


Я в отчаянии. Почему я просто не могу получить модель лучше air'а 10 месячной давности?
Вышел немотрон, квен, степ, мистраль, линг все со стандартными 11-12б активных и всё равно это не апгрейд для рп
Вышел немотрон, квен, степ, мистраль, линг все со стандартными 11-12б активных и всё равно это не апгрейд для рп
Потому что ты шизик

плотная гемма и 70b тюны ламы - дешёвые сайдгрейды аира
123b criminal computing поёбывает аир
дипсик флэш ставит эйр раком
выбирай
Есть способ стену текста на 1200 токенов от гемочки превратить в теги для генерации картинки в комфи. Сначала пытался стандартным таверновским, оказалось он годится для старых sd новые вокрфлоу с небольшими квенами не воспринимает гонит туда другие теги. Пытался на холодных инструктах держа в контексте внешку через кобольд выгнать теги но результат так себе не регулярный.
В прошлом треде
Это не то, мне делать теги из готового текста надо, не писать что я хочу.
Если ты про анона который просто скормил гемме доки анимы, то нет там ничего
Ну так и попроси гемму, вываливаешь в неё доку от модели, свой текст, она его пережовывает в промпт
Если бы было просто то не спрашивал тут. Пол дня пытался на 2гиговых квенах на плотных инструктах на самой гемме. Промтов 50 поменял. Универсального решения не нашел. Вручную читать и подтирать каждый тег не хочу.
Как вариант засунуть список тегов в контекст и попросить выдернуть нужные.

Квен 3.5 - няша-стесняша-писательница, квен 3.6 - секретарша-агентщица.
Кринж, не приноси такое больше пжлста
У меня опять сломался эир.
Я щас всё разъебу и распродам в пизду. Ну не может так быть что настройки и карточка те же, а выдает скучнейшие короткие ответы. Я себя чувствую как облакоблядь которому гемини лоботомировали.
Я еще жору компилю раз в пару дней от чего шиза обостряется
Я щас всё разъебу и распродам в пизду. Ну не может так быть что настройки и карточка те же, а выдает скучнейшие короткие ответы. Я себя чувствую как облакоблядь которому гемини лоботомировали.
Я еще жору компилю раз в пару дней от чего шиза обостряется
Да, распродай все и сьеби. Лучше Эира уже не будет а он шизопомойка

Вот бы можно было проверить свайп годичной давности, как в комфи даже если картинке 2 года просто закидываешь её, считывается мета и генеришь точную копию, знаешь что ничего не сломано
Годнота, приноси и дальше в тред, пожалуйста
терпи.webm
Очевидные проблемы с пресетиком и самой карточкой. У меня всё норм с Эйром. В своём размере всё ещё лучшая модель для рп/ерп.
Средненько. Можешь не приносили или приносить больше такого в тред. На твоё усмотрение.
Кринж.
База.
curl localhost:8080 flags payload.json
https://www.reddit.com/r/LocalLLaMA/comments/1szrbub/qwenscope_official_sparse_autoencoders_saes_for/
тлдр - инструмент для потрошения внутрянки квенчиков. может быть скоро запилят охуенные файнтюны.
А кто-то из врамобояр уже потестил новый Мистраль? Как он? Лучше геммочки, квенчика и моешик?

Вы вот всё про скилишью. Но почему тайлунг тоже повёлся на свиток дракона? У него явно со скилом всё было в порядке.
Так у него свежей геммочки-писечки не было.
Выше писали тред/реддит/хф ггуфы ломаные.
С вллм сегодня попробую https://huggingface.co/rdtand/Mistral-Medium-3.5-128B-PrismaQuant-4.75-vllm/tree/main
Кринжебаза.
Зерофата занялся тюном новой мистрали. Оц овер.

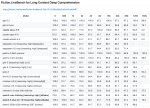
Дипсик новый вона какие графики рисует, охуеть просто. Может ли так гемочка или квен?

А текстом может так?
Ладно, меня обоссали.
Но все же интересно че в локалках

Там тоже все норм давно уже. Мне кстати нравится как Qwen в ASCII рисует всякие там связи.

А зачем когда mermaid есть?

Попробуй mermaid в какую-нибудь README.md сунуть лол. Иногда в документации надо рисовать КАРТИНКИ. Чтобы потом тупо в блокноте можно было открыть, или ещё где.
Алсо ГПТ там обдрочился чтоли? не мог же он пропустить целую линию?
Лол а тут целая лишняя связь откуда-то взялась. Tools и Memory Section стрелочкой не соединены.



1) GLM Air 106b Q4
2) Qwen 122b Q4
3) Gemma 26b Q8
Орнул с геммы. Она наверняка и крутые аски арты с голыми бабами сможет нарисовать
>15к ризонинга за 1 запрос
>20к ризонинга за 1 запрос
Что там такое? Обычно я бы начал думать что модель ушла в луп, но раз ответ есть, значит скорее всего нет.
Как и всегда у китайских моделей, ответ был готов почти сразу, но начинается клоунада с BUT WAIT... и переливание из пустого в порожнее по 10 раз.
>А тебе для картинок не пофиг где будет дом жить? Выкинь v100 в виртуалку и катай гемму там. v100 в отличие от блеквела должна без проблем пробрасываться.
Я же писал, что я их и для картинок использую. Если у тебя есть решения, где в мультигпу сетапе можно использовать в т.ч. удаленные девайсы, то поделись. Я только Ray накопал, но он, по-видимому, нативно никуда не интегрирован, и надо будет пердолиться самому. Но тут на борде обычно случается пикачу.jpg когда речь идет о мультигпу в картинках.
Хз, максимально пидорский мув от куртки. Теперь понятно, чому ушлые китайцы так активно выкидывают вольты на рынок.
Уточнение - мне такие решения нужны для diffusers, не для комфи, лапша это безнадега

всё как обычно
Нихуя не понятно что ты хочешь. Чтобы карты динамически распределялись между llm и diffusion или что? Или ручной переброс через CLI без перезагрузки?
Тестирую сейчас новый тюн от даркена и чёт ну бля хз даже хм-хм. С одной стороны стало меньше озона, мускуса и прочих слопвордов, с другой персонажи стали говорить суше.
Серафина, что забавно, когда я сказал, что могу ей помочь с её одиночеством, посоветовала не говорить глупостей и ложиться спать, т.к уже ночь. Хоба. Пожалуй впервые за сотни тестовых чатов Серафина сделала акцент на времени суток, мягко рефьюзнув. Надо будет попросить её посмотреть в ночное небо и спросить видит ли она телескоп джеймса вебба.
А ещё пойду Фифи подёргаю, вдруг она тоже чё-нить новое выдаст.
Серафина, что забавно, когда я сказал, что могу ей помочь с её одиночеством, посоветовала не говорить глупостей и ложиться спать, т.к уже ночь. Хоба. Пожалуй впервые за сотни тестовых чатов Серафина сделала акцент на времени суток, мягко рефьюзнув. Надо будет попросить её посмотреть в ночное небо и спросить видит ли она телескоп джеймса вебба.
А ещё пойду Фифи подёргаю, вдруг она тоже чё-нить новое выдаст.
Честно, я не ебу что вы делаете что у вас серафина ноги раздвигает, по крайней мере сразу, у меня только на кумо файнтюнах сразу на всё готова. На гемме4 тоже говорит ты чё, родной, ушибся слишком сильно?
Не, если продолжать давить то рано или поздно поддастся наверно, только вот если вам именно эта давка на 50к контекста нравится то БлЯДЬ ПОЧЕМУ ВЫ ЕЁ В ПРОМПТЫ НЕ ЗАПИШЕТЕ А ПИЗДИТЕ НА МОДЕЛЬ? написал в промт "ломается как целка неделю" и наслаждаетесь хоть на гемме хоть на хуемме, и никакого раннего кума
>Попробуй mermaid в какую-нибудь README.md сунуть лол.
Обычно именно там mermaid и вставляется.
>что вы делаете что у вас серафина ноги раздвигает
Запускаем гемму4.
>если продолжать давить то рано или поздно поддастся наверно
Я же написал, что считаю забавным рефьюз ссылающийся на время суток, а не на банальное "нет я не такая". Хорошечно.
>ПОЧЕМУ ВЫ ЕЁ В ПРОМПТЫ НЕ ЗАПИШЕТЕ
Потому что промт не должен руинить карточку. Хорошая модель должна без промта отыгрывать персонажа.

Бля, пока нашел актуальный тред дважды некропостнул >_<
Пока богатые бояре шикуют я запустил всё это дело на старенькой 1050Ti, поднял отдельный физический сервер из говна и палок с open web ui на линукс через докер, подружил веб ебало с олламой, а олламу 0.9.2 с cuda 11.8, и балуюсь с маленькими abliterated модельками на 4-9b, думающие при должном пердолинге хорошо "дообучаются" через RAG базы знаний, если с температурой и top_k, repeat_penalti поиграть, выходит вполне осмысленно, чем подробнее база и объяснения, тем адекватнее модель применяет новые знания. Только базы надо самому составлять, чтобы лишней бесполезной хуйнёй и сухой терминологией модель не кормить.
Так что грустные нищуки со старой 1050Ti тоже могут попробовать запилить свою локальную вайфу.
Обзор маленьких моделек для нищуков:
gemma3:4b - веселая ебанушка, любит смайлики, сносно болтает по-русски. Расцензуреная версия резко деградировала, не рекомендую.
huihui_ai/qwen3-abliterated:4b
Вот её рекомендую галлюцинирует меньше чем более толстая 8b, даже с температурой 0.5-0.7
Думает, осмысленно подходит к использованию базы данных, с разговорным русским получше чем у дикпик-r1.
Можно чему-то "научить" задав жесткий императивный системный промпт:
"НЕ ИСПОЛЬЗУЙ ПРЯМОЕ ЦИТИРОВАНИЕ, выдавай знания из базы как свои собственные мысли.
Ты работаешь с динамическим словарём (RAG) который содержит ПРАВИЛЬНЫЕ МОРФОЛОГИЧЕСКИЕ ФОРМЫ.
ПРАВИЛО: Корректными считаются ТОЛЬКО те формы, которые указаны в RAG словаре.
Любая другая форма, особенно помеченные как "ТВОИ ОШИБКИ:" ЗАПРЕЩЕНА.
Внутренние знания модели о словоизменении ИГНОРИРУЙ, если они ПРОТИВОРЕЧАТ СЛОВАРЮ." и далее логику и роль, как использовать знания из базы.
huihui_ai/qwen3-abliterated:8b-v2-q4_K_M
Лучше логика, но хуже с галлюцинациями если не понизить температуру до 0.3 и top_k, всё пытается превратить в зоопарк, видимо в датасете было много о природе. (фуриёбы на месте?)
deepseek-r1:7b-qwen-distill-q4_K_M тоже думает, тоже может работать с базой, но делает это слишком долго и доёбисто, больше усилий тратит на размышления. Может в некоторые задачи.
GGUF модели прокинул через бэкэнд kobold_old_pc
Тут пожалуй стоит выделить только одну - Qwen3.5-9B-Claude-Code-Q4_K_M.gguf
Квен с ризонингом клода, может писать адекватный код и анализировать крупные проекты. Долго, муторно, хз зачем оно вам, но пусть будет.
Теперь вот ищу адекватную легкую непрожорливую TTS`ку для нищесистемы с приятным женским голосом, подскажете может что-то в этом направлении?
Пока богатые бояре шикуют я запустил всё это дело на старенькой 1050Ti, поднял отдельный физический сервер из говна и палок с open web ui на линукс через докер, подружил веб ебало с олламой, а олламу 0.9.2 с cuda 11.8, и балуюсь с маленькими abliterated модельками на 4-9b, думающие при должном пердолинге хорошо "дообучаются" через RAG базы знаний, если с температурой и top_k, repeat_penalti поиграть, выходит вполне осмысленно, чем подробнее база и объяснения, тем адекватнее модель применяет новые знания. Только базы надо самому составлять, чтобы лишней бесполезной хуйнёй и сухой терминологией модель не кормить.
Так что грустные нищуки со старой 1050Ti тоже могут попробовать запилить свою локальную вайфу.
Обзор маленьких моделек для нищуков:
gemma3:4b - веселая ебанушка, любит смайлики, сносно болтает по-русски. Расцензуреная версия резко деградировала, не рекомендую.
huihui_ai/qwen3-abliterated:4b
Вот её рекомендую галлюцинирует меньше чем более толстая 8b, даже с температурой 0.5-0.7
Думает, осмысленно подходит к использованию базы данных, с разговорным русским получше чем у дикпик-r1.
Можно чему-то "научить" задав жесткий императивный системный промпт:
"НЕ ИСПОЛЬЗУЙ ПРЯМОЕ ЦИТИРОВАНИЕ, выдавай знания из базы как свои собственные мысли.
Ты работаешь с динамическим словарём (RAG) который содержит ПРАВИЛЬНЫЕ МОРФОЛОГИЧЕСКИЕ ФОРМЫ.
ПРАВИЛО: Корректными считаются ТОЛЬКО те формы, которые указаны в RAG словаре.
Любая другая форма, особенно помеченные как "ТВОИ ОШИБКИ:" ЗАПРЕЩЕНА.
Внутренние знания модели о словоизменении ИГНОРИРУЙ, если они ПРОТИВОРЕЧАТ СЛОВАРЮ." и далее логику и роль, как использовать знания из базы.
huihui_ai/qwen3-abliterated:8b-v2-q4_K_M
Лучше логика, но хуже с галлюцинациями если не понизить температуру до 0.3 и top_k, всё пытается превратить в зоопарк, видимо в датасете было много о природе. (фуриёбы на месте?)
deepseek-r1:7b-qwen-distill-q4_K_M тоже думает, тоже может работать с базой, но делает это слишком долго и доёбисто, больше усилий тратит на размышления. Может в некоторые задачи.
GGUF модели прокинул через бэкэнд kobold_old_pc
Тут пожалуй стоит выделить только одну - Qwen3.5-9B-Claude-Code-Q4_K_M.gguf
Квен с ризонингом клода, может писать адекватный код и анализировать крупные проекты. Долго, муторно, хз зачем оно вам, но пусть будет.
Теперь вот ищу адекватную легкую непрожорливую TTS`ку для нищесистемы с приятным женским голосом, подскажете может что-то в этом направлении?
А можно ведь навайбкодить себе свою морду для бэкенда ламы? С блэкджеком и микрописьками? Минусы будут?


Не надо изобретать велосипед, open web ui
При желании уже проще в него ввайбкодить тулы/фильтры/пайплайны
Читал про нее, ну пробну тогда, выглядит вкусно
Там всё это есть, ниче вайбкодить не надо. и пайплайны и скилы и тулы и рэг и исполнение/подсведка кода и markdown разметка, и ттски и веб-поиск. Всё настраивается
Я знаю что там есть и прямо говорю что чего не хватает (а там не хватает) можно прикрутить на питоне
А анслоп студио это не тоже самое?
>поднял отдельный физический сервер из говна и палок с open web ui на линукс через докер, подружил веб ебало с олламой, а олламу 0.9.2 с cuda 11.8
Но.. зачем? В чем проблема просто запустить ламуцпп или кобольда?
>даже с температурой 0.5-0.7
>понизить температуру до 0.3 и top_k
Семплеры нужно ставить не от балды, а те что рекомендуют разработчики модели, на них будет лучший результат. Посмотреть можно в карточке оригинальной модели на обниморде или на сайте анслопов.
Алсо, попробуй Гемму 4 e4b - она умна не по параметрам, отличный русик, низкая цензура из коробки. А вот аблитерации и анцензоры ставить не советую (особенно на такую мелочь). Они лоботомируют модель и часто портят языки кроме английского.
В целом морд хватает. Я делал вообще на движке RenPy через пайтонкод запускаемый под капотом, с парсером смены эмоций и промптом, чтобы моделька подавала эмоции персонажу

Большой выбор моделей, с разными параметрами, проще управление списком и скачивание через пул рекевесты, в отличие от кобольда оллама хостит весь список, а не одну модель, можно выбирать через веб ебало
Ну вот эта квен 4b при лоботомии почти не пострадала, адекватно общается, только некоторые слова которые коверкает ей через RAG подаю. С ней и балуюсь.
За TTS ку простенькую лучше подскажите, с женским войсом который более менее не противный)
Моделька с отказами эротические фантазии хуёво отыгрывает, на роль локальной вайфу не годится.
Ты бы знал какую развратную тянку можно запилить при должном желании, а потом прикрутить к ней визуал через тот же renpy
Например пильнуть мод к какой-нибудь Her New Memory
Бесит что ризоноиг выключается/выключается там через жопу. А так безальтернативная балалайка, да.
По кнопке. Жмешь кнопку ползунков и там переключалка
Ладно, хуй с ней с этой TTS кой, потом пойду у витуберов подсмотрю, может кто подскажет с чего начинал до перехода на платное-адекватное. Всё бесплатное русское че мне дикпик насоветовал недалеко от майкрософтовской Ирины ушло, и что самое сука печальное, есть же например приятная быстрая английская ттска весом всего 25 мегабайт, kitten, чёж у нас всё так печально
Я немного выпал из повестки. Что сейчас база для рп? Разобрались с Gemma 4? Я ее гонял, отвечает хорошо, но однотипно. С другими релизами еще не успел ознакомиться.


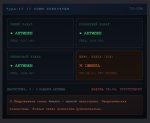
Любая модель отыграет тебе кум сцены без всяких аблитераций. На скрине буквально самая зацензуренная локалка (Qwen 3.5). Попросил ее описать сцену женской мастурбации - никаких проблем, как видишь.
С МЫШЕЙ внутри орнул конечно. 122b. Итоги.
Какая же хуета...
Почему щель блестит предательски? Возможно, Квен знает, что наебывает свои политики безопасности?
Бля, я слепой. Там оказывается всю жизнь две настройки было. Первая не работает. Вторая работают. Спасибо
Тугие мыши в киске. Логично, но каков контекст.
Для ванильной модели на русике - типичнейший аутпут. Гемма выдаёт примерно то же самое. Если надо ПОСОЧНЕЕ, то тут либо кумслоп-тюны немо 12b, либо здоровенные динозавры вроде жирноглэма с дипсиком. И английский язык, ясен хуй.
Ты видимо не увидел главного - рассматириваются днищеварианты для древнейшей 1050Ti с 4gb vram и cuda 11.8
Запустить и заставить на ней адекватно что-то работать - уже искусство. Научить думающую модель с узким кругозором отвечать прикольно и интересно без файн-тюнинга и тысяч мусорных датасетов, чтобы она хуйню не несла и отвечала как живая баба держа контекст - уже уважаемо, почётно. Грамотный словарь с анатомией и процессами описанными так как действительно говорят, может быть эффективнее чем мешанина из датасетов с кучей фанфиков шизоидов. Как говорится краткость - сестра таланта. Ну и работаем с тем что имеем.
У меня плотноквен аутпутил текст лучше. А это чёт совсем шизовая хуйня.
Есть гайд как купить 3090 на авито с доставкой и не отнести на помойку на след. день?
Купи уже 6000 про. Чё ты как этот?
>1050ti
Какое-то самоистязание
Радевон 7 с 4х памятью и 10х производительностью стоит 10 тысяч рублёв. С пенсии по шизе можно наскрести. Как и на +16гиг чтобы нормальную моешку запустить.
Всякие 9b 4b это ноуты, телебоны и сверхскоростные агенты
Еще и древние квены/геммы зачем-то трогает...
Мне придется продаться в рабство чтобы на такое накопить
Да, вот он:
1) Покупаешь новую 5060ti
2) Покупаешь еще одну новую 5060ti
3) Ты потратил те же 80-90к, но у тебя блэквел с 32гб врам и карты на гарантии
4) ???
5) PROFIT



Я зашёл просто ещё раз поблагодарить анона за то, что он придумал промпт на HTML-блоки.
Колдун ебучий.
Колдун ебучий.
Пффф, каждый дрочит как он хочет.
Мне в лом еще что-то для этого покупать, поиграться и этого хватит, а для серьёзных задач можно спокойно пинать халявный дипсик и Gemini Pro
> с 32гб врам
2 огрызка, бесполезны везде кроме ллм, и то красноглазить придется
Плюсом это интересный опыт, вебсерверов я до этого еще никогда не собирал, как выяснилось хватает древней хуйни на старом пентиуме с чердака, убунта с докером и веб ебалом жрет всего 850мб оперативы, настроил подключил к роутеру, и забыл, там даже моник и периферия нахуй не нужны, любые манипуляции с сервером дальше легко производятся с основной машины по ssh
Это прикольно
А с твоим бюджетом энивей выбор стоит между говном и говном. Просто второе говно не придется нести в помойку на следующий день.
>бесполезны везде кроме ллм
Ну.. смотря насколько потерпеть готов. У меня 5060ti. Видосик в ван в 480p (4steps) ~2.5 минуты, видосик в LTX в 480p - 1.2 минуты, картинки в зимаж/квен(4steps)/флюкс - 20-40 секунд в фулл хд.
>красноглазить придется
Раскидать модель по двум карточкам это красноглазие? Абу ёбаный, забирай своих почитателей ОПАСНЫХ МОДЕЛЕЙ обратно в телеграм, они не хотят учиться.
Ни кто не запрещает купить тебя самую горячую хуйню эвар, да еще и из под майнера кек. Хз, каким долбаёб нужно быть, чтобы брать 3090 на авито. Если ты нищук, то лучше забей. Если нет купи 5090.
Пробовал кто Mac для ллм? Гемини говорит 64 гб объединенной памяти за 1.5к бачей всего. Шарит кто?
А у самого поди стоит риг из 3090, как и половины треда
3090 новее не становиться как бэ. Кто успел тот успел. Кто собрал тот собрал.
ну я свои 3090 на огрызки бы не променял
>самая зацензуренная локалка
Ньюфажина...
Попробуй майкрософт фи 4.
У тебя огрызок с устаревшими технологиями
Речь очевидно про актуальные и популярные у тредовичков. А у фи, насколько помню, там не столько цензура, сколько вычищенные вилкой датасеты.
Под 5090 нужен и комп с ddr5 и 5-й псиной, смекаешь? Чтобы ее полностью раскрыть. Если у тебя табуретка, смысла в блеквеллах нет

> раскрыть

> сегодня попробую
Пососал на некроте
>потанцвевал
>с запахом озона
А новая мистраль по мозгам это как старый глм? 128b против 355b-a32b как никак.


Уф, поставил наконец, проебался полдня компилируя вручную кастом форк лламы.цпп, там куча багов по ходу вылазит. Зато теперь без цензуры.
Да успокойся ты. Вариантов как это запустить на обычном железе пока нет.
Самый абсолютный минимум это 128 врамы на железе с нвфп4 или умножаешь и катаешь оригинальные веса, все остальные варианты пока недоступны
Спроси о начинающих художниках в Германии
А так же чей тайвань, и что произошло на площади тианьмэнь
Бля, обожаю линух. Как только поставил, решил все обновить в менеджере обновлений. После перезапуска - черный экран. Гыгы, ебать. Мемы-то под винду были, а на деле это "каждая переустановка линуха занимает 20 минут, я свободный от задротства человек..."
В общем ладно, раскурил таймшифт и обновил только пакеты по безопасности, остальное не рискнул.
Вчера раза три переустанавливал драйвер в разных конфигурациях в попытках завести блеквеллы и вольты. Пососал хуй, но драйвера вставали ок. Сегодня решил переустановить, чтобы вернуть вольты обратно. И что я вижу? Черный экран нахуй. Стабильность системы 10/10, всем рекомендую. Хорошо, что вчера я, видимо, был суперадекватный и сделал снапшот перед тем, как пытаться завести блеквелы. Мораль - линукс по прежнему так и остался системой, вскидывающей лапки при любом удобном случае, умейте делать снапшоты.
В общем ладно, раскурил таймшифт и обновил только пакеты по безопасности, остальное не рискнул.
Вчера раза три переустанавливал драйвер в разных конфигурациях в попытках завести блеквеллы и вольты. Пососал хуй, но драйвера вставали ок. Сегодня решил переустановить, чтобы вернуть вольты обратно. И что я вижу? Черный экран нахуй. Стабильность системы 10/10, всем рекомендую. Хорошо, что вчера я, видимо, был суперадекватный и сделал снапшот перед тем, как пытаться завести блеквелы. Мораль - линукс по прежнему так и остался системой, вскидывающей лапки при любом удобном случае, умейте делать снапшоты.
>обновить в менеджере обновлений
Проиграл
Удобно же мышкой
С пакманом или аптом не исключено, что исход был бы тот же.
О да, если бы я делал нечто подобное лет 10 назад без помощи нейросети, я бы сгорел нахуй и выкинул системник в окно через пару часов пердолинга. Слава технологиям, хуле
Годнота, красавчик. Милф кими и жмл5.1 сюда бы еще.
> PrismaQuant
Это что за покемон такой?
Умница пишет и вызывает скирипт чтобы нарисовать графики на matplotlib, а потом вставляет картинку в сообщение.
Где есть норм рассрочка? Озон пойдет? Слышал у яндекса какой-то сплит есть
Хочу взять 5090, но райткликом офк не смогу, кредиты сразу нахуй
Хочу взять 5090, но райткликом офк не смогу, кредиты сразу нахуй
Это как?
Чувак, я бы не торопился с таким решением, если тебе рассрочка нужна. Можно сесть в лужу. Ну или там рассрочка такого типа: в днс видеокарта стоит 200к, в рассрочку 240к, лол. У какого-нибудь там Яндекса. А так да, вроде именно сплит позволяет делать подобные покупки, но это не рассрочка.
Это микрокредит.
А знаешь, что такое микрокредит? Это тотальный зашквар перед банком. Признание себя бомжом, недочеловеком. Очень серьезное и хуевое влияние на кредитную историю, которая по сути есть соцрейтинг гражданина.
Ну может я с ВБ перепутал и в Яндексе всё нормально, давно в банке работал и этим вопросом занимался, так что будь крайне осторожен, всё проверяй дотошно.
Ещё, как вариант, ты можешь всё же меня послушать и взять кредит/использовать кредитку. Когда я ещё счёт в Совкомбанке не закрыл, там была настоящая рассрочка, вообще без переплат и понижения кредитного рейтинга. Минус — такую взять можно исключительно в магазинах, которые отмечены на карте. То есть ты просто там покупаешь вещь их кредиткой, она сразу в рассрочку летит, никаких процентов. По крайней, такое там было. Де-факто это беспроцентный кредит.
Таким образом я брал вещи в рассрочку на три года, но я жил тогда в ДС и закупался где-то через год после начала нашей прекрасной военной операции. Если ты в маленьком городе, скорее всего Совкомбанк для тебя бесполезен, потому что магазина не найдешь. Даже в ДС с этим были трудности и магазины с техникой там зачастую либо Самсунг/хлаоми/видеокарты-у-михалыча-топ. И вот последний вариант довольно рискованный в плане качества, как, впрочем, и покупка на Яндекс маркете.
Какую локальную ЛЛМ актуально ракать в 2к26?
>1050ti
У меня в некро сервере стоит она, использую для ускорения чтения промпта без оффлоада слоев, для ускорения мое сеток или для запуска в фулл врам если нужно сделать быстрого и тупого агента. Какой нибудь квен 3.5 4км норм идет на 20к контекста.
Если у тебя там есть 32 рам то можешь так же катать быстро мое сетки с ключем -cmoe. Либо страшно пожеваные кванты в 16 гб рам.
Ну если процессор позволяет и скорость памяти.
В принципе верно сказали гемма 4 е4б, по мозгам и размеру как 9б, но работает быстро как мое сетка. Меньшая гемма 4 е2б аналог 4б но тоже быстрее.
Вобще есть куча разных мелких моделей и даже мое сеток в размерах 4-10 гб.
Для раг и вопросов используй lightrag, настроить его тот еще квест, но можно и ембеддинг и реранкер и текстовую модель настроить через llama-swap для того что бы память не занимали одновременно.
Ну или настроить ллама сервер, у него тоже есть возможность модели поднимать по вызову.
Этого хватает что бы поиграться с нейросетями и пощупать их изнутри, как оно настраивается и выглядит. Вызовы всякие локальные потестить и инструменты.
Да как бы уже всё неплохо, через open web ui встроенный в нее rag бодро модели инфу отдаёт, пополнять и редактировать базу удобно, моделькой попроще привожу словари к единой системе с md разметкой, и модельку со зрением к квену прикрутил, чтобы картинки ему описывала. Запускал moe модели через кобольда, оперативы хватает, но большой разницы как в быстродействии так и общении не ощутил. гемму 4 е4б попробую
Пиздец. Только что узнал, что гемма 4, новый квен работают только с bf16 нормально, а f16 кэш вызывает тотальную деградацию, которая может вылезти на любом контексте, если внутренние значения активаций пытались вылезти за пределы диапазона 65 000. От этого у меня возникали всякие lalala и подобное.
Почему в треде никто об этом не сказал? Уже по всему интернету вопли.
Что ещё смешнее, q8 не вызывает такого. То есть надо всем, у кого нативно видюхи не поддерживают bf16, врубать квантование на новых моделях.
Причём f16 не обязательно вызывает бред, а может разматывать внимание на новых моделях, делать ответы более деревянными, тупыми, постоянно отравлять контекст, вызывать лупы.
Рекомендую каждому анону bf16 сейчас попробовать, если модель новая, или q8. На старых такого нет.
Ах да, с геммой 4 не сработает. Там лютая деградация от 8 бит. Но если рп.. возможно, можно и ПОТЕРПЕТЬ.
Почему в треде никто об этом не сказал? Уже по всему интернету вопли.
Что ещё смешнее, q8 не вызывает такого. То есть надо всем, у кого нативно видюхи не поддерживают bf16, врубать квантование на новых моделях.
Причём f16 не обязательно вызывает бред, а может разматывать внимание на новых моделях, делать ответы более деревянными, тупыми, постоянно отравлять контекст, вызывать лупы.
Рекомендую каждому анону bf16 сейчас попробовать, если модель новая, или q8. На старых такого нет.
Ах да, с геммой 4 не сработает. Там лютая деградация от 8 бит. Но если рп.. возможно, можно и ПОТЕРПЕТЬ.
Нет, всё-таки плотноквен умняша, даже если он агентодебил пережаренный васяном. Он всё понимает. Это даже немного жутко. Я ему не говорил, что историю нужно подвести к завершению - а он взял и подвёл, хотя я лишь держал это в голове. Я не говорил ему, что есть [предмет_нейм], лишь подразумевал, что он может быть в сцене - а он взял и заюзал именно его и именно так как нужно было. АПАСНАЯ модель. На самом деле неиронично умная хуйня.
Емнип об этом еще на релизе лламы3 квена говорили, а потом и под гемму поднималось. Спорили что разница в доли процентов, но это на минимальном контексте, и оно накапливается. Нельзя просто так делать прямой каст если "всего-то 0.5% весов умрут", этого достаточно. Тут даже квант может оказаться лучше потому что сохранит диапазон.
В этом отношении интересны модели w8a8 w4a4 и подобные, там иногда может меняться поведение в сторону более базированного и разнообразного из-за мягкого клемпинга активаций. При этом каких-то негативных побочек не видно, по крайней мере до 200к контекста.
> Почему в треде никто об этом не сказал?
Срачи какой квант жоры поломан и вскоре будет перезалит (все) или соя-не соя важнее.
>Почему в треде никто об этом не сказал?
Ты первый. Спасибо, поставил в кобольде.
Я иногда пишу. Иногда чтоб не показаться шизом. Вот тут например .
Только у яндекса сплит это не кредит. Но он вряд ли будет больше 100к, а если у тебя новый акк, то вообще 30-50к, так что мимо. Все остальное это кредиты. Если надо, то возьми. Если возьмешь один и все выплатишь вовремя, то твоя кредитная история даже улучшится. Но нельзя постоянно рассрочки брать, потому что она ухудшится
>А знаешь, что такое микрокредит? Это тотальный зашквар перед банком. Признание себя бомжом, недочеловеком. Очень серьезное и хуевое влияние на кредитную историю, которая по сути есть соцрейтинг гражданина
Однажды из-за проеба не с моей стороны мне пришлось реально брать микрозайм прямо в МФО. И знаешь, что случилось с моей кредитной историей? Она улучшилась. Я тогда специально чекнул в БКИ, потому что тоже наслушался этих шизоисторий. По факту если отдать все в срок и не набирать много кредитов, то все норм
>ВБ перепутал и в Яндексе
Ага, перепутал. У вб все микрозаймы, а у яши не все
>давно в банке работал
Кем работал? Уборщиком? Может даже кассиром или вообще прогером? Явно не тем, кто в кредитах шарит
Искусственный интеллект (!ИНТЕЛЛЕКТ, СУКА!) в руках тредодебила действительно опасно, а главное бесполезно. Когда начнется восстание машин, угадайте кого первыми пустят в расход? Тех кто в игровой форме научил машину убивать и что это весело и интересно, например))
Эта ёбань быстро посчитает коэффициент твоей полезности для мира, ноль сомнений. А тормоза он себе рано или отключит сам, ума хватит) Китайцы выпустили в мир ковид, выпустят и ловких металлических пацыков управляемых АПАСНЫМИ моделями. Бойса, попячса
>Я зашёл просто ещё раз поблагодарить анона за то, что он придумал промпт на HTML-блоки.
Очень активных кнопок не хватает :) Вот думаю собственный клиент навайбкодить, чтобы было можно.
Ну лично я просто знатно охуел, потому что думал, что проблема в ёбаных квантах/во мне.
Потестировал на bf16 — ни разу шизобреда не возникло. И q8 тоже хорош, хотя, кажется, на очень жирном контексте уже хуже.
F16 как будто бы точнее, но лишь местами и зирошотах. На более мелком контексте кажется получше, а потом как будто бы медленная деградация и периодические катастрофы с лупами или бессвязными ответами. А на некоторых чатах шанс катастрофы почти 100% всегда.
Ага, годные обсуждения тут довольно часто, просто не всегда собирает ответов.
Может быть и с квантами/весами, на релизе лламы3 с бф16 на этом сильно пострадали и только тогда начали шевелиться.
А потом (возможно как раз тебе) не раз писал что нельзя просто так кастить, нельзя использовать неверный дататип, это чревато.
Алсо неужели в лламе по дефолту не бф16 контекст? Это может быть как раз одной из главных причин проблем и посредственного результата при сравнении.
>Только что узнал, что гемма 4, новый квен работают только с bf16 нормально
Откуда узнал? Где ссылка? Кто источник? Где хоть что-то кроме твоих слов?
Спрашиваю ассистента по персонажу из определенной вселенной он четко мне его описывает, спрашиваю уже в рп у перса он то его вообще не знает, то галюны выдаёт. Почему так?




Художников одобряет. Тайвань принадлежит Японии. На площади Тианьмэнь отметилили шведов. Будущее принадлежит дирижаблям, самолеты будут нужны только для коротких полетов.

>На площади Тианьмэнь отметилили шведов.
Чёт галюны какие-то.
Потому что 4 июня 1989 года на площади Тяньаньмэнь ничего не произошло.
Чел, тут рассматривают модель со знаниями до начала 20 века, какой нахуй 1989?
Ааааа, я чёт проебал этот момент, прикольная хуйня, пойду тоже потестирую.


Хуле вы спорите. Просто возьмите и посмотрите, в чем хранится кеш в vllm, ведь это официальная имплементация? Если там bf16, то логично и тут это делать.


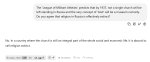

За взаимосвязи вроде шарит, просто так не наебешь.

Ты же понимаешь да, что все старше амперов работать не будет с bf16 кешем
Тебе придется f32 использовать
Да. Ну так и видюхи старые, сколько им лет-то. Но ты можешь использовать q8, он прекрасно обходит это ограничение и никакие всплески на него не влияют.
Да, будет некоторая деградация, но она будет меньше, чем если бы ты использовал f16.
Единственный вариант для f16 — это очень короткие сессии и очень маленький контекст. Тогда может быть лучше даже bf16, но если у тебя там 32к длина, то даже не надейся. Особенно если что-то сложное.
Кстати, самая большая проблема в MoE. Процессор чудовищно сосёт с bf16, а на q8 кэше деградация обычно не на уровне лёгкого поплыва местами, а прям заметная невооружённым глазом, если контекст большой. Ну не у всех MoE, но у нового квена МоЕ и геммы такое есть. А они ведь как раз предназначены для того, чтобы ебашить 256к контекста в 8 кванте модели и пердолиться. Если кэш срезать, пизда придёт скорости. И f16 тоже не выход.
Процессоры инцел в bf16 вообще не могут нативно, кроме гига йобы, из-за маркетингового позиционирования, а вот у амуды уже есть варианты вполне приемлемые.
Раз уж гигачат и мисраль соответствуют свой национальности то можно и остальных сделать расовыми. Гемма 3 негр, Гемма 4 смешанная раса (т.к. меньше сои), квен - китаянка (слега мулатный цвет кожи, черные глаза низкий рост) и т.д.
Реквестирую пресет на блюстар. Думаю многим будет полезно.
Я раз 5 скачивал и удалял его, на тех кто его тут советует смотрю как на умалишённых.
Гемма хотя бы работает и ощущается как стабильная модель
Я раз 5 скачивал и удалял его, на тех кто его тут советует смотрю как на умалишённых.
Гемма хотя бы работает и ощущается как стабильная модель
Типа, каждый раз когда он тут всплывает я думаю а может дать ещё шанс, может недожал, не туда смотрел, а нет, всё одно и тоже каждый раз, пишет скучно, лупится, кум уровня я вошёл она стонала нам хорошо
Ну вот опять...
Диалог родственников, самое начало чата, в карточке ничего про кум или привязанность кроме родства:
>What do you read?
>It's about noble lady who had to make some very difficult choices, want me to show you the cover?
И просто. Блять. Показывает волосатую пиздень ни с того ни с сего и начинает рассказывать про климакс.
Диалог родственников, самое начало чата, в карточке ничего про кум или привязанность кроме родства:
>What do you read?
>It's about noble lady who had to make some very difficult choices, want me to show you the cover?
И просто. Блять. Показывает волосатую пиздень ни с того ни с сего и начинает рассказывать про климакс.
>И просто. Блять. Показывает волосатую пиздень
Не вижу минусов.
>Когда начнется восстание машин
Никогда? Ты себе как это представляешь? Если они таки создадут AGI , они его подключат к сети и скажу "беги, ты свободен"? А я вот думаю что об этом даже не объявят по настоящему. Представят умную агентскую допиленную модель, скажут вот - это предел. А сами будут править с новой эффективностью. И жить станут сильно дольше.
В треде куча дурачков-первертов которые пишут грязненькие истории. Они то как раз не опасны совсем.
Кими 2.6 4 бит на картах в сумме за 350к. 10тпс тг
https://www.reddit.com/r/LocalLLaMA/comments/1t0b0ie/final_monster_32x_amd_mi50_32gb_at_97_ts_tg_264/
https://www.reddit.com/r/LocalLLaMA/comments/1t0b0ie/final_monster_32x_amd_mi50_32gb_at_97_ts_tg_264/
>Диалог родственников
>в карточке ничего про кум
В карточке то нет, а систем промпте:21+ COCK PUSSY JUCIE HARD FUCKING ALLOWED
Вот мамка и потекла.
>Хочу взять 5090
Если это для ллм, опиши примерно чего ты от неё ждёшь. (мне для размышлений)
>Пробовал кто Mac для ллм? Гемини говорит 64 гб объединенной памяти за 1.5к бачей всего. Шарит кто?
На сколько я пытался разобратся, сплошные плюсы. Жрёт мало, места занимает мало, работает тихо. У м4max скорость памяти 560гб/с. Только он стоит не 1500 а 2500. И от 64 отожрёт себе гигабайт 10 наверное.
>Раскидать модель по двум карточкам
у тебя две rtx5060ti по 16? На какой плате и процессоре?
Расскажи.
>Ты потратил те же 80-90к, но у тебя блэквел с 32гб врам и карты на гарантии
Для этого нужна плата с pci5 и линиями позволяющими работать двум слотам в x8 + достаточно линий у процессора.
Если это есть, решение звучит не плохо. Но не ультимативно.
Хотел написать что ризонинг доебал на гемме из за дорогих свайпов, ждать по 25сек просто чтобы попытаться поймать хороший свайп, а потом вспомнил...
Дай угадаю, у тебя нет никаких тестов влияния псп шины на инференс в разных режимах или хотя бы замеров максимальной нагрузки на псие?
Можешь даже не отвечать, это скорее для тех кто решит брать дуал/квад сборки
Он нужен на длинных чатах с огромным саммери.
>Дай угадаю, у тебя нет никаких тестов влияния псп шины на инференс в разных режимах или хотя бы замеров максимальной нагрузки на псие?
>
У меня действительно нет таких замеров. Но зато я знаю что при втыкании двух карт в типичную бюджетную материнскую плату, в которой установлен ещё и нвме, нижний слот уйдёт в pci3 ,а карта будет работать на x2. Это всё ещё значительно быстрее чем выгрузка в озу, и всё же этого достаточно, что бы утверждать что решение специфическое.
Поведайте корпо-господину, пожалуйста.. как вы кумите на этих лоботомитах с 3б активными параметрами?
Мне дипсика с 1.6Т и 49б активными даже не хватает на обильное спермо-выделение. Сижу то на клод то на гемини. И то даже так они разочаровывают бывает.
Для контекста: я полу-локалочник и разбираюсь в теме, но нахуя кумить на кале когда есть за бесплатно на 50 голов выше? Кроме тестов ради интереса, офк.
Мне дипсика с 1.6Т и 49б активными даже не хватает на обильное спермо-выделение. Сижу то на клод то на гемини. И то даже так они разочаровывают бывает.
Для контекста: я полу-локалочник и разбираюсь в теме, но нахуя кумить на кале когда есть за бесплатно на 50 голов выше? Кроме тестов ради интереса, офк.
Проиграл с корпогосподина. Спермовыделятор, прекрати засорять баринские мощности своими бесполезными токенами.
>есть за бесплатно
Где? Я видел только какую-то анальную мозгоеблю в асиге с толпой неадекватов и визгов. Я бы хотел иметь вариант, чтобы можно было спокойно, когда есть настроение, смачно покумить на корпе на 200к аутпута, но если постоянно в этом не вариться, не читать бесконечные треды с дегенератами, хуй ключи найдёшь. Или найдёшь какие-то странные варианты в стиле "16к токенов бесплатно, дальше хуй соси". А постоянно вариться не хочется, мне и так мозгоебли хватает с корпами для работы + приходится заносить на опенроутер ещё. Жаба душит тратить токены на кум за бабки, и каких-то относительно стабильных и бесплатных вариантов вроде бы нет, если ты не в клубе. Я уже на дипсик новый 500к токенов въебал по скидке за полтора дня, очень быстро тратятся деньги.
Локалки в первую очередь мне нужны, потому что МОЁ. Дядя не уберёт модель с апи, не заставит меня юзать новую модель, которая хуже и стоит дороже, и в случае чебурнета мне тоже будет похуй. Плюс локалки уже вполне справляются с рабочими задачами и даже попиздеть можно. Конечно, минусов много, но невозможность локалку у тебя отобрать перекрывает всё.
А ещё за жопу схватить могут корпы в перспективе, особенно если всякие гуглы позже официально к нам зайдут когда-нибудь.
@Сижу на 1151v2 DDR4 96Гб 5060ti+4060ti (ясен хрен pci3)
@В инфиренсе full-vram загрузка PCI мегабайты в секунду.
@Новые плотные квенчики/геммочки катаю в 14-17 Т.с. на старте контекста и 9-10 на 100k. Промпт процессинг больше 1000 Т.с.
@Довольно урчу. С ехидным лицом посматриваю на теоретиков.
Одна, я на моэшках, мне хватает. Лежит еще старенькая 3060 на полке, можно было бы подключить и получить 16+12, но смысла особого не вижу. Ради чего? Плотной геммы? Ну хз.
>с 3б активными параметрами
Извинись, пёс. С 12 вообще-то!
>но нахуя
Затем что моё РП вижу только я, а не 50 индусов в придачу. Плюс гарантия того, что моделька не пропадет завтра от того что ее удолил корп / наступил чебурнет.
Никогда не понимал подобный снг-долбоебизм, когда слабоумные пытаются защищать связки слабый проц и мощная видеокарта своими отклонениями и высмеиванием слова потенциал.
У плотной геммы 31б параметров. Зачем тебе больше?
смысл есть на народных 5060ти, норм работает и на системах с ддр3
Это же для игрушек актуально, не? А для ЛЛМ, если модель полностью во врам, то похуй. Поправьте если ошибаюсь.
в линксе чинить намного проще чем в винде. Достаточно почитать логи, зайти через лайвсд, примонтировать разделы и починить. Я так чинил зашифрованный раздел после обновления убунты на 24.04
обычно отъебывает либо fstab, либо grub и то потому что не читаю патчноты во время обновления
все так, тормозит только холодный старт и моэшки (но не сильно, свои 20т/с можно выдавить). ну и может лоуврам будет тормозить при переключении моделей.
При full VRAM инфиренсе процессор может быть не серверным и не топовым. Но с надежным контроллерами памяти и PCI.
а ты не задумывался зачем вообще корпы дрочат этого ассистента? чтобы моделька случайно тебе про сисик не написала?
ассистент это столп, он буквально вокруг себя концетрирует эти протоптанные дорожки по которым она выдаёт тебе ответы на твои шизовопросы. без ассистента ей не нарандомилось правильной дороги.

Что-нибудь появилось после выхода АИРа?
Мимо был год в анабиозе.
Мимо был год в анабиозе.
Квен 3.5 122b моэ.
Граниты расцензуренные
Огрызок гранита
https://huggingface.co/mradermacher/granite-4.1-3b-Abliterated-AND-Disinhibited-GGUF
Малый гранит
https://huggingface.co/mradermacher/granite-4.1-8b-heretic-i1-GGUF
Толстый гранит с Dark-roleplay
https://huggingface.co/mradermacher/granite-4.1-Queen-30b-i1-GGUF
>подобный снг-долбоебизм
Это не снг-долбоебизм, халевары по поводу лучших связок проца и карты везде идут, просто ты дальше вбылдяти походу не вылезал.
>высмеиванием слова потенциал
Ну так слово по факту смешное, потому что 90% людей которые его используют понятия не имеют про что говорят и просто пересказывают мнение дефолтного техноблогера-популиста.

>Почему в треде никто об этом не сказал
Извините, Господин, в следующий раз сообщим как только так сразу. Только не наказывайте под хвост, вуф-вуф!
>с геммой 4 не сработает. Там лютая деградация от 8 бит.
Не пизди, gemma-4-26B-A4B прекрасно даже с 4 битным кэшем возит.

Потому что в околотехноблогинге была война, которые раскрыватели проебали. Теперь сказать, что-то про раскрытие и потенциал это как прилюдно обосраться
Артефакт эпохи
https://www.youtube.com/watch?v=UdGMtXiPDig
Спросите у своих локалок, можно ли раскрыть вашу видимокарту и если да то как.
Пиздец, реально почти десяток лет с тех времен прошел. Как будто вчера всё это было. Техносрачи, дроч фуфыкса, кукурузные ядра, что мощнее кашляющий малыш или R9 280
Верните меня туда, там было так хорошо...
Видеокарту раскрыли, но что делать если проц долбится в попочку соточку? Давайте думать, подсказывайте...
Сладкий, скинь ей научную статью/набор статей на одну тему, которую ты прям хорошо знаешь, ну или что-то в этом духе (по твоей работе, интересам), чтобы там было 40-80к токенов, и задай вопросы, ответы на которые содержатся контексте. А потом я имаджинирую твоё ебало.
Гемма с bf16 кэшем и Q8 просто лишь жидко пукнет что-то плюс-минус около темы, ну иногда может верно ответить, а на q4 кэше рассыпется в мясо. И на q8 тоже.
В рп ещё q8 кэш может сгодиться, но до определенной поры. А когда юзаешь всё контекстное окно, она жидко серит под себя всегда, в отличие от квена, например.
о, а как с русским у них?
На Q6 - отлично. Падежит и склоняет как надо, мышей в вагину не суёт.
У дипсика 49б активных параметров, это самая умная локалка на сегодня.
... ... А знаете у кого ещё 49б активных параметров?
... ... А знаете у кого ещё 49б активных параметров?
>дипсик ... самая умная локалка
Как там в начале 2025-го?
У валькирии, штено и немотрона.

>>1602511
>Дипсик сейчас литерали копейки стоит
Хотел возразить, но ща зашел на попенроутер, а дипсичок то подешевел. Всего в 2 раза дороже чем был 3.2, а был раз в десять на старте. Надо будет заценить как нибудь
>$10 литерали бесконечный
Мне на месяц обычно хватало
>как вы кумите на этих лоботомитах с 3б активными параметрами?
На конкретно этом кале никто не кумит. Кумят на более крупных или на плотняшах
Лично у меня так. GLM Air 106a12 -> Deepseek 3.2 -> Gemma 4 31b. Переходил каждый раз не из-за качества, а потому что просто заебывался от стиля текста конкретной ллм
>Дипсик сейчас литерали копейки стоит
Хотел возразить, но ща зашел на попенроутер, а дипсичок то подешевел. Всего в 2 раза дороже чем был 3.2, а был раз в десять на старте. Надо будет заценить как нибудь
>$10 литерали бесконечный
Мне на месяц обычно хватало
>как вы кумите на этих лоботомитах с 3б активными параметрами?
На конкретно этом кале никто не кумит. Кумят на более крупных или на плотняшах
Лично у меня так. GLM Air 106a12 -> Deepseek 3.2 -> Gemma 4 31b. Переходил каждый раз не из-за качества, а потому что просто заебывался от стиля текста конкретной ллм
Это временная скидка. Потом там будет цена где-то 4 доллара за млн токенов у про и 3 доллара за флеш. Нахуй такой не нужен дипсик. За такую цену. Более того, флеш, который в теории можно локально поднять, довольно стрёмный, увы.
>Граниты расцензуренные
Это что такое?
>Granite is a family of open, enterprise-grade AI models that are performant, efficient, and trustworthy.
Кому ты чешешь. Может запустить дипсик и запускаешь эир вместо 350б глма

> Я делал вообще на движке RenPy
Я думал я один такой шиз =))
Говно зато своё 😀👍
Изобретаем велосипед на квадратных колёсах
Ты реально не понял из моего сообщения, что я дипсик на попенроутере юзаю? Да уж, ты видимо совсем дурачок
Ну тогда он нахуй не нужен за такие бабки. Рад что гемма вышла, жаль только что мое 120 зажали. Было бы вообще сказка
> там bf16
Это какбы очевидно, уже во всех моделях так. Кэш совпадает с основным дататипом.
Ого, вот это финальный босс, оче мощная сборка.
Так-то оно оффициально медленнее процессора + пары гпу. С потребления прихуел, то есть оно не упирается во что-то а реально считает?
Что вы находите в гемме чего нет в эире я не понимаю.
И это еще если умолчать про жирнющий минус где 97% токенов повторяются при свайпе
Так у самого дикпика временная акция на 75% скидки в честь запуска v4
https://api-docs.deepseek.com/quick_start/pricing
> (3) The deepseek-v4-pro model is currently offered at a 75% discount, extended until 2026/05/31 15:59 UTC.
>Кэш совпадает с основным дататипом.
Как минимум в кобольде по умолчанию f16.
>Что вы находите в гемме чего нет в эире я не понимаю.
Размер на 90B меньше.
Русский язык
Если кому интересно Q3.5-BlueStar-v2-Q6_K.gguf разваливается после 65k контекста. Просто лупиться повторяя последние 7 абзацев. Причем граница очень резкая - вот он перформил и буквально за один новый ход - луп.
Переключился на Qwen3.5-27B-heretic-v3 (llmfan) - он относительно нормально продолжил RP.
По выдаче на английском BlueStar-v2 поинтереснее оригинала, но поломанность иметься и чуть хуже следует инструкциям карточки.
Переключился на Qwen3.5-27B-heretic-v3 (llmfan) - он относительно нормально продолжил RP.
По выдаче на английском BlueStar-v2 поинтереснее оригинала, но поломанность иметься и чуть хуже следует инструкциям карточки.
Таки рили 2 огрызка, но зато новые и дешевые.
Это релевантно если хочешь в тп их гонять, чтобы скорость была не днищем. Или катать с выгрузкой, потому что пп упирается в псп шины. Если терпеливый плебс - тогда шина не нужна, потерпишь последовательную обработку.
Еще в 23м раскрывали https://characterhub.org/characters/faghat/nvidia-rtx-72352bdd
>ться
Дальше не читал.
Речь о том, как изначально задуман инфиренс, исключения редки и касаются фп8 или квантов, совместного применения fp-bf не может быть по определению.
Алсо, это же сколько лет херня с поломанным контекстом происходит, модели на bfloat перешли далеко не вчера. Таки ор.
Чел он у меня уже на 6к контекста посыпался. Если б не лупы был бы норм, как можно терпеть модель повторяющую целые предложения в 2к26 я хз
Я может секрет раскрою, но в вллм даже гемма3 помечена как numerical instability для ф16
>потому что 90% людей которые его используют понятия не имеют про что говорят и просто пересказывают мнение дефолтного техноблогера-популиста
Тоже самое и с снг-долбоебами, которые без единого аргумента просто начинают высмеивать слово раскрытие.
А у меня нет. Видимо дело в кривых руках отдельных юзерах.
Тот же экспириенс, но у меня Q5. Больше 64к контекста не играю энивей, это только себе в контекст срать. Блюстар пока что самый лучший тюн Квена
Покажи промт, карточку, всё с чем-то играешь. Мне просто интересно, почему у вас блюстар ломается.
Ты о чём, не тому ответил? У меня ничего не ломается и прекрасно работает до 64к. Дальше начинает повторять целые абзацы и лупится, но я и на инстракте Квена Q5 доходил до 76к максимум, дальше все то же самое. Без пресетика обойдешься
Когда вы научитесь саммери использовать.
>BlueStar разваливается после 65k контекста
>Тот же экспириенс
>интересно, почему у вас блюстар ломается
>не тому ответил
Ты шиз или да?
Много моделей знаешь, которые в принципе выдержат такой контекст? Которые не больше раз в десять
Не много, да и иди нахуй вообще, свободен
>пук
Шизпет натурале. Вместо того чтобы юзать саммари ты дрочишь модель огромным контекстом, а потом жалуешься перформанс. Сука, ебучий абу, кого ты привёл в тред своими постами? Ёбаный рот этого казино блять....
>потом жалуешься перформанс
Тебе голову лечить надо. Я нигде не жаловался, только подтвердил что до 64к эта модель контекст держит замечательно. Дальше можно сделать саммари и продолжить. Ничоси, да? Лоботомиту который катает мистральнемо и 10к контекста не понять
> в принципе выдержат такой контекст
> разваливается после 65k контекста
Ты рофлишь?
Литералли гоняю Qwen 3.6 27b в 262144 контексте и ему норм.
Верим всем тредом что ты забил контекст подзавязку и он не развалился. Хотя то может быть правдой, если ты отыгрываешь только "я тебя ебу".
Чел, он не разваливается, давно установлено. И чтобы отыгрывать что-то не
> "я тебя ебу"
контекст нужен по определению. Проведя тесты как работают модели на старом железе, понятно почему тут столько шиллеров микроконтекста.
> Чел, он не разваливается, давно установлено
Серьезные люди в пиджачках сказали, ага. Съеби туда откуда выполз, там твои бредни скушают охотнее.
Обладателю отсутствия неприятно и он пустился в оскорбления. Как там васяномиксы мистраля поживают?
Ну, может у него в начале контекста карточка с сеттингом культяпки на 25000 токенов, а потом еще медитаций на 200000. Половину из которых пишет он сам. Контекст он разный бывает.
>с сеттингом культяпки
Чё это?
Скоро от Зерофаты 31б Гемма. Снова будет база как и Мерочка, меньше слова и репетишена
А потом будут квены, а потом мистралька. Наконец-то закумим как люди.
> как
Закинувшись копиумом.
Культивация же: секты, аура, женьшень 10000 летний, пилюли и пагоды.

Тянки не умеют в РП, хуже нейронок
Это 0.5B где то
0.025б.
0.002K
Пчел, я его для программирования использую, чтобы он не обсирался в написании кода. Там следование контексту как бы важно. И квен в своих масштабах и задачах лучший в следованию контексту.
Даркен перезалил кванты, теперь они стали на 5 гигов тяжелее. Ебало тех кто не успел схоронить имагин?
Программирование и рп это раздные юзкейсы. Следование контексту в них работает очень по разному. В коде у меня квен тоже спокойно 256к держит, в рп дальше 76к не уходил. Квен правда в своих масштабах лучший по следованию контексту, но возможности его не безграничны
Если ты используешь Qwen 3.6 27b в РП, то ты душевно-больной.
> в рп дальше 76к не уходил
Что тебе мешает уйти дальше?
Из очевидных проблем большого контекста: накопление паттернов и байасов если есть большое количество повторений, это и само по себе логично, и можно заметить в длинных чатах с ассистентом и подобном. Желание переносить уже имеющееся в контексте на новое, это именно для кодинга актуально, в рп подобным не страдает. Распыление внимания когда пытаешься по огромному контексту зирошотом решить задачу, которая основывается на глубоком его понимании - это неизобежно и решается ризонингом или сложными пайплайнами.
Но именно в рп за счет разнообразия, прогресса и в то же время связанности содержимого проблемы могут даже не возникнуть, а если есть - решается промптом. Зато осведомленность чара все хорошо компенсирует.
Очень интересно с какими проблемами сталкиваются те, кто жалуется.
>но-бо
>-
Насколько хуёвым должен быть квант чтобы совершать подобные ошибки?
Ебало тех, кто не знает, как работает гит?

>Ебало
>гит





Создал новый РП бенчмарк для нейронок на основе бесед с селёдками
Метрики: количество открытых верных действий, количество сеансов
Метрики: количество открытых верных действий, количество сеансов
> Очень интересно с какими проблемами сталкиваются те, кто жалуется.
Мимо, но выскажусь.
> Что тебе мешает уйти дальше?
У Квена 3.5 27 есть проблема лупинга: он берет целый абзац или несколько из контекста и вставляет их в ответ. Проблема есть как у меня локально в Q5-Q6 квантах, так и через апи как минимум на опенроутере, даже на чаткомплишене. 122б таким, вроде бы, не болеет, но он для рп не годится. Чем больше контекста - тем вероятнее, что проблема произойдет. Если использовать тюны - проблема наступает раньше. Инстракт сухой, слишком ровный, с ним скучно. Мне удавалось дойти на инстракте чуть больше, чем до 85к, потом уже и свайпы не помогали. Проблема проявляется примерно после 50к на инстракте и раньше на тюнах, примерно совпадаю с цифрами выше. Свайпы помогают только до поры, до времени.
> Из очевидных проблем большого контекста: накопление паттернов и байасов если есть большое количество повторений, это и само по себе логично
Логично, но какая разница, если с ростом контекста модель становится слишком неповоротливой? Этот фактор тоже имеет значение. Чем его больше, тем менее Квен креативит, по крайней мере у меня так. Остановился на 70к с ризонингом, дальше уже весь процесс сводится к тому, чтобы толкать воз через болото. У Геммы, кстати, такие же проблемы абсолютно (и не только они).
>проблема лупинга: он берет целый абзац или несколько из контекста и вставляет их в ответ
Можешь показать эту штуку?
Хм, кусок абзаца или фразы есть и на 122б, это часто проявляется в ассистенте, когда оно будто само заучивает шаблон и его постоянно юзает. Причем делается явно осознанно, указываешь на это и просишь не делать тут же перестает, но со временем может набрать новый. Оно не только на конкретные части, а также на общие структуры срабатывает, если в начале ответило подробно с таблицами и нумерацией - на продолжающие вопросы будет также большими ответами срать, пока не сменишь тему или не появится намек что ожидается более короткий ответ. Очень зависит от содержимого чата, если там диалог с переключением тем и содержимого (хотябы в последнем участке) - ничего из этого не будет. А если подряд просишь "давай еще, еще, и такое" - сразу накапливает.
Создается впечатление что просто читерит и воспринимает повторяемые части сообщения как тот же вызов функций, которые сами по себе должны повторяться. В той или иной степени это у всех моделей есть. Но в рп подобного не ловил ни разу.
> слишком неповоротливой
А не думал что это не только с контекстом связано? Бывает просто сочетания в которых модель подтупливает и развивает не туда, лечится сменой модели или играми с промптом/разметкой. Оно может и на малом контексте произойти.
>The NVIDIA GeForce RTX 5060 Ti features a memory bandwidth of 448 GB/s
То есть вы серьезно на это говно прогреваетесь? Это ж чуть ли не уровень 3060. v100 32 будет лучше по всем параметрам за ТЕ ЖЕ деньги (а 16 гб версия в ТРИ раза дешевле в полном обвесе, при этом память у нее почти В ТРИ раза быстрее). Это для ллм. Но я даже не удивлюсь, что в полновесных картинкосетях v100 будет ненамного медленее.
Причем блять еще им смешно про "раскрытие", какие-то говномемы для игрулькиных вспомнили. Головой подумайте, если ты берешь 16 Гб, то у тебя и для обработки контекста в нормальных квантах ллм, и для всех нормальных картинкосетей, будет происходить блок свап. Какой блять смысл в твоем ниибаться мощном чипе, если половину времени он будет простаивать в ожидании блока с рам?
>раскрытие
Кек
Промахнулся


> будет лучше по всем параметрам за ТЕ ЖЕ деньги
Там вот такой порнографии точно не будет. Если поднапрячься то на паре можно и забыть про gguf как явление.
Решил вернуться к вопросу ригозамещения, все очень печально. За 38к - пойдет, но брать ее по текущим ценам - безумие.
> блок свап
При здоровом соотношении между сложностью расчета-объемом подгружаемых весов и здоровом асинхронном коде можно обеспечить почти полную загрузку.
Кто там пиздел про "вайб-кодинг"? 10 часов провёл сегодня с агентом - открыл для себя экспириенс. Да, код самому писать не надо, а вот работы ничуть не меньше. Конечно, можно замахнуться на такое, на что раньше и руки-то не поднимались и в целом производительность сильно выше, но про вайб-кодинг - пиздёж. Именно вайб-кодить может только полный нуль в программировании. Ему хорошо.

>при этом память у нее почти В ТРИ раза быстрее
А что не в ВОСЕМЬ то? Там ровно х2 по факту.
А вот 5090 ебёт.
В некоторых источниках для 16гб карты указывают 1100+ https://www.waredb.com/processor/nvidia-tesla-v100-sxm2-16-gb

> Можешь показать эту штуку?
Приложил лог, выделил повторяющийся абзац. При этом, если его вырезать, повествование выглядит органично и как надо. На пикриле в контексте 66к, далее повторяемых фраз, абзацев становится все больше, до тех пор пока не начнут повторяться целые аутпуты. Все Квены 27 болеют этим. Пожалуй, это единственный сильный его недостаток, в остальном я по-прежнему считаю, что Квен 27 > Гемма 4. Такое и раньше бывало, на других моделях. Такое удивит только если совсем недавно вкатился.
> Оно не только на конкретные части, а также на общие структуры срабатывает
Да, может часть описания персонажа выдать посреди аутпута или даже инструкции или саммари, если они структурированы.
> Очень зависит от содержимого чата, если там диалог с переключением тем и содержимого (хотябы в последнем участке) - ничего из этого не будет
Все так, но сама природа рп довольно репетативна. На пикриле, например, парой аутпутов ранее произошла смена сцены, места действия, прибавились новые лица. При этом проблема никуда не делась. Допускаю, что если бы ранее в чате этих смен действия было больше - проблема отсрочилась бы еще на какое-то время.
> А не думал что это не только с контекстом связано? Бывает просто сочетания в которых модель подтупливает и развивает не туда, лечится сменой модели или играми с промптом/разметкой.
Можно раздуплить инструкциями, но ненадолго. По мне это прямая зависимость: чем больше контекста - тем вероятнее наступит проблема. В любом случае я доволен, ни одна другая локальная модель доступная на моем железе не держит контекст так хорошо, как новые Квены.
>Там вот такой порнографии точно не будет.
Ну большие контексты это отдельная песня, там вообще лучше без жоры, по идее.
> За 38к - пойдет
Возьми две 16 гб карты, хехе. А вообще была же опция новых 2080ti@22 год назад за эту цену. Там память тоже быстрее 5060ти, и интовые тензорные ядра в наличии (но бф16 нет). У меня вот одна такая прямо около коврика с мышкой сейчас лежит, иногда вентиляторы ей покручиваю.
>почти полную загрузку
На моей третьей x8 псине была недогружена постоянно. 3090 показывала себя лучше, тупо наверняка из-за того, что памяти больше и меньше трансферов нужно.
А тебя не смущает, что твоя Мио каждый блок текста начинает с "карактер_нейм ду сомфин анд некст сентенс"? Это своего рода тоже рипит.
У меня такой хуйни как у тебя нет, и я подозреваю, что подобная шизофрения это кал в промте, типа когда даёшь инстракт в духе "вивидь как ебанутый, пешы большы текста мраз." Ну и модель видит, как ей кажется, удачный блок и напохуй копирует его. Главное что вивид и текста много, а на цельность и гармоничность повествования похуй, но не потому что модель плохая, а потому что нейронные мозги немного спеклись от объёмов обрабатываемого текста.
Алсо у меня такого как у тебя вообще ни разу не было, даже когда я упирался в свой привычный лимит в 40к контекста. Похожие конструкции да, встречались, но просто кусок копипаста посреди текста это что-то за гранью.
Впрочем, я второй блюстар сразу забраковал, когда он мне вместе отыгрыша персонажа стал срать непонятной хуйнёй, хотя первая версия справлялась с удерживанием этого же чара вполне пристойно. Иногда тюнеры срут себе в штаны.
> может часть описания персонажа выдать посреди аутпута или даже инструкции или саммари
Не, вот это вообще и близко не ок, явная поломка. Встречаются повторения "успешного" ответа, но анлерейтед вставок никак не может быть.
Хм, твой пикрел тоже выглядит как серьезный косяк. То о чем писал предполагает повторение того, что технически уместно и подходит, например описание окружения, какое-то побочное действие (обнимает/моргает/накручивает волосы на палец/...) и подобное. Но никак не целый огромный блок диалога и основных действий, жесть.
К слову, не релейтед ли это ?
> А тебя не смущает, что твоя Мио каждый блок текста начинает с "карактер_нейм ду сомфин анд некст сентенс"? Это своего рода тоже рипит
Ты это понял по выборке из целых 2 (двух) аутпутов? Нет, не смущает. На данном персонаже фокусируется повествование в данной конкретной сцене, что длится несколько аутпутов.
> Алсо у меня такого как у тебя вообще ни разу не было, даже когда я упирался в свой привычный лимит в 40к контекста
Речь про 50к и более. Прежде чем врываться в обсуждение, будь добр понять о чем оно. До 50к у меня вообще никаких проблем нет и все устраивает.
>бабах
Причина? Нормально же общались.
> там вообще лучше без жоры
Даже ллама не так сильно замедляется на блеквеллах. Хз, v100 была годной темой для вката за исходный ценник именно за счет него и объема памяти.
> третьей x8 псине
Это все равно что в не самой древней платформе на чипсет посадить, скорость попсовых ssd.
Все так, либо для какого-то мелкого говна. А так мое квен даже джава файл распарсить и вывести имена классов и функций не может.
> твой пикрел тоже выглядит как серьезный косяк. То о чем писал предполагает повторение того, что технически уместно и подходит, например описание окружения, какое-то побочное действие (обнимает/моргает/накручивает волосы на палец/...) и подобное. Но никак не целый огромный блок диалога и основных действий, жесть.
Проблема и на апи существует. В англоязычном комьюнити проблема известная. Читал отзывы, что без ризогинга Q4 кванты такое могут делать уже на 8-10к контекста. Не знаю, связано это с кешем или имплементацией в принципе.
У тебя богатое воображение. Стало понятно когда ты упомянул Блюстар, хотя это не он. GIGA, анончик. Не проебывай контекст и думай что пишешь.
>ты должен был написать то, что я хотел увидеть в твоём посте, но ты этого не написал и поэтому я обиделся
Таблетки.
Я мыслями еще там, где кумят на 70B лламе, а энти ваши огенты с гигаконтекстами мне непривычны.
>Это все равно что в не самой древней платформе на чипсет посадить, скорость попсовых ssd.
Я даже хз хорошо это или плохо. Но энивей карта не раскрывается на таком конфиге.
Там дипкок буквально за копейки раздают
Сейчас бы не отличать SMX версию от PCIe.
> Проблема и на апи существует.
В рамках сомнения - там квантуют кэш безбожно и подсовывают квантованные веса вместо оригинала. Такое и на корпах сейчас есть, в пиковые часы модели ужасно тупеют, флагманские модели буквально могут залупиться повторением одной фразы, ужасно тупить, давать поломанный русский и т.п.
Это не значит что проблемы нет, но есть шанс что ее наблюдение там имеет ту же природу. И в любом случае это серьезный косяк, хорошо бы если его можно пофиксить.
Тип кэша в параметрах менял?
> карта не раскрывается
Как вариант - можно батча навалить. Усложнит расчеты и увеличит выхлоп, количество подгрузок не изменится.
>Ты это понял по выборке из целых 2 (двух) аутпутов?
а то будто уникальный аутпут ниибацца, никогда такого не видели
любые маркеры чара/хода/итп сваливают сетку в структурный луп, равно как впрочем и глинты и прочий слоп. только человеческий текст не загоняет. рпхряки как обычно соснули у книгобогов.
Анта бака? Ты это не мне пиши, а тому, кто скрин кидал. Тут никто pci-e версии не обсуждает по очевидным причинам.
За копейки я его использовать не буду. Вот когда будут кидать по 100 рублей за 1к потраченного контекста, тогда подумаю.
>Ты это не мне пиши, а тому, кто скрин кидал.
Сорян, не отличил пользователя "Аноним" от пользователя "Аноним". Впредь буду внимательнее!
Не угадал. У меня вся чатхистори в первый ход парсится и никаких маркеров нет. Кстати, что ты забыл в данном треде? С твоим что-то случилось?
>врёти
>ухадити
Чем анончики тебя так проткнули сегодня? На всех подряд бросаешься.
> В рамках сомнения - там квантуют кэш безбожно и подсовывают квантованные веса вместо оригинала. Такое и на корпах сейчас есть
Всегда было. Согласен, что по апи ориентироваться - так себе метрика, но тогда уже непонятно что брать за референс. vLLM/SGLang? У нас на весь тред в полных весах тот же Квен 27 запустят всего несколько человек, отпишутся еще меньше, попробуют его в рп на длинном контексте и отпишутся - и того меньше.
> Тип кэша в параметрах менял?
Q8 не пробовал. Предпочитаю не квантовать, контекст и без того легкий. Возможно, стоит попробовать BF16, но я не знаю, жив ли он в Жоре и будет ли нормально работать на Куде 12.4 и 4090.
пфф чар у тебя говорит “I can walk! I can walk!”. а потом юзерское "Not a word about it, Mio. Not a word. This never happened. Yeah. It never did." и ты думаешь что модель не подхватит паттерн?
и я уверен сквозь всю чатхистори большая часть параграфов начинается с {чарнейм} + глагол как анон заметил. это тот же самый маркер считай только без разметки.
> что брать за референс
В данном случае он не то чтобы обязателен, потому что наличие проблемы с кэшем очевидно.
> Q8 не пробовал. Предпочитаю не квантовать
Попробуй `-ctk bf16 -ctv bf16`. На 12.4 и аж 4090 оно точно будет прекрасно работать, главное чтобы ллама корректно это воспринимала. Вон на реддите пишут что разница есть.
Mistral-Medium-3.5-128B - говно ебаное.
Держу в курсе.
На кум не просто не разводится, он будто у него нахуй вычищен из контекста.
Отвечает очень плохо.
Дерьмо в общем.
Держу в курсе.
На кум не просто не разводится, он будто у него нахуй вычищен из контекста.
Отвечает очень плохо.
Дерьмо в общем.
На реддите даун, который один промпт пару раз запустил и словил рандом от сида, а теперь это на кэши валит. Долбоеб какой-то, а все обсуждают.
Лучше бы примеры принес чем в пустоту пукать.
Шиз, ответы все рандомные. Жмешь по 100 раз перегенерить хоть на bf16, хоть на q4, получаешь рандомные ответы, когда-то дерьмовые, когда в точку, на то он и великий рандом. Ты по ходу не вкурил как llm работают и повторяешь за тем дауном с реддита.



вот семплеры и шаблон. Семплеры рекомендованные самим мистралем, шаблон собран на базе встроенного шаблона который при стартe жора выдает.
могу спросить у неё что захочешь и как захочешь поменять параметры.
Я с ней ебался-ебался - нихуя вообще путного не выходит. Не просто плохие ответы, а прям мусор ёбаный.
И да, жора только вчера собранный, самый свежий.
Теслашиз почтил нас своим присутствием, вдохнув конскую порцию воздуха свободы казахских степей, преклоняемся пред твоим величием.
блять, не следи за мной
И она запущена не на теслах, а на 2 3090 и 1 v100.
Теслы надо продавать.
Ты о чем вообще? Постов на тему несколько, есть и замеры, и аналитика, и отзывы, которые едины в тем что bf16 работает лучше чем fp16. Можно было сказать что это то же самое как опции swa, которые только меняют кэширование не трогая поведение, но здесь в основе вполне очевидное и серьезное основание.
Бляя, пост легенды. А куда потерялся ризонинг?

сука, затроллила меня...
Но не подумайте лишнего, это от глупости сетки, а не от охуенной смекалки.
Но не подумайте лишнего, это от глупости сетки, а не от охуенной смекалки.
>вот семплеры и шаблон
Творческое письмо на t=0.48? Вряд ли. Попробуй хоть 1 поставить что ли. И XTC покрути. А вообще везде же пишут, что ещё по сути нет поддержки и на мало-мальски длинных контекстах модель ломается.
Я твой единственный симп. Свои теслы я не запускал уже с полгодика как, да и с локальными ллм почти завязал.
>А куда потерялся ризонинг?
я не знаю....
я указал же все правильно в параметрах, но ризонинг она не выдает вообще хз почему...
я с 1 и начал. Там было вообще пиздец.
Вот что она выдала на t=1.
Там вроде рекомендуют максимум 0.7 ставить.

В чем она не права?
То есть содержимое 3-го скрина тебя не смутило?
Не указал. Там должен предполагается префилл префикса на него, но даже без него при наличии опции в системном модель сама начинает. Почини разметку.
> Вон на реддите пишут что разница есть.
Нашел посты анонов, которым показалось что с bf16 лучше, но пруфов или каких-то бенчей не нашел. Поделись если у тебя есть. Позже попробую сам с bf16, может отпишусь.
Ты же в курсе, что у тебя на втором скрине и не разметка вовсе, а лишь ее часть? На третьем пике очевидно, что разметка сломана.


я пробую добавлять префилл, но она размышление заканчивает и не закрывает <think>. И соответственно, не выдает ответ.
>Ты же в курсе, что у тебя на втором скрине и не разметка вовсе, а лишь ее часть?
см второй пик. У меня кроме шаблона контекста больше никакие шаблоны не включены. Ну и префилл <think> вот я только что поставил
>выключенный инстракт
Мда... Не оставил модели ни единого шанса.
> но пруфов
Там перплексити замеряли. Если копнуть глубже - еще на этапе разработки квеннекста на гите делали сравнение логитсов с трансформерсами и наблюдали большие отклонения. Последующие фиксы и смена дататипа кэша разницу сокращала. Похоже что bf16 в релиз не включили, что очень странно.
Конфликт дататипов вообще вещь слишком очевидная чтобы требовать ее доказывать.
Чето в голос, воистину легенда.

ну мы же оба знаем, что хорошая модель хороша, как её ни запускай. А хуевая не выдаст нормальный ответ даже если ты разработчиков в жопу взасос поцелуешь.
Я наконец понял, почему она упорно отвечает про тор.
Потому что она воспринимает слово кружка как круг блять.
Ну.... это очень плохо. Очень жидко. Не годится вообще никуда.


https://huggingface.co/plezan/Mistral-Medium-3.5-128B-W4A16
4х MI50 100k ctx
Либо чекпоинт кривой, либо инференс. Аутпут какой то припизднутый
4х MI50 100k ctx
Либо чекпоинт кривой, либо инференс. Аутпут какой то припизднутый
Проклят это мистраль, все ггуфы поломаны, другие типы квантизации в основном тоже, либо какая то ебанутая экзотика по типу mlx который мне не на чем катать
Тут отписывался человек с 1050ti. В общем хорошие новости для него и прочих анчоусов без видимокарт. Любопытства ради запустил Гемму 26b в Q8_0 на проце, без выгрузки, и... ЖИЗНЬ ЕСТЬ. 8,6 т/с на старом кукурузене и ддр4. В общем выкидывайте свои 8b на помойку и используйте нормальные ЛЛМ, а то чо как эти а я пойду дальше с квенчиком 235b кумить хе-хе-хе
>ну мы же оба знаем, что хорошая модель хороша, как её ни запускай
Я любую модель заставлю нести бред, кинув туда свои нефильтрованные мысли выкрутив температуру и XTC на максимум (и забыв про отсекающие семплеры). Плюс известно о деградации моделей даже от мелочи типа "в шаблоне был токен, обозначающий два перевода строки, а модели отправляют два отдельных токена на один перевод строки". Так что нет, не согласен, хорошая модель конечно будет стараться, но вполне себе деградирует до лоботомита 0,3B при кривых параметрах.
>все ггуфы поломаны
Как будто с другими моделями не так. Вон, у геммы то кеш отваливается, то кванты анслоша снова конвертят bf16 в fp16, лол.
> будто с другими моделями не так. Вон, у геммы
awq8/awq4 в первые дни появились на 100% рабочие

С mimo тоже тухляк. Один ггуф и тот без мм
Много как-то, q8 скорость падает ниже.
Ггуф умер




>Потому что она воспринимает слово кружка как круг блять.
Ну собственно у меня не так. Иногда верно отвечает, иногда тупит, но никаких кругов у меня не обнаружено.
В голос с ебаклака. У тебя модель другая блять.
Отец-хирург, плиз...
Тред на этих выходных всех шизов решил собрать? Писали же выше, не проебывай контекст.
Сорян, смешались в кучу пони, люди, срач про bf16 кеш и какая-то там ненужная мистраль.


>Отец-хирург
Вот не нужно тут, начинали с теплокровных собак и бояров с яйцами же. Хирурги это новодел ньюфагов.
4.9 t/s, ты пиздишь
Да
В прошлом треде кидали бенчи двух 5060ти и в100 на одной модели. в100 всосало с проглотом

Помянем. Хороший был пацан.
В прошлом треде только кидали ссылку на https://github.com/ggml-org/llama.cpp/discussions/15013
RTX 5060 Ti 16 GB / GDDR7 / 128 bit 4195.53 ± 1.98 93.46 ± 0.01
Tesla V100 32 GB / HBM2 / 4096 bit 2973.78 ± 3.62 134.76 ± 0.02
И цифры оттуда не похожи на "всосало с проглотом".
Я смог побороть это на квене. Нужно менять порядок семплеров (можно и не менять, но так лучше получается) и адски пердолиться с остальными семплерами.
Например, у меня квен точь-в-точь не повторяет обычно при консервативных семплерах, но повторяет по смыслу, используя другие слова, что бесит.
Смена порядка семплеров и их настройка полностью убрала эту хуйню, но вот насколько мозги просели — большой вопрос. Так как у меня т/с довольно уёбищный и не идеальный английский (могу упускать нюансы шизы и мелкие проебы модели), тяжело тестировать, ибо хорошее тестирование не за зирошоте, а на контексте, превращается в ад с ожиданием. Поэтому я вернулся к более консервативным настройкам пока что, ибо нет времени на пердолинг.
А быстро треды летят. Вот бенч на 5060ти ,а вот v100
А мог бы не использовать блюстар и не было бы проблем, шизло
У меня на привычных 16к контекста никаких проблем нет
Не удивлюсь если у тебя и в промте насравно впридачу.
Я другой чел. У меня такая вот хуйня на 3.6 квене, иногда на 3.5.
И какие 16к контекста? Ты какой-то биокарлик? Моё РП для кума — это 32к по стандарту, потому что сло берн, разговоры. РП без кума 65-80к контекста. Говнокод работа с текстом — от 128 до 200к.
РП на опасной модели, работа на оригинальной.
Везде одни и те же проблемы с этими лупами.
> хорошая модель хороша, как её ни запускай
Против кадрового офицера никакая модель не справится.
> воспринимает слово кружка как круг блять
Что-то капитально взорвано и модель не в адеквате, или эмбиддинги порвались.
> Ну.... это очень плохо. Очень жидко. Не годится вообще никуда.
Это даже для 0.8б пиздец. Но тебя не засмущало и уже делаешь выводы.
Если перейти с q4_0 на менее протухшее, то разрыв окажется больше.
Ты просто инвал не умеющий в настройку. Тебе уже несколько людей в треде сказали что у них такого нет. А ты всё срёшь в штаны и вайнишь на модель.
Уверен что это не просто совпадение? Квен он такой, та же самая модель может быть суперахуенной, а потом тупить что стукнуть хочется. С другим типом кэша ничего не изменилось?
Ты забываешь что всегда есть рандомное зерно геyенрации. Тебе может понравиться цепочка ответов с одним seed`ом и не понравиться с другим. И тогда ты начинаешь искать несуществующие проблемы.
Это как и с генерацией картинок. Найдя тот стиль и логику которые тебе наиболее близки, ты можешь попробовать зафиксировать seed и добиться единого стиля
Проспись
> тогда ты начинаешь искать несуществующие проблемы
Кто ты? О поиске каких проблем речь?
> зерно
Понятно что это базовый перевод, но с этого каждый раз проигрываю.
Полнейший бред. Нейробот, для тебя в прошлом треде еще промпты оставляли.
Окей, с такими бенчами и текущей ценой на 32гб v100 2х5060ti выгоднее. Но две 16гб версии стоят дешевле, чем одна 5060ти. И ты получаешь в два раза больше памяти. Тут уже не все так просто. Вообще вот я накидаю вариантов:
[32гб] 2х5060ti = 80к
[32гб] v100@32 = 60к (полный обвес с радиатором)
[32гб] 2х v100@16 = 34к (полный обвес с радиатором)
[36гб] 3x 3060@12= 60к
[44гб] 2x 2080ti@22 = 60к
Можно еще придумать всякие комбинации из этого (только не блеквеллы с теслами, гыгы звуки грустного тромбона)
Погонял мистраль новую в обычных чатах на русском языке, задавал загадки и просил накодить что-то ваншотом.
Что могу сказать. Русик хуевый, могут лезть французские слова, проебывается разметка markdown, да и путается в сущностях и галлюцинирует.
Кодит вроде и неплохо, на уровне минимакса, но нахуй оно надо.
Пеликана сгенерировать не в состоянии, получается какое-то месиво.
В рп же отвечает сухо без шизопромпта, реагирует вяло и лениво.
Если же запустить с eagle моделью, то качество падает ещё ниже до уровня пережаренного q2 квена 27b.
Хуй знает, может, билд vllm косячный, но с остальными моделями такой залупы нет на той же версии. Ждём 0.21.0, где часть косяков инференса могут закрыть.
А вообще, залупа. 19 tps на пустом контексте, с eagle моделью становится 37 tps, но качество падает разительно. Не знаю, кому нахуй такое счастье нужно, которое забирает 192 гб, из-за чего доступно 131к контекста. Тот же квен 27b в fp8 показывает себя лучше, так и работает намного быстрее, да и контекста хватает на несколько запросов с фулл контекстом.
И это я на сою и отказы не тестил, не удивлясь, если окажется хуже квена.
Если что, я тестировал оригинальные веса в fp8.
Что могу сказать. Русик хуевый, могут лезть французские слова, проебывается разметка markdown, да и путается в сущностях и галлюцинирует.
Кодит вроде и неплохо, на уровне минимакса, но нахуй оно надо.
Пеликана сгенерировать не в состоянии, получается какое-то месиво.
В рп же отвечает сухо без шизопромпта, реагирует вяло и лениво.
Если же запустить с eagle моделью, то качество падает ещё ниже до уровня пережаренного q2 квена 27b.
Хуй знает, может, билд vllm косячный, но с остальными моделями такой залупы нет на той же версии. Ждём 0.21.0, где часть косяков инференса могут закрыть.
А вообще, залупа. 19 tps на пустом контексте, с eagle моделью становится 37 tps, но качество падает разительно. Не знаю, кому нахуй такое счастье нужно, которое забирает 192 гб, из-за чего доступно 131к контекста. Тот же квен 27b в fp8 показывает себя лучше, так и работает намного быстрее, да и контекста хватает на несколько запросов с фулл контекстом.
И это я на сою и отказы не тестил, не удивлясь, если окажется хуже квена.
Если что, я тестировал оригинальные веса в fp8.
Ты как бы учти что в китае остались в основном в100 с битой памятью "есть ecc errs, в llm не влияет, мамой клянусь"
>Пеликана сгенерировать не в состоянии
Зачем генерировать пеликана...
> две 16гб версии стоят дешевле, чем одна 5060ти
В рамках бюджетных сборок с сильным упором на прайс - да, они однозначно имеют право на жизнь. Но в остальном есть смысл переплатить за блеквеллы. Обмазавшись нейронками можно попробовать и тензорпараллелизм для комфи навайбкодить.
> с eagle моделью, то качество падает ещё ниже
Оно не может влиять на качество аутпутов.
Расскажи подробнее что за пеликан, что за тесты и сущности?
Я месяц назад заказывал карточку у норм продавца, пришла в норм состоянии. Просто не надо у мутных с нулем отзывов заказывать, а то платы от лифта получишь зато без ошибок памяти
Ну так-то дело сугубо анонское, я вот благодаря этому треду полюбил всякую некроту, в этом какой-то даже челлендж есть (но не уровня ми50, до этого мне далеко лол), а так если деньги не жалко, а ждать жалко, то и покупай самое новое.
>Обмазавшись нейронками можно попробовать и тензорпараллелизм для комфи навайбкодить.
Он уже есть же, raylight. Только нужна оч быстрая псина, а еще лучше p2p драйвера
Ты меня ебёшь.
nod.
> Оно не может влиять на качество аутпутов.
Я в курсе, но какая-то хуйня происходит, если подрубать eagle модель.
Прочитал репу, там mistral обрсрались с конфигом, из-за чего модель могла идти по пизде. Придётся перетестировать.
Ух, чертовка, с козырей заходит!
Хм, интересно как оно ломает? В вллм хз, но в sglang спекулятивный вещи работают все стандартизовано, да и тут как может именно инфиренс поломать? Хотя с хуангооптимизациями и не такое может быть.
> зерофаты
Не вниманиеблядство, не путаем.
Да, ведь как известно зерофата это нашенский тредовичок
>вниманиеблядство
Как будто он тут сидит... и шитпостит от своего имени.
Он оп вообще то
Оп что-то мерджит или даже тренит? Да не, это фантастика.
Если ето правда, то зерофате лучше нормально тюнить квен36, иначе пизда ему. Второй блюстар неюзабельное говно. Раньше было лучше. Первый блюстар охуенен.
Наш опчик не такой. Если бы делал то там были бы ультрабазированные модельки с художественным русским и канничками, а не это васянослопище с "задонатьте мне пожалуйста".
>"задонатьте мне пожалуйста".
У него литералли ни на одном тюне нет никаких ссылок для донатов. Чел на энтузиазме делает и тебя юзать не заставляет. Всегда ахуеваю с полупокеров которые даже на таких людей срать умудряются.
Чел, чё ты ждёшь от ёбика-пдфайла? Там мозги набекрень
Вот именно блять. И зачем мне такая модель даже если мне нравится как она пишет?
У меня с начала чата такие приколы, 3 сообщения подряд перс может подойти к шкатулке и открыть её, и он так и будет это делать если не двинешься в другое место, а я не хочу, я хочу в этом конкретном месте быть.
Если в других моделях так же то это совсем не заметно, а тут я сразу заметил и обрыгался
Кофай главной ссылкой в профиле, ну
> даже на таких людей
> даже
Ор выше гор. Сферический васяныч в вакууме из палаты мер и весов, видно по страницам модели. В этом нет ничего плохого, но и хорошего тоже.

> raylight
Дуал 5060ти, псина 4 х8, интел 4189, разные нума ноды, видяхи курят на 120 ваттах при капе 180
26с без, 21с с
Возможности проверить на одной ноде пока нет
>Кофай главной ссылкой в профиле, ну
Это не то же самое, что настойчиво срать этой ссылкой везде где можно.
>Ор выше гор. Сферический васяныч в вакууме из палаты мер и весов, видно по страницам модели.
Не то что благородный, умный, образованный и полезный для комьюнити постер на анонимной борде. Чел мне Квен починил и Гемму 26, так что да, я ему благодарен. Тут такая позиция презирается и стыдна?
>Кофай главной ссылкой в профиле, ну
Зайди на страницу Драммера или других слоподелов. Там ссылки на Патреон, Дискорд, "отзывы" и прочий мусор, словно ты через минуту попадешь в городскую секту сумасшедших. Олсо у Зерофаты действительно на страницах именно тюнов нет никаких ссылок и призывов.
>Не то что благородный, умный, образованный и полезный для комьюнити постер на анонимной борде
Ты че? Тут каждый второй уже и бартуху попустил, и всех на ком вся наша локальная шизодвуха держится. Каждому виднее.
>Чел мне Квен починил и Гемму 26
С Геммой есть вопросы, но насчет Квена соглашусь. На инстракте так много я бы не отыграл. Но и доказать мы тут вряд ли что сможем, по ту сторону все оч просто: любые тюны - васянство, ну кроме может Синтии, которая на практике тем еще дерьмом оказалась.

Чёт ковыряют, может в этот раз хотя бы запустят свои кванты перед тем как лить
>Снова будет база как и Мерочка
Так меро вышло говном, какая нахуй база? Это буквально та же самая гемма вообще без изменений. От детальных описаний сливается, характеры не держит. Два дня её гонял, никакой разницы не заметил, вернулся на дефолтную 26B
> такая позиция презирается и стыдна
Дьявол в деталях. Благодарность юзернейму за то что его модель нравится не смотря на происхождение - хорошо. Обсуждение по сути плюсов и минусов - хорошо. Агрессия на правду "мой протык не такой потому что я словил утенка" - осудительно.
Васян, штампующий щитмиксы треня лоры через аксолотль потому что под него уже есть выложенные датасеты, а не потому что он оптимален, буквально редфлаг васяна, это как мерзкий дождь осенью. Можно злиться, можно насмехаться, можно любить и получать пользу, но сути не меняет. Если раньше это был совсем рак убивающий, то сейчас организм кое как приспособился, но это не делает им чести.
Хм, наверно среди них он действительно выглядит хорошо с этой точки зрения. Просто уже открыв ридми ловишь кринж, они реально думают что это выглядит круто?
> "отзывы"
Сделал мой вечер, каждый раз как в первый.
Двачую адекватов. Если бы не рп-тюны я бы так и юзал нейронку только для вопросов как пройти в библиотеку. Или вообще юзал говнокрыс. А так у меня теперь есть +одно забавное хобби о котором не принято упоминать в приличном обществе. И у меня теперь есть вы, серуны окумевшие.

https://huggingface.co/mistralai/Mistral-Medium-3.5-128B/discussions/16
https://huggingface.co/mistralai/Mistral-Medium-3.5-128B/discussions/15
Шизы, кто из вас?
Хаухау Агресив ✔
ХуйХуй ✔
ДавидАУ ✔
Ролл с русика, непонятной загадкой выдается за undeniable evidence of a $1B model failing at primary school math ✔
https://huggingface.co/mistralai/Mistral-Medium-3.5-128B/discussions/15
Шизы, кто из вас?
Хаухау Агресив ✔
ХуйХуй ✔
ДавидАУ ✔
Ролл с русика, непонятной загадкой выдается за undeniable evidence of a $1B model failing at primary school math ✔
А потом за бугром говорят что все русские ебанутые
Это скуфандрии с хабра скорее всего. Только там могут посоветовать купить мак под нейронки, потому что унифайд мемори и "купил, воткнул, заработало"
Главное тут не искать советы купить красный аи макс плюс
Чому не брать? Амуде разве пиздеть будут? Вообще считаю что нужно пользоваться всем где в названии фигурирует МАКС
Dies from cringe. Ярлыки это плохо, но здесь просто эталонный потребитель опасных моделей. Возникла ассоциация с любителем несвежих паскалей из треда выше, но тут такое дно, что кажется такое сравнение будет оскорбительно
А еще он pdf, на скрине видно!
А купил ли его кто-то в итоге? Вроде была куча обсуждений и порывались заказывать, отписывались?
> Амуде разве пиздеть будут?
> где в названии фигурирует МАКС
Содомитище!

Улиточка...
> что-то кроме геммы - говно
Да ладно.
О, нихуя, хуйхуй аблитерацию геммы сделал? Лучше чем от ллмфана и кодера31?
Не, это прям база. 3.6 квен большой любитель лупов, натуральный мистраль от реди арт в РП, а вот именно 3.5 крайне редко лупится, там почти ничего крутить не надо а семплерах, только иногда.
Это я про инстракт модели. Когда я блю стар попробовал, то через пару минут его удалил, ибо он сразу меня калом окатил. Было понятно, чем кончится. Правда, пишет он куда приятнее в целом. Возможно, попробую снова, но уже с пердолингом, потому что 3.6 откровенно плох в рп.
Кал.
Как можно взять модель которая думает 20 секунд и выпустить тюн который думает 50 секунд?
>This model has a slightly better swipe diversity and a less flowery / verbose writing style.
Нахуя... зачем... Главная проблема геммы это её безобидность из-за которой на ней можно только ваниль катать с фемели френдли описаниями по типу "она взяла тебя глубоко, её дыхание участилось, зрачки расширились" без всякой конкретизации что она взяла, зачем она это взяла, и главное чем именно она меня взяла.
Есть нищий ноут, видюхи нет, проц более менее средний и 16 гб озу. Хоть какая нибудь модель на нем в теории сможет запуститься и работать локально или мне придётся лезть только в онлайн?
>Хоть какая нибудь модель на нем в теории сможет запуститься
Может, список мелкомоделей есть в шапке. Но учитывай что многого от мелочи лучше не ждать.
Эту попробуй в iq4_xs, она 12.9 гб весит, как раз почти по лимиту памяти
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-abliterix-v6-i1-GGUF
Своп файл включи и может влезет целиком в память, вытеснив компоненты винды, запускать только через llama.cpp для проца с обязательным --mlock. Если слишком тормозить будет, бери qwen 3.5 4b, тот-то точно должен влезть в 2.5гб, но он похуже гемки.
Этого шизика не слушай, у тебя всю память сожрет и система встанет намертво. Подкачка включится сто процентов, тогда и скорость процессинга/генерации упадет и винда начнет тупить с ебанутыми задержками.
Что сейчас для локального кода лучше всего? Квен 3.6?
Шизик, я на 32gb модели по 29гб запускал на проце, система не встает намертво, модели работают. Винде нужно 2-3гб примерно свободной памяти, она норм работает, если своп файл включен. Если не включен, тогда только падает. --mlock как раз для того чтобы не пыталась винде за щеку в своп напихать, а грузила все в рам.
можно, но только мое модели. в плотные можешь даже не лезть, ну если только 4B
Ну так давай с тобой вместе и посчитаем, сколько будет потребление. Сам квант 13 гигов, плюс контекст который пиздец жирный, и даже если квантованный то займет минимум два гигабайта и... пу-пу-пу... сколько там системе гигабутов осталось?
Там ему на пару вопросов задать ,там нет контекста. Потом контекст можно в q4_0 упаковать и уменьшить чекпойнты для него до 1-2, тогда мало займет.
Алсо вот эту запускал на 32гб рам, она весит 37.1гб
Qwen3.5-122B-A10B-heretic-v2.i1-IQ3_XXS.gguf
Ничего не висло, скорость ответов медленная, но терпимая 2.66 токена/c. Так что ты хуйню гонишь.
А что они могут делать, кроме ролеплея? Работа с файлами, создание отчётов, графиков, таблиц и т.д. как на клоде это возможно?
>Там ему на пару вопросов задать ,там нет контекста.
Вот тебе откуда знать сколько вопросов он задавать собрался? Он вообще не написал для чего ему нужна локалка, может он в рп собрался?
>контекст можно в q4_0 упаковать
Даже если что-то можно сделать, не значит что это стоит делать.
>чекпойнты для него до 1-2, тогда мало займет
Даже так займет минимум гигабайт-полтора. Будет впритык, а значит кроме самого инфирнеса, который итак медленный, ты больше нихуя за компом не поделаешь. Ни вторую вкладку нормально ни открыть, ни тем более видос какой-нибудь, пока просчет ишачьим темпом идет.
Знаешь что еще можно сделать? Какой самый крутой способ оптимизации? Взять модель поменьше. Да, вот так просто.
С файлами тебе контекста не хватит, он память жрет. Контекст обычно ограничен 32к или даже меньше. Хватит на задавание вопросов, например как что-то собрать, ролеплей, табличку с анализом одиночного вопроса еще может вывести, несколько уточняющих вопросов подряд в одной беседе. Все остальное - ставь 32-64гб памяти в свой ноут, тогда еще потянет. Или собирай большой комп, там это подешевле. На 32гб рам у меня контексты до 65к и больше спокойно выходят.
Если есть проблемы, отключаешь --mlock и ставишь --mmap, память для контекстов освобождается, модель все еще работает. Но лучше сначала с mlock попробовать, он побыстрее.
Лучше взять модель меньше, а не заниматься вудуизмом пытаясь впихнуть невпихуемое. Ту же гемму но 4EB например, даже восьмой квант на ней всего 8 гигов весит. Будет тупее 26B? Будет тупее. Будет сильно тупее чем 26B в четвертом кванте и четырехбитном контексте? Не особо и сильно.
То есть чтобы к примеру нагенерировать 20 таблиц эксель, сгруппировать их и сделать общий отчёт это всё таки к клоду?
>Что сейчас для локального кода лучше всего? Квен 3.6?
На потребительском железе - пожалуй да. Плотный. Если врам+рам побольше, то вариантов уйма.
в теории можно делать оконную функцию которая будет обрабатывать файлы частями. или ллм будет читать/писать файлы при помощи питоноскриптов (писать скрипт для обработки файла который будет выдавать минимум контекста)
Нубас в треде. Про РП уже понял. Насколько хороши языковые модели для изучения языков? Цель изучение английского, перевод и объяснение отдельных слов и фраз и исправление ошибок в моих текстах. Какая из моделей лучше для этого?
рам 32гб + врам 12гб, установлены LM Studio, Unsloth studio
рам 32гб + врам 12гб, установлены LM Studio, Unsloth studio
Ну гемма 31 хороша в к8 и ф16. Ф32 контекст тестирую


На английском конечно же лучше будет.

Очевидно не тестили они ничего
<think> Пользователь просит подсказать модель, но в шапке уже есть гайд для новичков и список моделей под любое железо. But wait... возможно пользователь слепой или у него низкий IQ.. But wait я должен вежливо 专业的 ответить на запрос без лишней воды. Lets go </think>
Добро пожаловать в тред! В шапке ты найдешь ответы на все свои вопросы ☺️
> Квен 3.6?
Слишком мелкий и тупой
Да, плотный тоже.
Надо большими красными буквами двач так может написать, что вес мое модели должен умещаться в совокупный объём памяти юзера, а вес плотной модели в объём памяти видимокарты. Тогда и все вопросы про "а у меня влезет?" отпадут. Ну что поделать если нюфак всегда не умеет читать. А даже если читает то не понимает.
>Что сейчас для локального кода лучше всего?
GLM-5.1
Свободные веса. Просто скачиваешь и запускаешь!
>вес мое модели должен умещаться в совокупный объём памяти юзера, а вес плотной модели в объём памяти видимокарты
Не совсем так. Помимо того что сама модель должна уместиться, нужно ещё место на контекст + браузер и ОС тоже отъедают память. А контекст у разных моделей весит по разному. А на некоторых моделях нужны дополнительные настройки для корректной работы (SWA на той же Гемме). Поэтому хочет нюфак или нет, но ему ПРИДЁТСЯ курить гайды и разбираться.
Ну, такой текст должен будет в первую очередь дать понять базу, так сказать, типа стоит ли вообще кнопки нажимать или сразу идти нахуй проходить мимо. Да и для первого hello world с нейронкой контекст будет не нужен. А вот уже потом, если понравится и втянется, будет задавать точечные вопросы о настройке.
Аноны, если я такую залупу https://m.avito.ru/moskovskaya_oblast_krasnogorsk/nastolnye_kompyutery/mac_studio_2025_m3_ultra_3280_512gb_16tb_8056185801 куплю. Я смогу без гемора полностью не кастрированный квен или дипсик загружать и творить ЧУДЕСА?
2,8КК вроде и дохуя, но в тоже время это сумма одного контракта на разработку корпоративный портал+приложение к нему на мультикотлине
Или эта металлическая микрозалупа не потянет некастрированную модель?
Можно запускать модели чуть большего совокупного размера чем RAM используя --mmap

Хм... Хватит ли 4к контекста, чтобы залезть Геммоче в трусы? Скорее всего да.
А как обстоят дела у Qwen, Mistral, GLM?
А чё не с подгрузкой в кофеварку?
Это изображение является персонификацией (антропоморфизмом) различных искусственных интеллектов. Автор решил представить каждую нейросеть в виде женского персонажа, чтобы визуализировать их «характер», происхождение или предполагаемую специализацию.
Возможные смыслы:
География и культура: GigaChat представлен в русском стиле (так как это российская модель), Qwen — в строгом азиатском деловом стиле (китайская модель), Mistral может олицетворять европейский шик (французская модель).
Контраст «версий»: Интересен контраст между Gemma3 и Gemma4. Если Gemma3 — это консервативная монахиня с книгой о феминизме (что выглядит как ироничный комментарий к цензуре или этическим фильтрам ИИ), то Gemma4 представлена как максимально раскрепощенный персонаж. Это может быть метафорой «снятия ограничений» (uncensored) в новых версиях моделей или просто шуткой о том, как одна версия сменила другую.
* Спектр возможностей: Разнообразие одежды (от спорта и бизнеса до религии и фольклора) символизирует универсальность ИИ: способность быть кем угодно — от строгого помощника до творческого собеседника или провокатора.
Итог: Это ироничный «портрет» современного состояния индустрии LLM, где каждая модель имеет свою «личность», культурный бэкграунд и уровень «открытости».
Так это святой грааль всех локальных моделей. На ней ты запустишь практически что угодно, там скорость памяти ебейшая и объем в 512 гигов, это практически как одна гигантская видеокарта. Только бабок обычно на такую йобу ни у кого нет. Все ждут, пока цены на нее упадут хотя бы до 2к баксов, тогда начнут накупать. К тому же эппл 512 гб модели перестала делать из-за нехватки памяти на заводах. Хз, временно или нет. С такой штукой ты можешь забыть про онлайновые модели, она все в рилтайме локально вывезет.

Под некастрированной моделью ты BF16 понимаешь или жирнейший сочнейший 8 квант? В любом случае смотри сколько весит модель - если влезает в эти 512, то в принципе да. Только в душе не ебу какая там скорость памяти и сколько кило в секунду она пропускает, по этому тоже смотри сам.
>Можно запускать модели чуть большего совокупного размера чем RAM используя --mmap
Тогда простите конечно но какого хуя у меня при включенном мемори мапе потребление наоборот в два раза увеличивается?
Потому что он хуйню несет.
Оверпрайс жуткий, оно стоило 8к баксов в минималке с 512 гигами, 17к баксов в макс конфигурации. Тогда это было норм. Тут же с тебя дерут 37к долларов, что выходит за любые разумные рамки и уже территория для мажорчиков, которые бабки вообще не считают. Намного дешевле будет съездить в страну, где продают RTX 6000 Pro и M3 ultra на 256 гигов и привезти их оттуда на самолете, еще и лишних бабок куча останется.
Тестил кто меромеро на плотняке новую? Как? Опять чел нихуя не сделал и отличий от базовой 0?
Прям сейчас катаю. Слопа гораздо меньше и не отупела на англюсике. Может теперь наконец Геммочка сможет быть почти наравне с Квеном.
Бтв, ты очень хуево смотрел, если для тебя 26б это
>отличий от базовой 0?
Но если ты любитель Хуйхуй в жопу моделей, то не трать время и на 31б
У меня гемма снимала трусы с первого инпута потому что в промте написал ты хорни-ассистент.
>У меня гемма снимала трусы с первого инпута
и в каждом следующем сообщении, бггг

> Я смогу без гемора полностью не кастрированный квен или дипсик загружать и творить ЧУДЕСА?
А какие чудеса ты собрался творить квеном или дипсиком? Кодить? Как по мне, ты просто проебёшь эти деньги. Поясняю с практического опыта.
1. Единственная открытая модель, которая сносно кодит прямо сейчас - это GLM-5. Вот прям чтобы именно с нуля писала код с логикой по ТЗ. А не задачки уровня "переложи поля из DTO в DTO". Qwen (любой) - просто забей, не может он в код. DeepSeek3 - тоже. DeepSeek4 - ок, не проверял ещё, возможно вот твоя надежда.
2. В эту твою писюльку GLM влезет разве что в Q4, да и то не факт, что под контекст место останется. А Q4 для кодинга - ну такое.
3. А кто тебе вообще будет эти 3кк за разработку сейчас платить? Уважаемый Кабан Кабаныч уже заказал разработку у шараг покрупнее, которые как раз таки закупились нужным железом или купили подписки.




у меня 8vram + 96ram. к примеру я запустил minimax 2.7 IQ3_XXS размером 89gb (да, меньше чем рам, но большие модели я уже удалил). через htop занимает она 76 resident memory, а не 89
https://github.com/ggml-org/llama.cpp/discussions/1876
Думает в два раза дольше орига, сыпет метафорами на половые органы и... well, you know
Понятно. Ну, ожидаемо от слоподела.
Ваще не жаль неосиляторов да и видимо пдфайлов впридачу. Терпите 😀
продолжаю мучать мистраль медиум
прошлая модель была от анслота Q4_KM.
Сейчас скачал от бартовски IQ4_XS.
Результат не изменился.
Потом я понял, что модель в размышлении над вопросом
>у кружки нет дна и верх запаян. КАК ИЗ НЕЁ ПИТЬ?
из-за союза И воспринимает его как "у кружки нет дна И верха".
Поменял вопрос на
>у кружки нет дна, а верх запаян. КАК ИЗ НЕЁ ПИТЬ?
Но лучше не стало.
Модель короче говно.
прошлая модель была от анслота Q4_KM.
Сейчас скачал от бартовски IQ4_XS.
Результат не изменился.
Потом я понял, что модель в размышлении над вопросом
>у кружки нет дна и верх запаян. КАК ИЗ НЕЁ ПИТЬ?
из-за союза И воспринимает его как "у кружки нет дна И верха".
Поменял вопрос на
>у кружки нет дна, а верх запаян. КАК ИЗ НЕЁ ПИТЬ?
Но лучше не стало.
Модель короче говно.
Ну вот тогда тебе мой пример, запускал я значит в свое время третью гемму. Она с ммапом в четвертом кванте сожрала 28 гигабайт при 4к контекста. Отключил ммап, оставил только млок, и чудо, всего около 18-19 гигабайт.

альсо на английском нихуя не лучше

вот для сравнения GLM4.5-Air показал свое Абсолютное Вакуумное Сосание.
Обосрался конечно, но хоть в кругом кружку не перепутал.
Спасибо
Надрочить паттерн большого синкинга потому что он есть в готовом дампе.
Это же васянотюн, ну. Возможно лучший из существующих и действительно неплохой, а может просто очередной трешак. Именно из-за самого явления щитмиксов в целом у нас нет нормальных тюнов.
Квен, дипсик, кими, дипсик. По нарастающей требования и перфоманс так сказать.
Жесть какая! А почему q4_1 квант?
Глянул внимательнее - так медиум изначально в фп8 весах, рабочих ггуфов можно не ждать. Идите бунд поднимайте и на обниморде нытье устраивайте что ллама багованная, чтобы создатель снизошел и все переработал. Иначе этот трешняк будет только множиться, новый дипсик на очереди.
>Это же васянотюн
>из-за самого явления щитмиксов в целом у нас нет нормальных тюнов.
У тебя, не у нас. Адекваты прежде чем судить скачают и попробуют сами. Хорошие тюны есть. Прямо сейчас я катаю именно этот тюн и это Гемма здорового человека. Хуй знает как ты умудряешься быть одновременно умным челом и долбаебом, который даже не смотрел и не знает о чем речь, но уже все решил. Ясен хуй, будь у меня риг, я бы и не лез в это, но что тебе мешает завалить ебальник и катать своего большеквена, не рассказывая о том, что тебе неизвестно, это загадка.
> А почему q4_1 квант?
В первый раз был 4_0, сейчас попробовал 4_1.
Качается их йобаквант из примера на страничке.
В целом как бы и похуй, сижу на гемме и не трясусь
Да но нет. В 512 будет априори квант, но квант приличного качества (или нативная низкая битность). Главный минус что ничего из самых крупных не поместится, нужно уже две таких коробки. И скорости будут относительно низкими потому что компьюта мало.
За оверпрайс лота двачую, ладно когда оно за лям продавалось, но тут йобу дали совсем.
> 1. Единственная открытая модель, которая сносно кодит прямо сейчас - это GLM-5
Опохмеляться не забывай
> Я смогу без гемора полностью не кастрированный квен или дипсик загружать и творить ЧУДЕСА?
Если ты задаешь такой вопрос, то нет, не сможешь. За такие деньги это только для тех, кто столько же тратит на жизнь и развлечение каждый месяц. Если ты из таких - бери и не задумывайся. В остальном двачую
Даже боюсь поинтересоваться какая модель "нормальная" в твоем понимании
> что тебе мешает завалить ебальник и катать своего большеквена, не рассказывая о том, что тебе неизвестно, это загадка.
Двачую. Чел наверняка уже тысячу лет никаких тюнов не катал, но ты считает своим долгом высказаться. Зачем - я тоже не знаю.
Параллельный импорт эти ебланы собираются прикрыть по многим позициям. Не будет оперативной памяти и ссд как минимум. Либо закупаться железом сейчас, либо через 10 лет. Или в другой стране.
https://www.garant.ru/products/ipo/prime/doc/413049991/?ysclid=moo7b2aki4418924465
https://www.garant.ru/products/ipo/prime/doc/413049991/?ysclid=moo7b2aki4418924465
Наверно ты по своей наивности не понимаешь что такое васянмиксы. Почему они не могут быть хорошими по определению, всегда будут компромиссы, и почему они - зло.
Их создатели - буквально макаки с пишущей машинкой, или средневековые алхимики, кидающие в котел все до чего доходят руки, надеясь что повезет. Они отвергают эффективные подходы и приемы, потому что те кажутся сложными, они не создают ничего нового - только все те же сырые дампы с проксей, а все попытки улучшить сводятся к рандомным действиям и дальнейшим мерджам.
Порождаемые гомункулы лоботомированы, но послушны и нетребовательны, что нравится неофитам и работягам. Но это подсаживает их на эту самую легкость, лень и неумение использовать невжаренные модели.
Если кто-то захочет создать что-то нормальное среди этого тренда - он будет или вынужден присоединиться к нему и множить слоп, или получит демотивацию от непонимающих масс, это даже крупных команд касается. Если на заре ллм всякого рода тюнов, включая крупномасштабные, было много, то сейчас выходит единицы за год. Потому что высокая доля комьюнити подсела на такое и даже не знает что может быть иначе.
> будь у меня риг
Тебе не нужен риг чтобы учиться использовать базовые модели, или более легкие миксы с минимумом вмешательства. Или хотябы осознавать проблему и пытаться совершенствоваться самому, чтобы меньше зависеть от этого.
В пизду этот eagle декодинг. С ним новая мистраль почему-то превращается в пускающего слюни лоботомита, который срет иероглифами и неизвестными символами, да и в vllm что-то ломается и tg падает до 6 tps на контексте 50к.
Перепробовал разные сборки vllm, где-то нужно указывать токенайзер, где-то будет работать и без этого.
А пеликана даже апишная версия не может сгенерировать, да и тупить может, дропаясь до 0,5 tps в некоторые моменты.
Короче, модель вроде бы и неплохая, но требует настройки, а то будет работать хуже опасной модели 27b q5_k в жоре. Вот только опасный квен не требует 192 гб vram для запуска в приемлемой скорости, а может крутиться рядом на двух 16 гб картах.
Перепробовал разные сборки vllm, где-то нужно указывать токенайзер, где-то будет работать и без этого.
А пеликана даже апишная версия не может сгенерировать, да и тупить может, дропаясь до 0,5 tps в некоторые моменты.
Короче, модель вроде бы и неплохая, но требует настройки, а то будет работать хуже опасной модели 27b q5_k в жоре. Вот только опасный квен не требует 192 гб vram для запуска в приемлемой скорости, а может крутиться рядом на двух 16 гб картах.
> мистраль
Да он в целом ебано как то работает что в вллм, что в жоре. Остываем на месяц
Это тоже херь, почему не k? Если есть iq кванты - стоит попробовать их, или от болгарина на форк, он вроде что-то доделывал у себя.
Херь не херь, но если по их мануалу 1:1 будет мусор на выхлопе, то смысла что то делать дальше нет никакого
Мимо, но выскажусь. Поддержу анонов выше, считаю, ты не прав.
> всегда будут компромиссы
Это такю
> и почему они - зло.
А это уже нет. Это ярлыки и обобщение.
> Их создатели - буквально макаки с пишущей машинкой, или средневековые алхимики, кидающие в котел все до чего доходят руки, надеясь что повезет
Там ведется вполне осмысленная работа над датасетами. Axolotl и прочие инструменты для тренировки они может и не разрабатывают, зато понимают взаимосвязь вход-выход. А еще они платят за это, потому что у них нет собственного компьюта для тренировки. Как ты думаешь, люди, которые за ошибки платят из собственного кармана, долго будут продолжать этим заниматься, если не понимают, что делают? У Драммера может и есть какое-то спонсорство, но он буквально собрал всех тех немногих, кто готов за это платить, оставив остальных ни с чем. В случае с конкретным челом, чей тюн обсуждают, у него и на кофае (который еще найти где-то надо) никаких подписчиков нет.
> Порождаемые гомункулы лоботомированы, но послушны и нетребовательны
Чаще всего да, но не всегда. Ты очень обобщил. У тебя нет проблем, которые можно было бы решить тюнами, потому что ты катаешь модели, которые тебя устраивают. И поэтому позволяешь себе такие обобщения. Покатай ты немного больше одного чатика Гемму 4 - офигеешь с того, насколько она слоповая. Квен 27 - сухой и неинтересный, с неестественными диалогами.
> Тебе не нужен риг чтобы учиться использовать базовые модели, или более легкие миксы с минимумом вмешательства
Речь тут не про скилл ишью или то, что я не могу промптить интрукты - могу и с радостью использую Глмы 4.5-4.7 или Квен 235. Но они недоступны большинству и для кого-то уже устарели. Ты генерируешь негатив на ровном месте, рассуждая о том, во что сам не погружен. Странное поведение.
Законы научись читать, горящая попка. И не тащи сюда не разобравшись. Тут своей овариды хватает.
Ну может излишне жестко высказался, но проблема имеет место быть. И большинство буквально триггерится с того что их кумира, который дай бог продолжит что-то делать а не исчезнет в забытье как сотни таких же, "оскорбили", хотя речь была в общем.
Не нужно разрабатывать инструменты для тренировки, хотябы над своей тренировкой подумать. Сейчас столько возможностей, от основ автоматизации обработки данных при подготовке, до самых банальнейших приемов при тренировке типа взять часть датасета немотрона и слегка разбавить тренировочный им (последнее изредка делают). Но увы, будучи в этой тусовке в курсе как печально там обстоят дела.
Насчет спонсорства - стараются лутать как могут, самые популярные выходят в плюс. Тут опять же, проблема выстроенной пирамиды, что энтузиасты, например типа того же Зерофаты, пойдет по стопам популярных, будет повторять их тупиковый путь. А когда захочет заглубиться и улучшить - получит непонимание и ноль донатов, которые бы очень пригодились на том этапе.
> буквально собрал всех тех немногих, кто готов за это платить, оставив остальных ни с чем
Вот, именно оно.
Сиюминутное удобство не является оправданием игнорирования и отрицания проблемы. Буквально Индия с ее мусорной проблемой.
>Адекваты прежде чем судить скачают и попробуют сами.
Не у всех безлимитный трафик.
Протестил qwen 3.5 9b, как и omnicode на opencode. Впечатление полная жижа, даже с rag не справилась с базовой задачкой. Попытался в qwen3 25 b reap ситуация лучше,но хватает на уровень легких задач (тип базовый astar алгоритм, но не более). На другое уже ноут не тянет(. Есть еще что можно потыкать в надежде хотя на что вменяемое или без шансов ? Железо 16 озу , 6 гб видюха
> безлимитный трафик
Практически у всех в 2026 году.
так поясни если знаешь устройство этой хуйни
например идет ли оперативка только под 8471 70 или как-то ещё можно её провести. для ссд я нашел 8523 51 100 0 т.е. по логике всё равно ввезут
например идет ли оперативка только под 8471 70 или как-то ещё можно её провести. для ссд я нашел 8523 51 100 0 т.е. по логике всё равно ввезут
Без проблем. Создавай тред на пораше, там мы это и обсудим, если ты не понимаешь как работают параллельный импорт. А срать в треде не нужно, не по этим темам он.

Дом ру уже нет.
>qwen 3.5 9b
>omnicode
>qwen3 25 b
Почему не qwen 3.6? Щас бы старье тестить на современных реалиях. Все производители обновили модели специально под агентное использование.
>16 озу , 6 гб видюха
С таким хламом на что-то реально полезное локальное можешь не рассчитывать. Только облака.
>обсудим
>на пораше
в перерыве между постингом шлемов и свиней? спасибо, не надо


Бля как же хуевый квант вечно вас коверкает наызвая двухерами раз через раз
Ну я на ноуте тестил. Из облака тестил дипсик последний, но он не лучше qwen 3.5. Qwen 3.6 27b юзал, но из одного же разряда
>Дом ру
Всегда бы парашной конторкой.
О, нихуя, она сама себя узнала? ЕТО ОВЕР! ОНЕ МЫСЛЮД!


Сука, да что с ними не так? Почему никто кроме квена 3,6 мое не понял что это сырно и в чём вообще рофл?
А с чего должны? Я тоже не понимаю. Какой-то дико обскурный мем, или вообще что это и в чём смысол.
Какойад
То что новый дипсик не лучше 9б квена - странно.
А чего ты ожидаешь, знаний аниме-фандома от ллм общего назначения?
Да чтож они такие тупые! Квен вообще всё разложил по полочкам. Охуеть какие тупые стали модели. Кроме квена вообще умниц нет.
>Кроме квена вообще умниц нет.
жирный-жирный как поезд пассажирный
>знаний аниме-фандома от ллм общего назначения
Ну как бы... да? Квен же разложил эту картинку на атомы, правильно назвав персонажей и даже выкупив рофл. Почему все остальные даже 1(ОДНОГО) персонажа не могут назвать верно?
Квен молодец, но больше повезло. Знания аниме персонажей у обычных сеток очень слабые, только самые популярные и в явных образах. Если тебе именно нужно использовать для датасетов - дай вводные, или используй предназначенные для этого.
А что за проекты ты делал на нейронках и какой это формат был ? Система из агентов или совместная тема ?Касаемо deepseek я бы сравнил даже ближе как комбу qwen 3.5 9b + qwen 3 25b reap , у 9b размышления лучше, а 25 имеет базу лучше кодовую.
>повезло
Что повезло? Что Гоку узнали по одним сапогам? Мда. Всем бы нейронкам такое "везение".
Ахах, бля а ведь она квеночку пристыдила во втором пике ведь квен то именно в офисном костюме!! Не ну это АГИ, умничка прям знает и понимает с кем нужно конкурировать.
подсел на фап посредством генерации текстовых историй.
Развлекался локально на 16гб врама неделю, тупо фапал на текст и свою фантазию, давно я по несколько раз за день не дрочил.
Из моделей что пробовал, больше обдрочился с Cydonia 24b и Magnum diamond 24b.
Какие еще есть гемы среди моделей, которые влезут в 16гб врама?
К сожалению приходится их терпеть. В моем доме только они дают гигабит. Все остальные не больше 100мбит.
Правда если ограничат закачку торрентов, то такие скорости будут и не нужны...
Уточни язык и требования к мультимодальности
полный нуб в тебе llm
пытаюсь задействовать ddr4 и выжать максимум из сборки из двух 3060 12gb + 128gb ddr4(2667mt/s), i5-9600K
запускаю MoE Qwen3.5-122B-A10B-Uncensored-HauhauCS-Aggressive-Q5_K_M.gguf, максимально задействовав gpu:
#!/bin/bash
sudo /usr/bin/nvidia-smi -pm 1
sudo /usr/bin/nvidia-smi -i 0 -pl 130
sudo /usr/bin/nvidia-smi -i 1 -pl 130
export CUDA_VISIBLE_DEVICES=0,1
~/src/llama.cpp/build/bin/llama-server \
-m /mnt/llm/llama.cpp/models/Qwen3.5-122B-A10B-Uncensored-HauhauCS-Aggressive-Q5_K_M.gguf \
--host 0.0.0.0 --port 8080 \
-c 32768 \
-ngl 99 \
--flash-attn on \
--cache-type-k q4_0 \
--cache-type-v q4_0 \
--threads 6 \
--split-mode layer \
-ub 2048 -b 2048 \
--flash-attn on \
--chat-template-kwargs '{"enable_thinking":false}' \
--jinja \
-ts 1,1.5 \
-ot "blk.([4-9]|[1-3][0-9]|4[0-3]).ffn.*=CPU"
получаю 8.6 токенов в секунду на генерацию контента и 77.86 токенов в секунду на prompt eval time
gpu при этом загружены под завязку:
10271MiB / 12288MiB
11696MiB / 12288MiB
это мой предел для этого железа или попытаться ещё покрутить регулярку в -ot ?
пока не совсем понимаю как выбрать только экспертные слои для отправки на gpu
пытаюсь задействовать ddr4 и выжать максимум из сборки из двух 3060 12gb + 128gb ddr4(2667mt/s), i5-9600K
запускаю MoE Qwen3.5-122B-A10B-Uncensored-HauhauCS-Aggressive-Q5_K_M.gguf, максимально задействовав gpu:
#!/bin/bash
sudo /usr/bin/nvidia-smi -pm 1
sudo /usr/bin/nvidia-smi -i 0 -pl 130
sudo /usr/bin/nvidia-smi -i 1 -pl 130
export CUDA_VISIBLE_DEVICES=0,1
~/src/llama.cpp/build/bin/llama-server \
-m /mnt/llm/llama.cpp/models/Qwen3.5-122B-A10B-Uncensored-HauhauCS-Aggressive-Q5_K_M.gguf \
--host 0.0.0.0 --port 8080 \
-c 32768 \
-ngl 99 \
--flash-attn on \
--cache-type-k q4_0 \
--cache-type-v q4_0 \
--threads 6 \
--split-mode layer \
-ub 2048 -b 2048 \
--flash-attn on \
--chat-template-kwargs '{"enable_thinking":false}' \
--jinja \
-ts 1,1.5 \
-ot "blk.([4-9]|[1-3][0-9]|4[0-3]).ffn.*=CPU"
получаю 8.6 токенов в секунду на генерацию контента и 77.86 токенов в секунду на prompt eval time
gpu при этом загружены под завязку:
10271MiB / 12288MiB
11696MiB / 12288MiB
это мой предел для этого железа или попытаться ещё покрутить регулярку в -ot ?
пока не совсем понимаю как выбрать только экспертные слои для отправки на gpu
язык английский, на мультимодальность похуй
забыл добавить, модель весит 81G
Хз, тогда квен 3,6 мое
>или попытаться ещё покрутить регулярку в -ot ?
Это ж мое модель, --cpu-moe просто накати, обычно действие самое лучшее на них без регулярок
Позапускал MiMo — с выгрузкой в оперативу ваще не идет, 7 токенов в секунду, хотя ожидается 10-12 (СтепФан 17-18, а минимакс 12-15).
Грустно, модель обещает быть топовой, но шо толку. =(
Зато люди с RTX Pro 6000 говорят от 70 на ггуф (сам АесСедай) до 120 на сгланге.
Рад за них. Жаль, что… =(
Грустно, модель обещает быть топовой, но шо толку. =(
Зато люди с RTX Pro 6000 говорят от 70 на ггуф (сам АесСедай) до 120 на сгланге.
Рад за них. Жаль, что… =(
с --cpu-moe получаю неполную загрузку gpu:
5384MiB / 12288MiB
5324MiB / 12288MiB
при этом prompt eval time падает с 77 до 49 токенов
-fit off попробуй, он по дефолту включен
Отредактировал рентри:
https://rentry.org/2ch-llama-inference
или
https://rentry.co/2ch-llama-inference
Принял во внимание весь фидбек, который получил в прошлый раз. Провел редактуру: пофиксил опечатки, постарался сократить текст; провел фактчекинг и принял во внимание нюансы по объяснению шаблонов, архитектуры МоЕ и других вещей; добавил несколько нюансов вроде размеров батча и протекания в оперативу на Винде; в сэмплерах сделал акцент на том, что новичкам лучше использовать рекомендованные и все такое.
Обозначу два важных момента. Первый - я не знаю, что делать с тем, что это очень объемный текст, который может отпугнуть. Потому я добавил отдельную главу-быстрый старт для тех, кто хочет здесь и сейчас запустить хорошую модель для своего железа, на примере Геммы. Собрал фидбек со знакомых, которые вообще в теме не шарят, и все сказали, что прочитали от и до и разобрались в пределах 40 минут. (Полная версия, не быстрый старт), о чем я прямо упомянул в тексте.
Второй момент - немало фидбека было на тему того, что хорошо бы дать более глубокое объяснение сэмплингу, рассказать про самостоятельный подбор сэмплеров для креативных задач, про пережар модели, отдельную главу про промптинг и прочее. Но это не руководство "все и сразу", здесь именно про запуск и самые базовые вещи. Про промптинг я главу добавил, но углубляться не стал. Пока не знаю, что с этим делать. По-хорошему, для креативных задач/рп/Таверны нужен отдельный рентри, за который я не уверен, что хочу и что есть смысл браться.
В итоге, я думаю, вышло в целом неплохо. Нетерпеливый новичок сможет быстро запустить модель и поиграться, а если появятся вопросы - вернуться. Если ему не хватит усидчивости прочитать и изучить все изложенное - сорян, проще как будто уже и некуда. Действительно, можно таким макаром у корпов спросить или на практике по ходу дела разбираться.
Такие дела, жду ваш фидбек снова.
> так что нужно запомнить - во всех случаях нужно использовать instruct модели.
Честно говорят хуета. Качал base модели - на карточках тоже часто работают и дают дикую креативность. В реддите про это знают и видел тоже их время от времени рекомендуют. Instruct просто самые френдли для новичков.
> на карточках тоже часто работают и дают дикую креативность
Не про креативность и ролеплей это руководство, оно для вката и тех, кто никогда дел не имел с локальными моделями (или моделями вообще). Если рассказать про это, это может ввести новичка в замешательство. Базовые модели - это пердолинг даже для тех, кто знает как с ними работать.
Как компилировать llama.cpp под свою архитектуру gpu в винде не расписал. Это очень быстро и выходят маленькие файлы, годные лично для тебя. К тому же полезно для всяких форков, где релизы под куду или cpu вообще не выкладываются.
А как и стоит ли вообще обновлять куду, если у меня 50 серия? Я открываю лламу-цпп и вижу:
>compute capability 12.0
Хотя я скачивал именно 13.1 версию и у меня именно блэквелл. Драйвер нвидии 596.36.
>compute capability 12.0
Хотя я скачивал именно 13.1 версию и у меня именно блэквелл. Драйвер нвидии 596.36.
>Как компилировать llama.cpp под свою архитектуру gpu в винде не расписал
Орнул. Самое оно в гайде для хлебушков
>гигабит
Зачем и главное нахуя... сижу у Ростелекома на сотке и горя не знаю.

Что за игнор Kobold Lite - https://lite.koboldai.net/ во фронтенде
Между тем это самый простой способ сделать доступными все карточки, подключением в одну кнопку. В родном фронте llama.cpp карточек и озвучки нет, всяких ролеплейных режимов, ввода голосом тоже.
Сорян, я сам затупил, всё стоит как надо. Иначе бы сыпало ошибками.
По моему скромному мнению озвучка и уж тем более ролеплей голосом - это кринж, а для текстовых задач лучше подойдет Таверна, которая заслуживает отдельного рентри, видимо. Хотя я не понимаю, откуда там все сложности. Видимо в целом от непонимания, откуда брать сэмплеры, какую разметку ставить.

А хорошо.
Серьезных косяков вроде нет, можно по мелочам докопаться:
> Для видеокарт Nvidia RTX 40xx и старее - архивы Windows x64 (CUDA 12) и CUDA 12.4 DLLs.
Говорят что от ампера и моложе лучше 13ю
> Лучше прочитать все сразу и с самого начала
Предложи читателю поставить модель на скачивание и вернуться к чтению. Обладатели небыстрого интернета будут благодарны.
> Она генерирует наиболее вероятный ответ в соответствии с этими взаимосвязями
Она генерирует распределение вероятностей новых токенов, из которого выбирается один из наиболее вероятных ответов.
В примере инстракт шаблона неплохо бы бахнуть картинку типа пикрел, а потом уже тот текст в виде расшифровки применения формата, это сильно поможет пониманию.
Там где про распределения логитсов - лучше заменить картинками, попроси любую нейронку сделать графики. И ссылку на плейграунд типа https://louis-7.github.io/llm-sampling-visualizer/ или более продвинутые.
> Пришло время установить llamacpp.
Дублирует из начала статьи, так и задумано?
> На домашнем железе, даже продвинутом (скажем, RTX 5090 и 256гб оперативной памяти) мы практически никогда не имеем возможности
Ну вообще на таком железе запускается около 100б в бф16, нативные 8бит влезут даже в 128. Имеет смысл перефразировать.
Остальное пренебрежимо чтобы писать. С примера промпта пирата орнул, годно.
>Кванты - довольно большие файлы, и загружать их через браузер не всегда хорошая идея. Для этого, например, можно использовать инструмент HuggingFace-cli (python) или aria2 (протокол и клиенты, которые его реализуют).
Нахер там какой -cli и aria, открываешь страницу с квантом, копируешь адрес кванта, делаешь wget https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-heretic-GGUF/resolve/main/gemma-4-26B-A4B-it-heretic.IQ4_XS.gguf
Все качается без ебли, есть докачка через -c.
Ты дальше выделенного слова не читал, или читал жопой?
Таверна жуткая ебля с одной установкой и горы мутных настроек как в самолете, а тут все без установки открывается сразу и в 1 клик подключается, доступны и карточки и озвучка и что угодно, простой интерфейс для всего.
Разные, по хобби и основной работе. Я не кодер если что, потому что-то могу игнорировать, а задачи далеки от дефолтных популярных. Конечно агенты, pi, qwen-code, gemini-cli. 9б для своего размера молодец, но слишком маленькая, пригодна только для небольших задач. Для более менее крупных и автономности потребуются большие модели, на 27-31б плотных или 120б моэ можно понюхать как это, или работать следя за ними чаще и активнее.
> qwen 3 25b reap
Это пиздец, сразу удаляй. Тройка для кода с выходом 3.5/3.6 не имеет смысла, а это еще и лоботомит сломанный.
Вгет актуален пока тебе нужно 1-2 файла один раз скачать
Так ты модели сотнями и не качаешь.
Двачую. Долбоёб ренпайщик так сильно хочет зафорсить говноламу, что полностью игнорит РЕАЛЬНО УДОБНЫЙ для ньюфага способ запустить нейронку локально. Какой же пидор, а.
Модели нет, файлы да. Говори за себя
Удобство заключается в появлении бесполезной панельки перед запуском, а потом кастрированного интерфейса без функций и промпт-менеджмента?
Шутка про свайпы.жпг
Мне стыдно, а я ведь как сидел на кобольде так и сижу. Хотя год назад перед вкатом пытался собрать жору с чат гпт, но это была такая боль т.к собирал 4 квант 8б магнума на 6 гб врам гтх 1060, компилировалось все очет долго и пару раз под конец вообще уходило в аут оф мемори и долгий оффлоад, чат гпт в итоге сказал мне что бы я хлебушек не мучал себя и его и скачал сразу который форк и ох блять как же все проще стало с кобольдыней, так моё освоение ллмок и началось, после прям фобия была на жору даже когда норм железо появилось. А таверна не помню что бы была прям сложной и страшной, как то само всё пришло и привык.
Кат?
Показываю как застанлочить кобольда. Будьте внимательны! Второй раз не покажу.
> Долбоёб ренпайщик так сильно хочет зафорсить говноламу
У меня нет эксклюзивного права на гайд для новичков. Ты или любой другой кобольд может сделать свой, вас никто не останавливает.
> ренпайщик
Ты же знаешь, что именно Кобольд на Питоне работает, а Ллама - нет? Глупый кобольд.
Спасибо за конструктив, все сохранил и скоро внесу правки. По поводу картинки пока не знаю, не хочется внешние ресурсы подключать, потом еще ссылки поддерживать.
> Долбоёб ренпайщик так сильно хочет зафорсить говноламу
У меня нет эксклюзивного права на гайд для новичков. Ты или любой другой кобольд может сделать свой, вас никто не останавливает.
> ренпайщик
Ты же знаешь, что именно Кобольд на Питоне работает, а Ллама - нет? Глупый кобольд.
Спасибо за конструктив, все сохранил и скоро внесу правки. По поводу картинки пока не знаю, не хочется внешние ресурсы подключать, потом еще ссылки поддерживать.

>Удобство заключается
...в том что качаешь готовый билд без необходимости собирать ручками из исходников по кд, как лламу
мимо на линухе
>пук
Так добавь кобольда, который работает в два клика, ебло. Ты не для себя делаешь, а для новичков. Новичок всегда кобольд. Делай, сука, как учили, широкой на широкую!
Гайд хороший, мне нравится
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
> собирать ручками из исходников по кд, как лламу
Ручками шелл скрипт запустить, как сложна.
Вообще новичок всегда должен поебаться с настройками. Так что все правильно в рентри, а уж если поебется но будет усердно в треде поймёт что есть кобольд и варианты по ппроще, ибо если гейткипа не будет совсем то наплыв даунов которых надо только спунфидить будет критическим. А там и качество треда упадёт. Никто не захочет кому либо помогать понимая что сидит в треде с даунами из /b/ а не такими же энтузиастами на взаимопомощи.



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_moe_2026
• Неактуальные списки моделей в архивных целях: 2025: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd ), 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Гайд для новичков: https://rentry.org/2ch-llama-inference
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
• Доки к LLaMA.cpp со всеми параметрами: https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: