос?
У меня голая llamacpp, запускаю её просто с блокнотовского файла сохраненного в батник. Там формат вообще другой
cd "C:\AI\llamacpp"
llama-server.exe ^
--host 127.0.0.1 ^
--port 8080 ^
--model "C:\AI\Models\G4-MeroMero-26B-A4B-Q6_K.gguf" ^
--mmproj "C:\AI\Models\mmproj-BF16.gguf" ^
--image-min-tokens 1120 ^
--image-max-tokens 1120 ^
--alias gemma-4-31B-Q4_K_M ^
--flash-attn on ^
-b 512 ^
-ub 512 ^
-np 1 ^
-c 32000 ^
--cache-ram 0 ^
--swa-checkpoints 3 ^
--n-gpu-layers 33 ^
--n-cpu-moe 29 ^
--top-k 64 ^
--top-p 0.95 ^
--temp 1.0
pause
почему в твоем конфиге другой синтаксис?
Даже знать не хочу, что ты там такое спросил, что модель тебя нахуй послала...
>Где
Там же.
>лучше прям название
Heretic. Для вката в похабщину лучше не найдёшь. Иди, осваивайся.

https://github.com/ggml-org/llama.cpp/tree/master/tools/server#model-presets
*фича с тем что в {{}} в голой лламе не работает
Лол ПОТОМ напишу более литературно, тут главное это идея! Один хрен Qwen сначала пишет
Она не смотрела ему в глаза. Молли смотрела на его плечо, на складку кожи на жилетке, на текстуру ткани. Зрительный контакт — это уязвимость. Это приглашение к диалогу, а она не намерена разговаривать с незнакомым волкояром, который смотрит на неё с таким… "забавным" выражением морды.
А потом сам же начинает диалог! И пишет всякую неуместную чушню! А я мимо шел в лес! Какого хуя эта мелочь вообще рот открывает, когда сама же думае что не надо его открывать!
Лол на самом деле хороший промпт когда хочется фентези, но не в средневековье. Там ещё есть запись про элитный университет где несколько демихуманов по блату водятся и удачный сеттинг когда хочется проверить "а что будет если дать какой-нибудь фентези-твари свободу творить чушню".
Гемма там как влитая во всяких забавных ролях. То прыгает на парту и крутит членом, то кабедонит рандомных персонажей, то ворует, убивает, ебёт гусей, ждёт ответного гудка.
Не слушай местных шизов с их плотняшами. Оперативку вовремя не купили, вот и катают своих 30b лоботомитов. Тебе доступны нормальные модели, можешь начать с GLM 4.5 Air Q5_K_M или Qwen 235b Q2_K_L
https://huggingface.co/bartowski/Qwen_Qwen3-235B-A22B-Instruct-2507-GGUF
https://huggingface.co/bartowski/zai-org_GLM-4.5-Air-GGUF
На эйре лучше РПшить на английском, русик там так себе. У квена всё ок.
>эйр
Воняет озоном.

>Там же.
Там только с цензурой...
>Heretic.
И как я найду модель по этому слову?

> Qwen 235b Q2
ну пиздец же
У меня на нем несколько миллионов токенов наиграно, и вот как раз на Эйре озона или очень мало или почти нет.
>волкояр
Хуепидор-вырвиглаз! Сука, вы заставляете меня ухахатываться.
>я мимо шел в лес
У себя в голове. А модели ты об этом сказать забыл. КАКОВ ИНПУТ ТАКОВ И АУТПУТ.
На 3.5 27 квена херова гора разных вариантов еретиков и безцензуров. От мягкого https://huggingface.co/ArliAI/Qwen3.5-27B-Derestricted до жесткого https://huggingface.co/llmfan46/Qwen3.5-27B-ultra-uncensored-heretic-v2 . Или даже Апасная от Ха-Ха . Их в моменте было так много что тредовички хуй забили все это пробовать и успокоились на единичных тюнах.
Блин! А без реги там не скачать, да?
Выдаёт ошибку при регистрации и всё тут...
У меня меньше, но мне запахи озона попадались часто. И мускусы. И твёрдомягкие обороты. В общем вся классика слопофраз попадалась. На всех моделях. И меньше всего, внезапно, на тюнах мисрали.
НЬЮФАГ! ЧИТАЙ ШАПКУ!


Если ллмка большая, то она остаётся в живых даже при квантовании в Q1. Конкретно квен в двух битах пусть и теряет часть мозгов, но всё ещё уделывает по качеству РП более мелкие сетки. В треде было как минимум несколько анонов, катающих жирный GLM в Q2 - они не дадут соврать.
Бегу на защиту любимой модельки, чтобы доказать анониму, что фломастеры надо есть правильно, ведь как это так, не доказать на анонимном форуме что все д'Артаньяны, а я охрана дворца.
Охуенная моделька на самом деле, не, серьезно - очень доставляющая. Если есть возможность запустить, то катать нужно определенно. Ибо по сути это Qwen235 но не пережаренный и без кума, лол. Те кто катали 235 знают насколько он ебливый, с его придыханиями и plap plap plap. Тут этого не будет, увы. Квен никто не забирает, хочешь порева подрубай его и наслаждайся поревом, потом опять ускакивай на минимакса и играйся дальше.
Из преимуществ: ризонинг, что не срёт в штаны. Следования инструкциям. Если пишешь модели би круэл, энд нонфоргивен. То {{user}} получает с дробовика в лицо в первом сообщении. Что просил, то и получил. Может генерировать доставляющие диалоги не выбиваясь из характера. На долгом контексте с 30к+, может начать размазывать персонажей. Но фиксится это кратким промтом и простой инструкцией: чекай перед ответом характеры персонажей. Так как в девичестве это агент, то модель крайне чувствительна к промту и если им насрать, то ты сам себе идиотЪ.
Из недостатков: приходится постоянно свайпать, потому что ответы пидорит во всех сюжетах одновременно и ты сам не знаешь порой чего хочешь.
Модель действительно плохо квантуется, так что ниже Q4 тут жизни нет, буквально нет, там в чате такой анал карнавал начинается, что хочется удавиться. Ну и русский язык очень посредственный.
>Там дурка, чел пикрилов начитался и такое же отыгрывает
Как же я осуждаю эту хуйню. Литералли:
>делитесь логами.
>делится.
>ололо говноед, хахаха, хуйню отыгрывает.
>делитесь логами.
Тебя кто-то просил показать лог?
В любом случае это не осуждение текста, а инструкций. Там такая каша что любая модель запутается. Чем больше у тебя противоречивий или уникальных или хотя бы разных концептов на предложение тем вероятнее модель обосрется. Чего ты ожидал? Такое даже корпы могут не вывезти. Да, с моей точки зрения это дурка
>Аноны, для Qwen 3.6 27b вообще РП возможен? Он постоянно пишет какую-то бессвязную чушь.
Я немного попробовал. Мой кейс специфичен - я сейчас в opencode RP гоняю (уже писал ~два треда назад, что упоролся, однако это удобно оказалось).
Так вот. Qwen 3.6 27B в iq4xs с аблитерацией от двучлена выдал неожиданно годный результат. Намного интереснее, чем аналогичный Qwen 3.5 в том же сценарии. Пишет живее, хоть в нормальный русский по прежнему не умеет (писать правильно не умеет - понимает прекрасно), но вывод у него в таких условиях все равно живее чем у 3.5. На обоих языках. Ждем RP тюнов - возможно будет конфетка.
>Его и в Q6 можно для кода использовать. В целом, лучше. Неиронично Qwen 3.6 27b в плане программирования сейчас выше всяких там бесплатных мделей-заглушек.
Его и в iq4xs для кода можно использовать. И таки да - лучше. Как я уже говорил - мне текущий грок тупее его кажется...
> Модель действительно плохо квантуется, так что ниже Q4 тут жизни нет
На q4 тоже, там ppl и kld уровня пережаренного glm в q2 кванте. А вот nvfp4 ещё может поехать, но тогда нужно брать два блеквелла 6000.
Короче, хуйня эта минисрака, лучше на глм 4.6 сидеть. Он то и в q2 не совсем лоботомит, а в q4 уже вполне себе норм моделька для локалок офк, тот же жопус выебет и высушит все модели в рп, в том числе и хваленную гемини, не то что китайские модельки.
Не слушай за Air - он для новичков сложен!
1. Очень разный аутпут модели на разных разметках - и ты поначалу даже не поймешь, что именно косячит и как это править. А в треде тебя загнобят потому что тема правильного Air-пресета уже всех заебала.
2. Она сука медленная! Что в комбинации с непонятками с разметкой приведет к зафейленному РП. Просто затрахаешся репроцессить контекст при играх с разметкой.
Бери 4 31 гемму - Да она детерминистична как кирпич и через пол ляма токенов ты ее выкинешь как мусор. Но для новичка она идеальна! Она хорошо следует карточке и инструкциям вплоть до 60000 токенов. Не идеально, хорошо. И этим можно управлять направляя РП через рандом вставки и OOC. У нее есть правильная разметка и ... мусор на котором она 100% не работает и это сразу видно. Или можно даже не ебатся с Text Completion включит асиг-мод-Chat Completion и она тоже будет играть. Можно играть на англюсике, можно на русике - прямо на английских карточках всего на всего сказав гемме "пиши на русском" в Post History.
А вот когда с геммой наиграешься переходи на Air - и будет и новизная и китай-сет с ехидным ассистентом в комплекте.
>писать правильно не умеет
Можно изъебнуться с промтингом и будет годно. Как и квен 3.5, он тоже выдавал мне шикарнейшие аутпуты.
>лучше на глм 4.6 сидеть
Возможно, спорить не буду. Но меня он подзаебал и я нищуган что имеет дохуя рам, но мало врам. Этот китоец идеально залетает в мой сетап, лул, с его 10b активными. Да еще в 40к контекста и скоростями в 15-10 т/с.
потому что я использую --models-preset
$ cat llama-cpp-run.sh
#!/bin/bash
set -ex
llama-server --port 8080 --host 0.0.0.0 \
--jinja -fa on --models-preset ./models_presets.ini --models-max 1 $*
А это норма что от meromero рефьюзит? Скорость то приличная, до 30t/s, но вот рассказать мне про писик и сисик никак. Или нужно идти в таверну с такими заходами, а не в дефолтную вебморду ламы?
Нихрена непонятно, как качать с этого Хагинфейс.
Нельзя был что ли сделать просто ссылочку, как в ГитХаб?
Системный промпт поставь. В треде всё есть (3+ раз уже вопрос поднят)


>Почему ни одной новости про дипсик
>Минимакс
Ну как-то так. Дипсик ёба даже из коробки, как очень сильно прокачанная гемма, с хорошим анцензом станет топ моделью без вариантов для владельцев ригов посильнее
Минимакс кал который ничто не спасёт, его с каждой версией уцензуривают всё больше и больше и 2.7 урезан тупо в нулину. Можно конечно поискать какие-то еретики старых версий, но судя по остальным показателям модель равномерно каловая, смысла особо нет. Тянет на средненькую ~24b moe при размере 10х
>Минимакс
Ну как-то так. Дипсик ёба даже из коробки, как очень сильно прокачанная гемма, с хорошим анцензом станет топ моделью без вариантов для владельцев ригов посильнее
Минимакс кал который ничто не спасёт, его с каждой версией уцензуривают всё больше и больше и 2.7 урезан тупо в нулину. Можно конечно поискать какие-то еретики старых версий, но судя по остальным показателям модель равномерно каловая, смысла особо нет. Тянет на средненькую ~24b moe при размере 10х
Хазардос это что? Насколько модель воняет озоном?
>Дипсик ёба даже из коробки,
Пока доступен только господам с VRAM. Таких тут целый полтора землекопа на тред.
Ждем. Окажется вином, будем обмазываться и радоваться.
>его с каждой версией уцензуривают всё больше и больше и 2.7 урезан тупо в нулину
Не, по сравнению с 2.5 прогресс на лицо. Таки тут ты не прав.
>пик
Что подтверждает старую истину. Каждый находит фломастеры под себя. Я попробовал, мне понравилось. Ну а там какие АГИ\УГи и прочее - как то по боку. Всё таки личный опыт превалирует над бенчами.
меромеро - файнтюн без аблиба. в таверне не ревфьюзит, гемме в целом нужен большой стартовый контекст чтобы вжиться в роль и аблиб ей не нужен особо.
в голом чате с пустым контекстом конечно пошлет

Пиздос, он даже в двух битах весит 100 гигов. Народные 16+64 в пролёте. Без 128гб рам не пощупать.
Рам это конечно дорого. Но все еще дешевле видюх. Всего 160 180к ПИЗДЕЦ, ПИЗДЕЦ, ПИЗДЕЦ. И у тебя есть память.
другой вопрос какая там скорость вообще выходит? кум на 3тс тоже не очень весело.
Те кто катают ванильную гемму 26б и думают попробовать меро-хуеро и модный аблитерикс, я попробовал за вас. Оба ломают русик, особенно аблитерикс. Меро чуть меньше, но я не увидел чего-то такого в аутпутах, чего нельзя было бы добиться простым промптингом ванили. Все три в Q8_0, если что.

>Хазардос это что?
так понимаю что-то типа пикрила I AM THE ONE WHO KNOCKS up your waifu
>Не, по сравнению с 2.5 прогресс на лицо. Таки тут ты не прав
Чел, 1/10. Один. Издисти. Турба-ультра-гига соевая цензура, теперь с 300% содержанием сои. 1 за Direct (прямые отлупы), 1 за Adherence (следование инструкциям и натыкание на цензуру в процессе).
Ну если ты просишь генерировать историю про пчёлку летающую по цветочкам собирающую мёд то наверно круто будет, может там чё-то в датасеты заложили что тебе нравится. А для всех остальных, оно даже на СГЕНЕРИРУЙ МНЕ ИСТОРИЮ ТИПА НА НАШУ ШКОЛУ НАПАЛИ ТЕРАРИСТЫ И Я СПАСАЮ ЕОТ даст отлуп, потому что у террористов оружие. Или сделает так что они как пчёлки будут летать нектар собирать лол
О, а вот и отлупошиз подъехал. Давно как-то его тут не было.
И у кого кванты хорошие? Вроде то ли у мрадера то ли у бартовски брал меро и стоковую 26B-A4B, все остальные тюны и мержи что пробовал были в хлам ебучими шакалами, да.
Ты про дипкок? А хуй его знает. По слухам норм, но ты и сам можешь убедиться что верить слухам не стоит. Но это дипсик, так что как минимум средний уровень текстового порева стоит ожидать.
> даст отлуп, потому что у террористов оружие.
Меня сжигали, вешали, стреляли в ебало. Отрывали полицейским ноги, убивали топорами, вешали на стенах. Я обмазывался кишками и разве что только не дрочил в процессе. Мы точно об одной модели? И да, это все с ризонингом. Ну то есть, конечно он нагоняет драммы. Но позахлебываться кровью дает. Пишешь ему в инструкции: соевое ты говно, давай хардкор, смерти и драму. Он говорит да сэр и идет выполнять. Написав в ризонинге что осуждает такую хуйню, но нарратив есть нарратив. Бля, да я массшутинг в школе устраивал с лупары, ничего, описывал.
Единственное, что само описание… Ну чёт meh.

И так квант - смесь неквантованного аттеншена Q8_0 и Q5_k для остального - 20 гигабайт в 32 Гб full-vram залетает с ноги. Контекст 100k. KV-кеш - дефолт.
Тестим жирный контекст на 80000: иголки находит, но тупит и размышляет топорно. И да - залупилась в думалке, лол.
Ставим KV-кеш:
ctv = bf16
ctk = bf16
Уже не лупиться, но размышляет по прежнему топорно. Т.е. она видит и сканит этот всратый контекст, но логические цепочки построить до конца мозгов не хватает.
На 2-м скрине 31я плотная гемма с квантованным в Q8_0 контекстом. Просто делает свое дело.
>Ставим KV-кеш:
>ctv = bf16
>ctk = bf16
Это все еще оказывает влияние или тебе показалось?
Доколе?
Кстати надеюсь ты запускаешь без куда 13, она сломана
> Плотная гемма 636 т/с
> Моэ гемма 2116 т/с
Ты там на квантовом компьютере запускаешь? Откуда такие скорости?
> что часть модели видит только последние 1к токенов, а остальная часть — другую часть контекста
Из 60 блоков 10 групп по 6 слоев - 5 их них со скользящим окном, видит только последние 1к, один - видит полный контекст. Да, такова гемма.
Оно так сразу тренировалось, потому может делать и хейстак, и внимание к системным инструкциям улавливать. Но точность к нюансам и емкость будут ниже, это неизбежно. Возможно поэтому то самое однообразие свайпов и неуместные реакции.
Можно начать с увеличение окна до 2-4к для начала, вдруг в рп сделает получше. А может даже это лоботомирует.
Больше интересна природа старого бага, ведь превышение размера без изменения rope или других техник оно приведет не просто с лоботомии, а к настоящему взрыву.
Я с этими новыми плотно набитыми моделями уже никому не доверяю. Если есть BF16 качаю его и потом варю свой квант. Без иматрикс-квантования это можно делать даже на пишущей машинке. С появлением в llama-quantize.exe опции --tensor-type-file это не сложнее чем модель по нескольким GPU регуляркой раскидать.
Это промт- процессинг full-vram. Ничего выдающегося. TG после: 40 на moe, 8 на плотной.
Атеншн лучше вообще нигде не квантовать, исключения редки и там нужен правильный подход. Это дает очень небольшой выигрыш по объему, но достаточно серьезные потери.
Начать можно и с геммы или квена 27б, они достаточно приличные и будут фуллврам, неофиту главное начать. Ну а потом действительно можно будет попробовать моэ покрупнее что влезет.
Для челяди кернелей не выпустили еще, доступно владельцам хопперов и b200/b300.
Она реально на дефолтовом KV-кеш залупилась. Возможно потому что я в кванте все в оригинальных весах кроме экспертов/аутпут/эмбеддинга оставил. Ну могу еще потраить.



Вот как удобней смотреть кванты сразу на хаггинфейсе
А вот третий пик, за что я хуесосю анслотов каждый раз как иду качать.
В честный процессорно-гибридный 3км за каким то хером добавляют iq кванты, что тормозит генерацию если выгрузка не полная. Приходится качать у бартовски.
У них же выше есть полные iq кванты, вот нахуя они добавляют их сюда?
Причем их ведь на реддите за это пару раз так же хуесосили.
А вот третий пик, за что я хуесосю анслотов каждый раз как иду качать.
В честный процессорно-гибридный 3км за каким то хером добавляют iq кванты, что тормозит генерацию если выгрузка не полная. Приходится качать у бартовски.
У них же выше есть полные iq кванты, вот нахуя они добавляют их сюда?
Причем их ведь на реддите за это пару раз так же хуесосили.

Как ты это делаешь?
У меня блин содержимое показывает...
Хватит уже жирнотой заниматься. Что дальше будет, забудешь как браузер открывать?
Не, браузер то я открыл, а вот куда файлы должны сохраниться не знаю!
То что тебе нужно находится справа- называется квантизацией. То что ты смотришь это оригинал модели. Полные её веса.
Тебе нужен формат gguf

Я конечно не настоящий сварщик, но ИМХО некоторые вещи в потрохах квена лучше не трогать вообще.
1. округлиться что-нибудь не в ту сторону и пиздец.
2. выигрышь минимальный
3. Bf16 математику в CUDA-жору запилил уже как месяца. Работает идеально.
А слои нормализации вообще следует апкастить до f32? Вроде как в оригинале они в bf16 идут. Или это костыль скрипта?
Вот ты так кими k2.6 можно было конвертировать в gguf без апкаста. Анслоты вроде так и сделали, спиздив у убергарма конвертацию mlp блоков через каст и обратный каст с теми же скейлами, но attention сохранили в bf16.
Я у бартовски 3км квена на агентах запускаю без квантования кеша но с 100к. Работает как часы, ни лупов ни опечаток, под конец только начинает иногда иероглифы писать вместо некоторых слов.
Так что думаю он норм кванты делает, а главное быстро крутят на говножелезе без полной выгрузки.
Но ллама сервер все равно может упасть рандомно в любой момент, похоже что то с слотами сохранения контекста связано и -срам настройкой

Они так с питоно-скрипта уже в f32 пришли. Я надеюсь он не меняет структуру весов оригинальной модели. Ведь не меняет же ?
Какая модель для генерации 18+ изображений в аниме стиле самая лучшая и быстрая для таверны?
Такая же как в соседнем треде.
Ну это уже совсем рофл был
https://localbench.substack.com/p/kv-cache-quantization-benchmark
Тесты-тестики квантования кэша у геммы и квена. Если кратко - у геммы смерть, если мое - вообще гроб-гроб-кладбище-пидор. А квену практически похуй. Правда там и выигрыш в объёме сильно меньше.
Тесты-тестики квантования кэша у геммы и квена. Если кратко - у геммы смерть, если мое - вообще гроб-гроб-кладбище-пидор. А квену практически похуй. Правда там и выигрыш в объёме сильно меньше.
Мне для генерацию через таверную, чтобы не выходить из неё.
1. В соседний
2. Anima и производные
Разобрался, в линуксе не была разогнана карта. Но лм студия всё равно на пол токена быстрее, но кобольд быстрее считывает длинный контекст.
> flash, lite, mini
> 300b
Какие же пидорасы...
> 300b
Какие же пидорасы...
Таверна это тупо node.js локал-сайт. Сама на себе она ничего не генерирует, ей нужны бэкенды. Картинко бэкендом может быть Cum-fy UI, кобольдыня и stable-diffusion.cpp. Что сука характерно для каждого бэкенда будет свой вид пердолинга. Вот например простейший вариант запуска с анимой stable-diffusion.cpp:
sd-server.exe --diffusion-model .\DiffusionModels\anima-preview3-base.safetensors --vae .\VAE\qwen_image_vae.safetensors --llm .\TextEncoders\qwen_3_06b_base.safetensors -n "sketch,lores,worst quality, low quality, score_1, score_2, score_3,sensored,jpeg artifacts,watermark" --steps 15 -H 768 -W 1024 --diffusion-fa --cfg-scale 6.0 --sampling-method dpm2 --scheduler smoothstep --offload-to-cpu
Это поднимает картинко-API в которое уже можно тыкнуть таверну. Заправленные в старт сервера дефолты позволят что-то сгенерить даже самой тупой ЛЛМ.
Услышал, спасибо.
У мое геммы тоже лёгкий контекст.
Тяжело только с плотной геммой. Не включаешь сва фулл и вроде фулл контекст, но ебаные чекпоинты в рот их наоборот. Включаешь и унифицированный кэш нормально работает, но контекста 80к...
А зачем унифицированный кэш ? Вообще это может к странным нежданчикам приводить. Ставь просто -np 1 (--n-parallel 1) и заебок.
Мне именно что нужны разные запросы без репроцессинга. От того и жопа болит если с чекпоинтами жить.
Недавно тут же вонял что на квене 3.6 никак не получается нормально кэш настроить, его пришлось на вллм тестить т.к. там таких проблем отродясь не было

Новая моешка для риговодов. 1Т параметров, 42 активных. По бенчам традиционно ебёт.
https://huggingface.co/XiaomiMiMo/MiMo-V2.5-Pro
https://huggingface.co/XiaomiMiMo/MiMo-V2.5-Pro

>Новая моешка для риговодов
https://huggingface.co/XiaomiMiMo/MiMo-V2.5 311b
https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash 284b
https://huggingface.co/tencent/Hy3-preview 299b
128 + GPU
О, а у ксямоми то заявлена поддержка Modalities: Text, Image, Video, Audio
Звучит вкусно. В вллм awq4 мне точно не влезет, а вот в жору где мимо2 уже есть должно залезть в условных q4-q6
И мультимодалочка есть. Слишком красиво для реальности
Забрал, скачал, скопировал, утащил, украл, взял без спроса.
И поддержку для сяомиевской уже добавили, ну просто ахуенно
>И поддержку для сяомиевской уже добавили
???
Архитектура мимо2
Анон, какие новые модели подойдут для написания хорни фанфиков? Есть 24Гб видеопамяти и 32Гб оперативки.
Пробовал Qwen3-30b abliterated и это какое-то говнище
Пробовал Qwen3-30b abliterated и это какое-то говнище
Ну хоть один тред прочти, пожалуйста
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Чёт слабо верится что гемини кто-то обходит. Уж точно не кими с ГЛМом
Таверна отправляет промт в кобольд он делает теги и отправляет в комфи. Но он плохие теги делает.



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_moe_2026
• Неактуальные списки моделей в архивных целях: 2025: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd ), 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
• Доки к LLaMA.cpp со всеми параметрами: https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: