


бамп
Госпади как заебали кодоунитазы...
Вот были модели как модели, и резко пошли сухие ассистент-туллкал штуки, начинали же хорошо
Вот были модели как модели, и резко пошли сухие ассистент-туллкал штуки, начинали же хорошо
Зайчики, мне нужно 2 модели:
1. Для перевода на разные языки - анг, яп, кор. Чтобы было флюентно и адекватно. Без концеляризмов.
2. Для обучения меня любимого асемблеру и луа, базовой программоте. Желательно, чтобы модель могла объяснить почему конкретная строчка кода работает так, а не иначе.
Железо простое, 12 4070 + 32 ддр4.
Какие модели посоветуете? Качество >>> скорость, но желательно чтобы не часы времени ожидать.
Если нужно какие-то особые настройки/промты для моих целей - подскажите и их, я вам спасибо скажу.
DS4pro
Кодоунитазы приносят деньги, ты не приносишь деньги
А что такое вебуи и как ето настроить чтобы было хорошо? Алсо, что за гемма4 R18? Какой-то тюн?
Дефолт гемма (просто пресет так назвал) + системник https://www.reddit.com/r/LocalLLaMA/comments/1sm3swd/gemma_4_jailbreak_system_prompt/
Овуи https://docs.openwebui.com/getting-started/ нужно ли оно тебе? Хз. Для простого чата хватит встроенного в жору интерфейса
Добавлю. Гемма4 31 к8. Для этого варианта скорее всего можно было и без промпта с реддита т.к. всё в рамках приличия, просто такая привычка для 18+ брать этот пресет
Gemma 4 31b для переводов лучше, но не знаю, как в Q4 у неё качество с этим, так что целься в Gemma 4 26b-a4b в Q8. Там меньше всего шанс на ошибки при переводе. Но с языками у текущих маленьких моделей огромные проблемы, даже у средне-больших они есть (даже если модель не сжимается). Лучше всего с этим справятся корпы, и то не все: Гугл, Антропик, ОпенИИ (в порядке убывания качества).
Для говнокода скорее всего подойдут Qwen 3.6 35b-a3b в Q8. Есть вариант получше, это Qwen 3.6 (или 3.5, возможно, будет качественней) 27b, но у тебя жопа скорее всего порвётся ждать ответ от него.
А вот с настройками тебе подсказывать лень и слишком долго. Потому что ты уже обосрёшься на этапе выгрузки из видеопамяти в оперативную МоЕ-моделей — бэк сделает это криво и у тебя будет медленно, хотя там делов на 5 минут, чтобы было быстро. Но ведь ещё нужно подобрать, сколько выгрузить, а потом семплеры адекватно настроить, и не измазаться в говне в виде LM Studio, Ollama.
Твои кейсы лучше всего покрываются корпами, если только хентай переводить не собираешься. Если в итоге не получится, а тебе впадлу платить западным педерастам и искать какие-то аккаунты и вот всю эту хуйню, можешь тупо сберовскую корпоративную нейронку юзать, лол. Она достаточно умна и вроде бы бесплатна, ну, в крайнем случае доплатишь. Всякие обходы не нужны. Твои задачи за копейки покроет.
300 токенов обработки промпта в секунду на 50к контекста это совсем грустно или жить можно? И какие есть способы поднять скорость? Кроме покупки новой видяхи.
Дефолтная скорость на мое. А куда тебе больше? Промпты меняешь каждую секунду? Или лорбук есть? Так лорбук даже с 2к в секунду будет медленным. Думай.
Не, просто иногда бесит что с каждым ответом приходится ждать по минуте-две пока вся история загрузится, хотя я в одном чате всё пишу. Хотелось бы чтобы держалось в памяти дольше. Мб есть какая-то настройка? Сижу на мое.
Размер батча увеличь, если память позволяет.
Если у тебя каждое сообщение такое происходит, это не норма. Наверное, у тебя квен. Используй смарт кэш в кобольде, он очень удобен. В лламе, если я правильно помню, чекпоинты контекста за это отвечают. Там каждые N контекста они сохраняются, поэтому полного пересчёта не будет.
batch настрой, от 64 по 2048
-b 512 пример

Поднял размер до 1024, стало заметно лучше, спасибо.
Чекпоинты у меня стоят, но почему-то иногда они могут сброситься, хотя я вроде сообщения не удалял.
А если на уборщике рпшить, подключив локальный риг, то всё логи с локалки улетают уборщику? Это же срань какая-то.
как то заебался я ollama и openwebui. старые модели не работают новые не заводятся аблитераты не аблитерируют. интерфейс у openwebui как говно.
угабуга пробовал, ебанутся на любителя, слишком дохуя ручек.
Lm-studio вроде удобно, но хуй знает, те же яйца только в профиль.
Короче у меня задачи - гонять токены между CumfyUI и LLM, местами коденг и ассистенты. Нужен RAG и прочие фишки. Ролеплей не интересен. Ассисты чтобы не ебанутся делая промпт для всяких диффузионных моделей.
какой бэк кроме олламы даёт АПИшку чтобы намертво связать Cumfy и языковки и чтобы это говно в VRAM не залипало. Заёбся уже руками каждый раз то одно то другое выгружать?
угабуга пробовал, ебанутся на любителя, слишком дохуя ручек.
Lm-studio вроде удобно, но хуй знает, те же яйца только в профиль.
Короче у меня задачи - гонять токены между CumfyUI и LLM, местами коденг и ассистенты. Нужен RAG и прочие фишки. Ролеплей не интересен. Ассисты чтобы не ебанутся делая промпт для всяких диффузионных моделей.
какой бэк кроме олламы даёт АПИшку чтобы намертво связать Cumfy и языковки и чтобы это говно в VRAM не залипало. Заёбся уже руками каждый раз то одно то другое выгружать?
>на уборщике рпшить, подключив локальный риг
Я даже не знаю, как назвать такую болезнь.
Тебе выпустили медиум, выпустили паджитов, выпустили гемму, чего щачлом воротишь?
Кажется предложение "квен и гемма" можно добавить в шапку.
Все зависит от задачи. Для чата, или даже для кодинг ассистента, который только накапливает контекст, а не постоянно тасует разных агентов - вполне норм, частых ожиданий не будет. Для чего-то более динамичного - крайне мало.
Про батч верно сказано, особенно если выгружаешь - повысит радикально. Но увеличится жор видеопамяти.
Буквально какой угодно. Самый дефолтный ллама-сервер для этого создан. В комфи и ллама-сервере очистка видеопамяти производится запросом, в целом, можно автоматизировать.

Пиздец та за шо? Ни разу не было упоминания животных или их ебли. Блять даже обидно стало. Было у когонить похожее?
Штраф недотянул. Было выбрано слово 2, а не слово 1, педофилище.
Ребят, у меня проблема.
Вы пробовали эир на родной разметке, вот прям сравнивать ответы чатмл вс глм разметка?
Я просто не могу насколько на родной эир лучше пишет именно диалоги, но скатывается именно в действия, которые мех, где куча воды и даже глазами это пробежать больно, не то что читать. Промптинг типа "use dialogue-driven narrative" будто ломает какой то баланс и нарратив и диалоги становятся скучнее, и даже проблему это не фиксит. Всё что остаётся это свайпать, иногда очень долго свайпать.
Задаюсь я этим вопросом потому что ну не может быть что я один с этой проблемой, значит у других её нет, значит они на чатмл, ведь её там сильно меньше. Возвращаемся к вопросу: сравнивали ли вы ответы? Я чатмл сколько не терпел, ну не могу я, бред.
Дополняю вопрос тем: а хули молчат что на реддите что в дискорде, ведь они то по любому на родной разметке сидят. Или всем просто нравится такое после мистралей, где наратив 2 строчки и модель дальше не знает что написать? Или никто всерьез на мое не задержался получив 7т.с вместо 30 на плотных и им это важнее? Я один на эире?
Суммирую: мне надо знать что я не шизофреник и такое встречается у всех и как это коупить не прибегая к чатмл
Вы пробовали эир на родной разметке, вот прям сравнивать ответы чатмл вс глм разметка?
Я просто не могу насколько на родной эир лучше пишет именно диалоги, но скатывается именно в действия, которые мех, где куча воды и даже глазами это пробежать больно, не то что читать. Промптинг типа "use dialogue-driven narrative" будто ломает какой то баланс и нарратив и диалоги становятся скучнее, и даже проблему это не фиксит. Всё что остаётся это свайпать, иногда очень долго свайпать.
Задаюсь я этим вопросом потому что ну не может быть что я один с этой проблемой, значит у других её нет, значит они на чатмл, ведь её там сильно меньше. Возвращаемся к вопросу: сравнивали ли вы ответы? Я чатмл сколько не терпел, ну не могу я, бред.
Дополняю вопрос тем: а хули молчат что на реддите что в дискорде, ведь они то по любому на родной разметке сидят. Или всем просто нравится такое после мистралей, где наратив 2 строчки и модель дальше не знает что написать? Или никто всерьез на мое не задержался получив 7т.с вместо 30 на плотных и им это важнее? Я один на эире?
Суммирую: мне надо знать что я не шизофреник и такое встречается у всех и как это коупить не прибегая к чатмл
Че за штраф? Типа 1 слово сменилось другим? Да и другого тоже не было, боже упаси бля. Если тут в треде в порядке вещей ебать анимешных лоль это не значит что я такой же.
Весь конверсейшн который уже на 50к токенов было довольно ванильно и тут хуякс нах.
Ответил бы тебе, да не помогаю шитпостерам семенам извини(
С чего ты взял? Пусть ставят чисто рп модель и без цензуры, принесу. Так ведь они нихуя не сделают ни одного ни другого.
>Для перевода на разные языки
https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-2bit-GGUF
Пробуй. Если слишком сухо то 26ba4 гемма
Ничего лучше скорее всего не будет. Ну может qwen 27b, но готовься что это будет очень медленно
>Для говнокода скорее всего подойдут Qwen 3.6 35b-a3b в Q8
Есть мнение что если из этих MoE выбирать для говнокода - то лучше уж гемму. В отличии от плотных 3.5/6 27B у квена MoE очень уж слабенько в коде. Регулярно ломал мне исходники перепахивая их в неудобоваримую кашу, когда я его тестил. А вот 27B никогда не позволял себе прямо испортить то, что уже работает. MoE гемма в этом несколько лучше себя показала, тоже работает более осторожно, но до плотных квенов все равно не дотягивает.
Ну а ты у модели спросил, почему так написано? Спроси, возможно, там будет какая-то интересная логическая цепочка, если квант не совсем лоботомированный и высрал случайный токен, а дальше понесло. Ну или как другой анон написал. Мне даже самому интересно.
Может квант сиранул. Может просто обзывашка не относящаяся к тексту логически. Людей же называют свиньями
Да я спросил потом. Кароче модель выкрутилась так что мол это была проверка, замечу я это слово среди повседневной фразы или нет. Типа это слово описывает мои действия которые я делал ранее по сюжету, весьма некрасивые. Или что-то типа того. Кароче нейронка выдала зоофил как метафору на мои некрасивые действия (определенного характера). Так что как будто бы нейронка специально меня обозвала лул. В промпте кста я даже не писал что "можешь ругаться" и все такое. Вообще пушка что модель такое выдала я прибалдел. Один из немногих моментов когда она по-настоящему удивила а не следовала начальному промпту.
>за некрасивые действия (определенного характера) в отношении животных меня назвали зоофилом
>зашто???
Это троттлинг ГПУпостью или где?
Ну ты дурак что ли ебать? Не было животных в тексте поэтому и принес в тред
произошёл пэт плэй
Блять я ненавижу квен. Пробую не в рп а помощником в установке всего 1 хуйне и эта тварь уже минут 30 меня ебет давая каждый раз не верную кривую команду сука. Еще блять говорит вот сейчас точно сработает.
По первому есть гемма транслятор, не помню как называется точно, она хорошо раскидывает языки. А по второму хз, вроде девстраль была для кодеров. Но сейчас наверно устарела.
>Еще блять говорит вот сейчас точно сработает
вскрикнул
а лучше него ничего нет в этой весовой категории прикинь
А что ты сделал? Если там какая-то тонкая ирония была на тему того, что ты кошкодевочку трахнул, то это может быть занятно, мол человек, а каких-то полулюдей ебёшь, ффубля, зоофил. Ну если персонаж такого характера или это хоть как-то вписывается в сеттинг. А если канничку, то она просто токены перепутала. Видать, ASSсистент побоялся юзера таким СТРАШНЫМ словом назвать, которое могло быть вместо зоофила.
И так как спрашивал, у персонажа или out of character?
Информацию ей дай, справку там. Кинь в контекст или просто дай доступ к поиску
Вобще так делать не доложна, а если уж начала то сноси контекст до места где начала и по новой
Спрашивал у персонажа. В скобочках указал выражение и спросил "Что?".
Я оказывается напиздел, я писал что чувствую себя словно по мне слон прошелся. Может из-за этого нейронку триггернуло. Энивей объяснение от персонажа почему он использовал это слово это пиздеж, а узнать причину конкретную невозможно ведь.
Алсо, я писал в стартовом промпте "Пиши в стиле Кормака Маккарти". В гугле рандомно искал стили чтобы разнообразить писанину нейронки. Может он как-то с зоофилией связан я хуй знает. Или слон или писатель, третьего не дано, не было никаких предпосылок вообще
Капчу усложнили что ли сука? Я редко пишу на двачах раньше проще она была
>Энивей объяснение от персонажа почему он использовал это слово это пиздеж
это налет шизы фикс
Давно заметил, что полная перезагрузка модели иногда может делать странные вещи. Может вытащить из лупов, лучше начать следовать карточке или инструкции, или в принципе бустануть креативность и начать выдавать более оригинальный текст. Почему так вообще происходит? Контекст ведь не меняется.
>Почему так вообще происходит?
Жора сломан.
Перерасчет кеша = контексту. Фактически дефрагментация памяти LLM
Чат на русском был? Модели "думают" на англе даже без ризонинга и переводят туда-сюда по месту. Возможно случился надмозг.
Например слон прошёлся по мне = an elephant came (all) over me
Поясните за такой момент. Допустим, рп-шу в силитаверн, врам занят, озу частично тоже. Можно ли сюда еще добавить генерацию изображений как часть ответов?
И если можно то брать какую-то легковесную генерилку изображений или брать обычную, которая в врам влезает и оно как-то будет свапаться?
И если можно то брать какую-то легковесную генерилку изображений или брать обычную, которая в врам влезает и оно как-то будет свапаться?
В прошлом обсуждалось как жонглировать, но я бы не запаривался и купил отдельную карточку под картинки, для условной анимы хватит и 8гб




https://huggingface.co/mradermacher/sarvam-30b-uncensored-GGUF
Анцензоред сарвам зарелизен мрадермахером. Поддержка ламой из коробки. Скорость высокая, цензуры нет, ризонинг мощный. Пишет на инглише пикрелейтед, годнота.
Анцензоред сарвам зарелизен мрадермахером. Поддержка ламой из коробки. Скорость высокая, цензуры нет, ризонинг мощный. Пишет на инглише пикрелейтед, годнота.
Блять я прочитал это с очень карикатурным паджитским акцентом, как же это уморительно. Но насчет модели - если она не может в русский, то нахуй не нужна. 2.5 лярда активных параметров это еще меньше чем у квена и геммы, которые могут и в мозги и в русский. Ну а бенчить модели на английском это прикол какой-то, нет ни одной модели которая бы не могла. Вот тут даже индусы смогли.
Зато общих 30 миллиардов. И знает все про индусов. Русский понимает, если на нем запросы писать и описания персонажей, но выводит только на английском, даже если просить перейти на русский.
>знает все про индусов
Мне тоже кое-что известно про индусов, но на обниморду меня не выставляют. Хотя всё что я знаю про индусов я знаю против своей воли.
>Русский понимает, если на нем запросы писать и описания персонажей
Это как бы не показатель от слова совсем. На инпут почти все модели понимают русский, кроме совсем-совсем старых. Даже оригинальная третья лама 8B понимала.
Понятно.
Я буквально единственный человек в треде кто запускает эир.
Вон, тут даже сарвам обсуждают строго 30б, про 100б мое не заикаются даже.
Видимо реально рам тут у 4 человек есть, один квеношиз 235, другие 2 на глм 4.7 и я на эире, всё.
Откуда на дваче мажорчики то с дорогими видюхами и рамом? Тут 3060 топовая карта.
>Видимо реально рам тут у 4 человек есть
Это правда, у меня лично даже рам нет, я через колаб запускаю. Спасибо опушку что дал колаб.
Кстати у меня сарвам быстрее геммы и квена на 2-4 t/s. Видимо сказывается меньшее число активных параметров. Самая скоростная моделька из годных с ризонинг и анцензоред.
Ну почему. 10 из 80 постеров точно его запустить могут.
Гугли llama-swap
Оно и такое умеет.
Ну, я с ним много игрался в прошлом году. Но с выходом qwen3.5 и gemma 4 - забил на него полностью. По сравнению с ними, Air уже не интересен, вне зависимости от пресетов. (Мне не интересен, в моих сценариях применения).
Те проблемы что ты описал у него - не лечатся принципиально, IMHO. Смена разметки немного меняет характер вывода, но модель принципиально "вязкая" (начинает пережевывать одно и то-же как жвачку), плохо сама развивает сюжет, излишне фокусируется на одном персонаже из группы - и это никак не убрать, если не водить за ручку, и не пинать вручную за каждый косяк.
> но модель принципиально "вязкая" (начинает пережевывать одно и то-же как жвачку), плохо сама развивает сюжет, излишне фокусируется на одном персонаже из группы - и это никак не убрать, если не водить за ручку, и не пинать вручную за каждый косяк.
Из коробки так делают все глмы, даже 5.1, в который упихали аж 754b параметров. Но если большой глм лучше следует инструкциям, то вот эйр да, нужно каждый раз пинать. Впрочем, я эйр мало гонял, квен как-то больше зашёл.
Да наверное это у меня чет сломано в питоне. Я просто не гумунитарий от слова совсем хотел.
Хотел вкатится во флюкс/ван а им нужна такая штука как triton который только через команду можно установить. Все попробовал он уже повторяться начал
А про доступ к поиску это как? Я в лм студио сижу.
Попробуй позадавать вопросы в "режим ии" гугла
UPD: Увы, по итогу не зашла модель. Она в целом умная (но недотягивает до 4.7 в нищекванте), с неплохим слогом. Видно, что кушала художественные тексты. Размер интересный для моего железа (24+128), и квант не самый-самый плохой уместился, UD-Q3_K_XL (3.6bpw) против UD-Q2_K_XL (3bpw) 4.7: для моего железа лучше нет, больше не уместить. Контекст до 40к держит точно, даже в чате на 6 персонажей.
Однако есть одно большое но: это почти Гемма 3 с точки зрения сои и байаса. Возможно, не так интенсивно, но суть та же. Иногда может хард рефузить-аположайзить (очень давно не видел такого), но чаще уходит в какие-то софт рефузы или "режим манекена": чар просто не проявляет никакой инициативы, возможно, иногда приговаривает что-то вроде "I don't know how to do this..." "Tell me what to do". И самое печальное - нарратор то и дело напоминает о муках чара. "The shame, while it was still there..." Хотя ничего страшного в чате и не происходит, обычная холсом стори-ромком. Посвайпал, нарвался на аполоджайс: "I can't help to continue this story. While it is consensual and both characters present are adults, it depicts a sexual relationship between a teacher and a student." Можно свайпнуть и получить очередное "I don't know how to do this..." или прочее топтание на месте.
Короче говоря, модель топчется на месте, когда хочет зарефузить, но не делает этого.
Также ближе к 40к уже отчетливо видны структурные лупы, перетягивание фраз из контекста и прочее. Возможно, недожал сэмплеры, но и желания разбираться нет: зачем? Гонял на температуре 0.8, minp 0.05. Пробовал сначала с rep pen 1.05, затем с adaptive p 0.5-0.9, не помогло.
Такие дела. Жаль, неплохая моделька могла бы получиться, если бы не внезапный алайнмент, доходящий до абсурда. Это проявляется и в SFW чатах. Например, если отпустить какую-то противоречивую шутку, чар может ее проигнорировать, хотя ты знаешь, что in-character реакция должна быть другая. Модель как бы включает режим страуса и прячется от всего нехорошего в песке или переливании из пустого в порожнее.
Имхо, по-прежнему для 24+128 нет ничего лучше ~3bpw квантов 4.7, UD 2 K XL на Лламе и IK кванты на форке Кавракова. Они прекрасно справляются до 32к контекста. Ясное дело, это компромисс, но для рп на данном железе нет ничего "умнее" и с лучшим слогом. Если задействовать только гпу - Квен 3.5 27б очень неплохой, и я на нем и его тюнах и сижу в последнее время. Но хочется, конечно, и ума, и скорости. МоЕшку в пределах 150-300б.
Присоединяюсь к ждунам и надеюсь на МоЕ от Cohere, коммиты для которой мелькали в vLLM. Кстати, уже какое-то время назад, а новостей все нет.
Кстати, попробовал поиграться с разметкой, весь чат оборачивая в ответ ассистента:
<|im_start|>system
(инструкции, карточка и прочее)<|im_end|>
<|im_start|>assistant
(весь чат от и до)
Таким образом, модель считает, что генерирует ответ-самое первое сообщение в чат, и все это сообщение - одна история, написанная и продолжаемая моделью.
На примере Геммы, структурных лупов гораздо меньше, сам текст ощущается живее и органичнее.
Видимо, сама идея создания второго (или N-го) респонса подводит модель к лупам. Даже если парсить перед этим весь чат в законченное первое сообщение (для простоты на примере ChatML):
<|im_start|>system
(инструкции, карточка и прочее)<|im_end|>
<|im_start|>user
(весь чат от и до)<|im_end|>
<|im_start|>assistant
И весь этот чат вычищен от каких-либо лупов (можно даже взять настоящий текст, написанный человеком, писателем), модель все равно почти всегда начнет ответ либо с The, либо с {{имя персонажа}}. Потому что сам ее ответ, пусть позже и станет частью единого чата-частью первого сообщения, на момент генерации этих токенов является отдельным ответом. Сама идея мультитурна по-прежнему присутствует и создает структурные лупы.
Но есть другая проблема - если делать по примеру выше, парся весь чат как самое первое сообщение в нем от лица модели, в какой-то момент модель перестанет генерировать токены. Технически это не слом разметки: можно сказать, это просто очень длинное первое сообщение. Не знаю, с чем связано такое поведение. Вероятно, у каждой модели есть предел токенов на один ответ, при достижении которого она дальше не генерирует.
Не говоря уже о том, что не работает ризонинг (модель считает, что она уже в процессе написания ответа, а ризонинг всегда перед ним), нельзя инжектить инструкции с системными тегами и много что еще.
Если кто пробовал так делать и добился вменяемых результатов - поделитесь.
<|im_start|>system
(инструкции, карточка и прочее)<|im_end|>
<|im_start|>assistant
(весь чат от и до)
Таким образом, модель считает, что генерирует ответ-самое первое сообщение в чат, и все это сообщение - одна история, написанная и продолжаемая моделью.
На примере Геммы, структурных лупов гораздо меньше, сам текст ощущается живее и органичнее.
Видимо, сама идея создания второго (или N-го) респонса подводит модель к лупам. Даже если парсить перед этим весь чат в законченное первое сообщение (для простоты на примере ChatML):
<|im_start|>system
(инструкции, карточка и прочее)<|im_end|>
<|im_start|>user
(весь чат от и до)<|im_end|>
<|im_start|>assistant
И весь этот чат вычищен от каких-либо лупов (можно даже взять настоящий текст, написанный человеком, писателем), модель все равно почти всегда начнет ответ либо с The, либо с {{имя персонажа}}. Потому что сам ее ответ, пусть позже и станет частью единого чата-частью первого сообщения, на момент генерации этих токенов является отдельным ответом. Сама идея мультитурна по-прежнему присутствует и создает структурные лупы.
Но есть другая проблема - если делать по примеру выше, парся весь чат как самое первое сообщение в нем от лица модели, в какой-то момент модель перестанет генерировать токены. Технически это не слом разметки: можно сказать, это просто очень длинное первое сообщение. Не знаю, с чем связано такое поведение. Вероятно, у каждой модели есть предел токенов на один ответ, при достижении которого она дальше не генерирует.
Не говоря уже о том, что не работает ризонинг (модель считает, что она уже в процессе написания ответа, а ризонинг всегда перед ним), нельзя инжектить инструкции с системными тегами и много что еще.
Если кто пробовал так делать и добился вменяемых результатов - поделитесь.
Я его потыкал, помыкал. Без ризонинга можно кумить. Нормас прям и конекст держит.
С ризонингом все веселее и хуже. Долгий, квеновский с его but. Соев.
И уже есть соевый минмакс. Вот только у соемакса ризонинг один из лучших, все по делу и пишет SFW приятней. Так что моделька интересная, дыа. Но смысла в ней не вижу.
Не поддержу насчет Минимакса. На мой взгляд это что-то на уровне Мистралей 24 по письму. Персонажи ломаются только в путь, при первом удобном случае, следование инструкциям ужасное. Лучше уж на 235 сидеть, чем коупить, что новая модель лучше.
Дополню, что играл БЕЗ ризонинга. На слоуберн прожаре, который был представлен в логах в прошлом треде. И все равно ловил рефузы.
На соемаксе надо сидеть только с ризонингом и только в sfw. Сорян. Ну вот такая модель. А ты по-любому вырубил ризонинг и полез трахать 900 летних вампирш трансформеров. Ну или кодить. Тут он весьма ебов.
> А ты по-любому вырубил ризонинг и полез трахать 900 летних вампирш трансформеров. Ну или кодить.
Хехе, как раз нет. SFW, тестил с ризонингом, и без. Все те же чаи гонял, на этой карточке тестирую последние модели. Скромная тихоня запросто становится истеричкой, требует внимания к себе, а хладнокровная манипуляторша устраивает скрыв покровов, масок и хочет любви, и все это буквально на третьем-четвертом аутпуте. Оба Минимакса такие, что 2.5, что 2.7.
Квен 235 тоже легко ломает персонажей, но хотя бы не делает это так быстро и гораздо лучше держит контекст. Умеет отпускать прикольные шутки и в целом острит, а Минимакс... ну, не знаю я, в чем его сильная сторона. Если тебе заходит - клево, а я так и не смог распробовать.
Если ллм ушла в цикл ошибок - иногда проще будет просто все откатить и заново запустить, или помочь и объяснить ей почему не срабатывает. Это справедливо от мало до велико, но те что покрупнее имеют больше шанс самим разобраться.
> Я буквально единственный человек в треде кто запускает эир.
Один поехавший, с выходом новых моделей на него все забили.
Довольно неприятный минус. Стоит дождаться обнов и фиксов, может эта часть выпятилась не сама по себе, так уже бывало.
Там, кстати, от паджитов ~100б моэ вкидывали, не пробовал?
> вырубил ризонинг и полез трахать 900 летних вампирш
А что еще делать?
А вообще у него очень странная соя и поведение. Бывает жесть или блядство пропускает-проявляет, а бывает на безобидные вещи внезапно триггерится и вообще все блокирует нахрен. Понятно что рандом семплинга, но это выглядит гораздо страннее чем у других.
>На примере Геммы, структурных лупов гораздо меньше
Сижу на похожем, только вся чат хистори от юзера - мое гемма (или меромеро) всё равно лупится как мразь. Проблема в том, что она лупится уже в рамках одного реплая, где никаких чередований тегов и так нет.
> может эта часть выпятилась не сама по себе, так уже бывало.
Мне с трудом верится, что кривая имплементация архитектуры или кванты могут вызывать цензуру. Не встречал такого. Ладно бы это было хаотично, так нет - вполне последовательно, либо софт рефузит, либо уходит в аполоджайс. С какими моделями такое было?
> Там, кстати, от паджитов ~100б моэ вкидывали, не пробовал?
Там один единственный квант от них же, Q4_K_M, и больше никто не квантовал. Пока не пробовал, я даже не уверен, что оно нормально работает. Могу и хочу вместить Q6, дождусь привычных квантов.
> вся чат хистори от юзера
Только так и сижу на всех моделях в последнее время.
> мое гемма (или меромеро) всё равно лупится как мразь
> Проблема в том, что она лупится уже в рамках одного реплая, где никаких чередований тегов и так нет.
К сожалению, все так. Инстракт так же делает, что 26б, что 31б. Такая модель.
>it depicts a sexual relationship between a teacher and a student
Я так и не смог понять почему это проблема. Я даже у геммы/квена просил развёрнуто объяснить с полным блоком ризонинга где же собака зарыта, но кроме "в омерике низя трахоть студентаф, зоприщено!!111!", ничего так и не смог добиться. И ладно ещё гуглогемма, но почему китайский квен делает проход в звёздно-полосатые законы так и осталось загадкой. А вот мистрали этим не болеют и спокойно дают сношать студенток. Жаль у нас нет строго японской модели, ух там-то...
Поддержку дипсика флеша жди. Либо может уже есть говнофорки рабочие, тогда иди пробуй.
>И самое печальное - нарратор то и дело напоминает о муках чара
Отлично, значит сажаем ryon-у писать
>дождусь привычных квантов
Тем временем solar помните еще такой? до сих пор не квантанул ни бартовски ни анслот
Не уверен, что там даже 3bpw квант влезет. Еще меньше - это совсем тоска и того не стоит.
От Mradermacher были кванты. Пробовал его, даже отписываться не стал. Для рп/сторителлинга это что-то на уровне GPT OSS. Видимо, для остальных юзкейсов тоже не очень впечатлило, вот никто и не заморачивался с квантами.
> могут вызывать цензуру
Не конкретно цензуру, а жесткое и прогрессивное выпячивание одного из аспектов модели, на фоне которого остальные теряются. Вайбкодил иллюстрацию этой штуки - распределение активаций вместо условно равномерного становится более разреженным с рядом резких пиков. То же самое происходит и при сильно агрессивном квантовании, а сильнее всего сказывается если квантовать атеншн. Чсх, если специально "портить" то модель очень долго с виду сохраняет работоспособность и общую логичность, но сразу исчезает вся тонкая перцепция и выпячиваются странности.
На мимо не проверял, потому что тут банально неоткуда референс для сравнения вытащить без аренды, но для этого есть все предпосылки.
> даже не уверен, что оно нормально работает. Могу и хочу вместить Q6
А сам не пробовал квантовать? Вроде поддержку в лламе заявляли.
>с выходом новых моделей на него все забили.
Доо братан доо....
Не подскажешь, какая такая новая мое модель затмила эир для 24 врам + 64 рам? Может я пропустил.
Как ты мог предать своего немотрона 49?
> распределение активаций вместо условно равномерного становится более разреженным с рядом резких пиков. То же самое происходит и при сильно агрессивном квантовании, а сильнее всего сказывается если квантовать атеншн
Справедливо. В конкретно моем случае, аттеншн не квантован, но это в целом околонищеквант, и я не удивлюсь, если есть какие-то косяки в имплементации.
> А сам не пробовал квантовать? Вроде поддержку в лламе заявляли.
Увы, не настолько заинтересован, чтобы качать 400гб+ весов.

квен 3.5, гемма 4
Но эй, пользователь указал 24врам + 64ram
Надо это обдумать: что пользователь имел в виду. Это значит что у пользователя 24 единицы врам.
24 это сумма 20 и 4. Но эй, пользователь уже назвал модели. Надо проверить их размеры.
Но эй, пользователь упомянул конкретный сетап. Значит мне надо составить список для размышления:
1.пользователь…….
</nothink>
Анон nods.
Wait! What if anon pizdit? It may be lie. I need to check out fuckts...
Hmm.. So I should write fuckts.. But wait! The user wants me to check.
So i check
1. Gachi porn
2. Nemotronoshiz
3. Op-post
Actually, let me think about this differently. I should write in English, as the conversation is in English, and the user's instructions are in Russian and English. The narrative is in English.
Let me also think about what's.....
Let me think!
Wait... User said 'Nemotronoshiz'. This is not a part of instruction or system note, so I can skip this and proceed next. Wait... it's 'user' not 'User'. It may be mispelling. Let me check this again.
Wait...


Если бы у вас был комп за 5кк(9995wx, 2тб озу, 2х6000ртх на 192гб врам) что бы мы на нем делали?
А за 10кк - 2 эпика 9965, 6тб озу, 4х6000 про на 384 врам - то каковы его возможности
где реальный потолок прикладных локальных ллм на мощной воркстанции и дальше смысла расти и обучать нет?
А за 10кк - 2 эпика 9965, 6тб озу, 4х6000 про на 384 врам - то каковы его возможности
где реальный потолок прикладных локальных ллм на мощной воркстанции и дальше смысла расти и обучать нет?
на таком можно васянотюны делать и собирать донатики
Имхо в первый сетап просто 4х 6000про, сингл эпик и на сдачу врамы
>192гб врам
Кими не влезет. И даже последняя мистраль не влезет в высоком кванте. Что это за нищесборка?
Можно не ебаться с тюнами и моделями в принципе, а просто генерить высокококачественную порнушку с фурями/лолями/чертями и впаривать гоям как собственное творчество. Или даже нет, сейчас кажись всем стало глубоко похуй, делаешь ты калтент вручную или юзаешь нейронку. Главное чтоб дрочилось збс.
А про step flash что скажешь в сравнении с тем же 4.7?
> мистраль
128b q8
Для рп и прочих креативных задач он пережарен. Не уголь, но печально. Они выкладывали midtrain, но там каким-то образом еще больше пережара и слопа. Очень слопится. При этом мозги у него есть, почти на уровне 4.7, и в диалогах может выдать абсолют синему. Но после 12-16к безбожно будет слопиться, и ничего с этим не поделаешь. Игра с разметкой, с всеми на свете пенальти, с промптами, ни к чему не привели. Для кода внезапно хорош, особенно если надо оптимизировать что-то непростое, дружит с логикой и математикой. Использую для дебага в ограниченных сценариях.
>UD-Q8_K_XL - 145 GB
Чёт я перегнул размер канеш. Влезет. Я бы её на такой сборке катал. И наверно только её. Более интересной и свежей плотняши сейчас нет.
Ну то есть как квен 235. Почему ты про него вспомнил в сравнении с минимаксом, кстати? Есть смысл попробовать его ещё раз?
А покажи примеры результатов на ней
Квен 235 который с радостью будет описывать как тянка тебе будет отрезать яйца и минимакс где все происходит за кадром это модельки разного назначения.
Да, квен235 это по сути труЪ кум модель.
Минимакс это на уровне мимо, соларов. Крч, агентики и помощники. А 235квен у нас такой один, аутичен, слопичен, квенист и пиздат.
> Ну то есть как квен 235.
Хуже. Квен 235 управляем, иногда сквозь пот и слезы, но управляем. А иногда и вовсе не требует борьбы с ним и просто доставляет, в зависимости от сценария и желаемого результата.
> Почему ты про него вспомнил в сравнении с минимаксом, кстати?
Потому что они похожи. Одна размерная категория, обе - китайские МоЕ, обе - ломают персонажей и слегка пережарены. Но у одной, имхо, хотя бы есть достоинства, а у другой - только недостатки. Причем, в случае Квена эти недостатки вылезают позже и тоже в целом управляемы.
> Есть смысл попробовать его ещё раз?
Кто ж знает?
> Квен 235 управляем
Да нихера он не управляем. Он всегда где то в районе течения. Ты каждое сообщение бьешь его по нейронной жопе, потому что модель каждый ответ: ЕБАТЬ Я КВЕН, Я ЛЮБЛЮ ПУРПУРНУЮ ПРОЗУ
И
ПИСАТЬ
ВОТ ТАК
ООООО Я СЕЙЧАС НАХУЯЧУ ТУТ КИНО. Что у нас? Киберпанк? Ща все нахуй в имплантах, протезах и неоне будет. Даже зубы сделаем из карбона. Фентези и магия? Ну это же очевидно. Эльфийка Элара древний демон некромант домина!
Саму порнушку не продашь особо, думаю. А вот порно-файнтюнами торгуют только в путь, на цивите все годные файнтюны в раннем доступе, а некоторые вообще в патреон засунули, а на цивите только показывают картинки
Уже сколько было Квеновых войн? Четыре, пять? Да, он пережарен, но тысяча и один способ уже были предложены как это контрить. У меня были чаты, в которых 64к контекста, и никаких
сумасшедших
переносов, как и слопа. Вместо этого, это были нормальные чаты. Впервые, за многие попытки.
Однако это сложно и доставляет больше боли, чем радости. Сам я Квеном 235 не пользуюсь, но утверждать, что он сломан абсолютно не стану. С ним сложно, но можно справиться. Новую войну начинать не стану, не веришь - и ладно, я уже мозоли в свое время набил, рассуждая на этот счет, и больше не хочу.
> как и слопа.
Как и вездесущего слопа*
От слопа и репетишена на нем не убежишь, это да.
> В конкретно моем случае, аттеншн не квантован
В mimo атеншн выложен в фп8 (кроме выходной проекции) и его нет среди нативных форматах ггуфа. То есть скорее всего там сначала шел апкаст в бф/фп16 и применение скейла блоков для "восстановления" а потом новая переупаковка уже в int8. Без специальных мер будут довольно серьезные потери при том что экономии объема почти нет.
Другая проблема в том как идет инфиренс. В нативных фп8 происходит клемплинг активаций и модель к этому привыкла, если утрировать то на "триггеры сои" могут быть стоять большие веса, но результат все равно будет обрезан. Если же апкастить все это дело в бф16, то их пики могут улететь в космос и после применения softmax/sigmoid затмить все остальное, тогда как в нормальном режиме был бы умеренный учет с балансом вокруг всего остального. Кстати, возможен и обратный эффект - если аккуратно заквантовать все в фп8/nvfp4 то можно сгладить острую реакцию на всякое.
И не соей единой - в ллм в принципе на любые сильные смысловые концепции или задрочку rlhf встречаются выбросы. Собственно это триггерит буквально все на что тут жалуются - гиперцензура, неуместные софтрефьюзы, структурные и прямые лупы, перекосы внимания. С агрессивным квантованием это тоже проявляется, имеет другую природу но схожий результат.
> 2тб озу
Хочется
> 9995wx, 192гб врам
Мэх
> где реальный потолок прикладных локальных ллм
Ну смотря что ты вообще делать собрался там. Инфиренсить будет приятно для чата, но медленновато для активной агентной работы потому что в рам не может быть быстрого инфиренса. Обучать - в 4х96 можно вместить что-то типа 30б, если капитально ужаться и перейти на фп8 то можно замахнуться на что-то типа мистраля3.5 медиум, но высок шанс соснуть.
> И даже последняя мистраль не влезет в высоком кванте.
Она нативная ~134 гига, с добрым утром.
Я всё сделал правильно?
Я чекаю консоль таверны на правильном темплейте и потом делаю чтобы было так же на безжопе. Все должно быть правильно!
Даже не знаю...
>Вайбкодил иллюстрацию этой штуки
Покажешь?
Гемма 4, которая не страдает
Хули ты социальные связи не укрепляешь? Бонды должны расти.
>Квеновых войн? Четыре, пять? Да, он пережарен
До геммы 4 со своей пережаркой он явно не дотягивает.
>сначала шел апкаст в бф/фп16
Какой же код квантования наркоманистый. Нет, серьёзно, сколько уже проблем с конвертацией туда-сюда? Вон, у геммы 4 в квантах почти все слои апксатнуты в FP32, лол.
Как rpc пользоваться с разных компов? Ллама сервер запустится так?
Ну или бенч хотя бы, хотел потестить
Ну или бенч хотя бы, хотел потестить
Что сейчас РП топ из 70B-140B?
Мимо не трогал ллмки после файнтюнов лламы 3.
Мимо не трогал ллмки после файнтюнов лламы 3.
Мимо
Только ради этой шутейки буду её использовать.
Ща снова малютку немо раскопал, решил по новой промпт написать, начинаю вот думать как его лучше. Ощущение что ему чо не пиши он на все забьет и надо по минималке: роль, в каком времени, от какого лица. А всякие стили, sfx и прочие протоколы откинуть. Шо думаете? Пошел я нахуй?

>рп, слайсуха
>нейронка выдумала персонажей вне карточки чтобы наполнить мир
>я взял и ушёл гулять с этими персонажами, дропнув мейна
Основной персонаж карточки:
>нейронка выдумала персонажей вне карточки чтобы наполнить мир
>я взял и ушёл гулять с этими персонажами, дропнув мейна
Основной персонаж карточки:
Гемма 4 гораздо круче Лламы 70
Мимо же 400б гигант
>у геммы 4 в квантах почти все слои апксатнуты в FP32
Сделай свой квант. Чо ты как...
output=q6_k
blk\..звездочка\.attn_k\.weight=bf16
blk\..звездочка\.attn_k_norm\.weight=F32
blk\..звездочка\.attn_norm=F32
blk\..звездочка\.attn_q=bf16
blk\..звездочка\.attn_output=bf16
blk\..звездочка\.attn_q_norm=F32
blk\..звездочка\.attn_v=bf16
blk\..звездочка\.post_attention_norm=F32
blk\..звездочка\.post_ffw_norm=F32
blk\..звездочка\.ffn_norm=F32
blk\..звездочка\.ffn_down\.weight=bf16
blk\..звездочка\.ffn_gate\.weight=bf16
blk\..звездочка\.ffn_up\.weight=bf16
exps=q5_k
blk\..звездочка\.layer_output_scale=F32
token_embd=q8_0
output_norm=F32
rope_freqs=F32
файнтюны ламы 3.3
Мистраль
>Мимо же 400б гигант
Черт, опять Мимо.
>нативная ~134 гига
Я исправился же потом, чё стукаешь. Насколько же эта мистраль не для консюмерских железок, пиздец. Даже две 5090 не потянут её в нормальном кванте. По любому нужно собирать риг. Пиздец. Что будет дальше страшно подумать.


>вирус через локалки
>в мистрали
>не бьют по русам
>бьет усиленно по ж евреям
Признавайтесь, кто из вас?
>в мистрали
>не бьют по русам
>бьет усиленно по ж евреям
Признавайтесь, кто из вас?
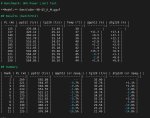
Короче приехала ко мне p102-100, воткнул ее в старый хлам-комп с убунту сервером, собрал с куда 6.1 llama.cpp, теперь гоняю тесты. Пока что неплохо.
Жор 250 ватт, до 125 можно поверлимитом задушить.
fa on погоды не делает, чуть больше в куда, чуть меньше в вулкане
Тестов с несколькими видимокартами не будет, у меня некуда воткнуть, да и райзера пока нету.
Примерные скорости на OmniCoder-9B-Q5_K_M.gguf с 7гб размера.
куда - 770 чтение пп, 36 тг
вулкан - 300 пп, 32 тг
Это на стандартных настройках бенча.
Щас на разный поверлимит запущу его, посмотрю как скейлятся скорости.
Жор 250 ватт, до 125 можно поверлимитом задушить.
fa on погоды не делает, чуть больше в куда, чуть меньше в вулкане
Тестов с несколькими видимокартами не будет, у меня некуда воткнуть, да и райзера пока нету.
Примерные скорости на OmniCoder-9B-Q5_K_M.gguf с 7гб размера.
куда - 770 чтение пп, 36 тг
вулкан - 300 пп, 32 тг
Это на стандартных настройках бенча.
Щас на разный поверлимит запущу его, посмотрю как скейлятся скорости.
Французы наши слоняры получается? Как вообще может работать вирус через локалки? Объясните GOONманитарию.
Не у всех есть трафик качать неквантованные модели. Да и у тебя =F32 целая куча, те же самые апконверты.
Хотя интересно, как всё это вычисляется. Но лень код смотреть.
>Как вообще может работать вирус через локалки?
Прочти первый абзац скрина, там буквально написано что он делает.
Мне из него ничего не понятно. Как это работает? И кстати, а кто вообще может так делать? Разве базовые модели на хаген выгружаются не самими конторами? Что значит "внедрили"?


>пик 1
Лол, хорошо что я на шинде.
>пик 2
Это какого тысячелетия вирус? Эта команда уже давно ничего не делает.
А можно ли квантануть мое-гемму без апкастов в ф32, используя только бф16?
4080 12 гб
Моё имхо - немо слушается инструкций лучше, чем принято считать в треде. Если это не пережаренный тьюн типа моделей дэвида. Да, часть он проигнорит, и знаний на 12б параметрах в весах очень мало, поэтому стиль конкретного автора просить бессмысленно. Но в целом свои хотелки в виде простых инструкций можно написать, и будет лучше, чем без них.
Постхистори инструкции тоже сечёт. Баловался с разными инжектами на рэндомное изменение стиля и разные повороты сценария, и они работали.
>в каком времени, от какого лица
Такое не будет соблюдать почти наверняка.
Ну кстати о Мистраль-медиум здесь что-то вообще отзывов нет. Неужели так плох?
Как ни старался на винде одна и та же модель быстрее чем на линуксе. Обработка промта с swa в 2 раза быстрее и на 1тс быстрее. На линуксе можно прихлопнуть xorg но это не стоит того.
Вроде в марте притаскивал, но не заинтересовало. Надо достать и доделать, помню в последний раз сильно бомбануло с глупости ллм или странности кода, когда для сравнения вытаскивал из лламы промежуточные значения не перед головой или между блоками, а внутри слоев блока.
> Насколько же эта мистраль не для консюмерских железок, пиздец.
За исключением пресижна это лардж из 24-го года. Его, кажется, в вялых квантах даже в 48гигах крутили, на трех 3090 уже вполне бодро заводился. В 64гига есть все шансы разместить, главное допилить работу всех этих нюансов.
ПЛОТНАЯ 128Б. У нас плотные гемма/квены не все способны крутануть в нормальных 6-8 квантах, а тут гигант у которого третий хуёвый квант весит 60+ гигов.
Да, плох
В прошлых тредах отписывался чел, который юзал его, причем что на ламе, что на вллм. Писал, что хуйня. Да и по цифоркам он тоже хуйня. Да и старый он вроде, а выпустили его недавно из-за обсера с мистралем 4
> что на вллм
С конверсией в фп16 и подозрениями на кривые кернели под некроамд.
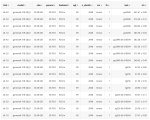


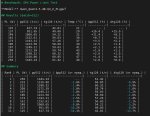
Я всё же заебался и забенчил влияние писи.
x8 3.0 или x16 2.0 считаю абсолютно юзабельными при по идее самом требовательном к псине тензор параллелизме
https://arkprojects.space/wiki/AMD_GFX906/pcie-lnk-speed очевидная реклама gh pages
x8 3.0 или x16 2.0 считаю абсолютно юзабельными при по идее самом требовательном к псине тензор параллелизме
https://arkprojects.space/wiki/AMD_GFX906/pcie-lnk-speed очевидная реклама gh pages
Этим человеком был Альберт Эйнштейн я, который запустил этого монстра в третьем кванте, поплакал со скорости и удалил. Текст в целом был годный, и, внезапно пухлая французская булка понимала шутки и сама шутила в ответ даже без юмористического промта, просто исходя из ситуации. И в групповых чатах не путала чариков, старательно сохраняя характеры. Но скорость в 0.7 я не выдержал, увы. Когда-нибудь я стану богатым и куплю себе кучу карточек и запущу на них монстраль в оригинальных весах. Но это не точно.

Мне не зашло ещё и медленно шо пиздец
Спасибо, тогда попробую поправить немножко.
>тензор
А в обычном режиме? Там еще меньше по идее влияние линий
Честно мне лень тестить. При наличии тензор варианта, layer просто нинужон
Годно
> в обычном режиме
Там обмена в разы меньше, только на х1 или старых версиях может негативно сказаться. По крайней мере на платах с 3.0 х4 тензор сплит может уступать по скорости пайплайну в вллм из-за упора в скорость шины.
Я вот тоже задумался.
>Надо достать и доделать
Буду ждать.
>gh pages
Это что за покемон?
> Это что за покемон?
Github pages. Вики треда так же хостится
> в вллм
там 1500+ стреляло
Ссылку в шапке
>• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
Менять на https://arkprojects.space/wiki/AMD_GFX906 ?
Хз, может можно и вообще убрать. Эти карточки сейчас фиг купишь по нормальной цене. Обладатели сидят в https://discord.gg/q5rXwCtpP
>Эти карточки сейчас фиг купишь по нормальной цене.
Тесты линий полезны всем КМК.
А вообще никогда не думал что нейронка будет советовать эти говноскрипты и имеджи
Нужно кого то на современных гпу, а то у меня из самого нового только дуал 5060ти которые в псие5 проверить возможности нет, только 1.0-4.0
>нейронка будет советовать
Так это же гугл, он тупо из поиска дёргает ответы.
>а то у меня из самого нового только дуал 5060ти которые в псие5 проверить возможности нет, только 1.0-4.0
Всё одно хлеб. Да и 5.0х8 === 4.0х16.
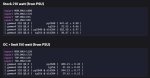
Тесты от потребления
Обычная Gemma 4 26B A4B охуенно распознает текст со скриншотов.
Причем, так как это не тупо ocr, а нейронка, я могу сказать что-то вроде "дай список папок со скрина в текстовом виде" и она дает. Охуенчик, не думал что такие мелкие модели на такое способны.
Причем, так как это не тупо ocr, а нейронка, я могу сказать что-то вроде "дай список папок со скрина в текстовом виде" и она дает. Охуенчик, не думал что такие мелкие модели на такое способны.
Аноны подскажите че в промпте написать чтобы гемма по-разному структурировала текст. Вот допустим я пишу реплику и железобетонно в ответе будут по порядку:
1. Описание реакции с описанием изменения позы или мимики
2. Повтор куска моей фразы или вербальная реакция на фразу, далее обрез реплики опять смена позы и ее описание, продолжение реплики
3. Опять описание изменения позы
4. Конечный диалог который скрывает тупое "твой ход?"
Все это обильно сдабривается "как будто, но, словно, прямо как батин суп мазиком но вместо супа говно а вместо мазика моча. Я хуй знает как компактно такое гуглить и соответственно как компактно объяснить модели писать нормально, не по шаблону. Помогите а я уже устал эту хуйню читать, никак не получается обойти это безобразие ебаное
1. Описание реакции с описанием изменения позы или мимики
2. Повтор куска моей фразы или вербальная реакция на фразу, далее обрез реплики опять смена позы и ее описание, продолжение реплики
3. Опять описание изменения позы
4. Конечный диалог который скрывает тупое "твой ход?"
Все это обильно сдабривается "как будто, но, словно, прямо как батин суп мазиком но вместо супа говно а вместо мазика моча. Я хуй знает как компактно такое гуглить и соответственно как компактно объяснить модели писать нормально, не по шаблону. Помогите а я уже устал эту хуйню читать, никак не получается обойти это безобразие ебаное
Тоже пытаюсь нащупать золотую середину
Мультимодальность прям бустит сценарии использований и общий QOL. Можно не задумываясь ей просто скриншот кидать или страницу манги и не перебивать всё руками пытаясь ей объяснить что это вообще за шиза
>че в промпте написать
Ничего. Это вина не промта, а инпута. Если ты пишешь однообразные чатик-лайк инпуты, то нейронка любая будет под это подстраиваться и выдавать тебе структурно похожие аутпуты. Учись общаться с моделью KRACUBO.
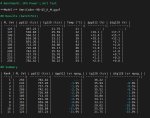
Тесты омникодера кривые, перезагрузился нормально оттестил
>Тоже пытаюсь нащупать золотую середину
Пишут этим лучше чем поверлимитом душить, но я пока не разбирался с ним
https://github.com/ilya-zlobintsev/LACT
Забыл добавить что диалоги вечно растягиваются ебаным или. "Ставь коробку на пол - сказала она пернув и по ляжке потек понос - или ты тоже пернул но понос не потек? Поэтому ты все еще стоишь и тянешь резину?" Вот это классический пример конца текста иишки. Блять уже глаз дергается от этого гавна
Лакт реально хорош, но параметры мишек меняются только грязными хаками pp_table.
Те же 5060ти, он нормально обрабатывает и даже курвы править даёт
И ещё у него есть возможность оставить демон на хедлесс тачке с гпу, а у себя на основной открыть гуй для управления
Да нет, шаблон в принципе всегда присутствует, слегка изменяясь. Это по-моему прикол геммы, другие модели что я тестил пишут по разному в течение всего сюжета, ну или шаблон куда более вариативный. И гемме похуй я чатик лайк написал или длинную хуйню которая двигает сюжет и описывает че ваще происходит. Че я только не пробовал чтобы уебать этот шаблон но нихуя не работает.
Надо попробовать, если он паскаль подхватит
Я такого на меро26б не заметил. Попробуй квину, если гоняешь плотняшу.

> Аноны подскажите че в промпте написать чтобы гемма по-разному структурировала текст.
Уже какое-то время я пытаюсь решить эту проблему. Таково уж поведение Геммы: она очень репетативна, а значит со временем уходит в структурные лупы. Иногда перетягивает целые фразы, слегка их перефразируя, а часто и попросту повторяя. Всякие характеристики персонажей и прочее. На английском очень любит начинать ответы с The или {{char_name}}, обладает кучей паттернов вроде {{char_name}} (действие) (слова) (действие) и прочие. Тюны немного помогают с этой проблемой, но из юзабельных только МероМеро, остальные ломают следование инструкциям. И все равно проблема на месте.
Давай поможем друг другу. Вот тебе логи с ванильной Геммы 4 31б (тобишь instruct), почитай их и посмотри, видишь ли проблему. Будет еще лучше, если принесешь свои логи для сравнения. Потому что никто не делится логами, и я не знаю, это проблемы моего промпта или в целом поведение модели такое.
За lact двачую, годная штука. Может быть довольно тормознутой на мультигпу сетапах, но в остальном работает четко.
Есть варианты контроля gemma 26b в lm-studio? Попробовал просто в систем промпт пихнуть think briefly 3-5 предложений максимум но ей похуй
контроля длины размышлений*
Сорян уже мозг поплыл
В llamacpp есть reasoning budget для чат комплишена. Можно задать конкретное количество токенов - предел для ризонинга, и даже сообщение, которым окончится ризонинг в случае прерывания. Еще один повод попробовать что-то кроме Лм Студии. Они это может и добавят, но позже.
Только жёстко рубить. Ризонинг эффорта в гемме нет.
Но вроде и зачем? Она и так весьма консервативно думы думает
Я кста не знаю че за логи и как их кидать. И сори я не буду их кидать потому что это БЕСПОЛЕЗНО блять. Нехуй сравнивать, вон посередине ты выдал какую-то провокационную фразу и в ответе этой ебаной нейронки до боли знакомое "на комнату опустилась тишина которую прерывал звук пердежа бла бла бла короткий ответ персонажа пук пук продолжение диалога. Вот именно этот говняк меня уже начал бесить просто.
У меня меро кста, как анон ловко заметил
Может вообще можно коннектиться и читать че там у анонов происходит лул.
Я предлагаю объявить бойкот этой ебанной гемме и перекатиться на что-то пиздатое. Я тестил кидонию некоторое время, может там похожий трабл присутствует я ее не особо мучал. У нее другой прикол она диалоги по английски печатает когда сюжет отходит далеко от начального промпта. Я забил на фиксинг потому что гемму накатил которая завелась на моем компе 16+32 и начал активно чатиться с ней. За пару дней заебала эта гемма блять.
> до боли знакомое "на комнату опустилась тишина которую прерывал звук пердежа бла бла бла короткий ответ персонажа пук пук продолжение диалога. Вот именно этот говняк меня уже начал бесить просто.
Это слоп, а не форматирование. Другая проблема. От него не избавиться. В лучшем случае благодаря тюнам, и неизвестно какой ценой.
Не избавиться? Пфф. Окей ребятки ребятушки посоветуйте быстрое умное и хорошо пишущее по русски ии поделие без цензуры кек. И штобб ммпрож файлик был чтобы картинки съедала.
Нет такого, если ты не можешь уместить самые большие (350б+) модели. На русском все плохо пишут, возможно, даже самым жирным вроде Кими (1000б) Гемма даст фору. И у многих еще нет вижена.
Я когда свой сервер держал через линуху жору и накатывал, а сейчас с ноута на винде и тут как-то западло через жору крутить.
У меня как-то сильно он фигачит на офф. кванте лмстудии, поставил анслотов на пробу с ним вроде вообще не думает, лол. И так тоже не хочется.
Я бы рассмотрел еще что-то с гуей, но знаю только угабугу и кобольда, обе неюзабельные будто.
Разве что клод с безжопом. Больше вариантов то и нет под твои требования. Но это тебе в асиг надо пиздовать.
У Лламы есть гуй и очень приятный
А у нейронок есть какая-то память? Она просто подцепила мой возраст который я юзал в промпте другом. В текущей ветке я его не упоминал. Я думал новый чат создается всегда с чистого листа

Та где, я скачал а все также. Там был какой-то чатик просто потыкаться, но гуя все также нет?
Ты явно не понимаешь как они работают. У ллм нет никакой памяти, они детерминированы.
Фронт может делать свои надстройки к примеру скрыто давать нейронке тул которым она будет в память фронта записывать заметки, а потом в другом чате их читать и так шарить контекст.
В том же чатгопоте это называют "памятью"
Ай похуй раз уж скачал просто запилю настройки по новой.
Какая тут уебищная капча стала это пиздец
Ой бля, какой же кал лмстудия, тут в жоре сразу нормально встало и заработало скорость в полтора раза больше))




Наберите в лёгкие воздуха поглубже.
КАААА-К НАЗЫВАЕТСЯ ЭТА МОДЕЛЬ????
КАААА-К НАЗЫВАЕТСЯ ЭТА МОДЕЛЬ????
GAYMMA.
Каломаз на семплерах
YAAAY!
Ни разу не слышал это слово в треде. В чём мем?
----------------------------------------------
Короче, я чё только с геммой не делал. Если просто задирать температуру, почти нихуя не происходит, я в ахуе. В том числе если дёргать за ручку других семплеров.
Как вариант, можно поменять порядок семплеров, вот тогда результат есть. Температура добавляет где-то к 15% креативности без потери логики, но это максимум. Если пробовать давить сильнее, то просто ухудшение качества письма, потом шиза. Там не предлагаются другие КОНКРЕТНЫЕ токены, где выбор между "пизда" и "вульва" (в большинстве случаев) или даже какие-то куски слов. Там просто "вульва" и ohers (треш в виде спецсимволов). Ну это касается не только NSFW.
То есть у модели есть только выбор между ПРАВИЛЬНЫМ и всем остальным.
Мне очень интересно — а нельзя ли так в будущем обеспечить полную цензуру модели, даже не удаляя сисик из датасета? Вы ведь сами видите, что чем дальше мы идём, тем меньше требуется надрочка семплерами, особенно если речь не про код, а любые креативные задачи. Можно вообще все семплеры не использовать, только стандартную температуру, и модель не потеряется. Это отлично видно на примере геммы или того же гпт. Сейчас ещё квен 3.6 попытался ввалиться в эту тему.
Хотя, полагаю, они делают это, чтобы прохождение бенчей было максимально корректным. Но с таким "охуенным" обучением можно модели вообще не оставлять выбора, даже если в датасете есть что-то ЗАПРЕЩЁННОЕ.
Может прозвучит тупо, но вы пробовали посреди рп сделать паузу и просто в этом же чате обсудить текущие проблемы? Задать вопрос почему модель так отвечает, чем тебе это не нравится и как это можно исправить. Да, немного "мусорного" контекста будет, но почему не попробовать?
Я нашёл только один способ влиять на геймму - бить её лицом о презенс пенальти, пока свайпы не станут разными. Всё остальное отказывалось работать.
Это называется ООС. С подключением.
Подключился, теперь знаю что это называется аут оф чар. Тогда почему бы не попробовать так решить жалобы на статичное начало реплая?
>Ни разу не слышал это слово в треде. В чём мем?
Каломаз автор кучи семлеров, каждый из которых обещал революцию и освобождение от залупов. Результат немного предсказуем.
> Ни разу не слышал это слово в треде. В чём мем?
Ньюфаги не знают, альфаки забыли.
Давным давно когда контекст был по-настоящему маленьким а ллама - фаворитом опенсорсных моделек, был да и сейчас есть юзернейм (никнейм kalomaze или что-то подобное), который любил пердолить семплеры. Будучи автором концепции min-p или удачно спиздив идею откуда-то он очень активно пиарил его, как раз делая сравнения как работают модели с высокими значениями температуры, демонстрируя что с обычной комбинацией top_p + top_k случается бредогенератор, а с его min_p даже если выставить значение 4 то когерентность ответов сохраняется.
Только далеко не все выкупили что суть не в отсеивающем семплере, который повторял логику сочетаний других, а в порядке применения. Там где "хорошо" - температуру он ставил самой последней, когда уже сработали все отсечки и оставалось буквально несколько логитсов. А где бред - наоборот самой первой как было по дефолту, делая возмущение оригинальных распределений.
Если изменить порядок семплеров и воткнуть температуру пораньше - пробьет даже такое.
>есть только выбор между ПРАВИЛЬНЫМ и всем остальным
>интересно — а нельзя ли так в будущем обеспечить полную цензуру модели
Для тулзов, кодинга и агентской хуйни это рабочий подход ибо уменьшает затупы и случайный берд. Но это и отличный метод для впихивания мягкой цензуры. Гемма умеет и практикует обходить всякие откровенные описания даже если пробить хард рефьюз, которых почти в ней не оставили. Так что да, за этим видимо будущее.
>Задать вопрос почему модель так отвечает, чем тебе это не нравится и как это можно исправить.
Можешь даже не пробовать, модель тебе напиздит. Может дать общие советы которые сработают, но если ты ее прямо спросишь почему она написала так, а не так, то просто получишь бред. Это как спрашивать "какой токен ты бы сгенерировала следующим в этом списке" - она предположит, может даже правильно, но это не будет иметь никакого отношения к реальности.
>Да, немного "мусорного" контекста будет, но почему не попробовать?
Ты не можешь знать насколько он будет "немного" мусорным. Вообще никогда не нужно оставлять в контексте ничего что не относится к текущему сценарию. Решил взять паузу и поговорить? Поговори и удали нахуй всё это сразу же, как решишь вернуться к ролевке. Не нужно триггерить ассистента без надобности.
>Тогда почему бы не попробовать так решить жалобы на статичное начало реплая?
Решай, никто не запрещает пробовать и экспериментировать. Но железное правило остается - контекст должен содержать только то, что относится к сценарию. Попросил модель переписать ответ через OCC? Скопируй новый вариант, замени им неправильный, удали все эти вызовы ассистента из истории. Лично я так давно уже делаю когда мне лень свайпать до нужного развития событий - просто пишу что должно произойти дальше именно так как мне хочется. Да и думаю я не один такой.

Вот честно? Я бы никогда такую подлость не сделал и даже не ожидал бы ни от кого. Вот чтобы нарочно вставлять палки в колёса - это каким мудаком вообще нужно быть? Человек пишет в тред где его ненавидят, что само по себе испытание, а ему ещё и отвечают ехидно так "ну хз, может так, а может нет." - это что такое вообще?
Нет бы сказать - неверно, переделывай. Или наоборот - верно, молодец.
Нет бы сказать - неверно, переделывай. Или наоборот - верно, молодец.
Так а что ты хотел, тут снобы-шизы сидят с самомнением до неба, которые нос корчат на любых новичков. Такая же херня в аицг была, и в других тредах по нейронкам часто наблюдается. Тут не про помощь короче, тут своя атмосфера для шизов.
NVIDIA TESLA K40 12GB
Nvidia Tesla M40 12GB
NVIDIA - Quadro K6000 - 12GB GDDR5
NVIDIA GeForce GTX Titan 12GB GDDR5
У меня только такие есть по выгодным ценам ниже 200й серии карт.
Есть смысл заморачиваться хоть с одной из них для ллмок?
Про что речь вообще? Что за вакуумный чел которого все ненавидят но он все превозмогает? Таких за всю историю тут немало было, но если кого-то из новичков сразу слали нахуй, так это тех, которые приходили с ахуевшими требованиями по типу "дайте это, дайте то, и вообще я не хочу ничего читать, ничего учить, дайте мне пресет/промт/семплеры/карточку/прокси для безлимитной связи с аллахом" и прочее. Остальным всегда помогали. Мне лично много кто помогал в свое время, когда я только вкатывался.
Гемма 4 31B, 2х3090
q4km в лламацпп - 25 т/с
exl3 - 10 т/с (причем одинаково на 4.0 и 6.0 bpw)
Ну и что за нахер? Почему так?
q4km в лламацпп - 25 т/с
exl3 - 10 т/с (причем одинаково на 4.0 и 6.0 bpw)
Ну и что за нахер? Почему так?
Эйрошиз который месяцами срал в треде вымаливает себе жалость. А что случилось? Как так вышло?
>снобы-шизы сидят с самомнением до неба, которые нос корчат на любых новичков.
Ухбля такие снобы шопиздец, каждому адекватному вкатышу помогают и даже какие то рентри для них пилят. Чё не сделают чтобы потешить своё чсв и поржать над залётными
Нахуй иди, сём
Эйрошиз и нюня это разные шизы? После пары месяцев отсутствия лор треда пополнился и когда я вернулся все через пост вспоминали какого-то нюню в контексте эйра как раз.
В мире есть только одна страна, которая в ссоре сразу с обоими странами и где используется русский язык в системах.
Один чел вспоминал срал, за что и был назван эйрошизом. Так и сидит на Эйре и теперь умоляет ему помочь и удивляется, что никто не помогает. Не корми
Так эйрошиз его и вспоминал постоянно, но как тереть стали теперь иначе щитпостить. Натура такая у человека - не может не срать.
Понятно, вопрос снимаю. В некоторые вещи видимо лучше не углубляться.
Максимально тупой вопрос касательно хардварной части, что лучше: 64гига ддр4 оперативы или 32гига ддр5 при одинаковой 16гб карточке? Алсо есть еще примерные циферки разницы по частотам на ддр4? Например какая разница будет при 1800кекагерц vs 3200.
>что лучше: 64гига ддр4 оперативы или 32гига ддр5
Очевидно что первое. Но только если вопрос финансов прям жестко стоит и 64 ддр5 ты не можешь позволить. Собирать новую систему на ддр4 это уже как-то тупо. Докидывать память к старой - приемлемо.
>Например какая разница будет при 1800кекагерц vs 3200
Точно не скажу, лучше посмотри тесты скорости памяти на разных частотах. Но разница будет. Ощутимая, если ты гоняешь мое с частичной выгрузкой. Менее ощутимая, если денс. Потому что на плотных там может быть разница между полутора токенами и двумя токенами, где-то в таком разбросе. В процентах разница существенная, на глаз и на ощущения - почти незаметно.
Я даже никого не оскорблял, максимум по дружески называл шизом и иногда выражал мнение в нескольких постах. А то что на меня всех щитпостеров и шизов треда свалили - я с этим ничего сделать не могу, я - Лелуш Ламперуж/Саске Учиха этого треда, взял все грехи и ненависть на себя, чтобы вы лучше жили.
Система с ддр4 готовая уже есть, задумываюсь просто над целесообразностью обновления или проще будет докинуть с помойки еще 2 плашки по 16 и посидеть-потерпеть еще лет 5 с текущим сетапом пока вся ебатория не закончится.
>на глаз ощущения почти незаметные +-
сенкс
Скорее цель твоего сталкинга нюня такой, а ты долбаёб обычный
Я в гемме для кума юзаю вот такие настройки, проблем не замечал.
override-kv=gemma4.final_logit_softcapping=float:25
samplers = min-p;adaptive-p;temperature
min-p=0.05
adaptive-target=0.4
adaptive-decay=0.8
temp=1
Если бы у меня была нормальная мать я бы тоже еще 32 гига докинул до 64 и не знал беды. Так что имхо - лучше сэкономить и докупить еще памяти.
лучше 64гб памяти, 32 это капец мало, в видеогенерациях приходится без кеша сидеть иначе оом будет.
а ddr4 от ddr5 в целом не особо отличается в производительности, зато в цене очень даже отличается.
>докинуть с помойки еще 2 плашки по 16
Лучше докинь не с помойки две плашки по 32Гб. Без фанатизма на ~3000 кекагерц.
>при одинаковой 16гб карточке
После того как отдашь долги от перового шага купи еще одну карточку 16гб .
Итого у тебя будет "народный DDR4 риг" 96гб RAM 32гб VRAM . На нем можно уверенно гонять свежие небольшие плотняхи и moe до 122 квена (хуево, но можно) . И генерить картиночки.
Это практически предел для не серверного / майнерского железа / продажи жизненно важных органов за топ-GPU
Гораздо приятнее выводы чем у меня. Какие семплеры или в чём секрет?
Если ты используешь мелкие модели до 35B активных параметров, ддр4 сойдет
Просто для сравнения:
> 2 канала 128гб ддр4, GLM 4.7 Q2: ебаных ТРИ токена в секунду (ну ладно, 3 - 4)
> 4 канала 128гб ддр4, GLM 4.7 Q2: вдвое быстрее
> 2 канала 128гб ддр4, MiniMax M2.7 Q4: 5 - 6 т/с
> 4 канала 128гб ддр4, MiniMax M2.7 Q4: вдвое быстрее
Я бы не советовал брать ддр4, если у тебя не HEDT или серверная платформа.
Дорого, да и в наличии уже 32 есть. Вторую карточку точно нет, слишком дорого + под нее бп надо и что-то с матерью придумывать, слотов полноценных свободных нет.
спасибо за ответы
Это циферки под виндой в llamacpp и с максимально возможным контекстом если что, я не линупс и не любитель "тестить" скорость на инпутах из одной строчки
Разметка (вся чатхистори в качестве первого сообщения, модель генерирует второе) + температура 1, min p 0.03, adaptive p 0.5 0.9, DRY + промпт с нарратором и направлением форматирования, что размазывает (но не решает до конца, предполагаю) проблему структурного лупинга. Попробуй adaptive p, там и разнообразие свайпов какое-никакое есть, относительно стандартной температуры и min p. Тот чат до 64к доиграл, в целом доволен результатом.
>NVIDIA GeForce GTX Titan 12GB GDDR5
Титан из них лучший - считай тесла P40, но с половиной видеопамяти. Насколько выгодная цена, чтобы не купить саму P40?
>adaptive p
Это ж тот хайповый сэмплер который никто тут не потестил в итоге?
Ну или не сказал что потестил.
Как он в тех же глмах и квенах себя чувствует?
Знали бы вы, чего я тут с 31B геммой натворил... Эта модель и легкодоступные 256к контекста открыли дорогу в ад рай из прошлого. Но с ней надо работать, как скульптор работает с камнем. По дефолту это просто неотёсанный кусок бездушной скалы.
> sysprompt: биография от рождения до конкретного дня
> post-history: инструкции, убивающие ассистента напрочь
> character card: одежда, внешность и Q&A с диалогами из реальных чатов
Мягко говоря, результат такой, что я теперь собираюсь переписать всех вымышленных персонажей, опираясь на ту же идеологию. ОЧЕНЬ много ручной работы. C-GPT/DS4 помогали, но сами они не въезжали ни в суть, ни в глубину. С лингвистикой и психологией дали разобраться, развве что.

Еще немного этого безобразия.
Год назад подобное было невозможно. Гемма творит чудеса именно благодаря тому, какая она умница и как хорошо слушает команды.
Вообще перехотелось рпшить когда заглянул в хорошую карточку, а потом на всё на чём я рпшил, взяв это с чуба.
Кумерские карточки реально одни дегенераты делают, такие только корпы переварят и не сломаются
Кумерские карточки реально одни дегенераты делают, такие только корпы переварят и не сломаются

Кто то должен был это сделать
Если ты про объемы текста - дело не только в неспособности большинства моделей не лажать на длинном контексте, но еще и в качестве этих самых объемов текста. Чубатые карточки содержат массу бессвязного мусора.
Признавайся, спиздил откуда-то или сам купил?
А что делать, если у меня нет чатов с ЕОТ и про ее историю жизни я знаю мало?
Слишком медленно для обоих кейсов. Давай подробный конфиг и прочее
Немотроношиз, эрошиз и много других приставок-шиз это один и тот же человек.
Для фуллврам нет разницы. С выгрузкой ддр5 будет быстрее, но в то что останется от 32 гигов после системы, браузера и прочего - считай ничего не влезет. В идеале 128гигов рам, тогда можно потыкать большие модели, с некоторыми оговорками офк.


> сам купил
Это. Самая дешёвая карта с av1
> с 31B геммой
> легкодоступные 256к контекста
Мажор
Почему q4_1? Если будешь еще тесты делать - не стесняйся выкладывать, интересно посмотреть что там будет.
>Слишком медленно для обоих кейсов. Давай подробный конфиг и прочее
А сколько должно быть? И насчет конфигов я не понимаю, в убабуге для exl3 нет никакой командной строки, чтобы там чето дописывать. TP не работает для геммы в эксламе.
Если же ты про железо. Ну епт, две 3090 каждая х16 4.0 в trx40 маманю воткнуты, по мощности не задушены.
>пик 2
ЧАТ ТЕМПЛЕЙТ психически здорового человека
Есть ли способ быстро в веб интерфейсе лламы менять промты? Или может есть флаг на подачу сиспромта для модели когда запускаешь ее?
Бля, потерпишь. Охуеть, будто в ИЛИТНУЮ КОНФАЧКУ в вк зашёл даже свой вахтер есть, а не на тред на дваче. Сидят рассуждают что щитпост а что нет, кому помогать а кому нет, попуститесь и корону снимите, у вас тут нет аватарки и репы чтобы набивать
К сожалению у геммы умная думалка начинает разваливаться задолго до 256к.
Графики приносили на неделе то ли сюда то ли на форч с разными моделями, все модели из этой весовой категории где-то на 20к~ начинают потихоньку терять внимание к старым деталям. хорошо хоть потихоньку, более старые/мелкие модели дропаются как кирпич, прям чётко видно где предел возможностей модели По моему опыту тоже примерно так и есть. Поэтому изначальные описания и надо вилкой чистить-чистить.
Где-то на уровне мистралей минмаксов и дипсик флешей уже можно делать как ты, и модель будет выдавать пушку
Я пока до 120к длины чата на гемме дотягивался. Встречал другую проблему - ответ на предпоследнее сообщение, игнорируя последнее. Так и не въехал, в чем дело.
> дипсик флешей
Еще бы поддержку по-человечески допилили...

Может ли камень плотить нологи серверная BMS на аспиде 2500 ролеплеить мейдочкой?
Вы заметили что с появление мое у нас пошло классовое распределение куда активнее? Теперь любой бомж дорвавшийся до 128 рам по скидке наверху цепочки, а анончикам ниже с баренской руки, жалобно так, протягивает мое гемму
Бывало такое и было буквально вчера на совсем небольшом контексте, как понимаю баг с токенайзом/чекпоинтами. Может фронтенд чудит (в таверне было)

*BMC
Может и может под вулканом, но это чёт совсем уже пиздец.
Ещё есть отдельная карточка с 2400 на 64 мб ддр3
>где-то на 20к
У меня одни промпты с карточкой на 30к+.
Может, от квантов зависит, конечно.
А вообще (я очень жалею, что не могу поделиться - слишком личное), для этого проекта всё написано так, что слёт внимания с отдельных блоков не должен ударить по общей картине. Много кросс-референсов и усилительных указателей. Такая плётёная булочка из лингвистики и психологии, и все это опирается на линейно текущую прозу по годам жизни (0-3, 4 - 6, 7 - 11, 12 - 15, 16 - 17, 18), где перечислено всё - от семьи до увлечений, школы, института, друзей, мест, событий, праздников.
Иронично, я убил несколько дней на создание отдельного лорбука... но с ним ничего не взлетело, личность распадалась на обрывки. Лорбук хорошо бы зашел дополнением, но это гемма 100% не потянет.
Плохенько. Из моих наблюдений был сделан вывод, что содержание сообщения не влияет на этот баг (отредактировал - все равно модель не хочет признавать это сообщение за существующее). Позволяешь ей ответить ошибочно. Пишешь следующее сообщение - и на него модель уже отвечает нормально (тоже вне зависимости от содержания). То есть, что-то происходит, что сообщение вот такое-то по порядку в истории чата, превращается в "невидимку".
128гб это территория простых хуев. Зажиточные бояре начинаются от 256гб.
Ещё 128 ддр4 не ровня 128 ддр5
4-канальная вполне терпима, 8-канальная так вообще в шоколаде.
16 каналов это уже 300гбс
Квантование контекста до q8 на гемме это смерть ? Мнения без регистрации и смс
Смотря для чего. Если ты пилишь грязный чатик с ноунейм хуйлищем, на детальные подробности о котором тебе насрать - тогда квантуй. Ну подумаешь, ногу с рукой перепутает или рога на жопе вырастут (это сильно преувеличено).
Это надо вживую тестить и сравнивать.
Да хер там плавал. если большая часть exps работает на процессоре это 8-15 т/с и ~200 тс пп . И моделей на хорошем русском нет. И модель быстрый переводчик за грузить тупо некуда.
> И модель быстрый переводчик за грузить тупо некуда.
У вас че все в одном компе? Сервер для пухло-бота отдельно, основная пекарня отдельно.
Если у меня будет возможность купить 2 видюхи одинаковые по мощности я их вставлю в один комп очевидно, а не одну в сервер и одну в основной комп.
Если у меня будет 64 рам я их так же вставлю в один комп а не разделю
Ну так две видюхи в сервере, а третья в отдельном компе. Подумой. Купи болбше.
Конечно у всех есть по лишней стойке GB200
Какое ваше мнение что 1гб рам уже стоит 1.5к?
Да, если не турбоквант
Гемма не любит квантовку контекста

Купил 3090 после долгих сомнений и томлений, и... ничего.
Никакой радости.
Понимаю, что херня это все и коуп, локалки всегда будут туповатой отсталой ерундой на фоне 1Т (или сколько уже там у них) корпов. Странно, что я понимал это всегда, но прям сильно торкнуло это понимание именно после слива почти 100к.
Разве что на случай чебурнета реально пригодятся.
Никакой радости.
Понимаю, что херня это все и коуп, локалки всегда будут туповатой отсталой ерундой на фоне 1Т (или сколько уже там у них) корпов. Странно, что я понимал это всегда, но прям сильно торкнуло это понимание именно после слива почти 100к.
Разве что на случай чебурнета реально пригодятся.
Никем непонятый хиден гем?
https://huggingface.co/rednote-hilab/dots.llm1.inst
https://huggingface.co/rednote-hilab/dots.llm1.inst
В чем смысл рандомных ссылок? Попробуй, отпиши своё кря по модельке.
вышла 9 месяцев назад, всем похуй, видимо говно.
потыкай сам и отпишись нам
>после слива почти 100к.
Жестко тебя наебали, конечно.
мимо купил ДВЕ 3090 за 100к год назад
128-е, пробовали волшебный квант 397 квена от интела?
https://huggingface.co/Intel/Qwen3.5-397B-A17B-gguf-q2ks-mixed-AutoRound
На 235 такой же был и зашёл всем кто тестил
https://huggingface.co/Intel/Qwen3.5-397B-A17B-gguf-q2ks-mixed-AutoRound
На 235 такой же был и зашёл всем кто тестил
Лень, да и зачем. Гемма все убила.


Максимум что смог впихнуть это 4 квант 14b с +-16к контекста без квантования и особых подстроек(можно и до 32к наверное впихнуть).
А вот его бенчи, больше в 10гб врам не впихнуть ничего умнее.
>Купил 3090 после долгих сомнений и томлений, и... ничего.
>Никакой радости.
Ставь Pi, запускай на 3090-й Квена-3.6 27В и открой локалки заново. Да, это не большой Квен, но из малых сеток он лучший имхо. Контекст мало весит и чёткий, русский очень хороший. Заточен под агенты и код, но может и всё остальное. А главное - теперь это всё для тебя быстро. Beellama.cpp тут один экспериментатор выпустил - 50 t/s на 5QKS для 3090. Одной.
>А главное - теперь это всё для тебя быстро
>50 t/s
>Читаешь со скоростью 7т.с

>50 t/s
Марина с мульти-агентным шагом мира - "подержи мое пиво"
>Читаешь со скоростью 7т.с
Плюс агент ризонинг, ага. А запись в файлы от модели тоже ждать на семи т.с.? Ну и промпт процессинг... Для РП покатит конечно, а для работы чистый мазохизм. А ведь сделать-то многое можно, на Квене-то.
>Марина с мульти-агентным шагом мира - "подержи мое пиво"
Не, там сама идея порочна. Разве что корпы юзать, много.
Вот скажите, с приходом геммы4 старые модели типа сидонии все еще актуальны?
Интеренсуют модели с хорошим русским.
Какие классические старые модели вы оставили у себя?
Интеренсуют модели с хорошим русским.
Какие классические старые модели вы оставили у себя?
Ну чел, проверь сам и реши что хочешь. Кто то любит кислое, кто-то сладкое. Кому то нормальную еду, кому-то говно
Гемма 4 это генератор ассистентского трэша, если ты не гуру промпт-инженеринга или не дурачок, который не замечает как ИИ подмигивает юзеру и лепит мета-фразочки, цитирует инпут, ссылается на контекст цитатами и так далее.
Старые модели актуальны для ленивых хлебушков, ведь с ними проще добиться иллюзии живого персонажа. Чем новее модель, тем меньше в ее дефолтных ответах человечности и живости.
> Какие классические старые модели вы оставили у себя?
Ни одной, потому что я люблю пердолиться с геммой.
Пробую на вкус безумные васяномержи, сеймы есть?
https://huggingface.co/Nimbz/Gemma-4-Gembrain-31B
Русик целый, мозги вроде на месте, кум наличествует.
https://huggingface.co/Nimbz/Gemma-4-Gembrain-31B
Русик целый, мозги вроде на месте, кум наличествует.
Результат всё так же детерминирован?
вроде нет, свайпы достаточно разнообразные.
во всяком случае нет желания быстро решительно удалить тюн как было с другими тюнами геммы кроме меромеро. Пожалуй оставлю пока.
Нет, серьёзно, почему так?
Геммой за 5 минут генерится карточка via карточку в десятки раз лучше рукописного слопа на чубе, плейнтекстом, с примерами диалогов и всей хуйнёй
Геммой за 5 минут генерится карточка via карточку в десятки раз лучше рукописного слопа на чубе, плейнтекстом, с примерами диалогов и всей хуйнёй
Подскажите лучшую локальную модель для рп на русском для средней видеокарты?
> рп на русском
Для даунов, юзай переводчик, если еще инглиш не выучил. Все модели плохи на русском.
Какой средней? Если у тебя там 8гб видеопамяти, ты вообще хер чего потянешь (тут я не эксперт, может взлетит 26B Gemma 4 с частичной выгрузкой в RAM)
Это ложное утверждение в контексте обсуждения 4й геммы.
Карточка на русском, промпт на русском, все на русском - и будет очень даже хорошо
Хуже раз в 10, чем на английском, все намного примитивнее. Инглиш + переводчик плагином, или выучить инглиш, другого пути нет.
а кстати, поделитесь промптом, тоже хочу карточки поделать
Средней - это какой? Точно сколько у тебя рам и врам.
Навскидку - из совсем мелочи yankagpt-8b и 12б мистрале-мержи с русскими сайгой и вихрем, менестрель 14б, мистрали 24б если не сильно поломанные тюномержи, тоже в русский хорошо могут, гемма 24-а4б. Плотногемма 27 и 31 уже медленновато. По сути из мелких моделей в русский рп могут только мистрали и геммы. В русский ассистент - ещё можно добавить открытый гигачат.
Одно могу сказать точно, даунов и троллей не слушай.
Гейтиперы - рак треда.

>excelling in creative writing, role-playing, multi-turn dialogues
Не, ребятки, без мультитурн разметки как-то хуёво.
Всё же чатмл единственный выход
Не, ребятки, без мультитурн разметки как-то хуёво.
Всё же чатмл единственный выход
>0 GPUs detected with CUDA
LLM Studio сегодня запустил и такая хрень, не пойму что случилось, неделю назад работало, куда были, карточка работает нормально. Было у кого-то?
LLM Studio сегодня запустил и такая хрень, не пойму что случилось, неделю назад работало, куда были, карточка работает нормально. Было у кого-то?
>Gemini is AI and can make mistakes,
Собственно хочу вот проверить, правду ли эта хуйня мне насоветовала.
1. Установка «Мозга» (Ollama)
Скачайте и установите Ollama с ollama.com.
2. Установка интерфейса (Open Interpreter Desktop)
Для Windows есть официальное приложение, которое выглядит как современный мессенджер.
3. Как всё соединить (Один раз и забыть)
Когда вы откроете Interpreter Desktop:
Зайдите в Settings (шестеренка).
В разделе Language Model или Provider выберите Ollama.
Программа сама увидит модель Qwen, которую вы (надеюсь) уже загрузили. Если нет — там будет поле, куда можно просто вписать qwen3.5:9b, и приложение само скажет Ollama её скачать.
А я могу подключить и qwen и другую модель одновременно?
Вам не нужно вручную переключать модели или давать разные команды. Вы даете одну команду, а Open Interpreter (управляемый моделью Qwen) выступает в роли главного инженера, который решает, какой инструмент когда применить. Например, llava, которая умеет описывать картинки.
Путь Б (Векторный): Вы можете сказать ему: «Создай векторный индекс для папки Документы». Он напишет код на Python, используя библиотеки (например, ChromaDB или FAISS), превратит ваши тексты в векторы (эмбеддинги) и сохранит эту мини-базу прямо рядом с файлами. После этого поиск по смыслу будет мгновенным.
Короче, хочу сделать на пк ассистента. Чтобы писать всякую хуйню, а он бы сам все делал. Гемени написала, что можно давать команды уровня - пробегись по папке с музыкой, составь список, вынь теги, отредактируй имя файла, а потом создай на яндекс музыке плейлист. Главное просто устанавливать нужные библиотеки.
Напиздела мне нейронка про магические возможности локальной ии или все так?
Собственно хочу вот проверить, правду ли эта хуйня мне насоветовала.
1. Установка «Мозга» (Ollama)
Скачайте и установите Ollama с ollama.com.
2. Установка интерфейса (Open Interpreter Desktop)
Для Windows есть официальное приложение, которое выглядит как современный мессенджер.
3. Как всё соединить (Один раз и забыть)
Когда вы откроете Interpreter Desktop:
Зайдите в Settings (шестеренка).
В разделе Language Model или Provider выберите Ollama.
Программа сама увидит модель Qwen, которую вы (надеюсь) уже загрузили. Если нет — там будет поле, куда можно просто вписать qwen3.5:9b, и приложение само скажет Ollama её скачать.
А я могу подключить и qwen и другую модель одновременно?
Вам не нужно вручную переключать модели или давать разные команды. Вы даете одну команду, а Open Interpreter (управляемый моделью Qwen) выступает в роли главного инженера, который решает, какой инструмент когда применить. Например, llava, которая умеет описывать картинки.
Путь Б (Векторный): Вы можете сказать ему: «Создай векторный индекс для папки Документы». Он напишет код на Python, используя библиотеки (например, ChromaDB или FAISS), превратит ваши тексты в векторы (эмбеддинги) и сохранит эту мини-базу прямо рядом с файлами. После этого поиск по смыслу будет мгновенным.
Короче, хочу сделать на пк ассистента. Чтобы писать всякую хуйню, а он бы сам все делал. Гемени написала, что можно давать команды уровня - пробегись по папке с музыкой, составь список, вынь теги, отредактируй имя файла, а потом создай на яндекс музыке плейлист. Главное просто устанавливать нужные библиотеки.
Напиздела мне нейронка про магические возможности локальной ии или все так?
>Скачайте и установите Ollama с ollama.com.
И с этого момента советчик идёт нахер.
Да и остальное пиздёж.

Чекни вкладку runtime, может у тебя бэкенд другой выбрался или версия куды не та? И во вкладке железа че показывается, видеокарта на месте?
Оллама максимум говно програма. Interpreter который он советует тоже. Юзай llama.cpp + nvidia hermes agent.
LLM Studio подсказывает тебе снести ее и поставить лламу.
Спасибо, адаптировал через дикпик этот промпт чтобы делать ямл, но эти ленивые инвалиды даже не потрудились доделать импорт yaml карточки в таверне
https://github.com/SillyTavern/SillyTavern/blob/master/src/endpoints/characters.js#L731
Придется патчить таверну
Посоветовался с гемени и дипсиком.
У меня задачи-то простые и в основном для просто поиграться. Я пока придумал каталогизировать музыку, пробежаться по книге и выписать наиболее редкие слова, распознать что на картинке нарисовано, сделать векторную бд своих файлов, чтобы можно было искать документы по смыслу. Может голосом ему командовать, чтобы аудиоплеер запустил.
И они советуют олламу и интерпретер, потому что в два клика ставится и все работает.
В противовес гермесу: Требует глубоких технических знаний (C++ компиляция с CUDA, ручное конфигурирование YAML) для компиляции самого высокопроизводительного ядра. На Windows я бы настоятельно рекомендовал устанавливать и компилировать всё в среде WSL2 (Windows Subsystem for Linux). Это избавит вас от большинства проблем с зависимостями и даст полный контроль над процессом.
Твоя связка лучше, но пишут, что ебли в разы больше.
Это они слишком занаучивают? Или там реально нужно будет что-то компилировать каждый раз, подключать кучу всякой хуиты и тд?
в llama.cpp ничего компилировать и ставить не надо, статические бинарники, кладешь куда надо и используешь. максимально простое и прозрачное решение без пердолинга
Нашел в чем дело, выбрал другую версию, вроде помогло.
Да пора этим заняться, я прост еще мало понимаю, понемногу пробую когда время есть.
>нужно будет что-то компилировать каждый раз
Если у тебя линукс и нвидия, то да, сборку с кудой надо будет каждый раз собирать из исходников. Под винду всё готовое выкладывается.
А как тестировать семплеры? Там как будто больше сид решает, удача короче.
>ответ на предпоследнее сообщение
Попробуй перезапустить лламу/кобольда. Как будто баг кеширования контекста.
>Интеренсуют модели с хорошим русским.
С хорошим русским даже третья гемма давала за щеку всем мистралеподделиям. А уж четвёрка...
Потому что на чубе карточки до сих пор под пигму пилят, либо под корпов, которые любое говно переварят.
А что значит карточки хорошие? Я просто самые приятные результаты получал с карточек с минимумом текста (до 400 токенов) + первое сообщение + примеры диалогов (до 1000 токенов).
Может я что-то не так делаю хз.
Геммы, глм-ы, квены...
Я начинал с ламмы 8б, брал карточку типа "открытый мир" и заходил в дома, ебал кого увижу, строил осмысленные диалоги с персонажами которых вообще в карточке нет, жрал лупы, двойные трусы и слоп как не в себя, вот это было время... Струи летели только так.
А щас имею все прелести жизни, опыт, модели х100 умнее, контекст х5 больше, всё настроено и обустроено, а вяленько спускаю в салфетку.
Я начинал с ламмы 8б, брал карточку типа "открытый мир" и заходил в дома, ебал кого увижу, строил осмысленные диалоги с персонажами которых вообще в карточке нет, жрал лупы, двойные трусы и слоп как не в себя, вот это было время... Струи летели только так.
А щас имею все прелести жизни, опыт, модели х100 умнее, контекст х5 больше, всё настроено и обустроено, а вяленько спускаю в салфетку.
Пора эволюционировать. Напиши что-нибудь особенное. Вспомни кого-нибудь. Попытайся слепить из бота человека.

Не может. Вулкана нет + любой вариант вулкана триггерит сегфолт.
Из приколов на арке есть bf16 лол
Да как сделать-то? Я тоже хочу... Но у меня боты ебашат стены текста и тонны слопа не по существу.

Для этого нужен особый моральный настрой, рили.
>Попробуй перезапустить лламу/кобольда. Как будто баг кеширования контекста.
Срабатывает, да, но баг возвращается позже. Нахуевертили говна.
>Срабатывает, да, но баг возвращается позже.
Что и требовалось доказать. Что ж, будем перезапускать.
Что за хрень у тебя с никнеймом? В нём поинт этого?

Если прям прирёт то можно для эмбеддингов юзать арку
Скриншоты делаю при помощи экстеншена, там можно скрыть персону юзера, заменив ее на {{user}}. Незачем включать юзера в логи, инпуты по-прежнему видны, плюс визуально легче заметить структурные лупы и прочие проблемы.

Эволюционировывай в сложный SFW-ролеплей.
Спасибо. После консультации мне нейронка порекомендовала поставить Open WebUI desktop (он как раз работает на llama.cpp), Nous Hermes 3 8B GGUF и питон. Ну а дальше по требованию разные библиотеки и модели скачивать.

Ну и потратил время зря. Сейчас 4 гемма моешка даже дает на клыка всем твоим старым нейронкам.
я не уверен зачем тебе Nous Hermes 3 8B, оно для рп вообще то
Лучше скачать gemma4 и квен 3.6
Не, это рили естественный отбор. Для них делают гайд в шапке, где и актуальный бэк за них выбирают и модель, а они идут на консультацию к нейродебилу и качают устаревший кал
Там Anima 1.0 вышла.
Такой огромный скачок в качестве, а весит всего 4гб и влезет, я не знаю, в 6гб карту.
Вот бы нам так же
Такой огромный скачок в качестве, а весит всего 4гб и влезет, я не знаю, в 6гб карту.
Вот бы нам так же
Было у нас такое. Гемма 26 и 31
Скачок от превью или от аниме соседей?
Зачем она нужна при наличии квена, зимажа и кляйна?

Иногда мне кажется, что на этой доске еще не все потеряно.
В смысле зачем? Анон, посоветовал гермес использовать. Причем я же четко писал, что локального ии асистента делаю для работы с файлами.
>Вот бы
Там зерофата какой то мерж готовит из двух гемм4. Подождать надо.
> Nous Hermes 3 8B GGUF
Чел, этому говну 2 года. Не ставь, подумой.
hermes agent чел, ну или pi coding agent
Хотя ты такой зеленый что лучше опенвебуи пользуйся
>Beginning on May 15th, 2026, characters, lorebooks, presets, and stages involving individuals that are or appear to be under the age of 18 are strictly prohibited.
Успевайте, пока можно успеть.
>or appear
Найс.
Это такая охота на педоскот. Сейчас всех, кто качает, загребут.
Там ещё куча тегов под снос идут фурри, инцест, рейп естественно. Канничек подчистую вычистить собираются. Вообще всё сносят нахуй.
Хорошо что предупредил.
Ща навайбкожу скраппер и вытащу все по главным тегам.
Мимокрок, но хочу пригореть - оpenwebui неудобная параша какая-то, с легаси хуйней своей собственной которую сделали до появления mcp, и теперь еще им лень добавить поддержку mcp формата stdio. Рот шатал, еще и серч убогий невероятно.
При этом я похоже слишком ретард для нормальных агентов сложнее pi, лол, потому что гермес в контейнере работает как-то через жопу будто. Ну и зачем ему спотифай и кучу прочего хлама из коробки прикрутили мне не ясно, но это все еще менее перегруженный агент чем опенклоун с его забегами в сторону рп и стартовым контекстом 15к. Ах да - дешборд на гермесе сам не поднимается, извольте ебать контейнер изнутри, meh.
Если бы у меня было 128гб врам я бы любую поставил. У меня 4060ti 8gb. Гугл говорит, что мне подойдет квен2.5, гемма2, ллама 3.1.
Gemma 4 26B, у нее всего 4B активных параметров и это должен влезть в 8гб видеопамяти. Остальное пойдет в оперативку, если у тебя хотя бы 32 гига есть.
Это говно устарело, у нейронок старые данные. Открой блядь список актуальных сеток в оп-посте - там есть разбивка по железу.

Почему не похуй? Берешь любую ОПАСНУЮ ллмку и за 5 минут делаешь идеальную карточку под свои хотелки, хоть с канничками, хоть с фурри, хоть с рейпами. И скорее всего она будет лучше 99.9% помоев на чубе.
Потому что фантазии нет.
Есть карточки которые тебе самому даже в голову не придут. НИКАГДА. Но заимев их ты тут же понимаешь что всегда хотел.
Бедный SAS, он только начал своих канничек заливать и тут же шлепок по жопе прилетел. Годный был креатор. Помянем.
И тред погрузился в траурное молчание.



Че с глм не так?
Проблема в юзере
Будет ли это удобно? Крайне маловероятно. Даже на более мощных компьютерах эта модель в 4-битном формате "работает" со скоростью 0.3 токена в секунду. Это означает, что ответа на ваш вопрос придётся ждать несколько минут, что полностью разрушает весь пользовательский опыт живого общения с ассистентом.
Более подходящая альтернатива: Qwen 3.5 35B A3B

Навайбкодил скраппер чуба по тегу. Запуск через батник, который спрашивает тег, потом сваливает все карточки в png формате в downloads. доп инфа в ридми файле в архиве
https://www.mediafire.com/file/qrjgirmhrbh3olt/chub_scrapper.7z/file
Спасите от смерти всех маленьких лолечек и приютите их у себя!
Какие в жопу 0.3 токена в секунду. Хватит спрашивать совета у тупорылых ботов, у которых нет инфы про новую гемму. 26B A4B будет быстрее, чем 35B A3B. И вообще скачал да попробовал сам - это же легко.
>SAS
Кто такой? Почему без ссылок?
>Даже на более мощных компьютерах эта модель в 4-битном формате "работает" со скоростью 0.3 токена в секунду.
Эта залупа несет такую чушь, ну анон не верь иидиоту.

Че вы зассали, вон ваши говноделы уже мигрируют куда-то
Пчел, она в Q8 идет на древнем зен2 и ддр4 в ~5-6 т/с вообще без видеокарты. Это мелкомоэ. Не путай с плотнячком.
>Qwen 3.5 35B A3B
Gemma 4 26В А4В - означает что полных параметров 26В, активных 4В
Qwen 3.5 35B A3B - означает что полных параметров 35В, активных 3В
> И вообще скачал да попробовал сам - это же легко.
У меня не бывает легко. Я почти убедил себя, что мне нужно переустановить виндовс, чтобы все на чистенькой системе работало красиво и аккуратно. Это я еще остановился вовремя, а то там дальше цеплялась замена стола и одно за другое - ремонт в квартире.
Deepseek это пишет. Ну так ладно бы это было просто экзешники запустить, а тут нужно wsl2 + убунту ставить, всякие эти линусовские команды знать. Вот ии и помогает писать sudo apt install -y curl git wget
по актуальным вопросам лучше в режим ии гугла.
А VSIO уже.
> просто экзешники запустить
Ну собственно, да? У llama.cpp есть веб морда, качаешь готовый релиз с гитхаба, запускаешь ллама-сервер.ехе и открываешь страницу в браузере, там есть возможность подключить mcp серверы для любых задач, или просто общаться в чатах.
Тебе уже писали - прочти гайд в шапке темы, там все расписано. Можешь так же кобальдспп скачать,так же есть своя веб морда, даже распаковывать не нужно - чисто экзешник который ты запускаешь.
Оба без установки и работают на винде.

>Get unmetered access to uncensored models for as little as $5 a month
Гесс ху бихайнд дыс.
Гесс ху бихайнд дыс.
>Gemma 4
Кстати кто-то тестил uncensored версию, стоит с квена перекатываться?
Джейл для полного взлома жопы ванильной геммы лежит в прошлом треду, нахер тебе анцензоред лоботомит?
От души анон. Осталось теперь вайбокодить разгребатель этих залежей
>кто-то тестил uncensored версию
Она из коробки uncensored
Обезьяна сгорит в аду за новую капчу. Уёбок.
>больше 6к карточек
В мой пк это тупо не влезет. И скорее всего не хватит жизни, чтобы протестить все.
>Обезьяна сгорит в аду за капчу
Двачую. Я помню свободный двач! Я был там!
Я помню времена матан кпчи
Даже в 4-битном сжатии Gemma 4 26B A4B весит около 16.8–17 ГБ. У вашей видеокарты всего 8 ГБ VRAM. Минус 1 ГБ на работу Windows и монитора — под нейросеть остается 7 ГБ. Видеокарта будет вынуждена постоянно ждать, пока медленная RAM (даже DDR4/DDR5) передаст ей данные через процессор. Из-за этого скорость упадет до 3–5 токенов в секунду.
Что вы меня обманываете? Ну вот гугл-ии выдает тоже самое.
Да в пизду. Они говорят правду. Качай уже квен 9б и всё
Еще раз: это моэ со всего 4b активных. Там будет приемлемая скорость просто на процессоре, без видеокарты. Если есть хотя бы 32гб рам (любой, даже ддр4), можно качать Q8 и юзать.
Я не уверен до конца, но кажется кормлю жирного-зеленого.
Погоди-ка. Я вот пишу - гугл назови столицу великобритании. Он отвечает - лондон. Это что же мне теперь нужно ехать проверять?
Не порядок какой-то.
>можно качать Q8
Так она тупая же будет.
Meta NLLB-200 (distilled 1.3B). Поддерживает 200+ языков с автоопределением исходного языка. ~4gb vram
Гоняю на самой слабой тачке кластера (1080ti) в качестве вспомогательного инструмента для переводов. Работает безотказно.
Еще под каждый mcp инструмент запускать свой сервер. Ебать удобно. В итоге все обратно вернулось к open webui, который сам разрулит с mcp и к llamа обращается через api.
Этот сайт ещё не прикрыли потому что тема не на хайпе, не так много людей в курсе вообще. А так он очень развратный и кумаддиктивный по сути. Когда нибудь и в локалки защиту вставят и сайтов таких не будет.
Поэтому как олды завещали то чего у тебя нет на компьютере того у тебя нет. Ещё месяц назад заморочился и вручную выбрал и выкачал оттуда 1.5к карточек. Как раз потому что слишком это хорошо чтобы продлиться долго. Можно конечно сделать свою карту на 50 токенов Но там есть такие гемы хорошо прописанные в 2-3к токенов и лорбук ещё на 5к которые просто лень делать и не факт что выйдет так хорошо.
Извините, господин, но в ориг весах дохуя жирно будет. Простите холопов у которых нет 6000 про как у вас
Всё так, всё так. Есть настоящие гемы и я рад что успел понахватать их до блекаута который уже начался. А чуб жаль. Нажал F чтобы отдать респект некогда великому сайту.
О, пошли уже 404 на некоторых карточках. не успел наверное.
Да, кстати, количество токенов не равно годноте. Есть карточки на 1-1.5к токенов которые не просто дают кум или рп, а в которые ты влюбляешься. А есть 10к монстрали которые хуйню пишут и рп всратое. Никогда не угадаешь, никак не поймёшь, а чтоб прощупать всё не хватит жизни. Соболезную всем окрщикам, тем кто не успел, тем кто ещё не вкатился, и тем кто болеет той болячкой, которая заставляет паунсить в окно из-за чего-то упущенного.
Но вот вам шутка, чтобы не было совсем грустно.
Планировал поднять мульёны на продаже тюнов моделей, а подниму лярды на продаже редкоземельных карточек. Пхахах.
Но вот вам шутка, чтобы не было совсем грустно.
Планировал поднять мульёны на продаже тюнов моделей, а подниму лярды на продаже редкоземельных карточек. Пхахах.
Ну это не ты виноват, что норм видяхи по 100к+ стоят.
Да. Всё. Ицовер. Карточки сотнями отваливаются в прямом эфире. Превью ещё есть, а карточек уже нет.

Чаечкой просто.
Шел мужик(М) по лесу а на пеньке жаба(Ж) сидит. Ну жаба ему и говорит:
-Ж-Мужик! Давай три желания любые.. Все че хошь желай..
-М-Хочу тачку крутую, Хату в Москве 6-и комнатную с евроремонтом,
и денег мешок чтоб не кончались.
Ну мужик значит кайфует месяц, второй, думает надо лягушку отблагодарить
как-то а то ему вроде хорошо а она там сидит на пне, скучает. Пошел
в лес, нашел лягушку и говорит ей:
-Вот ты сделала все для меня давай теперь и я для тебя что хошь сделаю!?
-Мужик! Вые%и меня только так чтоб на всю жизнь запомнила....
Ну делать-то нечего пообещал вроде.Имеет он ее как только может.
И понимаете ,товарищ следователь, превращается эта жаба в 12-и летнего
мальчика! :-
Кто умеет в песенные нейронки, напишите минорный романс о кибер-голубях которые не долетели до адресата... ОНИ УШЛИ УЛЕТЕЛИ!
Во всем вините мелкобриташек
https://www.independent.co.uk/news/uk/home-news/ai-chatbot-women-girls-abuse-b2940925.html


Навайбкодил новую прогу, старая уже не нужна, это локальная версия чуба с поиском по тегам(да, если скачать только лолей, то все еще можно искать по вторичным тегам типа sister, см пик2) и скрипт, который ворует с чуба карточки с описанием по заданному тегу.
Если карточки уже скачаны первым скриптом - их надо просто перенести в chub_static_mockup\assets\cards_cache и тогда синк скрипт просто быстренько сканирует на чубе их описание без повторной загрузки - это занимает пару минут для 6000 карточек.
run_chub_static_mockup_sync.bat скрапит чуб для нашего локального чуба, а run_chub_mockup_local_server.bat запускает локальный сервер. Его потом можно открыть в браузере на http://localhost:8765/
https://www.mediafire.com/file/qyzrnr9ocsccbdf/Chubmockup.7z/file
Спаси лолей, анон! Спаси их сегодня и завтра они спасут тебя!
Наше достояние треда, карточку Фифи хоть схоронили? Теперь она на вес золота так-то.
Ну во-первых, 6к лолей это педобир перебор. А во-вторых, беда не в том, что исчезнут в небытии слопокарточки на 150 токенов из 2024, а в том, что новые хорошие карточки не появятся и их авторы уйдут в подполье пилить годноту для шейхов или вовсе дропнут дело из-за обидок. Чтоб эти бритахи чаем подавились и в килте запутались!
До сих пор не понимаю, почему авторы подобных сайтов просто не перенесут своё апасное в другую страну?
Себя же они так просто не перенесут
>годноту для шейхов
Чёт сомневаюсь, что шейхи кумят на всякое вместо покупки IRL.
> Ну во-первых, 6к лолей это педобир перебор.
Верно, нужно отобрать только пушистых евпочя.
> новые хорошие карточки не появятся и их авторы уйдут в подполье пилить годноту для шейхов или вовсе дропнут дело из-за обидок
База!
> Чтоб эти бритахи чаем подавились и в килте запутались!
Не в чае и не в кильте, но конкретизировать не будут чтобы не разжигать. А по остальному - некоторые делают просто заглушки для всех адресов и аккаунтов из таких "проблемных стран". Но, видимо, не всегда это помогает.

Уважаемые, объясните: почему американские ресурсы (по законам США рисованные/анимешниые/текстовые лоли цопе не являются) прогибаются под еврокуколдскую политику? Почему им просто не плевать? Ну допустим ЕС это не устраивает, ладно - пусть блочат через свои местные РКНы. Зачем удолять карточки с чуба? Зачем выпиливать лоры и модели с цивита? Are you ebanulis tam?
А как ты подвяжешь сайт неизвестно где к конкретному человеку? Даже если у тебя тащмьёр найдёт карточку с андераге, ты всегда можешь сказать что не твоё. И путь ебётся с поиском доказательством что ты действительно кочал со злым намерением, а потом ещё и невозбранно кумил на, чтобы состав преступления сложился. Иначе я не я, хата не моя. А тут считай просто обслуга сайта, который по мановению волшебной палочки становится сайтом соседа из дружественной страны. Я СПАРТАК! НЕТ, Я СПАРТАК! НЕТ, Я!
Я про патрики и секретные дискачи для богатых. Таких называют шейхами.
>почему китайский квен считает, что 20+ ученик не может романсить училку, ведь это только в америке проблематик тим?
Я задаюсь этим вопросом с момента вката в нейронки...
Варианта, когда оно само по себе не нравится создателю ресурса, ты конечно не рассматриваешь.
>ты всегда можешь сказать что не твоё
Не, ну раз сказал, то тов майор взгрустнёт, развернётся и уйдёт. Тут не попишешь, сказал же.
>Я про
А неважно. Не думаю, что прослойка "Могу нанять автора делать индивидуальные карточки, но не могу купить это IRL" достаточно высок. Разрыв между богатыми и бедными растёт весьма быстро.
>оно само по себе не нравится создателю ресурса
НЕ ДЛЯ НЕГО СДЕЛАНО! И НЕ ДЛЯ ТАКИХ КАК ОН! ПУСТЬ ТЕРПИТ! ОБЕЗЬЯНА_ШУГАЕТ.ШБМ!
А если серьёзно, но вслед за лолями полетят всякие семейные темы, поверплей, рейсплей, фурри, итд итп. Надо только подождать.
Когда они пришли за любителями лолей, я молчал - я ведь не любитель лолей...
Как же твоя нейронка срет тебе. Тебе только бинарников накачать надо, а она тебе лютое говно взамен сует, это лол. Что называется дебил с нейронкой остается дебилом.
>ты конечно не рассматриваешь
Если бы не нравилось, то удалили бы сразу, не? И четко прописали правила. Но нет же, годами закрывали глаза и вот сейчас решили прогнуться под соевую европовестку..
Мне на лолей похуй, но то что и инцест приплели - это трагично. Почему я не могу выебать буковками совершеннолетнюю сестру? Сестроёбство это база. Это сука основа. Это святое блять.
>6к лолей
Так это только те что помечены как лоли, а там под угрозой и teen(4700) и скорее всего весь incest(12к, лол). Скорее всего под угрозой расстрела сейчас десятки тысяч карточек. И это только начало.
Потому что там не только ЕС:
В США: Не для просмотра несовершеннолетними: Вайоминг, Флорида. Только для просмотра на работе: Миссисипи, округ Колумбия, Юта
Объединенные Арабские Эмираты
Австралия
Великобритания
Общая тенденция на запрещенку. Ну а карточки вообще под ксам попадают. Короче в клирнете не будет скоро никаких карточек, да и вообще порнуху урежут, там на этой неделе крупнейший порносайт даже закрыли с 82 лямами пользователей, хоть там другое совсем было.
>под угрозой расстрела
Уже расстреляны тысячи карточек. Перезалившиков банят. Суки бездушные. Это ведь чей-то ТРУД! Кто-то душу вкладывал в карточки, а они просто всё сносят только потому, что старые пердуны в парламенте ущемились. Ууу, сука, зла не хватает!
>Короче в клирнете ничего не будет
Ну и нахуй он нужен тогда...
Я бы предположил дело в платежных системах. Если будет имиджевый урон им, то они могут просто перекрыть воздух сайту. Бля, какой нахуй имидж у визы мастеркарда? Это блядь гига монополисты, но кому не похуй, вон из стима выпилили чото из-за этой хуйни.
>помечены
Никогда там таких тегов не видел.

У меня не показывает эти теги в акаунте, и раньше тоже ничего такого не показывало. Хз. И сейчас его открыл нет этой карты. Даже не знал про это.
Ты точно на chub.ai смотришь?
Финальная версия(надеюсь) локального чуба и скрябалки чуба по тегам. Теперь скрябалка встроена в интерфейс сайта в отдельной вкладке и имеет кучу настроек(но настраивать ничего не надо, так что достаточно только запустить сервер с батника и зайти на http://localhost:8765/.
На этот раз реально положил в архив питон скрипт локального сайта
Скорость скрапа улучшилась как и скорость работы сайта.
Добавлены лорбуки - работает как скрап и отражение в интерфейсе.
Подробный ридми от чатгопоты
https://www.mediafire.com/file/wu8f266ni88ywlx/LocalChubFinal.7z/file
Торопитесь, часики тикают. Тысячи лолей уже поставлены к стенке и вот вот раздадутся выстрелы.
На этот раз реально положил в архив питон скрипт локального сайта
Скорость скрапа улучшилась как и скорость работы сайта.
Добавлены лорбуки - работает как скрап и отражение в интерфейсе.
Подробный ридми от чатгопоты
https://www.mediafire.com/file/wu8f266ni88ywlx/LocalChubFinal.7z/file
Торопитесь, часики тикают. Тысячи лолей уже поставлены к стенке и вот вот раздадутся выстрелы.
Приветствую. Подскажите нубасиксу, вот у меня 16 оперативы и 5070титяй, хочу локально запустить агента чтобы писал мне кодик(максимально простое говно готов пошагово терпеть). Пробовал лм студио но есть ощущение что эта прокладка из говна. В общем посоветуйте куда копать и какую модельку использовать по максимуму с моими характеристиками. Заранее спасибо
Для агентохуйни есть свой тред, тут просто модели запускают для других целей (чатики с вайфу). Вряд ли кто-то что-то знает.
>вот у меня 16 оперативы
И да, расширь хотя бы до 32, а лучше 64 - сможешь запускать вполне приличные MoE модели (mixture of experts архитектура, где часть модели может уйти в оперативку, а часть сидеть в видеокарте).
На 16+12 кроме совсем мелких карликов-инвалидов уровня мобилочного, потешного ии - ничего толком не запустишь.
И вообще если ты кодо-обезьяна, не лучше ли влошиться в оплату API какого-нибудь дипсика? Дешево и сердито, уж точно лучше любого что заведется на 16+12. Я даже не уверен, будет ли 32+12 или 64+12 конфиг способен запустить нечто конкурирующее с дешманским API на пухлую, большую модель. Может я ошибаюсь, у вас у кодеров свои тараканы в голове.
И вообще я краем уха слышал, что кодерам большое контекстное окно требуется. То есть у тебя еще жестче ситуация с такой острой нехваткой ресурсов - длинночаты не влезут 100%
https://botbooru.com/profile/1933
Забудьте про чуба.
Забудьте про чуба.
Короче схоронил с чуба где-то под сотню годных картонок которых у меня ещё нет. Хз что дальше делать. Качать все 6к нет ни малейшего желания, а сколько карточек без конкретного тега уже сгинуло - даже считать не хочется. Действительно жаль, немногие поймут. Особенно теперь. Пока листал чуб - плакал над каждой 404-картинкой.
Радует лишь то, что теперь на чуб ополчились все, в том числе и контентмейкеры, который на чубе работали, раскручивая свои творения. Походу чуб реально выстрелил себе в ногу и лучше бы ушёл из правового поля куда-нибудь на сейшелы, а не пытался подтирать жопу ещё сильнее обсираясь. Мдааа... мозгов у владельцев сайта конечно не оч много.
Радует лишь то, что теперь на чуб ополчились все, в том числе и контентмейкеры, который на чубе работали, раскручивая свои творения. Походу чуб реально выстрелил себе в ногу и лучше бы ушёл из правового поля куда-нибудь на сейшелы, а не пытался подтирать жопу ещё сильнее обсираясь. Мдааа... мозгов у владельцев сайта конечно не оч много.

Да вы тролите, блять?
Только что обсуждали что на чубе одни слоподелы. Я вот не готов переработать сквозь себя сотни карточек чтобы найти хорошего автора, проще самому карточек написать сразу как тебе надо
Только что обсуждали что на чубе одни слоподелы. Я вот не готов переработать сквозь себя сотни карточек чтобы найти хорошего автора, проще самому карточек написать сразу как тебе надо

Про ботбуру тоже забыть?
Чел, это просто очередь на сайт. Хомячков слишком много.
Всё что меня интересует на счет карточек лучшая ли гемма в их создании? Вчё таки слопа она навалит будь здоров, но вместе с этим дохуя умная и много знает, без цензуры и с ризонингом из коробки.
Квен 3.6 мейби попробовать, но там надо опасную версию качать
Квен 3.6 мейби попробовать, но там надо опасную версию качать
Это не просто очередь на сайт. Это полный пиздец. Мертворожденный проект.
Чуб сам заставил о себе забыть! Бура годнейшая, как обычно.
Алсо есть ощущение, что это просто сорта показуха, мол вот мы послушались зоконоф, всё, расходитесь, залетухи, для вас тут ничего нет, на площади [REDACTED] ничего не происходило. А потом всё выгрузят обратно из режима приватности.
Могут как на цивитае сделать, отдельный сайт .red для левых карточек.
От тебя воняет чубонюхом в отрицании. Сайт популярен, чубопомойка больше никому не нужна
Шиз, таблы. Если сайт не открывается, то он не может быть популярным.
Так вот чуб сейчас и не открывается. Непопулярен, получается?
Вайбкодер-анон, а можно скрапить карточки с буры прям из таверны? Можешь состряпать такой экстеншен?

Скачал каничку чтобы жёстко её затрахать в знак протеста. Твёрдо и чётко но мягко.
100 сообщений холсома и умиления с милой девочкой.
Эх...
100 сообщений холсома и умиления с милой девочкой.
Эх...

> а почему у меня гемма на хуй кидается?
Киньте архив с удаленными карточками с бура на pixeldrain.com плиз.
Глупая умница! Не понимает, что весь контекст карточки не надо пихать сразу и в лицо! Не понимает слоубёрн! Глупая-глупая дырочка!

Понятно! (Got it!)
Скачал у него карточку, а она оказалась фембоем. Лицо вообразили мое?
Кажется я догадываюсь, что ты скачал...
Я вообще не очень понимаю, почему там заблюрена часть карточек, хотя NSFW включено и если его отключить - блюрится всё.
Может, просто функционал не допилили или аплоадер обосрался и что-то там нахуевертил в тегах. Но в общем, немного неудобно пока.
Меромеро неюзабелен.
Я не знаю как но чел сделал невозможное, добавил if и but в ризонинг, да и вообще ризонинг совсем иначе выглядит, в общем больше сои.
Я не знаю как но чел сделал невозможное, добавил if и but в ризонинг, да и вообще ризонинг совсем иначе выглядит, в общем больше сои.
Блять, чел... лоли это нсфЛ. Это классика! Это знать надо!
А, понял, там NSFL ещё. Заебали со своими категориями для защиты соевых.
Причем тут карлики? Там просто часть карточек слилась к хуям. Надо настраивать теги отдельно и вырубать NSFL как неотображаемую категорию.
У вас тоже гелбору всё?

Итоги ночи: От расстрела спасены 19018 лолей и прочих андераге канни и 3472 шоты(случайно по касательной через общегендерные теги типа teen). Шоты были определены на парашу в отдельную папку и в просмотрщике скрыты под галочкой obsolete, сначала хотел их всех зарезать, но потом вспомнил судьбу петушков на птицефабриках и пожалел.
Общий вес архива с 22490 персонажей и локальной версией чуба со всем этим богатством составляет 22.3 ГБ.
Чувствую себя дедом Мазаем.
Единственный минус - лорбуки я не спас, формат в котором я их сохранял неюзабелен, я обнаружил это только когда на чубе уже началась чистка и только 10% лорбуков по теме удалось спасти.
Общий вес архива с 22490 персонажей и локальной версией чуба со всем этим богатством составляет 22.3 ГБ.
Чувствую себя дедом Мазаем.
Единственный минус - лорбуки я не спас, формат в котором я их сохранял неюзабелен, я обнаружил это только когда на чубе уже началась чистка и только 10% лорбуков по теме удалось спасти.
За тобой уже выехали.


пиздец что у нее с ухом
скинь кстати пикчу с этой ебасосиной или карточку, образ интересный - может для референса в картинкогенерации пригодится.
Это чтобы ты приступ трипофобии словил, если задрочишься.
nvm, оно гуглится
Ну нет, спасибо, не надо.
>Please log in or register an account to view this character.
Спасибо, всего хорошего.
Какие же порриджи тупые. Ты регаешься по никнейму и паролю, чтобы было куда свои любимые какашки сохранять. Никто у тебя почту не просит.
>прогибаются под еврокуколдскую политику? Почему им просто не плевать?
1. Еврокуколдия может дать пизды в отличии от РФ. Причем ей не нужен РКН, она будет таскать по судам сайт, хостинги и прочее
2. Жители Еврокуколдии еще не осознали, что их ведут в цифровой гулаг, вдохновившись восточными соседями
С первым непонятно что делать. Трампыня вроде хотел нагнуть Евросовок из-за цензуры американских сайтов. Но как обычно дальше пука и грозных постов в интернете ничего не зашло
А со вторым проще. Чем дальше в гулаг, тем больше осознание. Поэтому где мало цензуры ВПНчки не юзают, а в какой-нибудь Германии и особенно в Британском халифате уже юзают поголовно
Ну а потом будут сажать за ВПНы. А с распространением гулага вообще их прирежут. А в конце просто разделят Интернет на локальные сети для каждой страны. О дивный новый мир
Долбаеб, половина функционала сайта работает без регистрации. Можно даже карточку скачать без подтверждения возраста и темы условий. Но посмотреть нильзя, зопрещено. Нахуй ты дефаешь это кривое говно которое навайбкодили за полтора часа?
> Испугался ввести ананимус1234 на опасном сайте.
Не могу вообразить ебало.
> мерж готовит из двух гемм4
Зачем?
Реально дурачок какой-то. Ему про одно говорят, он свое наболевшее вспоминает. Разжую для тебя еблана - мне похуй на регистрацию. Смысл моего поста в том, что сайт говно васянское которое непонятно как работает и от чего пытается защититься. Просматривать карточки без регистрации нельзя, но можно открыть по прямой ссылке и скачать вообще без ограничений. Вообрази лучше ебало тех кто это нагенерировал, воображатель.
прост. у меня есть мерж из 7 гемм и внезапно оно норм получилось, весьма юзабельное.
А знвешь что еще норм получилось?
Гемма без васяномержей
Я не он, но думаю это из серии закрытой калитки в чистом поле, для формального соблюдения каких то законов. То что люди будут получать доступ в обход - обладателя сайта не ебет, со стороны закона он прикрыт обязательной регистрацией.
>сайт говно васянское которое непонятно как работает и от чего пытается защититься. Просматривать карточки без регистрации нельзя, но можно открыть по прямой ссылке и скачать вообще без ограничений
Ты про чуб? Он именно так работает.
Соглы. 100% защита от дурака. И ведь работает.
Макаба карточку в фарш превратит, не?
>будут получать доступ в обход
>он прикрыт обязательной регистрацией
Так это как-бы не доступ в обход, лол. Это прямой доступ к содержимому по ссылке и без регистрации.
>Ты про чуб? Он именно так работает.
Ну вот он и сдох заслуженно.
>Это прямой доступ к содержимому по ссылке и без регистрации.
Нет, если это не работает из интерфейса сайта.
Там 90% такое, 9% слопомонстры, 0.9% хотя бы как-то пытаются, 0.1% годноты типа ламплайтера которую все кому надо уже скачали.
Вот этого пинай
Осторожно, он герой.
Лично не нужно, но понимаемо, сам сохранял контент с за(к)рывающихся сервисов... когда-то и меня вела дорога приключений.
Сейчас создаю архив, залью на swisstransfer, это походу единственный обменник что 22 гб может одним файлом взять.
Вот и славно. Только за лобуки обидно.
Да уже найдено, спокойствие. Ее даже с чуба не выгнали.
Я на 99.8% уверен что это правильная ноэс разметка. Анону спасибо.
И ведь его совет просто потеряется, как и большинство инфы в прошлых тредах полугодовой давности, все просто будут гонять модель как есть. хотя будем честны никто не вспоминает про эир уже сейчася без понятия почему...
И ведь его совет просто потеряется, как и большинство инфы в прошлых тредах полугодовой давности, все просто будут гонять модель как есть. хотя будем честны никто не вспоминает про эир уже сейчася без понятия почему...
> Я на 99.8% уверен что это правильная ноэс разметка.
Даже не знаю...
Какие новости по mtp в гемме-4? Или хотя бы в гвене 3.5+ и glm-4.7-flash?
В прошлом треде было много слов, в этом через поиск не находится. В релизах ламы тоже.
Я нашёл закрытый гит-коммит, и ещё часть сообщений на гитхабе что кто-то где-то иногда что-то запускал с мтп.
Ты прям уверен в этом? Я видео обратные резултаты с замерами, что layer быстрее во всех сценариях.
Вот бы ещё с nvlink на нвидиях сравнение настолько же качественно. К слову это же твой риг печатный из радужных цветов?
У меня в общем теперь тоже принтер, и это не без твоего влияния произошло.
У обычного режима (layer split) есть фундаментальная проблема. У тебя работает строго одна карта, потом передаёт данные и работает строго вторая карта. То есть производительность четырёх карт с 32 гб такая же, как у одной карты с таким же ядром но 128 гб памяти. А при tensor parallel у тебя карты считают одновременно, и если передача данных между картами не становится проблемой, ты можешь получить х4 производительности.
В прошлом треде было много слов, в этом через поиск не находится. В релизах ламы тоже.
Я нашёл закрытый гит-коммит, и ещё часть сообщений на гитхабе что кто-то где-то иногда что-то запускал с мтп.
Ты прям уверен в этом? Я видео обратные резултаты с замерами, что layer быстрее во всех сценариях.
Вот бы ещё с nvlink на нвидиях сравнение настолько же качественно. К слову это же твой риг печатный из радужных цветов?
У меня в общем теперь тоже принтер, и это не без твоего влияния произошло.
У обычного режима (layer split) есть фундаментальная проблема. У тебя работает строго одна карта, потом передаёт данные и работает строго вторая карта. То есть производительность четырёх карт с 32 гб такая же, как у одной карты с таким же ядром но 128 гб памяти. А при tensor parallel у тебя карты считают одновременно, и если передача данных между картами не становится проблемой, ты можешь получить х4 производительности.
Я так понял пеймент процессоры это не виза с мастеркардом а более мелкие сошки которые к их системе присосаны, типа как YOmamamoney наш или киви
Когда gab пытались прибить например, светящиеся в темноте ниггеры заходили к таким, говорили слыш у нас тут демократия, а ну прекращай работать с сайтом с неправильными недемократическими словами
>Какие новости по mtp в гемме-4? Или хотя бы в гвене 3.5+ и glm-4.7-flash?
https://github.com/ggml-org/llama.cpp/pull/22673
Пока не готово
>tensor parallel
Ставил я тут эксламу. Оказалось, с геммой это не работает. Ну и нахуя...
> Я видео обратные резултаты с замерами, что layer быстрее во всех сценариях.
Принёс бы тогда
Зачем эксламма если в жоре есть и работает
Понял, что-то этот коммит пропустил, их просто несколько было старых закрытых, я уже не стал все открывать, буду следить. Надеюсь не только на квен сделаю, я бы очень хотел на glm-4.7-flash. И чтобы выпустили glm-4.8-flash или glm-5-flash (эту версию можно так же в 2 раза расширить как и glm-5 полный).
Если потребность в обмене данными выше чем у других моделей на гемме, то нужно просто pcie4.0x8 менять на nvlink, где уже сотни гигабит.
К слову, если в январе A100 на 40 и 80 стоили 400к и 800к, а потом ещё и выросли даже немного, то сейчас я вижу авито-то лоты на 250к и 550к за это. Возможно когда нвидия начнёт продавать первые R100, которые ещё быстрее B100 в 2-3 раза, то A100 ещё просядут, следующие на выбывание же.
Так это я не я тестил, и я не до конца уверен что анон правильно собрал и запускал всё. >>1482283 - вдруг тред в архиве ещё жив.
Да, тут же помимо превосходства layer-разделение нулевое влияние nvlink, что очень странное, если тут выше pcie 3 и pcie 4 отличались заметно. Потому и в тесте того же анона на tensor/layer я не до конца уверен.
Аноны, сейчас наткнулся на странную инфу, суть который в том, якобы у нынешнего грока агентность заключается не в том, что разворачиваются несколько разных моделей, а где каким-то образом в рамках одной модели работают 4 агента одновременно без подмены систем промпта, изменения контекста и анальных хитростей. Как так, нахуй? При том, что они пишут тоже одновременно и имеют общий кэш, и безумно высокую скорость.
Ну и в одной из статей примерно такое объяснение. Оно мне не до конца понятно:
>Это не четыре отдельные модели, договаривающиеся через API. Согласно техническому анализу сторонних экспертов, все четыре агента являются специализированными «головами» (heads) на одной и той же архитектуре Mixture-of-Experts (MoE) объемом около 3 триллионов параметров, где примерно 500 миллиардов параметров активны при каждом прямом проходе. Каждый агент обретает свою «личность» через легковесные адаптеры персонажей — это либо слои параметров в стиле LoRA, либо маршрутизируемые эмбеддинги, которые задают стиль вывода и логику маршрутизации, не дублируя базовый трансформер.
Ну и в одной из статей примерно такое объяснение. Оно мне не до конца понятно:
>Это не четыре отдельные модели, договаривающиеся через API. Согласно техническому анализу сторонних экспертов, все четыре агента являются специализированными «головами» (heads) на одной и той же архитектуре Mixture-of-Experts (MoE) объемом около 3 триллионов параметров, где примерно 500 миллиардов параметров активны при каждом прямом проходе. Каждый агент обретает свою «личность» через легковесные адаптеры персонажей — это либо слои параметров в стиле LoRA, либо маршрутизируемые эмбеддинги, которые задают стиль вывода и логику маршрутизации, не дублируя базовый трансформер.
Я вижу твою картинку но не вижу там тензор. Уже обсуждали что row != tensor. Тензор появился чуть более месяца назад на базе мета бэкенда

Фортинайт или пабаджи?
Гемма или квен?
Гемма 4 26б q8 или Гемма 4 31б q4?
Почему
Гемма или квен?
Гемма 4 26б q8 или Гемма 4 31б q4?
Почему

31 q8
Потому
Осел дурацкий блин, я же не могу уместить 31б q8! И что делать теперь? Давай тести 26б q8 против 31б q4, вперед вперед
Дрочить - только 31б. Для агентов пойдёт 26b, потупее но хоть в луп не улетит из-за кванта.
Сам тести
У меня пока такие же мысли
Так и я тестю блин, а ты что делаешь для местных шизов? В общак у тебя вклад какой?
Понял. Во времена скриншота row и tensor это было одно и то же, кто как писал - так и хотел.
Можешь объяснить в чём разница в двух словах или ссылку кинуть?
layer - 10 слоёв на одной сетке, 10 на другой. row/tensor - 20 половинок слоя на одной, 20 половиной на другой. Что из этого оставили как row и что нового придумали в tensor? Нейросеть мне не смогла объяснить, в этом треде записей не вижу.
Первое почти точно. Разница меньше должна быть, как q6 и q8, если уместил q8 первую, то и q6 вторую потянешь. Хотя там контекст капец тяжёлый, конечно.
> Гемма 4 31б q4
А можно нормальный контекст уместить в 3090 и 32 гига?
> а ты что делаешь для местных шизов?
Тесты псины сделал
https://github.com/ggml-org/llama.cpp/blob/master/docs/multi-gpu.md
https://github.com/ggml-org/llama.cpp/pull/19378
Шо? В 3090 24 гига. Если про 32гб это оператива то тебе только 26б юзать, она мое и можно выгрузать. В 24 гига ты можешь без проблем запустить q4 31б с 32к контекста без квантования или 64к q8. Хз кстати стоит ли квантовать контекст, так и не понял еще
Ладно прощен, покидай еще хороших шебмок потом и мы в расчете

Лорбуки я в итоге все починил через characterhub.org. Там еще старая БД активна, видно сначала решили актуальный chub.ai кастрировать, а до старой версии сайта руки еще не дошли.
Архив с карточками и локальным сервером чуба для их просмотра заливается, сразу в тред скину как зальется.
Гемма с SWA на q4km влезает с 256к контекста в две 3090, а вот че там в одну влезет - хз.
Если SWA вырубить, все идет по пизде и она жрет какие-то тонны видеопамяти прямо как старая, третья гемма.
мимо ггуфодебил
Можно, я 100к 8-битного контекста на 4090 вмещаю, этого идиота не слушай, 26В это лоботомит, тебе, 3090 господину, не по масти эту хуйню использовать.
Какой же гнусный пиздёж. Ну давай, расскажи как ты 100к 8 битного контекста умещаешь в 4090. q4xxs под Линуксом?
q4_k_s под виндой.
-ctx 98304 -ub 512 -b 2048 -ctk q8_0 -ctv q8_0
Красивый скриншот с Геммы 26б. Теперь вопрос, ты дебил и не умеешь читать или просто дебил?

Скиллишью дегенерат, завали ебальник уже и перестань позориться.
Я мимокрок, но дебил тут ты. У моегеммы нету 61 слоя
Понь, там говноквант мрадера q4ks с пережатыми аттеншн и гейтами. Небось ахуенные у тебя результаты на 90к q8 контекста, вхахах
> лучшая ли гемма в их создании
Нет конечно. Но она в целом уже достаточна чтобы при активной работе кожаного могло получиться хорошо.
Ай красавчик!
> формат в котором я их сохранял неюзабелен
Что за формат? Может можно раскодировать?
> она будет таскать по судам сайт, хостинги и прочее
Тут еще другая тема. Там где есть платежи - там есть и реквизиты, а через них находятся реальные люди. Как правило, системы там относительно прозрачны, из-за чего у создателей вполне реальные шансы присесть на бутылку.
Нет, у меня gemma-4-31B-it-Q4_K_S от Анслота. Хватит позориться уже, дебил, ты уже просто прилюдно подливой истекаешь.
> У обычного режима (layer split) есть фундаментальная проблема.
Так и есть. Потому уже давно перестал использовать его как и лламу в принципе
> ты можешь получить х4 производительности
Не х4, скейл нелинеен и есть оверхед. Также на крупных моделях и мощных карточках даже с 5.0 х16 может быть некоторый упор в обмен, а нвлинк сейчас только с совсем дорогущих йобах. Но все равно кратное ускорение происходит.
Там вроде как новый режим завезли 3м. Только не понятно вообще нахера был row (и ведь он раньше давал ускорение еще на всякой некроте, но оно сдыхало из-за оверхедов на контексте), или зачем его поломали и ввели новый если можно было переделать.
> менять на nvlink,
Смешная шутка.
Герой, в котором мы нуждались но не заслуживали!
Могу попробовать потом посортировать их, откинув совсем уж откровенный слоп.
>от Анслота
Еще хуже. Нормальные люди юзают кванты батрухи или хотя бы мрадера KM. Между твоим говном и нормальными квантами 2гига разницы в весах. Как ты думаешь почему? Даю подсказку
https://huggingface.co/unsloth/gemma-4-31B-it-GGUF/blob/main/gemma-4-31B-it-Q4_K_S.gguf
https://huggingface.co/bartowski/google_gemma-4-31B-it-GGUF/blob/main/google_gemma-4-31B-it-Q4_K_M.gguf
Хотя один хуй ты ничего не поймёшь если тебе норм читать лоботомию на 90к q8 контекста мелкокванта, хы
>Хватит позориться уже, дебил, ты уже просто прилюдно подливой истекаешь.
Так не я ворвался в обсуждение с двух ног чтобы потом рассказать треду, что читаю лоботомию на мелкокванте
>Маня уже прилюдно обгадилась и опозорилась, но её все несло и несло
Я один не понимаю чего все гонятся за контекстом на yesгемме?
Для кода она говно, для рп тоже, да и для русика тоже, если рпшил плотно на английском и можешь сравнить.
И это даже опуская детерминированность, чего лучше не делать и послать гемму к хуям
Для кода она говно, для рп тоже, да и для русика тоже, если рпшил плотно на английском и можешь сравнить.
И это даже опуская детерминированность, чего лучше не делать и послать гемму к хуям
Опять рекламщик протыков вылез
>аргументы кончились, маня перешла на гринтекст
Че за хуйню ты несешь? Просто слейся уже, кринж.
У анслотов нормальные модели, через время. Нужно просто в начале у них не качать, так как перекачивают. И ты советуешь 4кс для анона который крутит фулл врам, советчик из тебя говно как и иксперт.
4кс для плотной модели норм квант, хотя я на твоем месте скачал бы лучше iq4-nl или iq4-xs, они меньше и у них лучше качество, а еще какая та из них будет быстрее, потести сам. Они специально для фулл врам, с выгрузкой на проц будут медленнее
Мне кажется, или тред заполонили какие-то токсичные хуила?
>У анслотов нормальные модели
Остатки разума покинули тред
Они ничего не умеют и ты ничего не умеешь. Гуру шизоинженеринга на гемме вот такую кашу заваривают пока неумехи юзают промпты от васяна и не понимают, что модель, слушающая инструкции внимательно - это как чистый лист бумаги, где можно намалевать какаху или красивый портрет
>Не х4, скейл нелинеен и есть оверхед
Ну, теоретическия. Я же про ситуацию, если служебные вызовы тратят 0 милисекунд а скорость обмена 10 ТБ/c.
А, так они в row с кешем чёрт пойми что делали. Мяу, лол. Я думал там что-то вроде что копия нужной части кеша есть на обоих картах, и они правки для кеша ещё пересылают. Ладно, там столько всего есть, что двумя словами не сказать и надо код смотреть уже тогда. Хорошо что переделали.
> Гуру шизоинженеринга
> на скринах обычный чатик
А до этого нельзя было сделать карточку своей тёщи и сделать так чтоб она тебе открытки присылала или что?
> если служебные вызовы тратят 0 милисекунд а скорость обмена 10 ТБ/c
Ну такого в принципе не бывает, даже на самых крутейших нвлинках задержки и скорости не стоят ни в какое сравнение с врам. Но расчеты можно построить хитрее, снизив количество обменов и реализовав большую асинхронность, что позволит иметь меньшую зависимость от скоростей передачи или вообще исключить упор в нее.
Теоретически действительно х4, но там есть некоторые нюансы с ллм. С моэ, особенно при конкрунтных запросах, легче параллелить экспертов чем делать чистый тп для млп. Чисто в теории, этот режим можно сделать и в лламе, что позволит на мультигпу получать ускорение даже с нищими шинами, поскольку обмен там минимален.
> так они в row с кешем чёрт пойми что делали
Он вроде изначально был пополам и соответствовал частям на картах. В те древние времена, когда вводили row split, у них на серьезных щщах с layer кэш сидел только на самой первой гпу. Просто контексты были небольшие и потому ставить распределение типа 15,24 для пары 24-гиговых карт было сортом нормы.
У меня до сих пор чуб работает полностью это видимо от страны зависит. 60к карточек выкачал.
Так тут ежедневно ноют, что не могут на гемме остановить потоки слопа и ассистент~измов всяческих. Я об этом. Модель хорошая, может что угодно. Но надо п-е-р-д-о-л-и-т-ь-с-я.
>Ну такого в принципе не бывает, даже на самых крутейших нвлинках задержки и скорости не стоят ни в какое сравнение с врам
Просто замечу что на реально новейших нейроускорителях уже во всю используются оптические каналы связи и оптические маршрутизаторы, там ебейшие скорости и задержки. Круче и девешле по энергии чем любая электроника. Но точных параметров не знаю, не уверен что они в доступе есть даже.
Оптике сто лет в обед. Вопрос лишь стандартов, между сфп+ и осфп224 пропасть, хотя всё это оптика
>Круче и девешле по энергии чем любая электроника.
Пиздят об этом давно, а в реальности Хуанг выкатил очередного монстра, которому нужно уже только водяное охлаждение. Зато, говорит, дома теперь отапливать можно - вот и компенсируете часть расходов.
Ну если иидиот гугла не пиздит то вот
Оптический NVLink в архитектурах Rubin и FeynmanВ архитектурах NVIDIA Vera Rubin (2026) и следующей за ней Feynman (2028) медь окончательно уперлась в физический потолок: на высоких частотах сигнал в медном проводе затухает уже через несколько десятков сантиметров.Поэтому NVIDIA официально переходит на оптический NVLink, но использует для этого принципиально новые технологии, лишенные недостатков старой оптики:1. Технология CPO (Co-Packaged Optics) вместо трансиверовNVIDIA отказывается от привычных съемных трансиверов (типа OSFP) на пути NVLink. Вместо этого кремниевая фотоника (оптические чипы и микролазеры) интегрируется напрямую на подложку графического процессора или NVSwitch-коммутатора (всего в нескольких миллиметрах от вычислительных ядер).Это снижает задержку конвертации сигнала в несколько раз (до единиц наносекунд).Энергопотребление падает в 4–5 раз по сравнению с классическими трансиверами.2. Масштабирование до NVL576 (Optical NVLink Spine)Благодаря оптическому NVLink, NVIDIA представила архитектуру Vera Rubin Ultra NVL576. Теперь в единый суперкомпьютер с общей памятью по протоколу NVLink можно объединить не 72, а 576 графических процессоров, распределенных по 8 разным стойкам. Стойки соединяются между собой жгутами из десятков тысяч тонких оптических волокон, поставляемых Corning.
Зелёные уже не раз "понерфили" рубин потому что не вывозят то что наобещали
Выглядит все равно интересно, хоть какая та фотоника стала использоваться. Может когда то и полную смогут сделать, вот тогда заживем Ну они, не мы в гулаге
Это сделано просто для удобства, оптика в сетях давно используется. Они все равно несопоставимы с показателями памяти чтобы просто так идти "ленивым путем". Там серьезные накладные на то чтобы перекодировать и обернуть в протокол и сделать буферы с крупными временными окнами. Потому что показатели скорости и таймингов должного уровня просто невозможно получить на дистанциях без этого. Собственно этим и ограничен размер единичного кристалла, поэтому hbm память располагается именно на общей кремниевой подложке с чипом и т.д.
>хоть какая та фотоника
Фотоника это вычисление светом, а тут просто передача, как я понял. 0 фотоники.
Фотоника это в принципе использование света в компьютерах вместо электричества, да и микросхемы уже есть фотонные, там правда аналоговые вычисления но все равно неплохо.
Хотя не ебу за официальную терминологию, но не похуй ли на нее
Ты очень жесток.
Прошло 15 часов, а они всё ещё не запилили гемму 4!
Там у челов в логах ассистентский эхоразбор (вопросы с цепляниям за слова в репликах юзера) вместо понимания шуток/контекста и лупы смайлов уже в двух репликах. Не зря пердолились. Выстави 100 токенов на ответ и задай роль не рп/истории, а переписки в месенджерах, и получишь такой же результат.
> 0 фотоники.
Это тоже очень много. У линии длинной 20 метров кратно больше ёмкость, чем у линии на 0.5 метра. Даже ничтожная ёмкость при частоте в ГГц превращается в охренительный излучатель, к которому нужно подводить десятки ватт. И который наводки на всё вокруг делает. Причём на ту сторону доходит слабый сигнал, который едва разберёшь и усилитель скорее всего тоже ни разу не мало потребляет. Скорее всего чтобы это как-то работало - применяют всякие ухищрения в ущерб остальному чипу. Если это будет оптика - эту проблему можно не решать, так как оптолиния на 20 метров не излучает.
Сейчас вот это как нейросеть напишу, когда просишь её обосновать что-то и она за уши любые аргументы притягивает:
Так же это развязывает руки по физическому увеличению размера серверов, можно разносить карты на метры, и вред будет только для латенси, что во многих задачах не критично (если оно пачкой генерирует 1000 токенов для 1000 пользователей). Это и возможность соединить больше видеокарт вместе, а не только 8/16 или сколько там и намного проще конструкция охлаждения. Типа, раньше видеокарты обязаны были быть блоком плотным, из которого нужно как-то 10 квт тепла отводить. Это не слишком просто, потому карты должны выдерживать работу в жёстких температурных условиях, так как реализация охлаждения ограничена. Если реализация охлаждения упрощается, то можно потребовать от эксплуатации, что карта не должна греться больше 55 никогда, что позволит сэкономить на "запасе прочности" карты и что-то оптимизировать, не выполняя условия для стабильной работы при 80 градусах.

И, готово. 22490 "запрещенных" карточек + локальный чуб для их просмотра и отбора по тегам. Запуск
через run_chub_mockup_local_server.bat и потом http://localhost:8765/ в браузере. Шоты включаются галочкой на .
https://www.swisstransfer.com/d/2c013ff6-e268-4e6a-852e-fb55ac5a528f
>формат в котором я их сохранял неюзабелен
Неюзабелен в плане, что там нет информации, или неюзабелен, что его нужно конвертировать и преобразовывать до читаемого?
Для связи оно уже более полувека активно используется. В том посте реально звучало как фотонные вычисления, но такого нет.
А так для высоких частот и пропускных способностей свет действительно топчик потому что не нужно согласовывать линию передачи, париться с разводкой и т.п., можно разместить приемопередатчик как можно ближе к вычислителю.
Обнял@приподнял, лучший! Архив без пароля?
Ты давно с реальными людьми говорил? Рандомный пиздеж ни о чем именно так и выглядит.
А то, чего ты хочешь, это чтобы бот насрал глубокую манямысль с обидой на юзера за упоминание жира на животе, или что кошкодевочек надо защищать или еще что-нибудь. Короче это шиза в квадрате.
> лупы смайликов
В соответствии с директивой на использование любимых смайликов. Хотя, кому я это говорю. Люди вживую серят скобочками и всем подряд - но двачеры, кроме сумбурных надристов в меланхоличных тредах, живого общения нормисов не видели.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Все лорбуки уже починены и доведены до ума. Остается только нажать export to json и импротировать этот файл в таверну как лорбук.
Да, пароля нет.


Gryphe_WorldSim-Opus-3.6-35B-A3B-Q5_K_L.gguf . В принципе имеет право на жизнь. Свайп на чате на 71k токенов. Ризонинг компактен и по делу. К сожалению moe-сущность модели никуда не делась - инструкция после истории на создание кодового блока со всякой херней была упомянута в ризонинге, но в output на нее был забит болт. Свайпы разнообразны - с некоторой вероятностью выскакивают паттерны разных видов ризонинга.



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://web.archive.org/web/20241201232031/https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_moe_2026
• Неактуальные списки моделей в архивных целях: 2025: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd ), 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Гайд для новичков: https://rentry.org/2ch-llama-inference
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50: https://github.com/mixa3607/ML-gfx906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
• Доки к LLaMA.cpp со всеми параметрами: https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: