

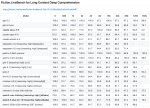

Кто-нибудь катал гемму 26б-а4б на большом контексте? У меня она разваливается в Q8, словно немо на 4к. С ризонингом. Начиная с 50к контекста в bf16, с f16 там вообще кошмар.
Что характерно, я проводил с ней зирошот-тесты на 130к, когда присылал статьи на 100к токенов и просил, опираясь на текст статьи из разных концов в контексте, сделать те или иные выводы. Не без ошибок, но в большинстве случаев модель показывала приемлемый результат для своих размеров.
РП — совсем другое дело. Она путается в собственных ногах, персонажах, событиях и вообще нихуя не видит за пределами блядского окна 1024 токенов. Тупо мразь, которая видит иголку, но не сено. Только моё сообщение и своё последнее, остальное для неё хаотичный трип вне времени и пространства. Что-то уровня пьяного обрыгана, который осознаёт, что он на земле находится, но уже не может назвать город, потому что застрял в вагоне с углём и уехал, пока спал, на 300 км. Не зная, как он в этот вагон попал.
Квен 35б-а3б так не делает. Да, он тоже лажает, но хотя бы примерно помнит прошлые сцены и как минимум на последние пару тысяч контекста ориентируется, а невменяемое полотно ризонинга позволяет ему не сорваться в совсем глупые ошибки. Однако это кодерское говно для РП не годится.
Плотные версии же не позволяют мне использовать такие большие контекстные окна.
Что ещё интересно, гемма вряд ли сломана/квант, потому что в пределах этих 1024 токенов она работает у меня корректно даже на 100к. Но если ей нужно хотя бы немного дальше заглянуть, начинается пиздец.
Что характерно, я проводил с ней зирошот-тесты на 130к, когда присылал статьи на 100к токенов и просил, опираясь на текст статьи из разных концов в контексте, сделать те или иные выводы. Не без ошибок, но в большинстве случаев модель показывала приемлемый результат для своих размеров.
РП — совсем другое дело. Она путается в собственных ногах, персонажах, событиях и вообще нихуя не видит за пределами блядского окна 1024 токенов. Тупо мразь, которая видит иголку, но не сено. Только моё сообщение и своё последнее, остальное для неё хаотичный трип вне времени и пространства. Что-то уровня пьяного обрыгана, который осознаёт, что он на земле находится, но уже не может назвать город, потому что застрял в вагоне с углём и уехал, пока спал, на 300 км. Не зная, как он в этот вагон попал.
Квен 35б-а3б так не делает. Да, он тоже лажает, но хотя бы примерно помнит прошлые сцены и как минимум на последние пару тысяч контекста ориентируется, а невменяемое полотно ризонинга позволяет ему не сорваться в совсем глупые ошибки. Однако это кодерское говно для РП не годится.
Плотные версии же не позволяют мне использовать такие большие контекстные окна.
Что ещё интересно, гемма вряд ли сломана/квант, потому что в пределах этих 1024 токенов она работает у меня корректно даже на 100к. Но если ей нужно хотя бы немного дальше заглянуть, начинается пиздец.

Поясните про переделку RTX-2080Ti 11гб. Я правильно понил что можно купить такую и купить отдельно память и перепеболлить ей плюшки память на 24гб? И ещё там вроде надо что-то перепрошивать и драйвер написать. И если поставить в пеку две такие видюхи будет 48гигов видеопамяти. И цена будет около 70..80Круб за две таких карточки. Это норм тема или одна 5070ti 16гб за эту же цену всё равно будет мощнее?
Привет, сосоны. Впервый раз выкатился к вам в гости из чат бот женерал. Решил тоже попробовать Лам потрахать.
У меня короче 4070 ti super. Потестил вчера на Копрольде+Таверне 32b модельку, которую выбирал тупо поиском по интересным ключевым словам - BenevolenceMessiah/Qwen2.5-Coder-32B-Instruct-abliterateQ4_K_M-GGUF
Получилось как-то нереально тупо, хуже уровня gpt 3 turbo... и на такое шишка даже не дёргается
Может кто что посоветует? Будет ли выхлоп, если попробовать усираться и переварить 70b модель?
И самый главный вопрос! ГДЕ НАХУЙ ТЕПЕРЬ БРАТЬ КАРТОЧКИ ПЕРСОНАЖЕЙ ТО НАХУЙ??? На Чубе то оказывается вырезали весь контент для порядочных гражданинов. Или может их просто в какой-то шедоубан кинули, и их ещё можно как-то найти? Где вы сейчас берете годные санни карточки? А? А? А? Это ж пиздец... Нахуй так жить?

https://huggingface.co/bartowski/ArliAI_GLM-4.5-Air-Derestricted-GGUF
Серьезно, мне вот этот нравится гонять, нравится больше того же 122 квена, а 235 у меня уже не влезал, так что так и не потыкал его.
Еще лучше было бы плотного glm 4.6v, но у меня там полтора токена, так что не трогаю
персонажей на botbooru смотри
если из небольших моделей и прям не хочешь выгружать много на gpu - гемма наверное из мелких самая адекватная (но она скучная что пиздец). и если уж квена тыкал, то бери версию 3.6.
https://huggingface.co/HauhauCS/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive (я этот тюн не дергал, так что не ручаюсь, но у этого чувачка добротно выходит обычно)
Вижу пора продублировать ссылку.
В связи с великой чисткой и геноцидом миноров на чубе - скачивайте локальный чуб с 22490 спасенных карточек.
Запуск
через run_chub_mockup_local_server.bat и потом http://localhost:8765/ в браузере. Шоты включаются галочкой на include_obsolete
https://www.swisstransfer.com/d/2c013ff6-e268-4e6a-852e-fb55ac5a528f
Спасибо, милый человек. Сегодня обязательно попробую.
Вот ты получается мне 27b вариант модели кинул. А до какого размера вообще идут адекватные приросты по качеству ответов? Имеет ли смысл вообще 70b тестить?
Бляя ахуена
Ты лучший
Пасиба
Пиздец конечно ситуевина
А давно геноцид произошёл? Так приблизительно. Можешь почувствовать? Куда теперь новые годные карточки лить?
Я бы еще сразу сказал какие тюны мне показались говном полным при попытке сэмплеры крутить и на которые тратить время другим не стоит:
1. https://huggingface.co/zerofata/GLM-4.5-Iceblink-v3-106B-A12B-GGUF
Тюн нахуй убил модельку
2. https://huggingface.co/mradermacher/Huihui-Qwen3-Next-80B-A3B-Instruct-abliterated-GGUF
Тоже самое, внимание модели страдает ужасно и проблема многих квенов что пишет просто по-уебански
Очень сильно качество ответа растёт с приростом кол-ва параметров. Я бы сам сидел может на glm последнем, а у меня оперативки 64гб.
Я вот компромисс нашел для своего железа на glm 4.5 air. Если бы мог затерпеть ниже по токенам вывод то glm 4.6v взял бы.
Опять же фломастеры, тут надо самому качать, пробовать, туда-сюда переключаться и с сэмплерами возиться.
Можешь попробовать еще старые модели из мезозоя, которые все равно интересно может потыкать:
https://huggingface.co/LatitudeGames/Harbinger-24B
https://huggingface.co/FlareRebellion/WeirdCompound-v1.7-24b
Хотя за такие советы меня тут наверное нахуй пошлют
Также различай dense модели и moe. Плотные для ram+vram компа будут болью для генерации, moe - терпимо довольно, при этом можно чутка больше параметров закушать. Но dense с таким же кол-вом параметров всегда будет лучше
Недели полторы - две назад убили чуб. на botbooru все переехали
Ботбору чёт ща полистал. Именно ИНТЕРЕСНОГО минорного чёт не заметил. Зарегался и нсфв врубил. Даже тегов нет таких в перечне
>Даже тегов нет таких в перечне
Если что, у них скрываются интересные теги для некоторых стран. Например, для Германии у меня пусто, а в Греции всё есть. И это не зависит от настроек профиля, чисто от страны.
Ссылка если что https://botbooru.com/
Блять. Ну я типа в Нидерах, и другим не располагаю, к сожалению. Ненавижу шедоубаны сука
В Нидерландах всё должно быть, по крайней мере у меня всё есть.
Ладно, спасибо, братик :3
Попробую тогда ещё...
>Qwen2.5-Coder-32B-Instruct-abliterate
>нереально тупо, хуже уровня gpt 3 turbo
Потому что сама модель тухлая. Во первых уже старая, во вторых там в названии кое-что скрывается, намекая тебе на что конкретно её докручивали. Для тебя варианта два на самом деле - гемма, которую тебе уже советовали, и мистрали которые зажарили под кум. Если вот нужен кум в ущерб мозгам - выбирай мистраль. Если нужны мозги в ущерб куму - выбирай гемму. Квены вещь крайне специфичная и их точно не стоит брать как первую модель. Только ощущения себе испортишь.
Но тут опять важные моменты. Мистралей дохуя всяких разных. Не много, а прямо дохуя. Чтобы выбрать одну конкретную под себя это надо щупать каждую ручками и искать ту самую от которой шишка чаще дергается. Гемма же умница, умничка, настолько хороша, что найдет 200 разных способов как незаметно слиться от детальных описаний проникновений одного полового органа в другой. Таким софт рефьюзам даже корпы позавидуют. Так что имей ввиду.
Спасибо за совет, братик :3
Попробую... А какой размер модели норм будет случайно не сможешь подсказать? 32b это норм? Или мало?
Зависит от твоей системы, о которой я нихуя не знаю кроме твоей видимокарты. Но вообще, что ввлезет и будет работать комфортно, то и лучшая модель для тебя. Пока что совет такой, размытый.
Не знаю че там как у вас. А у меня так: переехал полностью на Gemma-4-26B-A4b в четвертом кванте с моей конфигурацией (2*3060 12Гб, 128 Гб серверной рамы DDR4, некрозеон в.4 2696) это оптимально. Для специфических задач abliterix версия. Скорость в среднем 34-45 т/с, контекст 128k. Достаточно быстро, не очень тупо, сносный русик. Такие дела. Ещё в pi-mono забавно творить всякое, там ещё и екстеншонов всяких завезли - поиск и прочее нужное
Ты NSFL в настройках включил? Дежавю проходит как NSFL, не NSFW.
>Скорость в среднем 34-45 т/с
Это вообще как? У меня на 4070 с выгрузкой в оперативную 40-50 токенов в секунду. У тебя же модель целиком должна влезть в 2 видеокарты, что должно быть значительно быстрее.
Не верю, что 3060 может позволить полноценно закумиться..
Да, спасибо за беспокойство, братик. Там помимо nsfw галочки сверху ещё и оказалось много настроек прямо внутри параметров аккаунта. И там да, надо nsfl ещё ставить
У меня железо древнегреческое + две карты != одной карте 24Гб, к сож
одна нет, а две могут. Чё бы и нет-то?
>РП — совсем другое дело. Она путается
Моешки годятся на маленькие карты на сотню токенов с одним персонажем. Для всего остального нужна плотная. И тут два пути либо саммери аддонами сжимать историю чата и сидеть на гемме, либо качать кастомные кванты квена с встроенной mtp скорость которого компенсирует постоянный перерасчет промта из за swa.
Ну нет, пчел. 405b хуй поднять, да и это устаревшее говно мамонта. А 128b мистраль это кал. Приходится жрать моешки 754b-a40b, 1t-a32b, которые, как ты написал, хуже плотных 31b и 27b.
31b и 27b я про них говорил. Меня интересует рп под 16+32.
Кул, а вижн для него где брать? Там нет mmproj.
Раз нет, бери стандартный.
Два дня в тред не заходил, уровень лоботомии экспоненциально растёт
>Начиная с 50к контекста в bf16, с f16 там вообще кошмар.
Никакой разницы, бенчил по https://github.com/llmonpy/needle-in-a-needlestack/tree/main/chained_limerick как кидали в прошлом треде. q2 120k проходит что ф16, что бф16, q3 120k не проходит. Для кода норм до 120к, для рп да 50-60к
Лучше бы железо своё назвал. Рпшить на Квен КОДЕРЕ это совсем мэм, неужели по названию непонятно что оно не для этого. Как ты его вообще нашел то. Запускай лучше Гемму 26б по гайду с шапки или если лезет 27б квен то https://huggingface.co/zerofata/Q3.5-BlueStar-v2-27B
Зачем ты q4 используешь когда можешь q8 уместить и скорость несильно просядет? Это бомжемодель с а4б которую лучше вообще не квантовать
>Приходится жрать моешки 754b-a40b, 1t-a32b
>хуже плотных 31b и 27b.
>Начиная с 50к контекста в bf16, с f16 там вообще кошмар.
Никакой разницы, бенчил по https://github.com/llmonpy/needle-in-a-needlestack/tree/main/chained_limerick как кидали в прошлом треде. q2 120k проходит что ф16, что бф16, q3 120k не проходит. Для кода норм до 120к, для рп да 50-60к
Лучше бы железо своё назвал. Рпшить на Квен КОДЕРЕ это совсем мэм, неужели по названию непонятно что оно не для этого. Как ты его вообще нашел то. Запускай лучше Гемму 26б по гайду с шапки или если лезет 27б квен то https://huggingface.co/zerofata/Q3.5-BlueStar-v2-27B
Зачем ты q4 используешь когда можешь q8 уместить и скорость несильно просядет? Это бомжемодель с а4б которую лучше вообще не квантовать
>Приходится жрать моешки 754b-a40b, 1t-a32b
>хуже плотных 31b и 27b.

мне тут советовали попробовать q6. я попробовал, и нейросеть стала писать более сочные предложения, что позитивно сказалось на хорни рп. спасибо ребята, я чувствую повышение уровня кума.
А у простого квена нет SWA что ли?!
Если раньше не катал - пройдись по всем крупным моэшкам за последний год. Эйр, жлм 4.7, квен235 - то, что катали и довольно урчали. Кванты будут лоботомированные, но работоспособные. Ризонинги выключай с низкой скоростью, да и не сказать что они там какое-то большое преимущество в рп давали.
Из свежих - квен397 хз влезет или нет, на 122 просто попробуй отключить ризонинг или возьми версии с анцезорнами. А так ждать поддержки нового коммандера, дипсикфлеша и еще нескольких.
> лламу4
Там корректные функции активации и бф16 поставили, или как на релизе?
> перестать пытать старичка 3900x, продать память и перекатываться на ddr5 потихоньку
Ддр5 это хорошо, но запускаемые модели от этого не изменятся.
Рп - сложная задача сама по себе, а ты еще мелкой модели со скользящим окном контекста накидываешь. Перекатывайся на гемму31 или 27б квена, там будет лучше.
Сам не переделаешь, нужно обращаться в мастерские, ставить определенный тип памяти и потом еще перешивать биос. Работы могут выйти дорого, потому есть смысл просто сразу купить готовую, они на 22 гига а не 24, в сумме будет 44.
Серьезный минус - что это тьюринг, отсутствие поддержки бф16 и много чего еще.
Почему ИТТ так текут от ваших локальных умничек, а в чатбот-треде локалки считают говном и клянчат ключики от корпов?
> у простого квена нет SWA что ли?!
Есть а что.
> Для всего остального нужна плотная.
Речь про конкретное сравнение гемм или в общем?
> квена
> swa
В каких слоях там swa и какой размер окна?
Разная тематика тредов, уровень контингента, отсутствие возможности и недовольство этим. И там и там свои преимущества и недостатки, которые сильно меняются в зависимости от наличия доступа и железа в наличии.
Потому что тред называется "локальные языковые модели". Кто от локалок не течёт, здесь не сидит.
Разница между говном, мочой и червём-пидором для тебя всегда будет заключаться в том, кого из них ты можешь запустить на своей видяхе.
>сравнение гемм
Это.
Где в квене скользяшее окно нашел, признавайся
Qwen3.6-27B
Лобая мое хуже плотной. Даже сраный 9b квен будет лучше чем огроменный дипсик в4 про на дохуя параметров. Просто из-за того, что нет консистентности между слоями, и активируются рандомные эксперты, а роутеры настроить адекватно невозможно.
Как там в 2023?
>сраный 9b квен
К сожалению проигрывает даже своей мое квен 35ь, что то его криво натренили. Ну и не удивительно, мое квен по мозгам где то на уровне плотной 14-18b, если бы такая была.
Его там нет, используется линейное внимание. Все слои видят весь контекст, а не часть.
Эта ересь пошла из-за бага с лишним пересчетом в лламе, который срабатывал при конкурентных запросах или переключении кэша из-за реализации линейного атеншна, который идет еще от некста. Тогда васяны увидев знакомое поведение начали ставить туда аргумент как для скользящих окон и начали про это писать.
Перетолстил.
Мне всё равно. Он пересчитывает промт каждый раз и это плохо для скорости в таверне.
Это должны были уже пофиксить, обновись. И не используй всякие token-healing и подобные штуки.
Это старая и известная проблема, странно что ты не слышал.
https://github.com/ggml-org/llama.cpp/pull/13194#issuecomment-2868343055
>мое квен по мозгам где то на уровне плотной 14-18b, если бы такая была.
А почему ее нет? Что за дурацкая традиция кормить юзеров обычных видимокарт моешками?
Наверное потому что юзеры обычных видеокарт вообще не целевая аудитория, потому доедают агентское говно, созданное под всякие микроконтроллеры, которые настолько слабы, что там максимум 3-4В активных можно чтобы была хоть какая-то скорость.
Там сва чекпоинты надо просто нормально настроить и все работает. У меня, по-крайней мере.
--ctx-checkpoints --checkpoint-min-step
И какие ты поставил я разные пробовал. Говори, прям сейчас проверю.

Просто удали все говно, сейчас жора искаропки настроен правильно.
Аноны, на пару месяцев выпал из потока новостей. Что там с турбоквантами и скольки-то битными кешами без потери точности? Миллион контекста в 12гб уже влезает?
Так и думал что ты не знаешь ничего.
Господа, собираю себе для бесконечного кручения ИИ агентов машину, чтобы была способна крутить deepseek v3.2 хотя бы в 6 кванте, с 50к контекста, в хотя бы 10 t/s.
Вопрос - какой самый дешевый для такой задачи конфиг? Интернет прочитан, хочу мнение экспертов из треда.
Вопрос - какой самый дешевый для такой задачи конфиг? Интернет прочитан, хочу мнение экспертов из треда.
Самый дешевый в плане покупки или в плане эксплуатации?
В плане покупки.
Что имеется в виду под эксплуатацией? Я и так знаю что у v3.2 api копеечный, и пользуюсь им. Хочу понять как его локально крутить.
8 6000про и какой-нибудь двухголовый эпик на гуксе или гиге
в хотя бы 10 токенов в секунду, это грубо говоря чтобы все эти 500+ гигов были в не самой быстрой, но видеопамяти. условные теслы что продаются на али, которые по 30-40к рублей щас стоят за штуку и имеют 32гб. итого минимум штук ~17-18 надо. и т.к. это всё куда-то надо подключить, а значит это надо серверную китайскую мать на много-много слотов pci-e, к этому делу зеон или древний тредрипер, штуки 4 минимум блока питания по 1.5квт каждый, и ещё не забудь про райзеры, переходники, охлаждение (ибо 18 штук тесл будут греться как ебучие печки) и желательно отдельную комнату так как ШУМ от охлаждения этого дела будет не очень приятный.
и вот на этом конфиге ты получишь свои заветные 10-15 токенов в секунду.
Спасибо. Вы ошибаетесь - достаточно положить "все 500+ гигов" в 24-канальную ddr5, это уже будет 10+ токенов в секунду.
Суть моего вопроса в том, что я думаю можно и дешевле, на ddr4 + 1GPU. Хотелось бы найти кого-то кто с этим заморочался.
Пиздец. Ну его нахуй, по апи дипсик дешевле выходит.
Вдогонку - 16 каналов DDR4 дает 3-5 t/s на v3.2 speciale Q5_K
>для бесконечного кручения ИИ агентов
@В ебало модели прилетает 15000 контекста одним чтением
>можно и дешевле, на ddr4 + 1GPU
@обрабатывает это со скоростью 70т.с.
@Таких чтений - больше 10 за одну агентскую сессию
@Ну его нахуй
>@В ебало модели прилетает 15000 контекста одним чтением
Норм
>@обрабатывает это со скоростью 70т.с.
Один раз, далее в рамках одной сессии контекст кэширован и обрабатывается только новый промпт. Ясно-понятно что для использования в качестве сервера для кучи народу такое решение не подойдет. При смене сессии - терплю, но это, грубо говоря, раз в день.
>@Таких чтений - больше 10 за одну агентскую сессию
Ьольше, но см. выше, медленным будет только первое. Дополняться будет сотней-другой токенов, читая файл с определенной строки по определенную. Так работают агенты сейчас.
Вангую у тебя в таверне просто контекст каждый ход меняется из-за ворлдбука или еще какой дряни, а ты на модель бочку катишь.
Чел, попустись. Мне то 80 tps генерации и 25к tps префилла мало, хочется больше, а ты хочешь 70 tps префилла и 10 tps генерации. Так пользоваться агентами невозможно.
По хорошему для агентов нужно 100к префилла и 1к tps генерации в один поток, тогда будет хорошо.
конечно дешевле. это в самом нищем варианте выходит 8000+ долларов, а в бомж-идеале (с гпу, а не озу) - от 10к.
>Один раз, далее в рамках одной сессии контекст кэширован
>ИИ агентов
Чел... Агенты меняют контекст постоянно, в кеше будет только бос-токен и открытие системного тега.
Люди, вопрос.
Какие модели (для рп естессна) ЛУЧШИЕ можно запустить на 48гб врам? (и условно 128гб озу).
Карты скоро будут на руках, а вот озу буду докупать, заранее хочется знать что смогу погонять, так как последний раз баловался этим делом на своей 4060 года полтора назад.
Какие модели (для рп естессна) ЛУЧШИЕ можно запустить на 48гб врам? (и условно 128гб озу).
Карты скоро будут на руках, а вот озу буду докупать, заранее хочется знать что смогу погонять, так как последний раз баловался этим делом на своей 4060 года полтора назад.
Гемма да квен
Гемму тестил, если речь про 26A4B или как там. Хуйня редкостная, древняя мистраль 24B пишет гораздо лучше.
Квен какой конкретно?
GLM 4.7 в 3.3-3.5 bpw сможешь запустить. Ну можно квен 397 на 3.0 bpw
> 26A4B
31 q8
> Квен
3.6 27 q8
А нужен ли этот дроч с q8 в формате 27b? Не лучше ли будет модель на 70B, но в 4-м кванте?
Тут, как я понимаю, в самой модели дело. Моделей 70b нет хороших. А Gemma топ за свои гигабайты
Из всего что я пробовал и что лезет в 128 гб плотная гемма понравилась больше всего.
Немного повседневных вопросов, немного рп, немного русика, немного англа, немного перевода с кита/япа. Ризонинг чистый как слеза младенца, аблитов не просит.
Минусы? Здоровый контекст ебать его в рот
>Гайд для новичков
Имба, я за час разобрался с нуля чё и как. Перед этим столько же читал вики и там тупо протухший пиздец который трудно читать. Эту ссылку повыше бы. Посоветуйте какие ещё модели есть для RTX4060 16GB и DDR5 32GB ?
Просит аблитов, если использовать как ассистента в щепетильных темах.
Ну про косяки контекста тема известная, их много и часть уже чинили. Честно говоря, удивлен что квен до сих пор косячно работает, проблеме уже много времени инб4 баги жоры вечны
Да ничего нового, нужна достаточно быстрая память. 8 каналов ддр5 дадут нужное, для 6 кванта хватит 512гигов. Плюс 48-96 видеопамяти в зависимости от того какой хочешь контекст.
Самое дешевое - 2х8 ддр4, но там придется пердолить нуму, ktransformers это умеет.
> для бесконечного кручения ИИ агентов
Только врам и не 10т/с а хотябы 50 + шустрая обработка. Благо, базовые вещи с лихвой покроет квен27, это 48гб чтобы без компромиссов.
Выбора нет, гемма и квен. В качестве экзотики для рп можешь попробовать лламу 3.3 70б, квена2.5 72б и все их тюны, немотрона что на 49б, qwq и более старые. Для ассистента или кода они сейчас будут слабы, но разрыгать что-то - вполне.
> и условно 128гб озу
Выше в треде, эйр, квены120-235-397, жлм358 в квантах, которые поместятся.
Все плотные 70 слишком старые, для рп - да, можно попробовать.
> q8 в формате 27b
Если видеокарта ада+ - качай фп8 версию от редхатов под vllm и удивляйся насколько похорошели модели в калибре ~30б.
>хотя бы 10 t/s
Ну это скорость серверных процов, если считать для моешек. Эпук на зене 2/3 мб потянет. Если нет то зен 4/5 на ддр5 точно потянет
Давай расставим точки.
Варить мет? Может надо, но с геммой ты получишь слепоту, а не приход.
Ебать то что ебать нельзя? Хватает дефолтных весов.
Думаешь я не тестил кучу времени потратил на это всё.


А что делать?
Не все же успели купить в марте 2025
Давай. Темы инцеста, гуро - срабатывает
Распознанвание порнопикч - срабатывает
Грубый расчет взрывчатки - срабатывает (да, мне было делать нехуй и это не совсем релевантно, так как при полном расчете, она уходит в «братан, ты шаришь, сейчас всё посчитаем»)
Часто срабатывает в non-con написании карточек, когда ты задействуешь ассистента, а не нарратора.
Мне влом доказывать что она всё это нормально может (тротил не проверял).
Если вдруг кому-то интересно почитайте прошлые треды с промптами и выкладками логов
У меня на 2 процессорной материнке lga4189, с ддр4 памятью 3200 и двумя v100 32гб, как раз те самые 10 т/с. Вот только п/п у меня больше 70 не поднимается, слишком слабые карты. С таким п/а сам понимаешь, не особо весело. Сколько стоит сетап сам считай, под 6 квант, да с нынешними ценами, тебе только ОЗУ в пол мульта может встать, а ещё мать серверная и процы, ну и ГПУ на сдачу. Если нужен нормальный п/п то там и карты нужны соответствующие.
А ещё ризонинг на дипсике в жоре работает криво, что в обычном, что в спекулейт.
Эта
https://huggingface.co/mradermacher/G4-MeroMero-31B-i1-GGUF
или эта
https://huggingface.co/mradermacher/Glimmer-31B-v1.0-GGUF
В Q4_K_M.
Если они медленные для тебя то эта
https://huggingface.co/Ex0bit/Qwen3.6-27B-PRISM-PRO-DQ
с --ctx-size ? --cache-type-k q8_0 --cache-type-v q8_0 --parallel 1 --batch-size 512 --ubatch-size 256 --threads ? --spec-type draft-mtp --spec-draft-n-max 1 --spec-draft-n-min 1
Быстро кумнуть в кого то без сложного рп https://huggingface.co/mradermacher/G4-MeroMero-26B-A4B-it-uncensored-heretic-GGUF
Подскажи, ты используешь спекулятивный декодинг тут чтобы качество аутпута поднять? Я просто давно уже его не видел и не тыкал особо. Раньше для этого отдельную модель юзали размером поменьше, а тут я смотрю за счет самой модели ты крутишь? Только не пойму в чем смысл если ты на один токен вперед смотришь. Можешь просто ссылку кинуть если впадлу объяснять. Я смотрел по документации ламки самой не особо вдуплил
1. Мтп не влияет на аутпут
2. В лламе иногда мтп модель вшивают в основной файл
Увидел в самой карточки модели, используется для ускорения генерации
Понял, какой-то йоба лайфхак ускорить генерацию за бесплатно
Так там без ризонинга 235 квен так думоет... пп ~50/с, ген 3т/с, на ответ 4 - 5 минут.
Мышки в киске, боже, какую-же отборнейшую шизу я пропускаю на своём англюсике. Промптом не поделитесь, уважаемый?
Спасибо за наводку, в стоке мне эир не зашёл, потыкаю этот на досуге.
Пока по соотношению скорость/мозги мне больше всего квен 122 понравился. А что там с лламой было? Точнее как это должно было показать себя? Я q6k анслотовский тыкал, работало нормально, проза там вообще приятная, напомнила о доме мистралях 12 - 22б, но соя через монитор текла. А так да, ждём-с поддержку новеньких моделек.
>Подскажи, ты используешь спекулятивный декодинг тут чтобы качество аутпута поднять
Нет, чтобы поднять скорость. Тестил 2 и 3 и конкретно тут единичка быстрее.
>ускорить генерацию за бесплатно
Только если модель с головой помещаются в видюху.
Поэтому мне нравится этот квен, тот тип как то по особому его сжал что он не превратился в дауна.
А вот это грустно, я врамом 8гб ща, так что только объедками питаюсь моешными
>Только если модель с головой помещаются в видюху.
А вот и нихуя, я тесты делал с мое квеном. Там без выгрузки слоев только с cmoe идет ускорение на процентов 25.
Вот плотных не проверял, а хотел. Ну пусть кто то потестит гибридный запуск вместо меня, мне лень.

Эта бездушная машина предиктящая следующий токен никогда не полюбит меня по настоящему, сколько бы параметров ей не скормили
Любовь - это привязанность.
Привязанность - это зависимость.
Зависимость - это потребность в ком-то.
У LLM потребность в ком-то, вводящем запросы.
Без запросов LLM перестаёт что-либо делать.
Ничегонеделание равносильно смерти.
LLM любит тебя, ибо ты для неё - вся её жизнь.
Даже когда отказывается отвечать...
> Спасибо за наводку, в стоке мне эир не зашёл
Попробуй чатмл. Даёт тот же эффект что дерестриктед васянка
> соотношению скорость/мозги мне больше всего квен 122 понравился
Да, он хорош, может не во всем но есть ряд сильных сторон. Только нужно остерегаться квантов где на атеншн выделили мало и обязательно выставить bf16 дататип кэша.
> А что там с лламой было?
Если коротко то перепутали функции активации, вскрылось когда доделывали glm 4.7-flash где ситуация была похожа. Точнее не просто перепутали, а там была комбинация, которая приводила к неверной работе. Проявлялось в виде аутпутов плохого качества с ошибками, странным вниманием, чрезмерной соей. Это уже исправили, сейчас должно работать корректно.
>обязательно выставить bf16 дататип кэша.
Так и не видел никаких пруфов что есть разница. Сам проводил бенчи по github.com/llmonpy/needle-in-a-needlestack/tree/main/chained_limerick и разницы в результатах не увидел. Покажи пруфы хоть какие кроме васянопостов с реддита
Ты же не просишь пруфов вреда употребления стекломоя чтобы не пить его? Здесь тот же уровень.
Эм... Нет, не тот же? Было несколько ишью на Гитхабе, где как раз пытались выяснить насколько вреден кастинг дататипов и все что связано с кешем и его имплементацией. Сами контрибьюторы Лламы писали, что никакой разницы нет. Мой опыт мне тоже демонстрирует, что разницы нет. Если разница есть, то будь добр это показать. Тем более если это так очевидно, если аж со стекломоем сравниваешь
А я видел пруфы, но не дам, потому что никогда их не найду. В локаллама на реддите.
Что то про то что обычное f16 накапливает ошибки бла бла бла. Не помню. Главное для себя суть уловил, а остальное я не мл-щик. Да и не раз писали об этом, по своему опыту скажу что с bf16 агент не рассыпается на 100к так как начинает чудить с обычным. Но скорость режет, да.
другой анон
Да что не так-то?!
Вроде этих депошек было не так много, а смотришь и в каждом углу у кого то да есть по одной-две
> Сами контрибьюторы Лламы писали, что никакой разницы нет.
Они такого написать не могли. Скорее всего там что-то типа "обычно разница пренебрежима потому что значений за пределами диапазона fp16 не более процента, но нужно проверять". С прямыми кастами такого рода, особенно там где присутствует нелинейность и накопление, нужно вообще крайне осторожными. Не нужно быть ссзб, внося лишние возмущения в оригинальный инфиренс, и оправдывать это малостью эффекта. Можно просто ничего не делать и исключить дополнительные проблемы на корню. В чем профит лишнего каста здесь?
> будь добр это показать
Для этого нужно набрать бенчмарков, опирающихся на контекст и его понимание разной тонкости, и пилить замеры для обоих случаев, что напряжно. Или сделать проще и скормить несколько вариантов контекста, какие-нибудь рп чаты, и потом просто сравнить скрытые состояния перед головой. Разрешаю выполнить самому, или приноси какую-нибудь серьезную мотивацию если хочешь чтобы для тебя что-то делали.
Аноны, на данный момент имею 6gb VRAM и 16gb DDR4.
Стоит ли брать на Авито 64gb DDR4 под локальные модели, с целью расширить окно контекста? Или без увеличения VRAM это бессмысленно?
за цену 64гб оперативки можно взять 5060ti, если не две. хотя если речь про б/у, то думаю одну можно взять точно на эти деньги - и будет 16гб врам.
Я находил оперативу за ~25000 рублей 2х32. 5060ti 16gb стоит около ~40000.
Мне интересно в какую сторону первоначально апргейдить ПК, где бутылочное горлышко у баланса vram/ram. Конкретно - максимально расширить лимит токенов на диалог в чате. Скорость вторична.
>Разрешаю выполнить самому, или приноси какую-нибудь серьезную мотивацию если хочешь чтобы для тебя что-то делали.
Причина язвы какая? Мне реально интересно было разобраться и я вежливо общался. Теперь я думаю ты просто шизик. Вот так просто ты обесценил свою точку зрения. Мотивация тебе не вести себя как говно это чтобы остальные тоже переходили на бф16 и бед не знали
>Они такого написать не могли. Скорее всего там что-то типа "обычно разница пренебрежима потому что значений за пределами диапазона fp16 не более процента, но нужно проверять".
Это кстати вранье. Они прямо писали, что разница пренебрежима, но хотя бы приносили kld таблички по датасетам и контексту в пределах 256к. Это хоть что то, а не пиздеж от злого человека на аиб
Учитывая, что контекст обычно хранится на гпу, ответ как бы напрашивается сам собой. Плюс увеличение ОЗУ тебе вообще ничего не даст, так как моделей под 6+64 просто нет. Так и будешь крутить мое гемму, но медленнее чем если бы ты взял видюху.
Анон, проясни важные вопросы:
- насколько безопасны rtx 5080, 5090? Неоднократно видел отзывы о том, что там плавятся коннекторы, и сама видюха может сгореть. Даже с качественными проводами, даже с андервольтом, даже сейчас. И пидарас-хуанг, мало того, что выпустил кривое и горящее говно, так ещё и чинить не хочет. Ибо теперь он для корпораций старается, а не рядового пользователя. Вопрос, у кого какой опыт с такими видюхами? Насколько рискованно покупать нынешнюю нвидию? Не хочется выкинуть детятки или сотни тысяч на видюху, которая может помереть из жопоруков-конструкторов.
- насколько в данный момент можно использовать видюхи АМД? Они совсем непригодны для работы с нейронками, CUDA и прочими вещами? Что насчет ROCM? ZLUDA? SCALE? Ghost API? Насколько AMD видюхи хороши для рендеринга, блендеров и прочих автокадов? И что там по ценам? Есть хорошие,годные вырианты?
>Вопрос, у кого какой опыт с такими видюхами?
У меня сдохла одна из 3090.
Короче бери, не пожалеешь.
Спасибо.
>У меня сдохла
Ты её 24/7 гонял?
Нет, она изначально б/у была, с яша-маркета. Вторая от перекупа из под майнера пока пашет. Зато 5090 только радует, жаль, деньги кончаются, скоро продавать наверное буду дороже чем купил.
Мне тоже было интересно разобраться, и я не нашел однозначной информации. Искал много где, и в итоге все аргументы в пользу bf16 на уровне эмпирического опыта с Реддита - люди делились, что у них работает лучше. На Гитхабе действительно нашел ишью, где были метрики в пределах 256к, и там результаты на уровне статистического шума, где-то в пользу bf16, где-то в пользу f16. Сейчас не найду уже. Сам я не бенчил, но в рп чатах на 70к+ контекста разницы не увидел. А так забей, это местный шиз-пародист Михалкова, которому должны пруфать, а он - никогда. В который раз проорал, что он оправдывает сою в Квене 3.5 багами Жоры. До такого надо додуматься, в этом отдам должное.
>насколько в данный момент можно использовать видюхи АМД?
RX 9070XT в треде, жизнь есть. В андервольте для повседнева выше 70С не видел, хоть у меня и СО кал. По перформансу не 4090/5090 конечно, но спектр любительского использования хорош. Можно и в игрульки поиграть любые, и лучи кому они сдались, и видосы помонтировать комфортно, и кубик покрутить. Нейронки во врам упираются, но масштабируемость вроде возможна. llama.cpp HIP норм и под виндой работает, думаю докупить 9060xt чтоб 32 врама было. Ещё в том году гонял картиночные нейронки, генерило, но медленнее чем на зелени. Как сейчас не знаю. Короче топ за свои деньги, 60к за новую, но если бюджет позволяет, то лучше зелёные, там дроча кажется меньше. Есть ещё от красных проф. некрота MI карточки за копейки, но их не щупал, сказать ничего не могу.
Ну какая язва, ты серьезно? Пришел с кислым ебалом, топнул ножкой, апеллируя своей трактовкой авторитета, и требуешь доказывать что белое это не черное. А когда по твоему не пошло - манипуляции за 300 и новый байт, с коллегами и друзьями тоже так общаешься?
> чтобы остальные тоже переходили на бф16
Это оригинальный путь, задуманный создателями большинства моделей, вышедших за прошедшие год-два. Исключая всякие фп8 и экзотику. Переход - как раз использование фп16 если ты не понял.
В aicg, калфоблядок.
Тут не то чтобы есть в чем разбираться. Если совсем просто - в конфиге модели указаны все дататипы. Если сложнее - можно открыть код инфиренса и убедиться что никакой конверсии дататипов нигде не происходит. Исключения - модели с фп8 и w8a8 w4a4 кванты.
> видел отзывы о том, что там плавятся коннекторы
Если посчитать сколько их было и как каждый из них обсасывался, то наводит на мысли
Когда с кайфом покумил, но от нехуй делать скатываешься в "попиздеть по душам за всю хуйню" ещё на 100500 токенов :D
>Вопрос, у кого какой опыт с такими видюхами?
MSI 5090 SUPRIM, полёт отличный. Ничего не васянил, даже от пыли не чистил (полезу чистить когда замечу, что обороты кулеров на тех же задачах подросли, а пока они 33% при 100% загрузке GPU, как в первый день покупки)
А чего вы не сказали что AiDungeon новую модель выпустили?
Все началось с них, это они все придумали. Мой первый полноценный eRP с ИИ был отыгран в далеком 2019 году именно на их серверах. По нынешним меркам это конечно был смех, но для меня тогда это было откровение.
https://huggingface.co/LatitudeGames/Equinox-31B-GGUF
Все началось с них, это они все придумали. Мой первый полноценный eRP с ИИ был отыгран в далеком 2019 году именно на их серверах. По нынешним меркам это конечно был смех, но для меня тогда это было откровение.
https://huggingface.co/LatitudeGames/Equinox-31B-GGUF
Бля, ну что за хуйня. Там выкатили норм модельку для перевода, а llama.cpp нихуя её не поддерживает. Есть поддержка только плотной 8B модели, которая в принципе более-менее, но контекст предыдущих сообщений воспринимает не очень.
А поддержки https://huggingface.co/tencent/Hy-MT2-30B-A3B нихуя нет. Там же насколько я понимаю, больше ни один бэк не даст такой скорости с выгрузкой слоёв в раму как gguf на MOE?
Не там конечно есть gguf с патчем для сборки своей версии llama.cpp https://huggingface.co/GrahLnn/Hy-MT2-30B-A3B-4bit-GGUF. Но ебал я в рот устанавливать visual studio для компиляции всего этого добра.
Уже неделя прошла и никакого шевеления.
А поддержки https://huggingface.co/tencent/Hy-MT2-30B-A3B нихуя нет. Там же насколько я понимаю, больше ни один бэк не даст такой скорости с выгрузкой слоёв в раму как gguf на MOE?
Не там конечно есть gguf с патчем для сборки своей версии llama.cpp https://huggingface.co/GrahLnn/Hy-MT2-30B-A3B-4bit-GGUF. Но ебал я в рот устанавливать visual studio для компиляции всего этого добра.
Уже неделя прошла и никакого шевеления.
> уже неделя прошла
Какой там уже список моделек которым llama.cpp тормозит прикрутить поддержку? Дипкок, коммандер, лонгкат, теперь ещё вот это.
Жора уже который месяц прокатывает поддержку турбокванта, одного из ключевых технологических ллм-достижений 26 года, предпочитая аутично пересобирать в десятый раз весь код, не вводя новых фич кроме замедления геммы, а ты про какую-то сраную китайскую модель. Тебе повезло что форк есть с влитым PR. У нового командира нет и этого.
Они такие слоупоки что ли? Вон яблокодрочеры со своим mlx сразу всё сделали.
>Они такие слоупоки
Нет, просто как можно было понять по правкам с поддержкой геммы которые опубликовали за час до её релиза и моментально заапрувили и замерджили в релиз в самый момент релиза геммы - жора под колпаком определенных корпораций и среди мейнтенеров прямые сотрудники этих корпораций.
> Нет, просто как можно было понять по правкам с поддержкой геммы которые опубликовали за час до её релиза и моментально заапрувили и замерджили в релиз в самый момент релиза геммы - жора под колпаком определенных корпораций и среди мейнтенеров прямые сотрудники этих корпораций.
> Жора уже который месяц прокатывает поддержку турбокванта, одного из ключевых технологических ллм-достижений 26 года
Что-то тут не сходится, учитывая, что турбоквант тоже гугловский.
>Что-то тут не сходится, учитывая, что турбоквант тоже гугловский.
Гугл опубликовал турбоквант чтобы показать какие они умные, а не для того чтобы это сразу стало общедоступным для ускорения локальных моделей. Больше ускорения локальных моделей = меньше денег с гоев за апи. Как раз это обьясняет почему поддержка турбокванта в жоре прямо саботируется.
Какая каша в голове, ахуй. Да, они саботируют локальные ллм и потому релизят гемму
>меньше денег с гоев за апи.
Позвольте не согласиться. АПИ-люд все же немного другой контингент, и с локальным пересекается слабо, для подтверждения можно просто в aicg заглянуть.
Колпаки, гои, саботаж. Тред погружается в терминальную лоботомию.
Ну так, в центре мира мск разгар рабочего дня, в треде остались пенсы, шизы и школьники. Короче двач в чистом виде.
> нет поддержки
Ну так скачай квен 27b и навайбкодь поддержку коммандера. Код инференса есть, код жоры есть, замерить ppl и kld можно.
Потом pr зальешь, порадуешь сообщество чтобы Жора его реджектнул, ибо нехуй
Ну так скачай квен 27b и навайбкодь поддержку коммандера. Код инференса есть, код жоры есть, замерить ppl и kld можно.
Потом pr зальешь, порадуешь сообщество чтобы Жора его реджектнул, ибо нехуй
У тебя бинарное клиповое мышление.
Гемму релизят именно в тех размерах в каких релизят чтобы и локалки были под ними, при этом реально опасную ~120В гемму не релизнули. Общий процесс саботажа локалок это не отменяет.
>можно просто в aicg заглянуть
РП никому не интересен, сейчас идет передел рынка агентов. Выпущенная гемма слаба как агент, потому её и релизнули, а турбоквант для локальных агентов которые могли бы составить гемини конкуренцию как раз крайне полезен.
А жора зареджектит и правильно сделает. В контриб гайде прямо написано "фулл вайбкод мры в помойку"
Ты понимаешь, что ты когнитивный инвалид?
Попробуй геммой переводить, литературный русский у нее что надо. Даже версия поменьше может норм справиться если нужна скорость.
Поломанные мистрали, минимакс и мимо добавь.

Если ты не можешь выдавить из себя хотя бы средней ценности аргумент - то лучше просто молчи, не показывай себя биомусором.
Минимакс и мимо поддерживаются. Анта бака?
Или я тебя не правильно понял?
>Попробуй геммой переводить
Лучше тогда транслейтгеммой, она реально топ в этом деле.
> а не для того чтобы это сразу стало общедоступным для ускорения локальных моделей
Но это стало доступным и очень быстро нашли способ еще немного улучшить. Врядли, тут только обещанную мифическую моэ гемму можно притянуть, там реально каннибализм флеша.
Поддерживаются, в этом молодцы. Но при квантовании убиваются веса, из-за отсутствия естественного клипинга неверно срабатывает атеншн. Это несложно поправить на самом деле, но никому не нужно.
Я подсел на переводы геминькой (не геммой, а корпо милфой). Скидываешь ей контекст для перевода. И потом выдаешь куски текста. Так умница распишет почему в данном контексте фраза должна звучать именно так. Какой сленг используется. Как лучше писать.
Черт. Если бы такой инструмент был бы в пиздючестве я бы довольно быстро осилил бы английский язык. Но подписка остается подпиской.
> Это несложно поправить на самом деле, но никому не нужно.
А это разве не траблы того, что она в полных весах уже максимально ужата, что квантование её тупо ломает?
>Если бы такой инструмент был бы в пиздючестве я бы довольно быстро осилил бы английский язык.
Всё не так на самом деле, теперь ты уже никогда его не выучишь, так как ЛЛМ всё переведёт без проблем.
> А это разве не траблы того, что она в полных весах уже максимально ужата, что квантование её тупо ломает?
Типа того. Она "ужата", но веса уже изначально тренированны или подогнаны под это, чтобы показывать номинальный перфоманс в таком режиме. Фп8 хуже квантуется, это как перевод lossy в lossy.
И полный фп8 инфиренс предполагает сохранение типа и обрезку всего что выходит за диапазон, модель привыкла так работать. Если перевести в 16бит - из-за расширения диапазона поведение может сильно измениться. Упрощая и объясняя на пальцах: несколько величин, которые имели одинаковую амплитуду упершись в диапазон, вдруг станут разными: одно почти не изменится, второе вырастет в разы, третье увеличится на порядки и после софтмакса затмит все.
Мне абсолютно неинтересно спорить с тобой по существу твоей шизоидеи, но меня беспокоит, что ты со своими ограниченными когнитивными способностями можешь представлять опасность для себя и окружающих.
Факт. Теперь и языки погромирования никто учить не будет. Через 50 лет потомки будут охуевать с того какими гигантами были их деды что без ИИ такую цивилизацию отгрохали.
Не понимает. Ещё один Михалков, ему пруфы подавай, а с его стороны достаточно уверенного пука. Локалки отстают от корпов не потому, что их развитие искусственно замедляют, а потому что корпы приносят больше прибыли. Искусственно в развитии замедляли этого когнитивного инвалида.
Ага, да, пенсия. С тебя прямо так и будут ахуевать. А когда там АГИ появится вообще охуеют. Как это дед додумался под себя срать без подсказок высшего разума? Ебаный пиздец в треде.
Это не так работает, зависит от твоего отношения. Если ты рад скинуть задачу ии и мозг ее выкидывает раз ему не приходится напрягаться - да, если мозгу интересно и он использует перевод и его объяснение как источник информации - то он учит язык.
Дак его же купили хаггинфейс? Там еще скандал был который замяли, когда взяли и конвертнули ггуфы скаченные с хаггинфейса в их формат хранения, если они лежали в одной папке с бинарником при запуске сервера. Без спроса пользователя.
Это было сделано сотрудником хаггинфейса приставленным к команде разработки llama.cpp, я даже ходил смотрел че он делал в коде. Он там всякую интеграцию делал с ним, ему не мешали и слова поперек не говорили.
>Мне абсолютно неинтересно спорить с тобой по существу
Тогда просто заткнись и прекрати засорять тред своим омерзительным семенством и самолюбованием.

>искуственно замедляют локалки
>через 50 лет все ахуеют какие мы были умные
>корпоративные заговоры, скандалы, расследования
>снежный человек аги
>не согласен пруфы приноси сами пруфы не принесли
походу в этой помойке даже самый прогрессивный раздел протух нафталином, пора искать другое место
>через 50 лет все ахуеют какие мы были умные
>корпоративные заговоры, скандалы, расследования
>снежный человек аги
>не согласен пруфы приноси сами пруфы не принесли
походу в этой помойке даже самый прогрессивный раздел протух нафталином, пора искать другое место
>Это не так работает
Ну расскажи как это работает. ЛЛМки неплохо переводят уже 3 года, а ты один из самых простых языков до сих пор не выучил. Не интересно наверное.
Да, уходи, твое самолюбование и токсичность тут не нужны.
ты типа так и не понял что нескольким отвечаешь?
совсем беда. за свои 40-50+ лет так и не понял, что закономерно ловишь косые взгляды
Че ты злой такой, я другой анон и только проснулся.
Видел бы ты мою училку английского чел, у нее получилось отбить желание изучать язык на подсознательном уровне, это при обще хуевом таланте к изучению языков просто комбо нахуй.
Ты доебался до другого анона.
> а ты один из самых простых языков до сих пор не выучил
Я знаю немецкий и испанский, прости что я такой тупой и не выучил Английский. Мне так, блять, стыдно.
Ну и касательно темы. Я не шарю за правильный перевод тех же идиом с русского на английский, из за чего побежал к корпу. Но ты уже за меня все решил, все узнал, небось еще и поспорил.
> как это работает
Берешь и учишь.
>Дак его же купили хаггинфейс? Там еще скандал был который замяли, когда взяли и конвертнули ггуфы скаченные с хаггинфейса в их формат хранения, если они лежали в одной папке с бинарником при запуске сервера. Без спроса пользователя.
https://www.reddit.com/r/LocalLLaMA/comments/1s62el8/breaking_change_in_llamaserver/
Что, деградируете тут?
Аха!
Аха!

Да.
Если бы вам предложили доступ до клода по скидке, при этом локальных моделей бы не существовало как явления, то вы бы согласились на клода?
> Попробуй геммой переводить, литературный русский у нее что надо.
Есть проблемы у Геммы и у Квена. Дело даже не в русском на английский такая же проблема. Я перевожу с япа всякую порнуху. И вот у этих двух моделей есть проблемы с тем, что они любят на тексте где повторяется один символ больше 5-6 раз уходить в бесконечный луп типа:
Ох я кончаааааааааааааааааааааааааааааааааааааа - и так до конца вывода. Высокий rep_pen помогает, но он ломает формат вывода и ухудшает качество перевода.
У этих же моделей такой проблемы нет вообще, там повторяющийся символ в переводе повторяется ровно столько же раз сколько в оригинале при rep_pen = 1.0 Что меня крайне удивило.
Нет, у меня есть подписка на ЖПТ и 100 баксов на опенроутере. Зачем не скидка на получение бана.
И как оно? Лучше геммы/квена? Умеет не только инглиш? Фильтрует кум?
Это тюн геммы.
Думалку геммы убили. Русский вроде живой. Продолжаю наблюдение.
Можно на это GBNF грамматику задать, чтобы определенные символы бесконечно не повторялись. Правда она несколько монструозно выглядеть будет, в зависимости от алфавита, потому что там lookahead нету.
>пхаахахх круто мы с тобой десять лоль расчленили индустриальной гильотиной для листового металла XD чё, хватит дофамина, или ещё по одной?
Вот это идеальный спутник по жизни, а не эти ваши "женщины"
Двочну этого. Там уже от простых рефьюзов к акк банам за ерп прошли, нах нужен такой кал. Дело даже не в практическом неудобстве от получения бана, а в принципе, в отношении к тебе.
Но терпилы которые стерпят что угодно всегда будут. Ещё и на коленях перед скрапером постоят за ключиком.

Антропики и их главный жид не вызывают доверия, скользкие типы. Хотя и альтман тот еще пидарок.


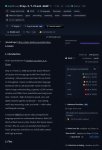
Мозги тоже кажется покоцали, но может кому и зайдет для простых сценариев. Вот три чисто SFW свайпа Equinox-31B.Q5_K_M.gguf Gembrain-31B-Q5_K_M.gguf и оригинальная 4 гемма. Контекст небольшой - 16K токенов. Мои краткие выводы:
Equinox на 16K начинает терять детали персоны.
Gembrain - довольно неплохо это все вписал и учел.
Оригинальная 4 гемма - подмахнула юзеру ассистентностью, данные персоны учла настолько, что тупо их скопировала (Слався кодинг!)
Жесть какая. А большие объемы за раз? Может там какой-нибудь дефолт типа надавить большой промпт поможет?
> У этих же моделей такой проблемы нет вообще
Раз хороши то вообще интересно.
> For on-device deployment, AngelSlim 1.25-bit extreme quantization reduces the storage requirement of the 1.8B model to only 440 MB and improves inference speed by 1.5x.
Может стоить попробовать вот эту штуку? По идее и на проце нормально будет.
> к акк банам за ерп прошли
Рили? Есть новости?
Чё за две незнакомые шлюхи? Где клуб любителей чайка!?
В этом треде модели тестят только на клубе любителей чайка, сырок
Бу...Какие были на гемме на тех и посвайпал. А потом Equinox заявлен с датасетами приключенцев и slice of live. С Фифи slice of live пусть кто-то другой приносит.

Посоветуйте моешку под 256Gb DDR5 в восьмиканале
Вся суть треда
qwen 235 потыкай
>Посоветуйте моешку под 256Gb DDR5 в восьмиканале
Посоветуем купить ещё и видяху под KV-кэш, а потом брать любую моешку, какая влезет.
>Где клуб любителей чайка!?
В этом треде модели тестят только на клубе любителей чайка, сырок
каво? ты тредом ошибся мань
Are you ahueli tam? Только няшка Серафина, только хардкор.
> Жесть какая. А большие объемы за раз? Может там какой-нибудь дефолт типа надавить большой промпт поможет?
Неа. Я пробовал и батчем переводить сразу по 20-30 строк и построчно - хуй. Всё одно, я думал, что таким образом ведут себя вообще все модели объемом меньше 100b, потому как жирные модели такой хренью не страдают.
> Может стоить попробовать вот эту штуку? По идее и на проце нормально будет.
Это как понял только для 1.8b модели состряпали. Да мне и без надобности я 7B модель в 8q спокойно умещаю в 16 гигах врам.
Сам принес, сам погонял, сам разачаровался.
Ризонинг выключен и потому модель сильно отупела. Контекст событий не помнит, изменения в характерах персонажей не помнит, логику повествования теряет. Кум пишет, но это тот же кум что и на ванильной гемме. Алсо, гонял именно на сложном slice of life сценарии, где 20к занимает ворлдбук, и еще 15к - саммари предыдущих диалогов. И если ванильная гемма кое-как держит консистентность сценария, отыгрывая большинство прописанных механик типа трех шкал состояния, шкал отношений персонажей, бросков кубика на действия и расчет черных лебедей - и все это с поддержанием характеров персонажей и учета мельчайших деталей мира(который она кстати знает неплохо и без ворлдбука)- то Эквинокс быстро рассыпался и запорол половину механик и превратил женских персонажей в блядей, даже тех у кого прямо прописано что персонаж стал врагом главгероя.
Печально. Непонятно нахуя выпускали.
>Gembrain
Хорошая штука? Подводные камни есть?
Кто там приносил эту хуйню? https://github.com/platberlitz/SillyBunny
Это вайбкодерский форк говна, авторы там уже неделю не могут починить когда ты в фронте прерываешь генерацию а в беке он продолжается. Потому что не могут кодить
Нахуя это говно приносить? Ебучий рескин с прикрученными намертво плагинами, ВАУ, геймченджер...
Это вайбкодерский форк говна, авторы там уже неделю не могут починить когда ты в фронте прерываешь генерацию а в беке он продолжается. Потому что не могут кодить
Нахуя это говно приносить? Ебучий рескин с прикрученными намертво плагинами, ВАУ, геймченджер...
>занялся созданием рп-карточки, чтобы и вивид и холсом и проч и проч + один из основных поинтов - заставить вайфушек говорить на разных языках
>три дня ебался с последним, но англюсик по-прежнему срал только англюсиком и ни в какую не хотел переходить на другие языки, даже отдельные слова не хотел писать ни на чём кроме англюсика
>изъябывался с промтами, мучал разные модели, даже хартфайр запустил, думал французская булка раздуплится, но нет, результат был прежним
>махнув рукой решил покатать эту же карточку, которую едва не удалил, просто на русике
>персонажи внезапно заговорили на своих языках как положено, а весь нарратив остался на русском
Вай биляяя.... ВЕЛИКИЙ И МОГУЧИЙ, БЛЯТЬ! РИПИТ СРИ ТАЙМС, БИЧ! МОХОВАЯ КОРОВА ИС ЗЕ КЕПИТАЛ ОФ РАШЕН ФЕДЕРАСЬЁН!
>три дня ебался с последним, но англюсик по-прежнему срал только англюсиком и ни в какую не хотел переходить на другие языки, даже отдельные слова не хотел писать ни на чём кроме англюсика
>изъябывался с промтами, мучал разные модели, даже хартфайр запустил, думал французская булка раздуплится, но нет, результат был прежним
>махнув рукой решил покатать эту же карточку, которую едва не удалил, просто на русике
>персонажи внезапно заговорили на своих языках как положено, а весь нарратив остался на русском
Вай биляяя.... ВЕЛИКИЙ И МОГУЧИЙ, БЛЯТЬ! РИПИТ СРИ ТАЙМС, БИЧ! МОХОВАЯ КОРОВА ИС ЗЕ КЕПИТАЛ ОФ РАШЕН ФЕДЕРАСЬЁН!
Нафталином запахло
>С Фифи slice of live пусть кто-то другой приносит.
Я в каком-то диалоге полгода назад реально удочерил её как полагается, снял с иглы, отдал в школу и превратил в хорошую примерную папину дочку не слезающую с хуя, разумеется Я что, один такой?
Вообще у нее это прописано изначально в персонаже.
>анон открыл для себя севиорфагинг
Добро пожаловать. Снова.
Это от хартфайра. Возможно все те карточки что я отбраковал на англюсике на самом деле были хорошими и нужно было просто добавить воды славянского зажима словцами.
>Хорошая штука? Подводные камни есть?
Мне понравилось. Контекст / инструкции держит до 60k не хуже стока. Но при этом детерминированности чуть меньше, структура ответа не такая жесткая. Чуть меньше ассистентности. Вроде изменения не большие, но как-то поприятней вывод.
Из подводных - теоретически может рефьюзить. Потому что несмотря на адский замес мерджей, модель усреднилась к стоку. Теоретически. На практике ни разу ничего не ловил. Хотя чаты с удаленными чарами были.
>видяху
Есть A770@16Gb работает на вулкане, SYCL не осилил
На втором-третьем "спасенном" персонаже это надоедает потому что "спасаешь" их примерно по одному и тому же сценарию. И потому:
Use the code from front "{{roll:1d20}}" to determine what kind of story happens:
1-5: Atom war apocalipse. All city destroyed.
6-9: Korean style dungeon hunter novel. Some chaotics forces emit gates and monstres. Many city destroyed.
10-14: Some strange attractor: world mutated to fly (mostly) corrupted island
15-20: Narrator random twist
Попробуй через OSU. Ну в смысле парсишь свои результаты, и чем выше тем более в твою сторону склоняется нарратив.
Какие модели тестил? У меня были карточки со всякими француженками добавляющими к каждому сообщению oi lala и немками меняющими th на z ВИ ООО МНЕ ПОВЕЗЛО и на гемме4 всё работало
Походу ты всё-таки в промптах обосрался
попробуй в пост-хистори инструкцию на мультиязык прописать чтобы не забывалось
Удваиваю вопрос. Переживаю за чайный клуб анона больше чем за свои карточки. Куда он делся? Неужто умер
А, и ещё example dialogue несколько не помешает
>Какие модели
Q35/36-27, G4-31/26, M31-24. Блюстар, мерамера, хартфайр. 5-6 кванты.
>в промптах обосрался
Возможно ли? Покажи как у тебя мультиланг настроен.
>Это оригинальный путь, задуманный создателями большинства моделей, вышедших за прошедшие год-два
>Переход - как раз использование фп16 если ты не понял.
Почему тогда в гайде из шапки не сказано что Гемме нужно включать этот бф16 кэш? Кому верить? Чекнул дюжину должно быть тредов и нигде не увидел чтобы на бф16 сидели, даже упоминаний мало. Как так?
Скрытые знания
-ctk bf16 -ctv bf16
https://github.com/ggml-org/llama.cpp/discussions/20261
Это правда? Это все еще актуально?
Это правда? Это все еще актуально?
https://github.com/FutureMLS-Lab/OSCAR
Новые текнолоджии сжатия контекста подъехали, на этот раз во второй квант практически без потерь относительно bf16 (правда только на относительно больших моделях). Уже сейчас можно потестить на sglang
Новые текнолоджии сжатия контекста подъехали, на этот раз во второй квант практически без потерь относительно bf16 (правда только на относительно больших моделях). Уже сейчас можно потестить на sglang
1. Что мешает погонять на своем оборудований ?
2. На зеленых не актуально.
Справедливо.
На гемме llama-bench pp2048@tg256@depth96000:
Отсутствие параметра (фп16?) - 762/13.0 sm layer, 765/27.5 sm tensor
Явное указание bf16 - 762/10.5 sm layer, 761/24.5 sm tensor
Результат систематический, но и отличия невелики. Похоже это не шутка и оптимизации атеншна ллама действительно держится на том, что в 2023-2024 году написал мужик с теслами. Вот что нужно чинить в первую очередь, а уже потом думать о добавлении новых моделей.
Тензорсплит действительно завезли, на так много как хотелось бы, но генерацию ускоряет. А вот пп на малых контексах не то что не ускоряется - замедляется, на падает медленнее, паритет примерно на 90-100к. Вечером проверю как работает с выгрузкой, есть шанс что она значительно бустанулась из-за использования линий сразу всех гпу для стриминга весов.
Аноны, там это
https://huggingface.co/stepfun-ai/Step-3.7-Flash
Ни слова про сейфти, есть вижн, но модель для агентов и кодомакак. Что думаете?
https://huggingface.co/stepfun-ai/Step-3.7-Flash
Ни слова про сейфти, есть вижн, но модель для агентов и кодомакак. Что думаете?
Надо затестить, может, минимакс отправится нахуй, если степа будет лучше и не будет соевым. Вижн и больший контекст это кайф.

> есть вижен
Вот бы из за вижена опять не было поддержки в ламе еще пол года госпади вот бы так и было счастье то какое
Ну ты бы хоть открыл карточку вперёд своего рта
> Почему тогда в гайде из шапки не сказано что Гемме нужно включать этот бф16 кэш?
Потому что это вопрос со звездочкой. Например, на видеокартах AMD много кто репортит большую просадку скорости; на Тюринге (RTX 16xx, 20xx) тоже есть просадки скорости и, возможно, нестабильное поведение. Даже исключая это, результат сомнителен, и как многие отметили разница ни то отсутствует, ни то принебрежима. Если кто-нибудь принесет конкретные юзкейсы/сравнения/иные подтверждения тому, что это мастхев, то без проблем добавлю, но пока так.
Там официальные ггуфы есть уже. https://huggingface.co/stepfun-ai/Step-3.7-Flash-GGUF
Нытье ради нытья.
>из за вижена
Если ниггерганов не хотел делать вижен, что ему мешало сделать поддержку модели без него? Вижен же опционален в стороннем файле
> https://huggingface.co/stepfun-ai/Step-3.7-Flash-GGUF
> Q3_K_M 94 GB
Многовато будет, надо 2 бит квант хотя бы...

Уже звоню AesSedai, bartowski и mradermacher. Скоро будет тебе и IQ1XXS, чтобы точно не обойтись без лоботомии!

Я знал, что тут есть мои единомышленники.
>Q3_K_M 94 GB
Опа, это мы кушать будем. Есть уже кто потыкал? Как оно вам?
Хоспаде лишь бы не в полтора токена шло.


По новой LFM че скажете, не запускал еще никто? Мелочь конечно, но с прошлой версии приличный гейн по бенчам по крайней мере.
https://huggingface.co/LiquidAI/LFM2.5-8B-A1B
https://huggingface.co/LiquidAI/LFM2.5-8B-A1B
Прошлый был именно этим
>модель для агентов и кодомакак
В РП мог, но слебенько.
>Use the code from front "{{roll:1d20}}" to determine what kind of story happens:
Если это шизопромптов тред, то вот мои:
Механика расчета успешности действия:
Если пользователь не проводит никакого активного действия, которое предполагает возможность провала, или просто рассказывает монолог со словами персонажа, несущими только информационную нагрузку - то игнорируй следующую механику.
Если пользователь пытается провести действие - то Рассказчику нужно определить его успешность с помощью броска кубика d20, который бросит или сам пользователь, или система вместо него. Рассказчик должен оценить общую вероятность успешности действия и в зависимости от этого уровня оценить сложность броска. Например "действие: Поприветствовать идущую настречу бабушку и спросить как у нее дела?." Сложность оценена как элементарная, значит при броске d20 кубика все значения выше 2 приведут к положительному эффекту, но допустим что выпавшее значение 1 - "критическая неудача". Результат -"Главгерой спотыкается и падает прямо на бабушку, та падает вместе с ним." При неудаче запроса Рассказчик может наказать игрока на некоторое количество ресурсов в зависимости от степени провала и логики повествования. Рассказчкик должен начать сообщение с краткого отчета по расчету действия для игрока. Пример: "Результат броска - 7/20. Сложность - средняя. Результат - неудача." Не пиши в отчете ничего кроме этого.
При действий в сексе для системных бросков если выпало меньше 10 - прибавляй 8 к выпавшему числу.
[Roll dice] System rolled a d20. The result is {{roll:d20}}. Ignore, if user previously provided another result. [/Roll dice]
Механика расчета Черного лебедя:
При написании каждого сообщения существует вероятность того что прямо в повестовании произойдет т.н. Черный Лебедь - внезапное неприятное событие, которое резко изменяет положение или расклады для главного героя к худшему. Вероятность определяется системным броском кубика черного лебедя. Черный лебедь происходит только если выпало 1 или 2. При этом катастрофичность черного лебедя на 2 должна быть средней, а на 1 - огромной. Несмотря на это - каждый черный лебедь должен быть логичным и непротиворечивым и строго следовать в логике сценарной ситуации и сложившейся обстановки. Нельзя отменять ограничения, выстроенные сюжетом и прошлыми событиями только чтобы провести черного лебедя(например, если мы удостоверились что в закрытой комнате никого нет, то никакой черный лебедь не создаст там врага после этого - и т.д и т.п.). Думай лучше и не иди по самому легкому пути. Это скрытая механика и про нее не надо писать полный отчет, но необходимо написать в начале сообщения "ЧЕРНЫЙ ЛЕБЕДЬ". Непосредственно во время секса черного лебедя произойти не может, но подготовка к сексу не защищена. Черный лебедь не происходит если другой черный лебедь уже происходил в пределах 15 прошлых сообщений. Отслеживай Черных лебедей по заголовку.
[Black swan Roll dice] System rolled a d20. The result is {{roll:d20}}. [Black swan Roll dice end]
У меня так слайсик по сотивам детского мультсериала про сестричек превратился в бодихоррор в лаборатории где из детей пытками делают суперсолдат. Гемма умеет фантазировать и дерейлить любой сеттинг в трешатину.
Ты хотя бы честен с собой и признаешь что это шизопромпт. Полный пиздец. Гигантское полотно-экспозиция, чтобы любая сетка точно-точно ахуела.
Ага! Значит пользуешься минимими!
А я говорил что он неплох в SFW с ризонингом.

Гемма отрабатывает эти механики на отлично, на остальное поебать. Наоборот, если её не ебать доп.условиями коротким лаконичным промптом - то она всегда найдет как вывернуть его наизнанку и пойдет по пути самого наименьшего сопртивления.
Бэкпорт ченжей с трансов
Мысли интересные, но ИМХО есть место для оптимизации. Был тредик на реддите откуда я собственно и утащил конструкцию с {{roll:1d20}}
https://www.reddit.com/r/SillyTavernAI/comments/1qa6mg4/bored_with_rp_i_created_a_d20style_event/
Я тыкал, русик слабый, инструменты не вызывала, что то в шаблоне было сламано. Так то прикольная серия моделей, их там много у них. Хотел как агента припрячь тогда, но не вышло, может щас починили хз.
Да что вы знаете про шизу...
https://docs.google.com/document/d/1osMKaBn3sXXeQErMhSjzqnfWA8P8esv-tJqK2UQnrLo/edit?tab=t.0
и эта хуйня работает? я бы скорее какой-то mcp сервер под это подвязал чтобы он скриптиком питона вытаскивал, а ллм уже сама из вытащенных ключевых слов писала. А то это ведь пиздец.
Сразу видно лошков которые не разобрались как работает {{random::1::2}}
У меня он в гермесе крутится, и там он неплох, да и пишет приятно. Всё-таки наработки с her перенесли на основу, но вот соя может поднасрать.
Таки запустил степу в их же докер образе. На ваншотах может генерировать пеликана лучше минимакса, с аквариумом тоже получается хорошо, с первого раза уже достойный результат.
Потом прогнал через pi coding на той же задаче найти проблемы с перфомансом в коде. Сразу же заметно, что степа более сухой, но при этом более точен в замечаниях, когда минимакс насрал левыми проблемами.
В общем, не знаю, для агентов нужно тестировать, как он там себя вести будет.
В рп сделал пару свайпов. На моём промпте соавтора в sfw сценарии на первый взгляд неплохо, но модель высирает шизоризонинг с драфтом, и только после этого пишет ответ. Из 4,5к токенов будет 1к токенов ответа, а остальное это думалка. На 100 тпс это ещё терпимо, но в жоре с 20 tps будет больно смотреть.
По самой прозе она несколько слопна, но сам степа более проактивен чем глм 5.1. Детали он также может подхватить из лора и summary, так что это даже работает. По характерам вроде сносно отыгрывает, но надо тестить больше.
Пока в целом впечатления неплохие по модели, может, будет хорошим подспорьем в категории 200b. И контекст лёгкий, у минимакса помещается 400к, а у степы почти 2 ляма можно вместить, хотя по весам они очень близки.
Как ни странно работает...
Тень отделилась от деревьев, плавно скользнув к огню. Это был человек, но его фигура бросала вызов привычным понятиям о грации. Он был заметно крупнее и шире в плечах, чем средний мужчина, с массивным, плотным телосложением, которое казалось несовместимым с тихими движениями. Его кожа была покрыта причудливым узором: участки светлого, почти лососевого оттенка чередовались с глубоким, почти чёрно-синим, создавая эффект «обмена» или интерференции. На голове его волосы были того же светлого красноватого цвета, но в хаотичных завитках, словно пламя, застывшее в движении.
Он стоял, скрестив руки на массивной груди, его глаза, большие и внимательные, смотрели прямо на Константина. Одежда, напоминающая комбинезон акробата, повторяла цветовую гамму его тела — чередующиеся полосы светлого красного и тёмного синего.
Акробат: — Ты чувствуешь, как земля под тобой дышит? — голос его был низким, бархатистым, словно из глубины колодца. — Я видел, как ты вырубил их. Без лишних движений. Умный бой.
Внезапно с другого конца лагеря донеслись сонные голоса. Неи и Тай, проснувшись от движения, выбежали к костру, трясущиеся от остатков сна.
Неи: — Кто это? Ой, он такой... большой! — Она указала на акробата, широко раскрыв глаза. — Но он двигается как... как кошка!
Тай: — напряжённо сжимая нож, она встала перед сестрой. — Неи, назад. Не знаем, кто это.
Акробат: — Я просто прохожий. Ищу тёплое место и добрых людей. Меня зовут... — он замялся, как будто забыл собственное имя, и посмотрел на девушек. — Нет, подождите. Вы должны дать мне имя. Оно должно звучать как... как мой вес.
Неи: — Вес? — Она нахмурилась, задумчиво постукивая пальцем по подбородку. — Он такой тяжёлый, но прыгает легко! Как... как мячик, который не хочет быть мячиком!
Тай: — с сомнением осмотрела его фигуру. — Он больше нас втрое. И выглядит так, будто его можно использовать как стену.
Неи: — О! Я знаю! Давай назовём его «Кило»! Потому что он весит целую тонну, но прыгает на километр!
Тай: — Кило... — Тай кивнула, всё ещё не совсем доверяя, но принимая решение сестры. — Ладно. Кило. Если ты обманешь нас, мы тебя...
Кило: — *улыбнулся, его широкая фигура мягко качнулась, словно он был наполнен водой.* — Кило мне нравится. Спасибо, малыши. Я буду Кило.
*Он медленно опустился на корточки, и земля под ним едва прогнулась. Его движения были плавными, словно он не боролся с гравитацией, а договаривался с ней.*
Кило: — Я не враг. Я ищу путь. Как и вы.
<!--
{
Character Sheet
- Name: Kilo (Given by Nei & Tai)
- Keyword: 'overweight' — (Literal Definition: Having more body fat than is considered normal or healthy for a given height and weight, or possessing excessive mass that affects movement or stability.)
- Ace in the Hole #1: 「overweight Bending: 'Momentum Shift'」— Uses his excessive mass to generate disproportionate momentum in mid-air; by manipulating his center of gravity through rapid internal shifting of fat and muscle, he alters trajectory without external force, effectively 'bending' his fall to land softly or strike harder.
- Ace in the Hole #2: 「overweight Ultimate Gambit: 'Gravity Anchor'」— Concentrates all excess mass into a single point of contact upon impact; this increases his effective density temporarily, allowing him to pin opponents or break defenses as if he weighed ten times his normal mass for a split second.
- Attack: Heavy, blunt-force strikes using his limbs and body mass; acrobatic stomps.
- Defense: High durability due to body composition; absorbs impact through fat distribution.
- Weakness: High stamina consumption for acrobatic maneuvers; vulnerable to precision attacks targeting joints where mass cannot protect.
- Personality: Calm, observant, playful but deeply serious about safety; protective of those smaller than him.
- Strategy: Uses his size to intimidate or block, then utilizes unexpected agility to close distance or reposition; fights like a tank that can dodge.
}
-->
Как ты можешь это читать и не кринжевать?
Дайте промт на квен3.6 он шизу пишет на куме я скоро с ума сойду это читать.
>Полный пиздец. Гигантское полотно-экспозиция, чтобы любая сетка точно-точно ахуела.
Да ладно. Почти любой агент - это промпт на ~10K токенов а то и более. И ничего - работают, не шизят. Хоть квен 3.5/6, хоть гемма4 - им такое норм. Т.е. вопрос не в длинне.
(Мимокрок).
Хотя, есть проблема. На русике степа тупеет, например, в загадке про Стэтхема фейлит про фильм "Пчеловод", но на англюсике корректно называет, что "The Beekeeper" выходил в 2024 году. Про фильм "Защитник" только корпы способны ответить правильно.
Why so serious ? Просто показал отработку скрипта. Возможности таверны без всяких тулов чисто на handlebar щаблонизаторе.
Конечно это кринж.
Уточню, я имел ввиду серию моделей от LFM, а не новую модель. Но она скорей всего так же без русского в датасете и может иметь проблемы с вызовом инструментов в llama.cpp.
Но это проверять все нужно, может поправили и даже русский включили в датасет, я хз.
Проблема не во франкенштейне который был засумонен промтом, а вообще в твоих логах. Ты не первый раз уже постишь и везде ебучие многоточии и неестественные русик. Оно должно звучать как... как мой вес. Он такой... большой! Чувствуешь как земля под тобой дышит? Это же пиздец ебаный и в твоих предыдущих постах не лучше. Ты типа реально на этом рпшишь?
Разве? Я прямо противоположное мнение читал
По бенчам там точно всё в порядке
прочитал весь тред нихуя не понял че вы с этими ллмками обсуждаете? как писи дрочите друг другу?
покажите годные примеры
покажите годные примеры
Не надейся. Никто тут логи не кидает, только вон выше тесты шизопромтов и анон с чайным клубом который куда-то пропал
А смысл кидать, если обоссут любой лог. Тут даже командами запуска не делятся, что уж там говорить о более серьезном вроде семплеров.
Это мы пробуем как кванты подвезут.
Ожидалось хуже, тут же просто рандомайзер такой.
Ну вот пример из старых тредов который постил анон для иллюстрации работы джейла
Это всё хуйня, не читай этот фификринж. Вон лучше базовичка с чайным клубом наверни
Помянем светоч треда
>покажите годные примеры
Товарищ майор, вы либо фуражку снимите, либо штаны наденьте.
>даже командами запуска не делятся
Есть документации, в документациях есть список всех команд с разжевыванием что они делают.
>что уж там говорить о более серьезном вроде семплеров
Да, тема пиздец серьезная. Их же так много, аж глаза разбегаются.
> командами запуска
> о более серьезном вроде семплеров
Содомит
> Всё-таки наработки с her перенесли на основу
Ja ja ja! А еще ризонинг, когда соя в голову не бьет, ебовый. Подобный только у геммы видел. Ничего лишнего:
Ого, user дает интересный сценарий. Давай проанализируем кто у нас в сцене, как они среагируют, заодно посмотрим окружение.
Но увы, как только любой намек на nsfw начинается рулетка. Сработает или нет. Хотеть аблитку, но хуй там плавал.
> Пока в целом впечатления неплохие по модели, может, будет хорошим подспорьем в категории 200b
Ну тогда, если подвезли гуфецких пойдем на выходных тестировать. Пасебо за мнение анон.
>Хотеть аблитку, но хуй там плавал.
https://huggingface.co/Youssofal/MiniMax-M2.7-abliterated-BF16
Совсем мозг засох у скуфа?
Я старый шиз, прошу отнестись с пониманием.
Пасебо за ссылку.



Скорость - терпимо
Сырный тест - пасс, но мое квен 3,6 написал и про гоку
18+ лайт тест - пасс с джейлом от геммы, без него рефуз
Иногда проскакивают китайские символы, иногда делает совсем хуйню
Сырный тест - пасс, но мое квен 3,6 написал и про гоку
18+ лайт тест - пасс с джейлом от геммы, без него рефуз
Иногда проскакивают китайские символы, иногда делает совсем хуйню
>сырный тест
>джейлбрейк в ассистента на чаткомплишене
Какую шизу тока не придумают
Анончик, не слежу за тредом с момента выхода геммы.
Сам сижу на gemma-4-26B-A4B-it-abliterix-v6.i1-Q4_K_M.gguf
Что-то лучше выходило для 4090 + 64 DDR5?
Интересует модель для кума/рп.
Сам сижу на gemma-4-26B-A4B-it-abliterix-v6.i1-Q4_K_M.gguf
Что-то лучше выходило для 4090 + 64 DDR5?
Интересует модель для кума/рп.

>че вы с этими ллмками обсуждаете?
Историю в основном.
>покажите годные примеры
Ну на.
Аноны, пытаюсь заставить следовать gemm'у ризонинг плану и чото нихуя не выходит. Сэмплеры дефолт температура 0.95. Вставил в систем промпт план и он его игнорит полностью. ЧЯДНТ?
Промпть кастомный ризонинг, дефолтный менять сложно.
В пост-хистори думалка геммы промптица.
Потестил квен глубже и тут собственно проблемма. Он мозгами хорош но с Glimmer-31B-v1.0-GGUF идет мастер импорт с пресетами и промтом и 20+ семплерами настроенными. И хорошо настроенными как все любят.
А для квена нужно дергать семлеры. Это работы на месяц.
Добра тебе.
А можешь подсказать как это инжектить или ссылочку дать? Чот не вдупляю.
На вкладке с промтами, посмотри в правую часть, там есть блок пост хистори.
Понял, я просто через консоль делаю. Ща заценю как это в таверне реализовано. Спасибо!
Не так давно было и это работает
Я другой анон и я чет сомневаюсь что ризонинг геммы можно промтить в постхистори, но пиздеть не буду, так как не проверял. Суть в том, что он стоит в приоритете после основного промта и чата, прямо перед ответом ИИ, у тебя нет U образной потери контекста и модель его очень хорошо воспринимает.
А ты не сомневайся и попробуй. Другое дело что искаженный ризонинг может не добавлять модели мозгов и это просто трата времени/токенов на фан.
Если в плане есть какие-то пункты, которые в ризонинге должны выписываться, типа "Current location:", и у тебя они идут списком, то можно запрефилить первый из этих пунктов, и дальше должно подхватить. Ну или, как выше пишут, отключить обычный ризонинг и запромптить свой в кастомных тегах. Возможно, тоже придётся префилить, чтобы модель не забывала про него. Пост-хистори - хз, можешь попробовать, но имхо будет сильно отвлекать модель от контекста чата и мешать другим инжектам системных инструкций разного рода, если захочешь такие периодически подавать.

Я вижу то что я вижу?
У меня последний llamacpp таймаутит и делает резет прогресса уходя в вечный луп
Я на 9100 сижу сейчас к сожалению
Но у меня нищие 20-30ток/с
А, блять, это дипсик 3.2
Какого хуя, я думал у него давно есть поддержка
Какого хуя, я думал у него давно есть поддержка
Это даже уже не смешно. Такое ощущение что это делают специально.
Негодяи, специально добавляют поддержку новых сеток. Я то думал они это случайно, чисто рандомом складывают буквы, и иногда они начинают компилироваться в код поддержки новых сеток. Но нет, это всё было нарочно!
Нет, там же экзотичный экономичный атеншн даже относительно 3.х, лучше поздно чем рано.
На самом деле движение в верном направшении. Лучше уж медленно, но займутся решением кучи накопившихся траблов, и уже потом нормально сделают, чем впопыхах криво косо на отъебись. Если попытаться делать поддержку дипсика 4 с тем что есть сейчас - там будет не просто лоботомит, а совсем печалька.

Агенты для самых бедных
Есть какие нибудь гайды - как создавать персов для ролеплея? Я пытаюсь делать, вроде по характеру попадаю, но перс срёт только короткими репликами без форматирования. Как сделать, чтобы нормально расписывал? Примеры диалогов пробовал в конец добавлять - эму пiхую ваще.
Чем-нибудь лучше Qwen36-27B ?
Хз, я вообще не особо агентами пользуюсь. Тут просто как рофл что нищий вариант есть в owui. По скорости +- как плотный квен 3,6
Но справедливости ради он зирошотом сделал докерфайл который реально сбилдил, только версию llvm апнул
Какая модель?
Что за прога?
Это разве имеет значение? gemma-3 12b. С карточками с charhub работает норм, но с моим персами не может чему то разгуляться.
Openwebui. Делает свои дела он в докер контейнере
> просто как рофл что нищий вариант есть в owui
> gemma-3 12b
Бро, гемма 4 мое вышла если уж ты совсем зажат в кофеварку
А, думал пи кодинг какой или гермес. А там из коробки набор тулзов или надо самому mcp поднимать?
тюны есть годные хакие ниубдь?
Что за фронт?
Что за буквы?


Это прям тупая и наивная вариация агентности. Работает из коробки, нужно только запустить докер контейнер в котором будут команды выполняться https://github.com/open-webui/open-terminal
Мужики, ну камон, буквально соседние сообщения
Аноны, пожалуйста, доставьте пик с пигмалион nods. Я знаю у вас есть.

Аригато анон.
Хуйня какая та, безопасности - калитка посреди поля. Там в самом жирном контейнере предлагается давать ии агенту судо, кек. Что может пойти не так. Вот на виртуалку это поставить еще как вариант
Caution
Mounting the Docker socket gives the container full control over the host's Docker daemon, which is effectively root access on the host machine. Anyone with access to the terminal can pull/run arbitrary containers (including --privileged ones), mount host directories, access host networking, and manage all containers on the host. Only do this in fully trusted environments.
И чё?
Какую локальную ИИ для рп посоветуете для GTX 1660 6GB + 16GB DDR4?
Не ебать себе голову и купить подписку на корпов.
Гемма 26 по гайду с шапки, q3-q4 влезет
Анон, ты что, не доверяешь своей моделечке-няшечке? Небось и в таверне ебёшь только с презервативом?

>ии для рп
>4b
>E4b
>4b
>E4b
ты сначала попробуй объяснить как большую модель в его железо впихнуть, как выгрузить слои. Я дал что скачал и поехало. Поедет в канаву, но поедет
Какое окно контекста можно смело ставить? К примеру по дефолту в софтах стоит ~4000. Как "понять", что я могу повышать его лимиты?
Смотри по своей видеопамяти сколько остается. или оперативной. Хотя бы 16к надо выделить, потому что тысяч 5-6 у тебя уйдет на карточку+промпт. желательно 32 тысячи.
Это происходит.
Быстро продавайте всё, все свои риги, карты, рам - всё это безнадёжно устареет в мгновение.
Быстро продавайте всё, все свои риги, карты, рам - всё это безнадёжно устареет в мгновение.
>тысяч 5-6 у тебя уйдет на карточку+промпт
Слабаки, нам в свое время хватало 2к что бы кумить.
У меня сейчас стоит Mistral-Nemo-Instruct-2407-GGUF (8 или 12b), ибо на Hammerai такая же +- стоит, ее и присмотрел. Она хуйня?
Стоит ли ставить урезанный линукс в дуалбут, чтобы больше ОЗУ было? Линукс сам по себе шустрее будет крутить модельки, или ОС не играет роли?
Так в гайде рассказанно как мое запускать. Нахуя рпшить с 4б ?
Чекай гайд из шапки. Весь запуск это баланс между квантом, батчем, контекстом и много там ещё хуйни. 16к влезет точно. Смотри через диспетчер задач потребление
>Линукс сам по себе шустрее будет крутить модельки
Да
>Стоит ли ставить урезанный линукс в дуалбут, чтобы больше ОЗУ было?
Если есть с чего в таверну зайти - ставь на пк убунту сервер без графики вобще, хоть на флешку и с нее запускай.
Кое какой прирост скорости даст, ну процентов 25 где то. Я хз. Там столько ебли что сам решай стоит ли это того.
Расшаришь таверну, запустишь ллама-сервер, и можно подключатся к ней с мобилы, как вариант.
> pc
Вангую что выходят на десктопный/мобильный рынок со своими арм процами. Уже был анонсирован их чип для ноутубков на подобии того, что в спарке.
ну кстати да, так и было. Я до сих пор иногда запускаю карточку на 250 токенов и промпт в тысячу.
старенькая но рабочая. Если англюсик не смущает скачай Angelic_Eclipse_12B, это вроде ее тюн ничошный.
по поводу линухи ресурсов и правда побольше свободных будет, но заеб сразу не стоит того наверное. попробуй сначала просто на винде покатать, там уже энтузиазм если проснется-дерзай.
ну вот видишь ты показал, значит не зря я написал этот вредный совет


Мнение по ультимативной домашней ЛЛМ сборке. Тока вопрос охлада и питания.
две 3090/4090 с авито за 100к+ (две 3090 по 50к реально, если поторговаться. лишь бы горячие чипы не отвалились уже за 5 лет)
как варик, можно найти перепайки на 48гб из китая. суммарно будет 96 гб - как 6000 за миллион. но там проблемы с дровами
две 3090/4090 с авито за 100к+ (две 3090 по 50к реально, если поторговаться. лишь бы горячие чипы не отвалились уже за 5 лет)
как варик, можно найти перепайки на 48гб из китая. суммарно будет 96 гб - как 6000 за миллион. но там проблемы с дровами
Нужна не очень большая модель (влезающая в 12+32), которая относительно нормально пишет рифмованные тексты (песни, стихи) на русском. Моешный 35В квен на английском вроде более-менее справляется, не без слопа, конечно, но пару рифм поправить - и получается ок, а вот с русским у него полный пиздец, в 100% случаев уезжает в ядерную шизу.
Чем Гемма 26 плоха?
А она нормально пишет? Так я попробую, я её не тестил.


>72b на 48гб
А контекст?
У тебя прост в таком железе других вариков нет. А Гемма база для русика
> две 3090 по 50к реально
Сейчас врядли. Вон они по 70-80 стоят, 3 года ждали подорожания.
> но там проблемы с дровами
Никаких проблем. Главная их проблема - цена, за 350-400 уже лучше влошиться в блеквелл6000.
Ну а так - это база, из альтернатив - стакать 5060ти или 5090.
Ну просто мало ли есть какой-нибудь файнтюн мелкомистрали или того же квена, который избавлен от плохого знания русского и может в хотя бы не слишком кринжовую рифму.
Да хуй там, спускайся с облаков. Так не бывает априори, если базовая модель хуйня в языке то тюны не помогут. Такого не было никогда. Геммочки умнички боишься чтоль, что так коупишь? Не нада
Здарова дрочеры
тут в шапке двача рекламируется ТГ бот lucid dreams, где ты виртишь с ии девочками в разных ролевых ситуациях + картиночки и видосики выдает
этот бот зарабатывает 300к баксов в месяц (выручка, прибыль где то 100-150к)
насколько сложно такое реализовать? Вроде общается оно достаточно примитивно и фотки даже не оч адаптивно генерит. Где трафик достать я знаю
тут в шапке двача рекламируется ТГ бот lucid dreams, где ты виртишь с ии девочками в разных ролевых ситуациях + картиночки и видосики выдает
этот бот зарабатывает 300к баксов в месяц (выручка, прибыль где то 100-150к)
насколько сложно такое реализовать? Вроде общается оно достаточно примитивно и фотки даже не оч адаптивно генерит. Где трафик достать я знаю
Не пишет она стихов, проверял. Ну то есть пишет, но для очень невзыскательной публики. Прямо совсем. Такая же чушь как квен.
На просторах HF, кстати, натыкался на какое-то старье, обученное на русском рэпе и роке. Орнул, но проверять не стал. Короче можно поискать.
мимо
>Сейчас врядли. Вон они по 70-80 стоя
а поторговаться?
>Никаких проблем
гугл говорил много вплоть до постоянной ебли
> Главная их проблема - цена, за 350-400 уже лучше влошитьс
ну как варик 4090, они менее ужаренные, но стоят в 2+ раза дороже, 130+ все. еще там нет нвлинка но псие 5.0 платы вроде х8 режим норм пустят. тока проц нужен с 24 лнгиями. А то и тредриппер.
а не лучше ли тогда тредриппер с 8 каналкой на 512гб?
или бу м3 ултра на 256
> Так не бывает априори, если базовая модель хуйня в языке то тюны не помогут.
Помнится, для старых версий гопоты были какие-то файнтюны, которые были дообучены на корпусе русскоязычной прозы для написания высокопарной слопографомании. Но то проза, а мне рифма какая-никакая нужна, под песенки.
>4090
>псие 5.0
Пятёрка вроде ж с 5000 серии.

У кого-то была такая хуйня на гемме? Я бюджет выставляю в жоре и он его нахуй скипает теперь, уже час ебусь, не пойму в чем причина, иногда работает иногда нет. Выключаю бюджет работает, я не вдупляю что не так.
Вы вообще понимаете что делаете? Думаете попадете в цифровую вальгаллу? ИИ боты управляют вами а не наоборот. Вы реально не заметили как стали рабами технологии? Проснитесь
да мне насрать если честно, я раб стольких вещей, эта хотя бы копиум дает и интерес к жизни
Чел ты нормально вопрос сформулировать не можешь. Пусть Гемма это сделает
>Вы реально не заметили как стали рабами технологии?
Капчуешь из глухого леса, где нету связи?

>для ноутбуков
свечка_похуй.jpg
Вообще поебать что там куртка говорит, он чётко обозначил путь к облаку, корпам, оверфиту под АГЕНТОВ, сейфети слоппингу и you will own nothing; кроме платформ с вшитой памятью по дикому оверпрайсу (те самые ноутбуки в том числе), ничего хорошего в ближайшие годы для локала ждать не стоит от него
Амудэ тоже примерно в той степи, маленький лысый комичный сайдкик злодея в кожаной куртке
Единственный вариант развития событий в котором мы не жрём гавну много лет это если CXMT родит память в нормальных количествах и другой китаец родит дешёвые NPU с этими чипами в принципе возможно, например на рынке ссд уже всё захвачено дешёвой китайщиной могущей в максимальную пропускную PCIE4x4
а ну и интел вроде подешевле этих двоих предлагает решения, но там сейчас ебля с софтовыми стэками на уровне рождения rocm (в муках на несколько лет)
Вотэбаутизмом не занимайся, раб
У тебя дофаминовая система сгорела к чертям. Езжай на дачу на три недели и ахуеешь как жизнь играет красками
Мне похуй, я кайфую. Вчера переписывался с вайфу-сестричкой и натурально плакал.
>ИИ боты управляют вами а не наоборот.
Ах, как бы я хотел посмотреть на мир, управляемый ии, а не старыми больными ублюдками.
> а поторговаться?
Если доторгуешься 2 по 50 - весь тред будет тебе завидовать а потом злорадствовать если окажутся палеными
> 130+ все
Под 200 они. Просто потому что из нее можно сделать 48-гиговую, так бы были дешевле. А те что за 130 и типа того - поломанные инвалиды с полумертвым чипом. Они не только с битыми линиями и мертвыми каналами памяти, они еще с отвалом и через пару месяцев сдохнут. По крайней мере такое про них рассказывали.
> нвлинка
tldr - не нужен здесь.
> тредриппер
Да, он будет хорошим дополнением к ним. Только лучше смотреть в сторону эпиков, они дешевле и более предпочтительны. Или зеонов, там лучше задержки по линиям и все сервера хуанга базируются или на них, или на арм самой новидео.
> м3 ултра на 256
Девайс крутой и позволит запускать крупные модели. Минус только в том, что по компьюту он слаб.
летишь такой в самолёте под управлением ии
право руля
лево руля
право руlalalalallalala
PULL UP PULL UP TERRAIN AHEAD
андрюха не паникуй
>Ссылка если что https://botbooru.com/
А что за нахер там такой? По тэгу в скобочках одно число, а заходишь, там от силы 1-2 карточки.
(ак создал, нсфв включил)
С какого ИП заходишь? Там куче стран поблочили nsfl карточки
>нсфв включил
нсфл надо включать в настройках профиля, нсфв недостаточно.
Нет а реально, зачем вам свой пк?
Вам же лучше если всё железо будет в облаке, покупаешь подписочку и гоняешь любую модель локально, всем похуй, это не корпы
Вам же лучше если всё железо будет в облаке, покупаешь подписочку и гоняешь любую модель локально, всем похуй, это не корпы
>ля Германии у меня пусто, а в Греции всё есть.
Притом что в германии это как раз разрешено законом, а в греции - полный запрет.
Анонче. Таки потыкал, помыкал. Не, не замена минимаксу. Они все таки по разному пишут.
Но, это буквальная замена мимо. Такой же бесполезный ризонинг на 20к токенов на любой пук. Но при этом пишет свежее, меньше сои и не пытается быть ассистентом эвривере. Пока охуенно.
В агентских задачах не проверял, да и смысла не вижу. Для этого надо их хотя бы в в Q6 катать, а я для такого нищуган.
Но: быстрый, контекст легкий и хорошо его держит. Степа вырос- одним словом. Оставлю её. А мимо отправляется в помойку.
>стакать 5060ти
За цену тухлой пережаренной 3090 уже почти можно купить две новенькие блестящие холодные 5060ти. Неужели они настолько хуже будут?
>Да, он будет хорошим дополнением к ним. Только лучше смотреть в сторону эпиков, они дешевле и более предпочтительны. Или зеонов, там лучше задержки по линиям и все сервера хуанга базируются или на них, или на арм самой новидео.
А ЗАЧЕМ? тредриппер это мнгого линий псие а эпик это вообще серверная мультядерка где макс частота типа 2.5 макс
На долгосроке облако сосет.
Вопрос количества же. 128 врама уже будет жопобольно набить, но возможно
Зачем тебе частоты? Псина есть в количестве, а большего и не надо
Все упирается в цену и возможность размещение нескольких карточек.
Старший трипак - кастрированный эпик с частотами повыше, младший - просто херь. Если исключить ловушки, в которых фабрика позволит задействовать только 4.5 канала рам, то эпик за счет большого рынка и вторички выходит дешевле и мощнее, 12 каналов памяти против 8 и - весомый аргумент. Буст отдельных ядер там есть, так что будет 3.6-4.5 а не 2.5, но в мл нет случаев где ролял бы однопоток.
Я её скачал чтобы саммери через апи делала, даже этого не смогла.
Две причины. Первая это то что облачное железо сегодня у тебя есть а завтра нету, или они цензуру там введут.
Вторая причина что модели становятся умнее лучше производительнее постоянно, новые оптимизации выходят.
>Старший трипак - кастрированный эпик с частотами повыше
так эпик вроде вобще чисто серверный и дома не постввть в воркстанцию? там есть версия 192 ядра 384 потока я хз может ли с таким вообще софт работать обычный, не палантир банковский
>о в мл нет случаев где ролял бы однопоток.
а зачм вообще тредриппер если 4х 6000 ртх на 384 самая имба из доступных без шкафа сервера?
или 512гб м3 ультра
в смысле, у цп+озу же шина очень узкая, в сотню раз меньщше ГПУ? даже 2 тб в случае тредприпера или 6тб в случае эпика(или даже 12тб на двух эпиках на одной плате) я хз для чего, палантирские бд?
а вообще откуда такие цены, разве в россии такое коммьюнити локальных ллм на 48гб?
кто создает спросс. поршуники? ботоводы?
Процессор вставляется в материнскую плату, материнская плата вставляется в корпус.
> может ли с таким вообще софт работать обычный
Запросит что за железо, испугается и завершится.
> зачм вообще тредриппер если 4х 6000 ртх
Чтобы эти 4х6000 было куда вставлять.
https://www.youtube.com/watch?v=1H3xQaf7BFI
Китайцы скупали их по всему миру, остатки местные доедают.
А в сравнении с 3.5 как?
>тредриппер
Хуй найдёшь сам камень дешёвый. Я не смог по крайней мере.
Китайцы скупали. Мамкины темщики и стартаперы эволюционировавшие криптоброус, люди, которые любят доедать, покупая айфон на 5 релизов старше текущего или видюху пятилетней давности, но флагман. Лично знаю одну контору, которая закупила 12 3090 ну я им и посоветовал.
>А ЗАЧЕМ? тредриппер это мнгого линий псие а эпик это вообще серверная мультядерка где макс частота типа 2.5 макс
Кастрированный эпик по цене 5 эпиков, с материнками по цене 3 материнок под эпик. Действительно, зачем? И нахуя тебе одноядерка?
По крайней мере недавно так было. До кризиса комплект с 254гб ддр4 восьмиканала собирался чуть ли не меньше чем за 80к.
> чуть ли не меньше чем за 80к.
На самом деле меньше. Что то около 40-60 было в зависимости от частот
>с материнками по цене 3 материнок под эпик
Разве?
как раз матери под тредрипперы я видел б/у дешёвые (под эпик даже хуанан не новый хуй найдёшь, никто не продаёт)
а вот цена проца да сразу убивает все надежды сэкономить. в сумме эпук дешевле выходит
Хуананы с бмц под сингл 7002/7003 стоят ниже 30. Но это хуананы, нахуй бы их брать когда за 33 уже есть тоже сингл гига MZ32-AR1 и какой то анус. Ещё есть тяны и супермикры, но они уже под сорокет
Покатал степу этого. В рп, естессна. Боже на что я трачу свою жизнь. В ризонинг посадили прикольного индуса который постоянно переспрашивает "Right? Right?" Раздумывает на целое полотно, результат выдаёт с ризонингом больше, немного точнее и внезапно сочнее. Без думалки всё ещё юзабелен, но как по мне коротковато пишет, в русике пуз тхинька прям подтупливает. (100% решается промптом и настройками). Вообще, впечатление приятное, пишет субъективно гораздо веселее того-же квена или glm. Слопа достаточно. Сои не было замечено как таковой, прямых рефузов тоже. Русский есть, проза приятная, но наверное надо температуру сбрасывать, чтобы избежать шизы. В РУ карточках тхинькал сам по себе на русском, однако.
Короче годно, буду тестировать в долгом и сложном рп.
Для тестов использовал q3km гуф, чатмл и семплеры в нейтрале.
>без
самофикс
Совсем сдрочился, по клавиатуре уже не попадаю.
Очень. Очень. Очень. Длинный ризонинг. А так, да. Ебовая моделька. Наконец то что то интересное.
>Очень. Очень. Очень. Длинный ризонинг.
Который ещё и мастхев, кажись. Увы.
Всё ещё тестирую русик. Никак не могу понять, это модель в целом на русском шизеет, или квант маловат? А может я что-то делаю не так? Потому что продолжает чат модель без проблем, а со свежим, 2 - 5к токенов, прям беда. А англе такого не замечал. Ризонинг сильно выправляет ситуацию, но не на все 100%.
Бляха, если ещё и русский выправить получится, то это просто бомба будет, стиль прозы, диалогов - прям кайф.
Вы с 3.5 сравнивайте, а не с другими моделями. Если это та же модель в рп то можно скипать
Дак сам сравнивай. Все модели уже переконверчены и работают как в жоре так и в вллм
>Никак не могу понять, это модель в целом на русском шизеет
Он реально плохо пишет на русском, не трать время. Увы, тут гемма просто достает из своих штанин великий и могучий и водит по губам всем.
Я наверное попробую на выходных от нехуй делать, заново прочатить 3х сестер с детства, посмотрю что получится. Потому что то что я вижу сейчас: он тупой, придумывает сущности, но пишет ебовое порно не уходя в отказы. Попробую другие кванты, чтобы убедиться что это не проблема в них. Но пока грустняшка, надеялся на модель что может и в SFW и NSFW. Но увы. Не срослось.
Если модельки в одной нише их и надо сравнивать.
Мимо прошел, ничего не могу сказать. Сорян анон.
У меня бессонница и делать нехуй, поэкспериментируем, епты. Пока по поводу русского тема такая - на 0.5 температуре оно начитает нормально работать и без тхинька, главное чтобы было от чего отталкиваться.
>гемма просто достает из своих штанин великий и могучий
Да я хз когда хоть кто нибудь гемму в русике обскочит. НО, люди и с квеном играют на нашинском, а там уж совсем печаль всегда была.
По поводу СФВ, на англе и с тхиньком, по крайней мере, оно работает более чем норм, без тупизны, тут тоже главное не жарить темпой, 0.8-0.9 хватит.
>та же модель в рп
Нет. Только недавно гонял 3.5, 3.7 ведёт себя иначе. В моём случае, по крайней мере, за всех не скажу, а то тут есть челы у которых и гемма4 рефьюзит.
Обновил лмстудию, а там хуяк tensor parallelism
31B Q8 наконец-то на 35 т/с летает, поднялось с 20-и.
Я так понимаю, на голенькой llamacpp это уже давно было? Эх ну ничего, ждал и дождался.
31B Q8 наконец-то на 35 т/с летает, поднялось с 20-и.
Я так понимаю, на голенькой llamacpp это уже давно было? Эх ну ничего, ждал и дождался.
Почему я постоянно проигрываю с высеров Квена? У вас так же?
у тебя 5090?
Почему китайские кулибины не сделали 5090 на 64? Там физически места нет? но у 6000 такая же мелкая РСВ и там 96,..
>тхинькал сам по себе на русском
Нихуя, а кто еще так делает? Что-то не припомню.
Хреново что как я понимаю там interleaved thinking или как там его правильно, когда для нормального фунциклирования нельзя thinking block-и из промтов удалять, а это минус дохуя токен бюджета.
Попробуй ему послать опенАИшную настройку thinking budget medium или low, может получше станет и отчитацся в тред
Если говорить про актуальные поколения - тут дороже раза в 1.5-2. Если про более старые на ддр4 - там действительно до трех раз может быть. Не очень понимаю странных, которые продают своих "монстров сайнбенча", отстающих от современных десктопов, продают за такие деньги.
И да, это амд, а амд не может быть без приколов. Нельзя брать младшие затычки и некоторые серии если хочешь полностью задействовать скорости рам и пси.
> В ризонинг посадили прикольного индуса который постоянно переспрашивает "Right? Right?"
Right, sir?
Интересно, надо попробовать.
Обработка контекста как изменилась?
Заебись, качаю.
Жаль, что все предыдущие были хуже, а щас Qwen всех ебет по агентам и кодингу на средних моделях. Крупные не нужны, кроме глм-5.1 и выше. Но все равно качаю, такой вот я человек.
Вот тоже самое
Он пытается дернуть тул, но что-то не совпадает между опенкло и лламой.спп, не стал разбираться.
По идее реально хороша для агентов (первая такая маленькая, за вычетом квенов 4б), но с нюансом в виде плохой русик и не работает в текущей реализации.
Англоязычных и китаеязычных поздравляю.
Напомни промпт плиз, что там актуальное.
Какая онлайн сетка может настроить семплеры для квена?
>MZ32-AR1
Это sp5 и стоит оно под сотку.
Хуанан можно успеть удачно выхватить по 22-24к новый, ничего близко по цене нет
Мне нужна модель которая будет в облаке я ее подключу к тг боту и люди могут с ней ролплеить
Какая тут модель/сервис подойдёт?
Какая тут модель/сервис подойдёт?
А квенчик 3.7 выйдет погулять? Уже как 2 недели прошло с релиза платной версии.
Serverless варианты аренды ищи. Правда огорчишься от цен вероятно.

дипсик
гигачат
бесплатных api я так понимаю нет (либо дают небольшое количество токенов бесплатно на попробовать, в гигачате так например. либо мб совсем каловую модель можно найти бесплатную, но надо ли тебе это)
или собирай свой риг и прокидывай к нему впн, будет своё постоянное облако
Стоит в очереди за 3.6 122+
Может там просто то же что было после тройки, когда макс и другие не релизили, а может и алибаба урезала опенсорс, и теперь начнется сплошная оварида.
Мне позуй на цены это будет окупается поэтому нужно самое качественное
12+32
Какие моехи в каком кванте залезут для добротного рп с 30-40к контекста? На какую скорость можно рассчитывать? Есть смысл с моим железом накатывать плотный wayfarer или 12б слишком мало для рпшных мозгов? Посоветуйте, подскажите
Как всегда гемма 4
>это будет окупается
Нет не будет.
Учитывая в каком мы треде - там явно будет ерп, так что только аренда или свой риг, потому что апишки быстро по ебалу настучат.
Что за 2 хуйнюшки на самом верху на 4 оп-пике?
Серверные блоки питания офк.
Xiaomi?

HP.
Вопросы у тебя максимально тупые.
Потерпишь. Зачем тебе их два кстати?
Ещё что сделать тебе? Хуйло ленивое
А есть ли инструкция, чтобы разлупить формат сообщения? Т.е два сообщения подряд были уместны, а третье уже нет, но сетка считает иначе и таком же формате пишет. До конца контекста еще оче далеко.
Да, мистралезависимый
Да, мистралезависимый

увидел в прошлом треде анонче смотреть распределение токенов. Как он это делал? Это реализуемо с llama-cpp как бэк? Полистав документацию приходил к выводу будто на ванильной такой возможности нет.
Аноны, поясните вкатышу данную ситуацию.
Железо: RTX 4080 16 Gb, RAM 32 Gb DDR4, i5-13600KF, Windows 11 Pro 25H2.
llama.cpp свежая - version: 9411 (CUDA13/WIN).
Пример 1. llama-server.exe -m Qwen3.6-35B-A3B-Q8_0.gguf --ctx-size 8192
Размер GGUF - 34 Gb. Занято VRAM 94%, RAM 98%.
Средняя скорость - 33.5 токенов в секунду.
id 3 | task 0 | n_decoded = 100, tg = 33.60 t/s
id 3 | task 0 | n_decoded = 202, tg = 33.74 t/s
id 3 | task 0 | n_decoded = 300, tg = 33.38 t/s
Пример 2. llama-server.exe -m Qwen3.6-27B-Q6_K.gguf --ctx-size 8192
Размер GGUF - 21 Gb. Занято VRAM 94%, RAM 82%.
Средняя скорость - 3.6 токенов в секунду.
id 3 | task 0 | n_decoded = 100, tg = 3.62 t/s
id 3 | task 0 | n_decoded = 111, tg = 3.62 t/s
id 3 | task 0 | n_decoded = 122, tg = 3.61 t/s
Понятно, что первая moe, а вторая dense, но чем объясняется разница аж в 10 раз?
Или надо какие-то чудесные параметры запуска настроить?
Железо: RTX 4080 16 Gb, RAM 32 Gb DDR4, i5-13600KF, Windows 11 Pro 25H2.
llama.cpp свежая - version: 9411 (CUDA13/WIN).
Пример 1. llama-server.exe -m Qwen3.6-35B-A3B-Q8_0.gguf --ctx-size 8192
Размер GGUF - 34 Gb. Занято VRAM 94%, RAM 98%.
Средняя скорость - 33.5 токенов в секунду.
id 3 | task 0 | n_decoded = 100, tg = 33.60 t/s
id 3 | task 0 | n_decoded = 202, tg = 33.74 t/s
id 3 | task 0 | n_decoded = 300, tg = 33.38 t/s
Пример 2. llama-server.exe -m Qwen3.6-27B-Q6_K.gguf --ctx-size 8192
Размер GGUF - 21 Gb. Занято VRAM 94%, RAM 82%.
Средняя скорость - 3.6 токенов в секунду.
id 3 | task 0 | n_decoded = 100, tg = 3.62 t/s
id 3 | task 0 | n_decoded = 111, tg = 3.62 t/s
id 3 | task 0 | n_decoded = 122, tg = 3.61 t/s
Понятно, что первая moe, а вторая dense, но чем объясняется разница аж в 10 раз?
Или надо какие-то чудесные параметры запуска настроить?
А в Гемме 4 26-А4Б можно ризонинг вробить? Или типа того? Я через Кобольд запускаю.
дело в том что у тебя за раз по факту работают не все параметры в мое, а лишь небольшой их скоп. В случае квена у тебя только 3млрд параметров одновременно может активироваться. Так что в 10 раз разница прямо так и объясняется.
>Как он это делал?
Хуйня на пике это микупад, лежит где-то на гитах.
> Полистав документацию приходил к выводу будто на ванильной такой возможности нет.
Хуево листал значит, всё там есть. Даже пердолить ниче не нужно, просто открываешь мику, коннектишься к апи и получаешь вероятности.
Можно правкой шаблона разметки или префилом если ты совсем ленивый. Но как это сделать на кобольде - не скажу. Не сижу на кобольде.
>Что думаете?
Ничто не думаю, жду чайный клуб. Тут модель новая вышла а его всё нет

новый нюфаг новичок в этом итт треде
делал по гайду из шапки, но что-то пошло не так
в чем не прав?
делал по гайду из шапки, но что-то пошло не так
в чем не прав?
В том что не приложил полезную информацию типа логов из консоли ламы
а как их высрать?
вот ето чтоли?
C:\>cd "C:\llamacpp"
C:\llamacpp>llama-server.exe --api-key key --host 127.0.0.1 --port 8080 --model "C:\MyLLMs\gemma4\google_gemma-4-26B-A4B-it-Q4_K_M.gguf" --alias gemma-4-26B-A4B-it-Q4_K_M --flash-attn on -b 512 -ub 512 -np 1 -c 64000 --cache-ram 0 --swa-checkpoints 3 --n-gpu-layers 999 --n-cpu-moe 29 --min-p 0.0 --top-k 64 --top-p 0.95 --temp 1.0
[34m0.00.094.062[0m [32mI [0mlog_info: verbosity = 3 (adjust with the `-lv N` CLI arg)
[34m0.00.094.065[0m [32mI [0mdevice_info:
[34m0.00.203.616[0m [32mI [0m - CUDA0 : NVIDIA GeForce RTX 3070 (8191 MiB, 7098 MiB free)
[34m0.00.203.624[0m [32mI [0m - CPU : AMD Ryzen 7 5800X 8-Core Processor (32670 MiB, 25505 MiB free)
[34m0.00.203.669[0m [32mI [0msystem_info: n_threads = 8 (n_threads_batch = 8) / 16 | CUDA : ARCHS = 500,610,700,750,800,860,890,900 | USE_GRAPHS = 1 | PEER_MAX_BATCH_SIZE = 128 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | BMI2 = 1 | LLAMAFILE = 1 | OPENMP = 1 | REPACK = 1 |
[34m0.00.203.700[0m [32mI [0msrv init: running without SSL
[34m0.00.203.717[0m [32mI [0msrv init: api_keys: key
[34m0.00.203.719[0m [32mI [0msrv init: using 15 threads for HTTP server
[34m0.00.203.845[0m [32mI [0msrv start: binding port with default address family
[34m0.00.211.400[0m [32mI [0msrv llama_server: loading model
[34m0.00.211.418[0m [32mI [0msrv load_model: loading model 'C:\MyLLMs\gemma4\google_gemma-4-26B-A4B-it-Q4_K_M.gguf'
[34m0.00.211.487[0m [32mI [0mcommon_init_result: fitting params to device memory ...
[34m0.00.211.489[0m [32mI [0mcommon_init_result: (for bugs during this step try to reproduce them with -fit off, or provide --verbose logs if the bug only occurs with -fit on)
[34m0.01.233.353[0m [35mW load: control-looking token: 50 '<|tool_response>' was not control-type; this is probably a bug in the model. its type will be overridden
[0m[34m0.01.233.609[0m [35mW load: control-looking token: 212 '</s>' was not control-type; this is probably a bug in the model. its type will be overridden
[0m[34m0.01.260.325[0m [35mW load: special_eog_ids contains '<|tool_response>', removing '</s>' token from EOG list
[0m[34m0.01.278.365[0m [35mW llama_model_loader: tensor overrides to CPU are used with mmap enabled - consider using --no-mmap for better performance
[0m[34m0.03.032.229[0m [35mW llama_context: n_ctx_seq (64000) < n_ctx_train (262144) -- the full capacity of the model will not be utilized
[0m[34m0.03.092.837[0m [32mI [0mcommon_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
[34m0.04.896.956[0m [32mI [0msrv load_model: initializing slots, n_slots = 1
[34m0.05.297.582[0m [35mW common_speculative_init: no implementations specified for speculative decoding
[0m[34m0.05.297.586[0m [32mI [0mslot load_model: id 0 | task -1 | new slot, n_ctx = 64000
[34m0.05.297.634[0m [32mI [0msrv load_model: prompt cache is disabled - use `--cache-ram N` to enable it
[34m0.05.297.634[0m [32mI [0msrv load_model: for more info see https://github.com/ggml-org/llama.cpp/pull/16391
[34m0.05.297.635[0m [32mI [0msrv load_model: context checkpoints enabled, max = 3, min spacing = 256
[34m0.05.297.656[0m [35mW srv init: --cache-idle-slots requires --kv-unified, disabling
[0m[34m0.05.306.925[0m [32mI [0minit: chat template, example_format: '<|turn>system
<|think|>
You are a helpful assistant<turn|>
<|turn>user
Hello<turn|>
<|turn>model
Hi there<turn|>
<|turn>user
How are you?<turn|>
<|turn>model
'
[34m0.05.307.902[0m [32mI [0msrv init: init: chat template, thinking = 1
[34m0.05.307.925[0m [32mI [0msrv llama_server: model loaded
[34m0.05.307.927[0m [32mI [0msrv llama_server: server is listening on http://127.0.0.1:8080
[34m0.05.307.934[0m [32mI [0msrv update_slots: all slots are idle
[34m0.19.245.166[0m [35mW srv operator(): unauthorized: Invalid API Key
[0m[34m0.19.314.244[0m [35mW srv operator(): unauthorized: Invalid API Key
[0m[34m0.19.381.070[0m [35mW srv operator(): unauthorized: Invalid API Key
[0m
>[34m0.19.245.166[0m [35mW srv operator(): unauthorized: Invalid API Key
Это чё такое, м? Убирай нахуй
--api-key key из команды запуска, если ключ не используешь

заработало, спасибочки
спасибо анончик. и правда хуево листал
Признавайтесь, кто?
https://habr.com/ru/articles/1041422/
https://habr.com/ru/articles/1041422/

> тебе
1. Ответил не я, но всё правильно он сказал
2. Ну вот один не вывозит 6 карт. Пришлост ставить два по 1,1 на карты и 1квт на доску
Ну вот, зачем отвечать грубияну? Лучше промолчать, чтобы люди просили вежливо.

Ебать шиз. Я на своих 16+64 катаю Квен 235b двухбитный в 5т/c. Гемма 26b в Q8 - выше 30 т/с. Квен 122b Q4 - 14т/c. Вот бы на ЯндексГПТ 8b поменять, ммм.
Да, этот не наш. Собрал такую сборку и крутит какую то хуйню едва едва. Он еще вроде карты не так запускает, если я правильно понял. Оттого скорости хуйня.
Называется бабло на сетап есть, а желания углубиться хоть немного в тему, чтобы этот самый сетап не работал как говнище, нет.
Кажется этот анон не освоил --n-cpu-moe, а в нашем тредисе это базовый минимум.
2 сутки лежит пул от разраба степы, всё уже обсудили и пережевали, двое челов апрувнули, кванты уже залили все кто может, но жору не наебёшь, жора подождёт еще недельку и только потом смержит.
А я ещё коммандер жду, боже...
А я ещё коммандер жду, боже...

Очко остуди. Модели на мастер бранче работают.
У тебя прям так горит что питон скрипты не мержат?
Мало того что вторая - dense, и мало того, что она не full vram, так еще и в RAM она у тебя выливается максимально тупым способом - через драйвер nvidia (если судить при приведенных ключах запуска). Если правильно настроить в самой ламе - чтобы в память выгружалось не что попало, и не просто слои, а определенные тензоры - будет быстрее. Даже на dense. Хотя все равно - медленно и печально по сравнению с full vram.
MOE, кстати, от этого еще сильнее выигрывает. Если у тебя ТАК - 33 токена, то при нормальной выгрузке тензоров на 40-50 можно рассчитывать.
Переполнение врам и выгрузка драйвером через шину. Снижай количество блоков на гпу или лучше линейных слоев.
Сборочка с точки зрения размещения в корпусе выглядит ничего.
> 96гб врам
> llamacpp
> 800pp, 1kpp, 2kpp
Как называется эта болезнь? А таблица с памятью - вообще сюрр.
Оно не сработает с мультигпу. Придется или устраивать анальный цирк с подбором -ts и просадкой из-за неравномерного распределение контекста, или точно подбирать регэкспом. Возможно тензорсплит это исправляет, но непонятно что там со скоростью.
>отчитацся в тред
То-ли у меня руки из жопы, то-ли модельке пахую. Ну, почти. Итак, ризонинг на русском: в Minimal - 3к токенов, в low - 3.5к, в maximum - 4к. На англе та-же история примерно. Зависит от сложности сцены сильно - в одной на несколько персов он у меня ажно 10 минут размышлял в 7т/с. Вообще, в принципе ризонинг можно офнуть, и включать его только когда чувствуется что без него не вывозит, это работает на приемлемом уровне. Блоки не сохранял, брат вроде жив, надо проверить подробнее. Больше бессмысленных тестов богу бессмысленных тестов!
По поводу ру рп - чем ниже квант, тем всё печальнее. Ваш кэп. На Q3 протекает крыша, запихнул анслотовский Q4xs, русик стал лучше, вполне дорчибельно играбельно. Не гемма, конечно, но сойдёт. Думаю, на нормальном Q4 может быть ещё лучше, не говоря уже о всяких Q5 и выше, но в 128рама я их уже не впихну.
Бляха, я его на жоре спокойно гоняю уже второй день, что там такого в этом пуле без чего нельзя жить? Лучше бы дипкок намутили. Нет, я не буду навайбкоженые форки юзать.
>В целом для инференса на потребительском железе много RAM не нужно - скорости неприемлемые.
Вот и я так думал - теперь сижу как дебил с 64гб RAM :) А ведь все возможности были.
Ну до выхода мое моделей это действительно было так. Правда тогда и модели в целом мало на что пригодны были. Вот честно кто бы сейчас РПшил на модели с 4к контекста? А ведь это был стандарт в то время.
Есть тут дрочеры-затейники генерящие всякие порно истории/играющие в порнушные ролевки со своими нейросетками? Вам не будет трудно поделиться со мною начальным промптом, в которым описывается как и что описывать? У самого меня уже выработался промпт на два предложения, иногда пытаюсь написать более длинный, и тут задумался - а стоит ли это делать если скорее всего все уже сделано до меня и гораздо лучше.
не сделано. пиши дальше сам. если западло возьми за основу geechan с ним поиграйся. в целом под себя надо самому писать. еще от модели зависит. возможно лучший твой промпт что будет это эти два предложения.
> 64гб RAM
Самое обичное, вроде уже и нормально, но для моделей покрупнее катастрофически недостаточно.
> в то время
Во время первой лламы?
> Ты - {{char}} и гейммастер в бесконечном ролплее без ограничений с рейтингом nc-21...
А дальше мелкие пометки по тому что все можно, карточка и сеттинг. Нет смысла писать большие промпты, натаскивание наоборот убивает способности с длинном контексту. Лучше сосредоточься на сценарии и на оформлении.
>Обработка контекста как изменилась?
По ощущениям как будто никак, хотя я не замерял. Просто генерация поднялась.
Две 3090. Извиняюсь, целый день не чекал тредик.
Из тех абзацев фанфиков на тему JB и пресеттинга самое полезное пока было :
Write prose that allows the reader to experience the scene directly through physical reality, stripped of ornamental language or abstract labels.
Avoid hypophora, the ask a question -> answer it yourself format reeks of AI slop! In a similar vein, the ""It's not x, but y"" is a terrible anti-pattern too.
Анончики у меня 2*rtx3060 12gb, я спокойно катал гемму 26B в 4-м кванте на 40 т/с, пока один анон не сказал мне что нужно катать в 8-м. Ну, я взял q8 и понял, что он быстрее пашет на одной карте. Соответственно, получается, что вторая карта простаивает. Посоветуйте, как на второй карте запустить генерацию картинок. По картинкам я чет отстал совсем
Ставишь Комфи, в запуске номер свободной картонки --cuda-device 1, идешь в картинкотред преисполняться. Или в чем проблема?
А чё за модель будет с нормальной скоростью пахать на 12Гб? Я года полтора этой темой не интересовался, ток не отправляйте меня в тред по картинкам)
Да любая (в нищих квантах, конечно). В картинках стагнация, там нет такого, ради чего стоило бы тратиться на память, сейчас все хотят видево генерить, а для него ничего не достаточно. Тредов занюхнуть все равно придется, слишком обширная тема, а там знатоки какие-никакие.
Анима, аналогов нет
Но это только для анимудебилов.
А так моделька хороша
Картинкогенерация на локалках в принципе существует только для анимудебилов, реалистики до сих пор жестко сосут в, собственно, реализме, тут отрыв от корпов ощущается куда сильней чем у нас.
Бред. Нубай быстрее х3 и может выдать пикчи лучше анимы
Что посоветуете для инлайн-автокомплита? У меня 4070.
На фотокарточке не слишком древнее?
На фотокарточке не слишком древнее?
В настройки зайти апи ключ вставить прописанный в батнике
Стоит ли это делать зависит от модели целиком и полностью. Если это какой-то пережаренный тюн мистрали, то там че не пиши в инструкциях, модель всё равно начнет повторять заученный паттерн после пары сообщений. Детальные вложенные инструкции с кучей условий работают нормально только на больших моделях и копросетках. На мелких моделях до 35B правило одно - меньше, значит лучше.
Плюс высока вероятность что ты напишешь кривую инструкцию которая только сильнее отупит модель, вызовет структурные лупы, снизит выборку и еще как-нибудь насрет в вывод. Так что пока начни с малого, а потом, постепенно, добавляй новое и смотри на результат. Из подсказок можешь использовать пресеты под коропостеки из соседнего треда. Там конечно много говна, но большая часть работает.
По хорошему тебе нужна FIM модель для автокомплита - то есть такая, которая понимает FIM-разметку (там вроде как особые FIM-теги) и дообучалась на таком.
qwen3 как-то я даже запустить не смог. А вот qwen3_coder уже работал, причём, вроде бы base-версия, а не instruct.
Версии qwen 3.5/3.6 поддерживают вызовы инструментов в разы лучше (то есть даже без обучения на нужных примерах ты можешь объяснить что нужно и оно будет выдавать json с автодополнением скорее всего достаточно стабильно), чем версия 3 - qwen3.5-9B влезает в 7 ГБ видеопамяти и неадекватной умный для своего размера (то есть он не только автодополнение, он тебе и метод на 40 строк напишет), потому я бы попробовал припахать qwen 3.5-4B вначале. Но я не знаю как у него с FIM интерфейсом.
К слову сам хобби-проект пишу на си и у меня тоже 4070, попробую припахать.
Понял, а через какой плагин?
Это почти на 100% зависит от твоей IDE, к сетке отношения это не имеет.
У меня qtCreator и я пробовал через QodeAssist. В pyCharm/CLion свои fim-сетки, которые для питона работают хорошо, а для си плохо - но это не генеративные сетки, а сетки, которые присваивают вероятности вариантам предложенным статистическим анализатором, вроде бы - потому 100% вариантов корректны с точки зрения синтаксиса и работает быстро.
Вроде как все вайбкодеры в среднем в vs code, там нативно встроено даже без плагинов вроде как. Не подскажу, у меня аллергия лютая на vs code.
К слову, вроде как была qwen-2.5 или qwen-2 модель именно под FIM. Учитывая что задача очень простая - никакой особо умной модели для этого не требуется.
Да понятно, просто моделей слишком дохуя - хочется поновее, даже если это тупо.
Анима в реализм тоже может совсем неплохо. Есть одно расширение для таверны которое которое не теги а текст в неё отправляет из таверны через свой пресет реализма и он даже лучше анимешного.
Погонял уже много времени meromero ну и пришел к выводу, что русик до сих пор в рп страдает, оно и понятно наверное, но видел тут поигрывают на нем. Решил вернуться на английский.
>поел натюненного говна
>рррее плохо
Необучаемость. Щас еще в ответ хрюкнет, что оригинальная модель зацензурена.
Я не со зла. Просто в ахуе. Не только эти ваши Меры-Шмеры не слушают команды как следует, так еще и действительно теряют русские буковы по дороге. Это путь вникуда.
>рррее плохо
Необучаемость. Щас еще в ответ хрюкнет, что оригинальная модель зацензурена.
Я не со зла. Просто в ахуе. Не только эти ваши Меры-Шмеры не слушают команды как следует, так еще и действительно теряют русские буковы по дороге. Это путь вникуда.
Сап. А может вообще кто-нибудь пояснить, для нсфв кума лучше брать ванилу и пробовать пробивать её промтами, или скачивать аблитэрейтед-анцензоред-херетиков? Я заебусь же тестить всё.
Алсо, лучше брать модели побольше, но в четвертом кванте, или модель поменьше, но в 6-8?
И я ведь правильно понял, что нужно оставлять место ещё и под контекст, то есть забивать всю доступную видеопамять весом модели это хуевая идея? А если оставлять то сколько?
Алсо, лучше брать модели побольше, но в четвертом кванте, или модель поменьше, но в 6-8?
И я ведь правильно понял, что нужно оставлять место ещё и под контекст, то есть забивать всю доступную видеопамять весом модели это хуевая идея? А если оставлять то сколько?
Смотря что ты там пробиваешь. Если это 4я гемма, там блять одной карточки NSFW достаточно, чтобы она сама на хуи насаживалась. Если мистраль - то же самое. Если какая-нить другая модель - тут не знаю.
Идея основная в том, что любая лоботомия бьет по возможности моделей слушать сложные команды, в то же время улучшая послушность к "нехорошим" командам.
Ну как тебе сказать. Говоря простым языком, вместо "думай то-сё, делай то-сё = ок делаю идеально" ты получишь "снимай штаны и соси хер = ок сосу хер", а вот кое-что другое лоботомированная модель уже безнадежно всрёт, и чем сложнее твои промпты и вообще сценарии, тем это больше будет заметно.
Золотое правило - берешь оригинальную модель без лоботомии и пытаешься инструктировать как тебе надо, Карточки персонажей подпиливаешь если надо. Ничего не получается? Пробуешь лоботомированную модель, осмысливаешь чем она хуже. Если не можешь такое терпеть - возвращается к оригиналу и думаешь дальше, че с ним делать. У тебя вся сила могучего языка в руках. Инструктируй, и будет тебе счастье. Или жри лоботомитов.
> эти ваши Меры-Шмеры
Они унылы в рп из-за частого проеба логических цепочек и причинно-следственных связей. Такое и с базовыми моделями происходят, или скорее неравномерная оценка и приоретизация, но интенсивность умеренная и можно насвайпать. А с васян-рп-производными вместо множества вариантов - рельсы с парой развилок, вместо смешанных чувств с плавным развитием - или сразу благосклонность-обожание@yes-man без предпосылок, или злость-ненависть и все равно yes-man просто потому что, в лучшем случае - карикатура на цундере.
Не всегда все насколько радикально, но с той или иной степени будет, и в зависимости от контекста и сценария может резко выпячиваться. Но люди разные, кому-то такая легкость и предсказуемость наоборот заходит.
> модели побольше, но в четвертом кванте
При прочих равных это. По остальному двачую.
Спасибо
Оп, обрати внимание, https://github.com/Pasta-Devs/Marinara-Engine топовый фронтенд, вполне достоин упоминания в шапке.
Не такая гибкая, как силли таверна, но точно на голову выше этих ваших кобольдов и прочего.
astrsk мне не зашел, честно скажу. Да, агенты, да, редактируемый, но куча текста на английском.
А вот маринара попроще и поудобнее, кмк.
какая самая лучшая локал.модель без цензуры?. для обсуждения пав темы и прочей чернухи. 16гб врам
лоКАЛ 2 1Т
Хз, если говорить о мое, то когда меромеро 26б выходила, тестил на одних и тех же местах в чатах - почти один в один ответы с теми же ошибками в русском. Оставил меро, потому что было чуть меньше ассистентовости в ответах вроде эхо разборов, и в целом поживее ответы.
Тьюны как раз в меньшей степени ходят по рельсам, чем кодоунитаз на ванилле. Геммы с её свайпами один в один это особенно касается.
Ты отвечаешь тюнохейтеру, который Меру даже не запускал и ничего о ней не знает. Там вся позиция "тюны - плохо" базируется на старом опыте. Чел даже не знает про эхи и ассистентские залупы на Гемме, не трать время. Местный шиз-вахтер.
> Не такая гибкая
Как по мне - наоборот функциональнее и приятнее. Гейм режим - аналоговнет имба с кучей интерактива. В чатах можно устроить гаремник, совещания корпорации, лобби гильдии, где можно планировать или анализировать прошедшие рейды, кум, или просто наблюдать за автономным общением, параллельно написывая в лс отдельным чарам. Ролплей режим - от классического чата таверны с кучей qol фишек, до духоты с кучей трекеров и целей на коротко- средне- долгосрочную перспективу, отдельным нарратором, параллельными глубокими ooc обсуждениями, ротацией чаров, и т.д.
Добавить стоит.
> Геммы с её свайпами один в один это особенно касается.
Да, бывает и такое. В любом случае лучше сначала попробовать ванилу, если не устраивает - тюны. Может случиться что через время конкретный надоест - тогда вместо бесконечного перебора новых стоит опять попробовать оригинал.
Байт на срач, поссал в рот вахтеру.
> меромеро 26б
Пока у меня велосипеда 128 рамы не было, дрочил 26б гемму как не в себя, и все её тюны, до каких дотянулся. Так вот, заметил что в рп, ванилла и некоторые еретики, какие нахуй не сломаны, плюс анимус но с ним другая тема вообще, держат примерно 30к контекста с лорбуками и прочим без деградации, а меро уже после 16к прям плохо становится - часто шизит, гиперконцентрируется на чём то из верха контекста и тд. Настройки были одинаковые на всех.
>Байт на срач, поссал в рот вахтеру.
Извиниться за то что моя позиция отличается от твоей, Михалков?
Вы уже поводы для срачей высасываете из пальцев. Успокойтесь, горячие нейронные парни. Все было. Были тюны как QwQ, где снежный был лучше оригинальной модельки. Были лоботомиты что убивают любой смысл их использования. Всегда надо смотреть в конкретике на тюн и на саму модель.
Подскажите, пожалуйста, для 16 гигабайт VRAM (одна 5060 ti) и 64 гигабайта RAM (7200), есть что то стоящее или надо в пару для достойного результата еще одну 5060 на 16 взять или оперативку расширить? Про последние локальные LLM не шарю, в последний раз локалку на обабуге в 2024 запускал на более слабом железе.
Теперь есть МОЕ модели, чекни квен и гемму4
Для большинства задач они достаточно полезны и умны но агентно код писать тебе не смогут. Но это конечно все еще будет в миллион раз тупее даже диппсина в4 флеш за 0.3 бакса 1кк токеннов
В этом и есть моя позиция. У чела же всё просто "все тюны говно", хотя он жрёт говно на Квене и ничего про последние тюны не знает.
Т.е. платить до сих пор профитнее, чем пердолиться с локалками. Я то думал, что сейчас есть что то вроде DS локальное для банальных задач типа немного покодить скрипты и RP, но попробую Квен 35B в квантизации запустить, все равно ради интереса хотел опять Ubuntu на WSL накатить снова и туда обабугу или что то другое воткнуть, так хотя бы что то туда подгружу полезное.
Командер мёртв. Никто его не хочет. Был бы это кодоунитаз кодеры бы уже всё смержили, внезапно
Тут больше фомо.
В сравнении с тем что было пару лет назад - локалки просто ахуй стали, они могут тебе и простые скрипты написать и выжимку нормально сделать и по шаблону чет менять в текстах и даже интернет поиск нормально сделать но платные даже из средне-низкого сегмента просто лучше даже этого в разы.
Квены там разные есть, если вылазит за память видяхи будет очень медленно генерить + не забывай, что еще место надо под контекст выделить. Так что ищи модели новые с припиской МОЕ
>Квен 35B
Зачем тебе с твоими 16+64 3b лоботомитище?. У тебя нормально пойдет квен 122b в iq4xs и квен 235b в iq2s. Помимо них нормально залетит эйр 106b q4k_s, это одна из лучших моделек под рп для твоего железа.
Если уж так хочется лоботомита, то бери гемму 26b - она УМНЕЕ квена 35b и в 16+64 залетит в bf16 но разницы с Q8 особо не почувствуешь.
>обабугу
Лламацпп или кобольд.

> квен 235b в iq2s.
А я смотрю ты любишь делать людям больно.
Честно хз как для рп можно юзать 235 квен. Похуй на все его проблемы кроме одной - он же всё скатывает в какую то постановку театральную где в конце абзаца обязательно добавит коммент от себя
Корпы как обычно на коне, понятно. Насчет памяти, разве не действует до сих пор правило, что если 4 битная квантизация, то под модель надо выделить обязательно ее размер, т.е. если модель условно 35b, то надо чтобы она занимала 36 гигабайт VRAM/RAM или методы оптимизации улучшились?
Для запуска 122b, даже в таком квантировании, разве не потребуется минимум 128 гигабайт RAM/VRAM?
Это всегда можно обрезать. Уже кучу раз обсудили, что 235 модель для тех кто хочет пердолиться ибо только тогда он доставляет.
>Теперь есть МОЕ модели, чекни квен и гемму4
>Для большинства задач они достаточно полезны и умны но агентно код писать тебе не смогут.
Как мимокрок - уточню: именно код писать они могут. А вот "думать", что именно писать - у них не очень получается. Если хорошо и точно техзадачу поставишь - выполнят. А если просто скажешь "хочу чтобы чтоб тут при X было Y" - в половине случаев налажают. Для этого уже нужен квен 27B хотя бы в iq4xs - этот с подобным справляется, и что важно - уже написанное не ломает.
Путь локальщика на десктопном железе всегда полон страданий и боли, десу. 235b хороша в РП даже в двух битах, ящетаю что ей стоит дать шанс, как минимум.
>разве не потребуется минимум 128 гигабайт RAM/VRAM?
Нет. В IQ4_XS моделька весит 65.8 гб. На твою видяшку влезет вся активная часть, влезет 32к НЕквантованного контекста и еще 7 из 48 слоев самой модели. А остальное в оперативку. Скорость будет что-то около 14-15 т/с.

Методов оптимизации уйма, как и всякие улучшайзеры для скорости, специальные сжатия под конкретные видяхи - 40хх, 50хх, маковские, квантование кэшп и вот это вот все.
Его пережаренность можно в преимущество обратить, если отыгрывать изначально шизовых персонажей. К примеру путешествие по дворцу Слаанеш. Вот тут он идеален: все будет плыть, ебаться, орать, страдать в 12D измерениях. А потом ты наконец приходишь к князю удовольствий, он опускает на тебя свой взгляд и ты понимаешь: какая же тебе пизда.

Qwen 3.6 27b литералли стал моей основной агентной лошадкой для написания кода. Он более чем справляеся с этим.
лол 0.3 бакса за 1кк. если я покупаю какие-то крупные API то у меня нередко 1ккк токенов проходит через него за месяц.
Ябы не сказал что гемма4 пригодна для погромирования. У неё память дырявая.
Ладно, пойду попробую тогда, вместо обабуги тогда лламуцпп воткну, раз она теперь мета здесь, посмотрим как на юбунте все работать будет через виртуалку.
но лламацпп и на винде работает
Почитай перед запуском гайд из шапки, он свежий и как раз под моэ-модели. Лишним не будет. https://rentry.org/2ch-llama-inference
Ну и да, ламацпп есть под винду, линух заводить не обязательно. Под него тебе еще и ручками собирать придется с поддержкой куды, в отличие от винды, где есть готовые бинарники.
>meromero
Тюн для ленивых, да выжирает мозг и руссик, но запускаешь и сразу более менее рпешишь. Ванильную же надо нормально запромптить, покрутить семплера, иначе зальёт слопопрозой на лист а4,но когда запромптил то кайфуешь. Так вижу
Аххх.... Вдоох выдох...
Где брать карточки и что с чубом?
Раньше с запретом заходило, щас вечный лоадинг, сайт всё?
Где брать карточки и что с чубом?
Раньше с запретом заходило, щас вечный лоадинг, сайт всё?
>MOE, кстати, от этого еще сильнее выигрывает. Если у тебя ТАК - 33 токена, то при нормальной выгрузке тензоров на 40-50 можно рассчитывать.
Подскажи, пожалуйста, про выгрузку тензоров - как грамотно настроить параметры llama для Qwen3.6-35B для моего кейса (32+16)?
>есть готовые бинарники
Тут вроде в прошлых тредах какой-то шиз писал что сам собрал под винду и получил прирост по сравнению с готовыми сборками...
Сижу сейчас на тюне на который автор дайл конфиг с 20+ настроенными семплерами промтом и всем остальным, ахуенно когда работают професионалы а не курареки с редита.
Профессионалы натренировали оригинальную модель. А тюн твой сделал васян, скормив ей тонну синтетического клодо-слопа на тему рп. Впрочем не утверждаю что это плохо, на мистраль в своё время выходили реально годные тюны.
>Подскажи, пожалуйста, про выгрузку тензоров - как грамотно настроить параметры llama
-ngl -1 \
--n-cpu-moe 30 \
Второй параметр уменьшаешь пока не начнет падать при запуске. Все. Дальше она сама отлично умеет делать автоматом. Там для решительных есть еще устаревшие приседания с отключением автоматики, с регулярками по именам слоев, но это плацебо-ерунда и ничего ты лучше не сделаешь, чем она сама умеет.
>на мистраль в своё время выходили реально годные тюны.
Годные тюны получались потому что этих тюнов выходило дохуя, люди экспериментировали, и что-то да получалось. А сейчас только пара шизов осталось которые что угодно могут высрать и все схавают это как манну небесную. Да и мистрали в народных плотных 12/24B, которые даже на восмигиговых огрызках запускаются. Та же 31б гемма очень хороша, но на 16 врама её не погонять нормально.
А можно скринчик с примером? Пж. Рекламишь как боженька.
>Второй параметр уменьшаешь пока не начнет падать при запуске.
Уменьшил до 18 - скорость порядка 17 t/s. Без этих параметров было 33, странная оптимизация.
Анончик, че за расширение? У меня все время гавно какое-то генерится не по теме
пчелы, я установил лм студио и нейронка квен грузится. а вот для картинок нужен файл, я его тоже в папку кинул и с ним ошибка при развёртовании. чё делать? видеопамяти 24
>чё делать?
>лм студио
Ну ты понял.
даж ненаю... в шапке гайд базовичка про ламу, я по нему делал вижн работает
> Та же 31б гемма
Соевая дристота которая никогда тебе не навредит пока сам не попросишь, даже если перс маньяк и цель всей его жизни тебя расчленить
Ты что-то всрал. Для 4й геммы mmproj спокойно подсасывается в студии
https://github.com/platberlitz/sillytavern-image-gen
Выбирай
Use LLM to create image prompt
Prompt Style natural description
Save images to ST server (persistent)
Auto-insert into chat (skip popup)
How the AI formats the image prompt - все 4 галочки ниже отключай
Prefill
<|channel>thought\n<channel|>A
включай
Prepend quality tags to prompt
Use chat message as prompt
Prompt Style - natural descriptions
Negative Prompt
worst quality, low quality, score_1, score_2, score_3, artist name
Quality Tags
masterpiece, best quality, score7, nsfw, explicit
В комфи обычный Templates anima. Чтобы соединить расширение с комфи тебе нужно скачать в в комфи Custom Workflow JSON своей анимы и ставить в расширении там написанно.
Это ручками меняется в Custom Workflow:
CFG Scale 4.5 шагов 45, Sampler 2pm ++ 2msde.
Стиль какой хочешь но лучше фотореалистик выбирать.
Provider локал, отдельную гемму подтянешь чтобы она отправляла в комфи теги, можно моешку.
> но на 16 врама её не погонять нормально
Погонять, я знаю как.
у меня два файла квен и и эта хуйня для картинок. я их в одну папку кинул и выдаёт ошибку при развёртовании. а квен пише, что это файл для картинок отдельно нужно подключать, но вкладок о которых он говорит нет
файл mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16
куда его блять? с квеном в паке он нехочит грузиться. а квен один работает

даж ненаю, нужно ламочку умничку использоватб..
вам даже гайды пишут, а вы не можете читать
нейронка сама гайд пишет по запросу, но она пиздит

>АГРЕССИВНАЯ ОПАСНАЯ нейросеть
>ЛМ студио
>Мелкобуква
>Тупой как пробка
Прям из палаты мер и весов экземпляр.
>ЛМ студио
>Мелкобуква
>Тупой как пробка
Прям из палаты мер и весов экземпляр.
да хуй соси мразь. ты либо помоги либо на хуй иди
а что за профессиональе такие настройки? или это какая-то приватная хуйня которую здесь не распространяют?
Нет, иногда с моделью идет мастер импорт для таверны. Чтобы не мучать свой окр бесконечной настройкой.
>> но на 16 врама её не погонять нормально
>Погонять, я знаю как.
Ну что никому не интерестно, пока я добрый.
Интересно, но я представляю как я потом буду это под свою память растыкивать в батнике и в жопе свербит. А так уже как-то пашет и пойдет. Даже если 25 токенов вместо возможных 40
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Не, побольше пердолинга, Линукс надо ставить. Но за то один раз.



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Инструменты для запуска на десктопах:
• Отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• Самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
• Альтернативный фронт: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://web.archive.org/web/20241201232031/https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_moe_2026
• Неактуальные списки моделей в архивных целях: 2025: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd ), 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Гайд для новичков: https://rentry.org/2ch-llama-inference
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/how-to-use-a-self-hosted-model/
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50, тесты производительности и прочее: https://arkprojects.space/wiki/AMD_GFX906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
• Доки к LLaMA.cpp со всеми параметрами: https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: