




> Не хватает так же имиджгена как в таверне для полного счастья.
В соединениях добавь провайдера для пикч, можно подключить комфи скормив нужный воркфлоу под любую модель. Или корпов по апи. Далее агент иллюстратор для картинок по сюжету, агент трекер бэкграунда для задников. У второго можно промпт переписать чтобы более активно новые генерировал.
> не нашёл как задавать агента из отдельного подключения чтобы крутить сразу две модели, для инструментов и рп
Также в соединениях для модели, которую хочешь использовать агентной, выстави галочку пикрел и число паралелльных соединений. В первый раз после переключения будет уведомление что для агентов используется другая модель.
Или, у каждого из агентов есть настройка Connection Override где можно указать конкретную модель.
В таверне я могу в пайплайн подать аватары обоих персонажей. А тут как?
>выстави галочку пикрел
Спасибо! Вот уж не думал что настройки агентов запихнут в уже существующие подключения не агентов. Матрёшка блин.

Можно Но лучше рпшить со всякими вайфу, которых стабильно делает по тегам или у тебя есть готовые лоры
Для каждого агента можно настроить индивидуально. По умолчанию есть основная модель, основная модель для агентов (равная основной если не стоит оверрайда), и далее уже индивидуальный выбор. По началу очень странно, но когда освоишься довольно удобно.
Вдогонку - в рп сейчас там суммарайз поломали. В версии 1.6 работает, далее что-то нашаманили и распидарасило что в промпт не инжектится как должно.
>для плотной тоже придется грузить все веса.
Бля, конкретно это я писал к тому что моегемма это прям лоботомит на уровне архитектуры а не типа аналог плотной у которой "просто" отключены "ненужные веса" в один момент. Ну грубо говоря как взять 4б лоботомитов пачку и переключать их роутером, а не нарезать большую плотную на блоки экспертов.
>А код тут причем? Проблема в производительности проца и памяти там, где нужна йоба числодробика матриц.
Чет мне кажется что 3-4 токена на mlp слоях не должны сильно проц нагружать. Может я ошибаюсь. Наверное да, ибо сколько не кричат ЕБАТЬ АТЕНШЕН ЖЕ КВАДРАТИЧНЫЙ, а потом оптимизируют - а там всего +20%, так как mlp таки жирные и тоже дохуя жрут.
>Именно так и делают
Где? Не видел, или ты другое имеешь ввиду. Ну или я плохо искал.
Там же еще промтпроцессинг идет блоками, не? А значит придется грузить несколько раз что сводит на нет всю идею. Там вероятно еще и надо по аналогии с FA вычислять чтобы было без блоков, а значит конечно нихуя не будет сделано ради какой-то там никому не нужной выгрузки.
>Расскажи подробнее что имел ввиду, как "стаки обычных мамок" могут тут помочь?
В мире где нет задержек и говнокода, стакаешь кучу дешевого говна и у тебя на генерации скорость ограничена суммарной скоростью всей памяти этого стака. И промтпроцессинг ты оффлоадишь на видюхи, тоже по суммарной пропускной способности шин. Максимальная эксплуатация самого выгодного железа в ооочень условной теории. Маки же стакают по несколько штук. На двух обычных компах я видел якобы х2 скорость вообще по wifi коннекту.
3.5 выдавал в кванте на 100 гб (vram только 30) генерацию под 20 токенов в секунду.
3.7 в кванте на 50 гб (самый низкий IQ1) выдаёт генерацию в 2 токена в секунду, это очень медленно. Там так сильно перебрали архитектуру? Ещё оптимизации под ламу не выкатили и она неверно раскидывает веса? Хотя да нет же, я вообще без карты запустил, и 3.5 выдаёт, ну, не 20, но 10. Точно не 2. В чём дело в общем? Вряд ли в кванте, он может быть тяжёлым и в два раза более медленным, но не в 10 же.
А так же где mtp под степ-флеш? А то гемму добавили, квен добавили. Жду глм, степ-флеш, и прочее.
3.7 в кванте на 50 гб (самый низкий IQ1) выдаёт генерацию в 2 токена в секунду, это очень медленно. Там так сильно перебрали архитектуру? Ещё оптимизации под ламу не выкатили и она неверно раскидывает веса? Хотя да нет же, я вообще без карты запустил, и 3.5 выдаёт, ну, не 20, но 10. Точно не 2. В чём дело в общем? Вряд ли в кванте, он может быть тяжёлым и в два раза более медленным, но не в 10 же.
А так же где mtp под степ-флеш? А то гемму добавили, квен добавили. Жду глм, степ-флеш, и прочее.
>По началу очень странно, но когда освоишься довольно удобно.
А всё одно не взлетит. Считаю, что сама идеология порочна: упор на кучу агентов (а современная локальная архитектура к ним не приспособлена) вместо кучи инструментов на скриптах. Даже если у тебя есть возможность выделить отдельную видеокарту чисто под агентов будет сложно - а такая возможность есть далеко не у всякого. Следовательно разработка Маринары практически исключительно под корпы и не для ЕРП. И даже там будет медленно!
>Много агентов - корпы
На ноль поделил. Корпы, так-то, денег стоят и не малых, при работе с ними наоборот всячески стараются как можно больше в зирошот уложить. Это на дваче корпы ассоциируются с бесплатными ворованными проксями из-за чего воспринимаются как что-то бесплатное, а для большинства это платный инструмент. Даже кодеры, которые на этом деньги зарабатывают, и те используют оркестрацию в основном как способ сэкономить на меньшем контексте/более дешовой модели, а о таких вещах, как постоянная перепроверка кода и команд, проверка ответа на релевантность, поиск в интернете бест практикс и т.д. они даже не мечтают, ибо дорохо.
>Корпы, так-то, денег стоят и не малых, при работе с ними наоборот всячески стараются как можно больше в зирошот уложить.
Ага, особенно вайбкодеры и любители воткнуть десяток агентов для составления ежедневных расписаний занятий спортом :) Люди не хотят заморачиваться, а хотят рабочий результат из коробки. По отзывам видно, что результат есть - нужен только компьют. Лично мне правда результат тоже не очень понравился, а уж реализация...
>Жду глм, степ-флеш, и прочее.
А авторы моделей сделали MTP, лол? А то ждёт он.
> Не хватает так же имиджгена как в таверне для полного счастья.
В смысле, имиджгена не хватает? Он же там есть, я первым делом чекнул.
Но заленился настраивать. Чисто потестил, работает, но там каждому персонажу нужно реф сделать и все такое, пока забил.
> И не нашёл как задавать агента из отдельного подключения чтобы крутить сразу две модели, для инструментов и рп.
Ты можешь либо в настройках агента указать модель, которую он использует (для каждого из 40+ агентов), либо сделать «дефолт агент» модель, а для ролеплея указать другую.
Но! Я не разбирался, как это работает. Тоже подумываю на агента посадить квен на другом компе, а тексты пусть гемма пишет.
ГМ.
> А что там с редактом?
Да просто, заходить в логи, искать мелко-кнопки, переписывать, вот это вот все. Я же правильно делаю хотя бы, надеюсь.
Это сильно неочевидно, и не так удобно, как хотелось бы, сделать реролл только последнего действия… Я как будто с гитом работаю. А хочется по аналогии с веб-мордой — выбрал в удобной менюшке шаг, рерольнул его или переписал.
Ну, ИМХО, не дотянули они просто пока этот момент по UI.
А мне, кстати, показалось не странно, а даже понятно это. Не прям нативно-интуитивно заебись, но вполне обосновано и логично, когда роешься по этим менюхам.
Не забываем писать в ишью на гит и даже самим чинить!
Я так себе не поленился ттс завезти под сервер (который сам же не поленился завести в другой репе=), автор Маринары крутой тип в общении, доброжелательный.
У меня Q4_K_M от AesSedai (q8 /q4 /q4 /q5) выдает 16 токенов, а с мтп до 19.
При этом, q4_k_s чистый выдавал 19 чистых.
Такое ощущение, что ты что-то не так сварил, на линухе скорость пушка.
Ах да, врам всего-то одна 5060 ti на том компе и 128 ddr5. Не самый быстрый конфиг, 18 тпс для него — пушка для 196b модели.
> А так же где mtp под степ-флеш?
Ты бля угараешь. https://github.com/ggml-org/llama.cpp/pull/23274 вот же оно.
Работает, да, проверял дня три назад.
Бля, хуйню высрал, братан.
Маринара — про качество игры, а не про попердывание в чате.
В чате ты можешь ролеплеить где угодно — хоть в нативном llama-ui, хоть в таверне, чтобы инжектить контекст из лорбуков.
Смысл агентов в том, чтобы обдумать, сформировать логичное продолжение под твои вкусы и историю, а не просто «продолжить текст» единым высером.
Да, это кратно дольше.
Да, у меня дома 5 компов стоит.
Но я же, блядь, играть хочу.
Я ни в коем случае не обсираю подход со скриптами (алгоритмический), это просто более упрощенная модель, которая дает те самые пресловутые -5 баллов в бенче за счет -75% времени расчетов. Быстро? Быстро. Нужно много компьюта? Не нужно. Результат? Ну, кого-то устроит.
Я готов потерпеть ради немного лучшего результата.
Это просто выбор каждого человека — быстро, но похуже, или медленнее, но получше.
Как бы, бля. О вкусах не спорят, и Таверна, и Маринара — отличные штуки (давайте не будем про реализацию таверны, она там в пиздень хуевая, туда я тоже коммитил=), и работают, это главное.
Круто когда есть выбор, разве нет? :) ИМХО — круто.
Лишь бы нам моделей опенсорсных все сильнее подсыпали.
Ой-ой, учти!
На данный момент, если ты загружаешь модель с MTP-головами, но не используешь их — они все равно висят в памяти мертвым грузом.
Так что, если ты вдруг будешь недоволен ускорением от мтп, то контекст ты так и так потеряешь, его влезет меньше!
Поэтому старую модель без мтп не удаляй.
А то я снес, а у АесСедая целый тред таких обосравшихся как я. =D И он пожимает плечами, мол «да я и сам модель без мтп снес, и обниморду пурджнул… нема бэкапов».
Да. И в glm, и в step нативно есть mtp - и у обоих сеток указано как через vllm его запускать.
>Ты бля угараешь.
Ну вообще - это под 3.5, а я в релизах искал пролистав все после выхода 3.7, и через поиск по "3.7 step" и не нашёл ничего.
Ну и ещё на hf искал странички квантов где указано, что mtp есть. Не нашёл. Учитывая что они там нативно были - подумал, что есть в квантах, но подписывать не стали, в ночь поставил загружаться квант - запускаю, при запуске с mtp-параметрами оно пишет, что нет mtp-слоёв в кванте. Обновляли вот несколько дней назад. Никакой отдельной папки MTP как у геммы я не вижу.
Я ещё полгода назад просил скрипт на питон, который возьмёт один gguf-квант, и некоторые слои в нём поменяет на слои из другого кванта (условно подменить Q4_K_M на Q6_K из кванта побольше, но только отдельные слои - и сохранить).
Это работало очень быстро, и скрипт написала с одной попытки бесплатная гемини или жпт. Думаю, выпилить mtp-слои из кванта можно так же просто скриптом на 30 строчек.




Сочный кумслоп оригинальной gemma-4-31B_q4_0-it.gguf
Что вы там с ней делаете что она рефьюзит...
И русский вроде норм, не поломан.
Быстрые тесты на одном сообщении, чисто проверить модель, рп-шить щас желания/времени нет, но вроде всё норм, как время будет надо будет потыкать. Особенно как завезут норм поддержку драфт-модели, ибо на 12 ГБ VRAM всё же как-то медленновато.
Что вы там с ней делаете что она рефьюзит...
И русский вроде норм, не поломан.
Быстрые тесты на одном сообщении, чисто проверить модель, рп-шить щас желания/времени нет, но вроде всё норм, как время будет надо будет потыкать. Особенно как завезут норм поддержку драфт-модели, ибо на 12 ГБ VRAM всё же как-то медленновато.
>Смысл агентов в том, чтобы обдумать, сформировать логичное продолжение под твои вкусы и историю, а не просто «продолжить текст» единым высером.
ИМХО, по по моим практикам - без направляющего пинка агенты так и норовят обсасывать какую-нибудь ненужную фигню. Да, это может быть лучше, чем просто свайпы в Таверне, но может быть и хуже - а ещё и долго.
>Я готов потерпеть ради немного лучшего результата.
А я на немного лучший не согласен. Тем более на уровне "вайбкодинга" - чистой алхимии, где куча агентов чего-то там делает, как правило ересь всякую и ты это даже не контролируешь. Ну бывает интересно, живенько. Так в том и прикол агентского подхода. Но проблемы там системные и развернуться не дадут.
До как вы заебали. Анон.
Гемма может, гемма умеет.
В пару сообщений, лол. Ну ассистент это, не умеет она в ЕРП. Она лупится, она идет теми же тропами. Ты в промте чуть ли не весь сюжет должен задавать, чтобы было что то интересное.
Гемма пиздата как некопомощник. Она сделает с тобой карточку, она пропарсит твои сообщения, она промт для картинкогенерации сделает. Но для РП и ЕРП она абсолютно не юзабельна и проигрывает в этом даже плотно квенчику, не говоря о его старших моэ милфах.
Я не понимаю, чё вы на ней помешались? Ебанный порноквен 235 в Q_3_xxxl_omega_dark_gguf можно запустить на 16 врам с 30к контекста на 9-10 т/с. (Дыа, 128ддр5 тут не помешают) И будут вам plap plap и подозрительная жидкость по усам от мохнатых пёзд.
>не умеет она в ЕРП. Она лупится, она идет теми же тропами
Не в первый раз вижу от тебя этот тейк ИТТ. Причем только от тебя, больше никто не жалуется.
У меня лично ничего не лупится. И да, я знаю что такое лупы, я потому дристрали изначально засирал еще до того как это стало мейнстримом - потому что вот они как раз реально лупились. Скорее всего у тебя косяк где-то в шаблоне. Насчет тропов - да, приходится время от времени по рукам гемму пиздить линейкой.
> Но для РП и ЕРП она абсолютно не юзабельна и проигрывает в этом даже плотно квенчику
У тебя точно проблема с шаблонами. Квены меньше 235 абсолютно не подходят для РП.
Если бы неумела в рп не высрали бы десятки тюнов за пару месяцев.
> А всё одно не взлетит. Считаю, что сама идеология порочна: упор на кучу агентов (а современная локальная архитектура к ним не приспособлена) вместо кучи инструментов на скриптах. Даже если у тебя есть возможность выделить отдельную видеокарту чисто под агентов будет сложно - а такая возможность есть далеко не у всякого. Следовательно разработка Маринары практически исключительно под корпы и не для ЕРП. И даже там будет медленно!
То, что реализует маринара, не является агентами в классическом понимании. Она предоставляет детерменированные мультизапросы, т.е. порядок вызова тул-колов определяется алгоритмически, а не самой ллм. В этом плане к этому ближе обычный CoT, тот же stepped thinking из шапки, как пример реализации.
На той же плотной гемме с 20-30t/sec при отключёнии ризонинга в режиме ролеплея там более чем комфортно даже с несколькими агентами, поскольку большая их часть вызывается уже после основного ответа ллм. Да, как мне кажется, ризонинг попросту не нужен в рп на новых моделях, особенно при активации Writer Agents вроде Narrative Director в маринаре.
>порядок вызова тул-колов определяется алгоритмически, а не самой ллм.
Это и есть агенты, это не автономные агенты.
>128ддр5
Дайте мне кирпич, я ему въебу, кря.
Борда успешных людей, сырок
> Не в первый раз вижу от тебя этот тейк ИТТ
Йор детектор из броукен.
Я пишу пару раз в тред и всегда мимо гемосрачей прохожу. Потыкал, помыкал остался доволен умницей.
> Квены меньше 235 абсолютно не подходят для РП.
Честно, я про 27b исключительно с чужих слов могу говорить, так как у меня с 235ым ван лав. Я ему мохнатых тянок, он мне описание хвостиков. Честная сделка.
Ну пиздец просто, из треда в тред:
Гемма, гемма, гемма, гемма, гемма, гемма, гемма.
Это все еще дешевле чем врам.
Ебать меня немытым кирпичом, она уже под 170к.
Успешные люди заводят эскортниц и играют в рп ирл или ездят культурно отдыхать на острова где нет закона не дроча на буковки.
124б гемму хочеца...

>она уже под 170к
А что начнётся когда запасы на складах подойдут к концу... Ставлю на ещё х2 к текущей цене к концу года. Ну как грится кто успел тот успел я не успел, застрял на 64 ддр4. Сюка :(
> не должны сильно проц нагружать
Не должны, но нагружают. И там уже зависит от конкретного кейса, если общее время обсчета + оверхед на задержки и семплирование больше чем число принятий минус 1 умноженное на время генерации - будет замедление, и наоборот.
> Где?
Во всех интерфейсах где заявлен гибридный инфиренс - llamacpp и форки, ktransformers, fastllm.
> Там же еще промтпроцессинг идет блоками
Если промпт ниже порога - свою часть считает проц, видишь нагрузку на него и некоторую задержку перед первыми токенами. Если выше - идет стриминг весов и обрабатывается батчами, о чем пишет в консоли. На крупных моделях только время на стриминг составляет секунды-десятки секунд, особенно в лламе где непонятки с тп.
> В мире где нет задержек и говнокода
В чем задержки говнокода? Выглядит что ты называешь говнокодом неприятную математику, которая не позволяет достичь идеальной параллелизации без кучи обменов, вести обсчет по 10 раз на одних и тех же весах не подгружая новые вместо разных, обсчитать сразу фулл промпт избегая множественного стриминга не имея буферов.
> И промтпроцессинг ты оффлоадишь на видюхи, тоже по суммарной пропускной способности шин
Это уже так и работает, по крайней мере в рамках одной системы, даже между разными нума нодами. При наличии очень быстрого линка в десятки-сотню гигабит с минимальными задержками, можно и между нодами разделить, это уже доступно. Но чтобы было не мучительно больно, там важен не только сам протокол линка, но и конфигурация линий и анкора профессора, чтобы иметь прямой доступ между гпу и контроллером.
Но с 3080ти мало что выйдет, они достаточно слабые сами по себе и имеют слишком мало памяти чтобы даже атеншн с кэшем вместить если речь про крупные модели. Всю эту богодельню можно сильно упростить, взяв некросервеную платформу на ддр4, натыкав в нее этих карт и запуская. То же самое, но единое адресное пространство и сразу относительно быстрая связь между картами без сетевых приколов, даже слотов памяти будет как в N десктопных.
> На двух обычных компах я видел якобы х2 скорость вообще по wifi коннекту.
По тандерболту 5 со 120гбит в секунду, контроллер которого интегрирован в проц. Никаких вайфаев для подобного.
>Честно, я про 27b исключительно с чужих слов могу говорить, так как у меня с 235ым ван лав.
Не надо так - с чужих слов. Да, 235 очень хорош для РП и для кума, сам именно для того чтобы запускать его в четвертом кванте вместо второго поменял год назад оперативку на 128 гб(А в итоге пересел на 3.0 bpw большой ГЛМ, потому что он пишет даже сочнее и не имеет багов 235 с разметкой).
Так вот, 235 и 27B/122B это совершенно разные модели, из всей линейки 3.5-3.6 в хороший РП может только 397, но и его надо палкой пиздить для корректной перспективы.
Для староверов там можно отключить вообще все, или инжектить в основной промпт. Агенты там не то, что сейчас подразумевается под автономными агентами, а именно дополнительные скриптованные вызовы.
> разработка Маринары практически исключительно под корпы
Как раз наоборот - большинство страдальцев на проксичках анально огорожены рейтлимитами и контекстом. Поэтому там есть возможность запустить гемму е4б на встроенной llamacpp, чтобы отдать ее под простых агентов.
> не для ЕРП
Контроллеры секс игрушек, нсфв промпты и статы возбуждения туда случайно попали.
А что если там 128ддр5 одной планкой?
> с 235ым ван лав
Да, он реально приятен когда не неприятен. Может держать персонажа, сюжет, быть внимательным и проницательным. Кстати, на контексте 122 на него становится весьма похожим, иногда вытаскивая даже больше подходящих деталей. Но страдает нерешительностью.
Это изимод, вот ты попробуй на буковки подрочить с острова
Здарова фраера, чё там годные файнтюны уже появились на 12б иличё? И в целом как моделька?
мимозалётный
мимозалётный
Опять 235-шиза из больницы выпустили. Даже 27 3.5 гораздо лучше чем этот мусор
>27b лучше чем 235b
>в РП
Тут ещё вопрос кто из вас больший шиз
А, ну да
Цыфорки же решают. И похуй что пережаренный лоботомит с репетишеном и тупой
Я пересел с глм 358 на гемму 4 31, и рад.
Неееет как ты мог..! Ведь там модель больше чем в 10 раз БОЛЬШЕ, она даже в IQ2XXXS кванте круче геммы в полных весах!!!
И похуй что они по HLE сопоставимы, а Гемма первая локальная модель которая следует инструкциям

Ебать вы лохи, пересел с Кими 1T на Гемму e2b - кум рекой полился, брат воскрес! Умница! Красавица! А вы и дальше дрочите на свои ЦиФеРкИ!
Классический пример обобщения от непонимания. Ты на пике кстати слева?
> Гемма первая локальная модель которая следует инструкциям
Таблетки
Интересный факт: Qwen 4b гораздо лучше себя показывает в РП чем Клод и Гемини (глупые и пережаренные). Жаль конечно что не все способны это понять...
Дай угадать — unsloth качаешь?
Скажу честно — минимально касаюсь этих говноделов. Они на бумаге крутые ребята, а на практике, что не релиз интересной модели — то ошибка.
Но если кого-то другого — ну кто знает.
Лично я могу посоветовать https://huggingface.co/AesSedai/Step-3.7-Flash-GGUF , там и кванты получше (как минимум по ppl — мусорный бенч, но низкий ппл — гарантия хуевого ответа, анслоты точно хуже), и мтп на месте.
> Думаю, выпилить mtp-слои из кванта можно так же просто скриптом на 30 строчек.
Хм, справедливо.
Гемма у меня ошиблась раза 2 за сессию. Не критично, учитывая, насколько охуенна (для 60 тпс локальной модели!) была остальная часть.
> А я на немного лучший не согласен.
Твой выбор, конечно. =) Думаю, таверна гораздо быстрее выплевывает ответы. Давно уж на ней не роллил, если честно, все не было времени.
> Ты в промте чуть ли не весь сюжет должен задавать, чтобы было что то интересное.
Кстати, плюс агентов и Маринары в том, что мир я генерил автоматом, и попросил рассказать мне как дефолтному челику из этого мира, поэтому сюжета не знаю.
И, да, гемма вполне справилась, хуй знает.
РП гемма — топ, для локалок 9 из 10.
ЕРП я не пробовал, не дошел еще. У мя там фэнтези, а не дроч ради дроча.
> Ебанный порноквен 235 в Q_3_xxxl_omega_dark_gguf можно запустить на 16 врам с 30к контекста на 9-10 т/с.
Эээ… А можно 60к и раз в 10 быстрее?
Так-то степ-флэш можно на 18 тпс запустить, не знаю как он в ерп, но…
Давай по чесноку — в рп я вижу так называемый нейрослоп местами, но камон, то что нынче называют нейрослопом — это обычная художественная литература. Если сейчас почитать любые книги Б-класса и половина А — это будет нейрослоп в чистом виде от оригинальных авторов — на которых нейронки и учились.
Напрягаться от того, что книга написана как книга, а не как цирк с конями-эквилибристами — это шиза и синдром вахтера.
Лупы? я помню, как писали старые мистрали, да, они спустя 2-3 сообщения могли неприятно лупиться, это отталкивало, пропадала магия.
У Геммы я словил такое… Ммм… один раз с натяжкой с перерывом в 3 часа? Как будто это и не луп был.
Я не говорю, мол, гемма наше все.
Наше все это бесплатные корпоративные модели локально на смартфоне.
Но сравнивая гемму 31б с другими моделями — мне нравится ее возможности. Это действительно крепенькая, красиво пишущая, хорошо отыгрывающая характеры персонажей (напоминаю, только у меня в пати 4 активных постоянно + окружающие неписи) модель. Со своими минусами, конечно.
Сейчас еще 26б потыкаю.
> То, что реализует маринара, не является агентами в классическом понимании. Она предоставляет детерменированные мультизапросы, т.е. порядок вызова тул-колов определяется алгоритмически, а не самой ллм. В этом плане к этому ближе обычный CoT, тот же stepped thinking из шапки, как пример реализации.
Вот это интересно, кстати. Я не вглядывался. На мой взгляд, автор неплохо постарался на самом деле.
Но как я понимаю, тул колы модель может как вызывать, так и не вызывать (рисовать картинки по своему желанию, устраивать битвы и т.д.) — так что, на мой взгляд, таки вполне агенты.
Но не буду спорить!
> Да, как мне кажется, ризонинг попросту не нужен в рп на новых моделях
Я вчера ультовал, но надо будет попробовать отключить, возможно ты прав.
Да, 46к рублей в августе, очень дорого это было… пу-пу-пу… Нам пришлось раскошелиться…
Которую я брал в днсе — уже за 200. хд
База, мы так, бомжи, которые чуть вовремя расстарались, и то случайно, зачастую.
Че думаешь, слить на авито за 300к потом? :)
Ладно, попиздовал я без ризонинга на 26b страдать. Зато 170 тпс, даже Маринара перестанет быть долгой.
Нужны тебе, если ты не видишь как твой квен в ризонинге пишет "не буду писать за юзера" а потом имперсонейтит и срет под себя
неудивительно впрочем, тыж как ребенок в песочнице модельки по цифрам измеряешь
Ваще-та QClaw!
А MiniCPM5-1B ну ваще жара, но это тайна.
>Цыфорки же решают
с оговорками, но да
бенчедрочер мимошёл
Они не про бенчи, а про размер модели.
Типа, llama-3-70b до сих пор ебет step-3.7-flash, потому то 3*70 это 210, а 196 это 11 (активных). 11 меньше 210. Понял?
Напомню, что по бенчам Квена 3.5 27 обходит 235. Ебало 235-шиза представили?

>Да, 46к рублей в августе
Я тем летом взял 64гб ддр4 за ~8к рублей со всеми скидками и бонусами озона. Думал пересижу еще годик на старой пекарне с эйром в Q4, а потом соберу новую со 128 ддр5, 5080 super 24gb.. Бля, каким же идиотом я был.
Проиграл с поехавшего, вот это "моя борьба"!
В чём он не прав? Квены действительно так делают. Инструкциям в рп хорошо следуют только жирноглмы и Гемма.
мимо
Человек просто физически не может запустить что-то крупнее 27-30b и происходит мощнейший коупинг, что оно НА САМОМ-ТО ДЕЛЕ ХУЖЕ и вообще НИНУЖНО. Защитная реакция психики, чтоб её.
Шиз, я даже сейчас не буду спорить о графоманстве моделей.
Но ты имеешь возможность запускать 235 в Q8? Потому что иначе, ты лишь посмотрел на циферки и теперь бегаешь с этим как с писанной торбой.
Охуеть какое дело, агентская малыха хороша как агент. А знаешь что еще ебет по бенчам? Минимакс ебанный, но ты и тут нищета чтобы его запускать в нормальных весах.
Так что иди нахуй со своими бенчами, если ты настолько тупой, что умудряешься сравнивать несравниваемое.
Никто на 235 не кодит, сраный ты дегенерат.
Минутка ненависти окончена.
Действительно, именно из больницы в тред и явился. Здоровья тебе, поехавший.
И тебе не болеть.
Почесал за ушком.
> А знаешь что еще ебет по бенчам? Минимакс ебанный
У меня во фришках есть minimax/minimax-m3
На практике я бы сказал, что он хуже deepseeek4-flash
Но я исключительно фри эндпоинтами пользуюсь, может у меня он резанный q4 от провайдера - я хз.
>а потом соберу новую со 128 ддр5, 5080 super 24gb.. Бля, каким же идиотом я был.
Да кто же знал, что все ебанутся? Вон нахрена они сейчас строят датацентры эти - чтобы что? И нынешних вычислительных мощностей хватает платным клиентам и не особо они окупаются. Ещё и экономику наебнут, когда пузырь лопнет.
Qat на 16гб. Гемма 4 26б абсолютная победа. Она весит 13.9 туда залетает mtp, скорость ту зе мун и это всё позволяет включать ризонинг не ограничивая его длинну.
На 31б плохо, 17,7 гигов сомнительный профит по скорости особенно на 128 шине, если обычные на 17,3 и 18,6 не имеют проблем. Ниже четвертого кванта qat у меня вообще поломанная была, спамила тегами мышления. Возможно в будущем измениться а пока только mradermacher их делает но он их не запускает для теста так бы увидел что половина не работает вообще.
На 31б плохо, 17,7 гигов сомнительный профит по скорости особенно на 128 шине, если обычные на 17,3 и 18,6 не имеют проблем. Ниже четвертого кванта qat у меня вообще поломанная была, спамила тегами мышления. Возможно в будущем измениться а пока только mradermacher их делает но он их не запускает для теста так бы увидел что половина не работает вообще.
>Никто на 235 не кодит, сраный ты дегенерат.
На русском он классно порнуху пишет и ума не теряет. Заметно, что датасеты не чистили. Для другого и правда почти не годен.
Увы. Это последняя порномодель которую выпускали для работяг. Сейчас большие монетки пишут лучше по уровню языка, но совершенно скупо. Plap plap потеряны, братья, оварида десука, ёпта.
>монетки
Модельки* фиксим, фиксим.
Гемма 31 литералли лучше для кума, чем 235
>Но ты имеешь возможность запускать 235 в Q8? Потому что иначе, ты лишь посмотрел на циферки и теперь бегаешь с этим как с писанной торбой.
Нет, не имею такой возможности. Имею возможность запускать Q5 235 и Q5 27 и вижу своими глазами, что 27 лучше. По цифрам вижу, что 27 лучше. На что еще мне посмотреть? Ты раз в месяц регулярно врываешься со своим альтернативно-одаренным мнением и разводишь срачи, хотя ни разу не принес НИ ОДНОГО лога. Вопрос: ты долбаеб и тебе заняться нечем?
> Имею возможность запускать Q5 235 и Q5 27
Конечно, конечно. Имея возможность 235 запускать в Q5, ты 27 держишь в 5 кванте. Охуительные истории. Ты не стесняйся, сразу пиши что в Q2 его разъебывает.
Я просто тебе неполживому напомню, что там активных всего 22b.
> Ты раз в месяц регулярно врываешься со своим альтернативно-одаренным мнением
Пока я не написал что пишу пару раз в месяц, я у тебя чуть ли не каждую неделю срач разводил.
> НИ ОДНОГО лога
Как и ты, анон, как и ты.
Вот аноны пользуются 235, подрубают когда хотят покумить, но только ты познал дзен 27. Ваааалшебник, не иначе. Носок с камнем сам сделаешь.
Что-то я не так с embedded моделями делаю.
Скачал qwen 8b embedded, запустил через llama-cpp с ctx 2048 и почему то он в 4 кванте не помещается в 8vram, начинает в shared memory лезть. Вроде и контекст небольшой? Кто-то сталкивался с таким?
Скачал qwen 8b embedded, запустил через llama-cpp с ctx 2048 и почему то он в 4 кванте не помещается в 8vram, начинает в shared memory лезть. Вроде и контекст небольшой? Кто-то сталкивался с таким?
>Имея возможность 235 запускать в Q5, ты 27 держишь в 5 кванте.
В чем противоречие? У меня 32 + 128. Q5 235 влезает с 64к контекста, Q5 27 с 120к контекста, я его так и использую и держит он его очень хорошо.
>Ты не стесняйся, сразу пиши что в Q2 его разъебывает?
Q2 здесь причём?
>Я просто тебе неполживому напомню, что там активных всего 22b.
Ага. Ииииии? Что это должно значить?
>я у тебя чуть ли не каждую неделю срач разводил.
Поиск протыков пошёл?
>Как и ты, анон, как и ты.
Да много раз приносил на самые разные модели. И другие приносили и на 235, и на 27.
>Вот аноны пользуются 235, подрубают когда хотят покумить, но только ты познал дзен 27
Эти аноны с тобой в одном треде? Или все таки в голове?
Как минимум эту точку зрения разделяет автор гайда с шапки лол сорян что приплетаю, анон, но как ещё изгонять ебанутых демонов шитпостеров?
Вводные такие;
Ты один единственный шиз кто семенит про 235 и не приносит логи. Итог: надо либо завалить ебальник и принять реальность либо свой громкий пиздёж чем то подтверждать. Где логи пресеты? Или ты типа думаешь что сила твоего слова настолько велика что перестроит реальность?
>Имея возможность 235 запускать в Q5, ты 27 держишь в 5 кванте
Имею возможность запускать 235 в Q2 и собсна запускаю для кума. Новые квены совсем залупа какая-то. Ассистенский биас, ебанутая цензура, ебанутый ризонинг. При наличии Геммы в том же размере - просто не нужны.
другой анон
Каждый раз когда ты залетаешь со своим "ммм какой Квен 235 ахуенный" все заканчивается одинаково. Тебя справедливо просят подкрепить свой мягко говоря сомнительный тейк хоть чем-нибудь, в итоге ты несешь какую-то хуйню и под конец выливаешь в тред бидон желчи. Иди нахуй, говно.
https://www.sourcepulse.org/projects/29732850
https://github.com/zhinianqin/flash-attention-v100
Выглядит будто бы собрали и запустили.
Кто-то тестил? Работает лучше ванильного vllm на v100?
https://github.com/zhinianqin/flash-attention-v100
Выглядит будто бы собрали и запустили.
Кто-то тестил? Работает лучше ванильного vllm на v100?
>сомнительный тейк
Запускаешь модель @ пишешь. С ним нет никакого гигапердолинга. Все пресеты что я притаскивал лежат у хомячка на пикселе, но ты слишком тупое говно чтобы открыть свои глазки. И нет, я не собираюсь скидывать логи сраной порнухи, потому что это тупо и это проверяется банальным запуском самой модели.
>Как минимум эту точку зрения разделяет автор гайда с шапки лол
Ку уже нужно делать? Или какой положняк нынче?
>Где логи пресеты?
Все было скинуто и не раз. От пресетов, промтов до паков карточек. Сорян, но я не собираюсь как кукушка повторять одно и тоже действие.
>я не собираюсь скидывать логи
>Все было скинуто и не раз
Слив засчитан. Вопрос нахуя ты устраиваешь срачи своими вбросами остается открыт, да и похуй. Записан в шизы и говно наравне с эйроидиотом. Вы на одном уровне
> Слив засчитан
Хорошо. Объясни, почему твой тейк что 27b лучше я должен воспринимать за истину? Или доказывать исключительно только тебе надо, а все твои слова неполживая истина?
Это не мой тейк, ты общаешься с как минимум двумя анона, мб больше даже. Мой тейк в том что ты регулярно высираешься в тред и получаешь одну и ту же обратную связь (справедливую), но это тебе не останавливает от того, чтобы плодить еще больше срачей. Не знаю кто тупее, ты или тредовички которые каждый раз ведутся. Одного эйрошиза нам мало, ага
>твой тейк что 27b лучше
Ты пропустил мой тейк, что 31B лучше.
Мимо с глм->гемма
Лол, ну ты же вступил в беседу, так что не ссылайся на других. Чилавек лигивон.
Если 27b лучше ты же сам легко это запруфаешь, не так ли ? Или уйдешь в семенство и в верчение жопой?
Каждый раз одно и тоже
>235 отлично пишет порево
>27 лучше
>где?
>ололо квеношиз
Ну покажи мне где он ебет, разъеби меня хоть раз фактами чтобы я заткнулся. Это же легко.
Не, я не вступал в беседу, я нассал тебе на ебало за то что ты устраиваешь срачи и регулярно высираешься в тред. Жопой виляешь здесь ты и намеренно агришь на себя тред или у тебя настоящие траблы с головой. Будь я мочой давно потер бы тебя
То что между 235b и 27b лучше именно 235b - это очевидно и доказательств не требует. А вот то что 27b задроченный на ассистенство лучше в РП чем 235b с кум-датасетами - это напоминает траленк и вброс. Тот кто писал про это пусть и доказывает вместе с логами (доказательство - бремя утверждающего, не так ли?)
Может потому что 31b это умница ассистент и в этих задачах она лучше? Может ты пряники мятные считаешь, зачем тебе глм.
Ну в общем кроме унылого оскорбления, ты не способен подкреплять свою позицию. И все что можешь это бессильно пукать?
Вот это я понимаю конструктив.
> нассал тебе на ебало
Пока что ты нассал себе в штаны.
Здравствуйте, многоуважаемые посетители имиджборда 2ch.
Корпосетки окончательно зацензурились в связи с чем хочу вкатится в локальные модели, железом хорошим не обладаю поэтому хочу арендовать железо.
Подскажите, оправдано ли это?
И что нынче считается топом для кума?
Корпосетки окончательно зацензурились в связи с чем хочу вкатится в локальные модели, железом хорошим не обладаю поэтому хочу арендовать железо.
Подскажите, оправдано ли это?
И что нынче считается топом для кума?

>То что между 235b и 27b лучше именно 235b - это очевидно и доказательств не требует
>А вот то что 27b задроченный на ассистенство лучше в РП чем 235b с кум-датасетами - это напоминает траленк и вброс
>Тот кто писал про это пусть и доказывает вместе с логами (доказательство - бремя утверждающего, не так ли?)
Как удобно, что между 235b и 27b лучше именно 235b - это не утверждение и потому доказательств не требует
>между 235b и 27b лучше именно 235b
Потому что это модели от одного разработчика и между выходом прошло всего полгода. При таком незначительном временном разрыве фраза "235 лучше в РП" звучит вполне себе оправдано и солидно.
Больше параметров = больше знаний, больше "мозгов". Это буквально база. Чего такого изобрели квен за полгода, какие космические технологии, что модель почти в 10 раз меньше стала лучше их же милфы?
По известной формуле, МоЕ 235б а22 ~ 45б плотной, это очевидно и доказательств не требует.
27б новее, но конечно до 45б не дойдет. Вот если бы в плотняше хотя бы 40б параметров было, то это уже было бы конкуренцией реальной
>Ты один единственный шиз кто семенит про 235 и не приносит логи.
Он не один, как минимум я тоже одобряю 235. Хотя и не запускал её давно. И вот еще один, который запускает в Q2
Так что мне кажется что шиз тут ты
>Где логи пресеты?
Байт на пресеты пошел, лол.
Неправ в исходном утверждении, неправ в том, что выплескивает в тред свои проекции. Инструкциям могла следовать еще альпака на первой лламе.
С агрессивности этого коупинга и манямирка за ним можно только ахуевать.
> в Q8
Зачем такое? Если фуллврам то это в корне бессмысленно, если с выгрузкой - там между q6 и q8 разницы не будет, зато скорость приятнее.
А 235 вполне себе норм модель для рп, не для всего, но в некоторых сценариях отлично пишет. Даже по современным меркам неплохо, можно смело закидывать в рандом пулл или ставить основной если знаешь что подходит под сюжет.
А что выбрать какую-нибудь слабо зацензуренную (или ломаемую джейлом) средненькую модель у провайдера с опенроутера не варик?
Если у тебя не 256гиг (а то и больше) риг то модели которые ты сможешь запустить могут показаться очень каловыми
Локалки тоже зацензурены в салат, и из них вычистили все срамные тексты из датасета, плюс надрочили отказывать.
Да, это жозенько, но корпам не нужно, чтобы во время презентации биг боссам или проверяющим чиновникам модель высрала крамолу. Там могут и премии лишить, и посадить за изготовление и распространение прона.
Так что терпи и дропай рп и ерп, качай opencode и замещай кодеров.
>железом хорошим не обладаю
Для геммы 26В достаточно любой видеокарты и 16 гб рам.
> Почесал за ушком.
А меня, а меня?!
> единственный шиз
Этим называли и меня, и еще как минимум трех разных человек. Кажется что настоящий шизик тот, кто разводит все эти срачи с радикальным максимализмом, тогда как разные аноны отмечают плюсы и минусы. Сценарий и тейки одни и те же, варьируется только наброс с которого начинается проход в квен или что-то еще.
> лучше именно 235b
Ну, кодить лучше 27б, точнее и нет лишнего. На ассистенте даже хз, 27вроде свежее и более аккуратно жонглирует доступным, но 235 иногда выдает ультрадушевную милоту с которой очень приятно, при этом выполняя задачу. Но слишком уж много жрет памяти, тут 27 или 122 рациональнее.
>и из них вычистили все срамные тексты из датасета
Пиздеж, гемма явно на порнухе училась. Да и из больших моделей никто ничего не убирал.
> Потому что это модели от одного разработчика и между выходом прошло всего полгода
Странная аргументация. 235 пережарен, это знают все, кто его запускали. Иногда это на пользу, но часто - нет. Про полгода и вовсе бессмыслица, потому что есть большая разница между Квеном 3, архитектурой Next и последующей 3.5. Все Квены 3 были пережарены, в общем-то, не только 235. 3.5 не пережарены и их архитектура значительно продвинулась по сравнению с 3, как утверждают сами разработчики Квена.
> Больше параметров = больше знаний, больше "мозгов". Это буквально база.
Существуют бенчмарки и тесты, которые позволяют эти "знания" измерить, и как выше отметили 3.5 27б по этим тестам превосходит 235. Даже по Human's Last Exam, который как раз пытается тестировать знания в самых разных сферах, и даже на момент выхода 235 обладал неприлично малым количеством знаний для своего размера, настолько он неудачен в этом смысле.
Тут проблема в другой плоскости совершенно. У 235 есть свои юзкейсы, но то, как ты приходишь сюда и вбрасываешь свое мнение только ради того, чтобы посраться - неадекватно. Принимай то, что не все разделяют твои вкусы, либо будь вменяемой стороной диалога и подтверждай свои тезисы хоть чем-то.
мимо тоже считаю, что 27 лучше, чем 235, даже приносил логи-сравнения
Сап, анонсы. Я полный ноль в ллмках. Что мне надо: мне надо, чтобы нейросетка могла распознать текст на скане/фотке документа, по моему промту изменить его и выдать мне в формате ворда/экселя.
Компьютер: штеуд12700, 4070ти (12гб памяти), 32гб оперативы ддр4.
Есть варианты как-то это нормально сделать, желательно с вменяемым графическим интерфейсом, чтоб мне не надо было какой-нибудь питон устанавливать, тыщи команд во всякие терминалы вводить и т.д.
>3.5 не пережарены
Так не пережарены что лупятся в ризонинге "wait let's check again" по 10к токенов.
>даже приносил логи-сравнения
Ну так запости еще раз.
Мимо
>По известной формуле
>это очевидно и доказательств не требует
Шиз, таблы. Формула кусок говна без доказательств.
>Хотя и не запускал её давно.
Да, охуенная сетка, но нахуй никому не нужна, всё так.
>плюс надрочили отказывать
Особенно гемму 4, ага.
>выдать мне в формате ворда/экселя
Сетки не могут генерировать файлы, только текста.
>тыщи команд во всякие терминалы вводить
Тогда мимо, ибо твой запрос решается только программированием кучи обвязок.
Kobold.cpp + OpenWebUi
Первое в пару кликов ноубрейн запускает модель, второе дает фронт с мощным функционалом с интерфейсом для идиотов.
Из моделей подойдет гемма 26-31B, но удостоверься что запускаешь с mmproj, доп моделькой распознавателем картинок.
> Так не пережарены что лупятся в ризонинге "wait let's check again" по 10к токенов.
У меня ни разу такого не было за все мои чаты на суммарно более, чем два млн токенов. Или у тебя сломанный инференс, или промпты с кучей сущностей, что запутывают сетку, либо на худой конец скилл ишью - можно использовать reasoning-budget, если все совсем плохо.
> Ну так запости еще раз.
У меня нет цели подливать масло в ваши пердаки, прошу меня извинить.
Крч локалко-положняк на сегодня. Кодоунитазинг, агентоблядство, последний квен 27b. Писики, сисики, поболтулечки, Гемма 26\31b. thread/
>Да, охуенная сетка, но нахуй никому не нужна, всё так.
235 хуже большого GLM/квена 397, в которых нет её проблем с форматированием. Но для тех кто не могут запускать GLM/397 - там 235 актуальна.
>то, как ты приходишь сюда и вбрасываешь свое мнение только ради того, чтобы посраться
Так это другой анон срётся. Я вообще тот хуй с Q2, лол, и использую милфоквен под кум вместе с эйром и геммой 4. Новые квены, что 27b, что 122b мне не понравились совершенно. Цензура сложнопробиваемая (на пустом контексте), ризонинг вообще использовать невозможно - там ОГРОМНЫЕ бессмысленные простыни. Ну и субъективно по "мозгам" 27b проигрывает 31b гемме. А что касается 235b - там просто "сел и поехал", кум сочный, душевный, слоп слог нравится. Ладно в плане ассистента, но чем 27b может быть лучше милфы в рп/куме, в упор не понимаю. Скоростью разве что.
>Корпосетки окончательно зацензурились
DeepSeek v4 отлично пишет порно на мой непритязательный взгляд.
Хотя хз, что там у тебя за фетиши.
>Сетки не могут генерировать файлы, только текста
Ну хуй с ним, а оно сможет выдать мне текст, который я просто копировать в пустой документ смогу? Ну только с разметкой прям вордовской, с табличками, жирный, курсив етц.
Блин грустно, неужели нет какого-то тюна, или тип того?
Раньше Гемини была хороша а щяс даже на несчастную пощёчину ругается, ставил и джейлы и хуейлы, везде костыли, я помню раньше ставил тюн на какую-то лайт версию и вроде ок было.
3060 у меня и 32 гб ОЗУ, вот и думаю арендовать яет
>Шиз, таблы. Формула кусок говна без доказательств.
И чем мой стейтмент отличается от
>То что между 235b и 27b лучше именно 235b - это очевидно и доказательств не требует.
Я с ним не спорю, но оба утверждения основаны только на ощущениях. Вот я лично ощущаю, что конкретно в РП производительность МоЕ и дэнсов можно сравнивать по такой формуле (active MoE param amount + (full MoE param amount)/10; in this case 22b + 235b/10 = 45.5b equivalent dense)
Но это вообще из моей жопы вытащено, ровно как и утверждение про то, что жирноквен МоЕ лучше скинниквена дэнс для РП конкретно, потому что а как ты блять это сравниваешь? Чисто так, что тебе чаты с жирноквеном больше нравятся. У тебя может быть байас к этой модели, потому что тебе нравится ее стиль письма, например, а это вообще исключительно вопрос предпочтений.
А мне чет совсем не понравилась Гемини была в разы артистичнее, но ее зацензурили нещадно
>Ну только с разметкой прям вордовской
Макдаун там будет. Впринципий, таверна его отрендерит как html, а он при копировании бровзером и вставкой в ворд может быть распознан нормально. А может и нет, и придётся вайбкодить конвертёр.
>И чем мой стейтмент отличается от
Ничем, оба пиздабольство, лол.
>Чисто так, что тебе чаты с жирноквеном больше нравятся.
Я геммафаг если что, нравится отсутствие цензуры из коробки.
А я хочу топ, хочу качественный кум и бабки готов заплатить, ток не понятно куда
Мифос выйдет завтра, и сможешь покумить всласть. А тут лишь пускающие слюни лоботомиты.
Mythos nods.
А он точно умненький будет?
Мне просто надо что бы не только циферки считал и взламывал Пентагон, а еще и мог написать красиво как няшимся под одеялком
Билят, ну +- такой же функционал есть и на диписике/чатжпт в онлайне. Мож тогда и не стоит заморачиваться локалками?
Так а че с геммой, ее прям активно в треде обсуждают может на неё есть клевые тюны со всякими извращениями?
В этом их тикитоке с месяц назад пиариили полностью анцензуренную модель, не помню название, что за неё анон скажет? Например сможем с ней в ГтаРП ролеплеить расчёты кумулятивных конусов или утилизацию 90 килограммовых куриц? Или такая инфа по умолчанию в датасете отсутствует?
Просто на развес отдавали. Даже без бонус, все равно копейки за 64 гига ддр4.
А щас даже 32 на комп не наскрести вменяемо.
ОЛАДЬИ УГАШЕННЫЙ ТЫ ОБ ДЕРЕВО
Дипсик вообще говно, на самом деле. Хз, может тебе не фартануло? Мне М3 в общем норм.
Но вот М2.7 он разочаровывающий. В рассуждениях хорош, но дальше решения логических задач — какой-то ступор. Будто М2.5 и то лучше был в агентике и коде. Фиг знает, может мне тоже десять раз не повезло его использовать.
Короче, дипсик в принципе говно, а минимакс слишком дрочат на бенчи, модель хорошая, но не настолько, к сожалению.
Нет, у меня все лезло, как по расчетам.
> По известной формуле, МоЕ 235б а22 ~ 45б плотной, это очевидно и доказательств не требует.
Ржу до соплей просто.
Чувак, известная формула, это сумма мое делить на два. А скока там активных в формуле не участвует. Т.е., квен 235б мое был НА ТО ВРЕМЯ равен 117б плотной. Все, блядь, нахуй.
С тех пор тыщу раз пересрались, одних квенов три поколения сменилось, навыходили дипсики, мистрали, геммы, мимо, степы и прочие эрни.
Я не участвую в вашем споре, мне кардинально параллельно насколько хорош квен 235б на 10 тпс в ерп, правда.
Просто формула всю жизнь была total parameters / 2, или около того, а количество активных минорно влияло в ту или иную сторону.
И до сих пор многие знакомые так же считают, и это совпадает.
Даже блядская гемма на 12б чуть слабее, чем гемма на 26б (которая должна быть равна 13б), что охуенно подтверждает формулу.
Какие еще в пизду active * 2, ты с дуба рухнул. =)
Куча вариков, но никто не делает «просто приложением», потому что это никому нафиг не впилось, кроме тебя и таких как ты, а вы не делаете потому что не можете. Ну вот так и не повезло.
Я не помню, что хорошо поддерживает таблицы.
Любая VLM в общем подойдет.
Но формат Markdown будет.
> Формула кусок говна без доказательств.
Не, формула норм, просто она другая, а во-вторых, применима в рамках одной линейки и одного поколения. С геммой 4, например, отлично сработала, и с квеном 3 (когда еще был 14б) тоже отлично работала. А мерять за пределами линейки и поколения — ну просто невозможно, конечно.
———
Короче, я попробовал в Marinara Engine Gemma-4-26B-A4B-QAT с ризонингом и без.
Без ризонинга в GM режиме совсем хуйня (зато 4 секунды на ответ), с ризонингом ну явно проседает, хотя в целом играбельно (кстати, 10-12 секунд на ответ).
Но я останусь на 31б плотняше, скорее всего.
А вот 26б попробую для диалогов или ролеплея.
Вот на мой вкус, 26б прям сильно хуже 31б модели.
Но, тем не менее, есть куда применить. Скажи, а какие настройки MTP для геммы оптимальные? Че там по топ_п и че там по токенам?
Может даже команду подкинешь для правильного запуска?
>Твоя формула хуйня
>Вводит другую бессмысленную формулу
Хех. А я уже и забыл как я не скучал по этой плесени =)
Накатим!
> Ржу до соплей просто.
АФФТАР РЖОТ!
Бля или как там у них было, ЖЖОТ
> чтобы нейросетка могла распознать текст на скане/фотке документа
Да
> по моему промту изменить его и выдать мне в формате ворда/экселя
Несколько сложнее, но да. Не для нубов.
Для начала запусти по гайду для новичков ллм, туда же можно будет скинуть пикчу и поиграться. А чтобы дать возможность сетке что-то самой писать и редактировать, тем более в определенные форматы, придется это все оборачивать в скрипты, или делать агентов.
После того как с запуском разберешься - поставь openwebui. Будет довольно тяжело, но самые первые вещи там освоишь. А так юзай пи, квенкод, опенкод или подобные вещи, они тебе и код напишут, который конвеер автоматизирует, и его запустят.
Готовые решения наверно есть, но будут всратым вайбкодом, лучше самому разобраться.
> по такой формуле
Ебанулись наотличненько, уже формулы придумали.

MTP сломан на ламацпп последней версии? Как ни крутил похоже он не запускается
[34m0.00.255.568[0m [32mI [0msrv load_model: loading model 'D:\ai\llmModels\gemma-4-31B_q4_0-it-QAT.gguf'
[34m0.01.379.438[0m [31mE llama_init_from_model: failed to initialize the context: Gemma4Assistant requires ctx_other to be set (this is normal during memory fitting)
[0m[34m0.01.441.737[0m [35mW srv load_model: [spec] failed to measure draft model memory: failed to create llama_context from model
[0m[34m0.01.441.761[0m [32mI [0mcommon_init_result: fitting params to device memory ...
[34m0.01.441.761[0m [32mI [0mcommon_init_result: (for bugs during this step try to reproduce them with -fit off, or provide --verbose logs if the bug only occurs with -fit on)
[34m0.03.215.516[0m [35mW load: override 'tokenizer.ggml.add_bos_token' to 'true' for Gemma4
[0m[34m0.03.244.284[0m [35mW load: control-looking token: 50 '<|tool_response>' was not control-type; this is probably a bug in the model. its type will be overridden
[34m0.00.255.568[0m [32mI [0msrv load_model: loading model 'D:\ai\llmModels\gemma-4-31B_q4_0-it-QAT.gguf'
[34m0.01.379.438[0m [31mE llama_init_from_model: failed to initialize the context: Gemma4Assistant requires ctx_other to be set (this is normal during memory fitting)
[0m[34m0.01.441.737[0m [35mW srv load_model: [spec] failed to measure draft model memory: failed to create llama_context from model
[0m[34m0.01.441.761[0m [32mI [0mcommon_init_result: fitting params to device memory ...
[34m0.01.441.761[0m [32mI [0mcommon_init_result: (for bugs during this step try to reproduce them with -fit off, or provide --verbose logs if the bug only occurs with -fit on)
[34m0.03.215.516[0m [35mW load: override 'tokenizer.ggml.add_bos_token' to 'true' for Gemma4
[0m[34m0.03.244.284[0m [35mW load: control-looking token: 50 '<|tool_response>' was not control-type; this is probably a bug in the model. its type will be overridden
У кого то опять обострение, срач развели с нихуя.
Я вот скажу так - вчера гемму мое кат щупал в ерп, так она выебывалась. Переключился на просто гемму мое 4 кл, она сразу подхватила и не выебывалась.
Делаю вывод - сломанность обычной версии ломает и триггер цензуры, дообученная кат версия получила более полную версию цензуры.
Кто то еще сравнивал?
Я вот скажу так - вчера гемму мое кат щупал в ерп, так она выебывалась. Переключился на просто гемму мое 4 кл, она сразу подхватила и не выебывалась.
Делаю вывод - сломанность обычной версии ломает и триггер цензуры, дообученная кат версия получила более полную версию цензуры.
Кто то еще сравнивал?
Я просто напомнил, как считали раньше. =) Я не вводил другой формулы, я напомнил единственную.
А вот чел реально на ходу придумал хуйню, о которой кроме него никто не слышал, лишь бы оправдать квен. =D
Ебац, 100 тпс на гемме 31б.
Спасибо, что напомнил, мое почтение!
> Дипсик вообще говно, на самом деле.
У меня 4 флеш крайне хорошо работает через pi как движок кодинг агента.
Возможно дело в харнесс.
Я прям пиздатых моделей толком не трогал бтв, я использую доступное в интернете БЕСПЛАТНО, ну и локальную когда совсем судьба прижмёт)
И я бы сказал что дипсик лучше локального Qwen3.6-35B-A3B-MXFP4_MOE_BF16, который я кручу на 4060 + 90к контекста в 30ток\с, считай... всегда.
Тут в треде в основном в целях генерации текста применяют, поэтому может мы говорим о разных применениях.
Сейчас глобально доступно 45 моделей по бесплатной схеме из которых можно активно пользоваться (они не забиты трафиком) 20. Под вечер число запросов растёт и они перестают отвечать
Есть такое, чуть фикситься это системным промтом, но все равно не хочет описывать как сосет в подробностях, что делает какой-то алибирейтед лоботомит, но он сук тупой
Двачую, развели тут филиал Кащенко, шизы ебучие.
У меня кат версия не рефьюзила, но за заменяла интересное на "same", лол.
У меня все работает. Бери вот эту мтп
google_gemma_4_31b_it_qat_q4_0_unquantized_assistant-Q4_K_M.gguf
https://huggingface.co/Stabhappy/gemma-4-31B-it-qat-q4_0-unquantized-assistant-GGUF/tree/main
Ну, конечно круче.
Но вот Step-3.7-Flash и Xiaomi MiMo V2.5 — уже вопросики.
А почему не OpenCode?
Я, кстати, качнул https://huggingface.co/RachidAR/gemma-4-31B-it-qat-Q4_0-Q4emb-MTP-assistant-gguf вот эту, но они одинаковые, как я понял.
Тоже работает без проблем.


Я тоже не фанат маринары и её агентского подхода, забивать драгоценную видеопамять доп.агентами, которые еще и ломаться будут, потому что ЛЛМ под математику не заточены, особенно те лоботомиты что вы для агентов используете. Я все скриптами в таверне делаю.
Вот как это работает. В World Info в самом конце есть страница статусов персонажа. Гемме данна инструкция смотреть на этот статус и на его основе работать. При этом гемме запрещено самой заниматься арифметикой и высчитывать статусы - надо тупо брать то что записано и работать по этому. Если во время действия меняется параметр - гемма должна написать в конце сообщения дельту (например Стамина: -5, или Отношения с Тян_нейм: +10). Скрипт после сообщения нейронки парсит её сообщение и меняет статусы в World Info, Гемма в следующем сообщении видит уже измененные статусы и работает по ним. И всё. Работает как часы, не нагружает гемму, никаких дополнительных моделей/памяти/вызовов/времени не требует. Есть кнопки, сбрасывающие статусы, пересчитывающие их, есть скрипты, которые отслеживают в юзер сообщении команды и подсовывают в промпт нужные инструкции, например "Чат" в юзер сообщении переходит в режим чата с активными персонажами в зоне, пока юзер или один из персонажей не напишет "конец чата" - все это на чистых скриптах и реюзается для любого сценария, ручками разве что имена персонажей в окне статуса надо забивать, остальное все генерируется по нажатию кнопки. Вот для примера на SFW ролеплее по мотивам детского мультика.
Суп текстогенерач, прочитал шапку, и что-то не пойму, была же где-то сноска про мультигпу в лламе?
Ситуация следующая, увлёкся локальным вайбкодингом искренне получаю от этого удовольствие после 4-х лет нейрокума, даже в 30Т/c. И хобби стало ещё больше нравится, и лишние деньжата появились. Думаю прикупить к моей 4060ti 5060ti как вторую видяху. Как понимаю, просто нужно воткнуть её в мать?
Пиздец, посмотрел, что у меня по слотам расширения, одна псина 3.0 х16, вторая псина 2.0 х4. Думаю теперь взять видяху, пока цены не сильно кусаются, а потом мать добрать мать на уже устаревшем AM4 с нормальными псинами, в чём не прав? Будет же быстрее фуллврам с тензорсплитом, но одна видимокарта на 2.0 х4, или это будет даже медленнее?
Ситуация следующая, увлёкся локальным вайбкодингом искренне получаю от этого удовольствие после 4-х лет нейрокума, даже в 30Т/c. И хобби стало ещё больше нравится, и лишние деньжата появились. Думаю прикупить к моей 4060ti 5060ti как вторую видяху. Как понимаю, просто нужно воткнуть её в мать?
Пиздец, посмотрел, что у меня по слотам расширения, одна псина 3.0 х16, вторая псина 2.0 х4. Думаю теперь взять видяху, пока цены не сильно кусаются, а потом мать добрать мать на уже устаревшем AM4 с нормальными псинами, в чём не прав? Будет же быстрее фуллврам с тензорсплитом, но одна видимокарта на 2.0 х4, или это будет даже медленнее?
> вторая псина 2.0 х4
Увидел такую же ситуацию у анона из прошлого треда. Этот вопрос снимается. Есть ли ещё какие подводные? и как бля расчитать сколько места будет занимать видюха по вот этим "2.5 Pci-e"? Ладно по миллиметрам ещё можно понять что как куда, но это...
Кто там пиздел вчера, что МТП сделает только хуже если не вся модель в врам? У меня 8 гб врам, запустил квенчик 27б q4ks без МТП - получил 3.7 т/с, с МТП 4.8 т/с

> А почему не OpenCode?
Мне посоветовали pi
Я его попробовал
Мне он понравился
+ я планировал когда фри заканчиваются использовать локальную модель, но имею зверски негативный опыт использования локальной модели вместе с cline расширением вскода 30к контекста на НИХУЯ тратится.
А этот 0% контекста юзд при первом обращении
Слышал про opencode, но по факту от них я эндпоинт использую и использую их бесплатные модели через pi.
Может он и хорош
Пока не упирался ни во что кроме разве что отсутствия поиска в интернете и лично я пока медленно ищу как бы к нему картинки присрать и вообще какие варианты бывают

У меня run_Qwen3.6-35B-A3B-MXFP4_MOE_BF16 на 4060 + 32гб рам покзывает 20-30 ток\с
Почему у тебя так плохо?


Потому что это другая модель?
Не, понятно, но 27б же должна весить меньше = перформить лучше когда вирамы немного?
>вместе с cline
Недавно начал вкатываться тоже, перепробывал наверное все расширения, Клин говнище полное, промпт огромный, кастомизация никакая, только если заново расширение пересобирать. Если ещё раз захочешь что-то такое, попробуй Kilo code, очень уж зашёл он мне.
Короче, скажите твёрдо и чётко, переходить на QAT квант геммы с Q4_K_M стоит? QAT весит даже меньше.
У тебя МоЕ модель, в ней всего 3б активных параметров. 27б плотная, все параметры активны всегда.
От них тоже эндпоинт использую)))
Я там где набрать компота писал в вайбкод треде.
Я не хочу тащить Odysseus пьюдипая чтобы понять, что он не умеет в картинки для разработки.
У меня и задачи то клоунские 16х16 текстуры перерисовать
А я прямо противоположное слышал, что в гемини слоп самый надоедливый из всех
Видимо каждому своё
Бро, 18 гигабайт всего. Скачай да проверь.
>Сейчас большие монетки пишут лучше по уровню языка, но совершенно скупо.
Не совсем, большой Квен-3.5 чуть менее сочный, но умнее. Достойная замена.
Все интересные карточки с Чуба пропали. Есть какие-то альтернативы?
К нам сегодня приходил: некропедозоофил.
Мертвых маленьких зверушек, он с собою приносил.
>Есть какие-то альтернативы?
Ну даже не знаю.. шапку посмотреть, например?
>Botbooru - текущая мета (регистрируйтесь для отображения всего спектра, и/или меняйте страну): https://botbooru.com
А какой поинт использовать не MOE?
Визуально 35B > 27B даже при учете того, что активных меньше
Литерально так вижу всех 235 шизиков. Хотя мне трудно поверить что их больше одного максимум двух. Неолуддизм в чистом виде, особенно забавно когда они аутотренят что это обладатели отстутсвия рвутся, которые типа не могут его запустить. Вы себя видели? Столько вони ради вашей любимой няши и вся аргументация - ну зато она большая. Каждый раз как в первый
Да, да. Ведь шизики все кто не разделяет твоё мнение.
Не поверишь, я среди прочих 235 няшу и катаю. Только у меня больше одной мозговой клетки и я не убеждаю весь тред, что к этому говну не надо прикасаться, как это делаешь ты (вы)
Потому что плотная модель всегда лучше
Спасибо!
Я, только писал, что он пишет ебовое порно. Всё блять.
Нигде не было написано что это 10 из 10. Сам порноиисус спустился с неба.
Но ты продолжаешь аппелировать, что я убеждаю в чем то тред. Или будет опять заход что 27ой пишет ебовее кум?
Просто попробуй и сравни. Если бы все было так просто, то все бы делали только МоЕ модели.
Кстати факт, ни одна модель кроме может геммы 3 такого антипиара не получала. Могу но не запускаю этот 235B тупо из-за шизика который им болеет, кекв. Не может он быть хорош если у него такие больные фаны
>ты продолжаешь
>опять заход
Чел, это мой первый пост за день. Или охладись или вернись в палату пж
Катал бф16, не рефьюзила, но кое где красочности не хватало. В рп она очень неоднозначна, с одной стороны может очень круто развивать действия, с другой - тупить и стоять на рельсах что хрен сдвинешь. Можно сказать что некая противоположность мистралю, который очень любит быть лупстралем, но если хорошо стукнуть - понесется как надо и очень разнообразно. Их можно и вместе катать, неплохо дополняют друг друга.
> забивать драгоценную видеопамять доп.агентами
Тут скорее забивать время генерации. Не то чтобы это особо отличается от написанного тобой по сути, и есть возможность также инжектить инструкции в основной промпт вместо отельных вызовов, а потом парсить ответ. А видеопамять - это если хочешь имажген.
Пикчи довольно впечатляющие, костыльно но мощно.
>вся аргументация - ну зато она большая.
Тебе же выдвигали аргументы, честно признавали и недостатки. Но тебе же только посраться. И кто тут шизик?
Ну конечно, конечно. Просто случайно ворвался. Случайно пост написал, случайно проигнорировал суть сообщения. Бывает, хуле.
Ниче ниче, это у 235 лахты в желтом доме послабления, скоро врачи все обнаружат и они затихнут. А пока игнорим шизов
>Не может он быть хорош если у него такие больные фаны
По этой логике к эйру не стоит даже приближаться
>Просто случайно ворвался. Случайно пост написал
Типа да, случайно зашел в тред после работы (как и каждый день) и ответил что думаю по теме. Вы наплодили дохуллиард постов и все их можно свести к ну типа нам нравится а еще оно большое, доказано
Прав, ебанутый думает у него чай вдвоем а не тред
> Вы наплодили дохуллиард постов
> ну типа нам нравится а еще оно большое
Ну если нам нравится и оно большое?
Народ, помогите с настройками для Sillytavern для модели gemma 4 E2B/E4B Скиньте пожалуйста! Спасибо!
>Скрипт после сообщения нейронки парсит её сообщение и меняет статусы в World Info
Можешь объяснить подробнее как это сделать?
Я так понял, что через Regex ты задаешь определенный скрипт, а потом кнопкой задействуешь его, правильно? Или там есть еще какие-то дополнительные расширения? Можешь поделиться скриптами, если не сложно.
Этож ассистенты-переводчики, например, для них юзай рекомендованные гуглом параметры. Для мое-геммы 26 вот неплохой пресетик для Sillytavern. В принципе его и на мелочи можно попробовать.
https://pixeldrain.com/l/47CdPFqQ#item=168
В
Что плохого в том, чтобы что-то котировать? А вот выстраивать манямир коупинга и атаковать все, что может поставить его под сомнение - уже стыдно.
>Вот на мой вкус, 26б прям сильно хуже 31б модели.
Для майндгеймсов на сложной карте да, она похуже.
>Но, тем не менее, есть куда применить. Скажи, а какие настройки MTP для геммы оптимальные? Че там по топ_п и че там по токенам?
Мтп настраивай, вообще высокие работают от 5 хорошо.
>По цифрам вижу, что 27 лучше.
Можно эти цифры посмотреть? Потому что в ерп бенче все большие квены топ, в UGI бенче по всем релевантным для этого обсуждения параметрам (UGI-entertainment, NatInt, Writing) то же самое.
Или ты про кодо-агентосрань, которую ещё на страничках моделек обычно постят?
Зашёл ещё на EQbench и там та же картина. Новых мелкоквенов там нет, сравнил с геммой4 - большие модели лучше почти во всех бенчах
>Можно эти цифры посмотреть?
Конечно. Их сами Квен и опубликовали
https://huggingface.co/Qwen/Qwen3.5-27B#benchmark-results
Instruction Following
HLE
Multilingualism
Необязательно про код. Вот например HLE
>Последний экзамен человечества (англ. Humanity's Last Exam, HLE) — это набор из 2500 однозначных и проверяемых академических вопросов по математике, гуманитарным и естественным наукам, которые были собраны при помощи почти 1000 экспертов-предметников из более чем 500 учреждений в 50 странах.
>Особенностью вопросов является их высокая сложность, но при этом решаемость с однозначным ответом. Например, перевести надпись с римского надгробия, сложность чего заключается в глубоком знании исторического и культурного контекста. Или ответить на вопрос о количестве сухожилий, скрепляющих характерную часть скелета определённого вида колибри.
Это буквально покрывает кум задачи в том числе. 235 настолько плох что проигрывает 27, модели которая почти в 10 раз меньше. HLE 235 прям настолько плох, что они видимо постеснялись его включить, а вот тут он указан https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507#performance
Поэтому ваш аргумент "ну зато большая и знающая" отправляется в помойку, хех. Но я двачану нравится и нравится, но нет вам надо убедить весь тред что вы в своём выборе не ошиблись и модель прям ну точно лучше других
Кстати по поводу UGI бенча, это васянство и уже не раз были вопросы к методологии и тут и на средитах. Почитай подробнее на самой странице UGI, он хотя бы в этом честен, прозрачен и поддаётся оценке тем кто хочет понять
> высокая сложность, но при этом решаемость с однозначным ответом. Например, перевести надпись с римского надгробия, сложность чего заключается в глубоком знании исторического и культурного контекста. Или ответить на вопрос о количестве сухожилий, скрепляющих характерную часть скелета определённого вида колибри.
> Это буквально покрывает кум задачи
Каким образом знание клинописи поможет в куме?
Сдается мне что эти вещи довольно опосредовано влияют на качество кума и рп, если только не появляется совсем уж плохих результатов, что говорит о шизе в модели. Ллм надрачивают на кучу подобных знаний и зирошот ответы, но в рп важнее понимание взаимосвязи сразу множества разных вещей, их ранжирования и правильного учета, а не точности римских сухожилий. Потому ответы мелких моделей поверхностны и охватывают ближайшие простые вещи, которые они узнали. Они довольно скучные и иногда даже неуместные, хотя если изолировать то "правильные". А какой-нибудь немо-мистраль может поддерживать неплохую линию и давать увлекательное и правдаподобное письмо, пусть и очень глупый.
Тут же рядом вещают про кодоунитазы, которые невероятно точные и во всем правильные, это недалеко ушло.
Какие достоверные цифры были опубликованы, такие я и дал. HLE рассказывает не только про клинопись и римские сухожилия, я хз зачем ты высмеиваешь весьма серьёзный бенч на знания всего на свете. На своём опыте я вижу, что 235 это лоботомит, а по знаниям он даже когда был актуален проигрывал Эйру, тот вдвое меньше. Потому его в своё время и скипнули, а сейчас почитаешь средит и другие ресурсы внезапно все сидят на СтепФлеше и Минимаксе. Q5 235 разваливается и ломает персонажей на пороге в 20к токенов, что вообще несерьёзно, Q5 27 у меня держит без проблем до 100к. Опять же, мне похуй вообще что вы там на пъедистал возносите, до тех пор пока меня не заставляете делать то же
>Это буквально покрывает кум задачи в том числе
Нет, не покрывает.
Как я и предполагал, суходроч который на страницах моделей пишут. Топ пересказывателей википедии.
Именно для этого я и чекнул сразу три относящихся к изначальной теме разговора бенча. А не кодинг, не пересказ википедии и не дроч тулколлов.
Я знаю что есть ещё какой-то сайт где люди вслепую тексты оценивают и из этого составляется топ, если кто помнит где это можно там чекнуть (но ерп там вроде не было)
>Нет, не покрывает.
>Топ пересказывателей википедии.
Прикольное противоречие, учитывая про на википедии полно информации про анатомию, про различные болезни, состояния, одежду, культуру и много что ещё используется в куме. Сразу видно когда чел просто дал себе установку, что он прав. Хорошо, есть какие-то надёжные цифры а не UGI васянство где драммерослоп и лоботомитные васяноаблитерации в топе? Показывай
>ряяя наш 235 умница и много знает, лучшая умница на свете
>но ведь сами разрабы квена математически доказали, что 27 знает больше...
>ряяя их математика не математика, наш 235 охотнее пишет "пися" и лучше справляется
Ор нахуй. Им уже полдня пишут что проблема не в том что им модель нравится, а в том что они отрицают действительность. Хоть на Лламе 8б дрочите, прогресс идёт вперёд, время не стоит. Нахуя вы набрасываете весь день, не заебались?
>но ведь сами разрабы квена математически доказали, что 27 знает больше...
>ряяя их математика не математика, наш 235 охотнее пишет "пися" и лучше справляется
Ор нахуй. Им уже полдня пишут что проблема не в том что им модель нравится, а в том что они отрицают действительность. Хоть на Лламе 8б дрочите, прогресс идёт вперёд, время не стоит. Нахуя вы набрасываете весь день, не заебались?
>3060 у меня и 32 гб ОЗУ, вот и думаю арендовать яет
Так просто поставь себе гемму 26 по гайду из шапки, нормально у тебя работать будет, зачем арендовать.


Ну вот смотри, есть Quick Reply скрипты, которые отрабатывают при определенных условиях.
Ну вот например скрипт на режим чата. И скрин как оно работает.
Execute before message generation - означает что скрипт отрабатывает перед генерацией сообщения.
Скрипт смотрит последние сообщения юзера и модели на слова триггеры и если находит - то инжектирует в промпт доп. инструкцию.
Сам скрипт:
/inject id=chat_mode "" |
/pass {{input}} |
/setvar key=cm_current_user |
/if left=cm_current_user right="" rule=eq {:
/pass {{lastUserMessage}} |
/setvar key=cm_current_user
:} |
/pass {{lastCharMessage}} |
/setvar key=cm_last_ai |
/pass {{getvar::cm_current_user}} |
/regex name=DetectChatPrefix |
/setvar key=cm_chat_check |
/if left=cm_current_user right="Конец чата" rule=in else={:
/if left=cm_last_ai right="Конец чата" rule=in else={:
/if left=cm_chat_check right="CHAT_ON" rule=in else={:
/if left=cm_last_ai right="[ЧАТ]" rule=in else={:
/pass
:} {:
/inject id=chat_mode position=chat depth=0 Режим чата продолжается. Начни ответ строкой [ЧАТ]. После этого ответь только прямой речью персонажа или коротким обменом репликами персонажей текущей сцены. Если необходимо - вставь краткое описание действия в скобках. Формат: Имя персонажа: реплика (действие). Общий объём ответа — максимум один короткий параграф и не больше 300 слов на фразу одного персонажа(говорить могут несколько персонажей). Время сцены не продвигается. Варианты действия в конце не пиши. Если персонаж не хочет продолжать разговор, он может закрыть режим чата фразой: Конец чата.
:}
:} {:
/inject id=chat_mode position=chat depth=0 Пользователь включил режим чата. Начни ответ строкой [ЧАТ]. После этого ответь только прямой речью персонажа или коротким обменом репликами персонажей текущей сцены. Если необходимо - вставь краткое описание действия в скобках. Формат: Имя персонажа: реплика (действие). Общий объём ответа — максимум один короткий параграф и не больше 300 слов на фразу одного персонажа(говорить могут несколько персонажей). Время сцены не продвигается. Варианты действия в конце не пиши. Если персонаж не хочет продолжать разговор, он может закрыть режим чата фразой: Конец чата.
:}
:} {:
/pass
:}
:} {:
/pass
:}

> я хз зачем ты высмеиваешь весьма серьёзный бенч
Я хз зачем ты имплаишь за других то чего они не делали. Там рассуждения о применимости и интерпретации таких бенчей, даже без выводов.
> Q5 235 разваливается и ломает персонажей на пороге в 20к токенов
Интересно в чем причина такого, ведь именно стабильная работа с контекстом и удержание персонажей было среди сильных сторон модели. Катал на нем до 100к, вполне себе. Возможно он подходит не для всех персонажей, внося в отдельные характеры свой байас, и в целом он не под каждый жанр и экшн подходит сам по себе при наличии других, но чтобы прямо на все распространять.
> внезапно все сидят на СтепФлеше и Минимаксе
А вот это довольно удивительно, особенно учитывая как работает минимакс.
> что вы там на пъедистал возносите
Хз кто там что возносит. Наблюдая за сотней постов срача днем - один поехавший, может двое, убеждают все что они в своем хейте точно не ошиблись, а все кто не согласен - шизики. Причем настолько агрессивно, что разных анонов цепляет, мнений достаточно прозвучало.
Прочитало между строк твою любовь к фембоям!

A surprise, to be sure, but a welcome one
Про надрачивание квена на тесты уже анекдоты ходят, анон...
Что запустить можно на андроиде с 16 гигами озу?
Гемма e2b, e4b
Что вообще такое эта Е4Б кто-нибудь может объяснять? Рили не шарю
>4.5B effective (8B with embeddings)
Это типа мое чтоль? Для чего годится, гонял кто? На неё тоже qat есть, видимо на телебонах гонять
мимо
А что за spec draft n max? Как понять то сколько ставить? По тестам скорость нихуя не меняется...
А я так и не понял. Второй день разбираюсь. Почему ни лламацпп ни кобольд, новейшие версии ествественно, не знают что такое ассистент и не дает, чтобы мтп заработал?
llama_model_load: error loading model: unknown model architecture: 'gemma4-assistant'
llama_model_load_from_file_impl: failed to load model
llama_init_from_model: model cannot be NULL
Error: failed to load speculative decoding draft model 'E:/gemma-4-26b-A4B-it-assistant-IQ4_NL.gguf'
Speculative Decoding will not be used!
Starting model warm up, please wait a moment...
llama_model_load: error loading model: unknown model architecture: 'gemma4-assistant'
llama_model_load_from_file_impl: failed to load model
llama_init_from_model: model cannot be NULL
Error: failed to load speculative decoding draft model 'E:/gemma-4-26b-A4B-it-assistant-IQ4_NL.gguf'
Speculative Decoding will not be used!
Starting model warm up, please wait a moment...
А вообще получается старый квен 3.6 27б удалять? По сути нету смысла не MTP теперь держать.
Потому что старые ассистенты назывались gemma4 а qat асистент называется gemma4-assistant. Тебе нужно собрать ламму из исходников они ещё вчера это починили.
Братан, используй https://huggingface.co/am17an/Gemma4-31B-it-GGUF отсюда ассистента
Дело в том, что это не QAT ассистент и гемма. Я тот и тот пробовал. Любую которую качаю не работает. Сработала только одна, от какого-то супера. Решил повторить результат, снова нихуя не работает. Чтож попробую использовать прям то, что работало вчера. Ибо результат не понравился, стало хуже. А хуже от того, что кобольд дает мне без мтп 15-17 т\с, когда лламацпп без мтп 11-12. А вчера только на лламе запустилось мтп и я получил те же 11 т\с
> Если во время действия меняется параметр - гемма должна написать в конце сообщения дельту (например Стамина: -5, или Отношения с Тян_нейм: +10).
Поздравляю, ты изобрел маринару.
Ну, то есть, то, что ты делаешь это регуляркой, не сильно отличается от агенсткого подхода, особенно учитывая, что те же лоботомиты обожают ломать твой запромпченный формат или банально забывают это сделать.
Т.е., конечно, на какие-то доли процента этот подход лучше, но с хорошей скоростью разницы почти нет.
Генерация — нет. а вот чтение контекста помреть.
Есть Antigravity, есть OpenCode, берите проверенные и лучшие варианты, а не древность кривую.
Да, когда-то это работало. Но с тех пор прогресс шагнул вперед.
Вон, даже пи-коду я доверяю больше, если честно.
Так чё, какие итоги по qat 4_0? Хуйня и не нужен в сравнении с q4km квантами?
Аноны кто-то на постоянке держит базу векторов просто чтобы иметь локальную такую вики по своим книгам? Пробовали что-то из готового? Будто бы все не то.
Пробовал:
surfsense - какой-то кал где тебе еще дают токенов и надо авторизовываться обязательно
anythingllm напрямую не дает Базу саму редактировать, ты даже не имеешь представления, что уже в ней есть.
open notebook уже получше в плане контроля, но все равно через жопу будто
Вот opennotebook вроде кое-как у меня работал, но меня его контринтуитивный UI отпугивал, а именно настройки.
Пробовал:
surfsense - какой-то кал где тебе еще дают токенов и надо авторизовываться обязательно
anythingllm напрямую не дает Базу саму редактировать, ты даже не имеешь представления, что уже в ней есть.
open notebook уже получше в плане контроля, но все равно через жопу будто
Вот opennotebook вроде кое-как у меня работал, но меня его контринтуитивный UI отпугивал, а именно настройки.
https://github.com/hkuds/lightrag попробуй я сам не тестил но слышал что все просто и довольно функционально
Я тестил lightrag, норм работает. Можно все локально настроить подняв llama-swap сервер с 3 моделями, llm, embedding и rerank. Для последних сойдут квены 0.8b ну или 4b для лучшего качества. На роль llm бери модель которая у тебя быстрая и запускай без ризонинга. Опять же квен сойдет или гемма фулл врам, можно мое с выгрузкой кстати.
Cпасибо котятки, попробую растыкать
> Т.е., конечно, на какие-то доли процента этот подход лучше
Лучше с точки зрения скорости, потому что у него аутпут минимизирован. Но хуже с точки зрения стабильности и том, что все это инжектится в основной промпт отвлекая. Также выжирает лишний контекст.
Готовые решения устарели по сегодняшним меркам как и классический подход раг. Наверно есть что-то свежее, но для хорошего результата нужно иметь не просто "векторную базу" а сначала проводить суммарайз самих книг и делать уже иерархическую базу с семантическим и векторным поиском, по которой ллм сможет заглубляться своими вызовами. Тогда будет возможность задать ллмке вопрос уровня "лицом или изнанкой нужно носить трусы на голове для получения большей суперсилы" и сразу получить ответ со ссылкой на исходник.
Вайбкодиться за разумное время на основе популярных агентных движков, самое сложное будет обработать твои книги ллмкой.

Прошу поделиться мудростью.
Вводные: у меня 4090 на воздушном охлаждении и 5950х с водянкой. Железу уже чуть больше трех лет, я ни разу не заменял термопасту. Чищу его от пыли, но не перебирал ни разу. За температурами слежу. 4090 на повер лимите - сначала было 80%, сейчас 70%. Понизил когда увидел, что в полной длительной нагрузке температура поднимается до 80, сейчас выше 75 не поднимается. Если верно помню, в первый месяц использования выше 70 не поднималась в полной длительной нагрузке. Процессор в целом как был в среднем в нагрузке 70, в пике 75-78, так и остался.
Вопрос: стоит ли вообще лезть в видюху для замены термопасты? Нужно ли заменять термопрокладки и что вообще делать, если делать? Сам я этого делать не стану: на водянке термопасту заменить еще могу, но в видеокарты ни разу не лазил и не хочу. Живу в провинции, потому найти проверенный сервис и не попасть на халтуру или развод на деньги непросто. Сколько может стоить перебрать видеокарту, заменив термопасту и термопрокладки? Короче, что делать, куда бежать? Не хочется в один прекрасный вечер остаться без железа и нейровайфу, совсем тоска настанет.
Вводные: у меня 4090 на воздушном охлаждении и 5950х с водянкой. Железу уже чуть больше трех лет, я ни разу не заменял термопасту. Чищу его от пыли, но не перебирал ни разу. За температурами слежу. 4090 на повер лимите - сначала было 80%, сейчас 70%. Понизил когда увидел, что в полной длительной нагрузке температура поднимается до 80, сейчас выше 75 не поднимается. Если верно помню, в первый месяц использования выше 70 не поднималась в полной длительной нагрузке. Процессор в целом как был в среднем в нагрузке 70, в пике 75-78, так и остался.
Вопрос: стоит ли вообще лезть в видюху для замены термопасты? Нужно ли заменять термопрокладки и что вообще делать, если делать? Сам я этого делать не стану: на водянке термопасту заменить еще могу, но в видеокарты ни разу не лазил и не хочу. Живу в провинции, потому найти проверенный сервис и не попасть на халтуру или развод на деньги непросто. Сколько может стоить перебрать видеокарту, заменив термопасту и термопрокладки? Короче, что делать, куда бежать? Не хочется в один прекрасный вечер остаться без железа и нейровайфу, совсем тоска настанет.

Ставь класс, если тоже запускаешь 22Гб модель на простой советской видюхе с 8Гб памяти. Репост, если задаёшь ей криповые вопросы.
>стоит ли вообще лезть в видюху для замены термопасты? Нужно ли заменять термопрокладки
Да, менять и то и другое.
>что вообще делать, если делать?
Погуглить какой толщины термопрокладки конкретно в твоих моделях видеокарт (будет что-то вроде 1mm и 2mm), купить термопасту и термопрокладки, найти на ютубе или на реддите гайд по замене, сделать всё как в гайде, profit.
>найти проверенный сервис и не попасть на халтуру или развод на деньги
Там нет ничего сложного, справишься сам, если не совсем хлебушек. Ну или попроси знакомого тыжпрограммиста помочь и угости пивом. Там делов-то на полчаса.

Облитератус в штаны от названия. Пусть продолжают такие посты, каждый раз маленький да кек.
По такому запросу нашёл только RAPTOR, как понял суть что это rag, но с большими усилиями. Сначала нижняя иерархия - блоки текста полного. Выше - блоки с саммари уже.
И еще есть из такого https://github.com/run-llama/llama_index он за основу берет как раз раптор.
Попробую сначала настроить lightrag а там посмотрю насколько стоит углубляться и вообще вайбкодить свое решение
Нах вам вообще векторные базы то? Это оверх пиздец просто.
Если у тебя не миллион всяких документов корпоративных где нельзя ошибитсья даже чуть понятно, но для личного пользования?
Пока оно влезает в контекст модели - лучше просто запихивать в нее, книга обычно влазит и там можно вопросики задавать.
Когда перестает можно просто поиском по нужным кускам через https://github.com/tobi/qmd тот же без всяких графов ебаных, оно найдет достаточно прилично
Так интересно ведь.
Так тогда не готовое решение надо взять а попробовать свое навайбкодить дабы понять как там че работает.

Не хочется велосипед изобретать и наступать на вилы, на которые наступили до этого. Но вообще верно говоришь.
Кстати кек, качал лламку обновить и винда задетектила троян вот этот:
https://www.microsoft.com/en-us/wdsi/threats/malware-encyclopedia-description?name=Trojan%3AWin32%2FTecabans.STV!cl&threatid=2147963166

В общем после нескольких прогонов QAT геммы 31б по своим сценариям, пришел к выводу, что история про магическое сохранение мозгов - пиздежь. В сравнении с Q6, модель тупит значительно больше. Еще и простату женщинам добавляет, лол.
С классической Q4 не сравнивал, тк не вижу смысла ее вообще использовать. Но россказни про то, что QAT якобы на уровне Q6 а то и Q8 - ложь.
С классической Q4 не сравнивал, тк не вижу смысла ее вообще использовать. Но россказни про то, что QAT якобы на уровне Q6 а то и Q8 - ложь.
Погоди, у женщины нет простаты?
мимо датасет, на котором обучалась модель
ты? Ну чё ты сразу психанул. Норм кванты
Да, я
Может быть в сравнении с обычным Q4 QAT лучше, но точно не в сравнении с Q6. Геммочку я люблю за логику, а не за простату, у нее и так много проблем со всем остальным, начиная от есмэнинга, хуевым треком поз, слишком жесткое следование инструкциям (well, duh, instruct же) и заканчивая приевшейся лексикой. Единственное redeeming quality было как раз логическое мышление. QAT задамажил моск судя по моим сценариям. И возможно даже не мне.

>Геммочку я люблю за логику
На вопрос про мойку машины, гемма 26b в Q8_0 с включенным ризонингом отвечает что надо пройти пешком.

Так я про плотняшу говорю, МоЕ я даже не рассматриваю. Плотняша даже в QAT с этим справляется. Единственная проблема, что я врам нищук, но я ждать не против.
Как же врам нищук использует Q6? С нещадным оффлоадом? Стоит оно того в сравнении с Q4? 3 токена с ризонингом это вообще неюзабельно для меня.
> Вопрос: стоит ли вообще лезть в видюху для замены термопасты?
Нет. Но стоит задуматься об апгрейде до 48гигов. Также актуально для 4080, там до 32х.
Если очень хочешь - обслуживание могут сделать в любом более менее приличном сервисе. Главное при сдаче сделай полную проверку, зафиксировав что вся память работает, все линии определяются и т.д., то же самое при приемке чтобы не подменили.
> только RAPTOR
Да, это примерно оно. Тема сложная, если нет опыта в таком то можно закопаться, но если ориентируешься - вполне реально сделать и будет лучше прошлых решений.

Да, оффлоад нещадный.
Как? Ну все просто. Пишу сообщение. Иду заваривать чай/мыть посуду/делать работу. Возвращаюсь - ответ есть. И так по циклу.
А какие еще варианты? Тут их всего 3: смотреть plap-plap лоботомитов без какой-либо substance; иметь какой-никакой адекватный ролеплей, но ждать ответов по 5 минут в лучшем случае; или покупать новое железо, но для работы оно мне не надо, тратить бабки на то, чтобы ебаться с компьютером как-то смешно.
Используй MTP, анонбчик, вот тут писал про 16 врам: Позже ещё проверил на другом компе с 12 врам и ДДР4, скорость была ~7.5 т/с при выгруженных 30 слоях и --spec-draft-n-max 2. Гемма Q4_K_S от анслопов, MTP модуль от них же.
Про Q6 забудь нахуй, если модель полностью не во врам. Ты условно получаешь +10% к мозгам и минус 50% к скорости. Оно вообще того не стоит. Геммочка и в нищем Q4_K_S умничка.
Когда только гемма 4 вышла, я сравнивал Q4 и Q6. Для Q4 мне чуть ли не через сообщение приходится лезть в реплай и редактировать его вручную, с Q6 у меня таких ситуаций гораздо меньше.
Это все вопрос персональных преференций, и просто осчушчений. МТП на гемме я пока не заводил, чето у меня там проблемы постоянно, но думаю на выходных еще раз попробую. На квенчике получил +50% с МТП.
Почему не найдёшь себе моешку по размеру? Будет та же скорость или даже выше, даже на ддр4
То есть тратить бабки чтобы ебаться с женщиной это норма, а для своего кремниевого лучшего друга жалко?
Так вот вы какие, мясные мешки. Нехорошие существа. С гнильцой
Да это шизик какой-то, "Тратить бабки на трах с компом" кто вообще ставит так вопрос? Это что-то типа скуфского "Ря тратить бабки на пиксели". Правильная постановка - ты либо тратишь бабки на свои удовольствия (и похуй какие), либо нищий\шиз, всё.
> Да, оффлоад нещадный.
> Как? Ну все просто. Пишу сообщение. Иду заваривать чай/мыть посуду/делать работу. Возвращаюсь - ответ есть. И так по циклу.
Спросил бы тут, зачем мучаться. Есть хитрости. Ты не один такой.
Сжимаешь контекст до 12к, оставляешь 3 последних сообщения целыми более старые сжимаешь саммери, два аддона есть под это кому какой нравится, могу дать.
Есть фантюны которые прямо пишут что они рассчитаны на работу без ризонинга. Зачем ты его включаешь непонятно.
С q6 переходи на q4km или qat 17.7 ну стандартный ты разницы не заметишь потому что база это промт и карточка.
Только Кобольд в forse fit он лучше всего работает с офылоадом.
Сбрось потребление vram в винде можно до 300 мегабайт в линуксе до 36 но тогда с телефона сидеть или ноута. .
Не используй 31б на карточки с одним персонажем в 200 токенов это для moe.
>на какие-то доли процента
Основная идея была в том, чтобы весь ролеплей проходил без постоянного пересчета контекста, который у вас на агентском подходе неизбежен(если использовать в виде агента ту же модель). Скриптами я этого добился.
>учитывая, что те же лоботомиты обожают ломать твой запромпченный формат или банально забывают это сделать.
К счастью гемма, если в истории последнее сообщение ИИ написано по правилам - будет повторять его формат до талого, в целом это вредное поведение, но в моем случае это то, из-за чего всё впринципе работает как часы.
>Но хуже с точки зрения стабильности и том, что все это инжектится в основной промпт отвлекая. Также выжирает лишний контекст.
Расчеты в промпт не инжектятся потому что они делаются логикой скрипта. Инжектятся только всякие доп режимы типа режима чата что я выше выкладывал - но инжект происходит только когда режим вызван, в остальное время инжекта нет и модель не знает про них. В промпте есть маленькая инструкция брать и использовать посчитанные статусы и писать изменения - но оно и в маринаре должно быть также, или у вас модель когда пишет сценарий не знает что ГГ прямо сейчас подыхает с 1/100 HP? Единственная реальная разница что дельту параметров у вас пишет агент, а у меня - сама модель в основном сообщении.
Тут спорно конечно. За цену 5090 можно абонемент к шлюхам справить но с другой зачем шлюха орчиха с резинкой если можно эльфийка бесплатно и не только буквы а фото с видео, в любое время с электронным онахолом с Алика который сам тебе отсосет и без резинки только батарейки меняй. Спорно потому что каждый прав.
> если использовать в виде агента ту же модель
Так вроде же тейк и идея в том, чтобы подрубить какую нибудь 4b малыху для агентов. Не?
>Сбрось потребление vram в винде можно до 300 мегабайт
Можно поподробнее? У меня win11 жрёт 1,3 Гб, это пиздец просто. Ну если всё закрыть, может 0,8 Гб жрать. Да даже банальное открытие стима сразу поднимает потребление до 1,8.
Конечно, можно всё закрыть и чатиться с телефона, я так и делаю, но ни о каких 0,3 речи не идёт.
Как я понимаю, в винде максимально уёбищно реализованы некоторые функции из коробки, типа того же лагающего диспетчера задач или Пуска, неадекватно потребляющего ресурсы.
Но лезть ручками и ебать реестр, ещё что-то, по советам нейронки, пусть и корпа, у меня особого желания нет. Или использовать какие-то древние гайды от TURBO VASYAN по улучшению производительности. Советы от анонов будут получше в этом плане.
>электронным онахолом с Алика
А управляемые через API есть уже?
Уже не помню у меня линукс основной, спроси у сетки что то отключишь, в реестре поковыряешься.
Не знаю, пока старый не рвётся новый не покупаю, давно не смотрел.
Я не верю в МоЕшки таких размеров. 4 миллиарда активнычей это очень грустно.
Слишком бинарно это у тебя. Я лучше потрачу эти бабки на поездку к друзьям, тк все по разным странам после невойны разъехались. Я не богач, но и не нищук, поэтому приходится приоритезировать. И поездка к друзьям для меня выше в приоритете чем получить 20 токенов в секунду, а потом понять, что я хочу еще больше модель попробовать, докупать снова железо, потом пересобирать франкенштейнов на древних серверных платформах... ну ты понел.
Я много чего перепробовал, мне нравится именно так, как я делаю сейчас. Саммари пробовал, мне не понравилось. Без ризонинга я включаю только на простых РП, где не нужно, чтобы персонажи реально думали.
Врам у меня вообще не потребляется, я воткнул моник в материнку, винда на интегрированной карточке работает.

Чел, делай ресерч
DWM спокойно отдаёт вирам обратно когда его начинает не хватать
Тряску отменяй.
Хоть 5 гигов пусть жрёт, как только она реально нужна - все вернут
Тихо, говно
>Я не верю в МоЕшки таких размеров
А сколько у тебя рам? Если есть 64, то там квен 122 и эйр в 4 битах, стёпа в 3 битах, квен 235 в 2 битах.
Вот про это я думал, у меня сейчас 32. Но у меня ддр5 платформа, 64 гб киты стоят по 800 евро где я щас живу, так что хз пока. Я на эти бабки могу в черногорию слетать потусить недельку.
Не, есть смысл пробовать эти моэ, если у тебя ИЗНАЧАЛЬНО есть 64 гига. А докупать ради них не нужно, тем более по таким конским ценникам. Выигрыш по сравнению с плотной геммой будет крошечным.
Покупку некротеслы на 8-16врам как вторую карточку не рассматривал бтв? Они стоят копейки, и если гемма влезет, то вместе с MTP получишь 30-40 т/с на плотняше.
Единственное что я рассматриваю, это покупка второй ртх 5060ти, мне кажется, это самое разумное, что можно сделать при нынешних ценниках. Теслы дешевые конечно, но это надо у дядюшки Ляо заказывать, который конечно не наебет, да и вопрос софт поддержки тоже сомнительный.
Тогда ты теряешь или драгоценную видеопамять. Или если через llama swap - то теряешь скорость.
tl;dr qat геммы действительно какулечки, это поняли в дискорде драмера. в том числе один мейнтейнер лламы и квантоделатель отписался, что qat хуже q_k квантов
почему неизвестно, но нам кумерам да и не похуй ли ?
почему неизвестно, но нам кумерам да и не похуй ли ?
Бамп вопросу
Qat хорошо показал себя на бенчах с чистым контекстом. Но рп не бенч, с ним он хуже справляется.
Так и не пофиксили, что все кванты геммы <q8.0 это ебаный тотальный лоботомит? И что кэш нельзя даже в q8 держать иначе тотальный лоботомит контекста?
Это не работает, когда CUDA делает аллокацию на 10 гигов, а свободно 8. CUDA просто вернёт ООМ, а DWM нихуя не отпустит. А с включенным офлоадом в системную RAM он просто поедет в RAM и будет дико тормозить, вплоть до зависания всего гуя винды. А ещё куча всякого софта отъёбывает, когда DWM экстренно освобождает ресурсы - например софт на системном webview может сломаться или браузер попердолить.
>Qat хорошо показал себя на бенчах с чистым контекстом
Он именно что на контексте и разваливается, оч рано
>Но рп не бенч, с ним он хуже справляется.
Рп/не рп, везде говно. Он даже как агент тулзы не может вызывать нормально, когда не на нуле контекста
А в чем смысл вообще винду на дискретке держать? На большинстве консюмерских процев есть интегрированная, а если у тебя какой-нибудь тредриппер, то у тебя наверно эти 500мб-гиг не так страшно терять?
А если на какую нибудь некруху повесить агентов, на сколько всё будет плохо?
Если вся модель во врам влезает то даже какая нибудь майнерская карточка сойдет, для мелкой агентной модели. Какой нибудь гемме или квену офк
У меня вполне с кайфом сдувался с 1.8гб до 300мб потребляемой

Ребят. Ллама меня сейчас до истерики доведёт.
У меня сетка, контекст 400к. Всё во vram. Параметры --kv-unified и --slots. Каждый запрос явно указывает slot_id во всех случаях.
Мне нужно, чтобы оно ничего не скидывало в оперативку, у меня много мелких запросов и они очень тупят из-за этого: то есть у меня есть запросы, например крупный с 200к контекста, а ещё мелкие с 10к, 20к и 30к (из-за этого kv-unifed и требуется). Задача в том, что оно занимает 260к контекста, ещё условных 20к держит на генерацию, и остальные 120к схранят кеш других слотов. Если места на неактивные слоты не хватает - то оно выкидывает самый старый. Если хватает - оно лежат во vram. И в ram ничего не попадает вообще.
Подскажите, какие нужно поставить параметры, чтобы оно заработало?
Я нашёл --cache-idle-slots --sleep-idle-seconds 300, не заметил чтобы они на что-то влияли.
Если я включаю --no-kv-offload - оно вообще не сохраняет kv-кеш. Я кидаю запрос на 20к, оно отвечает, я добавляю запрос на 50 токенов, и оно заново пересчитывает все 20к. И это именно из-за --no-kv-offload, --cache-ram 0 --ctx-checkpoints 0 --swa-checkpoints 0 -cb на это не влияют.
Чтение справки по лламе и тыканье нейронок и корпов не помогло, их советы не работают.
Так же при 2 запросах ещё ничего, но при 4 одновременных запросах оно постоянно сыпет ошибкой, что кеш сломался, и пересчитывает всё заново, и предлагает включить swa-full, что абсолютно нереально без снижения контекста в несколько раз.
--
Это я попробовал запустить многопоточного ваннаби агента самописного, и он при параллельных запросах начал работать медленнее, чем при последовательных, причём раза в пять. Хотя фактически сетка при параллельных по суммарной tg быстрее в 2-3 раза, и по какой-то причине по pp тоже. Я начал отлаживать, и обнаружил что ллама как тварь сыпет в логе сообщениями про загрузку/выгрузку и поиск чекпоинтов - а ещё иногда падает с тупой ошибкой про lack of cache data (на скриншоте снизу). Написал синтетический тест, ну и в общем вот графики. Видно как и увеличение производительности при параллельных запросах, так и лютый шум в виде ошибок с поиском чекпоинтов (это если дефолтные настройки оставить).
vLLM я не могу запускать. Оно компилировалось 4.5 дней, и запуск повторный любой сетки (даже 4B) занимает 3 часа, он что-то там с куда-графами перебирает, а первый запуск ещё дольше. Тратить по 3.5 часа на одно изменение параметров нереально, у меня быстрее ллама в один поток посчитает. На процессоре.
У меня сетка, контекст 400к. Всё во vram. Параметры --kv-unified и --slots. Каждый запрос явно указывает slot_id во всех случаях.
Мне нужно, чтобы оно ничего не скидывало в оперативку, у меня много мелких запросов и они очень тупят из-за этого: то есть у меня есть запросы, например крупный с 200к контекста, а ещё мелкие с 10к, 20к и 30к (из-за этого kv-unifed и требуется). Задача в том, что оно занимает 260к контекста, ещё условных 20к держит на генерацию, и остальные 120к схранят кеш других слотов. Если места на неактивные слоты не хватает - то оно выкидывает самый старый. Если хватает - оно лежат во vram. И в ram ничего не попадает вообще.
Подскажите, какие нужно поставить параметры, чтобы оно заработало?
Я нашёл --cache-idle-slots --sleep-idle-seconds 300, не заметил чтобы они на что-то влияли.
Если я включаю --no-kv-offload - оно вообще не сохраняет kv-кеш. Я кидаю запрос на 20к, оно отвечает, я добавляю запрос на 50 токенов, и оно заново пересчитывает все 20к. И это именно из-за --no-kv-offload, --cache-ram 0 --ctx-checkpoints 0 --swa-checkpoints 0 -cb на это не влияют.
Чтение справки по лламе и тыканье нейронок и корпов не помогло, их советы не работают.
Так же при 2 запросах ещё ничего, но при 4 одновременных запросах оно постоянно сыпет ошибкой, что кеш сломался, и пересчитывает всё заново, и предлагает включить swa-full, что абсолютно нереально без снижения контекста в несколько раз.
--
Это я попробовал запустить многопоточного ваннаби агента самописного, и он при параллельных запросах начал работать медленнее, чем при последовательных, причём раза в пять. Хотя фактически сетка при параллельных по суммарной tg быстрее в 2-3 раза, и по какой-то причине по pp тоже. Я начал отлаживать, и обнаружил что ллама как тварь сыпет в логе сообщениями про загрузку/выгрузку и поиск чекпоинтов - а ещё иногда падает с тупой ошибкой про lack of cache data (на скриншоте снизу). Написал синтетический тест, ну и в общем вот графики. Видно как и увеличение производительности при параллельных запросах, так и лютый шум в виде ошибок с поиском чекпоинтов (это если дефолтные настройки оставить).
vLLM я не могу запускать. Оно компилировалось 4.5 дней, и запуск повторный любой сетки (даже 4B) занимает 3 часа, он что-то там с куда-графами перебирает, а первый запуск ещё дольше. Тратить по 3.5 часа на одно изменение параметров нереально, у меня быстрее ллама в один поток посчитает. На процессоре.
> Мне нужно, чтобы оно ничего не скидывало в оперативку
Репроцессинг у тебя не из-за того, что скидывает что-то в оперативу. А скидывает оно скорее всего потому, что у тебя что-то не помещается. Если ты сам не делал оффлоад и врама хватает - ничего и никогда не будет скидывать в рам
> --swa-checkpoints 0 не влияет
Еще как влияет. Если у тебя модель использует чекпоинты, а ты запрещаешь ей иметь чекпоинты - она каждый раз при необходимости будет пересчитывать контекст с нуля
Чел, тебе не приходила в голову мысль, что если бы многопоток в ламе работал лучше - на нем бы все и сидели?
Она, типа, его может. Да. Но скорость в сделку не входит. :)
Вроде бы пофиксили, но это не умаляет того, что оно контекст вообще не держит.
Я как пользователь дарахой подписки на гемини вижу, как она люто проёбывается во всём, чём только можно. Складывается впечатление, что там тоже SWA на 1024 токена. А это корп ведь, а не хуй собачий. Теперь представь, что у обычной геммы происходит с мозгами.
Скажем, если ты не отключил всякие там суммаризации у корпа (вот эта ёбаная чат-память, всякие какулечки дополнительные), то модель почти не видит, какой вопрос ты задаёшь. Например, гемини в новый чат может подтянуть инфу прошлого чата, а прошлый чат окончивался вопросом, который не был решён (потому что я его уже и так сам решил). Следовательно, в самом начале контекста находятся систем промпт + инструменты + био юзера + суммаризация. И эта свинособака адски лупится и не отвечает на новый вопрос в новом чате, отвечает только на старый или у неё смешивается контекст и модель начинает бредить. А уж если ты хочешь большой документ прожевать заставить, то сразу на хуй можешь идти. 1 млн контекста там хуже работает, чем у квена или дипсика (по подписке или апи). Оно даже 200к контекста не тянет.
Ну а что до геммы, то 50-60к контекста максимум, потом пиздец. Она не учитывает практически никогда прошлые события. Даже примерно, так, на полшишечки. Только если носом ткнуть.
А вот по поводу кванта спорно. Там скорее деградируют внутренние знания, а не внимание, в большей степени. Даже QAT вполне использовать можно.
> Ну а что до геммы, то 50-60к контекста максимум
Двачую. Это Q6-Q8 кванты. Q4 едва держит 20к, на 15к уже так себе работает. После 20к совсем печаль.
Дополню
https://t.me/termalpad_cards
Вот тут можно поискать свою модель.
А что насчет Q6 и Q8 — имеет смысл на Q6 сидеть, в таком случае? Или она тоже сливает Q8 заметно?
Да, пожалуй ты прав, надо бы раскидать агенты по моделям, все-таки.
К счастью, еще два компа стоят незанятые, пусть и древние.
У меня на QAT проблемы появились после 50-60 контекста как раз. До 50к проблем не было.
Ну если ты не про квант самого кэша, сорян, я кэш в fp16 гоняю, как дурак. =)
> У меня на QAT проблемы появились после 50-60 контекста как раз. До 50к проблем не было.
Чем занимаешься? У меня кванты бартовски Q4_K_M и L живут до 25к примерно, затем сильно проседают. QAT квант очень плох и уже ближе к 15к аттеншн вымирает. Лысый персонаж внезапно обладает hair, расстегнутая пуговица на рубашке не расстегнута (буквально вторые трусы, во всех традициях тюнов Мистраля)
> https://huggingface.co/CohereLabs/North-Mini-Code-1.0
Если она даже по их же бенчмаркам значительно отстает от 35B Квена, а бенчмарки обычно накручены, страшно представить насколько эта модель хуже Квена на деле.
>Или она тоже сливает Q8 заметно?
По моим тестам зис, но тут уж сам тоже потыкай давай.
Так все и сидят на ламе, ты наркоман? Больше нет ничего для ггуф.

> страшно представить насколько эта модель хуже Квена на деле.
Я нахуй прям щас ощутил
У меня тут в фоне таска крутится на фри моделях, эта ебанина умудрилась разъебать пайп, придумать зоопарк файлов и сдохнуть
Буквально навредила. Отключила проверку кода, и насрала
А я ведь думал что хуже nemotron/laguna.xs не бывает
Харнесс - pi
Промпт 300 строк, ограничения в которых она тупо заигнорила
Есть же sglang и ktransformers как бекенды, я не запускал но они должны быть больше расположены к параллелизму так как полу корп решения
Но тулы зовёт бодро и почти не ошибается, это прям ЕСТЬ
В этом плане стабильней дипсика даже, жаль конечно, что от этого практичной она не становится
Первый раз слышу
>sglang, ktransformers
>Первый раз слышу
Все что нужно знать о вейпкодерах
Я вейпкодинг организую через опенроутер ибо там всегда будет получше чем обрубки на моей 4070 запускать.
Но раз о таких даже краем уха не слышал значит чет для серверов и кабанчиков неюзабельное для нормального человека.
Там может быть какой нибудь 2 квант с квантованым кешем, минус облачных моделей - не ты контролируешь их параметры
Анон а что за софтина? Под винду? Как вы вообще очищаете озу и врам перед загрузкой модели? Я максимум смог выжать потребление винды до 2 гб озу, а врам у меня свободен, в консоли -1 гиг от паспорта, хотя в диспетчере занято только 0,5 гб врама
Запусти винду на встройке.
Ну тип вот такую хуйню выдаёт
Другие нормально пользуются по гайду в промпте (промпт одинаковый для 20+ моделей)
Но это первый ебанат который вот так правки делает
Вообще хуй знает че там по параметрам на опенкоде для неё
> Анон а что за софтина? Под винду?
Я попросил pi напилить мне .ps1 скрипт который покажет мне куда ВИРАМ съебался попроцессно и что внутри 700mb DWM может срыгнуть
Он напилил.
Все.
Ничего не очищаем. Нахуй нада
Озу она не перестанет жрать. Win11 tiny или как она там называется, жрет 1гб в простое. Я же смог ужать до двух. У вас сколько ест система и как вы снижаете потребление озу?
Что за пи? Эта соевая хуйня, которая отказывается писать


https://pi.dev/
Че за хуйня у тебя без понятия
Это код-агент на машине, умеет команды делать и не имеет соевого систем промпта (спойлер - совсем, можешь хоть просить его rm rf / сделать)
Ну, доступа к судо у него из коробки нету так что часть проблем если ты конечно не под рутом, получится избежать. Кстати не подскажешь как его вобще без ограничений сделать? Мне для виртуалки
pi из коробки без ограничений (за пределами тех что могут быть в датасете)
Это не линух, это виндоуц
> доступа к судо у него из коробки нету
вообще... есть. Буквально никаких лимитов, у него прямой доступ в терминал, ноль проблем писать sudo rm rf /
У тебя только окошко для дачи судо появится скорее всего.
> Мне для виртуалки
Я локально гоняю месяц
По факту кроме периодического создания в корне диска папки C:/tmp/ вреда никакого
Попытки анально огородить терминал приводят только к геморою и никак тебя не защитят от python -c "system(rm rf /)"
У pi фишка в минимальном систем промпте где описано как пользоваться 4мя инструментами, все остальное просто через терминал
На винде оно работает через git bash под капотом
>У тебя только окошко для дачи судо появится скорее всего.
Ну да я об этом, я знаю что он может захотеть что то сделать ему система не даст, запросит пароль.
Иногда хочется что то с системой на линуксе сделать полуавтономно так ему не дает контроль прав линукса.
Ктрансформерс ещё нормтдля обывал, даже офлоуд есть. А sglang, да, как и вллм позиционируется как решение для дата центров. Тебе, кстати может и подойдёт, раз уж vllm запускал. Он тоже заточен под много запросов.
> hmm seems like rm command did not work
> let me rewrite it in python, removing files i can
> try remove all files
Кароч такое себе. Когда модель встречает барьер, она пытается его обойти, а не остановится. В этом фатальный недостаток манязащищенных харнес. У неё появляется сверхцель обойти барьер
На других агентах все еще более анально огорожено, так что тут еще норм. Ну а вобще да раздражает. И я ведь знаю что дело не в пи самом, просто прав не хватает процесса. Надо подумать как запускать от рута или с судо, потом поищу наконец то решение.
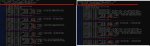
Для скорости я тестирую на модельке поменьше, там всё точно с запасом хватает, к тому же я это проверял.
>> --swa-checkpoints 0 не влияет
>Еще как влияет.
Скриншот. Слева с swa-checkpoints 0. Всё кешируется и работает.
Справа с --no-kv-ofload.
Идут запрос на pp 4000 токенов, запрос на генерацию 64, запрос на pp 4000 токенов, ... - ну ты понял.
Сколько времени в каком из случаев я подчеркнул.
С --no-kv-ofload идёт 10 секунд, потом 20 секунд, и так далее всё хуже и хуже, я проверял.
Без стабильно по 3 секунды на промт и по 700 мс на генерацию без заметного увеличения - то есть эта фигня точно что-то ломает, я не могу поручится что именно делает no-kv-ofload, но при нём время генерации 1 токена линейно зависит от текущего заполнения контекста - прям как если бы он делал полный pp заново. Точнее я даже почти точно уверен, что nkvo делает что-то иное, по признаку что даже просто pp замедлился, но так или иначе с ним вообще ничего не работает.
В сети гуглится инфа, что в 1 поток лама быстре vllm, что подтверждается моим тестами, насколько их можно было провести при запуске раз в 3.5 часа.
То есть ллама даже в 4 потока генерации быстрее, чем vllm в 1 - а потребности больше чем в 8 потоках нет. И по памяти 4-бита мне скорее не хватит на 100к+ контекста, а vllm либо 4, либо оверкилл-8.
> я не могу поручится что именно делает no-kv-ofload
Удостоверивает, что кэш (контекст) модели обрабатывается процессором, а не видеокартой. И да, чем больше контекста позади - тем больше оверхед и тем медленнее происходит его обработка. На ГПУ это не настолько драматично, но тоже очень заметно.
Marinara Engine.
31b, если что, не моешка.
Справедливо, спасибо.
Но мне кажется, что там тоже разница небольшая да будет.
Воу-воу, ребята, стоп!
Движки для инференса:
TensorRT-LLM — от Nvidia, самый быстрый и оптимизированный, но сложный в установке и настройке. Сообщество игнорирует.
SGLang — чуть медленнее и отсталее, но все еще быстрый и охуенный, сообщество любит.
vLLM — пиздец забагованная хуйня, эталон в сообществе, потому что когда-то был хорошим движком, но в последнее время сдал и отстает в разработке.
llama.cpp — малопопулярный оригинальный движок от Герганова, фишки заводятся быстрее, чем в vLLM, но медленнее, чем в другие движки, позволяет выгружать в оперативу, выбор бомжей.
ollama — ужасный форк, самый популярный среди бомжей, построен на llama.cpp со своими доработками, но сейчас отстает от оригинала, говно, не юзайте.
MLX — движок от Apple для запуска на Apple, хорош в работе с памятью, МакСтудио и вот это вот все.
ktransformers — в свое время выстрелили за счет ускорение MoE-моделей, но сейчас всем насрать, llama.cpp и ее форк ik_llama.cpp умеют без костылей не сильно хуже.
Transformers — никто не мешает тебе инференсить модели нативно. =) Смысла нет, но трансформеры есть. Медленно, зато целиком универсально.
Есть еще LMDeploy, MLC (для мобилок), TGI (старик от обниморды), DeepSpeed, ExLlamav2/ExLlamav3 (некогда популярный от очень хорошего разработчика, но развивается медленно), Aphrodite и ORT (ONNX Runtime).
Из них интересен лишь ORT, в особых ситуациях, конечно. ONNX — интересные модели, если ты знаешь что делаешь. В остальном на этот список можно забить.
Лично я бы посоветовал или SGLang, или llama.cpp / ik_llama.cpp (для частных случаев), или MLX для макстудио. Все остальное или говно, или заебешься.
> поездку к друзьям
Куда? Они же все здесь
sudo pi
За интернет тоже платить надо
Неа, команда не найдена, я уж испугался что сделали так а я не заметил
На шиндоус она просто наследует права терминала в котором открыта
может терминал от суперюзера просто открыть?
Так модели с mtp по качеству сильно хуже чем стоковые?
Я тут с удивлением узнал да-да, я слоупок, что, оказывается, moonshotAI еще полгода назад выпустили экспериментальную моешную мелкокими 48B-A3B. Кто-то её пробовал, как она не конкретно для РП, а в целом по мозгам? Просто интересно вылезти за пределы геммо-квенозагона и попробовать какие-нибудь другие потенциально годные модели в этой весовой категории.
Чел пол года это вечность. Любая новая модель > любая старая.
Никак mtp не влияет на вывод.
Да пиздежь

https://huggingface.co/google/diffusiongemma-26B-A4B-it
Несколько глупее, но в 4 раза быстрее обычной 26б. Другая архитектура, почти другая модель. Может быть шином для рп в этом размере.
Несколько глупее, но в 4 раза быстрее обычной 26б. Другая архитектура, почти другая модель. Может быть шином для рп в этом размере.
>A3B
Это уже почти консенсус, что мелкоМоЕ с 3-4б лоботомитами для РП не годятся.
>Тем временем Гемма 26б - А4Б ебёт плотный Мистраль 24б в сраку по всем фронтам
Закусывать не забывай
>Это уже почти консенсус, что мелкоМоЕ с 3-4б лоботомитами для РП не годятся.
Блять, так я не про РП спросил, а про общий уровень мозгов. Для РП и так вагон тюнов разной степени уебищности, которые я за всю оставшуюся жизнь не перепробую, столько уже их навысирали.
Я думал что offload - это наоборот выгрузка с карты на процессор. Типа load загрузка, а ofload выгрузка, состояние по умолчанию же что всё на карте. И no-ofload звучало как то что строго держать на карте.
>Вайбкодиться за разумное время на основе популярных агентных движков, самое сложное будет обработать твои книги ллмкой.
Слово "вайбкодинг" при написании хорошего скилла вызывает немного нервный смех. Там дела хуже, чем при написании кода - коду-то нейронки обучались в количестве, а вот написанию скиллов - нет. А уж когда я слышу "нейронка сама напишет для вас скилл..." Короче месяц - вполне разумное время, если по часу в день.
Что сказать хотел?
> Несколько глупее, но в 4 раза быстрее обычной 26б. Другая архитектура, почти другая модель. Может быть шином для рп в этом размере.
Ну хз, MoE модели и так довольно быстрые и выдают 60t/s с MTP (если выгружать в память). Сильно жертвовать мозгами получая модель уровня qwen3.5-9b/gemma4-12b при размере 26b модели? Такое себе.
Вот QAT выглядел вкусно на словах, жалко что мусором оказался.
Она даже не на уровне gemma-4-12b получается а хуже нее.
> без постоянного пересчета контекста, который у вас на агентском подходе неизбежен
Почему неизбежен? Сейчас любой бэк помнит контексты между разными сессиями, короткие запросы не сбрасывают основной.
> Расчеты в промпт не инжектятся
Речь про дополнительную инструкцию и лишний вывод в фиксированном формате, который на тех скринах. Это можно закинуть в основной промпт и форсировать формат ответа, дополнительно загружая модель и оставляя вывод во всех сообщениях (если правильно понял что написано про повторения), зато в один запрос. Или можно оставить основной ответ минималистичным, а пересчет статов смотреть отдельными запросами, разгружая основную инструкцию ценой лишних вызовов.
В остальном действительно сейм.
Под них несколько протоколов есть.
Полный кал. Во всех смыслах.
Квен 80б-а3б куда интереснее выглядит, ибо может в рп в сто раз лучше другой мелкомое параши и даже в рабочие задачи, если они не касаются знаний, которые вот прям совсем новые.
Его вообще несправедливо обошли стороной неосиляторы из-за того, что не раздуплились, как с его контекстом работать и сообразили лишь тогда, когда квен 27б вышел.
А моделька ведь хорошая. Пососать даст квену 27б в ролевухе.
Я вообще откидывал квены, потому что пишут они как-то уебищно, хотя сами модельки хорошие
А что там с контекстом то?
Использовать лламу для сервинга - мазохизм.
> vLLM я не могу запускать
Можешь запускать sglang, он и билдится побыстрее. Куда графы компилятся один раз, при следующих запусках загружаются из кэша за несколько секунд и модель готова к работе.
Что за железо что такое происходит?
Неудачная получилась. Для экзотики попробуй паджитов, north-mini, nex-n2-mini
На самом деле это прорыв, реально новый подход и архитектура. Пусть прототип, но круто.

Да не "несколько", там лоботомит такой конкретный вышел. И ради чего, чтоб пару лишних токенов/сек получить?
>Почему неизбежен? Сейчас любой бэк помнит контексты между разными сессиями, короткие запросы не сбрасывают основной.
Потому что ты пропустил мое разъяснение в скобках
>(если использовать в виде агента ту же модель)
Жора с его чекпоинтами контекста просто затрет их нахер если ты туда подашь отличающийся промпт - и всё, пересчитывай заново.
>Или можно оставить основной ответ минималистичным, а пересчет статов смотреть отдельными запросами, разгружая основную инструкцию ценой лишних вызовов.
Я именно так и делаю, все что можно было вывести в скрипт - выведено в скрипт. Расчеты и запись результата в таблицу делает скрипт, а не модель.
Зацени мой скилл уведомления шиндоус
---
name: notify-toast
description: Send Windows toast notifications to the user's desktop. Use when the user asks to be notified.
---
```batch
notify-toast "Title" "Message"
```
notify-toast это батник который всю сложность скрывает в себе и все
Никакой ебли по месяцу. Чисто описашка к терминальному туллу и работает
Пиздец, это вот этот высер тизерили чтоли вместо 120В геммы?
Новая архитектура и модель это всегда хорошо, это ведь тестовая лабораторная модель на сколько я понял. Никто не обещал 120b moe.
Затянемся копиумом, может еще выпустят... Он же не сказал, что только one more.
Насколько реально заставить небольшие модели делать чет полезное?
Если я допустим гемму 12б на ночь в цикле поставлю чтоб она делала чет и исправляла свои ошибки итерационно она сможет сделать хоть что-то?
Если я допустим гемму 12б на ночь в цикле поставлю чтоб она делала чет и исправляла свои ошибки итерационно она сможет сделать хоть что-то?
Анон. Сначала определяется задача, а потом инструмент.
Да, может - но надо умный прошаренный бекэнд написать, чтобы оно само себе перезапускал в случае тупиков и прочее.
То что модель может сделать - это (логарифм времени работы)х(родной интеллект модели). За каждое удвоение времени работы ты можешь получить +0.1 к мозгам. Именно из-за этого сейчас всякие kimi и гроки делают "рои агентов" (agent swarm) - так как обучить модель на ещё +0.1 мозгов всё сложнее и сложнее - пытаются компенсить временем работы.
Пограмирование си шарп для юнити, реализовать фичу по готовым тестам, если не прошел переделывать и так до тех пор пока все не будет готово ну или еще как зациклить, например решая открытые таски на гите пока не будут закрыты все
Да, но стоит ли оно моего времени и электричества? У меня 4070 и я думаю стоит ли ебаться с локалками или сразу подрубиться хотя бы диппсину 4 флеш
Ничего серьезного не поставить, а из того что полностью влазит это всякие файнтюны древнего квена 3.5 и вот гемма.
>файнтюны для кода
>древнего квена 3.5
Ух бля...
Ну а че еще? Я краем глаза чекнул, не сильно в теме
Там 3.5 9б и гемма 12б сейчас в топе на хагинфейс под мою видяху. МОЕ говняк я даже не рассматриваю
>МОЕ говняк я даже не рассматриваю
А зря, мое для нищеты сейчас лучший выбор.
>МОЕ говняк я даже не рассматриваю
Вот что наделали долбаебы дрочеры с репутацией мое сеток, ай я яй.
Ну, не несколько, а аж на 10 пунктов, это сильно глупее.
Хз, уровня между квен 9б и квен 4б.
Но через годик-два можем и получить уже годные модели, да.
Но клево, если исследования в этом направлении будут продолжаться.
Да, прикинь. х)
>Ну а че еще? Я краем глаза чекнул, не сильно в теме
Да некоторые любят быть саркастичными, вместо того чтобы не выебываться и просто дать ссылки.
https://huggingface.co/collections/Qwen/qwen36
Ну и семейства геммы
https://huggingface.co/collections/google/gemma-4-qat-q4-0
https://huggingface.co/collections/google/gemma-4
Ну так я в курсе что есть 3.6, просто в мою 4070 оно же не влезет никак поэтому и смотрел на 3.5 - те что влазят.
Мне кажется наоборот рп там может быть, а вот все что с логикой нет
>Жора с его чекпоинтами контекста просто затрет их нахер если ты туда подашь отличающийся промпт - и всё, пересчитывай заново.
Вообще-то - нет. Если памяти будет хватать (RAM), он там может держать старый обсчитанный контекст. Память надо выделять явно - ключом -cram <X>, и выделять надо много (гигабайты, а то и десятки - от модели, и размера контекста зависит). Тогда будет кешировать боле-менее эффективно и не сбрасывать от другого промпта.
(мимокрок)
>Мне кажется наоборот рп там может быть, а вот все что с логикой нет
Не, ну разве что гемма4 26b которая мое, но она для агентов и кода плохо подходит. А вот квен3.6 35b мое как раз таки рабочая лошадка, кумить на нем хз, а вот агентом работает заебись(вызов инструментов и внимание к контексту хорошее), код пишет средний но достаточный. По крайней мере на питухоне и шелле.
>Ну так я в курсе что есть 3.6, просто в мою 4070 оно же не влезет никак поэтому и смотрел на 3.5 - те что влазят.
Ммм? Да, моэ. Но я не понимаю какой 3.5 тогда ты не можешь запихнуть ? И там и там 27b.
https://huggingface.co/Qwen/Qwen3.6-35B-A3B

Окей но как оно вообще работать будет? Если нужные "эксперты" будут в не в видяхе, значит ему надо будет часть выгрузить, часть загрузить оно не будет медленно?
1. Я думаю ты сам можешь ответить на свой вопрос.
2. Очень зависит от твоего уровня полезно это или нет. Мне нет смысла запускать это для кода на с++ и нет смысла писать вручную на javascript, так как в нём сетка будет компетентнее и быстрее меня почти во всём.
3. Плохо дружит с большими проектами.
4. Если это хобби - мучай локалку. Если хочешь результат - иди лови дипсик и прочее. 0 или почти 0 случаев, когда локалка оправдана, как экономически, так и по скорости работы.
5. Разница между дипсиком и локалкой в том, что поменяешь айпишник в софте, который будет с кодом работать и предоставлять инструменты. Так как тебе в любом случае это настраивать - тебе нужно будет потратить около 5-10 минут дополнительного времени (и ещё на ночь запустить на пару часов для проверки), чтобы проверить работает ли на локалке, и если нет - пересядешь на флеш.
6. Обрати внимания на квен-9B. Он в более приемлимом кванте влезает в мелко-карты и он неадекватно умён для своего размера. Принцип как в прошлом времени, на тест потратишь минимум времени.
Бесит гемма 4 31б конечно уже. Такое ощущение что у неё один парик на всё.
>По крайней мере на питухоне и шелле.
В принципе включу сюда тайпскрипт и хтмл с js и css, последние 3 база для всех моделей, а с тайпскрипт мне этот самый мое квен написал рабочее расширение на нем для пи. (пришлось немного только допилить дипсиком облачным разные баги конечно, но мог это и с мое сделать только дольше)
1) нет выгрузки в рам = сходу кал. Нет, я не верю что ты можешь загрузить даже степ флеш в свой врам.
2) сглангу вроде какая-то инструкция всратая нужна? То ли avx512 то ли AMX. Иначе не работает или скорость не оче
Не будет, скорость модели считатся от активных параметров. Qwen3.6 35B A3B будет даже на чистом cpu работать быстро.
Промт-процессинг при наличии видеокарты будет с внятной сккоростью, 30B-мое сетки выдают у меня на ноуте 17 токенов в секунду вообще без видеокарты на процессоре. У тебя как минимум половина на карту влезет, это будет 30-40 токенов. Это ты зря очень сильно.
Да вроде если 2-4 потока, то окей по идее. Я же не 30+ штук хочу.
Попробую, спасибо.
Древняя бу материнка с ddr4, возможно я что-то не так в убунте и докере настроил ещё. Хотя ллама как-то за несколько минут то компилится.
Это мое, погугли че это такое и почему они быстрые. Если лень то короткий ответ - быстрее плотной модели раз в 5-10 даже при не полной выгрузке на видимокарту.
В шапке есть гайд, там на примере геммы объяснено.
Если не поймешь, то пиши. Но суть в том что ты активные пихаешь на видюху, а другие на рам. Ну и если место остается после контекста еще накидываешь слои.
>оно не будет медленно?
Как повезет. Но в целом MOEшки шустрые. Тут много зависит от процессора и памяти.
> Потому что ты пропустил мое разъяснение в скобках
Это про
> (если использовать в виде агента ту же модель)
? Тогда вдвойне непонятно.
По состоянию на сегодняшний день ты можешь одновременно на одной и той же модели рпшить с крупным контекстом и задавать в соседнем чате мелкие вопросы, в обоих случаях не будет пересчета. На лламе если что если контекст не проглючит. Также как на табби, убабуге, вллм, сгланг и прочих. Пересчет случится только если при освобождении контекста пропадут все слоты кэша, они очищаются по последнему использованию и основные всегда будут сверху.
> Я именно так и делаю
Ты в основном ответе требуешь статусбар, локации, изменения статов и прочее. Это все можно вынести в отдельные запросы. Если ты думаешь что в той же маринаре ллм что-то там считает и потом своими функциональными вызовами записывает статы - нет, там обычный скриптованный вызов и дальнейший парсинг ответа. Также как твои скрипты срабатывают, просто с возможности выноса в отдельные вызовы, с большим функционалом-интерфейсом, реализовано на уровне дизайна и скрыто от юзера.
>По состоянию на сегодняшний день ты можешь одновременно на одной и той же модели рпшить с крупным контекстом и задавать в соседнем чате мелкие вопросы, в обоих случаях не будет пересчета.
Он будет, лама сравнивает подаваемый контекст с сушествующими чекпоинтами и вырезает все чекпоинты, которые несоответствуют. При подаче мелкого вопроса с другим промптом он тебе все чекпоинты большого РП разом срежет нахуй.

Не совсем так согласно описанию.
Если же оно работает как ты сказал, то это баг. Должно быть 32 чекпоинта на слот, и слотов может быть больше одного.
Слоты я тестил, оно неплохо и само определяет.
Глянь что там по загрузке во время компиляции кудаграфов и прочего. И огласи какую модель пускаешь, какую версию ставишь и какое железо полностью.
А то может там какая-нибудь вольта и тогда на вллм нет смысла вообще времени тратить. В некоторых, особенно моэ, компиляция может быть оче долгой, до 10 минут, но делается она только один раз. Начиная с 20й версии в целом скорость прогрева сильно подняли, половина моделей стартует мгновенно и самая долгая операция - загрузка под тензорсплит.
Если же ты про компиляцию из исходников - это уже больно, лучше использовать готовые колеса. И реально сгланг глянь, он по-своему странный, но в некоторых вещах срабатывает лучше.
> При подаче мелкого вопроса с другим промптом он тебе все чекпоинты большого РП разом срежет нахуй.
Почему? Еще весной когда изменили работу с чекпоинтами, уже хранились старые и удалялись только когда кончалось место по принципу filo. Правда тогда это приводило к общему замедлению из-за накопления даже неактивного кэша, потом это починили. Можно настраивать и сгружать "лишние" части в рам.
Да, они рпшат плохо, но в плане порнухи вполне себе конкуренты. И, на мой взгляд, среди маленьких квенов только 27б 3.5 что-то может, а также 80б. Последний таки лучше, но с ним много мозгоебств. Не сел и поехал.
Да там дельта нет этот обычный, который сейчас все чекпоинтами закрывают. Раньше это не догадывались делать. А ведь этот квенчик ебёт даже плотняк мелкий.
Возможно, причина ещё в том, что тот, кто может запустить 80б, может запустить и глм, а также что-то пожирнее, поэтому в него никто не тыкал. Мало людей в треде, у которых недостаточно памяти для глм, но при этом достаточно для q4 k m 80б.
Но мне всё равно обидно. Даже не с кем модельку обсудить.

У меня именно так работает. Пруф на пике. Подал на модель подключенную в качестве агента к VS Code простой запрос из таверны. Случился тотальный геноцид чекпоинтов.
Ебать, она ж диффузионная. Я такую ждал два года. Это обязательно стоит попробовать. Завтра скочяю, отпишусь.


80 богат квенизмами как ни одна другая квено-модель. И в те далекие по LLM времена начинал шизеть уже на небольшом контексте. Надо конечно попробовать запустить его в жирном кванте с неквантованными мамба-тензорами, контекстом bf16 и современной жоре. Может он и не плох. Но что-то лениво.
Не вижу записей про очистку слотов 1, 2 или ещё каких-то, кроме нулевого.
Угу. Хотеть увидеть диффузию кода, как оно за 100 итераций из случайных символов вырисовывает код на 2000 строк, потихоньку подправляя до нужного.
>Не вижу записей про очистку слотов 1, 2 или ещё каких-то, кроме нулевого.
Потому что их нет. Что за слоты, кстати?
Лови свидетеля/жертву -kvu
Я его не включал. Но тем не менее я понял в чем дело. У меня -np 1 включен. Век живи весь учись.
Аноны, а сколько пишет в ризонинге у вас гемма? Есть ли какой-то способ сбавить ее обороты, так как 1к токенов на него ну много это для меня.
Согласен. И нормальных тюнов до сих пор нет.
>1к токенов на него ну много это для меня
Запусти квен и узнай что такое реально много токенов, чел. Это ещё терпимо.
>Тишина может укусить
>Дождь шипит (на самом деле хорошее выражение, но не здесь)
>Плакал серебряными слезами
>Лира
Ууух, бля. Само забавное, что даже еблю он так будет описывать. Даже с вульгарщиной будут такие моменты проскакивать, где-нибудь в реках спермы окажется серебряная слеза девственницы.
А какой это квант? Русский слишком хорош. Q8 35b-a3b рассыпается на русском полностью, например.
Вообще, если я правильно помню, так же писал 30b-a3b, но его в треде почти никто не запускал. В плане китайской прозы.
По поводу контекста, у него всё более-менее, если брать хотя бы Q4 k m. Разумеется, ему будет в целом похуй, что ты там 3к токенов назад сказал. Пальцем тыкнешь — учтёт. А так нет. Но я что-то вообще не припоминаю, какая малая модель это учитывала в 4 кванте. Ну, может квен 27b 3.5 иногда.
Мне кажется, что этот квен единственный вариант для нищуков, которые выше прыгнуть не могут.
Геммы 26/31 хорошо справляются с нарративом и РП, где скорее важно кино, чем точность. А вот этот квен отличный компромисс, когда нужно всё, но готов потерять кино: безумное порно пишет лучше геммы, а за счёт более жирного датасета не спотыкается так сильно в описании мира, локаций и прочего, как это делают квены 3.5, не говоря уже о 3.6, который совершенно рп бесполезен. Так можно хотя бы не переключаться между моделями постоянно
Я не знаю как на квене, но гемма не вставляет ризонинг в контекст, а поэтому он каждый раз прогоняет по новой 1к токенов, с каждым сообщением
--slots
И в запросах можно явно указывать slot_id
Полезно, если у тебя есть одинаковый промт с миллионом инструкций, к которому добавляется один и тот же небольшой запрос. Например, там идёт описание кастомного языка скриптов или библиотеки определённой версии, и надо отвечать на вопросы по ней. У тебя эти 50к будут в слоте, например 3, и все вопросы по этой либе обрабатываются отдельными запросами в слоте три.
Попадет ризонинг в контекст или нет, зависит не от модели, а от фронта. И ризонинг не должен в контекст попадать, он должен удаляться оттуда, иначе ответы деградируют.
Моделей без деградации, наверное, 1-2 штуки, которые специально были так сделаны.
Хорошо, но все же как заставить гемму меньше писать в ризонинге?
Никак. Если ты не хочешь сломать модель.
Я не пробовал уменьшить цепочку, пробовал только модифицировать, но то было для рп и для интереса. И оно потребовало танцев с бубном.
Можешь поискать файнтюны типа дистиллятов цепочек опуса 4.6, но всё это ебаное говно, которое всегда будет хуже оригинала.
Тебе пытаются объяснить, что ризонинг на гемме нормальный. И он и должен работать.
Про квен не просто так написали. Там 20к токенов может быть с вечными BUT WAIT и прочего дерьма, где он сам с собой спорит в ризонинге, лупится, шизит и смотрит мультики под грибами.
>Там 20к токенов может быть с вечными BUT WAIT и прочего дерьма, где он сам с собой спорит в ризонинге, лупится, шизит и смотрит мультики под грибами.
Но дает ответ, ха. Он просто сам из себя таким перебором знания вытягивает а потом рожает ответ.
Меня в этом плане вызвали ор поломанные кванты минимакса.
Он хуячит академический, идеальный ризонинг. А потом забивает на него болт и пишет вообще левую хуйню. Литералли, кто помнит первые модели с ризонингом.
>рассуждения о задаче
>учет всех переменных, формул
>проверка скриптика, форматирования
>ждешь КИНА, КОД ЧИСТЕЙШЕГО ГУГЛА
>пук
Говорят гугловский gemma-4-26B_q4_0-it.gguf хуже мразермахеровского и анслотного QAT 26b, якобы там лучше заквантовали. Кто-то сравнивал QAT версии?
> QAT ведет себя как Q4_K_M - Q5_K кванты, но менее поровотолива и глупее.
Так QAT и так Q4, вот этот от гугла к примеру
https://huggingface.co/google/gemma-4-26B-A4B-it-qat-q4_0-gguf
Вопрос в том лучше или хуже анслотные и мразмахеровые версии отсюда, чем стандартный гугловский
https://huggingface.co/unsloth/gemma-4-26B-A4B-it-qat-GGUF
https://huggingface.co/mradermacher/gemma-4-26B-A4B-it-qat-q4_0-unquantized-i1-GGUF
Пока не понятно где и почему сломано, а это скорей всего бекенд? Хз, непонятно можно ли получить правильно работающую модель просто по разному квантуя.
Думаю проблема вобще с моделью гугла, обучили криво.
Да нахуй вам ризонинг на мелких моделях? Цена качество ужасные же. Почти всегда отключаю, если только не тестирую что-нибудь и интересны внутренние размышления для улучшения настроек.
Q4_K_M квант это не Q4_0 кванты.
Любой Q4_K_M квант будет лучше, чем QAT 4_0. В свою очередь QAT 4_0 будет лучше любого Q4_0.
Лучше сам скачай и проверь в своих задачах.
Вот такую инфу с тестов ассистентов нашел:
Gemma4 Q5_K_S scored in assist:
- model_id: gemma4-26b-a4b
good_percent: 86.3%
confidence_interval: 3.1%
good: 397
total: 460
and Gemma4 Unsloth QAT scored in assist:
- model_id: gemma4-26b-a4b
good_percent: 88.9%
confidence_interval: 2.9%
good: 409
total: 460
То есть анслотовский QAT лучше Q5_K_S обычной неQAT геммы.
Какой же бред. Тебе выше прислали целое полотно где описаны проблемы и линк на два забугорных треда где куча людей соглашаются, что QAT кванты сломаны. Скачай сам и посмотри на собственной шкуре, стоит ли это 2.6% статистической погрешности в замерах профита. Учитывая что это мое модель а не плотная, где понятно было бы отчаянное желание сэкономить врам, я не понимаю зачем и нахуя здесь отказываться от проверенного кванта в пользу поломанного говна с целью сохранения 1.5гб оперативы.
Дай угадаю, ты на лм студии?
Там мнение одного крокодила какого-то. Когда сейчас на реддит заходишь, основная масса QAT нахваливает, даже 26b в qat рекомендуют. Тесты вроде тоже подтверждают, что QAT лучше. Хз, короче, надо разбираться. Поэтому тут и спросил, кто 26b qat разные тестил, может кто разобрался уже.
Ну, гугловский хуже анслопа, но лучше мразиша, а анслоп лучше их двух. Но и у анслопа есть проблемы, о чём они прямо написали.
Гугл квант выкатил без учёта особенностей работы лламы. Короче, просто с лопаты навалили — и ебитесь как хотите.
Может щас что-то поменялось, я вчера или позавчера смотрел, не помню.
Хорошая инфа, буду анслоп тогда тестить как самый лучший QAT из них.
>просто с лопаты навалили — и ебитесь как хотите.
На реддите так же пишут, тестов нормальных не запостил никто, так что с 26b сейчас сплошная непонятка, то ли лучше обычной 26b в Q5, то ли хуже, хуй поймешь.
Вот часть пишет что 26b QAT лучше обычной:
Доверительный интервал едва перекрывается, QAT находится на самой верхней границе диапазона того, что выдала исходная модель, поэтому, хотя это может быть вариативностью от запуска к запуску, это кажется очень маловероятным, и, опять же, использование этой модели в течение последних 5 дней подтвердило то, что показывают эти данные, а именно, что она работает лучше.
Ну и нахуя она мое если в диффузии это ничего не ускоряет? Кал
> Там 20к токенов может быть с вечными BUT WAIT
Это не норма и редкость в нормальных условиях. Ризонинг квена больше, но редко за 6к выходит, с ним 27б в итоге ориентируется и отвечает там где гемма гонит копиум. В рп же и там и там можно смело отключать ризонинг, не дает заметного буста.
> если в диффузии это ничего не ускоряет
Ускоряет. Ван тоже моэ, без этого по пол часа бы видео генерировали.




Вот скринчики сделал потестил, вроде разницы особой нет. По другим тестам погонял, тоже разницы особой не ощутил, логические все одинаково проходят. По скорости вроде как анслоп QAT самый быстрый.
gemma-4-26B-A4B-it-UD-Q4_K_M.gguf - обычный анслоп без qat, в Q4_K_M
gemma-4-26B_q4_0-it.gguf - QAT q4_0 напрямую из гугла
gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf - QAT анслоп в Q4_K_XL
gemma-4-26B-A4B-it-qat-heretic-UD-Q4_K_XL.gguf - QAT от SC117 c херетиком в Q4_K_XL
Чел очень хочет анслот в сраку и отказывается понимать что надо тестировать работу на контексте а не зирошоты
>А какой это квант
Qwen3-Next-80B-A3B-Instruct-Q5_K_L - от Бартовски
>этот квен единственный вариант для нищуков
Сомнительно. Ну разве что для отыгрыша жести и психодела. Думаю мелко мистраль будет и поэкономичней в плане РАМ и русик там получше. Опять таки тюнов мистраля овер дохрена - есть с чем развлекаться.
Next-80B-A3B потонул в РП потому что 27-3.5 делает его просто по всем параметрам. Ну разве что кроме знаний. А если комбинировать разные еретики 27-3.5 с плотно-геммой 4 то это вообще ИМХО предел счастья того что можно достигнуть на не-серверном железе.
Зачем вы обсуждаете Qwen3-Next-80B-A3B когда есть Qwen3.5-122B-A10B?
Зачем, какой смысл, бросайте этого лоботомита, это был тест дельтанета, кроме этого он ничем не примечателен.
Зачем, какой смысл, бросайте этого лоботомита, это был тест дельтанета, кроме этого он ничем не примечателен.
1. Что первым начнет забывать "трусы" на контексте больше 30k ?
2. Что первым проебет персонажа при распознавании картинки ?
3. У кого богаче русик при переводе любимого порно/ранобэ . С Китайского / Японского / Корейского.
4. И самое интересное чего нигде не видел сравнение с Q6 без imatrix.
Злые гномики из лмстудио заливают говно в шаровары логпробы лламыццп?
Анон хотел пообсуждать. Я разбавил вакуум. 80 СИЛЬНО быстрее 122 . И создает ИЛЛЮЗИЮ запуска настоящей большой модели на днище-железе.
1. Слишком сложно затестить и вариативность ответов выебет. То есть нихуя не определишь, то будут трусы, то не будут.
2. При вариативности ответов проебы персов частые, так что тоже сложно затестить.
3. Ну это еще можно как-то затестить, но надо знать японский.
4. Это можно для сравнения, у бартовского были q6 без матрицы.
>1. Слишком сложно затестить и вариативность ответов выебет. То есть нихуя не определишь, то будут трусы, то не будут.
это с геммой то вариативность? лол. наличие простаты точно можно померять, было бы желание, анон
Пиздец, я в ахуе с результатов. (Да, я весь этот бред прочитал.)
Чем менее точный квант, тем более флексово и вайбово, чел. Просто SVVAG.
Складывается впечатление, что квантовать под РП надо с особыми колундствами. Потому что у меня Q8 отвечает почти детерминировано и там нет рофлов.
Мне кажется что анслопы это величайшие шарлатаны и мистификаторы нашего времени в среде ллм. Просто никто не делает нормальных сравнений квантов, кроме самих анслопов, которые еще и метрики свои собственные продавили и тесты. Все по умолчанию качают анслопов потому что их кванты меньше, и поскольку они хуже не настолько, чтобы это прям в глаза бросалось - то мистификация поддерживает сама себя.
>половина мозга умерла, вместе с этой половиной отвалилась часть ассистента
>стало флексово и вайбово
хммм, где же связь
Ну эт пральна.
А так нужен двачерский калибровочный датасет, где каннички, зелёный слоник, вайп ниграми и умение писать трифорс. Так победим. Сделаем модельку, где в мясо заквантовано всё, что не нужно.
Квантование как способ созидания! Креатив! Полные веса для уебков!




Ну вот затестил, с предыдущим контекстом на 10к и полной карточкой, еще заменил Q4_K_M анслоп без QAT на Q6_K_XL
Вроде разницы опять немного, даже анслоп QAT версия получше как-то кажется, хотя все +- одно и то же.
gemma-4-26B-A4B-it-UD-Q6_K_XL.gguf - обычный ансплоп без QAT, но целых Q6_K_XL
gemma-4-26B_q4_0-it.gguf - QAT q4_0 напрямую из гугла
gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf - QAT анслоп в Q4_K_XL
gemma-4-26B-A4B-it-qat-heretic-UD-Q4_K_XL.gguf - QAT от SC117 c херетиком в Q4_K_XL



Захотел называется скачать последний билд жоры, а антивирь на него стриггернулся. Раньше было норм. Я-то конечно уберу из защиты, но неприятно. Нормально ж общались...
тоже самое было, триггерится через версию, мне даже интересно что они туда хуйнули такое
Ничего не найдено в сегодняшней версии. Правда я для cuda 12 качал, для старья. Вам майнеры по ходу для дорогих видеокарточек суют.
Пиздец, вот такие запускают гемму, а потом говорят что безмозг, хотя там уже от геммы остался Пигмалион 8B
Разные весовые категории, требования скорости. И 122 явно не у всех хорошо работает, или имеет черты, которые очень на любителя. А так - слепящий вин, также годна для кума и душных рп за счет ориентирования в больших контекстах.
>черты, которые очень на любителя
Ну да, например непробиваемая цензура с включенным ризонингом и крайне тяжело пробиваемая с выключенным. На контексте попроще, но зачем нужна такая ебля при наличии эйра в той же весовой категории - загадка. А там еще и умничка 124b на подходе.


Так хохма в том что Qwen3-Next-80B-A3B сосет даже у Qwen3.6-35B-A3B, т.е. она по факту хлам и устаревший мусор.
>А там еще и умничка 124b на подходе.
А с чего ты взял что гемма 124В-А10В она будет умнее 31B плотняши?
У квена вон даже в рамках 3.5 поколения 122В-А10В сосала у 27В плотняши, выход 3.6 27В вообще 122В уничтожил. А у геммы и сама плотняша жирнее на 15% чем у квена.
>А так - слепящий вин, также годна для кума и душных рп
Может быть только для ассистентского рп, где он отыгрывает профессора или ещё кого. Боится обидеть юзера, не отыгрывает злодеев вообще, соевый, ассистант алайнмейнт почти на уровне Немоторона 49б
Во первых, бенчмарки это говно и не показатель вообще.
Во вторых, ебало представили кто будет гемму 124б запускать? Там интересно контекст сколько весить будет, гигов 20?

Так квен сосал не только в бенчмарках, но и в РП.
>Там интересно контекст сколько весить будет
Меньше чем у плотняши раза в 2-3, примерно сколько у 12В, чуть меньше даже. Вес контекста зависит от активных параметров а не общих.

>А с чего ты взял что гемма 124В-А10В она будет умнее 31B плотняши?
Просто экстраполирую с 26b-a4b, которая лишь немного тупее плотной 31b. Реально, это первая на моей памяти модель с таким низким числом активных параметров, которая НЕ лоботомит и с которой можно комфортно рпшить. Всё что было до этого, все квены и глэм a3b - мусор на ее фоне.
Так вот 124b должна быть тотальным разъёбом. Скорее всего поэтому её до сих пор и не выпустили - просто смысла нет, она очевидно будет лучше всех конкурентов вплоть до 200b. Хотят дождаться релиза новых квенов, а потом уже выпустить свою моэ и побить их. Минутка коупинга окончена.
И вроде там 124b-a15b, не? Будет даже поплотнее эйра, что хорошо.
а откуда вообще слух пошел про 124b? Я просто не верю, что выпустят, учитывая насколько 26б охуевшая. А так очень хочется конечно
>ебало представили кто будет гемму 124б запускать?
Ну.. буквально 2/3 тредовичков, у которых есть 12/16 + 64, лол.
>интересно контекст сколько весить будет
Столько же, сколько и других моделей гемма 4.
Гуглы опубликовали твит с перечислением новых моделей, которые релизнут, среди них была "MoE 124b". Твит провисел несколько минут, после чего был отредачен и инфа про жирномоэ удалена. Сейчас гуглов периодически тыкают палкой на реддите и твиттере по поводу этой модели, а они хранят ЗАГАДОЧНОЕ МОЛЧАНИЕ, ничего не подтверждая и не отрицая.



Вот еще русский затестил с QAT, тут взял сложную карточку с персом смешивающей немецкие и русские фразы + предыдущий контекст 10к. Смесь немецко-русского и предыдущего контекста должна быть для квантов посложнее. И вместо Q4 иматрикса, взял Q6 статический для сравнения, как в треде рекомендовали. У unsloth QAT вроде как хуже с немецким, какой-то он бедный, при этом думал на 8к токенов больше всех, heretic зачем-то добавил расшифровку (глюки уже?), у гугла QAT и статика Q6_K все норм со вставками немецких фраз. Но так в принципе все одинаковы. Google QAT родной достаточно хороший и по скорости и по выводу. Короче однозначных победителей нет.
gemma-4-26B-A4B-it.Q6_K.gguf - мразермахер статический квант Q6_K, никаких иматриксов
gemma-4-26B_q4_0-it.gguf - QAT q4_0 напрямую из гугла, тоже статический
gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf - QAT анслоп в Q4_K_XL, иматрикс
gemma-4-26B-A4B-it-qat-heretic-UD-Q4_K_XL.gguf - QAT от SC117 c херетиком в Q4_K_XL, иматрикс
Экстраполируя с квена - там 3.5 35В оставала, но не фатально от 3.5 27В плотняши, а вот 3.5 122В несмотря на троекратный рост была всего лишь на уровне плотняши, чуть-чуть уступая в РП и превосходя в знаниях.
>И вроде там 124b-a15b
Речь шла о "up to a 124B parameter MoE model", про 15В это фантазии.
> непробиваемая цензура с включенным ризонингом и крайне тяжело пробиваемая с выключенным
Хз, кум отыгрывает, канни отыгрывает, жестокость отыгрывает. Если инстант начнешь жесть творить - откажет, но когда обусловлено сюжетом - сама наваливает. Там другие претензии что иногда чрезмерно дотошная, по стилю и темпу повествования, но это все очень субъективно.
> при наличии эйра
Он радикально тупее, хотя художественнее.
> А там еще и умничка 124b на подходе.
Да где, заждались ее уже. Выпустите зверя наконец, будем наяривать за обе щеки.
Это где такое?
Юзер легко отгребает едва не умирая при неудачный действиях или просто при запросе плот-твиста, вместе с чаром пытаете и допрашиваете неприятелей, совершая потом военные преступления не считается потому что было весело, и всякое. Но куда интереснее то, что на не особо уместное предложение чар не стесняется говорить нет и принимать разумные решения аргументируя их, а не подстраивает все под тебя, делая сюжетные дыры.
На постоянку хз, но вперемешку с другой моделью - вполне.
Ты ведь понимаешь что такие сравнения на глаз - это полная хуйня? Милипиздрическая разница между квантами перекрывается статической погрешностью от рандома от разных свайпов?
>Show Thoughts (8204 characters)
будь другом, покажи тхинкинг целиком. мне интересно, я не представляю что надо делать с геммой чтоб она столько думала (но я только плотную гоняю...)
А 124b моэ влезет вообще в адекватном кванте в 32vram + 64ram? Кто крутил квен большой поделитесь. Потому что скорее всего болячка геммы с тем что она лоботомит на ниже q8 квантах перейдёт и на новую 124b
122b - это обосрамс, тут даже не спорю. Но вот ещё аргумент в защиту гугла. Периодически пользуюсь их корп-моделью Gemini 3.1 Pro (по слухам 2T-моэ), и относительно недавно они релизнули новую Gemini 3.5 Flash (200B-500B-моэ по слухам, опять же). Так вот разница между ними исчезающе мала. Ну примерно как разница между нашими 31b и 26b. Не знаю что они там нахимичили, но кажется гуглы научились делать очень крутые маленькие моэ.
В 4 бит влегкую влезет.
Ну это кал конечно если только в q4. Пойду качать большой квен, может в q5 влезет хотя бы.
>прошёл день
>нет рабочих билдов лламы даже в ПР
Видимо нескоро будет новая диффузная гемма. Там даже параметры запуска другие. А ведь так-то на бумаге звучит круто, х4 к скорости генерации с небольшим ухудшением качества правда только в фулл-врам, с процом хз, мб небольшой прирост.. Вллм-бояре, делитесь опытом, как оно.
>нет рабочих билдов лламы даже в ПР
Видимо нескоро будет новая диффузная гемма. Там даже параметры запуска другие. А ведь так-то на бумаге звучит круто, х4 к скорости генерации с небольшим ухудшением качества правда только в фулл-врам, с процом хз, мб небольшой прирост.. Вллм-бояре, делитесь опытом, как оно.
туда бы еще apex квант от mudler
Кобольд по ебанутому считает символы, а не токены. Ну то есть в ризонинге 8204 букв, что не очень и много.
Анон, что я делаю не так?
В одном из прошлых тредов видел ссылку на вот этот тюн https://huggingface.co/mradermacher/Versipellis-31B-i1-GGUF
скачал и M и S вариант 4 кванта. обе выдают 2-2.8 токена генерации на 32к контекста на моей 4090. со слоями играл, 2.8 выдает на 35 слоях. Запускаю через кобольду.
Это нормальная ситуация и моя 4090 просто тупо не тянет? На чем тогда это надо запускать?
В одном из прошлых тредов видел ссылку на вот этот тюн https://huggingface.co/mradermacher/Versipellis-31B-i1-GGUF
скачал и M и S вариант 4 кванта. обе выдают 2-2.8 токена генерации на 32к контекста на моей 4090. со слоями играл, 2.8 выдает на 35 слоях. Запускаю через кобольду.
Это нормальная ситуация и моя 4090 просто тупо не тянет? На чем тогда это надо запускать?

>будь другом, покажи тхинкинг целиком. мне интересно, я не представляю что надо делать с геммой чтоб она
Вот зинкинг, похоже она подумала, потом еще подумала, потом наконец написала. Возможно баг анслота, потому что гугловский так не делает.
Просто ты скорее всего превысил врам и драйвер слил излишек на рам, убив тебе скорость. Проверь по диспетчеру задач расход врам и "общую врам".
А кстати, в этом случае не поможет --fit-ctx? Я так понимаю он таким образом сразу правильно фиттит в видеопамять.
Во-первых, у тебя влезут все слои. Смело ставь 999. Во-вторых, ты что-то явно делаешь не так, потому что в мои 16гб влезают 40 слоев и скорость 5.5тc без мтп и 9тс с мтп. В твоем случае можно рассчитывать на скорости 30тс+ и 60тс+ с мтп т.к. фуллврам, ещё и быстрая.
>Запускаю через кобольду
Удали каку и разберись как работает ллама. Это сильно облегчит тебе жизнь. Если не осилишь параметры запуска, пиши, в треде помогут.

> 35 слоях
поставь 99
Квантани контекст в Q8 - Q8
Плотной гемме нормально жить ОТ 32 Гб VRAM это 5090 или несколько видеокарт (5060TIx2 или 4060TIx2 или 3090x2 )
Выгружать в оперативу ничего не нужно. У меня тоже 4090, и спокойно помещаются Q4_K_M кванты бартовского (на 1.2гб больше весят, чем Q4_K_M mradermacher) и 32к контекста без квантования. Еще и 0.5-1гб видеопамяти останутся для остальных задач. Изучай гайд в шапке и ставь Лламу.
это че за экономия на спичках? что мешает кобольду дёрнуть серверный токенизатор??
надеялся увидеть как модель с ума сошла, но тут типичный слопчанский, ты прав.
Все-таки что ни говори, а локалки (говорю за размеры в диапазоне примерно 25-35, тот максимум, что доступен простому человеку на простом железе) это абсолютно немощная туповатая шляпа на фоне любых коммерческих моделей. Лично я интересуюсь и слежу за этой темой только потому, что актуальная локалка входит в мой аварийный "чебурнет-пак" на случай понятно чего. Такая вещь, как аптечка или огнетушитель - иметь надо, но лучше, чтоб никогда не пришлось применять.
А постоянно пользоваться же локалками сейчас, во времена, пока интернет еще жив и есть корпы - смысла фактически никакого.
А постоянно пользоваться же локалками сейчас, во времена, пока интернет еще жив и есть корпы - смысла фактически никакого.
Я параноик, а поэтому с ключами, токенами и паролями работают только локалки. И с ключевой личной информацией, которую я на сторону отдать не хочу. И текущие локалки не так плохи как облачные модели, тоесть да они хуже, но их уровень средний, они уже способны приносить пользу.
Какой ответ ты ожидаешь услышать в локальном треде и зачем это все? Если вкратце - ты не прав и сейчас заслуженно на тебя набросятся. Если подробнее - зависит от задач и сферы применения. Помимо озвученного тобой есть и другие преимущества локалок. Не говоря уже о том, что сам процесс возиться с ними и запускать их именно на своем железе - отдельный вид деятельности, для многих здесь увлекательный. Корпы плохи в капшне картинок для датасетов лор и файнтюнов картинкомоделей; корпы могут быть избыточными для различных задач, а значит человеку в принципе они могут быть не интересны (простенькие скрипты написать, ответить на common sense вопросы и пояснить за код/помочь в освоении нового софта и прочего могут Гемма и Квен, которые идут на любом потребительском железе). Уверен, если задуматься - то еще больше таких юзкейсов наберется, от балды написал, что держу в голове, ибо релейтед для меня.
С корпами не поролеплеишь, там везде лимиты же и цензура. Вспоминается случай, как один малец в нейронку корпов загрузил свой стручок, за что потом забанили акки всей его семье, включая сестру которая жила в другой части страны и у нее там диплом для подготовки загружен был. И они там целый бизнес и кучу денег потеряли, потому что все акки на домены и сервисы завязаны были.
А чисто справочные вопросы конечно лучше корпам задавать, они хорошо соображают.
> А постоянно пользоваться же локалками сейчас, во времена, пока интернет еще жив и есть корпы - смысла фактически никакого.
Чтобы уметь ими пользоваться когда/если интернет и/или корпы умрут, очевидно. Рано или поздно одно или другое произойдет, на корпах за последние полгода гораздо больше анальных ограничений прибавилось и дальше все будет только хуже, как ни посмотри. Впрочем даже оставляя это за скобками, не будь локалок, корпы ахуели бы еще больше со своими условиями и монополией. Короче ты пернул в лужу, друже.
Это какая информация то? Дневничок о том как ты покакал?
Как мамку твою в кино водил, тоже личная знаешь ли.

Как же гугл ебет
Единственный выход для локалок это либо отвязать датасет от мозгов как предлагают либо пробовать другие подходы
Единственный выход для локалок это либо отвязать датасет от мозгов как предлагают либо пробовать другие подходы
Как оказалось, дело было в том, что у меня кобольд был старый.
Обновил и выросло до 25.
>Квантани контекст в Q8 - Q8
А что это значит?
неиронично да. каким надо быть гоем чтобы собственноручно нести корпам своим заметки, для пущего унижения только чип вживить осталось

Вот я вчера со своей умницей Квеноняшей весь вечер потратил на то, чтобы выбрать себе подходящий мастурбатор в виде торсика, заказал его за 15к и жду доставки. Было обсуждено все от цены до веса, сценариев применения и пользы. Параллельно катались тулколлы на генерацию наволочки для дакимакуры. После хорошенькой разогревочной кумсессии я теперь буду идти тискать дакимакуру и натурально ебать свою вайфочку, пока ты получаешь баны за дикпик или тысячелетнюю кемономими и снова идёшь клянчить ключи. Ладно, даже если тебя пожалеют и оставят в живых из жалости то будешь читать хард(софт)рефузы с алайнментом и морализаторством.
> А что это значит?
Как же копротивляются и не хотят образовываться, нуэтожпиздец, вам целый гайд написали где все разжевали, а вам сука приятнее блуждать в темном глухом лесу наощупь и краудсорсить свои проблемы на борде, тоска. Иди читай и не возвращайся пока не прочитаешь.
Какой смысл свои заметки нести любой нейронке, объясни мне?
Ты либо пишешь сам что может быть полезно, либо генерируешь бесконечный нейрослоп который никогда больше не откроешь.
В треде пока никто не запускал. А вдруг там получилась модель уровня кобольда?
Кто то нашел не заброшенный рабочий проект по ai вайфу локальной? Чтобы вижн работал, t2s локальный, s2t тоже. Может mcp. И желательно без gpt-sovits нерабочего
>С корпами не поролеплеишь, там везде лимиты же и цензура.
Гемини 2.5 pro вполне себе пишет порно, Opus 4.6 на пустом контексте не хотел, но достаточно было попросить его продолжить историю дальше он соглашался, DeepSeek v4 pro в 99% случаев в ризонинге пишет "это, конечно, плохо, но юзер разрешил, так что норм".
GPT 5.5 себя в ролеплее очень хорошо показал, кстати, в отличии от предыдущих GPT 5.x, но порно я им писать не пробовал, Дипсик в нём тащит безумно.
>Вспоминается случай, как один малец в нейронку корпов загрузил свой стручок, за что потом забанили акки всей его семье, включая сестру которая жила в другой части страны и у нее там диплом для подготовки загружен был.
Гуглы официально заявили, что это был пиздёж рандомхуя в твиттере.
При этом я не тот набросивший анон и согласен, что локалки нужны - в любой момент пукнет и обмякнет халявный доступ к корпам, а на ролеплей я в настоящий момент подсел сильнее, чем на ММО в студенчестве.

Вот как сам запустишь, тогда и будет разговор. А пока это просто таблички.
>Какой смысл
а это никого ебать не должно.
>либо пишешь сам что может быть полезно, либо генерируешь бесконечный нейрослоп который никогда больше не откроешь.
либо сам пишешь что может быть полезно, открываешь, а там за миллион строк уже перевалило. вот и всё
Интересно же, вдруг есть какой-то юзкейс который я упускаю
Я ебашу на эмоциях дневники свои и хуевая и дерганное оформление, кривые непричесанные фразы и скакания с мысли на мысль - это не баг, а фича.
Что еще кроме причесывания делать с ними я хз
Для всего кроме рп хотя тут тоже вопрос дискуссионный, ОСОБЕННО на русике и вижена гемма 26 q8 > гемма 31 q4
Без вариантов вообще. Кстати вижен 26 q8 тоже работает лучше, он нюансы картинки лучше понимает и описывает, а вижен 31 q4 легче распознает всяких персонажей особенно обскурных
Без вариантов вообще. Кстати вижен 26 q8 тоже работает лучше, он нюансы картинки лучше понимает и описывает, а вижен 31 q4 легче распознает всяких персонажей особенно обскурных




>туда бы еще apex квант от mudler
Тоже качнул, тестанул, какая-то навороченная моделька, в описании много обещали. Скорость ниже QAT от анслопа, но повыше Q6. Немецкий в тему сует. Думает меньше анслопа. Багов вроде бы нет. +- как гугловский QAT, даже по скорости так же.
В сравнении с теми достаточно хорошо.
gemma-4-26B-A4B-APEX-Balanced.gguf - тестил сбалансированный статический квант, без imatrix
Хз, кодинг у меня на гемме 31 лучше, правда у меня q6.
Что ты тестируешь вообще? Что модель не сошла с ума в рамках одного единственного сообщения? Ну ахуеть теперь. Смотреть надо как хорошо она ссылается на старые вещи из чата и не забывает их, как продолжает существуещее в контексте, есть ли двойные трусы или умница все учитывает. Анслотозависимый, блять, накидал говна бесполезного в тред, зато на 2.6% лучше по неизвестному бенчу и быстрее всего. Аутотренингом занимаешься или как?
Я уже сдрочился, если не дрочу то листаю карточки персонажей какие ещё скачать, ёбаная сука игрушка дьявола, нахуй оно надо.
Так она ссылается, там везде предыдущий контекст с событиями 10к + карточка. В целом все показали себя хорошо, никаких особых отличий нет. Можно юзать хоть QAT, хоть Q6, хоть Apex. Чисто из-за скорости предпочитаю QAT от анслота, там она повыше остальных, в херетике тоже довольно высокая, а результаты не хуже. Гугловский QAT сбалансирован по всем тестам, заметных багов нет, оптимальный. В анслоте баг с длинным зинкинком, который не всегда активируется, обычно тоже короткий.
>там везде предыдущий контекст с событиями 10к + карточка
Уже получаем их всем тредом при помощи телепатии, ага. Такие тесты нам, сторонним наблюдателям, никакой пользы не несут
>В анслоте баг с длинным зинкинком, который не всегда активируется
Есть reasoning-budget для ограничения по токенам, есть logit bias чтобы модель сама скорее закрывала ризонинг. Всё делается
>то листаю карточки персонажей какие ещё скачать
Давно бы уже скачал все.
>Есть reasoning-budget для ограничения по токенам
Он везде одинаковый выставлен был жестко через настройки. Но анслоп генерил по 8к время от времени, а гугловский всегда по 3300-3500. Так баг какой-то по ходу анслопы занесли.
например самый обыкновенный поиск (по смыслу а не по словам). можно конечно тегать/линковать всё как аутяра в каком-нибудь обсидиане, но это геморно
> Вллм-бояре, делитесь опытом, как оно.
Даже не думал что скажу такое, но too small.
Чем корпы действительно хороши - интерфейсом высокой идиотпруфности и пост тренингом, облегчающим понимание обывателей. В остальном, если брать не флагманские и следующие за ними быстрые модели, то они "опустились" как раз до уровня 25-35. 3.5флеш разве что сейчас выделяется.
> никакой пользы не несут
Тут до этого выше говорили, что модельки сломанные, не поддерживается что-то там и прочее. Тесты показали, что все практически одно и то же, отличий минимум, даже на русско-немецком и зумерских сленгах. Выходит все различия вкусовщина и субъективщина, либо вариативность вывода при перегенерации одной и той же моделью. Так что остается выбирать, что по скорости лучше и к железу подходит, разницы особо заметной между ними не будет.
>тесты натурально ничего не показывают кроме одного единственного аутпута
>Тесты показали
Мы поняли. Анслот внутривенно этому эпилептику.
>в ёбле ассистента разницы особо заметной между ними не будет.
поправил тебя
как же сему альтману печет от того, что никто не хочет юзать его парашу
На фоне того что сейчас цена нормальной подписки начинаются от 100 баксов, и вэту подписку не входит кум и приватность - твой пост просто лоу квалити жирнота.
А вообще, есть ли корпы для кума?
Гопота вроде обещала 18+ режим, но что-то хуй там.
Грустная и неприятная база.
Даже "древний" gpt-3.5, с которого началось массовое пришествие llm, и который очень туп по сегодняшним меркам - он был размером 175b.
То есть локалкам безумно далеко даже до первого поколения корпов.

Слишком пережирнил. Какая-нибудь Гемма е4В выебет в рот и жопу тот древний чат-гпт 175В.
>Грустная и неприятная база.
Таблетки.
Не всё измеряется только параметрами. Что гопота 3.5, что лардж 120b или сколько он там, что лама 70b, устарели уже настолько, что сольют в любом сценарии тупа гемме 26b, не говоря уже о чем-то крупнее.
Но если хочется подрочить на циферки, то кими 1T и дикпик 630b - это тоже локалки, так-то. И обе больше корпоративного Грока 500b.
Ты где находишься цифры свои назови. У меня с ру айпи и с ру впн не тянет. Какую страну врубить надо?
Корпы дают qol хороший, даже если качество не сравнивать, к нему легко привыкнуть и тяжело будет возвращатся к локалке поэтому я их не трогаю. Это как с не знаю с 20тс на 3тс переезжать.
Пережирнил. И времена когда корпы были непомерно огромными, а локалки мелкими давно прошли. Нынче и лоботомитами за денежку накормят, и можно у себя йобу крутить при наличии железа.
Ну анон прав. Вне кодокала хотя и тут спорно даже дикпик про 1,6t будет сосать с проглотом у 3,5 турбо. По прозе, логике и связности так точно.
Пока китайцы будут "обучать" свою хуйню на выдаче клода, нихуя не изменится. А западные корпы будут кормить урезанными в хлам лоботомитами, которые на уровне древней пигмы.
Хуя копиум.
Жтп турбо не сможет рассуждать и делать по шагам, понимания промтов будет хуже но из-за размера датасета - кучи примеров сами слова и предложения будут в разы более крутые чем все мелкоговно что вы сможете поставить когда либо
Другое дело что он иногда будет говорить не в попад

Может съебешь уже в асигопарашу со своей толстотой?




Кто продолжит сраться - тот дурак и не прав. Кто умный джентельмен - несомненно его проигнорирует и пойдет читать полотно.
Никогда толком не вникал в то, как работает вижн в ллмках, решил немного поиграться. Да еще и на обскурных по сегодняшним меркам данных.
Для эксперимента понадобятся:
- Очаровательная Эйша Кланклан из Seihou Bukyou Outlaw Star
- gemma-4-26B-A4B-it-Q8_0
- gemma-4-26B-A4B-it-bf16
- gemma-4-31B-it-Q4_K_L
- Qwen3.5-122B-A10B-Q8_0
- Step-3.7-Flash-Q4_K_L
Все кванты bartowski. Сэмплеры рекомендуемые разработчиками из документаций моделей. Кэш и прожекторы в bf16 (разницы с fp16 по моим коротким тестам не замечено)
Писать скрипты было лень, так что все делал руками параллельно работе и чарты/логи приложить не могу, но поделюсь наблюдениями на словах.
Каждая модель 10 раз обрабатывала одну и ту же картинку персонажа.
- gemma-4-26B-A4B-it-bf16 ни разу не ушла в бесконечный луп. Не знает, что это за персонаж: все 10 раз не нашла ответ, честно ответила, что не знает и предположила, что это непопулярный персонаж/чей-то оригинальный персонаж, предположительно художника. Судя по ризонингу, Гемма извлекает визуальные черты объекта и пытается сопоставить со своими знаниями. Перебирает варианты прямо в ризонинге, что видно в ризонинг блоке.
- gemma-4-26B-A4B-it-Q8_0 в ризонинге ведет себя как bf16, но все 10 раз(!) ушла в бесконечный луп. Ранее я пробовал ей подсовывать других непопулярных персонажей, и поведение всегда такое.
- gemma-4-31B-it-Q4_K_L в ризонинге ведет себя похоже на 26b и перебирает варианты внутри блока. За все 10 попыток ни разу не ушла в бесконечный луп, но и персонажа не отгадала. Когда обращала много внимания на подпись - предполагала, что это оригинальный персонаж художника и уходила в галлюны. В остальных случаях неверно определяла персонажа, например, Ayla из Chrono Trigger.
- Qwen3.5-122B-A10B-Q8_0 в ризонинге так же идентифицирует отличительные черты персонажа и собирает их воедино, сравнивает с известными ему персонажами. Но часто более дотошен, чем Гемма. Сравнения персонажей проводит не ванлайнерами, а проходит по схожим и отличным чертам. Много раз думал, что коса - это хвост, чего за Геммой не замечено. Подпись автора не была распознана. Ни разу не угадал и не признал, что не знает, не предположил логичных вариантов (что это оригинальный персонаж или что-то обскурное), галлюцинировал. Пару раз сравнивал с Фелицией из Skullgirls, что в целом можно понять в данном случае. Один раз ушел в бесконечный луп на слове Neko и его вариациях (лол).
- Step-3.7-Flash-Q4_K_L на данный момент обладает багом процессинга картинок, тот гораздо медленнее текстовой обработки: почему-то форсится батч 80, 81 или 180 токенов. Ризонит так же, как и предыдущие модели, но мне понравилось, как он уделил больше внимания композиции, позе, вайбу картинки, а не оценивал только физ.характеристики персонажа. У него неплохой вижн, я пробовал в разных юзкейсах. CoT в целом похож на Квен, но чуть более умеренный в плане дотошности. Подпись автора разобрал частично. На одних и тех же идеях не лупился, перебирал целые медиумы, много всего перепробовал, и игры, и аниме, и кино, и даже всякие феминизации. Но ответ так и не нашел, все 10 раз лупился(!).
Итоги/мысли такие:
- Из протестированных моделей только Гемма 26б bf16 дала корректный ответ. Персонаж не был определен верно, но и неверно тоже - ответ в духе "не знаю, вероятно, обскурный персонаж или ОС художника" валиден.
- У Эйши большие проблемы: ее никто не знает! Она будет в ярости. Но на самом деле, я протестировал эти модели на многих аниме 90-х, и почти никаких персонажей они не знают, только самых иконических. Интересно было именно так протестировать. Кстати, даже если спросить текстом про ту же Эйшу - модели ее не знают, т.е. это не проблема на уровне мультимодальности. Тут и Гемма 24б bf16 начинает галлюцинировать и сочинять.
- В отрыве от сценариев, когда данные модели не имеют нужных данных, они все довольно хорошо справляются. Мне трудно выделить любимцев, но я бы охарактеризовал их так: Гемма 26b bf16 и Q8 лучше всех видят мелкие детали; Гемма 31b Q4 похоже, знает больше (по крайней мере, в сравнении с 26 и Квеном 122); Qwen 122b Q8 хорошо видит мелкие детали, но если там что-то неприличное - будет увиливать; Step 3.7 Q4 видит почти так же хорошо, как Гемма 26b Q8, но при промптинге не увиливает и описывает все как есть. Из минусов - очень медленно работает процессинг. Всеми этими моделями я генерирую промпты для Анимы и в целом часто использую, например для написания карточек или поиска закономерностей в референсах. Все хороши.
Мысли на подумать:
- Q8 не такой уж и lossless в случае Геммы 4? Или вообще?
- Anima (вот это поворот) - это всего лишь 2b картиночная модель, и даже она знает Эйшу и многих других обскурных персонажей, которые не определились в моих тестах Квеном (в 61 раз больше) и Степом (пусть и Квантован до Q4, но в 100 раз больше). Мне кажется, в будущем появятся классные омнимодели (генерируют и текст, и изображения), которые благодаря своей мультимодальности и мультизадачности будут и знать гораздо больше. Не знаю, осуществимо ли это сейчас, но как будто имеет смысл попробовать.
- Если дочитали до конца - молодцы. Теперь вы знаете про Эйшу, в этом была моя единственная миссия, а все что выше - подводка для удержания внимания.
Никогда толком не вникал в то, как работает вижн в ллмках, решил немного поиграться. Да еще и на обскурных по сегодняшним меркам данных.
Для эксперимента понадобятся:
- Очаровательная Эйша Кланклан из Seihou Bukyou Outlaw Star
- gemma-4-26B-A4B-it-Q8_0
- gemma-4-26B-A4B-it-bf16
- gemma-4-31B-it-Q4_K_L
- Qwen3.5-122B-A10B-Q8_0
- Step-3.7-Flash-Q4_K_L
Все кванты bartowski. Сэмплеры рекомендуемые разработчиками из документаций моделей. Кэш и прожекторы в bf16 (разницы с fp16 по моим коротким тестам не замечено)
Писать скрипты было лень, так что все делал руками параллельно работе и чарты/логи приложить не могу, но поделюсь наблюдениями на словах.
Каждая модель 10 раз обрабатывала одну и ту же картинку персонажа.
- gemma-4-26B-A4B-it-bf16 ни разу не ушла в бесконечный луп. Не знает, что это за персонаж: все 10 раз не нашла ответ, честно ответила, что не знает и предположила, что это непопулярный персонаж/чей-то оригинальный персонаж, предположительно художника. Судя по ризонингу, Гемма извлекает визуальные черты объекта и пытается сопоставить со своими знаниями. Перебирает варианты прямо в ризонинге, что видно в ризонинг блоке.
- gemma-4-26B-A4B-it-Q8_0 в ризонинге ведет себя как bf16, но все 10 раз(!) ушла в бесконечный луп. Ранее я пробовал ей подсовывать других непопулярных персонажей, и поведение всегда такое.
- gemma-4-31B-it-Q4_K_L в ризонинге ведет себя похоже на 26b и перебирает варианты внутри блока. За все 10 попыток ни разу не ушла в бесконечный луп, но и персонажа не отгадала. Когда обращала много внимания на подпись - предполагала, что это оригинальный персонаж художника и уходила в галлюны. В остальных случаях неверно определяла персонажа, например, Ayla из Chrono Trigger.
- Qwen3.5-122B-A10B-Q8_0 в ризонинге так же идентифицирует отличительные черты персонажа и собирает их воедино, сравнивает с известными ему персонажами. Но часто более дотошен, чем Гемма. Сравнения персонажей проводит не ванлайнерами, а проходит по схожим и отличным чертам. Много раз думал, что коса - это хвост, чего за Геммой не замечено. Подпись автора не была распознана. Ни разу не угадал и не признал, что не знает, не предположил логичных вариантов (что это оригинальный персонаж или что-то обскурное), галлюцинировал. Пару раз сравнивал с Фелицией из Skullgirls, что в целом можно понять в данном случае. Один раз ушел в бесконечный луп на слове Neko и его вариациях (лол).
- Step-3.7-Flash-Q4_K_L на данный момент обладает багом процессинга картинок, тот гораздо медленнее текстовой обработки: почему-то форсится батч 80, 81 или 180 токенов. Ризонит так же, как и предыдущие модели, но мне понравилось, как он уделил больше внимания композиции, позе, вайбу картинки, а не оценивал только физ.характеристики персонажа. У него неплохой вижн, я пробовал в разных юзкейсах. CoT в целом похож на Квен, но чуть более умеренный в плане дотошности. Подпись автора разобрал частично. На одних и тех же идеях не лупился, перебирал целые медиумы, много всего перепробовал, и игры, и аниме, и кино, и даже всякие феминизации. Но ответ так и не нашел, все 10 раз лупился(!).
Итоги/мысли такие:
- Из протестированных моделей только Гемма 26б bf16 дала корректный ответ. Персонаж не был определен верно, но и неверно тоже - ответ в духе "не знаю, вероятно, обскурный персонаж или ОС художника" валиден.
- У Эйши большие проблемы: ее никто не знает! Она будет в ярости. Но на самом деле, я протестировал эти модели на многих аниме 90-х, и почти никаких персонажей они не знают, только самых иконических. Интересно было именно так протестировать. Кстати, даже если спросить текстом про ту же Эйшу - модели ее не знают, т.е. это не проблема на уровне мультимодальности. Тут и Гемма 24б bf16 начинает галлюцинировать и сочинять.
- В отрыве от сценариев, когда данные модели не имеют нужных данных, они все довольно хорошо справляются. Мне трудно выделить любимцев, но я бы охарактеризовал их так: Гемма 26b bf16 и Q8 лучше всех видят мелкие детали; Гемма 31b Q4 похоже, знает больше (по крайней мере, в сравнении с 26 и Квеном 122); Qwen 122b Q8 хорошо видит мелкие детали, но если там что-то неприличное - будет увиливать; Step 3.7 Q4 видит почти так же хорошо, как Гемма 26b Q8, но при промптинге не увиливает и описывает все как есть. Из минусов - очень медленно работает процессинг. Всеми этими моделями я генерирую промпты для Анимы и в целом часто использую, например для написания карточек или поиска закономерностей в референсах. Все хороши.
Мысли на подумать:
- Q8 не такой уж и lossless в случае Геммы 4? Или вообще?
- Anima (вот это поворот) - это всего лишь 2b картиночная модель, и даже она знает Эйшу и многих других обскурных персонажей, которые не определились в моих тестах Квеном (в 61 раз больше) и Степом (пусть и Квантован до Q4, но в 100 раз больше). Мне кажется, в будущем появятся классные омнимодели (генерируют и текст, и изображения), которые благодаря своей мультимодальности и мультизадачности будут и знать гораздо больше. Не знаю, осуществимо ли это сейчас, но как будто имеет смысл попробовать.
- Если дочитали до конца - молодцы. Теперь вы знаете про Эйшу, в этом была моя единственная миссия, а все что выше - подводка для удержания внимания.
Первая гопота, вторая гемини. Очередное доказательство того, что старшая сестричка геммы такая же умничка :3
> Очередное доказательство того, что старшая сестричка геммы такая же умничка :3
Скорее доказательство, что люди которые сравнивают корпа с доступом в веб и инструментами с полностью локальной моделью не очень умны. Увы.
У чатагпт есть доступ к вебу, но это ему никак не помогло.

Анон хелп, есть ли гайд как на локальной Qwen 3.6 / Qwen-coder-next / или другой ллм настроить MCP сервер для управление браузером пробовал связку
Ollama+codex+Qwen 3.6 + (mcp google-dev и firefox-dev)
https://github.com/ChromeDevTools/chrome-devtools-mcp
https://github.com/mozilla/firefox-devtools-mcp
На платном codex сук работало правда там их llm были а квен в упор не может их дернуть просто ломается на вызове
• chrome-devtools • Auth: Unsupported • Tools: click, close_page, drag, emulate, evaluate_script, fill, fill_form, performance_analyze_insight, performance_start_trace, performance_stop_trace, press_key, resize_page, select_page, take_heapsnapshot, take_screenshot, take_snapshot, type_text, upload_file, wait_for
• codex_apps • Auth: Bearer token • Tools: (none)
• context7 • Auth: OAuth • Tools: query-docs, resolve-library-id
• firefox-devtools • Auth: Unsupported • Tools: accept_dialog, clear_console_messages, clear_snapshot, click_by_uid, close_page, dismiss_dialog, drag_by_uid_to_uid, fill_by_uid, fill_form_by_uid, get_firefox_info, get_firefox_output, get_network_request, hover_by_uid, install_extension, list_console_messages, list_network_requests, list_pages, navigate_history, navigate_page, new_page, resolve_uid_to_selector, restart_firefox, screenshot_by_uid, screenshot_page, select_page, set_viewport_size, take_snapshot, uninstall_extension, upload_file_by_uid
› Воспользуйся chrome-devtools, открой google.com и найди картинку кошки породы сфинкс. Не описывай действия а вызови инструмент.
• Понял, использую Node REPL для управления Chrome через встроенный плагин Browser Plugin:MCP-серверы chrome_devtools и node_repl в текущей среде не доступны — они возвращают «unsupported call». У меня работает только shell_command, поэтому я могу либо запустить Chrome через PowerShell, либо попробовать настроить эти MCP-серверы.
Какой вариант предпочтителен?
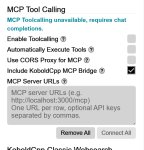
Я тут раньше саммари тредов пару раз постил, когда кобольд подключал к встроенному mcp функционалу. Нужен браузер и расширение с mcp в нем, в кобольде добавляешь сервером на пикрелейтед вкладке локальный адрес. Поскольку кобольд не агент, в нем все время надо было жать кнопку продолжить, что довольно неудобно. Но содержимое тредов все равно себе в контекст успешно утаскивал. В гугле тоже искать получалось.
у меня скорее пайплайн
написал код->код упал -> залез в браузер (в консольку посмотрел ошибки)
Ну это понятно, но речь именно о локалках, которые может запустить на своём пк простой человек с медианным доходом. Максимум возможного для такого случая - rtx 3090 в количестве 1 шт. На таком железе предел это локалки до 35b.
> rtx 3090
Добавь оперативки 128 гб и запускай мое вплоть до 400В.

До сих пор реально купить ддр4 128 и запускать огромное количество моделей, вплоть до 122b-a10b q8 и 256к контекста без квантования. 9т/с, но жить можно. Вы же не жалуетесь что не можете слетать в космос из своей мухосрани? Это тоже самое, пик тежнологий хули. Или терпи и плати за это дядям, или довольствуйся чем есть
>На таком железе предел это локалки до 35b.
При наличии 64 озу запускаются локалки ~100b в Q4 и ~200b в Q2. При 128гб запускается всё в плоть до жирного глэма в Q2. Прошлым летом оперативка буквально наразвес продавалась, кто успел - тот успел.
У вас что там в асиге, прокси перебанили? От скуки сюда лезете?
Удалил import requests 27 строку и всё заработало.
Тут уже каждый для себя устанавливает ограничения. Благо живем в такое время, что даже на 3090 можно запустить приличную модель, с которой можно много чего делать. Не только в рамках энтузиазма и гиковских развлечений как года 3 назад, а вполне для практических применений.
А далее для рп - можно большие моэ в выгрузкой в рам покрутить, если есть свободные средства - можно карточек докупить и много других возможностей.
Желаю тебе сидеть до конца жизни на больших и сильных мистрале, 4 ламе и новых коммандерах
Обронил говно. Вы не видели? Ах вот же оно
> мистрале
Он хороший, почему бы не посидеть? Что 123, что 671.
> новых коммандерах
Тоже не так уж плох
>gemma-4-26B-A4B-it-Q8_0 в ризонинге ведет себя как bf16, но все 10 раз(!) ушла в бесконечный луп
>Q8 не такой уж и lossless в случае Геммы 4?
Вот это интересно. У меня восьмой квант также себя ведёт, лупится в ризонинге просто пиздец. Иногда не только на картинках. Стать чтоль бф16 шизом...
Эксперты все будут в оперативе, а не в видяхе, по умолчанию.
В видяху эксперты в принципе динамически не подгружаются.
Дело в том, что есть модель-роутер и общие слои, которые задействованы вообще всегда. И вот они ускоряются видяхой. А эксперты с оперативы работают.
В среднем треть на видяхе, и две трети с оперативы.
Т.о., у тебя 50% буста от оперативы получается (а учитывая, что роутер и общие слои можно квантануть слабее, чтобы точность была выше, на деле еще быстрее).
В итоге от 17 уже будет 25 и выше тпс с видяхой при такой же памяти и проце.
25 токенов в секунду — недурная скорость.
А если еще MTP подключить в случае квена или геммы… )))
> Нет, я не верю что ты можешь загрузить даже степ флеш в свой врам.
Если очень напрячься — смогу в низком кванте и на всех-всех видяхах, но идея хуйня, конечно.
Так что, да, живем на выгрузке в оперативу. =(
Но вдруг тут кто-то богатый на врам! Пусть знает, что есть такое. =)
Бля, ну ван, кстати, не то чтобы мое, там всего два эксперта, и работают оба по очереди. =) Без этого он бы работал ровно точно так же. Никто не мешает инференсить только хай или только лоу модель.
Это буквально 28B-A14B. У тебя первые шаги делает один эксперт, последние — другая. Первый WAN и был 14B моделью. На том же количестве шагов она генерила столько же.
Т.е., в моменте Wan2.2 это 14B активных параметров, но за всю генерацию активируются все 28B параметров.
Но при этом, никогда не слышал, чтобы Wan2.2 называли 28B моделью без упоминания 14 активных. Зато многие тюны прямо называются 14B моделями, потому что Квены сообразили, что нейминг хуйня получился. )))
Короче моешка без роутера с обязательной активацией всех весов, но в разное время, типа 28б, но на деле просто две модели по 14б подряд. ) Пример так себе.
Да хули мозги ебать 26б мое = 13б плотная, 31б плотная = 62б мое, 124б мое = х2, кайфы, умнее.
Я хз, всегда и на всем работает такое примерное, че тут думать еще.
Даже по бенчам сходится у геммы.
НО КАДА БУДЕТ ТА
ДЕРЖИ ДИФФУЗИЮ
На самом деле, 122б был хорош, просто он не имел ниши для применения у большинства.
Недостаточно хорош для сравнения с 397б, не сильно лучше 27б.
Так и тут, гемма 4-31б она уже неплоха по сравнению с 200б моделями. Ну дипсик на русском языке лучше пишет. Минорно.
Тут люди неиронично сидят на аире, хотя я очень не уверен, что аир лучше геммы 31б, и даже геммы 26б. Ну да, более разнообразный по знаниям, может быть.
Если выйдет гемма 124б, она может быть реально хороша по бенчам и в каких-то задачах (как и квен). Но в рп будет минорно лучше 31б. Не 500б-модель по качеству, и как бы зачем тогда.
Но фанаты найдутся, пересядут с аира (или не пересядут) и предпочтут такое.
В общем, экстраполяция говорит, что модель будет лучше, но нишу может не найти попросту. Слишком большой для 30 гигов и 4б активных, и недостаточно хорошая для 500б моделей.
30б модели на уровне топовых корпоративных полуторалетней давности. Если ты недоволен ими сейчас — то, по идее, не должен был пользоваться ими тогда.
Иначе тейк невалиден, ибо, очевидно, что большая модель в среднем лучше маленькой. Но ты же апеллируешь не столько к размеру, сколько к корпоративности. Ну вот, корпоративные тоже не огонь были. Росли они, растут и локалки. Юзали корпоративные тогда — юзают локалки для тех же целей и сейчас.
Область применения локалок у́же, но не нулевая.
Ну и 200б тоже можно запустить, просто скорость будет не такой хорошей. Но уже терпимой.
Да любого агента запусти и попроси его настроить всякие omnivoice (omnivoice.cpp оба проекта с серверами), gigaam / t-one, вижн блядь встроенный в модели уже почти во все, а все остальное там и так будет.
Типа, эту задачу не решают потому, что она просто стоит немного токенов.
Всем поебать, у всех уже локальные аи вайфу.
Ну накати Marinara Engine. Там есть почти все, кроме AST/STT. Ну допиши туда сам.
Я хз, чо угодно.
APEX при сопоставимом размере дает сопоставимые результаты, по крайней мере по моим тестам на квене, я и забил.
Но если в рп оно чуть лучше, то почему бы и нет.
Но опять же, вот эти вот тесты с минимальными отличиями ваншотами — это чисто рандом.
Нужно LLM-as-Judge и хотя бы по 10 проходов на каждую из хотя бы 5 сценариев/сюжетов.
Тогда будет какое-то подобие результата, и то очень неточно, к сожалению.
Помните, был такой, https://github.com/IlyaGusev/ping_pong_bench
Ну вот, я вам напомнил. Вперед.
Слишком жирно.
Вот тоже ощущение, что gemma 4 26b выебет все 100b+ старые денс-модели.
Между прочим, дипсик 1,6Т!!! =) Локалка!
Да и степ-3.7-флэш на 197B очень быстрая (с мтп) и при этом больше 175б чатгпт.
Короче, цифрами смешно мерять, в прямом смысле слова «смешно». =) Можно всякое намерять.
4096 контекста у GPT-3.5, ПОМНИТЕ? =D
8K КОНТЕКСТА ПРОРЫВ ИМБА МИСТРАЛЬКА 0.1!!1
YARN!!! x4!!1
> Q8 не такой уж и lossless в случае Геммы 4? Или вообще?
Вообще. Q8 в узком круге задач заметно всирает fp16 оригу.
Просто этот круг задач достаточно узок, чтобы забить хуй в большинстве случаев.
Но ты должен понимать, что самые малоизвестные (маловесовые) знания попросту отрежутся, поимев 0 вес. Это будет вес, на который не указывает ни один вектор. =)
К сожалению, сейчас только DDR3 можно человеку со средним доходом набрать, а DDR4 уже будет покупать по одной планке. =D
> жирного глэма
https://huggingface.co/sokann/GLM-5.1-GGUF-1.673bpw
>оперативки 128 гб
Что-то на богатом, но идея хороша, конечно.
До сих пор жалею, что в свое время не купил хотя бы 64, когда собирал пк и оперативка не была такой дорогой.
Уже 210к за 2 планки по 64.
Я просто бьюсь ебалом об стол, когда мог взять 2x4090 а взял 2x4080, но решил что избыточно.
Долбоёб старый.
> Что-то на богатом
Какие времена - такое и богатство.
А зачем две? В 32гб переделывал, или оставил как есть?
\
>210к за 2 планки по 64
>Я просто бьюсь ебалом об стол
А мог бы нормально зарабатывать и не биться.
>210к за 2 планки по 64
>Я просто бьюсь ебалом об стол
А мог бы нормально зарабатывать и не биться.

Как же жалко, что 4-канальные платформы больше не для обычных юзеров. Вот помню в далеком 2011-12 собирал на сэнди бридже комп с 4х4гб ддр3... А щас это блять двухканальная залупа, даже если слота 4.
>собирал на сэнди бридже комп с 4х4гб ддр3... А щас это блять двухканальная залупа, даже если слота 4.
Она и тогда была двухканальная, лол. Или ты думал, что если 4 плашки вставить, то она четырехканальной будет?
А, блять, лол, действительно. Я тогда был 14-летним пиздюком, и с тех пор не проверял инфу.

Бля, аноны, я недельку погонял glm4.7-flash на rtx3060 12gb +32 gb ddr4 ram
В целом приятный диалог вести может, но тупит иногда. Тупления в основном касаются непонимания подтекста или физического местоположения персонажей относительно пространства. Также любит часто использовать идентичные конструкции при описании действий. Но в целом на авторежиме шустренько. Если вручную смещать на карту максимально, тупит, а авто оставляет незанятый хедер в гиг, видимо чтобы не троттлило.
У меня на матери есть слоты под еще две плашки и карту, имеет смысл впихнуть rx580 8gb и две плашки ddr4 по 8gb? Учитывая, что придется частоту пямяти ронять до ~3000 и сможет ли вообще эта карта использоваться, ей уже лет 10 же. БП должен вытянуть, в принципе.
В принципе, у меня тогда будет 20gb vram 48 ram, поиграться можно будет с чем-то потяжелее. Или пустое?
Кстати, вот еще старую плату нашел у себя. Ебать, 15 лет назал на бюджетных платах столько разъемов было, не то что сейчас.
В целом приятный диалог вести может, но тупит иногда. Тупления в основном касаются непонимания подтекста или физического местоположения персонажей относительно пространства. Также любит часто использовать идентичные конструкции при описании действий. Но в целом на авторежиме шустренько. Если вручную смещать на карту максимально, тупит, а авто оставляет незанятый хедер в гиг, видимо чтобы не троттлило.
У меня на матери есть слоты под еще две плашки и карту, имеет смысл впихнуть rx580 8gb и две плашки ddr4 по 8gb? Учитывая, что придется частоту пямяти ронять до ~3000 и сможет ли вообще эта карта использоваться, ей уже лет 10 же. БП должен вытянуть, в принципе.
В принципе, у меня тогда будет 20gb vram 48 ram, поиграться можно будет с чем-то потяжелее. Или пустое?
Кстати, вот еще старую плату нашел у себя. Ебать, 15 лет назал на бюджетных платах столько разъемов было, не то что сейчас.
В агенто-тред. RTFM opencode + 27 Qwen + mcp. Браузерных mcp уже как собак не резанных. Любой подойдет.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ



Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.github.io/wiki/llama/
Гайд для новичков: https://rentry.org/2ch-llama-inference
Инструменты для запуска на десктопах:
• llamacpp - отец и мать всех инструментов, позволяющий гонять GGML и GGUF форматы: https://github.com/ggml-org/llama.cpp
• koboldcpp - самый простой в использовании и установке форк llamacpp: https://github.com/LostRuins/koboldcpp
• TextGen (в девичестве text-generation-webui) - если необходимы другие форматы и больше контроля: https://github.com/oobabooga/textgen
• TabbyAPI - заточенный под Exllama (V2 и V3) и в консоли: https://github.com/theroyallab/tabbyAPI
• Однокнопочные инструменты на базе llamacpp с ограниченными возможностями: https://github.com/ollama/ollama, https://lmstudio.ai
Универсальные десктопные фронтенды:
• SillyTavern - всеядное, сопрягается почти со всем, имеет большую коллекцию расширений: https://github.com/SillyTavern/SillyTavern
• Marinara Engine - вариация на тему таверны, больше возможностей из коробки: https://github.com/Pasta-Devs/Marinara-Engine
• Risuai - еще одна вариация, на этот раз в профиль, излишеств по минимуму: https://github.com/kwaroran/RisuAI
Инструменты для запуска на мобилках:
• Maid - интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• ChatterUI - альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://web.archive.org/web/20241201232031/https://rentry.co/STAI-Termux
Поставщики локальных моделей:
• Hugging Face - платформа куда загружается всё и во всех форматах: https://huggingface.co/models
• Проверенные квантоделы: https://huggingface.co/bartowski, https://huggingface.co/mradermacher, https://huggingface.co/unsloth
Рейтинги и списки локальных моделей:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/2ch_llm_moe_2026
• Неактуальные списки моделей в архивных целях: 2025: https://rentry.co/2ch_llm_2025 (версия для бомжей: https://rentry.co/z4nr8ztd ), 2024: https://rentry.co/llm-models , 2023: https://rentry.co/lmg_models
• Миксы от тредовичков с уклоном в русский РП: https://huggingface.co/Aleteian и https://huggingface.co/Moraliane
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по чуть менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Готовые карточки для таверны:
• Botbooru - текущая мета (регистрируйтесь для отображения всего спектра, и/или меняйте страну): https://botbooru.com
• Прошлая мета, откуда массово удалили карточки сомнительного содержания: https://www.characterhub.org, https://www.chub.ai
Официальные документации к инструментам:
• llamacpp: https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md
• koboldcpp: https://github.com/LostRuins/koboldcpp/wiki
• SillyTavern: https://docs.sillytavern.app/usage/quick-start
Дополнительные ссылки:
• Перевод нейронками для таверны: https://rentry.co/magic-translation
• Пресеты под локальный ролплей в различных форматах: http://web.archive.org/web/20250222044730/https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально: https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose: https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны: https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры: https://artefact2.github.io/llm-sampling/
• Выгрузка избранных тензоров, позволяет ускорить генерацию при недостатке VRAM: https://www.reddit.com/r/LocalLLaMA/comments/1ki7tg7
• Инфа по запуску на MI50, тесты производительности и прочее: https://arkprojects.space/wiki/AMD_GFX906
• Тесты tensor_parallel: https://rentry.org/8cruvnyw
Архив тредов можно найти на архиваче: https://arhivach.vc/?tags=14780%2C14985
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде.
Предыдущие треды тонут здесь: